以下、本発明の実施の形態における画像復号化装置について図面を参照しながら説明する。
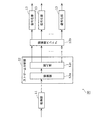
図1は、本発明の実施の形態における画像復号化装置の構成を示すブロック図である。
本発明の実施の形態における画像復号化装置100は、簡単な構成で復号化の並列処理を適切に実行する装置であって、デコーダ110とメモリ150とを備えている。
メモリ150は、デコーダ110に入力されるデータ、デコーダ110により中間的に生成されたデータ、およびデコーダ110により最終的に生成されて出力されるデータを記憶するための領域を有する。
具体的には、メモリ150は、ストリームバッファ151と、分割ストリームバッファ152と、フレームメモリ153とを備えている。
ストリームバッファ151には、画像符号化装置により生成されて送信された符号化ストリームが格納される。つまり、本実施の形態では、このストリームバッファ151が符号化ストリームを取得する取得部として構成されている。分割ストリームバッファ152には、デコーダ110により生成されるN個の分割ストリームが、上述の中間的に生成されたデータとして格納される。フレームメモリ153には、N個のデコードエンジン(復号化部)120によって生成されたN個の分割復号画像データが、上述の最終的に生成されて出力されるデータとして格納される。なお、復号画像データは、フレームメモリ153に格納され、表示装置に読み込まれて動画像として表示される。
デコーダ110は、メモリ150のストリームバッファ151に格納されている符号化ストリームを読み出して復号化することによって復号画像データを生成し、その復号画像データをメモリ150のフレームメモリ153に格納する。また、このデコーダ110は、ストリーム分割部130と、N個のデコードエンジン(第1デコードエンジン〜第Nデコードエンジン)120とを備えている。
なお、本実施の形態におけるデコードエンジン120は、HDの画像(1920×1088画素、60i)を2チャンネル分復号可能な処理能力を有する。
ストリーム分割部130は、後述するモード情報を取得し、そのモード情報に応じて符号化ストリームをN個の分割ストリーム(第1分割ストリーム〜第N分割ストリーム)に分割する。つまり、本実施の形態におけるストリーム分割部130は、符号化ストリームに含まれる符号化されたピクチャごとに、そのピクチャを複数のMBラインに分割する。そして、ストリーム分割部130は、それらの複数のMBラインのそれぞれを、生成対象であるN個の分割ストリームのうちの何れかの一部に割り当てることにより、N個の分割ストリームを生成する。
なお、MBラインは、ピクチャの左端から右端まで水平方向に配列された複数のマクロブロックからなる列を1つ有する構成単位である。また、ストリーム分割部130は、ピクチャがMBAFF(マクロブロックアダプティブフレームフィールド)で構成されていない場合には、ピクチャを複数のMBラインに分割するが、ピクチャがMBAFFで構成されている場合には、2つのMBラインを1つの構成単位(以下、MBラインペアという)として扱い、ピクチャを複数のMBラインペアに分割する。言い換えれば、ストリーム分割部130は、ピクチャがMBAFFで構成されている場合には、ピクチャを複数のMBラインに分割し、MBラインペアに属する2つのMBラインをそれぞれ同一の分割ストリームの一部に割り当てる。以下、ピクチャがMBAFFで構成されていないことを前提にして本発明を説明するが、本発明において、ピクチャがMBAFFで構成されていない場合と、MBAFFで構成されている場合とで異なる処理が必要なときには、その都度、MBAFFに対して特有の処理を説明する。また、MBAFFに対してその特有な処理などが必要とされない場合には、以下の説明において、MBラインをMBラインペアに置き換えることによって、その説明を、ピクチャがMBAFFで構成されている場合における本発明の説明に置き換えることができる。
ストリーム分割部130は、ピクチャを複数のMBラインに分割する際に、符号化ストリーム中のMBラインの直前、または、そのMBラインに属する2つのマクロブロックの間に、ヘッダがあれば、そのヘッダをそのMBラインに付随させて、分割ストリームの一部に割り当てる。
このようなストリーム分割部130によるMBラインごとの分割によって、ピクチャに含まれる、複数のMBラインにわたって配置されるスライスは分割されることになる。また、ストリーム分割部130は、N個の分割ストリームに分割するときには、N個の分割ストリームのそれぞれに跨るマクロブロック間の可変長復号処理における依存関係を除去しておく。
N個のデコードエンジン120は、それぞれ自らが処理すべき分割ストリームを分割ストリームバッファ152から読み出し、読み出した分割ストリームを並列に復号化することによりN個の分割復号画像データを生成する。例えば、第1デコードエンジン120は第1分割ストリームを分割ストリームバッファ152から読み出し、第2デコードエンジン120は第2分割ストリームを分割ストリームバッファ152から読み出し、第3デコードエンジン120は第3分割ストリームを分割ストリームバッファ152から読み出し、第4デコードエンジン120は第4分割ストリームを分割ストリームバッファ152から読み出す。そして、第1デコードエンジン120〜第4デコードエンジン120はそれぞれ第1分割ストリーム〜第4分割ストリームを並列に復号化する。
また、N個のデコードエンジン120は、分割ストリームを復号化するときには、フレームメモリ153に既に格納されている復号画像データを参照し、必要に応じて動き補償を行うことによって分割ストリームを復号化する。
さらに、N個のデコードエンジン120のそれぞれは、分割ストリームに含まれる画面内予測により符号化されたマクロブロックを復号化するときには、その復号化対象マクロブロックの左上、上および右上にあるマクロブロックを復号化したデコードエンジン120から、それらの復号化されたマクロブロックの情報を隣接MB情報として取得する。その隣接MB情報を取得したデコードエンジン120は、その隣接MB情報を用いて、復号化対象マクロブロックを復号化する。また、デコードエンジン120は、例えばデブロッキングフィルタ処理や動きベクトル予測処理を行う場合にも、上述と同様に、処理対象のマクロブロックの左上、上および右上にある復号化されたマクロブロックの情報を隣接MB情報として取得して、上述の処理を行う。
なお、本実施の形態では、説明を簡単にするために、以下、NをN=4として説明する。また、本実施の形態では、N(N=4)個のデコードエンジン120はそれぞれ、復号化対象のマクロブロックから見て、左、左上、上、および右上のマクロブロックの復号化が終了すると、それらの隣接MB情報を用いて、その復号化対象のマクロブロックの復号化を開始する。その結果、第1デコードエンジン120〜第4デコードエンジン120はそれぞれ、各MBラインにおいて水平方向に互いに異なる位置にあるマクロブロックを並列に復号化する。
図2Aは、ピクチャがMBAFFで構成されていない場合の復号化の順序を示す図である。
ピクチャがMBAFFで構成されていない場合、第1デコードエンジン120は第0MBラインを復号化し、第2デコードエンジン120が第1MBラインを復号化し、第3デコードエンジン120が第2MBラインを復号化し、第4デコードエンジン120が第3MBラインを復号化する。なお、第k(kは0以上の整数)MBラインは、ピクチャの上端からk番目にあるMBラインを示し、例えば、第0MBラインは、ピクチャの上端から0番目にあるMBラインである。
ここで、ピクチャの復号化が開始されるときには、まず、第1デコードエンジン120が第0MBラインの復号化を開始する。次に、第0MBラインの左端にある2つのマクロブロックの復号化が完了すると、第2デコードエンジン120が第1MBラインの左端のマクロブロックの復号化を開始する。そして、第1MBラインの左端にある2つのマクロブロックの復号化が完了すると、第3デコードエンジン120が第2MBラインの左端のマクロブロックの復号化を開始する。同様に、第2MBラインの左端にある2つのマクロブロックの復号化が完了すると、第4デコードエンジン120が第3MBラインの左端のマクロブロックの復号化を開始する。
したがって、第(k+1)MBラインは、第kMBラインに比べて、2マクロブロック分だけ遅れて、左端のマクロブロックから右端のマクロブロックまで復号化される。
図2Bは、ピクチャがMBAFFで構成されている場合の復号化の順序を示す図である。
ピクチャがMBAFFで構成されている場合、MBラインペアは、上述のように、ピクチャの左端から右端まで水平方向に配列された複数のマクロブロックからなる列(MBライン)を2つ有する構成単位である。MBラインペアは、上下にある2つのマクロブロック(マクロブロックペア)ごとにフィールド符号化されている。なお、マクロブロックペアでは、まず上のマクロブロックが復号化され、次に、下のマクロブロックが復号化される。この場合にも、ピクチャがMBAFFで構成されていない場合と同様に、第1デコードエンジン120は第0MBラインペアを復号化し、第2デコードエンジン120が第1MBラインペアを復号化し、第3デコードエンジン120が第2MBラインペアを復号化し、第4デコードエンジン120が第3MBラインペアを復号化する。なお、第k(kは0以上の整数)MBラインペアは、ピクチャの上端からk番目にある2つのMBラインからなる構成単位を示し、例えば、第0MBラインは、ピクチャの上端から0番目にある2つのMBラインからなる構成単位である。
ここで、ピクチャの復号化が開始されるときには、まず、第1デコードエンジン120が第0MBラインペアの復号化を開始する。次に、第0MBラインペアの左端にある2つのマクロブロックペアの復号化が完了すると、第2デコードエンジン120が第1MBラインペアの左上端のマクロブロックの復号化を開始する。そして、第1MBラインペアの左端にある2つのマクロブロックペアの復号化が完了すると、第3デコードエンジン120が第2MBラインペアの左上端のマクロブロックの復号化を開始する。同様に、第2MBラインペアの左端にある2つのマクロブロックペアの復号化が完了すると、第4デコードエンジン120が第3MBラインペアの左上端のマクロブロックの復号化を開始する。
したがって、第(k+1)MBラインペアは、第kMBラインペアに比べて、2マクロブロックペア分だけ遅れて、左端のマクロブロックペアから右端のマクロブロックペアまで復号化される。
なお、ピクチャがMBAFFで構成されていない場合、および、ピクチャがMBAFFで構成されている場合のそれぞれにおいて、第(k+1)MBラインまたは第(k+1)MBラインペアは、第kMBラインまたは第kMBラインペアに比べて、少なくとも2マクロブロック分または2マクロブロックペア分だけ遅れて復号化されればよい。つまり、3マクロブロック分または3マクロブロックペア分以上遅れて復号化されてもよい。例えば、第(k+1)MBラインまたは第(k+1)MBラインペアが、第kMBラインまたは第kMBラインペアに比べて、2マクロブロック分または2マクロブロックペア分だけ遅れて復号化される場合には、ピクチャの復号化にかかる時間を最短にすることができ、3マクロブロック分または3マクロブロックペア分以上遅れて復号化される場合には、その遅れる分量に応じてピクチャの復号化にかかる時間が長くなる。
このような本実施の形態における画像復号化装置100の特徴は、ストリーム分割部130による分割によって生成された、スライスの1つまたは複数の部分(スライス部分)からなるスライス部分群を1つの新たなスライスとして再構成することである。スライスの再構成は、スライスヘッダの挿入処理、スライス終端処理、およびMBアドレス情報の更新処理を含む。
図3は、スライスヘッダの挿入処理を説明するための説明図である。
例えば、ストリーム分割部130は、図3の(a)に示すピクチャp1を分割する。
ピクチャp1は、スライスA、スライスBおよびスライスCから構成されているとともに、MBラインL1〜L12から構成されている。
スライスAは、MBラインL1〜L7にわたって配置され、スライスヘッダhaと、そのスライスヘッダhaから連続して配置されている複数のマクロブロックmbaとを有する。スライスBは、MBラインL7〜L8にわたって配置され、スライスヘッダhbと、そのスライスヘッダhbから連続して配置されている複数のマクロブロックmbbとを有する。スライスCは、MBラインL9〜L12にわたって配置され、スライスヘッダhcと、そのスライスヘッダhcから連続して配置されている複数のマクロブロックmbcとを有する。なお、スライスヘッダには、そのスライスヘッダを有するスライスの復号化に必要な補助情報が含まれている。
ストリーム分割部130は、図3の(b)に示すように、上述のピクチャp1をMBラインごとに分割する。そして、ストリーム分割部130は、MBラインL1〜L12のそれぞれを先頭から順に、第1分割ストリーム〜第4分割ストリームの何れかの一部に割り当てる。例えば、ストリーム分割部130は、MBラインL1を第1分割ストリームの一部に割り当て、MBラインL2を第2分割ストリームの一部に割り当て、MBラインL3を第3分割ストリームの一部に割り当て、MBラインL4を第4分割ストリームの一部に割り当てる。そして、ストリーム分割部130は、第4分割ストリームへのMBラインの割り当てが終了すると、第1分割ストリームへのMBラインの割り当てを繰り返す。つまり、ストリーム分割部130は、MBラインL5を第1分割ストリームの一部に割り当て、MBラインL6を第2分割ストリームの一部に割り当て、MBラインL7を第3分割ストリームの一部に割り当て、MBラインL8を第4分割ストリームの一部に割り当てる。
その結果、第1分割ストリームは連続するMBラインL1,L5,L9を含み、第2分割ストリームは連続するMBラインL2,L6,L10を含み、第3分割ストリームは連続するMBラインL3,L7,L11を含み、第4分割ストリームは連続するMBラインL4,L8,L12を含む。
なお、MBラインL1〜L6と、MBラインL7の先頭側の6マクロブロックからなる集合と、MBラインL7の終端側の10マクロブロックからなる集合と、MBラインL8〜L12とは、それぞれスライスA〜Cの一部を構成するスライス部分である。そして、第1分割ストリームでは、スライスAのスライス部分であるMBラインL1,L5からスライス部分群(第1分割ストリームにおけるスライスA)が構成される。また、第2分割ストリームでは、スライスAのスライス部分であるMBラインL2,L6からスライス部分群(第2分割ストリームにおけるスライスA)が構成される。
ここで、単純にMBラインを分割ストリームに割り当てるだけでは、分割ストリームに含まれるスライスを適切にデコードエンジン120に認識させることができない場合がある。
例えば、第1分割ストリームには、上述のように連続するMBラインL1,L5,L9が含まれている。この場合、MBラインL1,L5はスライスAとして認識されるべきであり、MBラインL9はスライスCとして認識されるべきである。そのためには、第1分割ストリームにおいてスライスAの先頭となるべきMBラインL1の先頭にスライスAのスライスヘッダhaが配置されている必要があり、第1分割ストリームにおいてスライスCの先頭となるべきMBラインL9の先頭にスライスCのスライスヘッダhcが配置されている必要がある。図3に示す例では、スライスヘッダha,hcがそれぞれMBラインL1,L9の先頭に予め配されているため、ストリーム分割部130はMBラインL1,L5,L9をスライスヘッダha,hcとともに第1分割ストリームに割り当てればよい。
一方、第2分割ストリームには、上述のように連続するMBラインL2,L6,L10が含まれている。この場合、MBラインL2,L6はスライスAとして認識されるべきであり、MBラインL10はスライスCとして認識されるべきである。そのためには、第2分割ストリームにおいてスライスAの先頭となるべきMBラインL2の先頭にスライスAのスライスヘッダhaが配置されている必要があり、第2分割ストリームにおいてスライスCの先頭となるべきMBラインL10の先頭にスライスCのスライスヘッダhcが配置されている必要がある。
そこで、本実施の形態におけるストリーム分割部130は、MBラインを分割ストリームの一部に割り当てるときには、必要に応じてスライスヘッダha,hb,hcを複製することにより複製スライスヘッダha’,hb’,hc’を生成し、それらを分割ストリームに挿入する。
例えば、ストリーム分割部130は、スライスヘッダhaを複製することにより3つの複製スライスヘッダha’を生成し、その複製スライスヘッダha’をMBラインL2,L3,L4の直前に挿入する。さらに、ストリーム分割部130は、スライスヘッダhbを複製することにより1つの複製スライスヘッダhb’を生成し、その複製スライスヘッダhb’をMBラインL8の直前に挿入する。さらに、ストリーム分割部130は、スライスヘッダhcを複製することにより3つの複製スライスヘッダhc’を生成し、その複製スライスヘッダhc’をMBラインL10,L11,L12の直前に挿入する。
その結果、第2分割ストリームでは、スライスAの先頭となるMBラインL2の直前に、スライスAのスライスヘッダhaの複製である複製スライスヘッダha’が配置され、スライスCの先頭となるMBラインL10の直前に、スライスCのスライスヘッダhcの複製である複製スライスヘッダhc’が配置される。これにより、第2デコードエンジン120は、複製スライスヘッダha’,hc’から、第2分割ストリームのスライスAおよびスライスCのそれぞれの復号化に必要なパラメータを得ることができる。
次に、MBアドレス情報の更新処理について説明する。
ストリーム分割部130は、上述のように複製スライスヘッダを分割ストリームに挿入するときには、挿入される位置に応じて、複製スライスヘッダに含まれているMBアドレス情報を更新する。
つまり、符号化ストリームに含まれるピクチャを構成する各スライスのスライスヘッダには、そのスライスの先頭マクロブロックの上記ピクチャ内におけるアドレスを特定するためのMBアドレス情報“first_mb_in_slice”が含まれている。したがって、このようなスライスヘッダが複製されることによって生成された複製スライスヘッダには、当初、複製元のスライスヘッダのMBアドレス情報と同一のMBアドレス情報が含まれている。その結果、このような複製スライスヘッダが、ピクチャ内において複製元のスライスヘッダと異なる位置に挿入されれば、その複製スライスヘッダのMBアドレス情報により特定されるアドレスは、誤ったアドレスを指し示していることになる。つまり、複製スライスヘッダのMBアドレス情報により特定されるアドレスは、分割ストリームにおいてその複製スライスヘッダを有するスライスの先頭マクロブロックの上記ピクチャ内におけるアドレスを指し示さず、複製元のスライスヘッダを有するスライスの先頭マクロブロックのアドレスを指し示している。
例えば、ピクチャp1のスライスAのスライスヘッダhaには、そのスライスAの先頭マクロブロック(MBラインL1の先頭マクロブロック)のピクチャp1内におけるアドレスを示すMBアドレス情報が含まれている。このようなスライスヘッダhaが複製されることによって生成された複製スライスヘッダha’には、当初、MBラインL1の先頭マクロブロックのピクチャp1内におけるアドレスを特定するためのMBアドレス情報が含まれている。その結果、このような複製スライスヘッダha’が、MBラインL2の直前に挿入されれば、その複製スライスヘッダha’のMBアドレス情報により特定されるアドレスは、第2分割ストリームにおいてその複製スライスヘッダha’を有するスライスAの先頭マクロブロック(MBラインL2の先頭マクロブロック)のピクチャp1内におけるアドレスを指し示さず、MBラインL1の先頭マクロブロックのアドレスを指し示している。
そこで、本実施の形態におけるストリーム分割部130は、上述のように、複製スライスヘッダに含まれているMBアドレス情報を更新する。
図4は、MBアドレス情報の更新処理を説明するための説明図である。
ストリーム分割部130は、まず、符号化ストリームに含まれているSPS(シーケンスパラメータセット)から、ピクチャの水平方向のマクロブロックの数に関連する情報である“pic_width_in_mbs_minus1”を取得する。
さらに、ストリーム分割部130は、複製元のスライスヘッダに含まれるMBアドレス情報“first_mb_in_slice”を用いて、その複製元のスライスヘッダを有するスライスの先頭マクロブロックのアドレスを算出する。
次に、ストリーム分割部130は、算出された先頭マクロブロックのアドレスに基づいて、その先頭マクロブロックがピクチャ内において何行目のMBラインにあるかを示す値“mbposv”を算出する。なお、値“mbposv”は0以上の整数である。
そして、ストリーム分割部130は、直前に複製スライスヘッダが挿入されるMBラインが、複製元のスライスヘッダが配置されているMBラインから見てn行離れているときには、複製スライスヘッダのMBアドレス情報を“first_mb_in_slice[n]”=(“mbposv”+n)×(“pic_width_in_mbs_minus1”+1)により算出する。
なお、ピクチャがMBAFF(マクロブロックアダプティブフレームフィールド)で構成されている場合には、ストリーム分割部130は、複製スライスヘッダのMBアドレス情報を“first_mb_in_slice[n]”=(“mbposv”/2+n)×(“pic_width_in_mbs_minus1”+1)により算出する。
ストリーム分割部130は、複製スライスヘッダに当初含まれているMBアドレス情報を、上述のように算出されたMBアドレス情報に更新する。これにより、複製スライスヘッダのMBアドレス情報により特定されるアドレスは、分割ストリームにおいてその複製スライスヘッダを有するスライスの先頭マクロブロックのピクチャ内におけるアドレスを正しく指し示す。
次に、スライス終端処理について説明する。
符号化ストリームに含まれるピクチャを構成する各スライスの終端には、そのスライスの終端であることを示すスライス終端情報が設定されている。したがって、図3に示すように、単純に、ピクチャが複数のMBラインに分割され、その複数のMBラインがそれぞれ第1分割ストリーム〜第4分割ストリームの何れかの一部に割り当てられる場合には、分割ストリームに含まれるスライスの終端を適切にデコードエンジン120に認識させることができない場合がある。
そこで、本実施の形態におけるストリーム分割部130は、スライスヘッダの挿入処理と同様に、スライス終端処理も実行する。
図5は、スライス終端処理を説明するための説明図である。
例えば、図5の(a)に示すように、符号化ストリームのピクチャp1に含まれるスライスCは、スライスヘッダhcと、MBラインL9〜L12と、スライス終端情報ecとを含んでいる。
ストリーム分割部130はピクチャp1をMBラインごとに分割する。その結果、図5の(b)〜(e)に示すように、MBラインL9はスライスヘッダhcと共に第1分割ストリームに割り当てられ、MBラインL10は第2分割ストリームに割り当てられ、MBラインL11は第3分割ストリームに割り当てられ、MBラインL12は第4分割ストリームに割り当てられる。
さらに、ストリーム分割部130は、上述のスライスヘッダの挿入処理により、スライスヘッダhcを複製して3つの複製スライスヘッダhc’を生成し、それらの3つの複製スライスヘッダhc’をそれぞれ、第2分割ストリーム〜第4分割ストリームのMBラインL10,L11,L12の直前に挿入する。また、ストリーム分割部130は、上述のMBアドレス情報の更新処理により、挿入される複製スライスヘッダhc’の位置に応じて、その複製スライスヘッダhc’に含まれるMBアドレス情報を更新する。
ここで、ストリーム分割部130は、スライス終端処理として、第1分割ストリームにおけるスライスC(MBラインL9)の終端、第2分割ストリームにおけるスライスC(MBラインL10)の終端、第3分割ストリームにおけるスライスC(MBラインL11)の終端、および第4分割ストリームにおけるスライスC(MBラインL12)の終端を示すスライス終端情報ec’を生成する。そして、ストリーム分割部130は、その生成されたスライス終端情報ec’を、第1分割ストリーム〜第4分割ストリームのMBラインL9,L10,L11,L12の直後に設定する。なお、ストリーム分割部130は、符号化ストリームをMBラインごとに分割するときには、その符号化ストリームに元々含まれているスライス終端情報ecを破棄している。また、スライス終端情報ecとスライス終端情報ec’とが同一の情報であれば、最終的には、MBラインL12はスライス終端情報ec’(ec)と共に第4分割ストリームに割り当てられることになる。
これにより、各デコードエンジン120は、分割ストリームに含まれるスライスの終端を適切に認識することができる。
図6は、本実施の形態における画像復号化装置100の全体的な動きを示すフローチャートである。
まず、画像復号化装置100は、符号化ストリームを取得し(ステップS10)、その符号化ストリームから処理対象となる符号化されたピクチャを特定する(ステップS12)。さらに、画像復号化装置100は、処理対象のピクチャを分割することにより1つのMBラインを抽出する(ステップS14)。なお、MBラインの直前またはそのMBラインに属する2つのマクロブロック間にスライスヘッダがあれば、そのMBラインはそのスライスヘッダと共に抽出される。
次に、画像復号化装置100は、ステップS14の分割によって抽出された1つのMBラインを、生成対象となる第1〜第N分割ストリームの何れかに割り当てる前に、そのMBラインの直前にスライスヘッダを挿入する必要があるか否か、および、既に割り当てられているMBラインの直後にスライス終端情報を設定する必要があるか否かを判別する(ステップS16)。
画像復号化装置100は、ステップS16で、スライスヘッダを挿入する必要があると判別したとき、スライス終端情報を設定する必要があると判別したとき、または、その挿入および設定の両方を行う必要があると判別したときには(ステップS16のYes)、スライス再構成処理を実行する(ステップS18)。つまり、画像復号化装置100は、上述のスライスヘッダの挿入処理およびスライス終端処理の少なくとも一方を実行する。また、画像復号化装置100は、スライスヘッダの挿入処理を実行するときには、MBアドレス情報の更新処理も実行する。
そして、画像復号化装置100は、そのMBラインを生成対象となる第1〜第N分割ストリームの何れかに割り当てる(ステップS20)。このステップS20が繰り返し行われることによって、第1〜第N分割ストリームのそれぞれにMBラインが順次割り当てられ、第1〜第N分割ストリームが生成される。
画像復号化装置100は、第1〜第N分割ストリームのそれぞれに割り当てられたMBラインを並列に復号化する(ステップS22)。なお、第1〜第N分割ストリームのうちの何れかの分割ストリームにMBラインが割り当てられていない場合には、画像復号化装置100は、そのMBラインが割り当てられていない分割ストリームを除く、残りの分割ストリームを復号化する。
次に、画像復号化装置100は、ピクチャに含まれる全てのMBラインを割り当てたか否かを判別し(ステップS24)、割り当てていないと判別したときには(ステップS24のNo)、ステップS14からの処理を繰り返し実行する。一方、画像復号化装置100は、全てのMBラインを割り当てたと判別したときには(ステップS24のYes)、さらに、符号化ストリームに含まれる全てのピクチャを分割したか否かを判別する(ステップS26)。ここで、画像復号化装置100は、全てのピクチャを分割していないと判別したときには(ステップS26のNo)、ステップS12からの処理を繰り返し実行し、全てのピクチャを分割したと判別したときには(ステップS26のYes)、復号化処理を終了する。
なお、図6のフローチャートに示される処理動作は、本発明の画像復号化装置100の処理動作の一例であって、本発明は、このフローチャートに示される処理動作に限定されない。
例えば、図6のフローチャートでは、画像復号化装置100のストリーム分割部130が、ステップS18のスライス再構成処理で、スライスヘッダの挿入処理を行うが、スライスヘッダの挿入処理を行うことなく、スライスヘッダを必要とするデコードエンジン120に複製スライスヘッダを直接渡してもよい。また、図6のフローチャートでは、ストリーム分割部130が、ステップS18のスライス再構成処理で、MBアドレス情報の更新処理を行うが、その更新処理を行わなくてもよい。この場合、例えば、デコードエンジン120が、分割ストリームに含まれている複製スライスヘッダのMBアドレス情報を更新する。また、図6のフローチャートでは、ストリーム分割部130が、ステップS18のスライス再構成処理で、スライス終端処理を行うが、そのスライス再構成処理で行わなくてもよい。この場合、例えば、ステップS20でMBラインが第1〜第N分割ストリームの何れかの分割ストリームに割り当てられた後であって、次の新たなMBラインがストリーム分割部130からその何れかの分割ストリームに割り当てられる直前に、既に割り当てられているMBラインに対してスライス終端処理が行われてもよい。
ここで、ストリーム分割部130の構成および動作について詳細に説明する。
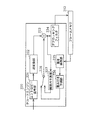
図7は、ストリーム分割部130の構成を示すブロック図である。
ストリーム分割部130は、スタートコード検出部131、EPB除去部132a、EPB挿入部132b、スライスヘッダ挿入部133、およびスライスデータ処理部134a,134bを備えている。
スタートコード検出部131は、ストリームバッファ151から符号化ストリームを読み出して、NALユニットごとにスタートコードを検出する。
EPB除去部132aは、EPB(エミュレーション防止バイト)を符号化ストリームから除去し、EPBが除去された符号化ストリームをスライスデータ処理部134a,134bに出力する。さらに、EPB除去部132aは、符号化ストリームに含まれているSPS(シーケンスパラメータセット)およびPPS(ピクチャパラメータセット)などのスライスより上層の情報を取得し、その情報が4つの分割ストリームのそれぞれに挿入されるように、その情報をEPB挿入部132bに出力する。
EPB挿入部132bは、符号化ストリームが分割されることによって生成される分割ストリームに、EPB除去部132aによって除去されたEPBを挿入する。
スライスヘッダ挿入部133は、上述のスライスヘッダの挿入処理およびMBアドレス情報の更新処理を実行する。なお、スライスヘッダ挿入部133は、所定のタイミングで、スライスヘッダの挿入処理をするか否かを示すスライスヘッダ処理内容通知M1をスライスデータ処理部134a,134bに送り、スライスデータ処理部134a,134bから終端処理完了通知M2を受けたときに、スライスヘッダの挿入処理を実行する。そして、スライスヘッダ挿入部133は、スライスヘッダの挿入処理によって、MBラインの直前にあるスライスヘッダと、MBアドレス情報が更新された複製スライスヘッダとをEPB挿入部132bに出力する。
スライスデータ処理部134a,134bは、EPBが除去された符号化ストリームを分割することにより4つの分割ストリームを生成し、その4つの分割ストリームを出力する。なお、スライスデータ処理部134a,134bから出力される分割ストリームには、上述のMBラインの直前またはその中にあるスライスヘッダおよび複製スライスヘッダが含まれていない。ここで、スライスデータ処理部134aは、CAVLD(Context Adaptive Variable Length Decoding)に応じた処理を実行し、CAVLC(Context-Adaptive Variable Length Coding)によって生成された符号化ストリームを4つの分割ストリームに分割する。また、スライスデータ処理部134bは、CABAD(Context-Adaptive Binary Arithmetic Decoding)に応じた処理を実行し、CABAC(Context-Adaptive Binary Arithmetic Coding)によって生成された符号化ストリームを4つの分割ストリームに分割する。
スライスデータ処理部134aは、スライスデータ層デコード部135a、マクロブロック層デコード部136a、スキップラン分割部137a、QP計算部138aおよび分割点検出部139aを備えている。
スライスデータ層デコード部135aは、符号化ストリームに含まれるスライスデータ層の符号化データを可変長復号化する。マクロブロック層デコード部136aは、符号化ストリームに含まれるマクロブロック層の符号化データを可変長復号化する。このような、スライスデータ層デコード部135aおよびマクロブロック層デコード部136aによる可変長復号化により、隣接するマクロブロック間の依存関係が除去される。なお、スライスデータ層デコード部135aおよびマクロブロック層デコード部136aは、処理対象のマクロブロックに隣接するマクロブロックに依存する情報(具体的には、CAVLCのnC(non-zero coefficient)など)のみを復号化してもよい。
スキップラン分割部137aは、スライスデータ層デコード部135aによって復号化されたMBスキップラン情報“mb_skip_run”を修正し、修正されたMBスキップラン情報を再び符号化し、符号化されたMBスキップラン情報を出力する。ここで、MBスキップラン情報は、連続してスキップされるマクロブロックの数を示している。
例えば、符号化ストリームのスライスの中で、連続してスキップされるマクロブロックの集合が複数のMBラインに跨って存在する場合、スライスデータ層デコード部135aによって復号化されたMBスキップラン情報は、その集合に含まれる連続してスキップされるマクロブロックの数を示している。このような場合に、ピクチャがMBラインごとに分割され、それらのMBラインが別々の分割ストリームに割り当てられると、それぞれの分割ストリームで、連続してスキップされるマクロブロックの数が変わってしまう。
そこで、スキップラン分割部137aは、上述の集合の一部を含むMBラインごとに、そのMBラインに含まれている上記一部を成す、連続してスキップされるマクロブロックの数を特定する。そして、スキップラン分割部137aは、MBラインごとに、MBスキップラン情報により示される数が、そのMBラインに対して特定された数となるように、MBスキップラン情報を修正する。
QP計算部138aは、マクロブロックごとに、マクロブロック層デコード部136aによって復号化された、そのマクロブロックのQP変化量“mb_qp_delta”をQP値(量子化パラメータの値)に変換し、そのQP値を出力する。なお、QP変化量は、マクロブロック(対象マクロブロック)に含まれており、その対象マクロブロックのQP値と、その対象マクロブロックの左隣のマクロブロック(左隣接マクロブロック)のQP値との差分を示す。
つまり、ピクチャがMBラインごとに分割され、MBラインのそれぞれが複数の分割ストリームの何れかに割り当てられると、MBラインの境界を挟んで互いに隣接していたマクロブロックはそれぞれ別々の分割ストリームに割り当てられる。その結果、その互いに隣接していた一方のマクロブロック(対象マクロブロック)を含む分割ストリームを復号化の対象とするデコードエンジン120は、対象マクロブロックのQP変化量から、その対象マクロブロックのQP値を導出することができない。
そこで、QP計算部138aは、ピクチャが分割される前に、マクロブロックごとに、そのマクロブロック(対象マクロブロック)のQP変化量に、左隣接マクロブロックのQP値を加算することによって、その対象マクロブロックのQP値を算出する。
分割点検出部139aは、符号化ストリームを4つの分割ストリームに分割する。つまり、分割点検出部139aは、ピクチャを複数のMBラインに分割し、MBラインのそれぞれを4つの分割ストリームの何れかに割り当てる。なお、分割点検出部139aは、MBラインの直前またはそのMBラインに属する2つのマクロブロック間にスライスヘッダがある場合には、そのスライスヘッダの割り当てを行うことなく、MBラインだけを分割ストリームに割り当てる。また、分割点検出部139aは、分割ストリームのそれぞれに、スキップラン分割部137aから取得したMBスキップラン情報と、QP計算部138aから取得したQP値とを含める。
さらに、分割点検出部139aは、分割ストリームのスライスの終端を検出し、スライスヘッダ挿入部133からスライスヘッダ処理内容通知M1を受けると、そのスライスヘッダ処理内容通知M1の示す内容に応じて、上述のスライス終端処理を実行する。また、分割点検出部139aは、スライス終端処理が完了すると、スライスヘッダ挿入部133に終端処理完了通知M2を送る。
スライスデータ処理部134bは、スライスデータ層デコード部135b、マクロブロック層デコード部136b、QP計算部138bおよび分割点検出部139bを備えている。
スライスデータ層デコード部135bは、符号化ストリームに含まれるスライスデータ層の符号化データを可変長復号化(算術復号化)する。マクロブロック層デコード部136bは、符号化ストリームに含まれるマクロブロック層の符号化データを可変長復号化(算術復号化)する。このような、スライスデータ層デコード部135bおよびマクロブロック層デコード部136bによる可変長復号化により、隣接するマクロブロック間の依存関係が除去される。
QP計算部138bは、上述のQP計算部138aと同様、マクロブロックごとに、マクロブロック層デコード部136bによって復号化された、そのマクロブロックのQP変化量“mb_qp_delta”をQP値(量子化パラメータの値)に変換し、そのQP値を出力する。
分割点検出部139bは、分割点検出部139aと同様、符号化ストリームを4つの分割ストリームに分割する。このとき、分割点検出部139bは、分割ストリームのそれぞれに、QP計算部138bから取得したQP値を含める。さらに、分割点検出部139bは、分割ストリームのスライスの終端を検出し、スライスヘッダ挿入部133からのスライスヘッダ処理内容通知M1を受けると、そのスライスヘッダ処理内容通知M1の示す内容に応じて、上述のスライス終端処理を実行する。また、分割点検出部139bは、スライス終端処理が完了すると、スライスヘッダ挿入部133に終端処理完了通知M2を送る。
ここで、スライスヘッダ挿入部133およびスライスデータ処理部134a,134bについて詳細に説明する。なお、スライスデータ処理部134a,134bについて共通する機能および処理動作を説明するときには、それらを区別することなくスライスデータ処理部134と総称する。
まず、スライスヘッダ挿入部133がスライスヘッダを挿入するタイミング、およびスライスデータ処理部134がスライス終端情報を挿入するタイミングについて説明する。
図8は、スライスヘッダ挿入部133およびスライスデータ処理部134の動作を説明するための説明図である。
スライスデータ処理部134は、スライスAおよびスライスBを含むピクチャをMBラインごとに分割し、EPB挿入部132bを介して、先頭側のMBラインから各MBラインを順次、分割ストリームバッファ152に含まれる4つの領域(第1領域df1〜第4領域df4)に格納する。このとき、スライスデータ処理部134は、1MBラインの格納ごとに、MBラインの格納先を第1領域df1、第2領域df2、第3領域df3、第4領域df4、第1領域df1の順に繰り返し変更する。
例えば、スライスデータ処理部134は、図8の(a)に示すように、スライスAのMBラインLa1を、分割ストリームバッファ152の第1領域df1に格納し、スライスAの次のMBラインLa2を、分割ストリームバッファ152の第2領域df2に格納し、スライスAの次のMBラインLa3を、分割ストリームバッファ152の第3領域df3に格納する。さらに、スライスデータ処理部134は、スライスAの次のスライスBのMBラインLb1を、分割ストリームバッファ152の第4領域df4に格納する。
その結果、分割ストリームバッファ152の4つの第1領域df1〜第4領域df4のそれぞれにMBラインが格納され、分割ストリームバッファ152は、スライスBの次のMBラインが再び第1領域df1に格納される直前の状態になる。
なお、スライスデータ処理部134は、MBラインLa3を第3領域df3に格納するときには、符号化ストリームにおいてMBラインLa3の直後にスライス終端情報eaがあっても、そのスライス終端情報eaを格納することなく、MBラインLa3だけを第3領域df3に格納する。そして、スライスデータ処理部134は、その後に、第3領域df3に新たなスライスに属するMBラインを格納するときになって、そのスライス終端情報eaに対応するスライス終端情報ea’を第3領域df3に格納する。また、スライスデータ処理部134がMBラインLb1を第4領域df4に格納するときには、事前に、スライスヘッダ挿入部133によってスライスBのスライスヘッダhbが第4領域df4に格納されている。また、ピクチャには、スライスAのMBラインLa1よりも前に、そのスライスAの他のMBラインが存在している。したがって、第1領域df1、第2領域df2および第3領域df3のMBラインLa1,La2,La3の直前には、スライスAの複製スライスヘッダが挿入されていない。
また、スライスデータ処理部134の分割点検出部139a,139bは、マクロブロックを出力するごとに、1MBラインの全てのマクロブロックが出力されたか否かを判別している。その結果、分割点検出部139a,139bは、全てのマクロブロックが出力されたと判別すると、MBラインの境界(MBラインの終端)を検出する。そして、分割点検出部139a,139bは、MBラインの境界を検出するごとに、マクロブロックの出力処理を中断し、MBラインの境界を検出したことをスライスヘッダ挿入部133に通知する。
したがって、MBラインの最後のマクロブロックが分割ストリームバッファ152に格納されて、分割ストリームバッファ152が上述のような図8の(a)に示す状態になったときにも、スライスヘッダ挿入部133は、スライスデータ処理部134の分割点検出部139a,139bから、MBラインの境界が検出されたことの通知を受ける。
MBラインの境界検出の通知を受けたスライスヘッダ挿入部133は、図8の(b)に示すように、スライスヘッダ処理内容通知M1をスライスデータ処理部134に送る。このスライスヘッダ処理内容通知M1は、スライスデータ処理部134から分割ストリームバッファ152へ次のMBラインが格納される直前に、スライスヘッダを分割ストリームバッファ152に出力して格納する予定があるか否かをそのスライスデータ処理部134に知らせる情報であって、「出力」または「非出力」を示す。つまり、「出力」を示すスライスヘッダ処理内容通知M1は、スライスデータ処理部134に対してスライス終端処理を促す通知である。
例えば、スライスヘッダ挿入部133は、スライスデータ処理部134から分割ストリームバッファ152へ次のMBラインLb2が格納される直前に、複製スライスヘッダhb’を分割ストリームバッファ152に出力して格納すべきと判断する。このとき、スライスヘッダ挿入部133は、「出力」を示すスライスヘッダ処理内容通知M1をスライスデータ処理部134に出力する。
スライスデータ処理部134は、スライスヘッダ処理内容通知M1を取得すると、そのスライスヘッダ処理内容通知M1が「出力」を示していれば、スライス終端情報を生成して分割ストリームバッファ152に格納した後に、終端処理完了通知M2をスライスヘッダ挿入部133に出力する。一方、スライスデータ処理部134は、スライスヘッダ処理内容通知M1が「非出力」を示していれば、スライス終端情報を分割ストリームバッファ152に格納することなく、終端処理完了通知M2をスライスヘッダ挿入部133に出力する。
例えば、スライスデータ処理部134は、「出力」を示すスライスヘッダ処理内容通知M1を取得すると、図8の(c)に示すように、スライス終端情報ea’を生成し、分割ストリームバッファ152の第1領域df1に格納する。その格納が完了すると、スライスデータ処理部134は、終端処理完了通知M2をスライスヘッダ挿入部133に出力する。
スライスヘッダ挿入部133は、スライスデータ処理部134から終端処理完了通知M2を取得すると、直前に出力したスライスヘッダ処理内容通知M1が「出力」を示していた場合には、EPB挿入部132bを介して、スライスヘッダを分割ストリームバッファ152に出力して格納し、その後、スライスヘッダ処理完了通知M3をスライスデータ処理部134に出力する。一方、直前に出力したスライスヘッダ処理内容通知M1が「非出力」を示していた場合には、スライスヘッダ挿入部133は、スライスヘッダを分割ストリームバッファ152に格納することなく、スライスヘッダ処理完了通知M3をスライスデータ処理部134に出力する。
例えば、スライスヘッダ挿入部133は、直前に出力したスライスヘッダ処理内容通知M1が「出力」を示していた場合に、スライスデータ処理部134から終端処理完了通知M2を取得すると、図8の(d)に示すように、複製スライスヘッダhb’を生成して分割ストリームバッファ152の第1領域df1に格納する。その後、スライスヘッダ挿入部133は、スライスヘッダ処理完了通知M3をスライスデータ処理部134に出力する。
スライスデータ処理部134の分割点検出部139a,139bは、スライスヘッダ挿入部133からスライスヘッダ処理完了通知M3を受けると、中断していたマクロブロックの出力処理を再開し、次のMBラインを出力して分割ストリームバッファ152に格納する。
例えば、スライスデータ処理部134は、図8の(d)に示すように、次のMBラインLb2を出力して分割ストリームバッファ152の第1領域df1に格納する。
このようなスライスヘッダ挿入部133およびスライスデータ処理部134による処理によって、分割ストリームバッファ152の各領域において、スライス終端情報、スライスヘッダ、次のMBラインの順に、これらのデータを適切なMBラインの境界に書き込むことができる。
図9は、スライスヘッダ挿入部133の構成を示すブロック図である。
なお、図9を用いて、分割点検出部139a,139bについて共通する機能および処理動作を説明するときには、それらを区別することなく分割点検出部139と総称する。
スライスヘッダ挿入部133は、NALタイプ判定部133a、ヘッダ挿入カウンタ133b、ヘッダアドレス更新部133cおよびヘッダバッファ133dを備えている。
NALタイプ判定部133aは、符号化ストリームのNALユニットを取得するごとに、そのNALユニットのタイプがスライスであるか否かを判別する。そして、NALタイプ判定部133aは、スライスであると判別したときには、そのNALユニットのタイプがスライスであることをヘッダバッファ133dおよびヘッダ挿入カウンタ133bに通知する。
ヘッダバッファ133dは、NALタイプ判定部133aからの通知を受けると、その通知に対応するNALユニットにスライスヘッダが含まれていれば、そのNALユニットからスライスヘッダを取り出して記憶する。さらに、ヘッダバッファ133dは、後のNALユニットに新たなスライスヘッダが含まれていれば、既に記憶しているスライスヘッダをその新たなスライスヘッダに置き換える。つまり、ヘッダバッファ133dは、常に最新のスライスヘッダを保持している。
ヘッダ挿入カウンタ133bは、複製スライスヘッダを生成して挿入するタイミングを特定するために、符号化ストリーム中のMBラインの境界(終端)が分割点検出部139で検出された数をカウントする。具体的には、ヘッダ挿入カウンタ133bは、0〜4(デコードエンジン120の総数)までの値をカウントする。ヘッダ挿入カウンタ133bは、NALタイプ判定部133aからの通知を受けると、その通知に対応するNALユニットにスライスヘッダが含まれていれば、カウント値を0にリセットする。さらに、ヘッダ挿入カウンタ133bは、MBラインの境界(MBラインの終端)が検出されたときには、カウント値を1だけカウントアップする。そして、ヘッダ挿入カウンタ133bは、カウント値が4に達した後に、さらにMBラインの境界が検出されたときには、カウントアップすることなく、カウント値を4に維持しておく。
このように、ヘッダ挿入カウンタ133bは、MBラインの境界が検出されたときには、カウント値を更新あるいは保持し、NALユニットにスライスヘッダが含まれていれば、カウント値を0にリセットする。
また、ヘッダ挿入カウンタ133bは、MBラインの境界が検出されたときには、その検出によって更新されたカウント値(MBライン境界の直後のスライスヘッダによってリセットされたカウント値=0を含む)に応じて、「出力」または「非出力」を示すスライスヘッダ処理内容通知M1を分割点検出部139に出力する。具体的には、ヘッダ挿入カウンタ133bは、MBラインの境界が検出された直後のカウント値が0〜3のときには、「出力」を示すスライスヘッダ処理内容通知M1を出力し、そのカウント値が4のときには、「非出力」を示すスライスヘッダ処理内容通知M1を出力する。また、ヘッダ挿入カウンタ133bは、MBラインの境界が検出されたときに限らず、カウント値が0になったときにも、「出力」を示すスライスヘッダ処理内容通知M1を出力する。
さらに、ヘッダ挿入カウンタ133bは、スライスヘッダ処理内容通知M1を分割点検出部139に出力した後に、その分割点検出部139から終端処理完了通知M2を受け取ると、その出力したスライスヘッダ処理内容通知M1が「出力」を示していた場合には、ヘッダバッファ133dに格納されているスライスヘッダをそのヘッダバッファ133dから出力させる。その後、ヘッダ挿入カウンタ133bはスライスヘッダ処理完了通知M3を分割点検出部139に出力する。なお、ヘッダバッファ133dからスライスヘッダが出力されるときには、スライスヘッダ挿入部133は、そのスライスヘッダに含まれているMBアドレス情報により示される値に応じて、分割ストリームバッファ152の格納先となる領域を選択する。そして、スライスヘッダ挿入部133は、その選択された格納先となる領域にスライスヘッダを格納する。一方、ヘッダ挿入カウンタ133bは、その出力したスライスヘッダ処理内容通知M1が「非出力」を示していた場合には、ヘッダバッファ133dに格納されているスライスヘッダをそのヘッダバッファ133dから出力させずに、格納された状態に維持しておく。その後、上述と同様、ヘッダ挿入カウンタ133bはスライスヘッダ処理完了通知M3を分割点検出部139に出力する。
ヘッダアドレス更新部133cは、MBラインの境界が検出された直後のカウント値(MBライン境界の直後のスライスヘッダによってリセットされたカウント値=0を含む)に応じて、ヘッダバッファ133dに格納されているスライスヘッダのMBアドレス情報“first_mb_in_slice”を更新する。
例えば、ヘッダアドレス更新部133cは、カウント値n=0のときには、MBアドレス情報を更新せず、カウント値n≠0のときには、MBアドレス情報を(“mbposv”+n)×(“pic_width_in_mbs_minus1”+1)に更新する。なお、ピクチャがMBAFFで構成されている場合には、ヘッダアドレス更新部133cは、MBアドレス情報を(“mbposv”/2+n)×(“pic_width_in_mbs_minus1”+1)により更新する。
図10は、分割ストリームバッファ152の第1領域df1〜第4領域df4に割り当てられるMBラインおよびスライスヘッダを示す図である。
例えば、ストリーム分割部130は、ストリームバッファ151に格納されている符号化ストリームのスライスA〜Cを、スライスA、スライスB、スライスCの順に読み出す。
この場合、まず、スライスヘッダ挿入部133のヘッダバッファ133dは、スライスAの先頭からスライスヘッダhaを取り出して記憶する。このとき、ヘッダ挿入カウンタ133bはカウント値を0にリセットする。したがって、ヘッダバッファ133dは、カウント値が0であるため、記憶しているスライスヘッダhaを出力することにより、そのスライスヘッダhaを分割ストリームバッファ152の第1領域df1に格納する。
スライスヘッダhaがヘッダバッファ133dから出力されると、スライスデータ処理部134は、符号化ストリーム中でスライスAのスライスヘッダhaに続く第1MBラインを出力することにより、その第1MBラインを分割ストリームバッファ152の第1領域df1に格納する。その結果、第1領域df1には、スライスヘッダha、スライスAに属する第1MBラインの順に、それらのデータが格納される。
第1MBラインがスライスデータ処理部134から出力されると、上述のヘッダ挿入カウンタ133bはカウント値を1にカウントアップする。したがって、ヘッダバッファ133dは、第1MBラインの終端でカウント値が1であるため、記憶しているスライスヘッダhaを複製スライスヘッダha’として出力することにより、その複製スライスヘッダha’を分割ストリームバッファ152の第2領域df2に格納する。なお、複製スライスヘッダha’のMBアドレス情報はヘッダアドレス更新部133cによって更新されている。
複製スライスヘッダha’がヘッダバッファ133dから出力されると、スライスデータ処理部134は、符号化ストリーム中で第1MBラインに続く第2MBラインを出力することにより、その第2MBラインを分割ストリームバッファ152の第2領域df2に格納する。
ここで、第2MBラインは、スライスAに属する複数のマクロブロックと、スライスBのスライスヘッダhbと、スライスBに属する複数のマクロブロックとを含んでいる。そこで、スライスデータ処理部134の分割点検出部139は、まず、第2MBラインに含まれるスライスAに属する全てのマクロブロックを第2領域df2に格納する。その格納が終了すると、分割点検出部139は、一時的にマクロブロックの出力処理を中断し、スライスヘッダ挿入部133からスライスヘッダ処理内容通知M1を受けるまで待機する。このとき、スライスヘッダ挿入部133は、スライスBのスライスヘッダhbを検出するため、カウント値を0にリセットし、「出力」を示すスライスヘッダ処理内容通知M1を分割点検出部139に送る。このスライスヘッダ処理内容通知M1を受けた分割点検出部139は、第2領域df2のスライスAの終端に対してスライス終端処理を行い、終端処理完了通知M2をスライスヘッダ挿入部133に送る。この終端処理完了通知M2を受けたスライスヘッダ挿入部133は、スライスBのスライスヘッダhbを第2領域df2に格納し、スライスヘッダ処理完了通知M3を分割点検出部139に送る。このスライスヘッダ処理完了通知M3を受けた分割点検出部139は、中断していた出力処理を再開し、第2MBラインに含まれる次のスライスBに属する複数のマクロブロックを第2領域df2に格納する。
その結果、第2領域df2には、複製スライスヘッダha’に続いて、スライスAに属する第2MBラインの一部を成す複数のマクロブロック、スライスヘッダhb、スライスBに属する第2MBラインの一部を成す複数のマクロブロックの順に、それらのデータが格納される。
第2MBラインがスライスデータ処理部134から出力されると、スライスヘッダ挿入部133のヘッダバッファ133dは、符号化ストリーム中でその第2MBラインに続くスライスCの先頭からスライスヘッダhcを取り出して記憶する。このとき、ヘッダ挿入カウンタ133bはカウント値を0にリセットする。したがって、ヘッダバッファ133dは、第2MBラインの終端でカウント値が0であるため、記憶しているスライスヘッダhcを出力することにより、そのスライスヘッダhcを分割ストリームバッファ152の第3領域df3に格納する。
スライスヘッダhcがヘッダバッファ133dから出力されると、スライスデータ処理部134は、符号化ストリーム中でスライスCのスライスヘッダhcに続く第3MBラインを出力することにより、その第3MBラインを分割ストリームバッファ152の第3領域df3に格納する。その結果、第3領域df3には、スライスヘッダhc、スライスCに属する第3MBラインの順に、それらのデータが格納される。
第3MBラインがスライスデータ処理部134から出力されると、上述のヘッダ挿入カウンタ133bはカウント値を1にカウントアップする。したがって、ヘッダバッファ133dは、第3MBラインの終端でカウント値が1であるため、記憶しているスライスヘッダhcを複製スライスヘッダhc’として出力することにより、その複製スライスヘッダhc’を分割ストリームバッファ152の第4領域df4に格納する。なお、複製スライスヘッダhc’のMBアドレス情報はヘッダアドレス更新部133cによって更新されている。
このような処理が繰り返されることにより、分割ストリームバッファ152の第1領域df1〜第4領域df4にデータが順次格納される。その結果、それらの第1領域df1〜第4領域df4のそれぞれに第1分割ストリーム〜第4分割ストリームが格納される。
図11Aおよび図11Bは、スライス終端情報が設定される位置を示す図である。
例えば、図11Aに示すように、ピクチャはスライスAとスライスBとを含み、スライスAに続くスライスBの先頭のマクロブロックはMBラインの左端にある。このような場合、スライスデータ処理部134の分割点検出部139は、スライスヘッダ挿入部133からスライスBのスライスヘッダhbが出力される直前に、そのスライスBの先頭MBラインから4MBライン前にある、スライスAのMBラインの終端に、スライスAのスライス終端情報ea’を設定する。さらに、スライスデータ処理部134の分割点検出部139は、スライスヘッダ挿入部133からスライスBの複製スライスヘッダhb’が出力される直前に、そのスライスBの先頭MBラインから3MBライン前にある、スライスAのMBラインの終端に、スライスAのスライス終端情報ea’を設定する。
このように、スライスの先頭のマクロブロックがMBラインの左端にある場合には、そのMBラインの1〜4MBライン前にある各MBラインの終端にスライス終端情報ea’が設定される。
また、図11Bに示すように、ピクチャはスライスAとスライスBとを含み、スライスAに続くスライスBの先頭のマクロブロックはMBラインの左端以外にある。このような場合、スライスデータ処理部134の分割点検出部139は、スライスヘッダ挿入部133からスライスBの複製スライスヘッダhb’が出力される直前に、そのスライスBのスライスヘッダhbを含むMBラインから3MBライン前にある、スライスAのMBラインの終端に、スライスAのスライス終端情報ea’を設定する。
このように、スライスの先頭のマクロブロックがMBラインの左端以外にある場合には、そのMBラインにおけるスライスの境界と、そのMBラインの1〜3MBライン前にある各MBラインの終端にスライス終端情報ea’が設定される。
ここで、分割点検出部139の動作について詳細に説明する。
図12は、分割点検出部139の動作を示すフローチャートである。
まず、分割点検出部139は、符号化ストリームの先頭側から処理対象とすべきデータ(例えばマクロブロック)を特定して出力し、分割ストリームバッファ152に格納する(ステップS100)。
ここで、分割点検出部139は、出力されるマクロブロックのアドレス(MBアドレス値)を管理している。つまり、出力されるマクロブロックが、符号化ストリームに含まれるスライスの先頭マクロブロックであれば、分割点検出部139は、出力されるマクロブロックのMBアドレス値を、そのスライスのスライスヘッダに含まれるMBアドレス情報により示される値に更新する。そして、分割点検出部139は、その先頭マクロブロックに続くマクロブロックを出力するごとに、そのMBアドレス値をインクリメントする。なお、MBアドレス値は0以上の整数である。
そして、分割点検出部139は、ステップS100でマクロブロックを出力するときには、そのマクロブロックのMBアドレス値に応じて、分割ストリームバッファ152内の格納先となる領域を選択し、その格納先となる領域にマクロブロックを格納する。具体的には、分割ストリームバッファ152に含まれる4つの領域に1番〜4番までの番号が割り振られている場合、分割点検出部139は、m=((MBアドレス値/W)%N+1)番目の領域を選択し、そのm番目の領域にマクロブロックを格納する。
なお、Wは、W=“pic_width_in_mbs_minus1”+1により示され、ピクチャの水平方向のマクロブロック数を示す。また、Nはデコードエンジン120の総数(N=4)であり、%は(MBアドレス値/W)をNで割ったときの余りを示す。
次に、分割点検出部139は、ステップS100で出力されたマクロブロックがMBラインの終端(境界)であったか否か、つまりマクロブロックの出力処理がMBラインの終端に達したか否かを判別する(ステップS102)。具体的には、分割点検出部139は、ステップS100で出力されたマクロブロックのMBアドレス値が(Wの倍数−1)となるか否かを判別する。MBアドレス値=(Wの倍数−1)のときには、出力処理がMBラインの終端に達し、MBアドレス値≠(Wの倍数−1)のときには、出力処理がMBラインの終端に達していない。
分割点検出部139は、終端に達していない判別すると(ステップS102のNo)、符号化ストリームにおいて次に処理対象とすべきデータがあるか否か、つまり出力処理を終了すべきか否かを判別する(ステップS114)。一方、分割点検出部139は、終端(MBラインの境界)に達したと判別すると、つまりMBラインの境界を検出すると(ステップS102のYes)、MBラインの境界を検出したことをスライスヘッダ挿入部133に通知するとともに出力処理を中断し、その後、スライスヘッダ挿入部133からスライスヘッダ処理内容通知M1を受けたか否かを判別する(ステップS104)。
分割点検出部139は、スライスヘッダ処理内容通知M1を受けていないと判別すると(ステップS104のNo)、スライスヘッダ処理内容通知M1を受けるまで待機する。一方、分割点検出部139は、スライスヘッダ処理内容通知M1を受けたと判別すると(ステップS104のYes)、そのスライスヘッダ処理内容通知M1が「出力」を示しているか否かを判別する(ステップS106)。
ここで、分割点検出部139は、「出力」を示していると判別すると(ステップS106のYes)、スライス終端処理を実行する(ステップS108)。つまり、分割点検出部139は、符号化ストリームがCABADで復号化される場合には、スライス終端情報として“end_of_slice_flag”に「1」を設定する。また、分割点検出部139は、符号化ストリームがCAVLDで復号化される場合には、スライス終端情報として“rbsp_slice_trailing_bits”を付与する。
分割点検出部139は、ステップS106で「出力」を示していないと判別した後(ステップS106のNo)、またはステップS108でスライス終端処理を実行した後には、スライスヘッダ挿入部133に終端処理完了通知M2を送る(ステップS110)。その後、分割点検出部139は、スライスヘッダ挿入部133からスライスヘッダ処理完了通知M3を受けたか否かを判別する(ステップS112)。ここで、分割点検出部139は、スライスヘッダ処理完了通知M3を受けていないと判別すると(ステップS112のNo)、スライスヘッダ処理完了通知M3を受けるまで待機する。一方、分割点検出部139は、ステップS112でスライスヘッダ処理完了通知M3を受けたと判別したとき(ステップS112のYes)、符号化ストリームにおいて次に処理対象とすべきデータがあるか否か、つまり出力処理を終了すべきか否かを判別する(ステップS114)。
ここで、分割点検出部139は、終了すべきと判別したときには(ステップS114のYes)、処理を終了し、終了すべきでないと判別したときには(ステップS114のNo)、再び、次の処理対象とすべきデータを出力して分割ストリームバッファ152に格納する(ステップS100)。
このように、本実施の形態における画像復号化装置100では、符号化されたピクチャは複数のMBライン(構成単位)に分割され、複数のMBラインのそれぞれが分割ストリームの一部としてN個のデコードエンジン120に割り当てられて復号化されるため、N個のデコードエンジン120による復号化処理の負担を均等にすることができ、復号化の並列処理を適切に実行することができる。例えば、H.264/AVCの符号化ピクチャが1スライスで構成されている場合であっても、その符号化ピクチャは複数のMBラインに分割されるため、その1スライスの復号化を1つのデコードエンジン120で負担することなく、N個のデコードエンジン120で均等に負担することができる。
ここで、符号化ピクチャが複数のMBラインに分割されると、複数のMBラインに跨るスライスが複数のスライス部分(例えば、図3に示す各MBラインL1〜L6や、MBラインL7のうちの先頭6マクロブロックの集合など)に分割され、それらのスライス部分が互いに異なる分割ストリームに割り当てられることがある。つまり、1つの分割ストリームには、符号化ピクチャのスライスの全体が含まれることなく、そのスライスの断片であるスライス部分が1つ以上集まって構成されるスライス部分群(例えば、図3に示す第2分割ストリームに含まれるMBラインL2,L6)が含まれることとなる。また、このようなスライス部分群(MBラインL2,L6)には、その先頭を示すスライスヘッダや、その終端を示すスライス終端情報が含まれていない場合がある。
そこで本発明では、ストリーム分割部130がそのスライス部分群を新たなスライスとして再構成するため、そのスライス部分群を含む分割ストリームを復号化するデコードエンジン120は、そのスライス部分群を認識して適切に復号化するための特別な処理を要することなく、スライス部分群を新たなスライスとして簡単に認識して適切に復号化することができる。つまり、本発明では、N個のデコードエンジン120のそれぞれに特別な処理を行う機能や構成を設ける必要がないため、画像復号化装置100の全体構成を簡単にすることができる。
また、本発明では、上記特許文献3の画像復号化装置と比べて、復号化処理の高速化を図ることができる。具体的には、上記特許文献3の画像復号化装置では、符号化ストリームの可変長復号化およびデブロッキングフィルタ処理の並列化を行っていない。つまり、上記特許文献3の画像復号化装置では、符号化ストリームを適切に分割していない、言い換えれば、符号化ストリームが分割されて生成されるデータが、従来のデコードエンジンで復号化可能なストリームとして構成されていない。一方、本発明の画像復号化装置100では、符号化ストリームを複数の分割ストリームに適切に分割しているため、デコードエンジン120のそれぞれは、図28に示すデコードエンジン220のように、可変長復号化およびデブロッキングフィルタ処理を並列に実行することができる。その結果、本発明の画像復号化装置では、復号化処理の高速化を図ることができる。
また、本発明では、上記特許文献4の画像復号化装置と比べて、従来のデコードエンジンを流用することができるというメリットがある。具体的には、上記特許文献4の画像復号化装置では、符号化ストリームを分割することなく、符号化ストリームにおいてMBラインの境界に行ヘッダを挿入している。したがって、上記特許文献4の画像復号化装置の複数のデコードエンジンは、行ヘッダを目印にして自らが処理すべきMBラインを符号化ストリームから抽出しなければならない。このとき、それらのデコードエンジンは、処理対象のMBラインが格納されている位置が既に特定されていれば、処理対象のMBラインを抽出するために符号化ストリームに対して不連続にアクセスする必要があり、その位置が特定されていなければ、符号化ストリームに先頭からアクセスし、処理対象でないMBラインを読み飛ばす必要がある。一方、本発明の画像復号化装置100では、符号化ストリームを複数の分割ストリームに適切に分割しているため、デコードエンジン120のそれぞれは、図28に示すデコードエンジン220のように、分割ストリームを通常の符号化ストリームとして扱って復号化することができる。このように、本発明の画像復号化装置では、従来のデコードエンジンを流用することができ、上記特許文献4の画像復号化装置では成し得ない効果を奏することができる。
また、このような本実施の形態における画像復号化装置100は、ストリーム分割部130に入力される上述のモード情報に応じて、高解像度デコード、高速デコード、および複数チャンネルデコードのうちの何れかを実行する。
図13A〜図13Cは、高解像度デコード、高速デコードおよび複数チャンネルデコードを説明するための説明図である。
画像復号化装置100のストリーム分割部130は、図13Aに示すように、高解像度デコードの実行を指示するモード情報を取得すると、4k2kの符号化ストリームを上述のように4つの分割ストリームに分割し、4つの分割ストリームのそれぞれを各デコードエンジン120に復号化させる。
例えば、4つのデコードエンジン120はそれぞれ、HDの画像(1920×1088画素、60i)を2チャンネル分復号可能な処理能力を有するため、画像復号化装置100は、4k2kの画像(3840×2160画素、60p)をリアルタイムに処理することができる。
また、画像復号化装置100のストリーム分割部130は、図13Bに示すように、高速デコードの実行を指示するモード情報を取得すると、HDの符号化ストリームを上述のように4つの分割ストリームに分割し、4つの分割ストリームのそれぞれを各デコードエンジン120に復号化させる。
例えば、4つのデコードエンジン120はそれぞれ、HDの画像(1920×1088画素、60i)を2チャンネル分復号可能な処理能力を有するため、画像復号化装置100は、HDの画像を8倍速(4×2)で処理することができる。
また、画像復号化装置100のストリーム分割部130は、図13Cに示すように、複数チャンネルデコードの実行を指示するモード情報を取得すると、複数のHDの符号化ストリームを分割することなく、その複数の符号化ストリームのそれぞれを各デコードエンジン120に復号化させる。なお、この複数チャンネルデコードの場合、ストリーム分割部130は、SPS、PPSおよびスライスなどの各種NALユニットの複製および挿入を行わず、分割ストリームバッファ152の各領域への符号化ストリーム(チャンネル)の振り分けのみを行う。
例えば、4つのデコードエンジン120はそれぞれ、HDの画像(1920×1088画素、60i)を2チャンネル分復号可能な処理能力を有するため、画像復号化装置100は、最大8チャンネル、つまり8つのHDの符号化ストリームを同時にデコードすることができる。また、最大チャンネル数以下のチャンネル(符号化ストリーム)を復号化する場合には、デコードエンジン120のクロック周波数を下げて消費電力の低減を図ることができる。例えば、4チャンネルを復号化する場合には、第1デコードエンジン120と第2デコードエンジン120のそれぞれに2チャンネルの復号化を実行させ、残りの第3デコードエンジン120と第4デコードエンジン120を停止させる。または、第1デコードエンジン120〜第4デコードエンジン120を使用し、それらのクロック周波数を1/2にする。
このように、本実施の形態における画像復号化装置100では、モード情報に応じて、復号化処理を高解像度デコードと高速デコードと複数チャンネルデコードに切り替えるため、ユーザの使い勝手を向上することができる。なお、画像復号化装置100における高解像度デコードおよび高速デコードはそれぞれ、符号化ストリームを4つの分割ストリームに分割してそれらを並列に復号化する処理であって、同一の処理である。つまり、高解像度デコードと高速デコードとでは、復号化対象の符号化ストリームの解像度・フレームレート(4k2kまたはHD)が異なるだけである。したがって、画像復号化装置100は、モード情報に応じて、復号化処理を、高解像度デコードまたは高速デコードと、複数チャンネルデコードとに切り替え、さらに符号化ストリームの解像度・フレームレートに応じて、復号化処理を高解像度デコードと高速デコードとに切り替えている。
(変形例1)
ここで、上記実施の形態では、ストリーム分割部130のヘッダアドレス更新部133cで複製スライスヘッダに含まれるMBアドレス情報を更新したが、ストリーム分割部130で更新することなく、デコードエンジン120が更新してもよい。つまり、変形例1では、ストリーム分割部130は、複製スライスヘッダに含まれるMBアドレス情報を変更することなく、その複製スライスヘッダを出力する。そして、デコードエンジン120は、複製スライスヘッダを取得して処理を行う前に、その複製スライスヘッダに含まれるMBアドレス情報を変更する。
図14は、変形例1に係るデコードエンジン120がMBアドレス情報を変更するための擬似コードを示す図である。
ここでは、ピクチャに含まれるk番目(kは0以上の整数)のMBラインは、(k%4)番目のデコードエンジン120によって復号化されることを前提とする。なお、0番目のデコードエンジン120は第1デコードエンジン120であり、1番目のデコードエンジン120は第2デコードエンジン120であり、2番目のデコードエンジン120は第3デコードエンジン120であり、3番目のデコードエンジン120は第4デコードエンジン120である。
まず、デコードエンジン120は、“n = mode_core_number”を実行することにより、自らのデコードエンジン120の番号を“n”に代入する。次に、デコードエンジン120は、“pic_width_in_mbs = pic_width_in_mbs_minus1 + 1”を実行することにより、ピクチャに含まれる水平方向のマクロブロックの数を“pic_width_in_mbs”に代入する。
そして、デコードエンジン120は、“org_header_num = ( first_mb_in_slice / pic_width_in_mbs ) % 4”を実行することにより、複製元のスライスヘッダを有するMBラインを復号化すべきデコードエンジン120の番号を“org_header_num”に代入する。つまり、“org_header_num”番目のデコードエンジン120が複製元のスライスヘッダを有するMBラインを復号化する。さらに、デコードエンジン120は、“org_mb_address =mbaff ? ( first_mb_in_slice * 2 ) : first_mb_in_slice”を実行することにより、ピクチャがMBAFFで構成されていれば、複製元のスライスヘッダのMBアドレス“org_mb_address”を“first_mb_in_slice * 2”として扱い、ピクチャがMBAFFで構成されていなければ、複製元のスライスヘッダのMBアドレス“org_mb_address”を“first_mb_in_slice”として扱う。
ここで、デコードエンジン120は、デコードエンジン120の番号“n”が“org_header_num”に等しければ、“mb_address = org_mb_address”を実行することにより、複製スライスヘッダに含まれるMBアドレス情報“mb_address”を“org_mb_address”に更新する。一方、デコードエンジン120は、デコードエンジン120の番号“n”が“org_header_num”と異なれば、まず、“d = ( n - org_header_num + 4 ) % 4”を実行することにより、その複製スライスヘッダが何番目の複製スライスヘッダであるかを判断する。そして、デコードエンジン120は、ピクチャがMBAFFで構成されていれば、複製スライスヘッダに含まれるMBアドレス情報“mb_address”を“(( first_mb_in_slice/ pic_width_in_mbs ) + d ) * pic_width_in_mbs * 2”に更新し、ピクチャがMBAFFで構成されていなければ、複製スライスヘッダのMBアドレス情報“mb_address”を“(( first_mb_in_slice / pic_width_in_mbs ) + d ) * pic_width_in_mbs”に更新する。
このように、変形例1では、ストリーム分割部130がMBアドレス情報を更新しないため、そのストリーム分割部130の処理負担を軽減し、その構成を簡単にすることができる。なお、本発明では、MBアドレス情報の更新のタイミングは、ストリーム分割部130で符号化ストリームが分割されるときに限らず、分割ストリームが生成された後であっても、デコードエンジン120で複製スライスヘッダが処理される前であれば、いつでもよい。
(変形例2)
ここで、上記実施の形態では、ストリーム分割部130は、複製スライスヘッダが必要とされる分割ストリームにのみ、その複製スライスヘッダを挿入したが、それ以外の分割ストリームに複製スライスヘッダを挿入してもよい。変形例2に係るストリーム分割部は、複製スライスヘッダが必要であるか否かに関わらず、複製元のスライスヘッダを含む分割ストリーム以外の全ての分割ストリームに複製スライスヘッダを挿入する。
図15は、変形例2に係る画像復号化装置のストリーム分割部、分割ストリームバッファおよび4つのデコードエンジンを示すブロック図である。
変形例2に係るストリーム分割部130cは、スライスヘッダ処理部133g、スライスデータ処理部134cおよび制御部160を備えている。なお、ストリーム分割部130cは、これらの構成要素以外にも、スタートコード検出部131、EPB除去部132aおよびEPB挿入部132bを備えているが、図15では、説明を簡単にするために、スタートコード検出部131などの構成要素を省略している。
分割ストリームバッファ152は、スライスヘッダ処理部133gおよびスライスデータ処理部134cから出力されるデータを蓄積し、その蓄積されたデータから分割ストリームを構成するための4つの領域(第1領域df1〜第4領域df4)を有する。
スライスデータ処理部134cは、上記実施の形態におけるスライスデータ処理部134a,134bと同様の機能および構成を有し、符号化ストリーム中の各ピクチャを複数のMBラインに分割し、それらのMBラインを先頭側から順に、第1領域df1、第2領域df2、第3領域df3および第4領域df4の何れかに格納する。例えば、スライスデータ処理部134cは、MBラインごとに、そのMBラインの格納先となる領域を、第1領域df1、第2領域df2、第3領域df3、第4領域df4の順に切り替えて、切り替えられた領域にMBラインを格納する。また、スライスデータ処理部134cは、符号化ストリーム中のMBラインの直前にスライスヘッダがあっても、そのMBラインだけを分割ストリームバッファ152の領域に格納し、MBラインの中にスライスヘッダがあっても、そのスライスヘッダを除くMBラインを分割ストリームバッファ152の領域に格納する。
スライスヘッダ処理部133gは、符号化ストリームに含まれるデータを先頭側から順次取得しているときに、その取得したデータがスライスヘッダである場合には、そのスライスヘッダを分割ストリームバッファ152の第1領域df1〜第4領域df4のそれぞれに同時に出力する。その結果、スライスヘッダが4つに複製される。つまり、符号化ストリームに含まれていた複製元のスライスヘッダが第1領域df1〜第4領域df4のいずれか1つの領域に格納され、残りの3つの領域に3つの複製スライスヘッダがそれぞれ格納される。
例えば、スライスヘッダ処理部133gがスライスヘッダを第1領域df1〜第4領域df4のそれぞれに同時に出力すると、複製元のスライスヘッダが第1領域df1に格納され、3つの複製スライスヘッダがそれぞれMBラインの先頭に挿入されるように、第2領域df2、第3領域df3および第4領域df4のそれぞれに格納される。
このようなスライスデータ処理部134cおよびスライスヘッダ処理部133gによる処理によって、分割ストリームバッファ152の各領域からは、MBラインの先頭に0または1つのスライスヘッダを有する分割ストリームだけでなく、MBラインの先頭に連続する複数のスライスヘッダ(複製スライスヘッダまたは複製元のスライスヘッダ)を有する分割ストリームが出力される。
制御部160は、上述のようなスライスヘッダ処理部133gによる処理を管理し、分割ストリームバッファ152の領域ごとに、その領域に格納されるMBラインの直前に連続して挿入されるスライスヘッダの数(総ヘッダ数)をカウントする。そして、制御部160は、その領域から出力される分割ストリームを復号化するデコードエンジン121(第1デコードエンジン121〜第4デコードエンジン121の全て)に、その総ヘッダ数を通知する。
第1デコードエンジン121〜第4デコードエンジン121はそれぞれ、ストリーム分割部130cから出力される分割ストリームを復号化する。このとき、第1デコードエンジン121〜第4デコードエンジン121はそれぞれ、制御部160から総ヘッダ数の通知を受けると、その総ヘッダ数の数に応じた処理を行う。つまり、デコードエンジン121は、総ヘッダ数が0の場合には、スライスヘッダについての処理を行わず、総ヘッダ数が1の場合には、MBラインの先頭に挿入されている1つのスライスヘッダを処理する。また、デコードエンジン121は、総ヘッダ数が2〜3の場合には、MBラインの先頭に連続して挿入されている2〜3個のスライスヘッダのうち最後のスライスヘッダ以外のスライスヘッダに対する処理をスキップし、その最後のスライスヘッダのみを処理する。
図16は、変形例2におけるストリーム分割部130cおよび4つのデコードエンジン121の動作を説明するための説明図である。
例えば、符号化ストリームに含まれるピクチャは、スライスA、スライスB、スライスCおよびスライスDを含む。ここで、スライスAはスライスヘッダhaおよび第1MBラインを含み、スライスBはスライスヘッダhbおよび第2MBラインを含み、スライスCはスライスヘッダhcおよび第3MBラインを含み、スライスDはスライスヘッダhdおよび第4MBラインを含む。
ストリーム分割部130cのスライスヘッダ処理部133gは、符号化ストリームのスライスヘッダhaを取得すると、そのスライスヘッダhaを第1領域df1〜第4領域df4のそれぞれに同時に出力する。その結果、そのスライスヘッダhaが第1分割ストリームの一部として第1領域df1に格納されるとともに、そのスライスヘッダhaと同一の3つの複製スライスヘッダha’のそれぞれが第2分割ストリーム、第3分割ストリーム、第4分割ストリームの一部として第2領域df2、第3領域df3、第4領域df4に格納される。そして、スライスデータ処理部134cは、第1MBラインを第1分割ストリームの一部として第1領域df1に格納する。
次に、スライスヘッダ処理部133gは、符号化ストリームのスライスヘッダhbを取得すると、そのスライスヘッダhbを第1領域df1〜第4領域df4のそれぞれに同時に出力する。その結果、そのスライスヘッダhbが第2分割ストリームの一部として第2領域df2に格納されるとともに、そのスライスヘッダhbと同一の3つの複製スライスヘッダhb’のそれぞれが第1分割ストリーム、第3分割ストリーム、第4分割ストリームの一部として第1領域df1、第3領域df3、第4領域df4に格納される。そして、スライスデータ処理部134cは、第2MBラインを第2分割ストリームの一部として第2領域df2に格納する。
ストリーム分割部130cは、このような処理をスライスCおよびスライスDに対しても繰り返し実行する。
その結果、第1領域df1からは、スライスヘッダha、第1MBライン、複製スライスヘッダhb’、複製スライスヘッダhc’および複製スライスヘッダhd’を含む第1分割ストリームが出力される。同様に、第2領域df2からは、複製スライスヘッダha’、スライスヘッダhb、第2MBライン、複製スライスヘッダhc’および複製スライスヘッダhd’を含む第2分割ストリームが出力される。第3領域df3からは、複製スライスヘッダha’、複製スライスヘッダhb’、スライスヘッダhc、第3MBラインおよび複製スライスヘッダhd’を含む第3分割ストリームが出力される。第4領域df4からは、複製スライスヘッダha’、複製スライスヘッダhb’、複製スライスヘッダhc’、スライスヘッダhdおよび第4MBラインを含む第4分割ストリームが出力される。
なお、第1領域df1〜第4領域df4のそれぞれには、第4MBラインの後に続くMBラインが順次格納され、図16に示す第1分割ストリーム〜第4分割ストリームの終端以降にも他のMBラインが続いて配置される。具体的には、符号化ストリームには、第4MBライン以降にも、スライスDに属する4MBライン以上のスライスデータが後続しており、図16に示す第1分割ストリーム〜第4分割ストリームの終端以降には、新たなスライスヘッダは後続していない。
つまり、第1分割ストリームでは、スライスヘッダhaが第1MBラインの前に配置され、複製スライスヘッダhb’、複製スライスヘッダhc’および複製スライスヘッダhd’からなる3つのスライスヘッダが第1MBラインの後に連続して配置される。
また、第2分割ストリームでは、複製スライスヘッダha’およびスライスヘッダhbからなる2つのスライスヘッダが第2MBラインの前に連続して配置され、複製スライスヘッダhc’および複製スライスヘッダhd’からなる2つのスライスヘッダが第2MBラインの後に連続して配置される。
また、第3分割ストリームでは、複製スライスヘッダha’、複製スライスヘッダhb’およびスライスヘッダhcからなる3つのスライスヘッダが第3MBラインの前に連続して配置され、複製スライスヘッダhd’が第3MBラインの後に配置される。
また、第4分割ストリームでは、複製スライスヘッダha’、複製スライスヘッダhb’、複製スライスヘッダhc’およびスライスヘッダhdからなる4つのスライスヘッダが第4MBラインの前に連続して配置される。
第1デコードエンジン121は、第1領域df1から出力される上述の第1分割ストリームの第1MBラインを復号化するとき、まず、制御部160から総ヘッダ数「1」の通知を受ける。その結果、第1デコードエンジン121は、スライスヘッダに対する処理をスキップすることなく、スライスヘッダhaを処理し、そのスライスヘッダhaに続く第1MBラインを復号化する。次に、第1デコードエンジン121は、制御部160から総ヘッダ数「3」の通知を受ける。その結果、第1デコードエンジン121は、第1MBラインを復号した後に、(総ヘッダ数−1=2)個のスライスヘッダに対する処理をスキップする。つまり、第1デコードエンジン121は、2個のスライスヘッダ(複製スライスヘッダhb’および複製スライスヘッダhc’)に対する処理をスキップし、複製スライスヘッダhd’を処理し、その複製スライスヘッダhd’に続くMBラインを復号化する。
また、第2デコードエンジン121は、第2領域df2から出力される上述の第2分割ストリームの第2MBラインを復号化するとき、まず、制御部160から総ヘッダ数「2」の通知を受ける。その結果、第2デコードエンジン121は、(総ヘッダ数−1=1)個のスライスヘッダに対する処理をスキップする。つまり、第2デコードエンジン121は、複製スライスヘッダha’に対する処理をスキップし、スライスヘッダhbを処理し、そのスライスヘッダhbに続く第2MBラインを復号化する。次に、第2デコードエンジン121は、制御部160から再び総ヘッダ数「2」の通知を受ける。その結果、第2デコードエンジン121は、(総ヘッダ数−1=1)個のスライスヘッダに対する処理をスキップする。つまり、第2デコードエンジン121は、複製スライスヘッダhc’に対する処理をスキップし、複製スライスヘッダhd’を処理し、その複製スライスヘッダhd’に続くMBラインを復号化する。
また、第3デコードエンジン121は、第3領域df3から出力される上述の第3分割ストリームの第3MBラインを復号化するとき、まず、制御部160から総ヘッダ数「3」の通知を受ける。その結果、第3デコードエンジン121は、(総ヘッダ数−1=2)個のスライスヘッダに対する処理をスキップする。つまり、第3デコードエンジン121は、複製スライスヘッダha’および複製スライスヘッダhb’に対する処理をスキップし、スライスヘッダhcを処理し、そのスライスヘッダhcに続く第3MBラインを復号化する。次に、第3デコードエンジン121は、制御部160から総ヘッダ数「1」の通知を受ける。その結果、第3デコードエンジン121は、スライスヘッダに対する処理をスキップすることなく、複製スライスヘッダhd’を処理し、その複製スライスヘッダhd’に続くMBラインを復号化する。
また、第4デコードエンジン121は、第4領域df4から出力される上述の第4分割ストリームの第4MBラインを復号化するとき、まず、制御部160から総ヘッダ数「4」の通知を受ける。その結果、第4デコードエンジン121は、(総ヘッダ数−1=3)個のスライスヘッダに対する処理をスキップする。つまり、第4デコードエンジン121は、複製スライスヘッダha’、複製スライスヘッダhb’および複製スライスヘッダhc’に対する処理をスキップし、スライスヘッダhdを処理し、そのスライスヘッダhdに続く第4MBラインを復号化する。
このように、変形例2では、ストリーム分割部130cが、複製スライスヘッダが必要であるか否かに関わらず、分割ストリームに複製スライスヘッダを挿入するため、ストリーム分割部130cにおけるその複製スライスヘッダの必要性の判断に要する処理負担を軽減することができる。さらに、ストリーム分割部130cは、符号化ストリームに含まれるスライスヘッダを取得すると、単純にそのスライスヘッダを出力すればよいため、上記実施の形態のストリーム分割部130のようにヘッダバッファ133dを備える必要がない。その結果、ストリーム分割部130cの構成を簡単にすることができる。
(変形例3)
ここで上記変形例2では、複製スライスヘッダが必要であるか否かに関わらず、複製元のスライスヘッダを含む分割ストリーム以外の全ての分割ストリームに複製スライスヘッダを挿入することにより、連続して配置された複数のスライスヘッダを含む分割ストリームを生成した。変形例3では、上記変形例2と同様、複製スライスヘッダが必要であるか否かに関わらず、複製元のスライスヘッダを含む分割ストリーム以外の全ての分割ストリームに複製スライスヘッダを挿入するが、連続してスライスヘッダを挿入する場合には、既に挿入されているスライスヘッダに新たなスライスヘッダを上書する。これにより、分割ストリームにおいて複数のスライスヘッダが連続して配置されるのを防ぐ。
図17は、変形例3に係る画像復号化装置のストリーム分割部、分割ストリームバッファおよび4つのデコードエンジンを示すブロック図である。
変形例3に係るストリーム分割部130dは、スライスヘッダ処理部133h、スライスデータ処理部134dおよび4つのバッファ(第1バッファ141〜第4バッファ144)を備えている。なお、ストリーム分割部130dは、これらの構成要素以外にも、スタートコード検出部131、EPB除去部132aおよびEPB挿入部132bを備えているが、図17では、説明を簡単にするために、スタートコード検出部131などの構成要素を省略している。
スライスデータ処理部134dは、上記実施の形態におけるスライスデータ処理部134a,134bと同様の機能および構成を有し、符号化ストリーム中の各ピクチャを複数のMBラインに分割し、それらのMBラインを先頭側から順に、第1バッファ141、第2バッファ142、第3バッファ143および第4バッファ144の何れかに出力する。例えば、スライスデータ処理部134dは、MBラインごとに、そのMBラインの出力先となるバッファを、第1バッファ141、第2バッファ142、第3バッファ143、第4バッファ144の順に切り替えて、切り替えられたバッファにMBラインを出力する。また、スライスデータ処理部134dは、符号化ストリーム中のMBラインの直前にスライスヘッダがあっても、そのMBラインだけをバッファに出力し、MBラインの中にスライスヘッダがあっても、そのスライスヘッダを除くMBラインをバッファに出力する。
スライスヘッダ処理部133hは、符号化ストリームに含まれるデータを先頭側から順次取得しているときに、その取得したデータがスライスヘッダである場合には、そのスライスヘッダを第1バッファ141〜第4バッファ144のそれぞれに同時に出力する。その結果、スライスヘッダが4つに複製される。つまり、符号化ストリームに含まれていた複製元のスライスヘッダが第1バッファ141〜第4バッファ144のいずれか1つのバッファに格納され、残りの3つのバッファに3つの複製スライスヘッダがそれぞれ格納される。
例えば、スライスヘッダ処理部133hがスライスヘッダを第1バッファ141〜第4バッファ144のそれぞれに同時に出力すると、複製元のスライスヘッダが第1バッファ141に格納され、3つの複製スライスヘッダが第2バッファ142、第3バッファ143および第4バッファ144のそれぞれに格納される。
バッファ(第1バッファ141〜第4バッファ144)は、少なくとも1つのスライスヘッダを格納し得る程度の容量を有し、スライスヘッダ処理部133hおよびスライスデータ処理部134dから出力されるデータを一時的に蓄積し、そのバッファに対応付けられた分割ストリームバッファ152の領域に出力する。なお、説明を簡単にするために、バッファが1つのスライスヘッダと1つのマクロブロックとを格納し得る容量を有するものとして、以下、説明する。
バッファは、スライスヘッダ処理部133hからスライスヘッダ(複製元のスライスヘッダまたは複製スライスヘッダ)を取得したときには、一時的に、そのスライスヘッダを保持し、そのスライスヘッダを保持している状態で次の新たなスライスヘッダを取得すると、既に保持しているスライスヘッダに、その新たなスライスヘッダを上書する。
また、バッファは、スライスヘッダを取得して保持した直後に、スライスデータ処理部134dからマクロブロックを取得して保持すると、その保持しているデータを、スライスヘッダ、マクロブロックの順に出力する。さらに、バッファは、先のマクロブロックに続いてスライスデータ処理部134dから新たなマクロブロックを取得するときには、既に保持しているスライスヘッダおよびマクロブロックを順次消去して新たなマクロブロックを保持し、その新たなマクロブロックを出力する。
つまり、バッファは、マクロブロックを取得するごとに、そのマクロブロックを直ぐに出力する。一方、バッファは、スライスヘッダを取得したときには、そのスライスヘッダを直ぐには出力せずに保持しておき、マクロブロックを取得して出力するときに、そのスライスヘッダをマクロブロックの前に出力する。また、バッファは、スライスヘッダを保持しているときに、新たなスライスヘッダを取得したときには、既に保持しているスライスヘッダに新たなスライスヘッダを上書きする。
このようなスライスデータ処理部134d、スライスヘッダ処理部133hおよびバッファによる処理によって、分割ストリームバッファ152の各領域(第1領域df1〜第4領域df4)には、連続するスライスヘッダを含まない分割ストリームが蓄積される。
デコードエンジン120は、上記実施の形態と同様、そのデコードエンジン120に対応付けられた分割ストリームバッファ152の領域から分割ストリームを読み出して復号化する。
図18は、バッファのポインタを示す図である。
バッファは、スライスヘッダをスライスヘッダ処理部133hから取得して記憶領域に書き込むときには、記憶領域のライトポインタWPをガードポインタGPまで巻き戻し、スライスヘッダをそのガードポインタGPから書き込む。これにより、既に格納されているスライスヘッダは上書されて消去される。また、バッファは、通常、記憶領域に書き込まれたデータをリードポインタRPから読み出して出力するが、そのリードポインタRPはガードポインタGPを超えないように設定されている。
そして、バッファは、スライスヘッダを記憶領域に書き込んだ直後に、マクロブロックを記憶領域に書き込むときだけ、そのガードポインタGPによるリードポインタRPのガードを外して、その書き込んだスライスヘッダとマクロブロックとを読み出して出力する。このように出力されたスライスヘッダとマクロブロックは、新たなスライスヘッダまたはマクロブロックが書き込まれるときに上書きされて消去されることとなる。
図19は、変形例3におけるストリーム分割部130dの動作を説明するための説明図である。
例えば、符号化ストリームに含まれるピクチャは、スライスA、スライスB、スライスCおよびスライスDを含む。ここで、スライスAはスライスヘッダhaおよび第1MBラインを含み、スライスBはスライスヘッダhb、第2MBラインおよび第3MBラインの一部を含み、スライスCはスライスヘッダhcおよび第3MBラインの残りの一部を含み、スライスDはスライスヘッダhdおよび第4MBラインを含む。
ストリーム分割部130dのスライスヘッダ処理部133hは、符号化ストリームのスライスヘッダhaを取得すると、そのスライスヘッダhaを第1バッファ141〜第4バッファ144のそれぞれに同時に出力する。その結果、そのスライスヘッダhaが第1分割ストリームの一部として第1バッファ141に出力されるとともに、そのスライスヘッダhaと同一の3つの複製スライスヘッダha’のそれぞれが第2分割ストリーム、第3分割ストリーム、第4分割ストリームの一部として第2バッファ142、第3バッファ143、第4バッファ144に出力される。その結果、第1バッファ141にはスライスヘッダhaが書き込まれ、第2バッファ142〜第4バッファ144のそれぞれには複製スライスヘッダha’が書き込まれる。
そして、スライスデータ処理部134dは、第1MBラインに含まれるマクロブロックを先頭側から順次、第1分割ストリームの一部として第1バッファ141に出力する。これにより、第1バッファ141には、スライスヘッダhaの直後にマクロブロックが書き込まれることになり、その第1バッファ141のリードポインタRPのガードが外される。したがって、第1バッファ141は、スライスヘッダhaと第1MBラインの先頭のマクロブロックを分割ストリームバッファ152の第1領域df1に出力する。第1MBラインの先頭マクロブロックが第1バッファ141に書き込まれた後に、その先頭マクロブロックの次に続く2番目以降のマクロブロックが第1バッファ141に順次書き込まれるときには、その第1バッファ141に書き込まれているスライスヘッダhaと先頭マクロブロックは2番目以降のマクロブロックによって上書きされて消去される。そして、第1バッファ141は、第1MBラインの2番目以降のマクロブロックを取得するごとに、既に書き込まれているデータを消去しながら、その2番目以降のマクロブロックを分割ストリームバッファ152の第1領域df1に順次出力する。
このようなストリーム分割部130dの処理によって、スライスヘッダhaおよび第1MBラインが、第1バッファ141を介して分割ストリームバッファ152の第1領域df1に格納される。
次に、スライスヘッダ処理部133hは、符号化ストリームのスライスヘッダhbを取得すると、そのスライスヘッダhbを第1バッファ141〜第4バッファ144のそれぞれに同時に出力する。その結果、そのスライスヘッダhbが第2分割ストリームの一部として第2バッファ142に出力されるとともに、そのスライスヘッダhbと同一の3つの複製スライスヘッダhb’のそれぞれが第1分割ストリーム、第3分割ストリーム、第4分割ストリームの一部として第1バッファ141、第3バッファ143、第4バッファ144に出力される。
その結果、第2バッファ142にはスライスヘッダhbが書き込まれ、第1バッファ141、第3バッファ143および第4バッファ144のそれぞれには複製スライスヘッダhb’が書き込まれる。つまり、第2バッファ142〜第4バッファ144のそれぞれに書き込まれていたスライスヘッダは、スライスヘッダhbまたは複製スライスヘッダhb’に上書される。
そして、スライスデータ処理部134dは、第2MBラインに含まれるマクロブロックを先頭側から順次、第2分割ストリームの一部として第2バッファ142に出力する。これにより、第2バッファ142には、スライスヘッダhbの直後にマクロブロックが書き込まれることになり、その第2バッファ142のリードポインタRPのガードが外される。したがって、第2バッファ142は、スライスヘッダhbと第2MBラインの先頭のマクロブロックを分割ストリームバッファ152の第2領域df2に出力する。第2MBラインの先頭マクロブロックが第2バッファ142に書き込まれた後に、その先頭マクロブロックの次に続く2番目以降のマクロブロックが第2バッファ142に順次書き込まれるときには、その第2バッファ142に書き込まれているスライスヘッダhbと先頭マクロブロックは2番目以降のマクロブロックによって上書きされて消去される。そして、第2バッファ142は、第2MBラインの2番目以降のマクロブロックを取得するごとに、既に書き込まれているデータを消去しながら、その2番目以降のマクロブロックを分割ストリームバッファ152の第2領域df2に順次出力する。
このようなストリーム分割部130dの処理によって、スライスヘッダhbおよび第2MBラインが、第2バッファ142を介して分割ストリームバッファ152の第2領域df2に格納される。
ここで、スライスBは、上述の第2MBラインと第3MBラインのうちの3マクロブロックを含んでいる。したがって、スライスデータ処理部134dは、第2MBラインを出力した後、引き続き第3MBラインの3マクロブロックを先頭側から順次、第3分割ストリームの一部として第3バッファ143に出力する。
これにより、第3バッファ143には、複製スライスヘッダhb’の直後にマクロブロックが書き込まれることになり、その第3バッファ143のリードポインタRPのガードが外される。したがって、第3バッファ143は、複製スライスヘッダhb’と第3MBラインの先頭のマクロブロックを分割ストリームバッファ152の第3領域df3に出力する。第3MBラインの先頭マクロブロックが第3バッファ143に書き込まれた後に、その先頭マクロブロックの次に続く2番目以降のマクロブロックが第3バッファ143に順次書き込まれるときには、その第3バッファ143に書き込まれている複製スライスヘッダhb’と先頭マクロブロックは2番目以降のマクロブロックによって上書きされて消去される。そして、第3バッファ143は、第3MBラインの2番目以降のマクロブロックを取得するごとに、既に書き込まれているデータを消去しながら、その2番目以降のマクロブロックを分割ストリームバッファ152の第3領域df3に順次出力する。
このようなストリーム分割部130dの処理によって、第3MBラインに含まれるスライスBの残りの3つのマクロブロックが、第3バッファ143を介して分割ストリームバッファ152の第3領域df3に格納される。
次に、スライスヘッダ処理部133hは、符号化ストリームのスライスヘッダhcを取得すると、そのスライスヘッダhcを第1バッファ141〜第4バッファ144のそれぞれに同時に出力する。その結果、そのスライスヘッダhcが第3分割ストリームの一部として第3バッファ143に出力されるとともに、そのスライスヘッダhcと同一の3つの複製スライスヘッダhc’のそれぞれが第1分割ストリーム、第2分割ストリーム、第4分割ストリームの一部として第1バッファ141、第2バッファ142、第4バッファ144に出力される。
その結果、第3バッファ143にはスライスヘッダhcが書き込まれ、第1バッファ141、第2バッファ142および第4バッファ144のそれぞれには複製スライスヘッダhc’が書き込まれる。つまり、第1バッファ141および第4バッファ144のそれぞれに書き込まれていたスライスヘッダは複製スライスヘッダhc’に上書される。
そして、スライスデータ処理部134dは、第3MBラインに含まれるスライスCのマクロブロックを先頭側から順次、第3分割ストリームの一部として第3バッファ143に出力する。これにより、第3バッファ143には、スライスヘッダhcの直後にマクロブロックが書き込まれることになり、その第3バッファ143のリードポインタRPのガードが外される。したがって、第3バッファ143は、スライスヘッダhcとスライスCの先頭のマクロブロックを分割ストリームバッファ152の第3領域df3に出力する。スライスCの先頭マクロブロックが第3バッファ143に書き込まれた後に、その先頭マクロブロックの次に続く2番目以降のマクロブロックが第3バッファ143に順次書き込まれるときには、その第3バッファ143に書き込まれているスライスヘッダhcと先頭マクロブロックは2番目以降のマクロブロックによって上書きされて消去される。そして、第3バッファ143は、スライスCの2番目以降のマクロブロックを取得するごとに、既に書き込まれているデータを消去しながら、その2番目以降のマクロブロックを分割ストリームバッファ152の第3領域df3に順次出力する。
このようなストリーム分割部130dの処理によって、スライスヘッダhcおよびスライスCのマクロブロックが、第3バッファ143を介して分割ストリームバッファ152の第3領域df3に格納される。
次に、スライスヘッダ処理部133hは、符号化ストリームのスライスヘッダhdを取得すると、そのスライスヘッダhdを第1バッファ141〜第4バッファ144のそれぞれに同時に出力する。その結果、そのスライスヘッダhdが第4分割ストリームの一部として第4バッファ144に出力されるとともに、そのスライスヘッダhdと同一の3つの複製スライスヘッダhd’のそれぞれが第1分割ストリーム、第2分割ストリーム、第3分割ストリームの一部として第1バッファ141、第2バッファ142、第3バッファ143に出力される。
その結果、第4バッファ144にはスライスヘッダhdが書き込まれ、第1バッファ141、第2バッファ142および第3バッファ143のそれぞれには複製スライスヘッダhd’が書き込まれる。つまり、第1バッファ141、第2バッファ142および第4バッファ144のそれぞれに書き込まれていたスライスヘッダは、スライスヘッダhdまたは複製スライスヘッダhd’に上書される。
そして、スライスデータ処理部134dは、第4MBラインに含まれるマクロブロックを先頭側から順次、第4分割ストリームの一部として第4バッファ144に出力する。これにより、第4バッファ144には、スライスヘッダhdの直後にマクロブロックが書き込まれることになり、その第4バッファ144のリードポインタRPのガードが外される。したがって、第4バッファ144は、スライスヘッダhdと第4MBラインの先頭のマクロブロックを分割ストリームバッファ152の第4領域df4に出力する。第4MBラインの先頭マクロブロックが第4バッファ144に書き込まれた後に、その先頭マクロブロックの次に続く2番目以降のマクロブロックが第4バッファ144に順次書き込まれるときには、その第4バッファ144に書き込まれているスライスヘッダhbと先頭マクロブロックは2番目以降のマクロブロックによって上書きされて消去される。そして、第4バッファ144は、第4MBラインの2番目以降のマクロブロックを取得するごとに、既に書き込まれているデータを消去しながら、その2番目以降のマクロブロックを分割ストリームバッファ152の第4領域df4に順次出力する。
このようなストリーム分割部130dの処理によって、スライスヘッダhdおよび第4MBラインは、第3バッファ143を介して分割ストリームバッファ152の第4領域df4に格納される。
このように、変形例3では、スライスヘッダ処理部133hが、複製スライスヘッダが必要であるか否かに関わらず、複製スライスヘッダを出力するため、スライスヘッダ処理部133hにおけるその複製スライスヘッダの必要性の判断に要する処理負担を軽減することができる。さらに、スライスヘッダ処理部133hは、符号化ストリームに含まれるスライスヘッダを取得すると、単純にそのスライスヘッダを出力すればよいため、上記実施の形態のスライスヘッダ挿入部133のようにヘッダバッファ133dを備える必要がない。その結果、スライスヘッダ処理部133hの構成を簡単にすることができる。
さらに、変形例3では、分割ストリームにおいてスライスヘッダが連続して挿入されることがないため、変形例2と比べて、連続するスライスヘッダに対する処理負担を軽減することができる。つまり、連続しているスライスヘッダの数をデコードエンジン120に通知するための処理や、デコードエンジン120がスライスヘッダに対してスキップすべきか否かを判別する処理などを省くことができる。その結果、ストリーム分割部130dおよびデコードエンジン120の機能構成を簡単にすることができ、デコードエンジン120に従来のデコードエンジンを流用することができる。
図20は、上記実施の形態またはその変形例に係る画像復号化装置の適用例を示す図である。
例えば、上記実施の形態またはその変形例に係る画像復号化装置は、図20に示すように、放送波を受信してその放送波に含まれる符号化ストリームを再生する再生装置101に備えられる。再生装置101は、BSデジタル放送の放送波を受信するアンテナ101aと装置本体101bとを備え、装置本体101bは上述の画像復号化装置を備える。
装置本体101bに備えられた画像復号化装置は、アンテナ101aによって受信された放送波から例えば4k2kの符号化ストリームを抽出する。そして、その画像復号化装置は、上述のように、抽出された符号化ストリームを分割してN個の分割ストリームを生成し、N個の分割ストリームを並列に復号化する。
以上、本発明に係る画像復号化装置および画像復号化方法について、実施の形態およびその変形例を用いて説明したが、本発明は、これらに限定されるものではない。
例えば、上記実施の形態およびその変形例では、画像復号化装置100は分割ストリームバッファ152などを備えていたが、これらを備えていなくてもよい。
図21は、本発明の画像復号化装置の最小構成を示すブロック図である。
画像復号化装置10は、本発明を実現するための最小構成を有し、取得部11、ストリーム分割部12、およびN個の復号化部13を備えている。
取得部11は、ストリームバッファ151、若しくはストリームバッファ151から画像復号化装置10に符号化ストリームを取り込むための取得装置(あるいは単なる取得口)に相当し、画像データが符号化された符号化ストリームを取得する。ストリーム分割部12は、ストリーム分割部130,130c,130dに相当する。つまり、ストリーム分割部12は、取得部11で取得された符号化ストリームに含まれる符号化ピクチャごとに、その符号化ピクチャを複数の構成単位に分割し、複数の構成単位のそれぞれを、生成対象であるN個(Nは2以上の整数)の分割ストリームのうちの何れかの一部に割り当てることにより、N個の分割ストリームを生成する。N個の復号化部13は、デコードエンジン120,121に相当し、ストリーム分割部12により生成されたN個の分割ストリームのそれぞれを並列に復号化する。また、ストリーム分割部12は、N個の分割ストリームを生成する際に、符号化ピクチャに含まれるスライスが複数のスライス部分に分割されて複数の分割ストリームに割り当てられるときには、分割ストリームごとに、その分割ストリームに割り当てられる少なくとも1つのスライス部分からなるスライス部分群が、N個の復号化部13の何れかにスライスとして認識されるように、スライス部分群を新たなスライスとして再構成する。
これにより、符号化ピクチャは例えば複数のマクロブロックラインなどの構成単位に分割され、複数のマクロブロックラインのそれぞれが分割ストリームの一部としてN個の復号化部に割り当てられて復号化されるため、N個の復号化部による復号化処理の負担を均等にすることができ、復号化の並列処理を適切に実行することができる。例えば、H.264/AVCの符号化ピクチャが1スライスで構成されている場合であっても、その符号化ピクチャは複数のマクロブロックラインに分割されるため、その1スライスの復号化を1つの復号化部で負担することなく、N個の復号化部で均等に負担することができる。
ここで、符号化ピクチャが複数のマクロブロックラインに分割されると、複数のマクロブロックラインに跨るスライスが複数のスライス部分に分割され、それらのスライス部分が互いに異なる分割ストリームに割り当てられることがある。つまり、1つの分割ストリームには、符号化ピクチャのスライスの全体が含まれることなく、そのスライスの断片であるスライス部分が1つ以上集まって構成されるスライス部分群が含まれることとなる。また、このようなスライス部分群には、その先頭を示すヘッダや、その終端を示す終端情報が含まれていない場合がある。
そこで本発明では、そのスライス部分群を新たなスライスとして再構成するため、そのスライス部分群を含む分割ストリームを復号化する復号化部13は、そのスライス部分群を認識して適切に復号化するための特別な処理を要することなく、スライス部分群を新たなスライスとして簡単に認識して適切に復号化することができる。つまり、本発明では、N個の復号化部13のそれぞれに特別な処理を行う機能や構成を設ける必要がないため、分割ストリームを復号化する復号化部に従来方式の復号化回路を流用することができ、画像復号化装置の全体構成を簡単にすることができる。
したがって、画像復号化装置10は、上記実施の形態およびその変形例における分割ストリームバッファ152などを必要とせず、それらがなくても上述の本発明に特有の作用効果を奏し、上記目的を達成することができる。
図22は、ストリーム分割部12の構成を示すブロック図である。
ストリーム分割部12は、例えば、複製部12a、アドレス更新部12b、および挿入部12cを備えている。
複製部12aおよび挿入部12cは、スライスヘッダ挿入部133またはスライスヘッダ処理部133g,133hに相当する。また、複製部12aは、符号化ピクチャに含まれるスライスの先頭にある、そのスライスの復号化に必要な補助情報を複製することにより複製補助情報を生成する。例えば、補助情報はスライスヘッダに相当し、複製補助情報は複製スライスヘッダに相当する。挿入部12cは、その複製補助情報を補助情報としてスライス部分群の先頭に挿入する。アドレス更新部12bは、ヘッダアドレス更新部133cに相当し、複製補助情報に含まれるアドレス情報を、スライス部分群に含まれる先頭のマクロブロックのアドレスを示すアドレス情報に更新する。なお、アドレス情報はMBアドレス情報である。
ここで、アドレス更新部12bは、ストリーム分割部12に備えられ、複製部12aによって生成された複製補助情報に含まれるアドレス情報を更新する。そして、挿入部12cは、アドレス更新部12bによって更新されたアドレス情報を含む複製補助情報をスライス部分群の先頭に挿入する。
これにより、スライス部分群の先頭のマクロブロックのアドレスを示すアドレス情報が、そのスライス部分群の補助情報に含まれているため、復号化部13は、特別な処理を行うことなく、そのアドレス情報を読み出すことによって、そのスライス部分群の先頭のマクロブロックのアドレスを適切に把握することができる。
なお、アドレス更新部12bはストリーム分割部12の外部にあってもよい。
図23は、本発明の画像復号化装置の他の最小構成を示すブロック図である。
画像復号化装置20は、本発明を実現するための他の最小構成を有し、取得部11、ストリーム分割部22、アドレス更新部12bおよびN個の復号化部13を備えている。ストリーム分割部22は、複製部12aと挿入部12cだけを備え、アドレス更新部12bは、ストリーム分割部22の外部に備えられている。この場合、アドレス更新部12bは、挿入部12cによってスライス部分群の先頭に挿入されている複製補助情報に含まれるアドレス情報を更新する。
また、アドレス更新部12bは、N個の復号化部13のそれぞれに備えられていてもよい。この場合、復号化部13は、その復号化部13が処理対象とする分割ストリームに対してアドレス情報の更新を行う機能を有する。つまり、上記実施の形態の変形例1がこの場合に相当する。
図24は、ストリーム分割部12の他の構成を示すブロック図である。
ストリーム分割部12は、補助情報処理部12d、分割出力部12e、およびN個のバッファ12fを備えている。ここで、符号化ストリームに含まれるスライスの先頭には、そのスライスの復号化に必要な補助情報がある。例えば、補助情報はスライスヘッダに相当する。N個のバッファ12fはそれぞれ、第1バッファ141〜第4バッファ144に相当し、N個の復号化部13にそれぞれ対応付けられている。分割出力部12eは、スライスデータ処理部134dに相当し、符号化ピクチャを複数の構成単位に分割し、複数の構成単位のそれぞれを、N個のバッファ12fのうちの何れかに出力する。補助情報処理部12dは、スライスヘッダ処理部133hに相当し、符号化ピクチャに含まれるデータを順次取得し、そのデータが補助情報であるときに、その補助情報をN個のバッファ12fに出力する。
ここで、N個のバッファ12fのそれぞれは、分割出力部12eから出力された構成単位に含まれるデータを取得するごとに、そのデータを出力する。また、N個のバッファ12fのそれぞれは、補助情報処理部12dから出力された補助情報を取得したときには、その補助情報を保持し、その補助情報の直後に構成単位のデータを取得したときにのみ、保持している補助情報をそのデータの前に出力し、補助情報の直後に新たな補助情報を取得したときには、補助情報をその新たな補助情報に上書きする。N個の復号化部13のそれぞれは、その復号化部13に対応付けられたバッファから出力される補助情報および構成単位のデータからなる分割ストリームを復号化する。
これにより、補助情報処理部12dが、符号化ストリームから得られる補助情報をN個のバッファ12fに単純に出力すれば、N個のバッファ12fに出力された補助情報のうち、N個の分割ストリームに必要とされる補助情報だけを、そのN個のバッファから適切なタイミングで出力させることができる。その結果、簡単な構成で、符号化ピクチャのスライスの先頭でなかったスライス部分群の先頭に、補助情報を適切に挿入することができる。
なお、上記実施の形態およびその変形例では、複製スライスヘッダを挿入したが、複製スライスヘッダを挿入しなくてもよい。例えば、複製元のスライスヘッダに含まれる、そのスライスヘッダを有するスライスの復号化に必要な補助情報だけを複製し、その複製によって生成された複製補助情報を挿入してもよい。
また、上記実施の形態およびその変形例では、1MBラインを1つの構成単位として扱い、ピクチャを複数の構成単位に分割したが、その構成単位は1MBラインに限らず、2MBラインや、3MBラインであってもよく、ピクチャの垂直方向に一列に配列される複数のマクロブロックであってもよい。例えば、ピクチャがMBAFFで構成されている場合には、2MBラインを構成単位として扱い、ピクチャがMBAFFで構成されていない場合には、1MBラインを構成単位として扱ってもよい。
また、上記実施の形態およびその変形例では、ストリーム分割部が複製スライスヘッダを分割ストリームに挿入し、デコードエンジンがその複製スライスヘッダが挿入された分割ストリームを読み出して復号化した。しかし、ストリーム分割部が複製スライスヘッダを分割ストリームに挿入することなく、その複製スライスヘッダをデコードエンジンに直接出力してもよい。例えば、ストリーム分割部は、デコードエンジンに読み込まれる分割ストリーム中のMBラインの直前に複製スライスヘッダが存在すべきか否かを判別し、存在すべきと判別したときには、そのMBラインがデコードエンジンに読み込まれる直前に、その複製スライスヘッダをデコードエンジンに出力する。ここで、ストリーム分割部は複製スライスヘッダ自体をデコードエンジンに出力することなく、複製スライスヘッダに含まれている一部の情報だけをデコードエンジンに出力してもよい。
なお、ブロック図(図1、図7、図9、図15および図17など)の各機能ブロックは典型的には集積回路であるLSI(Large Scale Integration)として実現される。これらは個別に1チップ化されても良いし、一部又は全てを含むように1チップ化されても良い。例えばメモリ以外の機能ブロックが1チップ化されていても良い。
ここでは、LSIとしたが、集積度の違いにより、IC(Integrated Circuit)、システムLSI、スーパーLSI、ウルトラLSIと呼称されることもある。
また、集積回路化の手法はLSIに限るものではなく、専用回路又は汎用プロセッサで実現してもよい。LSI製造後に、プログラムすることが可能なFPGA(Field Programmable Gate Array)や、LSI内部の回路セルの接続や設定を再構成可能なリコンフィギュラブル・プロセッサを利用しても良い。
さらには、半導体技術の進歩又は派生する別技術によりLSIに置き換わる集積回路化の技術が登場すれば、当然、その技術を用いて機能ブロックの集積化を行ってもよい。バイオ技術の適応等が可能性としてありえる。