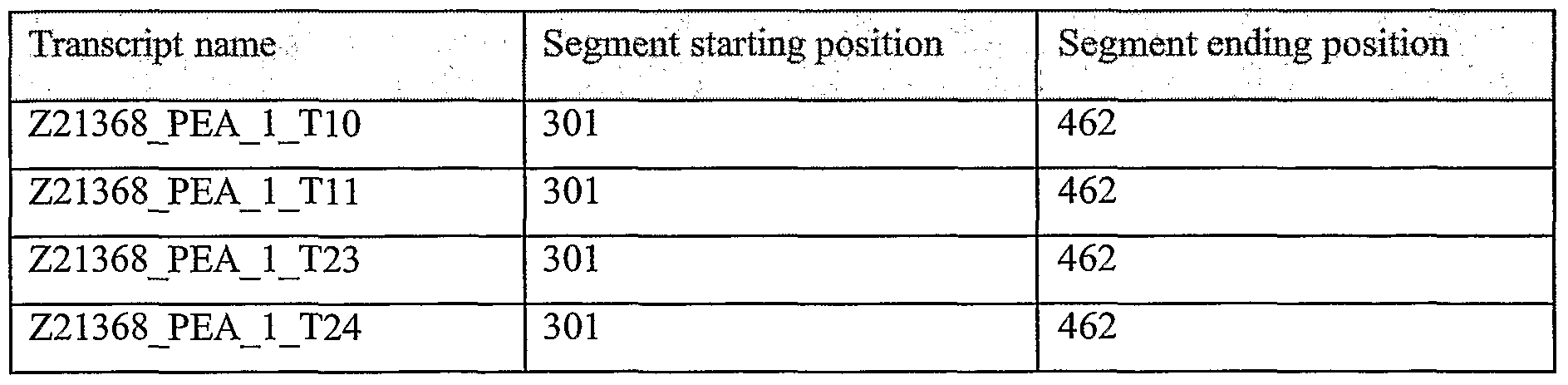
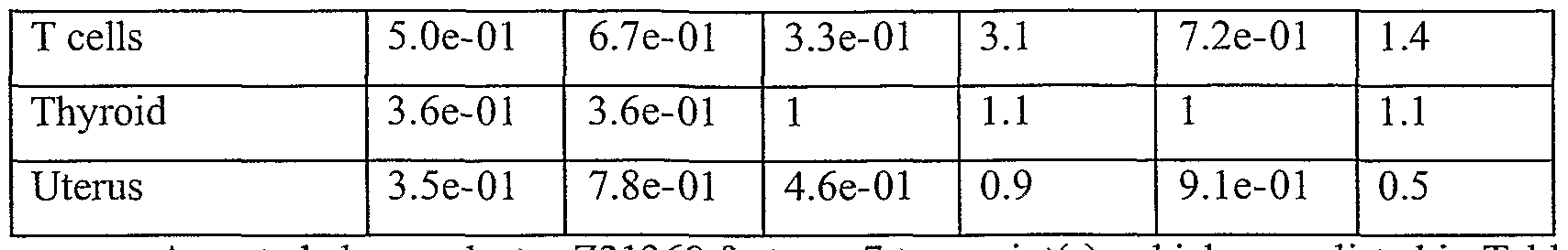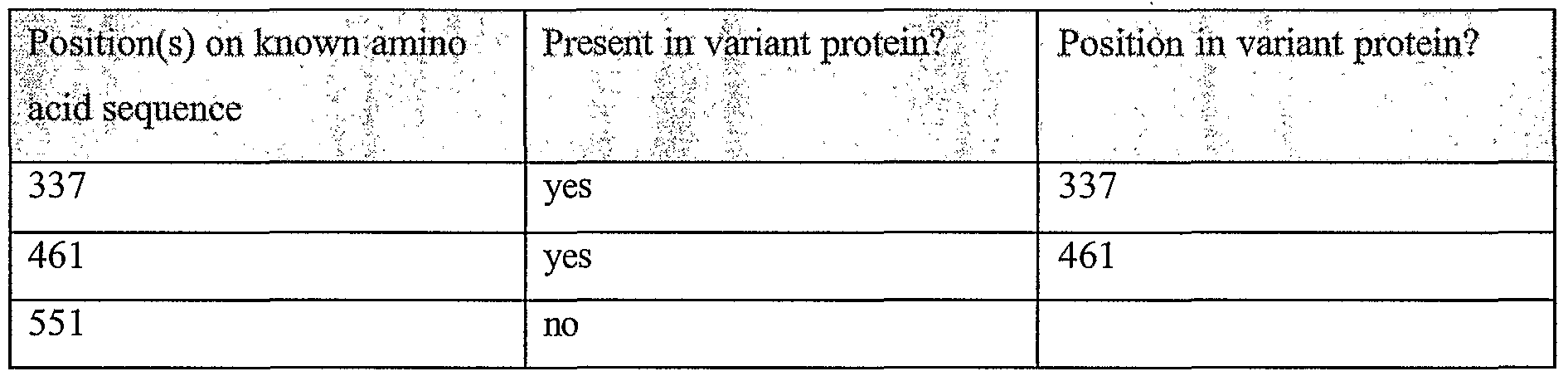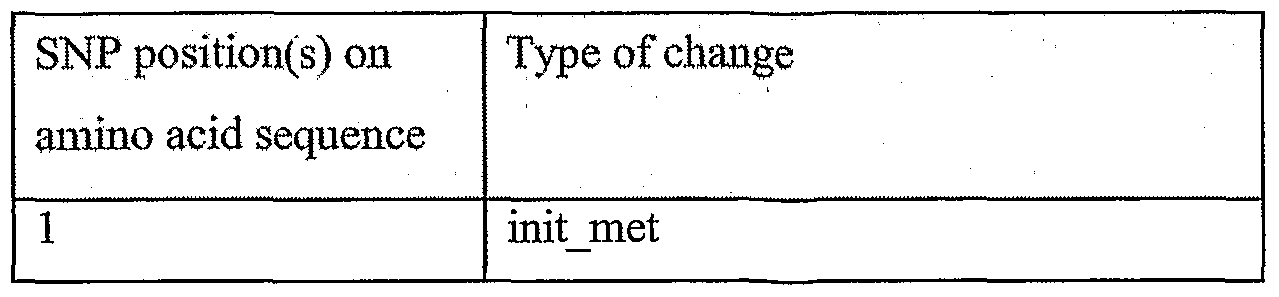NOVEL NUCLEOTIDE AND AMINO ACID SEQUENCES, AND ASSAYS AND METHODS OF USE THEREOF FOR DIAGNOSIS OF LUNG CANCER
FIELD OF THE INVENTION The present invention is related to novel nucleotide and protein sequences that are diagnostic markers for lung cancer, and assays and methods of use thereof.
BACKGROUND OF THE INVENTION
Lung cancer is the primary cause of cancer death among both men and women in the U. S., with an estimated 172,000 new cases being reported in 1994. The five-year survival rate among all lung cancer patients, regardless of the stage of disease at diagnosis, is only 13%. This contrasts with a five-year survival rate of 46% among cases detected while the disease is still localized. However, only 16% of lung cancers are discovered before the disease has spread.
Lung cancers are broadly classified into small cell or non-small cell lung cancers. Non-small cell lung cancers are further divided into adenocarcinomas, bronchoalveolar- alveolar, squamous cell and large cell carcinomas. Approximately, 75-85 percent of lung cancers are non-small cell cancers and 15-25 percent are small cell cancers of the lung.
Early detection is difficult since clinical symptoms are often not seen until the disease has reached an advanced stage. Currently, diagnosis is aided by the use of chest x-rays, analysis of the type of cells contained in sputum and fiberoptic examination of the bronchial passages.
Treatment regimens are determined by the type and stage of the cancer, and include surgery, radiation therapy and/or chemotherapy.
Early detection of primary, metastatic, and recurrent disease can significantly impact the prognosis of individuals suffering from lung cancer. Non- small cell lung cancer diagnosed at an early stage has a significantly better outcome than that diagnosed at more advanced stages.
Similarly, early diagnosis of small cell lung cancer potentially has a better prognosis.
Although current radiotherapeutic agents, chemotherapeutic agents and biological toxins are potent cytotoxins, they do not discriminate between normal and malignant cells, producing adverse effects and dose- limiting toxicities. There remains a need for lung cancer specific cancer markers. There remains a need for reagents and kits which can be used to detect the presence of lung cancer markers in samples from patients. There remains a need for methods of
screening and diagnosing individuals who have lung cancer and methods of monitoring response to treatment, disease progression and disease recurrence in patients diagnosed with lung cancer. There remains a need for reagents, kits and methods for determining the type of lung cancer that an individual who has lung cancer has. There remains a need for compositions which can specifically target lung cancer cells. There remains a need for imaging agents which can specifically bind to lung cancer cells. There remains a need for improved methods of imaging lung cancer cells. There remains a need for therapeutic agents which can specifically bind to lung cancer cells. There remains a need for improved methods of treating individuals who are suspected of suffering from lung cancer.
SUMMARY OF THE INVENTION
The background art does not teach or suggest markers for lung cancer that are sufficiently sensitive and/or accurate, alone or in combination.
The present invention overcomes these deficiencies of the background art by providing novel markers for lung cancer that are both sensitive and accurate. Furthermore, these markers are able to distinguish between different types of lung cancer, such as small cell or non- small cell lung cancer, and further between non- small cell lung cancer types, such as adenocarcinomas, squamous cell and large cell carcinomas. These markers are overexpressed in lung cancer specifically, as opposed to normal lung tissue. The measurement of these markers, alone or in combination, in patient (biological) samples provides information that the diagnostician can correlate with a probable diagnosis of lung cancer. The markers of the present invention, alone or in combination, show a high degree of differential detection between lung cancer and non-cancerous states.
According to preferred embodiments of the present invention, examples of suitable biological samples which may optionally be used with preferred embodiments of the present invention include but are not limited to blood, serum, plasma, blood cells, urine, sputum, saliva, stool, spinal fluid or CSF, lymph fluid, the external secretions of the skin, respiratory, intestinal, and genitourinary tracts, tears, milk, neuronal tissue, lung tissue, any human organ or tissue, including any tumor or normal tissue, any sample obtained by lavage (for example of the bronchial system or of the breast ductal system), and also samples of in vivo cell culture constituents. In a preferred embodiment, the biological sample comprises lung tissue and/or
sputum and/or a serum sample and/or a urine sample and/or any other tissue or liquid sample. The sample can optionally be diluted with a suitable eluant before contacting the sample to an antibody and/or performing any other diagnostic assay.
Information given in the text with regard to cellular localization was deteπnined according to four different software programs: (i) tmhmm (from Center for Biological Sequence Analysis, Technical University of Denmark DTU, http://www.cbs.dUi.dk/services/TMHMM/TMHMM2.0b.guide.php) or (ii) tmpred (from EMBnet, maintained by the ISREC Bionformatics group and the LICR Infoπnation Technology Office, Ludwig Institute for Cancer Research, Swiss Institute of Bioinformatics, http://www.ch.embnet.org/software/TMPRED_form.html for transmembrane region prediction; (iii) signalp hmm or (iv) signalpjtin (both from Center for Biological Sequence Analysis, Technical University of Denmark DTU, http://www.cbs. dtudk/services/SignalPΛackground/prediction.php) for signal peptide prediction. The terms "signalp Jimrn" and "signalpjnn" refer to two modes of operation for the program SignalP: hmm refers to Hidden Markov Model, while nn refers to neural networks. Localization was also determined through manual inspection of known protein localization and/or gene structure, and the use of heuristics by the individual inventor. In some cases for the manual inspection of cellular localization prediction inventors used the ProLoc computational platform [Einat Hazkani-Covo, Erez Levanon, Galit Rotman, Dan Graur and Amit Novik; (2004) "Evolution of multicellularity in metazoa: comparative analysis of the subcellular localization of proteins in Saccharomyces, Drosophila and Caenorhabditis." Cell Biology International 2004;28(3):171-8.], which predicts protein localization based on various parameters including, protein domains (e.g., prediction of trans-membranous regions and localization thereof within the protein), pi, protein length, amino acid composition, homology to pre- annotated proteins, recognition of sequence patterns which direct the protein to a certain organelle (such as, nuclear localization signal, NLS, mitochondria localization signal), signal peptide and anchor modeling and using unique domains from Pfam that are specific to a single compartment.
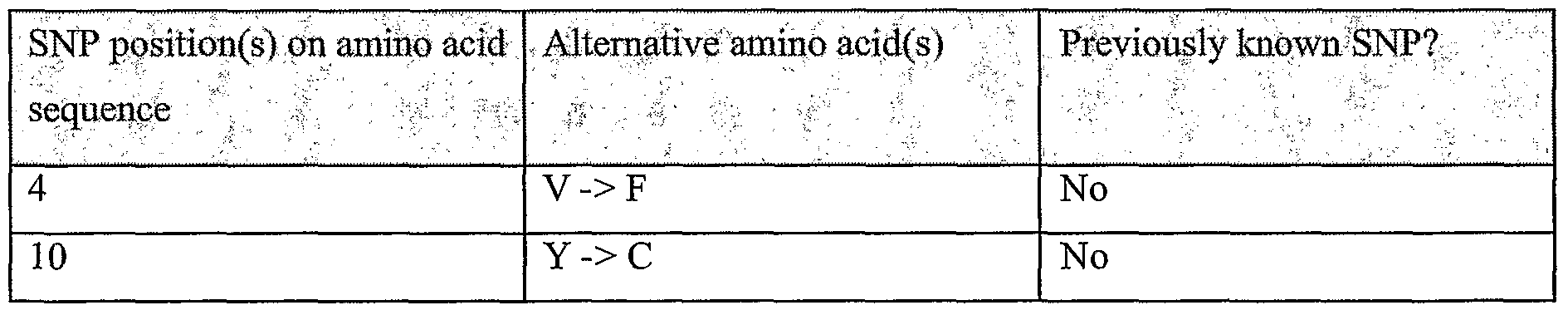
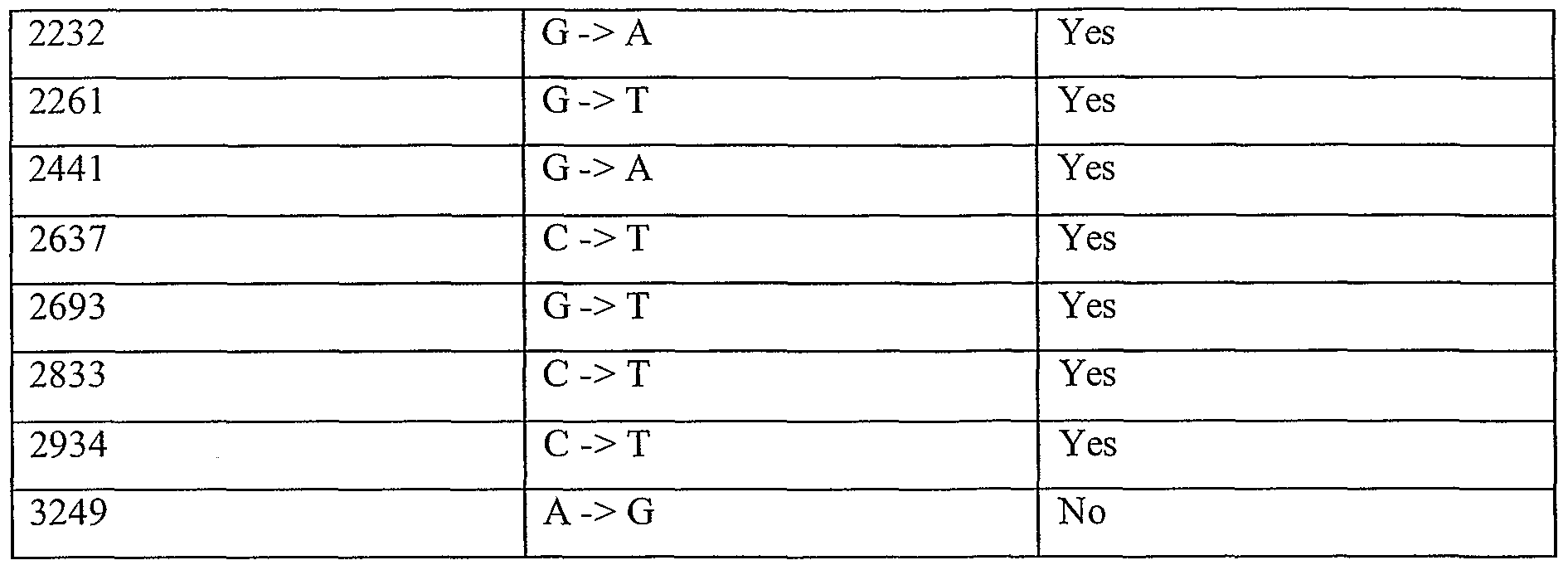
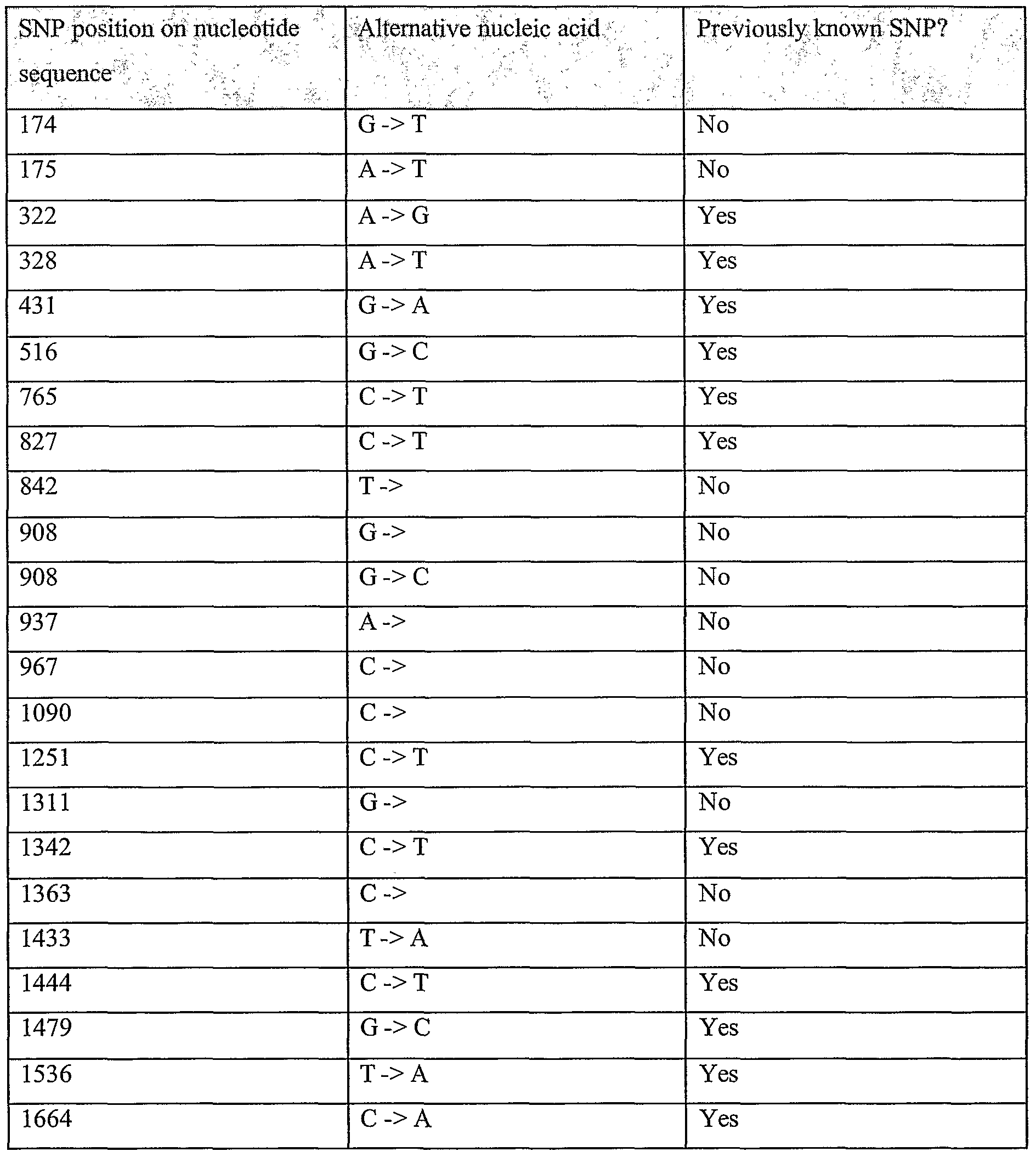
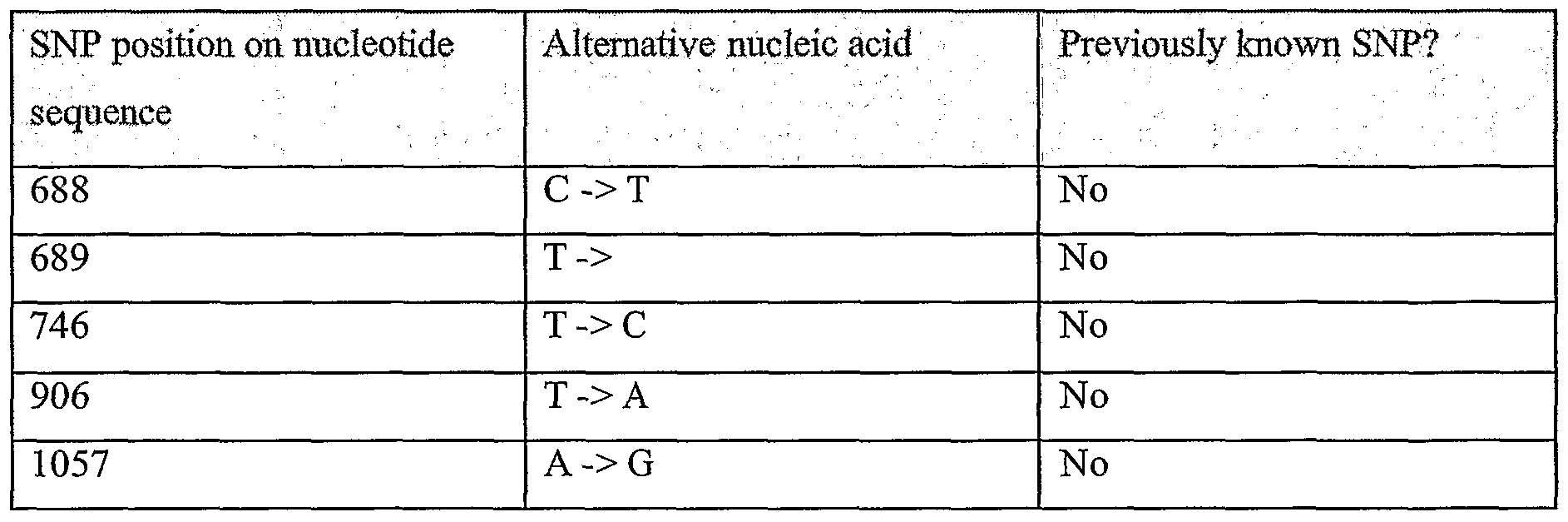
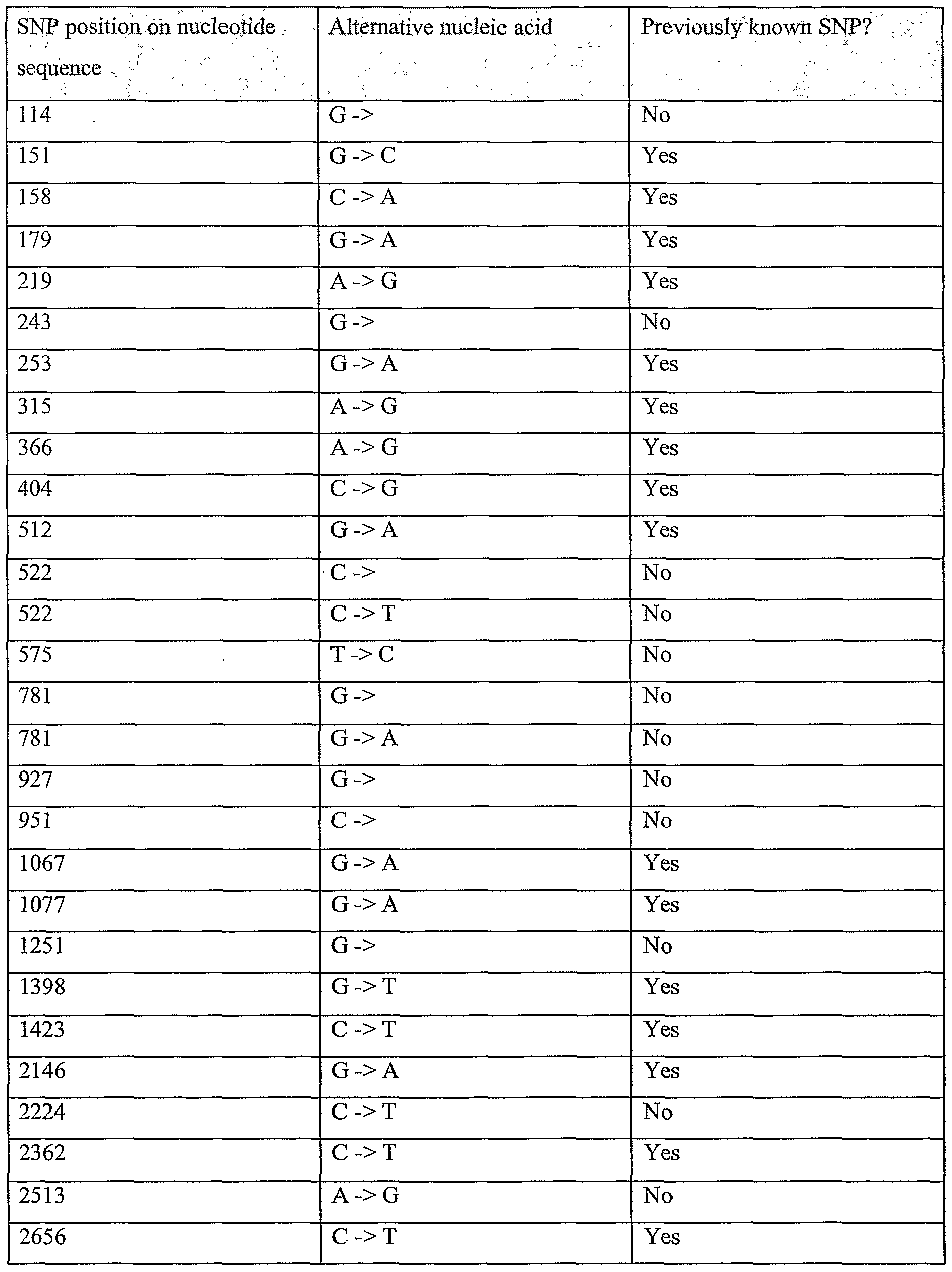
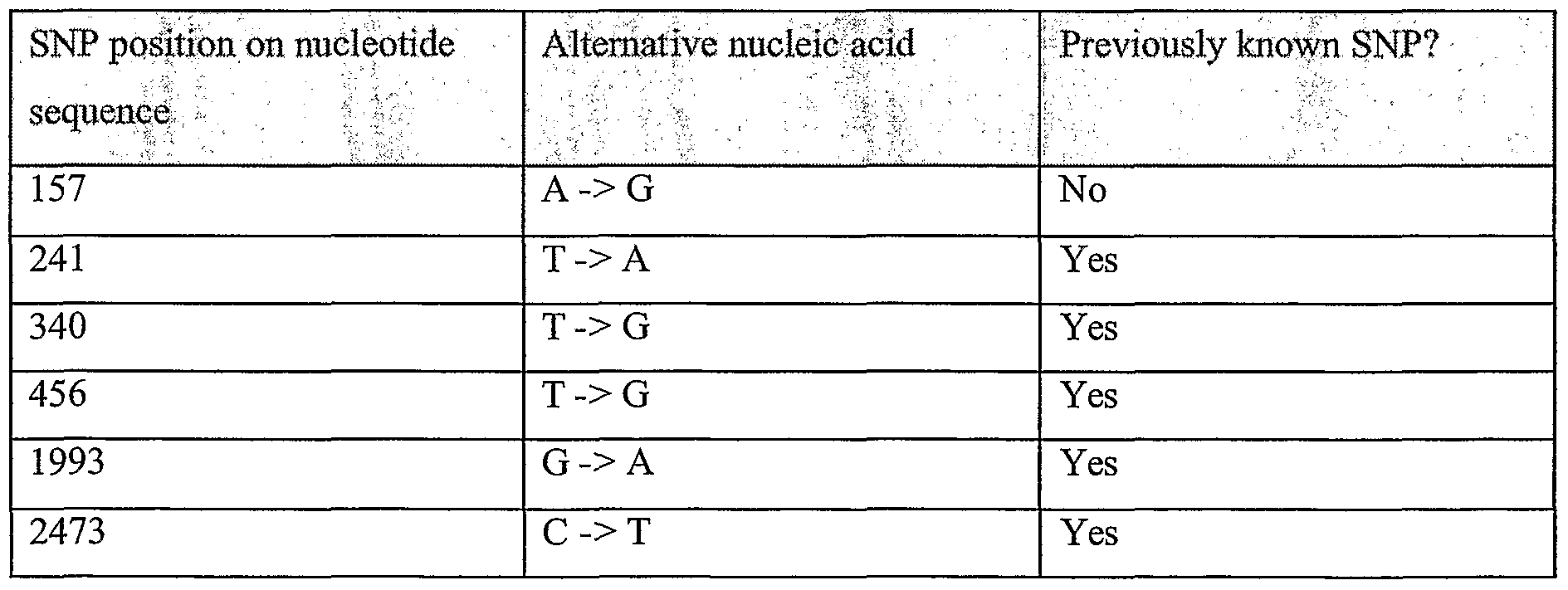
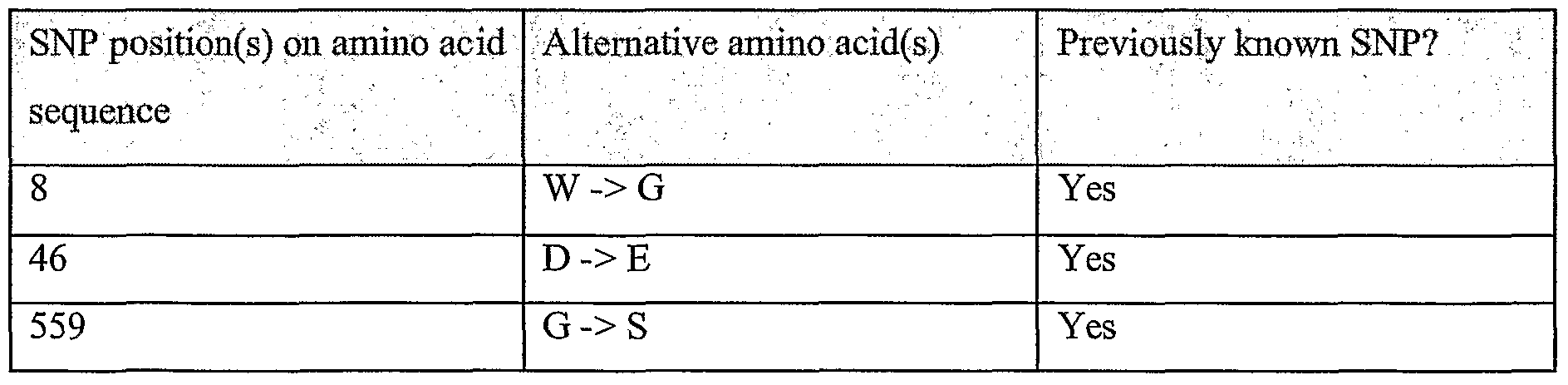
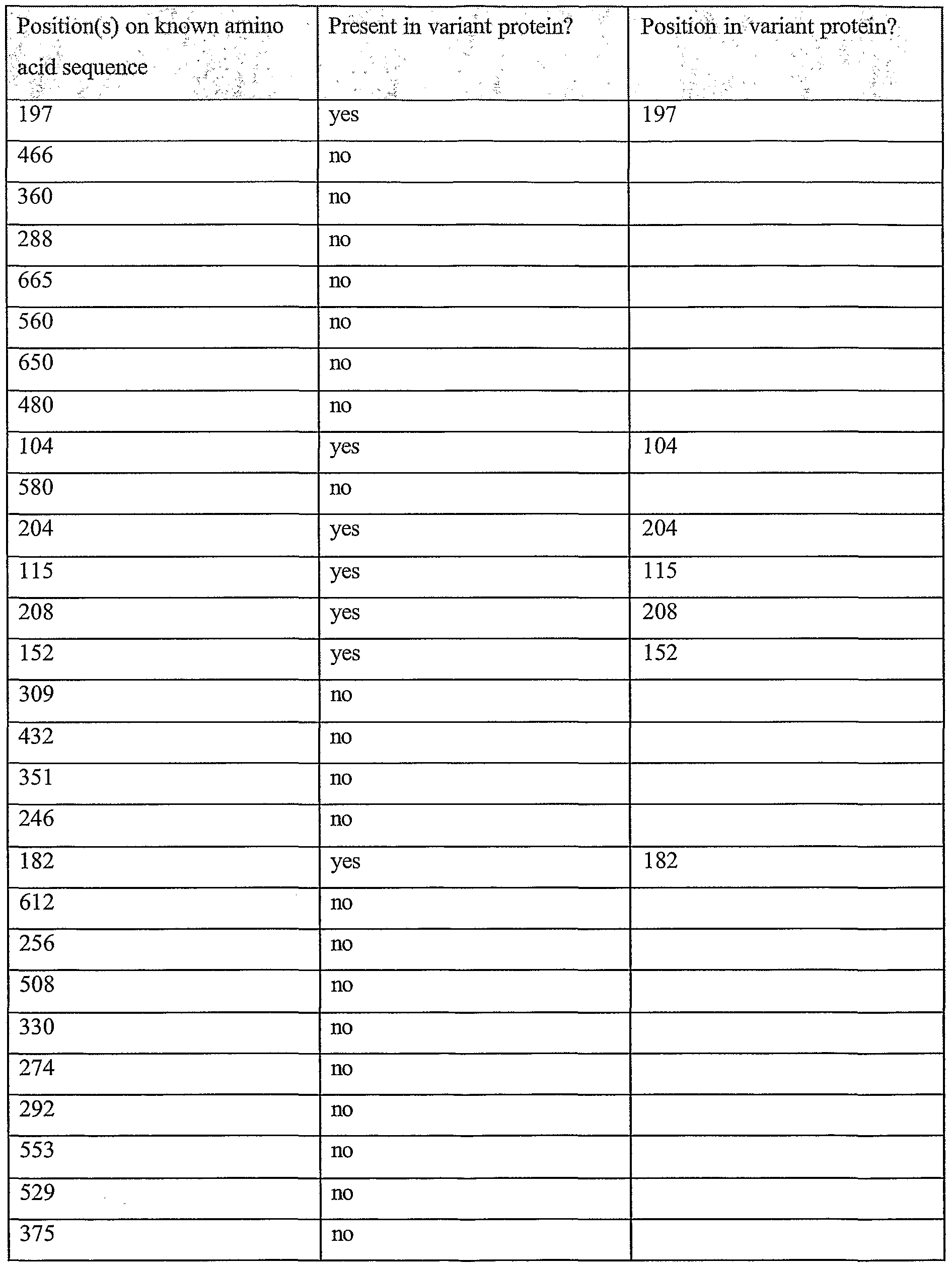
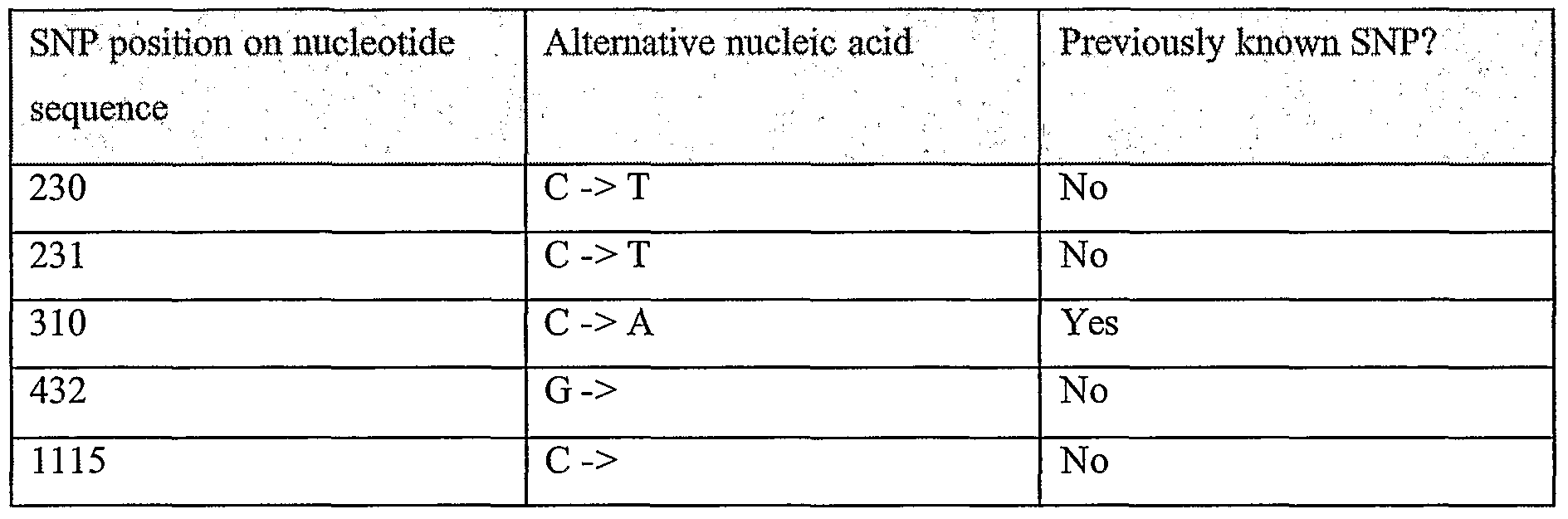
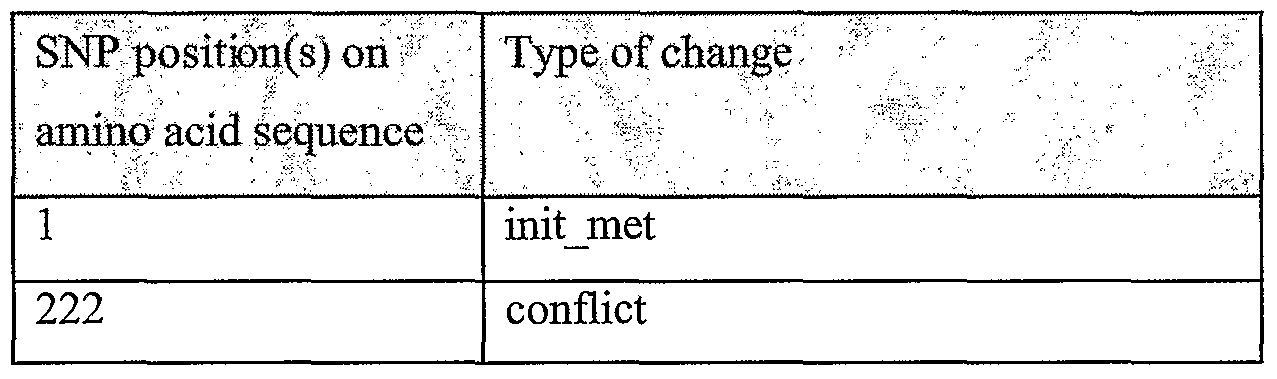
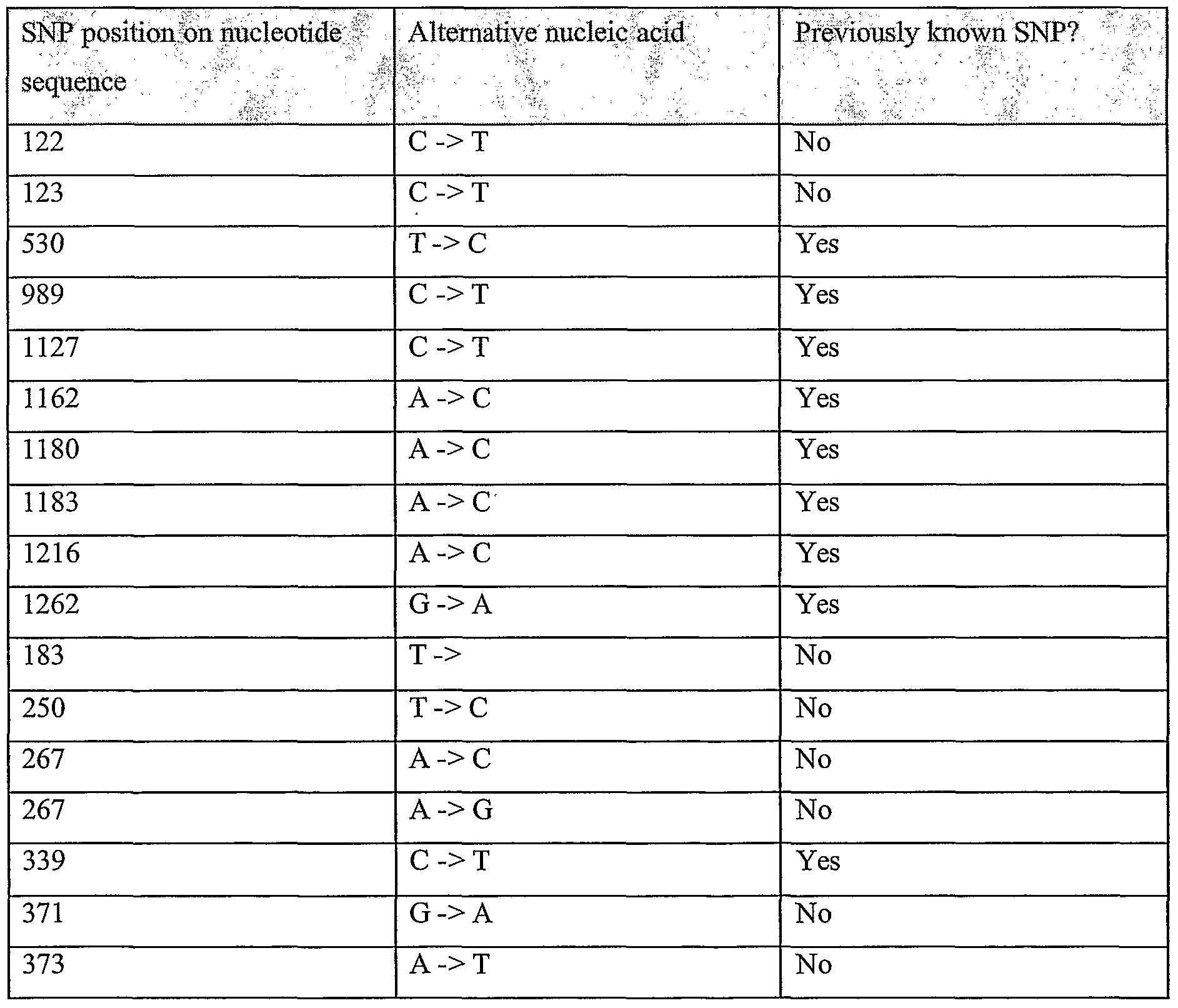
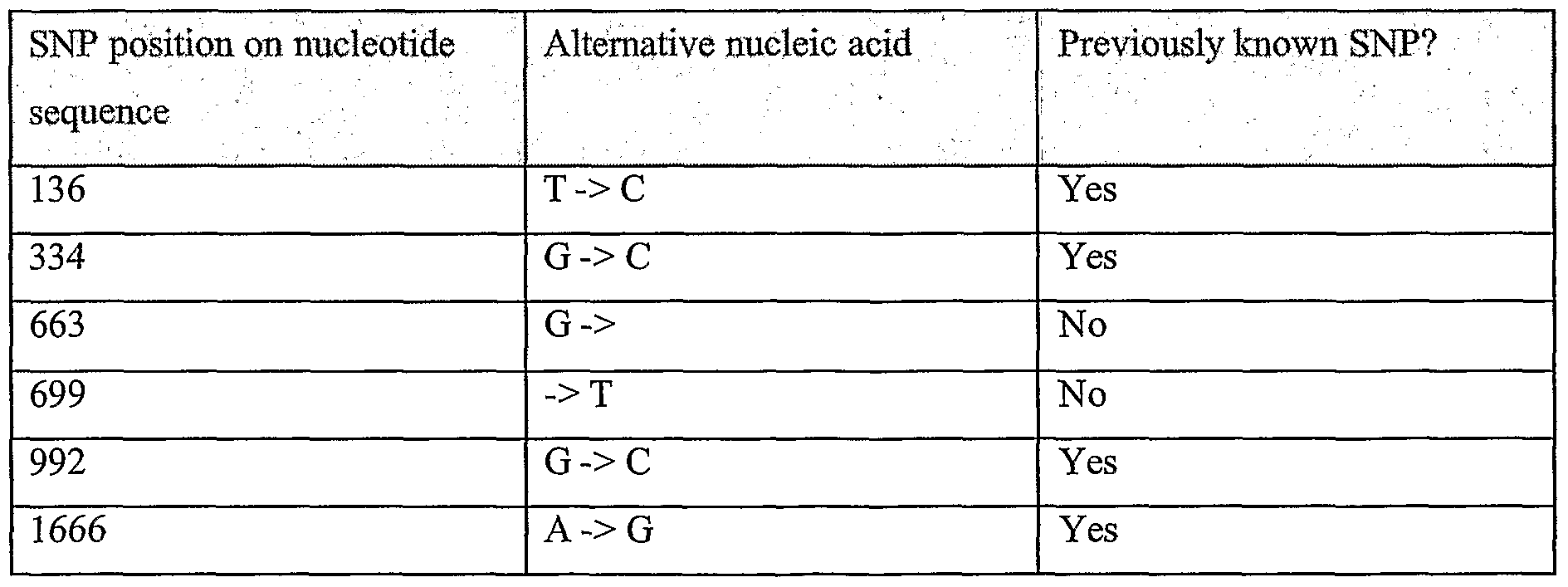
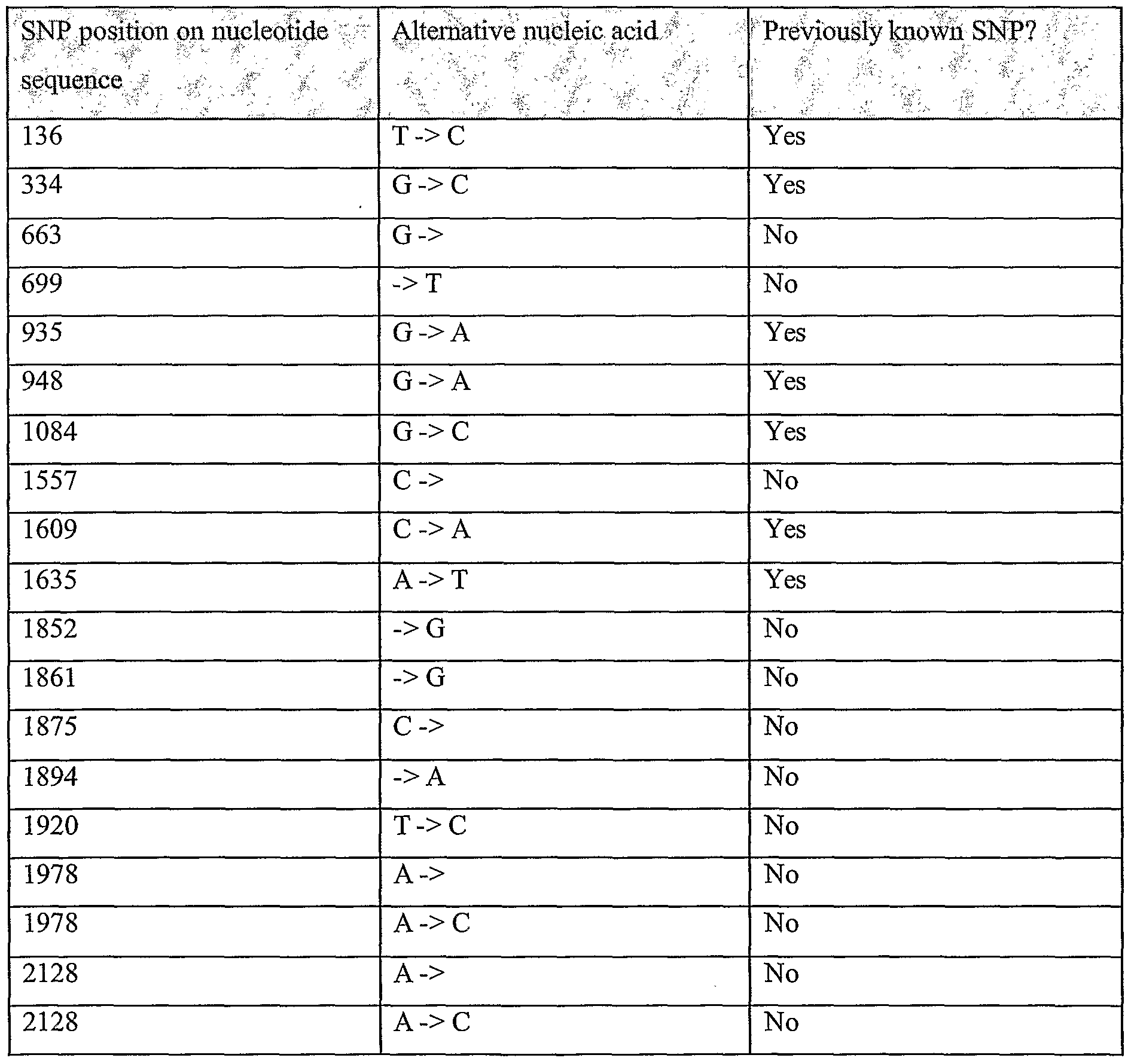
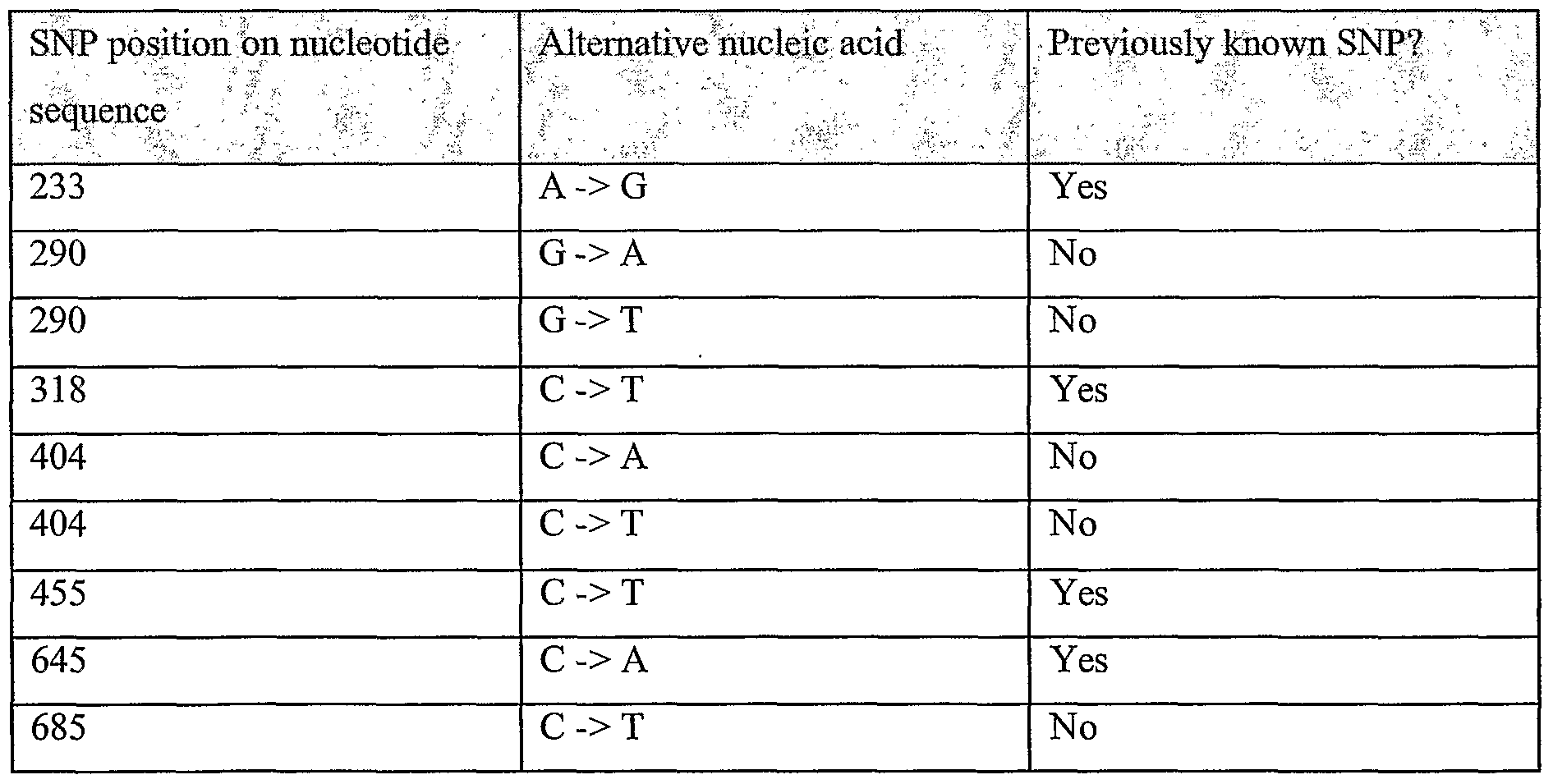
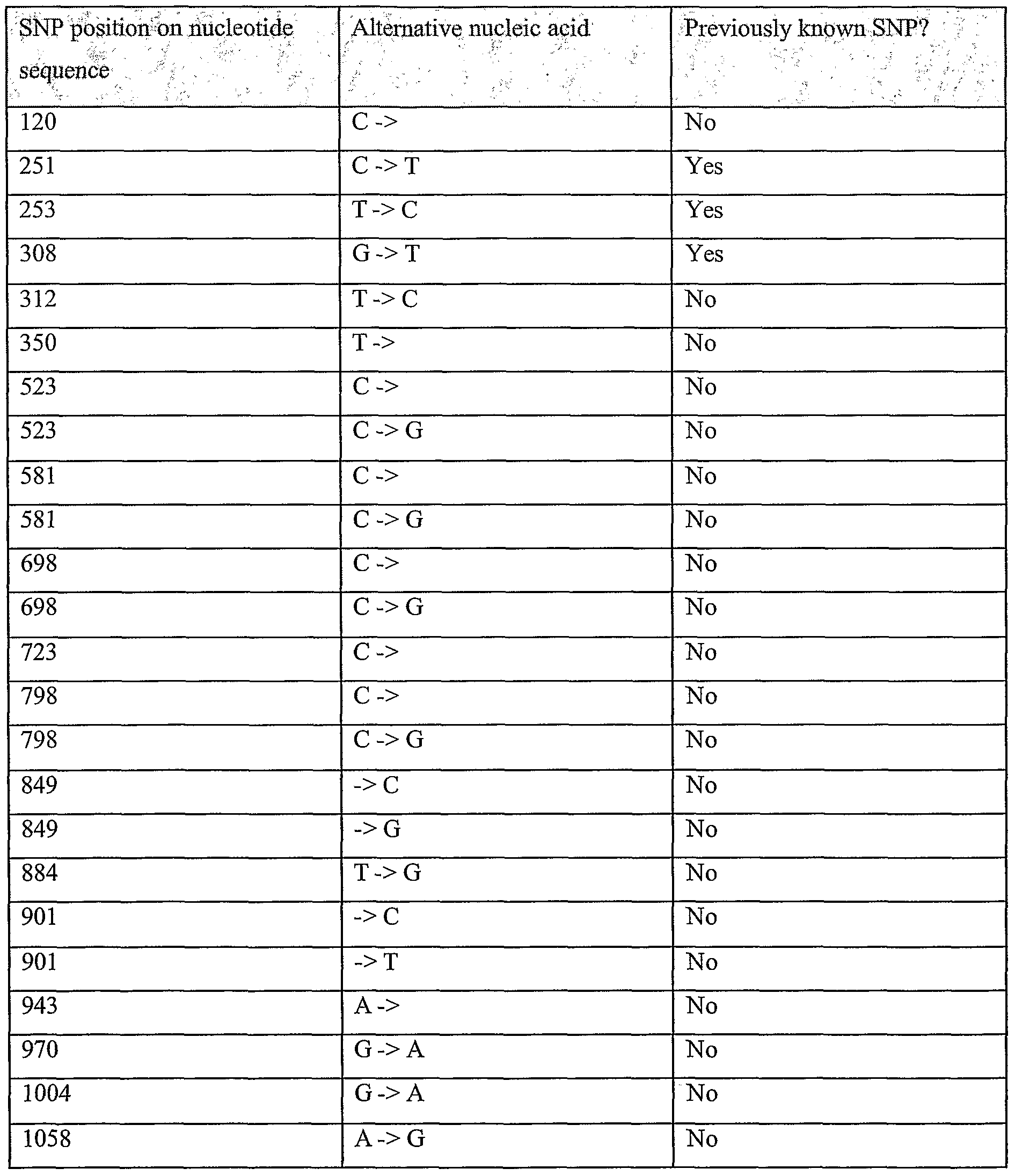
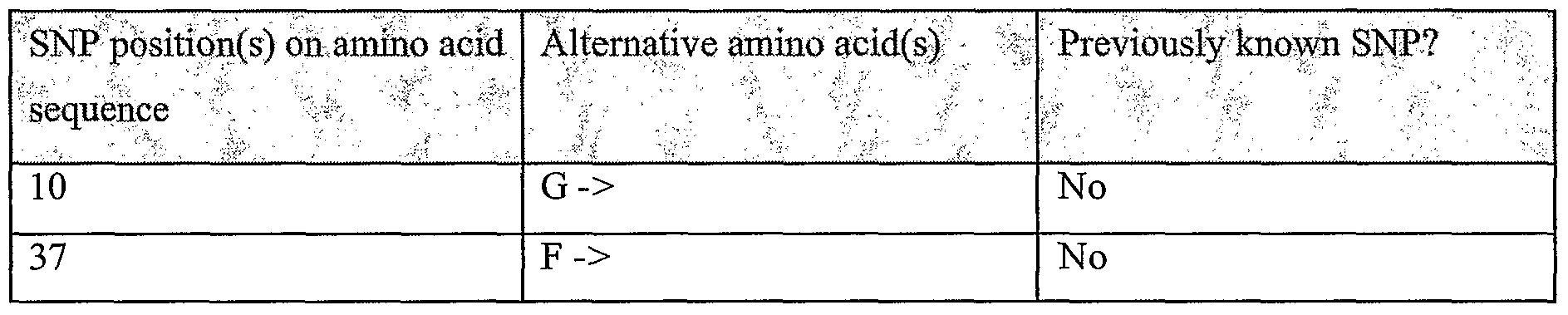
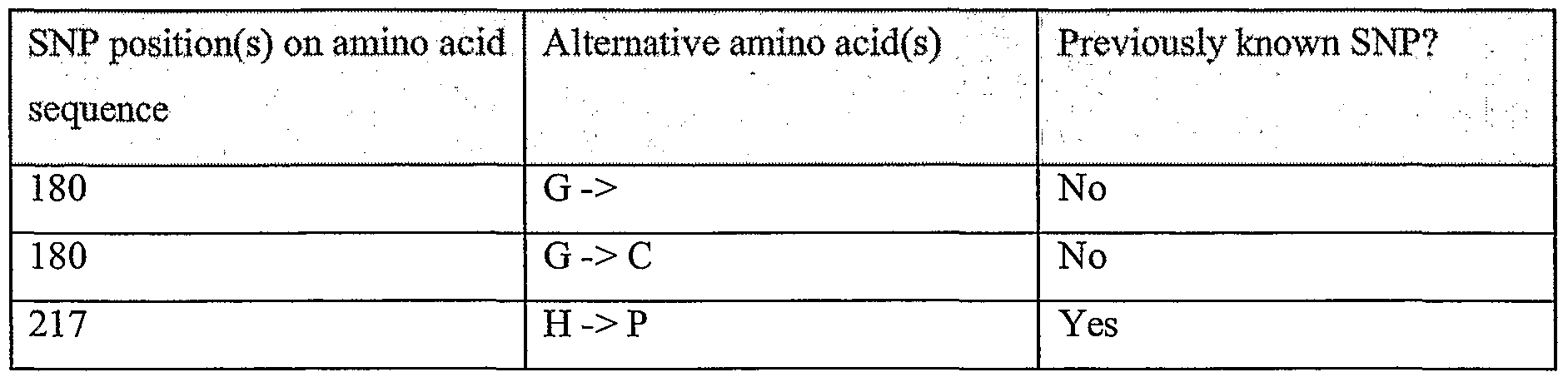
Information is given in the text with regard to SNPs (single nucleotide polymorphisms). A description of the abbreviations is as follows. "T - > C", for example, means that the SNP results in a change at the position given in the table from T to C. Similarly, "M - > Q", for example, means that the SNP has caused a change in the corresponding amino acid sequence, from methionine (M) to glutamine (Q). If, in place of a letter at the right hand side for the nucleotide sequence SNP, there is a space, it indicates that a frameshift has occurred. A frameshift may also be indicated with a hyphen (-). A stop codon is indicated with an asterisk at the right hand side (*). As part of the description of an SNP, a comment may be found in parentheses after the above description of the SNP itself. This comment may include an FTId, which is an identifier to a SwissProt entry that was created with the indicated SNP. An FTId is a unique and stable feature identifier, which allows construction of links directly from position- specific annotation in the feature table to specialized protein-related databases. The FTId is always the last component of a feature in the description field, as fellows: FTId=XXX_number, in which XXX is the 3- letter code for the specific feature key, separated by an underscore from a 6-digit number. In the table of the amino acid mutations of the wild type proteins of the selected splice variants of the invention, the header of the first column is "SNP position(s) on amino acid sequence", representing a position of a known mutation on amino acid sequence. SNPs may optionally be used as diagnostic markers according to the present invention, alone or in combination with one or more other SNPs and/or any other diagnostic marker. Preferred embodiments of the present invention comprise such SNPs, including but not limited to novel SNPs on the known (WT or wild type) protein sequences given below, as well as novel nucleic acid and/or amino acid sequences formed through such SNPs, and/or any SNP on a variant amino acid and/or nucleic acid sequence described herein.
Information given in the text with regard to the Homology to the known proteins was determined by Smith- Waterman version 5.1.2 using special (non default) parameters as follows: -model=sw.model -GAPEXT=O -GAPOP=100.0
-MATRIX=blosuml 00
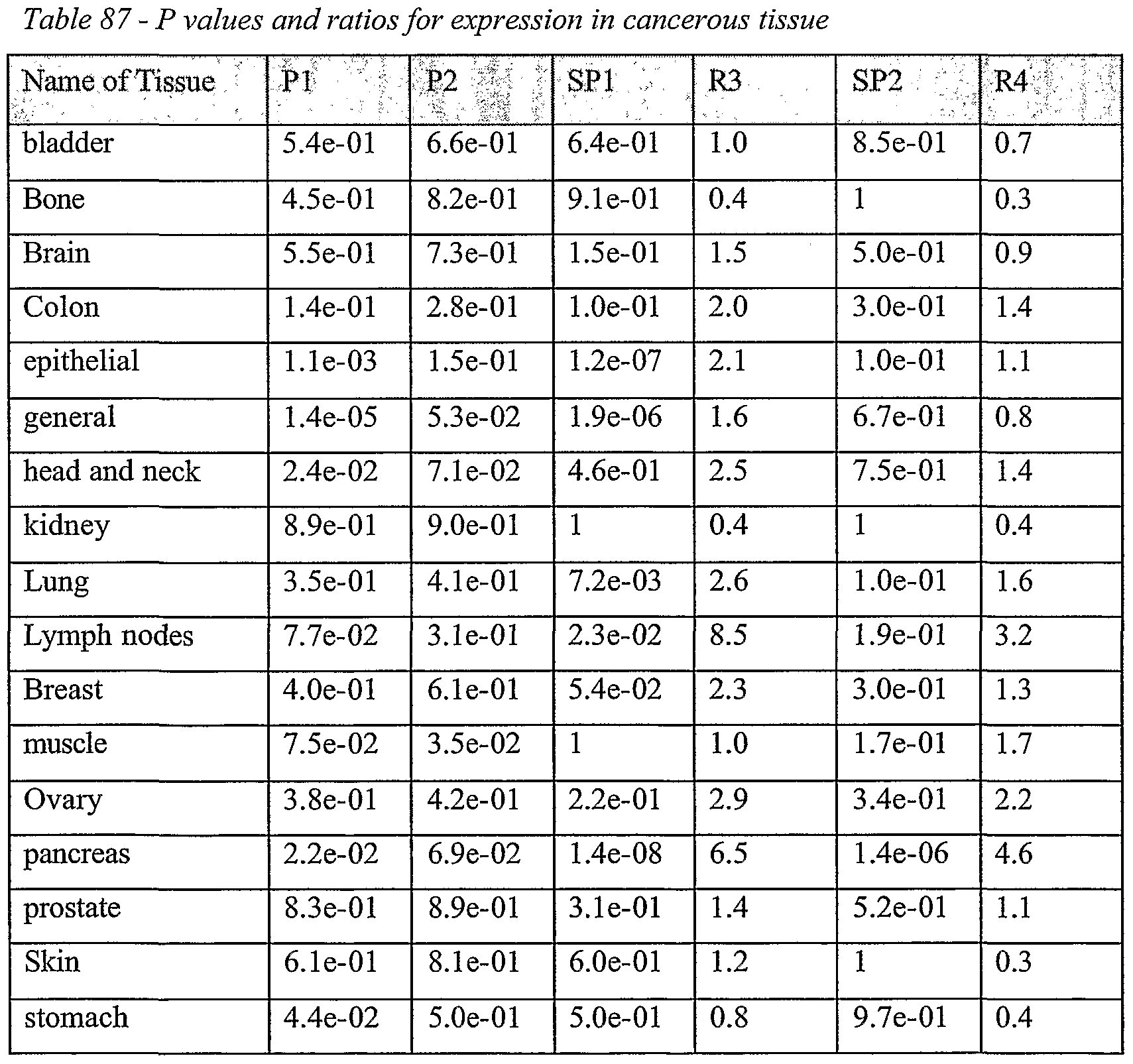
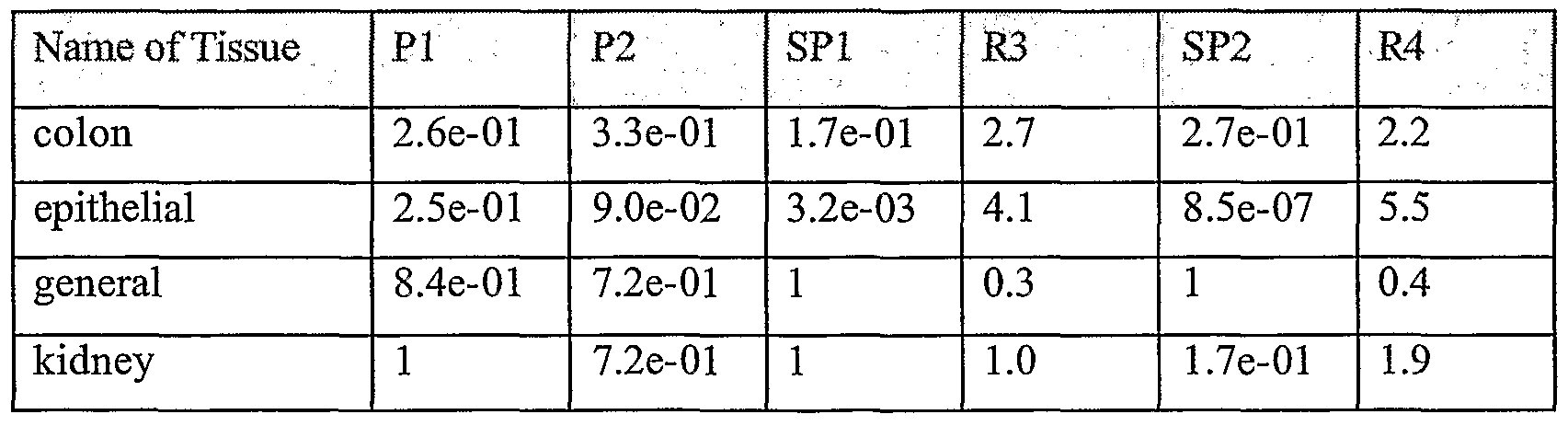
Information is given with regard to overexpression of a cluster in cancer based on ESTs. A key to the p values with regard to the analysis of such overexpression is as follows:
- library-based statistics: P- value without including the level of expression in cell- lines (Pl) - library based statistics: P- value including the level of expression in cell- lines (P2)
- EST clone statistics: P- value without including the level of expression in cell- lines (SPl)
- EST clone statistics: predicted overexpression ratio without including the level of expression in cell- lines (R3) - EST clone statistics: P- value including the level of expression in cell- lines (SP2)
- EST clone statistics: predicted overexpression ratio including the level of expression in cell- lines (R4)
Library-based statistics refer to statistics over an entire library, while EST clone statistics refer to expression only for ESTs from a particular tissue or cancer.
Information is given with regard to overexpression of a cluster in cancer based on microarrays. As a microarray reference, in the specific segment paragraphs, the unabbreviated tissue name was used as the reference to the type of chip for which expression was measured. There are two types of microarray results: those from microarrays prepared according to a design by the present inventors, for which the microarray fabrication procedure is described in detail in Materials and Experimental Procedures section herein; and those results from microarrays using Affymetrix technology. As a microarray reference, in the specific segment paragraphs, the unabbreviated tissue name was used as the reference to the type of chip for which expression was measured. For microarrays prepared according to a design by the present inventors, the probe name begins with the name of the cluster (gene), followed by an identifying number. Oligonucleotide microarray results taken from Affymetrix data were from chips available from Affymetrix Inc, Santa Clara, CA, USA (see for example data regarding the Human Genome Ul 33 (HG-Ul 33) Set at www.affymetrix.com/products/arrays/specific/hgul33.affx; GeneChip Human Genome U133A 2.0 Array at www.affymetrix.com/products/arrays/specific/hgul33av2.affx; and Human Genome Ul 33 Plus 2.0 Array at
www.affymetrix.com/products/arrays/specific/hgul33plus.affx). The probe names follow the
Affymetrix naming convention. The data is available from NCBI Gene Expression Omnibus
(see www.ncbi.nlm.nih.gov/projects/geo/ and Edgar et al, Nucleic Acids Research, 2002, Vol.
30, No. 1 207-210). The dataset (including results) is available from www.ncbi.nlm.nih.gov/geo/query/acc. cgi?acc=GSEl 133 for the Series GSEl 133 database
(published on March 2004); a reference to these results is as follows: Su et al (Proc Natl Acad
Sci U S A. 2004 Apr 20;101(16):6062-7. Epub 2004 Apr 09). Probes designed by the present inventors are listed below.
>H61775_O_11J) CCCCAGCTTTTATAGAGCGGCCCAAGGAAGAATATTTCCAAGAAGTAGGG
>M85491_0_0_25999
GACATCTTTGCATATCATGTCAGAGCTATAACATCATTGTGGAGAAGCTC
>M85491_0_14_0
GTCATGAAAATCAACACCGAGGTGCGGAGCTTCGGACCTGTGTCCCGCAG >Z21368_0_0_61857
AGTTCATCCTTCTTCAGTGTGACCAGTAAATTCTTCCCATACTCTTGAAG
>HUMGRP5E_0_0_16630
GCTGATATGGAAGTTGGGGAATCTGAATTGCCAGAGAATCTTGGGAAGAG
>HUMGRP5E_0_2_0 TCTCATAGAAGCAAAGGAGAACAGAAACCACCAGCCACCTCAACCCAAGG
>D56406_0_5_0
TCTGACTTTTACGGACTTGGCTTGTTAGAAGGCTGAAAGATGATGGCAGG
>F05068_0_0_5744
ACGGGAGGGAAGGAAGGTGTGCGGGAGGAGTTCTCTGTCTCCACTCCCCT >F05068_0_0_5754
CAAGGGGAACTGACCGTTGGTCCCGAAGGTCTAGAAGTGAATGGGAGCAG
>F05068_0_8_0
CTGGGCTTGGACTTCGGAGTTTTGCCATTGCCAGTGGGACGTCTGAGACT
>F05068_0_l_5751 TCTTAGCAGGTAGGTGCCGCAGACCCTGCGGGTTAAGAGGTGGGGTGGGG
>H38804 0 3 0
CGTAATTGCAGTGCATTTAGACAGGCATCTATTTGGACCTGTTTCTATCT
>HSENA78_0_l_0
TGAAGAGTGTGAGGAAAACCTATGTTTGCCGCTTAAGCTTTCAGCTCAGC
>R00299_0_8_0 CCAAGGCTCGTCTGCGCACCTTGTGTCTTGTAGGGTATGGTATGTGGGAC
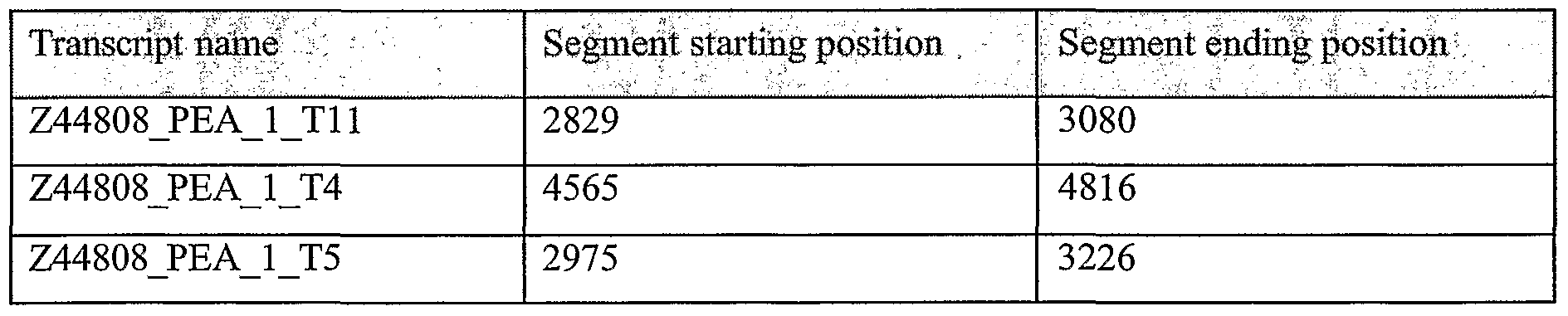
>Z44808_0_8_0
AAAAGCATGAGTTTCTGACCAGCGTTCTGGACGCGCTGTCCACGGACATG
>Z44808_0_0_72347
ATGTTCTTAGGAGGCAAGCCAGGAGAAGCCGGGTCTGACTTTTCAGCTCA >Z44808_0_0_72349
TCCTCCAGACCCAAAGCCACAACCCATCGCAAGTCAAGAACACTTTCCAG
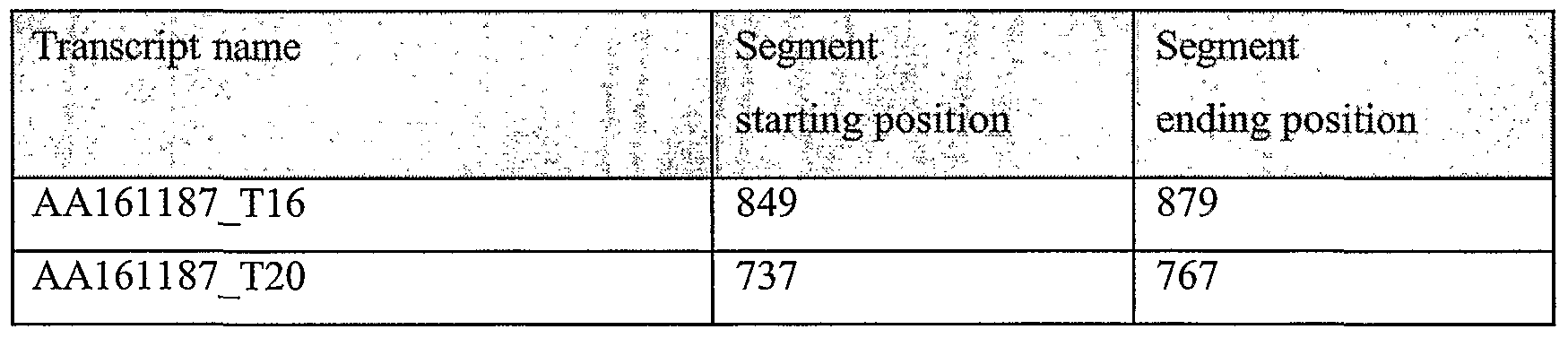
>AA161187_0_0_433
ACCCTGGGTGGGCAAAAACGTGCTTTCCCGGACGGGGTTGAAGGGGAGAA
>AA161187_0_0_430 TGGAGACTGTTGCCCCACTCTGCAGATGCAGAAACGGAGGCTTGGCTGCT
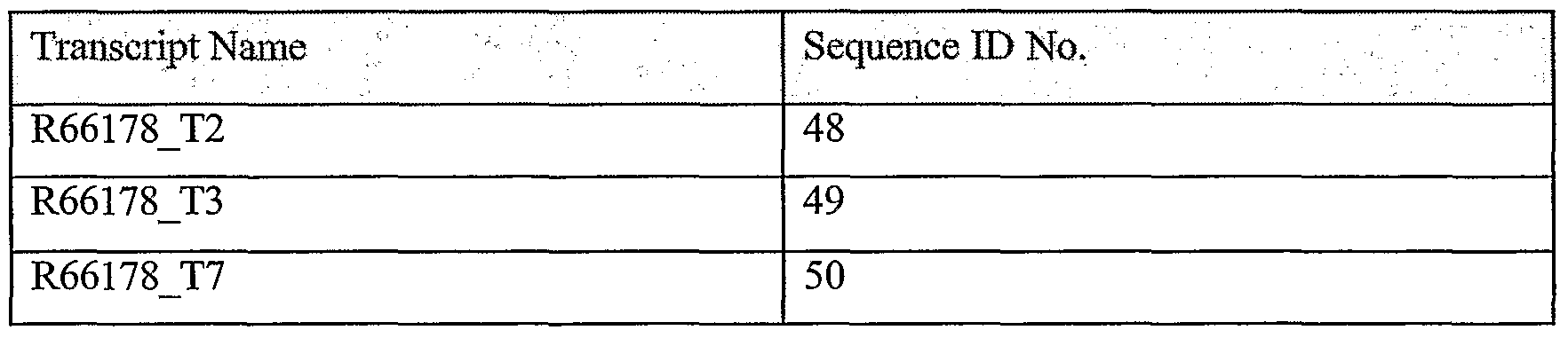
>R66178_0_7_0
CCAGTGTGGTATCCTGGGAAACTCGGTTAAAAGGTGAGGCAGAGTACCAG
>HUMPHOSLIP_0_0_18458
AAGGAAGCAGGACCAGTGGATGTGAGGCGTGGTCGAAGAACAACAGAAAG >HUMPHOSLIP_0_0_18487
ACAGGGGCCAGATGGTGACCCATGACCCAGCCTAAAAGGCAGCCAGAGGG
>AI076020_0_3_0
ATCAGCACTGCCACCTACACCACGGTGCCGCGCGTGGCCTTCTACGCCGG
>T23580_0_0_902 GTGAAACCCCATTGGCTTCATTGGCTCCTTGATTTAAACCACGCCCGGCT
>T23580_p_0_901
TGAGTCCGTGTTATATCATCTGGTCTCATTGATAGGCGGGATAGGGAGGG
>M79217_0_9_0
TTTGTGGAATAGCAACCCATGGTTATGGCGAGTGACCCGACGTGATCTGG >M62096_0_0_20588
AAGGCTTAGGTGCAAAGCCATTGGATACCATACCTGAGACCACACAGCCA
>M62096_0_7_0
ACCAGAAGCAGCTGTCCAGACTCCGAGACGAAATTGAGGAGAAGCAGAAA
>M78076_0_7_0
GAGAAGATGAACCCGCTGGAACAGTATGAGCGAAAGGTGAATGCGTCTGT >T99080_0_0_58896
AACTCACAGCAAGAGCTGTGTTCCAGTTAGCTTTGCTACCAGTTATGCAG
>T08446_0_9_0
CATTTCCACTACGAGAACGTTGACTTTGGCCACATTCAGCTCCTGCTGTC
>HUMCA1XIA_O_O_149O9 GCTGCAATCTAAGTTTCGGAATACTTATACCACTCCAGAAATAATCCTCG
>HUMCA1XIA_O_18_0
TTCAGAACTGTTAACATCGCTGACGGGAAGTGGCATCGGGTAGCAATCAG
>T11628_0_9_0
ACAAGATCCCCGTGAAGTACCTGGAGTTCATCTCGGAATGCATCATCCAG >T11628_0_0_45174
TAAACAATCAAAGAGCATGTTGGCCTGGTCCTTTGCTAGGTACTGTAGAG
>T11628_0_0_45161
TGCCTCGCCACAATGGCACCTGCCCTAAAATAGCTTCCCATGTGAGGGCT
>HUMCEA_0_0_96 CAAGAGGGGTTTGGCTGAGACTTTAGGATTGTGATTCAGCTTAGAGGGAC
>HUMCEA_0_0_15183
CCTGGTGGGAGCCCATGAGAAGCGAGTTCTCTGTGCAACGGACTTAGTAA
>HUMCEA_0_0_15182
GCTCCCTGGAGCATCAGCATCATATTCTGGGGTGGAGTCTATCTGGTTCT >HUMCEA_0_0_15168
TCCTGCCTGTCACCTGAAGTTCTAGATCATTCCCTGGACTCCACTCTATC
>HUMCEA_0_0_15180
TTTAACACAGGATTGGGACAGGATTCAGAGGGACACTGTGGCCCTTCTAC
>R35137_0_5_0 TATGTGGAGGTGGTGAACATGGACGCTGCAGTGCAGCAGCAGATGCTGAA
>Z25299 0 3 0
AACTCTGGCACCTTGGGCTGTGGAAGGCTCTGGAAAGTCCTTCAAAGCTG >HSSTROL3_0_0_12518
ATGAGAGTAACCTCACCCGTGCACTAGTTTACAGAGCATTCACTGCCCCA >HSSTROL3_0_0_12517 CAGAGATGAGAGCCTGGAGCATTGCAGATGCCAGGGACTTCACAAATGAA >HSS100PCB_0_0_12280
CTCAAAATGAAACTCCCTCTCGCAGAGCACAATTCCAATTCGCTCTAAAA >R20779_0_0_30670
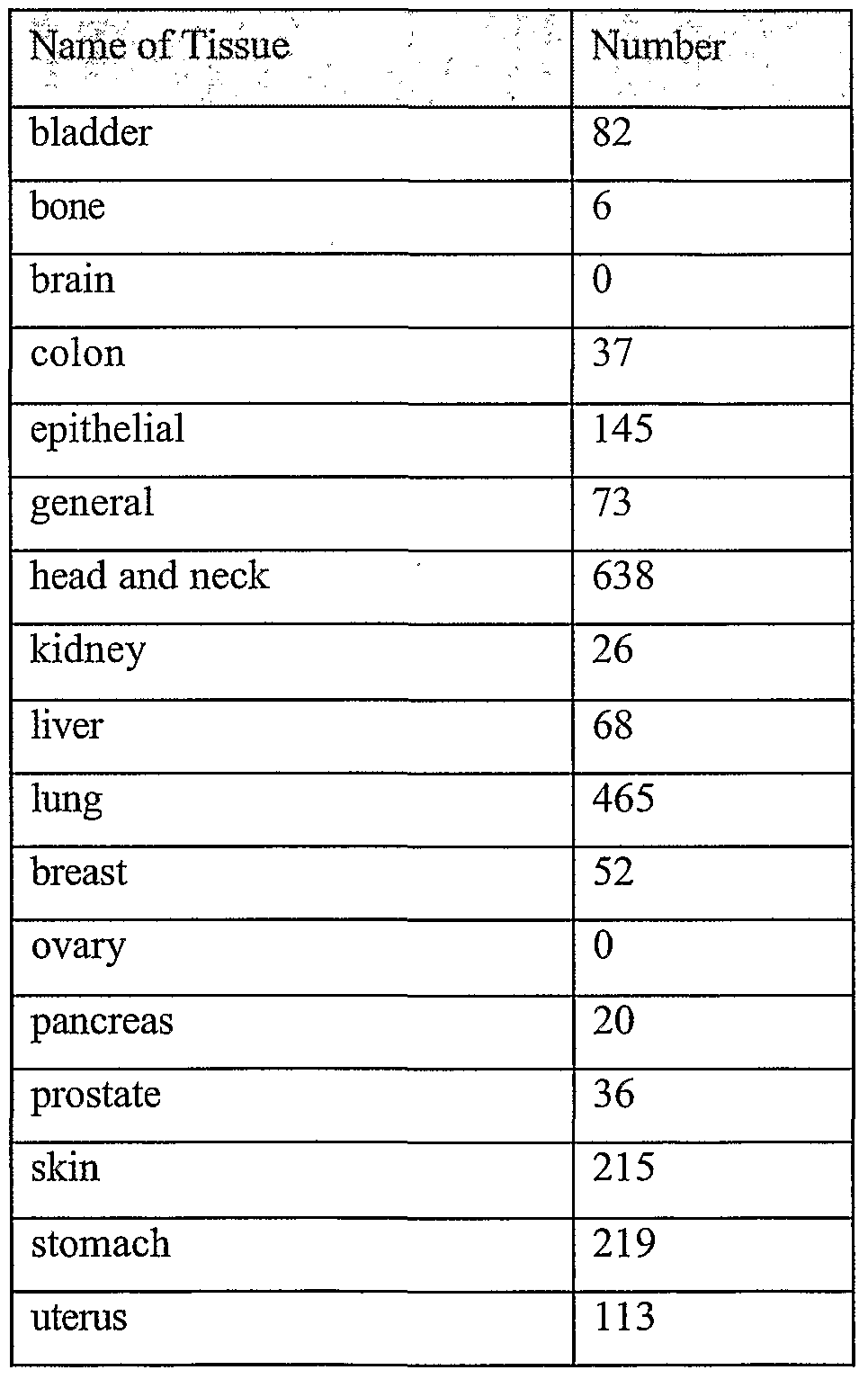
CCGCGTTGCTTCTAGAGGCTGAATGCCTTTCAAATGGAGAAGGCTTCCAT The following list of abbreviations for tissues was used in the TAA histograms. The term "TAA" stands for "Tumor Associated Antigen", and the TAA histograms, given in the text, represent the cancerous tissue expression pattern as predicted by the biomarkers selection engine, as described in detail in examples 1-5 below:
"BONE" for "bone"; "COL" for "colon";
"EPI" for "epithelial";
"GEN" for "general";
"LIVER" for "liver";
"LUN" for "lung"; "LYMPH" for "lymph nodes";
"MARROW" for "bone marrow";
"OVA" for "ovary";
"PANCREAS" for "pancreas";
"PRO" for "prostate"; "STOMACH" for "stomach";
"TCELL" for "T cells";
"THYROID" for "Thyroid";
"MAM" for "breast";
"BRAIN" for "brain"; "UTERUS" for "uterus";
"SKIN" for "skin";
"KIDNEY" for "kidney"; "MUSCLE" for "muscle"; "ADREN" for "adrenal"; "HEAD" for "head and neck"; "BLADDER" for "bladder";
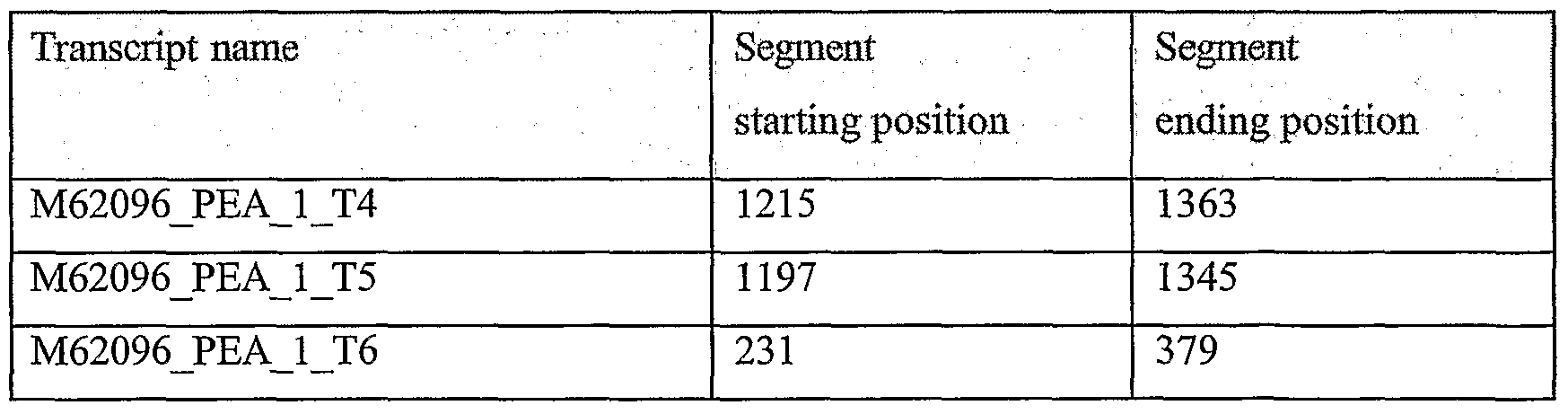
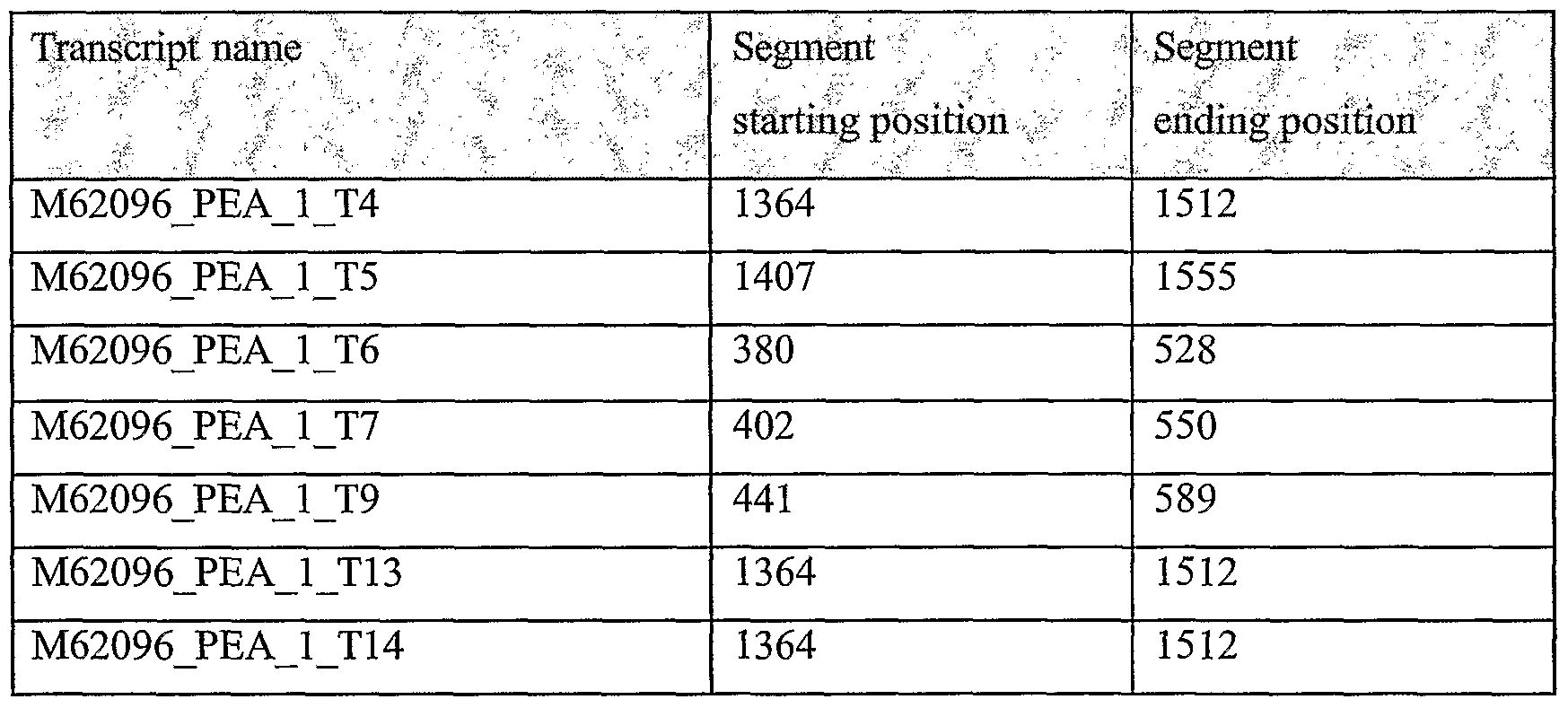
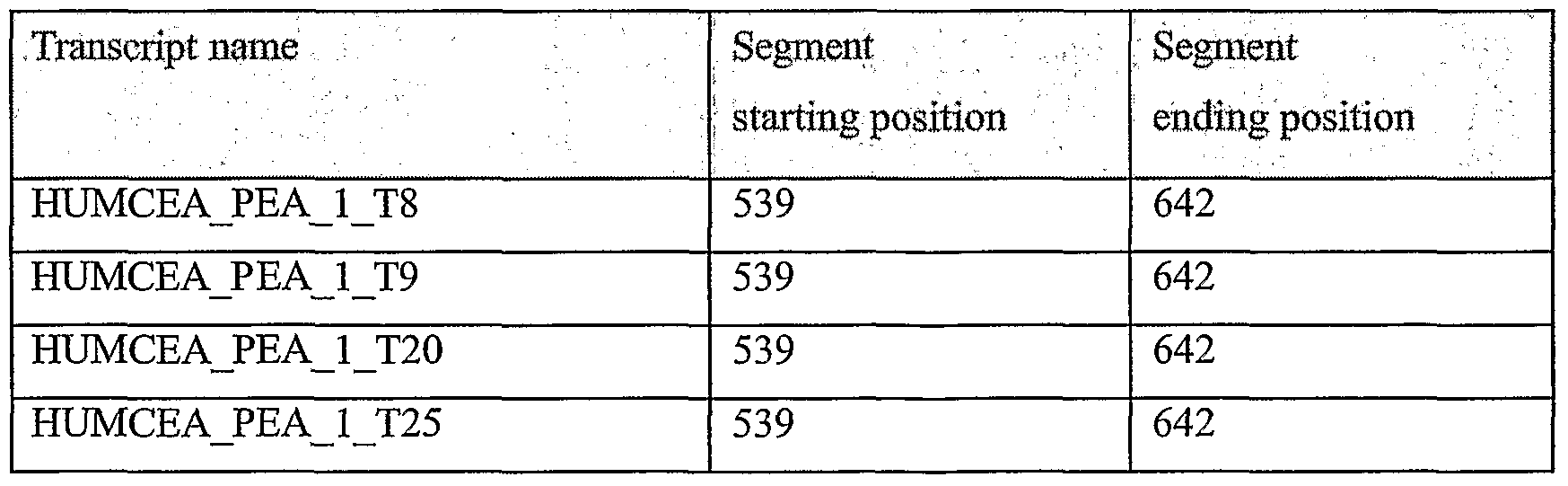
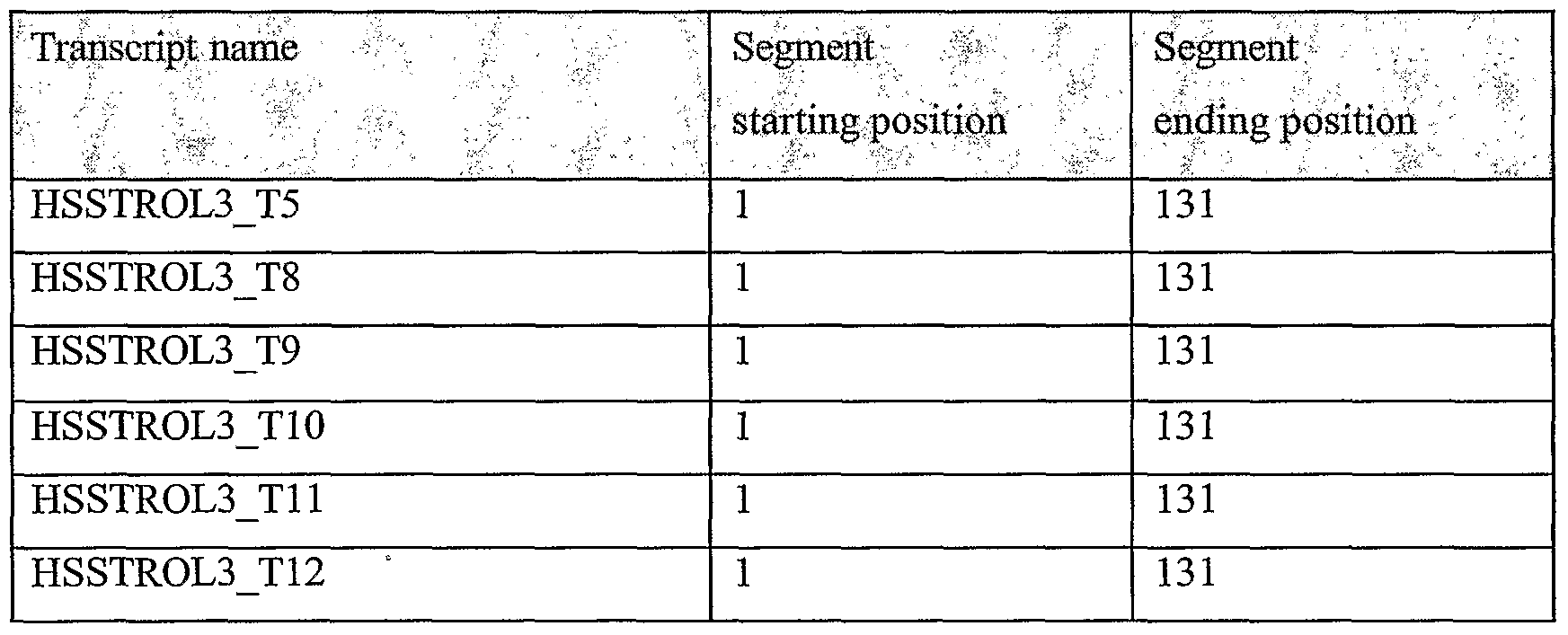
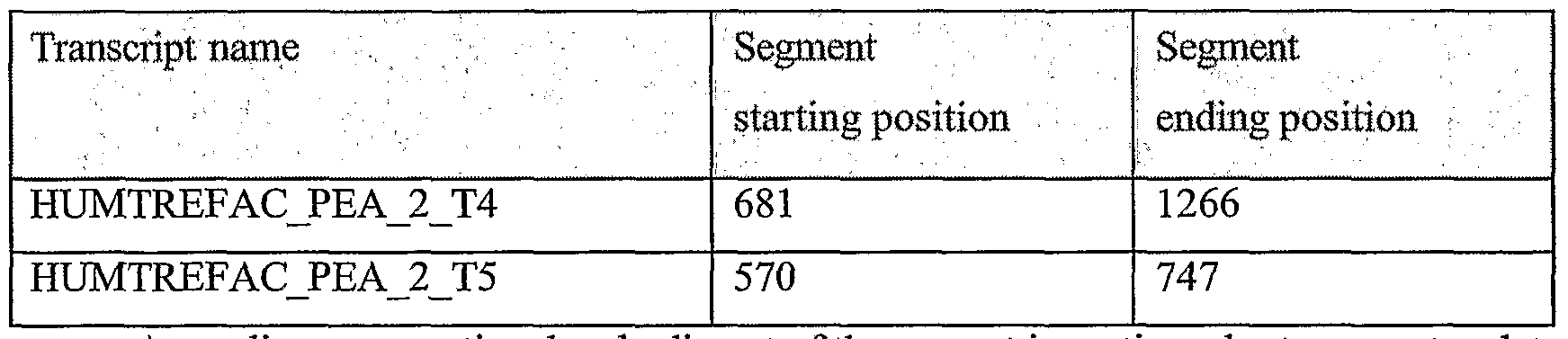
It should be noted that the terms "segment", "seg" and "node" are used interchangeably in reference to nucleic acid sequences of the present invention; they refer to portions of nucleic acid sequences that were shown to have one or more properties as described below. They are also the building blocks that were used to construct complete nucleic acid sequences as described in greater detail below. Optionally and preferably, they are examples of oligonucleotides which are embodiments of the present invention, for example as amplicons, hybridization units and/or from which primers and/or complementary oligonucleotides may optionally be derived, and/or for any other use. As used herein the phrase "lung cancer" refers to cancers of the lung including small cell lung cancer and non- small cell lung cancer, including but not limited to lung adenocarcinoma, squamous cell carcinoma, and adenocarcinoma.
The term "marker" in the context of the present invention refers to a nucleic acid fragment, a peptide, or a polypeptide, which is differentially present in a sample taken from subjects (patients) having lung cancer (or one of the above indicative conditions) as compared to a comparable sample taken from subjects who do not have lung cancer (or one of the above indicative conditions).
The phrase "differentially present" refers to differences in the quantity of a marker present in a sample taken from patients having lung cancer (or one of the above indicative conditions) as compared to a comparable sample taken from patients who do not have lung cancer (or one of the above indicative conditions). For example, a nucleic acid fragment may optionally be differentially present between the two samples if the amount of the nucleic acid fragment in one sample is significantly different from the amount of the nucleic acid fragment in the other sample, fcr example as measured by hybridization and/or NAT-based assays. A polypeptide is differentially present between the two samples if the amount of the polypeptide in one sample is significantly different from the amount of the polypeptide in the other sample. It
should be noted that if the marker is detectable in one sample and not detectable in the other, then such a marker can be considered to be differentially present.
As used herein the phrase "diagnostic" means identifying the presence or nature of a pathologic condition. Diagnostic methods differ in their sensitivity and specificity. The "sensitivity" of a diagnostic assay is the percentage of diseased individuals who test positive (percent of "true positives"). Diseased individuals not detected by the assay are "false negatives." Subjects who are not diseased and who test negative in the assay are termed "true negatives." The "specificity" of a diagnostic assay is 1 minus the false positive rate, where the "false positive" rate is defined as the proportion of those without the disease who test positive. While a particular diagnostic method may not provide a definitive diagnosis of a condition, it suffices if the method provides a positive indication that aids in diagnosis.
As used herein the phrase "diagnosing" refers to classifying a disease or a symptom, determining a severity of the disease, monitoring disease progression, forecasting an outcome of a disease and/or prospects of recovery. The term "detecting" may also optionally encompass any of the above.
Diagnosis of a disease according to the present invention can be effected by determining a level of a polynucleotide or a polypeptide of the present invention in a biological sample obtained from the subject, wherein the level determined can be correlated with predisposition to, or presence or absence of the disease. It should be noted that a "biological sample obtained from the subject" may also optionally comprise a sample that has not been physically removed from the subject, as described in greater detail below.
As used herein, the term "level" refers to expression levels of RNA and/or protein or to DNA copy number of a marker of the present invention.
Typically the level of the marker in a biological sample obtained from the subject is different (i.e., increased or decreased) from the level of the same variant in a similar sample obtained from a healthy individual (examples of biological samples are described herein).
Numerous well known tissue or fluid collection methods can be utilized to collect the biological sample from the subject in order to determine the level of DNA, RNA and/or polypeptide of the variant of interest in the subject. Examples include, but are not limited to, fine needle biopsy, needle biopsy, core needle biopsy and surgical biopsy (e.g., brain biopsy), and lavage. Regardless of the procedure
employed, once a biopsy/sample is obtained the level of the variant can be determined and a diagnosis can thus be made.
Determining the level of the same variant in normal tissues of the same origin is preferably effected along-side to detect an elevated expression and/or amplification and/or a decreased expression, of the variant as opposed to the normal tissues.
A "test amount" of a marker refers to an amount of a marker in a subject's sample that is consistent with a diagnosis of lung cancer (or one of the above indicative conditions). A test amount can be either in absolute amount (e.g., microgram/ml) or a relative amount (e.g., relative intensity of signals). A "control amount" of a marker can be any amount or a range of amounts to be compared against a test amount of a marker. For example, a control amount of a marker can be the amount of a marker in a patient with lung cancer (or one of the above indicative conditions) or a person without lung cancer (or one of the above indicative conditions). A control amount can be either in absolute amount (e.g., microgram/ml) or a relative amount (e.g., relative intensity of signals).
"Detect" refers to identifying the presence, absence or amount of the object to be detected.
A "label" includes any moiety or item detectable by spectroscopic, photo chemical, biochemical, immunochemical, or chemical means. For example, useful labels include 32P, 35S, fluorescent dyes, electron- dense reagents, enzymes (e.g., as commonly used in an ELISA), biotin-streptavadin, dioxigenin, haptens and proteins for which antisera or monoclonal antibodies are available, or nucleic acid molecules with a sequence complementary to a target. The label often generates a measurable signal, such as a radioactive, chromogenic, or fluorescent signal, that can be used to quantify the amount of bound label in a sample. The label can be incorporated in or attached to a primer or probe either covalently, or through ionic, van der Waals or hydrogen bonds, e.g., incorporation of radioactive nucleotides, or biotinylated nucleotides that are recognized by streptavadin. The label may be directly or indirectly detectable. Indirect detection can involve the binding of a second label to the first label, directly or indirectly. For example, the label can be the ligand of a binding partner, such as biotin, which is a binding partner for streptavadin, or a nucleotide sequence, which is the binding partner for a complementary sequence, to which it can specifically hybridize. The binding partner may itself
be directly detectable, for example, an antibody may be itself labeled with a fluorescent molecule. The binding partner also may be indirectly detectable, for example, a nucleic acid having a complementary nucleotide sequence can be a part of a branched DNA molecule that is in turn detectable through hybridization with other labeled nucleic acid molecules (see, e.g., P. D. Fahrlander and A. Klausner, Bio/Technology 6:1165 (1988)). Quantitation of the signal is achieved by, e.g., scintillation counting, densitometry, or flow cytometry.
Exemplary detectable labels, optionally and preferably for use with immunoassays, include but are not limited to magnetic beads, fluorescent dyes, radiolabels, enzymes (e.g., horse radish peroxide, alkaline phosphatase and others commonly used in an ELISA), and calorimetric labels such as colloidal gold or colored glass or plastic beads. Alternatively, the marker in the sample can be detected using an indirect assay, wherein, for example, a second, labeled antibody is used to detect bound marker- specific antibody, and/or in a competition or inhibition assay wherein, for example, a monoclonal antibody which binds to a distinct epitope of the marker are incubated simultaneously with the mixture. "Immunoassay" is an assay that uses an antibody to specifically bind an antigen. The immunoassay is characterized by the use of specific binding properties of a particular antibody to isolate, target, and/or quantify the antigen.
The phrase "specifically (or selectively) binds" to an antibody or "specifically (or selectively) immunoreactive with," when referring to a protein or peptide (or other epitope), refers to a binding reaction that is determinative of the presence of the protein in a heterogeneous population of proteins and other biologies. Thus, under designated immunoassay conditions, the specified antibodies bind to a particular protein at least two times greater than the background (non-specific signal) and do not substantially bind in a significant amount to other proteins present in the sample. Specific binding to an antibody under such conditions may require an antibody that is selected for its specificity for a particular protein. For example, polyclonal antibodies raised to seminal basic protein from specific species such as rat, mouse, or human can be selected to obtain only those polyclonal antibodies that are specifically immunoreactive with seminal basic protein and not with other proteins, except for polymorphic variants and alleles of seminal basic protein. This selection may be achieved by subtracting out antibodies that cross-react with seminal basic protein molecules from other species. A variety of immunoassay formats may be used to select antibodies specifically immunoreactive with a
particular protein. For example, solid-phase ELISA immunoassays are routinely used to select antibodies specifically immunoreactive with a protein (see, e.g., Harlow & Lane, Antibodies, A Laboratory Manual (1988), for a description of immunoassay formats and conditions that can be used to determine specific immunoreactivity). Typically a specific or selective reaction will be at least twice background signal or noise and more typically more than 10 to 100 times background.
According to preferred embodiments of the present invention, preferably any of the above nucleic acid and/or amino acid sequences further comprises any sequence having at least about 70%, preferably at least about 80%, more preferably at least about 90%, most preferably at least about 95% homology thereto.
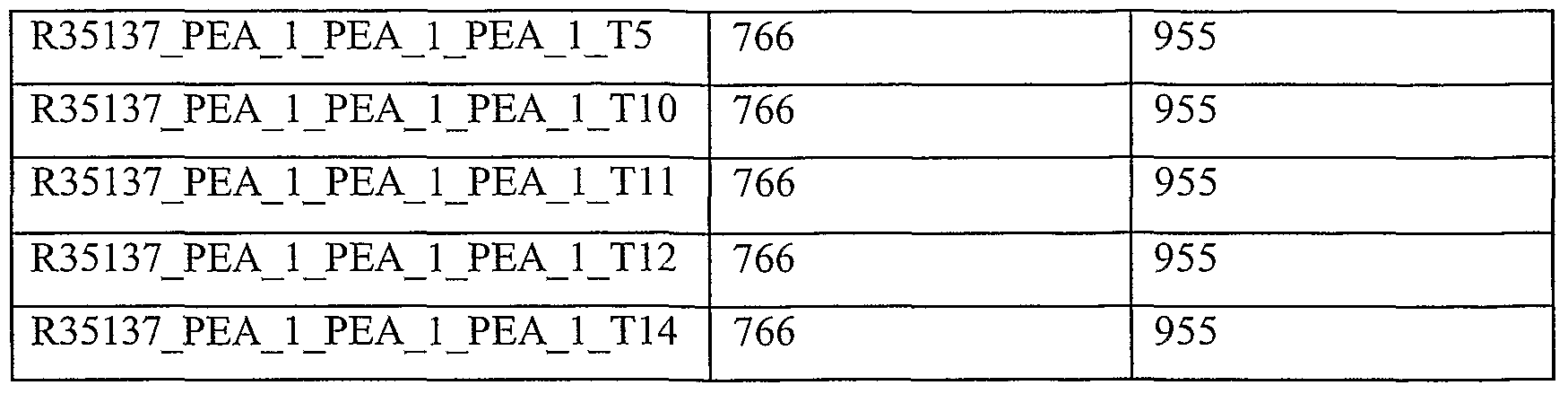
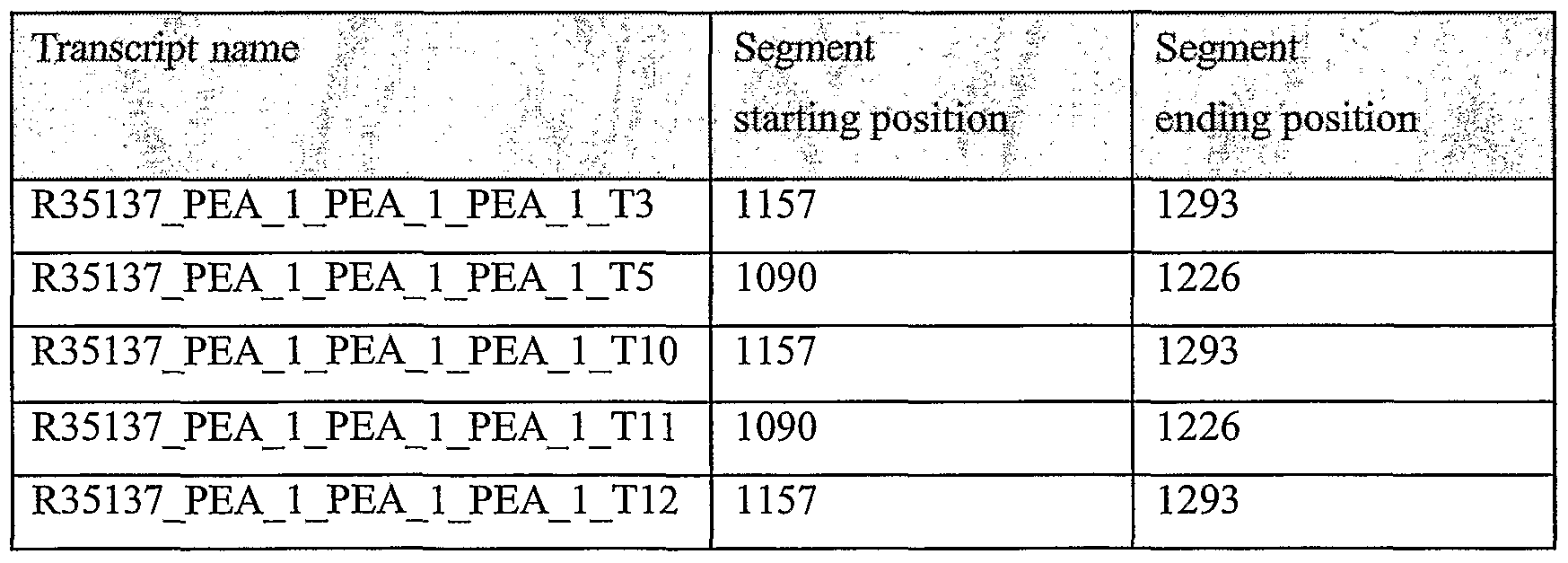
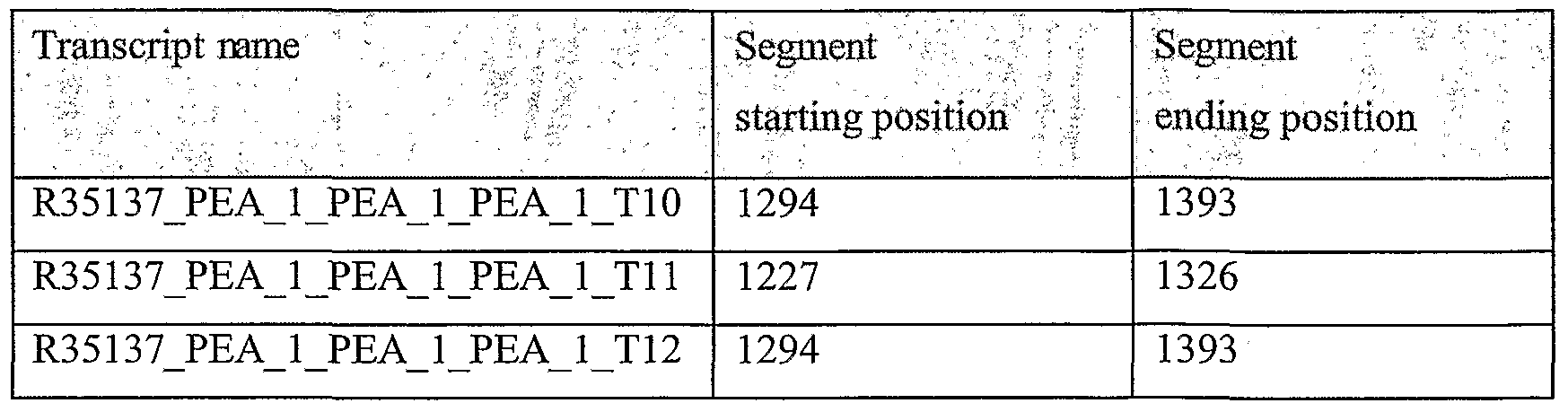
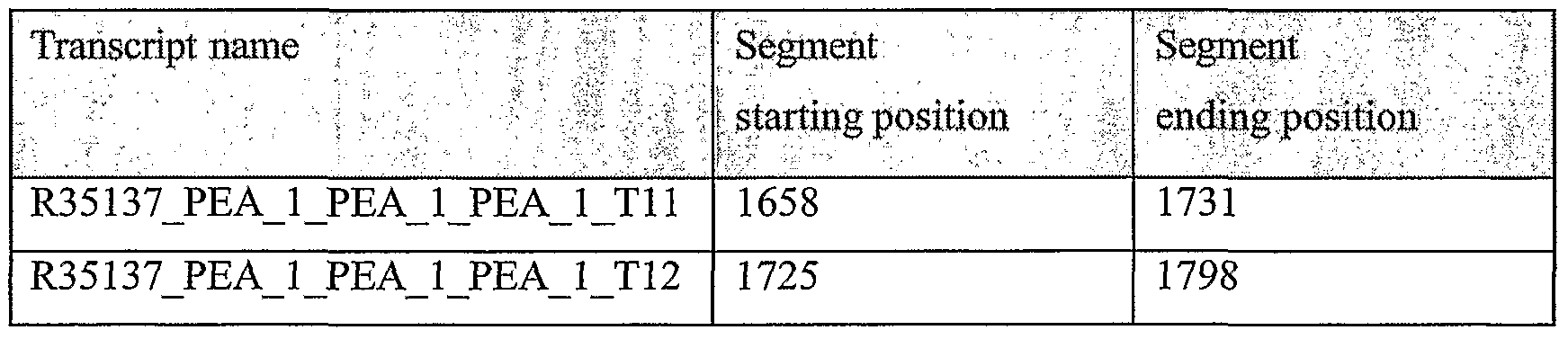
Unless otherwise noted, all experimental data relates to variants of the present invention, named according to the segment being tested (as expression was tested through RT-PCR as described).
All nucleic acid sequences and/or amino acid sequences shown herein as embodiments of the present invention relate to their isolated form, as isolated polynucleotides (including for all transcripts), oligonucleotides (including for all segments, amplicons and primers), peptides (including for all tails, bridges, insertions or heads, optionally including other antibody epitopes as described herein) and/or polypeptides (including for all proteins). It should be noted that oligonucleotide and polynucleotide, or peptide and polypeptide, may optionally be used interchangeably.
According to preferred embodiments of the present invention, there is provided an isolated polynucleotide comprising SEQ ID NOs: 1 and 2.
According to preferred embodiments of the present invention, there is provided an isolated polynucleotide comprising SEQ ID NOs: 1022, 1023, 1024, 1025, 1026 and 1027. According to preferred embodiments of the present invention, there is provided an isolated polypeptide comprising SEQ ID NOs: 1281 and 1282.
According to preferred embodiments of the present invention, there is provided an isolated polynucleotide comprising SEQ ID NOs: 3 and 4.
According to preferred embodiments of the present invention, there is provided an isolated polynucleotide comprising SEQ ID NOs: 1028, 1029, 1030, 1031, 1032, 1033, 1034, 1035, 1036, 1037 and 1038.
According to preferred embodiments of the present invention, there is provided an isolated polypeptide comprising SEQ ID NOs: 1283 and 1284.
According to preferred embodiments of the present invention, there is provided an isolated polynucleotide comprising SEQ ID NOs: 5, 6, 7 and 8. According to preferred embodiments of the present invention, there is provided an isolated polynucleotide comprising SEQ ID NOs: 1039, 1040, 1041, 1042, 1043, 1044, 1045, 1046, 1047, 1048, 1049, 1050, 1051, 1052, 1053, 1054, 1055, 1056, 1057, 1058, 1059, 1060, 1061, 1062, 1063, 1064, 1065 and 1066.
According to preferred embodiments of the present invention, there is provided an isolated polypeptide comprising SEQ ID NOs: 1285, 1286, 1287 and 1288.
According to preferred embodiments of the present invention, there is provided an isolated polynucleotide comprising SEQ ID NOs: 9, 10, 11, 12, 13, 14 and 15.
According to preferred embodiments of the present invention, there is provided an isolated polynucleotide comprising SEQ ID NOs: 1067, 1068, 1069, 1070, 1071, 1072, 1073, 1074, 1075, 1076, 1077, 1078, 1079, 1080, 1081, 1082, 1083, 1084, 1085, 1086, 1087, 1088, 1089, 1090, 1091, 1092, 1093, 1094, 1095, 1096, 1097, 1098, 1099 and 1100.
According to preferred embodiments of the present invention, there is provided an isolated polypeptide comprising SEQ ID NOs 1289, 1290, 1291, 1292, 1293 and 1294.
According to preferred embodiments of the present invention, there is provided an isolated polynucleotide comprising SEQ ID NOs: 20 and 21.
According to preferred embodiments of the present invention, there is provided an isolated polynucleotide comprising SEQ ID NOs: 1130, 1131, 1132, 1133 and 1134.
According to preferred embodiments of the present invention, there is provided an isolated polypeptide comprising SEQ ID NOs: 1299 and 1300. According to preferred embodiments of the present invention, there is provided an isolated polynucleotide comprising SEQ ID NOs: 22, 23 and 24.
According to preferred embodiments of the present invention, there is provided an isolated polynucleotide comprising SEQ ID NOs: 1135, 1136, 1137, 1138, 1139, 1140, 1141, 1142, 1143 and 1144. According to preferred embodiments of the present invention, there is provided an isolated polypeptide comprising SEQ ID NOs 1301, 1302 and 1303.
According to preferred embodiments of the present invention, there is provided an isolated polynucleotide comprising SEQ ID NOs: 25, 26 and 27.
According to preferred embodiments of the present invention, there is provided an isolated polynucleotide comprising SEQ ID NOs: 1145, 1146, 1147, 1148, 1149, 1 150, 1151, 1152, 1153, 1154, 1 155 and 1156.
According to preferred embodiments of the present invention, there is provided an isolated polypeptide comprising SEQ ID NOs 1304 and 1305.
According to preferred embodiments of the present invention, there is provided an isolated polynucleotide comprising SEQ ID NOs: 28. According to preferred embodiments of the present invention, there is provided an isolated polynucleotide comprising SEQ ID NOs: 1157, 1158, 1159, 1160, 1161, 1162, 1163, 1164, 1165, 1166, 1167, 1168, 1169, 1170 and 1171.
According to preferred embodiments of the present invention, there is provided an isolated polypeptide comprising SEQ ID NO: 1306. According to preferred embodiments of the present invention, there is provided an isolated polynucleotide comprising SEQ ID NOs: 29 and 30.
According to preferred embodiments of the present invention, there is provided an isolated polynucleotide comprising SEQ ID NOs: 1172, 1173, 1174, 1175, 1176, 1177, 1178, 1179, 1180, 1181, 1182, 1183, 1184, 1185, 1186, 1187, 1188, 1189, 1190 and 1191. According to preferred embodiments of the present invention, there is provided an isolated polypeptide comprising SEQ ID NOs 1307 and 1308.
According to preferred embodiments of the present invention, there is provided an isolated polynucleotide comprising SEQ ID NOs: 31.
According to preferred embodiments of the present invention, there is provided an isolated polynucleotide comprising SEQ ID NOs: 1192, 1193, 1194, 1195, 1196, 1197 and 1198.
According to preferred embodiments of the present invention, there is provided an isolated polypeptide comprising SEQ ID NO: 1309.
According to preferred embodiments of the present invention, there is provided an isolated polynucleotide comprising SEQ ID NOs: 32.
According to preferred embodiments of the present invention, there is provided an isolated polynucleotide comprising SEQ ID NOs: 1199, 1200, 1201, 1202, 1203, 1204, 1205, 1206, 1207, 1208, 1209, 1210, 1211, 1212, 1213, 1214 and 1215.
According to preferred embodiments of the present invention, there is provided an isolated polypeptide comprising SEQ ID NO. 1310.
According to preferred embodiments of the present invention, there is provided an isolated polynucleotide comprising SEQ ID NOs: 33.
According to preferred embodiments of the present invention, there is provided an isolated polynucleotide comprising SEQ ID NOs: 1216 and 1217, 1218, 1219, 1220, 1221, 1222, 1223, 1224, 1225, 1226 and 1227.
According to preferred embodiments of the present invention, there is provided an isolated polypeptide comprising SEQ ID NO: 1311.
According to preferred embodiments of the present invention, there is provided an isolated polynucleotide comprising SEQ ID NOs: 34. According to preferred embodiments of the present invention, there is provided an isolated polynucleotide comprising SEQ ID NOs: 1228, 1229, 1230, 1231, 1232 and 1223.
According to preferred embodiments of the present invention, there is provided an isolated polypeptide comprising SEQ ID NO: 1312.
According to preferred embodiments of the present invention, there is provided an isolated polynucleotide comprising SEQ ID NOs: 35.
According to preferred embodiments of the present invention, there is provided an isolated polynucleotide comprising SEQ ID NOs: 1234, 1235, 1236, 1237, 1238, 1239, 1240, 1241, 1242, 1243, 1244, 1245, 1246, 1247, 1248, 1249, 1250, 1251, 1252, 1253 and 1254.
According to preferred embodiments of the present invention, there is provided an isolated polypeptide comprising SEQ ID NO: 1313.
According to preferred embodiments of the present invention, there is provided an isolated polynucleotide comprising SEQ ID NOs: 36, 37, 38, 39 and 40.
According to preferred embodiments of the present invention, there is provided an isolated polynucleotide comprising SEQ ID NOs: 1255, 1256, 1257, 1258, 1259, 1260, 1261, 1262, 1263, 1264, 1265, 1266, 1267, 1268, 1269, 1270, 1271, 1272, 1273, 1274 and 1275.
According to preferred embodiments of the present invention, there is provided an isolated polypeptide comprising SEQ ID NOs 1314, 1315, 1316 and 1317.
According to preferred embodiments of the present invention, there is provided an isolated polynucleotide comprising SEQ ID NOs: 125, 126, 127, 128, 129 and 130. According to preferred embodiments of the present invention, there is provided an isolated polynucleotide comprising SEQ ID NOs: 887, 888, 889, 890, 891, 892, 893, 894, 895, 896, 897, 898, 899, 900, 901 and 902.
According to preferred embodiments of the present invention, there is provided an isolated polypeptide comprising SEQ ID NOs: 1394, 1395, 1396, 1397 and 1398. According to preferred embodiments of the present invention, there is provided an isolated polynucleotide comprising a transcript SEQ ID NOs: 131 and 132.
According to preferred embodiments of the present invention, there is provided an isolated polynucleotide comprising SEQ ID NOs: 903, 904, 905, 906, 907, 907, 908 and 909.
According to preferred embodiments of the present invention, there is provided an isolated polypeptide comprising SEQ ID NOs 1399 and 1400.
According to preferred embodiments of the present invention, there is provided an isolated polynucleotide comprising SEQ ID NOs: 99, 100, 101 and 102.
According to preferred embodiments of the present invention, there is provided an isolated polynucleotide comprising SEQ ID NOs: 742, 743, 744, 745, 746, 747, 748, 749, 750, 751, 752, 753, 754, 755, 756, 757, 758, 759, 760, 761, 762, 763, 764, 765, 766, 767, 768, 769, 770, 771, 772, 773, 774, 775, 776, 777, 778, 779, 780, 781, 782, 783, 784, 785, 786, 787 and 788.
According to preferred embodiments of the present invention, there is provided an isolated polypeptide comprising SEQ ID NOs 1372, 1373, 1374 and 1375. According to preferred embodiments of the present invention, there is provided an isolated polynucleotide comprising SEQ ID NOs: 134.
According to preferred embodiments of the present invention, there is provided an isolated polynucleotide comprising SEQ ID NOs: 913, 914, 915, 916, 917, 918, 919, 920, 921, 922, 923, 924, 925, 926, 927, 928, 929, 930, 931, 932, 933, 934, 935 and 936. According to preferred embodiments of the present invention, there is provided an isolated polypeptide comprising SEQ ID NO: 1402.
According to preferred embodiments of the present invention, there is provided an isolated polynucleotide comprising SEQ ID NO: 133.
According to preferred embodiments of the present invention, there is provided an isolated polynucleotide comprising SEQ ID NOs: 910, 911 and 912. According to preferred embodiments of the present invention, there is provided an isolated polynucleotide comprising SEQ ID NOs: 141, 142 and 142.
According to preferred embodiments of the present invention, there is provided an isolated polynucleotide comprising SEQ ID NOs: 961, 962, 963, 964, 965, 966, 967, 968, 969, 970, 971, 972, 973, 974, 975, 976, 977, 978, 979, 980, 981, 982, 983, 984, 985, 986, 987, 988, 989 and 990.
According to preferred embodiments of the present invention, there is provided an isolated polypeptide comprising :
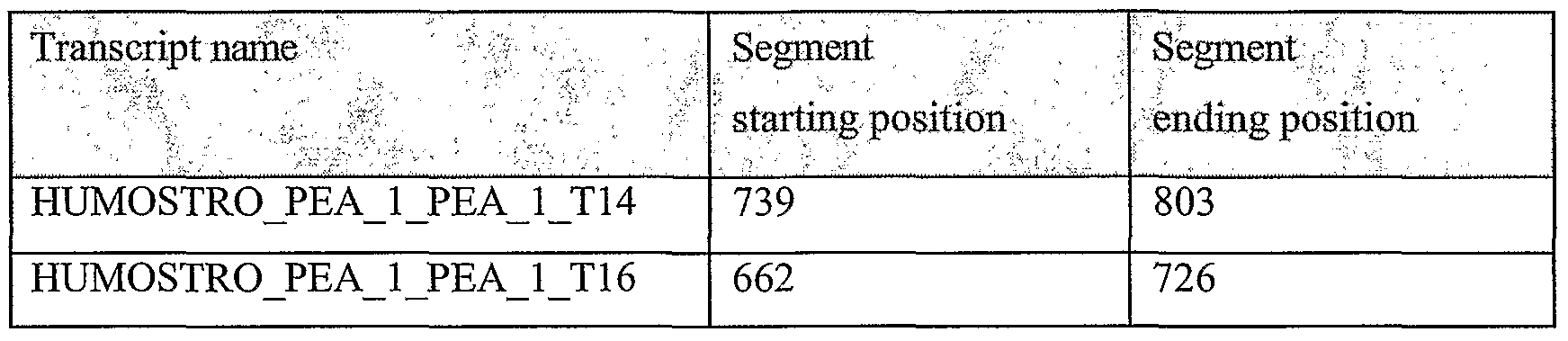
Protein Name
HUMOSTRO_PEA_1_PEA_1_P21 HUMOSTRO_PEA_1_PEA_1_P25
HUMOSTRO_PEA_1_PEA_1_P30
According to preferred embodiments of the present invention, there is provided an isolated polynucleotide comprising SEQ ID NOs: 51, 52, 53,, 54, 55, 56 and 57.
According to preferred embodiments of the present invention, there is provided an isolated polynucleotide comprising SEQ ID NOs: 518, 519, 520, 521, 522, 523, 524, 525, 526, 527, 528, 529, 530, 531, 532, 533, 534, 535, 536, 537, 538, 539, 540, 541, 542, 543, 544, 545, 546, 547,548, 549, 550, 551, 552, 553, 554, 555, 556, 557, 558, 559, 560, 561, 562, 563,, 564, 565, 566, 567, 568, 569 and 570.
According to preferred embodiments of the present invention, there is provided an isolated polypeptide comprising SEQ ID NOs 1327, 1328, 1329, 1330, 1331, 1332 and 1333.
According to preferred embodiments of the present invention, there is provided an isolated polynucleotide comprising SEQ ID NOs: 135, 136, 137, 138, 139 and 140.
According to preferred embodiments of the present invention, there is provided an isolated polynucleotide comprising SEQ ID NOs: 937, 938, 939, 940, 941, 942, 943, 944, 945, 946, 947, 948, 949, 950, 951, 952, 953, 954, 955, 956, 957, 958, 959 and 960.
According to preferred embodiments of the present invention, there is provided an isolated polypeptide comprising SEQ ID NOs 1403, 1404, 1405, 1406, 1407 and 1408.
According to preferred embodiments of the present invention, there is provided an isolated polynucleotide comprising SEQ ID NOs: 41, 42, 43, 44, 45, 46 and 47.. According to preferred embodiments of the present invention, there is provided an isolated polynucleotide comprising SEQ ID NOs: 482, 483, 484, 495, 486, 487, 488, 489, 490, 491, 492, 493, 494, 495, 496, 497, 498, 499, 500 and 501.
According to preferred embodiments of the present invention, there is provided an isolated polypeptide comprising SEQ ID NOs: 1318, 1319, 1320, 1321, 1322 and 1323. According to preferred embodiments of the present invention, there is provided an isolated polynucleotide comprising SEQ ID NOs: 121, 122, 123 and 124.
According to preferred embodiments of the present invention, there is provided an isolated polynucleotide comprising SEQ ID NOs: 876, 877, 878, 879, 880, 881, 882, 883, 884, 885 and 886. According to preferred embodiments of the present invention, there is provided an isolated polypeptide comprising SEQ ID NOs: 1390, 1391, 1392 and 1393.
According to preferred embodiments of the present invention, there is provided an isolated polynucleotide comprising SEQ ID NOs: 48, 49 and 50.
According to preferred embodiments of the present invention, there is provided an isolated polynucleotide comprising SEQ ID NOs: 502, 503, 504, 505, 506, 507, 508, 509, 510, 511, 512, 513, 514, 515, 516 and 517.
According to preferred embodiments of the present invention, there is provided an isolated polypeptide comprising SEQ ID NOs: 1324, 1325 and 1326.
According to preferred embodiments of the present invention, there is provided an isolated polynucleotide comprising SEQ ID NOs: 1464 and 1465.
According to preferred embodiments of the present invention, there is provided an isolated polynucleotide comprising a SEQ ID NOs: 1276, 1277, 1278, 1279 and 1280.
According to preferred embodiments of the present invention, there is provided an isolated polypeptide comprising SEQ ID NO: 1415. Protein Name Corresponding Transcript(s)
HSU33147_PEA_1_P5 HSU33147_PEA_1_T1 ; HSU33147_PEA_1_T2
According to preferred embodiments of the present invention, there is provided an isolated polynucleotide comprising SEQ ID NO: 58.
According to preferred embodiments of the present invention, there is provided an isolated polynucleotide comprising SEQ ID NOs: 571, 572, 573, 574, 575, 576, 577 and 578. According to preferred embodiments of the present invention, there is provided an isolated polypeptide comprising SEQ ID NO: 1334.
According to preferred embodiments of the present invention, there is provided an isolated polynucleotide comprising SEQ ID NOs: 74, 75, 76, 77, 78, 79, 80, 81 and 82.
According to preferred embodiments of the present invention, there is provided an isolated polynucleotide comprising SEQ ID NOs: 659, 660, 661, 662, 663, 664, 665, 666, 667, 668, 669, 670, 671, 672, 673, 674, 675, 676, 677, 678, 679, 680, 681, 682, 683, 684, 685, 686, 687, 688, 689, 690, 691, 692 and 693.
According to preferred embodiments of the present invention, there is provided an isolated polypeptide comprising SEQ ID NOs 1350, 1351, 1352, 1353, 1354, 1355, 1356 and 1357.
According to preferred embodiments of the present invention, there is provided an isolated polynucleotide comprising SEQ ID NOs:
Transcript Name
T23580_T10 According to preferred embodiments of the present invention, there is provided an isolated polynucleotide comprising SEQ ID NOs: 579, 580, 581, 582 and 583.
According to preferred embodiments of the present invention, there is provided an isolated polypeptide comprising SEQ ID NOs 1335.
According to preferred embodiments of the present invention, there is provided an isolated polynucleotide comprising SEQ ID NOs: 59, 60, 61, 62, 63 and 64.
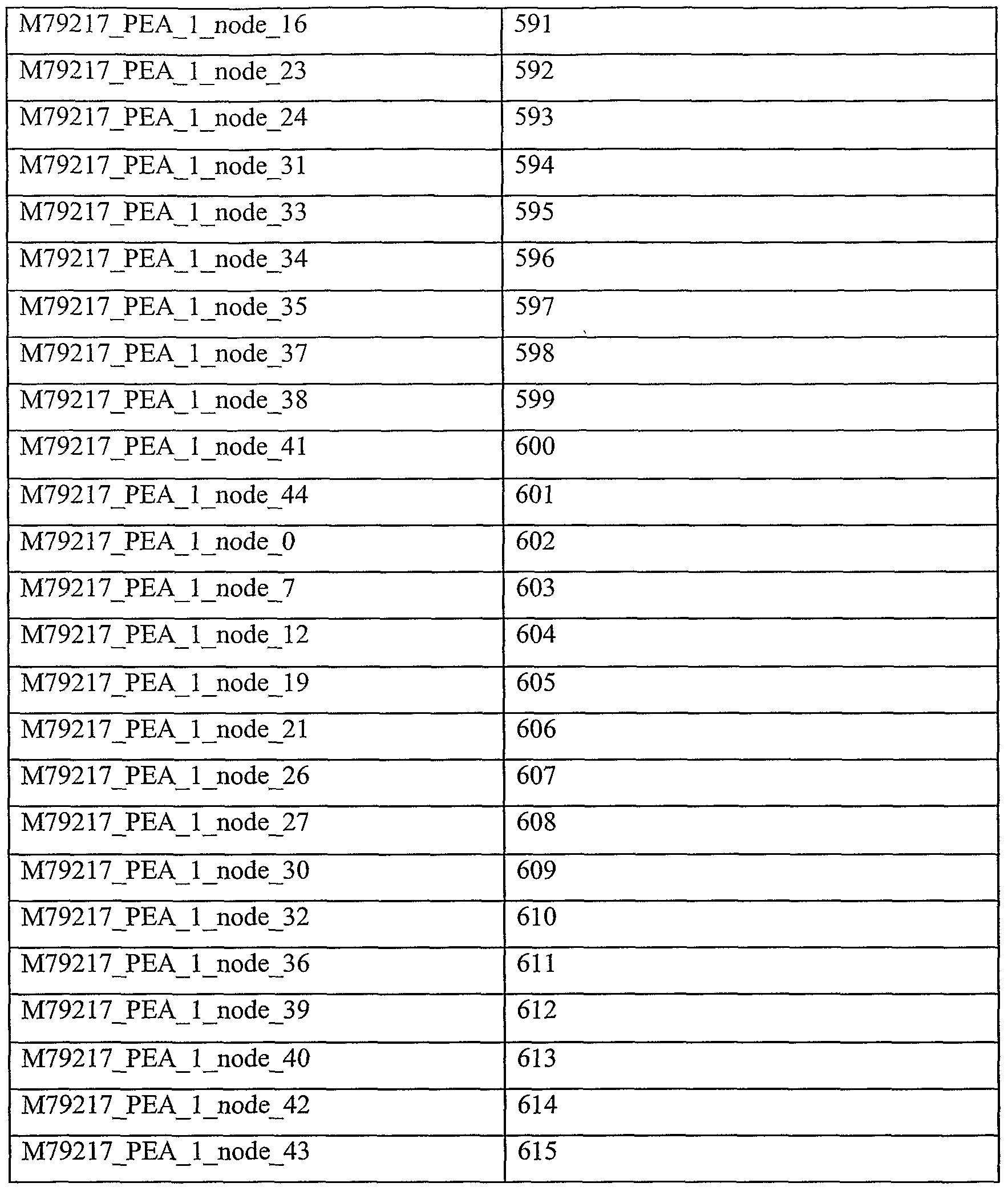
According to preferred embodiments of the present invention, there is provided an isolated polynucleotide comprising SEQ ID NOs: 584, 585, 586, 587, 588, 589, 590, 591, 592, 593, 594, 595, 596, 597, 598, 599, 600, 601, 602, 603, 604, 605, 606, 607, 608, 609, 610, 611, 612, 613, 614 and 615. According to preferred embodiments of the present invention, there is provided an isolated polypeptide comprising SEQ ID NOs: 1336, 1337, 1338, 1339 and 1340.
According to preferred embodiments of the present invention, there is provided an isolated polynucleotide comprising SEQ ID NOs: 65, 66, 67, 68, 69, 70, 71, 72 and 73.
According to preferred embodiments of the present invention, there is provided an isolated polynucleotide comprising SEQ ID NOs: 616, 617, 618, 619, 620, 621, 622, 623, 624, 625, 626, 627, 628, 629, 630, 631, 632, 633, 634, 635, 636, 637, 638, 639, 640, 641, 642, 643, 644, 645, 646, 647, 648, 649, 650, 651, 652, 653, 654, 655, 656, 657, 658 and 659.
According to preferred embodiments of the present invention, there is provided an isolated polypeptide comprising SEQ ID NOs: 1341, 1342, 1343, 1344, 1345, 1346, 1347, 1348 and 1349. According to preferred embodiments of the present invention, there is provided an isolated polynucleotide comprising SEQ ID NOs: 83, 84, 85, 86, 87, 88, 89, 90, 91, 92, 93, 94, 95 and 96.
According to preferred embodiments of the present invention, there is provided an isolated polynucleotide comprising SEQ ID NOs: 695, 696, 697, 698, 699, 700, 701, 702, 703, 704 and 705.
According to preferred embodiments of the present invention, there is provided an isolated polypeptide comprising SEQ ID NOs 1358, 1359, 1360, 1361, 1362, 1363, 1364, 1365, 1366, 1367, 1368 and 1369.
According to preferred embodiments of the present invention, there is provided an isolated polynucleotide comprising SEQ ID NOs: 97 and 98.
According to preferred embodiments of the present invention, there is provided an isolated polynucleotide comprising SEQ ID NOs: 706, 707, 708, 709, 710, 711, 712, 713, 714, 715, 716, 717, 718, 719, 720, 721, 722, 723, 724, 725, 726, 727, 728, 729, 730, 731, 732, 733, 734, 735, 736, 737, 738, 739, 740 and 741. According to preferred embodiments of the present invention, there is provided an isolated polypeptide comprising SEQ ID NOs: 1370 and 1371.
According to preferred embodiments of the present invention, there is provided an isolated polynucleotide comprising SEQ ID NOs: 103, 104, 105, 106, 107 and 108.
According to preferred embodiments of the present invention, there is provided an isolated polynucleotide comprising SEQ ID NOs: 789, 790, 791, 792, 793, 794, 795, 796, 797, 798, 799, 800, 801, 802, 803, 804, 805, 806, 807, 808, 8 09, 810, 811, 812 and 813.
According to preferred embodiments of the present invention, there is provided an isolated polypeptide comprising SEQ ID NOs: 1376, 1377, 1378 and 1379.
According to preferred embodiments of the present invention, there is provided an isolated polynucleotide comprising SEQ ID NOs: 114, 115, 116, 117, 118 and 119. According to preferred embodiments of the present invention, there is provided an isolated polynucleotide comprising SEQ ID NOs: 856, 857, 858, 859, 860, 861 , 862, 863, 864, 865, 866, 867, 868, 869, 870, 871, 872, 873, 874 and 875.
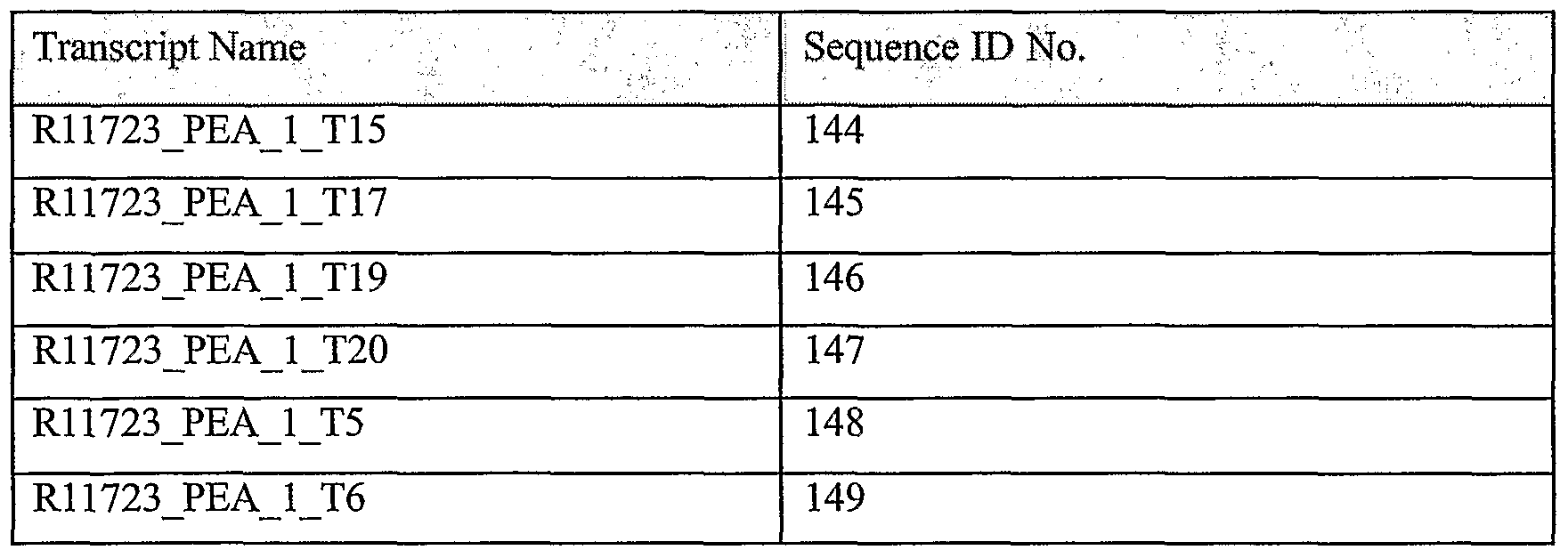
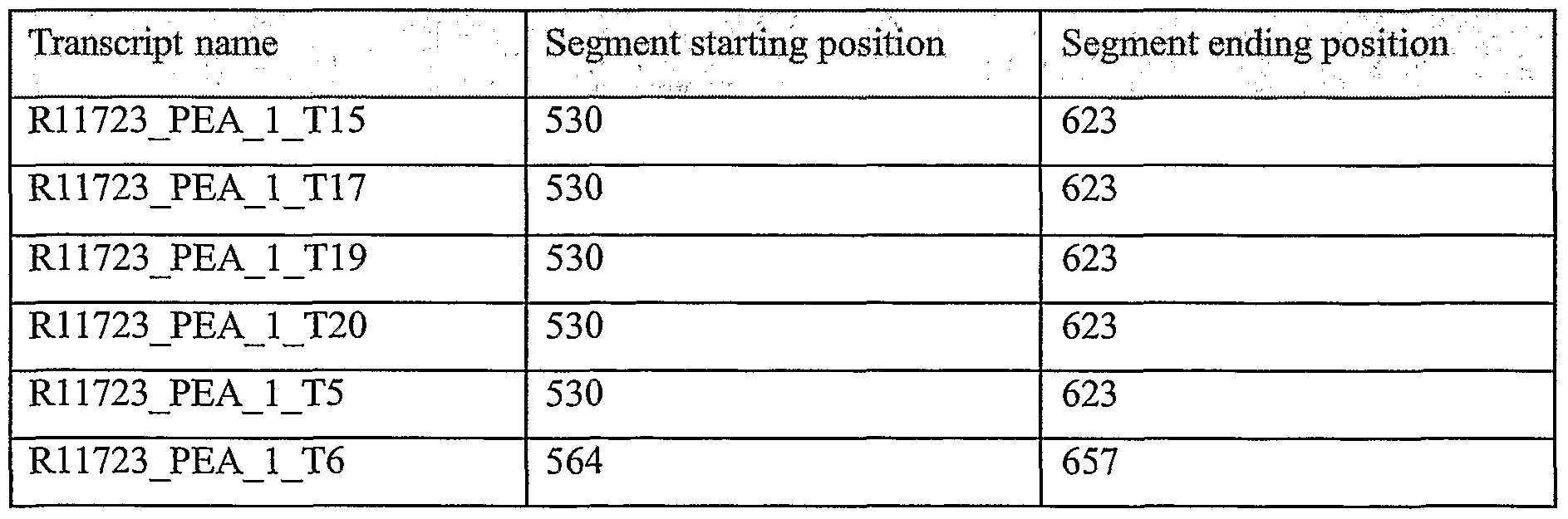
According to preferred embodiments of the present invention, there is provided an isolated polypeptide comprising SEQ ID NOs: 1385, 1386, 1387, 1388 and 1389. According to preferred embodiments of the present invention, there is provided an isolated polynucleotide comprising SEQ ID NOs: 144, 145, 146, 147, 148 and 149.
According to preferred embodiments of the present invention, there is provided an isolated polynucleotide comprising SEQ ID NOs: 991, 992, 993, 994, 995, 996, 997, 998, 999, 1000, 1001, 1002, 1003, 1004, 1005, 1006, 1007, 1008, 1009, 1010, 1011, 1012, 1013, 1014, 1015 and 1016.
According to preferred embodiments of the present invention, there is provided an isolated polypeptide comprising SEQ ID NOs: 1409, 1410, 1411, 1412 and 1413.
According to preferred embodiments of the present invention, there is provided an isolated polynucleotide comprising SEQ ID NO: 150. According to preferred embodiments of the present invention, there is provided an isolated polynucleotide comprising SEQ ID NOs: 1017, 1018, 1019, 1020 and 1021.
According to preferred embodiments of the present invention, there is provided an isolated polypeptide comprising SEQ ID NO: 1414.
According to preferred embodiments of the present invention, there is provided an isolated polynucleotide comprising SEQ ID NOs: 109, 110, 111 , 112 and 113.
According to preferred embodiments of the present invention, there is provided an isolated polynucleotide comprising SEQ ID NOs: 814, 815, 816, 817, 818, 819, 820, 821, 822, 823, 824, 825, 826, 827, 829, 830, 831, 832, 833, 834, 835, 836, 837, 838, 839, 840, 841, 842, 843, 844, 845, 846, 847, 848, 849, 850, 851, 852, 853, 854 and 855. According to preferred embodiments of the present invention, there is provided an isolated polypeptide comprising SEQ ID NOs 1380, 1381, 1382, 1383 and 1384.
According to preferred embodiments of the present invention, there is provided an isolated chimeric polypeptide encoding for.HSSTROL3_P4, comprising a first amino acid sequence being at least 90 % homologous to
MAPAAWLRSAAARALLPPMLLLLLQPPPLLARALPPDVHHLHAERRGPQPWHAALPSS PAP APATQEAPRPASSLRPPRCGVPDPSDGLSARNRQKRFVLSGGRWEKTDLTYRILRFP WQLVQEQVRQTMAEALKVWSDVTPLTFTEVHEGRADIMIDFARYW corresponding to amino acids 1 - 163 of MMl IJHUMAN, which also corresponds to amino acids 1 - 163 of HSSTROL3_P4, a bridging amino acid H corresponding to amino acid 164 of HSSTROL3_P4, a second amino acid sequence being at least 90 % homologous to GDDLPFDGPGGILAHAFFPKTHREGDVHFDYDETWTIGDDQGTDLLQVAAHEFGHVLG LQHTTAAKALMSAFYTFRYPLSLSPDDCRGVQHLYGQPWPTVTSRTPALGPQAGIDTN EIAPLEPDAPPDACEASFDAVSTIRGELFFFKAGFVWRLRGGQLQPGYPALASRHWQGL PSPVDAAFEDAQGHIWFFQGAQYWVYDGEKPVLGPAPLTELGLVRFPVHAALVWGPE
KNKIYFFRGRDYWRFHPSTRRVDSPVPRRATDWRGVPSEIDAAFQDADG corresponding to amino acids 165 - 445 of MMl IJHUMAN, which also corresponds to amino acids 165 - 445 of HSSTROL3JP4, and a third amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence
ALGVRQLVGGGHSSRFSHLVVAGLPHACHRKSGSSSQVLCPEPSALLSVAG corresponding to amino acids 446 - 496 of HSSTROL3 P4, wherein said first amino acid sequence, bridging amino acid, second amino acid sequence and third amino acid sequence are contiguous and in a sequential order.
According to preferred embodiments of the present invention, there is provided an isolated polypeptide encoding for a tail of HSSTROL3 P4, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence
ALGVRQLVGGGHSSRFSHLWAGLPHACHRKSGSSSQVLCPEPSALLSVAG in
HSSTROL3_P4.
According to preferred embodiments of the present invention, there is provided an isolated chimeric polypeptide encoding for HSSTROL3_P5, comprising a first amino acid sequence being at least 90 % homologous to
MAPAAWLRSAAARALLPPMLLLLLQPPPLLARALPPDVHHLHAERRGPQPWHAALPSS PAP APATQEAPRPASSLRPPRCGVPDPSDGLSARNRQKRFVLSGGRWEKTDLTYRILRFP WQLVQEQVRQTMAEALKVWSDVTPLTFTEVHEGRADIMIDFARYW coiresponding to amino acids 1 - 163 of MMI l HUMAN, which also corresponds to amino acids 1 - 163 of HSSTROL3_P5, a bridging amino acid H corresponding to amino acid 164 of HSSTROL3_P5, a second amino acid sequence being at least 90 % homologous to
GDDLPFDGPGGILAHAFFPKTHREGDVHFDYDETWTIGDDQGTDLLQVAAHEFGHVLG LQHTTAAKALMSAFYTFRYPLSLSPDDCRGVQHLYGQPWPTVTSRTPALGPQAGIDTN EIAPLEPDAPPDACEASFDAVSTIRGELFFFKAGFVWRLRGGQLQPGYPALASRHWQGL PSPVDAAFEDAQGHIWFFQ corresponding to amino acids 165 - 358 of MM 1 IJHUMAN, which also corresponds to amino acids 165 - 358 of HSSTROL3 P5, and a third amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence ELGFPSSTGRDESLEHCRCQGLHK corresponding to amino acids 359 - 382 of HSSTROL3_P5, wherein said first amino acid sequence, bridging amino acid, second amino acid sequence and third amino acid sequence are contiguous and in a sequential order.
According to preferred embodiments of the present invention, there is provided an isolated polypeptide encoding for a tail of HSSTROL3_P5, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence ELGFPSSTGRDESLEHCRCQGLHK in HSSTROL3_P5.
According to preferred embodiments of the present invention, there is provided an isolated chimeric polypeptide encoding for HSSTROL3_P7, comprising a first amino acid sequence being at least 90 % homologous to MAPAAWLRSAAARALLPPMLLLLLQPPPLLARALPPDVHHLHAERRGPQPWHAALPSS PAPAPATQEAPRPASSLRPPRCGWDPSDGLSARNRQKRFVLSGGRWEKTDLTYRILRFP WQLVQEQVRQTMAEALKVWSDVTPLTFTEVHEGRADIMIDFARYW corresponding to amino acids 1 - 163 of MMI l JHUMAN, which also corresponds to amino acids 1 - 163 of HSSTROL3_P7, a bridging amino acid H corresponding to amino acid 164 of HSSTROL3_P7, a second amino acid sequence being at least 90 % homologous to
GDDLPFDGPGGILAHAFFPKTHREGDVHFDYDETWTIGDDQGTDLLQVAAHEFGHVLG
LQHTTAAKALMSAFYTFRYPLSLSPDDCRGVQHLYGQPWPTVTSRTPALGPQAGIDTN ELAP LEPDAPPDACEASFDAVSTIRGELFFFKAGFVWRLRGGQLQPGYPALASRHWQGL PSPVDAAFEDAQGHIWFFQG corresponding to amino acids 165 - 359 of MMl IJHUMAN, which also corresponds to amino acids 165 - 359 of HSSTROL3_P7, and a third amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence TTGVSTPAPGV corresponding to amino acids 360 - 370 of HSSTROL3_P7, wherein said first amino acid sequence, bridging amino acid, second amino acid sequence and third amino acid sequence are contiguous and in a sequential order. According to preferred embodiments of the present invention, there is provided an isolated polypeptide encoding for a tail of HSSTROL3_P7, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence TTGVSTPAPGV in HSSTROL3_P7. According to preferred embodiments of the present invention, there is provided an isolated chimeric polypeptide encoding for HSSTROL3_P8, comprising a first amino acid sequence being at least 90 % homologous to
MAPAAWLRSAAARALLPPMLLLLLQPPPLLARALPPDVHHLHAERRGPQPWHAALPSS PAP APATQEAPRPASSLRPPRCGVPDPSDGLSARNRQKRFVLSGGRWEKTDLTYRILRFP WQLVQEQVRQTMAEALKVWSDVTPLTFTEVHEGRADIMIDFARYW corresponding to amino acids 1 - 163 of MMl IJHUMAN, which also corresponds to amino acids 1 - 163 of HSSTROL3JP8, a bridging amino acid H corresponding to amino acid 164 of HSSTROL3JP8, a second amino acid sequence being at least 90 % homologous to GDDLPFDGPGGILAHAFFPKTHREGDVHFDYDETWTIGDDQGTDLLQVAAHEFGHVLG LQHTTAAKALMSAFYTFRYPLSLSPDDCRGVQHLYGQPWPTVTSRTPALGPQAGIDTN EIAPLE corresponding to amino acids 165 - 286 of MMl IJHUMAN, which also corresponds to amino acids 165 - 286 of HSSTROL3JP8, and a third amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence VRPCLPVPLLLCWPL corresponding to amino acids 287 - 301 of HSSTROL3JP8, wherein
said first amino acid sequence, bridging amino acid, second amino acid sequence and third amino acid sequence are contiguous and in a sequential order.
According to preferred embodiments of the present invention, there is provided an isolated polypeptide encoding for a tail of HSSTROL3_P8, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence VRPCLPVPLLLCWPL in HSSTROL3 P8.
According to preferred embodiments of the present invention, there is provided an isolated chimeric polypeptide encoding for HSSTROL3_P9, comprising a first amino acid sequence being at least 90 % homologous to
MAPAAWLRS AAARALLPPMLLLLLQPPPLLARALPPDVHHLHAEPvRGPQPWHAALPSS PAPAPATQEAPRPASSLRPPRCGVPDPSDGLSARNRQK corresponding to amino acids 1 - 96 of MM11_HUMAN, which also corresponds to amino acids 1 - 96 of HSSTROL3_P9, a second amino acid sequence being at least 90 % homologous to RILRFPWQLVQEQVRQTMAEALKVWSDVTPLTFTEVHEGRADIMIDFARYW corresponding to amino acids 113 - 163 of MMl 1_HUMAN, which also corresponds to amino acids 97 - 147 of HSSTROL3 P9, a bridging amino acid H corresponding to amino acid 148 of HSSTROL3 P9, a third amino acid sequence being at least 90 % homologous to GDDLPFDGPGGILAHAFFPKTHREGDVHFDYDETWTIGDDQGTDLLQVAAHEFGHVLG LQHTTAAKALMSAFYTFRYPLSLSPDDCRGVQHLYGQPWPTVTSRTPALGPQAGIDTN EIAPLEPDAPPDACEASFDAVSTIRGELFFFKAGFVWRLRGGQLQPGYPALASRHWQGL PSPVDAAFEDAQGHIWFFQG corresponding to amino acids 165 - 359 of MMl IJHUMAN, which also corresponds to amino acids 149 - 343 of HSSTROL3 P9, and a fourth amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence TTGVSTPAPGV corresponding to amino acids 344 - 354 of HSSTROL3_P9, wherein said first amino acid sequence, second amino acid sequence, bridging amino acid, third amino acid sequence and fourth amino acid sequence are contiguous and in a sequential order.
According to preferred embodiments of the present invention, there is provided an isolated chimeric polypeptide encoding for an edge portion of HSSTROL3 P9, comprising a polypeptide having a length "n", wherein n is at least about 10 amino acids in length, optionally
at least about 20 amino acids in length, preferably at least about 30 amino acids in length, more preferably at least about 40 amino acids in length and most preferably at least about 50 amino acids in length, wherein at least two amino acids comprise KR, having a structure as follows: a sequence starting from any of amino acid numbers 96-x to 96; and ending at any of amino acid numbers 97+ ((n-2) - x), in which x varies from 0 to n-2.
According to preferred embodiments of the present invention, there is provided an isolated polypeptide encoding for a tail of HSSTROL3 P9, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence TTGVSTPAPGV in HSSTROL3_P9.
According to preferred embodiments of the present invention, there is provided an isolated chimeric polypeptide encoding for HUMCA 1XIA_P 14, comprising a first amino acid sequence being at least 90 % homologous to
MEPWSSRWKTKRWLWDFTVTTLALTFLFQAREVRGAAPVDVLKALDFHNSPEGISKTT GFCTNRKNSKGSDTAYRVSKQAQLSAPTKQLFPGGTFPEDFSILFTVKPKKGIQSFLLSIY NEHGIQQIGVEVGRSPVFLFEDHTGKPAPEDYPLFRTVNIADGKWHRVAISVEKKTVTM IVDCKKKTTKPLDRSERAIVDTNGITVFGTRILDEEVFEGDIQQFLITGDPKAAYDYCEH YSPDCDSSAPKAAQAQEPQIDEYAPEDIIEYDYEYGEAEYKEAESVTEGPTVTEETIAQT EANIVDDFQEYNYGTMESYQTEAPRHVSGTNEPNPVEEIFTEEYLTGEDYDSQRKNSED TLYENKEIDGRDSDLLVDGDLGEYDFYEYKEYEDKPTSPPNEEFGPGVPAETDITETSIN GHGAYGEKGQKGEPAVVEPGMLVEGPPGPAGPAGIMGPPGLQGPTGPPGDPGDRGPPG RPGLPGADGLPGPPGTMLMLPFRYGGDGSKGPTISAQEAQAQAILQQARIALRGPPGPM GLTGRPGPVGGPGSSGAKGESGDPGPQGPRGVQGPPGPTGKPGKRGRPGADGGRGMP GEPGAKGDRGFDGLPGLPGDKGHRGERGPQGPPGPPGDDGMRGEDGEIGPRGLPGEAG PRGLLGPRGTPGAPGQPGMAGVDGPPGPKGNMGPQGEPGPPGQQGNPGPQGLPGPQG PIGPPGEKGPQGKPGLAGLPGADGPPGHPGKEGQSGEKGALGPPGPQGPIGYPGPRGVK GADGVRGLKGSKGEKGEDGFPGFKGDMGLKGDRGEVGQIGPRGEDGPEGPKGRAGPT GDPGPSGQAGEKGKLGVPGLPGYPGRQGPKGSTGFPGFPGANGEKGARGVAGKPGPR GQRGPTGPRGSRGARGPTGKPGPKGTSGGDGPPGPPGERGPQGPQGPVGFPGPKGPPGP PGKDGLPGHPGQRGETGFQGKTGPPGPGGWGPQGPTGETGPIGERGHPGPPGPPGEQG LPGAAGKEGAKGDPGPQGISGKDGPAGLRGFPGERGLPGAQGAPGLKGGEGPQGPPGP
V corresponding to amino acids 1 - 1056 of CA1B_HUMAN_V5, which also corresponds to amino acids 1 - 1056 of HUMCA IXI A_P 14, and a second amino acid sequence being at least
70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence VSMMIINSQTIMVVNYSSSFITLML corresponding to amino acids 1057 - 1081 of
HUMCA1XIA_P14, wherein said first amino acid sequence and second amino acid sequence are contiguous and in a sequential order.
According to preferred embodiments of the present invention, there is provided an isolated polypeptide encoding for a tail of HUMCA1XIA_P14, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence
VSMMIINSQTIMVVNYSSSFITLML in HUMCA1XIA_P14.
According to preferred embodiments of the present invention, there is provided an isolated chimeric polypeptide encoding for HUMCAl XIA_P 15, comprising a first amino acid sequence being at least 90 % homologous to
MEPWSSRWKTKRWLWDFTVTTLALTFLFQAREVRGAAPVDVLKALDFHNSPEGISKTT GFCTNRKNSKGSDTAYRVSKQAQLSAPTKQLFPGGTFPEDFSILFTVKPKKGIQSFLLSIY NEHGIQQIGVEVGRSPVFLFEDHTGKPAPEDYPLFRTVNIADGKWHRVAISVEKKTVTM IVDCKKKTTKPLDRSERAIVDTNGITVFGTRILDEEVFEGDIQQFLITGDPKAAYDYCEH YSPDCDSSAPKAAQAQEPQIDEYAPEDIIEYDYEYGEAEYKEAESVTEGPTVTEETIAQT EANIVDDFQEYNYGTMESYQTEAPRHVSGTNEPNPVEEIFTEEYLTGEDYDSQRKNSED TLYENKEIDGRDSDLLVDGDLGEYDFYEYKEYEDKPTSPPNEEFGPGVPAETDITETSIN GHGAYGEKGQKGEPAVVEPGMLVEGPPGPAGPAGIMGPPGLQGPTGPPGDPGDRGPPG RPGLPGADGLPGPPGTMLMLPFRYGGDGSKGPTISAQEAQAQAILQQARIALRGPPGPM GLTGRPGPVGGPGSSGAKGESGDPGPQGPRGVQGPPGPTGKPGKRGRPGADGGRGMP GEPGAKGDRGFDGLPGLPGDKGHRGERGPQGPPGPPGDDGMRGEDGEIGPRGLPGEAG PRGLLGPRGTPGAPGQPGMAGVDGPPGPKGNMGPQGEPGPPGQQGNPGPQGLPGPQG
PIGPPGEK corresponding to amino acids 1 - 714 of CA IBJHUMAN, which also corresponds to amino acids 1 - 714 of HUMCA1XIA_P15, and a second amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence
MCCNLSFGILIPLQK corresponding to amino acids 715 - 729 of HUMC AlXI A JM 5, wherein said first amino acid sequence and second amino acid sequence are contiguous and in a sequential order.
According to preferred embodiments of the present invention, there is provided an isolated polypeptide encoding for a tail of HUMCA1XIA_P15, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence MCCNLSFGILIPLQK in HUMCA IXIAJPl 5.
According to preferred embodiments of the present invention, there is provided an isolated chimeric polypeptide encoding for HUMCA IXIA P 16, comprising a first amino acid sequence being at least 90 % homologous to
MEPWSSRWKTKRWLWDFTVTTLALTFLFQAREVRGAAPVDVLKALDFHNSPEGISKTT GFCTNRKNSKGSDTAYRVSKQAQLSAPTKQLFPGGTFPEDFSILFTVKPKKGIQSFLLSIY NEHGIQQIGVEVGRSPVFLFEDHTGKPAPEDYPLFRTVNIADGKWHRVAISVEKKTVTM IVDCKKKTTKPLDRSERAIVDTNGITVFGTRILDEEVFEGDIQQFLITGDPKAAYDYCEH YSPDCDSSAPKAAQAQEPQIDEYAPEDIIEYDYEYGEAEYKEAESVTEGPTVTEETIAQT EANIVDDFQEYNYGTMESYQTEAPRHVSGTNEPNPVEEIFTEEYLTGEDYDSQRKNSED TLYENKEIDGRDSDLLVDGDLGEYDFYEYKEYEDKPTSPPNEEFGPGVPAETDITETSIN GHGAYGEKGQKGEP AWEPGMLVEGPPGPAGP AGIMGPPGLQGPTGPPGDPGDRGPPG RPGLPGADGLPGPPGTMLMLPFRYGGDGSKGPTISAQEAQAQAILQQARIALRGPPGPM GLTGRPGPVGGPGSSGAKGESGDPGPQGPRGVQGPPGPTGKPGKRGRPGADGGRGMP GEPGAKGDRGFDGLPGLPGDKGHRGERGPQGPPGPPGDDGMRGEDGEIGPRGLPGEA corresponding to amino acids 1 - 648 of CA1B_HUMAN, which also corresponds to amino acids 1 - 648 of HUMCA1XIA P16, a second amino acid sequence being at least 90 % homologous to GMAGVDGPPGPKGNMGPQGEPGPPGQQGNPGPQGLPGPQGPIGPPGEK corresponding to amino acids 667 - 714 of CA1B_HUMAN, which also corresponds to amino acids 649 - 696 of HUMCA1XIA_P16, and a third amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence VSFSFSLFYKKVIKFACDKRFVGRHDERKWKLSLPLYLIYE corresponding to amino
acids 697 - 738 of HUMCA IXI A_P 16, wherein said first amino acid sequence, second amino acid sequence and third amino acid sequence are contiguous and in a sequential order.
According to preferred embodiments of the present invention, there is provided an isolated chimeric polypeptide encoding for an edge portion of HUMCA1XIA_P16, comprising a polypeptide having a length "n", wherein n is at least about 10 amino acids in length, optionally at least about 20 amino acids in length, preferably at least about 30 amino acids in length, more preferably at least about 40 amino acids in length and most preferably at least about 50 amino acids in length, wherein at least two amino acids comprise AG, having a structure as follows: a sequence starting from any of amino acid numbers 648-x to 648; and ending at any of amino acid numbers 649+ ((n-2) - x), in which x varies from 0 to n-2.
According to preferred embodiments of the present invention, there is provided an isolated polypeptide encoding for a tail of HUMCA IXI A_P 16, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence VSFSFSLFYKKVπCFACDKRFVGRHDERKVVKLSLPLYLIYE in HUMCA1XIA_P16.
According to preferred embodiments of the present invention, there is provided an isolated chimeric polypeptide encoding for HUMCA1XIA_P17, comprising a first amino acid sequence being at least 90 % homologous to MEPWSSRWKTKRWLWDFTVTTLALTFLFQAREVRGAAPVDVLKALDFHNSPEGISKTT GFCTNRKNSKGSDTAYRVSKQAQLSAPTKQLFPGGTFPEDFSILFTVKPKKGIQSFLLSIY NEHGIQQIGVEVGRSPVFLFEDHTGKPAPEDYPLFRTVNIADGKWHRVAISVEKKTVTM IVDCKKKTTKPLDRSERAIVDTNGITVFGTRILDEEVFEGDIQQFLITGDPKAAYDYCEH YSPDCDSSAPKAAQAQEPQIDE corresponding to amino acids 1 - 260 of CA1B_HUMAN, which also corresponds to amino acids 1 - 260 of HUMCA1XIA_P17, and a second amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence VRSTRPEKVFVFQ corresponding to amino acids 261 - 273 of HUMCA 1XIA_P 17, wherein said first amino acid sequence and second amino acid sequence are contiguous and in a sequential order. According to preferred embodiments of the present invention, there is provided an isolated polypeptide encoding for a tail of HUMCA1XIA_P17, comprising a polypeptide being
at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence VRSTRPEKVFVFQ in HUMCA 1XIA_P 17.
According to preferred embodiments of the present invention, there is provided an isolated chimeric polypeptide encoding for R20779_P2, comprising a first amino acid sequence being at least 90 % homologous to
MCAERLGQFMTLALVLATFDPARGTDATNPPEGPQDRSSQQKGRLSLQNTAEIQHCLV NAGDVGCGVFECFEKNSCEIRGLHGICMTFLHNAGKFDAQGKSFIKDALKCKAHALRH RFGCISRKCPAIREMVSQLQRECYLKHDLCAAAQENTRVIVEMIHFKDLLLHE corresponding to amino acids 1 - 169 of STC2JHUMAN, which also corresponds to amino acids 1 - 169 of R20779_P2, and a second amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence CYKIEITMPKRRKVKLRD corresponding to amino acids 170 - 187 of R20779 P2, wherein said first amino acid sequence and second amino acid sequence are contiguous and in a sequential order.
According to preferred embodiments of the present invention, there is provided an isolated polypeptide encoding for a tail of R20779_P2, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence CYKIEITMPKRRKVKLRD in R20779_P2.
According to preferred embodiments of the present invention, there is provided an isolated chimeric polypeptide encoding for HUMOSTRO_PEA_1_PEA_1_P21, comprising a first amino acid sequence being at least 90 % homologous to MRIAVICFCLLGITCAIPVKQADSGSSEEKQLYNKYPDAVATWLNPDPSQKQNLLAPQ corresponding to amino acids 1 - 58 of OSTP_HUMAN, which also corresponds to amino acids 1 - 58 of HUMOSTRO_PEA_1_PEA_1_P21, and a second amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence VFLNFS corresponding to amino acids 59 - 64 of HUMOSTRO_PEA_1_PEA_1_P21, wherein said first amino acid sequence and second amino acid sequence are contiguous and in a sequential order.
According to preferred embodiments of the present invention, there is provided an isolated polypeptide encoding for a tail of HUMOSTRO_PEA_1_PEA_1_P21, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence VFLNFS in HUMOSTROJPEA 1 JPEA_1_P21.
According to preferred embodiments of the present invention, there is provided an isolated chimeric polypeptide encoding for HUMOSTRO_PEA_1_PEA_1_P25, comprising a first amino acid sequence being at least 90 % homologous to MPJAVICFCLLGITCAIPVKQADSGSSEEKQ corresponding to amino acids 1 - 31 of OSTP_HUMAN, which also corresponds to amino acids 1 - 31 of
HUMOSTRO_PEA_1_PEA_1_P25, and a second amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence H corresponding to amino acids 32 - 32 of HUMOSTRO_PEA_1_PEA_1_P25, wherein said first amino acid sequence and second amino acid sequence are contiguous and in a sequential order.
According to preferred embodiments of the present invention, there is provided an isolated chimeric polypeptide encoding for HUMOSTRO_PEA_1_PEA_1_P30, comprising a first amino acid sequence being at least 90 % homologous to MRIAVICFCLLGITCAIPVKQADSGSSEEKQ corresponding to amino acids 1 - 31 of OSTP_HUMAN, which also corresponds to amino acids 1 - 31 of
HUMOSTRO_PEA_1_PEA_1_P30, and a second amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence VSIFYVFI corresponding to amino acids 32 - 39 of HUMOSTRO_PEA_1_PEA_1_P30, wherein said first amino acid sequence and second amino acid sequence are contiguous and in a sequential order.
According to preferred embodiments of the present invention, there is provided an isolated polypeptide encoding for a tail of HUMOSTRO_PEA_1_PEA_1_P30, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence VSIFYVFI in HUMOSTRO_PEA_1_PEA_1_P30.
According to preferred embodiments of the present invention, there is provided an isolated chimeric polypeptide encoding for HUMPHOSLIP_PEA_2_P10, comprising a first amino acid sequence being at least 90 % homologous to
MALFGALFLALLAGAHAEFPGCKIRVTSKALELVKQEGLRFLEQELETITIPDLRGKEGH FYYNISE corresponding to amino acids 1 - 67 of PLTPJHUMAN, which also corresponds to amino acids 1 - 67 of HUMPHOSLIP_PEA_2_P10, and a second amino acid sequence being at least 90 % homologous to
KVYDFLSTFITSGMRFLLNQQICPVLYHAGTVLLNSLLDTVPVRSSVDELVGIDYSLMK DPVASTSNLDMDFRGAFFPLTERNWSLPNRAVEPQLQEEERMVYVAFSEFFFDSAMES YFRAGALQLLLVGDKVPHDLDMLLRATYFGSIVLLSPAVIDSPLKLELRVLAPPRCTIKP SGTTISVTASVTIALVPPDQPEVQLSSMTMDARLSAKMALRGKALRTQLDLRRFRIYSN HSALESLALIPLQAPLKTMLQIGVMPMLNERTWRGVQIPLPEGINFVHEVVTNHAGFLTI GADLHFAKGLREVIEKNRPADVRASTAPTPSTAAV corresponding to amino acids 163 - 493 of PLTP_HUMAN, which also corresponds to amino acids 68 - 398 of HUMPHOSLIP_PEA_2_P10, wherein said first amino acid sequence and second amino acid sequence are contiguous and in a sequential order.
According to preferred embodiments of the present invention, there is provided an isolated chimeric polypeptide encoding for an edge portion of HUMPHOSLIP_PEA_2_P10, comprising a polypeptide having a length "n", wherein n is at least about 10 amino acids in length, optionally at least about 20 amino acids in length, preferably at least about 30 amino acids in length, more preferably at least about 40 amino acids in length and most preferably at least about 50 amino acids in length, wherein at least two amino acids comprise EK, having a structure as follows: a sequence starting from any of amino acid numbers 67-x to 67; and ending at any of amino acid numbers 68+ ((n-2) - x), in which x varies from 0 to n-2. According to preferred embodiments of the present invention, there is provided an isolated chimeric polypeptide encoding for HUMPHOSLIP_PEA_2_P12, comprising a first amino acid sequence being at least 90 % homologous to
MALFGALFLALLAGAHAEFPGCKIRVTSKALELVKQEGLRFLEQELETITIPDLRGKEGH FYYNISEVKVTELQLTSSELDFQPQQELMLQITNASLGLRFRRQLLYWFFYDGGYINAS AEGVSIRTGLELSRDPAGRMKVSNVSCQASVSRMHAAFGGTFKKVYDFLSTFITSGMRF LLNQQICPVLYHAGTVLLNSLLDTVPVRSSVDELVGIDYSLMKDPVASTSNLDMDFRG
AFFPLTERNWSLPNRAVEPQLQEEERMVYVAFSEFFFDSAMESYFRAGALQLLLVGDK VPHDLDMLLRATYFGSIVLLSPAVIDSPLKLELRVLAPPRCTIKPSGTTISVTASVTIALVP PDQPEVQLSSMTMDARLSAKMALRGKALRTQLDLRRFRIYSNHSALESLALIPLQAPLK TMLQIGVMPMLN corresponding to amino acids 1 - 427 of PLTP_HUMAN, which also corresponds to amino acids 1 - 427 of HUMPHOSLIP_PEA_2_P12, and a second amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence GKAGV corresponding to amino acids 428 - 432 of HUMPHOSLIP_PEA_2_P12, wherein said first amino acid sequence and second amino acid sequence are contiguous and in a sequential order.
According to preferred embodiments of the present invention, there is provided an isolated polypeptide encoding for a tail of HUMPHOSLIP_PEA_2_P12, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence GKAGV in HUMPHOSLIP_PEA_2_P12.
According to preferred embodiments of the present invention, there is provided an isolated chimeric polypeptide encoding for HUMPHOSLIP_PEA_2_P31, comprising a first amino acid sequence being at least 90 % homologous to MALFGALFLALLAGAHAEFPGCKIRVTSKALELVKQEGLRFLEQELETITIPDLRGKEGH FYYNISE corresponding to amino acids 1 - 67 of PLTP HUMAN, which also corresponds to amino acids 1 - 67 of HUMPHOSLIP_PEA_2_P31 , and a second amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence PGLERGADKFPWGGSSLFLALDLTLRPPVG corresponding to amino acids 68 - 98 of HUMPHOSLIP_PEA_2_P31 , wherein said first amino acid sequence and second amino acid sequence are contiguous and in a sequential order.
According to preferred embodiments of the present invention, there is provided an isolated polypeptide encoding for a tail of HUMPHOSLIP_PEA_2_P31, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence PGLERGADKFPWGGSSLFLALDLTLRPPVG in HUMPHOSLIP_PEA_2_P31.
According to preferred embodiments of the present invention, there is provided an isolated chimeric polypeptide encoding for HUMPHOSLIPJPEA 2JP33, comprising a first amino acid sequence being at least 90 % homologous to
MALFGALFLALLAGAHAEFPGCKIRVTSKALELVKQEGLRFLEQELETITIPDLRGKEGH FYYNISEVKVTELQLTSSELDFQPQQELMLQITNASLGLRFRRQLLYWFFYDGGYINAS AEGVSIRTGLELSRDPAGRMKVSNVSCQASVSRMHAAFGGTFKKVYDFLSTFITSGMRF LLNQQ corresponding to amino acids 1 - 183 of PLTP_HUMAN, which also corresponds to amino acids 1 - 183 of HUMPHOSLIPJPEA_2_P33, and a second amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence VWAATGRRVARVGMLSL corresponding to amino acids 184 - 200 of HUMPHOSLΪP_PEA_2JP33, wherein said first amino acid sequence and second amino acid sequence are contiguous and in a sequential order.
According to preferred embodiments of the present invention, there is provided an isolated polypeptide encoding for a tail of HUMPHOSLIPJPEA 2JP33, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence VWAATGRRVARVGMLSL in HUMPHOSLIP PEA 2JP33.
According to preferred embodiments of the present invention, there is provided an isolated chimeric polypeptide encoding for HUMPHOSLIP_PEA_2_P34, comprising a first amino acid sequence being at least 90 % homologous to
MALFGALFLALLAGAHAEFPGCKIRVTSKALELVKQEGLRFLEQELETITIPDLRGKEGH FYYNISEVKVTELQLTSSELDFQPQQELMLQITNASLGLRFRRQLLYWFFYDGGYINAS AEGVSIRTGLELSRDPAGRMKVSNVSCQASVSRMHAAFGGTFKKVYDFLSTFITSGMRF LLNQQICPVLYHAGTVLLNSLLDTVPV corresponding to amino acids 1 - 205 of PLTPJHUMAN, which also corresponds to amino acids 1 - 205 of
HUMPHOSLIP_PEA_2_P34, and a second amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence LWTSLLALTIPS corresponding to amino acids 206 - 217 of HUMPHOSLIP_PEA_2_P34, wherein said first amino acid sequence and second amino acid sequence are contiguous and in a sequential order.
According to preferred embodiments of the present invention, there is provided an isolated polypeptide encoding for a tail of HUMPHOSLIPJPEA 2 P34, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence LWTSLLALTIPS in HUMPHOSLIP_PEA_2_P34.
According to preferred embodiments of the present invention, there is provided an isolated chimeric polypeptide encoding for HUMPHOSLIP_PEA_2_P35, comprising a first amino acid sequence being at least 90 % homologous to MALFGALFLALLAGAHAEFPGCKIRVTSKALELVKQEGLRFLEQELETITIPDLRGKEGH FYYNISEVKVTELQLTSSELDFQPQQELMLQITNASLGLRFRRQLLYWF corresponding to amino acids 1 - 109 of PLTP_HUMAN, which also corresponds to amino acids 1 - 109 of HUMPHOSLIP_PEA_2_P35, a second amino acid sequence bridging amino acid sequence comprising of L, a third amino acid sequence being at least 90 % homologous to KVYDFLSTFITSGMRFLLNQQ corresponding to amino acids 163 - 183 of PLTP_HUMAN, which also corresponds to amino acids 111 - 131 of HUMPHOSLIP J>EA_2_P35, and a fourth amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence VWAATGRRVARVGMLSL corresponding to amino acids 132 - 148 of HUMPHOSLIP_PEA_2_P35, wherein said first amino acid sequence, second amino acid sequence, third amino acid sequence and fourth amino acid sequence are contiguous and in a sequential order.
According to preferred embodiments of the present invention, there is provided an isolated polypeptide encoding for an edge portion of HUMPHOSLIP_PEA_2_P35, comprising a polypeptide having a length "n", wherein n is at least about 10 amino acids in length, optionally at least about 20 amino acids in length, preferably at least about 30 amino acids in length, more preferably at least about 40 amino acids in length and most preferably at least about 50 amino acids in length, wherein at least two amino acids comprise FLK having a structure as follows (numbering according to HUMPHOSLIPJPEA_2_P35): a sequence starting from any of amino acid numbers 109- x to 109; and ending at any of amino acid numbers 111 + ((n-2) - x), in which x varies from 0 to n-2.
According to preferred embodiments of the present invention, there is provided an isolated polypeptide encoding for a tail of HUMPHOSLIP PEA 2 P35, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence VWAATGRRVARVGMLSL in HUMPHOSLIP_PEA_2_P35.
According to preferred embodiments of the present invention, there is provided an isolated chimeric polypeptide encoding for R38144_PEA_2_P6, comprising a first amino acid sequence being at least 90 % homologous to MPFRLLIPLGLLCALLPQHHGAPGPDGSAPDPAHYRERVKAMFYHAYDSYLENAFPFD ELRPLTCDGHDTWGSFSLTLIDALDTLLILGNVSEFQRVVEVLQDSVDFDIDVNASVFET NIRVVGGLLSAHLLSKKAGVEVEAGWPCSGPLLRMAEEAARKLLPAFQTPTGMPYGTV NLLHGVNPGETPVTCTAGIGTFIVEFATLSSLTGDPVFEDVARVALMRLWESRSDIGLV GNmDVLTGKWVAQDAGIGAGVDSYFEYLVKGAILLQDKKLMAMFLEYNKAIRNYTR FDDWYLWVQMYKGTVSMPVFQSLEAYWPGLQSLIGDIDNAMRTFLNYYTVWKQFGG LPEFYNIPQGYTVEKREGYPLRPELIESAMYLYRATGDPTLLELGRDA VESIEKISKVEC GFAT corresponding to amino acids 1 - 412 of CT31_HUMAN, which also corresponds to amino acids 1 - 412 of R38144_PEA_2_P6, and a second amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence LASFSHMSDQRSARPQAGQPHGWLPGRDCEIPLPPV corresponding to amino acids 413 - 449 of R38144_PEA_2_P6, wherein said first amino acid sequence and second amino acid sequence are contiguous and in a sequential order.
According to preferred embodiments of the present invention, there is provided an isolated polypeptide encoding for a tail of R38144_PEA_2_P6, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence LASFSHMSDQRSARPQAGQPHGWLPGRDCEIPLPPV in R38144_PEA_2_P6.
According to preferred embodiments of the present invention, there is provided an isolated chimeric polypeptide encoding for R38144_PEA_2_P13, comprising a first amino acid sequence being at least 90 % homologous to
MPFRLLIPLGLLCALLPQHHGAPGPDGSAPDPAHYRERVKAMFYHAYDSYLENAFPFD
ELRPLTCDGHDTWGSFSLTLID ALDTLLILGNVSEFQRVVEVLQDSVDFDIDVN ASVFET NIRVVGGLLSAHLLSKKAGVEVEAGWPCSGPLLRMAEEAARKLLPAFQTPTGMPYGTV NLLHGVNPGETPVTCTAGIGTFIVEFATLSSLTGDPVFEDVARVALMRLWESRSDIGLV GNHIDVLTGKWVAQDAGIGAGVDSYFEYLVKGAILLQDKKLMAMFLEYNKAIRNYTR FDDWYLWVQMYKGTVSMPVFQSLEAYWPGLQ corresponding to amino acids 1 - 323 of CT31_HUMAN, which also corresponds to amino acids 1 - 323 of R38144_PEA_2_P13, and a second amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence NLLKAQCTSTVPRGIPPS corresponding to amino acids 324 - 341 of R38144_PEA_2_P13, wherein said first amino acid sequence and second amino acid sequence are contiguous and in a sequential order.
According to preferred embodiments of the present invention, there is provided an isolated polypeptide encoding for a tail of R38144_PEA_2_P13, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence NLLKAQCTSTVPRGIPPS in R38144_PEA_2_P13.
According to preferred embodiments of the present invention, there is provided an isolated chimeric polypeptide encoding for R38144_PEA_2_P15, comprising a first amino acid sequence being at least 90 % homologous to MPFRLLIPLGLLCALLPQHHGAPGPDGSAPDPAHYRERVKAMFYHAYDSYLENAFPFD ELRPLTCDGHDTWGSFSLTLIDALDTLLILGNVSEFQRWEVLQDSVDFDIDVNASVFET NIRVVGGLLSAHLLSKKAGVEVEAGWPCSGPLLRMAEEAARKLLPAFQTPTGMPYGTV NLLHGVNPGETPVTCTAGIGTFIVEFATLSSLTGDPVFEDVARVALMRLWESRSDIGLV GNHIDVLTGKWVAQDAGIGAGVDSYFEYLVKGAILLQDKKLMAMFLE corresponding to amino acids 1 - 282 of CT3 IJHUMAN, which also corresponds to amino acids 1 - 282 of R38144_PEA_2_P15, and a second amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence PHWRH corresponding to amino acids 283 - 287 of R38144_PEA_2_P15, wherein said first amino acid sequence and second amino acid sequence are contiguous and in a sequential order.
According to preferred embodiments of the present invention, there is provided an isolated polypeptide encoding for a tail of R38144_PEA_2_P15, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence PHWRH in R38144_PEA_2_P 15.
According to preferred embodiments of the present invention, there is provided an isolated chimeric polypeptide encoding for R38144_PEA_2_P19, comprising a first amino acid sequence being at least 90 % homologous to
MPFRLLIPLGLLCALLPQHHGAPGPDGSAPDPAHYRERVKAMFYHAYDSYLENAFPFD ELRPLTCDGHDTWGSFSLTLIDALDTLLILGNVSEFQRVVEVLQDSVDFDIDVNASVFET NIRVVGGLLSAHLLSKKAGVEVEAGWPCSGPLLRMAEEAARKLLPAFQTPTGMPYGTV NLLHGVNPGETPVTCTAGIGTFIVEFATLSSLTGDPVFEDVARVALMRLWESRSDIGLV GNHIDVLTGKWVAQDAGIGAGVDSYFEYLVKGAILLQDKKLMAMFLEYNKAIRNYTR FDDWYLWVQMYKGTVSMPVFQSLEAYWPGLQSLIGDIDNAMRTFLNYYTVWKQFGG LPEFYNIPQGYTVEKREGYPLRPELIES AMYLYRATGDPTLLELGRDAVESIEKISKVEC GFAT corresponding to amino acids 1 - 412 of CT31 HUMAN, which also corresponds to amino acids 1 - 412 of R38144_PEA_2_P19, and a second amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence KRSRSVAQAGVQWCDHDSPQP corresponding to amino acids 413 - 433 of
R38144_PEA_2__P19, wherein said first amino acid sequence and second amino acid sequence are contiguous and in a sequential order.
According to preferred embodiments of the present invention, there is provided an isolated polypeptide encoding for a tail of R38144_PEA_2_P19, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence KRSRSVAQAGVQWCDHDSPQP in R38144_PEA_2_P19.
According to preferred embodiments of the present invention, there is provided an isolated chimeric polypeptide encoding for R38144_PEA_2_P24, comprising a first amino acid sequence being at least 90 % homologous to
MPFRLLIPLGLLCALLPQHHGAPGPDGSAPDPAHYRERVKAMFYHAYDSYLENAFPFD
ELRPLTCDGHDTWGSFSLTLIDALDTLLILGNVSEFQRVVEVLQDSVDFDIDVNASVFET NIR corresponding to amino acids 1 - 121 of CT31_HUMAN, which also corresponds to amino acids 1 - 121 of R38144_PEA_2_P24, and a second amino acid sequence being at least 90 % homologous to EYNKAIRNYTRFDDWYLWVQMYKGTVSMPVFQSLEAYWPGLQSLIGDIDNAMRTFLN YYTVWKQFGGLPEFYNIPQGYTVEKREGYPLRPELIESAMYLYRATGDPTLLELGRDA VESIEKISKVECGFATIKDLRDHKLDNRMESFFLAETVKYLYLLFDPTNFIHNNGSTFDA VITPYGECILGAGGYIFNTEAHPIDPAALHCCQRLKEEQWEVEDLMREFYSLKRSRSKFQ KNTVSSGPWEPPARPGTLFSPENHDQARERKPAKQKVPLLSCPSQPFTSKLALLGQVFL DSS corresponding to amino acids 282 - 578 of CT31_HUMAN, which also corresponds to amino acids 122 - 418 of R38144_PEA_2_P24, wherein said first amino acid sequence and second amino acid sequence are contiguous and in a sequential order.
According to preferred embodiments of the present invention, there is provided an isolated chimeric polypeptide encoding for an edge portion of R38144_PEA_2_P24, comprising a polypeptide having a length "n", wherein n is at least about 10 amino acids in length, optionally at least about 20 amino acids in length, preferably at least about 30 amino acids in length, more preferably at least about 40 amino acids in length and most preferably at least about 50 amino acids in length, wherein at least two amino acids comprise RE, having a structure as follows: a sequence starting from any of amino acid numbers 121-x to 121; and ending at any of amino acid numbers 122+ ((n-2) - x), in which x varies from 0 to n-2.
According to preferred embodiments of the present invention, there is provided an isolated chimeric polypeptide encoding for R38144_PEA_2_P36, comprising a first amino acid sequence being at least 90 % homologous to MPFRLLIPLGLLCALLPQHHGAPGPDGSAPDPAHYR corresponding to amino acids 1 - 36 of AAH16184, which also corresponds to amino acids 1 - 36 of R38144_PEA_2_P36, and a second amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence FWGMSQNSKEWLKCSRTAWTLILM corresponding to amino acids 37 - 60 of R38144_PEA_2_P36, wherein said first amino acid sequence and second amino acid sequence are contiguous and in a sequential order.
According to preferred embodiments of the present invention, there is provided an isolated polypeptide encoding for a tail of R38144JPEA_2_P36, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence FWGMSQNSKEWLKCSRTAWTLILM in R38144JPEA_2_P36.
According to preferred embodiments of the present invention, there is provided an isolated chimeric polypeptide encoding for R38144_PEA_2_P36, comprising a first amino acid sequence being at least 90 % homologous to MPFRLLIPLGLLCALLPQHHGAPGPDGSAPDPAHY corresponding to amino acids 1 - 35 of AAQ88943, which also corresponds to amino acids 1 - 35 of R38144_PEA_2_P36, and a second amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence RFWGMSQNSKEWLKCSRTAWTLILM corresponding to amino acids 36 - 60 of R38144_PEA_2_P36, wherein said first amino acid sequence and second amino acid sequence are contiguous and in a sequential order.
According to preferred embodiments of the present invention, there is provided an isolated polypeptide encoding for a tail of R38144_PEA_2_P36, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence RFWGMSQNSKEWLKCSRTAWTLILM in R38144_PEA_2_P36.
According to preferred embodiments of the present invention, there is provided an isolated chimeric polypeptide encoding for R38144_PEA_2_P36, comprising a first amino acid sequence being at least 90 % homologous to MPFRLLIPLGLLCALLPQHHGAPGPDGSAPDPAHYR corresponding to amino acids 1 - 36 of CT31_HUMAN, which also corresponds to amino acids 1 - 36 of R38144_PEA_2_P36, and a second amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence FWGMSQNSKEWLKCSRTAWTLILM corresponding to amino acids 37 - 60 of R38144_PEA_2_P36, wherein said first amino acid sequence and second amino acid sequence are contiguous and in a sequential order.
According to preferred embodiments of the present invention, there is provided an isolated polypeptide encoding for a tail of R38144_PEA_2_P36, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence FWGMSQNSKEWLKCSRTAWTLILM in R38144_PEA_2_P36.
According to preferred embodiments of the present invention, there is provided an isolated chimeric polypeptide encoding for AAl 61187_P6, comprising a first amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence HTREGTLGGQKRAFPDGVEGEKGRGRAWGAASRGSAVPLTIR corresponding to amino acids 1 - 42 of AA161187_P6, and a second amino acid sequence being at least 90 % homologous to
GPCGRRVITSRIVGGEDAELGRWPWQGSLRLWDSHVCGVSLLSHRWALTAAHCFETYS DLSDPSGWMVQFGQLTSMPSFWSLQAYYTRYFVSNIYLSPRYLGNSPYDIALVKLSAPV TYTKHIQPICLQASTFEFENRTDCWVTGWGYIKEDEALPSPHTLQEVQVAIINNSMCNH LFLKYSFRKDIFGDMVCAGNAQGGKDACFGDSGGPLACNKNGLWYQIGVVSWGVGC GRPNRPGVYTNISHHFEWIQKLMAQSGMSQPDPSWPLLFFPLLWALPLLGPV corresponding to amino acids 31 - 314 of TEST_HUMAN, which also corresponds to amino acids 43 - 326 of AA161187_P6, wherein said first amino acid sequence and second amino acid sequence are contiguous and in a sequential order.
According to preferred embodiments of the present invention, there is provided an isolated polypeptide encoding for a head of AAl 61187_P6, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence HTREGTLGGQKRAFPDGVEGEKGRGRAWGAASRGSAVPLTIR of AA161187_P6. According to preferred embodiments of the present invention, there is provided an isolated chimeric polypeptide encoding for AA161187JP13, comprising a first amino acid sequence being at least 90 % homologous to MGARGALLLALLLARAGLRKPESQEAAPLSGPCGRRVITSRIVGGEDAELGRWPWQGS LRLWDSHVCGVSLLSHRWALTAAHCFETYSDLSDPSGWMVQFGQLTSMPSFWSLQAY YTRYFVSNIYLSPRYLGNSPYDIALVKLSAPVTYTKHIQPICLQASTFEFENRTDCWVTG
WGYIKEDE corresponding to amino acids 1 - 183 of TEST_HUMAN, which also corresponds to amino acids 1 - 183 of AA161187_P13, and a second amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence GSSGRHHKQLYVQPPLPQVQFPQGHLWRHG corresponding to amino acids 184 - 213 of AAl 61187_P13, wherein said first amino acid sequence and second amino acid sequence are contiguous and in a sequential order.
According to preferred embodiments of the present invention, there is provided an isolated polypeptide encoding for a tail of AAl 61187_P13, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence GSSGRHHKQLYVQPPLPQVQFPQGHLWRHG in AA161187_P13.
According to preferred embodiments of the present invention, there is provided an isolated chimeric polypeptide encoding for AA161187_P14, comprising a first amino acid sequence being at least 90 % homologous to
MGARGALLLALLLARAGLRKPESQEAAPLSGPCGRRVITSRIVGGEDAELGRWPWQGS LRLWDSHVCGVSLLSHRWALTAAHCFETYSDLSDPSGWMVQFGQLTSMPSFWSLQAY YTRYFVSNIYLSPRYLGNSPYDIALVKLSAPVTYTKHIQPICLQASTFEFENRTDCWVTG WGYIKEDE corresponding to amino acids 1 - 183 of TEST_HUMAN, which also corresponds to amino acids 1 - 183 of AA161187_P14, and a second amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence GCCLSPSHYRPHSTAISPHPPGSSGRHHKQLYVQPPLPQVQFPQGHLWRHGLCWQCPRR EGCLLRECPCHHSQPRKASCVPVPYLTLMPTPGGGDCCPTLQMQKRRLGCCQGEEEDV HPVYPAP corresponding to amino acids 184 - 307 of AA161187_P14, wherein said first amino acid sequence and second amino acid sequence are contiguous and in a sequential order.
According to preferred embodiments of the present invention, there is provided an isolated polypeptide encoding for a tail of AAl 61187_P14, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence
GCCLSPSHYRPHSTAISPHPPGSSGRHHKQLYVQPPLPQVQFPQGHLWRHGLCWQCPRR
EGCLLRECPCHHSQPRKASCVPVPYLTLMPTPGGGDCCPTLQMQKRRLGCCQGEEEDV HPVYPAP in AA161187_P14.
According to preferred embodiments of the present invention, there is provided an isolated chimeric polypeptide encoding for AA161187_P18, comprising a first amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence HTREGTLGGQKRAFPDGVEGEKGRGRAWGAASRGSAVPLTIR corresponding to amino acids 1 - 42 of AA161187_P18, a second amino acid sequence being at least 90 % homologous to GPCGRRVITSRIVGGEDAELGRWPWQGSLRLWDSHVCGVSLLSHRWALTAAHCFET corresponding to amino acids 31 - 86 of TEST_HUMAN, which also corresponds to amino acids 43 - 98 of AAl 61187JP18, a third amino acid sequence being at least 90 % homologous to DLSDPSGWMVQFGQLTSMPSFWSLQAYYTRYFVSNIYLSPRYLGNSPYDIALVKLSAPV TYTKHIQPICLQASTFEFENRTDCWVTGWGYIKEDEALPSPHTLQEVQVAIINNSMCNH LFLKYSFRKDIFGDMVCAGNAQGGKDACF corresponding to amino acids 89 - 235 of TEST-HUMAN, which also corresponds to amino acids 99 - 245 of AA161187_P18, and a fourth amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence VSVPATTP SPGKHPVSLCLI corresponding to amino acids 246 - 265 of AA161187_P18, wherein said first amino acid sequence, second amino acid sequence, third amino acid sequence and fourth amino acid sequence are contiguous and in a sequential order.
According to preferred embodiments of the present invention, there is provided an isolated polypeptide encoding for a head of AAl 61187_P18, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence HTREGTLGGQKRAFPDGVEGEKGRGRAWGAASRGSAVPLTIR of AA161187_P18. According to preferred embodiments of the present invention, there is provided an isolated chimeric polypeptide encoding for an edge portion of AA161187_P18, comprising a polypeptide having a length "n", wherein n is at least about 10 amino acids in length, optionally at least about 20 amino acids in length, preferably at least about 30 amino acids in length, more preferably at least about 40 amino acids in length and most preferably at least about 50 amino acids in length, wherein at least two amino acids comprise TD, having a structure as follows: a
sequence starting from any of amino acid numbers 98-x to 99; and ending at any of amino acid numbers 99+ ((n-2) - x), in which x varies from 0 to n-2.
According to preferred embodiments of the present invention, there is provided an isolated polypeptide encoding for a tail of AA161187JP18, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence VSVPATTPSPGKHPVSLCLI in AAl 61187_P 18.
According to preferred embodiments of the present invention, there is provided an isolated chimeric polypeptide encoding for AA161187 P19, comprising a first amino acid sequence being at least 90 % homologous to
MGARGALLLALLLARAGLRKPESQEAAPLSGPCGRRVITSRIVGGEDAELGRWPWQGS LRLWDSHVCGVSLLSHRWALTAAHCFETYSDLSDPSGWMVQFGQLTSMPSFWSLQAY YTRYFVSNIYLSPRYLGNSPYDIALVKLSAPVTYTKHIQPICLQASTFEFENRTDCWVTG WGYIKEDE corresponding to amino acids 1 - 183 of TEST_HUMAN, which also corresponds to amino acids 1 - 183 of AA161187_P19, and a second amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence DKRTQ corresponding to amino acids 184 - 188 of AA161187_P19, wherein said first amino acid sequence and second amino acid sequence are contiguous and in a sequential order. According to preferred embodiments of the present invention, there is provided an isolated polypeptide encoding for a tail of AA161187_P19, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence DKRTQ in AA161187_P19. According to preferred embodiments of the present invention, there is provided an isolated chimeric polypeptide encoding for Z25299_PEA_2_P2, comprising a first amino acid sequence being at least 90 % homologous to
MKSSGLFPFLVLLALGTLAPWAVEGSGKSFKAGVCPPKKSAQCLRYKKPECQSDWQCP GKKRCCPDTCGIKCLDPVDTPNPTRRKPGKCPVTYGQCLMLNPPNFCEMDGQCKRDLK CCMGMCGKSCVSPVK corresponding to amino acids 1 - 131 of ALK1_HUMAN, which also corresponds to amino acids 1 - 131 of Z25299_PEA_2JP2, and a second amino acid sequence
being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence GKQGMRAH corresponding to amino acids 132 - 139 of Z25299JPEA_2_P2, wherein said first and second amino acid sequences are contiguous and in a sequential order. According to preferred embodiments of the present invention, there is provided an isolated polypeptide encoding for a tail of Z25299_PEA_2_P2, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence GKQGMRAH in Z25299_PEA_2_P2. According to preferred embodiments of the present invention, there is provided an isolated chimeric polypeptide encoding for Z25299_PEA_2_P3, comprising a first amino acid sequence being at least 90 % homologous to
MKSSGLFPFLVLLALGTLAPWAVEGSGKSFKAGVCPPKKSAQCLRYKKPECQSDWQCP GKKRCCPDTCGIKCLDPVDTPNPTRRKPGKCPVTYGQCLMLNPPNFCEMDGQCKRDLK CCMGMCGKSCVSPVK corresponding to amino acids 1 - 131 of ALK1JHUMAN, which also corresponds to amino acids 1 - 131 of Z25299JPEA_2_P3, and a second amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence GEKRHHKQLRDQEVDPLEMRRHSAG corresponding to amino acids 132 - 156 of Z25299_PEA_2_P3, wherein said first and second amino acid sequences are contiguous and in a sequential order.
According to preferred embodiments of the present invention, there is provided an isolated polypeptide encoding for a tail of Z25299_PEA_2_P3, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence GEKRHHKQLRDQEVDPLEMRRHSAG in Z25299_PEA_2_P3.
According to preferred embodiments of the present invention, there is provided an isolated chimeric polypeptide encoding for Z25299_PEA_2_P7, comprising a first amino acid sequence being at least 90 % homologous to MKSSGLFPFLVLLALGTLAPWAVEGSGKSFKAGVCPPKKSAQCLRYKKPECQSDWQCP GKKRCCPDTCGIKCLDPVDTPNP corresponding to amino acids 1 - 81 of ALK1JHUMAN,
which also corresponds to amino acids 1 - 81 of Z25299_PEA_2_P7, and a second amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence RGSLGSAQ corresponding to amino acids 82 - 89 of Z25299JPEA_2J?7, wherein said first and second amino acid sequences are contiguous and in a sequential order.
According to preferred embodiments of the present invention, there is provided an isolated polypeptide encoding for a tail of Z25299JPEA 2JP7, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence RGSLGSAQ in Z25299JPEA_2_P7.
According to preferred embodiments of the present invention, there is provided an isolated chimeric polypeptide encoding for Z25299_PEA_2_P10, comprising a first amino acid sequence being at least 90 % homologous to
MKSSGLFPFLVLLALGTLAPWAVEGSGKSFKAGVCPPKKSAQCLRYKKPECQSDWQCP GKKRCCPDTCGIKCLDPVDTPNPT corresponding to amino acids 1 - 82 of ALK1_HUMAN, which also corresponds to amino acids 1 - 82 of Z25299_PEA_2_P10.
According to preferred embodiments of the present invention, there is provided an isolated chimeric polypeptide encoding for R66178_P3, comprising a first amino acid sequence being at least 90 % homologous to MARMGLAGAAGRWWGLALGLTAFFLPGVHSQWQVNDSMYGFIGTDVVLHCSFANP LPSVKITQVTWQKSTNGSKQNVAΓYNPSMGVSVLAPYRERVEFLRPSFTDGTIRLSRLEL EDEGVYICEFATFPTGNRESQLNLTVMAKPTNWIEGTQA VLRAKKGQDDKVLVATCTS ANGKPPSWSWETRLKGEAEYQEIRNPNGTVTVISRYRLVPSREAHQQSLACIVNYHM DRFKESLTLNVQYEPEVTIEGFDGNWYLQRMDVKLTCKADANPPATEYHWTTLNGSLP KGVEAQNRTLFFKGPINYSLAGTYICEATNPIGTRSGQVEVNIT corresponding to amino acids 1 - 334 of PVRIJHUMAN, which also corresponds to amino acids 1 - 334 of R66178_P3, and a second amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence GEGHSLPISPGVLQTQNCGP corresponding to amino acids 335 - 354 of R66178 P3, wherein said first amino acid sequence and second amino acid sequence are contiguous and in a sequential order.
According to preferred embodiments of the present invention, there is provided an isolated polypeptide encoding for a tail of R66178_P3, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence GEGHSLPISPGVLQTQNCGP in R66178_P3.
According to preferred embodiments of the present invention, there is provided an isolated chimeric polypeptide encoding for R66178_P4, comprising a first amino acid sequence being at least 90 % homologous to MARMGLAGAAGRWWGLALGLTAFFLPGVHSQWQVNDSMYGFIGTDVVLHCSFANP LPSVKITQVTWQKSTNGSKQNVAIYNPSMGVSVLAPYRERVEFLRPSFTDGTIRLSRLEL EDEGVYICEFATFPTGNRESQLNLTVMAKPTNWIEGTQAVLRAKKGQDDKVLVATCTS ANGKPPSVVSWETRLKGEAEYQEIRNPNGTVTVISRYRLVPSREAHQQSLACIVNYHM DRFKESLTLNVQYEPEVTIEGFDGNWYLQRMDVKLTCKADANPPATEYHWTTLNGSLP KGVEAQNRTLFFKGPINYSLAGTYICEATNPIGTRSGQVEVNIT corresponding to amino acids 1 - 334 of PVR1_HUMAN, which also corresponds to amino acids 1 - 334 of R66178_P4, and a second amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence AFCQLIYPGKGRTRARMF corresponding to amino acids 335 - 352 of R66178_P4, wherein said first amino acid sequence and second amino acid sequence are contiguous and in a sequential order.
According to preferred embodiments of the present invention, there is provided an isolated polypeptide encoding for a tail of R66178_P4, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence AFCQLIYPGKGRTRARMF in R66178_P4.
According to preferred embodiments of the present invention, there is provided an isolated chimeric polypeptide encoding for R66178_P8, comprising a first amino acid sequence being at least 90 % homologous to MARMGLAGAAGRWWGLALGLTAFFLPGVHSQWQVNDSMYGFIGTDVVLHCSFANP LPSVKITQVTWQKSTNGSKQNVAIYNPSMGVS VLAPYRERVEFLRPSFTDGTIRLSRLEL EDEGVYICEFATFPTGNRESQLNLTVMAKPTNWIEGTQAVLRAKKGQDDKVLVATCTS
ANGKPPSVVSWETRLKGEAEYQEIRNPNGTVTVISRYRLVPSREAHQQSLACIVNYHM DRFKESLTLNVQYEPEVTIEGFDGNWYLQRMDVKLTCKADANPPATEYHWTTLNGSLP KGVEAQNRTLFFKGPINYSLAGTYICEATNPIGTRSGQVE corresponding to amino acids 1
- 330 of PVR1_HUMAN, which also corresponds to amino acids 1 - 330 of R66178_P8, and a second amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence NSPTPRLLPNMGGAPGRCPRPSLGAWRGASCWC corresponding to amino acids 331 - 363 of R66178 P8, wherein said first amino acid sequence and second amino acid sequence are contiguous and in a sequential order. According to preferred embodiments of the present invention, there is provided an isolated polypeptide encoding for a tail of R66178_P8, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence NSPTPRLLPNMGGAPGRCPRPSLGAWRGASCWC in R66178_P8. According to preferred embodiments of the present invention, there is provided an isolated chimeric polypeptide encoding for HSU33147_PEA_1_P5, comprising a first amino acid sequence being at least 90 % homologous to
MKLLMVLMLAALSQHCYAGSGCPLLENVISKTINPQVSKTEYKELLQEFIDDNATTNAI DELKECFLNQTDETLSNVE corresponding to amino acids 1 - 78 of MGBAJHUMAN, which also corresponds to amino acids 1 - 78 of HSU33147_PEA_1_P5, and a second amino acid sequence being at least 90 % homologous to QLIYDSSLCDLF corresponding to amino acids 82
- 93 of MGBA HUMAN, which also corresponds to amino acids 79 - 90 of HSU33147_PEA_1_P5, wherein said first amino acid sequence and second amino acid sequence are contiguous and in a sequential order. According to preferred embodiments of the present invention, there is provided an isolated chimeric polypeptide encoding for an edge portion of HSU33147_PEA_1_P5, comprising a polypeptide having a length "n", wherein n is at least about 10 amino acids in length, optionally at least about 20 amino acids in length, preferably at least about 30 amino acids in length, more preferably at least about 40 amino acids in length and most preferably at least about 50 amino acids in length, wherein at least two amino acids comprise EQ, having a
structure as follows: a sequence starting from any of amino acid numbers 78-x to 78; and ending at any of amino acid numbers 79+ ((n-2) - x), in which x varies from 0 to n-2.
According to preferred embodiments of the present invention, there is provided an isolated chimeric polypeptide encoding for HSU33147_PEA_1_P5, comprising a first amino acid sequence being at least 90 % homologous to
MKLLMVLMLAALSQHCYAGSGCPLLENVISKTINPQVSKTEYKELLQEFIDDNATTNAI DELKECFLNQTDETLSNVE corresponding to amino acids 1 - 78 of MGBA_HUMAN, which also corresponds to amino acids 1 - 78 of HSU33147_PEA_1_P5, and a second amino acid sequence being at least 90 % homobgous to QLIYDSSLCDLF corresponding to amino acids 82 - 93 of MGBA_HUMAN, which also corresponds to amino acids 79 - 90 of
HSU33147_PEA_1_P5, wherein said first amino acid sequence and second amino acid sequence are contiguous and in a sequential order.
According to preferred embodiments of the present invention, there is provided an isolated chimeric polypeptide encoding for an edge portion of HSU33147_PEA_1_P5, comprising a polypeptide having a length "n", wherein n is at least about 10 amino acids in length, optionally at least about 20 amino acids in length, preferably at least about 30 amino acids in length, more preferably at least about 40 amino acids in length and most preferably at least about 50 amino acids in length, wherein at least two amino acids comprise EQ, having a structure as follows: a sequence starting from any of amino acid numbers 78-x to 78; and ending at any of amino acid numbers 79+ ((n-2) - x), in which x varies from 0 to n-2.
According to preferred embodiments of the present invention, there is provided an isolated chimeric polypeptide encoding for M78076_PEA_l_P3, comprising a first amino acid sequence being at least 90 % homologous to
MGPASPAARGLSRRPGQPPLPLLLPLLLLLLRAQPAIGSLAGGSPGAAEAPGSAQVAGL CGRLTLHRDLRTGRWEPDPQRSRRCLRDPQRVLEYCRQMYPELQIARVEQATQAIPME
RWCGGSRSGSCAHPHHQWPFRCLPGEFVSEALLVPEGCRFLHQERMDQCESSTRRHQ
EAQEACSSQGLILHGSGMLLPCGSDRFRGVEYVCCPPPGTPDPSGTAVGDPSTRSWPPG
SRVEGAEDEEEEESFPQPVDDYFVEPPQAEEEEETVPPPSSHTLAVVGKVTPTPRPTDGV
DIYFGMPGEISEHEGFLRAKMDLEERRMRQINEVMREWAMADNQSKNLPKADRQALN EHFQSILQTLEEQVSGERQRLVETHATRVIALINDQRRAALEGFLAALQADPPQAERVLL
ALRRYLRAEQKEQRHTLRHYQHVAAVDPEKAQQMRFQVHTHLQVIEERVNQSLGLLD
QNPHLAQELRPQIQELLHSEHLGPSELEAPAPGGSSEDKGGLQPPDSKD corresponding to amino acids 1 - 517 of APP IJHUMAN, which also corresponds to amino acids 1 - 517 of M78076_PEA_l_P3, and a second amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence GE corresponding to amino acids 518 - 519 of M78076_PEA_l_P3, wherein said first amino acid sequence and second amino acid sequence are contiguous and in a sequential order.
According to preferred embodiments of the present invention, there is provided an isolated chimeric polypeptide encoding for M78076_PEA_l_P4, comprising a first amino acid sequence being at least 90 % homologous to
MGPASPAARGLSRRPGQPPLPLLLPLLLLLLRAQPAIGSLAGGSPGAAEAPGSAQVAGL CGRLTLHRDLRTGRWEPDPQRSRRCLRDPQRVLEYCRQMYPELQIARVEQATQAIPME RWCGGSRSGSCAHPHHQVVPFRCLPGEFVSEALLVPEGCRFLHQERMDQCESSTRRHQ EAQEACSSQGLILHGSGMLLPCGSDRFRGVEYVCCPPPGTPDPSGTAVGDPSTRSWPPG SRVEGAEDEEEEESFPQPVDDYFVEPPQAEEEEETVPPPSSHTLAWGKVTPTPRPTDGV DIYFGMPGEISEHEGFLRAKMDLEERRMRQINEVMREWAMADNQSKNLPKADRQALN EHFQSILQTLEEQVSGERQRLVETHATRVIALINDQRRAALEGFLAALQADPPQAERVLL ALRRYLRAEQKEQRΉTLRHYQHVAAVDPEKAQQMRFQVHTHLQVIEERVNQSLGLLD QNPHLAQELRPQIQELLHSEHLGPSELEAPAPGGSSEDKGGLQPPDSKDDTPMTLPKG corresponding to amino acids 1 - 526 of APPl HUMAN, which also corresponds to amino acids 1 - 526 of M78076_PEA_l_P4, and a second amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence ECLTVNPSLQIPLNP corresponding to amino acids 527 - 541 of M78076_PEA_l_P4, wherein said first amino acid sequence and second amino acid sequence are contiguous and in a sequential order.
According to preferred embodiments of the present invention, there is provided an isolated polypeptide encoding for a tail of M78076_PEA_l_P4, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence ECLTVNPSLQIPLNP in M78076_PEA_l_P4.
According to preferred embodiments of the present invention, there is provided an isolated chimeric polypeptide encoding for M78076_PEA_l_P12, comprising a first amino acid sequence being at least 90 % homologous to
MGPASPAARGLSRRPGQPPLPLLLPLLLLLLRAQPAIGSLAGGSPGAAEAPGSAQVAGL CGRLTLHRDLRTGRWEPDPQRSRRCLRDPQRVLEYCRQMYPELQIARVEQATQAIPME RWCGGSRSGSCAHPHHQVVPFRCLPGEFVSEALLVPEGCRFLHQERMDQCESSTRRHQ EAQEACSSQGLILHGSGMLLPCGSDRFRGVEYVCCPPPGTPDPSGTAVGDPSTRSWPPG SRVEGAEDEEEEESFPQPVDDYFVEPPQAEEEEETVPPPSSHTLAWGKVTPTPRPTDGV DIYFGMPGEISEHEGFLRAKMDLEERRMRQINEVMREWAMADNQSKNLPKADRQALN EHFQSILQTLEEQVSGERQRLVETHATRVIALINDQRRAALEGFLAALQADPPQAERVLL ALRRYLRAEQKEQRHTLRHYQHVAAVDPEKAQQMRFQVHTHLQVIEERVNQSLGLLD QNPHLAQELRPQIQELLHSEHLGPSELEAPAPGGSSEDKGGLQPPDSKDDTPMTLPKG corresponding to amino acids 1 - 526 of APPl HUMAN, which also corresponds to amino acids 1 - 526 of M78076_PEA_l_P12, and a second amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence ECVCSKGFPFPLIGDSEG corresponding to amino acids 527 - 544 of M78076_PEA_l_P12, wherein said first amino acid sequence and second amino acid sequence are contiguous and in a sequential order. According to preferred embodiments of the present invention, there is provided an isolated polypeptide encoding for a tail of M78076_PEA_l_P12, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence ECVCSKGFPFPLIGDSEG in M78076_PEA_l_P12. According to preferred embodiments of the present invention, there is provided an isolated chimeric polypeptide encoding for M78076_PEA_l_P14, comprising a first amino acid sequence being at least 90 % homologous to
MGPASPAARGLSRRPGQPPLPLLLPLLLLLLRAQPAIGSLAGGSPGAAEAPGSAQVAGL CGRLTLHRDLRTGRWEPDPQRSRRCLRDPQRVLEYCRQMYPELQIARVEQATQAIPME RWCGGSRSGSCAHPHHQVWFRCLPGEFVSEALLWEGCRFLHQERMDQCESSTRRHQ EAQEACSSQGLILHGSGMLLPCGSDRFRGVEYVCCPPPGTPDPSGTAVGDPSTRSWPPG
SRVEGAEDEEEEESFPQPVDDYFVEPPQAEEEEETVPPPSSHTLAVVGKVTPTPRPTDGV DIYFGMPGEISEHEGFLRAKMDLEERRMRQINEVMREWAMADNQSKNLPKADRQALN EHFQSILQTLEEQVSGERQRLVETHATRVIALINDQRRAALEGFLAALQADPPQAERVLL ALRRYLRAEQKEQRHTLRHYQHVAAVDPEKAQQMRFQVHTHLQVIEERVNQSLGLLD QNPHLAQELRPQIQELLHSEHLGPSELEAPAPGGSSEDKGGLQPPDSKDDTPMTLPKGST
EQDAASPEKEKMNPLEQYERKVNASVPRGFPFHSSEIQRDEL corresponding to amino acids 1 - 570 of APP1JHUMAN, which also corresponds to amino acids 1 - 570 of M78076_PEA_l_P14, and a second amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence
VRGGTAGYLGEETRGQRPGCDSQSHTGPSKKPSAPSPLPAGTSWDRGVP corresponding to amino acids 571 - 619 of M78076_PEA_l_P14, wherein said first amino acid sequence and second amino acid sequence are contiguous and in a sequential order.
According to preferred embodiments of the present invention, there is provided an isolated polypeptide encoding for a tail of M78076_PEA_l_P14, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence VRGGTAGYLGEETRGQRPGCDSQSHTGPSKKPSAPSPLPAGTSWDRGVP in M78076_PEA_l_P14. According to preferred embodiments of the present invention, there is provided an isolated chimeric polypeptide encoding for M78076_PEA_l_P21, comprising a first amino acid sequence being at least 90 % homologous to
MGPASPAARGLSRRPGQPPLPLLLPLLLLLLRAQPAIGSLAGGSPGAAEAPGSAQVAGL CGRLTLHRDLRTGRWEPDPQRSRRCLRDPQRVLEYCRQMYPELQIARVEQATQAIPME RWCGGSRSGSCAHPHHQWPFRCLPGEFVSEALLVPEGCRFLHQERMDQCESSTRRHQ EAQEACSSQGLILHGSGMLLPCGSDRFRGVEYVCCPPPGTPDPSGTAVGDPSTRSWPPG SRVEGAEDEEEEESFPQPVDDYFVEPPQAEEEEETVPPPSSHTLAVVGKVTPTPRPTDGV DIYFGMPGEISEHEGFLRAKMDLEERRMRQINEVMREWAMADNQSKNLPKADRQALN E corresponding to amino acids 1 - 352 of APP IJHUMAN, which also corresponds to amino acids 1 - 352 of M78076_PEA_l_P21, and a second amino acid sequence being at least 90 % homologous to
AERVLLALRRYLRAEQKEQRHTLRHYQHVAAVDPEKAQQMRFQVHTHLQVIEERVNQ SLGLLDQNPHLAQELRPQIQELLHSEHLGPSELEAPAPGGSSEDKGGLQPPDSKDDTPMT LPKGSTEQDAASPEKEKMNPLEQYERKVNASVPRGFPFHSSEIQRDELAPAGTGVSREA VSGLLIMGAGGGSLIVLSMLLLRRKKPYGAISHGVVEVDPMLTLEEQQLRELQRHGYE NPTYRFLEERP corresponding to amino acids 406 - 650 of APP1_HUMAN, which also corresponds to amino acids 353 - 597 of M78076_PEA_l_P21, wherein said first amino acid sequence and second amino acid sequence are contiguous and in a sequential order.
According to preferred embodiments of the present invention, there is provided an isolated chimeric polypeptide encoding for an edge portion of M78076_PEA_l_P21, comprising a polypeptide having a length "n", wherein n is at least about 10 amino acids in length, optionally at least about 20 amino acids in length, preferably at least about 30 amino acids in length, more preferably at least about 40 amino acids in length and most preferably at least about 50 amino acids in length, wherein at least two amino acids comprise EA, having a structure as follows: a sequence starting from any of amino acid numbers 352-x to 352; and ending at any of amino acid numbers 353+ ((n-2) - x), in which x varies fromO to n-2.
According to preferred embodiments of the present invention, there is provided an isolated chimeric polypeptide encoding for M78076_PEA_l_P24, comprising a first amino acid sequence being at least 90 % homologous to MGPASPAARGLSRRPGQPPLPLLLPLLLLLLRAQPAIGSLAGGSPGAAEAPGSAQVAGL CGRLTLHRDLRTGRWEPDPQRSRRCLRDPQRVLEYCRQMYPELQIARVEQATQAIPME RWCGGSRSGSCAHPHHQVVPFRCLPGEFVSEALLVPEGCRFLHQERMDQCESSTRPVHQ
EAQEACSSQGLILHGSGMLLPCGSDRFRGVEYVCCPPPGTPDPSGTAVGDPSTRSWPPG SRVEGAEDEEEEESFPQPVDDYFVEPPQAEEEEETVPPPSSHTLAVVGKVTPTPRPTDGV DIYFGMPGEISEHEGFLRAKMDLEERRMRQINEVMREWAMADNQSKNLPKADRQALN EHFQSILQTLEEQVSGERQRLVETHATRVIALINDQRRAALEGFLAALQADPPQAERVLL ALRRYLRAEQKEQRHTLRHYQHVAAVDPEKAQQMRFQVHTHLQVIEERVNQSLGLLD
QNPHLAQELRPQI corresponding to amino acids 1 - 481 of APP1_HUMAN, which also corresponds to amino acids 1 - 481 of M78076_PEA_l_P24, and a second amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence
RECLLPWLPLQISEGRS corresponding to amino acids 482 - 498 of M78076_PEA_l_P24,
wherein said first amino acid sequence and second amino acid sequence are contiguous and in a sequential order.
According to preferred embodiments of the present invention, there is provided an isolated polypeptide encoding for a tail of M78076_PEA_l_P24, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence
RECLLPWLPLQISEGRS in M78076_PEA_l_P24.
According to preferred embodiments of the present invention, there is provided an isolated chimeric polypeptide encoding for M78076_PEA_l_P2, comprising a first amino acid sequence being at least 90 % homologous to
MGPASPAARGLSRRPGQPPLPLLLPLLLLLLRAQPAIGSLAGGSPGAAEAPGSAQVAGL
CGRLTLHRDLRTGRWEPDPQRSRRCLRDPQRVLEYCRQMYPELQIARVEQATQAIPME
RWCGGSRSGSCAHPHHQVVPFRCLPGEFVSEALLVPEGCRFLHQERMDQCESSTRRHQ
EAQEACSSQGLILHGSGMLLPCGSDRFRGVEYVCCPPPGTPDPSGTAVGDPSTRSWPPG SRVEGAEDEEEEESFPQPVDDYFVEPPQAEEEEETVPPPSSHTLAVVGKVTPTPRPTDGV
DIYFGMPGEISEHEGFLRAKMDLEERRMRQINEVMREWAMADNQSKNLPKADRQALN
EHFQSILQTLEEQVSGERQRLVETHATRVIALINDQRRAALEGFLAALQADPPQAERVLL
ALRRYLRAEQKEQRHTLRHYQHVAAVDPEKAQQMRFQV corresponding to amino acids
1 - 449 of APPl HUMAN, which also corresponds to amino acids 1 - 449 of M78076JPEA_l_P2, and a second amino acid sequence being at least 70%, optionally at least
80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence
LTSFQLPNAPLFLRRPRLRLFSCPLDPLSVSWTPSYPLNTASLPLPSLSAQLPDPETWTLT
CCVFDPCFLALGFLLPPPSILCSVPWIFTAFPRIVFFFFFFLRQVLALSPRQESSVRSWLIAT STSWVQAILLPQPLE corresponding to amino acids 450 - 588 of M78076_PEA_l_P2, wherein said first amino acid sequence and second amino acid sequence are contiguous and in a sequential order.
According to preferred embodiments of the present invention, there is provided an isolated polypeptide encoding for a tail of M78076JPEA_l_P2, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence
LTSFQLPNAPLFLRRPRJLRLFSCPLDPLSVSWTPSYPLNTASLPLPSLSAQLPDPETWTLT CCVFDPCFLALGFLLPPPSILCSVPWIFTAFPRIVFFFFFFLRQVLALSPRQESSVRSWLIAT STSWVQAILLPQPLE in M78076_PEA_l_P2.
According to preferred embodiments of the present invention, there is provided an isolated chimeric polypeptide encoding for M78076_PEA_l_P25, comprising a first amino acid sequence being at least 90 % homologous to
MGPASPAARGLSRRPGQPPLPLLLPLLLLLLRAQPAIGSLAGGSPGAAEAPGSAQVAGL CGRLTLHRDLRTGRWEPDPQRSRRCLRDPQRVLEYCRQMYPELQIARVEQATQAIPME RWCGGSRSGSCAHPHHQVVPFRCLPGEFVSEALLVPEGCRFLHQERMDQCESSTRRHQ EAQEACSSQGLILHGSGMLLPCGSDRFRGVEYVCCPPPGTPDPSGTAVGDPSTRSWPPG SRVEGAEDEEEEESFPQPVDDYFVEPPQAEEEEETVPPPSSHTLAVVGKVTPTPRPTDGV DIYFGMPGEISEHEGFLRAKMDLEERRMRQINEVMREWAMADNQSKNLPKADRQALN EHFQSILQTLEEQVSGERQRLVETHATRVIALINDQRRAALEGFLAALQADPPQAERVLL
ALRRYLRAEQKEQRHTLRHYQHVAAVDPEKAQQMRFQ corresponding to amino acids 1 - 448 of APP IJHUMAN, which also corresponds to amino acids 1 - 448 of
M78076_PEA_l_P25, and a second amino acid sequence being at least 70%, optionally at least
80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence
PQNPNSQPRAAGSLEVIISHPFVRRLEILISPFQFQNSIPKNSQIVPAASPRGTSSP corresponding to amino acids 449 - 505 of M78076_PEA_l_P25, wherein said first amino acid sequence and second amino acid sequence are contiguous and in a sequential order.
According to preferred embodiments of the present invention, there is provided an isolated polypeptide encoding for a tail of M78076_PEA_l_P25, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence
PQNPNSQPRAAGSLEVIISHPFVRRLEILISPFQFQNSffKNSQIVPAASPRGTSSP in
M78076_PEA_l_P25.
According to preferred embodiments of the present invention, there is provided an isolated chimeric polypeptide encoding for M79217_PEA_1_P1, comprising a first amino acid sequence being at least 90 % homologous to
MTGYTMLRNGGAGNGGQTCMLRWSNRIRLTWLSFTLFVILVFFPLIAHYYLTTLDEAD
EAGKRIFGPRVGNELCEVKHVLDLCRIRESVSEELLQLEAKRQELNSEIAKLNLKIEACK KSIENAKQDLLQLKNVISQTEHSYKELMAQNQPKLSLPIRLLPEKDDAGLPPPKATRGC RLHNCFDYSRCPLTSGFPVYVYDSDQFVFGSYLDPLVKQAFQATARANVYVTENADIA CLYVILVGEMQEPVVLRPAELEKQLYSLPHWRTDGHNHVIINLSRKSDTQNLLYNVSTG RAMVAQSTFYTVQYRPGFDLVVSPLVHAMSEPNFMEIPPQVPVKRKYLFTFQGEKIESL RSSLQEARSFEEEMEGDPPADYDDRIIATLKAVQDSKLDQVLVEFTCKNQPKPSLPTEW ALCGEREDRLELLKLSTFALIITPGDPRLVISSGCATRLFEALEVGAVPVVLGEQVQLPY QDMLQWNEAALVVPKPRVTEVHFLLRSLSDSDLLAMRRQGRFLWETYFSTADSIFNTV LAMIRTRIQIPAAPIREEAAAEIPHRSGKAAGTDPNMADNGDLDLGPVETEPPYASPRYL RNFTLTVTDFYRSWNCAPGPFHLFPHTPFDPVLPSEAKFLGSGTGFRPIGGGAGGSGKEF QAALGGNVPREQFTVVMLTYEREEVLMNSLERLNGLPYLNKVVVVWNSPKLPSEDLL WPDIGVPIMVVRTEKNSLNNRFLPWNEIETEAILSIDDDAHLRHDEIMFGFRVWREARD RWGFPGRYHAWDIPHQSWLYNSNYSCELSMVLTGAAFFHKYYAYLYSYVMPQAIRD MVDEYINCEDIAMNFLVSHITRKPPIKVTSRWTFRCPGCPQALSHDDSHFHERHKCINFF VKVYGYMPLLYTQFRVDSVLFKTRLPHDKTKCFKFI corresponding to amino acids 13 - 931 of BAA25445, which also corresponds to amino acids 1 - 919 of M79217_PEA_1_P1.
According to preferred embodiments of the present invention, there is provided an isolated chimeric polypeptide encoding for M79217_PEA_1_P2, comprising a first amino acid sequence being at least 90 % homologous to MTGYTMLRNGGAGNGGQTCMLRWSNMRLTWLSFTLFVILVFFPLIAHYYLTTLDEAD EAGKRIFGPRVGNELCEVKHVLDLCRIRESVSEELLQLEAKRQELNSEIAKLNLKIEACK KSIENAKQDLLQLKNVISQTEHSYKELMAQNQPKLSLPIRLLPEKDDAGLPPPKATRGC RLHNCFDYSRCPLTSGFPVYVYDSDQFVFGSYLDPLVKQAFQATARANVYVTENADIA CLYVILVGEMQEP WLRPAELEKQLYSLPHWRTDGHNHVIINLSRKSDTQNLLYNVSTG RAMVAQSTFYTVQYRPGFDLWSPLVHAMSEPNFMEIPPQVPVKRKYLFTFQGEKIESL RSSLQEARSFEEEMEGDPPADYDDMIATLKAVQDSKLDQVLVEFTCKNQPKPSLPTEW ALCGEREDRLELLKLSTFALIITPGDPRLVISSGCATRLFEALEVGAVPWLGEQVQLPY QDMLQWNEAALWPKPRVTEVHFLLRSLSDSDLLAMRRQGRFLWETYFSTADSIFNTV LAMIRTMQIPAAPIREEAAAEIPHRSGKAAGTDPNMADNGDLDLGPVETEPPYASPRYL RNFTLTVTDFYRSWNCAPGPFHLFPHTPFDPVLPSEAKFLGSGTGFRPIGGGAGGSGKEF QAALGGNVPREQFTWMLTYEREEVLMNSLERLNGLPYLNKWWWNSPKLPSEDLL
WPDIGVPIMVVRTEKNSLNNRFLPWNEIETEAILSIDDDAHLRHDEIMFGFRVWREARD RIVGFPGRYHAWDIPHQSWLYNSNYSCELSMVLTGAAFFHK corresponding to amino acids 1 - 807 of EXL3_HUMAN, which also corresponds to amino acids 1 - 807 of M79217_PEA_1_P2, and a second amino acid sequence being at least 90 % homologous to AIRDMVDEYINCEDIAMNFLVSHITRKPPIKVTSRWTFRCPGCPQALSHDDSHFHERHK CINFFVKVYGYMPLLYTQFRVDSVLFKTRLPHDKTKCFKFI corresponding to amino acids 820 - 919 of EXL3JHUMAN, which also corresponds to amino acids 808 - 907 of M79217_PEA_1_P2, wherein said first amino acid sequence and second amino acid sequence are contiguous and in a sequential order. According to preferred embodiments of the present invention, there is provided an isolated chimeric polypeptide encoding for an edge portion of M79217_PEA_1_P2, comprising a polypeptide having a length "n", wherein n is at least about 10 amino acids in length, optionally at least about 20 amino acids in length, preferably at least about 30 amino acids in length, more preferably at least about 40 amino acids in length and most preferably at least about 50 amino acids in length, wherein at least two amino acids comprise KA, having a structure as follows: a sequence starting from any of amino acid numbers 807-x to 807; and ending at any of amino acid numbers 808+ ((n-2) - x), in which x varies from 0 to n-2.
According to preferred embodiments of the present invention, there is provided an isolated chimeric polypeptide encoding for M79217_PEA_1JP4, comprising a first amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence
PELRQPARLGLPECWDYRHEPRCPAQMGSHFΓVQAGLKLLASSKPPKCWDY corresponding to amino acids 1 - 51 of M79217_PEA_1_P4, and a second amino acid sequence being at least 90 % homologous to RVWREARDRIVGFPGRYHAWDIPHQSWLYNSNYSCELSMVLTGAAFFHKYYAYLYSY VMPQAIRDMVDEYINCEDIAMNFLVSHITRKPPIKVTSRWTFRCPGCPQALSHDDSHFH ERHKCINFFVKVYGYMPLLYTQFRVDSVLFKTRLPHDKTKCFKFI corresponding to amino acids 759 - 919 of EXL3_HUMAN, which also corresponds to amino acids 52 - 212 of M79217_PEA_1_P4, wherein said first amino acid sequence and second amino acid sequence are contiguous and in a sequential order.
According to preferred embodiments of the present invention, there is provided an isolated polypeptide encoding for a head of M79217_PEA_1_P4, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence PELRQPARLGLPECWDYRHEPRCP AQMGSHFIVQAGLKLLASSKPPKCWDY of M79217_PEA_1_P4.
