JP7107246B2 - 推定装置、推定方法、及びプログラム - Google Patents
推定装置、推定方法、及びプログラム Download PDFInfo
- Publication number
- JP7107246B2 JP7107246B2 JP2019029769A JP2019029769A JP7107246B2 JP 7107246 B2 JP7107246 B2 JP 7107246B2 JP 2019029769 A JP2019029769 A JP 2019029769A JP 2019029769 A JP2019029769 A JP 2019029769A JP 7107246 B2 JP7107246 B2 JP 7107246B2
- Authority
- JP
- Japan
- Prior art keywords
- observed
- data
- probability distribution
- censored
- censored data
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
Images






Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F17/00—Digital computing or data processing equipment or methods, specially adapted for specific functions
- G06F17/10—Complex mathematical operations
- G06F17/11—Complex mathematical operations for solving equations, e.g. nonlinear equations, general mathematical optimization problems
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F30/00—Computer-aided design [CAD]
- G06F30/20—Design optimisation, verification or simulation
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F17/00—Digital computing or data processing equipment or methods, specially adapted for specific functions
- G06F17/10—Complex mathematical operations
- G06F17/18—Complex mathematical operations for evaluating statistical data, e.g. average values, frequency distributions, probability functions, regression analysis
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N20/00—Machine learning
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N99/00—Subject matter not provided for in other groups of this subclass
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F2111/00—Details relating to CAD techniques
- G06F2111/10—Numerical modelling
Landscapes
- Engineering & Computer Science (AREA)
- Physics & Mathematics (AREA)
- Theoretical Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Data Mining & Analysis (AREA)
- Mathematical Physics (AREA)
- General Engineering & Computer Science (AREA)
- Computational Mathematics (AREA)
- Mathematical Analysis (AREA)
- Mathematical Optimization (AREA)
- Pure & Applied Mathematics (AREA)
- Software Systems (AREA)
- Operations Research (AREA)
- Databases & Information Systems (AREA)
- Algebra (AREA)
- Evolutionary Biology (AREA)
- Probability & Statistics with Applications (AREA)
- Bioinformatics & Computational Biology (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Life Sciences & Earth Sciences (AREA)
- Evolutionary Computation (AREA)
- Computing Systems (AREA)
- Geometry (AREA)
- Computer Hardware Design (AREA)
- Artificial Intelligence (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Medical Informatics (AREA)
- Complex Calculations (AREA)
- Management, Administration, Business Operations System, And Electronic Commerce (AREA)
Description
まず、本発明の実施形態の原理について説明する。
[参考文献1]Danial Lashkari and Polina Golland, "Convex clustering with exemplar-based models", In Advances in neural information processing systems, 2008, pp.825-832.
[参考文献2]DavidW Scott, "Parametric statistical modeling by minimum integrated square error", Technometrics, Vol.43, No.3, 2001, pp.274-285.
[参考文献3]Srabashi Basu, Ayanendranath Basu, and MCJones, "Robust and efficient parametric estimation for censored survival data", Annals of the Institute of Statistical Mathematics, Vol.58, No.2, 2006, pp.341-355.
<<<打ち切りデータ>>>
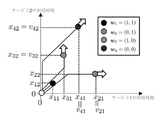
まず、打ち切りデータについて説明する。図1に、1次元の打ち切りデータの例を示す。図1の例に示すように、打ち切りデータの代表例である機器故障データを用いて説明する。
と書く。ここで、
と、
とは共にdx次元のベクトルであり、
、
である。xijが利用者iのサービスjの利用時間、wijが利用者iのサービスjの解約時刻が記録されたか(wij=1)、打ち切りにより記録されなかったか(wij=0)を表す。同様に、i番目の利用者の、観測終了時刻までの時間の長さを
と書く。vijが利用者iのサービスj利用開始時刻から観測終了時刻までの長さを表す。打ち切りにより観測値が観測されなかったとき(wij=0)には、xij=vijと設定されているとする。
次に、本発明の実施の形態で用いるモデルについて説明する。混合モデルで表される、観測値の確率密度関数は一般に下記式(1)で定義される。
がk番目コンポーネントの確率分布を表す。コンポーネントの確率分布
には、例えば下記式で表されるガウス分布が利用できる。

とσとは、ガウス分布の平均と標準偏差を表す。ただし、ebm(参考文献1)のアプローチに従い、コンポーネントの確率分布のパラメタ
はK=nとして、それぞれが観測データ点に対応するよう
と設定されたもの等であるとする。この場合には、観測値の確率密度関数は、観測データの各々に対する、各コンポーネントの混合モデルで表され、各コンポーネントに含まれる、ガウス分布の平均を、対応する観測値とする。本手法は打ち切りデータを扱うため、K=nとし、値が観測されていれば(wij=1)、μij=xij、そうでなければ(wij=0)、μij=xij+εと設定してもよい。εは0以上の値を取る確率分布(例えば指数分布)からランダムに生成した値を表す。また、データ数が多い場合には、例えばランダムに選んだ100個のデータのみを用いてもよいし、事前知識に基づいて設定したコンポーネントを用いてもよい。標準偏差σは交差検証法等により決定することが可能である。
の生成過程は次のように記述できる。まず、各サンプルについて観測終了までの時間の長さ
が既知のもと、打ち切りが起こるか否かを表す変数
が、下記式(2)の確率分布に従い生成される。

と、
とのうち、wij=1である、観測値が観測された要素の集合を
とし、wij=0である、観測値が観測されなかった集合を
とする。また、観測値が観測された要素と、観測値が観測されなかった要素とを区別しない場合に、観測データと呼ぶこととする。コンポーネントの確率分布
に、上記式(2)のガウス分布のように標準的な確率分布を利用すると、
を累積密度関数を用いて解析的に計算できる。
であり、少なくとも一つ観測された要素がある場合、
は下記式(4)で表される分布にしたがって生成される。
はデルタ関数であり、ftrはfを観測されなかった要素に関して周辺化した分布の切断分布であり、下記式で表される。


は

となる。ただし、
はそれぞれ
から
と
に対応する次元の要素を抜き出したベクトルである。
であり、一つも観測された要素がない場合、下記式(7)で示すように、デルタ関数のみの表現となる。
次に、提案手法の目的関数を定義する際に利用するダイバージェンスについて記す。良く知られるように、確率分布p(x)とq(x)とに対するカルバックライブラー(KL)ダイバージェンスは下記式(9)で定義される。


まず、目的関数としてKLダイバージェンスを利用する場合の提案手法を示す。打ち切りデータの確率分布を表すモデル
と、打ち切りデータから得られる真の確率分布
とのKLダイバージェンスは、上記式(9)の定義に従い、下記式(11)で与えられる。


に関する期待値を標本平均で置き換えれば、下記の式(13)が導かれる。

は、データから計算できる量であり、これを目的関数とすることでアルゴリズムを導く。具体的には、下記式(14)の最適化問題を解けばよい。


の更新を繰り返すことにより、最適化が可能となる。なお、参考文献1の手法と同様に、計算量の削減と収束を早めるため、パラメタ更新の際にθkがある閾値(例えば10-3/n)より小さい場合には、θk=0と設定した後に、全体を和が1になるように調整する、再正規化操作を行ってもよい。
次に、L2ダイバージェンスを利用する場合の提案手法を示す。KLダイバージェンスとは異なり、L2ダイバージェンスの定義から直接目的関数を定義することはせず、KLダイバージェンスを用いた際の目的関数に注目することにより新たな目的関数を定義する。
と、変数が与えられた下での観測値の真の分布
のKLダイバージェンスに対応する項と、観測値が観測されなかったことを表す変数のモデルの分布
と、真の分布
を用いた対数尤度比に対応する項との2つの項をそれぞれ
で重み付き和を取ることで構成されていることが分かる。


となる。更に、定数項(Const)を除去し、真の分布に関する平均を標本平均で置き換えた下記式の最適化を考える。

とおいた。これを目的関数とすることで、アルゴリズムを導出する。
は、行列・ベクトル形式で、下記式(16)、(17)のように表すことができる。


は、コンポーネントの分布にガウス分布を用いる場合、解析的に計算できる値であり、下記式(21)のように表すことができる。

に関して総和をとる際、
や
は
の値によって異なる値であることを明記しておく。これにより、目的関数は
に関する2次の形式で表現されることが分かる。よって、パラメタの推定値は下記で示す制約付きの2次最適化問題を解くことで得ることができる。



は正則化項、βはハイパーパラメタであり、パラメタの発散を防ぐ効果がある。
は、値が0以上かつ和が1であるから、下記式(25)の処理で条件を満たす
が得られる。

は、
ノルムを表す
次に、図5及び図6を参照して、本発明の実施の形態に係る推定装置1の構成について説明する。図5は、本発明の実施の形態に係る推定装置1として機能するコンピュータの概略構成を示すブロック図である。図6は、本発明の実施の形態に係る推定装置1の構成を示すブロック図である。
と、観測値が観測されなかったサンプルの観測データ
と、各サンプルについて観測値が観測されたか否かを表す変数
とを含む打ち切りデータ
をデータ記憶部41に格納する。サンプルは、例えば、上述の図1、3の例では各機器のこと、図2、4の例では各利用者のことである。
の各サンプルに対応する、観測値の分布を表す各コンポーネントの混合モデルで表される、観測データの確率密度関数を用いて表される、打ち切りデータ
の確率分布を表すモデル
と、入力部50が受け付けた打ち切りデータ
から得られる、当該打ち切りデータ
の真の確率分布
とのダイバージェンスである目的関数を最適化することにより、モデルのパラメタ
を推定する。
の真の確率分布
を求める。
の確率分布を表すモデル
と、当該打ち切りデータ
の真の確率分布
とのKLダイバージェンス、又はL2ダイバージェンスとして、パラメタを推定する。
は、上記式(8)で示すように、観測データの確率密度関数と、各サンプルについて予め与えられた、観測終了までの時間の長さとを用いて表される、観測データの確率分布
と、観測データの確率密度関数と、各サンプルについて予め与えられた、観測終了までの時間の長さとを用いて表される、変数が与えられた下での、変数の確率分布
と、を用いて表される。
をパラメタ記憶部42に格納する。
を取得し、パラメタ出力部30に当該パラメタ
を渡す。
が格納される。また、パラメタ記憶部42には、モデルのパラメタ
が格納される。
の入力を受け付ける。そして、入力部50は、受け付けた打ち切りデータ
を、データ処理部10に渡す。
を、外部装置2へ出力する。
図7は、本発明の実施の形態に係る推定処理ルーチンを示すフローチャートである。
が入力されると、推定装置1において、図7に示す推定処理ルーチンが実行される。
と、観測値が観測されなかったサンプルの観測データ
と、各サンプルについて観測値が観測されたか否かを表す変数
とを含む打ち切りデータ
の入力を受け付ける。また、入力部50は、各サンプルiについての観測終了時刻までの時間の長さの入力を受け付ける。
の確率分布を表すモデル
と、当該打ち切りデータ
の確率分布
とのKLダイバージェンス、又はL2ダイバージェンスとして、上記式(15)のパラメタ更新を繰り返すことにより、パラメタを推定するか、あるいは、上記式(24)、(25)を用いてパラメタを推定する。
を出力する。
2 外部装置
10 データ処理部
20 パラメタ推定部
30 パラメタ出力部
40 記憶部
41 データ記憶部
42 パラメタ記憶部
50 入力部
60 出力部
100 バス
110 CPU
120 メモリ
130 通信IF部
140 入力部
150 表示部
160 記憶部
170 プログラム
Claims (5)
- 観測値が観測されたサンプルの観測データと、観測値が観測されなかったサンプルの観測データと、各サンプルについて観測値が観測されたか否かを表す変数とを含む打ち切りデータの確率分布を表すモデルのパラメタを推定する推定装置であって、
前記打ち切りデータの入力を受け付ける入力部と、
前記入力部が受け付けた前記打ち切りデータの各サンプルに対応する、観測値の分布を表す各コンポーネントの混合モデルで表される、前記観測データの確率密度関数を用いて表される、前記打ち切りデータの確率分布を表すモデルと、前記入力部が受け付けた前記打ち切りデータから得られる、前記打ち切りデータの確率分布とのダイバージェンスである目的関数を最適化することにより、前記モデルのパラメタを推定するパラメタ推定部と、
を含む推定装置。 - 前記打ち切りデータの確率分布を表すモデルは、
前記観測データの確率密度関数と、各サンプルについて予め与えられた、観測終了までの時間の長さとを用いて表される、前記変数の確率分布と、
前記観測データの確率密度関数と、各サンプルについて予め与えられた、観測終了までの時間の長さとを用いて表される、前記変数が与えられた下での、前記観測データの確率分布と、
を用いて表される請求項1記載の推定装置。 - 前記目的関数は、前記打ち切りデータの確率分布を表すモデルと、前記打ち切りデータの確率分布とのカルバックライブラーダイバージェンス、又はL2ダイバージェンスである
請求項1又は2記載の推定装置。 - 観測値が観測されたサンプルの観測データと、観測値が観測されなかったサンプルの観測データと、各サンプルについて観測値が観測されたか否かを表す変数とを含む打ち切りデータの確率分布を表すモデルのパラメタを推定する推定方法であって、
入力部が、前記打ち切りデータの入力を受け付け、
パラメタ推定部が、前記入力部が受け付けた前記打ち切りデータの各サンプルに対応する、観測値の分布を表す各コンポーネントの混合モデルで表される、前記観測データの確率密度関数を用いて表される、前記打ち切りデータの確率分布を表すモデルと、前記入力部が受け付けた前記打ち切りデータから得られる、前記打ち切りデータの確率分布とのダイバージェンスである目的関数を最適化することにより、前記モデルのパラメタを推定する
推定方法。 - 観測値が観測されたサンプルの観測データと、観測値が観測されなかったサンプルの観測データと、各サンプルについて観測値が観測されたか否かを表す変数とを含む打ち切りデータの確率分布を表すモデルのパラメタを推定する処理をコンピュータに実行させるプログラムであって、
入力部が、前記打ち切りデータの入力を受け付け、
パラメタ推定部が、前記入力部が受け付けた前記打ち切りデータの各サンプルに対応する、観測値の分布を表す各コンポーネントの混合モデルで表される、前記観測データの確率密度関数を用いて表される、前記打ち切りデータの確率分布を表すモデルと、前記入力部が受け付けた前記打ち切りデータから得られる、前記打ち切りデータの確率分布とのダイバージェンスである目的関数を最適化することにより、前記モデルのパラメタを推定する
ことを含む処理をコンピュータに実行させるプログラム。
Priority Applications (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2019029769A JP7107246B2 (ja) | 2019-02-21 | 2019-02-21 | 推定装置、推定方法、及びプログラム |
| PCT/JP2020/004909 WO2020170867A1 (ja) | 2019-02-21 | 2020-02-07 | 推定装置、推定方法、及びプログラム |
| US17/431,791 US20220138375A1 (en) | 2019-02-21 | 2020-02-07 | Estimation device, estimation method, and program |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2019029769A JP7107246B2 (ja) | 2019-02-21 | 2019-02-21 | 推定装置、推定方法、及びプログラム |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2020135554A JP2020135554A (ja) | 2020-08-31 |
| JP7107246B2 true JP7107246B2 (ja) | 2022-07-27 |
Family
ID=72144974
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2019029769A Active JP7107246B2 (ja) | 2019-02-21 | 2019-02-21 | 推定装置、推定方法、及びプログラム |
Country Status (3)
| Country | Link |
|---|---|
| US (1) | US20220138375A1 (ja) |
| JP (1) | JP7107246B2 (ja) |
| WO (1) | WO2020170867A1 (ja) |
Families Citing this family (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP7107246B2 (ja) * | 2019-02-21 | 2022-07-27 | 日本電信電話株式会社 | 推定装置、推定方法、及びプログラム |
| US11921488B2 (en) * | 2020-12-15 | 2024-03-05 | Xerox Corporation | System and method for machine-learning-enabled micro-object density distribution control with the aid of a digital computer |
| US20230359882A1 (en) * | 2022-05-06 | 2023-11-09 | International Business Machines Corporation | Training a neural network to achieve average calibration |
| CN119128368B (zh) * | 2024-11-14 | 2025-02-21 | 中国建设银行股份有限公司 | 回归模型的构建方法及装置、程序产品、存储介质 |
Family Cites Families (21)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20040117051A1 (en) * | 2000-06-06 | 2004-06-17 | Ford Dean M. | Method of determining a cumulative distribution function confidence bound |
| US8438126B2 (en) * | 2007-07-13 | 2013-05-07 | The Regents Of The University Of California | Targeted maximum likelihood estimation |
| US8204714B2 (en) * | 2010-02-26 | 2012-06-19 | International Business Machines Corporation | Method and computer program product for finding statistical bounds, corresponding parameter corners, and a probability density function of a performance target for a circuit |
| US20140149205A1 (en) * | 2012-11-29 | 2014-05-29 | Adobe Systems Incorporated | Method and Apparatus for an Online Advertising Predictive Model with Censored Data |
| JP6194450B2 (ja) * | 2013-04-15 | 2017-09-13 | 株式会社メガチップス | 状態推定装置、プログラムおよび集積回路 |
| JP6366999B2 (ja) * | 2014-05-22 | 2018-08-01 | 株式会社メガチップス | 状態推定装置、プログラムおよび集積回路 |
| US10474770B2 (en) * | 2014-08-27 | 2019-11-12 | Nec Corporation | Simulation device, simulation method, and memory medium |
| US20190095556A1 (en) * | 2016-03-31 | 2019-03-28 | Nec Corporation | Information processing device, simulation method, and non-transitory recording medium storing simulation program |
| US20190057065A1 (en) * | 2016-04-01 | 2019-02-21 | Hitachi, Ltd. | Modeling device |
| WO2018138880A1 (ja) * | 2017-01-27 | 2018-08-02 | 三菱日立パワーシステムズ株式会社 | モデルパラメータ値推定装置及び推定方法、プログラム、プログラムを記録した記録媒体、モデルパラメータ値推定システム |
| US10528644B1 (en) * | 2017-06-30 | 2020-01-07 | Cadence Design Systems, Inc. | Estimation and visualization of a full probability distribution for circuit performance obtained with Monte Carlo simulations over scaled sigma sampling |
| JP6935765B2 (ja) * | 2018-02-13 | 2021-09-15 | 日本電信電話株式会社 | 動的分布推定装置、方法、及びプログラム |
| JP7064356B2 (ja) * | 2018-03-14 | 2022-05-10 | 株式会社日立製作所 | 将来状態推定装置および将来状態推定方法 |
| WO2019217876A1 (en) * | 2018-05-10 | 2019-11-14 | Equifax Inc. | Training or using sets of explainable machine-learning modeling algorithms for predicting timing of events |
| JP7172616B2 (ja) * | 2019-01-11 | 2022-11-16 | 日本電信電話株式会社 | データ解析装置、方法、及びプログラム |
| WO2020148940A1 (ja) * | 2019-01-18 | 2020-07-23 | 株式会社ヒデ・ハウジング | 日射量出現確率分布解析法、日射量出現確率分布解析システム、日射量出現確率分布解析プログラム、日射量正規化統計解析システム、日射量正規化統計解析法および日射量正規化統計解析プログラム |
| JP7107246B2 (ja) * | 2019-02-21 | 2022-07-27 | 日本電信電話株式会社 | 推定装置、推定方法、及びプログラム |
| JP7215579B2 (ja) * | 2019-06-26 | 2023-01-31 | 日本電信電話株式会社 | パラメタ推定装置、パラメタ推定方法、及びパラメタ推定プログラム |
| US11010222B2 (en) * | 2019-08-29 | 2021-05-18 | Sap Se | Failure mode specific analytics using parametric models |
| JP7268752B2 (ja) * | 2019-10-02 | 2023-05-08 | 日本電信電話株式会社 | パラメタ推定装置、パラメタ推定方法、及びパラメタ推定プログラム |
| JP7374868B2 (ja) * | 2020-08-28 | 2023-11-07 | 株式会社東芝 | 情報処理装置、情報処理方法およびプログラム |
-
2019
- 2019-02-21 JP JP2019029769A patent/JP7107246B2/ja active Active
-
2020
- 2020-02-07 US US17/431,791 patent/US20220138375A1/en not_active Abandoned
- 2020-02-07 WO PCT/JP2020/004909 patent/WO2020170867A1/ja not_active Ceased
Non-Patent Citations (2)
| Title |
|---|
| BASU, Srabashi et al.,"Robust and efficient parametric estimation for censored survival data",Annals of the Institute of Statistical Mathematics [online],The Institute of Statistical Mathmatics,2006年,Vol. 58, No. 2,p.341-355,[2020年03月18日検索],インターネット<URL: https://www.ism.ac.jp/editsec/aism/pdf/058_2_0341.pdf>,ISSN 0020-3157 |
| 幸島匡宏,ほか3名,"打ち切りデータに対する混合モデルのオンラインEM法の導出と大規模集客イベントにおける到着時間分布推定",第10回データ工学と情報マネジメントに関するフォーラム(第16回日本データベース学会年次大会) [Online],電子情報通信学会データ工学研究専門委員会 日本データベース学会 情報処理学会データベースシステム研究会,2018年03月,[2018年04月17日検索],インターネット<URL:http://db-event.jpn.org/deim2018/data/papers/272.pdf> |
Also Published As
| Publication number | Publication date |
|---|---|
| JP2020135554A (ja) | 2020-08-31 |
| US20220138375A1 (en) | 2022-05-05 |
| WO2020170867A1 (ja) | 2020-08-27 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP7107246B2 (ja) | 推定装置、推定方法、及びプログラム | |
| Taylor et al. | Performance estimation toolbox (PESTO): Automated worst-case analysis of first-order optimization methods | |
| Henseler | On the convergence of the partial least squares path modeling algorithm | |
| Song et al. | A Bayesian modeling approach for generalized semiparametric structural equation models | |
| Nakayama | Confidence intervals for quantiles using sectioning when applying variance-reduction techniques | |
| Jenkinson et al. | Numerical integration of the master equation in some models of stochastic epidemiology | |
| Fried et al. | Retrospective Bayesian outlier detection in INGARCH series | |
| CN114492823A (zh) | 消除量子噪声的方法及装置、电子设备和介质 | |
| US8813009B1 (en) | Computing device mismatch variation contributions | |
| Mohammadi et al. | An Introduction to the BDgraph for Bayesian Graphical Models | |
| Gåsemyr | On an adaptive version of the Metropolis–Hastings algorithm with independent proposal distribution | |
| Antoniano‐Villalobos et al. | A nonparametric model for stationary time series | |
| Song et al. | Wasserstein generative regression | |
| de la Fuente et al. | An efficient nonlinear programming strategy for PCA models with incomplete data sets | |
| Liu et al. | On Random Batch Methods (RBM) for interacting particle systems driven by Lévy processes | |
| Mudholkar et al. | Transformation of the bathtub failure rate data in reliability for using Weibull-model analysis | |
| Karimi et al. | An approximate expectation maximization algorithm for estimating parameters, noise variances, and stochastic disturbance intensities in nonlinear dynamic models | |
| EP3712784A2 (en) | System and method for signal pre-processing based on data driven models and data dependent model transformation | |
| Wang et al. | Constrained spline regression in the presence of AR (p) errors | |
| Yurko et al. | Demonstration of Emulator‐Based Bayesian Calibration of Safety Analysis Codes: Theory and Formulation | |
| Zhou | Convergence estimates of nonrestarted and restarted block‐Lanczos methods | |
| Chan et al. | Model predictive control of Hammerstein systems with multivariable nonlinearities | |
| Allal et al. | Parameter estimation for first-order random coefficient autoregressive (RCA) models based on Kalman filter | |
| Xiao et al. | Unified uncertainty analysis using the maximum entropy approach and simulation | |
| Wang et al. | Gaussian variational approximation for Bayesian Lasso quantile regression model with zero-or-one inflated proportional data |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20210527 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20220614 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20220627 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 7107246 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| S533 | Written request for registration of change of name |
Free format text: JAPANESE INTERMEDIATE CODE: R313533 |
|
| R350 | Written notification of registration of transfer |
Free format text: JAPANESE INTERMEDIATE CODE: R350 |