WO2012108006A1 - 検索プログラム、検索装置、および検索方法 - Google Patents
検索プログラム、検索装置、および検索方法 Download PDFInfo
- Publication number
- WO2012108006A1 WO2012108006A1 PCT/JP2011/052666 JP2011052666W WO2012108006A1 WO 2012108006 A1 WO2012108006 A1 WO 2012108006A1 JP 2011052666 W JP2011052666 W JP 2011052666W WO 2012108006 A1 WO2012108006 A1 WO 2012108006A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- hierarchy
- search
- character string
- classification code
- comparison
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Ceased
Links
Images










Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/20—Information retrieval; Database structures therefor; File system structures therefor of structured data, e.g. relational data
- G06F16/24—Querying
- G06F16/245—Query processing
- G06F16/2458—Special types of queries, e.g. statistical queries, fuzzy queries or distributed queries
- G06F16/2468—Fuzzy queries
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/30—Information retrieval; Database structures therefor; File system structures therefor of unstructured textual data
- G06F16/33—Querying
- G06F16/3331—Query processing
- G06F16/334—Query execution
- G06F16/3347—Query execution using vector based model
Definitions
- the present invention relates to a search program, a search device, and a search method for searching for information.
- the fuzzy search is, for example, when a search character string such as “landscape” and “photograph” is given, even if it is a character string “take a picture” that does not match the search character string, It is a search method that can be searched because the meaning is similar.
- a search method for such an ambiguous search, conventionally, a search method has been disclosed in which a plurality of keywords (a keyword includes a classification code) is converted into a vector and score calculation is performed (for example, see Patent Document 1 below). .
- a search method that uses a bitmap full-text index in a free word search is disclosed. This bitmap type full-text index forms a hierarchical structure with a block bitmap in which a bit string having the same number of bits as that character is arranged in each block for each character (for example, see Patent Document 2 below).
- the similarity is calculated between the input symbol string vector and the standard vector of the predetermined symbol string registered in the dictionary, and if there is an error, the search is performed to correct the word corresponding to the symbol string by dictionary search.
- a method is disclosed (for example, see Patent Document 3 below).
- an object of the present invention is to provide a search program, a search device, and a search method that can improve fuzzy search accuracy.
- a classification code for each search word hierarchy in the search character string and each of the comparison character string groups A classification code for each hierarchy of comparison words in the comparison character string, and the synonym dictionary data among the classification code for each hierarchy of the specified search word and the classification code for each hierarchy of each comparison word
- the classification code of the specific hierarchy is extracted from the hierarchy group that constitutes, and it is compared whether or not the classification code of the specific hierarchy of the extracted search word matches the classification code of the specific hierarchy of the comparison word Whether to determine for each character string, count the number of matches in the specific layer, and exclude comparison character strings in which the classification code of the specific layer of the comparison word is determined to be inconsistent based on the counted number of matches Determine whether or not
- the search character string and the comparison character string determined not to be excluded based on the classification code of each word in the search word and the classification code of each comparison word in the comparison character string determined not to be excluded
- a search program, a search device, and a search method are used
- search program search device, and search method of the present invention, it is possible to improve the fuzzy search accuracy.
- FIG. 1 is an explanatory diagram showing an example of the data structure of synonym dictionary data.
- FIG. 2 is an explanatory diagram illustrating an example of a classification map of the first hierarchy (major classification).
- FIG. 3 is an explanatory diagram illustrating an example of a classification map of the second hierarchy (medium classification).
- FIG. 4 is an explanatory diagram illustrating an example of a classification map of the third hierarchy (small classification).
- FIG. 5 is an explanatory diagram showing the link relationship between the classification map group and the target file group.
- FIG. 6 is a block diagram of a hardware configuration of the computer according to the embodiment.
- FIG. 7 is a flowchart showing the generation process of the classification map group M and the classification code file group C.
- FIG. 8 is a block diagram illustrating a functional configuration example of the search device according to the present embodiment.
- FIG. 9 is a block diagram illustrating a functional configuration example of the first search processing unit 804 illustrated in FIG. 8.
- FIG. 10 is an explanatory diagram showing a specific example 1 of similarity calculation by the first calculation unit 907.
- FIG. 11 is an explanatory diagram illustrating a specific example 2 of similarity calculation by the first calculator 907.
- FIG. 12 is a block diagram illustrating a functional configuration example of the second search processing unit 805 illustrated in FIG.
- FIG. 13 is an explanatory diagram illustrating a specific example 1 of similarity calculation by the second calculator 1204.
- FIG. 14 is an explanatory diagram showing a specific example 2 of similarity calculation by the second calculator 1204.
- FIG. 10 is an explanatory diagram showing a specific example 1 of similarity calculation by the first calculation unit 907.
- FIG. 11 is an explanatory diagram illustrating a specific example 2 of similarity calculation by the first calculator 907.
- FIG. 15 is an explanatory diagram illustrating a specific example 1 of similarity calculation by the second calculator 1204.
- FIG. 16 is an explanatory diagram showing a specific example 2 of similarity calculation by the second calculator 1204.
- FIG. 17 is a flowchart illustrating an example of a search processing procedure performed by the search device 800.
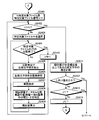
- FIG. 18 is a flowchart illustrating a detailed processing procedure example of the first search processing (steps S1706 and S1709) illustrated in FIG.
- FIG. 19 is a flowchart (part 1) illustrating a detailed processing procedure example of the intermediate classification code match count totaling process (step S1803) illustrated in FIG.
- FIG. 20 is a flowchart (part 2) illustrating a detailed processing procedure example of the intermediate classification code match count totaling process (step S1803) illustrated in FIG.
- FIG. 21 is a flowchart (part 1) illustrating a detailed processing procedure example of the similarity calculation processing (step S1804) illustrated in FIG.
- FIG. 22 is a flowchart (part 2) illustrating a detailed processing procedure example of the similarity calculation processing (step S1804) illustrated in FIG.
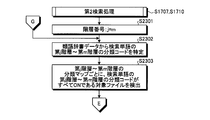
- FIG. 23 is a flowchart (part 1) illustrating a detailed processing procedure example of the second search processing (step S1707 and step S1710) illustrated in FIG.
- FIG. 24 is a flowchart (part 2) illustrating a detailed processing procedure example of the second search processing (step S1707 and step S1710) illustrated in FIG.
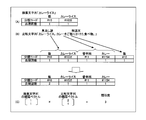
- the synonym dictionary data is data obtained by hierarchically classifying synonymous relationships between words. Also called a thesaurus. Specifically, for example, each word is coded, and a word that is conceptually in a lower layer is coded by adding a code of a word in the upper layer to the beginning.
- FIG. 1 is an explanatory diagram showing an example of the data structure of synonym dictionary data.
- the synonym dictionary data 100 is composed of three layers as an example. Note that the number of layers may be two or more.
- the first hierarchy as the highest hierarchy is “major classification”
- the second hierarchy as the intermediate hierarchy is “medium classification”
- the third hierarchy as the lowest hierarchy is “small classification”. To do.
- the large classification “food” belongs to the middle classification “rice” and “spicy” (other than this, there are “ramen” but omitted in FIG. 1), and the middle classification “rice” includes the small classification. “Curry rice”, “Hayashi rice”, “sushi” (other than this, there are “fried rice”, but not shown in FIG. 1).
- classification codes Two types are given to each word. One is a single classification code, and the other is a linked classification code.
- the single classification code is a classification code assigned to each word.
- the concatenated classification code is a classification code in which all the individual classification codes in the upper layer are concatenated at the head of the single classification code of the word.
- the single classification code of the small classification “Curry and Rice” is “# 32”, but the single classification code of the middle classification “rice” which is the upper hierarchy is “# 0”, which is higher than the middle classification “rice”.
- the single classification code of the major classification “food” which is a hierarchy is “# 1”. Therefore, the concatenated classification code of “curry and rice” is “# 1032” concatenated in order from the single classification code of the upper layer.
- classification code refers to “consolidation classification code”. Also, the large classification linked classification code is referred to as “major classification code”, the middle classification linked classification code is referred to as “medium classification code”, and the minor classification linked classification code is referred to as “small classification code”.
- the consolidated classification code is a code in which single classification codes are concatenated from the upper layer. Therefore, it can be seen from the code length and the digit which code is the individual classification code of which layer. For example, in FIG. 1, the large classification code and the medium classification code are 1 digit, and the small classification code is 2 digits. Therefore, if the code length is 1, the classification code is a major classification code. If the code length is 2, it is a medium classification code. It can also be seen that the leading digit is a large classification single classification code and the last digit is a medium classification single classification code.
- the code length is 4, it is a small classification code. It can also be seen that the first digit from the top is the single classification code of the large classification, the second digit is the single classification code of the middle classification, and the last two digits are the single classification code of the small classification.
- a classification map is a bitmap in which a bitmap-type full-text index is extended, and a set of bit strings indicating the presence or absence of words included in each classification code in each target file for an arbitrary hierarchy of the synonym dictionary data 100 It is.
- a map group in which classification maps of all layers are collected is referred to as a classification map group.
- the classification map has the number of hierarchies defined in the synonym dictionary data 100.
- the target file is a file in which a character string is described, and is, for example, a file in HTML (HyperText Markup Language) format, XML (Extensible Markup Language) format, or text format.
- Examples of the target file (group) include electronic dictionaries, electronic books, Web pages, electronic documents, and other data including character strings.
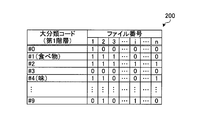
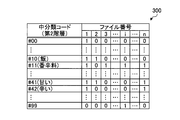
- 2 to 4 show classification maps for the target files F1 to Fn with file numbers 1 to n.
- words included by a classification code are not only words in the target layer but also words that are conceptually lower than words in the target layer when attention is paid to a certain layer. Specifically, for example, in addition to the word corresponding to the concatenated classification code of the target layer, the word corresponds to the concatenated classification code of the lower layer connected with the single classification code of the word of the target layer.
- FIG. 2 is an explanatory diagram illustrating an example of a classification map of the first hierarchy (major classification)
- FIG. 3 is an explanatory diagram illustrating an example of a classification map of the second hierarchy (medium classification)
- FIG. It is explanatory drawing which shows the example of the classification map of the 3rd hierarchy (small classification).
- bit hereinafter simply referred to as “bit” indicating whether or not the word corresponding to the classification code exists in each target file Fi is “existing” in this example. “1”, “0” when not present.
- bit strings corresponding to the number of the target files Fi are stored for each major classification. For example, for the large classification code # 1 (food), since each bit of the target files F1 to F3 is “1”, it can be seen that the word “food” exists in the target files F1 to F3. .
- the bit value is “1” if the word included in the major classification code exists.
- the major classification code # 1 (food) corresponds to the middle classification code # 10 belonging to the lower hierarchy of the major classification code # 1 (food) even if the word “food” does not exist in the target file F1.
- the value of the bit is “1”.
- bit strings corresponding to the number of target files Fi are stored for each medium classification. For example, for medium classification code # 10 (rice), since each bit of the target files F1 and F2 is “1”, it can be seen that the word “rice” exists in the target files F1 and F2. .
- the bit value is “1” if the word included in the middle classification code exists.
- the middle classification code # 10 (rice) corresponds to the minor classification code # 1032 belonging to the lower hierarchy of the middle classification code # 10 (rice) even if the word “rice” does not exist in the target file F1. If the word “curry rice” exists, the value of the bit is “1”.
- bit strings corresponding to the number of the target files Fi are stored for each small classification.
- each bit of the target files F1 and F2 is “1”, and therefore the word “curry and rice” exists in the target files F1 and F2. I understand.
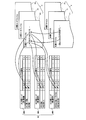
- FIG. 5 is an explanatory diagram showing the link relationship between the classification map group and the target file group.
- the classification map group M and the target file group F are linked by a classification code file group C.
- the classification code file Ci is a file in which a classification code corresponding to a word existing in the target file Fi and its appearance position are described for each target file Fi.
- the target file Fi and the classification code file Ci having the same file number i correspond to each other.
- the target file F1 corresponds to the classification code file C1.
- the appearance position is information for specifying the description position in the target file, and includes, for example, the number of characters from the first character in the target file.
- the comparison range with the search word can be defined.
- the target file group F is dictionary data
- the classification code and the appearance position are described for the headword and the word in the commentary
- a line feed code is embedded as a special code at the end.
- the classification code group for the headword and commentary described between the line feed code and the next line feed code becomes the comparison range with the search word. If no special code is embedded, each classification code is a comparison range.
- FIG. 6 is a block diagram of a hardware configuration example of the computer according to the embodiment.
- the computer includes a CPU (Central Processing Unit) 601, a ROM (Read Only Memory) 602, a RAM (Random Access Memory) 603, a magnetic disk drive 604, a magnetic disk 605, an optical disk drive 606, An optical disk 607, a display 608, an I / F (Interface) 609, a keyboard 610, a mouse 611, a scanner 612, and a printer 613 are provided.
- a bus 600 Each component is connected by a bus 600.
- the CPU 601 controls the entire computer.
- the ROM 602 stores programs such as a boot program, a search program of this embodiment, and a generation program.
- the RAM 603 is used as a work area for the CPU 601.
- the magnetic disk drive 604 controls the reading / writing of the data with respect to the magnetic disk 605 according to control of CPU601.
- the magnetic disk 605 stores data written under the control of the magnetic disk drive 604.
- the optical disk drive 606 controls the reading / writing of data with respect to the optical disk 607 according to the control of the CPU 601.
- the optical disk 607 stores data written under the control of the optical disk drive 606, and causes the computer to read data stored on the optical disk 607.
- the display 608 displays data such as a document, an image, and function information as well as a cursor, an icon, or a tool box.
- a CRT a CRT
- a TFT liquid crystal display a plasma display, or the like can be adopted.
- I / F An interface (hereinafter abbreviated as “I / F”) 609 is connected to a network 614 such as a LAN (Local Area Network), a WAN (Wide Area Network), or the Internet through a communication line, and the other via this network 614. Connected to other devices.
- the I / F 609 manages an internal interface with the network 614 and controls data input / output from an external device.
- a modem or a LAN adapter can be employed as the I / F 609.
- the keyboard 610 includes keys for inputting characters, numbers, various instructions, etc., and inputs data. Moreover, a touch panel type input pad or a numeric keypad may be used.
- the mouse 611 performs cursor movement, range selection, window movement, size change, and the like. A trackball or a joystick may be used as long as they have the same function as a pointing device.
- the scanner 612 optically reads an image and takes in the image data into the computer.
- the scanner 612 may have an OCR (Optical Character Reader) function.
- the printer 613 prints image data and document data.
- a laser printer or an ink jet printer can be employed as the printer 613.
- This generation process may be executed by the search device of the present embodiment, or may be executed by a generation device different from the search device. In any case, the computer in which the generation program of this embodiment is installed is executed.
- FIG. 7 is a flowchart showing generation processing of the classification map group M and the classification code file group C.
- step S704 the computer sets the classification code of the selected word in the j-th layer classification map.
- the computer scans the target file Fi and determines whether there is a character string that matches the selected word (step S706). When there is no matching character string (step S706: No), the process proceeds to step S712. As a result, the process moves to the next target file.
- step S706 the computer adds the classification code of the selected word and the appearance position of the selected word in the target file Fi to the classification code file Ci (step S707).
- the computer turns ON (“1”) the bit of the file number i in the classification code of the selected word in the classification map of the j-th layer (step S708). Thereafter, the computer extracts a classification code for each layer higher than the j-th hierarchy from the classification code of the selected word (step S709).
- the classification code of the j-th layer includes the classification code of the upper layer (first layer,..., (J ⁇ 1) -th layer).
- first layer first layer,..., (J ⁇ 1) -th layer.
- the first two digits of the minor classification code “# 1032” (curry and rice) that is the third hierarchy are the middle classification code
- the first two digits of the code are the middle classification code “# 10” (the second hierarchy) Rice).
- the first digit of the minor classification code “# 1032” (curry and rice) is a major classification code
- the first digit code is extracted as the major classification code “# 1” (food) in the first layer. To do.
- the computer sets the upper layer classification code extracted in step S709 in the upper layer classification map (step S710). Specifically, in the above example, for the middle classification code “# 10” (rice), the middle classification code “# 10” (rice) is set in the middle classification classification map. Similarly, for the large classification code “# 1” (food), the large classification code large classification code “# 1” (food) is set. Do not set if already set.
- the computer turns ON (“1”) the bit of the file number i in the extracted classification code set in each higher-level classification map in step S710 (step S711). If it is already ON, nothing is done.
- step S712 increments the file number i (step S712), and determines whether i> n is satisfied (step S713).
- n is the total number of files in the target file group F. If i> n is not satisfied (step S713: No), the process returns to step S706, and it is determined whether or not there is a character string that matches the selected word in the target file Fi.
- step S713 Yes
- the process returns to step S702, and the computer determines whether there is an unselected word in the j-th hierarchy in the synonym dictionary data 100 (step S702). If there is no unselected word in the j-th layer (step S702: No), the layer number j is incremented (step S714), and the computer determines whether j> m is satisfied (step S715).
- m is the number of layers.
- step S715: No If j> m is not satisfied (step S715: No), the process returns to step S702, and the computer determines whether or not there is an unselected word in the j-th hierarchy in the synonym dictionary data 100 (step S702). On the other hand, when j> m is satisfied (step S715: Yes), the generation process of the classification map group M and the classification code file group C is terminated.
- the classification map group M and the classification code file group C are automatically generated.
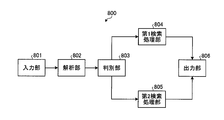
- FIG. 8 is a block diagram illustrating a functional configuration example of the search device according to the present embodiment.
- the search device 800 includes an input unit 801, an analysis unit 802, a determination unit 803, a first search processing unit 804, a second search processing unit 805, and an output unit 806.
- the input unit 801 to the output unit 806 may cause the CPU 601 to execute a program stored in a storage device such as the ROM 602, the RAM 603, the magnetic disk 605, and the optical disk 607 shown in FIG.
- the function is realized by the I / F 609.
- the input unit 801 accepts input of a search character string and specification of a search mode.
- the search mode indicates the type of search processing, and is one of a search process using an upper layer classification code (first search mode) or a search process using a lower layer classification code (second search mode) described later. It is.
- the analysis unit 802 analyzes the search character string input by the input unit 801. Specifically, for example, the analysis unit 802 decomposes the search character string into words by executing morphological analysis, and specifies the part of speech for each of the decomposed words. Then, the analysis unit 802 extracts, as search words, words corresponding to part-of-speech used in the fuzzy search, for example, nouns, verbs, adjectives, and adverbs, from the decomposed word group. The analysis unit 802 analyzes the comparison character string in the same manner as the search character string.
- the determination unit 803 determines which search process is the designated search mode. If the search mode is not designated, the determination unit 803 determines whether the number of search words analyzed by the analysis unit 802 is equal to or greater than a predetermined number of words. When the number is less than the predetermined number of words, the first search mode is specified, and when the number is more than the predetermined number of characters, the second search mode is specified.
- the search device 800 executes the search process in the search mode determined by the determination unit 803. As described above, if the number of search words is large, the number of fuzzy search hits may become enormous. Therefore, the search device 800 can select a hierarchical level to be searched step by step from the specified hierarchy in the second search mode. It will be expanded.
