WO2011105003A1 - 信号処理装置及び信号処理方法 - Google Patents
信号処理装置及び信号処理方法 Download PDFInfo
- Publication number
- WO2011105003A1 WO2011105003A1 PCT/JP2011/000358 JP2011000358W WO2011105003A1 WO 2011105003 A1 WO2011105003 A1 WO 2011105003A1 JP 2011000358 W JP2011000358 W JP 2011000358W WO 2011105003 A1 WO2011105003 A1 WO 2011105003A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- sound
- conversation
- sound source
- duration
- utterance
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Ceased
Links
Images


















Classifications
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/20—Speech recognition techniques specially adapted for robustness in adverse environments, e.g. in noise, of stress induced speech
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L25/00—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00
- G10L25/48—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00 specially adapted for particular use
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L17/00—Speaker identification or verification techniques
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L21/00—Speech or voice signal processing techniques to produce another audible or non-audible signal, e.g. visual or tactile, in order to modify its quality or its intelligibility
- G10L21/02—Speech enhancement, e.g. noise reduction or echo cancellation
- G10L21/0272—Voice signal separating
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04R—LOUDSPEAKERS, MICROPHONES, GRAMOPHONE PICK-UPS OR LIKE ACOUSTIC ELECTROMECHANICAL TRANSDUCERS; ELECTRIC HEARING AIDS; PUBLIC ADDRESS SYSTEMS
- H04R2225/00—Details of deaf aids covered by H04R25/00, not provided for in any of its subgroups
- H04R2225/43—Signal processing in hearing aids to enhance the speech intelligibility
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04R—LOUDSPEAKERS, MICROPHONES, GRAMOPHONE PICK-UPS OR LIKE ACOUSTIC ELECTROMECHANICAL TRANSDUCERS; ELECTRIC HEARING AIDS; PUBLIC ADDRESS SYSTEMS
- H04R25/00—Electric hearing aids
- H04R25/40—Arrangements for obtaining a desired directivity characteristic
- H04R25/407—Circuits for combining signals of a plurality of transducers
Definitions
- the present invention relates to a signal processing apparatus and a signal processing method for extracting a group that is talking in an environment where there is a voice or noise of another person around.
- the sound / silence evaluation of the separated sound source signal is performed using a phenomenon in which sound is alternately generated between the two sound sources in the established conversation.
- the degree of conversation establishment is calculated based on the combination of voice / silence.
- FIG. 1 shows the concept of the conversation establishment degree calculation method described in Patent Document 1. If one of the target audio signal and the received signal is voiced and the other is silent, the degree of establishment of the conversation is added, and if the voice is voiced or silent, the points are deducted. In addition, it is assumed that a conversation is established between a combination of sound sources with a high degree of conversation establishment.
- JP 2004-133403 A Japanese Patent Laid-Open No. 2002-6874 Japanese Patent Laid-Open No. 2004-243023 Japanese Unexamined Patent Publication No. 1-93298
- a conventional method may be used to find a conversation partner in a scene where a conversation such as a meeting is performed.
- a wearable microphone such as a hearing aid
- An object of the present invention is to provide a signal processing apparatus and a signal processing method capable of correctly detecting that a conversation is established even in a daily environment.
- the signal processing apparatus includes a separation unit that separates a mixed sound signal in which a plurality of sound sources are mixed for each sound source, and performs sound detection for each of the plurality of separated sound source signals.
- a speech detection unit that generates speech segment information that indicates speech / non-speech information for each sound source signal by determining whether or not the speech signal is present, and speech overlap continuation that calculates and analyzes the speech overlap duration using the speech segment information
- a degree of conversation is established based on at least one of a length extraction unit, a silence duration extraction unit that calculates and analyzes the silence duration, and the extracted speech overlap duration or silence duration.
- the conversation establishment degree calculation unit for calculating the conversation establishment degree is employed.
- the signal processing device instead of the utterance overlap duration extraction unit or the silence duration extraction unit, laughter is detected for each of the plurality of separated sound source signals, and the identification is performed.
- utterance ratio information is used as the identification parameter for the combination of the plurality of sound source signals.
- An utterance ratio calculation unit to be extracted; and the conversation establishment degree calculation unit calculates the conversation establishment degree using the voice section information and the utterance ratio information.
- the signal processing apparatus can avoid malfunction by making the conversation establishment degree low. For example, even in a device that is worn on a daily basis, such as a hearing aid, the signal processing device does not malfunction due to one's own words or the voices of others when he / she is not speaking.
- the signal processing method of the present invention includes a separation step of separating a mixed sound signal mixed with a plurality of sound sources for each sound source, and performing sound detection for each of the plurality of separated sound source signals.
- a speech detection step for determining whether or not speech is generated and generating speech segment information indicating speech / non-speech information for each sound source signal, and continuation of speech overlap using the speech segment information for the combination of the plurality of sound source signals.
- the degree of conversation is established based on at least one of the step of calculating and analyzing the length and the step of calculating and analyzing the silence duration and the extracted speech overlap duration or the silence duration. And a calculation step for calculating a conversation establishment degree shown.
- the present invention since it is possible to correctly detect that a conversation is established even in a daily environment, it is possible to easily adjust or record the voice in which the conversation is established. it can.
- the figure which shows the idea of the conversation establishment degree calculation method described in patent document 1 Diagram showing utterance overlap duration distribution of daily conversation data
- a diagram showing the distribution of silence duration of daily conversation data The block diagram which shows the principal part structure of the signal processing apparatus which concerns on Embodiment 1 of this invention.
- the figure showing an example which applied this invention to the remote control type hearing aid of the form which the main body and the earphone separated A diagram showing an example of a person's positional relationship when actually using a remote-controlled hearing aid
- require speech overlap analysis value Pc The figure showing the conversation partner detection rate by the simulation experiment of Embodiment 1 A figure showing the total overlap duration of laughter / utterance / silence for a conversation partner A figure showing the total continuation length of laughter / utterance / silence for non-conversational partners The figure which shows the result of calculating the ratio which is a conversation partner
- the block diagram which shows the principal part structure of the signal processing apparatus which concerns on Embodiment 2 of this invention.
- the degree of conversation establishment is calculated by paying attention to the overlap of utterances or the duration of silence.
- the present inventors will focus on the point of utterance overlap or silence duration.
- the present inventors actually collected about 10 minutes for each of the nine daily conversations, and analyzed the continuation length of the utterance overlap for the conversation partner and the utterance overlap for the non-conversation partner.
- FIG. 2 is a graph showing the distribution of lengths (continuation lengths) of sections in which speech overlaps continue at one time for each of a conversation partner and a non-conversation partner.
- the horizontal axis represents the length of a section in which one speech overlap continues
- the vertical axis represents the frequency.
- the length of the section in which a single utterance overlap continues is often short with the conversation partner, and the length of the section in which a single utterance overlap continues is long with a non-conversation partner. It turns out that there are many cases. Therefore, in the present embodiment, a parameter focusing on the length (continuation length) of a section in which the speech overlap continues at once is introduced, not just whether the speech overlap is large or small.
- the present inventors defined the state where both speakers are silent as silence, and similarly analyzed the duration of silence.
- FIG. 3 is a graph showing the distribution of the length (continuation length) of a section where silence continues at one time for each of a conversation partner and a non-conversation partner.
- the horizontal axis represents the length of a section where silence continues at one time
- the vertical axis represents frequency.
- FIG. 4 is a block diagram showing a main configuration of the signal processing apparatus 100 according to the present embodiment.
- the microphone array 110 is a sound collection device in which a plurality of microphones are arranged.
- the A / D (Analog-to-Digital) conversion unit 120 converts sound signals collected by the respective microphones into digital signals.
- the sound source separation unit 130 performs signal processing using a difference in arrival time of sound signals arriving at each microphone, thereby separating a mixed sound signal in which a plurality of sound sources are mixed for each sound source.
- the sound detection unit 140 determines whether the sound signal separated by the sound source separation unit 130 is sound, and generates sound section information indicating a sound / non-sound detection result for each sound source. The sound detection method in the sound detection unit 140 will be described later.
- the identification parameter extraction unit 150 determines (identifies) the conversation partner and extracts an identification parameter used when calculating the conversation establishment degree. Details of the identification parameter will be described later.
- the identification parameter extraction unit 150 includes an utterance overlap duration analysis unit 151 and a silence duration analysis unit 152.
