WO2012102149A1 - 符号化方法、符号化装置、周期性特徴量決定方法、周期性特徴量決定装置、プログラム、記録媒体 - Google Patents
符号化方法、符号化装置、周期性特徴量決定方法、周期性特徴量決定装置、プログラム、記録媒体 Download PDFInfo
- Publication number
- WO2012102149A1 WO2012102149A1 PCT/JP2012/050970 JP2012050970W WO2012102149A1 WO 2012102149 A1 WO2012102149 A1 WO 2012102149A1 JP 2012050970 W JP2012050970 W JP 2012050970W WO 2012102149 A1 WO2012102149 A1 WO 2012102149A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- encoding
- sample
- acoustic signal
- candidates
- interval
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Ceased
Links
Images









Classifications
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L19/00—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis
- G10L19/04—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis using predictive techniques
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L19/00—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis
- G10L19/02—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis using spectral analysis, e.g. transform vocoders or subband vocoders
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L19/00—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis
- G10L19/02—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis using spectral analysis, e.g. transform vocoders or subband vocoders
- G10L19/0212—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis using spectral analysis, e.g. transform vocoders or subband vocoders using orthogonal transformation
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L19/00—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L25/00—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00
- G10L25/90—Pitch determination of speech signals
Definitions
- the present invention relates to an audio signal encoding technique. More specifically, encoding of a frequency domain sample sequence obtained by converting an acoustic signal into the frequency domain, and periodic feature quantities (for example, fundamental frequency or The present invention relates to a technique for determining a pitch period.
- Adaptive coding for orthogonal transform coefficients such as DFT (Discrete Fourier Transform) and MDCT (Modified Discrete Cosine Transform) is known as a coding method for low-bit (for example, about 10 kbit / s to 20 kbit / s) speech and acoustic signals. It has been.
- AMR-WB + Extended-Adaptive-Multi-Rate-Wideband
- TCX transform-coded-excitation
- TwinVQ TransformTransdomain Weighted Interleave Vector Quantization
- a collection of samples after the entire MDCT coefficient is rearranged according to a fixed rule is encoded as a vector.
- a large component for each pitch period is extracted from the MDCT coefficient, information corresponding to the pitch period is encoded, and the remaining MDCT coefficient sequence from which the large component for each pitch period is further removed is rearranged.
- a method of encoding the subsequent MDCT coefficient sequence by vector quantization for each predetermined number of samples may be employed.
- Non-patent documents 1 and 2 can be exemplified as documents related to TwinVQ.
- Patent Document 1 can be exemplified as a technique for extracting and encoding samples at regular intervals.
- TCX quantization and coding There are various modifications to TCX quantization and coding. For example, consider a case where a sequence in which MDCT coefficients that have become discrete values by quantization are arranged from the lowest frequency is compressed by entropy coding. In this case, a plurality of samples are set as one symbol (coding unit), and the assigned code is adaptively controlled depending on the symbol immediately before the symbol. In general, a short code is assigned if the amplitude is small, and a long code is assigned if the amplitude is large. Since the assigned code is adaptively controlled depending on the symbol immediately before the symbol, if a small amplitude value continues, an increasingly shorter code is assigned, while a large amplitude suddenly appears after a sample with a small amplitude. A very long code is assigned.
- the conventional TwinVQ is designed on the assumption that vector quantization of fixed-length code that assigns the same codebook code to all the vectors composed of predetermined samples, and MDCT using variable-length coding No coding of the coefficients was envisaged.
- the present invention is implemented in an encoding technique for improving the quality of discrete signals, particularly audio-acoustic digital signals, by encoding with low bits with a low amount of computation, and the encoding. It is an object of the present invention to provide a technique for determining a periodic feature value that serves as an index for rearranging sample sequences.
- Auxiliary information is obtained by encoding an interval determination process for determining an interval T of samples corresponding to an integer multiple of the fundamental frequency of the signal from the set S of candidates for the interval T, and encoding the interval T determined by the interval determination process.
- One or a plurality of consecutive samples including samples corresponding to, and one or a sequence including samples corresponding to an integer multiple of the periodicity or fundamental frequency of the acoustic signal in the sample sequence A sample string after sorting is encoded as a sample string after sorting at least some samples included in the sample string so that all or some of the samples are collected.
- the interval determination process among the Z candidates of the interval T that can be represented by the auxiliary information, Z 2 selected without depending on the candidates that are the targets of the interval determination process in the past frames by a predetermined number of frames.
- a set of Y candidates (provided that Y ⁇ Z) that is a candidate for interval determination processing in a predetermined number of frames in the past (provided that Z 2 ⁇ Z)
- the interval T is determined as S.
- the interval determination process may further include an additional process of adding a value adjacent to a candidate for which the interval determination process has been performed in a past frame by a predetermined number of frames or / and a value having a predetermined difference to the set S.
- the interval determination process is selected from Z 1 candidates that are a part of Z candidates of the interval T that can be expressed by the auxiliary information, based on an acoustic signal of the current frame or / and an index obtained from the sample sequence
- the preliminary selection processing may be further included in which some of the candidates are Z 2 candidates (where Z 2 ⁇ Z 1 ).
- the interval determination process is performed based on an index obtained from an acoustic signal of the current frame and / or a sample sequence from Z 1 candidates that are a part of Z candidates of the interval T that can be expressed by auxiliary information.
- a set of a candidate selected in the preliminary selection process, a candidate selected in the preliminary selection process, and a value adjacent to the candidate selected in the preliminary selection process or / and a value having a predetermined difference are Z 2 You may further include the 2nd addition process made into a candidate.
- the interval determination process includes a second pre-selection process for selecting some of the candidates for the interval T included in the set S based on an acoustic signal of the current frame or / and an index obtained from the sample sequence, And a final selection process for determining the interval T for a set composed of some candidates selected in the two preliminary selection processes.
- the set S may include only Z 2 candidates.
- the index value indicating the level of stationarity of the sound signal of the current frame is (a-1)
- the “prediction gain of the acoustic signal in the current frame” is large.
- the “estimated value of the predicted gain of the acoustic signal in the current frame” is large
- (b-1) The difference between the “predictive gain of the previous frame” and the “predictive gain of the current frame” is small.
- (b-2) The difference between the “estimated value of the predicted gain of the previous frame” and the “estimated value of the predicted gain of the current frame” is small.
- (c-1) The “sum of the amplitudes of the samples of the acoustic signal included in the current frame” is large.
- the sample string encoding process outputs the code string obtained by encoding the sample string before rearrangement, the code string obtained by encoding the sample string after rearrangement, and auxiliary information, which has the smaller code amount. Processing may be included.
- the code amount of the code sequence obtained by encoding the sample sequence after the rearrangement or the sum of the estimated value and the code amount of the auxiliary information is obtained by encoding the sample sequence before the rearrangement. If the code amount is smaller than the code amount or the estimated value thereof, the code sequence obtained by encoding the rearranged sample sequence and the auxiliary information are output, and the sample sequence before rearrangement is encoded. If the code amount of the code string or the estimated value thereof is less than the code amount of the code string obtained by encoding the sample string after the rearrangement or the sum of the estimated value and the code amount of the auxiliary information, A code string obtained by encoding the sample string may be output.
- the code string output in the previous frame is a code string obtained by encoding the sample string after rearrangement
- the code string output in the previous frame is obtained by encoding the sample string before rearrangement.
- the ratio of candidates that are subject to the interval determination process in a predetermined number of frames in the set S may be larger than in the case of the generated code string.
- the set S may include only Z 2 candidates.
- the code sequence output in the previous frame encodes the sample sequence before rearrangement.
- the set S may include only Z 2 candidates.
- the method for determining the periodic feature value of the acoustic signal in units of frames is the periodicity for determining the periodic feature value of the acoustic signal from a set of periodic feature value candidates for each frame.
- the periodic feature quantity determination process depends on the candidate for the periodic feature quantity determination process in a predetermined number of frames in the Z candidates of the periodic feature quantity that can be expressed by the auxiliary information.
- the periodic feature quantity determination process further includes an additional process of adding a value adjacent to the candidate for the periodic feature quantity determination process in the past frame by a predetermined number of frames or / and a value having a predetermined difference to the set S. May be included.
- the set S may include only Z 2 candidates.
- the index value indicating the level of stationarity of the sound signal of the current frame is (a-1)
- the “prediction gain of the acoustic signal in the current frame” is large.
- the “estimated value of the predicted gain of the acoustic signal in the current frame” is large
- (b-1) The difference between the “predictive gain of the previous frame” and the “predictive gain of the current frame” is small.
- (b-2) The difference between the “estimated value of the predicted gain of the previous frame” and the “estimated value of the predicted gain of the current frame” is small.
- (c-1) The “sum of the amplitudes of the samples of the acoustic signal included in the current frame” is large.
- the samples included in the sample sequence in the frequency domain derived from the acoustic signal are replaced with one or a plurality of consecutive samples including samples corresponding to the periodicity or fundamental frequency of the acoustic signal, and Samples that have the same or similar index reflecting the sample size by rearranging one or more consecutive samples that contain samples corresponding to the periodicity of the acoustic signal or an integer multiple of the fundamental frequency
- a process that can be executed with a small amount of computation such as rearranging so that the data is collected, improvement in coding efficiency, reduction in quantization distortion, and the like are realized.
- the periodic feature value considered in the past frame and the interval candidate are taken into account, thereby efficiently determining the periodic feature value and the interval in the current frame. It can be carried out.
- FIG. The figure which shows the modification of embodiment of an encoding apparatus.
- the present invention within the framework of quantizing the frequency domain sample sequence derived from the acoustic signal of a predetermined time interval, while reducing the quantization distortion by rearranging the samples based on the frequency domain sample features,
- One of the features is an improvement in encoding that reduces the amount of code by using variable length encoding.
- the predetermined time interval is referred to as a frame.
- an improvement in coding is realized by concentrating samples having a large amplitude by rearranging samples according to periodicity.
- a sample sequence in the frequency domain derived from the acoustic signal for example, a DFT coefficient sequence or an MDCT coefficient sequence obtained by converting the audio acoustic digital signal in frame units from the time domain to the frequency domain
- a coefficient sequence to which processing such as normalization, weighting, and quantization is applied can be exemplified.
- an embodiment of the present invention will be described using an MDCT coefficient sequence as an example.
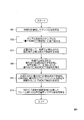
- the encoding process of the present invention includes, for example, a frequency domain transform unit 1, a weighted envelope normalization unit 2, a normalization gain calculation unit 3, a quantization unit 4, a rearrangement unit 5, and an encoding unit 6 of FIG.
- Encoding apparatus 100 or frequency domain transform unit 1, weighted envelope normalization unit 2, normalization gain calculation unit 3, quantization unit 4, rearrangement unit 5, coding unit 6, interval determination unit 7, and auxiliary information generation This is performed by the encoding device 100a of FIG.
- the encoding device 100 or the encoding device 100a does not necessarily include the frequency domain transform unit 1, the weighted envelope normalization unit 2, the normalization gain calculation unit 3, and the quantization unit 4.
- the encoding device 100 The rearrangement unit 5 and the encoding unit 6, and the encoding device 100 a may include the rearrangement unit 5, the encoding unit 6, the interval determination unit 7, and the auxiliary information generation unit 8.
- the interval determination unit 7 includes the rearrangement unit 5, the encoding unit 6, and the auxiliary information generation unit 8, but the configuration is not limited to such a configuration.
- the frequency domain conversion unit 1 converts the audio-acoustic digital signal into N-point MDCT coefficient sequences in the frequency domain in units of frames (step S1).
- the encoding side quantizes the MDCT coefficient sequence, encodes the quantized MDCT coefficient sequence, transmits the obtained code sequence to the decoding side, and the decoding side quantizes the code sequence.
- the MDCT coefficient sequence can be reconstructed, and the time-domain audio-acoustic digital signal can be reconstructed by inverse MDCT transformation.
- the amplitude of the MDCT coefficient has approximately the same amplitude envelope (power spectrum envelope) as the power spectrum of a normal DFT. For this reason, by assigning information proportional to the logarithmic value of the amplitude envelope, the quantization distortion (quantization error) of the MDCT coefficients in all bands can be uniformly distributed, and the overall quantization distortion can be reduced.
- the power spectrum envelope can be efficiently estimated using a linear prediction coefficient obtained by linear prediction analysis.
- a method for controlling such quantization error a method of adaptively assigning quantization bits of each MDCT coefficient (adjusting the quantization step width after flattening the amplitude), or weighted vector quantization is used.
- an example of the quantization method performed in the embodiment of the present invention will be described, it should be noted that the present invention is not limited to the quantization method described.
- Weighting envelope normalization unit 2 uses the power spectrum envelope coefficient sequence of the speech acoustic digital signal estimated using the linear prediction coefficient obtained by the linear prediction analysis for the speech acoustic digital signal in units of frames to input the MDCT coefficient sequence Are normalized, and a weighted normalized MDCT coefficient sequence is output (step S2).
- the weighted envelope normalization unit 2 uses the weighted power spectrum envelope coefficient sequence in which the power spectrum envelope is blunted to generate an MDCT coefficient sequence in units of frames. Normalize each coefficient of.
- the weighted normalized MDCT coefficient sequence does not have the amplitude gradient and the amplitude irregularity as large as the input MDCT coefficient sequence, but has a similar magnitude relationship to the power spectrum envelope coefficient sequence of the audio-acoustic digital signal. That is, the coefficient side region corresponding to the low frequency has a slightly large amplitude and has a fine structure resulting from the pitch period.
- Each coefficient W (1),..., W (N) of the power spectrum envelope coefficient sequence corresponding to each coefficient X (1),..., X (N) of the N-point MDCT coefficient sequence is linearly predicted. It can be obtained by converting the coefficients into the frequency domain. For example, the time signal x (t) at the time t becomes a past value x (t ⁇ 1),..., X ( tp) and the prediction residuals e (t) and the linear prediction coefficients alpha 1, ⁇ ⁇ ⁇ , represented by the formula (1) by alpha p.
- each coefficient W (n) [1 ⁇ n ⁇ N] of the power spectrum envelope coefficient sequence is expressed by Expression (2). exp ( ⁇ ) is an exponential function with the Napier number as the base, j is an imaginary unit, and ⁇ 2 is the predicted residual energy.
- the linear prediction coefficient may be obtained by performing linear prediction analysis on the audio-acoustic digital signal input to the frequency domain transform unit 1 by the weighted envelope normalization unit 2, or in the encoding device 100 or the encoding device 100a. May be obtained by linear predictive analysis of the audio-acoustic digital signal by other means not shown in FIG.
- the weighted envelope normalization unit 2 obtains each coefficient W (1),..., W (N) of the power spectrum envelope coefficient sequence using the linear prediction coefficient.
- the weighted envelope normalization unit 2 can use the coefficients W (1),..., W (N) of the power spectrum envelope coefficient sequence. Note that since the decoding apparatus 200 described later needs to obtain the same value as that obtained by the encoding apparatus 100 or the encoding apparatus 100a, a quantized linear prediction coefficient and / or power spectrum envelope coefficient sequence is used.
- linear prediction coefficient or “power spectrum envelope coefficient sequence” means a quantized linear prediction coefficient or power spectrum envelope coefficient sequence.
- the linear prediction coefficient is encoded by, for example, a conventional encoding technique, and the prediction coefficient code is transmitted to the decoding side.
- the conventional encoding technique is, for example, an encoding technique in which a code corresponding to the linear prediction coefficient itself is a prediction coefficient code, a code corresponding to the LSP parameter by converting the linear prediction coefficient into an LSP parameter, and a prediction coefficient code.
- An encoding technique for converting a linear prediction coefficient into a PARCOR coefficient and using a code corresponding to the PARCOR coefficient as a prediction coefficient code When the power spectrum envelope coefficient sequence is obtained by other means in the encoding apparatus 100 or in the encoding apparatus 100a, in other means in the encoding apparatus 100 or in the encoding apparatus 100a The linear prediction coefficient is encoded by a conventional encoding technique, and the prediction coefficient code is transmitted to the decoding side.
- the weighted envelope normalization unit 2 converts each coefficient X (1),..., X (N) of the MDCT coefficient sequence to a correction value W ⁇ (1) of each coefficient of the power spectrum envelope coefficient sequence corresponding to each coefficient. , ..., W ⁇ (N), by dividing each coefficient X (1) / W ⁇ (1), ..., X (N) / W ⁇ (N) of the weighted normalized MDCT coefficient sequence Process to get.
- the correction value W ⁇ (n) [1 ⁇ n ⁇ N] is given by Equation (3).
- ⁇ is a positive constant of 1 or less, and is a constant that dulls the power spectrum coefficient.
- the weighted envelope normalization unit 2 converts each coefficient X (1),..., X (N) of the MDCT coefficient sequence to the ⁇ power of each coefficient of the power spectrum envelope coefficient sequence corresponding to each coefficient (0 ⁇ ⁇ 1) values W (1) ⁇ ,..., W (N) ⁇ by dividing each coefficient X (1) / W (1) ⁇ ,. (N) / W (N) ⁇ is obtained.