- the first search processing unit 804 executes a search process using an upper layer classification code.
- a synonym vector unique to the search character string is generated using the classification code of the search word in the search character string and the classification code of the upper hierarchy word including the search word.
- a synonym vector unique to the comparison character string is generated using the classification code of the comparison word and the classification code of the upper layer word including the comparison word. Then, the first search processing unit 804 calculates both synonym vectors by the kernel method, and calculates the similarity between the search character string and the comparison character string. Details will be described later.
- the second search processing unit 805 executes a search process from the lowermost classification code.
- the search processing from the lowermost classification code generates a synonym vector unique to the search character string using the search word classification code in the search character string.
- a synonym vector unique to the comparison character string is generated using the classification code of the comparison word.
- the second search processing unit 805 calculates the similarity vector between the search character string and the comparison character string by calculating both synonym vectors by the kernel method.
- the classification code of the next higher hierarchy is identified and added to each synonym vector for the search character string and the comparison character string Similarly, the similarity is calculated.
- the second search processing unit 805 calculates the degree of similarity by going up one level and regenerating the synonym vector until the total number of comparison character strings having a degree of similarity equal to or higher than the predetermined number is reached. Will be. Details will be described later.
- the output unit 806 outputs the search result of the first search processing unit 804 or the second search processing unit 805. Specifically, for example, the output unit 806 displays the comparison character strings in order of descending similarity. Note that the output format by the output unit 806 is not limited to display on the display 608, but may be transmission to another communicable computer or print output. Further, writing to a storage area in the search device 800 may be performed.
- the search device 800 may include an input unit 801, an analysis unit 802, a first search processing unit 804, and an output unit 806. Further, the input unit 801, the analysis unit 802, the second search processing unit 805, And an output unit 806.
- FIG. 9 is a block diagram illustrating a functional configuration example of the first search processing unit 804 illustrated in FIG. 8.
- the first search processing unit 804 includes a first detection unit 901, a first specification unit 902, an extraction unit 903, a determination unit 904, a first counting unit 905, a determination unit 906, and a first calculation unit 907. Is provided.
- the first detection unit 901 classifies the highest hierarchy in the classification map group M in which a set of bit strings indicating the presence / absence of the word corresponding to each classification code in the synonym dictionary data 100 in each target file Fi is grouped by hierarchy. By referring to the map, a specific target file in which the classification code of the highest hierarchy to which the search word belongs is detected.
- the hierarchy to which the search word belongs includes not only the hierarchy in which the search word classification code exists, but also the higher hierarchy specified by the classification code. Such a hierarchy is referred to as an affiliation hierarchy.
- the first detection unit 901 goes back to the highest hierarchy classification code including the classification code of the search word, and detects a specific target file from the highest hierarchy classification map.
- the search word is “food”
- the classification code is the major classification code “# 1”
- the specific target files F1 to F3 are referred to by referring to the bit string “# 1” of the major classification map 200. Will be detected.
- the classification code is the middle classification code “# 42”. Since the middle classification code “# 42” belongs to the major classification code “# 4” (taste), by referring to the bit string of “# 4” of the major classification map 200, the specific target files F1, F2, and Fn are identified. Will be detected.
- the classification code is the small classification code “# 1032”. Since the small classification code “# 1032” belongs to the large classification code “# 1” (food), the specific target files F1 to F3 are detected by referring to the bit string of “# 1” of the large classification map 200. It will be. In this way, the target file Fi can be narrowed down to the minimum necessary range by going back to the highest hierarchy, regardless of the hierarchy classification code.
- the classification codes are the major classification codes “# 1” and “# 4”, “# 1” and “# 4” of the major classification map 200 are displayed. Refers to a bit string. Then, the target files F1 and F2 having the file numbers turned ON in both the bit strings “# 1” and “# 4” are detected as specific target files.
- the classification code of the search word “food” is the major classification code “# 1”, so the bit string “# 1” of the major classification map 200 is referred to.
- the classification code of the search word “spicy” is the middle classification code “# 42”. Since the middle classification code “# 42” belongs to the major classification code “# 4” (taste), the bit string “# 4” of the major classification map 200 is referred to. Then, the target files F1 and F2 having the file numbers turned ON in both the bit strings “# 1” and “# 4” are detected as specific target files.
- the target file Fi can be narrowed down by taking a logical product between bit strings of classification codes in the highest hierarchy. That is, since the first detection unit 901 can narrow down the search destination of subsequent fuzzy searches to a specific target file Fi, it is possible to prevent a search for useless target files Fi and to speed up the search process. . If the search device 800 cannot access the classification map group M, the words in all the target files F1 to Fn are to be compared.
- the first specifying unit 902 includes a classification code for each search word hierarchy in the search character string and a comparison character string group from the synonym dictionary data 100 obtained by hierarchically classifying and encoding the synonymous relationship between words. And a classification code for each hierarchy of comparison words in each comparison character string. Specifically, the first specifying unit 902 specifies, for example, a classification code from the synonym dictionary data 100 illustrated in FIG.
- the first specifying unit 902 specifies the classification code and the hierarchy of the search word in the search character string with reference to the synonym dictionary data 100.
- the search word in the search character string is a word extracted by the search character string input by the input unit 801 being decomposed into words by the analysis unit 802.
- the first specifying unit 902 specifies the higher-level classification code including the classification code of the hierarchy up to the highest hierarchy. For example, when the search word is “curry and rice”, the hierarchy is the third hierarchy (small classification), and the minor classification code is “# 1032”. Since the first two digits of the small classification code are the middle classification code, the first identifying unit 902 identifies “# 10” as the middle classification code. Furthermore, since the first digit of the small classification code is the large classification code, the first identifying unit 902 identifies “# 1” as the large classification code.
- the minor classification code “# 1032”, the middle classification code “# 10”, and the major classification code “# 1” are classified in the affiliation hierarchy (first to third hierarchies). It will be specified as a code. Such a specific method is the same for the comparison word.
- the comparison character string is one or more character strings (for example, delimited by a punctuation mark or a line feed code) described in a certain comparison unit.
- the comparison unit may be a single comparison word or one or a plurality of target files Fi.
- the comparison character string may be a certain item unit in a certain target file Fi.
- the target file Fi is dictionary data
- a headword and a character string serving as an explanation thereof are used as a comparison unit
- a word in the character string is used as a comparison word.
- the extraction unit 903 includes, among the group of hierarchies constituting the synonym dictionary data 100, the classification code for each level of the search word identified by the first identification unit 902 and the classification code for each level of each comparison word. Extract the classification code.
- the specific hierarchy refers to, for example, an intermediate hierarchy.
- the intermediate hierarchy is a hierarchy (group) that does not include at least the highest hierarchy and the lowest hierarchy.
- the second layer is an intermediate layer.
- the intermediate layer includes only the second layer, only the third layer, only the fourth layer, the second and third layers, the third and fourth layers, The second to fourth layers can be selected as the intermediate layer. It is assumed that which layer is set as an intermediate layer is set in advance.
- the specific hierarchy is an intermediate hierarchy. However, when a search is desired only for a certain hierarchy, a hierarchy (group) including the highest hierarchy and the lowest hierarchy may be used as the specific hierarchy.
- the first identification unit 902 identifies the minor classification code “# 1032”, the middle classification code “# 10”, and the major classification code “# 1”.
- the classification code “# 10” is extracted.
- the first identification unit 902 identifies the minor classification code “# 1033”, the middle classification code “# 10”, and the major classification code “# 1”.
- the classification code “# 10” is extracted.
- the extraction unit 903 also extracts the classification codes of the search words and comparison words in the upper hierarchy higher than the intermediate hierarchy.
- the large classification code “# 1” is extracted.
- the determination unit 904 determines, for each comparison character string, whether the classification code of the specific hierarchy of the search word extracted by the extraction unit 903 matches the classification code of the specific hierarchy of the comparison word. Specifically, for example, the determination unit 904 determines whether the classification code in the intermediate hierarchy of the search word matches the classification code in the intermediate hierarchy of the comparison word. In the above examples of curry rice and Hayashi rice, since both are the middle classification code “# 10”, they match.
- the determination unit 904 performs matching determination for each search word. For example, when there are three middle classification codes for the search word and one middle classification code for the comparison word, the matching determination is performed three times. On the other hand, there may be a plurality of comparison words in the comparison character string. In this case, the determination unit 904 performs matching determination for each search word. For example, when there is one middle classification code for the search word and four middle classification codes for the comparison word, the matching determination is performed four times.
- the determination unit 904 performs a match determination with each comparison word for each search word. For example, when there are two middle classification codes for the search word and three middle classification codes for the comparison word, the matching determination is performed six times.
- the determination unit 904 when all of the combinations of the search word and the comparison word match in the matching determination between the classification code of the intermediate hierarchy of the search word in the search character string and the classification code of the intermediate hierarchy of the comparison word in the comparison unit, Then, it is determined that the search character string matches the comparison character string in the comparison unit. Further, when a part of the combination of the search word and the comparison word matches, it may be determined that the search character string matches the comparison character string in the comparison unit.
- search character string does not match the comparison character string in the comparison unit. That is, in the case of partial match, whether the search character string and the comparison character string in the comparison unit are matched or not is set in advance.
- the determination unit 904 may perform a match determination between the classification codes in the upper hierarchy of the search word and the comparison word before performing the matching determination between the classification codes in the middle hierarchy of the search word and the comparison word. Then, when they match, the determination unit 904 further performs a match determination between the classification codes of the intermediate layers, and does not perform a match when they do not match.
- the determination unit 904 performs matching determination for each search word.
- the matching determination is performed three times.
- the determination unit 904 performs matching determination for each search word. For example, if the search word has one major classification code and the comparison word has four major classification codes, the matching determination is performed four times.
- the determination unit 904 performs a match determination with each comparison word for each search word. For example, if there are two major classification codes for the search word and three major classification codes for the comparison word, the match determination is performed six times.
- the determination unit 904 when the match determination between the upper-level classification codes of the search word and the comparison word is performed a plurality of times, only when all match, the determination code of the middle-level classification code of the search word and the comparison word is determined. . Further, even when there is a partial match, it is also possible to perform a match determination between the classification codes in the middle hierarchy of the search word and the comparison word. In the case where they do not all match, the determination of matching between the classification codes in the intermediate hierarchy of the search word and the comparison word is not performed. Handling in the case of partial match will be set in advance.
- the upper layer classification codes do not match, it is considered that they are not similar in the lower layer. Therefore, it is possible to perform a useless search by determining whether the upper layer classification codes match. This can be avoided and the search efficiency can be improved.
- the first counting unit 905 counts the number of matches in the specific hierarchy by the determining unit 904.
- the number of matches by the first counting unit 905 is the total number of matches in the target file group F to be compared.
- all target files or a specific target file Fi detected by the first detection unit 901 may be used.
- the counting unit in the first counting unit 905 one point is counted when there is a match between the classification codes in the intermediate hierarchy of the search word and the comparison word.
- one point may be counted. Furthermore, one point may be counted when the classification code of the intermediate hierarchy of all comparison words in the comparison unit matches the classification code of the intermediate hierarchy of the search word. Which counting method is to be used is determined according to the coincidence determination by the determination unit 904.
- the determination unit 906 determines whether or not to exclude the comparison character string in which the classification code for each layer of the comparison word is determined to be inconsistent by the determination unit 904. . Specifically, for example, the determination unit 906 sets a threshold value, and the determination unit 906 determines whether or not the number of matches in the intermediate hierarchy is equal to or greater than the threshold value. That is, the determination unit 906 determines whether or not the comparison character string in which the classification codes of the intermediate hierarchy are inconsistent is to be calculated by the first calculation unit 907 depending on whether or not the threshold value is greater than or equal to the threshold value.
- the determination unit 906 excludes the comparison character string in which the classification code of the intermediate hierarchy is inconsistent from the target of the fuzzy search.
- the determination unit 906 does not exclude the comparison character string in which the classification code of the intermediate hierarchy is mismatched from the target of the fuzzy search.
- the first calculation unit 907 calculates the search character string and the comparison character string determined not to be excluded based on the classification code for each layer of the comparison word in the comparison character string determined not to be excluded by the determination unit 906. Calculate similarity.
- the first calculation unit 907 also calculates the similarity between the search character string and the comparison character string that is determined by the determination unit 904 to match the middle layer classification code. In any case, the first calculation unit 907 calculates the similarity using the kernel method. The calculation result is given to the output unit 806. Specific examples will be described below.
- FIG. 10 is an explanatory diagram showing a specific example 1 of similarity calculation by the first calculation unit 907.
- Specific example 1 is an example in which one search word that becomes a search character string is compared with a comparison character string.
- the search word is “curry and rice”
- the comparison character string that is the comparison unit is the dictionary headword “curry and rice.”
- the explanatory sentence “food with curry on rice.”
- the first specifying unit 902 obtains the classification codes “# 1”, “# 10”, and “# 1032” for each hierarchy of the search word “curry and rice”. Since the search word is only “curry and rice”, each classification code “# 1”, “# 10”, and “# 1032” appears once.
- the appearance number of the large classification code “# 1” (food) is 4 times
- the appearance number of the medium classification code “# 10” (rice) is 2
- the small classification code “# 1032” (curry rice) 1 appears
- the middle classification code “# 11” spikeces
- the minor classification code “# 1154” appears once. Note that the number of appearances of classification codes “# 11” (spicy) and “# 1154” (curry) that do not match the classification code of the search word is excluded.
- the first calculation unit 907 vectorizes the number of appearances obtained in (A). This is called a synonym vector of the search character string. Similarly, the 1st calculation part 907 vectorizes the appearance frequency calculated
- FIG. 11 is an explanatory diagram showing a specific example 2 of similarity calculation by the first calculation unit 907.
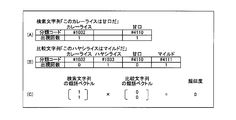
- Specific example 2 is an example in which a search character string is compared with a comparison character string.
- the search character string as a comparison unit is “this curry rice is sweet”, and the comparison character string is “this Hayashi rice is mild”.
- “Hayashi Rice” and “Mild” are extracted from the comparison character string “This Hayashi Rice is mild” by morphological analysis and word extraction by the analysis unit 802.
- the first specifying unit 902 obtains a classification code for each layer. In the comparison character string, each extracted word appears once, so each classification code “# 1”, “# 10”, “# 1033”, “# 4”, “# 41”, “# 4111” Appears once.
- the first calculation unit 907 vectorizes the number of appearances obtained in (A). This is called a synonym vector of the search character string. Similarly, the 1st calculation part 907 vectorizes the appearance frequency calculated
- FIG. 12 is a block diagram illustrating a functional configuration example of the second search processing unit 805 illustrated in FIG.
- the second search processing unit 805 includes a second detection unit 1201, a setting unit 1202, a second specifying unit 1203, a second calculation unit 1204, and a second counting unit 1205.
- the second detection unit 1201 refers to the classification map group M in which a set of bit strings indicating whether or not the word corresponding to each classification code in the synonym dictionary data 100 is present in each target file is classified according to the hierarchy. A specific target file Fi in which a classification code of the target hierarchy exists is detected.
- the lowest layer is the third layer.
- the second search processing unit 805 refers only to the small classification map 400 of FIG. Then, in the small classification map 400, the target file Fi that is ON in the bit string of the classification code of the search word is detected as a specific target file.
- the second detection unit 1201 detects the target file F1 that is ON in the bit string of the small classification code “# 1033” in the small classification map 400 as a specific target file.
- the classification code is also specified up to the classification code of the second hierarchy.
- the middle classification code is “# 10” (rice) in the first two digits. Therefore, the second detection unit 1201 detects the target files F1 and F2 that are ON in the bit string of the middle classification code “# 10” in the middle classification map 300 as specific target files. In this way, by moving the target hierarchy to a higher hierarchy, the target file F2 that was not detected in the third hierarchy can be included in the specific target file, and the range of the specific target file can be expanded. .
- the classification code is also specified up to the classification code of the first hierarchy.
- the major classification code is “# 1” (food) with the first digit. Therefore, the second detection unit 1201 detects the target files F1 to F3 that are ON in the bit string of the major classification code “# 1” in the major classification map 200 as specific target files. In this way, by moving the target hierarchy to a higher hierarchy, the target file F3 that is not detected in the second hierarchy can be included in the specific target file, and the range of the specific target file can be expanded. .
- the second detection unit 1201 detects the target file F1 that is ON in both bit strings of the small classification codes “# 1033” and “# 4111” in the small classification map 400 as a specific target file.
- the classification code is also specified up to the classification code of the second hierarchy.
- the middle classification code is “# 10” (rice) and “# 41” (sweet) in the first two digits. Therefore, the second detection unit 1201 detects the target files F1 and F2 that are ON in both bit strings of the middle classification codes “# 10” and “# 41” in the middle classification map 300 as specific target files. Become. In this way, by moving the target hierarchy to a higher hierarchy, the target file F2 that was not detected in the third hierarchy can be included in the specific target file, and the range of the specific target file can be expanded. .
- the classification code is also specified up to the classification code of the first hierarchy.
- the major classification codes are “# 1” (food) and “# 4” (flavor) in the first digit. Therefore, the second detection unit 1201 detects the target files F1 and F2 that are ON in both bit strings of the major classification codes “# 1” and “# 4” in the major classification map 200 as specific target files. Become. This is an example in which an attempt was made to expand the range of a specific target file, but as a result it did not.
- the second detection unit 1201 detects the target file F1 that is ON in both the bit strings of the small classification code “# 1033” and the medium classification code “# 41” in the small classification map 400 as a specific target file. It becomes.
- the second detection unit 1201 When the target hierarchy rises to the second hierarchy, the second detection unit 1201 has the target file F1 turned ON in both the bit strings of the middle classification codes “# 10” and “# 41” in the middle classification map 300. , F2 is detected as a specific target file.
- the target file F2 that was not detected in the third hierarchy can be included in the specific target file, and the range of the specific target file can be expanded. . If the search device 800 cannot access the classification map group M, the words in all the target files F1 to Fn are to be compared.
- the setting unit 1202 changes the target hierarchy to a higher hierarchy when the count result counted by the second counting unit 1205 is a predetermined number or less.
- the predetermined number is a value set in advance. Although the change criterion is set to a predetermined number or less, it may be determined as a percentage.
- the denominator is the total number of comparison character strings, the numerator is a predetermined number, and a predetermined probability is set.
- the setting unit 1202 changes the target hierarchy to a higher hierarchy.
- the width to be changed is one layer. For example, when the change is the third hierarchy, the change is the second hierarchy.
- the second detection unit 1201 detects a specific target file in which the classification code of the target hierarchy after the change of the search word exists.
- the second specifying unit 1203 specifies, from the synonym dictionary data 100, the classification code from the specified hierarchy of the search word in the search character string to the target hierarchy, and the specification of the comparison word in each comparison character string of the comparison character string group.
- a classification code from the hierarchy to the target hierarchy is specified for each comparison character string.
- the first specifying unit 902 specifies a classification code of a specific layer (for example, an intermediate layer) for the search word and the comparison word, but the second specifying unit 1203 specifies a classification code from the designated layer to the target layer. Each time the target hierarchy is changed, the second specifying unit 1203 specifies the classification code from the designated hierarchy to the changed target hierarchy.
- the search word is “curry rice”.
- the target hierarchy is also set to the third hierarchy in the initial state.