According to preferred embodiments of the present invention, there is provided an isolated chimeric polypeptide encoding for M79217_PEA_1_P8, comprising a first amino acid sequence being at least 90 % homologous to MTGYTMLRNGGAGNGGQTCMLRWSNRIRLTWLSFTLFVILVFFPLIAHYYLTTLDEAD EAGKRIFGPRVGNELCEVKHVLDLCRIRESVSEELLQLEAKRQELNSEIAKLNLKIEACK KSIENAKQDLLQLKNVISQTEHSYKELMAQNQPKLSLPIRLLPEKDDAGLPPPKATRGC RLHNCFDYSRCPLTSGFPVYVYDSDQFVFGSYLDPLVKQAFQATARANVYVTENADIA CLYVILVGEMQEPVVLRPAELEKQLYSLPHWRTDGHNHVIINLSRKSDTQNLLYNVSTG RAMVAQSTFYTVQYRPGFDLVVSPLVHAMSEPNFMEIPPQVPVKRKYLFTFQGEKIESL RSSLQEARSFEEEMEGDPPADYDDRIIATLKAVQDSKLDQVLVEFTCKNQPKPSLPTEW ALCGEREDRLELLKLSTFALIITPGDPRLVISSGCATRLFEALEVGAVPWLGEQVQLPY QDMLQWNEAALVVPKPRVTEVHFLLRSLSDSDLLAMRRQGRFLWETYFSTADSIFNTV LAMIRTRIQIPAAPIREEAAAEIPHRSGKAAGTDPNMADNGDLDLGPVETEPPYASPRYL RNFTLTVTDFYRSWNCAPGPFHLFPHTPFDPVLPSEAKFLGSGTGFRPIGGGAGGSGKEF QAALGGNVPREQFTWMLTYEREEVLMNSLERLNGLPYLNKVVVVWNSPKLPSEDLL WPDIGVPIMVVRTEKNSLNNRFLPWNEIETEAILSIDDDAHLRHDEIMFGFRVWREARD RIVGFPGRYHAWDIPHQSWLYNSNYSCELSMVLTGAAFFHK corresponding to amino acids 1 - 807 of EXL3 HUMAN, which also corresponds to amino acids 1 - 807 of M79217JPEA_1_P8, and a second amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence VRKSW corresponding to amino acids 808 - 812 of M79217_PEA_1_P8, wherein said first amino acid sequence and second amino acid sequence are contiguous and in a sequential order. According to preferred embodiments of the present invention, there is provided an isolated polypeptide encoding for a tail of M79217_PEA_1_P8, comprising a polypeptide being
at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence VRKSW in M79217_PEA_1_P8.
According to preferred embodiments of the present invention, there is provided an isolated chimeric polypeptide encoding for M62096_PEA_l_P4, comprising a first amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence MATYIH corresponding to amino acids 1 - 6 of M62096JPEA_l_P4, and a second amino acid sequence being at least 90 % homologous to VSKTGAEGAVLDEAKNINKSLSALGNVISALAEGTKTHVPYRDSKMTRILQDSLGGNC RTTIVICCSPSVFNEAETKSTLMFGQRAKTIKNTVSVNLELTAEEWKKKYEKEKEKNKT
LKNviQHLEMELNRWRNGEA VPEDEQISAKDQKNLEPCDNTPIIDNIAPWAGISTEEKE KYDEEISSLYRQLDDKDDEΓNQQSQLAEKLKQQMLDQDELLASTRRDYEKIQEELTRLQ IENEAAKDEVKEVLQALEELAVNYDQKSQEVEDKTRANEQLTDELAQKTTTLTTTQRE LSQLQELSNHQKKRATEILNLLLKDLGEIGGIIGTNDVKTLADVNGVIEEEFTMARLYIS KMKSEVKSLVNRSKQLESAQMDSNRKMNASERELAACQLLISQHEAKIKSLTDYMQN MEQKRRQLEESQDSLSEELAKLRAQEKMHEVSFQDKEKEHLTRLQDAEEMKKALEQQ MESHREAHQKQLSRLRDEIEEKQKIIDEIRDLNQKLQLEQEKLSSDYNKLKIEDQEREM KLEKLLLLNDKREQAREDLKGLEETVSRELQTLHNLRKLFVQDLTTRVKKSVELDNDD GGGSAAQKQKISFLENNLEQLTKVHKQLVRDNADLRCELPKLEKRLRATAERVKALES ALKEAKENAMRDRKRYQQEVDMKEAVRAKNMARRAHSAQIAKPIRPGHYPASSPTA
VHAIRGGGGSSSNSTHYQK corresponding to amino acids 239 - 957 of KF5C_HUMAN, which also corresponds to amino acids 7 - 725 of M62096_PEA_l_P4, wherein said first amino acid sequence and second amino acid sequence are contiguous and in a sequential order. According to preferred embodiments of the present invention, there is provided an isolated polypeptide encoding for a head of M62096_PEA_l_P4, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence MATYIH of M62096_PEA_l_P4. According to preferred embodiments of the present invention, there is provided an isolated chimeric polypeptide encoding for M62096_PEA_l_P5, comprising a first amino acid
sequence being at least 90 % homologous to
MTRILQDSLGGNCRTTIVICCSPSVFNEAETKSTLMFGQRAKTIKNTVSVNLELTAEEWK KKYEKEKEKNKTLKNVIQHLEMELNRWRNGEAVPEDEQISAKDQKNLEPCDNTPIIDNI APWAGISTEEKEKYDEEISSLYRQLDDKDDEINQQSQLAEKLKQQMLDQDELLASTRR DYEKIQEELTRLQIENEAAKDEVKEVLQALEELAVNYDQKSQEVEDKTRANEQLTDEL AQKTTTLTTTQRELSQLQELSNHQKKRATEILNLLLKDLGEIGGIIGTNDVKTLADVNG VIEEEFTMARLYISKMKSEVKSLVNRSKQLESAQMDSNRKMNASERELAACQLLISQHE AKIKSLTDYMQNMEQKRRQLEESQDSLSEELAKLRAQEKMHEVSFQDKEKEHLTRLQ DAEEMKKALEQQMESHREAHQKQLSRLRDEIEEKQKIIDEIRDLNQKLQLEQEKLSSDY NKLKIEDQEREMKLEKLLLLNDKREQAREDLKGLEETVSRELQTLHNLRKLFVQDLTT RVKKSVELDNDDGGGSAAQKQKISFLENNLEQLTKVHKQLVRDNADLRCELPKLEKRL RATAERVKALESALKEAKENAMRDRKRYQQEVDRIKEAVRAKNMARRAHSAQIAKPI
RPGHYPASSPTAVHAIRGGGGSSSNSTHYQK corresponding to amino acids 284 - 957 of KF5C_HUMAN, which also corresponds to amino acids 1 - 674 of M62096_PEA_l_P5. According to preferred embodiments of the present invention, there is provided an isolated chimeric polypeptide encoding for M62096_PEA_l_P3, comprising a first amino acid sequence being at least 90 % homologous to
MELNRWRNGEAVPEDEQISAKDQKNLEPCDNTPIIDMAPVVAGISTEEKEKYDEEISSL YRQLDDKDDEINQQSQLAEKLKQQMLDQDELLASTRRDYEKIQEELTRLQIENEAAKD EVKEVLQALEELAVNYDQKSQEVEDKTRANEQLTDELAQKTTTLTTTQRELSQLQELS NHQKKRATEILNLLLKDLGEIGGIIGTNDVKTLADVNGVIEEEFTMARLYISKMKSEVKS LVNRSKQLESAQMDSNRKMNASERELAACQLLISQHEAKIKSLTDYMQNMEQKRRQL EESQDSLSEELAKLRAQEKMHEVSFQDKEKEHLTRLQDAEEMKKALEQQMESHREAH QKQLSRLRDEIEEKQKIIDEIRDLNQKLQLEQEKLSSDYNKLKIEDQEREMKLEKLLLLN DKREQAREDLKGLEETVSRELQTLHNLRKLFVQDLTTRVKKSVELDNDDGGGSAAQK QKISFLENNLEQLTKVHKQLVRDNADLRCELPKLEKRLRATAERVKALESALKEAKEN AMRDRKRYQQEVDRIKEAVRAKNMARRAHSAQIAKPIRPGHYPASSPTAVHAIRGGGG
SSSNSTHYQK corresponding to amino acids 365 - 957 of KF5C_HUMAN, which also corresponds to amino acids 1 - 593 of M62O96_PEA_1JP3. According to preferred embodiments of the present invention, there is provided an isolated chimeric polypeptide encoding for M62096JPEA_l_P7, comprising a first amino acid
sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence MTQNFRLMWNILLFPLNFS corresponding to amino acids 1 - 19 of M62096JPEA_l_P7, and a second amino acid sequence being at least 90 % homologous to LNQKLQLEQEKLSSDYNKLKJEDQEREMKLEKLLLLNDKREQAREDLKGLEETVSREL QTLHNLRKLFVQDLTTRVKKSVELDNDDGGGSAAQKQKISFLENNLEQLTKVHKQLVR DNADLRCELPKLEKRLRATAERVKALESALKE AKENAMRDRKRYQQEVDRIKEA VRA KNMARRAHSAQIAKPIRPGHYPASSPTAVHAIRGGGGSSSNSTHYQK corresponding to amino acids 738 - 957 of KF5C_HUMAN, which also corresponds to amino acids 20 - 239 of M62096_PEA_l_P7, wherein said first amino acid sequence and second amino acid sequence are contiguous and in a sequential order.
According to preferred embodiments of the present invention, there is provided an isolated polypeptide encoding for a head of M62096_PEA_l_P7, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence MTQNFRLMWNILLFPLNFS of M62096_PEA_l_P7.
According to preferred embodiments of the present invention, there is provided an isolated chimeric polypeptide encoding for M62096_PEA_l_P8, comprising a first amino acid sequence being at least 90 % homologous to
MADPAECSIKVMCRFRPLNEAEILRGDKFIPKFKGDETWIGQGKPYVFDRVLPPNTTQ EQVYNACAKQIVKDVLEGYNGTIFAYGQTSSGKTHTMEGKLHDPQLMGIIPRIAHDIFD HIYSMDENLEFHIKVSYFEIYLDKIRDLLDVSKTNLAVHEDKNRVPYVKGCTERFVSSPE EVMDVIDEGKANRHVAVTNMNEHSSRSHSIFLINIKQENVETEKKLSGKLYLVDLAGSE KVSKTGAEGAVLDEAKNINKSLSALGNVISALAEGTKTHVPYRDSKMTRILQDSLGGN CRTTIVICCSPSVFNEAETKSTLMFGQRAKTIKNTVSVNLELTAEEWKKKYEKEKEKNK TLKNVIQHLEMELNRWRNGEAVPEDEQISAKDQKNLEPCDNTPIIDNIAPVVAGISTEEK EKYDEEISSLYRQLDDKDDEINQQSQLAEKLKQQMLDQDELLASTRRDYEKIQEELTRL QIENEAAKDEVKEVLQALEELAVNYDQKSQEVEDKTRANEQLTDELAQKTTTLTTTQR ELSQLQELSNHQKKRATEILNLLLKDLGEIGGIIGTNDVKTLADVNGVIEEEFTMARLYI SKMKSEVKSLVNRSKQLESAQMDSNRKMNASERELAACQLLISQHEAKIKSLTDYMQN
MEQKRRQLEESQDSLSEELAKLRAQEKMHEVSFQDKEKEHLTRLQDAEEMKKALEQQ MESHREAHQKQLSRLRDEIEEKQKIIDEIR corresponding to amino acids 1 - 736 of KF5C_HUMAN, which also corresponds to amino acids 1 - 736 of M62096_PEA_l_P8, and a second amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence E corresponding to amino acids 737 - 737 of M62096_PEA_l_P8, wherein said first amino acid sequence and second amino acid sequence are contiguous and in a sequential order.
According to preferred embodiments of the present invention, there is provided an isolated chimeric polypeptide encoding for M62096_PEA_l_P9, comprising a first amino acid sequence being at least 90 % homologous to
MADPAECSIKVMCRFRPLNEAEILRGDKFIPKFKGDETVVIGQGKPYVFDRVLPPNTTQ EQVYNACAKQIVKDVLEGYNGTIFAYGQTSSGKTHTMEGKLHDPQLMGIIPRIAHDIFD HIYSMDENLEFHIKVSYFEIYLDKIRDLLDVSKTNLAVHEDKNRVPYVKGCTERFVSSPE EVMDVIDEGKANRHVAVTNMNEHSSRSHSIFLINIKQENVETEKKLSGKLYLVDLAGSE KVSKTGAEGAVLDEAKNINKSLSALGNVISALAEGTKTHVPYRDSKMTRILQDSLGGN CRTTIVICCSPSVFNEAETKSTLMFGQRAKTIKNTVSVNLELTAEEWKKKYEKEKEKNK TLKNVIQHLEMELNRWRNGEAVPEDEQISAKDQKNLEPCDNTPIIDNIAP VVAGISTEEK EKYDEEISSLYRQLDDKDDEINQQSQLAEKLKQQMLDQDE corresponding to amino acids 1 - 454 of KF5C_HUMAN, which also corresponds to amino acids 1 - 454 of
M62096_PEA_l_P9, and a second amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence VKNAIYFFFHKVLLLLFVVDVCSRNLIGIEAFHNYRIMWKFLGRCPFTASYKLIITEFRK corresponding to amino acids 455 - 514 of M62096_PEA_l_P9, wherein said first amino acid sequence and second amino acid sequence are contiguous and in a sequential order.
According to preferred embodiments of the present invention, there is provided an isolated polypeptide encoding for a tail of M62096_PEA_l_P9, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence
VKNAIYFFFHKVLLLLFVVDVCSRNLIGIEAFHNYRIMWKFLGRCPFTASYKLIITEFRK in M62096_PEA_l_P9.
According to preferred embodiments of the present invention, there is provided an isolated chimeric polypeptide encoding forM62096_PEA_l_P10, comprising a first amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence
MTQNFRLMWNILLFPLNFS corresponding to amino acids 1 - 19 of M62096_PEA_l_P10, a second amino acid sequence being at least 90 % homologous to
LNQKLQLEQEKLSSDYNKLKIEDQEREMKLEKLLLLNDKREQAREDLKGLEETVSREL QTLHNLRKLFVQDLTTRVKK corresponding to amino acids 738 - 815 of KF5C_HUMAN, which also corresponds to amino acids 20 - 97 of M62096_PEA_l_P10, and a third amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence
VSSLCLNGTEKKIKDGREESFSVEISLA corresponding to amino acids 98 - 125 of M62096_PEA_l_P10, wherein said first amino acid sequence, second amino acid sequence and third amino acid sequence are contiguous and in a sequential order.
According to preferred embodiments of the present invention, there is provided an isolated polypeptide encoding for a head of M62096_PEA_l_P10, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence
MTQNFRLMWNILLFPLNFS of M62096_PEA_l_P10.
According to preferred embodiments of the present invention, there is provided an isolated polypeptide encoding for a tail of M62096_PEA_l_P10, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence
VSSLCLNGTEKKIKDGREESFSVEISLA in M62096_PEA_l_P10.
According to preferred embodiments of the present invention, there is provided an isolated chimeric polypeptide encoding for M62O96JPEA_1_P11, comprising a first amino acid sequence being at least 90 % homologous to MADPAECSIKVMCRFRPLNEAEILRGDKFIPKFKGDETWIGQGKPYVFDRVLPPNTTQ
EQVYNACAKQIVKDVLEGYNGTIF AYGQTSSGKTHTMEGKLHDPQLMGIIPRIAHDIFD
HIYSMDENLEFHIKVSYFEIYLDKIRDLLDVSKTNLAVHEDKNRVPYVKGCTERFVSSPE EVMDVIDEGKANRHVAVTNMNEHSSRSHSIFLINIKQENVETEKKLSGKLYLVDLAGSE KVSKTGAEGAVLDEAKNINKSLSALGNVISALAEGTKTHVPYRDSKMTRILQDSLGGN CRTTIVICCSPSVFNEAETKSTLMFGQRAKTIKNTVSVNLELTAEEWKKKYEKEKEKNK TLKNVIQHLEMELNRWRN corresponding to amino acids 1 - 372 of KF5C_HUMAN, which also corresponds to amino acids 1 - 372 of M62O96_PEA_1_P11, and a second amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence DFLAAHVFGKLLE corresponding to amino acids 373 - 385 of M62O96_PEA_1_P11, wherein said first amino acid sequence and second amino acid sequence are contiguous and in a sequential order.
According to preferred embodiments of the present invention, there is provided an isolated polypeptide encoding for a tail of M62O96_PEA_1_P11, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence DFLAAHVFGKLLE in M62O96_PEA_1_P11.
According to preferred embodiments of the present invention, there is provided an isolated chimeric polypeptide encoding for M62096_PEA_l_P12, comprising a first amino acid sequence being at least 90 % homologous to MADPAECSIKVMCRFRPLNEAEILRGDKFIPKFKGDETVVIGQGKPYVFDRVLPPNTTQ EQVYNACAKQIVKDVLEGYNGTIFAYGQTSSGKTHTMEGKLHDPQLMGIIPRIAHDIFD HIYSMDENLEFHIKVSYFEIYLDKIRDLLDVSKTNLAVHEDKNRVPYVKGCTERFVSSPE EVMDVIDEGKANRHVAVTNMNEHSSRSHSIFLINIKQENVETEKKLSGKLYLVDLAGSE KVSKTGAEGAVLDEAKNINKSLSALGNVISALAEGTKTHVPYRDSKMTRILQDSLGGN CRTTIVICCSPSVFNEAETKSTLMFGQR corresponding to amino acids 1 - 323 of
KF5C_HUMAN, which also corresponds to amino acids 1 - 323 of M62096JPEA_l_P12, and a second amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence V corresponding to amino acids 324 - 324 of M62O96_PEA_1JP12, wherein said first amino acid sequence and second amino acid sequence are contiguous and in a sequential order.
According to preferred embodiments of the present invention, there is provided an isolated chimeric polypeptide encoding for T99080_PEA_4_P5, comprising a first amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence MPASARLAGAGLLLAFLRALGCAGRAPGLS coπ-esponding to amino acids 1 - 30 of T99080_PEA_4_P5, and a second amino acid sequence being at least 90 % homologous to MAEGNTLISVDYEIFGKVQGVFFRKHTQAEGKKLGLVGWVQNTDRGTVQGQLQGPIS KVRHMQEWLETRGSPKSHIDKANFNNEKVILKLDYSDFQIVK corresponding to amino acids 1 - 99 of ACYO_HUMAN_V1, which also corresponds to amino acids 31 - 129 of T99080_PEA _4_P5, wherein said first amino acid sequence and second amino acid sequence are contiguous and in a sequential order.
According to preferred embodiments of the present invention, there is provided an isolated polypeptide encoding for a head of T99080_PEA_4_P5, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence MPASARLAGAGLLLAFLRALGCAGRAPGLS of T99080_PEA_4_P5.
According to preferred embodiments of the present invention, there is provided an isolated chimeric polypeptide encoding for T99080_PEA_4_P8, comprising a first amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence M corresponding to amino acids 1 - 1 of T99080_PEA_4_P8, and a second amino acid sequence being at least 90 % homologous to
QAEGKKLGLVGWVQNTDRGTVQGQLQGPISKVRHMQEWLETRGSPKSHIDKANFNNE KVILKLDYSDFQIVK corresponding to amino acids 28 - 99 of ACYO_HUMAN_V1, which also corresponds to amino acids 2 - 73 of T99080_PEA_4_P8, wherein said first amino acid sequence and second amino acid sequence are contiguous and in a sequential order.
According to preferred embodiments of the present invention, there is provided an isolated chimeric polypeptide encoding for T08446_PEA_l_P18, comprising a first amino acid sequence being at least 90 % homologous to MLSLSLCSHLWGPLILSALQARSTDSLDGPGEGSVQPLPTAGGPSVKGKPGKRLSAPRG PFPRLADCAHFHYENVDFGHIQLLLSPDREGPSLSGENELVFGVQVTCQGRSWPVLRSY
DDFRSLD AHLHRCIFDRRFSCLPELPPPPEGARAAQMLVPLLLQYLETLSGLVDSNLNC GPVLTWME corresponding to amino acids 1 - 185 of SNXQ_HUMAN, which also corresponds to amino acids 1 - 185 of T08446_PEA_l_P18, and a second amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence
LDNHGRRLLLSEEASLNIPAVAAAHVIKRYTAQAPDELSFEVGDIVSVIDMPPTEDRSW WRGKRGFQVGFFPSECVELFTERPGPGLKADADGPPCGIP APQGISSLTSA VPRPRGKLA GLLRTFMRSRPSRQRLRQRGILRQRVFGCDLGEHLSNSGQDVPQVLRCCSEFIEAHGVV DGIYRLSGVSSNIQRLRHEFDSEWPELSGPAFLQDIHSVSSLCKLYFRELPNPLLTYQLY GKFSEAMSVPGEEERLVRVHDVIQQLPPPHYRTLEYLLRHLARMARHSANTSMHARNL AIVWAPNLLRSMELESVGMGGAAAFREVRVQSVVVEFLLTHVDVLFSDTFTSAGLDPA GRCLLPRPKSLAGSCPSTRLLTLEEAQARTQGRLGTPTEPTTPKAPASPAERRKGERGEK QRKPGGSSWKTFFALGRGPSVPRKKPLPWLGGTRAPPQPSGSRPDTVTLRSAKSEESLS SQASGAGLQRLHRLRRPHSSSDAFPVGPAP AGSCESLSSSSSSESSSSESSSSSSESSAAGL GALSGSPSHRTSAWLDDGDELDFSPPRCLEGLRGLDFDPLTFRCSSPTPGDPAPPASPAP PAPASAFPPRVTPQAISPRGPTSPASPAALDISEPLAVSVPPAVLELLGAGGAPASATPTP ALSPGRSLRPHLIPLLLRGAEAPLTDACQQEMCSKLRGAQGPLGPDMESPLPPPPLSLLR PGGAPPPPPKNPARLMALALAERAQQVAEQQSQQECGGTPPASQSPFHRSLSLEVGGEP LGTSGSGPPPNSLAHPGAWVPGPPPYLPRQQSDGSLLRSQRPMGTSRRGLRGPAQVSAQ LRAGGGGRDAPEAAAQSPCSVPSQVPTPGFFSPAPRECLPPFLGVPKPGLYPLGPPSFQP SSPAPVWRSSLGPPAPLDRGENLYYEIGASEGSPYSGPTRSWSPFRSMPPDRLNASYGM LGQSPPLHRSPDFLLSYPPAPSCFPPDHLGYSAPQHPARRPTPPEPLYVNLALGPRGPSPA SSSSSSPPAHPRSRSDPGPPVPRLPQKQRAPWGPRTPHRVPGPWGPPEPLLLYRAAPPAY GRGGELHRGSLYRNGGQRGEGAGPPPPYPTPSWSLHSEGQTRSYC corresponding to amino acids 186 - 1305 of T08446_PEA_l_P18, wherein said first amino acid sequence and second amino acid sequence are contiguous and in a sequential order.
According to preferred embodiments of the present invention, there is provided an isolated polypeptide encoding for a tail of T08446_PEA_l_P18, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence
LDNHGRRLLLSEEASLNIPAVAAAHVIKRYTAQAPDELSFEVGDΓVSVIDMPPTEDRSW
WRGKRGFQVGFFPSECVELFTERPGPGLKADADGPPCGIP APQGISSLTSAVPRPRGKLA GLLRTFMRSRPSRQRLRQRGILRQRVFGCDLGEHLSNSGQDVPQVLRCCSEFIEAHGVV DGIYRLSGVSSNIQRLRHEFDSERIPELSGPAFLQDIHSVSSLCKLYFRELPNPLLTYQLY GKFSEAMSVPGEEERLVRVHDVIQQLPPPHYRTLEYLLRHLARMARHSANTSMHARNL AIVWAPNLLRSMELESVGMGGAAAFREVRVQSVVVEFLLTHVDVLFSDTFTSAGLDPA GRCLLPRPKSLAGSCPSTRLLTLEEAQARTQGRLGTPTEPTTPKAPASPAERRKGERGEK QRKPGGSSWKTFFALGRGPSVPRKKPLPWLGGTRAPPQPSGSRPDTVTLRSAKSEESLS SQASGAGLQRLHRLRRPHSSSDAFPVGPAP AGSCESLSSSSSSESSSSESSSSSSESSAAGL GALSGSPSHRTSAWLDDGDELDFSPPRCLEGLRGLDFDPLTFRCSSPTPGDPAPPASPAP PAPASAFPPRVTPQAISPRGPTSPASPAALDISEPLAVSVPPAVLELLGAGGAPASATPTP ALSPGRSLRPHLIPLLLRGAEAPLTDACQQEMCSKLRGAQGPLGPDMESPLPPPPLSLLR PGGAPPPPPKNP ARLMALALAERAQQVAEQQSQQECGGTPPASQSPFHRSLSLEVGGEP LGTSGSGPPPNSLAHPGAWVPGPPPYLPRQQSDGSLLRSQRPMGTSRRGLRGPAQVSAQ LRAGGGGRD APEAAAQSPCSVPSQVPTPGFFSPAPRECLPPFLGVPKPGLYPLGPPSFQP SSPAPVWRSSLGPPAPLDRGENLYYEIGASEGSPYSGPTRSWSPFRSMPPDRLNASYGM LGQSPPLHRSPDFLLSYPP APSCFPPDHLGYSAPQHP ARRPTPPEPLYVNLALGPRGPSPA SSSSSSPPAHPRSRSDPGPPVPRLPQKQRAPWGPRTPHRVPGPWGPPEPLLLYRAAPPAY GRGGELHRGSLYRNGGQRGEGAGPPPPYPTPSWSLHSEGQTRSYC IN
T08446_PEA__l_P18. According to preferred embodiments of the present invention, there is provided an isolated chimeric polypeptide encoding for T08446JPEA_l_P18, comprising a first amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence MLSLSLCSHLWGPLILSALQARSTDSLDGPGEGSVQPLPTAGGPSVKGKPGKRLSAPRG PFPRLADCAHFHYENVDFGHIQLLLSPDREGPSLSGENELVFGVQVTCQGRSWPVLRSY DDFRSLDAHLHRCIFDRRFSCLPELPPPPEGARAAQMLVPLLLQYLETLSGLVDSNLNC GPVLTWMELDNHGRRLLLSEEASLNIPAVAAAHVIKRYTAQAPDELSFEVGDIVSVIDM PPTEDRSWWRGKRGFQVGFFPSECVELFTERPGPGLKADADGPPCGIPAPQGISSLTSAV PRPRGKLAGLLRTFMRSRPSRQRLRQRGILRQRVFGCDLGEHLSNSGQDVPQ VLRCCSE FIEAHGVVDGIYRLSGVSSNIQRLRHEFDSERIPELSGPAFLQDIHSVSSLCKLYFRELPNP LLTYQLYGKFSEAMSVPGEEERLVRV corresponding to amino acids 1 - 443 of
T08446_PEA_l_P18, a second amino acid sequence being at least 90 % homologous to HDVIQQLPPPHYRTLEYLLRHLARMARHSANTSMHARNLAIVWAPNLLRSMELESVG MGGAAAFREVRVQSVVVEFLLTHVDVLFSDTFTSAGLDPAGRCLLPRPKSLAGSCPSTR LLTLEEAQARTQGRLGTPTEPTTPKAPASPAERRKGERGEKQRKPGGSSWKTFFALGRG PSVPRKKPLPWLGGTRAPPQPSGSRPDTVTLRSAKSEESLSSQASGAGLQRLHRLRRPHS SSDAFPVGPAPAGSCESLSSSSSSESSSSESSSSSSESSAAGLGALSGSPSHRTSAWLDDG DELDFSPPRCLEGLRGLDFDPLTFRCSSPTPGDPAPPASPAPPAPASAFPPRVTPQAISPRG PTSPASPAALDISEPLAVSVPPAVLELLGAGGAPASATPTPALSPGRSLRPHLIPLLLRGA EAPLTDACQQEMCSKLRGAQGPLGPDMESPLPPPPLSLLRPGGAPPPPPKNPARLMALA LAERAQQVAEQQSQQECGGTPPASQSPFHRSLSLEVGGEPLGTSGSGPPPNSLAHPGAW VPGPPPYLPRQQSDGSLLRSQRPMGTSRRGLRGPAQVSAQLRAGGGGRDAPEAAAQSP CSVPSQVPTPGFFSP APRECLPPFLGVPKPGLYPLGPPSFQPSSPAPVWRSSLGPP APLDR GENLYYEIGASEGSPYSG corresponding to amino acids 1 - 674 of Q9NT23, which also corresponds to amino acids 444 - 1117 of T08446_PEA_l_P18, a bridging amino acid P corresponding to amino acid 1118 of TO8446_PEA_1JP18, and a third amino acid sequence being at least 90 % homologous to
TRSWSPFRSMPPDRLNASYGMLGQSPPLHRSPDFLLSYPPAPSCFPPDHLGYSAPQHPAR RPTPPEPLYVNLALGPRGPSPASSSSSSPPAHPRSRSDPGPPVPRLPQKQRAPWGPRTPHR VPGPWGPPEPLLLYRAAPPAYGRGGELHRGSLYRNGGQRGEGAGPPPPYPTPSWSLHS EGQTRSYC corresponding to amino acids 676 - 862 of Q9NT23, which also corresponds to amino acids 1119 - 1305 of T08446_PEA_l_P18, wherein said first amino acid sequence, second amino acid sequence, bridging amino acid and third amino acid sequence are contiguous and in a sequential order.
According to preferred embodiments of the present invention, there is provided an isolated polypeptide encoding for a head of TO8446_PEA_1_P18, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence
MLSLSLCSHLWGPLILSALQARSTDSLDGPGEGSVQPLPTAGGPSVKGKPGKRLSAPRG PFPRLADCAHFHYENVDFGHIQLLLSPDREGPSLSGENΈLVFGVQVTCQGRSWPVLRSY DDFRSLDAHLHRCIFDRRPSCLPELPPPPEGARAAQMLVPLLLQYLETLSGLVDSNLNC GPVLTWMELDNHGRRLLLSEEASLNIPAVAAAHVIKRYTAQAPDELSFEVGDIVSVIDM
PPTEDRSWWRGKRGFQVGFFPSECVELFTERPGPGLKAD ADGPPCGIP APQGISSLTSAV PRPRGKLAGLLRTFMRSRPSRQRLRQRGILRQRVFGCDLGEHLSNSGQDVPQVLRCCSE FIEAHGVVDGIYRLSGVSSNIQRLRHEFDSERIPELSGPAFLQDIHSVSSLCKLYFRELPNP LLTYQLYGKFSEAMSVPGEEERLVRV of T08446_PEA_l_P 18. According to preferred embodiments of the present invention, there is provided an isolated chimeric polypeptide encoding for T08446_PEA_l_P18, comprising a first amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence MLSLSLCSHLWGPLILSALQARSTDSLDGPGEGSVQPLPTAGGPSVKGKPGKRLSAPRG PFPRLADCAHFHYENVDFGHIQLLLSPDREGPSLSGENELVFGVQ VTCQGRSWPVLRSY DDFRSLDAHLHRCIFDRRFSCLPELPPPPEGARAAQMLVPLLLQYLETLSGLVDSNLNC GPVLTWMELDNHGRRLLLSEEASLNIPAVAAAHVIKRYTAQAPDELSFEVGDIVSVIDM PPTEDRSWWRGKRGFQVGFFPSECVELFTERPGPGLKAD ADGPPCGIPAPQGISSLTSAV PRPRGKLAGLLRTFMRSRPSRQRLRQRGILRQRVFGCDLGEHLSNSGQDVPQVLRCCSE FIEAHGVVDGIYRLSGVSSNIQRLRHEFDSERIPELSGP AFLQDIHSVSSLCKLYFRELPNP
LLTYQLYGKFSEAMSVPGEEERLVRVHDVIQQLPPPHYRTLEYLLRHLARMARHSANT SMHARNLAIVWAPNLLRSMELESVGMGGAAAFREVRVQSWVEFLLTHVDVLFSDTF TSAGLDPAGRCLLPRPKSLAGSCPSTRLLTLEEAQARTQGRLGTPTEPTTPKAPASPAER RKGERGEKQRKPGGSSWKTFFALGRGPSVPRKKPLPWLGGTRAPPQPSGSRPDTVTLRS AKSEESLSSQASGAGLQRLHRLRRPHSSSDAFPVGPAPAGSCESLSSSSSSESSSSESSSSS SESSAAGLGALSGSPSHRTSAWLDDGDELDFSPPRCLEGLRGLDFDPLTFRCSSPTPGDP APPASPAPPAPASAFPPRVTPQAISPRGPTSPASPAALDISEPLAVSVPPAVLELLGAGGA PASATPTPALSPGRSLRPHLIPLLLRGAEAPLTDACQQEMCSKLRGAQGPLGPDMESPLP PPPLSLLRPGGAPPPPPKNPARLMALALAERAQQVAEQQSQQECGGTPPASQSPFHRSLS LEVGGEPLGTSGSGPPPNSLAHPGAWVPGPPPYLPRQQSDGSLLRSQRPMGTSRRG corresponding to amino acids 1 - 1010 of T08446JPEA_l_P18, and a second amino acid sequence being at least 90 % homologous to
LRGPAQVSAQLRAGGGGRDAPEAAAQSPCSVPSQVPTPGFFSPAPRECLPPFLGVPKPG LYPLGPPSFQPSSPAPVWRSSLGPPAPLDRGENLYYEIGASEGSPYSGPTRSWSPFRSMPP DRLNASYGMLGQSPPLHRSPDFLLSYPPAPSCFPPDHLGYSAPQHPARRPTPPEPLYVNL ALGPRGPSPASSSSSSPPAHPRSRSDPGPPVPRLPQKQRAPWGPRTPHRVPGPWGPPEPL
LLYRAAPPAYGRGGELHRGSLYRNGGQRGEGAGPPPPYPTPSWSLHSEGQTRSYC corresponding to amino acids 1 - 295 of Q96CP3, which also corresponds to amino acids 1011 - 1305 of T08446_PEA_l_P18, wherein said first amino acid sequence and second amino acid sequence are contiguous and in a sequential order. According to preferred embodiments of the present invention, there is provided an isolated polypeptide encoding for a head of T08446_PEA_l_P18, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence
MLSLSLCSHLWGPLILSALQARSTDSLDGPGEGSVQPLPTAGGPSVKGKPGKRLSAPRG PFPRLADCAHFHYENVDFGHIQLLLSPDREGPSLSGENELVFGVQVTCQGRSWPVLRSY DDFRSLDAHLHRCIFDRRFSCLPELPPPPEGARAAQMLVPLLLQYLETLSGLVDSNLNC GPVLTWMELDNHGRRLLLSEEASLNIPAVAAAHVIKRYTAQAPDELSFEVGDIVSVIDM PPTEDRSWWRGKRGFQVGFFPSECVELFTERPGPGLKADADGPPCGIPAPQGISSLTSAV PRPRGKLAGLLRTFMRSRPSRQRLRQRGILRQRVFGCDLGEHLSNSGQDVPQVLRCCSE FIEAHGVVDGIYRLSGVSSNIQRLRHEFDSERIPELSGP AFLQDIHSVSSLCKLYFRELPNP LLTYQLYGKFSEAMSVPGEEERLVRVHDVIQQLPPPHYRTLEYLLRHLARMARHSANT SMHARNLAIVWAPNLLRSMELESVGMGGAAAFREVRVQSVVVEFLLTHVDVLFSDTF TSAGLDPAGRCLLPRPKSLAGSCPSTRLLTLEEAQARTQGRLGTPTEPTTPKAPASPAER RKGERGEKQRKPGGSSWKTFFALGRGPSVPRKKPLPWLGGTRAPPQPSGSRPDTVTLRS AKSEESLSSQASGAGLQRLHRLRRPHSSSDAFPVGPAPAGSCESLSSSSSSESSSSESSSSS SESSAAGLGALSGSPSHRTSAWLDDGDELDFSPPRCLEGLRGLDFDPLTFRCSSPTPGDP APPASPAPPAPASAFPPRVTPQAISPRGPTSPASPAALDISEPLAVSVPPAVLELLGAGGA PASATPTPALSPGRSLRPHLIPLLLRGAEAPLTDACQQEMCSKLRGAQGPLGPDMESPLP PPPLSLLRPGGAPPPPPKNPARLMALALAERAQQVAEQQSQQECGGTPPASQSPFHRSLS LEVGGEPLGTSGSGPPPNSLAHPGAWVPGPPPYLPRQQSDGSLLRSQRPMGTSRRG OF
T08446_PEA_l_P18.
According to preferred embodiments of the present invention, there is provided an isolated chimeric polypeptide encoding for T08446_PEA_l_P18, comprising a first amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence MLSLSLCSHLWGPLILSALQARSTDSLDGPGEGSVQPLPTAGGPSVKGKPGKRLSAPRG
PFPRLADCAHFHYENVDFGHIQLLLSPDREGPSLSGENEL VFGVQVTCQGRSWPVLRSY DDFRSLDAHLHRCIFDRRFSCLPELPPPPEGARAAQ corresponding to amino acids 1 - 154 of T08446_PEA_l_P18, a second amino acid sequence being at least 90 % homologous to MLVPLLLQYLETLSGLVDSNLNCGPVLTWMELDNHGRRLLLSEEASLNIPAVAAAHVI KRYTAQAPDELSFEVGDIVSVIDMPPTEDRSWWRGKRGFQVGFFPSECVELFTERPGPG LKADADGPPCGIPAPQGISSLTSAVPRPRGKLAGLLRTFMRSRPSRQRLRQRGILRQRVF GCDLGEHLSNSGQDVPQVLRCCSEFIEAHGVVDGIYRLSGVSSNIQRLRHEFDSERIPEL SGPAFLQDIHSVSSLCKLYFRELPNPLLTYQLYGKFSEAMSVPGEEERLVRVHDVIQQLP PPHYRTLEYLLRHLARMARHSANTSMHARNLAIVWAPNLLRSMELESVGMGGAAAFR EVRVQSVWEFLLTHVD VLFSDTFTSAGLDP AGRCLLPRPKSLAGSCPSTRLLTLEEAQ
ARTQGRLGTPTEPTTPKAPASPAERRKGERGEKQRKPGGSSWKTFFALGRGPSVPRKKP LPWLGGTRAPPQPSGSRPDTVTLRSAKSEESLSSQASGAGLQRLHRLRRPHSSSDAFPVG PAPAGSCESLSSSSSSESSSSESSSSSSESSAAGLGALSGSPSHRTSAWLDDGDELDFSPPR CLEGLRGLDFDPLTFRCSSPTPGDPAPPASPAPPAPASAFPPRVTPQAISPRGPTSPASPAA LDISEPLAVSVPPA VLELLGAGGAPASATPTPALSPGRSLRPHLIPLLLRGAEAPLTDACQ QEMCSKLRGAQGPLGPDMESPLPPPPLSLLRPGGAPPPPPKNPARLMALALAERAQQVA EQQSQQECGGTPPASQSPFHRSLSLEVGGEPLGTSGSGPPPNSLAHPGAWVPGPPPYLPR
QQSDGSLLRSQRPMGTSRRGLRGPA corresponding to amino acids 1 - 861 ofBAC86902, which also corresponds to amino acids 155 - 1015 of T08446_PEA_l_P18, a third amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence QVSAQLRAGGGGRDAPEAAAQSPCSVPS corresponding to amino acids 1016 - 1043 of T08446_PEA_l_P18, a fourth amino acid sequence being at least 90 % homologous to QVPTPGFFSPAPRECLPPFLGVPKPGLYPLGPPSFQPSSPAPVWRSSLGPPAPLDRGENLY YEIGASEGSPYSGPTRSWSPFRSMPPDRLNASYGMLGQSPPLHRSPDFLLSYPPAPSCFPP DHLGYS corresponding to amino acids 862 - 989 of BAC86902, which also corresponds to amino acids 1044 - 1171 of T08446_PEA_l_P18, and a fifth amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence APQHPARRPTPPEPLYVNLALGPRGPSPASSSSSSPPAHPRSRSDPGPPVPRLPQKQRAP WGPRTPHRVPGPWGPPEPLLLYRAAPPAYGRGGELHRGSLYRNGGQRGEGAGPPPPYP
TPSWSLHSEGQTRSYC corresponding to amino acids 1172 - 1305 of T08446_PEA_l J?18, wherein said first amino acid sequence, second amino acid sequence, third amino acid sequence, fourth amino acid sequence and fifth amino acid sequence are contiguous and in a sequential order. According to preferred embodiments of the present invention, there is provided an isolated polypeptide encoding for a head of T08446_PEA_l_P18, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence MLSLSLCSHLWGPLILSALQARSTDSLDGPGEGSVQPLPTAGGPSVKGKPGKRLSAPRG PFPRLADCAHFHYENVDFGHIQLLLSPDREGPSLSGENELVFGVQVTCQGRSWPVLRSY DDFRSLDAHLHRCIFDRRFSCLPELPPPPEGARAAQ of T08446 PEA 1 P 18.
According to preferred embodiments of the present invention, there is provided an isolated polypeptide encoding for an edge portion of T08446_PEA_l_P18, comprising an amino acid sequence being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence encoding for QVSAQLRAGGGGRDAPEAAAQSPCSVPS, corresponding to T08446_PEA_l_P18.
According to preferred embodiments of the present invention, there is provided an isolated polypeptide encoding for a tail of TO8446_PEA_1JP18, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence APQHPARRPTPPEPLYVNLALGPRGPSPASSSSSSPPAHPRSRSDPGPPVPRLPQKQRAP WGPRTPHRVPGPWGPPEPLLLYRAAPPAYGRGGELHRGSLYRNGGQRGEGAGPPPPYP TPSWSLHSEGQTRSYC in T08446_PEA_l_P18. According to preferred embodiments of the present invention, there is provided an isolated chimeric polypeptide encoding for Tl 1628JPEA_1_P2, comprising a first amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence MGLSDGEWQLVLNVWGKVEADIPGHGQEVLIRLFKGHPETLEKFDKFKHLKSEDE corresponding to amino acids 1 - 55 of Tl 1628_PEA_1_P2, and a second amino acid sequence being at least 90 % homologous to
MKASEDLKKHGATVLTALGGILKKKGHHEAEIKPLAQSHATKHKIP VKYLEFISECIIQV LQSKΗPGDFGADAQGAMNKALELFRKDMASNYKELGFQG corresponding to amino acids 1 - 99 of Q8WVH6, which also corresponds to amino acids 56 - 154 of Tl 1628_PEA_1_P2, wherein said first amino acid sequence and second amino acid sequence are contiguous and in a sequential order.
According to preferred embodiments of the present invention, there is provided an isolated polypeptide encoding for a head of Tl 1628_PEA_1_P2, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence MGLSDGEWQLVLNVWGKVEADIPGHGQEVLIRLFKGHPETLEKFDKFKHLKSEDE of Tl 1628_PEA_1_P2.
According to preferred embodiments of the present invention, there is provided an isolated chimeric polypeptide encoding for Tl 1628_PEA_ 1_P5, comprising a first amino acid sequence being at least 90 % homologous to MKASEDLKKHGATVLTALGGILKKKGHHEAEIKPLAQSHATKHKIPVKYLEFISECIIQV LQSKHPGDFGADAQGAMNKALELFRKDMASNYKELGFQG corresponding to amino acids 56 - 154 of MYG_HUMAN_V1, which also corresponds to amino acids 1 - 99 of T11628_PEA_1_P5.
According to preferred embodiments of the present invention, there is provided an isolated chimeric polypeptide encoding for Tl 1628_PEA_1_P7, comprising a first amino acid sequence being at least 90 % homologous to
MGLSDGEWQLVLNVWGKVEADIPGHGQEVLIRLFKGHPETLEKFDKFKHLKSEDEMK ASEDLKKHGATVLTALGGILKKKGHHEAEIKPLAQSHATKHKIPVKYLEFISECIIQVLQ SKHPGDFGADAQGAMNK corresponding to amino acids 1 - 134 of MYG_HUMAN_V1, which also corresponds to amino acids 1 - 134 of Tl 1628_PEA_1_P7, and a second amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence G corresponding to amino acids 135 - 135 of T11628_PEA_1_P7, wherein said first amino acid sequence and second amino acid sequence are contiguous and in a sequential order. According to preferred embodiments of the present invention, there is provided an isolated chimeric polypeptide encoding for Tl 1628_PEA_l_P10, comprising a first amino acid
sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence MGLSDGEWQLVLNVWGKVEADIPGHGQEVLIRLFKGHPETLEKFDKFKHLKSEDE corresponding to amino acids 1 - 55 of Tl 1628_PEA_l_P10, and a second amino acid sequence being at least 90 % homologous to
MKASEDLKKHGATVLTALGGILKKKGHHEAEIKPLAQSHATKHKIPVKYLEFISECIIQV LQSKHPGDFGADAQGAMNKALELFRKDMASNYKELGFQG corresponding to amino acids 1 - 99 of Q8WVH6, which also corresponds to amino acids 56 - 154 of Tl 1628_PEA_l_P10, wherein said first amino acid sequence and second amino acid sequence are contiguous and in a sequential order.
According to preferred embodiments of the present invention, there is provided an isolated polypeptide encoding for a head of Tl 1628_PEA_1JP1O, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence MGLSDGEWQLVLNVWGKVEADIPGHGQEVLIRLFKGHPETLEKFDKFKHLKSEDE of T11628_PEA_l_P10.
According to preferred embodiments of the present invention, there is provided an isolated chimeric polypeptide encoding for R35137_PEA_1_PEA_1JPEA_1_P9, comprising a first amino acid sequence being at least 90 % homologous to MASSTGDRSQAVRHGLRAKVLTLDGMNPRVRRVEYAVRGPIVQRALELEQELRQGVK KPFTEVIRANIGDAQAMGQRPITFLRQVLALCVNPDLLSSPNFPDDAKKRAERILQACG GHSLGAYSVSSGIQLIREDVARYIERRDGGIPADPNNVFLSTGASDAIVTVLKLLVAGEG HTRTGVLIPIPQYPLYSATLAELGAVQVDYYLDEERAWALDVAELHRALGQARDHCRP RALCVINPGNPTGQVQTRECIEAVIRFAFEERLFLLADEV corresponding to amino acids 1 - 274 of ALAT_HUMAN_V1, which also corresponds to amino acids 1 - 274 of
R35137_PEA_1_PEA_1_PEA_1_P9, and a second amino acid sequerce being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence RGAGEREAGQQSAPVTPCALPGVPGQRVRRGFAVPLIQEGAHGDGAALRRAAGACLLP LHLQGLHGRVRAYEAGGGSRAMARPSSPDGPPPPPHLTWPCAGAGSAAAMWRW corresponding to amino acids 275 - 385 of R35137_PEA_1_PEA_1_PEA_1_P9, wherein said
first amino acid sequence and second amino acid sequence are contiguous and in a sequential order.
According to preferred embodiments of the present invention, there is provided an isolated polypeptide encoding for a tail of R35137_PEA_1JPEA_1J?EA_1_P9, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence
RGAGEREAGQQSAPVTPCALPGVPGQRVRRGFAVPLIQEGAHGDGAALRRAAGACLLP
LHLQGLHGRVRAYEAGGGSRAMARPSSPDGPPPPPHLTWPCAGAGSAAAMWRW in R35137_PEA_1JPEA_1_PEA_1_P9.
According to preferred embodiments of the present invention, there is provided an isolated chimeric polypeptide encoding for R35137_PEA_1_PEA_1_PEA_1_P8, comprising a first amino acid sequence being at least 90 % homologous to
MASSTGDRSQAVRHGLRAKVLTLDGMNPRVRRVEYAVRGPIVQRALELEQELRQGVK KPFTEVIRANIGD AQ AMGQRPITFLRQVLALCVNPDLLSSPNFPDDAKKRAERILQ ACG
GHSLGAYSVSSGIQLIREDVARYIERRDGGIPADPNNVFLSTGASDAIVTVLKLLVAGEG HTRTGVLIPIPQYPLYSATLAELGAVQVDYYLDEERAWALDVAELHRALGQARDHCRP RALCVINPGNPTGQVQTRECIEAVIRFAFEERLFLLADEVYQDNVYAAGSQFHSFKKVL
MEMGPPYAGQQELASFHSTSKGYMGEC corresponding to amino acids 1 - 320 of ALAT_HUMAN_V1, which also corresponds to amino acids 1 - 320 of
R35137_PEA_1_PEA_1_PEA_1_P8, and a second amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence VRTRRVGARGPWPGPPRPMGHPLLRT corresponding to amino acids 321 - 346 of R35137_PEA_1_PEA_1_PEA_1_P8, wherein said first amino acid sequence and second amino acid sequence are contiguous and in a sequential order.
According to preferred embodiments of the present invention, there is provided an isolated polypeptide encoding for a tail of R35137_PEA_1_PEA_1_PEA_1_P8, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence VRTRRVGARGPWPGPPRPMGHPLLRT in R35137_PEA_1_PEA_1JPEA_1JP8.
According to preferred embodiments of the present invention, there is provided an isolated chimeric polypeptide encoding for R35137_PEA_1_PEA__1_PEA_1_P11, comprising a first amino acid sequence being at least 90 % homologous to MASSTGDRSQAVRHGLRAKVLTLDGMNPRVRRVEYAVRGPIVQRALELEQELRQGVK KPFTEVIRANIGDAQAMGQRPITFLRQVLALCVNPDLLSSPNFPDDAKKRAERILQACG GHSLGAYSVSSGIQLIREDVARYIERRDGGIPADPNNVFLSTGASDAIVTVLKLLVAGEG HTRTGVLIPIPQYPLYSATLAELGAVQVDYYLDEERAWALDVAELHRALGQAR corresponding to amino acids 1 - 229 of ALAT_HUMAN_V1, which also corresponds to amino acids 1 - 229 of R35137_PEA_1_PEA_1_PEA_1_P11, and a second amino acid sequence being at least 90 % homologous to SGFGQREGTYHFRMTILPPLEKLRLLLEKLSRFHAKFTLEYS corresponding to amino acids 455 - 496 of ALAT_HUMAN_V1, which also corresponds to amino acids 230 - 271 of R35137_PEA_1_PEA_1_PEA_1_P11, wherein said first amino acid sequence and second amino acid sequence are contiguous and in a sequential order. According to preferred embodiments of the present invention, there is provided an isolated chimeric polypeptide encoding for an edge portion of
R35137_PEA_1_PEA_1_PEA_1_P11, comprising a polypeptide having a length "n", wherein n is at least about 10 amino acids in length, optionally at least about 20 amino acids in length, preferably at least about 30 amino acids in length, more preferably at least about 40 amino acids in length and most preferably at least about 50 amino acids in length, wherein at least two amino acids comprise RS, having a structure as follows: a sequence starting from any of amino acid numbers 229-x to 229; and ending at any of amino acid numbers 230+ ((n-2) - x), in which x varies from 0 to n-2.
According to preferred embodiments of the present invention, there is provided an isolated chimeric polypeptide encoding for R35137_PEA_1_PEA_1_PEA_1_P2, comprising a first amino acid sequence being at least 90 % homologous to
MASSTGDRSQAVRHGLRAKVLTLDGMNPRVRRVEYAVRGPIVQRALELEQELRQGVK KPFTEVIRANIGDAQAMGQRPITFLRQVLALCVNPDLLSSPNFPDDAKKRAERILQACG GHSLGAYSVSSGIQLIREDVARYIERRDGGIPADPNNVFLSTGASDAIVTVLKLLVAGEG HTRTGVLIPIPQYPLYSATLAELGAVQVDYYLDEERAWALDVAELHRALGQARDHCRP RALCVINPGNPTGQVQTRECIEAVIRFAFEERLFLLADEV corresponding to amino acids 1 -
274 of ALAT_HUMAN_V1, which also corresponds to amino acids 1 - 274 of R35137_PEA_1_PEA_1_PEA_1_P2, and a second amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence RGAGEREAGQQSAPVTPCALPGVPGQRVRRGFAVPLIQEGAHGDGAALRRAAGACLLP LHLQGLHGRVRVPRRLCGGGEHGRCSAAADAEADECAAVPAGARTGPAGPGGQPAR AHRPLLCAVPG corresponding to amino acids 275 - 399 of
R35137_PEA_1_PEA_1_PEA_1_P2, wherein said first amino acid sequence and second amino acid sequence are contiguous and in a sequential order. According to preferred embodiments of the present invention, there is provided an isolated polypeptide encoding for a tail of R35137_PEA_1_PEA_1JPEA_1_P2, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence RGAGEREAGQQSAPVTPCALPGVPGQRVRRGFAVPLIQEGAHGDGAALRRAAGACLLP LHLQGLHGRVRVPRRLCGGGEHGRCSAAADAEADECAAVPAGARTGPAGPGGQPAR AHRPLLCAVPG in R35137_PEA_1_PEA_1JΕA_1_P2.
According to preferred embodiments of the present invention, there is provided an isolated chimeric polypeptide encoding for R35137_PEA_1_PEA_1_PEA_1_P4, comprising a first amino acid sequence being at least 90 % homologous to
MASSTGDRSQAVRHGLRAKVLTLDGMNPRVRRVEYAVRGPIVQRALELEQELRQGVK KPFTEVIRANIGDAQAMGQRPITFLRQVLALCVNPDLLSSPNFPDDAKKRAERILQACG GHSLGAYSVSSGIQLIREDVARYIERJRDGGIPADPNNVFLSTGASDAIVTVLKLLVAGEG HTRTGVLIPIPQYPLYSATLAELGAVQVDYYLDEERAWALDVAELHRALGQARDHCRP RALCVINPGNPTGQVQTRECIEAVIRFAFEERLFLLADEVYQDNVYAAGSQFHSFKKVL MEMGPPYAGQQELASFHSTSKGYMGECGFRGGYVEVVNMDAAVQQQMLKLMSVRL CPPVPGQALLDLWSPPAPTDPSFAQFQAEKQAVLAELAAKAKLTEQVFNEAPGISCNP VQGAMYSFPRVQLPPRAVERAQELGLAPDMFFCLRLLEETGICWPGSGFGQREGTYH FRMTILPPLEKLRLLLEKLSRFHAKFTLE corresponding to amino acids 1 - 494 of ALAT_HUMAN_V1, which also corresponds to amino acids 1 - 494 of
R35137_PEA_1_PEA_1_PEA_1_P4, and a second amino acid sequence being at least 70%,
optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence SPGRLWSPLYLLLMPGGVGWGGCWAP ASLQVPNKAVWQSDSKKEALAAAWPAPTCL PFLQA corresponding to amino acids 495 - 555 of R35137_PEA_1_PEA_1_PEA_1_P4, wherein said first amino acid sequence and second amino acid sequence are contiguous and in a sequential order.
According to preferred embodiments of the present invention, there is provided an isolated polypeptide encoding for a tail of R35137_PEA_1_PEA_1_PEA_1_P4, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence
SPGRLWSPLYLLLMPGGVGWGGCWAPASLQVPNKAVWQSDSKKEALAAAWPAPTCL PFLQA in R35137_PEA_1_PEA_1_PEA_1_P4.
According to preferred embodiments of the present invention, there is provided an isolated chimeric polypeptide encoding for Rl 1723_PEA_ 1_P6, comprising a first amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence MWVLGIAATFCGLFLLPGFALQIQCYQCEEFQLNNDCSSPEFIVNCTVNVQDMCQKEV MEQSAGIMYRKSCASSAACLIASAGSPCRGLAPGREEQRALHKAGAVGGGVR corresponding to amino acids 1 - 110 of Rl 1723__PEA_1_P6, and a second amino acid sequence being at least 90 % homologous to
MYAQALLWGVLQRQAAAQHLHEHPPKLLRGHRVQERVDDRAEVEKRLREGEEDHV RPEVGPRPVVLGFGRSHDPPNLVGHPAYGQCHNNQPWADTSRRERQRKEKHSMRTQ corresponding to amino acids 1 - 112 of Q8IXM0, which also corresponds to amino acids 111 - 222 of R11723_PEA_1_P6, wherein said first and second amino acid sequences are contiguous and in a sequential order.
According to preferred embodiments of the present invention, there is provided an isolated polypeptide encoding for a head of Rl 1723_PEA_1_P6, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence
MWVLGIAATFCGLFLLPGFALQIQCYQCEEFQLNNDCSSPEFΓVNCTVNVQDMCQKEV
MEQSAGIMYRKSCASSAACLIASAGSPCRGLAPGREEQRALHKAGAVGGGVR of R11723_PEA_1_P6.
According to preferred embodiments of the present invention, there is provided an isolated chimeric polypeptide encoding for Rl 1723_PEA_1_P6, comprising a first amino acid sequence being at least 90 % homologous to
MWVLGIAATFCGLFLLPGFALQIQCYQCEEFQLNNDCSSPEFIVNCTVNVQDMCQKEV MEQSAGIMYRKSCASSAACLIASAG corresponding to amino acids 1 - 83 of Q96AC2, which also corresponds to amino acids 1 - 83 of Rl 1723_PEA_1_P6, and a second amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence
SPCRGLAPGREEQRALHKAGAVGGGVRMYAQALLVVGVLQRQAAAQHLHEHPPKLL RGHRVQERVDDRAEVEKRLREGEEDHVRPEVGPRPVVLGFGRSHDPPNLVGHPAYGQ
CHNNQPWADTSRRERQRKEKHSMRTQ corresponding to amino acids 84 - 222 of R11723_PEA_1_P6, wherein said first and second amino acid sequences are contiguous and in a sequential order.
According to preferred embodiments of the present invention, there is provided an isolated polypeptide encoding for a tail of Rl 1723JPEA 1 P6, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence SPCRGLAPGREEQRALHKAGAVGGGVRMYAQALLVVGVLQRQAAAQHLHEHPPKLL RGHRVQERVDDRAEVEKRLREGEEDHVRPEVGPRPVVLGFGRSHDPPNLVGHPAYGQ CHNNQPWADTSRRERQRKEKHSMRTQ IN R11723_PEA_1_P6.
According to preferred embodiments of the present invention, there is provided an isolated chimeric polypeptide encoding for Rl 1723_PEA_1_P6, comprising a first amino acid sequence being at least 90 % homologous to
MWVLGIAATFCGLFLLPGFALQIQCYQCEEFQLNNDCSSPEFIVNCTVNVQDMCQKEV MEQSAGIMYRKSCASSAACLIASAG corresponding to amino acids 1 - 83 of Q8N2G4, which also corresponds to amino acids 1 - 83 of R11723_PEA_1_P6, and a second amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence SPCRGLAPGREEQRALHKAGAVGGGVRMYAQALLWGVLQRQAAAQHLHEHPPKLL
RGHRVQERVDDRAEVEKRLREGEEDHVRPEVGPRPVVLGFGRSHDPPNLVGHPAYGQ CHNNQPWADTSRRERQRKEKHSMRTQ corresponding to amino acids 84 - 222 of Rl 1723_PEA_1_P6, wherein said first and second amino acid sequences are contiguous and in a sequential order. According to preferred embodiments of the present invention, there is provided an isolated polypeptide encoding for a tail of Rl 1723_PEA_1JP6, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence SPCRGLAPGREEQRALHKAGAVGGGVRMYAQALLVVGVLQRQAAAQHLHEHPPKLL RGHRVQERVDDRAEVEKRLREGEEDHVRPEVGPRPVVLGFGRSHDPPNLVGHPAYGQ CHNNQPWADTSRRERQRKEKHSMRTQ in R11723JPEA 1JP6.
According to preferred embodiments of the present invention, there is provided an isolated chimeric polypeptide encoding for R11723_PEA_1_P6, comprising a first amino acid sequence being at least 90 % homologous to MWVLGIAATFCGLFLLPGFALQIQCYQCEEFQLNNDCSSPEFIVNCTVNVQDMCQKEV MEQSAGIMYRKSCASSAACLIASAG corresponding to amino acids 24 - 106 of BAC85518, which also corresponds to amino acids 1 - 83 of R11723_PEA_1_P6, and a second amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence SPCRGLAPGREEQRALHKAGAVGGGVRMYAQALLWGVLQRQAAAQHLHEHPPKLL RGHRVQERVDDRAEVEKRLREGEEDHVRPEVGPRPVVLGFGRSHDPPNLVGHPAYGQ
CHNNQPWADTSRRERQRKEKHSMRTQ corresponding to amino acids 84 - 222 of
Rl 1723JPEA_1_P6, wherein said first and second amino acid sequences are contiguous and in a sequential order. According to preferred embodiments of the present invention, there is provided an isolated polypeptide encoding for a tail of Rl 1723_PEA_1_P6, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence SPCRGLAPGREEQRALHKAGAVGGGVRMYAQALLWGVLQRQAAAQHLHEHPPKLL RGHRVQERVDDRAEVEKRLREGEEDHVRPEVGPRPWLGFGRSHDPPNLVGHPAYGQ CHNNQPWADTSRRERQRKEKHSMRTQ in R11723_PEA_1_P6.
According to preferred embodiments of the present invention, there is provided an isolated chimeric polypeptide encoding for Rl 1723_PEA_1_P7, comprising a first amino acid sequence being at least 90 % homologous to
MWVLGIAATFCGLFLLPGFALQIQCYQCEEFQLNNDCSSPEFIVNCTVNVQDMCQKEV MEQSAG corresponding to amino acids 1 - 64 of Q96AC2, which also corresponds to amino acids 1 - 64 of Rl 1723_PEA_1_P7, and a second amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence SHCVTRLECSGTISAHCNLCLPGSNDHPT corresponding to amino acids 65 - 93 of Rl 1723_PEA_1_P7, wherein said first and second amino acid sequences are contiguous and in a sequential order.
According to preferred embodiments of the present invention, there is provided an isolated polypeptide encoding for a tail of Rl 1723_PEA_1_P7, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence SHCVTRLECSGTISAHCNLCLPGSNDHPT in Rl 1723_PEA_1_P7.
According to preferred embodiments of the present invention, there is provided an isolated chimeric polypeptide encoding for Rl 1723_PEA_1_P7, comprising a first amino acid sequence being at least 90 % homologous to MWVLGIAATFCGLFLLPGFALQIQCYQCEEFQLNNDCSSPEFIVNCTVNVQDMCQKEV MEQSAG corresponding to amino acids 1 - 64 of Q8N2G4, which also corresponds to amino acids 1 - 64 of Rl 1723_PEA_1_P7, and a second amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence SHCVTRLECSGTISAHCNLCLPGSNDHPT corresponding to amino acids 65 - 93 of
Rl 1723_PEA_1_P7, wherein said first and second amino acid sequences are contiguous and in a sequential order.
According to preferred embodiments of the present invention, there is provided an isolated polypeptide encoding for a tail of Rl 1723_PEA_1_P7, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at
least about 90% and most preferably at least about 95% homologous to the sequence
SHCVTRLECSGTISAHCNLCLPGSNDHPT in R11723_PEA_1_P7.
According to preferred embodiments of the present invention, there is provided an isolated chimeric polypeptide encoding for Rl 1723_PEA_1_P7, comprising a first amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence
MWVLG corresponding to amino acids 1 - 5 of R11723_PEA_1_P7, second amino acid sequence being at least 90 % homologous to
IAATFCGLFLLPGFALQIQCYQCEEFQLNNDCSSPEFIVNCTVNVQDMCQKEVMEQSAG corresponding to amino acids 22 - 80 of BAC85273, which also corresponds to amino acids 6 -
64 of R11723_PEA_1_P7, and a third amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least
95% homologous to a polypeptide having the sequence
SHCVTRLECSGTISAHCNLCLPGSNDHPT corresponding to amino acids 65 - 93 of R11723_PEA_1_P7, wherein said first, second and third amino acid sequences are contiguous and in a sequential order.
According to preferred embodiments of the present invention, there is provided an isolated polypeptide encoding for a head of Rl 1723_PEA_1_P7, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence
MWVLG of R11723_PEA_1JP7.
According to preferred embodiments of the present invention, there is provided an isolated polypeptide encoding for a tail of Rl 1723_PEA_1_P7, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence
SHCVTRLECSGTISAHCNLCLPGSNDHPT in R11723_PEA_1_P7.
According to preferred embodiments of the present invention, there is provided an isolated chimeric polypeptide encoding for Rl 1723_PEA_1_P7, comprising a first amino acid sequence being at least 90 % homologous to
MWVLGIAATFCGLFLLPGFALQIQCYQCEEFQLNNDCSSPEFIVNCTVNVQDMCQKEV
MEQSAG corresponding to amino acids 24 - 87 of BAC85518, which also corresponds to amino acids 1 - 64 of Rl 1723_PEA_1_P7, and a second amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence SHCVTRLECSGTISAHCNLCLPGSNDHPT corresponding to amino acids 65 - 93 of
Rl 1723_PEA_1_P7, wherein said first and second amino acid sequences are contiguous and in a sequential order.
According to preferred embodiments of the present invention, there is provided an isolated polypeptide encoding for a tail of Rl 1723_PEA__1_P7, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence SHCVTRLECSGTISAHCNLCLPGSNDHPT in R11723_PEA_1_P7.
According to preferred embodiments of the present invention, there is provided an isolated chimeric polypeptide encoding for Rl 1723_PEA_1_P13, comprising a first amino acid sequence being at least 90 % homologous to
MWVLGIAATFCGLFLLPGFALQIQCYQCEEFQLNNDCSSPEFIVNCTVNVQDMCQKEV MEQSA corresponding to amino acids 1 - 63 of Q96AC2, which also corresponds to amino acids 1 - 63 of R11723JPEA_1_P13, and a second amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence DTKRTNTLLFEMRHFAKQLTT corresponding to amino acids 64 - 84 of R11723_PEA_1_P13, wherein said first and second amino acid sequences are contiguous and in a sequential order.
According to preferred embodiments of the present invention, there is provided an isolated polypeptide encoding for a tail of Rl 1723_PEA_1_P 13, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence DTKRTNTLLFEMRHFAKQLTT in R11723_PEA_1_P13.
According to preferred embodiments of the present invention, there is provided an isolated chimeric polypeptide encoding for Rl 1723_PEA_l_P10, comprising a first amino acid sequence being at least 90 % homologous to
MWVLGIAATFCGLFLLPGFALQIQCYQCEEFQLNNDCSSPEFIVNCTVNVQDMCQKEV MEQSA corresponding to amino acids 1 - 63 of Q96AC2, which also corresponds to amino acids 1 - 63 of Rl 1723_PEA_l_P10, and a second amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence
DRVSLCHEAGVQWNNFSTLQPLPPRLK corresponding to amino acids 64 - 90 of R11723_PEA_l_P10, wherein said first and second amino acid sequences are contiguous and in a sequential order.
According to preferred embodiments of the present invention, there is provided an isolated polypeptide encoding for a tail of Rl 1723_PEA_1_P 10, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence DRVSLCHEAGVQWNNFSTLQPLPPRLK in Rl 1723 JPEAJ JPlO.
According to preferred embodiments of the present invention, there is provided an isolated chimeric polypeptide encoding for Rl 1723_PEA_l_P10, comprising a first amino acid sequence being at least 90 % homologous to
MWVLGIAATFCGLFLLPGFALQIQCYQCEEFQLNNDCSSPEFIVNCTVNVQDMCQKEV MEQSA corresponding to amino acids 1 - 63 of Q8N2G4, which also corresponds to amino acids 1 - 63 of Rl 1723_PEA_l_P10, and a second amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence DRVSLCHEAGVQWNNFSTLQPLPPRLK corresponding to amino acids 64 - 90 of R11723_PEA_l_P10, wherein said first and second amino acid sequences are contiguous and in a sequential order. According to preferred embodiments of the present invention, there is provided an isolated polypeptide encoding for a tail of Rl 1723JPEA_l_P10, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence DRVSLCHEAGVQWNNFSTLQPLPPRLK in Rl 1723_PEA_l_P10.
According to preferred embodiments of the present invention, there is provided an isolated chimeric polypeptide encoding for Rl 1723JPEA_l_P10, comprising a first amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence MWVLG corresponding to amino acids 1 - 5 of Rl 1723_PEA_l_P10, second amino acid sequence being at least 90 % homologous to
IAATFCGLFLLPGFALQIQCYQCEEFQLNNDCSSPEFIVNCTVNVQDMCQKEVMEQSA corresponding to amino acids 22 - 79 of BAC85273, which also corresponds to amino acids 6 - 63 of Rl 1723_PEA_l_P10, and a third amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence
DRVSLCHEAGVQWNNFSTLQPLPPRLK corresponding to amino acids 64 - 90 of Rl 1723_PEA_1 JPlO, wherein said first, second and third amino acid sequences are contiguous and in a sequential order. According to preferred embodiments of the present invention, there is provided an isolated polypeptide encoding for a head of Rl 1723_PEA_l_P10, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence MWVLG of R11723_PEA_l_P10. According to preferred embodiments of the present invention, there is provided an isolated polypeptide encoding for a tail of Rl 1723_PEA_l_P10, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence DRVSLCHEAGVQWNNFSTLQPLPPRLK in R11723_PEA_l_P10. According to preferred embodiments of the present invention, there is provided an isolated chimeric polypeptide encoding for R11723_PEA_l_P10, comprising a first amino acid sequence being at least 90 % homologous to
MWVLGIAATFCGLFLLPGFALQIQCYQCEEFQLNNDCSSPEFIVNCTVNVQDMCQKEV MEQSA corresponding to amino acids 24 - 86 of BAC85518, which also corresponds to amino acids 1 - 63 of Rl 1723_PEA_l_P10, and a second amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most
preferably at least 95% homologous to a polypeptide having the sequence DRVSLCHEAGVQWNNFSTLQPLPPRLK corresponding to amino acids 64 - 90 of Rl 1723_PEA_l_P10, wherein said first and second amino acid sequences are contiguous and in a sequential order. According to preferred embodiments of the present invention, there is provided an isolated polypeptide encoding for a tail of Rl 1723_PEA_l_P10, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence DRVSLCHEAGVQWNNFSTLQPLPPRLK in R11723_PEA_l_P10. According to preferred embodiments of the present invention, there is provided an isolated chimeric polypeptide encoding for R16276_PEA_1_P7, comprising a first amino acid sequence being at least 90 % homologous to
MQSVQSTSFCLRKQCLCLTFLLLHLLGQVAATQRCPPQCPG corresponding to amino acids 1 - 41 of NOV HUMAN, which also corresponds to amino acids 1 - 41 of R16276_PEA_1_P7, a bridging amino acid Q corresponding to amino acid 42 of
R16276 PEA 1 P7, a second amino acid sequence being at least 90 % homologous to CPATPPTCAPGVRAVLDGCSCCLVCARQRGESCSDLEPCDESSGLYCDRSADPSNQTGI CT corresponding to amino acids 43 - 103 of NOV HUMAN, which also corresponds to amino acids 43 - 103 of R16276_PEA_1_P7, and a third amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence GNPAPSAV corresponding to amino acids 104 - 111 of R16276JPEA_1_P7, wherein said first amino acid sequence, bridging amino acid, second amino acid sequence and third amino acid sequence are contiguous and in a sequential order. According to preferred embodiments of the present invention, there is provided an isolated polypeptide encoding for a tail of R16276_PEA_1_P7, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence GNPAPSAV in R16276_PEA_1_P7. According to preferred embodiments of the present invention, there is provided an isolated chimeric polypeptide encoding for R16276_PEA_1_P7, comprising a first amino acid
sequence being at least 90 % homologous to
MQSVQSTSFCLRKQCLCLTFLLLHLLGQVAATQRCPPQCPG corresponding to amino acids 1 - 41 of NOV_HUMAN, which also corresponds to amino acids 1 - 41 of R16276_PEA_1_P7, a bridging amino acid Q corresponding to amino acid 42 of R16276_PEA_1_P7, a second amino acid sequence being at least 90 % homologous to
CPATPPTCAPGVRAVLDGCSCCLVCARQRGESCSDLEPCDESSGLYCDRSADPSNQTGI CT corresponding to amino acids 43 - 103 of NOV-HUMAN, which also corresponds to amino acids 43 - 103 of R16276_PEA_1_P7, and a third amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence GNPAPSAV corresponding to amino acids 104 - 111 of R16276_PEA_1_P7, wherein said first amino acid sequence, bridging amino acid, second amino acid sequence and third amino acid sequence are contiguous and in a sequential order.
According to preferred embodiments of the present invention, there is provided an isolated polypeptide encoding for a tail of R16276_PEA_1_P7, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence GNPAPSAV in R16276_PEA_1_P7.
According to preferred embodiments of the present invention, there is provided an isolated chimeric polypeptide encoding for HUMCEA_PEA_1_P4, comprising a first amino acid sequence being at least 90 % homologous to
MESPSAPPHRWCIPWQRLLLTASLLTFWNPPTTAKLTIESTPFNVAEGKEVLLLVHNLPQ HLFGYSWYKGERVDGNRQIIGYVIGTQQATPGPAYSGREIIYPNASLLIQNIIQNDTGFYT LHVIKSDLVNEEATGQFRVYPELPKPSISSNNSKPVEDKDAVAFTCEPETQDATYLWWV NNQSLPVSPRLQLSNGNRTLTLFNVTRNDTASYKCETQNPVSARRSDSVILNVL corresponding to amino acids 1 - 234 of CEA5JHUMAN, which also corresponds to amino acids 1 - 234 of HUMCEA_PEA_1_P4, and a second amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence CEYICSSLAQAASPNPQGQRQDFSVPLRFKYTDPQPWTSRLSVTFCPRKTWADQVLTKN RRGGAASVLGGSGSTPYDGRNR corresponding to amino acids 235 - 315 of
HUMCEA_PEA_1_P4, wherein said first amino acid sequence and second amino acid sequence are contiguous and in a sequential order.
According to preferred embodiments of the present invention, there is provided an isolated polypeptide encoding for a tail of HUMCEA_PEA_1_P4, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence CEYICSSLAQAASPNPQGQRQDFSVPLRFKYTDPQPWTSRLSVTFCPRKTWADQVLTKN RRGGAASVLGGSGSTPYDGRNR in HUMCEA_PEA_1_P4.
According to preferred embodiments of the present invention, there is provided an isolated chimeric polypeptide encoding for HUMCEA_PEA_1_P5, comprising a first amino acid sequence being at least 90 % homologous to
MESPSAPPHRWCIPWQRLLLTASLLTFWNPPTTAKLTIESTPFNVAEGKEVLLLVHNLPQ HLFGYSWYKGERVDGNRQIIGYVIGTQQATPGPAYSGREIIYPNASLLIQNIIQNDTGFYT LHVIKSDLVNEEATGQFRVYPELPKPSISSNNSKPVEDKDA VAFTCEPETQDATYLWWV NNQSLPVSPRLQLSNGNRTLTLFNVTRNDTASYKCETQNPVSARRSDSVILNVLYGPDA PTISPLNTSYRSGENLNLSCHAASNPPAQYSWFVNGTFQQSTQELFIPNITVNNSGSYTC QAHNSDTGLNRTTVTTITVYAEPPKPFITSNNSNPVEDEDAVALTCEPEIQNTTYLWWV NNQSLPVSPRLQLSNDNRTLTLLSVTRNDVGPYECGIQNELSVDHSDPVILNVLYGPDD PTISPSYTYYRPGVNLSLSCHAASNPPAQYSWLIDGNIQQHTQELFISNITEKNSGLYTCQ ANNSASGHSRTTVKTITVSAELPKPSISSNNSKPVEDKDAVAFTCEPEAQNTTYLWWVN GQSLPVSPRLQLSNGNRTLTLFNVTRNDARAYVCGIQNSVSANRSDPVTLDVLYGPDTP ΠSPPDSSYLSGANLNLSCHSASNPSPQYSWRΓNGIPQQHTQVLFIAKITPNNNGTYACFV
SNLATGRNNSIVKSITVS corresponding to amino acids 1 - 675 of CEA5 JHUMAN, which also corresponds to amino acids 1 - 675 of HUMCEA_PEA_1_P5, and a second amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence GKWLPGASASYSGVESIWFSPKSQEDIFFPSLCSMGTRKSQILS corresponding to amino acids 676 - 719 of HUMCEA_PEA_1_P5, wherein said first amino acid sequence and second amino acid sequence are contiguous and in a sequential order. According to preferred embodiments of the present invention, there is provided an isolated polypeptide encoding for a tail of HUMCEA_PEA_1_P5, comprising a polypeptide
being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence GKWLPGASASYSGVESIWFSPKSQEDIFFPSLCSMGTRKSQILS in HUMCEA_PEA_1JP5.
According to preferred embodiments of the present invention, there is provided an isolated chimeric polypeptide encoding for HUMCEA_PEA_1_P19, comprising a first amino acid sequence being at least 90 % homologous to
MESPSAPPHRWCIPWQRLLLTASLLTFWNPPTTAKLTIESTPFNVAEGKEVLLLVHNLPQ HLFGYSWYKGERVDGNRQIIGYVIGTQQATPGPAYSGREIIYPNASLLIQNIIQNDTGFYT LHVIKSDLVNEEATGQFRVYPELPKPSISSNNSKP VEDKDA VAFTCEPETQDATYLWWV NNQSLPVSPRLQLSNGNRTLTLFNVTRNDTASYKCETQNPVSARRSDSVILN corresponding to amino acids 1 - 232 of CEA5_HUMAN, which also corresponds to amino acids 1 - 232 of HUMCEA_PEA_1_P19, and a second amino acid sequence being at least 90 % homologous to VLYGPDTPIISPPDSSYLSGANLNLSCHSASNPSPQYSWRINGIPQQHTQVLFIAKITPNNN GTYACFVSNLATGRNNSIVKSITVSASGTSPGLSAGATVGIMIGVLVGVALI corresponding to amino acids 589 - 702 of CEA5JHUMAN, which also corresponds to amino acids 233 - 346 of HUMCEA_PEA_1_P19, wherein said first amino acid sequence and second amino acid sequence are contiguous and in a sequential order.
According to preferred embodiments of the present invention, there is provided an isolated chimeric polypeptide encoding for an edge portion of HUMCEA PEA 1 P19, comprising a polypeptide having a length "n", wherein n is at least about 10 amino acids in length, optionally at least about 20 amino acids in length, preferably at least about 30 amino acids in length, more preferably at least about 40 amino acids in length and most preferably at least about 50 amino acids in length, wherein at least two amino acids comprise NV, having a structure as follows: a sequence starting from any of amino acid numbers 232-x to 232; and ending at any of amino acid numbers 233+ ((n-2) - x), in which x varies from 0 to n-2.
According to preferred embodiments of the present invention, there is provided an isolated chimeric polypeptide encoding for HUMCEA_PEA_l_P20, comprising a first amino acid sequence being at least 90 % homologous to MESPSAPPHRWCIPWQRLLLTASLLTFWNPPTTAKLTIESTPFNVAEGKEVLLLVHNLPQ HLFGYSWYKGERVDGNRQIIGYVIGTQQATPGPAYSGREIIYPNASLLIQNIIQNDTGFYT
LHVIKSDL1VTS[EEATGQFRVYP corresponding to amino acids 1 - 142 of CEA5JHUMAN, which also corresponds to amino acids 1 - 142 of HUMCEA_PEA_l_P20, and a second amino acid sequence being at least 90 % homologous to ELPKPSISSNNSKP VEDKDAVAFTCEPEAQNTTYLWWVNGQSLPVSPRLQLSNGNRTLT LFNVTRNDARA YVCGIQNSVSANRSDPVTLDVLYGPDTPIISPPDSSYLSGANLNLSCHS
ASNPSPQYSWRINGIPQQHTQVLFIAKITPNNNGTYACFVSNLATGRNNSIVKSITVSASG TSPGLSAGATVGIMIGVLVGVALI corresponding to amino acids 499 - 702 of CEA5_HUMAN, which also corresponds to amino acids 143 - 346 of HUMCEA_PEA_l_P20, wherein said first amino acid sequence and second amino acid sequence are contiguous and in a sequential order.
According to preferred embodiments of the present invention, there is provided an isolated chimeric polypeptide encoding for an edge portion of HUMCEA_PEA_l_P20, comprising a polypeptide having a length "n", wherein n is at least about 10 amino acids in length, optionally at least about 20 amino acids in length, preferably at least about 30 amino acids in length, more preferably at least about 40 amino acids in length and most preferably at least about 50 amino acids in length, wherein at least two amino acids comprise PE, having a structure as follows: a sequence starting from any of amino acid numbers 142-x to 142; and ending at any of amino acid numbers 143+ ((n-2) - x), in which x varies from 0 to n-2.
According to preferred embodiments of the present invention, there is provided an isolated chimeric polypeptide encoding for Z44808_PEA_l_P5, comprising a first amino acid sequence being at least 90 % homologous to
MLLPQLCWLPLLAGLLPPVPAQKFSALTFLRVDQDKDKDCSLDCAGSPQKPLCASDGR TFLSRCEFQRAKCKDPQLEIAYRGNCKDVSRCVAERKYTQEQARKEFQQVFIPECNDD GTYSQVQCHSYTGYCWCVTPNGRPISGTAVAHKTPRCPGSVNEKLPQREGTGKTDDAA APALETQPQGDEEDIASRYPTLWTEQVKSRQNKTNKNSVSSCDQEHQSALEEAKQPKN DNWIPECAHGGLYKPVQCHPSTGYCWCVLVDTGRPIPGTSTRYEQPKCDNTARAHPA KARDLYKGRQLQGCPGAKKHEFLTSVLDALSTDMVHAASDPSSSSGRLSEPDPSHTLEE RVVHWYFKLLDKNSSGDIGKKEIKPFKRFLRKKSKPKKCVKKFVEYCDVNNDKSISVQ ELMGCLGVAKEDGKADTKKRHTPRGHAESTSNRQ corresponding to amino acids 1 - 441 of SMO2_HUMAN, which also corresponds to amino acids 1 - 441 of Z44808_PEA_l_P5, and a second amino acid sequence being at least 70%, optionally at least 80%, preferably at least
85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence DAMVVS SRPKATTHRKSRTLSRR corresponding to amino acids 442 - 464 of Z44808_PEA_l_P5, wherein said first and second amino acid sequences are contiguous and in a sequential order. According to preferred embodiments of the present invention, there is provided an isolated polypeptide encoding for a tail of Z44808_PEA_l_P5, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence DAMVVSSRPKATTHRKSRTLSRR in Z44808_PEA_l_P5. According to preferred embodiments of the present invention, there is provided an isolated chimeric polypeptide encoding for Z44808_PEA_l_P6, comprising a first amino acid sequence being at least 90 % homologous to
MLLPQLCWLPLLAGLLPPVPAQKFSALTFLRVDQDKDKDCSLDCAGSPQKPLCASDGR TFLSRCEFQRAKCKDPQLEIAYRGNCKDVSRCVAERKYTQEQARKEFQQVFIPECNDD GTYSQVQCHSYTGYCWCVTPNGRPISGTA VAHKTPRCPGSVNEKLPQREGTGKTDDAA APALETQPQGDEEDIASRYPTLWTEQVKSRQNKTNKNSVSSCDQEHQSALEEAKQPKN DNVVIPECAHGGLYKPVQCHPSTGYCWCVLVDTGRPIPGTSTRYEQPKCDNTARAHPA KARDLYKGRQLQGCPGAKKHEFLTSVLDALSTDMVHAASDPSSSSGRLSEPDPSHTLEE RVVHWYFKLLDKNSSGDIGKKEIKPFKRFLRKKSKPKKCVKKFVEYCDVNNDKSISVQ ELMGCLGVAKEDGKADTKKRH corresponding to amino acids 1 - 428 of SMO2 HUMAN, which also corresponds to amino acids 1 - 428 of Z44808_PEA_l_P6, and a second amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence RSKRNL corresponding to amino acids 429 - 434 of Z44808_PEA_l_P6, wherein said first and second amino acid sequences are contiguous and in a sequential order.
According to preferred embodiments of the present invention, there is provided an isolated polypeptide encoding for a tail of Z44808JPEA_l_P6, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence RSKRNL in Z44808 PEA 1 P6.
According to preferred embodiments of the present invention, there is provided an isolated chimeric polypeptide encoding for Z44808_PEA_l_P7, comprising a first amino acid sequence being at least 90 % homologous to
MLLPQLCWLPLLAGLLPPVPAQKFSALTFLRVDQDKDKDCSLDCAGSPQKPLCASDGR TFLSRCEFQRAKCKDPQLEIAYRGNCKDVSRCVAERKYTQEQARKEFQQVFIPECNDD GTYSQVQCHSYTGYCWCVTPNGRPISGTAVAHKTPRCPGSVNEKLPQREGTGKTDDAA APALETQPQGDEEDIASRYPTLWTEQVKSRQNKTNKNSVSSCDQEHQSALEEAKQPKN DNVVIPECAHGGLYKPVQCHPSTGYCWCVLVDTGRPIPGTSTRYEQPKCDNTARAHPA KARDLYKGRQLQGCPGAKKHEFLTSVLDALSTDMVHAASDPSSSSGRLSEPDPSHTLEE RVVHWYFKXLDKNSSGDIGKKΕIKPFKRFLRKKSKPKKCVKKFVEYCDVNNDKSISVQ ELMGCLGVAKEDGKADTKKRHTPRGHAESTSNRQ corresponding to amino acids 1 - 441 of SMO2_HUMAN, which also corresponds to amino acids 1 - 441 of Z44808_PEA_l_P7, and a second amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence LLWLRGKVSFYCF corresponding to amino acids 442 - 454 of Z44808_PEA_l_P7, wherein said first and second amino acid sequences are contiguous and in a sequential order.
According to preferred embodiments of the present invention, there is provided an isolated polypeptide encoding for a tail of Z44808_PEA_l_P7, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence LLWLRGKVSFYCF in Z44808_PEA_l_P7.
According to preferred embodiments of the present invention, there is provided an isolated chimeric polypeptide encoding for Z448O8_PEA_1_P11, comprising a first amino acid sequence being at least 90 % homologous to
MLLPQLCWLPLLAGLLPPVPAQKFSALTFLRVDQDKDKDCSLDCAGSPQKPLCASDGR TFLSRCEFQRAKCKDPQLEIAYRGNCKDVSRCVAERKYTQEQARKEFQQVFIPECNDD GTYSQVQCHSYTGYCWCVTPNGRPISGTAVAHKTPRCPGSVNEKLPQREGTGKT corresponding to amino acids 1 - 170 of SMO2JHUMAN, which also corresponds to amino acids 1 - 170 of Z448O8_PEA_1_P11, and a second amino acid sequence being at least 90 % homologous to
DIASRYPTLWTEQVKSRQNKTNKNSVSSCDQEHQSALEEAKQPKNDNVVIPECAHGGL YKPVQCHPSTGYCWCVLVDTGRPIPGTSTRYEQPKCDNTARAHPAKARDLYKGRQLQ GCPGAKKHEFLTSVLDALSTDMVHAASDPSSSSGRLSEPDPSHTLEERVVHWYFKLLD KNSSGDIGKKEIKPFKRFLRKKSKPKKCVKKFVEYCDVNNDKSISVQELMGCLGVAKE DGKADTKKRHTPRGHAESTSNRQPRKQG corresponding to amino acids 188 - 446 of SMO2 JHUMAN, which also corresponds to amino acids 171 - 429 of Z448O8JPEA_1_P11, wherein said first and second amino acid sequences are contiguous and in a sequential order.
According to preferred embodiments of the present invention, there is provided an isolated chimeric polypeptide encoding for an edge portion of Z448O8_PEA_1_P11, comprising a polypeptide having a length "n", wherein n is at least about 10 amino acids in length, optionally at least about 20 amino acids in length, preferably at least about 30 amino acids in length, more preferably at least about 40 amino acids in length and most preferably at least about 50 amino acids in length, wherein at least two amino acids comprise TD, having a structure as follows: a sequence starting from any of amino acid numbers 170-x to -170; and ending at any of amino acid numbers 171+ ((n-2) - x), in which x varies from 0 to n-2.
According to preferred embodiments of the present invention, there is provided an isolated chimeric polypeptide encoding for H61775_P16, comprising a first amino acid sequence being at least 90 % homologous to MVWCLGLAVLSLVISQGADGRGKPEWSVVGRAGESWLGCDLLPPAGRPPLHVIEWL RFGFLLPIFIQFGLYSPRIDPDYVG corresponding to amino acids 11 - 93 of Q9P2J2, which also corresponds to amino acids 1 - 83 of H61775_P16, and a second amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence DCGFPAFRELKRAETVSPVFFTRRCIWEDLKSTGFSPAGGGRPPGGGPRTQEDSGLPCW RSSCSVTLQV corresponding to amino acids 84 - 152 of H61775_P16, wherein said first and second amino acid sequences are contiguous and in a sequential order.
According to preferred embodiments of the present invention, there is provided an isolated polypeptide encoding for a tail of H61775_P16, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence
DCGFP AFRELKRAETVSPVFFTRRCIWEDLKSTGFSPAGGGRPPGGGPRTQEDSGLPCW
RSSCSVTLQV in H61775_P16.
According to preferred embodiments of the present invention, there is provided an isolated chimeric polypeptide encoding for H61775 P16, comprising a first amino acid sequence being at least 90 % homologous to
MVWCLGLAVLSLVISQGADGRGKPEVVSVVGRAGESVVLGCDLLPPAGRPPLHVIEWL
RFGFLLPIFIQFGLYSPRIDPDYVG corresponding to amino acids 1 - 83 of AAQ88495, which also corresponds to amino acids 1 - 83 of H61775JP16, and a second amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence
DCGFP AFRELKRAETVSPVFFTRRCIWEDLKSTGFSPAGGGRPPGGGPRTQEDSGLPCW
RSSCSVTLQV corresponding to amino acids 84 - 152 of H61775_P16, wherein said first and second amino acid sequences are contiguous and in a sequential order.
According to preferred embodiments of the present invention, there is provided an isolated polypeptide encoding for a tail of H61775_P16, comprising a polypeptide being at least
70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about
90% and most preferably at least about 95% homologous to the sequence
DCGFPAFRELKRAETVSPVFFTRRCIWEDLKSTGFSPAGGGRPPGGGPRTQEDSGLPCW
RSSCSVTLQV in H61775_P16. According to preferred embodiments of the present invention, there is provided an isolated chimeric polypeptide encoding for H61775_P17, comprising a first amino acid sequence being at least 90 % homologous to
MVWCLGLAVLSLVISQGADGRGKPEVVSVVGRAGESVVLGCDLLPPAGRPPLHVIEWL
RFGFLLPIFIQFGLYSPRIDPDYVG corresponding to amino acids 11 - 93 of Q9P2J2, which also corresponds to amino acids 1 - 83 of H61775_P17.
According to preferred embodiments of the present invention, there is provided an isolated chimeric polypeptide encoding for H61775JP17, comprising a first amino acid sequence being at least 90 % homologous to
MWCLGLAVLSLVISQGADGRGKPEWSVVGRAGESVVLGCDLLPPAGRPPLHVIEWL RFGFLLPIFIQFGLYSPRIDPDYVG corresponding to amino acids 1 - 83 of AAQ88495, which also corresponds to amino acids 1 - 83 of H61775_P17.
According to preferred embodiments of the present invention, there is provided an isolated chimeric polypeptide encoding for M85491_PEA_1_P13, comprising a first amino acid sequence being at least 90 % homologous to
MALRRLGAALLLLPLLAAVEETLMDSTTATAELGWMVHPPSGWEEVSGYDENMNTIR TYQVCNVFESSQNNWLRTKFIRRRGAHRIHVEMKFSVRDCSSIPSVPGSCKETFNLYYY EADFDSATKTFPNWMENPWVKVDTIAADESFSQVDLGGRVMKINTEVRSFGPVSRSGF YLAFQDYGGCMSLIAVRVFYRKCPRIIQNGAIFQETLSGAESTSLVAARGSCIANAEEVD VPIKLYCNGDGEWLVPIGRCMCKAGFEAVENGTVCRGCPSGTFKANQGDEACTHCPIN SRTTSEGATNCVCRNGYYRADLDPLDMPCTTIPSAPQAVISSVNETSLMLEWTPPRDSG GREDLVYNIICKSCGSGRGACTRCGDNVQYAPRQLGLTEPRIYISDLLAHTQYTFEIQAV NGVTDQSPFSPQFASVNITTNQAAPSAVSIMHQVSRTVDSITLSWSQPDQPNGVILDYEL QYYEK corresponding to amino acids 1 - 476 of EPB2 HUMAN, which also corresponds to amino acids 1 - 476 of M85491_PEA_1_P13, and a second amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence VPIGWVLSPSPTSLRAPLPG corresponding to amino acids 477 - 496 of M85491_PEA_1_P13, wherein said first and second amino acid sequences are contiguous and in a sequential order.
According to preferred embodiments of the present invention, there is provided an isolated polypeptide encoding for a tail of M85491JPEA_1_P13, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence VPIGWVLSPSPTSLRAPLPG in M85491JPEA_1JP13.
According to preferred embodiments of the present invention, there is provided an isolated chimeric polypeptide encoding for M85491_PEA_1_P14, comprising a first amino acid sequence being at least 90 % homologous to
MALRRLGAALLLLPLLAAVEETLMDSTTATAELGWMVHPPSGWEEVSGYDENMNTIR TYQVCNVFESSQNNWLRTKFIRRRGAHRIHVEMKFSVRDCSSIPSVPGSCKETFNLYYY EADFDSATKTFPNWMENPWVKVDTIAADESFSQVDLGGRVMKINTEVRSFGPVSRSGF YLAFQDYGGCMSLIAVRVFYRKCPRIIQNGAIFQETLSGAESTSLVAARGSCIANAEEVD VPIKLYCNGDGEWLVPIGRCMCKAGFEAVENGTVCR corresponding to amino acids 1 -
270 of EPB2_HUMAN, which also corresponds to amino acids 1 - 270 of
M85491_PEA_1_P14, and a second amino acid sequence being at least 70%, optionally at least
80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence ERQDLTMLSRLVLNSWPQMILPPQPPKVLEL corresponding to amino acids 271 - 301 of
M85491_PEA_1_P14, wherein said first and second amino acid sequences are contiguous and in a sequential order.
According to preferred embodiments of the present invention, there is provided an isolated polypeptide encoding for a tail of M85491_PEA_1_P14, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence
ERQDLTMLSRLVLNSWPQMILPPQPPKVLEL in M85491_PEA_1_P14.
According to preferred embodiments of the present invention, there is provided an isolated chimeric polypeptide encoding for T39971_P6, comprising a first amino acid sequence being at least 90 % homologous to
MAPLRPLLILALLAWVALADQESCKGRCTEGFNVDKKCQCDELCSYYQSCCTDYTAEC KPQVTRGDVFTMPEDEYTVYDDGEEKNNATVHEQVGGPSLTSDLQAQSKGNPEQTPV LKPEEEAPAPEVGASKPEGIDSRPETLHPGRPQPPAEEELCSGKPFDAFTDLKNGSLFAFR GQYCYELDEKAVRPGYPKLIRDVWGIEGPIDAAFTRINCQGKTYLFKGSQYWRFEDGV LDPDYPRNISDGFDGIPDNVDAALALPAHSYSGRERVYFFKG corresponding to amino acids 1 - 276 of VTNC_HUMAN, which also corresponds to amino acids 1 - 276 of T39971_P6, and a second amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence TQGVVGD corresponding to amino acids 277 - 283 of T39971_P6, wherein said first and second amino acid sequences are contiguous and in a sequential order.
According to preferred embodiments of the present invention, there is provided an isolated polypeptide encoding for a tail of T39971_P6, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence TQGWGD in T39971 P6.
According to preferred embodiments of the present invention, there is provided an isolated chimeric polypeptide encoding for T39971 JP9, comprising a first amino acid sequence being at least 90 % homologous to
MAPLRPLLILALLAWVALADQESCKGRCTEGFNVDKKCQCDELCSYYQSCCTDYTAEC KPQVTRGDVFTMPEDEYTVYDDGEEKNNATVHEQVGGPSLTSDLQAQSKGNPEQTPV LKPEEEAPAPEVGASKPEGIDSPJ3ETLHPGRPQPPAEEELCSGKPFDAFTDLKNGSLFAFR GQYCYELDEKAVRPGYPKLIRDVWGIEGPIDAAFTRINCQGKTYLFKGSQYWRFEDGV LDPDYPRNISDGFDGIPDNVDAALALPAHSYSGRERVYFFKGKQYWEYQFQHQPSQEE CEGSSLSAVFEHFAMMQRDSWEDIFELLFWGRT corresponding to amino acids 1 - 325 of VTNC_HUMAN, which also corresponds to amino acids 1 - 325 of T39971JP9, and a second amino acid sequence being at least 90 % homologous to
SGMAPRPSLAKKQRFRHRNRKGYRSQRGHSRGRNQNSRRPSRATWLSLFSSEESNLGA NNYDDYRMDWLVPATCEPIQSVFFFSGDKYYRVNLRTRRVDTVDPPYPRSIAQYWLGC PAPGHL corresponding to amino acids 357 - 478 of VTNC_HUMAN, which also corresponds to amino acids 326 - 447 of T39971_P9, wherein said first and second amino acid sequences are contiguous and in a sequential order.
According to preferred embodiments of the present invention, there is provided an isolated chimeric polypeptide encoding for an edge portion of T39971_P9, comprising a polypeptide having a length "n", wherein n is at least about 10 amino acids in length, optionally at least about 20 amino acids in length, preferably at least about 30 amino acids in length, more preferably at least about 40 amino acids in length and most preferably at least about 50 amino acids in length, wherein at least two amino acids comprise TS, having a structure as follows: a sequence starting from any of amino acid numbers 325-x to 325; and ending at any of amino acid numbers 326 + ((n-2) - x), in which x varies from 0 to n-2. According to preferred embodiments of the present invention, there is provided an isolated chimeric polypeptide encoding for T39971_P11, comprising a first amino acid sequence being at least 90 % homologous to
MAPLRPLLILALLAWVALADQESCKGRCTEGFNVDKKCQCDELCSYYQSCCTDYTAEC KPQVTRGDVFTMPEDEYTVYDDGEEKNNATVHEQVGGPSLTSDLQAQSKGNPEQTPV LKPEEEAPAPEVGASKPEGIDSRPETLHPGRPQPPAEEELCSGKPFDAFTDLKNGSLFAFR GQYCYELDEKAVRPGYPKLIRDVWGIEGPIDAAFTRINCQGKTYLFKGSQYWRFEDGV
LDPDYPRNISDGFDGIPDNVDAALALPAHSYSGRERVYFFKGKQYWEYQFQHQPSQEE CEGSSLSAVFEHFAMMQRDSWEDIFELLFWGRTS corresponding to amino acids 1 - 326 of VTNCJHUMAN, which also corresponds to amino acids 1 - 326 of T39971_P11, and a second amino acid sequence being at least 90 % homologous to DKYYRVNLRTRRVDTVDPPYPRSIAQYWLGCPAPGHL corresponding to amino acids 442
- 478 of VTNCJHUMAN, which also corresponds to amino acids 327 - 363 of T39971 JPl 1, wherein said first and second amino acid sequences are contiguous and in a sequential order.
According to preferred embodiments of the present invention, there is provided an isolated chimeric polypeptide encoding for an edge portion of T39971_P11, comprising a polypeptide having a length "n", wherein n is at least about 10 amino acids in length, optionally at least about 20 amino acids in length, preferably at least about 30 amino acids in length, more preferably at least about 40 amino acids in length and most preferably at least about 50 amino acids in length, wherein at least two amino acids comprise SD, having a structure as follows: a sequence starting from any of amino acid numbers 326-x to 326; and ending at any of amino acid numbers 327 + ((n-2) - x), in which x varies from 0 to n-2.
According to preferred embodiments of the present invention, there is provided an isolated chimeric polypeptide encoding for T39971JP11, comprising a first amino acid sequence being at least 90 % homologous to MAPLRPLLILALLAWVALADQESCKGRCTEGFNVDKKCQCDELCSYYQSCCTDYTAEC KPQVTRGDVFTMPEDEYTVYDDGEEKNNATVHEQVGGPSLTSDLQAQSKGNPEQTPV LKPEEEAPAPEVGASKPEGIDSRPETLHPGRPQPPAEEELCSGKPFDAFTDLKNGSLFAFR GQYCYELDEKA VRPGYPKLIRDVWGIEGPIDAAFTRINCQGKTYLFKGSQYWRFEDGV LDPDYPRNISDGFDGIPDNVDAALALPAHSYSGRERVYFFKGKQYWEYQFQHQPSQEE CEGSSLSAVFEHFAMMQRDSWEDIFELLFWGRTS corresponding to amino acids 1 - 326 of Q9BSH7, which also corresponds to amino acids 1 - 326 of T39971_P11, and a second amino acid sequence being at least 90 % homologous to DKYYRVNLRTRRVDTVDPPYPRSIAQYWLGCPAPGHL corresponding to amino acids 442
- 478 of Q9BSH7, which also corresponds to amino acids 327 - 363 of T39971JP11, wherein said first and second amino acid sequences are contiguous and in a sequential order. According to preferred embodiments of the present invention, there is provided an isolated chimeric polypeptide encoding for an edge portion of T39971JP11, comprising a
polypeptide having a length "n", wherein n is at least about 10 amino acids in length, optionally at least about 20 amino acids in length, preferably at least about 30 amino acids in length, more preferably at least about 40 amino acids in length and most preferably at least about 50 amino acids in length, wherein at least two amino acids comprise SD, having a structure as follows: a sequence starting from any of amino acid numbers 326-x to 326; and ending at any of amino acid numbers 327 + ((n-2) - x), in which x varies from 0 to n-2.
According to preferred embodiments of the present invention, there is provided an isolated chimeric polypeptide encoding for T39971_P12, comprising a first amino acid sequence being at least 90 % homologous to MAPLRPLLILALLAWVALADQESCKGRCTEGFNVDKKCQCDELCSYYQSCCTDYTAEC KPQVTRGDVFTMPEDEYTVYDDGEEKNNATVHEQVGGPSLTSDLQAQSKGNPEQTPV LKPEEEAPAPEVGASKPEGIDSRPETLHPGRPQPPAEEELCSGKPFDAFTDLKNGSLFAFR
GQYCYELDEKAVRPGYPKLIRDVWGIEGPIDAAFTRINCQGKTYLFK corresponding to amino acids 1 - 223 of VTNCJHUMAN, which also corresponds to amino acids 1 - 223 of T39971_P12, and a second amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence VPGAVGQGRKHLGRV corresponding to amino acids 224 - 238 of T39971_P12, wherein said first and second amino acid sequences are contiguous and in a sequential order. According to preferred embodiments of the present invention, there is provided an isolated polypeptide encoding for a tail of T39971_P12, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence VPGAVGQGRKHLGRV in T39971_P12. According to preferred embodiments of the present invention, there is provided an isolated chimeric polypeptide encoding for T39971_P12, comprising a first amino acid sequence being at least 90 % homologous to
MAPLRPLLILALLAWVALADQESCKGRCTEGFNVDKKCQCDELCSYYQSCCTDYTAEC KPQVTRGDVFTMPEDEYTVYDDGEEKNNATVHEQVGGPSLTSDLQAQSKGNPEQTPV LKPEEEAPAPEVGASKPEGIDSRPETLHPGRPQPPAEEELCSGKPFDAFTDLKNGSLFAFR GQYCYELDEKAVRPGYPKLIRDVWGIEGPIDAAFTRTNCQGKTYLFK corresponding to
amino acids 1 - 223 of Q9BSH7, which also corresponds to amino acids 1 - 223 of T39971_P12, and a second amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence VPGAVGQGRKHLGRV corresponding to amino acids 224 - 238 of T39971_P12, wherein said first and second amino acid sequences are contiguous and in a sequential order.
According to preferred embodiments of the present invention, there is provided an isolated polypeptide encoding for a tail of T39971_P12, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence VPGAVGQGRKHLGRV in T39971_P12.
According to preferred embodiments of the present invention, there is provided an isolated chimeric polypeptide encoding for Z21368_PEA_1_P2, comprising a first amino acid sequence being at least 90 % homologous to MKYSCCALVLA VLGTELLGSLCSTVRSPRFRGRIQQERKNIRPNIILVLTDDQD VELGSL QVMNKTPJαMEHGGATFINAPVTTPMCCPSRSSMLTGKYVHNHNVYTNNENCSSPSW QAMHEPRTFA VYLNNTGYRTAFFGKYLNEYNGSYIPPGWREWLGLIKNSRFYNYTVCR NGIKEKHGFDYAKDYFTDLITNESINYFKMSKRMYPHRPVMMVISHAAPHGPEDSAPQ FSKLYPNASQHITPSYNYAPNMDKHWIMQYTGPMLPIHMEFTNILQRKRLQTLMSVDD SVERLYNMLVETGELENTYIIYTADHGYHIGQFGLVKGKSMPYDFDIRVPFFIRGPSVEP GSIVPQIVLNIDLAPTILDIAGLDTPPDVDGKSVLKLLDPEKPGNRFRTNKKAKIWRDTFL VERGKFLRKKEESSKNIQQSNHLPKYERVKELCQQARYQTACEQPGQKWQCIEDTSGK LRIHKCKGPSDLLTVRQSTRNLYARGFHDKDKECSCRESGYRASRSQRKSQRQFLRNQ GTPKYKPRFVHTRQTRSLSVEFEGEIYDINLEEEEELQVLQPRNIAKRHDEGHKGPRDLQ ASSGGNRGRMLADSSNAVGPPTTVRVTHKCFILPNDSmCERELYQSARAWKDHKAYI DKEIEALQDKIKNLREVRGHLKRRKPEECSCSKQSYYNKEKGVKKQEKLKSHLHPFKE AAQEVDSKLQLFKENNRRRKKERKEKRRQRKGEECSLPGLTCFTHDNNHWQTAPFWN corresponding to amino acids 1 - 761 of SUL IJHUMAN, which also corresponds to amino acids 1 - 761 of Z21368_PEA_1_P2, and a second amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence
PHKYSAHGRTRHFESATRTTNGAQKLSRI corresponding to amino acids 762 - 790 of Z21368_PEA_1_P2, wherein said first and second amino acid sequences are contiguous and in a sequential order.
According to preferred embodiments of the present invention, there is provided an isolated polypeptide encoding for a tail of Z21368_PEA_1_P2, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence PHKYSAHGRTRHFESATRTTNGAQKLSRI in Z21368_PEA_1_P2.
According to preferred embodiments of the present invention, there is provided an isolated chimeric polypeptide encoding for Z21368_PEA_1_P5, comprising a first amino acid sequence being at feast 90 % homologous to
MKYSCCALVLA VLGTELLGSLCSTVRSPRFRGRIQQERKNIRPNIILVLTDDQDVEL corresponding to amino acids 1 - 57 of Q7Z2W2, which also corresponds to amino acids 1 - 57 of Z21368_PEA_1JP5, second bridging amino acid sequence comprising A, and a third amino acid sequence being at least 90 % homologous to
FFGKYLNEYNGSYIPPGWREWLGLIKNSRFYNYTVCRNGIKEKHGFDYAKDYFTDLITN ESINYFKMSKRMYPHRPVMMVISHAAPHGPEDSAPQFSKLYPNASQHITPSYNYAPNM DKHWIMQYTGPMLPIHMEFTNILQRKRLQTLMSVDDSVERLYNMLVETGELENTYIIYT ADHGYHIGQFGLVKGKSMPYDFDIRVPFFIRGPSVEPGSIVPQIVLNIDLAPTILDIAGLDT PPDVDGKSVLKLLDPEKPGNPvFRTNKKAKIWRDTFLVERGKFLRKKEESSKNIQQSNHL PKYERVKELCQQARYQTACEQPGQKWQCIEDTSGKLRIHKCKGPSDLLTVRQSTRNLY ARGFHDKDKECSCRESGYRASRSQRKSQRQFLRNQGTPKYKPRFVHTRQTRSLSVEFE GEIYDINLEEEEELQVLQPRNIAKRHDEGHKGPRDLQASSGGNRGRMLADSSNAVGPPT TVRVTHKCFILPNDSIHCERELYQSARAWKDHKAYIDKEIEALQDKIKNLREVRGHLKR RKPEECSCSKQSYYNKEKGVKKQEKLKSHLHPFKEAAQEVDSKLQLFKENNRRRKKER KEKRRQRKGEECSLPGLTCFTHDNNHWQTAPFWNLGSFCACTSSNNNTYWCLRTVNE THNFLFCEFATGFLEYFDMNTDPYQLTNTVHTVERGILNQLHVQLMELRSCQGYKQCN PRPKNLDVGNKDGGSYDLHRGQLWDGWEG corresponding to amino acids 139 - 871 of Q7Z2W2, which also corresponds to amino acids 59 - 791 of Z21368_PEA_1_P5, wherein said first, second and third amino acid sequences are contiguous and in a sequential order.
According to preferred embodiments of the present invention, there is provided an isolated polypeptide encoding for an edge portion of Z21368_PEA_1_P5, comprising a polypeptide having a length "n", wherein n is at least about 10 amino acids in length, optionally at least about 20 amino acids in length, preferably at least about 30 amino acids in length, more preferably at least about 40 amino acids in length and most preferably at least about 50 amino acids in length, wherein at least two amino acids comprise LAF having a structure as follows (numbering according to Z21368_PEA_1_P5): a sequence starting from any of amino acid numbers 57-x to 57; and ending at any of amino acid numbers 59 + ((n-2) - x), in which x varies from 0 to n-2. According to preferred embodiments of the present invention, there is provided an isolated chimeric polypeptide encoding for Z21368_PEA_1_P5, comprising a first amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence
MKYSCCALVLAVLGTELLGSLCSTVRSPRFRGRIQQERKNIRPNIILVLTDDQDVELAFF GKYLNEYNGSYIPPGWREWLGLIKNSRFYNYTVCRNGIKEKHGFDYAKDYFTDLITNES INYFKMSKRMYPHRPVMMVISHAAPHGPEDSAPQFSKLYPNASQHITPSYNYAPNMDK HWIMQYTGPMLPIHMEFTNILQRKRLQTLMSVDDSVERLYNMLVETGELENTYIIYTAD HGYHIGQFGLVKGKSMPYDFDIRVPFFIRGPSVEPGSIVPQIVLNIDLAPTILDIAGLDTPP DVDGKSVLKLLDPEKPGNRFRTNKKAKIWRDTFLVERGKFLRKKEESSKNIQQSNHLP KYERVKELCQQARYQTACEQPGQKWQCIEDTSGKLRIHKCKGPSDLLTVRQSTRNLYA RGFHDKDKECSCRESGYRASRSQRKSQRQFLRNQGTPKYKPRFVHTRQTRSLSVEFEGE ΓYDINLEEEEELQVLQPRNIAKRHDEGHKGPRDLQASSGGNRGRMLADSSNAVGPPTTV RVTHKCFILPNDSIHCERELYQSARAWKDHKAYIDKEIEALQDKIKNLREVRGHLKRRK PEECSCSKQSYYTSFKEKGVKKQEKLKSHLHPFKEAAQEVDSKLQLFKENNRRRKKERKE KRRQRKGEECSLPGLTCFTHDNNHWQTAPFWNLGSFCACTSSNNNTYWCLRTVNETH
NFLFCEFATGFLEYFDMNTDPYQLTNTVHTVERGILNQLHVQLME corresponding to amino acids 1 - 751 of Z21368_PEA_1_P5, and a second amino acid sequence being at least 90 % homologous to LRSCQGYKQCNPRPKNLDVGNKDGGSYDLHRGQLWDGWEG corresponding to amino acids 1 - 40 of AAH12997, which also corresponds to amino acids 752 - 791 of Z21368_PEA_1_P5, wherein said first and second amino acid sequences are contiguous and in a sequential order.
According to preferred embodiments of the present invention, there is provided an isolated polypeptide encoding for a head of Z21368_PEA_1_P5, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence MKYSCCAL VLA VLGTELLGSLCSTVRSPRFRGRIQQERKNIRPNIILVLTDDQDVELAFF GKYLNEYNGSYIPPGWREWLGLIKNSRFYNYTVCRNGIKEKHGFDYAKDYFTDLITNES INYFKMSKRMYPHRP VMMVISHAAPHGPEDSAPQFSKLYPNASQHITPSYNYAPNMDK HWIMQYTGPMLPIHMEFTNILQRKRLQTLMSVDDSVERLYNMLVETGELENTYIIYTAD HGYHIGQFGLVKGKSMPYDFDIRVPFFIRGPSVEPGSIVPQIVLNIDLAPTILDIAGLDTPP DVDGKSVLKLLDPEKPGNRFRTNKKAKIWRDTFLVERGKFLRKKEESSKNIQQSNHLP KYERVKELCQQARYQTACEQPGQKWQCIEDTSGKLRIHKCKGPSDLLTVRQSTRNLYA RGFHDKDKECSCRESGYRASRSQRKSQRQFLRNQGTPKYKPRFVHTRQTRSLSVEFEGE IYDINLEEEEELQVLQPRNIAKRHDEGHKGPRDLQASSGGNRGRMLADSSNAVGPPTTV RVTHKCFILPNDSIHCERELYQSARAWKDHKAYIDKEIEALQDKIKNLREVRGHLKRRK PEECSCSKQSYYMCEKGVKKQEKLKSHLHPFKEAAQEVDSKLQLFKENNRRRKKERKE KRRQRKGEECSLPGLTCFTHDNNHWQTAPFWNLGSFCACTSSNNNTYWCLRTVNETH NFLFCEFATGFLEYFDMNTDPYQLTNTVHTVERGILNQLHVQLME of Z21368_PEA_1_P5.
According to preferred embodiments of the present invention, there is provided an isolated chimeric polypeptide encoding for Z21368_PEA_1_P5, comprising a first amino acid sequence being at least 90 % homologous to
MKYSCCALVLAVLGTELLGSLCSTVRSPRFRGRIQQERKNIRPNIILVLTDDQDVEL corresponding to amino acids 1 - 57 of SUL1_HUMAN, which also corresponds to amino acids 1 - 57 of Z21368_PEA_1_P5, and a second amino acid sequence being at least 90 % homologous to
AFFGKYLNEYNGSYIPPGWREWLGLIKNSRFYNYTVCRNGIKEKHGFDYAKDYFTDLIT NESINYFKMSKRMYPHRPVMMVISHAAPHGPEDSAPQFSKLYPNASQHITPSYNYAPN MDKHWIMQYTGPMLPIHMEFTNILQRKRLQTLMSVDDSVERLYNMLVETGELENTYII YTADHGYHIGQFGLVKGKSMPYDFDIRVPFFIRGPSVEPGSIVPQIVLNIDLAPTILDIAGL DTPPDVDGKSVLKLLDPEKPGNRFRTNKKAKIWRDTFLVERGKFLRKKEESSKNIQQSN HLPKYERVKELCQQARYQTACEQPGQKWQCIEDTSGKLRIHKCKGPSDLLTVRQSTRN
LYARGFHDKDKECSCRESGYRASRSQRKSQRQFLR]S[QGTPKYKPRFVHTRQTRSLSVE FEGEIYDINLEEEEELQVLQPRNIAKRHDEGHKGPRDLQASSGGNRGRMLADSSNAVGP PTTVRVTHKCFILPNDSIHCERELYQSARAWKDHKA YIDKEIEALQDKIKNLREVRGHL KRRKPEECSCSKQSYYNKEKGVKKQEKLKSHLHPFKEAAQEVDSKLQLFKENNRRRK KERKEKRRQRKGEECSLPGLTCFTHDNNHWQTAPFWNLGSFCACTSSNNNTYWCLRT VNETHNFLFCEF ATGFLEYFDMNTDPYQLTNTVHTVERGILNQLHVQLMELRSCQGYK QCNPRPKNLDVGNKDGGSYDLHRGQLWDGWEG corresponding to amino acids 138 - 871 of SUL1_HUMAN, which also corresponds to amino acids 58 - 791 of Z21368_PEA_1_P5, wherein said first and second amino acid sequences are contiguous and in a sequential order. According to preferred embodiments of the present invention, there is provided an isolated chimeric polypeptide encoding for an edge portion of Z21368_PEA_1_P5, comprising a polypeptide having a length "n", wherein n is at least about 10 amino acids in length, optionally at least about 20 amino acids in length, preferably at least about 30 amino acids in length, more preferably at least about 40 amino acids in length and most preferably at least about 50 amino acids in length, wherein at least two amino acids comprise LA, having a structure as follows: a sequence starting from any of amino acid numbers 57-x to 57; and ending at any of amino acid numbers 58 + ((n-2) - x), in which x varies from 0 to n-2.
According to preferred embodiments of the present invention, there is provided an isolated chimeric polypeptide encoding for Z21368_PEA_1_P15, comprising a first amino acid sequence being at least 90 % homologous to
MKYSCCALVLA VLGTELLGSLCSTVRSPRFRGRIQQERKNIRPNIILVLTDDQDVELGSL
QVMNKTRKIMEHGGATFINAFVTTPMCCPSRSSMLTGKYVHNHNVYTNNENCSSPSW QAMHEPRTFAVYLNNTGYRTAFFGKYLNEYNGSYIPPGWREWLGLIKNSRFYNYTVCR NGIKEKHGFDYAKDYFTDLITNESINYFKMSKRMYPHRPVMMVISHAAPHGPEDSAPQ FSKLYPNASQHITPSYNYAPNMDKHWIMQYTGPMLPIHMEFTNILQRKRLQTLMSVDD SVERLYNMLVETGELENTYIIYTADHGYHIGQFGLVKGKSMPYDFDIRVPFFIRGPSVEP GSIVPQΓVLNIDLAPTILDIAGLDTPPDVDGKSVLKLLDPEKPGNRFRTNKKAKIWRDTFL
VERG corresponding to amino acids 1 - 416 of SUL1_HUMAN, which also corresponds to amino acids 1 - 416 of Z21368_PEA_1_P15. According to preferred embodiments of the present invention, there is provided an isolated chimeric polypeptide encoding for Z21368_PEA_1_P16, comprising a first amino acid
sequence being at least 90 % homologous to
MKYSCCALVLAVLGTELLGSLCSTVRSPRFRGRIQQERKNIRPNIILVLTDDQDVELGSL QVMNKTRKIMEHGGATFINAFVTTPMCCPSRSSMLTGKYVHNHNVYTNNENCSSPSW QAMHEPRTFAVYLNNTGYRTAFFGKYLNEYNGSYIPPGWREWLGLIKNSRFYNYTVCR NGIKEKHGFDYAKDYFTDLITNESINYFKMSKRMYPHRPVMMVISHAAPHGPEDSAPQ FSKLYPNASQHITPSYNYAPNMDKHWIMQYTGPMLPIHMEFTNILQRKRLQTLMSVDD SVERLYNMLVETGELENTYIIYTADHGYHIGQFGLVKGKSMPYDFDIRVPFFIRGPSVEP GSIVPQIVLNIDLAPTILDIAGLDTPPDVDGKSVLKLLDPEKPGNR corresponding to amino acids 1 - 397 of SULIJHUMAN, which also corresponds to amino acids 1 - 397 of Z21368_PEA_1JP16, and a second amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence CVIVPPLSQPQIH corresponding to amino acids 398 - 410 of Z21368_PEA_1JP16, wherein said first and second amino acid sequences are contiguous and in a sequential order. According to preferred embodiments of the present invention, there is provided an isolated polypeptide encoding for a tail of Z21368JPEA_1_P16, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence CVIVPPLSQPQIH in Z21368_PEA_1_P16. According to preferred embodiments of the present invention, there is provided an isolated chimeric polypeptide encoding for Z21368_PEA_1_P22, comprising a first amino acid sequence being at least 90 % homologous to
MKYSCCALVLAVLGTELLGSLCSTVRSPRFRGRIQQERKNIRPNIILVLTDDQDVELGSL QVMNKTRKIMEHGGATFINAFVTTPMCCPSRSSMLTGKYVHNHNVYTNNENCSSPSW QAMHEPRTFAVYLNNTGYRTAFFGKYLNEYNGSYIPPGWREWLGLIKNSRFYNYTVCR NGIKEKHGFDYAK corresponding to amino acids 1 - 188 of SUL1JHUMAN, which also corresponds to amino acids 1 - 188 of Z21368_PEA_1_P22, and a second amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence ARYDGDQPRCAPRPRGLSPTVF corresponding to amino acids 189 - 210 of
Z21368_PEA_1_P22, wherein said first and second amino acid sequences are contiguous and in a sequential order.
According to preferred embodiments of the present invention, there is provided an isolated polypeptide encoding for a tail of Z21368JPEA_1_P22, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence ARYDGDQPRCAPRPRGLSPTVF in Z21368_PEA_1_P22.
According to preferred embodiments of the present invention, there is provided an isolated chimeric polypeptide encoding for Z21368JPEA_1_P23, comprising a first amino acid sequence being at least 90 % homologous to
MKYSCCALVLAVLGTELLGSLCSTVRSPRFRGRIQQERKMRPNIILVLTDDQDVELGSL QVMNKTRKIMEHGGATFINAFVTTPMCCPSRSSMLTGKYVHNHNVYTNNENCSSPSW QAMHEPRTFAVYLNNTGYRT corresponding to amino acids 1 - 137 of Q7Z2W2, which also corresponds to amino acids 1 - 137 of Z21368_PEA_1_P23, and a second amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence GLLHRLNH corresponding to amino acids 138 - 145 of Z21368_PEA_1_P23, wherein said first and second amino acid sequences are contiguous and in a sequential order.
According to preferred embodiments of the present invention, there is provided an isolated polypeptide encoding for a tail of Z21368_PEA_1_P23, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence GLLHRLNH in Z21368_PEA_1_P23.
According to preferred embodiments of the present invention, there is provided an isolated chimeric polypeptide encoding for Z21368_PEA_1_P23, comprising a first amino acid sequence being at least 90 % homologous to
MKYSCCALVLAVLGTELLGSLCSTVRSPRFRGRIQQERKNIRPNIILVLTDDQDVELGSL QVMNKTRKIMEHGGATFINAFVTTPMCCPSRSSMLTGKYVHNHNVYTNNENCSSPSW QAMHEPRTFAVYLNNTGYRT corresponding to amino acids 1 - 137 of SULIJHUMAN, which also corresponds to amino acids 1 - 137 of Z21368_PEA_1_P23, and a second amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more
preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence GLLHRLNH corresponding to amino acids 138 - 145 of Z21368JPEA_1_P23, wherein said first and second amino acid sequences are contiguous and in a sequential order.
According to preferred embodiments of the present invention, there is provided an isolated polypeptide encoding for a tail of Z21368JPEA_1_P23, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence GLLHRLNH in Z21368JPEA_1_P23.
According to preferred embodiments of the present invention, there is provided an isolated chimeric polypeptide encoding for HUMGRP5E_P4, comprising a first amino acid sequence being at least 90 % homologous to
MRGSELPLVLLALVLCLAPRGRAVPLPAGGGTVLTKMYPRGNHWAVGHLMGKKSTG ESSSVSERGSLKQQLRE YIRWEEAARNLLGLIEAKENRNHQPPQPKALGNQQPSWDSED
SSNFKDVGSKGK corresponding to amino acids 1 - 127 of GRPJHUMAN, which also corresponds to amino acids 1 - 127 of HUMGRP5E P4, and a second amino acid sequence being at least 90 % homologous to GSQREGRNPQLNQQ corresponding to amino acids 135 - 148 of GRPJHUMAN, which also corresponds to amino acids 128 - 141 of HUMGRP5EJP4, wherein said first and second amino acid sequences are contiguous and in a sequential order. According to preferred embodiments of the present invention, there is provided an isolated chimeric polypeptide encoding for an edge portion of HUMGRP5EJP4, comprising a polypeptide having a length "n", wherein n is at least about 10 amino acids in length, optionally at least about 20 amino acids in length, preferably at least about 30 amino acids in length, more preferably at least about 40 amino acids in length and most preferably at least about 50 amino acids in length, wherein at least two amino acids comprise KG, having a structure as follows: a sequence starting from any of amino acid numbers 127-x to 127; and ending at any of amino acid numbers 128 + ((n-2) - x), in which x varies from 0 to n-2.
According to preferred embodiments of the present invention, there is provided an isolated chimeric polypeptide encoding for HUMGRP5EJP5, comprising a first amino acid sequence being at least 90 % homologous to MRGSELPLVLLALVLCLAPRGRAVPLPAGGGTVLTKMYPRGNHWAVGHLMGKKSTG ESSSVSERGSLKQQLREYIRWEEAARNLLGLIEAKENRNHQPPQPKALGNQQPSWDSED
SSNFKDVGSKGK corresponding to amino acids 1 - 127 of GRPJHUMAN, which also corresponds to amino acids 1 - 127 of HUMGRP5E P5, and a second amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence DSLLQVLNVKEGTPS corresponding to amino acids 128 - 142 of HUMGRP5E_P5, wherein said first and second amino acid sequences are contiguous and in a sequential order.
According to preferred embodiments of the present invention, there is provided an isolated polypeptide encoding for a tail of HUMGRP5EJP5, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence DSLLQVLNVKEGTPS in HUMGRP5E_P5.
According to preferred embodiments of the present invention, there is provided an isolated chimeric polypeptide encoding for D56406_PEA_l_P2, comprising a first amino acid sequence being at least 90 % homologous to MMAGMKIQLVCMLLLAFSSWSLCSDSEEEMKALEADFLTNMHTSKJSKAHVPSWKMT LLNVCSLVNNLNSPAEETGEVHEEELVARRKLPTALDGFSLEAMLTIYQLHKICHSRAF QHWE corresponding to amino acids 1 - 120 of NEUT JHUMAN, which also corresponds to amino acids 1 - 120 of D56406_PEA_l_P2, second amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence
ARWLTPVIPALWEAETGGSRGQEMETIPANT corresponding to amino acids 121 - 151 of D564O6_PEA_1JP2, and a third amino acid sequence being at least 90 % homologous to LIQEDILDTGNDKNGKEEVIKRKIPYILKRQLYENKPRRPYILKRDSYYY corresponding to amino acids 121 - 170 of NEUT_HUMAN, which also corresponds to amino acids 152 - 201 of D56406_PEA_l_P2, wherein said first, second and third amino acid sequences are contiguous and in a sequential order.
According to preferred embodiments of the present invention, there is provided an isolated polypeptide encoding for an edge portion of D56406_PEA_l_P2, comprising an amino acid sequence being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the
sequence encoding for ARWLTPVIP ALWEAETGGSRGQEMETIP ANT, corresponding to D56406_PEA_l_P2.
According to preferred embodiments of the present invention, there is provided an isolated chimeric polypeptide encoding for D56406_PEA_l_P5, comprising a first amino acid sequence being at least 90 % homologous to MMAGMKIQLVCMLLLAFSSWSLC corresponding to amino acids 1 - 23 of NEUT_HUMAN, which also corresponds to amino acids 1 - 23 of D56406_PEA_l_P5, and a second amino acid sequence being at least 90 % homologous to SEEEMKALEADFLTNMHTSKISKAHVPSWKMTLLNVCSLVNNLNSPAEETGEVHEEEL VARRKLPTALDGFSLEAMLTIYQLHKICHSRAFQHWELIQEDILDTGNDKNGKEEVIKR KIPYILKRQLYENKPRRPYILKRDSYYY corresponding to amino acids 26 - 170 of NEUTJHUMAN, which also corresponds to amino acids 24 - 168 of D56406_PEA_l_P5, wherein said first and second amino acid sequences are contiguous and in a sequential order. According to preferred embodiments of the present invention, there is provided an isolated chimeric polypeptide encoding for an edge portion of D56406_PEA_l_P5, comprising a polypeptide having a length "n", wherein n is at least about 10 amino acids in length, optionally at least about 20 amino acids in length, preferably at least about 30 amino acids in length, more preferably at least about 40 amino acids in length and most preferably at least about 50 amino acids in length, wherein at least two amino acids comprise CS, having a structure as follows: a sequence starting from any of amino acid numbers 23-x to 24; and ending at any of amino acid numbers + ((n-2) - x), in which x varies from 0 to n-2.
According to preferred embodiments of the present invention, there is provided an isolated chimeric polypeptide encoding for D56406_PEA_l_P6, comprising a first amino acid sequence being at least 90 % homologous to MMAGMKIQLVCMLLLAFSSWSLCSDS EEEMKALEADFLTNMHTSK corresponding to amino acids 1 - 45 of NEUT_HUMAN, which also corresponds to amino acids 1 - 45 of D56406_PEA_l_P6, and a second amino acid sequence being at least 90 % homologous to LIQEDILDTGNDKNGKEEVIKRKIPYILKRQLYENKPRRPYILKRDSYYY corresponding to amino acids 121 - 170 of NEUT_HUMAN, which also corresponds to amino acids 46 - 95 of D56406_PEA_l_P6, wherein said first and second amino acid sequences are contiguous and in a sequential order.
According to preferred embodiments of the present invention, there is provided an isolated chimeric polypeptide encoding for an edge portion of D56406_PEA_l_P6, comprising a polypeptide having a length "n", wherein n is at least about 10 amino acids in length, optionally at least about 20 amino acids in length, preferably at least about 30 amino acids in length, more preferably at least about 40 amino acids in length and most preferably at least about 50 amino acids in length, wherein at least two amino acids comprise KL, having a structure as follows: a sequence starting from any of amino acid numbers 45-x to 46; and ending at any of amino acid numbers 46+ ((n-2) - x), in which x varies from 0 to n-2.
According to preferred embodiments of the present invention, there is provided an isolated chimeric polypeptide encoding for F05068_PEA_l_P7, comprising a first amino acid sequence being at least 90 % homologous to
MKLVSVALMYLGSLAFLGADTARLDVASEFRKK corresponding to amino acids 1 - 33 of ADML_HUMAN, which also corresponds to amino acids 1 - 33 of F05068_PEA_l_P7. According to preferred embodiments of the present invention, there is provided an isolated chimeric polypeptide encoding for F05068_PEA_l_P8, comprising a first amino acid sequence being at least 90 % homologous to
MKLVSVALMYLGSLAFLGADTARLDVASEFRKKWNKWALSRGKRELRMSSSYPTGLA DVKAGPAQTLIRPQDMKGASRSPED corresponding to amino acids 1 - 82 of ADML_HUMAN, which also corresponds to amino acids 1 - 82 of F05068_PEA_l_P8, and a second amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence R corresponding to amino acids 83 - 83 of F05068_PEA_l_P8, wherein said first and second amino acid sequences are contiguous and in a sequential order.
According to preferred embodiments of the present invention, there is provided an isolated chimeric polypeptide encoding for H14624_P15, comprising a first amino acid sequence being at least 90 % homologous to
MLQGPGSLLLLFLASHCCLGSARGLFLFGQPDFSYKRSNCKPIPANLQLCHGIEYQNMR LPNLLGHETMKEVLEQAGAWIPLVMKQCHPDTKKPLCSLFAPVCLDDLDETIQPCHSLC VQVKDRCAPVMSAFGFPWPDMLECDRFPQDNDLCIPLASSDHLLPATEE corresponding to amino acids 1 - 167 of Q9HAP5, which also corresponds to amino acids 1 - 167 of
H14624_P15, and a second amino acid sequence being at least 70%, optionally at least 80%,
preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence GKPSLLLPHSLLG corresponding to amino acids 168 - 180 of H14624_P15, wherein said first and second amino acid sequences are contiguous and in a sequential order. According to preferred embodiments of the present invention, there is provided an isolated polypeptide encoding for a tail of H14624_P15, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence GKPSLLLPHSLLG in H14624_P15. According to preferred embodiments of the present invention, there is provided an isolated chimeric polypeptide encoding for H38804_PEA_l_P5, comprising a first amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence MGRVRTLAGECSAQAQAQSLLAVVLSAPPSGGTPSARLSVRSPSPRDPWGLWAPVLQ corresponding to amino acids 1 - 57 of H38804_PEA_l_P5, and a second amino acid sequence being at least 90 % homologous to
MTGSNEFKLNQPPEDGISSVKFSPNTSQFLLVSSWDTSVRLYDVPANSMRLKYQHTGA VLDC AFYDPTHAWSGGLDHQLKMHDLNTDQENLVGTHDAPIRCVEYCPEVNVMVTG SWDQTVKLWDPRTPCNAGTFSQPEKVYTLSVSGDRLIVGTAGRRVLVWDLRNMGYVQ QRRESSLKYQTRCIRAFPNKQGYVLSSIEGRVA VEYLDPSPEVQKKKYAFKCHRLKENN IEQIYPVNAISFHNIHNTFATGGSDGFVNIWDPFNKKRLCQFHRYPTSIASLAFSNDGTTL AIASSYMYEMDDTEHPEDGFIRQVTDAETKPK corresponding to amino acids 1 - 324 of BUB3_HUMAN, which also corresponds to amino acids 58 - 381 of H38804_PEA_l_P5, wherein said first and second amino acid sequences are contiguous and in a sequential order. According to preferred embodiments of the present invention, there is provided an isolated polypeptide encoding for a head of H38804_PEA_l_P5, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence MGRVRTLAGECSAQAQAQSLLAWLSAPPSGGTPSARLSVRSPSPRDPWGLWAPVLQ of H38804 PEA 1 P5.
According to preferred embodiments of the present invention, there is provided an isolated chimeric polypeptide encoding for H38804_PEA_l_P17, comprising a first amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence MGRVRTLAGECSAQAQAQSLLAVVLSAPPSGGTPSARLSVRSPSPRDPWGLWAPVLQ corresponding to amino acids 1 - 57 of H38804_PEA_l_P17, and a second amino acid sequence being at least 90 % homologous to
MTGSNEFKLNQPPEDGISSVKFSPNTSQFLLVSSWDTSVRLYDVPANSMRLKYQHTGA VLDCAFYDPTHAWSGGLDHQLKMHDLNTDQENLVGTHDAPIRCVEYCPEVNVMVTG SWDQTVKLWDPRTPCNAGTFSQPEKVYTLSVSGDRLIVGTAGRRVLVWDLRNMGYVQ QRRESSLKYQTRCIRAFPNKQGYVLSSIEGRVA VEYLDPSPEVQKKKYAFKCHRLKENN IEQIYPVNAISFHNIHNTFATGGSDGFVNIWDPFNKKRLCQFHRYPTSIASLAFSNDGTTL AIASSYMYEMDDTEHPEDGIFIRQVTDAETKPKSPCT corresponding to amino acids 1 - 328 of BUB3JHUMAN, which also corresponds to amino acids 58 - 385 of H38804_PEA_l_P17, wherein said first and second amino acid sequences are contiguous and in a sequential order.
According to preferred embodiments of the present invention, there is provided an isolated polypeptide encoding for a head of H38804_PEA_l_P17, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence
MGRVRTLAGECSAQAQAQSLLAWLSAPPSGGTPSARLSVRSPSPRDPWGLWAPVLQ of H38804JPEA_l_P17.
According to preferred embodiments of the present invention, there is provided an isolated chimeric polypeptide encoding for HSENA78_P2, comprising a first amino acid sequence being at least 90 % homologous to
MSLLSSRAARVPGPSSSLCALLVLLLLLTQPGPIASAGPAAAVLRELRCVCLQTTQGVHP KMISNLQVFAIGPQCSKVEW corresponding to amino acids 1 - 81 of SZ05_HUMAN, which also corresponds to amino acids 1 - 81 of HSENA78_P2.
According to preferred embodiments of the present invention, there is provided an isolated chimeric polypeptide encoding for HUMODCA_P9, comprising a first amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at
least 90% and most preferably at least 95% homologous to a polypeptide having the sequence MKSLTATSSMKVLLPRTFWTRΪGLMKFLLL corresponding to amino acids 1 - 29 of HUMODCA_P9, and a second amino acid sequence being at least 90 % homologous to LVLRIATDDSKAVCRLSVKFGATLRTSRLLLERAKELNIDVVGVSFHVGSGCTDPETFV QAISDARCVFDMGAEVGFSMYLLDIGGGFPGSEDVKLKFEEITGVINPALDKYFPSDSG
VRiiAEPGRYYVASAFTLA VNΠAKKIVLKEQTGSDDEDESSEQTFMYYVNDGVYGSFN
CILYDHAHVKPLLQKRPKPDEKYYSSSIWGPTCDGLDRIVERCDLPEMHVGDWMLFEN MGAYTVAAASTFNGFQRPTIYYVMSGPAWQLMQQFQNPDFPPEVEEQDASTLPVSCA WESGMKRHRAACASASINV corresponding to amino acids 151 - 461 of DCOR_HUMAN, which also corresponds to amino acids 30 - 340 of HUMODCA_P9, wherein said first and second amino acid sequences are contiguous and in a sequential order.
According to preferred embodiments of the present invention, there is provided an isolated polypeptide encoding for a head of HUMODCA_P9, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence MKSLTATSSMKVLLPRTFWTRKLMKFLLL of HUMODCAJP9.
According to preferred embodiments of the present invention, there is provided an isolated chimeric polypeptide encoding for HUMODCA_P9, comprising a first amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence MKSLTATSSMKVLLPRTFWTRKLMKFLLL corresponding to amino acids 1 - 29 of HUMODCA_P9, and a second amino acid sequence being at least 90 % homologous to
LVLRIATDDSKAVCRLSVKFGATLRTSRLLLERAKELNIDVVGVSFHVGSGCTDPETFV QAISDARCVFDMGAEVGFSMYLLDIGGGFPGSEDVKLKFEEITGVINPALDKYFPSDSG VWIAEPGRYYVASAFTLAVMLAKKIVLKEQTGSDDEDESSEQTFMYYVNDGVYGSFN CILYDHAHVKPLLQKRPKPDEKYYSSSIWGPTCDGLDRΓVERCDLPEMHVGDWMLFEN MGAYTVAAASTFNGFQRPTIYYVMSGPAWQLMQQFQNPDFPPEVEEQDASTLPVSCA
WESGMKRHRAACASASINV corresponding to amino acids 40 - 350 of AAA59968, which also corresponds to amino acids 30 - 340 of HUMODCA_P9, wherein said first and second amino acid sequences are contiguous and in a sequential order.
According to preferred embodiments of the present invention, there is provided an isolated polypeptide encoding for a head of HUMODCA_P9, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence MKSLTATSSMKVLLPRTFWTRKLMKFLLL of HUMODCA_P9.
According to preferred embodiments of the present invention, there is provided an isolated chimeric polypeptide encoding for HUMODCA_P9, comprising a first amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence MKSLTATSSMKVLLPRTFWTRKLMKFLLL corresponding to amino acids 1 - 29 of HUMODCA_P9, and a second amino acid sequence being at least 90 % homologous to LVLRIATDDSKAVCRLSVKFGATLRTSRLLLERAKELNIDWGVSFHVGSGCTDPETFV QAISDARCVFDMGAEVGFSMYLLDIGGGFPGSED VKLKFEEITGVINP ALDKYFPSDSG VRIIAEPGRYYVASAFTLAVNIIAKKIVLKEQTGSDDEDESSEQTFMYYVNDGVYGSFN CILYDHAHVKPLLQKRPKPDEKYYSSSIWGPTCDGLDRIVERCDLPEMHVGDWMLFEN MGAYTVAAASTFNGFQRPTIYYVMSGPAWQLMQQFQNPDFPPEVEEQDASTLPVSCA WESGMKRHRAACASASINV corresponding to amino acids 86 - 396 of AAH14562, which also corresponds to amino acids 30 - 340 of HUMODCA_P9, wherein said first and second amino acid sequences are contiguous and in a sequential order. According to preferred embodiments of the present invention, there is provided an isolated polypeptide encoding for a head of HUMODCA_P9, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence MKSLTATSSMKVLLPRTFWTRKLMKFLLL of HUMODCA_P9. According to preferred embodiments of the present invention, there is provided an isolated chimeric polypeptide encoding for R00299JP3, comprising a first amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence MAEKALLCPSSAGLGTWPWVLNSAWPVLPLAVDQGVDWRPRGPV corresponding to amino acids 1 - 44 of R00299_P3, second amino acid sequence being at least 90 % homologous to
SSDQIEQLHRRFKQLSGDQPTIRKENFNNVPDLELNPIRSKIVRAFFDNRNLRKGPSGLA DEINFEDFLTIMSYFRPIDTTMDEEQVELSRKEKLRFLFHMYDSDSDGRITLEEYRNV corresponding to amino acids 74 - 191 of Q9NWT9, which also corresponds to amino acids 45 - 162 of R00299 P3, and a third amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence
VEELLSGNPHIEKESARSIADGAMMEAASVCMGQMEPDQVYEGITFEDFLKIWQGIDIE TKMHVRFLNMETMALCH corresponding to amino acids 163 - 238 of R00299_P3, wherein said first, second and third amino acid sequences are contiguous and in a sequential order. According to preferred embodiments of the present invention, there is provided an isolated polypeptide encoding for a head of R00299_P3, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence MAEKALLCPSSAGLGTWPWVLNSAWPVLPLAVDQGVDWRPRGPV of R00299_P3. According to preferred embodiments of the present invention, there is provided an isolated polypeptide encoding for a tail of R00299 P3, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence VEELLSGNPHIEKESARSIADGAMMEAASVCMGQMEPDQVYEGITFEDFLKIWQGIDIE TKMHVRFLNMETMALCH in R00299_P3.
According to preferred embodiments of the present invention, there is provided an isolated chimeric polypeptide encoding for R00299_P3, comprising a first amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence MAEKALLCPSSAGLGTWPWVLNSAWPVLPLAVDQGVDWRPRGPV corresponding to amino acids 1 - 44 of R00299_P3, and a second amino acid sequence being at least 90 % homologous to
SSDQIEQLHRRFKQLSGDQPTIRKENFNNVPDLELNPIRSKIVRAFFDNRNLRKGPSGLA DEINFEDFLTIMSYFRPIDTTMDEEQVELSRKEKLRFLFHMYDSDSDGRITLEEYRNVVE ELLSGNPHIEKESARSIADGAMMEAASVCMGQMEPDQVYEGITFEDFLKIWQGIDIETK MHVRFLNMETMALCH corresponding to amino acids 21 - 214 of TESC_HUMAN, which
also corresponds to amino acids 45 - 238 of R00299JP3, wherein said first and second amino acid sequences are contiguous and in a sequential order.
According to preferred embodiments of the present invention, there is provided an isolated polypeptide encoding for a head of R00299 P3, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence MAEKALLCPSSAGLGTWPWVLNSAWPVLPLAVDQGVDWRPRGPV of R00299JP3.
According to preferred embodiments of the present invention, there is provided an isolated chimeric polypeptide encoding for W60282_PEA_l_P14, comprising a first amino acid sequence being at least 90 % homologous to
MRILQLILLALATGLVGGETRIIKGFECKPHSQPWQAALFEKTRLLCGATLIAPRWLLTA AHCLKP corresponding to amino acids 1 - 66 of Q8IXD7, which also corresponds to amino acids 1 - 66 of W60282_PEA_l_P14, and a second amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence
TPASHLAMRQHHHH corresponding to amino acids 67 - 80 of W60282_PEA_l_P14, wherein said first and second amino acid sequences are contiguous and in a sequential order.
According to preferred embodiments of the present invention, there is provided an isolated polypeptide encoding for a tail of W60282JPEA_l_P14, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence TPASHLAMRQHHHH in W60282_PEA_l_P14.
According to preferred embodiments of the present invention, there is provided an isolated chimeric polypeptide encoding for Z41644_PEA_l_P10, comprising a first amino acid sequence being at least 90 % homologous to
MRLLAAALLLLLLALYTARVDGSKCKCSRKGPKIRYSDVKKLEMKPKYPHCEEKMVII TTKSVSRYRGQEHCLHPKLQSTKRFIKWYNAWNEKRR corresponding to amino acids 1 - 95 of SZ14_HUMAN, which also corresponds to amino acids 1 - 95 of Z41644JPEA_l_P10, and a second amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence YAPPLLTFLPTRPSCGSQDGKGPPHQVI corresponding to
amino acids 96 - 123 of Z41644_PEA_l_P10, wherein said first and second amino acid sequences are contiguous and in a sequential order.
According to preferred embodiments of the present invention, there is provided an isolated polypeptide encoding for a tail of Z41644JPEA_l_P10, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence YAPPLLTFLPTRPSCGSQDGKGPPHQVI in Z41644_PEA_l_P10.
According to preferred embodiments of the present invention, there is provided an isolated chimeric polypeptide encoding for Z41644_PEA_l_P10, comprising a first amino acid sequence being at least 90 % homologous to
MRLLAAALLLLLLALYTARVDGSKCKCSRKGPKIRYSDVKKLEMKPKYPHCEEKMVII TTKSVSRYRGQEHCLHPKLQSTKRFIKWYNAWNEKRR corresponding to amino acids 13 - 107 of Q9NS21, which also corresponds to amino acids 1 - 95 of Z41644_PEA_l_P10, and a second amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence YAPPLLTFLPTRPSCGSQDGKGPPHQVI corresponding to amino acids 96 - 123 of Z41644_PEA_l_P10, wherein said first and second amino acid sequences are contiguous and in a sequential order.
According to preferred embodiments of the present invention, there is provided an isolated polypeptide encoding for a tail of Z41644_PEA_l_P10, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence YAPPLLTFLPTRPSCGSQDGKGPPHQVI in Z41644_PEA_l_P10.
According to preferred embodiments of the present invention, there is provided an isolated chimeric polypeptide encoding for Z41644_PEA_1JP1O, comprising a first amino acid sequence being at least 90 % homologous to
MRLLAAALLLLLLALYTARVDGSKCKCSRKGPKIRYSDVKKLEMKPKYPHCEEKMVII TTKSVSRYRGQEHCLHPKLQSTKRFIKWYNAWNEKRR corresponding to amino acids 13 - 107 of AAQ89265, which also corresponds to amino acids 1 - 95 of Z41644_PEA_l_P10, and a second amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide
having the sequence YAPPLLTFLPTRPSCGSQDGKGPPHQVI corresponding to amino acids 96 - 123 of Z41644JPEA_l_P10, wherein said first and second amino acid sequences are contiguous and in a sequential order.
According to preferred embodiments of the present invention, there is provided an isolated polypeptide encoding for a tail of Z41644_PEA_l_P10, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence YAPPLLTFLPTRPSCGSQDGKGPPHQVI in Z41644JPEA_l_P10.
According to preferred embodiments of the present invention, there is provided an antibody capable of specifically binding to an epitope of an amino acid sequences.
Optionally the amino acid sequence corresponds to a bridge, edge portion, tail, head or insertion.
Optionally the antibody is capable of differentiating between a splice variant having said epitope and a corresponding known protein. According to preferred embodiments of the present invention, there is provided a kit for detecting lung cancer, comprising a kit detecting overexpression of a splice variant according to any of the above claims.
Optionally the kit comprises a NAT-based technology.
Optionally the kit further comprises at least one primer pair capable of selectively hybridizing to a nucleic acid sequence according to any of the above claims.
Optionally the kit further comprises at least one oligonucleotide capable of selectively hybridizing to a nucleic acid sequence according to any of the above claims.
Optionally the kit comprises an antibody according to any of the above claims.
Optionally the kit further comprises at least one reagent for performing an ELISA or a Western blot.
According to preferred embodiments of the present invention, there is provided a method for detecting lung cancer, comprising detecting overexpression of a splice variant according to any of the above claims.
Optionally the detecting overexpression is performed with a NAT-based technology. Optionally detecting overexpression is performed with an immunoassay.
Optionally the immunoassay comprises an antibody according to any of the above claims.
According to preferred embodiments of the present invention, there is provided a biomarker capable of detecting lung cancer, comprising any of the above nucleic acid sequences or a fragment thereof, or any of the above amino acid sequences or a fragment thereof.
According to preferred embodiments of the present invention, there is provided a method for screening for lung cancer, comprising detecting lung cancer cells with a biomarker or an antibody or a method or assay according to any of the above claims.
According to preferred embodiments of the present invention, there is provided a method for diagnosing lung cancer, comprising detecting lung cancer cells with a biomarker or an antibody or a method or assay according to any of the above claims.
According to preferred embodiments of the present invention, there is provided a method for monitoring disease progression and/or treatment efficacy and/or relapse of lung cancer, comprising detecting lung cancer cells with a biomarker or an antibody or a method or assay according to any of the above claims.
According to preferred embodiments of the present invention, there is provided a method of selecting a therapy for lung cancer, comprising detecting lung cancer cells with a biomarker or an antibody or a method or assay according to any of the above claims and selecting a therapy according to said detection.
Unless defined otherwise, all technical and scientific terms used herein have the meaning commonly understood by a person skilled in the art to which this invention belongs. The following references provide one of skill with a general definition of many of the terms used in this invention: Singleton et al., Dictionary of Microbiology and Molecular Biology (2nd ed. 1994); The Cambridge Dictionary of Science and Technology (Walker ed., 1988); The Glossary of Genetics, 5th Ed., R. Rieger et al. (eds.), Springer Verlag (1991); and Hale & Marham, The Harper Collins Dictionary of Biology (1991). AU of these are hereby incorporated by reference as if fully set forth herein. As used herein, the following terms have the meanings ascribed to them unless specified otherwise.
BRIEF DESCRIPTION OF DRAWINGS
Figure 1 is schematic summary of cancer biomarkers selection engine and the wet validation stages.
Figure 2. Schematic illustration, depicting grouping of transcripts of a given contig based on presence or absence of unique sequence regions.
Figure 3 is schematic summary of quantitative real-time PCR analysis. Figure 4 is schematic presentation of the oligonucleotide based microarray fabrication. Figure 5 is schematic summary of the oligonucleotide based microarray experimental flow. Figure 6 is a histogram showing Cancer and cell- line vs. normal tissue expression for
Cluster H61775, demonstrating overexpression in brain malignant tumors and a mixture of malignant tumors from different tissues.
Figure 7 is a histogram showing expression of transcripts of variants of the immunoglobulin superfamily, member 9,H61775 transcripts, which are detectable by amplicon as depicted in sequence name H61775seg8, in normal and cancerous lung tissues.
Figure 8 is a histogram showing expression of immunoglobulin superfamily, member 9, H61775 transcripts, which are detectable by amplicon as depicted in sequence name H61775seg8, in different normal tissues.
Figure 9 is a histogram showing Cancer and cell- line vs. normal tissue expression for Cluster M85491, demonstrating overexpression in epithelial malignant tumors and a mixture of malignant tumors from different tissues.
Figure 10 is a histogram showing over expression of the above -indicated Ephrin type-B receptor 2 precursor M85491 transcripts, which are detectable by amplicon as depicted in sequence name M85491seg24, in cancerous lung samples relative to the normal samples. Figure 11 is a histogram showing the expression of Ephrin type-B receptor 2 precursor
(Tyrosine-protein kinase receptor EPH-3) M85491 transcripts which are detectable by amplicon as depicted in sequence name M85491seg24 in different normal tissues.
Figure 12 is a histogram showing Cancer and cell- line vs. normal tissue expression for Cluster T39971, demonstrating overexpression in liver cancer, lung malignant tumors and pancreas carcinoma.
Figure 13 is a histogram showing Cancer and cell- line vs. normal tissue expression for Cluster Z21368, demonstrating overexpression in epithelial malignant tumors, a mixture of malignant tumors from different tissues and pancreas carcinoma.
Figure 14 is a histogram showing over expression of the Extracellular sulfatase SuIf-I Z21368 transcripts, which are detectable by amplicon as depicted in sequence name Z21368juncl7-21, in cancerous lung samples relative to the normal samples.
Figure 15 is a histogram showing the expression of Extracellular sulfatase SuIf-I
Z21368 transcripts, which are detectable by amplicon as depicted in sequence name Z21368 juncl7-21, in different normal tissues. . Figure 16 is a histogram showing over expression of the SUL1_HUMAN -
Extracellular sulfatase SuIf-I, Z21368 transcripts, which are detectable by amplicon as depicted in sequence name Z21368seg39, in cancerous lung samples relative to the normal samples.
Figure 17 is a histogram showing expression of SULl-HUMAN - Extracellular sulfatase SuIf- 1 , Z21368 transcripts, which are detectable by amplicon as depicted in sequence name Z21368seg39, in different normal tissues.
Figure 18 is a histogram showing the expression of SMO2_HUMAN SPARC related modular calcium-binding protein 2 precursor (Secreted modular calcium-binding protein 2) (SMOC-2) (Smooth muscle-associated protein 2) Z44808 transcripts which are detectable by amplicon as depicted in sequence name Z44808 junc8-l 1 in different normal tissues.
Figure 19 is a histogram showing over expression of the gastrin- releasing peptide (HUMGRP5E) transcripts, which are detectable by amplicon as depicted in sequence name HUMGRP5Ejunc3-7, in several cancerous lung samples relative to the normal samples.
Figure 20 is a histogram showing the expression of gastrin-releasing peptide (HUMGRP5E) transcripts, which are detectable by amplicon as depicted in sequence name HUMGRP5Ejunc3-7, in different normal tissues.
Figure 21 is a histogram showing Cancer and cell- line vs. normal tissue expression for Cluster F05068, demonstrating overexpression in uterine malignancies.
Figure 22 is a histogram showing Cancer and cell- line vs. normal tissue expression for Cluster H 14624, demonstrating overexpression in colorectal cancer, epithelial malignant tumors, a mixture of malignant tumors from different tissues, lung malignant tumors and pancreas carcinoma. Figure 23 is a histogram showing Cancer and cell- line vs. normal tissue expression for
Cluster H38804, demonstrating overexpression in transitional cell carcinoma, brain malignant tumors, a mixture of malignant tumors from different tissues and gastric carcinoma.
Figure 24 is a histogram showing Cancer and cell- line vs. normal tissue expression for Cluster HSENA78, demonstrating overexpression in epithelial malignant tumors and lung malignant tumors.
Figure 25 is a histogram showing Cancer and cell- line vs. normal tissue expression for Cluster HUMODCA, demonstrating overexpression in : brain malignant tumors, colorectal cancer, epithelial malignant tumors and a mixture of malignant tumors from different tissues.
Figure 26 is a histogram showing Cancer and cell- line vs. normal tissue expression for Cluster R00299, demonstrating overexpression in lung malignant tumors.
Figure 27 is a histogram showing Cancer and cell- line vs. normal tissus expression for Cluster Z41644, demonstrating overexpression in lung malignant tumors, breast malignant tumors and pancreas carcinoma.
Figure 28 is a histogram showing Cancer and cell- line vs. normal tissue expression for Cluster Z44808, demonstrating overexpression in colorectal cancer, lung cancer and pancreas carcinoma.
Figure 29 is a histogram showing over expression of the SMO2_HUMAN SPARC related modular calcium-binding protein 2 Z44808 transcripts, which are detectable by amplicon as depicted in sequence name Z44808junc8-ll, in cancerous lung samples relative to the normal samples.
Figure 30 is a histogram showing Cancer and cell- line vs. normal tissue expression for Cluster AAl 61187, demonstrating overexpression in brain malignant tumors, epithelial malignant tumors and a mixture of malignant tumors from different tissues.
Figure 31 is a histogram showing Cancer and cell- line vs. normal tissue expression for Cluster AAl 61187, demonstrating overexpression in brain malignant tumors and a mixture of malignant tumors from different tissues.
Figure 32 is a histogram showing Cancer and cell- line vs. normal tissue expression for Cluster HUMCAlXIA, demonstrating overexpression in bone malignant tumors, epithelial malignant tumors, a mixture of malignant tumors from different tissues and lung malignant tumors. Figure 33 is a histogram showing Cancer and cell- line vs. normal tissue expression for
Cluster HUMCEA, demonstrating overexpression in epithelial malignant tumors, a mixture of malignant tumors from different tissues and pancreas carcinoma.
Figure 34 is a histogram showing Cancer and cell- line vs. normal tissue expression for Cluster R35137, demonstrating overexpression in hepatocellular carcinoma. Figure 35 is a histogram showing Cancer and cell- line vs. normal tissue expression for
Cluster Z25299, demonstrating overexpression in brain malignant tumors, a mixture of malignant tumors from different tissues and ovarian carcinoma.
Figure 36 is a histogram showing down regulation of the Secretory leukocyte protease inhibitor Acid-stable proteinase inhibitor Z25299 transcripts, which are detectable by amplicon as depicted in sequence name Z25299 June 13- 14-21, in cancerous lung samples relative to the normal samples.
Figure 37 is a histogram showing down regulation of the Secretory leukocyte protease inhibitor Acid-stable proteinase inhibitor Z25299 transcripts, which are detectable by amplicon as depicted in sequence name Z25299 seg20, in cancerous lung samples relative to the normal samples.
Figure 38 is a histogram showing Cancer and cell- line vs. normal tissue expression for Cluster HSSTROL3, demonstrating overexpression in transitional cell carcinoma, epithelial malignant tumors, a mixture of malignant tumors from different tissues and pancreas carcinoma.
Figure 39 is a histogram showing over expression of the Stromelysin-3 HSSTROL3 transcripts, which are detectable by amplicon as depicted in sequence name HSSTROL3 seg24, in cancerous lung samples relative to the normal samples.
Figure 40 is a histogram showing the expression of Stromelysin-3
HSSTROL3 transcripts, which are detectable by amplicon as depicted in sequence name HSSTROL3 seg24, in different normal tissues.
Figure 41 is a histogram showing Cancer and cell- line vs. normal tissue expression for Cluster HUMTREFAC, demonstrating overexpression in a mixture of malignant tumors from different tissues, breast malignant tumors, pancreas carcinoma and prostate cancer.
Figure 42 is a histogram showing Cancer and cell- line vs. normal tissue expression for Cluster HSSlOOPCB, demonstrating overexpression in a mixture of malignant tumors from different tissues.
Figure 43 is a histogram showing Cancer and cell- line vs. normal tissue expression for Cluster HSU33147, demonstrating overexpression in a mixture of malignant tumors from different tissues. Figure 44 is a histogram showing Cancer and cell- line vs. normal tissue expression for
Cluster R20779, demonstrating overexpression in epithelial malignant tumors, a mixture of malignant tumors from different tissues and lung malignant tumors.
Figure 45 is a histogram showing Cancer and cell- line vs. normal tissue expression for Cluster R38144, demonstrating overexpression in epithelial malignant tumors, lung malignant tumors, skin malignancies and gastric carcinoma.
Figure 46 is a histogram showing Cancer and cell- line vs. normal tissue expression for Cluster HUMOSTRO, demonstrating overexpression in epithelial malignant tumors, a mixture of malignant tumors from different tissues, lung malignant tumors, breast malignant tumors, ovarian carcinoma and skin malignancies. Figure 47 is a histogram showing Cancer and cell- line vs. normal tissue expression for
Cluster HUMOSTRO, demonstrating overexpression in epithelial malignant tumors, a mixture of malignant tumors from different tissues and kidney malignant tumors.
Figure 48 is a histogram showing over expression of the Rl 1723 transcripts, which are detectable by amplicon as depicted in sequence name Rl 1723 segl3, in cancerous lung samples relative to the normal samples.
Figure 49 is a histogram showing the expression of Rl 1723 transcripts which are detectable by amplicon as depicted in sequence name Rl 1723segl3 in different normal tissues. Figure 50 is a histogram showing over expression of the Rl 1723 transcripts, which are detectable by amplicon as depicted in sequence name Rl 1723 juncl 1-18 in cancerous lung samples relative to the normal samples.
Figure 51 is a histogram showing Cancer and cell- line vs. normal tissue expression for
Cluster Rl 6276, demonstrating overexpression in: lung malignant tumors. Figures 52-53 are histograms, showing differential expression of the 6 sequences H61775seg8, HUMGRP5E junc3-7, M85491Seg24, Z21368 juncl7-21, HSSTROL3seg24 and Z25299seg20 in cancerous lung samples relative to the normal samples.
Figure 54a is a histogram showing the relative expression of trophinin associated protein (tastin) ) [T86235] variants (e.g., variant no. 23-26, 31, 32) in normal and tumor derived lung samples as determined by real time PCR using primers for SEQ ID NO: 1480. Figure 54b is a histogram showing the relative expression of trophinin associated protein
(tastin) ) [T86235] variants (e.g., variant no. 8-10, 22, 23, 26,27, 29-31, 33) in normal and tumor derived lung samples as determined micro- array analysis using oligos detailed in SEQ ID NO: 1512-1514.
Figure 55 is a histogram showing the relative expression of Homeo box ClO (HOXClO)
[N31842] variants (e.g., variant no. 3) in normal and tumor derived lung samples as determined by real time PCR using primers for SEQ ID NO: 1517.
Figures 56a-b are histograms showing on two different scales the relative expression of Nucleolar protein 4 (NOL4) [T06014] variants (e.g., variant no. 3, 11 and 12) in normal and tumor derived lung samples as determined by real time PCR using primers for SEQ ID NO: 1529. Figure 56a shows the results on scale:0-1200. Figure 56b shows the results on scale:0- 24.
Figures 57a-b is a histogram showing on two different scales the relative expression of Nucleolar protein 4 (NOL4) [T06014] variants (e.g., variant no. 3, 11 and 12) in normal and tumor derived lung samples as determined by real time PCR using primers for SEQ ID NO:
1532. Figure 57a shows the results on scale:0-2000. Figure 57b shows the results on scale:0-
42.
Figure 58 is a histogram showing the relative expression of AA281370 variants (e.g., variant no. 0, 1, 4 and 5) in normal and tumor derived lung samples as determined by real time PCR using primers for SEQ ID NO: 1558.
Figure 59 is a histogram showing the relative expression of Sulfatase 1 (SULFl)- [Z21368] variants (e.g., variant no. 13 and 14) in normal and tumor derived lung samples as determined by real time PCR using primers for SEQ ID NO: 1574.
Figure 60 is a histogram showing the relative expression of SRY (sex determining region Y)-box 2 (SOX2))- [HUMHMGBOX] variants (e.g., variant no. 0) in normal and tumor derived lung samples as determined by real time PCR using primers for SEQ ID NO: 1594.
Figure 61 is a histogram showing the relative expression of Plakophilin 1 (ectodermal dysplasia/skin fragility syndrome) (PKPl) -[HSB6PR] variants (e.g., variant no. 0, 5 and 6) in normal and tumor derived lung samples as determined by real time PCR using primers for SEQ ID NO: 1600.
Figure 62 is a histogram showing the relative expression of transcripts detectable by SEQ ID NOs: 1480, 1517, 1529, 1532, 1558, 1574, 1594, 1600, 1616, 1619, 1622, 1625 in noπnal and tumor derived lung samples as determined by real time PCR.
Figure 63 is an amino acid sequence alignment, using NCBI BLAST default parameters, demonstrating similarity between the AA281370 lung cancer biomarker if the present invention to WD40 domains of various proteins involved in MAPK signal transduction pathway. Figure 63a: amino acids at positions 40-790 of AA281370 polypeptide SEQ ID NO: 99 has 75% homology to mouse Mapkbpl protein (gi|47124622). Figure 63b: amino acids at positions 40- 886 of the AA281370 polypeptide SEQ ID NO: 99 has 70% homology to rat JNK-binding protein JNKBPl (gi|34856717).
Figure 64 is a histogram showing over expression of the Homo sapiens protease, serine, 21 (testisin) (PRSS21) AA161187 transcripts, which are detectable by amplicon as depicted in sequence name AA161187 seg25, in cancerous lung samples relative to the normal samples. Figure 65 is a histogram showing over expression of the protein tyrosine phosphatase, receptor type, S (PTPRS) M62069 transcripts, which are detectable by amplicon as depicted in sequence name M62069 segl9, in cancerous lung samples relative to the normal samples.
Figure 66 is a histogram showing over expression of the protein tyrosine phosphatase, receptor type, S (PTPRS) M62069 transcripts, which are detectable by amplicon as depicted in sequence name M62069 seg29, in cancerous lung samples relative to the normal samples.
Figure 67 is a histogram showing over expression of the above -indicated Homo sapiens collagen, type XI, alpha 1 (COLI lAl) transcripts which are detectable by amp Ikon as depicted in sequence name HUMCAlXlA seg55 in cancerous lung samples relative to the normal samples. Figure 68 is a histogram showing down regulation of the Homo sapiens secretory leukocyte protease inhibitor (antileukoproteinase) (SLPI) Z25299 transcripts which are detectable by amplicon as depicted in sequence name Z25299 seg23 in cancerous lung samples relative to the normal samples.
Figure 69 is a histogram showing the expression of Secretory leukocyte protease inhibitor Acid-stable proteinase inhibitor Z25299 transcripts which are detectable by amplicon as depicted in sequence name Z25299seg20 in different normal tissues.
Figure 70 is a histogram showing the expression of Secretory leukocyte protease inhibitor Acid-stable proteinase inhibitor Z25299 transcripts which are detectable by amplicon as depicted in sequence name Z25299seg23 in different normal tissues. Figure 71 is a histogram showing over expression of the Homo sapiens matrix metalloproteinase 11 (stromelysin 3) (MMPIl) HSSTROL3 transcripts which are detectable by amplicon as depicted in sequence name HSSTROL3 seg20-2 in cancerous lung samples relative to the normal samples.
Figure 72 is a histogram showing over expression of the Homo sapiens matrix metalloproteinase 11 (stromelysin 3) (MMPl 1) HSSTROL3 transcripts which are detectable by amplicon as depicted in sequence name HSSTROL3 junc21-27 in cancerous lung samples relative to the normal samples.
Figure 73 is a histogram showing the expression of Rl 1723 transcripts, which were detected by amplicon as depicted in the sequence name Rl 1723 juncl 1-18 in different normal tissues.
Figure 74 is a histogram showing over expression of the Homo sapiens fibroblast growth factor receptor- like 1 (FGFRLl) H53626 transcripts, which are detectable by amplicon as depicted in sequence name H53626 junc24-27FlR3 in cancerous lung samples relative to the normal samples. Figure 75 is a histogram showing the expression of the Homo sapiens fibroblast growth factor receptor- like 1 (FGFRLl) H53626 transcripts, which are detectable by amplicon as
depicted in sequence name H53626 seg25 in cancerous lung samples relative to the normal samples.
Figure 76 is a histogram showing Cancer and cell- line vs. normal tissue expression for Cluster H53626, demonstrating overexpression in epithelial malignant tumors, a mixture of malignant tumors from different tissues and myosarcoma.
Figure 77 is a histogram showing the expression of of Homo sapiens fibroblast growth factor receptor- like 1 (FGFRLl) H53626 transcripts, which are detectable by amplicon as depicted in sequence name H53626 seg25 in different normal tissues.
Figure 78 is a histogram showing the expression of of Homo sapiens fibroblast growth factor receptor- like 1 (FGFRLl) H53626 transcripts, which are detectable by amplicon as depicted in sequence name H53626 junc24-27FlR3 in different normal tissues.
Figure 79 shows PSEC Rl 1723 PEA 1 T5 PCR product; Lane 1: PCR product; and Lane 2: Low DNA Mass Ladder MW marker (Invitrogen Cat# 10068-013).
Figure 80: PSEC Rl 1723_PEA_1 T5 PCR product sequence; In Red- PSEC Forward primer; In Blue- PSEC Reverse complementary sequence; and Highlighted sequence- PSEC variant Rl 1723_PEA_1 T5 ORF.
Figure 81- PRSEC PCR product digested with Nhel and Hindlll; Lane 1- PRSET PCR product; Lane 2- Fermentas GeneRuler 1Kb DNA Ladder #SM0313.
Figure 82 shows a plasmid map of His PSEC T5 pRSETA. Figure 83: Protein sequence of PSEC variant Rl 1723_PEA_1 T5; In red- 6His tag; In blue- PSEC.
Figure 84 shows the DNA sequence of HisPSEC T5 pRSETA; bold- HisPSEC T5 open reading frame ; Italic- flanking DNA sequence which was verified by sequence analysis.
Figure 85 shows Western blot analysis of recombinant HisPSEC variant R11723_PEA_1 T5; lane l: molecular weight marker (ProSieve color, Cambrex, Cat #50550); lane 2: HisPSEC T5 pRSETA TO; lane 3: His HisPSEC T5 pRSETA T3; lane 4 :His HisPSEC T5 pRSETA To.n; lane 5: pRSET empty vector TO (negative control); lane 6: pRSET empty vector T3 (negative control); lane 7: pRSET empty vector To.n (negative control); and lane 8: His positive control protein (HisTroponinT7 pRSETA T3).
DESCRIPTION OF PREFERRED EMBODIMENTS
The present invention is of novel markers for lung cancer that are both sensitive and accurate. Furthermore, at least certain of these markers are able to distinguish between various types of lung cancer, such as small cell carcinoma; large cell carcinoma; squamous cell carcinoma; and adenocarcinoma, alone or in combination. These markers are differentially expressed, and preferably overexpressed, in lung cancer specifically, as opposed to normal lung tissue. The measurement of these markers, alone or in combination, in patient samples provides information that the diagnostician can correlate with a probable diagnosis of lung cancer. The markers of the present invention, alone or in combination, show a high degree of differential detection between lung cancer and non-cancerous states. The markers of the present invention, alone or in combination, can be used for prognosis, prediction, screening, early diagnosis, therapy selection and treatment monitoring of lung cancer. For example, optionally and preferably, these markers may be used for staging lung cancer and/or monitoring the progression of the disease. Furthermore, the markers of the present invention, alone or in combination, can be used for detection of the source of metastasis found in anatomical places other than lung.
Also, one or more of the markers may optionally be used in combination with one or more other lung cancer markers (other than those described herein). According to an optional embodiment of the present invention, such a combination may be used to differentiate between various types of lung cancer, such as small cell carcinoma; large cell carcinoma; squamous cell carcinoma; and adenocarcinoma. Furthermore, the markers of the present invention, alone or in combination, can be used for detection of other types of tumors by elimination (for example, for such detection of carcinoid tumors, which are 5% of lung cancers).
The markers of the present invention, alone or in combination, can be used for prognosis, prediction, screening, early diagnosis, staging, therapy selection and treatment monitoring of lung cancer. For example, optionally and preferably, these markers may be used for staging lung cancer and/or monitoring the progression of the disease. Furthermore, the markers of the present invention, alone or in combination, can be used for detection of the source of metastasis found in anatomical places other then lung. Also, one or more of the markers may optionally be used in combination with one or more other lung cancer markers (other than those described herein).
Biomolecular sequences (amino acid and/or nucleic acid sequences) uncovered using the methodology of the present invention and described herein can be efficiently utilized as tissue or pathological markers and/or as drugs or drug targets for treating or preventing a disease.
These markers are specifically released to the bloodstream under conditions of lung cancer, and/or are otherwise expressed at a much higher level and/or specifically expressed in lung cancer tissue or cells. The measurement of these markers, alone or in combination, in patient samples provides information that the diagnostician can correlate with a probable diagnosis of lung cancer.
The present invention therefore also relates to diagnostic assays for lung cancer and/or an indicative condition, and methods of use of such markers for detection of lung cancer and/or an indicative condition, optionally and preferably in a sample taken from a subject (patient), which is more preferably some type of blood sample.
In another embodiment, the present invention relates to bridges, tails, heads and/or insertions, and/or analogs, homologs and derivatives of such peptides. Such bridges, tails, heads and/or insertions are described in greater detail below with regard to the Examples.
As used herein a "tail" refers to a peptide sequence at the end of an amino acid sequence that is unique to a splice variant according to the present invention. Therefore, a splice variant having such a tail may optionally be considered as a chimera, in that at least a first portion of the splice variant is typically highly homologous (often 100% identical) to a portion of the corresponding known protein, while at least a second portion of the variant comprises the tail.
As used herein a "head" refers to a peptide sequence at the beginning of an amino acid sequence that is unique to a splice variant according to the present invention. Therefore, a splice variant having such a head may optionally be considered as a chimera, in that at least a first portion of the splice variant comprises the head, while at least a second portion is typically highly homologous (often 100% identical) to a portion of the corresponding known protein.
As used herein "an edge portion" refers to a connection between two portions of a splice variant according to the present invention that were not joined in the wild type or known protein. An edge may optionally arise due to a join between the above "known protein" portion of a variant and the tail, for example, and/or may occur if an internal portion of the wild type sequence is no longer present, such that two portions of the sequence are now contiguous in the splice variant that were not contiguous in the known protein. A "bridge" may optionally be an
edge portion as described above, but may also include a join between a head and a "known protein" portion of a variant, or a join between a tail and a "known protein" portion of a variant, or a join between an insertion and a "known protein" portion of a variant.
Optionally and preferably, a bridge between a tail or a head or a unique insertion, and a "known protein" portion of a variant, comprises at least about 10 amino acids, more preferably at least about 20 amino acids, most preferably at least about 30 amino acids, and even more preferably at least about 40 amino acids, in which at least one amino acid is from the tail/head/insertion and at least one amino acid is from the "known protein" portion of a variant. Also optionally, the bridge may comprise any number of amino acids from about 10 to about 40 amino acids (for example, 10, 11, 12, 13...37, 38, 39, 40 amino acids in length, or any number in between).
It should be noted that a bridge cannot be extended beyond the length of the sequence in either direction, and it should be assumed that every bridge description is to be read in such manner that the bridge length does not extend beyond the sequence itself. Furthermore, bridges are described with regard to a sliding window in certain contexts below. For example, certain descriptions of the bridges feature the following format: a bridge between two edges (in which a portion of the known protein is not present in the variant) may optionally be described as follows: a bridge portion of CONTIG-NAME_P1 (representing the name of the protein), comprising a polypeptide having a length "n", wherein n is at least about 10 amino acids in length, optionally at least about 20 amino acids in length, preferably at least about 30 amino acids in length, more preferably at least about 40 amino acids in length and most preferably at least about 50 amino acids in length, wherein at least two amino acids comprise XX (2 amino acids in the center of the bridge, one from each end of the edge), having a structure as follows (numbering according to the sequence of CONTIG-NAME_P1): a sequence starting from any of amino acid numbers 49-x to 49 (for example); and ending at any of amino acid numbers 50 + ((n-2) - x) (for example), in which x varies from 0 to n-2. In this example, it should also be read as including bridges in which n is any number of amino acids between 10-50 amino acids in length. Furthermore, the bridge polypeptide cannot extend beyond the sequence, so it should be read such that 49-x (for example) is not less than 1, nor 50 + ((n-2) — x) (for example) greater than the total sequence length.
In another embodiment, this invention provides antibodies specifically recognizing the splice variants and polypeptide fragments thereof of this invention. Preferably such antibodies differentially recognize splice variants of the present invention but do not recognize a corresponding known protein (such known proteins are discussed with regard to their splice variants in the Examples below).
In another embodiment, this invention provides an isolated nucleic acid molecule encoding for a splice variant according to the present invention, having a nucleotide sequence as set forth in any one of the sequences listed herein, or a sequence complementary thereto. In another embodiment, this invention provides an isolated nucleic acid molecule, having a nucleotide sequence as set forth in any one of the sequences listed herein, or a sequence complementary thereto. In another embodiment, this invention provides an oligonucleotide of at least about 12 nucleotides, specifically hybridizable with the nucleic acid molecules of this invention. In another embodiment, this invention provides vectors, cells, liposomes and compositions comprising the isolated nucleic acids of this invention. In another embodiment, this invention provides a method for detecting a splice variant according to the present invention in a biological sample, comprising: contacting a biological sample with an antibody specifically recognizing a splice variant according to the present invention under conditions whereby the antibody specifically interacts with the splice variant in the biological sample but do not recognize known corresponding proteins (wherein the known protein is discussed with regard to its splice variant(s) in the Examples below), and detecting said interaction; wherein the presence of an interaction correlates with the presence of a splice variant in the biological sample.
In another embodiment, this invention provides a method for detecting a splice variant nucleic acid sequences in a biological sample, comprising: hybridizing the isolated nucleic acid molecules or oligonucleotide fragments of at least about a minimum length to a nucleic acid material of a biological sample and detecting a hybridization complex; wherein the presence of a hybridization complex correlates with the presence of a splice variant nucleic acid sequence in the biological sample.
According to the present invention, the splice variants described herein are non-limiting examples of markers for diagnosing lung cancer. Each splice variant marker of the present
invention can be used alone or in combination, for various uses, including but not limited to, prognosis, prediction, screening, early diagnosis, determination of progression, therapy selection and treatment monitoring of lung cancer.
According to optional but preferred embodiments of the present invention, any marker according to the present invention may optionally be used alone or combination. Such a combination may optionally comprise a plurality of markers described herein, optionally including any subcombination of markers, and/or a combination featuring at least one other marker, for example a known marker. Furthermore, such a combination may optionally and preferably be used as described above with regard to determining a ratio between a quantitative or semi- quantitative measurement of any marker described herein to any other marker described herein, and/or any other known marker, and/or any other marker. With regard to such a ratio between any marker described herein (or a combination thereof) and a known marker, more preferably the known marker comprises the "known protein" as described in greater detail below with regard to each cluster or gene. According to other preferred embodiments of the present invention, a splice variant protein or a fragment thereof, or a splice variant nucleic acid sequence or a fragment thereof, may be featured as a biomarker for detecting lung cancer, such that a biomarker may optionally comprise any of the above.
According to still other preferred embodiments, the present invention optionally and preferably encompasses any amino acid sequence or fragment thereof encoded by a nucleic acid sequence corresponding to a splice variant protein as described herein. Any oligopeptide or peptide relating to such an amino acid sequence or fragment thereof may optionally also (additionally or alternatively) be used as a biomarker, including but not limited to the unique amino acid sequences of these proteins that are depicted as tails, heads, insertions, edges or bridges. The present invention also optionally encompasses antibodies capable of recognizing, and/or being elicited by, such oligopeptides or peptides.
The present invention also optionally and preferably encompasses any nucleic acid sequence or fragment thereof, or amino acid sequence or fragment thereof, corresponding to a splice variant of the present invention as described above, optionally for any application. Non-limiting examples of methods or assays are described below.
The present invention also relates to kits based upon such diagnostic methods or assays.
Nucleic acid sequences and Oligonucleotides
Various embodiments of the present invention encompass nucleic acid sequences described hereinabove; fragments thereof, sequences hybridizable therewith, sequences homologous thereto, sequences encoding similar polypeptides with different codon usage, altered sequences characterized by mutations, such as deletion, insertion or substitution of one or more nucleotides, either naturally occurring or artificially induced, either randomly or in a targeted fashion.
The present invention encompasses nucleic acid sequences described herein; fragments thereof, sequences hybridizable therewith, sequences homologous thereto [e.g., at least 50 %, at least 55 %, at least 60%, at least 65 %, at least 70 %, at least 75 %, at least 80 %, at least 85 %, at least 95 % or more say 100 % identical to the nucleic acid sequences set forth below], sequences encoding similar polypeptides with different codon usage, altered sequences characterized by mutations, such as deletion, insertion or substitution of one or more nucleotides, either naturally occurring or man induced, either randomly or in a targeted fashion. The present invention also encompasses homologous nucleic acid sequences (i.e., which form a part of a polynucleotide sequence of the present invention) which include sequence regions unique to the polynucleotides of the present invention.
In cases where the polynucleotide sequences of the present invention encode previously unidentified polypeptides, the present invention also encompasses novel polypeptides or portions thereof, which are encoded by the isolated polynucleotide and respective nucleic acid fragments thereof described hereinabove.
A "nucleic acid fragment" or an "oligonucleotide" or a "polynucleotide" are used herein interchangeably to refer to a polymer of nucleic acids. A polynucleotide sequence of the present invention refers to a single or double stranded nucleic acid sequences which is isolated and provided in the form of an RNA sequence, a complementary polynucleotide sequence (cDNA), a genomic polynucleotide sequence and/or a composite polynucleotide sequences (e.g., a combination of the above).
As used herein the phrase "complementary polynucleotide sequence" refers to a sequence, which results from reverse transcription of messenger RNA using a reverse
transcriptase or any other RNA dependent DNA polymerase. Such a sequence can be subsequently amplified in vivo or w vitro using a DNA dependent DNA polymerase.
As used herein the phrase "genomic polynucleotide sequence" refers to a sequence derived (isolated) from a chromosome and thus it represents a contiguous portion of a chromosome.
As used herein the phrase "composite polynucleotide sequence" refers to a sequence, which is composed of genomic and cDNA sequences. A composite sequence can include some exonal sequences required to encode the polypeptide of the present invention, as well as some intronic sequences interposing therebetween. The intronic sequences can be of any source, including of other genes, and typically will include conserved splicing signal sequences. Such intronic sequences may further include cis acting expression regulatory elements.
Preferred embodiments of the present invention encompass oligonucleotide probes. An example of an oligonucleotide probe which can be utilized by the present invention is a single stranded polynucleotide which includes a sequence complementary to the unique sequence region of any variant according to the present invention, including but not limited to a nucleotide sequence coding for an amino sequence of a bridge, tail, head and/or insertion according to the present invention, and/or the equivalent portions of any nucleotide sequence given herein (including but not limited to a nucleotide sequence of a node, segment or amplicon described herein). Alternatively, an oligonucleotide probe of the present invention can be designed to hybridize with a nucleic acid sequence encompassed by any of the above nucleic acid sequences, particularly the portions specified above, including but not limited to a nucleotide sequence coding for an amino sequence of a bridge, tail, head and/or insertion according to the present invention, and/or the equivalent portions of any nucleotide sequence given herein (including but not limited to a nucleotide sequence of a node, segment or amplicon described herein).
Oligonucleotides designed according to the teachings of the present invention can be generated according to any oligonucleotide synthesis method known in the art such as enzymatic synthesis or solid phase synthesis. Equipment and reagents for executing solid-phase synthesis are commercially available from, for example, Applied Biosystems. Any other means for such synthesis may also be employed; the actual synthesis of the oligonucleotides is well within the capabilities of one skilled in the art and can be accomplished via established methodologies as
detailed in, for example, "Molecular Cloning: A laboratory Manual" Sambrook et al., (1989);
"Current Protocols in Molecular Biology" Volumes I- III Ausubel, R. M., ed. (1994); Ausubel et al., "Current Protocols in Molecular Biology", John Wiley and Sons, Baltimore, Maryland
(1989); Perbal, "A Practical Guide to Molecular Cloning", John Wiley & Sons, New York (1988) and "Oligonucleotide Synthesis" Gait, M. J., ed. (1984) utilizing solid phase chemistry, e.g. cyanoethyl phosphoramidite followed by deprotection, desalting and purification by for example, an automated trityl-on method or HPLC.
Oligonucleotides used according to this aspect of the present invention are those having a length selected from a range of about 10 to about 200 bases preferably about 15 to about 150 bases, more preferably about 20 to about 100 bases, most preferably about 20 to about 50 bases.
Preferably, the oligonucleotide of the present invention features at feast 17, at least 18, at least
19, at least 20, at least 22, at least 25, at least 30 or at least 40, bases specifically hybridizable with the biomarkers of the present invention.
The oligonucleotides of the present invention may comprise heterocylic nucleosides consisting of purines and the pyrimidines bases, bonded in a 3' to 5' phosphodiester linkage.
Preferably used oligonucleotides are those modified at one or more of the backbone, internucleoside linkages or bases, as is broadly described hereinunder.
Specific examples of preferred oligonucleotides useful according to this aspect of the present invention include oligonucleotides containing modified backbones or non-natural internucleoside linkages. Oligonucleotides having modified backbones include those that retain a phosphorus atom in the backbone, as disclosed in U.S. Pat. NOs: 4,469,863; 4,476,301;
5,023,243; 5,177,196; 5,188,897; 5,264,423; 5,276,019; 5,278,302; 5,286,717; 5,321,131;
5,399,676; 5,405,939; 5,453,496; 5,455,233; 5,466, 677; 5,476,925; 5,519,126; 5,536,821;
5,541,306; 5,550,111; 5,563,253; 5,571,799; 5,587,361; and 5,625,050. Preferred modified oligonucleotide backbones include, for example, phosphorothioates, chiral phosphorothioates, phosphorodithioates, phosphotriesters, aminoalkyl phosphotriesters, methyl and other alkyl phosphonates including 3'-alkylene phosphonates and chiral phosphonates, phosphinates, phosphoramidates including 3'-amino phosphoramidate and aminoalkylphosphoramidates, thionophosphoramidates, thionoalkylphosphonates, thionoalkylphosphotriesters, and boranophosphates having normal 3'-5r linkages, 2'-5' linked analogs of these, and those having inverted polarity wherein the adjacent pairs of nucleoside
units are linked 3'-5' to 5'-3' or 2'-5' to 5'-2'. Various salts, mixed salts and free acid forms can also be used.
Alternatively, modified oligonucleotide backbones that do not include a phosphorus atom therein have backbones that are formed by short chain alkyl or cycloalkyl interaucleoside linkages, mixed heteroatom and alkyl or cycloalkyl internucleoside linkages, or one or more short chain heteroatomic or heterocyclic internucleoside linkages. These include those having morpholino linkages (formed in part from the sugar portion of a nucleoside); siloxane backbones; sulfide, sulfoxide and sulfone backbones; formacetyl and thioformacetyl backbones; methylene formacetyl and thioformacetyl backbones; alkene containing backbones; sulfamate backbones; methyleneimino and methylenehydrazino backbones; sulfonate and sulfonamide backbones; amide backbones; and others having mixed N, O, S and CH2 component parts, as disclosed in U.S. Pat. Nos. 5,034,506; 5,166,315; 5,185,444; 5,214,134; 5,216,141; 5,235,033; 5,264,562; 5,264,564; 5,405,938; 5,434,257; 5,466,677; 5,470,967; 5,489,677; 5,541,307; 5,561,225; 5,596,086; 5,602,240; 5,610,289; 5,602,240; 5,608,046; 5,610,289; 5,618,704; 5,623, 070; 5,663,312; 5,633,360; 5,677,437; and 5,677,439.
Other oligonucleotides which can be used according to the present invention, are those modified in both sugar and the internucleoside linkage, i.e., the backbone, of the nucleotide units are replaced with novel groups. The base units are maintained for complementation with the appropriate polynucleotide target. An example for such an oligonucleotide mimetic, includes peptide nucleic acid (PNA). United States patents that teach the preparation of PNA compounds include, but are not limited to, U.S. Pat. Nos. 5,539,082; 5,714,331; and 5,719,262, each of which is herein incorporated by reference. Other backbone modifications, which can be used in the present invention are disclosed in U.S. Pat. No: 6,303,374.
Oligonucleotides of the present invention may also include base modifications or substitutions. As used herein, "unmodified" or "natural" bases include the purine bases adenine (A) and guanine (G), and the pyrimidine bases thymine (T), cytosine (C) and uracil (U). Modified bases include but are not limited to other synthetic and natural bases such as 5- methylcytosine (5-me-C), 5-hydroxymethyl cytosine, xanthine, hypoxanthine, 2-ammoadenine, 6-methyl and other alkyl derivatives of adenine and guanine, 2-propyl and other alkyl derivatives of adenine and guanine, 2-thiouracil, 2-thiothymine and 2-thiocytosine, 5-halouracil and cytosine, 5-propynyl uracil and cytosine, 6-azo uracil, cytosine and thymine, 5-uracil
(pseudouracil), 4-thiouracil, 8-halo, 8-amino, 8-thiol, 8-thioalkyl, 8-hydroxyl and other 8- substituted adenines and guanines, S halo particularly 5-bromo, 5-trifluoromethyl and other 5- substituted uracils and cytosines, 7-methylguanine and 7-methyladenine, 8-azaguanine and 8- azaadenine, 7-deazaguanine and 7-deazaadenine and 3-deazaguanine and 3-deazaadenine. Further bases particularly useful for increasing the binding affinity of the oligomeric compounds of the invention include 5-substituted pyrimidines, 6-azapyrimidines and N-2, N-6 and 0-6 substituted purines, including 2-aminopropyladenine, 5-propynyluracil and 5-propynylcytosine. 5-methylcytosine substitutions have been shown to increase nucleic acid duplex stability by 0.6- 1.2 0C and are presently preferred base substitutions, even more particularly when combined with 2'-O-methoxyethyl sugar modifications.
Another modification of the oligonucleotides of the invention involves chemically linking to the oligonucleotide one or more moieties or conjugates, which enhance the activity, cellular distribution or cellular uptake of the oligonucleotide. Such moieties include but are not limited to lipid moieties such as a cholesterol moiety, cholic acid, a thioether, e.g., hexyl-S- tritylthiol, a thiocholesterol, an aliphatic chain, e.g., dodecandiol or undecyl residues, a phospholipid, e.g., di-hexadecyl-rac- glycerol or triethylammonium 1,2-di-O-hexadecyl-rac- glycero-3-H-phosphonate, a polyamine or a polyethylene glycol chain, or adamantane acetic acid, a palmityl moiety, or an octadecylamine or hexylamino-carbonyl-oxycholesterol moiety, as disclosed in U.S. Pat. No: 6,303,374. It is not necessary for all positions in a given oligonucleotide molecule to be uniformly modified, and in fact more than one of the aforementioned modifications may be incorporated in a single compound or even at a single nucleoside within an oligonucleotide.
It will be appreciated that oligonucleotides of the present invention may include further modifications for more efficient use as diagnostic agents and/or to increase bioavailability, therapeutic efficacy and reduce cytotoxicity.
To enable cellular expression of the polynucleotides of the present invention, a nucleic acid construct according to the present invention may be used, which includes at least a coding region of one of the above nucleic acid sequences, and further includes at least one cis acting regulatory element. As used herein, the phrase "cis acting regulatory element" refers to a polynucleotide sequence, preferably a promoter, which binds a trans acting regulator and regulates the transcription of a coding sequence located downstream thereto.
Any suitable promoter sequence can be used by the nucleic acid construct of the present invention.
Preferably, the promoter utilized by the nucleic acid construct of the present invention is active in the specific cell population transformed. Examples of cell type-specific and/or tissue- specific promoters include promoters such as albumin that is liver specific, lymphoid specific promoters [Calame et al., (1988) Adv. Immunol. 43:235-275]; in particular promoters of T-cell receptors [Winoto et al., (1989) EMBO J. 8:729-733] and immunoglobulins; [Banerji et al. (1983) Cell 33729-740], neuron- specific promoters such as the neurofilament promoter [Byrne et al. (1989) Proc. Natl. Acad. Sci. USA 86:5473-5477], pancreas-specific promoters [Edlunch et al. (1985) Science 230:912-916] or mammary gland-specific promoters such as the milk whey promoter (U.S. Pat. No. 4,873,316 and European Application Publication No. 264,166). The nucleic acid construct of the present invention can further include an enhancer, which can be adjacent or distant to the promoter sequence and can function in up regulating the transcription therefrom. The nucleic acid construct of the present invention preferably further includes an appropriate selectable marker and/or an origin of replication. Preferably, the nucleic acid construct utilized is a shuttle vector, which can propagate both in E. coli (wherein the construct comprises an appropriate selectable marker and origin of replication) and be compatible for propagation in cells, or integration in a gene and a tissue of choice. The construct according to the present invention can be, for example, a plasmid, a bacmid, a phagemid, a cosmid, a phage, a virus or an artificial chromosome.
Examples of suitable constructs include, but are not limited to, pcDNA3, pcDNA3.1 (+/-), pGL3, PzeoSV2 (+/-), pDisplay, pEF/myc/cyto, pCMV/myc/cyto each of which is commercially available from Invitrogen Co. (www.invitrogen.com). Examples of retroviral vector and packaging systems are those sold by Clontech, San Diego, Calif., includingRetro-X vectors pLNCX and pLXSN, which permit cloning into multiple cloning sites and the trasgene is transcribed from CMV promoter. Vectors derived from Mo-MuLV are also included such as pBabe, where the transgene will be transcribed from the 5'LTR promoter.
Currently preferred in vivo nucleic acid transfer techniques include transfection with viral or non- viral constructs, such as adenovirus, lentivirus, Herpes simplex I virus, or adeno- associated virus (AAV) and lipid-based systems. Useful lipids for lipid- mediated transfer of the
gene are, for example, DOTMA, DOPE, and DC-Choi [Tonkinson et al., Cancer Investigation, 14(1): 54-65 (1996)]. The most preferred constructs for use in gene therapy are viruses, most preferably adenoviruses, AAV, Antiviruses, or retroviruses. A viral construct such as a retroviral construct includes at least one transcriptional promoter/enhancer or locus -defining element(s), or other elements that control gene expression by other means such as alternate splicing, nuclear RNA export, or post-translational modification of messenger. Such vector constructs also include a packaging signal, long terminal repeats (LTRs) or portions thereof, and positive and negative strand primer binding sites appropriate to the virus used, unless it is already present in the viral construct. In addition, such a construct typically includes a signal sequence for secretion of the peptide from a host cell in which it is placed. Preferably the signal sequence for this purpose is a mammalian signal sequence or the signal sequence of the polypeptide variants of the present invention. Optionally, the construct may also include a signal that directs polyadenylation, as well as one or more restriction sites and a translation termination sequence. By way of example, such constructs will typically include a 5' LTR, a tRNA binding site, a packaging signal, an origin of second-strand DNA synthesis, and a 3' LTR or a portion thereof. Other vectors can be used that are non-viral, such as cationic lipids, polylysine, and dendrimers.
Hybridization assays Detection of a nucleic acid of interest in a biological sample may optionally be effected by hybridization-based assays using an oligonucleotide probe (non- limiting examples of probes according to the present invention were previously described).
Traditional hybridization assays include PCR, RT-PCR, Realtime PCR, RNase protection, in-situ hybridization, primer extension, Southern blots (DNA detection), dot or slot blots (DNA, RNA), and Northern blots (RNA detection) (NAT type assays are described in greater detail below). More recently, PNAs have been described (Nielsen et al. 1999, Current
Opin. Biotechnol. 10:71-75). Other detection methods include kits containing probes on a dipstick setup and the like.
Hybridization based assays which allow the detection of a variant of interest (i.e., DNA or RNA) in a biological sample rely on the use of oligonucleotides which can be 10, 15, 20, or
30 to 100 nucleotides long preferably from 10 to 50, more preferably from 40 to 50 nucleotides long.
Thus, the isolated polynucleotides (oligonucleotides) of the present invention are preferably hybridizable with any of the herein described nucleic acid sequences under moderate to stringent hybridization conditions.
Moderate to stringent hybridization conditions are characterized by a hybridization solution such as containing 10 % dextrane sulfate, 1 M NaCl, 1 % SDS and 5 x 10^ cpm 32P labeled probe, at 65 0C, with a final wash solution of 0.2 x SSC and 0.1 % SDS and final wash at 650C and whereas moderate hybridization is effected using a hybridization solution containing 10 % dextrane sulfate, 1 M NaCl, 1 % SDS and 5 x 106 cpm 32P labeled probe, at 65 0C, with a final wash solution of 1 x SSC and 0.1 % SDS and final wash at 50 0C.
More generally, hybridization of short nucleic acids (below 200 bp in length, e.g. 17-40 bp in length) can be effected using the following exemplary hybridization protocols which can be modified according to the desired stringency; (i) hybridization solution of 6 x SSC and 1 % SDS or 3 M TMACI, 0.01 M sodium phosphate (pH 6.8), 1 mM EDTA (pH 7.6), 0.5 % SDS, 100 μg/ml denatured salmon sperm DNA and 0.1 % nonfat dried milk, hybridization temperature of 1 - 1.5 0C below the Tm final wash solution of 3 M TMACI, 0.01 M sodium phosphate (pH 6.8), 1 mM EDTA (pH 7.6), 0.5 % SDS at 1 - 1.5 0C below the Tm; (H) hybridization solution of 6 x SSC and 0.1 % SDS or 3 M TMACI, 0.01 M sodium phosphate (pH 6.8), 1 mM EDTA (pH 7.6), 0.5 % SDS, 100 μg/ml denatured salmon sperm DNA and 0.1 % nonfat dried milk, hybridization temperature of 2 - 2.5 0C below the Tm, final wash solution of 3 M TMACI, 0.01 M sodium phosphate (pH 6.8), 1 mM EDTA (pH 7.6), 0.5 % SDS at 1 - 1.5 0C below the T1n, final wash solution of 6 x SSC, and final wash at 22 0C; (Ui) hybridization solution of 6 x SSC and 1 % SDS or 3 M TMACI, 0.01 M sodium phosphate (pH 6.8), 1 mM EDTA (pH 7.6), 0.5 % SDS, 100 μg/ml denatured salmon sperm DNA and 0.1 % nonfat dried milk, hybridization temperature.
The detection of hybrid duplexes can be carried out by a number of methods. Typically, hybridization duplexes are separated from unhybridized nucleic acids and the labels bound to the duplexes are then detected. Such labels refer to radioactive, fluorescent, biological or enzymatic
tags or labels of standard use in the art. A label can be conjugated to either the oligonucleotide probes or the nucleic acids derived from the biological sample.
Probes can be labeled according to numerous well known methods. Non- limiting examples of radioactive labels include 3H, 14C, 32P, and 35S. Non-limiting examples of detectable markers include ligands, fluorophores, chemiluminescent agents, enzymes, and antibodies. Other detectable markers for use with probes, which can enable an increase in sensitivity of the method of the invention, include biotin and radio- nucleotides. It will become evident to the person of ordinary skill that the choice of a particular label dictates the manner in which it is bound to the probe. For example, oligonucleotides of the present invention can be labeled subsequent to synthesis, by incorporating biotinylated dNTPs or rNTP, or some similar means (e.g., photo- cross- linking a psoralen derivative of biotin to RNAs), followed by addition of labeled streptavidin (e.g., phycoerythrin-conjugated streptavidin) or the equivalent. Alternatively, when fluorescently- labeled oligonucleotide probes are used, fluorescein, lissamine, phycoerythrin, rhodamine (Perkin Elmer Cetus), Cy2, Cy3, Cy3.5, Cy5, Cy5.5, Cy7, FluorX (Amersham) and others [e.g., Kricka et al. (1992), Academic Press San Diego, Calif] can be attached to the oligonucleotides.
Those skilled in the art will appreciate that wash steps may be employed to wash away excess target DNA or probe as well as unbound conjugate. Further, standard heterogeneous assay formats are suitable for detecting the hybrids using the labels present on the oligonucleotide primers and probes.
It will be appreciated that a variety of controls may be usefully employed to improve accuracy of hybridization assays. For instance, samples may be hybridized to an irrelevant probe and treated with RNAse A prior to hybridization, to assess false hybridization. Although the present invention is not specifically dependent on the use of a label for the detection of a particular nucleic acid sequence, such a label might be beneficial, by increasing the sensitivity of the detection. Furthermore, it enables automation. Probes can be labeled according to numerous well known methods.
As commonly known, radioactive nucleotides can be incorporated into probes of the invention by several methods. Non- limiting examples of radioactive labels include 3H, 14C, 32P, and 35S.
Those skilled in the art will appreciate that wash steps may be employed to wash away excess target DNA or probe as well as unbound conjugate. Further, standard heterogeneous assay formats are suitable for detecting the hybrids using the labels present on the oligonucleotide primers and probes. It will be appreciated that a variety of controls may be usefully employed to improve accuracy of hybridization assays.
Probes of the invention can be utilized with naturally occurring sugar-phosphate backbones as well as modified backbones including phosphorothioates, dithionates, alkyl phosphonates and a-nucleotides and the like. Probes of the invention can be constructed of either ribonucleic acid (RNA) or deoxyribonucleic acid (DNA), and preferably of DNA.
NAT Assays
Detection of a nucleic acid of interest in a biological sample may also optionally be effected by NAT-based assays, which involve nucleic acid amplification technology, such as PCR for example (or variations thereof such as real- time PCR for example).
As used herein, a "primer" defines an oligonucleotide which is capable of annealing to
(hybridizing with) a target sequence, thereby creating a double stranded region which can serve as an initiation point for DNA synthesis under suitable conditions.
Amplification of a selected, or target, nucleic acid sequence may be carried out by a number of suitable methods. See generally Kwoh et al., 1990, Am. Biotechnol. Lab. 8:14
Numerous amplification techniques have been described and can be readily adapted to suit particular needs of a person of ordinary skill. Non- limiting examples of amplification techniques include polymerase chain reaction (PCR), ligase chain reaction (LCR), strand displacement amplification (SDA), transcription-based amplification, the q3 replicase system and NASBA (Kwoh et al., 1989, Proc. Natl. Acad. Sci. USA 86, 1173-1177; Lizardi et al., 1988,
BioTechnology 6:1197-1202; Malek et al., 1994, Methods MoI. Biol., 28:253-260; and
Sambrook et al., 1989, supra).
The terminology "amplification pair" (or "primer pair") refers herein to a pair of oligonucleotides (oligos) of the present invention, which are selected to be used together in amplifying a selected nucleic acid sequence by one of a number of types of amplification processes, preferably a polymerase chain reaction. Other types of amplification processes
include ligase chain reaction, strand displacement amplification, or nucleic acid sequence-based amplification, as explained in greater detail below. As commonly known in the art, the oligos are designed to bind to a complementary sequence under selected conditions.
In one particular embodiment, amplification of a nucleic acid sample from a patient is amplified under conditions which favor the amplification of the most abundant differentially expressed nucleic acid. In one preferred embodiment, RT-PCR is carried out on an mRNA sample from a patient under conditions which favor the amplification of the most abundant mRNA. In another preferred embodiment, the amplification of the differentially expressed nucleic acids is carried out simultaneously. It will be realized by a person skilled in the art that such methods could be adapted for the detection of differentially expressed proteins instead of differentially expressed nucleic acid sequences.
The nucleic acid (i.e. DNA or RNA) for practicing the present invention may be obtained according to well known methods.
Oligonucleotide primers of the present invention may be of any suitable length, depending on the particular assay format and the particular needs and targeted genomes employed. Optionally, the oligonucleotide primers are at least 12 nucleotides in length, preferably between 15 and 24 molecules, and they may be adapted to be especially suited to a chosen nucleic acid amplification system. As commonly known in the art, the oligonucleotide primers can be designed by taking into consideration the melting point of hybridization thereof with its targeted sequence (Sambrook et al., 1989, Molecular Cloning -A Laboratory Manual, 2nd Edition, CSH Laboratories; Ausubel et al., 1989, in Current Protocols in Molecular Biology, John Wiley & Sons Inc., N.Y.).
It will be appreciated that antisense oligonucleotides may be employed to quantify expression of a splice isoform of interest. Such detection is effected at the pre-niRNA level. Essentially the ability to quantitate transcription from a splice site of interest can be effected based on splice site accessibility. Oligonucleotides may compete with splicing factors for the splice site sequences. Thus, low activity of the antisense oligonucleotide is indicative of splicing activity.
The polymerase chain reaction and other nucleic acid amplification reactions are well known in the art (various non- limiting examples of these reactions are described in greater detail below). The pair of oligonucleotides according to this aspect of the present invention are
preferably selected to have compatible melting temperatures (Tm), e.g., melting temperatures which differ by less than that 7 0C, preferably less than 5 0C, more preferably less than 4 0C, most preferably less than 3 0C, ideally between 3 0C and 0 0C.
Polymerase Chain Reaction (PCR): The polymerase chain reaction (PCR), as described in U.S. Pat. Nos. 4,683,195 and 4,683,202 to Mullis and MuWis et al., is a method of increasing the concentration of a segment of target sequence in a mixture of genomic DNA without cloning or purification. This technology provides one approach to the problems of low target sequence concentration. PCR can be used to directly increase the concentration of the target to an easily detectable level. This process for amplifying the target sequence involves the introduction of a molar excess of two oligonucleotide primers which are complementary to their respective strands of the double- stranded target sequence to the DNA mixture containing the desired target sequence. The mixture is denatured and then allowed to hybridize. Following hybridization, the primers are extended with polymerase so as to form complementary strands. The steps of denaturation, hybridization (annealing), and polymerase extension (elongation) can be repeated as often as needed, in order to obtain relatively high concentrations of a segment of the desired target sequence.
The length of the segment of the desired target sequence is determined by the relative positions of the primers with respect to each other, and, therefore, this length is a controllable parameter. Because the desired segments of the target sequence become the dominant sequences (in terms of concentration) in the mixture, they are said to be "PCR-amplifϊed."
Ligase Chain Reaction (LCR or LAR): The ligase chain reaction [LCR; sometimes referred to as "Ligase Amplification Reaction" (LAR)] has developed into a well-recognized alternative method of amplifying nucleic acids. In LCR, four oligonucleotides, two adjacent oligonucleotides which uniquely hybridize to one strand of target DNA, and a complementary set of adjacent oligonucleotides, which hybridize to the opposite strand are mixed and DNA ligase is added to the mixture. Provided that there is complete complementarity at the junction, ligase will covalently link each set of hybridized molecules. Importantly, in LCR, two probes are ligated together only when they base-pair with sequences in the target sample, without gaps or mismatches. Repeated cycles of denaturation, and ligation amplify a short segment of DNA. LCR has also been used in combination with PCR to achieve enhanced detection of single-base changes: see for example Segev, PCT Publication No. W09001069 Al (1990). However,
because the four oligonucleotides used in this assay can pair to form two short ligatable fragments, there is the potential for the generation of target- independent background signal. The use of LCR for mutant screening is limited to the examination of specific nucleic acid positions.
Self-Sustained Synthetic Reaction (3SR/NASBA): The self- sustained sequence replication reaction (3SR) is a transcription-based in vitro amplification system that can exponentially amplify RNA sequences at a uniform temperature. The amplified RNA can then be utilized for mutation detection. In this method, an oligonucleotide primer is used to add a phage RNA polymerase promoter to the 5' end of the sequence of interest. In a cocktail of enzymes and substrates that includes a second primer, reverse transcriptase, RNase H, RNA polymerase and ribo-and deoxyribonucleoside triphosphates, the target sequence undergoes repeated rounds of transcription, cDNA synthesis and second-strand synthesis to amplify the area of interest. The use of 3SR to detect mutations is kinetically limited to screening small segments of DNA (e.g., 200-300 base pairs).
Q-B eta (Q β) Replicase: In this method, a probe which recognizes the sequence of interest is attached to the replicatable RNA template for Qβ replicase. A previously identified major problem with false positives resulting from the replication of unhybridized probes has been addressed through use of a sequence-specific ligation step. However, available thermostable DNA ligases are not effective on this RNA substrate, so the ligation must be performed by T4 DNA ligase at low temperatures (37 degrees C). This prevents the use of high temperature as a means of achieving specificity as in the LCR, the ligation event can be used to detect a mutatbn at the junction site, but not elsewhere.
A successful diagnostic method must be very specific. A straight-forward method of controlling the specificity of nucleic acid hybridization is by controlling the temperature of the reaction. While the 3SR/NASBA, and Qβ systems are all able to generate a large quantity of signal, one or more of the enzymes involved in each cannot be used at high temperature (i.e., > 55 degrees C). Therefore the reaction temperatures cannot be raised to prevent non-specific hybridization of the probes. If probes are shortened in order to make them melt more easily at low temperatures, the likelihood of having more than one perfect match in a complex genome increases. For these reasons, PCR and LCR currently dominate the research field in detection technologies.
The basis of the amplification procedure in the PCR and LCR is the fact that the products of one cycle become usable templates in all subsequent cycles, consequently doubling the population with each cycle. The final }ield of any such doubling system can be expressed as:
(1+X)n =y, where "X" is the mean efficiency (percent copied in each cycle), "n" is the number of cycles, and "y" is the overall efficiency, or yield of the reaction. If every copy of a target DNA is utilized as a template in every cycle of a polymerase chain reaction, then the mean efficiency is
100 %. If 20 cycles of PCR are performed, then the yield will be 220, or 1,048,576 copies of the starting material. If the reaction conditions reduce the mean efficiency to 85 %, then the yield in those 20 cycles will be only 1.85^0, or 220,513 copies of the starting material. In other words, a PCR running at 85 % efficiency will yield only 21 % as much final product, compared to a reaction running at 100 % efficiency. A reaction that is reduced to 50 % mean efficiency will yield less than 1 % of the possible product.
In practice, routine polymerase chain reactions rarely achieve the theoretical maximum yield, and PCRs are usually run for more than 20 cycles to compensate for the lower yield. At 50 % mean efficiency, it would take 34 cycles to achieve the million- fold amplification theoretically possible in 20, and at lower efficiencies, the number of cycles required becomes prohibitive. In addition, any background products that amplify with a better mean efficiency than the intended target will become the dominant products.
Also, many variables can influence the mean efficiency of PCR, including target DNA length and secondary structure, primer length and design, primer and dNTP concentrations, and buffer composition, to name but a few. Contamination of the reaction with exogenous DNA (e.g., DNA spilled onto lab surfaces) or cross-contamination is also a major consideration. Reaction conditions must be carefully optimized for each different primer pair and target sequence, and the process can take days, even for an experienced investigator. The laboriousness of this process, including numerous technical considerations and other factors, presents a significant drawback to using PCR in the clinical setting. Indeed, PCR has yet to penetrate the clinical market in a significant way. The same concerns arise with LCR, as LCR must also be optimized to use different oligonucleotide sequences for each target sequence. In addition, both methods require expensive equipment, capable of precise temperature cycling. Many applications of nucleic acid detection technologies, such as in studies of allelic variation, involve not only detection of a specific sequence in a complex background, but also
the discrimination between sequences with few, or single, nucleotide differences. One method of the detection of allele-specific variants by PCR is based upon the fact that it is difficult for Taq polymerase to synthesize a DNA strand when there is a mismatch between the template strand and the 3' end of the primer. An allele-specific variant may be detected by the use of a primer that is perfectly matched with only one of the possible alleles; the mismatch to the other allele acts to prevent the extension of the primer, thereby preventing the amplification of that sequence. This method has a substantial limitation in that the base composition of the mismatch influences the ability to prevent extension across the mismatch, and certain mismatches do not prevent extension or have only a minimal effect. A similar 3'-mismatch strategy is used with greater effect to prevent ligation in the LCR.
Any mismatch effectively blocks the action of the thermostable ligase, but LCR still has the drawback of target-independent background ligation products initiating the amplification. Moreover, the combination of PCR with subsequent LCR to identify the nucleotides at individual positions is also a clearly cumbersome proposition for the clinical laboratory. The direct detection method according to various preferred embodiments of the present invention may be, for example a cycling probe reaction (CPR) or a branched DNA analysis.
When a sufficient amount of a nucleic acid to be detected is available, there are advantages to detecting that sequence directly, instead of making more copies of that target, (e.g., as in PCR and LCR). Most notably, a method that does not amplify the signal exponentially is more amenable to quantitative analysis. Even if the signal is enhanced by attaching multiple dyes to a single oligonucleotide, the correlation between the final signal intensity and amount of target is direct. Such a system has an additional advantage that the products of the reaction will rot themselves promote further reaction, so contamination of lab surfaces by the products is not as much of a concern. Recently devised techniques have sought to eliminate the use of radioactivity and/or improve the sensitivity in automatable formats. Two examples are the "Cycling Probe Reaction" (CPR), and "Branched DNA" (bDNA).
Cycling probe reaction (CPR): The cycling probe reaction (CPR), uses a long chimeric oligonucleotide in which a central portion is made of RNA while the two termini are made of DNA. Hybridization of the probe to a target DNA and exposure to a thermostable RNase H causes the RNA portion to be digested. This destabilizes the remaining DNA portions of the duplex, releasing the remainder of the probe from the target DNA and allowing another probe
molecule to repeat the process. The signal, in the foπn of cleaved probe molecules, accumulates at a linear rate. While the repeating process increases the signal, the RNA portion of the oligonucleotide is vulnerable to RNases that may carried through sample preparation.
Branched DNA: Branched DNA (bDNA), involves oligonucleotides with branched structures that allow each individual oligonucleotide to carry 35 to 40 labels (e.g., alkaline phosphatase enzymes). While this enhances the signal from a hybridization event, signal from non-specific binding is similarly increased.
The detection of at least one sequence change according to various preferred embodiments of the present invention may be accomplished by, for example restriction fragment length polymorphism (RFLP analysis), allele specific oligonucleotide (ASO) analysis, Denaturing/Temperature Gradient Gel Electrophoresis (DGGE/TGGE), Single -Strand Conformation Polymorphism (SSCP) analysis or Dideoxy fingerprinting (ddF).
The demand for tests which allow the detection of specific nucleic acid sequences and sequence changes is growing rapidly in clinical diagnostics. As nucleic acid sequence data for genes from humans and pathogenic organisms accumulates, the demand for fast, cost-effective, and easy-to-use tests for as yet mutations within specific sequences is rapidly increasing.
A handful of methods have been devised to scan nucleic acid segments for mutations. One option is to determine the entire gene sequence of each test sample (e.g., a bacterial isolate). For sequences under approximately 600 nucleotides, this may be accomplished using amplified material (e.g., PCR reaction products). This avoids the time and expense associated with cloning the segment of interest. However, specialized equipment and highly trained personnel are required, and the method is too labor- intense and expensive to be practical and effective in the clinical setting.
In view of the difficulties associated with sequencing, a given segment of nucleic acid may be characterized on several other levels. At the lowest resolution, the size of the molecule can be determined by electrophoresis by comparison to a known standard run on the same gel. A more detailed picture of the molecule may be achieved by cleavage with combinations of restriction enzymes prior to electrophoresis, to allow construction of an ordered map. The presence of specific sequences within the fragment can be detected by hybridization of a labeled probe, or the precise nucleotide sequence can be determined by partial chemical degradation or by primer extension in the presence of chain- terminating nucleotide analogs.
Restriction fragment length polymorphism (RFLP): For detection of single-base differences between like sequences, the requirements of the analysis are often at the highest level of resolution. For cases in which the position of the nucleotide in question is known in advance, several methods have been developed for examining single base changes without direct sequencing. For example, if a mutation of interest happens to fall within a restriction recognition sequence, a change in the pattern of digestion can be used as a diagnostic tool (e.g., restriction fragment length polymorphism [RFLP] analysis).
Single point mutations have been also detected by the creation or destruction of RFLPs. Mutations are detected and localized by the presence and size of the RNA fragments generated by cleavage at the mismatches. Single nucleotide mismatches in DNA heteroduplexes are also recognized and cleaved by some chemicals, providing an alternative strategy to detect single base substitutions, generically named the "Mismatch Chemical Cleavage" (MCC). However, this method requires the use of osmium tetroxide and piperidine, two highly noxious chemicals which are not suited for use in a clinical laboratory. RFLP analysis suffers from low sensitivity and requires a large amount of sample. When
RFLP analysis is used for the detection of point mutations, it is, by its nature, limited to the detection of only those single base changes which fall within a restriction sequence of a known restriction endonuclease. Moreover, the majority of the available enzymes have 4 to 6 base-pair recognition sequences, and cleave too frequently for many large-scale DNA manipulations. Thus, it is applicable only in a small fraction of cases, as most mutations do not fall within such sites.
A handful of rare-cutting restriction enzymes with 8 base-pair specificities have been isolated and these are widely used in genetic mapping, but these enzymes are few in number, are limited to the recognition of G+C-rich sequences, and cleave at sites that tend to be highly clustered. Recently, endonucleases encoded by group I introns have been discovered that might have greater than 12 base-pair specificity, but again, these are few in number.
Allele specific oligonucleotide (ASO): If the change is not in a recognition sequence, then allele-specific oligonucleotides (ASOs), can be designed to hybridize in proximity to the mutated nucleotide, such that a primer extension or ligation event can bused as the indicator of a match or a mis- match. Hybridization with radioactively labeled allelic specific oligonucleotides (ASO) also has been applied to the detection of specific point mutations. The method is based
on the differences in the melting temperature of short DNA fragments differing by a single nucleotide. Stringent hybridization and washing conditions can differentiate between mutant and wild-type alleles. The ASO approach applied to PCR products also has been extensively utilized by various researchers to detect and characterize point mutations in ras genes and gsp/gip oncogenes. Because of the presence of various nucleotide changes in multiple positions, the ASO method requires the use of many oligonucleotides to cover all possible oncogenic mutations.
With either of the techniques described above (i.e., RFLP and ASO), the precise location of the suspected mutation must be known in advance of the test. That is to say, they are inapplicable when one needs to detect the presence of a mutation within a gene or sequence of interest.
Denaturing/Temperature Gradient Gel Electrophoresis (DGGE/TGGE): Two other methods rely on detecting changes in electrophoretic mobility in response to minor sequence changes. One of these methods, termed "Denaturing Gradient Gel Electrophoresis" (DGGE) is based on the observation that slightly different sequences will display different patterns of local melting when electrophoretically resolved on a gradient gel. In this manner, variants can be distinguished, as differences in melting properties of homoduplexes versus heteroduplexes differing in a single nucleotide can detect the presence of mutations in the target sequences because of the corresponding changes in their electrophoretic mobilities. The fragments to be analyzed, usually PCR products, are "clamped" at one end by a long stretch of GC base pairs (30-80) to allow complete denaturation of the sequence of interest without complete dissociation of the strands. The attachment of a GC "clamp" to the DNA fragments increases the fraction of mutations that can be recognized by DGGE. Attaching a GC clamp to one primer is critical to ensure that the amplified sequence has a low dissociation temp erature. Modifications of the technique have been developed, using temperature gradients, and the method can be also applied to RNA:RNA duplexes.
Limitations on the utility of DGGE include the requirement that the denaturing conditions must be optimized for each type of DNA to be tested. Furthermore, the method requires specialized equipment to prepare the gels and maintain the needed high temperatures during electrophoresis. The expense associated with the synthesis of the clamping tail on one oligonucleotide for each sequence to be tested is also a major consideration. In addition, long
running times are required for DGGE. The long running time of DGGE was shortened in a modification of DGGE called constant denaturant gel electrophoresis (CDGE). CDGE requires that gels be performed under different denaturant conditions in order to reach high efficiency for the detection of mutations. A technique analogous to DGGE, termed temperature gradient gel electrophoresis
(TGGE), uses a thermal gradient rather than a chemical denaturant gradient. TGGE requires the use of specialized equipment which can generate a temperature gradient perpendicularly oriented relative to the electrical field. TGGE can detect mutations in relatively small fragments of DNA therefore scanning of large gene segments requires the use of multiple PCR products prior to running the gel.
Single-Strand Conformation Polymorphism (SSCP): Another common method, called "Single- Strand Conformation Polymorphism" (SSCP) was developed by Hayashi, Sekya and colleagues and is based on the observation that single strands of nucleic acid can take on characteristic conformations in non- denaturing conditions, and these conformations influence electrophoretic mobility. The complementary strands assume sufficiently different structures that one strand may be resolved from the other. Changes in sequences within the fragment will also change the conformation, consequently altering the mobility and allowing this to be used as an assay for sequence variations.
The SSCP process involves denaturing a DNA segment (e.g., a PCR product) that is labeled on both strands, followed by slow electrophoretic separation on a non-denaturing polyacrylamide gel, so that intra- molecular interactions can form and not be disturbed during the run. This technique is extremely sensitive to variations in gel composition and temperature. A serious limitation of this method is the relative difficulty encountered in comparing data generated in different laboratories, under apparently similar conditions. Dideoxy fingerprinting (ddF): The dideoxy fingerprinting (ddF) is another technique developed to scan genes for the presence of mutations. The ddF technique combines components of Sanger dideoxy sequencing with SSCP. A dideoxy sequencing reaction is performed using one dideoxy terminator and then the reaction products are electrophoresed on nondenaturing polyacrylamide gels to detect alterations in mobility of the termination segments as in SSCP analysis. While ddF is an improvement over SSCP in terms of increased sensitivity, ddF requires the use of expensive dideoxynucleotides and this technique is still limited to the
analysis of fragments of the size suitable for SSCP (i.e., fragments of 200-300 bases for optimal detection of mutations).
In addition to the above limitations, all of these methods are limited as to the size of the nucleic acid fragment that can be analyzed. For the direct sequencing approach, sequences of greater than 600 base pairs require cloning, with the consequent delays and expense of either deletion sub -cloning or primer walking, in order to cover the entire fragment. SSCP and DGGE have even more severe size limitations. Because of reduced sensitivity to sequence changes, these methods are not considered suitable for larger fragments. Although SSCP is reportedly able to detect 90 % of single-base substitutions within a 200 base-pair fragment, the detection drops to less than 50 % for 400 base pair fragments. Similarly, the sensitivity of DGGE decreases as the length of the fragment reaches 500 base-pairs. The ddF technique, as a combination of direct sequencing and SSCP, is also limited by the relatively small size of the DNA that can be screened.
According to a presently preferred embodiment of the present invention the step of searching for any of the nucleic acid sequences described here, in tumor cells or in cells derived from a cancer patient is effected by any suitable technique, including, but not limited to, nucleic acid sequencing, polymerase chain reaction, ligase chain reaction, self- sustained synthetic reaction, Qβ-Replicase, cycling probe reaction, branched DNA, restriction fragment length polymorphism analysis, mismatch chemical cleavage, heteroduplex analysis, allele- specific oligonucleotides, denaturing gradient gel electrophoresis, constant denaturant gel electrophoresis, temperature gradient gel electrophoresis and dideoxy fingerprinting.
Detection may also optionally be performed with a chip or other such device. The nucleic acid sample which includes the candidate region to be analyzed is preferably isolated, amplified and labeled with a reporter group. This reporter group can be a fluorescent group such as phycoerythrin. The labeled nucleic acid is then incubated with the probes immobilized on the chip using a fluidics station, describe the fabrication of fluidics devices and particularly microcapillary devices, in silicon and glass substrates.
Once the reaction is completed, the chip is inserted into a scanner and patterns of hybridization are detected. The hybridization data is collected, as a signal emitted from the reporter groups already incorporated into the nucleic acid, which is now bound to the probes
attached to the chip. Since the sequence and position of each probe immobilized on the chip is known, the identity of the nucleic acid hybridized to a given probe can be determined.
It will be appreciated that when utilized along with automated equipment, the above described detection methods can be used to screen multiple samples for a disease and/or pathological condition both rapidly and easily.
Amino acid sequences and peptides
The terms "polypeptide," "peptide" and "protein" are used interchangeably herein to refer to a polymer of amino acid residues. The terms apply to amino acid polymers in which one or more amino acid residue is an analog or mimetic of a corresponding naturally occurring amino acid, as well as to naturally occurring amino acid polymers. Polypeptides can be modified, e.g., by the addition of carbohydrate residues to form glycoproteins. The terms
"polypeptide," "peptide" and "protein" include glycoproteins, as well as non-glycoproteins.
Polypeptide products can be biochemically synthesized such as by employing standard solid phase techniques. Such methods include but are not limited to exclusive solid phase synthesis, partial solid phase synthesis methods, fragment condensation, classical solution synthesis. These methods are preferably used when the peptide is relatively short (i.e., 10 kDa) and/or when it cannot be produced by recombinant techniques (i.e., not encoded by a nucleic acid sequence) and therefore involves different chemistry. Solid phase polypeptide synthesis procedures are well known in the art and further described by John Morrow Stewart and Janis Dillaha Young, Solid Phase Peptide Syntheses (2nd
Ed., Pierce Chemical Company, 1984).
Synthetic polypeptides can optionally be purified by preparative high performance liquid chromatography [Creighton T. (1983) Proteins, structures and molecular principles. WH Freeman and Co. N.Y.], after which their composition can be confirmed via amino acid sequencing.
In cases where large amounts of a polypeptide are desired, it can be generated using recombinant techniques such as described by Bitter et al., (1987) Methods in Enzymol. 153:516-
544, Studier et al. (1990) Methods in Enzymol. 185:60-89, Brisson et al. (1984) Nature 310:511- 514, Takamatsu et al. (1987) EMBO J. 6:307-311, Coruzzi et al. (1984) EMBO J. 3:1671-1680 and Brogli et al., (1984) Science 224:838-843, Gurley et al. (1986) MoI. Cell. Biol. 6:559-565
and Weissbach & Weissbach, 1988, Methods for Plant Molecular Biology, Academic Press, NY, Section VIII, pp 421-463.
The present invention also encompasses polypeptides encoded by the polynucleotide sequences of the present invention, as well as polypeptides according to the amino acid sequences described herein. The present invention also encompasses homologues of these polypeptides, such homologues can be at least 50 %, at least 55 %, at least 60%, at least 65 %, at least 70 %, at least 75 %, at least 80 %, at least 85 %, at least 95 % or more say 100 % homologous to the amino acid sequences set forth below, as can be determined using BlastP software of the National Center of Biotechnology Information (NCBI) using default parameters, optionally and preferably including the following: filtering on (this option filters repetitive or low-complexity sequences from the query using the Seg (protein) program), scoring matrix is BLOSUM62 for proteins, word size is 3, E value is 10, gap costs are 11, 1 (initialization and extension), and number of alignments shown is 50. Optionally, nucleic acid sequence identity/homology may be determined by using BlastN software of the National Center of Biotechnology Information (NCBI) using default parameters, which preferably include using the DUST filter program, and also preferably include having an E value of 10, filtering low complexity sequences and a word size of 11. Finally, the present invention also encompasses fragments of the above described polypeptides and polypeptides having mutations, such as deletions, insertions or substitutions of one or more amino acids, either naturally occurring or artificially induced, either randomly or in a targeted fashion.
It will be appreciated that peptides identified according the present invention may be degradation products, synthetic peptides or recombinant peptides as well as peptidomimetics, typically, synthetic peptides and peptoids and semipeptoids which are peptide analogs, which may have, for example, modifications rendering the peptides more stable while in a body or more capable of penetrating into cells. Such modifications include, but are not limited to N terminus modification, C terminus modification, peptide bond modification, including, but not limited to, CH2-NH, CH2-S, CH2-S=O, O=C-NH, CH2-O, CH2-CH2, S=C-NH, CH=CH or CF=CH, backbone modifications, and residue modification. Methods for preparing peptidomimetic compounds are well known in the art and are specified. Further details in this respect are provided hereinunder.
Peptide bonds (-C0-NH-) within the peptide may be substituted, for example, by N- methylated bonds (-N(CH3)-CO-), ester bonds (-C(R)H-C-O-O-C(R)-N-), ketomethylen bonds (-C0-CH2-), α-aza bonds (-NH-N(R)-CO-), wherein R is any alkyl, e.g., methyl, carba bonds (- CH2-NH-), hydroxyethylene bonds (-CH(OH)-CEE-), thioamide bonds (-CS-NH-), olefmic double bonds (-CH=CH-), retro amide bonds (-NH-C0-), peptide derivatives (-N(R)-CH2-CO-), wherein R is the "normal" side chain, naturally presented on the carbon atom.
These modifications can occur at any of the bonds along the peptide chain and even at several (2-3) at the same time.
Natural aromatic amino acids, Trp, Tyr and Phe, may be substituted for synthetic non- natural acid such as Phenylglycine, TIC, naphthylelanine (NoI), ring- methylated derivatives of Phe, halogenated derivatives of Phe or o- methyl- Tyr.
In addition to the above, the peptides of the present invention may also include one or more modified amino acids or one or more non-amino acid monomers (e.g. fatty acids, complex carbohydrates etc). As used herein in the specification and in the claims section below the term "amino acid" or "amino acids" is understood to include the 20 naturally occurring amino acids; those amino acids often modified post-translationally in vivo, including, for example, hydroxyproline, phosphoserine and phosphothreonine; and other unusual amino acids including, but not limited to, 2-aminoadipic acid, hydroxylysine, isodesmosine, nor-valine, nor-leucine and ornithine. Furthermore, the term "amino acid" includes both D- and L-amino acids.
Table 1 non-conventional or modified amino acids which can be used with the present invention.
Table 1
Table 1 Cont.
α β 3
Since the peptides of the present invention are preferably utilized in diagnostics which require the peptides to be in soluble form, the peptides of the present invention preferably include one or more non-natural or natural polar amino acids, including but not limited to serine and threonine which are capable of increasing peptide solubility due to their hydroxyl-containing side chain.
The peptides of the present invention are preferably utilized in a linear form, although it will be appreciated that in cases where cyclicization does not severely interfere with peptide characteristics, cyclic forms of the peptide can also be utilized.
The peptides of present invention can be biochemically synthesized such as by using standard solid phase techniques. These methods include exclusive solid phase synthesis well known in the art, partial solid phase synthesis methods, fragment condensation, classical solution synthesis. These methods are preferably used when the peptide is relatively short (i.e., 10 kDa) and/or when it cannot be produced by recombinant techniques (i.e., not encoded by a nucleic acid sequence) and therefore involves different chemistry. Synthetic peptides can be purified by preparative high performance liquid chromatography and the composition of which can be confirmed via amino acid sequencing.
In cases where large amounts of the peptides of the present invention are desired, the peptides of the present invention can be generated using recombinant techniques such as described by Bitter et al., (1987) Methods in Enzymol. 153:516-544, Studier et al. (1990) Methods in Enzymol. 185:60-89, Brisson et al. (1984) Nature 310:511-514, Takamatsu et al. (1987) EMBO J. 6:307-311, Coruzzi et al. (1984) EMBO J. 3:1671-1680 and Brogli et al., (1984) Science 224:838-843, Gurley et al. (1986) MoI. Cell. Biol. 6:559-565 and Weissbach & Weissbach, 1988, Methods for Plant Molecular Biology, Academic Press, NY, Section VIII, pp 421-463 and also as described above.
Antibodies
"Antibody" refers to a polypeptide ligand that is preferably substantially encoded by an immunoglobulin gene or immunoglobulin genes, or fragments thereof, which specifically binds and recognizes an epitope (e.g., an antigen). The recognized immunoglobulin genes include the kappa and lambda light chain constant region genes, the alpha, gamma, delta, epsilon and mu
heavy chain constant region genes, and the myriad- immunoglobulin variable region genes. Antibodies exist, e.g., as intact immunoglobulins or as a number of well characterized fragments produced by digestion with various peptidases. This includes, e.g., Fab' and F(ab)'2 fragments. The term "antibody," as used herein, also includes antibody fragments either produced by the modification of whole antibodies or those synthesized de novo using recombinant DNA methodologies. It also includes polyclonal antibodies, monoclonal antibodies, chimeric antibodies, humanized antibodies, or single chain antibodies. "Fc" portion of an antibody refers to that portion of an immunoglobulin heavy chain that comprises one or more heavy chain constant region domains, CHl, CH2 and CH3, but does not include the heavy chain variable region.
The functional fragments of antibodies, such as Fab, F(ab')2, and Fv that are capable of binding to macrophages, are described as follows: (1) Fab, the fragment which contains a monovalent antigen-binding fragment of an antibody molecule, can be produced by digestion of whole antibody with the enzyme papain to yield an intact light chain and a portion of one heavy chain; (2) Fab', the fragment of an antibody molecule that can be obtained by treating whole antibody with pepsin, followed by reduction, to yield an intact light chain and a portion of the heavy chain; two Fab' fragments are obtained per antibody molecule; (3) (Fab')2, the fragment of the antibody that can be obtained by treating whole antibody with the enzyme pepsin without subsequent reduction; F(ab')2 is a dimer of two Fab' fragments held together by two disulfide bonds; (4) Fv, defined as a genetically engineered fragment containing the variable region of the light chain and the variable region of the heavy chain expressed as two chains; and (5) Single chain antibody ("SCA"), a genetically engineered molecule containing the variable region of the light chain and the variable region of the heavy chain, linked by a suitable polypeptide linker as a genetically fused single chain molecule. Methods of producing polyclonal and monoclonal antibodies as well as fragments thereof are well known in the art (See for example, Harlow and Lane, Antibodies: A Laboratory Manual, Cold Spring Harbor Laboratory, New York, 1988, incorporated herein by reference).
Antibody fragments according to the present invention can be prepared by proteolytic hydrolysis of the antibody or by expression in E. coli or mammalian cells (e.g. Chinese hamster ovary cell culture or other protein expression systems) of DNA encoding the fragment. Antibody fragments can be obtained by pepsin or papain digestion of whole antibodies by
conventional methods. For example, antibody fragments can be produced by enzymatic cleavage of antibodies with pepsin to provide a 5S fragment denoted F(ab')2. This fragment can be further cleaved using a thiol reducing agent, and optionally a blocking group for the sulfhydryl groups resulting from cleavage of disulfide linkages, to produce 3.5S Fab' monovalent fragments. Alternatively, an enzymatic cleavage using pepsin produces two monovalent Fab' fragments and an Fc fragment directly. These methods are described, for example, by Goldenberg, U.S. Pat. Nos. 4,036,945 and 4,331,647, and references contained therein, which patents are hereby incorporated by reference in their entirety. See also Porter, R. R. [Biochem. J. 73: 119-126 (1959)]. Other methods of cleaving antibodies, such as separation of heavy chains to form monovalent light-heavy chain fragments, further cleavage of fragments, or other enzymatic, chemical, or genetic techniques may also be used, so long as the fragments bind to the antigen that is recognized by the intact antibody.
Fv fragments comprise an association of VH and VL chains. This association may be noncovalent, as described in Inbar et al. [Proc. Nat'l Acad. Sci. USA 69:2659-62 (1972O]. Alternatively, the variable chains can be linked by an intermolecular disulfide bond or cross- linked by chemicals such as glutaraldehyde. Preferably, the Fv fragments comprise VH and VL chains connected by a peptide linker. These single- chain antigen binding proteins (sFv) are prepared by constructing a structural gene comprising DNA sequences encoding the VH and VL domains connected by an oligonucleotide. The structural gene is inserted into an expression vector, which is subsequently introduced into a host cell such as E. coli. The recombinant host cells synthesize a single polypeptide chain with a linker peptide bridging the two V domains. Methods for producing sFvs are described, for example, by [Whitlow and Filpula, Methods 2: 97-105 (1991); Bird et al., Science 242:423-426 (1988); Pack et al., Bio/Technology 11:1271-77 (1993); and U.S. Pat. No. 4,946,778, which is hereby incorporated by reference in its entirety. Another form of an antibody fragment is a peptide coding for a single complementarity- determining region (CDR). CDR peptides ("minimal recognition units") can be obtained by constructing genes encoding the CDR of an antibody of interest. Such genes are prepared, for example, by using the polymerase chain reaction to synthesize the variable region from RNA of antibody-producing cells. See, for example, Larrick and Fry [Methods, 2: 106-10 (1991)]. Humanized forms of non-human (e.g., murine) antibodies are chimeric molecules of immunoglobulins, immunoglobulin chains or fragments thereof (such as Fv, Fab, Fab', F(ab') or
other antigen-binding subsequences of antibodies) which contain minimal sequence derived from non-human immunoglobulin. Humanized antibodies include human immunoglobulins (recipient antibody) in which residues from a complementary determining region (CDR) of the recipient are replaced by residues from a CDR of a non-human species (donor antibody) such as mouse, rat or rabbit having the desired specificity, affinity and capacity. In some instances, Fv framework residues of the human immunoglobulin are replaced by corresponding non-human residues. Humanized antibodies may also comprise residues which are found neither in the recipient antibody nor in the imported CDR or framework sequences. In general, the humanized antibody will comprise substantially all of at least one, and typically two, variable domains, in which all or substantially all of the CDR regions correspond to those of a non- human immunoglobulin and all or substantially all of the FR regions are those of a human immunoglobulin consensus sequence. The humanized antibody optimally also will comprise at least a portion of an immunoglobulin constant region (Fc), typically that of a human immunoglobulin [Jones et al., Nature, 321:522-525 (1986); Riechmann et al, Nature, 332:323- 329 (1988); and Presta, Curr. Op. Struct. Biol, 2:593-596 (1992)].
Methods for humanizing non-human antibodies are well known in the art. Generally, a humanized antibody has one or more amino acid residues introduced into it from a source which is non- human. These non-human amino acid residues are often referred to as import residues, which are typically taken from an import variable domain. Humanization can be essentially performed following the method of Winter and co-workers [Jones et al., Nature, 321:522-525 (1986); Riechmann et al., Nature 332:323-327 (1988); Verhoeyen et al., Science, 239:1534- 1536 (1988)], by substituting rodent CDRs or CDR sequences for the corresponding sequences of a human antibody. Accordingly, such humanized antibodies are chimeric antibodies (U.S. Pat. No. 4,816,567), wherein substantially less than an intact human variable domain has been substituted by the corresponding sequence from a non-human species. In practice, humanized antibodies are typically human antibodies in which some CDR residues and possibly some FR residues are substituted by residues from analogous sites in rodent antibodies.
Human antibodies can also be produced using various techniques known in the art, including phage display libraries [Hoogenboom and Winter, J. MoI. Biol., 227:381 (1991); Marks et al., J. MoI. Biol., 222:581 (1991)]. The techniques of Cole et al. and Boerner et al. are also available for the preparation of human monoclonal antibodies (Cole et al., Monoclonal
Antibodies and Cancer Therapy, Alan R. Liss, p. 77 (1985) and Boerner et al., J. Immunol., 147(l):86-95 (1991)]. Similarly, human antibodies can be made by introduction of human immunoglobulin loci into transgenic animals, e.g., mice in which the endogenous immunoglobulin genes have been partially or completely inactivated. Upon challenge, human antibody production is observed, which closely resembles that seen in humans in all respects, including gene rearrangement, assembly, and antibody repertoire. This approach is described, for example, in U.S. Pat. Nos. 5,545,807; 5,545,806; 5,569,825; 5,625,126; 5,633,425; 5,661,016, and in the following scientific publications: Marks et al., Bio/Technology 10,: 779- 783 (1992); Lonberg et al., Nature 368: 856-859 (1994); Morrison, Nature 368 812-13 (1994); Fishwild et al., Nature Biotechnology 14, 845-51 (1996); Neuberger, Nature Biotechnology 14: 826 (1996); and Lonberg and Huszar, Intern. Rev. Immunol. 13, 65-93 (1995).