- a frame-by-frame weighted normalized MDCT coefficient sequence is obtained, but the weighted normalized MDCT coefficient sequence does not have as large an amplitude gradient or amplitude unevenness as the input MDCT coefficient sequence, but the input MDCT coefficient It has a magnitude relationship similar to the power spectrum envelope of the column, that is, one having a slightly large amplitude in the coefficient side region corresponding to a low frequency and a fine structure resulting from the pitch period.
- the inverse processing corresponding to the weighted envelope normalization process that is, the process of restoring the MDCT coefficient sequence from the weighted normalized MDCT coefficient sequence is performed on the decoding side, so the weighted power spectrum envelope coefficient sequence from the power spectrum envelope coefficient sequence It is necessary to set a common setting for the encoding side and the decoding side.
- “Normalized gain calculator 3” Next, the sum or energy value of the amplitude values over all frequencies is calculated so that the normalization gain calculation unit 3 can quantize each coefficient of the weighted normalization MDCT coefficient sequence with the given total number of bits for each frame. Then, the quantization step width is determined, and a coefficient (hereinafter referred to as gain) for dividing each coefficient of the weighted normalized MDCT coefficient sequence so as to be the quantization step width is obtained (step S3). Information representing this gain is transmitted to the decoding side as gain information. The normalization gain calculation unit 3 normalizes (divides) each coefficient of the weighted normalization MDCT coefficient sequence by this gain for each frame.
- the quantization unit 4 quantizes each coefficient of the weighted normalized MDCT coefficient sequence normalized by the gain for each frame with the quantization step width determined in the process of step S3 (step S4).
- the frame-by-frame quantized MDCT coefficient sequence obtained in the process of step S4 is input to the rearrangement unit 5 which is a main part of the present embodiment.
- the input of the rearrangement unit 5 is performed in steps S1 to S4.
- the coefficient sequence obtained in each process is not limited.
- a coefficient sequence to which normalization by the weighted envelope normalization unit 2 is not applied or a coefficient sequence to which quantization by the quantization unit 4 is not applied may be used.
- the input of the rearrangement unit 5 will be referred to as a “frequency domain sample string” or simply a “sample string” derived from an acoustic signal.
- the quantized MDCT coefficient sequence obtained in step S4 corresponds to a “frequency domain sample sequence”. In this case, the samples constituting the frequency domain sample sequence are included in the quantized MDCT coefficient sequence. It corresponds to the coefficient.
- the reordering unit 5 includes, for each frame, (1) all samples of the frequency domain sample sequence, and (2) frequency so that samples having the same or similar index that reflects the sample size are collected.
- a rearranged sample string obtained by rearranging at least a part of samples included in the region sample string is output (step S5).
- the “index reflecting the sample size” is, for example, the absolute value or power (square value) of the amplitude of the sample, but is not limited thereto.
- the rearrangement unit 5 includes (1) all samples in the sample sequence, and (2) one or a plurality of consecutive samples including samples corresponding to the periodicity or fundamental frequency of the acoustic signal in the sample sequence. Included in the sample sequence such that all or some of the samples and one or more consecutive samples including samples corresponding to the periodicity of the acoustic signal in the sample sequence or an integer multiple of the fundamental frequency are collected A rearranged sample sequence is output as a rearranged sample sequence.
- the absolute value and power of the amplitude corresponding to the fundamental frequency and harmonics (integer multiples of the fundamental frequency) and samples in the vicinity of them are the same as those of the samples corresponding to the frequency region excluding the fundamental frequency and harmonics.
- This is based on a remarkable feature in an acoustic signal that is larger than the absolute value or power of the amplitude, particularly voice or musical sound.
- the periodic feature amount (for example, pitch period) of the acoustic signal extracted from the acoustic signal such as voice or musical sound is equivalent to the fundamental frequency
- the periodic feature amount (for example, pitch) of the acoustic signal is equivalent to the fundamental frequency.
- the absolute value and power of the amplitude of the sample corresponding to the periodicity) and its integer multiples and the samples in the vicinity of them are larger than the absolute value and power of the amplitude of the sample corresponding to the frequency domain excluding the periodic feature and their integral multiples.
- the feature of being large is also recognized.
- T represents a symbol representing an interval (hereinafter simply referred to as an interval) between a sample corresponding to the periodicity or fundamental frequency of the acoustic signal and a sample corresponding to an integer multiple of the periodicity or fundamental frequency of the acoustic signal.
- the rearrangement unit 5 includes samples F (nT ⁇ 1) and F (nT + 1) before and after the sample F (nT) corresponding to an integer multiple of the interval T from the input sample sequence. Three samples F (nT-1), F (nT), and F (nT + 1) are selected.
- F (j) is a sample corresponding to the number j representing the sample index corresponding to the frequency.
- n is an integer in a range where 1 to nT + 1 do not exceed the preset upper limit N of the target sample.
- Let jmax be the maximum value of the number j representing the sample index corresponding to the frequency.
- N A collection of samples selected according to n is called a sample group.
- the upper limit N may be equal to jmax.
- the high-frequency sample index is generally small enough, so that it is large for improving the encoding efficiency described later.
- N may be a value smaller than jmax.
- N may be a value about half of jmax. If the maximum value of n determined based on the upper limit N is nmax, samples corresponding to each frequency from the lowest frequency to the first predetermined frequency nmax * T + 1 among the samples included in the input sample sequence Are subject to sorting.
- the symbol * represents multiplication.
- the rearrangement unit 5 generates the sample sequence A by arranging the selected samples F (j) in order from the beginning of the sample sequence while maintaining the magnitude relationship of the original number j. For example, when n represents each integer from 1 to 5, the rearrangement unit 5 uses the first sample group F (T-1), F (T), F (T + 1), and the second sample group. F (2T-1), F (2T), F (2T + 1), third sample group F (3T-1), F (3T), F (3T), F (3T + 1), fourth sample group F ( 4T-1), F (4T), F (4T + 1), and fifth sample group F (5T-1), F (5T), F (5T), F (5T + 1) are arranged from the head of the sample sequence.
- the rearrangement unit 5 arranges the unselected sample F (j) in order from the end of the sample row A while maintaining the magnitude relationship of the original number j.
- the unselected sample F (j) is a sample located between the sample groups constituting the sample row A, and such a continuous set of samples is referred to as a sample set. That is, in the above example, the first sample set F (1),..., F (T-2), the second sample set F (T + 2),. , F (3T-2), fourth sample set F (3T + 2), ..., F (4T-2), fifth sample set F (4T + 2),..., F (5T-2), the sixth sample set F (5T + 2),... F (jmax) are arranged in order from the end of the sample sequence A, and these samples constitute the sample sequence B .
- the input sample sequence F (j) (1 ⁇ j ⁇ jmax) is F (T ⁇ 1), F (T), F (T + 1), F (2T ⁇ 1). ), F (2T), F (2T + 1), F (3T-1), F (3T), F (3T + 1), F (4T-1), F (4T), F (4T + 1 ), F (5T-1), F (5T), F (5T), F (5T + 1), F (1), ..., F (T-2), F (T + 2), ..., F (2T-2) , F (2T + 2), ..., F (3T-2), F (3T + 2), ..., F (4T-2), F (4T + 2), ..., F (5T-2), F (5T + 2),... F (jmax) are rearranged (see FIG. 3).
- each sample In the low frequency band, each sample often has a large value in amplitude and power, even if it is a sample other than a sample corresponding to the periodicity and fundamental frequency of an acoustic signal or a sample that is an integer multiple of the sample. Therefore, the rearrangement of samples corresponding to each frequency from the lowest frequency to the predetermined frequency f may not be performed. For example, if the predetermined frequency f is nT + ⁇ , the samples F (1),..., F (nT + ⁇ ) before rearrangement are not rearranged, and after F (nT + ⁇ + 1) before rearrangement. This sample is subject to sorting.
- ⁇ is set in advance to an integer greater than or equal to 0 and somewhat smaller than T (for example, an integer not exceeding T / 2).
- n may be an integer of 2 or more.
- P samples F (1),..., F (P) from the sample corresponding to the lowest frequency before rearrangement are not rearranged, and after F (P + 1) before rearrangement Samples may be sorted.
- the predetermined frequency f is P.
- the criteria for the rearrangement for the collection of samples to be rearranged are as described above. Note that when the first predetermined frequency is set, the predetermined frequency f (second predetermined frequency) is smaller than the first predetermined frequency.
- the input sample sequence F (j) (1 ⁇ j ⁇ jmax) is F (1),..., F (T + 1), F (2T-1), F (2T), F (2T + 1), F (3T-1), F (3T), F (3T + 1), F (4T-1), F (4T), F (4T + 1), F (5T-1 ), F (5T), F (5T + 1), F (T + 2), ..., F (2T-2), F (2T + 2), ..., F (3T-2), F (3T + 2), ..., F (4T-2), F (4T + 2), ..., F (5T-2), F (5T + 2), ..., F (5T + 2), ..., F (5T + 2), ..., F (5T + 2), ..., F (5T + 2), ..., F (5T + 2), ..., F (5T + 2), ..., F (5T + 2), ..., F (5T + 2), ..., F (5T + 2), ..., F (5T + 2), ..., F (5T + 2),
- the upper limit N or first predetermined frequency for determining the maximum value of the number j to be rearranged is not set to a value common to all frames, and a different upper limit N or first predetermined frequency is set for each frame. May be.
- information specifying the upper limit N or the first predetermined frequency for each frame may be sent to the decoding side.
- the number of sample groups to be rearranged may be specified. In this case, the number of sample groups is set for each frame, and the sample group is set. May be sent to the decoding side. Of course, the number of sample groups to be rearranged may be common to all frames.
- the second predetermined frequency f may be set to a different second predetermined frequency f for each frame without being a value common to all frames. In this case, information specifying the second predetermined frequency for each frame may be sent to the decoding side.
- the reordering unit 5 may reorder at least some of the samples included in the input sample sequence so that the envelope of the sample index shows a downward trend as the frequency increases. .
- one or a plurality of consecutive samples including samples corresponding to periodicity or fundamental frequency and one or a plurality including samples corresponding to integer multiples of periodicity or fundamental frequency on the low frequency side.
- one or more consecutive samples including samples corresponding to periodicity or fundamental frequency, and integer multiples of periodicity or fundamental frequency may be performed to collect one or a plurality of consecutive samples including the corresponding sample.
- the sample group is arranged in the reverse order in the sample row A
- the sample set is arranged in the reverse order in the sample row B
- the sample row B is arranged on the low frequency side
- the sample row A is arranged behind the sample B. That is, in the above example, the sixth sample set F (5T + 2),...
- the reordering unit 5 may reorder at least some of the samples included in the input sample sequence so that the envelope of the sample index shows a tendency to increase as the frequency increases. .
- Interval T may be a decimal number (for example, 5.0, 5.25, 5.5, 5.75) instead of an integer.
- F (R (nT-1)), F (R (nT)), and F (R (nT + 1)) are selected with RT (nT) rounded off to nT.
- the encoding unit 6 encodes the input sample string after the rearrangement, and outputs the obtained code string (step S6).
- the encoding unit 6 performs encoding by switching the variable length encoding according to the amplitude deviation of the samples included in the input sample string after the rearrangement. That is, samples with large amplitude are collected on the low frequency side (or high frequency side) in the frame by rearrangement, and the encoding unit 6 performs variable length encoding suitable for the bias. If samples with the same or similar amplitude are gathered for each local area, as in the sample sequence after rearrangement, the average code amount is reduced by, for example, rice coding with different rice parameters for each area. it can.
- a case where samples having a large amplitude are collected on the low frequency side (side closer to the head of the frame) in the frame will be described as an example.
- the coding unit 6 applies Rice coding (also referred to as Golomb-Rice coding) for each sample in a region where samples having an index corresponding to a large amplitude are gathered.
- Rice coding also referred to as Golomb-Rice coding
- the encoding unit 6 applies entropy encoding (Huffman encoding, arithmetic encoding, etc.) for each of a plurality of samples.
- the application region of rice encoding and the rice parameter may be fixed, or one of a plurality of options having different combinations of the application region of rice encoding and the rice parameter can be selected. It may be a configuration.
- a variable length code (binary value surrounded by the symbol "") as shown below can be used as selection information for rice encoding, and the encoding unit 6 also outputs the selection information included in the code string. “1”: Rice coding is not applied.
- Rice coding is applied to the 1/32 region from the beginning with the Rice parameter set to 1.
- 001 Rice coding is applied as 2 in the 1/32 region from the beginning.
- 0001 Rice coding is applied to the area 1/16 from the head with the Rice parameter set to 1.
- 00001 Rice coding is applied to the area 1/16 from the beginning with the Rice parameter set to 2.
- 00000 Rice coding is applied with an area of 1/32 from the top as a Rice parameter of 3.
- the code amount of the code string corresponding to each rice encoding obtained by the encoding process is compared, and the option with the smallest code amount is selected.
- a method of selecting may be adopted.
- the average code amount can be reduced by, for example, run-length encoding the number of consecutive samples having an amplitude of 0.
- the encoding unit 6 applies (1) rice encoding for each sample in a region where samples having an index corresponding to a large amplitude are gathered, and (2) in a region other than this region, ( a) In a region where samples having an amplitude of 0 are continuous, encoding that outputs a code representing the number of consecutive samples having an amplitude of 0 is performed. (b) In the remaining region, entropy encoding is performed for each of a plurality of samples.
- a method for determining the interval T will be described.
- a determination method of selecting a candidate T i given a code amount as the interval T can be given.
- Auxiliary information for specifying rearrangement of samples included in the sample string for example, a code obtained by encoding the interval T, is output from the encoding unit 6.
- Z is a sufficiently large number.
- a considerable amount of calculation processing is required to calculate the actual code amount for all candidates, which may cause a problem from the viewpoint of efficiency.
- the preliminary selection processing is to approximately obtain the code amount of the code sequence corresponding to the sample sequence after sorting (in some cases, the sample sequence before sorting) obtained based on each candidate (code amount)
- An index that reflects the code amount of the code string, or an index that is associated with the code amount of the code string (however, the index here is different from the “code amount”) Is a process for selecting a candidate for a final selection process.
- the final selection process is a process of selecting the interval T based on the actual code amount of the code string corresponding to the sample string.
- the code amount of the code string corresponding to the sample string is actually calculated for each of the Y candidates obtained by the preliminary selection process, and the minimum code amount candidate T j gave (T j ⁇ S Y; however S Y denotes the set of Y number of candidate) is selected as the interval T.
- Y must satisfy at least Y ⁇ Z, but from the viewpoint of a significant reduction in the amount of calculation processing, for example, Y should be set to a value somewhat smaller than Z so as to satisfy Y ⁇ Z / 2. It is preferable to keep it.
- the processing for calculating the code amount requires a large amount of calculation processing amount.
- this calculation processing amount is A, and the calculation processing amount of the preliminary selection processing is assumed to be about one-tenth of the calculation processing amount A / 10, Z
- the calculation processing amount is ZA.
- the preliminary selection processing is performed for the Z candidates, and the Y candidates selected in the preliminary selection processing are encoded.
- the total calculation processing amount becomes (ZA / 10 + YA). In this case, if Y ⁇ 9Z / 10 is satisfied, it is understood that the interval T can be determined with a smaller amount of calculation processing by the method via the preliminary selection processing.
- the periodic feature amount of the acoustic signal often changes slowly over the plurality of frames in a steady signal section extending over the plurality of frames. Therefore, by considering the intervals T t-1 determined in temporally frame X t-1 of the previous one frame X t, to be able to efficiently determine the interval T t in the frame X t Conceivable.
- the interval T t-1 determined in the frame X t-1 because not always the appropriate intervals T t even frame X t, only intervals T t-1 determined in the frame X t-1 rather than take into account, the candidate interval T used in determining the interval T t-1 in the frame X t-1, the candidate interval T in determining the interval T t in the frame X t Preferably included.
- the encoding device 100 a includes an interval determining unit 7, and the interval determining unit 7 includes a rearranging unit 5, an encoding unit 6, and an auxiliary information generating unit 8. .
- step S71 Candidates for the interval T that can be expressed by auxiliary information specifying rearrangement of samples included in the sample string are encoding methods described later such as whether the auxiliary information is fixed-length encoded or variable-length encoded. Correspondingly, it is predetermined. Interval determining unit 7, Z number of candidate T 1 having different intervals T that this predetermined, T 2, ..., storing the predetermined Z 1 single candidate from among the T Z (Z 1 ⁇ Z). The purpose is to reduce the number of candidates for the preliminary selection process.
- the candidate to be pre-selection process, T 1, T 2, ... , of the T Z it is desirable to include as much of the Preferred as the interval T of the frame.
