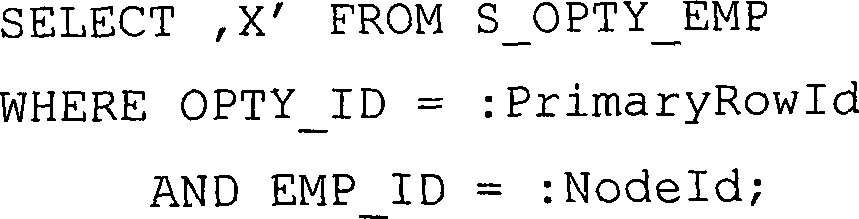-
EINLEITUNG
-
I. Technischer Bereich
-
Die vorliegende Erfindung betrifft
ein System und ein Verfahren zum Bereitstellen von Updates auf einem
Netzwerk von teilreplizierten relationalen Datenbanksystemen und
insbesondere zum Bereitstellen einer reduzierten Zahl von Updates,
die zwischen teilreplizierten Knoten in einem solchen System übertragen
werden.
-
II. Hintergrund
-
Relationale Datenbanken sind eine
häufig
verwendete Datenstruktur zum Darstellen von Daten in einer Geschäfts- oder sonstigen Umgebung.
Eine relationale Datenbank stellt Daten in der Form einer Kollektion von
zweidimensionalen Tabellen dar. Jede Tabelle umfasst eine Serie
von Zellen, die in Reihen und Spalten angeordnet sind. Eine Reihe
in einer Tabelle repräsentiert
typischerweise eine bestimmte Observation. Eine Spalte repräsentiert
entweder ein Datenfeld oder einen Zeiger auf eine Reihe in einer
anderen Tabelle.
-
So kann beispielsweise eine eine
organisatorische Struktur beschreibende Datenbank eine Tabelle haben,
um jede Position in der Organisation zu beschreiben, und eine andere
Tabelle, um jeden Mitarbeiter in der Organisation zu beschreiben.
Die Mitarbeitertabelle kann Informationen beinhalten, die für den Mitarbeiter spezifisch
sind, wie z. B. Name, Mitarbeiternummer, Alter, Gehalt usw. Die
Positionstabelle kann Informationen beinhalten, die für die Position
spezifisch sind, wie z. B. Positionsbezeichnung („Verkäufer", „Vizepräsident" usw.), eine Gehaltsklasse
und dergleichen. Die Tabellen können
bezogen werden, indem beispielsweise in jeder Reihe der Mitarbeitertabelle
ein Zeiger auf eine bestimmte Reihe in der Positionstabelle vorhanden
ist, so koordiniert, dass für
jede Reihe in der Mitarbeitertabelle ein Zeiger auf die bestimmte
Reihe in der Positionstabelle vorhanden ist, der die Position dieses
Mitarbeiters beschreibt. Ein relationales Datenbankmanagementsystem
(RDBMS) unterstützt
ein „Verbinden" dieser Tabellen
als Reaktion auf eine Abfrage von einem Benutzer, so dass der Benutzer,
der z. B. eine Anfrage über
einen bestimmten Mitarbeiter macht, einen Bericht über den
gewählten
Mitarbeiter erhalten kann, der nicht nur die Informationen in der
Mitarbeitertabelle, sondern auch die Informationen in der verwandten
Positionstabelle enthält.
-
Relationale Datenbanken können weitaus
komplexer sein als dieses Beispiel, mit mehreren Tabellen und einer
Vielzahl von Relationen dazwischen.
-
Mit der weit verbreiteten Verwendung
von kostenarmen tragbaren Computern ist es vorteilhaft, eine Datenbank
auf einen tragbaren Computer zu replizieren, auf die an Orten entfernt
vom zentralen Computer zugegriffen werden kann. Die replizierte
Datenbank kann dann vom Benutzer des tragbaren Computers referenziert
werden, ohne dass eine Bezugnahme auf die Hauptdatenbank notwendig
wäre, die
an einer zentralen Stelle verwaltet werden kann, die für den Benutzer
des tragbaren Computers mühsam
zu erreichen ist. Es kann jedoch eine Reihe von Schwierigkeiten
mit dem Gebrauch einer replizierten Datenbank verbunden sein.
-
Ein Nachteil besteht darin, dass
eine volle Kopie der zentralen Datenbank mehr Datenspeicherkapazität erfordert,
als dies wünschenswert
oder wirtschaftlich ist. So muss sich ein z. B. im Außendienst
tätiger Verkäufer auf
die Datenbank im Hinblick auf Informationen über Verkaufsmöglichkeiten
in seinem Verkaufsbereich beziehen, braucht aber keine Informationen über Verkaufsmöglichkeiten
außerhalb
seiner Bereiche. Ein möglicher
Ansatz zur Reduzierung der Menge an benötigter Datenspeicherkapazität besteht
darin, einfach nur den Teil der Datenbank zu replizieren, der vom
Benutzer benötigt
wird. Dieser Ansatz berücksichtigt
jedoch nicht, dass sich die Kriterien zum Bestimmen, welche Teile
der Daten benötigt
werden, wahrscheinlich im Laufe der Zeit ändern werden. So wird z. B.
dem Gebiet des Verkäufers
vielleicht eine neue Stadt hinzugefügt. Bei konventionellen Ansätzen würde der
Verkäufer
seine örtliche
Kopie der Datenbank erneut replizieren und dieses Mal Daten mit
der hinzugefügten
Stadt auswählen.
Eine solche Praxis ist jedoch unpraktisch, fehleranfällig und
zeitaufwändig.
-
Ein weiterer Nachteil einer replizierten
Datenbank sind die Schwierigkeiten, die bei dem Versuch auftreten,
Daten mit der replizierten Kopie zu aktualisieren. Eine an der replizierten
Datenbank vorgenommene Änderung
wird in der zentralen Datenbank nicht vorgenommen, was zu einer
Diskrepanz zwischen den in der replizierten Kopie der Datenbank
gespeicherten Informationen und den in der zentralen Datenbank gespeicherten
Informationen führt.
Es ist zwar möglich,
Modifikationen an der replizierten Kopie aufzuzeichnen und dieselbe
Modifikation auf die zentrale Datenbank anzuwenden, aber ein Problem
besteht darin, dass bei diesem Ansatz die Möglichkeit von Update-Kollisionen
besteht; d. h., wenn ein Benutzer einer replizierten Kopie eine Änderung
an Daten vornimmt, die auch von einem Benutzer der zentralen Kopie
oder vom Benutzer einer anderen replizierten Kopie geändert werden.
-
Es ist daher wünschenswert, die Möglichkeit
zu haben, eine oder mehrere teilreplizierte Kopien einer zentralen
Datenbank auf eine solche Weise zu verwalten, dass das Ausmaß der Replikation
leicht geändert werden
kann, ohne dass eine Auffrischung der gesamten replizierten Datenbank
notwendig wäre,
und so können
Updates zwischen Benutzern der zentralen Datenbank und Benutzern
der teilreplizierten Datenbanken koordiniert werden.
-
Zu früheren Vorschlägen zum
Verwalten eines Datenbanknetzes gehören die veröffentlichten europäischen Patentanmeldungen
459 345, 81 056 und 216 535. Dabei erfordert die 459 345 das Senden
mehrerer Anforderungen zwischen dem Knoten und einem Server-Pool
in SQL-Sprache; die 81 056 vermeidet eine durch einen zentralen
Knoten verwaltete Steuerung und arbeitet mit einer Status- und Steuertabelle
an jedem Knoten; und die 216 535 arbeitet mit einem Update-Erfassungsmodul
an jedem Knoten, das relevante Updates zu einem zentralen Datenumsetzer
weiterleitet.
-
ZUSAMMENFASSUNG
DER ERFINDUNG
-
Die Erfindung ist in ihren verschiedenen
Aspekten in den nachfolgenden unabhängigen Ansprüchen definiert.
Vorteilhafte Merkmale sind in den Unteransprüchen dargelegt.
-
Eine bevorzugte Ausgestaltung der
Erfindung wird nachfolgend ausführlicher
mit Bezug auf die Zeichnungen beschrieben. Diese Ausgestaltung hat
die Form eines Verfahrens zum Verwalten einer teilreplizierten Datenbank
auf eine solche Weise, dass an einer zentralen Datenbank oder einer
anderen teilreplizierten Datenbank vorgenommene Updates selektiv
zu der teilreplizierten Datenbank propagiert werden. Updates werden
zu einer teilreplizierten Datenbank propagiert, wenn davon ausgegangen
wird, dass der Besitzer der teilreplizierten Datenbank Einsicht
in die aktualisierten Daten hat. Sichtbarkeit wird anhand von vorbestimmten Regeln
bestimmt, die in einer Regeldatenbank gespeichert sind. In der bevorzugten
Ausgestaltung werden die gespeicherten Regeln anhand eines Dateninhalts
verschiedener Tabellen beurteilt, die eine logische Entität – Docking-Objekt
genannt – bilden,
die aktualisiert wird.
-
Wie nachfolgend beschrieben, werden
die gespeicherten Regeln anhand des Dateninhalts von einem oder
mehreren Docking-Objekten beurteilt, die nicht unbedingt aktualisiert
werden, die sich aber auf ein aktualisiertes Docking-Objekt beziehen.
Die Sichtbarkeitsattribute der verwandten Docking-Objekte können rekursiv
bestimmt werden.
-
Sichtbarkeitsänderungen werden ermittelt,
damit der Zentralcomputer die Knoten anweisen kann, das Docking-Objekt in seine teilreplizierte
Datenbank einzufügen.
Solche Sichtbarkeitsänderungen
werden ermittelt, um den Zentralcomputer zu befähigen, einen Knoten zum Entfernen
eines Docking-Objekts aus seiner teilreplizierten Datenbank anzuweisen.
-
Die vorbestimmten Regeln liegen in
deklarativer Form vor und spezifizieren die Sichtbarkeit von Daten auf
der Basis der Struktur der Daten ohne Bezug auf Dateninhalt.
-
KURZE BESCHREIBUNG
DER ZEICHNUNGEN
-
Die bevorzugte Ausgestaltung der
Erfindung wird nachfolgend beispielhaft unter Bezugnahme auf die Zeichnungen
ausführlicher
beschrieben. Dabei zeigt:
-
1 eine Übersicht über den
Betrieb von einer Ausgestaltung der vorliegenden Erfindung;
-
2 ein
Datenbankschema, das die Beziehung zwischen den verschiedenen Komponenten
zeigt, aus denen sich ein Docking-Objekt zusammensetzt;
-
3 Schritte,
die von einem Update-Manager zum Aktualisieren einer Datenbank durchgeführt werden;
-
4 Schritte,
die von einem Docking-Manager zum Senden und/oder Empfangen von
einem oder mehreren Transaktionsprotokollen durchgeführt werden;
-
5 die
Schritte, die von einem Mischprozessor zum Mischen von Transaktionsprotokolldatensätzen zu
einer existierenden Datenbank durchgeführt werden;
-
6 die
Schritte, die von einem Protokollmanager zum Herstellen eines teilweisen
Transaktionsprotokolls durchgeführt
werden;
-
7 die
Schritte, die von einem Sichtbarkeitskalkulator zum Berechnen der
Sichtbarkeit für
ein Docking-Objekt gemäß Aufruf
durch einen Protokollmanager durchgeführt werden;
-
8 die
Schritte, die zum Synchronisieren einer teilreplizierten Datenbank
als Reaktion auf eine Änderung
der Datensichtbarkeit durchgeführt
werden.
-
BESCHREIBUNG
EINER SPEZIFISCHEN AUSGESTALTUNG
-
Überblick
-
1 zeigt
einen Überblick über den
Betrieb einer Ausgestaltung der vorliegenden Erfindung. 1 zeigt ein zentrales Computersystem 1 und
drei ortsferne Computersysteme (oder „Knoten") 21-a, 21-b und 21-c.
Die einzelnen Knoten 21-a, 21-b und 21-c sind
in verschiedenen Zuständen
der Kommunikation mit dem zentralen Computersystem 1 dargestellt,
wie nachfolgend ausführlicher
erläutert
wird. Das zentrale Computersystem 1 beinhaltet eine zentrale
Datenbank 3, einen Docking-Manager 5, einen Mischprozessor 7 und
einen Protokollmanager 9. Das zentrale Computersystem 1 beinhaltet
darüber
hinaus bei Bedarf einen Update-Manager 11, der auf Benutzereingaben 13 anspricht.
-
Knoten 21-a ist ein Ferncomputersystem
wie z. B. ein mobiler Client, z. B. ein Laptop-Computer. Knoten 21-a beinhaltet
eine teilreplizierte Ferndatenbank 23a, einen Update-Manager 31-a,
der auf Benutzereingaben 33-a anspricht, einen Docking-Manager 25-a und
einen Mischmanager 27-a. Beim Betrieb reagiert der Update-Manager
auf Benutzereingaben 33-a und nimmt Änderungen an der Ferndatenbank 23-a gemäß Anweisungen
durch den Operator von Knoten 21-a vor. Vorgenommene Updates
werden in einem Knoten-Update-Protokoll 25-a aufgezeichnet.
-
Zu irgendeinem Zeitpunkt im Ermessen
des Operators von Knoten 21-a wird der Knoten-Docking-Manager 35-a aktiviert
und tritt mit dem zentralen Docking-Manager 5 in Kommunikation.
Das Update-Protokoll 35-a wird vom Knoten-Docking-Manger 25-a als
Eingabe genommen und zum zentralen Docking-Manager 5 geleitet.
Der zentrale Docking-Manager 5 erstellt ein Empfangener-Knoten-Update-Protokoll 19,
das alle im Update-Protokoll 35-a aufgezeichneten Informationen
enthält.
Bei Bedarf wird das Teilprotokoll 17-a vom zentralen Docking-Manager 5 als
Eingabe genommen und zum Knoten-Docking-Manager 25-a geleitet,
wie hierin ausführlicher
beschrieben wird.
-
Zu irgendeinem Zeitpunkt im Ermessen
des Operators des zentralen Computersystems 1 wird der Mischprozessor 7 aktiviert.
Der Mischprozessor 7 nimmt als Eingabe das Empfangener-Knoten-Update-Protokoll 19 und
leitet die darin beschriebenen Updates zur zentralen Datenbank 3.
Während
des Vorgangs des Übertragens
der Updates vom Empfangener-Knoten-Update-Protokoll 19 zeichnet
der Mischprozessor die zum zentralen Update-Protokoll 15 gesendeten
Updates auf. Bei Bedarf nimmt der Update-Manager 11, der auf
Benutzereingaben 12 anspricht, zusätzliche Änderungen an der zentralen
Datenbank 3 gemäß Anweisung durch
den Operator des zentralen Computersystems 1 vor. Die vom
Update-Manager 11 vorgenommenen Updates werden zusätzlich im
zentralen Update-Protokoll 15 aufgezeichnet.
-
Zu irgendeinem Zeitpunkt im Ermessen
des Operators des zentralen Computersystems 1 wird der
Protokollmanager 9 aktiviert. Der Protokollmanager 9 nimmt
als Eingabe das zentrale Update-Protokoll 15 und erzeugt
als Ausgabe einen Satz von Teilprotokollen 17-a, 17-b und 17-c gemäß Sichtbarkeitsregeln,
wie nachfolgend näher
beschrieben wird. Jedes der Teilprotokolle 17-a, 17-b und 17-c entspricht
einem der Knoten 21-a, 21-b und 21-c.
Wenn ein Knoten-Docking-Manager wie z. B. der Knoten-Docking-Manager 25-a mit
dem zentralen Docking-Manager 5 in Kommunikation tritt
und optional eine Übertragung
seines entsprechenden Teilprotokolls anfordert, dann nimmt der zentrale
Docking-Manager 5 als
Eingabe das entsprechende Teilprotokoll wie z. B. das Teilprotokoll 17-a und
sendet es zum Knoten-Docking-Manager
25-a. Der Knoten-Docking-Manager 25-a repliziert dann das
Teilprotokoll 17-a als Mischprotokoll 37-a.
