WO2003001362A2 - A method and apparatus for carrying out efficiently arithmetic computations in hardware - Google Patents
A method and apparatus for carrying out efficiently arithmetic computations in hardware Download PDFInfo
- Publication number
- WO2003001362A2 WO2003001362A2 PCT/IL2002/000318 IL0200318W WO03001362A2 WO 2003001362 A2 WO2003001362 A2 WO 2003001362A2 IL 0200318 W IL0200318 W IL 0200318W WO 03001362 A2 WO03001362 A2 WO 03001362A2
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- input
- output
- storage device
- value
- content
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Ceased
Links
Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F7/00—Methods or arrangements for processing data by operating upon the order or content of the data handled
- G06F7/60—Methods or arrangements for performing computations using a digital non-denominational number representation, i.e. number representation without radix; Computing devices using combinations of denominational and non-denominational quantity representations, e.g. using difunction pulse trains, STEELE computers, phase computers
- G06F7/72—Methods or arrangements for performing computations using a digital non-denominational number representation, i.e. number representation without radix; Computing devices using combinations of denominational and non-denominational quantity representations, e.g. using difunction pulse trains, STEELE computers, phase computers using residue arithmetic
- G06F7/728—Methods or arrangements for performing computations using a digital non-denominational number representation, i.e. number representation without radix; Computing devices using combinations of denominational and non-denominational quantity representations, e.g. using difunction pulse trains, STEELE computers, phase computers using residue arithmetic using Montgomery reduction
Definitions
- the present invention relates to the field of fast and efficient implementation of modular arithmetics in hardware. More particularly, the invention relates to a method and apparatus for carrying out modular arithmetic operations such as modular multiplication and exponentiation, utilizing Montgomery and straightforward methods.
- PKC Public Key Cryptosystems
- MMUL(A,B) A * B * 2- n m dN Which yields a reduced result , i.e., 0 ⁇ MMUL(A, B) ⁇ N .
- bits of integer values such as the n- bit integer A ⁇ (A n _ l ,...,A i , A Q ) 2 , are represented utilizing the notation
- An algorithm for computing Montgomery multiplication (in radix 2) can be carried out by the following steps:
- Step 1.4 called herein the reduction step, is an essential step without which the output of the algorithm, S , is not necessarily reduced.
- A,B ⁇ N as assumed, it can be shown (by induction) that before the reduction step (1.4) the result, S, is bounded by N + B .
- This Montgomery multiplication algorithm which computes MMUL(A,B) can be used for computing the regular modular multiplication A * B modN . This can be carried out in more than one way, as illustrated in the following steps: Method 1:
- Method 2 involves the computation of auxihary values, A' and 5' . This transforms the integers A and 5 to what is called the "Montgomery base”. The first Montgomery multiplication is applied to the transformed numbers, resulting in:
- Method 1 (computing the auxiliary value) is the main reason for which the Montgomery algorithm is not necessarily considered useful for computing a single modular multiplication, in comparison with a direct approach.
- Method 2 can be used efficiently when several modular multiplications are required. After converting the input to the Montgomery base, all multiplications are performed by means of the Montgomery multiplication algorithm, and the result is converted to the regular base at the end of the multiplications sequence. In such cases, the computational overhead of Method 2 is negligible, and the Montgomery algorithm substantially improves the efficiency in the overall calculations.
- the most typical example is the computation of the modular exponent A E modN (for an 7n-bit integer value exponent E , where with no lose of generality, we assume here that A ⁇ N), utilizing Method 2 and the Montgomery multiplication.
- the exponentiation result can be computed, for example, as described hereinbelow (left-to -right binary exponentiation):
- the computation of the pre-calculated value A' A * 2" modN (0 ⁇ .4' ⁇ N) converts the input to the Montgomery base
- the Montgomery multiplications and squaring (steps 2.1 and 2.2) correspond to the sequence of multiplications and squaring that implement the left-to-right binary exponentiation in the regular base
- the Montgomery multiplication by 1 (step 2.3) converts the result back to the regular base.
- Reduction (step 1.4) in intermediate steps, in each Montgomery multiplication implemented by algorithm 1, is required in order to make sure that the result remains bounded by N .
- the reduction is of vital importance in implementation of such chained algorithms, since it assures that the input to the subsequent Montgomery multiplication is properly bounded. If reduction is not performed, and the result of one Montgomery multiplication (without the reduction step) exceeds N, overflow or erroneous results may occur in subsequent steps.
- the main advantage in using the Montgomery multiplication lies in the hardware implementation of this multiplication operation.
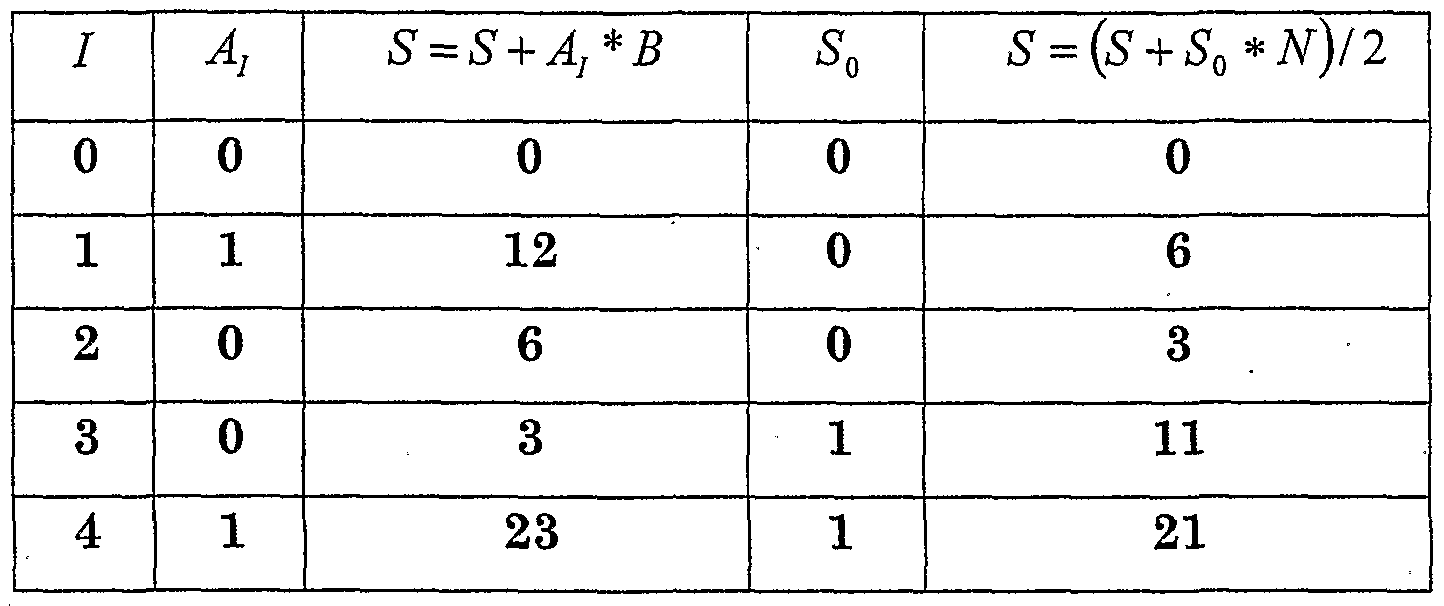
- Example 2 Table 2 illustrates the calculation of A E modN , for n-bits values A and N, and the -bit value E, utilizing the algorithm herein above.