- the speech overlap duration analysis unit 151 uses the speech segment information indicating the speech / non-speech detection result for each sound source determined by the speech detection unit 140 to use the duration of the speech overlap segment (hereinafter referred to as “speech overlap”). Continuation length analysis value ”).
- the silence duration analysis unit 152 uses the speech interval information indicating the sound / non-speech detection result for each sound source determined by the sound detection unit 140 to use the duration of the silence interval between sound sources (hereinafter referred to as “silence duration analysis”). Value) and analyze.
- the identification parameter extraction unit 150 extracts the utterance overlap duration analysis value and the silence duration analysis value as the identification parameters indicating the feature amount of daily conversation.
- a method for calculating the speech overlap analysis value and the silence analysis value in the identification parameter extraction unit 150 will be described later.
- the conversation establishment degree calculation unit 160 determines the conversation establishment degree based on the utterance overlap duration analysis value calculated by the utterance overlap duration analysis unit 151 and the silence duration analysis value calculated by the silence duration analysis unit 152. Is calculated. A method for calculating the conversation establishment degree in the conversation establishment degree calculation unit 160 will be described later.
- the conversation partner determination unit 170 uses the conversation establishment degree calculated by the conversation establishment degree calculation unit 160 to determine which sound source is the conversation partner.
- the output sound control unit 180 controls and outputs the output sound with respect to the sound signal separated by the sound source separation unit 130 so that the voice of the conversation partner determined by the conversation partner determination unit 170 can be easily heard. Specifically, the output sound control unit 180 performs directivity control for suppressing the direction of the sound source that is a non-conversational partner for the sound signal separated by the sound source separation unit 130.
- FIG. 5 shows an example in which the signal processing apparatus 100 according to the present embodiment is applied to a remote control type hearing aid (hereinafter abbreviated as “hearing aid”) 200 in a form in which the hearing aid main body and the earphone are separated.
- hearing aid a remote control type hearing aid
- the hearing aid 200 includes a hearing aid main body 210 and an earphone 260.
- the hearing aid main body 210 includes a microphone array 220, an A / D converter 230, a CPU 240, and a memory 250.
- the microphone array 220 has eight microphones arranged in a circle.
- the A / D converter 230 converts the sound signal collected by the microphone array 220 into a digital signal.
- the CPU 240 performs control and calculation of the hearing aid main body 210.
- the memory 250 stores data used for calculation.
- the earphone 260 that outputs a sound signal is connected to the hearing aid main body 210.
- the CPU 240 uses the memory 250 to perform the above-mentioned sound source separation, voice detection, speech overlap duration analysis, silence duration analysis, conversation establishment, in addition to normal hearing aid processing such as sound signal amplification in accordance with the user's hearing. Performs degree calculation, conversation partner determination, and output sound control.
- the hearing aid main body 210 is placed on a table, processes the sound collected by the microphone array 220 inside the hearing aid main body 210, and listens to the user wearing the earphone 260.
- the hearing aid main body 210 and the earphone 260 may be connected by wireless communication.
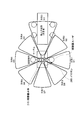
- FIG. 6 is a diagram showing an example of the positional relationship of people when the hearing aid 200 of FIG. 5 is actually used.
- the user of the hearing aid 200 wears the earphone 260.
- the hearing aid main body 210 is placed on a table, and the user has a conversation with a conversation partner in front. It is assumed that the hearing aid main body 210 is placed on the table so that the user of the hearing aid 200 comes to the front of the main body (in the direction of ⁇ in FIG. 5).
- a conversation with an irrelevant speaker is performed on the right side when viewed from the user of the hearing aid 200, which is a disturbing sound.
- FIG. 7 is a flowchart showing the operation of the hearing aid 200 equipped with the signal processing apparatus 100 according to the present embodiment.
- the operation of the hearing aid 200 will be described using the flowchart of FIG.
- S indicates each step of the flow.
- the following processing in each step of FIG. 7 is performed using the CPU 240 and the memory 250. In the CPU 240 and the memory 250, the process proceeds every short time unit (frame, here 10 msec).
- step S 110 the A / D conversion unit 120 A / D converts the sound signal input from the microphone array 110 (220) built in the hearing aid main body 210 and outputs the sound signal to the sound source separation unit 130.
- step S120 the sound source separation unit 130 separates the sound signal for each direction by using the difference in arrival time of the sound signal arriving at each microphone.
- the separated sound signals are assumed to be S1, S2, S3, S4, S5, S6, S7, and S8 in order counterclockwise from the front of the hearing aid 200 where the user is present.
- the front of the hearing aid 200 is the direction in which the user of the hearing aid 200 is present, and it is assumed that the sound signal S1 coming from this direction is the voice of the user.
- a speech detection method for example, power in a speech band (for example, 200 Hz to 4000 Hz) is calculated for each frame, smoothed in the time direction, and determined as speech when the power exceeds a threshold value.
- post-processing performs processing such as treating a short voice section as silent, or treating it as voice when there is a short period of silence when the voice continues. It is desirable.
- the voice detection method is not limited to the method based on the power of the voice band, and other methods such as a method of detecting a harmonic structure or a method of matching with a model may be used.
- the section determined as speech by the voice detection unit 140 is defined as the speech section.
- steps S140 and S150 is performed for each combination of the front sound signal S1 and the seven-direction sound signals S2 to S8 excluding the front.
- a section indicated by a square indicates an utterance section in which the sound signal S1 is determined to be speech based on speech section information indicating a speech / non-speech detection result generated by the speech detection unit 140. Yes.
- a section indicated by a square indicates an utterance section in which the sound signal Sk is determined to be speech.
- the speech overlap continuation length analysis unit 151 defines a portion where these sections overlap as speech overlap (FIG. 8C).
- the specific operation in the utterance overlap duration analysis unit 151 is as follows.
- the utterance overlap continuation length analysis unit 151 stores the frame as the start frame.
- the utterance overlap continuation length analysis unit 151 regards this as one utterance overlap and sets the time length from the start frame as the continuation length of the utterance overlap.
- the part surrounded by an ellipse represents the speech overlap before frame t.
- the utterance overlap continuation length analysis unit 151 obtains and stores a statistic regarding the continuation length of the utterance overlap before the frame t. Further, the utterance overlap continuation length analysis unit 151 calculates the utterance overlap analysis value Pc in the frame t using this statistic.
- the speech overlap analysis value Pc is preferably a parameter that indicates whether the duration of speech overlap is often short or long.
- the silence duration analysis unit 152 includes a section in which the sound signal S1 is determined to be non-sound based on the sound section information generated by the sound detection unit 140, and a section in which the sound signal Sk is determined to be non-speech.
- the part where is overlapped is defined as silence.
- the silence duration analysis unit 152 obtains the duration of the silence interval, and obtains and stores a statistic regarding the duration of the silence interval before the frame t. Further, the silence duration analysis unit 152 calculates the silence analysis value Ps in the frame t using this statistic.
- the silence analysis value Ps is also preferably a parameter indicating whether the duration is often short or long in silence.
- the silence duration analysis unit 152 stores and updates the statistics regarding the duration in the frame t.
- the statistic regarding the duration is as follows: (1) Sum of duration of speech overlap before frame t, (2) Number of speech overlap Nc, (3) Sum of duration of silence Ws, and (4) Number of silences Ns is included.
- the speech overlap duration analysis unit 151 and the silence duration analysis unit 152 calculate the average duration Ac of the speech overlap before the frame t and the average duration As of the silence interval before the frame t using the formula (1-1). , (1-2), respectively.
- the following parameters may be considered as parameters indicating whether there are many conversations with a short duration or many conversations with a long duration.
- T 1 second
- these statistics are initialized when silence continues for a certain period of time so as to express the nature of a single conversation.
- the statistics may be initialized every certain time (for example, 20 seconds). Further, as the statistic, it is possible to always use a statistic of speech overlap and silence continuation length within a certain past time window.
- the conversation establishment degree calculation unit 160 calculates the conversation establishment degree between the sound signal S1 and the sound signal Sk, and outputs the conversation establishment degree to the conversation partner determination unit 170.
- the conversation establishment degree C 1, k (t) in the frame t is defined as, for example, Expression (3).
- Frame t is initialized when silence continues for a certain period of time for sound sources in all directions.
- the conversation establishment degree calculation unit 160 starts counting when the sound source in any direction has power.
