以下に、本願の開示する分析装置、分析プログラムおよび分析方法の各実施例を図面に基づいて詳細に説明する。なお、各実施例は開示の技術を限定するものではない。そして、各実施例は、処理内容を矛盾させない範囲で適宜組み合わせることが可能である。
[分析装置の構成]
実施例1に係る分析装置について説明する。図1は、実施例1に係る分析装置の構成を示す図である。本実施例に係る分析装置10は、音声データを取得し、取得した音声データから、第1の確率モデルを用いて、有声音領域および無声音領域を検出する。また、本実施例に係る分析装置10は、検出された有声音領域および無声音領域に基づいて、第2の確率モデルを用いて、音声データにおける発話領域および沈黙領域を検出する。また、本実施例に係る分析装置10は、検出された発話領域および沈黙領域の会話特性を抽出し、抽出した会話特性に基づいて、会話スタイルを分析する。図1に示すように、分析装置10は、入力部11と、出力部12と、記憶部13と、制御部14とを有する。
入力部11は、ユーザの操作を受け付けて制御部14に受付内容を送信する。例えば、入力部11は、後述の分析処理を実行する指示を受け付けた場合には、この指示を制御部14に送信する。また、入力部11は、後述の第1の音声データ13aおよび第2の音声データ13bを受け付けた場合には、これらの音声データを制御部14に送信する。
出力部12は、受け付けた情報を出力する。例えば、出力部12は、後述の分析部14fからの分析結果を表示する。出力部12のデバイスの一例としては、LCD(Liquid Crystal Display)やプロジェクタなどの表示デバイスが挙げられる。
記憶部13は、制御部14で実行される各種プログラムを記憶する。また、記憶部13は、第1の音声データ13a、第2の音声データ13bを記憶する。
第1の音声データ13a、第2の音声データ13bについて説明する。第1の音声データ13aは、複数人、例えば、AおよびBの2人の会話を、Aに取り付けたマイク(microphone)により音声データに変換したものである。第1の音声データ13aには、AおよびBの会話が含まれるが、Aの音声の音量の方がBの音声の音量よりも大きくなる。これは、BよりもAの方がマイクに近いからである。また、第2の音声データ13bは、複数人、例えば、AおよびBの2人の会話を、Bに取り付けたマイクにより音声データに変換したものである。第2の音声データ13bには、AおよびBの会話が含まれるが、Bの音声の音量の方がAの音声の音量よりも大きくなる。これは、AよりもBの方がマイクに近いからである。なお、AとBとが互いに携帯電話を用いて会話を行う場合などには、互いの携帯電話にマイクを設けることにより、第1の音声データ13a、第2の音声データ13bを取得することができる。
ここで、日本語、英語、中国語などの任意の言語において共通する特徴について説明する。図2は、有声音および無声音の一例を説明するための図である。図2の例では、サンプリング周波数が16kHzである接話型マイクを用いて取得した音声データが示されている。図2の例では、横軸は時間を示し、縦軸は周波数を示し、図中の濃淡はスペクトルエントロピーの大小を示す。図2に示すように、有声音Vは、スペクトルエントロピーの変化が大きく、無声音Uよりも低い周波数の音声データの部分の音である。ここで、有声音は、母音「a」、「i」、「u」、「e」、「o」である。
また、無声音Uは、有声音Vよりも高い周波数の音声データの部分である。ここで、無声音は、母音以外の音、例えば「s」、「p」、「h」である。
図3は、発話が行われる発話領域、および発話が行われない沈黙領域の一例を説明するための図である。発話領域は、無声音領域および有声音領域を含む。図3の例は、発話の内容が「WaTaShiWaChouDeSu」の場合を示す。図3の例では、発話領域は、無声音「W」、有声音「a」、無声音「T」、有声音「a」、無声音「Sh」、有声音「i」、無声音「W」、有声音「a」を含む。また、図3の例では、発話領域は、無声音「Ch」、有声音「ou」を含む。また、図3の例では、発話領域は、無声音「D」、有声音「e」、無声音「S」、有声音「u」を含む。また、図3の例では、「WaTaShiWa」の発話領域と、「Chou」の発話領域と、「DeSu」の発話領域との間に、沈黙領域が存在することを示す。
記憶部13は、例えば、フラッシュメモリなどの半導体メモリ素子、または、ハードディスク、光ディスクなどの記憶装置である。なお、記憶部13は、上記の種類の記憶装置に限定されるものではなく、RAM(Random Access Memory)、ROM(Read Only Memory)であってもよい。
図1の説明に戻り、制御部14は、各種の処理手順を規定したプログラムや制御データを格納するための内部メモリを有し、これらによって種々の処理を実行する。制御部14は、図1に示すように、取得部14aと、第1の検出部14bと、第2の検出部14cと、特定部14dと、抽出部14eと、分析部14fとを有する。
取得部14aは、音声データを取得する。例えば、取得部14aは、第1の音声データ13aおよび第2の音声データ13bを取得する。なお、取得部14aは、入力部11が受け付けた第1の音声データ13aおよび第2の音声データ13bを、入力部11から取得することもできる。
第1の検出部14bは、取得部14aにより取得された音声データから、第1の確率モデルを用いて、有声音領域および無声音領域を検出する。例えば、第1の検出部14bは、まず、第1の音声データ13aおよび第2の音声データ13bのそれぞれの長さを比較する。そして、第1の検出部14bは、第1の音声データ13aおよび第2の音声データ13bの長さの差が許容誤差範囲内でない場合には、以降の処理を行うのに適さないため、エラー出力するように出力部12を制御し、以降の処理を行わない。一方、第1の検出部14bは、第1の音声データ13aおよび第2の音声データ13bの長さが同一であるか、または、それぞれの長さの差が許容誤差範囲内である場合には、以降の処理を行う。すなわち、第1の検出部14bは、第1の音声データ13aおよび第2の音声データ13bをフレーム化する。具体例を挙げて説明すると、第1の検出部14bは、下記の式(1)、式(2)を用いて、それぞれの音声データを、長さを256msとするフレーム化を行う。このとき、前後のフレームの重複部分の長さが128msとなるようにする。
S=floor(Y/X)・・・・・・・・・・・・・・・・式(1)