- the second specifying unit 1203 specifies the classification code “# 1032” in the third layer of the search word “curry and rice”.
- the second identification unit 1203 further identifies the classification code “# 10” (rice) in the second hierarchy of the search word “curry and rice”.
- the second specifying unit 1203 further specifies the classification code “# 1” (food) in the first hierarchy of the search word “curry and rice”.
- the classification code of the search word “spicy” is the middle classification code, not the classification code of the designated hierarchy (third hierarchy).
- the second identification unit 1203 cannot identify the classification code of the search word “spicy”. Thereafter, when the target hierarchy goes up to the second hierarchy, the second identification unit 1203 identifies the classification code “# 42” in the second hierarchy of the search word “spicy”. Furthermore, when the target hierarchy goes up to the first hierarchy, the second identification unit 1203 identifies the classification code “# 4” (taste) in the first hierarchy of the search word “spicy”.
- the second calculation unit 1204 calculates the similarity between the search character string and the comparison character string based on the classification code from the specified hierarchy of the search word to the target hierarchy and the classification code from the specified hierarchy of the comparison word to the target hierarchy. Calculate for each column. Specifically, the second calculation unit 1204 generates a synonym vector of a search character string using a classification code from a specified hierarchy to a target hierarchy in the search word.
- the second calculation unit 1204 generates a synonym vector of the comparison character string using the classification code from the designated layer to the target layer in the comparison word. Similar to the first calculation unit 907, the second calculation unit 1204 calculates the similarity by taking the inner product of the synonym vector of the search character string and the synonym vector of the comparison character string. Specific examples will be described later.
- the second counting unit 1205 counts the number of comparison character strings that are equal to or higher than the predetermined similarity in the comparison character string group whose similarity is calculated by the second calculation unit 1204.
- the predetermined similarity is a value set in advance.
- the output unit 806 outputs at least a predetermined similarity among the comparison character string groups in which the counting result counted by the second counting unit 1205 is greater than a predetermined number.
- a comparison character string of more than 1 degree will be output.
- FIG. 13 is an explanatory diagram showing a specific example 1 of similarity calculation by the second calculator 1204.
- Specific example 1 is an example in which one search word that becomes a search character string is compared with a comparison character string.
- the search word is “curry and rice”
- the comparison character string that is the comparison unit is the dictionary headword “curry and rice.”
- the explanatory sentence “food with curry on rice.”
- the designated hierarchy is the third hierarchy
- the target hierarchy is also the third hierarchy.
- the second specifying unit 1203 obtains the small classification code “# 1032” that is the target layer (third layer) of the search word “curry and rice”. Since the search word is only “curry and rice”, the number of appearances of the small classification code “# 1032” is one.
- the extracted words “curry and rice”, “curry”, “rice”, and “food” belong to the third layer, which is the target layer, are “curry and rice” and “curry”.
- Codes “# 1032” and “# 1154” are specified. Each of these appearances is once. Of these, the number of appearances of the classification code “# 1154” (curry) that does not match the classification code of the search word is excluded.
- the second calculation unit 1204 vectorizes the number of appearances obtained in (A). This is called a synonym vector of the search character string. Similarly, the 2nd calculation part 1204 vectorizes the appearance frequency calculated
- FIG. 14 is an explanatory diagram showing a specific example 2 of similarity calculation by the second calculation unit 1204.
- Specific example 2 is an example in the case where the target hierarchy goes up to the second hierarchy in specific example 1 of FIG. 13.
- the second identification unit 1203 identifies the classification codes in the second hierarchy of the extracted words “curry rice”, “curry”, “rice”, and “food”.
- “Curry and rice” itself is a small classification code “# 1032”, but the middle classification code is identified by “# 10” (rice) in the first two digits. “Curry” is also the minor classification code “# 1154”, but the middle classification code specifies “# 11” (spicy) in the first two digits. Since “rice” is a medium classification code, “# 10” is identified as it is.
- the middle class code “# 10” (rice) appears twice, and the middle class code “# 11” (spicy) appears once.
- the middle classification code “# 11” (spicy) is excluded because it does not exist in (A). Then, the number of appearances of the middle classification code “# 11” (spicy) specified this time and the number of appearances of the small classification code in the comparison character string shown in FIG. 13 are integrated.
- the second calculation unit 1204 vectorizes the number of appearances obtained in (A) to generate a synonym vector of the search character string. Similarly, the 2nd calculation part 1204 vectorizes the appearance frequency calculated
- FIG. 15 is an explanatory diagram showing a specific example 1 of similarity calculation by the second calculation unit 1204.
- Specific example 1 is an example in which a search character string (including a plurality of search words) is compared with a comparison character string.
- search character string is “this curry rice is sweet”
- comparison character string as a comparison unit is “this Hayashi rice is mild”.
- the designated hierarchy is the third hierarchy, and the target hierarchy is also the third hierarchy.
- (A) for the search character string “this curry and rice is sweet”, “curry and rice” and “sweet” are extracted by morphological analysis and word extraction by the analysis unit 802. For each extracted word, the second identification unit 1203 obtains the classification code of the target hierarchy (third hierarchy). In the case of this example, the small classification codes “# 1032” and “# 4110” of the extracted words “curry and rice” and “sweet” are specified. Each of these appearances is once.
- “Hayashi Rice” and “Mild” are extracted for the comparison character string “This Hayashi Rice is mild” by morphological analysis and word extraction by the analysis unit 802.
- the second identification unit 1203 obtains the classification code of the target hierarchy (third hierarchy).
- the small classification codes “# 1033” and “# 4111” of the extracted words “hayashi rice” and “mild” are specified. Each of these appearances is once. However, the appearance counts of the small classification codes “# 1033” and “# 4111” are excluded because they do not match the classification code of the search word.
- the second calculation unit 1204 vectorizes the number of appearances obtained in (A) to generate a synonym vector of the search character string. Similarly, the 2nd calculation part 1204 vectorizes the appearance frequency calculated
- FIG. 16 is an explanatory diagram showing a specific example 2 of similarity calculation by the second calculation unit 1204.
- Specific example 2 is an example in which the target hierarchy is changed from the third hierarchy to the second hierarchy in specific example 1 of FIG.
- the second identification unit 1203 uses the third hierarchy classification code as well as the second hierarchy classification code. Can also be obtained.
- the middle classification code “# 10” (rice) and “# 41” (sweet) are specified. Each of these appearances is once.
- the second specifying unit 1203 obtains the classification code of the second hierarchy in addition to the classification code of the third hierarchy. It is done.
- the middle classification code “# 10” (rice) “ # 41 "(sweet) is specified. Each of these appearances is once.
- the appearance counts of the small classification codes “# 1033” and “# 4111” are excluded because they do not match the classification code of the search word.
- the second calculation unit 1204 vectorizes the number of appearances obtained in (A) to generate a synonym vector of the search character string. Similarly, the 2nd calculation part 1204 vectorizes the appearance frequency calculated
- the similarity calculated using the third to second classification codes is higher than the similarity calculated using only the third hierarchy classification code shown in the first specific example of FIG. May be.
- the number of similarities greater than or equal to the predetermined similarity increases by expanding the hierarchy to the top. Therefore, it is possible to increase the number of fuzzy search hits with high similarity step by step.
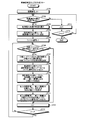
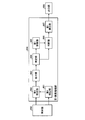
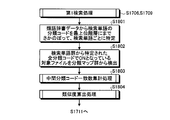
- FIG. 17 is a flowchart showing an example of a search processing procedure performed by the search device 800.
- the search device 800 waits for a search character string to be input by the input unit 801 (step S1701: No).
- a search character string is input (step S1701: Yes)
- the search device 800 causes the analysis unit 802 to analyze the search character string and break it down into words (step S1702).
- the search device 800 extracts a search word corresponding to the part of speech necessary for the fuzzy search from the decomposed word group (step S1703).
- the search device 800 determines whether or not a search mode is designated by the input unit 801 (step S1704).
- the search mode is designated (step S1704: Yes)
- the search device 800 determines whether the designated search mode is the first search mode or the second search mode (step S1705).
- step S1705 first search
- step S1706 second search
- step S1707 second search
- step S1704 determines whether the number of search words is equal to or greater than a predetermined number of words by the determination unit 803 (step S1708). . If the number is not equal to or greater than the predetermined number of words (step S1708: No), the search device 800 executes the first search process by the first search processing unit 804 (step S1709). On the other hand, if the number is greater than or equal to the predetermined number of words (step S1708: Yes), the search device 800 executes the second search process by the second search processing unit 805 (step S1710).
- the search device 800 executes an output process by the output unit 806 (step S1711). Thereby, the search process is terminated.
- the search device 800 executes the search process according to the specified content.
- the search mode is not designated, the first search process or the second search process is determined depending on the number of search words.
- the number of search words is large (a predetermined number of words or more)
- the number of hits in the ambiguous search can be increased stepwise by narrowing down the hierarchical range to be searched by executing the second search process.
- the number of search words is small (less than the predetermined number of words)
- the number of hits in the fuzzy search will not increase, so the range from the search word hierarchy to the top hierarchy is used as the search target range. The number of hits can be obtained appropriately.
- FIG. 18 is a flowchart illustrating a detailed processing procedure example of the first search processing (steps S1706 and S1709) illustrated in FIG.
- the search device 800 uses the first specifying unit 902 to specify the search word classification code from the synonym dictionary data 100 to the highest hierarchy for each search word (step S1801).
- the search device 800 detects, from the classification map group M, the target file of the file number that is ON with the bit string of the classification code for each hierarchy specified from each search word of the search word group (step S1802). ). Then, the search device 800 executes intermediate classification code match count totaling processing (step S1803) and similarity calculation processing (step S1804). Thereby, the first search process is terminated.
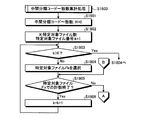
- FIG. 19 is a flowchart (part 1) illustrating a detailed processing procedure example of the intermediate classification code match count totaling process (step S1803) illustrated in FIG.
- the number of specific target files K is the number of target files detected in step S1802 in FIG.
- the search device 800 determines whether or not k> K (step S1903). If k> K is not satisfied (step S1903: NO), the search device 800 selects the specific target file Fk (step S1904). Then, the search device 800 determines whether or not the counting with the specific target file Fk has ended (step S1905). Specifically, the process ends when there are no more unselected comparison character strings.
- step S1905: Yes When the counting is finished (step S1905: Yes), the search device 800 increments the specific target file number k (step S1906) and returns to step S1903. On the other hand, when it is not the end of counting (step S1905: No), the process proceeds to step S2001 in FIG. In step S1903, when k> K is satisfied (step S1903: YES), the process proceeds to similarity calculation processing (step S1804).
- FIG. 20 is a flowchart (part 2) illustrating a detailed processing procedure example of the intermediate classification code coincidence count process (step S1803) illustrated in FIG.
- the search device 800 extracts a comparison character string in comparison units from the specific target file Fk (step S2001).
- the search device 800 causes the analysis unit 802 to perform a morphological analysis on the search character string and break it down into words (step S2002).
- the search device 800 extracts a comparison word corresponding to the part of speech necessary for the fuzzy search from the decomposed word group (step S2003).
- the range of the intermediate hierarchy is from the t1 hierarchy to the t2 hierarchy (t1 ⁇ t2, t1 ⁇ 1, t2 ⁇ m, and m is the lowest hierarchy number).
- the search device 800 determines whether j> t2 is satisfied (step S2010). If j> t2 is not satisfied (step S2010: No), the search device 800 increments the hierarchy number j (step S2011) and returns to step S2007.
- step S2010: Yes the process proceeds to step S1905 in FIG.
- step S183 the number of coincidence of classification codes in the intermediate hierarchy (from the t1 hierarchy to the t2 hierarchy) is counted.
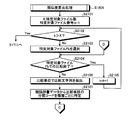
- FIG. 21 is a flowchart (part 1) illustrating a detailed processing procedure example of the similarity calculation processing (step S1804) illustrated in FIG.
- the number of specific target files K is the number of target files detected in step S1802 in FIG.
- the search device 800 determines whether or not k> K (step S2102). When k> K is satisfied (step S2102: YES), the process proceeds to an output process (step S1711). On the other hand, if k> K is not satisfied (step S2102: NO), the search device 800 selects the specific target file Fk (step S2103). Then, the search device 800 determines whether or not the comparison with the specific target file Fk is completed (step S2104). Specifically, the process ends when there are no more unselected comparison character strings.
- step S2104 When the comparison with the specific target file Fk is completed (step S2104: YES), since there is no comparison character string to be extracted, the search device 800 increments the specific target file number k (step S2105) and returns to step S2102. .
- step S2104 when the comparison with the specific target file Fk does not end (step S2104: No), the search device 800 extracts a comparison character string from the specific target file Fk in comparison units (step S2106).
- the first specifying unit 902 specifies the classification code of the comparison word for each hierarchy from the synonym dictionary data 100 (step S2107), and the process proceeds to step S2201 in FIG.
- FIG. 22 is a flowchart (part 2) illustrating a detailed processing procedure example of the similarity calculation processing (step S1804) illustrated in FIG.
- step S2203 NO
- step S2203 NO
- step S2203: NO the process returns to step S2104 in FIG.
- step S2202 YES
- the search apparatus 800 uses the determination unit 904 to determine the jth hierarchy between the search word in the search character string and the comparison word in the comparison character string. It is determined whether or not the classification codes match (step S2205).
- step S2205 If they do not match (step S2205: NO), the search device 800 determines whether or not the number N of intermediate classification code matches is greater than or equal to the threshold value Nt (step S2206). If N ⁇ Nt (step S2206: YES), it is not necessary to make the comparison character string having the mismatched comparison word a fuzzy search target, so the process returns to step S2104 by excluding it from the similarity calculation target. On the other hand, if N ⁇ Nt is not satisfied (step S2206: NO), the fuzzy search target is insufficient, and the process proceeds to step S2207.
- step S2205 If it is determined in step S2205 that they match (step S2205: YES), the process proceeds to step S2207.
- step S2207 the search device 800 increments the hierarchy number j (step S2207), and determines whether j> t2 is satisfied (step S2208). If j> t2 is not satisfied (step S2208: NO), the process returns to step S2205 because it is still an intermediate hierarchy.
- step S2208 Yes
- the search device 800 generates the synonym vector of the search character string and the synonym vector of the comparison character string by the first calculation unit 907, and searches the search character string by the kernel method. And the comparison character string are calculated (step S2209). Then, the process returns to step S2104 in FIG.
- the comparison character string is subject to the fuzzy search or excluded depending on the number of intermediate classification code matches N, depending on the situation. Can be selected. Therefore, a fuzzy search can be performed for an appropriate number of comparison character strings having high similarity.
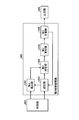
- FIG. 23 is a flowchart (part 1) illustrating a detailed processing procedure example of the second search processing (step S1707 and step S1710) illustrated in FIG.
- m is the hierarchy number of the designated hierarchy, for example, the lowest hierarchy number.
- the search device 800 uses the second specifying unit 1203 to specify the j-th to m-th class classification codes of the search word from the synonym dictionary data 100 (step S2302). Then, the search device 800 refers to the classification map of the j-th layer to the m-th layer and identifies the bit string of the classification code of the j-th layer to the m-th layer of the search word.
- the second detection unit 1201 detects a target file that is all ON in the specified bit string (step S2303). As a result, the search target is narrowed down to the specific target file. Thereafter, the process proceeds to step S2401 in FIG.
- FIG. 24 is a flowchart (part 2) illustrating a detailed processing procedure example of the second search processing (step S1707 and step S1710) illustrated in FIG.
- the number of specific target files K is the number of target files detected in step S2303 in FIG.
- the search device 800 determines whether or not k> K (step S2402). If k> K is not satisfied (step S2402: NO), the search device 800 selects the specific target file Fk (step S2403). Then, the search device 800 determines whether or not the comparison with the specific target file Fk is finished (step S2404). Specifically, the process ends when there are no more unselected comparison character strings.
- step S2404 If the comparison with the specific target file Fk does not end (step S2404: No), the search device 800 extracts a comparison character string from the specific target file Fk in comparison units (step S2405). Then, the search device 800 causes the analysis unit 802 to analyze the extracted comparison character string into words and decompose it into words (step S2406).
- the search device 800 extracts a comparison word corresponding to the part of speech necessary for the fuzzy search from the decomposed word group (step S2407).
- the search device 800 uses the second specifying unit 1203 to specify the classification codes of the comparison word from the j-th layer to the m-th layer from the synonym dictionary data 100 (step S2408).
- the second calculation unit 1204 generates a synonym vector of the search character string using the classification codes of the j-th layer to the m-th layer of the search word in the search character string.
- the search device 800 uses the second calculation unit 1204 to generate a synonym vector of the comparison character string using the classification codes of the j-th layer to the m-th layer of the comparison word in the comparison character string.
- the search device 800 uses the second calculation unit 1204 to calculate the similarity between the search character string and the comparison character string from both synonym vectors (step S2409). Then, the process returns to step S2404.
- step S2404 when the comparison with the specific target file Fk is completed in step S2404 (step S2404: Yes), the search device 800 increments the specific target file number k because there is no comparison character string to be extracted (step S2410). ), The process returns to step S2402.
- the comparison character string is subject to the fuzzy search or excluded from the comparison character string determined to be inconsistent with the search character string by the classification code of the intermediate layer. You can choose according to your needs. Therefore, a fuzzy search can be performed for an appropriate number of comparison character strings having high similarity.
- either the first search process or the second search process can be selected according to the number of search words constituting the search character string. That is, if the number of search words is small, the first search process is selected and the synonym vector of the search character string is large, but the similarity calculation is completed at one time, so the speed of the fuzzy search can be increased.
- the second search process is selected, and the search target range can be expanded step by step from the lower hierarchy. Efficiency can be improved.
- the fuzzy search accuracy can be improved by automatically selecting the target range of the fuzzy search.
- the search method described in the present embodiment can be realized by executing a program prepared in advance on a computer such as a personal computer or a workstation.
- This search program is recorded on a computer-readable recording medium such as a hard disk, a flexible disk, a CD-ROM, an MO, and a DVD, and is executed by being read from the recording medium by the computer.
- the search program may be distributed via a network such as the Internet.
