WO2013042218A1 - 計算機システム、ファイル管理方法及びメタデータサーバ - Google Patents
計算機システム、ファイル管理方法及びメタデータサーバ Download PDFInfo
- Publication number
- WO2013042218A1 WO2013042218A1 PCT/JP2011/071437 JP2011071437W WO2013042218A1 WO 2013042218 A1 WO2013042218 A1 WO 2013042218A1 JP 2011071437 W JP2011071437 W JP 2011071437W WO 2013042218 A1 WO2013042218 A1 WO 2013042218A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- file
- server
- metadata
- stored
- deleted
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Ceased
Links
Images



























Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/10—File systems; File servers
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/10—File systems; File servers
- G06F16/16—File or folder operations, e.g. details of user interfaces specifically adapted to file systems
- G06F16/162—Delete operations
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/10—File systems; File servers
- G06F16/18—File system types
- G06F16/182—Distributed file systems
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F3/00—Input arrangements for transferring data to be processed into a form capable of being handled by the computer; Output arrangements for transferring data from processing unit to output unit, e.g. interface arrangements
- G06F3/06—Digital input from, or digital output to, record carriers, e.g. RAID, emulated record carriers or networked record carriers
- G06F3/0601—Interfaces specially adapted for storage systems
- G06F3/0602—Interfaces specially adapted for storage systems specifically adapted to achieve a particular effect
- G06F3/0604—Improving or facilitating administration, e.g. storage management
- G06F3/0605—Improving or facilitating administration, e.g. storage management by facilitating the interaction with a user or administrator
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F3/00—Input arrangements for transferring data to be processed into a form capable of being handled by the computer; Output arrangements for transferring data from processing unit to output unit, e.g. interface arrangements
- G06F3/06—Digital input from, or digital output to, record carriers, e.g. RAID, emulated record carriers or networked record carriers
- G06F3/0601—Interfaces specially adapted for storage systems
- G06F3/0628—Interfaces specially adapted for storage systems making use of a particular technique
- G06F3/0629—Configuration or reconfiguration of storage systems
- G06F3/0631—Configuration or reconfiguration of storage systems by allocating resources to storage systems
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F3/00—Input arrangements for transferring data to be processed into a form capable of being handled by the computer; Output arrangements for transferring data from processing unit to output unit, e.g. interface arrangements
- G06F3/06—Digital input from, or digital output to, record carriers, e.g. RAID, emulated record carriers or networked record carriers
- G06F3/0601—Interfaces specially adapted for storage systems
- G06F3/0628—Interfaces specially adapted for storage systems making use of a particular technique
- G06F3/0646—Horizontal data movement in storage systems, i.e. moving data in between storage devices or systems
- G06F3/0647—Migration mechanisms
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F3/00—Input arrangements for transferring data to be processed into a form capable of being handled by the computer; Output arrangements for transferring data from processing unit to output unit, e.g. interface arrangements
- G06F3/06—Digital input from, or digital output to, record carriers, e.g. RAID, emulated record carriers or networked record carriers
- G06F3/0601—Interfaces specially adapted for storage systems
- G06F3/0668—Interfaces specially adapted for storage systems adopting a particular infrastructure
- G06F3/067—Distributed or networked storage systems, e.g. storage area networks [SAN], network attached storage [NAS]
Definitions
- the present invention relates to a storage device, a metadata server that manages metadata of files stored in the storage device, a business server that executes predetermined business processing, and an analysis that executes analysis processing on data used by the business server
- the present invention relates to a file management method in a computer system composed of a server.
- a business program running on the computer executes a process necessary for the business.
- the business program includes, for example, an autonomously operating program such as a document management system and an interactive program such as a document creation program used by a user.
- the system configuration can be changed and the storage capacity can be managed flexibly.
- business data stored in a file server is widely used to obtain useful information for corporate management by causing an analysis program that runs on a computer different from the business program to perform analysis processing such as statistical processing. ing.
- a business program may delete a file stored in a file server in the course of processing.
- the analysis program preferably obtains and analyzes all the files of the computer system including the files deleted from the file server in the past.
- the backup system periodically reads data stored in the file server and copies it to another backup storage device.
- the backup system since the same data is held in the file server and the backup storage device, the use efficiency of the storage area is poor.
- a method using a snapshot function provided in the file server As another method, there is a method using a snapshot function provided in the file server.
- the snapshot function By using the snapshot function, it is possible to hold a plurality of file server states at a certain past time while suppressing consumption of the storage area.
- the number of snapshots that can be created is limited, for example, it is not suitable for use in acquiring a file that existed at the time of going back to the past of five years or more.
- the archive system is a system that moves a file that satisfies a predetermined condition (for example, a file that has not been updated for a certain period of time) to another storage.
- a predetermined condition for example, a file that has not been updated for a certain period of time
- the archive system targets only files existing in the file system, for example, it is not possible to specify “deleted file” as a condition.
- Patent Document 1 discloses a technique for saving a file deleted by a user operation to a different storage area without actually deleting it and restoring it later.
- the present invention realizes a computer system that makes it possible to refer to all files that are under management of a business program, including deleted files that existed in the past, from an analysis program without making an extra copy. It is.
- a typical example of the invention disclosed in the present application is as follows. That is, a computer system comprising a file server that manages a plurality of files, a metadata server that manages metadata of the files, and a business server that executes predetermined business processing using the files,
- the file server, the metadata server, and the business server are connected to each other via a network, and the file server includes a first processor, a first memory connected to the first processor, and the first server.
- a first network interface connected to one processor, and a first storage medium connected to the first processor for storing the file
- the metadata server includes a second processor A second memory connected to the second processor and a second memory connected to the second processor.
- a storage device that provides a storage area is connected, and the second storage medium stores a metadata repository that manages the metadata of the file and the storage location of the file stored in the storage area
- the metadata server deletes the file stored in the file server by the business process executed by the business server.
- the file is stored in the storage area as a save file, and information indicating the storage position of the file in the file server; and information indicating the storage position of the save file in the storage area; Are stored in the metadata repository in association with each other.
- the metadata server can manage files deleted from the file server without creating an extra copy.
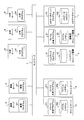
- FIG. 1 is a block diagram for explaining the outline of the processing of the present invention.
- the computer system 500 includes a metadata server 1, a evacuation storage device 2, a plurality of file servers 4, a plurality of business servers 5, and a plurality of analysis servers 6.
- the business server 5 is a computer that executes a predetermined business, and a business program 51 is operated.
- the business program 51 executes a predetermined business using a file stored in the file server 4.
- the business program 51 includes a file 1000-1 with a path name “/A/a.doc” and a file 1000-2 with a path name “/A/c.doc”. To execute a predetermined job.
- files 1000 when files are not distinguished, they are referred to as files 1000.
- the analysis server 6 is a computer that analyzes the file 1000, and an analysis program 61 is running.
- the analysis program 61 reads the files 1000-1 and 1000-2 used by the business program 51 and executes analysis processing such as statistical processing.
- the metadata server 1 is a computer that manages metadata of files stored in a plurality of file servers 4.
- the metadata server 1 of this embodiment is characterized in that it also manages metadata related to files deleted from the file server 4.
- Metadata refers to a set of attribute values set in a file.
- metadata includes file owner, file ownership group, access control information, file creation date, file update date, file metadata update date, file size, and other user-defined attributes Contains the value.
- the metadata server 1 manages a metadata repository in which file metadata is stored.
- the metadata repository includes a field for specifying a file stored in the file server 4, a field for specifying a file stored in the evacuation storage device 2, and a field indicating the state of the file.
- the field specifying the file stored in the file server 4 includes a path name and a storage name.
- the field for specifying the file stored in the evacuation storage device 2 includes a path name and a storage name.
- information indicating whether the file exists in the file server 4 is stored as a field indicating the state of the file.
- the business program 51 transmits a request to delete the file 1000-1 to the file server 4 whose identification name is “FS1” (step S1001).
- the file server 4 When the file server 4 detects the file deletion request, the file server 4 suspends the deletion of the file 1000-1 and notifies the metadata server 1 that the deletion request for the file 1000-1 has been received (step S1002).
- the metadata server 1 When the metadata server 1 receives the notification from the file server 4 (step S1003), the metadata server 1 updates the record corresponding to the file 1000-1 stored in the metadata repository 150 (step S1004). Specifically, “delete” indicating that the file 1000-1 is deleted is stored in the field indicating the file status.
- the metadata server 1 moves the file 1000-1 to the save storage device 2 (step S1005). Specifically, the metadata server 1 acquires the file 1000-1 from the file server 4 and stores it as the file 1008 in the file system 22 of the save storage device 2.
- the file 1008 is stored in the path name “r / FS1 / A / a.doc”.
- the path names in the evacuation storage device 2 are set so as not to overlap.
- the metadata server 1 instructs the file server 4 to delete the file 1000-1 (step S1006).
- the file server 4 deletes the file 1000-1 and responds to the business program 51 that the file 1000-1 has been deleted.
- the metadata server 1 updates the record corresponding to the metadata of the file 1000-1 in the metadata repository 150 (step S1007). Specifically, the path name “r / FS1 / A / a.doc” of the file 1008 and the save storage device 2 in which the file 1008 is stored in the field for specifying the file stored in the save storage device 2 The identification name “S1” is stored.
- FIG. 1 shows changes in the metadata repository 150 before and after the deletion of the file 1000-1.
- the analysis program 61 will explain the outline of the analysis processing for analyzing the current and past files.
- an analysis process after the file 1000-1 is deleted from the file server 4 by the business program 51 and the file 1000-1 is moved to the save storage device 2 will be described.
- the analysis program 61 inquires of the metadata server 1 about all files including the file currently stored and the file existing in the past (step S1011). Specifically, the analysis program 61 requests the metadata server 1 for a list of all files.
- the metadata server 1 generates a list based on the metadata repository 150, and responds the generated list to the analysis program 61 (step S1012).
- the list is composed of a plurality of entries including information for specifying a file.
- the entry includes a file path name, a storage device identification name, metadata of the file in the file server 4, and fields indicating the file status.
- the entry of the file 1000-1 deleted from the file server 4 further includes the path name of the file save destination and the identification name of the save storage device 2.
- the field indicating the file status of the entry stores information indicating that the file has been deleted.
- the analysis program 61 identifies the storage location of the file based on the list acquired from the metadata server 1.
- the analysis program 61 shows that two files having path names “/A/a.doc” and “/A/c.doc” exist in the file server 4. Furthermore, the analysis program 61 deletes the file having the path name “/A/a.doc” from the file server 4 among the files described above, and stores it in the evacuation storage apparatus 2 having the identification name “S1”. It can be seen that the file is stored as a file 1008 whose path name is “r / FS1 / A / a.doc”.
- the analysis program 61 refers to the list and acquires all files necessary for the analysis process (steps S1013 and S1014). That is, the analysis program 61 acquires the file 1000-2 stored in the file server 4 from the file server 4, and acquires the file 1008 corresponding to the file 1000-1 deleted from the file server 4 from the save storage device 2. To do.
- the metadata server 1 can manage the analysis program 61 to analyze the file deleted by the business program 51 during the business execution.
- a file that is deleted from the file server 4 and whose contents can be acquired by making an inquiry to the metadata server 1 as a file 1000-1 is referred to as a deleted file.
- a copy of the deleted file stored in the save storage device is called a save file.
- a file to be deleted and stored in the file server 4 before becoming a deleted file is called an original file.
- a file stored in the file server 4 and not deleted is called a normal file.
- FIG. 2 is a block diagram illustrating the configuration of the computer system 500 according to the first embodiment of the present invention.
- the computer system 500 includes a metadata server 1, a backup storage device 2, a backup storage device 3, a plurality of file servers 4, a plurality of business servers 5, a plurality of analysis servers 6, and a network 7.
- the metadata server 1, the backup storage device 2, the backup storage device 3, the file server 4, the business server 5, and the analysis server 6 can communicate with each other via the network 7.
- the network 7 can be configured using a LAN (Local Area Network), a WAN (Wide Area Network), the Internet, and the like.
- the present invention is not limited to the network 7 connection method.
- the metadata server 1 is a computer that manages metadata. Note that the metadata server 1 may be a virtual machine generated using a virtualization technique.
- the metadata server 1 includes a metadata server program 110 and a metadata repository 150. Other components will be described later.
- the evacuation storage device 2 is a storage device that stores various files.
- the storage device is a device that includes a controller (not shown), a network interface (not shown), and one or more storage media (not shown), and can provide a storage area of the storage medium to a computer. Show.
- the storage apparatus can configure RAID using a plurality of storage media, and can generate a plurality of logical storage areas as physical storage areas.
- a different file system can be constructed for each logical storage area.
- the evacuation storage device 2 includes a file sharing program 21 and a file system 22.
- the file sharing program 21 stores the file in the file system 22 and reads the file from the file system 22 in accordance with the file access request received from the metadata server 1 via the network 7. Other components will be described later.