Preferably, the antibody of this aspect of the present invention specifically binds at least one epitope of the polypeptide variants of the present invention. As used herein, the term "epitope" refers to any antigenic determinant on an antigen to which the paratope of an antibody binds.
Epitopic determinants usually consist of chemically active surface groupings of molecules such as amino acids or carbohydrate side chains and usually have specific three dimensional structural characteristics, as well as specific charge characteristics.
Optionally, a unique epitope may be created in a variant due to a change in one or more post-translational modifications, including but not limited to glycosylation and/or phosphorylation, as described below. Such a change may also cause a new epitope to be created, for example through removal of glycosylation at a particular site.
An epitope according to the present invention may also optionally comprise part or all of a unique sequence portion of a variant according to the present invention in combination with at least one other portion of the variant which is not contiguous to the unique sequence portion in the linear polypeptide itself, yet which are able to form an epitope in combination. One or more unique sequence portions may optionally combine with one or more other non- contiguous portions of the variant (including a portion which may have high homology to a portion of the known protein) to form an epitope.
Immunoassays
In another embodiment of the present invention, an immunoassay can be used to qualitatively or quantitatively detect and analyze markers in a sample. This method comprises: providing an antibody that specifically binds to a marker; contacting a sample with the antibody; and detecting the presence of a complex of the antibody bound to the marker in the sample. To prepare an antibody that specifically binds to a marker, purified protein markers can be used. Antibodies that specifically bind to a protein marker can be prepared using any suitable methods known in the art.
After the antibody is provided, a marker can be detected and/or quantified using any of a number of well recognized immunological binding assays. Useful assays include, for example, an enzyme immune assay (EIA) such as enzyme- linked immunosorbent assay (ELISA), a radioimmune assay (RIA), a Western blot assay, or a slot blot assay see, e.g., U.S. Pat. Nos. 4,366,241; 4,376,110; 4,517,288; and 4,837,168). Generally, a sample obtained from a subject can be contacted with the antibody that specifically binds the marker. ■
Optionally, the antibody can be fixed to a solid support to facilitate washing and subsequent isolation of the complex, prior to contacting the antibody with a sample. Examples of solid supports include but are not limited to glass or plastic in the form of, e.g., a microtiter plate, a stick, a bead, or a microbead. Antibodies can also be attached to a solid support.
After incubating the sample with antibodies, the mixture is washed and the antibody- marker complex formed can be detected. This can be accomplished by incubating the washed mixture with a detection reagent. Alternatively, the marker in the sample can be detected using an indirect assay, wherein, for example, a second, labeled antibody is used to detect bound marker- specific antibody, and/or in a competition or inhibition assay wherein, for example, a monoclonal antibody which binds to a distinct epitope of the marker are incubated simultaneously with the mixture. Throughout the assays, incubation and/or washing steps may be required after each combination of reagents. Incubation steps can vary from about 5 seconds to several hours, preferably from about 5 minutes to about 24 hours. However, the incubation time will depend upon the assay format, marker, volume of solution, concentrations and the like. Usually the assays will be carried out at ambient temperature, although they can be conducted over a range of temperatures, such as 10 0C to 40 0C.
The immunoassay can be used to determine a test amount of a marker in a sample from a subject. First, a test amount of a marker in a sample can be detected using the immunoassay methods described above. If a marker is present in the sample, it will form an antibody- marker complex with an antibody that specifically binds the marker under suitable incubation conditions described above. The amount of an antibody- marker complex can optionally be determined by comparing to a standard. As noted above, the test amount of marker need not be measured in absolute units, as long as the unit of measurement can be compared to a control amount and/or signal.
Preferably used are antibodies which specifically interact with the polypeptides of the present invention and not with wild type proteins or other isoforms thereof, for example. Such antibodies are directed, for example, to the unique sequence portions of the polypeptide variants of the present invention, including but not limited to bridges, heads, tails and insertions described in greater detail below. Preferred embodiments of antibodies according to the present invention are described in greater detail with regard to the section entitled "Antibodies". Radioimmunoassay (RIA): In one version, this method involves precipitation of the desired substrate and in the methods detailed hereinbelow, with a specific antibody and
425 radiolabeled antibody binding protein (e.g., protein A labeled with ϊ ) immobilized on a precipitable carrier such as agarose beads. The number of counts in the precipitated pellet is proportional to the amount of substrate. In an alternate version of the RIA, a labeled substrate and an unlabelled antibody binding protein are employed. A sample containing an unknown amount of substrate is added in varying amounts. The decrease in precipitated counts from the labeled substrate is proportional to the amount of substrate in the added sample.
Enzyme linked immunosorbent assay (ELISA): This method involves fixation of a sample (e.g., fixed cells or a proteinaceous solution) containing a protein substrate to a surface such as a well of a microtiter plate. A substrate specific antibody coupled to an enzyme is applied and allowed to bind to the substrate. Presence of the antibody is then detected and quantitated by a colorimetric reaction employing the enzyme coupled to the antibody. Enzymes commonly employed in this method include horseradish peroxidase and alkaline phosphatase. If well calibrated and within the linear range of response, the amount of substrate present in the sample
is proportional to the amount of color produced. A substrate Standard is generally employed to improve quantitative accuracy.
Western blot: This method involves separation of a substrate from other protein by means of an acrylamide gel followed by transfer of the substrate to a membrane (e.g., nylon or PVDF). Presence of the substrate is then detected by antibodies specific to the substrate, which are in turn detected by antibody binding reagents. Antibody binding reagents may be, for example, protein A, or other antibodies. Antibody binding reagents may be radiolabeled or enzyme linked as described hereinabove. Detection may be by autoradiography, colorimetric reaction or chemiluminescence. This method allows both quantitation of an amount of substrate and determination of its identity by a relative position on the membrane which is indicative of a migration distance in the acrylamide gel during electrophoresis.
Immunohistochemical analysis: This method involves detection of a substrate in situ in fixed cells by substrate specific antibodies. The substrate specific antibodies may be enzyme linked or linked to fluorophores. Detection is by microscopy and subjective evaluation. If enzyme linked antibodies are employed, a colorimetric reaction may be required.
Fluorescence activated cell sorting (FACS): This method involves detection of a substrate in situ in cells by substrate specific antibodies. The substrate specific antibodies are linked to fluorophores. Detection is by means of a cell sorting machine which reads the wavelength of light emitted from each cell as it passes through a light beam. This method may employ two or more antibodies simultaneously.
Radio- imaging Methods
These methods include but are not limited to, positron emission tomography (PET) single photon emission computed tomography (SPECT). Both of these techniques are non- invasive, and can be used to detect and/or measure a wide variety of tissue events and/or functions, such as detecting cancerous cells for example. Unlike PET, SPECT can optionally be used with two labels simultaneously. SPECT has some other advantages as well, for example with regard to cost and the types of labels that can be used. For example, US Patent No. 6,696,686 describes the use of SPECT for detection of breast cancer, and is hereby incorporated by reference as if fully set forth herein.
Display Libraries
According to still another aspect of the present invention there is provided a display library comprising a plurality of display vehicles (such as phages, viruses or bacteria) each displaying at least 6, at least 7, at least 8, at least 9, at least 10, 10-15, 12-17, 15-20, 15-30 or 20- 50 consecutive amino acids derived from the polypeptide sequences of the present invention.
Methods of constructing such display libraries are well known in the art. Such methods are described in, for example, Young AC, et al., "The three-dimensional structures of a polysaccharide binding antibody to Cryptococcus neoformans and its complex with a peptide from a phage display library: implications for the identification of peptide mimotopes" J MoI Biol 1997 Dec 12;274(4):622-34; Giebel LB et al. "Screening of cyclic peptide phage libraries identifies ligands that bind streptavidin with high affinities" Biochemistry 1995 Nov 28;34(47): 15430-5; Davies EL et al., "Selection of specific phage-display antibodies using libraries derived from chicken immunoglobulin genes" J Immunol Methods 1995 Oct 12;186(l):125-35; Jones C RT al. "Current trends in molecular recognition and bioseparation" J Chromatogr A 1995 JuI 14;707(l):3 -22; Deng SJ et al. "Basis for selection of improved carbohydrate-binding single-chain antibodies from synthetic gene libraries" Proc Natl Acad Sci U S A 1995 May 23;92(11):4992-6; and Deng SJ et al. "Selection of antibody single-chain variable fragments with improved carbohydrate binding by phage display" J Biol Chem 1994 Apr l;269(13):9533-8, which are incorporated herein by reference.
The following sections relate to Candidate Marker Examples (first section) and to Experimental Data for these Marker Examples (second section).
CANDIDATE MARKER EXAMPLES SECTION This Section relates to Examples of sequences according to the present invention, including illustrative methods of selection thereof.
Description of the methodology undertaken to uncover the biomolecular sequences of the present invention
Human ESTs and cDNAs were obtained from GenBank versions 136 (June 15, 2003 ftp.ncbi.nih.gov/genbank/release.notes/gbl36.release.notes); NCBI genome assembly of April 2003; RefSeq sequences from June 2003; Genbank version 139 (December 2003); Human
Genome from NCBI (Build 34) (from Oct 2003); and RefSeq sequences from December 2003; and from the LifeSeq library of Incyte Corporation (ESTs only; Wilmington, DE, USA). With regard to GenBank sequences, the human EST sequences from the EST (GBEST) section and the human mRNA sequences from the primate (GBPRI) section were used; also the human nucleotide RefSeq mRNA sequences were used (see for example www.ncbi.nlm.nih.gov/Genbank/GenbankOverview.html and for a reference to the EST section, see www.ncbi.nlm.nih.gov/dbEST/; a general reference to dbEST, the EST database in GenBank, may be found in Boguski et al, Nat Genet. 1993 Aug;4(4):332-3; all of which are hereby incorporated by reference as if fully set forth herein). Novel splice variants were predicted using the LEADS clustering and assembly system as described in Sorek, R., Ast, G. & Graur, D. Alu-containing exons are alternatively spliced. Genome Res 12, 1060-7 (2002); US patent No: 6,625,545; and U.S. Pat. Appl. No. 10/426,002, published as US20040101876 on May 27 2004; all of which are hereby incorporated by reference as if fully set forth herein. Briefly, the software cleans the expressed sequences from repeats, vectors and immunoglobulins. It then aligns the expressed sequences to the genome taking alternatively splicing into account and clusters overlapping expressed sequences into "clusters" that represent genes or partial genes.
These were annotated using the GeneCarta (Compugen, Tel- Aviv, Israel) platform. The GeneCarta platform includes a rich pool of annotations, sequence information (particularly of spliced sequences), chromosomal information, alignments, and additional information such as SNPs, gene ontology terms, expression profiles, functional analyses, detailed domain structures, known and predicted proteins and detailed homology reports.
A brief explanation is provided with regard to the method of selecting the candidates. However, it should noted that this explanation is provided for descriptive purposes only, and is not intended to be limiting in any way. The potential markers were identified by a computational process that was designed to find genes and/or their splice variants that are over- expressed in tumor tissues, by using databases of expressed sequences. Various parameters related to the information in the EST libraries, determined according to a manual classification process, were used to assist in locating genes and/or splice variants thereof that are over- expressed in cancerous tissues. The detailed description of the selection method is presented in Example 1
below. The cancer biomarkers selection engine and the following wet validation stages are schematically summarized in Figure 1.
EXAMPLE 1 Identification of differentially expressed gene products — Algorithm
In order to distinguish between differentially expressed gene products and constitutively expressed genes (i.e., house keeping genes ) an algorithm based on an analysis of frequencies was configured. A specific algorithm for identification of transcripts over expressed in cancer is described hereinbelow. Dry analysis
Library annotation — EST libraries are manually classified according to:
• Tissue origin
• Biological source — Examples of frequently used biological sources for construction of EST libraries include cancer cell- lines; normal tissues; cancer tissues; fetal tissues; and others such as normal cell lines and pools of normal cell- lines, cancer cell- lines and combinations thereof. A specific description of abbreviations used below with regard to these tissues/cell lines etc is given above.
• Protocol of library construction - various methods are known in the art for library construction including normalized library construction; non-normalized library construction; subtracted libraries; ORESTES and others. It will be appreciated that at times the protocol of library construction is not indicated.
The following rules are followed: EST libraries originating from identical biological samples are considered as a single library.
EST libraries which included above-average levels of contamination, such as DNA contamination for example, were eliminated. The presence of such contamination was determined as follows. For each library, the number of unspliced ESTs that are not fully contained within other spliced sequences was counted. If the percentage of such sequences (as compared to all other sequences) was at least 4 standard deviations above the average for all libraries being
analyzed, this library was tagged as being contaminated and was eliminated from further consideration in the below analysis (see also Sorek, R. & Safer, H.M. A novel algorithm for computational identification of contaminated EST libraries. Nucleic Acids Res 31, 1067-74 (2003)for further details). Clusters (genes) having at least five sequences including at least two sequences from the tissue of interest were analyzed. Splice variants were identified by using the LEADS software package as described above.
EXAMPLE 2 Identification of genes over expressed in cancer.
Two different scoring algorithms were developed.
Libraries score -candidate sequences which are supported by a number of cancer libraries, are more likely to serve as specific and effective diagnostic markers.
The basic algorithm - for each cluster the number of cancer and normal libraries contributing sequences to the cluster was counted. Fisher exact test was used to check if cancer libraries are significantly over-represented in the cluster as compared to the total number of cancer and normal libraries.
Library counting: Small libraries (e.g., less than 1000 sequences) were excluded from consideration unless they participate in the cluster. For this reason, the total number of libraries is actually adjusted for each cluster.
Clones no. score - Generally, when the number of ESTs is much higher in the cancer libraries relative to the normal libraries it might indicate actual over-expression. The algorithm -
Clone counting: For counting EST clones each library protocol class was given a weight based on our belief of how much the protocol reflects actual expression levels: (i) non-normalized : 1 (ii) normalized : 0.2 (iii) all other classes : 0.1
Clones number score - The total weighted number of EST clones from cancer libraries was compared to the EST clones from normal libraries. To avoid cases where one library
contributes to the majority of the score, the contribution of the library that gives most clones for a given cluster was limited to 2 clones. The score was computed as
where: c - weighted number of "cancer" clones in the cluster. C- weighted number of clones in all "cancer" libraries. n - weighted number of "normal" clones in the cluster.
N- weighted number of clones in all "normal" libraries.
Clones number score significance - Fisher exact test was used to check if EST clones from cancer libraries are significantly over-represented in the cluster as compared to the total number of EST clones from cancer and normal libraries. Two search approaches were used to find either general cancer-specific candidates or tumor specific candidates.
• Libraries/sequences originating from tumor tissues are counted as well as libraries originating from cancer cell- lines ("normal" cell- lines were ignored). • Only libraries/sequences originating from tumor tissues are counted
EXAMPLE 3
Identification of tissue specific genes
For detection of tissue specific clusters, tissue libraries/sequences were compared to the total number of libraries/sequences in cluster. Similar statistical tools to those described in above were employed to identify tissue specific genes. Tissue abbreviations are the same as for cancerous tissues, but are indicated with the header "normal tissue".
The algorithm - for each tested tissue T and for each tested cluster the following were examined:
1. Each cluster includes at least 2 libraries from the tissue T. At least 3 clones (weighed - as described above) from tissue T in the cluster; and
2. Clones from the tissue T are at least 40 % from all the clones participating in the tested cluster Fisher exact test P-values were computed both for library and weighted clone counts to check that the counts are statistically significant.
EXAMPLE 4
Identification of splice variants over expressed in cancer of clusters which are not over expressed in cancer
Cancer- specific splice variants containing a unique region were identified. Identification of unique sequence regions in splice variants
A Region is defined as a group of adjacent exons that always appear or do not appear together in each splice variant. A "segment" (sometimes referred also as "seg" or "node") is defined as the shortest contiguous transcribed region without known splicing inside.
Only reliable ESTs were considered for region and segment analysis. An EST was defined as unreliable if:
(i) Unspliced; (ii) Not covered by RNA;
(iii) Not covered by spliced ESTs; and
(iv) Alignment to the genome ends in proximity of long poly-A stretch or starts in proximity of long poly- T stretch.
Only reliable regions were selected for further scoring. Unique sequence regions were considered reliable if:
(i) Aligned to the genome; and (ii) Regions supported by more than 2 ESTs. The algorithm
Each unique sequence region divides the set of transcripts into 2 groups: (i) Transcripts containing this region (group TA).
(ii) Transcripts not containing this region (group TB).
The set of EST clones of every cluster is divided into 3 groups: (i) Supporting (originating from) transcripts of group TA (Sl). (ii) Supporting transcripts of group TB (S2). (iii) Supporting transcripts from both groups (S3). Library and clones number scores described above were given to Sl group.
Fisher Exact Test P- values were used to check if: Sl is significantly enriched by cancer EST clones compared to S2; and Sl is significantly enriched by cancer EST clones compared to cluster background
(S1+S2+S3). Identification of unique sequence regions and division of the group of transcripts accordingly is illustrated in Figure 2. Each of these unique sequence regions corresponds to a segment, also termed herein a "node".
Region 1 : common to all transcripts, thus it is not considered for detecting variants;
Region 2: specific to Transcript 1; Region 3: specific to Transcripts 2 and 3; Region 4: specific to Transcript 3; Region 5: specific to Transcript 1 and 2; Region 6: specific to Transcript 1.
EXAMPLE 5
Identification of cancer specific splice variants of genes over expressed in cancer
A search for EST supported (no mRNA) regions for genes of:
(i) known cancer markers
(ii) Genes shown to be over-expressed in cancer in published micro-array experiments. Reliable EST supported-regions were defined as supported by minimum of one of the following:
(i) 3 spliced ESTs; or
(ii) 2 spliced ESTs from 2 libraries;
(iii) 10 unspliced ESTs from 2 libraries, or (iv) 3 libraries.
Actual Marker Examples
The following examples relate to specific actual marker examples.
EXPERIMENTAL EXAMPLES SECTION This Section relates to Examples describing experiments involving these sequences, and illustrative, non- limiting examples of methods, assays and uses thereof. The materials and experimental procedures are explained first, as all experiments used them as a basis for the work that was performed.
The markers of the present invention were tested with regard to their expression in various cancerous and non- cancerous tissue samples. A description of the samples used in the panel is provided in Table 2 below. A description of the samples used in the normal tissue panel is provided in Table 3 below. Tests were then performed as described in the "Materials and Experimental Procedures" sectionbelow.
Table 2: Tissue samples in testing panel
Table 3: Tissue samples in normal panel:
Materials and Experimental Procedures
RNA preparation - RNA was obtained from Clontech (Franklin Lakes, NJ USA 07417, www.clontech.com), BioChain Inst. Inc. (Hayward, CA 94545 USA www.biochain.com), ABS (Wilmington, DE 19801, USA, http://www.absbioreagents.com) or Ambion (Austin, TX 78744 USA, http://www.ambion.com). Alternatively, RNA was generated from tissue samples using TRI- Reagent (Molecular Research Center), according to Manufacturer's instructions. Tissue and RNA samples were obtained from patients or from postmortem. Total RNA samples were treated with DNaseI (Ambion) and purified using RNeasy columns (Qiagen).
RT PCR - Purified RNA (1 μg) was mixed with 150 ng Random Hexamer primers (Invitrogen) and 500 μM dNTP in a total volume of 15.6 μl. The mixture was incubated for 5 min at 65 0C and then quickly chilled on ice. Thereafter, 5 μl of 5X SuperscriptII first strand buffer (Invitrogen), 2.4μl 0.1M DTT and 40 units RNasin (Promega) were added, and the mixture was incubated for 10 min at 25 0C, followed by further incubation at 42 0C for 2 min. Then, 1 μl (200units) of SuperscriptII (Invitrogen) was added and the reaction (final volume of 25μl) was incubated for 50 min at 42 0C and then inactivated at 70 0C for 15min. The resulting cDNA was diluted 1:20 in TE buffer (10 mM Tris pH=8, 1 mM EDTA pH=8).
Real-Time RT-PCR analysis- cDNA (5μl), prepared as described above, was used as a template in Real- Time PCR reactions using the SYBR Green I assay (PE Applied Biosystem) with specific primers and UNG Enzyme (Eurogentech or ABI or Roche). The amplification was effected as follows: 50 0C for 2 min, 95 0C for 10 min, and then 40 cycles of 95 0C for 15sec, followed by 60 0C for 1 min. Detection was performed by using the PE Applied Biosystem SDS 7000. The cycle in which the reactions achieved a threshold level (Ct) of fluorescence was registered and was used to calculate the relative transcript quantity in the RT reactions. The relative quantity was calculated using the equation C^efficiency^"0'. The efficiency of the PCR reaction was calculated from a standard curve, created by using serial dilutions of several reverse transcription (RT) reactions. To minimize inherent differences in the RT reaction, the resulting relative quantities were normalized to the geometric mean of the relative quantities of several housekeeping (HSKP) genes. Schematic summary of quantitative real-time PCR
analysis is presented in Figure 3. As shown, the x-axis shows the cycle number. The Cj =
Threshold Cycle point, which is the cycle that the amplification curve crosses the fluorescence threshold that was set in the experiment. This point is a calculated cycle number in which PCR product signal is above the background level (passive dye ROX) and still in the Geometric/Exponential phase (as shown, once the level of fluorescence crosses the measurement threshold, it has a geometrically increasing phase, during which measurements are most accurate, followed by a linear phase and a plateau phase; for quantitative measurements, the latter two phases do not provide accurate measurements). The y-axis shows the normalized reporter fluorescence. It should be noted that this type of analysis provides relative quantification.
The sequences of the housekeeping genes measured in all the examples in testing panel were as follows: Ubiquitin (GenBank Accession No. BC000449)
Ubiquitin Forward primer (SEQ ID NO: 326): ATTTGGGTCGCGGTTCTTG
Ubiquitin Reverse primer (SEQ ID NO: 327): TGCCTTGACATTCTCGATGGT
Ubiquitin-amplicon (SEQ ID NO: 328)
ATTTGGGTCGCGGTTCTTGTTTGTGGATCGCTGTGATCGTCACTTGACAATGCAGAT CTTCGTGAAGACTCTGACTGGTAAGACCATCACCCTCGAGG
TTGAGCCCAGTGACACCATCGAGAATGTCAAGGCA
SDHA (GenBank Accession No. NM_004168)
SDHA Forward primer (SEQ ID NO: 329): TGGGAACAAGAGGGCATCTG SDHA Reverse primer (SEQ ID NO: 330) : CCACCACTGCATCAAATTCATG SDHA-amplicon (SEQ ID NO: 331):
TGGGAACAAGAGGGCATCTGCTAAAGTTTCAGATTCCATTTCTGCTCAGTATCCAGT AGTGGATCATGAATTTGATGCAGTGGTGG
PBGD (GenBank Accession No. BCOl 9323),
PBGD Forward primer (SEQ ID NO: 332): TGAGAGTGATTCGCGTGGG
PBGD Reverse primer (SEQ ID NO: 333): CCAGGGTACGAGGCTTTCAAT PBGD-amplicon (SEQ ID NO: 334):
TGAGAGTGATTCGCGTGGGTACCCGCAAGAGCCAGCTTGCTCGCATACAGACGGAC AGTGTGGTGGCAACATTGAAAGCCTCGTACCCTGG
HPRTl (GenBank Accession No. NM_000194),
HPRTl Forward primer (SEQ ID NO: 1295): TGACACTGGCAAAACAATGCA HPRTl Reverse primer (SEQ ID NO: 1296): GGTCCTTTTC ACCAGC AAGCT HPRTl -amplicon (SEQ ID NO: 1297): TGACACTGGCAAAACAATGCAGACTTTGCTTTCCTTGGTCAGGCAGTATAATCCAA AGATGGTCAAGGTCGCAAGCTTGCTGGTGAAAAGGACC
The sequences of the housekeeping genes measured in all the examples on normal tissue samples panel were as follows:
RPL19 (GenBank Accession No. NM_000981),
RPL19 Forward primer (SEQ ID NO: 1298): TGGCAAGAAGAAGGTCTGGTTAG
RPLl 9 Reverse primer (SEQ ID NO: 1420): TGATCAGCCCATCTTTGATGAG
RPLl 9 -amplicon (SEQ ID NO: 1630): TGGCAAGAAGAAGGTCTGGTTAGACCCCAATGAGACCAATGAAATCGCCAATGCCA
ACTCCCGTCAGCAGATCCGGAAGCTCATCAAAGATGGGCTGATCA TATA box (GenBank Accession No. NM_003194),
TATA box Forward primer (SEQ ID NO: 1631) : CGGTTTGCTGCGGTAATCAT
TATA box Reverse primer (SEQ ID NO: 1632): TTTCTTGCTGCCAGTCTGGAC TATA box -amplicon (SEQ ID NO: 1633):
CGGTTTGCTGCGGTAATCATGAGGATAAGAGAGCCACGAACCACGGCACTGATTTT
CAGTTCTGGGAAAATGGTGTGCACAGGAGCCAAGAGTGAAGAACAGTCCAGACTG
GCAGCAAGAAA
Ubiquitin (GenBank Accession No. BC000449) Ubiquitin Forward primer (SEQ ID NO: 326): ATTTGGGTCGCGGTTCTTG
Ubiquitin Reverse primer (SEQ ID NO: 327): TGCCTTGACATTCTCGATGGT
Ubiquitin-amplicon (SEQ ID NO: 328)
ATTTGGGTCGCGGTTCTTGTTTGTGGATCGCTGTGATCGTCACTTGACAATGCAGAT CTTCGTGAAGACTCTGACTGGTAAGACCATCACCCTCGAGG TTGAGCCCAGTGACACCATCGAGAATGTCAAGGCA SDHA (GenBank Accession No. NM_004168)
SDHA Forward primer (SEQ ID NO: 329): TGGGAACAAGAGGGCATCTG SDHA Reverse primer (SEQ ID NO: 330): CCACCACTGCATCAAATTCATG SDHA- amplicon (SEQ ID NO: 331):
TGGGAACAAGAGGGCATCTGCTAAAGTTTCAGATTCCATTTCTGCTCAGTATCCAGT AGTGGATCATGAATTTGATGCAGTGGTGG
Oligonucleotide-based micro-array experiment protocol-
Microarray fabrication
Microarrays (chips) were printed by pin deposition using the MicroGrid II MGII 600 robot from BioRobotics Limited (Cambridge, UK). 50-mer oligonucleotides target sequences were designed by Compugen Ltd (Tel- Aviv, IL) as described by A. Shoshan et al, "Optical technologies and informatics", Proceedings of SPIE. VoI 4266, pp. 86-95 (2001). The designed oligonucleotides were synthesized and purified by desalting with the Sigma-Genosys system (The Woodlands, TX, US) and all of the oligonucleotides were joined to a C6 amino -modified linker at the 5' end, or being attached directly to CodeLink slides (Cat #25-6700-01. Amersham Bioscience, Piscataway, NJ, US). The 50-mer oligonucleotides, forming the target sequences, were first suspended in Ultra-pure DDW (Cat # 01-866- IA Kibbutz Beit-Haemek, Israel) to a concentration of 50μM. Before printing the slides, the oligonucleotides were resuspended in 30OmM sodium phosphate (pH 8.5) to final concentration of 15OmM and printed at 35-40% relative humidity at 210C.
Each slide contained a total of 9792 features in 32 subarrays. Of these features, 4224 features were sequences of interest according to the present invention and negative controls that were printed in duplicate. An additional 288 features (96 target sequences printed in triplicate) contained housekeeping genes from Human Evaluation Library2, Compugen Ltd, Israel.
Another 384 features are E.coli spikes 1-6, which are oligos to E-CoIi genes which are commercially available in the Array Control product (Array control- sense oligo spots, Ambion Inc. Austin, TX. Cat #1781, Lot #1 12K06).
Post-coupling processing of printed slides
After the spotting of the oligonucleotides to the glass (CodeLink) slides, the slides were incubated for 24 hours in a sealed saturated NaCl humidification chamber (relative humidity 70- 75%).
Slides were treated for blocking of the residual reactive groups by incubating them in blocking solution at 500C for 15 minutes (lOml/slide of buffer containing 0.1 M Tris, 5OmM ethanolamine, 0.1% SDS). The slides were then rinsed twice with Ultra-pure DDW (double distilled water). The slides were then washed with wash solution (lOml/slide. 4X SSC, 0.1% SDS)) at 500C for 30 minutes on the shaker. The slides were then rinsed twice with Ultra-pure DDW, followed by drying by centrifugation for 3 minutes at 800 rpm. Next, in order to assist in automatic operation of the hybridization protocol, the slides were treated with Ventana Discovery hybridization station barcode adhesives. The printed slides were loaded on a Bio-Optica (Milan, Italy) hematology staining device and were incubated for 10 minutes in 50ml of 3-Aminopropyl Triethoxysilane (Sigma A3648 lot #122K589). Excess fluid was dried and slides were then incubated for three hours in 20 mm/Hg in a dark vacuum desiccator (Pelco 2251, Ted Pella, Inc. Redding CA).
The following protocol was then followed with the Genisphere 900-RP (random primer), with mini elute columns on the Ventana Discovery HybStation™, to perform the microarray experiments. Briefly, the protocol was performed as described with regard to the instructions and information provided with the device itself. The protocol included cDNA synthesis and labeling. cDNA concentration was measured with the TBS-380 (Turner Biosystems. Sunnyvale, CA.) PicoFlour, which is used with the OliGreen ssDNA Quantitation reagent and kit.
Hybridization was performed with the Ventana Hybridization device, according to the provided protocols (Discovery Hybridization Station Tuscon AZ).
The slides were then scanned with GenePix 4000B dual laser scanner from Axon Instruments Inc, and analyzed by GenePix Pro 5.0 software.
Schematic summary of the oligonucleotide based microarray fabrication and the experimental flow is presented in Figures 4 and 5. Briefly, as shown in Figure 4, DNA oligonucleotides at 25uM were deposited (printed) onto Amersham 'CodeLink' glass slides generating a well defined 'spot'. These slides are covered with a long-chain, hydrophilic polymer chemistry that creates an active 3-D surface that covalently binds the DNA oligonucleotides 5 '-end via the
C6- amine modification. This binding ensures that the full length of the DNA oligonucleotides is available for hybridization to the cDNA and also allows lower background, high sensitivity and reproducibility.
Figure 5 shows a schematic method for performing the microarray experiments. It should be noted that stages on the left-hand or right-hand side may optionally be performed in any order, including in parallel, until stage 4 (hybridization). Briefly, on the left-hand side, the target oligonucleotides are being spotted on a glass microscope slide (although optionally other materials could be used) to form a spotted slide (stage 1). On the right hand side, control sample RNA and cancer sample RNA are Cy3 and Cy5 labeled, respectively (stage 2), to foπn labeled probes. It should be noted that the control and cancer samples come from corresponding tissues (for example, normal prostate tissue and cancerous prostate tissue). Furthermore, the tissue from which the RNA was taken is indicated below in the specific examples of data for particular clusters, with regard to overexpression of an oligonucleotide from a "chip" (microarray), as for example "prostate" for chips in which prostate cancerous tissue and normal tissue were tested as described above. In stage 3, the probes are mixed. In stage 4, hybridization is performed to form a processed slide. In stage 5, the slide is washed and scanned to form an image file, followed by data analysis in stage 6.
The following clusters were found to be overexpressed in lung cancer:
W60282_PEA_l F05068_PEA_l H38804_PEA_l HSENA 78
T 39971
(R00299)
H14624
Z41644_PEA_1 Z25299_PEA_2
HSSTROL3
HUMTREFACJPEA_2
HSSlOOPCB
HSU33147_PEA_1 HUMCAlXIA
H61775
HUMGRP5E
HUMODCA
AA161187 R66178
D56406_PEA_l
M85491_PEA_1
Z21368_PEA_1
HUMCAlXIA R20779
R38144_PEA_2
Z44808_PEA_l
HUMOSTRO_PEAJ_PEA_1
R11723_PEA_3 AI076020
T23580
M79217_PEA_1
M62096_PEA_1
M78076_PEA_1 T99080_PEA_4
T08446 PEA 1
_PEA_1
The following clusters were found to be overexpressed in lung small cell cancer: H61775 HUMGRP5E
M85491_PEA_1 Z44808_PEA_l AA161187 R66178 HUMPHOSLIP PEA 2
AI076020 T23580
M79217_PEA_1 M62096_PEA_1
M78076_PEA_1 T99080_PEA_4 T08446_PEA_1
The following clusters were found to be overexpressed in lung adenocarcinoma:
R00299
M85491_PEA_1
Z21368_PEA_1 HUMCAlXIA
AA161187
R66178
T11628 PEA 1
The following clusters were found to be overexpressed in lung squamous cell: HUMODCA R00299
D56406 JPEAJ Z44808_PEA_l Z21368_PEA_1 HUMCAlXIA AAl 61187 R66178
HUMCEAJPEAJ R35137 PEA 1 PEA 1 PEA 1
DESCRIPTION FOR CLUSTER H61775
Cluster H61775 features 2 transcript(s) and 6 segment(s) of interest, the names for which are given in Tables 4 and 5, respectively, the sequences themselves are given at the end of the application. The selected protein variants are given in table 6.
Table 4 - Transcripts of interest
Table 6 - Proteins of interest
Cluster H61775 can be used as a diagnostic marker according to overexpression of transcripts of this cluster in cancer. Expression of such transcripts in normal tissues is also given according to the previously described methods. The term "number" in the right hand column of the table and the numbers on the y-axis of figure 6 refer to weighted expression of ESTs in each category, as "parts per million" (ratio of the expression of ESTs for a particular cluster to the expression of all ESTs in that category, according to parts per million).
Overall, the following results were obtained as shown with regard to the histograms in Figure 6 and Table 7. This cluster is overexpressed (at least at a minimum level) in the following pathological conditions: brain malignant tumors and a mixture of malignant tumors from different tissues.
Table 7 - Normal tissue distribution
Table 8 - P values and ratios for expression in cancerous tissue
As noted above, contig H61775 features 2 transcript(s), which were listed in Table 3 above. A description of each variant protein according to the present invention is now provided.
Variant protein H61775_P16 according to the present invention has an amino acid sequence as given at the end of the application; it is encoded by transcript(s) H61775_T21. One or more alignments to one or more previously published protein sequences are given at the end of the application. A brief description of the relationship of the variant protein according to the present invention to each such aligned protein is as follows:
Comparison report between H61775JP16 and Q9P2J2 (SEQ ID NO:1694): 1.An isolated chimeric polypeptide encoding for H61775_P16, comprising a first amino acid sequence being at least 90 % homologous to
MVWCLGLAVLSLVISQGADGRGKPEWSWGRAGESWLGCDLLPPAGRPPLHVIEWL
RFGFLLPIFIQFGLYSPRIDPDYVG coπ-esponding to amino acids 11 - 93 of Q9P2J2, which also corresponds to amino acids 1 - 83 of H61775_P16, and a second amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence DCGFP AFRELKRAETVSPVFFTRRCIWEDLKSTGFSPAGGGRPPGGGPRTQEDSGLPCW RSSCSVTLQV corresponding to amino acids 84 - 152 of H61775_P16, wherein said first and second amino acid sequences are contiguous and in a sequential order.
2.An isolated polypeptide encoding for a tail of H61775JP16, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence
DCGFPAFRELKRAETVSPVFFTRRCIWEDLKSTGFSPAGGGRPPGGGPRTQEDSGLPCW RSSCSVTLQV in H61775JP16.
Comparison report between H61775JP16 and AAQ88495 (SEQ ID NO:1695):
1.An isolated chimeric polypeptide encoding for H61775_P16, comprising a first amino acid sequence being at least 90 % homologous to
MVWCLGLAVLSLVISQGADGRGKPEVVSVVGRAGESVVLGCDLLPPAGRPPLHVIEWL RFGFLLPIFIQFGLYSPRIDPDYVG corresponding to amino acids 1 - 83 of AAQ88495, which also corresponds to amino acids 1 - 83 of H61775_P16, and a second amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence
DCGFPAF RELKRAETVSPVFFTRRCIWEDLKSTGFSPAGGGRPPGGGPRTQEDSGLPCW RSSCSVTLQV corresponding to amino acids 84 - 152 of H61775_P16, wherein said first and second amino acid sequences are contiguous and in a sequential order.
2.An isolated polypeptide encoding for a tail of H61775_P16, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence DCGFPAFRELKRAETVSPVFFTRRCIWEDLKSTGFSPAGGGRPPGGGPRTQEDSGLPCW RSSCSVTLQV in H61775_P16.
The location of the variant protein was determined according to results from a number of different software programs and analyses, including analyses from SignalP and other specialized
programs. The variant protein is believed to be located as follows with regard to the cell: secreted. The protein localization is believed to be secreted because both signal-peptide prediction programs predict that this protein has a signal peptide, and neither trans -membrare region prediction program predicts that this protein has a trans -membrane region..
Variant protein H61775_P16 also has the following non-silent SNPs (Single Nucleotide Polymorphisms) as listed in Table 9, (given according to their position(s) on the amino acid sequence, with the alternative amino acid(s) listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein H61775_P16 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table9 - Amino acid mutations
Variant protein H61775_P16 is ercoded by the following transcript(s): H61775_T21, for which the sequence(s) is/are given at the end of the application. The coding portion of transcript H61775_T21 is shown in bold; this coding portion starts at position 261 and ends at position 716. The transcript also has the following SNPs as listed in Table 10 (given according to their position on the nucleotide sequence, with the alternative nucleic acid listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein H61775_P16 sequence provides support for the deduced sequence of this variant protein according to the present invention). Table 10 - Nucleic acid SNPs
Variant protein H61775_P17 according to the present invention has an amino acid sequence as given at the end of the application; it is encoded by transcript(s) H61775_T22. One or more alignments to one or more previously published protein sequences are given at the end of the application. A brief description of the relationship of the variant protein according to the present invention to each such aligned protein is as follows:
Comparison report between H61775_P17 and Q9P2J2: 1.An isolated chimeric polypeptide encoding for H61775_P17, comprising a first amino acid sequence being at least 90 % homologous to
MVWCLGLAVLSLVISQGADGRGKPEWSVVGRAGESVVLGCDLLPPAGRPPLHVIEWL
RFGFLLPIFIQFGLYSPRIDPDYVG corresponding to amino acids 11 - 93 of Q9P2J2, which also corresponds to amino acids 1 - 83 of H61775JP17. Comparison report between H61775JP17 and AAQ88495:
1.An isolated chimeric polypeptide encoding for H61775_P17, comprising a first amino acid sequence being at least 90 % homologous to
MVWCLGLAVLSLVISQGADGRGKPEWSVVGRAGESWLGCDLLPPAGRPPLHVIEWL
RFGFLLPIFIQFGLYSPRJDPDYVG corresponding to amino acids 1 - 83 of AAQ88495, which also corresponds to amino acids 1 - 83 of H61775_P17.
The location of the variant protein was deteπnined according to results from a number of different software programs and analyses, including analyses from SignalP and other specialized programs. The variant protein is believed to be located as follows with regard to the cell: secreted. The protein localization is believed to be secreted because both signal-peptide prediction programs predict that this protein has a signal peptide, and neither trans -membrane region prediction program predicts that this protein has a trans -membrane region..
Variant protein H61775_P17 also has the following non- silent SNPs (Single Nucleotide Polymorphisms) as listed in Table 11, (given according to their position(s) on the amino acid sequence, with the alternative amino acid(s) listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein H61775_P17 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 11 -Amino acid mutations
Variant protein H61775_P17 is encoded by the following transcript(s): H61775_T22, for which the sequence(s) is/are given at the end of the application. The coding portion of transcript H61775_T22 is shown in bold; this coding portion starts at position 261 and ends at position 509. The transcript also has the following SNPs as listed in Table 12 (given according to their position on the nucleotide sequence, with the alternative nucleic acid listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein H61775_P17 sequence provides support for the deduced sequence of this variant protein according to the present invention). Table 12 - Nucleic acid SNPs
As noted above, cluster H61775 features 6 segment(s), which were listed in Table 4 above and for which the sequence(s) are given at the end of the application. These segment(s) are portions of nucleic acid sequence(s) which are described herein separately because they are of particular interest. A description of each segment according to the present invention is now provided.
Segment cluster H61775_node_2 according to the present invention is supported by 17 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): H61775JT21 and H61775_T22. Table 13 below describes the starting and ending position of this segment on each transcript.
Table 13 - Segment location on transcripts
Segment cluster H61775_node_4 according to the present invention is supported by 20 libraries. The number of libraries was determined as previously described. This segment can be
found in the following transcrlpt(s): H61775_T21 and H61775JT22. Table 14 below describes the starting and ending position of this segment on each transcript.
Table 14 - Segment location on transcripts
Segment cluster H61775_node_6 according to the present invention is supported by 1 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): H61775_T22. Table 15 below describes the starting and ending position of this segment on each transcript.
Table 15 - Segment location on transcripts
Segment cluster H61775_node_8 according to the present invention is supported by 5 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): H61775_T21. Table 16 below describes the starting and ending position of this segment on each transcript.
Table 16 - Segment location on transcripts
According to an optional embodiment of the present invention, short segments related to the above cluster are also provided. These segments are up to about 120 bp in length, and so are included in a separate description.
Segment cluster H61775_node_0 according to the present invention is supported by 4 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): H61775JT21 and H61775JT22. Table 17 below describes the starting and ending position of this segment on each transcript.
Table 17 - Segment location on transcripts
Segment cluster H61775_node_5 according to the present invention can be found in the following transcript(s): H61775_T22. Table 18 below describes the starting and ending position of this segment on each transcript. Table 18 - Segment location on transcripts
Microarray (chip) data is also available for this gene as follows. As described above with regard to the cluster itself, various oligonucleotides were tested for being differentially expressed in various disease conditions, particularly cancer. The following oligonucleotides were found to hit this segment (with regard to lung cancer), shown in Table 19.
Table 19 - Oligonucleotides related to this gene
Variant protein alignment to the previously known protein:
Sequence name: /tmp/PswORJLCti/aLAXQjXhO7 :Q9P2J2
Sequence documentation:
Alignment of: H61775_P16 x Q9P2J2
Alignment segment 1/1:
Quality: 803.00 Escore: 0
Matching length: 83 Total length: 83
Matching Percent Similarity: 100.00 Matching Percent Identity: 100.00
Total Percent Similarity: 100.00 Total Percent Identity: 100.00 Gaps : 0
Alignment :
1 MVWCLGLAVLSLVI SQGADGRGKPEWS WGRAGESVVLGCDLLPP AGRP 50 I I I I I M i I I I I I I I I I I I M I I I M I I I I I I I I i I I I I M I I M I I I I I
11 MVWCLGLAVLSLVISQGADGRGKPEWSWGRAGESWLGCDLLPPAGRP 60
51 PLHVIEWLRFGFLLPIFIQFGLYSPRIDPDYVG 83
I I I I I I I I I I I I I Il I I Il I I I I I I I I I I I I Il 61 PLHVIEWLRFGFLLPIFIQFGLYSPRIDPDYVG 93
Sequence name: /tmp/PswORJLCti/aLAXQjXhO7 :AAQ88495
Sequence documentation:
Alignment of: H61775_P16 x AAQ88495
Alignment segment 1/1:
Quality: 803.00 Escore: 0
Matching length: 83 Total length: 83
Matching Percent Similarity: 100.00 Matching Percent Identity: 100.00 Total Percent Similarity: 100.00 Total Percent Identity: 100.00
Gaps : 0
Alignment: . . . . .
1 MVWCLGLAVLSLVISQGADGRGKPEVVSWGRAGESVVLGCDLLPPAGRP 50
M I M I I M I i I M M I I I M I M I I I I i I I M i I I I M I I M l I I I I I !
1 MVWCLGLAVLSLVISQGADGRGKPEVVSWGRAGESWLGCDLLPPAGRP 50
51 PLHVIEWLRFGFLLPIFIQFGLYSPRIDPDYVG 83
51 PLHVIEWLRFGFLLPIFIQFGLYSPRIDPDYVG 83
Sequence name: /tmp/naab8yR3GC/pSM412IL5o : Q9P2J2
Sequence documentation:
Alignment of: H61775_P17 x Q9P2J2
Alignment segment 1/1:
Quality: 803.00 Escore: 0
Matching length: 83 Total length: 83 Matching Percent Similarity: 100.00 Matching Percent Identity: 100.00
Total Percent Similarity: 100.00 Total Percent Identity: 100.00
Gaps : 0
Alignment :
1 MVWCLGLAVLSLVISQGADGRGKPEVVSWGRAGESVVLGCDLLPPAGRP 50 I I I I I I I I I I I I I I Il I I I I I I I I I I I I I I I I I I I I I I I I I I Il I 1 I I Il 11 MVWCLGLAVLSLVISQGADGRGKPEWSVVGRAGESVVLGCDLLPPAGRP 60
51 PLHVIEWLRFGFLLPIFIQFGLYSPRIDPDYVG 83
I I I I I I I I I I I I I I I I I I 1 I I I I I I I 1 I I I I I I
61 PLHVIEWLRFGFLLPIFIQFGLYSPRIDPDYVG 93
Sequence name: /tmp/naab8yR3GC/pSM412IL5o :AAQ88495
Sequence documentation:
Alignment of: H61775_P17 x AAQ88495
Alignment segment 1/1:
Quality: 803.00 Escore: 0 Matching length: 83 Total length: 83
Matching Percent Similarity: 100.00 Matching Percent Identity: 100.00
Total Percent Similarity: 100.00 Total Percent Identity: 100.00
Gaps : 0
Alignment:
1 MVWCLGLAVLSLVISQGADGRGKPEVVSVVGRAGESVVLGCDLLPPAGRP 50
1 MVWCLGLAVLSLVISQGADGRGKPEVVSVVGRAGESVVLGCDLLPPAGRP 50
51 PLHVIEWLRFGFLLPIFIQFGLYSPRIDPDYVG 83
I I I I I I I I I I I I I I I I I I l I I I I I I I I I I I I I I 51 PLHVIEWLRFGFLLPIFIQFGLYSPRIDPDYVG 83
Expression of immunoglobulin superfamily, member 9, H61775 transcripts which are detectable by amplicon as depicted in sequence name H61775seg8 in normal and cancerous lung tissues
Expression of immunoglobulin superfamily, member 9 transcripts detectable by or according to seg8 , H61775seg8 amplicon (SEQ ID NO: 1636) and H61775seg8F2 (SEQ ID NO: 1634) and H61775seg8R2 (SEQ ID NO: 1635) primers was measured by real time PCR. In parallel the expression of four housekeeping genes - PBGD (GenBank Accession No. BC019323; amplicon - PBGD-amplicon, SEQ ID NO:334, primers SEQ ID NOs 332 and 333), HPRTl (GenBank Accession No. NMJ)OOl 94; amplicon - HPRTl -amplicon, SEQ ID NO:1297; primers SEQ ID NOs 1295 and 1296), Ubiquitin (GenBank Accession No. BC000449; amplicon - Ubiquitin-amplicon, SEQ ID NO:328, primers SEQ ID NOs 326 and 327) and SDHA (GenBank Accession No. NM_004168; amplicon - SDHA-amplicon, SEQ ID NO:331; primers SEQ ID NOs 329 and 330) was measured similarly. For each RT sample, the expression of the above amplicon was normalized to the geometric mean of the quantities of the housekeeping genes. The normalized quantity of each RT sample was then divided by the median of the quantities of the normal post-mortem (PM) samples (Sample Nos. 47-50, 90-93, 96-99, Table 2, "Tissue samples in testing panel"), to obtain a value of fold up-regulation for each sample relative to median of the normal PM samples.
Figure 7 is a histogram showing over expression of the above- indicated immunoglobulin superfamily, member 9 transcripts in cancerous lung samples relative to the normal samples. The number and percentage of samples that exhibit at least 5 fold over-expression, out of the total number of samples tested, is indicated in the bottom. As is evident from Figure 7, the expression of immunoglobulin superfamily, member 9 transcripts detectable by the above amplicon(s) in cancer samples was significantly higher than
in the non-cancerous samples (Sample Nos. 47-50, 90-93, 96-99, Table 2 "Tissue samples in testing panel"). Notably an over- expression of at least 5 fold was found in 1 1 out of 15 adenocarcinoma samples, 12 out of 16 squamous cell carcinoma samples, 1 out of 4 samples of large cell carcinoma samples and in 8 out of 8 small cell carcinoma samples. Statistical analysis was applied to verify the significance of these results, as described below.
The P value for the difference in the expression levels of immunoglobulin superfamily, member 9 transcripts detectable by the above amplicon in lung cancer samples versus the normal tissue samples was deteπnined by T test as 6.5E-02. In adenocarcinoma, the minimum values were 7.62E-03 in squamous cell adenocarcinoma cancer and 1.5E-03 in small cell carcinoma.
Threshold of 5 fold overexpression was found to differentiate between cancer and normal samples with P value of 9.62E-04 in adenocarcinoma, 5.9E-04 in squamous cell carcinoma, and a threshold of 10 fold overexpression was found to differentiate between small cell adenocarcinoma cancer and normal samples with P value of 7.14E-05 as checked by exact fisher test. The above values demonstrate statistical significance of the results.
Primer pairs are also optionally and preferably encompassed within the present invention; for example, for the above experiment, the following primer pair was used as a non- limiting illustrative example only of a suitable primer pair: H61775seg8F2 forward primer; and
H61775seg8R2 reverse primer.
The present invention also preferably encompasses any amplicon obtained through the use of any suitable primer pair; for example, for the above experiment, the following amplicon was obtained as a non- limiting illustrative example only of a suitable amplicon: H61775seg8. H61775seg8F2 (SEQ ID NO: 1634)
GAAGGCTCTTGTCACTTACTAGCCAT
H61775seg8R2 (SEQ ID NO: 1635)
TGTCACCATATTTAATCCTCCCAA
H61775seg8 (SEQ ID NO: 1636) GAAGGCTCTTGTCACTTACTAGCCATGTGATTTTGGAAAGAAACTTAACATTAATTC
CTTCAGCTACAATGGAATTCTTGGGAGGATTAAATATGGTGACA
Expression of immunoglobulin superfamily, member 9,
H61775 transcripts which are detectable by amplicon as depicted in sequence name H61775seg8 in different normal tissues. Expression of immunoglobulin superfamily, member 9 transcripts detectable by or according to H61775 seg8 amplicon (SEQ ID NO: 1636) and H61775 seg8F2 (SEQ ID NO: 1634) and H61775 seg8R2 (SEQ ID NO: 1635) was measured by real time PCR. In parallel the expression of four housekeeping genes -RPLl 9 (GenBank Accession No. NM 000981; RPLl 9 amplicon, SEQ ID NO: 1630), TATA box (GenBank Accession No. NM_003194; TATA amplicon, SEQ ID NO: 1633), Ubiquitin (GenBank Accession No. BC000449; amplicon - Ubiquitin-amplicon, SEQ ID NO:328) and SDHA (GenBank Accession No. NM_004168; amplicon - SDHA-amplicon, SEQ ID NO:331) was measured similarly. For each RT sample, the expression of the above amplicon was normalized to the geometric mean of the quantities of the housekeeping genes. The normalized quantity of each RT sample was then divided by the median of the quantities of the ovary samples (Sample Nos. 18-20, Table 4, "Tissue sample in normal panel", above), to obtain a value of relative expression of each sample relative to median of the ovary samples.
H61775seg8F2 (SEQ ID NO: 1634)
GAAGGCTCTTGTCACTTACTAGCCAT
H61775seg8R2 (SEQ ID NO: 1635)
TGTCACCATATTTAATCCTCCCAA
H61775seg8 (SEQ ID NO: 1636) GAAGGCTCTTGTCACTTACTAGCCATGTGATTTTGGAAAGAAACTTAACATTAATTC
CTTCAGCTACAATGGAATTCTTGGGAGGATTAAATATGGTGACA
The results are demonstrated in Figure 8, showing expression of immunoglobulin superfamily, member 9, H61775 transcripts, which are detectable by amplicon as depicted in sequence name H61775seg8, in different normal tissues.
DESCRIPTION FOR CLUSTER M85491
Cluster M85491 features 2 transcript(s) and 11 segment(s) of interest, the names for which are given in Tables 20 and 21, respectively, the sequences themselves are given at the end of the application. The selected protein variants are given in table 22. Table 20 - Transcripts of interest
Table22 - Proteins of interest
These sequences are variants of the known protein Ephrin type-B receptor 2 [precursor] (SwissProt accession identifier EPB2_HUMAN; known also according to the synonyms EC 2.7.1.112; Tyrosine-protein kinase receptor EPH-3; DRT; Receptor protein- tyrosine kinase HEK5; ERK), SEQ ID NO: 1417, referred to herein as the previously known protein.
Protein Ephrin type-B receptor 2 [precursor] is known or believed to have the following function(s): Receptor for members of the ephrin- B family. The sequence for protein Ephrin type-B receptor 2 [precursor] is given at the end of the application, as "Ephrin type-B receptor 2 [precursor] amino acid sequence" (SEQ ID NO:1417). Known polymorphisms for this sequence are as shown in Table 23.
Table 23 - Amino acid mutations for Known Protein
Protein Ephrin type-B receptor 2 [precursor] localization is believed to be Type I membrane protein.
The following GO Annotation(s) apply to the previously known protein. The following annotation(s) were found: protein amino acid phosphorylation; transmembrane receptor protein tyrosine kinase signaling pathway; neurogenesis, which are annotation(s) related to Biological Process; protein tyrosine kinase; receptor; transmembrane-ephrin receptor; ATP binding; transferase, which are annotation(s) related to Molecular Function; and integral membrane protein, which are annotation(s) related to Cellular Component.
The GO assignment relies on information from one or more of the SwissProt/TremBl Protein knowledgebase, available from <http://www.expasy.ch/sprot/>; or Locuslink, available from <http://www.ncbi.nhΩ.nih.gov/projects/LocusLink/>.
Cluster M85491 can be used as a diagnostic marker according to overexpression of transcripts of this cluster in cancer. Expression of such transcripts in normal tissues is also given according to the previously described methods. The term "number" in the right hand column of the table and the numbers on the y-axis of figure 9 refer to weighted expression of ESTs in each category, as "parts per million" (ratio of the expression of ESTs for a particular cluster to the expression of all ESTs in that category, according to parts per million).
Overall, the following results were obtained as shown with regard to the histograms in Figure 9 and Table 24. This cluster is overexpressed (at least at a minimum level) in the following pathological conditions: epithelial malignant tumors and a mixture of malignant tumors from different tissues.
Table24 - Normal tissue distribution
As noted above, cluster M85491 features 2 transcript(s), which were listed in Table 20 above. These transcript(s) encode for protein(s) which are variant(s) of protein Ephrin type-B receptor 2 [precursor]. A description of each variant protein according to the present invention is now provided. Variant protein M85491 PEA 1 P13 according to the present invention has an amino acid sequence as given at the end of the application; it is encoded by transcript(s) M85491JPEA_1JT16. An alignment is given to the known protein (Ephrin type-B receptor 2 [precursor]) at the end of the application. One or more alignments to one or more previously published protein sequences are given at the end of the application. A brief description of the relationship of the variant protein according to the present invention to each such aligned protein is as follows:
Comparison report between M85491_PEA_1_P13 and EPB2_HUMAN:
1.An isolated chimeric polypeptide encoding for M85491_PEA_1_P13, comprising a first amino acid sequence being at least 90 % homologous to
MALRRLGAALLLLPLLAAVEETLMDSTTATAELGWMVHPPSGWEEVSGYDENMNTIR TYQVCNVFESSQNNWLRTKFIRRRGAHRIHVEMKFSVRDCSSPSVPGSCKETFNLYYY EADFDSATKTFPNWMENPWVKVDTIAADESFSQVDLGGRVMKINTEVRSFGPVSRSGF YLAFQDYGGCMSLIAVRVFYRKCPRIIQNGAIFQETLSGAESTSLVAARGSCIANAEEVD VPIKLYCNGDGEWLVPIGRCMCKAGFEAVENGTVCRGCPSGTFKANQGDEACTHCPIN SRTTSEGATNCVCRNGYYRADLDPLDMPCTTIPSAPQAVISSVNETSLMLEWTPPRDSG GREDLVYNIICKSCGSGRGACTRCGDNVQYAPRQLGLTEPRIYISDLLAHTQYTFEIQAV NGVTDQSPFSPQFASVNITTNQAAPSAVSIMHQVSRTVDSITLSWSQPDQPNGVILDYEL QYYEK corresponding to amino acids 1 - 476 of EPB2_HUMAN, which also corresponds to amino acids 1 - 476 of M85491_PEA_1_P13, and a second amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence VPIGWVLSPSPTSLRAPLPG corresponding to amino acids 477 - 496 of
M85491_PEA_1_P13, wherein said first and second amino acid sequences are contiguous and in a sequential order.
2.An isolated polypeptide encoding for a tail of M85491_PEA_ 1_P13, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence VPIGWVLSPSPTSLRAPLPG in M85491_PEA_1_P13.
The location of the variant protein was determined according to results from a number of different software programs and analyses, including analyses from SignalP and other specialized programs. The variant protein is believed to be located as follows with regard to the cell: secreted. The protein localization is believed to be secreted because both signal-peptide prediction programs predict that this protein has a signal peptide, and neither trans -membrane region prediction program predicts that this protein has a trans- membrane region.
Variant protein M85491_PEA_1_P13 is encoded by the following transcript(s):
M85491_PEA_1_T16, for which the sequence(s) is/are given at the end of the application. The coding portion of transcript M85491_PEA_1_T16 is shown in bold; this coding portion starts at position 143 and ends at position 1630. The transcript also has the following SNPs as listed in Table 26 (given according to their position on the nucleotide sequence, with the alternative nucleic acid listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein M85491_PEA_1_P13 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 26 - Nucleic acid SNPs
Variant protein M85491_PEA_1_P14 according to the present invention has an amino acid sequence as given at the end of the application; it is encoded by transcript(s) M85491_PEA_l_T20. An alignment is given to the known protein (Ephrin type-B receptor 2 [precursor]) at the end of the application. One or more alignments to one or more previously published protein sequences are given at the end of the application. A brief description of the relationship of the variant protein according to the present invention to each such aligned protein is as follows:
Comparison report between M85491_PEA_1_P14 and EPB2_HUMAN: 1.An isolated chimeric polypeptide encoding for M85491_PEA_1_P14, comprising a first amino acid sequence being at least 90 % homologous to MALRRLGAALLLLPLLAAVEETLMDSTTATAELGWMVHPPSGWEEVSGYDENMNTIR TYQVCNVFESSQNNWLRTKFIRRRGAHRIHVEMKFSVRDCSSIPSVPGSCKETFNLYYY EADFDSATKTFPNWMENPWVKVDTIAADESFSQVDLGGRVMKINTEVRSFGPVSRSGF YLAFQDYGGCMSLIAVRVFYRKCPRIIQNGAIFQETLSGAESTSLVAARGSCIANAEEVD VPIKLYCNGDGEWLVPIGRCMCKAGFEAVENGTVCR corresponding to amino acids 1 - 270 of EPB2_HUMAN, which also corresponds to amino acids 1 - 270 of M85491 JPEA_1 JP14, and a second amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence
ERQDLTMLSRLVLNSWPQMILPPQPPKVLEL corresponding to amino acids 271 - 301 of M85491_PEA_1_P14, wherein said first and second amino acid sequences are contiguous and in a sequential order.
2.An isolated polypeptide encoding for a tail of M85491_PEA_1_P14, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%,
more preferably at least about 90% and most preferably at least about 95% homologous to the sequence ERQDLTMLSRLVLNSWPQMILPPQPPKVLEL in M85491_PEA_1JP14.
The location of the variant protein was determined according to results from a number of different software programs and analyses, including analyses from SignalP and other specialized programs. The variant protein is believed to be located as follows with regard to the cell: secreted. The protein localization is believed to be secreted because both signal-peptide prediction programs predict that this protein has a signal peptide, and neither trans -membrane region prediction program predicts that this protein has a trans -membrane region..
Variant protein M85491_PEA_1JP14 is encoded by the following transcript(s): M85491_PEA_l_T20, for which the sequence(s) is/are given at the end of the application. The coding portion of transcript M85491_PEA__l_T20 is shown in bold; this coding portion starts at position 143 and ends at position 1045. The transcript also has the following SNPs as listed in Table 27 (given according to their position on the nucleotide sequence, with the alternative nucleic acid listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein M85491_PEA_1_P14 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 27- Nucleic acid SNPs
As noted above, cluster M85491 features 11 segment(s), which were listed in Table 21 above and for which the sequence(s) are given at the end of the application. These segment(s) are portions of nucleic acid sequence(s) which are described herein separately because they are
of particular interest. A description of each segment according to the present invention is now provided.
Segment cluster M85491_PEA_l_node_0 according to the present invention is supported by 5 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): M85491_PEA_1_T16 and M85491 J>EA_l_T20. Table 28 below describes the starting and ending position of this segment on each transcript.
Table 28 - Segment location on transcripts
Segment cluster M85491_PEA_l_node_13 according to the present invention is supported by 6 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): M85491_PEA_l_T20. Table 29 below describes the starting and ending position of this segment on each transcript. Table 29 - Segment location on transcripts
Segment cluster M85491_PEA_l_node_21 according to the present invention is supported by 18 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): M85491_PEA__1_T16. Table 30 below describes the starting and ending position of this segment on each transcript.
Table 30 - Segment location on transcripts
Segment cluster M85491_PEA_l_node_23 according to the present invention is supported by 18 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): M85491_PEA_1_T16. Table 31 below describes the starting and ending position of this segment on each transcript.
Table 31 - Segment location on transcripts
Segment cluster M85491 _PEA_l_node_24 according to the present invention is supported by 3 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): M85491_PEA_1_T16. Table 32 below describes the starting and ending position of this segment on each transcript.
Table 32- Segment location on transcripts
Segment cluster M85491_PEA_l_node_8 according to the present invention is supported by 25 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): M85491_PEA_1_T16 and M85491_PEA_l_T20. Table 33 below describes the starting and ending position of this segment on each transcript.
Table 33 - Segment location on transcripts
Microarray (chip) data is also available for this segment as follows. As described above with regard to the cluster itself, various oligonucleotides were tested for being differentially expressed in various disease conditions, particularly cancer. The following oligonucleotides were found to hit this segment (in relation to lung cancer), shown in Table 34.
Table 34 - Oligonucleotides related to this segment
Segment cluster M85491_PEA_l_node_9 according to the present invention is supported by 20 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): M85491_PEA_1_T16 and M85491_PEA_l_T20. Table 35 below describes the starting and ending position of this segment on each transcript.
Table 35 - Segment location on transcripts
According to an optional embodiment of the present invention, short segments related to the above cluster are also provided. These segments are up to about 120 bp in length, and so are included in a separate description.
Segment cluster M85491_PEA_l_node_10 according to the present invention is supported by 17 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): M85491_PEA_1_T16 and M85491_PEA_l_T20. Table 36 below describes the starting and ending position of this segment on each transcript.
Table36 - Segment location on transcripts
FM M85491 PEA 1 T20 857 953
Segment cluster M85491_PEA_l_node_18 according to the present invention is supported by 15 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): M85491_PEA_1_T16. Table 37 below describes the starting and ending position of this segment on each transcript.
Table 37 - Segment location on transcripts
Segment cluster M85491_PEA_l_node_19 according to the present invention is supported by 15 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): M85491_PEA_1_T16. Table 38 below describes the starting and ending position of this segment on each transcript.
Table 38 - Segment location on transcripts
Segment cluster M85491_PEA_l_node_6 according to the present invention is supported by 11 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): M85491_PEA_1_T16 andM85491_PEA_l_T20. Table 39 below describes the starting and ending position of this segment on each transcript.
Table 39 - Segment location on transcripts
Variant protein alignment to the previously known protein: Sequence name: /tmp/qfmsU9VtxS/DylcLC9j 8v:EPB2_HUMAN
Sequence documentation:
Alignment of: M85491_PEA_1_P13 x EPB2_HUMAN
Alignment segment 1/1:
Quality: 4726 .00
Escore : 0
Matching length: 476 Total length: 476
Matching Percent Similarity: 100.00 Matching Percent Identity: 100.00
Total Percent Similarity: 100.00 Total Percent Identity: 100.00
Gaps : 0
Alignment :
1 MALRRLGAALLLLPLLAAVEETLMDSTTATAELGWMVHPPSGWEEVSGYD 50
I I I I Il Il Il I I I I I ! I I I I I I I I I Il Il I I I I I I I I I I I I Il I I I I I I I
1 MALRRLGAALLLLPLLAAVEETLMDSTTATAELGWMVHPPSGWEEVSGYD 50
51 ENMNTIRTYQVCNVFESSQNNWLRTKFIRRRGAHRIHVEMKFSVRDCSSI 100 I I Il I I M I M M M M I M I I M M M Il I M M I I I I M M I M M M
51 ENMNTIRTYQVCNVFESSQNNWLRTKFIRRRGAHRIHVEMKFSVRDCSSI 100
101 PSVPGSCKETFNLYYYEADFDSATKTFPNWMENPWVKVDTIAADESFSQV 150
101 PSVPGSCKETFNLYYYEADFDSATKTFPNWMENPWVKVDTIAADESFSQV 150 . . . . .
151 DLGGRVMKINTEVRSFGPVSRSGFYLAFQDYGGCMSLIAVRVFYRKCPRI 200
I I I I Il I I I I I I I I 1 I I I I I I I I I I ) I I I I I I I I I Il I 1 I I I I I Il I I I I
151 DLGGRVMKINTEVRSFGPVSRSGFYLAFQDYGGCMSLIAVRVFYRKCPRI 200
201 IQNGAIFQETLSGAESTSLVAARGSCIANAEEVDVPIKLYCNGDGEWLVP 250
I I I I I I I I I I I I I I I I I I I I I I I I I 1 I I I I I I I I I Il I I I I Il I I I I I I I
201 IQNGAIFQETLSGAESTSLVAARGSCIANAEEVDVPIKLYCNGDGEWLVP 250
251 IGRCMCKAGFEAVENGTVCRGCPSGTFKANQGDEACTHCPINSRTTSEGA 300 I I I I I I I I I I I I I I I I I I I I I 1 I I I 1 M I I I I I I I I I I I I I I I I I I 1 I I I
251 IGRCMCKAGFEAVENGTVCRGCPSGTFKANQGDEACTHCPINSRTTSEGA 300
301 TNCVCRNGYYRADLDPLDMPCTTIPSAPQAVISSVNETSLMLEWTPPRDS 350
I I I I I I I I I I I I Il 1 I I I Il I I I I I I I I I I I I I I I I Il I I Il I I I I I I I I 301 TNCVCRNGYYRADLDPLDMPCTTIPSAPQAVISSVNETSLMLEWTPPRDS 350
351 GGREDLVYNIICKSCGSGRGACTRCGDNVQYAPRQLGLTEPRIYISDLLA 400
I I I I I I I I I I I I I Il I I I Il I I I Il Il I I I Il I I I I I I I I I I I I I I I I I I 351 GGREDLVYNIICKSCGSGRGACTRCGDNVQYAPRQLGLTEPRIYISDLLA 400 . . . . .
401 HTQYTFEIQAVNGVTDQSPFSPQFASVNITTNQAAPSAVSIMHQVSRTVD 450
I I I I I I I I I Il I I Il I I I I I I I I I I Il Il Il I I I I I I Il I I I I I I I I I I I
401 HTQYTFEIQAVNGVTDQSPFSPQFASVNITTNQAAPSAVSIMHQVSRTVD 450
451 SITLSWSQPDQPNGVILDYELQYYEK 476
451 SITLSWSQPDQPNGVILDYELQYYEK 476
Sequence name: /tmp/rmnzuDbot6/GiHbjeϋ8iR:EPB2_HUMAN
Sequence documentation:
Alignment of: M85491_PEA_1_P14 x EPB2_HUMAN
Alignment segment 1/1:
Quality: 2673.00 Escore: 0
Matching length: 270 Total length: 270 Matching Percent Similarity: 100.00 Matching Percent Identity: 100.00
Total Percent Similarity: 100.00 Total Percent Identity: 100.00
Gaps : 0
Alignment:
1 MALRRLGAALLLLPLLAAVEETLMDSTTATAELGWMVHPPSGWEEVSGYD 50
I I I I I I I l I I I I I I I I I I I l I I I I I I I I l I I I I I l I l I I I I l I l I I I I I I 1 MALRRLGAALLLLPLLAAVEETLMDSTTATAELGWMVHPPSGWEEVSGYD 50
51 ENMNTIRTYQVCNVFESSQNNWLRTKFIRRRGAHRIHVEMKFSVRDCSSI 100
51 ENMNTIRTYQVCNVFESSQNNWLRTKFIRRRGAHRIHVEMKFSVRDCSSI 100
101 PSVPGSCKETFNLYYYEADFDSATKTFPNWMENPWVKVDTIAADESFSQV 150
I I 1 I I I I I I I I I I I I I I I I I I I I I I I I I I I 1 I I I I I I I I I I I I I I I I I I I
101 PSVPGSCKETFNLYYYEADFDSATKTFPNWMENPWVKVDTIAADESFSQV 150
151 DLGGRVMKINTEVRSFGPVSRSGFYLAFQDYGGCMSLIAVRVFYRKCPRI 200 I I I I I I I I I I 1 I I I I M I 1 I I I I I I I I I I I I I I I I I I I I I I I I I I I I M I
151 DLGGRVMKINTEVRSFGPVSRSGFYLAFQDYGGCMSLIAVRVFYRKCPRI 200
201 IQNGAIFQETLSGAESTSLVAARGSCIANAEEVDVPIKLYCNGDGEWLVP 250
II I I I I I Il I 1 I I I I I I I I I I I I I I I I I I I I I I Il I Il I I I I Il I I I I Il 201 IQNGAIFQETLSGAESTSLVAARGSCIANAEEVDVPIKLYCNGDGEWLVP 250
251 IGRCMCKAGFEAVENGTVCR 270
Il I I I I I I I I Il I I I Il Il I
251 IGRCMCKAGFEAVENGTVCR 270
Expression of Ephrin type-B receptor 2 precursor (EC 2.7.1.112) (Tyrosine-protein kinase receptor EPH-3) M85491 transcripts which are detectable by amplicon as depicted in sequence name M85491seg24 in normal and cancerous lung tissues Expression of Ephrin type-B receptor 2 precursor (EC 2.7.1.112) (Tyrosine-protein kinase receptor EPH-3) transcripts detectable by or according to seg24, M85491seg24 amplicon (SEQ ID NO: 1639) andM85491seg24F (SEQ ID NO: 1637) and M85491seg24R(SEQ ID NO: 1638) primers was measured by real time PCR. In parallel the expression of four housekeeping genes -PBGD (GenBank Accession No. BCOl 9323; amplicon - PBGD-amplicon, SEQ ID NO:334), HPRTl (GenBank Accession No. NM_000194; amplicon - HPRTl -amplicon, SEQ ID NO:1297), Ubiquitin (GenBank Accession No. BC000449; amplicon - Ubiquitin- amplicon,
SEQ ID NO:328) and SDHA (GenBank Accession No. NM_004168; amplicon - SDHA- amplicon, SEQ ID NO:331) was measured similarly. For each RT sample, the expression of the above amplicon was normalized to the geometric mean of the quantities of the housekeeping genes. The normalized quantity of each RT sample was then divided by the median of the quantities of the normal post-mortem (PM) samples (Sample Nos. 47-50, 90-93, 96-99, Table 2 above, "Tissue samples in testing panel"), to obtain a value of fold up-regulation for each sample relative to median of the normal PM samples.
Figure 10 below is a histogram showing over expression of the above- indicated Ephrin type-B receptor 2 precursor (EC 2.7.1.112) (Tyrosine-protein kinase receptor EPH-3) transcripts in cancerous lung samples relative to the normal samples. Values represent the average of duplicate experiments. Error bars indicate the minimal and maximal values obtained. The number and percentage of samples that exhibit at least 3 fold over-expression, out of the total number of samples tested, is indicated in the bottom.
As is evident from Figure 10, the expression of Ephrin type-B receptor 2 precursor (EC 2.7.1.112) (Tyrosine-protein kinase receptor EPH-3) transcripts detectable by the above ampliconin cancer samples was significantly higher than in the non-cancerous samples (Sample Nos. 47-50, 90-93, 96-99 Table 2, "Tissue samples in testing panel".). Notably an over- expression of at least 3 fold was found in 9 out of 15 adenocarcinoma samples and in 4 out of 8 small cell carcinoma samples. Statistical analysis was applied to verify the significance of these results, as described below.
Threshold of 3 fold overexpression was found to differentiate between cancer and normal samples with P value of 7.42E-03 in adenocarcinoma and 5.69E-02 in small cell carcinoma as checked by exact fisher test. The above values demonstrate statistical significance of the results.
Primer pairs are also optionally and preferably encompassed within the present invention; for example, for the above experiment, the following primer pair was used as a non- limiting illustrative example only of a suitable primer pair: M85491seg24F forward primer; and M85491seg24RrQverse primer. The present invention also preferably encompasses any amplicon obtained through the use of any suitable primer pair; for example, for the above experiment, the following amplicon was obtained as a non- limiting illustrative example only of a suitable amplicon: M85491seg24
M85491seg24F (SEQ ID NO: 1637) - GGCGTCTTTCTCCCTCTGAAC M85491seg24R (SEQ ID NO: 1638) - GTCCCATTCTGGGTGCTGTG
M85491seg24 (SEQ ID NO: 1639)-
GGCGTCTTTCTCCCTCTGAACCTCAGTTTCCACCTGTGTCGAGTGTGGGTGAGACCC
CTCGCGGGGAGCTATGCAGGTTACGGAGAAAAGGCAGCACAGCACCCAGAATGGG
AC
Expression of Ephrin type-B receptor 2 precursor (EC 2.7.1.112) (Tyrosine-protein kinase receptor EPH-3)M85491 transcripts which are detectable by amplicon as depicted in sequence name M85491seg24 in different normal tissues
Expression of Ephrin type-B receptor 2 precursor transcripts detectable by or according to M85491 seg24 amplicon (SEQ ID NO: 1639) and M85491 seg24F (SEQ ID NO: 1637) and M85491 seg24R (SEQ ID NO: 1638) was measured by real time PCR. In parallel the expression of four housekeeping genes -RPLl 9 (GenBank Accession No. NM_000981 ; RPLl 9 amplicon, SEQ ID NO: 1630), TATA box (GenBank Accession No. NM_003194; TATA amplicon, SEQ ID NO: 1633), Ubiquitin (GenBank Accession No. BC000449; amplicon - Ubiquitin-amplicon, SEQ ID NO:328) and SDHA (GenBank Accession No. NM_004168; amplicon - SDHA- amplicon, SEQ ID NO:331) was measured similarly. For each RT sample, the expression of the above amplicon was normalized to the geometric mean of the quantities of the housekeeping genes. The normalized quantity of each RT sample was then divided by the
median of the quantities of the lung samples (Sample Nos. 15-17, Table 2, "Tissue sample on noπnal panel", above), to obtain a value of relative expression of each sample relative to median of the lung samples.
M85491seg24F (SEQ ID NO: 1637) - GGCGTCTTTCTCCCTCTGAAC M85491seg24R (SEQ ID NO: 1638) - GTCCCATTCTGGGTGCTGTG M85491seg24 (SEQ ID NO: 1639)-
GGCGTCTTTCTCCCTCTGAACCTCAGTTTCCACCTGTGTCGAGTGTGGGTGAGACCC CTCGCGGGGAGCTATGCAGGTTACGGAGAAAAGGCAGCACAGCACCCAGAATGGG AC
The results are shown in Figure 11, demonstrating the expression of Ephrin type-B receptor 2 precursor (Tyrosine-protein kinase receptor EPH-3) M85491 transcripts which are detectable by amplicon as depicted in sequence name M85491seg24 in different normal tissues.
DESCRIPTION FOR CLUSTER T39971
Cluster T39971 features 4 transcript(s) and 28 segment(s) of interest, the names for which are given in Tables 40 and 41, respectively, the sequences themselves are given at the end of the application. The selected protein variants are given in table 42. Table 40 - Transcripts of interest
Table 42 - Proteins of interest
These sequences are variants of the known protein Vitronectin precursor (SwissProt accession identifier VTNC_HUMAN; known also according to the synonyms Serum spreading factor; S-protein; V75), SEQ ID NO: 1418, referred to herein as the previously known protein.
Protein Vitronectin precursor is known or believed to have the following function(s): Vitronectin is a cell adhesion and spreading factor found in serum and tissues. Vitronectin interacts with glycosaminoglycans and proteoglycans. Is recognized by certain members of the integrin family and serves as a cell-to-substrate adhesion molecule. Inhibitor of the membrane- damaging effect of the teπninal cytolytic complement pathway. The sequence for protein Vitronectin precursor is given at the end of the application, as "Vitronectin precursor amino acid sequence". Known polymorphisms for this sequence are as shown in Table 4.
Table 43 - Amino acid mutations for Known Protein
Protein Vitronectin precursor localization is believed to be Extracellular.
The previously known protein also has the following indication(s) and/or potential therapeutic use(s): Cancer, melanoma. It has been investigated for clinical/therapeutic use in humans, for example as a target for an antibody or small molecule, and/or as a direct
therapeutic; available information related to these investigations is as follows. Potential pharmaceutically related or therapeutically related activity or activities of the previously known protein are as follows: Alphavbeta3 integrin antagonist; Apoptosis agonist. A therapeutic role for a protein represented by the cluster has been predicted. The cluster was assigned this field because there was information in the drug database or the public databases (e.g., described herein above) that this protein, or part thereof, is used or can be used for a potential therapeutic indication: Anticancer.
The following GO Annotation(s) apply to the previously known protein. The following annotation(s) were found: immune response; cell adhesion, which are annotation(s) related to Biological Process; protein binding; heparin binding, which are annotation(s) related to
Molecular Function; and extracellular space, which are annotation(s) related to Cellular
Component.
The GO assignment relies on information from one or more of the SwissProt/TremBl
Protein knowledgebase, available from <http://www.expasy.ch/sprot/>; or Locuslink, available from <http://www.ncbi.nlm.nih.gov/projects/LocusLink/>.
Cluster T39971 can be used as a diagnostic marker according to overexpression of transcripts of this cluster in cancer. Expression of such transcripts in normal tissues is also given according to the previously described methods. The term "number" in the right hand column of the table and the numbers on the y-axis of figure 12 refer to weighted expression of ESTs in each category, as "parts per million" (ratio of the expression of ESTs for a particular cluster to the expression of all ESTs in that category, according to parts per million).
Overall, the following results were obtained as shown with regard to the histograms in Figure 12 and Table 44. This cluster is overexpressed (at least at a minimum level) in the following pathological conditions: liver cancer, lung malignant tumors and pancreas carcinoma.
Table 44 - Normal tissue distribution
As noted above, cluster T39971 features 4 transcript(s), which were listed in Table 40 above. These transcript(s) encode for protein(s) which are variant(s) of protein Vitronectin precursor. A description of each variant protein according to the present invention is now provided.
Variant protein T39971_P6 according to the present invention has an amino acid sequence as given at the end of the application; it is encoded by transcript(s) T39971JT5. An alignment is given to the known protein (Vitronectin precursor) at the end of the application. One or more alignments to one or more previously published protein sequences are given at the end of the application. A brief description of the relationship of the variant protein according to the present invention to each such aligned protein is as follows:
Comparison report between T39971 JP6 and VTNC_HUMAN: 1.An isolated chimeric polypeptide encoding for T39971_P6, comprising a first amino acid sequence being at least 90 % homologous to MAPLRPLLILALLAWVALADQESCKGRCTEGFNVDKKCQCDELCSYYQSCCTDYTAEC KPQVTRGDVFTMPEDEYTVYDDGEEKNNATVHEQVGGPSLTSDLQAQSKGNPEQTPV LKPEEEAPAPEVGASKPEGIDSRPETLHPGRPQPPAEEELCSGKPFDAFTDLKNGSLFAFR GQYCYELDEKAVRPGYPKLIRDVWGIEGPIDAAFTRINCQGKTYLFKGSQYWRFEDGV LDPDYPRNISDGFDGIPDNVDAALALPAHSYSGRERVYFFKG corresponding to amino acids 1 - 276 of VTNCJHUMAN, which also corresponds to amino acids 1 - 276 of
T39971JP6, and a second amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence TQGVVGD corresponding to amino acids 277 - 283 of T39971_P6, wherein said first and second amino acid sequences are contiguous and in a sequential order.
2.An isolated polypeptide encoding for a tail of T39971_P6, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence TQGWGD in T39971_P6.
The location of the variant protein was determined according to results from a number of different software programs and analyses, including analyses from SignalP and other specialized programs. The variant protein is believed to be located as follows with regard to the cell: secreted. The protein localization is believed to be secreted because both signal-peptide prediction programs predict that this protein has a signal peptide, and neither trans -membrane region prediction program predicts that this protein has a trans -membrane region..
Variant protein T39971_P6 also has the following non-silent SNPs (Single Nucleotide Polymorphisms) as listed in Table 46, (given according to their position(s) on the amino acid sequence, with the alternative amino acid(s) listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein T39971_P6 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table46 - Amino acid mutations
Variant protein T39971_P6 is encoded by the following transcript(s): T39971_T5, for which the sequence(s) is/are given at the end of the application. The coding portion of transcript T39971_T5 is shown in bold; this coding portion starts at position 756 and ends at position
1604. The transcript also has the following SNPs as listed in Table47 (given according to their position on the nucleotide sequence, with the alternative nucleic acid listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein T39971_P6 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 47 - Nucleic acid SNPs
Variant protein T39971_P9 according to the present invention has an amino acid sequence as given at the end of the application; it is encoded by transcript(s) T39971_T10. An alignment is given to the known protein (Vitronectin precursor) at the end of the application. One or more alignments to one or more previously published protein sequences are given at the end of the application. A brief description of the relationship of the variant protein according to the present invention to each such aligned protein is as follows:
Comparison report between T39971_P9 and VTNCJHUMAN:
1.An isolated chimeric polypeptide encoding for T39971_P9, comprising a first amino acid sequence being at least 90 % homologous to
MAPLRPLLILALLAWVALADQESCKGRCTEGFNVDKKCQCDELCSYYQSCCTDYTAEC KPQVTRGDVFTMPEDEYTVYDDGEEKNNATVHEQVGGPSLTSDLQAQSKGNPEQTPV LKPEEEAPAPEVGASKPEGIDSRPETLHPGRPQPPAEEELCSGKPFDAFTDLKNGSLFAFR GQYCYELDEKAVRPGYPKLIRDVWGIEGPIDAAFTRINCQGKTYLFKGSQYWRFEDGV LDPDYPRNISDGFDGIPDNVDAALALPAHSYSGRERVYFFKGKQYWEYQFQHQPSQEE
CEGSSLSAVFEHFAMMQRDSWEDIFELLFWGRT corresponding to amino acids 1 - 325 of
VTNC_HUMAN, which also corresponds to amino acids 1 - 325 of T39971_P9, and a second amino acid sequence being at least 90 % homologous to
SGMAPRPSLAKKQRFRHRNRKGYRSQRGHSRGRNQNSRRPSRATWLSLFSSEESNLGA NNYDDYRMDWLVPATCEPIQSVFFFSGDKYYRVNLRTRRVDTVDPPYPRSIAQYWLGC PAPGHL corresponding to amino acids 357 - 478 of VTNCJHUMAN, which also corresponds to amino acids 326 - 447 of T39971_P9, wherein said first and second amino acid sequences are contiguous and in a sequential order.
2.An isolated chimeric polypeptide encoding for an edge portion of T39971_P9, comprising a polypeptide having a length "n", wherein n is at least about 10 amino acids in length, optionally at least about 20 amino acids in length, preferably at least about 30 amino acids in length, more preferably at least about 40 amino acids in length and most preferably at least about 50 amino acids in length, wherein at least two amino acids comprise TS, having a structure as follows: a sequence starting from any of amino acid numbers 325-x to 325; and ending at any of amino acid numbers 326 + ((n-2) - x), in which x varies from 0 to n-2.
The location of the variant protein was determined according to results from a number of different software programs and analyses, including analyses from SignalP and other specialized programs. The variant protein is believed to be located as follows with regard to the cell: secreted. The protein localization is believed to be secreted because both signal-peptide prediction programs predict that this protein has a signal peptide, and neither trans -membrane region prediction program predicts that this protein has a trans -membrane region.
Variant protein T39971_P9 also has the following non-silent SNPs (Single Nucleotide Polymorphisms) as listed in Table 48, (given according to their position(s) on the amino acid sequence, with the alternative amino acid(s) listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein T39971_P9 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table48 - Amino acid mutations
Variant protein T39971_P9 is encoded by the following transcript(s): T39971_T10, for which the sequence(s) is/are given at the end of the application. The coding portion of transcript T39971_T10 is shown in bold; this coding portion starts at position 756 and ends at position 2096. The transcript also has the following SNPs as listed in Table 49 (given according to then- position on the nucleotide sequence, with the alternative nucleic acid listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein T39971_P9 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 49 - Nucleic acid SNPs
Variant protein T39971_P11 according to the present invention has an amino acid sequence as given at the end of the application; it is encoded by transcript(s) T39971_T12. An alignment is given to the known protein (Vitronectin precursor) at the end of the application.
One or more alignments to one or more previously published protein sequences are given at the end of the application. A brief description of the relationship of the variant protein according to the present invention to each such aligned protein is as follows:
Comparison report between T3997 I Pl 1 and VTNC_HUMAN:
1.An isolated chimeric polypeptide encoding for T39971 JPl 1, comprising a first amino acid sequence being at least 90 % homologous to
MAPLRPLLILALLAWVALADQESCKGRCTEGFNVDKKCQCDELCSYYQSCCTDYTAEC KPQVTRGDVFTMPEDEYTVYDDGEEKJNNATVHEQVGGPSLTSDLQAQSKGNPEQTPV LKPEEEAPAPEVGASKPEGIDSRPETLHPGRPQPPAEEELCSGKPFDAFTDLKNGSLFAFR GQYCYELDEKAVRPGYPKLIRD VWGIEGPID AAFTRINCQGKTYLFKGSQYWRFEDGV LDPDYPRNISDGFDGIPDNVDAALALPAHSYSGRERVYFFKGKQYWEYQFQHQPSQEE
CEGSSLSAVFEHFAMMQRDSWEDIFELLFWGRTS corresponding to amino acids 1 - 326 of VTNCJHUMAN, which also corresponds to amino acids 1 - 326 of T39971_P11, and a second amino acid sequence being at least 90 % homologous to
DKYYRVNLRTRRVDTVDPPYPRSIAQYWLGCP APGHL corresponding to amino acids 442 - 478 of VTNC_HUMAN, which also corresponds to amino acids 327 - 363 of T39971 JPIl, wherein said first and second amino acid sequences are contiguous and in a sequential order. 2.An isolated chimeric polypeptide encoding for an edge portion of T39971 J?ll, comprising a polypeptide having a length "n", wherein n is at least about 10 amino acids in length, optionally at least about 20 amino acids in length, preferably at least about 30 amino acids in length, more preferably at least about 40 amino acids in length and most preferably at least about 50 amino acids in length, wherein at least two amino acids comprise SD, having a structure as follows: a sequence starting from any of amino acid numbers 326-x to 326; and ending at any of amino acid numbers 327 + ((n-2) - x), in which x varies from 0 to n-2.
Comparison report between T39971_P11 and Q9BSH7 (SEQ ID NO:1696): 1.An isolated chimeric polypeptide encoding for T39971JP11, comprising a first amino acid sequence being at least 90 % homologous to MAPLRPLLILALLAWVALADQESCKGRCTEGFNVDKKCQCDELCSYYQSCCTDYTAEC
KPQVTRGDVFTMPEDEYTVYDDGEEKNNATVHEQVGGPSLTSDLQAQSKGNPEQTPV LKPEEEAP APEVGASKPEGIDSRPETLHPGPvPQPPAEEELCSGKPFD AFTDLKNGSLF AFR GQYCYELDEKA VRPGYPKLIRD VWGIEGPID AAFTRINCQGKTYLFKGSQYWRFEDGV LDPDYPRNISDGFDGIPDNVDAALALPAHSYSGRERVYFFKGKQYWEYQFQHQPSQEE CEGSSLSAVFEHFAMMQRDSWEDIFELLFWGRTS corresponding to amino acids 1 - 326 of Q9BSH7, which also corresponds to amino acids 1 - 326 of T39971_P11, and a second amino acid sequence being at least 90 % homologous to
DKYYRVNLRTRRVDTVDPPYPRSIAQYWLGCPAPGHL corresponding to amino acids 442 - 478 of Q9BSH7, which also corresponds to amino acids 327 - 363 of T39971_P11, wherein said first and second amino acid sequences are contiguous and in a sequential order.
2.An isolated chimeric polypeptide encoding for an edge portion of T39971_P11, comprising a polypeptide having a length "n", wherein n is at least about 10 amino acids in length, optionally at least about 20 amino acids in length, preferably at least about 30 amino acids in length, more preferably at least about 40 amino acids in length and most preferably at least about 50 amino acids in length, wherein at least two amino acids comprise SD, having a structure as follows: a sequence starting from any of amino acid numbers 326-x to 326; and ending at any of amino acid numbers 327 + ((n-2) - x), in which x varies from 0 to n-2.
The location of the variant protein was determined according to results from a number of different software programs and analyses, including analyses from SignalP and other specialized programs. The variant protein is believed to be located as follows with regard to the cell: secreted. The protein localization is believed to be secreted because both signal-peptide prediction programs predict that this protein has a signal peptide, and neither trans -membrane region prediction program predicts that this protein has a trans -membrane region.. Variant protein T39971_P11 also has the following non-silent SNPs (Single Nucleotide
Polymorphisms) as listed in Table 50, (given according to their position(s) on the amino acid sequence, with the alternative amino acid(s) listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein T39971_P11 sequence provides support for the deduced sequence of this variant protein according to the present invention). Table50 - Amino acid mutations
Variant protein T39971_P11 is encoded by the following transcript(s): T39971_T12, for which the sequence(s) is/are given at the end of the application. The coding portion of transcript T39971_T12 is shown in bold; this coding portion starts at position 756 and ends at position 1844. The transcript also has the following SNPs as listed in Table 51 (given according to their position on the nucleotide sequence, with the alternative nucleic acid listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein T39971_P11 sequence provides support for the deduced sequence of this variant protein according to the present invention). Table 51 - Nucleic acid SNPs
Variant protein T39971 P12 according to the present invention has an amino acid sequence as given at the end of the application; it is encoded by transcript(s) T39971_T16. An alignment is given to the known protein (Vitronectin precursor) at the end of the application. One or more alignments to one or more previously published protein sequences are given at the end of the application. A brief description of the relationship of the variant protein according to the present invention to each such aligned protein is as follows:
Comparison report between T3997 IJP 12 and VTNC_HUMAN:
1.An isolated chimeric polypeptide encoding for T39971_P12, comprising a first amino acid sequence being at least 90 % homologous to MAPLRPLLILALLAWVALADQESCKGRCTEGFNVDKKCQCDELCSYYQSCCTDYTAEC
KPQVTRGDVFTMPEDEYTVYDDGEEKNNATVHEQVGGPSLTSDLQAQSKGNPEQTPV LKPEEEAP APEVGASKPEGIDSRPETLHPGRPQPP AEEELCSGKPFDAFTDLKNGSLFAFR GQYCYELDEKA VRPGYPKLIRD VWGIEGPID AAFTRINCQGKTYLFK corresponding to amino acids 1 - 223 of VTNCJHUMAN, which also corresponds to amino acids 1 - 223 of T39971_P12, and a second amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence VPGAVGQGRKHLGRV corresponding to amino acids 224 - 238 of T39971_P12, wherein said first and second amino acid sequences are contiguous and in a sequential order. 2.An isolated polypeptide encoding for a tail of T39971_P12, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence VPGAVGQGRKHLGRV in T39971_P12.
Comparison report between T39971_P12 and Q9BSH7:
1.An isolated chimeric polypeptide encoding for T39971_P12, comprising a first amino acid sequence being at least 90 % homologous to
MAPLRPLLILALLAWVALADQESCKGRCTEGFNVDKKCQCDELCSYYQSCCTDYTAEC KPQVTRGDVFTMPEDEYTVYDDGEEKNNATVHEQVGGPSLTSDLQAQSKGNPEQTPV LKPEEEAPAPEVGASKPEGIDSRPETLHPGRPQPPAEEELCSGKPFDAFTDLKNGSLFAFR
GQYCYELDEKAVRPGYPKLIRDVWGIEGPIDAAFTRINCQGKTYLFK corresponding to amino acids 1 - 223 of Q9BSH7, which also corresponds to amino acids 1 - 223 of T39971JP12, and a second amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence VPGAVGQGRKHLGRV corresponding to amino acids 224 - 238 of T39971_P12, wherein said first and second amino acid sequences are contiguous and in a sequential order.
2.An isolated polypeptide encoding for a tail of T39971_P12, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence VPGAVGQGRKHLGRV in T39971_P12.
The location of the variant protein was determined according to results from a number of different software programs and analyses, including analyses from SignalP and other specialized programs. The variant protein is believed to be located as follows with regard to the cell: secreted. The protein localization is believed to be secreted because both signal-peptide prediction programs predict that this protein has a signal peptide, and neither trans -membrane region prediction program predicts that this protein has a trans -membrane region.
Variant protein T39971_P12 also has the following non-silent SNPs (Single Nucleotide Polymorphisms) as listed in Table 52, (given according to their position(s) on the amino acid sequence, with the alternative amino acid(s) listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein T39971_P12 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 52 - Amino acid mutations
Variant protein T39971_P12 is encoded by the following transcript(s): T39971JT16, for which the sequence(s) is/are given at the end of the application. The coding portion of transcript T39971_T16 is shown in bold; this coding portion starts at position 756 and ends at position 1469. The transcript also has the following SNPs as listed in Table 53 (given according to their position on the nucleotide sequence, with the alternative nucleic acid listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein
T39971_P12 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 53 - Nucleic acid SNPs
As noted above, cluster T39971 features 28 segment(s), which were listed in Table 41 above and for which the sequence(s) are given at the end of the application. These segment(s) are portions of nucleic acid sequence(s) which are described herein separately because they are of particular interest. A description of each segment according to the present invention is now provided.
Segment cluster T39971_node_0 according to the present invention is supported by 76 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): T39971_T10, T39971JT12, T39971JT16 and T39971_T5. Table 54 below describes the starting and ending position of this segment on each transcript.
Table 54 - Segment location on transcripts
Segment cluster T39971_node_18 according to the present invention is supported by 1 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): T39971_T16. Table 55 below describes the starting and ending position of this segment on each transcript.
Table 55 - Segment location on transcripts
Segment cluster T39971 jnode_21 according to the present invention is supported by 99 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): T39971_T10, T39971JN2 and T39971_T5. Table 56 below describes the starting and ending position of this segment on each transcript.
Table56 - Segment location on transcripts
Segment cluster T39971_node_22 according to the present invention is supported by 7 libraries. The number of libraries was determined as previously described. This segment can be
found in the following transcript(s): T39971_T5. Table 57 below describes the starting and ending position of this segment on each transcript.
Table57 - Segment location on transcripts
Segment cluster T39971_node_23 according to the present invention is supported by 101 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): T39971JT10, T39971JT12 and T39971JT5. Table 58 below describes the starting and ending position of this segment on each transcript. Table 58 - Segment location on transcripts
Segment cluster T39971_node_31 according to the present invention is supported by 94 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): T39971_T10 and T39971JT5. Table 59 below describes the starting and ending position of this segment on each transcript.
Table 59 - Segment location on transcripts
Segment cluster T39971_node_33 according to the present invention is supported by 77 libraries. The number of libraries was deteπnined as previously described. This segment can be found in the following transcript(s): T39971_T10, T39971_T12 and T39971JT5. Table 60 below describes the starting and ending position of this segment on each transcript.
Table 60 - Segment location on transcripts
Segment cluster T39971_node_7 according to the present invention is supported by 87 libraries. The number of libraries was deteπnined as previously described. This segment can be found in the following transcript(s): T39971_T10, T39971JT12, T39971JT16 and T39971_T5. Table 61 below describes the starting and ending position of this segment on each transcript.
Table 61 - Segment location on transcripts
According to an optional embodiment of the present invention, short segments related to the above cluster are also provided. These segments are up to about 120 bp in length, and so are included in a separate description.
Segment cluster T39971_node_l according to the present invention can be found in the following transcript(s): T39971JT10, T39971JT12, T39971_T16 and T39971JT5. Table 62 below describes the starting and ending position of this segment on each transcript. Table 62 - Segment location on transcripts
Segment cluster T39971_node_10 according to the present invention is supported by 77 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): T39971_T10, T39971_T12, T39971_T16 and T39971_T5. Table 63 below describes the starting and ending position of this segment on each transcript.
Table 63 - Segment location on transcripts
Segment cluster T39971_node_l 1 according to the present invention is supported by 79 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): T39971_T10, T39971_T12, T39971JT16 and T39971JT5. Table 64 below describes the starting and ending position of this segment on each transcript.
Table 64 - Segment location on transcripts
Segment cluster T39971_node_12 according to the present invention can be found in the following transcript(s): T3997 IJTlO, T39971JT12, T39971JT16 and T39971JT5. Table 65 below describes the starting and ending position of this segment on each transcript.
Table 65 - Segment location on transcripts
Segment cluster T39971_node_15 according to the present invention is supported by 79 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): T39971JT10, T39971_T12, T39971JT16 and T39971JT5. Table 66 below describes the starting and ending position of this segment on each transcript.
Table 66 - Segment location on transcripts
Segment cluster T39971_node_16 according to the present invention can be found in the following transcript(s): T39971JT10, T39971JT12, T39971JT16 and T39971_T5. Table 67 below describes the starting and ending position of this segment on each transcript.
Table 67 - Segment location on transcripts
Segment cluster T39971_node_17 according to the present invention is supported by 86 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): T39971_T10, T39971JT12, T39971_T16 and T39971_T5. Table 68 below describes the starting and ending position of this segment on each transcript.
Table 68 - Segment location on transcripts
Segment cluster T39971_node_26 according to the present invention is supported by 85 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): T39971_T5. Table 69 below describes the starting and ending position of this segment on each transcript.
Table 69 - Segment location on transcripts
Segment cluster T39971_node_27 according to the present invention is supported by 90 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): T39971_T5. Table 70 below describes the starting and ending position of this segment on each transcript.
Table 70 - Segment location on transcripts
Segment cluster T39971__node_28 according to the present invention can be found in the following transcript(s): T39971_T10 and T39971JT5. Table 71 below describes the starting and ending position of this segment on each transcript.
Table 71 - Segment location on transcripts
Segment cluster T39971_node_29 according to the present invention is supported by 99 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): T39971_T10 and T39971_T5. Table 72 below describes the starting and ending position of this segment on each transcript.
Table 72 - Segment location on transcripts
Segment cluster T39971_node
^_3 according to the present invention is supported by 78 libraries. The number of libraries was deteπnined as previously described. This segment can be found in the following transcript(s): T39971_T10, T39971JT12, T39971_T16 and T39971_T5. Table 73 below describes the starting and ending position of this segment on each transcript.
Table 73 - Segment location on transcripts
Segment cluster T39971_node_30 according to the present invention can be found in the following transcript(s): T39971_T10 and T39971_T5. Table 74 below describes the starting and ending position of this segment on each transcript.
Table 74 - Segment location on transcripts
Segment cluster T39971_node_34 according to the present invention can be found in the following Iranscript(s): T39971_T10, T39971JT12 and T39971JT5. Table 75 below describes the starting and ending position of this segment on each transcript.
Table 75 - Segment location on transcripts
Segment cluster T39971_node_35 according to the present invention can be found in the following transcript(s): T39971_T10, T39971_T12 and T39971JT5. Table 76 below describes the starting and ending position of this segment on each transcript.
Table 76 - Segment location on transcripts
Segment cluster T39971_node_36 according to the present invention is supported by 51 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): T39971_T10, T39971_T12 and T39971_T5. Table 77 below describes the starting and ending position of this segment on each transcript.
Table 77 - Segment location on transcripts
Segment cluster T39971_node_4 according to the present invention can be found in the following transcript(s): T39971_T10, T39971_T12, T39971_T16 and T39971JT5. Table 78 below describes the starting and ending position of this segment on each transcript.
Table 78 - Segment location on transcripts
Segment cluster T39971_node_5 according to the present invention is supported by 80 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): T39971_T10, T39971JT12, T39971JT16 and T39971_T5. Table 79 below describes the starting and ending position of this segment on each transcript.
Table 79 - Segment location on transcripts
Segment cluster T39971_node_8 according to the present invention can be found in the following transcript(s): T39971JT10, T39971JT12, T39971JT16 and T39971JT5. Table 80 below describes the starting and ending position of this segment on each transcript.
Table 80 - Segment location on transcripts
Segment cluster T39971_node_9 according to the present invention can be found in the following transcript(s): T39971_T10, T39971JT12, T39971JT16 and T39971_T5. Table 81 below describes the starting and ending position of this segment on each transcript.
Table 81 - Segment location on transcripts
Variant protein alignment to the previously known protein:
Sequence name: /tmp/xkraCL2OcZ/43L7YcPH7x :VTNC_HUMAN
Sequence documentation:
Alignment of: T39971_P6 x VTNC_HUMAN
Alignment segment 1/1:
Quality: 2774.00 Escore: 0
Matching length: 278 Total length: 278 Matching Percent Similarity: 99.64 Matching Percent Identity: 99.64
Total Percent Similarity: 99.64 Total Percent Identity: 99.64
Gaps : 0
Alignment :
1 MAPLRPLLILALLAWVALADQESCKGRCTEGFNVDKKCQCDELCSYYQSC 50 I I I Ii I I I I I I 1 I I Il I I Il I 1 I I I I I I I Il I I I I I I I I 1 I I I I I I Il I I 1 MAPLRPLLILALLAWVALADQESCKGRCTEGFNVDKKCQCDELCSYYQSC 50
51 CTDYTAECKPQVTRGDVFTMPEDEYTVYDDGEEKNNATVHEQVGGPSLTS 100
I I I I I I I I I I I I I I I I I I I I I I I Il Il Il I I I I I I I I I I I I I I I I I I Il I
51 CTDYTAECKPQVTRGDVFTMPEDEYTVYDDGEEKNNATVHEQVGGPSLTS 100 . . . . .
101 DLQAQSKGNPEQTPVLKPEEEAPAPEVGASKPEGIDSRPETLHPGRPQPP 150
I I I I I I I I I I I I I I I I 1 I I I I I I I I I I I I I I I Il I Il I I I I I I I I I I Il I
101 DLQAQSKGNPEQTPVLKPEEEAPAPEVGASKPEGIDSRPETLHPGRPQPP 150
151 AEEELCSGKPFDAFTDLKNGSLFAFRGQYCYELDEKAVRPGYPKLIRDVW 200
II I Il I I I I I I I I I I I I Il I I I I I I I I I I I I I I I I Il I I Il I Il Il I I I I
151 AEEELCSGKPFDAFTDLKNGSLFAFRGQYCYELDEKAVRPGYPKLIRDVW 200
201 GIEGPIDAAFTRINCQGKTYLFKGSQYWRFEDGVLDPDYPRNISDGFDGI 250 I I I I I I I I I I I I I I I I I I I M I M Il I I I I I I M I I I I I I Il I I I M I I I
201 GIEGPIDAAFTRINCQGKTYLFKGSQYWRFEDGVLDPDYPRNISDGFDGI 250
251 PDNVDAALALPAHSYSGRERVYFFKGTQ 278
I I I I I I I I I I I Il I I I I Il I I I I I I I I 251 PDNVDAALALPAHSYSGRERVYFFKGKQ 278
Sequence name: /tmp/X4DeeuSlB4/yMubSR5FPs : VTNC_HUMAN
Sequence documentation:
Alignment of: T39971_P9 x VTNC_HUMAN
Alignment segment 1/1:
Quality: 4430.00 Escore: 0
Matching length: 447 Total length: 478
Matching Percent Similarity: 100.00 Matching Percent Identity: 100.00 Total Percent Similarity: 93.51 Total Percent Identity: 93.51
Gaps : 1
Alignment : . . . . .
1 MAPLRPLLILALLAWVALADQESCKGRCTEGFNVDKKCQCDELCSYYQSC 50
I I I I I I I I Il I I I Il I I I I I I I I I I I I I I I Il Il I I I I I Il I I I I I I I I I
1 MAPLRPLLILALLAWVALADQESCKGRCTEGFNVDKKCQCDELCSYYQSC 50
51 CTDYTAECKPQVTRGDVFTMPEDEYTVYDDGEEKNNATVHEQVGGPSLTS 100
I Il Il I I Il I I I Il I I I I Il I ! I Il I I I I I I I I I I I I I I I I Il I I I I I I I
51 CTDYTAECKPQVTRGDVFTMPEDEYTVYDDGEEKNNATVHEQVGGPSLTS 100
101 DLQAQSKGNPEQTPVLKPEEEAPAPEVGASKPEGIDSRPETLHPGRPQPP 150 M I M I I I M I I M M I M I M I I M I M I I I I I I I I I I I I I I I I I M M
101 DLQAQSKGNPEQTPVLKPEEEAPAPEVGASKPEGIDSRPETLHPGRPQPP 150
151 AEEELCSGKPFDAFTDLKNGSLFAFRGQYCYELDEKAVRPGYPKLIRDVW 200
I I 1 I I I I 1 I I I I I I I i I I I I 1 I I I I I I I 1 I I I I I I I I I I I I I Il I I 1 I I I
151 AEEELCSGKPFDAFTDLKNGSLFAFRGQYCYELDEKAVRPGYPKLIRDVW 200 . . . . .
201 GIEGPIDAAFTRINCQGKTYLFKGSQYWRFEDGVLDPDYPRNISDGFDGI 250
I I I I Il I I I I I Il 1 I I I I I I I 1 I I 1 I I I I I I I I I I I I I I I Il I I I Il I Il
201 GIEGPIDAAFTRINCQGKTYLFKGSQYWRFEDGVLDPDYPRNISDGFDGI 250
251 PDNVDAALALPAHSYSGRERVYFFKGKQYWEYQFQHQPSQEECEGSSLSA 300
I I I I I I I Il I I I I I I I 1 I I I I 1 I I Il I I I I I I I I I I 1 I I I I I I I I I I I I I
251 PDNVDAALALPAHSYSGRERVYFFKGKQYWEYQFQHQPSQEECEGSSLSA 300
301 VFEHFAMMQRDSWEDIFELLFWGRT 325 I I I I I I I I I I I I I I I I I I I I I I I I I
301 VFEHFAMMQRDSWEDIFELLFWGRTSAGTRQPQFISRDWHGVPGQVDAAM 350
326 SGMAPRPSLAKKQRFRHRNRKGYRSQRGHSRGRNQNSRRPSRAT 369
I I I l I I I I I I I I I I I I l I I I I I I I I I I l I I I I I I I I I I I I I I I I 351 AGRIYISGMAPRPSLAKKQRFRHRNRKGYRSQRGHSRGRNQNSRRPSRAT 400
370 WLSLFSSEESNLGANNYDDYRMDWLVPATCEPIQSVFFFSGDKYYRVNLR 419 ! 111111 I M I M I I M I M I M I I M M I I I I I I I I M M M I I I M I I
401 WLSLFSSEESNLGANNYDDYRMDWLVPATCEPIQSVFFFSGDKYYRVNLR 450
420 TRRVDTVDPPYPRSIAQYWLGCPAPGHL 447
M M I I M I M M M Il M I M M M Il 451 TRRVDTVDPPYPRSIAQYWLGCPAPGHL 478
Sequence name: /tmp/jvplVtnxNy/wxNSeFVZZw :VTNC_HUMAN
Sequence documentation:
Alignment of: T39971_P11 x VTNC_HUMAN
Alignment segment 1/1:
Quality: 3576.00 Escore: 0
Matching length: 363 Total length: 478
Matching Percent Similarity: 100.00 Matching Percent Identity: 100.00
Total Percent Similarity: 75.94 Total Percent Identity: 75.94 Gaps : 1
Alignment :
1 MAPLRPLLILALLAWVALADQESCKGRCTEGFNVDKKCQCDELCSYYQSC 50 I I I I I I I I M I I | | | | | I I I I M I I M M I I M I I I I I I I I I I I I I I I Il
1 MAPLRPLLILALLAWVALADQESCKGRCTEGFNVDKKCQCDELCSYYQSC 50
51 CTDYTAECKPQVTRGDVFTMPEDEYTVYDDGEEKNNATVHEQVGGPSLTS 100
I I I Il I I I I I I I I I I I I I I I I I I I I I I I I I I Il I I I I I I I I I I I I I I I I I 51 CTDYTAECKPQVTRGDVFTMPEDEYTVYDDGEEKNNATVHEQVGGPSLTS 100
101 DLQAQSKGNPEQTPVLKPEEEAPAPEVGASKPEGIDSRPETLHPGRPQPP 150
I 1 I I I I i I I I I I 1 I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I 1 I
101 DLQAQSKGNPEQTPVLKPEEEAPAPEVGASKPEGIDSRPETLHPGRPQPP 150
151 AEEELCSGKPFDAFTDLKNGSLFAFRGQYCYELDEKAVRPGYPKLIRDVW 200 I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I 1 I I I I I I Il I
151 AEEELCSGKPFDAFTDLKNGSLFAFRGQYCYELDEKAVRPGYPKLIRDVW 200
201 GIEGPIDAAFTRINCQGKTYLFKGSQYWRFEDGVLDPDYPRNISDGFDGI 250 I I I I I M I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I 1 I I Il Il I I I Il I
201 GIEGPIDAAFTRINCQGKTYLFKGSQYWRFEDGVLDPDYPRNISDGFDGI 250
251 PDNVDAALALPAHSYSGRERVYFFKGKQYWEYQFQHQPSQEECEGSSLSA 300
I I I I I I I I I I I I I I I I I Il I I I I I I I Il I I I I I I Il I Il I I Il 1 I I I Il I 251 PDNVDAALALPAHSYSGRERVYFFKGKQYWEYQFQHQPSQEECEGSSLSA 300
301 VFEHFAMMQRDSWEDIFELLFWGRTS 326
I I I I I Il I Il I I I I I I I I I I I I I I Il
301 VFEHFAMMQRDSWEDIFELLFWGRTSAGTRQPQFISRDWHGVPGQVDAAM 350 . . . . .
326 326
351 AGRIYISGMAPRPSLAKKQRFRHRNRKGYRSQRGHSRGRNQNSRRPSRAT 400
327 DKYYRVNLR 335
I I I Il I Il I
401 WLSLFSSEESNLGANNYDDYRMDWLVPATCEPIQSVFFFSGDKYYRVNLR 450
336 TRRVDTVDPPYPRSIAQYWLGCPAPGHL 363 I I I I I I I I I I I M M M I I M I I I I I I I
451 TRRVDTVDPPYPRSIAQYWLGCPAPGHL 478
Sequence name: /tmp/jvplVtnxNy/wxNSeFVZZw: Q9BSH7
Sequence documentation:
Alignment of: T39971_P11 x Q9BSH7
Alignment segment 1/1:
Quality: 3576.00
Escore: 0
Matching length: 363 Total length: 478
Matching Percent Similarity: 100.00 Matching Percent Identity: 100.00
Total Percent Similarity: 75.94 Total Percent Identity: 75.94
Gaps : 1
Alignment:
1 MAPLRPLLILALLAWVALADQESCKGRCTEGFNVDKKCQCDELCSYYQSC 50 I I Il I Il Il I I I I I I I I I Il Il I I I I I Il Il I I I Il I I I I I I I I I I Il I I
1 MAPLRPLLILALLAWVALADQESCKGRCTEGFNVDKKCQCDELCSYYQSC 50 . . . . .
51 CTDYTAECKPQVTRGDVFTMPEDEYTVYDDGEEKNNATVHEQVGGPSLTS 100
I I I I I I I I I I I I I I I 1 I 1 I I I I I I I I I I I I I I I I I I I 1 I 1 I I I I I I I I I I
51 CTDYTAECKPQVTRGDVFTMPEDEYTVYDDGEEKNNATVHEQVGGPSLTS 100
101 DLQAQSKGNPEQTPVLKPEEEAPAPEVGASKPEGIDSRPETLHPGRPQPP 150 I I I 1 I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I 1 I I 1 I I I I I I I
101 DLQAQSKGNPEQTPVLKPEEEAPAPEVGASKPEGIDSRPETLHPGRPQPP 150
151 AEEELCSGKPFDAFTDLKNGSLFAFRGQYCYELDEKAVRPGYPKLIRDVW 200
111111111!11!!111!!1!111IMIIIIIMIIIIIIIIMIIIIII 151 AEEELCSGKPFDAFTDLKNGSLFAFRGQYCYELDEKAVRPGYPKLIRDVW 200
201 GIEGPIDAAFTRINCQGKTYLFKGSQYWRFEDGVLDPDYPRNISDGFDGI 250
I I Il Il I I Il i Il I I I I I I I Il I I Il Il Il I I Il I Il I I I Il 11 I 1 I I I I
201 GIEGPIDAAFTRINCQGKTYLFKGSQYWRFEDGVLDPDYPRNISDGFDGI 250 . . . . .
251 PDNVDAALALPAHSYSGRERVYFFKGKQYWEYQFQHQPSQEECEGSSLSA 300
M I M Il I I I M I I I M M I M I M Il M I I I M I I M M M M I I I I M
251 PDNVDAALALPAHSYSGRERVYFFKGKQYWEYQFQHQPSQEECEGSSLSA 300
301 VFEHFAMMQRDSWEDIFELLFWGRTS 326
II I M I Il Il M I I M M I I I I I I I I
301 VFEHFAMMQRDSWEDIFELLFWGRTSAGTRQPQFISRDWHGVPGQVDAAM 350
326 326
351 AGRIYISGMAPRPSLAKKQRFRHRNRKGYRSQRGHSRGRNQNSRRPSRAM 400
327 DKYYRVNLR 335
Il Il I I I I I 401 WLSLFSSEESNLGANNYDDYRMDWLVPATCEPIQSVFFFSGDKYYRVNLR 450
336 TRRVDTVDPPYPRSIAQYWLGCPAPGHL 363
451 TRRVDTVDPPYPRSIAQYWLGCPAPGHL 478
Sequence name: /tmp/fgebv7ir4i/48bTBMziJ0 :VTNC_HUMAN
Sequence documentation:
Alignment of: T39971_P12 x VTNC_HUMAN
Alignment segment 1/1:
Quality: 2237.00 Escore: 0 Matching length: 223 Total length: 223
Matching Percent Similarity: 100.00 Matching Percent Identity: 100.00
Total Percent Similarity: 100.00 Total Percent Identity: 100.00
Gaps : 0
Alignment :
1 MAPLRPLLILALLAWVALADQESCKGRCTEGFNVDKKCQCDELCSYYQSC 50
1 MAPLRPLLILALLAWVALADQESCKGRCTEGFNVDKKCQCDELCSYYQSC 50
51 CTDYTAECKPQVTRGDVFTMPEDEYTVYDDGEEKNNATVHEQVGGPSLTS 100
I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I Il I I I I I 1 I I I M I 51 CTDYTAECKPQVTRGDVFTMPEDEYTVYDDGEEKNNATVHEQVGGPSLTS 100
101 DLQAQSKGNPEQTPVLKPEEEAPAPEVGASKPEGIDSRPETLHPGRPQPP 150
I I I I I I I I I I Il I I I I I I I I I Il I I Il I I I I I I I Il I I I I I I I I 1 I I Il I
101 DLQAQSKGNPEQTPVLKPEEEAPAPEVGASKPEGIDSRPETLHPGRPQPP 150 . . . . .
151 AEEELCSGKPFDAFTDLKNGSLFAFRGQYCYELDEKAVRPGYPKLIRDVW 200
I I I I I Il I I I I I Il I I I I I I Il I I I I I I I I Il I I I I I I I I I I I I I I I I I I
151 AEEELCSGKPFDAFTDLKNGSLFAFRGQYCYELDEKAVRPGYPKLIRDVW 200
201 GIEGPIDAAFTRINCQGKTYLFK 223
I I Il I I Il I Il I I I I I I I I I I I I 201 GIEGPIDAAFTRINCQGKTYLFK 223
Sequence name: /tmp/fgebv7ir4i/48bTBMziJ0 :Q9BSH7
Sequence documentation:
Alignment of: T39971_P12 x Q9BSH7
Alignment segment 1/1:
Quality: 2237.00 Escore: 0
Matching length: 223 Total length: 223 Matching Percent Similarity: 100.00 Matching Percent Identity: 100.00
Total Percent Similarity: 100.00 Total Percent Identity: 100.00
Gaps : 0
Alignment :
1 MAPLRPLLILALLAWVALADQESCKGRCTEGFNVDKKCQCDELCSYYQSC 50
I I I I I I I I I I I I I ! I I Il I i I I I I I I I Il I I I I I I I I I I I I I I I I I I I I I 1 MAPLRPLLILALLAWVALADQESCKGRCTEGFNVDKKCQCDELCSYYQSC 50
51 CTDYTAECKPQVTRGDVFTMPEDEYTVYDDGEEKNNATVHEQVGGPSLTS 100
II I I I Il I I I I I I I I I I I I I I I Il I I Il I I I I I I Il I I Il Il I I I I I i I I
51 CTDYTAECKPQVTRGDVFTMPEDEYTVYDDGEEKNNATVHEQVGGPSLTS 100 . . . . .
101 DLQAQSKGNPEQTPVLKPEEEAPAPEVGASKPEGIDSRPETLHPGRPQPP 150
I I I I I I Il I I I I I I I I Il I I I Il I I I Il Il Il I I I I Il I I I Il I Il Il I I
101 DLQAQSKGNPEQTPVLKPEEEAPAPEVGASKPEGIDSRPETLHPGRPQPP 150
151 AEEELCSGKPFDAFTDLKNGSLFAFRGQYCYELDEKAVRPGYPKLIRDVW 200
I M I I M I I M I M I M M I M M I I M I M I I I I M M I I I I M I M I I
151 AEEELCSGKPFDAFTDLKNGSLFAFRGQYCYELDEKAVRPGYPKLIRDVW 200
201 GIEGPIDAAFTRINCQGKTYLFK 223 I I I M I I I I I M I M I I M Il I I
201 GIEGPIDAAFTRINCQGKTYLFK 223
DESCRIPTION FOR CLUSTER Z21368
Cluster Z21368 features 7 transcript(s) and 34 segment(s) of interest, the names for which are given in Tables 82 and 83, respectively, the sequences themselves are given at the end of the application. The selected protein variants are given in table 84.
Table 82 - Transcripts of interest
These sequences are variants of the known protein Extracellular sulfatase SuIf- 1 precursor (SwissProt accession identifier SUL1_HUMAN; known also according to the synonyms EC 3.1.6.-; HSulf-1), SEQ ID NO: 1419, referred to herein as the previously known protein.
Protein Extracellular sulfatase SuIf-I precursor is known or believed to have the following function(s): Exhibits arylsulfatase activity and highly specific endoglucosamine-6-sulfatase activity. It can remove sulfate from the C- 6 position of glucosamine within specific subregions of intact heparin. Diminishes HSPG (heparan sulfate proteoglycans) sulfation, inhibits signaling by heparin- dependent growth factors, diminishes proliferation, and facilitates apoptosis in response to exogenous stimulation. The sequence for protein Extracellular sulfatase SuIf-I precursor is given at the end of the application, as "Extracellular sulfatase SuIf- 1 precursor amino acid sequence". Known polymorphisms for this sequence are as shown in Table 85.
Table 85 - Amino acid mutations for Known Protein
Protein Extracellular sulfatase SuIf-I precursor localization is believed to be Endoplasmic reticulum and Golgi stack. Also localized on the cell surface (By similarity).
The following GO Annotation(s) apply to the previously known protein. The following annotation(s) were found: apoptosis; metabolism; heparan sulfate proteoglycan metabolism, which are annotation(s) related to Biological Process; arylsulfatase; hydrolase, which are
annotation(s) related to Molecular Function; and extracellular space; endoplasmic reticulum; Golgi apparatus, which are annotation(s) related to Cellular Component.
The GO assignment relies on information from one or more of the SwissProt/TremBl Protein knowledgebase, available from <http://www.expasy.ch/sprot/>; or Locuslink, available from <http://www.ncbi.nlm.nih.gov/projects/LocusLink/>.
Cluster Z21368 can be used as a diagnostic marker according to overexpression of transcripts of this cluster in cancer. Expression of such transcripts in normal tissues is also given according to the previously described methods. The term "number" in the right hand column of the table and the numbers on the y-axis of figure 13 refer to weighted expression of ESTs in each category, as "parts per million" (ratio of the expression of ESTs for a particular cluster to the expression of all ESTs in that category, according to parts per million).
Overall, the following results were obtained as shown with regard to the histograms in Figure 13 and Table 86. This cluster is overexpressed (at least at a minimum level) in the following pathological conditions: epithelial malignant tumors, a mixture of malignant tumors from different tissues and pancreas carcinoma.
Table 86 - Normal tissue distribution
As noted above, cluster Z21368 features 7 transcript(s), which were listed in Table 1 above. These transcript(s) encode for protein(s) which are variant(s) of protein Extracellular sulfatase SuIf- 1 precursor. A description of each variant protein according to the present invention is now provided.
Variant protein Z21368_PEA_1_P2 according to the present invention has an amino acid sequence as given at the end of the application; it is encoded by transcript(s) Z21368_PEA_1_T5. An alignment is given to the known protein (Extracellular sulfatase SuIf-I precursor) at the end of the application. One or more alignments to one or more previously published protein sequences are given at the end of the application. A brief description of the relationship of the variant protein according to the present invention to each such aligned protein is as follows:
Comparison report between Z21368_PEA_1_P2 and SUL1JΪUMAN:
1.An isolated chimeric polypeptide encoding for Z21368_PEA_1_P2, comprising a first amino acid sequence being at least 90 % homologous to
MKYSCCALVLAVLGTELLGSLCSTVRSPRFRGRIQQERKNIRPNIILVLTDDQDVELGSL QVMNKTRKJMEHGGATFINAFVTTPMCCPSRSSMLTGKYVHNH]SIYYTNNENCSSPSW
QAMHEPRTFAVYLNNTGYRTAFFGKYLNEYNGSYIPPGWREWLGLIKNSRFYNYTVCR NGIKEKHGFDYAKDYFTDLITNESINYFKMSKRMYPHRPVMMVISHAAPHGPEDSAPQ FSKLYPNASQHITPSYNYAPNMDKHWIMQYTGPMLPIHMEFTNILQRKRLQTLMSVDD SVERLYNMLVETGELENTYIIYTADHGYHIGQFGLVKGKSMPYDFDIRVPFFIRGPSVEP GSIVPQIVLNIDLAPTILDIAGLDTPPDVDGKSVLKLLDPEKPGNRFRTNKKAKIWRDTFL VERGKFLRKKEESSKNIQQSNΉLPKYERVKELCQQARYQTACEQPGQKWQCIEDTSGK LRIHKCKGPSDLLTVRQSTRNLYARGFHDKDKECSCRESGYRASRSQRKSQRQFLRNQ GTPKYKPRFVHTRQTRSLSVEFEGEIYDINLEEEEELQVLQPRNIAKRHDEGHKGPRDLQ ASSGGNRGRMLADSSNAVGPPTTVRVTHKCFILPNDSMCERELYQSARAWKDHKAYI DKEIEALQDKIKNLREVRGHLKRRKPEECSCSKQSYYNKEKGVKKQEKLKSHLHPFKE AAQEVDSKLQLFKENNRRRKKERKEKRRQRKGEECSLPGLTCFTHDNNHWQTAPFWN
corresponding to amino acids 1 - 761 of SUL1_HUMAN, which also corresponds to amino acids 1 - 761 of Z21368JPEA_1_P2, and a second amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence PHKYSAHGRTRHFESATRTTNGAQKLSRI corresponding to amino acids 762 - 790 of
Z21368JPEA_1_P2, wherein said first and second amino acid sequences are contiguous and in a sequential order.
2.An isolated polypeptide encoding for a tail of Z21368_PEA_1_P2, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence PHKYSAHGRTRHFESATRTTNGAQKLSRI in Z21368_PEA_1_P2.
The location of the variant protein was determined according to results from a number of different software programs and analyses, including analyses from SignalP and other specialized programs. The variant protein is believed to be located as follows with regard to the cell: secreted. The protein localization is believed to be secreted because both signal-peptide prediction programs predict that this protein has a signal peptide, and neither trans -membrane region prediction program predicts that this protein has a trans -membrane region.
Variant protein Z21368_PEA_1_P2 is encoded by the following transcript(s):
Z21368_PEA_1_T5, for which the sequence(s) is/are given at the end of the application. The coding portion of transcript Z21368_PEA_1_T5 is shown in bold; this coding portion starts at position 529 and ends at position 2898.
Variant protein Z21368_PEA_1_P5 according to the present invention has an amino acid sequence as given at the end of the application; it is encoded by transcript(s) Z21368_PEA_1_T9. An alignment is given to the known protein (Extracellular sulfatase SuIf-I precursor) at the end of the application. One or more alignments to one or more previously published protein sequences are given at the end of the application. A brief description of the
relationship of the variant protein according to the present invention to each such aligned protein is as follows:
Comparison report between Z21368_PEA_1_P5 and Q7Z2W2 (SEQ ID NO:1697): 1.An isolated chimeric polypeptide encoding for Z21368_PEA_1_P5, comprising a first amino acid sequence being at least 90 % homologous to
MKYSCCALVLAVLGTELLGSLCSTVRSPRFRGRIQQERKNIRPNIILVLTDDQDVEL corresponding to amino acids 1 - 57 of Q7Z2W2, which also corresponds to amino acids 1 - 57 of Z21368_PEA_1_P5, second bridging amino acid sequence comprising A, and a third amino acid sequence being at least 90 % homologous to
FFGKYLNEYNGSYIPPGWREWLGLIKNSRFYNYTVCRNGIKEKHGFDYAKDYFTDLITN ESINYFKMSKRMYPHRP VMMVISHAAPHGPEDSAPQFSKLYPNASQHITPSYNYAPNM DKHWIMQYTGPMLPIHMEFTNILQRKRLQTLMSVDDSVERLYNMLVETGELENTYIIYT
ADHGYHiGQFGLVKGKSMP YDFDIRVPFFIRGPSVEPGSIVPQΓVLNIDLAPTILDIAGLDT PPDVDGKSVLKLLDPEKPGNRFRTNKKAKIWRDTFLVERGKFLRKKEESSKNIQQSNHL PKYERVKELCQQ ARYQTACEQPGQKWQCIEDTSGKLRIHKCKGPSDLLTVRQSTRNLY ARGFHDKDKECSCRESGYRASRSQRKSQRQFLRNQGTPKYKPRFVHTRQTRSLSVEFE GEIYDINLEEEEELQVLQPRNIAKRHDEGHKGPRDLQASSGGNRGRMLADSSNAVGPPT TVRVTHKCFILPNDSIHCERELYQSARAWKDHKA YIDKEIEALQDKIKNLREVRGHLKR RKPEECSCSKQSYYNKEKGVKKQEKLKSHLHPFKEAAQEVDSKLQLFKENNRRRKKER KEKRRQRKGEECSLPGLTCFTHDNNHWQTAPFWNLGSFCACTSSNNNTYWCLRTVNE THNFLFCEFATGFLEYFDMNTDPYQLTNTVHTVERGILNQLHVQLMELRSCQGYKQCN PRPKNLDVGNKDGGSYDLHRGQLWDGWEG corresponding to amino acids 139 - 871 of Q7Z2W2, which also corresponds to amino acids 59 - 791 of Z21368_PEA_1_P5, wherein said first, second and third amino acid sequences are contiguous and in a sequential order. 2.An isolated polypeptide encoding for an edge portion of Z21368_PEA_1_P5, comprising a polypeptide having a length "n", wherein n is at least about 10 amino acids in length, optionally at least about 20 amino acids in length, preferably at least about 30 amino acids in length, more preferably at least about 40 amino acids in length and most preferably at least about 50 amino acids in length, wherein at least three amino acids comprise LAF, the sequence having a structure as follows (numbering according to Z21368_PEA_1_P5): a
sequence starting from any of amino acid numbers 57-x to 57; and ending at any of amino acid numbers 59 + ((n-2) - x), in which x varies from 0 to n-2.
Comparison report between Z21368JPEAJJP5 and AAH12997 (SEQ ID NO: 1698): 1.An isolated chimeric polypeptide encoding for Z21368_PEA_1_P5, comprising a first amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence MKYSCCALVLAVLGTELLGSLCSTVRSPRFRGRIQQERKNIRPNIILVLTDDQDVELAFF GKYLNEYNGSYIPPGWREWLGLIKNSRFYNYTVCRNGIKEKHGFDYAKDYFTDLITNES INYFKMSKRMYPHRPVMMVISHAAPHGPEDSAPQFSKLYPNASQHITPSYNYAPNMDK HWIMQYTGPMLPIHMEFTNILQRKRLQTLMSVDDSVERLYNMLVETGELENTYIIYTAD HGYHIGQFGLVKGKSMPYDFDIRVPFFIRGPSVEPGSIVPQIVLNIDLAPTILDIAGLDTPP DVDGKSVLKLLDPEKPGNRFRTNKKAKIWRDTFLVERGKFLRKKEESSKNIQQSNHLP KYERVKELCQQARYQTACEQPGQKWQCIEDTSGKLRIHKCKGPSDLLTVRQSTRNLYA RGFHDKDKECSCRESGYRASRSQRKSQRQFLRNQGTPKYKPRFVHTRQTRSLSVEFEGE IYDINLEEEEELQVLQPRNIAKRHDEGHKGPRDLQASSGGNRGRMLADSSNAVGPPTTV RVTHKCFILPNDSIHCERELYQSARAWKDHKA YIDKEIEALQDKIKNLREVRGHLKRRK PEECSCSKQSYYNKEKGVKKQEKIXSHLHPFKEAAQEVDSKLQLFKENNRRRKKERKE KRRQRKGEECSLPGLTCFTHDNNHWQTAPFWNLGSFCACTSSNNNTYWCLRTVNETH NFLFCEFATGFLEYFDMNTDPYQLTNTVHTVERGILNQLHVQLME corresponding to amino acids 1 - 751 of Z21368_PEA_1JP5, and a second amino acid sequence being at least 90 % homologous to LRSCQGYKQCNPRPKNLDVGNKDGGSYDLHRGQLWDGWEG corresponding to amino acids 1 - 40 of AAH12997, which also corresponds to amino acids 752 - 791 of Z21368_PEA_1_P5, wherein said first and second amino acid sequences are contiguous and in a sequential order.
2.An isolated polypeptide encoding for a head of Z21368_PEA_1_P5, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence
MKYSCCALVLAVLGTELLGSLCSTVRSPRFRGRIQQERKNIRPNIILVLTDDQDVELAFF
GKYLNEYNGSYIPPGWREWLGLIKNSRFYNYTVCRNGIKEKHGFDYAKDYFTDLITNES INYFKMSKRMYPHRPVMMVISHAAPHGPEDSAPQFSKLYPNASQHITPSYNYAPNMDK HWIMQYTGPMLPIHMEFTNILQRKRLQTLMSVDDSVERLYNMLVETGELENTYIIYTAD HGYHIGQFGLVKGKSMPYDFDIRVPFFIRGPSVEPGSIVPQIVLNIDLAPTILDIAGLDTPP DVDGKSVLKLLDPEKPGNRFRTNKKAKIWRDTFLVERGKFLRKKEESSKNIQQSNHLP KYERVKELCQQARYQTACEQPGQKWQCIEDTSGKLRIHKCKGPSDLLTVRQSTRNLYA RGFHDKDKECSCRESGYRASRSQRKSQRQFLRNQGTPKYKPRFVHTRQTRSLSVEFEGE IYDINLEEEEELQVLQPRNIAKRHDEGHKGPRDLQASSGGNRGRMLADSSNAVGPPTTV RVTHKCFILPNDSIHCERELYQSARAWKDHKAYIDKEIEALQDKIKNLREVRGHLKRRK PEECSCSKQSYYNKEKGVKKQEKLKSHLHPFKEAAQEVDSKLQLFKENNRRRKKERKE KRRQRKGEECSLPGLTCFTHDNNHWQTAPFWNLGSFCACTSSNNNTYWCLRTVNETH NFLFCEFATGFLEYFDMNTDPYQLTNTVHTVERGILNQLHVQLM E OF
Z21368_PEA_1_P5.
Comparison report between Z21368_PEA_1_P5 and SUL1JHUMAN: 1.An isolated chimeric polypeptide encoding for Z21368_PEA_1_P5, comprising a first amino acid sequence being at least 90 % homologous to
MKYSCCALVLAVLGTELLGSLCSTVRSPRFRGRIQQERKNIRPNIILVLTDDQDVEL corresponding to amino acids 1 - 57 of SUL1_HUMAN, which also corresponds to amino acids 1 - 57 of Z21368_PEA_1_P5, and a second amino acid sequence being at least 90 % homologous to
AFFGKYLNEYNGSYIPPGWREWLGLIKNSRFYNYTVCRNGIKEKHGFDYAKDYFTDLIT NESINYFKMSKRMYPHRPVMMVISHAAPHGPEDSAPQFSKLYPNASQHITPSYNYAPN MDKHWIMQYTGPMLPIHMEFTNILQRKRLQTLMSVDDSVERLYNMLVETGELENTYII YTADHGYHIGQFGLVKGKSMPYDFDIRVPFFIRGPSVEPGSIVPQIVLNIDLAPTILDIAGL DTPPDVDGKSVLKLLDPEKPGNRFRTNKKAKIWRDTFLVERGKFLRJKKEESSKNIQQSN HLPKYERVKELCQQARYQTACEQPGQKWQCIEDTSGKLRIHKCKGPSDLLTVRQSTRN LYARGFHDKDKECSCRESGYRASRSQRKSQRQFLRNQGTPKYKPRFVHTRQTRSLSVE FEGEIYDINLEEEEELQVLQPRNIAKRHDEGHKGPRDLQASSGGNRGRMLADSSNAVGP PTTVRVTHKCFILPNDSIHCERELYQSARAWKDHKAYIDKEIEALQDKIKNLREVRGHL KRPJ^EECSCSKQSYYTSfKEKGVKKQEKLKSHLHPFKEAAQEVDSKLQLFKENNRRRK KERKEKRRQRKGEECSLPGLTCFTHDNNHWQTAPFWNLGSFCACTSSNNNTYWCLRT
VNETHNFLFCEFATGFLEYFDMNTDPYQLTNTVHTVERGILNQLHVQLMELRSCQGYK QCNPRPKNLDVGNKDGGSYDLHRGQLWDGWEG corresponding to amino acids 138 - 871 of SULl-HUMAN, which also corresponds to amino acids 58 - 791 of Z21368_PEA_1_P5, wherein said first and second amino acid sequences are contiguous and in a sequential order. 2.An isolated chimeric polypeptide encoding for an edge portion of Z21368_PEA_1_P5, comprising a polypeptide having a length "n", wherein n is at least about 10 amino acids in length, optionally at least about 20 amino acids in length, preferably at least about 30 amino acids in length, more preferably at least about 40 amino acids in length and most preferably at least about 50 amino acids in length, wherein at least two amino acids comprise LA, having a structure as follows: a sequence starting from any of amino acid numbers 57-x to 57; and ending at any of amino acid numbers 58 + ((n-2) - x), in which x varies from 0 to n-2.
The location of the variant protein was determined according to results from a number of different software programs and analyses, including analyses from SignalP and other specialized programs. The variant protein is believed to be located as follows with regard to the cell: secreted. The protein localization is believed to be secreted because both signal-peptide prediction programs predict that this protein has a signal peptide, and neither trans -membrane region prediction program predicts that this protein has a trans -membrane region..
Variant protein Z21368_PEA_1_P5 is encoded by the following transcript(s):
Z21368_PEA_1_T9, for which the sequence(s) is/are given at the end of the application. The coding portion of transcript Z21368_PEA_1_T9 is shown in bold; this coding portion starts at position 556 and ends at position 2928.
Variant protein Z21368_PEA_1_P15 according to the present invention has an amino acid sequence as given at the end of the application; it is encoded by transcript(s) Z21368_PEA_1_T23. An alignment is given to the known protein (Extracellular sulfatase SuIf- 1 precursor) at the end of the application. One or more alignments to one or more previously published protein sequences are given at the end of the application. A brief description of the
relationship of the variant protein according to the present invention to each such aligned protein is as follows:
Comparison report between Z21368_PEA_ 1JP15 and SUL IJHUMAN: 1.An isolated chimeric polypeptide encoding for Z21368_PEA_1_P15, comprising a first amino acid sequence being at least 90 % homologous to
MKYSCCALVLA VLGTELLGSLCSTVRSPRFRGRIQQERKNIRPNIILVLTDDQDVELGSL QVMNKTRKIMEHGGATFΓNAFVTTPMCCPSRSSMLTGKYVHNHNVYTNNENCSSPSW QAMHEPRTFAVYLNNTGYRTAFFGKYLNEYNGSYIPPGWREWLGLIKNSRFYNYTVCR NGIKEKHGFDYAKDYFTDLITNESINYFKMSKRMYPHRPVMMVISHAAPHGPEDSAPQ FSKLYPNASQHITPSYNYAPNMDKHWIMQYTGPMLPIHMEFTNILQRKRLQTLMSVDD SVERLYNMLVETGELENTYΠYTADHGYHIGQFGLVKGKSMPYDFDIRVPFFIRGPSVEP GSIVPQIVLNIDLAPTILDIAGLDTPPDVDGKSVLKLLDPEKPGNRFRTNKKAKIWRDTFL
VERG corresponding to amino acids 1 - 416 of SULIJHUMAN, which also corresponds to amino acids 1 - 416 of Z21368_PEA_1_P15.
The location of the variant protein was determined according to results from a number of different software programs and analyses, including analyses from SignalP and other specialized programs. The variant protein is believed to be located as follows with regard to the cell: secreted. The protein localization is believed to be secreted because both signatpeptide prediction programs predict that this protein has a signal peptide, and neither trans -membrane region prediction program predicts that this protein has a trans -membrane region-
Variant protein Z21368_PEA_1_P15 is encoded by the following transcript(s): Z21368JPEA_1_T23, for which the sequence(s) is/are given at the end of the application. The coding portion of transcript Z21368_PEA_1_T23 is shown in bold; this coding portion starts at position 691 and ends at position 1938.
Variant protein Z21368_PEA_1_P16 according to the present invention has an amino acid sequence as given at the end of the application; it is encoded by transcript(s) Z21368_PEA_1_T24. An alignment is given to the known protein (Extracellular sulfatase SuIf- 1 precursor) at the end of the application. One or more alignments to one or more previously
published protein sequences are given at the end of the application. A brief description of the relationship of the variant protein according to the present invention to each such aligned protein is as follows:
Comparison report between Z21368_PEA_1_P16 and SUL1_HUMAN:
1.An isolated chimeric polypeptide encoding for Z21368_PEA_1_P16, comprising a first amino acid sequence being at least 90 % homologous to
MKYSCCALVLAVLGTELLGSLCSTVRSPRFRGRIQQERKNIRPNIILVLTDDQDVELGSL QVMNKTRKIMEHGGATFINAFVTTPMCCPSRSSMLTGKYVHNHNVYTNNENCSSPSW QAMHEPRTFAVYLNNTGYRTAFFGKYLNEYNGSYIPPGWREWLGLIKNSRFYNYTVCR NGIKEKHGFDYAKDYFTDLITNESINYFKMSKRMYPHRPVMMVISHAAPHGPEDSAPQ FSKLYPNASQHITPSYNYAPNMDKHWIMQYTGPMLPIHMEFTNILQRKRLQTLMSVDD SVERLYNMLVETGELENTYΠYTADHGYHIGQFGLVKGKSMPYDFDIRVPFFIRGPSVEP
GSIVPQIVLNIDLAPTILDIAGLDTPPDVDGKSVLKLLDPEKPGNR corresponding to amino acids 1 - 397 of SUL1_HUMAN, which also corresponds to amino acids 1 - 397 of
Z21368_PEA_1_P16, and a second amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence CVTVPPLSQPQIH corresponding to amino acids 398 - 410 of Z21368_PEA_1_P16, wherein said first and second amino acid sequences are contiguous and in a sequential order.
2.An isolated polypeptide encoding for a tail of Z21368_PEA_1_P16, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence CVIVPPLSQPQIH in Z21368_PEA_1_P16.
The location of the variant protein was determined according to results from a number of different software programs and analyses, including analyses from SignalP and other specialized programs. The variant protein is believed to be located as follows with regard to the cell: secreted. The protein localization is believed to be secreted because both signal-peptide prediction programs predict that this protein ha s a signal peptide, and neither trans -membrane region prediction program predicts that this protein has a trans -membrane region..
Variant protein Z21368_PEA_1JP16 is encoded by the following transcript(s): Z21368_PEA_1_T24, for which the sequence(s) is/are given at the end of the application. The coding portion of transcript Z21368_PEA_1_T24 is shown in bold; this coding portion starts at position 691 and ends at position 1920.
Variant protein Z21368_PEA_1_P22 according to the present invention has an amino acid sequence as given at the end of the application; it is encoded by transcript(s) Z21368_PEA_l_T10. An alignment is given to the known protein (Extracellular sulfatase SuIf- 1 precursor) at the end of the application. One or more alignments to one or more previously published protein sequences are given at the end of the application. A brief description of the relationship of the variant protein according to the present invention to each such aligned protein is as follows:
Comparison report between Z21368_PEA_1_P22 and SUL1_HUMAN: 1.An isolated chimeric polypeptide encoding for Z21368_PEA_1_P22, comprising a first amino acid sequence being at least 90 % homologous to
MKYSCCALVLAVLGTELLGSLCSTVRSPRFRGRIQQERKNIRPNIILVLTDDQDVELGSL QVMNKTRKIMEHGGATFINAFVTTPMCCPSRSSMLTGKYVHNHNVYTNNENCSSPSW QAMHEPRTFAVYLNNTGYRTAFFGKYLNEYNGSYIPPGWREWLGLIKNSRFYNYTVCR NGIKEKHGFDYAK corresponding to amino acids 1 - 188 of SULl JHUMAN, which also corresponds to amino acids 1 - 188 of Z21368_PEA_1_P22, and a second amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence ARYDGDQPRCAPRPRGLSPTVF corresponding to amino acids 189 - 210 of Z21368_PEA_1_P22, wherein said first and second amino acid sequences are contiguous and in a sequential order.
2.An isolated polypeptide encoding for a tail of Z21368_PEA_1_P22, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence ARYDGDQPRCAPRPRGLSPTVF in Z21368_PEA_1_P22.
The location of the variant protein was determined according to results from a number of different software programs and analyses, including analyses from SignalP and other specialized programs. The variant protein is believed to be located as follows with regard to the cell: secreted. The protein localization is believed to be secreted because both signal-peptide prediction programs predict that this protein has a signal peptide, and neither trans -membrane region prediction program predicts that this protein has a trans- membrane region..
Variant protein Z21368_PEA_1_P22 is encoded by the following transcript(s): Z21368JPEA_l_T10, for which the sequence(s) is/are given at the end of the application. The coding portion of transcript Z21368_PEA_l_T10 is shown in bold; this coding portion starts at position 691 and ends at position 1320.
Variant protein Z21368JPEA_1_P23 according to the present invention has an amino acid sequence as given at the end of the application; it is encoded by transcript(s)
Z21368_PEA_1_T11. An alignment is given to the known protein (Extracellular sulfatase SuIf- 1 precursor) at the end of the application. One or more alignments to one or more previously published protein sequences are given at the end of the application. A brief description of the relationship of the variant protein according to the present invention to each such aligned protein is as follows:
Comparison report between Z21368JPEA_1_P23 and Q7Z2W2: 1.An isolated chimeric polypeptide encoding for Z21368_PEA_1_P23, comprising a first amino acid sequence being at least 90 % homologous to MKYsccALVLAVLGTELLGS LCSTVRSPRFRGRIQQERKNIRPNIILVLTDDQDVELGSL
QVMNKTRKIMEHGGATFINAFVTTPMCCPSRSSMLTGKYVHNHNVYTNNENCSSPSW QAMHEPRTF AVYLNNTGYRT corresponding to amino acids 1 - 137 of Q7Z2W2, which also corresponds to amino acids 1 - 137 of Z21368_PEA_1_P23, and a second amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence
GLLHRLNH corresponding to amino acids 138 - 145 of Z21368__PEA_1_P23, wherein said first and second amino acid sequences are contiguous and in a sequential order.
2.An isolated polypeptide encoding for a tail of Z21368_PEA_1_P23, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence GLLHRLNH in Z21368_PEA_1_P23.
Comparison report between Z21368_PEA_1_P23 and SUL IJHUMAN:
1.An isolated chimeric polypeptide encoding for Z21368_PEA_1_P23, comprising a first amino acid sequence being at least 90 % homologous to
MKYSCCALVLAVLGTELLGSLCSTVRSPRFRGRIQQERKNIRPNIILVLTDDQDVELGSL QV]VnSfKTRKIMEHGGATFINAFVTTPMCCPSRSSMLTGKYVHNHNVYTNNENCSSPSW QAMHEPRTFAVYLNNTGYRT corresponding to amino acids 1 - 137 of SUL1JHUMAN, which also corresponds to amino acids 1 - 137 of Z21368_PEA_1_P23, and a second amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence GLLHRLNH corresponding to amino acids 138 - 145 of Z21368_PEA_1_P23, wherein said first and second amino acid sequences are contiguous and in a sequential order. 2.An isolated polypeptide encoding for a tail ofZ21368_PEA_l_P23, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence GLLHRLNH in Z21368_PEA_1_P23.
The location of the variant protein was determined according to results from a number of different software programs and analyses, including analyses from SignalP and other specialized programs. The variant protein is believed to be located as follows with regard to the cell: secreted. The protein localization is believed to be secreted because both signal-peptide prediction programs predict that this protein has a signal peptide, and neither trans -membrane region prediction program predicts that this protein has a trans -membrane region..
Variant protein Z21368_PEA_1_P23 is encoded by the following transcript(s): Z21368_PEA_1_T11, for which the sequence(s) is/are given at the end of the application. The coding portion of transcript Z21368_PEA_1_T11 is shown in bold; this coding portion starts at position 691 and ends at position 1125.
As noted above, cluster Z21368 features 34 segment(s), which were listed in Table 2 above and for which the sequence(s) are given at the end of the application. These segment(s) are portions of nucleic acid sequence(s) which are described herein separately because they are of particular interest. A description of each segment according to the present invention is now provided.
Segment cluster Z21368_PEA_l_node_0 according to the present invention is supported by 8 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): Z21368_PEA_1_T9. Table 88 below describes the starting and ending position of this segment on each transcript. Table 88 - Segment location on transcripts
Segment cluster Z21368_PEA_l_node_15 according to the present invention is supported by 26 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): Z21368_PEA_l_T10, Z21368_PEA_1_T11, Z21368_PEA_1_T23, Z21368_PEA_1_T24, Z21368_PEAJ_T5, Z21368_PEA_1_T6 and Z21368_PEA_1_T9. Table 89 below describes the starting and ending position of this segment on each transcript.
Table 89 - Segment location on transcripts
Segment cluster Z21368_PEA_l_node_19 according to the present invention is supported by 24 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): Z21368_PEA_l_T10, Z21368_PEA_1_T11, Z21368_PEA_1_T23, Z21368_PEA_1_T24, Z21368_PEA_1_T5 and Z21368_PEA_1_T6. Table 90 below describes the starting and ending position of this segment on each transcript.
Table 90 - Segment location on transcripts
Segment cluster Z21368_PEA_l_node_2 according to the present invention is supported by 15 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): Z21368_PEA_l_T10, Z21368_PEA_1_T11, Z21368_PEA_1_T23, Z21368_PEA_1_T24, Z21368_PEA_1_T5 and Z21368_PEA_1_T6. Table 91 below describes the starting and ending position of this segment on each transcript.
Table 91 - Segment location on transcripts
Segment cluster Z21368_PEA_l_node_21 according to the present invention is supported by 37 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): Z21368_PEA_l_T10, Z21368_PEA_1_T23, Z21368_PEA_1_T24, Z21368_PEA_1_T5, Z21368_PEA_1_T6 and Z21368J>EA_l_T9. Table 92 below describes the starting and ending position of this segment on each transcript.
Table 92 - Segment location on transcripts
Segment cluster Z21368_PEA_l_node_33 according to the present invention is supported by 45 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): Z21368_PEA_l_T10, Z21368_PEA_1_T11, Z21368_PEA_1_T23, Z21368_PEA_1_T24, Z21368_PEA_1_T5, Z21368_PEA_1_T6 and Z21368_PEA_1_T9. Table 93 below describes the starting and ending position of this segment on each transcript.
Table 93 - Segment location on transcripts
Segment cluster Z21368_PEA_l_node_36 according to the present invention is supported by 44 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): Z21368_PEA_l_T10, Z21368_PEA_1_T11, Z21368_PEA_1_T23, Z21368_PEA_1_T24, Z21368_PEA_1_T5, Z21368_PEA_1_T6 and Z21368_PEA_1_T9. Table 94 below describes the starting and ending position of this segment on each transcript.
Table 94 - Segment location on transcripts
Segment cluster Z21368_PEA_l_node_37 according to the present invention is supported by 3 libraries. The number of libraries was determined as previously described. This segment
can be found in the following transcript(s): Z21368_PEA_1_T24. Table 95 below describes the starting and ending position of this segment on each transcript.
Table 95 - Segment location on transcripts
Segment cluster Z21368_PEA_l_node_39 according to the present invention is supported by 5 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): Z21368JPEA_1_T23 and Z21368_PEA_1_T24. Table 96 below describes the starting and ending position of this segment on each transcript. Table 96 - Segment location on transcripts
Segment cluster Z21368_PEA_l_node_4 according to the present invention is supported by 13 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): Z21368_PEA_l_T10, Z21368JPEA_1_T11, Z21368_PEA_1_T23 and Z21368_PEA_1_T24. Table 97 below describes the starting and ending position of this segment on each transcript.
Table 97 - Segment location on transcripts
Segment cluster Z21368_PEA_l_node_41 according to the present invention is supported by 49 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): Z21368_PEA_l_T10, Z21368_PEA_1_T11, Z21368_PEA_1_T5, Z21368JPEAJJT6 and Z21368_PEA_1_T9. Table 98 below describes the starting and ending position of this segment on each transcript.
Table 98 - Segment location on transcripts
Segment cluster Z21368_PEA_l_node_43 according to the present invention is supported by 52 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): Z21368_PEA_l_T10, Z21368_PEA_1_T11, Z21368_PEA_1_T5, Z21368_PEA_1_T6 and Z21368_PEA_1_T9. Table 99 below describes the starting and ending position of this segment on each transcript. Table 99 - Segment location on transcripts
Segment cluster Z21368_PEA_l_node_45 according to the present invention is supported by 64 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): Z21368_PEA_l_T10, Z21368_PEA_1_T11, Z21368_PEA_1_T5, Z21368_PEA_1_T6 and Z21368_PEA_1_T9. Table 100 below describes the starting and ending position of this segment on each transcript.
Table 100 - Segment location on transcripts
Segment cluster Z21368_PEA_l_node_53 according to the present invention is supported by 60 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): Z21368JPEA_l_T10, Z21368_PEA_1_T11, Z21368_PEA_1_T5, Z21368_PEA_1_T6 and Z21368_PEA_1_T9. Table 101 below describes the starting and ending position of this segment on each transcript.
Table 102 - Segment location on transcripts
Segment cluster Z21368_PEA_l_node_56 according to the present invention is supported by 50 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): Z21368_PEA_l_T10, Z21368_PEA_1_T11 and Z21368_PEA_1_T9. Table 102 below describes the starting and ending position of this segment on each transcript.
Table 102 - Segment location on transcripts
Segment cluster Z21368_PEA_l_node_58 according to the present invention is supported by 71 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): Z21368_PEA_l_T10, Z21368_PEA_1_T11, Z21368_PEA_1_T5, Z21368_PEA_1_T6 and Z21368_PEA_l_T9. Table 103 below describes the starting and ending position of this segment on each transcript.
Table 103 - Segment location on transcripts
Segment cluster Z21368_PEA_l_node_66 according to the present invention is supported by 142 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): Z21368_PEA_l_T10, Z21368_PEA_1_T11,
Z21368_PEA_1_T5, Z21368_PEA_1_T6 and Z21368_PEA_1_T9. Table 104 below describes the starting and ending position of this segment on each transcript.
Table 104 - Segment location on transcripts
Segment cluster Z21368_PEA_l_node_67 according to the present invention is supported by 181 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): Z21368_PEA_l_T10, Z21368_PEA_1_T11, Z21368_PEA_1_T5, Z21368_PEA_1_T6 and Z21368_PEA_1_T9. Table 105 below describes the starting and ending position of this segment on each transcript.
Table 105 - Segment location on transcripts
Segment cluster Z21368_PEA_l_node_69 according to the present invention is supported by 150 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): Z21368_PEA_l_T10, Z21368_PEA_1_T11,
Z21368_PEA_1_T5, Z21368_PEA_1 JT6 and Z21368_PEA_1_T9. Table 106 below describes the starting and ending position of this segment on each transcript.
Table 107 - Segment location on transcripts
According to an optional embodiment of the present invention, short segments related to the above cluster are also provided. These segments are up to about 120 bp in length, and so are included in a separate description.
Segment cluster Z21368_PEA_l_node_l l according to the present invention is supported by 26 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): Z21368_PEA_l_T10, Z21368_PEA_1_T11, Z21368_PEA_1_T23, Z21368_PEA_1_T24, Z21368_PEA_1_T5, Z21368_PEA_1_T6 and Z21368_PEA_1_T9. Table 107 below describes the starting and ending position of this segment on each transcript.
Table 107 - Segment location on transcripts
Segment cluster Z21368_PEA_l_node_12 according to the present invention is supported by 23 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): Z21368_PEA_l_T10, Z21368_PEA_1_T11, Z21368_PEA_1_T23, Z21368_PEA_1_T24, Z21368_PEA_1_T5, Z21368_PEA_1_T6 and Z21368_PEA_1_T9. Table 108 below describes the starting and ending position of this segment on each transcript.
Table 108 - Segment location on transcripts
Segment cluster Z21368_PEA_l_node_16 according to the present invention can be found in the following transcript(s): Z21368_PEA_l_T10, Z21368_PEA_1_T11, Z21368_PEA_1_T23, Z21368_PEA_1_T24, Z21368_PEA_1_T5, Z21368JPEA_1_T6 and Z21368_PEA_1_T9. Table 109 below describes the starting and ending position of this segment on each transcript.
Table 109 - Segment location on transcripts
Segment cluster Z21368_PEA_l_node_17 according to the present invention is supported by 19 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): Z21368_PEA_l_T10, Z21368_PEA_1_T11, Z21368_PEA_1_T23, Z21368_PEA_1_T24, Z21368_PEA_1_T5, Z21368_PEA_1_T6 and Z21368_PEA_1_T9. Table 110 below describes the starting and ending position of this segment on each transcript.
Table 110 - Segment location on transcripts
Segment cluster Z21368_PEA_l_node_23 according to the present invention is supported by 36 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): Z21368_PEA_1_T11, Z21368_PEA_1_T23, Z21368_PEA_1_T24, Z21368_PEA_1_T5, Z21368_PEA_1_T6 and Z21368JPEA_1_T9. Table 111 below describes the starting and ending position of this segment on each transcript.
Table 111 Segment location on transcripts
Segment cluster Z21368_PEA_l_node_24 according to the present invention is supported by 36 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): Z21368JPEA_l_T10, Z21368_PEA_1_T11, Z21368_PEA_1_T23, Z21368_PEA_1_T24, Z21368_PEA_1_T5, Z21368_PEA_1_T6 and Z21368_PEA_1_T9. Table 112 below describes the starting and ending position of this segment on each transcript.
Table 112 - Segment location on transcripts
Segment cluster Z21368_PEA_l_node_30 according to the present invention is supported by 39 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): Z21368_PEA_l_T10, Z21368_PEA_1_T11, Z21368_PEA_1_T23, Z21368_PEA_1_T24, Z21368_PEA_1_ T5, Z21368_PEA_1_T6 and
Z21368_PEA_1_T9. Table 113 below describes the starting and ending position of this segment on each transcript.
Table 113 - Segment location on transcripts
Segment cluster Z21368_PEA_l_node_31 according to the present invention is supported by 40 libraries. The number of libraries was deteπnined as previously described. This segment can be found in the following transcript(s): Z21368_PEA_l_T10, Z21368_PEA_1_T11, Z21368_PEA_1_T23, Z21368JPEA_1_T24, Z21368_PEA_1_T5, Z21368_PEA_1_T6 and Z21368_PEA_1_T9. Table 114 below describes the starting and ending position of this segment on each transcript.
Table 114 - Segment location on transcripts
Segment cluster Z21368_PEA_l_node_38 according to the present invention is supported by 45 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): Z21368_PEA_l_T10, Z21368_PEA_1_T11
5 Z21368_PEA_1_T23, Z21368_PEA_1_T24, Z21368_PEA_1_T5, Z21368_PEA_1_T6 and Z21368_PEA_1_T9. Table 115 below describes the starting and ending position of this segment on each transcript.
Table 115 - Segment location on transcripts
Segment cluster Z21368_PEA_l_node_47 according to the present invention is supported by 61 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): Z21368_PEA_ l_T10, Z21368_PEA_1_T11, Z21368_PEA_1_T5, Z21368_PEA_1_T6 and Z21368_PEA_1_T9. Table 116 below describes the starting and ending position of this segment on each transcript.
Table 116 - Segment location on transcripts
Segment cluster Z21368_PEA_l_node_49 according to the present invention is supported by 57 libraries. The number of libraries was deteπnined as previously described. This segment can be found in the following transcript(s): Z21368_PEA_l_T10, Z21368_PEA_1_T11, Z21368_PEA_1_T5, Z21368_PEA_1_T6 and Z21368_PEA_1_T9. Table 117 below describes the starting and ending position of this segment on each transcript.
Table 117 - Segment location on transcripts
Segment cluster Z21368_PEA_l_node_51 according to the present invention is supported by 46 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): Z21368_PEA_l_T10, Z21368_PEA_1_T11, Z21368_PEA_1_T5, Z21368_PEA_1_T6 and Z21368_PEA_1_T9. Table 118 below describes the starting and ending position of this segment on each transcript.
Table 118 - Segment location on transcripts
Segment cluster Z21368_PEA_l_node_61 according to the present invention is supported by 61 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): Z21368_PEA_l_T10, Z21368_PEA_1_T11, Z21368_PEA_1_T5, Z21368J
»EA_1_T6 and Z21368_PEA_1_T9. Table 119 below describes the starting and ending position of this segment on each transcript.
Tablell9 - Segment location on transcripts
Segment cluster Z21368_PEA_l_node_68 according to the present invention is supported by 87 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): Z21368_PEA_l_T10, Z21368_PEA_1_T11, Z21368_PEA_1_T5, Z21368_PEA_1_T6 and Z21368_PEA_1_T9. Table 120 below describes the starting and ending position of this segment on each transcript.
Table 120 - Segment location on transcripts
Segment cluster Z21368_PEA_l_node_7 according to the present invention is supported by 29 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): Z21368_PEA_l_T10, Z21368_PEA_1_T11, Z21368_PEA_1_T23, Z21368_PEA_1_T24, Z21368_PEA_1_T5, Z21368_PEA_1_T6 and Z21368_PEA_1_T9. Table 121 below describes the starting and ending position of this segment on each transcript.
Table 121 - Segment location on transcripts
Overexpression of at least a portion of this cluster was determined according to oligonucleotides and one or more chips. The results were as follows: Oligonucleotide Z21368_0_0_61857 was on the TAA chip and was found to be overexpressed in Lung cancer (general), in Lung adenocarcinoma, and in Lung squamous cell cancer.
Variant protein alignment to the previously known protein:
Sequence name: /tmp/5ER3vIMKE2/9L0Y71DlTQ: SϋLl_HUMAN
Sequence documentation:
Alignment of: Z21368 PEA 1 P2 x SULl HUMAN
Alignment segment 1/1:
Quality: 7664.00 Escore: 0 Matching length: 761 Total length: 761
Matching Percent Similarity: 100.00 Matching Percent Identity: 100.00
Total Percent Similarity: 100.00 Total Percent Identity: 100.00
Gaps : 0
Alignment :
1 MKYSCCALVLAVLGTELLGSLCSTVRSPRFRGRIQQERKNIRPNIILVLT 50
I I Il I I I I I I I I I I ! I I I I I I I I I I I I Il I I I I I Il I I I I I I I I I I I I I I
1 MKYSCCALVLAVLGTELLGSLCSTVRSPRFRGRIQQERKNIRPNIILVLT 50
51 DDQDVELGSLQVMNKTRKIMEHGGATFINAFVTTPMCCPSRSSMLTGKYV 100 I I I I I I I I I M I M I I I I I I I M I I I I I I I M I I I I I I I I I M I I I I I I I
51 DDQDVELGSLQVMNKTRKIMEHGGATFINAFVTTPMCCPSRSSMLTGKYV 100
101 HNHNVYTNNENCSSPSWQAMHEPRTFAVYLNNTGYRTAFFGKYLNEYNGS 150
I I I I I I I I Il Il I Il I I I I I I Il I I I I I I I I I I I I I I I Il I I I I I I I I I I 101 HNHNVYTNNENCSSPSWQAMHEPRTFAVYLNNTGYRTAFFGKYLNEYNGS 150
151 YIPPGWREWLGLIKNSRFYNYTVCRNGIKEKHGFDYAKDYFTDLITNESI 200
M M I I I I M M M I II I I I I I I I I I M I I M M I M I M I I I I I I I I I I
151 YIPPGWREWLGLIKNSRFYNYTVCRNGIKEKHGFDYAKDYFTDLITNESI 200 . . . . .
201 NYFKMSKRMYPHRPVMMVISHAAPHGPEDSAPQFSKLYPNASQHITPSYN 250
I I I Il 1 I I I I I I I I I I I I I 1 I I 1 I I I 1 I I I I I I I 1 I I I I I I I I I I I I I I I
201 NYFKMSKRMYPHRPVMMVISHAAPHGPEDSAPQFSKLYPNASQHITPSYN 250
251 YAPNMDKHWIMQYTGPMLPIHMEFTNILQRKRLQTLMSVDDSVERLYNML 300 I I I Il I I I Il I I I I I I I M I I I I I I I I I I I I I I I I Il M I I I I I I I I I I I
251 YAPNMDKHWIMQYTGPMLPIHMEFTNILQRKRLQTLMSVDDSVERLYNML 300
301 VETGELENTYIIYTADHGYHIGQFGLVKGKSMPYDFDIRVPFFIRGPSVE 350
I I I I I I I I I Il I I I Il I I I I Il Il I I I I I I I I I I I I I I I I I Il I I Il I I I 301 VETGELENTYIIYTADHGYHIGQFGLVKGKSMPYDFDIRVPFFIRGPSVE 350
351 PGSIVPQIVLNIDLAPTILDIAGLDTPPDVDGKSVLKLLDPEKPGNRFRT 400
I I I I I I I I I I I Il I Il I I I I I I I I I Il I I I I I I I I I I Il I Il I I I I I I I I
351 PGSIVPQIVLNIDLAPTILDIAGLDTPPDVDGKSVLKLLDPEKPGNRFRT 400 . . . . .
401 NKKAKIWRDTFLVERGKFLRKKEESSKNIQQSNHLPKYERVKELCQQARY 450
I I I I I I I Il I I Il I I Il I Il I I I I I I I I I I I I I I Il Il I I I I I I I Il I I I
401 NKKAKIWRDTFLVERGKFLRKKEESSKNIQQSNHLPKYERVKELCQQARY 450
451 QTACEQPGQKWQCIEDTSGKLRIHKCKGPSDLLTVRQSTRNLYARGFHDK 500
I I I I I I I I I I I I I I I I I I I I I I I I I I I I 1 Il I I Il I I I I I I I Il Il I I Il
451 QTACEQPGQKWQCIEDTSGKLRIHKCKGPSDLLTVRQSTRNLYARGFHDK 500
501 DKECSCRESGYRASRSQRKSQRQFLRNQGTPKYKPRFVHTRQTRSLSVEF 550
501 DKECSCRESGYRASRSQRKSQRQFLRNQGTPKYKPRFVHTRQTRSLSVEF 550
551 EGEIYDINLEEEEELQVLQPRNIAKRHDEGHKGPRDLQASSGGNRGRMLA 600
I Il M I M Il I M I M I M I M M I Il I I I Il I I I I I I M I M I M I I I I 551 EGEIYDINLEEEEELQVLQPRNIAKRHDEGHKGPRDLQASSGGNRGRMLA 600
601 DSSNAVGPPTTVRVTHKCFILPNDSIHCERELYQSARAWKDHKAYIDKEI 650
I I I I I I I I I I I I I I I I I I I I I I I I 1 I I I I I I I I I I I I I I I I I I I I I I I I I
601 DSSNAVGPPTTVRVTHKCFILPNDSIHCERELYQSARAWKDHKAYIDKEI 650
651 EALQDKIKNLREVRGHLKRRKPEECSCSKQSYYNKEKGVKKQEKLKSHLH 700
I i I I I I I I I I I I I I I I I I I I I 1 I I I I I I I I I I Il I I I I I I Il I I I I I Il I
651 EALQDKIKNLREVRGHLKRRKPEECSCSKQSYYNKEKGVKKQEKLKSHLH 700
701 PFKEAAQEVDSKLQLFKENNRRRKKERKEKRRQRKGEECSLPGLTCFTHD 750 I I I I I I I I 1 I I I I I I I I I I I I I I I I I I I I I I I I ) I I I I I Il I I I I Il I Il
701 PFKEAAQEVDSKLQLFKENNRRRKKERKEKRRQRKGEECSLPGLTCFTHD 750
751 NNHWQTAPFWN 761
I I I I I Il Il Il 751 NNHWQTAPFWN 761
Sequence name: /tmp/tt3yfXIUKV/YxSTFWr66h:Q7Z2W2
Sequence documentation:
Alignment of: Z21368_PEA_1_P5 x Q7Z2W2
Alignment segment 1/1:
Quality: 7869.00
Escore: 0
Matching length: 791 Total length: 871
Matching Percent Similarity: 99.87 Matching Percent Identity: 99.87 Total Percent Similarity: 90.70 Total Percent Identity: 90.70
Gaps : 1
Alignment: . . . . .
1 MKYSCCALVLAVLGTELLGSLCSTVRSPRFRGRIQQERKNIRPNIILVLT 50
I I I I I I I I I Il I I I I I I I I I I I I I I I I I I i I 1 I i I I I I I I I I I I I Il I I I
1 MKYSCCALVLAVLGTELLGSLCSTVRSPRFRGRIQQERKNIRPNIILVLT 50
51 DDQDVELA 58
I I I I I I I
51 DDQDVELGSLQVMNKTRKIMEHGGATFINAFVTTPMCCPSRSSMLTGKYV 100
59 FFGKYLNEYNGS 70 I I I I I I I I I I I I
101 HNHNVYTNNENCSSPSWQAMHEPRTFAVYLNNTGYRTVFFGKYLNEYNGS 150
71 YIPPGWREWLGLIKNSRFYNYTVCRNGIKEKHGFDYAKDYFTDLITNESI 120
II I I I I I Il Il Il Il I I I Il Il Il I I I I I I Il I Il I I I I I I I I I I Il i I I 151 YIPPGWREWLGLIKNSRFYNYTVCRNGIKEKHGFDYAKDYFTDLITNESI 200
121 NYFKMSKRMYPHRPVMMVISHAAPHGPEDSAPQFSKLYPNASQHITPSYN 170
I I Il I I I I I Il I I I I I Il I I I I I I I I I I I I I I I I I I Il I Il I I I I I I I I I
201 NYFKMSKRMYPHRPVMMVISHAAPHGPEDSAPQFSKLYPNASQHITPSYN 250 . . . . .
171 YAPNMDKHWIMQYTGPMLPIHMEFTNILQRKRLQTLMSVDDSVERLYNML 220
I I I I 11 I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I
251 YAPNMDKHWIMQYTGPMLPIHMEFTNILQRKRLQTLMSVDDSVERLYNML 300
221 VETGELENTYIIYTADHGYHIGQFGLVKGKSMPYDFDIRVPFFIRGPSVE 270 1111111 ! 1111111 ! 111111111111111111111 ! 1 ! M I I I I I I l I
301 VETGELENTYIIYTADHGYHIGQFGLVKGKSMPYDFDIRVPFFIRGPSVE 350
271 PGSIVPQIVLNIDLAPTILDIAGLDTPPDVDGKSVLKLLDPEKPGNRFRT 320
I I I I I Il I I I I I Il I I I I I I I I I I I I I I I Il I I I I I I I I I I I I I I I I I Il 351 PGSIVPQIVLNIDLAPTILDIAGLDTPPDVDGKSVLKLLDPEKPGNRFRT 400
321 NKKAKIWRDTFLVERGKFLRKKEESSKNIQQSNHLPKYERVKELCQQARY 370
I I I I I I I I I I 1 I I I I I I I I I I I I I I I I I I I 1 I I I I I I I I I I I I I I I 1 I I I
401 NKKAKIWRDTFLVERGKFLRKKEESSKNIQQSNHLPKYERVKELCQQARY 450 . . . . .
371 QTACEQPGQKWQCIEDTSGKLRIHKCKGPSDLLTVRQSTRNLYARGFHDK 420
I I I I I I Il I I I I I I Il I I I I Il I I I I I I I I I I I I Il I I I I I I I 1 I I I I I I
451 QTACEQPGQKWQCIEDTSGKLRIHKCKGPSDLLTVRQSTRNLYARGFHDK 500
421 DKECSCRESGYRASRSQRKSQRQFLRNQGTPKYKPRFVHTRQTRSLSVEF 470
I I I I I I I I I I I I I I I I Il I I I I I Il I I I I I I I I I I I I I I I I I I Il I I I I I 501 DKECSCRESGYRASRSQRKSQRQFLRNQGTPKYKPRFVHTRQTRSLSVEF 550
471 EGEIYDINLEEEEELQVLQPRNIAKRHDEGHKGPRDLQASSGGNRGRMLA 520 I I I I M I M I I I I I I I I I I I I I 1 ! M I I I I I I M I I I I I I I I I I I I I I I I
551 EGEIYDINLEEEEELQVLQPRNIAKRHDEGHKGPRDLQASSGGNRGRMLA 600
521 DSSNAVGPPTTVRVTHKCFILPNDSIHCERELYQSARAWKDHKAYIDKEI 570
I M M I I M I IM I I M I I MI M I MI I I I I I I I M II I I I III M I M 601 DSSNAVGPPTTVRVTHKCFILPNDSIHCERELYQSARAWKDHKAYIDKEI 650
571 EALQDKIKNLREVRGHLKRRKPEECSCSKQSYYNKEKGVKKQEKLKSHLH 620
651 EALQDKIKNLREVRGHLKRRKPEECSCSKQSYYNKEKGVKKQEKLKSHLH 700
621 PFKEAAQEVDSKLQLFKENNRRRKKERKEKRRQRKGEECSLPGLTCFTHD 670
I I I I I I I ! I I I I I I I I 1 I I I I I I I I I I I I I I I 1 I I I I I I I I 1 I I I I I I I I
701 PFKEAAQEVDSKLQLFKENNRRRKKERKEKRRQRKGEECSLPGLTCFTHD 750
671 NNHWQTAPFWNLGSFCACTSSNNNTYWCLRTVNETHNFLFCEFATGFLEY 720 I I I I I I I I I I I I I I I I I M M I I I I I I I I I I I I I I I I I I ) I I I 1 I I I I I I
751 NNHWQTAPFWNLGSFCACTSSNNNTYWCLRTVNETHNFLFCEFATGFLEY 800
721 FDMNTDPYQLTNTVHTVERGILNQLHVQLMELRSCQGYKQCNPRPKNLDV 770
I I I I Il I I 1 I Il Il I I I I I I I I I I Il I I I I I I I I I I I I I I I I i I I I I I I I 801 FDMNTDPYQLTNTVHTVERGILNQLHVQLMELRSCQGYKQCNPRPKNLDV 850
771 GNKDGGSYDLHRGQLWDGWEG 791
II Il I I I I I I I I I I Il I I Il I
851 GNKDGGSYDLHRGQLWDGWEG 871
Sequence name: /tmp/tt3yfXIUKV/YxSTFWr66h:AAH12997
Sequence documentation:
Alignment of: Z21368_PEA_1_P5 x AAH12997
Alignment segment 1/1:
Quality: 420 .00
Escore : 0
Matching length: 40 Total length: 40
Matching Percent Similarity: 100.00 Matching Percent Identity: 100.00
Total Percent Similarity: 100.00 Total Percent Identity: 100.00
Gaps : 0
Alignment :
752 LRSCQGYKQCNPRPKNLDVGNKDGGSYDLHRGQLWDGWEG 791
I I I I I I I I I I I I I I I I I I Il I I I I I Il I I I I I I I I I I I I I
1 LRSCQGYKQCNPRPKNLDVGNKDGGSYDLHRGQLWDGWEG 40
Sequence name: /tmp/tt3yfXIUKV/YxSTFWr66h: SUL1_HUMAN
Sequence documentation:
Alignment of: Z21368_PEA_1_P5 x SUL1_HUMAN
Alignment segment 1/1:
Quality: 7878.00 Escore: 0
Matching length: 791 Total length: 871 Matching Percent Similarity: 100.00 Matching Percent Identity: ,100.00
Total Percent Similarity: 90.82 Total Percent Identity: 90.82
Gaps : 1
Alignment :
1 MKYSCCALVLAVLGTELLGSLCSTVRSPRFRGRIQQERKNIRPNIILVLT 50
I I I I I I ! I I I I I I I I I I I I I I I I I I I i I I I I I I I I I I I I I I I I I I I I I I I 1 MKYSCCALVLAVLGTELLGSLCSTVRSPRFRGRIQQERKNIRPNIILVLT 50
51 DDQDVEL 57
IMMM
51 DDQDVELGSLQVMNKTRKIMEHGGATFINAFVTTPMCCPSRSSMLTGKYV 100 . . . . .
58 AFFGKYLNEYNGS 70
MMMMMMI
101 HNHNVYTNNENCSSPSWQAMHEPRTFAVYLNNTGYRTAFFGKYLNEYNGS 150
71 YIPPGWREWLGLIKNSRFYNYTVCRNGIKEKHGFDYAKDYFTDLITNESI 120
M Il M M M I I I M M I M I M M I M I M M I M M M M Il M M M
151 YIPPGWREWLGLIKNSRFYNYTVCRNGIKEKHGFDYAKDYFTDLITNESI 200
121 NYFKMSKRMYPHRPVMMVISHAAPHGPEDSAPQFSKLYPNASQHITPSYN 170 M I I M Il I M M M M I M M I Il I M I I I I I M M Il M I I I I I M M
201 NYFKMSKRMYPHRPVMMVISHAAPHGPEDSAPQFSKLYPNASQHITPSYN 250
171 YAPNMDKHWIMQYTGPMLPIHMEFTNILQRKRLQTLMSVDDSVERLYNML 220
I I I I I 1 I I I I I I I I I I I I Il ] I I I I I I I I I I I I 1 I I I I I I I I I I I I I I I I
251 YAPNMDKHWIMQYTGPMLPIHMEFTNILQRKRLQTLMSVDDSVERLYNML 300 . . . . .
221 VETGELENTYIIYTADHGYHIGQFGLVKGKSMPYDFDIRVPFFIRGPSVE 270
I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I Il I Il
301 VETGELENTYIIYTADHGYHIGQFGLVKGKSMPYDFDIRVPFFIRGPSVE 350
271 PGSIVPQIVLNIDLAPTILDIAGLDTPPDVDGKSVLKLLDPEKPGNRFRT 320
I M I I I II I M I I I I I I M I M I I I I M I I M I M M I I I I M M M I M
351 PGSIVPQIVLNIDLAPTILDIAGLDTPPDVDGKSVLKLLDPEKPGNRFRT 400
321 NKKAKIWRDTFLVERGKFLRKKEESSKNIQQSNHLPKYERVKELCQQARY 370 Il Il I I I I M I I M M I Il M I M Il I I I I Il M M I Il I M M I M M I
401 NKKAKIWRDTFLVERGKFLRKKEESSKNIQQSNHLPKYERVKELCQQARY 450
371 QTACEQPGQKWQCIEDTSGKLRIHKCKGPSDLLTVRQSTRNLYARGFHDK 420
M I M I I I I I I Il Il I I M I I M I I M M I Il Il M Il M Il M I M I M 451 QTACEQPGQKWQCIEDTSGKLRIHKCKGPSDLLTVRQSTRNLYARGFHDK 500
421 DKECSCRESGYRASRSQRKSQRQFLRNQGTPKYKPRFVHTRQTRSLSVEF 470
I M I M I I I I M M I M Il I I M M I I M M M M M M I M M I M M I
501 DKECSCRESGYRASRSQRKSQRQFLRNQGTPKYKPRFVHTRQTRSLSVEF 550 . . . . .
471 EGEIYDINLEEEEELQVLQPRNIAKRHDEGHKGPRDLQASSGGNRGRMLA 520
M M I I I M Il Il M Il Il M I Il M M I M Il I I I M I M M M M I M
551 EGEIYDINLEEEEELQVLQPRNIAKRHDEGHKGPRDLQASSGGNRGRMLA 600
521 DSSNAVGPPTTVRVTHKCFILPNDSIHCERELYQSARAWKDHKAYIDKEI 570
601 DSSNAVGPPTTVRVTHKCFILPNDSIHCERELYQSARAWKDHKAYIDKEI 650
571 EALQDKIKNLREVRGHLKRRKPEECSCSKQSYYNKEKGVKKQEKLKSHLH 620
111111111!111111!1111111!111111!111111IMIIIIIIIII 651 EALQDKIKNLREVRGHLKRRKPEECSCSKQSYYNKEKGVKKQEKLKSHLH 700
621 PFKEAAQEVDSKLQLFKENNRRRKKERKEKRRQRKGEECSLPGLTCFTHD 670 I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I ! 1 I I I I I I I I I I I
701 PFKEAAQEVDSKLQLFKENNRRRKKERKEKRRQRKGEECSLPGLTCFTHD 750 . . . . .
671 NNHWQTAPFWNLGSFCACTSSNNNTYWCLRTVNETHNFLFCEFATGFLEY 720
1111111!1111111111!11111!11111111IMIIMIIIIIMIII 751 NNHWQTAPFWNLGSFCACTSSNNNTYWCLRTVNETHNFLFCEFATGFLEY 800
721 FDMNTDPYQLTNTVHTVERGILNQLHVQLMELRSCQGYKQCNPRPKNLDV 770 I Il Il I Il I I I I I I I I I I Il I 1 I Il I I Il I I Il Il I I I I Il Il I I I Il Il
801 FDMNTDPYQLTNTVHTVERGILNQLHVQLMELRSCQGYKQCNPRPKNLDV 850
771 GNKDGGSYDLHRGQLWDGWEG 791 IMIIMIMMMMIIIII
851 GNKDGGSYDLHRGQLWDGWEG 871
Sequence name: /tmp/AVAZGWHuFO/RzHFOnHIsT: SULl_HϋMAN
Sequence documentation:
Alignment of: Z21368_PEA_1_P15 x SUL1_HUMAN
Alignment segment 1/1:
Quality: 4174.00
Escore: 0
Matching length: 416 Total length: 416
Matching Percent Similarity: 100.00 Matching Percent Identity: 100.00
Total Percent Similarity: 100.00 Total Percent Identity: 100.00
Gaps : 0
Alignment:
1 MKYSCCALVLAVLGTELLGSLCSTVRSPRFRGRIQQERKNIRPNIILVLT 50 I I I I I I I I I I I I I I I I I I I I I Il I Il I I I I I I I I Il I I I I I I I I I ! I I Il
1 MKYSCCALVLAVLGTELLGSLCSTVRSPRFRGRIQQERKNIRPNIILVLT 50 . . . . .
51 DDQDVELGSLQVMNKTRKIMEHGGATFINAFVTTPMCCPSRSSMLTGKYV 100
I I I Il Il I I I I I I I I I I I I Il I Il I I Il I I I I I I I I I I I I I Il I I I I Il I
51 DDQDVELGSLQVMNKTRKIMEHGGATFINAFVTTPMCCPSRSSMLTGKYV 100
101 HNHNVYTNNENCSSPSWQAMHEPRTFAVYLNNTGYRTAFFGKYLNEYNGS 150
I I I I I I I I I I I I I I Il Il I I I Il Il I Il I I I I I I I I I I I I I I I I I I I I I I
101 HNHNVYTNNENCSSPSWQAMHEPRTFAVYLNNTGYRTAFFGKYLNEYNGS 150
151 YIPPGWREWLGLIKNSRFYNYTVCRNGIKEKHGFDYAKDYFTDLITNESI 200 I I I I I M I I I I I M M I M Il I I I I I I I I Il Il I I Il I I I I I I I Il I I I I
151 YIPPGWREWLGLIKNSRFYNYTVCRNGIKEKHGFDYAKDYFTDLITNESI 200
201 NYFKMSKRMYPHRPVMMVISHAAPHGPEDSAPQFSKLYPNASQHITPSYN 250
1 I Il I I I I I I I I I I I I 1 I I I I I I I I I I I I I I I I I I I I I I I I I I I I I 1 I I I
201 NYFKMSKRMYPHRPVMMVISHAAPHGPEDSAPQFSKLYPNASQHITPSYN 250 . . . . .
251 YAPNMDKHWIMQYTGPMLPIHMEFTNILQRKRLQTLMSVDDSVERLYNML 300
I I I I I I I I I I I I Il I Il I Il I I Il I I I I I Il I I I I I I Il I I I Il I I I I Il
251 YAPNMDKHWIMQYTGPMLPIHMEFTNILQRKRLQTLMSVDDSVERLYNML 300
301 VETGELENTYIIYTADHGYHIGQFGLVKGKSMPYDFDIRVPFFIRGPSVE 350
I I I I I I I I I I I I I I I I I I I I Il I I I I I I I I I I I I I Il I Il I I I I I I I Il I
301 VETGELENTYIIYTADHGYHIGQFGLVKGKSMPYDFDIRVPFFIRGPSVE 350
351 PGSIVPQIVLNIDLAPTILDIAGLDTPPDVDGKSVLKLLDPEKPGNRFRT 400 I I I I I I I I I I I I I I M I I I I I I I I I I I I I I I I I I I I I I I I I M I I I M I I
351 PGSIVPQIVLNIDLAPTILDIAGLDTPPDVDGKSVLKLLDPEKPGNRFRT 400
401 NKKAKIWRDTFLVERG 416
401 NKKAKIWRDTFLVERG 416
Sequence name: /tmp/JhwgRdKqmt/kqSmjxkWWk: SUL1_HUMAN
Sequence documentation:
Alignment of: Z21368 PEA 1 P16 x SULl HUMAN
Alignment segment 1/1:
Quality: 3985.00 Escore: 0
Matching length: 397 Total length: 397
Matching Percent Similarity: 100.00 Matching Percent Identity: 100.00 Total Percent Similarity: 100.00 Total Percent Identity: 100.00
Gaps : 0
Alignment : . . . . .
1 MKYSCCALVLAVLGTELLGSLCSTVRSPRFRGRIQQERKNIRPNIILVLT 50
I M I I I I i M M M I MI I I I I I I I M I I I I I I M I I M I I I I M I I I I l
1 MKYSCCALVLAVLGTELLGSLCSTVRSPRFRGRIQQERKNIRPNIILVLT 50
51 DDQDVELGSLQVMNKTRKIMEHGGATFINAFVTTPMCCPSRSSMLTGKYV 100
I Il I I I I I I I I Il I I I I I I I I M M I I I I I I I I I I Il M I M I M I I I I I
51 DDQDVELGSLQVMNKTRKIMEHGGATFINAFVTTPMCCPSRSSMLTGKYV 100
101 HNHNVYTNNENCSSPSWQAMHEPRTFAVYLNNTGYRTAFFGKYLNEYNGS 150 M I M I M I M I I I I I I I I M M M I M I I I I M I I I M I M M I I I Il I
101 HNHNVYTNNENCSSPSWQAMHEPRTFAVYLNNTGYRTAFFGKYLNEYNGS 150
151 YIPPGWREWLGLIKNSRFYNYTVCRNGIKEKHGFDYAKDYFTDLITNESI 200
I M M I I M M I M I I I I M I I M I M I M I M M I M I I I M M I I Il I 151 YIPPGWREWLGLIKNSRFYNYTVCRNGIKEKHGFDYAKDYFTDLITNESI 200
201 NYFKMSKRMYPHRPVMMVISHAAPHGPEDSAPQFSKLYPNASQHITPSYN 250
I I I Il I I I I I I I I I I I I I I I I I I I I 1 I I I Il I Il I I I I I 1 I I 1 I I I I I I I
201 NYFKMSKRMYPHRPVMMVISHAAPHGPEDSAPQFSKLYPNASQHITPSYN 250
251 YAPNMDKHWIMQYTGPMLPIHMEFTNILQRKRLQTLMSVDDSVERLYNML 300
I I I I I 1 I I I I I I I I I I I I I I i Il I 1 I Il I I I I Il I I I I Il I Il I I I I I Il
251 YAPNMDKHWIMQYTGPMLPIHMEFTNILQRKRLQTLMSVDDSVERLYNML 300
301 VETGELENTYIIYTADHGYHIGQFGLVKGKSMPYDFDIRVPFFIRGPSVE 350 M I I I M I Il M I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I M I M M
301 VETGELENTYIIYTADHGYHIGQFGLVKGKSMPYDFDIRVPFFIRGPSVE 350
351 PGSIVPQIVLNIDLAPTILDIAGLDTPPDVDGKSVLKLLDPEKPGNR 397
I I I I I I I I I I I I I I I I I I I I I I I I I I I Il I I I I I I I I I 1 I Il I Il I I 351 PGSIVPQIVLNIDLAPTILDIAGLDTPPDVDGKSVLKLLDPEKPGNR 397
Sequence name: /tmp/GPlnIw3BOg/zXFdxqG4ow: SUL1_HUMAN
Sequence documentation:
Alignment of: Z21368_PEA_1_P22 x SUL1_HUMAN
Alignment segment 1/1:
Quality: 1897.00
Escore: 0
Matching length: 188 Total length: 188
Matching Percent Similarity: 100.00 Matching Percent Identity: 100.00 Total Percent Similarity: 100.00 Total Percent Identity: 100.00
Gaps : 0
Alignment : . . . . .
1 MKYSCCALVLAVLGTELLGSLCSTVRSPRFRGRIQQERKNIRPNIILVLT 50
1111111!11111111!1111111!111!11111!111111!111111Il
1 MKYSCCALVLAVLGTELLGSLCSTVRSPRFRGRIQQERKNIRPNIILVLT 50
51 DDQDVELGSLQVMNKTRKIMEHGGATFINAFVTTPMCCPSRSSMLTGKYV 100
I I I I Il I I I Il I I Il I I I Il I I I I Il I I I I Il I I I I I I I I I Il I I I I I I I
51 DDQDVELGSLQVMNKTRKIMEHGGATFINAFVTTPMCCPSRSSMLTGKYV 100
101 HNHNVYTNNENCSSPSWQAMHEPRTFAVYLNNTGYRTAFFGKYLNEYNGS 150 I M I M I M I M I I I I I I I I I I M I I M I I I M I I I I M M I I I I M Il I
101 HNHNVYTNNENCSSPSWQAMHEPRTFAVYLNNTGYRTAFFGKYLNEYNGS 150
151 YIPPGWREWLGLIKNSRFYNYTVCRNGIKEKHGFDYAK 188
I M I I I Il I I M M I M I I M I I M I I M I I M I I I M 151 YIPPGWREWLGLIKNSRFYNYTVCRNGIKEKHGFDYAK 188
Sequence name: /tmp/oji5Fs74fB/8xeB9KrGjp:Q7Z2W2
Sequence documentation:
Alignment of: Z21368_PEA_1_P23 x Q7Z2W2
Alignment segment 1/1:
Quality: 1368.00
Escore: 0.000511
Matching length: 137 Total length: 137
Matching Percent Similarity: 100.00 Matching Percent Identity: 100.00
Total Percent Similarity: 100.00 Total Percent Identity: 100.00
Gaps : 0
Alignment:
1 MKYSCCALVLAVLGTELLGSLCSTVRSPRFRGRIQQERKNIRPNIILVLT 50
I I I I I I I I I I I I I Il Il I I I I I I I I I I I I I I I I I I I I Il I I I I I I I I I 1 I
1 MKYSCCALVLAVLGTELLGSLCSTVRSPRFRGRIQQERKNIRPNIILVLT 50 . . . . .
51 DDQDVELGSLQVMNKTRKIMEHGGATFINAFVTTPMCCPSRSSMLTGKYV 100
I I I Il I I I I Il I I I Il Il I I I I I I I I I I I I I I I I I I I I I Il I I I I I I I I I
51 DDQDVELGSLQVMNKTRKIMEHGGATFINAFVTTPMCCPSRSSMLTGKYV 100
101 HNHNVYTNNENCSSPSWQAMHEPRTFAVYLNNTGYRT 137
I I I I I I I I I I I I I I I I I Il I I I I I I I I Il I I I I I I Il 101 HNHNVYTNNENCSSPSWQAMHEPRTFAVYLNNTGYRT 137
Sequence name: /tmp/oj i5Fs74fB/8xeB9KrGjp : SUL1_HUMAN
Sequence documentation:
Alignment of: Z21368_PEA_1_P23 x SUL1_HUMAN
Alignment segment 1/1:
Quality: 1368.00 Escore: 0.000511
Matching length: 137 Total length: 137 Matching Percent Similarity: 100.00 Matching Percent Identity: 100.00
Total Percent Similarity: 100.00 Total Percent Identity: 100.00
Gaps : 0
Alignment :
1 MKYSCCALVLAVLGTELLGSLCSTVRSPRFRGRIQQERKNIRPNIILVLT 50
I Il I I I Il Il I i I I I Il I I I Il I I I Il I I I I I I I I Il I I I I I I I I I I I Il 1 MKYSCCALVLAVLGTELLGSLCSTVRSPRFRGRIQQERKNIRPNIILVLT 50
51 DDQDVELGSLQVMNKTRKIMEHGGATFINAFVTTPMCCPSRSSMLTGKYV 100
I I I I I I I I I I I I I I I Il I I I Il Il I Il I I I I Il I I I I I I I I Il Il I I I I I
51 DDQDVELGSLQVMNKTRKIMEHGGATFINAFVTTPMCCPSRSSMLTGKYV 100 . . .
101 HNHNVYTNNENCSSPSWQAMHEPRTFAVYLNNTGYRT 137
101 HNHNVYTNNENCSSPSWQAMHEPRTFAVYLNNTGYRT 137
Expression of SUL1JHUMAN - Extracellular sulfatase Sulf-lZ21368 transcripts which are detectable by amplicon as depicted in sequence name Z21368juncl7-21 in normal and cancerous lung tissues
Expression of SUL IJHUMAN - Extracellular sulfatase SuIf-I transcripts detectable by or according to juncl7-21 segment, Z21368juncl7-21 amplicon (SEQ ID NO: 1642) and Z21368juncl7-21F (SEQ ID NO: 1640) Z21368juncl7-21R (SEQ ID NO: 1641) primers was measured by real time PCR. In parallel the expression of four housekeeping genes -PBGD (GenBank Accession No. BC019323; amplicon - PBGD-amplicon, SEQ ID NO:334), HPRTl (GenBank Accession No. NM_000194; amplicon - HPRTl -amplicon, SEQ ID NO: 1297), Ubiquitin (GenBank Accession No. BC000449; amplicon - Ubiquitin- amplicon, SEQ ID NO:328) and SDHA (GenBank Accession No. NM_004168; amplicon - SDHA- amplicon, SEQ ID NO:331) was measured similarly. For each RT sample, the expression of the above amplicon was normalized to the geometric mean of the quantities of the housekeeping genes. The normalized quantity of each RT sample was then divided by the median of the quantities of the normal post-mortem (PM) samples (Sample Nos. 47-50, 90-93, 96-99, Table2, "Tissue samples in testing panel", above), to obtain a value of fold up -regulation for each sample relative to median of the normal PM samples.
Figure 14 is a histogram showing over expression of the above -indicated SUL1_HUMAN - Extracellular sulfatase SuIf-I transcripts in cancerous lung samples relative to the normal samples. Values represent the average of duplicate experiments. Error bars indicate the minimal and maximal values obtained. As is evident from Figure 14, the expression of SULl JHUMAN - Extracellular sulfatase SuIf-I transcripts detectable by the above amplicon in cancer samples was significantly higher than in the non- cancerous samples (Sample Nos. 47-50, 90-93, 96-99 Table 2, "Tissue samples in testing panel"). Notably an over- expression of at least 5 fold was found in 10 out of 15 adenocarcinoma samples, 7 out of 16 squamous cell carcinoma samples, 0 out of 4 large cell carcinoma samples and in 0 out of 8 small cells carcinoma samples.
Threshold of 5 fold over-expression was found to differentiate between cancer and normal samples with P value of 3.56E-04 in adenocarcinoma, 9.66E-03 in squamous cell carcinomas checked by exact fisher test. The above values demonstrate statistical significance of the results.
Primer pairs are also optionally and preferably encompassed within the present invention; for example, for the above experiment, the following primer pair was used as a non- limiting illustrative example only of a suitable primer pair: Z21368juncl7-21F forward primer; and Z21368juncl 7-21 R reverse primer.
The present invention also preferably encompasses any amplicon obtained through the use of any suitable primer pair; for example, for the above experiment, the following amplicon was obtained as a non- limiting illustrative example only of a suitable amplicon: Z21368jιmcl7- 21.
Forward primer (SEQ ID NO: 1640): GGACGGATACAGCAGGAACG Reverse amplicon (SEQ ID NO: 1641): TATTTTCCAAAAAAGGCCAGCTC Amplicon (SEQ ID NO: 1642): GGACGGATACAGCAGGAACGAAAAAACATCCGACCCAACATTATTCTTGTGCTTAC CGATGATCAAGATGTGGAGCTGGCCTTTTTTGGAAAATA
Expression of SUL1_HUMAN - Extracellular sulfatase Sulf-lZ21368 transcripts, which are detectable by amplicon as depicted in sequence name Z21368 juncl7-21 in different normal tissues
Expression of SUL1_HUMAN - Extracellular sulfatase SuIf- 1 transcripts detectable by or according to Z21368 juncl7-21 amplicon (SEQ ID NO: 1642) and Z21368 juncl7-21F (SEQ ID NO: 1640) and Z21368 juncl7-21R (SEQ ID NO: 1641) was measured by real time PCR. In parallel the expression of four housekeeping genes -RPLl 9 (GenBank Accession No. NM_000981; RPL19 amplicon, SEQ ID NO:1630), TATA box (GenBank Accession No. NM_003194; TATA amplicon, SEQ ID NO: 1633), Ubiquitin (GenBank Accession No.
BC000449; amplicon - Ubiquitin-amplicon, SEQ ID NO:328) and SDHA (GenBank Accession
No. NM_004168; amplicon - SDHA-amplicon, SEQ ID NO:331) was measured similarly. For each RT sample, the expression of the above amplicon was normalized to the geometric mean of the quantities of the housekeeping genes. The noπnalized quantity of each RT sample was then divided by the median of the quantities of the breast samples (Sample Nos. 33-35 Table 3, "Tissue samples in normal panel", above), to obtain a value of relative expression of each sample relative to median of the breast samples.
Forward primer (SEQ ID NO: 1640): GGACGGATACAGCAGGAACG Reverse amplicon (SEQ ID NO: 1641): TATTTTCCAAAAAAGGCCAGCTC Amplicon (SEQ ID NO: 1642):
GGACGGATACAGCAGGAACGAAAAAACATCCGACCCAACATTATTCTTGTGCTTAC CGATGATCAAGATGTGGAGCTGGCCTTTTTTGGAAAATA
The results are shown in Figure 15, demonstrating the expression of Extracellular sulfatase SuIf- 1Z21368 transcripts, which are detectable by amplicon as depicted in sequence name Z21368 juncl7-21, in different normal tissues.
Expression of SULIJHUMAN - Extracellular sulfatase SuIf-I Z21368 transcripts which are detectable by amplicon as depicted in sequence name Z21368seg39 in normal and cancerous lung tissues
Expression of SUL1_HUMAN - Extracellular sulfatase SuIf-I transcripts detectable by or according to seg39, Z21368seg39 amplicon (SEQ ID NO: 1645) and primers Z21368seg39F (SEQ ID NO: 1643) and Z21368seg39R (SEQ ID NO: 1644) was measured by real time PCR.
In parallel the expression of four housekeeping genes -PBGD (GenBank Accession No.
BC019323; amplicon - PBGD-amplicon, SEQ ID NO:334), HPRTl (GenBank Accession No.
NMJ)OO 194; amplicon - HPRTl -amplicon, SEQ ID NO:1297), Ubiquitin (GenBank Accession
No. BC000449; amplicon - Ubiquitin- amplicon, SEQ ID NO:328) and SDHA (GenBank Accession No. NM_004168; amplicon - SDHA-amplicon, SEQ ID NO:331) was measured similarly. For each RT sample, the expression of the above amplicon was normalized to the
geometric mean of the quantities of the housekeeping genes. The normalized quantity of each RT sample was then divided by the median of the quantities of the normal post-mortem (PM) samples (Sample Nos. 47-50, 90-93, 96-99, Table 2, "Tissue samples in testing panel"), to obtain a value of fold up -regulation for each sample relative to median of the normal PM samples. Figure 16 is a histogram showing over expression of the above- indicated
SUL1_HUMAN - Extracellular sulfatase SuIf-I transcripts in cancerous lung samples relative to the normal samples. Values represent the average of duplicate experiments. Error bars indicate the minimal and maximal values obtained. As is evident from Figure 16, the expression of SUL1_HUMAN - Extracellular sulfatase SuIf-I transcripts detectable by the above amplicon in cancer samples was higher than in the noncancerous samples (Sample Nos. 47-50, 90-93, 96-99 Table 2, "Tissue samples in testing panel"). Notably an over-expression of at least 5 fold was found in 8 out of 15 adenocarcinoma samples, 5 out of 16 squamous cell carcinoma samples and 1 out of 4 large cell carcinoma samples . Statistical analysis was applied to verify the significance of these results, as described below.
The P value for the difference in the expression levels of SUL1_HLJMAN - Extracellular sulfatase SuIf- 1 transcripts detectable by the above amplicon in lung cancer samples versus the normal tissue samples was determined by T test as 2.17E-04 in adenocarcinoma, 9.94E-03 in squamous cell carcinoma and 2.17E- 01 in large cell carcinoma.
Threshold of 5fold overexpression was found to differentiate between cancer and normal samples with P value of 1.74E-02 in adenocarcinoma, 1.58E-01 in squamous cell carcinoma and 4.33E-01 in large cell carcinoma as checked by exact fisher test. The above values demonstrate statistical significance of the results.
Primer pairs are also optionally and preferably encompassed within the present invention; for example, for the above experiment, the following primer pair was used as a non- limiting illustrative example only of a suitable primer pair: Z21368seg39F forward primer; and Z21368seg39R reverse primer. The present invention also preferably encompasses any amplicon obtained through the use of any suitable primer pair; for example, for the above experiment, the following amplicon was obtained as a non- limiting illustrative example only of a suitable amplicon: Z21368seg39.
Primers: Forward primer Z21368seg39F (SEQ ID NO: 1643): GTTGCATTTCTCAGTGCTGGTTT Reverse primer Z21368seg39R (SEQ ID NO: 1644): AGGGTGCCGGGTGAGG Amplicon Z21368seg39 (SEQ ID NO: 1645):
GTTGCATTTCTCAGTGCTGGTTTCTAATCAGACCAGTGGATTGAGTTTCTCTACCATC CTCCCCACGTTCTTCTCTAAGCTGCCTCCAAGCCTCACCCGGCACCCT
Expression of SUL1_HUMAN - Extracellular sulfatase Sulf-lZ21368 transcripts which are detectable by amplicon as depicted in sequence name Z21368seg39 in different normal tissues
Expression of SUL1_HUMAN - Extracellular sulfatase SuIf-I transcripts detectable by or according to Z21368seg39 amplicon (SEQ ID NO: 1645) and Z21368seg39F (SEQ ID NO: 1643) Z21368seg39R (SEQ ID NO: 1644) was measured by real time PCR. In parallel the expression of four housekeeping genes -[ RPLl 9 (GenBank Accession No. NM_000981; RPL19 amplicon, SEQ ID NO:1630), TATA box (GenBank Accession No. NM_003194; TATA amplicon, SEQ ID NO:1633), UBC (GenBank Accession No. BC000449; amplicon - Ubiquitin-amplicon, SEQ ID NO:328) and SDHA (GenBank Accession No. NM_004168; amplicon- SDHA- amplicon, SEQ ID NO:331) was measured similarly. For each RT sample, the expression of the above amplicon was normalized to the geometric mean of the quantities of the housekeeping genes. The normalized quantity of each RT sample was then divided by the median of the quantities of the breast samples (Sample Nos. 33-35 Table 3, above), to obtain a value of relative expression of each sample relative to median of the breast samples.
Forward primer Z21368seg39F (SEQ ID NO: 1643): GTTGCATTTCTCAGTGCTGGTTT Reverse primer Z21368seg39R (SEQ ID NO: 1644): AGGGTGCCGGGTGAGG Amplicon Z21368seg39 (SEQ ID NO: 1645):
GTTGCATTTCTCAGTGCTGGTTTCTAATCAGACCAGTGGATTGAGTTTCTCTACCATC CTCCCCACGTTCTTCTCTAAGCTGCCTCCAAGCCTCACCCGGCACCCT
The results are demonstrated in Figure 17, showing expression of SUL1_HUMAN - Extracellular sulfatase SuIf-I, Z21368 transcripts, which are detectable by amplicon as depicted in sequence name Z21368seg39, in different normal tissues.
PBGD-amplicon, SEQ ID NO:334HPRT1 -amplicon, SEQ ID NO:1297Ubiquitin-amplicon, SEQ ID NO:328SDHA-amplicon, SEQ ID NO:331PBGD-amplicon, SEQ ID NO:334HPRT1- amplicon, SEQ ID NO:1297Ubiquitin-amplicon, SEQ ID NO:328SDHA-amplicon, SEQ ID NO:331RPL19 amplicon, SEQ ID NO:1630TATA amplicon, SEQ ID NO:1633Ubiquitin- amplicon, SEQ ID NO:328SDHA-amplicon, SEQ ID NO:331
DESCRIPTION FOR CLUSTER HUMGRP5E
Cluster HUMGRP5E features 2 transcript(s) and 5 segment(s) of interest, the names for which are given in Tables 160 and 161, respectively, the sequences themselves are given at the end of the application. The selected protein variants are given in table 162.
Table 160 - Transcripts of interest
These sequences are variants of the known protein Gastrin-releasing peptide precursor (SwissProt accession identifier GRP_HUMAN; known also according to the synonyms GRP; GRP-10), SEQ ID NO: 1421, referred to herein as the previously known protein.
Gastrin-releasing peptide is known or believed to have the following fimction(s): stimulates gastrin release as well as other gastrointestinal hormones. The sequence for protein Gastrin-releasing peptide precursor is given at the end of the application, as "Gastrin-releasing peptide precursor amino acid sequence". Known polymorphisms for this sequence are as shown in Table 163.
Tablel63 -Amino acid mutations for Known Protein
Protein Gastrin-releasing peptide localization is believed to be Secreted.
The previously known protein also has the following indication(s) and/or potential therapeutic use(s): Diabetes, Type II. It has been investigated for clinical/therapeutic use in humans, for example as a target for an antibody or small molecule, and/or as a direct therapeutic; available information related to these investigations is as follows. Potential pharmaceutically related or therapeutically related activity or activities of the previously known protein are as follows: Bombesin antagonist; Insulinotropin agonist. A therapeutic role for a protein represented by the cluster has been predicted. The cluster was assigned this field because there was information in the drug database or the public databases (e.g., described herein above) that this protein, or part thereof, is used or can be used for a potential therapeutic indication: Anorectic/Antiobesity; Releasing hormone; Anticancer; Respiratory; Antidiabetic.
The following GO Annotation(s) apply to the previously known protein. The following annotation(s) were found: signal transduction; neuropeptide signaling pathway, which are annotation(s) related to Biological Process; growth factor, which are annotation(s) related to Molecular Function; and secreted, which are annotation(s) related to Cellular Component.
The GO assignment relies on information from one or more of the SwissProt/TremBl Protein knowledgebase, available from <http://www.expasy.ch/sprot/>; or Locuslink, available from <http://www.ncbi.nhn.nih.gov/projects/LocusLink/>.
As noted above, cluster HUMGRP5E features 2 transcript(s), which were listed in Table 160 above. These transcript(s) encode for protein(s) which are variant(s) of protein Gastrin- releasing peptide precursor. A description of each variant protein according to the present invention is now provided.
Variant protein HUMGRP5E_P4 according to the present invention has an amino acid sequence as given at the end of the application; it is encoded by transcript(s) HUMGRP5E_T4. An alignment is given to the known protein (Gastrin-releasing peptide precursor) at the end of the application. One or more alignments to one or more previously published protein sequences are given at the end of the application. A brief description of the relationship of the variant protein according to the present invention to each such aligned protein is as follows:
Comparison report between HUMGRP5E P4 and GRP_HUMAN:
1.An isolated chimeric polypeptide encoding for HUMGRP5E_P4, comprising a first amino acid sequence being at least 90 % homologous to
MRGSELPLVLLALVLCLAPRGRAVPLPAGGGTVLTKMYPRGNHWAVGHLMGKKSTG ESSSVSERGSLKQQLREYIRWEEAARNLLGLIEAKENRNHQPPQPKALGNQQPSWDSED SSNFKDVGSKGK corresponding to amino acids 1 - 127 of GRP_HUMAN, which also corresponds to amino acids 1 - 127 of HUMGRP5E_P4, and a second amino acid sequence being at least 90 % homologous to GSQREGRNPQLNQQ corresponding to amino acids 135 - 148 of GRPJHUMAN, which also corresponds to amino acids 128 - 141 of HUMGRP5EJP4, wherein said first and second amino acid sequences are contiguous and in a sequential order. 2.An isolated chimeric polypeptide encoding for an edge portion of HUMGRP5E_P4, comprising a polypeptide having a length "n", wherein n is at least about 10 amino acids in length, optionally at least about 20 amino acids in length, preferably at least about 30 amino acids in length, more preferably at least about 40 amino acids in length and most preferably at least about 50 amino acids in length, wherein at least two amino acids comprise KG, having a structure as follows: a sequence starting from any of amino acid numbers 127-x to 127; and ending at any of amino acid numbers 128 + ((n-2) - x), in which x varies from 0 to n-2.
The location of the variant protein was determined according to results from a number of different software programs and analyses, including analyses from SignalP and other specialized programs. The variant protein is believed to be located as follows with regard to the cell: secreted. The protein localization is believed to be secreted because both signal-peptide prediction programs predict that this protein has a signal peptide, and neither trans-membrane region prediction program predicts that this protein has a trans -membrane region..
Variant protein HUMGRP5E_P4 also has the following non- silent SNPs (Single Nucleotide Polymorphisms) as listed in Table 164, (given according to their position(s) on the amino acid sequence, with the alternative amino acid(s) listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein HUMGRP5EJP4 sequence provides support for the deduced sequence of this variant protein according to the present invention). Table 164 -Amino acid mutations
Variant protein HUMGRP5E_JP4 is encoded by the following transcript(s): HUMGRP5E_T4, for which the sequence(s) is/are given at the end of the application. The coding portion of transcript HUMGRP5E_T4 is shown in bold; this coding portion starts at position 622 and ends at position 1044. The transcript also has the following SNPs as listed in Table 165 (given according to their position on the nucleotide sequence, with the alternative nucleic acid listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein HUMGRP5E_P4 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 165 - Nucleic acid SNPs
Variant protein HUMGRP5E_P5 according to the present invention has an amino acid sequence as given at the end of the application; it is encoded by transcript(s) HUMGRP5E_T5. An alignment is given to the known protein (Gastrin- releasing peptide precursor) at the end of the application. One or more alignments to one or more previously published protein sequences
are given at the end of the application. A brief description of the relationship of the variant protein according to the present invention to each such aligned protein is as follows:
Comparison report between HUMGRP5E P5 and GRPJHUMAN: LAn isolated chimeric polypeptide encoding for HUMGRP5E_P5, comprising a first amino acid sequence being at least 90 % homologous to
MRGSELPLVLLALVLCLAPRGRAVPLPAGGGTVLTKMYPRGNHWAVGHLMGKKSTG ESSSVSERGSLKQQLREYIRWEEAARNLLGLIEAKENRNHQPPQPKALGNQQPSWDSED SSNFKDVGSKGK corresponding to amino acids 1 - 127 of GRPJHUMAN, which also corresponds to amino acids 1 - 127 of HUMGRP5E_P5, and a second amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence DSLLQVLNVKEGTPS corresponding to amino acids 128 - 142 of HUMGRP5EJP5, wherein said first and second amino acid sequences are contiguous and in a sequential order. 2.An isolated polypeptide encoding for a tail of HUMGRP5EJP5, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence DSLLQVLNVKEGTPS in HUMGRP5E_P5.
The location of the variant protein was determined according to results from a number of different software programs and analyses, including analyses from SignalP and other specialized programs. The variant protein is believed to be located as follows with regard to the cell: secreted. The protein localization is believed to be secreted because both signal-peptide prediction programs predict that this protein has a signal peptide, and neither trans -membrane region prediction program predicts that this protein has a trans -membrane region.
Variant protein HUMGRP5EJP5 also has the following non- silent SNPs (Single Nucleotide Polymorphisms) as listed in Table 166, (given according to their position(s) on the amino acid sequence, with the alternative amino acid(s) listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein HUMGRP5E_P5 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 166 - Amino acid mutations
Variant protein HUMGRP5E P5 is encoded by the following transcript(s): HUMGRP5E_T5, for which the sequence(s) is/are given at the end of the application. The coding portion of transcript HUMGRP5E_T5 is shown in bold; this coding portion starts at position 622 and ends at position 1047. The transcript also has the following SNPs as listed in Table 167 (given according to their position on the nucleotide sequence, with the alternative nucleic acid listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein HUMGRP5E_P5 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 167 - Nucleic acid SNPs
As noted above, cluster HUMGRP5E features 5 segment(s), which were listed in Table 161 above and for which the sequence(s) are given at the end of the application. These segment(s) are portions of nucleic acid sequence(s) which are described herein separately because they are of particular interest. A description of each segment according to the present invention is now provided.
Segment cluster HUMGRP5E_node_0 according to the present invention is supported by 21 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): HUMGRP5E_T4 and HUMGRP5EJT5. Table 168 below describes the starting and ending position of this segment on each transcript.
Table 168 - Segment location on transcripts
Segment cluster HUMGRP5E_node_2 according to the present invention is supported by 27 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): HUMGRP5E_T4 and HUMGRP5EJT5. Table 169 below describes the starting and ending position of this segment on each transcript.
Table 169 - Segment location on transcripts
Segment cluster HUMGRP5E_node_8 according to the present invention is supported by
26 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): HUMGRP5E_T4 and HUMGRP5EJT5. Table 170 below describes the starting and ending position of this segment on each transcript.
Table 170 - Segment location on transcripts
According to an optional embodiment of the present invention, short segments related to the above cluster are also provided. These segments are up to about 120 bp in length, and so are included in a separate description.
Segment cluster HUMGRP5E_node_3 according to the present invention can be found in the following transcript(s): HUMGRP5E_T4 and HUMGRP5EJT5. Table 171 below describes the starting and ending position of this segment on each transcript.
Table 171 - Segment location on transcripts
Segment cluster HUMGRP5E_node_7 according to the present invention can be found in the following transcript(s): HUMGRP5E T5. Table 172 below describes the starting and ending position of this segment on each transcript.
Table 172 - Segment location on transcripts
Microarray (chip) data is also available for this gene as follows. As described above with regard to the cluster itself, various oligonucleotides were tested for being differentially expressed in various disease conditions, particularly cancer. The following oligonucleotides were found to hit this segment (with regard to lung cancer), shown in Table 173.
Table 173 - Oligonucleotides related to this gene
Variant protein alignment to the previously known protein:
Sequence name: /tmp/412zs2mwyT/B0wjOUAX0d:GRP_HUMAN
Sequence documentation:
Alignment of: HUMGRP5E_P4 x GRP_HUMAN
Alignment segment 1/1:
Quality: 1291.00 Escore: 0
Matching length: 141 Total length: 148
Matching Percent Similarity: 100.00 Matching Percent Identity: 100.00
Total Percent Similarity: 95.27 Total Percent Identity: 95.27 Gaps : 1
Alignment:
1 MRGSELPLVLLALVLCLAPRGRAVPLPAGGGTVLTKMYPRGNHWAVGHLM 50 I I I I I I M I I I | | | | | | | | | | I M I M I I I I I I I I I I I I I I I M I M I Il
1 MRGSELPLVLLALVLCLAPRGRAVPLPAGGGTVLTKMYPRGNHWAVGHLM 50
51 GKKSTGESSSVSERGSLKQQLREYIRWEEAARNLLGLIEAKENRNHQPPQ 100
I I Il Il I I I I I I I I I I I I I Il I Il I I I I Il Il Il Il I Il Il Il I i I Il I I 51 GKKSTGESSSVSERGSLKQQLREYIRWEEAARNLLGLIEAKENRNHQPPQ 100
101 PKALGNQQPSWDSEDSSNFKDVGSKGK GSQREGRNPQLNQQ 141
I I I I I I I I 1 I I I I I I I I I I I I I I Il I I I I I I I I I I I I I I I I
101 PKALGNQQPSWDSEDSSNFKDVGSKGKVGRLSAPGSQREGRNPQLNQQ 148
Sequence name: /tmp/lme91dnvfv/KbP5io8PtU: GRP_HUMAN
Sequence documentation:
Alignment of: HUMGRP5E_P5 x GRP_HUMAN
Alignment segment 1/1:
Quality: 1248 .00
Escore : 0
Matching length: 127 Total length : 127
Matching Percent Similarity: 100.00 Matching Percent Identity: 100.00
Total Percent Similarity: 100.00 Total Percent Identity: 100.00
Gaps : 0
Alignment:
1 MRGSELPLVLLALVLCLAPRGRAVPLPAGGGTVLTKMYPRGNHWAVGHLM 50
MRGSELPLVLLALVLCLAPRGRAVPLPAGGGTVLTKMYPRGNHWAVGHLM 50
GKKSTGESSSVSERGSLKQQLREYIRWEEAARNLLGLIEAKENRNHQPPQ 100
111111111111111111!11IMIIIIIIIII)IIMIIIIIIMIIII GKKSTGESSSVSERGSLKQQLREYIRWEEAARNLLGLIEAKENRNHQPPQ 100
PKALGNQQPSWDSEDSSNFKDVGSKGK 127
I I Il I I I 1 I Il Il Il I I I I I I Il I 1 Il PKALGNQQPSWDSEDSSNFKDVGSKGK 127
Expression of GRP HUMAN - gastrin-releasing peptide (HUMGRP5E) transcripts which are detectable by amplicon as depicted in sequence name HUMGRP5Ejunc3-7 in normal and cancerous lung tissues
Expression of GRPJHUMAN - gastrin-releasing peptide transcripts detectable by or according to HUMGRP5Ejunc3-7 amplicon (SEQ ID NO: 1648) and HUMGKP5Ejunc3-7F (SEQ ID NO: 1646) and HUMGRP5Ejunc3-7R (SEQ ID NO: 1647) primers was measured by real time PCR. In parallel the expression of four housekeeping genes PBGD (GenBank Accession No. BC019323; amplicon - PBGD- amplicon, SEQ ID NO:334), HPRTl (GenBank Accession No. NMJ)OOl 94; amplicon - HPRTl -amplicon, SEQ ID NO: 1297), Ubiquitin (GenBank Accession No. BC000449; amplicon - Ubiquitin- amplicon, SEQ ID NO:328) and SDHA (GenBank Accession No. NM_004168; amplicon - SDHA- amplicon, SEQ ID NO:331) was measured similarly. For each RT sample, the expression of the above amplicon was normalized to the geometric mean of the quantities of the housekeeping genes. The normalized quantity of each RT sample was then divided by the median of the quantities of the normal post- mortem (PM) samples (Sample Nos. 47-50, 90-93, 96-99, Table 2, "Tissue samples in testing sample",), to obtain a value of fold up -regulation for each sample relative to median of the normal PM samples.
Figure 19 is a histogram showing over expression of the above -indicated GRPJHUMAN - gastrin-releasing peptide transcripts in several cancerous lung samples relative to the normal samples. As is evident from Figure 19, the expression of GRPJHUMAN - gastrin-releasing peptide transcripts detectable by the above amplicon in several cancer samples was significantly higher than in the non- cancerous samples (Sample Nos. 47-50, 90-93, 96-99, Table 2, "Tissue samples in testing sample"). Notably an over- expression of at least 10 fold was found in 2 out of 15 adenocarcinoma samples, and in 7 out of 8 small cells carcinoma samples. Primer pairs are also optionally and preferably encompassed within the present invention; for example, for the above experiment, the following primer pair was used as a non- limiting illustrative example only of a suitable primer pair: HUMGRP5Ejunc3-7F forward primer; and HUMGRP5Ejunc3-7R reverse primer.
The present invention also preferably encompasses any amplicon obtained through the use of any suitable primer pair; for example, for the above experiment, the following amplicon
was obtained as a non- limiting illustrative example only of a suitable amplicon: HUMGRP5Ejunc3-7.
HUMGRP5Ejunc3-7F (SEQ ID NO: 1646) ACCAGCCACCTCAACCCA HUMGRP5Ejunc3-7R (SEQ ID NO: 1647)
CTGGAGCAGAGAGTCTTTGCCT HUMGRP5Ejunc3-7 (SEQ ID NO: 1648)
ACCAGCCACCTCAACCCAAGGCCCTGGGCAATCAGCAGCCTTCGTGGGATTCAGAG GATAGCAGCAACTTCAAAGATGTAGGTTCAAAAGGCAAAGACTCTCTGCTCCAG
Expression of GRP HUMAN - gastrin-releasing peptide (HUMGRP5E) transcripts which are detectable by amplicon as depicted in sequence name HUMGRP5Ejunc3-7 in different normal tissues Expression of GRP_HUMAN - gastrin-releasing peptide transcripts detectable byor according to HUMGRP5Ejunc3-7 amplicon (SEQ ID NO: 1648) and HUMGRP 5Ejunc3-7 F (SEQ ID NO: 1646) and HUMGRP 5Ejunc3-7R (SEQ ID NO: 1647) was measured by real time PCR. In parallel the expression of four housekeeping genes -RPLl 9 (GenBank Accession No. NM_000981; RPLl 9 amplicon, SEQ ID NO: 1630), TATA box (GenBank Accession No. NM_003194; TATA amplicon, SEQ ID NO: 1633), Ubiquitin (GenBank Accession No.
BC000449; amplicon - Ubiquitin- amplicon, SEQ ID NO:328) and SDHA (GenBank Accession No. NM_004168; amplicon - SDHA-amplicon, SEQ ID NO:331) was measured similarly. For each RT sample, the expression of the above amplicon was normalized to the geometric mean of the quantities of the housekeeping genes. The normalized quantity of each RT sample was then divided by the median of the quantities of the breast samples (Sample Nos. 33-35,Table 3, "Tissue samples on normal panel", above), to obtain a value of relative expression of each sample relative to median of the breast samples.
HUMGRP5Ejunc3-7F (SEQ ID NO: 1646)
ACCAGCCACCTCAACCCA
HUMGRP5Ejunc3-7R (SEQ ID NO: 1647)
CTGGAGCAGAGAGTCTTTGCCT
HUMGRP5Ejunc3-7 (SEQ ID NO: 1648)
ACCAGCCACCTCAACCCAAGGCCCTGGGCAATCAGCAGCCTTCGTGGGATTCAGAG GATAGCAGCAACTTCAAAGATGTAGGTTCAAAAGGCAAAGACTCTCTGCTCCAG The results are shown in Figure 20, demonstrating the expression of GRP_HUMAN - gastrin- releasing peptide (HUMGRP5E) transcripts which are detectable by amplicon as depicted in sequence name HUMGRP5Ejunc3-7 in different normal tissues.
DESCRIPTION FOR CLUSTER D56406
Cluster D56406 features 3 transcript(s) and 10 segment(s) of interest, the names for which are given in Tables 174 and 175, respectively, the sequences themselves are given at the end of the application. The selected protein variants are given in table 176.
Table 174 - Transcripts of interest
These sequences are variants of the known protein Neurotensin/neuromedin N precursor [Contains: Large neuromedin N (NmN- 125); Neuromedin N (NmN) (NN); Neurotensin (NT); Tail peptide] (SwissProt accession identifier NEUT_HUMAN), SEQ ID NO: 1422, referred to herein as the previously known protein.
Protein Neurotensin/neuromedin N precursor is known or believed to have the following function(s): Neurotensin may play an endocrine or paracrine role in the regulation of fat metabolism. It causes contraction of smooth muscle. The sequence for protein Neurotensin/neuromedin N precursor is given at the end of the application, as "Neurotensin/neuromedin N precursor [Contains: Large neuromedin N (NmN- 125); Neuromedin N (NmN) (NN); Neurotensin (NT); Tail peptide] amino acid sequence". Protein Neurotensin/neuromedin N precursor localization is believed to be Secreted; Packaged within secretory vesicles.
The following GO Annotation(s) apply to the previously known protein. The following annotation(s) were found: signal transduction, which are annotation(s) related to Biological Process; neuropeptide hormone, which are annotation(s) related to Molecular Function; and extracellular; soluble fraction, which are annotation(s) related to Cellular Component.
The GO assignment relies on information from one or more of the SwissProt/TremBl Protein knowledgebase, available from <http://www.expasy.ch/sprot/>; or Locuslink, available from <http://www.ncbi.nlm.nih.gov/projects/LocusLink/>.
As noted above, cluster D56406 features 3 transcript(s), which were listed in Table 174 above. These transcript(s) encode for protein(s) which are variant(s) of protein
Neurotensin/neuromedin N precursor. A description of each variant protein according to the present invention is now provided.
Variant protein D56406_PEA_l_P2 according to the present invention has an amino acid sequence as given at the end of the application; it is encoded by transcript(s)
D56406_PEA_l_T3. An alignment is given to the known protein (Neurotensin/neuromedin N precursor) at the end of the application. One or more alignments to one or more previously published protein sequences are given at the end of the application. A brief description of the relationship of the variant protein according to the present invention to each such aligned protein is as follows:
Comparison report between D56406_PEA_l_P2 and NEUT_HUMAN: 1.An isolated chimeric polypeptide encoding for D56406_PEA_l_P2, comprising a first amino acid sequence being at least 90 % homologous to MMAGMKIQLVCMLLLAFSSWSLCSDSEEEMKALEADFLTNMHTSKISKAHVPSWKMT LLNVCSLVNNLNSPAEETGEVHEEELVARRKLPTALDGFSLEAMLTIYQLHKICHSRAF QHWE corresponding to amino acids 1 - 120 of NEUT_HUMAN, which also corresponds to amino acids 1 - 120 of D56406_PEA_l_P2, second amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence ARWLTPVIPALWEAETGGSRGQEMETIPANT corresponding to amino acids 121 - 151 of D56406_PEA_l_P2, and a third amino acid sequence being at least 90 % homologous to LIQEDILDTGNDKNGKEEVKRKIPYILKRQLYENKPRRPYILKRDSYYY corresponding to amino acids 121 - 170 of NEUT_HUMAN, which also corresponds to amino acids 152 - 201 of D56406_PEA_l_P2, wherein said first, second and third amino acid sequences are contiguous and in a sequential order.
2.An isolated polypeptide encoding for an edge portion of D56406_PEA_l JP2, comprising an amino acid sequence being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence encoding for ARWLTPVIP ALWEAETGGSRGQEMETIPANT, corresponding to D56406_PEA_l_P2.
The location of the variant protein was determined according to results from a number of different software programs and analyses, including analyses from SignalP and other specialized programs. The variant protein is believed to be located as follows with regard to the cell: secreted. The protein localization is believed to be secreted because both signal-peptide prediction programs predict that this protein has a signal peptide, and neither trans -membrane region prediction program predicts that this protein has a trans- membrane region- Variant protein D56406_PEA_l_P2 also has the following non-silent SNPs (Single Nucleotide Polymorphisms) as listed in Table 177, (given according to their position(s) on the amino acid sequence, with the alternative amino acid(s) listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein D56406_PEA_l_P2 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 177 - Amino acid mutations
Variant protein D56406_PEA_l_P2 is encoded by the following transcript(s): D56406_PEA_l_T3, for which the sequence(s) is/are given at the end of the application. The coding portion of transcript D56406_PEA_l_T3 is shown in bold; this coding portion starts at position 106 and ends at position 708. The transcript also has the following SNPs as listed in
Table 178 (given according to their position on the nucleotide sequence, with the alternative nucleic acid listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein D56406_PEA_l_P2 sequence provides support for the deduced sequence of this variant protein according to the present invention). Table 178 - Nucleic acid SNPs
Variant protein D56406_PEA_l_P5 according to the present invention has an amino acid sequence as given at the end of the application; it is encoded by transcript(s) D56406_PEA_l_T6. An alignment is given to the known protein (Neurotensin/neuromedin N precursor) at the end of the application. One or more alignments to one or more previously published protein sequences are given at the end of the application. A brief description of the relationship of the variant protein according to the present invention to each such aligned protein is as follows: Comparison report between D56406_PEA_l_P5 and NEUT_HUMAN:
LAn isolated chimeric polypeptide encoding for D56406_PEA_l_P5, comprising a first amino acid sequence being at least 90 % homologous to MMAGMKIQLVCMLLLAFSSWSLC
corresponding to amino acids 1 - 23 of NEUTJHUMAN, which also corresponds to amino acids 1 - 23 of D56406_PEA_l_P5, and a second amino acid sequence being at least 90 % homologous to
SEEEMKALEADFLTNMHTSKISKAHVPSWKMTLLNVCSLVNNLNSPAEETGEVHEEEL VARRKLPTALDGFSLEAMLTIYQLHKJCHSRAFQHWELIQEDILDTGNDKNGKEEVIKR KIPYILKRQLYENKPRRPYILKRDSYYY corresponding to amino acids 26 - 170 of NEUTJHUMAN, which also corresponds to amino acids 24 - 168 of D56406_PEA_l_P5, wherein said first and second amino acid sequences are contiguous and in a sequential order. 2.An isolated chimeric polypeptide encoding for an edge portion of D56406_PEA_l_P5, comprising a polypeptide having a length "n", wherein n is at least about 10 amino acids in length, optionally at least about 20 amino acids in length, preferably at least about 30 amino acids in length, more preferably at least about 40 amino acids in length and most preferably at least about 50 amino acids in length, wherein at least two amino acids comprise CS, having a structure as follows: a sequence starting from any of amino acid numbers 23 -x to 23; and ending at any of amino acid numbers 24 + ((n-2) - x), in which x varies from 0 to n-2.
The location of the variant protein was determined according to results from a number of different software programs and analyses, including analyses from SignalP and other specialized programs. The variant protein is believed to be located as follows with regard to the cell: secreted. The protein localization is believed to be secreted because both signal-peptide prediction programs predict that this protein has a signal peptide, and neither trans -membrane region prediction program predicts that this protein has a trans -membrane region..
Variant protein D56406_PEA_l JP5 also has the following non-silent SNPs (Single Nucleotide Polymorphisms) as listed in Table 179, (given according to their position(s) on the amino acid sequence, with the alternative amino acid(s) listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein D56406_PEA_l_P5 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 179 - Amino acid mutations
Variant protein D56406_PEA_l_P5 is encoded by the following transcript(s): D56406_PEA_l_T6, for which the sequence(s) is/are given at the end of the application. The coding portion of transcript D56406_PEA_l_T6 is shown in bold; this coding portion starts at position 106 and ends at position 609. The transcript also has the following SNPs as listed in Table 180 (given according to their position on the nucleotide sequence, with the alternative nucleic acid listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein D56406 PEA 1 P5 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 180 -Nucleic acid SNPs
Variant protein D56406_PEA_l_P6 according to the present invention has an amino acid sequence as given at the end of the application; it is encoded by transcript(s) D56406_PEA_l_T7. An alignment is given to the known protein (Neurotensin/neuromedin N precursor) at the end of the application. One or more alignments to one or more previously published protein sequences are given at the end of the application. A brief description of the relationship of the variant protein according to the present invention to each such aligned protein is as follows: Comparison report between D56406_PEA_l_P6 and NEUT JHUMAN:
LAn isolated chimeric polypeptide encoding for D56406_PEA_l_P6, comprising a first amino acid sequence being at least 90 % homologous to
MMAGMKIQLVCMLLLAFSSWSLCSDSEEEMKALEADFLTNMHTSK corresponding to amino acids 1 - 45 of NEUT_HUMAN, which also corresponds to amino acids 1 - 45 of D56406_PEA_l_P6, and a second amino acid sequence being at least 90 % homologous to
LIQEDILDTGNDKNGKEEVIKRKIPYILKRQLYENKPRRPYILKRDSYYY corresponding to amino acids 121 - 170 of NEUT HUMAN, which also corresponds to amino acids 46 - 95 of D56406_PEA_l_P6, wherein said first and second amino acid sequences are contiguous and in a sequential order. 2.An isolated chimeric polypeptide encoding for an edge portion of D56406_PEA_l_P6, comprising a polypeptide having a length "n", wherein n is at least about 10 amino acids in length, optionally at least about 20 amino acids in length, preferably at least about 30 amino acids in length, more preferably at least about 40 amino acids in length and most preferably at least about 50 amino acids in length, wherein at least two amino acids comprise KL, having a structure as follows: a sequence starting from any of amino acid numbers 45-x to 45; and ending at any of amino acid numbers 46 + ((n-2) - x), in which x varies from 0 to n-2.
The location of the variant protein was determined according to results from a number of different software programs and analyses, including analyses from SignalP and other specialized programs. The variant protein is believed to be located as follows with regard to the cell: secreted. The protein localization is believed to be secreted because both signal-peptide prediction programs predict that this protein has a signal peptide, and neither trans -membrane region prediction program predicts that this protein has a trans -membrane region.
Variant protein D56406JPEA 1JP6 also has the following non-silent SNPs (Single Nucleotide Polymorphisms) as listed in Table 181, (given according to their position(s) on the amino acid sequence, with the alternative amino acid(s) listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein D56406_PEA_l_P6 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 181 -Amino acid mutations
Variant protein D56406_PEA_l_P6 is encoded by the following transcript(s): D564O6_PEA 1_T7, for which the sequence(s) is/are given at the end of the application. The coding portion of transcript D56406_PEA_l_T7 is shown in bold; this coding portion starts at position 106 and ends at position 390. The transcript also has the following SNPs as listed in Table 182 (given according to their position on the nucleotide sequence, with the alternative nucleic acid listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein D56406_PEA_l_P6 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 182 - Nucleic acid SNPs
As noted above, cluster D56406 features 10 segment(s), which were listed in Table 2 above and for which the sequence(s) are given at the end of the application. These segment(s) are portions of nucleic acid sequence(s) which are described herein separately because they are of particular interest. A description of each segment according to the present invention is now provided.
Segment cluster D56406_PEA_l_node_0 according to the present invention is supported by 48 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): D56406_PEA_l_T3, D56406_PEA_l_T6 and D56406_PEA_l_T7. Table 183 below describes the starting and ending position of this segment on each transcript.
Table 183 - Segment location on transcripts
Microarray (chip) data is also available for this segment as follows. As described above with regard to the cluster itself, various oligonucleotides were tested for being differentially
expressed in various disease conditions, particularly cancer. The following oligonucleotides were found to hit this segment (with regard to lung cancer), shown in Table 184.
Table 184 - Oligonucleotides related to this segment
Segment cluster D56406_PEA_l_node_13 according to the present invention is supported by 43 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): D56406_PEA_l_T3, D56406JPEA_l_T6 and D56406_PEA_l_T7. Table 185 below describes the starting and ending position of this segment on each transcript.
Table 185 - Segment location on transcripts
According to an optional embodiment of the present invention, short segments related to the above cluster are also provided. These segments are up to about 120 bp in length, and so are included in a separate description.
Segment cluster D56406_PEA_l_node_l 1 according to the present invention is supported by 1 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): D56406_PEA_l_T3. Table 186 below describes the starting and ending position of this segment on each transcript.
Table 186 - Segment location on transcripts
Segment cluster D56406_PEA_l_node_2 according to the present invention can be found in the following transcript(s): D56406_PEA_l_T3 and D56406_PEA_l_T7. Table 187 below describes the starting and ending position of this segment on each transcript.
Table 187 - Segment location on transcripts
Segment cluster D56406_PEA_l_node_3 according to the present invention is supported by 46 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): D56406_PEA_l_T3, D56406JPEA_l_T6 and D56406_PEA_l_T7. Table 188 below describes the starting and ending position of this segment on each transcript.
Table 188 - Segment location on transcripts
Segment cluster D56406_PEA_l_node_5 according to the present invention is supported by 48 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): D56406_PEA_l_T3 and D56406_PEA_l_T6. Table 189 below describes the starting and ending position of this segment on each transcript.
Table 189 - Segment location on transcripts
Segment cluster D56406_PEA_l_node_6 according to the present invention is supported by 34 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): D56406_PEA__l JT3 and D56406_PEA_l_T6. Table 190 below describes the starting and ending position of this segment on each transcript.
Table 190 - Segment location on transcripts
Segment cluster D56406_PEA_l_node_7 according to the present invention is supported by 32 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): D56406_PEA_l_T3 and D56406JPEA_l_T6. Table 191 below describes the starting and ending position of this segment on each transcript. Table 191 - Segment location on transcripts
Segment cluster D56406_PEA_l_node_8 according to the present invention can be found in the following transcript(s): D56406_PEA_l_T3 and D56406_PEA_l_T6. Table 192 below describes the starting and ending position of this segment on each transcript.
Table 192 - Segment location on transcripts
Segment cluster D56406_PEA_l_node_9 according to the present invention is supported by 31 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): D56406_PEA_l_T3 and D56406_PEA_l_T6. Table 193 below describes the starting and ending position of this segment on each transcript.
Table 193 - Segment location on transcripts
Variant protein alignment to the previously known protein: Sequence name: /tmp/jU49325aMA/8F0XuN7La5 :NEUT_HUMAN
Sequence documentation:
Alignment of: D56406_PEA_l_P2 x NEUT_HUMAN
Alignment segment 1/1:
Quality: 1591.00
Escore :
Matching length: 170 Total length: 201
Matching Percent Similarity: 100.00 Matching Percent Identity: 100.00 Total Percent Similarity: 84.58 Total Percent Identity: 84.58
Gaps: 1
Alignment : . . . . .