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- General Physics & Mathematics (AREA)
- Databases & Information Systems (AREA)
- General Engineering & Computer Science (AREA)
- Data Mining & Analysis (AREA)
- Computational Linguistics (AREA)
- Fuzzy Systems (AREA)
- Mathematical Physics (AREA)
- Software Systems (AREA)
- Automation & Control Theory (AREA)
- Probability & Statistics with Applications (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
Abstract
(A)において、検索単語「カレーライス」の階層別の分類コード「#1」,「#10」,「#1032」が得られる。(B)において、比較文字列「カレーライス。カレーをご飯にかけた食べ物。」については、大分類コード「#1」(食べ物)の出現回数は4回、中分類コード「#10」(飯)の出現回数は2回、小分類コード「#1032」(カレーライス)の出現回数は1回、中分類コード「#11」(香辛料)の出現回数は1回、小分類コード「#1154」(カレー)の出現回数は1回となる。(C)において、(A)で求めた出現回数をベクトル化する。(B)で求めた出現回数をベクトル化する。両類語ベクトルの内積をとることで類似度を算出する。(C)では、類似度は7となる。あいまい検索の対象範囲を自動的に取捨選択することにより、あいまい検索精度の向上を図ることができる。
Description
本発明は、情報を検索する検索プログラム、検索装置、および検索方法に関する。
一般に、あいまい検索とは、たとえば、「風景」および「写す」というような検索文字列を与えた場合に、検索文字列と不一致な文字列「写真を撮影する」であっても、検索文字列と意味が似ているため検索できる検索方法である。
このようなあいまい検索については、従来、複数のキーワード(キーワードには分類コードを含む)をベクトルに変換し、スコア計算を行う検索方法が開示されている(たとえば、下記特許文献1を参照。)。また、フリーワードの検索において、ビットマップ型の全文インデックスを用いて行う検索方法が開示されている。このビットマップ型の全文インデックスは、文字ごとに各ブロック内に当該文字と等しいビット数のビット列を配置したブロックビットマップと階層構成を形成する(たとえば、下記特許文献2を参照。)。
さらに、入力記号列のベクトルと、辞書に登録されている所定の記号列の標準ベクトルとの間で類似度を算出し、誤りがあれば、辞書検索による記号列に対応する単語に修正する検索方法が開示されている(たとえば、下記特許文献3を参照。)。
また、コールセンターなどの顧客からのお問い合わせの統計情報を活用し、携帯電話などのマニュアル検索においてあいまい検索を実現する技術も開示されている(たとえば、下記特許文献4,5を参照。)。また、類語入力とカーネル関数によるフィルタリング技術も開示されている(たとえば、下記特許文献1を参照。)。
しかしながら、上述した従来技術では、あいまい検索に際し、どこまでをあいまい検索の対象範囲とし、どこからをあいまい検索の対象範囲外とするかについては、人手により操作する必要があった。すなわち、あいまい検索の対象範囲が適切か否かについては、ユーザ依存となってしまうこととなる。したがって、ユーザが欲しいあいまい検索結果が得られなかったり、ユーザが欲しくないあいまい検索結果までもが得られてしまったりすることにより、あいまい検索精度が低下するという問題がある。
1つの側面では、本発明は、あいまい検索精度の向上を図ることができる検索プログラム、検索装置、および検索方法を提供することを目的とする。
1つの案では、単語間の類義関係を階層的に分類してコード化した類語辞書データの中から、検索文字列内の検索単語の階層ごとの分類コードと、比較文字列群の各々の比較文字列内の比較単語の階層ごとの分類コードと、を特定し、特定された前記検索単語の階層ごとの分類コードおよび前記各比較単語の階層ごとの分類コードの中から、前記類語辞書データを構成する階層群のうち特定階層の分類コードを抽出し、抽出された前記検索単語の前記特定階層の分類コードと前記比較単語の前記特定階層の分類コードとが一致するか否かを、比較文字列ごとに判定し、前記特定階層での一致数を計数し、計数された一致数に基づいて、前記比較単語の前記特定階層の分類コードが不一致と判定された比較文字列を除外するか否かを判断し、前記検索単語の階層ごとの分類コードと除外しないと判断された比較文字列内の前記比較単語の階層ごとの分類コードとに基づいて、前記検索文字列と前記除外しないと判断された比較文字列との類似度を算出し、算出された算出結果を出力する検索プログラム、検索装置、および検索方法を用いる。
本発明の検索プログラム、検索装置、および検索方法によれば、あいまい検索精度の向上を図ることができる。
以下に添付図面を参照して、本発明の検索プログラム、検索装置、および検索方法の実施の形態を詳細に説明する。
<類語辞書データ>
類語辞書データとは、単語間の類義関係を階層的に分類してコード化したデータである。シソーラスとも呼ばれる。具体的には、たとえば、各単語はコード化されており、概念的に下位階層となる単語には、上位階層の単語のコードを先頭につけてコード化される。
類語辞書データとは、単語間の類義関係を階層的に分類してコード化したデータである。シソーラスとも呼ばれる。具体的には、たとえば、各単語はコード化されており、概念的に下位階層となる単語には、上位階層の単語のコードを先頭につけてコード化される。
図1は、類語辞書データのデータ構造例を示す説明図である。図1では、類語辞書データ100は、例として3階層で構成されている。なお、階層数は、2以上であればよい。図1では、3階層であるため、最上位階層である第1階層を「大分類」、中間階層である第2階層を「中分類」、最下層である第3階層を「小分類」とする。
たとえば、大分類「食べ物」には、中分類「飯」,「香辛料」(これ以外にも「ラーメン」などあるが図1では省略)が属しており、中分類「飯」には、小分類「カレーライス」,「ハヤシライス」,「寿司」(これ以外にも「炒飯」などあるが図1では省略)が属している。
また、各単語には、2種類の分類コードが付与される。1つは、単独分類コードであり、もう1つは連結分類コードである。単独分類コードとは、各単語に付与される分類コードである。連結分類コードとは、その単語の単独分類コードの先頭に、上位階層のすべての単独分類コードが連結された分類コードである。
たとえば、小分類「カレーライス」の単独分類コードは「#32」であるが、その上位階層である中分類「飯」の単独分類コードは「#0」であり、中分類「飯」の上位階層である大分類「食べ物」の単独分類コードは「#1」である。したがって、「カレーライス」の連結分類コードは、上位階層の単独分類コードから順に連結した「#1032」となる。
以降、本明細書では、特に断りがない限り、「分類コード」と称した場合は「連結分類コード」を指すこととする。また、大分類の連結分類コードを、「大分類コード」と称し、中分類の連結分類コードを、「中分類コード」と称し、小分類の連結分類コードを、「小分類コード」と称す。
また、連結分類コードは、単独分類コードが上位階層から連結されたコードである。したがって、コード長と桁により、どのコードがどの階層の単独分類コードであるかがわかる。たとえば、図1では、大分類コードおよび中分類コードは1桁、小分類コードは2桁としている。したがって、コード長が1であれば、その分類コードは大分類コードである。コード長が2であれば、中分類コードである。また、先頭桁が大分類の単独分類コード、末尾の桁が中分類の単独分類コードであることがわかる。
さらに、コード長が4であれば、小分類コードである。また、先頭から1桁目が大分類の単独分類コード、2番目の桁が中分類の単独分類コード、末尾2桁が小分類の単独分類コードであることがわかる。
<分類マップ>
つぎに、分類マップについて説明する。分類マップとは、ビットマップ型の全文インデックスを拡張子、類語辞書データ100の任意階層について、各分類コードにより包含される単語の各対象ファイル内での存否を示すビット列の集合をまとめたビットマップである。全階層の分類マップをまとめたマップ群を、分類マップ群と称す。分類マップは、類語辞書データ100で定義された階層数存在することとなる。
つぎに、分類マップについて説明する。分類マップとは、ビットマップ型の全文インデックスを拡張子、類語辞書データ100の任意階層について、各分類コードにより包含される単語の各対象ファイル内での存否を示すビット列の集合をまとめたビットマップである。全階層の分類マップをまとめたマップ群を、分類マップ群と称す。分類マップは、類語辞書データ100で定義された階層数存在することとなる。
また、対象ファイルとは、文字列が記述されたファイルであり、たとえば、HTML(HyperText Markup Language)形式,XML(Extensible Markup Language)形式,テキスト形式のファイルである。対象ファイル(群)としては、たとえば、電子辞書、電子書籍、Webページ、電子文書、その他文字列を含むデータが挙げられる。図2~図4では、ファイル番号1~nの対象ファイルF1~Fnについての分類マップを示している。
また、「分類コードにより包含される単語」とは、ある階層に注目した場合、注目階層の単語のほか、注目階層の単語よりも下位階層に属する概念的に下位の単語である。具体的には、たとえば、注目階層の連結分類コードに対応する単語のほか、注目階層の単語の単独分類コードが連結された下位階層の連結分類コードに対応する単語である。
図2は、第1階層(大分類)の分類マップの例を示す説明図であり、図3は、第2階層(中分類)の分類マップの例を示す説明図であり、図4は、第3階層(小分類)の分類マップの例を示す説明図である。なお、図2~図4では、分類コードに対応する単語の各対象ファイルFi内での存否を示すビット(以下、単に、「ビット」)の値について、本例では「存在」を示す場合は“1”、不存在を示す場合は“0”とする。
図2に示した大分類コードの分類マップ(大分類マップ)200には、大分類ごとに、対象ファイルFiの数分のビット列が記憶されている。たとえば、大分類コード#1(食べ物)については、対象ファイルF1~F3の各ビットが“1”であるため、対象ファイルF1~F3には、「食べ物」という単語が存在していることがわかる。
ただし、大分類コードに対応する単語そのものが存在していなくても、大分類コードに包含される単語が存在していれば、ビットの値は“1”となる。たとえば、大分類コード#1(食べ物)について、対象ファイルF1に「食べ物」という単語が存在していなくても、大分類コード#1(食べ物)の下位階層に属する中分類コード#10に対応する単語「飯」が存在する場合は、ビットの値は“1”となる。
同様に、大分類コード#1(食べ物)について、大分類コード#1(食べ物)の下位階層に属する小分類コード#1032に対応する単語「カレーライス」が存在する場合は、ビットの値は“1”となる。
図3に示した中分類コードの分類マップ(中分類マップ)300には、中分類ごとに、対象ファイルFiの数分のビット列が記憶されている。たとえば、中分類コード#10(飯)については、対象ファイルF1,F2の各ビットが“1”であるため、対象ファイルF1,F2には、「飯」という単語が存在していることがわかる。
ただし、中分類コードに対応する単語そのものが存在していなくても、中分類コードに包含される単語が存在していれば、ビットの値は“1”となる。たとえば、中分類コード#10(飯)について、対象ファイルF1に「飯」という単語が存在していなくても、中分類コード#10(飯)の下位階層に属する小分類コード#1032に対応する単語「カレーライス」が存在する場合は、ビットの値は“1”となる。
図4に示した小分類コードの分類マップ(小分類マップ)400には、小分類ごとに、対象ファイルFiの数分のビット列が記憶されている。たとえば、小分類コード#1032(カレーライス)については、対象ファイルF1,F2の各ビットが“1”であるため、対象ファイルF1,F2には、「カレーライス」という単語が存在していることがわかる。
<分類マップ群と対象ファイル群とのリンク関係>
図5は、分類マップ群と対象ファイル群とのリンク関係を示す説明図である。分類マップ群Mと対象ファイル群Fとは、分類コードファイル群Cによってリンクされている。ここで、分類コードファイルCiとは、対象ファイルFiごとに、対象ファイルFi内に存在する単語に対応する分類コードとその出現位置が記述されたファイルである。
図5は、分類マップ群と対象ファイル群とのリンク関係を示す説明図である。分類マップ群Mと対象ファイル群Fとは、分類コードファイル群Cによってリンクされている。ここで、分類コードファイルCiとは、対象ファイルFiごとに、対象ファイルFi内に存在する単語に対応する分類コードとその出現位置が記述されたファイルである。
本実施例では、ファイル番号iが同一の対象ファイルFiおよび分類コードファイルCiどうしが対応する。たとえば、対象ファイルF1と分類コードファイルC1とが対応する。また、出現位置とは、対象ファイル内での記述位置を特定する情報であり、たとえば、対象ファイルにおける先頭文字からの文字数が挙げられる。
たとえば、図5において、対象ファイルF1に「カレーライスは中辛だ。」という文字列が記述されている場合、対象ファイルF1に対応する分類コードファイルC1には、「カレーライス」の分類コード「#1032」とその出現位置を示す「5」とを組み合わせた「#1032/5」が記述される。すなわち、対象ファイルF1の先頭文字から5番目の文字から「カレーライス」が記述されていることがわかる。
同様に、分類コードファイルC1には、「中辛」の分類コード「#4210」とその出現位置を示す「12」とを組み合わせた「#4210/12」が記述される。すなわち、対象ファイルF1の先頭文字から12番目の文字から「中辛」が記述されていることがわかる。このようなリンク関係があることにより、後述の第1特定部902や第2特定部1203で対象ファイルFi内の単語から分類コードを特定することが可能となる。
また、各分類コードファイルCi内に、特殊コードを埋め込むことで、検索単語との比較範囲を規定することができる。たとえば、対象ファイル群Fが辞書データである場合、見出し語およびその解説文内の単語について、分類コードおよび出現位置を記述しておき、末尾に特殊コードとして改行コードを埋め込んでおく。これにより、改行コードと次の改行コードとの間に記述されている見出し語および解説文についての分類コード群が、検索単語との比較範囲となる。なお、特殊コードが埋め込まれていない場合は、個々の分類コードが比較範囲となる。
<コンピュータのハードウェア構成例>
図6は、実施の形態にかかるコンピュータのハードウェア構成例を示すブロック図である。図6において、コンピュータは、CPU(Central Processing Unit)601と、ROM(Read Only Memory)602と、RAM(Random Access Memory)603と、磁気ディスクドライブ604と、磁気ディスク605と、光ディスクドライブ606と、光ディスク607と、ディスプレイ608と、I/F(Interface)609と、キーボード610と、マウス611と、スキャナ612と、プリンタ613と、を備えている。また、各構成部はバス600によってそれぞれ接続されている。
図6は、実施の形態にかかるコンピュータのハードウェア構成例を示すブロック図である。図6において、コンピュータは、CPU(Central Processing Unit)601と、ROM(Read Only Memory)602と、RAM(Random Access Memory)603と、磁気ディスクドライブ604と、磁気ディスク605と、光ディスクドライブ606と、光ディスク607と、ディスプレイ608と、I/F(Interface)609と、キーボード610と、マウス611と、スキャナ612と、プリンタ613と、を備えている。また、各構成部はバス600によってそれぞれ接続されている。
ここで、CPU601は、コンピュータの全体の制御を司る。ROM602は、ブートプログラムや本実施の形態の検索プログラム、生成プログラムなどのプログラムを記憶している。RAM603は、CPU601のワークエリアとして使用される。磁気ディスクドライブ604は、CPU601の制御にしたがって磁気ディスク605に対するデータのリード/ライトを制御する。磁気ディスク605は、磁気ディスクドライブ604の制御で書き込まれたデータを記憶する。
光ディスクドライブ606は、CPU601の制御にしたがって光ディスク607に対するデータのリード/ライトを制御する。光ディスク607は、光ディスクドライブ606の制御で書き込まれたデータを記憶したり、光ディスク607に記憶されたデータをコンピュータに読み取らせたりする。
ディスプレイ608は、カーソル、アイコンあるいはツールボックスをはじめ、文書、画像、機能情報などのデータを表示する。このディスプレイ608は、たとえば、CRT、TFT液晶ディスプレイ、プラズマディスプレイなどを採用することができる。
インターフェース(以下、「I/F」と略する。)609は、通信回線を通じてLAN(Local Area Network)、WAN(Wide Area Network)、インターネットなどのネットワーク614に接続され、このネットワーク614を介して他の装置に接続される。そして、I/F609は、ネットワーク614と内部のインターフェースを司り、外部装置からのデータの入出力を制御する。I/F609には、たとえばモデムやLANアダプタなどを採用することができる。
キーボード610は、文字、数字、各種指示などの入力のためのキーを備え、データの入力をおこなう。また、タッチパネル式の入力パッドやテンキーなどであってもよい。マウス611は、カーソルの移動や範囲選択、あるいはウィンドウの移動やサイズの変更などをおこなう。ポインティングデバイスとして同様に機能を備えるものであれば、トラックボールやジョイスティックなどであってもよい。
スキャナ612は、画像を光学的に読み取り、コンピュータ内に画像データを取り込む。なお、スキャナ612は、OCR(Optical Character Reader)機能を持たせてもよい。また、プリンタ613は、画像データや文書データを印刷する。プリンタ613には、たとえば、レーザプリンタやインクジェットプリンタを採用することができる。
<分類マップ群Mおよび分類コードファイル群Cの生成処理>
つぎに、分類マップ群Mおよび分類コードファイル群Cの生成処理について説明する。この生成処理は、本実施の形態の検索装置が実行してもよく、検索装置とは異なる生成装置が実行してもよい。いずれにしても、本実施の形態の生成プログラムがインストールされたコンピュータが実行する。
つぎに、分類マップ群Mおよび分類コードファイル群Cの生成処理について説明する。この生成処理は、本実施の形態の検索装置が実行してもよく、検索装置とは異なる生成装置が実行してもよい。いずれにしても、本実施の形態の生成プログラムがインストールされたコンピュータが実行する。
図7は、分類マップ群Mおよび分類コードファイル群Cの生成処理を示すフローチャートである。まず、コンピュータは、類語辞書データ100の階層番号jをj=1に設定する(ステップS701)。そして、コンピュータは、類語辞書データ100に第j階層の未選択の単語があるか否かを判断する(ステップS702)。未選択の単語がある場合(ステップS702:Yes)、コンピュータは、第j階層の未選択の単語を1つ選択する(ステップS703)。
そして、コンピュータは、選択単語の分類コードを第j階層の分類マップに設定する(ステップS704)。つぎに、コンピュータは、対象ファイルFiのファイル番号iをi=1に設定する(ステップS705)。そして、コンピュータは、対象ファイルFiを走査して、選択単語に一致する文字列があるか否かを判断する(ステップS706)。一致する文字列がない場合(ステップS706:No)、ステップS712に移行する。これにより、つぎの対象ファイルに移ることとなる。
一方、一致する文字列がある場合(ステップS706:Yes)、コンピュータは、選択単語の分類コードと選択単語の対象ファイルFiでの出現位置とを分類コードファイルCiに追加する(ステップS707)。
そして、コンピュータは、第j階層の分類マップにおいて選択単語の分類コードにおけるファイル番号iのビットをON(“1”)にする(ステップS708)。このあと、コンピュータは、選択単語の分類コードから、第j階層よりも上位階層ごとの分類コードを抽出する(ステップS709)。
上述したように、第j階層の分類コードには、その上位階層(第1階層,…,第(j-1)階層)の分類コードが含まれている。たとえば、第3階層である小分類コード「#1032」(カレーライス)の先頭2桁は、中分類コードであるため、先頭2桁のコードを第2階層である中分類コード「#10」(飯)として抽出する。同様に、小分類コード「#1032」(カレーライス)の先頭1桁は、大分類コードであるため、先頭1桁のコードを第1階層である大分類コード「#1」(食べ物)として抽出する。
そして、コンピュータは、ステップS709で抽出された上位階層の分類コードを、その上位階層の分類マップに設定する(ステップS710)。具体的には、上述の例では、中分類コード「#10」(飯)については、中分類の分類マップに中分類コード「#10」(飯)を設定する。同様に、大分類コード「#1」(食べ物)についても、大分類の分類マップ大分類コード「#1」(食べ物)を設定する。設定済みである場合は設定しない。
このあと、コンピュータは、ステップS710で各上位階層の分類マップに設定された抽出分類コードにおけるファイル番号iのビットをON(“1”)にする(ステップS711)。なお、すでにONである場合は何もしない。
そして、コンピュータは、ファイル番号iをインクリメントし(ステップS712)、i>nであるか否かを判断する(ステップS713)。nは対象ファイル群Fのファイル総数である。i>nでない場合(ステップS713:No)、ステップS706に戻り、対象ファイルFiに、選択単語に一致する文字列があるか否かを判断することとなる。
また、i>nである場合(ステップS713:Yes)、ステップS702に戻り、コンピュータは、類語辞書データ100に第j階層の未選択の単語があるか否かを判断する(ステップS702)。第j階層の未選択の単語がない場合(ステップS702:No)、階層番号jをインクリメントして(ステップS714)、コンピュータは、j>mであるか否かを判断する(ステップS715)。mは階層数である。図1のような類語辞書データ100を用いる場合は、m=3である。
j>mでない場合(ステップS715:No)、ステップS702に戻り、コンピュータは、類語辞書データ100に第j階層の未選択の単語があるか否かを判断する(ステップS702)。一方、j>mである場合(ステップS715:Yes)、分類マップ群Mおよび分類コードファイル群Cの生成処理を終了する。
この分類マップ群Mおよび分類コードファイル群Cの生成処理を実行することで、最終的に、対象ファイル群Fに固有な分類マップ群Mおよび分類コードファイル群Cが自動生成されることとなる。
<検索装置の機能的構成例>
図8は、本実施の形態の検索装置の機能的構成例を示すブロック図である。図8において、検索装置800は、入力部801と、解析部802と、判別部803と、第1検索処理部804と、第2検索処理部805と、出力部806とを備える。入力部801~出力部806は、具体的には、たとえば、図6に示したROM602、RAM603、磁気ディスク605、光ディスク607などの記憶装置に記憶されたプログラムをCPU601に実行させることにより、または、I/F609により、その機能を実現する。
図8は、本実施の形態の検索装置の機能的構成例を示すブロック図である。図8において、検索装置800は、入力部801と、解析部802と、判別部803と、第1検索処理部804と、第2検索処理部805と、出力部806とを備える。入力部801~出力部806は、具体的には、たとえば、図6に示したROM602、RAM603、磁気ディスク605、光ディスク607などの記憶装置に記憶されたプログラムをCPU601に実行させることにより、または、I/F609により、その機能を実現する。
入力部801は、検索文字列の入力や検索モードの指定を受け付ける。検索モードとは、検索処理の種別を示しており、後述する上位階層分類コードによる検索処理(第1検索モード)または最下層の分類コードからの検索処理(第2検索モード)のいずれかのモードである。
解析部802は、入力部801によって入力された検索文字列を解析する。具体的には、たとえば、解析部802は、形態素解析を実行することで検索文字列を単語に分解し、分解された単語の各々について品詞を特定する。そして、解析部802は、この分解された単語群のうち、あいまい検索で使用する品詞、たとえば、名詞、動詞、形容詞、副詞に該当する単語を、検索単語として抽出する。なお、解析部802は比較文字列も検索文字列と同様に解析する。
判別部803は、指定された検索モードがいずれの検索処理であるかを判別する。また、検索モードが指定されていない場合は、判別部803は、解析部802によって解析された検索単語の数が所定単語数以上であるか否かを判別する。所定単語数未満である場合は、第1検索モードが指定され、所定文字数以上である場合は、第2検索モードが指定される。
検索装置800は、判別部803で判別された検索モードで検索処理を実行することとなる。このように、検索単語の数が多いと、あいまい検索のヒット数が膨大になる可能性があるため、検索装置800は、第2検索モードにより、指定階層から段階的に検索対象となる階層を拡大していくこととする。
第1検索処理部804は、上位階層分類コードによる検索処理を実行する。上位階層分類コードによる検索処理とは、検索文字列内の検索単語の分類コードと検索単語を包含する上位階層の単語の分類コードを用いて検索文字列に固有の類語ベクトルを生成する。同様に、比較文字列内の比較単語についても、比較単語の分類コードと比較単語を包含する上位階層の単語の分類コードを用いて比較文字列に固有の類語ベクトルを生成する。そして、第1検索処理部804は、カーネル法による両類語ベクトルの演算をおこなって、検索文字列と比較文字列との類似度を算出することとなる。なお詳細については後述する。
また、第2検索処理部805は、最下層の分類コードからの検索処理を実行する。最下層の分類コードからの検索処理とは、検索文字列内の検索単語の分類コードとを用いて検索文字列に固有の類語ベクトルを生成する。同様に、比較対象となる比較文字列内の比較単語についても、比較単語の分類コードを用いて比較文字列に固有の類語ベクトルを生成する。そして、第2検索処理部805は、カーネル法による両類語ベクトルの演算をおこなって、検索文字列と比較文字列との類似度を算出することとなる。
このとき、所定類似度以上の比較文字列の総数が所定数未満である場合は、検索文字列および比較文字列について、1つ上位の階層の分類コードを特定して、それぞれの類語ベクトルに追加し、同様に類似度を算出する。このように、第2検索処理部805は、所定類似度以上の比較文字列の総数が所定数以上となるまで、1つ上位の階層に上がって類語ベクトルを再生成して、類似度を算出することとなる。なお詳細については後述する。
出力部806は、第1検索処理部804または第2検索処理部805の検索結果を出力する。具体的には、たとえば、出力部806は、類似度の高い順に比較文字列をランキング表示する。なお、出力部806による出力形式は、ディスプレイ608への表示に限らず、通信可能な他のコンピュータへの送信でもよく、印刷出力でもよい。また、検索装置800内の記憶領域への書込でもよい。
なお、検索装置800は、入力部801、解析部802、第1検索処理部804、および出力部806により構成してもよく、また、入力部801、解析部802、第2検索処理部805、および出力部806により構成してもよい。
<第1検索処理部804の機能的構成例>
図9は、図8に示した第1検索処理部804の機能的構成例を示すブロック図である。第1検索処理部804は、第1検出部901と、第1特定部902と、抽出部903と、判定部904と、第1計数部905と、判断部906と、第1算出部907とを備える。
図9は、図8に示した第1検索処理部804の機能的構成例を示すブロック図である。第1検索処理部804は、第1検出部901と、第1特定部902と、抽出部903と、判定部904と、第1計数部905と、判断部906と、第1算出部907とを備える。
第1検出部901は、類語辞書データ100内の各分類コードに対応する単語の各対象ファイルFi内での存否を示すビット列の集合を階層別にまとめた分類マップ群Mのうち最上位階層の分類マップを参照して、検索単語が所属する最上位階層の分類コードが存在する特定の対象ファイルを検出する。
ここで、検索単語が所属する階層とは、検索単語の分類コードが存在する階層のほか、当該分類コードにより特定されるより上位の階層も含む。このような階層を所属階層と称す。そして、第1検出部901は、検索単語の分類コードを包含する最上位階層の分類コードまでさかのぼり、最上位階層の分類マップから特定の対象ファイルを検出することとなる。
たとえば、検索単語が「食べ物」である場合、分類コードは大分類コード「#1」であるため、大分類マップ200の「#1」のビット列を参照することで、特定の対象ファイルF1~F3を検出することとなる。
また、検索単語が「辛い」である場合、分類コードは中分類コード「#42」である。この中分類コード「#42」は大分類コード「#4」(味)に属するため、大分類マップ200の「#4」のビット列を参照することで、特定の対象ファイルF1,F2,Fnを検出することとなる。
また、検索単語が「カレーライス」である場合、分類コードは小分類コード「#1032」である。この小分類コード「#1032」は大分類コード「#1」(食べ物)に属するため、大分類マップ200の「#1」のビット列を参照することで、特定の対象ファイルF1~F3を検出することとなる。このように、検索単語がどの階層の分類コードであっても、最上位階層までさかのぼることで、必要最小限の範囲で対象ファイルFiを絞り込むことができる。
また、検索単語が「食べ物」および「味」である場合、分類コードは大分類コード「#1」,「#4」であるため、大分類マップ200の「#1」,「#4」のビット列を参照する。そして、「#1」,「#4」の両ビット列でONになっているファイル番号の対象ファイルF1,F2を特定の対象ファイルとして検出することとなる。
また、検索単語が「食べ物」および「辛い」である場合、検索単語「食べ物」の分類コードは大分類コード「#1」であるため、大分類マップ200の「#1」のビット列を参照する。一方、検索単語「辛い」の分類コードは中分類コード「#42」である。この中分類コード「#42」は大分類コード「#4」(味)に属するため、大分類マップ200の「#4」のビット列を参照する。そして、「#1」,「#4」の両ビット列でONになっているファイル番号の対象ファイルF1,F2を特定の対象ファイルとして検出することとなる。
このように、検索単語が複数ある場合、最上位階層での分類コードのビット列どうしで論理積をとることで、対象ファイルFiを絞り込むことができる。すなわち、第1検出部901では、以降のあいまい検索の検索先を特定の対象ファイルFiに絞り込むことができるため、無駄な対象ファイルFiの検索を防止でき、検索処理の高速化を図ることができる。なお、検索装置800が分類マップ群Mにアクセスできない場合は、全対象ファイルF1~Fn内の単語が比較対象となる。
第1特定部902は、単語間の類義関係を階層的に分類してコード化した類語辞書データ100の中から、検索文字列内の検索単語の階層ごとの分類コードと、比較文字列群の各々の比較文字列内の比較単語の階層ごとの分類コードと、を特定する。第1特定部902は、具体的には、たとえば、図1に示した類語辞書データ100の中から分類コードを特定する。
まず、検索単語の階層ごとの分類コードの特定について説明する。第1特定部902は、類語辞書データ100を参照して、検索文字列内の検索単語の分類コードとその階層を特定する。ここで、検索文字列内の検索単語とは、入力部801によって入力された検索文字列が解析部802によって単語に分解されて抽出された単語である。
分類コードの階層が最上位でない場合は、第1特定部902は、当該階層の分類コードを包含する上位階層の分類コードを最上位階層まで特定する。たとえば、検索単語が「カレーライス」である場合、その階層は第3階層(小分類)、小分類コードは「#1032」となる。そして、小分類コードの先頭2桁は中分類コードであるため、第1特定部902は「#10」を中分類コードとして特定する。さらに、小分類コードの先頭1桁は大分類コードであるため、第1特定部902は「#1」を大分類コードとして特定する。
このように、検索単語「カレーライス」から、小分類コード「#1032」、中分類コード「#10」および大分類コード「#1」が所属階層(第1階層~第3階層)での分類コードとして特定されることとなる。このような特定の仕方は、比較単語についても同様である。
また、比較文字列とは、ある比較単位内に記述されている一または複数の文字列(たとえば、読点や改行コードで区切られている。)である。比較単位は、単一の比較単語でもよく、一または複数の対象ファイルFiでもよい。また、第1検出部901により特定の対象ファイルFiに絞り込まれている場合は、特定の対象ファイルFi内の文字列のみが対象となる。
また、比較文字列は、ある対象ファイルFi内のある項目単位でもよい。対象ファイルFiが辞書データである場合、見出し語およびその解説文となる文字列を比較単位とし、当該文字列内の単語を比較単語とする。
抽出部903は、第1特定部902によって特定された検索単語の階層ごとの分類コードおよび各比較単語の階層ごとの分類コードの中から、類語辞書データ100を構成する階層群のうち特定階層の分類コードを抽出する。ここで、特定階層とは、たとえば、中間階層を指す。中間階層とは、少なくとも最上位階層および最下位階層を含まない階層(群)である。
本例では、第1階層~第3階層であるため、第2階層が中間階層となる。また、第1階層~第5階層まである場合は、中間階層は、第2階層のみ、第3階層のみ、第4階層のみ、第2階層および第3階層、第3階層および第4階層、第2階層~第4階層が中間階層として選ぶことが可能である。どの階層を中間階層にするかは、あらかじめ設定されているものとする。なお、本例では、特定階層を中間階層としたが、ある階層のみターゲットとして検索をおこないたい場合は、最上位階層や最下位階層を含む階層(群)を特定階層としてもよい。
したがって、検索単語が「カレーライス」である場合は、第1特定部902により小分類コード「#1032」、中分類コード「#10」および大分類コード「#1」が特定されるため、中分類コード「#10」が抽出されることとなる。
同様に、比較単語が「ハヤシライス」である場合は、第1特定部902により小分類コード「#1033」、中分類コード「#10」および大分類コード「#1」が特定されるため、中分類コード「#10」が抽出されることとなる。
なお、抽出部903は、中間階層よりも上位の上位階層での検索単語および比較単語の分類コードも抽出する。上記のカレーライスとハヤシライスの例では、ともに大分類コード「#1」を抽出することとなる。
判定部904は、抽出部903によって抽出された検索単語の特定階層の分類コードと比較単語の特定階層の分類コードとが一致するか否かを、比較文字列ごとに判定する。具体的には、たとえば、判定部904は、検索単語の中間階層における分類コードと比較単語の中間階層における分類コードとの一致判定をおこなう。上記のカレーライスとハヤシライスの例では、ともに中分類コード「#10」であるため、一致することとなる。
また、検索文字列内の検索単語が複数存在する場合がある。この場合、判定部904は、検索単語ごとに一致判定をおこなう。たとえば、検索単語の中分類コードが3個で比較単語の中分類コードが1個の場合は、一致判定を3回おこなう。これに対し、比較文字列内の比較単語が複数存在する場合がある。この場合、判定部904は、検索単語ごとに一致判定をおこなう。たとえば、検索単語の中分類コードが1個で比較単語の中分類コードが4個の場合は、一致判定を4回おこなう。
さらに、検索単語および比較単語が複数存在する場合がある。この場合も、判定部904は、検索単語ごとに各比較単語との一致判定をおこなう。たとえば、検索単語の中分類コードが2個で比較単語の中分類コードが3個である場合、一致判定を6回おこなう。
判定部904では、検索文字列内の検索単語の中間階層の分類コードと比較単位内の比較単語の中間階層の分類コードとの一致判定において、検索単語と比較単語の組み合わせですべて一致した場合に、検索文字列と比較単位内の比較文字列とが一致したと判定する。また、検索単語と比較単語の組み合わせのうち一部一致した場合に、検索文字列と比較単位内の比較文字列とが一致したと判定することとしてもよい。
なお、検索単語と比較単語の組み合わせのうちすべて不一致の場合に、検索文字列と比較単位内の比較文字列とが不一致であると判定する。すなわち、一部一致の場合に、検索文字列と比較単位内の比較文字列とを一致とするか不一致とするかは、あらかじめ設定しておくこととなる。
なお、判定部904では、検索単語および比較単語の中間階層の分類コードどうしの一致判定をおこなう前に、検索単語および比較単語の上位階層の分類コードどうしの一致判定をおこなうこととしてもよい。そして、一致した場合に、判定部904は、さらに中間階層の分類コードどうしの一致判定をおこない、不一致の場合はおこなわないこととなる。
具体的には、たとえば、上記のカレーライスとハヤシライスの例では、ともに大分類コード「#1」であるため、中分類コードどうしの一致判定をおこなうこととなる。この場合も上記と同様、検索文字列内の検索単語が複数存在する場合がある。この場合、判定部904は、検索単語ごとに一致判定をおこなう。
たとえば、検索単語の大分類コードが3個で比較単語の大分類コードが1個の場合は、一致判定を3回おこなう。これに対し、比較文字列内の比較単語が複数存在する場合がある。この場合、判定部904は、検索単語ごとに一致判定をおこなう。たとえば、検索単語の大分類コードが1個で比較単語の大分類コードが4個の場合は、一致判定を4回おこなう。
さらに、検索単語および比較単語が複数存在する場合がある。この場合も、判定部904は、検索単語ごとに各比較単語との一致判定をおこなう。たとえば、検索単語の大分類コードが2個で比較単語の大分類コードが3個である場合、一致判定を6回おこなう。
判定部904では、検索単語および比較単語の上位階層の分類コードどうしの一致判定が複数回行われる場合、すべて一致した場合のみ、検索単語および比較単語の中間階層の分類コードどうしの一致判定をおこなう。また、一部一致した場合でも、検索単語および比較単語の中間階層の分類コードどうしの一致判定をおこなうこととしてもよい。なお、全部不一致の場合は、検索単語および比較単語の中間階層の分類コードどうしの一致判定をおこなわない。一部一致の場合の取り扱いは、あらかじめ設定しておくこととなる。
いずれにしても、上位階層の分類コードどうしが不一致であれば、それよりも下位の階層で類似していないと考えられるため、上位階層の分類コードの一致判定をおこなうことで、無駄な検索を回避でき、検索効率の向上を図ることができる。
第1計数部905は、判定部904による特定階層での一致数を計数する。第1計数部905による一致数は、比較対象となる対象ファイル群Fでの一致数の総和である。たとえば、全対象ファイルでもよく、第1検出部901によって検出された特定の対象ファイルFiであってもよい。なお、第1計数部905での計数単位については、検索単語と比較単語との中間階層の分類コードどうしで一致した場合に、1ポイント計数する。
また、比較単位内で1つでも検索単語の中間階層の分類コードと一致する比較単語の中間階層の分類コードがあれば、1ポイント計数することとしてもよい。さらに、比較単位内のすべての比較単語の中間階層の分類コードが検索単語の中間階層の分類コードと一致した場合に、1ポイント計数することとしてもよい。どの計数方法を採用するかは、判定部904での一致判定に従うこととなる。
判断部906は、第1計数部905によって計数された一致数に基づいて、判定部904によって比較単語の階層ごとの分類コードが不一致と判定された比較文字列を除外するか否かを判断する。具体的には、たとえば、判断部906ではしきい値が設定されており、判断部906は、中間階層での一致数がしきい値以上であるか否かを判断する。すなわち、判断部906は、しきい値以上であるか否かにより、中間階層の分類コードが不一致となった比較文字列を、第1算出部907の算出対象とするか否かを判断する。
そして、一致数がしきい値以上である場合は、十分類語が含まれていることとなり、中間階層の分類コードが不一致となった比較単語についてまで、あいまい検索の対象(第1算出部907による算出対象)とする必要はない。したがって、一致数がしきい値以上の場合は、判断部906は、中間階層の分類コードが不一致となった比較文字列を、あいまい検索の対象から除外する。
一方、一致数がしきい値未満である場合は、類語が少ないと考えられるため、中間階層の分類コードが不一致となった比較文字列を、あいまい検索の対象とする必要がある。したがって、一致数がしきい値未満の場合は、判断部906は、中間階層の分類コードが不一致となった比較文字列を、あいまい検索の対象から除外しない。
第1算出部907は、判断部906によって除外しないと判断された比較文字列内の比較単語の階層ごとの分類コードとに基づいて、検索文字列と除外しないと判断された比較文字列との類似度を算出する。また、第1算出部907は、検索文字列と判定部904によって中間階層の分類コードが一致すると判定された比較文字列とについても、類似度を算出する。いずれの場合でも、第1算出部907は、カーネル法を用いた類似度を算出する。算出結果は出力部806に与えられる。以下、具体例を説明する。
図10は、第1算出部907による類似度算出の具体例1を示す説明図である。具体例1は、検索文字列となる1つの検索単語で比較文字列と比較する例である。ここでは、検索単語を「カレーライス」とし、比較単位となる比較文字列を辞書の見出し語「カレーライス。」および解説文「カレーをご飯にかけた食べ物。」とする。
(A)において、第1特定部902により検索単語「カレーライス」の階層別の分類コード「#1」,「#10」,「#1032」が得られる。検索単語は「カレーライス」のみであるため、各分類コード「#1」,「#10」,「#1032」の出現回数は1回である。
(B)において、比較文字列「カレーライス。カレーをご飯にかけた食べ物。」については、解析部802による形態素解析および単語抽出により、「カレーライス」,「カレー」,「飯」,「食べ物」が抽出される。それぞれの抽出単語については、第1特定部902により階層別の分類コードが得られる。
本例の場合、大分類コード「#1」(食べ物)の出現回数は4回、中分類コード「#10」(飯)の出現回数は2回、小分類コード「#1032」(カレーライス)の出現回数は1回、中分類コード「#11」(香辛料)の出現回数は1回、小分類コード「#1154」(カレー)の出現回数は1回となる。なお、検索単語の分類コードと不一致の分類コード「#11」(香辛料),「#1154」(カレー)の出現回数は除外される。
(C)において、第1算出部907は(A)で求めた出現回数をベクトル化する。これを検索文字列の類語ベクトルと称す。同様に、第1算出部907は(B)で求めた出現回数をベクトル化する。これを比較文字列の類語ベクトルと称す。そして、第1算出部907は、両類語ベクトルの内積をとることで類似度を算出する。(C)では、類似度は7となる。
図11は、第1算出部907による類似度算出の具体例2を示す説明図である。具体例2は、検索文字列と比較文字列とを比較する例である。ここでは、比較単位となる検索文字列を「このカレーライスは甘口だ」とし、比較文字列を「このハヤシライスはマイルドだ」とする。
(A)において、検索文字列「このカレーライスは甘口だ」について、解析部802による形態素解析および単語抽出により、「カレーライス」,「甘口」が抽出される。それぞれの抽出単語については、第1特定部902により階層別の分類コードが得られる。検索文字列では、各抽出単語の出現回数は1回であるため、各分類コード「#1」,「#10」,「#1032」,「#4」,「#41」,「#4110」の出現回数は1回である。
(B)において、比較文字列「このハヤシライスはマイルドだ」について、解析部802による形態素解析および単語抽出により、「ハヤシライス」,「マイルド」が抽出される。それぞれの抽出単語については、第1特定部902により階層別の分類コードが得られる。比較文字列では、各抽出単語の出現回数は1回であるため、各分類コード「#1」,「#10」,「#1033」,「#4」,「#41」,「#4111」の出現回数は1回である。
なお、「#1032」(カレーライス)および「#4110」(甘口)は、比較文字列では出現していないため、出現回数は0となる。なお、検索単語の分類コードと不一致の分類コード「#1033」(ハヤシライス),「#4111」(マイルド)の出現回数は除外される。
(C)において、第1算出部907は(A)で求めた出現回数をベクトル化する。これを検索文字列の類語ベクトルと称す。同様に、第1算出部907は(B)で求めた出現回数をベクトル化する。これを比較文字列の類語ベクトルと称す。そして、第1算出部907は、両類語ベクトルの内積をとることで類似度を算出する。(C)では、類似度は4となる。つぎに、第2検索処理部805の詳細について説明する。
<第2検索処理部805の機能的構成例>
図12は、図8に示した第2検索処理部805の機能的構成例を示すブロック図である。第2検索処理部805は、第2検出部1201と、設定部1202と、第2特定部1203と、第2算出部1204と、第2計数部1205と、を備える。
図12は、図8に示した第2検索処理部805の機能的構成例を示すブロック図である。第2検索処理部805は、第2検出部1201と、設定部1202と、第2特定部1203と、第2算出部1204と、第2計数部1205と、を備える。
第2検出部1201は、類語辞書データ100内の各分類コードに対応する単語の各対象ファイル内での存否を示すビット列の集合を階層別にまとめた分類マップ群Mを参照して、検索単語の対象階層の分類コードが存在する特定の対象ファイルFiを検出する。
たとえば、図1の類語辞書データ100の場合、最下層は第3階層となる。ここで、たとえば、対象階層が第3階層である場合、第2検索処理部805は、図4の小分類マップ400のみを参照する。そして、小分類マップ400において、検索単語の分類コードのビット列でONになっている対象ファイルFiを特定の対象ファイルとして検出する。
たとえば、検索単語が「ハヤシライス」である場合、分類コードは小分類コード「#1033」である。したがって、第2検出部1201では、小分類マップ400における小分類コード「#1033」のビット列でONになっている対象ファイルF1を特定の対象ファイルとして検出することとなる。
また、対象階層が第2階層にまで上がった場合、分類コードも第2階層の分類コードまで特定することとなる。上記の検索単語「ハヤシライス」の場合、中分類コードは先頭2桁の「#10」(飯)である。したがって、第2検出部1201では、中分類マップ300における中分類コード「#10」のビット列でONになっている対象ファイルF1,F2を特定の対象ファイルとして検出することとなる。このように、対象階層をより上位の階層に移すことで、第3階層では検出されなかった対象ファイルF2を特定の対象ファイルに含めることができ、特定の対象ファイルの範囲を拡大することができる。
同様に、対象階層が第1階層にまで上がった場合、分類コードも第1階層の分類コードまで特定することとなる。上記の検索単語「ハヤシライス」の場合、大分類コードは先頭1桁の「#1」(食べ物)である。したがって、第2検出部1201では、大分類マップ200における大分類コード「#1」のビット列でONになっている対象ファイルF1~F3を特定の対象ファイルとして検出することとなる。このように、対象階層をより上位の階層に移すことで、第2階層では検出されなかった対象ファイルF3を特定の対象ファイルに含めることができ、特定の対象ファイルの範囲を拡大することができる。
たとえば、検索単語が「ハヤシライス」および「マイルド」である場合、分類コードは小分類コード「#1033」,「#4111」である。したがって、第2検出部1201では、小分類マップ400における小分類コード「#1033」,「#4111」の両ビット列でONになっている対象ファイルF1を特定の対象ファイルとして検出することとなる。
また、対象階層が第2階層にまで上がった場合、分類コードも第2階層の分類コードまで特定することとなる。上記の検索単語「ハヤシライス」および「マイルド」の場合、中分類コードは先頭2桁の「#10」(飯),「#41」(甘い)である。したがって、第2検出部1201では、中分類マップ300における中分類コード「#10」,「#41」の両ビット列でONになっている対象ファイルF1,F2を特定の対象ファイルとして検出することとなる。このように、対象階層をより上位の階層に移すことで、第3階層では検出されなかった対象ファイルF2を特定の対象ファイルに含めることができ、特定の対象ファイルの範囲を拡大することができる。
同様に、対象階層が第1階層にまで上がった場合、分類コードも第1階層の分類コードまで特定することとなる。上記の検索単語「ハヤシライス」および「マイルド」の場合、大分類コードは先頭1桁の「#1」(食べ物),「#4」(味)である。したがって、第2検出部1201では、大分類マップ200における大分類コード「#1」,「#4」の両ビット列でONになっている対象ファイルF1,F2を特定の対象ファイルとして検出することとなる。特定の対象ファイルの範囲を拡大しようと試みたが結果的に拡大しなかった例である。
また、複数の検索単語の階層が異なる場合については以下のようになる。たとえば、検索単語が「ハヤシライス」および「甘い」である場合、分類コードは小分類コード「#1033」と中分類コード「#41」である。したがって、第2検出部1201では、小分類マップ400における小分類コード「#1033」,中分類コード「#41」の両ビット列でONになっている対象ファイルF1を特定の対象ファイルとして検出することとなる。
そして、対象階層が第2階層にまで上がった場合、第2検出部1201では、中分類マップ300における中分類コード「#10」,「#41」の両ビット列でONになっている対象ファイルF1,F2を特定の対象ファイルとして検出することとなる。
このように、対象階層をより上位の階層に移すことで、第3階層では検出されなかった対象ファイルF2を特定の対象ファイルに含めることができ、特定の対象ファイルの範囲を拡大することができる。なお、検索装置800が分類マップ群Mにアクセスできない場合は、全対象ファイルF1~Fn内の単語が比較対象となる。
設定部1202は、単語間の類義関係を階層的に分類してコード化した類語辞書データ100を構成する階層群の中から指定された指定階層を対象階層に設定する。具体的には、たとえば、指定階層は、最下位層とする。対象階層は変数であり、初期値が指定階層である。対象階層は指定階層から1階層ずつ上がっていく。
具体的には、設定部1202は、第2計数部1205によって計数された計数結果が所定数以下である場合、対象階層をより上位の階層に変更する。所定数は、あらかじめ設定された値である。なお、変更基準を所定数以下としたが、パーセンテージで判断してもよい。具体的には、分母を比較文字列の総数とし、分子を所定数として、所定確率とする。
そして、計数結果を比較文字列の総数で割った値が所定確率以下である場合、設定部1202は、対象階層をより上位の階層に変更する。また、変更する幅は、1階層とする。たとえば、変更前が第3階層である場合、変更後は第2階層となる。また、対象階層が変更された場合、第2検出部1201では、検索単語の変更後の対象階層の分類コードが存在する特定の対象ファイルを検出することとなる。
第2特定部1203は、類語辞書データ100の中から、検索文字列内の検索単語の指定階層から対象階層までの分類コードと、比較文字列群の各々の比較文字列内の比較単語の指定階層から対象階層までの分類コードとを、比較文字列ごとに特定する。第1特定部902では、検索単語および比較単語について特定階層(たとえば、中間階層)の分類コードを特定したが、第2特定部1203では、指定階層から対象階層までの分類コードを特定する。第2特定部1203では、対象階層が変更される都度、指定階層から変更後の対象階層までの分類コードを特定することとなる。
ここで、検索単語を「カレーライス」とする。たとえば、指定階層が第3階層である場合、初期状態では対象階層も第3階層に設定される。第2特定部1203は、検索単語「カレーライス」の第3階層での分類コード「#1032」を特定する。また、対象階層が第2階層に上がった場合、第2特定部1203は、さらに、検索単語「カレーライス」の第2階層での分類コード「#10」(飯)を特定する。さらに、対象階層が第1階層である場合、第2特定部1203は、さらに、検索単語「カレーライス」の第1階層での分類コード「#1」(食べ物)を特定する。
また、ここで、検索単語を「辛い」とする。検索単語「辛い」の分類コードは中分類コードであり、指定階層(第3階層)の分類コードではない。この場合、対象階層が第3階層となるため、第2特定部1203は、検索単語「辛い」の分類コードは特定できないこととなる。このあと、対象階層が第2階層に上がった場合、第2特定部1203は、検索単語「辛い」の第2階層での分類コード「#42」を特定することとなる。さらに、対象階層が第1階層に上がった場合、第2特定部1203は、検索単語「辛い」の第1階層での分類コード「#4」(味)を特定することとなる。
第2算出部1204は、検索単語の指定階層から対象階層までの分類コードと比較単語の指定階層から対象階層までの分類コードに基づいて、検索文字列と比較文字列との類似度を比較文字列ごとに算出する。具体的には、第2算出部1204は、検索単語における指定階層から対象階層までの分類コードで検索文字列の類語ベクトルを生成する。
同様に、第2算出部1204は、比較単語における指定階層から対象階層までの分類コードで比較文字列の類語ベクトルを生成する。そして、第2算出部1204は、第1算出部907と同様に、検索文字列の類語ベクトルと比較文字列の類語ベクトルの内積をとることで類似度を算出する。具体例については後述する。
第2計数部1205は、第2算出部1204によって類似度が算出された比較文字列群のうち所定類似度以上となる比較文字列の数を計数する。所定類似度は、あらかじめ設定された値である。第2計数部1205によって計数された計数結果が所定数以下である場合、設定部1202により対象階層が1階層上がって再度、第2検出部1201および第2特定部1203による処理が実行されることとなる。
なお、第2検索処理部805による処理を実行した場合、出力部806は、第2計数部1205によって計数された計数結果が所定数よりも多いこととなった比較文字列群のうち少なくとも所定類似度以上の比較文字列を出力することとなる。
図13は、第2算出部1204による類似度算出の具体例1を示す説明図である。具体例1は、検索文字列となる1つの検索単語で比較文字列と比較する例である。ここでは、検索単語を「カレーライス」とし、比較単位となる比較文字列を辞書の見出し語「カレーライス。」および解説文「カレーをご飯にかけた食べ物。」とする。なお、指定階層は第3階層、対象階層も第3階層とする。
(A)において、第2特定部1203により検索単語「カレーライス」の対象階層(第3階層)となる小分類コード「#1032」が得られる。検索単語は「カレーライス」のみであるため、小分類コード「#1032」の出現回数は1回である。
(B)において、比較文字列「カレーライス。カレーをご飯にかけた食べ物。」については、解析部802による形態素解析および単語抽出により、「カレーライス」,「カレー」,「飯」,「食べ物」が抽出される。それぞれの抽出単語については、第2特定部1203により対象階層(第3階層)の分類コードが得られる。
本例の場合、抽出単語「カレーライス」,「カレー」,「飯」,「食べ物」のうち対象階層である第3階層に属する単語は「カレーライス」,「カレー」であるため、小分類コード「#1032」,「#1154」が特定される。また、これらの出現回数はそれぞれ1回である。このうち、検索単語の分類コードと不一致の分類コード「#1154」(カレー)の出現回数は除外される。
(C)において、第2算出部1204は(A)で求めた出現回数をベクトル化する。これを検索文字列の類語ベクトルと称す。同様に、第2算出部1204は(B)で求めた出現回数をベクトル化する。これを比較文字列の類語ベクトルと称す。そして、第2算出部1204は、両類語ベクトルの内積をとることで類似度を算出する。(C)では、類似度は1となる。
図14は、第2算出部1204による類似度算出の具体例2を示す説明図である。具体例2は、図13の具体例1において、対象階層が第2階層に上がった場合の例である。
(A)において、第2特定部1203により検索単語「カレーライス」の指定階層(第3階層)から対象階層(第2階層)までの分類コードとして、小分類コード「#1032」および中分類コード「#10」が得られる。検索単語は「カレーライス」のみであるため、小分類コード「#1032」および中分類コード「#10」の出現回数はそれぞれ1回である。
(B)において、比較文字列「カレーライス。カレーをご飯にかけた食べ物。」については、解析部802による形態素解析および単語抽出により、「カレーライス」,「カレー」,「飯」,「食べ物」が抽出される。それぞれの抽出単語については、第2特定部1203により指定階層(第3階層)から対象階層(第2階層)までの分類コードが得られる。
本例の場合、抽出単語「カレーライス」,「カレー」,「飯」,「食べ物」のうち指定階層である第3階層に属する単語は「カレーライス」,「カレー」であるため、小分類コード「#1032」,「#1154」が特定される。また、第2特定部1203は、抽出単語「カレーライス」,「カレー」,「飯」,「食べ物」の第2階層での分類コードを特定する。
「カレーライス」自体は、小分類コード「#1032」であるが、中分類コードは先頭2桁の「#10」(飯)が特定される。「カレー」も小分類コード「#1154」であるが、中分類コードは先頭2桁の「#11」(香辛料)が特定される。「飯」は中分類コードであるため、「#10」がそのまま特定される。
したがって、中分類コード「#10」(飯)の出現回数は2回、中分類コード「#11」(香辛料)の出現回数は1回である。このうち、中分類コード「#11」(香辛料)は、(A)に存在しないため除外される。そして、今回特定された中分類コード「#11」(香辛料)の出現回数と、図13に示した比較文字列での小分類コードの出現回数と、を統合する。
(C)において、第2算出部1204は、(A)で求めた出現回数をベクトル化して、検索文字列の類語ベクトルを生成する。同様に、第2算出部1204は(B)で求めた出現回数をベクトル化して、比較文字列の類語ベクトルを生成する。そして、第2算出部1204は、両類語ベクトルの内積をとることで類似度を算出する。(C)では、類似度は3となる。
図15は、第2算出部1204による類似度算出の具体例1を示す説明図である。具体例1は、検索文字列(複数の検索単語を含む)と比較文字列とを比較する例である。ここでは、検索文字列を「このカレーライスは甘口だ」とし、比較単位となる比較文字列を「このハヤシライスはマイルドだ」とする。なお、指定階層は第3階層、対象階層も第3階層とする。
(A)において、検索文字列「このカレーライスは甘口だ」については、解析部802による形態素解析および単語抽出により、「カレーライス」,「甘口」が抽出される。それぞれの抽出単語については、第2特定部1203により対象階層(第3階層)の分類コードが得られる。本例の場合、抽出単語「カレーライス」,「甘口」の小分類コード「#1032」,「#4110」が特定される。また、これらの出現回数はそれぞれ1回である。
(B)において、比較文字列「このハヤシライスはマイルドだ」については、解析部802による形態素解析および単語抽出により、「ハヤシライス」,「マイルド」が抽出される。それぞれの抽出単語については、第2特定部1203により対象階層(第3階層)の分類コードが得られる。本例の場合、抽出単語「ハヤシライス」,「マイルド」の小分類コード「#1033」,「#4111」が特定される。また、これらの出現回数はそれぞれ1回である。しかしながら、小分類コード「#1033」,「#4111」の出現回数は検索単語の分類コードと不一致のため、ともに除外される。
(C)において、第2算出部1204は(A)で求めた出現回数をベクトル化して、検索文字列の類語ベクトルを生成する。同様に、第2算出部1204は(B)で求めた出現回数をベクトル化して、比較文字列の類語ベクトルを生成する。そして、第2算出部1204は、両類語ベクトルの内積をとることで類似度を算出する。(C)では、類似度は0となる。
図16は、第2算出部1204による類似度算出の具体例2を示す説明図である。具体例2は、図15の具体例1において、対象階層を第3階層から第2階層に変更した例である。
(A)において、検索文字列「このカレーライスは甘口だ」の抽出単語「カレーライス」,「甘口」について、第2特定部1203により第3階層の分類コードのほか、第2階層の分類コードも得られる。本例の場合、抽出単語「カレーライス」,「甘口」の具体例1で特定された小分類コード「#1032」,「#4110」のほか、小分類コードの先頭2桁から中分類コード「#10」(飯),「#41」(甘い)が特定される。また、これらの出現回数はそれぞれ1回である。
(B)において、比較文字列「このハヤシライスはマイルドだ」の抽出単語「ハヤシライス」,「マイルド」について、第2特定部1203により第3階層の分類コードのほか、第2階層の分類コードも得られる。本例の場合、抽出単語「ハヤシライス」,「マイルド」の小分類コード「#1033」,「#4111」のほか、小分類コードの先頭2桁から中分類コード「#10」(飯),「#41」(甘い)が特定される。また、これらの出現回数はそれぞれ1回である。また、図15の具体例1と同様、小分類コード「#1033」,「#4111」の出現回数は検索単語の分類コードと不一致のため、ともに除外される。
(C)において、第2算出部1204は(A)で求めた出現回数をベクトル化して、検索文字列の類語ベクトルを生成する。同様に、第2算出部1204は(B)で求めた出現回数をベクトル化して、比較文字列の類語ベクトルを生成する。そして、第2算出部1204は、両類語ベクトルの内積をとることで類似度を算出する。(C)では、類似度は2となる。
このように、図15の具体例1に示した第3階層のみの分類コードで算出された類似度よりも、第3階層~第2階層の分類コードを用いて算出された類似度のほうが高くなることがある。このように、階層を上位にまで拡大していくことで所定類似度以上の類似度の数が増加することとなる。したがって、類似度の高いあいまい検索のヒット数を段階的に増加することができる。
<検索処理手順>
つぎに、図17~図25を用いて、検索装置800による検索処理手順について説明する。
つぎに、図17~図25を用いて、検索装置800による検索処理手順について説明する。
図17は、検索装置800による検索処理手順例を示すフローチャートである。まず、検索装置800は、入力部801により検索文字列が入力されるのを待ち受ける(ステップS1701:No)。そして、検索文字列が入力された場合(ステップS1701:Yes)、検索装置800は、解析部802により、検索文字列を形態素解析して単語に分解する(ステップS1702)。このあと、検索装置800は、分解された単語群の中からあいまい検索に必要な品詞に該当する検索単語を抽出する(ステップS1703)。
そして、検索装置800は、入力部801により検索モードの指定があったか否かを判断する(ステップS1704)。検索モードの指定があった場合(ステップS1704:Yes)、検索装置800は、指定された検索モードが第1検索モードであるか第2検索モードであるかを判断する(ステップS1705)。
第1検索モードである場合(ステップS1705:第1検索)、検索装置800は、第1検索処理部804により第1検索処理を実行する(ステップS1706)。一方、第2検索モードである場合(ステップS1705:第2検索)、検索装置800は、第2検索処理部805により第2検索処理を実行する(ステップS1707)。
また、ステップS1704において、検索モードの指定がない場合(ステップS1704:No)、検索装置800は、判別部803により検索単語の数が所定単語数以上であるか否かを判断する(ステップS1708)。所定単語数以上でない場合(ステップS1708:No)、検索装置800は、第1検索処理部804により第1検索処理を実行する(ステップS1709)。一方、所定単語数以上である場合(ステップS1708:Yes)、検索装置800は、第2検索処理部805により第2検索処理を実行する(ステップS1710)。
そして、検索装置800は、第1検索処理(ステップS1706、S1709)または第2検索処理(ステップS1707、S1710)が終了した場合、出力部806による出力処理を実行する(ステップS1711)。これにより、検索処理を終了する。
このように、検索装置800は、検索モードの指定が受け付けられている場合はその指定内容にしたがって検索処理を実行することになる。一方で、検索モードの指定がない場合は、検索単語の数の多さにより第1検索処理か第2検索処理かを決定することとなる。検索単語の数が多い(所定単語数以上)場合は、第2検索処理を実行することで、検索対象となる階層範囲を絞って段階的にあいまい検索のヒット数を増加させることができる。一方、検索単語の数が少ない(所定単語数未満)場合は、あいまい検索のヒット数が多くはならないと考えられるため、検索単語の階層から最上位階層までの範囲を検索対象範囲としてあいまい検索のヒット数を適切に得ることができる。
<第1検索処理手順>
図18は、図17に示した第1検索処理(ステップS1706、ステップS1709)の詳細な処理手順例を示すフローチャートである。まず、検索装置800は、第1特定部902により、類語辞書データ100から、検索単語の分類コードを、最上位階層にまでさかのぼって、検索単語ごとに特定する(ステップS1801)。
図18は、図17に示した第1検索処理(ステップS1706、ステップS1709)の詳細な処理手順例を示すフローチャートである。まず、検索装置800は、第1特定部902により、類語辞書データ100から、検索単語の分類コードを、最上位階層にまでさかのぼって、検索単語ごとに特定する(ステップS1801)。
つぎに、検索装置800は、検索単語群の各々の検索単語から特定された階層ごとの分類コードのビット列で、ONとなっているファイル番号の対象ファイルを分類マップ群Mから検出する(ステップS1802)。そして、検索装置800は、中間分類コード一致数集計処理(ステップS1803)、類似度算出処理(ステップS1804)を実行する。これにより、第1検索処理を終了する。
<中間分類コード一致数集計処理手順>
図19は、図18に示した中間分類コード一致数集計処理(ステップS1803)の詳細な処理手順例を示すフローチャート(その1)である。まず、検索装置800は、中間分類コード一致数NをN=0に設定する(ステップS1901)。つぎに、検索装置800は、特定対象ファイル数をKとし、特定対象ファイル番号kをk=1とする(ステップS1902)。特定対象ファイル数Kは、図18のステップS1802で検出された対象ファイル数である。
図19は、図18に示した中間分類コード一致数集計処理(ステップS1803)の詳細な処理手順例を示すフローチャート(その1)である。まず、検索装置800は、中間分類コード一致数NをN=0に設定する(ステップS1901)。つぎに、検索装置800は、特定対象ファイル数をKとし、特定対象ファイル番号kをk=1とする(ステップS1902)。特定対象ファイル数Kは、図18のステップS1802で検出された対象ファイル数である。
このあと、検索装置800は、k>Kであるか否かを判断する(ステップS1903)。k>Kでない場合(ステップS1903:No)、検索装置800は、特定対象ファイルFkを選択する(ステップS1904)。そして、検索装置800は、特定対象ファイルFkでの計数が終了したか否かを判断する(ステップS1905)。具体的には、未選択の比較文字列がなくなった場合に終了する。
計数終了である場合(ステップS1905:Yes)、検索装置800は、特定対象ファイル番号kをインクリメントし(ステップS1906)、ステップS1903に戻る。一方、計数終了でない場合(ステップS1905:No)、図20のステップS2001に移行する。なお、ステップS1903において、k>Kとなった場合(ステップS1903:Yes)、類似度算出処理(ステップS1804)に移行する。
図20は、図18に示した中間分類コード一致数集計処理(ステップS1803)の詳細な処理手順例を示すフローチャート(その2)である。まず、図19のステップS1905において計数終了でない場合(ステップS1905:No)、検索装置800は、特定対象ファイルFkから比較単位で比較文字列を抽出する(ステップS2001)。つぎに、検索装置800は、解析部802により、検索文字列を形態素解析して単語に分解する(ステップS2002)。このあと、検索装置800は、分解された単語群の中からあいまい検索に必要な品詞に該当する比較単語を抽出する(ステップS2003)。
このあと、検索装置800は、第1特定部902により、類語辞書データ100から比較単語の分類コードを階層ごとに特定する(ステップS2004)。そして、検索装置800は、階層番号jをj=1とし(ステップS2005)、j=t1であるか否かを判断する(ステップS2006)。ここでは、中間階層の範囲を第t1階層から第t2階層(t1<t2、t1≠1、t2≠m、mは最下層の階層番号)とする。
j=t1でない場合(ステップS2006:No)、図19のステップS1905に移行する。一方、j=t1である場合(ステップS2006:Yes)、検索装置800は、判定部904により、検索文字列内の検索単語および比較文字列内の比較単語において、第j階層での分類コードどうしを比較する(ステップS2007)。
そして、検索装置800は、第1計数部905により、第j階層での分類コードの一致数aを計数し(ステップS2008)、計数された一致数aを中間分類コード一致数N(初期値はN=0)に加算する(ステップS2009)。このあと、検索装置800は、j>t2であるか否かを判断する(ステップS2010)。j>t2でない場合(ステップS2010:No)、検索装置800は、階層番号jをインクリメントし(ステップS2011)、ステップS2007に戻る。
一方、j>t2である場合(ステップS2010:Yes)、図19のステップS1905に移行する。このような中間分類コード一致数集計処理(ステップS1803)により、中間階層(第t1階層から第t2階層)での分類コードの一致数が計数されることとなる。
<類似度算出処理手順>
図21は、図18に示した類似度算出処理(ステップS1804)の詳細な処理手順例を示すフローチャート(その1)である。まず、検索装置800は、特定対象ファイル数をKとし、特定対象ファイル番号kをk=1とする(ステップS2101)。特定対象ファイル数Kは、図18のステップS1802で検出された対象ファイル数である。
図21は、図18に示した類似度算出処理(ステップS1804)の詳細な処理手順例を示すフローチャート(その1)である。まず、検索装置800は、特定対象ファイル数をKとし、特定対象ファイル番号kをk=1とする(ステップS2101)。特定対象ファイル数Kは、図18のステップS1802で検出された対象ファイル数である。
つぎに、検索装置800は、k>Kであるか否かを判断する(ステップS2102)。k>Kである場合(ステップS2102:Yes)、出力処理(ステップS1711)に移行する。一方、k>Kでない場合(ステップS2102:No)、検索装置800は、特定対象ファイルFkを選択する(ステップS2103)。そして、検索装置800は、特定対象ファイルFkでの比較が終了したか否かを判断する(ステップS2104)。具体的には、未選択の比較文字列がなくなった場合に終了する。
特定対象ファイルFkでの比較が終了した場合(ステップS2104:Yes)、抽出すべき比較文字列がないため、検索装置800は、特定対象ファイル番号kをインクリメントし(ステップS2105)、ステップS2102に戻る。
一方、特定対象ファイルFkでの比較が終了しない場合(ステップS2104:No)、検索装置800は、比較単位で比較文字列を特定対象ファイルFkから抽出する(ステップS2106)。そして、検索装置800は、第1特定部902により、類語辞書データ100から比較単語の分類コードを階層ごとに特定し(ステップS2107)、図22のステップS2201に移行する。
図22は、図18に示した類似度算出処理(ステップS1804)の詳細な処理手順例を示すフローチャート(その2)である。まず、ステップS2107のあと、検索装置800は、階層番号jをj=1に設定し(ステップS2201)、j=t1であるか否かを判断する(ステップS2202)。j=t1でない場合(ステップS2202:No)、すなわち、上位階層である場合、検索装置800は、判定部904により、検索文字列の検索単語と比較文字列の比較単語との間で、第j階層の分類コードが一致するか否かを判定する(ステップS2203)。一致する場合(ステップS2203:Yes)、検索装置800は、階層番号jをインクリメントし(ステップS2204)、ステップS2202に戻る。
一方、不一致である場合(ステップS2203:No)、図21のステップS2104に戻る。また、ステップS2202において、j=t1である場合(ステップS2202:Yes)、検索装置800は、判定部904により、検索文字列の検索単語と比較文字列の比較単語との間で、第j階層の分類コードが一致するか否かを判定する(ステップS2205)。
不一致である場合(ステップS2205:No)、検索装置800は、中間分類コード一致数Nがしきい値Nt以上であるか否かを判断する(ステップS2206)。N≧Ntである場合(ステップS2206:Yes)、不一致な比較単語を有する比較文字列をあいまい検索の対象にする必要はないため、類似度算出対象から除外してステップS2104に戻る。一方、N≧Ntでない場合(ステップS2206:No)、あいまい検索の対象が不足しているため、ステップS2207に移行する。
また、ステップS2205において、一致すると判定された場合(ステップS2205:Yes)、ステップS2207に移行する。ステップS2207では、検索装置800は、階層番号jをインクリメントし(ステップS2207)、j>t2であるか否かを判断する(ステップS2208)。j>t2でない場合(ステップS2208:No)、まだ中間階層であるため、ステップS2205に戻る。
一方、j>t2である場合(ステップS2208:Yes)、検索装置800は、第1算出部907により検索文字列の類語ベクトルおよび比較文字列の類語ベクトルを生成して、カーネル法により検索文字列と比較文字列との類似度を算出する(ステップS2209)。そして、図21のステップS2104に戻る。
このように、中間階層(第t1階層~第t2階層)においては、中間分類コード一致数Nの多さに応じて、比較文字列をあいまい検索の対象にしたり除外したりと、状況に応じて取捨選択することができる。したがって、類似性の高い適切な数の比較文字列についてあいまい検索をおこなうことができる。
<第2検索処理手順>
図23は、図17に示した第2検索処理(ステップS1707、ステップS1710)の詳細な処理手順例を示すフローチャート(その1)である。図23において、まず、検索装置800は、階層番号jをj=mに設定する(ステップS2301)。mは指定階層の階層番号であり、たとえば、最下位の階層番号とする。
図23は、図17に示した第2検索処理(ステップS1707、ステップS1710)の詳細な処理手順例を示すフローチャート(その1)である。図23において、まず、検索装置800は、階層番号jをj=mに設定する(ステップS2301)。mは指定階層の階層番号であり、たとえば、最下位の階層番号とする。
つぎに、検索装置800は、第2特定部1203により、類語辞書データ100から検索単語の第j階層~第m階層の分類コードを特定する(ステップS2302)。そして、検索装置800は、第j階層~第m階層の分類マップを参照して、検索単語の第j階層~第m階層の分類コードのビット列を特定する。そして、検索装置800は、第2検出部1201により、特定されたビット列においてすべてONになっている対象ファイルを検出する(ステップS2303)。これにより、検索対象が特定対象ファイルに絞り込まれたこととなる。このあと、図24のステップS2401に移行する。
図24は、図18に示した第2検索処理(ステップS1707、ステップS1710)の詳細な処理手順例を示すフローチャート(その2)である。まず、図23のステップS2303のあと、検索装置800は、特定対象ファイル数をKとし、特定対象ファイル番号kをk=1とする(ステップS2401)。特定対象ファイル数Kは、図23のステップS2303で検出された対象ファイル数である。
つぎに、検索装置800は、k>Kであるか否かを判断する(ステップS2402)。k>Kでない場合(ステップS2402:No)、検索装置800は、特定対象ファイルFkを選択する(ステップS2403)。そして、検索装置800は、特定対象ファイルFkでの比較が終了したか否かを判断する(ステップS2404)。具体的には、未選択の比較文字列がなくなった場合に終了する。
特定対象ファイルFkでの比較が終了しない場合(ステップS2404:No)、検索装置800は、比較単位で比較文字列を特定対象ファイルFkから抽出する(ステップS2405)。そして、検索装置800は、解析部802により、抽出された比較文字列を形態素解析して単語に分解する(ステップS2406)。
このあと、検索装置800は、分解された単語群の中からあいまい検索に必要な品詞に該当する比較単語を抽出する(ステップS2407)。つぎに、検索装置800は、第2特定部1203により、類語辞書データ100から比較単語の第j階層~第m階層の分類コードを特定する(ステップS2408)。
そして、検索装置800は、第2算出部1204により、検索文字列内の検索単語の第j階層~第m階層の分類コードで検索文字列の類語ベクトルを生成する。同様に、検索装置800は、第2算出部1204により、比較文字列内の比較単語の第j階層~第m階層の分類コードで比較文字列の類語ベクトルを生成する。そして、検索装置800は、第2算出部1204により両類語ベクトルから検索文字列と比較文字列との類似度を算出する(ステップS2409)。そして、ステップS2404に戻る。
一方、ステップS2404において、特定対象ファイルFkでの比較が終了した場合(ステップS2404:Yes)、抽出すべき比較文字列がないため、検索装置800は、特定対象ファイル番号kをインクリメントし(ステップS2410)、ステップS2402に戻る。
また、ステップS2402において、k>Kである場合(ステップS2402:Yes)、検索装置800は、第2計数部1205により、ステップS2409で算出された類似度が所定類似度以上である比較文字列の数を計数する(ステップS2411)。そして、検索装置800は、計数結果がしきい値以上であるか否かを判断する(ステップS2412)。しきい値以上でない場合(ステップS2412:No)、検索装置800は、階層番号がj=1であるか否かを判断する(ステップS2413)。そして、j=1でない場合(ステップS2413:No)、検索装置800は、階層番号jをデクリメントして(ステップS2414)、図23のステップS2302に戻る。
一方、ステップS2412においてしきい値以上と判定された場合(ステップS2412:Yes)、または、ステップS2413において階層番号j=1と判定された場合(ステップS2413:Yes)、第2検索処理を終了する。
このように、上述した実施の形態では、中間階層の分類コードで検索文字列と不一致と判定された比較文字列に対して、比較文字列をあいまい検索の対象にしたり除外したりと、状況に応じて取捨選択することができる。したがって、類似性の高い適切な数の比較文字列についてあいまい検索をおこなうことができる。
また、分類マップ群Mを用いて対象ファイル群Fの絞込みをおこなうことで、類似性の高い比較文字列を含む対象ファイルに狙い撃ちしてあいまい検索を実行することができる。したがって、無駄なあいまい検索を未然に防止することができ、あいまい検索速度の向上を図ることができる。
また、検索文字列を構成する検索単語の個数の多さに応じて、第1検索処理と第2検索処理のいずれか一方を選択することができる。すなわち、検索単語の個数が少ないと第1検索処理が選択され、検索文字列の類語ベクトルが大きくなるものの、類似度計算は一度で完了するため、あいまい検索の高速化を図ることができる。
一方、検索単語の個数が多いと第2検索処理が選択され、下位階層から段階的に検索対象範囲を拡大していくことができるため、最初のうちは類語ベクトルの大きさが小さく済み、検索効率の向上を図ることができる。
以上説明したように、検索プログラム、検索装置、および検索方法によれば、あいまい検索の対象範囲を自動的に取捨選択することにより、あいまい検索精度の向上を図ることができるという効果を奏する。
なお、本実施の形態で説明した検索方法は、予め用意されたプログラムをパーソナル・コンピュータやワークステーション等のコンピュータで実行することにより実現することができる。本検索プログラムは、ハードディスク、フレキシブルディスク、CD-ROM、MO、DVD等のコンピュータで読み取り可能な記録媒体に記録され、コンピュータによって記録媒体から読み出されることによって実行される。また本検索プログラムは、インターネット等のネットワークを介して配布してもよい。
100 類語辞書データ
200 大分類マップ
300 中分類マップ
400 小分類マップ
800 検索装置
801 入力部
802 解析部
803 判別部
804 第1検索処理部
805 第2検索処理部
806 出力部
901 第1検出部
902 第1特定部
903 抽出部
904 判定部
905 第1計数部
906 判断部
907 第1算出部
1201 第2検出部
1202 設定部
1203 第2特定部
1204 第2算出部
1205 第2計数部
200 大分類マップ
300 中分類マップ
400 小分類マップ
800 検索装置
801 入力部
802 解析部
803 判別部
804 第1検索処理部
805 第2検索処理部
806 出力部
901 第1検出部
902 第1特定部
903 抽出部
904 判定部
905 第1計数部
906 判断部
907 第1算出部
1201 第2検出部
1202 設定部
1203 第2特定部
1204 第2算出部
1205 第2計数部
Claims (12)
- 単語間の類義関係を階層的に分類してコード化した類語辞書データの中から、検索文字列内の検索単語の階層ごとの分類コードと、比較文字列群の各々の比較文字列内の比較単語の階層ごとの分類コードと、を特定する特定工程と、
前記特定工程によって特定された前記検索単語の階層ごとの分類コードおよび前記各比較単語の階層ごとの分類コードの中から、前記類語辞書データを構成する階層群のうち特定階層の分類コードを抽出する抽出工程と、
前記抽出工程によって抽出された前記検索単語の前記特定階層の分類コードと前記比較単語の前記特定階層の分類コードとが一致するか否かを、比較文字列ごとに判定する判定工程と、
前記判定工程による前記特定階層での一致数を計数する計数工程と、
前記計数工程によって計数された一致数に基づいて、前記判定工程によって前記比較単語の前記特定階層の分類コードが不一致と判定された比較文字列を除外するか否かを判断する判断工程と、
前記検索単語の階層ごとの分類コードと前記判断工程によって除外しないと判断された比較文字列内の前記比較単語の階層ごとの分類コードとに基づいて、前記検索文字列と前記除外しないと判断された比較文字列との類似度を算出する算出工程と、
前記算出工程によって算出された算出結果を出力する出力工程と、
をコンピュータに実行させることを特徴とする検索プログラム。 - 前記特定階層は前記階層群の中の中間階層であることを特徴とする請求項1に記載の検索プログラム。
- 前記抽出工程は、
さらに、前記検索単語の階層ごとの分類コードおよび前記各比較単語の階層ごとの分類コードの中から、前記中間階層よりも上位となる上位階層の分類コードを抽出し、
前記判定工程は、
前記抽出工程によって抽出された前記検索単語の前記上位階層の分類コードと前記比較単語の前記上位階層の分類コードとが一致するか否かを、前記比較文字列ごとに判定し、一致すると判定された比較文字列ごとに、前記検索単語の前記中間階層の分類コードと前記比較単語の前記中間階層の分類コードとが一致するか否かを判定することを特徴とする請求項2に記載の検索プログラム。 - 前記検索単語の数が所定単語数以上であるか否かを判別する判別工程を前記コンピュータに実行させ、
前記特定工程は、
前記判別工程によって前記検索単語の数が所定単語数以上でないと判別された場合、前記類語辞書データの中から、前記検索文字列内の検索単語の階層ごとの分類コードと、前記比較文字列群の各々の比較文字列内の比較単語の階層ごとの分類コードとを、比較文字列ごとに特定することを特徴とする請求項1~3のいずれか一つに記載の検索プログラム。 - 前記類語辞書データ内の各分類コードに対応する単語の各対象ファイル内での存否を示すビット列の集合を階層別にまとめた分類マップ群のうち最上位階層の分類マップを参照して、前記検索単語の前記最上位階層の分類コードが存在する特定の対象ファイルを検出する検出工程を前記コンピュータに実行させ、
前記特定工程は、
前記類語辞書データの中から、前記検索文字列内の検索単語の階層ごとの分類コードと、前記検出工程によって検出された特定の対象ファイル内に存在する前記比較文字列群の各々の比較文字列内の比較単語の階層ごとの分類コードとを、比較文字列ごとに特定することを特徴とする請求項1~3のいずれか一つに記載の検索プログラム。 - 単語間の類義関係を階層的に分類してコード化した類語辞書データを構成する階層群の中から指定された指定階層を対象階層に設定する第1の設定工程と、
前記類語辞書データの中から、検索文字列内の検索単語の前記指定階層から前記対象階層までの分類コードと、比較文字列群の各々の比較文字列内の比較単語の前記指定階層から前記対象階層までの分類コードとを、比較文字列ごとに特定する特定工程と、
前記検索単語の前記指定階層から前記対象階層までの分類コードと前記比較単語の前記指定階層から前記対象階層までの分類コードに基づいて、前記検索文字列と前記比較文字列との類似度を比較文字列ごとに算出する算出工程と、
前記算出工程によって類似度が算出された比較文字列群のうち所定類似度以上となる前記比較文字列の数を計数する計数工程と、
前記計数工程によって計数された計数結果が所定数以下である場合、前記対象階層をより上位の階層に変更する第2の設定工程と、
前記計数工程によって計数された計数結果が前記所定数よりも多いこととなった比較文字列群のうち少なくとも前記所定類似度以上の比較文字列を出力する出力工程と、
をコンピュータに実行させることを特徴とする検索プログラム。 - 前記検索単語の文字数が所定文字数以上であるか否かを判別する判別工程を前記コンピュータに実行させ、
前記第1の設定工程は、
前記判別工程によって前記検索単語が所定文字数以上であると判別された場合、前記指定階層を前記対象階層に設定することを特徴とする請求項6に記載の検索プログラム。 - 前記類語辞書データ内の各分類コードに対応する単語の各対象ファイル内での存否を示すビット列の集合を階層別にまとめた分類マップ群を参照して、前記検索単語の前記対象階層の分類コードが存在する特定の対象ファイルを検出する検出工程を前記コンピュータに実行させ、
前記特定工程は、