- the conversation establishment degree may be obtained by using a time constant that forgets distant past data and adapts to the latest situation.
- step S160 the conversation partner determination unit 170 determines the sound source in which direction. Is the user's conversation partner. Then, conversation partner determination unit 170 outputs the determination result to output sound control unit 180.
- a sound source in one direction having a maximum value exceeding the threshold ⁇ from C 1, k (t) in all directions is defined as a conversation partner.
- ⁇ From C 1, k (t) in all directions, all sound sources in the direction exceeding the threshold ⁇ are set as conversation partners. -Only the front (S3 to S7, etc.), not all directions, is the search target. -When a conversation partner is determined immediately before, only the direction and the adjacent direction are searched (because speaker movement is not performed rapidly in time).
- step S170 the output sound control unit 180 controls the directivity in the direction determined to be the conversation partner, so that the input mixed sound is easily processed and output from the earphone 260.
- the identification parameter extraction unit 150 includes the utterance overlap duration analysis unit 151 and the sedimentation duration analysis unit 152 has been described.
- only one of the utterance overlap duration analysis unit 151 and the sunk duration analysis unit 152 may be provided.
- Equation (3) this is equivalent to setting either the weight w1 of the speech overlap analysis value Pc or the weight w2 of the silence analysis value Ps to 0.
- the identification parameter extraction unit 150 has at least one of the utterance overlap duration analysis unit 151 and the sedimentation duration analysis unit 152.
- the utterance overlap duration analysis unit 151 calculates and analyzes the utterance overlap duration using the speech section information
- the sunk duration analysis unit 152 calculates and analyzes the silence continuation length.
- the conversation establishment degree calculation unit 160 calculates the conversation establishment degree by using at least one of the utterance overlap continuation length and the silence continuation length. In this way, in this embodiment, daily speech overlap due to conflict, short speech overlap when the other party starts speaking before the end of the conversation, short silence during conversation, etc. The features of conversation can be used. For this reason, in the present embodiment, since the conversation establishment degree can be obtained correctly even in a simple daily conversation, it is possible to correctly detect that the conversation is established and to correctly determine the conversation partner. Become.
- the present inventors conducted a simulation experiment for detecting a conversation partner using voice data that actually recorded five daily conversations.
- the conventional method is a method disclosed in Patent Document 1, and the conversation establishment degree is updated using a time constant.
- the conversation establishment degree C 1, k (t) in the frame t is obtained using the equation (4).
- the method according to the present invention uses a method using speech overlap analysis and silence analysis, obtains the speech overlap analysis value and silence analysis value for each frame, and updates the conversation establishment degree. Further, the conversation establishment degree C 1, k (t) in the frame t was calculated using the equation (3).
- FIG. 9 shows the conversation partner correct answer rate according to the conventional method and the method according to the present invention.
- the method according to the present invention for determining the degree of establishment of conversation using the analysis value of the average duration of speech overlap and silence is significantly higher in conversation partner detection at any SN ratio level. Performance was obtained. From this, it was confirmed that the present invention is effective.
- the sound source separation unit 130 may separate the sound signal by using another sound source separation method such as independent component analysis (ICA: IndependentInComponent Analysis). Further, the sound source separation unit 130 may obtain only the magnitude of the power for each band for each direction, perform voice detection from the power for each direction, and perform the same operation.
- ICA IndependentInComponent Analysis
- a speaker identification unit for identifying a speaker may be provided so that when there are a plurality of speakers in the same direction, they can be separated for each speaker.
- FIG. 10 shows the total duration of speech / laughter / silence overlap (msec) for the conversation partner
- FIG. 11 shows the total duration of speech / laughter / silence overlap (msec) for the non-conversation partner.
- FIG. 12 shows the result of calculating the ratio of the conversation partner for the combination of speech / laughter / silence from these data. From FIG. 12, when laughter overlaps, the rate of being a conversation partner is very high at 92.28%, and the rate of being a conversation partner when one is uttered and the other is silent (62.23). %, 57.48%). Therefore, it can be said that the overlap of laughter is an important parameter that indicates the feature amount of everyday conversation and determines whether or not it is a conversation partner. Therefore, in the present embodiment, the degree of conversation establishment is calculated by paying attention to the overlap of laughter in addition to the combination of sound / silence.
- a method for evaluating the degree of conversation establishment for example, when laughter overlaps, a method such as adding the degree of conversation establishment is used.
- the weight of the added points is the same or larger than when one speaker speaks and the other speaker is silent.
- the present embodiment is an example in which the present invention is applied to a remote-control hearing aid as in the first embodiment.
- the shape of the remote control hearing aid is the same as in FIG.
- FIG. 13 is a block diagram showing a main configuration of the signal processing apparatus 300 according to the present embodiment.
- the same components as those of the signal processing device 100 of FIG. 4 are denoted by the same reference numerals as those in FIG.
- the signal processing device 300 in FIG. 13 includes an identification parameter extraction unit 310 and a conversation establishment degree calculation unit 320 in place of the identification parameter extraction unit 150 and the conversation establishment degree calculation unit 160, as compared with the signal processing apparatus 100 in FIG. To do.
- the identification parameter extraction unit 310 includes a laughter detection unit 311.
- the laughter detection unit 311 determines whether or not the sound signal separated by the sound source separation unit 130 is a laughter.
- a known technique is used as a method for detecting laughter from a sound signal.
- Known techniques include, for example, the following methods.
- Patent Document 2 a section in which voice power exceeds a predetermined threshold is determined as a voice section, and an rms amplitude value is obtained for each frame.
- Patent Document 2 extracts a section in which the average value exceeds a predetermined threshold, and a section in which the same vowel continues intermittently, such as “haha” or “hahaha” in speech recognition, Is disclosed.
- Patent Document 3 discloses a method for determining an envelope of a frequency band signal of a vowel, and determining whether the period of the amplitude peak is within a certain range when the amplitude peak of the envelope is equal to or greater than a certain value. It is disclosed.
- Non-Patent Document 1 discloses a method of modeling laughter by GMM (Gaussian Mixture Model) and discriminating laughter and non-laughter for each frame.
- Non-Patent Document 1 a method that is performed by comparing a laughter GMM that has been learned in advance with a non-laughter GMM is used.
- the conversation establishment degree calculation unit 320 calculates the degree of conversation establishment using the laughter section information obtained by the laughter detection section 311 and the voice section information obtained by the voice detection section 140. A method for calculating the conversation establishment degree in the conversation establishment degree calculation unit 320 will be described later.
- FIG. 14 is a flowchart showing the operation of the hearing aid 200 equipped with the signal processing device 300 according to the present embodiment. The operation of the hearing aid 200 will be described using the flowchart of FIG. In FIG. 14, steps common to those in FIG. 7 are denoted by the same reference numerals as those in FIG.
- steps S110, S120, and S130 sound collection, A / D conversion, separation, and sound detection are performed as in the first embodiment.
- the laughter detection unit 311 performs laughter / non-laughter determination on the sound signal Sk.
- the laughter detection unit 311 compares the feature parameter vector of the frame t with the laughter GMM and the non-laughter GMM learned in advance, and obtains the laughter likelihood and the non-laughter likelihood.
- the feature parameter vector is a total of 25 MFCC 12 dimensions (C1 to C12) obtained by performing acoustic analysis for each frame, 12 primary regression coefficients thereof ( ⁇ C1 to ⁇ C12), and 1 linear regression coefficient 1 dimension ( ⁇ E) of logarithmic power.
- a vector consisting of dimensions.
- MFCC Mel
- FIG. 15 is a table showing the concept of a method for calculating the degree of conversation establishment by a combination of utterance / laughter / silence.
- “utterance”, “silence”, and “laughter” are defined as follows. “Speech”: Frame in which the voice detection result is voice and the laughter detection result is non-laughter “Silence”: Frame in which the voice detection result is non-voice and laughter detection result is non-laughter “Laughter”: Voice A frame whose laughter detection result is laughter regardless of the detection result
- conversation establishment degree calculation unit 320 calculates conversation establishment degree C 1, k (t) in frame t using, for example, Expression (5).
- frame t is initialized when silence continues for a certain period of time for the sound source in all directions. Further, the degree of conversation establishment may be obtained using a time constant that forgets distant past data and adapts to the latest situation.
- the conversation establishment degree calculation unit 320 outputs the calculated conversation establishment degree to the conversation partner determination unit 170. Thereafter, as in the first embodiment, in step S160, conversation partner determination unit 170 determines a conversation partner. In step S170, the output control unit 180 controls the output sound.