1 MMAGMKIQLVCMLLLAFSSWSLCSDSEEEMKALEADFLTNMHTSKISKAH 50
I I I I I I I I I I I I I I I I I I Il I I I I I I I I I I I I I I I I I I I I I I 1 I I I I I I I
1 MMAGMKIQLVCMLLLAFSSWSLCSDSEEEMKALEADFLTNMHTSKISKAH 50
51 VPSWKMTLLNVCSLVNNLNSPAEETGEVHEEELVARRKLPTALDGFSLEA 100
I I I I I Il I I I I I i I I Il I I Il I I I I I I I Il 1 Il I I I I Il Il I I I I I I I I I
51 VPSWKMTLLNVCSLVNNLNSPAEETGEVHEEELVARRKLPTALDGFSLEA 100
101 MLTIYQLHKICHSRAFQHWEARWLTPVIPALWEAETGGSRGQEMETIPAN 150 I I I M I I I I M I I I I I M I I
101 MLTIYQLHKICHSRAFQHWE 120
151 TLIQEDILDTGNDKNGKEEVIKRKIPYILKRQLYENKPRRPYILKRDSYY 200
I I I I Il I I Il I I I I I I I I Il Il I I Il I I I I I Il I I I I I I I I Il I I I I Il 121 .LIQEDILDTGNDKNGKEEVIKRKIPYILKRQLYENKPRRPYILKRDSYY 169
201 Y 201
I
170 Y 170
Sequence name: /tmp/wWui8Kd4y9/zbf3ihRwnR:NEUT_HUMAN
Sequence documentation:
Alignment of: D56406_PEA_l_P5 x NEUT_HUMAN
Alignment segment 1/1:
Quality: 1572.00 Escore: 0 Matching length: 168 Total length: 170
Matching Percent Similarity: 100.00 Matching Percent Identity: 100.00
Total Percent Similarity: 98.82 Total Percent Identity: 98.82
Gaps : 1
Alignment:
1 MMAGMKIQLVCMLLLAFSSWSLC..SEEEMKALEADFLTNMHTSKISKAH 48
I I Il I Il I I I I I I I I i I I I I I I I I I I I I I I Il I Il Il I I I I I I Il I I I
1 MMAGMKIQLVCMLLLAFSSWSLCSDSEEEMKALEADFLTNMHTSKISKAH 50
49 VPSWKMTLLNVCSLVNNLNSPAEETGEVHEEELVARRKLPTALDGFSLEA 98 I I I M M I I I I I I M I I I I I I H I I I I I I I I I Il I I I I I I I I I M I I I I I
51 VPSWKMTLLNVCSLVNNLNSPAEETGEVHEEELVARRKLPTALDGFSLEA 100
99 MLTIYQLHKICHSRAFQHWELIQEDILDTGNDKNGKEEVIKRKIPYILKR 148
1!11111!11111111!1111111!11111111!11111!11111111Il
101 MLTIYQLHKICHSRAFQHWELIQEDILDTGNDKNGKEEVIKRKIPYILKR 150
149 QLYENKPRRPYILKRDSYYY 168
I I I 1 I 1 I I I I Il I ! 1 I I I 1 I
151 QLYENKPRRPYILKRDSYYY 170
Sequence name: /tmp/f5d07fF5D7/E4N5xjUIAN:NEUT_HUMAN
Sequence documentation:
Alignment of: D56406 PEA_1_P6 x NEUT_HUMAN
Alignment segment 1/1:
Quality: 844.00
Escore : 0 Matching length: 95 Total length: 170
Matching Percent Similarity: 100.00 Matching Percent
Identity: 100.00
Total Percent Similarity: 55.88 Total Percent Identity: 55.88
Gaps :
Alignment :
1 MMAGMKIQLVCMLLLAFSSWSLCSDSEEEMKALEADFLTNMHTSK 45 I I I I I I I M I I I I I I I I I I I I I I I I I I I I Il I I I I I I I I 1 M M I
1 MMAGMKIQLVCMLLLAFSSWSLCSDSEEEMKALEADFLTNMHTSKISKAH 50
45 45
51 VPSWKMTLLNVCSLVNNLNSPAEETGEVHEEELVARRKLPTALDGFSLEA 100
46 LIQEDILDTGNDKNGKEEVIKRKIPYILKR 75
I I I I I I I I Il I I I Il I I I Il I Il I Il I I ! I
101 MLTIYQLHKICHSRAFQHWELIQEDILDTGNDKNGKEEVIKRKIPYILKR 150
76 QLYENKPRRPYILKRDSYYY 95
I I I l I I I I I I I I I I l I I I I I
151 QLYENKPRRPYILKRDSYYY 170
DESCRIPTION FOR CLUSTER F05068 Cluster F05068 features 3 transcript(s) and 12 segment(s) of interest, the names for which are given in Tables 194and 195, respectively, the sequences themselves are given at the end of the application. The selected protein variants are given in table 196.
Table 194 - Transcripts of interest
These sequences are variants of the known protein ADM precursor [Contains: Adrenomedullin (AM); Proadrenomedullin N- 20 terminal peptide (ProAM-N20) (ProAM N- terminal 20 peptide) (PAMP)] (SwissProt accession identifier ADML_HUMAN), SEQ ID NO: 1423, referred to herein as the previously known protein.
Protein ADM precursor is known or believed to have the following function(s): AM and PAMP are potent hypotensive and vasodilatator agents. Numerous actions have been reported,
most related to the physiologic control of fluid and electrolyte homeostasis. In the kidney, AM is diuretic and natriuretic, and both AM and PAMP inhibit aldosterone secretion by direct adrenal actions. In pituitary gland, both peptides at physiologically relevant doses inhibit basal ACTH secretion. Both peptides appear to act in brain and pituitary gland to facilitate the loss of plasma volume, actions which complement their hypotensive effects in blood vessels. The sequence for protein ADM precursor is given at the end of the application, as "ADM precursor [Contains: Adrenomedullin (AM); Proadrenomedullin N-20 terminal peptide (ProAM-N20) (ProAM N- terminal 20 peptide) (PAMP)] amino acid sequence". Known polymorphisms for this sequence are as shown in Table 197. Table 197 - Amino acid mutations for Known Protein
Protein ADM precursor localization is believed to be Secreted.
The following GO Annotation(s) apply to the previously known protein. The following annotation(s) were found: cAMP biosynthesis; progesterone biosynthesis; signal transduction; cell-cell signaling; pregnancy; excretion; circulation; response to wounding, which are annotation(s) related to Biological Process; ligand; hormone, which are annotation(s) related to Molecular Function; and extracellular space; soluble fraction, which are annotation(s) related to Cellular Component.
The GO assignment relies on information from one or more of the SwissProt/TremBl Protein knowledgebase, available from <http://www.expasy.ch/sprot/>; or Locuslink, available from <http://www.ncbi.nhn.nih.gov/projects/LocusLink/>.
Cluster F05068 can be used as a diagnostic marker according to overexpression of transcripts of this cluster in cancer. Expression of such transcripts in normal tissues is also given according to the previously described methods. The term "number" in the right hand column of the table and the numbers on the y-axis of figure 21 refer to weighted expression of ESTs in
each category, as "parts per million" (ratio of the expression of ESTs for a particular cluster to the expression of all ESTs in that category, according to parts per million).
Overall, the following results were obtained as shown with regard to the histograms in Figure 21 and Table 198. This cluster is overexpressed (at least at a minimum level) in the following pathological conditions: uterine malignancies.
Table 198 - Normal tissue distribution
Table 199 - P values and ratios for expression in cancerous tissue
As noted above, cluster F05068 features 3 transcript(s), which were listed in Table 194 above. These transcript(s) encode for protein(s) which are variant(s) of protein ADM precursor. A description of each variant protein according to the present invention is now provided.
Variant protein F05068_PEA_l_P7 according to the present invention has an amino acid sequence as given at the end of the application; it is encoded by transcript(s) F05068_PEA_l_T3 and F05068_PEA_l_T6. An alignment is given to the known protein (ADM precursor) at the end of the application. One or more alignments to one or more previously published protein sequences are given at the end of the application. A brief description of the relationship of the variant protein according to the present invention to each such aligned protein is as follows:
Comparison report between F05068_PEA_l_P7 and ADMLJHUMAN:
1.An isolated chimeric polypeptide encoding for F05068_PEA_l_P7, comprising a first amino acid sequence being at least 90 % homologous to
MKLVSVALMYLGSLAFLGADTARLDVASEFRKK corresponding to amino acids 1 - 33 of ADML_HUMAN, which also corresponds to amino acids 1 - 33 of F05068_PEA_l_P7.
The location of the variant protein was determined according to results from a number of different software programs and analyses, including analyses from SignalP and other specialized programs. The variant protein is believed to be located as follows with regard to the cell: secreted. The protein localization is believed to be secreted because both signal-peptide prediction programs predict that this protein has a signal peptide, and neither trans -membrane region prediction program predicts that this protein has a trans -membrane region..
Variant protein F05068_PEA_l_P7 also has the following non-silent SNPs (Single Nucleotide Polymorphisms) as listed in Table 200, (given according to their position(s) on the amino acid sequence, with the alternative amino acid(s) listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein F05068JPEA_l_P7 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 200 - Amino acid mutations
Variant protein F05068_PEA_l_P7 is encoded by the following transcript(s):
F05068_PEA_l_T3 and F05068JPEA_l_T6, for which the sequence(s) is/are given at the end of the application.
The coding portion of transcript F05068_PEA_l_T3 is shown in bold; this coding portion starts at position 267 and ends at position 365. The transcript also has the following SNPs as listed in Table 201 (given according to their position on the nucleotide sequence, with the alternative nucleic acid listed; the last column indicates whether the SNP is known or not; the
presence of known SNPs in variant protein F05068_PEA_l_P7 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 201 - Nucleic acid SNPs
The coding portion of transcript F05068JPEA_l_T6 is shown in bold; this coding portion starts at position 267 and ends at position 365. The transcript also has the following SNPs as listed in Table 202 (given according to their position on the nucleotide sequence, with the alternative nucleic acid listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein F05068_PEA_l_P7 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 202 - Nucleic acid SNPs
Variant protein F05068_PEA_l_P8 according to the present invention has an amino acid sequence as given at the end of the application; it is encoded by transcript(s) F05068_PEA_l_T4. An alignment is given to the known protein (ADM precursor) at the end of the application. One or more alignments to one or more previously published protein sequences are given at the end of the application. A brief description of the relationship of the variant protein according to the present invention to each such aligned protein is as follows: Comparison report between F05068_PEA_l_P8 and ADML__HUMAN: 1.An isolated chimeric polypeptide encoding for F05068_PEA_l_P8, comprising a first amino acid sequence being at least 90 % homologous to
MKLVSVALMYLGSLAFLGADTARLDVASEFRKKWNKWALSRGKRELRMSSSYPTGLA DVKAGPAQTLIRPQDMKGASRSPED corresponding to amino acids 1 - 82 of ADML_HUMAN, which also corresponds to amino acids 1 - 82 of F05068JPEA_l_P8, and a second amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence R corresponding to amino acids 83 - 83 of F05068_PEA_l_P8, wherein said first and second amino acid sequences are contiguous and in a sequential order.
The location of the variant protein was determined according to results from a number of different software programs and analyses, including analyses from SignalP and other specialized programs. The variant protein is believed to be located as follows with regard to the cell: secreted. The protein localization is believed to be secreted because both signal-peptide prediction programs predict that this protein has a signal peptide, and neither trans -membrane region prediction program predicts that this protein has a trans -membrane region- Variant protein F05068_PEA_l_P8 also has the following non-silent SNPs (Single Nucleotide Polymorphisms) as listed in Table 203, (given according to their position(s) on the amino acid sequence, with the alternative amino acid(s) listed; the last column indicates whether
the SNP is known or not; the presence of known SNPs in variant protein F05068_PEA_l_P8 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 203 -Amino acid mutations
Variant protein F05068JPEA 1 JP8 is encoded by the following transcript(s): F05068_PEA_l_T4, for which the sequence(s) is/are given at the end of the application. The coding portion of transcript F05068_PEA_l_T4 is shown in bold; this coding portion starts at position 267 and ends at position 515. The transcript also has the following SNPs as listed in Table 204 (given according to their position on the nucleotide sequence, with the alternative nucleic acid listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein F05068_PEA_l_P8 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 204 - Nucleic acid SNPs
As noted above, cluster F05068 features 12 segment(s), which were listed in Table 2 above and for which the sequence(s) are given at the end of the application. These segment(s) are portions of nucleic acid sequence(s) which are described herein separately because they are of particular interest. A description of each segment according to the present invention is now provided.
Segment cluster F05068_PEA_l_node_0 according to the present invention is supported by 143 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): F05068_PEA_l_T3, F05068_PEA_l JT4 and F05068_PEA_l_T6. Table 205 below describes the starting and ending position of this segment on each transcript.
Table 205 - Segment location on transcripts
Segment cluster F05068_PEA_l_node_10 according to the present invention is supported by 127 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): F05068_PEA_l_T3, F05068_PEA_l_T4 and F05068_PEA_l_T6. Table 206 below describes the starting and ending position of this segment on each transcript. Table 206 - Segment location on transcripts
Segment cluster F05068_PEA_l_node_12 according to the present invention is supported by 123 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): F05068_PEA_l JT3, F05068_PEA_l_T4 and F05068_PEA_l_T6. Table 207 below describes the starting and ending position of this segment on each transcript.
Table 207 - Segment location on transcripts
Segment cluster F05068_PEA_l_node_13 according to the present invention is supported by 181 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): F05068J?EA_l_T3, F05068_PEA_l_T4 and F05068_PEA_l_T6. Table 208 below describes the starting and ending position of this segment on each transcript.
Table 208 - Segment location on transcripts
Segment cluster F05068_PEA_l_node_4 according to the present invention is supported by 15 libraries. The number of libraries was determined as previously described. This segment
can be found in the following transcript(s): F05068_PEA_l_T3 and F05068_PEA_l_T6. Table 209 below describes the starting and ending position of this segment on each transcript.
Table 209- Segment location on transcripts
Segment cluster F05068JPEA_l_node_8 according to the present invention is supported by 13 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): F05068_PEA_l_T4 and F05068_PEA_l_T6. Table 210 below describes the starting and ending position of this segment on each transcript.
Table 210 - Segment location on transcripts
According to an optional embodiment of the present invention, short segments related to the above cluster are also provided. These segments are up to about 120 bp in length, and so are included in a separate description
Segment cluster F05068_PEA_l_node_l 1 according to the present invention is supported by 112 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): F05068_PEA_l_T3, F05068_PEA_l_T4 and F05068_PEA_l_T6. Table 211 below describes the starting and ending position of this segment on each transcript.
Table 211 - Segment location on transcripts
Segment cluster F05068_PEA_l_node_3 according to the present invention is supported by 145 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): F05068_PEA_l_T3, F05068 _PEA_l_T4 and F05068_PEA_l_T6. Table 212 below describes the starting and ending position of this segment on each transcript.
Table 212 - Segment location on transcripts
Segment cluster F05068_PEA_l_node_5 according to the present invention is supported by 124 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): F05068_PEA_l_T3, F05068_PEA_l_T4 and F05068_PEA_l_T6. Table 213 below describes the starting and ending position of this segment on each transcript.
Table 213 - Segment location on transcripts
Segment cluster F05068_PEA_l_node_6 according to the present invention is supported by 110 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): F05068_PEA_l_T3, F05068_PEA_l_T4 and
F05068_PEA_l_T6. Table 214 below describes the starting and ending position of this segment on each transcript.
Table 214 - Segment location on transcripts
Segment cluster F05068_PEA_l_node_7 according to the present invention is supported by 109 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): F05068_PEA_l_T3, F05068_PEA_l_T4 and F05068_PEA_l_T6. Table 215 below describes the starting and ending position of this segment on each transcript.
Table 215 - Segment location on transcripts
Segment cluster F05068_PEA_l_node_9 according to the present invention is supported by 114 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): F05068_PEA_l_T3, F05068_PEA_l_T4 and F05068_PEA_l_T6. Table 216 below describes the starting and ending position of this segment on each transcript.
Table 216 - Segment location on transcripts
Variant protein alignment to the previously known protein:
Sequence name: /tmp/kEsi3RWsCN/lsvdhj fiNV:ADML_HUMAN
Sequence documentation:
Alignment of: F05068_PEA_l_P7 x ADML_HUMAN
Alignment segment 1/1:
Quality: 304.00 Escore: 0
Matching length: 33 Total length: 33
Matching Percent Similarity: 100.00 Matching Percent Identity: 100.00
Total Percent Similarity: 100.00 Total Percent Identity: 100.00 Gaps : 0
Alignment :
1 MKLVSVALMYLGSLAFLGADTARLDVASEFRKK 33
1 MKLVSVALMYLGSLAFLGADTARLDVASEFRKK 33
Sequence name: /tmp/tcrlWIx4kg/aghbr8Eh8n :ADML_HUMAN
Sequence documentation:
Alignment of: F05068_PEA_l_P8 x ADML_HUMAN
Alignment segment 1/1:
Quality: 791.00 Escore: 0
Matching length: 82 Total length: 82
Matching Percent Similarity: 100.00 Matching Percent Identity: 100.00
Total Percent Similarity: 100.00 Total Percent Identity: 100.00 Gaps : 0
Alignment:
1 MKLVSVALMYLGSLAFLGADTARLDVASEFRKKWNKWALSRGKRELRMSS 50 I I I I M I I I I I I I I I I I I I I M I I I I I I I I I I I I I I I I I M I I I I I I I I I
1 MKLVSVALMYLGSLAFLGADTARLDVASEFRKKWNKWALSRGKRELRMSS 50
51 SYPTGLADVKAGPAQTLIRPQDMKGASRSPED 82
51 SYPTGLADVKAGPAQTLIRPQDMKGASRSPED 82
DESCRIPTION FOR CLUSTER H14624
Cluster H 14624 features 1 transcript(s) and 15 segment(s) of interest, the names for which are given in Tables 217 and 218, respectively, the sequences themselves are given at the end of the application. The selected protein variants are given in table 219.
Table 217 - Transcripts of interest
Cluster H 14624 can be used as a diagnostic marker according to overexpression of transcripts of this cluster in cancer. Expression of such transcripts in normal tissues is also given according to the previously described methods. The term "number" in the right hand column of the table and the numbers on the y-axis of figure 22 refer to weighted expression of ESTs in each category, as "parts per million" (ratio of the expression of ESTs for a particular cluster to the expression of all ESTs in that category, according to parts per million).
Overall, the following results were obtained as shown with regard to the histograms in Figure 22 and Table 220. This cluster is overexpressed (at least at a minimum level) in the following pathological conditions: colorectal cancer, epithelial malignant tumors, a mixture of malignant tumors from different tissues, lung malignant tumors and pancreas carcinoma.
Table 220 - Normal tissue distribution
Table 221 - P values and ratios for expression in cancerous tissue
As noted above, contig H14624 features 1 transcript(s), which were listed in Table 217 above. A description of each variant protein according to the present invention is now provided.
Variant protein H14624JP15 according to the present invention has an amino acid sequence as given at the end of the application; it is encoded by transcript(s) H14624_T20. One or more alignments to one or more previously published protein sequences are given at the end of the application. A brief description of the relationship of the variant protein according to the present invention to each such aligned protein is as follows:
Comparison report between H14624JP15 and Q9HAP5 (SEQ ID NO: 1701): 1.An isolated chimeric polypeptide encoding for H14624JP15, comprising a first amino acid sequence being at least 90 % homologous to
MLQGPGSLLLLFLASHCCLGSARGLFLFGQPDFSYKRSNCKPIPANLQLCHGIEYQNMR LPNLLGHETMKEVLEQAGAWIPLVMKQCHPDTKKFLCSLFAPVCLDDLDETIQPCHSLC VQVKDRCAPVMSAFGFPWPDMLECDRFPQDNDLCIPLASSDHLLPATEE corresponding to amino acids 1 - 167 of Q9HAP5, which also corresponds to amino acids 1 - 167 of
H14624_P15, and a second amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence GKPSLLLPHSLLG corresponding to amino acids 168 - 180 of H14624_P15, wherein said first and second amino acid sequences are contiguous and in a sequential order.
2.An isolated polypeptide encoding for a tail of H14624_P15, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence GKPSLLLPHSLLG in H14624 P15.
The location of the variant protein was determined according to results from a number of different software programs and analyses, including analyses from SignalP and other specialized programs. The variant protein is believed to be located as follows with regard to the cell: secreted. The protein localization is believed to be secreted because both signal-peptide
prediction programs predict that this protein has a signal peptide, and neither trans -membrane region prediction program predicts that this protein has a trans -membrane region.
Variant protein H14624_P15 also has the following non- silent SNPs (Single Nucleotide Polymorphisms) as listed in Table 222, (given according to their position(s) on the amino acid sequence, with the alternative amino acid(s) listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein H14624_P15 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 222 - Amino acid mutations
Variant protein H14624_P15 is encoded by the following transcript(s): H14624JT20, for which the sequence(s) is/are given at the end of the application. The coding portion of transcript H14624_T20 is shown in bold; this coding portion starts at position 857 and ends at position 1396. The transcript also has the following SNPs as listed in Table 223 (given according to their position on the nucleotide sequence, with the alternative nucleic acid listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein H14624_P15 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 223 - Nucleic acid SNPs
As noted above, cluster H14624 features 15 segment(s), which were listed in Table 2 above and for which the sequence(s) are given at the end of the application. These segment(s) are portions of nucleic acid sequence(s) which are described herein separately because they are of particular interest. A description of each segment according to the present invention is now provided.
Segment cluster H14624_node_0 according to the present invention is supported by 3 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): H14624_T20. Table 224 below describes the starting and ending position of this segment on each transcript.
Table 224 - Segment location on transcripts
Segment cluster H14624_node_16 according to the present invention is supported by 3 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): H14624_T20. Table 225 below describes the starting and ending position of this segment on each transcript.
Table 225 - Segment location on transcripts
Segment cluster H14624_node_3 according to the present invention is supported by 67 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcriρt(s): H14624_T20. Table 226 below describes the starting and ending position of this segment on each transcript.
Table 226 - Segment location on transcripts
According to an optional embodiment of the present invention, short segments related to the above cluster are also provided. These segments are up to about 120 bp in length, and so are included in a separate description.
Segment cluster H14624_node_10 according to the present invention can be found in the following transcript(s): H14624_T20. Table 227 below describes the starting and ending position of this segment on each transcript.
Table 227 - Segment location on transcripts
Segment cluster H14624_node_l 1 according to the present invention is supported by 99 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): H14624JT20. Table 228 below describes the starting and ending position of this segment on each transcript.
Table 228 - Segment location on transcripts
Segment cluster H14624_node_12 according to the present invention can be found in the following transcript(s): H14624_T20. Table 229 below describes the starting and ending position of this segment on each transcript.
Table 229 - Segment location on transcripts
Segment cluster H14624_node_13 according to the present invention is supported by 124 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): H14624_T20. Table 230 below describes the starting and ending position of this segment on each transcript.
Table 230 - Segment location on transcripts
Segment cluster H14624_node_14 according to the present invention is supported by 114 libraries. The number of libraries was determined as previously described. This segment can be
found in the following transcript(s): H14624_T20. Table 231 below describes the starting and ending position of this segment on each transcript.
Table 231 - Segment location on transcripts
Segment cluster Hl 4624_node_l 5 according to the present invention is supported by 124 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): H14624 T20. Table 232 below describes the starting and ending position of this segment on each transcript.
Table 232 - Segment location on transcripts
Segment cluster H14624_node_4 according to the present invention is supported by 65 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): H14624_T20. Table 233 below describes the starting and ending position of this segment on each transcript.
Table 233 - Segment location on transcripts
Segment cluster H14624_node_5 according to the present invention can be found in the following transcript(s): H14624_T20. Table 234 below describes the starting and ending position of this segment on each transcript.
Table 234 - Segment location on transcripts
Segment cluster H14624_node_6 according to the present invention can be found in the following transcript(s): H14624_T20. Table 235 below describes the starting and ending position of this segment on each transcript.
Table 235 - Segment location on transcripts
Segment cluster H14624_node_7 according to the present invention can be found in the following transcript(s): H14624_T20. Table 236 below describes the starting and ending position of this segment on each transcript.
Table 236 - Segment location on transcripts
Segment cluster H14624_node_8 according to the present invention is supported by 85 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): H14624_T20. Table 237 below describes the starting and ending position of this segment on each transcript.
Table 237 - Segment location on transcripts
Segment cluster H14624_node_9 according to the present invention is supported by 87 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): H14624_T20. Table 238 below describes the starting and ending position of this segment on each transcript.
Table 238 - Segment location on transcripts
Variant protein alignment to the previously known protein:
Sequence name: /tmp/ϋpblSbFkrj /N4PrGQAB2V:Q9HAP5
Sequence documentation:
Alignment of: H14624_P15 x Q9HAP5
Alignment segment 1/1:
Quality: 1702.00 Escore: 0
Matching length: 167 Total length: 167
Matching Percent Similarity: 100.00 Matching Percent Identity: 100.00
Total Percent Similarity: 100.00 Total Percent Identity: 100.00
Gaps :
Alignment:
1 MLQGPGSLLLLFLASHCCLGSARGLFLFGQPDFSYKRSNCKPIPANLQLC 50 I I Il I I I I I I I I I I I I I I Il I I I I I I I I I I I I I I I Il I I I I Il Il I I I I I
1 MLQGPGSLLLLFLASHCCLGSARGLFLFGQPDFSYKRSNCKPIPANLQLC 50
51 HGIEYQNMRLPNLLGHETMKEVLEQAGAWIPLVMKQCHPDTKKFLCSLFA 100
I Il I I I Il I I I I I I I Il I I Il Il I I I I Il I I I Il I I I Il I Il Il I I I I I I
51 HGIEYQNMRLPNLLGHETMKEVLEQAGAWIPLVMKQCHPDTKKFLCSLFA 100
101 PVCLDDLDETIQPCHSLCVQVKDRCAPVMSAFGFPWPDMLECDRFPQDND 150
I I I I I I I I I I I I I Il I I I I I I Il I I I I I I I Il I Il I I I I I I I I I Il I I I I
101 PVCLDDLDETIQPCHSLCVQVKDRCAPVMSAFGFPWPDMLECDRFPQDND 150
151 LCIPLASSDHLLPATEE 167
151 LCIPLASSDHLLPATEE 167
DESCRIPTION FOR CLUSTER H38804
Cluster H38804 features 2 transcript(s) and 20 segment(s) of interest, the names for which are given in Tables 239 and 240, respectively, the sequences themselves are given at the end of the application. The selected protein variants are given in table 241.
Table 239 - Transcripts of interest
These sequences are variants of the known protein Mitotic checkpoint protein BUB3 (SwissProt accession identifier BUB3JHUMAN), SEQ ID NO: 1424, referred to herein as the previously known protein. Protein Mitotic checkpoint protein BUB3 is known or believed to have the following function(s): Required for kinetochore localization of BUBl. The sequence for protein Mitotic checkpoint protein BUB3 is given at the end of the application, as "Mitotic checkpoint protein BUB3 amino acid sequence". Known polymorphisms for this sequence are as shown in Table 242 Table 242 - Amino acid mutations for Known Protein
Protein Mitotic checkpoint protein BUB3 localization is believed to be Nuclear.
The following GO Annotation(s) apply to the previously known protein. The following annotation(s) were found: mitosis; mitotic checkpoint; mitotic spindle checkpoint; cell proliferation, which are annotation(s) related to Biological Process; and nucleus, which are annotation(s) related to Cellular Component.
The GO assignment relies on information from one or more of the SwissProt/TremBl Protein knowledgebase, available from <http://www.expasy.cli/sprot/>; or Locuslink, available from <http://www.ncbi.nrm.nih.gov/projects/LocusLink/>.
Cluster H38804 can be used as a diagnostic marker according to overexpression of transcripts of this cluster in cancer. Expression of such transcripts in normal tissues is also given according to the previously described methods. The term "number" in the right hand column of the table and the numbers on the y-axis of figure 23 refer to weighted expression of ESTs in each category, as "parts per million" (ratio of the expression of ESTs for a particular cluster to the expression of all ESTs in that category, according to parts per million).
Overall, the following results were obtained as shown with regard to the histograms in Figure 23 and Table 243. This cluster is overexpressed (at least at a minimum level) in the following pathological conditions: transitional cell carcinoma, brain malignant tumors, a mixture of malignant tumors from different tissues and gastric carcinoma.
Table 243 - Normal tissue distribution
Table 244 - P values and ratios for expression in cancerous tissue
As noted above, cluster H38804 features 2 transcript(s), which were listed in Table 239 above. These transcript(s) encode for protein(s) which are variant(s) of protein Mitotic
checkpoint protein BUB3. A description of each variant protein according to the present invention is now provided.
Variant protein H38804_PEA_l_P5 according to the present invention has an amino acid sequence as given at the end of the application; it is encoded by transcript(s)
H38804_PEA_l_T8. An alignment is given to the known protein (Mitotic checkpoint protein BUB3) at the end of the applicatbn. One or more alignments to one or more previously published protein sequences are given at the end of the application. A brief description of the relationship of the variant protein according to the present invention to each such aligned protein is as follows:
Comparison report between H388O4JPEA_1JP5 and BUB3_HUMAN: 1.An isolated chimeric polypeptide encoding for H38804_PEA_l_P5, comprising a first amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence
MGRVRTLAGECSAQAQAQSLLAWLSAPPSGGTPSARLSVRSPSPRDPWGLWAPVLQ corresponding to amino acids 1 - 57 of H38804_PEA_l_P5, and a second amino acid sequence being at least 90 % homologous to MTGSNEFKLNQPPEDGISSVKFSPNTSQFLLVSSWDTSVRLYDVPANSMRLKYQHTGA VLDCAFYDPTHAWSGGLDHQLKMHDLNTDQENLVGTHDAPIRCVEYCPEVNVMVTG SWDQTVKLWDPRTPCNAGTFSQPEKVYTLSVSGDRLIVGTAGRRVLVWDLRNMGYVQ QRRESSLKYQTRCIRAFPNKQGYVLSSIEGRVAVEYLDPSPEVQKKKYAFKCHRLKENN ffiQIYP VNAISFHNIHNTFATGGSDGFVNIWDPFNKKRLCQFHRYPTSIASLAFSNDGTTL AIASSYMYEMDDTEHPEDGIFIRQVTDAETKPK corresponding to amino acids 1 - 324 of BUB3_HUMAN, which also corresponds to amino acids 58 - 381 of H38804_PEA_l_P5, wherein said first and second amino acid sequences are contiguous and in a sequential order.
2.An isolated polypeptide encoding for a head of H38804JPEA_l_P5, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence
MGRVRTLAGECSAQAQAQSLLAVVLSAPPSGGTPSARLSVRSPSPRDPWGLWAPVLQ of H38804 PEA 1 P5.
The location of the variant protein was determined according to results from a number of different software programs and analyses, including analyses from SignalP and other specialized programs. The variant protein is believed to be located as follows with regard to the cell: secreted. The protein localization is believed to be secreted because one of the two signal- peptide prediction programs (HMM: Signal peptide,NN:NO) predicts that this protein has a signal peptide.. Variant protein H38804_PEA_l_P5 also has the following non-silent SNPs (Single
Nucleotide Polymorphisms) as listed in Table 245, (given according to their position(s) on the amino acid sequence, with the alternative amino acid(s) listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein H38804_PEA_l_P5 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 245 - Amino acid mutations
Variant protein H38804_PEA_l_P5 is encoded by the following transcript(s): H38804_PEA_l_T8, for which the sequence(s) is/are given at the end of the application. The coding portion of transcript H38804_PEA_l_T8 is shown in bold; this coding portion starts at position 475 and ends at position 1617. The transcript also has the following SNPs as listed in Table 246 (given according to their position on the nucleotide sequence, with the alternative nucleic acid listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein H38804_PEA_l_P5 sequence provides support for the deduced sequence of this variant protein according to the present invention). Table 246 - Nucleic acid SNPs
Variant protein H38804_PEA_l_P17 according to the present invention has an amino acid sequence as given at the end of the application; it is encoded by transcript(s) H38804_PEA_l_T24. An alignment is given to the known protein (Mitotic checkpoint protein BUB3) at the end of the application. One or more alignments to one or more previously published protein sequences are given at the end of the application. A brief description of the relationship of the variant protein according to the present invention to each such aligned protein is as follows:
Comparison report between H38804_PEA_l_P17 and BUB3_HUMAN: 1.An isolated chimeric polypeptide encoding for H38804_PEA_l_P17, comprising a first amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence
MGRVRTLAGECSAQAQAQSLLAVVLSAPPSGGTPSARLSVRSPSPRDPWGLWAPVLQ corresponding to amino acids 1 - 57 of H38804JPEA_l_P17, and a second amino acid sequence being at least 90 % homologous to
MTGSNEFKLNQPPEDGISSVKFSPNTSQFLLVSSWDTSVRLYDVPANSMRLKYQHTGA VLDCAFYDPTHAWSGGLDHQLKMHDLNTDQENLVGTHDAPIRCVEYCPEVNVMVTG SWDQTVKLWDPRTPCNAGTFSQPEKVYTLSVSGDRLIVGTAGRRVLVWDLRNMGYVQ QRRESSLKYQTRCIRAFPNKQGYVLSSIEGRVAVEYLDPSPEVQKKKYAFKCHRLKENN IEQIYPVNAISFHNIHNTFATGGSDGFVNIWDPFNKKRLCQFHRYPTSIASLAFSNDGTTL AIASSYMYEMDDTEHPEDGIFIRQVTDAETKPKSPCT corresponding to amino acids 1 - 328 of BUB3_HUMAN, which also corresponds to amino acids 58 - 385 of
H38804_PEA_l_P17, wherein said first and second amino acid sequences are contiguous and in a sequential order.
2.An isolated polypeptide encoding for a head of H38804_PEA_l_P17, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence
MGRVRTLAGECSAQAQAQSLLAVVLSAPPSGGTPSARLSVRSPSPRDPWGLWAPVLQ of H38804_PEA_l_P17.
The location of the variant protein was determined according to results from a number of different software programs and analyses, including analyses from SignalP and other specialized programs. The variant protein is believed to be located as follows with regard to the cell: secreted. The protein localization is believed to be secreted because one of the two signal- peptide prediction programs (HMM: Signal peptide,NN:NO) predicts that this protein has a signal peptide..
Variant protein H38804_PEA_l_P17 also has the following non-silent SNPs (Single Nucleotide Polymorphisms) as listed in Table 247, (given according to their positions) on the amino acid sequence, with the alternative amino acid(s) listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein H38804JPEA_l_P17 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 247 - Amino acid mutations
Variant protein H38804_PEA_l_P17 is encoded by the following transcript(s): H38804_PEA_l_T24, for which the sequence(s) is/are given at the end of the application. The coding portion of transcript H38804_PEA_l_T24 is shown in bold; this coding portion starts at position 475 and ends at position 1629. The transcript also has the following SNPs as listed in Table 248 (given according to their position on the nucleotide sequence, with the alternative nucleic acid listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein H38804_PEA_l_P17 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 248 - Nucleic acid SNPs
As noted above, cluster H38804 features 20 segment(s), which were listed in Table 2 above and for which the sequence(s) are given at the end of the application. These segment(s) are portions of nucleic acid sequence(s) which are described herein separately because they are of particular interest. A description of each segment according to the present invention is now provided.
Segment cluster H38804_PEA_l_node_0 according to the present invention is supported by 125 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): H38804_PEA_l_T24 and H38804_PEA_l_T8. Table 249 below describes the starting and ending position of this segment on each transcript.
Table 249 - Segment location on transcripts
Segment cluster H38804_PEA_l_node_l according to the present invention is supported by 9 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): H38804_PEA_l_T24 and H38804_PEA_l_T8. Table 250 below describes the starting and ending position of this segment on each transcript.
Table 250 - Segment location on transcripts
Segment cluster H38804_PEA_l_node_16 according to the present invention is supported by 214 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): H38804_PEA_l_T24 and H38804_PEA_l_T8. Table 251 below describes the starting and ending position of this segment on each transcript.
Table 251 - Segment location on transcripts
Segment cluster H38804_PEA_l_node_19 according to the present invention is supported by 198 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): H38804_PEA_l_T24 and H38804_PEA_l_T8. Table 252 below describes the starting and ending position of this segment on each transcript.
Table 252 - Segment location on transcripts
Segment cluster H38804_PEA_l_node_24 according to the present invention is supported by 180 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): H38804_PEA_l_T24 and H38804_PEA_l_T8. Table 253 below describes the starting and ending position of this segment on each transcript.
Table 253 - Segment location on transcripts
Segment cluster H38804JPEA_l_node_25 according to the present invention is supported by 28 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): H38804_PEA_l JT8. Table 254 below describes the starting and ending position of this segment on each transcript.
Table 254 - Segment location on transcripts
Segment cluster H38804_PEA_l_node_28 according to the present invention is supported by 38 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): H38804_PEA_l_T8. Table 255 below describes the starting and ending position of this segment on each transcript.
Table 255 - Segment location on transcripts
Transcript name Segment starting position Segment ending ' position
H38804_PEA_l_T8 2018 2607
Segment cluster H38804_PEA_l_node_29 according to the present invention is supported by 259 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): H38804_PEA_l_T24 and H38804_PEA__l_T8. Table 256 below describes the starting and ending position of this segment on each transcript.
Table 256 - Segment location on transcripts
Segment cluster H38804_PEA_l_node_30 according to the present invention is supported by 169 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): H38804_PEA_l_T24 and H38804_PEA_l_T8. Table 257 below describes the starting and ending position of this segment on each transcript.
Table 257 - Segment location on transcripts
According to an optional embodiment of the present invention, short segments related to the above cluster are also provided. These segments are up to about 120 bp in length, and so are included in a separate description.
Segment cluster H38804_PEA_l_node_10 according to the present invention is supported by 179 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): H38804JPEA_l_T24 and H38804_PEA_l_T8. Table 258 below describes the starting and ending position of this segment on each transcript. Table 258 - Segment location on transcripts
Segment cluster H38804_PEA_l_node_l 2 according to the present invention is supported by 181 libraries. The number of libraries was determined as previously described. This segment
can be found in the following transcπpt(s): H38804_PEA_l_T24 and H38804_PEA_l_T8. Table 259 bebw describes the starting and ending position of this segment on each transcript.
Table 259 - Segment location on transcripts
Segment cluster H38804_PEA_l_node_13 according to the present invention is supported by 187 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): H38804_PEA_l_T24 and H38804_PEA_l_T8. Table 260 below describes the starting and ending position of this segment on each transcript. Table 260 - Segment location on transcripts
Segment cluster H38804_PEA_l_node_14 according to the present invention is supported by 179 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): H38804_PEA_l_T24 and H38804_PEA_l_T8. Table 261 below describes the starting and ending position of this segment on each transcript.
Table 261 - Segment location on transcripts
Segment cluster H38804JPEA_l_node_2 according to the present invention is supported by 156 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): H38804JPEA_l_T24 and H38804_PEA_l_T8. Table 262 below describes the starting and ending position of this segment on each transcript.
Table 262 - Segment location on transcripts
Segment cluster H38804__PEA_l_node_20 according to the present invention is supported by 162 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): H38804_PEA_l_T24 and H38804_PEA_l_T8. Table 263 below describes the starting and ending position of this segment on each transcript.
Table 263 - Segment location on transcripts
Segment cluster H38804JDEA__l_node_23 according to the present invention can be found in the following transcript(s): H38804_PEA_l_T24 and H38804_PEA_l_T8. Table 264 below describes the starting and ending position of this segment on each transcript.
Table 264 - Segment location on transcripts
Segment cluster H38804_PEA_l_node_26 according to the present invention is supported by 21 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): H38804_PEA_l_T8. Table 265 below describes the starting and ending position of this segment on each transcript.
Table 265 - Segment location on transcripts
Segment cluster H38804_PEA_l_node_3 according to the present invention is supported by 162 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): H38804_PEA_l_T24 and H38804_PEA_l_T8. Table 266 below describes the starting and ending position of this segment on each transcript.
Table 266 - Segment location on transcripts
Segment cluster H38804_PEA_l_node_4 according to the present invention is supported by 172 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): H38804_PEA_l_T24 and H38804_PEA_l_T8. Table 267 below describes the starting and ending position of this segment on each transcript.
Table 267 - Segment location on transcripts
Segment cluster H38804_PEA_l_node_5 according to the present invention can be found in the following transcripts): H38804JPEA_l_T24 and H38804JPEA_l_T8. Table 268 below describes the starting and ending position of this segment on each transcript.
Table 268 - Segment location on transcripts
Variant protein alignment to the previously known protein:
Sequence name: /tmp/RR4oV8zYLg/Q10RqeqpIp :BUB3_HUMAN
Sequence documentation:
Alignment of: H38804_PEA_l_P5 x BUB3_HUMAN
Alignment segment 1/1:
Quality: 3244.00 Escore: 0
Matching length: 324 Total length: 324 Matching Percent Similarity: 100.00 Matching Percent Identity: 100.00
Total Percent Similarity: 100.00 Total Percent Identity: 100.00
Gaps : 0
Alignment:
58 MTGSNEFKLNQPPEDGISSVKFSPNTSQFLLVSSWDTSVRLYDVPANSMR 107 I I I I I I I I I I I I I Il I I 1 I I I I 1 I I I I I I I I I I I Il I I I I I I I I I I I I I I
1 MTGSNEFKLNQPPEDGISSVKFSPNTSQFLLVSSWDTSVRLYDVPANSMR 50 . . . . .
108 LKYQHTGAVLDCAFYDPTHAWSGGLDHQLKMHDLNTDQENLVGTHDAPIR 157
I Il I I I I I I Il I I I I I I Il I I I I Il I Il Il Il I I I I I Il I I I I I I Il I I I
51 LKYQHTGAVLDCAFYDPTHAWSGGLDHQLKMHDLNTDQENLVGTHDAPIR 100
158 CVEYCPEVNVMVTGSWDQTVKLWDPRTPCNAGTFSQPEKVYTLSVSGDRL 207
I I I 1 Il I I I I I I I I I I I I I Il I I I I I 1 I I I I I I I I I I I Il I I I I I I I I I I
101 CVEYCPEVNVMVTGSWDQTVKLWDPRTPCNAGTFSQPEKVYTLSVSGDRL 150
208 IVGTAGRRVLVWDLRNMGYVQQRRESSLKYQTRCIRAFPNKQGYVLSSIE 257 I I I I I I I I I M I I I I I I I I I 1 I M I I I I M Il I M I I I I I I I I I I I I I I I
151 IVGTAGRRVLVWDLRNMGYVQQRRESSLKYQTRCIRAFPNKQGYVLSSIE 200
258 GRVAVEYLDPSPEVQKKKYAFKCHRLKENNIEQIYPVNAISFHNIHNTFA 307
I I I I I Il I I I Il Il I I I I I I I I I I I I I Il I I Il I I I I I I I I I I I I I Il I I 201 GRVAVEYLDPSPEVQKKKYAFKCHRLKENNIEQIYPVNAISFHNIHNTFA 250
308 TGGSDGFVNIWDPFNKKRLCQFHRYPTSIASLAFSNDGTTLAIASSYMYE 357
I I I I I I Il I I I I I I I I Il Il I Il I Il Il Il I Il I Il I Il Il I I Il Il I I I 251 TGGSDGFVNIWDPFNKKRLCQFHRYPTSIASLAFSNDGTTLAIASSYMYE 300
358 MDDTEHPEDGIFIRQVTDAETKPK 381
301 MDDTEHPEDGIFIRQVTDAETKPK 324
Sequence name: /tmp/Db0dQEpSuo/Lr8HPXaeBg:BUB3_HUMAN
Sequence documentation:
Alignment of: H38804_PEA_l_P17 x BUB3_HUMAN
Alignment segment 1/1:
Quality: 3288.00
Escore: 0
Matching length: 328 Total length: 328
Matching Percent Similarity: 100.00 Matching Percent Identity: 100.00
Total Percent Similarity: 100.00 Total Percent Identity: 100.00
Gaps : 0
Alignment:
58 MTGSNEFKLNQPPEDGISSVKFSPNTSQFLLVSSWDTSVRLYDVPANSMR 107 I I I I Il I I I Il I I I I I I I I I I I Il I 1 I I Il I I Il I I I I I I I I I I I I I Il I
1 MTGSNEFKLNQPPEDGISSVKFSPNTSQFLLVSSWDTSVRLYDVPANSMR 50 . . . . .
108 LKYQHTGAVLDCAFYDPTHAWSGGLDHQLKMHDLNTDQENLVGTHDAPIR 157
I I I 1 I I I I I I I I I I I 1 I I I I I I I I I I 1 I I I I 1 I I I I I I I I I I I I I 1 I I I I 51 LKYQHTGAVLDCAFYDPTHAWSGGLDHQLKMHDLNTDQENLVGTHDAPIR 100
158 CVEYCPEVNVMVTGSWDQTVKLWDPRTPCNAGTFSQPEKVYTLSVSGDRL 207 111111!111111111IMIIIIIIIIIIIMIIIMIIMIIIIIIIII
101 CVEYCPEVNVMVTGSWDQTVKLWDPRTPCNAGTFSQPEKVYTLSVSGDRL 150
208 IVGTAGRRVLVWDLRNMGYVQQRRESSLKYQTRCIRAFPNKQGYVLSSIE 257 I Il Il I Il I M Il I M I M Il M I I I M M M I I M I Il Il I I I M I I Il 151 IVGTAGRRVLVWDLRNMGYVQQRRESSLKYQTRCIRAFPNKQGYVLSSIE 200
258 GRVAVEYLDPSPEVQKKKYAFKCHRLKENNIEQIYPVNAISFHNIHNTFA 307
I Il I Il Il I I M M M Il M I I I Il Il M I I I I M I I I I M I I I I Il M I 201 GRVAVEYLDPSPEVQKKKYAFKCHRLKENNIEQIYPVNAISFHNIHNTFA 250 . . . . .
308 TGGSDGFVNIWDPFNKKRLCQFHRYPTSIASLAFSNDGTTLAIASSYMYE 357
I M M I M I M M M I M M M M M M M M I M M M M I I M M I M
251 TGGSDGFVNIWDPFNKKRLCQFHRYPTSIASLAFSNDGTTLAIASSYMYE 300
358 MDDTEHPEDGIFIRQVTDAETKPKSPCT 385
I I M M I M I M M Il I Il I 1 I Il Il M
301 MDDTEHPEDGIFIRQVTDAETKPKSPCT 328
DESCRIPTION FOR CLUSTER HSENA78 Cluster HSENA78 features 1 transcript(s) and 7 segment(s) of interest, the names for which are given in Tables 269 and 270, respectively, the sequences themselves are given at the end of the application. The selected protein variants are given in table 271.
Table 269 - Transcripts of interest
Table 270 - Segments of interest
These sequences are variants of the known protein Small inducible cytokine B5 precursor
(SwissProt accession identifier SZ05_HUMAN; known also according to the synonyms CXCL5; Epithelial-derived neutrophil activating protein 78; Neutrophil- activating peptide ENA- 78), SEQ ID NO: 1425, referred to herein as the previously known protein.
Protein Small inducible cytokine B5 precursor is known or believed to have the following function(s): Involved in neutrophil activation. The sequence for protein Small inducible cytokine B5 precursor is given at the end of the application, as "Small inducible cytokine B5 precursor amino acid sequence". Protein Small inducible cytokine B5 precursor localization is believed to be Secreted.
The following GO Annotation(s) apply to the previously known protein. The following annotation(s) were found: chemotaxis; signal transduction; cell-cell signaling; positive control of cell proliferation, which are annotation(s) related to Biological Process; and chemokine, which are annotation(s) related to Molecular Function.
The GO assignment relies on information from one or more of the SwissProt/TremBl Protein knowledgebase, available from <http://www.expasy.ch/sprot/>; or Locuslink, available from <http://www.ncbi.nlm.nih.gov/projects/LocusLink/>.
Cluster HSENA78 can be used as a diagnostic marker according to overexpression of transcripts of this cluster in cancer. Expression of such transcripts in normal tissues is also given according to the previously described methods. The term "number" in the right hand column of the table and the numbers on the y-axis of figure 24 refer to weighted expression of ESTs in each category, as "parts per million" (ratio of the expression of ESTs for a particular cluster to the expression of all ESTs in that category, according to parts per million).
Overall, the following results were obtained as shown with regard to the histograms in Figure 24 and Table 272. This cluster is overexpressed (at least at a minimum level) in the following pathological conditions: epithelial malignant tumors and lung malignant tumors.
Table 272 - Normal tissue distribution
Table 273 - P values and ratios for expression in cancerous tissue
As noted above, cluster HSENA78 features 1 transcript(s), which were listed in Table 269 above. These transcript(s) encode for protein(s) which are variant(s) of protein Small inducible cytokine B5 precursor. A description of each variant protein according to the present invention is now provided.
Variant protein HSENA78JP2 according to the present invention has an amino acid sequence as given at the end of the application; it is encoded by transcript(s) HSENA78JT5. An alignment is given to the known protein (Small inducible cytokine B 5 precursor) at the end of the application. One or more alignments to one or more previously published protein sequences are given at the end of the application. A brief description of the relationship of the variant protein according to the present invention to each such aligned protein is as follows: Comparison report between HSENA78_P2 and SZ05_HUMAN: 1.An isolated chimeric polypeptide encoding for HSENA78_P2, comprising a first amino acid sequence being at least 90 % homologous to MSLLSSRAARVPGPSSSLCALLVLLLLLTQPGPIASAGPAAAVLRELRCVCLQTTQGVHP KMISNLQVFAIGPQCSKVEW corresponding to amino acids 1 - 81 of SZ05_HUMAN, which also corresponds to amino acids 1 - 81 of HSENA78_P2.
The location of the variant protein was determined according to results from a number of different software programs and analyses, including analyses from SignalP and other specialized programs. The variant protein is believed to be located as follows with regard to the cell: secreted. The protein localization is believed to be secreted because both signal-peptide prediction programs predict that this protein has a signal peptide, and neither trans -membrane region prediction program predicts that this protein has a trans -membrane region.. Variant protein HSENA78_P2 also has the following non-silent SNPs (Single Nucleotide
Polymorphisms) as listed in Table 274, (given according to their position(s) on the amino acid
sequence, with the alternative amino acid(s) listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein HSENA78_P2 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 274 - Amino acid mutations
Variant protein HSENA78_P2 is encoded by the following transcript(s): HSENA78_T5, for which the sequence(s) is/are given at the end of the application. The coding portion of transcript HSENA78_T5 is shown in bold; this coding portion starts at position 149 and ends at position 391. The transcript also has the following SNPs as listed in Table 275 (given according to their position on the nucleotide sequence, with the alternative nucleic acid listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein HSENA78_P2 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 275 - Nucleic acid SNPs
As noted above, cluster HSENA78 features 7 segment(s), which were listed in Table 270 above and for which the sequence(s) are given at the end of the application. These segment(s) are portions of nucleic acid sequence(s) which are described herein separately because they are of particular interest. A description of each segment according to the present invention is now provided.
Segment cluster HSENA78_node_0 according to the present invention is supported by 24 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): HSENA78_T5. Table 276 below describes the starting and ending position of this segment on each transcript.
Table 276 - Segment location on transcripts
Segment cluster HSENA78_node_2 according to the present invention is supported by 22 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): HSENA78_T5. Table 277 below describes the starting and ending position of this segment on each transcript.
Table 277 - Segment location on transcripts
Segment cluster HSENA78_node_6 according to the present invention is supported by 68 libraries. The number of libraries was determined as previously described. This segment can be
found in the following transcript(s): HSENA78_T5. Table 278 below describes the starting and ending position of this segment on each transcript.
Table 278 - Segment location on transcripts
Segment cluster HSENA78_node_9 according to the present invention is supported by 28 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): HSENA78_T5. Table 279 below describes the starting and ending position of this segment on each transcript. Table 279 - Segment location on transcripts
According to an optional embodiment of the present invention, short segments related to the above cluster are also provided. These segments are up to about 120 bp in length, and so are included in a separate description.
Segment cluster HSENA78_node_3 according to the present invention is supported by 1 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): HSENA78_T5. Table 280 below describes the starting and ending position of this segment on each transcript.
Table 280 - Segment location on transcripts
Segment cluster HSENA78_node_4 according to the present invention is supported by 17 libraries. The number of libraries was determined as previously described. This segment can be
found in the following transcript(s): HSENA78__T5 Table 281 below describes the starting and ending position of this segment on each transcπpt.
Table 281 - Segment location on transcripts
Segment cluster HSENA78_node_8 according to the present invention can be found in the following transcript(s): HSENA78_T5. Table 282 below describes the starting and ending position of this segment on each transcript.
Table 282 - Segment location on transcripts
Variant protein alignment to the previously known protein:
Sequence name: /tmp/5kiQY6MxWx/pLnTrxsCqk: SZ05_HUMAN
Sequence documentation:
Alignment of: HSENA78_P2 x SZ05_HUMAN
Alignment segment 1/1:
Quality: 767.00 Escore:
Matching length: 81 Total length: 81
Matching Percent Similarity: 100.00 Matching Percent Identity: 100.00
Total Percent Similarity: 100.00 Total Percent
Identity: 100.00
Gaps :
Alignment :
1 MSLLSSRAARVPGPSSSLCALLVLLLLLTQPGPIASAGPAAAVLRELRCV 50
1 MSLLSSRAARVPGPSSSLCALLVLLLLLTQPGPIASAGPAAAVLRELRCV 50
51 CLQTTQGVHPKMISNLQVFAIGPQCSKVEVV 81
51 CLQTTQGVHPKMISNLQVFAIGPQCSKVEW 81
DESCRIPTION FOR CLUSTER HUMODCA
Cluster HUMODCA features 1 transcript(s) and 17 segment(s) of interest, the names for which are given in Tables 283 and 284, respectively, the sequences themselves are given at the end of the application. The selected protein variants are given in table 285. Table 283 - Transcripts of interest
These sequences are variants of the known protein Ornithine decarboxylase (SwissProt accession identifier DCOR_HUMAN; known also according to the synonyms EC 4.1.1.17; ODC), SEQ ID NO: 1426, referred to herein as the previously known protein.
Protein Ornithine decarboxylase is known or believed to have the following function(s): Polyamine biosynthesis; first (rate- limiting) step. The sequence for protein Ornithine decarboxylase is given at the end of the application, as "Ornithine decarboxylase amino acid sequence". Known polymorphisms for this sequence are as shown in Table 286.
Table 286 - Amino acid mutations for Known Protein
The following GO Annotation(s) apply to the previously known protein. The following annotation(s) were found: polyamine biosynthesis, which are annotation(s) related to Biological Process; and ornithine decarboxylase; lyase, which are annotation(s) related to Molecular Function.
The GO assignment relies on information from one or more of the SwissProt/TremBl Protein knowledgebase, available from <http://www.expasy.ch/sprot/>; or Locuslink, available from <http://www.ncbi.nltn.nih.gov/projects/LocusLink/>.
Cluster HUMODCA can be used as a diagnostic marker according to overexpression of transcripts of this cluster in cancer. Expression of such transcripts in normal tissues is also given according to the previously described methods. The term "number" in the right hand column of the table and the numbers on the y-axis of figure 25 refer to weighted expression of ESTs in each category, as "parts per million" (ratio of the expression of ESTs for a particular cluster to the expression of all ESTs in that category, according to parts per million).
Overall, the following results were obtained as shown with regard to the histograms in Figure 25 and Table 287. This cluster is overexpressed (at least at a minimum level) in the following pathological conditions: brain malignant tumors, colorectal cancer, epithelial malignant tumors and a mixture of malignant tumors from different tissues. Table 287 - Normal tissue distribution
Table 288 - P values and ratios for expression in cancerous tissue
As noted above, cluster HUMODCA features 1 transcript(s), which were listed in Table 283 above. These transcript(s) encode for protein(s) which are variant(s) of protein Ornithine decarboxylase. A description of each variant protein according to the present invention is now provided.
Variant protein HUMODCA_P9 according to the present invention has an amino acid sequence as given at the end of the application; it is encoded by transcript(s) HUMODCA-Tl 7. An alignment is given to the known protein (Ornithine decarboxylase) at the end of the application. One or more alignments to one or more previously published protein sequences are given at the end of the application. A brief description of the relationship of the variant protein according to the present invention to each such aligned protein is as follows: Comparison report between HUMODCA_P9 and DCOR_HUMAN: 1.An isolated chimeric polypeptide encoding for HUMODCA_P9, comprising a first amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence MKSLTATSSMKVLLPRTFWTRKLMKFLLL corresponding to amino acids 1 - 29 of HUMODCA_P9, and a second amino acid sequence being at least 90 % homologous to
LVLRIATDDSKAVCRLSVKFGATLRTSRLLLERAKELNIDVVGVSFHVGSGCTDPETFV QAISDARCVFDMGAEVGFSMYLLDIGGGFPGSEDVKLKFEEITGVINP ALDKYFPSDSG VRIIAEPGRYYVASAFTLAVNIIAKKIVLKEQTGSDDEDESSEQTFMYYVNDGVYGSFN CILYDHAHVKPLLQKRPKPDEKYYSSSIWGPTCDGLDRIVERCDLPEMHVGDWMLFEN MGAYTVAAASTFNGFQRPTIYYVMSGPAWQLMQQFQNPDFPPEVEEQDASTLPVSCA WESGMKRHRAACASASINV corresponding to amino acids 151 - 461 of DCOR HUMAN, which also corresponds to amino acids 30 - 340 of HUMODCAJP9, wherein said first and second amino acid sequences are contiguous and in a sequential order.
2.An isolated polypeptide encoding for a head of HUMODCA_P9, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence MKSLTATS SMKVLLPRTFWTRKLMKFLLL of HUMODCA_P9.
Comparison report between HUMODCA_P9 and AAA59968 (SEQ ID NO:1702): 1.An isolated chimeric polypeptide encoding for HUMODCA_P9, comprising a first amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence MKSLTATSSMKVLLPRTFWTRKLMKFLLL corresponding to amino acids 1 - 29 of HUMODCAJP9, and a second amino acid sequence being at least 90 % homologous to
LVLRIATDDSKAVCRLSVKFGATLRTSRLLLERAKELNIDWGVSFHVGSGCTDPETFV QAISDARCVFDMGAEVGFSMYLLDIGGGFPGSEDVKLKFEEITGVINPALDKYFPSDSG VRIIAEPGRYYVASAFTLAVNΠAKKIVLKEQTGSDDEDESSEQTFMYYVNDGVYGSFN CILYDHAHVKPLLQKRPKPDEKYYSSSIWGPTCDGLDRΓVERCDLPEMHVGDWMLFEN MGAYTVAAASTFNGFQRPTIYYVMSGPAWQLMQQFQNPDFPPEVEEQDASTLPVSCA
WESGMKRHRAACASASINV corresponding to amino acids 40 - 350 of AAA59968, which also corresponds to amino acids 30 - 340 of HUMODCA P9, wherein said first and second amino acid sequences are contiguous and in a sequential order.
2.An isolated polypeptide encoding for a head of HUMODCA_P9, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence MKSLTATSSMKVLLPRTFWTRKLMKFLLL of HUMODCA_P9.
Comparison report between HUMODCA_P9 and AAH14562 (SEQ ID NO:1703):
1.An isolated chimeric polypeptide encoding for HUMODCA_P9, comprising a first amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence MKSLTATSSMKVLLPRTFWTRKLMKFLLL corresponding to amino acids 1 - 29 of HUMODCA_P9, and a second amino acid sequence being at least 90 % homologous to LVLRIATDDSKAVCRLSVKFGATLRTSRLLLERAKELNIDVVGVSFHVGSGCTDPETFV QAISDARCVFDMGAEVGFSMYLLDIGGGFPGSED VKLKFEEITGVINP ALDKYFPSDSG VRIIAEPGRYYVASAFTLAVNIIAKKIVLKEQTGSDDEDESSEQTFMYYVNDGVYGSFN CILYDHAHVKPLLQKRPKPDEKYYSSSIWGPTCDGLDRIVERCDLPEMHVGDWMLFEN MGAYTVAAASTFNGFQRPTIYYVMSGPAWQLMQQFQNPDFPPEVEEQDASTLPVSCA WESGMKRHRAACASASINV corresponding to amino acids 86 - 396 of AAH14562, which also corresponds to amino acids 30 - 340 of HUMODCA_P9, wherein said first and second amino acid sequences are contiguous and in a sequential order.
2.An isolated polypeptide encoding for a head of HUMODCAJP9, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence MKSLTATSSMKVLLPRTFWTRKLMKFLLL of HUMODCA_P9.
The location of the variant protein was determined according to results from a number of different software programs and analyses, including analyses from SignalP and other specialized programs. The variant protein is believed to be located as follows with regard to the cell: secreted. The protein localization is believed to be secreted because both signal-peptide prediction programs predict that this protein has a signal peptide, and neither trans -membrane region prediction program predicts that this protein has a trans -membrane region. Variant protein HUMODCA_P9 also has the following non-silent SNPs (Single
Nucleotide Polymorphisms) as listed in Table 289, (given according to their position(s) on the amino acid sequence, with the alternative amino acid(s) listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein HUMODCA_P9 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 289 - Amino acid mutations
Variant protein HUMODCA_P9 is encoded by the following transcript(s): HUMODCA_T17, for which the sequence(s) is/are given at the end of the application. The coding portion of transcript HUMODCA_T17 is shown in bold; this coding portion starts at position 528 and ends at position 1547. The transcript also has the following SNPs as listed in Table 290 (given according to their position on the nucleotide sequence, with the alternative nucleic acid listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein HUMODCAJP9 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 290 - Nucleic acid SNPs
As noted above, cluster HUMODCA features 17 segment(s), which were listed in Table 284 above and for which the sequence(s) are given at the end of the application. These segment(s) are portions of nucleic acid sequence(s) which are described herein separately because they are of particular interest. A description of each segment according to the present invention is now provided.
Segment cluster HUMODCA_node_l according to the present invention is supported by 76 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): HUM0DCA_T17. Table 291 below describes the starting and ending position of this segment on each transcript.
Table 291 - Segment location on transcripts
Segment cluster HUMODCA_node_25 according to the present invention is supported by 190 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): HUMODCA_T17. Table 292 below describes the starting and ending position of this segment on each transcript.
Table 292 - Segment location on transcripts
Segment cluster HUMODC A_node_32 according to the present invention is supported by 249 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): HUM0DCA_T17. Table 293 below describes the starting and ending position of this segment on each transcript.
Table 293 - Segment location on transcripts
Segment cluster HUMODC A_node_36 according to the present invention is supported by 348 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): HUM0DCA_T17. Table 294 below describes the starting and ending position of this segment on each transcript.
Table 294 - Segment location on transcripts
Segment cluster HUMODC A_node_39 according to the present invention is supported by 297 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): HUM0DCA_T17. Table 295 below describes the starting and ending position of this segment on each transcript.
Table 295 - Segment location on transcripts
Segment cluster HUMODCA_node_41 according to the present invention is supported by 230 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): HUMODCA T 17. Table 296 below describes the starting and ending position of this segment on each transcript.
Table 296 - Segment location on transcripts
According to an optional embodiment of the present invention, short segments related to the above cluster are also provided. These segments are up to about 120 bp in length, and so are included in a separate description.
Segment cluster HUMODCA_node_0 according to the present invention is supported by 9 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): HUMODCA_T17. Table 297 below describes the starting and ending position of this segment on each transcript.
Table 297 - Segment location on transcripts
Segment cluster HUMODCA_node_10 according to the present invention is supported by 107 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): HUMODCA_T17. Table 298 below describes the starting and ending position of this segment on each transcript.
Table 298 - Segment location on transcripts
Segment cluster HUMODCA_node_12 according to the present invention is supported by 132 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): HUMODC A_T17. Table 299 below describes the starting and ending position of this segment on each transcript.
Table 299 - Segment location on transcripts
Segment cluster HUMODCA_node_13 according to the present invention is supported by 126 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): HUM0DCA_T17. Table 300 below describes the starting and ending position of this segment on each transcript.
Table 300 - Segment location on transcripts
Segment cluster HUMODCA_node_2 according to the present invention is supported by 81 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): HUMODCA_T17. Table 301 below describes the starting and ending position of this segment on each transcript.
Table 301 - Segment location on transcripts
Segment cluster HUMODCA_node_27 according to the present invention is supported by 185 libraries. The number of libraries was determined as previously described. This segment can
be found in the following transcπpt(s): HUMODCA_T17. Table 302 below descπbes the starting and ending position of this segment on each transcript.
Table 302 - Segment location on transcripts
Segment cluster HUMODCA node 3 according to the present invention is supported by 85 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): HUMODCA_T17. Table 303 below describes the starting and ending position of this segment on each transcript. Table 303 - Segment location on transcripts
Segment cluster HUMODCA_node_30 according to the present invention is supported by 196 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): HUMODCA_T17. Table 304 below describes the starting and ending position of this segment on each transcript.
Table 304 - Segment location on transcripts
Segment cluster HUMODCA_node_34 according to the present invention is supported by
259 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): HUMODCA_T17. Table 305 below describes the starting and ending position of this segment on each transcript.
Table 305 - Segment location on transcripts
Segment cluster HUMODC A_node_38 according to the present invention is supported by 272 libraries. The number of libraries was deteπnined as previously described. This segment can be found in the following transcript(s): HUM0DCA_T17. Table 306 below describes the starting and ending position of this segment on each transcript.
Table 306 - Segment location on transcripts
Segment cluster HUMODCA_node_40 according to the present invention is supported by 239 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): HUM0DCA_T17. Table 307 below describes the starting and ending position of this segment on each transcript. Table 307 - Segment location on transcripts
Variant protein alignment to the previously known protein:
Sequence name: /tmp/y03EwE6i01/dRQ512K6e2 :DC0R HUMAN
Sequence documentation:
Alignment of: HUM0DCA_P9 x DCOR_HUMAN
Alignment segment 1/1:
Quality: 3056.00 Escore: 0
Matching length: 311 Total length: 311
Matching Percent Similarity: 100.00 Matching Percent Identity: 100.00
Total Percent Similarity: 100.00 Total Percent Identity: 100.00 Gaps: 0
Alignment :
30 LVLRIATDDSKAVCRLSVKFGATLRTSRLLLERAKELNIDVVGVSFHVGS 79 M I I I I I I I I I M I I M M I I I I I I I M I I I I I I I I I M I I I I I I I I I I I
151 LVLRIATDDSKAVCRLSVKFGATLRTSRLLLERAKELNIDVVGVSFHVGS 200
80 GCTDPETFVQAISDARCVFDMGAEVGFSMYLLDIGGGFPGSEDVKLKFEE 129
I I I I I I I I Il Il Il Il I Il Il I I I Il Il I I i I I I I I I I I I I I I I I I I I I I 201 GCTDPETFVQAISDARCVFDMGAEVGFSMYLLDIGGGFPGSEDVKLKFEE 250
130 ITGVINPALDKYFPSDSGVRIIAEPGRYYVASAFTLAVNIIAKKIVLKEQ 179
II I I I Il I I I I Il Il Il Il I I I I Il I I I I I I Il I I I I I I I I I I Il Il I I I
251 ITGVINPALDKYFPSDSGVRIIAEPGRYYVASAFTLAVNIIAKKIVLKEQ 300 . . . . .
180 TGSDDEDESSEQTFMYYVNDGVYGSFNCILYDHAHVKPLLQKRPKPDEKY 229
11 ! 1111 1 1 111111 ! 11 1111111 1 1 111 1 ! 1 ! 11 1 I M I I I I I I I I I I
301 TGSDDEDESSEQTFMYYVNDGVYGSFNCILYDHAHVKPLLQKRPKPDEKY 350
230 YSSSIWGPTCDGLDRIVERCDLPEMHVGDWMLFENMGAYTVAAASTFNGF 279 I I I I 1 I I I I I I 1 I I I I I I I I I I 1 I I I I I I I I I I I I I I I I I I I I I I I I 1 I I
351 YSSSIWGPTCDGLDRIVERCDLPEMHVGDWMLFENMGAYTVAAASTFNGF 400
280 QRPTIYYVMSGPAWQLMQQFQNPDFPPEVEEQDASTLPVSCAWESGMKRH 329
1 1 1 1 ! 11 1 1 111 ! 1 ! 1 1 1 ! 1 1 1 1 1 1 1 ! 1 1 1 1 1 1 I M I I I I I M I M I I I I 401 QRPTIYYVMSGPAWQLMQQFQNPDFPPEVEEQDASTLPVSCAWESGMKRH 450
330 RAACASASINV 340
I 1 I I I.I I l I l I
451 RAACASASINV 461
Sequence name: /tmp/y03EwE6i01/dRQ512K6e2 :AAA59968
Sequence documentation:
Alignment of: HUMODCA_P9 x AAA59968
Alignment segment 1/1:
Quality: 3056.00 Escore: 0
Matching length: 311 Total length: 311
Matching Percent Similarity: 100.00 Matching Percent Identity: 100.00 Total Percent Similarity: 100.00 Total Percent Identity: 100.00
Gaps : 0
Alignment : . . . . .
30 LVLRIATDDSKAVCRLSVKFGATLRTSRLLLERAKELNIDVVGVSFHVGS 79
I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I 1 I I I 1 I I I I
40 LVLRIATDDSKAVCRLSVKFGATLRTSRLLLERAKELNIDVVGVSFHVGS 89
80 GCTDPETFVQAISDARCVFDMGAEVGFSMYLLDIGGGFPGSEDVKLKFEE 129 I I I I I I I I I I I I I I I I I I Il I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I
90 GCTDPETFVQAISDARCVFDMGAEVGFSMYLLDIGGGFPGSEDVKLKFEE 139
130 ITGVINPALDKYFPSDSGVRIIAEPGRYYVASAFTLAVNIIAKKIVLKEQ 179 I I I I I I I I I M I I I I I I I I I I I I I I I I I I I I M M I I M I M M I I I I I I
140 ITGVINPALDKYFPSDSGVRIIAEPGRYYVASAFTLAVNIIAKKIVLKEQ 189
180 TGSDDEDESSEQTFMYYVNDGVYGSFNCILYDHAHVKPLLQKRPKPDEKY 229
I I I I I I I I Il I I I Il I I I I I I Il I I I I Il Il I I I I I I I I Il Il I I Il I Il 190 TGSDDEDESSEQTFMYYVNDGVYGSFNCILYDHAHVKPLLQKRPKPDEKY 239
230 YSSSIWGPTCDGLDRIVERCDLPEMHVGDWMLFENMGAYTVAAASTFNGF 279
I I Il I I I I Il I Il I I I Il I Il I I I I I I I I I I Il I I I I Il I I I I Il I Il I I
240 YSSSIWGPTCDGLDRIVERCDLPEMHVGDWMLFENMGAYTVAAASTFNGF 289 . . . . .
280 QRPTIYYVMSGPAWQLMQQFQNPDFPPEVEEQDASTLPVSCAWESGMKRH 329
I I I I I I I I I Il I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I Il I I I
290 QRPTIYYVMSGPAWQLMQQFQNPDFPPEVEEQDASTLPVSCAWESGMKRH 339
330 RAACASASINV 340
I I I I I I Il I I I
340 RAACASASINV 350
Sequence name: /tmp/y03EwE6i01/dRQ512K6e2 :AAH14562
Sequence documentation:
Alignment of: HUMODCA_P9 x AAH14562
Alignment segment 1/1:
Quality: 3056.00 Escore: 0
Matching length: 311 Total length: 311 Matching Percent Similarity: 100.00 Matching Percent Identity: 100.00
Total Percent Similarity: 100.00 Total Percent Identity: 100.00
Gaps : 0
Alignment :
30 LVLRIATDDSKAVCRLSVKFGATLRTSRLLLERAKELNIDVVGVSFHVGS 79
I I I I I I I I I Il I I ! I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I
86 LVLRIATDDSKAVCRLSVKFGATLRTSRLLLERAKELNIDVVGVSFHVGS 135 . . . . .
80 GCTDPETFVQAISDARCVFDMGAEVGFSMYLLDIGGGFPGSEDVKLKFEE 129
I Il I I I I I Il I I I I I I I I I I Il I I I I Il I I i I I I I I I I Il I I I I I Il I I I
136 GCTDPETFVQAISDARCVFDMGAEVGFSMYLLDIGGGFPGSEDVKLKFEE 185
130 ITGVINPALDKYFPSDSGVRIIAEPGRYYVASAFTLAVNIIAKKIVLKEQ 179
M M M I I I I I II I I I I M I I I I I I M I I M I M I I M M I M I I I M I I
186 ITGVINPALDKYFPSDSGVRIIAEPGRYYVASAFTLAVNIIAKKIVLKEQ 235
180 TGSDDEDESSEQTFMYYVNDGVYGSFNCILYDHAHVKPLLQKRPKPDEKY 229 Il I Il M I Il I Il M Il I I I M M M M I M Il I I M Il I I I Il M I I M
236 TGSDDEDESSEQTFMYYVNDGVYGSFNCILYDHAHVKPLLQKRPKPDEKY 285
230 YSSSIWGPTCDGLDRIVERCDLPEMHVGDWMLFENMGAYTVAAASTFNGF 279
I M I I Il I M M M M I I I I I I M Il I M I M M Il M M M M I M Il I 286 YSSSIWGPTCDGLDRIVERCDLPEMHVGDWMLFENMGAYTVAAASTFNGF 335
280 QRPTIYYVMSGPAWQLMQQFQNPDFPPEVEEQDASTLPVSCAWESGMKRH 329
I I Il I M I Il I M Il M I I M M M M M M I M I Il Il I Il I I M Il M
336 QRPTIYYVMSGPAWQLMQQFQNPDFPPEVEEQDASTLPVSCAWESGMKRH 385
330 RAACASASINV 340
II I M I M Il I
386 RAACASASINV 396
DESCRIPTION FOR CLUSTER R00299
Cluster R00299 features 1 transcript(s) and 12 segment(s) of interest, the names for which are given in Tables 308 and 309, respectively, the sequences themselves are given at the end of the application. The selected protein variants are given in table 310.
Table 308 - Transcripts of interest
These sequences are variants of the known protein Tescalcin (SwissProt accession identifier TESCJHUMAN; known also according to the synonyms TSC), SEQ ID NO: 1427, referred to herein as the previously known protein.
Protein Tescalcin is known or believed to have the following flmction(s): Binds calcium. The sequence for protein Tescalcin is given at the end of the application, as "Tescalcin amino acid sequence".
The following GO Annotation(s) apply to the previously known protein. The following annotation(s) were found: calcium binding, which are annotation(s) related to Molecular Function.
The GO assignment relies on information from one or more of the SwissProt/TremBl Protein knowledgebase, available from <http://www.expasy.ch/sprot/>; or Locuslink, available from <http://www.ncbi.nlm.nih.gov/projects/LocusLink/>.
Cluster R00299 can be used as a diagnostic marker according to overexpression of transcripts of this cluster in cancer. Expression of such transcripts in normal tissues is also given according to the previously described methods. The term "number" in the right hand column of the table and the numbers on the y-axis of figure 26 below refer to weighted expression of ESTs in each category, as "parts per million" (ratio of the expression of ESTs for a particular cluster to the expressbn of all ESTs in that category, according to parts per million).
Overall, the following results were obtained as shown with regard to the histograms in Figure 26 and Table 311. This cluster is overexpressed (at least at a minimum level) in the following pathological conditions: lung malignant tumors.
Table 311 - Normal tissue distribution
Table 312 - P values and ratios for expression in cancerous tissue
As noted above, cluster R00299 features 1 transcript(s), which were listed in Table 308 above. These transcript(s) encode for protein(s) which are variant(s) of protein Tescalcin. A description of each variant protein according to the present invention is now provided.
Variant protein R00299_P3 according to the present invention has an amino acid sequence as given at the end of the application; it is encoded by transcript(s) R00299_T2. An
alignment is given to the known protein (Tescalcin) at the end of the application. One or more alignments to one or more previously published protein sequences are given at the end of the application. A brief description of the relationship of the variant protein according to the present invention to each such aligned protein is as follows: Comparison report between R00299_P3 and Q9NWT9 (SEQ ID NO: 1704):
LAn isolated chimeric polypeptide encoding for R00299_P3, comprising a first amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence MAEKALLCPSSAGLGTWPWVLNSAWPVLPLAVDQGVDWRPRGPV corresponding to amino acids 1 - 44 of R00299JP3, second amino acid sequence being at least 90 % homologous to
SSDQIEQLHRRFKQLSGDQPTIRKENFNNVPDLELNPIRSKIVRAFFDNRNLRKGPSGLA DEΓNFEDFLTIMSYFRPIDTTMDEEQVELSRKEKLRFLFHMYDSDSDGRITLEEYRNV corresponding to amino acids 74 - 191 of Q9NWT9, which also corresponds to amino acids 45 - 162 of R00299 P3, and a third amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence
VEELLSGNPHIEKESARSIADGAMMEAASVCMGQMEPDQVYEGITFEDFLKIWQGIDIE TKMHVRFLNMETMALCH corresponding to amino acids 163 - 238 of R00299_P3, wherein said first, second and third amino acid sequences are contiguous and in a sequential order.
2.An isolated polypeptide encoding for a head of R00299_P3, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence MAEKALLCPSSAGLGTWPWVLNSAWPVLPLAVDQGVDWRPRGPV of R00299_P3. 3.An isolated polypeptide encoding for a tail of R00299_P3, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence VEELLSGNPHIEKESARSIADGAMMEAASVCMGQMEPDQVYEGITFEDFLKIWQGIDIE TKMHVRFLNMETMALCH in R00299_P3. Comparison report between R00299_P3 and TESC_HUMAN:
1.An isolated chimeric polypeptide encoding for R00299_P3, comprising a first amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence MAEKALLCPSSAGLGTWPWVLNSAWPVLPLAVDQGVDWRPRGPV corresponding to amino acids 1 - 44 of R00299_P3, and a second amino acid sequence being at least 90 % homologous to
SSDQIEQLHRRFKQLSGDQPTIRKENFNNVPDLELNPIRSKIVRAFFDNRNLRKGPSGLA DEINFEDFLTIMSYFRPIDTTMDEEQVELSRKEKLRFLFHMYDSDSDGRITLEEYRNVVE ELLSGNPHIEKESARSIADGAMMEAASVCMGQMEPDQVYEGITFEDFLKIWQGIDIETK MHVRPLNMETMALCH corresponding to amino acids 21 - 214 of TESC JHUMAN, which also corresponds to amino acids 45 - 238 of R00299_P3, wherein said first and second amino acid sequences are contiguous and in a sequential order.
2.An isolated polypeptide encoding for a head of R00299_P3, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence
MAEKALLCPSSAGLGTWPWVLNSAWPVLPLAVDQGVDWRPRGPV of R00299_P3.
The location of the variant protein was determined according to results from a number of different software programs and analyses, including analyses from SignalP and other specialized programs. The variant protein is believed to be located as follows with regard to the cell: secreted. The protein localization is believed to be secreted because one of the two signals peptide prediction programs (HMM:Signal peptide,NN:NO) predicts that this protein has a signal peptide.
Variant protein R00299 P3 also has the following non-silent SNPs (Single Nucleotide Polymorphisms) as listed in Table 313, (given according to their position(s) on the amino acid sequence, with the alternative amino acid(s) listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein R00299_P3 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 313 -Amino acid mutations
Variant protein R00299JP3 is encoded by the following transcript(s): R00299_T2, for which the sequence(s) is/are given at the end of the application. The coding portion of transcript R00299_T2 is shown in bold; this coding portion starts at position 142 and ends at position 855. The transcript also has the following SNPs as listed in Table 314 (given according to their position on the nucleotide sequence, with the alternative nucleic acid listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein R00299JP3 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 314 - Nucleic acid SNPs
As noted above, cluster R00299 features 12 segment(s), which were listed in Table 309 above and for which the sequence(s) are given at the end of the application. These segment(s) are portions of nucleic acid sequence(s) which are described herein separately because they are of particular interest. A description of each segment according to the present invention is now provided.
Segment cluster R00299_node_2 according to the present invention is supported by 3 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): R00299_T2. Table 315 below describes the starting and ending position of this segment on each transcript.
Table 315 - Segment location on transcripts
Segment cluster R00299_node_30 according to the present invention is supported by 75 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): R00299 T2. Table 316 below describes the starting and ending position of this segment on each transcript.
Table 316 - Segment location on transcripts
According to an optional embodiment of the present invention, short segments related to the above cluster are also provided. These segments are up to about 120 bp in length, and so are included in a separate description.
Segment cluster R00299_node_10 according to the present invention is supported by 46 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): R00299_T2. Table 317 below describes the starting and ending position of this segment on each transcript.
Table 317 - Segment location on transcripts
Segment cluster R00299_node_14 according to the present invention is supported by 61 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): R00299_T2. Table 318 below describes the starting and ending position of this segment on each transcript.
Table 318 - Segment location on transcripts
Segment cluster R00299_node_15 according to the present invention can be found in the following transcript(s): R00299_T2. Table 319 below describes the starting and ending position of this segment on each transcript.
Table 319 - Segment location on transcripts
Segment cluster R00299_node_20 according to the present invention is supported by 66 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): R00299_T2. Table 320 below describes the starting and ending position of this segment on each transcript.
Table 320 - Segment location on transcripts
Segment cluster R00299_node_23 according to the present invention is supported by 71 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): R00299_T2. Table 321 below describes the starting and ending position of this segment on each transcript.
Table 321 - Segment location on transcripts
Segment cluster R00299_node_25 according to the present invention is supported by 62 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): R00299_T2. Table 322 below describes the starting and ending position of this segment on each transcript.
Table 322 - Segment location on transcripts
Segment cluster R00299_node_28 according to the present invention can be found in the following transcript(s): R00299_T2. Table 323 below describes the starting and ending position of this segment on each transcript.
Table 323 - Segment location on transcripts
Segment cluster R00299_node_31 according to the present invention is supported by 48 libraries. The number of libraries was determined as previously described. This segment can be
found in the following transcript(s): R00299JT2. Table 324 below describes the starting and ending position of this segment on each transcript.
Table 324 - Segment location on transcripts
Segment cluster R00299_node_5 according to the present invention is supported by 45 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): R00299_T2. Table 325 below describes the starting and ending position of this segment on each transcript.
Table 325 - Segment location on transcripts
Segment cluster R00299_node_9 according to the present invention can be found in the following transcript(s): R00299_T2. Table 326 below describes the starting and ending position of this segment on each transcript.
Table 326 - Segment location on transcripts
Microarray (chip) data is also available for this gene as follows. As described above with regard to the cluster itself, various oligonucleotides were tested for being differentially expressed in various disease conditions, particularly cancer. The following oligonucleotide was found to hit this segment (with regard to lung cancer), shown in Table 327.
Table 327 - Oligonucleotide related to this gene
Variant protein alignment to the previously known protein:
Sequence name: /tmp/01eVDhrKQO/EjblgLomjM:Q9NWT9
Sequence documentation:
Alignment of: R00299_P3 x Q9NWT9
Alignment segment 1/1:
Quality: 1162.00
Escore: 0
Matching length: 118 Total length: 118
Matching Percent Similarity: 100.00 Matching Percent Identity: 100.00
Total Percent Similarity: 100.00 Total Percent Identity: 100.00
Gaps : 0
Alignment:
45 SSDQIEQLHRRFKQLSGDQPTIRKENFNNVPDLELNPIRSKIVRAFFDNR 94
74 SSDQIEQLHRRFKQLSGDQPTIRKENFNNVPDLELNPIRSKIVRAFFDNR 123
95 NLRKGPSGLADEINFEDFLTIMSYFRPIDTTMDEEQVELSRKEKLRFLFH 144
124 NLRKGPSGLADEINFEDFLTIMSYFRPIDTTMDEEQVELSRKEKLRFLFH 173
145 MYDSDSDGRITLEEYRNV 162
174 MYDSDSDGRITLEEYRNV 191
Sequence name: /tmp/OleVDhrKQ0/EjblgLomjM:TESC_HUMAN
Sequence documentation:
Alignment of: R00299_P3 x TESC_HUMAN
Alignment segment 1/1:
Quality: 1920.00 Escore: 0 Matching length: 194 Total length: 194
Matching Percent Similarity: 100.00 Matching Percent Identity: 100.00
Total Percent Similarity: 100.00 Total Percent Identity: 100.00
Gaps : 0
Alignment :
45 SSDQIEQLHRRFKQLSGDQPTIRKENFNNVPDLELNPIRSKIVRAFFDNR 94 I I I I 1 I I I I I I I I I I I I I I I I I I I I I I I I I I ! I I I I I I 1 I I I Ii I Il M I
21 SSDQIEQLHRRFKQLSGDQPTIRKENFNNVPDLELNPIRSKIVRAFFDNR 70
95 NLRKGPSGLADEINFEDFLTIMSYFRPIDTTMDEEQVELSRKEKLRFLFH 144
I I Il I I I I I I I I I I I I I I I I Il I Il I I I Il Il I I I I I I Il I I I I I I I I Il 71 NLRKGPSGLADEINFEDFLTIMSYFRPIDTTMDEEQVELSRKEKLRFLFH 120
145 MYDSDSDGRITLEEYRNVVEELLSGNPHIEKESARSIADGAMMEAASVCM 194 I I I Il I I Il I I I I I I I 1 I I I I I I Il I I 1 I Il I I I I I I I I I I I I I I I I I Il
121 MYDSDSDGRITLEEYRNVVEELLSGNPHIEKESARSIADGAMMEAASVCM 170 . . . .
195 GQMEPDQVYEGITFEDFLKIWQGIDIETKMHVRFLNMETMALCH 238
I I I I I I I I I I I I I I I I I l I I I I I I I I I I l I I I I I I I I I I I I I I I
171 GQMEPDQVYEGITFEDFLKIWQGIDIETKMHVRFLNMETMALCH 214
DESCRIPTION FOR CLUSTER W60282
Cluster W60282 features 1 transcript(s) and 6 segment(s) of interest, the names for which are given in Tables 328 and 329, respectively, the sequences themselves are given at the end of the application. The selected protein variants are given in table 330.
Table 328 - Transcripts of interest
These sequences are variants of the known protein Kallikrein 11 precursor (SwissProt accession identifier KLKB HUMAN; known also according to the synonyms EC 3.4.21.-; Hippostasin; Trypsin- like protease), SEQ ID NO: 1428, referred to herein as the previously known protein.
Protein Kallikrein 11 precursor is known or believed to have the following function(s): Possible multifunctional protease. Efficiently cleaves bz-Phe-Arg-4-methylcoumaryl-7-amide, a kallikrein substrate, and weakly cleaves other substrates for kallikrein and trypsin. The sequence for protein Kallikrein 11 precursor is given at the end of the application, as "Kallikrein 11 precursor amino acid sequence". Protein Kallikrein 11 precursor localization is believed to be Secreted.
The following GO Annotation(s) apply to the previously known protein. The following annotation(s) were found: proteolysis and peptidolysis, which are annotation(s) related to Biological Process; and chymotrypsin; trypsin; serine-type peptidase; hydrolase, which are annotation(s) related to Molecular Function.
The GO assignment relies on information from one or more of the SwissProt/TremBl Protein knowledgebase, available from <http://www.expasy.ch/sprot/>; or Locuslink, available from <http://www.ncbi.nhn.nih.gov/projects/LocusLink/>.
As noted above, cluster W60282 features 1 transcript(s), which were listed in Table 1 above. These transcript(s) encode for protein(s) which are variant(s) of protein Kallikrein 11
precursor. A description of each variant protein according to the present invention is now provided.
Variant protein W60282_PEA_l_P14 according to the present invention has an amino acid sequence as given at the end of the application; it is encoded by transcript(s)
W6O282_PEA_1_T11. An alignment is given to the known protein (Kallikrein 11 precursor) at the end of the application. One or more alignments to one or more previously published protein sequences are given at the end of the application. A brief description of the relationship of the variant protein according to the present invention to each such aligned protein is as follows: Comparison report between W60282_PEA_l_P14 and Q8IXD7 (SEQ ID NO:1705):
1.An isolated chimeric polypeptide encoding for W60282_PEA_l_P14, comprising a first amino acid sequence being at least 90 % homologous to
MRILQLILLALATGLVGGETRIIKGFECKPHSQPWQAALFEKTRLLCGATLIAPRWLLTA AHCLKP corresponding to amino acids 1 - 66 of Q8IXD7, which also corresponds to amino acids 1 - 66 of W60282_PEA_l_P14, and a second amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence TPASHLAMRQHHHH corresponding to amino acids 67 - 80 of W60282_PEA_l_P14, wherein said first and second amino acid sequences are contiguous and in a sequential order. 2.An isolated polypeptide encoding for a tail of W60282_PEA_l_P14, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence TPASHLAMRQHHHH in W60282_PEA_l_P14.
The location of the variant protein was determined according to results from a number of different software programs and analyses, including analyses from SignalP and other specialized programs. The variant protein is believed to be located as follows with regard to the cell: secreted. The protein localization is believed to be secreted because both signal-peptide prediction programs predict that this protein has a signal peptide, and neither trans -membrane region prediction program predicts that this protein has a trans-membrane region.
Variant protein W60282_PEA_l_P14 also has the following non-silent SNPs (Single Nucleotide Polymorphisms) as listed in Table 331, (given according to their position(s) on the ammo acid sequence, with the alternative amino acid(s) listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein W6O282_PEA_1JP14 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 331 -Amino acid mutations
Variant protein W60282_PEA_l_P14 is encoded by the following transcript(s): W6O282_PEA_1_T11, for which the sequence(s) is/are given at the end of the application. The coding portion of transcript W6O282_PEA_1_T11 is shown in bold; this coding portion starts at position 705 and ends at position 944. The transcript also has the following SNPs as listed in Table 332 (given according to their position on the nucleotide sequence, with the alternative nucleic acid listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein W60282_PEA_l_P14 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 332- Nucleic acid SNPs
As noted above, cluster W60282 features 6 segment(s), which were listed in Table 329 above and for which the sequence(s) are given at the end of the application. These segment(s)
are portions of nucleic acid sequence(s) which are described herein separately because they are of particular interest. A description of each segment according to the present invention is now provided.
Segment cluster W60282_PEA_l_node_10 according to the present invention is supported by 45 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): W6O282_PEA_1_T11. Table 333 below describes the starting and ending position of this segment on each transcript.
Table 333 - Segment location on transcripts
Segment cluster W60282_PEA_l_node_l 8 according to the present invention is supported by 49 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): W6O282_PEA_1_T11. Table 334 below describes the starting and ending position of this segment on each transcript.
Table 334 - Segment location on transcripts
Segment cluster W60282_PEA_l_node_22 according to the present invention is supported by 67 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): W6O282_PEA_1_T11. Table 335 below describes the starting and ending position of this segment on each transcript.
Table 335- Segment location on transcripts
Segment cluster W60282_PEA_l_node_5 according to the present invention is supported by 20 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): W6O282_PEA_1_T11. Table 336 below describes the starting and ending position of this segment on each transcript.
Table 336- Segment location on transcripts
According to an optional embodiment of the present invention, short segments related to the above cluster are also provided. These segments are up to about 120 bp in length, and so are included in a separate description.
Segment cluster W60282_PEA_l_node_21 according to the present invention is supported by 48 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): W6O282_PEA_1_T11. Table 337 below describes the starting and ending position of this segment on each transcript.
Table 337 - Segment location on transcripts
Segment cluster W60282_PEA_l_node_8 according to the present invention is supported by 39 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): W6O282_PEA_1_T11. Table 338 below describes the starting and ending position of this segment on each transcript.
Table 338 - Segment location on transcripts
Variant protein alignment to the previously known protein:
Sequence name: /tmp/rL7Wdc5hYg/eLOAfKIgqD:KLKB_HUMAN
Sequence documentation:
Alignment of: W60282_PEA_l_P14 x KLKB_HUMAN
Alignment segment 1/1:
Quality: 645.00 Escore: 0
Matching length: 72 Total length: 72
Matching Percent Similarity: 94.44 Matching Percent Identity: 94.44
Total Percent Similarity: 94.44 Total Percent Identity: 94.44 Gaps: 0
Alignment:
1 MRILQLILLALATGLVGGETRIIKGFECKPHSQPWQAALFEKTRLLCGAT 50
1 MRILQLILLALATGLVGGETRIIKGFECKPHSQPWQAALFEKTRLLCGAT 50
51 LIAPRWLLTAΔHCLKPTPASHL 72
51 LIAPRWLLTAAHCLKPRYIVHL 72
Sequence name: /tmp/rL7Wdc5hYg/eLOAfKIgqD:Q8IXD7
Sequence documentation:
Alignment of: W60282_PEA_l_P14 x Q8IXD7
Alignment segment 1/1:
Quality: 642.00 Escore: 0
Matching length: 66 Total length: 66
Matching Percent Similarity: 100.00 Matching Percent Identity: 100.00 Total Percent Similarity: 100.00 Total Percent Identity: 100.00
Gaps : 0
Alignment : . . . . .
1 MRILQLILLALATGLVGGETRIIKGFECKPHSQPWQAALFEKTRLLCGAT 50
1 MRILQLILLALATGLVGGETRIIKGFECKPHSQPWQAALFEKTRLLCGAT 50
51 LIAPRWLLTAAHCLKP 66
51 LIAPRWLLTAAHCLKP 66
DESCRIPTION FOR CLUSTER Z41644
Cluster Z41644 features 1 transcript(s) and 21 segment(s) of interest, the names for which are given in Tables 339 and 340, respectively, the sequences themselves are given at the end of the application. The selected protein variants are given in table 341.
Table 339 - Transcripts of interest
These sequences are variants of the known protein Small inducible cytokine B 14 precursor (SwissProt accession identifier SZ14_HUMAN; known also according to the synonyms CXCL14; Chemokine BRAK), SEQ ID NO: 1429, referred to herein as the previously known protein.
The sequence for protein Small inducible cytokine B 14 precursor is given at the end of the application, as "Small inducible cytokine B14 precursor amino acid sequence". Protein Small inducible cytokine B 14 precursor localization is believed to be Secreted.
The following GO Annotation(s) apply to the previously known protein. The following annotation(s) were found: chemotaxis; signal transduction; cell-cell signaling, which are annotation(s) related to Biological Process; and chemokine, which are annotation(s) related to Molecular Function. The GO assignment relies on information from one or more of the SwissProt/TremBl
Protein knowledgebase, available from <http://www.expasy.ch/sprot/>; or Locuslink, available from <http://www.ncbi.nhn.nih.gov/projects/LocusLink/>.
Cluster Z41644 can be used as a diagnostic marker according to overexpression of transcripts of this cluster in cancer. Expression of such transcripts in normal tissues is also given according to the previously described methods. The term "number" in the right hand column of the table and the numbers on the y-axis of figure 27 refer to weighted expression of ESTs in each category, as "parts per million" (ratio of the expression of ESTs for a particular cluster to the expression of all ESTs in that category, according to parts per million).
Overall, the following results were obtained as shown with regard to the histograms in Figure 27 and Table 342. This cluster is overexpressed (at least at a minimum level) in the following pathological conditions: lung malignant tumors, breast malignant tumors and pancreas carcinoma.
Table 342 - Normal tissue distribution
Table 343 - P values and ratios for expression in cancerous tissue
As noted above, cluster Z41644 features 1 transcript(s), which were listed in Table 339 above. These transcript(s) encode for protein(s) which are variant(s) of protein Small inducible cytokine B14 precursor. A description of each variant protein according to the present invention is now provided.
Variant protein Z41644_PEA_l_P10 according to the present invention has an amino acid sequence as given at the end of the application; it is encoded by transcript(s) Z41644_PEA_1_T5. An alignment is given to the known protein (Small inducible cytokine B14 precursor) at the end of the application. One or more alignments to one or more previously published protein sequences are given at the end of the application. A brief description of the relationship of the variant protein according to the present invention to each such aligned protein is as follows:
Comparison report between Z41644_PEA_1JP1O and SZ14_HUMAN: 1.An isolated chimeric polypeptide encoding for Z41644_PEA_l_P10, comprising a first amino acid sequence being at least 90 % homologous to
MRLLAAALLLLLLALYTARVDGSKCKCSRKGPKIRYSDVKKLEMKPKYPHCEEKMVII TTKSVSRYRGQEHCLHPKLQSTKRFIKWYNAWNEKRR corresponding to amino acids 1 - 95 of SZ14_HUMAN, which also corresponds to amino acids 1 - 95 of Z41644_PEA_l_P10, and a second amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence YAPPLLTFLPTRPSCGSQDGKGPPHQVI corresponding to amino acids 96 - 123 of Z41644_PEA_1 JPlO, wherein said first and second amino acid sequences are contiguous and in a sequential order.
2.An isolated polypeptide encoding for a tail of Z41644_PEA_l_P10, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence YAPPLLTFLPTRPSCGSQDGKGPPHQVI in Z41644_PEA_l_P10.
Comparison report between Z41644_PEA_l_P10 and Q9NS21 (SEQ ID NO:1706): LAn isolated chimeric polypeptide encoding for Z41644_PEA_l_P10, comprising a first amino acid sequence being at least 90 % homologous to
MRLLAAALLLLLLALYTARVDGSKCKCSRKGPKIRYSDVKKLEMKPKYPHCEEKMVII TTKSVSRYRGQEHCLHPKLQSTKRFIKWYNAWNEKRR corresponding to amino acids 13 - 107 of Q9NS21, which also corresponds to amino acids 1 - 95 of Z41644_PEA_l_P10, and a second amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence YAPPLLTFLPTRPSCGSQDGKGPPHQVI corresponding to amino acids
96 - 123 of Z41644_PEA_l_P10, wherein said first and second amino acid sequences are contiguous and in a sequential order.
2.An isolated polypeptide encoding for a tail of Z41644_PEA_l_P10, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence YAPPLLTFLPTRPSCGSQDGKGPPHQVI in Z41644_PEA_l_P10.
Comparison report between Z41644_PEA_l_P10 and AAQ89265 (SEQ ID NO:781): 1.An isolated chimeric polypeptide encoding for Z41644_PEA_l_P10, comprising a first amino acid sequence being at least 90 % homologous to MRLLAAALLLLLLALYTARVDGSKCKCSRKGPKIRYSDVKKLEMKPKYPHCEEKMVII TTKSVSRYRGQEHCLHPKLQSTKRFIKWYNAWNEKRR corresponding to amino acids 13 - 107 of AAQ89265, which also corresponds to amino acids 1 - 95 of Z41644_PEA_l_P10, and a second amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence YAPPLLTFLPTRPSCGSQDGKGPPHQVI corresponding to amino acids 96 - 123 of Z41644_PEA_l_P10, wherein said first and second amino acid sequences are contiguous and in a sequential order.
2.An isolated polypeptide encoding for a tail of Z41644_PEA_l_P10, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence YAPPLLTFLPTRPSCGSQDGKGPPHQVI in Z41644JPEAJUPlO.
The location of the variant protein was determined according to results from a number of different software programs and analyses, including analyses from SignalP and other specialized programs. The variant protein is believed to be located as follows with regard to the cell: secreted. The protein localization is believed to be secreted because both signal-peptide prediction programs predict that this protein has a signal peptide, and neither trans -membrane region prediction program predicts that this protein has a trans -membrane region..
Variant protein Z41644_PEA_l_P10 also has the following non-silent SNPs (Single Nucleotide Polymorphisms) as listed in Table 344, (given according to their position(s) on the amino acid sequence, with the alternative amino acid(s) listed; the last column indicates whether
the SNP is known or not; the presence of known SNPs in variant protein Z41644_PEA_l_P10 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 344 - Amino acid mutations
Variant protein Z41644_PEA_l_P10 is encoded by the following transcript(s): Z41644_PEA_1_T5, for which the sequence(s) is/are given at the end of the application. The coding portion of transcript Z41644_PEA_1_T5 is shown in bold; this coding portion starts at position 744 and ends at position 1112. The transcript also has the following SNPs as listed in Table 345 (given according to their position on the nucleotide sequence, with the alternative nucleic acid listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein Z41644_PEA_l_P10 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 345 - Nucleic acid SNPs
As noted above, cluster Z41644 features 21 segment(s), which were listed in Table 340 above and for which the sequence(s) are given at the end of the application. These segment(s) are portions of nucleic acid sequence(s) which are described herein separately because they are of particular interest. A description of each segment according to the present invention is now provided.
Segment cluster Z41644_PEA_l_node_0 according to the present invention is supported by 53 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): Z41644_PEA_1_T5. Table 346 below describes the starting and ending position of this segment on each transcript.
Table 346 - Segment location on transcripts
Segment cluster Z41644_PEA_l_node_ll according to the present invention is supported by 9 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): Z41644_PEA_1_T5. Table 347 below describes the starting and ending position of this segment on each transcript.
Table 347 - Segment location on transcripts
Segment cluster Z41644_PEA_l_node_12 according to the present invention is supported by 6 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): Z41644_PEA_1_T5. Table 348 below describes the starting and ending position of this segment on each transcript.
Table 348 - Segment location on transcripts
Segment cluster Z41644_PEA_l_node_15 according to the present invention is supported by 23 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): Z41644_PEA_1_T5. Table 349 below describes the starting and ending position of this segment on each transcript.
Table 349 - Segment location on transcripts
Segment cluster Z41644JPEA_l__node_20 according to the present invention is supported by 260 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): Z41644_PEA_1_T5. Table 350 below describes the starting and ending position of this segment on each transcript.
Table 350 - Segment location on transcripts
Segment cluster Z41644_PEA_l_node_24 according to the present invention is supported by 185 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): Z41644_PEA_1_T5. Table 351 below describes the starting and ending position of this segment on each transcript.
Table 351 - Segment location on transcripts
According to an optional embodiment of the present invention, short segments related to the above cluster are also provided. These segments are up to about 120 bp in length, and so are included in a separate description.
Segment cluster Z41644_PEA_l_node_l according to the present invention is supported by 53 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): Z41644_PEA_1_T5. Table 352 below describes the starting and ending position of this segment on each transcript.
Table 352 - Segment location on transcripts
Segment cluster Z41644_PEA_l_node_10 according to the present invention is supported by 138 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): Z41644_PEA_1_T5. Table 353 below describes the starting and ending position of this segment on each transcript.
Table 353 - Segment location on transcripts
Segment cluster Z41644_PEA_l_node_13 according to the present invention can be found in the following transcript(s): Z41644_PEA_1_T5. Table 354 below describes the starting and ending position of this segment on each transcript.
Table 354 - Segment location on transcripts
Segment cluster Z41644_PEA_l_node_16 according to the present invention is supported by 152 libraries. The number of libraries was determined as previously desciibed. This segment can be found in the following transcript(s): Z41644_PEA_1_T5. Table 355 below describes the starting and ending position of this segment on each transcript.
Table 355 - Segment location on transcripts
Segment cluster Z41644_PEA_l_node_17 according to the present invention can be found in the following transcript(s): Z41644_PEA_1_T5. Table 356 below describes the starting and ending position of this segment on each transcript.
Table 356 - Segment location on transcripts
Segment cluster Z41644_PEA_l_node_19 according to the present invention is supported by 112 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): Z41644_PEA_1_T5. Table 357 below describes the starting and ending position of this segment on each transcript.
Table 357 - Segment location on transcripts
Segment cluster Z41644_PEA_l_node_2 according to the present invention is supported by 58 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): Z41644_PEA_1_T5. Table 358 below describes the starting and ending position of this segment on each transcript. Table 358 - Segment location on transcripts
Segment cluster Z41644_PEA_l_node_21 according to the present invention can be found in the following transcript(s): Z41644_PEA_1_T5. Table 359 below describes the starting and ending position of this segment on each transcript.
Table 359 - Segment location on transcripts
Segment cluster Z41644_PEA_l_node_22 according to the present invention is supported by 164 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): Z41644_PEA_1_T5. Table 360 below describes the starting and ending position of this segment on each transcript.
Table 360 - Segment location on transcripts
Segment cluster Z41644_PEA_l_node_23 according to the present invention is supported by 169 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): Z41644_PEA_1_T5. Table 361 below describes the starting and ending position of this segment on each transcript.
Table 361 - Segment location on transcripts
Segment cluster Z41644_PEA_l_node_25 according to the present invention is supported by 138 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): Z41644_PEA_1_T5. Table 362 below describes the starting and ending position of this segment on each transcript.
Table 362 - Segment location on transcripts
Segment cluster Z41644_PEA_l_node_3 according to the present invention is supported by 75 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): Z41644_PEA_1_T5. Table 363 below describes the starting and ending position of this segment on each transcript.
Table 363 - Segment location on transcripts
Segment cluster Z41644_PEA_l_node_4 according to the present invention is supported by 61 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): Z41644_PEA_1_T5. Table 364 below describes the starting and ending position of this segment on each transcript.
Table 364 - Segment location on transcripts
Segment cluster Z41644_PEA_l_node_6 according to the present invention is supported by 101 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): Z41644_PEA_1_T5. Table 365 below describes the starting and ending position of this segment on each transcript.
Table 365 - Segment location on transcripts
Segment cluster Z41644_PEA_l_node_9 according to the present invention is supported by 134 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): Z41644_PEA_1_T5. Table 366 below describes the starting and ending position of this segment on each transcript.
Table 366 - Segment location on transcripts
Variant protein alignment to the previously known protein:
Sequence name: /tmp/p5SSvhT9Xp/HQeIMsUrfm: SZ14_HUMAN
Sequence documentation:
Alignment of: Z41644_PEA_l_P10 x SZ14_HUMAN
Alignment segment 1/1:
Quality: 953.00
Escore: 0
Matching length: 95 Total length: 95
Matching Percent Similarity: 100.00 Matching Percent Identity: 100.00
Total Percent Similarity: 100.00 Total Percent Identity: 100.00
Gaps : 0
Alignment :
1 MRLLAAALLLLLLALYTARVDGSKCKCSRKGPKIRYSDVKKLEMKPKYPH 50 I I I I I 1 I I I I I I I I I I I I I I I I I M I I I 1 I I I I I I I I I I I I i I I I ) I I I I
1 MRLLAAALLLLLLALYTARVDGSKCKCSRKGPKIRYSDVKKLEMKPKYPH 50
51 CEEKMVIITTKSVSRYRGQEHCLHPKLQSTKRFIKWYNAWNEKRR 95
I I I I I I I I I I I I I I I Il I Il I I I Il Il I I I I I I I I Il I I I Il Il I 51 CEEKMVIITTKSVSRYRGQEHCLHPKLQSTKRFIKWYNAWNEKRR 95
Sequence name: /tmp/p5SSvhT9Xp/HQeIMsϋrfm: Q9NS21
Sequence documentation:
Alignment of: Z41644_PEA_l_P10 x Q9NS21
Alignment segment 1/1:
Quality: 957.00
Escore: 0
Matching length: 96 Total length: 96
Matching Percent Similarity: 100.00 Matching Percent Identity: 98.96
Total Percent Similarity: 100.00 Total Percent Identity: 98.96
Gaps : 0
Alignment:
1 MRLLAAALLLLLLALYTARVDGSKCKCSRKGPKIRYSDVKKLEMKPKYPH 50
I I I I I I I 1 I I I I I I I I I I I I 1 I I I I I I I I I I I I I I I I I I I I I I I I I I I I I
13 MRLLAAALLLLLLALYTARVDGSKCKCSRKGPKIRYSDVKKLEMKPKYPH 62 . . . .
51 CEEKMVIITTKSVSRYRGQEHCLHPKLQSTKRFIKWYNAWNEKRRY 96
I I I Il I I I I I I I I I I I I I I I I I I I 1 I I I I I I I I I I I I I I I I I I I I :
63 CEEKMVIITTKSVSRYRGQEHCLHPKLQSTKRFIKWYNAWNEKRRF 108
Sequence name: /tmp/p5SSvhT9Xp/HQeIMsUrfm:AAQ89265
Sequence documentation:
Alignment of: Z41644_PEA_l_P10 x AAQ89265
Alignment segment 1/1:
Quality: 953 .00
Escore: 0
Matching length : 95 Total length: 95
Matching Percent Similarity: 100 . 00 Matching Percent Identity: 100.00
Total Percent Similarity: 100.00 Total Percent Identity: 100.00
Gaps :
Alignment :
1 MRLLAAALLLLLLALYTARVDGSKCKCSRKGPKIRYSDVKKLEMKPKYPH 50
13 MRLLAAALLLLLLALYTARVDGSKCKCSRKGPKIRYSDVKKLEMKPKYPH 62
51 CEEKMVIITTKSVSRYRGQEHCLHPKLQSTKRFIKWYNAWNEKRR 95
63 CEEKMVI ITTKSVSRYRGQEHCLHPKLQSTKRFIKWYNAWNEKRR 107
DESCRIPTION FOR CLUSTER Z44808
Cluster Z44808 features 5 transcript(s) and 21 segment(s) of interest, the names for which are given in Tables 367 and 368, respectively, the sequences themselves are given at the end of the application. The selected protein variants are given in table 369.
Table 367 - Transcripts of interest
Table 368 - Segments of interest
These sequences are variants of the known protein SPARC related modular calcium- binding protein 2 precursor (SwissProt accession identifier SM02_HUMAN; known also according to the synonyms Secreted modular calcium-binding protein 2; SMOC-2; Smooth muscle- associated protein 2; SMAP-2; MSTPl 17), SEQ ID NO: 1430, referred to herein as the previously known protein.
Protein SPARC related modular calcium-binding protein 2 precursor is known or believed to have the following function(s): calcium binding. The sequence for protein SPARC related modular calcium-binding protein 2 precursor is given at the end of the application, as "SPARC related modular calcium-binding protein 2 precursor amino acid sequence". Known polymorphisms for this sequence are as shown in Table 370.
Table 370 -Amino acid mutations for Known Protein
Protein SPARC related modular calcium-binding protein 2 precursor localization is believed to be Secreted.
Cluster Z44808 can be used as a diagnostic marker according to overexpression of transcripts of this cluster in cancer. Expression of such transcripts in normal tissues is also given according to the previously described methods. The term "number" in the right hand column of the table and the numbers on the y-axis of figure 28 refer to weighted expression of ESTs in each category, as "parts per million" (ratio of the expression of ESTs for a particular cluster to the expression of all ESTs in that category, according to parts per million).
Overall, the following results were obtained as shown with regard to the histograms in Figure 28 and Table 371. This cluster is overexpressed (at least at a minimum level) in the following pathological conditions: colorectal cancer, lung cancer and pancreas carcinoma.
Table 371 - Normal tissue distribution
Name of Tissue Number bladder 123 bone 304 brain 18 colon 0 epithelial 40 general 37 kidney 2 lung 0 breast 61 ovary 116 pancreas 0 prostate 128 stomach 36 uterus 195
Table 372 - P values and ratios for expression in cancerous tissue
As noted above, cluster Z44808 features 5 transcript(s), which were listed in Table 367 above. These transcript(s) encode for protein(s) which are variant(s) of protein SPARC related modular calcium-binding protein 2 precursor. A description of each variant protein according to the present invention is now provided.
Variant protein Z44808JPEA 1 P5 according to the present invention has an amino acid sequence as given at the end of the application; it is encoded by transcript(s) Z44808JPEA_l_T4. An alignment is given to the known protein (SPARC related modular calcium-binding protein 2 precursor) at the end of the application. One or more alignments to one or more previously published protein sequences are given at the end of the application. A brief description of the relationship of the variant protein according to the present invention to each such aligned protein is as follows:
Comparison report between Z44808_PEA_l_P5 and SMO2_HUMAN: 1.An isolated chimeric polypeptide encoding for Z44808_PEA_l_P5, comprising a first amino acid sequence being at least 90 % homologous to
MLLPQLCWLPLLAGLLPPVPAQKFSALTFLRVDQDKDKDCSLDCAGSPQKPLCASDGR TFLSRCEFQRAKCKDPQLEIAYRGNCKDVSRCVAERKYTQEQARKEFQQVFIPECNDD GTYSQVQCHSYTGYCWCVTPNGRPISGTAVAHKTPRCPGSVNEKLPQREGTGKTDDAA APALETQPQGDEEDIASRYPTLWTEQVKSRQNKTNKNSVSSCDQEHQSALEEAKQPKN DNWPECAHGGLYKPVQCHPSTGYCWCVLVDTGRPIPGTSTRYEQPKCDNTARAHPA KARDLYKGRQLQGCPGAKKHEFLTSVLDALSTDMVHAASDPSSSSGRLSEPDPSHTLEE
RVVBrWYFKLLDKNSSGDIGKKEIKPFKPJ7LRKKSKPKKCVKKFVEYCDVNNDKSISVQ
ELMGCLGVAKEDGKADTKKRHTPRGHAESTSNRQ corresponding to amino acids 1 - 441 of SMO2JRUMAN, which also corresponds to amino acids 1 - 441 of Z44808JPEA_l_P5, and a second amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence DAMVVSSRPKATTHRKSRTLSRR corresponding to amino acids 442 - 464 of Z44808_PEA_l_P5, wherein said first and second amino acid sequences are contiguous and in a sequential order.
2.An isolated polypeptide encoding for a tail of Z44808_PEA_l_P5, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence DAMVVSSRPKATTHRKSRTLSRR in Z44808_PEA_l_P5.
The location of the variant protein was determined according to results from a number of different software programs and analyses, including analyses from SignalP and other specialized programs. The variant protein is believed to be located as follows with regard to the cell: secreted. The protein localization is believed to be secreted because both signal-peptide prediction programs predict that this protein has a signal peptide, and neither trans -membrane region prediction program predicts that this protein has a trans -membrane region..
Variant protein Z44808JPEA_l_P5 is encoded by the following transcript(s):
Z44808_PEA_l_T4, for which the sequence(s) is/are given at the end of the application. The coding portion of transcript Z44808_PEA_l_T4 is shown in bold; this coding portion starts at position 586 and ends at position 1977. The transcript also has the following SNPs as listed in Table 373 (given according to their position on the nucleotide sequence, with the alternative nucleic acid listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein Z44808_PEA_l_P5 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 373 - Nucleic acid SNPs
Variant protein Z44808_PEA_l_P6 according to the present invention has an amino acid sequence as given at the end of the application; it is encoded by transcript(s) Z44808_PEA_l_T5. An alignment is given to the known protein (SPARC related modular calcium-binding protein 2 precursor) at the end of the application. One or more alignments to one or more previously published protein sequences are given at the end of the application. A brief description of the relationship of the variant protein according to the present invention to each such aligned protein is as follows:
Comparison report between Z44808_PEA_l_P6 and SMO2_HUMAN: 1.An isolated chimeric polypeptide encoding for Z44808_PEA_l_P6, comprising a first amino acid sequence being at least 90 % homologous to
MLLPQLCWLPLLAGLLPPVPAQKFSALTFLRVDQDKDKDCSLDCAGSPQKPLCASDGR TFLSRCEFQRAKCKDPQLEIAYRGNCKDVSRCVAERKYTQEQARKEFQQVFIPECNDD GTYSQVQCHSYTGYCWCVTPNGRPISGTAVAHKTPRCPGSVNEKLPQREGTGKTDDAA APALETQPQGDEEDIASRYPTLWTEQVKSRQNKTNKNSVSSCDQEHQSALEEAKQPKN
DNVVIPECAHGGLYKPVQCHPSTGYCWCVLVDTGRPIPGTSTRYEQPKCDNTARAHPA KARDLYKGRQLQGCPGAKKHEFLTSVLDALSTDMVHAASDPSSSSGRLSEPDPSHTLEE RVVHWYFKLLDKNSSGDIGKKΈIKPFKPJ^LRKKSKPKKCVKKFVEYCDVNNDKSISVQ
ELMGCLGVAKEDGKADTKKRH corresponding to amino acids 1 - 428 of SMO2JHUMAN, which also corresponds to amino acids 1 - 428 of Z44808_PEA_l_P6, and a second amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence RSKRNL corresponding to amino acids 429 - 434 of Z44808_PEA_l_P6, wherein said first and second amino acid sequences are contiguous and in a sequential order. 2.An isolated polypeptide encoding for a tail of Z44808_PEA_l_P6, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence RSKRNL in Z44808JPEA_l_P6.
The location of the variant protein was determined according to results from a number of different software programs and analyses, including analyses from SignalP and other specialized programs. The variant protein is believed to be located as follows with regard to the cell: secreted. The protein localization is believed to be secreted because both signal-peptide prediction programs predict that this protein has a signal peptide, and neither trans -membrane region prediction program predicts that this protein has a trans -membrane region..
Variant protein Z44808_PEA_l_P6 also has the following non-silent SNPs (Single Nucleotide Polymorphisms) as listed in Table 374, (given according to their position(s) on the amino acid sequence, with the alternative amino acid(s) listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein Z44808_PEA_l_P6 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 374 - Amino acid mutations
Variant protein Z44808_PEA_l_P6 is encoded by the following transcript(s): Z44808_PEA_l_T5, for which the sequence(s) is/are given at the end of the application. The coding portion of transcript Z44808_PEA_l_T5 is shown in bold; this coding portion starts at position 586 and ends at position 1887. The transcript also has the following SNPs as listed in Table 375 (given according to their position on the nucleotide sequence, with the alternative nucleic acid listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein Z44808_PEA_l_P6 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 375 - Nucleic acid SNPs
Variant protein Z44808_PEA_l_P7 according to the present invention has an amino acid sequence as given at the end of the application; it is encoded by transcript(s) Z44808_PEA_l_T9. An alignment is given to the known protein (SPARC related modular calcium-binding protein 2 precursor) at the end of the application. One or more alignments to
one or more previously published protein sequences are given at the end of the application. A brief description of the relationship of the variant protein according to the present invention to each such aligned protein is as follows:
Comparison report between Z44808_PEA_l_P7 and SM02_HUMAN:
LAn isolated chimeric polypeptide encoding for Z44808_PEA_l_P7, comprising a first amino acid sequence being at least 90 % homologous to
MLLPQLCWLPLLAGLLPPVPAQKFSALTFLRVDQDKDKDCSLDCAGSPQKPLCASDGR TFLSRCEFQRAKCKDPQLEIAYRGNCKDVSRCVAERKYTQEQARKEFQQVFIPECNDD GTYSQVQCHSYTGYCWCVTPNGRPISGTAVAHKTPRCPGSVNEKLPQREGTGKTDDAA APALETQPQGDEEDIASRYPTLWTEQVKSRQNKTNKNSVSSCDQEHQSALEEAKQPKN DNWIPECAHGGLYKPVQCHPSTGYCWCVLVDTGRPIPGTSTRYEQPKCDNTARAHPA KARDLYKGRQLQGCPGAKKHEFLTSVLDALSTDMVHAASDPSSSSGRLSEPDPSHTLEE RVVHWYFKLLDKNSSGDIGKKEIKPFΏIFLRKKSKPKKCVKKFVEYCDVNNDKSISVQ ELMGCLGVAKEDGKADTKKRHTPRGHAESTSNRQ corresponding to amino acids 1 - 441 of SM02_HUMAN, which also corresponds to amino acids 1 - 441 of Z44808_PEA_l_P7, and a second amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence LLWLRGKVSFYCF corresponding to amino acids 442 - 454 of Z448O8_PEA_1JP7, wherein said first and second amino acid sequences are contiguous and in a sequential order.
2.An isolated polypeptide encoding for a tail of Z44808_PEA_l_P7, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence LLWLRGKVSFYCF in Z44808_PEA_l_P7.
The location of the variant protein was determined according to results from a number of different software programs and analyses, including analyses from SignalP and other specialized programs. The variant protein is believed to be located as follows with regard to the cell: secreted. The protein localization is believed to be secreted because both signal-peptide
prediction programs predict that this protein has a signal peptide, and neither trans -membrane region prediction program predicts that this protein has a trans -membrane region..
Variant protein Z44808 J>EA_1JP7 also has the following non-silent SNPs (Single Nucleotide Polymorphisms) as listed in Table 376, (given according to their position(s) on the amino acid sequence, with the alternative amino acid(s) listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein Z44808_PEA_l_P7 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 376 - Amino acid mutations
Variant protein Z44808_PEA_l_P7 is encoded by the following transcript(s): Z44808_PEA_l_T9, for which the sequence(s) is/are given at the end of the application. The coding portion of transcript Z44808_PEA_l_T9 is shown in bold; this coding portion starts at position 586 and ends at position 1947. The transcript also has the following SNPs as listed in Table 377 (given according to their position on the nucleotide sequence, with the alternative nucleic acid listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein Z44808_PEA_l_P7 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 377 - Nucleic acid SNPs
Variant protein Z448O8_PEA_1_P11 according to the present invention has an amino acid sequence as given at the end of the application; it is encoded by transcript(s) Z448O8_PEA_1_T11. The identification of this transcript was performed using a non-EST based method for identification of alternative splicing, described in the following reference: "Sorek R et al., Genome Res. (2004) 14:1617-23." An alignment is given to the known protein (SPARC related modular calcium-binding protein 2 precursor) at the end of the application. One or more alignments to one or more previously published protein sequences are given at the end of the application. A brief description of the relationship of the variant protein according to the present invention to each such aligned protein is as follows:
Comparison report between Z448O8_PEA_1_P11 and SM02_HUMAN: 1.An isolated chimeric polypeptide encoding for Z448O8_PEA_1_P11, comprising a first amino acid sequence being at least 90 % homologous to MLLPQLCWLPLLAGLLPPVPAQKFSALTFLRVDQDKDKDCSLDCAGSPQKPLCASDGR TFLSRCEFQRAKCKDPQLEIAYRGNCKDVSRCVAERKYTQEQARKEFQQVFIPECNDD GTYSQVQCHSYTGYCWCVTPNGRPISGTAVAHKTPRCPGSVNEKLPQREGTGKT corresponding to amino acids 1 - 170 of SMO2_HUMAN, which also corresponds to amino acids 1 - 170 of Z448O8_PEA_1_P11, and a second amino acid sequence being at least 90 % homologous to DIASRYPTLWTEQVKSRQNKTNKNSVSSCDQEHQSALEEAKQPKNDNVVIPECAHGGL YKPVQCHPSTGYCWCVLVDTGRPIPGTSTRYEQPKCDNTARAHPAKARDLYKGRQLQ GCPGAKKHEFLTSVLDALSTDMVHAASDPSSSSGRLSEPDPSHTLEERVVHWYFKLLD KNSSGDIGKKEKPFKRFLRKKSKPKKCVKKFVEYCDVNNDKSISVQELMGCLGVAKE DGKADTKKRHTPRGHAESTSNRQPRKQG corresponding to amino acids 188 - 446 of SMO2_HUMAN, which also corresponds to amino acids 171 - 429 of Z448O8JPEA_1_P11, wherein said first and second amino acid sequences are contiguous and in a sequential order.
2.An isolated chimeric polypeptide encoding for an edge portion of Z448O8_PEA_1_P11, comprising a polypeptide having a length "n", wherein n is at least about 10 amino acids in length, optionally at least about 20 amino acids in length, preferably at least about 30 amino acids in length, more preferably at least about 40 amino acids in length and most preferably at least about 50 amino acids in length, wherein at least two amino acids comprise TD, having a
structure as follows: a sequence starting from any of amino acid numbers 170-x to -170; and ending at any of amino acid numbers 171+ ((n-2) - x), in which x varies from 0 to n-2.
The location of the variant protein was determined according to results from a number of different software programs and analyses, including analyses from SignalP and other specialized programs. The variant protein is believed to be located as follows with regard to the cell: secreted. The protein localization is believed to be secreted because both signal-peptide prediction programs predict that this protein has a signal peptide, and neither trans -membrane region prediction program predicts that this protein has a trans -membrane region.
Variant protein Z44808_PEA_l_Pl 1 also has the following non- silent SNPs (Single Nucleotide Polymorphisms) as listed in Table 378, (given according to their position(s) on the amino acid sequence, with the alternative amino acid(s) listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein Z448O8_PEA_1_P11 sequence provides support for the deduced sequence of this variant protein according to the present invention). Table 378 - Amino acid mutations
Variant protein Z448O8_PEA_1_P11 is encoded by the following transcript(s): Z448O8_PEA_1_T11, for which the sequence(s) is/are given at the end of the application. The coding portion of transcript Z44808_PEA_l_Tl 1 is shown in bold; this coding portion starts at position 586 and ends at position 1872. The transcript also has the following SNPs as listed in Table 379 (given according to their position on the nucleotide sequence, with the alternative nucleic acid listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein Z448O8_PEA_1_P11 sequence provides support for the deduced sequence of this variant protein according to the present invention). Table 379 - Nucleic acid SNPs
As noted above, cluster Z44808 features 21 segment(s), which were listed in Table 368 above and for which the sequence(s) are given at the end of the application. These segment(s) are portions of nucleic acid sequence(s) which are described herein separately because they are of particular interest. A description of each segment according to the present invention is now provided.
Segment cluster Z44808_PEA_l_node_0 according to the present invention is supported by 29 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): Z448O8_PEA_1_T11, Z44808_PEA_l_T4, Z44808_PEA_l_T5, Z44808_PEA_l_T8 and Z44808_PEA_l_T9. Table 380 below describes the starting and ending position of this segment on each transcript.
Table 380 - Segment location on transcripts
Segment cluster Z44808_PEA_l_node_16 according to the present invention is supported by 39 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): Z448O8_PEA_1_T11, Z44808_PEA_l_T4, Z44808_PEA_l_T5, Z44808_PEA_l_T8 and Z44808_PEA_l_T9. Table 381 below describes the starting and ending position of this segment on each transcript.
Table 381 - Segment location on transcripts
Segment cluster Z44808JPEA_l_node_2 according to the present invention is supported by 34 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): Z448O8_PEA_1_T11, Z44808_PEA_l_T4, Z44808_PEA_l_T5, Z44808_PEA_l_T8 and Z44808_PEA_l_T9. Table 382 below describes the starting and ending position of this segment on each transcript.
Table 382 - Segment location on transcripts
Segment cluster Z44808_PEA_l_node_24 according to the present invention is supported by 52 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): Z448O8_PEA_1_T11, Z44808_PEA_l_T4, Z44808_PEA_l_T5, Z44808_PEA_l_T8 and Z44808_PEA_l_T9. Table 383 below describes the starting and ending position of this segment on each transcript.
Table 383 - Segment location on transcripts
Segment cluster Z44808_PEA_l_node_32 according to the present invention is supported by 17 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): Z44808_PEA_l_T4 and Z44808JPEA_l_T8. Table 384 below describes the starting and ending position of this segment on each transcript. Table 384 - Segment location on transcripts
Segment cluster Z44808JPEA_l_node_33 according to the present invention is supported by 133 libraries. The number of libraries was determined as previously described. This segment
can be found in the following transcript(s): Z448O8_PEA_1_T11, Z44808_PEA_l_T4 and Z44808_PEA_l_T5. Table 385 below describes the starting and ending position of this segment on each transcript.
Table 385 - Segment location on transcripts
Segment cluster Z44808_PEA_l_node_36 according to the present invention is supported by 117 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): Z448O8_PEA_1_T11, Z44808_PEA_l_T4 and Z44808_PEA_l_T5. Table 386 below describes the starting and ending position of this segment on each transcript.
Table 386 - Segment location on transcripts
Segment cluster Z44808_PEA_l_node_37 according to the present invention is supported by 120 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): Z448O8JPEA_1_T11, Z44808_PEA_l_T4 and Z44808_PEA_l_T5. Table 387 below describes the starting and ending position of this segment on each transcript. Table 387 - Segment location on transcripts
Segment cluster Z44808_PEA_l_node_41 according to the present invention is supported by 2 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): Z44808_PEA_l_T9. Table 388 below describes the starting and ending position of this segment on each transcript.
Table 388 - Segment location on transcripts
According to an optional embodiment of the present invention, short segments related to the above cluster are also provided. These segments are up to about 120 bp in length, and so are included in a separate description.
Segment cluster Z44808_PEA_l_node_l 1 according to the present invention is supported by 25 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): Z44808_PEA_l_T4, Z44808_PEA_l_T5, Z44808_PEA_ l_T8 and Z44808_PEA_l_T9. Table 389 below describes the starting and ending position of this segment on each transcript. Table 389 - Segment location on transcripts
Segment cluster Z44808_PEA_l_node_13 according to the present invention is supported by 28 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): Z448O8_PEA_1_T11, Z44808_PEA_l_T4, Z44808_PEA_l_T5, Z44808_PEA_l_T8 and Z44808_PEA_l_T9. Table 390 below describes the starting and ending position of this segment on each transcript.
Table 390 - Segment location on transcripts
Segment cluster Z44808_PEA_l_node_l 8 according to the present invention is supported by 27 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s) : Z448O8_PEA_1_T11, Z44808_PEA_l_T4, Z44808_PEA_l_T5, Z44808_PEA_l_T8 and Z44808_PEA_l_T9. Table 391 below describes the starting and ending position of this segment on each transcript.
Table 391 - Segment location on transcripts
Segment cluster Z44808_PEA_l jnode_22 according to the present invention is supported by 33 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): Z448O8_PEA_1_T11, Z44808_PEA_l_T4, Z44808_PEA_l_T5, Z44808_PEA_l_T8 and Z44808_PEA_l_T9. Table 392 below describes the starting and ending position of this segment on each transcript.
Table 392 - Segment location on transcripts
Microarray (chip) data is also available for this segment as follows. As described above with regard to the cluster itself, various oligonucleotides were tested for being differentially expressed in various disease conditions, particularly cancer. The following oligonucleotides were found to hit this segment (with regard to lung cancer), shown in Table 393.
Table 393 - Oligonucleotides related to this segment
Segment cluster Z44808_PEA_l_node_26 according to the present invention is supported by 2 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): Z44808_PEA_ l_T5. Table 394 below describes the starting and ending position of this segment on each transcript.
Table 394 - Segment location on transcripts
Microarray (chip) data is also available for this segment as follows. As described above with regard to the cluster itself, various oligonucleotides were tested for being differentially expressed in various disease conditions, particularly cancer. The following oligonucleotides were found to hit this segment (with regard to lung cancer), shown in Table 395.
Table 395 - Oligonucleotides related to this segment
Segment cluster Z44808_PEA_l_node_30 according to the present invention is supported by 44 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): Z448O8_PEA_1_T11, Z44808_PEA_l_T4, Z44808_PEA_l_T5, Z44808_PEA_l_T8 and Z44808_PEA_l_T9. Table 396 below describes the starting and ending position of this segment on each transcript. Table 396 - Segment location on transcripts
Segment cluster Z44808_PEA_l_node_34 according to the present invention is supported by 70 libraries. The number of libraries was determined as previously described. This segment
can be found in the following transcript(s): Z44808_PEA_l JTl 1, Z44808_PEA_l JT4 and Z44808_PEA_l_T5. Table 397 below describes the starting and ending position of this segment on each transcript.
Table 397 - Segment location on transcripts
Segment cluster Z44808_PEA_l_node_35 according to the present invention can be found in the following transcript(s): Z448O8_PEA_1_T11, Z44808JPEAJ JT4 and Z44808_PEA_l_T5. Table 398 below describes the starting and ending position of this segment on each transcript.
Table 398 - Segment location on transcripts
Segment cluster Z44808_PEA_l_node_39 according to the present invention is supported by 1 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): Z44808_PEA_l_T9. Table 399 below describes the starting and ending position of this segment on each transcript.
Table 399 - Segment location on transcripts
Segment cluster Z44808_PEA_l_node_4 according to the present invention is supported by 33 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): Z448O8_PEA_1_T11, Z44808_PEA_l_T4, Z44808_PEA_l_T5, Z44808JPEA_l_T8 and Z44808_PEA_l_T9. Table 400 below describes the starting and ending position of this segment on each transcript.
Table 400 - Segment location on transcripts
Segment cluster Z44808_PEA_l_node_6 according to the present invention is supported by 30 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): Z448O8_PEA_1_T11, Z44808_PEA_l_T4, Z44808_PEA_l_T5, Z44808_PEA_l_T8 and Z44808_PEA_l_T9. Table 401 below describes the starting and ending position of this segment on each transcript. Table 401 - Segment location on transcripts
Segment cluster Z44808_PEA_l_node_8 according to the present invention is supported by 25 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): Z448O8_PEA_1_T11, Z44808_PEA_l_T4, Z44808_PEA_l_T5, Z44808_PEA_l_T8 and Z44808_PEA_l_T9. Table 402 below describes the starting and ending position of this segment on each transcript.
Table 402 - Segment location on transcripts
Variant protein alignment to the previously known protein: Sequence name: /tmp/vUqLu6eAVZ/K3JDuPvaLo : SM02_HUMAN
Sequence documentation:
Alignment of: Z44808_PEA__l_P5 x SMO2_HUMAN
Alignment segment 1/1:
Quality: 4440.00
Escore:
Matching length: 441 Total length: 441
Matching Percent Similarity: 100.00 Matching Percent Identity: 100.00 Total Percent Similarity: 100.00 Total Percent Identity: 100.00
Gaps : 0
Alignment : . . . . .
1 MLLPQLCWLPLLAGLLPPVPAQKFSALTFLRVDQDKDKDCSLDCAGSPQK 50
I I I I I I I I I Il I I I I I I I I I I Il I I I I I Il 1 I I I I I I I I I Il I I I I I I I I
1 MLLPQLCWLPLLAGLLPPVPAQKFSALTFLRVDQDKDKDCSLDCAGSPQK 50
51 PLCASDGRTFLSRCEFQRAKCKDPQLEIAYRGNCKDVSRCVAERKYTQEQ 100
I I I Il I I I I I Il I Il I I I I I I I I I I Il I I I Il I I I I I I I I I Il I Il I I I I
51 PLCASDGRTFLSRCEFQRAKCKDPQLEIAYRGNCKDVSRCVAERKYTQEQ 100
101 ARKEFQQVFIPECNDDGTYSQVQCHSYTGYCWCVTPNGRPISGTAVAHKT 150 I I I I I I I I I I I I M I I I I I I I I M I I M I I I I I I I I I ! I I I I I I M M M
101 ARKEFQQVFIPECNDDGTYSQVQCHSYTGYCWCVTPNGRPISGTAVAHKT 150
151 PRCPGSVNEKLPQREGTGKTDDAAAPALETQPQGDEEDIASRYPTLWTEQ 200
I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I Il I I I I I I Il I I I I I I Il I I 151 PRCPGSVNEKLPQREGTGKTDDAAAPALETQPQGDEEDIASRYPTLWTEQ 200
201 VKSRQNKTNKNSVSSCDQEHQSALEEAKQPKNDNWIPECAHGGLYKPVQ 250
I I I I I Il I I I I I I Il I I Il I I I I I I I I I I I I I I I I Il I I I I I Il Il I I I I
201 VKSRQNKTNKNSVSSCDQEHQSALEEAKQPKNDNWIPECAHGGLYKPVQ 250 . . . . .
251 CHPSTGYCWCVLVDTGRPIPGTSTRYEQPKCDNTARAHPAKARDLYKGRQ 300
I I I I I I I I I I I I I I I I Il I I I I I I I I I I I I I 1 I I I I I I I I I I I I Il I I I I
251 CHPSTGYCWCVLVDTGRPIPGTSTRYEQPKCDNTARAHPAKARDLYKGRQ 300
301 LQGCPGAKKHEFLTSVLDALSTDMVHAASDPSSSSGRLSEPDPSHTLEER 350 I I I M I I I I I I I I I I I I 1 I Il I Il I I M Il I I I M I I I I I I I I I I Il I I I
301 LQGCPGAKKHEFLTSVLDALSTDMVHAASDPSSSSGRLSEPDPSHTLEER 350
351 VVHWYFKLLDKNSSGDIGKKEIKPFKRFLRKKSKPKKCVKKFVEYCDVNN 400
I I I I I Il I I I I I I I I I I I I I I 1 I I I Il I I I I I I I I I Il I I I I I I I I I I I I 351 VVHWYFKLLDKNSSGDIGKKEIKPFKRFLRKKSKPKKCVKKFVEYCDVNN 400
401 DKSISVQELMGCLGVAKEDGKADTKKRHTPRGHAESTSNRQ 441
II I I I I I I I I I I I I I I I I I I Il I I I I I I I I I I Il I I Il I I I
401 DKSISVQELMGCLGVAKEDGKADTKKRHTPRGHAESTSNRQ 441
Sequence name: /tmp/QSUNfTsJ5y/kLOw5Vb6SD: SMO2_HUMAN
Sequence documentation:
Alignment of: Z44808_PEA_1_P6 x SMO2_HUMAN
Alignment segment 1/1:
Quality: 4310.00 Escore: 0
Matching length: 428 Total length: 428
Matching Percent Similarity: 100.00 Matching Percent Identity: 100.00 Total Percent Similarity: 100.00 Total Percent Identity: 100.00
Gaps : 0
Alignment : . . . . .
1 MLLPQLCWLPLLAGLLPPVPAQKFSALTFLRVDQDKDKDCSLDCAGSPQK 50
I I I I I I I Il I I I I I I I I I I I 1 I I I I I I I I I I I I I I I 1 I I I I I 1 I I I I I I I
1 MLLPQLCWLPLLAGLLPPVPAQKFSALTFLRVDQDKDKDCSLDCAGSPQK 50
51 PLCASDGRTFLSRCBFQRARCKDPQLEIAYRGNCKDVSRCVAERKYTQEQ 100
I I I I I I I I I I I I I Il I I I Il I I I I I I I I I I I I I Il I I I I I I I I I Il Il Il
51 PLCASDGRTFLSRCEFQRAKCKDPQLEIAYRGNCKDVSRCVAERKYTQEQ 100
101 ARKEFQQVFIPECNDDGTYSQVQCHSYTGYCWCVTPNGRPISGTAVAHKT 150 I I I I I M I I I I I I I M M I I I I I I I M I I I I M I I I I I I I I I I I I I I I I I
101 ARKEFQQVFIPECNDDGTYSQVQCHSYTGYCWCVTPNGRPISGTAVAHKT 150
151 PRCPGSVNEKLPQREGTGKTDDAAAPALETQPQGDEEDIASRYPTLWTEQ 200
I I I I I I I Il I I I I I I I I I I I I I I I I Il I Il I I I Il Il I I I I Il I I I I I I I 151 PRCPGSVNEKLPQREGTGKTDDAAAPALETQPQGDEEDIASRYPTLWTEQ 200
201 VKSRQNKTNKNSVSSCDQEHQSALEEAKQPKNDNWIPECAHGGLYKPVQ 250
I M I I I I I M I M I I I I M I I I I I I M I I I I I I I M M M I I I I M I M I
201 VKSRQNKTNKNSVSSCDQEHQSALEEAKQPKNDNWIPECAHGGLYKPVQ 250 . . . . .
251 CHPSTGYCWCVLVDTGRPIPGTSTRYEQPKCDNTARAHPAKARDLYKGRQ 300
1 I I I I 1 I I I I I I I I I 1 I I I I I I I I I I I I I 1 I I I I I I I I I I I I 1 I I I I I i I
251 CHPSTGYCWCVLVDTGRPIPGTSTRYEQPKCDNTARAHPAKARDLYKGRQ 300
301 LQGCPGAKKHEFLTSVLDALSTDMVHAASDPSSSSGRLSEPDPSHTLEER 350 I I I I I I I I I I M 1 I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I
301 LQGCPGAKKHEFLTSVLDALSTDMVHAASDPSSSSGRLSEPDPSHTLEER 350
351 VVHWYFKLLDKNSSGDIGKKEIKPFKRFLRKKSKPKKCVKKFVEYCDVNN 400
I I I I I I I I I I I I I I I Il I I I I Il I I I I I I I I I I I I Il I I I I I I I 1 I 1 I I I 351 VVHWYFKLLDKNSSGDIGKKEIKPFKRFLRKKSKPKKCVKKFVEYCDVNN 400
401 DKSISVQELMGCLGVAKEDGKADTKKRH 428
I I I Il Il I I I Il I I 1 I Il Il I I Il I I I I
401 DKSISVQELMGCLGVAKEDGKADTKKRH 428
Sequence name: /tmp/MZVdR4PVdM/5uN8RwViJl : SMO2_HUMAN
Sequence documentation:
Alignment of: Z44808_PEA_l_P7 x SMO2_HUMAN
Alignment segment 1/1:
Quality: 4440.00 Escore: 0
Matching length: 441 Total length: 441
Matching Percent Similarity: 100.00 Matching Percent Identity: 100.00 Total Percent Similarity: 100.00 Total Percent Identity: 100.00
Gaps : 0
Alignment : . . . . .
1 MLLPQLCWLPLLAGLLPPVPAQKFSALTFLRVDQDKDKDCSLDCAGSPQK 50
I I I I I I I I I I I I I I I I I Il I i I I I I I I I I I I I I I I I I I I I I I i I Il I I I I
1 MLLPQLCWLPLLAGLLPPVPAQKFSALTFLRVDQDKDKDCSLDCAGSPQK 50
51 PLCASDGRTFLSRCEFQRAKCKDPQLEIAYRGNCKDVSRCVAERKYTQEQ 100
I I I Il Il I I I Il I Il I Il I I I I I Il I I I I I Il I Il I Il Il I Il Il I I I I I
51 PLCASDGRTFLSRCEFQRAKCKDPQLEIAYRGNCKDVSRCVAERKYTQEQ 100
101 ARKEFQQVFIPECNDDGTYSQVQCHSYTGYCWCVTPNGRPISGTAVAHKT 150 I I I M I I I I I I I M I I I I M M I I I I I M I I I I I I I M M I I I I M I I M
101 ARKEFQQVFIPECNDDGTYSQVQCHSYTGYCWCVTPNGRPISGTAVAHKT 150
151 PRCPGSVNEKLPQREGTGKTDDAAAPALETQPQGDEEDIASRYPTLWTEQ 200
I I I I I I Il I I Il Il Il I I I I I I I I I I I I Il I Il I I Il I I I I Il I I I I I I I 151 PRCPGSVNEKLPQREGTGKTDDAAAPALETQPQGDEEDIASRYPTLWTEQ 200
201 VKSRQNKTNKNSVSSCDQEHQSALEEAKQPKNDNWIPECAHGGLYKPVQ 250
I I Il Il Il I I I I I I I I 1 I I I I I I Il I I I I I Il Il I Il I I Il I I I I I Il Il 201 VKSRQNKTNKNSVSSCDQEHQSALEEAKQPKNDNWIPECAHGGLYKPVQ 250 . . . . .
251 CHPSTGYCWCVLVDTGRPIPGTSTRYEQPKCDNTARAHPAKARDLYKGRQ 300
I I I I I I I I I I I I I I I I I I I I I I I I I I I 1 I Il ! I I
251 CHPSTGYCWCVLVDTGRPIPGTSTRYEQPKCDNTARAHPAKARDLYKGRQ 300
301 LQGCPGAKKHEFLTSVLDALSTDMVHAASDPSSSSGRLSEPDPSHTLEER 350 M MI I M I I M I I I I I M I I M I I I I II I M M I M I M M I I M I III
301 LQGCPGAKKHEFLTSVLDALSTDMVHAASDPSSSSGRLSEPDPSHTLEER 350
351 VVHWYFKLLDKNSSGDIGKKEIKPFKRFLRKKSKPKKCVKKFVEYCDVNN 400
I M M M I I M Il I I I I I Il I I I M I M I Il Il Il M I Il I M M I I I Il 351 VVHWYFKLLDKNSSGDIGKKEIKPFKRFLRKKSKPKKCVKKFVEYCDVNN 400
401 DKSISVQELMGCLGVAKEDGKADTKKRHTPRGHAESTSNRQ 441
I M Il M M I M Il I I M M M Il I Il I I M Il I I I I Il I I
401 DKSISVQELMGCLGVAKEDGKADTKKRHTPRGHAESTSNRQ 441
Sequence name: /tmp/3fGVxqLloe/J5mQduAdOF: SMO2_HUMAN
Sequence documentation:
Alignment of: Z448O8_PEA_1_P11 x SMO2_HUMAN
Alignment segment 1/1:
Quality: 4228.00 Escore: 0
Matching length: 429 Total length: 446
Matching Percent Similarity: 100.00 Matching Percent Identity: 100.00 Total Percent Similarity: 96.19 Total Percent Identity: 96.19
Gaps: 1
Alignment : . . . . .
1 MLLPQLCWLPLLAGLLPPVPAQKFSALTFLRVDQDKDKDCSLDCAGSPQK 50
I I I I I I I I I I I I I I I I I I I 1 I I I I I I I I I I I I I I I I I I I Il I I 1 I I I I I I
1 MLLPQLCWLPLLAGLLPPVP AQKFSALTFLRVDQDKDKDCSLDCAGSPQK 50
51 PLCASDGRTFLSRCEFQRAKCKDPQLEIAYRGNCKDVSRCVAERKYTQEQ 100
I I I Il I Il I Il I I I I Il I I I Il Il I I Il I I I I Il I I I I Il I Il I I I Il I I
51 PLCASDGRTFLSRCEFQRAKCKDPQLEIAYRGNCKDVSRCVAERKYTQEQ 100
101 ARKEFQQVFIPECNDDGTYSQVQCHSYTGYCWCVTPNGRPISGTAVAHKT 150 M I I M I I I M M I I M I M I I M M I M M M I I I I I M I M I I I I I M
101 ARKEFQQVFIPECNDDGTYSQVQCHSYTGYCWCVTPNGRPISGTAVAHKT 150
151 PRCPGSVNEKLPQREGTGKT DIASRYPTLWTEQ 183
M Il Il M M I M Il I M M I M M M M M Il 151 PRCPGSVNEKLPQREGTGKTDDAAAPALETQPQGDEEDIASRYPTLWTEQ 200
184 VKSRQNKTNKNSVSSCDQEHQSALEEAKQPKNDNWIPECAHGGLYKPVQ 233
II M M Il M M M M M M Il M I M Il M I M I I M M M M M M Il
201 VKSRQNKTNKNSVSSCDQEHQSALEEAKQPKNDNVVIPECAHGGLYKPVQ 250 . . . . .
234 CHPSTGYCWCVLVDTGRPIPGTSTRYEQPKCDNTARAHPAKARDLYKGRQ 283
11111111111111111111111111111111111111111111111111
251 CHPSTGYCWCVLVDTGRPIPGTSTRYEQPKCDNTARAHPAKARDLYKGRQ 300
284 LQGCPGAKKHEFLTSVLDALSTDMVHAASDPSSSSGRLSEPDPSHTLEER 333 I M I I M M Il 1 Il M Il 111 I I I I I I I I I I I M 1 I I I I M M M Il Il I
301 LQGCPGAKKHEFLTSVLDALSTDMVHAASDPSSSSGRLSEPDPSHTLEER 350
334 VVHWYFKLLDKNSSGDIGKKEIKPFKRFLRKKSKPKKCVKKFVEYCDVNN 383
I I I Il I I I 1 I Il I Il I I M Il I I M I I M I I I Il I I Il Il I Il I I I I Il I 351 VVHWYFKLLDKNSSGDIGKKEIKPFKRFLRKKSKPKKCVKKFVEYCDVNN 400
384 DKSISVQELMGCLGVAKEDGKADTKKRHTPRGHAESTSNRQPRKQG 429
II I I I I I I I I I I I I I I M I I Il I Il I M M Il Il I I I I M Il I I I I
401 DKSISVQELMGCLGVAKEDGKADTKKRHTPRGHAESTSNRQPRKQG 446
Expression of SMO2 HUMAN SPARC related modular calcium-binding protein 2 precursor Z44808 transcripts which are detectable by amplicon as depicted in sequence name Z44808junc8-l 1 in normal and cancerous lung tissues
Expression of SMO2JHUMAN SPARC related modular calcium-binding protein 2 precursor (Secreted modular calcium-binding protein 2) (SMOC-2) (Smooth muscle -associated protein 2) transcripts detectable by or according to junc8-l 1, Z44808 junc8-l 1 amplicon (SEQ ID NO: 1651) and Z44808junc8- 1 IF (SEQ ID NO: 1649) and Z44808junc8-l IR (SEQ ID NO: 1650) primers was measured by real time PCR. In parallel the expression of four housekeeping genes -PBGD (GenBank Accession No. BC019323; amplicon - PBGD-amplicon, SEQ ID NO:334), HPRTl (GenBank Accession No. NM_000194; amplicon- HPRTl -amplicon, SEQ ID NO:1297), Ubiquitin (GenBank Accession No. BC000449; amplicon - Ubiquitin-amplicon, SEQ ID NO:328) and SDHA (GenBank Accession No. NM_004168; amplicon - SDHA- amplicon, SEQ ID NO:331) was measured similarly. For each RT sample, the expression of the above amplicon was normalized to the geometric mean of the quantities of the housekeeping
genes. The normalized quantity of each RT sample was then divided by the median of the quantities of the normal post-mortem (PM) samples (Sample Nos. 47-50, 90-93, 96-99, Table 2, "Tissue samples in testing panel", above), to obtain a value of fold up-regulation for each sample relative to median of the normal PM samples. Figure 29 is a histogram showing over expression of the above -indicated
SM02_HUMAN SPARC related modular calcium-binding protein 2 precursor transcripts in cancerous lung samples relative to the noπnal samples.
As is evident from Figure 29, the expression of SM02_HUMAN SPARC related modular calcium-binding protein 2 precursor Iranscripts detectable by the above amplicon in several cancer samples was significantly higher than in the non-cancerous samples (Sample Nos. 47-50, 90-93, 96-99 Table 2, "Tissue samples in testing panel"). Notably an over- expression of at least 5 fold was found in 2 out of 15 adenocarcinoma samples and in 3 out of 8 small cells carcinoma samples.
Primer pairs are also optionally and preferably encompassed within the present invention; for example, for the above experiment, the following primer pair was used as a non- limiting illustrative example only of a suitable primer pair: Z44808junc8-llF forward primer; and Z44808junc8-ll R reverse primer.
The present invention also preferably encompasses any amplicon obtained through the use of any suitable primer pair; for example, for the above experiment, the following amplicon was obtained as a non- limiting illustrative example only of a suitable amplicon: Z44808junc8-l 1 Forward primer (SEQ ID NO: 1649): GAAGGCACAGGAAAAACAGATATTG Reverse primer (SEQ ID NO: 1650): TGGTGCTCTTGGTCACAGGAT Amplicon (SEQ ID NO: 1651): GAAGGCACAGGAAAAACAGATATTGCATCACGTTACCCTACCCTTTGGACTGAACA GGTTAAAAGTCGGCAGAACAAAACCAATAAGAATTCAGTGTCATCCTGTGACCAAG AGCACCA
Expression of SMO2_HUMAN SPARC related modular calcium-binding protein 2 precursor (Secreted modular calcium-binding protein 2) (SMOC-2) (Smooth muscle-associated protein 2) Z44808 transcripts which are detectable by amplicon as depicted in sequence name Z44808 junc8-l 1 in different normal tissues
Expression of SM02_HUMAN SPARC related modular calcium-binding protein 2 precursor (Secreted modular calcium-binding protein 2) (SMOC- 2) (Smooth muscle-associated protein 2) transcripts detectable by or according to Z44808 junc8-l 1 amplicon (SEQ ID NO: 1651) and primers: Z44808 jιιnc8-l IF(SEQ ID NO: 1649) and Z44808junc8-llR (SEQ ID NO: 1650) was measured by real time PCR. In parallel the expression of four housekeeping genes - RPL19 (GenBank Accession No. NM_000981; RPL19 amplicon, SEQ ID NO:1630), TATA box (GenBank Accession No. NM_003194; TATA amplicon, SEQ ID NO: 1633), Ubiquitin (GenBank Accession No. BC000449; amplicon - Ubiquitin-amplicon, SEQ ID NO:328) and SDHA (GenBank Accession No. NM_004168; amplicon - SDHA- amplicon, SEQ ID NO:331) was measured similarly. For each RT sample, the expression of the above amplicon was normalized to the geometric mean of the quantities of the housekeeping genes. The normalized quantity of each RT sample was then divided by the median of the quantities of the ovary samples (Sample Nos. 18-20, Table 3), to obtain a value of relative expression of each sample relative to median of the ovary samples.
Primers:
Forward primer (SEQ ID NO: 1649): GAAGGCACAGGAAAAACAGATATTG Reverse primer (SEQ ID NO: 1650): TGGTGCTCTTGGTCACAGGAT Amplicon (SEQ ID NO: 1651):
GAAGGCACAGGAAAAACAGATATTGCATCACGTTACCCTACCCTTTGGACTGAACA GGTTAAAAGTCGGCAGAACAAAACCAATAAGAATTCAGTGTCATCCTGTGACCAAG AGCACCA
The results are demonstrated in Figure 18, showing the expression of SM02_HUMAN
SPARC related modular calcium-binding protein 2 precursor (Secreted modular calcium- binding protein 2) (SMOC-2) (Smooth muscle- associated protein 2) Z44808 transcripts which are detectable by amplicon as depicted in sequence name Z44808 junc8-l 1 in different normal tissues.
DESCRIPTION FOR CLUSTER AAl 61187 Cluster AA161187 features 7 transcript(s) and 20 segment(s) of interest, the names for which are given in Tables 403 and 404, respectively, the sequences themselves are given at the end of the application. The selected protein variants are given in table 405.
Table 403 - Transcripts of interest
Table 405 - Proteins of interest
These sequences are variants of the known protein Testisin precursor (SwissProt accession identifier TEST_HUMAN; known also according to the synonyms EC 3.4.21.-;
Eosinophil serine protease 1; ESP- 1; UNQ266/PRO303), SEQ ID NO: 1431, referred to herein as the previously known protein.
Protein Testisin precursor is known or believed to have the following function(s): Could regulate proteolytic events associated with testicular germ cell maturation. The sequence for protein Testisin precursor is given at the end of the application, as "Testisin precursor amino
acid sequence". Protein Testisin precursor localization is believed to be attached to the membrane by a GPI- anchor.
The following GO Annotation(s) apply to the previously known protein. The following annotation(s) were found: serine-type peptidase, which are annotation(s) related to Molecular Function; and membrane fraction; cytoplasm; plasma membrane, which are annotation(s) related to Cellular Component.
The GO assignment relies on information from one or more of the SwissProt/TremBl Protein knowledgebase, available from <http://www.expasy.ch/sprot/>; or Locuslink, available from <http://www.ncbi.nlm.nih.gov/projects/LocusLink/>.
Cluster AAl 61187 can be used as a diagnostic marker according to overexpression of transcripts of this cluster in cancer. Expression of such transcripts in normal tissues is also given according to the previously described methods. The term "number" in the left hand column of the table and the numbers on the y-axis of figure 30 refer to weighted expression of ESTs in each category, as "parts per million" (ratio of the expression of ESTs for a particular cluster to the expression of all ESTs in that category, according to parts per million).
Overall, the following results were obtained as shown with regard to the histograms in Figure 30 and Table 406. This cluster is overexpressed (at least at a minimum level) in the following pathological conditions: brain malignant tumors, epithelial malignant tumors and a mixture of malignant tumors from different tissues.
Table 406 - Normal tissue distribution
Table 407 - P values and ratios for expression in cancerous tissue
As noted above, cluster AA161187 features 7 transcript(s), which were listed in Table 403 above. These transcript(s) encode for protein(s) which are variant(s) of protein Testisin precursor. A description of each variant protein according to the present invention is now provided.
Variant protein AA161187_P1 according to the present invention has an amino acid sequence as given at the end of the application; it is encoded by transcript(s) AA161187_T0.
The location of the variant protein was determined according to results from a number of different software programs and analyses, including analyses from SignalP and other specialized programs. The variant protein is believed to be located as follows with regard to the cell: secreted. The protein localization is believed to be secreted because both signal-peptide prediction programs predict that this protein has a signal peptide.
Variant protein AA161187_P1 also has the following non- silent SNPs (Single Nucleotide Polymorphisms) as listed in Table 408, (given according to their position(s) on the amino acid sequence, with the alternative amino acid(s) listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein AAl 61187_P1 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 408 - Amino acid mutations
Variant protein AA161187_P1 is encoded by the following transcript(s): AA161187_T0, for which the sequence(s) is/are given at the end of the application. The coding portion of transcript AAl 61187JT0 is shown in bold; this coding portion starts at position 107 and ends at position 1048. The transcript also has the following SNPs as listed in Table 409 (given according to their position on the nucleotide sequence, with the alternative nucleic acid listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein AA161187_P1 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 409 - Nucleic acid SNPs
Variant protein AAl 61187_P6 according to the present invention has an amino acid sequence as given at the end of the application; it is encoded by transcript(s) AA161187_T7. An alignment is given to the known protein (Testisin precursor) at the end of the application. One or more alignments to one or more previously published protein sequences are given at the end of
the application. A brief description of the relationship of the variant protein according to the present invention to each such aligned protein is as follows:
Comparison report between AAl 61187_P6 and TESTJHUMAN:
1.An isolated chimeric polypeptide encoding for AAl 61187_P6, comprising a first amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence HTREGTLGGQKRAFPDGVEGEKGRGRAWGAASRGSAVPLTIR corresponding to amino acids 1 - 42 of AAl 61187_P6, and a second amino acid sequence being at least 90 % homologous to GPCGRRVITSRIVGGED AELGRWPWQGSLRLWDSHVCGVSLLSHRWALTAAHCFETYS DLSDPSGWMVQFGQLTSMPSFWSLQAYYTRYFVSNIYLSPRYLGNSPYDIALVKLSAPV TYTKHIQPICLQASTFEFENRTDCWVTGWGYIKEDEALPSPHTLQEVQVAIINNSMCNH LFLKYSFRKDIFGDMVCAGNAQGGKDACFGDSGGPLACNKNGLWYQIGVVSWGVGC GRPNRPGVYTNISHHFEWIQKLMAQSGMSQPDPSWPLLFFPLLWALPLLGPV corresponding to amino acids 31 - 314 of TESTJHUMAN, which also corresponds to amino acids 43 - 326 of AA161187_P6, wherein said first amino acid sequence and second amino acid sequence are contiguous and in a sequential order.
2.An isolated polypeptide encoding for a head of AA161187_P6, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence HTREGTLGGQKRAFPDGVEGEKGRGRAWGAASRGSAVPLTIR of AA161187_P6.
The location of the variant protein was determined according to results from a number of different software programs and analyses, including analyses from SignalP and other specialized programs. The variant protein is believed to be located as follows with regard to the cell: membrane. The protein localization is believed to be membrane because although it is a partial protein, because both trans-membrane region prediction programs predict that this protein has a trans- membrane region. Variant protein AA161187_P6 also has the following non-silent SNPs (Single Nucleotide
Polymorphisms) as listed in Table 410, (given according to their position(s) on the amino acid
sequence, with the alternative amino acid(s) listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein AAl 61187_P6 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 410 - Amino acid mutations
The glycosylation sites of variant protein AA161187JP6, as compared to the known protein Testisin precursor, are described in Table 411 (given according to their position(s) on the amino acid sequence in the first column; the second column indicates whether the glycosylation site is present in the variant protein; and the last column indicates whether the position is different on the variant protein).
Table 411 - Glycosylation site(s)
Variant protein AA161187_P6 is encoded by the following transcript(s): AA161187_T7, for which the sequence(s) is/are given at the end of the application. The coding portion of transcript AA161187_T7 is shown in bold; this coding portion starts at position 1 and ends at position 979. The transcript also has the following SNPs as listed in Table 412 (given according to their position on the nucleotide sequence, with the alternative nucleic acid listed; the last
column indicates whether the SNP is known or not; the presence of known SNPs in variant protein AAl 61187_P6 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 412 - Nucleic acid SNPs
Variant protein AAl 61187_P13 according to the present invention has an amino acid sequence as given at the end of the application; it is encoded by transcript(s) AAl 61187_T15. An alignment is given to the known protein (Testisin precursor) at the end of the application. One or more alignments to one or more previously published protein sequences are given at the end of the application. A brief description of the relationship of the variant protein according to the present invention to each such aligned protein is as follows:
Comparison report between AA161187_P13 and TESTJtIUMAN:
1.An isolated chimeric polypeptide encoding for AA161 187_P13, comprising a first amino acid sequence being at least 90 % homologous to
MGARGALLLALLLARAGLRKPESQEAAPLSGPCGRRVITSRIVGGEDAELGRWPWQGS LRLWDSHVCGVSLLSHRW ALTAAHCFETYSDLSDPSGWMVQFGQLTSMPSFWSLQAY YTRYFVSNIYLSPRYLGNSPYDIALVKLSAPVTYTKHIQPICLQASTFEFENRTDCWVTG WGYIKEDE corresponding to amino acids 1 - 183 of TEST_HUMAN, which also corresponds to amino acids 1 - 183 of AAl 61187 Pl 3, and a second amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence GSSGRHHKQLYVQPPLPQVQFPQGHLWRHG corresponding to amino acids 184 - 213 of AA161187_P13, wherein said first amino acid sequence and second amino acid sequence are contiguous and in a sequential order.
2.An isolated polypeptide encoding for a tail of AA161187_P13, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence GSSGRHHKQLYVQPPLPQVQFPQGHLWRHG in AA161187_P13.
The location of the variant protein was determined according to results from a number of different software programs and analyses, including analyses from SignalP and other specialized programs. The variant protein is believed to be located as follows with regard to the cell: secreted. The protein localization is believed to be secreted because both signal-peptide prediction programs predict that this protein has a signal peptide, and neither trans -membrane region prediction program predicts that this protein has a trans -membrane region.
Variant protein AA161187_P13 also has the following non-silent SNPs (Single Nucleotide Polymorphisms) as listed in Table 413, (given according to their position(s) on the amino acid sequence, with the alternative amino acid(s) listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein AAl 61187_P13 sequence provides support for the deduced sequence of this variant protein according to the present invention). Table 413 - Amino acid mutations
The glycosylation sites of variant protein AAl 61187_P13, as compared to the known protein Testisin precursor, are described in Table 414 (given according to their position(s) on the amino acid sequence in the first column; the second column indicates whether the glycosylation site is present in the variant protein; and the last column indicates whether the position is different on the variant protein).
Table 414 - Glycosylation site(s)
Variant protein AA161187_P13 is encoded by the following transcript(s): AAl 61187_T15, for which the sequence(s) is/are given at the end of the application. The coding portion of transcript AA161187_T15 is shown in bold; this coding portion starts at position 107 and ends at position 745. The transcript also has the following SNPs as listed in Table 415 (given according to their position on the nucleotide sequence, with the alternative nucleic acid listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein AA161187_P13 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 415 - Nucleic acid SNPs
Variant protein AAl 61187_P14 according to the present invention has an amino acid sequence as given at the end of the application; it is encoded by transcript(s) AA161187_T16. An alignment is given to the known protein (Testisin precursor) at the end of the application. One or more alignments to one or more previously published protein sequences are given at the end of the application. A brief description of the relationship of the variant protein according to the present invention to each such aligned protein is as follows:
Comparison report between AA161187_P14 and TESTJHUMAN: 1.An isolated chimeric polypeptide encoding for AA161187_P14, comprising a first amino acid sequence being at least 90 % homologous to
MGARGALLLALLLARAGLRKPESQEAAPLSGPCGRRVITSRΓVGGEDAELGRWPWQGS LRLWDSHVCGVSLLSHRWALTAAHCFETYSDLSDPSGWMVQFGQLTSMPSFWSLQAY
YTRYFVSNIYLSPRYLGNSPYDIAL VKLSAPVTYTKHIQPICLQASTFEFENRTDCWVTG WGYIKEDE corresponding to amino acids 1 - 183 of TEST_HUMAN, which also corresponds to amino acids 1 - 183 of AA 161187_P14, and a second amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence
GCCLSPSHYRPHSTAISPHPPGSSGRHHKQLYVQPPLPQVQFPQGHLWRHGLCWQCPRR EGCLLRECPCHHSQPRKASCVPVPYLTLMPTPGGGDCCPTLQMQKRRLGCCQGEEEDV HPVYPAP corresponding to amino acids 184 - 307 of AA161187_P14, wherein said first amino acid sequence and second amino acid sequence are contiguous and in a sequential order. 2.An isolated polypeptide encoding for a tail of AA161187_P14, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence GCCLSPSHYRPHSTAISPHPPGSSGRHHKQLYVQPPLPQVQFPQGHLWRHGLCWQCPRR EGCLLRECPCHHSQPRKASCVPVPYLTLMPTPGGGDCCPTLQMQKRRLGCCQGEEEDV HPVYPAP in AA161187_P14.
The location of the variant protein was determined according to results from a number of different software programs and analyses, including analyses from SignalP and other specialized programs. The variant protein is believed to be located as follows with regard to the cell: secreted. The protein localization is believed to be secreted because both signal-peptide prediction programs predict that this protein has a signal peptide, and neither trans -membrane region prediction program predicts that this protein has a trans -membrane region.
Variant protein AA161187_P14 also has the following non- silent SNPs (Single Nucleotide Polymorphisms) as listed in Table 416, (given according to their position(s) on the amino acid sequence, with the alternative amino acid(s) listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein AA161187_P14 sequence provides support for the deduced sequence of this variant protein according to the present invention). Table 416 - Amino acid mutations
The glycosylation sites of variant protein AA161187_P14, as compared to the known protein Testisin precursor, are described in Table 417 (given according to their position(s) on the amino acid sequence in the first column; the second column indicates whether the glycosylation site is present in the variant protein; and the last column indicates whether the position is different on the variant protein).
Table 417 - Glycosylation site(s)
Variant protein AA161187_P14 is encoded by the following transcript(s): AA 161187_T 16, for which the sequence(s) is/are given at the end of the application. The coding portion of transcript AA161187__T16 is shown in bold; this coding portion starts at position 107 and ends at position 1027. The transcript also has the following SNPs as listed in Table 418 (given according to their position on the nucleotide sequence, with the alternative nucleic acid listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein AAl 61187_P14 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 418 - Nucleic acid SNPs
Variant protein AA161187_P18 according to the present invention has an amino acid sequence as given at the end of the application; it is encoded by transcript(s) AA161187_T20. An alignment is given to the known protein (Testisin precursor) at the end of the application. One or more alignments to one or more previously published protein sequences are given at the end of the application. A brief description of the relationship of the variant protein according to the present invention to each such aligned protein is as follows:
Comparison report between AA161187JP18 and TEST_HUMAN:
1.An isolated chimeric polypeptide encoding for AA161187_P18, comprising a first amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence HTREGTLGGQKRAFPDGVEGEKGRGRAWGAASRGSA VPLTIR corresponding to amino acids 1 - 42 of AA161187_P18, a second amino acid sequence being at least 90 % homologous to
GPCGRRVITSRIVGGEDAELGRWPWQGSLRLWDSHVCGVSLLSHRWALTAAHCFET corresponding to amino acids 31 - 86 of TEST_HUMAN, which also corresponds to amino acids 43 - 98 of AA161187_P18, a third amino acid sequence being at least 90 % homologous to DLSDPSGWMVQFGQLTSMPSFWSLQAYYTRYFVSNIYLSPRYLGNSPYDIALVKLSAPV TYTKHIQPICLQASTFEFENRTDCWVTGWGYIKEDEALPSPHTLQEVQVAIINNSMCNH LFLKYSFRKDIFGDMVCAGNAQGGKDACF corresponding to amino acids 89 - 235 of TEST_HUMAN, which also corresponds to amino acids 99 - 245 of AAl 61187 P18, and a fourth amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence VSVPATTPSPGKHPVSLCLI corresponding to amino acids 246 - 265 of AA161187_P18, wherein said first amino acid sequence, second amino acid sequence, third amino acid sequence and fourth amino acid sequence are contiguous and in a sequential order. 2.An isolated polypeptide encoding for a head of AA161187_P18, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence HTREGTLGGQKRAFPDGVEGEKGRGRAWGAASRGSAVPLTIR of AA161187_P18.
3.An isolated chimeric polypeptide encoding for an edge portion of AA161187_P18, comprising a polypeptide having a length "n", wherein n is at least about 10 amino acids in length, optionally at least about 20 amino acids in length, preferably at least about 30 amino acids in length, more preferably at least about 40 amino acids in length and most preferably at least about 50 amino acids in length, wherein at least two amino acids comprise TD, having a structure as follows: a sequence starting from any of amino acid numbers 98-x to 98; and ending at any of amino acid numbers 99 + ((n-2) - x), in which x varies from 0 to n-2.
4.An isolated polypeptide encoding for a tail of AA161187_P18, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence VSVPATTPSPGKHPVSLCLI in AA161187JP18.
The location of the variant protein was determined according to results from a number of different software programs and analyses, including analyses from SignalP and other specialized programs. The variant protein is believed to be located as follows with regard to the cell: membrane. The protein localization is believed to be membrane because although it is a partial protein, because both trans-membrane region prediction programs predict that this protein has a trans- membrane region.
Variant protein AA161187_P18 also has the following non-silent SNPs (Single Nucleotide Polymorphisms) as listed in Table 419, (given according to their position(s) on the amino acid sequence, with the alternative amino acid(s) listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein AA161187_P18 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 419 - Amino acid mutations
The glycosylation sites of variant protein AA161187_P18, as compared to the known protein Testisin precursor, are described in Table 420 (given according to their position(s) on the amino acid sequence in the first column; the second column indicates whether the glycosylation site is present in the variant protein; and the last column indicates whether the position is different on the variant protein). Table 420 - Glycosylation site(s)
Variant protein AA161187 P18 is encoded by the following transcript(s): AAl 61187_T20, for which the sequence(s) is/are given at the end of the application. The coding portion of transcript AAl 61187_T20 is shown in bold; this coding portion starts at position 1 and ends at position 796. The transcript also has the following SNPs as listed in Table 421 (given according to their position on the nucleotide sequence, with the alternative nucleic acid listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein AAl 61187_P18 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 421 - Nucleic acid SNPs
Variant protein AAl 61187_P19 according to the present invention has an amino acid sequence as given at the end of the application; it is encoded by transcript(s) AAl 61187_T21. An alignment is given to the known protein (Testisin precursor) at the end of the application. One or more alignments to one or more previously published protein sequences are given at the end of the application. A brief description of the relationship of the variant protein according to the present invention to each such aligned protein is as follows:
Comparison report between AA161187_P19 and TEST JHUMAN: 1.An isolated chimeric polypeptide encoding for AA161187_P19, comprising a first amino acid sequence being at least 90 % homologous to
MGARGALLLALLLARAGLRKPESQEAAPLSGPCGRRVITSRIVGGEDAELGRWPWQGS LRLWDSHVCGVSLLSHRWALTAAHCFETYSDLSDPSGWMVQFGQLTSMPSFWSLQAY YTRYFVSNIYLSPRYLGNSPYDIALVKLSAPVTYTKHIQPICLQASTFEFENRTDCWVTG WGYIKEDE corresponding to amino acids 1 - 183 of TEST_HUMAN, which also corresponds to amino acids 1 - 183 of AAl 61187_P19, and a second amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence DKRTQ corresponding to amino acids 184 - 188 of AA161187_P19, wherein said first amino acid sequence and second amino acid sequence are contiguous and in a sequential order. 2.An isolated polypeptide encoding for a tail of AAl 61187JP 19, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence DKRTQ in AA161187_P19.
The location of the variant protein was determined according to results from a number of different software programs and analyses, including analyses from SignalP and other specialized programs. The variant protein is believed to be located as follows with regard to the cell:
secreted. The protein localization is believed to be secreted because both signal-peptide prediction programs predict that this protein has a signal peptide, and neither trans -membrane region prediction program predicts that this protein has a trans- membrane region.
Variant protein AA161187_P19 also has the following non-silent SNPs (Single Nucleotide Polymorphisms) as listed in Table 422, (given according to their position(s) on the amino acid sequence, with the alternative amino acid(s) listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein AA161187 P19 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 422 -Amino acid mutations
The glycosylation sites of variant protein AAl 61187_P19, as compared to the known protein Testisin precursor, are described in Table 423 (given according to their position(s) on the amino acid sequence in the first column; the second column indicates whether the glycosylation site is present in the variant protein; and the last column indicates whether the position is different on the variant protein).
Table 423 - Glycosylation site(s)
Variant protein AA161187_P19 is encoded by the following transcript(s): AAl 61187_T21, for which the sequence(s) is/are given at the end of the application. The coding portion of transcript AAl 61187JT21 is shown in bold; this coding portion starts at position 107
and ends at position 670. The transcript also has the following SNPs as listed in Table 424 (given according to their position on the nucleotide sequence, with the alternative nucleic acid listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein AA161187_P19 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 424 - Nucleic acid SNPs
As noted above, cluster AAl 61187 features 20 segment(s), which were listed in Table 404 above and for which the sequence(s) are given at the end of the application. These seginent(s) are portions of nucleic acid sequence(s) which are described herein separately because they are of particular interest. A description of each segment according to the present invention is now provided.
Segment cluster AA161187_node_0 according to the present invention is supported by 21 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): AA161187_T0, AA161187_T15, AA161187_T16, AA161187_T21 and AA161187_T22. Table 425 below describes the starting and ending position of this segment on each transcript.
Table 425 - Segment location on transcripts
Segment cluster AAl 61187_node_6 according to the present invention is supported by 3 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): AA161187_T7 and AA161187_T20. Table 426 below describes the starting and ending position of this segment on each transcript.
Table 426 - Segment location on transcripts
Segment cluster AA161187_node_14 according to the present invention is supported by
35 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): AA161187_T0, AA161187_T7, AA161187_T15, AA161187_T16, AA161187_T20, AA161187JT21 and AA161187_T22. Table 427 below describes the starting and ending position of this segment on each transcript. Table 427 - Segment location on transcripts
Segment cluster AA161187_node_16 according to the present invention is supported by 2 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): AA161187_T22. Table 428 below describes the starting and ending position of this segment on each transcript.
Table 428 - Segment location on transcripts
Segment cluster AA161187_node_25 according to the present invention is supported by 13 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): AA161187_T16 and AA161187JT20. Table 429 below describes the starting and ending position of this segment on each transcript.
Table 429 - Segment location on transcripts
Microarray (chip) data is also available for this segment as follows. As described above with regard to the cluster itself, various oligonucleotides were tested for being differentially expressed in various disease conditions, particularly cancer. The following oligonucleotides were found to hit this segment (in relation to lung cancer), shown in Table 430.
Table 430 - Oligonucleotides related to this segment
Segment cluster AAl 61187_node_26 according to the present invention is supported by 39 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): AA161187_T0, AA161187JT7, AA161187_T15, AA161187JT16 and AA161187_T20. Table 431 below describes the starting and ending position of this segment on each transcript.
Table 431 - Segment location on transcripts
Segment cluster AA161187_node_28 according to the present invention is supported by 4 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): AA161187_T21. Table 432 below describes the starting and ending position of this segment on each transcript.
Table 432 - Segment location on transcripts
According to an optional embodiment of the present invention, short segments related to the above cluster are also provided. These segments are up to about 120 bp in length, and so are included in a separate description.
Segment cluster AAl 61187_node_4 according to the present invention is supported by 22 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): AA161187_T0, AA161187_T15, AA161187JT16, AA161187_T21 and AA161187_T22. Table 433 below describes the starting and ending position of this segment on each transcript.
Table 433 - Segment location on transcripts
Segment cluster AAl 61187_node_7 according to the present invention can be found in the following transcript(s): AA161187_T7 and AA161187_T20. Table 434 below describes the starting and ending position of this segment on each transcript.
Table 434 - Segment location on transcripts
Segment cluster AA161187_node_8 according to the present invention is supported by 23 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): AA161187_T0, AA161187_T7, AA161187_T15, AA161187_T16, AA161187_T20, AA161187_T21 and AA161187JT22. Table 435 below describes the starting and ending position of this segment on each transcript.
Table 435 - Segment location on transcripts
Segment cluster AA161187_node_9 according to the present invention is supported by 24 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): AA161187_T0, AA161187_T7, AA161187JT15, AA161187_T16, AA161187_T20, AA161187_T21 and AA161187_T22. Table 436 below describes the starting and ending position of this segment on each transcript.
Table 436 - Segment location on transcripts
Segment cluster AAl 61187_node_10 according to the present invention is supported by 25 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): AA161187_T0, AA161187JT7, AA161187JT15, AA161187_T16, AA161187_T20, AA161187_T21 and AA161187_T22. Table 437 below describes the starting and ending position of this segment on each transcript.
Table 437 - Segment location on transcripts
Segment cluster AA161187_node_12 according to the present invention can be found in the following transcript(s): AA161187_T0, AA161187_T7, AA161187_T15, AA161187_T16, AA161187_T21 and AA161187_T22. Table 438 below describes the starting and ending position of this segment on each transcript. Table 438 - Segment location on transcripts
Segment cluster AAl 61187_node_13 according to the present invention is supported by 25 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcripts): AA161187_T0, AA161187JT7, AA161187_T15, AA161187_T16, AA161187_T20, AA161187_T21 and AA161187_T22. Table 439 below describes the starting and ending position of this segment on each transcript.
Table 439 - Segment location on transcripts
Segment cluster AA161187_node_19 according to the present invention is supported by 4 libraries. The number of libraries was determined as previously described. This segment can be
found in the following transcript(s): AA161 187_T16. Table 440 below describes the starting and ending position of this segment on each transcript.
Table 440 - Segment location on transcripts
Segment cluster AA161187_node_20 according to the present invention is supported by 28 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): AA161187_T0, AA161187_T7, AA161187_T16 and AA161187_T20. Table 441 below describes the starting and ending position of this segment on each transcript.
Table 441 - Segment location on transcripts
Segment cluster AA161187_node_21 according to the present invention is supported by 31 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): AA161187_T0, AA161187_T7, AA161187_T15, AA161187_T16 and AA161187_T20. Table 442 below describes the starting and ending position of this segment on each transcript.
Table 442 - Segment location on transcripts
Segment cluster AA161187_node_22 according to the present invention is supported by 34 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): AA161187JT0, AA161187_T7, AA161187_T15, AA161187JT16 and AA161187JT20. Table 443 below describes the starting and ending position of this segment on each transcript.
Table 443 - Segment location on transcripts
Segment cluster AA161187_node_23 according to the present invention is supported by 31 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): AA161187JT0, AA161187_T7, AA161187_T16 and AA161187JT20. Table 444 below describes the starting and ending position of this segment on each transcript.
Table 444 - Segment location on transcripts
Segment cluster AAl 61187_node_24 according to the present invention is supported by 12 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): AA161187_T16 and AA161187_T20. Table 445 below describes the starting and ending position of this segment on each transcript.
Table 445 - Segment location on transcripts
Variant protein alignment to the previously known protein:
Sequence name: TEST HUMAN
Sequence documentation:
Alignment of: AA161187_P6 x TEST_HUMAN
Alignment segment 1/1:
Quality: 2894.00
Escore: 0
Matching length: 284 Total length: 284
Matching Percent Similarity: 100.00 Matching Percent Identity: 100.00
Total Percent Similarity: 100.00 Total Percent Identity: 100.00
Gaps : 0
Alignment:
43 GPCGRRVITSRIVGGEDAELGRWPWQGSLRLWDSHVCGVSLLSHRWALTA 92
I I I I I I I Il I Il I I Il Il I I I I I 1 I I I I I I I I I I Il I I I i I I I I I I Il Il
31 GPCGRRVITSRIVGGEDAELGRWPWQGSLRLWDSHVCGVSLLSHRWALTA 80 . . . . .
93 AHCFETYSDLSDPSGWMVQFGQLTSMPSFWSLQAYYTRYFVSNIYLSPRY 142
I I I I I Il I I I I I I I I I I Il I I I I I I I I I I I I I I I I Il I I I I I I I I I I Il I
81 AHCFETYSDLSDPSGWMVQFGQLTSMPSFWSLQAYYTRYFVSNIYLSPRY 130
143 LGNSPYDIALVKLSAPVTYTKHIQPICLQASTFEFENRTDCWVTGWGYIK 192 I I I Il I Il I I I I I I Il I I I Il Il I I I I I I I I I I I I I I I I I I I Il I I I Il I
131 LGNSPYDIALVKLSAPVTYTKHIQPICLQASTFEFENRTDCWVTGWGYIK 180
193 EDEALPSPHTLQEVQVAIINNSMCNHLFLKYSFRKDIFGDMVCAGNAQGG 242 I I I I M I M I I I Il I I I I I I I I I I I I I I I I I Il Il I I I Il I I I I I I I I I I
181 EDEALPSPHTLQEVQVAIINNSMCNHLFLKYSFRKDIFGDMVCAGNAQGG 230
243 KDACFGDSGGPLACNKNGLWYQIGVVSWGVGCGRPNRPGVYTNISHHFEW 292
I I I I I i I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I Il I I I I I I I I
231 KDACFGDSGGPLACNKNGLWYQIGVVSWGVGCGRPNRPGVYTNISHHFEW 280 . . .
293 IQKLMAQSGMSQPDPSWPLLFFPLLWALPLLGPV 326
281 IQKLMAQSGMSQPDPSWPLLFFPLLWALPLLGPV 314
Sequence name: TEST_HUMAN
Sequence documentation:
Alignment of: AA161187_P13 x TEST_HUMAN
Alignment segment 1/1:
Quality: 1829.00 Escore: 0 Matching length: 183 Total length: 183
Matching Percent Similarity: 100.00 Matching Percent Identity: 100.00
Total Percent Similarity: 100.00 Total Percent Identity: 100.00
Gaps: 0
Alignment :
1 MGARGALLLALLLARAGLRKPESQEAAPLSGPCGRRVITSRIVGGEDAEL 50 I I I I I I I I I I Il I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I
1 MGARGALLLALLLARAGLRKPESQEAAPLSGPCGRRVITSRIVGGEDAEL 50
51 GRWPWQGSLRLWDSHVCGVSLLSHRWALTAAHCFETYSDLSDPSGWMVQF 100
Il I I I I Il I Il I Il I I I I I I I 1 I I I I I I I Il I I I Il Il I Il I I I I I I I Il 51 GRWPWQGSLRLWDSHVCGVSLLSHRWALTAAHCFETYSDLSDPSGWMVQF 100
101 GQLTSMPSFWSLQAYYTRYFVSNIYLSPRYLGNSPYDIALVKLSAPVTYT 150
I I I I I I I I I I Il I I I Il I I I Il I Il I I I I I Il I I Il I I I I I I I I I I Il I I
101 GQLTSMPSFWSLQAYYTRYFVSNIYLSPRYLGNSPYDIALVKLSAPVTYT 150 . . .
151 KHIQPICLQASTFEFENRTDCWVTGWGYIKEDE 183
I Il Il I Il Il I I I Il I I Il I I Il I I I I I Il I I I
151 KHIQPICLQASTFEFENRTDCWVTGWGYIKEDE 183
Sequence name: TEST_HUMAN
Sequence documentation:
Alignment of: AA161187_P14 x TESTJHUMAN
Alignment segment 1/1:
Quality: 1829.00 Escore: 0
Matching length: 183 Total length: 183
Matching Percent Similarity: 100.00 Matching Percent Identity: 100.00
Total Percent Similarity: 100.00 Total Percent Identity: 100.00 Gaps: 0
Alignment :
i MGARGALLLALLLΆRΆGLRKPESQEAΆPLSGPCGRRVITSRIVGGEDΆEL 50 I I I I I I I I I M I I I I I I I I I I I I I I I I I I I I I 1 I I I I I I I I I 1 I I I I I I I
1 MGARGALLLALLLARAGLRKPESQEAAPLSGPCGRRVITSRIVGGEDAEL 50
51 GRWPWQGSLRLWDSHVCGVSLLSHRWALTAAHCFETYSDLSDPSGWMVQF 100
I I I I I I I I I I I I I Il Il I I I I I I i I I I I I 1 I I I I I I I Il I Il I I Il I I I I 51 GRWPWQGSLRLWDSHVCGVSLLSHRWALTAAHCFETYSDLSDPSGWMVQF 100
101 GQLTSMPSFWSLQAYYTRYFVSNIYLSPRYLGNSPYDIALVKLSAPVTYT 150
HMIIIMMMIIIMMIMIIIMIIIMIIMMIMIMIIMI 101 GQLTSMPSFWSLQAYYTRYFVSNIYLSPRYLGNSPYDIALVKLSAPVTYT 150 . . .
151 KHIQPICLQASTFEFENRTDCWVTGWGYIKEDE 183
M M M I M M M M M M M M Il M M M M
151 KHIQPICLQASTFEFENRTDCWVTGWGYIKEDE 183
Sequence name: TEST_HUMAN
Sequence documentation:
Alignment of: AA161187_P18 x TEST_HUMAN
Alignment segment 1/1:
Quality: 1957.00 Escore: 0
Matching length: 203 Total length: 205
Matching Percent Similarity: 100.00 Matching Percent Identity: 100.00
Total Percent Similarity: 99.02 Total Percent Identity: 99.02 Gaps : 1
Alignment :
43 GPCGRRVITSRIVGGEDAELGRWPWQGSLRLWDSHVCGVSLLSHRWALTA 92 M I I I I M M III I I I III I M I M I I I I I M I I M I I M I I II III IM
31 GPCGRRVITSRIVGGEDAELGRWPWQGSLRLWDSHVCGVSLLSHRWALTA 80
93 AHCFET.. DLSDPSGWMVQFGQLTSMPSFWSLQAYYTRYFVSNIYLSPRY 140
I l I M I I I M M M I I I I l M I I M I I l I M M I I l M I I M I I l I M 81 AHCFETYSDLSDPSGWMVQFGQLTSMPSFWSLQAYYTRYFVSNIYLSPRY 130
141 LGNSPYDIALVKLSAPVTYTKHIQPICLQASTFEFENRTDCWVTGWGYIK 190
I I I 1 ! I I I I I I I I I I I I I I I I I I 1 I I I I I I I I I I I I I I I I I I I I I I I I I I
131 LGNSPYDIALVKLSAPVTYTKHIQPICLQASTFEFENRTDCWVTGWGYTK 180
191 EDEALPSPHTLQEVQVAIINNSMCNHLFLKYSFRKDIFGDMVCAGNAQGG 240
1 I I I I I I I I I I I I I I I Il I I I 1 I I I I I I I I I I I I I I I I I I I I I I I I I I Il
181 EDEALPSPHTLQEVQVAIINNSMCNHLFLKYSFRKDIFGDMVCAGNAQGG 230
241 KDACF 245 I I I I I
231 KDACF 235
Sequence name: TEST_HUMAN
Sequence documentation:
Alignment of: AA161187_P19 x TEST_HUMAN
Alignment segment 1/1:
Quality: 1829.00 Escore: 0
Matching length: 183 Total length: 183 Matching Percent Similarity: 100.00 Matching Percent Identity: 100.00
Total Percent Similarity: 100.00 Total Percent Identity: 100.00
Gaps : 0
Alignment:
i MGΆRGALLLALLLARΆGLRKPESQEAΆPLSGPCGRRVITSRIVGGEDΆEL 50
11111111111 ! 11 ! 11 ! 11111 I M I I M I I I I I I I I I I I I M M I I I ! 1 MGARGALLLALLLARAGLRKPESQEAAPLSGPCGRRVITSRI VGGEDAEL 50 . . . . .
51 GRWPWQGSLRLWDSHVCGVSLLSHRWALTAAHCFETYSDLSDPSGWMVQF 100
M I l M M I l Il I I I I I M I Il I l I l I Il I I I I 1 M I I l I l 1 I I I I I I I I
51 GRWPWQGSLRLWDSHVCGVSLLSHRWALTAAHCFETYSDLSDPSGWMVQF 100
101 GQLTSMPSFWSLQAYYTRYFVSNIYLSPRYLGNSPYDIALVKLSAPVTYT 150
Il M I I Il I I I I I Il I I I I M I I Il M I I Il Il I I I I I M Il M I I I I I I
101 GQLTSMPSFWSLQAYYTRYFVSNIYLSPRYLGNSPYDIALVKLSAPVTYT 150
151 KHIQPICLQASTFEFENRTDCWVTGWGYIKEDE 183 M I M I I I M I I Il I I Il I M I Il Il I I M I Il
151 KHIQPICLQASTFEFENRTDCWVTGWGYIKEDE 183
Expression of Homo sapiens protease, serine, 21 (testisin) (PRSS21) AA161187 transcripts which are detectable by amplicon as depicted in sequence name AA161187 seg25 in normal and cancerous lung tissues
Expression of Homo sapiens protease, serine, 21 (testisin) (PRSS21) transcripts detectable by or according to seg25, AA161187 seg25 amplicon (SEQ ID NO:1654) and primers
AA161187 segl7F2 (SEQ ID NO:1652) and AA161187 segl7R2 (SEQ ID NO:1653) was measured by real time PCR. In parallel the expression of four housekeeping genes -PBGD
(GenBank Accession No. BC019323; amplicon - PBGD-amplicon, SEQ ID NO:334), HPRTl
(GenBank Accession No. NMJ)OO 194; amplicon - HPRTl -amplicon, SEQ ID NO: 1297), Ubiquitin (GenBank Accession No. BC000449; amplicon - Ubiquitin-amplicon, SEQ ID NO:328) and SDHA (GenBank Accession No. NM_004168; amplicon - SDHA- amplicon, SEQ ID NO:331), was measured similarly. For each RT sample, the expression of the above amplicon was normalized to the geometric mean of the quantities of the housekeeping genes. The normalized quantity of each RT sample was then divided by the median of the quantities of the normal post-mortem (PM) samples (Sample Nos. 47-50, 90-93, 96-99, Table 2, above), to obtain a value of fold up -regulation for each sample relative to median of the normal PM samples. Figure 64 is a histogram showing over expression of the above- indicated Homo sapiens protease, serine, 21 (testisin) (PRSS21) transcripts in cancerous lung samples relative to the normal samples.
As is evident from Figure 64, the expression of Homo sapiens protease, serine, 21 (testisin) (PRSS21) transcripts detectable by the above amplicon(s) was higher in a few cancer samples than in the non-cancerous samples (Sample Nos. 46-50, 90-93, 96-99 Table 2). Notably an over-expression of at least 6 fold was found in 1 out of 15 adenocarcinoma samples, 3 out of 16 squamous cell carcinoma samples, 1 out of 4 large cell carcinoma samples.
Primer pairs are also optionally and preferably encompassed within the present invention; for example, for the above experiment, the following primer pair was used as a non- limiting illustrative example only of a suitable primer pair: AA161187 segl7F2 forward primer; and AAl 61187 segl7R2 reverse primer. The present invention also preferably encompasses any amplicon obtained through the use of any suitable primer pair; for example, for the above experiment, the following amplicon was obtained as a non- limiting illustrative example only of a suitable amplicon: AAl 61187 seg25.
Primers:
Forward primer AA161187 segl7F2 (SEQ ID NO:1652): CCCTGTGCCTTATTTGACCCT
Reverse primer AAl 61187 segl7R2 (SEQ ID NO: 1653) : GCTGGGTAGACTGGGTGCA Amplicon AA161187 seg25 (SEQ ID NO:1654):
CCTGTGCCTTATTTGACCCTCATGCCAACCCCGGGAGGTGGAGACTGTTGCCCCACT CTGCAGATGCAGAAACGGAGGCTTGGCTGCTGCCAGGGGGAGGA
DESCRIPTION FOR CLUSTER R66178
Cluster R66178 features 3 transcript(s) and 16 segment(s) of interest, the names for which are given in Tables 446 and 447, respectively, the sequences themselves are given at the end of the application. The selected protein variants are given in table 448.
Table 446 - Transcripts of interest
Table 447 - Segments of interest
Table 448 - Proteins of interest
These sequences are variants of the known protein Poliovirus receptor related protein 1 precursor (SwissProt accession identifier PVR1_HUMAN; known also according to the synonyms Herpes virus entry mediator C; HveC; Nectin 1; Herpesvirus Ig- like receptor; HIgR; CDl 11 antigen), SEQ ID NO: 1432, referred to herein as the previously known protein.
Protein Poliovirus receptor related protein 1 precursor is known or believed to have the following function(s): probably involved in cell adhesion; receptor for alphaherpesvirus (HSV-
1, HSV-2 and Pseudorabies virus) entry into cells. The sequence for protein Poliovirus receptor related protein 1 precursor is given at the end of the application, as "Poliovirus receptor related protein 1 precursor amino acid sequence". Protein Poliovirus receptor related protein 1 precursor localization is believed to be Type I membrane protein (isoforms alpha and delta). Secreted (isoform gamma).
The following GO Annotation(s) apply to the previously known protein. The following annotation(s) were found: immune response; cell-cell adhesion, which are annotation(s) related to Biological Process; cell adhesion receptor; protein binding; coreceptor, which are annotation(s) related to Molecular Function; and adherens junction; integral membrane protein, which are annotation(s) related to Cellular Component.
The GO assignment relies on information from one or more of the SwissProt/TremBl Protein knowledgebase, available from <http://www.expasy.ch/sprot/>; or Locuslink, available from <http://www.ncbi.nlm.nih.gov/projects/LocusLink/>.
As noted above, cluster R66178 features 3 transcript(s), which were listed in Table 1 above. These transcript(s) encode for protein(s) which are variant(s) of protein Poliovirus receptor related protein 1 precursor. A description of each variant protein according to the present invention is now provided.
Variant protein R66178_P3 according to the present invention has an amino acid sequence as given at the end of the application; it is encoded by transcript(s) R66178_T2. An alignment is given to the known protein (Poliovirus receptor related protein 1 precursor) at the end of the application. One or more alignments to one or more previously published protein sequences are given at the end of the application. A brief description of the relationship of the variant protein according to the present invention to each such aligned protein is as follows: Comparison report between R66178_P3 and PVR1_HUMAN:
1.An isolated chimeric polypeptide encoding for R66178_P3, comprising a first amino acid sequence being at least 90 % homologous to
MARMGLAGAAGRWWGLALGLTAFFLPGVHSQWQVNDSMYGFIGTDWLHCSFANP LPSVKITQVTWQKSTNGSKQNVAIYNPSMGVSVLAPYRERVEFLRPSFTDGTIRLSRLEL EDEGVYICEFATFPTGNRESQLNLTVMAKPTNWIEGTQAVLRAKKGQDDKVLVATCTS ANGKPPSVVSWETRLKGEAEYQEIRJSIPNGTVTVISRYRLVPSREAHQQSLACIVNYHM
DRFKESLTLNVQYEPEVTIEGFDGNWYLQRMDVKLTCKADANPPATEYHWTTLNGSLP KGVEAQNRTLFFKGPINYSLAGTYICEATNPIGTRSGQ VEVNIT corresponding to amino acids 1 - 334 of PWlJHUMAN, which also corresponds to amino acids 1 - 334 of R66178_P3, and a second amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence GEGHSLPISPGVLQTQNCGP corresponding to amino acids 335 - 354 of R66178_P3, wherein said first amino acid sequence and second amino acid sequence are contiguous and in a sequential order.
2.An isolated polypeptide encoding for a tail of R66178_P3, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence GEGHSLPISPGVLQTQNCGP in R66178_P3.
The location of the variant protein was determined according to results from a number of different software programs and analyses, including analyses from SignalP and other specialized programs. The variant protein is believed to be located as follows with regard to the cell: secreted. The protein localization is believed to be secreted because both signal-peptide prediction programs predict that this protein has a signal peptide, and neither trans -membrane region prediction program predicts that this protein has a trans -membrane region. Variant protein R66178JP3 also has the following non-silent SNPs (Single Nucleotide
Polymorphisms) as listed in Table 449, (given according to their position(s) on the amino acid sequence, with the alternative amino acid(s) listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein R66178_P3 sequence provides support for the deduced sequence of this variant protein according to the present invention). Table 449 - Amino acid mutations
The glycosylation sites of variant protein R66178_P3, as compared to the known protein Poliovirus receptor related protein 1 precursor, are described in Table 450 (given according to their position(s) on the amino acid sequence in the first column; the second column indicates whether the glycosylation site is present in the variant protein; and the last column indicates whether the position is different on the variant protein).
Table 450 - Glycosylation site(s)
Variant protein R66178_P3 is encoded by the following transcript(s): R66178JT2, for which the sequence(s) is/are given at the end of the application. The coding portion of transcript R66178_T2 is shown in bold; this coding portion starts at position 634 and ends at position
1695. The transcript also has the following SNPs as listed in Table 451 (given according to their position on the nucleotide sequence, with the alternative nucleic acid listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein R66178_P3 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 451 -Nucleic acid SNPs
Variant protein R66178_P4 according to the present invention has an amino acid sequence as given at the end of the application; it is encoded by transcript(s) R66178_T3. An alignment is given to the known protein (Poliovirus receptor related protein 1 precursor) at the end of the application. One or more alignments to one or more previously published protein sequences are given at the end of the application. A brief description of the relationship of the variant protein according to the present invention to each such aligned protein is as follows: Comparison report between R66178_P4 and PVR1_HUMAN: 1.An isolated chimeric polypeptide encoding for R66178 P4, comprising a first amino acid sequence being at least 90 % homologous to
MARMGLAGAAGRWWGLALGLTAJFFLPGVHSQWQVNDSMYGFIGTDWLHCSFANP LPSVKITQVTWQKSTNGSKQNVAIYNPSMGVSVLAPYRERVEFLRPSFTDGTIRLSRLEL EDEGVYICEFATFPTGNRESQLNLTVMAKPTNWIEGTQAVLRAKKGQDDKVLVATCTS ANGKPPSVVSWETRLKGEAEYQEIRNPNGTVTVISRYRLVPSREAHQQSLACIVNYHM DRPKESLTLNVQYEPEVTIEGFDGNWYLQRMDVKLTCKADANPPATEYHWTTLNGSLP KGVEAQNRTLFFKGPINYSLAGTYICEATNPIGTRSGQVEVNIT corresponding to amino acids 1 - 334 of PVR1_HUMAN, which also corresponds to amino acids 1 - 334 of R66178_P4, and a second amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence AFCQLIYPGKGRTRARMF corresponding to amino acids 335 - 352 of R66178_P4, wherein said first amino acid sequence and second amino acid sequence are contiguous and in a sequential order.
2.An isolated polypeptide encoding for a tail of R66178_P4, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence AFCQLIYPGKGRTRARMF in R66178_P4.
The location of the variant protein was determined according to results from a number of different software programs and analyses, including analyses from SignalP and other specialized programs. The variant protein is believed to be located as follows with regard to the cell: secreted. The protein localization is believed to be secreted because both signal-peptide prediction programs predict that this protein has a signal peptide, and neither trans -membrane region prediction program predicts that this protein has a trans -membrane region.
Variant protein R66178_P4 also has the following non-silent SNPs (Single Nucleotide Polymorphisms) as listed in Table 452, (given according to their position(s) on the amino acid sequence, with the alternative amino acid(s) listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein R66178_P4 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 452 -Amino acid mutations
The glycosylation sites of variant protein R66178_P4, as compared to the known protein Poliovirus receptor related protein 1 precursor, are described in Table 453 (given according to their position(s) on the amino acid sequence in the first column; the second column indicates whether the glycosylation site is present in the variant protein; and the last column indicates whether the position is different on the variant protein).
Table 453 - Glycosylation site(s)
Variant protein R66178_P4 is encoded by the following transcript(s): R66178_T3, for which the sequence(s) is/are given at the end of the application. The coding portion of transcript R66178 T3 is shown in bold; this coding portion starts at position 634 and ends at position 1689. The transcript also has the following SNPs as listed in Table 454 (given according to their position on the nucleotide sequence, with the alternative nucleic acid listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein R66178_P4 sequence provides support for the deduced sequence of this variant protein according to the present invention). Table 454 - Nucleic acid SNPs

Variant protein R66178_P8 according to the present invention has an amino acid sequence as given at the end of the application; it is encoded by transcript(s) R66178_T7. An alignment is given to the known protein (Poliovirus receptor related protein 1 precursor) at the end of the application. One or more alignments to one or more previously published protein sequences are given at the end of the application. A brief description of the relationship of the variant protein according to the present invention to each such aligned protein is as follows: Comparison report between R66178_P8 and PVR1_HUMAN: 1.An isolated chimeric polypeptide encoding for R66178 P8, comprising a first amino acid sequence being at least 90 % homologous to MARMGLAGAAGRWWGLALGLTAFFLPGVHSQVVQVNDSMYGFIGTDVVLHCSFANP LPSVKITQVTWQKSTNGSKQNVAIYNPSMGVSVLAPYRERVEFLRPSFTDGTIRLSRLEL EDEGVYICEFATFPTGNRESQLNLTVMAKPTNWIEGTQAVLRAKKGQDDKVLVATCTS ANGKPPSVVSWETRLKGEAEYQEIRNPNGTVTVISRYRLVPSREAHQQSLACIVNYHM DRFKESLTLNVQYEPEVTIEGFDGNWYLQRMDVKLTCKADANPPATEYHWTTLNGSLP KGVEAQNRTLFFKGPINYSLAGTYICEATNPIGTRSGQVE corresponding to amino acids 1 - 330 of PVRl-HUMAN, which also corresponds to amino acids 1 - 330 of R66178_P8, and a second amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence NSPTPRLLPNMGGAPGRCPRPSLGAWRGASCWC corresponding to amino acids 331 - 363 of R66178_P8, wherein said first amino acid sequence and second amino acid sequence are contiguous and in a sequential order.
2.An isolated polypeptide encoding for a tail of R66178_P8, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence NSPTPRLLPNMGGAPGRCPRPSLGAWRGASCWC in R66178_P8.
The location of the variant protein was determined according to results from a number of different software programs and analyses, including analyses from SignalP and other specialized programs. The variant protein is believed to be located as follows with regard to the cell: secreted. The protein localization is believed to be secreted because both signal-peptide
prediction programs predict that this protein has a signal peptide, and neither trans- membrane region prediction program predicts that this protein has a trans -membrane region.
Variant protein R66178_P8 also has the following non-silent SNPs (Single Nucleotide Polymorphisms) as listed in Table 455, (given according to their position(s) on the amino acid sequence, with the alternative amino acid(s) listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein R66178_P8 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 455 -Amino acid mutations
The glycosylation sites of variant protein R66178_P8, as compared to the known protein
Poliovirus receptor related protein 1 precursor, are described in Table 456 (given according to their position(s) on the amino acid sequence in the first column; the second column indicates whether the glycosylation site is present in the variant protein; and the last column indicates whether the position is different on the variant protein). Table 456 - Glycosylation site(s)
Variant protein R66178_P8 is encoded by the following transcript(s): R66178_T7, for which the sequence(s) is/are given at the end of the application. The coding portion of transcript R66178_T7 is shown in bold; this coding portion starts at position 634 and ends at position 1722. The transcript also has the following SNPs as listed in Table 457 (given according to their position on the nucleotide sequence, with the alternative nucleic acid listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein R66178_P8 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 457 - Nucleic acid SNPs
As noted above, cluster R66178 features 16 segment(s), which were listed in Table 2 above and for which the sequence(s) are given at the end of the application. These segment(s) are portions of nucleic acid sequence(s) which are described herein separately because they are of particular interest. A description of each segment according to the present invention is now provided.
Segment cluster R66178_node_0 according to the present invention is supported by 19 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): R66178_T2, R66178JT3 and R66178_T7. Table 458 below describes the starting and ending position of this segment on each transcript. Table 458 - Segment location on transcripts
Segment cluster R66178_node_6 according to the present invention is supported by 39 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): R66178JT2, R66178_T3 and R66178JT7. Table 459 below describes the starting and ending position of this segment on each transcript.
Table 459 - Segment location on transcripts
Segment cluster R66178_node_8 according to the present invention is supported by 39 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): R66178_T2, R66178_T3 and R66178JT7. Table 460 below describes the starting and ending position of this segment on each transcript.
Table 460 - Segment location on transcripts
Microarray (chip) data is also available for this segment as follows. As described above with regard to the cluster itself, various oligonucleotides were tested for being differentially expressed in various disease conditions, particularly cancer. The following oligonucleotides were found to hit this segment (in relation to lung cancer), shown in Table 461.
Table 461 - Oligonucleotides related to this segment
Segment cluster R66178_node_15 according to the present invention is supported by 40 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): R66178_T2, R66178JT3 and R66178JT7. Table 462 below describes the starting and ending position of this segment on each transcript.
Table 462 - Segment location on transcripts
Segment cluster R66178_node_24 according to the present invention is supported by 10 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): R66178_T2. Table 463 below describes the starting and ending position of this segment on each transcript. Table 463 - Segment location on transcripts
Segment cluster R66178_node_26 according to the present invention is supported by 24 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): R66178_T7. Table 464 below describes the starting and ending position of this segment on each transcript.
Table 464 - Segment location on transcripts
Segment cluster R66178_node_27 according to the present invention is supported by 12 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): R66178_T7. Table 465 below describes the starting and ending position of this segment on each transcript.
Table 465 - Segment location on transcripts
According to an optional embodiment of the present invention, short segments related to the above cluster are also provided. These segments are up to about 120 bp in length, and so are included in a separate description.
Segment cluster R66178_node_4 according to the present invention is supported by 21 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): R66178_T2, R66178_T3 and R66178_T7. Table 466 below describes the starting and ending position of this segment on each transcript.
Table 466 - Segment location on transcripts
Segment cluster R66178_node_5 according to the present invention can be found in the following transcript(s): R66178JT2, R66178_T3 and R66178_T7. Table 467 below describes the starting and ending position of this segment on each transcript.
Table 467 - Segment location on transcripts
Segment cluster R66178_node_9 according to the present invention is supported by 44 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): R66178JT2, R66178_T3 and R66178JT7. Table 468 below describes the starting and ending position of this segment on each transcript.
Table 468 - Segment location on transcripts
Segment cluster R66178_node_l 1 accordmg to the present invention is supported by 44 libraries. The number of libraπes was determined as previously described. This segment can be found in the following transcπpt(s): R66178JT2, R66178_T3 and R66178JT7. Table 469 below describes the starting and ending position of this segment on each transcript.
Table 469 - Segment location on transcripts
Segment cluster R66178_node_16 according to the present invention can be found in the following transcripts): R66178JT2 and R66178_T3. Table 470 below describes the starting and ending position of this segment on each transcript.
Table 470 - Segment location on transcripts
Segment cluster R66178_node_18 according to the present invention is supported by 13 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): R66178JT3. Table 471 below describes the starting and ending position of this segment on each transcript.
Table 471 - Segment location on transcripts
Segment cluster R66178_node_19 according to the present invention can be found in the following transcript(s): R66178_T3. Table 472 below describes the starting and ending position of this segment on each transcript.
Table 472 - Segment location on transcripts
Segment cluster R66178_node_20 according to the present invention is supported by 12 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): R66178_T3. Table 473 below describes the starting and ending position of this segment on each transcript.
Table 473 - Segment location on transcripts
Segment cluster R66178_node_21 according to the present invention is supported by 11 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): R66178_T3. Table 474 below describes the starting and ending position of this segment on each transcript. Table 474 - Segment location on transcripts
Variant protein alignment to the previously known protein:
Sequence name: PVRl_HUMAN
Sequence documentation:
Alignment of: R66178 P3 x PVRl HUMAN
Alignment segment 1/1:
Quality: 3286.00 Escore: 0
Matching length: 334 Total length: 334 Matching Percent Similarity: 100.00 Matching Percent Identity: 100.00
Total Percent Similarity: 100.00 Total Percent Identity: 100.00
Gaps : 0
Alignment :
1 MARMGLAGAAGRWWGLALGLTAFFLPGVHSQWQVNDSMYGFIGTDWLH 50
I I I I I I I I I I I I I 1 I I I I I 1 I Il I I I ! I I I I I 1 I I I I I I I I I I I I I 1 I I I
1 MARMGLAGAAGRWWGLALGLTAFFLPGVHSQVVQVNDSMYGFIGTDVVLH 50
51 CSFANPLPSVKITQVTWQKSTNGSKQNVAIYNPSMGVSVLAPYRERVEFL 100
51 CSFANPLPSVKITQVTWQKSTNGSKQNVAIYNPSMGVSVLAPYRERVEFL 100
101 RPSFTDGTIRLSRLELEDEGVYICEFATFPTGNRESQLNLTVMAKPTNWI 150
M I Il Il M I I I M M I I I I I M M Il I I M M I I I I I I Il Il I I Il I Il 101 RPSFTDGTIRLSRLELEDEGVYICEFATFPTGNRESQLNLTVMAKPTNWI 150
151 EGTQAVLRAKKGQDDKVLVATCTSANGKPPSWSWETRLKGEAEYQEIRN 200
I l I l I l I l I I I I M I l I I I I l M M M I I M I l M I l I I I I I I M I I I I l
151 EGTQAVLRAKKGQDDKVLVATCTSANGKPPSWSWETRLKGEAEYQEIRN 200 . . . . .
201 PNGTVTVISRYRLVPSREAHQQSLACIVNYHMDRFKESLTLNVQYEPEVT 250
M Il M I I I I I Il I Il Il I I I M I M I M Il I I I I Il Il M M I M I I Il
201 PNGTVTVISRYRLVPSREAHQQSLACIVNYHMDRFKESLTLNVQYEPEVT 250
251 IEGFDGNWYLQRMDVKLTCKADANPPATEYHWTTLNGSLPKGVEAQNRTL 300
I I M I I I M M I Il Il M I M I M Il I Il M M I I Il Il I Il I I I I M Il
251 IEGFDGNWYLQRMDVKLTCKADANPPATEYHWTTLNGSLPKGVEAQNRTL 300
301 FFKGPINYSLAGTYICEATNPIGTRSGQVEVNIT 334 I M I I Il Il I I I M M I I Il Il I M Il M Il Il I
301 FFKGPINYSLAGTYICEATNPIGTRSGQVEVNIT 334
Sequence name: PVR1_HUMAN
Sequence documentation:
Alignment of: R66178_P4 x PVR1_HUMAN
Alignment segment 1/1:
Quality: 3294.00
Escore: 0
Matching length: 336 Total length: 336
Matching Percent Similarity: 99.70 Matching Percent Identity: 99.70
Total Percent Similarity: 99.70 Total Percent Identity: 99.70
Gaps : 0
Alignment:
1 MARMGLAGAAGRWWGLALGLTAFFLPGVHSQVVQVNDSMYGFIGTDWLH 50
1 MARMGLAGAAGRWWGLALGLTAFFLPGVHSQWQVNDSMYGFIGTDVVLH 50 . . . . .
51 CSFANPLPSVKITQVTWQKSTNGSKQNVAIYNPSMGVSVLAPYRERVEFL 100
M M M I M M M M M M M M I I I M I M M M M I I I I M M I M M
51 CSFANPLPSVKITQVTWQKSTNGSKQNVAIYNPSMGVSVLAPYRERVEFL 100
101 RPSFTDGTIRLSRLELEDEGVYICEFATFPTGNRESQLNLTVMAKPTNWI 150
101 RPSFTDGTIRLSRLELEDEGVYICEFATFPTGNRESQLNLTVMAKPTNWI 150
151 EGTQAVLRAKKGQDDKVLVATCTSANGKPPSVVSWETRLKGEAEYQEIRN 200
I I I I I I 1 I I I ! Il I I I I 1 I I I I I I I I Il I I I I I Il 1 I I 1 I I Il I Il I I I I 151 EGTQAVLRAKKGQDDKVLVATCTSANGKPPSVVSWETRLKGEAEYQEIRN 200
201 PNGTVTVISRYRLVPSREAHQQSLACIVNYHMDRFKESLTLNVQYEPEVT 250
1 I I I I I I I I I Il I I I I I I I I I I I I I Il I Il I I I I Il I I I 1 I I I I I I I I Il
201 PNGTVTVISRYRLVPSREAHQQSLACIVNYHMDRFKESLTLNVQYEPEVT 250 . . . . .
251 IEGFDGNWYLQRMDVKLTCKADANPPATEYHWTTLNGSLPKGVEAQNRTL 300
I I I I I I I I I I I I I I I I I I I I I I I I I Il I I I I I I I Il I I Il I I Il I I Il I I
251 IEGFDGNWYLQRMDVKLTCKADANPPATEYHWTTLNGSLPKGVEAQNRTL 300
301 FFKGPINYSLAGTYICEATNPIGTRSGQVEVNITAF 336
I I I I Il I I I Il I I I I I I I I I Il I I Il I I I I I I I I I 301 FFKGPINYSLAGTYICEATNPIGTRSGQVEVNITEF 336
Sequence name: PVR1__HUMAN
Sequence documentation:
Alignment of: R66178__P8 x PVR1_HUMAN
Alignment segment 1/1:
Quality: 3250.00 Escore: 0
Matching length: 330 Total length: 330 Matching Percent Similarity: 100.00 Matching Percent Identity: 100.00
Total Percent Similarity: 100.00 Total Percent Identity: 100.00
Gaps : 0
Alignment :
1 MARMGLAGAAGRWWGLALGLTAFFLPGVHSQVVQVNDSMYGFIGTDVVLH 50
I I I I I I I I I I I I I 1 I I I I I I I I I I I I I I I I I I I i i I I I I I I I I I I I I I I I 1 MARMGLAGAAGRWWGLALGLTAFFLPGVHSQVVQVNDSMYGFIGTDVVLH 50
51 CSFANPLPSVKITQVTWQKSTNGSKQNVAIYNPSMGVSVLAPYRERVEFL 100
I I I I I I I I I I I I I I I I I I I I Il I I I I I Il i I I I I I I I I I I I i I I I I I I I I
51 CSFANPLPSVKITQVTWQKSTNGSKQNVAIYNPSMGVSVLAPYRERVEFL 100 . . . . .
101 RPSFTDGTIRLSRLELEDEGVYICEFATFPTGNRESQLNLTVMAKPTNWI 150
I I I I I I I I I I l I I l I I l I I I I I I I I l I l I I I I I I l I I l I I I I I l I I l I l I
101 RPSFTDGTIRLSRLELEDEGVYICEFATFPTGNRESQLNLTVMAKPTNWI 150
151 EGTQAVLRAKKGQDDKVLVATCTSANGKPPSWSWETRLKGEAEYQEIRN 200
I I I I Il I I I I I Il I I I I I I Il I I I I I Il I I Il I I I I I I I I Il I I I I Il I I
151 EGTQAVLRAKKGQDDKVLVATCTSANGKPPSWSWETRLKGEAEYQEIRN 200
201 PNGTVTVISRYRLVPSREAHQQSLACIVNYHMDRFKESLTLNVQYEPEVT 250 M I I I I I I MII I I I I I M III M I M I I I I M I I I MI I M I II I M I I
201 PNGTVTVISRYRLVPSREAHQQSLACIVNYHMDRFKESLTLNVQYEPEVT 250
251 IEGFDGNWYLQRMDVKLTCKADANPPATEYHWTTLNGSLPKGVEAQNRTL 300
251 IEGFDGNWYLQRMDVKLTCKADANPPATEYHWTTLNGSLPKGVEAQNRTL 300
301 FFKGPINYSLAGTYICEATNPIGTRSGQVE 330
301 FFKGPINYSLAGTYICEATNPIGTRSGQVE 330
DESCRIPTION FOR CLUSTER HUMPHOSLIP
Cluster HUMPHOSLIP features 7 transcript(s) and 53 segment(s) of interest, the names for which are given in Tables 475 and 476, respectively, the sequences themselves are given at the end of the application. The selected protein variants are given in table 477. Table 475 - Transcripts of interest
Table 477 - Proteins of interest
These sequences are variants of the known protein Phospholipid transfer protein precursor (SwissProt accession identifier PLTPJHUMAN; known also according to the synonyms Lipid transfer protein II), SEQ ID NO: 1433, referred to herein as the previously known protein.
Protein Phospholipid transfer protein precursor is known or believed to have the following function(s): Converts HDL into larger and smaller particles. May play a key role in extracellular phospholipid transport and modulation of HDL particles. The sequence for protein Phospholipid transfer protein precursor is given at the end of the application, as "Phospholipid transfer protein precursor amino acid sequence". Known polymorphisms for this sequence are as shown in Table 478.
Table 478 - Amino acid mutations for Known Protein
Protein Phospholipid transfer protein precursor localization is believed to be Secreted.
The following GO Annotation(s) apply to the previously known protein. The following annotation(s) were found: lipid metabolism; lipid transport, which are annotation(s) related to Biological Process; lipid binding, which are annotation(s) related to Molecular Function; and extracellular, which are annotation(s) related to Cellular Component.
The GO assignment relies on information from one or more of the SwissProt/TremBl Protein knowledgebase, available from <http://www.expasy.ch/sprot/>; or Locuslink, available from <http://www.ncbi.nkn.nih.gov/projects/LocusLink/>.
For this cluster, at least one oligonucleotide was found to demonstrate overexpression of the cluster, although not of at feast one transcript/segment as listed below. Microarray (chip) data is also available for this cluster as follows. Various oligonucleotides were tested for being differentially expressed in various disease conditions, particularly cancer, as previously described. The following oligonucleotides were found to hit this cluster but not other segments/transcripts below, shown in Table 479, with regard to lung cancer.
Table 479 - Oligonucleotides related to this cluster
As noted above, cluster HUMPHOSLIP features 7 transcript(s), which were listed in Table 1 above. These transcript(s) encode for protein(s) which are variant(s) of protein Phospholipid transfer protein precursor. A description of each variant protein according to the present invention is now provided.
Variant protein HUMPHOSLIP_PEA_2_P10 according to the present invention has an amino acid sequence as given at the end of the application; it is encoded by transcript(s) HUMPHOSLIP_PEA_2_T17. An alignment is given to the known protein (Phospholipid transfer protein precursor) at the end of the application. One or more alignments to one or more previously published protein sequences are given at the end of the application. A brief description of the relationship of the variant protein according to the present invention to each such aligned protein is as follows: Comparison report between HUMPHOSLIP JPEA_2 JP 10 and PLTP JIUMAN:
LAn isolated chimeric polypeptide encoding for HUMPHOSLIP JPEA_2 JP 10, comprising a first amino acid sequence being at least 90 % homologous to MALFGALFLALLAGAHAEFPGCKIRVTSKALELVKQEGLRFLEQELETITIPDLRGKEGH FYYNISE corresponding to amino acids 1 - 67 of PLTP JIUMAN, which also corresponds to amino acids 1 - 67 of HUMPHOSLIP JPEA_2 JP 10, and a second amino acid sequence being at least 90 % homologous to
KVYDFLSTFITSGMRFLLNQQICPVLYHAGTVLLNSLLDTVPVRSSVDELVGIDYSLMK DPVASTSNLDMDFRGAFFPLTERNWSLPNRAVEPQLQEEERMVYVAFSEFFFDSAMES
YFRAGALQLLLVGDKVPHDLDMLLRATYFGSIVLLSPA VIDSPLKLELRVLAPPRCTIKP SGTTISVTASVTIALVPPDQPEVQLSSMTMDARLSAKMALRGKALRTQLDLRRFRIYSN HSALESLALIPLQAPLKTMLQIGVMPMLNERTWRGVQIPLPEGINFVHEVVTNHAGFLTI GADLHFAKGLREVIEKNRPADVRASTAPTPSTAAV corresponding to amino acids 163 - 493 of PLTPJHUMAN, which also corresponds to amino acids 68 - 398 of
HUMPHOSLIP_PEA_2_P10, wherein said first amino acid sequence and second amino acid sequence are contiguous and in a sequential order.
2.An isolated chimeric polypeptide encoding for an edge portion of HUMPHOSLIP_PEA_2_P10, comprising a polypeptide having a length "n", wherein n is at least about 10 amino acids in length, optionally at least about 20 amino acids in length, preferably at least about 30 amino acids in length, more preferably at least about 40 amino acids in length and most preferably at least about 50 amino acids in length, wherein at least two amino acids comprise EK, having a structure as follows: a sequence starting from any of amino acid numbers 67-x to 67; and ending at any of amino acid numbers 68+ ((n-2) - x), in which x varies from O to n-2.
The location of the variant protein was determined according to results from a number of different software programs and analyses, including analyses from SignalP and other specialized programs. The variant protein is believed to be located as follows with regard to the cell: secreted. The protein localization is believed to be secreted because both signal-peptide prediction programs predict that this protein has a signal peptide, and neither trans -membrane region prediction program predicts that this protein has a trans -membrane region.
Variant protein HUMPHOSLIPJPEA__2_P10 also has the following non-silent SNPs (Single Nucleotide Polymorphisms) as listed in Table 480, (given according to their position(s) on the amino acid sequence, with the alternative amino acid(s) listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein HUMPHO SLIP_PEA_2_P 10 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 480 - Amino acid mutations
The glycosylation sites of variant protein HUMPHOSLIP_PEA_2_P10, as compared to the known protein Phospholipid transfer protein precursor, are described in Table 481 (given according to their position(s) on the amino acid sequence in the first column; the second column indicates whether the glycosylation site is present in the variant protein; and the last column indicates whether the position is different on the variant protein).
Table 481 - Glycosylation site(s)
Variant protein HUMPHOSLIP_PEA_2_P10 is encoded by the following transcript(s): HUMPHOSLIP_PEA_2_T17, for which the sequence(s) is/are given at the end of the application. The coding portion of transcript HUMPHOSLIP_PEA_2_T17 is shown in bold; this coding portion starts at position 276 and ends at position 1469. The transcript also has the following SNPs as listed in Table 482 (given according to their position on the nucleotide sequence, with the alternative nucleic acid listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein HUMPHOSLIP_PEA_2_P10 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 482 - Nucleic acid SNPs
Variant protein HUMPHOSLIP_PEA_2_P12 according to the present invention has an amino acid sequence as given at the end of the application; it is encoded by transcript(s) HUMPHOSLIP_PEA_2_T19. An alignment is given to the known protein (Phospholipid transfer protein precursor) at the end of the application. One or more alignments to one or more
previously published protein sequences are given at the end of the application. A brief description of the relationship of the variant protein according to the present invention to each such aligned protein is as follows:
Comparison report between HUMPHOSLIP_PEA_2_P12 and PLTP JHUMAN: 1.An isolated chimeric polypeptide encoding for HUMPHO8LIPJPEA 2 P12, comprising a first amino acid sequence being at least 90 % homologous to
MALFGALFLALLAGAHAEFPGCKIRVTSKALELVKQEGLRFLEQELETITIPDLRGKEGH FYYNISEVKVTELQLTSSELDFQPQQELMLQITNASLGLRFRRQLLYWFFYDGGYINAS AEGVSIRTGLELSRDPAGRMKVSNVSCQASVSRMHAAFGGTFKKVYDFLSTFITSGMRF LLNQQICPVLYHAGTVLLNSLLDTVPVRSSVDELVGIDYSLMKDPVASTSNLDMDFRG AFFPLTERNWSLPNRAVEPQLQEEERMVYVAFSEFFFDSAMESYFRAGALQLLLVGDK VPHDLDMLLRATYFGSIVLLSPAVIDSPLKLELRVLAPPRCTIKPSGTTISVTASVTIALVP PDQPEVQLSSMTMDARLSAKMALRGKALRTQLDLRRFRΓYSNHSALESLALIPLQAPLK
TMLQIGVMPMLN corresponding to amino acids 1 - 427 of PLTP_HUMAN, which also corresponds to amino acids 1 - 427 of HUMPHOSLIP_PEA_2_P12, and a second amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence GKAGV corresponding to amino acids 428 - 432 of HUMPHOSLIP_PEA_2_P12, wherein said first amino acid sequence and second amino acid sequence are contiguous and in a sequential order.
2.An isolated polypeptide encoding for a tail of HUMPHOSLIP_PEA_2_P12, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence GKAGV in HUMPHOSLBP_PEA_2_P12.
The location of the variant protein was determined according to results from a number of different software programs and analyses, including analyses from SignalP and other specialized programs. The variant protein is believed to be located as follows with regard to the cell: secreted. The protein localization is believed to be secreted because both signal-peptide prediction programs predict that this protein has a signal peptide, and neither trans -membrane region prediction program predicts that this protein has a trans -membrane region.
Variant protein HUMPHOSLIP_PEA_2_P12 also has the following non- silent SNPs (Single Nucleotide Polymorphisms) as listed m Table 483, (given according to their position(s) on the amino acid sequence, with the alternative amino acid(s) listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein HUMPHOSLIP_PEA_2_P12 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 483 - Amino acid mutations
The glycosylation sites of variant protein HUMPHOSLIP_PEA_2_P12, as compared to the known protein Phospholipid transfer protein precursor, are described in Table 484 (given
according to their position(s) on the amino acid sequence in the first column; the second column indicates whether the glycosylation site is present in the variant protein; and the last column indicates whether the position is different on the variant protein).
Table 484 - Glycosylation site(s)
Variant protein HUMPHOSLIP_PEA_2_P12 is encoded by the following transcript(s): HUMPHOSLIP_PEA_2_T19, for which the sequence(s) is/are given at the end of the application. The coding portion of transcript HUMPHOSLIP_PEA_2_T19 is shown in bold; this coding portion starts at position 276 and ends at position 1571. The transcript also has the following SNPs as listed in Table 485 (given according to their position on the nucleotide sequence, with the alternative nucleic acid listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein HUMPHOSLIP_PEA_2J>12 sequence provides support for the deduced sequence of this variant protein according to the present invention). Table 485 - Nucleic acid SNPs
Variant protein HUMPHOSLIP_PEA_2JP30 according to the present invention has an amino acid sequence as given at the end of the application; it is encoded by transcript(s) HUMPHOSLIP_PEA_2_T6. The location of the variant protein was determined according to results from a number of different software programs and analyses, including analyses from SignalP and other specialized programs. The variant protein is believed to be located as follows with regard to the cell: secreted. The protein localization is believed to be secreted because both signal-peptide prediction programs predict that this protein has a signal peptide, and neither trans- membrane region prediction program predicts that this protein has a trans -membrane region.
Variant protein HUMPHOSLIP_PEA_2_P30 also has the following non-silent SNPs (Single Nucleotide Polymorphisms) as listed in Table 486, (given according to their position(s) on the amino acid sequence, with the alternative amino acid(s) listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein
HUMPHO SLIP_PEA_2_P30 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 486 - Amino acid mutations
Variant protein HUMPHOSLIP_PEA_2_P30 is encoded by the following transcript(s): HUMPHOSLIP_PEA_2_T6, for which the sequence(s) is/are given at the end of the application. The coding portion of transcript HUMPHOSLIP_PEA_2_T6 is shown in bold; this coding portion starts at position 276 and ends at position 431. The transcript also has the following SNPs as listed in Table 487 (given according to their position on the nucleotide sequence, with the alternative nucleic acid listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein HUMPHO SLIP_PEA_2JP30 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 487- Nucleic acid SNPs
Variant protein HUMPHOSLIP_PEA_2_P31 according to the present invention has an amino acid sequence as given at the end of the application; it is encoded by transcript(s) HUMPHOSLIP_PEA_2_T7. An alignment is given to the known protein (Phospholipid transfer
protein precursor) at the end of the application. One or more alignments to one or more previously published protein sequences are given at the end of the application. A brief description of the relationship of the variant protein according to the present invention to each such aligned protein is as follows: Comparison report between HUMPHO SLIP_PEA_2_P31 and PLTPJHUMAN:
1.An isolated chimeric polypeptide encoding for HϋMPHOSLIPJPEA_2_P31 , comprising a first amino acid sequence being at least 90 % homologous to MALFGALFLALLAGAHAEFPGCKIRVTSKALELVKQEGLRFLEQELETITIPDLRGKEGH FYYNISE corresponding to amino acids 1 - 67 of PLTP-HUMAN, which also corresponds to amino acids 1 - 67 of HUMPHOSLIP_PEA_2_P31 , and a second amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence PGLERGADKFPWGGSSLFLALDLTLRPPVG corresponding to amino acids 68 - 98 of HUMPHOSLIP_PEA_2_P31, wherein said first amino acid sequence and second amino acid sequence are contiguous and in a sequential order.
2.An isolated polypeptide encoding for a tail of HUMPHOSLIP_PEA_2_P31 , comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence PGLERGADKFPWGGSSLFLALDLTLRPPVG in HUMPHOSLIP_PEA_2_P31.
The location of the variant protein was determined according to results from a number of different software programs and analyses, including analyses from SignalP and other specialized programs. The variant protein is believed to be located as follows with regard to the cell: secreted. The protein localization is believed to be secreted because both signal-peptide prediction programs predict that this protein has a signal peptide, and neither trans -membrane region prediction program predicts that this protein has a trans -membrane region.
Variant protein HUMPHOSLIP_PEA_2JP31 also has the following non-silent SNPs (Single Nucleotide Polymorphisms) as listed in Table 488, (given according to their position(s) on the amino acid sequence, with the alternative amino acid(s) listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein
HUMPHOSLIP_PEA_2_P31 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 488 - Amino acid mutations
The glycosylation sites of variant protein HUMPHOSLIP_PEA_2_P31, as compared to the known protein Phospholipid transfer protein precursor, are described in Table 489(given according to their position(s) on the amino acid sequence in the first column; the second column indicates whether the glycosylation site is present in the variant protein; and the last column indicates whether the position is different on the variant protein).
Table 489 - Glycosylation site(s)
Variant protein HUMPHOSLIP_PEA_2_P31 is encoded by the following transcript(s): HUMPHOSLIP_PEA_2_T7, for which the sequence(s) is/are given at the end of the application. The coding portion of transcript HUMPHOSLIP_PEA_2_T7 is shown in bold; this coding portion starts at position 276 and ends at position 569. The transcript also has the following SNPs as listed in Table 490 (given according to their position on the nucleotide sequence, with the alternative nucleic acid listed; the last column indicates whether the SNP is known or not;
the presence of known SNPs in variant protein HUMPHOSLIP_PEA_2_P31 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 490 - Nucleic acid SNPs
Variant protein HUMPHOSLIP_PEA_2_P33 according to the present invention has an amino acid sequence as given at the end of the application; it is encoded by transcript(s) HUMPHOSLIP_PEA_2_T14. An alignment is given to the known protein (Phospholipid transfer protein precursor) at the end of the application. One or more alignments to one or more previously published protein sequences are given at the end of the application. A brief description of the relationship of the variant protein according to the present invention to each such aligned protein is as follows:
Comparison report between HUMPHOSLIP_PEA_2_P33 and PLTP_HUMAN: 1.An isolated chimeric polypeptide encoding for HUMPHOSLIP_PEA_2_P33, comprising a first amino acid sequence being at least 90 % homologous to MALFGALFLALLAGAHAEFPGCKIRVTSKALELVKQEGLRFLEQELETITIPDLRGKEGH
FYYNISEVKVTELQLTSSELDFQPQQELMLQITNASLGLRFRRQLLYWFFYDGGYINAS AEGVSIRTGLELSRDPAGRMKVSNVSCQASVSRMHAAFGGTFKKVYDFLSTFITSGMRF LLNQQ corresponding to amino acids 1 - 183 of PLTP_HUMAN, which also corresponds to amino acids 1 - 183 of HUMPHOSLIP_PEA_2_P33, and a second amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence VWAATGRRVARVGMLSL corresponding to amino acids 184 - 200 of HUMPHOSLIP_PEA_2_P33, wherein said first amino acid sequsnce and second amino acid sequence are contiguous and in a sequential order. 2.An isolated polypeptide encoding for a tail of HUMPHOSLIP_PEA_2_P33, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence VWAATGRRVARVGMLSL in HUMPHOSLIP_PEA_2_P33.
The location of the variant protein was determined according to results from a number of different software programs and analyses, including analyses from SignalP and other specialized programs. The variant protein is believed to be located as follows with regard to the cell: secreted. The protein localization is believed to be secreted because both signal-peptide prediction programs predict that this protein has a signal peptide, and neither trans -membrane region prediction program predicts that this protein has a trans -membrane region.
Variant protein HUMPHOSLIP_PEA_2_P33 also has the following non-silent SNPs (Single Nucleotide Polymorphisms) as listed in Table 491, (given according to their position(s) on the amino acid sequence, with the alternative amino acid(s) listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein HUMPHOSLIP_PEA_2_P33 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 491 - Amino acid mutations
The glycosylation sites of variant protein HUMPHOSLIP_PEA_2_P33, as compared to the known protein Phospholipid transfer protein precursor, are described in Table 492 (given according to their position(s) on the amino acid sequence in the first column; the second column indicates whether the glycosylation site is present in the variant protein; and the last column indicates whether the position is different on the variant protein).
Table 492 - Glycosylation siie(s)
Variant protein HUMPHOSLIP_PEA_2_P33 is encoded by the following transcript(s): HUMPHOSLIP_PEA_2_T14, for which the sequence(s) is/are given at the end of the application. The coding portion of transcript HUMPHOSLIP_PEA_2_T14 is shown in bold; this coding portion starts at position 276 and ends at position 875. The transcript also has the following SNPs as listed in Table 493 (given according to their position on the nucleotide sequence, with the alternative nucleic acid listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein HUMPHOSLIP_PEA_2_P33 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 493 - Nucleic acid SNPs
Variant protein HUMPHOSLIP_PEA_2_P34 according to the present invention has an amino acid sequence as given at the end of the application; it is encoded by transcript(s) HUMPHOSLIP_PEA_2_T16. An alignment is given to the known protein (Phospholipid transfer protein precursor) at the end of the application. One or more alignments to one or more previously published protein sequences are given at the end of the application. A brief description of the relationship of the variant protein according to the present invention to each such aligned protein is as follows:
Comparison report between HUMPHOSLIP_PEA_2_P34 and PLTP_HUMAN: LAn isolated chimeric polypeptide encoding for HUMPHOSLIP_PEA_2_P34, comprising a first amino acid sequence being at least 90 % homologous to MALFGALFLALLAGAHAEFPGCKIRVTSKALELVKQEGLRFLEQELETITIPDLRGKEGH FYYNISEVKVTELQLTSSELDFQPQQELMLQITNASLGLRFRRQLLYWFFYDGGYINAS AEGVSIRTGLELSRDPAGRMKVSNVSCQASVSRMHAAFGGTFKKVYDFLSTFITSGMRF LLNQQICPVLYHAGTVLLNSLLDTVPV corresponding to amino acids 1 - 205 of
PLTP_HUMAN, which also corresponds to amino acids 1 - 205 of
HUMPHOSLIP_PEA_2_P34, and a second amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence LWTSLLALTIPS corresponding to amino acids 206 - 217 of HUMPHOSLIP_PEA_2_P34, wherein said first amino acid sequence and second amino acid sequence are contiguous and in a sequential order.
2.An isolated polypeptide encoding for a tail of HUMPHOSLIP_PEA_2_P34, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence LWTSLLALTIPS in HUMPHOSLIPJPEA 2 P34.
The location of the variant protein was determined according to results from a number of different software programs and analyses, including analyses from SignalP and other specialized programs. The variant protein is believed to be located as follows with regard to the cell: secreted. The protein localization is believed to be secreted because both signal-peptide prediction programs predict that this protein has a signal peptide, and neither trans -membrane region prediction program predicts that this protein has a trans -membrane region.
Variant protein HUMPHOSLIP_PEA_2_P34 also has the following non-silent SNPs (Single Nucleotide Polymorphisms) as listed in Table 494, (given according to their position(s) on the amino acid sequence, with the alternative amino acid(s) listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein HUMPHOSLIP_PEA_2_P34 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 494 - Amino acid mutations
The glycosylation sites of variant protein HUMPHOSLIP_PEA_2_P34, as compared to the known protein Phospholipid transfer protein precursor, are described in Table 495 (given according to their position(s) on the amino acid sequence in the first column; the second column indicates whether the glycosylation site is present in the variant protein; and the last column indicates whether the position is different on the variant protein).
Table 495 - Glycosylation site(s)
Variant protein HUMPHOSLIP_PEA_2_P34 is encoded by the following transcript(s): HUMPHOSLIP_PEA_2_T16, for which the sequence(s) is/are given at the end of the application. The coding portion of transcript HUMPHOSLIP_PEA_2_T16 is shown in bold; this coding portion starts at position 276 and ends at position 926. The transcript also has the following SNPs as listed in Table 496 (given according to their position on the nucleotide sequence, with the alternative nucleic acid listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein HUMPHOSLIP_PEA_2_P34 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 496 - Nucleic acid SNPs
Variant protein HUMPHOSLIP_PEA_2_P35 according to the present invention has an amino acid sequence as given at the end of the application; it is encoded by transcript(s) HUMPHOSLIP_PEA_2_T18. An alignment is given to the known protein (Phospholipid transfer protein precursor) at the end of the application. One or more alignments to one or more previously published protein sequences are given at the end of the application. A brief description of the relationship of the variant protein according to the present invention to each such aligned protein is as follows: Comparison report between HUMPHOSLIP_PEA_2_P35 and PLTP_HUMAN:
1.An isolated chimeric polypeptide encoding for HUMPHOSLIP_PEA_2_P35, comprising a first amino acid sequence being at least 90 % homologous to MALFGALFLALLAGAHAEFPGCKIRVTSKALELVKQEGLRFLEQELETITIPDLRGKEGH FYYNISEVKVTELQLTSSELDFQPQQELMLQITNASLGLRFRRQLLYWF corresponding to amino acids 1 - 109 of PLTP_HUMAN, which also corresponds to amino acids 1 - 109 of HUMPHOSLIP_PEA_2_P35, a second amino acid sequence bridging amino acid sequence comprising of L, a third amino acid sequence being at least 90 % homologous to
KVYDFLSTFITSGMRFLLNQQ coπ-esponding to amino acids 163 - 183 of PLTP_HUMAN, which also corresponds to amino acids 111 - 131 of HUMPHOSLIPJPEA_2_P35, and a fourth amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence VWAATGRRVARVGMLSL corresponding to amino acids 132 - 148 of HUMPHOSLP_PEA_2_P35, wherein said first amino acid sequence, second amino acid sequence, third amino acid sequence and fourth amino acid sequence are contiguous and in a sequential order.