- the interval determining unit 7 for example, Z number of candidate T 1, T 2, ..., at equal intervals from the T Z
- the selected Z 1 candidate is the target of the preliminary selection process.
- the interval determination unit 7 performs the above-described selection process for Z 1 candidates that are the targets of the preliminary selection process.
- various specific processing contents of the preliminary selection processing can be considered, but as a method based on an index that is recognized to be related to the magnitude of the code amount of the code sequence corresponding to the sample sequence after the rearrangement, for example, It is conceivable to determine Z 2 candidates based on the degree of concentration of the sample index in the low band and the number of consecutive samples having zero amplitude from the highest frequency toward the low band on the frequency axis.
- the interval determination unit 7 performs the rearrangement of the sample sequence described above based on the candidate, and is included in, for example, a region of 1/4 from the lower frequency side of the rearranged sample sequence.
- the sum of absolute values of the amplitudes of the samples is obtained as an index that is associated with the magnitude of the code amount of the code sequence corresponding to the sample sequence, and if the sum is larger than a predetermined threshold, the candidate is selected. .
- the interval determination unit 7 performs the rearrangement of the sample sequences described above based on the candidates for each candidate, and zeros from the highest frequency toward the lower frequency side in the sample sequence after the rearrangement.
- the number of consecutive samples having an amplitude is obtained as an index that is associated with the magnitude of the code amount of the code sequence corresponding to the sample sequence, and if this number is large compared to a predetermined threshold, the candidate is selected. .
- the rearrangement unit 5 performs the rearrangement.
- the determined number of candidates is Z 2 , and the value of Z 2 can be changed for each frame.
- Preliminary selection processing as follows if you set the value of Z 2 in advance.
- interval determination unit 7 performs sorting sample sequence described above based on each candidate sample is arranged sample sequence from the lower frequency side, for example, 1 ⁇ 4 of after being changed
- the sum of the absolute values of the amplitudes of the samples included in the region is obtained as an index that is associated with the magnitude of the code amount of the code sequence corresponding to the sample sequence, and Z 2 candidates are selected from the larger sum value. .
- the sample sequence described above based on each candidate is rearranged, and the amplitude of zero from the highest frequency toward the low frequency side in the sample sequence after the samples are rearranged
- the number of consecutive samples is obtained as an index that is associated with the magnitude of the code amount of the code string corresponding to the sample string, and Z 2 candidates are selected from the larger number of consecutive numbers.
- the rearrangement unit 5 rearranges the sample columns. In this case, the value of Z 2 is the same in every frame. Naturally, at least the relationship of Z> Z 1 > Z 2 is satisfied.
- step S72 Additional processing
- the interval determination unit 7 performs a process of adding one or a plurality of candidates to the candidate set S Z2 obtained by the preliminary selection process of (A). Purpose of this additional processing is to prevent the search range of the interval T in the final selection process described above too value of Z 2 is small when the value of Z 2 is may vary for each frame is too narrow, Alternatively, even if the value of Z 2 is a large value to some extent, the possibility that the appropriate interval T is determined in the above-described final selection process is expanded as much as possible.
- T Z ⁇ means the front and rear when introduced to the based on the magnitude of the value sequence T 1 ⁇ T 2 ⁇ ... ⁇ T Z). This is because the candidates T k-1 and T k + 1 may not be included in the Z 1 candidates that are the targets of the preliminary selection process of (A). However, if the candidates T k-1 and T k + 1 ⁇ S Z1 and the candidates T k-1 and T k + 1 are not included in the set S Z2 , the candidates T k-1 and T k + 1 are added. You may make it not. Further, the candidate to be added may be selected from the set S Z.
- T k ⁇ (where T k ⁇ S Z ) and / or T k + ⁇ (where T k + ⁇ S Z ) may be added as a new candidate.
- a set of Z 2 + Q candidates is S Z3 . Subsequently, the process (D1) or (D2) is performed.
- step S73 Preliminary selection process (step S73) (D1-Step S731)
- the interval determination unit 7 performs the above-described preliminary selection processing for Z 2 + Q candidates included in the set S Z3 when the frame for which the interval T is determined is the first frame in time. carry out.
- the number of candidates narrowed down by this preliminary selection process is assumed to be Y.
- Y satisfies Y ⁇ Z 2 + Q.
- the same processing as the preliminary selection process in (A) may be performed (however, the number of candidates to be output is different). (That is, Y ⁇ Z 2 )). In this case, it should be noted that the value of Y can change from frame to frame.
- the preliminary selection process having a different content from the preliminary selection process in (A) is performed, for example, the Z 2 + Q candidates included in the set S Z3 are rearranged based on the respective sample sequences described above.
- the approximate code amount (estimated code amount) is obtained by using a predetermined approximate expression that approximately obtains the code amount of the code string obtained by encoding the sample string after the rearrangement.
- the rearrangement unit 5 rearranges the sample columns.
- the rearranged sample sequence obtained in the preliminary selection processing in (A) may be used.
- a candidate whose approximate code amount is equal to or less than a predetermined threshold may be determined as a candidate for (E) code amount calculation processing described later ( In this case, the determined number of candidates is Y), and if the value of Y is preset, Y candidates from the smaller approximate code amount are subjected to (E) final selection processing described later.
- Y candidates are stored in the memory, and these Y candidates are used in the later-described processing (C) or (D2) when determining the interval T in the second frame in terms of time. After the process (D1), the final selection process (E) is performed.
- the code string obtained by encoding the sample sequence after rearrangement in the preliminary selection process in (A) is always selected in the preliminary selection process in (D1). Only the candidate added by the addition process of (B) performs a process of selecting a candidate by comparing the index and the threshold, and the candidate selected here and the candidate selected by the preliminary selection process of (A) May be candidates for the final selection process of (E).
- the Y value is set to a fixed value set in advance, and Y candidates are selected from the one with the smaller approximate code amount ( It is more preferable to determine the candidate for the final selection process of E).
- the set S P will be described later with respect to the set S Y of candidates that are targets of the final selection process (E) described later when the interval T is determined in the frame X t ⁇ 1 and the set S Y (C the additional processing) is a union of the set S W candidates to be added.
- the set S Y is stored in the memory.
- Y,
- W, and at least
- ⁇ Z is an essential condition.
- the above-described preliminary selection process is performed on at most Z 2 + Q + Y + W candidates included in the union set S Z3 ⁇ S P. The number of candidates narrowed down by this preliminary selection process is assumed to be Y.
- Y satisfies Y ⁇
- the same processing as the preliminary selection processing in (B) described above may be performed (however, the number of candidates to be output) Are different (ie, Y ⁇ Z 2 )). In this case, it should be noted that the value of Y can change from frame to frame. If the preliminary selection process different from the preliminary selection process in (B) described above is performed, for example, for each of
- the approximate code amount (estimated code amount) is obtained by using a predetermined approximate expression that approximately obtains the code amount of the code string obtained by encoding the sample string after the rearrangement.
- the rearrangement unit 5 rearranges the sample columns. For the candidates for which the rearranged sample sequence is obtained in the preliminary selection processing in (A), the rearranged sample sequence obtained in the preliminary selection processing in (A) may be used.
- a candidate whose approximate code amount is equal to or less than a predetermined threshold may be determined as a candidate for the final selection process (E) described later (
- the number of candidates determined is Y)
- Y candidates from the smaller approximate code amount are selected in the final selection process (E) described later. What is necessary is just to determine as a candidate used as object.
- the Y candidates are stored in the memory, and these Y candidates are used in the process (D2) performed when determining the interval T in the next frame in terms of time. After the process (D2), the final selection process (E) is performed.
- the code sequence code obtained by encoding the sample sequence after the rearrangement in the preliminary selection process of (A) is always selected in the preliminary selection process in (D2).
- step S74 The interval determination unit 7 performs a process of adding one or a plurality of candidates to the candidate set S Y that is a target of the final selection process (E) described later when determining the interval T in the frame X t ⁇ 1 .
- the candidate to be added may be selected from the set S Z.
- T m ⁇ (where T m ⁇ S Z ) and / or T m + ⁇ (where T m + ⁇ S Z ) may be added as a new candidate.
- step S75 For each of the Y candidates, the interval determination unit 7 rearranges the sample sequences described above based on the candidates, encodes the sample sequences after the rearrangement to obtain a code sequence, and calculates the actual code sequence. A code amount is obtained, and a candidate given the minimum code amount is selected as the interval T. The rearrangement unit 5 rearranges the sample strings, and the encoding unit 6 encodes the rearranged sample strings. For the candidates for which the rearranged sample sequence is obtained in the preliminary selection processing in (A) or (D), the encoding unit 6 encodes the rearranged sample sequence obtained in the preliminary selection processing as an input. Can be done.
- the additional processing (B), the additional processing (C), and the preliminary selection processing (D) are not essential, and an implementation configuration in which at least one of them is not performed may be employed.
- the additional processing of (B) is not performed, if the number of elements (candidates) of the set S Z3 is expressed as
- , since Q 0,
- Z 2 .
- the “first frame” is “the first frame in time”, but the present invention is not limited to such a frame.
- the “first frame” may be any frame other than the frame satisfying the condition A of the following (1) to (3) (see FIG. 9). ⁇ Condition A> About the frame (1) The frame is not the first in time, (2) The previous frame is encoded according to the encoding method of the present invention, and (3) The previous frame has been subjected to the above-described rearrangement process.
- the set S Y is expressed as “candidates for the final selection process (E) described later when determining the interval T in the immediately preceding frame X t ⁇ 1 .
- the set S Y is “the target of the final selection process (E) described later when determining the interval T in each of a plurality of frames temporally before the target frame for determining the interval T”. It may be a “union of candidate sets”. That is, if the number of past frames is m, the set S Y is a set of candidates S t that are targets of final selection processing (E) described later when determining the interval T in the frame X t ⁇ 1 .
- m is preferably one of 1 , 2 , and 3 depending on the values of Z, Z 1 , Z 2 , and Q.
- the calculation processing amount of the processing for calculating the code amount is A and the calculation processing amount of the preliminary selection processing is an arithmetic processing amount A / 10 of about 1/10, Z, Z 1 , Z 2 , Q, W
- the amount of calculation processing when each processing of (A), (B), (C), (D2) is performed is at most ((Z 1 + Z 2 + Q + Y + W) A / 10 + YA).
- Z 2 + Q ⁇ 3Z 2 and Y + W ⁇ 3Y the amount of calculation processing is ((Z 1 + 3Z 2 + 3Y) A / 10 + YA).
- the ratio of the may be determined in a ratio of S P against S Z3, may be determined in a ratio of S Z3 for S P, occupy the S P in S Z3 ⁇ S P may be determined in a percentage, it may be determined as the occupancy of S Z3 in S Z3 ⁇ S P.
- Whether or not the continuity of a certain signal section is large can be determined, for example, based on whether or not the index value indicating the continuity is greater than or equal to a threshold value or greater than the threshold value.
- the index value indicating the magnitude of continuity is, for example, as shown below.
- a frame for which the interval T is determined is referred to as a current frame
- a frame immediately before the current frame is referred to as a previous frame.
- the index value representing the magnitude of stationarity is (a-1)
- the “prediction gain of the acoustic signal of the current frame” is large.
- (a-2) The “estimated value of the predicted gain of the acoustic signal of the current frame” is large.
- (d-1) The difference between the “sum of the amplitudes of the samples of the acoustic signals included in the previous frame” and the “sum of the amplitudes of the samples of the acoustic signals included in the current frame” is small.
- (d-2) “The sum of the amplitudes of the samples included in the sample sequence obtained by converting the sample sequence of the acoustic signal included in the previous frame into the frequency domain” and “the sample sequence of the acoustic signal included in the current frame The difference with the ⁇ sum of the amplitudes of the samples included in the sample sequence obtained by conversion to the frequency domain '' is small, (e-1) “Power of sound signal of current frame” is large, (e-2) “Power of the sample sequence obtained by converting the sample sequence of the acoustic signal of the current frame into the frequency domain” is large.
- the prediction gain is the ratio of the energy of the original signal to the energy of the prediction error signal in predictive coding, and this value is included in the weighted normalized MDCT coefficient sequence of the frame output from the weighted envelope normalization unit 2.
- the ratio of the sum of absolute values of sample values included in the MDCT coefficient sequence of the frame output by the frequency domain transform unit 1 to the sum of absolute values of sample values or included in the weighted normalized MDCT coefficient sequence of the frame Is approximately proportional to the value of the ratio of the sum of the squares of the sample values included in the MDCT coefficient sequence of the frame to the sum of the squares of the sample values.
- the value of any of the above ratios can be used as a value that is equivalent in magnitude to the “predicted gain of the acoustic signal of the frame”.
- the prediction gain of the acoustic signal of the frame is the m-th order PARCOR coefficient corresponding to the linear prediction coefficient of the frame used in the weighted envelope normalization unit 2, and k m It is E calculated by.
- the PARCOR coefficients corresponding to the linear prediction coefficients are all-order PARCOR coefficients before quantization.
- the PARCOR coefficient corresponding to the linear prediction coefficient the PARCOR coefficient before quantization of some orders (for example, from the first order to the P second order, where P 2 ⁇ P), or the partial or all orders
- the calculated E becomes an “estimated value of the predicted gain of the acoustic signal of the frame”. “The sum of the amplitudes of the samples of the acoustic signal included in the frame” is the sum of the absolute values of the sample values of the audio-acoustic digital signal included in the frame, or the MDCT coefficient of the frame output by the frequency domain transform unit 1 The sum of the absolute values of the sample values contained in the column.
- the power of the acoustic signal of the frame means the sum of the squares of the sample values of the audio-acoustic digital signal included in the frame, or the value of the sample included in the MDCT coefficient sequence of the frame output from the frequency domain transform unit 1 Is the sum of the squares of
- any one of the exemplified (a) to (f) may be used for the determination of the magnitude of the continuity, or a logical sum between two or more of the exemplified (a) to (f) is used. Or logical product may be used to determine the magnitude of stationarity.
- the interval determination unit 7 uses, for example, only the “prediction gain of the acoustic signal of the current frame” in (a) to calculate the “prediction gain of the acoustic signal of the current frame” G and a predetermined threshold ⁇ . If ⁇ ⁇ G is established in the meantime, it is determined that the stationarity is large.
- the interval determination unit 7 uses, for example, both the criteria (c) and (e) to calculate the “sum of the amplitudes of the samples of the acoustic signal included in the current frame” Ac and a predetermined threshold value ⁇ .
- ⁇ ⁇ Ac is established and ⁇ ⁇ Pc is established between “the power of the acoustic signal of the current frame” Pc and a predetermined threshold value ⁇ , it is determined that the stationarity is large, or ( Using the criteria of a), (c), and (f), ⁇ ⁇ G is established between the “prediction gain of the acoustic signal of the current frame” G and a predetermined threshold value ⁇ or “included in the current frame” ⁇ ⁇ Ac between the sum of the amplitudes of the samples of the sound signal to be recorded “Ac” and a predetermined threshold value ⁇ , and “the power of the sound signal of the previous frame” and “the power of the sound signal of the current frame” When P diff ⁇ holds between the difference P diff between and a predetermined threshold value ⁇ , it is determined that the stationarity is large.
- Such constancy of the ratio of S Z3 and S P is changed by the size determination is for example it is specified in a look-up table in advance interval the determination unit 7.
- the ratio of S Z3 in ⁇ S P for high proportion of S P (relatively S Z3 is lowered, or the S Z3 ⁇ S P of S P ratio is) set to exceed 50%, if the continuity is not greater, so that the ratio of S Z3 ⁇ S such that the ratio of S P is lower in P (relatively S Z3 is high to, or so as not to exceed 50% ratio of S P in S Z3 ⁇ S P), or the ratio is set to be the same level.
- the candidates included in the S P and S Z3 For example, the number of candidates included in the set S Z3 is reduced by a process of selecting candidates from those having a large index similar to the above-described preliminary selection process of (A) so that the number matches the ratio.
- the ratio of S P (or the ratio of S Z3 ) is determined with reference to the lookup table in the process of (D2), and the values of S P and S Z3 are determined.
- the number of candidates included to conform to the ratio for example, adjusting the number of candidates included in the set S P by the processing of selecting a candidate from having a large similar indicators and the process described above (a). According to such processing, it is possible to reduce the number of candidates to be processed in (D2), and at the same time, it is possible to increase the ratio of the set that will include the current frame interval T as a candidate. It becomes possible to determine the interval T well. Incidentally, if the continuity is not greater, it may be an empty set S P. In other words, in this case, candidates that have been subjected to the final selection process (E) in the past frame are not included in the preliminary selection process (D) in the current frame.
- the look-up table implementation to set the different ratios of S Z3 and S P according to the degree of constancy of magnitude are possible.
- the values of Z 1 , Z 2 , Q, and W are set in advance in the look-up table according to the determination result of the continuity in relation to the value of Y.
- the object to be determined by the method is not limited to the interval T.