- the backup storage device 3 is a storage device that stores various files. However, the backup storage device 3 is used particularly for the purpose of backing up files.
- the backup storage device 3 includes a backup program 31 and a file system 32. Other components will be described later.
- the file server 4 is a computer that stores various files and manages the files.
- the file server 4 stores files necessary for the business program 51 to execute business processing.
- the file server 4 includes a file sharing program 411 and a file system 452. Other components will be described later.
- the file server 4 is also recognized as a kind of storage device.
- the business server 5 is a computer that executes a program necessary for realizing business processing.
- the business server 5 may be a virtual machine generated using a virtualization technique.
- the business server 5 includes a business program 51.
- the business program 51 is a program for performing predetermined business processing, and acquires data necessary for business processing from the file server 4 and executes predetermined business processing. Other components will be described later.
- the analysis server 6 is a computer that executes a program necessary for realizing analysis processing.
- the analysis server 6 may be a virtual computer generated using a virtualization technique.
- the analysis server 6 includes an analysis program 61.
- the analysis program 61 is stored in the file server 4, reads a file used by the business program 51 for business processing, and executes analysis processing using the read file.
- FIG. 3 is a block diagram illustrating the configuration of the metadata server 1 according to the first embodiment of the present invention.
- the metadata server 1 includes a memory 11, a processor 12, a network interface 13, and a local storage 15, and each component is connected to each other via an internal bus 16.
- the processor 12 executes a program stored in the memory 11.
- the functions of the metadata server 1 can be realized.
- the memory 11 stores the metadata server program 110.
- the metadata server program 110 is a program for realizing the functions provided in the metadata server 1 and includes a plurality of subprograms.
- the metadata server program 110 includes an inquiry processing program 111, a metadata management program 112, a file deletion detection program 113, a file save program 114, and a file proxy read program 115.
- the inquiry processing program 111 is a program that executes processing for inquiries from the file server 4 and the analysis server 6.
- the metadata management program 112 is a program for managing metadata.
- the file deletion detection program 113 is a program that detects that a file is deleted from the file server 4.
- the file save program 114 is a program for copying a file to the save storage device 2.
- the file proxy read program 115 is a program for reading a file from the save storage device 2.
- subprograms may be executed as independent processes, or may be executed as a partial program such as a library constituting the metadata server program 110. Details of processing executed by each subprogram will be described later with reference to the drawings.
- the memory 11 also stores a list 116 generated when an inquiry from the analysis server 6 is received.
- the list 116 stores information necessary for acquiring a file from the file server 4 or the evacuation storage device 2.
- the local storage 15 is a storage medium included in the metadata server 1, and a hard disk drive (HDD), a solid state drive (SSD), and a nonvolatile memory (NVRAM) can be considered.
- HDD hard disk drive
- SSD solid state drive
- NVRAM nonvolatile memory
- the local storage 15 stores the metadata repository 150.
- the metadata repository 150 may be stored in the memory 11 or may be stored in a storage device connected to the metadata server 1.
- the metadata repository 150 includes a storage management table 151, a namespace management table 152, a metadata management table 153, and a file save management table 154.
- a storage management table 151 includes a storage management table 151, a namespace management table 152, a metadata management table 153, and a file save management table 154.
- FIG. 4 is an explanatory diagram showing an example of the configuration of the storage management table 151 according to the first embodiment of this invention.
- the storage management table 151 stores information about storage devices managed by the metadata server 1. Specifically, the storage management table 151 includes one or more records, and each record includes a storage ID 1511, a storage name 1512, a type 1513, and an IP address 1514.
- Each record of the storage management table 151 corresponds to one storage device managed by the metadata server 1.
- the storage ID 1511 stores an identifier for the metadata server 1 to uniquely identify the storage device.
- the storage name 1512 stores the identification name set for the storage device in the computer system 500.
- Type 1513 stores the usage type of the storage device. For example, “file server” is stored when the storage device is the file server 4, and “archive storage” is stored when the storage device stores the archive file.
- the IP address 1514 stores an IP address assigned to the storage device.
- the first record includes a storage ID 1511 “s1000”, a storage name 1512 “FS1”, a type 1513 “file server”, and an IP address 1514 “192.168.10.100”.
- the information of the file server 4 is stored.
- information of the file server 4 is stored in the second record, and information of the evacuation storage device 2 is stored in the third record.
- FIG. 5 is an explanatory diagram showing an example of the configuration of the name space management table 152 in the first embodiment of the present invention.
- the name space management table 152 stores information related to the name space in the storage device managed by the metadata server 1.
- the name space is a logical unit for identifying a storage area in which a file is stored.
- the file server 4 it is known that names such as a shared name and a public name correspond to a name space. The same concept is known for the evacuation storage apparatus 2.
- the name space management table 152 includes one or more records, and each record includes a name space ID 1521, a name space name 1522, a storage ID 1523, a capacity 1524, a protocol 1525, a usage amount 1526, and a usage 1527.
- Each record of the name space management table 152 corresponds to a name space in the file server 4 and the evacuation storage device 2.
- the namespace ID 1521 stores an identifier for the metadata server 1 to uniquely identify the namespace.
- the name space name 1522 stores a name for the storage apparatus to uniquely identify the name space.
- the storage ID 1523 stores an identifier of a storage device that provides a logical storage area corresponding to the name space.
- the storage ID 1523 is the same as the storage ID 1511.
- the capacity 1524 stores the capacity of a logical storage area corresponding to the name space.
- the protocol 1525 stores a protocol used when accessing a logical storage area corresponding to the name space.
- the usage amount 1526 stores the usage amount of the logical storage area corresponding to the name space.
- Use 1527 stores the use of the logical storage area corresponding to the name space. For example, when the logical storage area is used by the business program 51, “primary” is stored. In the case of a logical storage area for storing a save file, “save” is stored.
- the first record and the second record store information related to the name space on the file server 4 whose storage ID 1523 is “s1000”.
- Name space ID 1521 of the first record is “n1001”
- name space name 1522 is “share1”
- storage ID 1523 is “s1000”
- capacity 1524 is “20 TB”
- protocol 1525 is “nfs”
- usage amount “5TB” is stored in 1526
- “primary” is stored in the usage 1527.
- the second record stores information about the name space name 1522, that is, the name space whose share name is “share2”.
- information on the name space name 1522 of the other file server 4 that is, the name space whose share name is “share3” is stored.
- the fourth record stores information related to the name space whose name space name 1522 of the evacuation storage apparatus 2 is “r”.
- FIG. 6 is an explanatory diagram showing an example of the configuration of the metadata management table 153 according to the first embodiment of this invention.
- the metadata management table 153 stores information indicating the storage location of the file and metadata. Specifically, the metadata management table 153 includes one or more records, and each record includes a metadata ID 1531, a path 1532, a namespace ID 1533, original metadata 1534, and a file status 1535.
- Each record of the metadata management table 153 corresponds to a file stored in the file server 4 and a deleted file.
- the metadata ID 1531 stores an identifier for identifying metadata.
- the path 1532 stores a path name indicating a storage location where the file is stored.
- Name space ID 1533 stores an identifier for identifying the name space of the logical storage area in which the file is stored.
- the namespace ID 1533 is the same as the namespace ID 1521.
- Original metadata 1534 stores metadata (not shown) in the file server 4.
- the file status 1535 stores information indicating whether or not the file exists in the file server 4. Specifically, “exist” is stored when the file exists in the file server 4, and “deleted” is stored when the file does not exist in the file server 4.
- the record in which “exist” is stored in the file status 1535 indicates that the file corresponding to the record is stored in the storage location indicated by the path 1532 and the name space ID 1533.
- the record in which “deleted” is stored in the file state 1535 is not currently stored in the storage location indicated by the path 1532 and the namespace ID 1533, and indicates that the file is currently a deleted file.
- the file metadata is managed for each file by the file server 4, and the metadata server 1 can be acquired from the file server 4 through an API (Application Programming Interface) provided for each type of name space.
- API Application Programming Interface
- the metadata management table 153 stores records corresponding to the metadata of all files managed by the metadata server 1.
- the first record represents metadata corresponding to the file “/share1/a.doc” stored in the name space “share1” of the file server 4, and “100” is stored in the metadata ID 1531.
- the path 1532 of the first record stores “/share1/a.doc” that is the path name of the corresponding file, and the namespace ID 1533 stores “n1001” that is the identifier of the namespace “share1”.
- the original metadata 1534 of the first record stores the metadata of the corresponding file in the file server 4, but is not shown here. Furthermore, “exist” is stored in the file state 1535 of the first record.
- the second record represents metadata corresponding to the file “/share1/b.doc” stored in the name space “share1” of the file server 4, and “110” is stored in the metadata ID 1531. Further, “deleted” is stored in the file status 1535 of the second record. Therefore, the file “/share1/b.doc” is not currently stored in the storage location indicated by the path 1532 and the name space ID 1533 but represents a deleted file.
- the third record represents metadata corresponding to the file “/share1/c.doc” stored in the name space “share1” of the file server 4, and “120” is stored in the metadata ID 1531.
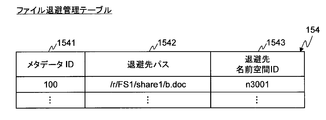
- FIG. 7 is an explanatory diagram showing an example of the configuration of the file save management table 154 according to the first embodiment of this invention.
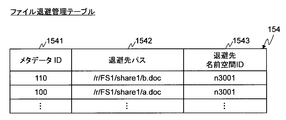
- the file save management table 154 stores information on the save file storage location (save destination). Specifically, the file save management table 154 includes one or more records, and each record includes a metadata ID 1541, a save destination path 1542, and a save destination namespace ID 1543.
- Each record of the file save management table 154 corresponds to a save file stored in the save storage device 2.
- the metadata server 1 detects that a file is deleted from the file server 4 and updates the file save management table 154 when the file is moved to the save storage device 2.
- the metadata ID 1541 stores an identifier for identifying metadata.
- the metadata ID 1541 is the same as the metadata ID 1531.
- the save destination path 1542 stores a path name indicating a storage location where the save file is stored.
- the save destination namespace ID 1543 stores an identifier for identifying the name space in which the save file is stored.
- the first record stores information related to the save file corresponding to the file “/share1/b.doc” in FIG.
- the save destination path 1542 stores the save file path name “/r/FS1/share1/b.doc” corresponding to the file “/share1/b.doc”.
- the save destination namespace ID 1543 stores an identifier “n3001” of the name space in which the save file “/r/FS1/share1/b.doc” is stored.
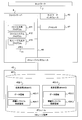
- FIG. 8 is a block diagram illustrating the configuration of the file server 4 in the first embodiment of the present invention.
- the file server 4 includes a memory 41, a processor 42, a network interface 43, and a storage interface 44, and is connected to the storage device 45.
- the processor 42 executes a program stored in the memory 41.
- the processor 42 executes the program, the function of the file server 4 can be realized.
- the memory 41 stores a file sharing program 411, a file system program 412, and a storage input / output program 413.
- the file sharing program 411 is a program that provides a function for the business program 51, the analysis program 61, and the metadata server program 110 to access a file stored in the storage device 45 via the network 7.
- the file system program 412 is a program that configures a file system for storing files in the storage apparatus 45 and manages file input / output.
- the storage input / output program 413 is a program that manages data read / write processing for the storage device 45.
- the file server 4 realizes a file sharing function via the network 7 by the processor 42 executing the above-described program.
- the storage device 45 generates a storage volume 451 inside.
- the storage volume 451 is configured from a storage area of a storage medium such as a heart disk drive, a solid state drive, and a nonvolatile memory provided in the storage device 45.
- the storage volume 451 includes two name spaces 452-1 and 452-2.
- “share1” is set as the identification name
- “share1” is set as the identification name
- the name spaces 452-1 and 452-2 include data areas 453-1 and 453-2 and concealed file storage areas 454-1 and 454-2, respectively.
- the data areas 453-1 and 453-2 are areas for storing files that can be referred to by the business program 51.
- the concealed file storage areas 454-1 and 454-2 are areas for temporarily storing files deleted by the business program 51.
- the files stored in the concealed file storage areas 454-1 and 454-2 are handled as files that do not exist in the business program 51. That is, the business program 51 cannot recognize the files stored in the concealed file storage areas 454-1 and 454-2.
- the data areas 453-1 and 453-2 and the concealed file storage areas 454-1 and 454-2 may be included in different storage volumes 451, each of which is one directory in a single file system tree. It may be. Further, the name spaces 452-1 and 452-2 may be included in different storage volumes 451, or each may be one directory in a single file system tree.
- two name spaces are defined in the storage volume 451, but this does not limit the present invention, and two or more name spaces may be defined.
- data areas 453-1 and 453-2 are not distinguished, they are referred to as data areas 453.
- concealed file storage areas 454-1 and 454-2 are not distinguished, they are expressed as concealed file storage areas 454.
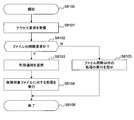
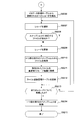
- FIG. 9 is a flowchart for explaining processing executed by the metadata management program 112 in the first embodiment of the present invention.