2.An isolated polypeptide encoding for an edge portion of HUMPHOSLIP_PEA_2_P35, comprising a polypeptide having a length "n", wherein n is at least about 10 amino acids in length, optionally at least about 20 amino acids in length, preferably at least about 30 amino acids in length, more preferably at least about 40 amino acids in length and most preferably at least about 50 amino acids in length, wherein at least two amino acids comprise FLK having a structure as follows (numbering according to HUMPHO SLIP_PEA_2_P35): a sequence starting from any of amino acid numbers 109-x to 109; and ending at any of amino acid numbers 111 + ((n-2) - x), in which x varies from 0 to n-2.
3.An isolated polypeptide encoding for a tail of HUMPHOSLIP_PEA_2_P35, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence VWAATGRRVARVGMLSL in HUMPHOSLIP_PEA_2_P35.
The location of the variant protein was determined according to results from a number of different software programs and analyses, including analyses from SignalP and other specialized programs. The variant protein is believed to be located as follows with regard to the cell: secreted. The protein localization is believed to be secreted because both signal-peptide prediction programs predict that this protein has a signal peptide, and neither trans -membrane region prediction program predicts that this protein has a trans- membrane region.
Variant protein HUMPHOSLIP_PEA_2_P35 also has the following non-silent SNPs (Single Nucleotide Polymorphisms) as listed in Table 497, (given according to their position(s) on the amino acid sequence, with the alternative amino acid(s) listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein
HUMPHOSLIP_PEA_2_P35 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 497 -Amino acid mutations
The glycosylation sites of variant protein HUMPHOSLIP_PEA_2_P35, as compared to the known protein Phospholipid transfer protein precursor, are described in Table 498 (given according to their position(s) on the amino acid sequence in the first column; the second column indicates whether the glycosylation site is present in the variant protein; and the last column indicates whether the position is different on the variant protein). Table 498 - Glycosylation site(s)
Variant protein HUMPHOSLIP_PEA_2_P35 is encoded by the following transcript(s): HUMPHOSLIP_PEA_2__T18, for which the sequence(s) is/are given at the end of the application. The coding portion of transcript HUMPHOSLIP_PEA_2_T18 is shown in bold; this coding portion starts at position 276 and ends at position 719. The transcript also has the following SNPs as listed in Table 499 (given according to their position on the nucleotide sequence, with the alternative nucleic acid listed; the last column indicates whether the SNP is
known or not; the presence of known SNPs in variant protein HUMPHOSLIP_PEA_2_P35 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 499 - Nucleic acid SNPs
As noted above, cluster HUMPHOSLIP features 53 segment(s), which were listed in Table 2 above and for which the sequence(s) are given at the end of the application. These segment(s) are portions of nucleic acid sequence(s) which are described herein separately because they are of particular interest. A description of each segment according to the present invention is now provided.
Segment cluster HUMPHOSLIP_PEA_2_node_0 according to the present invention is supported by 150 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): HUMPHOSLIP_PEA_2_T6, HUMPHOSLIP_PEA_2_T7, HUMPHOSLIP_PEA_2_T14, HUMPHOSLIP_PEA_2_T16,
HUMPHOSLIP_PEA_2_T17, HUMPHOSLIP_PEA_2_T18 and HUMPHOSLIPJPEA_2_T19. Table 500 below describes the starting and ending position of this segment on each transcript.
Table 500 - Segment location on transcripts
Segment cluster HUMPHOSLIP_PEA_2_node_l 9 according to the present invention is supported by 186 libraries. The number of libraπes was determined as previously described. This segment can be found in the following transcπpt(s): HUMPHOSLIP_PEA_2_T6, HUMPHOSLIP_PEA_2_T7, HUMPHOSLIPJPEA_2_T14, HUMPHOSLIPJPEA_2_T16 and HUMPHOSLIP_PEA_2_T19. Table 501 below describes the starting and ending position of this segment on each transcript.
Table 501 - Segment location on transcripts
Segment cluster HUMPHOSLIPJPEA_2_node_34 according to the present invention is supported by 191 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): HUMPHOSLIP_PEA_2_T6, HUMPHOSLIP_PEA_2_T7, HUMPHOSLPJPEA_2_T14, HUMPHOSLIP_PEA_2_T16,
HUMPHOSLIP_PEA_2jri7, HUMPHOSLIP_PEA_2_T18 and HUMPHOSLIP_PEA_2_T19. Table 502 below describes the starting and ending position of this segment on each transcript.
Table 502 - Segment location on transcripts
Segment cluster HUMPHOSLIP_PEA_2_node_68 according to the present invention is supported by 131 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): HUMPHOSLIP_PEA_2_T6, HUMPHOSLIP_PEA_2_T7, HUMPHOSLIP_PEA_2_T14, HUMPHOSLIP_PEA_2_T16, HUMPHOSLIP_PEA_2_T17, HUMPHOSLIP_PEA_2_T18 and HUMPHOSLIP_PEA_2_T19. Table 503 below describes the starting and ending position of this segment on each transcript.
Table 503 - Segment location on transcripts
Segment cluster HUMPHOSLIP_PEA__2_node_70 according to the present invention is supported by 5 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): HUMPHOSLIP_PEA_2_T6, HUMPHOSLIP_PEA_2JT7, HUMPHO SLIP_PEA_2_T 14, HUMPHOSLIP_PEA_2_T16, HUMPHOSLIPJPEA_2_T17, HUMPHO SLIP_PEA_2_T 18 and HUMPHOSLIP_PEA_2_T19. Table 504 below describes the starting and ending position of this segment on each transcript.
Table 504 - Segment location on transcripts
Segment cluster HUMPHOSLIP_PEA_2_node_75 according to the present invention is supported by 14 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): HUMPHOSLIP_PEA_2_T6, HUMPHOSLIP_PEA_2_T7, HUMPHOSLIP_PEA_2_T14, HUMPHOSLIP_PEA_2_T16,
HUMPHOSLIP_PEA_2_T17, HUMPHOSLIP_PEA_2_T18 and HUMPHOSLIP_PEA_2_T19. Table 505 below describes the starting and ending position of this segment on each transcript.
Table 505 - Segment location on transcripts
According to an optional embodiment of the present invention, short segments related to the above cluster are also provided. These segments are up to about 120 bp in length, and so are included in a separate description.
Segment cluster HUMPHOSLIP_PEA_2_node_2 according to the present invention is supported by 159 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): HUMPHOSLIPJPEA_2_T6,
HUMPHOSLIP_PEA_2_T7, HUMPHOSLIP_PEA_2_T14, HUMPHOSLIP_PEA_2_T16, HUMPHOSLIP_PEA_2_T17, HUMPHOSLIP_PEA_2_T18 and HUMPHOSLIP_PEA_2_T19. Table 506 below describes the starting and ending position of this segment on each transcript.
Table 506 - Segment location on transcripts
Segment cluster HUMPHOSLIP_PEA_2_node_3 according to the present invention can be found in the following transcript(s): HUMPHOSLIP_PEA_2_T7, HUMPHOSLIP_PEA_2_T14, HUMPHOSLIP_PEA_2_T16, HUMPHOSLIP_PEA_2_T17, HUMPHOSLIP_PEA_2_T18 and HUMPHOSLIP_PEA_2_T19. Table 507 below describes the starting and ending position of this segment on each transcript.
Table 507 - Segment location on transcripts
Segment cluster HUMPHOSLIP_PEA_2_node_4 according to the present invention can be found in the following transcript(s): HUMPHOSLIP_PEA_2_T7, HUMPHOSLIP_PEA_2_T14, HUMPHOSLIP_PEA_2_T16, HUMPHOSLIP_PEA_2_T17, HUMPHOSLIP_PEA_2_T18 and HUMPHOSLIP_PEA_2_T19. Table 508 below describes the starting and ending position of this segment on each transcript.
Table 508 - Segment location on transcripts
Segment cluster HUMPHOSLIP_PEA_2_node_6 according to the present invention can be found in the following transcript(s): HUMPHOSLIP_PEA_2_T7, HUMPHOSLIP_PEA_2_T14, HUMPHOSLIP_PEA_2_T16, HUMPHOSLIP_PEA_2_T17, HUMPHOSLIP_PEA_2_T18 and HUMPHOSLIP_PEA_2_T19. Table 509 below describes the starting and ending position of this segment on each transcript.
Table 509 - Segment location on transcripts
Segment cluster HUMPHOSLIP_PEA_2_node_7 according to the present invention can be found in the following transcript(s): HUMPHOSLIP_PEA_2_T6, HUMPHOSLIP_PEA_2_T7, HUMPHOSLIP_PEA_2_T14, HUMPHOSLIP_PEA_2_T16, HUMPHOSLIP_PEA_2_T17, HUMPHOSLIP_PEA_2_T18 and HUMPHOSLIP_PEA_2_T19. Table 510 below describes the starting and ending position of this segment on each transcript.
Table 510 - Segment location on transcripts
Segment cluster HUMPHOSLIP_PEA_2_node_8 according to the present invention is supported by 171 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): HUMPHOSLIP_PEA_2_T6, HUMPHOSLIP_PEA_2_T7, HUMPHOSLIP_PEA_2_T14, HUMPHOSLIP_PEA_2_T16, HUMPHOSLIP_PEA_2_T17, HUMPHOSLIP_PEA_2_T18 and HUMPHOSLIP_PEA_2_T19. Table 511 below describes the starting and ending position of this segment on each transcript.
Table 511 - Segment location on transcripts
Segment cluster HUMPHOSLIP_PEA_2_node_9 according to the present invention is supported by 168 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): HUMPHOSLIP_PEA_2_T6, HUMPHOSLIP_PEA_2_T7, HUMPHOSLIP_PEA_2_T14, HUMPHOSLIP_PEA_2_T16, HUMPHOSLIPJPEA_2_T17, HUMPHO SLIP_PEA_2_T 18 and HUMPHOSLIP_PEA_2_T19. Table 512 below describes the starting and ending position of this segment on each transcript.
Table 512 - Segment location on transcripts
Segment cluster HUMPHOSLIP_PEA_2_node_14 according to the present invention is supported by 6 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): HUMPHOSLIP_PEA_2_T7. Table 513 below describes the starting and ending position of this segment on each transcript.
Table 513 - Segment location on transcripts
Segment cluster HUMPHOSLIP_PEA_2_node_15 according to the present invention can be found in the following transcript(s): HUMPHOSLIP_PEA_2_T6,
HUMPHOSLIP_PEA_2_T7, HUMPHO SLIP_PEA_2_T 14, HUMPHOSLIP_PEA_2_T16, HUMPHOSLIP_PEA_2_T18 and HUMPHOSLIP_PEA_2_T19. Table 514 below describes the starting and ending position of this segment on each transcript.
Table 514 - Segment location on transcripts
Segment cluster HUMPHOSLIP_PEA_2_node_16 according to the present invention is supported by 179 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): HUMPHOSLIP_PEA_2_T6, HUMPHOSLIP_PEA_2_T7, HUMPHO SLIP_PEA_2_T 14, HUMPHOSLIP_PEA_2_T16,
HUMPHOSLIP_PEA_2_T18 and HUMPHOSLIP_PEA_2_T19. Table 515 below describes the starting and ending position of this segment on each transcript.
Table 515 - Segment location on transcripts
Segment cluster HUMPHOSLIP_PEA_2_node_l 7 according to the present invention can be found in the following transcript(s): HUMPHOSLIP_PEA_2_T6, HUMPHOSLIPJPEA_2_T7, HUMPHOSLIP_PEA_2_T14, HUMPHOSLIP_PEA_2_T16, HUMPHOSLIP_PEA_2_T18 and HUMPHOSLIP_PEA_2_T19. Table 516 below describes the starting and ending position of this segment on each transcript.
Table 516 - Segment location on transcripts
Segment cluster HUMPHOSLIP_PEA_2_node_23 according to the present invention is supported by 168 libraries. The number of libraries was determined as previously described.
This segment can be found in the following transcriρt(s): HUMPHOSLIP_PEA_2_T6,
HUMPHOSLIP_PEA_2_T7, HUMPHOSLIP_PEA_2_T14, HUMPHOSLIP_PEA_2_T16, HUMPHOSLIP_PEA_2_T17, HUMPHOSLIP_PEA_2_T18 and HUMPHOSLIP_PEA_2_T19.
Table 517 below describes the starting and ending position of this segment on each transcript.
Table 517 - Segment location on transcripts
Segment cluster HUMPHO SLIP_PEA_2_node_24 according to the present invention can be found in the following transcript(s): HUMPHOSLIP_PEA_2_T6, HUMPHOSLIP_PEA_2_T7, HUMPHO SLIP_PEA_2_T 14, HUMPHOSLIP_PEA_2_T16, HUMPHOSLIPJPEA_2_T17, HUMPHOSLIP_PEA_2_T18 and HUMPHOSLIP_PEA_2_T19. Table 518 below describes the starting and ending position of this segment on each transcript.
Table 518 - Segment location on transcripts
Segment cluster HUMPHOSLIP PEA 2_node_25 according to the present invention is supported by 5 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): HUMPHOSLIP_PEA_2_T14 and HUMPHOSLIP_PEA_2_T18. Table 519 below describes the starting and ending position of this segment on each transcript.
Table 519- Segment location on transcripts
Segment cluster HUMPHOSLIP_PEA_2_node_26 according to the present invention is supported by 163 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): HUMPHOSLIP_PEA_2_T6, HUMPHOSLIP_PEA_2_T7, HUMPHOSLIP_PEA_2_T14, HUMPHOSLIP_PEA_2_T16, HUMPHOSLIPJPEA 2 T17, HUMPHOSLIP_PEA_2_T18 and HUMPHOSLIPJPEA_2_T19. Table 520 below describes the starting and ending position of this segment on each transcript.
Table 520 - Segment location on transcripts
Segment cluster HUMPHOSLIP_PEA_2_node_29 according to the present invention can be found in the following transcript(s): HUMPHOSLIP_PEA_2_T6, HUMPHOSLIP_PEA_2_T7, HUMPHOSLIP_PEA_2_T14, HUMPHOSLIP_PEA_2_T17, HUMPHOSLIP_PEA_2_T18 and HUMPHOSLIP_PEA_2_T19. Table 521 below describes the starting and ending position of this segment on each transcript.
Table 521 - Segment location on transcripts
Segment cluster HUMPHOSLIP_PEA_2_node_30 according to the present invention is supported by 181 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): HUMPHOSLIP_PEA_2_T6, HUMPHOSLIP_PEA_2_T7, HUMPHO SLIP_PEA_2_T 14, HUMPHOSLIP_PEA_2_T16, HUMPHOSLJP_PEA_2_T17, HUMPHOSLIP_PEA_2_T18 and HUMPHOSLIP_PEA_2_T19. Table 522 below describes the starting and ending position of this segment on each transcript.
Table 522- Segment location on transcripts
Segment cluster HUMPHOSLIP_PEA_2_node_33 according to the present invention is supported by 173 libraries. The number of libraries was determined as previously described.
This segment can be found in the following transcript(s): HUMPHOSLIPJPEA_2_T6, HUMPHOSLIP_PEA_2_T7, HUMPHOSLIP_PEA_2_T14, HUMPHOSLIP_PEA_2_T16, HUMPHOSLIP_PEA_2_T17, HUMPHOSLIP_PEA_2_T18 and HUMPHOSLIP_PEA_2_T19. Table 523 below describes the starting and ending position of this segment on each transcript.
Table 523 - Segment location on transcripts
Segment cluster HUMPHOSLIP_PEA_2_node_36 according to the present invention is supported by 163 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): HUMPHOSLIP_PEA_2_T6,
HUMPHOSLIP_PEA_2_T7, HUMPHOSLIP_PEA_2_T14, HUMPHO SLIP_PEA_2_T 16, HUMPHOSLIP_PEA_2_T17, HUMPHOSLIP_PEA_2_T18 and HUMPHOSLIP_PEA_2_T19. Table 524 below describes the starting and ending position of this segment on each transcript.
Table 524- Segment location on transcripts
Segment cluster HUMPHOSLIP_PEA_2_node_37 according to the present invention can be found in the following transcript(s): HUMPHOSLIP_PEA_2_T6, HUMPHOSLIP_PEA_2_T7, HUMPHOSLIP_PEA_2_T14, HUMPHOSLIP_PEA_2_T16, HUMPHOSLIP_PEA_2_T17, HUMPHOSLIP_PEA_2_T18 and HUMPHOSLIP_PEA_2_T19. Table 525 below describes the starting and ending position of this segment on each transcript.
Table 525 - Segment location on transcripts
Segment cluster HUMPHOSLIP_PEA_2_node_39 according to the present invention is supported by 166 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): HUMPHOSLIP_PEA_2_T6, HUMPHOSLIP_PEA_2_T7, HUMPHOSLIP_PEA_2_T14, HUMPHOSLIPJPEA_2_T16, HUMPHOSLIP_PEA_2_T17, HUMPHOSLIP_PEA_2_T18 and HUMPHOSLIP_PEA_2_T19. Table 525 below describes the starting and ending position of this segment on each transcript.
Table 525 - Segment location on transcripts
Segment cluster HUMPHOSLIP_PEA_2_node_40 according to the present invention is supported by 199 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): HUMPHOSLIP_PEA_2_T6, HUMPHOSLIP_PEA_2_T7, HUMPHOSLIP_PEA_2_T14, HUMPHOSLIP_PEA_2_T16, HUMPHOSLIP_PEA_2_T17, HUMPHOSLIP_PEA_2_T18 and HUMPHOSLIP_PEA_2_T19. Table 526 below describes the starting and ending position of this segment on each transcript.
Table 526 - Segment location on transcripts
Segment cluster HUMPHO SLIP_PEA_2_node_41 according to the present invention is supported by 186 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): HUMPHOSLIP_PEA_2_T6, HUMPHOSLIP_PEA_2_T7, HUMPHO SLIPJPEA_2_T 14, HUMPHOSLIPJPEA_2_T16, HUMPHOSLIP_PEA_2_T17, HUMPHOSLIP_PEA_2_T18 and HUMPHOSLIP_PEA_2_T19. Table 527 below describes the starting and ending position of this segment on each transcript.
Table 527 - Segment location on transcripts
Segment cluster HUMPHOSLIP_PEA_2_node_42 according to the present invention can be found in the following transcript(s): HUMPHOSLIP_PEA_2_T6, HUMPHOSLIP_PEA_2_T7, HUMPHOSLIPJ>EA_2_T14, HUMPHOS LIP_PEA_2_T 16, HUMPHOSLIP_PEA_2_T17, HUMPHOSLIP_PEA_2_T18 and HUMPHOSLIP_PEA_2_T19. Table 528 below describes the starting and ending position of this segment on each transcript. Table 528 - Segment location on transcripts
Segment cluster HUMPHOSLIP_PEA_2_node_44 according to the present invention is supported by 185 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): HUMPHOSLIP_PEA_2_T6, HUMPHOSLIP J>EA_2_T7, HUMPHOSLIP_PEA_2_T14, HUMPHOSLIP_PEA_2_T16, HUMPHOSLIP J>EA_2_T17, HUMPHOSLIP_PEA_2_T18 and HUMPHOSLIP_PEA_2_T19. Table 529 below describes the starting and ending position of this segment on each transcript.
Table 529 - Segment location on transcripts
Segment cluster HUMPHOSLIP_PEA_2_node_45 according to the present invention is supported by 197 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): HUMPHOSLIP_PEA_2_T6, HUMPHOSLIP_PEA_2_T7, HUMPHOSLIP_PEA_2_T14, HUMPHOSLIP_PEA_2_T16,
HUMPHOSLIP_PEA_2_T17, HUMPHOSLIPJPEA_2_T18 and HUMPHOSLIP_PEA_2_T19. Table 530 below describes the starting and ending position of this segment on each transcript.
Table 530 - Segment location on transcripts
Segment cluster HUMPHOSLIP_PEA_2_node_47 according to the present invention is supported by 223 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): HUMPHOSLIP_PEA_2_T6, HUMPHOSLIP_PEA_2_T7, HUMPHOSLIP_PEA_2_T14, HUMPHOSLIP_PEA_2_T16, HUMPHOSLIP_PEA_2_T17, HUMPHOSLIP_PEA_2_T18 and HUMPHOSLIP_PEA_2_T19. Table 531 below describes the starting and ending position of this segment on each transcript.
Table 531 - Segment location on transcripts
Segment cluster HUMPHOSLIP_PEA_2_node_51 according to the present invention can be found in the following transcript(s): HUMPHOSLIP_PEA_2_T6, HUMPHOSLIP J
>EA_2_T7, HUMPHO SLIP_PEA_2_T 14, HUMPHOSLIP JPEA_2_T 16, HUMPHOSLIP_PEA_2__T17, HUMPHOSLIP_PEA_2_T18 and HUMPHOSLIP JPEA_2_T19. Table 532 below describes the starting and ending position of this segment on each transcript.
Table 532 - Segment location on transcripts
Segment cluster HUMPHOSLIP_PEA_2_node_52 according to the present invention is supported by 235 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): HUMPHOSLIP_PEA_2_T6, HUMPHOSLIP_PEA_2_T7, HUMPHOSLIP_PEA_2_T14, HUMPHOSLIP_PEA_2_T16, HUMPHOSLIP_PEA_2_T17, HUMPHOSLIP_PEA_2_T18 and HUMPHOSLIP_PEA_2_T19. Table 533 below describes the starting and ending position of this segment on each transcript. Table 533 - Segment location on transcripts
Segment cluster HUMPHOSLIP_PEA_2_node_53 according to the present invention is supported by 5 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): HUMPHOSLIP_PEA_2_T19. Table 534 below describes the starting and ending position of this segment on each transcript.
Table 534 - Segment location on transcripts
Segment cluster HUMPHOSLIP_PEA_2_node_54 according to the present invention is supported by 236 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): HUMPHOSLIP_PEA_2_T6, HUMPHOSLIP_PEA_2_T7, HUMPHOSLIPJPEA_2_T14, HUMPHOSLIP_PEA_2_T16, HUMPHOSLIP_PEA_2_T17, HUMPHOSLIP_PEA_2_T18 and HUMPHOSLIP_PEA_2_T19. Table 535 below describes the starting and ending position of this segment on each transcript.
Table 535 - Segment location on transcripts
Segment cluster HUMPHO SLIPJPEA_2_node_55 according to the present invention is supported by 232 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): HUMPHOSLIP_PEA_2_T6, HUMPHOSLIP_PEA_2_T7, HUMPHOSLIP_PEA_2_T14, HUMPHOSLIP_PEA_2_T16, HUMPHOSLIP_PEA_2_T17, HUMPHO SLIPJ>EA_2_T 18 and HUMPHOSLIP_PEA_2_T19. Table 536 below describes the starting and ending position of this segment on each transcript.
Table 536 - Segment location on transcripts
Segment cluster HUMPHO8LΪPJPEA_2_node_58 according to the present invention can be found in the following transcript(s): HUMPHOSLIP_PEA_2_T6, HUMPHOSLIP_PEA_2_T7, HUMPHOSLIPJPEA_2_T14, HUMPHOSLIP_PEA_2_T16, HUMPHOSLIP_PEA_2_T17, HUMPHOSLIP_PEA_2_T18 and HUMPHOSLIP_PEA_2_T19. Table 537 below describes the starting and ending position of this segment on each transcript.
Table 537 - Segment location on transcripts
Segment cluster HUMPHOSLIP_PEA_2_node_59 according to the present invention is supported by 230 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): HUMPHOSLIP_PEA_2_T6, HUMPHOSLIP_PEA_2_T7, HUMPHOSLIP_PEA_2_T14, HUMPHOSLIP_PEA_2_T16, HUMPHOSLIP J>EA_2_T17, HUMPHOSLIP_PEA_2_T18 and HUMPHOSLIP_PEA_2_T19. Table 538 below describes the starting and ending position of this segment on each transcript.
Table 538 - Segment location on transcripts
Segment cluster HUMPHOSLIP_PEA_2_node_60 according to the present invention can be found in the following transcπpt(s): HUMPHOSLIP_PEA_2_T6, HUMPHOSLIP_PEA_2_T7, HUMPHOSLIP_PEA_2_T14, HUMPHOSLIP_PEA_2_T16, HUMPHOSLIP_PEA_2_T17, HUMPHOSLIP_PEA_2_T18 and HUMPHOSLIP_JPEA_2_T19. Table 539 below describes the starting and ending position of this segment on each transcript.
Table 539 - Segment location on transcripts
Segment cluster HUMPHOSLIP_PEA_2_node_61 according to the present invention can be found in the following transcript(s) : HUMPHOSLIP_PEA_2_T6,
HUMPHOSLIP_PEA_2_T7, HUMPHOSLIP_PEA_2_T14, HUMPHOSLIP_PEA_2_T16, HUMPHOSLIP_PEA_2_T17, HUMPHOSLIP_PEA_2_T18 and HUMPHOSLIP_PEA_2_T19. Table 540 below describes the starting and ending position of this segment on each transcript.
Table 540 - Segment location on transcripts
Segment cluster HUMPHO8LΪP_PEA_2jαode_62 according to the present invention can be found in the following transcript(s): HUMPHOSLIP_PEA_2_T6, HUMPHOSLIP_PEA_2_T7, HUMPHOSLIP_PEA_2_T14, HUMPHOSLIP_PEA_2_T16, HUMPHOSLIP_PEA_2_T17, HUMPHO SLIP_PEA_2_T 18 and HUMPHOSLIP_PEA_2_T19. Table 541 below describes the starting and ending position of this segment on each transcript.
Table 541 - Segment location on transcripts
Segment cluster HUMPHOSLIP_PEA_2_node_63 according to the present invention can be found in the following transcript(s): HUMPHOSLIP_PEA_2_T6, HUMPHOSLIP_PEA_2_T7, HUMPHOSLIP_PEA_2_T14, HUMPHOSLIP_PEA_2_T16, HUMPHOSLIP_PEA_2_T17, HUMPHOSLIP_PEA_2_T18 and HUMPHOSLIP_PEA_2_T19. Table 542 below describes the starting and ending position of this segment on each transcript.
Table 542 - Segment location on transcripts
Segment cluster HUMPHOSLIP_PEA_2_node_64 according to the present invention can be found in the following transcript(s): HUMPHOSLIP_PEA_2_T6, HUMPHOSLIP_PEA_2_T7, HUMPHO SLIP_PEA_2_T 14, HUMPHOSLIP_PEA_2_T16, HUMPHOSLIP_PEA_2_T17, HUMPHOSLIP_PEA_2_T18 and HUMPHOSLIP_PEA_2_T19. Table 543 below describes the starting and ending position of this segment on each transcript.
Table 543 - Segment location on transcripts
Segment cluster HUMPHOSLIP_PEA_2_node_65 according to the present invention can be found in the following transcript(s): HUMPHOSLIP_PEA_2_T6,
HUMPHOSLIP_PEA_2_T7, HUMPHO SLIP_PEA_2_T14, HUMPHOSLIP_PEA_2_T16, HUMPHOSLIP_PEA_2_T17, HUMPHOSLIP_PEA_2_T18 and HUMPHOSLIP_PEA_2_T19. Table 544 below describes the starting and ending position of this segment on each transcript.
Table 544 - Segment location on transcripts
Segment cluster HUMPHOSLIP_PEA_2_node_66 according to the present invention is supported by 180 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): HUMPHOSLIP_PEA_2_T6, HUMPHOSLIP_PEA_2_T7, HUMPHOSLIP_PEA_2_T14, HUMPHOSLIP_PEA_2_T16,
HUMPHOSLIP_PEA_2_T17, HUMPHOSLIP_PEA_2_T18 and HUMPHOSLIP_PEA_2_T19. Table 545 below describes the starting and ending position of this segment on each transcript.
Table 545 - Segment location on transcripts
Segment cluster HUMPHOSLIPJPEA_2_node_67 according to the present invention can be found in the following transcript(s): HUMPHOSLIP_PEA_2_T6, HUMPHOSLIP_PEA_2_T7, HUMPHOSLIP_PEA_2_T14, HUMPHOSLIPJ>EA_2_T16, HUMPHOSLIP_PEA_2_T17, HUMPHOSLIP_PEA_2_T18 and HUMPHOSLIP_PEA_2_T19. Table 546 below describes the starting and ending position of this segment on each transcript.
Table 546 - Segment location on transcripts
Segment cluster HUMPHOSLIP_PEA_2_node_69 according to the present invention can be found in the following transcript(s): HUMPHOSLIP_PEA_2_T6, HUMPHOSLIP_PEA_2_T7, HUMPHO SLIP_PEA_2_T 14, HUMPHOSLIP_PEA_2_T16, HUMPHOSLIP_PEA_2_T17, HUMPHOSLIP_PEA_2_T18 and HUMPHOSLIP_PEA_2_T19. Table 547 below describes the starting and ending position of this segment on each transcript.
Table 547 - Segment location on transcripts
Segment cluster HUMPHO SLIP_PEA_2_node_71 according to the present invention can be found in the following transcript(s): HUMPHOSLIP_PEA_2_T6, HUMPHOSLIP_PEA_2_T7, HUMPHOSLIP JPEA_2_T14, HUMPHOSLIP_PEA_2_T16, HUMPHOSLIP_PEA_2_T17, HUMPHOSLIP_PEA_2_T18 and HUMPHOSLIP_PEA_2_T19. Table 548 below describes the starting and ending position of this segment on each transcript.
Table 548 - Segment location on transcripts
Segment cluster HUMPHOSLIP_PEA_2_node_72 according to the present invention is supported by 7 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): HUMPHOSLIP_PEA_2_T6, HUMPHOSLIP_PEA_2_T7, HUMPHO SLIP_PEA_2_T 14, HUMPHOSLIP_PEA_2_T16,
HUMPHOSLIP_PEA_2_T17, HUMPHO SLIPJ3E A_2_T 18 and HUMPHOSLIPJPEA_2_T19. Table 549 below describes the starting and ending position of this segment on each transcript.
Table 549 - Segment location on transcripts
Segment cluster HUMPHOSLIP_PEA_2_node_73 according to the present invention is supported by 5 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): HUMPHOSLIP_PEA_2_T6, HUMPHOSLIP_PEA_2_T7, HUMPHOSLIP_PEA_2_T14, HUMPHOSLIP_PEA_2_T16, HUMPHOSLIP_PEA_2_T17, HUMPHOSLIP_PEA_2_T18 and HUMPHOSLIPJPEA_2_T19. Table 550 below describes the starting and ending position of this segment on each transcript.
Table 550 - Segment location on transcripts
Segment cluster HUMPHOSLIP_PEA_2_node_74 according to the present invention is supported by 10 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): HUMPHOSLIP_PEA_2_T6, HUMPHOSLIP_PEA_2_T7, HUMPHOSLIPJ>EA__2_T14, HUMPHOSLIPJPEA_2_T16, HUMPHOSLIP_PEA_2_T17, HUMPHOSLIP_PEA_2_T18 and HUMPHOSLIP_PEA_2_T19. Table 551below describes the starting and ending position of this segment on each transcript.
Table 551 - Segment location on transcripts
Variant protein alignment to the previously known protein:
Sequence name: PLTP_HUMAN
Sequence documentation:
Alignment of: HUMPHOSLIP_PEA_2_P10 x PLTP_HUMAN
Alignment segment 1/1:
Quality: 3716.00 Escore: 0
Matching length: 398 Total length: 493 Matching Percent Similarity: 100.00 Matching Percent Identity: 100.00
Total Percent Similarity: 80.73 Total Percent Identity: 80.73
Gaps : 1
Alignment :
1 MALFGALFLALLAGAHAEFPGCKIRVTSKALELVKQEGLRFLEQELETIT 50
I I Il I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I 1 MALFGALFLALLAGAHAEFPGCKIRVTSKALELVKQEGLRFLEQELETIT 50
51 IPDLRGKEGHFYYNISE 67
M M I I M I I I M M I I
51 IPDLRGKEGHFYYNISEVKVTELQLTSSELDFQPQQELMLQITNASLGLR 100 . . . . .
67 67
101 FRRQLLYWFFYDGGYINASAEGVSIRTGLELSRDPAGRMKVSNVSCQASV 150
68 KVYDFLSTFITSGMRFLLNQQICPVLYHAGTVLLNSLL 105
151 SRMHAAFGGTFKKVYDFLSTFITSGMRFLLNQQICPVLYHAGTVLLNSLL 200
106 DTVPVRSSVDELVGIDYSLMKDPVASTSNLDMDFRGAFFPLTERNWSLPN 155
1111111111111111111!11!!1!1111111!111!1!1IMlIlIII 201 DTVPVRSSVDELVGIDYSLMKDPVASTSNLDMDFRGAFFPLTERNWSLPN 250
156 RAVEPQLQEEERMVYVAFSEFFFDSAMESYFRAGALQLLLVGDKVPHDLD 205
!111!11111111!11!111111111111111!IMIIIIIIIIIIIIII 251 RAVEPQLQEEERMVYVAFSEFFFDSAMESYFRAGALQLLLVGDKVPHDLD 300 . . . . .
206 MLLRATYFGSIVLLSPAVIDSPLKLELRVLAPPRCTIKPSGTTISVTASV 255
I I I Il I I I Il I I I Il Il I I I I I I I I I I 1 I Il I I I I I Il Il Il I Il I I I Il
301 MLLRATYFGSIVLLSPAVIDSPLKLELRVLAPPRCTIKPSGTTISVTASV 350
256 TIALVPPDQPEVQLSSMTMDARLSAKMALRGKALRTQLDLRRFRIYSNHS 305
II Il I I Il I I I I I I I I I I I I Il I Il ! I I I I I I I I I I Il I Il I Il I I I I Il
351 TIALVPPDQPEVQLSSMTMDARLSAKMALRGKALRTQLDLRRFRIYSNHS 400
306 ALESLALIPLQAPLKTMLQIGVMPMLNERTWRGVQIPLPEGINFVHEWT 355 1!!11IMIMIIIIIMIIMIIIMIIIIMMIIIIIIIIMIMI!
401 ALESLALIPLQAPLKTMLQIGVMPMLNERTWRGVQIPLPEGINFVHEWT 450
356 NHAGFLTIGADLHFAKGLREVIEKNRPADVRASTAPTPSTAAV 398
I M M M M MI M IMM IM I M I I M M M M M M M M 451 NHAGFLTIGADLHFAKGLREVIEKNRPADVRASTAPTPSTAAV 493
Sequence name: PLTP_HUMAN
Sequence documentation:
Alignment of: HUMPHOSLIP_PEA_2_P12 x PLTP_HUMAN
Alignment segment 1/1:
Quality: 4101.00 Escore: 0
Matching length: 427 Total length: 427
Matching Percent Similarity: 100.00 Matching Percent Identity: 100.00 Total Percent Similarity: 100.00 Total Percent Identity: 100.00
Gaps : 0
Alignment: . . . . .
1 MALFGALFLALLAGAHAEFPGCKIRVTSKALELVKQEGLRFLEQELETIT 50
I I I I I I I I I I I I I Il I I I I I I I I I I I I I I I I I Il I I I I I I I I I I I I I I I I
1 MALFGALFLALLAGAHAEFPGCKIRVTSKALELVKQEGLRFLEQELETIT 50
51 IPDLRGKEGHFYYNISEVKVTELQLTSSELDFQPQQELMLQITNASLGLR 100
I I Il I I Il Il Il Il I Il I I Il I Il Il I I I I I I I I I Il Il I I I I I I Il I I I
51 IPDLRGKEGHFYYNISEVKVTELQLTSSELDFQPQQELMLQITNASLGLR 100
101 FRRQLLYWFFYDGGYINASAEGVSIRTGLELSRDPAGRMKVSNVSCQASV 150 I I I I I I I I I I I M I I I I I I M I I I M M I M I I M I I M I I I I I I I Il I I
101 FRRQLLYWFFYDGGYINASAEGVSIRTGLELSRDPAGRMKVSNVSCQASV 150
151 SRMHAAFGGTFKKVYDFLSTFITSGMRFLLNQQICPVLYHAGTVLLNSLL 200
I I I I I I I I I I I I I I I I I I I I I I I 1 Il I I I 1 I I I I I I I I I I I I I I I I I I I I
151 SRMHAAFGGTFKKVYDFLSTFITSGMRFLLNQQICPVLYHAGTVLLNSLL 200 . . . . .
201 DTVPVRSSVDELVGIDYSLMKDPVASTSNLDMDFRGAFFPLTERNWSLPN 250
I I Il I I I I I I I I I I I Il I I I I I I 1 I I I I I Il I Il I I I I I I I I I Il I I I I I
201 DTVPVRSSVDELVGIDYSLMKDPVASTSNLDMDFRGAFFPLTERNWSLPN 250
251 RAVEPQLQEEERMVYVAFSEFFFDSAMESYFRAGALQLLLVGDKVPHDLD 300
I I I Il I I I I 1 Il I I I I I I I I I I I I I I I I I I I I I I I I I Il I I I 11 I I I I I I
251 RAVEPQLQEEERMVYVAFSEFFFDSAMESYFRAGALQLLLVGDKVPHDLD 300
301 MLLRATYFGSIVLLSPAVIDSPLKLELRVLAPPRCTIKPSGTTISVTASV 350 I ] M I I I I I M I I I I I I I I I I I I I M I I I I M I I I I I I I M I I M I I M I
301 MLLRATYFGSIVLLSPAVIDSPLKLELRVLAPPRCTIKPSGTTISVTASV 350
351 TIALVPPDQPEVQLSSMTMDARLSAKMALRGKALRTQLDLRRFRIYSNHS 400
I I I I I I I I I I I Il I I I I I I I I I I I I I I I I I I I I I I I I I 1 I I I I I I I I I Il 351 TIALVPPDQPEVQLSSMTMDARLSAKMALRGKALRTQLDLRRFRIYSNHS 400
401 ALESLALIPLQAPLKTMLQIGVMPMLN 427
I I Il I Il I I I I I Il III I I I Il I Il I I
401 ALESLALIPLQAPLKTMLQIGVMPMLN 427
Sequence name: PLTP HUMAN
Sequence documentation:
Alignment of: HUMPHOSLIP_PEA_2_P31 x PLTP_HUMAN
Alignment segment 1/1:
Quality: 639.00 Escore: 0 Matching length: 67 Total length: 67
Matching Percent Similarity: 100.00 Matching Percent Identity: 100.00
Total Percent Similarity: 100.00 Total Percent Identity: 100.00
Gaps : 0
Alignment:
1 MALFGALFLALLAGAHAEFPGCKIRVTSKALELVKQEGLRFLEQELETIT 50
1 MALFGALFLALLAGAHAEFPGCKIRVTSKALELVKQEGLRFLEQELETIT 50
51 IPDLRGKEGHFYYNISE 67
51 IPDLRGKEGHFYYNISE 67
Sequence name: PLTP_HUMAN
Sequence documentation:
Alignment of: HUMPHOSLIP_PEA_2_P33 x PLTP_HUMAN
Alignment segment 1/1:
Quality: 1767.00
Escore: 0
Matching length: 184 Total length: 184
Matching Percent Similarity: 100.00 Matching Percent Identity: 99.46
Total Percent Similarity: 100.00 Total Percent Identity: 99.46
Gaps : 0
Alignment:
1 MALFGALFLALLAGAHAEFPGCKIRVTSKALELVKQEGLRFLEQELETIT 50
I I I I I I I I I I Il Il Il I I I I I I I Il I I I I I I I Il I I I I I I I I I I I I i I Il
1 MALFGALFLALLAGAHAEFPGCKIRVTSKALELVKQEGLRFLEQELETIT 50 . . . . .
51 IPDLRGKEGHFYYNISEVKVTELQLTSSELDFQPQQELMLQITNASLGLR 100
Il Il I Il I I I Il I I I Il Il I I I I I I I I I I I Il I Il Il Il I I I I I I Il I Il
51 IPDLRGKEGHFYYNISEVKVTELQLTSSELDFQPQQELMLQITNASLGLR 100
101 FRRQLLYWFFYDGGYINASAEGVSIRTGLELSRDPAGRMKVSNVSCQASV 150
101 FRRQLLYWFFYDGGYINASAEGVSIRTGLELSRDPAGRMKVSNVSCQASV 150
151 SRMHAAFGGTFKKVYDFLSTFITSGMRFLLNQQV 184
1 I I I I I I I I I I I I I I I I Il I I I I I I I I I I I I I I :
151 SRMHAAFGGTFKKVYDFLSTFITSGMRFLLNQQI 184
Sequence name: PLTP__HUMAN
Sequence documentation:
Alignment of: HUMPHOSLIP_PEA_2_P34 x PLTP_HUMAN
Alignment segment 1/1:
Quality: 1971.00
Escore: 0
Matching length: 205 Total length: 205
Matching Percent Similarity: 100.00 Matching Percent Identity: 100.00
Total Percent Similarity: 100.00 Total Percent Identity: 100.00
Gaps : 0
Alignment:
1 MALFGALFLALLAGAHAEFPGCKIRVTSKALELVKQEGLRFLEQELETIT 50
1 MALFGALFLALLAGAHAEFPGCKIRVTSKALELVKQEGLRFLEQELETIT 50
51 IPDLRGKEGHFYYNISEVKVTELQLTSSELDFQPQQELMLQITNASLGLR 100 I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I
51 IPDLRGKEGHFYYNISEVKVTELQLTSSELDFQPQQELMLQITNASLGLR 100
101 FRRQLLYWFFYDGGYINASAEGVSIRTGLELSRDPAGRMKVSNVSCQASV 150 I I I 1 I I I I I I I I I I I I I 1 I I I I I I I I I I I 1 I I I I I I I I I I I I I 1 I I I I I I
101 FRRQLLYWFFYDGGYINASAEGVSIRTGLELSRDPAGRMKVSNVSCQASV 150
151 SRMHAAFGGTFKKVYDFLSTFITSGMRFLLNQQICPVLYHAGTVLLNSLL 200
I I I I I I I I I I I I I I I I I I I I I I I I I I I I I Il 11 I I I I I Il I I I I I I I I I I 151 SRMHAAFGGTFKKVYDFLSTFITSGMRFLLNQQICPVLYHAGTVLLNSLL 200
201 DTVPV 205
Mill
201 DTVPV 205
Sequence name: PLTP_HUMAN
Sequence documentation:
Alignment of: HUMPHOSLIP_PEA_2_P35 x PLTP_HUMAN
Alignment segment 1/1:
Quality: 1158.00 Escore: 0 Matching length: 132 Total length: 184
Matching Percent Similarity: 100.00 Matching Percent Identity: 98.48
Total Percent Similarity: 71.74 Total Percent Identity: 70.65
Gaps : 1
Alignment :
1 MALFGALFLALLAGAHAEFPGCKIRVTSKALELVKQEGLRFLEQELETIT 50
I I I Il I I I I I I I I I I I I I I i Ii I I I I I I I I i I I I I I I I i I I I I I I I I I I I
1 MALFGALFLALLAGAHAEFPGCKIRVTSKALELVKQEGLRFLEQELETIT 50
51 IPDLRGKEGHFYYNISEVKVTELQLTSSELDFQPQQELMLQITNASLGLR 100 I I I I Il M M I I I M I I I M I I M M I M I Il M I I I M M I I I I M I I I
51 IPDLRGKEGHFYYNISEVKVTELQLTSSELDFQPQQELMLQITNASLGLR 100
101 FRRQLLYWFL 110
IMMIIII: 101 FRRQLLYWFFYDGGYINASAEGVSIRTGLELSRDPAGRMKVSNVSCQASV 150
111 KVYDFLSTFITSGMRFLLNQQV 132
MMMMIMMMMMM:
151 SRMHAAFGGTFKKVYDFLSTFITSGMRFLLNQQI 184
DESCRIPTION FOR CLUSTER AI076020
Cluster AI076020 features 1 transcript(s) and 8 segment(s) of interest, the names for which are given in Tables 552 and 553, respectively, the sequences themselves are given at the end of the application. The selected protein variants are given in table 554.
Table 552 - Transcripts of interest
Table 553 - Segments of interest
Table 554 - Proteins of interest
These sequences are variants of the known protein Clq-related factor precursor
(SwissProt accession identifier C1RF_HUMAN), SEQ ID NO: 1434, referred to herein as the previously known protein.
The sequence for protein Clq-related factor precursor is given at the end of the application, as "Clq-related factor precursor amino acid sequence".
The following GO Annotation(s) apply to the previously known protein. The following annotation(s) were found: locomotory behavior, which are annotation(s) related to Biological Process.
The GO assignment relies on information from one or more of the SwissProt/TremBl Protein knowledgebase, available from <http://www.expasy.ch/sprot/>; or Locuslink, available from <http://www.ncbi.nhn.nih.gov/projects/LocusLink/>.
Cluster AI076020 can be used as a diagnostic marker according to overexpression of transcripts of this cluster in cancer. Expression of such transcripts in normal tissues is also given according to the previously described methods. The term "number" in the right hand column of the table and the numbers on the y-axis of figure 31 refer to weighted expression of ESTs in each category, as "parts per million" (ratio of the expression of ESTs for a particular cluster to the expression of all ESTs in that category, according to parts per million).
Overall, the following results were obtained as shown with regard to the histograms in
Figure 31 and Table 555. This cluster is overexpressed (at least at a minimum level) in the following pathological conditions: brain malignant tumors and a mixture of malignant tumors from different tissues.
Table 555 - Normal tissue distribution
Table 556 - P values and ratios for expression in cancerous tissue
As noted above, cluster AI076020 features 1 transcript(s), which were listed in Table 1 above. These transcript(s) encode for protein(s) which are variant(s) of protein Clq-related factor precursor. A description of each variant protein according to the present invention is now provided.
Variant protein AI076020_Pl according to the present invention has an amino acid sequence as given at the end of the application; it is encoded by transcript(s) AI076020_T0. The location of the variant protein was determined according to results from a number of different software programs and analyses, including analyses from SignalP and other specialized programs. The variant protein is believed to be located as follows with regard to the cell: secreted. The protein localization is believed to be secreted because both signal-peptide prediction programs predict that this protein has a signal peptide, and neither trans -membrane region prediction program predicts that this protein has a trans -membrane region.
Variant protein AI076020_Pl also has the following non-silent SNPs (Single Nucleotide Polymorphisms) as listed in Table 557, (given according to their position(s) on the amino acid sequence, with the alternative amino acid(s) listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein AI076020_Pl sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 557 - Amino acid mutations
Variant protein AI076020_Pl is encoded by the following transcript(s): AI076020_T0, for which the sequence(s) is/are given at the end of the application. The coding portion of transcript AI076020_T0 is shown in bold; this coding portion starts at position 261 and ends at position 1034. The transcript also has the following SNPs as listed in Table 558(given according to their position on the nucleotide sequence, with the alternative nucleic acid listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein AI076020_Pl sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 558 - Nucleic acid SNPs
As noted above, cluster AI076020 features 8 segments), which were listed in Table 2 above and for which the sequence(s) are given at the end of the application. These segment(s) are portions of nucleic acid sequence(s) which are described herein separately because they are of particular interest. A description of each segment according to the present invention is now provided.
Segment cluster AI076020_node_0 according to the present invention is supported by 28 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): AI076020_T0. Table 559 below describes the starting and ending position of this segment on each transcript.
Table 559 - Segment location on transcripts
Microarray (chip) data is also available for this segment as follows. As described above with regard to the cluster itself, various oligonucleotides were tested for being differentially expressed in various disease conditions, particularly cancer. The following oligonucleotides were found to hit this segment (in relation to lung cancer), shown in Table 560.
Table 560 - Oligonucleotides related to this segment
Segment cluster AI076020_node_3 according to the present invention is supported by 30 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): AI076020_T0. Table 561 below describes the starting and ending position of this segment on each transcript.
Table 561 - Segment location on transcripts
Segment cluster AI076020_node_8 according to the present invention is supported by 35 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): AI076020_T0. Table 562 below describes the starting and ending position of this segment on each transcript.
Table 562 - Segment location on transcripts
According to an optional embodiment of the present invention, short segments related to the above cluster are also provided. These segments are up to about 120 bp in length, and so are included in a separate description.
Segment cluster AI076020_node_l according to the present invention is supported by 19 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): AI076020_T0. Table 563 below describes the starting and ending position of this segment on each transcript.
Table 563 - Segment location on transcripts
Segment cluster AI076020_node_4 according to the present invention is supported by 28 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): AI076020_T0. Table 564 below describes the starting and ending position of this segment on each transcript.
Table 564 - Segment location on transcripts
Segment cluster AI076020_node_5 according to the present invention is supported by 31 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): AI076020_T0. Table 565 below describes the starting and ending position of this segment on each transcript.
Table 565 - Segment location on transcripts
Segment cluster AI076020_node_6 according to the present invention is supported by 32 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): AI076020_T0. Table 566 below describes the starting and ending position of this segment on each transcript.
Table 566 - Segment location on transcripts
Segment cluster AI076020__node_7 according to the present invention is supported by 33 libraries. The number of libraries was deteπnined as previously described. This segment can be found in the following transcript(s): AI076020_T0. Table 567below describes the starting and ending position of this segment on each transcript.
Table 567 - Segment location on transcripts
DESCRIPTION FOR CLUSTER T23580
Cluster T23580 features 1 transcript(s) and 5 segment(s) of interest, the names for which are given in Tables 568 and 569, respectively, the sequences themselves are given at the end of the application. The selected protein variants are given in table 570. Table 568 - Transcripts of interest
Table 570 - Proteins of interest
These sequences are variants of the known protein Neuronal protein NP25 (SwissProt accession identifier TAG3_HUMAN; known also according to the synonyms Neuronal protein 22; NP22; Transgelin-3), SEQ ID NO: 1435, referred to herein as the previously known protein and also as NP25_HUMAN, which is the former SwissProt accession identifier.
The sequence for protein Neuronal protein NP25 is given at the end of the application, as "Neuronal protein NP25 amino acid sequence".
The following GO Annotation(s) apply to the previously known protein. The following annotation(s) were found: central nervous system development, which are annotation(s) related to Biological Process.
The GO assignment relies on information from one or more of the SwissProt/TremBl Protein knowledgebase, available from <http://www.expasy.ch/sprot/>; or Locuslink, available from <http://www.ncbi.nlm.mh.gov/projects/LocusLink/>.
For this cluster, at least one oligonucleotide was found to demonstrate overexpression of the cluster, although not of at least one transcript/segment as listed below. Microarray (chip) data is also available for this cluster as follows. Various oligonucleotides were tested for being differentially expressed in various disease conditions, particularly cancer, as previously described. The following oligonucleotides were found to hit this cluster but not other segments/transcripts below, shown in Table 571, with regard to lung cancer.
Table 571 - Oligonucleotides related to this cluster
As noted above, cluster T23580 features 1 transcript(s), which were listed in Table 1 above. These transcript(s) encode for protein(s) which are variant(s) of protein Neuronal protein NP25. A description of each variant protein according to the present invention is now provided.
Variant protein T23580_P5 according to the present invention has an amino acid sequence as given at the end of the application; it is encoded by transcript(s) T23580_T10. The location of the variant protein was determined according to results from a number of different software programs and analyses, including analyses from SignalP and other specialized programs. The variant protein is believed to be located as follows with regard to the cell: secreted. The protein localization is believed to be secreted because one of the two signatpeptide prediction programs (HMM:Signal peptide,NN:NO) predicts that this protein has a signal peptide.
Variant protein T23580_P5 also has the following non-silent SNPs (Single Nucleotide Polymorphisms) as listed in Table 572, (given according to their position(s) on the amino acid sequence, with the alternative amino acid(s) listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein T23580_P5 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 572 -Amino acid mutations
Variant protein T23580_P5 is encoded by the following transcript(s): T23580_T10, for which the sequence(s) is/are given at the end of the application. The coding portion of transcript T23580_T10 is shown in bold; this coding portion starts at position 1066 and ends at position 1485. The transcript also has the following SNPs as listed in Table 573 (given according to their position on the nucleotide sequence, with the alternative nucleic acid listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein T23580_P5 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 573 - Nucleic acid SNPs
As noted above, cluster T23580 features 5 segment(s), which were listed in Table 2 above and for which the sequence(s) are given at the end of the application. These segment(s) are portions of nucleic acid sequence(s) which are described herein separately because they are of particular interest. A description of each segment according to the present invention is now provided.
Segment cluster T23580_node_17 according to the present invention is supported by 10 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): T23580_T10. Table 574 below describes the starting and ending position of this segment on each transcript.
Table 574 - Segment location on transcripts
Segment cluster T23580_node_18 according to the present invention is supported by 102 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): T23580JT10. Table 575 below describes the starting and ending position of this segment on each transcript.
Table 575 - Segment location on transcripts
Segment cluster T23580_node_21 according to the present invention is supported by 79 libraries. The number of libraries was deteπnined as previously described. This segment can be found in the following transcript(s): T23580_T10. Table 576 below describes the starting and ending position of this segment on each transcript.
Table 576 - Segment location on transcripts
According to an optional embodiment of the present invention, short segments related to the above cluster are also provided. These segments are up to about 120 bp in length, and so are included in a separate description.
Segment cluster T23580_node_19 according to the present invention can be found in the following transcript(s): T23580_T10. Table 577 below describes the starting and ending position of this segment on each transcript. Table 577 - Segment location on transcripts
Segment cluster T23580_node_20 according to the present invention can be found in the following transcript(s): T23580_T10. Table 578 below describes the starting and ending position of this segment on each transcript.
Table 578 - Segment location on transcripts
DESCRIPTION FOR CLUSTER M79217
Cluster M79217 features 6 transcript(s) and 32 segment(s) of interest, the names for which are given in Tables 579 and 580, respectively, the sequences themselves are given at the end of the application. The selected protein variants are given in table 581.
Table 579 - Transcripts of interest
Table 581 - Proteins of interest
These sequences are variants of the known protein Exostosin- like 3 (SwissProt accession identifier EXL3_HUMAN; known also according to the synonyms EC 2.4.1.223; Glucuronyl- galactosyl-proteoglycan 4- alpha-N-acetylglucosaminyltransferase; Putative tumor suppressor protein EXTL3; Multiple exostosis-like protein 3; Hereditary multiple exostoses gene isolog; EXT-related protein 1), SEQ ID NO: 1436, referred to herein as the previously known protein.
Protein Exostosin- like 3 is known or believed to have the following function(s): Probable glycosyltransferase (By similarity). The sequence for protein Exostosin- like 3 is given at the end of the application, as "Exostosin- like 3 amino acid sequence". Protein Exostosin- like 3 localization is believed to be Type II membrane protein. Endoplasmic reticulum.
The following GO Annotation(s) apply to the previously known protein. The following annotation(s) were found: cell growth and/or maintenance, which are annotation(s) related to Biological Process; transferase, transferring glycosyl groups, which are annotation(s) related to Molecular Function; and endoplasmic reticulum; integral membrane protein, which are annotation(s) related to Cellular Component.
The GO assignment relies on information from one or more of the SwissProt/TremBl Protein knowledgebase, available from <http://www.expasy.ch/sprot/>; or Locuslink, available from <http://www.ncbi.nrm.nih.gov/projects/LocusLink/>.
As noted above, cluster M79217 features 6 transcript(s), which were listed in Table 1 above. These transcript(s) encode for protein(s) which are variant(s) of protein Exostosin- like 3. A description of each variant protein according to the present invention is now provided.
Variant protein M79217_PEA_1_P1 according to the present invention has an amino acid sequence as given at the end of the application; it is encoded by transcript(s) M79217_PEA_1_T1. An alignment is given to the known protein (Exostosin- like 3) at the end of the application. One or more alignments to one or more previously published protein
sequences are given at the end of the application. A brief description of the relationship of the variant protein according to the present invention to each such aligned protein is as follows: Comparison report between M79217_PEA_1_P1 and BAA25445 (SEQ ID NO: 1437): 1.An isolated chimeric polypeptide encoding for M79217_PEA_1_P1, comprising a first amino acid sequence being at least 90 % homologous to
MTGYTMLRNGGAGNGGQTCMLRWSNRIRLTWLSFTLFVILVFFPLIAHYYLTTLDEAD EAGKRIFGPRVGNELCEVKHVLDLCPJRESVSEELLQLEAKRQELNSEIAKLNLKIEACK KSIENAKQDLLQLKNVISQTEHSYKELMAQNQPKLSLPIRLLPEKDDAGLPPPKATRGC RLHNCFDYSRCPLTSGFPVYVYDSDQFVFGSYLDPLVKQAFQATARANVYVTENADIA CLYVILVGEMQEPVVLPJPAELEKQLYSLPHWRTDGHNHVIINLSRKSDTQNLLYNVSTG RAMVAQSTFYTVQYRPGFDLVVSPLVHAMSEPNFMEIPPQVPVKRKYLFTFQGEKIESL RSSLQEARSFEEEMEGDPPADYDDRIIATLKA VQDSKLDQVLVEFTCKNQPKPSLPTEW ALCGEREDRLELLKLSTFALIITPGDPRLVISSGCATRLFEALEVGAVPVVLGEQVQLPY QDMLQWNEAALWPKPRVTEVHFLLRSLSDSDLLAMRRQGRFLWETYFSTADSIFNTV LAMIRTRIQIPAAPIREEAAAEIPHRSGKAAGTDPNMADNGDLDLGPVETEPPYASPRYL RNFTLTVTDFYRSWNCAPGPFHLFPHTPFDPVLPSEAKFLGSGTGFRPIGGGAGGSGKEF QAALGGNVPREQFTVVMLTYEREEVLMNSLERLNGLPYLNKWVVWNSPKLPSEDLL WPDIGVPIMVVRTEKNSLNNRFLPWNEIETEAILSIDDDAHLRHDEIMFGFRVWREARD RIVGFPGRYHAWDIPHQSWLYNSNYSCELSMVLTGAAFFHKYYAYLYSYVMPQAIRD MVDEYINCEDIAMNFLVSHITRKPPIKVTSRWTFRCPGCPQALSHDDSHFHERHKCINFF VKVYGYMPLLYTQFRVDSVLFKTRLPHDKTKCFKFI corresponding to amino acids 13 - 931 of BAA25445, which also corresponds to amino acids 1 - 919 of M79217_PEA_1_P1.
The location of the variant protein was determined according to results from a number of different software programs and analyses, including analyses from SignalP and other specialized programs. The variant protein is believed to be located as follows with regard to the cell: membrane. The protein localization is believed to be membrane because the Signalp_hmrn software predicts that this protein has a signal anchor region.
Variant protein M79217_PEA_1_P1 is encoded by the following transcript(s):
M79217_PEA_1_T1, for which the sequence(s) is/are given at the end of the application. The
coding portion of transcript M79217_PEA_1_T1 is shown in bold; this coding portion starts at position 1074 and ends at position 3830. The transcript also has the following SNPs as listed in Table 582 (given according to their position on the nucleotide sequence, with the alternative nucleic acid listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein M79217_PEA_1_P1 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 582 - Nucleic acid SNPs
Variant protein M79217_PEA_1_P2 according to the present invention has an amino acid sequence as given at the end of the application; it is encoded by transcript(s) M79217_PEA_1_T8. An alignment is given to the known protein (Exostosin-like 3) at the end of the application. One or more alignments to one or more previously published protein sequences are given at the end of the application. A brief description of the relationship of the variant protein according to the present invention to each such aligned protein is as follows:
Comparison report between M79217_PEA_1_P2 and EXL3_HUMAN:
1.An isolated chimeric polypeptide encoding for M79217_PEA_1JP2, comprising a first amino acid sequence being at least 90 % homologous to
MTGYTMLRNGGAGNGGQTCMLRWSNRIRLTWLSFTLFVILVFFPLIAHYYLTTLDEAD EAGKRIFGPRVGNELCEVKHVLDLCRIRESVSEELLQLEAKRQELNSEIAKLNLKIEACK KSIENAKQDLLQLKNVISQTEHSYKELMAQNQPKLSLPIRLLPEKDDAGLPPPKATRGC RLHNCFDYSRCPLTSGFP VYVYDSDQFVFGSYLDPLVKQAFQATARANVYVTENADIA CLYVILVGEMQEPVVLRP AELEKQLYSLPHWRTDGHNHVIINLSRKSDTQNLLYNVSTG RAMVAQSTFYTVQYRPGFDLVVSPLVHAMSEPNFMEIPPQVPVKRKYLFTFQGEKIESL RSSLQEARSFEEEMEGDPPADYDDRIIATLKAVQDSKLDQVLVEFTCKNQPKPSLPTEW ALCGEREDRLELLKLSTFALIITPGDPRLVISSGCATRLFEALEVGAVP WLGEQVQLPY QDMLQWNEAALVVPKPRVTEVHFLLRSLSDSDLLAMRRQGRFLWETYFSTADSIFNTV LAMIRTRIQIPAAPIREEAAAEIPHRSGKAAGTDPNMADNGDLDLGPVETEPPYASPRYL RNFTLTVTDFYRSWNCAPGPFHLFPHTPFDPVLPSEAKFLGSGTGFRPIGGGAGGSGKEF QAALGGNVPREQFTVVMLTYEREEVLMNSLERLNGLPYLNKVVWWNSPKLPSEDLL WPDIGVPIMVVRTEKNSLNNRFLPWNEIETEAILSIDDDAHLRHDEIMFGFRVWREARD RIVGFPGRYHAWDIPHQSWLYNSNYSCELSMVLTGAAFFHK corresponding to amino acids 1 - 807 of EXL3JHUMAN, which also corresponds to amino acids 1 - 807 of M79217_PEA_1_P2, and a second amino acid sequence being at least 90 % homobgous to AIRDMVDEYINCEDIAMNFLVSHITRKPPIKVTSRWTFRCPGCPQALSHDDSHFHERHK CINFFVKVYGYMPLLYTQFRVDSVLFKTRLPHDKTKCFKFI corresponding to amino acids 820 - 919 of EXL3_HUMAN, which also corresponds to amino acids 808 - 907 of M79217_PEA_1_P2, wherein said first amino acid sequence and second amino acid sequence are contiguous and in a sequential order.
2.An isolated chimeric polypeptide encoding for an edge portion of M79217_PEA_1_P2, comprising a polypeptide having a length "n", wherein n is at least about 10 amino acids in length, optionally at least about 20 amino acids in length, preferably at least about 30 amino acids in length, more preferably at least about 40 amino acids in length and most preferably at least about 50 amino acids in length, wherein at least two amino acids comprise KA, having a structure as follows: a sequence starting from any of amino acid numbers 807-x to 807; and ending at any of amino acid numbers 808+ ((n-2) - x), in which x varies from 0 to n-2.
The location of the variant protein was determined according to results from a number of different software programs and analyses, including analyses from SignalP and other specialized programs. The variant protein is believed to be located as follows with regard to the cell: membrane. The protein localization is believed to be membrane because the Signalpjhmm software predicts that this protein has a signal anchor region.
Variant protein M79217_PEA_1_P2 also has the following non-silent SNPs (Single Nucleotide Polymorphisms) as listed in Table 583, (given according to their position(s) on the amino acid sequence, with the alternative amino acid(s) listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein M79217_PEA_1_P2 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 583 -Amino acid mutations
The glycosylation sites of variant protein M79217_PEA_1_P2, as compared to the known protein Exostosin- like 3, are described in Table 584 (given according to their position(s) on the amino acid sequence in the first column; the second column indicates whether the glycosylation site is present in the variant protein; and the last column indicates whether the position is different on the variant protein).
Table 584 - Glycosylation site(s)
Variant protein M79217_PEA_1 JP2 is encoded by the following transcript(s): M79217_PEA_1_T8, for which the sequence(s) is/are given at the end of the application. The coding portion of transcript M79217_PEA_1_T8 is shown in bold; this coding portion starts at position 748 and ends at position 3468. The transcript also has the following SNPs as listed in Table 585 (given according to their position on the nucleotide sequence, with the alternative nucleic acid listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein M79217_PEA_1_P2 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 585 - Nucleic acid SNPs
Variant protein M79217_PEA_1__P4 according to the present invention has an amino acid sequence as given at the end of the application; it is encoded by transcript(s) M79217_PEA_l_T10. An alignment is given to the known protein (Exostosin- like 3) at the end of the application. One or more alignments to one or more previously published protein sequences are given at the end of the application. A brief description of the relationship of the variant protein according to the present invention to each such aligned protein is as follows: Comparison report between M79217_PEA_1_P4 and EXL3JHUMAN: 1.An isolated chimeric polypeptide encoding for M79217_PEA_1_P4, comprising a first amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence PELRQPARLGLPECWDYRHEPRCPAQMGSHFIVQAGLKLLASSKPPKCWDY corresponding to amino acids 1 - 51 of M79217_PEA_1JP4, and a second amino acid sequence being at least 90 % homologous to
RVWREARDRIVGFPGRYHAWDIPHQSWLYNSNYSCELSMVLTGAAFFHKYYAYLYSY VMPQAIRDMVDEYINCEDIAMNFLVSHITRKPPIKVTSRWTFRCPGCPQALSHDDSHFH ERHKCINFFVKVYGYMPLLYTQFRVDSVLFKTRLPHDKTKCFKFI corresponding to amino acids 759 - 919 of EXL3_HUMAN, which also corresponds to amino acids 52 - 212 of M79217_PEA_1_P4, wherein said first amino acid sequence and second amino acid sequence are contiguous and in a sequential order.
2.An isolated polypeptide encoding for a head of M79217_PEA_1_P4, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%,
more preferably at least about 90% and most preferably at least about 95% homologous to the sequence PELRQPARLGLPECWD YRHEPRCP AQMGSHFIVQAGLKLLASSKPPKCWDY ofM79217 PEA 1 P4.
The location of the variant protein was determined according to results from a number of different software programs and analyses, including analyses from SignalP and other specialized programs. The variant protein is believed to be located as follows with regard to the cell: membrane. The protein localization is believed to be membrane because although it is a partial protein, because both trans-membrane region prediction programs predict that this protein has a trans -membrane region.
Variant protein M79217_PEA_1_P4 also has the following non-silent SNPs (Single Nucleotide Polymorphisms) as listed in Table 586, (given according to their position(s) on the amino acid sequence, with the alternative amino acid(s) listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein M79217_PEA_1_P4 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 586 - Amino acid mutations
The glycosylation sites of variant protein M79217_PEA_1_P4, as compared to the known protein Exostosin-like 3, are described in Table 587 (given according to their position(s) on the amino acid sequence in the first column; the second column indicates whether the glycosylation site is present in the variant protein; and the last column indicates whether the position is different on the variant protein).
Table 587 - Glycosylation site(s)
Variant protein M79217_PEA_1_P4 is encoded by the following transcript(s): M79217_PEA_l_T10, for which the sequerce(s) is/are given at the end of the application. The coding portion of transcript M79217_PEA_l_T10 is shown in bold; this coding portion starts at position 1 and ends at position 637. The transcript also has the following SNPs as listed in Table 588 (given according to their position on the nucleotide sequence, with the alternative nucleic acid listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein M79217_PEA_1_P4 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 588 - Nucleic acid SNPs
Variant protein M79217_PEA_1_P8 according to the present invention has an amino acid sequence as given at the end of the application; it is encoded by transcript(s) M79217_PEA_1_T15. An alignment is given to the known protein (Exostosin-like 3) at the end of the application. One or more alignments to one or more previously published protein sequences are given at the end of the application. A brief description of the relationship of the variant protein according to the present invention to each such aligned protein is as follows: Comparison report between M79217_PEA_1_P8 and EXL3 JHUMAN: 1.An isolated chimeric polypeptide encoding for M79217_PEA_1_P8, comprising a first amino acid sequence being at least 90 % homologous to
MTGYTMLRNGGAGNGGQTCMLRWSNRIRLTWLSFTLFVILVFFPLIAHYYLTTLDEAD EAGKRIFGPRVGNELCEVKHVLDLCRIRESVSEELLQLEAKRQELNSEIAKLNLKIEACK KSIENAKQDLLQLKNVISQTEHSYKELMAQNQPKLSLPIRLLPEKDDAGLPPPKATRGC
RLHNCFDYSRCPLTSGFPVYVYDSDQFVFGSYLDPLVKQAFQATARANVYVTENADIA CLYVILVGEMQEPVVLRP AELEKQLYSLPHWRTDGHNHVIINLSRKSDTQNLLYNVSTG RAMVAQSTFYTVQYRPGFDLVVSPLVHAMSEPNFMEIPPQVPVKRKYLFTFQGEKIESL RSSLQEARSFEEEMEGDPPADYDDRIIATLKAVQDSKLDQVLVEFTCKNQPKPSLPTEW ALCGEREDRLELLKLSTFALIITPGDPRLVISSGCATRLFEALEVGAVPVVLGEQVQLPY QDMLQWNEAALVVPKPRVTEVHFLLRSLSDSDLLAMRRQGRFLWETYFSTADSIFNTV LAMIRTRIQIPAAPIREEAAAEIPHRSGKAAGTDPNMADNGDLDLGPVETEPPYASPRYL RNFTLTVTDFYRSWNCAPGPFHLFPHTPFDPVLPSEAKFLGSGTGFRPIGGGAGGSGKEF QAALGGNVPREQFTVVMLTYEREEVLMNSLERLNGLPYLNKVVVVWNSPKLPSEDLL WPDIGVPIMVVRTEKNSLNNRFLPWNEIETEAILSIDDDAHLRHDEIMFGFRVWREARD
RIVGFPGRYHAWDIPHQSWLYNSNYSCELSMVLTGAAFFHK corresponding to amino acids 1 - 807 of EXL3JHUMAN, which also corresponds to amino acids 1 - 807 of M79217_PEA_1_P8, and a second amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence VRKSW corresponding to amino acids 808 - 812 of M79217_PEA_1_P8, wherein said first amino acid sequence and second amino acid sequence are contiguous and in a sequential order.
2.An isolated polypeptide encoding for a tail of M79217_PEA_1_P8, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence VRKSW in M79217_PEA_1_P8.
The location of the variant protein was determined according to results from a number of different software programs and analyses, including analyses from SignalP and other specialized programs. The variant protein is believed to be located as follows with regard to the cell: membrane. The protein localization is believed to be membrane because the Signalp_hmm software predicts that this protein has a signal anchor region.
Variant protein M79217_PEA_1_P8 also has the following non-silent SNPs (Single Nucleotide Polymorphisms) as listed in Table 589, (given according to their position(s) on the amino acid sequence, with the alternative amino acid(s) listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein M79217_PEA_1_P8
sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 589 -Amino acid mutations
The glycosylation sites of variant protein M79217_PEA_1_P8, as compared to the known protein Exostosin-like 3, are described in Table 590 (given according to their position(s) on the amino acid sequence in the first column; the second column indicates whether the glycosylation site is present in the variant protein; and the last column indicates whether the position is different on the variant protein). Table 590 - Glycosylation site(s)
Variant protein M79217_PEA_1_P8 is encoded by the following transcript(s): M79217_PEA_1_T15, for which ths sequence(s) is/are given at the end of the application. The coding portion of transcript M79217_PEA_1_T15 is shown in bold; this coding portion starts at position 748 and ends at position 3183. The transcript also has the following SNPs as listed in Table 591 (given according to their position on the nucleotide sequence, with the alternative nucleic acid listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein M79217_PEA_1__P8 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 591 - Nucleic acid SNPs
Variant protein M79217_PEA_1_P11 according to the present invention has an amino acid sequence as given at the end of the application; it is encoded by transcript(s) M79217_PEA_1_T18. The location of the variant protein was determined according to results from a number of different software programs and analyses, including analyses from SignalP and other specialized programs. The variant protein is believed to be located as follows with regard to the cell: secreted. The protein localization is believed to be secreted because one of the two signal-peptide prediction programs (HMM:Signal peptide,NN:NO) predicts that this protein has a signal peptide.
Variant protein M79217_PEA_1__P11 also has the following non-silent SNPs (Single Nucleotide Polymorphisms) as listed in Table 592, (given according to their position(s) on the amino acid sequence, with the alternative amino acid(s) listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein M79217_PEA_1JP11 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 592 - Amino acid mutations
Variant protein M79217_PEA_1_P11 is encoded by the following transcript(s): M79217_PEA_1_T18, for which the sequence(s) is/are given at the end of the application. The
coding portion of transcript M79217JPEA_1_T18 is shown in bold; this coding portion starts at position 1354 and ends at position 1674. The transcript also has the following SNPs as listed in Table 593 (given according to their position on the nucleotide sequence, with the alternative nucleic acid listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein M79217_PEA_1_P11 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 593 - Nucleic acid SNPs
As noted above, cluster M79217 features 32 segment(s), which were listed in Table 2 above and for which the sequence(s) are given at the end of the application. These segment(s) are portions of nucleic acid sequence(s) which are described herein separately because they are
of particular interest. A description of each segment according to the present invention is now provided.
Segment cluster M79217_PEA_l_node_2 according to the present invention is supported by 2 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): M79217_PEA_1_T3. Table 594 below describes the starting and ending position of this segment on each transcript.
Table 594 - Segment location on transcripts
Segment cluster M79217_PEA_l_node_4 according to the present invention is supported by 8 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): M79217_PEA_1_T8, M79217_PEA_1_T15 and M79217_PEA_1_T18. Table 595 below describes the starting and ending position of this segment on each transcript.
Table 595 - Segment location on transcripts
Segment cluster M79217_PEA_l_node_9 according to the present invention is supported by 2 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): M79217_PEA_1_T1. Table 596 below describes the starting and ending position of this segment on each transcript.
Table 596 - Segment location on transcripts
Segment cluster M79217_PEA_l_node_10 according to the present invention is supported by 33 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): M79217_PEA_1_T1, M79217_PEA_1_T3, M79217_PEA_1_T8, M79217_PEA_1 JT 15 and M79217_PEA_1_T18. Table 597 below describes the starting and ending position of this segment on each transcript.
Table 597- Segment location on transcripts
Microarray (chip) data is also available for this segment as follows. As described above with regard to the cluster itself, various oligonucleotides were tested for being differentially expressed in various disease conditions, particularly cancer. The following oligonucleotides were found to hit this segment (in relation to lung cancer), shown in Table 598. Table 598 - Oligonucleotides related to this segment
Segment cluster M79217_PEA_l_node_l 1 according to the present invention is supported by 42 libraries. The number of libraries was determined as previously described. This segment can be found in the following trans cript(s): M79217_PEA_1_T1, M79217JPEA_1_T3, M79217_PEA_1_T8 and M79217_PEA_1_T15. Table 599 below describes the starting and ending position of this segment on each transcript.
Table 599 - Segment location on transcripts
Segment cluster M79217_PEA_l_node_13 according to the present invention is supported by 35 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): M79217_PEA_1_T1, M79217_PEA_1_T3, M79217_PEA_1_T8 and M79217_PEA_1_T15. Table 600 below describes the starting and ending position of this segment on each transcript.
Table 600 - Segment location on transcripts
Segment cluster M79217_PEA_l_node_14 according to the present invention is supported by 65 libraries. The number of libraries was determined as previously described. This
segment can be found in the following transcript(s): M79217_PEA_1__T1, M79217_PEA_1_T3, M79217_PEA_1_T8 and M79217_PEA_1_T15. Table 601 below describes the starting and ending position of this segment on each transcript.
Table 601 - Segment location on transcripts
Segment cluster M79217_PEA_l_jnode_16 according to the present invention is supported by 51 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): M79217JPEA_1_T1, M79217_PEA_1_T3, M79217_PEA_1_T8 and M79217_PEA_1_T15. Table 602 below describes the starting and ending position of this segment on each transcript.
Table 602 - Segment location on transcripts
Segment cluster M79217_PEA_l_node_23 according to the present inventbn is supported by 50 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): M79217_PEA_1_T1, M79217_PEA_1_T3,
M79217_PEA_1_T8, M79217_PEA_l_T10 and M79217_PEA_1_T15. Table 603 below describes the starting and ending position of this segment on each transcript.
Table 603 - Segment location on transcripts
Segment cluster M79217_PEA_l_node_24 according to the present invention is supported by 2 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): M79217_PEA_1_T15. Table 604 below describes the starting and ending position of this segment on each transcript.
Table 604 - Segment location on transcripts
Segment cluster M79217JPEA_l_node_31 according to the present invention is supported by 50 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): M79217_PEA_1_T1, M79217_PEA_1_T3, M79217_PEA_1_T8 and M79217_PEA_l_T10. Table 605 below describes the starting and ending position of this segment on each transcript.
Table 605 - Segment location on transcripts
Segment cluster M79217_PEA_l__node_33 according to the present invention is supported by 71 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): M79217_PEA_1_T1, M79217_PEA_1 JT3, M79217_PEA_1_T8 and M79217_PEA_l_T10. Table 606 below describes the starting and ending position of this segment on each transcript.
Table 606 - Segment location on transcripts
Segment cluster M79217_PEA_l_node_34 according to the present invention is supported by 51 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): M79217_PEA_1_T1, M79217_PEA_1_T3, M79217_PEA_1_T8 and M79217_PEA_l_T10. Table 607 below describes the starting and ending position of this segment on each transcript.
Table 607 - Segment location on transcripts
Segment cluster M79217_PEA_l_node_35 according to the present invention is supported by 53 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): M79217_PEA_1_T1, M79217_PEA_1_T3, M79217JPEA_1_T8 and M79217_PEA_l_T10. Table 608 below describes the starting and ending position of this segment on each transcript.
Table 608 - Segment location on transcripts
Segment cluster M79217_PEA_l_node_37 according to the present invention is supported by 58 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): M79217_PEA_1_T1, M79217_PEA_1_T3, M79217_PEA_1_T8 and M79217_PEA_l_T10. Table 609 below describes the starting and ending position of this segment on each transcript.
Table 609 - Segment location on transcripts
Segment cluster M79217_PEA__l_node_38 according to the present invention is supported by 62 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): M79217_PEA_1_T1, M79217_PEA_1_T3, M79217_PEA_1_T8 and M79217_PEA_l_T10. Table 610 below describes the starting and ending position of this segment on each transcript.
Table 610 - Segment location on transcripts
Segment cluster M79217_PEA_l_node_41 according to the present invention is supported by 171 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): M79217JPEA_1_T1, M79217_PEA_1_T3, M79217_PEA_1_T8, M79217_PEA_l_T10 and M79217_PEA_1_T18. Table 611 below describes the starting and ending position of this segment on each transcript.
Table 611- Segment location on transcripts
Segment cluster M79217_PEA_l__node_44 according to the present invention is supported by 89 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): M79217_PEA_1_T1, M79217_PEA_1_T3, M79217_PEA_1_T8, M79217_PEA_l_T10 and M79217_PEA_1_T18. Table 612 below describes the starting and ending position of this segment on each transcript.
Table 612 - Segment location on transcripts
According to an optional embodiment of the present invention, short segments related to the above cluster are also provided. These segments are up to about 120 bp in length, and so are included in a separate description.
Segment cluster M79217_PEA_l_node_0 according to the present invention is supported by 4 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): M79217JPEA_1_T3. Table 613 below describes the starting and ending position of this segment on each transcript.
Table 613 - Segment location on transcripts
Segment cluster M79217_PEA_l_node_7 according to the present invention is supported by 11 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): M79217_PEA_1_T3, M79217_PEA_1_T8, M79217_PEA_1_T15 and M79217JPEA_l_T18. Table 614 below describes the starting and ending position of this segment on each transcript.
Table 614 - Segment location on transcripts
Segment cluster M79217_PEA_l_node_12 according to the present invention can be found in the following transcript(s): M79217_PEA_1_T1, M79217_PEA_1_T3, M79217_PEA_1_T8 and M79217_PEA_l_T15. Table 615 below describes the starting and ending position of this segment on each transcript.
Table 615 - Segment location on transcripts
Segment cluster M79217_PEA_l_node_19 according to the present invention is supported by 1 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): M79217_PEA_l_T10. Table 616 below describes the starting and ending position of this segment on each transcript.
Table 616 - Segment location on transcripts
Segment cluster M79217_PEA_l_node_21 according to the present invention is supported by 1 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): M79217_PEA_l_T10. Table 617 below describes the starting and ending position of this segment on each transcript.
Table 617 - Segment location on transcripts
Segment cluster M79217_PEA_l_node_26 according to the present invention is supported by 40 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): M79217_PEA_1_T1, M79217_PEA_1_T3 and M79217_PEA_l_T10. Table 618 below describes the starting and ending position of this segment on each transcript.
Table 618 - Segment location on transcripts
Segment cluster M79217_PEA_l_jiode_27 according to the present invention is supported by 46 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): M79217_PEA_1_T1, M79217_PEA_1_T3, M79217_PEA_1_T8 and M79217JPEA_l_T10. Table 619 below describes the starting and ending position of this segment on each transcript.
Table 619 - Segment location on transcripts
Segment cluster M79217_PEA_l_node_30 according to the present invention is supported by 47 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): M79217_PEA_1_T1, M79217_PEA_1_T3, M79217_PEA_1_T8 and M79217_PEA_l_T10. Table 620 below describes the starting and ending position of this segment on each transcript.
Table 620 - Segment location on transcripts
Segment cluster M79217_PEA_l_node_32 according to the present invention is supported by 40 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): M79217_PEA_ 1_T1, M79217JPEA_1_T3, M79217JPEA_1_T8 and M79217JPEA_l_T10. Table 621 below describes the starting and ending position of this segment on each transcript.
Table 621 - Segment location on transcripts
Segment cluster M79217_PEA_l_node_36 according to the present invention is supported by 42 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): M79217JPEAJMTl, M79217_PEA_1_T3, M79217_PEA_1_T8 and M79217_PEA_l_T10. Table 622 below describes the starting and ending position of this segment on each transcript.
Table 622 - Segment location on transcripts
Segment cluster M79217JPEA_l_node_39 according to the present invention is supported by 57 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): M79217_PEA_1_T1, M79217_PEA_1_T3, M79217_PEA_1_T8 and M79217_PEA_l_T10. Table 623 below describes the starting and ending position of this segment on each transcript.
Table 623 - Segment location on transcripts
Segment cluster M79217_PEA_l_node_40 according to the present invention is supported by 59 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): M79217JPEAJMT1, M79217_PEA_1_T3, M79217_PEA_1_T8 and M79217_PEA_l_T10. Table 624 below describes the starting and ending position of this segment on each transcript.
Table 624 - Segment location on transcripts
Segment cluster M79217_PEA_l_node_42 according to the present invention is supported by 99 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): M79217_PEA_1_T1, M79217_PEA_1_T3, M79217_PEA_1_T8, M79217_PEA_l_T10 and M79217_PEA_1_T18. Table 625 below describes the starting and ending position of this segment on each transcript.
Table 625 - Segment location on transcripts
Segment cluster M79217JPEA_l_node_43 according to the present invention is supported by 90 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): M79217JPEA_1_T1, M79217_PEA_1_T3, M79217_PEA_1_T8, M79217_PEA_l_T10 and M79217_PEA_1_T18. Table 626 below describes the starting and ending position of this segment on each transcript.
Table 626 - Segment location on transcripts
Variant protein alignment to the previously known protein: Sequence name: BAA25445
Sequence documentation:
Alignment of: M79217_PEA_1_P1 x BAA25445
Alignment segment 1/1:
Quality: 9101.00 Escore: 0 Matching length: 919 Total length: 919
Matching Percent Similarity: 100.00 Matching Percent Identity: 100.00
Total Percent Similarity: 100.00 Total Percent Identity: 100.00
Gaps : 0
Alignment :
1 MTGYTMLRNGGAGNGGQTCMLRWSNRIRLTWLSFTLFVILVFFPLIAHYY 50
I I I I I I I I I I I I I I I I I I i I I I I I I I I I I I I I I I I I I I I I I I I i I I I I I I
13 MTGYTMLRNGGAGNGGQTCMLRWSNRIRLTWLSFTLFVILVFFPLIAHYY 62
51 LTTLDEADEAGKRIFGPRVGNELCEVKHVLDLCRIRESVSEELLQLEAKR 100
I I I I I I I I i I I I I I I Il I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I
63 LTTLDEADEAGKRIFGPRVGNELCEVKHVLDLCRIRESVSEELLQLEAKR 112
101 QELNSEIAKLNLKIEACKKSIENAKQDLLQLKNVISQTEHSYKELMAQNQ 150 I I I I I I Il I I I I I I I I I I I I I Il Il I M Il M I M I Il M I I I I M I M I
113 QELNSEIAKLNLKIEACKKSIENAKQDLLQLKNVISQTEHSYKELMAQNQ 162
151 PKLSLPIRLLPEKDDAGLPPPKATRGCRLHNCFDYSRCPLTSGFPVYVYD 200
I I I I Il I I I I Il I I I I I I I I I I Il I I I I I I I I I I I I I I I I 1 Il I I I I I Il 163 PKLSLPIRLLPEKDDAGLPPPKATRGCRLHNCFDYSRCPLTSGFPVYVYD 212
201 SDQFVFGSYLDPLVKQAFQATARANVYVTENADIACLYVILVGEMQEPW 250
I I I I I Il Il I I Il I I I I I I I I I I I I I I I Il I I I I I I I I I Il I I I I I I I I I
213 SDQFVFGSYLDPLVKQAFQATARANVYVTENADIACLYVILVGEMQEPVV 262 . . . . .
251 LRPAELEKQLYSLPHWRTDGHNHVIINLSRKSDTQNLLYNVSTGRAMVAQ 300
I I I I I I Il I I I I I I Il I I I I I I I I I I I I I I I I I I I I I I I I I I I Il I Il I I
263 LRPAELEKQLYSLPHWRTDGHNHVIINLSRKSDTQNLLYNVSTGRAMVAQ 312
301 STFYTVQYRPGFDLVVSPLVHAMSEPNFMEIPPQVPVKRKYLFTFQGEKI 350
I I I Il I I I I I I I I I I I I I I I I I I I Il I I Il I I I I Il I Il I I Il I I I I I I I 313 STFYTVQYRPGFDLVVSPLVHAMSEPNFMEIPPQVPVKRKYLFTFQGEKI 362
351 ESLRSSLQEARSFEEEMEGDPPADYDDRIIATLKAVQDSKLDQVLVEFTC 400 I I I I I I M I M I I I I I I I I I I I I I M I I I I I M M I I I I I I I I Il I I I I I
363 ESLRSSLQEARSFEEEMEGDPPADYDDRIIATLKAVQDSKLDQVLVEFTC 412
401 KNQPKPSLPTEWALCGEREDRLELLKLSTFALIITPGDPRLVISSGCATR 450
I I I I I I I I I I I I I I I I I I Il I I I I I I I I I I I I I I 1 Il I I I I I I I 1 I I I I I
413 KNQPKPSLPTEWALCGEREDRLELLKLSTFALIITPGDPRLVISSGCATR 462 . . . . .
451 LFEALEVGAVPWLGEQVQLPYQDMLQWNEAALVVPKPRVTEVHFLLRSL 500
I I I I I I I I I I I I I I I I I Il I I I I I I I I Il I I Il I I I I Il I Il I I I Il I I I
463 LFEALEVGAVPVVLGEQVQLPYQDMLQWNEAALVVPKPRVTEVHFLLRSL 512
501 SDSDLLAMRRQGRFLWETYFSTADSIFNTVLAMIRTRIQIPAAPIREEAA 550
I I I I I I I I I I I Il Il I I Il I I I I Il I I I I Il I I I I I I I I I I I I Il I I Il I
513 SDSDLLAMRRQGRFLWETYFSTADSIFNTVLAMIRTRIQIPAAPIREEAA 562
551 AEIPHRSGKAAGTDPNMADNGDLDLGPVETEPPYASPRYLRNFTLTVTDF 600 I I M I I I I I I I I M I I I I I I I I I I I I I I I I I I M I I I I I I I I I I I I I I I I
563 AEIPHRSGKAAGTDPNMADNGDLDLGPVETEPPYASPRYLRNFTLTVTDF 612
601 YRSWNCAPGPFHLFPHTPFDPVLPSEAKFLGSGTGFRPIGGGAGGSGKEF 650
M I M I I I I I I M I I M I I I I M I M I I I I I M I I I I I I I I M I M I I M 613 YRSWNCAPGPFHLFPHTPFDPVLPSEAKFLGSGTGFRPIGGGAGGSGKEF 662
651 QAALGGNVPREQFTVVMLTYEREEVLMNSLERLNGLPYLNKVVVVWNSPK 700
II I Il Il I I I I Il Il Il I I I I Il I Il I I I Il I I Il I I Il I Il I I I I I Il I
663 QAALGGNVPREQFTVVMLTYEREEVLMNSLERLNGLPYLNKVVWWNSPK 712 . . . . .
701 LPSEDLLWPDIGVPIMVVRTEKNSLNNRFLPWNEIETEAILSIDDDAHLR 750
I M Il I M I M M M I I I M Il M MM Il I M M Il I M M M Il Il M
713 LPSEDLLWPDIGVPIMWRTEKNSLNNRFLPWNEIETEAILSIDDDAHLR 762
751 HDEIMFGFRVWREARDRIVGFPGRYHAWDIPHQSWLYNSNYSCELSMVLT 800
763 HDEIMFGFRVWREARDRIVGFPGRYHAWDIPHQSWLYNSNYSCELSMVLT 812
801 GAAFFHKYYAYLYSYVMPQAIRDMVDEYINCEDIAMNFLVSHITRKPPIK 850
I I I I I I I I I I I I I I I 1 I I I I I I I I I I I I I I I I I I I Il I ! I I I I I I I I i I I 813 GAAFFHKYYAYLYSYVMPQAIRDMVDEYINCEDIAMNFLVSHITRKPPIK 862
851 VTSRWTFRCPGCPQALSHDDSHFHERHKCINFFVKVYGYMPLLYTQFRVD 900
I I I I I I Il I I I I I I I I I I I I Il Il I I I I Il I Il Il I I I I I I I I I Il I I Il
863 VTSRWTFRCPGCPQALSHDDSHFHERHKCINFFVKVYGYMPLLYTQFRVD 912
901 SVLFKTRLPHDKTKCFKFI 919
I I I I I I I I I I I I I I I I Il I 913 SVLFKTRLPHDKTKCFKFI 931
Sequence name: EXL3_HUMAN
Sequence documentation:
Alignment of: M79217_PEA_1_P2 x EXL3_HUMAN
Alignment segment 1/1:
Quality: 8873.00 Escore: 0 Matching length: 907 Total length: 919
Matching Percent Similarity: 100.00 Matching Percent Identity: 100.00
Total Percent Similarity: 98.69 Total Percent Identity: 98.69 Gaps: 1
Alignment:
1 MTGYTMLRNGGAGNGGQTCMLRWSNRIRLTWLSFTLFVILVFFPLIAHYY 50 I I I I I I I I I I I I I I I I I I I I I I I I I I I I ! I I I I I I I I I I I I I I I i M I I I
1 MTGYTMLRNGGAGNGGQTCMLRWSNRIRLTWLSFTLFVILVFFPLIAHYY 50
51 LTTLDEADEAGKRIFGPRVGNELCEVKHVLDLCRIRESVSEELLQLEAKR 100
I I I I I Il I I I I Il I I i I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I 51 LTTLDEADEAGKRIFGPRVGNELCEVKHVLDLCRIRESVSEELLQLEAKR 100
101 QELNSEIAKLNLKIEACKKSIENAKQDLLQLKNVISQTEHSYKELMAQNQ 150
I I I Il I I I I I I Il I Il I Il I Il I I I I Il I I Il I Il I I I I I I I I I I I I I Il
101 QELNSEIAKLNLKIEACKKSIENAKQDLLQLKNVISQTEHSYKELMAQNQ 150 . . . . .
151 PKLSLPIRLLPEKDDAGLPPPKATRGCRLHNCFDYSRCPLTSGFPVYVYD 200
I I I I I Il I I I I Il I I I I I Il I I I I I I I Il I I I Il I I I I I Il I I I Il I I I I
151 PKLSLPIRLLPEKDDAGLPPPKATRGCRLHNCFDYSRCPLTSGFPVYVYD 200
201 SDQFVFGSYLDPLVKQAFQATARANVYVTENADIACLYVILVGEMQEPW 250
I I I I I I Il I I I I Il I Il I I I I I I I I I I I I I I Il I I I I Il I I I I I I I I I Il 201 SDQFVFGSYLDPLVKQAFQATARANVYVTENADIACLYVILVGEMQEPW 250
251 LRPAELEKQLYSLPHWRTDGHNHVIINLSRKSDTQNLLYNVSTGRAMVAQ 300 I I I I M I I I I I I Il M I I I I I I I I I I I I I M I I M M I M I I I I I I I I M
251 LRPAELEKQLYSLPHWRTDGHNHVIINLSRKSDTQNLLYNVSTGRAMVAQ 300
301 STFYTVQYRPGFDLVVSPLVHAMSEPNFMEIPPQVPVKRKYLFTFQGEKI 350
I I I I I I I Il I I I I 1 I I I Il I I I I I I I I I I I I I I I I 1 I I I I I 11 I I I I I I I
301 STFYTVQYRPGFDLVVSPLVHAMSEPNFMEIPPQVPVKRKYLFTFQGEKI 350 . . . . .
351 ESLRSSLQEARSFEEEMEGDPPADYDDRIIATLKAVQDSKLDQVLVEFTC 400
I 1 I I Il I I I I I I I I I 1 I I I I Il I Il I I I I I I Il I Il I I Il Il I I I I I I 1 I
351 ESLRSSLQEARSFEEEMEGDPPADYDDRIIATLKAVQDSKLDQVLVEFTC 400
401 KNQPKPSLPTEWALCGEREDRLELLKLSTFALIITPGDPRLVISSGCATR 450
I I I I I I I Il I I I I I I I I I I I I I I Il I I I I I I I I I I I I I I I Il Il I I I I I I
401 KNQPKPSLPTEWALCGEREDRLELLKLSTFALIITPGDPRLVISSGCATR 450
451 LFEALEVGAVPVVLGEQVQLPYQDMLQWNEAALVVPKPRVTEVHFLLRSL 500 I I I I I I I I I I I I I I I I I I M I I I I I I I M I I I Il I 1 I I Il I I I I I I I I I 1
451 LFEALEVGAVPVVLGEQVQLPYQDMLQWNEAALVVPKPRVTEVHFLLRSL 500
501 SDSDLLAMRRQGRFLWETYFSTADSIFNTVLAMIRTRIQIPAAPIREEAA 550
I I Il I I I I I I I I Il I I I I I I Il I I I I I I I Il Il I I I Il I I Il Il I I I I Il 501 SDSDLLAMRRQGRFLWETYFSTADSIFNTVLAMIRTRIQIPAAPIREEAA 550
551 AEIPHRSGKAAGTDPNMADNGDLDLGPVETEPPYASPRYLRNFTLTVTDF 600
M I I M I M I M I M I I I M I I M I I I I M I I M M I I I M I I I M I I I I
551 AEIPHRSGKAAGTDPNMADNGDLDLGPVETEPPYASPRYLRNFTLTVTDF 600 . . . . .
601 YRSWNCAPGPFHLFPHTPFDPVLPSEAKFLGSGTGFRPIGGGAGGSGKEF 650
I I I I I I I I I I M M M I M I I Il I M M M I I I M I M I I I Mill I I M
601 YRSWNCAPGPFHLFPHTPFDPVLPSEAKFLGSGTGFRPIGGGAGGSGKEF 650
651 QAALGGNVPREQFTWMLTYEREEVLMNSLERLNGLPYLNKWVVWNSPK 700
651 QAALGGNVPREQFTVVMLTYEREEVLMNSLERLNGLPYLNKVVVVWNSPK 700
701 LPSEDLLWPDIGVPIMVVRTEKNSLNNRFLPWNEIETEAILSIDDDAHLR 750
I I I I I I I I I I I I I I I I I I I I I I ! I I I I I I I I I I I I I I I I I I I I I I I I I I I 701 LPSEDLLWPDIGVPIMWRTEKNSLNNRFLPWNEIETEAILSIDDDAHLR 750
751 HDEIMFGFRVWREARDRIVGFPGRYHAWDIPHQSWLYNSNYSCELSMVLT 800
I I I I I I I I Il I I I I I I I I I I I I 1 I I I ! 1 I I I I I I I I I I I I I I I I I I I I I I
751 HDEIMFGFRVWREARDRIVGFPGRYHAWDIPHQSWLYNSNYSCELSMVLT 800 . . . . .
801 GAAFFHK AIRDMVDEYINCEDIAMNFLVSHITRKPPIK 838
I I I I I I I I I I I I I I I I I I I I I I I Il I I I I I Il I I I I I I
801 GAAFFHKYYAYLYSYVMPQAIRDMVDEYINCEDIAMNFLVSHITRKPPIK 850
839 VTSRWTFRCPGCPQALSHDDSHFHERHKCINFFVKVYGYMPLLYTQFRVD 888
I I I I I I Il I I I Il I I I Il I Il I I I Il I Il I I I I I I Il Il I I Il I Il I I I I
851 VTSRWTFRCPGCPQALSHDDSHFHERHKCINFFVKVYGYMPLLYTQFRVD 900
889 SVLFKTRLPHDKTKCFKFI 907 I I I I I I 11 I I I I I I I I I I I
901 SVLFKTRLPHDKTKCFKFI 919
Sequence name: EXL3_HUMAN
Sequence documentation:
Alignment of: M79217_PEA_1_P4 x EXL3__HUMAN
Alignment segment 1/1:
Quality: 1668.00
Escore: 0
Matching length: 162 Total length: 162
Matching Percent Similarity: 100.00 Matching Percent Identity: 99.38
Total Percent Similarity: 100.00 Total Percent Identity: 99.38
Gaps : 0
Alignment:
51 YRVWREARDRIVGFPGRYHAWDIPHQSWLYNSNYSCELSMVLTGAAFFHK 100 : I I I Il I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I
758, FRVWREARDRIVGFPGRYHAWDIPHQSWLYNSNYSCELSMVLTGAAFFHK 807 . . . . .
101 YYAYLYSYVMPQAIRDMVDEYINCEDIAMNFLVSHITRKPPIKVTSRWTF 150
I I Il I I I I Il I I I Il I I Il I ! I I I I I I Il Il I I I I I I I I I I I I I I I I I Il
808 YYAYLYSYVMPQAIRDMVDEYINCEDIAMNFLVSHITRKPPIKVTSRWTF 857
151 RCPGCPQALSHDDSHFHERHKCINFFVKVYGYMPLLYTQFRVDSVLFKTR 200 I I I I I I Il Il I I Il I I I I Il Il I I Il I I I I I I I Il I I I I I I I I Il I I I I I
858 RCPGCPQALSHDDSHFHERHKCINFFVKVYGYMPLLYTQFRVDSVLFKTR 907
201 LPHDKTKCFKFI 212 I I I M I I I I I I I
908 LPHDKTKCFKFI 919
Sequence name: EXL3_HUMAN
Sequence documentation:
Alignment of: M79217_PEA_1_P8 x EXL3_HUMAN
Alignment segment 1/1:
Quality: 7947.00
Escore: 0
Matching length: 807 Total length: 807
Matching Percent Similarity: 100.00 Matching Percent Identity: 100.00
Total Percent Similarity: 100.00 Total Percent Identity: 100.00
Gaps : 0
Alignment:
1 MTGYTMLRNGGAGNGGQTCMLRWSNRIRLTWLSFTLFVILVFFPLIAHYY 50
1111 ! 1111 ! M I I I I I M I M I I I M I M I I I I I I I I I I I I I I M I I I I 1 MTGYTMLRNGGAGNGGQTCMLRWSNRIRLTWLSFTLFVILVFFPLIAHYY 50 . . . . .
51 LTTLDEADEAGKRIFGPRVGNELCEVKHVLDLCRIRESVSEELLQLEAKR 100
11111111111111111111111111111111111111111111111111
51 LTTLDEADEAGKRIFGPRVGNELCEVKHVLDLCRIRESVSEELLQLEAKR 100
101 QELNSEIAKLNLKIEACKKSIENAKQDLLQLKNVISQTEHSYKELMAQNQ 150 11 M I I I I 1 I 1 I I I 1 I I I I I I I 1 I I 1 I I I I I 1 I I I I 1 I I 1 I I I I I I 1 I I I
101 QELNSEIAKLNLKIEACKKSIENAKQDLLQLKNVISQTEHSYKELMAQNQ 150
151 PKLSLPIRLLPEKDDAGLPPPKATRGCRLHNCFDYSRCPLTSGFPVYVYD 200
I 1 I I I I I 1 I I I I 11 I I I I I I I I I I I I 1 I I I I 1 I I I I I I 1 I I I I I I I 1 I 1 I 151 PKLSLPIRLLPEKDDAGLPPPKATRGCRLHNCFDYSRCPLTSGFPVYVYD 200
201 SDQFVFGSYLDPLVKQAFQATARANVYVTENADIACLYVILVGEMQEPW 250
I 1 I I I 1 I I I I 1 I Il I I I I I I I I I I I Il 111 I I I I I I I 1 I I I I I I 1 I I 1 I I
201 SDQFVFGSYLDPLVKQAFQATARANVYVTENADIACLYVILVGEMQEPW 250 . . . . .
251 LRPAELEKQLYSLPHWRTDGHNHVIINLSRKSDTQNLLYNVSTGRAMVAQ 300
I 11 I I I 1 I I I 1 I I I I I I I Il I I I 11 I 1 I I I 1 I I I I I I Il I i Il Il I I I I I
251 LRPAELEKQLYSLPHWRTDGHNHVIINLSRKSDTQNLLYNVSTGRAMVAQ 300
301 STFYTVQYRPGFDLVVSPLVHAMSEPNFMEIPPQVPVKRKYLFTFQGEKI 350 I Il I Il I I 1 Il 1 I I I 1 Il I I I I I I I I Il 11 I I I 1 I I I I I I I I Il I I 1 I 1 I
301 STFYTVQYRPGFDLVVSPLVHAMSEPNFMEIPPQVPVKRKYLFTFQGEKI 350
351 ESLRSSLQEARSFEEEMEGDPPADYDDRIIATLKAVQDSKLDQVLVEFTC 400 I I I I I I I M I I I I I I I I I I I I I 1 I I I I I I I I M I I I I I I I I I I I M I I I I
351 ESLRSSLQEARSFEEEMEGDPPADYDDRIIATLKAVQDSKLDQVLVEFTC 400
401 KNQPKPSLPTEWALCGEREDRLELLKLSTFALIITPGDPRLVISSGCATR 450
I I I I I 1 Il I I Il I I I I I I I I I I Il I I Il I I I I I I I I I Il I I I I I I I I I I I 401 KNQPKPSLPTEWALCGEREDRLELLKLSTFALIITPGDPRLVISSGCATR 450
451 LFEALEVGAVPVVLGEQVQLPYQDMLQWNEAALVVPKPRVTEVHFLLRSL 500
I I I I I I I I 1 I I I I I I I I I Il I I I I 1 I I I I I I I I I I I I I 1 I I I I I I I I 1 I I
451 LFEALEVGAVPVVLGEQVQLPYQDMLQWNEAALVVPKPRVTEVHFLLRSL 500
501 SDSDLLAMRRQGRFLWETYFSTADSIFNTVLAMIRTRIQIPAAPIREEAA 550
I I I I I I i I I I I I I I I I I I I 1 I I I I I i I I I Il I I I I I I I I I I I I I I I I I I i 501 SDSDLLAMRRQGRFLWETYFSTADSIFNTVLAMIRTRIQIPAAPIREEAA 550
551 AEIPHRSGKAAGTDPNMADNGDLDLGPVETEPPYASPRYLRNFTLTVTDF 600 I I I Il I I I I I I I I I I I I I I I Il I I I I 1 I I I I I I Il 1 I I Il M I I I I I I I I
551 AEIPHRSGKAAGTDPNMADNGDLDLGPVETEPPYASPRYLRNFTLTVTDF 600
601 YRSWNCAPGPFHLFPHTPFDPVLPSEAKFLGSGTGFRPIGGGAGGSGKEF 650
I I I I l I I I I I I I l I I 1 I I l I I I I I I I I I I I I I I I I l I I I l I I l I I I I I I I 601 YRSWNCAPGPFHLFPHTPFDPVLPSEAKFLGSGTGFRPIGGGAGGSGKEF 650
651 QAALGGNVPREQFTVVMLTYEREEVLMNSLERLNGLPYLNKVVWWNSPK 700 I I I l I I I I I I I I I I I l I I I I I I I I I I I I I I I l I l I I I I I I I I I l I I I I I I
651 QAALGGNVPREQFTWMLTYEREEVLMNSLERLNGLPYLNKWWWNSPK 700 . . . . .
701 LPSEDLLWPDIGVPIMWRTEKNSLNNRFLPWNEIETEAILSIDDDAHLR 750
I I I I I I I I I I I I I I I I I I Il I I I I I I I I I I I I I I I I I I I I Il Il I I Il I I
701 LPSEDLLWPDIGVPIMVVRTEKNSLNNRFLPWNEIETEAILSIDDDAHLR 750
751 HDEIMFGFRVWREARDRIVGFPGRYHAWDIPHQSWLYNSNYSCELSMVLT 800
I I I I I I I I I I I Il I I I I I I I I I I I I I I I I I I Il I I Il I I Il I I I Il I I I I 751 HDEIMFGFRVWREARDRIVGFPGRYHAWDIPHQSWLYNSNYSCELSMVLT 800
801 GAAFFHK 807 I I I I I I I
801 GAAFFHK 807
DESCRIPTION FOR CLUSTER M62096
Cluster M62096 features 9 transcripts) and 42 segment(s) of interest, the names for which are given in Tables 627 and 628, respectively, the sequences themselves are given at the end of the application. The selected protein variants are given in table 629.
Table 627 - Transcripts of interest
Table 629 - Proteins of interest
These sequences are variants of the known protein Kinesin heavy chain isoform 5C (SwissProt accession identifier KF5C_HUMAN; known also according to the synonyms Kinesin heavy chain neuron- specific 2), SEQ ID NO: 1438, referred to herein as the previously known protein.
Protein Kinesin heavy chain isoform 5 C is known or believed to have the following function(s): Kinesin is a microtubule-associated force-producing protein that may play a role in organelle transport. The sequence for protein Kinesin heavy chain isoform 5C is given at the end of the application, as "Kinesin heavy chain isoform 5C amino acid sequence". Known polymorphisms for this sequence are as shown in Table 630.
Table 630 -Amino acid mutations for Known Protein
The following GO Annotation(s) apply to the previously known protein. The following annotation(s) were found: organelle organization and biogenesis, which are annotation(s) related to Biological Process; microtubule motor; ATP binding, which are annotation(s) related to Molecular Function; and kinesin, which are annotation(s) related to Cellular Component.
The GO assignment relies on information from one or more of the SwissProt/TremBl Protein knowledgebase, available from <http://www.expasy.ch/sprot/>; or Locuslink, available from <http://www.ncbi.nlm.nih.gov/projects/LocusLink/>.
As noted above, cluster M62096 features 9 transcript(s), which were listed in Table 1 above. These transcript(s) encode for protein(s) which are variant(s) of protein Kinesin heavy chain isoform 5 C. A description of each variant protein according to the present invention is now provided.
Variant protein M62096_PEA_l_P4 according to the present invention has an amino acid sequence as given at the end of the application; it is encoded by transcript(s)
M62096_PEA_l_T6. An alignment is given to the known protein (Kinesin heavy chain isoform 5C) at the end of the application. One or more alignments to one or more previously published protein sequences are given at the end of the application. A brief description of the relationship of the variant protein according to the present invention to each such aligned protein is as follows:
Comparison report between M62096_PEA_l_P4 and KF5C_HUMAN: 1.An isolated chimeric polypeptide encoding for M62096_PEA_l_P4, comprising a first amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence MATYIH corresponding to amino acids 1 - 6 of M62096_PEA_l_P4, and a second amino acid sequence being at least 90 % homologous to
VSKTGAEGAVLDEAKNINKSLSALGNVISALAEGTKTHVPYRDSKMTRILQDSLGGNC RTTIVICCSPSVFNEAETKSTLMFGQPvAKTIKNTVSVNLELTAEEWKKKYEKEKEKNKT LKNVIQHLEMELNRWRNGEAVPEDEQISAKDQKNLEPCDNTPIIDNIAPWAGISTEEKE KYDEEISSLYRQLDDKDDEINQQSQLAEKLKQQMLDQDELLASTRRDYEKIQEELTRLQ IENEAAKDEVKEVLQALEELAVNYDQKSQEVEDKTRANEQLTDELAQKTTTLTTTQRE
LSQLQELSNHQKKRATEILNLLLKDLGEIGGIIGTNDVKTLADVNGVIEEEFTMARLYIS KMKSEVKSLVNRSKQLESAQMDSNRKMNASERELAACQLLISQHEAKIKSLTDYMQN MEQKRRQLEESQDSLSEELAKLRAQEKMHEVSFQDKEKEHLTRLQDAEEMKKALEQQ MESHREAHQKQLSRLRDEIEEKQKIIDEIRDLNQKLQLEQEKLSSDYNKLKIEDQEREM KLEKLLLLNDKREQAREDLKGLEETVSRELQTLHNLRKLFVQDLTTRVKKSVELDNDD GGGSAAQKQKISFLENNLEQLTKVHKQLVRDNADLRCELPKLEKRLRATAERVKALES ALKEAKENAMRDRKRYQQEVDRIKEAVRAKNMARRAHSAQIAKPIRPGHYPASSPTA
VHAIRGGGGSSSNSTHYQK corresponding to amino acids 239 - 957 of KF5C_HUMAN, which also corresponds to amino acids 7 - 725 of M62O96_PEA_1JP4, wherein said first amino acid sequence and second amino acid sequence are contiguous and in a sequential order.
2.An isolated polypeptide encoding for a head of M62096_PEA_l_P4, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence MATYIH of M62096_PEA_l_P4.
The location of the variant protein was determined according to results from a number of different software programs and analyses, including analyses from SignalP and other specialized programs. The variant protein is believed to be located as follows with regard to the cell: intracellularly. The protein localization is believed to be intracellularly because neither of the trans- membrane region prediction programs predicted a trans -membrane region for this protein. In addition both signal-peptide prediction programs predict that this protein is a non- secreted protein.
Variant protein M62096_PEA_l_P4 is encoded by the following transcript(s): M62096_PEA_ l_T6, for which the sequence(s) is/are given at the end of the application. The coding portion of transcript M62096_PEA_l_T6 is shown in bold; this coding portion starts at position 108 and ends at position 2282. The transcript also has the following SNPs as listed in Table 631 (given according to their position on the nucleotide sequence, with the alternative nucleic acid listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein M62096_PEA_l_P4 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 631 - Nucleic acid SNPs
Variant protein M62096_PEA_l_P5 according to the present invention has an amino acid sequence as given at the end of the application; it is encoded by transcript(s)
M62096_PEA_l_T7. An alignment is given to the known protein (Kinesin heavy chain isoform 5C) at the end of the application. One or more alignments to one or more previously published protein sequences are given at the end of the application. A brief description of the relationship of the variant protein according to the present invention to each such aligned protein is as follows:
Comparison report between M62096_PEA_l_P5 and KF5C_HUMAN: 1.An isolated chimeric polypeptide encoding for M62096_PEA_l_P5, comprising a first amino acid sequence being at least 90 % homologous to MTRILQDSLGGNCRTTIVICCSPSVFNEAETKSTLMFGQRAKTIKNTVSVNLELTAEEWK KKYEKEKEKNKTLKNVIQHLEMELNRWRNGEAVPEDEQISAKDQKNLEPCDNTPIIDNI APWAGISTEEKEKYDEEISSLYRQLDDKDDEINQQSQLAEKLKQQMLDQDELLASTRR DYEKIQEELTRLQIENEAAKDEVKEVLQALEELAVNYDQKSQEVEDKTRANEQLTDEL AQKTTTLTTTQRELSQLQELSNHQKKRATEILNLLLKDLGEIGGIIGTNDVKTLADVNG VIEEEFTMARLYISKMKSEVKSLVNRSKQLESAQMDSNRKMNASERELAACQLLISQHE AKIKSLTDYMQNMEQKRRQLEESQDSLSEELAKLRAQEKMHEVSFQDKEKEHLTRLQ DAEEMKKALEQQMESHREAHQKQLSRLRDEIEEKQKIIDEIRDLNQKLQLEQEKLSSDY NKLKIEDQEREMKLEKLLLLNDKREQAREDLKGLEETVSRELQTLHNLRKLFVQDLTT RVKKSVELDNDDGGGSAAQKQKISFLENNLEQLTKVHKQLVRDNADLRCELPKLEKRL RATAERVKALESALKEAKENAMRDRKRYQQEVDRIKEAVRAKNMARRAHSAQIAKPI RPGHYPASSPTAVHAIRGGGGSSSNSTHYQK corresponding to amino acids 284 - 957 of KF5C_HUMAN, which also corresponds to amino acids 1 - 674 of M62096_PEA_l_P5.
The location of the variant protein was determined according to results from a number of different software programs and analyses, including analyses from SignalP and other specialized programs. The variant protein is believed to be located as follows with regard to the cell: intracellularly. The protein localization is believed to be intracellularly because neither of the trans- membrane region prediction programs predicted a trans -membrane region for this protein. In addition both signal-peptide prediction programs predict that this protein is a non-secreted protein.
Variant protein M62096_PEA_l_P5 is encoded by the following transcript(s): M62096_PEA_l_T7, for which the sequence(s) is/are given at the end of the application. The coding portion of transcript M62096_PEA_l_T7 is shown in bold; this coding portion starts at position 283 and ends at position 2304. The transcript also has the following SNPs as listed in Table 632 (given according to their position on the nucleotide sequence, with the alternative nucleic acid listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein M62096_PEA_l_P5 sequence provides support for the deduced sequence of this -variant protein according to the present invention).
Table 632 - Nucleic acid SNPs
Variant protein M62096_PEA_l_P3 according to the present invention has an amino acid sequence as given at the end of the application; it is encoded by transcript(s) M62096_PEA_l_T9. An alignment is given to the known protein (Kinesin heavy chain isoform 5C) at the end of the application. One or more alignments to one or more previously published protein sequences are given at the end of the application. A brief description of the relationship of the variant protein according to the present invention to each such aligned protein is as follows:
Comparison report between M62096_PEA_l_P3 and KP5C_HUMAN:
1.An isolated chimeric polypeptide encoding for M62096_PEA_l_P3, comprising a first amino acid sequence being at least 90 % homologous to MELNRWRNGEAVPEDEQISAKDQKNLEPCDNTPIIDNIAP VVAGISTEEKEKYDEEISSL
YRQLDDKDDEINQQSQLAEKLKQQMLDQDELLASTRRDYEKIQEELTRLQIENEAAKD EVKEVLQALEELAVNYDQKSQEVEDKTRANEQLTDELAQKTTTLTTTQRELSQLQELS NHQKKRATEILNLLLKDLGEIGGIIGTNDVKTLADVNGVIEEEFTMARLYISKMKSEVKS LVNRSKQLESAQMDSNRKMNASERELAACQLLISQHEAKIKSLTDYMQNMEQKRRQL EESQDSLSEELAKLRAQEKMHEVSFQDKEKEHLTRLQDAEEMKKALEQQMESHREAH QKQLSRLRDEIEEKQKIIDEIRDLNQKLQLEQEKLSSDYNKLKIEDQEREMKLEKLLLLN DKREQAREDLKGLEETVSRELQTLHNLRKLFVQDLTTRVKKSVELDNDDGGGSAAQK QKISFLENNLEQLTKVHKQLVRDNADLRCELPKLEKJRLRATAERVKALESALKEAKEN AMRDRKRYQQEVDRIKEAVRAKNMARRAHSAQIAKPIRPGHYPASSPTAVHAIRGGGG
SSSNSTHYQK corresponding to amino acids 365 - 957 of KF5C_HUMAN, which also corresponds to amino acids 1 - 593 of M62096_PEA_l_P3.
The location of the variant protein was determined according to results from a number of different software programs and analyses, including analys es from SignalP and other specialized programs. The variant protein is believed to be located as follows with regard to the cell: intracellularly. The protein localization is believed to be intracellularly because neither of the trans- membrane region prediction programs predicted a trans -membrane region for this protein.
In addition both signal-peptide prediction programs predict that this protein is a non-secreted protein.
Variant protein M62096_PEA_l_P3 is encoded by the following transcript(s): M62096_PEA_l_T9, for which the sequence(s) is/are given at the end of the application. The coding portion of transcript M62096_PEA_l_T9 is shown in bold; this coding portion starts at position 565 and ends at position 2343. The transcript also has the following SNPs as listed in Table 633 (given according to their position on the nucleotide sequence, with the alternative nucleic acid listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein M62096_PEA_l_P3 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 633 - Nucleic acid SNPs
SNP position on nucleotide Alternative nucleic acid Previously known SNP? sequence
5818 G -> T No
Variant protein M62O96_PEA_1JP7 according to the present invention has an amino acid sequence as given at the end of the application; it is encoded by transcript(s)
M62O96_PEA_1_T11. An alignment is given to the known protein (Kinesin heavy chain isoform 5C) at the end of the application. One or more alignments to one or more previously published protein sequences are given at the end of the application. A brief description of the relationship of the variant protein according to the present invention to each such aligned protein is as follows:
Comparison report between M62O96_PEA_1JP7 and KF5CJHUMAN: 1.An isolated chimeric polypeptide encoding for M62096JPEA_l_P7, comprising a first amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence MTQNFPvLMWNILLFPLNFS corresponding to amino acids 1 - 19 of
M62096_PEA_l_P7, and a second amino acid sequence being at least 90 % homologous to LNQKLQLEQEKLSSDYNKLKIEDQEREMKLEKLLLLNDKREQAREDLKGLEETVSREL QTLHNLRKLFVQDLTTRVKKSVELDNDDGGGSAAQKQKISFLENNLEQLTKVHKQLVR DNADLRCELPKLEKRLRATAERVKALESALKEAKENAMRDRXRYQQEVDRIKEAVRA KNMARRAHSAQIAKPIRPGHYPASSPTAVHAIRGGGGSSSNSTHYQK corresponding to amino acids 738 - 957 of KF5C_HUMAN, which also corresponds to amino acids 20 - 239 of M62096JPEA_l_P7, wherein said first amino acid sequence and second amino acid sequence are contiguous and in a sequential order.
2.An isolated polypeptide encoding for a head of M62096_PEA_l_P7, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence MTQNFRLMWNILLFPLNFS of M62096_PEA_l_P7.
The location of the variant protein was determined according to results from a number of different software programs and analyses, including analyses from SignalP and other specialized programs. The variant protein is believed to be located as follows with regard to the cell: secreted. The protein localization is believed to be secreted because one of the two signal- peptide prediction programs (HMM :Non- secretory protein,NN:YES) predicts that this protein has a signal peptide.
Variant protein M62096_PEA_l_P7 is encoded by the following transcript(s): M62O96_PEA_1_T11, for which the sequence(s) is/are given at the end of the application. The coding portion of transcript M62O96_PEA_1_T11 is shown in bold; this coding portion starts at position 633 and ends at position 1349. The transcript also has the following SNPs as listed in Table 634 (given according to their position on the nucleotide sequence, with the alternative nucleic acid listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein M62096_PEA_l_P7 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 634 - Nucleic acid SNPs
Variant protein M62096_PEA_l_P8 according to the present invention has an amino acid sequence as given at the end of the application; it is encoded by transcript(s)
M62096_PEA_l_T13. An alignment is given to the known protein (Kinesin heavy chain isoform 5C) at the end of the application. One or more alignments to one or more previously published protein sequences are given at the end of the application. A brief description of the relationship of the variant protein according to the present invention to each such aligned protein is as follows:
Comparison report between M62096_PEA_l_P8 and KF5C_HUMAN:
1.An isolated chimeric polypeptide encoding for M62096_PEA_l_P8, comprising a first amino acid sequence being at least 90 % homologous to
MADPAECSIKVMCRFRPLNEAEILRGDKFIPKFKGDETVVIGQGKPYVFDRVLPPNTTQ EQVYNACAKQIVKDVLEGYNGTIFAYGQTSSGKTHTMEGKLHDPQLMGIIPRIAHDIFD HIYSMDENLEFHIKVSYFEIYLDKIRDLLDVSKTNLAVHEDKNRVPYVKGCTERPVSSPE EVMDVIDEGKANRHVAVTNMNEHSSRSHSIFLINIKQENVETEKKLSGKLYLVDLAGSE KVSKTGAEGAVLDEAKNINKSLSALGNVISALAEGTKTHVPYRDSKMTRILQDSLGGN CRTTIVICCSPSVFNEAETKSTLMFGQRAKTIKNTVSVNLELTAEEWKKKYEKEKEKNK TLKNVIQHLEMELNRWRNGEAVPEDEQISAKDQKNLEPCDNTPIIDNIAPVVAGISTEEK EKYDEEISSLYRQLDDKDDEINQQSQLAEKLKQQMLDQDELLASTRRDYEKIQEELTRL QIENEAAKDEVKEVLQALEELAVNYDQKSQEVEDKTRANEQLTDELAQKTTTLTTTQR ELSQLQELSNHQKKRATEILNLLLKDLGEIGGIIGTNDVKTLADVNGVIEEEFTMARLYI SKMKSEVKSLVNRSKQLESAQMDSNRKMNASERELAACQLLISQHEAKIKSLTD YMQN MEQKRRQLEESQDSLSEELAKLRAQEKMHEVSFQDKEKEHLTRLQDAEEMKKALEQQ MESHREAHQKQLSRLRDEIEEKQKIIDEIR corresponding to amino acids 1 - 736 of
KF5CJHUMAN, which also corresponds to amino acids 1 - 736 of M62096_PEA_l_P8, and a second amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence E corresponding to amino acids 737 - 737 of M62096 PEA 1 P8, wherein said first amino acid sequence and second amino acid sequence are contiguous and in a sequential order.
The location of the variant protein was determined according to results from a number of different software programs and analyses, including analyses from SignalP and other specialized programs. The variant protein is believed to be located as follows with regard to the cell: intracellularly. The protein localization is believed to be intracellularly because neither of the trans- membrane region prediction programs predicted a trans -membrane region for this protein. In addition both signal-peptide prediction programs predict that this protein is a non-secreted protein. Variant protein M62096_PEA_l_P8 also has the following non-silent SNPs (Single
Nucleotide Polymorphisms) as listed in Table 635, (given according to their position(s) on the
amino acid sequence, with the alternative amino acid(s) listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein M62096_PEA_l_P8 sequence provides support for the deduced sequence of this variant protein according to the present invention). Table 635 - Amino acid mutations
Variant protein M62096JPEA_l_P8 is encoded by the following transcript(s): M62096_PEA_l_T13, for which the sequence(s) is/are given at the end of the application. The coding portion of transcript M62096_PEA_l_T13 is shown in bold; this coding portion starts at position 396 and ends at position 2606. The transcript also has the following SNPs as listed in Table 636 (given according to their position on the nucleotide sequence, with the alternative nucleic acid listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein M62096_PEA_l_P8 sequence provides support for the deduced sequence of this variant protein according to the present invention). Table 636 - Nucleic acid SNPs
Variant protein M62096_PEA_l_P9 according to the present invention has an amino acid sequence as given at the end of the application; it is encoded by transcript(s) M62096_PEA_l_T14. An alignment is given to the known protein (Kinesin heavy chain isoform 5C) at the end of the application. One or more alignments to one or more previously published protein sequences are given at the end of the application. A brief description of the relationship of the variant protein according to the present invention to each such aligned protein is as follows:
Comparison report between M62096_PEA_l_P9 and KF5C_HUMAN:
1.An isolated chimeric polypeptide encoding for M62096_PEA_l_P9, comprising a first amino acid sequence being at least 90 % homologous to
MADP AECSIKVMCRPRPLNEAEILRGDKPIPKFKGDETWIGQGKP YVFDRVLPPNTTQ EQVYNACAKQIVKDVLEGYNGTIFAYGQTSSGKTHTMEGKLHDPQLMGIIPRIAHDIFD HIYSMDENLEFHIKVSYFEIYLDKIRDLLDVSKTNLAVHEDKNRVPYVKGCTERPVSSPE EVMDVIDEGKANRHVAVTNMNEHSSRSHSIFLINIKQENVETEKKLSGKLYLVDLAGSE KVSKTGAEGAVLDEAKNINKSLSALGNVISALAEGTKTHVPYRDSKMTRILQDSLGGN CRTTIVICCSPSVFNEAETKSTLMFGQRAKTIKNTVSVNLELTAEEWKKKYEKEKEKNK TLKNVIQHLEMELNRWRNGEAVPEDEQISAKDQKNLEPCDNTPIIDNIAPVVAGISTEEK EKYDEEISSLYRQLDDKDDEINQQSQLAEKLKQQMLDQDE corresponding to amino acids 1 - 454 of KF5C_HUMAN, which also corresponds to amino acids 1 - 454 of M62096_PEA_l_P9, and a second amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence VKNAIYFFFHKVLLLLFVVDVCSRNLIGIEAFHNYRIMWKFLGRCPFTASYKLIITEFRK corresponding to amino acids 455 - 514 of M62O96_PEA_1JP9, wherein said first amino acid sequence and second amino acid sequence are contiguous and in a sequential order.
2.An isolated polypeptide encoding for a tail of M62096_PEA_l JP9, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence
VKNAΓYFFFHKVLLLLFVVDVCSRNLIGIEAFHNYRIMWKFLGRCPFTASYKLIITEFRK in M62096_PEA_l_P9.
The location of the variant protein was determined according to results from a number of different software programs and analyses, including analyses from SignalP and other specialized programs. The variant protein is believed to be located as follows with regard to the cell: intracellularly. The protein localization is believed to be intracellularly because neither of the trans- membrane region prediction programs predicted a trans -membrane region for this protein. In addition both signal-peptide prediction programs predict that this protein is a non-secreted protein.
Variant protein M62096_PEA_l_P9 also has the following non- silent SNPs (Single Nucleotide Polymorphisms) as listed in Table 637, (given according to their position(s) on the amino acid sequence, with the alternative amino acid(s) listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein M62096_PEA_l_P9 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 637 - Amino acid mutations
Variant protein M62096_PEA_l_P9 is encoded by the following transcript(s): M62096_PEA_l_T14, for which the sequence(s) is/are given at the end of the application. The coding portion of transcript M62096_PEA_l_T14 is shown in bold; this coding portion starts at position 396 and ends at position 1937. The transcript also has the following SNPs as listed in Table 638 (given according to their position on the nucleotide sequence, with the alternative nucleic acid listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein M62096_PEA_l_P9 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 638 - Nucleic acid SNPs
Variant protein M62096_PEA_l_P10 according to the present invention has an amino acid sequence as given at the end of the application; it is encoded by transcript(s) M62096_PEA_l_T15. An alignment is given to the known protein (Kinesin heavy chain isoform 5C) at the end of the application. One or more alignments to one or more previously
published protein sequences are given at the end of the application. A brief description of the relationship of the variant protein according to the present invention to each such aligned protein is as follows:
Comparison report between M62096_PEA_l _P10 and KF5C_HUMAN: LAn isolated chimeric polypeptide encoding for M62096_PEA_l_P10, comprising a first amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence MTQNFRLMWNILLFPLNFS corresponding to amino acids 1 - 19 of M62096_PEA_l_P10, a second amino acid sequence being at least 90 % homologous to LNQKLQLEQEKLSSDYNKLKIEDQEREMKLEKLLLLNDKREQAREDLKGLEETVSREL QTLHNLRKLFVQDLTTRVKK corresponding to amino acids 738 - 815 of KF5C_HUMAN, which also corresponds to amino acids 20 - 97 of M62096_PEA_l_P10, and a third amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence VSSLCLNGTEKKIKDGREESFSVEISLA con-esponding to amino acids 98 - 125 of
M62096_PEA_l_P10, wherein said first amino acid sequence, second amino acid sequence and third amino acid sequence are contiguous and in a sequential order.
2.An isolated polypeptide encoding for a head of M62096_PEA_l_P10, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence MTQNFRLMWNILLFPLNFS of M62096_PEA_l_P10.
3.An isolated polypeptide encoding for a tail of M62096_PEA_l_P10, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence VSSLCLNGTEKKIKDGREESFSVEISLA in M62096_PEA_l_P10.
The location of the variant protein was determined according to results from a number of different software programs and analyses, including analyses from SignalP and other specialized programs. The variant protein is believed to be located as follows with regard to the cell: secreted. The protein localization is believed to be secreted because one of the two signal-
peptide prediction programs (HMM :Non- secretory protein,NN:YES) predicts that this protein has a signal peptide.
Variant protein M62096_PEA_l_P10 is encoded by the following transcript(s): M62096_PEA_l_T15, for which the sequence(s) is/are given at the end of the application. The coding portion of transcript M62096_PEA_l_T15 is shown in bold; this coding portion starts at position 633 and ends at position 1007.
Variant protein M62O96_PEA_1_P11 according to the present invention has an amino acid sequence as given at the end of the application; it is encoded by transcript(s) M62096_PEA_l_T4. An alignment is given to the known protein (Kinesin heavy chain isoform 5C) at the end of the application. One or more alignments to one or more previously published protein sequences are given at the end of the application. A brief description of the relationship of the variant protein according to the present invention to each such aligned protein is as follows: Comparison report between M62096_PEA_l JP 11 and KF5C_HUMAN:
LAn isolated chimeric polypeptide encoding for M62O96_PEA_1_P11, comprising a first amino acid sequence being at least 90 % homologous to
MADPAECSIKVMCRFRPLNEAEILRGDKFIPKFKGDETVVIGQGKPYVFDRVLPPNTTQ EQVYNACAKQIVKDVLEGYNGTIFAYGQTSSGKTHTMEGKLHDPQLMGIIPRIAHDIFD HIYSMDENLEFHIKVSYFEIYLDKIRDLLDVSKTNLAVHEDKNRVPYVKGCTERFVSSPE EVMDVIDEGKANRHVAVTNMNEHSSRSHSIFLINIKQENVETEKKLSGKLYLVDLAGSE KVSKTGAEGAVLDEAKNINKSLSALGNVISALAEGTKTHVPYRDSKMTRILQDSLGGN CRTTIVICCSPSWNEAETKSTLMFGQRAKTIKNTVSVNLELTAEEWKKKYEKEKEKNK TLKNVIQHLEMELNRWRN corresponding to amino acids 1 - 372 of KF5CJΪUMAN, which also corresponds to amino acids 1 - 372 of M62O96_PEA_1_P11, and a second amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence DFLAAHVFGKLLE corresponding to amino acids 373 - 385 of M62O96_PEA_1_P11, wherein said first amino acid sequence and second amino acid sequence are contiguous and in a sequential order.
2.An isolated polypeptide encoding for a tail of M62O96_PEA_1_P11, comprising a polypeptide being at feast 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence DFLAAHVFGKLLE in M62096JPEA_l JPl 1.
The location of the variant protein was determined according to results from a number of different software programs and analyses, including analyses from SignalP and other specialized programs. The variant protein is believed to be located as follows with regard to the cell: intracellularly. The protein localization is believed to be intracellularly because neither of the trans- membrane region prediction programs predicted a trans -membrane region for this protein. In addition both signal-pep tide prediction programs predict that this protein is a non- secreted protein.
Variant protein M62096JPEA_l JPl 1 also has the following non-silent SNPs (Single Nucleotide Polymorphisms) as listed in Table 639, (given according to their position(s) on the amino acid sequence, with the alternative amino acid(s) listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein M62O96_PEA_1_P11 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 639 - Amino acid mutations
Variant protein M62096_PEA_l JPl 1 is encoded by the following transcript(s): M62096_PEA_l_T4, for which the sequence(s) is/are given at the end of the application. The coding portion of transcript M62096_PEA_l_T4 is shown in bold; this coding portion starts at position 396 and ends at position 1550. The transcript also has the following SNPs as listed in Table 640 (given according to their position on the nucleotide sequence, with the alternative nucleic acid listed; the last column indicates whether the SNP is known or not; the presence of
known SNPs in variant protein M62O96__PEA_1JP11 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 640 - Nucleic acid SNPs
Variant protein M62096_PEA_l_P12 according to the present invention has an amino acid sequence as given at the end of the application; it is encoded by transcript(s) M62096_PEA_l_T5. An alignment is given to the known protein (Kinesin heavy chain isoform 5C) at the end of the application. One or more alignments to one or more previously published protein sequences are given at the end of the application. A brief description of the relationship of the variant protein according to the present invention to each such aligned protein is as follows:
Comparison report between M62096_PEA_l_P12 and KF5CJHUMAN:
LAn isolated chimeric polypeptide encoding for M62096_PEA_l_P12, comprising a first amino acid sequence being at least 90 % homologous to
MADPAECSIKVMCRFRPLNEAEILRGDKFIPKFKGDETVVIGQGKPYVFDRVLPPNTTQ EQVYNACAKQIVKDVLEGYNGTIFAYGQTSSGKTHTMEGKLHDPQLMGIIPRIAHDIFD HIYSMDENLEFHIKVSYFEIYLDKIRDLLDVSKTNLAVHEDKNRVPYVKGCTERFVSSPE EVMDVIDEGKANRHVAVTNMNEHSSRSHSIFLINIKQENVETEKKLSGKLYLVDLAGSE KVSKTGAEGAVLDEAKNINKSLSALGNVISALAEGTKTHVPYRDSKMTRILQDSLGGN CRTTIVICCSPSVFNEAETKSTLMFGQR corresponding to amino acids 1 - 323 of KF5C_HUMAN, which also corresponds to amino acids 1 - 323 of M62096_PEA_l_P12, and a second amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence V corresponding to amino acids 324 - 324 of M62096_PEA_l_P12,
wherein said first amino acid sequence and second amino acid sequence are contiguous and in a sequential order.
The location of the variant protein was determined according to results from a number of different software programs and analyses, including analyses from SignalP and other specialized programs. The variant protein is believed to be located as follows with regard to the cell: intracellularly. The protein localization is believed to be intracellularly because neither of the trans- membrane region prediction programs predicted a trans -membrane region for this protein. In addition both signal-peptide prediction programs predict that this protein is a non-secreted protein.
Variant protein M62096JPEA_l_P12 also has the following non-silent SNPs (Single Nucleotide Polymorphisms) as listed in Table 641, (given according to their position(s) on the amino acid sequence, with the alternative amino acid(s) listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein M62096_PEA_l_P12 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 641 -Amino acid mutations
Variant protein M62096_PEA_l_P12 is encoded by the following transcript(s): M62096_PEA_l_T5, for which the sequence(s) is/are given at the end of the application. The coding portion of transcript M62096_PEA_l_T5 is shown in bold; this coding portion starts at position 378 and ends at position 1349. The transcript also has the following SNPs as listed in Table 642 (given according to their position on the nucleotide sequence, with the alternative nucleic acid listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein M62096_PEA_l_P12 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 642 - Nucleic acid SNPs
As noted above, cluster M62096 features 42 segment(s), which were listed in Table 2 above and for which the sequence(s) are given at the end of the application. These segment(s) are portions of nucleic acid sequence(s) which are described herein separately because they are of particular interest. A description of each segment according to the present invention is now provided.
Segment cluster M62096_PEA_l_node_0 according to the present invention is supported by 14 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): M62096JPEA_l_T4, M62096JPEA_l_T5, M62096_PEA_l_T13 and M62096_PEA_l_T14. Table 643 below describes the starting and ending position of this segment on each transcript.
Table 643 - Segment location on transcripts
Segment cluster M62096_PEA_l_node_2 according to the present invention is supported by 12 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): M62096_PEA_l_T4, M62096_PEA_l_T5, M62096_PEA_l_T13 and M62096JPEA_l_T14. Table 644 below describes the starting and ending position of this segment on each transcript.
Table 644 - Segment location on transcripts
Segment cluster M62096_PEA_l_node_15 according to the present invention is supported by 28 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): M62096_PEA_l_T4, M62096_PEA_l_T5, M62096_PEA_l_T13 and M62096_PEA_l_T14. Table 645 below describes the starting and ending position of this segment on each transcript.
Table 645 - Segment location on transcripts
Segment cluster M62096_PEA_l_node_17 according to the present invention is supported by 1 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): M62096_PEA_ l_T7. Table 646 below describes the starting and ending position of this segment on each transcript.
Table 646 - Segment location on transcripts
Segment cluster M62096_PEA_l_node_19 according to the present invention is supported by 3 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): M62096JPEA_l_T6 and M62096_PEA_l_T9. Table 647 below describes the starting and ending position of this segment on each transcript.
Table 647 - Segment location on transcripts
Segment cluster M62096_PEA_l_node_23 according to the present invention is supported by 36 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): M62096_PEA_l_T4, M62096_PEA_l_T5, M62096_PEA_l_T6, M62096_PEA_l_T7, M62096_PEA_l_T9, M62096_PEA_l_T13 and M62096JPEAJJT14. Table 648 below describes the starting and ending position of this segment on each transcript.
Table 648 - Segment location on transcripts
Segment cluster M62096_PEA_l_node_27 according to the present invention is supported by 35 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): M62096_PEA_l_T4, M62096_PEA_l_T5, M62096JPEA_l_T6, M62096_PEA_l_T7, M62096JPEA_l_T9, M62096_PEA_l_T13 and M62096_PEA_l_T14. Table 649 below describes the starting and ending position of this segment on each transcript.
Table 649 - Segment location on transcripts
Segment cluster M62096_PEA_l_node_29 according to the present invention is supported by 1 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): M62096_PEA_l_T4. Table 650 below describes the starting and ending position of this segment on each transcript.
Table 650 - Segment location on transcripts
Segment cluster M62096_PEA_l_node_31 according to the present invention is supported by 24 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): M62096_PEA_l_T4, M62096_PEA_l JT5, M62096_PEA_l_T6, M62096_PEAJ_T7, M62096_PEA_l_T9, M62096_PEA_l_T13 and M62096_PEA_l_T14. Table 651 below describes the starting and ending position of this segment on each transcript.
Table 651 - Segment location on transcripts
Segment cluster M62096_PEA_ l_node_34 according to the present invention is supported by 3 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): M62096_PEA_l_T14. Table 652 below describes the starting and ending position of this segment on each transcript.
Table 652 - Segment location on transcripts
Segment cluster M62096_PEA_l_node_36 according to the present invention is supported by 26 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): M62096_PEA_l_T4, M62096_PEA_l_T5, M62096_PEA_l_T6, M62096_PEA_l_T7, M62096_PEA_l_T9 and M62096JPEA_l_T13. Table 653 below describes the starting and ending position of this segment on each transcript.
Table 653 - Segment location on transcripts
Segment cluster M62096_PEA_l_node_38 according to the present invention is supported by 24 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): M62096_PEA_l_T4, M62096_PEA_l_T5, M62096_PEA__l_T6, M62096_PEA_l_T7, M62096_PEA_l_T9 and M62096_PEA_l_T13. Table 654 below describes the starting and ending position of this segment on each transcript.
Table 654 - Segment location on transcripts
Segment cluster M62096_PEA_l_node_40 according to the present invention is supported by 21 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): M62096_PEA_l JT4, M62096_PEA_l_T5, M62096_PEA_l_T6, M62096_PEA_l_T7, M62096J>EA_l_T9 and M62096_PEA_l_T13. Table 655 below describes the starting and ending position of this segment on each transcript.
Table 655 - Segment location on transcripts
Segment cluster M62096_PEA_l_node_48 according to the present invention is supported by 7 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): M62096_PEA_ l_T13. Table 656 below describes the starting and ending position of this segment on each transcript. Table 656 - Segment location on transcripts
Segment cluster M62096_PEA_l_node_50 according to the present invention is supported by 3 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): M62O96_PEA_1_T11 and M62096_PEA_l_T15. Table 657 below describes the starting and ending position of this segment on each transcript.
Table 657 - Segment location on transcripts
Segment cluster M62096_PEA_l_node_56 according to the present invention is supported by 1 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): M62096_PEA_l_T15. Table 658 below describes the starting and ending position of this segment on each transcript.
Table 658 - Segment location on transcripts
Segment cluster M62096_PEA_l_node_60 according to the present invention is supported by 13 libraries. The number of libraries was determined as previously described. This
segment can be found in the following transcript(s): M62096JPEA_l_T4, M62096_PEA_l_T5, M62096_PEA_l_T6, M62096_PEA_l_T7, M62096_PEA_l_T9 and M62O96_PEA_1_T11. Table 659 below describes the starting and ending position of this segment on each transcript.
Table 659 - Segment location on transcripts
Segment cluster M62096_PEA_l_node_65 according to the present invention is supported by 51 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): M62096_PEA_l_T4, M62096_PEA_l_T5, M62096_PEA_l_T6, M62096_PEA_l_T7, M62096_PEA_l_T9 and M62O96_PEA_1_T11. Table 660 below describes the starting and ending position of this segment on each transcript.
Table 660 - Segment location on transcripts
Segment cluster M62096_JPEA_l_node_69 according to the present invention is supported by 85 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): M62096_PEA_l_T4, M62096_PEA_l_T5, M62096_PEA_l_T6, M62096_PEA_l_T7, M62096_PEA_l_T9 and M62O96_PEA_1_T11. Table 661 below describes the starting and ending position of this segment on each transcript.
Table 661 - Segment location on transcripts
Segment cluster M62096_PEA_l_node_71 according to the present invention is supported by 178 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): M62096_PEA_l_T4, M62096_PEA_l_T5, M62096JPEA_l_T6, M62096_PEA_l_T7, M62096_PEA_l_T9 and M62O96_PEA_1_T11. Table 662 below describes the starting and ending position of this segment on each transcript.
Table 662 - Segment location on transcripts
According to an optional embodiment of the present invention, short segments related to the above cluster are also provided. These segments are up to about 120 bp in length, and so are included in a separate description.
Segment cluster M62096_PEA_l_node_l according to the present invention can be found in the following transcript(s): M62096_PEA_l_T4, M62096_PEA_l_T13 and M62096_PEA_l_T14. Table 663 below describes the starting and ending position of this segment on each transcript.
Table 663 - Segment location on transcripts
Segment cluster M62096_PEA_l_node_4 according to the present invention is supported by 12 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): M62096_PEA_l_T4, M62096_PEA_l_T5, M62O96_PEA_1JT13 and M62096_PEA_l_T14. Table 664 below describes the starting and ending position of this segment on each transcript.
Table 664 - Segment location on transcripts
Segment cluster M62096_PEA__l_node_6 according to the present invention is supported by 13 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): M62096_PEA_l_T4, M62O96_PEA_1JT5, M62096_PEA_l_T13 and M62096_PEA_l_T14. Table 665 below describes the starting and ending position of this segment on each transcript.
Table 665 - Segment location on transcripts
Segment cluster M62096_PEA_l_node_7 according to the present invention is supported by 19 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): M62096_PEA_l_T4, M62096_PEA_l_T5, M62096_PEA_l_T13 and M62096_PEA_l_T14. Table 666 below describes the starting and ending position of this segment on each transcript.
Table 666 - Segment location on transcripts
Segment cluster M62096_PEA_l_node_9 according to the present invention is supported by 18 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): M62096JPEA_l_T4, M62096_PEA_l_T5, M62096_PEA_l_T13 and M62096JPEA_l_T14. Table 667 below describes the starting and ending position of this segment on each transcrip t.
Table 667 - Segment location on transcripts
Segment cluster M62096_PEA_l_node_l 1 according to the present invention is supported by 22 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): M62096_PEA_l_T4, M62096_PEA_l_T5, M62096_PEA_l_T13 and M62096_PEA_l_T14. Table 668 below describes the starting and ending position of this segment on each transcript.
Table 668 - Segment location on transcripts
Segment cluster M62096_PEA_l_node_13 according to the present invention is supported by 24 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): M62096_PEA_l_T4, M62096JPEA_l_T5, M62096JPEA_l_T13 and M62096JPEA_l_T14. Table 669 below describes the starting and ending position of this segment on each transcript.
Table 669 - Segment location on transcripts
Segment cluster M62096_PEA_l_node_21 according to the present invention is supported by 33 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): M62096_PEA_l_T4, M62096JPEA_l_T5, M62096_PEA_l_T6, M62096_PEA_l_T7, M62096_PEA_l_T9, M62096_PEA_l_T13 and M62096_PEA_l_T14. Table 670 below describes the starting and ending position of this segment on each transcript.
Table 670 - Segment location on transcripts
Segment cluster M62096_PEA_l__node_25 according to the present invention is supported by 3 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): M62096_PEA_l_T5 and M62096_PEA_l_T9. Table 671 below describes the starting and ending position of this segment on each transcript.
Table 671 - Segment location on transcripts
Segment cluster M62096_PEA_l_node_33 according to the present invention is supported by 20 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): M62096_PEA_ l_T4, M62096_PEA_l_T5, M62096_PEA_l_T6, M62096_PEA_l_T7, M62096_PEA_l_T9, M62096_PEA_l_T13 and M62096_PEA_l_T14. Table 672 below describes the starting and ending position of this segment on each transcript.
Table 672 - Segment location on transcripts
Segment cluster M62096_PEA_l_node_42 according to the present invention is supported by 17 libraries. The number of libraries was deteπnined as previously described. This segment can be found in the following transcript(s): M62096_PEA_l_T4, M62096_PEA_l_T5, M62096_PEA_l_T6, M62096_PEA_l_T7, M62096_PEA_l_T9 and M62096_PEA_l_T13. Table 673 below describes the starting and ending position of this segment on each transcript.
Table 673 - Segment location on transcripts
Segment cluster M62096_PEA_l_node_44 according to the present invention is supported by 19 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): M62096_PEA_l_T4, M62096JPEA_l_T5, M62096_PEA_l_T6, M62096_PEA_l_T7, M62096_PEA_l_T9 and M62096_PEA_l_T13. Table 674 below describes the starting and ending position of this segment on each transcript.
Table 674 - Segment location on transcripts
Segment cluster M62096_PEA_l_node_47 according to the present invention is supported by 21 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): M62096_PEA_l_T4, M62096_PEA_l_T5, M62096_PEA_l_T6, M62096_PEA_l_T7, M62096_PEA_l_T9 andM62096_PEA_l_T13. Table 675 below describes the starting and ending position of this segment on each transcript.
Table 675 - Segment location on transcripts
Microarray (chip) data is also available for this segment as follows. As described above with regard to the cluster itself, various oligonucleotides were tested for being differentially expressed in various disease conditions, particularly cancer. The following oligonucleotides were found to hit this segment (in relation to lung cancer), shown in Table 676.
Table 676 - Oligonucleotides related to this segment
Segment cluster M62096_PEA_l_node_51 according to the present invention is supported by 11 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): M62096_PEA_l_T4, M62096_PEA_l_T5, M62096_PEA_l_T6, M62096_PEA_l_T7, M62096_PEA_l_T9, M62O96_PEA_1_T11 and M62096_PEA_l_T15. Table 677 below describes the starting and ending position of this segment on each transcript.
Table 677 - Segment location on transcripts
Segment cluster M62096_PEA_l_node_53 according to the present invention is supported by 10 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): M62096_PEA_l_T4, M62096_PEA_l_T5, M62096_PEA_l_T6, M62096_PEA_l_T7, M62096_PEA_l_T9, M62O96_PEA_1_T11 and M62096_PEA_l_T15. Table 678 below describes the starting and ending position of this segment on each transcript.
Table 678 - Segment location on transcripts
Segment cluster M62096_PEA_l_node_55 according to the present invention is supported by 9 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): M62096_PEA_l_T4, M62096_PEA_l_T5, M62096_PEA_l_T6, M62096_PEA_l_T7, M62096_PEA_l_T9, M62O96_PEA_1_T11 and M62096JPEA_l_T15. Table 679 below describes the starting and ending position of this segment on each transcript.
Table 679 - Segment location on transcripts
Segment cluster M62096_PEA_l_node_58 according to the present invention is supported by 9 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): M62096_PEA_l_T4, M62096JPEA_l_T5, M62096JPEAJ JT6, M62096_PEA_l_T7, M62096_PEA_l_T9 and M62O96_PEA_1_T11. Table 680 below describes the starting and ending position of this segment on each transcript.
Table 680 - Segment location on transcripts
Segment cluster M62096_PEA_l_node_62 according to the present invention is supported by 14 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): M62096_PEA_l_T4, M62096_PEA_l_T5, M62096_PEA_l_T6, M62096_PEAJ_T7, M62096_PEA_l_T9 and M62O96_PEA_1_T11. Table 681 below describes the starting and ending position of this segment on each transcript.
Table 681 - Segment location on transcripts
Segment cluster M62096_PEA_l_node_66 according to the present invention is supported by 23 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): M62096_PEA_l_T4, M62096_PEA_l_T5, M62096_PEA_l_T6, M62096JPEA_l_T7, M62096_PEA_l_T9 and M62O96_PEA_1_T11. Table 682 below describes the starting and ending position of this segment on each transcript.
Table 682 - Segment location on transcripts
Segment cluster M62096_PEA_l_node_67 according to the present invention can be found in the following transcript(s): M62096_PEA_l_T4, M62096_PEA_l_T5, M62096_PEA_l_T6, M62096_PEA_l_T7, M62096_PEA_l_T9 and M62O96_PEA_1_T11. Table 683 below describes the starting and ending position of this segment on each transcript.
Table 683 - Segment location on transcripts
Segment cluster M62096JPEA_l_node_68 according to the present invention can be found in the following transcript(s): M62096_PEA_l_T4, M62096_PEA_l_T5, M62096_PEA_l_T6, M62096_PEA_l_T7, M62096_PEA_l_T9 and M62O96_PEA_1_T11. Table 684below describes the starting and ending position of this segment on each transcript.
Table 684 - Segment location on transcripts
Segment cluster M62096_PEA_l_node_70 according to the present invention is supported by 55 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): M62096_PEA_l_T4, M62096_PEA_l_T5, M62096_PEA_l_T6, M62096_PEA_l_T7, M62096_PEA_l JT9 and M62O96_PEA_1_T11. Table 685 below describes the starting and ending position of this segment on each transcript. Table 685 - Segment location on transcripts
Variant protein alignment to the previously known protein:
Sequence name: KF5C_HϋMAN
Sequence documentation:
Alignment of: M62096_PEA_l_P4 x KF5C_HUMAN
Alignment segment 1/1:
Quality: 6936.00 Escore: 0
Matching length: 719 Total length: 719
Matching Percent Similarity: 100.00 Matching Percent Identity: 100.00
Total Percent Similarity: 100.00 Total Percent Identity: 100.00 Gaps : 0
74] Alignment :
7 VSKTGAEGAVLDEAKNINKSLSALGNVISALAEGTKTHVPYRDSKMTRIL 56
I I I I I I I I I I I I I I Il I I I I I Il I I I I I 1 I I I I I I I I I I I I I I I I I ! I I I 239 VSKTGAEGAVLDEAKNINKSLSALGNVISALAEGTKTHVPYRDSKMTRIL 288
57 QDSLGGNCRTTIVICCSPSVFNEAETKSTLMFGQRAKTIKNTVSVNLELT 106
I I I I I Il Il Il I I I I I I I Il I Il I I I I I I I I I Il I I I I I I I I I I I I I I I I
289 QDSLGGNCRTTIVICCSPSVFNEAETKSTLMFGQRAKTIKNTVSVNLELT 338 . . . . .
107 AEEWKKKYEKEKEKNKTLKNVIQHLEMELNRWRNGEAVPEDEQISAKDQK 156
I I Il I Il Il Il I I I I I I I I Il Il I I I Il I I I I I I I I Il I I I I I I I I I I I I
339 AEEWKKKYEKEKEKNKTLKNVIQHLEMELNRWRNGEAVPEDEQISAKDQK 388
157 NLEPCDNTPIIDNIAPWAGISTEEKEKYDEEISSLYRQLDDKDDEINQQ 206 I I I I I I I I 1 I I I I I I I I I I I I I I I I I Il I I I I I Il I Il I I I Il I I I I I I I
389 NLEPCDNTPIIDNIAPWAGISTEEKEKYDEEISSLYRQLDDKDDEINQQ 438
207 SQLAEKLKQQMLDQDELLASTRRDYEKIQEELTRLQIENEAAKDEVKEVL 256 M I I M M M I I I M I I I I I I I I I I M I I M I I I I M I I I I I I M M I I I
439 SQLAEKLKQQMLDQDELLASTRRDYEKIQEELTRLQIENEAAKDEVKEVL 488
257 QALEELAVNYDQKSQEVEDKTRANEQLTDELAQKTTTLTTTQRELSQLQE 306
M M M M Il I I I M Il I Il Il Il I M I Il Il I I I M Il M Il I M I I M 489 QALEELAVNYDQKSQEVEDKTRANEQLTDELAQKTTTLTTTQRELSQLQE 538
307 LSNHQKKRATEILNLLLKDLGEIGGIIGTNDVKTLADVNGVIEEEFTMAR 356
I Il M I I Il I I M I Il Il M I Il M I Il Il I M Il M I M Il I I Il I M I
539 LSNHQKKRATEILNLLLKDLGEIGGIIGTNDVKTLADVNGVIEEEFTMAR 588 . . . . .
357 LYISKMKSEVKSLVNRSKQLESAQMDSNRKMNASERELAACQLLISQHEA 406
1 I I I I I I I I I I I I I I I I I I I I I I 1 I I I I i I I I I I I I I I I I I I I I I I I I I I 589 LYISKMKSEVKSLVNRSKQLESAQMDSNRKMNASERELAACQLLISQHEA 638
407 KIKSLTDYMQNMEQKRRQLEESQDSLSEELAKLRAQEKMHEVSFQDKEKE 456 !1111!1IMIIIIIIIIIIIIIMIIIII]IIIIIIIIIIIIIII]II!
639 KIKSLTDYMQNMEQKRRQLEESQDSLSEELAKLRAQEKMHEVSFQDKEKE 688
457 HLTRLQDAEEMKKALEQQMESHREAHQKQLSRLRDEIEEKQKIIDEIRDL 506 I I Il I Il Il I I I Il Il I Il Il I I I Il I Il I Il I I Il I Il Il Il I Il I I I I 689 HLTRLQDAEEMKKALEQQMESHREAHQKQLSRLRDEIEEKQKIIDEIRDL 738
507 NQKLQLEQEKLSSDYNKLKIEDQEREMKLEKLLLLNDKREQAREDLKGLE 556
I M M I M M I I M M M M M I M I M M M M M M M M M M M M
739 NQKLQLEQEKLSSDYNKLKIEDQEREMKLEKLLLLNDKREQAREDLKGLE 788
557 ETVSRELQTLHNLRKLFVQDLTTRVKKSVELDNDDGGGSAAQKQKISFLE 606
789 ETVSRELQTLHNLRKLFVQDLTTRVKKSVELDNDDGGGSAAQKQKISFLE 838
607 NNLEQLTKVHKQLVRDNADLRCELPKLEKRLRATAERVKALESALKEAKE 656
I I I I Il I 1 I I I I I M I I M Il M I M M I Il M M I Il II Il I M M I M
839 NNLEQLTKVHKQLVRDNADLRCELPKLEKRLRATAERVKALESALKEAKE 888
657 NAMRDRKRYQQEVDRIKEAVRAKNMARRAHSAQIAKPIRPGHYPASSPTA 706 M M I I M Il M M M M M M I Il M M M I I I I Il M I Il I I M Il M
889 NAMRDRKRYQQEVDRIKEAVRAKNMARRAHSAQIAKPIRPGHYPASSPTA 938
707 VHAIRGGGGSSSNSTHYQK 725
I I Il I I I I I I Il I I I Il I I 939 VHAIRGGGGSSSNSTHYQK 957
Sequence name: KF5C_HUMAN
Sequence documentation:
Alignment of: M62096_PEA_l_P5 x KF5C_HUMAN
Alignment segment 1/1:
Quality: 6520.00 Escore: 0
Matching length: 674 Total length: 674
Matching Percent Similarity: 100.00 Matching Percent Identity: 100.00 Total Percent Similarity: 100.00 Total Percent Identity: 100.00
Gaps : 0
Alignment: . . . . .
1 MTRILQDSLGGNCRTTIVICCSPSVFNEAETKSTLMFGQRAKTIKNTVSV 50
I I I I I I I I I I I I I I Il I I I I I Il Il I Il I I I I Il I Il I Il I I I I I I I I I I 284 MTRILQDSLGGNCRTTIVICCSPSVFNEAETKSTLMFGQRAKTIKNTVSV 333
51 NLELTAEEWKKKYEKEKEKNKTLKNVIQHLEMELNRWRNGEAVPEDEQIS 100
334 NLELTAEEWKKKYEKEKEKNKTLKNVIQHLEMELNRWRNGEAVPEDEQIS 383
101 AKDQKNLEPCDNTPIIDNIAPVVAGISTEEKEKYDEEISSLYRQLDDKDD 150
I I I I I I I I I I I I I I ! 1 i I I I ! I I Il I I I I I I I I Il I I I I I I I I I I I I I I I 384 AKDQKNLEPCDNTPIIDNIAPVVAGISTEEKEKYDEEISSLYRQLDDKDD 433
151 EINQQSQLAEKLKQQMLDQDELLASTRRDYEKIQEELTRLQIENEAAKDE 200
M M I M I I I I I II M I M I M I I I I I I I I I M I I I I I I M I I I I I M I I
434 EINQQSQLAEKLKQQMLDQDELLASTRRDYEKIQEELTRLQIENEAAKDE 483 . . . . .
201 VKEVLQALEELAVNYDQKSQEVEDKTRANEQLTDELAQKTTTLTTTQREL 250
M I Il Il M I Il I I I M I I I M I M I I I M I I M Il M I I I I I I I Il I I I
484 VKEVLQALEELAVNYDQKSQEVEDKTRANEQLTDELAQKTTTLTTTQREL 533
251 SQLQELSNHQKKRATEILNLLLKDLGEIGGIIGTNDVKTLADVNGVIEEE 300
I Il I I I I I I I M I I I I M I I M I I M I I I I M I I I M I I Il Il I I M I I I
534 SQLQELSNHQKKRATEILNLLLKDLGEIGGIIGTNDVKTLADVNGVIEEE 583
301 FTMARLYISKMKSEVKSLVNRSKQLESAQMDSNRKMNASERELAACQLLI 350 I I Il I M M I I I I I I I I I I I I I I I M M I I I I M I I M M I I I I I M I I I
584 FTMARLYISKMKSEVKSLVNRSKQLESAQMDSNRKMNASERELAACQLLI 633
351 SQHEAKIKSLTDYMQNMEQKRRQLEESQDSLSEELAKLRAQEKMHEVSFQ 400
II I I M I I M I I M I M I I Il I M I I M M I I I I M M I M I M M I M I 634 SQHEAKIKSLTDYMQNMEQKRRQLEESQDSLSEELAKLRAQEKMHEVSFQ 683
401 DKEKEHLTRLQDAEEMKKALEQQMESHREAHQKQLSRLRDEIEEKQKIID 450
M I M I I M I I I M I M M M I I M I M I I M I M I M I I I I I I I M I M
684 DKEKEHLTRLQDAEEMKKALEQQMESHREAHQKQLSRLRDEIEEKQKIID 733 . . . . .
451 EIRDLNQKLQLEQEKLSSDYNKLKIEDQEREMKLEKLLLLNDKREQARED 500
I I I I I I I I I I I I I I I I I I I I 1 I I I I I I I I I I I I I I I I I I I 1 I I I I I I I I I 734 EIRDLNQKLQLEQEKLSSDYNKLKIEDQEREMKLEKLLLLNDKREQARED 783
501 LKGLEETVSRELQTLHNLRKLFVQDLTTRVKKSVELDNDDGGGSAAQKQK 550 I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I 1 I I I I I I I I I 1
784 LKGLEETVSRELQTLHNLRKLFVQDLTTRVKKSVELDNDDGGGSAAQKQK 833
551 ISFLENNLEQLTKVHKQLVRDNADLRCELPKLEKRLRATAERVKALESAL 600
I Il I I I I I I I I I I I I I I I I I I I 1 I I I I I I I I I I I i I I I I I I I I I I I I I I I 834 ISFLENNLEQLTKVHKQLVRDNADLRCELPKLEKRLRATAERVKALESAL 883
601 KEAKENAMRDRKRYQQEVDRIKEAVRAKNMARRAHSAQIAKPIRPGHYPA 650
I I I I I I I I Il I I I I Il I I Il I I I Il I I I Il I I I I I I I I I I I I I I I I I Il I
884 KEAKENAMRDRKRYQQEVDRIKEAVRAKNMARRAHSAQIAKPIRPGHYPA 933
651 SSPTAVHAIRGGGGSSSNSTHYQK 674
I Il I I I I I I I Il Il I Il Il I I I I I
934 SSPTAVHAIRGGGGSSSNSTHYQK 957
Sequence name: KF5C_HUMAN
Sequence documentation:
Alignment of: M62096_PEA_l_P3 x KF5CJBUMAN
Alignment segment 1/1:
Quality: 5726.00 Escore: 0
Matching length: 593 Total length: 593
Matching Percent Similarity: 100.00 Matching Percent Identity: 100.00
Total Percent Similarity: 100.00 Total Percent Identity: 100.00 Gaps: 0
Alignment :
1 MELNRWRNGEAVPEDEQISAKDQKNLEPCDNTPIIDNIAPVVAGISTEEK 50 I I I I I I I I I I I I I I I I I M ! Ml I I I I I I I I I I I I I I I I I I I I I I I I 1 I I
365 MELNRWRNGEAVPEDEQISAKDQKNLEPCDNTPIIDNIAPVVAGISTEEK 414
51 EKYDEEISSLYRQLDDKDDEINQQSQLAEKLKQQMLDQDELLASTRRDYE 100
Il I I I I I I I I 1 I Il I Il I Il Il I I I Il I I Il Il I I I I I I I I I Il I I I I I I 415 EKYDEEISSLYRQLDDKDDEINQQSQLAEKLKQQMLDQDELLASTRRDYE 464
101 KIQEELTRLQIENEAAKDEVKEVLQALEELAVNYDQKSQEVEDKTRANEQ 150
I I I I I I I I I I Il I Il I I I I I I Il I I I I Il I I I I Il I I I I I I I Il I I I I Il
465 KIQEELTRLQIENEAAKDEVKEVLQALEELAVNYDQKSQEVEDKTRANEQ 514 . . . . .
151 LTDELAQKTTTLTTTQRELSQLQELSNHQKKRATEILNLLLKDLGEIGGI 200
I I Il I Il I Il Il I I I I Il I I I I Il I I Il Il I I I I I I I I I Il I I I I I Il I I
515 LTDELAQKTTTLTTTQRELSQLQELSNHQKKRATEILNLLLKDLGEIGGI 564
201 IGTNDVKTLADVNGVIEEEFTMARLYISKMKSEVKSLVNRSKQLESAQMD 250
565 IGTNDVKTLADVNGVIEEEFTMARLYISKMKSEVKSLVNRSKQLESAQMD 614
251 SNRKMNASERELAACQLLISQHEAKIKSLTDYMQNMEQKRRQLEESQDSL 300
I I I I I I I I I I I I ! I I I I I 1 I I I I I I I I I I 1 I I I I Il I ! I I I I I I I I I I I I 615 SNRKMNASERELAACQLLISQHEAKIKSLTDYMQNMEQKRRQLEESQDSL 664
301 SEELAKLRAQEKMHEVSFQDKEKEHLTRLQDAEEMKKALEQQMESHREAH 350
I Il I I I I I I Il I I Il I I I Il I I I I I I Il I I I 1 Il I I I I I I Il I I I I I I Il
665 SEELAKLRAQEKMHEVSFQDKEKEHLTRLQDAEEMKKALEQQMESHREAH 714 . . . . .
351 QKQLSRLRDEIEEKQKIIDEIRDLNQKLQLEQEKLSSDYNKLKIEDQERE 400
I I I I I I I I I I Il Il I I Il I I I I I I I I I I I I I I I I I I I I I I I I I Il I Il I I
715 QKQLSRLRDEIEEKQKIIDEIRDLNQKLQLEQEKLSSDYNKLKIEDQERE 764
401 MKLEKLLLLNDKREQAREDLKGLEETVSRELQTLHNLRKLFVQDLTTRVK 450
I 1 I I I Il Il I Il I I I I I Il I Il I I I I I I I I I I I I I I I I I I I I I Il I I I I I
765 MKLEKLLLLNDKREQAREDLKGLEETVSRELQTLHNLRKLFVQDLTTRVK 814
451 KSVELDNDDGGGSAAQKQKISFLENNLEQLTKVHKQLVRDNADLRCELPK 500 I I I I I I M I Il I I I I I I I I M I M I I I I I I M I M I I I I I I I I I I I M I I
815 KSVELDNDDGGGSAAQKQKISFLENNLEQLTKVHKQLVRDNADLRCELPK 864
501 LEKRLRATAERVKALESALKEAKENAMRDRKRYQQEVDRIKEAVRAKNMA 550
I I I I I I I Il Il I I Il I Il Il I I I I I I I I I I I I Il I I I I I Il I I I I Il I I I 865 LEKRLRATAERVKALESALKEAKENAMRDRKRYQQEVDRIKEAVRAKNMA 914
551 RRAHSAQIAKPIRPGHYPASSPTAVHAIRGGGGSSSNSTHYQK 593
I I I I I I I I I Il I I I I I I I I I I I Il I I I I I Il I Il I I I I I Il Il
915 RRAHSAQIAKPIRPGHYPASSPTAVHAIRGGGGSSSNSTHYQK 957
Sequence name: KF5C_HUMAN
Sequence documentation:
Alignment of: M62096_PEA_l_P7 x KF5C_HUMAN
Alignment segment 1/1:
Quality: 2117.00 Escore: 0 Matching length: 220 Total length: 220
Matching Percent Similarity: 100.00 Matching Percent Identity: 100.00
Total Percent Similarity: 100.00 Total Percent Identity: 100.00
Gaps : 0
Alignment :
20 LNQKLQLEQEKLSSDYNKLKIEDQEREMKLEKLLLLNDKREQAREDLKGL 69
I Il I I I I Il I I I Il I Il I I I I I I I Il I Il I I I I I Il I Il Il I I I I Il I 1 I 738 LNQKLQLEQEKLSSDYNKLKIEDQEREMKLEKLLLLNDKREQAREDLKGL 787
70 EETVSRELQTLHNLRKLFVQDLTTRVKKSVELDNDDGGGSAAQKQKISFL 119 I I M I I I Il I I I M I I I I I Il I I I I M M I I I M I I I I I I I M M I I I I I
788 EETVSRELQTLHNLRKLFVQDLTTRVKKSVELDNDDGGGSAAQKQKISFL 837
120 ENNLEQLTKVHKQLVRDNADLRCELPKLEKRLRΆTΆERVKALESALKEAK 169
I I I I I I I I I I I I I I I I I I 1 I I I I I I I 1 I I I I I I I I I I I I I I I I I I I I I I I
838 ENNLEQLTKVHKQLVRDNADLRCELPKLEKRLRATAERVKALESALKEAK 887 . . . . .
170 ENAMRDRKRYQQEVDRIKEAVRAKNMARRAHSAQIAKPIRPGHYPASSPT 219
I I I I I I I I I I I I I I I Il I I I I I I I I i I I I I I i I I I I I I I I I I I I I I I I I I
888 ENAMRDRKRYQQEVDRIKEAVRAKNMARRAHSAQIAKPIRPGHYPASSPT 937
220 AVHAIRGGGGSSSNSTHYQK 239
I I I Il I I I I I I Il I I I I I I I
938 AVHAIRGGGGSSSNSTHYQK 957
Sequence name: KF5C_HUMAN
Sequence documentation:
Alignment of: M62096_PEA_l_P8 x KF5CJHUMAN
Alignment segment 1/1:
Quality: 7146.00 Escore: 0
Matching length: 737 Total length: 737
Matching Percent Similarity: 100.00 Matching Percent Identity: 99.86
Total Percent Similarity: 100.00 Total Percent Identity: 99.86 ' Gaps : 0
Alignment :
1 MADPAECSIKVMCRFRPLNEAEILRGDKFIPKFKGDETVVIGQGKPYVFD 50 I i I I I I I I I I I I I I 1 I I I I I I M I I I M I I I I I I I I I I I I I I I I I I I i M
1 MADPAECSIKVMCRFRPLNEAEILRGDKFIPKFKGDETVVIGQGKPYVFD 50
51 RVLPPNTTQEQVYNACAKQIVKDVLEGYNGTIFAYGQTSSGKTHTMEGKL 100
Il I I I I I I I I I I I I I I I I I I I I I I I I I I I I Il I I I I I I I I I I I I I I Il I I 51 RVLPPNTTQEQVYNACAKQIVKDVLEGYNGTIFAYGQTSSGKTHTMEGKL 100
101 HDPQLMGIIPRIAHDIFDHIYSMDENLEFHIKVSYFEIYLDKIRDLLDVS 150
I I Il I I I I I I I I I Il I I I I I Il I Il I I I I I I I I I I I I I I I I Il Il I I I I I
101 HDPQLMGIIPRIAHDIFDHIYSMDENLEFHIKVSYFEIYLDKIRDLLDVS 150 . . . . .
151 KTNLAVHEDKNRVPYVKGCTERFVSSPEEVMDVIDEGKANRHVAVTNMNE 200
I I I I I Il Il I I I I Il I Il Il I I Il I I I I I I I I I I I I I I I Il I I I I I Il I I
151 KTNLAVHEDKNRVPYVKGCTERFVSSPEEVMDVIDEGKANRHVAVTNMNE 200
201 HSSRSHSIFLINIKQENVETEKKLSGKLYLVDLAGSEKVSKTGAEGAVLD 250
I I I I Il I I I I I Il I Il I Il Il I I I I I Il I I I Il I I I I I I Il I I Il I I I Il 201 HSSRSHSIFLINIKQENVETEKKLSGKLYLVDLAGSEKVSKTGAEGAVLD 250
251 EAKNINKSLSALGNVISALAEGTKTHVPYRDSKMTRILQDSLGGNCRTTI 300 I I I I I I I I I I I I I I I I I I I I I I I I Il I I I I I I I I I I I I I I I I I I I I I I I I
251 EAKNINKSLSALGNVISALAEGTKTHVPYRDSKMTRILQDSLGGNCRTTI 300
301 VICCSPSVFNEAETKSTLMFGQRAKTIKNTVSVNLELTAEEWKKKYEKEK 350
I I I I I I I I I I 1 I I I I I I I I I I I I I 1 I I I I I I I I I I I 1 I I I I I Il I i I I I I
301 VICCSPSVFNEAETKSTLMFGQRAKTIKNTVSVNLELTAEEWKKKYEKEK 350 . . . . .
351 EKNKTLKNVIQHLEMELNRWRNGEAVPEDEQISAKDQKNLEPCDNTPIID 400
I I I I I I I I I I I 1 I I 1 Il I Il I I I I Il I Il I I I I I I I I I I I I I Il I I I 1 I 1
351 EKNKTLKNVIQHLEMELNRWRNGEAVPEDEQISAKDQKNLEPCDNTPIID 400
401 NIAPVVAGISTEEKEKYDEEISSLYRQLDDKDDEINQQSQLAEKLKQQML 450
Il Il I I I I I I I I I I I I 1 I I Il I I I I I I I I I I I Il I I 1 I I I I I I I I I I I Il
401 NIAPVVAGISTEEKEKYDEEISSLYRQLDDKDDEINQQSQLAEKLKQQML 450
451 DQDELLASTRRDYEKIQEELTRLQIENEAAKDEVKEVLQALEELAVNYDQ 500 IM I I I I I I I I I I I I I I I I I I I ] I I I I I I I I I I I I I I I I I I Il I I 1 M I
451 DQDELLASTRRDYEKIQEELTRLQIENEAAKDEVKEVLQALEELAVNYDQ 500
501 KSQEVEDKTRANEQLTDELAQKTTTLTTTQRELSQLQELSNHQKKRATEI 550
I 1 I I I I 1 I I M I I I I I I I 1 I I Il I Il I I I I I I I I Il I I 1 I I I I I I I I I I I 501 KSQEVEDKTRANEQLTDELAQKTTTLTTTQRELSQLQELSNHQKKRATEI 550
551 LNLLLKDLGEIGGIIGTNDVKTLADVNGVIEEEFTMARLYISKMKSEVKS 600
I I I I 1 I I I Il I I I I I I I I I I I I I I I I I I I I I I I I Il Il I I I 1 Il I I I I I I
551 LNLLLKDLGEIGGIIGTNDVKTLADVNGVIEEEFTMARLYISKMKSEVKS 600 . . . . .
601 LVNRSKQLESAQMDSNRKMNASERELAACQLLISQHEAKIKSLTDYMQNM 650
I I I I I I I I I I Il I I I I Il I Il I I I 1 I Il I I I I I I I I I I I I I I I I I Il Il I
601 LVNRSKQLESAQMDSNRKMNASERELAACQLLISQHEAKIKSLTDYMQNM 650
651 EQKRRQLEESQDSLSEELAKLRAQEKMHEVSFQDKEKEHLTRLQDAEEMK 700
651 EQKRRQLEESQDSLSEELAKLRAQEKMHEVSFQDKEKEHLTRLQDAEEMK 700
701 KALEQQMESHREAHQKQLSRLRDEIEEKQKIIDEIRE 737
I i I I I I I I 1 I I 1 Il i I I I I 11 I I I Il I I I I ! I I I I I : 701 KALEQQMESHREAHQKQLSRLRDEIEEKQKIIDEIRD 737
Sequence name: KF5C_HUMAN
Sequence documentation:
Alignment of: M62096_PEA_l_P9 x KF5C_HϋMAN
Alignment segment 1/1:
Quality: 4434.00
Escore: 0
Matching length: 454 Total length: 454
Matching Percent Similarity: 100.00 Matching Percent Identity: 100.00
Total Percent Similarity: 100.00 Total Percent Identity: 100.00
Gaps : 0
Alignment:
1 MADPAECS IKVMCRFRPLNEAEILRGDKFI PKFKGDETVVIGQGKPYVFD 50
I I I I I I 1 I I I I I I I I I I I I I I I I I I I I I I I I I i I I I I I I I I I Il I I I I I I
1 MADPAECSIKVMCRFRPLNEAEILRGDKFIPKFKGDETVVIGQGKPYVFD 50
51 RVLPPNTTQEQVYNACAKQIVKDVLEGYNGTIFAYGQTSSGKTHTMEGKL 100
M I I M M I I M I I I I I I M I M I I M I I M I M M I I I I I I II M I I M
51 RVLPPNTTQEQVYNACAKQIVKDVLEGYNGTIFAYGQTSSGKTHTMEGKL 100
101 HDPQLMGIIPRIAHDIFDHIYSMDENLEFHIKVSYFEIYLDKIRDLLDVS 150 I I I I I I M I I I I Il I Il I Il I Il I I I I I Il I Il Il I I I I I I I Il Il I Il I
101 HDPQLMGIIPRIAHDIFDHIYSMDENLEFHIKVSYFEIYLDKIRDLLDVS 150
151 KTNLAVHEDKNRVPYVKGCTERFVSSPEEVMDVIDEGKANRHVAVTNMNE 200
I I I I M I I I I I I I I M M I I I M M I M I M M I I I I I M I I Il I I I I M 151 KTNLAVHEDKNRVPYVKGCTERFVSSPEEVMDVIDEGKANRHVAVTNMNE 200
201 HSSRSHSIFLINIKQENVETEKKLSGKLYLVDLAGSEKVSKTGAEGAVLD 250
I I I I I I I I Il I I I I I I I I I M I I Il Il I Il I I I M M I I I I I MM M I I
201 HSSRSHSIFLINIKQENVETEKKLSGKLYLVDLAGSEKVSKTGAEGAVLD 250 . . . . .
251 EAKNINKSLSALGNVISALAEGTKTHVPYRDSKMTRILQDSLGGNCRTTI 300
M M I I I I I I I I I I I Il I I I I I I I I I M M I I I M I I I I M I III I I I I I
251 EAKNINKSLSALGNVISALAEGTKTHVPYRDSKMTRILQDSLGGNCRTTI 300
301 VICCSPSVFNEAETKSTLMFGQRAKTIKNTVSVNLELTAEEWKKKYEKEK 350
I I I I I I I I M I I I I I M M I I I I I I I I I Il I I I M I I I I I Il MM I I I I
301 VICCSPSVFNEAETKSTLMFGQRAKTIKNTVSVNLELTAEEWKKKYEKEK 350
351 EKNKTLKNVIQHLEMELNRWRNGEAVPEDEQISAKDQKNLEPCDNTPIID 400 Il I I I I I I I I I I M I I I I Il I I I I I Il M Il M I I Il I I Il I 111 M I M
351 EKNKTLKNVIQHLEMELNRWRNGEAVPEDEQISAKDQKNLEPCDNTPIID 400
401 NIAPVVAGISTEEKEKYDEEISSLYRQLDDKDDEINQQSQLAEKLKQQML 450
I I I I I i I 1 I I I I I I I I I I I i I I I I I I I I I I I I I I 11 I I I I i I I I I I I 1 I I
401 NIAPVVAGISTEEKEKYDEEISSLYRQLDDKDDEINQQSQLAEKLKQQML 450
451 DQDE 454
III! 451 DQDE 454
Sequence name: KF5CJΪUMAN
Sequence documentation:
Alignment of: M62096_PEA_l_P10 x KF5C_HUMAN
Alignment segment 1/1:
Quality: 747 .00
Escore : 0
Matching length: 78 Total length: 78
Matching Percent Similarity: 100.00 Matching Percent Identity: 100.00
Total Percent Similarity: 100.00 Total Percent Identity: 100.00
Gaps : 0
Alignment :
20 LNQKLQLEQEKLSSDYNKLKIEDQEREMKLEKLLLLNDKREQAREDLKGL 69 I I i I I I I 1 I I I I I I I I Il I 1 I I I I I I I I I I I I I I I I I Il I I I I 1 I I I I M
738 LNQKLQLEQEKLSSDYNKLKIEDQEREMKLEKLLLLNDKREQAREDLKGL 787
70 EETVSRELQTLHNLRKLFVQDLTTRVKK 97
I M M I I M I I M I M M M M M I I U 788 EETVSRELQTLHNLRKLFVQDLTTRVKK 815
Sequence name: KF5C_HUMAN
Sequence documentation:
Alignment of: M62O96_PEA_1_P11 x KF5C_HUMAN
Alignment segment 1/1:
Quality: 3634.00
Escore: 0
Matching length: 372 Total length: 372
Matching Percent Similarity: 100.00 Matching Percent Identity: 100.00
Total Percent Similarity: 100.00 Total Percent Identity: 100.00
Gaps : 0
Alignment:
1 MADPAECSIKVMCRFRPLNEAEILRGDKFIPKFKGDETVVIGQGKPYVFD 50
I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I i I I I I I I I I I I I I
1 MADPAECSIKVMCRFRPLNEAEILRGDKFIPKFKGDETVVIGQGKPYVFD 50 . . . . .
51 RVLPPNTTQEQVYNACAKQIVKDVLEGYNGTIFAYGQTSSGKTHTMEGKL 100
M M III Ii I I I I I I I II I IMII I II I I I IIM I I I I I I I IIIM I U I
51 RVLPPNTTQEQVYNACAKQIVKDVLEGYNGTIFAYGQTSSGKTHTMEGKL 100-
101 HDPQLMGIIPRIAHDIFDHIYSMDENLEFHIKVSYFEIYLDKIRDLLDVS 150
I I I M Il I M M I M I M I M I M M M I M Il M III M I I M M M M
101 HDPQLMGIIPRIAHDIFDHIYSMDENLEFHIKVSYFEIYLDKIRDLLDVS 150
151 KTNLAVHEDKNRVPYVKGCTERFVSSPEEVMDVIDEGKANRHVAVTNMNE 200 I M M I M M M I M M M M M M I M M M M M M I M I M IM I M
151 KTNLAVHEDKNRVPYVKGCTERFVSSPEEVMDVIDEGKANRHVAVTNMNE 200
201 HSSRSHSIFLINIKQENVETEKKLSGKLYLVDLAGSEKVSKTGAEGAVLD 250
M M M Il Il M I M Il I I M I M I I M M I Il I M I I M Il I I M M M 201 HSSRSHSIFLINIKQENVETEKKLSGKLYLVDLAGSEKVSKTGAEGAVLD 250
251 EAKNINKSLSALGNVISALAEGTKTHVPYRDSKMTRILQDSLGGNCRTTI 300
I I M Il Il M Il Il M I M I M I I I M M M I I I I M M M M M I I I M
251 EAKNINKSLSALGNVISALAEGTKTHVPYRDSKMTRILQDSLGGNCRTTI 300 . . . . .
301 VICCSPSVFNEAETKSTLMFGQRAKTIKNTVSVNLELTAEEWKKKYEKEK 350
301 VICCSPSVFNEAETKSTLMFGQRAKTIKNTVSVNLELTAEEWKKKYEKEK 350
351 EKNKTLKNVIQHLEMELNRWRN 372
351 EKNKTLKNVIQHLEMELNRWRN 372
Sequence name: KF5C_HUMAN
Sequence documentation:
Alignment of: M62096 PEA 1 P12 x KF5C HUMAN
Alignment segment 1/1:
Quality: 3145.00
Escore: 0
Matching length: 323 Total length: 323 Matching Percent Similarity: 100.00 Matching Percent Identity: 100.00
Total Percent Similarity: 100.00 Total Percent Identity: 100.00
Gaps : 0
Alignment :
1 MADPAECSIKVMCRFRPLNEAEILRGDKFIPKFKGDETVVIGQGKPYVFD 50
I 1 I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I 1 I I I I I I I I I I
1 MADPAECSIKVMCRFRPLNEAEILRGDKFIPKFKGDETVVIGQGKPYVFD 50 . . . . .
51 RVLPPNTTQEQVYNACAKQIVKDVLEGYNGTIFAYGQTSSGKTHTMEGKL 100
I I I I I I I I I I I I I Il Il I I I I I I i I I I I I I I I I I I I 1 I I I I I I I I I Il I I
51 RVLPPNTTQEQVYNACAKQIVKDVLEGYNGTIFAYGQTSSGKTHTMEGKL 100
101 HDPQLMGIIPRIAHDIFDHIYSMDENLEFHIKVSYFEIYLDKIRDLLDVS 150
I Il I I Il I 1 I I I I Il I I I I I I I 1 I I I I I 1 I I I I I I I I I Il I I I I I I I I I I
101 HDPQLMGIIPRIAHDIFDHIYSMDENLEFHIKVSYFEIYLDKIRDLLDVS 150
151 KTNLAVHEDKNRVPYVKGCTERFVSSPEEVMDVIDEGKANRHVAVTNMNE 200 I I I I I I I I I I I I I I I I M I I M 1 M I M I I I I I I I I I M I 1 I M I 1 I I M
151 KTNLAVHEDKNRVPYVKGCTERFVSSPEEVMDVIDEGKANRHVAVTNMNE 200
201 HSSRSHSIFLINIKQENVETEKKLSGKLYLVDLAGSEKVSKTGAEGAVLD 250
I I I I I I Il Il I Il I I Il Il I I I Il Il I I I I Il Il I I I I I Il I I I I I I I I I 201 HSSRSHSIFLINIKQENVETEKKLSGKLYLVDLAGSEKVSKTGAEGAVLD 250
251 EAKNINKSLSALGNVISALAEGTKTHVPYRDSKMTRILQDSLGGNCRTTI 300
II I I Il I I Il I Il I Il I I Il Il t I I Il I I I Il I I I I I I Il Il Il I Il Il I
251 EAKNINKSLSALGNVISALAEGTKTHVPYRDSKMTRILQDSLGGNCRTTI 300
301 VICCSPSVFNEAETKSTLMFGQR 323
I I I I I I Il I I I I I I I I I I I Il Il 301 VICCSPSVFNEAETKSTLMFGQR 323
Expression o/Homo sapiens protein tyrosine phosphatase, receptor type, S (PTPRS) M62069 transcripts which are detectable by amplicon as depicted in sequence name M62069 segl9 in normal and cancerous lung tissues
Expression of Homo sapiens protein tyrosine phosphatase, receptor type, S (PTPRS) transcripts detectable by or according to segl9, M62069 segl9 amplicon (SEQ ID NO: 1657) and M62069 segl9F (SEQ ID NO: 1655) and M62069 segl9R (SEQ ID NO: 1656) primers was measured by real time PCR. In parallel the expression of four housekeeping genes -PBGD (GenBank Accession No. BC019323; amplicon - PBGD- amplicon, SEQ ID NO:334), HPRTl (GenBank Accession No. NM_000194; amplicon - HPRTl -amplicon, SEQ ID NO:1297), Ubiquitin (GenBank Accession No. BC000449; amplicon - Ubiquitin-amplicon, SEQ ID NO:328) and SDHA (GenBank Accession No. NM_004168; amplicon - SDHA-amplicon, SEQ ID NO:331), was measured similarly. For each RT sample, the expression of the above amplicon was normalized to the geometric mean of the quantities of the housekeeping genes. The normalized quantity of each RT sample was then divided by the median of the quantities of the normal post-mortem (PM) samples (Sample Nos. 47-50, 90-93, 96-99, Table 2, above), to obtain a value of fold up -regulation for each sample relative to median of the normal PM samples.
Figure 65 is a histogram showing over expression of the above- indicated Homo sapiens protein tyrosine phosphatase, receptor type, S (PTPRS) transcripts in cancerous lung samples relative to the normal samples. Values represent the average of duplicate experiments. Error bars indicate the minimal and maximal values obtained.
As is evident from Figure 65, the expression of Homo sapiens protein tyrosine phosphatase, receptor type, S (PTPRS) transcripts detectable by the above amplicon(s) in cancer samples was significantly higher than in the non-cancerous samples (Sample Nos. 47-50, 90-93, 96-99 Table 2). Notably an over- expression of at least 5 fold was found in 2 out of 15 adenocarcinoma samples, and in 8 out of 8 small cells carcinoma samples.
Primer pairs are also optionally and preferably encompassed within the present invention; for example, for the above experiment, the following primer pair was used as a non- limiting illustrative example only of a suitable primer pair: M62069 segl9F forward primer; and M62069 segl9R reverse primer. The present invention also preferably encompasses any amplicon obtained through the use of any suitable primer pair; for example, for the above experiment, the following amplicon was obtained as a non- limiting illustrative example only of a suitable amplicon: M62069 segl9.
Forward primer -M62069 segl9F (SEQ ID NO: 1655): GCTGATTGTCCCCATGAAGG Reverse primer- M62069 segl9 (SEQ ID NO: 1656): TGGCATACGGGAACTCAGTG
Amplicon (SEQ ID NO: 1657):
GCTGATTGTCCCCATGAAGGCCAGCCTTGAAGCTTGGTCAGTCTCCCTAACTGTATG ATTGATCCCCACTTATTGCACTACATCACTGAGTTCCCGTATGC
Expression o/Homo sapiens protein tyrosine phosphatase, receptor type, S (PTPRS) M62069 transcripts which are detectable by amplicon as depicted in sequence name M62069 seg29 in normal and cancerous lung tissues
Expression of Homo sapiens protein tyrosine phosphatase, receptor type, S (PTPRS) transcripts detectable by or according to seg29, M62069 seg29 amplicon (SEQ ID NO: 1660) and M62069 seg29F (SEQ ID NO: 1658) and M62069 seg29R (SEQ ID NO: 1659) primers was measured by real time PCR. In parallel the expression of four housekeeping genes -PBGD (GenBank Accession No. BC019323; amplicon - PBGD-amplicon, SEQ ID NO:334), HPRTl (GenBank Accession No. NM_000194; amplicon - HPRTl -amplicon, SEQ ID NO:1297), Ubiquitin (GenBank Accession No. BC000449; amplicon - Ubiquitin- amplicon, SEQ ID NO:328) and SDHA (GenBank Accession No. NM_004168; amplicon - SDHA-amplicon, SEQ ID NO:331), was measured similarly. For each RT sample, the expression of the above amplicon was normalized to the geometric mean of the quantities of the housekeeping genes. The normalized quantity of each RT sample was then divided by the median of the quantities of
the normal post-mortem (PM) samples (Sample Nos. 47-50, 90-93, 96-99, Table 2, above), to obtain a value of fold up -regulation for each sample relative to median of the normal PM samples.
Figure 66 is a histogram showing over expression of the above- indicated Homo sapiens protein tyrosine phosphatase, receptor type, S (PTPRS) transcripts in cancerous lung samples relative to the normal samples. Values represent the average of duplicate experiments. Error bars indicate the minimal and maximal values obtained.
As is evident from Figure 66, the expression of Homo sapiens protein tyrosine phosphatase, receptor type, S (PTPRS) transcripts detectable by the above amplicon(s) in cancer samples was significantly higher than in the non-cancerous samples (Sample Nos. 47-50, 90-93,
96-99 Table 2). Notably an over- expression of at least 5 fold was found in 2 out of 15 adenocarcinoma samples, and in 7 out of 8 small cells carcinoma samples.
Primer pairs are also optionally and preferably encompassed within the present invention; for example, for the above experiment, the following primer pair was used as a non- limiting illustrative example only of a suitable primer pair: M62069 seg29F forward primer; and M62069 seg29R reverse primer.
The present invention also preferably encompasses any amplicon obtained through the use of any suitable primer pair; for example, for the above experiment, the following amplicon was obtained as a non- limiting illustrative example only of a suitable amplicon: M62069 seg29. Forward primer -M62069 seg29F: ATTGAATAATTCAGCACCTGAGGC Reverse primer- M62069 seg29R: TTCATATGGCTACTCCCCACCT Amplicon:
ATTGAATAATTCAGCACCTGAGGCTGGTGGATGATTCTTTGCAATTTGGCAGGAATG GGAGAGTCGGGAGCAGTAGTTGGCAAGGTGGGGAGTAGCCATATGAA
DESCRIPTION FOR CLUSTER M78076
Cluster M78076 features 9 transcript(s) and 35 segment(s) of interest, the names for which are given in Tables 686 and 687, respectively, the sequences themselves are given at the end of the application. The selected protein variants are given in table 688.
Table 686 - Transcripts of interest
Table 688 - Proteins of interest
These sequences are variants of the known protein Amyloid- like protein 1 precursor (SwissProt accession identifier APP IJHPLJMAN; known also according to the synonyms APLP; APLP-I), SEQ ID NO: 1439, referred to herein as the previously known protein. Protein Amyloid- like protein 1 precursor is known or believed to have the following function(s): May play a role in postsynaptic function. The C-terminal gamma-secretase processed fragment, ALIDl, activates transcription activation through APBBl (Fe65) binding (By similarity). Couples to JIP signal transduction through C-teπninal binding. May interact with cellular G-protein signaling pathways. Can regulate neurite outgrowth through binding to components of the extracellular matrix such as heparin and collagen I. The gamma-CTF peptide, C30, is a potent enhancer of neuronal apoptosis (By similarity). The sequence for protein Amyloid- like protein 1 precursor is given at the end of the application, as "Amyloid- like protein 1 precursor amino acid sequence". Known polymorphisms for this sequence are as shown in Table 689. Table 689 - Amino acid mutations for Known Protein
Protein Amyloid- like protein 1 precursor localization is believed to be Type I membrane protein. C-terminally processed in the Golgi complex.
The following GO Annotation(s) apply to the previously known protein. The following annotation(s) were found: endocytosis; apoptosis; cell adhesion; neurogenesis; cell death, which
are annotation(s) related to Biological Process; protein binding; heparin binding, which are annotation(s) related to Molecular Functio n; and basement membrane; coated pit; integral membrane protein, which are annotation(s) related to Cellular Component.
The GO assignment relies on information from one or more of the SwissProt/TremBl Protein knowledgebase, available from <http://www.expasy.ch/sprot/>; or Locuslink, available from <http://www.ncbi.nlm.nih.gov/projects/LocusLink/>.
As noted above, cluster M78076 features 9 transcript(s), which were listed in Table 1 above. These transcript(s) encode for protein(s) which are variant(s) of protein Amyloid- like protein 1 precursor. A description of each variant protein according to the present invention is now provided.
Variant protein M78076_PEA_l_P3 according to the present invention has an amino acid sequence as given at the end of the application; it is encoded by transcript(s) M78076_PEA_l_T2. An alignment is given to the known protein (Amyloid- like protein 1 precursor) at the end of the application. One or more alignments to one or more previously published protein sequences are given at the end of the application. A brief description of the relationship of the variant protein according to the present invention to each such aligned protein is as follows:
Comparison report between M78076_PEA_l_P3 and APP1_HUMAN: 1.An isolated chimeric polypeptide encoding for M78076_PEA_l_P3, comprising a first amino acid sequence being at least 90 % homologous to
MGPASPAARGLSRJRPGQPPLPLLLPLLLLLLRAQPAIGSLAGGSPGAAEAPGSAQVAGL CGRLTLHRDLRTGRWEPDPQRSRRCLRDPQRVLEYCRQMYPELQIARVEQATQAIPME RWCGGSRSGSCAHPHHQVVPFRCLPGEFVSEALLVPEGCRFLHQERMDQCESSTRRHQ EAQEACSSQGLILHGSGMLLPCGSDRFRGVEYVCCPPPGTPDPSGTAVGDPSTRSWPPG SRVEGAEDEEEEESFPQPVDDYFVEPPQAEEEEETVPPPSSHTLAVVGKVTPTPRPTDGV DIYFGMPGEISEHEGFLRAKMDLEERRMRQINEVMREWAMADNQSKNLPKADRQALN EHFQSILQTLEEQVSGERQRLVETHATRVIALINDQRRAALEGFLAALQADPPQAERVLL ALRRYLRAEQKEQRHTLRHYQHVAAVDPEKAQQMRFQVHTHLQVIEERVNQSLGLLD QNPHLAQELRPQIQELLHSEHLGPSELEAPAPGGSSEDKGGLQPPDSKD corresponding to amino acids 1 - 517 of APP1_HUMAN, which also corresponds to amino acids 1 - 517 of
M78076JPEA_l_P3, and a second amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence GE corresponding to amino acids 518 - 519 of M78076_PEA_l JP3, wherein said first amino acid sequence and second amino acid sequence are contiguous and in a sequential order.
The location of the variant protein was determined according to results from a number of different software programs and analyses, including analyses from SignalP and other specialized programs. The variant protein is believed to be located as follows with regard to the cell: secreted. The protein localization is believed to be secreted because both signal-peptide prediction programs predict that this protein has a signal peptide, and neither trans -membrane region prediction program predicts that this protein has a trans -membrane region.
Variant protein M78076_PEA_l_P3 also has the following non-silent SNPs (Single Nucleotide Polymorphisms) as listed in Table 690, (given according to their position(s) on the amino acid sequence, with the alternative amino acid(s) listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein M78076_PEA_l_P3 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 690 - Amino acid mutations
The glycosylation sites of variant protein M78076_PEA_l_P3, as compared to the known protein Amyloid- like protein 1 precursor, are described in Table 691 (given according to their position(s) on the amino acid sequence in the first column; the second column indicates whether the glycosylation site is present in the variant protein; and the last column indicates whether the position is different on the variant protein).
Table 691- Glycosylation site(s)
Variant protein M78076_PEA_l_P3 is encoded by the following transcript(s): M78076_PEA_l_T2, for which the sequence(s) is/are given at the end of the application. The coding portion of transcript M78076_PEA_l_T2 is shown in bold; this coding portion starts at position 142 and ends at position 1698. The transcript also has the following SNPs as listed in Table 692 (given according to their position on the nucleotide sequence, with the alternative nucleic acid listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein M78076_PEA_l_P3 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 692 - Nucleic acid SNPs
Variant protein M78076_PEA_l_P4 according to the present invention has an amino acid sequence as given at the end of the application; it is encoded by transcript(s) M78076_PEA_l_T3. An alignment is given to the known protein (Amyloid- like protein 1 precursor) at the end of the application. One or more alignments to one or more previously published protein sequences are given at the end of the application. A brief description of the relationship of the variant protein according to the present invention to each such aligned protein is as follows: Comparison report between M78076_PEA_l_P4 and APPIJΪUMAN:
1.An isolated chimeric polypeptide encoding for M78076_PEA_l_P4, comprising a first amino acid sequence being at least 90 % homologous to
MGPASPAARGLSRRPGQPPLPLLLPLLLLLLRAQPAIGSLAGGSPGAAEAPGSAQVAGL CGRLTLHRDLRTGRWEPDPQRSRRCLRDPQRVLEYCRQMYPELQIARVEQATQAIPME RWCGGSRSGSCAHPHHQVVPFRCLPGEFVSEALLVPEGCRFLHQERMDQCESSTRRHQ EAQEACSSQGLILHGSGMLLPCGSDRFRGVEYVCCPPPGTPDPSGTA VGDPSTRSWPPG SRVEGAEDEEEEESFPQPVDDYFVEPPQAEEEEETVPPPSSHTLAVVGKVTPTPRPTDGV DIYFGMPGEISEHEGFLRAKMDLEERRMRQΓNEVMREWAMADNQSKNLPKADRQALN EHFQSILQTLEEQVSGERQRLVETHATRVIALINDQRRAALEGFLAALQADPPQAERVLL ALRRYLRAEQKEQRHTLRHYQHVAAVDPEKAQQMRFQVHTHLQVIEERVNQSLGLLD QNPHLAQELRPQIQELLHSEHLGPSELEAPAPGGSSEDKGGLQPPDSKDDTPMTLPKG corresponding to amino acids 1 - 526 of APP IJHUMAN, which also corresponds to amino acids 1 - 526 of M78076_PEA_l_P4, and a second amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence
ECLTVNPSLQIPLNP corresponding to amino acids 527 - 541 of M78076_PEA_l_P4, wherein said first amino acid sequence and second amino acid sequence are contiguous and in a sequential order.
2.An isolated polypeptide encoding for a tail of M78076_PEA_l_P4, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%,
more preferably at least about 90% and most preferably at least about 95% homologous to the sequence ECLTVNPSLQIPLNP in M78076_PEA_l_P4.
The location of the variant protein was determined according to results from a number of different software programs and analyses, including analyses from SignalP and other specialized programs. The variant protein is believed to be located as follows with regard to the cell: secreted. The protein localization is believed to be secreted because both signal-peptide prediction programs predict that this protein has a signal peptide, and neither trans -membrane region prediction program predicts that this protein has a trans -membrane region. Variant protein M78076_PEA_l_P4 also has the following non-silent SNPs (Single
Nucleotide Polymorphisms) as listed in Table 693, (given according to their position(s) on the amino acid sequence, with the alternative amino acid(s) listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein M78076_PEA_l_P4 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 693 -Amino acid mutations
The glycosylation sites of variant protein M78076_PEA_l_P4, as compared to the known protein Amyloid- like protein 1 precursor, are described in Table 694(grven according to their position(s) on the amino acid sequence in the first column; the second column indicates whether the glycosylation site is present in the variant protein; and the last column indicates whether the position is different on the variant protein).
Table 694 - Glycosylation site(s)
Variant protein M78076_PEA_l_P4 is encoded by the following transcript(s): M78076_PEA_l_T3, for which the sequence(s) is/are given at the end of the application. The coding portion of transcript M78076_PEA_l_T3 is shown in bold; this coding portion starts at position 142 and ends at position 1764. The transcript also has the following SNPs as listed in Table 695 (given according to their position on the nucleotide sequence, with the alternative nucleic acid listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein M78076_PEA_l_P4 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 695 - Nucleic acid SNPs
Variant protein M78076_PEA_l_P12 according to the present invention has an amino acid sequence as given at the end of the application; it is encoded by transcript(s) M78076_PEA_l_T13. An alignment is given to the known protein (Amyloid- like protein 1 precursor) at the end of the application. One or more alignments to one or more previously published protein sequences are given at the end of the application. A brief description of the relationship of the variant protein according to the present invention to each such aligned protein is as follows:
Comparison report between M78076_PEA_l_P12 and APP1_HUMAN: 1.An isolated chimeric polypeptide encoding for M78076_PEA_l_P12, comprising a first amino acid sequence being at least 90 % homologous to
MGPASPAARGLSRRPGQPPLPLLLPLLLLLLRAQPAIGSLAGGSPGAAEAPGSAQVAGL CGRLTLHRDLRTGRWEPDPQRS RPVCLRDPQRVLEYCRQMYPELQIARVEQATQAIPME RWCGGSRSGSCAHPHHQVVPFRCLPGEFVSEALLVPEGCRFLHQERMDQCESSTRRHQ EAQEACSSQGLILHGSGMLLPCGSDRFRGVEYVCCPPPGTPDPSGTAVGDPSTRSWPPG SRVEGAEDEEEEESFPQPVDDYFVEPPQAEEEEETVPPPSSHTLAVVGKVTPTPRPTDGV DΓYFGMPGEISEHEGFLRAKMDLEERRMRQINEVMREWAMADNQSKNLPKADRQALN EHFQSILQTLEEQVSGERQRLVETHATRVIALINDQRRAALEGFLAALQADPPQAERVLL ALRRYLRAEQKEQRHTLRHYQHVAAVDPEKAQQMRFQVHTHLQVIEERVNQSLGLLD QNPHLAQELRPQIQELLHSEHLGPSELEAPAPGGSSEDKGGLQPPDSKDDTPMTLPKG corresponding to amino acids 1 - 526 of APP IJHUMAN, which also corresponds to amino acids 1 - 526 of M78076_PEA_l_P12, and a second amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence ECVCSKGFPFPLIGDSEG corresponding to amino acids 527 - 544 of M78076_PEA_l_P12, wherein said first amino acid sequence and second amino acid sequence are contiguous and in a sequential order.
2.An isolated polypeptide encoding for a tail of M78076_PEA_l_P12, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence ECVCSKGFPFPLIGDSEG in M78076_PEA_l_P12.
The location of the variant protein was determined according to results from a number of different software programs and analyses, including analyses from SignalP and other specialized programs. The variant protein is believed to be located as follows with regard to the cell: secreted. The protein localization is believed to be secreted because both signal-peptide prediction programs predict that this protein has a signal peptide, and neither trans -membrane region prediction program predicts that this protein has a trans -membrane region.
Variant protein M78076_PEA_l_P12 also has the following non-silent SNPs (Single Nucleotide Polymorphisms) as listed in Table 696, (given according to their position(s) on the amino acid sequence, with the alternative amino acid(s) listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein M78076_PEA_l_P12 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 696 - Amino acid mutations
The glycosylation sites of variant protein M78076_PEA_l_P12, as compared to the known protein Amyloid- like protein 1 precursor, are described in Table 697 (given according to their position(s) on the amino acid sequence in the first column; the second column indicates whether the glycosylation site is present in the variant protein; and the last column indicates whether the position is different on the variant protein).
Table 697- Glycosylation site(s)
Variant protein M78076_PEA_l_P12 is encoded by the following transcript(s): M78076_PEA_l_T13, for which the sequence(s) is/are given at the end of the application. The coding portion of transcript M78076_PEA_l_T13 is shown in bold; this coding portion starts at position 142 and ends at position 1773. The transcript also has the following SNPs as listed in Table 698 (given according to their position on the nucleotide sequence, with the alternative nucleic acid listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein M78076JPEA_l_P12 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 698 - Nucleic acid SNPs
Variant protein M78076_PEA_l_P14 according to the present invention has an amino acid sequence as given at the end of the application; it is encoded by transcript(s) M78076_PEA_l_T15. An alignment is given to the known protein (Amyloid- like protein 1 precursor) at the end of the application. One or more alignments to one or more previously published protein sequences are given at the end of the application. A brief description of the
relationship of the variant protein according to the present invention to each such aligned protein is as follows:
Comparison report between M78076_PEA_l_P14 and APP1_HUMAN: LAn isolated chimeric polypeptide encoding for M78076_PEA_l_P14, comprising a first amino acid sequence being at least 90 % homologous to
MGPASPAARGLSRRPGQPPLPLLLPLLLLLLRAQPAIGSLAGGSPGAAEAPGSAQVAGL CGRLTLHRDLRTGRWEPDPQRSRRCLRDPQRVLEYCRQMYPELQIARVEQATQAIPME RWCGGSRSGSCAHPHHQVVPFRCLPGEFVSEALLVPEGCRFLHQERMDQCESSTRRHQ EAQEACSSQGLILHGSGMLLPCGSDRFRGVEYVCCPPPGTPDPSGTAVGDPSTRSWPPG SRVEGAEDEEEEESFPQPVDDYFVEPPQAEEEEETVPPPSSHTLAVVGKVTPTPRPTDGV DIYFGMPGEISEHEGFLRAKMDLEERRMRQINEVMREWAMADNQSKNLPKADRQALN EHFQSILQTLEEQVSGERQRLVETHATRVIALINDQRRAALEGFLAALQADPPQAERVLL ALRRYLRAEQKEQRHTLRHYQHVAAVDPEKAQQMRFQVHTHLQVIEERVNQSLGLLD QNPHLAQELRPQIQELLHSEHLGPSELEAPAPGGSSEDKGGLQPPDSKDDTPMTLPKGST EQDAASPEKEKMNPLEQYERKVNASVPRGFPFHSSEIQRDEL corresponding to amino acids 1 - 570 of APP1JHUMAN, which also corresponds to amino acids 1 - 570 of M78076_PEA_l_P14, and a second amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence VRGGTAGYLGEETRGQRPGCDSQSHTGPSKKPSAPSPLPAGTSWDRGVP corresponding to amino acids 571 - 619 of M78076_PEA_l_P14, wherein said first amino acid sequence and second amino acid sequence are contiguous and in a sequential order.
2.An isolated polypeptide encoding for a tail of M78076_PEA_l_P14, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence VRGGTAGYLGEETRGQRPGCDSQSHTGPSKKPSAPSPLPAGTSWDRGVP in M78076_PEA_l_P14.
The location of the variant protein was determined according to results from a number of different software programs and analyses, including analyses from SignalP and other specialized programs. The variant protein is believed to be located as follows with regard to the cell:
secreted. The protein localization is believed to be secreted because both signal-peptide prediction programs predict that this protein has a signal peptide, and neither trans -membrane region prediction program predicts that this protein has a trans -membrane region.
Variant protein M78076_PEA_l_P14 also has the following non-silent SNPs (Single Nucleotide Polymorphisms) as listed in Table 699, (given according to their position(s) on the amino acid sequence, with the alternative amino acid(s) listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein M78076_PEA_l_P14 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 699- Amino acid mutations
The glycosylation sites of variant protein M78076_PEA_l_P14, as compared to the known protein Amyloid- like protein 1 precursor, are described in Table 700 (given according to
their position(s) on the amino acid sequence in the first column; the second column indicates whether the glycosylation site is present in the variant protein; and the last column indicates whether the position is different on the variant protein).
Table 700 - Glycosylation site(s)
Variant protein M78076_PEA_l_P14 is encoded by the following transcript(s): M78076_PEA_l_T15, for which the sequence(s) is/are given at the end of the application. The coding portion of transcript M78076_PEA_l_T15 is shown in bold; this coding portion starts at position 142 and ends at position 1998. The transcript also has the following SNPs as listed in Table 701 (given according to their position on the nucleotide sequence, with the alternative nucleic acid listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein M78076_PEA_l_P14 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 701 - Nucleic acid SNPs
Variant protein M78076_PEA_l_P21 according to the present invention has an amino acid sequence as given at the end of the application; it is encoded by transcript(s) M78076_PEA_l_T23. An alignment is given to the known protein (Amyloid- like protein 1 precursor) at the end of the application. One or more alignments to one or more previously published protein sequences are given at the end of the application. A brief description of the relationship of the variant protein according to the present invention to each such aligned protein is as follows:
Comparison report between M78076_PEA__l_P21 and APP IJHUMAN:
1.An isolated chimeric polypeptide encoding for M78076_PEA_l_P21, comprising a first amino acid sequence being at least 90 % homologous to
MGPASPAARGLSRRPGQPPLPLLLPLLLLLLRAQPAIGSLAGGSPGAAEAPGSAQVAGL CGRLTLHRDLRTGRWEPDPQRSRRCLRDPQRVLEYCRQMYPELQIARVEQATQAIPME RWCGGSRSGSCAHPHHQVVPFRCLPGEFVSEALLVPEGCRFLHQERMDQCESSTRRHQ EAQEACSSQGLILHGSGMLLPCGSDRFRGVEYVCCPPPGTPDPSGTAVGDPSTRSWPPG SRVEGAEDEEEEESFPQPVDDYFVEPPQAEEEEETVPPPSSHTLAVVGKVTPTPRPTDGV DIYFGMPGEISEHEGFLRAKMDLEERRMRQINEVMREWAMADNQSKNLPKADRQALN
E corresponding to amino acids 1 - 352 of APP1_HUMAN, which also corresponds to amino acids 1 - 352 of M78076_PEA_l_P21, and a second amino acid sequence being at least 90 % homologous to
AERVLLALRRYLRAEQKEQRHTLRHYQHVAAVDPEKAQQMRFQVHTHLQVIEERVNQ SLGLLDQNPHLAQELRPQIQELLHSEHLGPSELEAPAPGGSSEDKGGLQPPDSKDDTPMT LPKGSTEQDAASPEKEKMNPLEQYERKVNASVPRGFPFHSSEIQRDELAPAGTGVSREA VSGLLIMGAGGGSLIVLSMLLLRRKKPYGAISHGVVEVDPMLTLEEQQLRELQRHGYE NPTYRFLEERP corresponding to amino acids 406 - 650 of APP IJHUMAN, which also corresponds to amino acids 353 - 597 of M78076_PEA_l_P21, wherein said first amino acid sequence and second amino acid sequence are contiguous and in a sequential order. 2.An isolated chimeric polypeptide encoding for an edge portion of M78076JPEA_l JP21, comprising a polypeptide having a length "n", wherein n is at least about 10 amino acids in length, optionally at least about 20 amino acids in length, preferably at least about 30 amino acids in length, more preferably at least about 40 amino acids in length and most preferably at least about 50 amino acids in length, wherein at least two amino acids comprise EA, having a structure as follows: a sequence starting from any of amino acid numbers 352-x to 352; and ending at any of amino acid numbers 353+ ((n-2) - x), in which x varies from 0 to n-2.
The location of the variant protein was determined according to results from a number of different software programs and analyses, including analyses from SignalP and other specialized programs. The variant protein is believed to be located as follows with regard to the cell: membrane. The protein localization is believed to be membrane because although both signal- peptide prediction programs agree that this protein has a signal peptide, both trans -membrane
region prediction programs predict that this protein has a trans -membrane region downstream of this signal peptide.
Variant protein M78076_PEA_l_P21 also has the following non-silent SNPs (Single Nucleotide Polymorphisms) as listed in Table 702, (given according to their position(s) on the amino acid sequence, with the alternative amino acid(s) listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein M78076_PEA_l_P21 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 702 -Amino acid mutations
The glycosylation sites of variant protein M78076_PEA_l_P21, as compared to the known protein Amyloid- like protein 1 precursor, are described in Table 703 (given according to their position(s) on the amino acid sequence in the first column; the second column indicates
whether the glycosylation site is present in the variant protein; and the last column indicates whether the position is different on the variant protein).
Table 703- Glycosylation site(s)
Variant protein M78076_PEA_l_P21 is encoded by the following transcript(s):
M78076_PEA_l_T23, for which the sequence(s) is/are given at the end of the application. The coding portion of transcript M78076_PEA_l_T23 is shown in bold; this coding portion starts at position 142 and ends at position 1932. The transcript also has the following SNPs as listed in Table 704 (given according to their position on the nucleotide sequence, with the alternative nucleic acid listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein M78076_PEA_l_P21 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 704 -Nucleic acid SNPs
Variant protein M78076_PEA_l_P24 according to the present invention has an amino acid sequence as given at the end of the application; it is encoded by transcript(s) M78076_PEA_l_T26. An alignment is given to the known protein (Amyloid- like protein 1 precursor) at the end of the application. One or more alignments to one or more previously published protein sequences are given at the end of the application. A brief description of the relationship of the variant protein according to the present invention to each such aligned protein is as follows:
Comparison report between M78076_PEA_l_P24 and APP1_HUMAN: 1.An isolated chimeric polypeptide encoding for M78076_PEA_l_P24, comprising a first amino acid sequence being at least 90 % homologous to MGPASPAARGLSRRPGQPPLPLLLPLLLLLLRAQPAIGSLAGGSPGAAEAPGSAQVAGL
CGRLTLHRDLRTGRWEPDPQRSRRCLRDPQRVLEYCRQMYPELQIARVEQATQAIPME RWCGGSRSGSCAHPHHQVVPFRCLPGEFVSEALLVPEGCRFLHQERMDQCESSTRRHQ EAQEACSSQGLILHGSGMLLPCGSDRFRGVEYVCCPPPGTPDPSGTAVGDPSTRSWPPG SRVEGAEDEEEEESFPQPVDDYFVEPPQAEEEEETVPPPSSHTLAVVGKVTPTPRPTDGV DIYFGMPGEISEHEGFLRAKMDLEERRMRQINEVMREWAMADNQSKNLPKADRQALN EHFQSILQTLEEQVSGERQRLVETHATRVIALINDQRRAALEGFLAALQADPPQAERVLL ALRRYLRAEQKEQRHTLRHYQHVAAVDPEKAQQMRFQVHTHLQVIEERVNQSLGLLD QNPHLAQELRPQI corresponding to amino acids 1 - 481 of APP1_HUMAN, which also corresponds to amino acids 1 - 481 of M78076_PEA_l_P24, and a second amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence RECLLPWLPLQISEGRS corresponding to amino acids 482 - 498 of M78076_PEA_l_P24, wherein said first amino acid sequence and second amino acid sequence are contiguous and in a sequential order. 2.An isolated polypeptide encoding for a tail of M78076_PEA_l_P24, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence RECLLPWLPLQISEGRS in M78076_PEA_l_P24.
The location of the variant protein was determined according to results from a number of different software programs and analyses, including analyses from SignalP and other specialized programs. The variant protein is believed to be located as follows with regard to the cell: secreted. The protein localization is believed to be secreted because both signal-peptide prediction programs predict that this protein has a signal peptide, and neither trans -membrane region prediction program predicts that this protein has a trans -membrane region.
Variant protein M78076_PEA_l_P24 also has the following non-silent SNPs (Single Nucleotide Polymorphisms) as listed in Table 705, (given according to their position(s) on the amino acid sequence, with the alternative amino acid(s) listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein M78076_PEA_l_P24 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 705 - Amino acid mutations
The glycosylation sites of variant protein M78076_PEA_l_P24, as compared to the known protein Amyloid- like protein 1 precursor, are described in Table 706 (given according to their position(s) on the amino acid sequence in the first column; the second column indicates whether the glycosylation site is present in the variant protein; and the last column indicates whether the position is different on the variant protein).
Table 706 - Glycosylation site(s)
Variant protein M78076_PEA_l_P24 is encoded by the following transcript(s): M78076_PEA_l_T26, for which the sequence(s) is/are given at the end of the application. The coding portion of transcript M78076JPEA_l_T26 is shown in bold; this coding portion starts at position 142 and ends at position 1635. The transcript also has the following SNPs as listed in Table 707 (given according to their position on the nucleotide sequence, with the alternative nucleic acid listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein M78076_PEA_l_P24 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 707 - Nucleic acid SNPs
Variant protein M78076_PEA_l_P2 according to the present invention has an amino acid sequence as given at the end of the application; it is encoded by transcript(s) M78076_PEA_l_T27. An alignment is given to the known protein (Amyloid- like protein 1 precursor) at the end of the application. One or more alignments to one or more previously published protein sequences are given at the end of the application. A brief description of the relationship of the variant protein according to the present invention to each such aligned protein is as follows: Comparison report between M78076_PEA_l_P2 and APP1_HUMAN:
1.An isolated chimeric polypeptide encoding for M78076_PEA_l_P2, comprising a first amino acid sequence being at least 90 % homologous to
MGPASPAARGLSRRPGQPPLPLLLPLLLLLLRAQPAIGSLAGGSPGAAEAPGSAQVAGL CGRLTLHRDLRTGRWEPDPQRSRRCLRDPQRVLEYCRQMYPELQIARVEQATQAIPME RWCGGSRSGSCAHPHHQWPFRCLPGEFVSEALLVPEGCRFLHQERMDQCESSTRRHQ EAQEACSSQGLILHGSGMLLPCGSDRFRGVEYVCCPPPGTPDPSGTAVGDPSTRSWPPG SRVEGAEDEEEEESFPQPVDDYFVEPPQAEEEEETVPPPSSHTLAVVGKVTPTPRPTDGV DIYFGMPGEISEHEGFLRAKMDLEERRMRQINEVMREWAMADNQSKNLPKADRQALN EHFQSILQTLEEQVSGERQRLVETHATRVIALINDQRRAALEGFLAALQADPPQAERVLL ALRRYLRAEQKEQRHTLRHYQHVAAVDPEKAQQMRFQV corresponding to amino acids 1 - 449 of APP1_HUMAN, which also corresponds to amino acids 1 - 449 of M78076_PEA_l_P2, and a second amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence
LTSFQLPNAPLFLRRPRLRLFSCPLDPLSVSWTPSYPLNTASLPLPSLSAQLPDPETWTLT CCVFDPCFLALGFLLPPPSILCSVPWIFTAFPRIVFFFFFFLRQVLALSPRQESSVRSWLIAT STSWVQAILLPQPLE corresponding to amino acids 450 - 588 of M78076_PEA_l_P2, wherein said first amino acid sequence and second amino acid sequence are contiguous and in a sequential order.
2.An isolated polypeptide encoding for a tail of M78076_PEA_l JP2, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence
LTSFQLPNAPLFLRRPRLRLFSCPLDPLSVSWTPSYPLNTASLPLPSLSAQLPDPETWTLT CCVFDPCFLALGFLLPPPSILCSVPWIFTAFPRIVFFFFFFLRQVLALSPRQESSVRSWLIAT STSWVQAILLPQPLE in M78076_PEA_l_P2.
The location of the variant protein was determined according to results from a number of different software programs and analyses, including analyses from SignalP and other specialized programs. The variant protein is believed to be located as follows with regard to the cell: membrane. The protein localization is believed to be membrane because although both signal- peptide prediction programs agree that this protein has a signal peptide, both trans -membrane region prediction programs predict that this protein has a trans -membrane region downstream of this signal peptide.
Variant protein M78076_PEA_l_P2 also has the following non-silent SNPs (Single Nucleotide Polymorphisms) as listed in Table 708, (given according to their position(s) on the amino acid sequence, with the alternative amino acid(s) listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein M78076_PEA_l_P2 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 708 - Amino acid mutations
The glycosylation sites of variant protein M78076_PEA_l_P2, as compared to the known protein Amyloid- like protein 1 precursor, are described in Table 709 (given according to their position(s) on the amino acid sequence in the first column; the second column indicates whether the glycosylation site is present in the variant protein; and the last column indicates whether the position is different on the variant protein).
Table 709 - Glycosylation site(s)
Variant protein M78076JPEA_l JP2 is encoded by the following transcript(s): M78076_PEA_l__T27, for which the sequence(s) is/are given at the end of the application. The coding portion of transcript M78076_PEA_l_T27 is shown in bold; this coding portion starts at position 142 and ends at position 1905. The transcript also has the following SNPs as listed in Table 710 (given according to their position on the nucleotide sequence, with the alternative nucleic acid listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein M78076_PEA_l_P2 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 710 - Nucleic acid SNPs
Variant protein M78076_PEA_l_P25 according to the present invention has an amino acid sequence as given at the end of the application; it is encoded by transcript(s) M78076JPEA_l_T28. An alignment is given to the known protein (Amyloid- like protein 1 precursor) at the end of the application. One or more alignments to one or more previously published protein sequences are given at the end of the application. A brief description of the relationship of the variant protein according to the present invention to each such aligned protein is as follows: Comparison report between M78076_PEA_l_P25 and APP1_HUMAN:
LAn isolated chimeric polypeptide encoding for M78076_PEA_l_P25, comprising a first amino acid sequence being at least 90 % homologous to
MGPASPAARGLSRRPGQPPLPLLLPLLLLLLRAQPAIGSLAGGSPGAAEAPGSAQVAGL CGRLTLHRDLRTGRWEPDPQRSRRCLRDPQRVLEYCRQMYPELQIARVEQATQAIPME RWCGGSRSGSCAHPHHQWPFRCLPGEFVSEALLVPEGCRFLHQERMDQCESSTRRHQ EAQEACSSQGLILHGSGMLLPCGSDRFRGVEYVCCPPPGTPDPSGTAVGDPSTRSWPPG SRVEGAEDEEEEESFPQPVDDYFVEPPQAEEEEETVPPPSSHTLAVVGKVTPTPRPTDGV DIYFGMPGEISEHEGFLRAKMDLEERRMRQINEVMREWAMADNQSKNLPKADRQALN
EHFQSILQTLEEQVSGERQRLVETHATRVIALINDQRRAALEGFLAALQADPPQAERVLL ALRRYLRAEQKEQRHTLRHYQHVAAVDPEKAQQMRFQ corresponding to amino acids 1 - 448 of APP1_HUMAN, which also corresponds to amino acids 1 - 448 of M78076_PEA_l_P25, and a second amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence
PQNPNSQPRAAGSLEVIISHPFVRJRLEILISPFQFQNSIPKNSQIVPAASPRGTSSP corresponding to amino acids 449 - 505 of M78076_PEA_l_P25, wherein said first amino acid sequence and second amino acid sequence are contiguous and in a sequential order. 2.An isolated polypeptide encoding for a tail of M78076_PEA_l_P25, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence PQNPNSQPRAAGSLEVIISHPFVRRLEILISPFQFQNSIPKNSQIVPAASPRGTSSP in M78076_PEA_l_P25.
The location of the variant protein was determined according to results from a number of different software programs and analyses, including analyses from SignalP and other specialized programs. The variant protein is believed to be located as follows with regard to the cell: secreted. The protein localization is believed to be secreted because both signatpeptide prediction programs predict that this protein has a signal peptide, and neither trans -membrane region prediction program predicts that this protein has a trans -membrane region.
Variant protein M78076_PEA_l_P25 also has the following non-silent SNPs (Single Nucleotide Polymorphisms) as listed in Table 711, (given according to their position(s) on the amino acid sequence, with the alternative amino acid(s) listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein M78076_PEA_l_P25 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 711 -Amino acid mutations
The glycosylation sites of variant protein M78076_PEA_l_P25, as compared to the known protein Amyloid- like protein 1 precursor, are described in Table 712 (given according to their position(s) on the amino acid sequence in the first column; the second column indicates whether the glycosylation site is present in the variant protein; and the last column indicates whether the position is different on the variant protein).
Table 712- Glycosylation site(s)
Variant protein M78076_PEA_l JP25 is encoded by the following transcript(s): M78076_PEA_l_T28, for which the sequence(s) is/are given at the end of the application. The
coding portion of transcript M78076_PEA_l_T28 is shown in bold; this coding portion starts at position 142 and ends at position 1656. The transcript also has the following SNPs as listed in Table 713 (given according to their position on the nucleotide sequence, with the alternative nucleic acid listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein M78076_PEA_l_P25 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 713 - Nucleic acid SNPs
As noted above, cluster M78076 features 35 segment(s), which were listed in Table 2 above and for which the sequence(s) are given at the end of the application. These segment(s) are portions of nucleic acid sequence(s) which are described herein separately because they are of particular interest. A description of each segment according to the present invention is now provided.
Segment cluster M78076_PEA_l_node_0 according to the present invention is supported by 47 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): M78076_PEA_l_T2, M78076_PEA_l_T3, M78076_PEA_l_T5, M78076_PEA_l_T13, M78076_PEA_l_T15, M78076_PEA_l_T23, M78076_PEA_l_T26, M78076__PEA_l_T27 and M78076_PEA_l_T28. Table 714 below describes the starting and ending position of this segment on each transcript.
Table 714 - Segment location on transcripts
Segment cluster M78076_PEA_l_node_10 according to the present invention is supported by 70 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): M78076_PEA_l_T2, M78076JPEA_l_T3, M78076_PEA_l_T5, M78076_PEA_l_T13, M78076_PEA_l_T15, M78076_PEA_l_T23, M78076_PEA_l_T26, M78076_PEA_l_T27 and M78076_PEA_l JT28. Table 715 below describes the starting and ending position of this segment on each transcript.
Table 715 - Segment location on transcripts
Segment cluster M78076_PEA_l_node_15 according to the present invention is supported by 74 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): M78076JPEA_l_T2, M78076_PEA_l_T3, M78076JPEA_l_T5, M78076_PEA_l_T13, M78076_PEA_l_T15, M78076_PEA_l_T23, M78076_PEA_l_T26, M78076_PEA_l_T27 and M78076_PEA_l_T28. Table 716 below describes the starting and ending position of this segment on each transcript.
Table 716 - Segment location on transcripts
Segment cluster M78076_PEA_l_node_l 8 according to the present invention is supported by 95 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): M78076_PEA_l_T2, M78076_PEA_l_T3, M78076_PEA_l_T5, M78076JΕA_l_T13, M78076J>EA_ l_T15, M78076_PEA_l_T23, M78076_PEA_l_T26, M78076_PEA_l_T27 and M78076_PEA_l_T28. Table 717 below describes the starting and ending position of this segment on each transcript.
Table 717 - Segment location on transcripts
Segment cluster M78076_PEA_l_node_20 according to the present invention is supported by 99 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): M78076_PEA_l_T2, M78076_PEA_l_T3, M78076_PEA_l_T5, M78076_PEA_l_T13, M78076_PEA_l_T15, M78076_PEA_l_T23, M78076_PEA_l_T26, M78076_PEA_l_T27 and M78076_PEA_l_T28. Table 718 below describes the starting and ending position of this segment on each transcript.
Table 718 - Segment location on transcripts
Segment cluster M78076_PEA_l_node_24 according to the present invention is supported by 105 libraries. The number of libraries was determined as previously described.
This segment can be found in the following transcript(s): M78076_PEA_l_T2,
M78076_PEA_l_T3, M78076_PEA_l_T5, M78076_PEA_l_T13, M78076_PEA_l_T15, M78076_PEA_l_T26, M78076_PEA_l_T27 and M78076_PEA_l_T28. Table 719 below describes the starting and ending position of this segment on each transcript.
Table 719 - Segment location on transcripts
Segment cluster M78076_PEA_l_node_26 according to the present invention is supported by 99 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): M78076_PEA_l_T2, M78076_PEA_l_T3, M78076_PEA_l_T5, M78076JPEA_l_T13, M78076_PEA._l_T15, M78076_PEA_l_T23, M78076_PEA_l_T26, M78076_PEA_l_T27 and M78076_PEA_l_T28. Table 720 below describes the starting and ending position of this segment on each transcript.
Table 720 - Segment location on transcripts
Segment cluster M78076_PEA_l_node_29 according to the present invention is supported by 2 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): M78076_PEA_l_T27. Table 721 below describes the starting and ending position of this segment on each transcript.
Table 721 - Segment location on transcripts
Segment cluster M78076_PEA_l_node_32 according to the present invention is supported by 2 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): M78076_PEA_l_T26 and M78076_PEA_l_T27. Table 722 below describes the starting and ending position of this segment on each transcript. Table 722 - Segment location on transcripts
Segment cluster M78076_PEA_l_node__35 according to the present invention is supported by 4 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): M78076_PEA_l_T2 and
M78076_PEA_l_T5. Table 723 below describes the starting and ending position of this segment on each transcript.
Table 723- Segment location on transcripts
Segment cluster M78076_PEA_l_node_37 according to the present invention is supported by 11 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): M78076_PEA_l_T3 and M78076_PEA_l_T5. Table 724 below describes the starting and ending position of this segment on each transcript.
Table 724 - Segment location on transcripts
Segment cluster M78076_PEA_l_node_46 according to the present invention is supported by 3 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): M78076JPEA_l_T15. Table 725 below describes the starting and ending position of this segment on each transcript.
Table 725 - Segment location on transcripts
Segment cluster M78076_PEA_l_node_47 according to the present invention is supported by 155 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): M78076_PEA_l_T2, M78076JPEA_l_T3, M78076_PEA_l_T5, M78076_PEA_l_T13, M78076JPEA_l_T15 and M78076JPEA_l_T23. Table 726 below describes the starting and ending position of this segment on each transcript.
Table 726 - Segment location on transcripts
Segment cluster M78076_PEA_l_node_54 according to the present invention is supported by 133 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): M78076_PEA_l_T2, M78076_PEA_l_T3, M78076_PEA_l_T5, M78076_PEA_l_T13, M78076_PEA_l_T15, M78076_PEA_l_T23 and M78076_PEA_l_T28. Table 727 below describes the starting and ending position of this segment on each transcript.
Table 727 - Segment location on transcripts
According to an optional embodiment of the present invention, short segments related to the above cluster are also provided. These segments are up to about 120 bp in length, and so are included in a separate description.
Segment cluster M78076_PEA_l_node_l according to the present invention is supported by 47 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): M78076_PEA_l_T2, M78076JPEA_l_T3, M78076JPEA_l_T5, M78076_PEA_l_T13, M78076_PEA_l_T15, M78076JPEA_l_T23, M78076_PEA_l_T26, M78076_PEA_l_T27 and M78076_PEA_l_T28. Table 728 below describes the starting and ending position of this segment on each transcript.
Table 728- Segment location on transcripts
Segment cluster M78076_PEA_l_node_2 according to the present invention can be found in the following transcript(s): M78076_PEA_l_T2, M78076_PEA_l_T3, M78076_PEA_l_T5,
M78076_PEA_l_T13, M78076_PEA_l_T15, M78076JPEA_l_T23, M78076_PEA_l_T26, M78076_PEA_l_T27 and M78076JPEA_l_T28. Table 729 below describes the starting and ending position of this segment on each transcript.
Table 729 - Segment location on transcripts
Segment cluster M78076JPEA_l_node_3 according to the present invention is supported by 52 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): M78076_PEA_l_T2, M78076_PEA_l_T3, M78076_PEA_l_T5, M78076_PEA_l_T13, M78076_PEA_l_T15, M78076_PEA_l_T23, M78076_PEA_l_T26, M78076_PEA_l_T27 and M78076_PEA_l_T28. Table 730 below describes the starting and ending position of this segment on each transcript.
Table 730 - Segment location on transcripts
Segment cluster M78076_PEA_l jnode_6 according to the present invention is supported by 59 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): M78076_PEA_l_T2, M78076_PEA_l_T3, M78076_PEA_l_T5, M78076_PEA_l_T13, M78076_PEA_l_T15, M78076_PEA_l_T23, M78076_PEA_l_T26, M78076_PEA_l_T27 and M78076_PEA_l_T28. Table 731 below describes the starting and ending position of this segment on each transcript.
Table 731 - Segment location on transcripts
Segment cluster M78076_PEA_l_node_7 according to the present invention is supported by 64 libraries. The number of libraries was determined as previously described. This segment
can be found in the following transcript(s): M78076_PEAJ_T2, M78076_PEA_l_T3, M78076_PEA__l_T5, M78076_PEA_l_T13, M78076_PEA_l_T15, M78076JPEA_l_T23, M78076_PEA_l_T26, M78076_PEA_l_T27 and M78076_PEA_l_T28. Table 732 below describes the starting and ending position of this segment on each transcript.
Table 732 - Segment location on transcripts
Segment cluster M78076_PEA_l_node_l 2 according to the present invention is supported by 71 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): M78076_PEA_l_T2, M78076_PEA__l_T3, M78076_PEA_l_T5, M78076_PEA_l_T13, M78076_PEA_l_T15, M78076_PEA_l_T23, M78076JPEA_l_T26, M78076_PEA_l_T27 and M78076_PEA_l_T28. Table 733 below describes the starting and ending position of this segment on each transcript.
Table 733- Segment location on transcripts
Segment cluster M78076_PEA_l_node_22 according to the present invention is supported by 92 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): M78076_PEA_l_T2, M78076JPEA_l_T3, M78076_PEA_l_T5, M78076_PEA_l_T13, M78076_PEA_l_T15, M78076_PEA_l_T23, M78076_PEA_l_T26, M78076JPEA_l_T27 and M78076_PEA_l_T28. Table 734 below describes the starting and ending position of this segment on each transcript.
Table 734 - Segment location on transcripts
Segment cluster M78076_PEA_l_node_27 according to the present invention can be found in the following transcript(s): M78076_PEA_l_T27. Table 735 below describes the starting and ending position of this segment on each transcript.
Table 735 - Segment location on transcripts
Segment cluster M78076_PEA_l_node_30 according to the present invention is supported by 90 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): M78076_PEA_l_T2, M78076_PEA_l_T3, M78076_PEA_l_T5, M78076_PEA_l_T13, M78076_PEA_l_T15, M78076_PEA_l_T23, M78076_PEA_l_T26 and M78076__PEA_l_T27. Table 736 below describes the starting and ending position of this segment on each transcript.
Table 736 - Segment location on transcripts
Segment cluster M78076_PEA_l_node_31 according to the present invention is supported by 89 libraries. The number of libraries was determined as previously described. This
segment can be found m the following transcript(s): M78076_PEA_l_T2, M78076JPEA_l_T3, M78076_PEA_l_T5, M78076_PEA_l_T13, M78076_PEA_l_T15, M78076_PEA_l_T23, M78076_PEA_l_T26 and M78076_PEA_l_T27. Table 737 below describes the starting and ending position of this segment on each transcript.
Table 737- Segment location on transcripts
Segment cluster M78076_PEA_l_node_34 according to the present invention is supported by 103 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): M78076_PEA_l_T2,
M78076_PEA_l_T3, M78076_PEA_l_T5, M78076_PEA_l_T13, M78076_PEA_l_T15 and M78076_PEA_l_T23. Table 738 below describes the starting and ending position of this segment on each transcript.
Table 738 - Segment location on transcripts
Segment cluster M78076_PEA_l_node_36 according to the present invention can be found in the following transcript(s): M78076_PEA_l_T2, M78076_PEA_l_T3, M78076_PEA_l_T5, M78076_PEA_l_T13, M78076_PEA_l_T15 and M78076_PEA_l_T23. Table 739 below describes the starting and ending position of this segment on each transcript.
Table 739 - Segment location on transcripts
Segment cluster M78076_PEA_l_node_41 according to the present invention can be found in the following transcript(s): M78076_PEA_l_T3 and M78076_PEA_l_T5. Table 740 below describes the starting and ending position of this segment on each transcript.
Table 740 - Segment location on transcripts
Segment cluster M78076_PEA_l_node_42 according to the present invention can be found in the following transcript(s): M78076_PEA_l_T2, M78076_PEA_l_T3, M78076_PEA_l_T5, M78076_PEA_l_T15 and M78076_PEA_l_T23. Table 741 below describes the starting and ending position of this segment on each transcript.
Table 741 - Segment location on transcripts
Segment cluster M78076_PEA_l_node_43 according to the present invention is supported by 110 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): M78076_PEA_l_T2, M78076JPEA_l_T3, M78076_PEA_l_T5, M78076_PEA_l_T15 and M78076_PEA_l_T23. Table 742 below describes the starting and ending position of this segment on each transcript.
Table 742 - Segment location on transcripts
Microarray (chip) data is also available for this segment as follows. As described above with regard to the cluster itself, various oligonucleotides were tested for being differentially expressed in various disease conditions, particularly cancer. The following oligonucleotides were found to hit this segment (in relation to lung cancer), shown in Table 743.
Table 743 - Oligonucleotides related to this segment
Segment cluster M78076_PEA_l_node_45 according to the present invention is supported by 132 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): M78076_PEA_l_T2,
M78076_PEA_l_T3, M78076_PEA_l_T5, M78076_PEA_l_T13, M78076_PEA_l_T15 and M78076_PEA_l_T23. Table 744 below describes the starting and ending position of this segment on each transcript.
Table 744 - Segment location on transcripts
Microarray (chip) data is also available for this segment as follows. As described above with regard to the cluster itself, various oligonucleotides were tested for being differentially expressed in various disease conditions, particularly cancer. The following oligonucleotides were found to hit this segment (in relation to lung cancer), shown in Table 745.
Table 745 - Oligonucleotides related to this segment
Segment cluster M78076_PEA_l_node_49 according to the present invention is supported by 129 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): M78076_PEA_l_T2, M78076JPEA_l_T3, M78076_PEA_l_T5, M78076_PEA_l_T13, M78076_PEA_l_T15 and M78076_PEA_l_T23. Table 746 below describes the starting and ending position of this segment on each transcript.