- the identification parameter extraction unit 310 has a configuration including the laughter detection unit 311.
- the laughter detection unit 311 detects laughter, and the conversation establishment determination unit 320 evaluates the degree of conversation establishment focusing on the overlap of laughter.
- the conversation establishment degree can be obtained correctly, it is possible to correctly detect that the conversation is established, and to correctly determine the conversation partner.
- the voice detection unit 140 and the laughter detection unit 311 are described as separate components. However, a voice laughter detection unit that divides the input signal into three of speech / laughter / silence may be provided.
- the conversation establishment degree is calculated by paying attention to the speaker's utterance ratio.
- the inventors will focus on the point where the speaker's utterance ratio is focused.
- the present inventors In order to analyze how much unidirectional chatting that one speaker keeps speaking in actual daily conversation, the present inventors analyzed the time window from nine sets of conversation data including daily conversation. The above utterance interval ratio was obtained by changing the length (time window width).
- FIG. 16 is a graph showing an example of transition of the utterance interval ratio Rb for each time window width of a set of conversations.
- the horizontal axis represents the elapsed time from the start of conversation, and the vertical axis represents the utterance interval ratio.
- the time window width N is shown for each of 5 seconds, 10 seconds, 20 seconds, and 30 seconds.
- one-way chatter is suppressed by multiplying the conversation establishment degree by a weight less than 1 according to the value of the utterance interval ratio in the past N seconds.
- the present embodiment is an example in which the present invention is applied to a remote-control hearing aid as in the first embodiment.
- the shape of the remote control hearing aid is the same as in FIG.
- FIG. 17 is a block diagram showing a main configuration of the signal processing apparatus 400 according to the present embodiment.
- the signal processing device 400 of FIG. 17 includes an identification parameter extraction unit 410 and a conversation establishment degree calculation unit 420 in place of the identification parameter extraction unit 150 and the conversation establishment degree calculation unit 160, as compared with the signal processing apparatus 100 of FIG. To do.
- the identification parameter extraction unit 410 has an utterance ratio calculation unit 411.
- the utterance ratio calculation unit 411 calculates the utterance section ratio as the utterance ratio information from the voice section information calculated by the voice detection unit 140.
- the conversation establishment degree calculation unit 420 obtains the conversation establishment degree from the voice section information calculated by the voice detection unit 140 and the utterance section ratio calculated by the utterance ratio calculation unit 411. A method for calculating the conversation establishment degree in the conversation establishment degree calculation unit 420 will be described later.
- FIG. 18 is a flowchart showing the operation of the hearing aid 200 equipped with the signal processing apparatus 400 according to the present embodiment. The operation of the hearing aid 200 will be described using the flowchart of FIG. In FIG. 18, the steps common to those in FIG. 7 are denoted by the same reference numerals as those in FIG.
- steps S110, S120, and S130 sound collection, A / D conversion, separation, and sound detection are performed as in the first embodiment.
- a section determined as speech by the voice detection unit 140 is defined as an utterance section.
- step S320 the conversation establishment degree calculation unit 420 calculates the conversation establishment degree between the sound signal S1 and the sound signal Sk.
- conversation establishment degree calculation section 420 obtains conversation establishment degree C 1, k (t) in frame t, for example, as shown in equation (7).
- the conversation establishment degree calculation unit 420 outputs the calculated conversation establishment degree to the conversation partner determination unit 170. Thereafter, as in the first embodiment, in step S160, conversation partner determination unit 170 determines a conversation partner. In step S170, the output control unit 180 controls the output sound.
- the identification parameter extraction unit 410 has a configuration including the utterance ratio calculation unit 411.
- the utterance ratio calculation unit 411 calculates the utterance section ratio as the utterance ratio information from the voice section information
- the conversation establishment degree calculation unit 420 calculates the conversation establishment degree using the voice section information and the utterance ratio information.
- the utterance ratio calculation unit 411 sets the utterance interval ratio Rb 1, k so that the degree of establishment of the conversation is lowered when the utterance interval ratio between itself and the other party is extremely biased.
- the conversation establishment degree calculation unit 420 calculates the conversation establishment degree using the utterance interval ratio Rb 1, k .
- the degree of conversation establishment is calculated by paying attention to the overlap length of utterances or the duration of silence, the overlap of laughter, and the utterance ratio of speakers.
- the present embodiment is an example in which the present invention is applied to a remote-control hearing aid as in the first embodiment.
- the shape of the remote control hearing aid is the same as in FIG.
- FIG. 19 is a block diagram showing a main configuration of the signal processing apparatus 500 according to the present embodiment.
- the signal processing device 500 of FIG. 19 includes an identification parameter extraction unit 510 and a conversation establishment degree calculation unit 520 in place of the identification parameter extraction unit 150 and the conversation establishment degree calculation unit 160 with respect to the signal processing apparatus 100 of FIG. To do.
- the identification parameter extraction unit 510 includes an utterance overlap duration analysis unit 511, a silence duration analysis unit 512, a laughter detection unit 311, and an utterance ratio calculation unit 513.
- the laughter section information obtained by the laughter detection unit 311 is also output to the utterance overlap duration analysis unit 511, the silence duration analysis unit 512, and the utterance ratio calculation unit 513. Then, in the utterance overlap duration analysis unit 511, the silence duration analysis unit 512, and the utterance ratio calculation unit 513, the laughing section information together with the voice section information from the voice detection unit 140, the utterance overlap duration analysis and the silence duration analysis And used to calculate the utterance ratio.
- This embodiment is different from the utterance overlap duration analysis unit 151, the silence duration analysis unit 152, and the utterance ratio calculation unit 411 of the first embodiment and the third embodiment in this point.
- FIG. 20 is a flowchart showing the operation of the hearing aid 200 equipped with the signal processing apparatus 500 according to the present embodiment. The operation of the hearing aid 200 will be described using the flowchart of FIG. In FIG. 20, the same steps as those in FIG. 14 are denoted by the same reference numerals as those in FIG.
- steps S110, S120, S130, and S210 sound collection and A / D conversion, separation, voice detection, and laughter / non-laughter determination are performed as in the second embodiment.
- “utterance”, “silence”, and “laughter” are defined as follows. “Speech”: Frame in which the voice detection result is voice and the laughter detection result is non-laughter “Silence”: Frame in which the voice detection result is non-voice and laughter detection result is non-laughter “Laughter”: Voice A frame whose laughter detection result is laughter regardless of the detection result
- the speech overlap duration analysis unit 511 calculates and analyzes the overlap length of speech segments that do not include the laughter of the sound signal S1 and the sound signal Sk.
- the silence duration analysis unit 512 obtains and analyzes the duration of a silence interval that does not include laughter based on the utterance / laughter / silence classification.
- step S420 the utterance ratio calculation unit 513 calculates the ratio of the utterance section that does not include the laughter of the sound signal S1 and the sound signal Sk.
- step S430 the conversation establishment degree calculation unit 520 calculates the degree of conversation establishment between the sound signal S1 and the sound signal Sk.
- conversation establishment degree calculation unit 520 obtains conversation establishment degree C 1, k (t) in frame t, for example, as shown in equation (8).
- step S160 conversation partner determination unit 170 determines a conversation partner.
- step S170 the output control unit 180 controls the output sound.
- the identification parameter extraction unit 510 has a configuration including the utterance overlap duration analysis unit 511, the silence duration analysis unit 512, and the laughter detection unit 311.
- the conversation establishment degree calculation unit 520 calculates the degree of conversation establishment using the utterance overlap duration, the silence continuation length, the laughter section information indicating the laughter section, or the utterance ratio information indicating the ratio of the length of the utterance section. . For this reason, this embodiment can evaluate the degree of conversation establishment using the characteristics of the appearance of crosstalk or laughter peculiar to everyday conversation. Can be sought. Thereby, this Embodiment can detect correctly that the conversation is materialized, and can determine a conversation partner correctly.
- the utterance overlap duration analysis unit 511 and the silence duration analysis unit 512 calculate the utterance overlap duration and the silence duration by taking into account the laughing section information.
- this embodiment can accurately extract utterance sections that do not include laughter, the duration of utterance overlap and silence sections can be obtained correctly, and the conversation establishment degree can be calculated more correctly. Will be able to.