- the metadata management program 112 executes this processing periodically or according to a user request in order to update the metadata repository 150.
- the metadata management program 112 starts processing (step S8000), refers to the name space management table 152, and selects one name space to be processed (step S8001).
- the metadata management program 112 selects one file to be processed from the files stored in the selected name space (step S8002).
- a method for selecting a file a method of tracing the file system tree in the name space in order from the upper directory can be considered.
- the metadata management program 112 acquires the metadata of the file to be processed from the file server 4 (step S8003).
- the metadata management program 112 updates the metadata management table 153 based on the acquired metadata (step S8004). Specifically, the following processing is executed.
- the metadata management program 112 determines whether a record corresponding to the selected file has been registered. Specifically, the metadata management program 112 determines whether there is a record in which the path 1532 and the namespace ID 1533 match the identifier of the processing target namespace and the path name of the processing target file.
- a method of determining whether the acquired metadata matches the original metadata may be used. For example, an inode number which is file identification information in the file server 4 can be used.
- the metadata management program 112 When it is determined that the record corresponding to the selected file is not registered, the metadata management program 112 registers a new record in the metadata management table 153. At this time, the metadata management program 112 generates an identifier for uniquely identifying the metadata, and stores the generated identifier in the metadata ID 1531.
- the metadata management program 112 stores the path name of the processing target file in the selected name space in the path 1532 and stores the identifier of the selected name space in the name space ID 1533. Further, the metadata management program 112 stores the acquired metadata in the original metadata 1534 and stores “exist” in the file state 1535.
- the metadata management program 112 stores the acquired metadata in the original metadata 1534 of the existing record.
- the metadata management program 112 determines whether or not processing has been completed for all files stored in the processing target namespace (step S8005).
- the metadata management program 112 returns to step S8002 and executes similar processing (steps S8002 to S8005).
- the metadata management program 112 determines whether processing has been completed for all namespaces to be managed ( Step S8006).
- the metadata management program 112 returns to step S8001 and executes the same processing (steps S8001 to S8006).
- the metadata management program 112 ends the processing (step S8007).
- FIG. 10 is a flowchart for explaining processing executed by the file sharing program 411 according to the first embodiment of the present invention.
- the file server 4 When the file server 4 receives an access request for a file from the business program 51 or another program, the file server 4 executes processing described below.
- step S8100 When the file sharing program 411 starts processing (step S8100), it receives an access request for a predetermined file from the business program 51 or another program via the network 7 (step S8101).
- the file sharing program 411 determines whether or not the received access request is a file deletion request (step S8102).
- the file sharing program 411 instructs the file system program 412 to execute processing according to the received access request (step S8105). Thereafter, the file sharing program 411 transmits a response to the source program of the access request, and ends the process (step S8106).
- the file sharing program 411 indicates to the file deletion detection program 113 of the metadata server 1 that it has received an access request including a file deletion request. Notification is made (step S8103).
- deletion notification A file requested to be deleted by the business program 51 or another program is called a deletion target file.
- the deletion target file is finally moved to the save storage device 2 by the metadata server 1.
- the file to be deleted is moved to the evacuation storage apparatus 2 and “deleted” is stored in the file status 1535 of the metadata management table 153, the file becomes a deleted file.
- deletion notification includes information such as the path name of the deletion target file, the name space in which the deletion target file is stored, the identification name of the file server, and the metadata of the deletion target file.
- the file sharing program 411 When the file sharing program 411 receives a response to the deletion notification from the file deletion detection program 113, the file sharing program 411 executes processing for the deletion target file according to the response (step S8104).
- the response transmitted from the file deletion detection program 113 includes an instruction from the file saving program 114. Specifically, the following processing is executed.
- the file sharing program 411 moves the deletion target file to the concealed file storage area 454 when the received response includes an instruction to conceal the deletion target file.
- the business program 51 cannot access the deletion target file. That is, the business program 51 recognizes that the file has been deleted.
- the file sharing program 411 deletes the deletion target file when the received response includes an instruction to delete the deletion target file.
- the file sharing program 411 outputs instructions to the file system program 412, thereby realizing the deletion process and the deletion process for the file to be deleted.
- the file to be deleted stored in the concealed file storage area 454 is referred to as a concealed file.
- the file sharing program 411 ends the process when the process for the file to be deleted ends (step S8106).
- the file sharing program 411 executes the process, but may be executed by another program such as the file system program 412.
- FIG. 11A, FIG. 11B, and FIG. 11C are flowcharts for explaining processing executed by the file deletion detection program 113 in the first embodiment of the present invention.
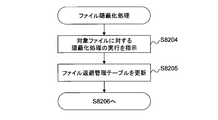
- the file deletion detection program 113 when starting the process (step S8200), detects that a file is deleted from the file server 4 (step S8201). The file deletion detection program 113 recognizes the file as a deletion target file.
- the file deletion detection program 113 can detect that a file is deleted from the file server 4 by receiving a deletion notification from the file sharing program 411 (see step S8103).
- the notification includes the path name, name space name, metadata, and the like of the file to be deleted.
- the file deletion detection program 113 updates the record corresponding to the deletion target file in the metadata management table 153 (step S8202).
- the file deletion detection program 113 refers to the metadata management table 153 based on the information included in the received deletion notification, identifies the record corresponding to the deletion target file, and the file status 1535 of the record. Store “delete” in.
- the file deletion detection program 113 executes file concealment processing for the deletion target file on the file server 4 (step S8203). In the file concealment process, the following process is executed.
- the file deletion detection program 113 instructs the file server 4 that has transmitted the deletion notification to execute a concealment process for the deletion target file (step S8204).
- the file sharing program 411 of the file server 4 that has received the concealment processing execution instruction moves the deletion target file to the concealment file storage area 454.
- the deleted file is handled as a hidden file.
- the path name of the concealment file may be automatically determined by the file sharing program 411 or the file system program 412, or may be automatically determined by the file deletion detection program 113.
- the file deletion detection program 113 updates the file save management table 154 (step S8205). Specifically, the following processing is executed.
- the file deletion detection program 113 adds a new record to the file save management table 154, and stores the metadata ID 1531 of the record corresponding to the deletion target file in the metadata ID 1541 of the record.
- the file deletion detection program 113 stores the path name of the concealed file in the save destination path 1542, and stores the identifier of the name space in which the concealed file is stored in the save destination name space ID 1543.
- the file deletion detection program 113 executes a concealed file save process (step S8206) and ends the process (step S8210).
- the save process for the concealment file the following process is executed.
- the file deletion detection program 113 calls the file saving program 114 to instruct execution of saving processing for the hidden file.
- the file save program 114 that has received the execution instruction for the save process copies the concealment file to the name space on the save storage device 2 (step S8207).
- the duplicated file becomes the save file.
- the path name of the save file is determined to be a unique path name in the name space in which the save file is stored.
- the file evacuation program 114 notifies the completion of the evacuation process for the concealment file together with the information on the evacuation file.
- the file deletion detection program 113 updates the file save management table 154 based on the information included in the received completion notification (step S8208). Specifically, the path name of the save file is stored in the save destination path 1542 of the record added in step S8205, and the identifier of the name space in which the save file is stored is stored in the save destination namespace ID 1543.
- the file deletion detection program 113 instructs the file server 4 to delete the concealment file (step S8209).
- the file server 4 that has received the instruction deletes the hidden file from the name space corresponding to the hidden file storage area 454.
- the file server 4 may periodically inquire of the metadata server 1 whether there is a file to be deleted. In this case, the file deletion detection program 113 may not instruct the deletion of the concealment file.
- FIG. 12 is an explanatory diagram showing the metadata management table 153 after the file is moved in the first embodiment of the present invention.
- FIG. 13 is an explanatory diagram showing the file save management table 154 after the file is moved in the first embodiment of this invention.
- the second record is a record for storing information of the save file corresponding to the file whose metadata identifier is “100”, that is, the file “share1 / a.doc”.
- the path name of the save file corresponding to the file “share1 / a.doc” is “r / FS1 / share1 / a.doc”, and the save destination name.
- the space ID 1543 is the name space identified by “n3001”, that is, the name space “r” of the save storage device 2.
- FIG. 14 is a flowchart for explaining processing executed by the inquiry processing program 111 according to the first embodiment of the present invention.
- the inquiry processing program 111 executes processing when the analysis program 61 requests the output of a list of files managed by the metadata server 1.
- step S8300 When the inquiry processing program 111 starts processing (step S8300), it receives a file inquiry from the analysis program 61 (step S8301).
- the inquiry may include conditions for the file to be output.
- Conditions include, for example, a file containing a specific character string in the path name, a file updated at a specific time zone, a file of a specific owner, a file with specific access rights, a specific file server or name A file stored in a space, a file stored in a specific file server or name space, or the like can be considered.
- it is possible to specify a condition regarding the deleted file such as being a deleted file, not being a deleted file, both a deleted file and a file that is not a deleted file.
- the logical sum and logical product of a set of files satisfying the above-described conditions can be specified.
- the inquiry processing program 111 refers to the metadata repository 150 and generates a list 116 of files that satisfy the specified condition on the memory 11 (step S8302). Specifically, the inquiry processing program 111 generates the list 116 with reference to the storage management table 151, the name space management table 152, and the metadata management table 153.
- 15A and 15B are explanatory diagrams illustrating an example of a configuration of the list 116 according to the first embodiment of this invention.
- the list 116 stores information on each file managed by the metadata server 1. Specifically, the list 116 includes a metadata ID 1161, a path 1162, original metadata 1163, a storage ID 1164, an IP address 1165, a name space ID 1166, a file status 1167, and save destination information 1168.
- the metadata ID 1161 stores an identifier for identifying metadata.
- the metadata ID 1161 is the same as the metadata ID 1531.
- the path 1162 stores a path indicating a storage location where the file is stored.
- the path 1162 is the same as the path 1532.
- Original metadata 1163 stores file metadata.
- the original metadata 1163 is the same as the original metadata 1153.
- the storage ID 1164 stores the identifier of the storage device in which the file is stored.
- the storage ID 1164 is the same as the storage ID 1511.
- the IP address 1165 stores the IP address assigned to the storage device.
- the IP address 1165 is the same as the IP address 1514.
- the namespace ID 1166 stores an identifier for the metadata server 1 to uniquely identify the namespace.
- the namespace ID 1166 is the same as the namespace ID 1521.
- the file status 1167 stores information indicating whether or not the file exists in the file server 4.
- File state 1167 is the same as file state 1535.
- the save destination information 1168 stores information related to the save file. If it is not a save file, no information is stored in the save destination information 1168.
- the save destination information 1168 includes a save destination path 11681, a storage ID 11682, an IP address 11683, and a save destination namespace ID 11684.
- the save destination path 11681 stores a path indicating a storage location where the save file is stored.
- the save destination path 11681 is the same as the save destination path 1542.
- the storage ID 11682 stores the identifier of the storage device in which the save file is stored.
- the storage ID 11682 is the same as the storage ID 1511.
- the IP address 11683 stores the IP address assigned to the storage device in which the save file is stored.
- the IP address 11683 is the same as the IP address 1514.
- the save destination namespace ID 11684 stores an identifier for identifying the name space in which the save file is stored.
- the save destination namespace ID 11684 is the same as the save destination namespace ID 1543.
- step S8302 information is stored in the metadata ID 1161, the path 1162, the original metadata 1163, the storage ID 1164, the IP address 1165, the namespace ID 1166, and the file status 1167.
- the inquiry processing program 111 selects one entry corresponding to the deleted file from the generated list (step S8303). Specifically, the inquiry processing program 111 selects an entry in which “deleted” is stored in the file status 1167. If there are a plurality of entries corresponding to the deleted file, a method of selecting the entries in order from the top of the entries can be considered.
- the inquiry processing program 111 refers to the file save management table 154 and acquires save destination information in the deleted file corresponding to the selected entry (step S8304).
- the inquiry processing program 111 identifies a record that matches the metadata ID 1161 of the selected entry from the file save management table 154.
- the inquiry processing program 111 acquires the save destination path 1542 and the save destination namespace ID 1543 from the specified record. Furthermore, the inquiry processing program 111 uses the save destination name space ID 1543, and from the storage management table 151 and the name space management table 152, the identification name, IP address, and name space of the save storage device 2 in which the save file is stored. Get the distinguished name.
- the inquiry processing program 111 updates the list 116 based on the information acquired in step S8304 (step S8305). Specifically, the information acquired in step S8304 is stored in the save destination information 1169 of the selected entry.
- the inquiry processing program 111 determines whether or not processing has been completed for the entries corresponding to all the deleted files included in the list 116 (step S8306).
- step S8303 If it is determined that the processing for the entries corresponding to all the deleted files has not been completed, the inquiry processing program 111 returns to step S8303 and executes the same processing (step S8303 to step S8306).
- the inquiry processing program 111 transmits the generated list 116 to the analysis program 61 that is the transmission source of the output request for the file list. Is finished (steps S8307, S8308).
- FIG. 16 is a flowchart for explaining file analysis processing executed by the analysis program 61 according to the first embodiment of the present invention.
- the analysis program 61 executes an analysis process periodically or according to a user instruction.
- the analysis program 61 When the analysis program 61 starts the analysis process (step S8400), it sends an inquiry about the files stored in all the file servers 4 to the inquiry processing program 111 of the metadata server 1 (step S8401).
- the output request may include conditions for files to be included in the list 116.
- the analysis program 61 waits for a response from the metadata server 1. That is, the process waits until the list 116 is transmitted from the metadata server 1.
- the analysis program 61 selects one entry to be processed from the received list 116 (step S8402). For example, a method of selecting from the top entry in the list 116 in order is conceivable.
- the analysis program 61 acquires information on the file read destination corresponding to the entry (step S8403). Specifically, the following processing is executed.
- the analysis program 61 determines whether “deleted” is stored in the file status 1167 of the selected entry. If “deleted” is stored in the file status 1167, it can be seen that the selected entry is an entry related to the deleted file.
- the analysis program 61 acquires information stored in the save destination information 1168. That is, the save destination path 11681, storage ID 11682, IP address 11683, and save destination namespace ID 11684 are acquired.
- the analysis program 61 acquires a path 1162, a storage ID 1164, an IP address 1165, and a namespace ID 1166.
- the analysis program 61 reads a file corresponding to the selected entry from the storage device that is the read destination based on the information acquired in step S8403 (step S8404).
- the analysis program 61 executes a predetermined analysis process based on the contents of the read file and the original metadata 1163 of the selected entry (step S8405).
- the analysis program 61 determines whether or not processing has been completed for all entries in the acquired list 116 (step S8406).
- step S8402 If it is determined that processing has not been completed for all entries, the analysis program 61 returns to step S8402 and executes similar processing (steps S8402 to S8406).
- the analysis program 61 ends the analysis processing (step S8407).
- the storage device in which the file is stored may be a storage device that cannot be accessed from the analysis program 61.
- this corresponds to a case where the file sharing protocol for reading a file is not supported by the analysis program 61.
- the analysis program 61 transmits a read request for a desired file to the file proxy read program 115.
- the file proxy read program 115 that has received the request reads the file from the storage device in place of the analysis program 61 and returns the read file to the analysis program 61.
- the file server 4 when the file server 4 receives a file deletion request from the business program 51, the file server 4 transmits a deletion notification of the file to the metadata server 1 in the course of processing. Thereafter, the file server 4 executes the concealment process according to the instruction of the metadata server 1.
- the file server 4 receives a deletion request for a certain number of files from the business program 51, and when a certain time has elapsed since the deletion notification was transmitted, Are collectively transmitted to the metadata server 1.
- the file server 4 automatically transmits a plurality of file deletion notifications without receiving an instruction from the metadata server 1 when receiving a file deletion request. File concealment processing is executed.
- the file server 4 of the second embodiment is different from the file server 4 of the first embodiment in that a new concealment file management table 415 (not shown) is provided in the memory 41. Since other configurations are the same as those of the first embodiment, description thereof is omitted.
- FIG. 17 is an explanatory diagram showing an example of the configuration of the concealment file management table 415 in the second embodiment of the present invention.
- the concealment file management table 415 stores information regarding the concealment file. Specifically, the concealed file management table 415 includes a path 4151, a namespace ID 4152, original metadata 4153, and a concealed file path 4154.
- the path 4151 stores the path name of the file before the concealment process is executed.
- the namespace ID 4152 stores the identification name of the namespace in which the file was stored before the concealment process was executed.
- Original metadata 4153 stores the metadata of the file before the concealment process is executed.
- the concealment file path 4154 stores the path name of the concealment file.
- FIG. 18 is a flowchart for explaining processing executed by the file sharing program 411 according to the second embodiment of the present invention.
- step S8600 When the file sharing program 411 starts processing (step S8600), it receives an access request for a predetermined file from the business program 51 or another program via the network 7 (step S8601).
- the file sharing program 411 determines whether or not the received access request is a file deletion request (step S8602).
- the file sharing program 411 instructs the file system program 412 to execute processing according to the received access request (step S8607). Thereafter, the file sharing program 411 transmits a response to the access request transmission source program, and ends the processing (step S8608).
- the file sharing program 411 moves the deletion target file to the concealed file storage area 454 (step S8603). As a result, it is recognized that the file to be deleted is deleted from the business program 51.
- the file sharing program 411 updates the concealed file management table 415 (step S8604). That is, the file sharing program 411 stores the concealed file information in the concealed file management table 415.
- the file sharing program 411 generates a new record and stores the path name, namespace identification name, and metadata stored before the deletion target file is moved to the concealed file storage area 454.
- the path name of the concealment file is stored in the generated record.
- the path name of the concealment file is determined by the file sharing program 411 so as not to be duplicated in the concealment file management table 415.
- the file sharing program 411 determines whether it is necessary to send a file deletion notification to the metadata server 1 (step S8605). For example, the file sharing program 411 may store a file when a predetermined number of records are registered in the concealed file management table 415 or when a preset time has elapsed since the previous deletion notification. It is determined that a deletion notification needs to be transmitted.
- the file sharing program 411 ends the process (step S8608).
- the file sharing program 411 transmits a file deletion notification to the metadata server 1 (step S8606).
- the notification includes information on all records stored in the hidden file management table 415, that is, information on all hidden files. Thereafter, the file sharing program 411 ends the process (step S8608).
- step S8605 and step S8606 is executed in the course of the processing for the access request from the business program 51. These two processings are periodically executed as processing independent of the processing for the access request. May be.
- the file deletion detection program 113 When the file deletion detection program 113 receives the deletion notification from the file sharing program 411, the file deletion detection program 113 executes the processing shown in FIG. However, when the deletion notification is received, the deletion file is concealed by the file server 4, and therefore the process of step S8203 is not executed.
- the third embodiment extends the second embodiment so that in addition to the deleted file, the analysis program 61 can also read data partially erased from the file by overwriting the file, changing the file size, or the like. Is characterized by the management.
- erased data data that is erased by deleting a file, overwriting the file, or reducing the file size is called erased data.
- erase data is generated by the above-described processing, it cannot be read from the file server 4, but a file that can be acquired by inquiring the metadata server 1 is called a deleted file.
- a file from which a part of data is erased by overwriting the file or reducing the file size is called a partially erased file.
- the file on the file server 4 in which the erase data is stored is called an original file.
- a file for saving erased data is called a save file.
- erase data generated in one access process is stored.
- the configuration of the computer system 500 according to the third embodiment and the configuration of the metadata server 1 are the same as those of the first embodiment, and thus the description thereof is omitted.
- the configuration of the file server 4 of the third embodiment is the same as that of the second embodiment, and the description thereof is omitted.
- the file saving management table 154 included in the metadata server 1 and the concealed file management table 415 included in the file server 4 are different.
- FIG. 19 is an explanatory diagram showing an example of the configuration of the file save management table 154 according to the third embodiment of this invention.
- the file save management table 154 in the third embodiment is stored in the memory 11 of the metadata server 1.
- the file save management table 154 stores information for managing the correspondence between erased data and save files. Specifically, the file save management table 154 includes one or more records, and each record includes a metadata ID 1541, a save destination path 1542, a save destination namespace ID 1543, and an address range 1544.
- Each record of the file evacuation management table 154 corresponds to information on erase data generated in one access process.
- an address range 1544 is newly added.
- the address range 1544 stores the address range on the original file where the erase data was stored.
- the metadata server 1 When the metadata server 1 detects that the data has been erased in the file server 4, the metadata server 1 moves the erased data to the save file and updates the file save management table 154.
- the first record stores information related to erased data in the file “/share1/b.doc”.
- the metadata ID 1541 an identifier “110” of metadata corresponding to the file “/share1/b.doc” is stored.
- the save destination path 1542 stores the path name “/r/FS1/share1/b.doc” of the save file storage destination.
- the save destination name space ID 1543 stores an identifier “n3001” of the name space in which the save file “/r/FS1/share1/b.doc” is stored.
- the address range 1544 stores the address range [10, 20) of erased data in the original file “/share1/b.doc”.
- FIG. 20 is an explanatory diagram showing an example of the configuration of the concealment file management table 415 in the third embodiment of the present invention.
- the concealed file management table 415 in the third embodiment is stored in the memory 41 of the file server 4.
- the concealed file management table 415 stores information for managing the association between erased data and concealed files.
- the concealed file management table 415 includes one or more records, and each record includes a path 4151, a namespace ID 4152, original metadata 4153, a concealed file path 4154, an address range 4155, and an erase type 4156. Consists of
- Each record of the concealment file management table 415 corresponds to information on erase data generated in one access process.
- an address range 4155 and an erasure type 4156 are newly added.
- the address range 4155 stores an address range in which erase data in the original file was stored.
- the erase type 4156 stores the cause of the erase data.
- deletion type 4156 When deletion data is generated by deleting a file, the deletion type 4156 stores “delete” which is information indicating that the file has been deleted. When erase data is generated by overwriting a part of the file or reducing the size of the file, “partial erase”, which is information indicating that part of the data of the file has been erased, is stored in the erase type 4156.
- the file server 4 reads the erased data from the original file and erases it to the concealed file when the erased data is generated, that is, when processing such as deleting the file, overwriting the file, or reducing the file size is requested.
- the data is written and the concealed file management table 415 is updated.
- FIG. 21 is a flowchart for explaining processing executed by the file sharing program 411 according to the third embodiment of the present invention.
- the erased data is stored in the concealed file storage area 454. This is different from the second embodiment.
- step S8700 when the file sharing program 411 starts processing (step S8700), it receives an access request for a file from the business program 51 or another program via the network 7 (step S8701).
- the file sharing program 411 determines whether or not erased data is generated when processing corresponding to the received access request is executed (step S8702). That is, it is determined whether or not the received access request is a request for erasing data from the file. For example, in the case of a request for deleting a file, overwriting data to the file, or reducing the file size, it is determined that erase data is generated when processing corresponding to the received access request is executed.
- step S8705 If it is determined that no erasure data is generated, the file sharing program 411 proceeds to step S8705.
- the file sharing program 411 moves the erasure data to the concealed file storage area 454 (step S8703).
- the file sharing program 411 identifies the address range of the erase data, generates a concealment file for storing the erase data in the concealment file storage area 454, and erases the generated concealment file. Store the data.
- the path name of the concealment file is determined so as not to overlap with other concealment files stored in the concealment file storage area 454.
- the file sharing program 411 updates the concealed file management table 415 based on the generated concealed file information (step S8704).
- the file sharing program 411 adds a new record to the concealed file management table 415.
- the file sharing program 411 stores the path name of the original file in the path 4151 of the added record, stores the name space identifier in which the original file is stored in the name space ID 4152, and stores the meta data of the original file in the original metadata 4153. Store the data.
- the file sharing program 411 stores the path name of the concealment file generated in the concealment file path 4154, and stores the address range of the erasure data in the address range 4155. Further, the file sharing program 411 stores “delete” in the deletion type 4156 when the file is deleted, and stores “partially delete” when the file is not deleted.
- the file sharing program 411 executes a process corresponding to the received access request on the file (step S8705).
- the file sharing program 411 determines whether or not it is necessary to send a deletion notification (step S8706).
- the deletion notification includes a notification notifying that an access request for generating erasure data has been received.
- the file sharing program 411 ends the processing (step S8708).
- the file sharing program 411 When it is determined that it is necessary to notify the metadata server 1 that deletion data has been generated, that is, it is necessary to notify the metadata server 1, the file sharing program 411 notifies the metadata server 1 that deletion data has been generated (step S). S8707).
- the notification includes information on all records stored in the hidden file management table 415, that is, information on all hidden files. Thereafter, the file sharing program 411 ends the process (step S8708).
- step 8706 and step S8707 was performed in the process of the process with respect to an access request, you may perform periodically as a process independent of the process with respect to an access request.
- FIG. 22 is a flowchart for explaining processing executed by the file deletion detection program 113 in the third embodiment of the present invention.
- step S8800 When the file deletion detection program 113 starts processing (step S8800), it detects the occurrence of erase data in the file server 4 (step S8801).
- the file deletion detection program 113 can detect that deletion data has occurred in the file server 4 by receiving a deletion notification notifying that deletion data has occurred from the file server 4.
- the deletion notification includes information stored in the concealed file management table 415.
- the file deletion detection program 113 executes processing for each erased data, that is, for each record of the concealed file management table 415.
- the file deletion detection program 113 determines whether or not deletion data to be processed has occurred due to file deletion based on the concealed file management table 415 included in the received deletion notification (step S8802). That is, it is determined whether the file containing the deletion data to be processed is a deletion file or a partial deletion file.
- the file deletion detection program 113 determines that the deletion data is generated by deleting the file.
- the file deletion detection program 113 determines that the erased data is generated by overwriting the file or reducing the file size.
- the file deletion detection program 113 When it is determined that the deletion data is generated by deleting the file, the file deletion detection program 113 identifies the record corresponding to the file to be processed in the metadata management table 153 and displays “deleted” in the file status 1535 of the record. Is stored (step S8803). Thereafter, the file deletion detection program 113 proceeds to step S8804.
- the file deletion detection program 113 adds a record corresponding to the processing target file to the metadata management table 153 (step S8808).
- the file deletion detection program 113 stores an identifier that does not overlap with other records in the metadata ID 1531 of the added record.
- the file deletion detection program 113 stores the path name and metadata of the file to be processed in the path 1532 and original metadata 1534 of the added record.
- the file deletion detection program 113 stores the identifier of the name space in which the processing target file is stored in the name space ID 1533. Further, the file deletion detection program 113 stores “partially erased” in the file state 1535.
- the information stored in the added record can be acquired based on the information included in the deletion notification received from the file server 4.
- the file deletion detection program 113 updates the file save management table 154 (step S8804). Specifically, the file deletion detection program 113 adds a record corresponding to the concealed file in which the deletion data to be processed is stored.
- the same metadata ID 1531 of the record specified in step S8804 or the metadata ID 1531 of the record added in step S8808 is stored.
- the save destination path 1542 stores the path name of the concealment file
- the save destination name space ID 1543 stores the name space identifier in which the concealment file is stored
- the address range 1544 stores the concealment file. Stores the address range of stored erase data. Information stored in the added record can be acquired based on information included in the deletion notification received from the file server 4.
- the file deletion detection program 113 moves the concealed file to the evacuation storage device 2 (step S8805). Specifically, the file deletion detection program 113 copies the concealment file onto the name space of the evacuation storage apparatus 2 and moves the deletion data to be processed to the evacuation file. At this time, the path name of the save file is determined so as not to overlap with other save files stored in the save storage device 2.
- the file deletion detection program 113 updates the file save management table 154 (step S8806). Specifically, the file deletion detection program 113 changes the save destination path 1542 of the record added in step S8804 to the path name of the save file.
- the file deletion detection program 113 instructs the file server 4 to delete the concealment file (step S8807). Thereafter, the file deletion detection program 113 ends the process (step S8809).
- FIG. 23 and 24 are explanatory diagrams illustrating an example of the metadata management table 153 according to the third embodiment of this invention.
- FIG. 25 is an explanatory diagram showing an example of the file save management table 154 according to the third embodiment of this invention.
- FIG. 23 shows the metadata management table 153 before data is overwritten on the file “/share1/a.doc”.
- Information of the file “/share1/a.doc” is recorded in the first record of the metadata management table 153. It can be seen from the information stored in the record that the file “/share1/a.doc” is stored in the file server 4 and the update time is “10:00”.
- FIG. 24 shows the metadata management table 153 after the file “/share1/a.doc” is overwritten with data, and the metadata server 1 moves the erased data to the evacuation storage device 2.
- a second record having a metadata ID 1531 of “101” is added.
- This record represents that the metadata server 1 manages the file “/share1/a.doc” at the time when the update time is “10:00” as a partially erased file. Therefore, “partially erased” is stored in the file state 1535 of the record.
- FIG. 25 shows the file evacuation management table 154 after data is overwritten on the file “/share1/a.doc” and the metadata server 1 moves the erased data to the evacuation storage device 2.
- the first record of the file save management table 154 in FIG. 25 stores the erase data of the partially erased file corresponding to the second record in the metadata management table 153 in FIG. 24 and information related to the save file.
- the second record is a record related to the erase data of the partially erased file corresponding to the second record of the metadata management table 153 of FIG.
- the erase data is stored in the name space “r” of the save storage device 2 as a file whose path name is “A / r / s1000 / share / a.doc_diff”. You can see that.
- the erased data is data stored in the range of addresses “0” to “29” of the original file.
- FIG. 26 is a flowchart for explaining processing executed by the file proxy read program 115 according to the third embodiment of the present invention.
- the file proxy read program 115 accepts a read request for a normal file, a deleted file, and a partially erased file, and returns the file contents to the request source. If the requested file is a deleted file or a partially erased file, the requested file is temporarily restored, and the contents of the restored file are responded.
- the file proxy read program 115 starts processing (step S8900), and receives a file read request from the analysis program 61 or the like (step S8901).
- the received file read request includes information for the request source program to specify the file. For example, it includes information such as a file path name, namespace name, metadata, and other identifiers (metadata ID, inode number in the file system).
- the file proxy read program 115 identifies the corresponding record in the metadata management table 153 based on the information included in the received file read request (step 8902).
- the file proxy reading program 115 refers to the file status 1535 of the identified record and determines whether or not the file to be read is a normal file (step S8903).
- the file status 1535 is “deleted” or “partially erased”, it is determined that the file to be read is a deleted file or a partially erased file. On the other hand, when the file status 1535 is “existing”, it is determined to be a normal file.
- the file proxy read program 115 executes a restoration process for restoring the file to be read ( Step S8904). As a result, the file is temporarily restored in the evacuation storage device 2. Details of the restoration process will be described later with reference to FIG.
- the file proxy read program 115 transmits the restored file to the request source, and ends the processing (steps S8905 and S8907).
- the file proxy read program 115 specifies the storage destination of the file to be read (step S8906). Specifically, the file storage destination is specified based on the identifier of the file server 4, the identifier of the namespace, the path name, and the like.
- the file proxy reading program 115 reads the file to be read from the specified storage destination file server 4, transmits the read file to the request source, and ends the processing (steps S 8905 and S 8907). .
- FIG. 27 is a flowchart for explaining the details of the restoration processing in the third embodiment of the present invention.
- step S9000 When the file proxy reading program 115 starts processing (step S9000), the record relating to the file to be read is extracted from the metadata management table 153 (step S9001). Here, a record that is the same file to be read and whose time series is newer than the record specified in step S8903 is extracted.
- the file proxy read program 115 matches the path 1532 and the namespace ID 1533 with the file to be read, and the update time included in the original metadata 1534 is after the update time of the file to be read. That is, a record with a new update time is extracted.
- the file proxy read program 115 determines whether or not the file to be read is currently a deleted file (step S9002). Specifically, the file proxy read program 115 identifies the record with the latest update time stored in the original metadata 1534 among the extracted records, and whether the file status 1535 of the record is “deleted”. Determine whether or not.
- the file proxy read program 115 duplicates the deleted file as a temporary file in the work area based on the deleted file record extracted in step S9001 (step S9001). S9003).
- the work area is a storage area of the evacuation storage device 2.
- the file proxy read program 115 is currently stored in the file server 4 based on the record extracted in step S9001.
- the read target file is read, and the read file is copied as a temporary file in the work area (step S9007).
- the file proxy read program 115 selects, from the extracted records, a record with the latest update time after the record specified in step S9003 as a record to be processed (step S9004).
- the file proxy read program 115 overwrites the temporary file with the deletion data stored in the save file (step S9005). Specifically, the following processing is executed.
- the file proxy read program 115 identifies the corresponding save file record from the file save management table 154 based on the record information selected in step S9004.
- the file proxy read program 115 acquires the deletion data by reading the save file from the save storage device 2 based on the specified record.
- the file proxy read program 115 refers to the address range 1544 of the specified record, and overwrites the read deletion data in the same address range on the temporary file. Further, the file proxy reading program 115 changes the file size of the temporary file to the file size stored in the original metadata 1534 of the selected record in the metadata management table 153.
- the temporary file has the same content as the file at the time when the record selected in step S9004 is added to the metadata management table 153.
- the file proxy read program 115 determines whether or not the processing has been completed for all the records extracted in step 9001 (step S9006).
- step 9001 If it is determined that the processing has not been completed for all the records extracted in step 9001, the file proxy read program 115 returns to step S9004 and executes the same processing (steps S9004 to S9006).
- step S9008 If it is determined that the processing has not been completed for all the records extracted in step 9001, the file proxy read program 115 ends the processing (step S9008).
- the metadata server 1 reads the file and transmits the read file to the analysis server 6.
- the present invention is not limited to this, and the analysis server 6 may acquire the file. In this case, the following processing is executed.
- step S 8905 the file proxy reading program 115 generates a list 116 and transmits the generated list 116 to the analysis server 6.
- the method for generating the list 116 uses the same method as in the first embodiment. Note that information on the storage location of the temporary file in the work area is stored in the save destination path 11681 of the record corresponding to the temporary file in the list 116.
- the analysis server 6 reads the file based on the received list 116. Note that the processing is the same as that of the first embodiment, and thus description thereof is omitted.
- each erased data is stored in one save file or concealed file, but the present invention is not limited to this.
- the erasure data may be stored together in several files, or may be stored in a database or block storage.
- the fourth embodiment extends the first embodiment, and when a file having the same content as the deleted file is stored in the backup storage device 3, a save file corresponding to the deleted file is not generated. As a result, duplicate files having the same contents can be reduced in the computer system 500.
- the configuration of the computer system 500, the configuration of the metadata server 1, and the configuration of the file server 4 of the fourth embodiment are the same as those of the first embodiment, description thereof is omitted.
- the configuration of each table managed by the metadata server 1 and the file server 4 is the same as that of the first embodiment, and thus the description thereof is omitted.
- FIG. 28 is an explanatory diagram showing an example of the configuration of the storage management table 151 according to the fourth embodiment of this invention.
- the storage ID 1511, the storage name 1512, the type 1513, and the IP address 1514 are the same as those in the first embodiment, and thus description thereof is omitted.
- the metadata server 1 is different from the first embodiment in that the backup storage device 3 is managed in addition to the file server 4 and the evacuation storage device 2. That is, information of the backup storage device 3 is stored in the fourth record of the storage management table 151 shown in FIG. Note that “backup” is stored in the record type 1513 corresponding to the backup storage device 3.
- FIG. 29 is an explanatory diagram showing an example of the configuration of the name space management table 152 in the fourth embodiment of the present invention.
- Name space ID 1521, name space name 1522, storage ID 1523, capacity 1524, protocol 1525, usage amount 1526, and usage 1527 are the same as those in the first embodiment, and thus description thereof is omitted.
- the fifth record of the name space management table 152 stores name space information in the backup storage device 3. Note that “backup” is stored in the usage 1527 of the record corresponding to the backup storage device 3.
- FIG. 30 is an explanatory diagram showing an example of the configuration of the metadata management table 153 according to the fourth embodiment of the present invention.
- the metadata management table 153 is stored in the memory 11 of the metadata server 1.
- the metadata management table 153 according to the fourth embodiment is different from the first embodiment in that a hash value 1536 is added.
- the hash value 1536 stores a hash value representing the contents of the file corresponding to the entry.
- the hash value is a value acquired by applying a predefined hash function to the contents of the file.
- various known algorithms for example, SHA256 can be used for the hash function.
- the hash value calculated from the file “/BU/x.doc” is “e001” in the hash value 1536 of the record.
- the hash value is a value expressed in hexadecimal.
- the metadata management program 112 in this embodiment makes an inquiry to the backup program 31 of the backup storage device 3 in order to store the backup file information in the metadata management table 153, and the backup file stored in the backup storage device 3 Get metadata for. Further, the metadata management program 112 may read out a database or the like that holds a list of backup files managed by the backup program 31.
- the hash value of the backup file may be calculated when the metadata management program 112 reads the backup file from the backup storage device 3, or may be calculated by the backup program 31 and transmitted to the metadata management program 112.
- FIG. 31 is a flowchart for explaining processing executed by the file deletion detection program 113 according to the fourth embodiment of the present invention.
- the file deletion detection program 113 in the fourth embodiment detects a deletion target file
- the file deletion detection program 113 determines whether or not a backup file having the same content as the file exists. If there is a backup file having the same content, the file deletion detection program 113 adds the backup file to the file save management table 154 as a save file corresponding to the file to be deleted. Further, the file deletion detection program 113 deletes the deletion target file without generating a concealment file in the file server 4.
- the file deletion detection program 113 when starting the process (step S9100), detects that the file is deleted from the file server 4 (step S9101).
- step S9101 is the same process as step S8201.
- the deletion notification transmitted from the file server 4 includes the hash value of the deletion target file.
- the hash value of the deletion target file can be calculated by applying a hash function to the deletion target file read from the file server 4 by the file deletion detection program 113.
- the file deletion detection program 113 updates the record corresponding to the deletion target file in the metadata management table 153 (step S9102).
- the process of step S9202 is the same process as step S8202.
- the file deletion detection program 113 refers to the metadata management table 153 and searches for a backup file having the same content as the deletion target file (step S9103). Specifically, the following processing is executed.
- the file deletion detection program 113 acquires the hash value 1536 of the deletion target file.
- the file deletion detection program 113 extracts an entry in which “BU” is stored in the file state 1535, and compares the hash value 1536 of the extracted entry with the hash value 1536 of the file to be deleted.
- An entry that matches the hash value 1536 of the deletion target file is a backup file having the same content as the deletion target file.
- the method for determining the contents of a file is not limited to the method described above.
- a method for comparing file metadata, a method for comparing file sizes, a method combining these, and the like may be used.
- the file deletion detection program 113 determines whether a backup file having the same content as the deletion target file exists as a result of the search process described above (step S9104).
- the file deletion detection program 113 executes file concealment processing for the deletion target file on the file server 4 (step S9106).
- the file deletion detection program 113 instructs the file server 4 that has notified the deletion of the file to execute the concealment process for the file to be deleted (step S9107), and ends the process (step S9108).
- step S9106 and step S9107 is the same process as step S8203 and step S8204, description is abbreviate
- step S9104 If it is determined in step S9104 that a backup file having the same content as the file to be deleted exists, the file deletion detection program 113 updates the file save management table 154 and ends the process (steps S9105 and S9108).
- the file deletion detection program 113 adds information related to the backup file to the file save management table 154 as save file information corresponding to the file to be deleted.
- the metadata ID 1541 stores the value of the metadata ID 1531 of the record corresponding to the backup file
- the save destination path 1542 stores the path name of the path 1532 of the record corresponding to the backup file
- the save destination namespace ID 1543 stores the identifier of the namespace ID 1533 of the record corresponding to the backup file.
- a file having the same content as the file to be deleted is searched from the files stored in the backup storage device 3, but in addition to this, a search is performed from all storage devices managed by the metadata server 1. May be.
- the file server 4 does not transmit a file deletion notification to the metadata server 1 when the business program 51 requests the file deletion. Therefore, the metadata server 1 determines whether or not a file is periodically deleted from the file server 4. For this determination, the snapshot function of the file server 4 is used.
- the file server 4 is different in that it has a snapshot function.
- the configuration of each table managed by the metadata server 1 and the file server 4 is the same as that of the first embodiment, and thus the description thereof is omitted.
- 32A and 32B are flowcharts for explaining processing executed by the metadata management program 112 in the fifth embodiment of the present invention.
- the metadata management program 112 collects metadata of files stored in the file server 4, detects files deleted from the file server 4, and moves them to the evacuation storage device 2.
- the metadata management program 112 instructs the file server 4 to create a snapshot of a namespace that is a collection target of metadata (step S9201). Receiving the instruction, the file server 4 creates a snapshot of the specified name space.
- the metadata management program 112 selects one file to be processed from the files included in the created snapshot (step S9202).
- the process of step 9202 is different from the process of step S8002 (see FIG. 9) in that a file included in the snapshot is selected.
- the metadata management program 112 acquires the metadata of the selected file from the file server 4 (step S9203).
- the metadata management program 112 updates the metadata management table 153 based on the acquired metadata (step S9204).
- the process of step S9204 is the same process as the process of step S8004 (see FIG. 9).
- the metadata management program 112 determines whether or not processing has been completed for all files included in the snapshot (step S9205).
- the metadata management program 112 returns to step S9202 and executes the same processing (step S9202 to step S9205).
- the metadata management program 112 selects records that have not been updated in the processing from step S9201 to step S9205 from among the records in the metadata management table 153. Extract (step S9206).
- the metadata management program 112 selects one record to be processed from the extracted records (step S9207).
- the metadata management program 112 determines whether or not a file corresponding to the record to be processed is included in the snapshot (step S9208).
- the metadata management program 112 proceeds to step S9212.
- the metadata management program 112 updates the processing target record (step S9209). Specifically, “delete” is stored in the file status 1535 of the record to be processed.
- the metadata management program 112 acquires a file corresponding to the record to be processed from the snapshot of the previous generation of the snapshot created in step S9201 (step S9210).
- the previous generation snapshot was created in the last execution of this process.
- the previous generation snapshot may be stored in the file server 4 or may be stored in the save storage device 2.
- the metadata management program 112 moves the file acquired from the previous generation snapshot to the evacuation storage apparatus 2 as the evacuation file of the deleted file corresponding to the record to be processed (step S9211).
- the metadata management program 112 updates the file saving management table 154 (step S9212).
- the process of step S9212 is the same process as the process of step S8208 (see FIG. 11C).
- the metadata management program 112 determines whether the processing has been completed for all the records extracted in step S9206 (step S9213).
- step S9206 If it is determined in step S9206 that processing has not been completed for all the records extracted, the metadata management program 112 returns to step S9207 and executes similar processing (steps S9207 to S9213).
- step S9206 If it is determined in step S9206 that the processing has been completed for all the records extracted, the metadata management program 112 instructs the file server 4 to delete the previous generation snapshot, and the processing ends ( Step S9214, Step S9215).
- the file server 4 that has received the instruction deletes the instructed snapshot.
- the file server 4 since the file server 4 does not need to notify the deletion of the file, even if the file server 4 does not have the function of notifying the deletion of the file, the deleted file is moved to the save storage device 2. can do.
- the concealment file is deleted according to the instruction from the metadata server 1. This is because even when a failure occurs in the file server 4, the metadata server 1, or the network 7, and the file saving process being executed is interrupted, the metadata server 1 stores the file to the saving storage device 2. This is to prevent the hidden file from being deleted by the file server 4 until the movement is completed.
- the file server 4 can detect the failure and can communicate with the metadata server 1. Delays file deletion notification until
- the operation when it is detected that the file server 4 cannot communicate with the metadata server 1, the operation may be continued by switching to the file deletion notification method of the second embodiment. .
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Human Computer Interaction (AREA)
- Data Mining & Analysis (AREA)
- Databases & Information Systems (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
Abstract
Description
Claims (20)
- 複数のファイルを管理するファイルサーバと、前記ファイルのメタデータを管理するメタデータサーバと、前記ファイルを用いて所定の業務処理を実行する業務サーバと、を備える計算機システムであって、
前記ファイルサーバ、前記メタデータサーバ、及び前記業務サーバは、ネットワークを介して互いに接続され、
前記ファイルサーバは、第1のプロセッサと、前記第1のプロセッサに接続される第1のメモリと、前記第1のプロセッサに接続される第1のネットワークインタフェースと、前記第1のプロセッサに接続され、前記ファイルを格納する第1の記憶媒体と、を有し、
前記メタデータサーバは、第2のプロセッサと、前記第2のプロセッサに接続される第2のメモリと、前記第2のプロセッサに接続される第2のネットワークインタフェースと、前記第2のプロセッサに接続される第2の記憶媒体と、を有し、
前記業務サーバは、第3のプロセッサと、前記第3のプロセッサに接続される第3のメモリと、前記第3のプロセッサに接続される第3のネットワークインタフェースと、を有し、
前記メタデータサーバには、コントローラと、複数の記憶媒体とを有し、前記ファイルサーバから削除された前記ファイルを格納する保存領域を提供するストレージ装置が接続され、
前記第2の記憶媒体には、前記ファイルのメタデータと、前記保存領域に格納される前記ファイルの格納位置と、を管理するメタデータリポジトリが格納され、
前記メタデータサーバは、
前記業務サーバが実行する業務処理によって前記ファイルサーバに格納される前記ファイルが削除されることを検出した場合に、前記ファイルを退避ファイルとして前記保存領域に格納し、
前記ファイルサーバにおける前記ファイルの格納位置を示す情報と、前記保存領域における前記退避ファイルの格納位置を示す情報とを対応づけて前記メタデータリポジトリに格納する、ことを特徴とする計算機システム。 - 請求項1に記載の計算機システムであって、
前記計算機システムは、さらに、前記ファイルに対して所定の分析処理を実行する分析サーバを備え、
前記分析サーバは、第4のプロセッサと、前記第4のプロセッサに接続される第4のメモリと、前記第4のプロセッサに接続される第4のネットワークインタフェースと、を有し、
前記メタデータサーバは、前記分析サーバから前記ファイルの問い合わせ要求を受信した場合に、前記ファイルの問い合わせ要求によって読み出される対象ファイルの格納位置を特定して、前記特定された対象ファイルの格納位置を前記分析サーバに通知し、
前記分析サーバは、前記メタデータサーバから受信した通知に基づいて、前記対象ファイルを前記ファイルサーバ又は前記保存領域から取得して、前記分析処理を実行することを特徴とする計算機システム。 - 請求項2に記載の計算機システムであって、
前記ファイルサーバは、前記ファイルサーバ、前記メタデータサーバ、前記業務サーバ、及び前記分析サーバに割り当てられる第1の記憶領域と、前記ファイルサーバ、前記メタデータサーバ、及び前記分析サーバに割り当てられる第2の記憶領域とを有し、
削除される前の前記ファイルは前記第1の記憶領域に格納され、
前記ファイルサーバは、前記業務サーバが実行する業務処理によって前記ファイルサーバから前記ファイルが削除されることを検出して、前記ファイルを前記第1の記憶領域から前記第2の記憶領域に移動し、
前記メタデータサーバは、
前記第2の記憶領域に格納される前記ファイルを取得して、前記取得されたファイルを前記退避ファイルとして前記保存領域に格納し、
前記ファイルサーバにおける前記ファイルの格納位置を示す情報として、前記第1の記憶領域における前記ファイルの格納位置を示す情報を前記メタデータリポジトリに格納し、
前記ファイルの削除指示を前記ファイルサーバに送信し、
前記ファイルサーバは、前記削除指示を受信した場合に、前記ファイルを前記第2の記憶領域から削除することを特徴とする計算機システム。 - 請求項3に記載の計算機システムであって、
前記メタデータサーバは、
前記ファイルの問い合わせ要求を受信した場合に、前記メタデータリポジトリに格納される情報に基づいて、前記ファイルサーバに格納される前記ファイル及び前記保存領域に格納される前記退避ファイルの格納位置の情報を含むリスト情報を生成し、