Table 746 - Segment location on transcripts
Segment cluster M78076_PEA_l_node_50 according to the present invention is supported by 125 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): M78076_PEA_l_T2,
M78076_PEA_l_T3, M78076_PEA_l_T5, M78076JPEA_l_T13, M78076_PEA_l_T15 and M78076_PEA_l_T23. Table 747 below describes the starting and ending position of this segment on each transcript.
Table 747 - Segment location on transcripts
Segment cluster M78076_PEA_l_node_51 according to the present invention is supported by 123 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): M78076_PEA_l_T2, M78076_PEA_l_T3, M78076_PEA_l_T5, M78076_PEA_l_T13, M78076_PEA_l_T15 and M78076_PEA_l_T23. Table 748 below describes the starting and ending position of this segment on each transcript.
Table 748 - Segment location on transcripts
Segment cluster M78076_PEA_l_node_52 according to the present invention can be found in the following transcript(s): M78076_PEA_l_T2, M78076_PEA_l_T3,
M78076_PEA_l_T5, M78076JPEA__l_T13, M78076_PEA_l_T15 and M78076_PEA_l_T23. Table 749 below describes the starting and ending position of this segment on each transcript.
Table 749 - Segment location on transcripts
Segment cluster M78076_PEA_l_node_53 according to the present invention can be found in the following transcript(s): M78076JPEA_l_T2, M78076_PEA_l_T3, M78076_PEA_l_T5, M78076_PEA_l_T13, M78076_PEA_l_T15, M78076_PEA_l_T23 and M78076_PEA_l_T28. Table 750 below describes the starting and ending position of this segment on each transcript.
Table 750 - Segment location on transcripts
Variant protein alignment to the previously known protein:
Sequence name: APP1_HUMAN
Sequence documentation:
Alignment of: M78076_PEA_l_P3 x APP1_HUMAN
Alignment segment 1/1:
Quality: 5132.00 Escore: 0
Matching length: 517 Total length: 517 Matching Percent Similarity: 100.00 Matching Percent Identity: 100.00
Total Percent Similarity: 100.00 Total Percent Identity: 100.00
Gaps : 0
Alignment:
1 MGPASPAARGLSRRPGQPPLPLLLPLLLLLLRAQPAIGSLAGGSPGAAEA 50
I I I I l I l I I I I I l I I I I I I I I I I I I l I I I I I I I I I I I I I I I l I I I I I I l I 1 MGPASPAARGLSRRPGQPPLPLLLPLLLLLLRAQPAIGSLAGGSPGAAEA 50
51 PGSAQVAGLCGRLTLHRDLRTGRWEPDPQRSRRCLRDPQRVLEYCRQMYP 100
I I I Il I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I 1 I I I I I I I I I I
51 PGSAQVAGLCGRLTLHRDLRTGRWEPDPQRSRRCLRDPQRVLEYCRQMYP 100
101 ELQIARVEQATQAIPMERWCGGSRSGSCAHPHHQVVPFRCLPGEFVSEAL 150
I I I I I 1 Il Il Il I I 1 I I I I I Il I I I I I I I 1 Il I I I Il I I I I Il I I I I I I I
101 ELQIARVEQATQAIPMERWCGGSRSGSCAHPHHQWPFRCLPGEFVSEAL 150
151 LVPEGCRFLHQERMDQCESSTRRHQEAQEACSSQGLILHGSGMLLPCGSD 200 I I I M I M M I I I I I I I I I I I I I I I I I I I I I I I I I M I I I I I I I I I I I I I
151 LVPEGCRFLHQERMDQCESSTRRHQEAQEACSSQGLILHGSGMLLPCGSD 200
201 RFRGVEYVCCPPPGTPDPSGTAVGDPSTRSWPPGSRVEGAEDEEEEESFP 250 1 I I I I I I I I I I I I I I Il I I I I Il I I I I Il I I I I I I I Il I I I I I I I I Il I I 201 RFRGVEYVCCPPPGTPDPSGTAVGDPSTRSWPPGSRVEGAEDEEEEESFP 250
251 QPVDDYFVEPPQAEEEEETVPPPSSHTLAVVGKVTPTPRPTDGVDIYFGM 300
I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I 1 I Il I I I I I I I I I I I Il Il
251 QPVDDYFVEPPQAEEEEETVPPPSSHTLAVVGKVTPTPRPTDGVDIYFGM 300 . . . . .
301 PGEISEHEGFLRAKMDLEERRMRQINEVMREWAMADNQSKNLPKADRQAL 350
I I I I I I I I I I Il I Il I I I I Il I I I I I I I I I I I I I Il I Il I I I I I I Il I I I
301 PGEISEHEGFLRAKMDLEERRMRQINEVMREWAMADNQSKNLPKADRQAL 350
351 NEHFQSILQTLEEQVSGERQRLVETHATRVIALINDQRRAALEGFLAALQ 400
I I Il I I I Il I I I I I I I I Il I I I I I I I Il Il I I Il I I I I I I I Il I I I I Il I 351 NEHFQSILQTLEEQVSGERQRLVETHATRVIALINDQRRAALEGFLAALQ 400
401 ADPPQAERVLLALRRYLRAEQKEQRHTLRHYQHVAAVDPEKAQQMRFQVH 450 I I I I I I I I I I I I I I I I M I I I I I I I I I I Il I I I I I I I I I I M I I I I I Il I
401 ADPPQAERVLLALRRYLRAEQKEQRHTLRHYQHVAAVDPEKAQQMRFQVH 450
451 THLQVIEERVNQSLGLLDQNPHLAQELRPQIQELLHSEHLGPSELEAPAP 500
I I I I I I Il I 1 I I I I I I I I I I I I I 1 I 1 I I I ! I I I I I I I I I I I I I I I I I I I I
451 THLQVIEERVNQSLGLLDQNPHLAQELRPQIQELLHSEHLGPSELEAPAP 500
501 GGSSEDKGGLQPPDSKD 517
I Il Il I I I I I I I I I I I I
501 GGSSEDKGGLQPPDSKD 517
Sequence name: APP1_HUMAN
Sequence documentation:
Alignment of: M78076_PEA_l_P4 x APP1_HUMAN
Alignment segment 1/1:
Quality: 5223.00 Escore: 0 Matching length: 526 Total length: 526
Matching Percent Similarity: 100.00 Matching Percent Identity: 100.00
Total Percent Similarity: 100.00 Total Percent Identity: 100.00
Gaps : 0
Alignment :
1 MGPASPAARGLSRRPGQPPLPLLLPLLLLLLRAQPAIGSLAGGSPGAAEA 50 11111111111 ! 1111111 I ] I I I I I M I I I I I I I I I I I I I I i I I I I I I I l MGPASPΆARGLSRRPGQPPLPLLLPLLLLLLRAQPAIGSLAGGSPGAAEA 50
51 PGSAQVAGLCGRLTLHRDLRTGRWEPDPQRSRRCLRDPQRVLEYCRQMYP -100
I I I I 1 I I I I I I 1 I I I I I I I I I I I I I I I I I I 1 I I I I I I I I I I I 1 I I I I I I I 51 PGSAQVAGLCGRLTLHRDLRTGRWEPDPQRSRRCLRDPQRVLEYCRQMYP 100
101 ELQIARVEQATQAIPMERWCGGSRSGSCAHPHHQVVPFRCLPGEFVSEAL 150
II I I I I I I I I I I I I I I Il I I I I I I 1 I I I I I I I Il I I I I I I I I I I I I Il I I
101 ELQIARVEQATQAIPMERWCGGSRSGSCAHPHHQWPFRCLPGEFVSEAL 150 . . . . .
151 LVPEGCRFLHQERMDQCESSTRRHQEAQEACSSQGLILHGSGMLLPCGSD 200
I I I I I I 1 I I I I I I Il I I I Il Il I I I I I I Il I I I I Il I I I I I I I I I I I I I I
151 LVPEGCRFLHQERMDQCESSTRRHQEAQEACSSQGLILHGSGMLLPCGSD 200
201 RFRGVEYVCCPPPGTPDPSGTAVGDPSTRSWPPGSRVEGAEDEEEEESFP 250
I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I Il I Il
201 RFRGVEYVCCPPPGTPDPSGTAVGDPSTRSWPPGSRVEGAEDEEEEESFP 250
251 QPVDDYFVEPPQAEEEEETVPPPSSHTLAWGKVTPTPRPTDGVDIYFGM 300 I M I I I I I M I I I M I I I I I I M I I I I I I I I I I M I I M M I I I I I M I I
251 QPVDDYFVEPPQAEEEEETVPPPSSHTLAVVGKVTPTPRPTDGVDIYFGM 300
301 PGEISEHEGFLRAKMDLEERRMRQINEVMREWAMADNQSKNLPKADRQAL 350
I I I I I I I I I I I I I Il I I I I Il I I I I I I I I Il I Il I I I I I I I I Il I I I I I I 301 PGEISEHEGFLRAKMDLEERRMRQINEVMREWAMADNQSKNLPKADRQAL 350
351 NEHFQSILQTLEEQVSGERQRLVETHATRVIALINDQRRAΑLEGFLAALQ 400
I I I I I I I I I I I I I I 1 I I Il I I Il I I I I I I I I I I I I I I Il i I I I I I I 1 I I I
351 NEHFQSILQTLEEQVSGERQRLVETHATRVIALINDQRRAALEGFLAALQ 400
401 ADPPQAERVLLALRRYLRAEQKEQRHTLRHYQHVAAVDPEKAQQMRFQVH 450
I M I I M I M I I M M I I I I I M I M I I I I I I I I M I I M M I M I I I I I
401 ADPPQAERVLLALRRYLRAEQKEQRHTLRHYQHVAAVDPEKAQQMRFQVH 450
451 THLQVIEERVNQSLGLLDQNPHLAQELRPQIQELLHSEHLGPSELEAPAP 500 M I M M I I I M I M M M M I 1 I M M M M I I I M M I I M I M I I I I
451 THLQVIEERVNQSLGLLDQNPHLAQELRPQIQELLHSEHLGPSELEAPAP 500
501 GGSSEDKGGLQPPDSKDDTPMTLPKG 526
I I Il I M I I I M M M M I M M I M 501 GGSSEDKGGLQPPDSKDDTPMTLPKG 526
Sequence name: APP1_HUMAN
Sequence documentation:
Alignment of: M78076_PEA_l_P12 x APP1_HUMAN
Alignment segment 1/1:
Quality: 5223.00
Escore: 0
Matching length: 526 Total length: 526
Matching Percent Similarity: 100.00 Matching Percent Identity: 100.00 Total Percent Similarity: 100.00 Total Percent Identity: 100.00
Gaps : 0
Alignment : . . . . .
1 MGPASPAARGLSRRPGQPPLPLLLPLLLLLLRAQPAIGSLAGGSPGAAEA 50
I I 1 I I I I I I I I I I I I I I I I 1 I I I I I I I I I I I I I I I I I I I i I I I I I I I I I I
1 MGPASPAARGLSRRPGQPPLPLLLPLLLLLLRAQPAIGSLAGGSPGAAEA 50
51 PGSAQVAGLCGRLTLHRDLRTGRWEPDPQRSRRCLRDPQRVLEYCRQMYP 100
I I I I I I I Il I I I I I I I I I I I I I I I I I I I I I I I I I Il i I Il I I I I Il I I 1 I
51 PGSAQVAGLCGRLTLHRDLRTGRWEPDPQRSRRCLRDPQRVLEYCRQMYP 100
101 ELQIARVEQATQAIPMERWCGGSRSGSCAHPHHQWPFRCLPGEFVSEAL 150 I I I I I I I I I I I I I I M I I I I I I I I I I I I I I I I I I I I I I I I I I M I I I I M
101 ELQIARVEQATQAIPMERWCGGSRSGSCAHPHHQWPFRCLPGEFVSEAL 150
151 LVPEGCRFLHQERMDQCESSTRRHQEAQEACSSQGLILHGSGMLLPCGSD 200
I I I I I I I Il 1 I I I Il I Il I I I I I Il I I Il I I I Il Il I I Il Il I Il I Il Il 151 LVPEGCRFLHQERMDQCESSTRRHQEAQEACSSQGLILHGSGMLLPCGSD 200
201 RFRGVEYVCCPPPGTPDPSGTAVGDPSTRSWPPGSRVEGAEDEEEEESFP 250
II I I I I I Il I Il Il I III I Il Il I Il I I Il I I I I I I Il I Il I I Il I I I I I 201 RFRGVEYVCCPPPGTPDPSGTAVGDPSTRSWPPGSRVEGAEDEEEEESFP 250 . . . . .
251 QPVDDYFVEPPQAEEEEETVPPPSSHTLAVVGKVTPTPRPTDGVDIYFGM 300
I I I I I 1 I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I 251 QPVDDYFVEPPQAEEEEETVPPPSSHTLAVVGKVTPTPRPTDGVDIYFGM 300
301 PGEISEHEGFLRAKMDLEERRMRQINEVMREWAMADNQSKNLPKADRQAL 350 11111!111!1111111111!1!111111111I]IIMIMIIIIIIIII
301 PGEISEHEGFLRAKMDLEERRMRQINEVMREWAMADNQSKNLPKADRQAL 350
351 NEHFQSILQTLEEQVSGERQRLVETHATRVIALINDQRRAALEGFLAALQ 400
M I M I 1 I I I I I 11 M I Il I I I Il M Il I Il Il I I I Il Il M M M Il I I 351 NEHFQSILQTLEEQVSGERQRLVETHATRVIALINDQRRAALEGFLAALQ 400
401 ADPPQAERVLLALRRYLRAEQKEQRHTLRHYQHVAAVDPEKAQQMRFQVH 450
I Il Il I I Il Il I Il I Il I I I I Il Il Il I I I I Il I Il ! Il I Il I Il Il I I I
401 ADPPQAERVLLALRRYLRAEQKEQRHTLRHYQHVAAVDPEKAQQMRFQVH 450 . . . . .
451 THLQVIEERVNQSLGLLDQNPHLAQELRPQIQELLHSEHLGPSELEAPAP 500
Il Il I Il I I Il Il I I Il I I Il Il I 1 Il Il Il Il I Il I Il Il Il I I I I Il I
451 THLQVIEERVNQSLGLLDQNPHLAQELRPQIQELLHSEHLGPSELEAPAP 500
501 GGSSEDKGGLQPPDSKDDTPMTLPKG 526
I 1 Il M I I M Il M I I Il I I Il M I I
501 GGSSEDKGGLQPPDSKDDTPMTLPKG 526
Sequence name: APP1_HUMAN
Sequence documentation:
Alignment of: M78076_PEA_l_P14 x APP1_HUMAN
Alignment segment 1/1:
Quality: 5672.00 Escore: 0
Matching length: 575 Total length: 575 Matching Percent Similarity: 99.48 Matching Percent Identity: 99.48
Total Percent Similarity: 99.48 Total Percent Identity: 99.48
Gaps : 0
Alignment :
1 MGPASPAARGLSRRPGQPPLPLLLPLLLLLLRAQPAIGSLAGGSPGAAEA 50
I I I I I I I I I I I Il I I I I I I I I Il I I I I I I I I I I I I I I I i I I I I I I I I I Il l MGPASPAARGLSRRPGQPPLPLLLPLLLLLLRAQPAIGSLAGGSPGAAEA 50
51 PGSAQVAGLCGRLTLHRDLRTGRWEPDPQRSRRCLRDPQRVLEYCRQMYP 100
I I I I Il I I I I I I I I Il I I I Il I Il I Il Il I I I I I I I I I I I I I I I I I I I I I
51 PGSAQVAGLCGRLTLHRDLRTGRWEPDPQRSRRCLRDPQRVLEYCRQMYP 100 . . . . .
101 ELQIARVEQATQAIPMERWCGGSRSGSCAHPHHQWPFRCLPGEFVSEAL 150 I I I I I Il Il I Il I I I I I Il I I I I I I I I I I I Il Il Il I I I I Il I I Il Il Il
101 ELQIARVEQATQAIPMERWCGGSRSGSCAHPHHQWPFRCLPGEFVSEAL 150
151 LVPEGCRFLHQERMDQCESSTRRHQEAQEACSSQGLILHGSGMLLPCGSD 200
151 LVPEGCRFLHQERMDQCESSTRRHQEAQEACSSQGLILHGSGMLLPCGSD 200
201 RFRGVEYVCCPPPGTPDPSGTAVGDPSTRSWPPGSRVEGAEDEEEEESFP 250
I I Il I i I I I I I I I I I I I I I I I I I 1 I I I I I I I I I I I I I I I I I I I I I I I i I I 201 RFRGVEYVCCPPPGTPDPSGTAVGDPSTRSWPPGSRVEGAEDEEEEESFP 250
251 QPVDDYFVEPPQAEEEEETVPPPSSHTLAVVGKVTPTPRPTDGVDIYFGM 300
I I I I Il I I I I I I I I I Il I Il I I Il I I Il I I Il I I I I Il I I I Il I I I I I I' I
251 QPVDDYFVEPPQAEEEEETVPPPSSHTLAVVGKVTPTPRPTDGVDIYFGM 300 . . . . .
301 PGEISEHEGFLRAKMDLEERRMRQINEVMREWAMADNQSKNLPKADRQAL 350
I I I I I I I I I I I I I I I I I I Il I I I I I I Il I I I I I I I I I I Il I I I I I I I I I I
301 PGEISEHEGFLRAKMDLEERRMRQINEVMREWAMADNQSKNLPKADRQAL 350
351 NEHFQSILQTLEEQVSGERQRLVETHATRVIALINDQRRAALEGFLAALQ 400 I I I I I I Il I I I I I Il I I I I I I Il I Il I I I I I I I I Il Il I I Il I I I Il I Il
351 NEHFQSILQTLEEQVSGERQRLVETHATRVIALINDQRRAALEGFLAALQ 400
401 ADPPQAERVLLALRRYLRAEQKEQRHTLRHYQHVAAVDPEKAQQMRFQVH 450 I I I ] M I I I I I I I I I M I I I I I I M I Il I I I I I I I I I I I I I I M I I I I I I
401 ADPPQAERVLLALRRYLRAEQKEQRHTLRHYQHVAAVDPEKAQQMRFQVH 450
451 THLQVIEERVNQSLGLLDQNPHLAQELRPQIQELLHSEHLGPSELEAPAP 500
I I Il I I I I Il I I I Il I I I I I Il I I I I I I I Il I I I Il I I I I Il I I I I I Il I 451 THLQVIEERVNQSLGLLDQNPHLAQELRPQIQELLHSEHLGPSELEAPAP 500
501 GGSSEDKGGLQPPDSKDDTPMTLPKGSTEQDAASPEKEKMNPLEQYERKV 550
M I II I III I MI M I MI I I I I M M MII I M I I I III I I IIII MII
501 GGSSEDKGGLQPPDSKDDTPMTLPKGSTEQDAASPEKEKMNPLEQYERKV 550
551 NASVPRGFPFHSSEIQRDELVRGGT 575
551 NASVPRGFPFHSSEIQRDELAPAGT 575
Sequence name: APP1_HUMAN
Sequence documentation:
Alignment of: M78076_PEA_l_P21 x APP1_HUMAN
Alignment segment 1/1:
Quality: 5822.00 Escore: 0
Matching length: 597 Total length: 650
Matching Percent Similarity: 100.00 Matching Percent Identity: 100.00
Total Percent Similarity: 91.85 Total Percent Identity: 91.85 Gaps : 1
Alignment:
1 MGPASPAARGLSRRPGQPPLPLLLPLLLLLLRAQPAIGSLAGGSPGAAEA 50 I M I I I M I I I I M I I I I I I I M I M I I I I I I I M I I I I M I I I M I I I I
1 MGPASPAARGLSRRPGQPPLPLLLPLLLLLLRAQPAIGSLAGGSPGAAEA 50
51 PGSAQVAGLCGRLTLHRDLRTGRWEPDPQRSRRCLRDPQRVLEYCRQMYP 100
I I I I I I I I I I I 1 I I I I I 1 I M I I I I I 1 I I I I I I I I I I I I I 1 I I I I I I I I I
51 PGSAQVAGLCGRLTLHRDLRTGRWEPDPQRSRRCLRDPQRVLEYCRQMYP 100 . . . . .
101 ELQIARVEQATQAIPMERWCGGSRSGSCAHPHHQVVPFRCLPGEFVSEAL 150
I I I 1 I I I I I I I I i Il 1 I I I I 1 I I I I I I I I I I I I I I I I I I I I I I I I I I I I I
101 ELQIARVEQATQAIPMERWCGGSRSGSCAHPHHQVVPFRCLPGEFVSEAL 150
151 LVPEGCRFLHQERMDQCESSTRRHQEAQEACSSQGLILHGSGMLLPCGSD 200
I I I I I Il Il I I I I I I I I I I I I I I I Il Il I Il I I I I I I I I I I Il I I I I I I I '
151 LVPEGCRFLHQERMDQCESSTRRHQEAQEACSSQGLILHGSGMLLPCGSD 200
201 RFRGVEYVCCPPPGTPDPSGTAVGDPSTRSWPPGSRVEGAEDEEEEESFP 250 I I M I I I M I Il I I I I I I I M I I I I I M I I I I I I I I I I I I I I I I I I I M I
201 RFRGVEYVCCPPPGTPDPSGTAVGDPSTRSWPPGSRVEGAEDEEEEESFP 250
251 QPVDDYFVEPPQAEEEEETVPPPSSHTLAVVGKVTPTPRPTDGVDIYFGM 300
I Il I I I I I I I I I I Il I I I I I I I I I Il Il I I I I I I I Il Il I I Il I Il I I Il 251 QPVDDYFVEPPQAEEEEETVPPPSSHTLAVVGKVTPTPRPTDGVDIYFGM 300
301 PGEISEHEGFLRAKMDLEERRMRQINEVMREWAMADNQSKNLPKADRQAL 350
I I I I I I Il I I I I I I I I I I Il Il I I I I Il I I I I Il I I Il Il I Il I I I I I I I 301 PGEISEHEGFLRAKMDLEERRMRQINEVMREWAMADNQSKNLPKADRQAL 350 . . . . .
351 NE 352
I I 351 NEHFQSILQTLEEQVSGERQRLVETHATRVIALINDQRRAALEGFLAALQ 400
353 AERVLLALRRYLRAEQKEQRHTLRHYQHVAAVDPEKAQQMRFQVH 397
401 ADPPQAERVLLALRRYLRAEQKEQRHTLRHYQHVAAVDPEKAQQMRFQVH 450
398 THLQVIEERVNQSLGLLDQNPHLAQELRPQIQELLHSEHLGPSELEAPAP 447
I I I I I I Il I I I I i I I I I I I I I Il I I I I I I I I I I I I I I I Il I I I I I I I I I I 451 THLQVIEERVNQSLGLLDQNPHLAQELRPQIQELLHSEHLGPSELEAPAP 500
448 GGSSEDKGGLQPPDSKDDTPMTLPKGSTEQDAASPEKEKMNPLEQYERKV 497
II I Il I 1 I Il I I I Il I I I I I I Il I I I I I Il Il I I Il I I I Il I I I I I I I Il
501 GGSSEDKGGLQPPDSKDDTPMTLPKGSTEQDAASPEKEKMNPLEQYERKV 550 . . . . .
498 NASVPRGFPFHSSEIQRDELAPAGTGVSREAVSGLLIMGAGGGSLIVLSM 547
M I I I I I I M I I I M I I M I I I I I I I I I I I I I I M I I I M I I M I I I I I I
551 NASVPRGFPFHSSEIQRDELAPAGTGVSREAVSGLLIMGAGGGSLIVLSM 600
548 LLLRRKKPYGAISHGVVEVDPMLTLEEQQLRELQRHGYENPTYRFLEERP 597
IMMMIMIIMMMMMMMIMIMMMMMMIIMMM
601 LLLRRKKPYGAISHGWEVDPMLTLEEQQLRELQRHGYENPTYRFLEERP 650
Sequence name: APP1_HUMAN
Sequence documentation:
Alignment of: M78076_PEA_l_P24 x APPl_HϋMAN
Alignment segment 1/1:
Quality: 4791.00 Escore: 0
Matching length: 485 Total length: 485 Matching Percent Similarity: 99.79 Matching Percent Identity: 99.59
Total Percent Similarity: 99.79 Total Percent Identity: 99.59
Gaps : 0
Alignment :
1 MGPASPAARGLSRRPGQPPLPLLLPLLLLLLRAQPAIGSLAGGSPGAAEA 50 I I I I I I I I I I I I I I I I I I I I I I I I I I I I I Il I I ! I I I I I I Il I I I I I I I I 1 MGPASPAARGLSRRPGQPPLPLLLPLLLLLLRAQPAIGSLAGGSPGAAEA 50
51 PGSAQVAGLCGRLTLHRDLRTGRWEPDPQRSRRCLRDPQRVLEYCRQMYP 100
I I Il I I I I I I I I I I I I I I I I I I Il I Il I I I Il I I Il Il I I I I I Il I I I I I
51 PGSAQVAGLCGRLTLHRDLRTGRWEPDPQRSRRCLRDPQRVLEYCRQMYP 100 . . . . .
101 ELQIARVEQATQAIPMERWCGGSRSGSCAHPHHQWPFRCLPGEFVSEAL 150
I I I I Il I I I I I Il I I I Il I I I I I I I I I I I I I I I I I I I I I Il I I I I Il Il I
101 ELQIARVEQATQAIPMERWCGGSRSGSCAHPHHQWPFRCLPGEFVSEAL 150
151 LVPEGCRFLHQERMDQCESSTRRHQEAQEACSSQGLILHGSGMLLPCGSD 200
M I I I M M I I I I I I M I M M I I I I M M I M M I I I I I I M I I I M I I
151 LVPEGCRFLHQERMDQCESSTRRHQEAQEACSSQGLILHGSGMLLPCGSD 200
201 RFRGVEYVCCPPPGTPDPSGTAVGDPSTRSWPPGSRVEGAEDEEEEESFP 250 I I Il I M M Il Il M I I M M Il M Il I M Il Il I I I M Il Il M Il Il I
201 RFRGVEYVCCPPPGTPDPSGTAVGDPSTRSWPPGSRVEGAEDEEEEESFP 250
251 QPVDDYFVEPPQAEEEEETVPPPSSHTLAVVGKVTPTPRPTDGVDIYFGM 300
1111!111111111111111111!1!111111I)III)IIIIIIMIIII 251 QPVDDYFVEPPQAEEEEETVPPPSSHTLAVVGKVTPTPRPTDGVDIYFGM 300 . . . . .
301 PGEISEHEGFLRAKMDLEERRMRQINEVMREWAMADNQSKNLPKADRQAL 350
I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I
301 PGEISEHEGFLRAKMDLEERRMRQINEVMREWAMADNQSKNLPKADRQAL 350
351 NEHFQSILQTLEEQVSGERQRLVETHATRVIALINDQRRAALEGFLAALQ 400 I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I
351 NEHFQSILQTLEEQVSGERQRLVETHATRVIALINDQRRAALEGFLAALQ 400
401 ADPPQAERVLLALRRYLRAEQKEQRHTLRHYQHVAAVDPEKAQQMRFQVH 450 I I I I I I I I I I I I I I I I Il I I Il I I I I I I I I I I I I I I Il I I I I I I I I I I I I
401 ADPPQAERVLLALRRYLRAEQKEQRHTLRHYQHVAAVDPEKAQQMRFQVH 450
451 THLQVIEERVNQSLGLLDQNPHLAQELRPQIRECL 485 I 451 THLQVIEERVNQSLGLLDQNPHLAQELRPQIQELL 485
Sequence name: APPl_HUMAN
Sequence documentation:
Alignment of: M78076_PEA_l_P2 x APPl_HUMAN
Alignment segment 1/1:
Quality: 4474.00 Escore: 0
Matching length: 454 Total length: 454
Matching Percent Similarity: 99.56 Matching Percent Identity: 99.34 Total Percent Similarity: 99.56 Total Percent Identity: 99.34
Gaps : 0
Alignment : . . . . .
1 MGPASPAARGLSRRPGQPPLPLLLPLLLLLLRAQPAIGSLAGGSPGAAEA 50
1111111!111111111111!11!!111111111!1111IMIMIIIII
1 MGPASPAARGLSRRPGQPPLPLLLPLLLLLLRAQPAIGSLAGGSPGAAEA 50
51 PGSAQVAGLCGRLTLHRDLRTGRWEPDPQRSRRCLRDPQRVLEYCRQMYP 100
Il I I I I I I I I I I I Il I I I I Il I Il I I I I I I I I I I I I I I I I I I I I I I I I I I
51 PGSAQVAGLCGRLTLHRDLRTGRWEPDPQRSRRCLRDPQRVLEYCRQMYP 100
101 ELQIARVEQATQAIPMERWCGGSRSGSCAHPHHQWPFRCLPGEFVSEAL 150 11111111111!!11!11!1111111!111!11!1111!!1!!IMIII!
101 ELQIARVEQATQAIPMERWCGGSRSGSCAHPHHQWPFRCLPGEFVSEAL 150
151 LVPEGCRFLHQERMDQCESSTRRHQEAQEACSSQGLILHGSGMLLPCGSD 200 11111!!1111111111!11!1111!11!!1111!111!!MMIMIII 151 LVPEGCRFLHQERMDQCESSTRRHQEAQEACSSQGLILHGSGMLLPCGSD 200
201 RFRGVEYVCCPPPGTPDPSGTAVGDPSTRSWPPGSRVEGAEDEEEEESFP 250
I I I I I I I i I I I I I I I I i I I I I I I I 1 I I I I I I I I I I ! I I I I I I I I I I I I I 1
201 RFRGVEYVCCPPPGTPDPSGTAVGDPSTRSWPPGSRVEGAEDEEEEESFP 250
251 QPVDDYFVEPPQAEEEEETVPPPSSHTLAVVGKVTPTPRPTDGVDIYFGM 300
I I I I I I I I I I I I I I I I I I I I 1 I I I I I I I I I I I I I I I I I Il I I I I I I I I I I
251 QPVDDYFVEPPQAEEEEETVPPPSSHTLAVVGKVTPTPRPTDGVDIYFGM 300
301 PGEISEHEGFLRAKMDLEERRMRQINEVMREWAMADNQSKNLPKADRQAL 350 M I M I I M I M M M M M I I I M I M I M I I I I M I I I M I I M M M
301 PGEISEHEGFLRAKMDLEERRMRQINEVMREWAMADNQSKNLPKADRQAL 350
351 NEHFQSILQTLEEQVSGERQRLVETHATRVIALINDQRRAALEGFLAALQ 400
M M Il Il I I M I I Il I I M M Il M Il I Il M M I Il I I M M Il Il Il 351 NEHFQSILQTLEEQVSGERQRLVETHATRVIALINDQRRAALEGFLAALQ 400
401 ADPPQAERVLLALRRYLRAEQKEQRHTLRHYQHVAAVDPEKAQQMRFQVL 450
M Il I I I M I I I I M Il I M I M I I I M Il I M M I M Il M M Il Il I
401 ADPPQAERVLLALRRYLRAEQKEQRHTLRHYQHVAAVDPEKAQQMRFQVH 450
451 TSFQ 454
I : I 451 THLQ 454
Sequence name: APP1_HUMAN
Sequence documentation:
Alignment of: M78076_PEA_l_P25 x APP1_HUMAN
Alignment segment 1/1:
Quality: 4455.00 Escore: 0
Matching length: 448 Total length: 448
Matching Percent Similarity: 100.00 Matching Percent Identity: 100.00
Total Percent Similarity: 100.00 Total Percent Identity: 100.00 Gaps: 0
Alignment :
1 MGPASPAARGLSRRPGQPPLPLLLPLLLLLLRAQPAIGSLAGGSPGAAEA 50 I I I I I I I I I I I I I I I I I M I I I I I I I I I I I M I I Il I I I I I Il I I Il I I I
1 MGPASPAARGLSRRPGQPPLPLLLPLLLLLLRAQPAIGSLAGGSPGAAEA 50
51 PGSAQVAGLCGRLTLHRDLRTGRWEPDPQRSRRCLRDPQRVLEYCRQMYP 100
M I M M M I I I M I I I M I M M I I I I I I M M I I M I I I I M M I I I I 51 PGSAQVAGLCGRLTLHRDLRTGRWEPDPQRSRRCLRDPQRVLEYCRQMYP 100
101 ELQIARVEQATQAIPMERWCGGSRSGSCAHPHHQWPFRCLPGEFVSEAL 150
M I I M M M I M Il I I I Il I Il M M Il Il Il Il I Il Il M I I M M M
101 ELQIARVEQATQAIPMERWCGGSRSGSCAHPHHQWPFRCLPGEFVSEAL 150 . . . . .
151 LVPEGCRFLHQERMDQCESSTRRHQEAQEACSSQGLILHGSGMLLPCGSD 200
I I I I I I I I I I I I I I I I I I I I I I I l I I I I I I I I I I 1 I I I I I I I I I I I I I I I
151 LVPEGCRFLHQERMD'QCESSTRRHQEAQEACSSQGLILHGSGMLLPCGSD 200
201 RFRGVEYVCCPPPGTPDPSGTAVGDPSTRSWPPGSRVEGAEDEEEEESFP 250 I I I I I I Il I I Il I I I I M I Il I I I I Il I Il Il I I I I I Il Il Il I I I I I I I
201 RFRGVEYVCCPPPGTPDPSGTAVGDPSTRSWPPGSRVEGAEDEEEEESFP 250
251 QPVDDYFVEPPQAEEEEETVPPPSSHTLAVVGKVTPTPRPTDGVDIYFGM 300
I I I I Il Il I I I I Il I I I I I 1 I I I I I I I I I I I Il I I I I I Il 1 I I Il I I I I I 251 QPVDDYFVEPPQAEEEEETVPPPSSHTLAVVGKVTPTPRPTDGVDIYFGM 300
301 PGEISEHEGFLRAKMDLEERRMRQINEVMREWAMADNQSKNLPKADRQAL 350
1 I I I I I Il I I Il I I I I I I I I I I I I I I I I I I I I I I I Il I I Il I I I I I I I I I
301 PGEISEHEGFLRAKMDLEERRMRQINEVMREWAMADNQSKNLPKADRQAL 350 . . . . .
351 NEHFQSILQTLEEQVSGERQRLVETHATRVIALINDQRRAALEGFLAALQ 400
I I I I I I I I I Il I I I Il I I I I I I I I I I I I Il I I Il I Il I I I I Il I I Il I I I 351 NEHFQSILQTLEEQVSGERQRLVETHATRVIALINDQRRAALEGFLAALQ 400
401 ADPPQAERVLLALRRYLRAEQKEQRHTLRHYQHVAAVDPEKAQQMRFQ 448
I M I M M I I M I I I I M M I M I I M I I I I I I M I I I I I I M I I I M
401 ADPPQAERVLLALRRYLRAEQKEQRHTLRHYQHVAAVDPEKAQQMRFQ 448
DESCRIPTION FOR CLUSTER T99080
Cluster T99080 features 14 transcript(s) and 11 segment(s) of interest, the names for which are given in Tables 751 and 752, respectively, the sequences themselves are given at the end of the application. The selected protein variants are given in table 753. Table 751 - Transcripts of interest
Table 753 - Proteins of interest
These sequences are variants of the known protein Acylphosphatase, organ- common type isozyme (SwissProt accession identifier ACYO-HUMAN; known also according to the synonyms EC 3.6.1.7; Acylphosphate phosphohydrolase; Acylphosphatase, erythrocyte isozyme), SEQ ID NO: 1440, referred to herein as the previously known protein.
The sequence for protein Acylphosphatase, organ-common type isozyme is given at the end of the application, as "Acylphosphatase, organ-common type isozyme amino acid sequence". Known polymorphisms for this sequence are as shown in Table 754.
Table 754 -Amino acid mutations for Known Protein
The following GO Annotation(s) apply to the previously known protein. The following annotation(s) were found: phosphate metabolism, which are annotation(s) related to Biological Process; and acylphosphatase, which are annotation(s) related to Molecular Function.
The GO assignment relies on information from one or more of the SwissProt/TremBl Protein knowledgebase, available from <http://www.expasy.ch/sprot/>; or Locuslink, available from <http://www.ncbi.nlm.nih.gov/projects/LocusLink/>.
As noted above, cluster T99080 features 14 transcript(s), which were listed in Table 1 above. These transcript(s) encode for protein(s) which are variant(s) of protein Acylphosphatase, organ-common type isozyme. A description of each variant protein according to the present invention is now provided.
Variant protein T99080_PEA_4_Pl according to the present invention has an amino acid sequence as given at the end of the application; it is encoded by transcript(s) T99080JPEA_4_T0. The location of the variant protein was determined according to results from a number of different software programs and analyses, including analyses from SignalP and other specialized programs. The variant protein is believed to be located as follows with regard to the cell: secreted. The protein localization is believed to be secreted because both signal-peptide prediction programs predict that this protein has a signal peptide, and neither trans- membrane region prediction program predicts that this protein has a trans -membrane region.
Variant protein T99O8O_PEA_4_P1 also has the following non-silent SNPs (Single Nucleotide Polymorphisms) as listed in Table 755, (given according to their position(s) on the amino acid sequence, with the alternative amino acid(s) listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein T99080_PEA_4_Pl sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 755 - Amino acid mutations
Variant protein T99080_PEA_4_Pl is encoded by the following transcript(s): T99080_PEA_4_T0, for which the sequence(s) is/are given at the end of the application. The coding portion of transcript T99080_PEA_4_T0 is shown in bold; this coding portion starts at position 226 and ends at position 411. The transcript also has the following SNPs as listed in Table 756 (given according to their position on the nucleotide sequence, with the alternative nucleic acid listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein T99O8OJPEA_4_P1 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 756 - Nucleic acid SNPs
Variant protein T99080JPEA 4 P2 according to the present invention has an amino acid sequence as given at the end of the application; it is encoded by transcript(s) T99080_PEA_4_T2. The location of the variant protein was determined according to results from a number of different software programs and analyses, including analyses from SignalP and other specialized programs. The variant protein is believed to be located as follows with regard to the cell: membrane. The protein localization is believed to be membrane because although it is a partial protein, because both trans -membrane region prediction programs predict that this protein has a trans -membrane region.
Variant protein T99080JPEA_4_P2 is encoded by the following transcript(s): T99080_PEA_4_T2, for which the sequence(s) is/are given at the end of the application. The
coding portion of transcript T99080_PEA_4_T2 is shown in bold; this coding portion starts at position 1 and ends at position 192. The transcript also has the following SNPs as listed in Table 757 (given according to their position on the nucleotide sequence, with the alternative nucleic acid listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein T99080_PEA_4_P2 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 757- Nucleic acid SNPs
Variant protein T99080_PEA_4_P5 according to the present invention has an amino acid sequence as given at the end of the application; it is encoded by transcript(s) T99080_PEA_4_T6. An alignment is given to the known protein (Acylphosphatase, organ- common type isozyme) at the end of the application. One or more alignments to one or more previously published protein sequences are given at the end of the application. A brief description of the relationship of the variant protein according to the present invention to each such aligned protein is as follows:
Comparison report between T99080_PEA_4_P5 and ACYO_HUMAN_V1 (SEQ ID NO: 1441):
1.An isolated chimeric polypeptide encoding for T99080_PEA_4_P5, comprising a first amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence MPASARLAGAGLLLAFLRALGCAGRAPGLS corresponding to amino acids 1 - 30 of T99080_PEA_4_P5, and a second amino acid sequence being at least 90 % homologous to
MAEGNTLISVDYEIFGKVQGVFFRKHTQAEGKKLGLVGWVQNTDRGTVQGQLQGPIS KVRHMQEWLETRGSPKSHIDKANFNNEKVILKLDYSDFQIVK corresponding to amino acids 1 - 99 of AC YOJHUM AN_V1, which also corresponds to amino acids 31 - 129 of T99080_PEA_4_P5, wherein said first amino acid sequence and second amino acid sequence are contiguous and in a sequential order.
2.An isolated polypeptide encoding for a head of T99080_PEA_4_P5, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence MPASARLAGAGLLLAFLRALGCAGRAPGLS of T99080_PEA_4JP5.
It should be noted that the known protein sequence (ACYOJHUMAN) has one or more changes than the sequence given at the end of the application and named as being the amino acid sequence for ACYOJHUMANJVl. These changes were previously known to occur and are listed in the table below. Table 758 - Changes to ACYO_HUMAN_V1
The location of the variant protein was determined according to results from a number of different software programs and analyses, including analyses from SignalP and other specialized programs. The variant protein is believed to be located as follows with regard to the cell: secreted. The protein localization is believed to be secreted because both signal-peptide prediction programs predict that this protein has a signal peptide, and neither trans -membrane region prediction program predicts that this protein has a trans -membrane region.
Variant protein T99080_PEA_4_P5 also has the following non- silent SNPs (Single Nucleotide Polymorphisms) as listed in Table 759, (given according to their position(s) on the amino acid sequence, with the alternative amino acid(s) listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein T99080JPEA_4JP5
sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 759 - Amino acid mutations
Variant protein T99080_PEA_4_P5 is encoded by the following transcript(s):
T99080_PEA_4_T6, for which the sequence(s) is/are given at the end of the application. The coding portion of transcript T99080_PEA_4_T6 is shown in bold; this coding portion starts at position 226 and ends at position 612. The transcript also has the following SNPs as listed in Table 760 (given according to their position on the nucleotide sequence, with the alternative nucleic acid listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein T99080_PEA_4_P5 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 760 - Nucleic acid SNPs
Variant protein T99080_PEA_4_P8 according to the present invention has an amino acid sequence as given at the end of the application; it is encoded by transcript(s) T99080JPEA_4_T9. An alignment is given to the known protein (Acylphosphatase, organ- common type isozyme) at the end of the application. One or more alignments to one or more previously published protein sequences are given at the end of the application. A brief
description of the relationship of the variant protein according to the present invention to each such aligned protein is as follows:
Comparison report between T99080_PEA_4_P8 and ACYO_HUMAN_V1: 1.An isolated chimeric polypeptide encoding for T99080_PEA_4_P8, comprising a first amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence M corresponding to amino acids 1 - 1 of T99080_PEA_4_P8, and a second amino acid sequence being at least 90 % homologous to
QAEGKKLGLVGWVQNTDRGTVQGQLQGPISKVRHMQEWLETRGSPKSHIDKANFNNE KVILKLDYSDFQIVK corresponding to amino acids 28 - 99 of ACYO_HUMAN_V1 , which also corresponds to amino acids 2 - 73 of T99080_PEA_4_P8, wherein said first amino acid sequence and second amino acid sequence are contiguous and in a sequential order.
It should be noted that the known protein sequence (ACYO_HUMAN) has one or more changes than the sequence given at the end of the application and named as being the amino acid sequence for ACYO_HUMAN_V1. These changes were previously known to occur and are listed in the table below.
Table 761 - Changes to ACYOJiUMANJVl
The location of the variant protein was determined according to results from a number of different software programs and analyses, including analyses from SignalP and other specialized programs. The variant protein is believed to be located as follows with regard to the cell: intracellularly. The protein localization is believed to be intracellularly because neither of the trans- membrane region prediction programs predicted a trans -membrane region for this protein. In addition both signatpeptide prediction programs predict that this protein is a non-secreted protein.
Variant protein T99080_PEA__4JP8 is encoded by the following transcript(s): T99080_PEA_4_T9, for which the sequence(s) is/are given at the end of the application. The coding portion of transcript T99080_PEA_4_T9 is shown in bold; this coding portion starts at position 162 and ends at position 380. The transcript also has the following SNPs as listed in Table 762 (given according to their position on the nucleotide sequence, with the alternative nucleic acid listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein T99080_PEA_4_P8 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 762 - Nucleic acid SNPs
Variant protein T99080_PEA_4_P9 according to the present invention has an amino acid sequence as given at the end of the application; it is encoded by transcript(s) T99080_PEA_4_T10. The location of the variant protein was determined according to results from a number of different software programs and analyses, including analyses from SignalP and other specialized programs. The variant protein is believed to be located as follows with regard to the cell: membrane. The protein localization is believed to be membrane because although it is a partial protein, because both trans -membrane region prediction programs predict that this protein has a trans -membrane region.
Variant protein T99080_PEA_4_P9 is encoded by the following transcript(s): T99080_PEA_4_T10, for which the sequence(s) is/are given at the end of the application. The coding portion of transcript T99080JPEA_4__T10 is shown in bold; this coding portion starts at position 1 and ends at position 261. The transcript also has the following SNPs as listed in Table
763 (given according to their position on the nucleotide sequence, with the alternative nucleic acid listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein T99080JPEA 4JP9 sequence provides support for the deduced sequence of this variant protein according to the present invention). Table 763 - Nucleic acid SNPs
Variant protein T99080_PEA_4_P10 according to the present invention has an amino acid sequence as given at the end of the application; it is encoded by transcript(s) T99080_PEA_4_Tl 1. The location of the variant protein was determined according to results from a number of different software programs and analyses, including analyses from SignalP and other specialized programs. The variant protein is believed to be located as follows with regard to the cell: membrane. The protein localization is believed to be membrane because although it is a partial protein, because both trans -membrane region prediction programs predict that this protein has a trans -membrane region.
Variant protein T99080_PEA_4_P10 is encoded by the following transcript(s): T99080_PEA_4_Tl 1, for which the sequence(s) is/are given at the end of the application. The coding portion of transcript T99080_PEA_4_Tl 1 is shown in bold; this coding portion starts at position 1 and ends at position 240. The transcript also has the following SNPs as listed in Table 764 (given according to their position on the nucleotide sequence, with the alternative nucleic acid listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein T99080_PEA_4_P10 sequence provides support for the deduced sequence of this variant protein according to the present invention). Table 764 - Nucleic acid SNPs
Variant protein T99080_PEA_4_P12 according to the present invention has an amino acid sequence as given at the end of the application; it is encoded by transcript(s) T99080_PEA_4_T14. The location of the variant protein was determined according to results from a number of different software programs and analyses, including analyses from SignalP and other specialized programs. The variant protein is believed to be located as follows with regard to the cell: membrane. The protein localization is believed to be membrane because although it is a partial protein, because both trans -membrane region prediction programs predict that this protein has a trans -membrane region.
Variant protein T99080_PEA_4_P12 is encoded by the following transcript(s): T99080_PEA_4_T14, for which the sequence(s) is/are given at the end of the application. The coding portion of transcript T99080_PEA_4_T14 is shown in bold; this coding portion starts at position 1 and ends at position 282.
Variant protein T99080_PEA_4_P13 according to the present invention has an amino acid sequence as given at the end of the application; it is encoded by transcript(s) T99080_PEA_4_T17. The location of the variant protein was determined according to results from a number of different software programs and analyses, including analyses from SignalP and other specialized programs. The variant protein is believed to be located as follows with regard to the cell: membrane. The protein localization is believed to be membrane because although it is a partial protein, because both trans -membrane region prediction programs predict that this protein has a trans- membrane region.
Variant protein T99080_PEA_4JP13 is encoded by the following transcript(s): T99080_PEA_4_T17, for which the sequence(s) is/are given at the end of the application. The coding portion of transcript T99080_PEA_4_T17 is shown in bold; this coding portion starts at position 1 and ends at position 207.
Variant protein T99080_PEA_4JP14 according to the present invention has an amino acid sequence as given at the end of the application; it is encoded by transcript(s) T99080_PEA_4_T18. The location of the variant protein was determined according to results from a number of different software programs and analyses, including analyses from SignalP and other specialized programs. The variant protein is believed to be located as follows with regard to the cell: secreted. The protein localization is believed to be secreted because both signal-peptide prediction programs predict that this protein has a signal peptide, and neither trans- membrane region prediction program predicts that this protein has a trans -membrane region.
Variant protein T99080_PEA_4_P14 also has the following non-silent SNPs (Single Nucleotide Polymorphisms) as listed in Table 765, (given according to their position(s) on the amino acid sequence, with the alternative amino acid(s) listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein T99080_PEA_4_P14 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 765 -Amino acid mutations
Variant protein T99080_PEA_4_P14 is encoded by the following transcript(s):
T99080_PEA_4_T18, for which the sequence(s) is/are given at the end of the application. The coding portion of transcript T99080_PEA_4_T18 is shown in bold; this coding portion starts at
position 226 and ends at position 480. The transcript also has the following SNPs as listed in Table 766 (given according to their position on the nucleotide sequence, with the alternative nucleic acid listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein T99080_PEA_4_P14 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 766 - Nucleic acid SNPs
Variant protein T99080_PEA_4_P15 according to the present invention has an amino acid sequence as given at the end of the application; it is encoded by transcript(s)
T99080_PEA_4_T19. The location of the variant protein was determined according to results from a number of different software programs and analyses, including analyses from SignalP and other specialized programs. The variant protein is believed to be located as follows with regard to the cell: secreted. The protein localization is believed to be secreted because both signal-peptide prediction programs predict that this protein has a signal peptide, and neither trans- membrane region prediction program predicts that this protein has a trans- membrane region.
Variant protein T99080_PEA_4_P15 also has the following non-silent SNPs (Single Nucleotide Polymorphisms) as listed in Table 767, (given according to their position(s) on the amino acid sequence, with the alternative amino acid(s) listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein T99080_JPEA_4_P15 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 767 - Amino acid mutations
Variant protein T99080_PEA_4_P15 is encoded by the following transcript(s): T99080_PEA_4_T19, for which the sequence(s) is/are given at the end of the application. The coding portion of transcript T99080_PEA_4_T19 is shown in bold; this coding portion starts at position 226 and ends at position 459. The transcript also has the following SNPs as listed in Table 768 (given according to their position on the nucleotide sequence, with the alternative nucleic acid listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein T99080_PEA_4_P15 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 768 - Nucleic acid SNPs
Variant protein T99080JPEA 4JP16 according to the present invention has an amino acid sequence as given at the end of the application; it is encoded by transcript(s) T99080_PEA_4_T20. The location of the variant protein was determined according to results from a number of different software programs and analyses, including analyses from SignalP and other specialized programs. The variant protein is believed to be located as follows with regard to the cell: secreted. The protein localization is believed to be secreted because both signal-peptide prediction programs predict that this protein has a signal peptide, and neither
trans- membrane region prediction program predicts that this protein has a trans -membrane region.
Variant protein T99080JPEA_4_P16 also has the following non- silent SNPs (Single Nucleotide Polymorphisms) as listed in Table 769, (given according to their position(s) on the amino acid sequence, with the alternative amino acid(s) listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein T99080_PEA_4_P16 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 769 - Amino acid mutations
Variant protein T99080_PEA_4_P16 is encoded by the following transcript(s): T99080_PEA_4_T20, for which the sequence(s) is/are given at the end of the application. The coding portion of transcript T99080JPEA_4_T20 is shown in bold; this coding portion starts at position 226 and ends at position 501. The transcript also has the following SNPs as listed in Table 770 (given according to their position on the nucleotide sequence, with the alternative nucleic acid listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein T99080_PEA_4_P16 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 770 - Nucleic acid SNPs
Variant protein T99080_PEA_4_P17 according to the present invention has an amino acid sequence as given at the end of the application; it is encoded by transcript(s) T99080_PEA_4_T21. The location of the variant protein was determined according to results
from a number of different software programs and analyses, including analyses from SignalP and other specialized programs. The variant protein is believed to be located as follows with regard to the cell: secreted. The protein localization is believed to be secreted because both signal-peptide prediction programs predict that this protein has a signal peptide, and neither trans- membrane region prediction program predicts that this protein has a trans -membrane region
Variant protein T99080_PEA_4_P17 also has the following non-silent SNPs (Single Nucleotide Polymorphisms) as listed in Table 771, (given according to their position(s) on the amino acid sequence, with the alternative amino acid(s) listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein T99080_PEA_4_P17 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 771 - Amino acid mutations
Variant protein T99080_PEA_4_P17 is encoded by the following transcript(s): T99080_PEA_4_T21, for which the sequence(s) is/are given at the end of the application. The coding portion of transcript T99080_PEA_4_T21 is shown in bold; this coding portion starts at position 226 and ends at position 426. The transcript also has the following SNPs as listed in Table 772 (given according to their position on the nucleotide sequence, with the alternative nucleic acid listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein T99080_PEA_4_P17 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 772 - Nucleic acid SNPs
As noted above, cluster T99080 features 11 segment(s), which were listed in Table 2 above and for which the sequence(s) are given at the end of the application. These segment(s) are portions of nucleic acid sequence(s) which are described herein separately because they are of particular interest. A description of each segment according to the present invention is now provided.
Segment cluster T99080_PEA_4_node_l according to the present invention is supported by 5 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): T99080_PEA_4_T0, T99080_PEA_4_T6, T99080_PEA_4_T13, T99080_PEA_4_T18, T99080_PEA_4_T19, T99080_PEA_4_T20 and T99080_PEA_4_T21. Table 773 below describes the starting and ending position of this segment on each transcript. Table 773 - Segment location on transcripts
Segment cluster T99080_PEA_4_node_6 according to the present invention is supported by 3 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): T99080_PEA_4_T17 and T99080_PEA_4_T21. Table 774 below describes the starting and ending position of this segment on each transcript.
Table 774 - Segment location on transcripts
Segment cluster T99080_PEA_4_node_l 1 according to the present invention is supported by 7 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): T99080_PEA_4_T14 and T99080_PEA_4_T20. Table 775 below describes the starting and ending position of this segment on each transcript.
Table 775 - Segment location on transcripts
Segment cluster T99080_PEA_4_node_19 according to the present invention is supported by 59 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): T99080_PEA_4_T0, T99080_PEA_4_T2 and T99080_PEA_4_T4. Table 776 below describes the starting and ending position of this segment on each transcript.
Table 776 - Segment location on transcripts
Segment cluster T99080_PEA_4_node_20 according to the present invention is supported by 98 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): T99080_PEA_4_T0, T99080_PEA_4_T2, T99080_PEA_4_T4, T99080_PEA_4_T6, T99080_PEA_4_T9, T99080_PEA_4_T10, T99080_PEA_4_Tl l, T99080_PEA_4_T13, T99080_PEA_4_T18 and T99080_PEA_4_T19. Table 777 below describes the starting and ending position of this segment on each transcript.
Table 777 - Segment location on transcripts
According to an optional embodiment of the present invention, short segments related to the above cluster are also provided. These segments are up to about 120 bp in length, and so are included in a separate description.
Segment cluster T99080_PEA_4_node_3 according to the present invention is supported by 40 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): T99080_PEA_4_T2, T99080_PEA_4_T9, T99080_PEA_4_T10, T99080JPEA_4_Tl l, T99080_PEA_4_T14 and T99080_PEA_4_T17. Table 778 below describes the starting and ending position of this segment on each transcript.
Table 778 - Segment location on transcripts
Segment cluster T99080_PEA_4_node_5 according to the present invention is supported by 57 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): T99080_PEA_4_T0, T99080_PEA_4_T2, T99080_PEA_4_T6, T99080_PEA_4_T10, T99080_PEA_4_Tl l, T99080_PEA_4_T14, T99080_PEA_4_T17, T99080JPEA_4_T18, T99080_PEA_4_T19, T99080_PEA_4_T20 and T99080_PEA_4_T21. Table 779 below describes the starting and ending position of this segment on each transcript.
Table 779 - Segment location on transcripts
Segment cluster T99080_PEA_4_node_8 according to the present invention is supported by 12 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): T99080JΕA_4_T9, T99080_PEA_4_T10, T99080_PEA_4_T14, T99080_PEA_4_T18 and T99080_PEA_4_T20. Table 780 below describes the starting and ending position of this segment on each transcript.
Table 780 - Segment location on transcripts
Microarray (chip) data is also available for this segment as follows. As described above with regard to the cluster itself, various oligonucleotides were tested for being differentially expressed in various disease conditions, particularly cancer. The following oligonucleotides were found to hit this segment (in relation to lung cancer), shown in Table 781.
Table 781 - Oligonucleotides related to this segment
Segment cluster T99080_PEA_4__node_13 according to the present invention is supported by 2 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): T99080_PEA_4_T4. Table 782 below describes the starting and ending position of this segment on each transcript.
Table 782 - Segment location on transcripts
Segment cluster T99080_PEA_4_node_15 according to the present invention is supported by 6 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): T99080_PEA_4_Tl 1 and T99080_PEA_4_T19. Table 783 below describes the starting and ending position of this segment on each transcript.
Table 783 - Segment location on transcripts
Segment cluster T99080_PEA_4_node_18 according to the present invention is supported by 5 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): T99080_PEA_4_T0 and T99080_PEA_4_T2. Table 784 below describes the starting and ending position of this segment on each transcript.
Table 784 - Segment location on transcripts
Variant protein alignment to the previously known protein:
Sequence name: ACYO_HUMAN_V1
Sequence documentation:
Alignment of: T99080_PEA__4_P5 x ACYO_HUMAN_V1
Alignment segment 1/1:
Quality: 973.00 Escore: 0
Matching length: 99 Total length: 99
Matching Percent Similarity: 100.00 Matching Percent Identity: 100.00
Total Percent Similarity: 100.00 Total Percent Identity: 100.00 Gaps : 0
Alignment :
31 MAEGNTLISVDYEIFGKVQGVFFRKHTQAEGKKLGLVGWVQNTDRGTVQG 80
1 MAEGNTLISVDYEIFGKVQGVFFRKHTQAEGKKLGLVGWVQNTDRGTVQG 50
81 QLQGPISKVRHMQEWLETRGSPKSHIDKANFNNEKVILKLDYSDFQIVK 129
I 1 I 1 I I I I I I 11 I I I I I I I I I I 1 I I I I I I I 11 I I I I I 1 I I I I I I I I I I 1
51 QLQGPISKVRHMQEWLETRGSPKSHIDKANFNNEKVILKLDYSDFQIVK 99
Sequence name: ACYO_HUMAN_V1
Sequence documentation:
Alignment of: T99080_PEA_4__P8 x ACYO_HUMAN_V1
Alignment segment 1/1:
Quality: 711.00
Escore: 0
Matching length: 72 Total length: 72
Matching Percent Similarity: 100.00 Matching Percent Identity: 100.00
Total Percent Similarity: 100.00 Total Percent Identity: 100.00
Gaps : 0
Alignment:
2 QAEGKKLGLVGWVQNTDRGTVQGQLQGPISKVRHMQEWLETRGSPKSHID 51
28 QAEGKKLGLVGWVQNTDRGTVQGQLQGPISKVRHMQEWLETRGSPKSHID 77
52 KANFNNEKVILKLDYSDFQIVK 73
78 KANFNNEKVILKLDYSDFQIVK 99
DESCRIPTION FOR CLUSTER T08446
Cluster T08446 features 2 transcript(s) and 36 segment(s) of interest, the names for which are given in Tables 785 and 786, respectively, the sequences themselves are given at the end of the application. The selected protein variants are given in table 787.
Table 785 - Transcripts of interest
Table 787 - Proteins of interest
These sequences are variants of the known protein Sorting nexin 26 (SwissProt accession identifier SNXQ_HUMAN), SEQ ID NO: 1442, referred to herein as the previously known protein. Protein Sorting nexin 26 is known or believed to have the following function(s): May be involved in several stages of intracellular trafficking (By similarity). The sequence for protein Sorting nexin 26 is given at the end of the application, as "Sorting nexin 26 amino acid sequence".
The following GO Annotation(s) apply to the previously known protein. The following annotation(s) were found: intracellular protein traffic, which are annotation(s) related to Biological Process; and protein transporter, which are annotation(s) related to Molecular Function.
The GO assignment relies on information from one or more of the SwissProt/TremBl Protein knowledgebase, available from <http://www.expasy.ch/sprot/>; or Locuslink, available from <http://www.ncbi.nhn.nih.gov/projects/LocusLink/>.
As noted above, cluster T08446 features 2 transcript(s), which were listed in Table 1 above. These transcript(s) encode for protein(s) which are variant(s) of protein Sorting nexin 26. A description of each variant protein according to the present invention is now provided.
Variant protein TO8446_PEA_1_P18 according to the present invention has an amino acid sequence as given at the end of the application; it is encoded by transcript(s) T08446_PEA_l_T2. An alignment is given to the known protein (Sorting nexin 26) at the end of the application. One or more alignments to one or more previously published protein sequences are given at the end of the application. A brief description of the relationship of the variant protein according to the present invention to each such aligned protein is as follows: Comparison report between T08446_PEA_l_P 18 and SNXQ_HUMAN: LAn isolated chimeric polypeptide encoding for T08446_PEA_l_P18, comprising a first amino acid sequence being at least 90 % homologous to
MLSLSLCSHLWGPLILSALQARSTDSLDGPGEGSVQPLPTAGGPSVKGKPGKRLSAPRG PFPRLADCAHFHYENVDFGHIQLLLSPDREGPSLSGENELVFGVQVTCQGRSWPVLRSY DDFRSLDAHLHRCIFDRRFSCLPELPPPPEGARAAQMLVPLLLQYLETLSGLVDSNLNC GPVLTWME corresponding to amino acids 1 - 185 of SNXQJHUMAN, which also corresponds to amino acids 1 - 185 of T08446JPEA_l_P18, and a second amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence LDNHGRRLLLSEEASLNIPAVAAAHVIKRYTAQAPDELSFEVGDIVSVIDMPPTEDRSW WRGKPvGFQVGFFPSECVELFTERPGPGLKADADGPPCGIPAPQGISSLTSAVPRPRGKLA GLLRTFMRSRPSRQRLRQRGILRQRVFGCDLGEHLSNSGQDVPQVLRCCSEFIEAHGVV DGIYRLSGVSSNIQRLRHEFDSERIPELSGP AFLQDIHSVSSLCKLYFRELPNPLLTYQLY
GKFSEAMSVPGEEERLVRVHDVIQQLPPPHYRTLEYLLRHLARMARHSANTSMHARNL AIVWAPNLLRSMELESVGMGGAAAFREVRVQSVVVEFLLTHVDVLFSDTFTSAGLDPA GRCLLPRPKSLAGSCPSTRLLTLEEAQARTQGRLGTPTEPTTPKAPASPAERRKGERGEK QRKPGGSSWKTFFALGRGPSVPRKKPLPWLGGTRAPPQPSGSRPDTVTLRSAKSEESLS SQASGAGLQRLHRLRRPHSSSDAFPVGPAPAGSCESLSSSSSSESSSSESSSSSSESSAAGL GALSGSPSHRTSAWLDDGDELDFSPPRCLEGLRGLDFDPLTFRCSSPTPGDPAPPASPAP PAPASAFPPRVTPQAISPRGPTSPASPAALDISEPLAVSVPPAVLELLGAGGAPASATPTP ALSPGRSLRPHLIPLLLRGAEAPLTDACQQEMCSKLRGAQGPLGPDMESPLPPPPLSLLR PGGAPPPPPKNPARLMALALAERAQQVAEQQSQQECGGTPPASQSPFHRSLSLEVGGEP LGTSGSGPPPNSLAHPGAWVPGPPPYLPRQQSDGSLLRSQRPMGTSRRGLRGPAQVSAQ LRAGGGGRD APEAAAQSPCSVPSQVPTPGFFSP APRECLPPFLGVPKPGLYPLGPPSFQP SSPAPVWRSSLGPPAPLDRGENLYYEIGASEGSPYSGPTRSWSPFRSMPPDRLNASYGM LGQSPPLHRSPDFLLSYPPAPSCFPPDHLGYSAPQHPARRPTPPEPLYVNLALGPRGPSPA SSSSSSPPAHPRSRSDPGPPVPRLPQKQRAPWGPRTPHRVPGPWGPPEPLLLYRAAPPAY
GRGGELHRGSLYRNGGQRGEGAGPPPPYPTPSWSLHSEGQTRSYC corresponding to amino acids 186 - 1305 of T08446_PEA_l_P18, wherein said first amino acid sequence and second amino acid sequence are contiguous and in a sequential order.
2.An isolated polypeptide encoding for a tail of T08446_PEA_l_P18, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the
37
863 sequence
LDNHGRRLLLSEEASLNIPAVAAAHVIKRYTAQAPDELSFEVGDIVSVIDMPPTEDRSW WRGKRGFQVGFFPSECVELFTERPGPGLKADADGPPCGIP APQGISSLTSAVPRPRGKLA GLLRTFMRSRPSRQRLRQRGILRQRVFGCDLGEHLSNSGQDVPQVLRCCSEFIEAHGVV DGIYRLSGVSSNIQRLRHEFDSERIPELSGPAFLQDIHSVSSLCKLYFRELPNPLLTYQLY GKFSEAMSVPGEEERLVRVHDVIQQLPPPHYRTLEYLLRHLARMARHSANTSMHARNL AΓVWAPNLLRSMELESVGMGGAAAFREVRVQSVVVEFLLTHVDVLFSDTFTSAGLDPA GRCLLPRPKSLAGSCPSTRLLTLEEAQARTQGRLGTPTEPTTPKAP ASPAERRKGERGEK QRKPGGSSWKTFFALGRGPSVPRKKPLPWLGGTRAPPQPSGSRPDTVTLRSAKSEESLS SQASGAGLQRLHRLRRPHSSSDAFPVGPAPAGSCESLSSSSSSESSSSESSSSSSESSAAGL GALSGSPSHRTSAWLDDGDELDFSPPRCLEGLRGLDFDPLTFRCSSPTPGDP APPASP AP PAPASAFPPRVTPQAISPRGPTSPASPAALDISEPLAVSVPPAVLELLGAGGAPASATPTP ALSPGRSLRPHLIPLLLRGAEAPLTDACQQEMCSKLRGAQGPLGPDMESPLPPPPLSLLR PGGAPPPPPKNPARLMALALAERAQQVAEQQSQQECGGTPPASQSPFHRSLSLEVGGEP LGTSGSGPPPNSLAHPGAWVPGPPPYLPRQQSDGSLLRSQRPMGTSRRGLRGPAQVSAQ LRAGGGGRDAPEAAAQSPCSVPSQVPTPGFFSPAPRECLPPFLGVPKPGLYPLGPPSFQP SSPAPVWRSSLGPPAPLDRGENLYYEIGASEGSPYSGPTRSWSPFRSMPPDRLNASYGM LGQSPPLHRSPDFLLSYPPAPSCFPPDHLGYSAPQHP ARRPTPPEPLYVNLALGPRGPSPA SSSSSSPPAHPRSRSDPGPPVPRLPQKQRAPWGPRTPHRVPGPWGPPEPLLLYRAAPPAY GRGGELHRGSLYRNGGQRGEGAGPPPPYPTPSWSLHSEGQTRSYC IN
T08446_PEA_l_P18.
Comparison report between T08446_PEA_l_P18 and Q9NT23 (SEQ ID NO: 1443): 1.An isolated chimeric polypeptide encoding for T08446_PEA_l_P18, comprising a first amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence
MLSLSLCSHLWGPLILSALQARSTDSLDGPGEGSVQPLPTAGGPSVKGKPGKPJLSAPRG PFPRLADCAHFHYENVDFGHIQLLLSPDREGPSLSGENELVFGVQVTCQGRSWPVLRSY DDFRSLDAHLHRCIFDRRFSCLPELPPPPEGARAAQMLVPLLLQYLETLSGLVDSNLNC GPVLTWMELDNHGRRLLLSEEASLNIPAVAAAHVIKRYTAQAPDELSFEVGDIVSVIDM
PPTEDRSWWRGKRGFQVGFFPSECVELFTERPGPGLKADADGPPCGIPAPQGISSLTSAV PRPRGKLAGLLRTFMRSRPSRQRLRQRGILRQRVFGCDLGEHLSNSGQDVPQVLRCCSE FIEAHGVVDGIYRLSGVSSNIQRLRHEFDSERIPELSGPAFLQDIHSVSSLCKLYFRELPNP LLTYQLYGKFSEAMSVPGEEERLVRV corresponding to amino acids 1 - 443 of T08446_PEA_l_P18, a second amino acid sequence being at least 90 % homologous to
HDVIQQLPPPHYRTLEYLLRHLARMARHSANTSMHARNLAIVWAPNLLRSMELESVG MGGAAAFREVRVQSVVVEFLLTHVDVLFSDTFTSAGLDPAGRCLLPRPKSLAGSCPSTR LLTLEEAQARTQGRLGTPTEPTTPKAPASPAERRKGERGEKQRKPGGSSWKTFFALGRG PSVPRKKPLPWLGGTRAPPQPSGSRPDTVTLRSAKSEESLSSQASGAGLQRLHRLRRPHS SSDAFPVGPAPAGSCESLSSSSSSESSSSESSSSSSESSAAGLGALS GSPSHRTSAWLDDG DELDFSPPRCLEGLRGLDFDPLTFRCSSPTPGDPAPPASPAPPAPASAFPPRVTPQAISPRG PTSPASPAALDISEPLAVSVPPAVLELLGAGGAPASATPTPALSPGRSLRPHLIPLLLRGA EAPLTDACQQEMCSKLRGAQGPLGPDMESPLPPPPLSLLRPGGAPPPPPKNP ARLMALA LAERAQQVAEQQSQQECGGTPPASQSPFHRSLSLEVGGEPLGTSGSGPPPNSLAHPGAW VPGPPPYLPRQQSDGSLLRSQRPMGTSRRGLRGPAQVSAQLRAGGGGRDAPEAAAQSP CSVPSQVPTPGFFSPAPRECLPPFLGVPKPGLYPLGPPSFQPSSPAPVWRSSLGPPAPLDR GENLYYEIGASEGSPYSG corresponding to amino acids 1 - 674 of Q9NT23, which also corresponds to amino acids 444 - 1117 of T08446_PEA_l_P18, a bridging amino acid P corresponding to amino acid 1118 of T08446_PEA_l_P18, and a third amino acid sequence being at least 90 % homologous to
TRSWSPFRSMPPDRLNASYGMLGQSPPLHRSPDFLLSYPPAPSCFPPDHLGYSAPQHPAR RPTPPEPLYVNLALGPRGPSPASSSSSSPPAHPRSRSDPGPPVPRLPQKQRAPWGPRTPHR VPGPWGPPEPLLLYRAAPPAYGRGGELHRGSLYRNGGQRGEGAGPPPPYPTPSWSLHS
EGQTRSYC corresponding to amino acids 676 - 862 of Q9NT23, which also corresponds to amino acids 1119 - 1305 of T08446_PEA_l_P18, wherein said first amino acid sequence, second amino acid sequence, bridging amino acid and third amino acid sequence are contiguous and in a sequential order.
2.An isolated polypeptide encoding for a head of T08446_PEA_l_P18, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence
MLSLSLCSHLWGPLILSALQARSTDSLDGPGEGSVQPLPTAGGPSVKGKPGKRLSAPRG PFPRLADCAHFHYENVDFGHIQLLLSPDREGPSLSGENELVFGVQVTCQGRSWP VLRSY DDFRSLDAHLHRCIFDRRFSCLPELPPPPEGARAAQMLVPLLLQYLETLSGL VDSNLNC GPVLTWMELDNHGRRLLLSEEASLNIPAVAAAHVIKRYTAQAPDELSFEVGDIVSVIDM PPTEDRSWWRGKRGFQVGFFPSECVELFTERPGPGLKADADGPPCGIPAPQGISSLTSAV PRPRGKLAGLLRTFMRSRPSRQRLRQRGILRQRVFGCDLGEHLSNSGQDVPQ VLRCCSE FIEAHGWDGIYRLSGVSSNIQRLRHEFDSERIPELSGP AFLQDIHSVSSLCKL YFRELPNP LLTYQLYGKFSEAMSVPGEEERLVRV of TO8446_PEA_1_P18.
Comparison report between T08446_PEA_l_P18 and Q96CP3 (SEQ ID NO: 1444):
1.An isolated chimeric polypeptide encoding for T08446_PEA_l_P18, comprising a first amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence MLSLSLCSHLWGPLILSALQARSTDSLDGPGEGSVQPLPTAGGPSVKGKPGKRLSAPRG PFPRLADCAHFHYENVDFGHIQLLLSPDREGPSLSGENELVFGVQVTCQGRSWPVLRSY DDFRSLDAHLHRCIFDRRFSCLPELPPPPEGARAAQMLVPLLLQYLETLSGLVDSNLNC GPVLTWMELDNHGRRLLLSEEASLNIPAVAAAHVIKRYTAQAPDELSFEVGDIVSVIDM PPTEDRSWWRGKRGFQVGFFPSECVELFTERPGPGLKADADGPPCGIPAPQGISSLTSAV PRPRGKLAGLLRTFMRSRPSRQRLRQRGILRQRVFGCDLGEHLSNSGQDVPQVLRCCSE FIEAHGVVDGIYRLSGVSSNIQRLRHEFDSERIPELSGPAFLQDIHSVSSLCKLYFRELPNP LLTYQLYGKFSEAMSVPGEEERLVRVHDVIQQLPPPHYRTLEYLLRHLARMARHSANT SMHARNLAIVWAPNLLRSMELESVGMGGAAAFREVRVQSWVEFLLTHVDVLFSDTF TSAGLDPAGRCLLPRPKSLAGSCPSTRLLTLEEAQARTQGRLGTPTEPTTPKAPASPAER RKGERGEKQRKPGGSSWKTFFALGRGPSVPRKKPLPWLGGTRAPPQPSGSRPDTVTLRS AKSEESLSSQASGAGLQRLHRLRRPHSSSDAFPVGPAPAGSCESLSSSSSSESSSSESSSSS SESSAAGLGALSGSPSHRTSAWLDDGDELDFSPPRCLEGLRGLDFDPLTFRCSSPTPGDP APPASPAPPAPASAFPPRVTPQAISPRGPTSPASPAALDISEPLAVSVPPAVLELLGAGGA PASATPTPALSPGRSLRPHLIPLLLRGAEAPLTDACQQEMCSKLRGAQGPLGPDMESPLP PPPLSLLRPGGAPPPPPKNPARLMALALAERAQQVAEQQSQQECGGTPPASQSPFHRSLS LEVGGEPLGTSGSGPPPNSLAHPGAWVPGPPPYLPRQQSDGSLLRSQRPMGTSRRG
corresponding to amino acids 1 - 1010 of T08446_PEA_l_P18, and a second amino acid sequence being at least 90 % homologous to
LRGPAQVSAQLRAGGGGRDAPEAAAQSPCSVPSQVPTPGFFSPAPRECLPPFLGVPKPG LYPLGPPSFQPSSPAPVWRSSLGPPAPLDRGENLYYEIGASEGSPYSGPTRSWSPFRSMPP DRLNASYGMLGQSPPLHRSPDFLLSYPPAPSCFPPDHLGYSAPQHPARRPTPPEPLYVNL ALGPRGPSPASSSSSSPPAHPRSRSDPGPPVPRLPQKQRAPWGPRTPHRVPGPWGPPEPL LLYRAAPPAYGRGGELHRGSLYRNGGQRGEGAGPPPPYPTPSWSLHSEGQTRSYC corresponding to amino acids 1 - 295 of Q96CP3, which also corresponds to amino acids 1011 - 1305 of T08446_PEA_l_P18, wherein said first amino acid sequence and second amino acid sequence are contiguous and in a sequential order.
2.An isolated polypeptide encoding for a head of T08446_PEA_l_P18, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence MLSLSLCSHLWGPLILSALQARSTDSLDGPGEGSVQPLPTAGGPSVKGKPGKRLSAPRG PFPRLADCAHFHYENVDFGHIQLLLSPDREGPSLSGENELVFGVQVTCQGRSWPVLRSY DDFRSLDAHLHRCIFDRRFSCLPELPPPPEGARAAQMLVPLLLQ YLETLSGLVDSNLNC
GPVLTWMELDNHGRRLLLSEEASLNIPAVAAAHVIKRYTAQAPDELSFEVGDIVSVIDM PPTEDRSWWRGKRGFQVGFFPSECVELFTERPGPGLKADADGPPCGIPAPQGISSLTSAV PRPRGKLAGLLRTFMRSRPSRQRLRQRGILRQRVFGCDLGEHLSNSGQDVPQVLRCCSE FIEAHGVVDGIYRLSGVSSNIQRLRHEFDSERIPELSGPAFLQDIHSVSSLCKLYFRELPNP LLTYQLYGKFSEAMSVPGEEERLVRVHDVIQQLPPPHYRTLEYLLRHLARMARHSANT SMHARNLAIVWAPNLLRSMELESVGMGGAAAFREVRVQSWVEFLLTHVDVLFSDTF TSAGLDPAGRCLLPRPKSLAGSCPSTRLLTLEEAQARTQGRLGTPTEPTTPKAPASPAER RKGERGEKQRKPGGSSWKTFFALGRGPSVPRKKPLPWLGGTRAPPQPSGSRPDTVTLRS AKSEESLSSQASGAGLQRLHRLRRPHSSSDAFPVGPAPAGSCESLSSSSSSESSSSESSSSS SESSAAGLGALSGSPSHRTSAWLDDGDELDFSPPRCLEGLRGLDFDPLTFRCSSPTPGDP APPASPAPPAPASAFPPRVTPQAISPRGPTSPASPAALDISEPLAVSVPPAVLELLGAGGA PASATPTPALSPGRSLRPHLIPLLLRGAEAPLTDACQQEMCSKLRGAQGPLGPDMESPLP PPPLSLLRPGGAPPPPPKNPARLMALALAERAQQVAEQQSQQECGGTPPASQSPFHRSLS
LEVGGEPLGTSGSGPPPNSLAHPGAWVPGPPPYLPRQQSDGSLLRSQRPMGTSRRG of T08446_PEA_l_P18.
Comparison report between TO8446JPEA_1JP18 and BAC86902 (SEQ ID NO: 1445): 1.An isolated chimeric polypeptide encoding for TO8446_PEA_1_P18, comprising a first amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence MLSLSLCSHLWGPLILSALQARSTDSLDGPGEGSVQPLPTAGGPSVKGKPGKRLSAPRG PFPRLADCAHFHYENVDFGHIQLLLSPDREGPSLSGENELVFGVQVTCQGRSWPVLRSY DDFRSLDAHLHRCIFDRRFSCLPELPPPPEGARAAQ corresponding to amino acids 1 - 154 of T08446_PEA_l_P18, a second amino acid sequence being at least 90 % homologous to MLVPLLLQYLETLSGLVDSNLNCGPVLTWMELDNHGRRLLLSEEASLNIPAVAAAHVI KRYTAQAPDELSFEVGDIVSVIDMPPTEDRSWWRGKRGFQVGFFPSECVELFTERPGPG LKADADGPPCGIPAPQGISSLTSAVPRPRGKLAGLLRTFMRSRPSRQRLRQRGILRQRVF GCDLGEHLSNSGQDVPQVLRCCSEFIEAHGVVDGIYRLSGVSSNIQRLRHEFDSERIPEL SGPAFLQDIHSVSSLCKLYFRELPNPLLTYQLYGKFSEAMSVPGEEERLVRVHDVIQQLP PPHYRTLEYLLRHLARMARHSANTSMHARNLAIVWAPNLLRSMELESVGMGGAAAFR EVRVQSVWEFLLTHVDVLFSDTFTSAGLDPAGRCLLPRPKSLAGSCPSTRLLTLEEAQ ARTQGRLGTPTEPTTPKAPASPAERRKGERGEKQRKPGGSSWKTFFALGRGPSVPRKKP LPWLGGTRAPPQPSGSRPDTVTLRSAKSEESLSSQASGAGLQRLHRLRRPHSSSDAFPVG PAPAGSCESLSSSSSSESSSSESSSSSSESSAAGLGALSGSPSHRTSAWLDDGDELDFSPPR CLEGLRGLDFDPLTFRCSSPTPGDPAPPASPAPPAPASAFPPRVTPQAISPRGPTSPASPAA LDISEPLAVSVPPAVLELLGAGGAPASATPTPALSPGRSLRPHLIPLLLRGAEAPLTDACQ QEMCSKLRGAQGPLGPDMESPLPPPPLSLLRPGGAPPPPPKNPARLMALALAERAQQVA EQQSQQECGGTPPASQSPFHRSLSLEVGGEPLGTSGSGPPPNSLAHPGAWVPGPPPYLPR QQSDGSLLRSQRPMGTSRRGLRGPA corresponding to amino acids 1 - 861 of BAC86902, which also corresponds to amino acids 155 - 1015 of T08446_PEA_l_P18, a third amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence QVSAQLRAGGGGRDAPEAAAQSPCSVPS corresponding to amino acids 1016 - 1043 of
T08446_PEA_l_P18, a fourth amino acid sequence being at least 90 % homologous to QVPTPGFFSPAPRECLPPFLGVPKPGLYPLGPPSFQPSSPAP VWRSSLGPPAPLDRGENLY YEIGASEGSPYSGPTRSWSPFRSMPPDRLNASYGMLGQSPPLHRSPDFLLSYPPAPSCFPP DHLGYS corresponding to amino acids 862 - 989 of BAC86902, which also corresponds to amino acids 1044 - 1171 of T08446_PEA_l_P18, and a fifth amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence
APQHPARRPTPPEPLYVNLALGPRGPSPASSSSSSPPAHPRSRSDPGPPVPRLPQKQRAP WGPRTPHRVPGPWGPPEPLLLYRAAPPAYGRGGELHRGSLYRNGGQRGEGAGPPPPYP TPSWSLHSEGQTRSYC corresponding to amino acids 1172 - 1305 of TO8446_PEA_1_P18, wherein said first amino acid sequence, second amino acid sequence, third amino acid sequence, fourth amino acid sequence and fifth amino acid sequence are contiguous and in a sequential order.
2.An isolated polypeptide encoding for a head of T08446_PEA_l_P18, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence
MLSLSLCSHLWGPLILSALQARSTDSLDGPGEGSVQPLPTAGGPSVKGKPGKRLSAPRG PFPRLADCAHFHYENVDFGHIQLLLSPDREGPSLSGENELVFGVQVTCQGRSWPVLRSY DDFRSLDAHLHRCIFDRRFSCLP ELPPPPEGARAAQ of TO8446_PEA_1_P18.
3.An isolated polypeptide encoding for an edge portion of T08446_PEA_l_P18, comprising an amino acid sequence being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence encoding for QVSAQLRAGGGGRDAPEAAAQSPCSVPS, corresponding to TO8446_PEA_1_P18.
4.An isolated polypeptide encoding for a tail of T08446JPEA_l_P18, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence APQHPARRPTPPEPLYVNLALGPRGPSPASSSSSSPPAHPRSRSDPGPPVPRLPQKQRAP
WGPRTPHRVPGPWGPPEPLLLYRAAPPAYGRGGELHRGSLYRNGGQRGEGAGPPPPYP TPSWSLHSEGQTRSYC in T08446_PEA_l_P18.
The location of the variant protein was determined according to results from a number of different software programs and analyses, including analyses from SignalP and other specialized programs. The variant protein is believed to be located as follows with regard to the cell: secreted. The protein localization is believed to be secreted because both signal-peptide prediction programs predict that this protein has a signal peptide, and neither trans -membrane region prediction program predicts that this protein has a trans -membrane region. Variant protein TO8446_PEA_1_P18 also has the following non- silent SNPs (Single
Nucleotide Polymorphisms) as listed in Table 788, (given according to their position(s) on the amino acid sequence, with the alternative amino acid(s) listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein T08446_PEA_l_P18 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 788 - Amino acid mutations
Variant protein T08446_PEA_l_P18 is encoded by the following transcript(s): T08446_PEA_l_T2, for which the sequence(s) is/are given at the end of the application. The coding portion of transcript T08446_PEA_l_T2 is shown in bold; this coding portion starts at position 228 and ends at position 4142. The transcript also has the following SNPs as listed in Table 789 (given according to their position on the nucleotide sequence, with the alternative nucleic acid listed; the last column indicates whether the SNP is known or not; the presence of
known SNPs in variant protein TO8446JPEA_1_P18 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 789 - Nucleic acid SNPs
Variant protein T08446_PEA_l_P19 according to the present invention has an amino acid sequence as given at the end of the application; it is encoded by transcript(s) T08446_PEA_l_T22. The location of the variant protein was determined according to results from a number of different software programs and analyses, including analyses from SignalP and other specialized programs. The variant protein is believed to be located as follows with regard to the cell: secreted. The protein localization is believed to be secreted because both signal-peptide prediction programs predict that this protein has a signal peptide, and neither trans- membrane region prediction program predicts that this protein has a trans -membrane region. Variant protein T08446_PEA_l_P19 also has the following non-silent SNPs (Single
Nucleotide Polymorphisms) as listed in Table 790, (given according to their position(s) on the amino acid sequence, with the alternative amino acid(s) listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein T08446_PEA_l_P19
sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 790 - Amino acid mutations
Variant protein T08446_PEA_l_P19 is encoded by the following transcript(s):
T08446_PEA_l_T22, for which the sequence(s) is/are given at the end of the application. The coding portion of transcript T08446_PEA_l_T22 is shown in bold; this coding portion starts at position 228 and ends at position 965. The transcript also has the following SNPs as listed in Table 791 (given according to their position on the nucleotide sequence, with the alternative nucleic acid listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein T08446_PEA_l_P19 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 791 - Nucleic acid SNPs
As noted above, cluster T08446 features 36 segment(s), which were listed in Table 2 above and for which the sequence(s) are given at the end of the application. These segment(s) are portions of nucleic acid sequence(s) which are described herein separately because they are of particular interest. A description of each segment according to the present invention is now provided.
Segment cluster T08446_PEA_l_node_2 according to the present invention is supported by 1 libraries. The number of libraries was determined as previously described. This segment
can be found in the following transcript(s): T08446_PEA_l_T2 and T08446_PEA_ l_T22. Table 792 below describes the starting and ending position of this segment on each transcript.
Table 792 - Segment location on transcripts
Segment cluster T08446_PEA_l_node_9 according to the present invention is supported by 17 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): T08446_PEA_l_T2 and T08446_PEA_l_T22. Table 793 below describes the starting and ending position of this segment on each transcript.
Table 793 - Segment location on transcripts
Segment cluster T08446_PEA_l_node_15 according to the present invention is supported by 0 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): T08446_PEA_l_T22. Table 794 below describes the starting and ending position of this segment on each transcript.
Table 794 - Segment location on transcripts
Segment cluster T08446_PEA_l_node_17 according to the present invention is supported by 22 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): T08446JPEA_l_T2. Table 794 below describes the starting and ending position of this segment on each transcript.
Table 794 - Segment location on transcripts
Segment cluster T08446_PEA_l_node_25 according to the present invention is supported by 24 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): T08446_PEA_l_T2. Table 12 below describes the starting and ending position of this segment on each transcript.
Table 12 - Segment location on transcripts
Segment cluster T08446_PEA_l_node_29 according to the present invention is supported by 25 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): T08446_PEA_l_T2. Table 795 below describes the starting and ending position of this segment on each transcript. Table 795 - Segment location on transcripts
Segment cluster T08446_PEA_l_node_38 according to the present invention is supported by 20 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): T08446_PEA_l_T2. Table 796 below describes the starting and ending position of this segment on each transcript.
Table 796 - Segment location on transcripts
Segment cluster T08446_PEA_l_node_43 according to the present invention is supported by 15 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): T08446_PEA_l_T2. Table 797 below describes the starting and ending position of this segment on each transcript.
Table 797 - Segment location on transcripts
Segment cluster T08446_PEA_l_node_51 according to the present invention is supported by 19 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): T08446_PEA_l_T2. Table 798 below describes the starting and ending position of this segment on each transcript.
Table 798 - Segment location on transcripts
875
Segment cluster T08446_PEA_l_node_52 according to the present invention is supported by 15 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): T08446_PEA_l_T2. Table 799 below describes the starting and ending position of this segment on each transcript.
Table 799 - Segment location on transcripts
Segment cluster T08446_PEA_l_node_55 according to the present invention is supported by 21 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): T08446_PEA_l_T2. Table 800 below describes the starting and ending position of this segment on each transcript.
Table 800 - Segment location on transcripts
Segment cluster T08446JPEA_l_node_57 according to the present invention is supported by 37 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): T08446_PEA_l_T2. Table 801 below describes the starting and ending position of this segment on each transcript.
Table 801 - Segment location on transcripts
Segment cluster T08446_PEA_l_node_59 according to the present invention is supported by 36 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): T08446_PEA_l_T2. Table 802 below describes the starting and ending position of this segment on each transcript.
Table 802 - Segment location on transcripts
Segment cluster T08446_PEA_ l_node_62 according to the present invention is supported by 36 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): T08446_PEA_l_T2. Table 803 below describes the starting and ending position of this segment on each transcript.
Table 803 - Segment location on transcripts
Segment cluster T08446JPEA_l_node_63 according to the present invention is supported by 64 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): T08446_PEA_l_T2. Table 804 below describes the starting and ending position of this segment on each transcript.
Table 804 - Segment location on transcripts
According to an optional embodiment of the present invention, short segments related to the above cluster are also provided. These segments are up to about 120 bp in length, and so are included in a separate description.
Segment cluster T08446_PEA_ljnode_3 according to the present invention is supported by 14 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): T08446_PEA_l_T2 and T08446_PEA_l_T22. Table 805 below describes the starting and ending position of this segment on each transcript.
Table 805 - Segment location on transcripts
Segment cluster T08446_PEA_l_node_5 according to the present invention is supported by 17 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): T08446_PEA_l_T2 and T08446_PEA_l_T22. Table 806 below describes the starting and ending position of this segment on each transcript.
Table 806 - Segment location on transcripts
878
Microarray (chip) data is also available for this segment as follows. As described above with regard to the cluster itself, various oligonucleotides were tested for being differentially expressed in various disease conditions, particularly cancer. The following oligonucleotides were found to hit this segment (in relation to lung cancer), shown in Table 807.
Table 807 - Oligonucleotides related to this segment
Segment cluster T08446_PEA_l_node_7 according to the present invention is supported by 19 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): T08446_PEA_l_T2 and T08446_PEA_l_T22. Table 808 below describes the starting and ending position of this segment on each transcript.
Table 808- Segment location on transcripts
Microarray (chip) data is also available for this segment as follows. As described above with regard to the cluster itself, various oligonucleotides were tested for being differentially expressed in various disease conditions, particularly cancer. The following oligonucleotides were found to hit this segment (in relation to lung cancer), shown in Table 809.
Table 809- Oligonucleotides related to this segment
Segment cluster T08446JPEA_l_node_12 according to the present invention is supported by 14 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcπpt(s): T08446_PEA_l_T2 and T08446JPEA_l_T22. Table 810 below describes the starting and ending position of this segment on each transcript.
Table 810- Segment location on transcripts
Segment cluster T08446_PEA_l_node_13 according to the present invention is supported by 0 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): T08446_PEA_l JT22. Table 811 below describes the starting and ending position of this segment on each transcript.
Table 811 - Segment location on transcripts
Segment cluster T08446_PEA_l_node_19 according to the present invention is supported by 19 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): T08446_PEA_l_T2. Table 812 below describes the starting and ending position of this segment on each transcript.
Table 812 - Segment location on transcripts
Segment cluster T08446_PEA_l_node_21 according to the present invention is supported by 21 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcπpt(s): T08446_PEA_l_T2. Table 813 below describes the starting and ending position of this segment on each transcript.
Table 813 - Segment location on transcripts
Segment cluster T08446_PEA_ ljtiode_23 according to the present invention is supported by 22 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): T08446_PEA_l_T2. Table 814 below describes the starting and ending position of this segment on each transcript.
Table 814 - Segment location on transcripts
Segment cluster T08446_PEA_l_node_27 according to the present invention is supported by 23 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): T08446_PEA_l_T2. Table 815 below describes the starting and ending position of this segment on each transcript.
Table 815 - Segment location on transcripts
Segment cluster T08446JPEA_l _node_32 according to the present invention is supported by 23 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): T08446JPEA_l_T2. Table 816 below describes the starting and ending position of this segment on each transcript.
Table 816- Segment location on transcripts
Segment cluster T08446_PEA_l_node_34 according to the present invention is supported by 22 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): T08446_PEA_l_T2. Table 817 below describes the starting and ending position of this segment on each transcript.
Table 817- Segment location on transcripts
Segment cluster T08446_PEA_ l_node_45 according to the present invention is supported by 19 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): T08446_PEA_l_T2. Table 818 below describes the starting and ending position of this segment on each transcript.
Table 818- Segment location on transcripts
Segment cluster T08446_PEA_l_node_46 according to the present invention is supported by 18 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): T08446_PEA_l JT2. Table 819 below describes the starting and ending position of this segment on each transcript.
Table 819- Segment location on transcripts
Segment cluster T08446_PEA_l_node_48 according to the present invention is supported by 19 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): T08446_PEA_l_T2. Table 820 below describes the starting and ending position of this segment on each transcript.
Table 820- Segment location on transcripts
Segment cluster T08446_PEA_l_node_54 according to the present invention can be found in the following transcript(s): T08446_PEA_l_T2. Table 821 below describes the starting and ending position of this segment on each transcript. Table 821- Segment location on transcripts
Segment cluster T08446_PEA_l_node_58 according to the present invention is supported by 13 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): T08446_PEA_l_T2. Table 822 below describes the starting and ending position of this segment on each transcript.
Table 822- Segment location on transcripts
Segment cluster T08446_PEA_l_node_60 according to the present invention is supported by 27 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): T08446_PEA_l_T2. Table 823 below describes the starting and ending position of this segment on each transcript.
Table 823 - Segment location on transcripts
Segment cluster T08446_PEA_l_node_61 according to the present invention is supported by 25 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): T08446_PEA_l_T2. Table 824 below describes the starting and ending position of this segment on each transcript.
Table 824 - Segment location on transcripts
Segment cluster T08446_PEA_l_node_64 according to the present invention can be found in the following transcript(s): T08446_PEA_l_T2. Table 825 below describes the starting and ending position of this segment on each transcript.
Table 825 - Segment location on transcripts
Segment cluster T08446_PEA_l_node_65 according to the present invention is supported by 39 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): T08446_PEA_l_T2. Table 826 below describes the starting and ending position of this segment on each transcript.
Table 826 - Segment location on transcripts
Segment cluster T08446_PEA_l_node_66 according to the present invention is supported by 29 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): T08446_PEA_l_T2. Table 827 below describes the starting and ending position of this segment on each transcript.
Table 827 - Segment location on transcripts
Variant protein alignment to the previously known protein: Sequence name: SNXQ_HUMAN
Sequence documentation:
Alignment of: T08446_PEA_l_P18 x SNXQ_HUMAN
Alignment segment 1/1:
Quality: 1835.00 Escore: 0 Matching length: 185 Total length: 185
Matching Percent Similarity: 100.00 Matching Percent Identity: 100.00
Total Percent Similarity: 100.00 Total Percent Identity: 100.00
Gaps : 0
Alignment:
1 MLSLSLCSHLWGPLILSALQARSTDSLDGPGEGSVQPLPTAGGPSVKGKP 50
I I I I I I I I I I I I I I I I I I I I I 1 I I I I I I I I I 1 I I I I Il I I I I I I I I I I I I
1 MLSLSLCSHLWGPLILSALQARSTDSLDGPGEGSVQPLPTAGGPSVKGKP 50 . . . . .
51 GKRLSAPRGPFPRLADCAHFHYENVDFGHIQLLLSPDREGPSLSGENELV 100
I I Il I I I I I Il I I I Il I I Il I I I I I I I I I I I I I I I I I I I I I Il I I 1 I I 1 I
51 GKRLSAPRGPFPRLADCAHFHYENVDFGHIQLLLSPDREGPSLSGENELV 100
101 FGVQVTCQGRSWPVLRSYDDFRSLDAHLHRCIFDRRFSCLPELPPPPEGA 150
I I Il I I Il I Il I Il Il I I I I I I I I I I I I Il I Il I I Il I I I I I I I Il I Il I
101 FGVQVTCQGRSWPVLRSYDDFRSLDAHLHRCIFDRRFSCLPELPPPPEGA 150
151 RAAQMLVPLLLQYLETLSGLVDSNLNCGPVLTWME 185 I I M M I I I I I I I I I I I M I I I I I I I Il M I I I I I
151 RAAQMLVPLLLQYLETLSGLVDSNLNCGPVLTWME 185
Sequence name: Q9NT23
Sequence documentation:
Alignment of: T08446_PEA_l_P18 x Q9NT23
Alignment segment 1/1:
Quality: 8548.00 Escore: 0
Matching length: 862 Total length: 862 Matching Percent Similarity: 99.88 Matching Percent Identity: 99.88
Total Percent Similarity: 99.88 Total Percent Identity: 99.88
Gaps : 0
Alignment :
444 HDVIQQLPPPHYRTLEYLLRHLARMARHSANTSMHARNLAIVWAPNLLRS 493
Il I I I I I I I I I I Il I I I I I I I I I I I I i I I I I I I I I I I I I I I I I I I I I I I I 1 HDVIQQLPPPHYRTLEYLLRHLARMARHSANTSMHARNLAIVWAPNLLRS 50
494 MELESVGMGGAAAFREVRVQSWVEFLLTHVDVLFSDTFTSAGLDPAGRC 543
I I I I 1 I I I Il ! I Il Il I I I Il I I I I I I Il Il I Il I I I I I I I I I I I I I I I I
51 MELESVGMGGAAAFREVRVQSVVVEFLLTHVDVLFSDTFTSAGLDPAGRC 100 . . . . .
544 LLPRPKSLAGSCPSTRLLTLEEAQARTQGRLGTPTEPTTPKAPASPAERR 593
I I I Il I I I I I I 1 I I I I I I Il I I I I Il I I I I I I Il Il I I I I I I I I Il I I I I
101 LLPRPKSLAGSCPSTRLLTLEEAQARTQGRLGTPTEPTTPKAPASPAERR 150
594 KGERGEKQRKPGGSSWKTFFALGRGPSVPRKKPLPWLGGTRAPPQPSGSR 643
I I I Il I I I I I I I Il I I I I I I I I I I I Il I I I I I I Il I I I Il I I Il I I I Il I 151 KGERGEKQRKPGGSSWKTFFALGRGPSVPRKKPLPWLGGTRAPPQPSGSR 200
644 PDTVTLRSAKSEESLSSQASGAGLQRLHRLRRPHSSSDAFPVGPAPAGSC 693 I I M I M I I I I M I I M I I I I I M I I I I I M I I I I I I I I I I I I I I I M I I
201 PDTVTLRSAKSEESLSSQASGAGLQRLHRLRRPHSSSDAFPVGPAPAGSC 250
694 ESLSSSSSSESSSSESSSSSSESSAAGLGALSGSPSHRTSAWLDDGDELD 743
I I I I I I I I I I 1 I I I I I I I I Il I I I I I I 1 I I I I I 1 I I I I I 1 I I 1 Il I I I I I
251 ESLSSSSSSESSSSESSSSSSESSAAGLGALSGSPSHRTSAWLDDGDELD 300 . . . . .
744 FSPPRCLEGLRGLDFDPLTFRCSSPTPGDPAPPASPAPPAPASAFPPRVT 793
301 FSPPRCLEGLRGLDFDPLTFRCSSPTPGDPAPPASPAPPAPASAFPPRVT 350
794 PQAISPRGPTSPASPAALDISEPLAVSVPPAVLELLGAGGAPASATPTPA 843
I I Il Il M I I I I I I Il I M Il I I Il I Il I I Il M Il Il M Il I I Il I I M
351 PQAISPRGPTSPASPAALDISEPLAVSVPPAVLELLGAGGAPASATPTPA 400
844 LSPGRSLRPHLIPLLLRGAEAPLTDACQQEMCSKLRGAQGPLGPDMESPL 893 I I M I I I Il Il I M M I M M M M I I M Il M Il I M I Il I I I M I I M
401 LSPGRSLRPHLIPLLLRGAEAPLTDACQQEMCSKLRGAQGPLGPDMESPL 450
894 PPPPLSLLRPGGAPPPPPKNPARLMALALAERAQQVAEQQSQQECGGTPP 943
II I I I I I Il Il I M M Il M M M I I M Il Il I M I Il I M I I I I M M I 451 PPPPLSLLRPGGAPPPPPKNPARLMALALAERAQQVAEQQSQQECGGTPP 500
944 ASQSPFHRSLSLEVGGEPLGTSGSGPPPNSLAHPGAWVPGPPPYLPRQQS 993
Il M Il I I Il Il I I I I Il M M Il M M Il I M Il M M Il Il I I Il M I
501 ASQSPFHRSLSLEVGGEPLGTSGSGPPPNSLAHPGAWVPGPPPYLPRQQS 550 . . . . .
994 DGSLLRSQRPMGTSRRGLRGPAQVSAQLRAGGGGRDAPEAAAQSPCSVPS 1043
M M M M M M I M I I I M M Il M M Il I M M M Il Il Il I M Il I I
551 DGSLLRSQRPMGTSRRGLRGPAQVSAQLRAGGGGRDAPEAAAQSPCSVPS 600
1044 QVPTPGFFSPAPRECLPPFLGVPKPGLYPLGPPSFQPSSPAPVWRSSLGP 1093
601 QVPTPGFFSPAPRECLPPFLGVPKPGLYPLGPPSFQPSSPAPVWRSSLGP 650
1094 PAPLDRGENLYYEIGASEGSPYSGPTRSWSPFRSMPPDRLNASYGMLGQS 1143
I 1 I I I I I I I I 1 I I I I I I I I I I I I 1 I I I Il I I I I I I I I I I I I I I I I I Il I 651 PAPLDRGENLYYEIGASEGSPYSGLTRSWSPFRSMPPDRLNASYGMLGQS 700
1144 PPLHRSPDFLLSYPPAPSCFPPDHLGYSAPQHPARRPTPPEPLYVNLALG 1193
II 1 I I I I I I I I I I I I I Il I Il I I I I Il I I I Il I I I Il I I I 1 I I I I I I I I I
701 PPLHRSPDFLLSYPPAPSCFPPDHLGYSAPQHPARRPTPPEPLYVNLALG 750 . . . . .
1194 PRGPSPASSSSSSPPAHPRSRSDPGPPVPRLPQKQRAPWGPRTPHRVPGP 1243
I I I Il I I I Il Il I I Il I I I Il I I I I I Il 1 I I I Il I Il I Il I Il I I I I I Il
751 PRGPSPASSSSSSPPAHPRSRSDPGPPVPRLPQKQRAPWGPRTPHRVPGP 800
1244 WGPPEPLLLYRAAPPAYGRGGELHRGSLYRNGGQRGEGAGPPPPYPTPSW 1293
I I I I I I I I I I I I I I I I I Il I I I I I I I I I I Il I Il I I I I Il I I I I I I I I I I 801 WGPPEPLLLYRAAPPAYGRGGELHRGSLYRNGGQRGEGAGPPPPYPTPSW 850
1294 SLHSEGQTRSYC 1305 I I I I I I I I I I I I
851 SLHSEGQTRSYC 862
Sequence name: Q96CP3
Sequence documentation:
Alignment of: T08446_PEA_l_P18 x Q96CP3
Alignment segment 1/1:
Quality: 3019.00
Escore: 0
Matching length: 295 Total length: 295
Matching Percent Similarity: 100.00 Matching Percent Identity: 100.00
Total Percent Similarity: 100.00 Total Percent Identity: 100.00
Gaps : 0
Alignment:
1011 LRGPAQVSAQLRAGGGGRDAPEAAAQSPCSVPSQVPTPGFFSPAPRECLP 1060
I I I I i I I I I I I Il Il I I I I I Il I I I I I I I I I I I I I I I I I I I I I I I I I I I !
1 LRGPAQVSAQLRAGGGGRDAPEAAAQSPCSVPSQVPTPGFFSPAPRECLP 50 . . . . .
1061 PFLGVPKPGLYPLGPPSFQPSSPAPVWRSSLGPPAPLDRGENLYYEIGAS 1110
I Il I I I Il I I Il I I I I I I I I Il I Il Il I Il I Il I I I I I I I I I I I I Il I I I
51 PFLGVPKPGLYPLGPPSFQPSSPAPVWRSSLGPPAPLDRGENLYYEIGAS 100
1111 EGSPYSGPTRSWSPFRSMPPDRLNASYGMLGQSPPLHRSPDFLLSYPPAP 1160 I I I I I I I I I I I I I ! I Il I I I I I I I I I I Il I I I I Il I I I I I I I Il I I I I I I
101 EGSPYSGPTRSWSPFRSMPPDRLNASYGMLGQSPPLHRSPDFLLSYPPAP 150
1161 SCFPPDHLGYSAPQHPARRPTPPEPLYVNLALGPRGPSPASSSSSSPPAH 1210 I I I I I I I I I I I M I I I I M I I I M Il I I I M I M I I I I I I I I I I I I I I I I
151 SCFPPDHLGYSAPQHPARRPTPPEPLYVNLALGPRGPSPASSSSSSPPAH 200
1211 PRSRSDPGPPVPRLPQKQRAPWGPRTPHRVPGPWGPPEPLLLYRAAPPAY 1260
I I I I 1 I I I I I I 1 I Il I I I I I I I I I I I I I I I I I I I I I ! Il I I I I i I I I I I I
201 PRSRSDPGPPVPRLPQKQRAPWGPRTPHRVPGPWGPPEPLLLYRAAPPAY 250 . . . .
1261 GRGGELHRGSLYRNGGQRGEGAGPPPPYPTPSWSLHSEGQTRSYC 1305
I I I I I I I I I I I I I I I I Il I I Il I Il I Il I I I I I I Il I I I I I I I I I 251 GRGGELHRGSLYRNGGQRGEGAGPPPPYPTPSWSLHSEGQTRSYC 295
Sequence name: BAC86902
Sequence documentation:
Alignment of: T08446_PEA_l_P18 x BAC86902
Alignment segment 1/1:
Quality: 9651.00 Escore: 0 Matching length: 991 Total length: 1019
Matching Percent Similarity: 99.90 Matching Percent Identity: 99.90
Total Percent Similarity: 97.15 Total Percent Identity: 97.15
Gaps : 1
Alignment:
155 MLVPLLLQYLETLSGLVDSNLNCGPVLTWMELDNHGRRLLLSEEASLNIP 204 ! 111 ! 111111111 I ) I I I I I I I I I M I M I I I I I I I I I I I I I I I I M I I
1 MLVPLLLQYLETLSGLVDSNLNCGPVLTWMELDNHGRRLLLSEEASLNIP 50
205 AVAAAHVIKRYTAQAPDELSFEVGDIVSVIDMPPTEDRSWWRGKRGFQVG 254
Il I M I M ! I I I I I I I I Il Il Il Il I I Il I I I Il I ! I I I I I I Il I I I I Il 51 AVAAAHVIKRYTAQAPDELSFEVGDIVSVIDMPPTEDRSWWRGKRGFQVG 100
255 FFPSECVELFTERPGPGLKADADGPPCGIPAPQGISSLTSAVPRPRGKLA 304 11111!1111!1!111111!1111!11111111111111!!IMIMIM
101 FFPSECVELFTERPGPGLKADADGPPCGIPAPQGISSLTSAVPRPRGKLA 150 . . . . .
305 GLLRTFMRSRPSRQRLRQRGILRQRVFGCDLGEHLSNSGQDVPQVLRCCS 354 ! ! 11 1 1 1 1 1 11 11 1 1 11 1 1 11 11 ! 1 1 1 ! ! M I I M M I M M M I I M I I
151 GLLRTFMRSRPSRQRLRQRGILRQRVFGCDLGEHLSNSGQDVPQVLRCCS 200
355 EFIEAHGVVDGIYRLSGVSSNIQRLRHEFDSERIPELSGPAFLQDIHSVS 404
Il I I I I I I I I ! I Il Il Il I I Il I I ! Il I I I Il I I I I I I Il I Il I I I I Il I
201 EFIEAHGVVDGIYRLSGVSSNIQRLRHEFDSERIPELSGPAFLQDIHSVS 250
405 SLCKLYFRELPNPLLTYQLYGKFSEAMSVPGEEERLVRVHDVIQQLPPPH 454 I I I M M I M II M I M M M M M I I I M I M M I I M I M M I M M I
251 SLCKLYFRELPNPLLTYQLYGKFSEAMSVPGEEERLVRVHDVIQQLPPPH 300
455 YRTLEYLLRHLARMARHSANTSMHARNLAIVWAPNLLRSMELESVGMGGA 504
I Il I I Il I I I Il I Il I I I I I I Il I I Il Il I I I I I I I Il I Il I I Il I Il Il 301 YRTLEYLLRHLARMARHSANTSMHARNLAIVWAPNLLRSMELESVGMGGA 350
505 AAFREVRVQSVVVEFLLTHVDVLFSDTFTSAGLDPAGRCLLPRPKSLAGS 554
Il I I I I I I I I I I I I I I I I I I I I I I I I I I Il I I I I I I I I 1 I I I I I I I I I I I
351 AAFREVRVQSVVVEFLLTHVDVLFSDTFTSAGLDPAGRCLLPRPKSLAGS 400
555 CPSTRLLTLEEAQARTQGRLGTPTEPTTPKAPASPAERRKGERGEKQRKP 604
I I I I I I I I Il I I 1 I I I 1 I I I I I I I I Il I I I Il Il 1 I I I I I I I I I I I I I I I
401 CPSTRLLTLEEAQARTQGRLGTPTEPTTPKAPASPAERRKGERGEKQRKP 450
605 GGSSWKTFFALGRGPSVPRKKPLPWLGGTRAPPQPSGSRPDTVTLRSAKS 654 I I I I I I I I I I I I I I I I I I I I I I I I I I I I M I I I M I I I I M M I I I I M I
451 GGSSWKTFFALGRGPSVPRKKPLPWLGGTRAPPQPSGSRPDTVTLRSAKS 500
655 EESLSSQASGAGLQRLHRLRRPHSSSDAFPVGPAPAGSCESLSSSSSSES 704
I I I I I I I I I I Il I I I I I I I Il I I 1 I I I I I Il I I I I I Il I I 1 I I I Il Il I I 501 EESLSSQASGAGLQRLHRLRRPHSSSDAFPVGPAPAGSCESLSSSSSSES 550
705 SSSESSSSSSESSAAGLGALSGSPSHRTSAWLDDGDELDFSPPRCLEGLR 754
I I I I I I I I I I I I I I I I I I I I I I I I I I Il I I Il I I I I I I I I I I I I I Il I I I
551 SSSESSSSSSESSAAGLGALSGSPSHRTSAWLDDGDELDFSPPRCLEGLR 600 . . . . .
755 GLDFDPLTFRCSSPTPGDPAPPASPAPPAPASAFPPRVTPQAISPRGPTS 804
I I I I I I I Il I I I I I I I I I Il I Il Il I I I Il Il I I I I I I I I I I I I I I I I I I 601 GLDFDPLTFRCSSPTPGDPAPPASPAPPAPASAFPPRVTPQAISPRGPTS 650
805 PASPAALDISEPLAVSVPPAVLELLGAGGAPASATPTPALSPGRSLRPHL 854
I M MII I III M M M I I IIIM I I I M I I MI I I III I I MI M II M
651 PASPAALDISEPLAVSVPPAVLELLGAGGAPASATPTPALSPGRSLRPHL 700
855 IPLLLRGAEAPLTDACQQEMCSKLRGAQGPLGPDMESPLPPPPLSLLRPG 904 M I M I I I I M I M M I I I I I M M I I Il I Il I M I I I I I I I I I I M M I
701 IPLLLRGAEAPLTDACQQEMCSKLRGAQGPLGPDMESPLPPPPLSLLRPG 750
905 GAPPPPPKNPARLMALALAERAQQVAEQQSQQECGGTPPASQSPFHRSLS 954
I I I 1 I I I I I I I I I I I I I I I I I I I I 1 I I I I I 1 I I I I I I I I I I I I I I I I I I I
751 GAPPPPPKNPARLMALALAERAQQVAEQQSQQECGGTPPASQSPFHRSLS 800 . . . . .
955 LEVGGEPLGTSGSGPPPNSLAHPGAWVPGPPPYLPRQQSDGSLLRSQRPM 1004
I I I I I I I I I I I I I I I I I I I I I I Il i I I I I ! I I I I I Il I I I I I I I I I I I I I
801 LEVGGEPLGTSGSGPPPNSLAHPGAWVPGPPPYLPRQQSDGSLLRSQRPM 850
1005 GTSRRGLRGPAQVSAQLRAGGGGRDAPEAAAQSPCSVPSQVPTPGFFSPA 1054
I I I I I I I I I I 1 Il I I Il I I I I I
851 GTSRRGLRGPA QVPTPGFFSPA 872
1055 PRECLPPFLGVPKPGLYPLGPPSFQPSSPAPVWRSSLGPPAPLDRGENLY 1104 I I I I I I M M I I I I I I 1 I I I I I I I 1 I I I I M I 1 I I I I I I I I I I I I I I I I I
873 PRECLPPFLGVPKPGLYPLGPPSFQPSSPAPVWRSSLGPPAPLDRGENLY 922
1105 YEIGASEGSPYSGPTRSWSPFRSMPPDRLNASYGMLGQSPPLHRSPDFLL 1154
I I I I I I I I I I I Il I I I I I I I I I I I I I I I I I I Il I I I I I Il I I I I I I I I I I 923 YEIGASEGSPYSGPTRSWSPFRSMPPDRLNASYGMLGQSPPLHRSPDFLL 972
1155 SYPPAPSCFPPDHLGYSAP 1173
II I Il I Il I I I I I ! I I I I
973 SYPPAPSCFPPDHLGYSPP 991
DESCRIPTION FOR CLUSTER HUMCAlXIA
Cluster HUMCAlXIA features 4 transcript(s) and 46 segment(s) of interest, the names for which are given in Tables 828 and 829, respectively, the sequences themselves are given at the end of the application. The selected protein variants are given in table 830
Table 828 - Transcripts of interest
Table 830 - Proteins of interest
These sequences are variants of the known protein Collagen alpha 1 (SwissProt accession identifier CA1B_HUMAN), SEQ ID NO: 1446, referred to herein as the previously known protein.
Protein Collagen alpha 1 is known or believed to have the following function(s): May play an important role in fibrillogenesis by controlling lateral growth of collagen II fibrils. The sequence for protein Collagen alpha 1 is given at the end of the application, as "Collagen alpha 1 amino acid sequence". Known polymorphisms for this sequence are as shown in Table 831.
Table 831 - Amino acid mutations for Known Protein
The following GO Annotation(s) apply to the previously known protein. The following annotation(s) were found: cartilage condensation; vision; hearing; cell-cell adhesion; extracellular matrix organization and biogenesis, which are annotation(s) related to Biological Process; extracellular matrix structural protein; extracellular matrix protein, adhesive, which are annotation(s) related to Molecular Function; and extracellular matrix; collagen; collagen type XI, which are annotation(s) related to Cellular Component.
The GO assignment relies on information from one or more of the SwissProt/TremBl Protein knowledgebase, available from <http://www.expasy.ch/sprot/>; or Locuslink, available from ^ttp^/www.ncbi.nlm.nih.gov/projects/LocusLinl^.
Cluster HUMCAlXIA can be used as a diagnostic marker according to overexpression of transcripts of this cluster in cancer. Expression of such transcripts in normal tissues is also given according to the previously described methods. The term "number" in the right hand column of the table and the numbers on the y-axis of figure 32 refer to weighted expression of ESTs in each category, as "parts per million" (ratio of the expression of ESTs for a particular cluster to the expression of all ESTs in that category, according to parts per million).
Overall, the following results were obtained as shown with regard to the histograms in Figure 32 and Table 832. This cluster is overexpressed (at least at a minimum level) in the following pathological conditions: bone malignant tumors, epithelial malignant tumors, a mixture of malignant tumors from different tissues and lung malignant tumors.
Table 832 - Normal tissue distribution
Table 833 - P values and ratios for expression in cancerous tissue
As noted above, cluster HUMCAlXIA features 4 transcript(s), which were listed in Table 1 above. These transcript(s) encode for protein(s) which are variant(s) of protein Collagen alpha L A description of each variant protein according to the present invention is now provided.
Variant protein HUMCA 1XIA_P 14 according to the present invention has an amino acid sequence as given at the end of the application; it is encoded by transcript(s) HUMCA1XIA_T16. An alignment is given to the known protein (Collagen alpha 1) at the end
of the application. One or more alignments to one or more previously published protein sequences are given at the end of the application. A brief description of the relationship of the variant protein according to the present invention to each such aligned protein is as follows:
Comparison report between HUMCA1XIA_P14 and CA1B_HUMAN_V5 (SEQ ID NO: 1447):
LAn isolated chimeric polypeptide encoding for HUMCA 1XIA_P 14, comprising a first amino acid sequence being at least 90 % homologous to
MEPWSSRWKTKRWLWDFTVTTLALTFLFQAREVRGAAPVDVLKALDFHNSPEGISKTT GFCTNRKNSKGSDTAYRVSKQAQLSAPTKQLFPGGTFPEDFSILFTVKPKKGIQSFLLSIY NEHGIQQIGVEVGRSPVFLFEDHTGKPAPEDYPLFRTVNIADGKWHRVAISVEKKTVTM IVDCKKKTTKPLDRSERAIVDTNGITVFGTRILDEEVFEGDIQQFLITGDPKAA YDYCEH YSPDCDSSAPKAAQAQEPQIDEYAPEDIIEYDYEYGEAEYKEAESVTEGPTVTEETIAQT EANIVDDFQEYNYGTMESYQTEAPRHVSGTNEPNPVEEIFTEEYLTGEDYDSQRKNSED TLYENKEIDGRDSDLLVDGDLGEYDFYEYKEYEDKPTSPPNEEFGPGVPAETDITETSIN GHGAYGEKGQKGEPAVVEPGMLVEGPPGPAGPAGIMGPPGLQGPTGPPGDPGDRGPPG RPGLPGADGLPGPPGTMLMLPFRYGGDGSKGPTISAQEAQAQAILQQARIALRGPPGPM GLTGRPGPVGGPGSSGAKGESGDPGPQGPRGVQGPPGPTGKPGKRGRPGADGGRGMP GEPGAKGDRGFDGLPGLPGDKGHRGERGPQGPPGPPGDDGMRGEDGEIGPRGLPGEAG PRGLLGPRGTPGAPGQPGMAGVDGPPGPKGNMGPQGEPGPPGQQGNPGPQGLPGPQG PIGPPGEKGPQGKPGLAGLPGADGPPGHPGKEGQSGEKGALGPPGPQGPIGYPGPRGVK GADGVRGLKGSKGEKGEDGFPGFKGDMGLKGDRGEVGQIGPRGEDGPEGPKGRAGPT GDPGPSGQAGEKGKLGVPGLPGYPGRQGPKGSTGFPGFPGANGEKGARGVAGKPGPR GQRGPTGPRGSRGARGPTGKPGPKGTSGGDGPPGPPGERGPQGPQGPVGFPGPKGPPGP PGKDGLPGHPGQRGETGFQGKTGPPGPGGVVGPQGPTGETGPIGERGHPGPPGPPGEQG LPGAAGKEGAKGDPGPQGISGKDGPAGLRGFPGERGLPGAQGAPGLKGGEGPQGPPGP
V corresponding to amino acids 1 - 1056 of CA1B_HUMAN_V5, which also corresponds to amino acids 1 - 1056 of HUMCA 1XIA_P 14, and a second amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence VSMMIINSQTIMWNYSSSFITLML corresponding to amino acids 1057 - 1081 of
HUMCA 1XIA_P 14, wherein said first amino acid sequence and second amino acid sequence are contiguous and in a sequential order.
2.An isolated polypeptide encoding for a tail of HUMCA 1XIA_P 14, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence VSMMIINSQTIMVVNYSSSFITLML in HUMCA 1XIA_P 14.
It should be noted that the known protein sequence (CA1B_HUMAN) has one or more changes than the sequence given at the end of the application and named as being the amino acid sequence for CA1B HUMANJV5. These changes were previously known to occur and are listed in the table below.
Table 834 - Changes to CAlBJiUMAN JV5
The location of the variant protein was determined according to results from a number of different software programs and analyses, including analyses from SignalP and other specialized programs. The variant protein is believed to be located as follows with regard to the cell: secreted. The protein localization is believed to be secreted because both signatpeptide prediction programs predict that this protein has a signal peptide, and neither trans -membrane region prediction program predicts that this protein has a trans -membrane region.
Variant protein HUMCA 1XIA_P 14 also has the following non- silent SNPs (Single Nucleotide Polymorphisms) as listed in Table 835, (given according to their position(s) on the amino acid sequence, with the alternative amino acid(s) listed; the last column indie ates whether the SNP is known or not; the presence of known SNPs in variant protein HUMCA IXLAJP 14 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 835 - Amino acid mutations
Variant protein HUMCA 1XIA_P 14 is encoded by the following transcript(s): HUMCA 1XIA_T 16, for which the sequence(s) is/are given at the end of the application. The coding portion of transcript HUMCA IXIA T 16 is shown in bold; this coding portion starts at position 319 and ends at position 3561. The transcript also has the following SNPs as listed in Table 836 (given according to their position on the nucleotide sequence, with the alternative nucleic acid listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein HUMCA1XIA_P14 sequence provides support for the deduced sequence of this variant protein according to the present invention). Table 836 - Nucleic acid SNPs
Variant protein HUMCA 1XIA_P 15 according to the present invention has an amino acid sequence as given at the end of the application; it is encoded by transcript(s) HUMCA 1XIA_T 17. An alignment is given to the known protein (Collagen alpha 1) at the end of the application. One or more alignments to one or more previously published protein sequences are given at the end of the application. A brief description of the relationship of the variant protein according to the present invention to each such aligned protein is as follows:
Comparison report between HUMCA1XIA_P15 and CA1B_HUMAN: 1.An isolated chimeric polypeptide encoding for HUMCA1XIA_P15, comprising a first amino acid sequence being at least 90 % homologous to
MEPWSSRWKTKRWLWDFTVTTLALTFLFQAREVRGAAPVDVLKALDFHNSPEGISKTT GFCTNRKNSKGSDTAYRVSKQAQLSAPTKQLFPGGTFPEDFSILFTVKPKKGIQSFLLSIY NEHGIQQIGVEVGRSPVFLFEDHTGKPAPEDYPLFRTVNIADGKWHRVAISVEKKTVTM IVDCKKKTTKPLDRSERAIVDTNGITVFGTRILDEEVFEGDIQQFLITGDPKAAYDYCEH YSPDCDSSAPKAAQAQEPQIDEYAPEDIIEYDYEYGEAEYKEAESVTEGPTVTEETIAQT EANIVDDFQEYNYGTMESYQTEAPRHVSGTNEPNPVEEIFTEEYLTGEDYDSQRKNSED TLYENKEIDGRDSDLLVDGDLGEYDFYEYKEYEDKPTSPPNEEFGPGVPAETDITETSIN GHGAYGEKGQKGEPAWEPGMLVEGPPGPAGPAGIMGPPGLQGPTGPPGDPGDRGPPG RPGLPGADGLPGPPGTMLMLPFRYGGDGSKGPTISAQEAQAQAILQQARIALRGPPGPM GLTGRPGPVGGPGSSGAKGESGDPGPQGPRGVQGPPGPTGKPGKRGRPGADGGRGMP GEPGAKGDRGFDGLPGLPGDKGHRGERGPQGPPGPPGDDGMRGEDGEIGPRGLPGEAG PRGLLGPRGTPGAPGQPGMAGVDGPPGPKGNMGPQGEPGPPGQQGNPGPQGLPGPQG
PIGPPGEK corresponding to amino acids 1 - 714 of CA1B_HUMAN, which also corresponds to amino acids 1 - 714 of HUMCA1XIA_P15, and a second amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence MCCNLSFGILIPLQK corresponding to amino acids 715 - 729 of HUMCA1XIA_P15, wherein
said first amino acid sequence and second amino acid sequence are contiguous and in a sequential order.
2.An isolated polypeptide encoding for a tail of HUMCA 1XIA_P 15, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence MCCNLSFGILIPLQK in HUMCA1XIA_P15.
The location of the variant protein was determined according to results from a number of different software programs and analyses, including analyses from SignalP and other specialized programs. The variant protein is believed to be located as follows with regard to the cell: secreted. The protein localization is believed to be secreted because both signal-peptide prediction programs predict that this protein has a signal peptide, and neither trans -membrane region prediction program predicts that this protein has a trans -membrane region.
Variant protein HUMCAlXIA-P 15 also has the following non- silent SNPs (Single Nucleotide Polymorphisms) as listed in Table 837, (given according to their position(s) on the amino acid sequence, with the alternative amino acid(s) listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein HUMCA1XIA_P15 sequence provides support for the deduced sequence of this variant protein according to the present invention). Table 837- Amino acid mutations
The glycosylation sites of variant protein HUMCA1XIA_P15, as compared to the known protein Collagen alpha 1, are described in Table 838 (given according to their position(s) on the amino acid sequence in the first column; the second column indicates whether the glycosylation
site is present in the variant protein; and the last column indicates whether the position is different on the variant protein).
Table 838 - Glycosylation site(s)
Variant protein HUMCA 1XIA_P 15 is encoded by the following transcript(s):
HUMCA1XIA_T17, for which the sequence(s) is/are given at the end of the application. The coding portion of transcript HUMCA 1XIA_T 17 is shown in bold; this coding portion starts at position 319 and ends at position 2505. The transcript also has the following SNPs as listed in Table 839 (given according to their position on the nucleotide sequence, with the alternative nucleic acid listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein HUMCA IXIA P 15 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 839 - Nucleic acid SNPs
Variant protein HUMCA 1XIA_P 16 according to the present invention has an amino acid sequence as given at the end of the application; it is encoded by transcript(s) HUMCA1XIA_T19. An alignment is given to the known protein (Collagen alpha 1) at the end of the application. One or more alignments to one or more previously published protein
sequences are given at the end of the application. A brief description of the relationship of the variant protein according to the present invention to each such aligned protein is as follows: Comparison report between HUMCA 1XIA_P 16 and CA1B_HUMAN: 1.An isolated chimeric polypeptide encoding for HUMCA IXIA Pl 6, comprising a first amino acid sequence being at least 90 % homologous to
MEPWSSRWKTKRWLWDFTVTTLALTFLFQAREVRGAAPVDVLKALDFHNSPEGISKTT GFCTNRKNSKGSDTAYRVSKQAQLSAPTKQLFPGGTFPEDFSILFTVKPKKGIQSFLLSIY NEHGIQQIGVEVGRSPVFLFEDHTGKP APEDYPLFRTVNIADGKWHRVAISVEKKTVTM IVDCKKKTTKPLDRSERAIVDTNGITVFGTRILDEEVFEGDIQQFLITGDPKAA YDYCEH YSPDCDSSAPKAAQAQEPQIDEYAPEDIIEYDYEYGEAEYKEAESVTEGPTVTEETIAQT EANIVDDFQEYNYGTMESYQTEAPRHVSGTNEPNPVEEIFTEEYLTGEDYDSQRKNSED TLYENKEIDGRDSDLLVDGDLGEYDFYEYKEYEDKPTSPPNEEFGPGVPAETDITETSIN GHGAYGEKGQKGEPAVVEPGMLVEGPPGPAGPAGIMGPPGLQGPTGPPGDPGDRGPPG RPGLPGADGLPGPPGTMLMLPFRYGGDGSKGPTISAQEAQAQAILQQARIALRGPPGPM GLTGRPGPVGGPGSSGAKGESGDPGPQGPRGVQGPPGPTGKPGKRGRPGADGGRGMP GEPGAKGDRGFDGLPGLPGDKGHRGERGPQGPPGPPGDDGMRGEDGEIGPRGLPGEA corresponding to amino acids 1 - 648 of CAlB-HUMAN, which also corresponds to amino acids 1 - 648 of HUMCA IXI A P 16, a second amino acid sequence being at least 90 % homologous to GMAGVDGPPGPKGNMGPQGEPGPPGQQGNPGPQGLPGPQGPIGPPGEK corresponding to amino acids 667 - 714 of CAlB HUMAN, which also corresponds to amino acids 649 - 696 of HUMCA 1XIA_P 16, and a third amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence VSFSFSLFYKKVIKFACDKRFVGRHDERKVVKLSLPLYLIYE corresponding to amino acids 697 - 738 of HUMCA 1XIA_P 16, wherein said first amino acid sequence, second amino acid sequence and third amino acid sequence are contiguous and in a sequential order.
2.An isolated chimeric polypeptide encoding for an edge portion of HUMCA 1XIA_P 16, comprising a polypeptide having a length "n", wherein n is at least about 10 amino acids in length, optionally at least about 20 amino acids in length, preferably at least about 30 amino acids in length, more preferably at least about 40 amino acids in length and most preferably at least about 50 amino acids in length, wherein at least two amino acids comprise AG, having a
structure as follows: a sequence starting from any of amino acid numbers 648-x to 648; and ending at any of amino acid numbers 649+ ((n-2) - x), in which x varies from 0 to n-2.
3.An isolated polypeptide encoding for a tail of HUMCA 1XIA_P 16, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence VSFSFSLFYKKVIKFACDKRFVGRHDERKVVKLSLPLYLIYE in HUMCAlXIA P16.
The location of the variant protein was determined according to results from a number of different software programs and analyses, including analyses from SignalP and other specialized programs. The variant protein is believed to be located as follows with regard to the cell: secreted. The protein localization is believed to be secreted because both signal-peptide prediction programs predict that this protein has a signal peptide, and neither trans -membrane region prediction program predicts that this protein has a trans -membrane region.
Variant protein HUMCA1XIA_P16 also has the following non-silent SNPs (Single Nucleotide Polymorphisms) as listed in Table 840, (given according to their position(s) on the amino acid sequence, with the alternative amino acid(s) listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein HUMCA IXIA P 16 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 840 - Amino acid mutations
The glycosylation sites of variant protein HUMCA 1XIA_P 16, as compared to the known protein Collagen alpha 1, are described in Table 841 (given according to their position(s) on the amino acid sequence in the first column; the second column indicates whether the glycosylation
site is present in the variant protein; and the last column indicates whether the position is different on the variant protein).
Table 841 - Glycosylation site(s)
Variant protein HUMCA 1XIA_P 16 is encoded by the following transcript(s):
HUMCA 1XIA_T 19, for which the sequence(s) is/are given at the end of the application. The coding portion of transcript HUMCAlXIA-T 19 is shown in bold; this coding portion starts at position 319 and ends at position 2532. The transcript also has the following SNPs as listed in Table 842 (given according to their position on the nucleotide sequence, with the alternative nucleic acid listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein HUMCA 1XIA_P 16 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 842 - Nucleic acid SNPs
Variant protein HUMCA 1XIA_P 17 according to the present invention has an amino acid sequence as given at the end of the application; it is encoded by transcript(s)
HUMCA 1XIAJT20. An alignment is given to the known protein (Collagen alpha 1) at the end of the application. One or more alignments to one or more previously published protein sequences are given at the end of the application. A brief description of the relationship of the variant protein according to the present invention to each such aligned protein is as follows: Comparison report between HUMCA 1XIA_P 17 and CA IB JHUMAN:
LAn isolated chimeric polypeptide encoding for HUMCA 1XIA_P 17, comprising a first amino acid sequence being at least 90 % homologous to
MEPWSSRWKTKRWLWDFTVTTLALTFLFQAREVRGAAPVDVLKALDFHNSPEGISKTT GFCTNRKNSKGSDTAYRVSKQAQLSAPTKQLFPGGTFPEDFSILFTVKPKKGIQSFLLSIY NEHGIQQIGVEVGRSPVFLFEDHTGKPAPEDYPLFRTVNIADGKWHRVAISVEKKTVTM IVDCKKKTTKPLDRSERAIVDTNGITVFGTRILDEEVFEGDIQQFLITGDPKAA YDYCEH YSPDCDSSAPKAAQAQEPQIDE corresponding to amino acids 1 - 260 of CAl BJHUMAN, which also corresponds to amino acids 1 - 260 of HUMCA1XIA_P17, and a second amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence VRSTRPEKVFVFQ corresponding to amino acids 261 - 273 of HUMCA1XLA_P17, wherein said first amino acid sequence and second amino acid sequence are contiguous and in a sequential order.
2.An isolated polypeptide encoding for a tail of HUMCA1XIA_P17, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence VRSTRPEKVFVFQ in HUMCA1XIA_P17.
The location of the variant protein was determined according to results from a number of different software programs and analyses, including analyses from SignalP and other specialized programs. The variant protein is believed to be located as follows with regard to the cell: secreted. The protein localization is believed to be secreted because both signal-peptide prediction programs predict that this protein has a signal peptide, and neither trans -membrane region prediction program predicts that this protein has a trans -membrane region. Variant protein HUMCA1XIA_P17 also has the following non-silent SNPs (Single
Nucleotide Polymorphisms) as listed in Table 843, (given according to their position(s) on the
amino acid sequence, with the alternative amino acid(s) listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein HUMCA 1XIA_P 17 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 843 - Amino acid mutations
The glycosylation sites of variant protein HUMCA 1XIA_P 17, as compared to the known protein Collagen alpha 1, are described in Table 844 (given according to their position(s) on the amino acid sequence in the first column; the second column indicates whether the glycosylation site is present in the variant protein; and the last column indicates whether the position is different on the variant protein).
Table 844 - Glycosylation site(s)
Variant protein HUMCA 1XIA_P 17 is encoded by the following transcript(s): HUMCA 1XIA_T2O, for which the sequence(s) is/are given at the end of the application. The coding portion of transcript HUMCA 1XIA_T2O is shown in bold; this coding portion starts at position 319 and ends at position 1137. The transcript also has the following SNPs as listed in Table 845 (given according to their position on the nucleotide sequence, with the alternative nucleic acid listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein HUMCA 1XIA_P 17 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 845 - Nucleic acid SNPs
As noted above, cluster HUMCAlXIA features 46 segment(s), which were listed in Table 2 above and for which the sequence(s) are given at the end of the application. These segment(s) are portions of nucleic acid sequence(s) which are described herein separately because they are of particular interest. A description of each segment according to the present invention is now provided.
Segment cluster HUMCA lXIA_node_0 according to the present invention is supported by 13 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): HUMCA IXIAJT 16, HUMCA1XIA_T17, HUMCA1XIA_T19 and HUMCA 1XIAJT20. Table 846 below describes the starting and ending position of this segment on each transcript.
Table 846 - Segment location on transcripts
Segment cluster HUMCA lXIA_node_2 according to the present invention is supported by 9 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): HUMCA IXIAJT 16, HUMCA1XIA_T17,
HUMCA lXIAjr 19 and HUMCA 1XIAJT20. Table 847 below describes the starting and ending position of this segment on each transcript.
Table 847 - Segment location on transcripts
Segment cluster HUMCAl XI A_node_4 according to the present invention is supported by 5 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): HUMCA 1XIA_T 16, HUMCA 1XIA_T 17, HUMCA1XIA_T19 and HUMCA1XIA_T2O. Table 848 below describes the starting and ending position of this segment on each transcript.
Table 848 - Segment location on transcripts
Microarray (chip) data is also available for this segment as follows. As described above with regard to the cluster itself, various oligonucleotides were tested for being differentially expressed in various disease conditions, particularly cancer. The following oligonucleotides were found to hit this segment (in relation to lung cancer), shown in Table 849.
Table 849 - Oligonucleotides related to this segment
Segment cluster HUMCA lXIA_node_6 according to the present invention is supported by 5 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): HUMCA IXIAJT 16, HUMCA IXIAJT 17, HUMCAl XIAJTl 9 and HUMCA 1XIA_T2O. Table 850 below describes the starting and ending position of this segment on each transcript.
Table 850 - Segment location on transcripts
Microarray (chip) data is also available for this segment as follows. As described above with regard to the cluster itself, various oligonucleotides were tested for being differentially expressed in various disease conditions, particularly cancer. The following oligonucleotides were found to hit this segment (in relation to lung cancer), shown in Table 851.
Table 851 - Oligonucleotides related to this segment
Segment cluster HUMCA lXIA_node_8 according to the present invention is supported by 5 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): HUMCA 1XIA_T 16, HUMCA IXIAJT 17,
HUMCA IXIAJT 19 and HUMCA1XIAJT20. Table 852 below describes the starting and ending position of this segment on each transcript.
Table 852 - Segment location on transcripts
Segment cluster HUMCA lXIA_node_9 according to the present invention is supported by 2 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): HUMCA1XIAJT20. Table 853 below describes the starting and ending position of this segment on each transcript.
Table 853 - Segment location on transcripts
Segment cluster HUMCAlXIA_node_18 according to the present invention is supported by 6 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): HUMCA1XIA_T16, HUMCA1XIAJT17 and
HUMCAlXIA JTl 9. Table 854 below describes the starting and ending position of this segment on each transcript.
Table 854 - Segment location on transcripts
Segment cluster HUMCA lXIA_node_54 according to the present invention is supported by 2 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): HUMCAl XIA_T 19. Table 855 below describes the starting and ending position of this segment on each transcript.
Table 855 - Segment location on transcripts
Segment cluster HUMCAlXIA_node_55 according to the present invention is supported by 4 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): HUMCA1XIA_T17 and HUMCAlXI A_T19. Table 856 below describes the starting and ending position of this segment on each transcript.
Table 856 - Segment location on transcripts
Segment cluster HUMCAlXIA_node_92 according to the present invention is supported by 2 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): HUMCAlXIA-T 16. Table 857 below describes the starting and ending position of this segment on each transcript.
Table 857 - Segment location on transcripts
According to an optional embodiment of the present invention, short segments related to the above cluster are also provided. These segments are up to about 120 bp in length, and so are included in a separate description.
Segment cluster HUMCAlXIA_node_l 1 according to the present invention is supported by 3 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): HUMCA1XIAJT16, HUMCA1XIA_T17 and HUMCA 1XIA_T 19. Table 858 below describes the starting and ending position of this segment on each transcript.
Table 858 - Segment location on transcripts
Segment cluster HUMCAlXIA_node_15 according to the present invention is supported by 5 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): HUMCA1XIA_T16, HUMCA IXIAJT 17 and HUMCAlXIA-T 19. Table 859 below describes the starting and ending position of this segment on each transcript.
Table 859 - Segment location on transcripts
Segment cluster HUMCAl XIA_node_l 9 according to the present invention is supported by 3 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): HUMCA1XIA_T16, HUMCA1XIAJT17 and HUMCA1XIA_T19. Table 860 below describes the starting and ending position of this segment on each transcript.
Table 860 - Segment location on transcripts
Segment cluster HUMCA lXIA_node_21 according to the present invention is supported by 2 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): HUMCA1XIAJT16, HUMCA1XIA_T17 and HUMCA1XIA_T19. Table 861 below describes the starting and ending position of this segment on each transcript.
Table 861 - Segment location on transcripts
Segment cluster HUMCA lXIA_node_23 according to the present invention is supported by 3 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): HUMCAIXIA-TIO, HUMCA1XIA_T17 and HUMCA 1XIA_T 19. Table 862 below describes the starting and ending position of this segment on each transcript.
Table 862 - Segment location on transcripts
Segment cluster HUMCAlXIA_node_25 according to the present invention is supported by 3 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): HUMCA 1XIA_T 16, HUMCA1XIA_T17 and HUMCA1XIA_T19. Table 863 below describes the starting and ending position of this segment on each transcript.
Table 863- Segment location on transcripts
Segment cluster HUMCA lXIA_node_27 according to the present invention is supported by 2 libraries. The number of libraries was determined as previously described. This segment
can be found in the following transcript(s): HUMCA 1XIA_T 16, HUMCA IXIAJT 17 and HUMCA1XIA_T19. Table 864 below describes the starting and ending position of this segment on each transcript.
Table 864 - Segment location on transcripts
Segment cluster HUMCA lXIA_node_29 according to the present invention is supported by 3 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): HUMCA1XIA_T16, HUMCA1XIA_T17 and HUMCA IXIAJTl 9. Table 865 below describes the starting and ending position of this segment on each transcript.
Table 865 - Segment location on transcripts
Segment cluster HUMC Al XIA_node_31 according to the present invention is supported by 3 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): HUMCA1XIAJT16, HUMCA1XIAJT17 and HUMCA1XIAJT19. Table 866 below describes the starting and ending position of this segment on each transcript.
Table 866- Segment location on transcripts
Segment cluster HUMCAlXlA_node_33 according to the present invention is supported by 3 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): HUMCA1XIAJT16, HUMCA IXIAJT 17 and HUMCA1XIA_T19. Table 867 below describes the starting and ending position of this segment on each transcript.
Table 867 - Segment location on transcripts
Segment cluster HUMCAlXIA_node_35 according to the present invention is supported by 4 libraries. The number of libraries was determined as previously described. This segment can be found in the following tran'script(s): HUMCA1XIA_T16, HUMCA IXIAJT 17 and HUMCA1XIAJT19. Table 868 below describes the starting and ending position of this segment on each transcript.
Table 868 - Segment location on transcripts
Segment cluster HUMCAlXIA_node_37 according to the present invention is supported by 4 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): HUMCA1XIAJT16, HUMCA1XIAJT17 and HUMCA1XIA_T19. Table 869 below describes the starting and ending position of this segment on each transcript.
Table 869 - Segment location on transcripts
Segment cluster HUMCAlXIA_node_39 according to the present invention is supported by 5 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): HUMCA IXIAJT 16, HUMCA1XIA_T17 and HUMCA1XIA_T19. Table 870 below describes the starting and ending position of this segment on each transcript.
Table 870 - Segment location on transcripts
Segment cluster HUMCAl XI A_node_41 according to the present invention is supported by 4 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): HUMCA IXIAJT 16, HUMCA1XIAJT17 and HUMCA 1XIA_T 19. Table 871 below describes the starting and ending position of this segment on each transcript.
Table 871 - Segment location on transcripts
Segment cluster HUMCAl XI A_node_43 according to the present invention is supported by 5 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): HUMCA1XIA_T16, HUMCA1XIA_T17 and HUMCAl XIA_T 19. Table 872 below describes the starting and ending position of this segment on each transcript.
Table 872 - Segment location on transcripts
Segment cluster HUMCAlXIA_node_45 according to the present invention is supported by 4 libraries. The number of libraries was determined as previously described. This segment
can be found in the following transcript(s): HUMCA IXIAJT 16 and HUMCA IXIAJTl 7. Table 873 below describes the starting and ending position of this segment on each transcript.
Table 873 - Segment location on transcripts
Segment cluster HUMCA lXIA_node_47 according to the present invention is supported by 5 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): HUMCA IXIAJT 16, HUMCA1XIAJT17 and HUMCA1XIAJT19. Table 874 below describes the starting and ending position of this segment on each transcript.
Table 874 - Segment location on transcripts
Segment cluster HUMCA lXIA_node_49 according to the present invention is supported by 5 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): HUMCA IXIAJT 16, HUMCAlXIA JTl 7 and HUMCA 1 XIAJT 19. Table 875 below describes the starting and ending position of this segment on each transcript.
Table 875 - Segment location on transcripts
Segment cluster HUMCA lXIA_node_51 according to the present invention is supported by 7 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): HUMCA1XIA_T16, HUMCA1XIA_T17 and HUMCAl XIAJTl 9. Table 876 below describes the starting and ending position of this segment on each transcript.
Table 876 - Segment location on transcripts
Segment cluster HUMCAlXIA_node_57 according to the present invention is supported by 4 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): HUMCA 1XIA_T 16. Table 877 below describes the starting and ending position of this segment on each transcript. Table 877 - Segment location on transcripts
Segment cluster HUMCAlXIA_node_59 according to the present invention is supported by 3 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): HUMCA 1XIA_T 16. Table 878 below describes the starting and ending position of this segment on each transcript.
Table 878 - Segment location on transcripts
Segment cluster HUMCA lXIA_node_62 according to the present invention is supported by 3 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): HUMCA1XIA_T16. Table 879 below describes the starting and ending position of this segment on each transcript.
Table 879 - Segment location on transcripts
Segment cluster HUMCA lXIA_node_64 according to the present invention is supported by 4 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): HUMCA1XIA_T16. Table 880 below describes the starting and ending position of this segment on each transcript. Table 880 - Segment location on transcripts
Segment cluster HUMCA lXIA_node_66 according to the present invention is supported by 4 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): HUMCAl XIA_T 16. Table 881 below describes the starting and ending position of this segment on each transcript.
Table 881 - Segment location on transcripts
Segment cluster HUMCAlXIA_node_68 according to the present invention is supported by 7 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): HUMCA1XIA_T16. Table 882 below describes the starting and ending position of this segment on each transcript.
Table 882 - Segment location on transcripts
Segment cluster HUMCA lXIA_node_70 according to the present invention is supported by 6 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): HUMCA1XIA_T16. Table 883 below describes the starting and ending position of this segment on each transcript.
Table 883 - Segment location on transcripts
Segment cluster HUMCA lXIA_node_72 according to the present invention is supported by 6 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): HUMCA 1XIA_T 16. Table 884 below describes the starting and ending position of this segment on each transcript.
Table 884 - Segment location on transcripts
Segment cluster HUMCA lXIA_node_74 according to the present invention is supported by 5 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): HUMCAl XIAJTl 6. Table 885 below describes the starting and ending position of this segment on each transcript.
Table 885 - Segment location on transcripts
Segment cluster HUMCA lXIA_node_76 according to the present invention is supported by 6 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): HUMCA1XIA_T16. Table 886 below describes the starting and ending position of this segment on each transcript.
Table 886 - Segment location on transcripts
Segment cluster HUMCAlXIA_node_78 according to the present invention is supported by 6 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): HUMCA1XIA_T16. Table 887 below describes the starting and ending position of this segment on each transcript.
Table 887 - Segment location on transcripts
Segment cluster HUMCAlXIA_node_81 according to the present invention is supported by 8 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): HUMCA1XIA_T16. Table 888 below describes the starting and ending position of this segment on each transcript.
Table 888 - Segment location on transcripts
Segment cluster HUMCA lXIA_node_83 according to the present invention is supported by 7 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): HUMCA1XIA_T16. Table 889 below describes the starting and ending position of this segment on each transcript.
Table 889 - Segment location on transcripts
Segment cluster HUMCA lXIA_node_85 according to the present invention is supported by 6 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): HUMCA1XIA_T16. Table 890 below describes the starting and ending position of this segment on each transcript.
Table 890 - Segment location on transcripts
Segment cluster HUMCAlXIA_node_87 according to the present invention is supported by 10 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): HUMCA1XIA_T16. Table 891 below describes the starting and ending position of this segment on each transcript.
Table 891 - Segment location on transcripts
Segment cluster HUMCA lXIA_node_89 according to the present invention is supported by 9 libraries. The number of libraries was determined as previously described. This segment
can be found in the following transcript(s): HUMCA 1XIA_T 16. Table 892 below describes the starting and ending position of this segment on each transcript.
Table 892 - Segment location on transcripts
Segment cluster HUMCA lXIA_node_91 according to the present invention is supported by 11 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): HUMCA1XIA_T16. Table 893 below describes the starting and ending position of this segment on each transcript.
Table 893 - Segment location on transcripts
Variant protein alignment to the previously known protein:
Sequence name: CA1B_HUMAN_V5
Sequence documentation:
Alignment of: HUMCAlXIA P14 x CA1B_HUMAN_V5
Alignment segment 1/1:
Quality: 10456.00 Escore: 0 Matching length: 1058 Total length: 1058
Matching Percent Similarity: 99.91 Matching Percent Identity: 99.91
Total Percent Similarity: 99.91 Total Percent Identity: 99.91
Gaps : 0
Alignment:
1 MEPWSSRWKTKRWLWDFTVTTLALTFLFQAREVRGAAPVDVLKALDFHNS 50
I i ! I I I I I I I I I I I I I I I I I I I I I I 1 I I I I Il I I I I I I I I Il I I I Il Il I l MEPWSSRWKTKRWLWDFTVTTLALTFLFQAREVRGAAPVDVLKALDFHNS 50
51 PEGISKTTGFCTNRKNSKGSDTAYRVSKQAQLSAPTKQLFPGGTFPEDFS 100 I I I I I I 1 I I I I I I I I I I I I I I I I Il I I I I I I I I I I I I I I I I M M I I I I I
51 PEGISKTTGFCTNRKNSKGSDTAYRVSKQAQLSAPTKQLFPGGTFPEDFS 100
101 ILFTVKPKKGIQSFLLSIYNEHGIQQIGVEVGRSPVFLFEDHTGKPAPED 150
I I I I I I I I I I I I Il I I I I I I Il I I I Il I I Il I I Il I I I I I I I I I Il I I I I 101 ILFTVKPKKGIQSFLLSIYNEHGIQQIGVEVGRSPVFLFEDHTGKPAPED 150
151 YPLFRTVNIADGKWHRVAISVEKKTVTMIVDCKKKTTKPLDRSERAIVDT 200
I I I I I I III I I I I I I I I I I I I I I I I Il I I I I I I I I I Il Il I I I I I I Il Il
151 YPLFRTVNIADGKWHRVAISVEKKTVTMIVDCKKKTTKPLDRSERAIVDT 200 . . . . .
201 NGITVFGTRILDEEVFEGDIQQFLITGDPKAAYDYCEHYSPDCDSSAPKA 250
I I I 1 I I I I I 1 I I I I I I I I I 1 I I I I I I I I I I I I I I I I I 1 I I I 1 I I I I I I Il
201 NGITVFGTRILDEEVFEGDIQQFLITGDPKAAYDYCEHYSPDCDSSAPKA 250
251 AQAQEPQIDEYAPEDIIEYDYEYGEAEYKEAESVTEGPTVTEETIAQTEA 300 I I I I Il I Il Il I I I Il I I I I M 1 I I Il I I I I I I I Il I I I I I I I I Il I I I I
251 AQAQEPQIDEYAPEDIIEYDYEYGEAEYKEAESVTEGPTVTEETIAQTEA 300
301 NIVDDFQEYNYGTMESYQTEAPRHVSGTNEPNPVEEIFTEEYLTGEDYDS 350
I Il I I I I I I I Il I I Il Il I I I Il I I I Il I I I Il I Il I I Il I Il I Il I I Il 301 NIVDDFQEYNYGTMESYQTEAPRHVSGTNEPNPVEEIFTEEYLTGEDYDS 350
351 QRKNSEDTLYENKEIDGRDSDLLVDGDLGEYDFYEYKEYEDKPTSPPNEE 400
II I I I I I Il I I I I I I I I I I I I I I I I ! I I I I I Il I I Il I I I I Il I I Il I I I
351 QRKNSEDTLYENKEIDGRDSDLLVDGDLGEYDFYEYKEYEDKPTSPPNEE 400 . . . . .
401 FGPGVPAETDITETSINGHGAYGEKGQKGEPAVVEPGMLVEGPPGPAGPA 450
Il I I I I I I I Il I Il I I I I I Il Il Il I I 1 I I I I I I Il I I I I I Il I I I Il Il
401 FGPGVPAETDITETSINGHGAYGEKGQKGEPAVVEPGMLVEGPPGPAGPA 450
451 GIMGPPGLQGPTGPPGDPGDRGPPGRPGLPGADGLPGPPGTMLMLPFRYG 500
I I I I I I I I I I Il I I Il I I I I I I I I I Il I I I I I I I I I I I Il I Il I I I Il I I 451 GIMGPPGLQGPTGPPGDPGDRGPPGRPGLPGADGLPGPPGTMLMLPFRYG 500
501 GDGSKGPTISAQEAQAQAILQQARIALRGPPGPMGLTGRPGPVGGPGSSG 550 I M I I I I I M I IM MIIM M I M I I M I I M I M I I IM M MI M M
501 GDGSKGPTISAQEAQAQAILQQARIALRGPPGPMGLTGRPGPVGGPGSSG 550
551 AKGESGDPGPQGPRGVQGPPGPTGKPGKRGRPGADGGRGMPGEPGAKGDR 600
I M M M I Il Il M I M M I I M M M M M I M M M M M M I M M I 551 AKGESGDPGPQGPRGVQGPPGPTGKPGKRGRPGADGGRGMPGEPGAKGDR 600
601 GFDGLPGLPGDKGHRGERGPQGPPGPPGDDGMRGEDGEIGPRGLPGEAGP 650
I I I I I I I I I I 1 I I I I I I I I I I I I I I I I 1 I I I I I 1 I I I I I I I I I I I I I I I I
601 GFDGLPGLPGDKGHRGERGPQGPPGPPGDDGMRGEDGEIGPRGLPGEAGP 650
651 RGLLGPRGTPGAPGQPGMAGVDGPPGPKGNMGPQGEPGPPGQQGNPGPQG 700
I I I I I I I I I I 1 i I I I I I I I I I I I I I I ! I I I I I Il I I I I I I I I I I I I I I I I
651 RGLLGPRGTPGAPGQPGMAGVDGPPGPKGNMGPQGEPGPPGQQGNPGPQG 700
701 LPGPQGPIGPPGEKGPQGKPGLAGLPGADGPPGHPGKEGQSGEKGALGPP 750 I I I M I I I I I M I Il I Il I Il I I I I I Il I I I I I I I I I I I I I I I I I I I Il I
701 LPGPQGPIGPPGEKGPQGKPGLAGLPGADGPPGHPGKEGQSGEKGALGPP 750
751 GPQGPIGYPGPRGVKGADGVRGLKGSKGEKGEDGFPGFKGDMGLKGDRGE 800
I I I I I I I I I I I I I I I I I Il I I I I I I I I Il I I I I I I I I I I I I I I Il I I I I I 751 GPQGPIGYPGPRGVKGADGVRGLKGSKGEKGEDGFPGFKGDMGLKGDRGE 800
801 VGQIGPRGEDGPEGPKGRAGPTGDPGPSGQAGEKGKLGVPGLPGYPGRQG 850
I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I Il I
801 VGQIGPRGEDGPEGPKGRAGPTGDPGPSGQAGEKGKLGVPGLPGYPGRQG 850 . . . . .
851 PKGSTGFPGFPGANGEKGARGVAGKPGPRGQRGPTGPRGSRGARGPTGKP 900
851 PKGSTGFPGFPGANGEKGARGVAGKPGPRGQRGPTGPRGSRGARGPTGKP 900
901 GPKGTSGGDGPPGPPGERGPQGPQGPVGFPGPKGPPGPPGKDGLPGHPGQ 950
M I M Il M Il I I I I M Il M M I I I I Il M M Il Il I I I Il I Il I I I Il 901 GPKGTSGGDGPPGPPGERGPQGPQGPVGFPGPKGPPGPPGKDGLPGHPGQ 950
951 RGETGFQGKTGPPGPGGVVGPQGPTGETGPIGERGHPGPPGPPGEQGLPG 1000 Il I Il Il I I Il Il M M I I M M I I I M Il Il Il Il M M M M I M I M
951 RGETGFQGKTGPPGPGGVVGPQGPTGETGPIGERGHPGPPGPPGEQGLPG 1000
1001 AAGKEGAKGDPGPQGISGKDGPAGLRGFPGERGLPGAQGAPGLKGGEGPQ 1050
1001 AAGKEGAKGDPGPQGISGKDGPAGLRGFPGERGLPGAQGAPGLKGGEGPQ 1050
1051 GPPGPVVS 1058
1051 GPPGPVGS 1058
Sequence name: CA1B_HUMAN
Sequence documentation:
Alignment of: HUMCA1XIA_P15 x CA1B_HUMAN
Alignment segment 1/1:
Quality: 7073.00
Escore : 0
Matching length: 714 Total length: 714
Matching Percent Similarity: 100.00 Matching Percent Identity: 100.00
Total Percent Similarity: 100.00 Total Percent Identity: 100.00
Gaps : 0
Alignment :
1 MEPWSSRWKTKRWLWDFTVTTLALTFLFQAREVRGAAPVDVLKALDFHNS 50 I I I I I I I I I I I I I I I I I I M I Il I I I I I I I I I I I I I I I I I I I I I 1 I I I I I
1 MEPWSSRWKTKRWLWDFTVTTLALTFLFQAREVRGAAPVDVLKALDFHNS 50
51 PEGISKTTGFCTNRKNSKGSDTAYRVSKQAQLSAPTKQLFPGGTFPEDFS 100
I I I I I I Il I I I I I I I I I I I Il I I I Il I I Il I I I I Il 1 I I I I I I I I I I I I I 51 PEGISKTTGFCTNRKNSKGSDTAYRVSKQAQLSAPTKQLFPGGTFPEDFS 100
101 ILFTVKPKKGIQSFLLSIYNEHGIQQIGVEVGRSPVFLFEDHTGKPAPED 150
I I Il I I I Il I Il Il I I I I I I Il I I I Il I I I I I I I I I I I I I I I Il I I I I I I
101 ILFTVKPKKGIQSFLLSIYNEHGIQQIGVEVGRSPVFLFEDHTGKPAPED 150 . . . . .
151 YPLFRTVNIADGKWHRVAISVEKKTVTMIVDCKKKTTKPLDRSERAIVDT 200
I I I I I I I I I I I I I I I I I I I I I I I I I Il I I I I I I Il Il I I I I Il I Il Il Il
151 YPLFRTVNIADGKWHRVAISVEKKTVTMIVDCKKKTTKPLDRSERAIVDT 200
201 NGITVFGTRILDEEVFEGDIQQFLITGDPKAAYDYCEHYSPDCDSSAPKA 250
II I I I Il I I Il I I I I I Il Il I I 11 I I I I I I Il I I I I Il I I I I I Il Il I I I
201 NGITVFGTRILDEEVFEGDIQQFLITGDPKAAYDYCEHYSPDCDSSAPKA 250
251 AQAQEPQIDEYAPEDIIEYDYEYGEAEYKEAESVTEGPTVTEETIAQTEA 300 M I I M I I M I M M I M I I M M I I I I M I I M M M I M I I I I I I M I
251 AQAQEPQIDEYAPEDIIEYDYEYGEAEYKEAESVTEGPTVTEETIAQTEA 300
301 NIVDDFQEYNYGTMESYQTEAPRHVSGTNEPNPVEEIFTEEYLTGEDYDS 350
Il M M M Il M M M M M I M M M M Il Il I M I M M Il Il M I M 301 NIVDDFQEYNYGTMESYQTEAPRHVSGTNEPNPVEEIFTEEYLTGEDYDS 350
351 QRKNSEDTLYENKEIDGRDSDLLVDGDLGEYDFYEYKEYEDKPTSPPNEE 400
I I I I I I I I I I I I I I I I I I I I I I I I I I 1 I I I I I I I I I I I I I I I I ! I I I I I I
351 QRKNSEDTLYENKEIDGRDSDLLVDGDLGEYDFYEYKEYEDKPTSPPNEE 400
401 FGPGVPAETDITETSINGHGAYGEKGQKGEPAVVEPGMLVEGPPGPAGPA 450
I I I I I I I I I I I I I I I I I I I I I I 1 I I I I I I I I I 1 I I I I I I I I I I I I I I I I I
401 FGPGVPAETDITETSINGHGAYGEKGQKGEPAVVEPGMLVEGPPGPAGPA 450
451 GIMGPPGLQGPTGPPGDPGDRGPPGRPGLPGADGLPGPPGTMLMLPFRYG 500 I I I I I I I I I 1 I I I ! I I M I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I
451 GIMGPPGLQGPTGPPGDPGDRGPPGRPGLPGADGLPGPPGTMLMLPFRYG 500
501 GDGSKGPTISAQEAQAQAILQQARIALRGPPGPMGLTGRPGPVGGPGSSG 550
I I I I I I I I Il I I I I I Il I I I I I I I I I I I I I I I I I I I I I I I I I I I I I Il I I 501 GDGSKGPTISAQEAQAQAILQQARIALRGPPGPMGLTGRPGPVGGPGSSG 550
551 AKGESGDPGPQGPRGVQGPPGPTGKPGKRGRPGADGGRGMPGEPGAKGDR 600
I I I I I I I I I Il I I I I Il I I Il Il I Il Il Il Il I Il I Il I I Il I Il Il Il I
551 AKGESGDPGPQGPRGVQGPPGPTGKPGKRGRPGADGGRGMPGEPGAKGDR 600 . . . . .
601 GFDGLPGLPGDKGHRGERGPQGPPGPPGDDGMRGEDGEIGPRGLPGEAGP 650
I I Il I I Il I I I I Il I I I I I Il I I I I Il I I Il Il I Il I I Il I I I I I I Il I I 601 GFDGLPGLPGDKGHRGERGPQGPPGPPGDDGMRGEDGEIGPRGLPGEAGP 650
651 RGLLGPRGTPGAPGQPGMAGVDGPPGPKGNMGPQGEPGPPGQQGNPGPQG 700
I I I Il I Il I Il I I Il I I Il Il Il I Il Il I I Il Il I Il I I I I I Il I I I Il I 651 RGLLGPRGTPGAPGQPGMAGVDGPPGPKGNMGPQGEPGPPGQQGNPGPQG 700
701 LPGPQGPIGPPGEK 714 I I I I I I I I M I I I I
701 LPGPQGPIGPPGEK 714
Sequence name: CA1B_HUMAN
Sequence documentation:
Alignment of: HUMCA1XIA_P16 x CA1B_HUMAN
Alignment segment 1/1:
Quality: 6795.00
Escore: 0
Matching length: 696 Total length: 714
Matching Percent Similarity: 100.00 Matching Percent Identity: 100.00
Total Percent Similarity: 97.48 Total Percent Identity: 97.48
Gaps : 1
Alignment:
1 MEPWSSRWKTKRWLWDFTVTTLALTFLFQAREVRGAAPVDVLKALDFHNS 50
I M I I I I M I M I M I I M I I I I I I I I I I I M I I M I I M I I M I I M I I
1 MEPWSSRWKTKRWLWDFTVTTLALTFLFQAREVRGAAPVDVLKALDFHNS 50 . . . . .
51 PEGISKTTGFCTNRKNSKGSDTAYRVSKQAQLSAPTKQLFPGGTFPEDFS 100
I I I I I I I I I I I I 1 I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I
51 PEGISKTTGFCTNRKNSKGSDTAYRVSKQAQLSAPTKQLFPGGTFPEDFS 100
101 ILFTVKPKKGIQSFLLSIYNEHGIQQIGVEVGRSPVFLFEDHTGKPAPED 150 I I I I I I I I I I I I I I I i I I M I I I I I I I I I I I 1 I ! I I I I I I I I I I I I I I I I
101 ILFTVKPKKGIQSFLLSIYNEHGIQQIGVEVGRSPVFLFEDHTGKPAPED 150
151 YPLFRTVNIADGKWHRVAISVEKKTVTMIVDCKKKTTKPLDRSERAIVDT 200
I Il I I I Il I I I I I I I I I I I I I I Il Il 1 I I I I I I Il Il I I I I I I I I Il I I I 151 YPLFRTVNIADGKWHRVAISVEKKTVTMIVDCKKKTTKPLDRSERAIVDT 200
201 NGITVFGTRILDEEVFEGDIQQFLITGDPKAAYDYCEHYSPDCDSSAPKA 250
I I I I Il I I I I I I I I I I I I I I I I I I I I Il I I I I I I I I I I I I I I I I I I I I ! I
201 NGITVFGTRILDEEVFEGDIQQFLITGDPKAAYDYCEHYSPDCDSSAPKA 250 . . . . .
251 AQAQEPQIDEYAPEDIIEYDYEYGEAEYKEAESVTEGPTVTEETIAQTEA 300
I I I I I I I I I Il Il I Il I I I I I I I I I I I I I Il Il Il I Il I I I I I Il Il I ! I
251 AQAQEPQIDEYAPEDIIEYDYEYGEAEYKEAESVTEGPTVTEETIAQTEA 300
301 NIVDDFQEYNYGTMESYQTEAPRHVSGTNEPNPVEEIFTEEYLTGEDYDS 350
I I I I I I I I I I I I I I I I I I I I I I I I I I I I Il Il I Il I I Il I I I I I I I Il I I
301 NIVDDFQEYNYGTMESYQTEAPRHVSGTNEPNPVEEIFTEEYLTGEDYDS 350
351 QRKNSEDTLYENKEIDGRDSDLLVDGDLGEYDFYEYKEYEDKPTSPPNEE 400 I M M I I M I | | | | | | | | | | I I M I I I M M I I M Il I I I I I I I I I I I I I
351 QRKNSEDTLYENKEIDGRDSDLLVDGDLGEYDFYEYKEYEDKPTSPPNEE 400
401 FGPGVPAETDITETSINGHGAYGEKGQKGEPAWEPGMLVEGPPGPAGPA 450
MMMIMMMIIMMMIIMIIMIIMIMIMIMMIIIMI 401 FGPGVPAETDITETSINGHGAYGEKGQKGEPAWEPGMLVEGPPGPAGPA 450
451 GIMGPPGLQGPTGPPGDPGDRGPPGRPGLPGADGLPGPPGTMLMLPFRYG 500
I I I I I I I I I I I I I I I I I Il 1 I I I I I I I I 1 I I I I I I I I I I I I I I I I I I I I I
451 GIMGPPGLQGPTGPPGDPGDRGPPGRPGLPGADGLPGPPGTMLMLPFRYG 500
501 GDGSKGPTISAQEAQAQAILQQARIALRGPPGPMGLTGRPGPVGGPGSSG 550 I I I I I I I I I I I I I I 1 I I I I 1 I I I I I I I I I I I I I I I I I I I 1 I I I I I I I I I I
501 GDGSKGPTISAQEAQAQAILQQARIALRGPPGPMGLTGRPGPVGGPGSSG 550
551 AKGESGDPGPQGPRGVQGPPGPTGKPGKRGRPGADGGRGMPGEPGAKGDR 600 I I I I I I I I I M I I I 1 I I I I Il I I I I I I I I I I I I I I I M I M I I I I I I I I I
551 AKGESGDPGPQGPRGVQGPPGPTGKPGKRGRPGADGGRGMPGEPGAKGDR 600
601 GFDGLPGLPGDKGHRGERGPQGPPGPPGDDGMRGEDGEIGPRGLPGEA.. 648
I Il I I Il I I I I I I I Il I Il I I I Il I I I I Il I I I I I Il Il I I I Il I I Il 601 GFDGLPGLPGDKGHRGERGPQGPPGPPGDDGMRGEDGEIGPRGLPGEAGP 650
649 GMAGVDGPPGPKGNMGPQGEPGPPGQQGNPGPQG 682
I I I I I I I Il I I I I I I I I I I I I I I Il Il I I I I I I I
651 RGLLGPRGTPGAPGQPGMAGVDGPPGPKGNMGPQGEPGPPGQQGNPGPQG 700
683 LPGPQGPIGPPGEK 696
I I I I I I Il I Il I I I 701 LPGPQGPIGPPGEK 714
Sequence name: CA1B_HUMAN
Sequence documentation:
Alignment of: HUMCA1XIA_P17 x CA1B_HUMAN
Alignment segment 1/1:
Quality: 2561.00 Escore: 0
Matching length: 260 Total length: 260
Matching Percent Similarity: 100.00 Matching Percent Identity: 100.00
Total Percent Similarity: 100.00 Total Percent Identity: 100.00 Gaps: 0
Alignment :
1 MEPWSSRWKTKRWLWDFTVTTLALTFLFQAREVRGAAPVDVLKALDFHNS 50 I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I M I I I I I I I I I I
1 MEPWSSRWKTKRWLWDFTVTTLALTFLFQAREVRGAAPVDVLKALDFHNS 50
51 PEGISKTTGFCTNRKNSKGSDTAYRVSKQAQLSAPTKQLFPGGTFPEDFS 100
I I Il I I i I Il Il I Il I I Il I I I I I I I I I I I Il I Il Il I Il I Il Il I I I I I 51 PEGISKTTGFCTNRKNSKGSDTAYRVSKQAQLSAPTKQLFPGGTFPEDFS 100
101 ILFTVKPKKGIQSFLLSIYNEHGIQQIGVEVGRSPVFLFEDHTGKPAPED 150
II I I Il Il I I I Il I Il I I Il I I Il Il Il I I I I Il I Il I I I I I I I Il Il Il
101 ILFTVKPKKGIQSFLLSIYNEHGIQQIGVEVGRSPVFLFEDHTGKPAPED 150 . . . . .
151 YPLFRTVNIADGKWHRVAISVEKKTVTMIVDCKKKTTKPLDRSERAIVDT 200
I I 1 I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I
151 YPLFRTVNΪADGKWHRVAISVEKKTVTMIVDCKKKTTKPLDRSERΑIVDT 200
201 NGITVFGTRILDEEVFEGDIQQFLITGDPKAAYDYCEHYSPDCDSSAPKA 250 1 I I I I I I II I I I I I I I I 1 I I I M I I I I I 1 I I I I I I I I I I I I I I I I I I 1 I 1
201 NGITVFGTRILDEEVFEGDIQQFLITGDPKAAYDYCEHYSPDCDSSAPKA 250
251 AQAQEPQIDE 260
I I i Il I I I I I 251 AQAQEPQIDE " 260
Expression of Homo sapiens collagen, type XI, alpha 1 (COLI lAl) HUMCAlXlA transcripts which are detectable by amplicon as depicted in sequence name HUMCAlXlA seg55 in normal and cancerous lung tissues
Expression of Homo sapiens collagen, type XI, alpha 1 (COLI lAl) transcripts detectable by or according to seg55, HUMCAlXlA seg55 amplicon (SEQ ID NO: 1663) and primers HUMCAlXlA seg55F (SEQ ID NO:1661) and HUMCAlXlA seg55R (SEQ ID NO:1662) was measured by real time PCR. In parallel the expression of four housekeeping genes -PBGD (GenBank Accession No. BC019323; amplicon - PBGD-amplicon, SEQ ID NO:334), HPRTl (GenBank Accession No. NM_000194; amplicon - HPRTl -amplicon, SEQ ID NO:1297), Ubiquitin (GenBank Accession No. BC000449; amplicon - Ubiquitin- amplicon, SEQ ID NO:328) and SDHA (GenBank Accession No. NM_004168; amplicon - SDHA-amplicon, SEQ ID NO:331), was measured similarly. For each RT sample, the expression of the above amplicon was normalized to the geometric mean of the quantities of the housekeeping genes. The normalized quantity of each RT sample was then divided by the median of the quantities of the normal post-mortem (PM) samples (Sample Nos. 47-50, 90-93, 96-99, Table 2, above), to obtain a value of fold up -regulation for each sample relative to median of the normal PM samples. Figure 67 is a histogram showing over expression of the above- indicated Homo sapiens collagen, type XI, alpha 1 (COLl IAl) transcripts in cancerous lung samples relative to the
normal samples. Values represent the average of duplicate experiments. Error bars indicate the minimal and maximal values obtained.
As is evident from Figure 67, the expression of Homo sapiens collagen, type XI, alpha 1
(COLl IAl) transcripts detectable by the above amplicon(s) in cancer samples was significantly higher than in the non-cancerous samples (Sample Nos. 47-50, 90-93, 96-99 Table 2). Notably an over- expression of at least 5 fold was found in 11 out of 15 adenocarcinoma samples, 11 out of 16 squamous cell carcinoma samples, and in 2 out of 4 large cell carcinoma samples.
Primer pairs are also optionally and preferably encompassed within the present invention; for example, for the above experiment, the following primer pair was used as a non- limiting illustrative example only of a suitable primer pair: HUMCAlXlA seg55F forward primer; and HUMCAlXlA seg55R reverse primer.
The present invention also preferably encompasses any amplicon obtained through the use of any suitable primer pair; for example, for the above experiment, the following amplicon was obtained as a non- limiting illustrative example only of a suitable amplicon: HUMCAlXlA seg55.
Forward primer -HUMCAlXlA seg55F (SEQ ID NO:1661):
TTCTCATAGTATTCCATTGATTGGGTA
Reverse primer- HUMCAlXlA seg55R (SEQ ID NO:1662): CACCGGTATGGAGAATAGCGA
Amplicon (SEQ ID NO: 1663):
TTCTCATAGTATTCCATTGATTGGGTATACCAGGTTCTGTTTACTTTTACTTGGCAGT
TGATAGAATAGGTGTAGTTTATACTTTTTCGCTATTCTCCATACCGGTG
DESCRIPTION FOR CLUSTER Tl 1628
Cluster Tl 1628 features 6 transcript(s) and 25 segment(s) of interest, the names for which are given in Tables 894 and 895, respectively, the sequences themselves are given at the end of the application. The selected protein variants are given in table 896.
Table 894 - Transcripts of interest
Table 896 - Proteins of interest
These sequences are variants of the known protein Myoglobin (SwissProt accession identifier MYG_HUMAN), SEQ ID NO: 1448, referred to herein as the previously known protein.
Protein Myoglobin is known or believed to have the following function(s): Serves as a reserve supply of oxygen and facilitates the movement of oxygen within muscles. The sequence for protein Myoglobin is given at the end of the application, as "Myoglobin amino acid sequence". Known polymorphisms for this sequence are as shown in Table 897.
Table 897 ' - Amino acid mutations for Known Protein
As noted above, cluster Tl 1628 features 6 transcript(s), which were listed in Table 1 above. These transcript(s) encode for protein(s) which are variant(s) of protein Myoglobin. A description of each variant protein according to the present invention is now provided.
Variant protein Tl 1628_PEA_1_P2 according to the present invention has an amino acid sequence as given at the end of the application; it is encoded by transcript(s) Tl 1628_PEA_1_T3. An alignment is given to the known protein (Myoglobin) at the end of the application. One or more alignments to one or more previously published protein sequences are given at the end of the application. A brief description of the relationship of the variant protein according to the present invention to each such aligned protein is as follows:
Comparison report between Tl 1628_PEA_1_P2 and Q8WVH6 (SEQ ID NO:1450): 1.An isolated chimeric polypeptide encoding for T11628_PEA_1_P2, comprising a first amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence
MGLSDGEWQLVLNVWGKVEADIPGHGQEVLIRLFKGHPETLEKFDKFKHLKSEDE corresponding to amino acids 1 - 55 of Tl 1628_PEA_1_P2, and a second amino acid sequence being at least 90 % homologous to MKASEDLKKHGATVLTALGGILKKKGHHEAEIKPLAQSHATKHKIPVKYLEFISECIIQV LQSKHPGDFGADAQGAMNKALELFRKDMASNYKELGFQG corresponding to amino acids 1 - 99 of Q8WVH6, which also corresponds to amino acids 56 - 154 of Tl 1628_PEA_1_P2, wherein said first amino acid sequence and second amino acid sequence are contiguous and in a sequential order.
2.An isolated polypeptide encoding for a head of Tl 1628_PEA_1_P2, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence
MGLSDGEWQLVLNVWGKVEADIPGHGQEVLIRLFKGHPETLEKFDKFKHLKSEDE of Tl 1628 PEA 1 P2.
The location of the variant protein was determined according to results from a number of different software programs and analyses, including analyses from SignalP and other specialized programs. The variant protein is believed to be located as follows with regard to the cell: intracellularly. The protein localization is believed to be intracellularly because neither of the trans- membrane region prediction programs predicted a trans -membrane region for this protein. In addition both signal-peptide prediction programs predict that this protein is a non- secreted protein. Variant protein Tl 1628_PEA_1_P2 also has the following non-silent SNPs (Single
Nucleotide Polymorphisms) as listed in Table 898, (given according to their position(s) on the amino acid sequence, with the alternative amino acid(s) listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein Tl 1628_PEA_1_P2 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 898 -Amino acid mutations
Variant protein Tl 1628_PEA_1_P2 is encoded by the following transcript(s): Tl 1628_PEA_1_T3, for which the sequence(s) is/are given at the end of the application. The coding portion of transcript Tl 1628_PEA_1_T3 is shown in bold; this coding portion starts at position 220 and ends at position 681. The transcript also has the following SNPs as listed in Table 899 (given according to their position on the nucleotide sequence, with the alternative nucleic acid listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein T11628_PEA_1_P2 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 899- Nucleic acid SNPs
Variant protein T11628_PEA_1_P5 according to the present invention has an amino acid sequence as given at the end of the application; it is encoded by transcript(s) Tl 1628_PEA_1_T9. An alignment is given to the known protein (Myoglobin) at the end of the application. One or more alignments to one or more previously published protein sequences are given at the end of the application. A brief description of the relationship of the variant protein according to the present invention to each such aligned protein is as follows:
Comparison report between Tl 1628_PEA_1_P5 and MYG_HUMAN_V1 (SEQ ID NO:1449):
LAn isolated chimeric polypeptide encoding for T11628_PEA_1_P5, comprising a first amino acid sequence being at least 90 % homologous to
MKASEDLKKHGATVLTALGGILKKKGHHEAEIKPLAQSHATKHKIPVKYLEFISECIIQV LQSKHPGDFGADAQGAMNBCALELFRKDMASNYKELGFQG corresponding to amino acids 56 - 154 of MYG_HUMAN_V1, which also corresponds to amino acids 1 - 99 of Tl 1628 PEA 1 P5.
It should be noted that the known protein sequence (MYG_HUMAN) has one or more changes than the sequence given at the end of the application and named as being the amino acid sequence for MYGJHUMAN V1. These changes were previously known to occur and are listed in the table below.
Table 900 - Changes to MYGJiUMAN _ V1
The location of the variant protein was determined according to results from a number of different software programs and analyses, including analyses from SignalP and other specialized programs. The variant protein is believed to be located as follows with regard to the cell: intracellularly. The protein localization is believed to be intracellularly because neither of the trans -membrane region prediction programs predicted a trans -membrane region for this protein. In addition both signal-peptide prediction programs predict that this protein is a non- secreted protein. Variant protein Tl 1628_PEA_1_P5 also has the following non- silent SNPs (Single
Nucleotide Polymorphisms) as listed in Table 901, (given according to their position(s) on the amino acid sequence, with the alternative amino acid(s) listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein Tl 1628_PEA_1_P5 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 901 - Amino acid mutations
Variant protein Tl 1628_PEA_1_P5 is encoded by the following transcript(s): Tl 1628_PEA_1_T9, for which the sequence(s) is/are given at the end of the application. The coding portion of transcript Tl 1628_PEA_1_T9 is shown in bold; this coding portion starts at position 211 and ends at position 507. The transcript also has the following SNPs as listed in Table 902 (given according to their position on the nucleotide sequence, with the alternative nucleic acid listed; the last column indicates whether the SNP is known or not; the presence of
known SNPs in variant protein Tl 1628_PEA_1__P5 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 902 - Nucleic acid SNPs
Variant protein Tl 1628_PEA_1_P7 according to the present invention has an amino acid sequence as given at the end of the application; it is encoded by transcript(s) Tl 1628_PEA_1_T11. An alignment is given to the known protein (Myoglobin) at the end of the
application. One or more alignments to one or more previously published protein sequences are given at the end of the application. A brief description of the relationship of the variant protein according to the present invention to each such aligned protein is as follows:
Comparison report between Tl 1628JPEA_1_P7 and M YG JHUMANJVl: LAn isolated chimeric polypeptide encoding for Tl 1628_PEA_1_P7, comprising a first amino acid sequence being at least 90 % homologous to
MGLSDGEWQLVLNVWGKVEADIPGHGQEVLIRLFKGHPETLEKFDKPKHLKSEDEMK ASEDLKKHGATVLTALGGILKKKGHHEAEIKPLAQSHATKHKIPVKYLEFISECIIQVLQ SKHPGDFGADAQGAMNK corresponding to amino acids 1 - 134 of MYG_HUMAN_V1, which also corresponds to amino acids 1 - 134 of Tl 1628_PEA_1 JP7, and a second amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence G corresponding to amino acids 135 - 135 of Tl 1628_PEA_1 JP7, wherein said first amino acid sequence and second amino acid sequence are contiguous and in a sequential order.
It should be noted that the known protein sequence (MYG_HUMAN) has one or more changes than the sequence given at the end of the application and named as being the amino acid sequence for MYG_HUMAN_V1. These changes were previously known to occur and are listed in the table below. Table 903 - Changes to MYG_HUMAN_V1
The location of the variant protein was deteπnined according to results from a number of different software programs and analyses, including analyses from SignalP and other specialized programs. The variant protein is believed to be located as follows with regard to the cell: intracellularly. The protein localization is believed to be intracellularly because neither of the trans- membrane region prediction programs predicted a trans- membrane region for this protein.
In addition both signal-peptide prediction programs predict that this protein is a non-secreted protein.
Variant protein Tl 1628_PEA_1_P7 also has the following non- silent SNPs (Single Nucleotide Polymorphisms) as listed in Table 904, (given according to their position(s) on the amino acid sequence, with the alternative amino acid(s) listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein Tl 1628_PEA_1_P7 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 904 - Amino acid mutations
Variant protein Tl 1628_PEA_1_P7 is encoded by the following transcript(s): Tl 1628_PEA_1_T11, for which the sequence(s) is/are given at the end of the application. The coding portion of transcript Tl 1628JPEA_1_T11 is shown in bold; this coding portion starts at position 319 and ends at position 723. The transcript also has the following SNPs as listed in Table 905 (given according to their position on the nucleotide sequence, with the alternative nucleic acid listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein T11628_PEA_1_P7 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 905 -Nucleic acid SNPs
Variant protein Tl 1628_PEA_l_P10 according to the present invention has an amino acid sequence as given at the end of the application; it is encoded by transcript(s) Tl 1628_PEA_1_T4. An alignment is given to the known protein (Myoglobin) at the end of the application. One or more alignments to ore or more previously published protein sequences are given at the end of the application. A brief description of the relationship of the variant protein according to the present invention to each such aligned protein is as follows:
Comparison report between T11628_PEA_l_P10 and Q8WVH6 (SEQ ID NO: 1450): 1.An isolated chimeric polypeptide encoding for Tl 1628_PEA_l_P10, comprising a first amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence MGLSDGEWQLVLNVWGKVEADIPGHGQEVLIRLFKGHPETLEKFDKFKHLKSEDE corresponding to amino acids 1 - 55 of T11628_PEA_l_P10, and a second amino acid sequence being at least 90 % homologous to MKASEDLKKHGATVLTALGGILKKKGHHEAEIKPLAQSHATKHKIPVKYLEFISECIIQV
LQSKHPGDFGADAQGAMNKALELFRKDMASNYKELGFQG corresponding to amino acids 1 - 99 of Q8WVH6, which also corresponds to amino acids 56 - 154 of Tl 1628_PEA_1JP1O, wherein said first amino acid sequence and second amino acid sequence are contiguous and in a sequential order.
2.An isolated polypeptide encoding for a head of T11628_PEA_l_P10, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence
MGLSDGEWQLVLNVWGKVEADIPGHGQEVLIRLFKGHPETLEKFDKFKHLKSEDE of Tl 1628 PEA 1 PlO.
The location of the variant protein was determined according to results from a number of different software programs and analyses, including analyses from SignalP and other specialized programs. The variant protein is believed to be located as follows with regard to the cell: intracellularly. The protein localization is believed to be intracellularly because neither of the trans- membrane region prediction programs predicted a trans -membrane region for this protein. In addition both signal-peptide prediction programs predict that this protein is a non- secreted protein.
Variant protein Tl 1628_PEA_l_P10 also has the following non-silent SNPs (Single Nucleotide Polymorphisms) as listed in Table 906, (given according to their position(s) on the amino acid sequence, with the alternative amino acid(s) listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein Tl 1628_PEA_l_P10 sequence provides support for the deduced sequence of this variant protein according to the present invention). Table 906 - Amino acid mutations
Variant protein Tl 1628_PEA_l_P10 is encoded by the following transcript(s): T11628_PEA_1_T4, for which the sequence(s) is/are given at the end of the application. The coding portion of transcript Tl 1628JPEA_1_T4 is shown in bold; this coding portion starts at position 205 and ends at position 666. The transcript also has the following SNPs as listed in Table 907 (given according to their position on the nucleotide sequence, with the alternative nucleic acid listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein T11628_PEA_l_P10 sequence provides support for the deduced sequence of this variant protein according to the present invention). Table 907 - Nucleic acid SNPs
As noted above, cluster Tl 1628 features 25 segment(s), which were listed in Table 2 above and for which the sequence(s) are given at the end of the application. These segment(s) are portions of nucleic acid sequence(s) which are described herein separately because they are of particular interest. A description of each segment according to the present invention is now provided.
Segment cluster Tl 1628_PEA_l_node_7 according to the present invention is supported by 9 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): Tl 1628_PEA_1_T3. Table 908 below describes the starting and ending position of this segment on each transcript.
Table 908 - Segment location on transcripts
Segment cluster T11628_PEA_l_node_l l according to the present invention is supported by 1 libraries. The number of libraries was determined as previously described. This segment can be found in tte following transcript(s): T11628_PEA_1_T5. Table 909 below describes the starting and ending position of this segment on each transcript.
Table 909 - Segment location on transcripts
Segment cluster T11628_PEA_l_node_16 according to the present invention is supported by 38 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): Tl 1628JPEA_1_T11. Table 910 below describes the starting and ending position of this segment on each transcript.
Table 910 - Segment location on transcripts
Segment cluster Tl 1628_PEA_l_node_22 according to the present invention is supported by 1 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): Tl 1628_PEA_1_T9. Table 911 below describes the starting and ending position of this segment on each transcript.
Table 911 - Segment location on transcripts
Segment cluster Tl 1628JPEA_l_node_25 according to the present invention is supported by 129 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): Tl 1628_PEAJ_T3, Tl 1628_PEA_1_T4, T11628_PEA_1_T5, T11628_PEA_1_T7, T11628_PEA_1_T9 and Tl 1628_PEA_1_T11. Table 912 below describes the starting and ending position of this segment on each transcript.
Table 912- Segment location on transcripts
Microarray (chip) data is also available for this segment as follows. As described above with regard to the cluster itself, various oligonucleotides were tested for being differentially expressed in various disease conditions, particularly cancer. The following oligonucleotides were found to hit this segment (in relation to lung cancer), shown in Table 913.
Table 913 - Oligonucleotides related to this segment
Segment cluster Tl 1628_PEA_l_node_31 according to the present invention is supported by 137 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): T11628_PEA_1_T3, T11628_PEA_1_T4, T11628_PEA_1_T5, T11628_PEA_1_T7, T11628_PEA_1_T9 and T11628_PEA_1_T11. Table 914 below describes the starting and ending position of this segment on each transcript.
Table 914 - Segment location on transcripts
Segment cluster Tl 1628_PEA_l_node_37 according to the present invention is supported by 99 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): Tl 1628JPEA_1_T3, Tl 1628_PEA_1_T4, T11628_PEA_1_T5, T11628_PEA_1_T7, T11628_PEA_1_T9 and T11628_PEA_1_T11. Table 915 below describes the starting and ending position of this segment on each transcript.
Table 915 - Segment location on transcripts
According to an optional embodiment of the present invention, short segments related to the above cluster are also provided. These segments are up to about 120 bp in length, and so are included in a separate description.
Segment cluster T11628_PEA_l_node_0 according to the present invention is supported by 1 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): Tl 1628_PEA_1_T4. Table 916 below describes the starting and ending position of this segment on each transcript.
Table 916 - Segment location on transcripts
Segment cluster Tl 1628JPEA_l_node_4 according to the present invention is supported by 2 libraries. The number of libraries was deteπnined as previously described. This segment can be found in the following transcript(s): Tl 1628_PEA_1_T4. Table 917 below describes the starting and ending position of this segment on each transcript.
Table 917 - Segment location on transcripts
Segment cluster T11628_PEA_l_node_9 according to the present invention is supported by 16 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): T11628_PEA_1_T5 and T11628_PEA_1_T7. Table 918 below describes the starting and ending position of this segment on each transcript.
Table 918 - Segment location on transcripts
Segment cluster Tl 1628_PEA_l_node_13 according to the present invention can be found in the following transcript(s): T11628_PEA_1_T7. Table 919 below describes the starting and ending position of this segment on each transcript.
Table 919 - Segment location on transcripts
Segment cluster Tl 1628JPEA_l_node_14 according to the present invention is supported by 1 libraries. The number of libraπes was determined as previously described. This segment can be found in the following transcript(s): Tl 1628_PEA_1_T7. Table 920 below describes the starting and ending position of this segment on each transcript.
Table 920 - Segment location on transcripts
Segment cluster T11628_PEA_l_node_17 according to the present invention is supported by 55 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): Tl 1628_PEA_1_T11. Table 921 below describes the starting and ending position of this segment on each transcript.
Table 921 - Segment location on transcripts
Segment cluster T11628_PEA_l_node_18 according to the present invention is supported by 98 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): T11628_PEA_1_T3, T11628_PEA_1_T4, T11628_PEA_1_T5, T11628_PEA_1_T7 and T11628_PEA_1_T11. Table 922 below describes the starting and ending position of this segment on each transcript.
Table 922 - Segment location on transcripts
Segment cluster Tl 1628_PEA_l_node_19 according to the present invention can be found in the following transcript(s): T11628_PEA_1_T3, T11628_PEA_1_T4, Tl 1628_PEA_1_T5, Tl 1628_PEA_1_T7 and Tl 1628_PEA_1_T11. Table 923 below describes the starting and ending position of this segment on each transcript.
Table 923 - Segment location on transcripts
Segment cluster Tl 1628_PEA_l_node_24 according to the present invention is supported by 112 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): T11628_PEA_1_T3, T11628_PEA_1_T4, T11628_PEA_1_T5, T11628_PEA_1_T7, T11628_PEA_1_T9 and T11628_PEA_1 JTI l. Table 924 below describes the starting and ending position of this segment on each transcript. Table 924 - Segment location on transcripts
Segment cluster Tl 1628_PEA_l_node_27 according to the present invention is supported by 119 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): T11628_PEA_1_T3, T11628JPEA_1_T4, Tl 1628_PEA_1_T5, Tl 1628_PEA_1_T7, Tl 1628_PEA_1_T9 and Tl 1628_PEA_1_T11. Table 925 below describes the starting and ending position of this segment on each transcript.
Table 925 - Segment location on transcripts
Microarray (chip) data is also available for this segment as follows. As described above with regard to the cluster itself, various oligonucleotides were tested for being differentially expressed in various disease conditions, particularly cancer. The following oligonucleotides were found to hit this segment (in relation to lung cancer), shown in Table 926
Table 926 - Oligonucleotides related to this segment
Segment cluster Tl 1628_PEA_l_node_28 according to the present invention is supported by 115 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): Tl 1628JPEA_1_T3, Tl 1628JPEA_1_T4, Tl 1628_PEA_1_T5, Tl 1628_PEA_1_T7 and Tl 1628_PEA_1_T9. Table 927 below describes the starting and ending position of this segment on each transcript.
Table 927 - Segment location on transcripts
Segment cluster T11628_PEA_l_node_29 according to the present invention is supported by 113 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): T11628_PEA_1_T3, T11628_PEA_1_T4, Tl 1628_PEA_1_T5, Tl 1628_PEA_1_T7 and Tl 1628_PEA_1_T9. Table 928 below describes the starting and ending position of this segment on each transcript.
Table 928 - Segment location on transcripts
Segment cluster Tl 1628_PEA_l_node_30 according to the present invention can be found in the following transcript(s): T11628_PEA_1_T3, Tl 1628JPEA_1_T4, Tl 1628_PEA_1_T5, Tl 1628_PEA_1_T7, Tl 1628_PEA_1_T9 and Tl 1628_PEA_1_T11. Table 929 below describes the starting and ending position of this segment on each transcript.
Table 929 - Segment location on transcripts
Segment cluster Tl 1628_PEA_l_node_32 according to the present invention can be found in the following transcript(s): T11628_PEA_1_T3, T11628_PEA_1_T4, T11628_PEA_1_T5, T11628_PEA_1_T7, T11628_PEA_1_T9 and T11628_PEA_1_T11. Table 930 below describes the starting and ending position of this segment on each transcript.
Table 930 - Segment location on transcripts
Segment cluster Tl 1628_PEA_l_node_33 according to the present invention can be found in the following transcript(s): T11628_PEA_1_T3, T11628_PEA_1_T4, T11628_PEA_1_T5, T11628_PEA_1_T7, T11628_PEA_1_T9 ard T11628_PEA_1_T11. Table 931 below describes the starting and ending position of this segment on each transcript.
Table 931 - Segment location on transcripts
Segment cluster T11628_PEA_l_node_34 according to the present invention is supported by 122 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): T11628_PEA_1_T3, T11628_PEA_1_T4, T11628_PEA_1_T5, T11628_PEA_1_T7, T11628_PEA_1_T9 and T11628_PEA_l_Tl l. Table 932 below describes the starting and ending position of this segment on each transcript. Table 932 - Segment location on transcripts
Segment cluster T11628_PEA_l_node_35 according to the present invention is supported by 126 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): Tl 1628JPEA_1_T3, T11628_PEA_1_T4, T11628_PEA_1_T5, T11628_PEA_1_T7, T11628_PEA_1_T9 and T11628_PEA_l_Tl l. Table 933 below describes the starting and ending position of this segment on each transcript.
Table 933 - Segment location on transcripts
Segment cluster T11628_PEA_l_node_36 according to the present invention is supported by 122 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): T11628_PEA_1_T3, T11628_PEA_1_T4,
Tl 1628_PEA_1_T5, Tl 1628_PEA_1_T7, Tl 1628_PEA_1_T9 and Tl 1628 JPEAJJTl 1. Table 934 below describes the starting and ending position of this segment on each transcript.
Table 934 - Segment location on transcripts
Variant protein alignment to the previously known protein:
Sequence name: Q8WVH6
Sequence documentation:
Alignment of: T11628_PEA_1_P2 x Q8WVH6
Alignment segment 1/1:
Quality: 962.00 Escore: 0
Matching length: 99 Total length: 99
Matching Percent Similarity: 100.00 Matching Percent Identity: 100.00
Total Percent Similarity: 100.00 Total Percent Identity: 100.00 Gaps : 0
Alignment:
56 MKASEDLKKHGATVLTALGGILKKKGHHEAEIKPLAQSHATKHKIPVKYL 105 I I I I I I I I I I I I I I I I I I 1 I I I I I I I I I M I I I I I I I I I I I I I I I I I I I I
1 MKASEDLKKHGATVLTALGGILKKKGHHEAEIKPLAQSHATKHKIPVKYL 50
106 EFISECIIQVLQSKHPGDFGADAQGAMNKALELFRKDMASNYKELGFQG 154
I I I I I I Il I I I I Il I I I I 1 I I I I I I I I I Il I I I I I I I I I I I I Il I I I I I 51 EFISECIIQVLQSKHPGDFGADAQGAMNKALELFRKDMASNYKELGFQG 99
Sequence name: MYG_HUMAN_V1
Sequence documentation:
Alignment of: T11628_PEA_1_P5 x MYG_HUMAN_V1
Alignment segment 1/1:
Quality: 962.00
Escore: 0
Matching length: 99 Total length: 99
Matching Percent Similarity: 100.00 Matching Percent Identity: 100.00 Total Percent Similarity: 100.00 Total Percent Identity: 100.00
Gaps : 0
Alignment : . . . . .
1 MKASEDLKKHGATVLTALGGILKKKGHHEAEIKPLAQSHATKHKIPVKYL 50
56 MKASEDLKKHGATVLTALGGILKKKGHHEAEIKPLAQSHATKHKIPVKYL 105
51 EFISECIIQVLQSKHPGDFGADAQGAMNKALELFRKDMASNYKELGFQG 99
!1111111!1!IMIIIIMIIIMIIIIIIIIIIIIMIIIIIIIMI 106 EFISECIIQVLQSKHPGDFGADAQGAMNKALELFRKDMASNYKELGFQG 154
Sequence name: MYG_HUMAN_V1
Sequence documentation:
Alignment of: T11628_PEA_1_P7 x MYG_HUMAN_V1
Alignment segment 1/1:
Quality: 1315.00 Escore: 0
Matching length: 134 Total length: 134 Matching Percent Similarity: 100.00 Matching Percent Identity: 100.00
Total Percent Similarity: 100.00 Total Percent Identity: 100.00
Gaps : 0
Alignment :
1 MGLSDGEWQLVLNWGKVEADIPGHGQEVLIRLFKGHPETLEKFDKFKHL 50 I I I I Il 1 I I I i I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I Il I 1 MGLSDGEWQLVLNVWGKVEADIPGHGQEVLIRLFKGHPETLEKFDKFKHL 50
51 KSEDEMKASEDLKKHGATVLTALGGILKKKGHHEAEIKPLAQSHATKHKI 100
I I I I I I I I Il I I I I I I I I I I Il I I I Il I Il I Il I Il I I I Il I I I I I Il I I
51 KSEDEMKASEDLKKHGATVLTALGGILKKKGHHEAEIKPLAQSHATKHKI 100 . . .
101 PVKYLEFISECIIQVLQSKHPGDFGADAQGAMNK 134
M M M i I I M I M I I I I I I M I I I I I I M I I I I
101 PVKYLEFISECIIQVLQSKHPGDFGADAQGAMNK 134
Sequence name: Q8WVH6
Sequence documentation:
Alignment of: T11628_PEA_l__P10 x Q8WVH6
Alignment segment 1/1:
Quality: 962.00 Escore: 0
Matching length: 99 Total length: 99
Matching Percent Similarity: 100.00 Matching Percent Identity: 100.00
Total Percent Similarity: 100.00 Total Percent Identity: 100.00 Gaps: 0
Alignment :
56 MKASEDLKKHGATVLTALGGILKKKGHHEAEIKPLAQSHATKHKIPVKYL 105
I I I I I I I I I I l I I I i I I I I I I I I I I I I I I ! I I I I I I I I l I I I I I I I I I I I
1 MKASEDLKKHGATVLTALGGILKKKGHHEAEIKPLAQSHATKHKIPVKYL 50
106 EFISECIIQVLQSKHPGDFGADAQGAMNKALELFRKDMASNYKELGFQG 154
I I I l I l I I I I I I l I I I I I I I I I I I I I I I I I I I I I I I I I I I l I I I I I I I I
51 EFI SECIIQVLQSKHPGDFGADAQGAMNKALELFRKDMASNYKELGFQG 99
DESCRIPTION FOR CLUSTER HUMCEA
Cluster HUMCEA features 5 transcript(s) and 42 segment(s) of interest, the names for which are given in Tables 935 and 936, respectively, the sequences themselves are given at the end of the application. The selected protein variants are given in table 937.
Table 935 - Transcripts of interest
Table 937 - Proteins of interest
These sequences are variants of the known protein Carcinoembryonic antigen- related cell adhesion molecule 5 precursor (SwissProt accession identifier CEA5JHUMAN; known also according to the synonyms Carcinoembryonic antigen; CEA; Meconium antigen 100; CD66e antigen), SEQ ID NO: 1451 , referred to herein as the previously known protein.
The sequence for protein Carcinoembryonic antigen-related cell adhesion molecule 5 precursor is given at the end of the application, as "Carcinoembryonic antigen- related cell adhesion molecule 5 precursor amino acid sequence". Known polymorphisms for this sequence are as shown in Table 938 Table 938 - Amino acid mutations for Known Protein
Protein Carcinoembryonic antigen-related cell adhesion molecule 5 precursor localization is believed to be attached to the membrane by a GPI-anchor.
The previously known protein also has the following indication(s) and/or potential therapeutic use(s): Cancer. It has been investigated for clinical/therapeutic use in humans, for example as a target for an antibody or small molecule, and/or as a direct therapeutic; available information related to these investigations is as follows. Potential pharmaceutically related or therapeutically related activity or activities of the previously known protein are as follows: Immunostimulant. A therapeutic role for a protein represented by the cluster has been predicted. The cluster was assigned this field because there was information in the drug database or the public databases (e.g., described herein above) that this protein, or part thereof, is used or can be used for a potential therapeutic indication: Imaging agent; Anticancer; Immunostimulant; Immunoconjugate; Monoclonal antibody, murine; Antisense therapy; antibody.
The following GO Annotation(s) apply to the previously known protein. The following annotation(s) were found: integral plasma membrane protein; membrane, which are annotation(s) related to Cellular Component.
The GO assignment relies on information from one or more of the SwissProt/TremBl Protein knowledgebase, available from <http://www.expasy.ch/sprot/>; or Locuslink, available from <http://www.ncbi.nlm.nih.gov/projects/LocusLink/>.
Cluster HUMCEA can be used as a diagnostic marker according to overexpression of transcripts of this cluster in cancer. Expression of such transcripts in normal tissues is also given according to the previously described methods. The term "number" in the right hand column of the table and the numbers on the y-axis of figure 33 refer to weighted expression of ESTs in each category, as "parts per million" (ratio of the expression of ESTs for a particular cluster to the expression of all ESTs in that category, according to parts per million).
Overall, the following results were obtained as shown with regard to the histograms in
Figure 33 and Table 939. This cluster is overexpressed (at least at a minimum level) in the following pathological conditions: epithelial malignant tumors, a mixture of malignant tumors from different tissues and pancreas carcinoma.
Table 939 - Normal tissue distribution
Table 940 - P values and ratios for expression in cancerous tissue
For this cluster, at least one oligonucleotide was found to demonstrate overexpression of the cluster, although not of at least one transcript/segment as listed below. Microarray (chip) data is also available for this cluster as follows. Various oligonucleotides were tested for being differentially expressed in various disease conditions, particularly cancer, as previously described. The following oligonucleotides were found to bit this cluster but not other segments/transcripts below (in relation to lung cancer), shown in Table 941.
Table 941 - Oligonucleotides related to this cluster
As noted above, cluster HUMCEA features 5 transcript(s), which were listed in Table 1 above. These transcript(s) encode for protein(s) which are variant(s) of protein Carcinoembryonic antigen-related cell adhesion molecule 5 precursor. A description of each variant protein according to the present invention is now provided.
Variant protein HUMCEA_PEA_1_P4 according to the present invention has an amino acid sequence as given at the end of the application; it is encoded by transcript(s) HUMCEA_PEA_1_T8. An alignment is given to the known protein (Carcinoembryonic antigen- related cell adhesion molecule 5 precursor) at the end of the application. One or more alignments to one or more previously published protein sequences are given at the end of the application. A brief description of the relationship of the variant protein according to the present invention to each such aligned protein is as follows:
Comparison report between HUMCEA_PEA_1_P4 and CEA5_HUMAN: LAn isolated chimeric polypeptide encoding for HUMCEA_PEA_1_P4, comprising a first amino acid sequence being at least 90 % homologous to
MESPSAPPHRWCIPWQRLLLTASLLTFWNPPTTAKLTIESTPFNVAEGKEVLLLVHNLPQ HLFGYSWYKGERVDGNRQIIGYVIGTQQATPGPAYSGREIIYPNASLLIQNIIQNDTGFYT LHVIKSDLVNEEATGQFRVYPELPKPSISSNNSKPVEDKDAVAFTCEPETQDATYLWWV NNQSLPVSPRLQLSNGNRTLTLFNVTRNDTASYKCETQNPVSARRSDSVILNVL corresponding to amino acids 1 - 234 of CEA5JHUMAN, which also corresponds to amino acids 1 - 234 of HUMCEA_PEA_1_P4, and a second amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence CEYICSSLAQAASPNPQGQRQDFSVPLRFKYTDPQPWTSRLSVTFCPRKTWADQVLTKN RRGGAASVLGGSGSTPYDGRNR corresponding to amino acids 235 - 315 of
HUMCEA_PEA_1_P4, wherein said first amino acid sequence and second amino acid sequence are contiguous and in a sequential order.
2.An isolated polypeptide encoding for a tail of HUMCEA_PEA_1_P4, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence
CEYICSSLAQAASPNPQGQRQDFSVPLRFKYTDPQPWTSRLSVTFCPRKTW ADQVLTKN RRGGAASVLGGSGSTPYDGRNR in HUMCEA PEA 1 P4.
The location of the variant protein was determined according to results from a number of different software programs and analyses, including analyses from SignalP and other specialized programs. The variant protein is believed to be located as follows with regard to the cell: secreted. The protein localization is believed to be secreted because both signal-peptide prediction programs predict that this protein has a signal peptide, and neither trans -membrane region prediction program predicts that this protein has a trans -membrane region.
Variant protein HUMCEA_PEA_1_P4 also has the following non- silent SNPs (Single Nucleotide Polymorphisms) as listed in Table 942, (given according to their position(s) on the amino acid sequence, with the alternative amino acid(s) listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein HUMCEA_PEA_1_P4 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 942 -Amino acid mutations
The glycosylation sites of variant protein HUMCEA_PEA_1_P4, as compared to the known protein Carcinoembryonic antigen-related cell adhesion molecule 5 precursor, are described in Table 943 (given according to their position(s) on the amino acid sequence in the first column; the second column indicates whether the glycosylation site is present in the variant protein; and the last column indicates whether the position is different on the variant protein).
Table 943 - Glycosylation site(s)
Variant protein HUMCEA_PEA_1_P4 is encoded by the following transcript(s): HUMCEA_PEA_1_T8, for which the sequence(s) is/are given at the end of the application. The coding portion of transcript HUMCEA_PEA_1_T8 is shown in bold; this coding portion starts at position 115 and ends at position 1059. The transcript also has the following SNPs as listed in Table 944 (given according to their position on the nucleotide sequence, with the alternative nucleic acid listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein HUMCEA_PEA_1_P4 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 944 - Nucleic acid SNPs
Valiant protein HUMCEA_PEA_1_P5 according to the present invention has an amino acid sequence as given at the end of the application; it is encoded by transcript(s) HUMCEA_PEA_1_T9. An alignment is given to the known protein (Carcinoembryonic antigen- related cell adhesion molecule 5 precursor) at the end of the application. One or more alignments to one or more previously published protein sequences are given at the end of the application A brief description of the relationship of the variant protein according to the present invention to each such aligned protein is as follows: Comparison report between HUMCEA_PEA_1_P5 and CEA5_HUMAN:
1.An isolated chimeric polypeptide encoding for HUMCEA_PEA_1_P5, comprising a first amino acid sequence being at least 90 % homologous to
MESPSAPPHRWCIPWQRLLLTASLLTFWNPPTTAKLTIESTPFNVAEGKEVLLLVHNLPQ HLFGYSWYKGERVDGNRQIIGYVIGTQQATPGPAYSGREIIYPNASLLIQNIIQNDTGFYT LHVIKSDLVNEEATGQFRVYPELPKPSISSNNSKPVEDKDAVAFTCEPETQDATYLWWV NNQSLPVSPRLQLSNGNRTLTLFNVTRNDTASYKCETQNPVSARRSDSVILNVLYGPDA PTISPLNTSYRSGENLNLSCHAASNPPAQYSWFVNGTFQQSTQELFIPNITVNNSGSYTC QAHNSDTGLNRTTVTTITVYAEPPKPFITSNNSNPVEDEDAVALTCEPEIQNTTYLWWV NNQSLPVSPRLQLSNDNRTLTLLSVTRNDVGPYECGIQNELSVDHSDPVILNVLYGPDD PTISPSYTYYRPGVNLSLSCHAASNPPAQYSWLIDGNIQQHTQELFISNITEKNSGLYTCQ ANNSASGHSRTTVKTITVSAELPKPSISSNNSKPVEDKDAVAFTCEPEAQNTTYLWWVN GQSLPVSPRLQLSNGNRTLTLFNVTRNDARAYVCGIQNSVSANRSDPVTLDVLYGPDTP IISPPDSSYLSGANLNLSCHSASNPSPQYSWRINGIPQQHTQVLFIAKITPNNNGTYACFV SNLATGRNNSIVKSITVS corresponding to amino acids 1 - 675 of CEA5_HUMAN, which
also corresponds to amino acids 1 - 675 of HUMCEA_PEA_1_P5, and a second amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence GKWLPGASASYSGVESIWFSPKSQEDIFFPSLCSMGTRKSQILS corresponding to amino acids 676 - 719 of HUMCEA_PEA_1_P5, wherein said first amino acid sequence and second amino acid sequence are contiguous and in a sequential order.
2.An isolated polypeptide encoding for a tail of HUMCEA_PEA_1_P5, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence GKWLPGASASYSGVESIWFSPKSQEDIFFPSLCSMGTRKSQILS in HUMCEA PEA 1 P5.
The location of the variant protein was determined according to results from a number of different software programs and analyses, including analyses from SignalP and other specialized programs. The variant protein is believed to be located as follows with regard to the cell: secreted. The protein localization is believed to be secreted because both signal-peptide prediction programs predict that this protein has a signal peptide, and neither trans -membrane region prediction program predicts that this protein has a trans -membrane region.
Variant protein FfUMCEA_PEA_l_P5 also has the following non-silent SNPs (Single Nucleotide Polymorphisms) as listed in Table 945, (given according to their position(s) on the amino acid sequence, with the alternative amino acid(s) listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein HUMCEA_PEA_1_P5 sequence provides support for the deduced sequence of this variant protein according to the present invention). Table 945 - Amino acid mutations
The glycosylation sites of variant protein HUMCEA_PEA_1_P5, as compared to the known protein Carcinoembryonic antigen- related cell adhe sion molecule 5 precursor, are described in Table 946 (given according to their position(s) on the amino acid sequence in the first column; the second column indicates whether the glycosylation site is present in the variant protein; and the last column indicates whether the position is different on the variant protein).
Table 946 - Glycosylation site(s)
Variant protein HUMCEA_PEA_1_P5 is encoded by the following transcript(s): HUMCEA_PEA_1_T9, for which the sequence(s) is/are given at the end of the application. The coding portion of transcript HUMCEAJP EA_1_T9 is shown in bold; this coding portion starts at position 115 and ends at position 2271. The transcript also has the following SNPs as listed in Table 947 (given according to their position on the nucleotide sequence, with the alternative nucleic acid listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein HUMCEA_PEA_1_P5 sequence provides support for the deduced sequence of this variant protein according to the present invention). Table 947 - Nucleic acid SNPs
Variant protein HUMCEA_PEA_1_P14 according to the present invention has an amino acid sequence as given at the end of the application; it is encoded by transcript(s) HUMCEA_PEA_l_T20. The location of the variant protein was determined according to results from a number of different software programs and analyses, including analyses from SignalP and other specialized programs. The variant protein is believed to be located as follows with regard to the cell: secreted. The protein localization is believed to be secreted because both signal-peptide prediction programs predict that this protein has a signal peptide, and neither trans- membrane region prediction program predicts that this protein has a trans -membrane region.
Variant protein HUMCEA_PEA_1_P14 also has the following non-silent SNPs (Single Nucleotide Polymorphisms) as listed in Table 948, (given according to their position(s) on the amino acid sequence, with the alternative amino acid(s) listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein
HUMCEA_PEA_1_P14 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 948 -Amino acid mutations
Variant protein HUMCEA_PEA_1_P14 is encoded by the following transcript(s): HUMCEA_PEA_l_T20, for which the sequence(s) is/are given at the end of the application. The coding portion of transcript HUMCEA_PEA_l_T20 is shown in bold; this coding portion starts at position 115 and ends at position 1821. The transcript also has the following SNPs as listed in Table 949 (given according to their position on the nucleotide sequence, with the alternative nucleic acid listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein HUMCEA_PEA_1_P14 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 949 - Nucleic acid SNPs
Variant protein HUMCEA_PEA_1_P19 according to the present invention has an amino acid sequence as given at the end of the application; it is encoded by transcript(s) HUMCEA_PEA_1_T25. An alignment is given to the known protein (Carcinoembryonic antigen-related cell adhesion molecule 5 precursor) at the end of the application. One or more alignments to one or more previously published protein sequences are given at the end of the application. A brief description of the relationship of the variant protein according to the present invention to each such aligned protein is as follows: Comparison report between HUMCEA_PEA_1_P 19 and CEA5_HUMAN:
1.An isolated chimeric polypeptide encoding for HUMCEA_PEA_1_P19, comprising a first amino acid sequence being at least 90 % homologous to
MESPSAPPHRWCIPWQRLLLTASLLTFWNPPTTAKLTIESTPFNVAEGKEVLLLVHNLPQ HLFGYSWYKGERVDGNRQIIGYVIGTQQATPGPAYSGREIIYPNASLLIQNIIQNDTGFYT LHVIKSDLVNEEATGQFRVYPELPKPSISSNNSKPVEDKDAVAFTCEPETQDATYLWWV NNQSLPVSPRLQLSNGNRTLTLFNVTRNDTASYKCETQNPVSARRSDSVILN corresponding to amino acids 1 - 232 of CEA5_HUMAN, which also corresponds to amino acids 1 - 232 of HUMCEA_PEA_1_P19, and a second amino acid sequence being at least 90 % homologous to VLYGPDTPIISPPDSSYLSGANLNLSCHSASNPSPQYSWRJNGIPQQHTQVLFIAKITPNNN GTYACFVSNLATGRNNSIVKSITVSASGTSPGLSAGATVGIMIGVLVGVALI corresponding to amino acids 589 - 702 of CEA5_HUMAN, which also corresponds to amino acids 233 - 346 of HUMCEA_PEA_1_P19, wherein said first amino acid sequence and second amino acid sequence are contiguous and in a sequential order.
2.An isolated chimeric polypeptide encoding for an edge portion of
HUMCEA_PEA_1_P19, comprising a polypeptide having a length "n", wherein n is at least about 10 amino acids in length, optionally at least about 20 amino acids in length, preferably at least about 30 amino acids in length, more preferably at least about 40 amino acids in length and most preferably at least about 50 amino acids in length, wherein at least two amino acids comprise NV, having a structure as follows: a sequence starting from any of amino acid numbers 232-x to 232; and ending at any of amino acid numbers 233+ ((n-2) - x), in which x varies from 0 to n-2.
The location of the variant protein was determined according to results from a number of different software programs and analyses, including analyses from SignalP and other specialized programs. The variant protein is believed to be located as follows with regard to the cell: membrane. The protein localization is believed to be membrane because of manual inspection of known protein localization and/or gene structure. Variant protein HUMCEAJPEA 1 P19 also has the following non-silent SNPs (Single
Nucleotide Polymorphisms) as listed in Table 950, (given according to their position(s) on the amino acid sequence, with the alternative amino acid(s) listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein HUMCEA_PEA_1_P19 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 950 - Amino acid mutations
The glycosylation sites of variant protein HUMCEA_PEA_1_P19, as compared to the known protein Carcinoembryonic antigen-related cell adhesion molecule 5 precursor, are described in Table 951 (given according to their position(s) on the amino acid sequence in the first column; the second column indicates whether the glycosylation site is present in the variant protein; and the last column indicates whether the position is different on the variant protein).
Table 951 - Glycosylation site(s)
Variant protein HUMCEA_PEA_1_P19 is encoded by the following transcript(s): HUMCEAJPEA_1_T25, for which the sequence(s) is/are given at the end of the application. The coding portion of transcript HUMCEA_PEA_1_T25 is shown in bold; this coding portion starts at position 115 and ends at position 1152. The transcript also has the following SNPs as listed in Table 952 (given according to their position on the nucleotide sequence, with the alternative nucleic acid listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein HUMCEA_PEA_1_P19 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 952 - Nucleic acid SNPs
Variant protein HUMCEA_PEA_l_P20 according to the present invention has an amino acid sequence as given at the end of the application; it is encoded by transcript(s) HUMCEA_PEA_1_T26. An alignment is given to the known protein (Carcinoembryonic antigen-related cell adhesion molecule 5 precursor) at the end of the application. One or more alignments to one or more previously published protein sequences are given at the end of the application. A brief description of the relationship of the variant protein according to the present invention to each such aligned protein is as follows: Comparison report between HUMCEA_PEA_l_P20 and CEA5_HUMAN:
1.An isolated chimeric polypeptide encoding for HUMCEA_PEA_l_P20, comprising a first amino acid sequence being at least 90 % homologous to
MESPSAPPHRWCIPWQRLLLTASLLTFWNPPTTAKLTIESTPFNVAEGKEVLLLVHNLPQ HLFGYSWYKGERVDGNRQIIGYVIGTQQATPGPAYSGREIIYPNASLLIQNΠQNDTGFYT LHVIKSDLVNEEATGQFRVYP corresponding to amino acids 1 - 142 of CEA5_HUMAN, which also corresponds to amino acids 1 - 142 of HUMCEA_PEA_l_P20, and a second amino acid sequence being at least 90 % homologous to
ELPKPSISSNNSKPVEDKDAVAFTCEPEAQNTTYLWWVNGQSLPVSPRLQLSNGNRTLT LFNVTRNDARAYVCGIQNSVSANRSDPVTLDVLYGPDTPIISPPDSSYLSGANLNLSCHS
ASNPSPQYSWRINGIPQQHTQ VLFIAKITPNNNGTYACFVSNLATGRNNSIVKSITVSASG TSPGLSAGATVGIMIGVLVGVALI corresponding to amino acids 499 - 702 of CEA5_HUMAN, which also corresponds to amino acids 143 - 346 of HUMCEA_PEA_l_P20, wherein said first amino acid sequence and second amino acid sequence are contiguous and in a sequential order.
2.An isolated chimeric polypeptide encoding for an edge portion of
HUMCEA_PEA_l_P20, comprising a polypeptide having a length "n", wherein n is at least about 10 amino acids in length, optionally at least about 20 amino acids in length, preferably at least about 30 amino acids in length, more preferably at least about 40 amino acids in length and most preferably at least about 50 amino acids in length, wherein at least two amino acids comprise PE, having a structure as follows: a sequence starting from any of amino acid numbers 142-x to 142; and ending at any of amino acid numbers 143+ ((n-2) - x), in which x varies from 0 to n-2.
The location of the variant protein was determined according to results from a number of different software programs and analyses, including analyses from SignalP and other specialized programs. The variant protein is believed to be located as follows with regard to the cell: membrane. The protein localization is believed to be membrane because of manual inspection of known protein localization and/or gene structure. Variant protein HUMCEA_PEA_l_P20 also has the following non-silent SNPs (Single
Nucleotide Polymorphisms) as listed in Table 953, (given according to their position(s) on the amino acid sequence, with the alternative amino acid(s) listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein HUMCEA_PEA_l_P20 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 953 - Amino acid mutations
The glycosylation sites of variant protein HUMCEA_PEA_l_P20, as compared to the known protein Carcinoembryonic antigen-related cell adhesion molecule 5 precursor, are described in Table 954 (given according to their position(s) on the amino acid sequence in the first column; the second column indicates whether the glycosylation site is present in the variant protein; and the last column indicates whether the position is different on the variant protein).
Table 954 - Glycosylation site(s)
Variant protein HUMCEA_PEA_l_P20 is encoded by the following transcript(s): HUMCEA_PEA_1_T26, for which the sequence(s) is/are given at the end of the application. The coding portion of transcript HUMCEA_PEA_1_T26 is shown in bold; this coding portion starts at position 115 and ends at position 1152. The transcript also has the following SNPs as listed in Table 955 (given according to their position on the nucleotide sequence, with the alternative nucleic acid listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein HUMCEA_PEA_l_P20 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 955 - Nucleic acid SNPs
As noted above, cluster HUMCEA features 42 segment(s), which were listed in Table 2 above and for which the sequence(s) are given at the end of the application. These segment(s) are portions of nucleic acid sequence(s) which are described herein separately because they are of particular interest. A description of each segment according to the present invention is now provided.
Segment cluster HUMCEAJPEA_l_node_0 according to the present invention is supported by 56 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): HUMCEA_PEA_1_T8, HUMCEA_PEA_1_T9, HUMCEA_PEA_l_T20, HUMCEA_PEA_1_T25 and
HUMCEA_PEA__1_T26. Table 956 below describes the starting and ending position of this segment on each transcript.
Table 956 - Segment location on transcripts
Segment cluster HUMCEA_PEA_l_node_2 according to the present invention is supported by 83 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): HUMCEA_PEA_1_T8, HUMCEA_PEA_1_T9, HUMCEA_PEA_l_T20, HUMCEAJPEA_1_T25 and HUMCEA_PEA_1_T26. Table 957 below describes the starting and ending position of this segment on each transcript.
Table 957 - Segment location on transcripts
Segment cluster HUMCEA_PEA_l_node_l 1 according to the present invention is supported by 6 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): HUMCEA_PEA_1_T8. Table 958 below describes the starting and ending position of this segment on each transcript.
Table 958 - Segment location on transcripts
Microarray (chip) data is also available for this segment as follows. As described above with regard to the cluster itself, various oligonucleotides were tested for being differentially expressed in various disease conditions, particularly cancer. The following oligonucleotides were found to hit this segment (in relation to lung cancer), shown in Table 959.
Table 959 - Oligonucleotides related to this segment
Segment cluster HUMCEA_PEA_l_node_12 according to the present invention is supported by 83 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): HUMCEA_PEA_1_T8, HUMCEA_PEA_1_T9 and HUMCEA_PEA_l_T20. Table 960 below describes the starting and ending position of this segment on each transcript.
Table 960 - Segment location on transcripts
Segment cluster HUMCEA_PEA_l_node_31 according to the present invention is supported by 87 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): HUMCEA_PEA_1_T8,
HUMCEA_PEA_1_T9 and HUMCEA_PEA_l_T20. Table 961 below describes the starting and ending position of this segment on each transcript.
Table 961 - Segment location on transcripts
Segment cluster HUMCEA_PEA_l_node_36 according to the present invention is supported by 94 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): HUMCEA_PEA_1_T8, HUMCEA_PEA_1_T9 and HUMCEA_PEA_1_T26. Table 962 below describes the starting and ending position of this segment on each transcript.
Table 962 - Segment location on transcripts
Segment cluster HUMCEA_PEA_l_node_44 according to the present invention is supported by 112 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): HUMCEA_PEA_1_T8, HUMCEA_PEA_1_T9, HUMCEA_PEA_1_T25 and HUMCEA_PEA_1_T26. Table 963 below describes the starting and ending position of this segment on each transcript.
Table 963 - Segment location on transcripts
Segment cluster HUMCEA_PEA_l_node_46 according to the present invention is supported by 15 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): HUMCEA_PEA_1_T9. Table 964 below describes the starting and ending position of this segment on each transcript.
Table 964 - Segment location on transcripts
Segment cluster HUMCEA_PEA_l_node_63 according to the present invention is supported by 68 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): HUMCEA_PEA_1_T8, HUMCEA_PEA_1_T25 and HUMCEA_PEA_1_T26. Table 965 below describes the starting and ending position of this segment on each transcript. Table 965 - Segment location on transcripts
Segment cluster HUMCEA_PEA_l_node_65 according to the present invention is supported by 54 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): HUMCEA_PEA_1_T8, HUMCEA_PEA_1_T25 and HUMCEA_PEA_1_T26. Table 966 below describes the starting and ending position of this segment on each transcript.
Table 966 - Segment location on transcripts
Segment cluster HUMCEA_PEA_l__node_67 according to the present invention is supported by 2 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): HUMCEA_PEA_l_T20. Table 967 below describes the starting and ending position of this segment on each transcript. Table 967 - Segment location on transcripts
According to an optional embodiment of the present invention, short segments related to the above cluster are also provided. These segments are up to about 120 bp in length, and so are included in a separate description.
Segment cluster HUMCEAJPEA_l_node_3 according to the present invention is supported by 67 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): HUMCEA_PEA_1_T8, HUMCEA_PEA_1_T9, HUMCEA_PEA_l_T20, HUMCEA_PEA_1_T25 and HUMCEAJPEA_1_T26. Table 968 below describes the starting and ending position of this segment on each transcript.
Table 968 - Segment location on transcripts
Segment cluster HUMCEA_PEA_l_node_7 according to the present invention is supported by 73 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): HUMCEA_PEA_1_T8, HUMCEA_PEA_1_T9, HUMCEA_PEA_l_T20 and HUMCEA_PEA_1_T25. Table 969 below describes the starting and ending position of this segment on each transcript. Table 969 - Segment location on transcripts
Segment cluster HUMCEA_PEA_l_node_8 according to the present invention is supported by 67 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): HUMCEA_PEA_1_T8, HUMCEA_PEA_1_T9, HUMCEA_PEA_l_T20 and HUMCEA_PEA_1_T25. Table 970 below describes the starting and ending position of this segment on each transcript.
Table 970- - Segment location on transcripts
Segment cluster HUMCEA_PEA_l_node_9 according to the present invention is supported by 71 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): HUMCEAJPEA 1 T8, HUMCEA_PEA_1_T9, HUMCEA_PEA_l_T20 and HUMCEA_PEA_1_T25. Table 971 below describes the starting and ending position of this segment on each transcript.
Table 971 - Segment location on transcripts
Segment cluster HUMCEA_PEA_l_node_10 according to the present invention is supported by 67 libraries. The number of libraries was determined as previously described. This
segment can be found in the following transcript(s): HUMCEA_PEA_1_T8, HUMCEA_PEA_1_T9, HUMCEA_PEA_l_T20 and HUMCEA_PEA_1_T25. Table 972 below describes the starting and ending position of this segment on each transcript.
Table 972 - Segment location on transcripts
Segment cluster HUMCEA_PEA_l_node_15 according to the present invention can be found in the following transcript(s): HUMCEA_PEA_1_T8, HUMCEA_PEA_1_T9 and HUMCEA_PEA_l_T20. Table 973 below describes the starting and ending position of this segment on each transcript.
Table 973 - Segment location on transcripts
Segment cluster HUMCEA_PEA_l_node__16 according to the present invention can be found in the following transcript(s): HUMCEA_PEA_1_T8, HUMCEA_PEA_1_T9 and HUMCEA_PEA_l_T20. Table 974 below describes the starting and ending position of this segment on each transcript.
Table 974 - Segment location on transcripts
Segment cluster HUMCEA_PEA_l_node_17 according to the present invention can be found in the following transcript(s): HUMCEA_PEA_1_T8, HUMCEA__PEA_1_T9 and HUMCEA_PEA_l_T20. Table 975 below describes the starting and ending position of this segment on each transcript.
Table 975 - Segment location on transcripts
Segment cluster HUMCEA_PEA_l_node_l 8 according to the present invention can be found in the following transcript(s): HUMCEA_PEA_1_T8, HUMCEA JPEA_1_T9 and HUMCEA_PEA_l_T20. Table 976 below describes the starting and ending position of this segment on each transcript.
Table 976 - Segment location on transcripts
Segment cluster HUMCEA_PEA_l_node_19 according to the present invention is supported by 69 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): HUMCEA_PEA_1_T8, HUMCEA_PEA_1_T9 and HUMCEA_PEA_l_T20. Table 977 below describes the starting and ending position of this segment on each transcript.
Table 977 - Segment location on transcripts
Segment cluster HUMCEAJPEA_1 jnode_20 according to the present invention can be found in the following transcript(s): HUMCEAJPEA_1_T8, HUMCEA_PEA_1_T9 and HUMCEA_PEA__l_T20. Table 978 below describes the starting and ending position of this segment on each transcript. Table 978 - Segment location on transcripts
Segment cluster HUMCEA_PEA_l_node_21 according to the present invention can be found in the following transcript(s): HUMCEA_PEA_1_T8, HUMCEA_PEA_1_T9 and
HUMCEA_PEA_l_T20. Table 979 below describes the starting and ending position of this segment on each transcript.
Table 979 - Segment location on transcripts
Segment cluster HUMCEA_PEA_l_node_22 according to the present invention is supported by 77 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): HUMCEA_PEA_1_T85 HUMCEA_PEA_1_T9 and HUMCEA_PEA_l_T20. Table 980 below describes the starting and ending position of this segment on each transcript.
Table 980 - Segment location on transcripts
Segment cluster HUMCEA_PEA_l_node_23 according to the present invention is supported by 72 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): HUMCEA_PEA_1_T8, HUMCEA_PEA_1_T9 and HUMCEA_PEA_l_T20. Table 981 below describes the starting and ending position of this segment on each transcript.
Table 981 - Segment location on transcripts
Segment cluster HUMCEA_PEA_l_node_24 according to the present invention can be found in the following transcπpt(s): HUMCEA_PEA_1_T8, HUMCEA_PEA_1_T9 and HUMCEAJPEA_l__T20. Table 982 below describes the starting and ending position of this segment on each transcript.
Table 982 - Segment location on transcripts
Segment cluster HUMCEA_PEA_l_node_27 according to the present invention can be found in the following transcript(s): HUMCEA_PEA_1_T8, HUMCEA_PEA_1_T9 and HUMCEA_PEA_1 JT20. Table 983 below describes the starting and ending position of this segment on each transcript.
Table 983 - Segment location on transcripts
Segment cluster HUMCEAJPEA_l_node_29 according to the present invention can be found in the following transcript(s): HUMCEA JPEA_1_T8, HUMCEA_PEA_1_T9 and HUMCEA_PEA_l_T20. Table 984 below describes the starting and ending position of this segment on each transcript.
Table 984 - Segment location on transcripts
Segment cluster HUMCEA_PEA_l_node_30 according to the present invention is supported by 67 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): HUMCEAJPEA_1_T8, HUMCEA_PEA_1_T9 and HUMCEA_PEA_l_T20. Table 985 below describes the starting and ending position of this segment on each transcript. Table 985 - Segment location on transcripts
Segment cluster HUMCEA_PEA_l_node_33 according to the present invention can be found in the following transcript(s): HUMCEA_PEA_1_T8, HUMCEA_PEA_1_T9 and
HUMCEA_PEA_1_T26. Table 986 below describes the starting and ending position of this segment on each transcript.
Table 986 - Segment location on transcripts
Segment cluster HUMCEA_PEA_l_node_34 according to the present invention is supported by 80 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): HUMCEA_PEA_1_T8, HUMCEA_PEA__1_T9 and HUMCEA_PEA_1_T26. Table 987 below describes the starting and ending position of this segment on each transcript.
Table 987 - Segment location on transcripts
Segment cluster HUMCEA_PEA_l_node_35 according to the present invention is supported by 75 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): HUMCEA_PEA_1_T8, HUMCEA_PEA_1_T9 and HUMCEA_PEA_1_T26. Table 988 below describes the starting and ending position of this segment on each transcript.
Table 988 - Segment location on transcripts
Segment cluster HUMCEA_PEA_l_node_45 according to the present invention is supported by 9 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): HUMCEA_PEA_1_T9. Table 989 below describes the starting and ending position of this segment on each transcript.
Table 989 - Segment location on transcripts
Segment cluster HUMCEAJPEA_l_node_50 according to the present invention is supported by 64 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): HUMCEA_PEA_1_T8, HUMCEA_PEA_1_T25 and HUMCEA_PEA_1_T26. Table 990 below describes the starting and ending position of this segment on each transcript. Table 990 - Segment location on transcripts
Segment cluster HUMCEA_PEA_l_node_51 according to the present invention is supported by 88 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): HUMCEA_PEA_1_T8, HUMCEA_PEA__1_T25 and HUMCEA_PEA_1_T26. Table 991 below describes the starting and ending position of this segment on each transcript.
Table 991 - Segment location on transcripts
Segment cluster HUMCEA_PEA_l_node_56 according to the present invention is supported by 75 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): HUMCEA_PEA_1_T8, HUMCEA_PEA_1_T25 and HUMCEA_PEA_1_T26. Table 992 below describes the starting and ending position of this segment on each transcript. Table 992 - Segment location on transcripts
Segment cluster HUMCEA_PEA_l_node_57 according to the present invention is supported by 82 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): HUMCEA_PEA_1_T8,
HUMCEAJPEA_1_T25 and HUMCEA_PEA_1_T26. Table 993 below describes the starting and ending position of this segment on each transcript.
Table 993 - Segment location on transcripts
Segment cluster HUMCEA_PEA_l_node_58 according to the present invention is supported by 63 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): HUMCEA_PEA_1_T8, HUMCEA_PEA_1_T25 and HUMCEA_PEA_1_T26. Table 994 below describes the starting and ending position of this segment on each transcript.
Table 994 - Segment location on transcripts
Segment cluster HUMCEA_PEA_l_node_60 according to the present invention is supported by 55 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): HUMCEA_PEA_1_T8, HUMCEA_PEA_1_T25 and HUMCEA_PEA_1_T26. Table 995 below describes the starting and ending position of this segment on each transcript.
Table 995 - Segment location on transcripts
Segment cluster HUMCEA_PEA_l_node_61 according to the present invention can be found in the following transcript(s): HUMCEA_PEA_1_T8, HUMCEA_PEA_1_T25 and HUMCEAJPEA_1_T26. Table 996 below descπbes the starting and ending position of this segment on each transcript.
Table 996 - Segment location on transcripts
Segment cluster HUMCEA_PEA_l_node_62 according to the present invention is supported by 60 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): HUMCEA_PEA_1_T8, HUMCEAJPEA_1_T25 and HUMCEA_PEA_1_T26. Table 997 below describes the starting and ending position of this segment on each transcript. Table 997 - Segment location on transcripts
Segment cluster HUMCEA_PEA_l_node_64 according to the present invention is supported by 45 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): HUMCEA_PEA_1_T8, HUMCEA_PEA_1_T25 and HUMCEA_PEA_1_T26. Table 998 below describes the starting and ending position of this segment on each transcript.
Table 998 - Segment location on transcripts
Variant protein alignment to the previously known protein: Sequence name: CEA5_HUMAN
Sequence documentation:
Alignment of: HUMCEA PEA_1 P4 x CEA5 HUMAN
Alignment segment 1/1:
Quality: 2320.00
Escore:
Matching length: 234 Total length: 234
Matching Percent Similarity: 100.00 Matching Percent Identity: 100.00 Total Percent Similarity: 100.00 Total Percent Identity: 100.00
Gaps : 0
Alignment : . . . . .
1 MESPSAPPHRWCIPWQRLLLTASLLTFWNPPTTAKLTIESTPFNVAEGKE 50
111111111111!!11!11!111IMIIIIMIIIIIIIIIIIIIIIIII 1 MESPSAPPHRWCIPWQRLLLTASLLTFWNPPTTAKLTIESTPFNVAEGKE 50
51 VLLLVHNLPQHLFGYSWYKGERVDGNRQIIGYVIGTQQATPGPAYSGREI 100 Il I Il I Il Il I I Il Il I Il I I Il I I Il Il Il I I I Il I I I Il I Il Il Il Il
51 VLLLVHNLPQHLFGYSWYKGERVDGNRQIIGYVIGTQQATPGPAYSGREI 100
101 IYPNASLLIQNIIQNDTGFYTLHVIKSDLVNEEATGQFRVYPELPKPSIS 150 I M I M M Il M I I I I I Il Il I M M I Il I Il Il I I M M Il I M M Il I
101 IYPNASLLIQNIIQNDTGFYTLHVIKSDLVNEEATGQFRVYPELPKPSIS 150
151 SNNSKPVEDKDAVAFTCEPETQDATYLWWVNNQSLPVSPRLQLSNGNRTL 200
I M I I M I I Il I I I I M Il I Il Il M I M I M M M M M I I Il I M M I 151 SNNSKPVEDKDAVAFTCEPETQDATYLWWVNNQSLPVSPRLQLSNGNRTL 200
201 TLFNVTRNDTASYKCETQNPVSARRSDSVILNVL 234
M I M IM Il I M I I I I I I M M M I Il I I I I Il
201 TLFNVTRNDTASYKCETQNPVSARRSDSVILNVL 234
Sequence name: CEA5_HUMAN
Sequence documentation:
Alignment of: HUMCEA_PEA_1_P5 x CEA5_HUMAN
Alignment segment 1/1:
Quality: 6692.00 Escore: 0 Matching length: 675 Total length: 675
Matching Percent Similarity: 100.00 Matching Percent Identity: 100.00
Total Percent Similarity: 100.00 Total Percent Identity: 100.00
Gaps : 0
Alignment:
1 MESPSAPPHRWCIPWQRLLLTASLLTFWNPPTTAKLTIESTPFNVAEGKE 50
I I I I I I I Il I I I I Il I I I I I I I I I Il I Il I I I I I I I I I I Il I I Il I I I I I
1 MESPSAPPHRWCIPWQRLLLTASLLTFWNPPTTAKLTIESTPFNVAEGKE 50
51 VLLLVHNLPQHLFGYSWYKGERVDGNRQIIGYVIGTQQATPGPAYSGREI 100 I I M I I I I I I I I I I I I I I I I I M I I M I I M I I I M I I I I I I M I I I I I I
51 VLLLVHNLPQHLFGYSWYKGERVDGNRQIIGYVIGTQQATPGPAYSGREI 100
101 IYPNASLLIQNIIQNDTGFYTLHVIKSDLVNEEATGQFRVYPELPKPSIS 150
I I I 11 I I 1 I I I I I 1 I I I I I I I I I I I I I I I I I I I I I I I I I 1 I I I I I I I I I I
101 IYPNASLLIQNIIQNDTGFYTLHVIKSDLVNEEATGQFRVYPELPKPSIS 150 . . . . .
151 SNNSKPVEDKDAVAFTCEPETQDATYLWWVNNQSLPVSPRLQLSNGNRTL 200
I I I I I I I I I I I I I 11 I Il I I I I I I I I I I I I I I I I I I I I I I I I I ! I I 1 I I I
151 SNNSKPVEDKDAVAFTCEPETQDATYLWWVNNQSLPVSPRLQLSNGNRTL 200
201 TLFNVTRNDTASYKCETQNPVSARRSDSVILNVLYGPDAPTISPLNTSYR 250
I I I I I I I I I I I I I I Il I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I 1 I-
201 TLFNVTRNDTASYKCETQNPVSARRSDSVILNVLYGPDAPTISPLNTSYR 250
251 SGENLNLSCHAASNPPAQYSWFVNGTFQQSTQELFIPNITVNNSGSYTCQ 300 I I I I I I I I I I I I I I I I I I I Il I I M I I I I I I I I I I M I M I I I I M I I I I
251 SGENLNLSCHAASNPPAQYSWFVNGTFQQSTQELFIPNITVNNSGSYTCQ 300
301 AHNSDTGLNRTTVTTITVYAEPPKPFITSNNSNPVEDEDAVALTCEPEIQ 350
I I I I I I I I I I I I Il I I I I I I I I I I I I I Il I I I I I I I I I I I I I I I I I I I I I 301 AHNSDTGLNRTTVTTITVYAEPPKPFITSNNSNPVEDEDAVALTCEPEIQ 350
351 NTTYLWWVNNQSLPVSPRLQLSNDNRTLTLLSVTRNDVGPYECGIQNELS 400
I I I I I I I Il I I I I I I Il I I I I I I I I I I I I I Il I I I I I I I I I I Il Il I I I I
351 NTTYLWWVNNQSLPVSPRLQLSNDNRTLTLLSVTRNDVGPYECGIQNELS 400 . . . . .
401 VDHSDPVILNVLYGPDDPTISPSYTYYRPGVNLSLSCHAASNPPAQYSWL 450
401 VDHSDPVILNVLYGPDDPTISPSYTYYRPGVNLSLSCHAASNPPAQYSWL 450
451 IDGNIQQHTQELFISNITEKNSGLYTCQANNSASGHSRTTVKTITVSAEL 500
451 IDGNIQQHTQELFISNITEKNSGLYTCQANNSASGHSRTTVKTITVSAEL 500
501 PKPSISSNNSKPVEDKDAVAFTCEPEAQNTTYLWWVNGQSLPVSPRLQLS 550
I I I Il I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I i I I I I I I I I I 501 PKPSISSNNSKPVEDKDAVAFTCEPEAQNTTYLWWVNGQSLPVSPRLQLS 550
551 NGNRTLTLFNVTRNDARAYVCGIQNSVSANRSDPVTLDVLYGPDTPIISP 600
I I I Il I I I I I I I I I I I I I I I I I I I I I I I I Il I I 1 I I I I I I I I I I I I I I I I
551 NGNRTLTLFNVTRNDARAYVCGIQNSVSANRSDPVTLDVLYGPDTPIISP 600 . . . . .
601 PDSSYLSGANLNLSCHSASNPSPQYSWRINGIPQQHTQVLFIAKITPNNN 650
I Il I I I I I I I 1 I Il Il I I I Il I I I I I I I I I I I I I I Il I I I I I I I I I I I I I
601 PDSSYLSGANLNLSCHSASNPSPQYSWRINGIPQQHTQVLFIAKITPNNN 650
651 GTYACFVSNLATGRNNSIVKSITVS 675
651 GTYACFVSNLATGRNNSIVKSITVS 675
Sequence name: CEA5_HUMAN
Sequence documentation:
Alignment of: HUMCEA_PEA_1_P19 x CEA5_HUMAN
Alignment segment 1/1:
Quality: 3298.00 Escore: 0
Matching length: 346 Total length: 702 Matching Percent Similarity: 100.00 Matching Percent Identity: 100.00
Total Percent Similarity: 49.29 Total Percent Identity: 49.29
Gaps : 1
Alignment :
1 MESPSAPPHRWCIPWQRLLLTASLLTFWNPPTTAKLTIESTPFNVAEGKE 50
1 MESPSAPPHRWCIPWQRLLLTASLLTFWNPPTTAKLTIESTPFNVAEGKE 50
51 VLLLVHNLPQHLFGYSWYKGERVDGNRQIIGYVIGTQQATPGPAYSGREI 100
I M I I Il I I M I I I I I I Il I I I Il Il I I Il I I Il I I I I I I M M Il I M 1
51 VLLLVHNLPQHLFGYSWYKGERVDGNRQIIGYVIGTQQATPGPAYSGREI 100 . . . . .
101 IYPNASLLIQNIIQNDTGFYTLHVIKSDLVNEEATGQFRVYPELPKPSIS 150
M M M M I I M M M I M M I M M M M M I M M M M I M M M M
101 IYPNASLLIQNIIQNDTGFYTLHVIKSDLVNEEATGQFRVYPELPKPSIS 150
151 SNNSKPVEDKDAVAFTCEPETQDATYLWWVNNQSLPVSPRLQLSNGNRTL 200
II Il I M M I M Il Il M M Il I M I I Il Il M M M I M M M Il I M I
151 SNNSKPVEDKDAVAFTCEPETQDATYLWWVNNQSLPVSPRLQLSNGNRTL 200
201 TLFNVTRNDTASYKCETQNPVSARRSDSVILN 232 M M M Il I M Il Il Il M Il M I M Il M Il
201 TLFNVTRNDTASYKCETQNPVSARRSDSVILNVLYGPDAPTISPLNTSYR 250
232 232
251 SGENLNLSCHAASNPPAQYSWFVNGTFQQSTQELFIPNITVNNSGSYTCQ 300 . . . . .
232 232
301 AHNSDTGLNRTTVTTITVYAEPPKPFITSNNSNPVEDEDAVALTCEPEIQ 350
232 232
351 NTTYLWWVNNQSLPVSPRLQLSNDNRTLTLLSVTRNDVGPYECGIQNELS 400
232 232
401 VDHSDPVILNVLYGPDDPTISPSYTYYRPGVNLSLSCHAASNPPAQYSWL 450
232 232
451 IDGNIQQHTQELFISNITEKNSGLYTCQANNSASGHSRTTVKTITVSAEL 500
232 232
501 PKPSISSNNSKPVEDKDAVAFTCEPEAQNTTYLWWVNGQSLPVSPRLQLS 550 . . . . .
233 VLYGPDTPIISP 244
!1!!1!1IMII
551 NGNRTLTLFNVTRNDARAYVCGIQNSVSANRSDPVTLDVLYGPDTPIISP 600
245 PDSSYLSGANLNLSCHSASNPSPQYSWRINGIPQQHTQVLFIAKITPNNN 294
601 PDSSYLSGANLNLSCHSASNPSPQYSWRINGIPQQHTQVLFIAKITPNNN 650
295 GTYACFVSNLATGRNNSIVKSITVSASGTSPGLSAGATVGIMIGVLVGVA 344
111!111111!11111111!1111IMIIIIIIMIIIIIIIMIIIMI 651 GTYACFVSNLATGRNNSIVKSITVSASGTSPGLSAGATVGIMIGVLVGVA 700
345 LI 346
I I
701 LI 702
Sequence name: CEA5JHUMAN
Sequence documentation:
Alignment of: HUMCEA_PEA_1_P20 x CEA5_HUMAN
Alignment segment 1/1:
Quality: 3294.00 Escore: 0
Matching length: 346 Total length: 702
Matching Percent Similarity: 100.00 Matching Percent Identity: 100.00 Total Percent Similarity: 49.29 Total Percent Identity: 49.29
Gaps : 1
Alignment :
1 MESPSAPPHRWCIPWQRLLLTASLLTFWNPPTTAKLTIESTPFNVAEGKE 50
Il I I I I I I I I I I I I I I Il I I I I I I I I I I I I 1 I I I I Il I I I I I I i I I I I I I
1 MESPSAPPHRWCIPWQRLLLTASLLTFWNPPTTAKLTIESTPFNVAEGKE 50
51 VLLLVHNLPQHLFGYSWYKGERVDGNRQIIGYVIGTQQATPGPAYSGREI 100 ■ I I I I I I I I I I I I M I I I M I I I I I I I I M M I 1 I I I I I I I I M I I M I M
51 VLLLVHNLPQHLFGYSWYKGERVDGNRQIIGYVIGTQQATPGPAYSGREI 100
101 IYPNASLLIQNIIQNDTGFYTLHVIKSDLVNEEATGQFRVYP 142
I I I I I I Il I I I I I I I I Il Il I I I I Il I I I I I I I Il I I I I I Il 101 IYPNASLLIQNIIQNDTGFYTLHVIKSDLVNEEATGQFRVYPELPKPSIS 150
142 142
151 SNNSKPVEDKDAVAFTCEPETQDATYLWWVNNQSLPVSPRLQLSNGNRTL 200 . . . . .
142 142
201 TLFNVTRNDTASYKCETQNPVSARRSDSVILNVLYGPDAPTISPLNTSYR 250
142 142
251 SGENLNLSCHAASNPPAQYSWFVNGTFQQSTQELFIPNITVNNSGSYTCQ 300
142 142
301 AHNSDTGLNRTTVTTITVYAEPPKPFITSNNSNPVEDEDAVALTCEPEIQ 350
142 142
351 NTTYLWWVNNQSLPVSPRLQLSNDNRTLTLLSVTRNDVGPYECGIQNELS 400 . . . . .
142 142
401 VDHSDPVILNVLYGPDDPTISPSYTYYRPGVNLSLSCHAASNPPAQYSWL 450
143 EL 144
I I 451 IDGNIQQHTQELFISNITEKNSGLYTCQANNSASGHSRTTVKTITVSAEL 500
145 PKPSISSNNSKPVEDKDAVAFTCEPEAQNTTYLWWVNGQSLPVSPRLQLS 194 I I I I I I I I I I I I I I I I M I M M I I I I I I I I I I I I I I I I I I I I I Il I I I I
501 PKPSISSNNSKPVEDKDAVAFTCEPEAQNTTYLWWVNGQSLPVSPRLQLS 550
195 NGNRTLTLFNVTRNDARAYVCGIQNSVSANRSDPVTLDVLYGPDTPIISP 244 I I Il Il I I I I I I I I 111 I I I I I Il I I I I I I I Il I I I I I I I Il I I I Il I I I 551 NGNRTLTLFNVTRNDARAYVCGIQNSVSANRSDPVTLDVLYGPDTPIISP 600
245 PDSSYLSGANLNLSCHSASNPSPQYSWRINGIPQQHTQVLFIAKITPNNN 294
M IM M M I I II M IIM III IM M I I IM I I M I I M I I II II M I I
601 PDSSYLSGANLNLSCHSASNPSPQYSWRINGIPQQHTQVLFIAKITPNNN 650 . . . . .
295 GTYACFVSNLATGRNNSIVKSITVSASGTSPGLSAGATVGIMIGVLVGVA 344
I M I M I I I Il I M Il I I I I I Il I I M I I I M I M M I M I I I M M I M
651 GTYACFVSNLATGRNNSIVKSITVSASGTSPGLSAGATVGIMIGVLVGVA 700
345 LI 346
701 LI 702
DESCRIPTION FOR CLUSTER R35137
Cluster R35137 features 6 transcript(s) and 20 segment(s) of interest, the names for which are given in Tables 999 and 1000, respectively, the sequences themselves are given at the end of the application. The selected protein variants are given in table 1001.
Table 999 - Transcripts of interest
Table 1000 - Segments of interest
Table 1001 - Proteins of interest
These sequences are variants of the known protein Alanine aminotransferase (SwissProt accession identifier ALAT_HUMAN; known also according to the synonyms EC 2.6.1.2; Glutamic— pyruvic transaminase; GPT; Glutamic—alanine transaminase), SEQ ID NO: 1452, referred to herein as the previously known protein.
Protein Alanine aminotransferase is known or believed to have the following function(s): Participates in cellular nitrogen metabolism and also in liver gluconeogenesis starting with precursors transported from skeletal muscles. The sequence for protein Alanine aminotransferase is given at the end of the application, as "Alanine aminotransferase amino acid sequence". Known polymorphisms for this sequence are as shown in Table 1002.
Table 1002 -Amino acid mutations for Known Protein
Protein Alanine aminotransferase localization is believed to be Cytoplasmic.
Cluster R35137 can be used as a diagnostic marker according to overexpression of transcripts of this cluster in cancer. Expression of such transcripts in normal tissues is also given according to the previously described methods. The term "number" in the right hand column of the table and the numbers on the y-axis of figure 34 refer to weighted expression of ESTs in each category, as "parts per million" (ratio of the expression of ESTs for a particular cluster to the expression of all ESTs in that category, according to parts per million).
Overall, the following results were obtained as shown with regard to the histograms in
Figure 34 and Table 1003. This cluster is overexpressed (at least at a minimum level) in the following pathological conditions: hepatocellular carcinoma.
Table 1003 - Normal tissue distribution
Table 1004 - P values and ratios for expression in cancerous tissue
As noted above, cluster R35137 features 6 transcript(s), which were listed in Table 1 above. These transcript(s) encode for protein(s) which are variant(s) of protein Alanine aminotransferase. A description of each variant protein according to the present invention is now provided.
Variant protein R35137_PEA_1_PEA_1_PEA_1_P9 according to the present invention has an amino acid sequence as given at the end of the application; it is encoded by transcript(s) R35137_PEA_l_PEA_l_PEA_l_T10. An alignment is given to the known protein (Alanine aminotransferase) at the end of the application. One or more alignments to one or more previously published protein sequences are given at the end of the application. A brief description of the relationship of the variant protein according to the present invention to each such aligned protein is as follows: Comparison report between R35137J?EA_1_PEA_1_PEA_1_P9 and
ALAT_HIJMAN_V1 (SEQ ID NO: 1453):
LAn isolated chimeric polypeptide encoding for R35137_PEA_ 1_PEA_1_PEA_1_P9, comprising a first amino acid sequence being at least 90 % homologous to MASSTGDRSQAVRHGLRAKVLTLDGMNPRVRRVEYAVRGPIVQRALELEQELRQGVK KPFTEVIRANIGDAQAMGQRPITFLRQVLALCVNPDLLSSPNFPDDAKKRAERILQACG
GHSLGAYSVSSGIQLIREDVARYIERRDGGIPADPNNVFLSTGASDAIVTVLKLLVAGEG HTRTGVLIPIPQYPLYSATLAELGAVQVDYYLDEERAWALDVAELHRALGQARDHCRP RALCVINPGNPTGQVQTRECIEAVIRFAFEERLFLLADEV corresponding to amino acids 1 - 274 of ALAT JHUMANJVl, which also corresponds to amino acids 1 - 274 of R35137_PEA_1_PEA_1 JPEA_1_P9, and a second amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence RGAGEREAGQQSAPVTPCALPGVPGQRVRRGFAVPLIQEGAHGDGAALRRAAGACLLP LHLQGLHGRVRAYEAGGGSRAMARPSSPDGPPPPPHLTWPCAGAGSAAAMWRW corresponding to amino acids 275 - 385 of R35137_PEA_1_PEA_1_PEA_1_P9, wherein said first amino acid sequence and second amino acid sequence are contiguous and in a sequential order.
2.An isolated polypeptide encoding for a tail of R35137_PEA_1_PEA_1_PEA_1_P9, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence
RGAGEREAGQQSAPVTPCALPGVPGQRVRRGFAVPLIQEGAHGDGAALRRAAGACLLP LHLQGLHGRVRAYEAGGGSRAMARPSSPDGPPPPPHLTWPCAGAGSAAAMWRW in R35137_PEA_1_PEA_1_PEA_1_P9.
It should be noted that the known protein sequence (ALATJHUMAN) has one or more changes than the sequence given at the end of the application and named as being the amino acid sequence for ALAT_HUMAN_V1. These changes were previously known to occur and are listed in the table below. Table 1005 - Changes to ALAT_HUMAN_V1
The location of the variant protein was determined according to results from a number of different software programs and analyses, including analyses from SignalP and other specialized programs. The variant protein is believed to be located as follows with regard to the cell: intracellularly. The protein localization is believed to be intracellularly because neither of the trans- membrane region prediction programs predicted a trans -membrane region for this protein. In addition both signal-peptide prediction programs predict that this protein is a non- secreted protein.
Variant protein R35137_PEA_1_PEA_1_PEA_1_P9 is encoded by the following transcript(s): R35137_PEA_l_PEA_l_PEA_l_T10, for which the sequence(s) is/are given at the end of the application. The coding portion of transcript
R35137_PEA_l_PEA_l_PEA_ljriO is shown in bold; this coding portion starts at position 271 and ends at position 1425. The transcript also has the following SNPs as listed in Table 1006 (given according to their position on the nucleotide sequence, with the alternative nucleic acid listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein R35137JPEA_1_PEA_1_PEA_1_P9 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 1006 - Nucleic acid SNPs
Variant protein R35137_PEA_1_PEA_1JPEA_1_P8 according to the present invention has an amino acid sequence as given at the end of the application; it is encoded by transcript(s) R35137_PEA_1_PEA_1_PEA_1_T11. An alignment is given to the known protein (Alanine aminotransferase) at the end of the application. One or more alignments to one or more previously published protein sequences are given at the end of the application. A brief description of the relationship of the variant protein according to the present invention to each such aligned protein is as follows: Comparison report between R35137_PEA_1_PEA_1_PEA_1_P8 and
AIAT JHUMANJVl :
1.An isolated chimeric polypeptide encoding for R35137_PEA_1_PEA_1_PEA_1_P8, comprising a first amino acid sequence being at least 90 % homologous to MASSTGDRSQAVRHGLRAKVLTLDGMNPRVRRVEYAVRGPIVQRALELEQELRQGVK KPFTEVIRANIGDAQAMGQRPITFLRQVLALCVNPDLLSSPNFPDDAKKRAERILQACG GHSLGAYSVSSGIQLIREDVARYIERRDGGIPADPNNVFLSTGASDAIVTVLKLLVAGEG HTRTGVLIPIPQYPLYSATLAELGAVQVDYYLDEERAWALDVAELHRALGQARDHCRP RALCVINPGNPTGQVQTRECIEAVIRFAFEERLFLLADEVYQDNVYAAGSQFHSFKKVL MEMGPPYAGQQELASFHSTSKGYMGEC corresponding to amino acids 1 - 320 of ALAT_HUMAN_V1, which also corresponds to amino acids 1 - 320 of
R35137_PEA_1_PEA_1_PEA_1_P8, and a second amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence VRTRRVGARGPWPGPPRPMGHPLLRT corresponding to amino acids 321 - 346 of
R35137_PEA__1_PEA_1_PEA_1_P8, wherein said first amino acid sequence and second amino acid sequence are contiguous and in a sequential order.
2.An isolated polypeptide encoding for a tail of R35137_PEA_1_PEA_1JPEA_1JP8, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence VRTRRVGARGPWPGPPRPMGHPLLRT in R35137_PEA_1_PEA_1_PEA_1_P8.
It should be noted that the known protein sequence (ALAT_HUMAN) has one or more changes than the sequence given at the end of the application and named as being the amino acid sequence for ALAT_HUMAN_V1 • These changes were previously known to occur and are listed in the table below.
Table 1007 - Changes to ALAT_HUMAN_V1
The location of the variant protein was determined according to results from a number of different software programs and analyses, including analyses from SignalP and other specialized programs. The variant protein is believed to be located as follows with regard to the cell: intracellularly. The protein localization is believed to be intracellularly because neither of the trans- membrane region prediction programs predicted a trans- membrane region for this protein.
In addition both signal-peptide prediction programs predict that this protein is a non-secreted protein.
Variant protein R35137_PEA_1_PEA_1_PEA_1_P8 also has the following non-silent
SNPs (Single Nucleotide Polymorphisms) as listed in Table 1008, (given according to their position(s) on the amino acid sequence, with the alternative amino acid(s) listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein
R35137_PEA_1_PEA_1_PEA_1_P8 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 1008 ~ Amino acid mutations
Variant protein R35137_PEA_1_PEA_1JPEA_1_P8 is encoded by the following transcript(s): R35137JPEA_1_PEA_1_PEA_1_T11, for which the sequence(s) is/are given at the end of the application. The coding portion of transcript
R35137_PEA_1_PEA_1_PEA_1_T11 is shown in bold; this coding portion starts at position 271 and ends at position 1308. The transcript also has the following SNPs as listed in Table 1009 (given according to their position on the nucleotide sequence, with the alternative nucleic acid listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein R35137_PEA_1_PEA_1_PEA_1_P8 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 1009 - Nucleic acid SNPs
Variant protein R35137_PEA_1_PEA_1_PEA_1_P11 according to the present invention has an amino acid sequence as given at the end of the application; it is encoded by transcript(s) R35137_PEA_1_PEA_1_PEA_1_T14. An alignment is given to the known protein (Alanine aminotransferase) at the end of the application. One or more alignments to one or more previously published protein sequences are given at the end of the application. A brief description of the relationship of the variant protein according to the present invention to each such aligned protein is as follows: Comparison report between R35137_PEA_1_PEA_1_PEA_1_P11 and
ALAT_HUMAN_V1 :
1.An isolated chimeric polypeptide encoding for R35137_PEA_1_PEA_1JPEA_1_P11, comprising a first amino acid sequence being at least 90 % homologous to MASSTGDRSQAVRHGLRAKVLTLDGMNPRVRRVEYAVRGPIVQRALELEQELRQGVK KPFTEVIRANIGDAQAMGQRPITFLRQVLALCVNPDLLSSPNFPDDAKKRAERILQACG GHSLGAYSVSSGIQLIREDVARYIERRDGGIPADPNNVFLSTGASDATVTVLKLLVAGEG HTRTGVLIPIPQYPLYSATLAELGAVQVDYYLDEERAWALDVAELHRALGQAR corresponding to amino acids 1 - 229 of ALAT_HUMAN_V1, which also corresponds to amino acids 1 - 229 of R35137_PEA_1_PEA_1JPEA_1_P11, and a second amino acid sequence being at least 90 % homologous to SGFGQREGTYHFRMTILPPLEKLRLLLEKLSRFHAKFTLEYS corresponding to amino acids 455 - 496 of ALAT_HUMAN_V1, which also corresponds to
amino acids 230 - 271 of R35137_PEA__1_PEA_1 J»EA_1_P11, wherein said first amino acid sequence and second amino acid sequence are contiguous and in a sequential order.
2.An isolated chimeric polypeptide encoding for an edge portion of
R35137_PEA_1_PEA_1_PEA_1_P11, comprising a polypeptide having a length "n", wherein n is at least about 10 amino acids in length, optionally at least about 20 amino acids in length, preferably at least about 30 amino acids in length, more preferably at least about 40 amino acids in length and most preferably at least about 50 amino acids in length, wherein at least two amino acids comprise RS, having a structure as follows: a sequence starting from any of amino acid numbers 229-x to 229; and ending at any of amino acid numbers 230+ ((n-2) - x), in which x varies from 0 to n-2.
It should be noted that the known protein sequence (ALAT_HUMAN) has one or more changes than the sequence given at the end of the application and named as being the amino acid sequence for ALAT_HUMAN_V1. These changes were previously known to occur and are listed in the table below.
Table 1010 - Changes to ALAT_HUMAN_V1
The location of the variant protein was determined according to results from a number of different software programs and analyses, including analyses from SignalP and other specialized programs. The variant protein is believed to be located as follows with regard to the cell: intracellularly. The protein localization is believed to be intracellular Iy because neither of the trans- membrane region prediction programs predicted a trans -membrane region for this protein. In addition both signal-peptide prediction programs predict that this protein is a non-secreted protein.
Variant protein R35137JPEA_1_PEA_1JPEA_1_P11 also has the following non-silent SNPs (Single Nucleotide Polymorphisms) as listed in Table 1011, (given according to their position(s) on the amino acid sequence, with the alternative amino acid(s) listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein R35137_PEA_1_PEA_1 _PEA_1_P11 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 1011 - Amino acid mutations
Variant protein R35137_PEA_1_PEA_1_PEA_1_P11 is encoded by the following transcript(s): R35137_PEA_1_PEA_1_PEA_1_T14, for which the sequence(s) is/are given at the end of the application. The coding portion of transcript
R35137_PEA_1_PEA_1_PEA_1_T14 is shown in bold; this coding portion starts at position 271 and ends at position 1083. The transcript also has the following SNPs as listed in Table 1012 (given according to their position on the nucleotide sequence, with the alternative nucleic acid listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein R35137_PEA_1_PEA_1_PEA_1_P11 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 1012 - Nucleic acid SNPs
Variant protein R35137_PEA_1_PEA_1_PEA_1_P2 according to the present invention has an amino acid sequence as given at the end of the application; it is encoded by transcript(s) R35137JPEA_1_PEA_1_PEA_1_T3. An alignment is given to the known protein (Alanine aminotransferase) at the end of the application. One or more alignments to one or more previously published protein sequences are given at the end of the application. A brief description of the relationship of the variant protein according to the present invention to each such aligned protein is as follows: Comparison report between R35137_PEA_1_PEA_1_PEA_1_P2 and
ALAT_HUMAN_V1:
1.An isolated chimeric polypeptide encoding for R35137_PEA_1_PEA_1JPEA_1_P2, comprising a first amino acid sequence being at least 90 % homologous to MASSTGDRSQAVRHGLRAKVLTLDGMNPRVRRVEYAVRGPIVQRALELEQELRQGVK KPFTEVIRANIGDAQAMGQRPITFLRQVLALCVNPDLLSSPNFPDDAKKRAERILQACG GHSLGAYSVSSGIQLIREDVARYIERRDGGIPADPNNVFLSTGASDAIVTVLKLLVAGEG HTRTGVLIPIPQYPLYSATLAELGAVQVDYYLDEERAWALDVAELHRALGQARDHCRP RALCVINPGNPTGQVQTRECIEAVIRFAFEERLFLLADEV corresponding to amino acids 1 - 274 of ALAT__HUMAN_V1, which also corresponds to amino acids 1 - 274 of R35137_PEA_1_PEA_1_PEA_1_P2, and a second amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence RGAGEREAGQQSAPVTPCALPGVPGQRVRRGFAVPLIQEGAHGDGAALRPvAAGACLLP LHLQGLHGRVRVPRRLCGGGEHGRCSAAAD AEADECAAVP AGARTGPAGPGGQP AR AHRPLLCAVPG corresponding to amino acids 275 - 399 of
R35137_PEA_1_PEA_1_PEA_1_P2, wherein said first amino acid sequence and second amino acid sequence are contiguous and in a sequential order.
2.An isolated polypeptide encoding for a tail of R35137JPEA_1_PEA_1_PEA_1_P2, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least
about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence
RGAGEREAGQQSAPVTPCALPGVPGQRVRRGFA VPLIQEGAHGDGAALRRAAGACLLP LHLQGLHGRVRVPRRLCGGGEHGRCSAAADAEADECAA VPAGARTGPAGPGGQPAR AHRPLLCAVPG in R35137_PEA_1_PEA_1_PEA_1_P2.
It should be noted that the known protein sequence (ALATJHUMAN) has one or more changes than the sequence given at the end of the application and named as being the amino acid sequence for ALAT_HUMAN_V1. These changes were previously known to occur and are listed in the table below.
Table 1013 - Changes to ALATJiVMANJVl
The location of the variant protein was determined according to results from a number of different software programs and analyses, including analyses from SignalP and other specialized programs. The variant protein is believed to be located as follows with regard to the cell: intracellularly. The protein localization is believed to be intracellularly because neither of the trans- membrane region prediction programs predicted a trans -membrane region for this protein. In addition both signal-peptide prediction programs predict that this protein is a non- secreted protein.
Variant protein R35137_PEA_1_PEA_1_PEA_1_P2 also has the following non-silent SNPs (Single Nucleotide Polymorphisms) as listed in Table 1014, (given according to their position(s) on the amino acid sequence, with the alternative amino acid(s) listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein R35137_PEA_1_PEA_1_PEA_1_P2 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 1014 - Amino acid mutations
Variant protein R35137_PEA_1_PEA_1_PEA_1_P2 is encoded by the following transcript(s): R35137JPEA_1_PEA_1_PEA_1_T3, for which the sequence(s) is/are given at the end of the application. The coding portion of transcript R35137_PEA_1_PEA_1_PEA_1_T3 is shown in bold; this coding portion starts at position 271 and ends at position 1467. The transcript also has the following SNPs as listed in Table 1015 (given according to their position on the nucleotide sequence, with the alternative nucleic acid listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein R35137_PEA_1_PEA_1_PEA_1_P2 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 1015 - Nucleic acid SNPs
Variant protein R35137_PEA_1_PEA_1_PEA_1JP4 according to the present invention has an amino acid sequence as given at the end of the application; it is encoded by transcript(s) R35137_PEA_1_PEA_1_PEA_1_T5. An alignment is given to the known protein (Alanine aminotransferase) at the end of the application. One or more alignments to one or more previously published protein sequences are given at the end of the application. A brief description of the relationship of the variant protein according to the present invention to each such aligned protein is as follows: Comparison report between R35137_PEA_1_PEA_1_PEA_1_P4 and
ALAT_HUMAN_V1:
1.An isolated chimeric polypeptide encoding for R35137_PEA_1_PEA_1_PEA_1_P4, comprising a first amino acid sequence being at least 90 % homologous to MASSTGDRSQAVRHGLRAKVLTLDGMNPRVRRVEYAVRGPIVQRALELEQELRQGVK KPFTEVIRANIGDAQAMGQRPITFLRQVLALCVNPDLLSSPNFPDDAKKRAERILQACG GHSLGAYSVSSGIQLIREDVARYIERRDGGIPADPNNVFLSTGASDAIVTVLKLLVAGEG HTRTGVLIPIPQYPLYSATLAELGAVQVDYYLDEERAWALDVAELHRALGQARDHCRP RALCVINPGNPTGQVQTRECIEAVIRFAFEERLFLLADEVYQDNVYAAGSQFHSFKKVL MEMGPPYAGQQELASFHSTSKGYMGECGFRGGYVEVVNMDAAVQQQMLKLMSVRL CPPVPGQALLDLWSPP APTDPSFAQFQAEKQAVLAELAAKAKLTEQVFNEAPGISCNP VQGAMYSFPRVQLPPRAVERAQELGLAPDMFFCLRLLEETGICWPGSGFGQREGTYH FRMTILPPLEKLRLLLEKLSRFHAKFTLE corresponding to amino acids 1 - 494 of ALAT_HUMAN_V1, which also corresponds to amino acids 1 - 494 of R35137_PEA_1_PEA_1_PEA_1_P4, and a second amino acid sequence being at least 70%,
optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence SPGRLWSPLYLLLMPGGVGWGGCWAPASLQVPNKAVWQSDSKKEALAAAWPAPTCL PFLQA corresponding to amino acids 495 - 555 of R35137_PEA_1_PEA_1_PEA_1_P4, wherein said first amino acid sequence and second amino acid sequence are contiguous and in a sequential order.
2.An isolated polypeptide encoding for a tail of R35137_PEA_1_PEA_1JPEA_1_P4, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence
SPGRLWSPLYLLLMPGGVGWGGCWAP ASLQVPNKAVWQSDSKKEAL AAAWP APTCL PFLQA in R35137_PEA_1_PEA_1_PEA_1_P4.
It should be noted that the known protein sequence (ALAT_HUMAN) has one or more changes than the sequence given at the end of the application and named as being the amino acid sequence for ALAT_HUMAN_V1. These changes were previously known to occur and are listed in the table below.
Table 1016 - Changes to ALAT_ HUMAN_V1
The location of the variant protein was determined according to results from a number of different software programs and analyses, including analyses from SignalP and other specialized programs. The variant protein is believed to be located as follows with regard to the cell: intracellularly. The protein localization is believed to be intracellularly because neither of the trans- membrane region prediction programs predicted a trans -membrane region for this protein.
In addition both signal-peptide prediction programs predict that this protein is a non-secreted protein.
Variant protein R35137_PEA_1JPEA_1_PEA_1_P4 also has the following non-silent SNPs (Single Nucleotide Polymorphisms) as listed in Table 1017, (given according to their position(s) on the amino acid sequence, with the alternative amino acid(s) listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein R35137_PEA_1_PEA_1_PEA_1_P4 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 1017 - Amino acid mutations
Variant protein R35137_PEA_1_PEA_1_PEA_1_P4 is encoded by the following transcript(s): R35137_PEA_1_PEA_1_PEA_1_T5, for which the sequence(s) is/are given at the end of the application. The coding portion of transcript R35137_PEA_1_PEA_1_PEA_1_T5 is shown in bold; this coding portion starts at position 271 and ends at position 1935. The transcript also has the following SNPs as listed in Table 1018 (given according to their position on the nucleotide sequence, with the alternative nucleic acid listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein R35137_PEA_1JPEA_1_PEA_1_P4 sequence provides support for the deduced sequence of this variant protein according to the present invention). Table 1018 - Nucleic acid SNPs
As noted above, cluster R35137 features 20 segment(s), which were listed in Table 2 above and for which the sequence(s) are given at the end of the application. These segment(s) are portions of nucleic acid sequence(s) which are described herein separately because they are of particular interest. A description of each segment according to the present invention is now provided.
Segment cluster R35137_PEA_l_PEA_l_PEA_l_node_2 according to the present invention is supported by 19 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): R35137_PEA_1_PEA_1_PEA_1_T3, R35137_PEA_1_PEA_1_PEA_1_T5, R35137_PEA_l_PEA_l_PEA_l_T10, R35137_PEA_1_PEA_1_PEA_1_T11, R35137_PEA_1JPEA_1_PEA_1_T12 and R35137_PEA_l_PEA_l_PEA_l_T14. Table 1019 below describes the starting and ending position of this segment on each transcript.
Table 1019 - Segment location on transcripts
Transcript name Segment Segment starting position ending position
R35137JPEA_1_ _PEA _1_ PEA X T3 1 266
R35137_PEA_1_ JPEA _1_ PEA X _T5 1 266
R35137_PEA_1_ JPEA _1 JPEA X TlO 1 266
R35137_PEA_1. _PEA _1_ JPEA X _T11 1 266
R35137_PEA_1_ _PEA _1_ JPEA X _T12 1 266
R35137_PEA_1 _PEA _1 _PEA X _T14 1 266
Segment cluster R35137_PEA_l_PEA_l_PEA_l_node_3 according to the present invention is supported by 24 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): R35137_PEA_1_PEA_1_PEA_1_T3, R35137_PEA_1_PEA_1_PEA_1_T5, R35137_PEA_1_PEA_1_PEA_1_T10, R35137_PEA_1_PEA_1_PEA_1_T11 , R35137_PEA_1_PEA_1_PEA_1_T12 and R35137_PEA_1_PEA_1_PEA_1_T14. Table 1020 below describes the starting and ending position of this segment on each transcript.
Table 1020 - Segment location on transcripts
Segment cluster R35137_PEA_l_PEA_l_PEA_l_node_9 according to the present invention is supported by 25 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): R35137_PEA_1_PEA_1JPEA_1_T3, R35137_PEA_1_PEA_1_PEA_1_T5, R35137_PEA_1_PEA_1_PEA_1_T10, R35137_PEA_1_PEA_1_PEA_1_T11 ,
R35137_PEA_1_PEA_1_PEA_1_T12 and R35137_PEA_lJPEA_lJPEA_l_T14. Table 1021 below describes the starting and ending position of this segment on each transcript.
Table 1021 - Segment location on transcripts
Segment cluster R35137_PEA_l_PEA_l_PEA_l_node_l 1 according to the present invention is supported by 30 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): R35137_PEA_1_PEA_1_PEA_1_T3, R35137_PEA_1_PEA_1_PEA_1_T5, R35137_PEA_l_PEA_l_PEA_l_T10, R35137_PEA_1_PEA_1_PEA_1_T11, R35137_PEA_1_PEA_1_PEA_ 1_T12 and R35137_PEA_l_PEA_l_PEA_l_T14. Table 1022 below describes the starting and ending position of this segment on each transcript.
Table 1022 - Segment location on transcripts
Segment cluster R35137_PEA_l_PEA_l_PEA_l_node_16 according to the present invention is supported by 23 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s):
R35137_PEA_1_PEA_1_PEA_1_T3, R35137_PEA_1_PEA_1_PEA_1_T5, R35137_PEA_l_PEA_l_PEA_l_T10, R35137_PEA_1JPEA_1_PEA_1_T11 and R35137_PEA_1_PEA_1_PEA_1_T12. Table 1023 below describes the starting and ending position of this segment on each transcript. Table 1023 - Segment location on transcripts
Segment cluster R35137_PEA_l_PEA_l_PEA_l_node_18 according to the present invention is supported by 24 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s):
R35137_PEA_1_PEA_1_PEA_1_T3, R35137_PEA_1_PEA_1_PEA_1_T5, R35137_PEA_l_PEA_l_PEA_l_T10, R35137_PEA_1JPEA_1_PEA_1_T11 and
R35137_PEA_l_PEA_l_PEA_ljri2. Table 1024 below describes the starting and ending position of this segment on each transcript.
Table 1024 - Segment location on transcripts
Microarray (chip) data is also available for this segment as follows. As described above with regard to the cluster itself, various oligonucleotides were tested for being differentially expressed in various disease conditions, particularly cancer. The following oligonucleotides were found to hit this segment (in relation to lung cancer), shown in Table 1025.
Table 1025 - Oligonucleotides related to this segment
Segment cluster R35137_PEA_l_PEA_l_PEA_l_node_20 according to the present invention is supported by 29 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): R35137_PEA_1_PEA_1_PEA_1_T3, R35137_PEA_1_PEA_1_PEA_1_T5,
R35137_PEA_l_PEA_l_PEA_l_T10, R35137_PEA_1_PEA_1_PEA_1_T11 and R35137_PEA_1_PEA_1_PEA_1_T12. Table 1026 below describes the starting and ending position of this segment on each transcript.
Table 1026 - Segment location on transcripts
Segment cluster R35137_PEA_l_PEA_l_PEA_l_node_27 according to the present invention is supported by 39 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): R35137_PEA_1_PEA_1_PEA_1_T3, R35137_PEA_1_PEA_1_PEA_1_T5, R35137_PEA_l_PEA_l_PEA_l_T10, R35137_PEA_1_PEA_1_PEA_1_T11, R35137_PEA_1_PEA_1_PEA_1_T12 and R35137_PEA_l_PEA_l_PEA_l_T14. Table 1027 below describes the starting and ending position of this segment on each transcript.
Table 1027 - Segment location on transcripts
According to an optional embodiment of the present invention, short segments related to the above cluster are also provided. These segments are up to about 120 bp in length, and so are included in a separate description.
Segment cluster R35137_PEA_l_PEA_l_PEA_l_node_5 according to the present invention is supported by 20 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): R35137JPEA J JPEA_1JPEA_1_T3, R35137_PEA_1_PEA_1_PEA_1_T5, R35137_PEA_l_PEA_l_PEA_l_T10, R35137_PEA_1_PEA_1_PEA_1_T11,
R35137_PEA_1_PEA_1_PEA_1_T12 and R35137_PEA_l_PEA_l_PEA_l_T14. Table 1028 below describes the starting and ending position of this segment on each transcript.
Table 1028 - Segment location on transcripts
Segment cluster R35137_PEA_l_PEA_l_PEA_l_node_7 according to the present invention is supported by 23 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): R35137_PEA_1_PEA_1_PEA_1_T3, R35137_PEA_1_PEA_1_PEA_1_T5, R35137J>EA_l_PEA_l_PEAJ_T10, R35137_PEA_1_PEA_1_PEA_1_T11, R35137_PEA_1_PEA_1JPEA_1_T12 and R35137_PEA_1_PEA_1_PEA_1_T14. Table 1029 below describes the starting and ending position of this segment on each transcript.
Table 1029 - Segment location on transcripts
Segment cluster R35137_PEA_l_PEA_lJPEA_l_node_12 according to the present invention is supported by 22 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s):
R35137_PEA_1_PEA_1_PEA_1_T3, R35137_PEA_1_PEA_1_PEA_1_T5, R35137_PEA_l_PEA_l_PEA_l_T10, R35137_PEA_1_PEA_1_PEA_1_T11 and R35137_PEA_1_PEA_1_PEA_1_T12. Table 1030 below describes the starting and ending position of this segment on each transcript. Table 1030 - Segment location on transcripts
Segment cluster R35137_PEA_l_PEA_l_PEA_l_node_14 according to the present invention is supported by 23 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s):
R35137_PEA_1_PEA_1_PEA_1_T3, R35137_PEA_1_PEAJ_PEA_1_T5, R35137_PEA_l_PEA_l_PEA_l_T10, R35137_PEA_1_PEA_1_PEA_1_T11 and
R35137_PEA_1JPEA_1_PEA_1_T12. Table 1031 below describes the starting and ending position of this segment on each transcript.
Table 1031 - Segment location on transcripts
Segment cluster R35137_PEA_l_PEA_l_PEA_l_node_15 according to the present invention is supported by 6 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): R35137_PEA_1_PEA_1_PEA_1_T3, R35137_PEA_l_PEA_l_PEA_l_T10 and R35137_PEA_1_PEA_1 JPEA_1_T12. Table 1032 below describes the starting and ending position of this segment on each transcript.
Table 1032 - Segment location on transcripts
Segment cluster R35137_PEA_l_PEA_l_PEA_l_node_17 according to the present invention is supported by 5 libraries. The number of libraries was determined as previously described. This segment can be found in the following trans cript(s): R35137_PEA_1_PEA_1J>EA_1_T1O, R35137_PEA_1_PEA_1_PEA_1_T11 and
R35137JPEA_1JPEA_1_PEA_1_T12. Table 1033 below describes the starting and ending position of this segment on each transcript.
Table 1033 - Segment location on transcripts
Segment cluster R35137_PEA_l_PEA_l_PEA_l_node_21 according to the present invention is supported by 6 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s):
R35137_PEA_1_PEA_1_PEA_1_T11 and R35137_PEA_l_PEA_l_PEA_l_T12. Table 1034 below describes the starting and ending position of this segment on each transcript.
Table 1034 - Segment location on transcripts
Segment cluster R35137_PEA_l_PEA_l_PEA_l_node_22 according to the present invention is supported by 31 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): R35137_PEA_1_PEA_1_PEA_1_T3, R35137_PEA_1_PEA_1_PEA_1_T5, R35137JPEA_1_PEA_1_PEA_1JT1O, R35137_PEA_1_PEA_1_PEA_1_T11 and R35137_PEA_1_PEA_1_PEA_1_T12. Table 1035 below describes the starting and ending position of this segment on each transcript.
Table 1035 - Segment location on transcripts
Transcript name Segment Segment starting position ending position
R35137_PEA_1_ _PEA 1 PEA _1_ T3 1625 1697
R35137_PEA_1_ _PEA _1. PEA _1_ T5 1558 1630
R35137_PEA_1. _PEA J PEA _1_ _T10 1725 1797
R35137_PEA_1_ _PEA J JPEA _1_ .TI l 1732 1804
R35137JPEAJ. _PEA _1_ JPEA _1_ _T12 1799 1871
Segment cluster R35137_PEA_l_PEA_l_PEA_l_node_23 according to the present invention is supported by 29 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): R35137_PEA_1_PEA_1_PEA_1_T3, R35137_PEA_1_PEA_1_PEA_1_T5, R35137_PEA_l_PEA_l_PEA_l_T10, R35137_PEA_1_PEA_1_PEA_1_T11, R35137_PEA_1_PEA_1_PEA_1_T12 and R35137_PEA_l_PEA_l_PEA_l_T14. Table 1036 below describes the starting and ending position of this segment on each transcript.
Table 1036 - Segment location on transcripts
Segment cluster R35137_PEA_l_PEA_l_PEA_l_node_24 according to the present invention is supported by 5 libraries. The number of libraries was determined as previously
described. This segment can be found in the following transcript(s):
R35137JPEA_1JPEA_1_PEA_1_T1 1 and R35137_PEA_1_PEA_1JPEA_1_T12. Table 1037 below describes the starting and ending position of this segment on each transcript.
Table 1037 - Segment location on transcripts
Segment cluster R35137_PEA_l_PEA_l_PEA_l_node_25 according to the present invention is supported by 30 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): R35137_PEA_1_PEA_1_PEA_1_T3, R35137_PEA_1_PEA_1_PEA_1_T5, R35137JPEAJJPEA_l_PEA_l_T10, R35137_PEA_1_PEA_1_PEA_1_T11, R35137_PEA_1_PEA_1_PEA_1_T12 and R35137_PEA_l_PEA_l_PEA_l_T14. Table 1038 below describes the starting and ending position of this segment on each transcript.
Table 1038 - Segment location on transcripts
Segment cluster R35137_PEA_l_PEA_l_PEA_l_node_26 according to the present invention is supported by 29 libraries. The number of libraries was determined as previously
described. This segment can be found in the following transcript(s): R35137_PEA_1_PEA_1_PEA_1_T3, R35137_PEA_1JPEA_1JPEA_1_T10, R35137JPEA_1_PEA_1_PEA_1_T11, R35137JPEA_1_PEA_1JPEA_1_T12 and R35137_PEA_1_PEA_1_PEA_1_T14. Table 1039 below describes the starting and ending position of this segment on each transcript.
Table 1039 - Segment location on transcripts
Variant protein alignment to the previously known protein: Sequence name: ALAT_HUMAN_V1
Sequence documentation:
Alignment of: R35137__PEA_1_PEA_1_PEA_1_P9 x ALAT_HUMAN_V1
Alignment segment 1/1:
Quality: 2619.00 Escore: 0
Matching length: 274 Total length: 274 Matching Percent Similarity: 100.00 Matching Percent Identity: 100.00
Total Percent Similarity: 100.00 Total Percent Identity: 100.00
Gaps: 0
Alignment :
1 MASSTGDRSQAVRHGLRAKVLTLDGMNPRVRRVEYAVRGPIVQRALELEQ 50
1111 ! 11111111 ! ! 11 I M I I I I I I I I M ) I I I I I I I I I I M I I I I I M 1 MASSTGDRSQAVRHGLRAKVLTLDGMNPRVRRVEYAVRGPIVQRALELEQ 50
51 ELRQGVKKPFTEVIRANIGDAQAMGQRPITFLRQVLALCVNPDLLSSPNF 100
I I I l I l I I l I I I I 1 I I I I I I I I I I I I I I I I l I I l I I I I l I I I I l I l I I I l
51 ELRQGVKKPFTEVIRANIGDAQAMGQRPITFLRQVLALCVNPDLLSSPNF 100 . . . . .
101 PDDAKKRAERILQACGGHSLGAYSVSSGIQLIREDVARYIERRDGGIPAD 150
1111111 ! 1 ! ! ! I M I I I I I I I I M I I I I M I I I I I M I I I I M I I M I I 101 PDDAKKRAERILQACGGHSLGAYSVSSGIQLIREDVARYIERRDGGIPAD 150
• • • • • 151 PNNVFLSTGASDAIVTVLKLLVAGEGHTRTGVLIPIPQYPLYSATLAELG 200
II I I I M Il I I I I M I I I I I I I M Il I M I M I Il Il I I I I M I I M I I I
151 PNNVFLSTGASDAIVTVLKLLVAGEGHTRTGVLIPIPQYPLYSATLAELG 200
201 AVQVDYYLDEERAWALDVAELHRALGQARDHCRPRALCVINPGNPTGQVQ 250 MMMMMIMMMMIIMMIIMIMMIMMIMMMMM
201 AVQVDYYLDEERAWALDVAELHRALGQARDHCRPRALCVINPGNPTGQVQ 250
251 TRECIEAVIRFAFEERLFLLADEV 274
251 TRECIEAVIRFAFEERLFLLADEV 274
Sequence name: ALAT_HUMAN_V1
Sequence documentation:
Alignment of: R35137_PEA_1_PEA_1_PEA_1_P8 x ALAT_HUMAN_V1
Alignment segment 1/1:
Quality: 3088.00 Escore: 0
Matching length: 320 Total length: 320
Matching Percent Similarity: 100.00 Matching Percent Identity: 100.00 Total Percent Similarity: 100.00 Total Percent Identity: 100.00
Gaps : 0
Alignment: . . . . .
1 MASSTGDRSQAVRHGLRAKVLTLDGMNPRVRRVEYAVRGPIVQRALELEQ 50
I I I I I I I I I I I I I I I I I I I I I I I I I I I I I i I I I I I I I I I I ] I I I Il I I i I l MASSTGDRSQAVRHGLRΆKVLTLDGMNPRVRRVEYAVRGPIVQRALELEQ 50
51 ELRQGVKKPFTEVIRANIGDAQAMGQRPITFLRQVLALCVNPDLLSSPNF 100 Il I I I I Il I I I I I 1 I M I I I I I I I I I I I I I I I I I I I I I I I I M I Il I I I I
51 ELRQGVKKPFTEVIRANIGDAQAMGQRPITFLRQVLALCVNPDLLSSPNF 100
101 PDDAKKRAERILQACGGHSLGAYSVSSGIQLIREDVARYIERRDGGIPAD 150
101 PDDAKKRAERILQACGGHSLGAYSVSSGIQLIREDVARYIERRDGGIPAD 150
151 PNNVFLSTGASDAIVTVLKLLVAGEGHTRTGVLIPIPQYPLYSATLAELG 200
M I I Il M M Il M I M M M I I I I M I I Il M I Il I M Il M I Il M M
151 PNNVFLSTGASDAIVTVLKLLVAGEGHTRTGVLIPIPQYPLYSATLAELG 200 . . . . .
201 AVQVDYYLDEERAWALDVAELHRALGQARDHCRPRALCVINPGNPTGQVQ 250
M I I Il M M Il Il I M M M I M M M I M M I I M I I Il M M I Il I I
201 AVQVDYYLDEERAWALDVAELHRALGQARDHCRPRALCVINPGNPTGQVQ 250
251 TRECIEAVIRFAFEERLFLLADEVYQDNVYAAGSQFHSFKKVLMEMGPPY 300
II M M Il M M Il I M M M I Il M M M M I M M I M M I M Il M I
251 TRECIEAVIRFAFEERLFLLADEVYQDNVYAAGSQFHSFKKVLMEMGPPY 300
301 AGQQELASFHSTSKGYMGEC 320 I Il Il M M M Il M I Il M
301 AGQQELASFHSTSKGYMGEC 320
Sequence name: ALAT_HUMAN_V1
Sequence documentation:
Alignment of: R35137_PEA_1_PEA_1_PEA_1_P11 x ALAT_HUMAN_V1
Alignment segment 1/1:
Quality: 2487.00
Escore: 0
Matching length: 271 Total length: 496
Matching Percent Similarity: 100.00 Matching Percent Identity: 100.00
Total Percent Similarity: 54.64 Total Percent Identity: 54.64
Gaps : 1
Alignment:
1 MASSTGDRSQAVRHGLRAKVLTLDGMNPRVRRVEYAVRGPIVQRALELEQ 50
1 MASSTGDRSQAVRHGLRAKVLTLDGMNPRVRRVEYAVRGPIVQRALELEQ 50 . . . . .
51 ELRQGVKKPFTEVIRANIGDAQAMGQRPITFLRQVLALCVNPDLLSSPNF 100
MMMMIMMMMMMMMMMMIMMIMMMMIMM
51 ELRQGVKKPFTEVIRANIGDAQAMGQRPITFLRQVLALCVNPDLLSSPNF 100
101 PDDAKKRAERILQACGGHSLGAYSVSSGIQLIREDVARYIERRDGGIPAD 150
101 PDDAKKRAERILQACGGHSLGAYSVSSGIQLIREDVARYIERRDGGIPAD 150
151 PNNVFLSTGASDAIVTVLKLLVAGEGHTRTGVLIPIPQYPLYSATLAELG 200
1 I I I I I I I I I I I I I I I I I I I I I I I I I I I I Il I I I I I I I I 1 I Il I I I I I I I 151 PNNVFLSTGASDAIVTVLKLLVAGEGHTRTGVLIPIPQYPLYSATLAELG 200
201 AVQVDYYLDEERAWALDVAELHRALGQAR 229
I I I I I I I I I I Il I I 1 I ! I I I I I I I I I Il I
201 AVQVDYYLDEERAWALDVAELHRALGQARDHCRPRALCVINPGNPTGQVQ 250 . . . . .
229 229
251 TRECIEAVIRFAFEERLFLLADEVYQDNVYAAGSQFHSFKKVLMEMGPPY 300
229 229
301 AGQQELASFHSTSKGYMGECGFRGGYVEWNMDAAVQQQMLKLMSVRLCP 350
229 229
351 PVPGQALLDLVVSPPAPTDPSFAQFQAEKQAVLAELAAKAKLTEQVFNEA 400
229 229
401 PGISCNPVQGAMYSFPRVQLPPRAVERAQELGLAPDMFFCLRLLEETGIC 450
230 ....SGFGQREGTYHFRMTILPPLEKLRLLLEKLSRFHAKFTLEYS 271
M MM MM M MM M I I I I M II M I I I I I I M I I M II
451 WPGSGFGQREGTYHFRMTILPPLEKLRLLLEKLSRFHAKFTLEYS 496
Sequence name: ALAT__HUMAN_V1
Sequence documentation:
Alignment of: R35137_PEA_1_PEA_1_PEA_1_P2 x ALAT_HUMAN_V1
Alignment segment 1/1:
Quality: 2619.00 Escore: 0 Matching length: 274 Total length: 274
Matching Percent Similarity: 100.00 Matching Percent Identity: 100.00
Total Percent Similarity: 100.00 Total Percent Identity: 100.00
Gaps : 0
Alignment:
1 MASSTGDRSQAVRHGLRAKVLTLDGMNPRVRRVEYAVRGPIVQRALELEQ 50
I I I I I I I I I I I I I I I I I I I Il Il I I I I I Il I Il I I I Il I I I Il I Il Il I I
1 MASSTGDRSQAVRHGLRAKVLTLDGMNPRVRRVEYAVRGPIVQRALELEQ 50
51 ELRQGVKKPFTEVIRANIGDAQAMGQRPITFLRQVLALCVNPDLLSSPNF 100 I I I I I I I I I I I I I I I I I I I I I I I I M M Il I I I I I M I I I I I I I I I I I I I
51 ELRQGVKKPFTEVIRANIGDAQAMGQRPITFLRQVLALCVNPDLLSSPNF 100
101 PDDAKKRAERILQACGGHSLGAYSVSSGIQLIREDVARYIERRDGGIPAD 150
I I I I I I I I I I I I I i I I I I I Il I I I I I I I I I I I I I I I I I I I I I I I I I I I I I
101 PDDAKKRAERILQACGGHSLGAYSVSSGIQLIREDVARYIERRDGGIPAD 150 . . . . .
151 PNNVFLSTGASDAIVTVLKLLVAGEGHTRTGVLIPIPQYPLYSATLAELG 200
M I I I I M I M I I I I I M I I M I H M M M I I M I I I M I I I I I I M M
151 PNNVFLSTGASDAIVTVLKLLVAGEGHTRTGVLIPIPQYPLYSATLAELG 200
201 AVQVDYYLDEERAWALDVAELHRALGQARDHCRPRALCVINPGNPTGQVQ 250 I M I M I Il Il M I I I I M Il I Il M M M Il M I I 1 M M Il I M I I M
201 AVQVDYYLDEERAWALDVAELHRALGQARDHCRPRALCVINPGNPTGQVQ 250
251 TRECIEAVIRFAFEERLFLLADEV 274 Il Il I I Il Il I I M I I Il Il I I M
251 TRECIEAVIRFAFEERLFLLADEV 274
Sequence name: ALAT_HUMAN_V1
Sequence documentation:
Alignment of: R35137_PEA_1_PEA_1_PEA_1_P4 x ALAT_HUMAN__V1
Alignment segment 1/1:
Quality: 4785.00 Escore: 0
Matching length: 494 Total length: 494 Matching Percent Similarity: 100.00 Matching Percent Identity: 100.00
Total Percent Similarity: 100.00 Total Percent Identity: 100.00
Gaps : 0
Alignment :
1 MASSTGDRSQAVRHGLRAKVLTLDGMNPRVRRVEYAVRGPIVQRALELEQ 50
1 MASSTGDRSQAVRHGLRAKVLTLDGMNPRVRRVEYAVRGPIVQRALELEQ 50
51 ELRQGVKKPFTEVIRANIGDAQAMGQRPITFLRQVLALCVNPDLLSSPNF 100 11111!11!!11111111111IMIIIIIIIIIMIIMIIIIIIIIIII
51 ELRQGVKKPFTEVIRANIGDAQAMGQRPITFLRQVLALCVNPDLLSSPNF 100 . . . . .
101 PDDAKKRAERILQACGGHSLGAYSVSSGIQLIREDVARYIERRDGGIPAD 150
I Il I I I I Il Il I M I M Il I M I I I Il I I I M Il M I I I Il I I I M I I I I
101 PDDAKKRAERILQACGGHSLGAYSVSSGIQLIREDVARYIERRDGGIPAD 150
151 PNNVFLSTGASDAIVTVLKLLVAGEGHTRTGVLIPIPQYPLYSATLAELG 200
M M I M I M M M I M M M M M M M M I M I I I M I I M I I M M I
151 PNNVFLSTGASDAIVTVLKLLVAGEGHTRTGVLIPIPQYPLYSATLAELG 200
201 AVQVDYYLDEERAWALDVAELHRALGQARDHCRPRALCVINPGNPTGQVQ 250 I I I M M I I M I I I M Il I Il Il I M I Il Il M I I M M Il Il I I I I M I
201 AVQVDYYLDEERAWALDVAELHRALGQARDHCRPRALCVINPGNPTGQVQ 250
251 TRECIEAVIRFAFEERLFLLADEVYQDNVYAAGSQFHSFKKVLMEMGPPY 300
I I I I I 1 I I I I I I I I I I Il I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I
251 TRECIEAVIRFAFEERLFLLADEVYQDNVYAAGSQFHSFKKVLMEMGPPY 300 . . . . .
301 AGQQELASFHSTSKGYMGECGFRGGYVEVVNMDAAVQQQMLKLMSVRLCP 350
I I I I I I I I I I I I I I I I I I I I I I I I Il I I Il I I I I I Il I Il I I 1 I I I I I I I
301 AGQQELASFHSTSKGYMGECGFRGGYVEVVNMDAAVQQQMLKLMSVRLCP 350
351 PVPGQALLDLVVSPPAPTDPSFAQFQAEKQAVLAELAAKAKLTEQVFNEA 400
I I I I 1 I I I I I I I I I I I I I I I Il I Il I I I I I I I 1 I I I I I I I I I I I I I I I I I
351 PVPGQALLDLVVSPPAPTDPSFAQFQAEKQAVLAELAAKAKLTEQVFNEA 400
401 PGISCNPVQGAMYSFPRVQLPPRAVERAQELGLAPDMFFCLRLLEETGIC 450 I I M I I M I I I I I I I I I I 1 I I I I I I I I I ] I I I I I I I I I I M I I I I I I I I I
401 PGISCNPVQGAMYSFPRVQLPPRAVERAQELGLAPDMFFCLRLLEETGIC 450
451 WPGSGFGQREGTYHFRMTILPPLEKLRLLLEKLSRFHAKFTLE 494
M I M I I I I I I M I I MI I I I I I M I I I I I I M I I I M M M I I 451 VVPGSGFGQREGTYHFRMTILPPLEKLRLLLEKLSRFHAKFTLE 494
DESCRIPTION FOR CLUSTER Z25299
Cluster Z25299 features 5 transcript(s) and 11 segment(s) of interest, the names for which are given in Tables 1040 and 1041, respectively, the sequences themselves are given at the end of the application. The selected protein variants are given in table 1042.
Table 1040 - Transcripts of interest
These sequences are variants of the known protein Antileukoproteinase 1 precursor (SwissProt accession identifier ALK1_HUMAN; known also according to the synonyms ALP; HUSI-I; Seminal proteinase inhibitor; Secretory leukocyte protease inhibitor; BLPI; Mucus proteinase inhibitor; MPI; WAP four- disulfide core domain protein 4; Protease inhibitor WAP4), SEQ ID NO: 1454, referred to herein as the previously known protein.
Protein Antileukoproteinase 1 precursor is known or believed to have the following functions): Acid- stable proteinase inhibitor with strong affinities for trypsin, chymo trypsin, elastase, and cathepsin G. May prevent elastase- mediated damage to oral and possibly other mucosal tissues. The sequence for protein Antileukoproteinase 1 precursor is given at the end of the application, as "Antileukoproteinase 1 precursor amino acid sequence". Protein Antileukoproteinase 1 precursor localization is believed to be Secreted.
It has been investigated for clinical/therapeutic use in humans, for example as a target for an antibody or small molecule, and/or as a direct therapeutic; available information related to these investigations is as follows. Potential pharmaceutically related or therapeutically related activity or activities of the previously known protein are as follows: Elastase inhibitor; Tryptase inhibitor. A therapeutic role for a protein represented by the cluster has been predicted. The cluster was assigned this field because there was information in the drug database or the public databases (e.g., described herein above) that this protein, or part thereof, is used or can be used for a potential therapeutic indication: Anti- inflammatory; Antiasthma. The following GO Annotation(s) apply to the previously known protein. The following annotation(s) were found: proteinase inhibitor; serine protease inhibitor, which are annotation(s) related to Molecular Function.
The GO assignment relies on information from one or more of the SwissProt/TremBl Protein knowledgebase, available from <http://www.expasy.ch/sprot/>; or Locuslink, available from <http://www.ncbi.nhn.nih.gov/projects/LocusLink/>.
Cluster Z25299 can be used as a diagnostic marker according to overexpression of transcripts of this cluster in cancer. Expression of such transcripts in normal tissues is also given according to the previously described methods. The term "number" in the right hand column of the table and the numbers on the y-axis of figure 35 refer to weighted expression of ESTs in each category, as "parts per million" (ratio of the expression of ESTs for a particular cluster to the expression of all ESTs in that category, according to parts per million).
Overall, the following results were obtained as shown with regard to the histograms in Figure 35 and Table 1043. This cluster is overexpressed (at least at a minimum level) in the
following pathological conditions: brain malignant tumors, a mixture of malignant tumors from different tissues and ovarian carcinoma.
Table 1043 - Normal tissue distribution
Table 1044 - P values and ratios for expression in cancerous tissue
As noted above, cluster Z25299 features 5 transcript(s), which were listed in Table 1 above. These transcript(s) encode for protein(s) which are variant(s) of protein Antileukoproteinase 1 precursor. A description of each variant protein according to the present invention is now provided.
Variant protein Z25299_PEA_2_P2 according to the present invention has an amino acid sequence as given at the end of the application; it is encoded by trarBcript(s) Z25299_PEA_2_T1. An alignment is given to the known protein (Antileukoproteinase 1 precursor) at the end of the application. One or more alignments to one or more previously published protein sequences are given at the end of the application. A brief description of the relationship of the variant protein according to the present invention to each such aligned protein is as follows:
Comparison report between Z25299_PEA_2_P2 and ALK1_HUMAN: 1.An isolated chimeric polypeptide encoding for Z25299_PEA_2_P2, comprising a first amino acid sequence being at least 90 % homologous to
MKSSGLFPFLVLLALGTLAPWAVEGSGKSFKAGVCPPKKSAQCLRYKKPECQSDWQCP GKKRCCPDTCGIKCLDPVDTP]SnPTRRKPGKCPVTYGQCL]Vn^ISIPPNFCEMDGQCICRDLK CCMGMCGKSCVSPVK corresponding to amino acids 1 - 131 of ALK1JHUMAN, which also
corresponds to amino acids 1 - 131 of Z25299_PEA_2_P2, and a second amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence GKQGMRAH corresponding to amino acids 132 - 139 of Z25299_PEA_2_P2, wherein said first and second amino acid sequences are contiguous and in a sequential order.
2.An isolated polypeptide encoding for a tail of Z25299_PEA_2_P2, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence GKQGMRAH in Z25299_PEA_2_P2.
The location of the variant protein was determined according to results from a number of different software programs and analyses, including analyses from SignalP and other specialized programs. The variant protein is believed to be located as follows with regard to the cell: secreted. The protein localization is believed to be secreted because both signal-peptide prediction programs predict that this protein has a signal peptide, and neither trans -membrane region prediction program predicts that this protein has a trans -membrane region..
Variant protein Z25299_PEA_2_P2 also has the following non-silent SNPs (Single Nucleotide Polymorphisms) as listed in Table 1045, (given according to their position(s) on the amino acid sequence, with the alternative amino acid(s) listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein Z25299_PEA_2_P2 sequence provides support for the deduced sequence of this variant protein according to the present invention).
TablelO45 -Amino acid mutations
Variant protein Z25299_PEA_2_P2 is encoded by the following transcript(s): Z25299_PEA_2_T1, for which the sequence(s) is/are given at the end of the application. The coding portion of transcript Z25299_PEA_2_T1 is shown in bold; this coding portion starts at position 124 and ends at position 540. The transcript also has the following SNPs as listed in Table 1046 (given according to their position on the nucleotide sequence, with the alternative nucleic acid listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein Z25299_PEA_2_P2 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 1046 - Nucleic acid SNPs
Variant protein Z25299_PEA_2_P3 according to the present invention has an amino acid sequence as given at the end of the application; it is encoded by transcript(s) Z25299_PEA_2_T2. An alignment is given to the known protein (Antileukoproteinase 1 precursor) at the end of the application. One or more alignments to one or more previously published protein sequences are given at the end of the application. A brief description of the relationship of the variant protein according to the present invention to each such aligned protein is as follows: Comparison report between Z25299_PEA_2_P3 and ALKl JHUMAN:
1.An isolated chimeric polypeptide encoding for Z25299_PEA_2_P3, comprising a first amino acid sequence being at least 90 % homologous to
MKSSGLFPFLVLLALGTLAPWAVEGSGKSFKAGVCPPKKSAQCLRYKKPECQSDWQCP GKKRCCPDTCGIKCLDPVDTPNPTRRKPGKCPVTYGQCLMLNPPNFCEMDGQCKRDLK CCMGMCGKSCVSPVK corresponding to amino acids 1 - 131 of ALK1_HUMAN, which also corresponds to amino acids 1 - 131 of Z25299_PEA_2_P3, and a second amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence GEKRHHKQLRDQEVDPLEMRRHSAG corresponding to amino acids 132 - 156 of Z25299_PEA_2_P3, wherein said first and second amino acid sequences are contiguous and in a sequential order.
2.An isolated polypeptide encoding for a tail of Z25299_PEA_2_P3, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence GEKRHHKQLRDQEVDPLEMRRHSAG in Z25299_PEA_2_P3.
The location of the variant protein was determined according to results from a number of different software programs and analyses, including analyses from SignalP and other specialized programs. The variant protein is believed to be located as follows with regard to the cell: secreted. The protein localization is believed to be secreted because both signatpeptide
prediction programs predict that this protein has a signal peptide, and neither trans -membrane region prediction program predicts that this protein has a trans -membrane region..
Variant protein Z25299_PEA_2_P3 also has the following non-silent SNPs (Single Nucleotide Polymorphisms) as listed in Table 1047, (given according to their position(s) on the amino acid sequence, with the alternative amino acid(s) listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein Z25299_PEA_2_P3 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 1047 - Amino acid mutations
Variant protein Z25299JPEA_2_P3 is encoded by the following transcript(s): Z25299_PEA_2_T2, for which the sequence(s) is/are given at the end of the application. The coding portion of transcript Z25299_PEA_2JT2 is shown in bold; this coding portion starts at position 124 and ends at position 591. The transcript also has the following SNPs as listed in Table 1048 (given according to their position on the nucleotide sequence, with the alternative nucleic acid listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein Z25299_PEA_2_P3 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 1048 - Nucleic acid SNPs
Variant protein Z25299_PEA_2_P7 according to the present invention has an amino acid sequence as given at the end of the application; it is encoded by transcript(s) Z25299_PEA_2_T6. An alignment is given to the known protein (Antileukoproteinase 1 precursor) at the end of the application. One or more alignments to one or more previously published protein sequences are given at the end of the application. A brief description of the relationship of the variant protein according to the present invention to each such aligned protein is as follows: Comparison report between Z25299_PEA_2_P7 and ALK1_HUMAN:
1.An isolated chimeric polypeptide encoding for Z25299_PEA_2JP7, comprising a first amino acid sequence being at least 90 % homologous to
MKSSGLFPFLVLLALGTLAPWAVEGSGKSFKAGVCPPKKSAQCLRYKKPECQSDWQCP GKKRCCPDTCGIKCLDPVDTPNP corresponding to amino acids 1 - 81 OfALKl-HUMAN, which also corresponds to amino acids 1 - 81 of Z25299_PEA_2_P7, and a second amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence RGSLGSAQ corresponding to amino acids 82 - 89 of Z25299JPEA_2_P7, wherein said first and second amino acid sequences are contiguous and in a sequential order. 2.An isolated polypeptide encoding for a tail of Z25299JPEA_2JP7, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%,
more preferably at least about 90% and most preferably at least about 95% homologous to the sequence RGSLGSAQ in Z25299_PEA_2_P7.
The location of the variant protein was determined according to results from a number of different software programs and analyses, including analyses from SignalP and other specialized programs. The variant protein is believed to be located as follows with regard to the cell: secreted. The protein localization is believed to be secreted because both signal-peptide prediction programs predict that this protein has a signal peptide, and neither trans- membrane region prediction program predicts that this protein has a trans -membrane region..
Variant protein Z25299_PEA_2_P7 also has the following non- silent SNPs (Single Nucleotide Polymorphisms) as listed in Table 1049, (given according to their position(s) on the amino acid sequence, with the alternative amino acid(s) listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein Z25299_PEA_2_P7 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 1049 - Amino acid mutations
Variant protein Z25299_PEA_2_P7 is encoded by the following transcript(s): Z25299_PEA_2_T6, for which the sequence(s) is/are given at the end of the application. The coding portion of transcript Z25299_PEA_2_T6 is shown in bold; this coding portion starts at position 124 and ends at position 390. The transcript also has the following SNPs as listed in Table 1050 (given according to their position on the nucleotide sequence, with the alternative nucleic acid listed; the last column indicates whether the SNP is known or not; the presence of
known SNPs in variant protein Z25299JPEA_2_P7 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 1050 - Nucleic acid SNPs
Variant protein Z25299_PEA_2_P10 according to the present invention has an amino acid sequence as given at the end of the application; it is encoded by transcript(s) Z25299_PEA_2_T9. An alignment is given to the known protein (Antileukoproteinase 1 precursor) at the end of the application. One or more alignments to one or more previously published protein sequences are given at the end of the application. A brief description of the relationship of the variant protein according to the present invention to each such aligned protein is as follows:
Comparison report between Z25299_PEA_2_P10 and ALK1_HUMAN:
1.An isolated chimeric polypeptide encoding for Z25299_PEA_2_P10, comprising a first amino acid sequence being at least 90 % homologous to
MKSSGLFPFLVLLALGTLAPWAVEGSGKSFKAGVCPPKKSAQCLRYKKPECQSDWQCP GKKRCCPDTCGIKCLDPVDTPNPT corresponding to amino acids 1 - 82 of ALK1_HUMAN, which also corresponds to amino acids 1 - 82 of Z25299_PEA_2_P10.
The location of the variant protein was deteπnined according to results from a number of different software programs and analyses, including analyses from SignalP and other specialized programs. The variant protein is believed to be located as follows with regard to the cell: secreted. The protein localization is believed to be secreted because both signal-peptide prediction programs predict that this protein has a signal peptide, and neither trans -membrane region prediction program predicts that this protein has a trans- membrane region..
Variant protein Z25299_PEA_2_P10 also has the following non- silent SNPs (Single Nucleotide Polymorphisms) as listed in Table 1051, (given according to their position(s) on the amino acid sequence, with the alternative amino acid(s) listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein Z25299_PEA_2_P10 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 1051 - Amino acid mutations
Variant protein Z25299_PEA_2_P10 is encoded by the following transcript(s): Z25299_PEA_2_T9, for which the sequence(s) is/are given at the end of the application. The coding portion of transcript Z25299_PEA__2_T9 is shown in bold; this coding portion starts at position 124 and ends at position 369. The transcript also has the following SNPs as listed in Table 1052 (given according to their position on the nucleotide sequence, with the alternative
nucleic acid listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein Z25299_PEA_2_P10 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 1052 - Nucleic acid SNPs
As noted above, cluster Z25299 features 11 segment(s), which were listed in Table 2 above and for which the sequence(s) are given at the end of the application. These segment(s) are portions of nucleic acid sequence(s) which are described herein separately because they are of particular interest. A description of each segment according to the present invention is now provided.
Segment cluster Z25299_PEA_2_node_20 according to the present invention is supported by 6 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): Z25299_PEA_2_T1. Table 1053 below describes the starting and ending position of this segment on each transcript.
Table 1053 - Segment location on transcripts
Segment cluster Z25299_PEA_2_node_21 according to the present invention is supported by 162 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): Z25299_PEA_2_T1, Z25299_PEA_2_T6 and Z25299_PEA_2_T9. Table 1054 below describes the starting and ending position of this segment on each transcript.
Table 1054 - Segment location on transcripts
Segment cluster Z25299_PEA_2_node_23 according to the present invention is supported by 2 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): Z25299_PEA_2_T2. Table 1055 below describes the starting and ending position of this segment on each transcript.
Table 1055 - Segment location on transcripts
Segment cluster Z25299_PEA_2_node_24 according to the present invention is supported by 2 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): Z25299_PEA_2_T2 and Z25299_PEA_2_T3. Table 1056 below describes the starting and ending position of this segment on each transcript.
Table 1056 - Segment location on transcripts
Segment cluster Z25299_PEA_2_node_8 according to the present invention is supported by 218 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): Z25299_PEA_2_T1, Z25299_PEA_2_T2, Z25299_PEA_2_T3, Z25299_PEA_2_T6 and Z25299_PEA_2_T9. Table 1057 below describes the starting and ending position of this segment on each transcript.
Table 1057 - Segment location on transcripts
According to an optional embodiment of the present invention, short segments related to the above cluster are also provided. These segments are up to about 120 bp in length, and so are included in a separate description.
Segment cluster Z25299_PEA_2_node_12 according to the present invention is supported by 228 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): Z25299_PEA_2_T1, Z25299_PEA_2_T2, Z25299_PEA_2_T3, Z25299_PEA_2_T6 and Z25299_PEA_2_T9. Table 1058 below describes the starting and ending position of this segment on each transcript. Table 1058 - Segment location on transcripts
Segment cluster Z25299_PEA_2_node_l 3 according to the present invention is supported by 246 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): Z25299_PEA_2_T1, Z25299_PEA_2_T2, Z25299_PEA_2_T3, Z25299_PEA_2_T6 and Z25299_PEA_2_T9. Table 1059 below describes the starting and ending position of this segment on each transcript.
Table 1059 - Segment location on transcripts
Segment cluster Z25299JPEA_2_node_14 according to the present invention can be found in the following transcript(s): Z25299_PEA_2_T1, Z25299_PEA_2_T2, Z25299_PEA_2_T3, Z25299_PEA_2_T6 and Z25299_PEA_2_T9. Table 1060 below describes the starting and ending position of this segment on each transcript.
Table 1060 - Segment location on transcripts
Segment cluster Z25299_PEA__2_node_17 according to the present invention can be found in the following transcript(s): Z25299__PEA__2_T1, Z25299_PEA_2_T2 and Z25299_PEA__2_T3. Table 1061 below describes the starting and ending position of this segment on each transcript.
Table 1061 - Segment location on transcripts
Segment cluster Z25299_PEA_2_node_18 according to the present invention is supported by 221 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): Z25299_PEA_2_T1, Z25299_PEA_2_T2, Z25299_PEA_2_T3 and Z25299_PEA_2_T6. Table 1062 below describes the starting and ending position of this segment on each transcript. Table 1062 - Segment location on transcripts
Segment cluster Z25299_PEA_2_node_19 according to the present invention is supported by 197 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): Z25299_PEA_2_T1, Z25299_PEA_2_T2, Z25299_PEA_2_T3 and Z25299_PEA_2_T6. Table 1063 below describes the starting and ending position of this segment on each transcript.
Table 1063 - Segment location on transcripts
Variant protein alignment to the previously known protein:
Sequence name: /tmp/oXgeQ4MeyL/K6VqblMQu2 :ALK1_HUMAN
Sequence documentation:
Alignment of: Z25299_PEA_2_P2 x ALK1_HUMAN
Alignment segment 1/1:
Quality: 1371.00 Escore: 0
Matching length: 131 Total length: 131
Matching Percent Similarity: 100.00 Matching Percent Identity: 100.00
Total Percent Similarity: 100.00 Total Percent Identity: 100.00 Gaps : 0
Alignment :
1 MKSSGLFPFLVLLALGTLAPWAVEGSGKSFKAGVCPPKKSAQCLRYKKPE 50 I I I I M I ! I I I I I M I I M I I I I I I I I I I I I I ] I I I M I I I I I I I I I I I I
1 MKSSGLFPFLVLLALGTLAPWAVEGSGKSFKAGVCPPKKSAQCLRYKKPE 50
51 CQSDWQCPGKKRCCPDTCGIKCLDPVDTPNPTRRKPGKCPVTYGQCLMLN 100 I Il I I I I I Il I I I I I I I I I i Il I I Il I I I I I I Il I I I I I I Il I II I I I I I 51 CQSDWQCPGKKRCCPDTCGIKCLDPVDTPNPTRRKPGKCPVTYGQCLMLN 100
101 PPNFCEMDGQCKRDLKCCMGMCGKSCVSPVK 131
I M I I I I I M I I I I M I M I M M I M I M I
101 PPNFCEMDGQCKRDLKCCMGMCGKSCVSPVK 131
Sequence name: /tmp/rbf314VLIm/yR43i4SbP4 :ALK1_HUMAN
Sequence documentation:
Alignment of: Z25299_PEA_2_P3 x ALK1_HUMAN
Alignment segment 1/1:
Quality: 1371.00 Escore: 0 Matching length: 131 Total length: 131
Matching Percent Similarity: 100.00 Matching Percent Identity: 100.00
Total Percent Similarity: 100.00 Total Percent Identity: 100.00
Gaps : 0
Alignment :
1 MKSSGLFPFLVLLALGTLAPWAVEGSGKSFKAGVCPPKKSAQCLRYKKPE 50
I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I Il I I I
1 MKSSGLFPFLVLLALGTLAPWAVEGSGKSFKAGVCPPKKSAQCLRYKKPE 50
51 CQSDWQCPGKKRCCPDTCGIKCLDPVDTPNPTRRKPGKCPVTYGQCLMLN 100 I I I I M I I I I M I I I M I I I I M I I I I Il I M M I I I I I M 1 I M 1 I ] I I
51 CQSDWQCPGKKRCCPDTCGIKCLDPVDTPNPTRRKPGKCPVTYGQCLMLN 100
101 PPNFCEMDGQCKRDLKCCMGMCGKSCVSPVK 131
II Il Il I I I I I I I I I I Il Il I I I Il I Il I I I 101 PPNFCEMDGQCKRDLKCCMGMCGKSCVSPVK 131
Sequence name: /tmp/KCtSXACZXe/rK4T6LKeRX :ALKl_HUMAN
Sequence documentation:
Alignment of: Z25299_PEA_2_P7 x ALK1_HUMAN
Alignment segment 1/1:
Quality: 835.00 Escore: 0
Matching length: 81 Total length: 81
Matching Percent Similarity: 100.00 Matching Percent Identity: 100.00 Total Percent Similarity: 100.00 Total Percent Identity: 100.00
Gaps : 0
Alignment: . . . . .
1 MKSSGLFPFLVLLALGTLAPWAVEGSGKSFKAGVCPPKKSAQCLRYKKPE 50
I I I I I I I I I I I I I Il I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I Il I I
1 MKSSGLFPFLVLLALGTLAPWAVEGSGKSFKAGVCPPKKSAQCLRYKKPE 50
51 CQSDWQCPGKKRCCPDTCGIKCLDPVDTPNP 81
I I I I Il I I I Il I I Il I I I Il I I I i I I Il I Il 51 CQSDWQCPGKKRCCPDTCGIKCLDPVDTPNP 81
Sequence name: /tmp/LcBlcAxB6c/NSI9pqfxoU:ALK1_HUMAN
Sequence documentation:
Alignment of: Z25299_PEA_2_P10 x ALK1_HUMAN
Alignment segment 1/1:
Quality: 844.00 Escore: 0
Matching length: 82 Total length: 82 Matching Percent Similarity: 100.00 Matching Percent Identity: 100.00
Total Percent Similarity: 100.00 Total Percent Identity: 100.00
Gaps : 0
Alignment:
1 MKSSGLFPFLVLLALGTLAPWAVΕGSGKSFKAGVCPPKKSAQCLRYKKPE 50
Il Il I I Il I I Il I I I I I Il Il I I I I I I Il I I I I I I I I I I Il I I Il Il I I I 1 MKSSGLFPFLVLLALGTLAPWAVEGSGKSFKAGVCPPKKSAQCLRYKKPE 50
51 CQSDWQCPGKKRCCPDTCGIKCLDPVDTPNPT 82
I I I I I I I I Il I Il I I I I I Il I I Il I I Il I I I I
51 CQSDWQCPGKKRCCPDTCGIKCLDPVDTPNPT 82
Expression of Secretory leukocyte protease inhibitor Acid-stable proteinase inhibitor Z25299 transcripts, which are detectable by amplicon as depicted in sequence name Z25299 juncl3-14-
21 in normal and cancerous lung tissues
Expression of Secretory leukocyte protease inhibitor Acid-stable proteinase inhibitor transcripts detectable by or according to juncl3-14-21, Z25299 juncl3- 14-21 amplicon (SEQ ID NO: 1666) and Z25299 juncl3-14-21F (SEQ ID NO: 1664) and Z25299 juncl3-14-21R (SEQ ID NO: 1665) primers was measured by real time PCR. In parallel the expression of four housekeeping genes -PBGD (GenBank Accession No. BCO 19323; amplicon - PBGD- amplicon, SEQ ID NO:334), HPRTl (GenBank Accession No. NM_000194; amplicon - HPRTl- amplicon, SEQ ID NO: 1297), Ubiquitin (GenBank Accession No. BC000449; amplicon - Ubiquitin-amplicon, SEQ ID NO:328) and SDHA (GenBank Accession No. NM 004168; amplicon - SDHA- amplicon, SEQ ID NO:331) was measured similarly. For each RT sample, the expression of the above amplicon was normalized to the geometric mean of the quantities of the housekeeping genes. The normalized quantity of each RT sample was then divided by the median of the quantities of the normal post-mortem (PM) samples (Sample Nos. 47-50, 90-93, 96-99, Table 2 "Tissue sample in testing panel", above), to obtain a value of fold differential expression for each sample relative to median of the normal PM samples.
Figure 36 is a histogram showing down regulation of the above -indicated Secretory leukocyte protease inhibitor Acid- stable proteinase inhibitor transcripts in cancerous lung samples relative to the noπnal samples.
As is evident from Figure 36, the expression of Secretory leukocyte protease inhibitor Acid- stable proteinase inhibitor transcripts detectable by the above amplicon(s) in cancer samples was significantly lower than in the non-cancerous samples (Sample Nos. 47-50, 90-93, 96-99 Table 2, "Tissue sample in testing panel" ). Statistical analysis was applied to verify the significance of these results, as described below.
The P value for the difference in the expression levels of Secretory leukocyte protease inhibitor Acid-stable proteinase inhibitor transcripts detectable by the above amplicon(s) in lung cancer samples versus the normal tissue samples was determined by T test as 1.98E-04. This value demonstrates statistical significance of the results.
Primer pairs are also optionally and preferably encompassed within the present invention; for example, for the above experiment, the following primer pair was used as a non- limiting illustrative example only of a suitable primer pair: Z25299 juncl3-14-21F forward primer; and Z25299 juncl3-14-21R reverse primer. The present invention also preferably encompasses any amplicon obtained through the use of any suitable primer pair; for example, for the above experiment, the following amplicon was obtained as a non- limiting illustrative example only of a suitable amplicon: Z25299 June 13- 14-21.
Forward primer (SEQ ID NO: 1664): ACCCCAAACCCAACTTGATTC Reverse primer (SEQ ID NO: 1665): TCAGTGGTGGAGCCAAGTCTC Amplicon (SEQ ID NO: 1666):
ACCCCAAACCCAACTTGATTCCTGCCATATGGAGGAGGCTCTGGAGTCCTGCTCTGT GTGGTCCAGGTCCTTTCCACCCTGAGACTTGGCTCCACCACTGA
Z25299 transcripts, which are detectable by amplicon as depicted in sequence name Z25299 seg20 in normal and cancerous lung tissues
Expression of Secretory leukocyte protease inhibitor Acid-stable proteinase inhibitor transcripts detectable by or according to seg20, Z25299 seg20 amplicon (SEQ ID NO: 1669) and Z25299 seg20F (SEQ ID NO: 1667) and Z25299 seg20R (SEQ ID NO: 1668) primers was measured by real time PCR. In parallel the expression of four housekeeping genes -PBGD (GenBank Accession No. BC019323; amplicon - PBGD-amplicon, SEQ ID NO:334), HPRTl (GenBank Accession No. NM_000194; amplicon - HPRTl -amplicon, SEQ ID NO: 1297), Ubiquitin (GenBank Accession No. BC000449; amplicon - Ubiquitin-amplicon, SEQ ID NO:328) and SDHA (GenBank Accession No. NM_004168; amplicon - SDHA-amplicon, SEQ ID NO:331) was measured similarly. For each RT sample, the expression of the above amplicon was normalized to the geometric mean of the quantities of the housekeeping genes. The normalized quantity of each RT sample was then divided by the median of the quantities of the normal post-mortem (PM) samples (Sample Nos. 47-50, 90-93, 96-99, Table 2, "Tissue samples in testing panel", above). Then the reciprocal of this ratio was calculated, to obtain a value of fold down- regulation for each sample relative to median of the normal PM samples.
Figure 37 is a histogram showing down regulation of the above- indicated Secretory leukocyte protease inhibitor Acid- stable proteinase inhibitor transcripts in cancerous lung samples relative to the normal samples. The number and percentage of samples that exhibit at least 5 fold down regulation, out of the total number of samples tested is indicated in the bottom. As is evident from Figure 37, the expression of Secretory leukocyte protease inhibitor
Acid-stable proteinase inhibitor transcripts detectable by the above amplicon(s) in cancer samples was significantly lower than in the non-cancerous samples (Sample Nos. 47-50, 90-93, 96-99 Table 2, "Tissue sample in testing panel"). Notably an down regulation of at least 5 fold was found in 6 out of 15 adenocarcinoma samples, 9 out of 16 squamous cell carcinoma samples, 3 out of 4 large cell carcinoma samples and in 8 out of 8 small cell carcinoma samples.
Statistical analysis was applied to verify the significance of these results, as described below.
The P value for the difference in the expression levels of Secretory leukocyte protease inhibitor Acid-stable proteinase inhibitor transcripts detectable by the above amplicon(s) in lung cancer samples versus the normal tissue samples was determined by T test as 9.43 E-02 in adenocarcinoma, 5.62E-02 in squamous cell carcinoma, 3.38E-01 in large cell carcinoma and 3.78E-02 in small cell carcinoma.
Threshold of 5 fold down regulation was found to differentiate between cancer and normal samples with P value of 3.73E-02 in adenocarcinoma, 1.10E-02 in squamous cell carcinoma, 2.64E-02 in large cell carcinoma and 7.14E-05 in small cell carcinoma checked by exact fisher test. The above values demonstrate statistical significance of the results.
Primer pairs are also optionally and preferably encompassed within the present invention; for example, for the above experiment, the following primer pair was used as a non- limiting illustrative example only of a suitable primer pair: Z25299 seg20F forward primer; and Z25299 seg20R reverse primer. The present invention also preferably encompasses any amplicon obtained through the use of any suitable primer pair; for example, for the above experiment, the following amplicon was obtained as a non- limiting illustrative example only of a suitable amplicon: Z25299 seg20. Forward primer (SEQ ID NO: 1667): CTCCTGAACCCTACTCCAAGCA Reverse primer (SEQ ID NO: 1668): CAGGCGATCCTATGGAAATCC Amplicon (SEQ ID NO: 1669) :
CTCCTGAACCCTACTCCAAGCACAGCCTCTGTCTGACTCCCTTGTCCTTCAAGAGAA
CTGTTCTCCAGGTCTCAGGGCCAGGATTTCCATAGGATCGCCTG
Expression o/Homo sapiens secretory leukocyte protease inhibitor (antileukoproteinase) (SLPI)
Z25299 transcripts which are detectable by amplicon as depicted in sequence name Z25299 seg23 in normal and cancerous lung tissues
Expression of Homo sapiens secretory leukocyte protease inhibitor (antileukoproteinase) (SLPI) transcripts detectable by or according to seg23, Z25299 seg23 amplicon (SEQ ID NO: 1672) and primers Z25299 seg23F (SEQ ID NO: 1670) and Z25299 seg23R (SEQ ID NO: 1671) was measured by real time PCR. In parallel the expression of four housekeeping genes -PBGD (GenBank Accession No. BC019323; amplicon - PBGD-amplicon, SEQ ID NO:334), HPRTl (GenBank Accession No. NM_000194; amplicon - HPRTl -amplicon, SEQ ID NO:1297), Ubiquitin (GenBank Accession No. BC000449; amplicon - Ubiquitin- amplicon, SEQ ID NO:328) and SDHA (GenBank Accession No. NM_004168; amplicon - SDHA-amplicon, SEQ ID NO:331), was measured similarly. For each RT sample, the expression of the above amplicon was normalized to the geometric mean of the quantities of the housekeeping genes. The normalized quantity of each RT sample was then divided by the median of the quantities of the normal post-mortem (PM) samples (Sample Nos. 47-50, 90-93, 96-99, Table 2, above). Then the reciprocal of this ratio was calculated, to obtain a value of fold down-regulation for each sample relative to median of the normal PM samples.
Figure 68 is a histogram showing down regulation of the above- indicated Homo sapiens secretory leukocyte protease inhibitor (antileukoproteinase) (SLPI) transcripts in cancerous lung samples relative to the normal samples.
As is evident from Figure 68, the expression of Homo sapiens secretory leukocyte protease inhibitor (antileukoproteinase) (SLPI) transcripts detectable by the above amplicon(s) in cancer samples was significantly lower than in the non-cancerous samples (Sample Nos. 46- 50, 90-93, 96-99 Table 2). Notably down regulation of at least 10 fold was found in 7 out of 15 adenocarcinoma samples, 9 out of 16 squamous cell carcinoma samples, 3 out of 4 large cell carcinoma samples and in 8 out of 8 small cells carcinoma samples.
Primer pairs are also optionally and preferably encompassed within the present invention; for example, for the above experiment, the following primer pair was used as a non- limiting illustrative example only of a suitable primer pair: Z25299 seg23F forward primer; and Z25299 seg23R reverse primer.
The present invention also preferably encompasses any amplicon obtained through the use of any suitable primer pair; for example, for the above experiment, the following amplicon was obtained as a non- limiting illustrative example only of a suitable amplicon: Z25299 seg23.
Primers:
Forward primer Z25299 seg23F (SEQ ID NO: 1670): CAAGCAATTGAGGGACCAGG Reverse primer Z25299 seg23R (SEQ ID NO: 1671): CAAAAAACATTGTTAATGAGAGAGATGAC
Amplicon Z25299 seg23F (SEQ ID NO: 1672): CAAGCAATTGAGGGACCAGGAAGTGGATCCTCTAGAGATGAGGAGGCATTCTGCTG GATGACTTTTAAAAATGTTTTCTCCAGAGTCATCTCTCTCATTAACAATGTTTTTTG
Expression of Secretory leukocyte protease inhibitor Acid-stable proteinase inhibitor Z25299 transcripts which are detectable by amplicon as depicted in sequence name Z25299seg20 in different normal tissues
Expression of Secretory leukocyte protease inhibitor transcripts detectable by or according to Z25299seg20 amplicon (SEQ ID NO: 1669) and primers: Z25299seg23F (SEQ ID NO: 1667) Z25299seg20R (SEQ ID NO: 1668) was measured by real time PCR. In parallel the expression of four housekeeping genes -RPLl 9 (GenBank Accession No. NM_000981; RPLl 9 amplicon, SEQ ID NO: 1630), TATA box (GenBank Accession No. NM_003194; TATA amplicon, SEQ ID NO: 1633), Ubiquitin (GenBank Accession No. BC000449; amplicon - Ubiquitin- amplicon, SEQ ID NO:328) and SDHA (GenBank Accession No. NM_004168; amplicon - SDHA- amplicon, SEQ ID NO:331) was measured similarly. For each RT sample, the expression of the above amplicon was normalized to the geometric mean of the quantities of the housekeeping genes. The normalized quantity of each RT sample was then divided by the median of the quantities of the ovary samples (Sample Nos. 18-20, Table 3), to obtain a value of relative expression of each sample relative to median of the ovary samples.
Primers: Forward primer (SEQ ID NO: 1667): CTCCTGAACCCTACTCCAAGCA
Reverse primer (SEQ ID NO: 1668): CAGGCGATCCTATGGAAATCC Amplicon (SEQ ID NO: 1669):
CTCCTGAACCCTACTCCAAGCACAGCCTCTGTCTGACTCCCTTGTCCTTCAAGAGAA CTGTTCTCCAGGTCTCAGGGCCAGGATTTCCATAGGATCGCCTG
The results are demonstrated in Figure 69, showing the expression of Secretory leukocyte protease inhibitor Acid-stable proteinase inhibitor Z25299 transcripts which are detectable by amplicon as depicted in sequence name Z25299seg20 in different normal tissues.
Expression of Secretory leukocyte protease inhibitor Z25299 transcripts which are detectable by amplicon as depicted in sequence name Z25299seg23 in different normal tissues
Expression of Secretory leukocyte protease inhibitor transcripts detectable by or according to Z25299seg23 amplicon (SEQ ID NO: 1672) and primers: Z25299seg23F (SEQ ID NO: 1670) Z25299seg23R (SEQ ID NO: 1671) was measured by real time PCR. In parallel the expression of four housekeeping genes -RPL19 (GenBank Accession No. NM 000981; RPL19 amplicon, SEQ ID NO: 1630), TATA box (GenBank Accession No. NM_003194; TATA amplicon, SEQ ID NO: 1633), Ubiquitin (GenBank Accession No. BC000449; amplicon - Ubiquitin-amplicon, SEQ ID NO:328) and SDHA (GenBank Accession No. NM_004168; amplicon - SDHA- amplicon, SEQ ID NO:331) was measured similarly. For each RT sample, the expression of the above amplicon was normalized to the geometric mean of the quantities of the housekeeping genes. The normalized quantity of each RT sample was then divided by the median of the quantities of the ovary samples (Sample Nos. 18-20, Table 3), to obtain a value of relative expression of each sample relative to median of the ovary samples.
Primers: Forward primer Z25299 seg23F (SEQ ID NO: 1670): CAAGCAATTGAGGGACCAGG
Reverse primer Z25299 seg23R (SEQ ID NO: 1671):
CAAAAAACATTGTTAATGAGAGAGATGAC
Amplicon Z25299 seg23F (SEQ ID NO: 1672):
CAAGCAATTGAGGGACCAGGAAGTGGATCCTCTAGAGATGAGGAGGCATTCTGCTG GATGACTTTTAAAAATGTTTTCTCCAGAGTCATCTCTCTCATTAACAATGTTTTTTG
The results are demonstrated in Figure 70, showing the expression of Secretory leukocyte protease inhibitor Acid-stable proteinase inhibitor Z25299 transcripts which are detectable by amplicon as depicted in sequence name Z25299seg23 in different normal tissues.
DESCRIPTION FOR CLUSTER HSSTROL3
Cluster HSSTROL3 features 6 transcript(s) and 16 segment(s) of interest, the names for which are given in Tables 1064 and 1065, respectively, the sequences themselves are given at the end of the application. The selected protein variants are given in table 1066.
Table 1064 - Transcripts of interest
Table 1066 - Proteins of interest
These sequences are variants of the known protein Stromelysin-3 precursor (SwissProt accession identifier MM11_HUMAN; known also according to the synonyms EC 3.4.24.-; Matrix metalloproteinase-11; MMP-11; ST3; SL-3), SEQ ID NO: 1455, referred to herein as the previously known protein.
Protein Stromelysin-3 precursor is known or believed to have the following function(s): May play an important role in the progression of epithelial malignancies. The sequence for protein Stromelysin-3 precursor is given at the end of the application, as "Stromelysin-3 precursor amino acid sequence".
The following GO Annotation(s) apply to the previously known protein. The following annotation(s) were found: proteolysis and peptidolysis; developmental processes; morphogenesis, which are annotation(s) related to Biological Process; stromelysin 3; calcium binding; zinc binding; hydrolase, which are annotation(s) related to Molecular Function; and extracellular matrix, which are annotation(s) related to Cellular Component.
The GO assignment relies on information from one or more of the SwissProt/TremBl Protein knowledgebase, available from <http://www.expasy.ch/sprot/>; or Locuslink, available from <http://www.ncbi.nhn.nih.gov/projects/LocusLink/>.
Cluster HSSTROL3 can be used as a diagnostic marker according to overexpression of transcripts of this cluster in cancer. Expression of such transcripts in normal tissues is also given according to the previously described methods. The term "number" in the left hand column of the table and the numbers on the y-axis of figure 38 refer to weighted expression of ESTs in each category, as "parts per million" (ratio of the expression of ESTs for a particular cluster to the expression of all ESTs in that category, according to parts per million).
Overall, the following results were obtained as shown with regard to the histograms in Figure 38 and Table 1067. This cluster is overexpressed (at least at a minimum level) in the following pathological conditions: transitional cell carcinoma, epithelial malignant tumors, a mixture of malignant tumors from different tissues and pancreas carcinoma.
Table 1067 - Normal tissue distribution
Table 1068 - P values and ratios for expression in cancerous tissue
As noted above, cluster HSSTROL3 features 6 transcript(s), which were listed in Table 1 above. These transcript(s) encode for protein(s) which are variant(s) of protein Stromelysin-3 precursor. A description of each variant protein according to the present invention is now provided.
Variant protein HSSTROL3_P4 according to the present invention has an amino acid sequence as given at the end of the application; it is encoded by transcript(s) HSSTROL3_T5. An alignment is given to the known protein (Stromelysin-3 precursor) at the end of the application. One or more alignments to one or more previously published protein sequences are given at the end of the application. A brief description of the relationship of the variant protein according to the present invention to each such aligned protein is as follows:
Comparison report between HSSTROL3_P4 and MMl 1_HUMAN: 1.An isolated chimeric polypeptide encoding for HSSTROL3_P4, comprising a first amino acid sequence being at least 90 % homologous to
MAPAAWLRSAAARALLPPMLLLLLQPPPLLARALPPDVHHLHAERRGPQPWHAALPSS PAPAPATQEAPRPASSLRPPRCGVPDPSDGLSARNRQKRFVLSGGRWEKTDLTYRILRFP
WQLVQEQVRQTMAEALKVWSDVTPLTFTEVHEGRADIMIDFARYW corresponding to amino acids 1 - 163 of MMl IJHPLJMAN, which also corresponds to amino acids 1 - 163 of
HSSTROL3 P4, a bridging amino acid H corresponding to amino acid 164 of HSSTROL3_P4, a second amino acid sequence being at least 90 % homologous to GDDLPFDGPGGILAHAFFPKTHREGDVHFDYDETWTIGDDQGTDLLQVAAHEFGHVLG
LQHTTAAKALMSAFYTFRYPLSLSPDDCRGVQHLYGQPWPTVTSRTPALGPQAGIDTN
EIAPLEPDAPPDACEASFDA VSTIRGELFFFKAGFVWRLRGGQLQPGYPALASRHWQGL
PSPVDAAFEDAQGHIWFFQGAQYWVYDGEKPVLGPAPLTELGLVRFPVHAALVWGPE
KNKIYFFRGRDYWRFHPSTRRVDSPVPRRATDWRGVPSEIDAAFQDADG corresponding to amino acids 165 - 445 of MMl IJHUMAN, which also corresponds to amino acids 165 - 445 of HSSTROL3 P4, and a third amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence
ALGVRQLVGGGHSSRFSHLWAGLPHACHRKSGSSSQVLCPEPSALLSVAG corresponding to amino acids 446 - 496 of HSSTROL3 P4, wherein said first amino acid sequence, bridging amino acid, second amino acid sequence and third amino acid sequence are contiguous and in a sequential order.
2.An isolated polypeptide encoding for a tail of HSSTROL3 P4, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence ALGVRQLVGGGHSSRFSHLVVAGLPHACHRKSGSSSQVLCPEPSALLSVAG in
HSSTROL3_P4.
The location of the variant protein was determined according to results from a number of different software programs and analyses, including analyses from SignalP and other specialized programs. The variant protein is believed to be located as follows with regard to the cell:
secreted. The protein localization is believed to be secreted because both signal-peptide prediction programs predict that this protein has a signal peptide, and neither trans -membrane region prediction program predicts that this protein has a trans -membrane region.
Variant protein HSSTROL3_P4 also has the following non-silent SNPs (Single Nucleotide Polymorphisms) as listed in Table 1069, (given according to their position(s) on the amino acid sequence, with the alternative amino acid(s) listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein HSSTROL3_P4 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 1069 -Amino acid mutations
Variant protein HSSTROL3 P4 is encoded by the following transcript(s): HSSTROL3_T5, for which the sequence(s) is/are given at the end of the application. The coding portion of transcript HSSTROL3_T5 is shown in bold; this coding portion starts at position 24 and ends at position 1511. The transcript also has the following SNPs as listed in Table 1070 (given according to their position on the nucleotide sequence, with the alternative nucleic acid listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein HSSTROL3_P4 sequence provides support for the deduced sequence of this variant protein according to the present invention). Table 1070 - Nucleic acid SNPs
Variant protein HSSTROL3_P5 according to the present invention has an amino acid sequence as given at the end of the application; it is encoded by transcript(s) HSSTROL3_T8 and HSSTROL3_T9. An alignment is given to the known protein (Stromelysin-3 precursor) at the end of the application. One or more alignments to one or more previously published protein sequences are given at the end of the application. A brief description of the relationship of the variant protein according to the present invention to each such aligned protein is as follows:
Comparison report between HSSTROL3_P5 and MMl 1_HUMAN:
1.An isolated chimeric polypeptide encoding for HSSTROL3_P5, comprising a first amino acid sequence being at least 90 % homologous to
MAPAAWLRSAAARALLPPMLLLLLQPPPLLARALPPDVHHLHAERRGPQPWHAALPSS PAPAPATQEAPRPASSLRPPRCGVPDPSDGLSARNRQKRFVLSGGRWEKTDLTYRILRFP WQLVQEQVRQTMAEALKVWSDVTPLTFTEVHEGRADIMIDFARYW corresponding to amino acids 1 - 163 of MMl IJHUMAN, which also corresponds to amino acids 1 - 163 of HSSTROL3_P5, a bridging amino acid H corresponding to amino acid 164 of HSSTROL3J>5, a second amino acid sequence being at least 90 % homologous to GDDLPFDGPGGILAHAFFPKTHREGDVHFDYDETWTIGDDQGTDLLQVAAHEFGHVLG LQHTTAAKALMSAFYTFRYPLSLSPDDCRGVQHLYGQPWPTVTSRTPALGPQAGIDTN EIAPLEPDAPPDACEASFDAVSTIRGELFFFKAGFVWRLRGGQLQPGYPALASRHWQGL PSPVDAAFEDAQGHIWFFQ corresponding to amino acids 165 - 358 of MMl IJHUMAN, which also corresponds to amino acids 165 - 358 of HSSTROL3 P5, and a third amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence ELGFPSSTGRDESLEHCRCQGLHK corresponding to amino acids 359 - 382 of HSSTROL3_P5, wherein said first amino acid sequence, bridging amino acid, second amino acid sequence and third amino acid sequence are contiguous and in a sequential order. 2.An isolated polypeptide encoding for a tail of HSSTROL3_P5, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence ELGFPSSTGRDESLEHCRCQGLHK in HSSTROL3JP5.
The location of the variant protein was determined according to results from a number of different software programs and analyses, including analyses from SignalP and other specialized programs. The variant protein is believed to be located as follows with regard to the cell: secreted. The protein localization is believed to be secreted because both signatpeptide prediction programs predict that this protein has a signal peptide, and neither trans -membrane region prediction program predicts that this protein has a trans -membrane region. Variant protein HSSTROL3JP5 also has the following non-silent SNPs (Single
Nucleotide Polymorphisms) as listed in Table 1071, (given according to their position(s) on the
amino acid sequence, with the alternative amino acid(s) listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein HSSTROL3_P5 sequence provides support for the deduced sequence of this variant protein according to the present invention). Table 1071 - Amino acid mutations
Variant protein HSSTROL3_P5 is encoded by the following transcript(s): HSSTROL3JT8 and HSSTROL3JT9, for which the sequence(s) is/are given at the end of the application.
The coding portion of transcript HSSTROL3 T8 is shown in bold; this coding portion starts at position 24 and ends at position 1169. The transcript also has the following SNPs as listed in Table 1072 (given according to their position on the nucleotide sequence, with the alternative nucleic acid listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein HSSTROL3_P5 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 1072 - Nucleic acid SNPs
The coding portion of transcript HSSTROL3_T9 is shown in bold; this coding portion starts at position 24 and ends at position 1169. The transcript also has the following SNPs as listed in Table 1073 (given according to their position on the nucleotide sequence, with the alternative nucleic acid listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein HSSTROL3_P5 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 1073 - Nucleic acid SNPs
Variant protein HSSTROL3_P7 according to the present invention has an amino acid sequence as given at the end of the application; it is encoded by transcript(s) HSSTROL3_T10. An alignment is given to the known protein (Stromelysin-3 precursor) at the end of the application. One or more alignments to one or more previously published protein sequences are given at the end of the application. A brief description of the relationship of the variant protein according to the present invention to each such aligned protein is as follows: Comparison report between HSSTROL3_P7 and MMl 1_HUMAN: 1.An isolated chimeric polypeptide encoding for HSSTROL3_P7, comprising a first amino acid sequence being at least 90 % homologous to
MAPAAWLRSAAARALLPPMLLLLLQPPPLLARALPPDVHHLHAERRGPQPWHAALPSS PAP APATQEAPRPASSLRPPRCGVPDPSDGLSARNRQKRFVLSGGRWEKTDLTYRILRFP WQLVQEQVRQTMAEALKVWSDVTPLTFTEVHEGRADIMDFARYW corresponding to amino acids 1 - 163 of MMl 1_HUMAN, which also corresponds to amino acids 1 - 163 of
HSSTROL3JP7, a bridging amino acid H corresponding to amino acid 164 of HSSTROL3_P7, a second amino acid sequence being at least 90 % homologous to
GDDLPFDGPGGILAHAFFPKTHREGDVHFDYDETWTIGDDQGTDLLQVAAHEFGHVLG LQHTTAAKALMSAFYTFRYPLSLSPDDCRGVQHLYGQPWPTVTSRTPALGPQAGIDTN EIAPLEPDAPPDACEASFDAVSTIRGELFFFKAGFVWRLRGGQLQPGYPALASRHWQGL PSPVDAAFEDAQGHIWFFQG corresponding to amino acids 165 - 359 of MMl INHUMAN, which also corresponds to amino acids 165 - 359 of HSSTROL3_P7, and a third amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence TTGVSTPAPGV corresponding to amino acids 360 - 370 of HSSTROL3_P7, wherein said first amino acid sequence, bridging amino acid, second amino acid sequence and third amino acid sequence are contiguous and in a sequential order.
2.An isolated polypeptide encoding for a tail of HSSTROL3_P7, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence TTGVSTPAPGV in HSSTROL3_P7.
The location of the variant protein was determined according to results from a number of different software programs and analyses, including analyses from SignalP and other specialized programs. The variant protein is believed to be located as follows with regard to the cell: secreted. The protein localization is believed to be secreted because both signal-peptide prediction programs predict that this protein has a signal peptide, and neither trans -membrane region prediction program predicts that this protein has a trans -membrane region.
Variant protein HSSTROL3_P7 also has the following non-silent SNPs (Single Nucleotide Polymorphisms) as listed in Table 1074, (given according to their position(s) on the amino acid sequence, with the alternative amino acid(s) listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein HSSTROL3_P7 sequence provides support for the deduced sequence of this variant protein according to the present invention). Table 1074 - Amino acid mutations
Variant protein HSSTROL3_P7 is encoded by the following transcript(s): HSSTROL3_T10, for which the sequence(s) is/are given at the end of the application. The coding portion of transcript HSSTROL3_T10 is shown in bold; this coding portion starts at position 24 and ends at position 1133. The transcript also has the following SNPs as listed in Table 1075 (given according to their position on the nucleotide sequence, with the alternative nucleic acid listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein HSSTROL3_P7 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 1075 - Nucleic acid SNPs
Variant protein HSSTROL3 P8 according to the present invention has an amino acid sequence as given at the end of the application; it is encoded by transcript(s) HSSTROL3 T11. An alignment is given to the known protein (Stromelysin-3 precursor) at the end of the application. One or more alignments to one or more previously published protein sequences are given at the end of the application. A brief description of the relationship of the variant protein according to the present invention to each such aligned protein is as follows: Comparison report between HSSTROL3_P8 and MMl 1_HUMAN: 1.An isolated chimeric polypeptide encoding for HSSTROL3_P8, comprising a first amino acid sequence being at least 90 % homologous to
MAPAAWLRSAAARALLPPMLLLLLQPPPLLARALPPDVHHLHAERRGPQPWHAALPSS PAPAPATQEAPRPASSLRPPRCGVPDPSDGLSARNRQKRFVLSGGRWEKTDLTYRILRFP WQLVQEQVRQTMAEALKVWSDVTPLTFTEVHEGRADIMIDFARYW corresponding to amino acids 1 - 163 of MMl IJHUMAN, which also corresponds to amino acids 1 - 163 of
HSSTROL3_P8, a bridging amino acid H corresponding to amino acid 164 of HSSTROL3JP8, a second amino acid sequence being at least 90 % homologous to
GDDLPFDGPGGILAHAFFPKTHREGDVHFDYDETWTIGDDQGTDLLQVAAHEFGHVLG LQHTTAAKALMSAFYTFRYPLSLSPDDCRGVQHLYGQPWPTVTSRTPALGPQAGIDTN EIAPLE corresponding to amino acids 165 - 286 of MMl 1_HUMAN, which also corresponds
to amino acids 165 - 286 of HSSTROL3_P8, and a third amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence VRPCLPVPLLLCWPL corresponding to amino acids 287 - 301 of HSSTROL3_P8, wherein said first amino acid sequence, bridging amino acid, second amino acid sequence and third amino acid sequence are contiguous and in a sequential order.
2.An isolated polypeptide encoding for a tail of HSSTROL3 P8, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence VRPCLPVPLLLCWPL in HSSTROL3JP8.
The location of the variant protein was determined according to results from a number of different software programs and analyses, including analyses from SignalP and other specialized programs. The variant protein is believed to be located as follows with regard to the cell: secreted. The protein localization is believed to be secreted because both signatpeptide prediction programs predict that this protein has a signal peptide, and neither trans -membrane region prediction program predicts that this protein has a trans -membrane region.
Variant protein HSSTROL3JP8 also has the following non-silent SNPs (Single Nucleotide Polymorphisms) as listed in Table 1076, (given according to their position(s) on the amino acid sequence, with the alternative amino acid(s) listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein HSSTROL3_P8 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 1076 - Amino acid mutations
Variant protein HSSTROL3_P8 is encoded by the following transcript(s): HSSTROL3_T11, for which the sequence(s) is/are given at the end of the application. The coding portion of transcript HSSTROL3_T11 is shown in bold; this coding portion starts at position 24 and ends at position 926. The transcript also has the following SNPs as listed in Table 1077 (given according to their position on the nucleotide sequence, with the alternative nucleic acid listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein HSSTROL3_P8 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 1077 - Nucleic acid SNPs
Variant protein HSSTROL3_P9 according to the present invention has an amino acid sequence as given at the end of the application; it is encoded by transcript(s) HSSTROL3_T12. An alignment is given to the known protein (Stromelysin-3 precursor) at the end of the application. One or more alignments to one or more previously published protein sequences are given at the end of the application. A brief description of the relationship of the variant protein according to the present invention to each such aligned protein is as follows: Comparison report between HSSTROL3_P9 and MMl 1_HUMAN: 1.An isolated chimeric polypeptide encoding for HSSTROL3 P9, comprising a first amino acid sequence being at least 90 % homologous to
MAPAAWLRSAAARALLPPMLLLLLQPPPLLARALPPDVHHLHAERRGPQPWHAALPSS PAPAPATQEAPRPASSLRPPRCGVPDPSDGLSARNRQK corresponding to amino acids 1 - 96 of MM11_HUMAN, which also corresponds to amino acids 1 - 96 of HSSTROL3_P9, a second amino acid sequence being at least 90 % homologous to
RILRFPWQLVQEQVRQTMAEALKVWSDVTPLTFTEVHEGRADIMIDFARYW corresponding to amino acids 113 - 163 of MMl 1_HUMAN, which also corresponds to amino acids 97 - 147 of HSSTROL3 P9, a bridging amino acid H corresponding to amino acid 148 of HSSTROL3JP9, a third amino acid sequence being at least 90 % homologous to GDDLPFDGPGGILAHAFFPKTHREGDVHFDYDETWTIGDDQGTDLLQVAAHEFGHVLG LQHTTAAKALMSAFYTFRYPLSLSPDDCRGVQHLYGQPWPTVTSRTPALGPQAGIDTN EIAPLEPDAPPDACEASFDAVSTIRGELFFFKAGFVWRLRGGQLQPGYPALASRHWQGL PSPVDAAFEDAQGHIWFFQG corresponding to amino acids 165 - 359 of MMl IJHUMAN, which also corresponds to amino acids 149 - 343 of HSSTROL3_P9, and a fourth amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence TTGVSTPAPGV corresponding to amino acids 344 - 354 of HSSTROL3_P9, wherein said first amino acid sequence, second amino acid sequence, bridging amino acid, third amino acid sequence and fourth amino acid sequence are contiguous and in a sequential order.
m i
2.An isolated chimeric polypeptide encoding for an edge portion of HSSTROL3 P9, comprising a polypeptide having a length "n", wherein n is at least about 10 amino acids in length, optionally at least about 20 amino acids in length, preferably at least about 30 amino acids in length, more preferably at least about 40 amino acids in length and most preferably at least about 50 amino acids in length, wherein at least two amino acids comprise KJR., having a structure as follows: a sequence starting from any of amino acid numbers 96-x to 96; and ending at any of amino acid numbers 97+ ((n-2) - x), in which x varies from 0 to n-2.
3.An isolated polypeptide encoding for a tail of HSSTROL3_P9, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence TTGVSTPAPGV in HSSTROL3_P9.
The location of the variant protein was determined according to results from a number of different software programs and analyses, including analyses from SignalP and other specialized programs. The variant protein is believed to be located as follows with regard to the cell: secreted. The protein localization is believed to be secreted because both signal-peptide prediction programs predict that this protein has a signal peptide, and neither trans -membrane region prediction program predicts that this protein has a trans -membrane region.
Variant protein HSSTROL3 P9 also has the following non-silent SNPs (Single Nucleotide Polymorphisms) as listed in Table 1078, (given according to their position(s) on the amino acid sequence, with the alternative amino acid(s) listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein HSSTROL3_P9 sequence provides support for the deduced sequence of this variant protein according to the present invention). Table 1078 - Amino acid mutations
Variant protein HSSTROL3_P9 is encoded by the following transcript(s): HSSTROL3_T12, forwhich the sequence(s) is/are given at the end of the application. The coding portion of transcript HSSTROL3_T12 is shown in bold; this coding portion starts at position 24 and ends at position 1085. The transcript also has the following SNPs as listed in Table 1079 (given according to their position on the nucleotide sequence, with the alternative nucleic acid listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein HSSTROL3 P9 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 1079 - Nucleic acid SNPs
As noted above, cluster HSSTROL3 features 16 segment(s), which were listed in Table 2 above and for which the sequence(s) are given at the end of the application. These segment(s) are portions of nucleic acid sequence(s) which are described herein separately because they are of particular interest. A description of each segment according to the present invention is now provided.
Segment cluster HSSTROL3_node_6 according to the present invention is supported by 14 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): HSSTROL3_T5, HSSTROL3JT8, HSSTROL3_T9, HSSTROL3JT10, HSSTROL3JT11 and HSSTROL3JT12. Table 1080 below describes the starting and ending position of this segment on each transcript.
Table 1080 - Segment location on transcripts
Segment cluster HSSTROL3_node_10 according to the present invention is supported by
21 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): HSSTROL3JT5, HSSTROL3_T8, H8STROL3JT9, HSSTROL3_T10, HSSTROL3_T11 and HSSTROL3JT12. Table 1081 below describes the starting and ending position of this segment on each transcript. Table 1081 - Segment location on transcripts
Segment cluster HSSTROL3_node_13 according to the present invention is supported by 36 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): HSSTROL3_T5, HSSTROL3_T8, HSSTROL3 T9, HSSTROL3JT10, HSSTROL3_T11 and HSSTROL3_T12. Table 1082 below describes the starting and ending position of this segment on each transcript.
Table 1082 - Segment location on transcripts
Segment cluster HSSTROL3_node_ 15 according to the present invention is supported by 47 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): HSSTROL3JT5, HSSTROL3_T8, HSSTROL3_T9,
HSSTROL3_T10, HSSTROL3_T11 and HSSTROL3_T12. Table 1083 below describes the starting and ending position of this segment on each transcript.
Table 1083 - Segment location on transcripts
Segment cluster HSSTROL3_node_19 according to the present invention is supported by 63 libraries. The number of libraries was deteπnined as previously described. This segment can be found in the following transcript(s): HSSTROL3JT5, HSSTROL3_T8, HSSTROL3_T9, HSSTROL3JT10, HSSTROL3_T11 and HSSTROL3_T12. Table 1084 below describes the starting and ending position of this segment on each transcript.
Table 1084 - Segment location on transcripts
Segment cluster HSSTROL3_node_21 according to the present invention is supported by 61 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): HSSTROL3JT5, HSSTROL3JT8, HSSTROL3_T9, HSSTROL3 T10, HSSTROL3_T11 and HSSTROL3JT12. Table 1085 below describes the starting and ending position of this segment on each transcript.
Table 1085 - Segment location on transcripts
Segment cluster HSSTROL3_node_24 according to the present invention is supported by 7 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): HSSTROL3_T8 and HSSTROL3_T9. Table 1086 below describes the starting and ending position of this segment on each transcript.
Table 1086 - Segment location on transcripts
Segment cluster HSSTROL3_node_25 according to the present invention is supported by 13 libraries. The number of libraries was determined as previously described. This segment can
be found in the following transcript(s): HSSTROL3_T8. Table 1087 below describes the starting and ending position of this segment on each transcript.
Table 1087 - Segment location on transcripts
Segment cluster HSSTROL3_node_26 according to the present invention is supported by 55 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): HSSTROL3JT5, HSSTROL3JT8, HSSTROL3_T9 and HSSTROL3 T11. Table 1088 below describes the starting and ending position of this segment on each transcript.
Table 1088 - Segment location on transcripts
Segment cluster HSSTROL3_node_28 according to the present invention is supported by 10 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): HSSTROL3_T5, HSSTROL3JT9 and HSSTROL3_T10. Table 1089 below describes the starting and ending position of this segment on each transcript.
Table 1089 - Segment location on transcripts
Segment cluster HSSTROL3_node_29 according to the present invention is supported by 109 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): HSSTROL3JT5, HSSTROL3_T8, HSSTROL3JT9, HSSTROL3JT10, HSSTROL3JT11 and HSSTROL3JT12. Table 1090 below describes the starting and ending position of this segment on each transcript.
Table 1090 - Segment location on transcripts
According to an optional embodiment of the present invention, short segments related to the above cluster are also provided. These segments are up to about 120 bp in length, and so are included in a separate description.
Segment cluster HSSTROL3_node_l 1 according to the present invention is supported by 25 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): HSSTROL3 JT5, HSSTROL3_T8, HSSTROL3JT9, HSSTROL3JT10 and HSSTROL3JT11. Table 1091 below describes the starting and ending position of this segment on each transcript.
Table 1091 - Segment location on transcripts
Segment cluster HSSTROL3_node__17 according to the present invention is supported by 45 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): HSSTROL3JT5, HSSTROL3JT8, HSSTROL3JT9, HSSTROL3_T10, HSSTROL3JT11 and HSSTROL3JT12. Table 1092 below describes the starting and ending position of this segment on each transcript.
Table 1092 - Segment location on transcripts
Segment cluster HSSTROL3_node_18 according to the present invention can be found in the following transcript(s): HSSTROL3_T5, HSSTROL3_T8, HSSTROL3_T9, HSSTROL3_T10, HSSTROL3_T11 and HSSTROL3_T12. Table 1093 below describes the starting and ending position of this segment on each transcript.
Table 1093 - Segment location on transcripts
Segment cluster HSSTROL3_node_20 according to the present invention is supported by 1 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): HSSTROL3_T11. Table 1094 below describes the starting and ending position of this segment on each transcript.
Table 1094 - Segment location on transcripts
Segment cluster HSSTROL3_node_27 according to the present invention is supported by 50 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): HSSTROL3JT5, HSSTROL3JT8, HSSTROL3_T9, HSSTROL3_T10, HSSTROL3JT11 and HSSTROL3_T12. Table 1095 below describes the starting and ending position of this segment on each transcript.
Table 1095 - Segment location on transcripts
Variant protein alignment to the previously known protein:
Sequence name: MM11_HUMAN
Sequence documentation:
Alignment of: HSSTROL3_P4 x MM11JHUMAN
Alignment segment 1/1:
Quality: 4444.00 Escore: 0
Matching length: 445 Total length: 445 Matching Percent Similarity: 99.78 Matching Percent Identity: 99.78
Total Percent Similarity: 99.78 Total Percent Identity: 99.78
Gaps : 0
Alignment :
1 MAPAAWLRSAAARALLPPMLLLLLQPPPLLARALPPDVHHLHAERRGPQP 50
11!111!1!1IMIIIIIIII)IMIIIIIIIIIIMIIIMIIIIIMI 1 MAPAAWLRSAAARALLPPMLLLLLQPPPLLARALPPDVHHLHAERRGPQP 50
51 WHAALPSSPAPAPATQEAPRPASSLRPPRCGVPDPSDGLSARNRQKRFVL 100 I I I Il Il Il I I Il Il I I I I I Il Il I I I Il I Il Il Il I I I Il I I I I Il Il I
51 WHAALPSSPAPAPATQEAPRPASSLRPPRCGVPDPSDGLSARNRQKRFVL 100 . . . . .
101 SGGRWEKTDLTYRILRFPWQLVQEQVRQTMAEALKVWSDVTPLTFTEVHE 150
1111 ! M M I I M M M M M M M I I I M I M M M M I M M I M M ! 101 SGGRWEKTDLTYRILRFPWQLVQEQVRQTMAEALKVWSDVTPLTFTEVHE 150
151 GRADIMIDFARYWHGDDLPFDGPGGILAHAFFPKTHREGDVHFDYDETWT 200
I ! I ! I M M I I I I I I l I I M I l I I M I l I M I I 11 I l I I I l I M I M I I
151 GRADIMIDFARYWDGDDLPFDGPGGILAHAFFPKTHREGDVHFDYDETWT 200
201 IGDDQGTDLLQVAAHEFGHVLGLQHTTAAKALMSAFYTFRYPLSLSPDDC 250 I I I Il M I I I M M I I I I I I M I M Il Il Il I M I Il I I M Il I Il Il Il
201 IGDDQGTDLLQVAAHEFGHVLGLQHTTAAKALMSAFYTFRYPLSLSPDDC 250
251 RGVQHLYGQPWPTVTSRTPALGPQAGIDTNEIAPLEPDAPPDACEASFDA 300
I I M I! I I M M M M I I M M I M M I I I I Il Il I M M M M Il I Il I 251 RGVQHLYGQPWPTVTSRTPALGPQAGIDTNEIAPLEPDAPPDACEASFDA 300
301 VSTIRGELFFFKAGFVWRLRGGQLQPGYPALASRHWQGLPSPVDAAFEDA 350
M M M M M Il M M Il I I M I I I I I I M I I Il M I I I M Il I M Il I I
301 VSTIRGELFFFKAGFVWRLRGGQLQPGYPALASRHWQGLPSPVDAAFEDA 350 . . . . .
351 QGHIWFFQGAQYWVYDGEKPVLGPAPLTELGLVRFPVHAALVWGPEKNKI 400
351 QGHIWFFQGAQYWVYDGEKPVLGPAPLTELGLVRFPVHAALVWGPEKNKI 400
401 YFFRGRDYWRFHPSTRRVDSPVPRRATDWRGVPSEIDAAFQDADG 445 I I I I I I M I I I 1 I I I I I I I I I I I I I I 1 I I I I I I I I I I I I I I I I I I
401 YFFRGRDYWRFHPSTRRVDSPVPRRATDWRGVPSEIDAAFQDADG 445
Sequence name: MM11_HUMAN
Sequence documentation:
Alignment of: HSSTROL3_P5 x MM11_HUMAN
Alignment segment 1/1:
Quality: 3566.00 Escore: 0
Matching length: 358 Total length: 358 Matching Percent Similarity: 99.72 Matching Percent Identity: 99.72
Total Percent Similarity: 99.72 Total Percent Identity: 99.72
Gaps : 0
Alignment:
i MΆPΆAWLRSAAΆRALLPPMLLLLLQPPPLLARALPPDVHHLHAERRGPQP so I I I I I I I I I I I I I I I I I I I I i I I I I I I I 1 I i I I I I I I I I I I I I I I I I ! I I
1 MAPAAWLRSAAARALLPPMLLLLLQPPPLLARALPPDVHHLHAERRGPQP 50 . . . . .
51 WHAALPSSPAPAPATQEAPRPASSLRPPRCGVPDPSDGLSARNRQKRFVL 100
I I Il I I I I I I I I Il Il I I I I I I Il I I I I I I I I I I ! I I I I I I I I I I I I I Il
51 WHAALPSSPAPAPATQEAPRPASSLRPPRCGVPDPSDGLSARNRQKRFVL 100
101 SGGRWEKTDLTYRILRFPWQLVQEQVRQTMAEALKVWSDVTPLTFTEVHE 150
I I I I I I I I I I I I Il I I Il I I I Il Il Il I I I I Il I I I I I I I I I I I Il I I I I
101 SGGRWEKTDLTYRILRFPWQLVQEQVRQTMAEALKVWSDVTPLTFTEVHE 150
151 GRADIMIDFARYWHGDDLPFDGPGGILAHAFFPKTHREGDVHFDYDETWT 200 I I Il M I I I I I I I Il I I M I I I I I Il I I I I I I I I I I Il 1 I I I I I I I I Il
151 GRADIMIDFARYWDGDDLPFDGPGGILAHAFFPKTHREGDVHFDYDETWT 200
201 IGDDQGTDLLQVAAHEFGHVLGLQHTTAAKALMSAFYTFRYPLSLSPDDC 250
I Il I I I I Il Il I I I I Il I I I Il I I Il I I I I I I Il I I Il I Il I I I I I Il Il 201 IGDDQGTDLLQVAAHEFGHVLGLQHTTAAKALMSAFYTFRYPLSLSPDDC 250
251 RGVQHLYGQPWPTVTSRTPALGPQAGIDTNEIAPLEPDAPPDACEASFDA 300
II I I I I I I I I I I Il Il I I I I I I Il I I I I I I Il I I I I I I Il I Il I I Il I I I
251 RGVQHLYGQPWPTVTSRTPALGPQAGIDTNEIAPLEPDAPPDACEASFDA 300 . . . . .
301 VSTIRGELFFFKAGFVWRLRGGQLQPGYPALASRHWQGLPSPVDAAFEDA 350
I I I Il I I Il I I I I I I I I Il I I Il I I I Il I I Il I I I I Il I I Il I Il Il I I I 301 VSTIRGELFFFKAGFVWRLRGGQLQPGYPALASRHWQGLPSPVDAAFEDA 350
351 QGHIWFFQ 358
351 QGHIWFFQ 358
Sequence name: MM11_HUMAN
Sequence documentation:
Alignment of: HSSTROL3 P7 x MMIl HUMAN
Alignment segment 1/1:
Quality: 3575.00 Escore: 0
Matching length: 359 Total length: 359 Matching Percent Similarity: 99.72 Matching Percent Identity: 99.72
Total Percent Similarity: 99.72 Total Percent Identity: 99.72
Gaps : 0
Alignment :
1 MAPAAWLRSAAARALLPPMLLLLLQPPPLLARALPPDVHHLHAERRGPQP 50
1 MAPAAWLRSAAARALLPPMLLLLLQPPPLLARALPPDVHHLHAERRGPQP 50
51 WHAALPSSPAPAPATQEAPRPASSLRPPRCGVPDPSDGLSARNRQKRFVL 100
I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I 1 I I I I I I Il I I I I I I I I I I
51 WHAALPSSPAPAPATQEAPRPASSLRPPRCGVPDPSDGLSARNRQKRFVL 100
101 SGGRWEKTDLTYRILRFPWQLVQEQVRQTMAEALKVWSDVTPLTFTEVHE 150
I I I I I Il I I I 1 I I I I I I I I I 1 I I I I I I I I I I I I I I I I I I Il I 1 I I I I I I I
101 SGGRWEKTDLTYRILRFPWQLVQEQVRQTMAEALKVWSDVTPLTFTEVHE 150
151 GRADIMIDFARYWHGDDLPFDGPGGILAHAFFPKTHREGDVHFDYDETWT 200 I I I I I M M I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I
151 GRADIMIDFARYWDGDDLPFDGPGGILAHAFFPKTHREGDVHFDYDETWT 200
201 IGDDQGTDLLQVAAHEFGHVLGLQHTTAAKALMSAFYTFRYPLSLSPDDC 250
I I I I I I I I I I I I Il I I I I I I Il I Il I I I I I I Il I I I Il Il I I Il I I I I I I 201 IGDDQGTDLLQVAAHEFGHVLGLQHTTAAKALMSAFYTFRYPLSLSPDDC 250
251 RGVQHLYGQPWPTVTSRTPALGPQAGIDTNEIAPLEPDAPPDACEASFDA 300
I I I I I I I I I I I I I I Il I I I I I I I I I I I I I I Il I Il Il I I I I I I I I I Il I h
251 RGVQHLYGQPWPTVTSRTPALGPQAGIDTNEIAPLEPDAPPDACEASFDA 300 . . . . .
301 VSTIRGELFFFKAGFVWRLRGGQLQPGYPALASRHWQGLPSPVDAAFEDA 350
II I Il I I 1 I I Il I I I I Il Il I Il I I I I I I I Il I I I Il Il Il Il I I I Il Il
301 VSTIRGELFFFKAGFVWRLRGGQLQPGYPALASRHWQGLPSPVDAAFEDA 350
351 QGHIWFFQG 359
I I I I I I I I I 351 QGHIWFFQG 359
Sequence name: MM11_HUMAN
Sequence documentation:
Alignment of: HSSTROL3_P8 x MM11_HUMAN
Alignment segment 1/1:
Quality: 2838.00 Escore: 0
Matching length: 286 Total length: 286 Matching Percent Similarity: 99.65 Matching Percent Identity: 99.65
Total Percent Similarity: 99.65 Total Percent Identity: 99.65
Gaps : 0
Alignment :
1 MAPAAWLRSAAARALLPPMLLLLLQPPPLLARALPPDVHHLHAERRGPQP 50
I I I Il I I I I I I I I I Il I I I I I I I I I I I i I I I I I Il Il Il I I I I I I I I ! I I l MAPAAWLRSAAARALLPPMLLLLLQPPPLLARALPPDVHHLHAERRGPQP 50
51 WHAALPSSPAPAPATQEAPRPASSLRPPRCGVPDPSDGLSARNRQKRFVL 100
I I I I Il I I I I 1 I I Il Il Il I I I I I Il I I Il I I I I I I I I Il I I I I I I Il Il
51 WHAALPSSPAPAPATQEAPRPASSLRPPRCGVPDPSDGLSARNRQKRFVL 100 . . . . .
101 SGGRWEKTDLTYRILRFPWQLVQEQVRQTMAEALKVWSDVTPLTFTEVHE 150
I I I I I I I I I I I 1 I 1 I I I Il I I I I I I I I I I I IIl I I I I I I I I I I I I I I I I I I
101 SGGRWEKTDLTYRILRFPWQLVQEQVRQTMAEALKVWSDVTPLTFTEVHE 150
151 GRADIMIDFARYWHGDDLPFDGPGGILAHAFFPKTHREGDVHFDYDETWT 200 I I I I I I I I I I I I I I I I I I I I I I I I I I I I 1 I I I I I I Il I I I I I I I Il I Il
151 GRADIMIDFARYWDGDDLPFDGPGGILAHAFFPKTHREGDVHFDYDETWT 200
201 IGDDQGTDLLQVAAHEFGHVLGLQHTTAAKALMSAFYTFRYPLSLSPDDC 250
I I I I I I Il I I Il I I I I I I I Il I M I I I I I I I Il I I I Il I I Il I Il I I I I I 201 IGDDQGTDLLQVAAHEFGHVLGLQHTTAAKALMSAFYTFRYPLSLSPDDC 250
251 RGVQHLYGQPWPTVTSRTPALGPQAGIDTNEIAPLE 286
I I I I I I Il Il I I I I I I I I I I I I I I Il I I Il Il I I 1 I 251 RGVQHLYGQPWPTVTSRTPALGPQAGIDTNEIAPLE 286
Sequence name: MM11_HUMAN
Sequence documentation:
Alignment of: HSSTROL3_P9 x MM11_HUMAN
Alignment segment 1/1:
Quality: 3316.00 Escore: 0
Matching length: 343 Total length: 359
Matching Percent Similarity: 99.71 Matching Percent Identity: 99.71 Total Percent Similarity: 95.26 Total Percent Identity: 95.26
Gaps : 1
Alignment : . . . . . i MAPAAWLRSAAARALLPPMLLLLLQPPPLLARALPPDVHHLHAERRGPQP 50
I I I I I I I I I 1 I I I I I I I I I I I I I I I I I I I I Il I I I 1 I I I I I I Il I I I I I I
1 MAPAAWLRSAAARALLPPMLLLLLQPPPLLARALPPDVHHLHAERRGPQP 50
51 WHAALPSSPAPAPATQEAPRPASSLRPPRCGVPDPSDGLSARNRQK.... 96
II I I I I I I I I I I I I I I I I I I I Il I Il I I I I Il I I I I I I I 1 I I I I I I
51 WHAALPSSPAPAPATQEAPRPASSLRPPRCGVPDPSDGLSARNRQKRFVL 100
97 RILRFPWQLVQEQVRQTMAEALKVWSDVTPLTFTEVHE 134 I I M I I I I I I I I I I I 1 I I I I I I I I I I I I I I I I I I M M
101 SGGRWEKTDLTYRILRFPWQLVQEQVRQTMAEALKVWSDVTPLTFTEVHE 150
135 GRADIMIDFARYWHGDDLPFDGPGGILAHAFFPKTHREGDVHFDYDETWT 184
I I Il I I I I I I Il I I Il I I I Il Il I I Il I I I I I I I I I I I I Il I I I I I Il I 151 GRADIMIDFARYWDGDDLPFDGPGGILAHAFFPKTHREGDVHFDYDETWT 200
185 IGDDQGTDLLQVAAHEFGHVLGLQHTTAAKALMSAFYTFRYPLSLSPDDC 234
201 IGDDQGTDLLQVAAHEFGHVLGLQHTTAAKALMSAFYTFRYPLSLSPDDC 250 . . . . .
235 RGVQHLYGQPWPTVTSRTPALGPQAGIDTNEIAPLEPDAPPDACEASFDA 284
I 1 I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I l I I I I I 1 I I I I I I
251 RGVQHLYGQPWPTVTSRTPALGPQAGIDTNEIAPLEPDAPPDACEASFDA 300
285 VSTIRGELFFFKAGFVWRLRGGQLQPGYPALASRHWQGLPSPVDAAFEDA 334 I I I I I I 1 I I I I I I I I I 1 I I I I I I I I ] M I M M I I I Il I M I M I I I I I I
301 VSTIRGELFFFKAGFVWRLRGGQLQPGYPALASRHWQGLPSPVDAAFEDA 350
335 QGHIWFFQG 343
I I I I I I I I I 351 QGHIWFFQG 359
Expression of Stromelysin-3 precursor HSSTROL3 transcripts which are detectable by amplicon as depicted in sequence name HSSTROL3 seg24 in normal and cancerous Lung tissues
Expression of Stromelysin-3 precursor (EC 3.4.24.-) (Matrix metalloproteinase-11) (MMP-11) (ST3) (SLr 3) transcripts detectable by or according to seg24, HSSTROL3 seg24 amplicon (SEQ ID NO: 1675) and HSSTROL3 seg24F (SEQ ID NO: 1673) and HSSTROL3 seg24R (SEQ ID NO: 1674) primers was measured by real time PCR. In parallel the expression of four housekeeping genes -PBGD (GenBank Accession No. BC019323; amplicon - PBGD- amplicon, SEQ ID NO:334), HPRTl (GenBank Accession No. NM_000194; amplicon - HPRTl -amplicon, SEQ ID NO: 1297), Ubiquitin(GenBank Accession No. BC000449; amplicon - Ubiquitin-amplicon, SEQ ID NO:328) and SDHA (GenBank Accession No. NM_004168; amplicon - SDHA-amplicon, SEQ ID NO:331) was measured similarly. For each RT sample, the expression of the above amplicon was normalized to the geometric mean of the quantities of the housekeeping genes. The normalized quantity of each RT sample was then divided by the median of the quantities of the normal post-mortem (PM) samples (Sample Nos. 47-50, 90-93, 96-99, Table 2 "Tissue samples in testing panel", above), to obtain a value of fold up-regulation for each sample relative to median of the normal PM samples. Figure 39 is a histogram showing over expression of the above- indicated Stromelysin-3 precursor transcripts in cancerous lung samples relative to the normal samples. Values
represent the average of duplicate experiments. Error bars indicate the minimal and maximal values obtained.)
As is evident from Figure 39, the expression of Stromelysin-3 precursor transcripts detectable by the above amplicon(s) in cancer samples was significantly higher than in the non- cancerous samples (Sample Nos. 47-50, 90-93, 96-99 Table 2, "Tissue samples in testing panel"). Notably an over- expression of at least 5 fold was found in 13 out of 15 adenocarcinoma samples, 8 out of 16 squamous cell carcinoma samples, 3 out of 4 large cell carcinoma samples and in 7 out of 8 small cell carcinoma samples.
Threshold of 5 fold overexpression was found to differentiate between cancer and normal samples with P value of 4.04E-04 in adenocarcinoma, 9.89E-02 in squamous cell carcinoma, 6:04E-02 in Large cell carcinoma, 3.14E-03 in small cell carcinoma as checked by exact fisher test. The above values demonstrate statistical significance of the results.
Primer pairs are also optionally and preferably encompassed within the present invention; for example, for the above experiment, the following primer pair was used as a non- limiting illustrative example only of a suitable primer pair: HSSTROL3 seg24F forward primer; and HSSTROL3 seg24R reverse primer.
The present invention also preferably encompasses any amplicon obtained through the use of any suitable primer pair; for example, for the above experiment, the following amplicon was obtained as a non- limiting illustrative example only of a suitable amplicon: HSSTROL3 seg24.
Forward Primer (SEQ ID NO: 1673): ATTTCCATCCTCAACTGGCAGA Reverse Primer (SEQ ID NO: 1674): TGCCCTGGAACCCACG Amplicon (SEQ ID NO: 1675):
ATTTCCATCCTCAACTGGCAGAGATGAGAGCCTGGAGCATTGCAGATGCCAGGGAC TTCACAAATGAAGGCACAGCATGGGAAACCTGCGTGGGTTCCAGGGCA
Expression of Stromelysin-3 precursor HSSTROL3 transcripts which are detectable by amplicon as depicted in sequence name HSSTROL3 seg24 in different normal tissues
Expression of Stromelysin-3 precursor transcripts detectable by or according to
HSSTROL3 seg24 amplicon (SEQ ID NO: 1675) and HSSTROL3 seg24F (SEQ ID NO: 1673)
and HSSTROL3 seg24R (SEQ ID NO: 1674) was measured by real time PCR. In parallel the expression of four housekeeping genes Ubiquitin(GenBank Accession No. BC000449; amplicon - Ubiquitin-amplicon, SEQ ID NO:328) and SDHA (GenBank Accession No. NM__004168; amplicon - SDHA- amplicon, SEQ ID NO:331), RPL 19 (GenBank Accession No. NM_OOO981; RPLl 9 amplicon, SEQ ID NO: 1630), TATA box (GenBank Accession No. NM_003194; TATA amplicon, SEQ ID NO: 1633) was measured similarly. For each RT sample, the expression of the above amplicon was normalized to the geometric mean of the quantities of the housekeeping genes. The normalized quantity of each RT sample was then divided by the median of the quantities of the lung samples (Sample Nos. 15-17, Table 2 "Tissue samples in normal panel", above), to obtain a value of relative expression of each sample relative to median of the lung samples.
Forward Primer (SEQ ID NO: 1673): ATTTCCATCCTCAACTGGCAGA Reverse Primer (SEQ ID NO: 1674): TGCCCTGGAACCCACG Amplicon (SEQ ID NO: 1675): ATTTCCATCCTCAACTGGCAGAGATGAGAGCCTGGAGCATTGCAGATGCCAGGGAC TTCACAAATGAAGGCACAGCATGGGAAACCTGCGTGGGTTCCAGGGCA
The results are demonstrated in Figure 40, showing the expression of Stromelysin-3 HSSTROL3 transcripts, which are detectable by amplicon as depicted in sequence name HSSTROL3 seg24, in different normal tissues.
Expression o/Homo sapiens matrix metalloproteinase 11 (stromelysin 3) (MMPI l)H1S1SJKOLi transcripts -which are detectable by amplicon as depicted in sequence name HSSTROL3 seg20-
21 in normal and cancerous lung tissues Expression of Homo sapiens matrix metalloproteinase 11 (stromelysin 3) (MMPI l) transcripts detectable by or according to seg20-21, HSSTROL3 seg20-21 amplicon (SEQ ID NO: 1678) and primers HSSTROL3 seg20-21F (SEQ ID NO: 1676) and HSSTROL3 seg20-21R (SEQ ID NO: 1677) was measured by real time PCR. In parallel the expression of four housekeeping genes -PBGD (GenBank Accession No. BC019323; amplicon - PBGD-amplicon, SEQ ID NO:334), HPRTl (GenBank Accession No. NM_000194; amplicon - HPRTl -amplicon, SEQ ID NO-.1297), Ubiquitin (GenBank Accession No. BC000449; amplicon - Ubiquitin-
amplicon, SEQ ID NO:328) and SDHA (GenBank Accession No. NM_004168; amplicon - SDHA- amplicon, SEQ ID NO:331), was measured similarly. For each RT sample, the expression of the above amplicon was normalized to the geometric mean of the quantities of the housekeeping genes. The normalized quantity of each RT sample was then divided by the median of the quantities of the normal post-mortem (PM) samples (Sample Nos. 47-50, 90-93, 96-99, Table 2, above), to obtain a value of fold up-regulation for each sample relative to median of the normal PM samples.
Figure 71 is a histogram showing over expression of the above -indicated Homo sapiens matrix metalloproteinase 11 (stromelysin 3) (MMPI l) transcripts in cancerous lung samples relative to the normal samples.
As is evident from Figure 71, the expression of Homo sapiens matrix metalloproteinase 11 (stromelysin 3) (MMPl 1) transcripts detectable by the above amplicon(s) in cancer samples was significantly higher than in the non-cancerous samples (Sample Nos. 46-50, 90-93, 96-99 Table 2, ). Notably an over- expression of at least 6 fold was found in 11 out of 15 adenocarcinoma samples, 6 out of 16 squamous cell carcinoma samples, 1 out of 4 large cell carcinoma samples and in 6 out of 8 small cells carcinoma samples.
Primer pairs are also optionally and preferably encompassed within the present invention; for example, for the above experiment, the following primer pair was used as a non- limiting illustrative example only of a suitable primer pair: HSSTROL3 seg20-21F forward primer; and HSSTROL3 seg20-21R reverse primer. The present invention also preferably encompasses any amplicon obtained through the use of any suitable primer pair; for example, for the above experiment, the following amplicon was obtained as a non- limiting illustrative example only of a suitable amplicon: HSSTROL3 seg20-21.
Primers:
Forward primer HSSTROL3 seg20-21F (SEQ ID NO: 1676): TCTGCTGGCCACTGTGACTG Reverse primer HSSTROL3 seg20-21R (SEQ ID NO: 1677): GAAGAAAAAGAGCTCGCCTCG Amplicon HSSTROL3 seg20-21 (SEQ ID NO: 1678): TCTGCTGGCCACTGTGACTGCAGCATATGCCCTCAGCATGTGTCCCTCTCTCCCACC CCAGCCAGACGCCCCGCCAGATGCCTGTGAGGCCTCCTTTGACGCGGTCTCCACCA TCCGAGGCGAGCTCTTTTTCTTC
Expression o/Homo sapiens matrix metalloproteinase 11 (stromelysin 3) (MMPI l) HSSTROL3 transcripts which are detectable by amplicon as depicted in sequence name HSSTROL3 junc21-
27 in normal and cancerous lung tissues Expression of Homo sapiens matrix metalloproteinase 11 (stromelysin 3) (MMPI l) transcripts detectable by or according to junc21-27, HSSTROL3 junc21-27 amplicon (SEQ ID NO: 1681) and primers HSSTROL3 junc21-27F (SEQ ID NO: 1679) and HSSTROL3 junc21- 27R (SEQ ID NO: 1680) was measured by real time PCR. In parallel the expression of four housekeeping genes -PBGD (GenBank Accession No. BC019323; amplicon - PBGD-amplicon, SEQ ID NO:334), HPRTl (GenBank Accession No. NM_000194; amplicon - HPRTl -amplicon, SEQ ID NO:1297), Ubiquitin (GenBank Accession No. BC000449; amplicon - Ubiquitin-
amplicon, SEQ ID NO:328) and SDHA (GenBank Accession No. NM_004168; amplicon - SDHA-amplicon, SEQ ID NO:331), was measured similarly. For each RT sample, the expression of the above amplicon was normalized to the geometric mean of the quantities of the housekeeping genes. The normalized quantity of each RT sample was then divided by the median of the quantities of the normal post-mortem (PM) samples (Sample Nos. 47-50, 90-93, 96-99, Table 2, above), to obtain a value of fold up-regulation for each sample relative to median of the normal PM samples.
Figure 72 is a histogram showing over expression of the above -indicated Homo sapiens matrix metalloproteinase 11 (stromelysin 3) (MMPI l) transcripts in cancerous lung samples relative to the normal samples.
As is evident from Figure 72, the expression of Homo sapiens matrix metalloproteinase 11 (stromelysin 3) (MMPl 1) transcripts detectable by the above amplicon(s) in cancer samples was significantly higher than in the non-cancerous samples (Sample Nos. 46-50, 90-93, 96-99 Table 2, ). Notably an over- expression of at least 10 fold was found in 15 out of 15 adenocarcinoma samples, 13 out of 16 squamous cell carcinoma samples, 3 out of 4 large cell carcinoma samples and in 5 out of 8 small cells carcinoma samples.
Primer pairs are also optionally and preferably encompassed within the present invention; for example, for the above experiment, the following primer pair was used as a non- limiting illustrative example only of a suitable primer pair: HSSTROL3 junc21-27F forward primer; and HSSTROL3 junc21-27R reverse primer. The present invention also preferably encompasses any amplicon obtained through the use of any suitable primer pair; for example, for the above experiment, the following amplicon was obtained as a non- limiting illustrative example only of a suitable amplicon: HSSTROL3 junc21-27.
Primers:
Forward primer HSSTROL3 junc21-27F (SEQ ID NO: 1679): ACATTTGGTTCTTCCAAGGGACTAC
Reverse primer HSSTROL3 junc21-27R (SEQ ID NO: 1680): TCGATCTCAGAGGGCACCC Amplicon HSSTROL3 junc21 -27 (SEQ ID NO: 1681):
ACATTTGGTTCTTCCAAGGGACTACTGGCGTTTCCACCCCAGCACCCGGCGTGTAGA CAGTCCCGTGCCCCGCAGGGCCACTGACTGGAGAGGGGTGCCCTCTGAGATCGA
DESCRIPTION FOR CLUSTER HUMTREFAC
Cluster HUMTREFAC features 2 transcript(s) and 7 segment(s) of interest, the names for which are given in Tabbs 1096 and 1097, respectively, the sequences themselves are given at the end of the application. The selected protein variants are given in table 1098.
Table 1096 - Transcripts of interest
Table 1097 - Segments of interest
Table 1098 - Proteins of interest
These sequences are variants of the known protein Trefoil factor 3 precursor (SwissProt accession identifier TFF3_HUMAN; known also according to the synonyms Intestinal trefoil factor; hPl.B), SEQ ID NO: 1456, referred to herein as the previously known protein.
Protein Trefoil factor 3 precursor is known or believed to have the following function(s): May have a role in promoting cell migration (motogen). The sequence for protein Trefoil factor
3 precursor is given at the end of the application, as "Trefoil factor 3 precursor amino acid sequence". Known polymorphisms for this sequence are as shown in Table 1099.
Table 1099 -Amino acid mutations for Known Protein
Protein Trefoil factor 3 precursor localization is believed to be Secreted.
The following GO Annotation(s) apply to the previously known protein. The following annotation(s) were found: defense response; digestion, which are annotation(s) related to Biological Process; and extracellular, which are annotation(s) related to Cellular Component.
The GO assignment relies on information from one or more of the SwissProt/TremBl Protein knowledgebase, available from <http://www.expasy.ch/sprot/>; or Locuslinlc, available from <http://www.ncbi.nlm.nih.gov/projects/LocusLink/>.
Cluster HUMTREFAC can be used as a diagnostic marker according to overexpression of transcripts of this cluster in cancer. Expression of such transcripts in normal tissues is also given according to the previously described methods. The term "number" in the right hand column of the table and the numbers on the y-axis of figure 41 refer to weighted expression of ESTs in each category, as "parts per million" (ratio of the expression of ESTs for a particular cluster to the expression of all ESTs in that category, according to parts per million).
Overall, the following results were obtained as shown with regard to the histograms in
Figure 41 and Table 1100. This cluster is overexpressed (at least at a minimum level) in the following pathological conditions: a mixture of malignant tumors from different tissues, breast malignant tumors, pancreas carcinoma and prostate cancer.
Table 1100 - Normal tissue distribution
Table 1101 - P values and ratios for expression in cancerous tissue
As noted above, cluster HUMTREFAC features 2 transcript(s), which were listed in Table 1 above. These transcript(s) encode for protein(s) which are variant(s) of protein Trefoil factor 3 precursor. A description of each variant protein according to the present invention is now provided.
Variant protein HUMTREFAC_PEA_2_P7 according to the present invention has an amino acid sequence as given at the end of the application; it is encoded by transcript(s) HUMTREF AC_PEA_2_T5. The location of the variant protein was determined according to results from a number of different software programs and analyses, including analyses from
SignalP and other specialized programs. The variant protein is believed to be located as follows with regard to the cell: secreted. The protein localization is believed to be secreted because both signal-peptide prediction programs predict that this protein has a signal peptide, and neither trans- membrane region prediction program predicts that this protein has a trans -membrane region.
Variant protein HUMTREFAC_PEA_2_P7 also has the following non-silent SNPs (Single Nucleotide Polymorphisms) as listed in Table 1102, (given according to their position(s) on the amino acid sequence, with the alternative amino acid(s) listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein HUMTREF AC_PEA_2_P7 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 1102 - Amino acid mutations
Variant protein HUMTREF AC_PEA_2_P7 is encoded by the following transcript(s): HUMTREF AC JPEA_2_T5, for which the sequence(s) is/are given at the end of the application. The coding portion of transcript HUMTREF AC_PEA_2_T5 is shown in bold; this coding portion starts at position 278 and ends at position 688. The transcript also has the following
SNPs as listed in Table 1103 (given according to their position on the nucleotide sequence, with the alternative nucleic acid listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein HUMTREFAC_PEA_2_P7 sequence provides support for the deduced sequence of this variant protein according to the present invention). Table 1103 - Nucleic acid SNPs
Variant protein HUMTREF AC_PEA_2_P8 according to the present invention has an amino acid sequence as given at the end of the application; it is encoded by transcript(s) HUMTREF AC_PEA_2_T4. An alignment is given to the known protein (Trefoil factor 3 precursor) at the end of the application. One or more alignments to one or more previously published protein sequences are given at the end of the application. A brief description of the
relationship of the variant protein according to the present invention to each such aligned protein is as follows:
Comparison report between HUMTREFAC_PEA_2_P8 and TFF3_HUMAN: LAn isolated chimeric polypeptide encoding for HUMTREF AC_PEA_2JP8, comprising a first amino acid sequence being at least 90 % homologous to
MAARALCMLGLVLALLSSSSAEEYVGL corresponding to amino acids 1 - 27 of TFF3_HUMAN, which also corresponds to amino acids 1 - 27 of HUMTREF AC_PEA_2_P8, and a second amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence WKVHLPKGEGFSSG corresponding to amino acids 28 - 41 of HUMTREF AC_PEA__2JP8, wherein said first amino acid sequence and second amino acid sequence are contiguous and in a sequential order.
2.An isolated polypeptide encoding for a tail of HUMTREF AC_PEA_2_P8, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence WKVHLPKGEGFSSG in HUMTREF AC_PEA_2_P 8.
The location of the variant protein was determined according to results from a number of different software programs and analyses, including analyses from SignalP and other specialized programs. The variant protein is believed to be located as follows with regard to the cell: secreted. The protein localization is believed to be secreted because both signal-peptide prediction programs predict that this protein has a signal peptide, and neither trans -membrane region prediction program predicts that this protein has a trans -membrane region.
Variant protein HUMTREFAC_PEA_2_P8 also has the following non-silent SNPs (Single Nucleotide Polymorphisms) as listed in Table 1104, (given according to their position(s) on the amino acid sequence, with the alternative amino acid(s) listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein HUMTREF AC_PEA_2_P8 sequence provides support for the deduced sequence of this variant protein according to the present invention). Table 1104 - Amino acid mutations
Variant protein HUMTREFAC_PEA_2_P8 is encoded by the following transcript(s): HUMTREF ACJPEA__2_T4, for which the sequence(s) is/are given at the end of the application. The coding portion of transcript HUMTREF AC PEA 2 T4 is shown in bold; this coding portion starts at position 278 and ends at position 400. The transcript also has the following
SNPs as listed in Table 1105 (given according to their position on the nucleotide sequence, with the alternative nucleic acid listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein HUMTREF AC_PEA_2JP8 sequence provides support for the deduced sequence of this variant protein according to the present invention). Table 1105 - Nucleic acid SNPs
As noted above, cluster HUMTREFAC features 7 segment(s), which were listed in Table 2 above and for which the sequence(s) are given at the end of the application. These segment(s)
are portions of nucleic acid sequence(s) which are described herein separately because they are of particular interest. A description of each segment according to the present invention is now provided.
Segment cluster HUMTREF AC_PEA_2_node_0 according to the present invention is supported by 188 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): HUMTREFACJPEA_2_T4 and HUMTREF AC_PEA_2_T5. Table 1106 below describes the starting and ending position of this segment on each transcript.
Table 1106 - Segment location on transcripts
Segment cluster HUMTREF AC_PEA_2_node_9 according to the present invention is supported by 150 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): HUMTREF AC_PEA_2_T4 and
HUMTREF ACJPE A_2_T5. Table 1107 below describes the starting and ending position of this segment on each transcript.
Table 1107 - Segment location on transcripts
According to an optional embodiment of the present invention, short segments related to the above cluster are also provided. These segments are up to about 120 bp in length, and so are included in a separate description.
Segment cluster HUMTREFAC_PEA_2_node_2 according to the present invention is supported by 4 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): HUMTREFAC_PEA_2_T4. Table 1108 below describes the starting and ending position of this segment on each transcript.
Table 1108 - Segment location on transcripts
Segment cluster HUMTREF AC_PEA_2_node_3 according to the present invention is supported by 10 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): HUMTREFAC_PEA_2_T4 and HUMTREF AC_PEA_2_T5. Table 1109 below describes the starting and ending position of this segment on each transcript.
Table 1109 - Segment location on transcripts
Segment cluster HUMTREF AC_PEA_2_node_4 according to the present invention is supported by 197 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): HUMTREFAC_PEA_2_T4 and HUMTREFAC_PEA_2_T5. Table 1110 below describes the starting and ending position of this segment on each transcript.
Table 1110 - Segment location on transcripts
Segment cluster HUMTREF AC_PEA_2_node_5 according to the present invention is supported by 187 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): HUMTREF AC_PEA_2_T4 and HUMTREFAC_PEA_2_T5. Table 1111 below describes the starting and ending position of this segment on each transcript.
Table 1111 - Segment location on transcripts
Segment cluster HUMTREF AC_PEA_2_node_8 according to the present invention can be found in the following transcript(s): HUMTREFAC_PEA_2_T4 and HUMTREFAC_PEA_2_T5. Table 1112 below describes the starting and ending position of this segment on each transcript. Table 1112 - Segment location on transcripts
Variant protein alignment to the previously known protein:
Sequence name: TFF3_HUMAN
Sequence documentation:
Alignment of: HUMTREFAC_PEA_2_P8 x TFF3_HUMAN
Alignment segment 1/1:
Quality: 246.00
Escore: 0
Matching length: 27 Total length: 27
Matching Percent Similarity: 100.00 Matching Percent Identity: 100.00
Total Percent Similarity: 100.00 Total Percent Identity: 100.00
Gaps : 0
Alignment:
1 MAARALCMLGLVLALLSSSSAEEYVGL 27
I l I I I I l I I I I I I I 1 I I I I I l I l I l I I
1 MAARALCMLGLVLALLSSSSAEEYVGL 27
DESCRIPTION FOR CLUSTER HSSlOOPCB
Cluster HSSlOOPCB features 1 transcript(s) and 3 segment(s) of interest, the names for which are given in Tables 1113 and 1114, respectively, the sequences themselves are given at the end of the application. The selected protein variants are given in table 1115.
Table 1113 - Transcripts of interest
Table 1114 - Segments of interest
Table 1115 - Proteins of interest
These sequences are variants of the known protein S-IOOP protein (SwissProt accession identifier Sl 0P_HUMAN), SEQ ID NO: 1457, referred to herein as the previously known protein, which binds two calcium ions.
The sequence for protein S-100P protein is given at the end of the application, as "S-100P protein amino acid sequence". Known polymorphisms for this sequence are as shown in Table 1116.
Table 1116 - Amino acid mutations for Known Protein
The following GO Annotation(s) apply to the previously known protein. The following annotation(s) were found: calcium binding; protein binding, which are annotation(s) related to Molecular Function.
The GO assignment relies on information from one or more of the SwissProt/TremBl Protein knowledgebase, available from <http://www.expasy.ch/sprot/>; or Locuslink, available from <http://www.ncbi.nlm.nih.gov/projects/LocusLink/>.
Cluster HSSlOOPCB can be used as a diagnostic marker according to overexpression of transcripts of this cluster in cancer. Expression of such transcripts in normal tissues is also given according to the previously described methods. The term "number" in the right hand column of the table and the numbers on the y-axis of figure 42 refer to weighted expression of ESTs in each category, as "parts per million" (ratio of the expression of ESTs for a particular cluster to the expression of all ESTs in that category, according to parts per million).
Overall, the following results were obtained as shown with regard to the histograms in
Figure 42 and Table 1117. This cluster is overexpressed (at least at a minimum level) in the following pathological conditions: a mixture of malignant tumors from different tissues.
Table 1117 - Normal tissue distribution
Table 1118 - P values and ratios for expression in cancerous tissue
As noted above, cluster HSSlOOPCB features 1 transcript(s), which were listed in Table 1 above. These transcript(s) encode for protein(s) which are variant(s) of protein S-100P protein. A description of each variant protein according to the present invention is now provided.
Variant protein HSS100PCB_P3 according to the present invention has an amino acid sequence as given at the end of the application; it is encoded by transcript(s) HSS100PCB_Tl. The location of the variant protein was determined according to results from a number of different software programs and analyses, including analyses from SignalP and other specialized programs. The variant protein is believed to be located as follows with regard to the cell: secreted. The protein localization is believed to be secreted because both signal-peptide
prediction programs predict that this protein has a signal peptide, and neither trans -membrane region prediction program predicts that this protein has a trans -membrane region.
Variant protein HSS100PCB_P3 also has the following non-silent SNPs (Single Nucleotide Polymorphisms) as listed in Table 1119, (given according to their position(s) on the amino acid sequence, with the alternative amino acid(s) listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein HSS100PCB_P3 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 1119 - Amino acid mutations
Variant protein HSS100PCB P3 is encoded by the following transcript(s): HSS100PCB_Tl, for which the sequence(s) is/are given at the end of the application. The coding portion of transcript HSS100PCB_Tl is shown in bold; this coding portion starts at position 1057 and ends at position 1533. The transcript also has the following SNPs as listed in Table 1120 (given according to their position on the nucleotide sequence, with the alternative nucleic acid listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein HSS100PCB_P3 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 1120 - Nucleic acid SNPs
As noted above, cluster HSSlOOPCB features 3 segment(s), which were listed in Table 2 above and for which the sequence(s) are given at the end of the application. These segment(s) are portions of nucleic acid sequence(s) which are described herein separately because they are of particular interest. A description of each segment according to the present invention is now provided.
Segment cluster HSS100PCB_node_3 according to the present invention is supported by 16 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): HSSIOOPCBJTI. Table 1121 below describes the starting and ending position of this segment on each transcript.
Table 1121 - Segment location on transcripts
Segment cluster HSS100PCB_node_4 according to the present invention is supported by 29 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): HSS100PCBJT1. Table 1122 below describes the starting and ending position of this segment on each transcript.
Table 1123 - Segment location on transcripts
Segment cluster HSS100PCB_node_5 according to the present invention is supported by 141 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): HSS100PCB_Tl. Table 1124 below describes the starting and ending position of this segment on each transcript.
Table 1124 - Segment location on transcripts
DESCRIPTION FOR CLUSTER HSU33147
Cluster HSU33147 features 2 transcript(s) and 5 segment(s) of interest, the names for which are given in Tables 1125 and 1126, respectively, the sequences themselves are given at the end of the application. The selected protein variants are given in table 1127.
Table 1125 - Transcripts of interest
Table 1126 - Segments of interest
Table 1127 ' - Proteins of interest
These sequences are variants of the known protein Mammaglobin A precursor (SwissProt accession identifier MGBA_HUMAN; known also according to the synonyms Mammaglobin 1; Secretoglobin family 2A member 2), SEQ ID NO: 1416, referred to herein as the previously known protein.
The sequence for protein Mammaglobin A precursor is given at the end of the application, as "Mammaglobin A precursor amino acid sequence".
It has been investigated for clinical/therapeutic use in humans, for example as a target for an antibody or small molecule, and/or as a direct therapeutic; available information related to these investigations is as follows. Potential pharmaceutically related or therapeutically related activity or activities of the previously known protein are as follows: Immunostimulant. A therapeutic role for a protein represented by the cluster has been predicted. The cluster was assigned this field because there was information in the drug database or the public databases (e.g., described herein above) that this protein, or part thereof, is used or can be used for a potential therapeutic indication: Anticancer.
The following GO Annotation(s) apply to the previously known protein. The following annotation(s) were found: steroid binding, which are annotation(s) related to Molecular Function.
The GO assignment relies on information from one or more of the SwissProt/TremBl Protein knowledgebase, available from <http://www.expasy.ch/sprot/>; or Locuslink, available from <http://www.ncbi.nhn.nih.gov/projects/LocusLink/>.
Cluster HSU33147 can be used as a diagnostic marker according to overexpression of transcripts of this cluster in cancer. Expression of such transcripts in normal tissues is also given according to the previously described methods. The term "number" in the left hand column of the table and the numbers on the y-axis of figure 43 refer to weighted expression of ESTs in each category, as "parts per million" (ratio of the expression of ESTs for a particular cluster to the expression of all ESTs in that category, according to parts per million).
Overall, the following results were obtained as shown with regard to the histograms in Figure 43 and Table 1128. This cluster is overexpressed (at least at a minimum level) in the following pathological conditions: a mixture of malignant tumors from different tissues.
Table 1128 - Normal tissue distribution
Table 1129 - P values and ratios for expression in cancerous tissue
As noted above, cluster HSU33147 features 2 transcript(s), which were listed in Table 1 above. These transcript(s) encode for protein(s) which are variant(s) of protein Mammaglobin A precursor. A description of each variant protein according to the present invention is now provided.
Variant protein HSU33147_PEA_1_P5 according to the present invention has an amino acid sequence as given at the end of the application; it is encoded by transcript(s)
HSU33147_PEA_1_T1. An alignment is given to the known protein (Mammaglobin A precursor) at the end of the application. One or more alignments to one or more previously published protein sequences are given at the end of the application. A brief description of the relationship of the variant protein according to the present invention to each such aligned protein is as follows:
Comparison report between HSU33147_PEA_1_P5 and MGBA_HUMAN: 1.An isolated chimeric polypeptide encoding for HSU33147_PEA_1_P5, comprising a first amino acid sequence being at least 90 % homologous to
MKLLMVLMLAALSQHCYAGSGCPLLENVISKTINPQVSKTEYKELLQEFIDDNATTNAI DELKECFLNQTDETLSNVE corresponding to amino acids 1 - 78 of MGBA_HUMAN, which also corresponds to amino acids 1 - 78 of HSU33147_PEA_1_P5, and a second amino acid sequence being at least 90 % homologous to QLIYDS SLCDLF corresponding to amino acids 82 - 93 of MGBA_HUMAN, which also corresponds to amino acids 79 - 90 of
HSU33147_PEA_1_P5, wherein said first amino acid sequence and second amino acid sequence are contiguous and in a sequential order.
2.An isolated chimeric polypeptide encoding for an edge portion of
HSU33147_PEA_1_P5, comprising a polypeptide having a length "n", wherein n is at least about 10 amino acids in length, optionally at least about 20 amino acids in length, preferably at least about 30 amino acids in length, more preferably at least about 40 amino acids in length and most preferably at least about 50 amino acids in length, wherein at feast two amino acids comprise EQ, having a structure as follows: a sequence starting from any of amino acid numbers 78-x to 78; and ending at any of amino acid numbers 79+ ((n-2) - x), in which x varies from 0 to n-2.
The location of the variant protein was determined according to results from a number of different software programs and analyses, including analyses from SignalP and other specialized programs. The variant protein is believed to be located as follows with regard to the cell: secreted. The protein localization is believed to be secreted because both signal-peptide prediction programs predict that this protein has a signal peptide, and neither trans -membrane region prediction program predicts that this protein has a trans- membrane region.
The glycosylation sites of variant protein HSU33147_PEA_1_P5, as compared to the known protein Mammaglobin A precursor, are described in Table 1130 (given according to their position(s) on the amino acid sequence in the first column; the second column indicates whether the glycosylation site is present in the variant protein; and the last column indicates whether the position is different on the variant protein).
Table 1130 - Glycosylation site(s)
Variant protein HSU33147_PEA_1_P5 is encoded by the following transcript(s): HSU33147_PEA_1_T1, for which the sequence(s) is/are given at the end of the application. The coding portion of transcript HSU33147_PEA_1_T1 is shown in bold; this coding portion starts at position 72 and ends at position 341. The transcript also has the following SNPs as listed in Table 1131 (given according to their position on the nucleotide sequence, with the alternative nucleic acid listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein HSU33147_PEA_1_P5 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 1131 - Nucleic acid SNPs
As noted above, cluster HSU33147 features 5 segment(s), which were listed in Table 2 above and for which the sequence(s) are given at the end of the application. These segment(s) are portions of nucleic acid sequence(s) which are described herein separately because they are of particular interest. A description of each segment according to the present invention is now provided.
Segment cluster HSU33147_PEA_l_node_0 according to the present invention is supported by 38 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): HSU33147_PEA_1_T1 and HSU33147_PEA_1_T2. Table 1132 below describes the starting and ending position of this segment on each transcript.
Table 1132 - Segment location on transcripts
Segment cluster HSU33147_PEA_l_node_2 according to the present invention is supported by 44 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): HSU33147_PEA_1_T1 and HSU33147J>EA_1_T2. Table 1133 below describes the starting and ending position of this segment on each transcript.
Table 1133 - Segment location on transcripts
Segment cluster HSU33147_PEA_l_node_4 according to the present invention is supported by 3 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): HSU33147_PEA_1_T2. Table 1134 below describes the starting and ending position of this segment on each transcript.
Table 1134 - Segment location on transcripts
Segment cluster HSU33147_PEA_l_node_7 according to the present invention is supported by 35 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): HSU33147JPEA_1_T1. Table 1135 below describes the starting and ending position of this segment on each transcript.
Table 1135 - Segment location on transcripts
According to an optional embodiment of the present invention, short segments related to the above cluster are also provided. These segments are up to about 120 bp in length, and so are included in a separate description.
Segment cluster HSU33147_PEA_l_node_3 according to the present invention can be found in the following transcript(s): HSU33147_PEA_1_T2. Table 1136 below describes the starting and ending position of this segment on each transcript.
Table 1136 - Segment location on transcripts
Variant protein alignment to the previously known protein:
Sequence name: MGBA_HUMAN
Sequence documentation:
Alignment of: HSU33147_PEA_1_P5 x MGBAJHUMAN
Alignment segment 1/1:
Quality: 776.00 Escore: 0
Matching length: 90 Total length: 93
Matching Percent Similarity: 100.00 Matching Percent Identity: 100.00
Total Percent Similarity: 96.77 Total Percent Identity: 96.77 Gaps:
Alignment :
1 MKLLMVLMLAALSQHCYAGSGCPLLENVISKTINPQVSKTEYKELLQEFI 50 I I I I I I I I I I I I I I Il I Il I I I I I I I I I I I I I I I I I I I I I I I I I I I 1 I I I
1 MKLLMVLMLAALSQHCYAGSGCPLLENVISKTINPQVSKTEYKELLQEFI 50
51 DDNATTNAIDELKECFLNQTDETLSNVE...QLIYDSSLCDLF 90
51 DDNATTNAIDELKECFLNQTDETLSNVEVFMQLIYDSSLCDLF 93
DESCRIPTION FOR CLUSTER R20779
Cluster R20779 features 1 transcript(s) and 24 segment(s) of interest, the names for which are given in Tables 1137 and 1138, respectively, the sequences themselves are given at the end of the application. The selected protein variants are given in table 1139.
Table 1137 - Transcripts of interest
Table 1138 - Segments of interest
Table 1139 -Proteins of interest
These sequences are variants of the known protein Stanniocalcin 2 precursor (SwissProt accession identifier STC2_HUMAN; known also according to the synonyms STC-2; Stanniocalcin-related protein; STCRP; STC-related protein), SEQ ID NO: 1458, referred to herein as the previously known protein.
Protein Stanniocalcin 2 precursor is known or believed to have the following function(s): Has an anti-hypocalcemic action on calcium and phosphate homeostasis. The sequence for protein Stanniocalcin 2 precursor is given at the end of the application, as "Stanniocalcin 2 precursor amino acid sequence". Protein Stanniocalcin 2 precursor localization is believed to be Secreted (Potential).
The following GO Annotation(s) apply to the previously known protein. The following annotation(s) were found: cell surface receptor linked signal transduction; cell-cell signaling; nutritional response pathway, which are annotation(s) related to Biological Process; hormone, which are annotation(s) related to Molecular Function; and extracellular, which are armotation(s) related to Cellular Component.
The GO assignment relies on information from one or more of the SwissProt/TremBl Protein knowledgebase, available from <http://www.expasy.ch/sprot/>; or Locuslmk, available from <http://www.ncbi.nlm.nih.gov/projects/LocusLink/>.
Cluster R20779 can be used as a diagnostic marker according to overexpression of transcripts of this cluster in cancer. Expression of such transcripts in normal tissues is also given according to the previously described methods. The term "number" in the right hand column of the table and the numbers on the y-axis of figure 44 refer to weighted expression of ESTs in each category, as "parts per million" (ratio of the expression of ESTs for a particular cluster to the expression of all ESTs in that category, according to parts per million).
Overall, the following results were obtained as shown with regard to the histograms in Figure 44 and Table 1140. This cluster is overexpressed (at least at a minimum level) in the following pathological conditions: epithelial malignant tumors, a mixture of malignant tumors from different tissues and lung malignant tumors.
Table 1140 - Normal tissue distribution
Name of Tissue > Number bone 825 brain 0 colon 0 epithelial 32 general 38 kidney 22 liver 9 lung 11 lymph nodes 0 breast 215 muscle 35 ovary 36 pancreas 4 prostate 80 skin 99 stomach 0 uterus 4
Table 1141 - P values and ratios for expression in cancerous tissue
As noted above, cluster R20779 features 1 transcript(s), which were listed in Table 1 above. These transcript(s) encode for protein(s) which are variant(s) of protein Stanniocalcin 2 precursor. A description of each variant protein according to the present invention is now provided.
Variant protein R20779_P2 according to the present invention has an amino acid sequence as given at the end of the application; it is encoded by transcript(s) R20779_T7. An alignment is given to the known protein (Stanniocalcin 2 precursor) at the end of the application. One or more alignments to one or more previously published protein sequences are given at the end of the application. A brief description of the relationship of the variant protein according to the present invention to each such aligned protein is as follows:
Comparison report between R20779_P2 and STC2 JHUMAN: 1.An isolated chimeric polypeptide encoding for R20779_P2, comprising a first amino acid sequence being at least 90 % homologous to MCAERLGQFMTLALVLATFDPARGTDATNPPEGPQDRSSQQKGRLSLQNTAEIQHCLV NAGDVGCGVFECFENNSCEIRGLHGICMTFLHNAGKFDAQGKSFIKDALKCKAHALRH RFGCISRKCPAIREMVSQLQRECYLKHDLCAAAQENTRVΓVΈMIHFKDLLLHE corresponding to amino acids 1 - 169 of STC2_HUMAN, which also corresponds to amino acids 1 - 169 of R20779_P2, and a second amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least
95% homologous to a polypeptide having the sequence CYKIEITMPKRRKVKLRD corresponding to amino acids 170 - 187 of R20779_P2, wherein said first amino acid sequence and second amino acid sequence are contiguous and in a sequential order.
2.An isolated polypeptide encoding for a tail of R20779_P2, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence CYKIEITMPKRRKVKLRD in R20779 P2.
The location of the variant protein was determined according to results from a number of different software programs and analyses, including analyses from SignalP and other specialized programs. The variant protein is believed to be located as follows with regard to the cell: secreted. The protein localization is believed to be secreted because both signal-peptide prediction programs predict that this protein has a signal peptide, and neither trans -membrane region prediction program predicts that this protein has a trans -membrane region. Variant protein R20779_P2 also has the following non- silent SNPs (Single Nucleotide
Polymorphisms) as listed in Table 1142, (given according to their position(s) on the amino acid sequence, with the alternative amino acid(s) listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein R20779_P2 sequence provides support for the deduced sequence of this variant protein according to the present invention). Table 1142 - Amino acid mutations
The glycosylation sites of variant protein R20779_P2, as compared to the known protein Stanniocalcin 2 precursor, are described in Table 1143 (given according to their position(s) on the amino acid sequence in the first column; the second column indicates whether the
glycosylation site is present in the variant protein; and the last column indicates whether the position is different on the variant protein).
Table 1143 - Glycosylation site(s)
Variant protein R20779_P2 is encoded by the following trarκcript(s): R20779_T7, for which the sequence(s) is/are given at the end of the application. The coding portion of transcript R20779_T7 is shown in bold; this coding portion starts at position 1397 and ends at position 1957. The transcript also has the following SNPs as listed in Table 1144 (given according to their position on the nucleotide sequence, with the alternative nucleic acid listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein R20779_P2 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 1144 - Nucleic acid SNPs
As noted above, cluster R20779 features 24 segment(s), which were listed in Table 2 above and for which the sequence(s) are given at the end of the application. These segment(s) are portions of nucleic acid sequence(s) which are described herein separately because they are of particular interest. A description of each segment according to the present invention is now provided.
Segment cluster R20779_node_0 according to the present invention is supported by 31 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): R20779_T7. Table 1145 below describes the starting and ending position of this segment on each transcript.
Table 1145 - Segment location on transcripts
Segment cluster R20779_node_2 according to the present invention is supported by 55 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): R20779JT7. Table 1146 below describes the starting and ending position of this segment on each transcript.
Table 1146 - Segment location on transcripts
Segment cluster R20779_nodeJ7 according to the present invention is supported by 63 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): R20779_T7. Table 1147 below describes the starting and ending position of this segment on each transcript.
Table 1147 - Segment location on transcripts
Segment cluster R20779_node_9 according to the present invention is supported by 66 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): R20779_T7. Table 1148 below describes the starting and ending position of this segment on each transcript.
Table 1148 - Segment location on transcripts
Segment cluster R20779_node_18 according to the present invention is supported by 61 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): R20779JT7. Table 1149 below describes the starting and ending position of this segment on each transcript.
Table 1149 - Segment location on transcripts
Segment cluster R20779_node_21 according to the present invention is supported by 106 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): R20779_T7. Table 1150 below describes the starting and ending position of this segment on each transcript.
Table 1150 - Segment location on transcripts
Segment cluster R20779_node_24 according to the present invention is supported by 100 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): R20779_T7. Table 1151 below describes the starting and ending position of this segment on each transcript.
Table 1151 - Segment location on transcripts
Segment cluster R20779_node_27 according to the present invention is supported by 26 libraries. The number of libraries was determined as previously described. This segment can be
found in the following transcript(s): R20779_T7. Table 1152 below describes the starting and ending position of this segment on each transcript.
Table 1152 - Segment location on transcripts
Segment cluster R20779_node_28 according to the present invention is supported by 31 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): R20779JT7. Table 1153 below describes the starting and ending position of this segment on each transcript. Table 1153- Segment location on transcripts
Segment cluster R20779_node_30 according to the present invention is supported by 34 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): R20779_T7. Table 1154 below describes the starting and ending position of this segment on each transcript.
Table 1154 - Segment location on transcripts
Segment cluster R20779_node_31 according to the present invention is supported by 46 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): R20779_T7. Table 1155 below describes the starting and ending position of this segment on each transcript.
Table 1155 - Segment location on transcripts
Segment cluster R20779_node_32 according to the present invention is supported by 88 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): R20779JT7. Table 1156 below describes the starting and ending position of this segment on each transcript.
Table 1156 - Segment location on transcripts
According to an optional embodiment of the present invention, short segments related to the above cluster are also provided. These segments are up to about 120 bp in length, and so are included in a separate description.
Segment cluster R20779jnode_l according to the present invention is supported by 27 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): R20779_T7. Table 1157 below describes the starting and ending position of this segment on each transcript.
Table 1157 - Segment location on transcripts
Segment cluster R20779_node_3 according to the present invention is supported by 52 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): R20779_T7. Table 1158 below describes the starting and ending position of this segment on each transcript.
Table 1158 - Segment location on transcripts
Segment cluster R20779_node_10 according to the present invention can be found in the following transcript(s): R20779_T7. Table 1159 below describes the starting and ending position of this segment on each transcript.
Table 1159 - Segment location on transcripts
Segment cluster R20779_node_l 1 according to the present invention is supported by 58 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): R20779_T7. Table 1160 below describes the starting and ending position of this segment on each transcript. Table 1160 - Segment location on transcripts
Segment cluster R20779_node_14 according to the present invention is supported by 1 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): R20779_T7. Table 1161 below describes the starting and ending position of this segment on each transcript.
Table 1161 - Segment location on transcripts
Segment cluster R20779_node_17 according to the present invention is supported by 54 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): R20779JT7. Table 1162 below describes the starting and ending position of this segment on each transcript.
Table 1162 - Segment location on transcripts
Segment cluster R20779_node_19 according to the present invention can be found in the following transcript(s): R20779_T7. Table 1163 below describes the starting and ending position of this segment on each transcript. Table 1163 - Segment location on transcripts
Segment cluster R20779_node_20 according to the present invention is supported by 53 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): R20779JT7. Table 1164 below describes the starting and ending position of this segment on each transcript.
Table 1164 - Segment location on transcripts
Segment cluster R20779_node_22 according to the present invention is supported by 76 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): R20779_T7. Table 1165 below describes the starting and ending position of this segment on each transcript.
Table 1165 - Segment location on transcripts
Segment cluster R20779_node_23 according to the present invention is supported by 81 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): R20779_T7. Table 1166 below describes the starting and ending position of this segment on each transcript.
Table 1166 - Segment location on transcripts
Segment cluster R20779__node_25 according to the present invention can be found in the following transcript(s): R20779_T7. Table 1167 below describes the starting and ending position of this segment on each transcript.
Table 1167 - Segment location on transcripts
Segment cluster R20779_node_29 according to the present invention can be found in the following transcript(s): R20779_T7. Table 1168 below describes the starting and ending position of this segment on each transcript.
Table 1168 - Segment location on transcripts
Variant protein alignment to the previously known protein:
Sequence name: STC2_HUMAN
Sequence documentation:
Alignment of: R20779_P2 x STC2_HUMAN
Alignment segment 1/1:
Quality: 1688.00 Escore: 0
Matching length: 171 Total length: 171
Matching Percent Similarity: 99.42 Matching Percent Identity: 99.42 Total Percent Similarity: 99.42 Total Percent Identity: 99.42
Gaps : 0
Alignment : . . . . .
1 MCAERLGQFMTLALVLATFDPARGTDATNPPEGPQDRSSQQKGRLSLQNT 50
1 , MCAERLGQFMTLALVLATFDPARGTDATNPPEGPQDRSSQQKGRLSLQNT 50
51 AEIQHCLVNAGDVGCGVFECFENNSCEIRGLHGICMTFLHNAGKFDAQGK 100 I I Il Il I Il I I Il I Il Il I I I I Il Il I Il I Il I Il I Il I Il Il I I Il I I I
51 AEIQHCLVNAGDVGCGVFECFENNSCEIRGLHGICMTFLHNAGKFDAQGK 100
101 SFIKDALKCKAHALRHRFGCISRKCPAIREMVSQLQRECYLKHDLCAAAQ 150 M I I M I M M M M M M M M I M I I M M M M M M M M M M M
101 SFIKDALKCKAHALRHRFGCISRKCPAIREMVSQLQRECYLKHDLCAAAQ 150
151 ENTRVIVEMIHFKDLLLHECY 171
151 ENTRVIVEMIHFKDLLLHEPY 171
DESCRIPTION FOR CLUSTER R38144
Cluster R38144 features 6 transcript(s) and 24 segment(s) of interest, the names for which are given in Tables 1169 and 1170, respectively, the sequences themselves are given at the end of the application. The selected protein variants are given in table 1171.
Table 1169 - Transcripts of interest
Table 1171 - Proteins of interest
These sequences are variants of the known protein Putative alpha- mannosidase C20orf31 precursor (SwissProt accession identifier CT31_HUMAN; known also according to the synonyms EC 3.2.1), SEQ ID NO: 1459, referred to herein as the previously known protein.
The sequence for protein Putative alpha-mannosidase C20orf31 precursor is given at the end of the application, as "Putative alpha-mannosidase C20orf31 precursor amino acid sequence". Known polymorphisms for this sequence are as shown in Table 1172.
Table 1172 - Amino acid mutations for Known Protein
Protein Putative alpha-mannosidase C20orf31 precursor localization is believed to be Secreted (Potential).
The following GO Annotation(s) apply to the previously known protein. The following annotation(s) were found: carbohydrate metabolism; N-linked glycosylation, which are annotation(s) related to Biological Process; mannosyl- oligosaccharide 1,2- alpha-mannosidase; calcium binding; hydrolase, acting on glycosyl bonds, which are annotation(s) related to Molecular Function; and membrane, which are annotation(s) related to Cellular Component.
The GO assignment relies on information from one or more of the SwissProt/TremBl Protein knowledgebase, available from <http://www.expasy.ch/sprot/>; or Locuslink, available from <http://www.ncbi.nlm.nih. gov/projects/LocusLink/>.
Cluster R38144 can be used as a diagnostic marker according to overexpression of transcripts of this cluster in cancer. Expression of such transcripts in normal tissues is also given according to the previously described methods. The term "number" in the right hand column of the table and the numbers on the y-axis of figure 45 refer to weighted expression of ESTs in each category, as "parts per million" (ratio of the expression of ESTs for a particular cluster to the expression of all ESTs in that category, according to parts per million).
Overall, the following results were obtained as shown with regard to the histograms in Figure 45 and Table 1173. This cluster is overexpressed (at least at a minimum level) in the
following pathological conditions: epithelial malignant tumors, lung malignant tumors, skin malignancies and gastric carcinoma.
Table 1173 - Normal tissue distribution
Table 1174 - P values and ratios for expression in cancerous tissue
As noted above, cluster R38144 features 6 transcript(s), which were listed in Table 1 above. These transcript(s) encode for protein(s) which are variant(s) ofprotein Putative alpha - mannosidase C20orf31 precursor. A description of each variant protein according to the present invention is now provided.
Variant protein R38144_PEA_2_P6 according to the present invention has an amino acid sequence as given at the end of the application; it is encoded by transcript(s) R38144_PEA_2_T6. An alignment is given to the known protein (Putative alpha- mannosidase C20orf31 precursor) at the end of the application. One or more alignments to one or more previously published protein sequences are given at the end of the application. A brief description of the relationship of the variant protein according to the present invention to each such aligned protein is as follows:
Comparison report between R38144_PEA_2_P6 and CT3 IJHUMAN : 1.An isolated chimeric polypeptide encoding for R38144_PEA_2_P6, comprising a first amino acid sequence being at least 90 % homologous to
MPFRLLIPLGLLCALLPQHHGAPGPDGSAPDPAHYRERVKAMFYHAYDSYLENAFPFD ELRPLTCDGHDTWGSFSLTLIDALDTLLILGNVSEFQRVVEVLQDSVDFDIDVNASVFET NIRVVGGLLSAHLLSKKAGVEVEAGWPCSGPLLRMAEEAARKLLPAFQTPTGMPYGTV NLLHGVNPGETPVTCTAGIGTFIVEFATLSSLTGDPVFEDVARVALMRLWESRSDIGLV GNHIDVLTGKWVAQDAGIGAGVDSYFEYLVKGAILLQDKKLMAMFLEYNKAIRNYTR FDDWYLWVQMYKGTVSMPVFQSLEAYWPGLQSLIGDIDNAMRTFLNYYTVWKQFGG LPEFYNIPQGYTVEKREGYPLPJ5ELIESAMYLYRATGDPTLLELGRDAVESIEKISKVEC GFAT corresponding to amino acids 1 - 412 of CT3 IJHUMAN, which also corresponds to amino acids 1 - 412 of R38144_PEA_2_P6, and a second amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence LASFSHMSDQRSARPQAGQPHGVVLPGRDCEIPLPPV corresponding to amino acids 413 - 449 of R38144_PEA_2_P6, wherein said first amino acid sequence and second amino acid sequence are contiguous and in a sequential order. 2.An isolated polypeptide encoding for a tail of R38144_PEA_2_P6, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence LASFSHMSDQRSARPQAGQPHGWLPGRDCEIPLPPV in R38144_PEA_2_P6.
The location of the variant protein was determined according to results from a number of different software programs and analyses, including analyses from SignalP and other specialized programs. The variant protein is believed to be located as follows with regard to the cell: secreted. The protein localization is believed to be secreted because both signal-peptide prediction programs predict that this protein has a signal peptide, and neither trans -membrane region prediction program predicts that this protein has a trans -membrane region.
Variant protein R38144_PEA_2_P6 also has the following non- silent SNPs (Single Nucleotide Polymorphisms) as listed in Table 1175, (given according to their position(s) on the amino acid sequence, with the alternative amino acid(s) listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein R38144_PEA_2_P6 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 1175 - Amino acid mutations
The glycosylation sites of variant protein R38144_PEA_2_P6, as compared to the known protein Putative alpha- mannosidase C20orf31 precursor, are described in Table 1176 (given according to their position(s) on the amino acid sequence in the first column; the second column indicates whether the glycosylation site is present in the variant protein; and the last column indicates whether the position is different on the variant protein).
Table 1176 - Glycosylation site(s)
Variant protein R38144_PEA_2JP6 is encoded by the following transcript(s): R38144_PEA_2_T6, for which the sequence(s) is/are given at the end of the application. The coding portion of transcript R38144_PEA_2_T6 is shown in bold; this coding portion starts at position 91 and ends at position 1437. The transcript also has the following SNPs as listed in Table 1177 (given according to their position on the nucleotide sequence, with the alternative nucleic acid listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein R38144_PEA_2JP6 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 1177 - Nucleic acid SNPs
Variant protein R38144_PEA_2_P13 according to the present invention has an amino acid sequence as given at the end of the application; it is encoded by transcript(s) R38144_PEA_2_T13. An alignment is given to the known protein (Putative alpha- mannosidase C20orβl precursor) at the end of the application. One or more alignments to one or more previously published protein sequences are given at the end of the application. A brief description of the relationship of the variant protein according to the present invention to each such aligned protein is as follows:
Comparison report between R38144_PEA_2_P13 and CT3 IJHUMAN: 1.An isolated chimeric polypeptide encoding for R38144_PEA_2_P13, comprising a first amino acid sequence being at least 90 % homologous to MPFRLLIPLGLLCALLPQHHGAPGPDGSAPDP AHYRERVKAMFYHA YDSYLENAFPFD
ELRPLTCDGHDTWGSFSLTLIDALDTLLILGNVSEFQRVVEVLQDSVDFDIDVNASVFET NIRVVGGLLSAHLLSKKAGVEVEAGWPCSGPLLRMAEEAARKLLPAFQTPTGMPYGTV NLLHGVNPGETPVTCTAGIGTFIVEFATLSSLTGDPVFEDVARVALMRLWESRSDIGLV GNHIDVLTGKWVAQDAGIGAGVDSYFEYLVKGAILLQDKKLMAMFLEYNKAIRNYTR
FDDWYLWVQMYKGTVSMPVFQSLEAYWPGLQ corresponding to amino acids 1 - 323 of CT3 IJHUMAN, which also corresponds to amino acids 1 - 323 of R38144JPEA_2JP13, and a second amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence NLLKAQCTSTVPRGIPPS corresponding to amino acids 324 - 341 of R38144_PEA_2_P13, wherein said first amino acid sequence and second amino acid sequence are contiguous and in a sequential order.
2.An isolated polypeptide encoding for a tail of R38144_PEA_2_P13, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence NLLKAQCTSTVPRGIPPS in R38144_PEA_2_P13.
The location of the variant protein was determined according to results from a number of different software programs and analyses, including analyses from SignalP and other specialized programs. The variant protein is believed to be located as follows with regard to the cell:
secreted. The protein localization is believed to be secreted because both signa 1-peptide prediction programs predict that this protein has a signal peptide, and neither trans -membrane region prediction program predicts that this protein has a trans -membrane region.
Variant protein R38144_PEA_2_P13 also has the following non-silent SNPs (Single Nucleotide Polymorphisms) as listed in Table 1178, (given according to their position(s) on the amino acid sequence, with the alternative amino acid(s) listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein R38144_PEA_2_P13 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 1178 - Amino acid mutations
The glycosylation sites of variant protein R38144_PEA_2_P13, as compared to the known protein Putative alpha- mannosidase C20orf31 precursor, are described in Table 1179 (given according to their position(s) on the amino acid sequence in the first column; the second column indicates whether the glycosylation site is present in the variant protein; and the last column indicates whether the position is different on the variant protein).
Table 1179 - Glycosylation site(s)
Variant protein R38144_PEA_2_P13 is encoded by the following transcript(s): R38144_PEA_2_T13, for which the sequence(s) is/are given at the end of the application. The coding portion of transcript R38144_PEA_2_T13 is shown in bold; this coding portion starts at position 91 and ends at position 1113. The transcript also has the following SNPs as listed in Table 1180 (given according to their position on the nucleotide sequence, with the alternative nucleic acid listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein R38144_PEA_2_P13 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 1180 - Nucleic acid SNPs
Variant protein R38144_PEA_2_P15 according to the present invention has an amino acid sequence as given at the end of the application; it is encoded by transcript(s) R38144JPEA_2_T15. An alignment is given to the known protein (Putative alpha- mannosidase C20orf31 precursor) at the end of the application. One or more alignments to one or more previously published protein sequences are given at the end of the application. A brief description of the relationship of the variant protein according to the present invention to each such aligned protein is as follows: Comparison report between R38144_PEA_2_P15 and CT31_HUMAN:
1.An isolated chimeric polypeptide encoding for R38144_PEA_2_P15, comprising a first amino acid sequence being at least 90 % homologous to
MPFRLLIPLGLLCALLPQHHGAPGPDGSAPDPAHYRERVKAMFYHAYDSYLENAFPFD ELRPLTCDGHDTWGSFSLTLIDALDTLLILGNVSEFQRVVEVLQDSVDFDIDVNASVFET NIRVVGGLLSAHLLSKKAGVEVEAGWPCSGPLLRMAEEAARKLLPAFQTPTGMPYGTV NLLHGVNPGETPVTCTAGIGTFIVEFATLSSLTGDPVFEDVARVALMRLWESRSDIGLV GNHIDVLTGKWVAQDAGIGAGVDSYFEYLVKGAILLQDKKLMAMFLE corresponding to amino acids 1 - 282 of CT31_HUMAN, which also corresponds to amino acids 1 - 282 of R38144_PEA_2_P15, and a second amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence PHWRH corresponding to amino acids 283 - 287 of R38144_PEA_2_P15, wherein said first amino acid sequence and second amino acid sequence are contiguous and in a sequential order.
2.An isolated polypeptide encoding for a tail of R38144_PEA_2_P15, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%,
more preferably at least about 90% and most preferably at least about 95% homologous to the sequence PHWRH in R38144_PEA_2J>15.
The location of the variant protein was determined according to results from a number of different software programs and analyses, including analyses from SignalP and other specialized programs. The variant protein is believed to be located as follows with regard to the cell: secreted. The protein localization is believed to be secreted because both signal-peptide prediction programs predict that this protein has a signal peptide, and neither trans -membrane region prediction program predicts that this protein has a trans -membrane region. Variant protein R38144JPE A_2_P 15 also has the following non- silent SNPs (Single
Nucleotide Polymorphisms) as listed in Table 1181, (given according to their position(s) on the amino acid sequence, with the alternative amino acid(s) listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein R38144_PEA_2_P15 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 1181 - Amino acid mutations
The glycosylation sites of variant protein R38144_PEA_2_P15, as compared to the known protein Putative alpha- mannosidase C20orf31 precursor, are described in Table 1182 (given according to their position(s) on the amino acid sequence in the first column; the second column indicates whether the glycosylation site is present in the variant protein; and the last column indicates whether the position is different on the variant protein).
Table 1182 - Glycosylation site(s)
Variant protein R38144_PEA_2_P15 is encoded by the following transcript(s): R38144_PEA_2_T15, for which the sequence(s) is/are given at the end of the application. The coding portion of transcript R38144_PEA_J2_T15 is shown in bold; this coding portion starts at position 91 and ends at position 951. The transcript also has the following SNPs as listed in Table 1183 (given according to their position on the nucleotide sequence, with the alternative nucleic acid listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein R38144_PEA_2_P15 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 1183- Nucleic acid SNPs
Variant protein R38144_PEA_2_P19 according to the present invention has an amino acid sequence as given at the end of the application; it is encoded by transcript(s) R38144_PEA_2_T19. An alignment is given to the known protein (Putative alpha- mannosidase C20orβl precursor) at the end of the application. One or more alignments to one or more previously published protein sequences are given at the end of the application. Abrief description of the relationship of the variant protein according to the present invention to each such aligned protein is as follows: Comparison report between R38144_PEA_2_P19 and CT31 JHUMAN:
1.An isolated chimeric polypeptide encoding for R38144_PEA_2_P19, comprising a first amino acid sequence being at least 90 % homologous to
MPFRLLIPLGLLCALLPQHHGAPGPDGSAPDPAHYRERVKAMFYHAYDSYLENAFPFD ELRPLTCDGHDTWGSFSLTLIDALDTLLILGNVSEFQRWEVLQDSVDFDIDVNASVFET NIRWGGLLSAHLLSKKAGVEVEAGWPCSGPLLRMAEEAARKLLPAFQTPTGMPYGTV NLLHGVNPGETPVTCTAGIGTFIVEFATLSSLTGDPVFEDVARVALMRLWESRSDIGLV GNHIDVLTGKWVAQDAGIGAGVDSYFEYLVKGAILLQDKKLMAMFLEYNKAIRNYTR FDDWYLWVQMYKGTVSMPVFQSLEAYWPGLQSLIGDIDNAMRTFLNYYTVWKQFGG LPEFYNIPQGYTVEKREGYPLRPELIESAMYLYRATGDPTLLELGRDAVESIEKISKVEC GFAT corresponding to amino acids 1 - 412 of CT3 IJHUMAN, which also corresponds to amino acids 1 - 412 of R38144_PEA_2_P19, and a second amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence KRSRSVAQAGVQWCDHDSPQP corresponding to amino acids 413 - 433 of R38144_PEA_2_P19, wherein said first amino acid sequence and second amino acid sequence are contiguous and in a sequential order.
2.An isolated polypeptide encoding for a tail of R38144_PEA_2_P19, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence KRSRSVAQAGVQWCDHDSPQP in R38144JPEA_2_P19.
The location of the variant protein was determined according to results from a number of different software programs and analyses, including analyses from SignalP and other specialized programs. The variant protein is believed to be located as follows with regard to the cell: secreted. The protein localization is believed to be secreted because both signal-peptide prediction programs predict that this protein has a signal peptide, and neither trans- membrane region prediction program predicts that this protein has a trans -membrane region.
Variant protein R38144_PEA_2_P19 also has the following non- silent SNPs (Single Nucleotide Polymorphisms) as listed in Table 1184, (given according to their position(s) on the amino acid sequence, with the alternative amino acid(s) listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein R38144_PEA_2JP19 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 1184- Amino acid mutations
The glycosylation sites of variant protein R38144_PEA_2_P19, as compared to the known protein Putative alpha- mannosidase C20orβl precursor, are described in Table 1185(given according to their position(s) on the amino acid sequence in the first column; the second column indicates whether the glycosylation site is present in the variant protein; and the last column indicates whether the position is different on the variant protein).
Table 1185- Glycosylation site(s)
Variant protein R38144_PEA_2_P19 is encoded by the following transcript(s): R38144^JPEA_2_T19, for which the sequence(s) is/are given at the end of the application. The coding portion of transcript R38144_PEA_2_T19 is shown in bold; this coding portion starts at position 91 and ends at position 1389. The transcript also has the following SNPs as listed in Table 1186 (given according to their position on the nucleotide sequence, with the alternative nucleic acid listed; the last column indicates whether the SNP is known or not; the presence of
known SNPs in variant protein R38144JPEA_2_P19 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 1186- Nucleic acid SNPs
Variant protein R38144_PEA_2_P24 according to the present invention has an amino acid sequence as given at the end of the application; it is encoded by transcript(s) R38144_PEA_2_T27. An alignment is given to the known protein (Putative alpha- mannosidase C20orf31 precursor) at the end of the application. One or more alignments to one or more previously published protein sequences are given at the end of the application. A brief description of the relationship of the variant protein according to the present invention to each such aligned protein is as follows: Comparison report between R38144_PEA_2_P24 and CT31_HUMAN:
1.An isolated chimeric polypeptide encoding for R38144_PEA_2_P24, comprising a first amino acid sequence being at least 90 % homologous to
MPFRLLIPLGLLCALLPQHHGAPGPDGSAPDPAHYRERVKAMFYHAYDSYLENAFPFD ELRPLTCDGHDTWGSFSLTLIDALDTLLILGNVSEFQRVVEVLQDSVDFDIDVNASVFET NIR corresponding to amino acids 1 - 121 of CT3 IJHUMAN, which also corresponds to amino acids 1 - 121 of R38144_PEA_2_P24, and a second amino acid sequence being at least 90 % homologous to
EYNKAIRNYTRFDDWYLWVQMYKGTVSMPVFQSLEAYWPGLQSLIGDIDNAMRTFLN YYTVWKQFGGLPEFYNIPQGYTVEKREGYPLRPELIESAMYLYRATGDPTLLELGRDA VESIEKISKVECGFATIKDLRDHKLDNRMESFFLAETVKYLYLLFDPTNFIHNNGSTFDA VITPYGECILGAGGYIFNTEAHPIDPAALHCCQRLKEEQWEVEDLMREFYSLKRSRSKFQ KNTVSSGPWEPPARPGTLFSPENHDQARERKPAKQKVPLLSCPSQPFTSKLALLGQVFL DSS corresponding to amino acids 282 - 578 of CT3 I HUMAN, which also corresponds to amino acids 122 - 418 of R38144_PEA_2_P24, wherein said first amino acid sequence and second amino acid sequence are contiguous and in a sequential order.
2.An isolated chimeric polypeptide encoding for an edge portion of R38144_PEA_2_P24, comprising a polypeptide having a length "n", wherein n is at least about 10 amino acids in length, optionally at least about 20 amino acids in length, preferably at least about 30 amino
acids in length, more preferably at least about 40 amino acids in length and most preferably at least about 50 amino acids in length, wherein at least two amino acids comprise RE, having a structure as follows: a sequence starting from any of amino acid numbers 121-x to 121; and ending at any of amino acid numbers 122+ ((n-2) - x), in which x varies from 0 to n-2.
The location of the variant protein was determined according to results from a number of different software programs and analyses, including analyses from SignalP and other specialized programs. The variant protein is believed to be located as follows with regard to the cell: secreted. The protein localization is believed to be secreted because both signal-peptide prediction programs predict that this protein has a signal peptide, and neither trans -membrane region prediction program predicts that this protein has a trans -membrane region.
Variant protein R38144JPEA_2_P24 also has the following non-silent SNPs (Single Nucleotide Polymorphisms) as listed in Table 1187, (given according to their position(s) on the amino acid sequence, with the alternative amino acid(s) listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein R38144_PEA_2_P24 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 1187- Amino acid mutations
The glycosylation sites of variant protein R38144_PEA_2_P24, as compared to the known protein Putative alpha- mannosidase C20orf31 precursor, are described in Table 1188 (given according to their position(s) on the amino acid sequence in the first column; the second column indicates whether the glycosylation site is present in the variant protein; and the last column indicates whether the position is different on the variant protein).
Table 1188- Glycosylation siteζs)
Variant protein R38144_PEA_2_P24 is encoded by the following transcript(s): R38144_PEA_2_T27, for which the sequence(s) is/are given at the end of the application. The coding portion of transcript R38144_PEA_2_T27 is shown in bold; this coding portion starts at
position 91 and ends at position 1344. The transcript also has the following SNPs as listed in Table 1 189 (given according to their position on the nucleotide sequence, with the alternative nucleic acid listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein R38144_PEA_2_P24 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 1189 - Nucleic acid SNPs
Variant protein R38144_PEA_2_P36 according to the present invention has an amino acid sequence as given at the end of Hie application; it is encoded by transcript(s) R38144_PEA_2_T10. An alignment is given to the known protein (Putative alpha- mannosidase C20orf31 precursor; SEQ ID NO:1459) at the end of the application. One or more alignments to one or more previously published protein sequences are given at the end of the application. A brief description of the relationship of the variant protein according to the present invention to each such aligned protein is as follows: Comparison report between R38144_PEA_2JP36 and AAH16184 (SEQ ID NO: 1460):
1.An isolated chimeric polypeptide encoding for R38144_PEA_2_P36, comprising a first amino acid sequence being at least 90 % homologous to
MPFRLLIPLGLLCALLPQHHGAPGPDGSAPDPAHYR corresponding to amino acids 1 - 36 of AAH16184, which also corresponds to amino acids 1 - 36 of R38144_PEA_2_P36, and a second amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence FWGMSQNSKEWLKCSRTAWTLILM corresponding to amino acids 37 - 60 of R38144_PEA_2_P36, wherein said first amino acid sequence and second amino acid sequence are contiguous and in a sequential order. 2.An isolated polypeptide encoding for a tail of R38144_PEA_2_P36, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence FWGMSQNSKEWLKCSRTAWTLILM in R38144_PEA_2_P36.
Comparison report between R38144_PEA_2_P36 and AAQ88943 (SEQ ID NO:1461):
1.An isolated chimeric polypeptide encoding for R38144_PEA_2_P36, comprising a first amino acid sequence being at least 90 % homologous to
MPFRLLIPLGLLCALLPQHHGAPGPDGSAPDPAHY corresponding to amino acids 1 - 35 of AAQ88943, which also corresponds to amino acids 1 - 35 of R38144_PEA_2_P36, and a second amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence RFWGMSQNSKEWLKCSRTAWTLILM corresponding to amino acids 36 - 60 of R38144_PEA_2_P36, wherein said first amino acid sequence and second amino acid sequence are contiguous and in a sequential order. 2.An isolated polypeptide encoding for a tail of R38144_PEA_2_P36, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence RFWGMSQNSKEWLKCSRTAWTLILM in R38144_PEA_2_P36.
Comparison report between R38144_PEA_2_P36 and CT31_HUMAN:
1.An isolated chimeric polypeptide encoding for R38144JPEA_2_P36, comprising a first amino acid sequence being at least 90 % homologous to
MPFRLLIPLGLLCALLPQHHGAPGPDGSAPDPAHYR corresponding to amino acids 1 - 36 of CT31_HUMAN, which also corresponds to amino acids 1 - 36 of R38144_PEA_2_P36, and a second amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence FWGMSQNSKEWLKCSRTAWTLILM corresponding to amino acids 37 - 60 of R38144_PEA_2_P36, wherein said first amino acid sequence and second amino acid sequence are contiguous and in a sequential order. 2.An isolated polypeptide encoding for a tail of R38144_PEA_2_P36, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence FWGMSQNSKEWLKCSRTAWTLILM in R38144_PEA_2_P36.
The location of the variant protein was determined according to results from a number of different software programs and analyses, including analyses from SignalP and other specialized
programs. The variant protein is believed to be located as follows with regard to the cell: secreted. The protein localization is believed to be secreted because both signal-peptide prediction programs predict that this protein has a signal peptide, and neither trans -membrane region prediction program predicts that this protein has a trans -membrane region.
Variant protein R38144_PEA_2JP36 also has the following non-silent SNPs (Single Nucleotide Polymorphisms) as listed in Table 1190, (given according to their position(s) on the amino acid sequence, with the alternative amino acid(s) listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein R38144_PEA_2_P36 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 1190 - Amino acid mutations
The glycosylation sites of variant protein R38144_PEA_2_P36, as compared to the known protein Putative alpha- mannosidase C20orf31 precursor, are described in Table 1191 (given according to their position(s) on the amino acid sequence in the first column; the second column indicates whether the glycosylation site is present in the variant protein; and the last column indicates whether the position is different on the variant protein).
Table 1191 - Glycosylation site(s)
Variant protein R38144_PEA_2JP36 is encoded by the following transcript(s): R38144_PEA_2_T10, for which the sequence(s) is/are given at the end of the application. The coding portion of transcript R38144_PEA_2_T10 is shown in bold; this coding portion starts at position 91 and ends at position 270. The transcript also has the following SNPs as listed in Table 1192 (given according to their position on the nucleotide sequence, with the alternative nucleic acid listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein R38144_PEA_2_P36 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 1192- Nucleic acid SNPs
As noted above, cluster R38144 features 24 segment(s), which were listed in Table 2 above and for which the sequence(s) are given at the end of the application. These segment(s) are portions of nucleic acid sequence(s) which are described herein separately because they are of particular interest. A description of each segment according to the present invention is now provided.
Segment cluster R38144_PEA_2_node_21 according to the present invention is supported by 108 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): R38144_PEA_2_T6, R38144_PEA_2_T10, R38144_PEA_2_T13, R38144_PEA_2_T15 and R38144_PEA_2_T19. Table 1193 below describes the starting and ending position of this segment on each transcript.
Table 1193- Segment location on transcripts
Segment cluster R38144_PEA_2_node_26 according to the present invention is supported by 98 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): R38144_PEA_2_T6, R38144_PEA_2_T10, R38144_PEA_2_T13, R38144_PEA_2_T15 and R38144_PEA_2_T19. Table 1194 below describes the starting and ending position of this segment on each transcript.
Table 1194- Segment location on transcripts
Segment cluster R38144_PEA_2_node_29 according to the present invention is supported by 98 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): R38144_PEA_2_T6, R38144_PEA_2_T10, R38144_PEA_2_T13, R38144JPEA_2_T19 and R38144_PEA_2_T27. Table 1195 below describes the starting and ending position of this segment on each transcript.
Table 1195- Segment location on transcripts
Segment cluster R38144_PEA_2_node_31 according to the present invention is supported by 95 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): R38144_PEA_2_T6, R38144_PEA_2_T10, R38144_PEA_2_T15, R38144_PEA_2_T19 and R38144JPEA_2_T27. Table 1196 below describes the starting and ending position of this segment on each transcript.
Table 1196 - Segment location on transcripts
Segment cluster R38144_PEA_2_node_46 according to the present invention is supported by 147 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): R38144_PEA_2_T6, R38144_PEA_2JT10, R38144_PEA_2_T13, R38144_PEA_2_T15 and R38144_PEA_2_T27. Table 1197 below describes the starting and ending position of this segment on each transcript.
Table 1197- Segment location on transcripts
Segment cluster R38144_PEA_2_node_47 according to the present invention is supported by 147 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): R38144_PEA_2_T6, R38144_PEA_2JT10, R38144_PEA_2_T13, R38144_PEA_2_T15 and R38144_PEA_2_T27. Table 1198 below describes the starting and ending position of this segment on each transcript.
Table 1198- Segment location on transcripts
Segment cluster R38144_PEA_2_node_49 according to the present invention is supported by 1 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): R38144_PEA_2_T19. Table 1199 below describes the starting and ending position of this segment on each transcript.
Table 1199- Segment location on transcripts
According to an optional embodiment of the present invention, short segments related to the above cluster are also provided. These segments are up to about 120 bp in length, and so are included in a separate description.
Segment cluster R38144_PEA_2_node_0 according to the present invention is supported by 101 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): R38144_PEA_2_T6, R38144_PEA_2_T10, R38144_PEA_2_T13, R38144_PEA_2_T15, R38144_PEA_2_T19 and R38144_PEA_2_T27. Table 1200 below describes the starting and ending position of this segment on each transcript.
Table 1201- Segment location on transcripts
Segment cluster R38144_PEA_2_node_l according to the present invention is supported by 105 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): R38144_PEA_2_T6, R38144_PEA_2_T10, R38144_PEA_2_T13, R38144_PEA_2_T15, R38144_PEA_2_T19 and R38144_PEA_2_T27. Table 1202 below describes the starting and ending position of this segment on each transcript.
Table 1202- Segment location on transcripts
Segment cluster R38144_PEA_2_node_4 according to the present invention is supported by 107 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): R38144_PEA_2_T6, R38144JPEA_2_T13, R38144_PEA_2_T15, R38144_PEA_2_T19 and R38144_PEA_2_T27. Table 1203 below describes the starting and ending position of this segment on each transcript.
Table 1203- Segment location on transcripts
Segment cluster R38144_PEA_2_node_5 according to the present invention can be found in the following transcript(s): R38144_PEA_2_T6, R38144_PEA_2_T13, R38144_PEA_2_T15, R38144_PEA_2_T19 and R38144_PEA_2_T27. Table 1204 below describes the starting and ending position of this segment on each transcript.
Table 1204- Segment location on transcripts
Segment cluster R38144_PEA_2_node_7 according to the present invention is supported by 92 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): R38144_PEA_2_T6, R38144_PEA_2_T13, R38144_PEA_2_T15, R38144_PEA_2_T19 and R38144_PEA_2_T27. Table 1205 below describes the starting and ending position of this segment on each transcript.
Table 1205- Segment location on transcripts
Segment cluster R38144_PEA_2_node_l 1 according to the present invention is supported by 106 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): R38144_PEA_2_T6, R38144_PEA_2_T10, R38144_PEA_2_T13, R38144_PEA_2_T15, R38144_PEA_2_T19 and R38144_PEA_2_T27. Table 1206 below describes the starting and ending position of this segment on each transcript.
Table 1206- Segment location on transcripts
Segment cluster R38144_PEA_2_node_14 according to the present invention can be found in the following transcript(s): R38144_PEA_2_T6, R38144_PEA_2_T10, R38144JPEA_2jri3, R38144_PEA_2_T15 and R38144_PEA_2_T19. Table 1207 below describes the starting and ending position of this segment on each transcript.
Table 1207- Segment location on transcripts
Segment cluster R38144_PEA_2_node_15 according to the present invention is supported by 105 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): R38144_PEA_2_T6, R38144_PEA_2_T10, R38144_PEA_2_T13, R38144_PEA_2_T15 and R38144_PEA_2_T19. Table 1208 below describes the starting and ending position of this segment on each transcript.
Table 1208- Segment location on transcripts
Segment cluster R38144_PEA_2_node_16 according to the present invention is supported by 106 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): R38144_PEA_2_T6, R38144_PEA_2_T10, R38144_PEA_2_T13, R38144_PEA_2_T15 and R38144_PEA_2_T19. Table 1209 below describes the starting and ending position of this segment on each transcript.
Table 1209- Segment location on transcripts
Segment cluster R38144_PEA_2_node_19 according to the present invention is supported by 93 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): R38144_PEA_2_T6, R38144_PEA_2_T10, R38144_PEA_2_T13, R38144_PEA_2_T15 and R38144_PEA_2_T19. Table 1210 below describes the starting and ending position of this segment on each transcript.
Table 1210- Segment location on transcripts
Segment cluster R38144_PEA_2_node_20 according to the present invention can be found in the following transcript(s): R38144_PEA_2_T6, R38144_PEA_2__T10, R38144_PEA_2_T13, R38144_PEA_2_T15 and R38144_PEA_2_T19. Table 1211 below describes the starting and ending position of this segment on each transcript.
Table 1211- Segment location on transcripts
Segment cluster R38144_PEA_2_node_36 according to the present invention is supported by 95 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): R38144_PEA_2_T6, R38144_PEA_2_T10, R38144_PEA_2_T13, R38144_PEA_2_T15, R38144_JPEA_2_T19 and R38144_PEA_2_T27. Table 1212 below describes the starting and ending position of this segment on each transcript.
Table 1212- Segment location on transcripts
Segment cluster R38144_PEA_2__node_37 according to the present invention is supported by 97 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): R38144_PEA_2_T6, R38144_PEA_2_T10, R38144_PEA_2_T13, R38144_PEA_2_T15, R38144JPEA_2_T19 and R38144_PEA_2_T27. Table 1213 below describes the starting and ending position of this segment on each transcript.
Table 1213- Segment location on transcripts
Segment cluster R38144_PEA_2_node_43 according to the present invention can be found in the following transcript(s): R38144_PEA_2_T6. Table 1214 below describes the starting and ending position of this segment on each transcript.
Table 1214- Segment location on transcripts
Segment cluster R38144_PEA_2_node_44 according to the present invention can be found in the following transcript(s): R38144JPEA_2_T6. Table 1215 below describes the starting and ending position of this segment on each transcript.
Table 1215- Segment location on transcripts
Segment cluster R38144_PEA_2_node_45 according to the present invention can be found in the following transcript(s): R38144_PEA_2_T6, R38144_PEA_2_T10, R38144_PEA_2_T13, R38144_PEA_2_T15 and R38144_PEA_2_T27. Table 1216 below describes the starting and ending position of this segment on each transcript.
Table 1216- Segment location on transcripts
Segment cluster R38144_PEA_2_node_51 according to the present invention is supported by 1 libraπes. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): R38144_PEA_2_T19. Table 1217 below describes the starting and ending position of this segment on each transcript.
Table 1217 - Segment location on transcripts
Variant protein alignment to the previously known protein:
Sequence name: CT31_HUMAN
Sequence documentation:
Alignment of: R38144_PEA_2_P6 x CT31_HUMAN
Alignment segment 1/1:
Quality: 4031.00 Escore: 0
Matching length: 413 Total length: 413
Matching Percent Similarity: 100.00 Matching Percent Identity: 99.76
Total Percent Similarity: 100.00 Total Percent Identity: 99.76
Gaps : 0
Alignment:
1 MPFRLLIPLGLLCALLPQHHGAPGPDGSAPDPAHYRERVKAMFYHAYDSY 50
I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I 1 I I I I I I I I I I I I I I Il
1 MPFRLLIPLGLLCALLPQHHGAPGPDGSAPDPAHYRERVKAMFYHAYDSY 50 . . . . .
51 LENAFPFDELRPLTCDGHDTWGSFSLTLIDALDTLLILGNVSEFQRVVEV 100
I I I I Il I I I Il I I I I I I I I I I I I I I I 1 I I I I I I I I I I I I I I I 1 I I I I I I I
51 LENAFPFDELRPLTCDGHDTWGSFSLTLIDALDTLLILGNVSEFQRWEV 100
101 LQDSVDFDIDVNASVFETNIRVVGGLLSAHLLSKKAGVEVEAGWPCSGPL 150
I I I I I I I I I I Il I I I I I Il I Il Il I Il I I Il Il I I Il I I Il I I I I I I I I I
101 LQDSVDFDIDVNASVFETNIRVVGGLLSAHLLSKKAGVEVEAGWPCSGPL 150
151 LRMAEEAARKLLPAFQTPTGMPYGTVNLLHGVNPGETPVTCTAGIGTFIV 200 I I Il I I I I M Il | | | | I I I M I I I I I M I I I M I Il I M I I Il M I Il I I
151 LRMAEEAARKLLPAFQTPTGMPYGTVNLLHGVNPGETPVTCTAGIGTFIV 200
201 EFATLSSLTGDPVFEDVARVALMRLWESRSDIGLVGNHIDVLTGKWVAQD 250
II I I I I I I Il I I I I I I I I I I I I I Il I I Il I I I I I I I I I Il I I I I Il I Il I 201 EFATLSSLTGDPVFEDVARVALMRLWESRSDIGLVGNHIDVLTGKWVAQD 250
251 AGIGAGVDSYFEYLVKGAILLQDKKLMAMFLEYNKAIRNYTRFDDWYLWV 300
I I I Il I I Il Il I I I I Il I I I I I I I I Il Il I I I I I Il Il Il I I I I I I I I Il 251 AGIGAGVDSYFEYLVKGAILLQDKKLMAMFLEYNKAIRNYTRFDDWYLWV 300 . . . . .
301 QMYKGTVSMPVFQSLEAYWPGLQSLIGDIDNAMRTFLNYYTVWKQFGGLP 350
I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I 1 I I I I I I I I I I I I I I I I I I
301 QMYKGTVSMPVFQSLEAYWPGLQSLIGDIDNAMRTFLNYYTVWKQFGGLP 350
351 EFYNIPQGYTVEKREGYPLRPELIESAMYLYRATGDPTLLELGRDAVESI 400 I I I I I I I I I I 1 I I I I I 1 I I I I I I I I I I I I I I I I I I I I I I I I I I I I I ! I I I
351 EFYNIPQGYTVEKREGYPLRPELIESAMYLYRATGDPTLLELGRDAVESI 400
401 EKISKVECGFATL 413
I I I I I I I 1 I 1 I I : 401 EKISKVECGFATI 413
Sequence name: CT31_HUMAN
Sequence documentation:
Alignment of: R38144_PEA_2_P13 x CT31_HUMAN
Alignment segment 1/1:
Quality: 3167.00
Escore: 0
Matching length: 326 Total length: 326
Matching Percent Similarity: 100.00 Matching Percent Identity: 99.39
Total Percent Similarity: 100.00 Total Percent Identity: 99.39
Gaps : 0
Alignment:
1 MPFRLLIPLGLLCALLPQHHGAPGPDGSAPDPAHYRERVKAMFYHAYDSY 50
I I I I I 1 I I I I I I I I M I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I
1 MPFRLLIPLGLLCALLPQHHGAPGPDGSAPDPAHYRERVKAMFYHAYDSY 50 . . . . .
51 LENAFPFDELRPLTCDGHDTWGSFSLTLIDALDTLLILGNVSEFQRWEV 100
I I I I I I I I I I I Il I I I I I I Il I I I I I Il I I I I I I I I I I I I I Il I I I I I I I
51 LENAFPFDELRPLTCDGHDTWGSFSLTLIDALDTLLILGNVSEFQRVVEV 100
101 LQDSVDFDIDVNASVFETNIRVVGGLLSAHLLSKKAGVEVEAGWPCSGPL 150
M M I I M I I I M I I M M I I I M I I M M M I I M I M I I I I I I M I I I
101 LQDSVDFDIDVNASVFETNIRWGGLLSAHLLSKKAGVEVEAGWPCSGPL 150
151 LRMAEEAARKLLPAFQTPTGMPYGTVNLLHGVNPGETPVTCTAGIGTFIV 200 I Il Il M M I I Il Il I M I M Il Il I M Il Il Il I Il Il Il I Il M M I I
151 LRMAEEAARKLLPAFQTPTGMPYGTVNLLHGVNPGETPVTCTAGIGTFIV 200
201 EFATLSSLTGDPVFEDVARVALMRLWESRSDIGLVGNHIDVLTGKWVAQD 250
M I Il I I I Il Il M M M I I M I M M I Il M Il Il I Il Il I Il I M I M 201 EFATLSSLTGDPVFEDVARVALMRLWESRSDIGLVGNHIDVLTGKWVAQD 250
251 AGIGAGVDSYFEYLVKGAILLQDKKLMAMFLEYNKAIRNYTRFDDWYLWV 300
Il Il Il I I Il I Il I I Il I Il Il Il Il Il I Il I Il Il I Il Il I Il I Il I Il
251 AGIGAGVDSYFEYLVKGAILLQDKKLMAMFLEYNKAIRNYTRFDDWYLWV 300
301 QMYKGTVSMPVFQSLEAYWPGLQNLL 326
I I
301 QMYKGTVSMPVFQSLEAYWPGLQSLI 326
Sequence name: CT31_HUMAN
Sequence documentation:
Alignment of: R38144_PEA_2_P15 x CT31_HUMAN
Alignment segment 1/1:
Quality: 2725.00 Escore: 0
Matching length: 282 Total length: 282
Matching Percent Similarity: 100.00 Matching Percent Identity: 100.00
Total Percent Similarity: 100.00 Total Percent Identity: 100.00 Gaps : 0
Alignment :
1 MPFRLLIPLGLLCALLPQHHGAPGPDGSAPDPAHYRERVKAMFYHAYDSY 50 I M I I I M I M I I I I I I I M I M I I I M I I I I I I I M I i I I I I I M I I I I
1 MPFRLLI PLGLLCALLPQHHGAPGPDGSAPDPAHYRERVKAMFYHAYDS Y 50
51 LENAFPFDELRPLTCDGHDTWGSFSLTLIDALDTLLILGNVSEFQRVVEV 100
I 1 I I 1 I I I 1 I I I I I I I Il I I i I I I I I I I I I I I I 1 I I I I I I I I I I I I I I ! I
51 LENAFPFDELRPLTCDGHDTWGSFSLTLIDALDTLLILGNVSEFQRVVEV 100 . . . . .
101 LQDSVDFDIDVNASVFETNIRVVGGLLSAHLLSKKAGVEVEAGWPCSGPL 150
I I I I I I I I I 1 I I I I I I I I I I I I I I I Il I Il I I I I I Il I I I I I I I I I Il I I
101 LQDSVDFDIDVNASVFETNIRWGGLLSAHLLSKKAGVEVEAGWPCSGPL 150
151 LRMAEEAARKLLPAFQTPTGMPYGTVNLLHGVNPGETPVTCTAGIGTFIV 200
I I I Il I Il I I I I I I I I I I I I I I I I I I I I I I I I I I I I Il I I I I I I I I Il I I
151 LRMAEEAARKLLPAFQTPTGMPYGTVNLLHGVNPGETPVTCTAGIGTFIV 200
201 EFATLSSLTGDPVFEDVARVALMRLWESRSDIGLVGNHIDVLTGKWVAQD 250 I I I I I I I I I 1 I I Il I I I I I I I I M I I I I I I I I I I I I I I I I I I I I I I I I I I
201 EFATLSSLTGDPVFEDVARVALMRLWESRSDIGLVGNHIDVLTGKWVAQD 250
251 AGIGAGVDSYFEYLVKGAILLQDKKLMAMFLE 282
I I I i I I I I I Il I I Il I I I I I I Il I I I I I I I I I 251 AGIGAGVDSYFEYLVKGAILLQDKKLMAMFLE 282
Sequence name: CT31_HUMAN
Sequence documentation:
Alignment of: R38144_PEA_2_P19 x CT31_HUMAN
Alignment segment 1/1:
Quality: 4029.00 Escore: 0
Matching length: 412 Total length: 412
Matching Percent Similarity: 100.00 Matching Percent Identity: 100.00 Total Percent Similarity: 100.00 Total Percent Identity: 100.00
Gaps : 0
Alignment : . . . . .
1 MPFRLLIPLGLLCALLPQHHGAPGPDGSAPDPAHYRERVKAMFYHAYDSY 50
I I I I I I I Il i I I I I I I I I I I I I I Il Il I I I I I I I I Il I I I Il I I I I I Il I
1 MPFRLLIPLGLLCALLPQHHGAPGPDGSAPDPAHYRERVKAMFYHAYDSY 50
51 LENAFPFDELRPLTCDGHDTWGSFSLTLIDALDTLLILGNVSEFQRWEV 100
I I I I I I I I I I I I I I I I I I I I Il I I I I I I Il I Il I I I I I I I I I I I 1 I I I I I
51 LENAFPFDELRPLTCDGHDTWGSFSLTLIDALDTLLILGNVSEFQRVVEV 100
101 LQDSVDFDIDVNASVFETNIRWGGLLSAHLLSKKAGVEVEAGWPCSGPL 150 I I I I I M I I I I I I I I I I I I I I I I M I I I M I M I I I I I I M M I I I I I I I
101 LQDSVDFDIDVNASVFETNIRWGGLLSAHLLSKKAGVEVEAGWPCSGPL 150
151 LRMAEEAARKLLPAFQTPTGMPYGTVNLLHGVNPGETPVTCTAGIGTFIV 200
I I I I I I Il I I I I I I Il I I I I Il I I I I I I I I Il I I I I I Il I I I Il I I I I I I 151 LRMAEEAARKLLPAFQTPTGMPYGTVNLLHGVNPGETPVTCTAGIGTFIV 200
201 EFATLSSLTGDPVFEDVARVALMRLWESRSDIGLVGNHIDVLTGKWVAQD 250
I I I I I I 1 I I I I I I I I I I I I I I I I I I I I I I I I I I I I Il I I I I I I I I I I I I I
201 EFATLSSLTGDPVFEDVARVALMRLWESRSDIGLVGNHIDVLTGKWVAQD 250
251 AGIGAGVDSYFEYLVKGAILLQDKKLMAMFLEYNKAIRNYTRFDDWYLWV 300
II I I I I Il I I I I I I Il I Il I I I I I I I I I I I I I I I I I I I I I I I I I I I I Il I
251 AGIGAGVDSYFEYLVKGAILLQDKKLMAMFLEYNKAIRNYTRFDDWYLWV 300
301 QMYKGTVSMPVFQSLEAYWPGLQSLIGDIDNAMRTFLNYYTVWKQFGGLP 350 I I I I I I I I I I I I I I I I I I I M I I I M I I I I I M I I I I I I I I I Il I M I I I
301 QMYKGTVSMPVFQSLEAYWPGLQSLIGDIDNAMRTFLNYYTVWKQFGGLP 350
351 EFYNIPQGYTVEKREGYPLRPELIESAMYLYRATGDPTLLELGRDAVESI 400
I I I Il I I Il I Il I I I I Il Il I I I I I Il Il I I I I I I I I I I I I I Il I I I I I I 351 EFYNIPQGYTVEKREGYPLRPELIESAMYLYRATGDPTLLELGRDAVESI 400
401 EKISKVECGFAT 412
M I I I I I I M I I
401 EKISKVECGFAT 412
Sequence name: CT31_HUMAN
Sequence documentation:
Alignment of: R38144 PEA 2 P24 x CT31 HUMAN
Alignment segment 1/1:
Quality: 4063.00 Escore: 0 Matching length: 418 Total length: 578
Matching Percent Similarity: 100.00 Matching Percent Identity: 100.00
Total Percent Similarity: 72.32 Total Percent Identity: 72.32
Gaps : 1
Alignment :
1 MPFRLLIPLGLLCALLPQHHGAPGPDGSAPDPAHYRERVKAMFYHAYDSY 50
I I I I I I I I I I Il I I I Il I I I i I I Il Il I I I I I I I I I I I I I I I I I I I I I I I
1 MPFRLLIPLGLLCALLPQHHGAPGPDGSAPDPAHYRERVKAMFYHAYDSY 50
51 LENAFPFDELRPLTCDGHDTWGSFSLTLIDALDTLLILGNVSEFQRWEV 100 I I I I M M I Il M M I I I I I I I I I I I I I I M I I I I I I I I I I M I I I M M
51 LENAFPFDELRPLTCDGHDTWGSFSLTLIDALDTLLILGNVSEFQRVVEV 100
101 LQDSVDFDIDVNASVFETNIR 121
I I I I I I Il I Il I I Il I I I Il I 101 LQDSVDFDIDVNASVFETNIRVVGGLLSAHLLSKKAGVEVEAGWPCSGPL 150
121 121
151 LRMAEEAARKLLPAFQTPTGMPYGTVNLLHGVNPGETPVTCTAGIGTFIV 200 . . . . .
121 121
201 EFATLSSLTGDPVFEDVARVALMRLWESRSDIGLVGNHIDVLTGKWVAQD 250
122 EYNKAIRNYTRFDDWYLWV 140 I I I I I I I I I I I I I I I I M I
251 AGIGAGVDSYFEYLVKGAILLQDKKLMAMFLEYNKAIRNYTRFDDWYLWV 300
141 QMYKGTVSMPVFQSLEAYWPGLQSLIGDIDNAMRTFLNYYTVWKQFGGLP 190
I I ! Il I I I I I 1 I I I I I I I I I I I I I I I I I I I I I I Il I I I I I I I I I I I Il I I 301 QMYKGTVSMPVFQSLEAYWPGLQSLIGDIDNAMRTFLNYYTVWKQFGGLP 350
191 EFYNIPQGYTVEKREGYPLRPELIESAMYLYRATGDPTLLELGRDAVESI 240
I I I I I Il Il I Il I I I I I I I I I I I I I I Il I I I I I I I I I I I I I I I I I I I I Il
351 EFYNIPQGYTVEKREGYPLRPELIESAMYLYRATGDPTLLELGRDAVESI 400 . . . . .
241 EKISKVECGFATIKDLRDHKLDNRMESFFLAETVKYLYLLFDPTNFIHNN 290
I I I I I I I I I Il I I I I I I I I 1 I I I I Il I I I I Il I I I I I I I Il I I I I Il I I I
401 EKISKVECGFATIKDLRDHKLDNRMESFFLAETVKYLYLLFDPTNFIHNN 450
291 GSTFDAVITPYGECILGAGGYIFNTEAHPIDPAALHCCQRLKEEQWEVED 340
I I I I I I I I I I I I I I I I I I I I I I I I I I I Il I I I ! I I I I I Il I I I I I I I I I I
451 GSTFDAVITPYGECILGAGGYIFNTEAHPIDPAALHCCQRLKEEQWEVED 500
341 LMREFYSLKRSRSKFQKNTVSSGPWEPPARPGTLFSPENHDQARERKPAK 390 M I I I M M M M M I M I I I I I M I M M I I M I M I I M M I I I I I M
501 LMREFYSLKRSRSKFQKNTVSSGPWEPPARPGTLFSPENHDQARERKPAK 550
391 QKVPLLSCPSQPFTSKLALLGQVFLDSS 418
II M M Il Il I Il M M I M I I M M M 551 QKVPLLSCPSQPFTSKLALLGQVFLDSS 578
Sequence name: AAHl 6184
Sequence documentation:
Alignment of: R38144_PEA_2_P36 x AAH16184
Alignment segment 1/1:
Quality: 364.00 Escore: 0
Matching length: 36 Total length: 36
Matching Percent Similarity: 100.00 Matching Percent Identity: 100.00 Total Percent Similarity: 100.00 Total Percent Identity: 100.00
Gaps : 0
Alignment: . . .
1 MPFRLLIPLGLLCALLPQHHGAPGPDGSAPDPAHYR 36
I I I I I I I I I I Il Il I Il Il Il I Il I I I I I I I I I I I I
1 MPFRLLIPLGLLCALLPQHHGAPGPDGSAPDPAHYR 36
Sequence name: AAQ88943
Sequence documentation:
Alignment of: R38144_PEA_2_P36 x AAQ88943
Alignment segment 1/1:
Quality: 362.00 Escore: 0
Matching length: 37 Total length: 37
Matching Percent Similarity: 97.30 Matching Percent Identity: 97.30
Total Percent Similarity: 97.30 Total Percent Identity: 97.30 Gaps : 0
Alignment :
1 MPFRLLI PLGLLCALLPQHHGAPGPDGSAPDPAHYRF 37
M M M M I M I M I M I I M I M M I I M M M I I
1 MPFRLLIPLGLLCALLPQHHGAPGPDGSAPDPAHYSF 37
Sequence name: CT31 HUMAN
Sequence documentation:
Alignment of: R38144 PEA 2 P36 x CT31 HUMAN
Alignment segment 1/1:
Quality: 364.00
Escore: 0
Matching length: 36 Total length: 36
Matching Percent Similarity: 100.00 Matching Percent Identity: 100.00
Total Percent Similarity: 100.00 Total Percent Identity: 100.00
Gaps : 0
Alignment:
1 MPFRLLIPLGLLCALLPQHHGAPGPDGSAPDPAHYR 36
1 MPFRLLIPLGLLCALLPQHHGAPGPDGSAPDPAHYR 36
DESCRIPTION FOR CLUSTER HUMOSTRO
Cluster HUMOSTRO features 3 transcript(s) and 30 segment(s) of interest, the names for which are given in Tables 1218 and 1219, respectively, the sequences themselves are given at the end of the application. The selected protein variants are given in table 1220.
Table 1218 - Transcripts of interest
Table 1219- Segments of interest
Table 1220- Proteins of interest
These sequences are variants of the known protein Osteopontin precursor (SwissProt accession identifier OSTP_HUMAN; known also according to the synonyms Bone sialoprotein 1; Urinary stone protein; Secreted phosphoprotein 1; SPP-I; Nephropontin; Uropontin), SEQ ID NO: 1462, referred to herein as the previously known protein.
Protein Osteopontin precursor is known or believed to have the following function(s): Binds tightly to hydroxyapatite. Appears to form an integral part of the mineralized matrix. Probably important to cell- matrix interaction. Acts as a cytokine involved in enhancing production of interferon- gamma and interleukin-12 and reducing production of interleukin-10 and is essential in the pathway that leads to type I immunity (By similarity). The sequence for protein Osteopontin precursor is given at the end of the application, as "Osteopontin precursor amino acid sequence". Known polymorphisms for this sequence are as shown in Table 1221. Table 1221- Amino acid mutations for Known Protein
Protein Osteopontin precursor localization is believed to be Secreted.
The previously known protein also has the following indication(s) and/or potential therapeutic use(s): Regeneration, bone. It has been investigated for clinical/therapeutic use in humans, for example as a target for an antibody or small molecule, and/or as a direct therapeutic; available information related to these investigations is as follows. Potential pharmaceutically related or therapeutically related activity or activities of the previously known protein are as follows: Bone formation stimulant. A therapeutic role for a protein represented by the cluster has been predicted. The cluster was assigned this field because there was information in the drug database or the public databases (e.g., described herein above) that this protein, or part thereof, is used or can be used for a potential therapeutic indication: Musculoskeletal.