- the utterance ratio calculation unit 513 in the identification parameter extraction unit 510 by providing the utterance ratio calculation unit 513 in the identification parameter extraction unit 510, it becomes possible to suppress unilateral chat.
- devices worn on a daily basis such as hearing aids, do not malfunction due to their own words or the voices of others when they are not speaking.
- Embodiments 1 to 4 the present invention has been described on the assumption that the present invention is applied to a remote-control hearing aid.
- the present invention is applied to a hearing aid using a wearable microphone such as an ear-hook type or an ear-hole type. It is also possible.
- a wearable microphone unlike a remote-controlled hearing aid, it is difficult to separate and collect a user's voice by directing the prescribed direction of the microphone array toward the user. Therefore, the present invention can be applied to a method for detecting a user's voice by adding a bone conduction microphone to a hearing aid and detecting a cranial vibration due to a spontaneous voice as disclosed in Patent Document 4.
- the present invention can detect a spontaneous voice by being applied to a method of detecting a voice of a mouth by wearing a headset microphone.
- the present embodiment does not include a sound source separation unit, and only determines whether there is a user's own voice and whether other sounds are voices every short time, so that the user and other speakers The conversation establishment degree may be obtained.
- the present invention can be applied to an audio recorder, a digital still camera, a movie, a telephone conference system, and the like.
- a digital recording device such as an audio recorder, a digital still camera, or a movie can suppress and record a disturbing sound such as a conversation of another person other than the conversation to be recorded.
- the conversation partner of the voice sent from the other quiet site is extracted and By suppressing voices other than, you can hold a meeting smoothly. Also, if there is an interference sound at both sites, for example, the same effect can be obtained by detecting the loudest voice entering the microphone, finding the conversation partner, and suppressing other voices. it can.
- the signal processing device and the signal processing method according to the present invention are useful as a signal processing device in various fields such as a hearing aid, an audio recorder, a digital still camera, a movie, and a telephone conference system.
Landscapes
- Engineering & Computer Science (AREA)
- Physics & Mathematics (AREA)
- Health & Medical Sciences (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Human Computer Interaction (AREA)
- Computational Linguistics (AREA)
- Acoustics & Sound (AREA)
- Multimedia (AREA)
- Signal Processing (AREA)
- Telephonic Communication Services (AREA)
- Machine Translation (AREA)
- Obtaining Desirable Characteristics In Audible-Bandwidth Transducers (AREA)
- Interconnected Communication Systems, Intercoms, And Interphones (AREA)
Abstract
Description
本実施の形態では、発話の重なり又は沈黙の継続長に着目して、会話成立度を算出する。本実施の形態の具体的な構成及び動作を説明する前に、先ず、本発明者らが、発話の重なり又は沈黙の継続長に着目した点について説明する。
・全ての方向のC1,k(t)から、閾値θを超える方向の音源は、すべて会話相手とする。
・全ての方向ではなく、前方(S3~S7など)のみを探索対象とする。
・直前に会話相手が判定されている場合、その方向及び隣り合う方向のみを探索対象とする(話者移動は時間的に急速には行われないため)。
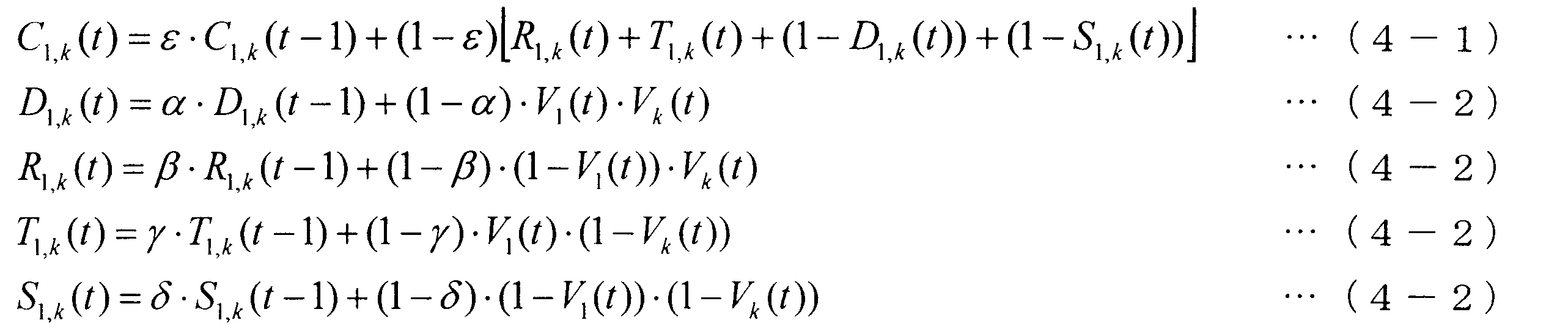
本実施の形態では、笑いの重なりに着目して、会話成立度を算出する。本実施の形態の具体的な構成及び動作を説明する前に、先ず、本発明者らが、笑いの重なりに着目した点について説明する。
「発話」:音声検出結果が音声で、かつ、笑い検出結果が非笑いであるフレーム
「無音」:音声検出結果が非音声で、かつ、笑い検出結果が非笑いであるフレーム
「笑い」:音声検出結果に関わらず、笑い検出結果が笑いであるフレーム

本実施の形態は、話者の発話比率に着目して、会話成立度を算出する。本実施の形態の具体的な構成及び動作を説明する前に、先ず、本発明者らが、話者の発話比率に着目した点について説明する。


本実施の形態では、発話の重なり又は沈黙の継続長、笑いの重なり、及び、話者の発話比率に着目して、会話成立度を算出する。
「発話」:音声検出結果が音声で、かつ、笑い検出結果が非笑いであるフレーム
「無音」:音声検出結果が非音声で、かつ、笑い検出結果が非笑いであるフレーム
「笑い」:音声検出結果に関わらず、笑い検出結果が笑いであるフレーム

110,220 マイクロホンアレイ
120,230 A/D変換部
130 音源分離部
140 音声検出部
150,310,410,510 識別パラメータ抽出部
151,511 発話重なり継続長分析部
152,512 沈黙継続長分析部
160,320,420,520 会話成立度計算部
170 会話相手判定部
180 出力音制御部
200 補聴器
210 補聴器本体
240 CPU
250 メモリ
260 イヤホン
311 笑い検出部
411,513 発話比率計算部
Claims (15)
- 複数の音源が入り混じった混合音信号を音源毎に分離する分離部と、
前記分離された複数の音源信号のそれぞれについて音声検出を行い、前記複数の音源信号が音声か否か判定して、音源信号毎に音声/非音声情報を示す音声区間情報を生成する音声検出部と、
前記音声区間情報を用いて、発話重なり継続長を計算し分析する発話重なり継続長抽出部と、前記沈黙継続長を計算し分析する沈黙継続長抽出部の少なくとも一方と、
抽出された前記発話重なり継続長又は前記沈黙継続長に基づいて、会話が成立している度合いを示す会話成立度を計算する会話成立度計算部と、
を具備する信号処理装置。 - 請求項1記載の信号処理装置において、
前記発話重なり継続長抽出部または前記沈黙継続長抽出部に代えて、
前記分離された複数の音源信号のそれぞれについて笑い検出を行い、前記識別パラメータとして、笑い区間情報を抽出する笑い検出部、を具備し、
前記会話成立度計算部は、
前記複数の音源信号の組み合わせについて、前記音声区間情報及び前記笑い区間情報を用いて、前記会話成立度を計算する、
信号処理装置。 - 請求項1記載の信号処理装置において、
前記発話重なり継続長抽出部または前記沈黙継続長抽出部に代えて、
前記複数の音源信号の組み合わせについて、前記識別パラメータとして、発話比率情報を抽出する発話比率計算部、を具備し、
前記会話成立度計算部は、
前記音声区間情報及び前記発話比率情報を用いて、前記会話成立度を計算する、
信号処理装置。 - 前記抽出部は、
前記発話重なり継続長分析部及び前記沈黙継続長分析部の少なくとも一方において、前記発話重なり継続長又は前記沈黙の継続長の長短の割合を、前記識別パラメータとして抽出する、
請求項1記載の信号処理装置 - 前記抽出部は、
前記発話重なり継続長分析部及び前記沈黙継続長分析部の少なくとも一方において、前記発話重なり継続長又は前記沈黙の継続長の平均値を、前記識別パラメータとして抽出する、
請求項1記載の信号処理装置。 - 前記会話成立度計算部は、
前記複数の音源信号で笑いが同時に検出された場合に、前記会話成立度を高くする、
請求項2記載の信号処理装置。 - 前記会話成立度計算部は、
前記複数の音源信号のうち、第1の音源信号で笑いが検出され、第2の音源信号で笑いが検出されなかった場合には、前記第一の音源信号と前記第2の音源信号との前記会話成立度を変化させない、又は、前記会話成立度を低くする、
請求項2記載の信号処理装置。 - 前記発話比率計算部は、
前記複数の音源信号のうち、過去一定時間窓内における第1の音源信号と第2の音源信号との発話区間比を、前記発話比率情報とする、