m=floor((S−256)/128)+1・・・・・・・・式(2)
なお、「floor(x)」は、x以下の最大の整数を算出するための関数であり、Yは、第1の音声データ13aおよび第2の音声データ13bのそれぞれのデータ量(byte)であり、Xは、1(byte)のデータに対応する長さ(ms)である。
このような処理によって、第1の音声データ13aおよび第2の音声データ13bのそれぞれについてm個のフレームが得られたものとして、以下、説明を続ける。なお、以下の説明では、第1の音声データ13aから得られたm個のフレームの各々を、「第1フレーム(1)」、「第1フレーム(2)」、・・・、「第1フレーム(m)」と表記する場合がある。同様に、第2の音声データ13bから得られたm個のフレームの各々を、「第2フレーム(1)」、「第2フレーム(2)」、・・・、「第2フレーム(m)」と表記する場合がある。また、上記で説明したフレームの長さ、前後のフレームの重複部分の長さは、一例であり、任意の値を採用できる。
そして、第1の検出部14bは、第1フレーム(1)〜第1フレーム(m)、第2フレーム(1)〜第2フレーム(m)の全てのフレームについて、下記の処理を行う。すなわち、第1の抽出部14bは、自己相関係数のピークの数、自己相関係数のピークの最大値、およびスペクトルエントロピーの3つの特徴量を抽出する。
そして、第1の検出部14bは、全てのフレームについて抽出した3つの特徴量のそれぞれの平均値および標準偏差を算出する。そして、第1の検出部14bは、確率モデルである隠れマルコフモデル(Hidden Markov Model;HMM)を用いて、有声音領域および無声音領域を検出する。
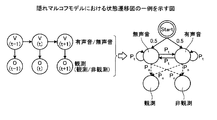
有声音領域および無声音領域の検出方法について、具体例を挙げて説明する。図4は、隠れマルコフモデルにおける状態遷移図の一例を示す図である。図4の例では、第1の検出部14bは、全てのフレームについて抽出した上記の3つの特徴量、並びに、各特徴量の平均値および標準偏差を観測結果(observation)として用いて、EM法(Expectation-Maximization algorithm)により、状態遷移確率(transition possibility)Ptを算出する。ここで、状態遷移確率Ptは、例えば、有声音の状態のままでいる確率、有声音の状態から無声音の状態に遷移する確率、無声音の状態のままでいる確率、無声音の状態から有声音の状態に遷移する確率である。なお、図4の例では、発話は、有声音および無声音の両方とも同一の確率で開始すると考えられるので、発話の開始における有声音および無声音の状態の確率はともに「0.5」である。また、図4の例では、初期の状態遷移確率Ptとして、有声音の状態のままでいる確率「0.95」、有声音の状態から無声音の状態に遷移する確率「0.05」が与えられる。さらに、図4の例では、初期の状態遷移確率Ptとして、無声音の状態のままでいる確率「0.95」、無声音の状態から有声音の状態に遷移する確率「0.05」が与えられる。第1の検出部14bは、状態遷移確率Ptを再び算出することを所定回数繰り返す。これにより、精度の高い状態遷移確率Ptを算出することができる。
また、図4の例では、第1の検出部14bは、全てのフレームについて抽出した上記の3つの特徴量、並びに、各特徴量の平均値および標準偏差を観測結果として用いて、ビタビアルゴリズム(Viterbi algorithm)により、観測確率(observation possibility)Poを算出する。ここで、観測確率Poは、例えば、有声音の状態から観測(observed)を出力する確率、有声音の状態から非観測(not observed)を出力する確率、無声音の状態から観測を出力する確率、および無声音の状態から非観測を出力する確率である。なお、観測確率は、出力確率(emission possibility)とも称される。
そして、図4の例では、状態遷移確率Ptおよび観測確率Poが算出された場合には、第1の検出部14bは、全てのフレームについて抽出した上記の3つの特徴量に基づいて、ビタビアルゴリズムを用いて、次のような処理を行う。すなわち、第1の検出部14bは、発話が行われている各フレームにおいて、発話されている音が有声音であるか、または、無声音であるかを検出する。そして、第1の検出部14bは、有声音が検出された領域を有声音領域とし、無声音が検出された領域を無声音領域とする。
このように、分析装置10は、周囲のノイズに強い自己相関係数のピークの数、自己相関係数のピークの最大値、およびスペクトルエントロピーなどの特徴量を用いて、有声音領域および無声音領域を検出する。したがって、分析装置10によれば、周囲のノイズの影響により、有声音領域および無声音領域を検出する精度が低下することを抑制することができる。また、周囲のノイズに強い特徴量を用いるため、第1の音声データ13aおよび第2の音声データ13bをフレーム化する際に、フレームの個数をより少なくすることができる。したがって、分析装置10によれば、より簡易な処理で有声音領域および無声音領域を検出することができる。
第2の検出部14cは、第1の検出部14bにより検出された有声音領域および無声音領域に基づいて、隠れマルコフモデルを用いて、音声データにおける発話領域および沈黙領域を検出する。
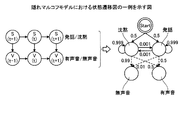
発話領域および沈黙領域の検出方法について、具体例を挙げて説明する。図5は、隠れマルコフモデルにおける状態遷移図の一例を示す図である。図5の例では、状態遷移確率Ptおよび観測確率Poは、予め定められた値である。図5の例では、状態遷移確率Ptは、例えば、沈黙の状態である沈黙状態のままでいる確率、沈黙状態から発話の状態である発話状態に遷移する確率、発話状態のままでいる確率、および発話状態から沈黙状態に遷移する確率である。なお、図5の例では、発話の開始における沈黙状態および発話状態の確率はともに「0.5」である。また、図5の例では、状態遷移確率Ptとして、沈黙状態のままでいる確率「0.999」、沈黙状態から発話状態に遷移する確率「0.001」が定められている。また、図5の例では、状態遷移確率Ptとして、発話状態のままでいる確率「0.999」、発話状態から沈黙状態に遷移する確率「0.001」が定められている。