- the value obtained in the preceding step 7 (/+1) is followed by the result obtained in step 2.1 ⁇ 1+1 , and the result obtained in step 2.2, T ⁇ y
- A 212
- N 249.
- the Montgomery multiplication MMUL(A,B) is utilized for the calculation of Montgomery multiplication, Montgomery square, and Montgomery multiplication by 1.
- the accumulated result may be greater than N, and reduction may be required in order to obtain the (correctly reduced) results of the Montgomery multiplication.
- Dedicated circuitry is required for detecting the cases where the result is greater than N, and for performing the appropriate subtraction (i.e., the required reduction).
- the additional storage of A, 2* A and 3* ⁇ may be bypassed at the cost of (cumbersome) setting the hardware control accordingly: adding 2* A may be implemented by shifting the stored value of A and then feeding it to the accumulator, and adding 3*A may be implemented by adding the value of A and the shifted value of A to the accumulator.
- Analogous methods use larger values of m, more storage or hardware/control, but a smaller number (l+[k/m]) of iterations.
- scanning m bits of M and L in each iteration yields 2 2m combinations for the quantity that is to be added.
- Storage of 15 quantities is needed unless extra hardware/control is used for adding 2(A+B) and/or adding S(A+B) by using the stored value of (A+B).
- the apparatus depicted in Fig. 1 utilizes three registers R0, Rl, and R2, a 1:4 multiplexer (MUX), and a Carry Save Adder (CSA), to carry out the calculation of A*B+C*D+G.
- the registers R0 and R2 are n.-bits each, while register Rl is of n+1 bits.
- Each of the registers, R0, Rl, and R2 is connected to one of the MUX's inputs, In2,In3, and Inl , respectively, while the MUX's input InO is constantly fed by a "0" value (an n-bit value).
- the multiplexer MUX has two control inputs, CO and Cl, such that for each state of the control inputs, CO and Cl, a corresponding input is selected, and output on the MUX's output (out).
- the CSA is of n+2 bits, to allow over flow of 2 bits, and it is utilized for adding the- value of the selected input (InO,I ⁇ l,In2, or In3), retrieved via the MUX's output out, to its present content.
- the result of this addition is stored in the CSA, which is then subject to a right shift performed to the CSA content. Shifting the bits of an even binary value to the right is equivalent to the division of that value by 2 (in step 1.3 above).
- the following operations are performed: ⁇ 1) selection of the respective value on InO, Inl, In2, and In3 ;
- bits (MSB) of the calculated result, and another n LSBs, of the calculated result, are obtained on the CSA 0 output, during the iterations.
- serial approach The main drawback of the serial approach is that it is time- consuming (the addition of n+1 cycles is required to obtain the CSA content). On the other hand, although performance is significantly improved utilizing the parallel approach, it is considered costly in terms of hardware means.
- This apparatus is efficiently utilized to perform Montgomery multiplication by applying the Montgomery method, as described in Patent Application WO 98/50851 and US 6,185,596.
- This method requires testing, after each iteration of the Montgomery process, if the addition result exceeds the modulus value N. In such cases, the result does not exceed 2 *N . Consequently, dedicated hardware is utilized in those implementations for testing the result in each iteration, and for subtracting the modulus value N from the result, whenever it exceeds the modulus value.
- the present invention is directed to a method for carrying out modular arithmetic computations involving multiplication operations by utilizing a non-reduced and extended Montgomery multiplication between a first A and a second B integer values, in which the number of iterations required is greater than the number of bits n of an odd modulo value N, the method comprising: a) providing an accumulating device (S) capable of storing n+2 bit values, of adding n+2-bit values (X) to it content (S + X ⁇ S), and of dividing its content by 2 (S/2 ⁇ S ); b) whenever desired, setting the content of the device to a zero value ("0"- - S) an performing in the device at least s(>n+l) iterations, while in each iteration choosing one bit, in sequence, from the value of the first integer value A (A ⁇ ;0 ⁇ I ⁇ s ⁇ l ), starting from its least significant bit
- a j and the second integer value B (S + A j * B - S); b.2) adding to the resulting content of the device the product of its current least significant bit S 0 and N (S + S Q * N ⁇ S); b.3) dividing the resulting content of the device by 2 (572 - S); and b.4) obtaining a non-reduced and extended Montgomery multiplication result by repeating steps b.l) to b.3) s-1 additional times while in each time using the previous result (S).
- the Montgomery multiplication result can be obtained by unifying steps b.l) to b.3) into a single step, by providing a first storing device (R2) for storing the modulo value N, a second storing device (R0) for storing the value of the second integer B, a third storing device (Rl) for storing the sum of the modulo N and the second integer value B, providing an arbitration circuitry having a first (Inl), second (In2) and third (In3), inputs from the first (R2), second (R0) and third (Rl), storage devices respectively, and having an additional zero input (InO), the arbitration device receives a first (Cl) and a second (CO) control inputs, and is capable of selecting one of its other inputs as it output, such that: whenever its first (Cl) and second (CO) control inputs are zero, selecting the additional zero input (InO); whenever its first control input (Cl) is one and its second control input (CO) is zero, selecting its second input (In2); whenever its first
- the computation is carried out by applying the bits of the first integer value A (A t ;0 ⁇ I ⁇ s), one by one, in sequence, starting from its least significant bit (A Q ), to the first control input (Cl), and providing circuitry for producing the state (K j ) of the second control input (CO) according to the state of the selected bit of the first integer value (A t ), the state of the least significant bit of the second integer value (5 0 ), and according to the state of the least significant bit of the accumulating device (S 0 ).
- the state of the second control input (CO) can be produced by circuitry comprising a logical AND gate, and a logical XOR gate, where the inputs of the logical AND gate are receiving the states of the first control input (Cl) and the state of the least significant bit (5 0 ) of the second integer value B, and where the inputs of the logical XOR gate are receiving the output from the logical AND gate and the state of the least significant bit of the accumulating device (S Q ), and where the output of the logical XOR gate is utilized as the state of the second control input (CO).