請求項3記載の信号処理装置。 - 複数の音源が入り混じった混合音信号を音源毎に分離する分離部と、
前記分離された複数の音源信号のそれぞれについて音声検出を行い、前記複数の音源信号が音声か否か判定して、音源信号毎に音声/非音声情報を示す音声区間情報を生成する音声検出部と、
前記複数の音源信号、又は、前記音声区間情報に基づいて、日常会話の特徴量を示す識別パラメータを抽出する抽出部と、
抽出された前記識別パラメータに基づいて、会話が成立している度合いを示す会話成立度を計算する会話成立度計算部と、を具備し、
前記抽出部は、
前記分離された複数の音源信号のそれぞれについて笑い検出を行って、笑い区間情報を抽出する笑い検出部と、
前記複数の音源信号の組み合わせについて、前記音声区間情報及び前記笑い区間情報を用いて、発話重なりの連続する区間の長さを示す発話重なり継続長を計算し分析する発話重なり継続長分析部、及び、沈黙の連続する区間の長さを示す沈黙継続長を計算し分析する沈黙継続長分析部の少なくとも一方と、
前記複数の音源信号の組み合わせについて、発話比率情報を抽出する発話比率計算部と、を具備し、
前記発話重なり継続長、前記沈黙継続長、前記笑い区間情報、又は、前記発話比率情報を、前記識別パラメータとして抽出する、
信号処理装置。 - 複数のマイクロホンを配置したマイクロホンアレイと、
前記マイクロホンアレイから入力されたアナログ領域の混合音信号をデジタル領域の信号に変換するA/D変換部と、
デジタル領域の前記混合音信号を入力とする請求項1記載の信号処理装置と、
前記会話成立度に応じて、デジタル領域の前記混合音信号を加工して出力する出力音制御部と、
を具備する信号処理装置。 - 前記出力音制御部は、
指向性制御によりデジタル領域の前記混合音信号を加工して出力する、
請求項10記載の信号処理装置。 - 複数のマイクロホンを配置したマイクロホンアレイと、
前記マイクロホンアレイから入力されたアナログ領域の混合音信号をデジタル領域の信号に変換するA/D変換部と、
前記変換されたデジタル領域の前記混合音信号を音源毎に分離する分離部と、
前記分離された複数の音源信号のそれぞれについて音声検出を行い、前記複数の音源信号が音声か否か判定して、音源信号毎に音声/非音声情報を示す音声区間情報を生成する音声検出部と、
前記複数の音源信号の組み合わせについて、前記音声区間情報を用いて、発話重なり継続長を計算し分析する発話重なり継続長抽出部、及び、前記沈黙継続長を計算し分析する沈黙継続長抽出部の少なくとも一方と、
抽出された前記発話重なり継続長又は前記沈黙継続長に基づいて、会話が成立している度合いを示す会話成立度を計算する会話成立度計算部と、
前記会話成立度に応じて、デジタル領域の前記混合音信号を加工して出力する出力音制御部と、
を具備する補聴器。 - 複数の音源が入り混じった混合音信号を音源毎に分離するステップと、
前記分離された複数の音源信号のそれぞれについて音声検出を行い、前記複数の音源信号が音声か否か判定して、音源信号毎に音声/非音声情報を示す音声区間情報を生成するステップと、
前記複数の音源信号の組み合わせについて、前記音声区間情報を用いて、発話重なり継続長を計算し分析するステップ、及び、前記沈黙継続長を計算し分析するステップの少なくとも一方と、
抽出された前記発話重なり継続長又は前記沈黙継続長に基づいて、会話が成立している度合いを示す会話成立度を計算するステップと、
を記録した記憶媒体。 - 複数の音源が入り混じった混合音信号を音源毎に分離する分離ステップと、
前記分離された複数の音源信号のそれぞれについて音声検出を行い、前記複数の音源信号が音声か否か判定して、音源信号毎に音声/非音声情報を示す音声区間情報を生成する音声検出ステップと、
前記複数の音源信号の組み合わせについて、前記音声区間情報を用いて、発話重なり継続長を計算し分析するステップ、及び、前記沈黙継続長を計算し分析するステップの少なくとも一方と、
抽出された前記発話重なり継続長又は前記沈黙継続長に基づいて、会話が成立している度合いを示す会話成立度を計算する計算ステップと、
を有する信号処理方法。 - 前記抽出ステップは、
前記分離された複数の音源信号のそれぞれについて笑い検出を行って、笑い区間情報を抽出する笑い検出ステップと、
複数の音源信号の組み合わせについて、前記音声区間情報及び前記笑い区間情報を用いて、発話重なりの連続する区間の長さを示す発話重なり継続長を計算し分析する発話重なり継続長分析ステップ、及び、沈黙の連続する区間の長さを示す沈黙継続長を計算し分析する沈黙継続長分析ステップの少なくとも一方と、
前記複数の音源信号の組み合わせについて、発話比率情報を抽出する発話比率計算ステップと、を有し、
前記発話重なり継続長、前記沈黙継続長、前記笑い区間情報、又は、前記発話比率情報を、前記識別パラメータとして抽出する、
請求項14記載の信号処理方法。
Priority Applications (6)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US13/262,690 US8498435B2 (en) | 2010-02-25 | 2011-01-24 | Signal processing apparatus and signal processing method |
| CN201180001707.9A CN102388416B (zh) | 2010-02-25 | 2011-01-24 | 信号处理装置及信号处理方法 |
| EP11746976.7A EP2541543B1 (en) | 2010-02-25 | 2011-01-24 | Signal processing apparatus and signal processing method |
| JP2011523238A JP5607627B2 (ja) | 2010-02-25 | 2011-01-24 | 信号処理装置及び信号処理方法 |
| US13/927,424 US8644534B2 (en) | 2010-02-25 | 2013-06-26 | Recording medium |
| US13/927,429 US8682012B2 (en) | 2010-02-25 | 2013-06-26 | Signal processing method |
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2010039698 | 2010-02-25 | ||
| JP2010-039698 | 2010-02-25 |
Related Child Applications (3)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| US13/262,690 A-371-Of-International US8498435B2 (en) | 2010-02-25 | 2011-01-24 | Signal processing apparatus and signal processing method |
| US13/262,690 Continuation US8498435B2 (en) | 2010-02-25 | 2011-01-24 | Signal processing apparatus and signal processing method |
| US13/927,424 Division US8644534B2 (en) | 2010-02-25 | 2013-06-26 | Recording medium |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2011105003A1 true WO2011105003A1 (ja) | 2011-09-01 |
Family
ID=44506438
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2011/000358 Ceased WO2011105003A1 (ja) | 2010-02-25 | 2011-01-24 | 信号処理装置及び信号処理方法 |
Country Status (5)
| Country | Link |
|---|---|
| US (3) | US8498435B2 (ja) |
| EP (1) | EP2541543B1 (ja) |
| JP (1) | JP5607627B2 (ja) |
| CN (1) | CN102388416B (ja) |
| WO (1) | WO2011105003A1 (ja) |
Cited By (15)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2012042768A1 (ja) * | 2010-09-28 | 2012-04-05 | パナソニック株式会社 | 音声処理装置および音声処理方法 |
| JP2013140534A (ja) * | 2012-01-06 | 2013-07-18 | Fuji Xerox Co Ltd | 音声解析装置、音声解析システムおよびプログラム |
| JP2013225002A (ja) * | 2012-04-20 | 2013-10-31 | Nippon Telegr & Teleph Corp <Ntt> | データ分析装置、データ分析方法およびデータ分析プログラム |
| JP2013225003A (ja) * | 2012-04-20 | 2013-10-31 | Nippon Telegr & Teleph Corp <Ntt> | 音声データ分析装置、音声データ分析方法および音声データ分析プログラム |
| JP2015004928A (ja) * | 2013-06-24 | 2015-01-08 | 日本電気株式会社 | 応答対象音声判定装置、応答対象音声判定方法および応答対象音声判定プログラム |
| JP2016133774A (ja) * | 2015-01-22 | 2016-07-25 | 富士通株式会社 | 音声処理装置、音声処理方法および音声処理プログラム |
| JP2016170405A (ja) * | 2015-03-10 | 2016-09-23 | パナソニックIpマネジメント株式会社 | 音声処理装置、音声処理方法及び音声処理プログラム |
| JP2017063419A (ja) * | 2015-09-24 | 2017-03-30 | ジーエヌ リザウンド エー/エスGn Resound A/S | 雑音を受ける発話信号の客観的知覚量を決定する方法 |
| JP2017161731A (ja) * | 2016-03-09 | 2017-09-14 | 本田技研工業株式会社 | 会話解析装置、会話解析方法およびプログラム |
| JP2018097239A (ja) * | 2016-12-15 | 2018-06-21 | カシオ計算機株式会社 | 音声再生装置及びプログラム |
| JPWO2019139101A1 (ja) * | 2018-01-12 | 2021-01-28 | ソニー株式会社 | 情報処理装置、情報処理方法およびプログラム |
| WO2021125037A1 (ja) * | 2019-12-17 | 2021-06-24 | ソニーグループ株式会社 | 信号処理装置、信号処理方法、プログラムおよび信号処理システム |
| JP2023534154A (ja) * | 2020-07-15 | 2023-08-08 | メタ プラットフォームズ テクノロジーズ, リミテッド ライアビリティ カンパニー | 個別化された音プロファイルを使用するオーディオシステム |
| WO2025204676A1 (ja) * | 2024-03-27 | 2025-10-02 | ソニーグループ株式会社 | オーディオ信号処理装置、オーディオ信号処理方法、およびプログラム |