- This method can also be used as a method for determining the periodic feature amount (for example, fundamental frequency, pitch period, etc.) of an acoustic signal, which is information for specifying the sample group at the time of sample rearrangement. it can. That is, the interval determination unit 7 may function as a periodic feature value determination device, and the interval T may be determined as the periodic feature value without outputting a code string obtained by encoding the sample string after the rearrangement. .
- interval T may be read as “pitch period”, or the value obtained by dividing the sampling frequency of the sample sequence by “interval T” is “ The fundamental frequency and the pitch period for sample rearrangement can be determined with a small amount of calculation processing.
- the encoding unit 6 or the auxiliary information generation unit 8 includes auxiliary information for specifying rearrangement of samples included in the sample sequence, that is, information indicating the periodicity of the acoustic signal, information indicating the fundamental frequency, or the period of the acoustic signal. Information indicating the interval T between the sample corresponding to the frequency or the fundamental frequency and the sample corresponding to the periodicity of the acoustic signal or the integer multiple of the fundamental frequency. Note that when the encoding unit 6 outputs auxiliary information, a process of obtaining auxiliary information may be performed in the encoding process of the sample sequence, or a process of obtaining auxiliary information as a process different from the encoding process.
- auxiliary information for specifying rearrangement of samples included in the sample string is also output for each frame.
- the auxiliary information for specifying the rearrangement of the samples included in the sample string is obtained by encoding the periodicity, the fundamental frequency, or the interval T for each frame.
- This encoding may be fixed length encoding or variable length encoding to reduce the average code amount.
- auxiliary information and a code that can uniquely identify the auxiliary information are stored in association with each other, and a code corresponding to the input auxiliary information is output.
- variable length encoding information obtained by variable length encoding the difference between the interval T between the previous frame and the current frame may be used as information indicating the interval T.
- the difference value of the interval T and a code that can uniquely identify the difference value are stored in association with each other, and the difference between the interval T of the input previous frame and the interval T of the current frame is stored. The corresponding code is output.
- information obtained by variable-length coding the difference between the fundamental frequency of the previous frame and the fundamental frequency of the current frame may be used as information representing the fundamental frequency.
- the upper limit value of n or the above upper limit N may be included in the auxiliary information.
- the number of samples included in each sample group is a total of 3 samples including a sample corresponding to periodicity, a fundamental frequency or an integral multiple thereof (hereinafter referred to as a central sample) and one sample before and after the sample.
- a central sample An example of a fixed number is shown.
- the number of samples included in the sample group and the sample index are variable, the number of samples included in the sample group and the combination of sample indexes are different from the other options.
- Information indicating one selected from the above is also included in the auxiliary information.
- the rearrangement unit 5 performs rearrangement corresponding to each option, and the encoding unit 6 uses the code amount of the code string corresponding to each option. And the method of selecting the option with the smallest code amount may be employed. In this case, auxiliary information for specifying rearrangement of samples included in the sample string is output from the encoding unit 6 instead of the rearrangement unit 5. This method is also valid when n can be selected.
- the options include, for example, options related to the interval T, options related to the combination of the number of samples included in the sample group and the sample index, and options related to n, and all combinations of these options may be a considerable number. is expected.
- Calculation of the final code amount for all combinations of these options requires a processing amount, which may be a problem from the viewpoint of efficiency.
- the encoding unit 6 obtains an approximate code amount that is an estimated value of the code amount by a simple and approximate method for all combinations of options. For example, a predetermined plurality of candidates from the one having the smallest approximate code amount are obtained. Narrow down a plurality of candidates that are estimated to be preferable, such as by selecting an option that gives the smallest code amount among the narrowed candidates (selected candidates), and the final code with a small amount of processing The amount can be reduced almost optimally.
- the candidates for the interval T are narrowed down to a small number, and for each candidate, the number of samples included in the sample group is combined, The most preferable option may be selected.
- measure the sum of the sample indices approximately, and select the choice based on the concentration of the sample indices in the low frequency range or the number of consecutive samples with zero amplitude from the highest frequency to the low frequency range on the frequency axis. You may decide. Specifically, the sum of the absolute values of the amplitudes of the sample sequences after the rearrangement is obtained for a region that is 1/4 from the low frequency side of the entire sample sequence, and if the sum is larger than a predetermined threshold value, It is assumed that this is a preferred permutation. Also, according to the method of selecting the option with the longest number of consecutive samples with zero amplitude from the highest frequency of the sample sequence after rearrangement toward the low frequency side, samples with large indexes are concentrated in the low frequency range. It is assumed that this is also a preferable rearrangement.
- the processing amount is small, but the rearrangement of samples included in the sample sequence that minimizes the final code amount may not be selected. For this reason, it is only necessary to select a plurality of candidates by the approximation process as described above, and finally calculate the code amount accurately for only a small number of candidates and select the most preferable one (the code amount is small).
- the rearrangement unit 5 also outputs a sample string before rearrangement (a sample string that has not been rearranged), and the encoding unit 6 obtains a code string by variable-length encoding the sample string before rearrangement.
- the sum of the code amount of the code string obtained by variable-length coding the sample string before rearrangement, and the code amount of the code string obtained by variable-length coding the sample string after rearrangement and the code amount of the auxiliary information The code amount is compared.
- the rearranged sample sequence is obtained by variable length encoding.
- the encoded code string and auxiliary information are output.
- Code amount of code sequence obtained by variable length coding of sample sequence before rearrangement and total code of code amount of code sequence obtained by variable length coding of sample sequence after rearrangement and code amount of auxiliary information
- a code string obtained by variable-length coding the sample string before rearrangement a code string obtained by variable-length coding the sample string after rearrangement, and auxiliary information Either of these is output. Which is output is determined in advance.
- the second auxiliary information indicating whether or not the sample sequence corresponding to the code sequence is the sample sequence that has been rearranged is also output (see FIG. 10). It is sufficient to use 1 bit as the second auxiliary information.
- the rearranged sample sequence is variable length.
- an approximate code amount of the code string obtained by variable-length coding of the rearranged sample string may be used.
- a code obtained by obtaining an approximate code amount of a code string obtained by variable length coding of a sample string before rearrangement that is, an estimated value of the code string, and variable length coding of the sample string before rearrangement.
- an approximate code amount of the code sequence obtained by variable length coding of the sample sequence before rearrangement that is, an estimated value of the code amount may be used.
- a quantized parameter can be used in common by an encoding device and a decoding device.
- the encoding unit 6 uses the i-th quantized PARCOR coefficient k (i) obtained by another means (not shown) in the encoding apparatus 100 to (1-k (i) * k ( i)) is multiplied by each order, and an estimated value of the prediction gain expressed by the reciprocal number is calculated. If the calculated estimated value is larger than a predetermined threshold, the rearranged sample sequence is variable-length encoded. The obtained code string is output, and if not, a code string obtained by variable-length coding the sample string before rearrangement is output.
- the second auxiliary information indicating whether or not the sample string corresponding to the code string is a reordered sample string is output. There is no need. That is, there is a high possibility that the effect is small at the time of noisy speech that cannot be predicted or silence, so that it is less wasteful of auxiliary information and calculation if it is decided not to rearrange.
- the rearrangement unit 5 calculates the prediction gain or the estimated value of the prediction gain, and performs the rearrangement on the sample string when the prediction gain or the estimated value of the prediction gain is larger than a predetermined threshold value. Is output to the encoding unit 6, otherwise, the sample sequence itself input to the rearrangement unit 5 is output to the encoding unit 6 without being rearranged with respect to the sample sequence.
- the sample sequence output from the rearrangement unit 5 may be variable length encoded.
- the threshold value is set in advance as a common value on the encoding side and the decoding side.
- the decoding process will be described with reference to FIGS.
- the MDCT coefficients are reconstructed by processing in the reverse order to the encoding processing by the encoding device 100 or the encoding device 100a.
- At least the gain information, the auxiliary information, and the code string are input to the decoding device 200.
- the second auxiliary information is also input to the decoding device 200.
- the decoding unit 11 decodes the input code string according to the selection information for each frame, and outputs a frequency domain sample string (step S11). Naturally, a decoding method corresponding to the encoding method executed to obtain the code string is executed.
- the details of the decoding process performed by the decoding unit 11 correspond to the details of the encoding process performed by the encoding unit 6 of the encoding device 100. Therefore, the description of the encoding process is incorporated herein and the decoding corresponding to the executed encoding is performed. Is a decoding process performed by the decoding unit 11, and this is a detailed description of the decoding process. Note that what encoding method is executed is specified by the selection information.
- the selection information includes, for example, information for specifying an application region and a rice parameter for Rice coding, information indicating an application region for run-length encoding, and information for specifying the type of entropy encoding
- the decoding method corresponding to these encoding methods is applied to the corresponding region of the input code string. Since the decoding process corresponding to the Rice encoding, the decoding process corresponding to the entropy encoding, and the decoding process corresponding to the run length encoding are all well known, description thereof will be omitted.
- the recovery unit 12 obtains the original sample arrangement from the frequency domain sample sequence output by the decoding unit 11 in accordance with the input auxiliary information for each frame (step S12).
- the “original sample arrangement” corresponds to a “frequency domain sample string” input to the rearrangement unit 5 of the encoding apparatus 100.
- the information specifying the rearrangement is included in the auxiliary information. Therefore, the recovery unit 12 can restore the sequence of original samples to the frequency domain sample sequence output by the decoding unit 11 based on the auxiliary information.
- the recovery unit 12 uses the frequency domain sample sequence output by the decoding unit 11 as the original. If the samples are output after being returned and indicate that the rearrangement is not performed, the sample sequence in the frequency domain output by the decoding unit 11 is output as it is.
- the recovery unit 12 uses, for example, the (1-k (i) * k) using the i-th quantized PARCOR coefficient k (i) input from another means (not shown) in the decoding device 200. (i)) is multiplied for each order to calculate an estimated value of the prediction gain represented by the reciprocal number, and when the calculated estimated value is larger than a predetermined threshold, the frequency domain sample sequence output by the decoding unit 11 Are output after arranging the original samples, and if not, the frequency-domain sample string output by the decoding unit 11 is output as it is.
- the details of the recovery process performed by the recovery unit 12 correspond to the details of the rearrangement process performed by the rearrangement unit 5 of the encoding device 100. Therefore, the description of the rearrangement process is incorporated herein, and the reverse process of the rearrangement process ( It is specified that the reverse sorting) is the recovery process performed by the recovery unit 12, and this will be a detailed description of the recovery process.
- the reverse process of the rearrangement process It is specified that the reverse sorting is the recovery process performed by the recovery unit 12, and this will be a detailed description of the recovery process.
- the rearrangement unit 5 collects the sample group on the low frequency side and F (T-1), F (T), F (T + 1), F (2T-1), F (2T), F (2T +1), F (3T-1), F (3T), F (3T + 1), F (4T-1), F (4T), F (4T + 1), F (5T-1), F (5T), F (5T), F (5T), F (5T + 1), F (1), ..., F (T-2), F (T + 2), ..., F (2T-2), F (2T + 2), ..., F (3T-2), F (3T + 2), ..., F (4T-2), F (4T + 2), ..., F (5T-2), F (5T + 2), ..., F (5T + 2), ...
- F (jmax) In the above-described example in which the recovery unit 12 outputs the frequency domain sample sequences F (T ⁇ 1), F (T), F (T + 1), and F (2T ⁇ 1), F (2T), F (2T + 1), F (3T-1), F (3T), F (3T + 1), F (4T-1), F (4T), F (4T + 1), F (5T-1), F (5T), F (5T), F (5T), F (5T + 1), F (1), ..., F (T-2), F (T + 2), ..., F (2T-2 ), F (2T + 2), ..., F (3T-2), F (3T + 2), ..., F (4T-2), F (4T + 2), ..., F (5T-2), F (5T + 2), ... F (jmax) is input.
- the auxiliary information includes, for example, information on the interval T, information indicating that n is an integer of 1 to 5, and information specifying that the sample group includes 3 samples. ing. Therefore, based on this auxiliary information, the recovery unit 12 inputs the sample sequences F (T-1), F (T), F (T + 1), F (2T-1), F (2T), F (2T + 1), F (3T-1), F (3T), F (3T + 1), F (4T-1), F (4T), F (4T), F (4T + 1), F (5T-1 ), F (5T), F (5T), F (5T + 1), F (1), ..., F (T-2), F (T + 2), ..., F (2T-2), F (2T + 2) , ..., F (3T-2), F (3T + 2), ..., F (4T-2), F (4T + 2), ..., F (5T-2), F (5T + 2), ... F (jmax) can be returned to the original sample sequence F (j) (1 ⁇ j ⁇ jmax).
- the inverse quantization unit 13 performs inverse quantization on the original sample sequence F (j) (1 ⁇ j ⁇ jmax) output by the recovery unit 12 for each frame (step S13). If described in correspondence with the above example, the “weighted normalized MDCT coefficient sequence normalized by gain” input to the quantization unit 4 of the encoding apparatus 100 is obtained by inverse quantization.
- the gain multiplication unit 14 multiplies each coefficient of the “weighted normalized MDCT coefficient sequence normalized by gain” output from the inverse quantization unit 13 for each frame by the gain specified by the gain information.
- a “normalized weighted normalized MDCT coefficient sequence” is obtained (step S14).
- the weighted envelope inverse normalization unit 15 divides the weighted power spectrum envelope value by each coefficient of the “normalized weighted normalized MDCT coefficient sequence” output from the gain multiplication unit 14 for each frame.
- An MDCT coefficient sequence is obtained (step S15).
- time domain conversion unit 16 converts the “MDCT coefficient sequence” output from the weighted envelope inverse normalization unit 15 into the time domain for each frame to obtain a frame-based audio-acoustic digital signal (step S16).
- high-efficiency coding can be performed (that is, the average code length) by coding a sample sequence rearranged according to the fundamental frequency. Can be reduced).
- samples with the same or similar index are concentrated for each local region by rearranging the samples included in the sample string, not only the efficiency of variable-length coding but also the reduction of quantization distortion and the amount of code can be reduced. Reduction is possible.
- the encoding device / decoding device may include an input unit to which a keyboard or the like can be connected, an output unit to which a liquid crystal display or the like can be connected, a CPU (Central Processing Unit) [cache memory, or the like. ] RAM (Random Access Memory) or ROM (Read Only Memory) and external storage device as a hard disk, and data exchange between these input unit, output unit, CPU, RAM, ROM, and external storage device It has a bus that can be connected. If necessary, the encoding / decoding device may be provided with a device (drive) that can read and write a storage medium such as a CD-ROM.
- a device drive
- the external storage device of the encoding device / decoding device stores a program for executing encoding / decoding and data necessary for processing of this program [not limited to the external storage device, for example, a program It may be stored in a ROM which is a read-only storage device. ]. Data obtained by the processing of these programs is appropriately stored in a RAM or an external storage device.
- a storage device that stores data, addresses of storage areas, and the like is simply referred to as a “storage unit”.
- the storage unit of the encoding device there are a program for rearranging the samples included in the frequency domain sample sequence derived from the audio-acoustic signal, a program for encoding the sample sequence obtained by the rearrangement, and the like. It is remembered.
- the storage unit of the decoding device stores a program for decoding the input code sequence, a program for restoring the sample sequence obtained by decoding to a sample sequence before being rearranged by the encoding device, and the like. Has been.
- each program stored in the storage unit and data necessary for the processing of each program are read into the RAM as necessary, and interpreted and executed by the CPU.
- the encoding is realized by the CPU realizing a predetermined function (sorting unit, encoding unit).
- each program stored in the storage unit and data necessary for processing each program are read into the RAM as necessary, and are interpreted and executed by the CPU.
- the encoding is realized by the CPU realizing a predetermined function (decoding unit, recovery unit).
- processing functions in the hardware entity (encoding device / decoding device) described in the above embodiment are realized by a computer, the processing contents of the functions that the hardware entity should have are described by a program. Then, by executing this program on a computer, the processing functions in the hardware entity are realized on the computer.
- the program describing the processing contents can be recorded on a computer-readable recording medium.
- the computer-readable recording medium may be any recording medium such as a magnetic recording device, an optical disk, a magneto-optical recording medium, and a semiconductor memory.
- a magnetic recording device a hard disk device, a flexible disk, a magnetic tape or the like, and as an optical disk, a DVD (Digital Versatile Disc), a DVD-RAM (Random Access Memory), a CD-ROM (Compact Disc Read Only) Memory), CD-R (Recordable) / RW (ReWritable), etc.
- magneto-optical recording media MO (Magneto-Optical disc), etc., semiconductor memory, EEP-ROM (Electronically Erasable and Programmable-Read Only Memory), etc. Can be used.
- this program is distributed by selling, transferring, or lending a portable recording medium such as a DVD or CD-ROM in which the program is recorded. Furthermore, the program may be distributed by storing the program in a storage device of the server computer and transferring the program from the server computer to another computer via a network.
- a computer that executes such a program first stores a program recorded on a portable recording medium or a program transferred from a server computer in its own storage device.