- the number of iterations s utilized for carrying out the Montgomery multiplication is n+2, thereby an extended Montgomery multiplication result is obtained, in which n+2 iterations are performed.
- the method may further comprise allowing modular arithmetic operations to be carried out, by utilizing for the first (R2), second (RO), and third (Rl) storage devices an n+2 bits shift registers having a serial input into their most significant bit locations, and which may be capable of outputting their content in parallel, providing the first storage device (R2) with a serial output, from its least significant bit location (R2 ⁇ ), and allowing it to perform cyclic bit rotation, allowing the second storage device (R0) to receive on its serial input the least significant bit (S 0 ) of the accumulating device, providing a fourth storage device
- the accumulating device consist of n+2 addition and latching stages, each of which consists of a first and a second flip flop devices and a full adder device having three inputs, except for the first stage wherein the second flip flop is excluded.
- the first input of the full adder is connected to the output of a first flip-flop device
- the second input of the full adder is connected to the output of a second flip flop device of the subsequent addition and latching stage
- the third input of the full adder is connected to the respective bit output of the arbitration device (MUX, ⁇ i ⁇ n + 1).
- the method may further comprise adding the output from the third arbitration device (MX3), via the serial input of the accumulating device, to the addition result of the ( ⁇ +l)-th addition and latching stage by providing the (rc+lj-th addition and latching stages with a first and second half adder devices, and a third flip flop device, connecting the input of the first flip flop device to the sum output of the second half adder, connecting the input of the second flip flop device to the carry output of the second half adder, and connecting the output of the flip flop device to the second input of the full adder of the (n+2)-th addition and latching stage, connecting the first input of the second half adder to the carry output of the full adder of the (n.+l)-th addition and latching stage, and it second input, to the carry output of the first half adder, connecting the first input of the first half adder to the sum output of the full adder, and connecting the second input of the second half adder to the output of the third arbitration device (MX3); and
- the state of the second control input (CO) can be determined utilizing the least significant bit of the second storage device (R0), the output of the fourth arbitration device (MX4), the carry output of the full adder of the first addition and latching stage, and the sum output of the full adder of the second addition and latching stage.
- the least significant bit of the second storage device (RO) and the output of the fourth arbitration device (MX4) is carried out by connecting the least significant bit of the second storage device (RO) and the output of the fourth arbitration device (MX4), to the inputs of an AND logical gate, providing an additional half adder and an additional flip flop device, connecting the first input of the half adder to the sum output of the full adder of the second addition and latching stage, and its second input to the carry output of the full adder of the first addition and latching stage, connecting the sum output of the half adder to the input of the additional flip flop device, and connecting the output of the AND logical gate and the output of the flip flop device to the inputs of a XOR gate, and utilizing the output of the XOR gate to determine the state of the second control input (CO).
- RO the least significant bit of the second storage device
- MX4 arbitration device MX4 arbitration device
- the method may further comprise carrying out non-reduced Montgomery squaring of an integer value B, by loading the first (R2), second (RO), and third (Rl), storage devices with the values of the modulus N, the integer B, and the sum of the modulus and the integer (N+B), respectively, setting the first (MX1), second (MX2), third (MX3) and fourth (MX4), arbitration devices to select the inputs of the circuitry for producing the state (K ⁇ ) of the second control input (CO), the circuitry for producing the state (K j ) of the second control input (CO), the zero value ("0"), and the output of the sixth storage device (RS), respectively, loading the content of the sixth storage device (RS) with the content of the second storage device (RO), and loading the content of the accumulating device with a zero value, performing the non-reduced and extended Montgomery multiplication wherein the content of the sixth storage device (R5) is shifted by one bit to the right in each cycle, and obtaining the non-reduced Montgomery
- the method may also comprise carrying out Montgomery multiplication of a first (A) and second (B) integer values, by loading the first (R2), second (RO), third (Rl), and fourth (R3) storage devices with the values of the modulus N, the second integer (B), the sum of the modulus and the second integer (N+B), and the first integer (A), respectively, setting the first (MX1),, second (MX2), third (MX3) and fourth (MX4), arbitration devices to select the inputs of the circuitry for producing the state (K t ) of the second control input (CO), the circuitry for producing the state (K ; ) of the second control input (CO), the zero value ("0"), and the output of the fourth storage device (R3), respectively, loading the content of the accumulating device with a zero value, performing the non-reduced and extended Montgomery multiplication wherein the content of the fourth storage device (R3) is shifted by one bit to the right in each cycle, and obtaining the non-reduced Montgomery multiplication result in the
- E' (e 0 ,e l ,...,e m _ 2 ) 2 , loading the content of the first, second, third, and fifth, storage devices with the values of the modulus JV, the adjusted operand (A' ), the sum of the modulus and the adjusted operand (N + A'), and the adjusted exponent value E' , respectively, obtaining the bit length m of the exponent value E and performing the following steps m-1 times:
- the modular exponentiation result is obtained by performing non-reduced and extended Montgomery multiplication of the content of the second storage device (RO) by 1 to obtain the final reduced result in the accumulating device.
- the method may further comprise carrying out modular multiplication of a first
- the present invention is directed to an apparatus for carrying out extended and non-reduced Montgomery multiplication of a first (A) and second (B) integer values, in which the number of iterations (s) required is greater the number of bits (n) in the modulo value (N), and in which the Montgomery multiplication result is smaller than twice the modulo value (2xIV), comprising: a first storage device (R2) for storing the modulo value (N); a second storage device (RO) for storing the value of the first integer values (A); a third storage device (Rl) for storing the sum of the first integer value and the modulo (A+N); an arbitration circuitry having a first (Inl), second (In2) and third (In3), inputs from the first (R2), second (RO), and third (Rl), storage devices, and having a fourth input which is zero ("0"), the arbitration
- the circuitry utilized for producing the state (K j ) of the second control input comprises:
- the first (R2), second (RO), and third (Rl) storage devices can be n+2 bits shift registers having a serial input into their most significant bit locations, and which may be capable of outputting their content in parallel.
- the first storage device (R2) may also have a serial output, from its least significant bit location (R2 0 ), allowing it to perform cyclic bit rotation.
- the accumulating device may consist of n+2 addition and latching stages, each of which consists of a first and a second flip flop devices and a full adder device having three inputs, except for the first stage wherein the second flip flop is excluded, comprising: a) means for connecting the first input of the full adder to the output of a first flip-flop device; b) means for connecting the second input of the full adder to the output of a second flip flop device of the subsequent addition and latching stage; and c) means for connecting the third input of the full adder to the respective bit output of the arbitration device (MUX t 0 ⁇ i ⁇ n + l).