| WO2025229916A1 (ja) * | 2024-04-30 | 2025-11-06 | 京セラ株式会社 | 音処理システム及び音処理方法 |
Families Citing this family (20)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2012001928A1 (ja) * | 2010-06-30 | 2012-01-05 | パナソニック株式会社 | 会話検出装置、補聴器及び会話検出方法 |
| TWI403304B (zh) * | 2010-08-27 | 2013-08-01 | Ind Tech Res Inst | 隨身語能偵知方法及其裝置 |
| WO2013006324A2 (en) | 2011-07-01 | 2013-01-10 | Dolby Laboratories Licensing Corporation | Audio playback system monitoring |
| US9135915B1 (en) * | 2012-07-26 | 2015-09-15 | Google Inc. | Augmenting speech segmentation and recognition using head-mounted vibration and/or motion sensors |
| US20140081637A1 (en) * | 2012-09-14 | 2014-03-20 | Google Inc. | Turn-Taking Patterns for Conversation Identification |
| US9814879B2 (en) | 2013-05-13 | 2017-11-14 | Cochlear Limited | Method and system for use of hearing prosthesis for linguistic evaluation |
| US20160049163A1 (en) * | 2013-05-13 | 2016-02-18 | Thomson Licensing | Method, apparatus and system for isolating microphone audio |
| EP2876900A1 (en) | 2013-11-25 | 2015-05-27 | Oticon A/S | Spatial filter bank for hearing system |
| CN103903632A (zh) * | 2014-04-02 | 2014-07-02 | 重庆邮电大学 | 一种多声源环境下的基于听觉中枢系统的语音分离方法 |
| JP6641832B2 (ja) * | 2015-09-24 | 2020-02-05 | 富士通株式会社 | 音声処理装置、音声処理方法および音声処理プログラム |
| CN106920543B (zh) * | 2015-12-25 | 2019-09-06 | 展讯通信(上海)有限公司 | 语音识别方法及装置 |
| US9812149B2 (en) * | 2016-01-28 | 2017-11-07 | Knowles Electronics, Llc | Methods and systems for providing consistency in noise reduction during speech and non-speech periods |
| DK3396978T3 (da) | 2017-04-26 | 2020-06-08 | Sivantos Pte Ltd | Fremgangsmåde til drift af en høreindretning og en høreindretning |
| CN107895582A (zh) * | 2017-10-16 | 2018-04-10 | 中国电子科技集团公司第二十八研究所 | 面向多源信息领域的说话人自适应语音情感识别方法 |
| CN110858476B (zh) * | 2018-08-24 | 2022-09-27 | 北京紫冬认知科技有限公司 | 一种基于麦克风阵列的声音采集方法及装置 |
| WO2021164001A1 (en) | 2020-02-21 | 2021-08-26 | Harman International Industries, Incorporated | Method and system to improve voice separation by eliminating overlap |
| EP4184948B1 (en) * | 2021-11-17 | 2025-10-15 | Sivantos Pte. Ltd. | A hearing system comprising a hearing instrument and a method for operating the hearing instrument |
| US20240089671A1 (en) | 2022-09-13 | 2024-03-14 | Oticon A/S | Hearing aid comprising a voice control interface |
| CN116524948A (zh) * | 2023-06-02 | 2023-08-01 | 阿里巴巴(中国)有限公司 | 语音分离方法及模型产品、电子设备及计算机存储介质 |
| US20250140241A1 (en) | 2023-10-30 | 2025-05-01 | Reflex Technologies, Inc. | Apparatus and method for speech processing using a densely connected hybrid neural network |
Citations (9)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH0193298A (ja) | 1987-10-02 | 1989-04-12 | Pilot Pen Co Ltd:The | 自己音声感度抑圧型補聴器 |
| JP2001045454A (ja) * | 1999-08-03 | 2001-02-16 | Fuji Xerox Co Ltd | 対話情報配信システムおよび対話情報配信装置並びに記憶媒体 |
| JP2002006874A (ja) | 2000-06-27 | 2002-01-11 | Sharp Corp | 音声処理装置、動画像処理装置、音声・動画像処理装置及び音声・動画像処理プログラムを記録した記録媒体 |
| JP2003530051A (ja) * | 2000-03-31 | 2003-10-07 | クラリティー リミテッド ライアビリティ カンパニー | 音声信号抽出のための方法及び装置 |
| JP2004133403A (ja) | 2002-09-20 | 2004-04-30 | Kobe Steel Ltd | 音声信号処理装置 |
| JP2004243023A (ja) | 2003-02-17 | 2004-09-02 | Masafumi Matsumura | 笑い検出装置、情報処理装置および笑い検出方法 |
| JP2005037953A (ja) * | 2004-07-26 | 2005-02-10 | Sharp Corp | 音声処理装置、動画像処理装置、音声・動画像処理装置及び音声・動画像処理プログラムを記録した記録媒体 |
| JP2005202035A (ja) * | 2004-01-14 | 2005-07-28 | Toshiba Corp | 対話情報分析装置 |
| WO2009104332A1 (ja) * | 2008-02-19 | 2009-08-27 | 日本電気株式会社 | 発話分割システム、発話分割方法および発話分割プログラム |
Family Cites Families (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US7236929B2 (en) * | 2001-05-09 | 2007-06-26 | Plantronics, Inc. | Echo suppression and speech detection techniques for telephony applications |
| US7596498B2 (en) * | 2005-09-02 | 2009-09-29 | Microsoft Corporation | Monitoring, mining, and classifying electronically recordable conversations |
| JP4087400B2 (ja) * | 2005-09-15 | 2008-05-21 | 株式会社東芝 | 音声対話翻訳装置、音声対話翻訳方法および音声対話翻訳プログラム |
| JP4364251B2 (ja) * | 2007-03-28 | 2009-11-11 | 株式会社東芝 | 対話を検出する装置、方法およびプログラム |
-
2011
- 2011-01-24 WO PCT/JP2011/000358 patent/WO2011105003A1/ja not_active Ceased
- 2011-01-24 JP JP2011523238A patent/JP5607627B2/ja active Active
- 2011-01-24 US US13/262,690 patent/US8498435B2/en active Active
- 2011-01-24 CN CN201180001707.9A patent/CN102388416B/zh active Active
- 2011-01-24 EP EP11746976.7A patent/EP2541543B1/en active Active
-
2013
- 2013-06-26 US US13/927,424 patent/US8644534B2/en active Active
- 2013-06-26 US US13/927,429 patent/US8682012B2/en active Active
Patent Citations (9)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH0193298A (ja) | 1987-10-02 | 1989-04-12 | Pilot Pen Co Ltd:The | 自己音声感度抑圧型補聴器 |
| JP2001045454A (ja) * | 1999-08-03 | 2001-02-16 | Fuji Xerox Co Ltd | 対話情報配信システムおよび対話情報配信装置並びに記憶媒体 |
| JP2003530051A (ja) * | 2000-03-31 | 2003-10-07 | クラリティー リミテッド ライアビリティ カンパニー | 音声信号抽出のための方法及び装置 |
| JP2002006874A (ja) | 2000-06-27 | 2002-01-11 | Sharp Corp | 音声処理装置、動画像処理装置、音声・動画像処理装置及び音声・動画像処理プログラムを記録した記録媒体 |
| JP2004133403A (ja) | 2002-09-20 | 2004-04-30 | Kobe Steel Ltd | 音声信号処理装置 |
| JP2004243023A (ja) | 2003-02-17 | 2004-09-02 | Masafumi Matsumura | 笑い検出装置、情報処理装置および笑い検出方法 |
| JP2005202035A (ja) * | 2004-01-14 | 2005-07-28 | Toshiba Corp | 対話情報分析装置 |