-
Zu einem späteren Zeitpunkt im Ermessen
des Operators von Knoten 21-a wird der Mischprozessor 27-a aktiviert.
Der Mischprozessor 27-a nimmt als Eingabe das Mischprotokoll 37-a und
sendet die darin beschriebenen Updates zur teilreplizierten Datenbank 23-a.
-
Zusätzlich zum Knoten 21-a zeigt 1 auch zwei zusätzliche
Knoten 21-b und 21-c. Knoten 21-b ist in
Kommunikation mit dem zentralen Computer 1 dargestellt.
Aber im Gegensatz zu Knoten 21-a hat der Operator von Knoten 21-b lediglich
das Senden seiner Updates zum zentralen Computersystem 1 angefordert
und hat keine Änderungen
angefordert, die an anderer Stelle an seiner teilreplizierten Datenbank 23-b vorgenommen
wurden. Dies kann beispielsweise dann der Fall sein, wenn der Operator
ein dringendes Update hat, das so bald wie möglich vorgenommen werden muss,
aber nicht genügend
Zeit hat, um Updates von anderen Knoten zu empfangen. Demgemäß zeigt 1 nur das Übertragen
des Knoten-Update-Protokolls 35-a vom Knoten-Docking-Manager 25-b zum
zentralen Docking-Manager 5 und
keine Übertragung
vom zentralen Docking-Manager 5 zum
Knoten-Docking-Manager 25-b. Demgemäß wird der Mischmanager für Knoten 21-b nicht
aktiviert und ist nicht dargestellt.
-
Ebenso ist Knoten 21-c als
nicht in Kommunikation mit dem zentralen Computersystem 1 dargestellt. Demgemäß wird der
Docking-Manager für
Knoten 21-c nicht aktiviert und ist nicht dargestellt.
-
Mit dem oben beschriebenen Zyklus
können
an jedem der Knoten 21-a, 21-b und 21-c vorgenommene Updates
zum zentralen Computersystem 1 gesendet werden, so dass
die zentrale Datenbank 3 entsprechend aktualisiert werden
kann. Darüber
hinaus werden die einzelnen Updates, die an jedem der Knoten 21-a, 21-b und 21c vorgenommen
wurden, sowie Updates am zentralen Computersystem 1, zurück zu jedem
der Knoten 21-a, 21-b und 21-c geleitet,
so dass jede der Teildatenbanken 23-a, 23-b und 23-c miteinander
und mit der zentralen Datenbank 3 synchron gehalten werden.
-
Datenbankstruktur
-
Die Synchronisation der zentralen
Datenbank 3 mit Knotendatenbanken 23-a, 23-b und 23-c erfolgt mit
einem als Docking-Objekt bezeichneten Konstrukt. Ein Docking-Objekt
besteht aus Membertabellen (einschließlich einer Primärtabelle),
Sichtbarkeitsregeln, Sichtbarkeitsevents und verwandten Docking-Objekten.
-
Eine Membertabelle ist eine Tabelle
der relationalen Datenbank, die ein Docking-Objekt bildet. Wenn ein
Docking-Objekt von
der zentralen Datenbank 3 zu einer der Knotendatenbanken 23-a, 23-b oder 23-c propagiert
wird, dann hat die Propagierung die Form einer Einfügung in
jede der Membertabellen in Verbindung mit dem jeweiligen Docking-Objekt.
Ebenso besteht, wenn ein Docking-Objekt aus einer Datenbank genommen
werden soll, diese Herausnahme aus dem Löschen von Datensätzen aus
den Membertabellen in Verbindung mit dem Docking-Objekt. So kann
beispielsweise ein Docking-Objekt, das eine Verkaufsmöglichkeit
repräsentiert,
Tabellen beinhalten, die die Möglichkeit
(Opportunity) selbst repräsentieren
(z. B. „S_OPTY"), das Produkt, dessen
Verkauf durch die Möglichkeit
repräsentiert
wird (z. B. „S_OPTY_PROD"), den Kontakt für die Möglichkeit (z.
B. „S_OPTY_CONTACT"), usw. Jede dieser
Tabellen gilt als eine Membertabelle des „Opportunity-Docking-Objekts".
-
Eine Primärtabelle ist eine Membertabelle,
die kontrolliert, ob eine bestimmte Instanz eines Docking-Objekts für einen
bestimmten Knoten sichtbar ist. Die Primärtabelle hat einen Primary-Row-ID-Wert,
der zum Identifizieren einer Reihe der Primärtabelle verwendet wird, die
aktualisiert, gelöscht
oder eingefügt
wird. So kann beispielsweise das „Opportunity-Docking-Objekt" als Primärtabelle
die Tabelle S_OPTY haben. Die Reihen-ID dieser Tabelle, d. h. S_OPTY.row_id,
ist die Primary-Row-ID für
das Opportunity-Docking-Objekt.
-
Eine Sichtbarkeitsregel ist ein Kriterium,
das bestimmt, ob eine bestimmte Instanz eines Docking-Objekts für einen
bestimmten Knoten 21 „sichtbar" ist. Wenn ein Docking-Objekt
für einen
bestimmten Knoten sichtbar ist, dann empfängt dieser Knoten Updates für Daten
in dem Docking-Objekt. Es gibt zwei Typen von Sichtbarkeitsregeln,
je nach dem Feld RULE_TYPE. Eine Sichtbarkeitsregel mit einem RULE_TYPE
von „R" wird als SQL-Regel
bezeichnet. Eine SQL-Regel beinhaltet einen Satz von SQL-Statements
(Structured Query Language = strukturierte Abfragesprache), der
beurteilt wird, um zu ermitteln, ob Daten, die den in den SQL-Statements
vorgegebenen Kriterien entsprechen, im Docking-Objekt vorhanden
sind. Wenn ja, dann ist das Docking-Objekt für den Knoten sichtbar. Eine
Sichtbarkeitsregel mit einem RULE_TYPE von „O" wird als Docking-Objekt-Regel bezeichnet.
Eine Docking-Objekt-Regel gibt ein anderes Docking-Objekt für die Abfrage auf
Sichtbarkeit vor. Wenn das vorgegebene Docking-Objekt sichtbar ist,
dann ist auch das Docking-Objekt, das darauf zeigt, sichtbar.
-
Ein verwandtes Docking-Objekt ist
ein Docking-Objekt, das propagiert oder gelöscht wird, wenn das betrachtete Docking-Objekt
propagiert oder gelöscht
wird. So kann beispielsweise ein Opportunity-Docking-Objekt verwandte
Docking-Objekte haben, die die Verkaufskontakte, die Organisationen,
die zu verkaufenden Produkte und die Aktivitäten repräsentieren, die zum Verfolgen
der Möglichkeit
nötig sind.
Wenn ein Opportunity-Docking-Objekt von der zentralen Datenbank 3 zu
einer der Knotendatenbanken 23 propagiert wird, dann werden
auch die verwandten Docking-Objekte propagiert.
-
2 zeigt
ein Datenbankschema, das die Beziehung zwischen den verschiedenen
Komponenten zeigt, aus denen sich ein Docking-Objekt zusammensetzt.
Das Schema ist eine Metadatenbank, weil es die Daten, auf die zugegriffen
wird, in der Datenbank nicht beschreibt. Stattdessen ist das Schema
eine separate Datenbank, die die Struktur der Datenbank definiert,
auf die zugegriffen wird. Das heißt, es handelt sich um eine
Datenbank, die Tabellen umfasst, die die Beziehungen und Datenkontexte
einer anderen Datenbank umfassen.
-
Jede der in 2 gezeigten Tabellen ist eine Tabelle
in einer relationalen Datenbank und hat somit eine Reihen-Spalten-Form. Viele
Spalten repräsentieren
Felder, die aller, illustrierten Tabellen gemeinsam sind. Solche
Felder beinhalten beispielsweise eine ROW_ID zum Identifizieren
einer bestimmten Reihe in der Tabelle, sowie Felder zum Verfolgen
von Datum und Uhrzeit, zu dem/der eine Reihe erstellt und zuletzt
modifiziert wurde, sowie die Identität des Benutzers, der die Reihe
erstellt oder modifiziert hat. Darüber hinaus enthält jede
Tabelle Felder, die für
diese Tabelle spezifisch sind und die nachfolgend ausführlich beschrieben
werden.
-
Tabelle S_DOBJ 61 beschreibt
die Docking-Objekte in einer Anwendung. Tabelle S_DOBJ 61 beinhaltet
die Felder OBJ_NAME und PRIMARY_TABLE_ID. Das Feld OBJ_NAME definiert den
Namen des beschriebenen Docking-Objekts. Feld PRIMARY_TABLE_ID dient
zum Identifizieren der Primärtabelle
in Verbindung mit diesem Docking-Objekt.
-
Tabelle S_DOBJ_INST 63 beschreibt,
ob eine bestimmte Instanz eines Docking-Objekts, mit der Tabelle
S_DOBJ 61 beschrieben, in einer Datenbank eines bestimmten
Knotens vorhanden ist. Tabelle S_DOBJ_INST 63 enthält die Felder
NODE_ID, DOBJ_ID und PR_TBL_ROW_ID. Das Feld NODE_ID zeigt auf eine
bestimmte Knotentabelle 65. Feld DOBJ_ID zeigt auf das
Docking-Objekt, auf das die Docking-Objekt-Instanz zutrifft. Feld
PR_TBL_ROW_ID dient zum Wählen
einer bestimmten Reihe in der Primärtabelle des Docking-Objekts.
Dieser Wert identifiziert die Docking-Objekt-Instanz.
-
Tabelle S_REL_DOBJ 67 beschreibt
die verwandten Docking-Objekte eines bestimmten Docking-Objekts,
beschrieben von der Tabelle S_DOBJ 61. Tabelle S_REL_DOBJ 67 beinhaltet
die Felder DOBJ_ID, REL_DOBJ_ID und SQL_STATEMENT. Feld DOBJ_ID
identifiziert das Docking-Objekt,
das ein bestimmtes verwandtes Docking-Objekt besitzt. Feld REL_DOBJ_ID
identifiziert das verwandte Docking-Objekt, das im Besitz des von
DOBJ_ID identifizierten Docking-Objekts ist. Feld SQL_STATEMENT
ist ein SQL-Statement, das ausgeführt werden kann, um den Primary-ID-Wert
des verwandten Docking-Objekts zu erhalten.
-
Tabelle S_DOBJ_TBL 69 beschreibt
die Membertabellen eines bestimmten Docking-Objekts, beschrieben
durch Tabelle S_DOBJ 61. Tabelle S_DOBJ_TBL 69 beinhaltet
die Felder DOBJ_ID, TBL_ID und VIS_EVENT_FLG. Feld DOBJ_ID identifiziert
das Docking-Objekt, das die von der Reihe beschriebene Membertabelle
enthält.
Feld TBL_ID identifiziert die jeweilige Tabelle in der Datenbank,
die die von der Reihe beschriebene Membertabelle ist. Feld VIS_EVENT_FLG
ist ein Flag, der anzeigt, ob eine Änderung an diesem Docking-Objekt
zu einem Sichtbarkeitsevent führen kann.
Der Wert „Y" bedeutet, dass eine Änderung
in einem Sichtbarkeitsevent enden kann; der Wert „N" bedeutet, dass dies
nicht der Fall ist.
-
Tabelle S_DOBJ_VIS_RULE 71 enthält die Sichtbarkeitsregeln
in Verbindung mit einem bestimmten Docking-Objekt. S_DOBJ_VIS_RULE 71 enthält die Felder
DOBJ_ID, RULE_SEQUENCE, RULE_TYPE, SQL_STATEMENT und CHECK_DOBJ_ID.
Feld DOBJ_ID identifiziert das Docking-Objekt, mit dem eine bestimmte Sichtbarkeitsregel
assoziiert ist. Das Feld RULE_SEQUENCE ist eine Sequenznummer, die
die Sequenz in Bezug auf andere Sichtbarkeitsregeln in der Tabelle
S_DOBJ_VIS_RULE 71 anzeigt, in der die jeweilige Sichtbarkeitsregel
angewendet werden soll. RULE_TYPE gibt vor, ob die jeweilige Sichtbarkeitsregel vom
Typ „R" ist, was eine SQL-Sichtbarkeitsregel
bedeutet, oder vom Typ „O", was eine Docking-Objekt-Sichbarkeitsregel
bedeutet.
-
Wenn RULE_TYPE gleich „R" ist, dann hat Feld
CHECK_DOBJ_ID keine Bedeutung und Feld SQL_STATEMENT enthält ein SQL-Statement,
das anhand der Primary-ROW-ID der Primärtabelle in Verbindung mit
diesem Docking-Objekt und einem bestimmten Knoten 21 beurteilt
wird. Wenn das SQL-Statement Datensätze zurückgibt, dann wird das Docking-Objekt als für den Knoten 21 sichtbar
angesehen, für
den die Sichtbarkeit ermittelt wird.
-
Wenn RULE_TYPE gleich „O" ist, dann haben
sowohl das Feld CHECK-DOBJ-ID als auch das Feld SQL_STATEMENT Bedeutung.
Feld CHECK_DOBJ_ID gibt ein Docking-Objekt vor, dessen Sichtbarkeit
ermittelt werden soll. Wenn das vorgegebene Docking-Objekt als sichtbar
angesehen wird, dann ist auch das Docking-Objekt in Verbindung mit
der Sichtbarkeitsregel sichtbar. Das Feld SQL_STATEMENT enthält ein SQL-Statement,
das bei Ausführung
die Row-ID des Docking-Objekts zurückgibt, das von CHECK_DOBJ_ID identifiziert
wird, das der Docking-Objekt-Instanz in Verbindung mit der Sichtbarkeitsregel
entspricht.
-
Tabelle S_APP_TBL 73 ist
eine Anwendungstabelle, die alle Tabellen beschreibt, die in einer
bestimmten Anwendung verwendet werden. Darauf zeigt Tabelle S_DOBJ_TBL 69 für jede Membertabelle
in einem Docking-Objekt und Tabelle S_DOBJ für die Primärtabelle in einem Docking-Objekt.
S_APP_TBL 73 zeigt auf Tabelle S_APP_COL 75, bei
der es sich um eine Anwendungsspaltentabelle handelt, die die Spalten
von Daten in einer bestimmten Anwendung beschreibt. S_APP_TBL 73 zeigt
auf Tabelle S_APP_COL 75 direkt durch einen Primary-Key
und indirekt durch Mittel wie z. B. eine Foreign-Key-(=Fremdschlüssel)-Spalten-Tabelle 81, eine
User-Key-Spalten-Tabelle 83 und eine Spaltengruppentabelle 85.
Die Beziehung zwischen Anwendungstabelle, Anwendungsspaltentabelle,
Foreign-Key-Spaltentabelle, User-Key-Spaltentabelle
und Spaltengruppentabelle sind in der Technik hinlänglich bekannt
und werden nicht näher
beschrieben.
-
Update-Verarbeitung
-
3 zeigt
Schritte, die von einem Update-Manager 31 wie z. B. dem
Update-Manager 31-a, 31-b oder 31-c beim
Aktualisieren einer Datenbank wie z. B. einer Knotendatenbank 23-a, 23-b oder 23-c als
Reaktion auf eine Benutzereingabe durchgeführt werden. Die Abarbeitung
des Update-Managers 31 beginnt in Schritt 101.
In Schritt 103 akzeptiert der Update-Manager 31 vom
Benutzer Eingaben 33 in der Form eines Befehls, der eine Änderung
der Daten in der Datenbank 23 anfordert. Die Anforderung
kann in der Form einer Aufforderung zum Löschen einer Reihe einer Tabelle,
zum Hinzufügen
einer Reihe zu einer Tabelle oder zum Ändern des Wertes einer Zelle
in einer bestimmten Spalte einer bestimmten Reihe in einer Tabelle
vorliegen. In Schritt 105 wendet der Update-Manager 31 das angeforderte
Update mit einem hinlänglich
bekannten Mittel auf die Datenbank 23 an. In Schritt 107 erstellt
der Update-Manager 31 einen Protokolldatensatz, der das
Update beschreibt und es auf das Update-Protokoll 35 schreibt.
-
Der Inhalt eines Protokolldatensatzes
beschreibt das vorgenommene Update. Jeder Protokolldatensatz zeigt
die Knotenkennung des das Update vornehmenden Knotens, eine Identifikation
der aktualisierten Tabelle sowie eine Identifikation des vorgenommenen
Update-Typs an, d. h. eine Einfügung
einer neuen Reihe, eine Löschung
einer existierenden Reihe oder ein Update an einer existierenden
Reihe. Für
eine Einfügung beinhaltet
der Protokolldatensatz zusätzlich
eine Kennung der eingefügten
Reihe, einschließlich
ihres Primary-Key und der Werte der übrigen Spalten in der Reihe.
Für eine
Löschung
identifiziert der Protokolldatensatz den Primary-Key der gelöschten Reihe.
Für ein
Update identifiziert der Protokolldatensatz den Primary-Key der aktualisierten
Reihe, die Spalte in der zu aktualisierenden Reihe, den alten Wert
der Zelle an der adressierten Reihe und Spalte sowie den neuen Wert
der Zelle.
-
Nach dem Schreiben eines Protokolldatensatzes
in Schritt 107 verlässt
der Update-Prozessor die Routine für dieses Update. Die vorangegangene
Beschreibung der Update-Verarbeitung
beinhaltet vorzugsweise zusätzliche
Schritte, die für
die vorliegende Erfindung ohne Belang sind, wie z. B. die Gewährleistung einer
Berechtigung des Benutzers für
die Durchführung
des Updates, zum Einspeichern und Kommittieren des Schreibvorgangs
auf die Datenbank, um ein Rollback im Falle eines Software- oder
Hardware-Ausfalls und dergleichen zu ermöglichen. Diese Schritte sind
in der Technik hinlänglich
bekannt und werden nicht näher
beschrieben.
-
Ein im zentralen Computersystem 1 laufender
Update-Manager 11 arbeitet
auf analoge Weise, mit der Ausnahme, dass er die zentrale Datenbank 3 aktualisiert
und ihre Protokolldatensätze
auf das zentrale Update-Protokoll 11 schreibt.
-
Docking-Verarbeitung
-
4 zeigt
Schritte, die von einem Docking-Manager 25 wie z. B. dem
Docking-Manager 25-a, 25-b oder 25-c zum
Senden und/oder Empfangen von einem oder mehreren Transaktionsprotokollen
durchgeführt werden.
Der Docking-Manager 25 wird
vom Benutzer eines Fernknotens wie z. B. Knoten 21-a, 21-b oder 21-c aufgerufen,
wodurch der Benutzer anfordert, dass der Knoten am zentralen Computer 1 andockt,
um ein Update-Protokoll wie z. B. das Update-Protokoll 25-a zum zentralen
Computer 1 heraufzuladen, ein Teilprotokoll wie z. B. das
Teilprotokoll 17-a herunterzuladen oder beides. Der Ablauf
des Docking-Managers 25 beginnt
in Schritt 121. In Schritt 123 schaltet sich der
Docking-Manager 25 beim zentralen Computer 1 unter
der Steuerung des zentralen Docking-Managers 5 an. Bei
diesem Anschalten kann es sich um eine beliebige Verbindung handeln,
die einen Datenaustausch ermöglicht.
Es ist vorgesehen, dass die üblichste
Verbindungsform eine Telefonleitung in Verbindung mit einem Modem
ist, aber es können
auch andere Datenverbindungsformen verwendet werden, wie z. B. ein
LAN oder eine TCP/IP-Verbindung. Schritt 125 prüft, ob der
Benutzer angefordert hat, dass das Knoten-Update-Protokoll 35-a zum zentralen
Computer 1 heraufgeladen wird. Wenn ja, dann geht der Ablauf
mit Schritt 127 weiter; wenn nicht, dann wird Schritt 127 übersprungen
und es geht mit Schritt 129 weiter. In Schritt 127 lädt der Docking-Manager 25 sein
Update-Protokoll auf den zentralen Computer 1 herauf. Das
Upload kann mit beliebigen bekannten Datenübertragungsmitteln wie z. B. XMODEM,
ZMODEM, KERMIT, FTP, ASCII-Transfer oder einem beliebigen anderen
Verfahren zum Übertragen
von Daten erfolgen. In Schritt 25 prüft der Docking-Manager 25,
ob der Benutzer das Herunterladen eines Teilprotokolls wie z. B. Teilprotokoll 17-a vom
zentralen Computer 1 angefordert hat. Wenn ja, dann geht
der Ablauf mit Schritt 131 weiter; wenn nicht, dann wird
Schritt 131 übersprungen
und es geht mit Schritt 133 weiter. In Schritt 131 lädt der Docking-Manager 25 sein
Teilprotokoll vom zentralen Computer 1 herunter. Das Download
kann mit beliebigen bekannten Datenübertragungsmitteln wie XMODEM,
ZMODEM, KERMIT, FTP, ASCII-Transfer oder einem beliebigen anderen
Verfahren zum Übertragen
von Daten erfolgen. In Schritt 133 verlässt der Docking-Manager 25 die
Routine, nachdem der angeforderte Datentransfer abgeschlossen wurde.
-
Mischverarbeitung
-
Mischverarbeitung wird durch einen
Prozessor wie z. B. den Knotenmischprozessor 27-a, 27-b oder 27-c oder
den zentralen Mischprozessor 7 durchgeführt. Der Mischprozess dient
zum Aktualisieren seiner zugehörigen
Datenbank mit einer Transaktion, die von einem Benutzer eines Computers
eingegeben wurde, der sich ortsfern von dem Computer befindet, an
dem die Mischverarbeitung durchgeführt wird. Mischverarbeitung ist
analog zur Update-Verarbeitung und in ihrer Form ähnlich der
Update-Verarbeitung, wie oben mit Bezug auf 3 offenbart, jedoch mit drei Unterschieden.
Zunächst
ist die Eingabe in einen Mischprozessor kein Update, das direkt
von einem Benutzer eingegeben wurde, sondern eher eine Protokolldatei,
die von einem Computer ortsfern von dem Computer erhalten wird,
an dem die Mischung durchgeführt
wird. Ein zweiter Unterschied ist der, dass, wie in 1 gezeigt, die Mischverarbeitung kein
Protokoll erzeugt, wenn sie an einem Knoten durchgeführt wird.
Die Funktion eines Protokolls an einem Knoten ist es, eine Transaktion
zur Propagierung zum zentralen Computersystem 1 und von
dort zu anderen Knoten nach Bedarf aufzuzeichnen. Eine Transaktion, die
Gegenstand eines Mischvorgangs in einem Knoten ist, wurde zum zentralen
Computersystem 1 weitergeleitet und braucht nicht nochmal
kommuniziert zu werden.
-
Ein dritter Unterschied ist der,
dass die Mischverarbeitung mehrere im Konflikt stehende Transaktionen erkennen
und lösen
können
muss. Man nehme beispielsweise einmal an, ein Feld enthält den Wert „Keith
Palmer". Es sei
ferner angenommen, dass ein Benutzer am Knoten 27-a eine
Transaktion zum Aktualisieren dieses Feld auf „Carl Lake" und ein Benutzer am Knoten 27-b eine
Transaktion zum Aktualisieren deselben Felds auf „Greg Emerson" eingibt. Ohne Kollisionserfassung
können
Daten zwischen verschiedenen Knoten verfälscht werden. Wenn die Transaktion
für Benutzer 27-a gemischt
wird, dann wird das Feld von „Keith
Palmer" auf „Carl Lake" aktualisiert. Ohne
Kollisionshandling würde
das Feld, wenn die Transaktion für
Knoten 27-b gemischt wird, auf „Greg Emerson" aktualisiert, und
die zentrale Datenbank wäre
dann nicht mehr mit der Datenbank von Knoten 27-a synchron.
Ferner aktualisiert jeder Knoten, wenn eine Mischverarbeitung an
jedem der Knoten 27-a und 27-b durchgeführt wird,
seine Datenbank mit den Transaktionen des anderen, so dass wenigstens
ein Knoten verbleibt, der nicht mit dem anderen Knoten und mit der
zentralen Datenbank synchron ist.
-
Daher muss eine Mischverarbeitung
auch ein Mittel zum Erkennen und Korrigieren von Kollisionen haben.
In dem obigen Beispiel besteht eine einfache Möglichkeit zum Erfassen und
Korrigieren einer Kollision darin, den Wert in der Datenbank mit
dem Wert zu vergleichen, den das Mischprotokoll als den vorherigen
Wert in der Knotendatenbank reflektiert. Wenn die beiden Werte nicht übereinstimmen,
dann kann der Mischprozessor 7 die Transaktion zurückweisen
und eine Korrekturtransaktion erzeugen, die zu dem Knoten gesendet
wird, von dem die im Konflikt stehende Transaktion stammte. Wenn
in dem obigen Beispiel die Transaktion für Knoten 27-b zum
Mischprozessor 7 gesendet wurde, dann würde Mischprozessor 7 „Keith
Palmer", dem vorherigem
Wert des Feldes gemäß Aufzeichnung
vom Knoten 27-b, mit „Carl
Lake" vergleichen,
dem aktuellen Wert des Feldes gemäß Aufzeichnung in der zentralen
Datenbank 3. Nach dem Erkennen der Fehlübereinstimmung kann der Mischprozessor 7 dann
eine Transaktion zum Ändern
des Wertes „Greg
Emerson" auf „Carl Lake" und zum Schreiben
dieser Aktion auf das Update-Protokoll 15 erzeugen. In
einem nachfolgenden Docking-Vorgang würde diese Transaktion zurück zum Knoten 27-b geleitet,
damit seine Datenbank 23-b mit den anderen Datenbanken
synchron wird.
-
Das obige ist ein Beispiel für eine Kollision
und eine resultierende Korrekturmaßnahme. Weitere Kollisionstypen
sind beispielsweise unter anderem ein Update an einer Reihe, die
zuvor gelöscht
wurde, das Einfügen
einer Reihe, die zuvor eingefügt
wurde, und dergleichen. Mischverarbeitung muss jede dieser Kollisionen
erkennen und korrigieren. Dies kann mit Hilfe von beliebigen aus
einer Reihe von hinlänglich
bekannten Verfahren geschehen und wird hier nicht weiter erörtert.
-
5 zeigt
die Schritte, die vom Mischprozessor wie z. B. dem zentralen Mischprozessor 7 durchgeführt werden.
Die Figur zeigt zwar einen Mischprozessor 7, der auf die
zentrale Datenbank 3 und auf das Transaktionsprotokoll 15 schreibt,
ist aber gleichermaßen
repräsentativ
für einen
Knotenmischprozessor wie z. B. den Knotenmischprozessor 27-a, 27-b oder r,
der eine Knotendatenbank 23-a, 23-b oder 23-c aktualisiert.
Die Mischverarbeitung beginnt mit Schritt 141. In Schritt 143 findet
der Mischprozessor 7 die erste unverarbeitete Aktion auf
dem empfangenen Protokoll 19. In Schritt 147 wählt der
Mischprozessor 7 eine Transaktion aus dem empfangenen Protokoll 19.
In Schritt 149 versucht der Mischprozessor 149,
Datenbank 3 gemäß der in
Schritt 147 gewählten
Transaktion zu aktualisieren. In Schritt 151 ermittelt
der Mischprozessor 7, ob das Datenbank-Update von Schritt 149 aufgrund
einer Kollision erfolglos verlaufen ist. Wenn ja, dann fährt der Mischprozessor
mit Schritt 153 fort, wo eine Korrekturtransaktion erzeugt
wird. Nach der Erzeugung der Korrekturtransaktion kehrt der Mischprozessor
zu Schritt 149 zurück
und versucht noch einmal, die Datenbank 3 zu aktualisieren.
Wurde in Schritt 151 keine Kollision erfasst, dann geht
die Ausführung
mit Schritt 157 weiter. In Schritt 157 prüft der Mischprozessor,
ob er auf einem zentralen Computer 1 läuft. Wenn ja, dann wird Schritt 155 zum
Aufzeichnen der Transaktion auf Protokoll 15 ausgeführt. In
jedem Fall, entweder wenn Schritt 157 ermittelt, dass die
Mischverarbeitung an einem Knoten erfolgt, oder nach Schritt 155,
geht die Ausführung
mit Schritt 159 weiter. In Schritt 159 wird geprüft, ob im
Protokoll 19 noch Transaktionen zur Verarbeitung übrig sind.
Wenn ja, dann wird die Ausführung
von Schritt 147 wiederholt, wo die nächste Transaktion gewählt wird. Wenn
nicht, dann wird die Mischverarbeitungsroutine in Schritt 161 verlassen.
-
Protokollmanagement
-
6 zeigt
die Schritte, die vom Protokollmanager 9 zur Vorbereitung
eines Transaktionsteilprotokolls wie z. B. des Transaktionsteilprotokolls 17-a, 17-b oder 17-c ausgeführt werden
müssen.
Das in 6 beschriebene
Verfahren wird für
jeden Knoten ausgeführt,
der zum Andocken am zentralen Computersystem 1 zur Verfügung steht.
Der Protokollmanager 9 beginnt mit der Ausführung in Schritt 171.
In Schritt 173 sucht der Protokollmanager 9 die
erste unverarbeitete Transaktion für den Knoten, dessen teilweises
Transaktionsprotokoll erstellt wird. In Schritt 175 wählt Protokollmanager 9 eine
Transaktion zur Verarbeitung aus. In Schritt 177 prüft der Protokollmanager 9,
ob die gewählte
Transaktion vom selben Knoten stammt, für den die Verarbeitung durchgeführt wird.
Wenn ja, dann braucht die Transaktion nicht zurück zu dem Knoten geleitet zu
werden und die Routine geht mit Schritt 179 weiter. In
Schritt 179 wird geprüft,
ob noch zu verarbeitende Transaktionen übrig sind. Wenn ja, dann geht
die Routine wieder zurück
zu Schritt 175. Wenn nicht, dann geht die Routine weiter
zu Schritt 189, wo die letzte Transaktion aufgezeichnet
wurde, die für
diesen Knoten verarbeitet wurde, und wird dann in Schritt 191 beendet.
Wenn die Transaktion von einem anderen als demselben Knoten wie dem
Knoten stammt, für
den die Verarbeitung durchgeführt
wird, dann geht die Routine zu Schritt 181. In Schritt 181 wird
ein Sichtbarkeitskalkulator aufgerufen, der ermittelt, ob die gewählte Transaktion
für den
verarbeiteten Knoten sichtbar ist. Die Sichtbarkeitskalkulator-Routine
wird nachfolgend ausführlicher
beschrieben. In Schritt 183 prüft der Mischprozessor 9,
ob der Sichtbarkeitskalkulator ermittelt hat, dass die Transaktion sichtbar
ist. Wenn sie nicht sichtbar ist, dann fährt die Routine mit Schritt 179 fort,
die wie oben offenbart abläuft.
Wenn die Transaktion sichtbar ist, dann geht die Routine weiter
zu Schritt 185. In Schritt 185 wird ein Datensatz
für diese
Transaktion auf das Transaktionsteilprotokoll für den verarbeiteten Knoten
geschrieben, z. B. Transaktionsteilprotokoll 17-a für Knoten 21-a.
In Schritt 187 zeichnet der Protokollmanager 9 die
letzte Transaktion auf, die für
diesen Knoten verarbeitet wurde, und geht dann weiter zu Schritt 179,
wo ermittelt wird, ob zusätzliche
Transaktionen gewählt
oder die Routine verlassen wird, wie oben offenbart wurde.
-
Sichtbarkeitsberechnung
-
7 zeigt
eine Ablauftabelle, die den Ablauf in einem Sichtbarkeitskalkulator
zum Berechnen der Sichtbarkeit für
ein Docking-Objekt gemäß Aufruf
durch Schritt 181 des Protokollmanagers 9 beschreibt.
Der Sichtbarkeitskalkulator wird mit der Knoten-ID des Knotens aufgerufen,
für den
die Sichtbarkeit berechnet wird, dem Docking-Objekt, für den die
Sichtbarkeit berechnet wird, und der Reihen-ID des Docking-Objekts,
dessen Sichtbarkeit berechnet wird. Der Sichtbarkeitskalkulator
benutzt diese Informationen in Verbindung mit Informationen, die
von Metadaten erhalten wurden, die in dem in 2 gezeigten Schema gespeichert wurden,
um zu ermitteln, ob eine bestimmte Transaktion, die eine bestimmte
Reihe eines bestimmten Docking-Objekts aktualisiert, für einen
bestimmten Knoten sichtbar ist.
-
Der Sichtbarkeitskalkulator beginnt
mit der Ausführung
in Schritt 201. In Schritt 203 kommt der Sichtbarkeitskalkulator
vorgabemäßig zu dem
Ergebnis, dass die Transaktion nicht sichtbar ist. Daher verlässt er, wenn
nicht der Sichtbarkeitskalkulator ermittelt, dass eine Transaktion
sichtbar ist, die Routine mit dem Ergebnis "nicht sichtbar". In Schritt 205 wählt der
Sichtbarkeitskalkulator die erste Sichtbarkeitsregel in Verbindung mit
dem Docking-Objekt. Dies erfolgt durch Suchen der Tabelle S_DOBJ_VIS_RULE 71 in
Verbindung mit dem aktuellen Docking-Objekt, auf das die Tabelle
S_DOBJ 61 zeigt. In Schritt 205 wählt der
Sichtbarkeitskalkulator die Reihe der Tabelle S_DOBJ_VIS_RULE 71 mit
dem niedrigsten Wert für
Feld RULE_SEQUENCE.
-
In Schritt 207 prüft der Sichtbarkeitskalkulator
das Feld RULE_TYPE auf einen Wert von „R". Der Wert „R" bedeutet, dass die Regel eine SQL-Sichtbarkeitsregel
ist. Wenn ja, dann fährt
der Sichtbarkeitskalkulator mit Schritt 209 fort. In Schritt 209 holt
der Sichtbarkeitskalkulator ein SQL-Statement aus dem Feld SQL_STATEMENT
und führt
es aus.
-
Ein Beispiel für ein SQL-Statement könnte so
lauten:
-
-
Dieses SQL-Statement bewirkt, dass
eine Anfrage an die Anwendungstabelle S_OPTY_EMP gerichtet wird.
Die Anfrage wählt
alle Datensätze,
die zwei Kriterien erfüllen.
Erstens müssen
die gewählten
Datensätze
ein Feld OPTY_ID haben, das eine Row-ID oder ein Key ist, entsprechend
der Primary-Row-ID
des Docking-Objekts, dessen Sichtbarkeit ermittelt wird. Zweitens
müssen
die gewählten
Datensätze
ein Feld EMP_ID haben, das beispielsweise eine Kennung für einen
bestimmten Mitarbeiter sein kann, entsprechend der Node-ID des Knotens,
für den
die Sichtbarkeit ermittelt wird. In gewöhnlicher Sprache, dieses SQL-Statement
gibt nur dann Datensätze
zurück,
wenn eine Reihe in einer Tabelle gefunden wird, die Mitarbeitern
mit Möglichkeiten
entspricht, wobei die Möglichkeit
gleich der aktualisierten ist, und wenn der Mitarbeiter, dem die Möglichkeit
zugewiesen wurde, der Operator des Knotens ist.
-
Dies ist ein simplistisches Beispiel,
das zur Vermittlung eines maximalen Verständnisses gegeben wird. Es sind
komplexere SQL-Statements möglich.
Wie z. B. die Regel:
-
-
Diese Regel fragt Tabelle S_ACCT_POSTN
(die sich auf einen bestimmten Account mit einer bestimmten Position
in der Organisation bezieht, die für den Account verantwortlich
ist) und Tabelle S_EMP_POSTN (die sich auf den Mitarbeiter bezieht,
der einer bestimmten Position entspricht) ab. Die Bedingung „ap.POSITION_ID
= ep.POSITION_ID" verlangt
das Suchen einer Reihe in der Account-zu-Position-Tabelle, die dieselbe
Position hat wie die Reihe in der Mitarbeiter-zu-Position-Tabelle.
Die Bedingung „ep.EMP_ID
= :NodeId" verlangt
ferner, dass die gewählte
Reihe in der Mitarbeiter-zu-Position-Tabelle eine Mitarbeiter-ID
hat, die gleich der ID des Benutzers des Knotens ist, für den die
Sichtbarkeit ermittelt wird. In gewöhnlicher Sprache, diese Bedingung
erlaubt Sichtbarkeit, wenn der Mitarbeiter die Position bekleidet,
die für
den Account in dem aktualisierten Docking-Objekt verantwortlich
ist.
-
Es gibt keine besondere Grenze für die Komplexität der Bedingungen
in dem SQL-Statement, das zum Beurteilen der Sichtbarkeit benutzt
wird. Besondere Implementationen von SQL können Begrenzungen auferlegen,
und aufgrund von Betriebsmittelfaktoren kann es wünschenswert
sein, weniger komplexe Statements zu benutzen, aber diese Beschränkungen
sind kein inhärenter
Bestandteil der Erfindung.
-
Schritt 211 beurteilt, ob
die Ausführung
des SQL_STATEMENT in Schritt 209 Datensätze ergeben hat. Wenn Datensätze zurückgegeben
wurden, dann bedeutet dies, dass der Knoten, für den die Sichtbarkeit geprüft wurde,
für das
verarbeitete Docking-Objekt sichtbar ist. Wenn also Datensätze zurückgegeben
werden, dann fährt
der Sichtbarkeitskalkulator mit Schritt 213 fort. In Schritt 213 wird
die Transaktion als sichtbar markiert. Da keine weiteren Regeln
beurteilt zu werden brauchen, um die Sichtbarkeit zu ermitteln,
fährt der Sichtbarkeitskalkulator
mit Schritt 228 fort. In Schritt 228 werden die
Datenbanken synchronisiert, indem ermittelt wird, ob die berechnete
Sichtbarkeit das Einfügen
oder Löschen
eines Docking-Objekts in der teilreplizierten Datenbank eines bestimmten
Knotens erfordert. Dies kann beispielsweise dann auftreten, wenn
ermittelt wird, dass ein Knoten für ein Docking-Objekt aufgrund
einer Änderung
an einem zugehörigen
Docking-Objekt sichtbar ist. So kann beispielsweise einem Besitzer
eines Knotens eine besondere Aktivität zugewiesen werden, die sich
auf eine bestimmte Verkaufsmöglichkeit
bezieht. Infolgedessen muss dem Knoten eine Kopie des Objektes gegeben
werden, das die Verkaufsmöglichkeit
repräsentiert.
-
8 zeigt
die Schritte, die zum Synchronisieren einer teilreplizierten Datenbank
als Reaktion auf eine Änderung
der Datensichtbarkeit durchgeführt
werden. Der Ablauf beginnt in Schritt 241. In Schritt 243 referenziert
der Sichtbarkeitskalkulator die soeben errechnete Sichtbarkeit für ein Docking-Objekt.
Wenn das Docking-Objekt
sichtbar ist, dann fährt
die Routine mit Schritt 245 fort. Schritt 245 referenziert
die S_DOBJ,INST Tabelle, um zu prüfen, ob eine Reihe für das Docking-Objekt
für den
aktuellen Knoten existiert. Wenn eine Reihe existiert, dann bedeutet
dies, dass der fragliche Knoten bereits eine Kopie des referenzierten
Docking-Objekts hat, und die Routine fährt mit Schritt 255 fort,
wo sie endet. Wenn jedoch keine Reihe für das Docking-Objekt an dem
verarbeiteten Knoten existiert, dann bedeutet dies, dass der fragliche
Knoten keine Kopie des Docking-Objektes auf seiner teilreplizierten
Datenbank hat. Die Routine fährt
dann mit Schritt 247 fort, wo eine Transaktion erzeugt
wird, um den Knoten anzuweisen, das Docking-Objekt in seine teilreplizierte
Datenbank einzufügen.
-
Wenn Schritt 243 ermittelt,
dass das Docking-Objekt nicht sichtbar ist, dann fährt die
Routine mit Schritt 249 fort. Schritt 249 referenziert
die S_DOBJ_INST Tabelle, um zu prüfen, ob keine Reihe für das Docking-Objekt
für den
aktuellen Knoten existiert. Wenn in Schritt 243 ermittelt
wird, dass keine Reihe in der Tabelle S_DOBJ_INST für das aktuelle
Docking-Objekt für
die aktuelle Reihe existiert, dann bedeutet dies, dass der fragliche
Knoten keine Kopie des referenzierten Docking-Objekts hat, und die
Routine geht zu Schritt 255, wo sie endet. Wenn jedoch
eine Reihe für
das Docking-Objekt an dem verarbeiteten Knoten existiert, dann bedeutet
dies, dass der fragliche Knoten eine Kopie des Docking-Objekts auf
seiner teilreplizierten Datenbank hat. Die Routine fährt dann
mit Schritt 251 fort, wo eine Transaktion erzeugt wird,
um den Knoten zum Löschen des
Docking-Objekts aus seiner teilreplizierten Datenbank anzuweisen.
-
Wieder mit Bezug auf 7, nach der Datensynchronisationsroutine
von Schritt 228 fährt
der Sichtbarkeitskalkulator mit Schritt 229 fort und endet
dort. Gemäß 6 kann, wie zuvor beschrieben,
das sich daraus ergebende Sichtbarkeitsergebnis vom Protokollmanager
in Schritt 183 überprüft werden,
um das Schreiben der Transaktion zu bestimmen.
-
Wieder mit Bezug auf 7, wenn in Schritt 211 ermittelt
wird, dass keine Datensätze
durch die Ausführung
des SQL-Statements in Schritt 209 zurückgegeben wurden, dann fährt die
Routine mit Schritt 215 fort. In Schritt 215 wird
geprüft,
ob es noch Sichtbarkeitsregeln zu beurteilen gibt. Wenn nicht, dann
fährt der
Sichtbarkeitskalkulator mit Schritt 228 zum Synchronisieren
der Datenbank fort, und dann mit Schritt 229, wo er endet.
In diesem Fall bleibt die Vorgabemarkierung "nicht sichtbar", die in Schritt 203 gesetzt
wurde, gesetzt. Dieser Wert wird auch vom Protokollmanager wie in 6, Schritt 183,
gezeigt verwendet, um die Transaktion zu ermitteln, aber nicht zu
schreiben.
-
Wieder mit Bezug auf 7, wenn noch Regeln beurteilt werden
müssen,
dann fährt
die Routine mit Schritt 217 fort, wo die nächste zu
verarbeitende Regel gewählt
wird. Dann geht es weiter mit Schritt 207, um mit dem Verarbeiten
der neuen Regel zu beginnen.
-
Der vorangegangene Text enthielt
eine Beschreibung der Verarbeitung der SQL-Sichtbarkeitsregel, d. h.
Sichtbarkeitsregeln vom Typ „R". Wenn in Schritt 207 ermittelt
wird, dass die Sichtbarkeitsregel nicht vom Typ „R" ist, dann ist die Sichtbarkeitsregel
vom Typ „O". Typ „O" bedeutet eine Docking-Objekt-Sichtbarkeitsregel.
In einem solchen Fall wird das verarbeitete Docking-Objekt als sichtbar
angesehen, wenn es sich auf ein bestimmtes verwandtes Docking-Objekt
bezieht, das sichtbar ist. Wenn das Feld RULE_TYPE nicht gleich „R" ist, dann geht die
Routine weiter zu Schritt 221. In Schritt 221 wird
das verwandte Docking-Objekt, dessen Sichtbarkeit ermittelt werden
soll, dahingehend überprüft, ob das
aktuelle Docking-Objekt sichtbar ist. Die verwandte Docking-Objekt-Kennung wird aus
dem Feld CHECK_DOBJ_ID in Tabelle S_DOBJ_VIS_RULE 71 erhalten.
In Schritt 223 ermittelt der Sichtbarkeitskalkulator, welche
Reihe im verwandten Docking-Objekt in Bezug auf Sichtbarkeit abgefragt
werden muss. Um dies zu ermitteln, holt der Sichtbarkeitskalkulator
ein vorbestimmtes SLQ-Statement aus dem Feld SQL_STATEMENT und führt es aus.
Das SQL-Statement ist eine Abfrage, die eine oder mehrere Reihen
des Docking-Objekts
auswählt,
die beispielsweise dem Docking-Objekt entsprechen, für das der
Sichtbarkeitskalkulator aufgerufen wurde.
-
Man nehme beispielsweise an, dass
angezeigt werden soll, dass ein Datensatz für eine Verkaufsmöglichkeit
sichtbar sein soll, wenn der Knoten Einsicht zu einem Verkaufsangebot
hat, das für
diese Verkaufsmöglichkeit
vorgelegt wurde. Dies kann mit dem folgenden SQL-Statement erfolgen:
-
-
Dieses SQL-Statement greift auf eine
Tabelle S_DOC_QUOTE zu, die alle Verkaufsangebote enthält. Die
WHERE-Klausel gibt eine Rückspeicherung
aller Reihen vor, in denen die Opportunity-ID der Reihe der Row-ID
der Möglichkeit
entspricht, für
die Sichtbarkeit errechnet wird. Der Sichtbarkeitsmanager ruft die
vorgegebenen Row-IDs
ab und identifiziert dadurch Reihen der S_DOC_QUOTE Tabelle, deren
Sichtbarkeit geprüft
werden muss.
-
Nach dem Ermitteln eines verwandten
Docking-Objekts und der Row-ID dieses verwandten Docking-Objekts,
von dessen Sichtbarkeit die Sichtbarkeit des aktuellen Docking-Objekts abhängig ist,
fährt der Sichtbarkeitskalkulator
mit Schritt 225 fort. In Schritt 225 ruft sich
der Sichtbarkeitskalkulator rekursiv selbst auf, um die Sichtbarkeit
des verwandten Docking-Objekts zu ermitteln. Der rekursiv aufgerufene
Sichtbarkeitskalkulator arbeitet auf dieselbe Weise wie der Sichtbarkeitskalkulator,
der vom Protokollmanager 9 aufgerufen wurde, einschließlich der
Fähigkeit,
sich selbst rekursiv weiter aufzurufen. Nach Abschluss des rekursiven
Aufrufs gibt er einen Sichtbarkeitsindikator für das verwandte Docking-Objekt
zurück,
und die Routine fährt
mit Schritt 227 fort. In Schritt 227 ermittelt
der Sichtbarkeitskalkulator, ob das verwandte Docking-Objekt als
sichtbar ermittelt wurde. Wenn ja, dann fährt der Sichtbarkeitskalkulator
mit Schritt 213 fort, um das ursprünglich aktuelle Docking-Objekt
als sichtbar zu markieren, und dann mit Schritt 228, um
die Datenbank zu synchronisieren, und dann mit Schritt 229 zum
Beenden. Wenn das verwandte Docking-Objekt nicht als sichtbar ermittelt wurde,
dann geht die Routine über
zu Schritt 215, um zu ermitteln, ob noch zusätzliche
Sichtbarkeitsregeln beurteilt werden müssen.
-
Somit kann der Sichtbarkeitskalkulator
in Verbindung mit dem Protokollmanager ermitteln, welche Teilmenge
von Update-Transaktionsdaten zu einem bestimmten Knoten geleitet
werden müssen.
Mit diesem Vorgang wird die Übertragung
von unnötigen
Daten vom zentralen Computer 1 zu verschiedenen Knoten
wie z. B. den Knoten 21-a, 21-b und 21-c reduziert,
die teilreplizierte Datenbanken nutzen, und es werden die Systemressourcen
wie z. B. Plattenkapazität
zum Speichern sowie die zum Verarbeiten benötigte CPU-Zeit reduziert, die
sonst notwendig wären,
um eine vollreplizierte Datenbank an jedem Fernknoten zu verwalten.
-
Der Betrieb des Protokollmanagers 9 in
Verbindung mit dem Sichtbarkeitskalkulator wie hierin beschrieben
geht aus der Beschreibung und den Zeichnungen hervor.