- the accumulating device may further comprise means for adding the output from the third arbitration device (MX3), via the serial input of the accumulating device, to the addition result of the (n+l)-th addition and latching stage, comprising: a) a first and second half adder devices, and a third flip flop device; b) means for connecting the input of the first flip flop device to the sum output of the second half adder; c) means for connecting the input of the second flip flop device to the carry output of the second half adder, and for connecting the output of the flip flop device to the second input of the full adder of the (n+2)-th addition and latching stage; d) means for connecting the first input of the second half adder to the carry output of the full adder of the (n+l)-th addition and latching stage, and it second input, to the carry output of the first half adder; e) means for connecting the first input of the first half adder to the sum output of the full adder, and for connecting the second input of the second half
- the state of the second control input (CO) is can be determined utilizing the least significant bit of the second storage device (RO), the output of the fourth arbitration device (MX4), the carry output of the full adder of the first addition and latching stage, and the sum output of the full adder of the second addition and latching stage, comprising: a) means for connecting the least significant bit of the second storage device (RO) and the output of the fourth arbitration device (MX4), to the inputs of an AND logical gate; b) an additional half adder and an additional flip flop device; .
- Fig. 1 is a block diagram schematically illustrating a prior art apparatus for carrying out multiplication and addition operations
- Fig. 2 is a block diagram schematically illustrating a preferred embodiment of the invention for computing a non -reduced and extended
- Fig. 3 schematically illustrates one preferred embodiment of the invention for generating the i bit
- Fig 4 is a block diagram schematically illustrating a preferred embodiment of the invention for carrying out modular arithmetic operations, utihzing Montgomery multiplication;
- Fig 5 schematically illustrates a process for computing interleaved
- FIG. 6A and 6B schematically illustrates a possible embodiment of a CSA device according the method of the invention.
- Fig 7A and 7B are flowcharts illustrating methods for carrying out exponentiation by utilizing the PKI apparatus.
- the present invention refers to a method and apparatus for carrying out modular arithmetic operations, which is fast and efficient in terms of hardware means.
- At the core of the preferred embodiment of the invention is the computation of the • modular multiplication of two integers A and B modulo N (hereinafter A ⁇ B mod N), based on a modified (extended) Montgomery method.
- NRMM ⁇ S (A,B) will be used hereinafter to denote NRMM ⁇ S) ⁇ A,B,N) .
- NRMM ⁇ (A,B) The computation of NRMM ⁇ (A,B) is carried out by repeating steps 1.1, 1.2, and 1.3, s( ⁇ n) iterations, without performing the reduction step 1.4.
- the result of such computation is also termed as non-reduced and extended Montgomery multiplication. It is important to note that the result obtained by this non-reduced and extended Montgomery multiplication is not necessarily reduced (i.e., NRMM ⁇ (A, B,N) may be greater that the modulus N).
- N is an n-bit integer with A, B ⁇ 2*N, N is odd, and s ⁇ n)
- a E modN can be implemented by means of a sequence of Montgomery multiplications and Montgomery squaring.
- a MMUL(A, A) operation with an n bits long operand A (A ⁇ N) may produce a non-reduced result larger than N but smaller than 2*N .
- an implementation" of (n+2) bits accumulator (CSA) may be utilized according to the method of the invention.
- the computation of the non reduced extended Montgomery multiplication is implicitly based on adding the value K ⁇ N (for some K ⁇ 0 ' ) to the product A * B .
- the value of K is not known in advance, and is constructed iteratively. In the preferred embodiment of the invention, in each iteration of the process, another bit K j of the integer K is computed, as will be described hereinafter.
- the modulus value N may be added to the product of A * 5 any number of times, and could still be considered as the same result modulo N, that is, the result after adding K*N yields the same residue modulo IV if it is reduced to the range [0, N).
- the value of K is chosen in away that A * B + K *N is divisible by 2 s .
- the result may be always divided by 2, without a remainder (i.e., by a right shift).
- a modification of the classical Montgomery multiplication method is utilized to facilitate implementations for modular arithmetic computations, which can be realized completely by hardware.
- the computation of B) A * B * 2 ⁇ " modN is obtained in a process of n iterations, wherein n is the number of bits in the modulus N.
- n is the number of bits in the modulus N.
- the exponentiation process A E modN (A ⁇ N) can be implemented by means of a sequence of Montgomery multiplications and Montgomery squaring (MMUL(X,A), MMUL(X,X)) operations, that even with an n bits long operand X (X ⁇ N), and certainly with an n+1 bits operand X ⁇ 2 * N , may produce a non-reduced result larger than N but smaller than 2 * N .
- the CSA can provide the CSA[ (603) output which is used to speed up the process of producing the K ⁇ bit. This realization can . be easily implemented in hardware.
- FIG. 2 An apparatus based on the determination of K j , according to a preferred embodiment of the invention, is illustrated in Fig. 2.
- An additional shift register, R3, is used in this apparatus for feeding the A ⁇ bits of A .
- the CSA which is of s+2 bits, acts as an additional storage device, and thus there is no need for an additional storage device for partial results that are obtained in intermediate steps.
- the value of ' K ⁇ is realized from the values of A s , R0 0 , and CSA[ (603).
- the value of K j is realized utihzing appropriate circuitry 602 (for which a possible implementation is illustrated in Fig. 3), which receives A ; , i?0 0 , and CSA[ , as inputs.
- the bit 5 0 is placed in a latching device 200, which receives the LSB of register RO (R0 0 ).
- Fig. 3 demonstrates one possible implementation of a circuitry 602 for providing the K j bit.
- the realization in Fig. 3 is carried out utilizing an AND gate 300 and an Exclusive Or (XOR) gate 301, wherein the inputs of the AND gate are the bits A j and 5 0 , and the XOR gate inputs are the output of the AND gate 300, and CSA[ 603.
- the CSA[ 603 output from the CSA produces an expected value for the CSA LSB, and therefore speeds and simplifies the realization of the K j bit.
- the method of the invention is utilized for a fast and efficient computation of the extended and non-reduced Montgomery multiplication , wherein A and B are smaller than 2 * N , and N is up to n bits (and s ⁇ n + 2).
- This apparatus can be modified to allow modular products computation of integers, which have more the n-hits, which is also known as the Montgomery interleaved modular multiplication, as will be discussed later.
- Fig. 4 depicts an apparatus, according to a preferred, embodiment of the invention, for carrying out arithmetic operations based on the extended non- reduced Montgomery modular multiplication.