また、図5の例では、観測確率Poは、例えば、沈黙状態において無声音が検出される確率、沈黙状態において有声音が検出される確率、発話状態において無声音が検出される確率、および発話状態において有声音が検出される確率である。なお、図5の例では、観測確率Poとして、沈黙状態において無声音が検出される確率「0.99」、沈黙状態において有声音が検出される確率「0.01」が定められている。また、図5の例では、観測確率Poとして、発話状態において無声音が検出される確率「0.5」、発話状態において有声音が検出される確率「0.5」が定められている。
そして、図5の例では、第2の検出部14cは、全てのフレームについて、第1の検出部14bにより検出された有声音および無声音に基づいて、ビタビアルゴリズムを用いて、沈黙状態であるか、または、発話状態であるかを検出する。そして、第2の検出部14cは、沈黙状態の領域を沈黙領域とし、発話状態の領域を発話領域とする。
このように、分析装置10は、隠れマルコフモデルを用いて、沈黙領域および発話領域を検出する。したがって、分析装置10によれば、2人の会話において、発話が重複しても、精度よく、沈黙領域および発話領域を検出することができる。
特定部14dは、第2の検出部14cにより検出された発話領域での有声音領域における音量が閾値以上の場合に、音声取得装置に最も近い人物を発話領域において発話した人物として特定する。また、特定部14dは、第2の検出部14cにより検出された発話領域での有声音領域における音量が閾値未満の場合に、音声取得装置に最も近い人物以外の人物を発話領域において発話した人物として特定する。
例えば、特定部14dは、第1の音声データ13aについて、発話領域での有声音領域として検出されたフレームの音量の平均値Et1を算出する。同様に、特定部14dは、第2の音声データ13bについて、発話領域での有声音領域として検出されたフレームの音量の平均値Et2を算出する。
そして、特定部14dは、第1の音声データ13aにおいて発話領域での有声音領域として検出されたフレームの全てについて、音量が所定の閾値以上であるか否かを判定する。特定部14dは、音量が所定の閾値以上であるフレームについては、第1の音声データ13aを取得した音声取得装置であるマイクに最も近い人物、例えばAを、このフレームにおいて発話した人物として特定する。これは、BよりもAの方がマイクに近いため、第1の音声データ13aにおいて、Aの音声の音量の方がBの音声の音量よりも大きくなるからである。また、特定部14dは、音量が所定の閾値未満であるフレームについては、第1の音声データ13aを取得した音声取得装置であるマイクに最も近い人物以外の人物を、このフレームにおいて発話した人物として特定する。なお、閾値として、「0.2Et1」や「0.5Et1」が挙げられるが、閾値はこれに限られず、発話した人物を特定可能な値であれば任意の値を採用できる。
また、特定部14dは、第2の音声データ13bにおいて発話領域での有声音領域として検出されたフレームの全てについて、音量が所定の閾値以上であるか否かを判定する。特定部14dは、音量が所定の閾値以上であるフレームについては、第2の音声データ13bを取得したマイクに最も近い人物、例えばBを、このフレームにおいて発話した人物として特定する。また、特定部14dは、音量が所定の閾値未満であるフレームについては、第2の音声データ13bを取得したマイクに最も近い人物以外の人物を、このフレームにおいて発話した人物として特定する。なお、閾値として、「0.2Et2」や「0.5Et2」が挙げられるが、閾値はこれに限られず、発話した人物を特定可能な値であれば任意の値を採用できる。
すなわち、特定部14dは、各音声データについて、音量が閾値以上であるフレームにおいて発話する人物として、既知である、対応するマイクに最も近い人物を特定する。また、会話を行う人数が2人であることが既知である場合には、特定部14dは、音量が閾値未満であるフレームにおいて発話する人物として、既知である、対応するマイクに最も近い人物以外の人物を特定する。上記の第1の音声データ13aから人物を特定する場面の例では、特定部14dは、音量が所定の閾値未満であるフレームについては、第1の音声データ13aを取得したマイクに最も近い人物以外の人物Bを、発話した人物として特定する。また、上記の第2の音声データ13bから人物を特定する場面の例では、特定部14dは、音量が所定の閾値未満であるフレームについては、第2の音声データ13bを取得したマイクに最も近い人物以外の人物Aを、発話した人物として特定する。なお、特定部14dによる人物を特定する方法はこれに限られず、種々の方法を用いることができる。
抽出部14eは、音声データから会話特性を抽出する。例えば、抽出部14eは、Aが発話したと特定されたフレームから、有声音領域の数、有声音領域の長さの平均値、および有声音領域の長さの標準偏差を算出する。また、抽出部14eは、Aが発話したと特定されたフレームから、発話領域の数、発話領域の長さの平均値、および発話領域の長さの標準偏差を算出する。また、抽出部14eは、Aの沈黙領域のフレームから、沈黙領域の数、沈黙領域の長さの平均値、および沈黙領域の長さの標準偏差を算出する。
また、抽出部14eは、会話全体の時間の長さに対するAの発話時間の長さの割合を算出する。なお、抽出部14eは、Aの発話領域の長さの合計を、Aの発話時間の長さとして、かかる割合を算出する。また、抽出部14eは、Bの発話時間に対するAの発話時間の割合を算出する。また、抽出部14eは、Aが発話したと特定されたフレームから、音量の標準偏差およびスペクトルエントロピーの標準偏差を算出する。また、抽出部14eは、Aが発話したと特定されたフレームから算出した音量の標準偏差と、スペクトルエントロピーの標準偏差との和を、変化の度合いとして算出する。
また、抽出部14eは、Bが発話したと特定されたフレームから、有声音領域の数、有声音領域の長さの平均値、および有声音領域の長さの標準偏差を算出する。また、抽出部14eは、Bが発話したと特定されたフレームから、発話領域の数、発話領域の長さの平均値、および発話領域の長さの標準偏差を算出する。また、抽出部14eは、Bの沈黙領域のフレームから、沈黙領域の数、沈黙領域の長さの平均値、および沈黙領域の長さの標準偏差を算出する。
また、抽出部14eは、会話全体の時間の長さに対するBの発話時間の長さの割合を算出する。なお、抽出部14eは、Bの発話領域の長さの合計を、Bの発話時間の長さとして、かかる割合を算出する。また、抽出部14eは、Aの発話時間に対するBの発話時間の割合を算出する。また、抽出部14eは、Bが発話したと特定されたフレームから、音量の標準偏差およびスペクトルエントロピーの標準偏差を算出する。また、抽出部14eは、Bが発話したと特定されたフレームから算出した音量の標準偏差と、スペクトルエントロピーの標準偏差との和を、変化の度合いとして算出する。