| JP2005037953A (ja) * | 2004-07-26 | 2005-02-10 | Sharp Corp | 音声処理装置、動画像処理装置、音声・動画像処理装置及び音声・動画像処理プログラムを記録した記録媒体 |
| WO2009104332A1 (ja) * | 2008-02-19 | 2009-08-27 | 日本電気株式会社 | 発話分割システム、発話分割方法および発話分割プログラム |
Non-Patent Citations (2)
| Title |
|---|
| AKINORI ITO ET AL.: "Smile and Laughter Recognition using Speech Processing and Face Recognition from Conversation Video", 26 May 2005, TOHOKU UNIVERSITY |
| See also references of EP2541543A4 |
Cited By (21)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2012042768A1 (ja) * | 2010-09-28 | 2012-04-05 | パナソニック株式会社 | 音声処理装置および音声処理方法 |
| JPWO2012042768A1 (ja) * | 2010-09-28 | 2014-02-03 | パナソニック株式会社 | 音声処理装置および音声処理方法 |
| US9064501B2 (en) | 2010-09-28 | 2015-06-23 | Panasonic Intellectual Property Management Co., Ltd. | Speech processing device and speech processing method |
| JP2013140534A (ja) * | 2012-01-06 | 2013-07-18 | Fuji Xerox Co Ltd | 音声解析装置、音声解析システムおよびプログラム |
| JP2013225002A (ja) * | 2012-04-20 | 2013-10-31 | Nippon Telegr & Teleph Corp <Ntt> | データ分析装置、データ分析方法およびデータ分析プログラム |
| JP2013225003A (ja) * | 2012-04-20 | 2013-10-31 | Nippon Telegr & Teleph Corp <Ntt> | 音声データ分析装置、音声データ分析方法および音声データ分析プログラム |
| JP2015004928A (ja) * | 2013-06-24 | 2015-01-08 | 日本電気株式会社 | 応答対象音声判定装置、応答対象音声判定方法および応答対象音声判定プログラム |
| JP2016133774A (ja) * | 2015-01-22 | 2016-07-25 | 富士通株式会社 | 音声処理装置、音声処理方法および音声処理プログラム |
| JP2016170405A (ja) * | 2015-03-10 | 2016-09-23 | パナソニックIpマネジメント株式会社 | 音声処理装置、音声処理方法及び音声処理プログラム |
| JP2017063419A (ja) * | 2015-09-24 | 2017-03-30 | ジーエヌ リザウンド エー/エスGn Resound A/S | 雑音を受ける発話信号の客観的知覚量を決定する方法 |
| JP2017161731A (ja) * | 2016-03-09 | 2017-09-14 | 本田技研工業株式会社 | 会話解析装置、会話解析方法およびプログラム |
| JP2018097239A (ja) * | 2016-12-15 | 2018-06-21 | カシオ計算機株式会社 | 音声再生装置及びプログラム |
| JPWO2019139101A1 (ja) * | 2018-01-12 | 2021-01-28 | ソニー株式会社 | 情報処理装置、情報処理方法およびプログラム |
| JP7276158B2 (ja) | 2018-01-12 | 2023-05-18 | ソニーグループ株式会社 | 情報処理装置、情報処理方法およびプログラム |
| US11837233B2 (en) | 2018-01-12 | 2023-12-05 | Sony Corporation | Information processing device to automatically detect a conversation |
| WO2021125037A1 (ja) * | 2019-12-17 | 2021-06-24 | ソニーグループ株式会社 | 信号処理装置、信号処理方法、プログラムおよび信号処理システム |
| JPWO2021125037A1 (ja) * | 2019-12-17 | 2021-06-24 | ||
| US12148432B2 (en) | 2019-12-17 | 2024-11-19 | Sony Group Corporation | Signal processing device, signal processing method, and signal processing system |
| JP2023534154A (ja) * | 2020-07-15 | 2023-08-08 | メタ プラットフォームズ テクノロジーズ, リミテッド ライアビリティ カンパニー | 個別化された音プロファイルを使用するオーディオシステム |
| WO2025204676A1 (ja) * | 2024-03-27 | 2025-10-02 | ソニーグループ株式会社 | オーディオ信号処理装置、オーディオ信号処理方法、およびプログラム |
| WO2025229916A1 (ja) * | 2024-04-30 | 2025-11-06 | 京セラ株式会社 | 音処理システム及び音処理方法 |
Also Published As
| Publication number | Publication date |
|---|---|
| US8644534B2 (en) | 2014-02-04 |
| EP2541543A4 (en) | 2013-11-20 |
| CN102388416A (zh) | 2012-03-21 |
| EP2541543B1 (en) | 2016-11-30 |
| JP5607627B2 (ja) | 2014-10-15 |
| US20130289982A1 (en) | 2013-10-31 |
| US20140012576A1 (en) | 2014-01-09 |
| CN102388416B (zh) | 2014-12-10 |
| US8682012B2 (en) | 2014-03-25 |
| US20120020505A1 (en) | 2012-01-26 |
| JPWO2011105003A1 (ja) | 2013-06-17 |
| EP2541543A1 (en) | 2013-01-02 |
| US8498435B2 (en) | 2013-07-30 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP5607627B2 (ja) | 信号処理装置及び信号処理方法 | |
| CN102474681B (zh) | 交谈检测装置、助听器和交谈检测方法 | |
| CN103155036B (zh) | 语音处理装置及语音处理方法 | |
| CN110268470B (zh) | 音频设备滤波器修改 | |
| Chatterjee et al. | ClearBuds: wireless binaural earbuds for learning-based speech enhancement | |
| US20180054688A1 (en) | Personal Audio Lifestyle Analytics and Behavior Modification Feedback | |
| CN100356446C (zh) | 近端讲话人检测方法 | |
| Bramsløw et al. | Improving competing voices segregation for hearing impaired listeners using a low-latency deep neural network algorithm | |
| JP2009178783A (ja) | コミュニケーションロボット及びその制御方法 | |
| JP7577960B2 (ja) | 話者予測方法、話者予測装置、およびコミュニケーションシステム | |
| US11736873B2 (en) | Wireless personal communication via a hearing device | |
| JP2013142843A (ja) | 動作解析装置、音声取得装置、および、動作解析システム | |
| US12452610B2 (en) | Methods for synthesis-based clear hearing under noisy conditions | |
| EP3288035B1 (en) | Personal audio analytics and behavior modification feedback | |
| Dekens et al. | A Multi-sensor Speech Database with Applications towards Robust Speech Processing in hostile Environments. | |
| JP2012252060A (ja) | 話者判別装置、話者判別プログラム及び話者判別方法 | |
| CN108257607A (zh) | 一种多通道语音信号处理方法 | |
| CN108133711A (zh) | 具有降噪模块的数字信号监测设备 | |
| Brandstein et al. | Speaker Recognition Using Real vs. Synthetic Parallel Data for DNN Channel Compensation |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| WWE | Wipo information: entry into national phase |
Ref document number: 201180001707.9 Country of ref document: CN |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 2011523238 Country of ref document: JP |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 13262690 Country of ref document: US |
|
| REEP | Request for entry into the european phase |
Ref document number: 2011746976 Country of ref document: EP |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 2011746976 Country of ref document: EP |
|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 11746976 Country of ref document: EP Kind code of ref document: A1 |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |