JP4328532B2 - 化合物の性質最適化のための2dまたは3d−化合物構造式の階層位相ツリーを発生させるための方法 - Google Patents
化合物の性質最適化のための2dまたは3d−化合物構造式の階層位相ツリーを発生させるための方法 Download PDFInfo
- Publication number
- JP4328532B2 JP4328532B2 JP2002572763A JP2002572763A JP4328532B2 JP 4328532 B2 JP4328532 B2 JP 4328532B2 JP 2002572763 A JP2002572763 A JP 2002572763A JP 2002572763 A JP2002572763 A JP 2002572763A JP 4328532 B2 JP4328532 B2 JP 4328532B2
- Authority
- JP
- Japan
- Prior art keywords
- graph
- topological
- phase
- molecular
- tsp
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Expired - Fee Related
Links
- 150000001875 compounds Chemical class 0.000 title claims description 117
- 238000000034 method Methods 0.000 title claims description 68
- 238000005457 optimization Methods 0.000 title description 4
- 125000005647 linker group Chemical group 0.000 claims description 59
- 239000000126 substance Substances 0.000 claims description 55
- 229910052799 carbon Inorganic materials 0.000 claims description 48
- 125000005842 heteroatom Chemical group 0.000 claims description 32
- 125000001424 substituent group Chemical group 0.000 claims description 32
- OKTJSMMVPCPJKN-UHFFFAOYSA-N Carbon Chemical compound [C] OKTJSMMVPCPJKN-UHFFFAOYSA-N 0.000 claims description 26
- 239000012634 fragment Substances 0.000 claims description 23
- 238000012913 prioritisation Methods 0.000 claims description 16
- 238000007385 chemical modification Methods 0.000 claims description 13
- 238000006467 substitution reaction Methods 0.000 claims description 13
- 229910052739 hydrogen Inorganic materials 0.000 claims description 11
- 238000012986 modification Methods 0.000 claims description 11
- 230000004048 modification Effects 0.000 claims description 11
- 239000001257 hydrogen Substances 0.000 claims description 10
- 238000012360 testing method Methods 0.000 claims description 10
- UFHFLCQGNIYNRP-UHFFFAOYSA-N Hydrogen Chemical compound [H][H] UFHFLCQGNIYNRP-UHFFFAOYSA-N 0.000 claims description 7
- 230000002378 acidificating effect Effects 0.000 claims description 7
- 125000002015 acyclic group Chemical group 0.000 claims description 7
- 230000003247 decreasing effect Effects 0.000 claims description 7
- 230000002950 deficient Effects 0.000 claims description 6
- 238000002372 labelling Methods 0.000 claims description 6
- 238000001228 spectrum Methods 0.000 claims description 4
- 125000004432 carbon atom Chemical group C* 0.000 claims description 3
- 238000009826 distribution Methods 0.000 claims description 3
- 238000013507 mapping Methods 0.000 claims description 2
- GNFTZDOKVXKIBK-UHFFFAOYSA-N 3-(2-methoxyethoxy)benzohydrazide Chemical compound COCCOC1=CC=CC(C(=O)NN)=C1 GNFTZDOKVXKIBK-UHFFFAOYSA-N 0.000 claims 15
- 239000002062 molecular scaffold Substances 0.000 claims 1
- 238000004458 analytical method Methods 0.000 description 41
- 238000000819 phase cycle Methods 0.000 description 25
- 125000004429 atom Chemical group 0.000 description 23
- 229940079593 drug Drugs 0.000 description 19
- 239000003814 drug Substances 0.000 description 19
- 230000000694 effects Effects 0.000 description 18
- 230000008569 process Effects 0.000 description 13
- 238000005556 structure-activity relationship Methods 0.000 description 12
- 229920003266 Leaf® Polymers 0.000 description 10
- 125000004122 cyclic group Chemical group 0.000 description 9
- 238000012216 screening Methods 0.000 description 9
- 238000004422 calculation algorithm Methods 0.000 description 8
- 230000015572 biosynthetic process Effects 0.000 description 7
- 238000003786 synthesis reaction Methods 0.000 description 7
- 238000011282 treatment Methods 0.000 description 7
- 238000006243 chemical reaction Methods 0.000 description 6
- ZUOUZKKEUPVFJK-UHFFFAOYSA-N diphenyl Chemical compound C1=CC=CC=C1C1=CC=CC=C1 ZUOUZKKEUPVFJK-UHFFFAOYSA-N 0.000 description 6
- VYFYYTLLBUKUHU-UHFFFAOYSA-N dopamine Chemical compound NCCC1=CC=C(O)C(O)=C1 VYFYYTLLBUKUHU-UHFFFAOYSA-N 0.000 description 6
- 125000003118 aryl group Chemical group 0.000 description 5
- 238000003556 assay Methods 0.000 description 5
- 238000004590 computer program Methods 0.000 description 5
- 239000003446 ligand Substances 0.000 description 5
- 230000007935 neutral effect Effects 0.000 description 5
- 230000000704 physical effect Effects 0.000 description 5
- 230000003595 spectral effect Effects 0.000 description 5
- 238000004617 QSAR study Methods 0.000 description 4
- 239000000370 acceptor Substances 0.000 description 4
- 239000000556 agonist Substances 0.000 description 4
- 238000013459 approach Methods 0.000 description 4
- 238000004364 calculation method Methods 0.000 description 4
- 230000010365 information processing Effects 0.000 description 4
- 230000003993 interaction Effects 0.000 description 4
- 238000012545 processing Methods 0.000 description 4
- 238000012357 Gap analysis Methods 0.000 description 3
- 102100030140 Thiosulfate:glutathione sulfurtransferase Human genes 0.000 description 3
- 125000001931 aliphatic group Chemical group 0.000 description 3
- 235000010290 biphenyl Nutrition 0.000 description 3
- 239000004305 biphenyl Substances 0.000 description 3
- 238000013461 design Methods 0.000 description 3
- 229960003638 dopamine Drugs 0.000 description 3
- 238000011156 evaluation Methods 0.000 description 3
- 238000013467 fragmentation Methods 0.000 description 3
- 238000006062 fragmentation reaction Methods 0.000 description 3
- 230000006870 function Effects 0.000 description 3
- 125000000524 functional group Chemical group 0.000 description 3
- 125000004435 hydrogen atom Chemical group [H]* 0.000 description 3
- 238000007726 management method Methods 0.000 description 3
- 238000013439 planning Methods 0.000 description 3
- 230000009257 reactivity Effects 0.000 description 3
- 238000003860 storage Methods 0.000 description 3
- 238000012916 structural analysis Methods 0.000 description 3
- 238000012549 training Methods 0.000 description 3
- 150000001260 acyclic compounds Chemical class 0.000 description 2
- 125000003277 amino group Chemical group 0.000 description 2
- 238000013477 bayesian statistics method Methods 0.000 description 2
- 230000000975 bioactive effect Effects 0.000 description 2
- 230000004071 biological effect Effects 0.000 description 2
- 125000003178 carboxy group Chemical group [H]OC(*)=O 0.000 description 2
- 230000001413 cellular effect Effects 0.000 description 2
- 238000007621 cluster analysis Methods 0.000 description 2
- 238000004040 coloring Methods 0.000 description 2
- 230000000295 complement effect Effects 0.000 description 2
- 229940125904 compound 1 Drugs 0.000 description 2
- 239000000470 constituent Substances 0.000 description 2
- 238000012217 deletion Methods 0.000 description 2
- 230000037430 deletion Effects 0.000 description 2
- 238000002405 diagnostic procedure Methods 0.000 description 2
- 229940000406 drug candidate Drugs 0.000 description 2
- 238000000605 extraction Methods 0.000 description 2
- 229910052736 halogen Inorganic materials 0.000 description 2
- 150000002367 halogens Chemical group 0.000 description 2
- 125000002887 hydroxy group Chemical group [H]O* 0.000 description 2
- 239000011159 matrix material Substances 0.000 description 2
- 238000005259 measurement Methods 0.000 description 2
- 238000012544 monitoring process Methods 0.000 description 2
- 230000036961 partial effect Effects 0.000 description 2
- 238000012805 post-processing Methods 0.000 description 2
- 229920006395 saturated elastomer Polymers 0.000 description 2
- 238000007423 screening assay Methods 0.000 description 2
- 230000001953 sensory effect Effects 0.000 description 2
- 238000000638 solvent extraction Methods 0.000 description 2
- 238000007619 statistical method Methods 0.000 description 2
- IIACRCGMVDHOTQ-UHFFFAOYSA-N sulfamic acid Chemical group NS(O)(=O)=O IIACRCGMVDHOTQ-UHFFFAOYSA-N 0.000 description 2
- 230000001988 toxicity Effects 0.000 description 2
- 231100000419 toxicity Toxicity 0.000 description 2
- 230000009466 transformation Effects 0.000 description 2
- 239000007848 Bronsted acid Substances 0.000 description 1
- 239000003341 Bronsted base Substances 0.000 description 1
- 0 CC1(C*CCC1)NC(C1C(CC(C(CC2)CCC2Cl)O)=CCCC1)O Chemical compound CC1(C*CCC1)NC(C1C(CC(C(CC2)CCC2Cl)O)=CCCC1)O 0.000 description 1
- 101150049660 DRD2 gene Proteins 0.000 description 1
- 230000002159 abnormal effect Effects 0.000 description 1
- 239000002253 acid Substances 0.000 description 1
- 239000013543 active substance Substances 0.000 description 1
- 150000001298 alcohols Chemical class 0.000 description 1
- 238000003491 array Methods 0.000 description 1
- 238000010420 art technique Methods 0.000 description 1
- 230000006399 behavior Effects 0.000 description 1
- 238000004166 bioassay Methods 0.000 description 1
- 150000001721 carbon Chemical class 0.000 description 1
- 230000008859 change Effects 0.000 description 1
- 238000012512 characterization method Methods 0.000 description 1
- 150000005829 chemical entities Chemical class 0.000 description 1
- 239000003086 colorant Substances 0.000 description 1
- 238000010835 comparative analysis Methods 0.000 description 1
- 230000000052 comparative effect Effects 0.000 description 1
- 230000002860 competitive effect Effects 0.000 description 1
- 238000010276 construction Methods 0.000 description 1
- 238000002790 cross-validation Methods 0.000 description 1
- 238000007405 data analysis Methods 0.000 description 1
- 238000003066 decision tree Methods 0.000 description 1
- 238000000354 decomposition reaction Methods 0.000 description 1
- 230000007812 deficiency Effects 0.000 description 1
- 238000001212 derivatisation Methods 0.000 description 1
- 238000001514 detection method Methods 0.000 description 1
- 238000009510 drug design Methods 0.000 description 1
- 239000003596 drug target Substances 0.000 description 1
- 238000005516 engineering process Methods 0.000 description 1
- 230000007613 environmental effect Effects 0.000 description 1
- 230000007717 exclusion Effects 0.000 description 1
- 238000004880 explosion Methods 0.000 description 1
- 238000011049 filling Methods 0.000 description 1
- 230000008571 general function Effects 0.000 description 1
- 230000002068 genetic effect Effects 0.000 description 1
- 125000000623 heterocyclic group Chemical group 0.000 description 1
- 238000009396 hybridization Methods 0.000 description 1
- 238000000338 in vitro Methods 0.000 description 1
- 230000000977 initiatory effect Effects 0.000 description 1
- 238000009434 installation Methods 0.000 description 1
- 125000003010 ionic group Chemical group 0.000 description 1
- 238000002898 library design Methods 0.000 description 1
- 238000004519 manufacturing process Methods 0.000 description 1
- 239000000463 material Substances 0.000 description 1
- 239000002207 metabolite Substances 0.000 description 1
- 239000000178 monomer Substances 0.000 description 1
- 230000000877 morphologic effect Effects 0.000 description 1
- 229940127285 new chemical entity Drugs 0.000 description 1
- 239000002547 new drug Substances 0.000 description 1
- 150000002894 organic compounds Chemical class 0.000 description 1
- 238000011045 prefiltration Methods 0.000 description 1
- 238000007639 printing Methods 0.000 description 1
- 238000011002 quantification Methods 0.000 description 1
- 108020003175 receptors Proteins 0.000 description 1
- 102000005962 receptors Human genes 0.000 description 1
- 238000011084 recovery Methods 0.000 description 1
- 238000011160 research Methods 0.000 description 1
- 125000006413 ring segment Chemical group 0.000 description 1
- 239000002904 solvent Substances 0.000 description 1
- 241000894007 species Species 0.000 description 1
- 150000003413 spiro compounds Chemical class 0.000 description 1
- 125000003003 spiro group Chemical group 0.000 description 1
- 238000002907 substructure search Methods 0.000 description 1
- 230000009897 systematic effect Effects 0.000 description 1
- 235000019801 trisodium phosphate Nutrition 0.000 description 1
- 108010064245 urinary gonadotropin fragment Proteins 0.000 description 1
- 238000010200 validation analysis Methods 0.000 description 1
Images




Classifications
-
- G—PHYSICS
- G16—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR SPECIFIC APPLICATION FIELDS
- G16C—COMPUTATIONAL CHEMISTRY; CHEMOINFORMATICS; COMPUTATIONAL MATERIALS SCIENCE
- G16C20/00—Chemoinformatics, i.e. ICT specially adapted for the handling of physicochemical or structural data of chemical particles, elements, compounds or mixtures
- G16C20/80—Data visualisation
Landscapes
- Engineering & Computer Science (AREA)
- Bioinformatics & Computational Biology (AREA)
- Chemical & Material Sciences (AREA)
- Crystallography & Structural Chemistry (AREA)
- Life Sciences & Earth Sciences (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Data Mining & Analysis (AREA)
- Computing Systems (AREA)
- Theoretical Computer Science (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
- Investigating Or Analysing Biological Materials (AREA)
- Organic Low-Molecular-Weight Compounds And Preparation Thereof (AREA)
- Management, Administration, Business Operations System, And Electronic Commerce (AREA)
Description
グラフ:ノード(頂点)から構成され、エッジにより接続される数学的構成物。本発明において私達は、グラフの2つの種類、分子グラフとツリーとを区別する。
ノード(頂点):特定の(化学)対象を表すグラフまたはツリー中の1つまたはそれ以上のエッジの最終点、これは円(または別の記号)により、またはネームタグ(例えばラインコード、位相シーケンスコード(TSC)またはモルコード)により視覚化され得る。グラフにより表される対象に応じて、ノードの物的解釈は変化し得る(即ち、分子グラフ中のノードは原子を表し、位相構造ツリー中のノードは、一般に化合物、(下位構造)テンプレートまたは分子グラフである。)。
リーフノード:ツリー中のエンドノード、本発明においてこれは、インプットデータストリーム中に存在する化学的実体(およびその分子グラフ)のために、充分に分解された構造ノードを表す。リーフノードは、ユニークな登録IDによりラベル付けされる。
エッジ:分子グラフ中またはツリー(例えば位相構造ツリー(TST))中の2つのノードを連結し、分子グラフ中の単一または多重ラインおよびツリー中の単一ラインにより視覚化され得る。
分子グラフ:化合物の構造式のためのモデル、この中でノード(頂点)は原子を表し(種類、数および原子価により特徴付けられる)、エッジは化学結合を表す。各化合物は、無向水素欠乏分子グラフG(V,E)1(この中でV(v1,v2,...) は頂点(ノード、原子)のセットであり、E(e1,e2,...) はエッジ(化学結合)のセットである。)として扱われる(視覚化され得る)。インプットデータからのあらゆる化合物iのために、このグラフは、G(i) と省略される。このグラフ中の頂点(原子)は、あらゆる共通の非水素原子であり得、その中で炭素は、薬物様化合物に対して仮想参照とみなされる。エッジ(化学結合)は、一重、二重、三重、部分二重/芳香族タイプであり得る。
テンプレート:基本位相コンポーネント(位相鍵特徴参照)、例えば環、リンカー、分子鎖、から構成される全炭素下位構造、これは、主として、現実の薬物分子の固定(rigid)および特徴的なコンポーネントであると仮定される。同義語は、フレームワークである。テンプレート(フレームワーク)は、その位相タイプのあらゆる化学誘導体を集めるための標識分子であるとみなされる、即ち、化学誘導体の様々なクラスを含む。これは、インプットデータストリーム中において、理論的に可能であるかまたは実際に存在し得る。
スカフォード:テンプレートに類似するが、化学的に(即ち、ヘテロ原子の存在により)修飾されている。即ち、それは、固定フレームだけでなく、リガンド標的相互作用のための特異な確定幾何学的配置の機能モチーフも表し得る。
コア:現実の薬物中に存在する最高順位の位相要素(全炭素下位構造)、これは、位相構造ツリー中のルートノードとして機能する。
ツリー:エッジリンクされたノードのアセンブリ、その中で円形パスは存在しない。ノード(頂点)およびエッジの意味は、ツリーにより表される対象に依存する(例えばTSTは、さまざまな複雑なものの分子および下位構造テンプレートから構成される)。本発明において動的ツリーは、階層位相構造ツリーを構成するために、大量インプットストリームから on the fly で、および柔軟なユーザーコントロール下でツリーおよび化合物を視覚化して、使用される。
位相クラス:下位構造カテゴリー(またはクラス)、これは、所定化合物中に存在することができ、いくつかの原子が、環(R)、リンカー(L)、分子鎖(C)またはこれらの妥当な組み合わせを形成するという性質により特徴付けられ得る。定義により、参照位相クラスは、炭素のみのテンプレートであり、これは、定義により、固有特異の生体活性を示さないことが予想される。これらの種類に加えてこれらの位相クラスは、使用するあらゆる位相鍵特徴のためにルール定義された発見的基準により特徴付け(およびスコア付け)られる。各位相クラスは、サイズ(または長さ)、原子価(または飽和度、例えば芳香族、脂肪族など)または官能修飾の数および種類(例えばヘテロ原子の数、ドナー/アクセプター性、正/負電荷、酸性/塩基性基など)によりサブクラスに再分割され得る。
位相鍵特徴:分子中に存在する構造的(即ち、位相的)および化学的特徴、これは、位相クラス(即ち、環、リンカーまたは分子鎖)を定義付けするか、または化学修飾を全炭素位相参照テンプレートに導入する(例えば特定の下位構造要素の優先付けに影響を及ぼすヘテロ原子および/または置換基)。
環(R):各分子グラフG内で、存在するあらゆる環は、その下位構造に対するハミルトニアンパスの長さ(例えば環原子の数、または環サイズ、r=3,4,5,...)により特徴付けられる環式部分グラフを形成する。
リンカー(L):分子グラフ中に存在する長さl(l=0,1,2,3,...、リンカー骨格中の結合数)の非環式の直鎖または分枝鎖、これは定義により、少なくとも2つの異なる環(分枝リンカーに対してはそれ以上)に属する頂点で開始し、終了する。
置換基(S):全サイズs(sは、置換基中の原子数である)の非環式付着物、これは、分子グラフ中に存在する環、リンカーまたは分子鎖のいずれかに結合している化学官能基(例えばハロゲン、アミノ基、カルボキシル基、ヒドロキシ基、スルホアミド基、脂肪族鎖など)として知られている。置換基は、ヘテロ原子分子置換鎖に対する具体例として見ることができる。
分子鎖(C):長さc(cは、分子鎖中の原子数である)の直鎖または分枝の非環式下位構造、これは、分子グラフ中のリンカーまたは単一環頂点のいずれにも加わらない。環またはリンカーに結合している非環式炭素骨格は、脂肪族置換基として扱われる。
ヘテロ原子(H):分子グラフの環、リンカーまたは分子鎖に存在するあらゆる炭素置換物。しかしながらヘテロ原子は、位相(結合数および空間配置)だけでなく、電子特性(孤立電子対または電子ギャップ)においても炭素と異なり、そうして塩基性/酸性、水素結合、溶解性、化学反応性および生体活性(標的結合、薬動力学特性、毒性など)に影響を及ぼす。そうしてヘテロ原子は、その性質の化学反応に対して、異なるサブクラス(HBドナー/アクセプター、酸性/塩基性、負/中性/正電荷原子など)に再分割され得、それぞれの位相サブクラスに個々に影響を及ぼす。
位相シーケンスパス(TSP):TST中の優先付けされた下位構造テンプレートの接続シーケンスパス、これは、TST中で追加の仮想参照分子(または独立標識テンプレート)として扱われる個々の下位構造シェルにTSCを分割することによって、TCCから創造される。少なくとも1つのTCC中に共存することによって、これらの仮想ツリーノードは、インプットストリーム中に存在する現存化合物中でクローズネイバーシップ(close neighbourship)を反映するエッジにより接続される。
最大位相下位構造(LTS):分子の残りの部分、これは、分子中の全ての置換基を除去した後に残る。これは、TST中でTCCを超えて配置される。実際の化合物の構造は、LTSまたはTCCノードの特定の化学誘導体のために表示するツリーリーフノードとしてLTSに結び付けられる。
位相クラスタ中心:最大位相下位構造(LTS)に相当する全炭素。下位構造要素の優先度を変化させずに、分子グラフ中の全てのヘテロ原子ノードを炭素原子にモーフィングすることにより、LTSから発生する。
本発明は、大量の化合物における自動コンピューターベース2D/3D構造分析のための新規グラフベース法を基礎とする。それは、表示(仮想)下位構造テンプレートを発生させるため、およびこれらを動的ツリーのコレクション(即ち、位相構造フォレスト(TSF)および位相構造ツリー(TST)、以下を参照)に配置するために、位相鍵特徴(下位構造要素)を使用する。これは、誘導体をツリー中の適切な祖先ノードに付着させることにより、インプットデータセット中の下位構造タイプに存在する化学変換のあらゆる種類を監視する位相参照構造として、これらの標識テンプレートを使用することにより、達成される。そうして、表示構造を自己類似分析により見つけなければならない未知数のクラスタを有するという問題が、構成により回避される。
以下、図を参照する:
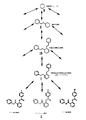
図1: 2D-分子グラフから位相クラスタ中心(TCC)を発生させるための、選択ステップおよび中間結果。
図2: ルートノード(コア)およびTCCの間に位相シーケンスパス(TSP)を発生させる例、および位相シーケンスコード(TSC)のネームタグとしての使用。TCC(および相互のTSPノード)は、表示参照構造(たいてい、生態学的活性が欠けている仮想標識テンプレート)として、位相最近接の化学誘導体を収集およびグルーピングするために使用される。
図3: 2D構造(文献から得られたドーパミンD1/D2アゴニスト)の小さなセットのためのインプットデータ(Sybyl Line Notation(表記法)、(SLN))。このデータセットを、本明細書中に記載する本発明に基づく組織内コンピュータープログラムを用いて、図4を生じさせるために使用した。
図4: 文献からのドーパミンD1/D2アゴニストのコンピューター発生TSTに対する例。該結果を、本明細書中に記載する本発明に基づく組織内コンピュータープログラムを使用することにより発生させた。
インプットデータの適切な選択は、標的性質のために適切なプレフィルターを適用することにより達成され、これは、解釈を容易にし、特別な作業のための解決についての結果の焦点を合わせる。
・活性またはヒット統計に対する構造デターミナントに関するヒット分析のための特定スクリーニングアッセイにおける、活性物質。
・様々な下位構造クラス中の偽陽性および偽陰性の両方に対する候補およびそれらの確度評価を査定するための、特定スクリーニングアッセイにおける不活性物質。
・薬物保存書庫のバイオプロファイリングのためのスクリーニング履歴、および特権付与または乱雑テンプレートの検索における、あらゆる活性化合物。
・薬物保存書庫プロファイリング、ギャップ分析、テンプレート配向R群デコンボリューション、化合物合成および化合物購入のための、全薬物保存書庫またはそのサブセットの全化合物。
・特許ギャップおよび組織内知識探査を識別するための、競合(特許)構造/活性データ。
・間接標的分類のための、内因性(活性)化合物(バイオエフェクタ)または活性代謝生成物。
・異常スカフォード、SAR分析およびテンプレート選択のための、天然(活性)薬物。
各化合物(即ち、図1中の化合物1)は、無向水素欠乏分子グラフG(V,E)2(この中でV(v1,v2,...) は頂点(即ち、原子)のセットであり、E(e1,e2,...) はエッジ(即ち、化学結合)のセットである。)として扱われる。インプットデータからのあらゆる化合物 i のために、このグラフは、G(i) と省略される。各化合物のグラフは、部分グラフに分割され得、これは、環(R)、リンカー(L)、置換基(S)および分子鎖(C)のような位相テンプレートとして、または原子プロパティのためのモジュレーター、例えばヘテロ原子H={vi#炭素}としてのそれらのコネクティビティプロパティにより位相クラスT={R,L,S,C}に関してそれぞれ定義され、これらは、物理的および化学的性質(例えば溶解性および反応性)、並びにそうして生物学的標的に対する化学親和性を介して、新しい薬物候補についてのテンプレートの重要度に影響を及ぼす。環およびリンカークラスを、あらゆる特定化合物中に存在する環およびリンカータイプのあらゆる有効およびユニークな組合せRx Ly RZ に対する化合物または下位構造の新しい位相クラスを創造するために使用し得る(即ち、R5は五員環化合物のサブクラスであり、R6-L2-R6は、2つの六員環に接合している長さ2のリンカーの存在により特徴づけられるサブセットであるなど)。同じ処置を、分子鎖クラス内で適用し得る。データ分析のより後のフェーズ中における作業、例えばファーマコフォア認知のために、いくつかのセット(S,H)は、標的および/または溶媒相互作用に対する官能性を特性評価することを可能にするさらなるサブセット中への分割(即ち、水素結合ドナーDまたはアクセプターA中への分割による)、または分子中に存在するブレンステッド酸IAまたはブレンステッド塩基IBから生ずるイオン性基中への分割、または分極電荷基(即ち、正、中性または負電荷原子)中への分割、を要求する。化合物中の構造特徴のQSAR、QSPRまたは有意分析のために、それらのグラフは、同等のライングラフ(Estrada E., 繰り返しライングラフシーケンスの一般化スペクトルモーメント. QSPR研究への新規アプローチ, J. Chem. Inf. Comput. Sci., 39 (1), 90-95 (1999))への変換を要求し得る。
G内における、あらゆる存在する環は、その下位構造(例えば環の原子数または環サイズ、r=3,4,5,...)のために、ハミルトニアンパスの長さにより特徴づけられる環式部分グラフを形成する。その化合物のためのあらゆる環は、サブクラス(セット)Rrを形成し、これは、分子中に存在する環のサイズrにより定義づけられるが、スコア付けスキームによる優先度において異なり得る(即ち、高度に置換された環は、同じサイズの単置換環よりも高く順位付けされる)。環の分類についてさらなる考察を必要とし得る特別な場合は、それぞれ、リンカー系に対しても特別な場合として分類され得るような、RmRnとして標識付けられるスピロ化合物、および輪状環系、Rm:Rnであり、しかしながらこれらは、同じ環系の同一の頂点(スピロcmpdsについて)、または隣接する頂点(輪状環について)で開始および終了する(以下を参照)。
・全体の演算処置をコンピューターのサブパートのために記載するシーケンス
・分子中の位相鍵特徴を識別する技術
・相互に関連する異なる位相鍵特徴をスコア付け(クラス間スコア付け)するためのルール
・位相鍵特徴をクラス内スコア付けするためのルール
・TCCを創造するためのアルゴリズム
・位相シーケンスパス(TSP)をTCCから所定化合物のために創造するための技術
・TSTノードおよび(下位)構造を(フラグメント)位相シーケンスコード(TSC)により標識付けるための技術
・ノード(位相シーケンスパス(TSP))をTST中に創造およびリンクさせるためのルール
・TSTの(標的インプットデータによる)統計的および生物学的構造分析のための技術
・位相的に分析したデータセットの記憶および回収のための技術
・TCCノードレベルを超えたサブツリースコア付けおよび構築のための技術
大規模データセット(目下、包括的にインプットデータと呼ばれる。)の構造ベース分析のための全体の処置は、いくつかのステップで進行する(図1参照):
I. プレフィルターをかけた分子構造の連続インプット、およびさらなる分析のためのその水素欠乏分子グラフの発生。
II. 分子グラフ中に存在する位相鍵特徴のクラスおよびサブクラスの識別および標識付け。
III. あらゆる位相クラスに対するクラス内優先付けの実行、および分子グラフ中の頂点の適切な標識付け。
IV. 分子グラフ中のあらゆる置換基の削除(LTSの創造)、および分子グラフ中に存在する位相サブクラスの官能度の評価。
V. 位相クラスタ中心(TCC)フレームワークの発生、およびそれの位相シーケンスコード(TSC)による標識付け。LTSのTCCへのリンク。
VI. LTSへのインプット構造のための実際の分子グラフのリンク(例えばTCCおよびあらゆるTSPノードとの成長多様リンク付けリストの部分として)。
VIII. 実際のTCC(例えばTST中の各化合物に対する祖先ノード)および各下位構造ノード(例えば結び付けられた子ノードの統計のため)に結び付けられる特別な記憶分野の更新(例えば統計的バイオプロフィルサブツリー母集団をスクリーニングするため)。
IX. TCCまたはLTSを超える構造リーフ(例えば化合物)の数が、事前定義された臨界数を超える場合、細部のそのレベルでの水平順序付けを、適切なグラフの不変特徴を各化合物のために計算することにより達成することができる、これは、マハラノビス距離のような正確な距離を基準に構造を分類および順位付けするために使用することができる。
X. 次ぎの化合物のための I. を用いる処理(新規化合物が入手できる限り)。
XI. 統計分析、ヒット確認、ファーマコフォア認知のため、または化学誘導体中におけるフレームワークギャップおよび/またはギャップ検索における、選択(または全ての)TCCおよびあらゆるそれらのサブツリーに対する後処理の実行。
XII. 化合物リーフのために、入手できるTSCデータの配置および処理に対する人工技術(art technique)の状態を使用して、化合物登録コード(例えばベイナンバー)による構造データを置き換える、TSTの得られたフォレストのディスク上への記憶。
続けて、いくつかのプロセスステップを、さらに詳細に記載する。
あらゆる化合物およびそれと結び付けられるグラフGについて、環要素だけがグラフ中の自己回帰歩行のための開始および終了点であるということにより、位相クラス要素をアルゴリズム的に決定し得る(Bemis GW; Murcko MA, 既知薬物のプロパティ. 1. 分子フレームワーク, J. Med. Chem, 39 (15) (1996), 2887-2893)。分子グラフのあらゆるパスは分析され、訪問された(visited)頂点は、原子標識によりマークされ得る。R、L、Cからの位相クラスの各場合における置換基の数が計数され、スコア付けプロセスにおいて使用するために記憶される場合、環内で終わらないまたは環の部分ではないあらゆるパスは、切り取られ得る。

位相鍵特徴のクラスのために、発見的ルールベース優先付けスキームは、以下のスコア付けにより(重要度の順序の減少において)定義され、これは、連続的にトップダウンで適用され、あらゆる特定化合物のために必要とされる(図1参照):
(1)環
(2)リンカー
(3)へテロ原子
(4)置換基
(5)分子鎖。
位相クラスのためのこの定義から、あらゆる所定分子に対する位相ルートノード(最高順位の位相クラス要素)は、環系、または厳格な非環式化合物の場合に分子鎖、のいずれかであり得ることが生ずる。リンカーの定義が、末端環の存在と連結される場合、リンカーに対するスコア付けも、環の優先度と連結される。
位相クラス、環、リンカーおよび分子鎖内における自然順位を、スコア付けルールの同じシーケンスを適用することにより(優先度順序の減少において(図1参照))定めることができ、これは、以下の基準シーケンスにより説明される:
a)位相サブクラス/下位構造中の置換度(例えば環、リンカーまたは分子鎖中のヘテロ原子および置換基の数)。輪状環は、環置換の特別な場合であるとみなされ、これは、環下位構造のハミルトニアンパスに沿って頂点から開始する多重自己復帰歩行の存在により、または最小環の最小セット(smallest set of smallest ring)(SSSR、Petitjean J., Tao Fan B. および Doucet J-P, J. Chem. Inf. Comput.. Sci., 2000, 40, 1015-1017; および Lipkus AH, 単純な位相ディスクリプタスペース中での化学環の探査, J. Chem. Inf. Comput. Sci, 2001, 41, 430-438 も参照)の分析により識別され得る。
b)位相サブクラスまたは部分グラフ中に存在する頂点(原子)の数。(分枝)リンカーのために優先度は、末端環の順位の減少(最高のものから開始)、置換度の減少およびパス長さの増加に対して厳密に、あらゆる可能なパスに連続的に割り当てられる。単結合によりつながれている環は、定義により1つのリンカー長さにより分類され得る(上記のビフェニルの例を参照)。最短パス/最小環サイズは、置換度に次いで、最高の優先度を有する。等しいリンカー長さに対する非ユニークスコア付けの場合、最高優先度の環につながっているリンカーが、順位付けにおいて有利である。これがまだ非ユニークである場合、より高度に置換されているリンカーが優先される。
d)あらゆるポイントa)〜c)が等しい場合、位相サブクラス内の飽和度が考慮される:特に芳香環(完全飽和)は、最高の優先度を有し、環の標識ストリングに添え字「Ar」を付けることにより特別に標識付けられ、または不飽和結合の数は、フラグメント(環、リンカーまたは分子鎖)のためのネームタグに追加され得る。部分または完全飽和環系は、より大きな空間複雑度およびキラル中心の可能な存在の故に、より低い優先度を有する。不飽和リンカーおよび分子鎖は、統一性のために、同様に扱われる。
ルール(1)〜(5)およびa)〜d)をいくつかの任意分子グラフに適用する一般的関数により、位相スカフォードを発生および順位付けするプロセスを、実施例1(図1)で説明する。
いったんあらゆる位相クラスが分子中で識別され、上記の優先付けスキームが各位相クラスタのために再帰的に適用されると、切り取られた分子グラフの各サブクラス中における頂点(原子)は、クラス、クラス内スコア付けおよび優先度情報により標識および特徴付けられる(例えばR5(1)は、分子中に存在する全ての環中で最高(#1)優先度の五員環を意味し、L4(2)は、リンカー長さ4(即ち、4つの結合および3つの原子の長さ)および優先度2が存在することを示す、図1参照)。
各TCCノードを超えて存在する構造を、構造ベースディスクリプタ(例えばグラフ不変量)により特徴付け、分類することができる。これらは、
・(仮想)クラスタ中心(TCCノード)または分類カテゴリ(即ち、活性または不活性)のための中心に対するあらゆる化合物の「化学的距離」(即ち、マハラノビス距離またはユークリッド距離)を測定するため、および
・その距離に基づき化学誘導体を分類するため、または
・同じTCC中の化学修飾を生体活性に関して区別するため、および最後に
・計算ディスクリプタと、物性および/または生体活性データのいずれかとを相関させるため
に使用することができる。
分析されるあらゆる化合物に対するあらゆるTCCサブツリーは、動的階層位相構造フォレストまたはツリー(TSFまたはTST)中に集められ、これらは、下位構造要素中の化学修飾度を減少させるため、およびツリーノード中の下位構造サイズを増加させるためにトップダウンで組織され(Moen S, 動的ツリーの作図, IEEE Software, 1990年7月, 21-28 参照)、これは、最小だが最高スコアの下位構造Tm(i)(例えば環、または非環式化合物に対して分子鎖)から位相シーケンスパス(TSP)に対する炭素モーフィングルートノードTSPj(i)(即ち、j=1)として開始し、より低い優先度の残りのフラグメントを減少スコアの順序でTSPjに接続することにより、妥当な接続パスを創造し、これは最終的に、化合物中の最大全炭素下位構造としてTCCノードで終了する。
実施例2(図2)では、R6(1)と標識付けられた中心芳香族六員環は、インプット構造1のためのTSPルートノードとして識別されている。位相リンケージの次ぎの領域は、(フラグメント)位相シーケンスコード(TSC)L3(1)-R6(2)を有し、これは、まず新しいTSTノードR6-L3-R6(即ち、3つの結合リンカーによりつながれている2つの六員環芳香環)を構築するために使用され、最後にTSC L2(2)-R6(3)を有する最終フラグメントは、R6(1)-[L3(1)-R6(2)]-L3(2)-R6(3)と標識付けられたTCC下位構造ノードを発生させるために追加される。処理される各新規化合物のために、同じ処置を続け、こうしてTSPルートフラグメントから連続的に位相リンケージ領域を追加することにより下位構造サイズを成長させ、それらのTSCタグを有する新規ノードを、最後に分子のためのあらゆる位相クラスが作り上げられるまで創造し、充分な位相シーケンスパスが構築され、これは、TCCノードで終わり、これを超えて、実際の薬物が挿入され得る。中間モーフィングプロセスにより、化学修飾されたTSTノードは識別され、適切な全炭素TSTノードに、そのテンプレートタイプのあらゆる修飾構造を表示する共通の位相クラスタ中心として正確に割り当てられる。
交差要素の検索における文字列大小比較の代りに、周知の他の技術、例えばクリーク検出、最大共通下位構造検索またはフィンガープリントスクリーニングが有用であり得る。
追加の情報分野は、あらゆる試験系(バイオプロファイリング)に対する生体活性参照を含有し得、この中でそのようなテンプレートは、活性であると見出されている(特権付与テンプレートまたはスカフォードを参照)。これらの情報分野を、実際の分子グラフに結び付けることができ、これは、正規のTSTノードまたはリーフノードとしてTCCノードを超えて、濃縮因子を監視するため、決定ツリーに基づくプロセス管理に使用するため、または代りのデータ分割スキームを適用するためにリンクされる。これらの情報アレーに基づき、次ぎの作業を有効に処理し得る:
・活性/不活性R群デコンボリューションのための位相スカフォードに対するSARプロファイリング
・スカフォードに対するベイズ統計による生体活性のためのフレームワークベース確度分析
・インプットデータのために異なるフィルターから発生したTSTに対してブール演算を適用することによる、推定偽陽性/偽陰性についてのチェック
・活性テンプレートクラス、スクリーニングプール、化合物保存書庫、HTS履歴に対するバイオプロフィルにおける特権付与スカフォードおよび購入リスト選択のためのギャップ分析
・スペクトルモーメントのような構造に対する計算グラフ不変量に基づく生体活性または物性のための(正規化)判別分析
・マハラノビス距離を介するTSTノード間の化学的距離の計算
・構造集束知識抽出のための特許構造およびSARの包含
・特異的だが構造的に異なった標的位相および官能プロトタイプ分子の3D配列のための選択、および薬物/標的相互作用の機械的分析(生体等配電子および等官能基の識別)
・活性スクリーニングヒットのためのバイオエフェクタデータベースおよび組織内分子フレームワークの比較分析(間接標的分析)
・逆合成計画および反応ライブラリ検索のためのスカフォードの使用。
特異試験系における活性および不活性化合物のための位相構造フォレスト中での化学的に意味のある位相シーケンスコード(TSC)およびモルコードの使用により、両方のデータセットにおいて対応する母集団を、それらの同一ノードタグ(TSCまたはモルコード)により容易に識別することができる。こうして、アッセイ中の活性/不活性に対する化学修飾の結果は、同一位相フレームワークに対して認定され得、次ぎのファーマコフォア分析、SARおよび構造性質分析を一般に支援する。さらなる分析を、計算化合物ディスクリプタを比較することにより、またはこれらの「クラスタ」中に存在する置換基およびヘテロ原子をさらにカテゴリー分類することにより(例えばHBドナーまたはアクセプター、イオン性酸性/塩基性基などに分類することにより)行い、両方の群(それぞれ活性/不活性)内で、共通位相フレームワークの他に化学特徴のほとんどを共有するこれらのパートナーを見出すことができる。
ファーマコフォア断片化の妥当性確認をするための代りの方法として、SIMCA法((Wold S および Sjostrom M "ケモメトリックス(Chemometrics): 理論および適用" 中, Kowalski, B.R. (編), ACS Washington, 1977)またはHQSAR法(米国特許第5751605号)を適用し得る。
あらゆるTCCノードを超えて、化学誘導体のセットDの各メンバーは、位相構造ツリー中に個々のリーフとして配置される。Dは、TCCノードより下で2つの部分群、実際に占有されている部分およびそのTCC中におけるあらゆる可能な変形物に対するその補数(complement)に、化学スペースを分割する。同じことが、TCCより上のあらゆるノードおよびその子ノード(サブツリー)に対してあてはまる。TCCの特定位相サブクラスTkにおけるあらゆる可能な修飾を、あらゆる特定位置pを事前定義された新しい郡Vpに変換するために、形式的にオペレータ:
より容易なギャップ充填は、活性および不活性化合物を比較するために同様に上記したように、存在する化学保存書庫に対するTSTと実際の購入リストとを比較することにより達成され得る。
図1は、化合物における位相分析のための選択ステップ、および例示のインプット構造1から、演算処置ステップ(I.〜VII.)、優先付けルール(1)〜(5)およびa)〜d)を、位相特徴に対する再帰的構造分割スキームにおいて適用することにより発生した中間結果を示す。Xは、任意のヘテロ原子を表す。
図1(X=任意ヘテロ原子)に示されるように処理されている化合物1のための位相シーケンスパス(TSP)の構築例。インプットデータ中に存在し得るが、まだ結び付けられていない近い位相隣接物に対する推定リンクは、双頭の破線矢印により示されており、これは、TST中における細部のあらゆる中間レベルで、可能なリンケージを示す。双頭矢印は、位相構造ツリー中の上下の移動を準備するポインター情報を示す。最低レベルの細部(TSTルート、赤8)は、一般的な六員環であり、これは、トップの優先度を有する。この中心フレームワークの周りの位相領域のこの拡張から、ルールベース優先付けスキームの後の細部レベルにより構造が拡張する。TSTノードに結び付けられる位相シーケンスコード(TSC)ラベル(赤)を、大規模データセットを通じて、および非常に複雑な位相構造フォレスト(異なるルート構造を有する異なるTSTのコレクション)を通じてナビゲートするために、グラフ(構造)の代りに使用することができる。TST中の各ノードにも分析分野を結び付けることができ、これは、サブツリー母集団、スクリーン(バイオプロフィル)のための生体データ(活性/不活性)などに対するブックキーピングアクティビティを準備する。各ノードを超えて化学変形物の実例が列挙され、これも、これらサブツリーの位相サブクラス中における実際に可能な変形物に対するそれらの可算補数により、位相ギャップおよび誘導体を定義する。TCC構造(例えば7)は、逆合成の合成計画、反応ライブラリ検索のため、および異なるスカフォード間でSARを比較するために理想のツールであると考えることができる。
文献(Wilcox R.E., Tseng T., Brusniak M.K., Ginsburg B., Pearlman R.S. Teeter M., Durand C., Starr S. および Neve K.A., 組換えD1対D2ドーパミンレセプターでのアゴニスト親和性のCoMFAベース予測, J. Med. Chem., 1998, 41, 4385-4399)から得られたドーパミンD1およびD2アゴニストセットのためのインプットデータを、図3に示す。構造は、SLN(Sybyl Line Notation, Tripos Inc. セントルイス)でコード化されているが、Sybyl Mol2ファイル、MDL Molファイル、スマイルフォーマットまたはSLNを、一般に、本明細書中で記載した本発明に基づき、組織内コンピュータープログラムを使用して位相構造ツリーを創造するために使用することができる。
図4は、本明細書中で記載した本発明に基づき、組織内コンピュータープログラムにより発生した自動製造TSFについての結果を示し、実施例3からのデータについてこの特許で記載した方法のいくつかを示す。
a)ユーザーが、合成作業のための最も有望なテンプレートの検索において、位相ツリーを通じて対話式にナビゲートすることを可能にする、
b)生体活性(または所定の他の物性スペクトル)またはテンプレート若しくはスカフォードについて誘導された統計データのいずれかのためのノード、およびサブツリー中の誘導体のための化合物ノードのプロパティをカラーコード化する、並びに
c)薬物候補ギャップの識別のために、各位相クラスタ中心に対するデータセット中に存在する利用可能な誘導体を列挙する
ようにプログラムすることができる。
ツリーリーフ(これらは、それらの化合物名または登録IDによりタグ付けされる)を除いて、位相シーケンスコード(ノードラベル)は、各構造(ツリーノード)の上に配置される。
Claims (14)
- 化合物のセット内で構造的、又は位相的及び/又は機能的ギャップについてのコンピュータによる自動的な識別のための方法であって、
a)化合物の2D-または3D-構造の分子グラフ(1)の入力を受け付けるステップ、
b)水素欠乏分子グラフ(2)を生成するステップ、
c)所定の優先順位付けのルールに逐次従って、分子グラフ内に存する位相鍵特徴と、分子グラフ(3、4、5、6)内の一致した頂点のラベル付けとの、所定のクラスとサブクラスを識別するステップ、
e)(i)分子グラフ内の全ての置換基を除去し、(ii)分子グラフ内の全てのヘテロ原子を炭素原子に変形することにより、最大の全炭素位相鍵グラフ(TCC)を創造するステップと、
g)最高順位の位相鍵特徴(8)を伴う全炭素位相鍵特徴グラフに到達するまで、最大の全炭素位相鍵グラフ(TCC)(7)から、ステップc)で識別された夫々最も低い順位の位相鍵特徴を繰り返して除去し、このことにより、夫々が前よりもより少ない位相鍵特徴しか有さない全炭素位相鍵特徴グラフ(10、9、8、7)の階層パス(TSP)を創造するステップ、
h)ステップe)の後またはステップg)の後、ステップa)の分子グラフ(1)を最大の全炭素位相鍵特徴グラフ(TCC)(7)とリンクするステップ、
i)上記化合物のセットのうちの一つ又はそれ以上の更なる化合物の2D-または3D-構造の分子グラフ(1)に対して、上記a)からh)のステップを繰り返すステップ、
j)更なる化合物についてのステップg)の階層パス(TSP)内の全炭素位相鍵特徴グラフに、前に分析された化合物についてのステップg)の階層パス(TSP)内の全炭素位相鍵特徴グラフを共有させることにより、ツリー状構造(TST)を創造するステップ、及び、
k)更なる化合物が、前に分析された化合物についてのステップg)の階層パス(TSP)内の全炭素位相鍵特徴グラフと共通して、ステップg)の階層パス(TSP)内に全炭素位相鍵特徴グラフを有さない場合に、更なるツリー状構造(TST)を創造することによって、フォレスト状構造(TSF)を成長させるステップ
を含み、
I)ステップg)の階層パス(TSP)内の任意の全炭素位相鍵特徴グラフ(10、9、8)の位相鍵特徴を修正するステップ、及び、
II)修正によって生じた化合物の分子グラフ(1、2)を、既存の分子グラフ(1、2)と比較することによって、位相的及び機能的ギャップを識別するステップ
を含む
方法。 - ステップe)にて、分子グラフ内の全ての分子鎖を除去することを、更に含むことを特徴とする請求項1に記載の方法。
- ステップg)の全炭素位相鍵特徴グラフ(10、9、8)に従って、個々の分子グラフ(1)に対して位相鍵特徴から階層構造ラインコード(TSC)を創造し、それを最大の全炭素位相鍵特徴グラフ(TCC)(7)とリンクするステップを
更に含むことを特徴とする請求項1に記載の方法。 - ステップg)の階層パス内の対応する全炭素位相鍵特徴グラフ(10、9、8)に関して、若しくは、対応する階層構造ラインコード(TSC)に対して、ブール演算を適用し、実際に共有する位相鍵特徴を様々な分子グラフ(1)内で識別するステップを含む、請求項1乃至3のいずれか一に記載の方法。
- ツリー状構造(TST)及び/又はフォレスト状構造(TSF)をグラフ的に視覚化するステップを、更に含むことを特徴とする請求項1乃至4のいずれか一に記載の方法。
- ステップg)の階層パス(TSP)内の全炭素位相鍵特徴グラフ(10、9、8)を各々標識付ける表示ネームタグを、創造するステップを、更に含むことを特徴とする請求項1乃至5のいずれか一に記載の方法。
- 位相鍵特徴が、環、リンカー、ヘテロ原子、置換基および/または非環式鎖から本質的になる群から選ばれる1個または数個の位相クラスを含むことを特徴とする請求項1乃至6のいずれか一に記載の方法。
- 位相鍵特徴が、環のサイズ若しくは長さ、リンカー及び分子鎖、原子価、ヘテロ原子の数、ドナー/アクセプター性、正/負電荷、並びに、酸性/塩基性基を含む群から選択される一つ若しくはそれ以上の位相サブクラスを含むことを特徴とする請求項1乃至7に記載の方法。
- ステップc)の位相鍵特徴クラスの順位付けを、発見的ルール:環>リンカー>ヘテロ原子>置換基>分子鎖、により優先度を減少させることで定義することを特徴とする請求項7又は8に記載の方法。
- ステップg)の位相鍵特徴のクラス内およびクラス間順位付けが、
A)位相鍵特徴のサブクラスの相対重要度(importance)を、置換度に関して順位付けするステップ、及び、
B)特異フラグメント中のあらゆる特定の化学修飾の有意度(significance)を評価するための基準を、フラグメントのために、空間3D-コンフォメーションにおけるフラグメントサイズおよび幾何柔軟度に関して導くステップ
を含むことを特徴とする請求項1〜9のいずれかに記載の方法。 - ステップg)の階層パス(TSP)内の全炭素位相鍵特徴グラフ(10、9、8)の構造、及びそれらの表示ネームタグを、一種若しくはそれ以上の生物学的標的または測定若しくは計算されたプロパティ/ディスクリプタで生体活性試験をするための統計データにリンクするステップを、更に含むことを特徴とする請求項6乃至10のいずれか一に記載の方法。
- 構造を色付け、及び/又は、
ツリー状構造内のステップg)の階層パス(TSP)内の全炭素位相鍵特徴グラフ(10、9、8)の構造を再配置し、及び/又は、
ステップg)の階層パス(TSP)内の全炭素位相鍵特徴グラフ(10、9、8)及びそれらの表示ネームタグの構造にリンクされる統計データ若しくはプロパティ/ディスクリプタに基づいて、構造、下位構造および/または分類データ群間のディスクリプタベース化学的距離を測定する
ステップを、更に含むことを特徴とする請求項11に記載の方法。 - ステップg)の階層パス(TSP)内の全炭素位相鍵特徴グラフ(10、9、8)のカラースペクトルをマッピングし、
ステップg)の階層パス(TSP)内の全炭素位相鍵特徴グラフ(10、9、8)及びそれらの表示ネームタグの構造にリンクされる統計データ若しくはプロパティ/ディスクリプタに基づいて、分子スカフォード、位相フラグメトおよび化学誘導体中に存在する標的配向可能性を定量する着色ツリー状構造(TST)及びフォレスト状構造(TSF)を生成することを特徴とする請求項12に記載の方法。 - 統計データが、度数分布、確率および/または濃縮係数であり得ることを特徴とする請求項11乃至13のいずれか一に記載の方法。
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| GBGB0106441.9A GB0106441D0 (en) | 2001-03-15 | 2001-03-15 | Method for generating a hierarchical topological tree of 2D or 3D-structural formulas of chemical compounds for property optimization of chemical compounds |
| PCT/EP2002/002685 WO2002074035A2 (en) | 2001-03-15 | 2002-03-12 | Method for generating a hierarchical topological tree of 2d or 3d-structural formulas of chemical compounds for property optimisation of chemical compounds |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2004537085A JP2004537085A (ja) | 2004-12-09 |
| JP4328532B2 true JP4328532B2 (ja) | 2009-09-09 |
Family
ID=9910770
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2002572763A Expired - Fee Related JP4328532B2 (ja) | 2001-03-15 | 2002-03-12 | 化合物の性質最適化のための2dまたは3d−化合物構造式の階層位相ツリーを発生させるための方法 |
Country Status (7)
| Country | Link |
|---|---|
| US (2) | US20040088118A1 (ja) |
| EP (1) | EP1405247A2 (ja) |
| JP (1) | JP4328532B2 (ja) |
| AU (1) | AU2002256662A1 (ja) |
| CA (1) | CA2440819A1 (ja) |
| GB (1) | GB0106441D0 (ja) |
| WO (1) | WO2002074035A2 (ja) |
Families Citing this family (35)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US7801684B2 (en) * | 2005-04-22 | 2010-09-21 | Syngenta Participations Ag | Methods, systems, and computer program products for producing theoretical mass spectral fragmentation patterns of chemical structures |
| WO2006124287A2 (en) * | 2005-05-02 | 2006-11-23 | Brown University | Importance ranking for a hierarchical collection of objects |
| JP5075362B2 (ja) * | 2005-07-05 | 2012-11-21 | 智久 石川 | 化合物の生理活性の定量的予測方法 |
| EP1762954B1 (en) * | 2005-08-01 | 2019-08-21 | F.Hoffmann-La Roche Ag | Automated generation of multi-dimensional structure activity and structure property relationships |
| EP2180435A4 (en) * | 2007-08-22 | 2011-01-05 | Fujitsu Ltd | CONNECTIVE PROPERTY PREDICTIVE DEVICE, PROPERTY PRESENCE METHOD AND PROGRAM FOR CARRYING OUT THE METHOD |
| US8236849B2 (en) * | 2008-10-15 | 2012-08-07 | Ohio Northern University | Model for glutamate racemase inhibitors and glutamate racemase antibacterial agents |
| US9123003B2 (en) * | 2011-06-15 | 2015-09-01 | Hewlett-Packard Development Company, L.P. | Topologies corresponding to models for hierarchy of nodes |
| US9977876B2 (en) | 2012-02-24 | 2018-05-22 | Perkinelmer Informatics, Inc. | Systems, methods, and apparatus for drawing chemical structures using touch and gestures |
| US10168885B2 (en) * | 2012-03-21 | 2019-01-01 | Zymeworks Inc. | Systems and methods for making two dimensional graphs of complex molecules |
| US9535583B2 (en) * | 2012-12-13 | 2017-01-03 | Perkinelmer Informatics, Inc. | Draw-ahead feature for chemical structure drawing applications |
| US8854361B1 (en) | 2013-03-13 | 2014-10-07 | Cambridgesoft Corporation | Visually augmenting a graphical rendering of a chemical structure representation or biological sequence representation with multi-dimensional information |
| US9751294B2 (en) | 2013-05-09 | 2017-09-05 | Perkinelmer Informatics, Inc. | Systems and methods for translating three dimensional graphic molecular models to computer aided design format |
| US10372713B1 (en) | 2014-07-10 | 2019-08-06 | Purdue Pharma L.P. | Chemical formula extrapolation and query building to identify source documents referencing relevant chemical formula moieties |
| US20160092595A1 (en) * | 2014-09-30 | 2016-03-31 | Alcatel-Lucent Usa Inc. | Systems And Methods For Processing Graphs |
| CN104392253B (zh) * | 2014-12-12 | 2017-05-10 | 南京大学 | 一种草图数据集的交互式类别标注方法 |
| US10192020B1 (en) | 2016-09-30 | 2019-01-29 | Cadence Design Systems, Inc. | Methods, systems, and computer program product for implementing dynamic maneuvers within virtual hierarchies of an electronic design |
| US10210299B1 (en) | 2016-09-30 | 2019-02-19 | Cadence Design Systems, Inc. | Methods, systems, and computer program product for dynamically abstracting virtual hierarchies for an electronic design |
| US10282505B1 (en) * | 2016-09-30 | 2019-05-07 | Cadence Design Systems, Inc. | Methods, systems, and computer program product for implementing legal routing tracks across virtual hierarchies and legal placement patterns |
| EP3590056A1 (en) | 2017-03-03 | 2020-01-08 | Perkinelmer Informatics, Inc. | Systems and methods for searching and indexing documents comprising chemical information |
| JP7006297B2 (ja) * | 2018-01-19 | 2022-01-24 | 富士通株式会社 | 学習プログラム、学習方法および学習装置 |
| US11093842B2 (en) | 2018-02-13 | 2021-08-17 | International Business Machines Corporation | Combining chemical structure data with unstructured data for predictive analytics in a cognitive system |
| JP7133534B2 (ja) * | 2019-11-14 | 2022-09-08 | 株式会社 ディー・エヌ・エー | 化合物の構造を自動生成するための化合物構造自動生成装置、化合物構造自動生成プログラム及び化合物構造自動生成方法 |
| US20210287765A1 (en) * | 2020-03-13 | 2021-09-16 | Collaborative Drug Discovery, Inc. | Systems and methods for generating and searching a chemical compound database |
| CN111899807B (zh) * | 2020-06-12 | 2024-05-28 | 中国石油天然气股份有限公司 | 一种分子结构生成方法、系统、设备及存储介质 |
| US12597492B2 (en) * | 2020-11-23 | 2026-04-07 | International Business Machines Corporation | Topology-driven completion of chemical data |
| US12511869B2 (en) | 2020-12-16 | 2025-12-30 | Ro5 Inc. | System and method for pharmacophore-conditioned generation of molecules |
| CN112735540B (zh) * | 2020-12-18 | 2024-01-05 | 深圳先进技术研究院 | 一种分子优化方法、系统、终端设备及可读存储介质 |
| US12265562B1 (en) * | 2021-03-12 | 2025-04-01 | Accencio LLC | System and method for evaluating data using and applying a virtual landscape |
| CN113434619B (zh) * | 2021-06-25 | 2024-06-04 | 南京领航交通科技有限公司 | 一种4g的高速公路智能交通路况监控系统 |
| CN116264106A (zh) * | 2021-12-14 | 2023-06-16 | 中国科学院大连化学物理研究所 | 化学反应规则库的生成方法及生成化学反应网络的方法 |
| CN114446413B (zh) * | 2022-02-17 | 2024-05-28 | 北京百度网讯科技有限公司 | 一种分子性质预测方法、装置及电子设备 |
| CN114722247B (zh) * | 2022-04-11 | 2025-10-24 | 苏州创腾软件有限公司 | 基于化学编辑器的化合物名称生成方法及装置 |
| US12587274B2 (en) | 2023-03-28 | 2026-03-24 | Quantum Generative Materials Llc | Satellite optimization management system based on natural language input and artificial intelligence |
| US12368503B2 (en) | 2023-12-27 | 2025-07-22 | Quantum Generative Materials Llc | Intent-based satellite transmit management based on preexisting historical location and machine learning |
| US12603701B2 (en) | 2023-12-27 | 2026-04-14 | Quantum Generative Materials Llc | Distributed satellite constellation management and control system |
Family Cites Families (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US4642762A (en) * | 1984-05-25 | 1987-02-10 | American Chemical Society | Storage and retrieval of generic chemical structure representations |
-
2001
- 2001-03-15 GB GBGB0106441.9A patent/GB0106441D0/en not_active Ceased
-
2002
- 2002-03-12 AU AU2002256662A patent/AU2002256662A1/en not_active Abandoned
- 2002-03-12 WO PCT/EP2002/002685 patent/WO2002074035A2/en not_active Ceased
- 2002-03-12 US US10/472,028 patent/US20040088118A1/en not_active Abandoned
- 2002-03-12 EP EP02726157A patent/EP1405247A2/en not_active Ceased
- 2002-03-12 JP JP2002572763A patent/JP4328532B2/ja not_active Expired - Fee Related
- 2002-03-12 CA CA002440819A patent/CA2440819A1/en not_active Abandoned
-
2006
- 2006-10-27 US US11/588,894 patent/US20070043511A1/en not_active Abandoned
Also Published As
| Publication number | Publication date |
|---|---|
| CA2440819A1 (en) | 2002-09-26 |
| WO2002074035A3 (en) | 2004-01-29 |
| WO2002074035A2 (en) | 2002-09-26 |
| US20070043511A1 (en) | 2007-02-22 |
| GB0106441D0 (en) | 2001-05-02 |
| AU2002256662A1 (en) | 2002-10-03 |
| US20040088118A1 (en) | 2004-05-06 |
| EP1405247A2 (en) | 2004-04-07 |
| JP2004537085A (ja) | 2004-12-09 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP4328532B2 (ja) | 化合物の性質最適化のための2dまたは3d−化合物構造式の階層位相ツリーを発生させるための方法 | |
| US6904423B1 (en) | Method and system for artificial intelligence directed lead discovery through multi-domain clustering | |
| US6813615B1 (en) | Method and system for interpreting and validating experimental data with automated reasoning | |
| Deshpande et al. | Frequent substructure-based approaches for classifying chemical compounds | |
| Walters et al. | Prediction of ‘drug-likeness’ | |
| US6768982B1 (en) | Method and system for creating and using knowledge patterns | |
| Wawer et al. | Local structural changes, global data views: graphical substructure− activity relationship trailing | |
| Harper et al. | Methods for mining HTS data | |
| US20050177280A1 (en) | Methods and systems for discovery of chemical compounds and their syntheses | |
| US20040117164A1 (en) | Method and system for artificial intelligence directed lead discovery in high throughput screening data | |
| Stumpfe et al. | Methods for SAR visualization | |
| Varin et al. | Compound set enrichment: a novel approach to analysis of primary HTS data | |
| Leland et al. | Managing the combinatorial explosion | |
| Kruger et al. | Automated identification of chemical series: classifying like a medicinal chemist | |
| Medina‐Franco et al. | Consensus models of activity landscapes | |
| Flower | DISSIM: a program for the analysis of chemical diversity | |
| Zhang et al. | AnalogExplorer: A New Method for Graphical Analysis of Analog Series and Associated Structure–activity Relationship Information | |
| Ertl et al. | The scaffold tree: an efficient navigation in the scaffold universe | |
| Klein et al. | Scaffold hunter: facilitating drug discovery by visual analysis of chemical space | |
| Kayastha et al. | From bird’s eye views to molecular communities: two-layered visualization of structure–activity relationships in large compound data sets | |
| WO2002021423A2 (en) | Method and system for obtaining knowledge based recommendations | |
| Jancura et al. | Dividing protein interaction networks for modular network comparative analysis | |
| Swanson | The Entrance of Informatics into | |
| Tandon | Deep painting: cheminformatics approaches to connect the biological profiles of compounds with their structural information | |
| Chen | Substructure and maximal common substructure searching |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20050307 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20080129 |
|
| A601 | Written request for extension of time |
Free format text: JAPANESE INTERMEDIATE CODE: A601 Effective date: 20080430 |
|
| A602 | Written permission of extension of time |
Free format text: JAPANESE INTERMEDIATE CODE: A602 Effective date: 20080509 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20080729 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20081028 |
|
| A601 | Written request for extension of time |
Free format text: JAPANESE INTERMEDIATE CODE: A601 Effective date: 20090128 |
|
| A602 | Written permission of extension of time |
Free format text: JAPANESE INTERMEDIATE CODE: A602 Effective date: 20090204 |
|
| A601 | Written request for extension of time |
Free format text: JAPANESE INTERMEDIATE CODE: A601 Effective date: 20090302 |
|
| A602 | Written permission of extension of time |
Free format text: JAPANESE INTERMEDIATE CODE: A602 Effective date: 20090309 |
|
| A601 | Written request for extension of time |
Free format text: JAPANESE INTERMEDIATE CODE: A601 Effective date: 20090327 |
|
| A602 | Written permission of extension of time |
Free format text: JAPANESE INTERMEDIATE CODE: A602 Effective date: 20090403 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20090428 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20090602 |
|
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20090615 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20120619 Year of fee payment: 3 |
|
| R150 | Certificate of patent or registration of utility model |
Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20120619 Year of fee payment: 3 |
|
| S111 | Request for change of ownership or part of ownership |
Free format text: JAPANESE INTERMEDIATE CODE: R313113 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20120619 Year of fee payment: 3 |
|
| R350 | Written notification of registration of transfer |
Free format text: JAPANESE INTERMEDIATE CODE: R350 |
|
| LAPS | Cancellation because of no payment of annual fees |