このようにして算出された有声音領域の数、有声音領域の長さの平均値、および有声音領域の長さの標準偏差の各会話特性は、有声音の長さがどの位長いのかを示す指標となる。また、発話領域の数、発話領域の長さの平均値、および発話領域の長さの標準偏差の各会話特性は、対応する人物が、常に会話において長く続けて話すのか、または、少ししか話さないのかを示す指標となる。また、沈黙領域の数、沈黙領域の長さの平均値、および沈黙領域の長さの標準偏差の各会話特性は、話者の話し方が、長く続けて話すのか、または、中断(沈黙)を多くはさみながら話すのかを示す指標となる。また、会話全体の時間の長さに対するある人物の発話時間の長さの割合、および他の人物の発話時間に対するある人物の発話時間の割合Rtの各会話特性は、会話の参加状態を示す指標となる。また、音量の標準偏差、スペクトルエントロピーの標準偏差、および変化の度合いの各会話特性は、感情の変化が激しい情熱的な話者であるのか、または、感情の変化が小さい静かな話者であるのかを示す指標となる。
分析部14fは、抽出された会話特性に基づいて、会話スタイルを分析する。具体例について説明する。分析部14fは、他の人物の発話時間に対するある人物の発話時間の割合Rtが、所定値、例えば1.5以上である場合には、この「ある人物」は、会話においてよく話す人物であると分析する。また、分析部14fは、割合Rtが、所定値、例えば0.66以下である場合には、この「ある人物」は、会話においてあまり話さない、いわゆる聞き役の人物であると分析する。なお、分析部14fは、割合Rtが、所定値、例えば0.66より大きく、1.5未満である場合には、会話に対する参加状況において両者は対等であると分析する。
図6は、会話スタイルの分析方法の一例を説明するための図である。図6では、会話全体の時間の長さに対するAの発話時間の長さの割合が25.72%である場合が例示されている。また、図6では、会話全体の時間の長さに対するBの発話時間の長さの割合が43.71%である場合が例示されている。また、図6では、Aの発話時間に対するBの発話時間の割合Rtが1.70である場合が例示されている。この場合、分析部14fは、Bは会話においてよく話す人物であると分析する。また、この場合、Bの発話時間に対するAの発話時間の割合Rtが0.66以下となるので、分析部14fは、Aはあまり話さない、いわゆる聞き役の人物であると分析する。
また、分析部14fは、ある人物の発話領域の数に対する有声音領域の数の割合、および発話領域の長さの平均値が、他の人物の発話領域の数に対する有声音領域の数の割合、および発話領域の長さの平均値よりも大きい場合には、次の処理を行う。すなわち、分析部14fは、「ある人物」は会話において長く続けて話しがちな人物であると分析する。また、分析部14fは、ある人物の沈黙領域の長さの平均値が、他の人物の沈黙領域の長さの平均値よりも大きく、かつある人物の沈黙領域の長さの標準偏差が、所定値、例えば、6.0以上である場合には、次の処理を行う。すなわち、分析部14fは、「ある人物」は、相手の話を聞いて、相手の内容に合わせて自分の発話を中断するため、発話の長さが一定しない人物であると分析する。
図7は、会話スタイルの分析方法の一例を説明するための図である。図7では、Aの有声音領域の数が83、有声音領域の長さの平均値が0.42546(s)、有声音領域の長さの標準偏差が0.5010である場合が例示されている。また、図7では、Aの発話領域の数が28、発話領域の長さの平均値が1.58(s)、発話領域の長さの標準偏差が1.7803である場合が例示されている。また、図7では、Aの沈黙領域の数が29、沈黙領域の長さの平均値が4.4055(s)、沈黙領域の長さの標準偏差が6.8001である場合が例示されている。また、図7では、Bの有声音領域の数が150、有声音領域の長さの平均値が0.40416(s)、有声音領域の長さの標準偏差が0.4198である場合が例示されている。また、図7では、Bの発話領域の数が40、発話領域の長さの平均値が1.8796(s)、発話領域の長さの標準偏差が1.4928である場合が例示されている。また、図7では、Bの沈黙領域の数が41、沈黙領域の長さの平均値が2.3614(s)、沈黙領域の長さの標準偏差が2.7527である場合が例示されている。この場合、分析部14fは、Bは会話においてよく話す人物であると分析する。また、この場合、Bの発話時間に対するAの発話時間の割合Rtが0.66以下となるので、分析部14fは、Aはあまり話さない、いわゆる聞き役の人物であると分析する。この場合、Bの発話領域の数に対する有声音領域の数の割合、および発話領域の長さの平均値が、Aの発話領域の数に対する有声音領域の数の割合、および発話領域の長さの平均値よりも大きい。そのため、分析部14fは、Bは会話において長く続けて話しがちな人物であると分析する。また、Aの沈黙領域の長さの平均値が、Bの沈黙領域の長さの平均値よりも大きく、かつAの沈黙領域の長さの標準偏差が、所定値、例えば、6.0以上である。そのため、分析部14fは、Aは、相手の話を聞いて、相手の内容に合わせて自分の発話を中断するため、発話の長さが一定しない人物であると分析する。
また、分析部14fは、ある人物の音量の標準偏差、スペクトルエントロピーの標準偏差、または変化の度合いが、それぞれに対応する基準値以上である場合には、「ある人物」は感情の変化が激しい情熱的な話者であると分析する。また、分析部14fは、ある人物の音量の標準偏差、スペクトルエントロピーの標準偏差、または変化の度合いが、それぞれに対応する基準値未満である場合には、「ある人物」は感情の変化が小さい静かな話者であると分析する。
図8は、会話スタイルの分析方法の一例を説明するための図である。図8では、Aの変化の度合いが0.2824であり、Bの変化の度合いが0.2662である場合が例示されている。ここで、変化の度合いに対応する基準値を、例えば、0.27とする場合には、分析部14fは、Aは感情の変化が激しい情熱的な話者であると分析する。また、分析部14fは、Bは感情の変化が小さい静かな話者であると分析する。
また、分析部14fは、ある人物と、他の人物との関係を分析することもできる。例えば、分析部14fは、他の人物の発話時間に対するある人物の発話時間の割合Rtが、所定値、例えば1.0以上である場合には、「ある人物」は「他の人物」に対してよく話しかけているため、ある人物と他の人物との関係が友達や家族であると分析できる。一方、割合Rtが、所定値、例えば1.0未満である場合には、この「ある人物」は「他の人物」の話を聞こうとしているため、ある人物と他の人物との関係が会社の同僚やビジネスパートナーであると分析できる。
また、分析部14fは、ある人物と他の人物との会話において、ある人物の発話領域の長さの平均値が、所定値、例えば、1.85(s)以上である場合には、ある人物と他の人物との関係が友達や家族であると分析できる。これは、「ある人物」は「他の人物」に対してよく話しかけているためである。一方、分析部14fは、ある人物と他の人物との会話において、ある人物の発話領域の長さの平均値が、所定値、例えば、1.85(s)未満である場合には、ある人物と他の人物との関係が会社の同僚やビジネスパートナーであると分析できる。
また、分析部14fは、ある人物と他の人物との会話において、ある人物の沈黙領域の長さの平均値が、所定値、例えば、3.00(s)以下である場合には、同様の理由で、ある人物と他の人物との関係が友達や家族であると分析できる。一方、分析部14fは、ある人物の沈黙領域の長さの平均値が、所定値、例えば、3.00(s)より大きい場合には、ある人物と他の人物との関係が会社の同僚やビジネスパートナーであると分析できる。
また、分析部14fは、ある人物と他の人物との会話において、ある人物の変化の度合いが、所定値、例えば、0.33以上である場合には、同様の理由で、ある人物と他の人物との関係が友達や家族であると分析できる。一方、分析部14fは、ある人物の変化の度合いが、所定値、例えば、0.33未満である場合には、ある人物と他の人物との関係が会社の同僚やビジネスパートナーであると分析できる。
図9は、人物Aが、人物B、C、D、Eのそれぞれと会話したときに抽出された会話特性の一例を示す図である。図9の例では、AとBとの関係は同僚である。また、図9の例では、AとCとの関係はビジネスパートナーである。また、図9の例では、AとDとの関係は友達である。また、図9の例では、AとEとの関係は家族である。
図9の例では、AとBとの会話におけるAの割合Rtが0.9である場合が例示されている。また、図9の例では、AとCとの会話におけるAの割合Rtが0.8である場合が例示されている。また、図9の例では、AとDとの会話におけるAの割合Rtが1.3である場合が例示されている。また、図9の例では、AとEとの会話におけるAの割合Rtが1.5である場合が例示されている。このような場合、分析部14fは、割合Rtに基づいて、Aと、BおよびCとの関係は同僚またはビジネスパートナーであると分析する。また、分析部14fは、割合Rtに基づいて、Aと、DおよびEとの関係は友達または家族であると分析する。
また、図9の例では、AとBとの会話におけるAの発話領域の長さの平均値が1.816(s)である場合が例示されている。また、図9の例では、AとCとの会話におけるAの発話領域の長さの平均値が1.759(s)である場合が例示されている。また、図9の例では、AとDとの会話におけるAの発話領域の長さの平均値が1.926(s)である場合が例示されている。また、図9の例では、AとEとの会話におけるAの発話領域の長さの平均値が1.883(s)である場合が例示されている。このような場合、分析部14fは、Aの発話領域の長さの平均値に基づいて、Aと、BおよびCとの関係は同僚またはビジネスパートナーであると分析する。また、分析部14fは、Aの発話領域の長さの平均値に基づいて、Aと、DおよびEとの関係は友達または家族であると分析する。
また、図9の例では、AとBとの会話におけるAの沈黙領域の長さの平均値が3.18027(s)である場合が例示されている。また、図9の例では、AとCとの会話におけるAの沈黙領域の長さの平均値が3.2259(s)である場合が例示されている。また、図9の例では、AとDとの会話におけるAの沈黙領域の長さの平均値が2.53642(s)である場合が例示されている。また、図9の例では、AとEとの会話におけるAの沈黙領域の長さの平均値が2.75958(s)である場合が例示されている。このような場合、分析部14fは、Aの沈黙領域の長さの平均値に基づいて、Aと、BおよびCとの関係は同僚またはビジネスパートナーであると分析する。また、分析部14fは、Aの沈黙領域の長さの平均値に基づいて、Aと、DおよびEとの関係は友達または家族であると分析する。
また、図9の例では、AとBとの会話におけるAの変化の度合いが0.316486である場合が例示されている。また、図9の例では、AとCとの会話におけるAの変化の度合いが0.288189である場合が例示されている。また、図9の例では、AとDとの会話におけるAの変化の度合いが0.342278である場合が例示されている。また、図9の例では、AとEとの会話におけるAの変化の度合いが0.370805である場合が例示されている。このような場合、分析部14fは、Aの変化の度合いに基づいて、Aと、BおよびCとの関係は同僚またはビジネスパートナーであると分析する。また、分析部14fは、Aの変化の度合いに基づいて、Aと、DおよびEとの関係は友達または家族であると分析する。
そして、分析部14fは、分析結果を出力装置12に送信する。これにより、分析結果が出力装置12により出力され、分析結果が発話者にフィードバックされる。
制御部14は、ASIC(Application Specific Integrated Circuit)やFPGA(Field Programmable Gate Array)などの集積回路またはCPU(Central Processing Unit)やMPU(Micro Processing Unit)などの電子回路である。
[処理の流れ]
次に、本実施例に係る分析装置10の処理の流れを説明する。図10〜図12は、実施例1に係る分析処理の手順を示すフローチャートである。この分析処理の実行タイミングとしては様々なタイミングが考えられる。例えば、分析処理は、入力部11から分析処理を実行する指示を制御部14が受信した場合に実行される。
図10に示すように、取得部14aは、第1の音声データ13aおよび第2の音声データ13bを取得する(ステップS101)。第1の検出部14bは、第1の音声データ13aおよび第2の音声データ13bのそれぞれの長さが同一であるか否かを判定する(ステップS102)。ここで言う「同一」は、長さの差が許容誤差範囲内である場合も含む。
長さが同一でない場合(ステップS102否定)には、第1の検出部14bは、エラー出力するように出力部12を制御し(ステップS103)、処理を終了する。一方、長さが同一である場合(ステップS102肯定)には、第1の検出部14bは、第1の音声データ13aおよび第2の音声データ13bをフレーム化する(ステップS104)。
第1の検出部14bは、全てのフレームについて、自己相関係数のピークの数、自己相関係数のピークの最大値、およびスペクトルエントロピーの3つの特徴量を抽出する(ステップS105)。第1の検出部14bは、全てのフレームについて抽出した3つの特徴量のそれぞれの平均値および標準偏差を算出する(ステップS106)。第1の検出部14bは、変数Nに0を設定する(ステップS107)。
第1の検出部14bは、隠れマルコフモデルにおける有声音および無声音の状態遷移について、初期の状態遷移確率Ptを設定する(ステップS108)。第1の検出部14bは、変数Nの値を1つインクリメントする(ステップS109)。
第1の検出部14bは、変数Nの値が5以上であるか否かを判定する(ステップS110)。変数Nの値が5以上でない場合(ステップS110否定)には、第1の検出部14bは、全てのフレームについて抽出した上記の3つの特徴量、並びに、各特徴量の平均値および標準偏差を観測結果として用いて、EM法により、状態遷移確率Ptを算出し(ステップS111)、ステップS109へ戻る。
一方、変数Nの値が5以上である場合(ステップS110肯定)には、第1の検出部14bは、全てのフレームについて抽出した上記の3つの特徴量、並びに、各特徴量の平均値および標準偏差を観測結果として用いて、EM法により、状態遷移確率Ptを算出する(ステップS112)。
第1の検出部14bは、全てのフレームについて抽出した上記の3つの特徴量、並びに、各特徴量の平均値および標準偏差を観測結果として用いて、ビタビアルゴリズムにより、観測確率Poを算出する(ステップS113)。
第1の検出部14bは、全てのフレームについて抽出した上記の3つの特徴量に基づいて、ビタビアルゴリズムを用いて、次のような処理を行う。すなわち、第1の検出部14bは、発話が行われている各フレームにおいて、発話されている音が有声音であるか、または、無声音であるかを検出する。そして、第1の検出部14bは、有声音が検出された領域を有声音領域とし、無声音が検出された領域を無声音領域とする(ステップS114)。
第2の検出部14cは、全てのフレームについて、有声音および無声音に基づいて、ビタビアルゴリズムを用いて、沈黙状態であるか、または、発話状態であるかを検出することで、沈黙領域および発話領域を検出する(ステップS115)。
特定部14dは、第1の音声データ13aについて、発話領域での有声音領域として検出されたフレームの音量の平均値Et1を算出するとともに、第2の音声データ13bについて、発話領域での有声音領域として検出されたフレームの音量の平均値Et2を算出する(ステップS116)。特定部14dは、第1の音声データ13aにおいて発話領域での有声音領域として検出されたフレームのうち、未判定のフレームを1つ選択して、選択されたフレームの音量Ejが所定の閾値、例えば0.2Et1以上であるか否かを判定する(ステップS117)。選択されたフレームの音量が所定の閾値以上である場合(ステップS117肯定)には、特定部14dは、第1の音声データ13aを取得したマイクに最も近い人物を、このフレームにおいて発話した人物として特定する(ステップS118)。一方、選択されたフレームの音量が所定の閾値未満である場合(ステップS117否定)には、特定部14dは、第1の音声データ13aを取得したマイクに最も近い人物以外の人物を、このフレームにおいて発話した人物として特定する(ステップS119)。
特定部14dは、第1の音声データ13aにおいて発話領域での有声音領域として検出されたフレームの中に、上記ステップS118で未判定のフレームがあるか否かを判定する(ステップS120)。未判定のフレームがある場合(ステップS120肯定)には、ステップS117に戻る。一方、未判定のフレームがない場合(ステップS120否定)には、図11に示すように、特定部14dは、次のような処理を行う。すなわち、特定部14dは、第2の音声データ13bにおいて発話領域での有声音領域として検出されたフレームのうち、未判定のフレームを1つ選択して、選択されたフレームの音量Ejが所定の閾値、例えば0.2Et2以上であるか否かを判定する(ステップS121)。
選択されたフレームの音量が所定の閾値以上である場合(ステップS121肯定)には、特定部14dは、第2の音声データ13bを取得したマイクに最も近い人物を、このフレームにおいて発話した人物として特定する(ステップS122)。一方、選択されたフレームの音量が所定の閾値未満である場合(ステップS121否定)には、特定部14dは、第2の音声データ13bを取得したマイクに最も近い人物以外の人物を、このフレームにおいて発話した人物として特定する(ステップS123)。
特定部14dは、第2の音声データ13bにおいて発話領域での有声音領域として検出されたフレームの中に、上記ステップS121で未判定のフレームがあるか否かを判定する(ステップS124)。未判定のフレームがある場合(ステップS124肯定)には、ステップS121に戻る。一方、未判定のフレームがない場合(ステップS124否定)には、図12に示すように、抽出部14eは、次のような処理を行う。すなわち、抽出部14eは、ある人物が発話したと特定されたフレームから、有声音領域の数、有声音領域の長さの平均値、および有声音領域の長さの標準偏差を算出する(ステップS125)。抽出部14eは、ある人物が発話したと特定されたフレームから、発話領域の数、発話領域の長さの平均値、および発話領域の長さの標準偏差を算出する(ステップS126)。抽出部14eは、ある人物の沈黙領域のフレームから、沈黙領域の数、沈黙領域の長さの平均値、および沈黙領域の長さの標準偏差を算出する(ステップS127)。
抽出部14eは、会話全体の時間の長さに対するある人物の発話時間の長さの割合を算出する(ステップS128)。抽出部14eは、他の人物の発話時間に対するある人物の発話時間の割合を算出する(ステップS129)。抽出部14eは、ある人物が発話したと特定されたフレームから、音量の標準偏差およびスペクトルエントロピーの標準偏差を算出する(ステップS130)。抽出部14eは、ある人物が発話したと特定されたフレームから算出した音量の標準偏差と、スペクトルエントロピーの標準偏差との和を、変化の度合いとして算出する(ステップS131)。