前記類語辞書データの中から、前記検索文字列内の検索単語の前記指定階層から前記対象階層までの分類コードと、前記検出工程によって検出された特定の対象ファイル内に存在する比較文字列群の各々の比較文字列内の比較単語の前記指定階層から前記対象階層までの分類コードとを、比較文字列ごとに特定することを特徴とする請求項6または7に記載の検索プログラム。 - 単語間の類義関係を階層的に分類してコード化した類語辞書データの中から、検索文字列内の検索単語の階層ごとの分類コードと、比較文字列群の各々の比較文字列内の比較単語の階層ごとの分類コードと、を特定する特定手段と、
前記特定手段によって特定された前記検索単語の階層ごとの分類コードおよび前記各比較単語の階層ごとの分類コードの中から、前記類語辞書データを構成する階層群のうち特定階層の分類コードを抽出する抽出手段と、
前記抽出手段によって抽出された前記検索単語の前記特定階層の分類コードと前記比較単語の前記特定階層の分類コードとが一致するか否かを、比較文字列ごとに判定する判定手段と、
前記判定手段による前記特定階層での一致数を計数する計数手段と、
前記計数手段によって計数された一致数に基づいて、前記判定手段によって前記比較単語の前記特定階層の分類コードが不一致と判定された比較文字列を除外するか否かを判断する判断手段と、
前記検索単語の階層ごとの分類コードと前記判断手段によって除外しないと判断された比較文字列内の前記比較単語の階層ごとの分類コードとに基づいて、前記検索文字列と前記除外しないと判断された比較文字列との類似度を算出する算出手段と、
前記算出手段によって算出された算出結果を出力する出力手段と、
を備えることを特徴とする検索装置。 - 単語間の類義関係を階層的に分類してコード化した類語辞書データを構成する階層群の中から指定された指定階層を対象階層に設定する第1の設定手段と、
前記類語辞書データの中から、検索文字列内の検索単語の前記指定階層から前記対象階層までの分類コードと、比較文字列群の各々の比較文字列内の比較単語の前記指定階層から前記対象階層までの分類コードとを、比較文字列ごとに特定する特定手段と、
前記検索単語の前記指定階層から前記対象階層までの分類コードと前記比較単語の前記指定階層から前記対象階層までの分類コードに基づいて、前記検索文字列と前記比較文字列との類似度を比較文字列ごとに算出する算出手段と、
前記算出手段によって類似度が算出された比較文字列群のうち所定類似度以上となる前記比較文字列の数を計数する計数手段と、
前記計数手段によって計数された計数結果が所定数以下である場合、前記対象階層をより上位の階層に変更する第2の設定手段と、
前記計数手段によって計数された計数結果が前記所定数よりも多いこととなった比較文字列群のうち少なくとも前記所定類似度以上の比較文字列を出力する出力手段と、
を備えることを特徴とする検索装置。 - コンピュータが、
単語間の類義関係を階層的に分類してコード化した類語辞書データの中から、検索文字列内の検索単語の階層ごとの分類コードと、比較文字列群の各々の比較文字列内の比較単語の階層ごとの分類コードと、を特定する特定工程と、
前記特定工程によって特定された前記検索単語の階層ごとの分類コードおよび前記各比較単語の階層ごとの分類コードの中から、前記類語辞書データを構成する階層群のうち特定階層の分類コードを抽出する抽出工程と、
前記抽出工程によって抽出された前記検索単語の前記特定階層の分類コードと前記比較単語の前記特定階層の分類コードとが一致するか否かを、比較文字列ごとに判定する判定工程と、
前記判定工程による前記特定階層での一致数を計数する計数工程と、
前記計数工程によって計数された一致数に基づいて、前記判定工程によって前記比較単語の前記特定階層の分類コードが不一致と判定された比較文字列を除外するか否かを判断する判断工程と、
前記検索単語の階層ごとの分類コードと前記判断工程によって除外しないと判断された比較文字列内の前記比較単語の階層ごとの分類コードとに基づいて、前記検索文字列と前記除外しないと判断された比較文字列との類似度を算出する算出工程と、
前記算出工程によって算出された算出結果を出力する出力工程と、
を実行することを特徴とする検索方法。 - コンピュータが、
単語間の類義関係を階層的に分類してコード化した類語辞書データを構成する階層群の中から指定された指定階層を対象階層に設定する第1の設定工程と、
前記類語辞書データの中から、検索文字列内の検索単語の前記指定階層から前記対象階層までの分類コードと、比較文字列群の各々の比較文字列内の比較単語の前記指定階層から前記対象階層までの分類コードとを、比較文字列ごとに特定する特定工程と、
前記検索単語の前記指定階層から前記対象階層までの分類コードと前記比較単語の前記指定階層から前記対象階層までの分類コードに基づいて、前記検索文字列と前記比較文字列との類似度を比較文字列ごとに算出する算出工程と、
前記算出工程によって類似度が算出された比較文字列群のうち所定類似度以上となる前記比較文字列の数を計数する計数工程と、
前記計数工程によって計数された計数結果が所定数以下である場合、前記対象階層をより上位の階層に変更する第2の設定工程と、
前記計数工程によって計数された計数結果が前記所定数よりも多いこととなった比較文字列群のうち少なくとも前記所定類似度以上の比較文字列を出力する出力工程と、
を実行することを特徴とする検索方法。
Priority Applications (4)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2012556690A JP5510563B2 (ja) | 2011-02-08 | 2011-02-08 | 検索プログラム、検索装置、および検索方法 |
| EP11858244.4A EP2674874A4 (en) | 2011-02-08 | 2011-02-08 | Search program, search apparatus, and search method |
| PCT/JP2011/052666 WO2012108006A1 (ja) | 2011-02-08 | 2011-02-08 | 検索プログラム、検索装置、および検索方法 |
| US13/961,159 US20130318124A1 (en) | 2011-02-08 | 2013-08-07 | Computer product, retrieving apparatus, and retrieval method |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| PCT/JP2011/052666 WO2012108006A1 (ja) | 2011-02-08 | 2011-02-08 | 検索プログラム、検索装置、および検索方法 |
Related Child Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| US13/961,159 Continuation US20130318124A1 (en) | 2011-02-08 | 2013-08-07 | Computer product, retrieving apparatus, and retrieval method |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2012108006A1 true WO2012108006A1 (ja) | 2012-08-16 |
Family
ID=46638249
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2011/052666 Ceased WO2012108006A1 (ja) | 2011-02-08 | 2011-02-08 | 検索プログラム、検索装置、および検索方法 |
Country Status (4)
| Country | Link |
|---|---|
| US (1) | US20130318124A1 (ja) |
| EP (1) | EP2674874A4 (ja) |
| JP (1) | JP5510563B2 (ja) |
| WO (1) | WO2012108006A1 (ja) |
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2017194762A (ja) * | 2016-04-18 | 2017-10-26 | 富士通株式会社 | インデックス生成プログラム、インデックス生成装置、インデックス生成方法、検索プログラム、検索装置および検索方法 |
| JP2018182466A (ja) * | 2017-04-07 | 2018-11-15 | 富士通株式会社 | 符号化プログラム、符号化方法および符号化装置 |
Families Citing this family (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US11126720B2 (en) | 2012-09-26 | 2021-09-21 | Bluvector, Inc. | System and method for automated machine-learning, zero-day malware detection |
| JP6543922B2 (ja) * | 2014-12-10 | 2019-07-17 | 富士通株式会社 | インデックス生成プログラム |
| CN104615590A (zh) * | 2015-03-02 | 2015-05-13 | 浪潮集团有限公司 | 一种项目名称的提取方法和装置 |
| JP6737117B2 (ja) * | 2016-10-07 | 2020-08-05 | 富士通株式会社 | 符号化データ検索プログラム、符号化データ検索方法および符号化データ検索装置 |
| CN109857860A (zh) * | 2019-01-04 | 2019-06-07 | 平安科技(深圳)有限公司 | 文本分类方法、装置、计算机设备及存储介质 |
| CN112434293B (zh) * | 2020-11-13 | 2024-08-02 | 三六零数字安全科技集团有限公司 | 文件特征提取方法、设备、存储介质及装置 |
Citations (10)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH06208590A (ja) * | 1993-01-12 | 1994-07-26 | Nippon Denshika Jisho Kenkyusho:Kk | 単語間の類似度算出方法 |
| JPH0869476A (ja) | 1994-08-30 | 1996-03-12 | Hokkaido Nippon Denki Software Kk | 検索システム |
| JPH08166966A (ja) | 1994-12-15 | 1996-06-25 | Sony Corp | 辞書検索装置、データベース装置、文字認識装置、音声認識装置、および文章修正装置 |
| JPH09288683A (ja) | 1995-09-04 | 1997-11-04 | Matsushita Electric Ind Co Ltd | 情報フィルタ装置及び情報フィルタリング方法 |
| JP2000172717A (ja) * | 1998-03-12 | 2000-06-23 | Kdd Corp | 文書検索方法及び文書検索装置 |
| JP2002251401A (ja) * | 2001-02-22 | 2002-09-06 | Canon Inc | 文書検索装置および方法ならびに記憶媒体 |
| JP3374243B2 (ja) | 2000-03-08 | 2003-02-04 | 株式会社カナック | 問題解決データベース検索システム |
| JP3548955B2 (ja) | 2000-10-13 | 2004-08-04 | 株式会社カナック | 問題解決データベース検索システム及び問題解決データベース検索プログラムを記録したコンピュータ読み取り可能な記憶媒体 |
| JP2009289088A (ja) * | 2008-05-29 | 2009-12-10 | Fujitsu Ltd | 連字シーケンスマップ生成プログラム、情報検索プログラム、連字シーケンスマップ生成装置、情報検索装置、連字シーケンスマップ生成方法、および情報検索方法 |
| JP2010117764A (ja) * | 2008-11-11 | 2010-05-27 | Nippon Telegr & Teleph Corp <Ntt> | 単語間関連度判定装置、単語間関連度判定方法、プログラムおよび記録媒体 |
Family Cites Families (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| AUPQ138199A0 (en) * | 1999-07-02 | 1999-07-29 | Telstra R & D Management Pty Ltd | A search system |
| US6810376B1 (en) * | 2000-07-11 | 2004-10-26 | Nusuara Technologies Sdn Bhd | System and methods for determining semantic similarity of sentences |
| US8392453B2 (en) * | 2004-06-25 | 2013-03-05 | Google Inc. | Nonstandard text entry |
| US8364467B1 (en) * | 2006-03-31 | 2013-01-29 | Google Inc. | Content-based classification |
-
2011
- 2011-02-08 EP EP11858244.4A patent/EP2674874A4/en not_active Withdrawn
- 2011-02-08 JP JP2012556690A patent/JP5510563B2/ja not_active Expired - Fee Related
- 2011-02-08 WO PCT/JP2011/052666 patent/WO2012108006A1/ja not_active Ceased
-
2013
- 2013-08-07 US US13/961,159 patent/US20130318124A1/en not_active Abandoned
Patent Citations (10)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH06208590A (ja) * | 1993-01-12 | 1994-07-26 | Nippon Denshika Jisho Kenkyusho:Kk | 単語間の類似度算出方法 |
| JPH0869476A (ja) | 1994-08-30 | 1996-03-12 | Hokkaido Nippon Denki Software Kk | 検索システム |
| JPH08166966A (ja) | 1994-12-15 | 1996-06-25 | Sony Corp | 辞書検索装置、データベース装置、文字認識装置、音声認識装置、および文章修正装置 |
| JPH09288683A (ja) | 1995-09-04 | 1997-11-04 | Matsushita Electric Ind Co Ltd | 情報フィルタ装置及び情報フィルタリング方法 |
| JP2000172717A (ja) * | 1998-03-12 | 2000-06-23 | Kdd Corp | 文書検索方法及び文書検索装置 |
| JP3374243B2 (ja) | 2000-03-08 | 2003-02-04 | 株式会社カナック | 問題解決データベース検索システム |
| JP3548955B2 (ja) | 2000-10-13 | 2004-08-04 | 株式会社カナック | 問題解決データベース検索システム及び問題解決データベース検索プログラムを記録したコンピュータ読み取り可能な記憶媒体 |
| JP2002251401A (ja) * | 2001-02-22 | 2002-09-06 | Canon Inc | 文書検索装置および方法ならびに記憶媒体 |
| JP2009289088A (ja) * | 2008-05-29 | 2009-12-10 | Fujitsu Ltd | 連字シーケンスマップ生成プログラム、情報検索プログラム、連字シーケンスマップ生成装置、情報検索装置、連字シーケンスマップ生成方法、および情報検索方法 |
| JP2010117764A (ja) * | 2008-11-11 | 2010-05-27 | Nippon Telegr & Teleph Corp <Ntt> | 単語間関連度判定装置、単語間関連度判定方法、プログラムおよび記録媒体 |
Non-Patent Citations (1)
| Title |
|---|
| See also references of EP2674874A4 |
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2017194762A (ja) * | 2016-04-18 | 2017-10-26 | 富士通株式会社 | インデックス生成プログラム、インデックス生成装置、インデックス生成方法、検索プログラム、検索装置および検索方法 |
| JP2018182466A (ja) * | 2017-04-07 | 2018-11-15 | 富士通株式会社 | 符号化プログラム、符号化方法および符号化装置 |
Also Published As
| Publication number | Publication date |
|---|---|
| EP2674874A4 (en) | 2017-09-06 |
| US20130318124A1 (en) | 2013-11-28 |
| JP5510563B2 (ja) | 2014-06-04 |
| EP2674874A1 (en) | 2013-12-18 |
| JPWO2012108006A1 (ja) | 2014-07-03 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP5510563B2 (ja) | 検索プログラム、検索装置、および検索方法 | |
| CN111832289B (zh) | 一种基于聚类和高斯lda的服务发现方法 | |
| US8266077B2 (en) | Method of analyzing documents | |
| CN112256939B (zh) | 一种针对化工领域的文本实体关系抽取方法 | |
| CN110750640B (zh) | 基于神经网络模型的文本数据分类方法、装置及存储介质 | |
| CN102918532B (zh) | 在搜索结果排序中对垃圾的检测 | |
| Sarawagi et al. | Open-domain quantity queries on web tables: annotation, response, and consensus models | |
| JP5710581B2 (ja) | 質問応答装置、方法、及びプログラム | |
| CN119226441A (zh) | 一种基于特征提取的知识数据库检索方法 | |
| JPH11110414A (ja) | データベースからテキストを検索するための方法および装置 | |
| CN105005556A (zh) | 一种基于地质大数据的标引关键词提取方法和系统 | |
| JP7493937B2 (ja) | 文書における見出しのシーケンスの識別方法、プログラム及びシステム | |
| CN106708929A (zh) | 视频节目的搜索方法和装置 | |
| US11868313B1 (en) | Apparatus and method for generating an article | |
| CN116629258B (zh) | 基于复杂信息项数据的司法文书的结构化分析方法及系统 | |
| CN108875065B (zh) | 一种基于内容的印尼新闻网页推荐方法 | |
| Sharma et al. | Resume classification using elite bag-of-words approach | |
| CN106570196A (zh) | 视频节目的搜索方法和装置 | |
| CN119577115A (zh) | 基于大语言模型重排序技术的智能专利检索方法及系统 | |
| CN119474274A (zh) | 文档的问答对生成和问答方法、装置、计算机设备和可读存储介质 | |
| CN112214511A (zh) | 一种基于wtp-wcd算法的api推荐方法 | |
| CN115391479B (zh) | 用于文档搜索的排序方法、装置、电子介质及存储介质 | |
| Hassan et al. | Crime news analysis: Location and story detection | |
| CN112949287B (zh) | 热词挖掘方法、系统、计算机设备和存储介质 | |
| CN119903190B (zh) | 一种结合生成式语言模型与语义文档图谱的多文档问答检索方法 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 11858244 Country of ref document: EP Kind code of ref document: A1 |
|
| ENP | Entry into the national phase |
Ref document number: 2012556690 Country of ref document: JP Kind code of ref document: A |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 2011858244 Country of ref document: EP |