- the computer reads the program stored in its own recording medium and executes the process according to the read program.
- the computer may directly read the program from a portable recording medium and execute processing according to the program, and the program is transferred from the server computer to the computer.
- the processing according to the received program may be executed sequentially.
- the program is not transferred from the server computer to the computer, and the above-described processing is executed by a so-called ASP (Application Service Provider) type service that realizes a processing function only by an execution instruction and result acquisition. It is good.
- the program in this embodiment includes information that is used for processing by an electronic computer and that conforms to the program (data that is not a direct command to the computer but has a property that defines the processing of the computer).
- the hardware entity is configured by executing a predetermined program on the computer.
- a predetermined program on the computer.
- at least a part of these processing contents may be realized in hardware.
Landscapes
- Engineering & Computer Science (AREA)
- Physics & Mathematics (AREA)
- Computational Linguistics (AREA)
- Signal Processing (AREA)
- Health & Medical Sciences (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Human Computer Interaction (AREA)
- Acoustics & Sound (AREA)
- Multimedia (AREA)
- Spectroscopy & Molecular Physics (AREA)
- Compression, Expansion, Code Conversion, And Decoders (AREA)
- Compression Or Coding Systems Of Tv Signals (AREA)
Abstract
Description
(a-1)「現在のフレームの上記音響信号の予測利得」が大きい、
(a-2)「現在のフレームの上記音響信号の予測利得の推定値」が大きい、
(b-1)「直前のフレームの予測利得」と「現在のフレームの予測利得」との差分が小さい、
(b-2)「直前のフレームの予測利得の推定値」と「現在のフレームの予測利得の推定値」との差分が小さい、
(c-1)「現在のフレームに含まれる上記音響信号のサンプルの振幅の和」が大きい、
(c-2)「現在のフレームに含まれる上記音響信号のサンプル列を周波数領域に変換して得られたサンプル列に含まれるサンプルの振幅の和」が大きい、
(d-1)「直前のフレームに含まれる上記音響信号のサンプルの振幅の和」と「現在のフレームに含まれる上記音響信号のサンプルの振幅の和」との差分が小さい、
(d-2)「直前のフレームに含まれる上記音響信号のサンプル列を周波数領域に変換して得られたサンプル列に含まれるサンプルの振幅の和」と「現在のフレームに含まれる上記音響信号のサンプル列を周波数領域に変換して得られたサンプル列に含まれるサンプルの振幅の和」との差分が小さい、
(e-1)「現在のフレームの上記音響信号のパワー」が大きい、
(e-2)「現在のフレームの上記音響信号のサンプル列を周波数領域に変換して得られたサンプル列のパワー」が大きい、
(f-1)「直前のフレームの上記音響信号のパワー」と「現在のフレームの上記音響信号のパワー」との差分が小さい、
(f-2)「直前のフレームの上記音響信号のサンプル列を周波数領域に変換して得られたサンプル列のパワー」と「現在のフレームの上記音響信号のサンプル列を周波数領域に変換して得られたサンプル列のパワー」との差分が小さい、の少なくともいずれか一つの条件を満たす場合に、大きくなる値である。
(a-1)「現在のフレームの上記音響信号の予測利得」が大きい、
(a-2)「現在のフレームの上記音響信号の予測利得の推定値」が大きい、
(b-1)「直前のフレームの予測利得」と「現在のフレームの予測利得」との差分が小さい、
(b-2)「直前のフレームの予測利得の推定値」と「現在のフレームの予測利得の推定値」との差分が小さい、
(c-1)「現在のフレームに含まれる上記音響信号のサンプルの振幅の和」が大きい、
(c-2)「現在のフレームに含まれる上記音響信号のサンプル列を周波数領域に変換して得られたサンプル列に含まれるサンプルの振幅の和」が大きい、
(d-1)「直前のフレームに含まれる上記音響信号のサンプルの振幅の和」と「現在のフレームに含まれる上記音響信号のサンプルの振幅の和」との差分が小さい、
(d-2)「直前のフレームに含まれる上記音響信号のサンプル列を周波数領域に変換して得られたサンプル列に含まれるサンプルの振幅の和」と「現在のフレームに含まれる上記音響信号のサンプル列を周波数領域に変換して得られたサンプル列に含まれるサンプルの振幅の和」との差分が小さい、
(e-1)「現在のフレームの上記音響信号のパワー」が大きい、
(e-2)「現在のフレームの上記音響信号のサンプル列を周波数領域に変換して得られたサンプル列のパワー」が大きい、
(f-1)「直前のフレームの上記音響信号のパワー」と「現在のフレームの上記音響信号のパワー」との差分が小さい、
(f-2)「直前のフレームの上記音響信号のサンプル列を周波数領域に変換して得られたサンプル列のパワー」と「現在のフレームの上記音響信号のサンプル列を周波数領域に変換して得られたサンプル列のパワー」との差分が小さい、の少なくともいずれか一つの条件を満たす場合に、大きくなる値である。
「符号化処理」
最初に図1~図4を参照して符号化処理を説明する。本発明の符号化処理は、例えば、周波数領域変換部1と重み付け包絡正規化部2と正規化利得計算部3と量子化部4と並べ替え部5と符号化部6とを備える図1の符号化装置100、または、周波数領域変換部1と重み付け包絡正規化部2と正規化利得計算部3と量子化部4と並べ替え部5と符号化部6と間隔決定部7と補助情報生成部8を備える図10の符号化装置100aにより行われる。ただし、符号化装置100または符号化装置100aは周波数領域変換部1と重み付け包絡正規化部2と正規化利得計算部3と量子化部4とは必ずしも備える必要は無く、例えば、符号化装置100は並べ替え部5と符号化部6、符号化装置100aは並べ替え部5と符号化部6と間隔決定部7と補助情報生成部8とにより構成されることもある。なお、図10に例示される符号化装置100aでは間隔決定部7が並べ替え部5と符号化部6と補助情報生成部8を含むが、このような構成に限定されるものではない。
まず、周波数領域変換部1がフレーム単位で音声音響ディジタル信号を周波数領域のN点のMDCT係数列に変換する(ステップS1)。
重み付け包絡正規化部2が、フレーム単位の音声音響ディジタル信号に対する線形予測分析によって求められた線形予測係数を用いて推定された音声音響ディジタル信号のパワースペクトル包絡係数列によって、入力されたMDCT係数列の各係数を正規化し、重み付け正規化MDCT係数列を出力する(ステップS2)。ここでは聴覚的に歪が小さくなるような量子化の実現のために、重み付け包絡正規化部2は、パワースペクトル包絡を鈍らせた重み付けパワースペクトル包絡係数列を用いて、フレーム単位でMDCT係数列の各係数を正規化する。この結果、重み付け正規化MDCT係数列は、入力されたMDCT係数列ほどの大きな振幅の傾きや振幅の凹凸を持たないが、音声音響ディジタル信号のパワースペクトル包絡係数列と類似の大小関係を有するもの、すなわち、低い周波数に対応する係数側の領域にやや大きな振幅を持ち、ピッチ周期に起因する微細構造をもつもの、となる。
N点のMDCT係数列の各係数X(1),・・・,X(N)に対応するパワースペクトル包絡係数列の各係数W(1),・・・,W(N)は、線形予測係数を周波数領域に変換して得ることができる。例えば、全極型モデルであるp次自己回帰過程により、時刻tの時間信号x(t)は、p時点まで遡った過去の自分自身の値x(t-1),・・・,x(t-p)と予測残差e(t)と線形予測係数α1,・・・,αpによって式(1)で表される。このとき、パワースペクトル包絡係数列の各係数W(n)[1≦n≦N]は式(2)で表される。exp(・)はネイピア数を底とする指数関数、jは虚数単位、σ2は予測残差エネルギーである。

<例1>
重み付け包絡正規化部2は、MDCT係数列の各係数X(1),・・・,X(N)を当該各係数に対応するパワースペクトル包絡係数列の各係数の補正値Wγ(1),・・・,Wγ(N)で除算することによって、重み付け正規化MDCT係数列の各係数X(1)/Wγ(1),・・・,X(N)/Wγ(N)を得る処理を行う。補正値Wγ(n)[1≦n≦N]は式(3)で与えられる。但し、γは1以下の正の定数であり、パワースペクトル係数を鈍らせる定数である。
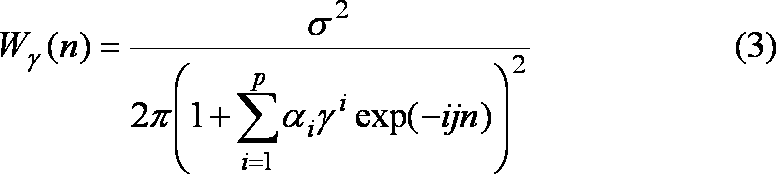
重み付け包絡正規化部2は、MDCT係数列の各係数X(1),・・・,X(N)を当該各係数に対応するパワースペクトル包絡係数列の各係数のβ乗(0<β<1)の値W(1)β,・・・,W(N)βで除算することによって、重み付け正規化MDCT係数列の各係数X(1)/W(1)β,・・・,X(N)/W(N)βを得る処理を行う。
次に、正規化利得計算部3が、フレームごとに、重み付け正規化MDCT係数列の各係数を与えられた総ビット数で量子化できるように、全周波数に亘る振幅値の和またはエネルギー値を用いて量子化ステップ幅を決定し、この量子化ステップ幅になるように重み付け正規化MDCT係数列の各係数を割り算する係数(以下、利得という。)を求める(ステップS3)。この利得を表す情報は、利得情報として復号側へ伝送される。正規化利得計算部3は、フレームごとに、重み付け正規化MDCT係数列の各係数をこの利得で正規化(除算)する。
次に、量子化部4が、フレームごとに、利得で正規化された重み付け正規化MDCT係数列の各係数をステップS3の処理で決定された量子化ステップ幅で量子化する(ステップS4)。
ステップS4の処理で得られたフレーム単位の量子化MDCT係数列は、本実施形態の要部である並べ替え部5の入力となるが、並べ替え部5の入力は、ステップS1~ステップS4の各処理で得られた係数列に限定されない。例えば、重み付け包絡正規化部2による正規化が適用されていない係数列や量子化部4による量子化が適用されていない係数列であってもよい。このことを明示的に理解するため、以下、並べ替え部5の入力を音響信号に由来する「周波数領域のサンプル列」あるいは単に「サンプル列」と呼称することにする。この実施形態では、ステップS4の処理で得られた量子化MDCT係数列が「周波数領域のサンプル列」に相当し、この場合、周波数領域のサンプル列を構成するサンプルは量子化MDCT係数列に含まれる係数に相当する。
この並べ替え処理の具体例を説明する。例えば、並べ替え部5は、(1)サンプル列の全てのサンプルを含み、かつ、(2)サンプル列のうちの音響信号の周期性または基本周波数に対応するサンプルを含む一つまたは連続する複数のサンプルおよび、サンプル列のうちの音響信号の周期性または基本周波数の整数倍に対応するサンプルを含む一つまたは連続する複数のサンプル、の全部または一部のサンプルが集まるようにサンプル列に含まれる少なくとも一部のサンプルを並べ替えたもの、を並べ替え後のサンプル列として出力する。つまり、音響信号の周期性または基本周波数に対応するサンプルを含む一つまたは連続する複数のサンプルおよび、当該音響信号の周期性または基本周波数の整数倍に対応するサンプルを含む一つまたは連続する複数のサンプルが集まるように、入力されたサンプル列に含まれる少なくとも一部のサンプルが並べ替えられる。
このように並べ替えられた後のサンプル列は、周波数を横軸とし、サンプルの指標を縦軸とした場合に、サンプルの指標の包絡線が周波数の増大に伴って増大傾向を示すことになる。換言すれば、並べ替え部5は、サンプルの指標の包絡線が周波数の増大に伴って増大傾向を示すように入力されたサンプル列に含まれる少なくとも一部のサンプルを並べ替えると言ってもよい。
符号化部6が、入力された並べ替え後のサンプル列を符号化し、得られた符号列を出力する(ステップS6)。符号化部6は、入力された並べ替え後のサンプル列に含まれるサンプルの振幅の偏りに応じて可変長符号化を切り替えて符号化する。つまり、並べ替えによってフレーム内で低域側(あるいは高域側)に振幅の大きなサンプルが集められているので、符号化部6はその偏りに適した可変長符号化を行う。並べ替え後のサンプル列のように、局所的な領域ごとに同等か同程度の振幅を持つサンプルが集まっていると、例えば領域ごとに異なるライスパラメータでライス符号化することによって平均符号量を削減できる。以下、フレーム内で低域側(フレームの先頭に近い側)に振幅の大きなサンプルが集められている場合を例に採って説明する。
具体例として、符号化部6は、大きな振幅に対応する指標をもつサンプルが集まっている領域ではサンプルごとにライス符号化(ゴロム-ライス符号化ともいう)を適用する。
"1":ライス符号化を適用しない。
"01":ライス符号化を先頭から1/32の領域にライスパラメータを1として適用する。
"001":ライス符号化を先頭から1/32の領域にライスパラメータを2として適用する。
"0001":ライス符号化を先頭から1/16の領域にライスパラメータを1として適用する。
"00001":ライス符号化を先頭から1/16の領域にライスパラメータを2として適用する。
"00000":ライス符号化を先頭から1/32の領域にライスパラメータを3として適用する。
間隔Tの決定方法について説明する。簡便な決定方法の一例として、間隔Tの異なるZ個の候補T1,T2,…,TZを予め用意しておき、並べ替え部5が各候補Ti(i=1,2,…,Z)についてサンプル列に含まれるサンプルの並べ替えを実施し、後述する符号化部6が各候補Tiに基づいて得られたサンプル列に対応する符号列の符号量を得て、最小の符号量を与えた候補Tiを間隔Tとして選択するという決定方法を挙げることができる。サンプル列に含まれるサンプルの並べ替えを特定する補助情報、例えば、間隔Tを符号化して得られる符号、は符号化部6から出力される。
サンプル列に含まれるサンプルの並べ替えを特定する補助情報によって表現することが可能な間隔Tの候補は、補助情報を固定長符号化するか可変長符号化するか等の後述する符号化方法と対応して予め定められている。間隔決定部7は、この予め定められている間隔Tの異なるZ個の候補T1,T2,…,TZの中から予め決定されたZ1個の候補を記憶しておく(Z1<Z)。その目的は予備選択処理の対象となる候補の数を少なくすることにある。予備選択処理の対象となる候補には、T1,T2,…,TZのうち、そのフレームの間隔Tとして好ましいものをできるだけ多く含むことが望まれる。しかし実際には予備選択処理を行う前の段階では好ましさは不明であるので、間隔決定部7は、例えば、Z個の候補T1,T2,…,TZの中から等間隔に選択したZ1個の候補を予備選択処理の対象とする。例えば「Z個の候補T1,T2,…,TZの中の奇数番目の候補を予備選択処理の対象とする」(この場合、Z1=ceil(Z/2)となる。ceil(・)は天井関数である)という基準でZ個の候補T1,T2,…,TZの中のZ1個の候補を予備選択処理の対象とすればよい。Z個の候補の集合をSZとし(SZ={T1,T2,…,TZ})、Z1個の候補の集合をSZ1とする。
次に、間隔決定部7は、(A)の予備選択処理で得られた候補の集合SZ2に一つまたは複数の候補を追加する処理を行う。この追加処理を行う目的は、フレームごとにZ2の値が変わりえる場合にZ2の値が小さくなりすぎて上述の最終選択処理における間隔Tの探索範囲が狭くなりすぎることを防止すること、あるいは、Z2の値がある程度大きな値であったとしても、上述の最終選択処理において適切な間隔Tが決定される可能性を少しでも広げること、である。なお、本発明の間隔Tの決定方法の目的は、演算処理量を従来技術より少なくすることであるから、集合SZ2の要素(候補)の数を|SZ2|と表せば|SZ2|=Z2であり、追加される候補の数をQとすると、QがZ2+Q<Zを満たすことが必須条件となる。さらに好ましい条件は、QがZ2+Q<Z1を満たすことである。追加される候補は、例えば、集合SZ2に含まれる候補Tkの前後の候補Tk-1,Tk+1∈SZとしてもよい(ここでの「前後」とは、集合SZ={T1,T2,…,TZ}に値の大きさに基づく順序T1<T2<…<TZを導入したときの前後を意味する)。この理由は(A)の予備選択処理の対象であるZ1個の候補に候補Tk-1,Tk+1が含まれていない可能性があるからである。ただし、候補Tk-1,Tk+1∈SZ1であって候補Tk-1,Tk+1が集合SZ2に含まれない場合、候補Tk-1,Tk+1を追加しないようにしてもよい。また、追加される候補は、集合SZから選択されればよく、例えば、集合SZ2に含まれる候補Tkについて、Tk-α(ただし、Tk-α∈SZ)および/またはTk+β(ただし、Tk+β∈SZ)を新しい候補として追加するようにしてもよい。ここでα,βは例えば予め定められた正の実数値である。α=βであってもよい。Tk-αおよび/またはTk+βが集合SZ2に含まれる他の候補と重複する場合は、このTk-αおよび/またはTk+βを追加しないようにする(追加しても意味がないからである)。Z2+Q個の候補の集合をSZ3とする。続いて、(D1)または(D2)の処理が行われる。
(D1-ステップS731)間隔決定部7は、間隔Tを決定する対象のフレームが時間的に先頭のフレームである場合、集合SZ3に含まれるZ2+Q個の候補について上述の予備選択処理を実施する。この予備選択処理で絞り込まれた候補の数をY個とする。YはY<Z2+Qを満たす。
間隔決定部7は、フレームXt-1において間隔Tを決定する際に後述の(E)の最終選択処理の対象となった候補の集合SYに一つまたは複数の候補を追加する処理を行う。集合SYに対して追加される候補は、例えば、集合SYに含まれる候補Tmの前後の候補Tm-1,Tm+1∈SZとしてもよい(ここでの「前後」とは、集合SZ={T1,T2,…,TZ}に値の大きさに基づく順序T1<T2<…<TZを導入したときの前後を意味する)。また、追加される候補は、集合SZから選択されればよく、例えば、集合SYに含まれる候補Tmについて、Tm-γ(ただし、Tm-γ∈SZ)および/またはTm+η(ただし、Tm+η∈SZ)を新しい候補として追加するようにしてもよい。ここでγ,ηは例えば予め定められた正の実数値である。γ=ηであってもよい。Tm-γおよび/またはTm+ηが集合SYに含まれる他の候補と重複する場合は、このTm-γおよび/またはTm+ηを追加しないようにする(追加しても意味がないからである)。続いて、(D2)の処理が行われる。