抽出部14eは、他の人物が発話したと特定されたフレームから、有声音領域の数、有声音領域の長さの平均値、および有声音領域の長さの標準偏差を算出する(ステップS132)。抽出部14eは、他の人物が発話したと特定されたフレームから、発話領域の数、発話領域の長さの平均値、および発話領域の長さの標準偏差を算出する(ステップS133)。抽出部14eは、他の人物の沈黙領域のフレームから、沈黙領域の数、沈黙領域の長さの平均値、および沈黙領域の長さの標準偏差を算出する(ステップS134)。
抽出部14eは、会話全体の時間の長さに対する他の人物の発話時間の長さの割合を算出する(ステップS135)。抽出部14eは、ある人物の発話時間に対する他の人物の発話時間の割合を算出する(ステップS136)。抽出部14eは、他の人物が発話したと特定されたフレームから、音量の標準偏差およびスペクトルエントロピーの標準偏差を算出する(ステップS137)。抽出部14eは、他の人物が発話したと特定されたフレームから算出した音量の標準偏差と、スペクトルエントロピーの標準偏差との和を、変化の度合いとして算出する(ステップS138)。
分析部14fは、抽出された会話特性に基づいて、会話スタイルを分析する(ステップS139)。分析部14fは、分析結果を出力装置12に送信し(ステップS140)、処理を終了する。
[実施例1の効果]
上述してきたように、本実施例に係る分析装置10は、音声データから、第1の確率モデルを用いて、有声音領域および無声音領域を検出する。本実施例に係る分析装置10は、検出された有声音領域および無声音領域に基づいて、第2の確率モデルを用いて、音声データにおける発話領域および沈黙領域を検出する。本実施例に係る分析装置10は、検出された発話領域および沈黙領域の会話特性を抽出する。本実施例に係る分析装置10は、抽出された会話特性に基づいて、会話スタイルを分析する。このように、本実施例によれば、話者の会話スタイルを分析する際に、会話の内容を特定せずに、発話領域および沈黙領域の会話特性に基づいて会話スタイルを分析するため、処理に時間を要することなく簡易に会話スタイルを分析することができる。
また、本実施例によれば、話者の会話スタイルを分析する際に、会話の内容を特定せずに、会話スタイルを分析するため、会話の内容が知られることなく、話者のプライバシーを保護しつつ、会話スタイルを分析することができる。
また、本実施例によれば、話者の会話スタイルを分析する際に、日本語、英語、中国語などの各種言語に共通の特徴を用いて、発話領域および沈黙領域を検出するので、言語に依存することなく、会話スタイルを分析することができる。
また、本実施例に係る分析装置10は、周囲のノイズに強い自己相関係数のピークの数、自己相関係数のピークの最大値、およびスペクトルエントロピーなどの特徴量を抽出し、抽出した特徴量を用いて、有声音領域および無声音領域を検出する。したがって、本実施例に係る分析装置10によれば、周囲のノイズの影響により、有声音領域および無声音領域を検出する精度が低下することを抑制することができる。また、周囲のノイズに強い特徴量を用いているため、本実施例に係る分析装置10は、第1の音声データ13aおよび第2の音声データ13bをフレーム化する際に、フレームの個数をより少なくすることができる。したがって、分析装置10によれば、より簡易な処理で有声音領域および無声音領域を検出することができる。
また、本実施例に係る分析装置10は、発話領域における音量が閾値以上の場合に、マイクに最も近い人物を発話領域において発話した人物として特定する。また、本実施例に係る分析装置10は、発話領域における音量が閾値未満の場合に、マイクに最も近い人物以外の人物を発話領域において発話した人物として特定する。本実施例に係る分析装置10は、特定した人物ごとに、会話スタイルを分析する。したがって、本実施例に係る分析装置10によれば、音量の大きさの判定という簡易な処理で人物を特定することができる結果、簡易な処理で人物ごとの会話スタイルを分析できる。
また、本実施例に係る分析装置10は、確率モデルとして隠れマルコフモデルを用いて、沈黙領域および発話領域を検出する。したがって、本実施例に係る分析装置10によれば、2人の会話において、発話が重複しても、精度よく、沈黙領域および発話領域を検出することができる。
さて、これまで開示の装置に関する実施例について説明したが、本発明は上述した実施例以外にも、種々の異なる形態にて実施されてよいものである。そこで、以下では、本発明に含まれる他の実施例を説明する。
また、各種の負荷や使用状況などに応じて、各実施例において説明した各処理の各ステップでの処理の順番を変更できる。例えば、会話の人数が2人であり、開示の装置は、この2人の属性(名前など)について既知である場合には、図11に示すステップS121〜124の処理を省略することもできる。
また、図示した各装置の各構成要素は機能概念的なものであり、必ずしも物理的に図示の如く構成されていることを要しない。すなわち、各装置の分散・統合の具体的状態は図示のものに限られず、その全部または一部を、各種の負荷や使用状況などに応じて、任意の単位で機能的または物理的に分散・統合して構成することができる。例えば、図1に示す抽出部14eと分析部14fとが統合されてもよい。
[分析プログラム]
また、上記の実施例で説明した分析装置の各種の処理は、あらかじめ用意されたプログラムをパーソナルコンピュータやワークステーションなどのコンピュータシステムで実行することによって実現することもできる。そこで、以下では、図13を用いて、上記の実施例で説明した分析装置と同様の機能を有する分析プログラムを実行するコンピュータの一例を説明する。図13は、分析プログラムを実行するコンピュータを示す図である。
図13に示すように、実施例2におけるコンピュータ300は、CPU(Central Processing Unit)310、ROM(Read Only Memory)320、HDD(Hard Disk Drive)330、RAM(Random Access Memory)340を有する。これら300〜340の各部は、バス400を介して接続される。
ROM320には、上記の実施例1で示す取得部14aと、第1の検出部14bと、第2の検出部14cと、特定部14dと、抽出部14eと、分析部14fと同様の機能を発揮する分析プログラム320aが予め記憶される。なお、分析プログラム320aについては、適宜分離しても良い。
そして、CPU310が、分析プログラム320aをROM320から読み出して実行する。
そして、HDD330には、第1の音声データ、第2の音声データが設けられる。これら第1の音声データ、第2の音声データのそれぞれは、図1に示した第1の音声データ13a、第2の音声データ13bのそれぞれに対応する。
そして、CPU310は、第1の音声データと、第2の音声データとを読み出してRAM340に格納する。さらに、CPU310は、RAM340に格納された第1の音声データと、第2の音声データとを用いて、分析プログラムを実行する。なお、RAM340に格納される各データは、常に全てのデータがRAM340に格納される必要はなく、処理に必要なデータのみがRAM340に格納されれば良い。
なお、上記した分析プログラムについては、必ずしも最初からROM320に記憶させておく必要はない。
例えば、コンピュータ300に挿入されるフレキシブルディスク(FD)、CD−ROM、DVDディスク、光磁気ディスク、ICカードなどの「可搬用の物理媒体」にプログラムを記憶させておく。そして、コンピュータ300がこれらからプログラムを読み出して実行するようにしてもよい。
さらには、公衆回線、インターネット、LAN、WANなどを介してコンピュータ300に接続される「他のコンピュータ(またはサーバ)」などにプログラムを記憶させておく。そして、コンピュータ300がこれらからプログラムを読み出して実行するようにしてもよい。
以上説明した実施形態及びその変形例に関し、更に以下の付記を開示する。
(付記1)音声データを取得する取得部と、
前記取得部により取得された音声データから、第1の確率モデルを用いて、有声音領域および無声音領域を検出する第1の検出部と、
前記第1の検出部により検出された有声音領域および無声音領域に基づいて、第2の確率モデルを用いて、前記音声データにおける発話領域および沈黙領域を検出する第2の検出部と、
前記第2の検出部により検出された発話領域および沈黙領域の会話特性を抽出する抽出部と、
前記抽出部により抽出された会話特性に基づいて、会話スタイルを分析する分析部と
を有することを特徴とする分析装置。
(付記2)前記第1の検出部は、前記音声データの各フレームについて、自己相関係数のピークの数、自己相関係数のピークの最大値、およびスペクトルエントロピーを抽出し、抽出した自己相関係数のピークの数、自己相関係数のピークの最大値、およびスペクトルエントロピーに基づいて、有声音領域および無声音領域を検出する
ことを特徴とする付記1に記載の分析装置。
(付記3)前記取得部は、音声取得装置により取得された複数人の会話における音声データを取得し、
前記第2の検出部により検出された発話領域における音量が閾値以上の場合に、前記音声取得装置に最も近い人物を該発話領域において発話した人物として特定するとともに、前記第2の検出部により検出された発話領域における音量が閾値未満の場合に、前記音声取得装置に最も近い人物以外の人物を該発話領域において発話した人物として特定する特定部をさらに有し、
前記分析部は、前記特定部により特定された人物ごとに、会話スタイルを分析する
ことを特徴とする付記1または2に記載の分析装置。
(付記4)コンピュータに、
音声データを取得し、
取得された音声データから、第1の確率モデルを用いて、有声音領域および無声音領域を検出し、
検出された有声音領域および無声音領域に基づいて、第2の確率モデルを用いて、前記音声データにおける発話領域および沈黙領域を検出し、
検出された発話領域および沈黙領域の会話特性を抽出し、
抽出された会話特性に基づいて、会話スタイルを分析する
処理を実行させることを特徴とする分析プログラム。
(付記5)前記有声音領域および無声音領域を検出する処理は、前記音声データの各フレームについて、自己相関係数のピークの数、自己相関係数のピークの最大値、およびスペクトルエントロピーを抽出し、抽出した自己相関係数のピークの数、自己相関係数のピークの最大値、およびスペクトルエントロピーに基づいて、有声音領域および無声音領域を検出する
ことを特徴とする付記4に記載の分析プログラム。
(付記6)前記音声データを取得する処理は、音声取得装置により取得された複数人の会話における音声データを取得し、
検出された発話領域における音量が閾値以上の場合に、前記音声取得装置に最も近い人物を該発話領域において発話した人物として特定するとともに、検出された発話領域における音量が閾値未満の場合に、前記音声取得装置に最も近い人物以外の人物を該発話領域において発話した人物として特定する処理をさらに前記コンピュータに実行させ、
前記会話スタイルを分析する処理は、前記特定された人物ごとに、会話スタイルを分析する
ことを特徴とする付記4または5に記載の分析プログラム。
(付記7)コンピュータが実行する分析方法であって、
音声データを取得し、
取得された音声データから、第1の確率モデルを用いて、有声音領域および無声音領域を検出し、
検出された有声音領域および無声音領域に基づいて、第2の確率モデルを用いて、前記音声データにおける発話領域および沈黙領域を検出し、
検出された発話領域および沈黙領域の会話特性を抽出し、
抽出された会話特性に基づいて、会話スタイルを分析する
ことを特徴とする分析方法。
(付記8)前記有声音領域および無声音領域を検出する方法は、前記音声データの各フレームについて、自己相関係数のピークの数、自己相関係数のピークの最大値、およびスペクトルエントロピーを抽出し、抽出した自己相関係数のピークの数、自己相関係数のピークの最大値、およびスペクトルエントロピーに基づいて、有声音領域および無声音領域を検出する
ことを特徴とする付記7に記載の分析方法。
(付記9)前記音声データを取得する方法は、音声取得装置により取得された複数人の会話における音声データを取得し、
検出された発話領域における音量が閾値以上の場合に、前記音声取得装置に最も近い人物を該発話領域において発話した人物として特定するとともに、検出された発話領域における音量が閾値未満の場合に、前記音声取得装置に最も近い人物以外の人物を該発話領域において発話した人物として特定する方法をさらに前記コンピュータが実行し、
前記会話スタイルを分析する方法は、前記特定された人物ごとに、会話スタイルを分析する
ことを特徴とする付記7または8に記載の分析方法。