JP5352780B2 - プロセッサ - Google Patents
プロセッサ Download PDFInfo
- Publication number
- JP5352780B2 JP5352780B2 JP2010509892A JP2010509892A JP5352780B2 JP 5352780 B2 JP5352780 B2 JP 5352780B2 JP 2010509892 A JP2010509892 A JP 2010509892A JP 2010509892 A JP2010509892 A JP 2010509892A JP 5352780 B2 JP5352780 B2 JP 5352780B2
- Authority
- JP
- Japan
- Prior art keywords
- processor
- data
- bus
- address
- token
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Expired - Fee Related
Links
Images





Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F15/00—Digital computers in general; Data processing equipment in general
- G06F15/76—Architectures of general purpose stored program computers
- G06F15/80—Architectures of general purpose stored program computers comprising an array of processing units with common control, e.g. single instruction multiple data processors
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F15/00—Digital computers in general; Data processing equipment in general
- G06F15/76—Architectures of general purpose stored program computers
- G06F15/82—Architectures of general purpose stored program computers data or demand driven
- G06F15/825—Dataflow computers
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F15/00—Digital computers in general; Data processing equipment in general
- G06F15/76—Architectures of general purpose stored program computers
- G06F15/82—Architectures of general purpose stored program computers data or demand driven
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/22—Microcontrol or microprogram arrangements
- G06F9/28—Enhancement of operational speed, e.g. by using several microcontrol devices operating in parallel
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/30—Arrangements for executing machine instructions, e.g. instruction decode
- G06F9/38—Concurrent instruction execution, e.g. pipeline or look ahead
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/30—Arrangements for executing machine instructions, e.g. instruction decode
- G06F9/38—Concurrent instruction execution, e.g. pipeline or look ahead
- G06F9/3836—Instruction issuing, e.g. dynamic instruction scheduling or out of order instruction execution
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Software Systems (AREA)
- Computer Hardware Design (AREA)
- Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Computing Systems (AREA)
- Multi Processors (AREA)
- Bus Control (AREA)
Description
プロセッサ12の間には、一組のバス20が矩形の格子状に配置される。各プロセッサ12の列の間には、Y軸方向に延びる一対のバスが設けられる。一方の+Yは、Y軸の正方向へのデータ転送を、他方の−Yは、Y軸の負方向へのデータ転送を行う。プロセッサ12の各行の間には、X軸方向に延びる一対のバスが設けられる。一方の+Xは、X軸の正方向へのデータ転送、他方の−Xは、X軸の負方向へのデータ転送を担う。バス20の各ペアは、図1では単一の線で表現されているが、図2にはプロセッサ12の1つを囲む各バス20の部分が示されている。すなわち、図2は、基本ユニットとなる1つのプロセッサ・タイル22を示している。この基本ユニットは、チップ10全体に渡って繰り返されてチップ全体を構成する。各プロセッサ12は、その4辺において隣接する4つのバス20のそれぞれと接続されており、したがって、各プロセッサは、データを4方向のうちのいずれかの方向に転送するために、データを適切なバスへと導く。
この装置は、修正2の補数エンコーディングにおいて実行される固定小数点数演算を用いる。標準的な2の補数演算は、0用の1つのビット列と、連続する正の整数をコード化する奇数個のビット列と、連続する負の整数をコード化する偶数個のビット列とを有する。負の整数のビット列は、正の整数のビット列よりも1ビット多い。標準演算では、オーバーフロー時は、ステータスフラッグがセットされる。対照的に、本実施の形態では、無効を排除して、0のいずれか一方の側に位置する同数の奇数個のビット列を用いたコード化を発生させつつ、無効(nullity)Фを最上位負整数のビット列と同一であるとする修正2の補数演算が用いられる。符号付き無限大(±∞)は、無効及び符号付き無限大を排除し、0のいずれか一方の側に位置する同数の偶数個の連続(有限)整数を残しつつ、残りの最上位正整数及び最上位負整数用のビット列と同一視される。オーバーフロー時には、演算は、符号付き無限大を丸める。この整数の基礎コード化の下では、数は、固定小数点形式i.fで表される。但し、iは、整数ビットであり、fは、小数点以下部分ビットである。今述べたように、iビットは、修正2の補数エンコーディングを用いた、符号、無限大、及び無効を表すビットパターンを含む。すなわち、これは、整数部分と小数点以下部分が同じビット数である場合、小数点以下部分は、整数部分より正確であることを意味する。通常、数は、符号が付いていることを明確にするために、±(i.f)の形式で記載される。本実施の形態で使われる修正2の補数演算の詳細は、GB0625735.6に開示されている。無効の定義は、以下の原理による。すなわち、無効は、無限大から無限大を減算した結果であり、無効は、無限大に0を乗算した結果であり、任意の数を無効に加算した結果は無効であり、任意の数に無効を乗算した結果は無効である。
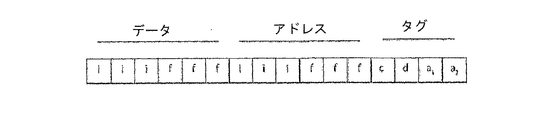
図4を参照すると、バスは、ビットグループにあるデータや情報をトークンの形式で伝達する。各トークンは、3つのフィールドから成る。すなわち、整数ビットiと小数点以下部分ビットfを含む第1グループのビットからなるデータフィールドと、整数ビットiと小数点以下部分ビットfを含む第2グループのビットからなるアドレスフィールドと、トークンのステータスを様々な方法で示すタグとして用いられるc、d、a1、a2の4つのビットのグループからなるタグフィールドとである。各トークンは、以下に説明されるようにcとdのタグで特定される、コントロールトークンとデータトークンの2種類に分かれる。
データフィールドは、それ全体で1つの数として解釈される。アドレスフィールドが、±∞の数又はФのいずれかである場合、アドレスフィールドは、単一の第1アドレスiとして解釈される。それ以外の場合、アドレスフィールドは、iビットによって定義される第1アドレスa1と、fビットによって定義される第2アドレスa2という2つのアドレスとして解釈される。タグフィールドは、4つのビットを表し、4ビットの各々は、セットされたり、あるいはクリアである。cタグが設定される場合、データフレームは、制御を運ぶ。それ以外は、cタグは制御を運んでいない。制御を運んでいるデータフレームは、コントロールトークンと呼ばれる。dタグが設定される場合、データフレームは、データを運ぶ。それ以外は、dタグは、データを運んでいない。データを運んでいるデータフレームは、データトークンと呼ばれる。a1タグが設定される場合、データフレームは、±∞の第1アドレスa1、あるいはゼネラルアドレスiに依然として伝送される。それ以外の場合には、このアドレスに伝送されない。a2タグが設定される場合、データフレームは、第2アドレスa2に依然として伝送される。そうでない場合は、もはやこのアドレスには伝送されない。アドレスフィールドが無効Фであれば、データフレームは、バスには乗っていない。アドレスa1、a2は、同じプロセッサをターゲットとしても、あるいは、別々のプロセッサをターゲットとしてもよい。2つの別々のアドレスを用いることで、単一のスレッドから2つの平行スレッドに許容出力するよう制御することが可能になる。対象となるプロセッサが異なる場合、データフレームは、第2アドレスa2の前に第1アドレスa1に送られることになる。a1タグとa2タグとが両方クリアである場合、データフレームは、空であり、プロセッサによる書き込まれる。
上述したように、各タプル12は、左右上下の4つの線条バス20に重ね合わせられるように接続されている。図3は、タプル12とゼネラル、アップアドレス、又はダウンアドレスの線条バスとの接続を示す。本実施の形態のチップでは、4つの異なるバスが各タプルに接続されているが、他の実施の形態では、共有のために適切な空間的・時間的トレードオフがある場合には、隣接するタプル同士の間でバスを共有してもよい。チップのすべてのバスは、集合的に「バス」と称される。
上述したように、タプル12は、見かけ上矩形の行列のアレイに配置される。各タプルは、左右上下4つの線条バスに重ね合わせられている。1の線条バスにおける最初と最後のタプルは、アドレス±∞とされて出入力を司る。一方、中間のタプルは、プロセッサとなる。オンチップ出入力装置は、トークンを関連するバスに伝達したり、出入力タプルにおいて関連するバスからトークンを外したりする。出入力タプルが、周辺機器からチップへと入力される対象のトークンである場合には、タプルは、反対側の線状バス上にある出力装置にトークンを書き込む。これにより、出入力タプルの接続テストが可能となる。トークンが外側境界バス上の出入力タプルに到着した場合、そのトークンは、出力装置に書き込まれる。もし、トークンがその出入力タプルをターゲットとしていない場合、そのトークンが先のターゲットによって捕捉されなかったために、トークンは到着する。すなわち、ハードウェアやコンパイラのエラーである。オフチッププロセッサは、このエラーを検証してもよい。出入力タプルがコントロールトークンを捕捉する動きは、アーキテクチャに依存するので、出入力処理の条件付けに用いることもできる。本実施の形態のチップにおいて、出入力タプルでコントロールトークンは用いられないが、出入力タプルは、チップ内のある場所にトークンを書き込んで、何らかの条件を報告してもよい。
図5を参照すると、各プロセッサ12は、8つの物理メモリセルu、v、w、r、l、z、g、nからなる8−タプルから成る。セルは、0から7まで番号が付いている。したがって、uは、タプルの0番目のエレメントとして認められ、nは、7番目のエレメントとして認められる。0から番号付けすることは、目標のターゲットを検出するためのアドレスをマスキングする際のハードウェアにおいて行われているように、モジュール演算を行う上で有益である。物理8−タプルは、マニピュレータ又は出入力装置12でもあるプロセッサ12によって操作されるデータをホールドする。いずれの種類の装置も、隣接する4つの線条バスのいずれかに書き込みすることができる。物理タプルは、ラベル−x、+x、−y、+yのバーチャルセルで書き込みアドレスを受け取ことによって、ラベルされたバスに書き込みをするように調整されている。このように、タプルの各物理セルに対応する4つのバーチャルメモリセルが存在し、全体で以下の32のバーチャルセルを提供する。
(u-x、u+x、u-y、u+y、v-x、v+x、v-y、v+y、w-x、w+x、w-y、w+y、r-x、r+x、r-y、r+y、l-x、l+x、l-y、l+y、z-x、z+x、z-y、z+y、g-x、g+x、g-y、g+y、n-x、n+x、n-y、n+y)
u×v+w→r’
write(r’,r)
jump(r’,l,z,g,n)
Jump to(l)if r’<0
Jump to(z)if r’=0
Jump to(g)if r’>0
Jump to(n)if r’=Ф
上述したように、各プロセッサは、プロセッサへの32のアドレスを示すために確保された5アドレスビットを有するアドレスPを有る。プロセッサにデータフレームが到着すると、データフレームは検査される。最初に、Pがiと合致し、a1がセットされ、dもセットされる場合、データフィールドは、バスからプロセッサに書き込まれ、a1がクリアされ、このアドレスへの伝達は、もはや必要なくなったことを示す。次に、第二に、Pがfと合致し、a1がクリアで、a2がセットされ、dがセットされている場合、データフィールドは、バスからプロセッサへとに書き込まれ、a2とdがクリアされる。これは、伝達がどこに対しても不要となったことを示す。第三に、Pがiと合致し、a1がセットされ、cがセットされている場合には、単一サイクルのプロセッサの実行が開始され、a1がクリアされる。これは、このアドレスへの伝達はもはや必要なくなったことを示す。次に、第四に、Pがfと合致し、a1がクリアでa2がセットされ、cがセットされている場合、単一サイクルのプロセッサの実行が開始されてa2がクリアされ、cもクリアされる。これは、どこへも伝達が不要となったことを示す。注意すべきは、iとfが同じプロセッサで実行を開始する度に、単一サイクルのみのプロセッサの実行が開始される。第五に、Pがfと合致し、a1がセットされている場合、第1のアドレスへの伝達が失敗する。これは、エラーである。データは、プロセッサへ書き込まれず、実行は開始されない。データフレームは、データをどこにも伝達させずに、バスに沿って終点まで通過する。
バスの終点にあるデータフレームに、cあるいはdのいずれか一方がセットされていた場合、出入力装置によって、データフレームは、チップの外部に書き込まれる。単一のアドレスがアップアドレスバスで∞、あるいは、ダウンアドレスバスで−∞の場合、そのバスフレームは、出入力装置を正しく目標とし、オフチップデバイスによって、有効データフレームとして扱われる。他のアドレスは、伝達エラーを示し、オフチップデバイスによって適切なエラー処理が施される。
タプルは、その位置においてバスフレームからトークンを受け取ったり、バスフレームへトークンを書き込んだりする。タプルは、そのバスフレームに書き込みをする前にバスフレームからトークンを受け取る。そのため、バスフレームを再利用することができる。これにより、バスの帯域幅を効率的に利用できることになる。また、孤立したチップ内における通信が隣接するタプル間での移動に限定されているとき、バスは、常にトークンを受け渡し可能な状態にあることになる。バスのこの準備は、たとえば、右と下向きの線条バスを隣接するタプルへの短い書き込み用とし、左と上向きのバスの領域においてのみ長い書き込みや隣接していないタプルへのジャンプを行うことによって、広範囲での応用が可能になる。長いジャンプは、バスの容量を越えないような密度で維持される必要がある。チップ上のどこにおいても迅速な通信を可能とするように、チップ内の領域で長短の配置の間での切替は可能である。
コントロールタグcとデータタグdがクリアならば、バスフレームは、コピーされていない。コントロールタグがセットされているが、データタグがクリアな場合は、タグ及びコントロールナンバ全体がコピーされる。データタグがセットされている場合、バスフレーム全体がコピーされる。このように、有効なデータのみを移動させるために、実質的なパワーが使用される。
プロセッサのメモリセルuiのいずれかをターゲットとするバスフレームに、タグdがセットされている場合、フレームのデータフィールドが、乗算器のメモリセルuに書き込まれる。同様に、メモリセルviのいずれかをターゲットとするデータフィールドは、乗算器のメモリセルvに書き込まれ、メモリセルwiのいずれかをターゲットとするデータフィールドは、加算器のフィールドwに書き込まれる。同様に、メモリセルriのいずれかをターゲットとするデータフィールドは、ルータのデータフレームアドレスフィールドに書き込まれ、該ルータが付加的な動作を実行する。データフィールドがr-xをターゲットとする場合、バス−Xが出力先として選択される。同様に、データフィールドがr+x、r-y、r+yをターゲットとしている場合には、対応するバス−X、−Y、+Yが出力先として選択される。
好ましい実施の形態の記載において用いられる記号を以下にまとめる。
-x:デカルト座標系の原点から負のX軸を示す下付き添字。
-x:デカルト座標系の原点から正のX軸を示す下付き添字。
-y:デカルト座標系の原点から負のY軸を示す下付き添字。
+y:デカルト座標系の原点から正のY軸を示す下付き添字。
a1:±(a1・a2)の形式で最初に現れるアドレス。
a1:トークンがアドレスa1に伝達されるべきなのか、あるいはすでに伝達されたのかを示すバスフレームのタグビット。
a2:±(a1・a2)の形式で2番目に現れるアドレス。
a2:トークンがアドレスa2に伝達されるべきなのか、あるいはすでに伝達されたのかを示すバスフレームのタグビット。
c:フレームが制御を含むか否かを示すバスフレームのタグビット。
d:フレームがデータを含むか否かを示すバスフレームのタグビット。
f:固定小数点の小数点以下部分ビット。
g:物理8−タプルの6番目のセル、0より大きい結果の場合にジャンプするアドレス。
i:固定小数点の整数ビット、符号、無限大及び無効を示すビットパターンを含む。
l:物理8−タプルの4番目のセル、結果が0より小さい場合にジャンプするアドレス。
n:物理8−タプルの7番目のセル、結果が無効の場合にジャンプするアドレス。
P:プロセッサのアドレス。これは、物理8−タプルの0番目のセルuのアドレスである。
r、r’:物理8−タプルの3番目のセル。インストラクション・フラグメントu×v+w→r’の演算結果のアドレス。演算結果は、一時変数r’にホールドされる。
u:物理8−タプルの0番目のセル。インストラクション・フラグメントu×v+w→r’の第1の引数。
v:物理8−タプルの1番目のセル。インストラクション・フラグメントu×v+w→r’の第2の引数。
w:物理8−タプルの2番目のセル。インストラクション・フラグメントu×v+w→r’の第3の引数。
z:物理8−タプルの5番目のセル。解が0の場合にジャンプするアドレス。
上述した実施の形態には、数多くの効果がある。
n−c→c’
が実行される。この演算は、冪等であり、故に
n−c’→c
である。
12 プロセッサ
20 バス
Claims (19)
- 各々がインストラクションを実行するように配置された複数のプロセッサと、前記プロセッサ間でデータトークン及びコントロールトークンを搬送するように配置されたバスとを有し、
各プロセッサは、バスを介してコントロールトークンを受け取る場合に、前記インストラクションを実行し、前記インストラクションを実行する際には、データに演算を行って結果を生成し、データ対象プロセッサとなるべきプロセッサを特定し、特定されたデータ対象プロセッサに出力データを伝送し、制御対象プロセッサとなるべきプロセッサを特定し、特定した制御対象プロセッサにコントロールトークンを伝送することを特徴とする処理装置。 - 各プロセッサは、任意のデータ対象プロセッサのアドレスと一緒に前記バスに前記出力データを書き込むように配置されていることを特徴とする請求項1記載の処理装置。
- 各プロセッサは、前記出力データが並列に送られる複数のデータ対象プロセッサを特定できることを特徴とする請求項1又は2記載の処理装置。
- 前記バスは、前記特定されたデータ対象プロセッサに前記出力データを伝送するように配置され、前記出力データは、前記データ対象プロセッサに書き込まれることを特徴とする請求項1乃至3のいずれか一に記載の処理装置。
- 各プロセッサは、コントロールトークンが伝送される前記制御対象プロセッサのアドレスと共にバスに前記コントロールトークンを書き込むことによって前記コントロールトークンを伝送するように、配置されていることを特徴とする請求項1乃至4のいずれか一に記載の処理装置。
- 各プロセッサは、前記インストラクションを実行する際、コントロールトークンを並列に伝送できる複数の制御対象プロセッサを特定できることを特徴とする請求項1乃至5のいずれか一に記載の処理装置。
- 各プロセッサは、特定された対象プロセッサのいずれかに前記出力データ及びコントロールトークンを伝送するときに、他のコントロールトークンを受け取るまでは前記インストラクションを再度実行しないことを特徴とする請求項1乃至6のいずれか一に記載の処理装置。
- 各プロセッサは、同一のインストラクションを実行するように配置されていることを特徴とする請求項1乃至7のいずれか一に記載の処理装置。
- 各プロセッサは、唯一のインストラクションを実行するように配置されていることを特徴とする請求項1乃至8のいずれか一に記載の処理装置。
- 前記インストラクションは、
a×b+c −> r’
の乗算及び加算であることを特徴とする請求項1乃至9のいずれか一に記載の処理装置。 - 各プロセッサは、前記結果に基づいて対象プロセッサを選択するように配置されていることを特徴とする請求項1乃至10のいずれか一に記載の処理装置。
- 各プロセッサは、前記結果が、ゼロ未満、ゼロ、ゼロよりも大、又は無効のいずれに該当するかを判別し、それに応じて、対象プロセッサを選択するように配置されていることを特徴とする請求項11記載の処理装置
- 各プロセッサは、前記インストラクションへの入力が記憶される複数のメモリセルを有することを特徴とする請求項1乃至12のいずれか一に記載の処理装置。
- 各プロセッサは、対象プロセッサのアドレスが記憶される複数のメモリセルを有することを特徴とする請求項1乃至13のいずれか一に記載の処理装置。
- 各プロセッサは、前記オペレーションの結果が記憶される複数のメモリセルを有することを特徴とする請求項1乃至14のいずれか一に記載の処理装置。
- 各プロセッサの全メモリは、電源投入時には固定値に設定されることを特徴とする請求項1乃至15のいずれか一に記載の処理装置。
- 各々が複数のプロセッサからなる複数のチップを有し、各チップは、トークンが他のチップに転送される複数の出力装置を有し、
各チップ上の各プロセッサは、関係するアドレスを有し、前記アドレスは範囲の内部にあり、
前記範囲の外側にある対象アドレスを有するトークンを出力装置によって受け取ると、前記対象アドレスの変更を実行し、前記トークンを前記他のチップに転送することを特徴とする請求項1乃至16のいずれか一に記載の処理装置。 - 前記出力装置は、前記変更を実行するように配置されていることを特徴とする請求項17に記載の処理装置。
- 前記変更を実行するために配置された、さらなるオフチップ装置を有することを特徴とする請求項17に記載の処理装置。
Applications Claiming Priority (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| GBGB0710377.3A GB0710377D0 (en) | 2007-05-31 | 2007-05-31 | Processors |
| GB0710377.3 | 2007-05-31 | ||
| PCT/GB2008/001821 WO2008145995A2 (en) | 2007-05-31 | 2008-05-30 | Processors |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2010528387A JP2010528387A (ja) | 2010-08-19 |
| JP5352780B2 true JP5352780B2 (ja) | 2013-11-27 |
Family
ID=38289590
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2010509892A Expired - Fee Related JP5352780B2 (ja) | 2007-05-31 | 2008-05-30 | プロセッサ |
Country Status (8)
| Country | Link |
|---|---|
| US (1) | US8495340B2 (ja) |
| EP (1) | EP2153343A2 (ja) |
| JP (1) | JP5352780B2 (ja) |
| KR (1) | KR20100084605A (ja) |
| CN (2) | CN101802810B (ja) |
| CA (1) | CA2689248C (ja) |
| GB (3) | GB0710377D0 (ja) |
| WO (1) | WO2008145995A2 (ja) |
Families Citing this family (8)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| GB0900667D0 (en) * | 2009-01-16 | 2009-02-25 | Univ Reading The | Processors |
| GB2471067B (en) | 2009-06-12 | 2011-11-30 | Graeme Roy Smith | Shared resource multi-thread array processor |
| US8656137B2 (en) * | 2011-09-01 | 2014-02-18 | Qualcomm Incorporated | Computer system with processor local coherency for virtualized input/output |
| JP6449702B2 (ja) * | 2015-03-30 | 2019-01-09 | ルネサスエレクトロニクス株式会社 | 半導体装置 |
| CN115082282B (zh) * | 2015-06-10 | 2025-10-31 | 无比视视觉技术有限公司 | 用于处理图像的图像处理器和方法 |
| US9690494B2 (en) * | 2015-07-21 | 2017-06-27 | Qualcomm Incorporated | Managing concurrent access to multiple storage bank domains by multiple interfaces |
| US10652925B2 (en) * | 2018-09-25 | 2020-05-12 | Apple Inc. | Medium access control and channel access for access operations |
| CN114297130B (zh) * | 2021-12-28 | 2025-05-30 | 深圳云天励飞技术股份有限公司 | 芯片系统中的数据传输处理方法及相关装置 |
Family Cites Families (19)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPS59146345A (ja) | 1983-02-10 | 1984-08-22 | Masahiro Sowa | コントロ−ルフロ−並列計算機方式 |
| US5152000A (en) * | 1983-05-31 | 1992-09-29 | Thinking Machines Corporation | Array communications arrangement for parallel processor |
| JPH0743700B2 (ja) * | 1990-07-17 | 1995-05-15 | 三菱電機株式会社 | データ駆動型情報処理装置 |
| US5765011A (en) | 1990-11-13 | 1998-06-09 | International Business Machines Corporation | Parallel processing system having a synchronous SIMD processing with processing elements emulating SIMD operation using individual instruction streams |
| JPH05233853A (ja) * | 1992-02-24 | 1993-09-10 | Sharp Corp | 演算処理装置 |
| US5842033A (en) | 1992-06-30 | 1998-11-24 | Discovision Associates | Padding apparatus for passing an arbitrary number of bits through a buffer in a pipeline system |
| US5361385A (en) * | 1992-08-26 | 1994-11-01 | Reuven Bakalash | Parallel computing system for volumetric modeling, data processing and visualization |
| JP2652524B2 (ja) * | 1994-10-19 | 1997-09-10 | 株式会社エーユーイー研究所 | 電子回路の組み立て方法およびその電子回路 |
| US5737524A (en) * | 1995-05-22 | 1998-04-07 | International Business Machines Corporation | Add-in board with programmable configuration registers for use in PCI bus computers |
| EP1041472B2 (de) * | 1999-03-30 | 2007-04-18 | FESTO AG & Co | 1-Chip-Rechneranordnung |
| US6553442B1 (en) * | 1999-11-09 | 2003-04-22 | International Business Machines Corporation | Bus master for SMP execution of global operations utilizing a single token with implied release |
| US6507904B1 (en) * | 2000-03-31 | 2003-01-14 | Intel Corporation | Executing isolated mode instructions in a secure system running in privilege rings |
| US7035996B2 (en) | 2002-01-17 | 2006-04-25 | Raytheon Company | Generating data type token value error in stream computer |
| US7581081B2 (en) * | 2003-03-31 | 2009-08-25 | Stretch, Inc. | Systems and methods for software extensible multi-processing |
| JP4527571B2 (ja) * | 2005-03-14 | 2010-08-18 | 富士通株式会社 | 再構成可能演算処理装置 |
| US7853774B1 (en) * | 2005-03-25 | 2010-12-14 | Tilera Corporation | Managing buffer storage in a parallel processing environment |
| US7962717B2 (en) * | 2007-03-14 | 2011-06-14 | Xmos Limited | Message routing scheme |
| WO2009146267A1 (en) * | 2008-05-27 | 2009-12-03 | Stillwater Supercomputing, Inc. | Execution engine |
| TW201044185A (en) * | 2009-06-09 | 2010-12-16 | Zillians Inc | Virtual world simulation systems and methods utilizing parallel coprocessors, and computer program products thereof |
-
2007
- 2007-05-31 KR KR1020097024885A patent/KR20100084605A/ko not_active Ceased
- 2007-05-31 GB GBGB0710377.3A patent/GB0710377D0/en not_active Ceased
-
2008
- 2008-05-30 JP JP2010509892A patent/JP5352780B2/ja not_active Expired - Fee Related
- 2008-05-30 EP EP08750720A patent/EP2153343A2/en not_active Withdrawn
- 2008-05-30 CN CN2008801015505A patent/CN101802810B/zh not_active Expired - Fee Related
- 2008-05-30 US US12/601,999 patent/US8495340B2/en not_active Expired - Fee Related
- 2008-05-30 GB GB0921638.3A patent/GB2462770B/en not_active Expired - Fee Related
- 2008-05-30 GB GB1202099.6A patent/GB2486092B/en not_active Expired - Fee Related
- 2008-05-30 CA CA2689248A patent/CA2689248C/en not_active Expired - Fee Related
- 2008-05-30 WO PCT/GB2008/001821 patent/WO2008145995A2/en not_active Ceased
- 2008-05-30 CN CN2013101789424A patent/CN103365823A/zh active Pending
Also Published As
| Publication number | Publication date |
|---|---|
| GB2462770A (en) | 2010-02-24 |
| GB2462770B (en) | 2012-05-02 |
| CN101802810B (zh) | 2013-06-12 |
| CN103365823A (zh) | 2013-10-23 |
| JP2010528387A (ja) | 2010-08-19 |
| HK1138661A1 (en) | 2010-08-27 |
| GB2486092A (en) | 2012-06-06 |
| GB0710377D0 (en) | 2007-07-11 |
| GB0921638D0 (en) | 2010-01-27 |
| US20100228949A1 (en) | 2010-09-09 |
| WO2008145995A3 (en) | 2009-01-15 |
| CA2689248C (en) | 2017-09-05 |
| WO2008145995A2 (en) | 2008-12-04 |
| KR20100084605A (ko) | 2010-07-27 |
| GB2486092B (en) | 2012-07-18 |
| CA2689248A1 (en) | 2008-12-04 |
| CN101802810A (zh) | 2010-08-11 |
| US8495340B2 (en) | 2013-07-23 |
| GB201202099D0 (en) | 2012-03-21 |
| EP2153343A2 (en) | 2010-02-17 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP5352780B2 (ja) | プロセッサ | |
| EP3729279B1 (en) | A unified memory organization for neural network processors | |
| EP0539595A1 (en) | Data processor and data processing method | |
| US10282338B1 (en) | Configuring routing in mesh networks | |
| US8050256B1 (en) | Configuring routing in mesh networks | |
| US5081575A (en) | Highly parallel computer architecture employing crossbar switch with selectable pipeline delay | |
| US8151088B1 (en) | Configuring routing in mesh networks | |
| KR101703797B1 (ko) | 벡터 소팅 알고리즘 및 다른 알고리즘들을 지원하기 위한 트리 구조를 갖춘 기능 유닛 | |
| CN112463218B (zh) | 指令发射控制方法及电路、数据处理方法及电路 | |
| KR20100092805A (ko) | 재구성 가능한 구조의 프로세서 | |
| CN117421048A (zh) | 多线程计算中的混合的标量操作和向量操作 | |
| US20110185151A1 (en) | Data Processing Architecture | |
| KR100765567B1 (ko) | 산술 논리 유닛 및 스택을 가지는 데이터 프로세서, 멀티미디어 장치 및 컴퓨터 판독가능 기록 매체 | |
| EP2254057B1 (en) | Simd processor array system and data transfer method thereof | |
| US7124280B2 (en) | Execution control apparatus of data driven information processor for instruction inputs | |
| US9317474B2 (en) | Semiconductor device | |
| US9092212B2 (en) | Processors | |
| EP1251425A2 (en) | Very long instruction word information processing device and system | |
| JP2655243B2 (ja) | 複合化ベクトル並列計算機 | |
| US20050240388A1 (en) | Logical simulation device | |
| CN100440193C (zh) | 数据处理系统的引擎装置以及相应的数据处理系统和方法 | |
| CN117009287A (zh) | 一种于弹性队列存储的动态可重构处理器 | |
| WO2013137459A1 (ja) | データ供給装置及びデータ処理装置 | |
| Pechanek et al. | An introduction to an array memory processor for application specific acceleration | |
| van de Snepscheut | The Construction of a Processor |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20110513 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20120425 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20120510 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20130214 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20130508 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20130701 |
|
| A711 | Notification of change in applicant |
Free format text: JAPANESE INTERMEDIATE CODE: A711 Effective date: 20130709 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20130716 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A821 Effective date: 20130709 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20130807 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 5352780 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| LAPS | Cancellation because of no payment of annual fees |