間隔決定部7はY個の候補のそれぞれについて、各候補に基づく上記で説明したサンプル列の並べ替えを行い、並べ替え後のサンプル列を符号化して符号列を得て、符号列の実際の符号量を求め、最小の符号量を与えた候補を間隔Tとして選択する。サンプル列の並べ替えは並べ替え部5が行ない、並べ替え後のサンプル列の符号化は符号化部6が行う。(A)または(D)における予備選択処理で並べ替え後のサンプル列が得られている候補については、予備選択処理で得られた並べ替え後のサンプル列を入力として符号化部6が符号化を行えばよい。
<条件A>
フレームについて、
(1)当該フレームが時間的に先頭ではなく、
(2)一つ前のフレームが本発明の符号化方法に従って符号化されたものであり、かつ、
(3)一つ前のフレームが上述の並べ替え処理の適用を受けている。
音声や楽音などの音響信号では複数のフレームに跨る定常的な信号区間では現在のフレームと過去のフレームとの相関が高いことが多い。定常信号の持つこのような性質を利用して、(D2)の処理にてSZ3とSPの比率を変えることによって圧縮性能を維持しつつ、より処理演算量を下げることができる。なお、ここでの比率は、SZ3に対するSPの比として定められていてもよいし、SPに対するSZ3の比として定められていてもよいし、SZ3∪SPにおけるSPの占有率として定められていてもよいし、SZ3∪SPにおけるSZ3の占有率として定められていてもよい。
(a-1)「現フレームの音響信号の予測利得」が大きい、
(a-2)「現フレームの音響信号の予測利得の推定値」が大きい、
(b-1)「直前フレームの音響信号の予測利得」と「現フレームの音響信号の予測利得」との差分が小さい、
(b-2)「直前フレームの音響信号の予測利得の推定値」と「現フレームの音響信号の予測利得の推定値」との差分が小さい
(c-1)「現フレームに含まれる音響信号のサンプルの振幅の和」が大きい、
(c-2)「現フレームに含まれる音響信号のサンプル列を周波数領域に変換して得られたサンプル列に含まれるサンプルの振幅の和」が大きい、
(d-1)「直前フレームに含まれる音響信号のサンプルの振幅の和」と「現フレームに含まれる音響信号のサンプルの振幅の和」との差分が小さい、
(d-2)「直前フレームに含まれる音響信号のサンプル列を周波数領域に変換して得られたサンプル列に含まれるサンプルの振幅の和」と「現フレームに含まれる音響信号のサンプル列を周波数領域に変換して得られたサンプル列に含まれるサンプルの振幅の和」との差分が小さい、
(e-1)「現フレームの音響信号のパワー」が大きい、
(e-2)「現フレームの音響信号のサンプル列を周波数領域に変換して得られたサンプル列のパワー」が大きい、
(f-1)「直前フレームの音響信号のパワー」と「現フレームの音響信号のパワー」との差分が小さい、
(f-2)「直前フレームの音響信号のサンプル列を周波数領域に変換して得られたサンプル列のパワー」と「現フレームの音響信号のサンプル列を周波数領域に変換して得られたサンプル列のパワー」との差分が小さい、
ほど大きくなる値である。
「フレームの音響信号の予測利得」は、重み付け包絡正規化部2で用いる当該フレームの線形予測係数と対応するm次のPARCOR係数をkmとしたとき、
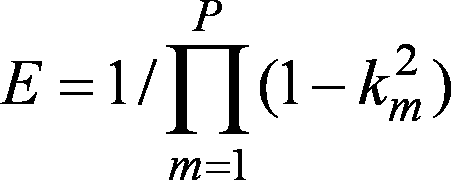
により計算されるEのことである。ここで、線形予測係数と対応するPARCOR 係数は、量子化前の全次のPARCOR係数とする。なお、線形予測係数と対応するPARCOR 係数として、一部の次数(例えば、1次からP2次まで。ただし、P2<P。)の量子化前のPARCOR係数、または、一部または全次の量子化後のPARCOR係数、を用いてEを計算した場合は、計算されたEは「フレームの音響信号の予測利得の推定値」となる。
「フレームに含まれる音響信号のサンプルの振幅の和」とは、当該フレームに含まれる音声音響ディジタル信号のサンプル値の絶対値の総和、または、周波数領域変換部1が出力した当該フレームのMDCT係数列に含まれるサンプルの値の絶対値の総和、である。
「フレームの音響信号のパワー」とは、当該フレームに含まれる音声音響ディジタル信号のサンプル値の二乗の総和、または、周波数領域変換部1が出力した当該フレームのMDCT係数列に含まれるサンプルの値の二乗の総和、である。
G<ε1 ⇒ SZ3∪SPにおけるSPの比率:10%
ε1≦G<ε2 ⇒ SZ3∪SPにおけるSPの比率:20%
…
εk-1≦G<εk ⇒ SZ3∪SPにおけるSPの比率:80%
εk≦G ⇒ SZ3∪SPにおけるSPの比率:90%
と予め定めておくのである。ここでは(a)の基準の「現フレームの音響信号の予測利得」だけを用いる例について説明したが、他の基準はもとより、上記(a)~(f)のうち二つ以上の間の論理和や論理積を定常性の大小判定に用いる場合であっても、ルックアップテーブルに、定常性の大小の程度に応じてSZ3とSPの異なる比率を設定しておくことができる。
G<ε1 ⇒ Z2=16,Q=30
ε1≦G<ε2 ⇒ Z2=12,Q=20
…
εk-1≦G<εk ⇒ Z2=4,Q=4
εk≦G ⇒ Z2=2,Q=0
と予め定めておくのである。ここでは(a)の基準の「現フレームの音響信号の予測利得」だけを用いる例について説明したが、他の基準はもとより、上記(a)~(f)のうち二つ以上の間の論理和や論理積を定常性の大小判定に用いる場合であっても、ルックアップテーブルに、定常性の大小の程度に応じたZ1,Z2,Qの値を設定しておくことができる。
これまで少ない演算処理量で間隔Tを決定する方法を説明したが、当該方法によって決定されるべき対象は間隔Tに限定されない。当該方法は、例えば、サンプルの並べ替えの際に上記サンプル群を特定するための情報である音響信号の周期性特徴量(例えば基本周波数やピッチ周期など)を決定する方法としても使用することができる。すなわち、間隔決定部7を周期性特徴量決定装置として機能させ、並べ替え後のサンプル列を符号化して得られる符号列を出力することなく、間隔Tを周期性特徴量として決定してもよい。この場合、上述の[間隔Tの決定方法]の説明にて、「間隔T」を「ピッチ周期」に読み替えればよく、または、サンプル列のサンプリング周波数を「間隔T」で除算した値を「基本周波数」とすればよく、少ない演算処理量でサンプルの並べ替えのための基本周波数やピッチ周期を決定することができる。
符号化部6または補助情報生成部8は、サンプル列に含まれるサンプルの並べ替えを特定する補助情報、すなわち、音響信号の周期性を表す情報、または基本周波数を表す情報、または音響信号の周期性または基本周波数に対応するサンプルと音響信号の周期性または基本周波数の整数倍に対応するサンプルとの間隔Tを表す情報を出力する。なお、符号化部6が補助情報を出力する場合、サンプル列の符号化処理の中で補助情報を得る処理を行ってもよいし、当該符号化処理と別の処理として補助情報を得る処理を行ってもよい。例えば間隔Tをフレーム毎に決定する場合は、サンプル列に含まれるサンプルの並べ替えを特定する補助情報もフレーム毎に出力されることになる。サンプル列に含まれるサンプルの並べ替えを特定する補助情報は、周期性、基本周波数または間隔Tをフレーム毎に符号化して得られる。この符号化は固定長符号化であってもよいし、可変長符号化して平均符号量を削減してもよい。固定長符号化する場合は、例えば、補助情報と当該補助情報を一意に特定可能な符号とが対応付けられて記憶されており、入力された補助情報に対応する符号を出力する構成となる。可変長符号化する場合は、前フレームの間隔Tと現フレームの間隔Tの差分を可変長符号化した情報を間隔Tを表す情報としもよい。この場合は、例えば、間隔Tの差分値と当該差分値を一意に特定可能な符号とが対応付けられて記憶されており、入力された前フレームの間隔Tと現フレームの間隔Tの差分に対応する符号を出力する構成となる。同様に、前フレームの基本周波数と現フレームの基本周波数の差分を可変長符号化した情報を基本周波数を表す情報としてもよい。また、nを複数の選択肢から選択可能な場合には、nの上限値あるいは上述の上限Nを補助情報に含めてもよい。
また、この実施形態では、各サンプル群に含まれるサンプルの個数が、周期性や基本周波数ないしその整数倍に対応するサンプル(以下、中心サンプルという)とその前後1サンプルの計3サンプルであるという固定された個数の例を示したが、サンプル群に含まれるサンプルの個数やサンプルインデックスを可変とする場合には、サンプル群に含まれるサンプルの個数とサンプルインデックスの組み合わせが異なる複数の選択肢の中から選択された一つを表す情報も補助情報に含める。
例えば、選択肢として、
(1)中心サンプルのみ、F(nT)
(2)中心サンプルとその前後1サンプルの計3サンプル、F(nT-1),F(nT),F(nT+1)
(3)中心サンプルとその前2サンプルの計3サンプル、F(nT-2),F(nT-1),F(nT)
(4)中心サンプルとその前3サンプルの計4サンプル、F(nT-3),F(nT-2),F(nT-1),F(nT)
(5)中心サンプルとその後2サンプルの計3サンプル、F(nT),F(nT+1),F(nT+2)
(6)中心サンプルとその後3サンプルの計4サンプル、F(nT),F(nT+1),F(nT+2),F(nT+3)
が設定されている場合に、(4)が選択されたならば、この(4)が選択されたことを表す情報が補助情報に含められる。この例であれば、選択された選択肢を表す情報として3ビットあれば十分である。
なお、サンプル列に含まれるサンプルの並べ替えによる利点が無い場合も考えられる。このような場合には並べ替え前のサンプル列を符号化すべきである。そこで、並べ替え部5からは並べ替え前のサンプル列(並べ替えを行っていないサンプル列)も出力し、符号化部6は並べ替え前のサンプル列も可変長符号化して符号列を得て、並べ替え前のサンプル列を可変長符号化して得られる符号列の符号量と、並べ替え後のサンプル列を可変長符号化して得られる符号列の符号量と補助情報の符号量との合計符号量とを比較する。
続いて図5~図6を参照して復号処理を説明する。
復号装置200では、符号化装置100または符号化装置100aによる符号化処理と逆順の処理でMDCT係数が再構成される。復号装置200には、少なくとも、上記利得情報と、上記補助情報と、上記符号列が入力される。なお、符号化装置100aから第2補助情報が出力された場合にはこの第2補助情報も復号装置200に入力される。
まず、復号部11が、フレームごとに、入力された符号列を選択情報に応じて復号して周波数領域のサンプル列を出力する(ステップS11)。当然であるが、符号列を得るために実行された符号化方法に対応する復号方法が実行される。復号部11による復号処理の詳細は符号化装置100の符号化部6による符号化処理の詳細に対応するので、当該符号化処理の説明をここに援用し、実行された符号化に対応する復号が復号部11の行う復号処理であることを明記し、これをもって復号処理の詳細な説明とする。なお、どのような符号化方法が実行されたかは選択情報によって特定される。選択情報に、例えば、ライス符号化の適用領域とライスパラメータを特定する情報と、ランレングス符号化の適用領域を表す情報と、エントロピー符号化の種類を特定する情報が含まれている場合には、これらの符号化方法に応じた復号方法が入力された符号列の対応する領域に適用される。ライス符号化に対応する復号処理、エントロピー符号化に対応する復号処理、ランレングス符号化に対応する復号処理はいずれも周知であるから説明を省略する。
次に、回復部12が、フレームごとに、入力された補助情報に従って、復号部11が出力した周波数領域のサンプル列から元のサンプルの並びを得る(ステップS12)。ここで「元のサンプルの並び」とは、符号化装置100の並べ替え部5に入力された「周波数領域のサンプル列」に相当する。上述のとおり、符号化装置100の並べ替え部5による並べ替え方法や並べ替え方法に対応する並べ替えの選択肢は種々あるが、並べ替えが実行された場合には実行された並べ替えは一つであり、その並べ替えを特定する情報は補助情報に含まれている。よって、回復部12は補助情報に基づいて復号部11が出力した周波数領域のサンプル列を元のサンプルの並びに戻すことができる。
そして、補助情報には、例えば、間隔Tに関する情報や、nが1以上5以下の各整数であることを表す情報や、サンプル群には3サンプルが含まれることを特定する情報などが含められている。従って、回復部12は、この補助情報に基づいて、入力されたサンプル列F(T-1),F(T),F(T+1),F(2T-1),F(2T),F(2T+1),F(3T-1),F(3T),F(3T+1),F(4T-1),F(4T),F(4T+1),F(5T-1),F(5T),F(5T+1),F(1),…,F(T-2),F(T+2),…,F(2T-2),F(2T+2),…,F(3T-2),F(3T+2),…,F(4T-2),F(4T+2),…,F(5T-2),F(5T+2),…F(jmax)を元のサンプルの並びF(j)(1≦j≦jmax)に戻すことができる。
次に、逆量子化部13が、フレームごとに、回復部12が出力した元のサンプルの並びF(j)(1≦j≦jmax)を逆量子化する(ステップS13)。上述の例に対応させて述べれば、逆量子化によって、符号化装置100の量子化部4に入力された「利得で正規化された重み付け正規化MDCT係数列」が得られる。
次に、利得乗算部14が、フレームごとに、逆量子化部13が出力した「利得で正規化された重み付け正規化MDCT係数列」の各係数に、上記利得情報で特定される利得を乗じて、「正規化された重み付け正規化MDCT係数列」を得る(ステップS14)。
次に、重み付け包絡逆正規化部15が、フレームごとに、利得乗算部14が出力した「正規化された重み付け正規化MDCT係数列」の各係数に重み付けパワースペクトル包絡値を除算することで「MDCT係数列」を得る(ステップS15)。
次に、時間領域変換部16が、フレームごとに、重み付け包絡逆正規化部15が出力した「MDCT係数列」を時間領域に変換してフレーム単位の音声音響ディジタル信号を得る(ステップS16)。
上述の実施形態に関わる符号化装置/復号装置は、キーボードなどが接続可能な入力部、液晶ディスプレイなどが接続可能な出力部、CPU(Central Processing Unit)〔キャッシュメモリなどを備えていてもよい。〕、メモリであるRAM(Random Access Memory)やROM(Read Only Memory)と、ハードディスクである外部記憶装置、並びにこれらの入力部、出力部、CPU、RAM、ROM、外部記憶装置間のデータのやり取りが可能なように接続するバスなどを備えている。また必要に応じて、符号化装置/復号装置に、CD-ROMなどの記憶媒体を読み書きできる装置(ドライブ)などを設けるとしてもよい。
本発明は上述の実施形態に限定されるものではなく、本発明の趣旨を逸脱しない範囲で適宜変更が可能である。また、上記実施形態において説明した処理は、記載の順に従って時系列に実行されるのみならず、処理を実行する装置の処理能力あるいは必要に応じて並列的にあるいは個別に実行されるとしてもよい。
Claims (23)
- フレーム単位の音響信号に由来する周波数領域のサンプル列の符号化方法であって、
フレーム毎に、上記音響信号の周期性に対応するサンプルの間隔T、または、上記音響信号の基本周波数の整数倍に対応するサンプルの間隔Tを、間隔Tの候補の集合Sの中から決定する間隔決定ステップと、
上記間隔決定ステップで決定された間隔Tを符号化して補助情報を得る補助情報生成ステップと、
(1)上記サンプル列の全てのサンプルが含まれ、かつ、
(2)上記間隔決定ステップで決定された間隔Tに基づいて、上記サンプル列のうちの上記音響信号の周期性または基本周波数に対応するサンプルを含む一つまたは連続する複数のサンプルおよび、上記サンプル列のうちの上記音響信号の周期性または基本周波数の整数倍に対応するサンプルを含む一つまたは連続する複数のサンプル、の全部または一部のサンプルが集まるように上記サンプル列に含まれる少なくとも一部のサンプルを並べ替えたもの、
を並べ替え後のサンプル列として、上記並べ替え後のサンプル列を符号化して符号列を得るサンプル列符号化ステップとを有し、
上記間隔決定ステップは、
上記補助情報で表現可能な間隔TのZ個の候補のうちの、所定フレーム数だけ過去のフレームにおいて間隔決定ステップの対象となった候補に依存せずに選択されたZ2個の候補(ただし、Z2<Z)と、上記所定フレーム数だけ過去のフレームにおいて間隔決定ステップの対象となった候補と、によるY個の候補(ただし、Y<Z)により構成される集合を上記集合Sとして、上記間隔Tを決定するステップである
ことを特徴とする符号化方法。 - 請求項1に記載の符号化方法であって、
上記間隔決定ステップは、
上記所定フレーム数だけ過去のフレームにおいて間隔決定ステップの対象となった候補に隣接する値または/および所定の差分を持つ値を上記集合Sに加える追加ステップを更に含む
ことを特徴とする符号化方法。 - 請求項1または請求項2に記載の符号化方法であって、
上記間隔決定ステップは、
上記補助情報で表現可能な間隔TのZ個の候補のうちの一部であるZ1個の候補から、現在のフレームの上記音響信号または/およびサンプル列から求まる指標に基づいて選択した一部の候補を上記Z2個の候補(ただしZ2<Z1)とする予備選択ステップを更に含む
ことを特徴とする符号化方法。 - 請求項1または請求項2に記載の符号化方法であって、
上記間隔決定ステップは、
上記補助情報で表現可能な間隔TのZ個の候補のうちの一部であるZ1個の候補から、現在のフレームの上記音響信号または/およびサンプル列から求まる指標に基づいて一部の候補を選択する予備選択ステップと、
上記予備選択ステップで選択された候補と、上記予備選択ステップで選択された候補に隣接する値または/および所定の差分を持つ値とのセットを上記Z2個の候補とする第二追加ステップを更に含む
ことを特徴とする符号化方法。 - 請求項1から請求項4の何れかに記載の符号化方法であって、
上記間隔決定ステップは、
現在のフレームの上記音響信号または/およびサンプル列から求まる指標に基づいて、上記集合Sに含まれる間隔Tの候補のうちの一部の候補を選択する第二予備選択ステップと、
上記第二予備選択ステップで選択された一部の候補により構成される集合を対象として上記間隔Tを決定する最終選択ステップとを含む
こと特徴とする符号化方法。 - 請求項1から請求項5の何れかに記載の符号化方法であって、
現在のフレームの上記音響信号の定常性の大きさを表す指標値が大きいほど、上記集合Sにて、上記所定フレーム数だけ過去のフレームにおいて間隔決定ステップの対象となった候補が占める割合が大きい
ことを特徴とする符号化方法。 - 請求項1から請求項6の何れかに記載の符号化方法であって、
現在のフレームの上記音響信号の定常性の大きさを表す指標値が所定の条件より小さい場合には、上記集合Sには上記Z2個の候補のみが含まれる
ことを特徴とする符号化方法。 - 請求項6または請求項7に記載の符号化方法であって、上記現在のフレームの上記音響信号の定常性の大きさを表す指標値は、
(a-1)「現在のフレームの上記音響信号の予測利得」が大きい、
(a-2)「現在のフレームの上記音響信号の予測利得の推定値」が大きい、
(b-1)「直前のフレームの予測利得」と「現在のフレームの予測利得」との差分が小さい、
(b-2)「直前のフレームの予測利得の推定値」と「現在のフレームの予測利得の推定値」との差分が小さい、
(c-1)「現在のフレームに含まれる上記音響信号のサンプルの振幅の和」が大きい、