前記生成されたリスト情報を前記分析サーバに送信することを特徴とする計算機システム。 - 請求項3に記載の計算機システムであって、
前記ファイルサーバは、前記業務サーバが実行する業務処理によって前記ファイルサーバから前記ファイルが削除されることを検出した場合に、前記ファイルが削除される旨の通知を前記メタデータサーバに送信し、
前記メタデータサーバは、前記ファイルサーバからの通知を受信することによって、前記ファイルサーバから前記ファイルが削除されることを検出することを特徴とする計算機システム。 - 請求項5に記載の計算機システムであって、
前記ファイルサーバは、前記ファイルサーバから所定の数の前記ファイルが削除されることを検出した場合、又は、前回送信した前記ファイルが削除される旨の通知から所定時間経過した場合に、前記メタデータサーバに前記ファイルが削除された旨の通知を送信することを特徴とする計算機システム。 - 請求項3に記載の計算機システムであって、
前記ファイルは、複数のデータを含み、
前記ファイルサーバは、
前記業務サーバが実行する業務処理によって前記ファイルから削除されるデータである削除データが発生するか否かを判定し、
前記削除データが発生すると判定された場合、前記ファイルに含まれる前記削除データを前記第2の記憶領域に移動し、
前記メタデータサーバは、前記第2の記憶領域に格納される前記削除データを、前記退避ファイルとして前記保存領域に格納することを特徴とする計算機システム。 - 請求項7に記載の計算機システムであって、
前記メタデータサーバは、
前記分析サーバから前記ファイルの問い合わせ要求を受信した場合に、前記メタデータリポジトリを参照して、前記対象ファイルに対応する前記削除データが存在するか否かを判定し、
前記対象ファイルに対応する前記削除データが存在すると判定された場合、前記ファイルサーバに格納される前記対象ファイルを読み出し、
前記保存領域に格納される前記削除データに対応する前記退避ファイルを取得して、前記読み出された対象ファイルに、前記退避ファイルから取得された前記削除データを上書きすることによって、前記対象ファイルを復元し、
前記復元された対象ファイルを前記分析サーバに送信することを特徴とする計算機システム。 - 請求項3に記載の計算機システムであって、
前記計算機システムは、さらに、コントローラと、複数の記憶媒体とを有し、前記ファイルサーバに格納される前記ファイルのバックアップファイルを格納するバックアップストレージ装置を備え、
前記メタデータサーバは、
前記業務サーバが実行する業務処理によって前記ファイルサーバに格納される前記ファイルが削除されることを検出した場合に、前記バックアップストレージ装置に前記削除されるファイルと同一内容のバックアップファイルが格納されているか否かを判定し、
前記バックアップストレージ装置に前記削除されるファイルと同一内容のバックアップファイルが格納されていると判定された場合、当該バックアップファイルの格納位置を前記退避ファイルの格納位置として前記メタデータリポジトリに格納することを特徴とする計算機システム。 - 請求項2に記載の計算機システムであって、
前記ファイルサーバは、任意の時点の前記ファイルサーバの状態を記録したスナップショットを生成するスナップショット生成機能を有し、
前記メタデータサーバは、
前記ファイルサーバに、現在の前記ファイルサーバの状態を記録した第1のスナップショットの生成指示を送信し、
前記生成された第1のスナップショットを参照して、前記メタデータリポジトリに格納される前記メタデータを更新し、
前記メタデータのうち更新されなかった前記メタデータを抽出して、前記第1のスナップショットに、前記抽出されたメタデータに対応するファイルが存在するか否かを判定し、
前記第1のスナップショットに、前記抽出されたメタデータに対応するファイルが存在しないと判定された場合、前記第1のスナップショットより時系列が前の第2のスナップショットを取得して、当該第2のスナップショットから前記抽出されたメタデータに対応するファイルを取得し、
前記取得されたファイルを前記退避ファイルとして前記保存領域に格納することを特徴とする計算機システム。 - 複数のファイルを管理するファイルサーバと、前記ファイルのメタデータを管理するメタデータサーバと、前記ファイルを用いて所定の業務処理を実行する業務サーバと、前記ファイルに対して所定の分析処理を実行する分析サーバと、を備える計算機システムにおけるファイル管理方法であって、
前記ファイルサーバ、前記メタデータサーバ、前記業務サーバ、及び分析サーバは、ネットワークを介して互いに接続され、
前記ファイルサーバは、第1のプロセッサと、前記第1のプロセッサに接続される第1のメモリと、前記第1のプロセッサに接続される第1のネットワークインタフェースと、前記第1のプロセッサに接続され、前記ファイルを格納する第1の記憶媒体と、を有し、
前記メタデータサーバは、第2のプロセッサと、前記第2のプロセッサに接続される第2のメモリと、前記第2のプロセッサに接続される第2のネットワークインタフェースと、前記第2のプロセッサに接続される第2の記憶媒体と、を有し、
前記業務サーバは、第3のプロセッサと、前記第3のプロセッサに接続される第3のメモリと、前記第3のプロセッサに接続される第3のネットワークインタフェースと、を有し、
前記分析サーバは、第4のプロセッサと、前記第4のプロセッサに接続される第4のメモリと、前記第4のプロセッサに接続される第4のネットワークインタフェースと、を有し、
前記メタデータサーバには、コントローラと、複数の記憶媒体とを有し、前記ファイルサーバから削除された前記ファイルを格納する保存領域を提供するストレージ装置が接続され、
前記第2の記憶媒体には、前記ファイルのメタデータと、前記保存領域に格納される前記ファイルの格納位置と、を管理するメタデータリポジトリが格納され、
前記方法は、
前記メタデータサーバが、前記業務サーバが実行する業務処理によって前記ファイルサーバに格納される前記ファイルが削除されることを検出した場合に、前記ファイルを退避ファイルとして前記保存領域に格納する第1のステップと、
前記メタデータサーバが、前記ファイルサーバにおける前記ファイルの格納位置を示す情報と、前記保存領域における前記退避ファイルの格納位置を示す情報とを対応づけて前記メタデータリポジトリに格納する第2のステップと、
前記メタデータサーバが、前記分析サーバから前記ファイルの問い合わせ要求を受信した場合に、前記ファイルの問い合わせ要求によって読み出される対象ファイルの格納位置を特定し、前記特定された対象ファイルの格納位置を前記分析サーバに通知する第3のステップと、
前記分析サーバが、前記メタデータサーバから受信した通知に基づいて、前記対象ファイルを前記ファイルサーバ又は前記保存領域から取得して、前記分析処理を実行する第4のステップと、を含むことを特徴とするファイル管理方法。 - 請求項11に記載のファイル管理方法であって、
前記ファイルサーバは、前記ファイルサーバ、前記メタデータサーバ、前記業務サーバ、及び前記分析サーバに割り当てられる第1の記憶領域と、前記ファイルサーバ、前記メタデータサーバ、及び前記分析サーバに割り当てられる第2の記憶領域とを有し、
削除される前の前記ファイルは前記第1の記憶領域に格納され、
前記第1のステップは、
前記ファイルサーバが、前記業務サーバが実行する業務処理によって前記ファイルサーバから前記ファイルが削除されることを検出して、前記ファイルを前記第1の記憶領域から前記第2の記憶領域に移動するステップと、
前記メタデータサーバが、前記第2の記憶領域に格納される前記ファイルを取得して、前記取得されたファイルを前記退避ファイルとして前記保存領域に格納するステップと、を含み、
前記第2のステップは、
前記メタデータサーバが、前記ファイルサーバにおける前記ファイルの格納位置を示す情報として、前記第1の記憶領域における前記ファイルの格納位置を示す情報が前記メタデータリポジトリに格納するステップと、
前記メタデータサーバが、前記ファイルの削除指示を前記ファイルサーバに送信するステップと、
前記ファイルサーバが、前記削除指示を受信した場合に、前記ファイルを前記第2の記憶領域から削除するステップと、を含むことを特徴とするファイル管理方法。 - 請求項12に記載のファイル管理方法であって、
前記第3のステップは、
前記メタデータサーバが、
前記メタデータリポジトリに格納される情報に基づいて、前記ファイルサーバに格納される前記ファイル及び前記保存領域に格納される前記退避ファイルの格納位置の情報を含むリスト情報を生成するステップと、
前記生成されたリスト情報を前記分析サーバに送信するステップと、を含むことを特徴とするファイル管理方法。 - 請求項12に記載のファイル管理方法であって、
前記第1のステップでは、前記ファイルサーバから送信された前記ファイルが削除される旨の通知を受信することによって、前記ファイルサーバから前記ファイルが削除されることを検出することを特徴とするファイル管理方法。 - 請求項14に記載のファイル管理方法であって、
前記ファイルサーバは、前記ファイルサーバから所定の数の前記ファイルが削除されることを検出した場合、又は、前回送信した前記ファイルが削除される旨の通知から所定時間経過した場合に、前記メタデータサーバに前記ファイルが削除された旨の通知を送信することを特徴とするファイル管理方法。 - 請求項12に記載のファイル管理方法であって、
前記ファイルは、複数のデータを含み、
前記第1のステップは、
前記ファイルサーバが、
前記業務サーバが実行する業務処理によって前記ファイルから削除されるデータである削除データが発生するか否かを判定するステップと、
前記削除データが発生すると判定された場合、前記ファイルに含まれる前記削除データを前記第2の記憶領域に移動するステップと、
前記メタデータサーバが、前記第2の記憶領域に格納される前記削除データを、前記退避ファイルとして前記保存領域に格納するステップと、を含むことを特徴とするファイル管理方法。 - 請求項16に記載のファイル管理方法であって、
前記第3のステップは、
前記メタデータサーバが、
前記メタデータリポジトリを参照して、前記対象ファイルに対応する前記削除データが存在するか否かを判定するステップと、
前記対象ファイルに対応する前記削除データが存在すると判定された場合、前記ファイルサーバに格納される前記対象ファイルを読み出すステップと、
前記保存領域に格納される前記削除データに対応する前記退避ファイルを取得して、前記読み出された対象ファイルに、前記退避ファイルから取得された前記削除データを上書きすることによって、前記対象ファイルを復元するステップと、
前記復元された対象ファイルを前記分析サーバに送信するステップと、を含むことを特徴とするファイル管理方法。 - 請求項12に記載のファイル管理方法であって、
前記計算機システムは、さらに、コントローラと、複数の記憶媒体とを有し、前記ファイルサーバに格納される前記ファイルのバックアップファイルを格納するバックアップストレージ装置を備え、
前記第1のステップは、前記メタデータサーバが、前記業務サーバが実行する業務処理によって前記ファイルサーバに格納される前記ファイルが削除されることを検出した場合に、前記バックアップストレージ装置に前記削除されるファイルと同一内容のバックアップファイルが格納されているか否かを判定するステップを含み、
前記第2のステップは、前記メタデータサーバが、前記バックアップストレージ装置に前記削除されるファイルと同一内容のバックアップファイルが格納されていると判定された場合、当該バックアップファイルの格納位置を前記退避ファイルの格納位置として前記メタデータリポジトリに格納するステップを含むことを特徴とするファイル管理方法。 - 請求項11に記載のファイル管理方法であって、
前記ファイルサーバは、任意の時点の前記ファイルサーバの状態を記録したスナップショットを生成するスナップショット生成機能を有し、
前記第1のステップは、
前記メタデータサーバが、
現在の前記ファイルサーバの状態を記録した第1のスナップショットの生成指示を前記ファイルサーバに送信するステップと、
前記生成された第1のスナップショットを参照して、前記メタデータリポジトリに格納される前記メタデータを更新するステップと、
前記メタデータのうち更新されなかった前記メタデータを抽出して、前記第1のスナップショットに前記抽出されたメタデータに対応するファイルが存在するか否かを判定するステップと、を含み、
前記第2のステップは、
前記メタデータサーバが、
前記第1のスナップショットに前記抽出されたメタデータに対応するファイルが存在しないと判定された場合、前記第1のスナップショットより時系列が前の第2のスナップショットを取得して、当該第2のスナップショットから前記抽出されたメタデータに対応するファイルを取得するステップと、
前記取得されたファイルを前記退避ファイルとして前記保存領域に格納するステップと、を含むことを特徴とするファイル管理方法。 - プロセッサと、前記プロセッサに接続されるメモリと、前記プロセッサに接続されるネットワークインタフェースと、前記プロセッサに接続されるローカルストレージを備え、ネットワークを介して接続されるファイルサーバに格納される複数のファイルのメタデータを管理するメタデータサーバであって、
前記メタデータサーバは、前記ファイルに対して所定の分析処理を実行する分析サーバ、及び、前記ファイルサーバから削除された前記ファイルを格納する退避用ストレージ装置が接続され、
前記メモリには、前記メタデータを管理するメタデータ管理プログラム、前記ファイルサーバから前記ファイルが削除されることを検出するファイル削除検出プログラム、前記ファイルサーバから削除される前記ファイルを前記退避用ストレージに移動させるファイル退避プログラム、及び、前記分析サーバからの前記ファイルの問い合わせ要求を処理する問い合わせ処理プログラムが格納され、
前記ローカルストレージには、前記ファイルのメタデータを管理するメタデータ管理テーブルと、前記保存領域に格納される前記ファイルを管理するファイル退避管理テーブルとを含むメタデータリポジトリが格納され、
前記メタデータ管理プログラムを実行する前記プロセッサが、前記ファイルサーバに格納される前記ファイルのメタデータを取得して前記メタデータ管理テーブルを更新し、
前記ファイル削除検出プログラムを実行する前記プロセッサが、前記ファイルサーバに格納される前記ファイルが削除されることを検出し、
前記ファイル退避プログラムを実行するプロセッサが、前記ファイルを退避ファイルとして前記退避用ストレージ装置にコピーし、
前記ファイル退避プログラムを実行するプロセッサが、前記退避用ストレージ装置における前記退避ファイルの格納位置を示す情報を前記ファイル退避管理テーブルに格納し、
前記問い合わせ処理プログラムを実行するプロセッサが、前記ファイルの問い合わせ要求を受信した場合に、前記ファイルの問い合わせ要求によって読み出される対象ファイルの格納位置を特定して、前記特定された対象ファイルの格納位置を含むリストを生成し、
前記問い合わせ処理プログラムを実行するプロセッサが、前記生成されたリストを前記分析サーバに送信することを特徴とするメタデータサーバ。
Priority Applications (5)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2013534501A JP5697754B2 (ja) | 2011-09-21 | 2011-09-21 | 計算機システム、ファイル管理方法及びメタデータサーバ |
| EP11872681.9A EP2759942A4 (en) | 2011-09-21 | 2011-09-21 | COMPUTER SYSTEM, FILE MANAGEMENT METHOD AND METADATA SERVER |
| CN2011800698234A CN103460197A (zh) | 2011-09-21 | 2011-09-21 | 计算机系统、文件管理方法以及元数据服务器 |
| US14/003,972 US9396198B2 (en) | 2011-09-21 | 2011-09-21 | Computer system, file management method and metadata server |
| PCT/JP2011/071437 WO2013042218A1 (ja) | 2011-09-21 | 2011-09-21 | 計算機システム、ファイル管理方法及びメタデータサーバ |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| PCT/JP2011/071437 WO2013042218A1 (ja) | 2011-09-21 | 2011-09-21 | 計算機システム、ファイル管理方法及びメタデータサーバ |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2013042218A1 true WO2013042218A1 (ja) | 2013-03-28 |
Family
ID=47914030
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2011/071437 Ceased WO2013042218A1 (ja) | 2011-09-21 | 2011-09-21 | 計算機システム、ファイル管理方法及びメタデータサーバ |
Country Status (5)
| Country | Link |
|---|---|
| US (1) | US9396198B2 (ja) |
| EP (1) | EP2759942A4 (ja) |
| JP (1) | JP5697754B2 (ja) |
| CN (1) | CN103460197A (ja) |
| WO (1) | WO2013042218A1 (ja) |
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2020123314A (ja) * | 2019-01-30 | 2020-08-13 | ベイジン バイドゥ ネットコム サイエンス アンド テクノロジー カンパニー リミテッド | 情報をバックアップするための方法及び装置 |
| CN111708730A (zh) * | 2019-03-18 | 2020-09-25 | 北京沃东天骏信息技术有限公司 | 数据管理方法、终端设备、管理系统及存储介质 |
Families Citing this family (27)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CA2783223C (en) * | 2012-07-19 | 2014-07-15 | Microsoft Corporation | Global recently used files list |
| US9384208B2 (en) * | 2013-01-22 | 2016-07-05 | Go Daddy Operating Company, LLC | Configuring a cached website file removal using a pulled data list |
| JPWO2014122733A1 (ja) * | 2013-02-06 | 2017-01-26 | 株式会社日立製作所 | 計算機、データアクセス管理方法及び記録媒体 |
| US10191965B2 (en) | 2013-08-16 | 2019-01-29 | Vmware, Inc. | Automatically determining whether a revision is a major revision or a minor revision by selecting two or more criteria, determining if criteria should be weighted and calculating a score has exceeded a threshold |
| US9292507B2 (en) * | 2013-08-16 | 2016-03-22 | Vmware, Inc. | Automated document revision trimming in a collaborative multi-user document store |
| US10162843B1 (en) * | 2014-05-05 | 2018-12-25 | EMC IP Holding Company LLC | Distributed metadata management |
| US20170039376A1 (en) * | 2015-08-05 | 2017-02-09 | Dell Products L.P. | Systems and methods for providing secure data |
| US10250433B1 (en) * | 2016-03-25 | 2019-04-02 | WatchGuard, Inc. | Method and system for peer-to-peer operation of multiple recording devices |