- the apparatus also termed Public Key Interface (PKI) herein, is based on 6 registers (each of n+2 bits), R0, Rl, R2, R3, R4, R5 and a Carry Save Adder (of n+2 bits), CSA, with some control (not shown).
- PKI apparatus is capable of performing various arithmetic and modular arithmetic operations, as will explained hereinbelow.
- the control input Cl of the MUX is connected to the output of MX4, which acts as an arbitrator for selecting between the serial outputs of registers R3 and R5.
- Registers R2, R3 and R4 have serial inputs and serial outputs, and are capable of performing cyclic bit rotation.
- the other MUX control input, CO is connected to the output of MX1, which acts as an arbitrator to select the input value from register R4, or from the circuitry that produces the value K j .
- the register R4 has a serial input, which is connected to the output of MX2, which acts as an arbitration for selecting between the input of the CSA 0 value, the output of R4 (useful when cyclic bit rotation of R4 is performed), or the value of K ⁇ 602.
- the third multiplexer, MX3, selects the input to the CSA serial input, and may select a "0" value or the output of MX4.
- register R5 is utilized only for carrying out squaring operations which are involved in more complex arithmetic computations (i.e., exponentiation).
- register R5 is loaded with the content of register R0. Therefore, one may implement the same apparatus without register R5, and read the subsequent bits of register R0 utilizing multiplexing techniques.
- a possible embodiment of the CSA is illustrated in Figs. 6A and 6B.
- the CSA illustrated in Figs 6A and 6B is based on a serial approach, wherein a set of n Full Adders (FA) are serially connected.
- the CSA 600 depicted in Fig. 6A is an n bits CSA, in which each FA has 3 inputs, and 2 outputs, a Carry (C) and Sum (S), each of which is the input of a Flip-Flop (FF) device.
- Each FA receives the following inputs: the output of the FF which receives the S output of the subsequent FA; the output of the FF which receives its own C output, and a corresponding input from the MUX (MUX, ⁇ , MUX tract -2 ,..., MUX 0 ). In this way, the right-shift of the CSA content, and the addition of the MUX output, out, are effected.
- the leftmost FA device 610 receives an input from another two stages, 611 and 612, depicted in Fig 6B.
- the additional stages, 611 and 612, depicted in Fig. 6B are utilized to expand the n bit CSA 600 of Fig. 6A, into a (n+2) bit CSA.
- the n-th stage 611 in Fig. 6B is utilized for the addition of MX ⁇ I ⁇ * 2" to the CSA content.
- MX ⁇ I ⁇ * 2 the addition of 4 bits is performed by the n-t . stage 611, it should be understood that in practice only 3 bits are summed by this stage. More particularly, when performing the Montgomery based computations, the input received from MX3 is always in zero state, and when performing regular multiplication, which are part of an interleaved multiplication, the input received from the (n+ ⁇ )-th stage 612 is in zero state.
- the C output 604 of the first stage FA, and the S output 608 of the second stage FA are connected to the Half Adder (HA) 607 which its S output is connected to a FF from which the output CSA[ 603 is provided for the circuitry utilized for determining K, .
- the HA 607 may be replaced by a logical XOR gate, or any device capable of realizing the ⁇ operation (i.e., base 2 modular addition).
- the serial output of the_ CSA, CSA 0 is not provided via an FF device, but instead it is obtained directly from the ⁇ 9 output of the first stage's FA.
- K J LSB(CSA + R5 J * R0 0 )
- the control inputs of MXl, MX2, MX3, and MX4 are set to select the input of K ⁇ , K j , "0", and R5 respectively. It should be noted that for this computation the input selection made for MX2 does not affect the result.
- the control input of MX3 is set to select the R4 input.
- the value of K is obtained in the R4 register.
- the content of R5 may be loaded (Fig. 5) with the content of register RO, utilizing conventional parallel/serial techniques (not illustrated) or by software.
- the NRSQR process may be utilized to compute (B * B + K* N+ CSA)/2 S , or ⁇ B* B + K* N)l 2 S by zeroing the content of the CSA in the initialization steps.
- the control inputs of MXl and MX4 are set to select the inputs of K j and R3, respectively.
- the control inputs of MX2 and MX3 are set to select the inputs of Kj and "0", respectively, when a simple NRMM ⁇ is performed, or alternatively, the input of K ⁇ and R4, respectively, as part of an interleaved multiplication
- K o LSB ⁇ CSA + R0 0 )
- the control inputs of MXl, MX3, and MX4 are set to select the input of K f , "0", and R3 respectively (the selection of MX2 does not affect this operation).
- the value of K is obtained in the R4 register, and the final result is obtained in the CSA, as the s cycles of the calculation are finished.
- an external control may be utilized for forcing "1" at the MX4 output, at the first cycle, and "0" at the remaining cycles (illustrated by dashed lines in Fig. 4).
- the computation of (B + K * N)/2 S can be obtained by zeroing the content of the CSA in the initialization steps.
- R4 R4/2 + CSA 0 *2"- 1
- the control inputs of MXl, MX2, MX3, and MX4 are set to select the inputs of R4, CSA Q , "0", and R3, respectively. After performing n iterations, the n LSBs of the result are obtained in the register R4, and n MSBs of the result are obtained in the CSA. Montgomery exponent
- the PKI apphcation of an exponent calculation is based on the exponent process that was described hereinabove, for computing.
- a E modN A ⁇ N with no lose of generality.
- R4 ⁇ 1 than O ⁇ CS.
- R0 NRMM ⁇ S) (R0,R3) .
- Rl R0 + R2
- a sequence of Montgomery squaring and multiplication are performed in the loop, i the above process.
- the operation of the PKI apparatus utilizing process 2 is further illustrated in Fig 7A, in a form of a flowchart.
- the operation is initiated in steps 730 and 731, in which the values A',E N, and m -1 are input to the PKI apparatus.
- a sequence of operations (steps 4.1. to 4.3. here above) are performed in a loop starting in steps 732a and 732b, where a right shift is performed to the content of register R4, the CSA content is zeroed, and an NRMSQR ⁇ s) of the content of RO is performed.
- step 732c the NRMSQR ⁇ s) result, which is obtained in the CSA, is loaded into register RO, and the addition result of the content of the CSA and the register R2 is loaded into register Rl.
- step 732d The operation of step 4.3. of the exponent process hereinabove is carried out in step 732d, where the LSB of R4 is examined, and if it equals "1" the CSA content is zeroed and a NRMM ⁇ of the content of registers RO and R3 is performed, the result of which is then stored in RO and also added to the content of R2 and stored in the register Rl.
- step 732e the value of the loop index i is decrement by 1, and in step 732f it is checked if the loop index i equals zero.
- i is not zeroed another iteration of the process is performed, as the operation is proceeded in step 732a, otherwise, the CSA content is zeroed and a MMULBYl ⁇ operation is performed to the content of RO.
- the exponentiation (reduced) result is obtained in the CSA after performing the MMULBYl ⁇ operation to eliminate the 2 s element.
- Fig. 7A is carried out utilizing an external control (not shown). This control may be performed by software utilizing a processor/controller, or by the addition of dedicated hardware.
- R0 NRMM s) (R0,R3)
- R1 R0 + R2
- Fig.7B The PKI operations in this process are illustrated in Fig.7B.
- This process is initiated in steps 750 and 751, in which the values A',E',N, and m-1, are input to the PKI apparatus, and a Flag is set to "1".
- the operations performed in steps 5.1. to 5.4. in the exponent process here above begins in step 752a, in which a right shift is performed to the content of register R4.
- step 752b the LSB of R4 is examined, and if it equals "1" another test is performed in step 752c, to determine if the Flag is in the state of "1". If the Flag state is "1", register R3 is loaded with the content of register RO, and the flag state is reset to "0".
- step 752c the CSA content is zeroed and a NRMM ⁇ operation is performed to the content of registers RO and R3, the result of which is obtained in the CSA, and which is then loaded into the R3 register. The operation continues by passing the control to step 752d.
- step 752b the operation proceed in step 752d, where the CSA content is zeroed and a NRSQR ⁇ operation of the content of RO is carried out, the result of which is obtained in the CSA.
- the NRSQR ⁇ result is then loaded into register RO, and it is also added to the content of register R2.
- the addition result of the contents of the CSA and register R2 is stored in register Rl.
- step 752f the loop index i is decrement by 1.
- step 752e i is examined to determine if it equal zero. If i is not zeroed, another iteration is performed as the control is passed to step 752a.
- the CSA content is zeroed and a NRMM ⁇ operation of the RO and R3 contents is performed, the result of which is obtained in the CSA, and loaded into register RO.
- the addition of the contents of register R2 and the CSA is stored in register Rl, the CSA content is zeroed and a MMULBYl ⁇ is performed.
- the final result (reduced) is then obtained in the CSA.
- the method of the invention substantially improves the security of the PKI apparatus, particularly against attacks, which are based on the detection of subtraction operation, as performed in the conventional Montgomery Multiplication methods.
- attacks which are based on the detection of subtraction operation, as performed in the conventional Montgomery Multiplication methods.
- the user's secret (private) key is computed by revealing the reduction operations performed (W. Schindler "A Timing Attack against RSA with the. Chinese Reminder Theorem", Second International Workshop Worcester, MA, USA, August 2000).
- a common method, which is currently used, against such attacks is to perform additional (dummy) subtraction operations, which of course consumes more time and power. Since in the method of the invention subtractions are not performed, it is not possible to reveal the secret key utilizing such methods.
- the method of the invention can be utilized to implement a right-to-left exponentiation process with two PKI apparatus operating in parallel.
- a parallel implementations further improves the security of the system. Since it is difficult to follow and identify when and which operations are performed by such a parallel system, the opponent task becomes even more problematical.
- Fig 5 the values loaded into each register (RO, Rl, R2, R3, and R4), and the input selection of each of the multiplexers (MXl, MX2, MX3, and MX4), are described, for different steps (1,11, III, and IV) of the Montgomery interleaved multiplication.
- the registers are loaded with the respective values, the MUXs control input is set to provide the corresponding input, and a process of s iterations is performed, for calculating the respective product.
- each integer may consist of I partial values, each of which is of n-bit.
- step I the computation of A 0 * B° +N° *K° )/2 ⁇ " is performed by loading registers RO, Rl, R2, and R3, with 5°,5 0 + N 0 ,N° , and A 0 , respectively.
- the control inputs of MXl, MX2, MX3., and MX4 are set to select the inputs of K j , K J , "0", R3, respectively.
- a 0 * 5° * 2 ⁇ * modN 0 remains in the CSA. Since in this step MX2 selects the K ⁇ output, register R4 is -loaded with bits of the K° value, which are required for the computation of the next step.
- step II regular multiplication is performed, to calculate 4° - 5 1 + N 1 - K° + CSA ( j wherein CSA ⁇ is the result that was obtained in the previous step, step I.
- the values B B l + N N ⁇ , and A 0 are loaded into the R0, Rl, R2, and R3, registers, respectively, and the control inputs of MXl, MX2, MX3 travers and MX4, are set to select the inputs of i? 4 , CSA Q , "0" , R3, respectively.
- the right shift of the bits of R3 is a cyclic bit rotation, so that there is actually no need to reload R3 with the value of A 0 . Since in this step the apparatus is utilized for the calculation of regular multiphcation, the n LSBs of the result are fed into the serial-in of the R4 register, and the n MSBs of the result remain in the CSA.
- step III the calculation of
- LSBs of the result are loaded into the R4 register, and the n MSBs (which may also be of n+1 bits) of the result are obtained in the CSA.
- steps I to VI may be greater than N, and thus reduction may be required. If it is required, reduction is performed by software after each step. Alternatively, one may implement the same method of interleaved multiplication by utilizing an extended non-reduced approach without needing to reduce the obtained result after each step. In addition, the computation of greater values may be carried out utihzing software for storing temporary result of the interleaved multiphcation.