(c-2)「現在のフレームに含まれる上記音響信号のサンプル列を周波数領域に変換して得られたサンプル列に含まれるサンプルの振幅の和」が大きい、
(d-1)「直前のフレームに含まれる上記音響信号のサンプルの振幅の和」と「現在のフレームに含まれる上記音響信号のサンプルの振幅の和」との差分が小さい、
(d-2)「直前のフレームに含まれる上記音響信号のサンプル列を周波数領域に変換して得られたサンプル列に含まれるサンプルの振幅の和」と「現在のフレームに含まれる上記音響信号のサンプル列を周波数領域に変換して得られたサンプル列に含まれるサンプルの振幅の和」との差分が小さい、
(e-1)「現在のフレームの上記音響信号のパワー」が大きい、
(e-2)「現在のフレームの上記音響信号のサンプル列を周波数領域に変換して得られたサンプル列のパワー」が大きい、
(f-1)「直前のフレームの上記音響信号のパワー」と「現在のフレームの上記音響信号のパワー」との差分が小さい、
(f-2)「直前のフレームの上記音響信号のサンプル列を周波数領域に変換して得られたサンプル列のパワー」と「現在のフレームの上記音響信号のサンプル列を周波数領域に変換して得られたサンプル列のパワー」との差分が小さい、の少なくともいずれか一つの条件を満たす場合に、大きくなる値である
ことを特徴とする符号化方法。 - 請求項1から請求項5の何れかに記載の符号化方法であって、
上記サンプル列符号化ステップは、
上記並べ替え前のサンプル列を符号化して得られる符号列と、上記並べ替え後のサンプル列を符号化して得られる符号列と上記補助情報、のうち符号量が少ない方を出力するステップを含む
ことを特徴とする符号化方法。 - 請求項1から請求項5の何れかに記載の符号化方法であって、
上記サンプル列符号化ステップは、
上記並べ替え後のサンプル列を符号化して得られる符号列の符号量またはその推定値と上記補助情報の符号量との合計が、上記並べ替え前のサンプル列を符号化して得られる符号列の符号量またはその推定値より少ない場合には、上記並べ替え後のサンプル列を符号化して得られる符号列と上記補助情報とを出力し、
上記並べ替え前のサンプル列を符号化して得られる符号列の符号量またはその推定値が、上記並べ替え後のサンプル列を符号化して得られる符号列の符号量またはその推定値と上記補助情報の符号量との合計より少ない場合には、上記並べ替え前のサンプル列を符号化して得られる符号列を出力する
ことを特徴とする符号化方法。 - 請求項9または請求項10に記載の符号化方法であって、
直前のフレームで出力した符号列が並べ替え後のサンプル列を符号化して得られた符号列である場合のほうが、直前のフレームで出力した符号列が並べ替え前のサンプル列を符号化して得られた符号列である場合よりも、上記集合Sにて、上記所定フレーム数だけ過去のフレームにおいて間隔決定ステップの対象となった候補が占める割合が大きい
ことを特徴とする符号化方法。 - 請求項9から請求項11のいずれかに記載の符号化方法であって、
直前のフレームで出力した符号列が並べ替え前のサンプル列を符号化して得られた符号列である場合には、上記集合Sには上記Z2個の候補のみが含まれる
ことを特徴とする符号化方法。 - 請求項9から請求項11のいずれかに記載の符号化方法であって、
現在のフレームが時間的に先頭にあるフレームである場合、直前のフレームが上記の符号化方法以外で符号化された場合、直前のフレームで出力した符号列が並べ替え前のサンプル列を符号化して得られた符号列である場合、の何れかに該当する場合には、上記集合Sには上記Z2個の候補のみが含まれる
ことを特徴とする符号化方法。 - フレーム単位の音響信号の周期性特徴量を決定する方法であって、
フレーム毎に、上記音響信号の周期性特徴量を、周期性特徴量の候補の集合の中から決定する周期性特徴量決定ステップと、
周期性特徴量決定ステップで得られた周期性特徴量を符号化して補助情報を得る補助情報生成ステップとを有し、
上記周期性特徴量決定ステップは、
上記補助情報で表現可能な周期性特徴量のZ個の候補のうちの、所定フレーム数だけ過去のフレームにおいて周期性特徴量決定ステップの対象となった候補に依存せずに選択されたZ2個の候補(ただし、Z2<Z)と、上記所定フレーム数だけ過去のフレームにおいて周期性特徴量決定ステップの対象となった候補と、によるY個の候補(ただし、Y<Z)により構成される集合を周期性特徴量の候補の集合Sとして、上記周期性特徴量を決定するステップである
ことを特徴とする周期性特徴量決定方法。 - 請求項14に記載の周期性特徴量決定方法であって、
上記周期性特徴量決定ステップは、
上記所定フレーム数だけ過去のフレームにおいて周期性特徴量決定ステップの対象となった候補に隣接する値または/および所定の差分を持つ値を上記集合Sに加える追加ステップを更に含む
ことを特徴とする周期性特徴量決定方法。 - 請求項14または請求項15に記載の周期性特徴量決定方法であって、
現在のフレームの上記音響信号の定常性の大きさを表す指標値が大きいほど、上記集合Sにて、上記所定フレーム数だけ過去のフレームにおいて周期性特徴量決定ステップの対象となった候補が占める割合が大きい
ことを特徴とする周期性特徴量決定方法。 - 請求項16に記載の周期性特徴量決定方法であって、
現在のフレームの上記音響信号の定常性の大きさを表す指標値が所定の条件より小さい場合には、上記集合Sには上記Z2個の候補のみが含まれる
ことを特徴とする周期性特徴量決定方法。 - 請求項16または請求項17に記載の周期性特徴量決定方法であって、上記現在のフレームの上記音響信号の定常性の大きさを表す指標値は、
(a-1)「現在のフレームの上記音響信号の予測利得」が大きい、
(a-2)「現在のフレームの上記音響信号の予測利得の推定値」が大きい、
(b-1)「直前のフレームの予測利得」と「現在のフレームの予測利得」との差分が小さい、
(b-2)「直前のフレームの予測利得の推定値」と「現在のフレームの予測利得の推定値」との差分が小さい、
(c-1)「現在のフレームに含まれる上記音響信号のサンプルの振幅の和」が大きい、
(c-2)「現在のフレームに含まれる上記音響信号のサンプル列を周波数領域に変換して得られたサンプル列に含まれるサンプルの振幅の和」が大きい、
(d-1)「直前のフレームに含まれる上記音響信号のサンプルの振幅の和」と「現在のフレームに含まれる上記音響信号のサンプルの振幅の和」との差分が小さい、
(d-2)「直前のフレームに含まれる上記音響信号のサンプル列を周波数領域に変換して得られたサンプル列に含まれるサンプルの振幅の和」と「現在のフレームに含まれる上記音響信号のサンプル列を周波数領域に変換して得られたサンプル列に含まれるサンプルの振幅の和」との差分が小さい、
(e-1)「現在のフレームの上記音響信号のパワー」が大きい、
(e-2)「現在のフレームの上記音響信号のサンプル列を周波数領域に変換して得られたサンプル列のパワー」が大きい、
(f-1)「直前のフレームの上記音響信号のパワー」と「現在のフレームの上記音響信号のパワー」との差分が小さい、
(f-2)「直前のフレームの上記音響信号のサンプル列を周波数領域に変換して得られたサンプル列のパワー」と「現在のフレームの上記音響信号のサンプル列を周波数領域に変換して得られたサンプル列のパワー」との差分が小さい、の少なくともいずれか一つの条件を満たす場合に、大きくなる値である
ことを特徴とする周期性特徴量決定方法。 - フレーム単位の音響信号に由来する周波数領域のサンプル列の符号化装置であって、
フレーム毎に、上記音響信号の周期性に対応するサンプルの間隔T、または、上記音響信号の基本周波数の整数倍に対応するサンプルの間隔Tを、間隔Tの候補の集合Sの中から決定する間隔決定部と、
上記間隔決定部によって決定された間隔Tを符号化して補助情報を得る補助情報生成部と、
(1)上記サンプル列の全てのサンプルが含まれ、かつ、
(2)上記間隔決定部によって決定された間隔Tに基づいて、上記サンプル列のうちの上記音響信号の周期性または基本周波数に対応するサンプルを含む一つまたは連続する複数のサンプルおよび、上記サンプル列のうちの上記音響信号の周期性または基本周波数の整数倍に対応するサンプルを含む一つまたは連続する複数のサンプル、の全部または一部のサンプルが集まるように上記サンプル列に含まれる少なくとも一部のサンプルを並べ替えたもの、
を並べ替え後のサンプル列として、上記並べ替え後のサンプル列を符号化して符号列を得るサンプル列符号化部とを含み、
上記間隔決定部は、
上記補助情報で表現可能な間隔TのZ個の候補のうちの、所定フレーム数だけ過去のフレームにおいて間隔決定部による処理対象となった候補に依存せずに選択されたZ2個の候補(ただし、Z2<Z)と、上記所定フレーム数だけ過去のフレームにおいて間隔決定部による処理対象となった候補と、によるY個の候補(ただし、Y<Z)により構成される集合を上記集合Sとして、上記間隔Tを決定する
ことを特徴とする符号化装置。 - 請求項19に記載の符号化装置であって、
上記サンプル列符号化部は、
上記並べ替え後のサンプル列を符号化して得られる符号列の符号量またはその推定値と上記補助情報の符号量との合計が、上記並べ替え前のサンプル列を符号化して得られる符号列の符号量またはその推定値より少ない場合には、上記並べ替え後のサンプル列を符号化して得られる符号列と上記補助情報とを出力し、
上記並べ替え前のサンプル列を符号化して得られる符号列の符号量またはその推定値が、上記並べ替え後のサンプル列を符号化して得られる符号列の符号量またはその推定値と上記補助情報の符号量との合計より少ない場合には、上記並べ替え前のサンプル列を符号化して得られる符号列を出力する
ことを特徴とする符号化装置。 - フレーム単位の音響信号の周期性特徴量を決定する周期性特徴量決定装置であって、
フレーム毎に、上記音響信号の周期性特徴量を、周期性特徴量の候補の集合の中から決定する周期性特徴量決定部と、
周期性決定部によって得られた周期性特徴量を符号化して補助情報を得る補助情報生成部とを含み、
上記周期性決定部は、
上記補助情報で表現可能な周期性特徴量のZ個の候補のうちの、所定フレーム数だけ過去のフレームにおいて周期性特徴量決定部による処理対象となった候補に依存せずに選択されたZ2個の候補(ただし、Z2<Z)と、上記所定フレーム数だけ過去のフレームにおいて周期性特徴量決定部による処理対象となった候補と、によるY個の候補(ただし、Y<Z)により構成される集合を周期性特徴量の候補の集合Sとして、上記周期性特徴量を決定する
ことを特徴とする周期性特徴量決定装置。 - 請求項1から請求項13のいずれかに記載された符号化方法、または、請求項14から請求項18のいずれかに記載された周期性特徴量決定方法、の各ステップをコンピュータに実行させるためのプログラム。
- 請求項1から請求項13のいずれかに記載された符号化方法、または、請求項14から請求項18のいずれかに記載された周期性特徴量決定方法、の各ステップをコンピュータに実行させるためのプログラムを記録した、コンピュータが読み取り可能な記録媒体。
Priority Applications (8)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| RU2013134463/08A RU2554554C2 (ru) | 2011-01-25 | 2012-01-18 | Способ кодирования, кодер, способ определения величины периодического признака, устройство определения величины периодического признака, программа и носитель записи |
| ES12739924.4T ES2558508T3 (es) | 2011-01-25 | 2012-01-18 | Método de codificación, codificador, método de determinación de la cantidad de una característica periódica, aparato de determinación de la cantidad de una característica periódica, programa y medio de grabación |
| JP2012554739A JP5596800B2 (ja) | 2011-01-25 | 2012-01-18 | 符号化方法、周期性特徴量決定方法、周期性特徴量決定装置、プログラム |
| EP12739924.4A EP2650878B1 (en) | 2011-01-25 | 2012-01-18 | Encoding method, encoder, periodic feature amount determination method, periodic feature amount determination apparatus, program and recording medium |
| KR1020167017192A KR101740359B1 (ko) | 2011-01-25 | 2012-01-18 | 부호화 방법, 부호화 장치, 주기성 특징량 결정 방법, 주기성 특징량 결정 장치, 프로그램, 기록 매체 |
| CN201280006378.1A CN103329199B (zh) | 2011-01-25 | 2012-01-18 | 编码方法、编码装置、周期性特征量决定方法、周期性特征量决定装置、程序、记录介质 |
| KR1020137019179A KR20130111611A (ko) | 2011-01-25 | 2012-01-18 | 부호화 방법, 부호화 장치, 주기성 특징량 결정 방법, 주기성 특징량 결정 장치, 프로그램, 기록 매체 |
| US13/981,125 US9711158B2 (en) | 2011-01-25 | 2012-01-18 | Encoding method, encoder, periodic feature amount determination method, periodic feature amount determination apparatus, program and recording medium |
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2011-013426 | 2011-01-25 | ||
| JP2011013426 | 2011-01-25 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2012102149A1 true WO2012102149A1 (ja) | 2012-08-02 |
Family
ID=46580721
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2012/050970 Ceased WO2012102149A1 (ja) | 2011-01-25 | 2012-01-18 | 符号化方法、符号化装置、周期性特徴量決定方法、周期性特徴量決定装置、プログラム、記録媒体 |
Country Status (8)
| Country | Link |
|---|---|
| US (1) | US9711158B2 (ja) |
| EP (1) | EP2650878B1 (ja) |
| JP (1) | JP5596800B2 (ja) |
| KR (2) | KR20130111611A (ja) |
| CN (1) | CN103329199B (ja) |
| ES (1) | ES2558508T3 (ja) |
| RU (1) | RU2554554C2 (ja) |
| WO (1) | WO2012102149A1 (ja) |
Cited By (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2014054556A1 (ja) * | 2012-10-01 | 2014-04-10 | 日本電信電話株式会社 | 符号化方法、符号化装置、プログラム、および記録媒体 |
| JP2017501427A (ja) * | 2013-10-18 | 2017-01-12 | フラウンホーファー−ゲゼルシャフト・ツール・フェルデルング・デル・アンゲヴァンテン・フォルシュング・アインゲトラーゲネル・フェライン | オーディオ信号のスペクトルのスペクトル係数のコード化 |
| JP2017227904A (ja) * | 2014-03-24 | 2017-12-28 | 日本電信電話株式会社 | 符号化方法、符号化装置、プログラム、および記録媒体 |
| JP2018013795A (ja) * | 2014-05-01 | 2018-01-25 | 日本電信電話株式会社 | 符号化装置、復号装置、符号化方法、復号方法、符号化プログラム、復号プログラム、記録媒体 |
| CN112992165A (zh) * | 2014-07-28 | 2021-06-18 | 日本电信电话株式会社 | 编码方法、装置、程序以及记录介质 |
Families Citing this family (8)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN110349590B (zh) * | 2014-01-24 | 2023-03-24 | 日本电信电话株式会社 | 线性预测分析装置、方法以及记录介质 |
| WO2015162979A1 (ja) | 2014-04-24 | 2015-10-29 | 日本電信電話株式会社 | 周波数領域パラメータ列生成方法、符号化方法、復号方法、周波数領域パラメータ列生成装置、符号化装置、復号装置、プログラム及び記録媒体 |
| PL3699910T3 (pl) * | 2014-05-01 | 2021-11-02 | Nippon Telegraph And Telephone Corporation | Urządzenie generujące sekwencję okresowej połączonej obwiedni, sposób generowania sekwencji okresowej połączonej obwiedni, program do generowania sekwencji okresowej połączonej obwiedni i nośnik rejestrujący |
| JP6499206B2 (ja) * | 2015-01-30 | 2019-04-10 | 日本電信電話株式会社 | パラメータ決定装置、方法、プログラム及び記録媒体 |
| JP6758890B2 (ja) * | 2016-04-07 | 2020-09-23 | キヤノン株式会社 | 音声判別装置、音声判別方法、コンピュータプログラム |
| US10146500B2 (en) * | 2016-08-31 | 2018-12-04 | Dts, Inc. | Transform-based audio codec and method with subband energy smoothing |
| CN106373594B (zh) * | 2016-08-31 | 2019-11-26 | 华为技术有限公司 | 一种音调检测方法及装置 |
| CN108665036A (zh) * | 2017-04-02 | 2018-10-16 | 田雪松 | 位置编码方法 |
Citations (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH06131000A (ja) * | 1992-10-15 | 1994-05-13 | Nec Corp | 基本周期符号化装置 |
| JPH1152994A (ja) * | 1997-08-05 | 1999-02-26 | Kokusai Electric Co Ltd | 音声符号化装置 |
| JP2004187290A (ja) * | 2002-11-21 | 2004-07-02 | Nippon Telegr & Teleph Corp <Ntt> | ディジタル信号処理方法、その処理器、そのプログラム、及びそのプログラムを格納した記録媒体 |
| JP2006126592A (ja) * | 2004-10-29 | 2006-05-18 | Casio Comput Co Ltd | 音声符号化装置、音声復号装置、音声符号化方法及び音声復号方法 |
| WO2006121101A1 (ja) * | 2005-05-13 | 2006-11-16 | Matsushita Electric Industrial Co., Ltd. | 音声符号化装置およびスペクトル変形方法 |
| JP2009156971A (ja) | 2007-12-25 | 2009-07-16 | Nippon Telegr & Teleph Corp <Ntt> | 符号化装置、復号化装置、符号化方法、復号化方法、符号化プログラム、復号化プログラム、および記録媒体 |
| JP2009253706A (ja) * | 2008-04-07 | 2009-10-29 | Casio Comput Co Ltd | 符号化装置、復号装置、符号化方法、復号方法及びプログラム |
Family Cites Families (17)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US5765127A (en) * | 1992-03-18 | 1998-06-09 | Sony Corp | High efficiency encoding method |
| JP3277705B2 (ja) * | 1994-07-27 | 2002-04-22 | ソニー株式会社 | 情報符号化装置及び方法、並びに情報復号化装置及び方法 |
| JP4005154B2 (ja) * | 1995-10-26 | 2007-11-07 | ソニー株式会社 | 音声復号化方法及び装置 |
| JP2001285073A (ja) * | 2000-03-29 | 2001-10-12 | Sony Corp | 信号処理装置及び方法 |
| US6587816B1 (en) | 2000-07-14 | 2003-07-01 | International Business Machines Corporation | Fast frequency-domain pitch estimation |
| WO2003038812A1 (en) * | 2001-11-02 | 2003-05-08 | Matsushita Electric Industrial Co., Ltd. | Audio encoding and decoding device |
| WO2003077235A1 (en) | 2002-03-12 | 2003-09-18 | Nokia Corporation | Efficient improvements in scalable audio coding |
| RU2383941C2 (ru) * | 2005-06-30 | 2010-03-10 | ЭлДжи ЭЛЕКТРОНИКС ИНК. | Способ и устройство для кодирования и декодирования аудиосигналов |
| US7599840B2 (en) * | 2005-07-15 | 2009-10-06 | Microsoft Corporation | Selectively using multiple entropy models in adaptive coding and decoding |
| KR100883656B1 (ko) | 2006-12-28 | 2009-02-18 | 삼성전자주식회사 | 오디오 신호의 분류 방법 및 장치와 이를 이용한 오디오신호의 부호화/복호화 방법 및 장치 |
| JP4871894B2 (ja) * | 2007-03-02 | 2012-02-08 | パナソニック株式会社 | 符号化装置、復号装置、符号化方法および復号方法 |
| US20090319261A1 (en) | 2008-06-20 | 2009-12-24 | Qualcomm Incorporated | Coding of transitional speech frames for low-bit-rate applications |
| MY154452A (en) * | 2008-07-11 | 2015-06-15 | Fraunhofer Ges Forschung | An apparatus and a method for decoding an encoded audio signal |
| EP2144230A1 (en) * | 2008-07-11 | 2010-01-13 | Fraunhofer-Gesellschaft zur Förderung der angewandten Forschung e.V. | Low bitrate audio encoding/decoding scheme having cascaded switches |
| ES2592416T3 (es) * | 2008-07-17 | 2016-11-30 | Fraunhofer-Gesellschaft zur Förderung der angewandten Forschung e.V. | Esquema de codificación/decodificación de audio que tiene una derivación conmutable |
| US8207875B2 (en) | 2009-10-28 | 2012-06-26 | Motorola Mobility, Inc. | Encoder that optimizes bit allocation for information sub-parts |
| US8924222B2 (en) * | 2010-07-30 | 2014-12-30 | Qualcomm Incorporated | Systems, methods, apparatus, and computer-readable media for coding of harmonic signals |
-
2012
- 2012-01-18 KR KR1020137019179A patent/KR20130111611A/ko not_active Ceased
- 2012-01-18 KR KR1020167017192A patent/KR101740359B1/ko active Active
- 2012-01-18 US US13/981,125 patent/US9711158B2/en active Active
- 2012-01-18 ES ES12739924.4T patent/ES2558508T3/es active Active
- 2012-01-18 JP JP2012554739A patent/JP5596800B2/ja active Active
- 2012-01-18 CN CN201280006378.1A patent/CN103329199B/zh active Active
- 2012-01-18 EP EP12739924.4A patent/EP2650878B1/en active Active
- 2012-01-18 RU RU2013134463/08A patent/RU2554554C2/ru active
- 2012-01-18 WO PCT/JP2012/050970 patent/WO2012102149A1/ja not_active Ceased
Patent Citations (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH06131000A (ja) * | 1992-10-15 | 1994-05-13 | Nec Corp | 基本周期符号化装置 |
| JPH1152994A (ja) * | 1997-08-05 | 1999-02-26 | Kokusai Electric Co Ltd | 音声符号化装置 |
| JP2004187290A (ja) * | 2002-11-21 | 2004-07-02 | Nippon Telegr & Teleph Corp <Ntt> | ディジタル信号処理方法、その処理器、そのプログラム、及びそのプログラムを格納した記録媒体 |
| JP2006126592A (ja) * | 2004-10-29 | 2006-05-18 | Casio Comput Co Ltd | 音声符号化装置、音声復号装置、音声符号化方法及び音声復号方法 |
| WO2006121101A1 (ja) * | 2005-05-13 | 2006-11-16 | Matsushita Electric Industrial Co., Ltd. | 音声符号化装置およびスペクトル変形方法 |
| JP2009156971A (ja) | 2007-12-25 | 2009-07-16 | Nippon Telegr & Teleph Corp <Ntt> | 符号化装置、復号化装置、符号化方法、復号化方法、符号化プログラム、復号化プログラム、および記録媒体 |
| JP2009253706A (ja) * | 2008-04-07 | 2009-10-29 | Casio Comput Co Ltd | 符号化装置、復号装置、符号化方法、復号方法及びプログラム |
Non-Patent Citations (3)
| Title |
|---|
| J. HERRE; E. ALLAMANCHE; K. BRANDENBURG; M. DIETZ; B. TEICHMANN; B. GRILL; A. JIN; T. MORIYA; N. IWAKAMI; T. NORIMATSU: "The Integrated Filterbank Based Scalable MPEG-4, Audio Coder", 105TH CONVENTION AUDIO ENGINEERING SOCIETY, 1998, pages 4810 |
| See also references of EP2650878A4 |
| T. MORIYA; N. IWAKAMI; A. JIN; K. IKEDA; S. MIKI: "A Design of Transform Coder for Both Speech and Audio Signals at 1 bit/sample", PROC. ICASSP '97, 1997, pages 1371 - 1384 |
Cited By (15)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| EP3252762A1 (en) * | 2012-10-01 | 2017-12-06 | Nippon Telegraph and Telephone Corporation | Encoding method, encoder, program and recording medium |
| WO2014054556A1 (ja) * | 2012-10-01 | 2014-04-10 | 日本電信電話株式会社 | 符号化方法、符号化装置、プログラム、および記録媒体 |
| JP5893153B2 (ja) * | 2012-10-01 | 2016-03-23 | 日本電信電話株式会社 | 符号化方法、符号化装置、プログラム、および記録媒体 |
| EP2887349A4 (en) * | 2012-10-01 | 2016-04-27 | Nippon Telegraph & Telephone | CODING METHOD, CODING DEVICE, PROGRAM AND RECORDING MEDIUM |
| EP3525208A1 (en) * | 2012-10-01 | 2019-08-14 | Nippon Telegraph and Telephone Corporation | Encoding method, encoder, program and recording medium |
| CN104704559B (zh) * | 2012-10-01 | 2017-09-15 | 日本电信电话株式会社 | 编码方法以及编码装置 |
| CN104704559A (zh) * | 2012-10-01 | 2015-06-10 | 日本电信电话株式会社 | 编码方法、编码装置、程序、以及记录介质 |
| US10115401B2 (en) | 2013-10-18 | 2018-10-30 | Fraunhofer-Gesellschaft Zur Foerderung Der Angewandten Forschung E.V. | Coding of spectral coefficients of a spectrum of an audio signal |
| US9892735B2 (en) | 2013-10-18 | 2018-02-13 | Fraunhofer-Gesellschaft Zur Foerderung Der Angewandten Forschung E.V. | Coding of spectral coefficients of a spectrum of an audio signal |
| JP2018205758A (ja) * | 2013-10-18 | 2018-12-27 | フラウンホーファー−ゲゼルシャフト・ツール・フェルデルング・デル・アンゲヴァンテン・フォルシュング・アインゲトラーゲネル・フェライン | オーディオ信号のスペクトルのスペクトル係数のコード化 |
| JP2017501427A (ja) * | 2013-10-18 | 2017-01-12 | フラウンホーファー−ゲゼルシャフト・ツール・フェルデルング・デル・アンゲヴァンテン・フォルシュング・アインゲトラーゲネル・フェライン | オーディオ信号のスペクトルのスペクトル係数のコード化 |
| US10847166B2 (en) | 2013-10-18 | 2020-11-24 | Fraunhofer-Gesellschaft Zur Foerderung Der Angewandten Forschung E.V. | Coding of spectral coefficients of a spectrum of an audio signal |
| JP2017227904A (ja) * | 2014-03-24 | 2017-12-28 | 日本電信電話株式会社 | 符号化方法、符号化装置、プログラム、および記録媒体 |
| JP2018013795A (ja) * | 2014-05-01 | 2018-01-25 | 日本電信電話株式会社 | 符号化装置、復号装置、符号化方法、復号方法、符号化プログラム、復号プログラム、記録媒体 |
| CN112992165A (zh) * | 2014-07-28 | 2021-06-18 | 日本电信电话株式会社 | 编码方法、装置、程序以及记录介质 |
Also Published As
| Publication number | Publication date |
|---|---|
| RU2013134463A (ru) | 2015-03-10 |
| CN103329199B (zh) | 2015-04-08 |
| JPWO2012102149A1 (ja) | 2014-06-30 |
| KR20130111611A (ko) | 2013-10-10 |
| US9711158B2 (en) | 2017-07-18 |
| RU2554554C2 (ru) | 2015-06-27 |
| EP2650878A1 (en) | 2013-10-16 |
| US20130311192A1 (en) | 2013-11-21 |
| KR101740359B1 (ko) | 2017-05-26 |
| CN103329199A (zh) | 2013-09-25 |
| JP5596800B2 (ja) | 2014-09-24 |
| EP2650878B1 (en) | 2015-11-18 |
| KR20160080115A (ko) | 2016-07-07 |
| ES2558508T3 (es) | 2016-02-04 |
| EP2650878A4 (en) | 2014-11-05 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP5596800B2 (ja) | 符号化方法、周期性特徴量決定方法、周期性特徴量決定装置、プログラム | |
| JP5612698B2 (ja) | 符号化方法、復号方法、符号化装置、復号装置、プログラム、記録媒体 | |
| US11024319B2 (en) | Encoding method, decoding method, encoder, decoder, program, and recording medium | |
| CN104321814B (zh) | 频域基音周期分析方法和频域基音周期分析装置 | |
| JP5893153B2 (ja) | 符号化方法、符号化装置、プログラム、および記録媒体 | |
| JP5694751B2 (ja) | 符号化方法、復号方法、符号化装置、復号装置、プログラム、記録媒体 | |
| CN106463134B (zh) | 用于对线性预测系数进行量化的方法和装置及用于反量化的方法和装置 | |
| JP5663461B2 (ja) | 符号化方法、符号化装置、プログラム、記録媒体 | |
| JPWO2013129528A1 (ja) | 符号化装置、この方法、プログラムおよび記録媒体 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 12739924 Country of ref document: EP Kind code of ref document: A1 |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 2012739924 Country of ref document: EP |
|
| ENP | Entry into the national phase |
Ref document number: 2012554739 Country of ref document: JP Kind code of ref document: A |
|
| ENP | Entry into the national phase |
Ref document number: 20137019179 Country of ref document: KR Kind code of ref document: A |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 13981125 Country of ref document: US |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| ENP | Entry into the national phase |
Ref document number: 2013134463 Country of ref document: RU Kind code of ref document: A |