The following GO Annotation(s) apply to the previously known protein. The following annotation(s) were found: ossification; anti-apoptosis; inflammatory response; cell- matrix adhesion; cell-cell signaling, which are annotation(s) related to Biological Process; defense/immunity protein; cytokine; integrin ligand; protein binding; growth factor; apoptosis inhibitor, which are annotation(s) related to Molecular Function; and extracellular matrix, which are annotation(s) related to Cellular Component.
The GO assignment relies on information from one or more of the SwissProt/TremBl Protein knowledgebase, available from <http://www.expasy.ch/sprot/>; or Locuslink, available from <http://www.ncbi.nhn.nih.gov/projects/LocusLink/>.
Cluster HUMOSTRO can be used as a diagnostic marker according to overexpression of transcripts of this cluster in cancer. Expression of such transcripts in normal tissues is also given according to the previously described methods. The term "number" in the right hand column of
the table and the numbers on the y-axis of figure 46 refer to weighted expression of ESTs in each category, as "parts per million" (ratio of the expression of ESTs for a particular cluster to the expression of all ESTs in that category, according to parts per million).
Overall, the following results were obtained as shown with regard to the histograms in Figure 46 and Table 1222. This cluster is overexpressed (at least at a minimum level) in the following pathological conditions: epithelial malignant tumors, a mixture of malignant tumors from different tissues, lung malignant tumors, breast malignant tumors, ovarian carcinoma and skin malignancies.
Table 1222- Normal tissue distribution
Table 1223- P values and ratios for expression in cancerous tissue
As noted above, cluster HUMOSTRO features 3 transcript(s), which were listed in Table 1 above. These transcript(s) encode for protein(s) which are variant(s) of protein Osteopontin precursor. A description of each variant protein according to the present invention is now provided.
Variant protein HUMOSTRO_PEA_1_PEA_1_P21 according to the present invention has an amino acid sequence as given at the end of the application; it is encoded by transcript(s) HUMOSTRO_PEA_1_PEA_1_T14. An alignment is given to the known protein (Osteopontin precursor) at the end of the application. One or more alignments to one or more previously published protein sequences are given at the end of the application. A brief description of the relationship of the variant protein according to the present invention to each such aligned protein is as follows:
Comparison report between HUMOSTRO_PEA_1_PEA_1_P21 and OSTPJHUMAN: 1.An isolated chimeric polypeptide encoding for HUMOSTRO_PEA_1_PEA_1_P21, comprising a first amino acid sequence being at least 90 % homologous to
MRIAVICFCLLGITCAIPVKQADSGSSEEKQLYNKYPDAVATWLNPDPSQKQNLLAPQ corresponding to amino acids 1 - 58 of OSTPJHUMAN, which also corresponds to amino acids 1 - 58 of HUMOSTRO_PEA_1_PEA_1_P21, and a second amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence VFLNFS corresponding to amino acids 59 - 64 of HUMOSTROJPEA_1JPEA_1JP21, wherein said first amino acid sequence and second amino acid sequence are contiguous and in a sequential order.
2.An isolated polypeptide encoding for a tail of HUMOSTRO_PEA_ 1_PEA_1_P21, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence VFLNFS in HUMOSTRO_PEA_1_PEA_1_P21.
The location of the variant protein was determined according to results from a number of different software programs and analyses, including analyses from SignalP and other specialized programs. The variant protein is believed to be located as follows with regard to the cell:
secreted. The protein localization is believed to be secreted because of manual inspection of known protein localization and/or gene structure.
Variant protein HUMOSTRO_PEA_1_PEA_1_P21 also has the following non-silent SNPs (Single Nucleotide Polymorphisms) as listed in Table 1224, (given according to their position(s) on the amino acid sequence, with the alternative amino acid(s) listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein HUMOSTRO_PEA_1_PEA_1_P21 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 1224- Amino acid mutations
The glycosylation sites of variant protein HUMOSTRO_PEA_1_PEA_1_P21, as compared to the known protein Osteopontin precursor, are described in Table 1225 (given according to their position(s) on the amino acid sequence in the first column; the second column indicates whether the glycosylation site is present in the variant protein; and the last column indicates whether the position is different on the variant protein).
Table 1225- Glycosylation site(s)
Variant protein HUMOSTRO_PEA_1_PEA_1_P21 is encoded by the following transcript(s): HUMOSTRO_PEA_1_PEA_1_T14, for which the sequence(s) is/are given at the end of the application. The coding portion of transcript HUMOSTRO_PEA_1_PEA_1_T14 is
shown in bold; this coding portion starts at position 199 and ends at position 390. The transcript also has the following SNPs as listed in Table 1226 (given according to their position on the nucleotide sequence, with the alternative nucleic acid listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein
HUMOSTRO_PEA_1_PEA_1_P21 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 1226- Nucleic acid SNPs
Variant protein HUMOSTRO_PEA_1_PEA_1_P25 according to the present invention has an amino acid sequence as given at the end of the application; it is encoded bytranscript(s) HUMOSTRO_PEA_1_PEA_1_T16. An alignment is given to the known protein (Osteopontin precursor) at the end of the application. One or more alignments to one or more previously published protein sequences are given at the end of the application. A brief description of the relationship of the variant protein according to the present invention to each such aligned protein is as follows: Comparison report between HUMOSTRO_PEA_1_PEA_1_P25 and OSTP_HUM AN:
LAn isolated chimeric polypeptide encoding for HUMOSTRO_PEA_1_PEA_1_P25, comprising a first amino acid sequence being at least 90 % homologous to MRIAVICFCLLGITCAIPVKQADSGSSEEKQ corresponding to amino acids 1 - 31 of OSTP_HUMAN, which also corresponds to amino acids 1 - 31 of HUMOSTRO_PEA_1_PEA_1_P25, and a second amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence H corresponding to amino acids 32 - 32 of HUMOSTRO_PEA_1_PEA_1_P25, wherein said first amino acid sequence and second amino acid sequence are contiguous and in a sequential order.
The location of the variant protein was determined according to results from a number of different software programs and analyses, including analyses from SignalP and other specialized programs. The variant protein is believed to be located as follows with regard to the cell: secreted. The protein localization is believed to be secreted because both signal-peptide prediction programs predict that this protein has a signal peptide, and neither trans -membrane region prediction program predicts that this protein has a trans -membrane region.
Variant protein HUMOSTRO_PEA__1_PEA_1_P25 also has the following non-silent SNPs (Single Nucleotide Polymorphisms) as listed in Table 1227, (given according to their position(s) on the amino acid sequence, with the alternative amino acid(s) listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein HUMOSTRO_PEA_1_PEA_1_P25 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 1227- Amino acid mutations
The glycosylation sites of variant protein HUMOSTRO_PEA_1_PEA_1_P25, as compared to the known protein Osteopontin precursor, are described in Table 1228 (given according to their position(s) on the amino acid sequence in the first column; the second column indicates whether the glycosylation site is present in the variant protein; and the last column indicates whether the position is different on the variant protein).
Table 1228- Glycosylation site(s)
Variant protein HUMOSTRO_PEA_1_PEAJ_P25 is encoded by the following transcript(s): HUMOSTRO_PEA_1_PEA_1_T16, for which the sequence(s) is/are given at the end of the application. The coding portion of transcript HUMOSTRO_PEA_1_PEA_1_T16 is shown in bold; this coding portion starts at position 199 and ends at position 294. The transcript also has the following SNPs as listed in Table 1229 (given according to their position on the nucleotide sequence, with the alternative nucleic acid listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein
HUMOSTRO_PEA_1_PEA_1_P25 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 1229- Nucleic acid SNPs
Variant protein HUMOSTRO_PEA_1_PEA_1_P30 according to the present invention has an amino acid sequence as given at the end of the application; it is encoded by transcript(s) HUMOSTRO_PEA_1_PEA_1_T30. An alignment is given to the known protein (Osteopontin precursor) at the end of the application. One or more alignments to one or more previously published protein sequences are given at the end of the application. A brief description of the relationship of the variant protein according to the present invention to each such aligned protein is as follows: Comparison report between HUMOSTRO_PEA_1_PEA_1_P30 and OSTP_HUMAN:
1.An isolated chimeric polypeptide encoding for HUMOSTRO_PEA_1_PEA_1_P30, comprising a first amino acid sequence being at least 90 % homologous to MRIAVICFCLLGITCAIPVKQADSGSSEEKQ corresponding to amino acids 1 - 31 of OSTP_HUMAN, which also corresponds to amino acids 1 - 31 of HUMOSTRO_PEA_1_PEA_1_P30, and a second amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most
preferably at least 95% homologous to a polypeptide having the sequence VSIFYVFI corresponding to amino acids 32 - 39 of HUMOSTRO_PEA_1_PEA_1_P30, wherein said first amino acid sequence and second amino acid sequence are contiguous and in a sequential order.
2.An isolated polypeptide encoding for a tail of HUMOSTRO_PEA_1_PEA_1_P30, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence VSIFYVFI in HUMOSTRO_PEA_1_PEA_1_P30.
The location of the variant protein was determined according to results from a number of different software programs and analyses, including analyses from SignalP and other specialized programs. The variant protein is believed to be located as follows with regard to the cell: secreted. The protein localization is believed to be secreted because both signal-peptide prediction programs predict that this protein has a signal peptide, and neither trans -membrane region prediction program predicts that this protein has a trans -membrane region.
Variant protein HUMOSTRO_PEA_1_PEA_1_P30 also has the following non-silent SNPs (Single Nucleotide Polymorphisms) as listed in Table 1230, (given according to their position(s) on the amino acid sequence, with the alternative amino acid(s) listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein HUMOSTRO_PEA_1_PEA_1 JP30 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 1230- Amino acid mutations
The glycosylation sites of variant protein HUMOSTRO_PEA_1_PEA_1_P30, as compared to the known protein Osteopontin precursor, are described in Table 1231 (given according to their position(s) on the amino acid sequence in the first column; the second column
indicates whether the glycosylation site is present in the variant protein; and the last column indicates whether the position is different on the variant protein).
Table 1231- Glycosylation site(s)
Variant protein HUMOSTRO_PEA_1_PEA_1_P30 is encoded by the following transcript(s): HUMOSTRO_PEA_1_PEA_1_T30, for which the sequence(s) is/are given at the end of the application. The coding portion of transcript HUMOSTRO_PEA_1_PEA_1_T30 is shown in bold; this coding portion starts at position 199 and ends at position 315. The transcript also has the following SNPs as listed in Table 1232 (given according to their position on the nucleotide sequence, with the alternative nucleic acid listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein
HUMOSTRO_PEA_1_PEA_1_P30 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 1232- Nucleic acid SNPs
As noted above, cluster HUMOSTRO features 30 segment(s), which were listed in Table 2 above and for which the sequence(s) are given at the end of the application. These segment(s) are portions of nucleic acid sequence(s) which are described herein separately because they are
of particular interest. A description of each segment according to the present invention is now provided.
Segment cluster HUMOSTRO_PEA_l_PEA_l_node_0 according to the present invention is supported by 333 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): HUMOSTRO_PEA_1JPEA_1_T14, HUMOSTRO_PEA_1_PEA_1_T16 and HUMOSTRO_PEA_1 JPEA 1JT30. Table 1233below describes the starting and ending position of this segment on each transcript.
Table 1234- Segment location on transcripts
Segment cluster HUMOSTRO_PEA_l_PEA_ l_node_10 according to the present invention is supported by 4 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): HUMOSTRO_PEA_1_PEA_1_T16. Table 1235 below describes the starting and ending position of this segment on each transcript.
Table 1235- Segment location on transcripts
Segment cluster HUMOSTRO_PEA_l_PEA_l_node_16 according to the present invention is supported by 6 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s):
HUMOSTRO_PEA_1_PEA_1_T14. Table 1236 below describes the starting and ending position of this segment on each transcript.
Table 1236- Segment location on transcripts
Segment cluster HUMOSTRO_PEA_l_PEA_l_node_23 according to the present invention is supported by 334 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s):
HUMOSTRO_PEA_1_PEA_1_T14 and HUMOSTRO_PEA_1_PEA_1_T16. Table 1237 below describes the starting and ending position of this segment on each transcript.
Table 1237 - Segment location on transcripts
Segment cluster HUMOSTRO_PEA_l_PEA_l_node_31 according to the present invention is supported by 350 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s):
HUMOSTRO_PEA_1_PEA_1_T14 and HUMOSTRO_PEA_1_PEA_1_T16. Table 1238 below describes the starting and ending position of this segment on each transcript.
Table 1238- Segment location on transcripts
Segment cluster HUMOSTRO_PEA_l_PEA_l_node_43 according to the present invention is supported by 192 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s):
HUMOSTRO J>EA_1_PEA_1_T14 and HUMOSTRO_PEA_1_PEA_1_T16. Table 1239 below describes the starting and ending position of this segment on each transcript.
Table 1239 - Segment location on transcripts
According to an optional embodiment of the present invention, short segments related to the above cluster are also provided. These segments are up to about 120 bp in length, and so are included in a separate description.
Segment cluster HUMOSTRO_PEA_l_PEA_l_node_3 according to the present invention is supported by 353 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): HUMOSTRO_PEA_1_PEA_1_T14, HUMOSTRO_PEA_1_PEA_1_T16 and HUMOSTRO_PEA_1_PEA_1_T30. Table 1240 below describes the starting and ending position of this segment on each transcript.
Table 1240- Segment location on transcripts
Segment cluster HUMOSTRO_PEA_1 JPEA_l_node_5 according to the present invention is supported by 353 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): HUMOSTRO_PEA_1JPEA_1_T14, HUMOSTRO_PEA_1JPEA_1_T16 and HUMOSTRO_PEA_1_PEA_1_T30. Table 1241 below describes the starting and ending position of this segment on each transcript.
Table 1241- Segment location on transcripts
Segment cluster HUMOSTRO_PEA_l_PEA_l_node_7 according to the present invention is supported by 357 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s):
HUMOSTRO_PEA_1_PEA_1_T14, HUMOSTRO_PEA_1_PEA_1_T16 and HUMOSTRO_PEA_1_PEA_1_T30. Table 1242 below describes the starting and ending position of this segment on each transcript.
Table 1242- Segment location on transcripts
Segment cluster HUMOSTRO_PEA_l_PEA_l_node_8 according to the present invention is supported by 1 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): HUMOSTRO_PEA_1_PEA_1_T30. Table 1243 below describes the starting and ending position of this segment on each transcript.
Table 1243- Segment location on transcripts
Segment cluster HUMOSTROJPEA l_PEA_l_node_15 according to the present invention is supported by 366 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s):
HUMOSTRO_PEA_1_PEA_1_T14 and HUMOSTRO_PEA_1_PEA_1_T16. Table 1244 below describes the starting and ending position of this segment on each transcript.
Table 1244 - Segment location on transcripts
Segment cluster HUMOSTRO_PEA_l_PEA_l_node_17 according to the present invention is supported by 261 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s):
HUMOSTRO_PEA_1_PEA_1_T14 and HUMOSTRO_PEA_l_PEA_l_T16. Table 1245 below describes the starting and ending position of this segment on each transcript.
Table 1245 - Segment location on transcripts
Segment cluster HUMOSTRO_PEA_l_PEA_l_node_20 according to the present invention can be found in the following transcript(s): HUMOSTRO_PEA_1_PEA_1_T14 and HUMOSTRO_PEA_1_PEA_1_T16. Table 1246 below describes the starting and ending position of this segment on each transcript.
Table 1246 - Segment location on transcripts
Segment cluster HUMOSTRO_PEA_l_PEA_l_node_21 according to the present invention is supported by 315 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s):
HUMOSTRO_PEA_1_PEA_1_T14 and HUMOSTRO_PEA_1_PEA_1_T16. Table 1247 below describes the starting and ending position of this segment on each transcript. Table 1247 - Segment location on transcripts
Segment cluster HUMOSTROJPEA__1_PEA_1 jnode_22 according to the present invention is supported by 322 libraries. The number of libraries was detennined as previously described. This segment can be found in the following transcript(s):
HUMOSTRO_PEA_1_PEA_1_T14 and HUMOSTRO_PEA_1_PEA_1_T16. Table 1248 below describes the starting and ending position of this segment on each transcript.
Table 1248 - Segment location on transcripts
Segment cluster HUMOSTRO_PEA_l_PEA_l_node_24 according to the present invention is supported by 270 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s):
HUMOSTROJ?EA_1JPEA_1_T14 and HUMOSTRO_PEA_1_PEA_1_T16. Table 1249 below describes the starting and ending position of this segment on each transcript.
Table 1249 - Segment location on transcripts
Segment cluster HUMOSTRO_PEA_l_PEA_l_node_26 according to the present invention can be found in the following transcript(s): HUMOSTRO_PEA_1_PEA_1_T14 and HUMOSTRO_PEA_1_PEA_1_T16. Table 1250 below describes the starting and ending position of this segment on each transcript.
Table 1250 - Segment location on transcripts
Segment cluster HUMOSTRO_PEA_l_PEA_l_node_27 according to the present invention is supported by 260 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s):
HUMOSTRO_PEA_1_PEA_1_T14 and HUMOSTRO_PEA_1_PEA_1_T16. Table 1251 below describes the starting and ending position of this segment on each transcript.
Table 1251 - Segment location on transcripts
Segment cluster HUMOSTRO_PEA_l_PEA_l_node_28 according to the present invention is supported by 273 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s):
HUMOSTRO_PEA_1_PEA_1_T14 and HUMOSTRO_PEA_l_PEA_l_T16. Table 1252 below describes the starting and ending position of this segment on each transcript.
Table 1252- Segment location on transcripts
Segment cluster HUMOSTRO_PEA_l_PEA_l_node_29 according to the present invention is supported by 272 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s):
HUMOSTRO_PEA_1_PEA_1_T14 and HUMOSTRO_PEA_1_PEA_1_T16. Table 1253 below describes the starting and ending position of this segment on each transcript.
Table 1253- Segment location on transcripts
Segment cluster HUMOSTRO_PEA_l_PEA_ l_node_30 according to the present invention can be found in the following transcript(s): HUMOSTRO_PEA_1_PEA_1_T14 and HUMOSTRO_PEA_1_PEA_1_T16. Table 1254 below describes the starting and ending position of this segment on each transcript.
Table 1254- Segment location on transcripts
Segment cluster HUMOSTRO_PEA_lJPEA_l_node_32 according to the present invention is supported by 293 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): HUMOSTRO_PEA_1_PEA_1_T14 and HUMOSTRO_PEA_1_PEA_1_T16. Table 1255 below describes the starting and ending position of this segment on each transcript.
Table 1255- Segment location on transcripts
Segment cluster HUMOSTRO_PEA_l_PEA_l_node_34 according to the present invention is supported by 301 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s):
HUMOSTRO_PEA_1_PEA_1_T14 and HUMOSTRO_PEA_1 JPEA_1_T16. Table 1256 below describes the starting and ending position of this segment on each transcript.
Table 1256 - Segment location on transcripts
Segment cluster HUMOSTRO_PEA_l_PEA_l_node_36 according to the present invention is supported by 292 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s):
HUMOSTRO_PEA_1_PEA_1_T14 and HUMOSTRO_PEA_1_PEA_1_T16. Table 1257 below describes the starting and ending position of this segment on each transcript.
Table 1257 - Segment location on transcripts
Segment cluster HUMOSTRO_PEA_1_PEA_1 jαode_37 according to the present invention is supported by 295 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s):
HUMOSTRO_PEA_1_PEA_1_T14 and HUMOSTRO JPEA_1JPEA_1_T16. Table 1258 below describes the starting and ending position of this segment on each transcript.
Table 1258- Segment location on transcripts
Segment cluster HUMOSTRO_PEA_l_PEA_l_node_38 according to the present invention can be found in the following transcript(s): HUMOSTRO_PEA_1_PEA_1_T14 and HUMOSTRO_PEA_1_PEA_1_T16. Table 1259 below describes the starting and ending position of this segment on each transcript.
Table 1259 - Segment location on transcripts
Segment cluster HUMOSTRO_PEA_l_PEA_l_node_39 according to the present invention is supported by 268 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s):
HUMOSTRO_PEA_1_PEA_1_T14 and HUMOSTRO_PEA_1_PEA_1_T16. Table 1260 below describes the starting and ending position of this segment on each transcript.
Table 1260 - Segment location on transcripts
Segment cluster HUMOSTRO_PEA_l_PEA_l_node_40 according to the present invention can be found in the following transcript(s): HUMOSTRO_PEA_1_PEA_1_T14 and HUMOSTRO_PEA_1_PEA_1_T16. Table 1261 below describes the starting and ending position of this segment on each transcript.
Table 1261 - Segment location on transcripts
Segment cluster HUMOSTRO_PEA_l_PEA_l_node_41 according to the present invention can be found in the following transcript(s): HUMOSTRO_PEA__1_PEA_1_T14 and HUMOSTRO_PEA_1_PEA_1_T16. Table 1262 below describes the starting and ending position of this segment on each transcript. Table 1262 - Segment location on transcripts
Segment cluster HUMOSTRO_PEA_l_PEA_l_node_42 according to the present invention is supported by 224 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s):
HUMOSTRO_PEA_1_PEA_1_T14 and HUMOSTRO_PEA_1_PEA_1_T16. Table 1263 below describes the starting and ending position of this segment on each transcript.
Table 1263 - Segment location on transcripts
Variant protein alignment to the previously known protein:
Sequence name: OSTP_HUMAN
Sequence documentation:
Alignment of: HUMOSTRO_PEA_1_PEA_1_P21 x OSTP_HϋMAN
Alignment segment 1/1:
Quality: 578.00 Escore: 0
Matching length: 58 Total length: 58 Matching Percent Similarity: 100.00 Matching Percent Identity: 100.00
Total Percent Similarity: 100.00 Total Percent Identity: 100.00
Gaps : 0
Alignment:
1 MRIAVICFCLLGITCAIPVKQADSGSSEEKQLYNKYPDAVATWLNPDPSQ 50
I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I Il
1 MRIAVICFCLLGITCAIPVKQADSGSSEEKQLYNKYPDAVATWLNPDPSQ 50
51 KQNLLAPQ 58
I I I I I I I 1
51 KQNLLAPQ 58
Sequence name: OSTP__HUMAN
Sequence documentation:
Alignment of: HUMOSTRO_PEA_1_PEA_1_P25 x OSTP_HUMAN
Alignment segment 1/1:
Quality: 301 .00
Escore : 0
Matching length: 31 Total length: 31
Matching Percent Similarity: 100.00 Matching Percent Identity: 100.00
Total Percent Similarity: 100.00 Total Percent Identity: 100.00 Gaps : 0
Alignment :
1 MRIAVICFCLLGITCAIPVKQADSGSSEEKQ 31 I I I I I I I I I I I I I I I M I I I I I I I I I I M I I
1 MRIAVICFCLLGITCAIPVKQADSGSSEEKQ 31
Sequence name : OSTP_HUMAN
Sequence documentation:
Alignment of: HUMOSTRO_PEA_1_PEA_1_P30 x OSTP_HUMAN
Alignment segment 1/1:
Quality: 301.00 Escore: 0
Matching length: 31 Total length: 31 Matching Percent Similarity: 100.00 Matching Percent Identity: 100.00
Total Percent Similarity: 100.00 Total Percent Identity: 100.00
Gaps:
Alignment:
1 MRIAVICFCLLGITCAIPVKQADSGSSEEKQ 31
1 MRIAVICFCLLGITCAIPVKQADSGSSEEKQ 31
DESCRIPTION FOR CLUSTER Rl 1723
Cluster Rl 1723 features 6 transcript(s) and 26 segment(s) of interest, the names for which are given in Tables 1264 and 1265, respectively, the sequences themselves are given at the end of the application. The selected protein variants are given in table 1266.
Table 1264 - Transcripts of interest
Table 1265 - Segments of interest
Table 1266- Proteins of interest
Cluster Rl 1723 can be used as a diagnostic marker according to overexpression of transcripts of this cluster in cancer. Expression of such transcripts in normal tissues is also given according to the previously described methods. The term "number" in the right hand column of the table and the numbers on the y-axis of figure 47 refer to weighted expression of ESTs in each category, as "parts per million" (ratio of the expression of ESTs for a particular cluster to the expression of all ESTs in that category, according to parts per million).
Overall, the following results were obtained as shown with regard to the histograms in
Figure 47 and Table 1267. This cluster is overexpressed (at least at a minimum level) in the following pathological conditions: epithelial malignant tumors, a mixture of malignant tumors from different tissues and kidney malignant tumors.
Table 1267 - Normal tissue distribution
Table 1268 - P values and ratios for expression in cancerous tissue
As noted above, contig Rl 1723 features 6 transcript(s), which were listed in Table 1 above. A description of each variant protein according to the present invention is now provided.
Variant protein Rl 1723_PEA_1_P2 according to the present invention has an amino acid sequence as given at the end of the application; it is encoded by transcript(s) Rl 1723_PEA_1_T6. The location of the variant protein was determined according to results
from a number of different software programs and analyses, including analyses from SignalP and other specialized programs. The variant protein is believed to be located as follows with regard to the cell: secreted. The protein localization is believed to be secreted because both signal-peptide prediction programs predict that this protein has a signal peptide, and neither trans- membrane region prediction program predicts that this protein has a trans -membrane region..
Variant protein Rl 1723_PEA_1_P2 also has the following non- silent SNPs (Single Nucleotide Polymorphisms) as listed in Table 1269, (given according to their position(s) on the amino acid sequence, with the alternative amino acid(s) listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein Rl 1723_PEA_1_P2 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 1269 - Amino acid mutations
Variant protein Rl 1723_PEA_1_P2 is encoded by the following transcript(s): Rl 1723JPEA_1_T6, for which the sequence(s) is/are given at the end of the application. The coding portion of transcript Rl 1723_PEA_1_T6 is shown in bold; this coding portion starts at position 1716 and ends at position 2051. The transcript also has the following SNPs as listed in Table 1270 (given according to their position on the nucleotide sequence, with the alternative nucleic acid listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein Rl 1723_PEA_1_P2 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 1270 - Nucleic acid SNPs
Variant protein Rl 1723JPEA 1 P6 according to the present invention has an amino acid sequence as given at the end of the application; it is encoded by transcript(s) Rl 1723_PEA_1_T15. One or more alignments to one or more previously published protein sequences are given at the end of the application. A brief description of the relationship of the variant protein according to the present invention to each such aligned protein is as follows:
Comparison report between R11723_PEA_1_P6 and Q8IXM0 (SEQ ID NO:1707): 1.An isolated chimeric polypeptide encoding for Rl 1723_PEA_1_P6, comprising a first amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence
MWVLGIAATFCGLFLLPGFALQIQCYQCEEFQLNNDCSSPEFIVNCTVNVQDMCQKEV MEQSAGIMYRKSCASSAACLIASAGSPCRGLAPGREEQRALHKAGAVGGGVR corresponding to amino acids 1 - 110 of Rl 1723_PEA_1_P6, and a second amino acid sequence being at least 90 % homologous to
MYAQALLWGVLQRQAAAQHLHEHPPKLLRGHRVQERVDDRAEVEKRLREGEEDHV
RPEVGPRPVVLGFGRSHDPPNLVGHPAYGQCHNNQPWADTSRRERQRKEKHSMRTQ corresponding to amino acids 1 - 112 of Q8IXM0, which also corresponds to amino acids 111 -
222 of R11723_PEA_1_P6, wherein said first and second amino acid sequences are contiguous and in a sequential order.
2.An isolated polypeptide encoding for a head of R11723_PEA_1_P6, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence
MWVLGIAATFCGLFLLPGFALQIQCYQCEEFQLNNDCSSPEFIVNCTVNVQDMCQKEV MEQSAGIMYRKSCASSAACLIASAGSPCRGLAPGREEQRALHKAGAVGGGVR of R11723_PEA_1_P6.
Comparison report between Rl 1723_PEA_1_P6 and Q96AC2 (SEQ ID NO: 1708): LAn isolated chimeric polypeptide encoding for R11723_PEA_1_P6, comprising a first amino acid sequence being at least 90 % homologous to MWVLGIAATFCGLFLLPGFALQIQCYQCEEFQLNNDCSSPEFIVNCTVNVQDMCQKEV MEQSAGIMYRKSCASSAACLIASAG corresponding to amino acids 1 - 83 of Q96AC2, which also corresponds to amino acids 1 - 83 of Rl 1723_PEA_1_P6, and a second amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence SPCRGLAPGREEQRALHKAGAVGGGVRMYAQALLVVGVLQRQAAAQHLHEHPPKLL RGHRVQERVDDRAEVEKRLREGEEDHVRPEVGPRPWLGFGRSHDPPNLVGHPAYGQ CHNNQPWADTSRRERQRKEKHSMRTQ corresponding to amino acids 84 - 222 of R11723_PEA_1_P6, wherein said first and second amino acid sequences are contiguous and in a sequential order.
2.An isolated polypeptide encoding for a tail of R11723_PEA_1_P6, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence
SPCRGLAPGREEQRALHKAGAVGGGVRMYAQALLWGVLQRQAAAQHLHEHPPKLL RGHRVQERVDDRAEVEKRLREGEEDHVRPEVGPRP WLGFGRSHDPPNLVGHPAYGQ CHNNQPWADTSRRERQRKEKHSMRTQ in Rl 1723_PEA_1_P6.
Comparison report between Rl 1723_PEA_1_P6 and Q8N2G4 (SEQ ID NO: 1709): 1.An isolated chimeric polypeptide encoding for Rl 1723_PEA_1_P6, comprising a first amino acid sequence being at least 90 % homologous to MWVLGIAATFCGLFLLPGFALQIQCYQCEEFQLNNDCSSPEFIVNCTVNVQDMCQKEV MEQSAGIMYRKSCASSAACLIASAG corresponding to amino acids 1 - 83 of Q8N2G4, which also corresponds to amino acids 1 - 83 of Rl 1723_PEA_1_P6, and a second amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence SPCRGLAPGREEQRALHKAGAVGGGVRMYAQALLVVGVLQRQAAAQHLHEHPPKLL RGHRVQERVDDRAEVEKRLREGEEDHVRPEVGPRPWLGFGRSHDPPNLVGHPAYGQ CHNNQPWADTSRRERQRKEKHSMRTQ corresponding to amino acids 84 - 222 of R11723_PEA_1_P6, wherein said first and second amino acid sequences are contiguous and in a sequential order. 2.An isolated polypeptide encoding for a tail of Rl 1723_PEA_ 1_P6, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence SPCRGLAPGREEQRALHKAGAVGGGVRMYAQALLVVGVLQRQAAAQHLHEHPPKLL RGHRVQERVDDRAEVEKRLREGEEDHVRPEVGPRPWLGFGRSHDPPNLVGHPAYGQ CHNNQPWADTSRRERQRKEKHSMRTQ in R11723_PEA_1_P6.
Comparison report between Rl 1723_PEA_1_P6 and BAC85518 (SEQ ID NO: 1710): 1.An isolated chimeric polypeptide encoding for R11723_PEA_1_P6, comprising a first amino acid sequence being at least 90 % homologous to
MWVLGIAATFCGLFLLPGFALQIQCYQCEEFQLNNDCSSPEFIVNCTVNVQDMCQKEV MEQSAGIMYRKSCASSAACLIASAG corresponding to amino acids 24 - 106 of BAC85518, which also corresponds to amino acids 1 - 83 of R11723_PEA_1_P6, and a second amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence SPCRGLAPGREEQRALHKAGAVGGGVRMYAQALLWGVLQRQAAAQHLHEHPPKLL
RGHRVQERVDDRAEVEKRLREGEEDHVRPEVGPRPVVLGFGRSHDPPNLVGHPAYGQ CHNNQPWADTSRRERQRKEKHSMRTQ corresponding to amino acids 84 - 222 of Rl 1723_PEA_1_P6, wherein said first and second amino acid sequences are contiguous and in a sequential order.
2.An isolated polypeptide encoding for a tail of Rl 1723_PEA_1_P6, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence
SPCRGLAPGREEQRALHKAGAVGGGVRMYAQALLVVGVLQRQAAAQHLHEHPPKLL RGHRVQERVDDRAEVEKRLREGEEDHVRPEVGPRPVVLGFGRSHDPPNLVGHPAYGQ CHNNQPWADTSRRERQRKEKHSMRTQ in R11723_PEA_1_P6.
The location of the variant protein was determined according to results from a number of different software programs and analyses, including analyses from SignalP and other specialized programs. The variant protein is believed to be located as follows with regard to the cell: secreted. The protein localization is believed to be secreted because both signal-peptide prediction programs predict that this protein has a signal peptide, and neither trans -membrane region prediction program predicts that this protein has a trans -membrane region..
Variant protein R11723_PEA_1_P6 also has the following non-silent SNPs (Single Nucleotide Polymorphisms) as listed in Table , (given according to their 1271 position(s) on the amino acid sequence, with the alternative amino acid(s) listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein Rl 1723_PEA_1_P6 sequence provides support for the deduced sequence of this variant protein according to the present invention). Table 1271- Amino acid mutations
Variant protein Rl 1723_PEA_1_P6 is encoded by the following transcript(s): Rl 1723_PEA_1_T15, for which the sequence(s) is/are given at the end of the application. The coding portion of transcript Rl 1723_PEA_1_T15 is shown in bold; this coding portion starts at position 434 and ends at position 1099. The transcript also has the following SNPs as listed in Table 1272 (given according to their position on the nucleotide sequence, with the alternative nucleic acid listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein Rl 1723_PEA_1_P6 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 1272 - Nucleic acid SNPs
Variant protein Rl 1723_PEA_1_P7 according to the present invention has an amino acid sequence as given at the end of the application; it is encoded by transcript(s) Rl 1723_PEA_1_T17. One or more alignments to one or more previously published protein sequences are given at the end of the application. A brief description of the relationship of the variant protein according to the present invention to each such aligned protein is as follows:
Comparison report between Rl 1723_PEA_1_P7 and Q96AC2: 1.An isolated chimeric polypeptide encoding for Rl 1723_PEA_1_P7, comprising a first amino acid sequence being at least 90 % homologous to
MWVLGIAATFCGLFLLPGFALQIQCYQCEEFQLNNDCSSPEFΓVNCTVNVQDMCQKEV
MEQSAG corresponding to amino acids 1 - 64 of Q96AC2, which also corresponds to amino
acids 1 - 64 of Rl 1723_PEA_1_P7, and a second amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence SHCVTRLECSGTISAHCNLCLPGSNDHPT corresponding to amino acids 65 - 93 of Rl 1723_PEA_1_P7, wherein said first and second amino acid sequences are contiguous and in a sequential order.
2.An isolated polypeptide encoding for a tail of Rl 1723_PEA_1_P7, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence SHCVTRLECSGTISAHCNLCLPGSNDHPT in Rl 1723JPEAJJP7. Comparison report between Rl 1723_PEA_1_P7 and Q8N2G4:
1.An isolated chimeric polypeptide encoding for Rl 1723JPEA_1_P7, comprising a first amino acid sequence being at least 90 % homologous to
MWVLGIAATFCGLFLLPGFALQIQCYQCEEFQLNNDCSSPEFIVNCTVNVQDMCQKEV MEQSAG corresponding to amino acids 1 - 64 of Q8N2G4, which also corresponds to amino acids 1 - 64 of Rl 1723_PEA_1_P7, and a second amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence SHCVTRLECSGTISAHCNLCLPGSNDHPT corresponding to amino acids 65 - 93 of Rl 1723_PEA_1_P7, wherein said first and second amino acid sequences are contiguous and in a sequential order.
2.An isolated polypeptide encoding for a tail of Rl 1723_PEA_1_P7, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence SHCVTRLECSGTISAHCNLCLPGSNDHPT in Rl 1723_PEA_1_P7.
Comparison report between R11723_PEA_1_P7 and BAC85273: 1.An isolated chimeric polypeptide encoding for Rl 1723_PEA_1_P7, comprising a first amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence MWVLG corresponding to amino acids 1 - 5 of R11723_PEA_1_P7, second
amino acid sequence being at least 90 % homologous to
IAATFCGLFLLPGFALQIQCYQCEEFQLNNDCSSPEFIVNCTVNVQDMCQKEVMEQSAG corresponding to amino acids 22 - 80 of BAC85273, which also corresponds to amino acids 6 - 64 of Rl 1723_PEA_1__P7, and a third amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence
SHCVTRLECSGTISAHCNLCLPGSNDHPT corresponding to amino acids 65 - 93 of Rl 1723_PEA_1_P7, wherein said first, second and third amino acid sequences are contiguous and in a sequential order. 2.An isolated polypeptide encoding for a head of Rl 1723_PEA_1JP7, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence MWVLG of R11723_PEA_1_P7.
3.An isolated polypeptide encoding for a tail of R11723_PEA_1_P7, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence SHCVTRLECSGTISAHCNLCLPGSNDHPT in R11723_PEA_1_P7.
Comparison report between Rl 1723_PEA_1_P7 and BAC85518: 1.An isolated chimeric polypeptide encoding for R11723_PEA_1_P7, comprising a first amino acid sequence being at least 90 % homologous to
MWVLGIAATFCGLFLLPGFALQIQCYQCEEFQLNNDCSSPEFIVNCTVNVQDMCQKEV MEQSAG corresponding to amino acids 24 - 87 of BAC85518, which also corresponds to amino acids 1 - 64 of Rl 1723_PEA_1_P7, and a second amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence SHCVTRLECSGTISAHCNLCLPGSNDHPT corresponding to amino acids 65 - 93 of Rl 1723_PEA_1_P7, wherein said first and second amino acid sequences are contiguous and in a sequential order. 2.An isolated polypeptide encoding for a tail of Rl 1723_PEA_1 JP7, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%,
more preferably at least about 90% and most preferably at least about 95% homologous to the sequence SHCVTRLECSGTISAHCNLCLPGSNDHPT in R11723_PEA_1_P7.
The location of the variant protein was determined according to results from a number of different software programs and analyses, including analyses from SignalP and other specialized programs. The variant protein is believed to be located as follows with regard to the cell: secreted. The protein localization is believed to be secreted because both signal-peptide prediction programs predict that this protein has a signal peptide, and neither trans -membrane region prediction program predicts that this protein has a trans- membrane region..
Variant protein R11723_PEA_1_P7 also has the following non-silent SNPs (Single Nucleotide Polymorphisms) as listed in Table 1273, (given according to their position(s) on the amino acid sequence, with the alternative amino acid(s) listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein Rl 1723_PEA_1JP7 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 1273- Amino acid mutations
Variant protein Rl 1723_PEA_1_P7 is encoded by the following transcript(s): R11723_PEA_1_T17, for which the sequence(s) is/are given at the end of the application. The coding portion of transcript Rl 1723_PEA_1_T17 is shown in bold; this coding portion starts at position 434 and ends at position 712. The transcript also has the following SNPs as listed in Table 1274 (given according to their position on the nucleotide sequence, with the alternative nucleic acid listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein Rl 1723_PEA_1_P7 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 1274- Nucleic acid SNPs
Variant protein Rl 1723_PEA_1_P13 according to the present invention has an amino acid sequence as given at the end of the application; it is encoded by transcript(s) Rl 1723_PEA_1_T19. One or more alignments to one or more previously published protein sequences are given at the end of the application. A brief description of the relationship of the variant protein according to the present invention to each such aligned protein is as follows: Comparison report between Rl 1723_PEA_1_P13 and Q96AC2:
1.An isolated chimeric polypeptide encoding for Rl 1723_PEA_1_P13, comprising a first amino acid sequence being at least 90 % homologous to
MWVLGIAATFCGLFLLPGFALQIQCYQCEEFQLNNDCSSPEFIVNCTVNVQDMCQKEV MEQSA corresponding to amino acids 1 - 63 of Q96AC2, which also corresponds to amino acids 1 - 63 of Rl 1723_PEA_1_P13, and a second amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence DTKRTNTLLFEMRHFAKQLTT corresponding to amino acids 64 - 84 of R11723_PEA_1_P133 wherein said first and second amino acid sequences are contiguous and in a sequential order.
2.An isolated polypeptide encoding for a tail of R11723_PEA_1_P13, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence DTKRTNTLLFEMRHFAKQLTT in Rl 1723_PEA_1_P13.
The location of the variant protein was determined according to results from a number of different software programs and analyses, including analyses from SignalP and other specialized programs. The variant protein is believed to be located as follows with regard to the cell:
secreted. The protein localization is believed to be secreted because both signal-peptide prediction programs predict that this protein has a signal peptide, and neither trans -membrane region prediction program predicts that this protein has a trans -membrane region..
Variant protein Rl 1723_PEA_1_P13 is encoded by the following transcript(s):
Rl 1723_PEA_1 JT19 and Rl 1723_PEA_1_T5, for which the sequence(s) is/are given at the end of the application. The coding portion of transcript R11723_PEA_1_T19 is shown in bold; this coding portion starts at position 434 and ends at position 685. The transcript also has the following SNPs as listed in Table 1275 (given according to their position on the nucleotide sequence, with the alternative nucleic acid listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein Rl 1723_PEA_1_P13 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 1275 - Nucleic acid SNPs
Variant protein Rl 1723JPEA_l_P10 according to the present invention has an amino acid sequence as given at the end of the application; it is encoded by transcript(s) Rl 1723_PEA_l_T20. One or more alignments to one or more previously published protein sequences are given at the end of the application. A brief description of the relationship of the variant protein according to the present invention to each such aligned protein is as follows:
Comparison report between Rl 1723_PEA_l_P10 and Q96AC2:
1.An isolated chimeric polypeptide encoding for Rl 1723_PEA_l_P10, comprising a first amino acid sequence being at least 90 % homologous to
MWVLGIAATFCGLFLLPGFALQIQCYQCEEFQLNNDCSSPEFIVNCTVNVQDMCQKEV MEQSA corresponding to amino acids 1 - 63 of Q96AC2, which also corresponds to amino acids 1 - 63 of Rl 1723_PEA_l_P10, and a second amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence
DRVSLCHEAGVQWNNFSTLQPLPPRLK corresponding to amino acids 64 - 90 of
Rl 1723_PEA_l_P10, wherein said first and second amino acid sequences are contiguous and in a sequential order.
2.An isolated polypeptide encoding for a tail of Rl 1723_PEA_l_P10, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence DRVSLCHEAGVQWNNFSTLQPLPPRLK in R11723_PEA_l_P10.
Comparison report between Rl 1723_PEA_l_P10 and Q8N2G4: 1.An isolated chimeric polypeptide encoding for Rl 1723_PEA_l_P10, comprising a first amino acid sequence being at least 90 % homologous to
MWVLGIAATFCGLFLLPGFALQIQCYQCEEFQLNNDCSSPEFIVNCTVNVQDMCQKEV MEQSA corresponding to amino acids 1 - 63 of Q8N2G4, which also corresponds to amino acids 1 - 63 of R11723_PEA I PlO, and a second amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence DRVSLCHEAGVQWNNFSTLQPLPPRLK corresponding to amino acids 64 - 90 of Rl 1723_PEA_l_P10, wherein said first and second amino acid sequences are contiguous and in a sequential order. 2.An isolated polypeptide encoding for a tail of Rl 1723_PEA_l_P10, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence DRVSLCHEAGVQWNNFSTLQPLPPRLK in R11723_PEA_l_P10.
Comparison report between Rl 1723_PEA_1_P 10 and BAC85273 :
1.An isolated chimeric polypeptide encoding for Rl 1723_PEA_l_P10, comprising a first amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence MWVLG corresponding to amino acids 1 - 5 of R11723_PEA_l_P10, second amino acid sequence being at least 90 % homologous to
IAATFCGLFLLPGFALQIQCYQCEEFQLNNDCSSPEFIVNCTVNVQDMCQKE VMEQSA corresponding to amino acids 22 - 79 of BAC85273, which also corresponds to amino acids 6 - 63 of R11723_PEA_l_P10, and a third amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence
DRVSLCHEAGVQWNNFSTLQPLPPRLK corresponding to amino acids 64 - 90 of R11723_PEA_l_P10, wherein said first, second and third amino acid sequences are contiguous and in a sequential order.
2.An isolated polypeptide encoding for a head of Rl 1723_PEA_l_P10, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence MWVLG of Rl 1723_PEA_l_P10.
3.An isolated polypeptide encoding for a tail of R11723_PEA_l_P10, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence DRVSLCHEAGVQWNNFSTLQPLPPRLK in R11723_PEA_l_P10.
Comparison report between Rl 1723_PEA_l_P10 and BAC85518: 1.An isolated chimeric polypeptide encoding for R11723JPEA_l_P10, comprising a first amino acid sequence being at least 90 % homologous to
MWVLGIAATFCGLFLLPGFALQIQCYQCEEFQLNNDCSSPEFIVNCTVNVQDMCQKEV MEQSA corresponding to amino acids 24 - 86 of BAC85518, which also corresponds to amino acids 1 - 63 of Rl 1723JPEA_l_P10, and a second amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence
DRVSLCHEAGVQWNNFSTLQPLPPRLK corresponding to amino acids 64 - 90 of
Rl 1723_PEA_l_P10, wherein said first and second amino acid sequences are contiguous and in a sequential order.
2.An isolated polypeptide encoding for a tail of Rl 1723_PEA_l_P10, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence DRVSLCHEAGVQWNNFSTLQPLPPRLK in Rl 1723_PEA_l_P10.
The location of the variant protein was determined according to results from a number of different software programs and analyses, including analyses from SignalP and other specialized programs. The variant protein is believed to be located as follows with regard to the cell: secreted. The protein localization is believed to be secreted because both signal-peptide prediction programs predict that this protein has a signal peptide, and neither trans -membrane region prediction program predicts that this protein has a trans -membrane region..
Variant protein R11723_PEA_l_P10 also has the following non-silent SNPs (Single Nucleotide Polymorphisms) as listed in Table 1276, (given according to their position(s) on the amino acid sequence, with the alternative amino acid(s) listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein Rl 1723_PEA_l_P10 sequence provides support for the deduced sequence of this variant protein according to the present invention). Table 1276 - Amino acid mutations
Variant protein Rl 1723_PEA_l_P10 is encoded by the following transcript(s): R11723_PEA_l_T20, for which the sequence(s) is/are given at the end of the application. The coding portion of transcript Rl 1723_PEA_l_T20 is shown in bold; this coding portion starts at position 434 and ends at position 703. The transcript also has the following SNPs as listed in Table 1277 (given according to their position on the nucleotide sequence, with the alternative nucleic acid listed; the last column indicates whether the SNP is known or not; the presence of
known SNPs in variant protein Rl 1723_PEA_l_P10 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 1277- Nucleic acid SNPs
As noted above, cluster Rl 1723 features 26 segment(s), which were listed in Table 2 above and for which the sequence(s) are given at the end of the application. These segment(s) are portions of nucleic acid sequence(s) which are described herein separately because they are of particular interest. A description of each segment according to the present invention is now provided.
Segment cluster Rl 1723_PEA_l_node_13 according to the present invention is supported by 5 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): Rl 1723_PEA_1_T19, Rl 1723_PEA_1_T5 and R11723_PEA_1_T6. Table 1278 below describes the starting and ending position of this segment on each transcript. Table 1278- Segment location on transcripts
Segment cluster Rl 1723_PEA_l_node_16 according to the present invention is supported by 3 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): R11723_PEA_1_T17, R11723_PEA_1_T19 and
R11723_PEA_l_T20. Table 1279 below describes the starting and ending position of this segment on each transcript.
Table 1279- Segment location on transcripts
Segment cluster Rl 1723_PEA_l_node_19 according to the present invention is supported by 45 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): Rl 1723_PEA_1_T5 and Rl 1723_PEA_1_T6. Table 1280 below describes the starting and ending position of this segment on each transcript. Table 1280- Segment location on transcripts
Segment cluster Rl 1723_PEA_l_node_2 according to the present invention is supported by 29 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): Rl 1723_PEA_1_T15, Rl 1723_PEA_1_T17, R11723JPEAJJT19, R11723_PEA_l_T20, R11723_PEA_1_T5 and R11723_PEA_l_T6. Table 1281 below describes the starting and ending position of this segment on each transcript.
Table 1281- Segment location on transcripts
Segment cluster Rl 1723_PEA_l_node_22 according to the present invention is supported by 65 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): R11723_PEA_1_T5 and R11723_PEA_1_T6. Table 1282 below describes the starting and ending position of this segment on each transcript.
Table 1282- Segment location on transcripts
Segment cluster Rl 1723_PEA_l_node_31 according to the present invention is supported by 70 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): R11723_PEA_1_T15, R11723_PEA_1_T5 and R11723_PEA_1_T6. Table 1283 below describes the starting and ending position of this segment on each transcript (it should be noted that these transcripts show alternative polyadenylation) .
Table 1283 - Segment location on transcripts
According to an optional embodiment of the present invention, short segments related to the above cluster are also provided. These segments are up to about 120 bp in length, and so are included in a separate description.
Segment cluster Rl 1723_PEA_l_node_10 according to the present invention is supported by 38 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): Rl 1723_PEA_1_T15, Rl 1723_PEA_1_T17, Rl 1723_PEA_1_T19, Rl 1723_PEA_l_T20, Rl 1723_PEA_1_T5 and Rl 1723_PEA_1_T6. Table 1284 below describes the starting and ending position of this segment on each transcript.
Table 1284 - Segment location on transcripts
Segment cluster Rl 1723_PEA_l_node_l 1 according to the present invention is supported by 42 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): R11723_PEA_1_T15, R11723_PEA_1_T17, Rl 1723_PEA_1_T19, Rl 1723_PEA_ljr20, Rl 1723_PEA_1_T5 and Rl 1723_PEA_1_T6. Table 1285 below describes the starting and ending position of this segment on each transcript.
Table 1285 - Segment location on transcripts
Segment cluster Rl 1723_PEA_l_node_15 according to the present invention can be found in the following transcript(s): R11723_PEA_l_T20. Table 1286 below describes the starting and ending position of this segment on each transcript. Table 1286 - Segment location on transcripts
Segment cluster Rl 1723_PEA_l_node_18 according to the present invention is supported by 40 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): Rl 1723JPEA_1_T15, Rl 1723_PEA_1_T5 and Rl 1723_PEA_1_T6. Table 1287 below describes the starting and ending position of this segment on each transcript.
Table 1287- Segment location on transcripts
Segment cluster Rl 1723_PEA_l_node_20 according to the present invention can be found in the following transcript(s): R11723_PEA_1_T5 and R11723_PEA_1_T6. Table 1288 below describes the starting and ending position of this segment on each transcript.
Table 1288- Segment location on transcripts
Segment cluster Rl 1723_PEA_l_node_21 according to the present invention is supported by 36 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): R11723JPEA_1_T5 and R11723_PEA_1_T6. Table 1289 below describes the starting and ending position of this segment on each transcript.
Table 1289 - Segment location on transcripts
Segment cluster Rl 1723_PEA_l_node_23 according to the present invention is supported by 39 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): R11723_PEA_1_T5 and R11723_PEA_1_T6. Table 1290 below describes the starting and ending position of this segment on each transcript.
Table 1290 - Segment location on transcripts
Segment cluster Rl 1723_PEA_l_node_24 according to the present invention is supported by 51 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): Rl 1723_PEA_1_T15, Rl 1723_PEA_1_T5 and R11723_PEA_1_T6. Table 1291 below describes the starting and ending position of this segment on each transcript.
Table 1291 - Segment location on transcripts
Segment cluster Rl 1723_PEA_l_node_25 according to the present invention is supported by 54 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): R11723_PEA_1_T15, R11723_PEA_1 JT5 and R11723_PEA_1_T6. Table 1292 below describes the starting and ending position of this segment on each transcript.
Table 1292 - Segment location on transcripts
Segment cluster Rl 1723_PEA_l_node_26 according to the present invention is supported by 62 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): R11723_PEA_1_T15, R11723_PEA_1_T5 and R11723_PEA_1_T6. Table 1293 below describes the starting and ending position of this segment on each transcript.
Table 1293 - Segment location on transcripts
Segment cluster R11723_PEA_l_node_27 according to the present invention is supported by 67 libraries. The number of libraries was determined as previously described. This segment
can be found in the following transcript(s): Rl 1723_PEA_1_T15, R11723JPEAJ JT5 and R11723_PEA_1_T6. Table 1294 below describes the starting and ending position of this segment on each transcript.
Table 1294 - Segment location on transcripts
Segment cluster Rl 1723_PEA_l_node_28 according to the present invention can be found in the following transcript(s): R11723_PEA_1_T15, R11723_PEA_1_T5 and R11723_PEA_1_T6. Table 1295 below describes the starting and ending position of this segment on each transcript.
Table 1295 - Segment location on transcripts
Segment cluster R11723_PEA_l_node_29 according to the present invention is supported by 69 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): R11723_PEA_1_T15, R11723_PEA_1_T5 and Rl 1723_PEA_1_T6. Table 1296 below describes the starting and ending position of this segment on each transcript.
Table 1296 - Segment location on transcripts
Segment cluster Rl 1723_PEA_l_node_3 according to the present invention can be found in the following transcript(s): R11723_PEA_1_T15, Rl 1723_PEA_1_T17, R11723_PEA_1_T19, R11723_PEA_l_T20, R11723_PEA_1_T5 and R11723_PEA_1_T6. Table 1297 below describes the starting and ending position of this segment on each transcript.
Table 1297 - Segment location on transcripts
Segment cluster Rl 1723_PEA_l_node_30 according to the present invention can be found in the following transcript(s): R11723_PEA_1_T15, R11723_PEA_1_T5 and Rl 1723_PEA_1_T6. Table 1298 below describes the starting and ending position of this segment on each transcript.
Table 1298 - Segment location on transcripts
Segment cluster Rl 1723_PEA_l_node_4 according to the present invention is supported by 25 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): Rl 1723_PEA_1_T15, Rl 1723JPEA_1_T17, Rl 1723_PEA_1_T19, Rl 1723_PEA_l_T20, Rl 1723_PEA_1_T5 and Rl 1723_PEA_1_T6. Table 1299 below describes the starting and ending position of this segment on each transcript.
Table 1299 - Segment location on transcripts
Segment cluster Rl 1723_PEA_l_node_5 according to the present invention is supported by 26 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): R11723_PEA_1_T15, Rl 1723JPEA_1_T17, R11723_PEA_1_T19, R11723_PEA_l_T20, R11723_PEA_1_T5 and Rl 1723_PEA_1_T6. Table 1300 below describes the starting and ending position of this segment on each transcript.
Table 1300 - Segment location on transcripts
Segment cluster Rl 1723_PEA_l_node_6 according to the present invention is supported by 27 libraries. The number of libraries was deteπnined as previously described. This segment can be found in the following transcript(s): Rl 1723_PEA_1_T15, Rl 1723_PEA_1_T17, Rl 1723_PEA_1_T19, Rl 1723_PEA_1 JT20, Rl 1723_PEA_1_T5 and Rl 1723_PEA_1_T6. Table 1301 below describes the starting and ending position of this segment on each transcript.
Table 1301 - Segment location on transcripts
Segment cluster Rl 1723_PEA_l_node_7 according to the present invention is supported by 29 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): Rl 1723_PEA_1_T15, Rl 1723_PEA_1_T17, R11723_PEA_1_T19, R11723_PEA_l_T20, R11723_PEA_1_T5 and R11723_PEA_1_T6. Table 1302 below describes the starting and ending position of this segment on each transcript. Table 1302 - Segment location on transcripts
Segment cluster Rl 1723_PEA_l_node_8 according to the present invention is supported by 2 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): Rl 1723_PEA_1_T6. Table 1303 below describes the starting and ending position of this segment on each transcript.
Table 1303 - Segment location on transcripts
Variant protein alignment to the previously known protein:
Sequence name: /tmp/gp6eQTLWqk/mFtjUpUzhb:Q8IXM0
Sequence documentation:
Alignment of: R11723_PEA_1_P6 x Q8IXM0
Alignment segment 1/1:
Quality: 1128.00 Escore: 0
Matching length: 112 Total length: 112
Matching Percent Similarity: 100.00 Matching Percent Identity: 100.00
Total Percent Similarity: 100.00 Total Percent Identity: 100.00 Gaps : 0
Alignment :
111 MYAQALLVVGVLQRQAAAQHLHEHPPKLLRGHRVQERVDDRAEVEKRLRE 160 I I I M I ) I I I I I I ! I ! I ) I M I ) I I I [ I I I I I M I I I I I I I I I I I I I I I I
1 MYAQALLVVGVLQRQAAAQHLHEHPPKLLRGHRVQERVDDRAEVEKRLRE 50
161 GEEDHVRPEVGPRPVVLGFGRSHDPPNLVGHPAYGQCHNNQPWADTSRRE 210 I I Il I I Il I Il I Il I I I I Il Il Il I I I I I I I I I I I I I I I I Il I I Il Il I I 51 GEEDHVRPEVGPRPWLGFGRSHDPPNLVGHPAYGQCHNNQPWADTSRRE 100
211 RQRKEKHSMRTQ 222
I I I I I I I Il I I I
101 RQRKEKHSMRTQ 112
Sequence name: /tmp/gp6eQTLWqk/mFtjUpUzhb:Q96AC2
Sequence documentation:
Alignment of: R11723_PEA 1 P6 x Q96AC2
Alignment segment 1/1:
Quality: 835.00 Escore: 0 Matching length: 83 Total length: 83
Matching Percent Similarity: 100.00 Matching Percent Identity: 100.00
Total Percent Similarity: 100.00 Total Percent Identity: 100.00
Gaps : 0
Alignment :
1 MWVLGIAATFCGLFLLPGFALQIQCYQCEEFQLNNDCSSPEFIVNCTVNV 50
I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I
1 MWVLGIAATFCGLFLLPGFALQIQCYQCEEFQLNNDCSSPEFIVNCTVNV 50
51 QDMCQKEVMEQSAGIMYRKSCASSAACLIASAG 83 I I I I I I I I I I ) I I I I I I I I I I I I I I I I I I I I I I
51 QDMCQKEVMEQSAGIMYRKSCASSAACLIASAG 83
Sequence name: /tmp/gp6eQTLWqk/mFtjUpUzhb:Q8N2G4
Sequence documentation:
Alignment of: R11723_PEA_1_P6 x Q8N2G4
Alignment segment 1/1:
Quality: 835.00
Escore: 0
Matching length: 83 Total length: 83
Matching Percent Similarity: 100.00 Matching Percent Identity: 100.00
Total Percent Similarity: 100.00 Total Percent Identity: 100.00
Gaps : 0
Alignment:
1 MWVLGIAATFCGLFLLPGFALQIQCYQCEEFQLNNDCSSPEFIVNCTVNV 50 M I I I M I I I I M i I I I I M I M I I I I I M I I I M I I M I I I I I I I I M I
1 MWVLGIAATFCGLFLLPGFALQIQCYQCEEFQLNNDCSSPEFIVNCTVNV 50 . . .
51 QDMCQKEVMEQSAGIMYRKSCASSAACLIASAG 83
I l I M I M I l I M I I I I I M I l I l I l I l I I I I 1 51 QDMCQKEVMEQSAGIMYRKSCASSAACLIASAG 83
Sequence name: /tmp/gp6eQTLWqk/mFtjUpUzhb:BAC85518
Sequence documentation:
Alignment of: R11723_PEA_1_P6 x BAC85518
Alignment segment 1/1:
Quality: 835.00 Escore: 0
Matching length: 83 Total length: 83
Matching Percent Similarity: 100.00 Matching Percent Identity: 100.00
Total Percent Similarity: 100.00 Total Percent Identity: 100.00 Gaps: 0
Alignment :
1 MWVLGIAATFCGLFLLPGFALQIQCYQCEEFQLNNDCSSPEFIVNCTVNV 50
24 MWVLGIAATFCGLFLLPGFALQIQCYQCEEFQLNNDCSSPEFIVNCTVNV 73
51 QDMCQKEVMEQSAGIMYRKSCASSAACLIASAG 83
Il M M M I Il I Il Il I M M Il I I Il I I Il I I 74 QDMCQKEVMEQSAGIMYRKSCASSAACLIASAG 106
Sequence name: /tmp/VXjdFlzdBX/bexTxThOTh:Q96AC2
Sequence documentation:
Alignment of: R11723_PEA_1_P7 x Q96AC2
Alignment segment 1/1:
Quality: 654.00 Escore: 0
Matching length: 64 Total length: 64
Matching Percent Similarity: 100.00 Matching Percent Identity: 100.00 Total Percent Similarity: 100.00 Total Percent Identity: 100.00
Gaps : 0
Alignment : . . . . .
1 MWVLGIAATFCGLFLLPGFALQIQCYQCEEFQLNNDCSSPEFIVNCTVNV 50
I I I Il I i I I I I Il I I I I Il I Il I Il I I I I I I I I I I I I I Il Il I I I I I I Il
1 MWVLGIAATFCGLFLLPGFALQIQCYQCEEFQLNNDCSSPEFIVNCTVNV 50
51 QDMCQKEVMEQSAG 64
I I I I I I I I I I Il I I 51 QDMCQKEVMEQSAG 64
Sequence name: /tmp/VXjdFlzdBX/bexTxThOTh: Q8N2G4
Sequence documentation:
Alignment of: R11723_PEA_1_P7 x Q8N2G4
Alignment segment 1/1:
Quality: 654.00 Escore: 0
Matching length: 64 Total length: 64 Matching Percent Similarity: 100.00 Matching Percent Identity: 100.00
Total Percent Similarity: 100.00 Total Percent Identity: 100.00
Gaps : 0
Alignment :
1 MWVLGIAATFCGLFLLPGFALQIQCYQCEEFQLNNDCSSPEFIVNCTVNV 50
I I I Il I Il I Il Il I Il I I I I Il I I I I Il Il Il I Il I Il I I I Il Il Il I Il 1 MWVLGIAATFCGLFLLPGFALQIQCYQCEEFQLNNDCSSPEFIVNCTVNV 50
51 QDMCQKEVMEQSAG 64
II I Il I I I I Il I I I
51 QDMCQKEVMEQSAG 64
Sequence name: /tmp/VXjdFlzdBX/bexTxThOTh:BAC85273
Sequence documentation:
Alignment of: R11723_PEA_1_P7 x BAC85273
Alignment segment 1/1:
Quality: 600 .00
Escore : 0
Matching length : 59 Total length : 59
Matching Percent Similarity: 100.00 Matching Percent Identity: 100.00
Total Percent Similarity: 100.00 Total Percent Identity: 100.00
Gaps : 0
Alignment :
6 IAATFCGLFLLPGFALQIQCYQCEEFQLNNDCSSPEFIVNCTVNVQDMCQ 55
M I M M M I I I I I I I I I I M I M I I I M M I I I I M I I M I M I I I I M
22 IAATFCGLFLLPGFALQIQCYQCEEFQLNNDCSSPEFIVNCTVNVQDMCQ 71
56 KEVMEQSAG • 64 MIIIMII
72 KEVMEQSAG 80
Sequence name: /tmp/VXjdFlzdBX/bexTxThOTh:BAC85518
Sequence documentation:
Alignment of: R11723_PEA_1_P7 x BAC85518
Alignment segment 1/1:
Quality: 654.00
Escore: 0
Matching length: 64 Total length: 64
Matching Percent Similarity: 100.00 Matching Percent Identity: 100.00
Total Percent Similarity: 100.00 Total Percent Identity: 100.00
Gaps : 0
Alignment:
1 MWVLGIAATFCGLFLLPGFALQIQCYQCEEFQLNNDCSSPEFIVNCTVNV 50
I I I Il I Il I I I Ii I I Il Il Il I Il Il I I Il I I I I I I I I Il Il I I I I Il I I
24 MWVLGIAATFCGLFLLPGFALQIQCYQCEEFQLNNDCSSPEFIVNCTVNV 73
51 QDMCQKEVMEQSAG 64
74 QDMCQKEVMEQSAG
Sequence name: /tmp/OLMSexEmIh/pc7Z7XmlYR: Q96AC2
Sequence documentation:
Alignment of: R11723_PEA_l_P10 x Q96AC2
Alignment segment 1/1:
Quality: 645.00 Escore: 0
Matching length: 63 Total length: 63
Matching Percent Similarity: 100.00 Matching Percent Identity: 100.00
Total Percent Similarity: 100.00 Total Percent Identity: 100.00 Gaps : 0
Alignment :
1 MWVLGIAATFCGLFLLPGFALQIQCYQCEEFQLNNDCSSPEFIVNCTVNV 50 I I M I I I I I I I Il I I I I I I I M I M I I I Il M I I I I I I I I M M I M I I I
1 MWVLGIAATFCGLFLLPGFALQIQCYQCEEFQLNNDCSSPEFIVNCTVNV 50
51 QDMCQKEVMEQSA 63
I I I 1 I I I I 1 I I I I
51 QDMCQKEVMEQSA 63
Sequence name: /tmp/OLMSexEmIh/pc7Z7XmlYR:Q8N2G4
Sequence documentation:
Alignment of: R11723_PEA_l_P10 x Q8N2G4
Alignment segment 1/1:
Quality: 645.00 Escore: 0
Matching length: 63 Total length: 63
Matching Percent Similarity: 100.00 Matching Percent Identity: 100.00 Total Percent Similarity: 100.00 Total Percent Identity: 100.00
Gaps : 0
Alignment: . . . . .
1 MWVLGIAATFCGLFLLPGFALQIQCYQCEEFQLNNDCSSPEFIVNCTVNV 50
I I I I I I I I ! I I I I I I I I I 1 I I I I I I 1 I I 1 I I I i I I I I I I I I I I I I I I I I I l MWVLGIAΆTFCGLFLLPGFALQIQCYQCEEFQLNNDCS SPEFIVNCTVNV 50
51 QDMCQKEVMEQSA 63
I I I I 1 I 1 I I I I I I
51 QDMCQKEVMEQSA 63
Sequence name: /tmp/OLMSexEmIh/pc7Z7XmlYR:BAC85273
Sequence documentation:
Alignment of: R11723_PEA_l_P10 x BAC85273
Alignment segment 1/1:
Quality: 591.00 Escore: 0
Matching length: 58 Total length: 58 Matching Percent Similarity: 100.00 Matching Percent Identity: 100.00
Total Percent Similarity: 100.00 Total Percent Identity: 100.00
Gaps : 0
Alignment :
6 IAATFCGLFLLPGFALQIQCYQCEEFQLNNDCSSPEFIVNCTVNVQDMCQ 55 1 1 1 1 11 1 1 1 1 1 1 1 1 1 1 1 1 1 111 1 1 1 1 1 1 1 1 1 1 1 1 ! M ) I M I I I I I I M I
22 IAATFCGLFLLPGFALQIQCYQCEEFQLNNDCSSPEFIVNCTVNVQDMCQ 71
56 KEVMEQSA 63
I I I I I I I I
72 KEVMEQSA 79
Sequence name: /tmp/OLMSexEmIh/pc7Z7XmlYR:BAC85518
Sequence documentation:
Alignment of: R11723_PEA_l_P10 x BAC85518
Alignment segment 1/1:
Quality: 645.00 Escore: 0 Matching length: 63 Total length: 63
Matching Percent Similarity: 100.00 Matching Percent Identity: 100.00
Total Percent Similarity: 100.00 Total Percent Identity: 100.00
Gaps : 0
Alignment :
1 MWVLGIAATFCGLFLLPGFALQIQCYQCEEFQLNNDCSSPEFIVNCTVNV 50 I I I I I I I I I I I I I I I I I I I I I Il I I I I I I I I I I I I I I I I I I I I I I I I I I I
24 MWVLGIAATFCGLFLLPGFALQIQCYQCEEFQLNNDCSSPEFIVNCTVNV 73
51 QDMCQKEVMEQSA 63
I I I Il I I I I I I I I 74 QDMCQKEVMEQSA 86
Alignment of: R11723 PEA 1 P13 x Q96AC2
Alignment segment 1/1:
Quality: 645.00
Escore: 0
Matching length: 63 Total length: 63 Matching Percent Similarity: 100.00 Matching Percent Identity: 100.00
Total Percent Similarity: 100.00 Total Percent Identity: 100.00
Gaps :
Alignment :
1 MWVLGIAATFCGLFLLPGFALQIQCYQCEEFQLNNDCSSPEFIVNCTVNV 50
I I I I I I I I I I I I I I I I I I 1 I I I I 1 I I I I I I I I I I I I I I I I I I I I I I I I I I
1 MWVLGIAATFCGLFLLPGFALQIQCYQCEEFQLNNDCSSPEFIVNCTVNV 50
51 QDMCQKEVMEQSA 63
I I Il I I I I I I I i I 51 QDMCQKEVMEQSA 63
It should be noted that the nucleotide transcript sequence of known protein (PSEC, also referred to herein as the "wild type" or WT protein) feature at least one SNP that appears to affect the coding region, in addition to certain silent SNPs. This SNP does not have an effect on the Rl 1723_PEA_1_T5 splice variant sequence): "G-> " resulting in a missing nucleotide (affects amino acids from position 91 onwards). The missing nucleotide creates a frame shift, resulting in a new protein. This SNP was not previously identified and is supported by 5 ESTs out of ~70 ESTs in this exon.
It should be noted that the variants of this cluster are variants of the hypothetical protein
PSECOl 81 (referred to herein as "PSEC"). Furthermore, use of the known protein (WT protein) for detection of lung cancer, alone or in combination with one or more variants of this cluster and/or of any other cluster and/or of any known marker, also comprises an embodiment of the present invention.
Expression of Rl 1723 transcripts which are detectable by amplicon as depicted in sequence name Rl 1723 segl3 in normal and cancerous lung tissues
Expression of transcripts detectable by or according to Rl 1723 segl3, Rl 1723 segl3 amplicon (SEQ ID NO: 1684), and Rl 1723 segl3F (SEQ ID NO: 1682), and Rl 1723 segl3R (SEQ ID NO: 1683), primers was measured by real time PCR. In parallel the expression of four housekeeping genes PBGD (GenBank Accession No. BC019323; amplicon - PBGD-amplicon, SEQ ID NO:334), HPRTl (GenBank Accession No. NM_000194; amplicon - HPRTl- amplicon, SEQ ID NO:1297), and SDHA (GenBank Accession No. NM_004168; amplicon -
SDHA- amplicon, SEQ ID NO:331), Ubiquitin (GenBank Accession No. BC000449; amplicon - Ubiquitin-amplicon, SEQ ID NO:328) was measured similarly. For each RT sample, the expression of the above amplicon was normalized to the geometric mean of the quantities of the housekeeping genes. The normalized quantity of each RT sample was then divided by the median of the quantities of the normal post-mortem (PM) samples (Sample Nos. 47-50, 90-93, 96-99, Table 2 "Tissue samples in testing panel", above), to obtain a value of fold up-regulation for each sample relative to median of the normal PM samples.
Figure 48 is a histogram showing over expression of the above- indicated transcripts in cancerous lung samples relative to the normal samples. The number and percentage of samples that exhibit at least 5 fold over- expression, out of the total number of samples tested is indicated in the bottom.
As is evident from Figure 48, the expression of transcripts detectable by the above amplicon(s) in cancer samples was higher than in the non-cancerous samples (Sample Nos. 47-
50, 90-93, 96-99 Table 2 "Tissue samples in testing panel"). Notably an over- expression of at least 5 fold was found in 10 out of 15 adenocarcinoma samples, and in 4 out of 8 small cells carcinoma samples.
Primer pairs are also optionally and preferably encompassed within the present invention; for example, for the above experiment, the following primer pair was used as a non- limiting illustrative example only of a suitable primer pair: Rl 1723 segl3F forward primer; and Rl 1723 segl 3R reverse primer.
The present invention also preferably encompasses any amplicon obtained through the use of any suitable primer pair; for example, for the above experiment, the following amplicon was obtained as a non- limiting illustrative example only of a suitable amplicon: Rl 1723 segl3.
R11723segl3F (SEQ ID NO: 1682), - ACACTAAAAGAACAAACACCTTGCTC Rl 1723segl3R (SEQ ID NO: 1683), - TCCTCAGAAGGCACATGAAAGA
Rl 1723segl3 - amplicon (SEQ ID NO: 1684),:
ACACTAAAAGAACAAACACCTTGCTCTTCGAGATGAGACATTTTGCCAAGCA GTTGACCACTTAGTTCTCAAGAAGCAACTATCTCTTTCATGTGCCTTCTGAGGA
Expression of Rl 1723 transcripts which are detectable by amplicon as depicted in sequence name Rl 1723segl3 in different normal tissues
Expression of Rl 1723 transcripts detectable by or according to Rl 1723segl3 amplicon (SEQ ID NO: 1684), and Rl 1723segl3F (SEQ ID NO: 1682),, Rl 1723segl3R (SEQ ID NO: 1683), was measured by real time PCR. In parallel the expression of four housekeeping genes RPL19 (GenBank Accession No. NM_000981; RPL19 amplicon, SEQ ID NO:1630), TATA box (GenBank AccessionNo. NM_003194; TATA amplicon, SEQ ID NO: 1633), UBC (GenBank Accession No. BC000449; amplicon - Ubiquitin-amplicon, SEQ ID NO:328) and SDHA (GenBank Accession No. NM_004168; amplicon - SDHA- amplicon, SEQ ID NO:331) was measured similarly. For each RT sample, the expression of the above amplicon was normalized to the geometric mean of the quantities of the housekeeping genes. The normalized quantity of each RT sample was then divided by the median of the quantities of the ovary samples (Sample Nos. 18-20, Table 2 "Tissue samples in normal panel" above), to obtain a value of relative expression of each sample relative to median of the ovary samples.
Rl 1723segl3F (SEQ ID NO: 1682), - ACACTAAAAGAACAAACACCTTGCTC
Rl 1723segl3R (SEQ ID NO: 1683), - TCCTCAGAAGGCACATGAAAGA
Rl 1723segl3 - amplicon (SEQ ID NO: 1684),:
ACACTAAAAGAACAAACACCTTGCTCTTCGAGATGAGACATTTTGCCAAGCAGTTG
ACCACTTAGTTCTCAAGAAGCAACTATCTCTTTCATGTGCCTTCTGAGGA The results are presented in Figure 49, showing the expression of Rl 1723 transcripts which are detectable by amplicon as depicted in sequence name Rl 1723segl3 in different normal tissues.
Expression of Rl 1723 transcripts, which are detectable by amplicon as depicted in sequence name Rl 1723 juncl 1-18 in normal and cancerous lung tissues.
Expression of transcripts detectable by or according to juncl 1-18, Rl 1723 juncl 1-18 amplicon (SEQ ID NO: 1687) and Rl 1723 juncl 1-18F (SEQ ID NO: 1685) and Rl 1723 juncl 1- 18R (SEQ ID NO: 1686) primers was measured by real time PCR (this junction is found in the known protein sequence or "wild type" (WT) sequence, also termed herein the PSEC sequence). In parallel the expression of four housekeeping genes PBGD (GenBank Accession No. BC019323; amplicon - PB GD- amplicon, SEQ ID NO:334), HPRTl (GenBank Accession No.
NMJ)OO 194; amplicon - HPRTl -amplicon, SEQ ID NO: 1297), SDHA (GenBank Accession No. NM_004168; amplicon - SDHA- amplicon, SEQ ID NO:331), and Ubiquitin (GenBank Accession No. BC000449; amplicon - Ubiquitin- amplicon, SEQ ID NO:328) was measured similarly. For each RT sample, the expression of the above amplicon was normalized to the geometric mean of the quantities of the housekeeping genes. The normalized quantity of each RT sample was then divided by the median of the quantities of the normal post-mortem (PM) samples (Sample Nos. 47-50, 90-93, 96-99, Table 2, above: "Tissue samples in lung cancer testing panel"), to obtain a value of fold up-regulation for each sample relative to median of the normal PM samples. Figure 50 is a histogram showing over expression of the above -indicated transcripts in cancerous lung samples relative to the normal samples. Values represent the average of duplicate experiments. Error bars indicate the minimal and maximal values obtained.
As is evident from Figure 50, the expression of transcripts detectable by the above amplicon in cancer samples was higher than in the non-cancerous samples (Sample Nos. 47-50, 90-93, 96-99 Table 2 "Tissue samples in lung cancer testing panel"). Notably an over- expression of at least 5 fold was found in 11 out of 15 adenocarcinoma samples, 4 out of 16 squamous cell carcinoma samples, 1 out of 4 large cell carcinoma samples and in 5 out of 8 small cells carcinoma samples.
Primer pairs are also optionally and preferably encompassed within the present invention; for example, for the above experiment, the following primer pair was used as a non- limiting illustrative example only of a suitable primer pair: RI l 723 junc 11 - 18F forward primer; and Rl 1723 juncl 1-18R reverse primer.
The present invention also preferably encompasses any amplicon obtained through the use of any suitable primer pair; for example, for the above experiment, the following amplicon was obtained as a non- limiting illustrative example only of a suitable amplicon: Rl 1723 juncl 1- 18.
Rl 1723juncl 1-18F (SEQ ID NO: 1685)- AGTGATGGAGCAAAGTGCCG Rl 1723 juncl 1-18R (SEQ ID NO: 1686)- CAGCAGCTGATGCAAACTGAG Rl 1723 juncl 1-18 - amplicon (SEQ ID NO: 1687)
AGTGATGGAGCAAAGTGCCGGGATCATGTACCGCAAGTCCTGTGCATCATCAGCGG CCTGTCTCATCGCCTCTGCCGGGTACCAGTCCTTCTGCTCCCCAGGGAAACTGAACT CAGTTTGCATCAGCTGCTG
Expression of Rl 1723 transcripts, which were detected by amplicon as depicted in the sequence name R11723 juncl l-18 in different noπnal tissues.
Expression of Rl 1723 transcripts detectable by or according to R11723segl3 amplicon (SEQ ID NO: 1687) and RU723juncll-18F (SEQ ID NO: 1685), RIl 723 juncl 1-18R(SEQ ID NO: 1686) was measured by real time PCR. In parallel the expression of four housekeeping genes RPLl 9 (GenBank Accession No. NM_000981; RPLl 9 amplicon, SEQ ID NO: 1630), TATA box (GenBank Accession No. NM_003194; TATA amplicon, SEQ ID NO: 1633), UBC (GenBank Accession No. BC000449; amplicon - Ubiquitin- amplicon, SEQ ID NO:328) and SDHA (GenBank Accession No. NM_004168; amplicon - SDHA- amplicon, SEQ ID NO:331) was measured similarly. For each RT sample, the expression of the above amplicon was normalized to the geometric mean of the quantities of the housekeeping genes. The normalized quantity of each RT sample was then divided by the median of the quantities of the ovary samples (Sample Nos. 18-20 Table 3 above), to obtain a value of relative expression of each sample relative to median of the ovary samples.
R11723juncl l-18F (SEQ ID NO: 1685)- AGTGATGGAGCAAAGTGCCG Rl 1723 juncl 1-18R (SEQ ID NO: 1686)- CAGCAGCTGATGCAAACTGAG Rl 1723 juncl 1-18 - amplicon (SEQ ID NO: 1687)
AGTGATGGAGCAAAGTGCCGGGATCATGTACCGCAAGTCCTGTGCATCATCAGCGG CCTGTCTCATCGCCTCTGCCGGGTACCAGTCCTTCTGCTCCCCAGGGAAACTGAACT CAGTTTGCATCAGCTGCTG
The results are demonstrated in Figure 73, showing the expression of Rl 1723 transcripts, which were detected by amplicon as depicted in the sequence name Rl 1723 juncl 1-18 in different normal tissues.
Cloning of this variant Full length validation
RNA preparation
Human adult papillary adenocarcinoma ovary RNA pool (lot# ILS 1408) was obtained from ABS (http://www.absbioreagents, Wilmington, DE 19801, USA com). Total RNA samples were treated with DNaseI (Ambion Cat # 1906). RT PCR
RT preparation
Purified RNA (1 ug) was mixed with 150 ng Random Hexamer primers (Invitrogen Cat # 48190-011) and 500 uM dNTP (Takara, Cat # B9501-1) in a total volume of 15.6ul DEPC- Ff2O (Beit Haemek, Cat # 01-852-1A). The mixture was incubated for 5 min at 65°C and then quickly chilled on ice. Thereafter, 5 ul of 5X Superscript II first strand buffer (Invitrogen, Cat # Y00146), 2.4ul 0.IM DTT (Invitrogen, Cat #Y00147) and 40 units RNasin (Promega, Cat # N251A) were added, and the mixture was incubated for 2 min at 42°C. Then, 1 ul (200units) of SuperscriptII (Invitrogen, Cat #18064-022) was added and the reaction was incubated for 50 min at 420C and then inactivated at 7O0C for 15min. The resulting cDNA was diluted 1 :20 in TE buffer (10 mM Tris pH=8, 1 mM EDTA pH=8). PCR amplification and analysis cDNA (5ul), prepared as described above, was used as a template in PCR reactions. The amplification was done using AccuPower PCR PreMix (Bioneer, Korea, Cat# K2016), under the following conditions: IuI - of each primer (1 OuM) PSECfor- TGCTGTCGCCTCCTCTGATG PSECrev- CCTCAGAAGGCACATGAAAG plus 13Ol - H2O were added into AccuPower PCR PreMix tube with a reaction program of 5 minutes at 940C; 35 cycles of: [30 seconds at 940C, 30 seconds at 52°C, 40 seconds at 72°C] and 10 minutes at 72°C. At the end of the PCR amplification, products were analyzed on agarose gels stained with ethidium bromide and visualized with UV light. PCR product was extracted
from the gel using QiaQuick™ gel extraction kit (Qiagen™, Cat #28706). The extracted DNA product (Figure 79) was sequenced by direct sequencing using the gene specific primers from above (Hy- Labs, Israel), resulting in the expected sequence of PSEC variant R11723_PEA_1 T5 (Figure 80). It was concluded that the predicted PSEC variant Rl 1723_PEA_1 T5 is indeed a naturally expressed variant in an adult papillary adenocarcinoma ovary human tissue as shown in Figure 79.
Cloning of PSEC variant R11723_PEA_1 T5 into bacterial expression vector
The PSEC splice variant R11723_PEA_1 T5 coding sequence was prepared for cloning by PCR amplification using the fragment described above as template and Platinum Pfx DNA polymerase (Invitrogen Cat # 11708021) under the following conditions: 5ul - Amplification XlO buffer (Invitrogen Cat # 11708021); 2ul - PCR product from above; IuI - dNTPs (1OmM each); lμl MgSO4 (5OmM) 5ul enhancer solution (Invitrogen Cat # 11708021); 33M- H2O; IuI- of each primer (lOuM) and 1.25 units of Tag polymerase [Platinum Pfx DNA polymerase (Invitrogen Cat # 11708021)] in a total reaction volume of 50ul with a reaction program of 3 minutes at 940C; 29 cycles of: [30 seconds at 940C, 30 seconds at 580C, 40 seconds at 680C] and 7 minutes at 68 0C. The Primers listed below include specific sequences of the nucleotide sequence corresponding to the splice variant and Nhel and HindIII restriction sites.
PSEC Nhelfor- ATAGCTAGCATGTGGGTCCTAGGCATCGCGG PSEC Hindlllrev- CCCAAGCTTCTAAGTGGTCAACTGCTTGGC
The PCR product was then double digested with Nhel and HindIII (New England Biolabs (UK) LTD) (Figure 81), and inserted into pRSET-A (Invitrogen, Cat# V351-20), previously digested with the same enzymes, in- frame to an N- terminal 6His-tag, to give HisPSEC T5 pRSET (Figure 82). The coding sequence encodes for a protein having the 6His- tag at the N' end (6His residues in a row at one end of the protein), and 8 additional amino acids encoded by the pRSET vector.
The sequence of the PSEC insert in the final plasmid, as well as its flanking regions, were verified by sequencing and found to be identical to the desired sequences. The complete sequence of His PSEC T5 pRESTA, including the sequenced regions, is shown in Figure 84. Figure 83 shows the translated sequence of PSEC variant Rl 1723_PEA_1 T5.
Bacterial culture and induction of protein expression
HisPSEC pRSETA DNA was transformed into competent DH5a cells (Invitrogen Cat#l 8258-012). Ampicillin resistant transformants were screened and positive clones were further analyzed by restriction enzyme digestion and sequence verification.
In order to express the recombinant protein, HisPSEC pRSETA DNA was further transformed into competent BL21Gold cells (Stratagene Cat#230134) and BL21star (Invitrogen Cat# 44-0054). Ampicillin resistant transformants were screened and positive clones were selected. Bacterial cells containing the HisPSEC T5 pRSET vector or empty pRSET vector (as negative control) were grown in LB medium, supplemented with Ampicillin (50 ug/ml) and chloramphenicol (34 ug/ml), until O.D.όOOnm reached 0.55. This value was reached in about 3 hours. ImM IPTG (Roche, Cat #724815) was added and the cells were grown at 370C overnight. 1 ml aliquots of each culture were removed for gel analysis at time zero, 3 hrs after induction and following overnight incubation (TO ,T3 and TO/N, respectively).
Expression Results
The time course of small- scale expression of PSEC in BL21Gold is demonstrated in Figure 85. The expression of a recombinant protein with the appropriate molecular weight (9.2 kDa) was visualized by Western Blot with anti-His antibodies (BD Clontech, Ref 631212, Figure 85), but not by Coomassie staining (data not shown). Similar expression pattern was obtained with BL21 star as well (data not shown).
These results show that the protein encoded by PSEC variant Rl 1723_PEA_1 T5 is indeed expressed in bacterial cells.
DESCRIPTION FOR CLUSTER Rl 6276
Cluster Rl 6276 features 1 transcript(s) and 5 segment(s) of interest, the names for which are given in Tables 1305 and 1306, respectively, the sequences themselves are given at the end of the application. The selected protein variants are given in table 1307.
Table 1305 - Transcripts of interest
Table 1306 - Segments of interest
Table 1307 - Proteins of interest
These sequences are variants of the known protein NOV protein homolog precursor
(SwissProt accession identifier NOVJHUMAN; known also according to the synonyms NovH; Nephroblastoma overexpressed gene protein homolog), SEQ ID NO: 1463, referred to herein as the previously known protein.
Protein NOV protein homolog precursor is known or believed to have the following function(s): Immediate- early protein, likely to play a role in cell growth regulation (By similarity). The sequence for protein NOV protein homolog precursor is given at the end of the application, as "NOV protein homolog precursor amino acid sequence". Known polymorphisms for this sequence are as shown in Table 1308.
Table 1308 - Amino acid mutations for Known Protein
Protein NOV protein homolog precursor localization is believed to be Secreted.
The following GO Annotation(s) apply to the previously known protein. The following annotation(s) were found: regulation of cell growth, which are annotation(s) related to Biological Process; insulin- like growth factor binding; growth factor, which are annotation(s) related to Molecular Function; and extracellular, which are annotation(s) related to Cellular Component.
The GO assignment relies on infoπnation from one or more of the SwissProt/TremBl Protein knowledgebase, available from <http://www.expasy.ch/sprot/>; or Locuslink, available from <http://www.ncbi.nhn.nih.gov/projects/LocusLink/>.
Cluster Rl 6276 can be used as a diagnostic marker according to overexpression of transcripts of this cluster in cancer. Expression of such transcripts in normal tissues is also given according to the previously described methods. The term "number" in the right hand column of the table and the numbers on the y-axis of figure 51 refer to weighted expression of ESTs in each category, as "parts per million" (ratio of the expression of ESTs for a particular cluster to the expression of all ESTs in that category, according to parts per million).
Overall, the following results were obtained as shown with regard to the histograms in Figure 51 and Table 1309. This cluster is overexpressed (at least at a minimum level) in the following pathological conditions: lung malignant tumors.
Table 1310 - Normal tissue distribution
Table 1311 - P values and ratios for expression in cancerous tissue
As noted above, cluster Rl 6276 features 1 transcript(s), which were listed in Table 1 above. These transcript(s) encode for protein(s) which are variant(s) of protein NOV protein homolog precursor. A description of each variant protein according to the present invention is now provided.
Variant protein R16276_PEA_1_P7 according to the present invention has an amino acid sequence as given at the end of the application; it is encoded by transcript(s) R16276_PEA_1_T6. An alignment is given to the known protein (NOV protein homolog precursor) at the end of the application. One or more alignments to one or more previously published protein sequences are given at the end of the application. A brief description of the relationship of the variant protein according to the present invention to each such aligned protein is as follows:
Comparison report between R16276_PEA_1_P7 and N0V_HUMAN:
1.An isolated chimeric polypeptide encoding for R16276_PEA_1_P7, comprising a first amino acid sequence being at least 90 % homologous to
MQSVQSTSFCLRKQCLCLTFLLLHLLGQVAATQRCPPQCPG corresponding to amino acids 1 - 41 of NOV_HUMAN, which also corresponds to amino acids 1 - 41 of R16276_PEA_1_P7, a bridging amino acid Q corresponding to amino acid 42 of R16276_PEA_1_P7, a second amino acid sequence being at least 90 % homologous to CPATPPTCAPGVRAVLDGCSCCLVCARQRGESCSDLEPCDESSGLYCDRSADPSNQTGI CT corresponding to amino acids 43 - 103 of NOV_HUMAN, which also corresponds to amino acids 43 - 103 of R16276_PEA_1_P7, and a third amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence GNPAPSAV corresponding to amino acids 104 - 111 of R16276_PEA_1_P7, wherein said first amino acid
sequence, bridging amino acid, second amino acid sequence and third amino acid sequence are contiguous and in a sequential order.
2.An isolated polypeptide encoding for a tail of R16276_PEA_1_P7, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence GNPAPSAV in R16276_PEA_1_P7.
The location of the variant protein was determined according to results from a number of different software programs and analyses, including analyses from SignalP and other specialized programs. The variant protein is believed to be located as follows with regard to the cell: secreted. The protein localization is believed to be secreted because both signal-peptide prediction programs predict that this protein has a signal peptide, and neither trans -membrane region prediction program predicts that this protein has a trans -membrane region.
Variant protein R16276_PEA_1_P7 also has the following non-silent SNPs (Single Nucleotide Polymorphisms) as listed in Table 1312, (given according to their position(s) on the amino acid sequence, with the alternative amino acid(s) listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein R16276_PEA_1 JP7 sequence provides support for the deduced sequence of this variant protein according to the present invention). Table 1313 - Amino acid mutations
The glycosylation sites of variant protein R16276_PEA_1_P7, as compared to the known protein NOV protein homolog precursor, are described in Table 1314 (given according to their position(s) on the amino acid sequence in the first column; the second column indicates whether the glycosylation site is present in the variant protein; and the last column indicates whether the position is different on the variant protein).
Table 1314 - Glycosylation site(s)
Variant protein R16276JPEA_1_P7 is encoded by the following transcript(s): Rl 6276_PEA_1_T6, for which the sequence(s) is/are given at the end of the application. The coding portion of transcript Rl 6276_PEA_1_T6 is shown in bold; this coding portion starts at position 445 and ends at position 777. The transcript also has the following SNPs as listed in Table 1315 (given according to their position on the nucleotide sequence, with the alternative nucleic acid listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein R16276_PEA_1_P7 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 1315 - Nucleic acid SNPs
As noted above, cluster Rl 6276 features 5 segment(s), which were listed in Table 2 above and for which the sequence(s) are given at the end of the application. These segment(s) are portions of nucleic acid sequence(s) which are described herein separately because they are of particular interest. A description of each segment according to the present invention is now provided.
Segment cluster R16276_PEA_l_node_0 according to the present invention is supported by 35 libraries. The number of libraries was determined as previously described. This segment
can be found in the following transcript(s): R16276_PEA_1_T6. Table 1316 below describes the starting and ending position of this segment on each transcript.
Table 1316 - Segment location on transcripts
Segment cluster R16276_PEA_l_node_6 according to the present invention is supported by 2 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): Rl 6276_PEA_1_T6. Table 1317 below describes the starting and ending position of this segment on each transcript.
Table 1317 - Segment location on transcripts
According to an optional embodiment of the present invention, short segments related to the above cluster are also provided. These segments are up to about 120 bp in length, and so are included in a separate description
Segment cluster R16276_PEA_l_node_l according to the present invention is supported by 37 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): R16276_PEA_1_T6. Table 1318 below describes the starting and ending position of this segment on each transcript.
Table 1318 - Segment location on transcripts
Segment cluster R16276_PEA_l_node_4 according to the present invention is supported by 38 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): R16276_PEA_1_T6. Table 1319 below describes the starting and ending position of this segment on each transcript.
Table 1319 - Segment location on transcripts
Segment cluster R16276_PEA_l_node_5 according to the present invention is supported by 37 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): R16276_PEA_1_T6. Table 1320 below describes the starting and ending position of this segment on each transcript.
Table 1320 - Segment location on transcripts
Variant protein alignment to the previously known protein:
Sequence name: NOV HUMAN
Sequence documentation:
Alignment of: R16276_PEA_1_P7 x N0V_HUMAN
Alignment segment 1/1:
Quality: 1042.00 Escore: 0
Matching length: 103 Total length: 103
Matching Percent Similarity: 100.00 Matching Percent Identity: 99.03
Total Percent Similarity: 100.00 Total Percent Identity: 99.03 Gaps: 0
Alignment:
1 MQSVQSTSFCLRKQCLCLTFLLLHLLGQVAATQRCPPQCPGQCPATPPTC 50 I I I I I I I I I I I I I I I I I I I I Il I I I I I I I Il I I I I I I I Il I : I M I I I I I
1 MQSVQSTSFCLRKQCLCLTFLLLHLLGQVAATQRCPPQCPGRCPATPPTC 50
51 APGVRAVLDGCSCCLVCARQRGESCSDLEPCDESSGLYCDRSADPSNQTG 100
I I I I I I I i I I I I I I I I I I I I I I I I Il I Il I I I I I I I I I I I I I I I I I I I I I 51 APGVRAVLDGCSCCLVCARQRGESCSDLEPCDESSGLYCDRSADPSNQTG 100
101 ICT 103
I I I
101 ICT 103
Combined expression of 6 sequences H61775seg8, HUMGRP5E junc3-7, M85491Seg24, Z21368 juncl7-21, HSSTROL3seg24 and Z25299seg20 in normal and cancerous lung tissues. Expression of immunoglobulin superfamily, member 9, gastrin- releasing peptide, Ephrin type-B receptor 2 precursor, SUL IJHUMAN, Stromelysin-3 precursor (EC 3.4.24.-) (Matrix metalloproteinase-11) (MMP-I l) (ST3) (SL- 3) and Secretory leukocyte protease inhibitor Acid- stable proteinase inhibitor transcripts detectable by or according to H61775seg8 (SEQ ID NO: 1636), HUMGRP5E junc3-7 (SEQ ID NO: 1648), M85491Seg24 (SEQ ID NO: 1639), Z21368 juncl7-21 (SEQ ID NO: 1642), HSSTROL3seg24 (SEQ ID NO: 1675) and Z25299seg20 amplicons (SEQ ID NO: 1669) and H61775seg8F (SEQ ID NO: 1634), H61775seg8R (SEQ ID NO: 1635), HUMGRP5E junc3-7F (SEQ ID NO: 1646), HUMGRP5E junc3-7R (SEQ ID NO: 1647), M85491Seg24F (SEQ ID NO: 1637), M85491Seg24R (SEQ ID NO: 1638), Z21368 juncl7-21F (SEQ ID NO: 1640), Z21368 juncl7-21R (SEQ ID NO: 1641), HSSTROL3seg24F (SEQ ID NO: 1673), HSSTROL3seg24R (SEQ ID NO: 1674), Z25299seg20F (SEQ ID NO: 1667), Z25299seg20R (SEQ ID NO: 1668) primers was measured by real time PCR. In parallel the expression of four housekeeping genes -PBGD (GenBank Accession No. BC019323; amplicon - PBGD-amplicon, SEQ ID NO:334), HPRTl (GenBank Accession No. NM_000194; amplicon - HPRTl -amplicon, SEQ ID NO: 1297), Ubiquitin (GenBank Accession No. BC000449; amplicon - Ubiquitin-amplicon, SEQ ID NO:328) and SDHA (GenBank Accession No. NM_004168; amplicon - SDHA- amplicon, SEQ ID NO:331) was measured similarly. For each RT sample, the expression of the above amplicons was normalized to the geometric mean of the quantities of the housekeeping genes. The normalized quantity of each RT sample of each amplicon was then divided by the median of the quantities of the normal post-mortem (PM) samples detected for the same amplicon (Sample Nos. 47-50, 90-93, 96-99, Table 2,, "Tissue samplesin testing panel", above), to obtain a value of fold up-regulation for each sample relative to median of the normal PM samples. The reciprocal of this ratio was calculated for Z25299seg20 (SEQ ID NO: 1669), to obtain a value of fold down-regulation for each sample relative to median of the normal PM samples. Figures 52-53 are histograms showing differential expression of the above -indicated transcripts in cancerous lung samples relative to the normal samples. The number and percentage
of samples that exhibit at least 5 fold differential of at least one of the sequences, out of the total number of samples tested is indicated in the bottom.
As is evident from Figures 52-53, differential expression of at least 5 fold in at least one of the sequences was found in 15 out of 15 adenocarcinoma samples, 14 out of 16 squamous cell carcinoma samples, 4 out of 4 large cell carcinoma samples and in 8 out of 8 small cell carcinoma samples.
Statistical analysis was applied to verify the significance of these results, as described below. Threshold of 5 fold differential expression of at least one of the amplicons was found to differentiate between cancer and normal samples with P value of 7.82E-06 in adenocarcinoma, 2.63E-04 in squamous cell carcinoma, 8.24E-03 in large cell adenocarcinoma and 3.57E-04 in small cell carcinoma as checked by exact fisher test.
The above values demonstrate statistical significance of the results.
DESCRIPTION FOR CLUSTER H53626
Cluster H53626 features 2 transcript(s) and 20 segment(s) of interest, the names for which are given in Tables 1321 and 1322, respectively, the sequences themselves are given at the end of the application.
Table 1321 - Transcripts of interest
Table 1322 - Segments of interest
Cluster H53626 can be used as a diagnostic marker according to overexpression of transcripts of this cluster in cancer. Expression of such transcripts in normal tissues is also given according to the previously described methods. The term "number" in the right hand column of the table and the numbers on the y-axis of figure 76 below refer to weighted expression of ESTs
in each category, as "parts per million" (ratio of the expression of ESTs for a particular cluster to the expression of all ESTs in that category, according to parts per million).
Overall, the following results were obtained as shown with regard to the histograms in Figure 76 and Table 1324. This cluster is overexpressed (at least at a minimum level) in the following pathological conditions: epithelial malignant tumors, a mixture of malignant tumors from different tissues and myosarcoma.
Table 1324 - Normal tissue distribution
Name of Tissue Number adrenal 4 bone 233 brain 33 colon 0 epithelial 12 general 17 head and neck 0 kidney 8 lung 25 breast 8 muscle 0 ovary 7 pancreas 10 prostate 8 skin 0 stomach 73
Thyroid 0 uterus 0
Table 1325 - P values and ratios for expression in cancerous tissue
As noted above, contig H53626 features 2 transcript(s), which were listed in Table 1321 above. A description of each variant protein according to the present invention is now provided.
Variant protein H53626_PEA_1_P4 according to the present invention has an amino acid sequence as given at the end of the application; it is encoded by transcript(s) H53626_PEA_1_T15. The alignment to the wild type protein is given at the end of the
application. A brief description of the relationship of the variant protein according to the present invention to the wild type protein is as follows:
Comparison report between H53626_PEA_1_P4 and wild type Q8N441 (SEQ ID NO:1699): 1.An isolated chimeric polypeptide encoding for H53626_PEA_1_P4, comprising a first amino acid sequence being at least 90 % homologous to
MTPSPLLLLLLPPLLLGAFPPAAAARGPPKMADKVVPRQVARLGRTVRLQCPVEGDPPP LTMWTKDGRTIHSGWSRFRVLPQGLKVKQVEREDAGVYVCKATNGFGSLSVNYTLVV LDDISPGKESLGPDSSSGGQEDPASQQWARPRFTQPSKMRRRVIARPVGSSVRLKCVAS GHPRPDITWMKDDQALTRPEAAEPRKKKWTLSLKNLRPEDSGKYTCRVSNRAGAINAT YKVDVIQRTRSKPVLTGTHPVNTTVDFGGTTSFQCKVRSDVKPVIQWLKRVEYGAEGR HNSTIDVGGQKFWLPTGDVWSRPDGSYLNKLLITRARQDDAGMYICLGANTMGYSFR SAFLTVLP corresponding to amino acids 1 - 357 of Q8N441, which also corresponds to amino acids 1 - 357 of H53626_PEA_1_P4, second amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence
GARLPRHATPCWCPDPPPGPGVPPTGWGPTLPSRAVLARSSAEGGQPRGTVSTAPGMG LGCSPGLCVGVPLPTSFPLALA corresponding to amino acids 358 - 437 of H53626JPEA 1JP4, and a third amino acid sequence being at least 90 % homologous to DPKPPGPPVASSSSATSLPWPWIGIPAGA VFILGTLLLWLCQAQKKPCTPAP APPLPGH RPPGTARDRSGDKDLPSLAALSAGPGVGLCEEHGSPAAPQHLLGPGPVAGPKLYPKLY TDIHTHTHTHSHTHSHVEGKVHQHIHYQC corresponding to amino acids 358 - 504 of Q8N441, which also corresponds to amino acids 438 - 584 of H53626_PEA_1_P4, wherein said first, second and third amino acid sequences are contiguous and in a sequential order. 2.An isolated polypeptide encoding for an edge portion of H53626_PEA_1_P4, comprising an amino acid sequence being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence encoding for GARLPRHATPCWCPDPPPGPGVPPTGWGPTLPSRAVLARSSAEGGQPRGTVSTAPGMG LGCSPGLCVGVPLPTSFPLALA, corresponding to H53626_PEA_1_P4.
The location of the variant protein was determined according to results from a number of different software programs and analyses, including analyses from SignalP and other specialized programs. The variant protein is believed to be located as follows with regard to the cell: membrane. The protein localization is believed to be membrane because although both signal- peptide prediction programs agree that this protein has a signal peptide, both trans- membrane region prediction programs predict that this protein has a trans -membrane region downstream of this signal peptide..
Variant protein H53626_PEA_1_P4 also has the following non-silent SNPs (Single Nucleotide Polymorphisms) as listed in Table 1326, (given according to their position(s) on the amino acid sequence, with the alternative amino acid(s) listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein H53626_PEA_1_P4 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 1326 - Amino acid mutations
Variant protein H53626_PEA_1_P4 is encoded by the following transcript(s): H53626_PEA_1_T15, for which the sequence(s) is/are given at the end of the application. The coding portion of transcript H53626_PEA_1_T15 is shown in bold; this coding portion starts at position 17 and ends at position 1771. The transcript also has the following SNPs as listed in Table 1327 (given according to their position on the nucleotide sequence, with the alternative
nucleic acid listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein H53626__PEA_1JP4 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 1327 - Nucleic acid SNPs
Variant protein H53626_PEA_1_P5 according to the present invention has an amino acid sequence as given at the end of the application; it is encoded by transcript(s) H53626_PEA_1_T16. The alignment to the wild type protein is given at the end of the application. A brief descrip tion of the relationship of the variant protein according to the present invention to the wild type protein is as follows:
Comparison report between H53626_PEA_1_P5 and wild type Q9H4D7 (SEQ ID NO: 1700):
1.An isolated chimeric polypeptide encoding for H53626_PEA_1_P5, comprising a first amino acid sequence being at least 90 % homologous to MTPSPLLLLLLPPLLLGAFPPAAAARGPPKMADKVVPRQVARLGRTVRLQCPVEGDPPP LTMWTKDGRTIHSGWSRFRVLPQGLKVKQVEREDAGVΎVCKATNGFGSLSVNYTLVV LDDISPGKESLGPDSSSGGQEDP ASQQWARPRFTQPSKMRRRVIARPVGSSVRLKCVAS GHPRPDITWMKDDQALTRPEAAEPRKKKWTLSLKNLRPEDSGKYTCRVSNRAGAINAT
YKVDVIQRTRSKPVLTGTHPVNTTVDFGGTTSFQCK corresponding to amino acids 1 - 269 of Q9H4D7, which also corresponds to amino acids 1 - 269 of H53626JPEA_1_P5, and a second amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence
TQNRQGHLWPPRPRPLACRGPWSSASQPALSSSWAPCSCGFARPRRSRAPPRLPLPCLG TARRGRP ATAAETRTFPRWPPSALAL VWGCVRSMGLRQPPSTYWAQAQLLALSCTPNS
TQTSTHTHTHTLTHTHTWRARSTSTSTISARRHRICSGHGGAGQTGRLGGWRTELQTKA
GDPWRGGMASTPGSLCVRHSPWTHTHRHTHYLDACMHTHARTRAP corresponding to amino acids 270 - 490 of H53626_PEA_1_P5, wherein said first and second amino acid sequences are contiguous and in a sequential order. 2.An isolated polypeptide encoding for a tail of H53626_PEA_1_P5, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence
TQNRQGHLWPPRPRPLACRGPWSSASQPALSSSWAPCSCGFARPRRSRAPPRLPLPCLG TARRGRPATAAETRTFPRWPPSALALVWGCVRSMGLRQPPSTYWAQAQLLALSCTPNS
TQTSTHTHTHTLTHTHTWRARSTSTSTISARRHRICSGHGGAGQTGRLGGWRTELQTKA
GDPWRGGMASTPGSLCVRHSPWTHTHRHTHYLDACMHTHARTRAP in H53626_PEA_1_P5.
Comparison report between H53626_PEA_1_P5 and wild type Q8N441 : 1.An isolated chimeric polypeptide encoding for H53626_PEA_1_P5, comprising a first amino acid sequence being at least 90 % homologous to
MTPSPLLLLLLPPLLLGAFPPAAAARGPPKMADKVVPRQVARLGRTVRLQCPVEGDPPP LTMWTKDGRTIHSGWSRFRVLPQGLKVKQVEREDAGVYVCKATNGFGSLSVNYTLVV LDDISPGKESLGPDSSSGGQEDPASQQWARPRFTQPSKMRRRVIARPVGSSVRLKCVAS GHPRPDITWMKDDQALTRPEAAEPRKKKWTLSLKNLRPEDSGKYTCRVSNRAGAINAT YKVDVIQRTRSKPVLTGTHPVNTTVDFGGTTSFQCK corresponding to amino acids 1 - 269 of Q8N441, which also corresponds to amino acids 1 - 269 of H53626_PEA_1_P5, and a second amino acid sequence being at least 70%, optionally at least 80%, preferably at least 85%, more preferably at least 90% and most preferably at least 95% homologous to a polypeptide having the sequence TQNRQGHLWPPRPRPLACRGPWSSASQPALSSSWAPCSCGFARPRRSRAPPRLPLPCLG TARRGRPATAAETRTFPRWPPSALALVWGCVRSMGLRQPPSTYWAQAQLLALSCTPNS TQTSTHTHTHTLTHTHTWRARSTSTSTISARRHRICSGHGGAGQTGRLGGWRTELQTKA GDPWRGGMASTPGSLCVRHSPWTHTHRHTHYLDACMHTHARTRAP corresponding to amino acids 270 - 490 of H53626_PEA_1_P5, wherein said first and second amino acid sequences are contiguous and in a sequential order.
2.An isolated polypeptide encoding for a tail of H53626_PEA_1JP5, comprising a polypeptide being at least 70%, optionally at least about 80%, preferably at least about 85%, more preferably at least about 90% and most preferably at least about 95% homologous to the sequence TQNRQGHLWPPRPRPLACRGPWSSASQPALSSSWAPCSCGFARPRRSRAPPRLPLPCLG TARPvGRPATAAETRTFPRWPPSALALVWGCVRSMGLRQPPSTYWAQAQLLALSCTPNS TQTSTHTHTHTLTHTHTWRARSTSTSTISARRHRICSGHGGAGQTGRLGGWRTELQTKA GDPWRGGMASTPGSLCVRHSPWTHTHRHTHYLDACMHTHARTRAP in H53626_PEA_1_P5.
The location of the variant protein was determined according to results from a number of different software programs and analyses, including analyses from SignalP and other specialized programs. The variant protein is believed to be located as follows with regard to the cell: secreted. The protein localization is believed to be secreted because both signal-peptide prediction programs predict that this protein has a signal peptide, and neither trans -membrane region prediction program predicts that this protein has a trans -membrane region..
Variant protein H53626_PEA_1_P5 also has the following non-silent SNPs (Single Nucleotide Polymorphisms) as listed in Table 1328 (given according to their position(s) on the amino acid sequence, with the alternative amino acid(s) listed; the last column indicates whether the SNP is known or not; the presence of known SNPs in variant protein H53626JPEA 1_P5 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 1328 - Amino acid mutations
Variant protein H53626_PEA_1_P5 is encoded by the following transcript(s): H53626_PEA_1_T16, for which the sequence(s) is/are given at the end of the application. The coding portion of transcript H53626_PEA_1_T16 is shown in bold; this coding portion starts at position 17 and ends at position 1489. The transcript also has the following SNPs as listed in Table 1329 (given according to their position on the nucleotide sequence, with the alternative nucleic acid listed; the last column indicates whether the SNP is known or not; the presence of
known SNPs in variant protein H53626_PEA_1_P5 sequence provides support for the deduced sequence of this variant protein according to the present invention).
Table 1329 - Nucleic acid SNPs
As noted above, cluster H53626 features 20 segment(s), which were listed in Table 2 above and for which the sequence(s) are given at the end of the application. These segment(s) are portions of nucleic acid sequence(s) which are described herein separately because they are
of particular interest. A description of each segment according to the present invention is now provided.
Segment cluster H53626_PEA_1 jnode_15 according to the present invention is supported by 25 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): H53626JPEA_1_T15 and H53626_PEA_1_T16. Table 1330 below describes the starting and ending position of this segment on each transcript.
Table 1330 - Segment location on transcripts
Segment cluster H53626_PEA_l_node_22 according to the present invention is supported by 42 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): H53626_PEA_1_T15 and H53626_PEA_1_T16. Table 1332 below describes the starting and ending position of this segment on each transcript.
Table 1332 - Segment location on transcripts
Segment cluster H53626_PEA_l_node_25 according to the present invention is supported by 41 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): H53626_PEA_1_T15. Table 1334 below describes the starting and ending position of this segment on each transcript.
Table 1334 - Segment location on transcripts
Segment cluster H53626_PEA_l_node_26 according to the present invention is supported by 5 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): H53626_PEA_1_T15. Table 1336 below describes the starting and ending position of this segment on each transcript.
Table 1336 - Segment location on transcripts
Segment cluster H53626_PEA_l_node_27 according to the present invention is supported by 106 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): H53626_PEA_1_T15 and H53626_PEA_1_T16. Table 1338 below describes the starting and ending position of this segment on each transcript.
Table 1338 - Segment location on transcripts
Segment cluster H53626_PEA_l_node_34 according to the present invention is supported by 121 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): H53626_PEA_1_T15 and H53626_PEA_1_T16. Table 1340 below describes the starting and ending position of this segment on each transcript.
Table 1340- Segment location on transcripts
Segment cluster H53626_PEA_l_node_35 according to the present invention is supported by 85 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): H53626_PEA_1_T15 and H53626_PEA_1_T16. Table 1342 below describes the starting and ending position of this segment on each transcript.
Table 1342 - Segment location on transcripts
Microarray (chip) data is also available for this segment as follows. As described above with regard to the cluster itself, various oligonucleotides were tested for being differentially expressed in various disease conditions, particularly cancer. The following oligonucleotides were found to hit this segment, shown in Table 1343.
Table 1343 - Oligonucleotides related to this segment
Segment cluster H53626_PEA_l_node_36 according to the present invention is supported by 69 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): H53626_PEA_1_T15 and H53626_PEA_1_T16. Table 1344 below describes the starting and ending position of this segment on each transcript.
Table 1344 - Segment location on transcripts
Microarray (chip) data is also available for this segment as follows. As described above with regard to the cluster itself, various oligonucleotides were tested for being differentially expressed in various disease conditions, particularly cancer. The following oligonucleotides were found to hit this segment, shown in Table 13455.
Table 1345 - Oligonucleotides related to this segment
According to an optional embodiment of the present invention, short segments related to the above cluster are also provided. These segments are up to about 120 bp in length, and so are included in a separate description.
Segment cluster H53626_PEA_l_node_l 1 according to the present invention is supported by 12 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): H53626_PEA_1_T15 and H53626_PEA_1_T16. Table 1346 below describes the starting and ending position of this segment on each transcript.
Table 1346 - Segment location on transcripts
Segment cluster H53626_PEA_l_node_12 according to the present invention is supported by 11 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): H53626_PEA_1_T15 and H53626_PEA_1_T16. Table 1347 below describes the starting and ending position of this segment on each transcript.
Table 1347 - Segment location on transcripts
Segment cluster H53626_PEA_1 _node_16 according to the present invention can be found in the following transcripts): H53626_PEA_1_T15 and H53626_PEA_1_T16. Table 1348 below describes the starting and ending position of this segment on each transcript.
Table 1348 - Segment location on transcripts
Segment cluster H53626_PEA_l_node_19 according to the present invention is supported by 25 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): H53626_PEA_1_T15 and H53626_PEA_1_T16. Table 1349 below describes the starting and ending position of this segment on each transcript.
Table 1349 - Segment location on transcripts
Segment cluster H53626_PEA_l_node_20 according to the present invention is supported by 27 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): H53626_PEA_1_T15 and H53626_PEA_1_T16. Table 1350 below describes the starting and ending position of this segment on each transcript.
Table 1350 - Segment location on transcripts
Segment cluster H53626_PEA_l_node_24 according to the present invention is supported by 34 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): H53626_PEA_1_T15 and H53626_PEA_1_T16. Table 1351 below describes the starting and ending position of this segment on each transcript.
Table 1351 - Segment location on transcripts
Segment cluster H53626_PEA_l_node_28 according to the present invention is supported by 66 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): H53626_PEA_1_T15 and H53626_PEA_1_T16. Table 1352 below describes the starting and ending position of this segment on each transcript. Table 1352 - Segment location on transcripts
Segment cluster H53626_PEA_l_node_29 according to the present invention is supported by 73 libraries. The number of libraries was determined as previously described. This segment
can be found in the following transcript(s): H53626_PEA_1_T15 and H53626_PEA_1_T16. Table 1353 below describes the starting and ending position of this segment on each transcript.
Table 1353 - Segment location on transcripts
Segment cluster H53626_PEA_l_node_30 according to the present invention is supported by 71 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): H53626_PEA_1_T15 and H53626_PEA_1_T16. Table 1354 below describes the starting and ending position of this segment on each transcript. Table 1354 - Segment location on transcripts
Segment cluster H53626_PEA_l_node_31 according to the present invention is supported by 67 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): H53626_PEA_1_T15 and H53626__PEA_1_T16. Table 1355 below describes the starting and ending position of this segment on each transcript.
Table 1355 - Segment location on transcripts
Segment cluster H53626_PEA_l_node_32 according to the present invention is supported by 65 libraries. The number of libraries was determined as previously described. This segment can be found in the following transcript(s): H53626_PEA_1_T15 and H53626JPEA 1 T16. Table 1356 below describes the starting and ending position of this segment on each transcript.
Table 1356 - Segment location on transcripts
Segment cluster H53626_PEA_l_node_33 according to the present invention can be found in the following transcript(s): H53626_PEA_1_T15 and H53626_PEA_1_T16. Table 1357 below describes the starting and ending position of this segment on each transcript.
Table 1357 - Segment location on transcripts
Variant protein alignment to the previously known protein:
Sequence name: /tmp/KlMec2ReKO/eglEUS2AXY :Q8N441
Sequence documentation:
Alignment of: H53626_PEA_1_P4 x Q8N441
Alignment segment 1/1:
Quality: 4882.00 Escore: 0
Matching length: 504 Total length: 584 Matching Percent Similarity: 100.00 Matching Percent Identity: 100.00
Total Percent Similarity: 86.30 Total Percent Identity: 86.30
Gaps : 1
Alignment :
1 MTPSPLLLLLLPPLLLGAFPPAAAARGPPKMADKWPRQVARLGRTVRLQ 50
1 ! 111111 ! 1111 I M I I I I M I I I I I I I I I I I I I I I I I I I I I I I I I I I I 1 MTPSPLLLLLLPPLLLGAFPPAAAARGPPKMADKVVPRQVARLGRTVRLQ 50
51 CPVEGDPPPLTMWTKDGRTIHSGWSRFRVLPQGLKVKQVEREDAGVYVCK 100
I I I I I I l I I I l I l I I I I I l I I I I I I I I I I I I I I I I I I I l I l I I I l I I l I I
51 CPVEGDPPPLTMWTKDGRTIHSGWSRFRVLPQGLKVKQVEREDAGVYVCK 100 . . . . .
101 ATNGFGSLSVNYTLWLDDISPGKESLGPDSSSGGQEDPASQQWARPRFT 150
I I I I l M I I I I I I I I l M I I l I I I I I M I I I I I I I I I I l I I I I I l I l I l I
101 ATNGFGSLSVNYTLWLDDISPGKESLGPDSSSGGQEDPASQQWARPRFT 150
151 QPSKMRRRVIARPVGSSVRLKCVASGHPRPDITWMKDDQALTRPEAAEPR 200
I I I Il M Il Il I M Il M I M I I I M M I I I I I I I M I Il I I Il M I I Il
151 QPSKMRRRVIARPVGSSVRLKCVASGHPRPDITWMKDDQALTRPEAAEPR 200
201 KKKWTLSLKNLRPEDSGKYTCRVSNRAGAINATYKVDVIQRTRSKPVLTG 250 I I I M I I M I I Il M I I I I I I I I I M I M Il I I Il I M I I I Il I I I I I I I
201 KKKWTLSLKNLRPEDSGKYTCRVSNRAGAINATYKVDVIQRTRSKPVLTG 250
251 THPVNTTVDFGGTTSFQCKVRSDVKPVIQWLKRVEYGAEGRHNSTIDVGG 300
I I I Il I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I Il I I I I
251 THPVNTTVDFGGTTSFQCKVRSDVKPVIQWLKRVEYGAEGRHNSTIDVGG 300 . . . . .
301 QKFVVLPTGDVWSRPDGSYLNKLLITRARQDDAGMYICLGANTMGYSFRS 350
I I I I I I I Il I Il I I I Il I I Il I I I I I I I I I I I I I Il I I Il I I I I I I I I Il
301 QKFVVLPTGDVWSRPDGSYLNKLLITRARQDDAGMYICLGANTMGYSFRS 350
351 AFLTVLPGARLPRHATPCWCPDPPPGPGVPPTGWGPTLPSRAVLARSSAE 400
I I I I I I I 351 AFLTVLP 357
401 GGQPRGTVSTAPGMGLGCSPGLCVGVPLPTSFPLALADPKPPGPPVASSS 450 I I I I I I I I 1 I I I I
358 DPKPPGPPVASSS 370
451 SATSLPWPWIGIPAGAVFILGTLLLWLCQAQKKPCTPAPAPPLPGHRPP 500 I I Il I I I I I Il I I I I Il M I I I I I I I I I I I Il I Il I I I Il I I I I I I I I Il 371 SATSLPWPVVIGIPAGAVFILGTLLLWLCQAQKKPCTPAPAPPLPGHRPP 420
501 GTARDRSGDKDLPSLAALSAGPGVGLCEEHGSPAAPQHLLGPGPVAGPKL 550
I I I I I I I I I I I I I I I Il I I I I I I I I I I I I I I I I I I I I I I I I Il I I I I I I I
421 GTARDRSGDKDLPSLAALSAGPGVGLCEEHGSPAAPQHLLGPGPVAGPKL 470 . . .
551 YPKLYTDIHTHTHTHSHTHSHVEGKVHQHIHYQC 584
I I I I I I I I I I I I III I I I I I I I Il I I I I I I I I I I 471 YPKLYTDIHTHTHTHSHTHSHVEGKVHQHIHYQC 504
Sequence name: /tmp/oSUZaRW3WK/oSh3fN5ZtO :Q9H4D7
Sequence documentation:
Alignment of: H53626_PEA_1_P5 x Q9H4D7
Alignment segment 1/1:
Quality: 2644.00 Escore: 0
Matching length: 269 Total length: 269
Matching Percent Similarity: 100.00 Matching Percent Identity: 100.00
Total Percent Similarity: 100.00 Total Percent Identity: 100.00 Gaps : 0
Alignment:
1 MTPSPLLLLLLPPLLLGAFPPAAAARGPPKMADKVVPRQVARLGRTVRLQ 50 I I M M I I I I ! I I I M I i I I I I I I I I I I I I I I I I I I I I I ! I I M M I I I I
1 MTPSPLLLLLLPPLLLGAFPPAAAARGPPKMADKVVPRQVARLGRTVRLQ 50
51 CPVEGDPPPLTMWTKDGRTIHSGWSRFRVLPQGLKVKQVEREDAGVYVCK 100
M I M I I I I I M I I MI I I I M I I M M I M I M I M I I M I M I I M I I 51 CPVEGDPPPLTMWTKDGRTIHSGWSRFRVLPQGLKVKQVEREDAGVYVCK 100
101 ATNGFGSLSVNYTLVVLDDISPGKESLGPDSSSGGQEDPASQQWARPRFT 150
I I 1 I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I
101 ATNGFGSLSVNYTLVVLDDISPGKESLGPDSSSGGQEDPASQQWARPRFT 150
151 QPSKMRRRVIARPVGSSVRLKCVASGHPRPDITWMKDDQALTRPEAAEPR 200
I I I I I I I I Il I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I 1 I I I I I I I
151 QPSKMRRRVIARPVGSSVRLKCVASGHPRPDITWMKDDQALTRPEAAEPR 200
201 KKKWTLSLKNLRPEDSGKYTCRVSNRAGAINATYKVDVIQRTRSKPVLTG 250 I I M I I I I I I I I I I I I I I I I M I I I I I M M I I I I I I I I I I M I I I I I I I
201 KKKWTLSLKNLRPEDSGKYTCRVSNRAGAINATYKVDVIQRTRSKPVLTG 250
251 THPVNTTVDFGGTTSFQCK 269
I I Il I I I I I Il I I I I I Il I 251 THPVNTTVDFGGTTSFQCK 269
Sequence name: /tmp/oSUZaRW3WK/oSh3fN5ZtO :Q8N441
Sequence documentation:
Alignment of: H53626_PEA_1_P5 x Q8N441
Alignment segment 1/1:
Quality: 2644.00
Escore: 0
Matching length: 269 Total length: 269
Matching Percent Similarity: 100.00 Matching Percent Identity: 100.00 Total Percent Similarity: 100.00 Total Percent Identity: 100.00
Gaps : 0
Alignment : . . . . .
1 MTPSPLLLLLLPPLLLGAFPPAAAARGPPKMADKVVPRQVARLGRTVRLQ 50
1 MTPSPLLLLLLPPLLLGAFPPAAAARGPPKMADKVVPRQVARLGRTVRLQ 50
51 CPVEGDPPPLTMWTKDGRTIHSGWSRFRVLPQGLKVKQVEREDAGVYVCK 100 I Il M I M I M M M M M M Il I I M I I I I I I I M M I I Il I I I I I M I
51 CPVEGDPPPLTMWTKDGRTIHSGWSRFRVLPQGLKVKQVEREDAGVYVCK 100
101 ATNGFGSLSVNYTLVVLDDISPGKESLGPDSSSGGQEDPASQQWARPRFT 150 I I Il M I I Il I I I Il I I I M I I M Il Il M I I I M Il I I I I I I M I I I I I
101 ATNGFGSLSVNYTLVVLDDISPGKESLGPDSSSGGQEDPASQQWARPRFT 150
151 QPSKMRRRVIARPVGSSVRLKCVASGHPRPDITWMKDDQALTRPEAAEPR 200
M M M M I M I I M M M M M M M M M M M M M I M M M M M 151 QPSKMRRRVIARPVGSSVRLKCVASGHPRPDITWMKDDQALTRPEAAEPR 200
201 KKKWTLSLKNLRPEDSGKYTCRVSNRAGAINATYKVDVIQRTRSKPVLTG 250
M Il I Il M Il I Il M Il Il M I M M M Il I M M Il I I M Il M I M I
201 KKKWTLSLKNLRPEDSGKYTCRVSNRAGAINATYKVDVIQRTRSKPVLTG 250
251 THPVNTTVDFGGTTSFQCK 269
I I I I I I I I I I 1 I I I I I I I I 251 THPVNTTVDFGGTTSFQCK 269
Expression ø/Homo sapiens fibroblast growth factor receptor- like 1 (FGFRLl) H53626 transcripts, which are detectable by amplicon as depicted in sequence name H53626junc24-
27Fl R3 in normal and cancerous lung tissues. Expression of Homo sapiens fibroblast growth factor receptor- like 1
(FGFRL l)transcripts detectable by or according to junc24-27, H53626 junc24-27FlR3 amplicon (SEQ ID NO: 1690) and H53626 junc24-27Fl (SEQ ID NO: 1688) and H53626 junc24-27R3 (SEQ ID NO: 1689) primers was measured by real time PCR. In parallel the expression of four housekeeping genes -PBGD (GenBank Accession No. BC019323; amplicon - PBGD- amplicon, SEQ ID NO:334), HPRTl (GenBank Accession No. NM_000194; amplicon - HPRTl -amplicon, SEQ ID NO: 1297), UBC (GenBank Accession No. BC000449; amplicon - Ubiquitin-amplicon, SEQ ID NO:328) and SDHA (GenBank Accession No. NM_004168; amplicon - SDHA- amplicon, SEQ ID NO:331), was measured similarly. For each RT sample, the expression of the above amplicon was normalized to the geometric mean of the quantities of the housekeeping genes. The normalized quantity of each RT sample was then divided by the median of the quantities of the normal post-mortem (PM) samples (Sample Nos. 47-50, 90-93, 96-99, Table 2, above), to obtain a value of fold up -regulation for each sample relative to median of the normal PM samples.
Figure 74 is a histogram showing over expression of the above -indicated Homo sapiens fibroblast growth factor receptor- like 1 (FGFRLl) transcripts in cancerous lung samples relative to the normal samples.
As is evident from Figure 74, the expression of Homo sapiens fibroblast growth factor receptor- like 1 (FGFRLl) transcripts detectable by the above amplicon(s) was higher in several cancer samples than in the non-cancerous samples (Sample Nos. 46-50, 90-93, 96-99 Table 2). Notably an over- expression of at least 5 fold was found in 7 out of 15 adenocarcinoma samples.
Primer pairs are also optionally and preferably encompassed within the present invention; for example, for the above experiment, the following primer pair was used as a non- limiting illustrative example only of a suitable primer pair: H53626 junc24-27Fl forward primer; and H53626 junc24-27R3 reverse primer. The present invention also preferably encompasses any amplicon obtained through the use of any suitable primer pair; for example, for the above experiment, the following amplicon was obtained as a non- limiting illustrative example only of a suitable amplicon: H53626 junc24- 27F1R3. Forward primer (SEQ ID NO: 1688): GTCCTTCCAGTGCAAGACCCA Reverse primer(SEQ ID NO: 1689): TGGGCCTGGCAAAGCC Amplicon (SEQ ID NO: 1690):
GTCCTTCCAGTGCAAGACCCAAAACCGCCAGGGCCACCTGTGGCCTCCTCGTCCTC GGCCACTAGCCTGCCGTGGCCCGTGGTCATCGGCATCCCAGCCGGCGCTGTCTTCAT CCTGGGCACCCTGCTCCTGTGGCTTTGCCAGGCCCA
Expression o/Homo sapiens fibroblast growth factor receptor- like 1 (FGFRLl) H53626 transcripts, which are detectable by amplicon as depicted in sequence name H53626 seg25 in normal and cancerous lung tissues.
Expression of Homo sapiens fibroblast growth factor receptor- like 1 (FGFRLl) transcripts detectable by or according to seg25, H53626 seg25 amplicon (SEQ ID NO: 1693) and H53626 seg25F (SEQ ID NO: 1691) and H53626 seg25R (SEQ ID NO: 1692) primers was measured by real time PCR. In parallel the expression of four housekeeping genes -PBGD (GenBank Accession No. BC019323; amplicon - PBGD-amplicon, SEQ ID NO:334), HPRTl (GenBank Accession No. NM_000194; amplicon- HPRTl -amplicon, SEQ ID NO:1297), UBC (GenBank Accession No. BC000449; amplicon - Ubiquitin- amplicon, SEQ ID NO:328) and SDHA (GenBank Accession No. NM_004168; amplicon - SDHA-amplicon, SEQ ID NO:331), was measured similarly. For each RT sample, the expression of the above amplicon was normalized to the geometric mean of the quantities of the housekeeping genes. The normalized quantity of each RT sample was then divided by the median of the quantities of the normal post-
mortem (PM) samples (Sample Nos. 47-50, 90-93, 96-99, Table 2, above), to obtain a value of fold up-regulation for each sample relative to median of the normal PM samples.
As is evident from Figure 75, the expression of Homo sapiens fibroblast growth factor receptor- like 1 (FGFRLl) transcripts detectable by the above amplicon(s) was higher in a few cancer samples than in the non-cancerous samples (Sample Nos. 46-50, 90-93, 96-99 Table 2). Notably an over- expression of at least 5 fold was found in 3 out of 15 adenocarcinoma samples.
Primer pairs are also optionally and preferably encompassed within the present invention; for example, for the above experiment, the following primer pair was used as a non- limiting illustrative example only of a suitable primer pair: H53626 seg25F forward primer; and H53626 seg25R reverse primer.
The present invention also preferably encompasses any amplicon obtained through the use of any suitable primer pair; for example, for the above experiment, the following amplicon was obtained as a non- limiting illustrative example only of a suitable amplicon: H53626 seg25. Forward primer (SEQ ID NO: 1691);CCGACGGCTCCTACCTCAA
Reverse primer (SEQ ID NO: 1692): GGAAGCTGTAGCCCATGGTGT Amplicon (SEQ ID NO: 1693):
CCGACGGCTCCTACCTCAATAAGCTGCTCATCACCCGTGCCCGCCAGGACGATGCG GGCATGTACATCTGCCTTGGCGCCAACACCATGGGCTACAGCTTCC
Expression of Homo sapiens fibroblast growth factor receptor- like 1 (FGFRLl) H53626 transcripts, which are detectable by amplicon as depicted in sequence name H53626 seg25 in different normal tissues.
Expression of Homo sapiens fibroblast growth factor receptor- like 1 (FGFRLl) transcripts detectable by or according to H53626 seg25 amplicon (SEQ ID NO: 1693) and H53626 seg25F (SEQ ID NO: 1691) and H53626 seg25R (SEQ ID NO: 1692) was measured by real time PCR. In parallel the expression of four housekeeping genes: RPLl 9 (GenBank Accession No. NM_000981; RPLl 9 amplicon, SEQ ID NO: 1630), TATA box (GenBank Accession No. NM_003194; TATA amplicon, SEQ ID NO:1633), UBC (GenBank Accession No. BC000449; amplicon - Ubiquitin-amplicon, SEQ ID NO:328) and SDHA (GenBank Accession No.
NM_004168; amplicon - SDHA-amplicon, SEQ ID NO:331) was measured similarly. For each RT sample, the expression of the above amplicon was normalized to the geometric mean of the quantities of the housekeeping genes. The normalized quantity of each RT sample was then divided by the median of the quantities of the lung samples (Sample Nos. 15-17 Table 3 above), to obtain a value of relative expression of each sample relative to median of the lung samples.
Forward primer (SEQ ID NO: 1691);CCGACGGCTCCTACCTCAA Reverse primer (SEQ ID NO: 1692): GGAAGCTGTAGCCCATGGTGT Amplicon (SEQ ID NO: 1693): CCGACGGCTCCTACCTCAATAAGCTGCTCATCACCCGTGCCCGCCAGGACGATGCG GGCATGTACATCTGCCTTGGCGCCAACACCATGGGCTACAGCTTCC
The results are demonstrated in Figure 77, showing the expression of of Homo sapiens fibroblast growth factor receptor- like 1 (FGFRLl) H53626 transcripts, which are detectable by amplicon as depicted in sequence name H53626 seg25 in different normal tissues.
Expression of Homo sapiens fibroblast growth factor receptor- like 1 (FGFRLl) H53626 transcripts which are detectable by amplicon as depicted in sequence name H53626 junc24-
27Fl R3 in different normal tissues
Expression of Homo sapiens fibroblast growth factor receptor- like 1 (FGFRLl) transcripts detectable by or according to H53626 junc24-27FlR3 amplicon (SEQ ID NO: 1690) and H53626 junc24-27Fl (SEQ ID NO: 1688) and H53626 junc24-27R3 (SEQ ID NO: 1689) was measured by real time PCR. In parallel the expression of four housekeeping genes — RPLl 9 (GenBank Accession No. NM_000981; RPLl 9 amplicon, SEQ ID NO: 1630), TATA box (GenBank Accession No. NM_003194; TATA amplicon, SEQ ID NO: 1633; primers SEQ ID NOs 1631 and 1632), UBC (GenBank Accession No. BC000449; amplicon - Ubiquitin- amplicon, SEQ ID NO:328) and SDHA (GenBank Accession No. NM_004168; amplicon - SDHA-amplicon, SEQ ID NO:331) was measured similarly. For each RT sample, the
expression of the above amplicon was normalized to the geometric mean of the quantities of the housekeeping genes. The normalized quantity of each RT sample was then divided by the median of the quantities of the lung samples (Sample Nos. 15-17 Table 3 above), to obtain a value of relative expression of each sample relative to median of the lung samples.
Forward primer (SEQ ID NO: 1688): GTCCTTCCAGTGCAAGACCCA Reverse primer(SEQ ID NO: 1689): TGGGCCTGGCAAAGCC Amplicon (SEQ ID NO: 1690):
GTCCTTCCAGTGCAAGACCCAAAACCGCCAGGGCCACCTGTGGCCTCCTCGTCCTC GGCCACTAGCCTGCCGTGGCCCGTGGTCATCGGCATCCCAGCCGGCGCTGTCTTCAT CCTGGGCACCCTGCTCCTGTGGCTTTGCCAGGCCCA
The results are demonstrated in Figure 78, showing the expression of Homo sapiens fibroblast growth factor receptor- like 1 (FGFRLl) H53626 transcripts, which are detectable by amplicon as depicted in sequence name H53626 junc24-27Fl R3 in different normal tissues.
Expression oftrophinin associated protein (tastin) [T86235] transcripts which are detectable by amplicon as depicted in SEQ ID NO: 1480 in normal and cancerous lung tissues
Expression of trophinin associated protein (tastin) transcripts detectable by SEQ ID NO:1480 (e.g., variant no. 23-26 31, 32- represented by SEQ IDs 1485-1488, 1609, 1610) was measured by real time PCR. In parallel the expression of four housekeeping genes - PBGD
(GenBank Accession No. BC019323; amplicon - SEQ ID NO.1471), HPRTl (GenBank
Accession No. NM_000194; amplicon - SEQ ID NO:1468), Ubiquitin (GenBank Accession No.
BC000449; amplicon - SEQ ID NO:1474) and SDHA (GenBank Accession No. NM_004168; amplicon - SEQ ID NO: 1477), was measured similarly. For each RT sample, the expression of
SEQ ID NO:1480 was normalized to the geometric mean of the quantities of the housekeeping genes. The normalized quantity of each RT sample was then divided by the median of the quantities of the normal post-mortem (PM) samples (Sample Nos. 47-50, 90-93, 96-99, Table 2,
"Tissue samples in testing panel", above), to obtain a value of fold up -regulation for each sample relative to median of the normal PM samples.
Figure 54a is a histogram showing over expression of the above- indicated trophinin associated protein (tastin) transcripts in cancerous lung samples relative to the normal samples. The number and percentage of samples that exhibit at least 5 fold over- expression, out of the total number of samples tested is indicated in the bottom. As is evident from Figure 54a, the expression of trophinin associated protein (tastin) transcripts detectable by SEQ ID NO: 1480 in cancer samples was significantly higher than in the non-cancerous samples (Sample Nos. 46-50, 90-93, 96-99 Table 2, "Tissue samples in testing panel"). Notably an over- expression of at least 5 fold was found in 6 out of 15 adenocarcinoma samples, 8 out of 16 squamous cell carcinoma samples, 2 out of 4 large cell carcinoma samples and in 8 out of 8 small cells carcinoma samples.
Statistical analysis was applied to verify the significance of these results, as described below.
The P value for the difference in the expression levels of trophinin associated protein (tastin) transcripts detectable by SEQ ID NO: 1480 in lung cancer samples versus the normal lung samples was determined by T test as 1.61E-04.
Threshold of 5 fold overexpression was found to differentiate between cancer and normal samples with P value of 1.49E-02 as checked by exact fisher test. The above values demonstrate statistical significance of the results.
According to the present invention, trophinin associated protein (tastin) is a non- limiting example of a marker for diagnosing lung cancer. The trophinin associated protein (tastin) marker of the present invention, can be used alone or in combination, for various uses, including but not limited to, prognosis, prediction, screening, early diagnosis, therapy selection and treatment monitoring of lung cancer. Although optionally any method may be used to detected overexpression and/or differential expression of this marker, preferably a NAT-based technology is used. Therefore, optionally and preferably, any nucleic acid molecule capable of selectively hybridizing to trophinin associated protein (tastin) as previously defined is also encompassed within the present invention. Primer pairs are also optionally and preferably encompassed within the present invention; for example, for the above experiment, the following primer pair was used as a non- limiting illustrative example only of a suitable primer pair: trophinin associated protein (tastin)- TAA-seg 44- forward primer (SEQ ID NO: 1478):
AGACTCCAACCCACAGCCC; and trophinin associated protein (tastin) - TAA-seg 44- Reverse primer (SEQ ID NO: 1479): CAGCTCAGCCAACCTTGCA.
The present invention also preferably encompasses any amplicon obtained through the use of any suitable primer pair; for example, for the above experiment, the following amplicon was obtained as a non- limiting illustrative example only of a suitable amplicon: trophinin associated protein (tastin) amplicon, SEQ ID NO: 1480:
AGACTCCAACCCACAGCCCAGCTGTGGCTGCACAGTGAGCCTGATGGGAGGTGGGG AACAGGGACAGGGGGCCACCTGGGCTTCTTCACAGAGAGGTCAGCAGGAAGGCTT GGCTACAGTGCAAGGTTGGCTGAGCTG According to other preferred embodiments of the present invention, trophinin associated protein (tastin) or a fragment thereof comprises a biomarker for detecting lung cancer. Optionally and more preferably, trophinin associated protein (tastin) splice variants, as depicted in SEQ ID NO: 1485-1488, 1609, 1610 (e.g., variant no. 23-26, 31, 32), or a fragment thereof comprise a biomarker for detecting lung cancer. Optionally and more preferably, the fragment of trophinin associated protein (tastin) comprises segment_TAA-44 - SEQ ID NO: 1507. Also optionally and more preferably, any suitable method may be used for detecting a fragment such as trophinin associated protein (tastin) _segment_ TAA-44 - SEQ ID no 1507 for example. Most preferably, NAT-based technology used, such as any nucleic acid molecule capable of specifically hybridizing with the fragment. Optionally and most preferably, a primer pair is used for obtaining the fragment.
According to still other preferred embodiments, the present invention optionally and preferably encompasses any amino acid sequence or fragment thereof encoded by a nucleic acid sequence corresponding to trophinin associated protein (tastin) as described above, including but not limited to SEQ ID NOs: 1492-1501, 1612. Any oligopeptide or peptide relating to such an amino acid sequence or fragment thereof may optionally also (additionally or alternatively) be used as a biomarker, including but not limited to the unique amino acid sequences of these proteins that are depicted in SEQ ID Nos: 1508-1511, 1613. The present invention also optionally encompasses antibodies capable of recognizing, and/or being elicited by, such oligopeptides or peptides. The present invention also optionally and preferably encompasses any nucleic acid sequence or fragment thereof, or amino acid sequence or fragment thereof, corresponding to trophinin associated protein (tastin) as described above, optionally for any application.
Expression of trophinin associated protein (tastin) [T86235J transcripts which are detectable by oligonucleotides as depicted in SEQ ID NOs:1512-1514 in normal and cancerous lung tissues
Expression of trophinin associated protein (tastin) [T86235J transcripts detectable by oligonucleotides SEQ ID NOs: 1512-1514 (e.g., variants no. 8-10, 22, 23, 26, 27, 29-31, 33 - represented by SEQ IDs 1481-1485, 1488-1491, 1609, 1611) was measured with oligonucleotide-based micro-arrays. The segments detected by the above oligonucleotides as depicted in SEQ ID NOs: 1512-1514 are for example nucleotide sequences as depicted in SEQ IDs 1503, 1504, 1506.
The results of image intensities for each feature were normalized according to the ninetieth percentile of the image intensities of all the features on the chip. Then, feature image intensities for replicates of the same oligonucleotide on the chip and replicates of the same sample were averaged. Outlying results were discarded.
For every oligonucleotide (SEQ ID NOs: 1512-1514 ) the averaged intensity determined for every sample was divided by the averaged intensity of all the normal samples (Sample Nos.
48,50, 90-92, 96-99, Table 2, "Tissue samples in testing panel", above), to obtain a value of fold
up-regulation for each sample relative to the averaged normal samples. These data are presented in a histogram in Figure 54b. As is evident from Figure 54b, the expression of trophinin associated protein (tastin) [T86235J transcripts detectable with oligonucleotides according to SEQ ID NOs: 1512-1514 in cancer samples was significantly higher than in the normal samples. According to the present invention, trophinin associated protein (tastin) is a non- limiting example of a marker for diagnosing lung cancer. Although optionally any method may be used to detected overexpression and/or differential expression of this marker, preferably a NAT- based technology is used. Therefore, optionally and preferably, any nucleic acid molecule capable of selectively hybridizing to trophinin associated protein (tastin) as previously defined is also encompassed within the present invention. Oligonucleotides are also optionally and preferably encompassed within the present invention; for example, for the above experiment, the following oligonucleotides were used as a non- limiting illustrative example only of a suitable oligonucleotides: SEQ ID NOs: 1512-1514 SEQ ID 7572: CATGGTAACACGGCCTCCATGGCTGAGTAGGGGACTAGGAAGGGTAAAAG SEQ ID 1513: TGTACATCTAGGGCCTCTCAGTTAGGGGCTTCAATCCATTCCTCATGAGG
SEQ ID 1514: TGTGAACACAAGAGGTCCTCACCTCACTGTGAGCTGCACACCTGCCCTGC
According to other preferred embodiments of the present invention, trophinin associated protein (tastin) or a fragment thereof comprises a biomarker for detecting lung cancer. Optionally and more preferably, trophinin associated protein (tastin) splice variants, as depicted in SEQ ID NO: 1481-1485, 1488-1491, 1609, 1611 (e.g., variant no. 8-10, 22, 23, 26, 27, 29- 31, 33), or a fragment thereof comprise a biomarker for detecting lung cancer. Optionally and more preferably, the fragment of trophinin associated protein (tastin) comprises segment_TAA- 14, 35 and 42 - SEQ ID no. 1503, 1504, 1506 . Also optionally and more preferably, any suitable method may be used for detecting a fragment such as trophinin associated protein (tastin) _segment_TAA-14, 35 and 42 - SEQ ID NOs 1503, 1504 and 1506 for example. Most preferably, NAT-based technology used, such as any nucleic acid molecule capable of
specifically hybridizing with the fragment. Optionally and most preferably, a primer pair is used for obtaining the fragment.
According to other preferred embodiments of the present invention, trophinin associated protein (tastin) splice variants containing the unique segments as depicted in SEQ ID Nos 1502 and 1505, for example as these included in variants 9 and 29 (SEQ ID NOs: 1482 and 1490, respectively), are useful as biomarkers for detecting lung cancer.
The present invention also optionally and preferably encompasses any nucleic acid sequence or fragment thereof, or amino acid sequence or fragment thereof, corresponding to trophinin associated protein (tastin) as described above, optionally for any application.
Expression ofHomeo box ClO (HOXClO) [N31842] transcripts which are detectable by amplicon as depicted in SEQ ID NO: 1517 in normal and cancerous lung tissues Expression of Homeo box ClO (HOXClO) transcripts detectable by SEQ ID NO: 1517 (e.g., variant no. 3, represented by SEQ ID 1519) was measured by real time PCR. In parallel the expression of four housekeeping genes - PBGD (GenBank Accession No. BCO 19323; amplicon - SEQ ID NO:1471), HPRTl (GenBank Accession No. NM_000194; amplicon - SEQ ID NO:3), Ubiquitin (GenBank Accession No. BC000449; amplicon - SEQ ID NO:9) and SDHA (GenBank Accession No. NM_004168; amplicon - SEQ ID NO: 1477), was measured similarly. For each RT sample, the expression of SEQ ID NO:1517 was normalized to the geometric mean of the quantities of the housekeeping genes. The normalized quantity of each RT sample was then divided by the median of the quantities of the normal post-mortem (PM) samples (Sample Nos. 47-50, 90-93, 96-99, Table 2, "Tissue samples in testing panel", above), to obtain a value of fold up -regulation for each sample relative to median of me normal PM samples. Figure 55 is a histogram showing over expression of the above- indicated Homeo box
ClO (HOXClO) transcripts in cancerous lung samples relative to the normal samples. The number and percentage of samples that exhibit at least 20 fold over- expression, out of the total number of samples tested is indicated in the bottom.
As is evident from Figure 55, the expression of Homeo box ClO (HOXClO) transcripts detectable by SEQ ID NO: 1517 in cancer samples was significantly higher than in the noncancerous samples (Sample Nos. 46-50, 90-93, 96-99, Table 2, "Tissue samples in testing
panel"). Notably an over- expression of at least 20 fold was found in 6 out of 15 adenocarcinoma samples, 9 out of 16 squamous cell carcinoma samples, and in 3 out of 4 large cell carcinoma samples.
Statistical analysis was applied to verify the significance of these results, as described below.
The P value for the difference in the expression levels of Homeo box ClO (HOXClO) transcripts detectable by SEQ ID NO: 1517 in lung cancer samples versus the normal lung samples was determined by T test as 4.43E-03.
Threshold of 20 fold overexpression was found to differentiate between cancer and normal samples with P value of 2.88E-02 as checked by exact fisher test. The above values demonstrate statistical significance of the results.
According to the present invention, Homeo box ClO (HOXClO) is a non- limiting example of a marker for diagnosing lung cancer. The Homeo box ClO (HOXClO) marker of the present invention, can be used alone or in combination, for various uses, including but not limited to, prognosis, prediction, screening, early diagnosis, therapy selection and treatment monitoring of lung cancer. Although optionally any method may be used to detected overexpression and/or differential expression of this marker, preferably a NAT-based technology is used. Therefore, optionally and preferably, any nucleic acid molecule capable of selectively hybridizing to Homeo box ClO (HOXClO) as previously defined is also encompassed within the present invention. Primer pairs are also optionally and preferably encompassed within the present invention; for example, for the above experiment, the following primer pair was used as a non- limiting illustrative example only of a suitable primer pair: Homeo box ClO (HOXClO) -forward primer (SEQ ID NO: 1515): GCGAAAC GCGATTTGTTGTT; and Homeo box C 10 (HOXC 10) -Reverse primer (SEQ ID NO:1516): CATCTGGAGGAGGGAGGGA.
The present invention also preferably encompasses any amplicon obtained through the use of any suitable primer pair; for example, for the above experiment, the following amplicon
was obtained as a non- limiting illustrative example only of a suitable amplicon: Homeo box ClO (HOXClO) amplicon (SEQ ID NO: 1517):
GCGAAACGCGATTTGTTGTTTGTGGGTCTGATTTGTGCGTGCGGCTTGGGCTCCTGC GGCTTTTGGCTCGGCCGGGGGCCTTGGGCAGCGAGGCTGGAGCCGGAAGAGGTGG AGGTGAAGGGCTGCCCGCCACGTCCCTCCCTCCTCCAGATG .
According to other preferred embodiments of the present invention, Homeo box ClO (HOXClO) or a fragment thereof comprises a biomarker for detecting lung cancer. Optionally and more preferably, Homeo box ClO (HOXClO) splice variants, as depicted in SEQ ID NO:54 (e.g., variant no. 3), or a fragment thereof comprise a biomarker for detecting lung cancer. Optionally and more preferably, the fragment of Homeo box ClO (HOXClO) comprises segment_TAA-seg 6 (SEQ ID NO: 1526). Also optionally and more preferably, any suitable method may be used for detecting a fragment such as Homeo box ClO (HOXClO) _segment_ TAA-seg 6 (SEQ ID NO: 1526) for example. Most preferably, NAT-based technology used, such as any nucleic acid molecule capable of specifically hybridizing with the fragment. Optionally and most preferably, a primer pair is used for obtaining the fragment.
According to other preferred embodiments of the present invention, Homeo box ClO (HOXClO) splice variants containing the unique segments as depicted in SEQ ID NOs: 1524 and 1525, for example transcripts as depicted in SEQ ID NO: 1515, 1519 and 1520, comprise a biomarker for detecting lung cancer.
According to still other preferred embodiments, the present invention optionally and preferably encompasses any amino acid sequence or fragment thereof encoded by a nucleic acid sequence corresponding to trophinin associated protein (tastin) as described above, including but not limited to SEQ ID NOs: 1521 and 1522. Any oligopeptide or peptide relating to such an amino acid sequence or fragment thereof may optionally also (additionally or alternatively) be used as a biomarker, including but not limited to the unique amino acid sequence of the protein SEQ ID NO: 1522, as depicted in SEQ ID NO:1523. The present invention also optionally encompasses antibodies capable of recognizing, and/or being elicited by, such oligopeptides or peptides. The present invention also optionally and preferably encompasses any nucleic acid sequence or fragment thereof, or amino acid sequence or fragment thereof, corresponding to trophinin associated protein (tastin) as described above, optionally for any application.
Expression of Nucleolar protein 4 (NOL4)- [T06014] transcripts which are detectable by amplicon as depicted in SEQ IDs NO: 1529 in normal and cancerous lung tissues Expression of Nucleolar protein 4 (NOL4) transcripts detectable by SEQ ID NOs: 1529 (e.g., variant no. 3, 11 and 12, represented by SEQ IDs 1533, 1537, 1538) was measured by real time PCR. In parallel the expression of four housekeeping genes - PBGD (GenBank Accession No. BC019323; amplicon - SEQ ID NO:1471), HPRTl (GenBank Accession No. NM_000194; amplicon - SEQ ID NO: 1468), Ubiquitin (GenBank Accession No. BC000449; amplicon - SEQ ID NO:1474) and SDHA (GenBank Accession No. NM_004168; amplicon - SEQ ID NO:1477), was measured similarly. For each RT sample, the expression of SEQ ID NO: 1529 was normalized to the geometric mean of the quantities of the housekeeping genes. The normalized quantity of each RT sample was then divided by the median of the quantities of the normal postmortem (PM) samples (Sample Nos. 47-50, 90-93, 96-99, Table 2, above, "Tissue samples in testing panel"), to obtain a value of fold up-regulation for each sample relative to median of the normal PM samples.
Figures 56a and b are histograms showing over expression of the above -indicated Nucleolar protein 4 (NOL4) transcripts in cancerous lung samples relative to the normal samples. The number and percentage of samples that exhibit at least 200 fold or 6 fold over-
expression, out of the total number of samples tested is indicated in the bottom of figures 56a and 56b respectively.
As is evident from Figure 56a, the expression of Nucleolar protein 4 (NOL4) transcripts detectable by SEQ ID NO: 1529 in the samples originate from small cell carcinoma of the lung was significantly higher than in the non-cancerous samples (Sample Nos. 46-50, 90-93, 96-99, Table 2, "Tissue samples in testing panel"). Notably an over- expression of at least 200 fold was found in 8 out of 8 small cell carcinoma samples. As is evident from Figures 56b, over expression of at least 6 fold was observed also in 2 out of 15 adenocarcinoma samples, 3 out of 16 squamous cell carcinoma samples. Statistical analysis was applied to verify the significance of these results, as described below.
The P value for the difference in the expression levels of Nucleolar protein 4 (NOL4) transcripts detectable by SEQ ID TSfO: 1529 in lung cancer samples versus the normal lung samples was determined by T test as 1.36E-02. Threshold of 6 fold overexpression was found to differentiate between cancer and normal samples with P value of 2.52E-02 as checked by exact fisher test.
The P value for the difference in the expression levels of Nucleolar protein 4 (NOL4) transcripts detectable by SEQ ID NO: 1529 in lung small cell carcinoma samples versus the normal lung samples was determined by T test as 3.86E-03. Threshold of 200 fold overexpression was found to differentiate between small cell carcinoma and normal lung samples with P value of 7.94E-06 as checked by exact fisher test. The above values demonstrate statistical significance of the results.
According to the present invention, Nucleolar protein 4 (NOL4) is a non- limiting example of a marker for diagnosing lung cancer. The Nucleolar protein 4 (NOL4) marker of the present invention, can be used alone or in combination, for various uses, including but not limited to, prognosis, prediction, screening, early diagnosis, therapy selection and treatment monitoring of lung cancer. Although optionally any method may be used to detected overexpression and/or differential expression of this marker, preferably aNAT-based technology is used. Therefore, optionally and preferably, any nucleic acid molecule capable of selectively hybridizing to Nucleolar protein 4 (NOL4) as previously defined is also
encompassed within the present invention. Primer pairs are also optionally and preferably encompassed within the present invention; for example, for the above experiment, the following primer pair was used as a non- limiting illustrative example only of a suitable primer pair: Nucleolar protein 4 (NOL4)-TAA-segl- forward primer (SEQ ID NO: 1527): CTCGCTCCCTTGCTCACAC; and Nucleolar protein 4 (NOL4)-TAA-segl -Reverse primer (SEQ ID NO:1528): AAAGGGAAAGCGGGATGTTT.
The present invention also preferably encompasses any amplicon obtained through the use of any suitable primer pair; for example, for the above experiment, the following amplicon was obtained as a non- limiting illustrative example only of a suitable amplicon: Nucleolar protein 4 (NOL4) amplicon (SEQ ID NO: 1529):
CTCGCTCCCTTGCTCACACACACGCACACACTCAGCCTGGCCGAGCAGGAGCCACT GACCATTTTGCAAGTGTCAGGACCAGCTACAGCGCGGTGGGCGCAAACATCCCGCT TTCCCTTT .
According to other preferred embodiments of the present invention, Nucleolar protein 4 (NOL4) or a fragment thereof comprises a biomarker for detecting lung cancer. Optionally and more preferably, Nucleolar protein 4 (NOL4) splice variants, as depicted in SEQ ID NO: 1529 (e.g., variants nos. 3, 11 and 12), or a fragment thereof comprise a biomarker for detecting lung cancer. Optionally and more preferably, the fragment of Nucleolar protein 4 (NOL4) comprises segment_TAA-seg-l (SEQ ID NO: 1552). Also optionally and more preferably, any suitable method may be used for detecting a fragment such as Nucleolar protein 4 (NOL4)_segment_ TAA-seg-1 (SEQ ID NO: 1552) for example. Most preferably, NAT-based technology used, such as any nucleic acid molecule capable of specifically hybridizing with the fragment. Optionally and most preferably, a primer pair is used for obtaining the fragment.
According to other preferred embodiments of the present invention, Nucleolar protein 4 (NOL4) splice variants containing the unique segments as depicted in SEQ ID NOs: 1554 and 1555, for example transcripts as depicted in SEQ ID NOs: 1534-1536 and 1539-1541, comprises a biomarker for detecting lung cancer. According to still other preferred embodiments, the present invention optionally and preferably encompasses any amino acid sequence or fragment thereof encoded by a nucleic acid
sequence corresponding to Nucleolar protein 4 (NOL4) as described above, including but not limited to SEQ ID Nos: 1542, 1547 and 1543; 1548, 1545, 1546, and 1549-1551. Any oligopeptide or peptide relating to such an amino acid sequence or fragment thereof may optionally also (additionally or alternatively) be used as a biomarker, including but not limited to the unique amino acid sequence of the protein SEQ ID NO: 1543, 1546, 1549 as depicted in SEQ ID NO: 1544.
The present invention also optionally encompasses antibodies capable of recognizing, and/or being elicited by, such oligopeptides or peptides.
The present invention also optionally and preferably encompasses any nucleic acid sequence or fragment thereof, or amino acid sequence or fragment thereof, corresponding to Nucleolar protein 4 (NOL4) as described above, optionally for any application.
Expression of Nucleolar protein 4 (NOL4)- [T06014] transcripts which are detectable by amplicon as depicted in SEQ IDs NO: 1532 in normal and cancerous lung tissues
Expression of Nucleolar protein 4 (NOL4) transcripts detectable by SEQ ID NOs: 1532 (e.g., variant no. 3, 11 and 12, represented by SEQ IDs 1533, 1537, 1538) was measured by real time PCR. In parallel the expression of four housekeeping genes - PBGD (GenBank Accession No. BC019323; amplicon - SEQ ID NO: 1471), HPRTl (GenBank Accession No. NM_000194; amplicon - SEQ ID NO: 1468), Ubiquitin (GenBank Accession No. BC000449; amplicon - SEQ ID NO: 1474) and SDHA (GenBank Accession No. NM_004168; amplicon - SEQ ID NO: 1481), was measured similarly. For each RT sample, the expression of SEQ ID NO: 1532 was normalized to the geometric mean of the quantities of the housekeeping genes. The normalized quantity of each RT sample was then divided by the median of the quantities of the normal post- mortem (PM) samples (Sample Nos. 47-50, 90-93, 96-99, Table 2, "Tissue samples in testing panel", above), to obtain a value of fold up-regulation for each sample relative to median of the normal PM samples.
Figures 57a and b are histograms showing over expression of the above- indicated Nucleolar protein 4 (NOL4) transcripts in cancerous lung samples relative to the normal samples. The number and percentage of samples that exhibit at least 400 fold or 6 fold over-
expression, out of the total number of samples tested is indicated in the bottom of figures 57a and b respectively.
As is evident from Figure 57a, the expression of Nucleolar protein 4 (NOL4) transcripts detectable by SEQ ID NO: 1532 in the samples originate from small cell carcinoma of the lung was significantly higher than in the non-cancerous samples (Sample Nos. 46-50, 90-93, 96-99, Table 2, "Tissue samples in testing panel"). Notably an over- expression of at least 400 fold was found in 8 out of 8 small cell carcinoma samples. As is evident from Figure 4b, over expression of at least 6 fold was observed also in 4 out of 15 adenocarcinoma samples, 3 out of 16 squamous cell carcinoma samples. Statistical analysis was applied to verify the significance of these results, as described below.
The P value for the difference in the expression levels of Nucleolar protein 4 (NOL4) transcripts detectable by SEQ ID NO: 1532 in lung cancer samples versus the normal lung samples was determined by T test as 1.70E-02. Threshold of 6 fold overexpression was found to differentiate between cancer and normal samples with P value of 1.80E-02 as checked by exact fisher test.
The P value for the difference in the expression levels of Nucleolar protein 4 (NOL4) transcripts detectable by SEQ ID NO: 1532 in lung small cell carcinoma samples versus the normal lung samples was determined by T test as 7.08E-03. Threshold of 400 fold overexpression was found to differentiate between small cell carcinoma and normal lung samples with P value of 1.03E-04 as checked by exact fisher test. The above values demonstrate statistical significance of the results.
According to the present invention, Nucleolar protein 4 (NOL4) is a non- limiting example of a marker for diagnosing lung cancer. The Nucleolar protein 4 (NOL4) marker of the present invention, can be used alone or in combination, for various uses, including but not limited to, prognosis, prediction, screening, early diagnosis, therapy selection and treatment monitoring of lung cancer. Although optionally any method may be used to detected overexpression and/or differential expression of this marker, preferably aNAT-based technology is used. Therefore, optionally and preferably, any nucleic acid molecule capable of selectively hybridizing to Nucleolar protein 4 (NOL4) as previously defined is also
encompassed within the present invention. Primer pairs are also optionally and preferably encompassed within the present invention; for example, for the above experiment, the following primer pair was used as a non- limiting illustrative example only of a suitable primer pair: Nucleolar protein 4 (NOL4) -TAA-seg 3-forward primer (SEQ ID NO: 1530): ACATCCCCCTGGAACGGAT; and Nucleolar protein 4 (NOL4>TAA-seg 3-Reverse primer (SEQ ID NO: 1531): CAGAAATTAGCAAAGCATTGATGG.
The present invention also preferably encompasses any amplicon obtained through the use of any suitable primer pair; for example, for the above experiment, the following amplicon was obtained as a non- limiting illustrative example only of a suitable amplicon: Nucleolar protein 4 (NOL4) amplicon (SEQ ID NO: 1532):
ACATCCCCCTGGAACGGATATCTGTTTGGGGCACTACAATCTATCCTGTAGAACTAT GGCCAAATCTCCATCAATGCTTTGCTAATTTCTG.
According to other preferred embodiments of the present invention, Nucleolar protein 4 (NOL4) or a fragment thereof comprises a biomarker for detecting lung cancer. Optionally and more preferably, Nucleolar protein 4 (NOL4) splice variants, as depicted in SEQ ID NO: 1533, 1537, 1538 (e.g., variants nos. 3, 11, 12), or a fragment thereof comprise a biomarker for detecting lung cancer. Optionally and more preferably, the fragment of Nucleolar protein 4 (NOL4) comprises segment_TAA-seg-3 (SEQ ID NO: 1553). Also optionally and more preferably, any suitable method may be used for detecting a fragment such as Nucleolar protein 4 (NOL4)_segment_ TAA-seg-3 (SEQ ID NO: 1553) for example. Most preferably, NAT- based technology used, such as any nucleic acid molecule capable of specifically hybridizing with the fragment. Optionally and most preferably, a primer pair is used for obtaining the fragment. According to still other preferred embodiments, the present invention optionally and preferably encompasses any amino acid sequence or fragment thereof encoded by a nucleic acid sequence corresponding to Nucleolar protein 4 (NOL4) as described above, including but not limited to SEQ ID NOs: SEQ ID Nos: 1542, 1547 and 1548. Any oligopeptide or peptide relating to such an amino acid sequence or fragment thereof may optionally also (additionally or alternatively) be used as a biomarker.
The present invention also optionally encompasses antibodies capable of recognizing, and/or being elicited by, such oligopeptides or peptides.
The present invention also optionally and preferably encompasses any nucleic acid sequence or fragment thereof, or amino acid sequence or fragment thereof, corresponding to Nucleolar protein 4 (NOL4) as described above, optionally for any application.
Expression o/AA281370 transcripts which are detectable by amplicon as depicted in SEQ ID NO: 1558 in normal and cancerous lung tissues
AA281370 gene was identified by a computational process described above as over expressed in lung cancer. The AA281370 encoded proteins (SEQ ID NO: 1563, 1564) contain several WD40 domains, which are found in a number of eukaryotic proteins that cover a wide variety of functions, including adaptor/regulatory modules in signal transduction, pre-mRNA processing and cytoskeleton assembly. As is demonstrated in Figure 63, the WD40 domain region of AA281370 encoded protein, depicted in SEQ ID NO: 1564, has several similarities that might suggest involvement in signal transduction MAPK pathway. For example, the region of the AA281370 polypeptide SEQ ID NO: 1564 located between amino acids at positions 40- 790 has 75% homology to the WD40 domain region of mouse Mapkbpl protein (gi|47124622 ) (figure 63a); and the amino acids at positions 40-886 of the AA281370 polypeptide SEQ ID NO: 1564 has 70% homology to rat JNK-binding protein JNKBPl (gi|34856717) (figure 63b).
Expression of AA281370 transcripts detectable by SEQ ID NO: 1558 (e.g., variant no. 0, 1, 4 and 5, represented in SEQ IDs 1559-1562) was measured by real time PCR. In parallel the expression of four housekeeping genes - PBGD (GenBank Accession No. BCOl 9323; amplicon
- SEQ ID NO:1471), HPRTl (GenBank Accession No. NM_000194; amplicon - SEQ ID
NO: 1468), Ubiquitin (GenBank Accession No. BC000449; amplicon - SEQ ID NO: 1474) and
SDHA (GenBank Accession No. NM_004168; amplicon - SEQ ID NO: 1477), was measured similarly. For each RT sample, the expression of SEQ ID NO: 1558 was normalized to the geometric mean of the quantities of the housekeeping genes. The normalized quantity of each
RT sample was then divided by the median of the quantities of the normal post-mortem (PM) samples (Sample Nos. 47-50, 90-93, 96-99, Table 2, "Tissue samples in testing panel", above), to obtain a value of fold up-regulation for each sample relative to median of the normal PM samples. Figure 58 is a histogram showing over expression of the above- indicated AA281370 transcripts in cancerous lung samples relative to the normal samples. The number and percentage of samples that exhibit at least 6 fold over- expression, out of the total number of samples tested is indicated in the bottom.
As is evident from Figures 58, the expression of AA281370 transcripts detectable by SEQ ID NO:1558 in cancer samples was significantly higher than in the noncancerous samples (Sample Nos. 46-50, 90-93, 96-99, Table 2, "Tissue samples in testing panel"). Notably an over- expression of at least 6 fold was found in 8 out of 8 small cell carcinoma, 2 out of 16 squamous cell carcinoma samples, and in 1 out of 4 large cell carcinoma samples.
Statistical analysis was applied to verify the significance of these results, as described below.
The P value for the difference in the expression levels .of AA281370 transcripts detectable by SEQ ID NO:1558 in lung cancer samples versus the normal lung samples was determined by T test as 8.58E-07.
Threshold of 6 fold overexpression was found to differentiate between cancer and normal samples with P value of 4.81E-02 as checked by exact fisher test. The above values demonstrate statistical significance of the results.
According to the present invention, AA281370 transcripts are a non- limiting example of a marker for diagnosing lung cancer. The AA281370 marker of the present invention, can be used alone or in combination, for various uses, including but not limited to, prognosis, prediction, screening, early diagnosis, therapy selection and treatment monitoring of lung cancer. Although optionally any method may be used to detected overexpression and/or differential expression of this marker, preferably a NAT-based technology is used. Therefore, optionally and preferably, any nucleic acid molecule capable of selectively hybridizing to AA281370 as previously defined is also encompassed within the present invention. Primer pairs are also optionally and preferably encompassed within the present invention; for example, for
the above experiment, the following primer pair was used as a non- limiting illustrative example only of a suitable primer pair: AA281370- forward primer (SEQ ID NO: 1556): GGTTCGGATGGACTACACTTTGTC; and AA281370-Reverse primer (SEQ ID NO: 1557): CCACGTACTTCTGGGTGATGTC . The present invention also preferably encompasses any amplicon obtained through the use of any suitable primer pair; for example, for the above experiment, the following amplicon was obtained as a non- limiting illustrative example only of a suitable amplicon: AA281370- amplicon (SEQ ID NO: 1558): GGTTCGGATGGACTACACTTTGTCCGTACCCACCACGTAGCAGAGAAAACCACCTT GTATGACATGGACATTGACATCACCCAGAAGTACGTGG.
According to other preferred embodiments of the present invention, AA281370 or a fragment thereof comprises a biomarker for detecting lung cancer. Optionally and more preferably, AA281370 splice variants, as depicted in SEQ ID NO:1558 (e.g., variants no: 0, 1, 4 and 5), or a fragment thereof comprise a biomarker for detecting lung cancer. Optionally and more preferably, the fragment of AA281370 comprises segmentJTAA seg 10 SEQ ID NO: 1567, Also optionally and more preferably, any suitable method may be used for detecting a fragment such as AA281370_segment_TAA seg 10 SEQ ID NO: 1567 for example. Most preferably, NAT-based technology used, such as any nucleic acid molecule capable of specifically hybridizing with the fragment. Optionally and most preferably, a primer pair is used for obtaining the fragment.
According to other preferred embodiments, the present invention also optionally and preferably encompasses AA281370 splice variants containing the unique segments as depicted in SEQ ID NO: 1568, for example transcripts 4 and 5, as depicted in SEQ ID NOs: 1561 and 1562, comprises a biomarker for detecting lung cancer. According to still other preferred embodiments, the present invention optionally and preferably encompasses any amino acid sequence or fragment thereof encoded by a nucleic acid sequence corresponding to AA281370 as described above, including but not limited to SEQ ID NOs: 1563- 1566. Any oligopeptide or peptide relating to such an amino acid sequence or fragment thereof may optionally also (additionally or alternatively) be used as a biomarker, including but not limited to the unique amino acid sequence of the proteins SEQ ID NOs: 1563- 1566, as depicted in SEQ ID NOs: 1569, 1570 and 1571.
The present invention also optionally encompasses antibodies capable of recognizing, and/or being elicited by, such oligopeptides or peptides.
The present invention also optionally and preferably encompasses any nucleic acid sequence or fragment thereof, or amino acid sequence or fragment thereof, corresponding to AA281370 as described above, optionally for any application.
Expression ofSulfatase 1 (SULF 1)-[Z21368] , transcripts which are detectable by amplicon as depicted in SEQ ID NO: 1574 in normal and cancerous lung tissues
SULFl is a secreted protein which is found in the extracellular matrix. It is known to be downregulated in many epithelial cancer types.
Expression of Sulfatase 1 (SULFl) transcripts detectable by SEQ ID NO:1574 (e.g., variant no. 13 and 14, represented in SEQ ID 1578, 1579) was measured by real time PCR. In parallel the expression of four housekeeping genes - PBGD (GenBank Accession No. BC019323; amplicon - SEQ ID NO:1471), HPRTl (GenBank Accession No. NM_000194; amplicon - SEQ ID NO:1468), Ubiquitin (GenBank Accession No. BC000449; amplicon - SEQ ID NO:1474) and SDHA (GenBank Accession No. NM_004168; amplicon - SEQ ID NO:1477), was measured similarly. For each RT sample, the expression of SEQ ID NO: 1574 was normalized to the geometric mean of the quantities of the housekeeping genes. The noπnalized quantity of each RT sample was then divided by the median of the quantities of the normal post- mortem (PM) samples (Sample Nos. 47-50, 90-93, 96-99, Table 2, "Tissue samples in testing panel", above), to obtain a value of fold up -regulation for each sample relative to median of the normal PM samples.
Figure 59 is a histogram showing over expression of the above- indicated Sulfatase 1 (SULFl) transcripts in cancerous lung samples relative to the normal samples. The number and percentage of samples that exhibit at least 8 fold over- expression, out of the total number of samples tested is indicated in the bottom.
As is evident from Figure 59, the expression of Sulfatase 1 (SULFl) transcripts detectable by SEQ ID NO: 1574 in cancer samples originate from non-cell carcinoma was significantly higher than in the non-cancerous samples (Sample Nos. 46-50, 90-93, 96-99, Table 2, "Tissue samples in testing panel"). Notably an over- expression of at least 8 fold was found in 11 out of 15 adenocarcinoma samples, 11 out of 16 squamous cell carcinoma samples, and in 4 out of 4 large cell carcinoma samples.
Statistical analysis was applied to verify the significance of these results, as described below.
The P value for the difference in the expression levels of Sulfatase 1 (SULFl) transcripts detectable by SEQ ID NO: 1574 in lung cancer samples versus the normal lung samples was determined by T test as 3.18E-07.
Threshold of 8 fold overexpression was found to differentiate between cancer and normal samples with P value of 1.18E-04 as checked by exact fisher test.
The above values demonstrate statistical significance of the results. According to the present invention, Sulfatase 1 (SULFl) is a non- limiting example of a marker for diagnosing lung cancer. The Sulfatase 1 (SULFl) marker of the present invention, can be used alone or in combination, for various uses, including but not limited to, prognosis, prediction, screening, early diagnosis, therapy selection and treatment monitoring of lung cancer. Although optionally any method may be used to detected overexpression and/or differential expression of this marker, preferably a NAT-based technology is used. Therefore, optionally and preferably, any nucleic acid molecule capable of selectively hybridizing to Sulfatase 1 (SULFl) as previously defined is also encompassed within the present invention. Primer pairs are also optionally and preferably encompassed within the present invention; for example, for the above experiment, the following primer pair was used as a non- limiting illustrative example only of a suitable primer pair: Sulfatase 1 (SULFl) -forward primer (SEQ ID NO: 1572): ACTCACTCAGAGACTAACACAAAGGAAG; and Sulfatase 1 (SULFl) - Reverse primer (SEQ ID NO: 1573): AGTATGGGAAGAATTTACTGGTCACA
The present invention also preferably encompasses any amplicon obtained through the use of any suitable primer pair; for example, for the above experiment, the following amplicon was obtained as a non- limiting illustrative example only of a suitable amplicon: Sulfatase 1 (SULFl) -amplicon (SEQ ID NO: 1574):
ACTCACTCAGAGACTAACACAAAGGAAGTAATTTCTTACCTGGTCATTATTTAGTCT ACAATAAGTTCATCCTTCTTCAGTGTGACCAGTAAATTCTTCCCATACT.
According to other preferred embodiments of the present invention, Sulfatase 1 (SULFl) or a fragment thereof comprises a biomarker for detecting lung cancer. Optionally and more preferably, Sulfatase 1 (SULFl) splice variants, as depicted in SEQ ID NO: 1578, 1579 (e.g., variants no: 13 and 14), or a fragment thereof comprise a biomarker for detecting lung cancer.
Optionally and more preferably, the fragment of Sulfatase 1 (SULFl) comprises segment_TAA seg 5 - SEQ ID NO: 1587. Also optionally and more preferably, any suitable method may be used for detecting a fragment such as Sulfatase 1 (SULFl) _segment_ TAA seg 5 — SEQ ID NO: 1587 for example. Most preferably, NAT-based technology used, such as any nucleic acid molecule capable of specifically hybridizing with the fragment. Optionally and most preferably, a primer pair is used for obtaining the fragment.
According to other preferred embodiments of the present invention, Sulfatase 1 (SULFl) splice variants containing the unique segments as depicted in SEQ ID NOs: 1588-1591, for example transcripts as depicted in SEQ ID NOs: 1575-1577, comprises a biomarker for detecting lung cancer.
According to still other preferred embodiments, the present invention optionally and preferably encompasses any amino acid sequence or fragment thereof encoded by a nucleic acid sequence corresponding to Sulfatase 1 (SULFl) as described above, including but not limited to SEQ ID NOs:1586, 1580, 1582, 1584. Any oligopeptide or peptide relating to such an amino acid sequence or fragment thereof may optionally also (additionally or alternatively) be used as a biomarker, including but not limited to the unique amino acid sequence of the protein SEQ ID NO: 1580, 1582, 1584, as depicted in SEQ ID NO: 1581, 1583, 1585, respectively.
The present invention also optionally encompasses antibodies capable of recognizing, and/or being elicited by, such oligopeptides or peptides.
The present invention also optionally and preferably encompasses any nucleic acid sequence or fragment thereof, or amino acid sequence or fragment thereof, corresponding to Nucleolar protein 4 (NOL4) as described above, optionally for any application.
Expression of SRY (sex determining region Y) -box 2 (SOX2)) -[HUMHMGBOX], transcripts which are detectable by the amplicon as depicted in SEQ ID NO: 1594 in normal and cancerous lung tissues
Expression of SOX2 transcripts detectable by SEQ ID NO: 1594 (e.g., variant no. 0 represented by SEQ ID 1595) was measured by real time PCR. In parallel the expression of four housekeeping genes - PBGD (GenBank Accession No. BC019323; amplicon - SEQ ID NO:1471), HPRTl (GenBank Accession No. NM_000194; amplicon - SEQ ID NO: 1468), Ubiquitin (GenBank Accession No. BC000449; amplicon - SEQ ID NO: 1474) and SDHA (GenBank Accession No. NM_004168; amplicon - SEQ ID NO: 1477), was measured similarly. For each RT sample, the expression of SEQ ID NO: 1594 was normalized to the geometric mean of the quantities of the housekeeping genes. The normalized quantity of each RT sample was then divided by the median of the quantities of the normal post-mortem (PM) samples (Sample Nos. 47-50, 90-93, 96-99, Table 2, "Tissue samples in testing panel", above), to obtain a value of fold up-regulation for each sample relative to median of the normal PM samples. Figure 60 is a histogram showing over expression of the above- indicated SOX2 transcripts in cancerous lung samples relative to the normal samples. The number and percentage of samples that exhibit at least 5 fold over- expression, out of the total number of samples tested is indicated in the bottom.
As is evident from Figure 60, the expression of SOX2 transcripts detectable by SEQ ID NO: 1594 in cancer samples originate from lung carcinoma was significantly higher than in the non-cancerous samples (Sample Nos. 46-50, 90-93, 96-99, Table 2, 'Tissue samples in testing panel"). Notably an over- expression of at least 5 fold was found in 4 out of 15 adenocarcinoma samples, 10 out of 16 squamous cell carcinoma samples, in 2 out of 4 large cell carcinoma, and in 7 out of 8 small cell carcinoma samples. Statistical analysis was applied to verify the significance of these results, as described below.
The P value for the difference in the expression levels of SOX2 transcripts detectable by SEQ ID NO: 1594 in lung cancer samples versus the normal lung samples was determined by T test as 4.38E-05. Threshold of 5 fold overexpression was found to differentiate between cancer and normal samples with P value of 8.09E-04 as checked by exact fisher test.
The above values demonstrate statistical significance of the results.
According to the present invention, SOX2 is a non- limiting example of a marker for diagnosing lung cancer. The SOX2 marker of the present invention, can be used alone or in combination, for various uses, including but not limited to, prognosis, prediction, screening, early diagnosis, therapy selection and treatment monitoring of lung cancer. Although optionally any method may be used to detected overexpression and/or differential expression of this marker, preferably a NAT-based technology is used. Therefore, optionally and preferably, any nucleic acid molecule capable of selectively hybridizing to SOX2 as previously defined is also encompassed within the present invention. Primer pairs are also optionally and preferably encompassed within the present invention; for example, for the above experiment, the following primer pair was used as a non- limiting illustrative example only of a suitable primer pair: SOX2 -forward primer (SEQ ID NO: 1592): GGCGGCGGCAGGAT; and SOX2 -Reverse primer (SEQ ID NO: 1593): GTCGGGAGCGCAGGG.
The present invention also preferably encompasses any amplicon obtained through the use of any suitable primer pair; for example, for the above experiment, the following amplicon was obtained as a non- limiting illustrative example only of a suitable amplicon: SOX2 - amplicon (SEQ ID NO: 1594): GGCGGCGGCAGGATCGGCCAGAGGAGGAGGGAAGCGCTTTTTTTGATCCTGATTCC AGTTTGCCTCTCTCTTTTTTTCCCCCAAATTATTCTTCGCCTGATTTTCCTCGCGGAG CCCTGCGCTCCCGAC.
According to other preferred embodiments of the present invention, SOX2 or a fragment thereof comprises a biomarker for detecting lung cancer. Optionally and more preferably, SOX2 splice variants, as depicted in SEQ ID NO: 1595 (e.g., variants no: 0), or a fragment thereof comprise a biomarker for detecting lung cancer. Optionally and more preferably, the fragment of SOX2 comprises segmentJTAA seg 2 — SEQ ID NO: 1597. Also optionally and more preferably, any suitable method may be used for detecting a fragment such as SOX2 _segment_ TAA seg 2 - SEQ ID NO: 1597 for example. Most preferably, NAT-based technology used, such as any nucleic acid molecule capable of specifically hybridizing with the fragment. Optionally and most preferably, a primer pair is used for obtaining the fragment.
According to still other preferred embodiments, the present invention optionally and preferably encompasses any amino acid sequence or fragment thereof encoded by a nucleic acid sequence corresponding to SOX2 as described above, including but not limited to SEQ ID NOs:
SEQ ID NO: 1596. Any oligopeptide or peptide relating to such an amino acid sequence or fragment thereof may optionally also (additionally or alternatively) be used as a biomarker.
The present invention also optionally encompasses antibodies capable of recognizing, and/or being elicited by, such oligopeptides or peptides.
The present invention also optionally and preferably encompasses any nucleic acid sequence or fragment thereof, or amino acid sequence or fragment thereof, corresponding to SOX2 as described above, optionally for any application.
Expression ofPlakophilin 1 (ectodermal dysplasia/ skin fragility syndrome) (PKPl) -[HSB6PR], transcripts which are detectable by the amplicon as depicted in SEQ ID NO: 1600 in normal and cancerous lung tissues
Expression of PKPl transcripts detectable by SEQ ID NO: 1600 (e.g., variant no. O5 5 and 6-represented by SEQ IDs 1601-1603) was measured by real time PCR. In parallel the expression of four housekeeping genes - PBGD (GenBank Accession No. BC019323; amplicon - SEQ ID NO:1471), HPRTl (GenBank Accession No. NM_000194; amplicon - SEQ ID NO: 1468), Ubiquitin (GenBank Accession No. BC000449; amplicon - SEQ ID NO: 1474) and SDHA (GenBank Accession No. NM_004168; amplicon - SEQ ID NO: 1477), was measured similarly. R»r each RT sample, the expression of SEQ ID NO: 1600 was noπnalized to the geometric mean of the quantities of the housekeeping genes. The normalized quantity of each RT sample was then divided by the median of the quantities of the normal post-mortem (PM) samples (Sample Nos. 47-50, 90-93, 96-99, Table 2, "Tissue samples in testing panel" above), to obtain a value of fold up-regulation for each sample relative to median of the normal PM samples. Figure 61 is a histogram showing over expression of the above- indicated PKPl transcripts in cancerous lung samples relative to the normal samples. The number and
percentage of samples that exhibit at least 7 fold over-expression, out of the total number of samples tested is indicated in the bottom.
As is evident from Figure 61, the expression of PKPl transcripts detectable by SEQ ID
NO: 1600 in cancer samples originate from lung carcinoma was significantly higher than in the non-cancerous samples (Sample Nos. 46-50, 90-93, 96-99, Table 2, "Tissue samples in testing panel"). Notably an over- expression of at least 7 fold was found in 11 out of 16 squamous cell carcinoma samples, and in 1 out of 4 large cell carcinoma.
Statistical analysis was applied to verify the significance of these results, as described below. The P value for the difference in the expression levels of PKPl transcripts detectable by
SEQ ID NO: 1600 in lung cancer samples versus the normal lung samples was determined by T test as 3.18E-03.
Threshold of 7 fold overexpression was found to differentiate between cancer and normal samples with P value of 3.50E-02 as checked by exact fisher test. The above values demonstrate statistical significance of the results.
According to the present invention, PKPl is a non- limiting example of a marker for diagnosing lung cancer. The PKPl marker of the present invention, can be used alone or in combination, for various uses, including but not limited to, prognosis, prediction, screening, early diagnosis, therapy selection and treatment monitoring of lung cancer. Although optionally any method may be used to detected overexpression and/or differential expression of this marker, preferably a NAT-based technology is used. Therefore, optionally and preferably, any nucleic acid molecule capable of selectively hybridizing to PKPl as previously defined is also encompassed within the present invention. Primer pairs are also optionally and preferably encompassed within the present invention; for example, for the above experiment, the following primer pair was used as a non- limiting illustrative example only of a suitable primer pair: PKPl -forward primer (SEQ ID NO: 1598): CCCCAGACTCTGTGCACTTCA; and PKPl -Reverse primer (SEQ ID NO: 1599): TGGGCTCTGCTCTGTCTTAGTGTA
The present invention also preferably encompasses any amplicon obtained through the use of any suitable primer pair; for example, for the above experiment, the following amplicon was obtained as a non- limiting illustrative example only of a suitable amplicon: PKPl -
amplicon (SEQ ID NO: 1600):
CCCCAGACTCTGTGCACTTCAGACCAGCAGCAGCAGGAGGGCTCCCGAGGGCCTTA TGAGAAAACCTGTGTGGACATCCCTTGGTGTACACTAAGACAGAGCAGAGCCCA
According to other preferred embodiments of the present invention, PKPl or a fragment thereof comprises a biomarker for detecting lung cancer. Optionally and more preferably, PKPl splice variants, as depicted in SEQ ID NO: 1601-1603 (e.g., variants no: 0, 5 and 6), or a fragment thereof comprise a biomarker for detecting lung cancer. Optionally and more preferably, the fragment of PKPl comprises segment_TAA seg 34-SEQ ID NO: 1608. Also optionally and more preferably, any suitable method may be used for detecting a fragment such as PKPl_segment_ TAA seg 34-SEQ ID NO: 1608 for example. Most preferably, NAT-based technology used, such as any nucleic acid molecule capable of specifically hybridizing with the fragment. Optionally and most preferably, a primer pair is used for obtaining the fragment.
According to other preferred embodiments of the present invention, PKPl splice variants containing the unique segment_8 as depicted in SEQ ID NO: 1607, for example variant 6, as depicted in SEQ ID NO: 1603, are suitable as biomarkers for detecting lung cancer.
According to still other preferred embodiments, the present invention optionally and preferably encompasses any amino acid sequence or fragment thereof encoded by a nucleic acid sequence corresponding to PKPl as described above, including but not limited to SEQ ID NOs:
1604-1606. Any oligopeptide or peptide relating to such an amino acid sequence or fragment thereof may optionally also (additionally or alternatively) be used as a biomarker.
The present invention also optionally encompasses antibodies capable of recognizing, and/or being elicited by, such oligopeptides or peptides.
The present invention also optionally and preferably encompasses any nucleic acid sequence or fragment thereof, or amino acid sequence or fragment thereof, corresponding to PKPl as described above, optionally for any application.
Combined expression of 12 sequences (SEQ ID NO: 1480, 1517, 1529, 1532, 1558, 1574, 1594, 1600, 1616, 1619, 1622, 1625) in normal and cancerous lung tissues.
Expression of several transcripts detectable by SEQ ID NOs: 1480, 1517, 1529, 1532, 1558, 1574, 1594, 1600, 1616, 1619, 1622, 1625 was measured by real time PCR (the expression of each SEQ ID was checked separately). In parallel the expression of four housekeeping genes - PBGD (GenBank Accession No. BC019323; amplicon - SEQ ID NO:1471), HPRTl (GenBank Accession No. NM_000194; amplicon - SEQ ID NO: 1468), Ubiquitin (GenBank Accession No. BC000449; amplicon - SEQ ID NO: 1474) and SDHA (GenBank Accession No. NM_004168; amplicon - SEQ ID NO: 1477), was measured similarly. For each RT sample, the expression of SEQ ID NOs: 1480, 1517, 1529, 1532, 1558, 1574, 1594, 1600, 1616, 1619, 1622, 1625 was normalized to the geometric mean of the quantities of the housekeeping genes. The noπnalized quantity of each RT sample was then divided by the median of the quantities of the normal postmortem (PM) samples (Sample Nos. 47-50, 90-93, 96-99, Table 2, "Tissue samples in testing panel", above), to obtain a value of fold up-regulation for each sample relative to median of the normal PM samples.
Figure 62 is a histogram showing over expression of the above- indicated transcripts in cancerous lung samples relative to the normal samples. The number and percentage of samples that exhibit at least 10 fold over- expression of at least one of the SEQ IDs, out of the total number of samples tested is indicated in the bottom.
As is evident from Figure 62, an over- expression of at least 10 fold in at least one of the SEQ IDs was found in 15 out of 15 adenocarcinoma samples, 15 out of 16 squamous cell carcinoma samples, 4 out of 4 large cell carcinoma samples, and in 8 out of 8 small-cell samples.
Statistical analysis was applied to verify the significance of these results, as described below. Threshold of 10 fold overexpression of at least one of the amplicons as depicted in SEQ ID NOs: 1480, 1517, 1529, 1532, 1558, 1574, 1594, 1600, 1616, 1619, 1622, 1625, was found to differentiate between cancer and normal samples with P value of 2.37E-08 as checked by exact fisher test.
The above values demonstrate statistical significance of the results.
Kits and Diagnostic Assays and Methods
The markers described with regard to any of Examples above can be used alone, in combination with other markers described above, and/or with other entirely different markers, including but not limited to UbcHlO (see US Patent Application Nos: 60/535,904 and 60/572,122; attorney refs: 27080 and 28045, filed on January 13 and May 19 2004, respectively), Troponin (see US Patent Application No: 60/539,129; attorney ref: 26940), Sim2 (see PCT Application No. WO 2004/012847), PE-10 (SP-A), TTF-I, Cytokeratin 5/6, to aid in the diagnosis of lung cancer. All of these applications are hereby incorporated by reference as if fully set forth herein. These markers can be used in combination with other markers for a number of uses, including but not limited to, progno sis, prediction, screening, early diagnosis, therapy selection and treatment monitoring of lung cancer, and also optionally including staging of the disease. Used together, they may provide more information for the diagnostician, increasing the percentage of true positive and true negative diagnoses and decreasing the percentage of false positive or false negative diagnoses, as compared to the results obtained with a single marker alone.
Assays and methods according to the present invention, as described above, include but are not limited to, immunoassays, hybridization assays and NAT-based assays. The combination of the markers of the present invention with other markers described above, and/or with other entirely different markers to aid in the diagnosis of lung cancer could be carried out as a mix of NAT-based assays, immunoassays and hybridization assays. According to preferred embodiments of the present invention, the assays are NAT-based assays, as described for example with regard to the Examples above. In yet another aspect, the present invention provides kits for aiding a diagnosis of lung cancer, wherein the kits can be used to detect the markers of the present invention. For example, the kits can be used to detect any one or combination of markers described above, which markers are differentially present in samples of a lung cancer patients and normal patients. The kits of the invention have many applications. For example, the kits can be used to differentiate if a subject has a small cell lung cancer, non-small cell lung cancer, adenocarcinoma, bronchoalveolar- alveolar, squamous cell or large cell carcinomas or has a negative diagnosis,
thus aiding a lung cancer diagnosis. In another example, the kits can be used to identify compounds that modulate expression of the markers in in vitro lung cells or in vivo animal models for lung cancer.
In one embodiment, a kit comprises: (a) a substrate comprising an adsorbent thereon, wherein the adsorbent is suitable for binding a marker, and (b) a washing solution or instructions for making a washing solution, wherein the combination of the adsorbent and the washing solution allows detection of the marker as previously described.
Optionally, the kit can further comprise instructions for suitable operational parameters in the form of a label or a separate insert. For example, the kit may have standard instructions informing a consumer/kit user how to wash the probe after a sample of seminal plasma or other tissue sample is contacted on the probe.
In another embodiment, a kit comprises (a) an antibody that specifically binds to a marker; and (b) a detection reagent. Such kits can be prepared from the materials described above. In either embodiment, the kit may optionally further comprise a standard or control information, and/or a control amount of material, so that the test sample can be compared with the control information standard and/or control amount to determine if the test amount of a marker detected in a sample is a diagnostic amount consistent with a diagnosis of lung cancer.
Therapeutic applications of splice variants of the present invention
Splice variants described herein (including any polynucleotide, oligonucleotide, polypeptide, peptide or fragments thereof) or antibodies that specifically bind thereto may optionally be used for therapeutic applications, for example to treat the diseases described herein with regard to diagnostic applications thereof. A "variant-treatable" disease refers to any disease that is treatable by using a splice variant of any of the therapeutic proteins according to the present invention. "Treatment" also encompasses prevention, amelioration, elimination and control of the disease and/or pathological condition. The diseases for which such variants may be useful therapeutic agents are described in greater detail below for each of the variants. The variants themselves are described by "cluster" or by gene, as these variants are splice variants of known proteins. Therefore, a "cluster-related disease" or a "variant-related disease" refers to a disease that
may be treated by a particular protein, with regard to the description of such diseases below a therapeutic protein variant according to the present invention.
The term "biologically active", as used herein, refers to a protein having structural, regulatory, or biochemical functions of a naturally occurring molecule. Likewise, "immunologically active" refers to the capability of the natural, recombinant, or synthetic ligand, or any oligopeptide thereof, to induce a specific immune response in appropriate animals or cells and to bind with specific antibodies.
The term "modulate", as used herein, refers to a change in the activity of at least one receptor mediated activity. For example, modulation may cause an increase or a decrease in protein activity, binding characteristics, or any other biological, functional or immunological properties of a ligand.
METHODS OF TREATMENT As mentioned hereinabove the novel therapeutic protein variants of the present invention and compositions derived therefrom (i.e., peptides, oligonucleotides) can be used to treat cluster- related diseases.
Thus, according to an additional aspect of the present invention mere is provided a method of treating cluster-related disease in a subject. The subject according to the present invention is a mammal, preferably a human which has at least one type of the cluster-related diseases described hereinabove.
As mentioned hereinabove, the biomolecular sequences of the present invention can be used to treat subjects with the above -described diseases.
The subject according to the present invention is a mammal, preferably a human which is diagnosed with one of the diseases described hereinabove, or alternatively is predisposed to having one of the diseases described hereinabove.
As used herein the term "treating" refers to preventing, curing, reversing, attenuating, alleviating, rrrinirrrizing, suppressing or halting the deleterious effects of the above-described diseases.
Treating, according to the present invention, can be effected by specifically upregulating or alternatively downregulating the expression of at least one of the polypeptides of the present invention in the subject.
Optionally, upregulation may be effected by administering to the subject at least one of the polypeptides of the present invention (e.g., recombinant or synthetic) or an active portion thereof, as described herein. However, since the bioavailability of large polypeptides may potentially be relatively small due to high degradation rate and low penetration rate, administration of polypeptides is preferably confined to small peptide fragments (e.g., about 100 amino acids). The polypeptide or peptide may optionally be administered in a pharmaceutical composition, described in more detail bebw.
It will be appreciated that treatment of the above-described diseases according to the present invention may be combined with other treatment methods known in the art (i.e., combination therapy). Thus, treatment of malignancies using the agents of the present invention may be combined with, for example, radiation therapy, antibody therapy and/or chemotherapy. Alternatively or additionally, an upregulating method may optionally be effected by specifically upregulating the amount (optionally expression) in the subject of at least one of the polypeptides of the present invention or active portions thereof.
As is mentioned hereinabove and in the Examples section which follows, the biomolecular sequences of this aspect of the present invention may be used as valuable therapeutic tools in the treatment of diseases in which altered activity or expression of the wild-type gene product is known to contribute to disease onset or progression. For example in case a disease is caused by overexpression of a membrane bound receptor, a soluble variant thereof may be used as an antagonist which competes with the receptor for binding the ligand, to thereby terminate signaling from the receptor. Examples of such diseases are listed in the Examples section which follows.
It will be appreciated that the polypeptides of the present invention may also have agonistic properties. These include increasing the stability of the ligand (e.g., IL-4), protection from proteolysis and modification of the pharmacokinetic properties of the ligand (i.e., increasing the half- life of the ligand, while decreasing the clearance thereof). As such, the biomolecular sequences of this aspect of the present invention may be used to treat conditions or diseases in
which the wild-type gene product plays a favorable role, for example, increasing angiogenesis in cases of diabetes or ischemia.
Upregulating expression of the therapeutic protein variants of the present invention may be effected via the administration of at least one of the exogenous polynucleotide sequences of the present invention, ligated into a nucleic acid expression construct designed for expression of coding sequences in eukaryotic cells (e.g., mammalian cells), as described above. Accordingly, the exogenous polynucleotide sequence may be a DNA or RNA sequence encoding the variants of the present invention or active portions thereof.
It will be appreciated that the nucleic acid construct can be administered to the individual employing any suitable mode of administration, described hereinbelow (i.e., in- vivo gene therapy). Alternatively, the nucleic acid construct is introduced into a suitable cell via an appropriate gene delivery vehicle/method (transfection, transduction, homologous recombination, etc.) and an expression system as needed and then the modified cells are expanded in culture and returned to the individual (i.e., ex- vivo gene therapy). Nucleic acid constructs are described in greater detail above.
It will be appreciated that the present methodology may also be effected by specifically upregulating the expression of the variants of the present invention endogenously in the subject. Agents for upregulating endogenous expression of specific splice variants of a given gene include antisense oligonucleotides, which are directed at splice sites of interest, thereby altering the splicing pattern of the gene. This approach has been successfully used for shifting the balance of expression of the two isoforms of Bcl-x [Taylor (1999) Nat. Biotechnol. 17:1097- 1100; and Mercatante (2001) J. Biol. Chem. 276:16411-16417]; IL- 5R [Karras (2000) MoI. Pharmacol. 58:380-387]; and c-myc [Giles (1999) Antisense Acid Drug Dev. 9:213-220].
For example, interleukin 5 and its receptor play a critical role as regulators of hematopoiesis and as mediators in some inflammatory diseases such as allergy and asthma. Two alternatively spliced isoforms are generated from the IL- 5R gene, which include (i.e., long form) or exclude (i.e., short form) exon 9. The long form encodes for the intact membrane-bound receptor, while the shorter form encodes for a secreted soluble non- functional receptor. Using 2'-0-MOE- oligonucleotides specific to regions of exon 9, Karras and co-workers (supra) were able to significantly decrease the expression of the wild type receptor and increase the expression of the shorter isoforms. Design and synthesis of oligonucleotides which can be used according to the
present invention are described hereinbelow and by Sazani and KoIe (2003) Progress in Moleclular and Subcellular Biology 31 :217-239.
Upregulating expression of the polypeptides of the present invention in a subject may be effected via the administration of at least one of the exogenous polynucleotide sequences of the present invention (e.g., SEQ ID NOs: 3, 7, 11 , 15 , 19, 23, 27, 31 , 35, 39 or 43) ligated into a nucleic acid expression construct designed for expression of coding sequences in eukaryotic cells (e.g., mammalian cells). Accordingly, the exogenous polynucleotide sequence may be a DNA or RNA sequence encoding the variants of the present invention or active portions thereof.
It will be appreciated that the nucleic acid construct can be administered to the individual employing any suitable mode of administration, described hereinbelow (i.e., in- vivo gene therapy). Alternatively, the nucleic acid construct is introduced into a suitable cell via an appropriate gene delivery vehicle/method (transfection, transduction, homologous recombination, etc.) and an expression system as needed and then the modified cells are expanded in culture and returned to the individual (i.e., ex- vivo gene therapy). Preferably, the promoter utilized by the nucleic acid construct of the present invention is active in the specific cell population transformed. Examples of cell type-specific and/or tissue- specific promoters include promoters, such as albumin that is liver specific [Pinkert et al., (1987) Genes Dev. 1:268-277], lymphoid specific promoters [Calame et al., (1988) Adv. Immunol. 43:235-275]; in particular promoters of T-cell receptors [Winoto et al., (1989) EMBO J. 8:729-733] and immunoglobulins; [Banerji et al. (1983) Cell 33729-740], neuron- specific promoters such as the neurofilament promoter [Byrne et al. (1989) Proc. Natl. Acad. Sci. USA 86:5473-5477], pancreas- specific promoters [Edlunch et al. (1985) Science 230:912-916] or mammary gland- specific promoters such as the milk whey promoter (U.S. Pat. No. 4,873,316 and European Patent Application No. EP 264,166). Examples of suitable constructs include, but are not limited to, pcDNA3, pcDNA3.1 (+/-), pGL3, PzeoSV2 (+/-), pDisplay, pEF/myc/cyto, pCMV/myc/cyto each of which is commercially available from Invitrogen Co. (www.invitrogen.com). Examples of retroviral vector and packaging systems are those sold by Clontech, San Diego, Calif, including Retro-X vectors pLNCX and pLXSN, which permit cloning into multiple cloning sites and the trasgene is transcribed from CMV promoter. Vectors derived from Mo-MuLV are also included such as pBabe, where the transgene will be transcribed from the 5'LTR promoter.
Currently preferred in vivo nucleic acid transfer techniques include transfection with viral or non- viral constructs, such as adenovirus, lentivirus, Herpes simplex I virus, or adeno- associated virus (AAV) and lipid-based systems. Useful lipids for lipid- mediated transfer of the gene are, for example, DOTMA, DOPE, and DC-Choi [Tonkinson et al., Cancer Investigation, 14(1): 54-65 (1996)]. The most preferred constructs for use in gene therapy are viruses, most preferably adenoviruses, AAV, lentiviruses, or retroviruses. A viral construct such as a retroviral construct includes at least one transcriptional promoter/enhancer or locus -defining element(s), or other elements that control gene expression by other means such as alternate splicing, nuclear RNA export, or post-translational modification of messenger. Such vector constructs also include a packaging signal, long terminal repeats (LTRs) or portions thereof, and positive and negative strand primer binding sites appropriate to the virus used, unless it is already present in the viral construct. In addition, such a construct typically includes a signal sequence for secretion of the peptide from a host cell in which it is placed. Preferably the signal sequence for this purpose is a mammalian signal sequence or the signal sequence of the polypeptide variants of the present invention. Optionally, the construct may also include a signal that directs polyadenylation, as well as one or more restriction sites and a translation termination sequence. By way of example, such constructs will typically include a 5' LTR, a tRNA binding site, a packaging signal, an origin of second-strand DNA synthesis, and a 31 LTR or a portion thereof. Other vectors can be used that are non- viral, such as cationic lipids, polylysine, and dendrimers. It will be appreciated that the present methodology may also be performed by specifically upregulating the expression of the splice variants of the present invention endogenously in the subject. Agents for upregulating endogenous expression of specific splice variants of a given gene include antisense oligonucleotides, which are directed at splice sites of interest, thereby altering the splicing pattern of the gene. This approach has been successfully used for shifting the balance of expression of the two isoforms of Bcl-x [Taylor (1999) Nat. Biotechnol. 17:1097-1100; and Mercatante (2001) J. Biol. Chem. 276:16411-16417]; IL-5R [Karras (2000) MoI. Pharmacol. 58:380-387]; and c-myc [Giles (1999) Antisense Acid Drug Dev. 9:213-220].
For example, interleukin 5 and its receptor play a critical role as regulators of hematopoiesis and as mediators in some inflammatory diseases such as allergy and asthma. Two alternatively spliced isoforms are generated from the IL- 5R gene, which include (i.e., long form) or exclude (i.e., short form) exon 9. The long form encodes for the intact membrane-bound receptor, while the
shorter form encodes for a secreted soluble non- functional receptor. Using 2'-0-MOE- oligonucleotides specific to regions of exon 9, Karras and co-workers (supra) were able to significantly decrease the expression of the wild type receptor and increase the expression of the shorter isoforms. Design and synthesis of oligonucleotides which can be used according to the present invention are described hereinbelow and by Sazani and KoIe (2003) Progress in Moleclular and Subcellular Biology 31:217-239.
Treatment can preferably effected by agents which are capable of specifically downregulating expression (or activity) of at least one of the polypeptide variants of the present invention. Down regulating the expression of the therapeutic protein variants of the present invention may be achieved using oligonucleotide agents such as those described in greater detail below. SiKNA molecules - Small interfering KNA (siKNA) molecules can be used to down- regulate expression of the therapeutic protein variants of the present invention. RNA interference is a two-step process. The first step, which is termed as the initiation step, input dsRNA is digested into 21-23 nucleotide (nt) small interfering RNAs (siKNA), probably by the action of Dicer, a member of the RNase III family of dsRNA- specific ribonucleases, which processes (cleaves) dsRNA (introduced directly or via a transgene or a virus) in an ATP -dependent manner. Successive cleavage events degrade the RNA to 19-21 bp duplexes (siRNA), each with 2- nucleotide 3' overhangs [Hutvagner and Zamore Curr. Opin. Genetics and Development 12:225- 232 (2002); and Bernstein Nature 409:363-366 (2001)].
In the effector step, the siKNA duplexes bind to a nuclease complex to from the RNA- induced silencing complex (RISC). An ATP-dependent unwinding of the siRNA duplex is required for activation of the RISC. The active RISC then targets the homologous transcript by base pairing interactions and cleaves the mRNA into 12 nucleotide fragments from the 3' terminus of the siRNA [Hutvagner and Zamore Curr. Opin. Genetics and Development 12:225-232 (2002); Hammond et al. (2001) Nat. Rev. Gen. 2:110-119 (2001); and Sharp Genes. Dev. 15:485-90 (2001)]. Although the mechanism of cleavage is still to be elucidated, research indicates that each RISC contains a single siRNA and an RNase [Hutvagner and Zamore Curr. Opin. Genetics and Development 12:225-232 (2002)]. Because of the remarkable potency of RNAi, an amplification step within the RNAi pathway has been suggested. Amplification could occur by copying of the input dsRNAs which
would generate more siRNAs, or by replication of the siRNAs formed. Alternatively or additionally, amplification could be effected by multiple turnover events of the RISC [Hammond et al. Nat. Rev. Gen. 2:110-119 (2001), Sharp Genes. Dev. 15:485-90 (2001); Hutvagner and Zamore Curr. Opin. Genetics and Development 12:225-232 (2002)]. For more information on RNAi see the following reviews Tuschl ChemBiochem. 2:239-245 (2001); Cullen Nat. Immunol. 3:597-599 (2002); and Brantl Biochem. Biophys. Act. 1575:15-25 (2002).
Synthesis of RNAi molecules suitable for use with the present invention can be effected as follows. First, the mRNA sequence is scanned downstream of the AUG start codon for AA dinucleotide sequences. Occurrence of each AA and the 3' adjacent 19 nucleotides is recorded as potential siRNA target sites. Preferably, siRNA target sites are selected from the open reading frame, as untranslated regions (UTRs) are richer in regulatory protein binding sites. UTR-binding proteins and/or translation initiation complexes may interfere with binding of the siRNA endonuclease complex [Tuschl ChemBiochem. 2:239-245]. It will be appreciated though, that siRNAs directed at untranslated regions may also be effective, as demonstrated for GAPDH wherein siRNA directed at the 5 ' UTR mediated about 90 % decrease in cellular GAPDH mRNA and completely abolished protein level (www.ambion.com/techlib/tn/91/912.html).
Second, potential target sites are compared to an appropriate genomic database (e.g., human, mouse, rat etc.) using any sequence alignment software, such as the BLAST software available from the NCBI server (www.ncbi.nlm.nih.gov/BLAST/). Putative target sites which exhibit significant homology to other coding sequences are filtered out.
Qualifying target sequences are selected as template for siRNA synthesis. Preferred sequences are those including low G/C content as these have proven to be more effective in mediating gene silencing as compared to those with G/C content higher than 55 %. Several target sites are preferably selected along the length of the target gene for evaluation. Target sites are selected from the unique nucleotide sequences of each of the polynucleotides of the present invention, such that each polynucleotide is specifically down regulated. For better evaluation of the selected siRNAs, a negative control is preferably used in conjunction. Negative control siRNA preferably include the same nucleotide composition as the siRNAs but lack significant homology to the genome. Thus, a scrambled nucleotide sequence of the siRNA is preferably used, provided it does not display any significant homology to any other gene.
DNAzyme molecules - Another agent capable of downregulating expression of the polypeptides of the present invention is a DNAzyme molecule capable of specifically cleaving an mRNA transcript or DNA sequence of the polynucleotides of the present invention. DNAzymes are single- stranded polynucleotides which are capable of cleaving both single and double stranded target sequences (Breaker, R.R. and Joyce, G. Chemistry and Biology 1995;2:655; Santoro, S.W. & Joyce, G.F. Proc. Natl, Acad. Sci. USA 1997;943:4262) A general model (the "10-23" model) for the DNAzyme has been proposed. "10-23" DNAzymes have a catalytic domain of 15 deoxyribonucleotides, flanked by two substrate- recognition domains of seven to nine deoxyribonucleotides each. This type of DNAzyme can effectively cleave its substrate RNA at ρurine:pyrimidine junctions (Santoro, S.W. & Joyce, G.F. Proc. Natl, Acad. Sci. USA 199; for rev of DNAzymes see Khachigian, LM [Curr Opin MoI Ther 4:119-21 (2002)].
Target sites for DNAzymes are selected from the unique nucleotide sequences of each of the polynucleotides of the present invention, such that each polynucleotide is specifically down regulated. Examples of construction and amplification of synthetic, engineered DNAzymes recognizing single and double -stranded target cleavage sites have been disclosed in U.S. Pat. No. 6,326,174 to Joyce et al. DNAzymes of similar design directed against the human Urokinase receptor were recently observed to inhibit Urokinase receptor expression, and successfully inhibit colon cancer cell metastasis in vivo (Itoh et al , 20002, Abstract 409, Ann Meeting Am Soc Gen Ther www.asgt.org). In another application, DNAzymes complementary to bcr-abl oncogenes were successful in inhibiting the oncogenes expression in leukemia cells, and lessening relapse rates in autologous bone marrow transplant in cases of CML and ALL.
Antisense molecules - Downregulation of the polynucleotides of the present invention can also be effected by using an antisense polynucleotide capable of specifically hybridizing with an mRNA transcript encoding the polypeptide variants of the present invention.
The term "antisense", as used herein, refers to any composition containing nucleotide sequences, which are complementary to a specific DNA or RNA sequence.
The term "antisense strand" is used in reference to a nucleic acid strand that is complementary to the "sense" strand. Antisense molecules also include peptide nucleic acids and may be produced by any method including synthesis or transcription. Once introduced into a cell, the complementary nucleotides combine with natural sequences produced by the cell to form
duplexes and block either transcription or translation. The designation "negative" is sometimes used in reference to the antisense strand, and "positive" is sometimes used in reference to the sense strand. Antisense oligonucleotides are also used for modulation of alternative splicing in vivo and for diagnostics in vivo and in vitro (Khelifi C. et al., 2002, Current Pharmaceutical Design 8:451- 1466; Sazani, P., and KoIe. R. Progress in Molecular and Cellular Biology, 2003, 31:217-239).
Design of antisense molecules which can be used to efficiently downregulate expression of the polypeptides of the present invention must be effected while considering two aspects important to the antisense approach. The first aspect is delivery of the oligonucleotide into the cytoplasm of the appropriate cells, while the second aspect is design of an oligonucleotide which specifically binds the designated mRNA within cells in a way which inhibits translation thereof.
The prior art teaches of a number of delivery strategies which can be used to efficiently deliver oligonucleotides into a wide variety of cell types [see, for example, Luft J MoI Med 76: 75- 6 (1998); Kronenwett et al. Blood 91: 852-62 (1998); Rajur et al. Bioconjug Chem 8: 935-40 (1997); Lavigne et al. Biochem Biophys Res Commun 237: 566-71 (1997) and Aoki et al. (1997) Biochem Biophys Res Commun 231: 540-5 (1997)].
In addition, algorithms for identifying those sequences with the highest predicted binding affinity for their target mRNA based on a thermodynamic cycle that accounts for the energetics of structural alterations in both the target mRNA and the oligonucleotide are also available [see, for example, Walton et al. Biotechnol Bioeng 65: 1-9 (1999)].
Such algorithms have been successfully used to implement an antisense approach in cells. For example, the algorithm developed by Walton et al. enabled scientists to successfully design antisense oligonucleotides for rabbit beta-globin (RBG) and mouse tumor necrosis factor- alpha (TNF alpha) transcripts. The same research group has more recently reported that the antisense activity of rationally selected oligonucleotides against three model target mRNAs (human lactate dehydrogenase A and B and rat gρl30) in cell culture as evaluated by a kinetic PCR technique proved effective in almost all cases, including tests against three different targets in two cell types with phosphodiester and phosphorothioate oligonucleotide chemistries.
In addition, several approaches for designing and predicting efficiency of specific oligonucleotides using an in vitro system were also published (Matveeva et al., Nature Biotechnology 16: 1374 - 1375 (1998)].
Several clinical trials have demonstrated safety, feasibility and activity of antisense oligonucleotides. For example, antisense oligonucleotides suitable for the treatment of cancer have been successfully used [Holmund et al., Curr Opin MoI Ther 1:372-85 (1999)], while treatment of hematological malignancies via antisense oligonucleotides targeting c-myb gene, p53 and Bcl-2 had entered clinical trials and had been shown to be tolerated by patients [Gerwitz Curr Opin MoI Ther 1:297-306 (1999)].
More recently, antisense-mediated suppression of human heparanase gene expression has been reported to inhibit pleural dissemination of human cancer cells in a mouse model [Uno et al., Cancer Res 61:7855-60 (2001)]. Thus, the current consensus is that recent developments in the field of antisense technology which, as described above, have led to the generation of highly accurate antisense design algorithms and a wide variety of oligonucleotide delivery systems, enable an ordinarily skilled artisan to design and implement antisense approaches suitable for downregulating expression of known sequences without having to resort to undue trial and error experimentation. Target sites for antisense molecules are selected from the unique nucleotide sequences of each of the polynucleotides of the present invention, such that each polynucleotide is specifically down regulated.
Ribozymes - Another agent capable of downregulating expression of the polypeptides of the present invention is a ribozyme molecule capable of specifically cleaving an mRNA transcript encoding the polypeptide variants of the present invention. Ribθ2ymes are being increasingly used for the sequence- specific inhibition of gene expression by the cleavage of mRNAs encoding proteins of interest [Welch et al., Curr Opin Biotechnol. 9:486-96 (1998)]. The possibility of designing ribozymes to cleave any specific target RNA has rendered them valuable tools in both basic research and therapeutic applications. In therapeutics area, ribozymes have been exploited to target viral RNAs in infectious diseases, dominant oncogenes in cancers and specific somatic mutations in genetic disorders [Welch et al., Clin Diagn Virol. 10:163-71 (1998)]. Most notably, several ribozyme gene therapy protocols for HIV patients are already in Phase 1 trials. More recently, ribozymes have been used for transgenic animal research, gene target validation and pathway elucidation. Several ribozymes are in various stages of clinical trials. ANGIOZYME was the first chemically synthesized ribozyme to be studied in human clinical trials. ANGIOZYME specifically inhibits formation of the VEGF -r (Vascular Endothelial Growth Factor receptor), a key
component in the angiogenesis pathway. Ribozyme Pharmaceuticals, Inc., as well as other firms have demonstrated the importance of anti- angiogenesis therapeutics in animal models. HEPTAZYME, a ribozyme designed to selectively destroy Hepatitis C Virus (HCV) RNA, was found effective in decreasing Hepatitis C viral RNA in cell culture assays (Ribozyme Pharmaceuticals, Incorporated - WEB home page).
Alternatively, down regulation of the polypeptide variants of the present invention may be achieved at the polypeptide level using downregulating agents such as antibodies or antibody fragments capabale of specifically binding the polypeptides of the present invention and inhibiting the activity thereof (i.e., neutralizing antibodies). Such antibodies can be directed for example, to the heterodimerizing domain on the variant, or to a putative ligand binding domain. Further description of antibodies and methods of generating same is provided below.
PHARMACEUTICAL COMPOSITIONS AND DELIVERY THEREOF The present invention features a pharmaceutical composition comprising a therapeutically effective amount of a therapeutic agent according to the present invention, which is preferably a therapeutic protein variant as described herein. Optionally and alternatively, the therapeutic agent could be an antibody or an oligonucleotide that specifically recognizes and binds to the therapeutic protein variant, but not to the corresponding full length known protein.
Alternatively, the pharmaceutical composition of the present invention includes a therapeutically effective amount of at least an active portion of a therapeutic protein variant polypeptide.
The pharmaceutical composition according to the present invention is preferably used for the treatment of cluster-related diseases.
"Treatment" refers to both therapeutic treatment and prophylactic or preventative measures. Those in need of treatment include those already with the disorder as well as those in which the disorder is to be prevented. Hence, the mammal to be treated herein may have been diagnosed as having the disorder or may be predisposed or susceptible to the disorder. "Mammal" for purposes of treatment refers to any animal classified as a mammal, including humans, domestic and farm animals, and zoo, sports, or pet animals, such as dogs, horses, cats, cows, etc. Preferably, the mammal is human.
A "disorder" is any condition that would benefit from treatment with the agent according to the present invention. This includes chronic and acute disorders or diseases including those pathological conditions which predispose the mammal to the disorder in question. Non- limiting examples of disorders to be treated herein are described with regard to specific examples given herein.
The term "therapeutically effective amount" refers to an amount of agent according to the present invention that is effective to treat a disease or disorder in a mammal. In the case of cancer, the therapeutically effective amount of the agent may reduce the number of cancer cells; reduce the tumor size; inhibit (i.e., slow to some extent and preferably stop) cancer cell infiltration into peripheral organs; inhibit (i.e., slow to some extent and preferably stop) tumor metastasis; inhibit, to some extent, tumor growth; and/or relieve to some extent one or more of the symptoms associated with the cancer. To the extent the agent may prevent growth and/or kill existing cancer cells, it may be cytostatic and/or cytotoxic. For cancer therapy, efficacy can, for example, be measured by assessing the time to disease progression (TTP) and/or determining the response rate (RR).
The therapeutic agents of the present invention can be provided to the subject per se, or as part of a pharmaceutical composition where they are mixed with a pharmaceutically acceptable carrier.
As used herein a "pharmaceutical composition" refers to a preparation of one or more of the active ingredients described herein with other chemical components such as physiologically suitable carriers and excipients. The purpose of a pharmaceutical composition is to facilitate administration of a compound to an organism.
Herein the term "active ingredient" refers to the preparation accountable for the biological effect. Hereinafter, the phrases "physiologically acceptable carrier" and "pharmaceutically acceptable carrier" which may be interchangeably used refer to a carrier or a diluent that does not cause significant irritation to an organism and does not abrogate the biological activity and properties of the administered compound. An adjuvant is included under these phrases. One of the ingredients included in the pharmaceutically acceptable carrier can be for example polyethylene glycol (PEG), a biocompatible polymer with a wide range of solubility in both organic and aqueous media (Mutter et al. (1979).
Herein the term "excipient" refers to an inert substance added to a pharmaceutical composition to further facilitate administration of an active ingredient. Examples, without limitation, of excipients include calcium carbonate, calcium phosphate, various sugars and types of starch, cellulose derivatives, gelatin, vegetable oils and polyethylene glycols. Techniques for formulation and administration of drugs may be found in "Remington's
Pharmaceutical Sciences," Mack Publishing Co., Easton, PA, latest edition, which is incorporated herein by reference.
Suitable routes of administration may, for example, include oral, rectal, transmucosal, especially transnasal, intestinal or parenteral delivery, including intramuscular, subcutaneous and intramedullary injections as well as intrathecal, direct intraventricular, intravenous, intraperitoneal, intranasal, or intraocular injections. Alternately, one may administer a preparation in a local rather than systemic manner, for example, via injection of the preparation directly into a specific region of a patient's body.
Pharmaceutical compositions of the present invention may be manufactured by processes well known in the art, e.g., by means of conventional mixing, dissolving, granulating, dragee- making, levigating, emulsifying, encapsulating, entrapping or lyophilizing processes.
Pharmaceutical compositions for use in accordance with the present invention may be formulated in conventional manner using one or more physiologically acceptable carriers comprising excipients and auxiliaries, which facilitate processing of the active ingredients into preparations which, can be used pharmaceutically. Proper formulation is dependent upon the route of administration chosen.
For injection, the active ingredients of the invention may be formulated in aqueous solutions, preferably in physiologically compatible buffers such as Hank's solution, Ringer's solution, or physiological salt buffer. For transmucosal administration, penetrants appropriate to the barrier to be permeated are used in the formulation. Such penetrants are generally known in the art.
For oral administration, the compounds can be formulated readily by combining the active compounds with pharmaceutically acceptable carriers well known in the art. Such carriers enable the compounds of the invention to be formulated as tablets, pills, dragees, capsules, liquids, gels, syrups, slurries, suspensions, and the like, for oral ingestion by a patient. Pharmacological preparations for oral use can be made using a solid excipient, optionally grinding the resulting
mixture, and processing the mixture of granules, after adding suitable auxiliaries if desired, to obtain tablets or dragee cores. Suitable excipients are, in particular, fillers such as sugars, including lactose, sucrose, mannitol, or sorbitol; cellulose preparations such as, for example, maize starch, wheat starch, rice starch, potato starch, gelatin, gum tragacanth, methyl cellulose, hydroxypropylmethyl- cellulose, sodium carbomethylcellulose; and/or physiologically acceptable polymers such as polyvinylpyrrolidone (PVP). If desired, disintegrating agents may be added, such as cross- linked polyvinyl pyrrolidone, agar, or alginic acid or a salt thereof such as sodium alginate.
Dragee cores are provided with suitable coatings. For this purpose, concentrated sugar solutions may be used which may optionally contain gum arabic, talc, polyvinyl pyrrolidone, carbopol gel, polyethylene glycol, titanium dioxide, lacquer solutions and suitable organic solvents or solvent mixtures. Dyestuffs or pigments may be added to the tablets or dragee coatings for identification or to characterize different combinations of active compound doses.
Pharmaceutical compositions, which can be used orally, include push- fit capsules made of gelatin as well as soft, sealed capsules made of gelatin and a plasticizer, suchsas glycerol or sorbitol. The push- fit capsules may contain the active ingredients in admixture with filler such as lactose, binders such as starches, lubricants such as talc or magnesium stearate and, optionally, stabilizers. In soft capsules, the active ingredients may be dissolved or suspended in suitable liquids, such as fatty oils, liquid paraffin, or liquid polyethylene glycols. In addition, stabilizers may be added. All formulations for oral administration should be in dosages suitable for the chosen route of administration.
For buccal administration, the compositions may take the form of tablets or lozenges formulated in conventional manner.
For administration by nasal inhalation, the active ingredients for use according to the present invention are conveniently delivered in the form of an aerosol spray presentation from a pressurized pack or a nebulizer with the use of a suitable propellant, e.g., dichlorodifluoromethane, trichlorofluoromethane, dichloro-tetrafluoroethane or carbon dioxide. In the case of a pressurized aerosol, the dosage unit may be determined by providing a valve to deliver a metered amount. Capsules and cartridges of, e.g., gelatin for use in a dispenser may be formulated containing a powder mix of the compound and a suitable powder base such as lactose or starch. The preparations described herein may be formulated for parenteral administration, e.g., by bolus injection or continuous infusion. Formulations for injection may be presented in unit dosage
form, e.g., in ampoules or in multidose containers with optionally, an added preservative. The compositions may be suspensions, solutions or emulsions in oily or aqueous vehicles, and may contain formulatory agents such as suspending, stabilizing and/or dispersing agents.
Pharmaceutical compositions for parenteral administration include aqueous solutions of the active preparation in water-soluble form. Additionally, suspensions of the active ingredients may be prepared as appropriate oily or water based injection suspensions. Suitable lipophilic solvents or vehicles include fatty oils such as sesame oil, or synthetic fatty acids esters such as ethyl oleate, triglycerides or liposomes. Aqueous injection suspensions may contain substances, which increase the viscosity of the suspension, such as sodium carboxymethyl cellulose, sorbitol or dextran. Optionally, the suspension may also contain suitable stabilizers or agents which increase the solubility of the active ingredients to allow for the preparation of highly concentrated solutions.
Alternatively, the active ingredient may be in powder form for constitution with a suitable vehicle, e.g., sterile, pyrogen- free water based solution, before use.
The preparation of the present invention may also be formulated in rectal compositions such as suppositories or retention enemas, using, e.g., conventional suppository bases such as cocoa butter or other glycerides.
Pharmaceutical compositions suitable for use in context of the present invention include compositions wherein the active ingredients are contained in an amount effective to achieve the intended purpose. More specifically, a therapeutically effective amount means an amount of active ingredients effective to prevent, alleviate or ameliorate symptoms of disease or prolong the survival of the subject being treated.
Determination of a therapeutically effective amount is well within the capability of those skilled in the art.
For any preparation used in the methods of the invention, the therapeutically effective amount or dose can be estimated initially from in vitro assays. For example, a dose can be formulated in animal models and such information can be used to more accurately determine useful doses in humans.
Toxicity and therapeutic efficacy of the active ingredients described herein can be determined by standard pharmaceutical procedures in vitro, in cell cultures or experimental animals. The data obtained from these in vitro and cell culture assays and animal studies can be used in formulating a range of dosage for use in human. The dosage may vary depending upon the
dosage form employed and the route of administration utilized. The exact formulation, route of administration and dosage can be chosen by the individual physician in view of the patient's condition. (See e.g., Fingl, et al., 1975, in "The Pharmacological Basis of Therapeutics", Ch. 1 p.l).
Depending on the severity and responsiveness of the condition to be treated, dosing can be of a single or a plurality of administrations, with course of treatment lasting from several days to several weeks or until cure is effected or diminution of the disease state is achieved.
The amount of a composition to be administered will, of course, be dependent on the subject being treated, the severity of the affliction, the manner of administration, the judgment of the prescribing physician, etc. Compositions including the preparation of the present invention formulated in a compatible pharmaceutical carrier may also be prepared, placed in an appropriate container, and labeled for treatment of an indicated condition.
Pharmaceutical compositions of the present invention may, if desired, be presented in a pack or dispenser device, such as an FDA approved kit, which may contain one or more unit dosage forms containing the active ingredient. The pack may, for example, comprise metal or plastic foil, such as a blister pack. The pack or dispenser device may be accompanied by instructions for administration. The pack or dispenser may also be accommodated by a notice associated with the container in a form prescribed by a governmental agency regulating the manufacture, use or sale of pharmaceuticals, which notice is reflective of approval by the agency of the form of the compositions or human or veterinary administration. Such notice, for example, may be of labeling approved by the U.S. Food and Drug Administration for prescription drugs or of an approved product insert.
IMMUNOGENIC COMPOSITIONS A therapeutic agent according to the present invention may optionally be a molecule, which promotes a specific immunogenic response against at least one of the polypeptides of the present invention in the subject. The molecule can be polypeptide variants of the present invention, a fragment derived therefrom or a nucleic acid sequence encoding thereof. Although such a molecule can be provided to the subject per se, the agent is preferably administered with an immunostimulant in an immunogenic composiiton. An immunostimulant may be any substance that enhances or potentiates an immune response (antibody and/or cell- mediated) to an exogenous
antigen. Examples of immunostimulants include adjuvants, biodegradable microspheres (e.g., polylactic galactide) and liposomes into which the compound is incorporated (see e.g., U.S. Pat. No. 4,235,877). Vaccine preparation is generally described in, for example, M. F. Powell and M. J. Newman, eds., "Vaccine Design (the subunit and adjuvant approach)," Plenum Press (NY, 1995). Illustrative immunogenic compositions may contain DNA encoding one or more of the polypeptides as described above, such that the polypeptide is generated in situ. The DNA may be present within any of a variety of delivery systems known to those of ordinary skill in the art, including nucleic acid expression systems (see below), bacteria and viral expression systems. Numerous gene delivery techniques are well known in the art, such as those described by Rolland, Crit. Rev. Therap. Drug Carrier Systems 15:143-198, 1998, and references cited therein.
Appropriate nucleic acid expression systems contain the necessary DNA sequences for expression in the subject (such as a suitable promoter and terminating signal). Bacterial delivery systems involve the administration of a bacterium (such as Bacillus-Cahnette-Guerrin) that expresses an immunogenic portion of the polypeptide on its cell surface or secretes such an epitope. In a preferred embodiment, the DNA may be introduced using a viral expression system (e.g., vaccinia or other pox virus, retrovirus, or adenovirus), which may involve the use of a non-pathogenic (defective), replication competent virus. Suitable systems are disclosed, for example, in Fisher- Hoch et al., Proc. Natl. Acad. Sci. USA 86:317-321, 1989; Flexner et al., Ann. N.Y Acad. ScL 569:86-103, 1989; Flexner et al., Vaccine 8:17-21, 1990; U.S. Pat. Nos. 4,603,112, 4,769,330, and 5,017,487; WO 89/01973; U.S. Pat. No. 4,777,127; GB 2,200,651; EP 0,345,242; WO 91/02805; Berkner, Biotechniques 6:616-627, 1988; Rosenfeld et al., Science 252:431-434, 1991; KoMs et al., Proc. Natl. Acad. Sci. USA 91:215-219, 1994; Kass-Eisler et al., Proc. Natl. Acad. Sci. USA 90:11498-11502, 1993; Guzman et al., Circulation 88:2838-2848, 1993; and Guzman et al., Cir. Res. 73:1202-1207, 1993. Techniques for incorporating DNA into such expression systems are well known to those of ordinary skill in the art. The DNA may also be "naked," as described, for example, in Ulmer et al., Science 259:1745-1749, 1993 and reviewed by Cohen, Science 259:1691- 1692, 1993. The uptake of naked DNA may be increased by coating the DNA onto biodegradable beads, which are efficiently transported into the cells.
It will be appreciated that an immunogenic composition may comprise both a polynucleotide and a polypeptide component. Such immunogenic compositions may provide for an enhanced immune response.
Any of a variety of immunostimulants may be employed in the immunogenic compositions of this invention. For example, an adjuvant may be included. Most adjuvants contain a substance designed to protect the antigen from rapid catabolism, such as aluminum hydroxide or mineral oil, and a stimulator of immune responses, such as lipid A, Bortadella pertussis or Mycobacterium tuberculosis derived proteins. Suitable adjuvants are commercially available as, for example,
Freund's Incomplete Adjuvant and Complete Adjuvant (Difco Laboratories, Detroit, Mich.); Merck Adjuvant 65 (Merck and Company, Inc., Rahway, NJ.); AS-2 (SmithKline Beecham, Philadelphia, Pa.); aluminum salts such as aluminum hydroxide gel (alum) or aluminum phosphate; salts of calcium, iron or zinc; an insoluble suspension of acylated tyrosine; acylated sugars; cationically or anionically derivatized polysaccharides; polyphosphazenes; biodegradable microspheres; monophosphoryl lipid A and quil A. Cytokines, such as GM-CSF or interleukin-2,-7, or - 12, may also be used as adjuvants.
The adjuvant composition may be designed to induce an immune response predominantly of the ThI type. High levels of ThI -type cytokines (e.g., IFN- .gamma., TNF.alpha., IL-2 and IL- 12) tend to favor the induction of cell mediated immune responses to an administered antigen. In contrast, high levels of Th2-type cytokines (e.g., IL-4, IL-5, IL-6 and EL-IO) tend to favor the induction of humoral immune responses. Following application of an immunogenic composition as provided herein, the subject will support an immune response that includes ThI - and Th2-type responses. The levels of these cytokines may be readily assessed using standard assays. For a review of the families of cytokines, see Mosmann and Coffinan, Ann. Rev. Immunol. 7:145-173, 1989.
Preferred adjuvants for use in eliciting a predominantly ThI -type response include, for example, a combination of monophosphoryl lipid A, preferably 3- de- O- acylated monophosphoryl lipid A (3D-MPL), together with an aluminum salt. MPL adjuvants are available from Corixa Corporation (Seattle, Wash.; see U.S. Pat. Nos. 4,436,727; 4,877,611; 4,866,034 and 4,912,094). CpG-containing oligonucleotides (in which the CpG dinucleotide is unmethylated) also induce a predominantly ThI response. Such oligonucleotides are well known and are described, for example, in WO 96/02555, WO 99/33488 and U.S. Pat. Nos. 6,008,200 and 5,856,462. Immunostimulatory DNA sequences are also described, for example, by Sato et al., Science 273:352, 1996. Another preferred adjuvant is a saponin, preferably QS21 (Aquila Biopharmaceuticals Inc., Framingham, Mass.), which may be used alone or in combination with other adjuvants. For example, an
enhanced system involves the combination of a monophosphoryl lipid A and saponin derivative, such as the combination of QS21 and 3D-MPL as described in WO 94/00153, or a less reactogenic composition where the QS21 is quenched with cholesterol, as described in WO 96/33739. Other preferred foπnulations comprise an oil- in- water emulsion and tocopherol. A particularly potent adjuvant formulation involving QS21, 3D-MPL and tocopherol in an oil- in- water emulsion is described in WO 95/17210.
Other preferred adjuvants include Montanide ISA 720 (Seppic, France), SAF (Chiron, Calif, United States), ISCOMS (CSL), MF-59 (Chiron), the SBAS series of adjuvants (e.g., SBAS-2 or SBAS-4, available from SmithKline Beecham, Rixensart, Belgium), Detox (Corixa, Hamilton, Mont.), RC -529 (Corixa, Hamilton, Mont.) and other aminoalkyl glucosaminide 4- phosphates (AGPs), such as those described in pending U.S. patent application Ser. Nos. 08/853,826 and 09/074,720.
A delivery vehicle may be employed within the immunogenic composition of the present invention to facilitate production of an antigen- specific immune response that targets tumor cells. Delivery vehicles include antigen presenting cells (APCs), such as dendritic cells, macrophages, B cells, monocytes and other cells that may be engineered to be efficient APCs. Such cells may be genetically modified to increase the capacity for presenting the antigen, to improve activation and/or maintenance of the T cell response, to have anti- tumor effects per se and/or to be immunologically compatible with the receiver (i.e., matched HLA haplotype). APCs may generally be isolated from any of a variety of biological fluids and organs, including tumor and peritumoral tissues, and may be autologous, allogeneic, syngeneic or xenogeneic cells.
Dendritic cells are highly potent APCs (Banchereau and Steinman, Nature 392:245-251, 1998) and have been shown to be effective as a physiological adjuvant for eliciting prophylactic or therapeutic antitumor immunity (see Timmernan and Levy, Ann. Rev. Med. 50:507-529, 1999). In general, dendritic cells may be identified based on their typical shape (stellate in situ, with marked cytoplasmic processes (dendrites) visible in vitro), their ability to take up, process and present antigens with high efficiency and their ability to activate naive T cell responses. Dendritic cells may, of course, be engineered to express specific cell- surface receptors or ligands that are not commonly found on dendritic cells in vivo or ex vivo, and such modified dendritic cells are contemplated by the present invention. As an alternative to dendritic cells, secreted vesicles
antigen- loaded dendritic cells (called exosomes) may be used within an immunogenic composition (see Zitvogel et al, Nature Med. 4:594-600, 1998).
Dendritic cells and progenitors may be obtained from peripheral blood, bone marrow, tumor- infiltrating cells, peritumoral tissues- infiltrating cells, lymph nodes, spleen, skin, umbilical cord blood or any other suitable tissue or fluid. For example, dendritic cells may be differentiated ex vivo by adding a combination of cytokines such as GM-CSF, IL-4, IL- 13 and/or TNF.alpha. to cultures of monocytes harvested from peripheral blood. Alternatively, CD34 positive cells harvested from peripheral blood, umbilical cord blood or bone marrow may be differentiated into dendritic cells by adding to the culture medium combinations of GM-CSF, IL-3, TNF.alpha., CD40 ligand, LPS, fit3 ligand and/or other compound(s) that induce differentiation, maturation and proliferation of dendritic cells.
Dendritic cells are categorized as "immature" and "mature" cells, which allows a simple way to discriminate between two well characterized phenotypes. Immature dendritic cells are characterized as APC with a high capacity for antigen uptake and processing, which correlates with the high expression of Fey receptor and mannose receptor. The mature phenotype is typically characterized by a lower expression of these markers, but a high expression of cell surface molecules responsible for T cell activation such as class I and class II MHC, adhesion molecules (e.g., CD54 and CDIl) and costimulatory molecules (e.g., CD40, CD80, CD86 and 4- IBB).
APCs may generally be transfected with at least one polynucleotide encoding a polypeptide of the present invention, such that variant II, or an immunogenic portion thereof, is expressed on the cell surface. Such transfection may take place ex vivo, and a composition comprising such transfected cells may then be used for therapeutic purposes, as described herein. Alternatively, a gene delivery vehicle that targets a dendritic or other antigen presenting cell may be administered to the subject, resulting in transfection that occurs in vivo. In vivo and ex vivo transfection of dendritic cells, for example, may generally be performed using any methods known in the art, such as those described in WO 97/24447, or the gene gun approach described by Mahvi et al., Immunology and cell Biology 75:456-460, 1997. Antigen loading of dendritic cells may be achieved by incubating dendritic cells or progenitor cells with a polypeptide of the present inventio, DNA (naked or within a plasmid vector) or RNA; or with antigen-expressing recombinant bacterium or viruses (e.g., vaccinia, fowlpox, adenovirus or lentivirus vectors). Prior to loading, the polypeptide may be covalently conjugated to an immunological partner that provides T cell
help (e.g., a carrier molecule) such as described above. Alternatively, a dendritic cell may be pulsed with a non- conjugated immunological partner, separately or in the presence of the polypeptide.
It is appreciated that certain features of the invention, which are, for clarity, described in the context of separate embodiments, may also be provided in combination in a single embodiment. Conversely, \arious features of the invention, which are, for brevity, described in the context of a single embodiment, may also be provided separately or in any suitable subcombination.
Although the invention has been described in conjunction with specific embodiments thereof, it is evident that many alternatives, modifications and variations will be apparent to those skilled in the art. Accordingly, it is intended to embrace all such alternatives, modifications and variations that fall within the spirit and broad scope of the appended claims. All publications, patents and patent applications mentioned in this specification are herein incorporated in their entirety by reference into the specification, to the same extent as if each individual publication, patent or patent application was specifically and individually indicated to be incorporated herein by reference. In addition, citation or identification of any reference in this application shall not be construed as an admission that such reference is available as prior art to the present invention.