Landscapes
- Physics & Mathematics (AREA)
- Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Mathematical Analysis (AREA)
- Mathematical Optimization (AREA)
- Pure & Applied Mathematics (AREA)
- Computational Mathematics (AREA)
- Theoretical Computer Science (AREA)
- Computing Systems (AREA)
- Mathematical Physics (AREA)
- General Engineering & Computer Science (AREA)
- Complex Calculations (AREA)
- Hardware Redundancy (AREA)
- Apparatus For Radiation Diagnosis (AREA)
Abstract
Description











Claims

Priority Applications (5)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2003507688A JP2004534266A (en) | 2001-06-21 | 2002-04-22 | Method and apparatus for efficiently performing arithmetic operations in hardware |
| AU2002256871A AU2002256871A1 (en) | 2001-06-21 | 2002-04-22 | A method and apparatus for carrying out efficiently arithmetic computations in hardware |
| US10/481,573 US20040167952A1 (en) | 2001-06-21 | 2002-04-22 | Method and apparatus for carrying out efficiently arithmetic computations in hardware |
| DE60220682T DE60220682D1 (en) | 2001-06-21 | 2002-04-22 | METHOD AND DEVICE FOR CARRYING OUT EFFICIENT ARITHMETIC OPERATIONS IN HARDWARE |
| EP02726404A EP1421472B1 (en) | 2001-06-21 | 2002-04-22 | A method and apparatus for carrying out efficiently arithmetic computations in hardware |
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| IL143951 | 2001-06-21 | ||
| IL14395101A IL143951A0 (en) | 2001-06-21 | 2001-06-21 | A method and apparatus for carrying out efficiently arithmetic computations in hardware |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| WO2003001362A2 true WO2003001362A2 (en) | 2003-01-03 |
| WO2003001362A3 WO2003001362A3 (en) | 2004-03-04 |
Family
ID=11075541
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/IL2002/000318 Ceased WO2003001362A2 (en) | 2001-06-21 | 2002-04-22 | A method and apparatus for carrying out efficiently arithmetic computations in hardware |
Country Status (8)
| Country | Link |
|---|---|
| US (1) | US20040167952A1 (en) |
| EP (1) | EP1421472B1 (en) |
| JP (1) | JP2004534266A (en) |
| AT (1) | ATE364867T1 (en) |
| AU (1) | AU2002256871A1 (en) |
| DE (1) | DE60220682D1 (en) |
| IL (1) | IL143951A0 (en) |
| WO (1) | WO2003001362A2 (en) |
Cited By (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| EP1443699A1 (en) * | 2003-01-23 | 2004-08-04 | Hitachi, Ltd. | Information processing means and IC card |
| JP2007212701A (en) * | 2006-02-09 | 2007-08-23 | Renesas Technology Corp | Residual arithmetic processor |
| WO2009019437A1 (en) | 2007-08-08 | 2009-02-12 | Cilag Gmbh International | Injection device with locking mechanism for syringe carrier |
Families Citing this family (28)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP4544870B2 (en) * | 2004-01-26 | 2010-09-15 | 富士通セミコンダクター株式会社 | Arithmetic circuit device |
| US20060140399A1 (en) * | 2004-12-28 | 2006-06-29 | Young David W | Pre-calculation mechanism for signature decryption |
| DE602005020991D1 (en) * | 2005-10-28 | 2010-06-10 | Telecom Italia Spa | METHOD OF SCALARMULTIPLICATION IN GROUPS ELLIR SUB-CHANNEL BAGS-RESISTANT CRYPTOSYSTEMS |
| US7805479B2 (en) * | 2006-03-28 | 2010-09-28 | Michael Andrew Moshier | Scalable, faster method and apparatus for montgomery multiplication |
| US7912886B2 (en) * | 2006-12-14 | 2011-03-22 | Intel Corporation | Configurable exponent FIFO |
| EP2208165A4 (en) * | 2007-11-02 | 2010-11-24 | Certicom Corp | Signed montgomery arithmetic |
| JP5097138B2 (en) * | 2009-01-15 | 2012-12-12 | シャープ株式会社 | Arithmetic circuit and encryption circuit for Montgomery multiplication |
| WO2011092552A1 (en) * | 2010-01-28 | 2011-08-04 | Nds Limited | Exponentiation system |
| FR2974202B1 (en) | 2011-04-18 | 2013-04-12 | Inside Secure | METHOD FOR MULTIPLICATION OF MONTGOMERY |
| FR2974201B1 (en) * | 2011-04-18 | 2013-04-12 | Inside Secure | MONTGOMERY MULTIPLICATION CIRCUIT |
| US20130301826A1 (en) * | 2012-05-08 | 2013-11-14 | Intel Corporation | System, method, and program for protecting cryptographic algorithms from side-channel attacks |
| US9535656B2 (en) | 2014-03-14 | 2017-01-03 | International Business Machines Corporation | Pipelined modular reduction and division |
| KR102132261B1 (en) | 2014-03-31 | 2020-08-06 | 삼성전자주식회사 | Method and apparatus for computing montgomery multiplication performing final reduction wihhout comparator |
| CN108242994B (en) | 2016-12-26 | 2021-08-13 | 阿里巴巴集团控股有限公司 | Key processing method and device |
| US12309127B2 (en) | 2017-01-20 | 2025-05-20 | Enveil, Inc. | End-to-end secure operations using a query vector |
| US10903976B2 (en) | 2017-01-20 | 2021-01-26 | Enveil, Inc. | End-to-end secure operations using a query matrix |
| US11777729B2 (en) | 2017-01-20 | 2023-10-03 | Enveil, Inc. | Secure analytics using term generation and homomorphic encryption |
| US11507683B2 (en) | 2017-01-20 | 2022-11-22 | Enveil, Inc. | Query processing with adaptive risk decisioning |
| US11196541B2 (en) | 2017-01-20 | 2021-12-07 | Enveil, Inc. | Secure machine learning analytics using homomorphic encryption |
| US11290252B2 (en) | 2017-01-20 | 2022-03-29 | Enveil, Inc. | Compression and homomorphic encryption in secure query and analytics |
| US10902133B2 (en) | 2018-10-25 | 2021-01-26 | Enveil, Inc. | Computational operations in enclave computing environments |
| US10817262B2 (en) * | 2018-11-08 | 2020-10-27 | Enveil, Inc. | Reduced and pipelined hardware architecture for Montgomery Modular Multiplication |
| CN111475135B (en) * | 2019-01-23 | 2023-06-16 | 阿里巴巴集团控股有限公司 | a multiplier |
| US11508263B2 (en) | 2020-06-24 | 2022-11-22 | Western Digital Technologies, Inc. | Low complexity conversion to Montgomery domain |
| US11468797B2 (en) | 2020-06-24 | 2022-10-11 | Western Digital Technologies, Inc. | Low complexity conversion to Montgomery domain |
| US11601258B2 (en) | 2020-10-08 | 2023-03-07 | Enveil, Inc. | Selector derived encryption systems and methods |
| US12217018B2 (en) | 2021-09-20 | 2025-02-04 | Pqsecure Technologies, Llc | Method and architecture for performing modular addition and multiplication sequences |
| US12500736B2 (en) * | 2023-08-14 | 2025-12-16 | Microsoft Technology Licensing, Llc | Montgomery multiplier architecture |
Family Cites Families (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US6748410B1 (en) * | 1997-05-04 | 2004-06-08 | M-Systems Flash Disk Pioneers, Ltd. | Apparatus and method for modular multiplication and exponentiation based on montgomery multiplication |
| JP3542278B2 (en) * | 1998-06-25 | 2004-07-14 | 株式会社東芝 | Montgomery reduction device and recording medium |
| DE60139401D1 (en) * | 2000-05-15 | 2009-09-10 | Sandisk Il Ltd | ENLARGEMENT OF THE AREA OF COMPUTER BODIES OF ALL NUMBERS |
-
2001
- 2001-06-21 IL IL14395101A patent/IL143951A0/en unknown
-
2002
- 2002-04-22 AU AU2002256871A patent/AU2002256871A1/en not_active Abandoned
- 2002-04-22 AT AT02726404T patent/ATE364867T1/en not_active IP Right Cessation
- 2002-04-22 DE DE60220682T patent/DE60220682D1/en not_active Expired - Lifetime
- 2002-04-22 EP EP02726404A patent/EP1421472B1/en not_active Expired - Lifetime
- 2002-04-22 US US10/481,573 patent/US20040167952A1/en not_active Abandoned
- 2002-04-22 JP JP2003507688A patent/JP2004534266A/en active Pending
- 2002-04-22 WO PCT/IL2002/000318 patent/WO2003001362A2/en not_active Ceased
Non-Patent Citations (2)
| Title |
|---|
| ARAZI B: "DOUBLE-PRECISION MODULAR MULTIPLICATION BASED ON A SINGLE-PRECISIONMODULAR MULTIPLIER AND A STANDARD CPU" IEEE JOURNAL ON SELECTED AREAS IN COMMUNICATIONS, IEEE INC. NEW YORK, US, vol. 11, no. 5, 1 June 1993 (1993-06-01), pages 761-769, XP000399844 ISSN: 0733-8716 * |
| BLUM T ET AL: "Montgomery modular exponentiation on reconfigurable hardware" COMPUTER ARITHMETIC, 1999. PROCEEDINGS. 14TH IEEE SYMPOSIUM ON ADELAIDE, SA, AUSTRALIA 14-16 APRIL 1999, LOS ALAMITOS, CA, USA,IEEE COMPUT. SOC, US, 14 April 1999 (1999-04-14), pages 70-77, XP010332298 ISBN: 0-7695-0116-8 * |
Cited By (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| EP1443699A1 (en) * | 2003-01-23 | 2004-08-04 | Hitachi, Ltd. | Information processing means and IC card |
| JP2007212701A (en) * | 2006-02-09 | 2007-08-23 | Renesas Technology Corp | Residual arithmetic processor |
| WO2009019437A1 (en) | 2007-08-08 | 2009-02-12 | Cilag Gmbh International | Injection device with locking mechanism for syringe carrier |
Also Published As
| Publication number | Publication date |
|---|---|
| JP2004534266A (en) | 2004-11-11 |
| AU2002256871A1 (en) | 2003-01-08 |
| WO2003001362A3 (en) | 2004-03-04 |
| ATE364867T1 (en) | 2007-07-15 |
| EP1421472A2 (en) | 2004-05-26 |
| DE60220682D1 (en) | 2007-07-26 |
| IL143951A0 (en) | 2003-09-17 |
| US20040167952A1 (en) | 2004-08-26 |
| EP1421472B1 (en) | 2007-06-13 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| WO2003001362A2 (en) | A method and apparatus for carrying out efficiently arithmetic computations in hardware | |
| US8504602B2 (en) | Modular multiplication processing apparatus | |
| JP3784156B2 (en) | Modular multiplication method | |
| KR101062558B1 (en) | Computer-readable storage media, systems, and methods for computing cryptographic techniques | |
| JPH11305996A (en) | Method and device for increasing data processing speed of calculation device using multiplication | |
| JP4875700B2 (en) | Randomized modular polynomial reduction method and hardware therefor | |
| US7986779B2 (en) | Efficient elliptic-curve cryptography based on primality of the order of the ECC-group | |
| US20120057695A1 (en) | Circuits for modular arithmetic based on the complementation of continued fractions | |
| JPH11305995A (en) | Method and device for accelerating data processing of calculator | |
| US20090006512A1 (en) | NORMAL-BASIS TO CANONICAL-BASIS TRANSFORMATION FOR BINARY GALOIS-FIELDS GF(2m) | |
| EP2350811A1 (en) | Method and apparatus for modulus reduction | |
| US5828590A (en) | Multiplier based on a variable radix multiplier coding | |
| JP3726966B2 (en) | Multiplier and encryption circuit | |
| JP3551113B2 (en) | Divider | |
| TW200413954A (en) | Information processing method | |
| US6807555B2 (en) | Modular arithmetic apparatus and method having high-speed base conversion function | |
| Vollala et al. | Energy efficient modular exponentiation for public-key cryptography based on bit forwarding techniques | |
| US7266577B2 (en) | Modular multiplication apparatus, modular multiplication method, and modular exponentiation apparatus | |
| US20040210613A1 (en) | Method and apparatus for modular multiplication | |
| WO2002073395A2 (en) | A method and apparatus for multiplication and/or modular reduction processing | |
| US10318245B2 (en) | Device and method for determining an inverse of a value related to a modulus | |
| WO2003023601A2 (en) | Method and apparatus for efficient computation of modular exponent | |
| KR20100062565A (en) | Method for calculating negative inverse of modulus | |
| JP4182226B2 (en) | Remainder calculation method, apparatus and program | |
| US12010231B2 (en) | Computer processing architecture and method for supporting multiple public-key cryptosystems based on exponentiation |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| AK | Designated states |
Kind code of ref document: A2 Designated state(s): AE AG AL AM AT AU AZ BA BB BG BR BY BZ CA CH CN CO CR CU CZ DE DK DM DZ EC EE ES FI GB GD GE GH GM HR HU ID IL IN IS JP KE KG KP KR KZ LC LK LR LS LT LU LV MA MD MG MK MN MW MX MZ NO NZ OM PH PL PT RO RU SD SE SG SI SK SL TJ TM TN TR TT TZ UA UG US UZ VN YU ZA ZM ZW |
|
| AL | Designated countries for regional patents |
Kind code of ref document: A2 Designated state(s): GH GM KE LS MW MZ SD SL SZ TZ UG ZM ZW AM AZ BY KG KZ MD RU TJ TM AT BE CH CY DE DK ES FI FR GB GR IE IT LU MC NL PT SE TR BF BJ CF CG CI CM GA GN GQ GW ML MR NE SN TD TG |
|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application | ||
| DFPE | Request for preliminary examination filed prior to expiration of 19th month from priority date (pct application filed before 20040101) | ||
| WWE | Wipo information: entry into national phase |
Ref document number: 10481573 Country of ref document: US Ref document number: 2003507688 Country of ref document: JP |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 2002726404 Country of ref document: EP |
|
| REG | Reference to national code |
Ref country code: DE Ref legal event code: 8642 |
|
| WWP | Wipo information: published in national office |
Ref document number: 2002726404 Country of ref document: EP |
|
| WWG | Wipo information: grant in national office |
Ref document number: 2002726404 Country of ref document: EP |