| US10831381B2 (en) | 2016-03-29 | 2020-11-10 | International Business Machines Corporation | Hierarchies of credential and access control sharing between DSN memories |
| US10769116B2 (en) * | 2016-06-10 | 2020-09-08 | Apple Inc. | System and method for performing operations on a hierarchy of content |
| CN106446155A (zh) * | 2016-09-22 | 2017-02-22 | 北京百度网讯科技有限公司 | 用于在云存储系统中清理数据的方法和装置 |
| US11126740B2 (en) | 2016-11-04 | 2021-09-21 | Microsoft Technology Licensing, Llc | Storage isolation for containers |
| US11856331B1 (en) * | 2017-05-10 | 2023-12-26 | Waylens, Inc. | Extracting and transmitting video analysis metadata for a remote database |
| CN108595503A (zh) * | 2018-03-19 | 2018-09-28 | 网宿科技股份有限公司 | 文件处理方法及服务器 |
| US11106378B2 (en) | 2018-11-21 | 2021-08-31 | At&T Intellectual Property I, L.P. | Record information management based on self describing attributes |
| US11347881B2 (en) * | 2020-04-06 | 2022-05-31 | Datto, Inc. | Methods and systems for detecting ransomware attack in incremental backup |
| CN110569146B (zh) * | 2019-08-27 | 2023-12-01 | 深圳震有科技股份有限公司 | 一种数据备份及配置方法、设备、存储介质及系统 |
| US11334364B2 (en) | 2019-12-16 | 2022-05-17 | Microsoft Technology Licensing, Llc | Layered composite boot device and file system for operating system booting in file system virtualization environments |
| US12164948B2 (en) | 2020-06-04 | 2024-12-10 | Microsoft Technology Licensing, Llc | Partially privileged lightweight virtualization environments |
| CN112286448B (zh) * | 2020-10-16 | 2022-10-14 | 杭州宏杉科技股份有限公司 | 对象访问方法、装置、电子设备及机器可读存储介质 |
| US12248435B2 (en) | 2021-03-31 | 2025-03-11 | Nutanix, Inc. | File analytics systems and methods |
| US12197398B2 (en) | 2021-03-31 | 2025-01-14 | Nutanix, Inc. | Virtualized file servers and methods to persistently store file system event data |
| US12242455B2 (en) | 2021-03-31 | 2025-03-04 | Nutanix, Inc. | File analytics systems and methods including receiving and processing file system event data in order |
| US12367108B2 (en) | 2021-03-31 | 2025-07-22 | Nutanix, Inc. | File analytics systems and methods including retrieving metadata from file system snapshots |
| US12248434B2 (en) | 2021-03-31 | 2025-03-11 | Nutanix, Inc. | File analytics systems including examples providing metrics adjusted for application operation |
| US12182264B2 (en) | 2022-03-11 | 2024-12-31 | Nutanix, Inc. | Malicious activity detection, validation, and remediation in virtualized file servers |
| US12517874B2 (en) | 2022-09-30 | 2026-01-06 | Nutanix, Inc. | Data analytics systems for file systems including tiering |
Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2008017049A (ja) | 2006-07-04 | 2008-01-24 | Canon Inc | 画像形成装置、画像形成システムおよびファイル管理方法 |
| JP2010061268A (ja) * | 2008-09-02 | 2010-03-18 | Ntt Docomo Inc | データ退避装置、データ復元装置及び端末管理システム |
| JP2011090531A (ja) * | 2009-10-23 | 2011-05-06 | Hitachi-Lg Data Storage Inc | 情報記憶装置 |
Family Cites Families (23)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| AU2002249939A1 (en) * | 2001-01-11 | 2002-07-24 | Z-Force Communications, Inc. | File switch and switched file system |
| US7475098B2 (en) * | 2002-03-19 | 2009-01-06 | Network Appliance, Inc. | System and method for managing a plurality of snapshots |
| US20040153481A1 (en) * | 2003-01-21 | 2004-08-05 | Srikrishna Talluri | Method and system for effective utilization of data storage capacity |
| US7379954B2 (en) * | 2003-07-08 | 2008-05-27 | Pillar Data Systems, Inc. | Management of file system snapshots |
| US7886299B2 (en) * | 2004-06-01 | 2011-02-08 | Hitachi, Ltd. | Method of dynamically balancing workload of a storage system |
| US7013681B1 (en) * | 2004-11-19 | 2006-03-21 | Milliken & Company | Edgecomb resistant weft insertion warp knit fabric |
| US7885970B2 (en) * | 2005-01-20 | 2011-02-08 | F5 Networks, Inc. | Scalable system for partitioning and accessing metadata over multiple servers |
| CN1972200B (zh) * | 2005-02-21 | 2010-12-22 | 索尼计算机娱乐公司 | 网络系统、构成网络上节点的计算机及网络可视化方法 |
| JP4836533B2 (ja) * | 2005-09-27 | 2011-12-14 | 株式会社日立製作所 | ストレージシステムにおけるファイルシステムマイグレーション方法、ストレージシステム及び管理計算機 |
| US20070185926A1 (en) * | 2005-11-28 | 2007-08-09 | Anand Prahlad | Systems and methods for classifying and transferring information in a storage network |
| JP4795787B2 (ja) * | 2005-12-09 | 2011-10-19 | 株式会社日立製作所 | ストレージシステム、nasサーバ、及びスナップショット方法 |
| US7716240B2 (en) * | 2005-12-29 | 2010-05-11 | Nextlabs, Inc. | Techniques and system to deploy policies intelligently |
| US7774391B1 (en) * | 2006-03-30 | 2010-08-10 | Vmware, Inc. | Method of universal file access for a heterogeneous computing environment |
| US8055698B2 (en) * | 2007-01-30 | 2011-11-08 | Microsoft Corporation | Network recycle bin |
| US7827201B1 (en) * | 2007-04-27 | 2010-11-02 | Network Appliance, Inc. | Merging containers in a multi-container system |
| CN201061268Y (zh) * | 2007-06-14 | 2008-05-21 | 蔡忠广 | 魔术胸罩 |
| US8224831B2 (en) * | 2008-02-27 | 2012-07-17 | Dell Products L.P. | Virtualization of metadata for file optimization |
| US8019732B2 (en) * | 2008-08-08 | 2011-09-13 | Amazon Technologies, Inc. | Managing access of multiple executing programs to non-local block data storage |
| US20100082700A1 (en) * | 2008-09-22 | 2010-04-01 | Riverbed Technology, Inc. | Storage system for data virtualization and deduplication |
| JP2010092177A (ja) * | 2008-10-06 | 2010-04-22 | Hitachi Ltd | 情報処理装置、及びストレージシステムの運用方法 |
| US9274714B2 (en) * | 2008-10-27 | 2016-03-01 | Netapp, Inc. | Method and system for managing storage capacity in a storage network |
| JP5360978B2 (ja) | 2009-05-22 | 2013-12-04 | 株式会社日立製作所 | ファイルサーバ、及びファイルサーバにおけるファイル操作通知方法 |
| US9015212B2 (en) * | 2012-10-16 | 2015-04-21 | Rackspace Us, Inc. | System and method for exposing cloud stored data to a content delivery network |
-
2011
- 2011-09-21 WO PCT/JP2011/071437 patent/WO2013042218A1/ja not_active Ceased
- 2011-09-21 US US14/003,972 patent/US9396198B2/en not_active Expired - Fee Related
- 2011-09-21 EP EP11872681.9A patent/EP2759942A4/en not_active Withdrawn
- 2011-09-21 CN CN2011800698234A patent/CN103460197A/zh active Pending
- 2011-09-21 JP JP2013534501A patent/JP5697754B2/ja not_active Expired - Fee Related
Patent Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2008017049A (ja) | 2006-07-04 | 2008-01-24 | Canon Inc | 画像形成装置、画像形成システムおよびファイル管理方法 |
| JP2010061268A (ja) * | 2008-09-02 | 2010-03-18 | Ntt Docomo Inc | データ退避装置、データ復元装置及び端末管理システム |
| JP2011090531A (ja) * | 2009-10-23 | 2011-05-06 | Hitachi-Lg Data Storage Inc | 情報記憶装置 |
Non-Patent Citations (1)
| Title |
|---|
| See also references of EP2759942A4 |
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2020123314A (ja) * | 2019-01-30 | 2020-08-13 | ベイジン バイドゥ ネットコム サイエンス アンド テクノロジー カンパニー リミテッド | 情報をバックアップするための方法及び装置 |
| CN111708730A (zh) * | 2019-03-18 | 2020-09-25 | 北京沃东天骏信息技术有限公司 | 数据管理方法、终端设备、管理系统及存储介质 |
Also Published As
| Publication number | Publication date |
|---|---|
| EP2759942A1 (en) | 2014-07-30 |
| JPWO2013042218A1 (ja) | 2015-03-26 |
| JP5697754B2 (ja) | 2015-04-08 |
| US20140040331A1 (en) | 2014-02-06 |
| EP2759942A4 (en) | 2015-05-06 |
| CN103460197A (zh) | 2013-12-18 |
| US9396198B2 (en) | 2016-07-19 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP5697754B2 (ja) | 計算機システム、ファイル管理方法及びメタデータサーバ | |
| US12327036B2 (en) | Managing digital assets stored as components and packaged files | |
| JP5991699B2 (ja) | 情報処理装置、情報処理システム、バックアップ方法、およびプログラム | |
| US7974950B2 (en) | Applying a policy criteria to files in a backup image | |
| US20200278792A1 (en) | Systems and methods for performing storage operations using network attached storage | |
| US9128940B1 (en) | Method and apparatus for performing file-level restoration from a block-based backup file stored on a sequential storage device | |
| JP5895099B2 (ja) | 移行先ファイルサーバ及びファイルシステム移行方法 | |
| US9037541B2 (en) | Metadata for data storage array | |
| US11520665B2 (en) | Optimizing incremental backup for clients in a dedupe cluster to provide faster backup windows with high dedupe and minimal overhead | |
| US20050216788A1 (en) | Fast backup storage and fast recovery of data (FBSRD) | |
| US20120246271A1 (en) | Method and system for transferring duplicate files in hierarchical storag management system | |
| JP4267353B2 (ja) | データ移行支援システム、および、データ移行支援方法 | |
| JP5650982B2 (ja) | ファイルの重複を排除する装置及び方法 | |
| CN101201724B (zh) | 数据存储装置以及重布置数据的方法 | |
| US8015155B2 (en) | Non-disruptive backup copy in a database online reorganization environment | |
| JP2008033912A (ja) | Nas向けのcdpの方法および装置 | |
| JP2016524220A (ja) | 効率的なデータ複製及びガベージコレクション予測 | |
| JP4741371B2 (ja) | システム、サーバ装置及びスナップショットの形式変換方法 | |
| JP2007226347A (ja) | 計算機システム、計算機システムの管理装置、及びデータのリカバリー管理方法 | |
| JP2009230624A (ja) | ストレージシステム | |
| JP2015510174A (ja) | ロケーション非依存のファイル | |
| CN113795827B (zh) | 用于重复数据删除云分层的垃圾收集 | |
| JP2006527874A (ja) | 1つのターゲット・ボリュームと1つのソース・ボリュームとの間の関連性を管理するための方法、システム、及びプログラム | |
| US20070300034A1 (en) | Virtual storage control apparatus | |
| US20120060005A1 (en) | Techniques for copying on write |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 11872681 Country of ref document: EP Kind code of ref document: A1 |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 2011872681 Country of ref document: EP |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 14003972 Country of ref document: US |
|
| ENP | Entry into the national phase |
Ref document number: 2013534501 Country of ref document: JP Kind code of ref document: A |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |