WO2013179579A1 - 隠れ変数モデル推定装置および方法 - Google Patents
隠れ変数モデル推定装置および方法 Download PDFInfo
- Publication number
- WO2013179579A1 WO2013179579A1 PCT/JP2013/002900 JP2013002900W WO2013179579A1 WO 2013179579 A1 WO2013179579 A1 WO 2013179579A1 JP 2013002900 W JP2013002900 W JP 2013002900W WO 2013179579 A1 WO2013179579 A1 WO 2013179579A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- hidden
- model
- hidden variable
- reference value
- probability
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Ceased
Links
Images




Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N5/00—Computing arrangements using knowledge-based models
- G06N5/02—Knowledge representation; Symbolic representation
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F17/00—Digital computing or data processing equipment or methods, specially adapted for specific functions
- G06F17/10—Complex mathematical operations
- G06F17/18—Complex mathematical operations for evaluating statistical data, e.g. average values, frequency distributions, probability functions, regression analysis
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N7/00—Computing arrangements based on specific mathematical models
- G06N7/01—Probabilistic graphical models, e.g. probabilistic networks
Definitions
- the present invention relates to a hidden variable model estimation apparatus, a hidden variable model estimation method, and a hidden variable model estimation program for multivariate data having series dependency, and in particular, by approximating a model posterior probability and maximizing its lower bound.
- the present invention relates to a hidden variable model estimation apparatus, a hidden variable model estimation method, and a hidden variable model estimation program for estimating a hidden variable model of multivariate data having series dependency.
- data having sequence dependency examples include, for example, data having time dependency, sentences depending on character sequences, gene data depending on base sequences, and the like.
- Sensor data acquired from automobiles, health checkup test value history, power demand history, and other data are all multivariate data having “series dependency (temporal dependency in this example)”.
- Such data analysis is applied to many industrially important fields. For example, by analyzing sensor data acquired from an automobile, it is conceivable to realize a quick repair by analyzing the cause of the failure of the automobile. In addition, it is conceivable to estimate the risk of the disease and prevent the disease by analyzing the test value history of the medical examination. Moreover, it is conceivable to prepare for excess or deficiency by predicting the demand for power by analyzing the power demand history.
- Such data is generally modeled using a series-dependent hidden variable model (for example, a hidden Markov model).
- a hidden Markov model For example, in order to use a hidden Markov model, it is necessary to determine the number of hidden states, the type of observation probability distribution, and distribution parameters. When the number of hidden states and the type of observation probability distribution are known, it is possible to estimate parameters using an Expectation Maximization method (see Non-Patent Document 1, for example).
- Non-Patent Document 2 proposes a method for maximizing the variational free energy by the variational Bayes method as a method for determining the number of hidden states.
- Non-Patent Document 3 proposes a non-parametric Bayes method using hierarchical Dirichlet process prior distribution as a method for determining the number of hidden states.
- Non-Patent Document 4 describes that a perfect marginal likelihood function is approximated with respect to a mixed model, which is a typical example of a hidden variable model having no time dependence, and its lower bound is maximized.
- Non-Patent Document 2 when the lower bound of the marginal likelihood function is maximized, the hidden state on the variational distribution and the independence of the distribution parameters are assumed. There is a problem of getting worse.
- Non-Patent Document 3 an optimization algorithm based on the Monte Carlo method is known, but there is a problem that the amount of calculation becomes very large.
- the observation probability distribution is a mixed polynomial curve.
- the hidden state is omitted because it does not affect the following discussion.
- the observation for a certain hidden state is a polynomial curve
- it is necessary to correctly select the order of the curve such as a linear curve (straight line), a quadratic curve, and a cubic curve.
- the number of hidden states is 3 and there are two straight lines and quadratic curves
- the number of hidden states is 5 and when there are three cubic curves and two quartic curves, all models are candidates.
- the number of candidates for this model is about 100,000 when the number of hidden states is 10 and the maximum degree of the curve is 10.
- the number of candidates is several billion. .
- the number of model candidates increases exponentially with the complexity of the model to be searched. Therefore, calculation by the methods described in Non-Patent Document 2 and Non-Patent Document 3 has been practically difficult.
- the present invention realizes model selection at high speed even when the number of model candidates increases exponentially with the number of hidden states and types of observation probabilities in the learning problem of hidden variable models with series dependence on multivariate data.
- the purpose is to be able to.
- the hidden variable model estimation apparatus is a variation that calculates a variation probability by maximizing a reference value defined as an approximate lower bound of a Laplace approximation of a marginal log likelihood function with respect to an estimator for a complete variable.
- Probability calculator, model estimation unit that estimates the optimal hidden variable model by estimating the type and parameters of observation probability for each hidden state, and variation probability calculator when calculating variation probability And a convergence determination unit that determines whether or not the reference value has converged.
- the hidden variable model estimation method calculates the variation probability by maximizing a reference value defined as a lower bound of an approximate amount obtained by Laplace approximation of a marginal log likelihood function with respect to an estimator for a complete variable. Estimating the optimal hidden variable model by estimating the type and parameters of the observation probability for each hidden state, and determining whether or not the reference value used in calculating the variation probability has converged Features.
- the hidden variable model estimation program is a computer program that maximizes a variational probability by maximizing a reference value defined as a lower bound of an approximate value obtained by Laplace approximation of a marginal log-likelihood function with respect to an estimate for a complete variable.
- Variational probability calculation processing that computes the model, the model estimation processing that estimates the optimal hidden variable model by estimating the type and parameters of the observation probability for each hidden state, and the variational probability calculation processing A convergence determination process for determining whether or not the reference value used in the calculation has converged is executed.
- model selection can be performed at high speed.
- Equation (1) is the most representative model of the hidden variable model having series dependency, as an example.
- the set of x and z is called a “perfect variable”.
- x is called an incomplete variable.
- the simultaneous distribution of hidden Markov models for perfect variables is defined as P (x, z) in equation (1).
- the variational distribution for the hidden variable of the hidden Markov model is the distribution q (z n tk) of the kth hidden state z n tk at time t, and j from the kth state from time t-1 to time t. It is expressed as a distribution q (z n t-1k, z n tj) that makes a transition to the second state.
- K represents the number of hidden states.
- ⁇ ( ⁇ 1, ..., ⁇ K, ⁇ 1, ..., ⁇ K, ⁇ 1, ..., ⁇ K) represents model parameters.
- ⁇ k represents the initial probability of the kth hidden state
- ⁇ k represents the transition probability from the kth hidden state
- ⁇ k represents the observation parameter for the kth hidden state.
- S1, ..., SK represent the types of observation probabilities corresponding to ⁇ k.
- the candidates that can be changed from S1 to SK are, for example, ⁇ normal distribution, lognormal distribution, exponential distribution ⁇ in the case of multivariate data generation probability, or ⁇ 0th order curve, 1
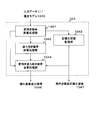
- FIG. FIG. 1 is a block diagram showing a first embodiment of the hidden variable model estimation apparatus of the present invention.
- the hidden variable model estimation device 100 includes a data input device 101, a hidden state number setting unit 102, an initialization processing unit 103, a hidden variable variation probability calculation processing unit 104, a model optimization processing unit 105, and optimality.
- the determination processing unit 106, the optimum model selection processing unit 107, and the model estimation result output device 108 are provided.
- the hidden variable model estimation apparatus 100 receives input data 111, optimizes the number of hidden states and the type of observation probability for the input data 111, and outputs the result as a model estimation result 112.
- FIG. 2 is a block diagram illustrating an example of the hidden variable variation probability calculation processing unit 104.
- the hidden variable variation probability calculation processing unit 104 includes a forward probability calculation processing unit 1041, a normalized constant storage unit 1042, a backward probability calculation processing unit 1043, and a forward backward probability summation processing unit 1044.
- the hidden variable variation probability calculation processing unit 104 is input with the input data 111 and the estimated model 1045 estimated by the model optimization processing unit 105, and the hidden variable variation probability 1046, forward probability normalization constant 1047, and so on. Is output.
- the hidden state number setting unit 102 selects and sets the number of hidden states of the model from the input candidate values for the number of hidden states.
- the set number of hidden states is denoted as K.
- the initialization processing unit 103 performs initialization processing for estimation.
- initialization can be performed by any method.
- the observation probability type is set randomly for each hidden state, and the parameters for each observation probability are set randomly according to the set type, or the variation probability of the hidden variable is set randomly. Can be mentioned.
- Equation (2) the equal sign is established by maximizing the variation probability q (zN).
- the Laplace approximation of the marginal likelihood of the numerator perfect variable using the maximum likelihood estimator for the perfect variable yields the following expression (3) as an approximation formula of the marginalized log likelihood function.
- the superscript bar represents the maximum likelihood estimator for the complete variable.
- D * represents the dimension of the subscript parameter *.
- Equation (4) The underlined part in equation (4) is B.
- B is referred to in equation (8) below.
- the forward probability calculation processing unit 1041 receives input data 111 and an estimated model. Then, the forward probability calculation processing unit 1041 calculates the probability of z n t when the observation (x n 1,..., X n t) from time 1 to time t is obtained as the forward probability. However, the forward probability is calculated in consideration of the model complexity calculated by the optimization criterion A (for example, a term related to ⁇ tk in the equation (4)). Further, the forward probability calculation processing unit 1041 causes the normalization constant storage unit 1042 to store a normalization constant for setting the sum of the hidden states of the probability of z n t to 1.
- backward probability calculation processing unit 1043 observed from time t + 1 to T (x n t + 1, ..., x n T) the probability of x n t when is obtained as a backward probability calculate.
- the normalization constant obtained simultaneously with the forward probability calculation is read from the normalization constant storage unit 1042.
- the backward probability is calculated in consideration of the model complexity calculated by the optimization criterion A (for example, the term related to ⁇ tk in the equation (4)).
- the forward / backward probability summation processing unit 1044 calculates a variation distribution from the forward probability and the backward probability. For example, the forward / backward probability summation processing unit 1044 calculates q (z n tk) as the probability of z n tk when x n 1,..., X n T is obtained. The forward / backward probability summation processing unit 1044 calculates q (z n tk) as the product of the forward probability and the backward probability by the following equation (5).
- the forward / backward probability summation processing unit 1044 calculates q (z n t-1j, z n tk) by the following equation (6) (the definition of q ⁇ on the left side of equation (6) is (See equation (7)).
- the forward probability and backward probability are calculated by the following equation (7).
- f t nk (the first expression of Equation (7)) represents the forward probability
- b t nk (the second expression of Equation (7)) represents the backward probability. More specifically, in formula (7), both the forward probability and the backward probability are described as recurrence formulas.
- the normalization constant is calculated by ⁇ t n.
- the backward probability calculation processing unit 1043 may calculate the backward probability using the normalization constant calculated when the forward probability calculation processing unit 1041 calculates the forward probability.
- the model optimization processing unit 105 optimizes the model (parameter ⁇ and its type S) with respect to Equation (4). Specifically, a model that maximizes G in Equation (4) by fixing q and q ⁇ to the variation distribution (q (i) ) of the hidden variable calculated by the hidden variable variation probability calculation processing unit 104. Is calculated.
- the important point in this process is that the G defined by equation (4) can decompose the optimization function for each component, so the combination of component types (which type from S1 to SK is specified) ) without considering the is that which can be optimized separately phi K from SK and parameters phi 1 from S1. As a result, when optimizing the component type, it is possible to avoid the combination explosion and perform the optimization.
- the optimality determination processing unit 106 determines the convergence of the optimization criterion A calculated by Expression (4). If it is not determined that the optimization criterion A has converged, the process of the optimality determination processing unit 106 is repeated from the hidden variable variation probability calculation processing unit 104. Note that the calculation of the optimization criterion A calculated by equation (4) requires exponential time complexity for the calculation of ⁇ zn q (zn) log q (zn) because the hidden state is not independent. It is possible to efficiently calculate using the normalized constant stored in the normalized constant storage unit 1042. For example, in the case of a hidden Markov model, it is calculated as in the following equation (8).
- Expression (8) is an underlined part in Expression (4).
- the hidden variable variation probability calculation processing unit 104 calculates the hidden state number K set by the hidden state number setting unit 102 by the loop processing of the optimality determination processing unit 106.
- the model corresponding to the larger optimization criterion A among the optimization criterion A and the optimization criterion A calculated in the previous loop processing is set as the optimum model.
- the process proceeds to the model estimation result output device 108, and when there is a candidate that has not been optimized yet, the process proceeds to the hidden state number setting unit 102. Move.
- the model estimation result output device 108 outputs an optimal number of hidden states, types of observation probabilities, parameters, variation distribution, and the like as a model estimation result output result 112.
- Hidden state number setting unit 102, initialization processing unit 103, hidden variable variation probability calculation processing unit 104 (forward probability calculation processing unit 1041, normalized constant storage unit 1042, backward probability calculation processing unit 1043, forward backward probability summation processing unit 1044), the model optimization processing unit 105, the optimality determination processing unit 106, the optimal model selection processing unit 107, and the model estimation result output device 108 are realized by a CPU of a computer that operates according to a hidden variable model estimation program, for example.
- the CPU may read the hidden variable model estimation program from a computer-readable recording medium in which the hidden variable model estimation program is recorded, and operate as each element described above.
- the device 108 may be realized by separate hardware.
- the forward probability calculation processing unit 1041, the normalization constant storage unit 1042, the backward probability calculation processing unit 1043, and the forward backward probability summation processing unit 1044 are realized by separate hardware. It may be.
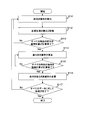
- FIG. 3 is a flowchart showing an example of processing progress of the first embodiment of the present invention.
- Input data 111 is input via the data input device 101 (step S100).
- the hidden state number setting unit 102 selects and sets the number of hidden states that have not yet been optimized among the input candidate values for the number of hidden states (step S101).
- the initialization processing unit 103 performs initialization of parameters and hidden variable variation probabilities for estimation with respect to the set number of hidden states (step S102).
- the hidden variable variation probability calculation processing unit 104 calculates the variation probability of the hidden variable (step S103).
- the model optimization processing unit 105 estimates the type of observation probability and parameters for each hidden state (step S104). It can be said that this process is optimization of each hidden state model.
- step S105 If it is determined in step S105 that the optimization criterion A has not converged, the processes in steps S103 to S105 are repeated.
- the optimal model selection processing unit 107 determines the model (number of hidden states, types of observation probabilities, and the like optimized in the loop processing of the latest steps S103 to S105. Parameter) and the optimization standard A of the model optimized in the loop processing of the previous step S103 to S105 are compared, and the model corresponding to the optimization standard A having the larger value is compared. Is set as an optimal model (step S106).
- the hidden state number setting unit 102 determines whether or not candidates for the estimated number of hidden states remain (step S107). If candidates for the number of hidden states remain, the processes in steps S102 to S107 are repeated. On the other hand, if no candidate for the number of hidden states remains, the model estimation result output device 108 outputs the model estimation result (step S108), and the processing is completed.
- the forward probability calculation processing unit 1041 calculates the forward probability f t (i) nk for the t-th time of the n-th data (step S111). At this time, the forward probability calculation processing unit 1041 also calculates a normalization constant and stores it in the normalization constant storage unit 1042 (step S112).
- the forward probability calculation processing unit 1041 confirms whether the calculation of the forward probability has been completed for all times t (step S113), and if not completed, repeats the processing of steps S111 and S112. If completed, the process proceeds to step S114.
- the forward / backward probability summation processing unit 1044 performs forward processing and backward probability summation processing on all times of the nth data, and calculates variation distribution (step S116).
- the forward / backward probability summation processing unit 1044 confirms whether the variation distribution calculation processing has been completed for all data regarding n (step S117). If not completed, the processing from step S111 onward is repeated, and if completed, the processing ends.
- Model selection can be realized at high speed.
- FIG. FIG. 5 is a block diagram showing a second embodiment of the hidden variable model estimation apparatus of the present invention.
- the hidden variable model estimation apparatus 200 of the second embodiment does not include the optimum model selection processing unit 107 and selects the number of hidden states.
- a processing unit 201 is provided.
- the hidden state number setting unit 102 the initialization processing unit 103, the hidden variable variation probability calculation processing unit 104, the model optimization processing unit 105, the optimality determination processing unit 106, and the model estimation result output device 108 This is the same as in the first embodiment.
- the hidden variable model estimation apparatus 100 of the first embodiment performs model optimization on the number of hidden state candidates and selects a model that maximizes the optimization criterion A.
- the hidden state number selection processing unit 201 models the reduced hidden state as a model. Remove from.
- the hidden state number selection processing unit 201 selects a hidden state that satisfies the state of the following expression (9) for q (z n tk) calculated by the hidden variable variation probability calculation processing unit 104. Remove.
- ⁇ shown on the right side of Equation (9) is a threshold value that is input simultaneously with the input data 111. That is, the hidden state number selection processing unit 201 removes hidden states that are equal to or less than the threshold ⁇ .
- the hidden state number setting unit 102, the initialization processing unit 103, the hidden variable variation probability calculation processing unit 104, the hidden state number selection processing unit 201, the model optimization processing unit 105, and the optimality determination processing unit 106 and the model estimation result output device 108 are realized by a CPU of a computer that operates according to a hidden variable model estimation program, for example.
- the CPU may read the hidden variable model estimation program from a computer-readable recording medium in which the hidden variable model estimation program is recorded, and operate as each element described above.
- each of these elements in the second embodiment may be realized by separate hardware.
- a time series is obtained for multidimensional time series data acquired from a plurality of sensors installed in a car, for example, as in “travel mode”. Can be broken down into several different properties. When considering failure diagnosis and detection of abnormal behavior from sensor data, the sensor behavior varies greatly depending on the travel mode. Therefore, it is necessary to break down into modes and analyze, and it is very important to automate this.
- the models to be estimated are the number of hidden states, the regression order (Sk) for each hidden state, the regression parameter ( ⁇ k), the initial probability ( ⁇ k), the transition probability ( ⁇ k), and the variational distribution (q).
- the initialization processing unit 103 randomly sets the regression order and other parameters for the K hidden states as initialization processing.
- the model is estimated by the optimality determination processing unit 106 from the hidden variable variation probability calculation processing unit 104.
- Different driving conditions are different, such as a first order polynomial from X to Y corresponding to, and a second order polynomial from X to Y corresponding to a state where the engine speed increases rapidly and the speed gradually increases (rapid acceleration) It is automatically separated as a regression model with orders and coefficients.
- the optimum model selection processing unit 107 automatically selects the best number of hidden states, so that, for example, the number of different driving characteristics (modes) depending on the driver is automatically detected and separated into an appropriate number of driving modes. It is possible to do.
- the input data is a multi-dimensional logical vector time series in which logical values indicating whether or not the patient has high blood pressure (1 if applied, 0 if not applied) are arranged for a plurality of diseases.
- the model to be estimated is a hidden Markov model of multidimensional Bernoulli observation.
- FIG. 6 is a block diagram showing an outline of the hidden variable model estimation apparatus of the present invention.
- the hidden variable model estimation apparatus of the present invention includes a variation probability calculation unit 71, a model estimation unit 72, and a convergence determination unit 73.
- the variation probability calculation unit 71 (for example, the hidden variable variation probability calculation processing unit 104) is a reference value (for example, a lower limit of an approximate amount obtained by Laplace approximation of a marginal log likelihood function with respect to an estimation amount for a complete variable (for example, The variation probability is calculated by maximizing the optimization criterion A).
- the model estimation unit 72 estimates an optimal hidden variable model by estimating the type and parameter of the observation probability for each hidden state.
- variation probability calculation unit 71 calculates variation probability
- the model estimation unit 72 estimates an optimal hidden variable model
- the convergence determination unit 73 performs a loop process for determining whether or not the reference value has converged. It may be configured to include a hidden state removal unit (for example, hidden state number selection processing unit 201) that repeatedly removes a hidden state that satisfies a predetermined condition in accordance with the calculation result of the variation probability calculation unit.
- a hidden state removal unit for example, hidden state number selection processing unit 201
- model estimation unit 72 may be configured to estimate a hidden Markov model as a hidden variable model.
Landscapes
- Engineering & Computer Science (AREA)
- Physics & Mathematics (AREA)
- General Physics & Mathematics (AREA)
- Theoretical Computer Science (AREA)
- Data Mining & Analysis (AREA)
- Mathematical Physics (AREA)
- Mathematical Analysis (AREA)
- Computational Mathematics (AREA)
- Mathematical Optimization (AREA)
- Pure & Applied Mathematics (AREA)
- Software Systems (AREA)
- General Engineering & Computer Science (AREA)
- Algebra (AREA)
- Probability & Statistics with Applications (AREA)
- Computing Systems (AREA)
- Evolutionary Computation (AREA)
- Artificial Intelligence (AREA)
- Life Sciences & Earth Sciences (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Bioinformatics & Computational Biology (AREA)
- Evolutionary Biology (AREA)
- Operations Research (AREA)
- Databases & Information Systems (AREA)
- Computational Linguistics (AREA)
- Complex Calculations (AREA)
- Management, Administration, Business Operations System, And Electronic Commerce (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
Description
本発明は、系列依存性を持つ多変量データの隠れ変数モデル推定装置、隠れ変数モデル推定方法、および隠れ変数モデル推定プログラムに関し、特に、モデル事後確率を近似し、その下界を最大化する事によって系列依存性を持つ多変量データの隠れ変数モデルを推定する隠れ変数モデル推定装置、隠れ変数モデル推定方法、および隠れ変数モデル推定プログラムに関する。
系列依存性を持つデータが種々存在する。系列依存性を持つデータの例として、例えば、時間依存性を有するデータや、文字系列に依存する文章、塩基系列に依存する遺伝子データ等が挙げられる。
自動車から取得されるセンサデータ、健康診断の検査値履歴、電力需要履歴などに代表されるデータは、すべて「系列依存性(本例では時間的な依存性)」を持つ多変量データである。このようなデータの分析は、産業上重要な数多くの分野に適用される。例えば、自動車から取得されるセンサデータの分析によって、自動車の故障原因を解析して素早い修理を実現することが考えられる。また、健康診断の検査値履歴の分析によって、疾患のリスクの推定および疾患の予防を実現することが考えられる。また、電力需要履歴の分析によって、電力の需要を予測して過不足に備えられるようにすることが考えられる。
このようなデータに対しては、系列依存性を持つ隠れ変数モデル(例えば、隠れマルコフモデル)を用いてモデル化する事が一般的である。例えば、隠れマルコフモデルを利用するためには、隠れ状態数、観測確率分布の種類、及び分布パラメータを決定する必要がある。隠れ状態数と観測確率分布の種類がわかっている場合には、Expectation Maximization法(例えば非特許文献1参照)を利用してパラメータを推定する事が可能である。
隠れ状態数や観測確率の種類を決定する問題は、一般的に「モデル選択問題」や「システム同定問題」と呼ばれ、信頼性のあるモデルを構築するために極めて重要な問題である。そのための技術が種々提案されている。
例えば、非特許文献2では、隠れ状態数を決定する方法として、変分ベイズ法によって変分自由エネルギーを最大化する方法が提案されている。また、例えば、非特許文献3では、隠れ状態数を決定する方法として、階層Dirichlet過程事前分布を用いたノンパラメトリックベイズ法が提案されている。
また、非特許文献4では、時間依存性のない隠れ変数モデルの代表例である混合モデルに対して、完全周辺尤度関数を近似し、その下界を最大化することが述べられている。
C. Bishop, Pattern Recognition and Machine Learning, Springer, 2007, pp.610-629
Beal, M. J. Variational Algorithms for Approximate Bayesian Inference. Chapter3, PhD thesis, University College London, 2003
van Gael, J., Saatci, Y, Teh, Y.-W., and Ghahramani, Z. Beam sampling for the infinite hidden Markov model. In ICML, 2008.
Ryohei Fujimaki, Satoshi Morinaga: Factorized Asymptotic Bayesian Inference for Mixture Modeling. Proceedings of the the fifteenth international conference on Artificial Intelligence and Statistics (AISTATS), 2012
非特許文献2に記載の方法では、周辺化尤度関数の下界を最大化する際に、変分分布上における隠れ状態と分布パラメータの独立性を仮定するため、周辺化尤度の近似精度が悪くなるという問題がある。
非特許文献3に記載の方法では、モンテカルロ法に基づく最適化アルゴリズムが知られているが、計算量が非常に多くなるという問題がある。
非特許文献2に記載の方法と非特許文献3に記載の方法で観測確率の種類を決定することは、計算量が極めて多くなるという問題のため、事実上困難である。
この計算量の問題を、観測確率分布が混合多項式曲線となる場合を例に説明する。なお、隠れ状態については、以下の議論には影響しないため省略する。ある隠れ状態に対する観測が多項式曲線となる場合には、1次曲線(直線)、2次曲線、3次曲線など曲線の次数を正しく選ぶ必要がある。上記の方法では、例えば、隠れ状態数が3で直線と2次曲線が2つの場合、隠れ状態数が5で3次曲線が3つと4次曲線が2つの場合等の全てのモデルの候補に対して情報量基準を計算する必要があった。このモデルの候補の数は、例えば隠れ状態数が10で、曲線の最大次数を10とすると約十万通りとなり、隠れ状態数が20で曲線の最大次数を20とすると数百億通りとなる。このようにモデルの候補の数は、探索すべきモデルの複雑さと共に指数的に増加する。従って、非特許文献2および非特許文献3に記載の方法による計算は、事実上困難であった。
また、非特許文献4に記載の技術では、隠れ変数間の独立性が必要となり、系列依存性のある隠れ変数モデルに適用できなかった。非特許文献4に記載の技術では、隠れ変数間の系列依存性を考慮していないため、隠れ変数の変分分布が、非特許文献4の式(15)として算出される。しかし、隠れ変数間に系列依存性がある場合には、この式は適切でなく、適切なモデルが得られる保証はない。さらに、隠れ変数間の遷移確率が算出できないという問題がある。
そこで、本発明は、多変量データに対する系列依存性を持つ隠れ変数モデルの学習問題において、隠れ状態数および観測確率の種類と共にモデルの候補数が指数的に増加しても高速にモデル選択を実現できるようにすることを目的とする。
本発明による隠れ変数モデル推定装置は、周辺化対数尤度関数を完全変数に対する推定量に関してラプラス近似した近似量の下界として定義される基準値を最大化することによって変分確率を計算する変分確率計算部と、各隠れ状態に対して観測確率の種類とパラメータを推定することで最適な隠れ変数モデルを推定するモデル推定部と、変分確率計算部が変分確率を計算する際に用いた基準値が収束したか否かを判定する収束判定部とを備えることを特徴とする。
また、本発明による隠れ変数モデル推定方法は、周辺化対数尤度関数を完全変数に対する推定量に関してラプラス近似した近似量の下界として定義される基準値を最大化することによって変分確率を計算し、各隠れ状態に対して観測確率の種類とパラメータを推定することで最適な隠れ変数モデルを推定し、変分確率を計算する際に用いた基準値が収束したか否かを判定することを特徴とする。
また、本発明による隠れ変数モデル推定プログラムは、コンピュータに、周辺化対数尤度関数を完全変数に対する推定量に関してラプラス近似した近似量の下界として定義される基準値を最大化することによって変分確率を計算する変分確率計算処理、各隠れ状態に対して観測確率の種類とパラメータを推定することで最適な隠れ変数モデルを推定するモデル推定処理、および、変分確率計算処理で変分確率を計算する際に用いた基準値が収束したか否かを判定する収束判定処理を実行させる。
本発明によれば、隠れ状態数および観測確率の種類と共にモデルの候補数が指数的に増加しても高速にモデル選択を行える。
以下、本発明の実施形態を図面を参照して説明する。なお、以下の説明では便宜的に、数式内の表記と、文章中の表記とが異なる場合がある。例えば、記号“~”を数式内では、変数の上部に記載するが、文章中では便宜的に右側に記載する等の違いがある。このような数式内の表記と文章中の表記との相違は、当業者が理解し得る範囲内の相違である。
本発明の隠れ変数モデル推定装置は、系列依存性を持つ隠れ変数モデルを推定する。以下の説明では、系列依存性を持つデータの例として時間依存性を持つデータを例にして説明するが、本発明におけるデータは系列依存性を持つデータであればよく、時間依存性を持つデータに限定されない。例えば、文字系列に依存するデータ、塩基系列に依存するデータ、あるいはその他の系列に依存するデータであってもよい。
また、以下の説明では、系列依存性を持つ隠れ変数モデルの最も代表的なモデルである隠れマルコフモデル(式(1)参照)を例にして具体的な説明を行う。

なお、以下の説明では時間依存するデータ列xn(n=1,...,N)が入力されると仮定する。ここで、各xnは、長さTnの多変量データ列(xn=xn1, ..., xnT,t=1,...,N)であるとする。次に、観測変数xntに対する隠れ変数znt=(znt1, ..., zntK)を定義する。zntk=1は、xntがk番目の隠れ状態から生成されたデータである事を意味し、zntk=0は、そうでない事を意味する。また、Σk=1
K zntk = 1である。xとzの組は「完全変数」と呼ばれる。なお、その対比としてxを不完全変数と呼ぶ。完全変数に関する隠れマルコフモデルの同時分布は、式(1)中のP(x、z)として定義される。なお、隠れマルコフモデルの隠れ変数に対する変分分布は、時刻tにおけるk番目の隠れ状態zntkの分布q(zntk)、及び、時刻t-1から時刻tにおいてk番目の状態からj番目の状態へ遷移する分布q(znt-1k, zntj)と表される。
式(1)において、Kは隠れ状態数を表す。また、θ=(α1, ...,αK, β1, ..., βK,φ1, ..., φK)は、モデルのパラメータを表す。ここで、αkはk番目の隠れ状態の初期確率を表し、βkはk番目の隠れ状態からの遷移確率を表し、φkはk番目の隠れ状態に対する観測パラメータを表す。また、S1, ..., SKは、φkに対応する観測確率の種類を表す。なお、S1からSKとなりうる候補は、例えば、多変量データの生成確率の場合には{正規分布、対数正規分布、指数分布}であったり、多項曲線出力の場合では、{0次曲線、1次曲線、2次曲線、3次曲線}であったりする。
なお、本明細書では具体的な例はすべて隠れマルコフを用いて説明をするが、その拡張モデル(例えば隠れセミマルコフモデル、因子化隠れマルコフモデルなど)の類似のモデルにも本発明を適用可能である。同様に、本明細書では、ターゲット変数をXとした分布について説明しているが、回帰や判別のように、観測分布が条件付モデルP(Y|X)(Yはターゲットとなる確率変数)である場合に関しても本発明を適用可能である。
実施形態1.
図1は、本発明の隠れ変数モデル推定装置の第1の実施形態を示すブロック図である。隠れ変数モデル推定装置100は、データ入力装置101と、隠れ状態数設定部102と、初期化処理部103と、隠れ変数変分確率計算処理部104と、モデル最適化処理部105と、最適性判定処理部106と、最適モデル選択処理部107と、モデル推定結果出力装置108とを備える。隠れ変数モデル推定装置100には、入力データ111が入力され、入力データ111に対して隠れ状態数および観測確率の種類を最適化し、モデル推定結果112として出力する。
図1は、本発明の隠れ変数モデル推定装置の第1の実施形態を示すブロック図である。隠れ変数モデル推定装置100は、データ入力装置101と、隠れ状態数設定部102と、初期化処理部103と、隠れ変数変分確率計算処理部104と、モデル最適化処理部105と、最適性判定処理部106と、最適モデル選択処理部107と、モデル推定結果出力装置108とを備える。隠れ変数モデル推定装置100には、入力データ111が入力され、入力データ111に対して隠れ状態数および観測確率の種類を最適化し、モデル推定結果112として出力する。
また、図2は、隠れ変数変分確率計算処理部104の例を示すブロック図である。隠れ変数変分確率計算処理部104は、前向き確率計算処理部1041と、正規化定数記憶部1042と、後ろ向き確率計算処理部1043と、前向き後ろ向き確率合算処理部1044を備える。隠れ変数変分確率計算処理部104には、入力データ111と、モデル最適化処理部105で推定された推定モデル1045とが入力され、隠れ変数変分確率1046と、前向き確率正規化定数1047とを出力する。
入力装置101は、入力データ111を入力するための入力インタフェース装置である。入力装置101には、入力データ111が入力される際に、観測確率の種類や、隠れ状態数の候補値など、モデルの推定に必要なパラメータも同時に入力される。
隠れ状態数設定部102は、入力された隠れ状態数の候補値からモデルの隠れ状態数を選択して設定する。以下、設定された隠れ状態数をKと表記する。
初期化処理部103は、推定のための初期化処理を実施する。なお、初期化は任意の方法によって実施することが可能である。例としては、観測確率の種類を隠れ状態ごとにランダムに設定し、設定された種類に従って、各観測確率のパラメータをランダムに設定する方法や、隠れ変数の変分確率をランダムに設定する方法が挙げられる。
隠れ変数変分確率計算処理部104は、隠れ変数の変分確率を計算する。ここで、パラメータθは初期化処理部103あるいはモデル最適化処理部106で計算されているため、隠れ変数変分確率計算処理部104は、その値を利用する。隠れ変数変分確率計算処理部104は、次に定義する最適化基準Aを最大化することによって変分確率を計算する。最適化基準Aとは、周辺化対数尤度関数を完全変数に対する推定量(例えば最尤推定量や最大事後確率推定量)に関してラプラス近似した近似量の下界として定義される。なお、この下界は、完全変数に対する推定量の最適性と対数関数の凹性を用いることで導出することが可能である。
この手順を、隠れマルコフモデルを例に説明する。まず、周辺化対数尤度関数の下界を考える。この下界は、以下の式(2)で示される

なお、式(2)において、変分確率q(zN)を最大化する事で等号が成立する。ここで、完全変数に対する最尤推定量を用いて分子の完全変数の周辺化尤度をラプラス近似する事で、周辺化対数尤度関数の近似式として、以下に示す式(3)を得る。

ただし、上付きのバーは完全変数に対する最尤推定量を表す。また、D*は下付きのパラメータ*の次元を表す。
次に、式(3)に対して最尤推定量が対数尤度関数を最大化する性質と、対数関数が凹関数である事を利用して、式(3)の下界を以下の式(4)のように算出する。

隠れ変数の変分分布q(zntk)及びq(znt-1k, zntj)は、式(4)をqについて最大化する事によって算出される。ただし、上付き(i)を、隠れ変数変分確率計算処理部104、モデル最適化処理部105、最適判定処理部106の繰り返し計算における、(i)回目の繰り返しを表すとすると、q(i)はq~= q(i-1)、θ=θ(i-1)と固定する。
なお、式(4)において下線を付した部分をBとする。Bは、後述の式(8)で参照する。
図2を参照して、隠れ変数変分確率計算処理部104が備える要素について説明する。前向き確率計算処理部1041には、入力データ111と推定モデルが入力される。そして、前向き確率計算処理部1041は、時刻1から時刻tまでの観測(xn1, ..., xnt)が得られた場合のzntの確率を前向き確率として算出する。ただし、前向き確率は、最適化基準Aで算出されるモデル複雑度(例えば式(4)ではδtkに関する項)を考慮して算出される。また、前向き確率計算処理部1041は、zntの確率の隠れ状態に関する和を1とするための正規化定数を、正規化定数記憶部1042に記憶させる。
同様に、後ろ向き確率計算処理部1043は、時刻t+1からTまでの観測(xnt+1, ..., xnT)が得られた場合のxntの確率を後ろ向き確率として算出する。なお、後ろ向き確率の計算の際に、前向き確率算出と同時に得られる正規化定数を正規化定数記憶部1042から読み込む。ただし、後ろ向き確率は最適化基準Aで算出されるモデル複雑度(例えば式(4)ではδtkに関する項)を考慮して算出される。
最後に、前向き後ろ向き確率合算処理部1044は、前向き確率と後ろ向き確率から、変分分布を算出する。例えば、前向き後ろ向き確率合算処理部1044は、q(zntk)をxn1, ..., xnTが得られたときのzntkの確率として計算する。前向き後ろ向き確率合算処理部1044は、前向き確率と後ろ向き確率の積として、以下の式(5)の計算によって、q(zntk)を計算する。

また、前向き後ろ向き確率合算処理部1044は、xn1, ..., xnt-1が得られたときのznt-1jの確率と、隠れ状態jから隠れ状態kへ遷移する確率と、隠れ状態kにおいてxntが観測される確率と、(xnt+1, ..., xnT)が得られた場合のxntの確率の積として、q(znt-1j, zntk)を算出する。具体的には、前向き後ろ向き確率合算処理部1044は、以下の式(6)の計算によってq(znt-1j, zntk)を算出する(式(6)左辺のq~の定義は式(7)を参照)。

この手順を隠れマルコフモデルを例に説明すると、前向き確率及び後ろ向き確率は、以下の式(7)の計算によって算出される。

ただし、ftnk(式(7)の第1式)が前向き確率を表し、btnk(式(7)の第2式)が後ろ向き確率を表す。より具体的には、式(7)において、前向き確率と後ろ向き確率の両者とも、漸化式として記述されている。そして、前向き確率はt=1から順に算出することが可能であり、後ろ向き確率はt=Tから順に算出することが可能である。なお、正規化定数はζtnで算出される。後ろ向き確率計算処理部1043は、前向き確率計算処理部1041が前向き確率を算出する際に計算した正規化定数を利用して後ろ向き確率を算出すればよい。
また、式(5)の第3式において、δに関する乗算が含まれているが、これは、最適化基準Aで算出されるモデル複雑度を考慮していることを意味する。
モデル最適化処理部105は、式(4)に対してモデル(パラメータθ及びその種類S) を最適化する。具体的には、q及びq~を隠れ変数変分確率計算処理部104で算出された隠れ変数の変分分布(q(i))に固定し、式(4)におけるGを最大化するモデルを算出する。この処理において重要な点は、式(4)によって定義されたGは、コンポーネントごとに最適化の関数を分解する事が可能なため、コンポーネント種類の組合せ(S1からSKのどの種類を指定するか)を考慮することなく、S1からSK及びパラメータφ1からφKを別々に最適化する事が可能な点である。これによって、コンポーネントの種類を最適化する際に、組み合わせ爆発を回避して最適化を実行する事が可能となる。
最適性判定処理部106は、式(4)で計算される最適化基準Aの収束を判定する。最適化基準Aが収束したと判定していない場合には、隠れ変数変分確率計算処理部104から最適性判定処理部106の処理を繰り返す。なお、式(4)で計算される最適化基準Aの算出は、隠れ状態が独立ではないためΣzn q(zn) log q(zn)の計算に指数時間の計算量を必要とするが、正規化定数記憶部1042に記憶されている正規化定数を利用して効率的に計算をする事が可能である。例えば隠れマルコフモデルの場合には、以下の式(8)のように計算される。

式(8)に示すBは、式(4)において下線を付した部分である。
隠れ変数変分確率計算処理部104から最適性判定処理部106の処理を繰り返し、変分分布とモデルを更新する事で、適切なモデルを選択する事が可能となる。なお、この繰り返しによって最適化基準Aが単調に増加する事が保証される。
最適化基準Aが収束している場合、隠れ状態数設定部102で設定された隠れ状態数Kに対して、隠れ変数変分確率計算処理部104から最適性判定処理部106のループ処理で算出される最適化基準Aと、その1つ前のループ処理で算出された最適化基準Aのうち、大きい方の最適化基準Aに対応するモデルを最適なモデルとして設定する。全ての候補値についてモデルの最適化が完了した場合には、処理がモデル推定結果出力装置108へ移り、まだ最適化の済んでいない候補が存在する場合には、隠れ状態数設定部102へ処理が移る。
モデル推定結果出力装置108は、最適な隠れ状態数、観測確率の種類、パラメータ、変分分布などをモデル推定結果出力結果112として出力する。
隠れ状態数設定部102、初期化処理部103、隠れ変数変分確率計算処理部104(前向き確率計算処理部1041、正規化定数記憶部1042、後ろ向き確率計算処理部1043、前向き後ろ向き確率合算処理部1044)、モデル最適化処理部105、最適性判定処理部106、最適モデル選択処理部107およびモデル推定結果出力装置108は、例えば、隠れ変数モデル推定プログラムに従って動作するコンピュータのCPUによって実現される。CPUが、隠れ変数モデル推定プログラムを記録したコンピュータ読み取り可能な記録媒体から隠れ変数モデル推定プログラムを読み込み、上記の各要素として動作すればよい。
また、隠れ状態数設定部102、初期化処理部103、隠れ変数変分確率計算処理部104、モデル最適化処理部105、最適性判定処理部106、最適モデル選択処理部107およびモデル推定結果出力装置108が別々のハードウェアで実現されていてもよい。また、隠れ変数変分確率計算処理部104においても、前向き確率計算処理部1041、正規化定数記憶部1042、後ろ向き確率計算処理部1043、前向き後ろ向き確率合算処理部1044が別々のハードウェアで実現されていてもよい。
図3は、本発明の第1の実施形態の処理経過の例を示すフローチャートである。データ入力装置101を介して入力データ111が入力される(ステップS100)。
次に、隠れ状態数設定部102は、入力された隠れ状態数の候補値のうち、まだ最適化の行なわれていない隠れ状態数を選択し設定する(ステップS101)。
次に、初期化処理部103は、設定された隠れ状態数に対して、推定のため、パラメータや隠れ変数変分確率の初期化処理を実施する(ステップS102)。
次に、隠れ変数変分確率計算処理部104は、隠れ変数の変分確率を計算する(ステップS103)。
次に、モデル最適化処理部105は、各隠れ状態に対して観測確率の種類とパラメータの推定を実施する(ステップS104)。この処理は、各隠れ状態のモデルの最適化であると言うことができる。
次に、最適性判定処理部106は、最適化基準A が収束したかを判定する。(例えば、S105)。最適性判定処理部106は、直近のステップS103~S105のループ処理において得られた最適化基準Aと、その1つ前のステップS103~S105のループ処理で得られた最適化基準Aの差を計算し、その差の絶対値が予め定められた閾値以下になっていれば、最適化基準A が収束したと判定してよい。また、その差の絶対値が閾値より大きければ、最適性判定処理部106は、最適化基準A が収束していないと判定してよい。なお、絶対値による最適化基準Aの差の算出は一例であり、例えば相対的な差によって収束を判定する等の方法を採用してもよい。
ステップS105において、最適化基準A が収束していないと判定された場合には、ステップS103~S105の処理を繰り返す。
ステップS105において、最適化基準A が収束したと判定された場合、最適モデル選択処理部107は、直近のステップS103~S105のループ処理において最適化されたモデル(隠れ状態数、観測確率の種類、パラメータ)の最適化基準Aと、その1つ前のステップS103~S105のループ処理で最適化されたモデルの最適化基準Aとを比較し、値の大きい方の最適化基準Aに対応するモデルを、最適なモデルとして設定する(ステップS106)。
次に、隠れ状態数設定部102は、推定されていない隠れ状態数の候補が残っているか否かを判定する(ステップS107)。隠れ状態数の候補が残っている場合には、ステップS102~S107の処理を繰り返す。一方、隠れ状態数の候補が残っていない場合には、モデル推定結果出力装置108がモデル推定結果を出力し(ステップS108)、処理を完了する。
図4は、本実施形態における隠れ変数変分確率計算処理部104の動作(換言すれば、ステップS103の処理経過)を示すフローチャートである。
前向き確率計算処理部1041は、n番目のデータのt番目の時刻に対する前向き確率ft(i)nkを算出する(ステップS111)。このとき、前向き確率計算処理部1041は、正規化定数も算出し、正規化定数記憶部1042に記憶させる(ステップS112)。
続いて、前向き確率計算処理部1041は、すべての時刻tに対して前向き確率の算出が完了したかを確認し(ステップS113)、未完了の場合にはステップS111,S112の処理を繰り返す。完了した場合には、ステップS114の処理に移る。
後ろ向き確率計算処理部1043は、n番目のデータのt番目の時刻に対する後ろ向き確率bt(i)nkを算出する(ステップS114)。そして、後ろ向き確率計算処理部1043は、すべての時刻tに対して後ろ向き確率の算出が完了したかを確認し(ステップS115)、未完了の場合にはステップS114の処理を繰り返す。完了した場合には、ステップS116の処理に移る。
前向き後ろ向き確率合算処理部1044は、n番目のデータのすべての時刻に対して前向き確率、後ろ向き確率の合算処理を行い、変分分布の計算を行う(ステップS116)。
続いて、前向き後ろ向き確率合算処理部1044は、nに関してすべてのデータに対して変分分布の算出処理が完了しているかを確認する(ステップS117)。未完了の場合には、ステップS111以降の処理を繰り返し、完了した場合には、処理を終了する。
隠れ状態数および観測確率の種類と共にモデルの候補数が指数的に増加する場合であっても、上記のような本発明の動作(特に、隠れ変数変分確率計算処理部104の動作)によって、高速にモデル選択を実現することができる。
また、非特許文献4に記載の技術と本発明を比較すると、既に説明したように、非特許文献4に記載の技術では、隠れ変数間の独立性が必要となり、系列依存性のある隠れ変数モデルに適用できなかった。これに対し本発明は、系列依存性を持つ多変量データの隠れ変数モデルを推定することができる。
実施形態2.
図5は、本発明の隠れ変数モデル推定装置の第2の実施形態を示すブロック図である。第2の実施形態の隠れ変数モデル推定装置200は、第1の実施形態の隠れ変数モデル推定装置100(図1参照)と比較して、最適モデル選択処理部107を備えず、隠れ状態数選択処理部201を備える。
図5は、本発明の隠れ変数モデル推定装置の第2の実施形態を示すブロック図である。第2の実施形態の隠れ変数モデル推定装置200は、第1の実施形態の隠れ変数モデル推定装置100(図1参照)と比較して、最適モデル選択処理部107を備えず、隠れ状態数選択処理部201を備える。
データ入力装置101、隠れ状態数設定部102、初期化処理部103、隠れ変数変分確率計算処理部104、モデル最適化処理部105、最適性判定処理部106およびモデル推定結果出力装置108に関しては、第1の実施形態と同様である。
また、第1の実施形態の隠れ変数モデル推定装置100は、隠れ状態数の候補に対してモデル最適化を行い、最適化基準Aを最大化するモデルを選択する。これに対して、第2の実施形態の隠れ変数モデル推定装置200では、隠れ変数変分確率計算処理部104の処理の後で、隠れ状態数選択処理部201が、小さくなった隠れ状態をモデルから除去する。
具体的には、隠れ状態数選択処理部201は、隠れ変数変分確率計算処理部104で算出されたq(zntk)に対して、以下の式(9)の状態を満たす隠れ状態を除去する。

式(9)の右辺に示すεは、入力データ111と同時に入力される閾値である。すなわち、隠れ状態数選択処理部201は、閾値ε以下である隠れ状態を除去する。
式(9)による隠れ状態の除去は、以下の理由によって正しく動く事が説明される。まず、式(7)の前向き確率を観察すると、小さい隠れ状態(すなわち小さいδtkに対応する隠れ状態)に対する前向き確率は小さくなる。また、後ろ向き確率では、小さい隠れ状態は前の状態に対する寄与が小さい。従って、前向き確率と後ろ向き確率から算出される変分分布は、小さい隠れ状態に対する確率が繰り返し最適化を通して徐々に小さくなっていく(前の更新ステップにおいて小さい隠れ状態ほど、次の更新ステップでも小さくなりやすくなるため)。このような構成とする事で、隠れ変数モデル推定装置100のように複数の隠れ状態数の候補に対して最適化をする必要がなく、隠れ状態数、観測確率の種類とパラメータ、変分分布を同時に推定し、計算コストを抑える事が可能という利点がある。
第2の実施形態において、隠れ状態数設定部102、初期化処理部103、隠れ変数変分確率計算処理部104、隠れ状態数選択処理部201、モデル最適化処理部105、最適性判定処理部106およびモデル推定結果出力装置108は、例えば、隠れ変数モデル推定プログラムに従って動作するコンピュータのCPUによって実現される。CPUが、隠れ変数モデル推定プログラムを記録したコンピュータ読み取り可能な記録媒体から隠れ変数モデル推定プログラムを読み込み、上記の各要素として動作すればよい。また、第2の実施形態におけるこれらの各要素が別々のハードウェアで実現されていてもよい。
以下、本発明の第1の実施形態の応用例を、自動車のセンサデータに対する走行モード分析を例にして説明する。以下の例では理解を容易にするため1次元の例を説明するが、多次元でも同様に適用可能である。
第1の実施形態の隠れ変数モデル推定装置を利用することで、自動車に設置された複数のセンサから取得される多次元時系列データに対して、例えば「走行モード」のように、時系列を、複数の異なる性質へ分解することができる。センサデータからの故障診断や異常挙動の検出を考えた場合に、走行モードによってセンサの振る舞いは大きく異なる。そのため、モードへ分解し分析する事が必要であり、これを自動化する事は非常に重要である。
例えば、エンジン回転数をXとし、速度をYとした、多項回帰出力の隠れマルコフモデルを考える。このとき、推定すべきモデルは、隠れ状態数、各隠れ状態に対する回帰次数(Sk)、回帰パラメータ(φk)、初期確率(αk)、遷移確率(βk)、変分分布(q)である。
まず、エンジン回転数と速度の時系列データとともに、隠れ状態数の候補値としてK=1から10までを隠れ変数モデル推定装置100に入力する。隠れ状態数設定部102は、K=1から10まで順に隠れ状態数を設定する。次に、初期化処理部103は、初期化処理として、K個の隠れ状態に対して、回帰次数及びその他のパラメータをランダムに設定する。次に、隠れ変数変分確率計算処理部104から最適性判定処理部106によってモデルの推定を行う。この処理を通じて、例えば、エンジン回転数が一定で速度が増加している状態(等加速)に対応するXからYへの0次多項式、エンジン回転数も速度も減少している状態(減速中)に対応するXからYへの1次多項式、エンジン回転数が急激に増加し速度が徐々に増加する状態(急加速)に対応するXからYへの2次多項式など、異なる走行状態が、異なる次数と係数を持つ回帰モデルとして自動的に分離される。さらに、最適モデル選択処理部107が、最もよい隠れ状態数を自動選択するため、例えばドライバーに応じて異なる運転特性(モード)の数を、自動的に検出し、適切な数の走行モードに分離する事が可能である。
以下、本発明の第2の実施形態の応用例を、診療ログ(レセプトデータ)からの疾病パタン分析を例にして説明する。例えば、心筋梗塞などは高血圧や糖尿病といった生活習慣病を事前に併発している事が多く、また生活習慣病は一度治ったとしても、再発する事が多い。そのような疾病のパタンを分析する事で、疾病のリスク低減への方策検討や、生活習慣指導へ活用する事が可能である。
本例では、高血圧にかかっているかどうかの論理値(かかっていれば1、かかっていなければ0)を複数の疾病について並べた、多次元の論理値ベクトル時系列を入力データとする。推定するモデルは、多次元のベルヌーイ観測の隠れマルコフモデルとする。
まず、入力データとともに、隠れ状態数としてKmax、選択のしきい値εを入力する。隠れ状態の候補値はKmaxに設定され、ベルヌーイ分布のパラメータがランダムに初期化される。次に、隠れ変数変分確率計算処理部104から最適性判定処理部106によってモデルの推定を行う。この処理を通じて、高血圧と糖尿病が合併しているパタン、高脂血症が治ったり再発したりを繰り返すパタン(薬による治療中)、生活習慣病がほとんど発生しないパタンなどに分離するとともに、典型的ではないパタンに対応する隠れ状態は小さくなり、隠れ状態数選択処理部201によって除去され、最終的な推定結果として典型的なパタンのみを抽出する事が可能である。
図6は、本発明の隠れ変数モデル推定装置の概要を示すブロック図である。本発明の隠れ変数モデル推定装置は、変分確率計算部71と、モデル推定部72と、収束判定部73とを備える。
変分確率計算部71(例えば、隠れ変数変分確率計算処理部104)は、周辺化対数尤度関数を完全変数に対する推定量に関してラプラス近似した近似量の下界として定義される基準値(例えば、最適化基準A)を最大化することによって変分確率を計算する。
モデル推定部72(例えば、モデル最適化処理部105)は、各隠れ状態に対して観測確率の種類とパラメータを推定することで最適な隠れ変数モデルを推定する。
収束判定部73(例えば、最適化判定処理部106)は、変分確率計算部71が変分確率を計算する際に用いた基準値が収束したか否かを判定する。
また、変分確率計算部71が変分確率を計算し、モデル推定部72が最適な隠れ変数モデルを推定し、収束判定部73が、基準値が収束したか否かを判定するループ処理を繰り返し、基準値が収束したときに、当該基準値と、その1つ前のループ処理における基準値とを比較し、大きい方の基準値に対応する隠れ変数モデルを最適な隠れ変数モデルとして選択する最適モデル選択部(例えば、最適モデル選択処理部107)を備える構成であってもよい。
また、変分確率計算部71が変分確率を計算し、モデル推定部72が最適な隠れ変数モデルを推定し、収束判定部73が、基準値が収束したか否かを判定するループ処理を繰り返し、変分確率計算部の計算結果に応じて、所定の条件を満たす隠れ状態を除去する隠れ状態除去部(例えば、隠れ状態数選択処理部201)を備える構成であってもよい。
また、モデル推定部72が、隠れ変数モデルとして隠れマルコフモデルを推定する構成であってもよい。
この出願は、2012年5月31に出願された米国仮出願61/653,855を基礎とする優先権を主張し、その開示の全てをここに取り込む。
以上、実施形態を参照して本願発明を説明したが、本願発明は上記の実施形態に限定されるものではない。本願発明の構成や詳細には、本願発明のスコープ内で当業者が理解し得る様々な変更をすることができる。
本発明は、系列依存性を持つ多変量データの隠れ変数モデル推定装置に好適に適用される。
101 データ入力装置
102 隠れ状態数設定部
103 初期化処理部
104 隠れ変数変分確率計算処理部
105 モデル最適化処理部
106 最適性判定処理部
107 最適モデル選択処理部
108 モデル推定結果出力装置
201 隠れ状態数選択処理部
102 隠れ状態数設定部
103 初期化処理部
104 隠れ変数変分確率計算処理部
105 モデル最適化処理部
106 最適性判定処理部
107 最適モデル選択処理部
108 モデル推定結果出力装置
201 隠れ状態数選択処理部
Claims (12)
- 周辺化対数尤度関数を完全変数に対する推定量に関してラプラス近似した近似量の下界として定義される基準値を最大化することによって変分確率を計算する変分確率計算部と、
各隠れ状態に対して観測確率の種類とパラメータを推定することで最適な隠れ変数モデルを推定するモデル推定部と、
変分確率計算部が変分確率を計算する際に用いた基準値が収束したか否かを判定する収束判定部とを備える
ことを特徴とする隠れ変数モデル推定装置。 - 変分確率計算部が変分確率を計算し、モデル推定部が最適な隠れ変数モデルを推定し、収束判定部が、基準値が収束したか否かを判定するループ処理を繰り返し、
基準値が収束したときに、当該基準値と、その1つ前のループ処理における基準値とを比較し、大きい方の基準値に対応する隠れ変数モデルを最適な隠れ変数モデルとして選択する最適モデル選択部を備える
請求項1に記載の隠れ変数モデル推定装置。 - 変分確率計算部が変分確率を計算し、モデル推定部が最適な隠れ変数モデルを推定し、収束判定部が、基準値が収束したか否かを判定するループ処理を繰り返し、
変分確率計算部の計算結果に応じて、所定の条件を満たす隠れ状態を除去する隠れ状態除去部を備える
請求項1に記載の隠れ変数モデル推定装置。 - モデル推定部は、隠れ変数モデルとして隠れマルコフモデルを推定する請求項1から請求項3のうちのいずれか1項に記載の隠れ変数モデル推定装置。
- 周辺化対数尤度関数を完全変数に対する推定量に関してラプラス近似した近似量の下界として定義される基準値を最大化することによって変分確率を計算し、
各隠れ状態に対して観測確率の種類とパラメータを推定することで最適な隠れ変数モデルを推定し、
変分確率を計算する際に用いた基準値が収束したか否かを判定する
ことを特徴とする隠れ変数モデル推定方法。 - 変分確率を計算し、最適な隠れ変数モデルを推定し、基準値が収束したか否かを判定するループ処理を繰り返し、
基準値が収束したときに、当該基準値と、その1つ前のループ処理における基準値とを比較し、大きい方の基準値に対応する隠れ変数モデルを最適な隠れ変数モデルとして選択する
請求項5に記載の隠れ変数モデル推定方法。 - 変分確率を計算し、最適な隠れ変数モデルを推定し、基準値が収束したか否かを判定するループ処理を繰り返し、
変分確率の計算結果に応じて、所定の条件を満たす隠れ状態を除去する
請求項5に記載の隠れ変数モデル推定方法。 - 隠れ変数モデルとして隠れマルコフモデルを推定する請求項5から請求項7のうちのいずれか1項に記載の隠れ変数モデル推定方法。
- コンピュータに、
周辺化対数尤度関数を完全変数に対する推定量に関してラプラス近似した近似量の下界として定義される基準値を最大化することによって変分確率を計算する変分確率計算処理、
各隠れ状態に対して観測確率の種類とパラメータを推定することで最適な隠れ変数モデルを推定するモデル推定処理、および、
変分確率計算処理で変分確率を計算する際に用いた基準値が収束したか否かを判定する収束判定処理
を実行させるための隠れ変数モデル推定プログラム。 - コンピュータに、
変分確率計算処理、モデル推定処理、収束判定処理のループ処理を繰り返し実行させ、
基準値が収束したときに、当該基準値と、その1つ前のループ処理における基準値とを比較し、大きい方の基準値に対応する隠れ変数モデルを最適な隠れ変数モデルとして選択する最適モデル選択処理
を実行させる請求項9に記載の隠れ変数モデル推定プログラム。 - コンピュータに、
変分確率計算処理、モデル推定処理、収束判定処理のループ処理を繰り返し実行させ、
変分確率計算処理の計算結果に応じて、所定の条件を満たす隠れ状態を除去する隠れ状態除去処理
を実行させる請求項9に記載の隠れ変数モデル推定プログラム。 - コンピュータに、
モデル推定処理で、隠れ変数モデルとして隠れマルコフモデルを推定させる
請求項9から請求項11のうちのいずれか1項に記載の隠れ変数モデル推定プログラム。
Priority Applications (5)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| EP13797356.6A EP2858012A4 (en) | 2012-05-31 | 2013-04-30 | Hidden-variable-model estimation device and method |
| SG11201407897YA SG11201407897YA (en) | 2012-05-31 | 2013-04-30 | Latent variable model estimation apparatus and method |
| MX2014013721A MX338266B (es) | 2012-05-31 | 2013-04-30 | Aparato y metodo de estimacion de modelo de variable oculta. |
| JP2014518252A JP6020561B2 (ja) | 2012-05-31 | 2013-04-30 | 隠れ変数モデル推定装置および方法 |
| CN201380009657.8A CN104160412B (zh) | 2012-05-31 | 2013-04-30 | 潜变量模型估计装置和方法 |
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US201261653855P | 2012-05-31 | 2012-05-31 | |
| US61/653,855 | 2012-05-31 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2013179579A1 true WO2013179579A1 (ja) | 2013-12-05 |
Family
ID=49671535
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2013/002900 Ceased WO2013179579A1 (ja) | 2012-05-31 | 2013-04-30 | 隠れ変数モデル推定装置および方法 |
Country Status (7)
| Country | Link |
|---|---|
| US (1) | US9043261B2 (ja) |
| EP (1) | EP2858012A4 (ja) |
| JP (1) | JP6020561B2 (ja) |
| CN (1) | CN104160412B (ja) |
| MX (1) | MX338266B (ja) |
| SG (1) | SG11201407897YA (ja) |
| WO (1) | WO2013179579A1 (ja) |
Cited By (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2015145978A1 (ja) * | 2014-03-28 | 2015-10-01 | 日本電気株式会社 | エネルギー量推定装置、エネルギー量推定方法、及び、記録媒体 |
| JP2015191667A (ja) * | 2014-03-28 | 2015-11-02 | エヌイーシー(チャイナ)カンパニー, リミテッドNEC(China)Co.,Ltd. | リレーショナルモデル決定用の方法と装置 |
| WO2015166637A1 (ja) * | 2014-04-28 | 2015-11-05 | 日本電気株式会社 | メンテナンス時期決定装置、劣化予測システム、劣化予測方法および記録媒体 |
| WO2016009599A1 (ja) * | 2014-07-14 | 2016-01-21 | 日本電気株式会社 | Cm計画支援システムおよび売上予測支援システム |
| JP2016194913A (ja) * | 2015-03-31 | 2016-11-17 | 日本電気株式会社 | 区分線形モデル生成システム及び生成方法 |
| JP2016194909A (ja) * | 2015-03-31 | 2016-11-17 | 日本電気株式会社 | 区分的線形モデル生成システム及び生成方法 |
Families Citing this family (18)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US4826397A (en) | 1988-06-29 | 1989-05-02 | United Technologies Corporation | Stator assembly for a gas turbine engine |
| US8909582B2 (en) | 2013-02-04 | 2014-12-09 | Nec Corporation | Hierarchical latent variable model estimation device, hierarchical latent variable model estimation method, and recording medium |
| US9489632B2 (en) * | 2013-10-29 | 2016-11-08 | Nec Corporation | Model estimation device, model estimation method, and information storage medium |
| US9355196B2 (en) * | 2013-10-29 | 2016-05-31 | Nec Corporation | Model estimation device and model estimation method |
| WO2015143580A1 (en) * | 2014-03-28 | 2015-10-01 | Huawei Technologies Co., Ltd | Method and system for verifying facial data |
| JP6301853B2 (ja) * | 2015-02-18 | 2018-03-28 | 株式会社日立製作所 | 経年変化予測システム |
| US10315116B2 (en) * | 2015-10-08 | 2019-06-11 | Zynga Inc. | Dynamic virtual environment customization based on user behavior clustering |
| CN105205502B (zh) * | 2015-10-30 | 2019-01-01 | 山东大学 | 一种基于马尔柯夫蒙特卡罗的负荷特性综合分类方法 |
| EP3385889A4 (en) | 2015-12-01 | 2019-07-10 | Preferred Networks, Inc. | ANOMALIC DETECTION SYSTEM, ANOMALY DETECTION METHOD, ANOMALIC DETECTION PROGRAM, AND METHOD OF GENERATING A LEARNED MODEL |
| JP6243080B1 (ja) * | 2017-08-03 | 2017-12-06 | 株式会社日立パワーソリューションズ | プリプロセッサおよび異常予兆診断システム |
| CN108388218B (zh) * | 2018-02-08 | 2020-06-19 | 中国矿业大学 | 基于潜变量过程迁移模型的修正自适应批次过程优化方法 |
| WO2019186996A1 (ja) * | 2018-03-30 | 2019-10-03 | 日本電気株式会社 | モデル推定システム、モデル推定方法およびモデル推定プログラム |
| US20200111575A1 (en) * | 2018-10-04 | 2020-04-09 | Babylon Partners Limited | Producing a multidimensional space data structure to perform survival analysis |
| JP7197789B2 (ja) * | 2019-03-01 | 2022-12-28 | 富士通株式会社 | 最適化装置及び最適化装置の制御方法 |
| WO2020261447A1 (ja) * | 2019-06-26 | 2020-12-30 | 日本電信電話株式会社 | パラメタ推定装置、パラメタ推定方法、及びパラメタ推定プログラム |
| DE112020007371T5 (de) * | 2020-10-15 | 2023-05-25 | Robert Bosch Gesellschaft mit beschränkter Haftung | Verfahren und Einrichtung für ein neuronales Netzwerk basierend auf energiebasierten Modellen einer latenten Variable |
| US11204931B1 (en) * | 2020-11-19 | 2021-12-21 | International Business Machines Corporation | Query continuous data based on batch fitting |
| US12462082B2 (en) * | 2022-10-03 | 2025-11-04 | Xilinx, Inc. | Satisfying circuit design constraints using a combination of machine learning models |
Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2009139769A (ja) * | 2007-12-07 | 2009-06-25 | Sony Corp | 信号処理装置、信号処理方法及びプログラム |
| JP2012042664A (ja) * | 2010-08-18 | 2012-03-01 | Nippon Telegr & Teleph Corp <Ntt> | 音源パラメータ推定装置と音源分離装置とそれらの方法と、プログラムと記憶媒体 |
| WO2012128207A1 (ja) * | 2011-03-18 | 2012-09-27 | 日本電気株式会社 | 多変量データの混合モデル推定装置、混合モデル推定方法および混合モデル推定プログラム |
Family Cites Families (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US7809159B2 (en) * | 2003-10-30 | 2010-10-05 | Nec Corporation | Estimation system, estimation method, and estimation program for estimating object state |
| US8037043B2 (en) * | 2008-09-09 | 2011-10-11 | Microsoft Corporation | Information retrieval system |
| US8565538B2 (en) * | 2010-03-16 | 2013-10-22 | Honda Motor Co., Ltd. | Detecting and labeling places using runtime change-point detection |
| CN101865828B (zh) * | 2010-05-31 | 2012-05-23 | 湖南大学 | 用于维护复杂体系光谱校正模型预测能力的方法 |
-
2012
- 2012-09-13 US US13/614,997 patent/US9043261B2/en active Active
-
2013
- 2013-04-30 CN CN201380009657.8A patent/CN104160412B/zh active Active
- 2013-04-30 MX MX2014013721A patent/MX338266B/es active IP Right Grant
- 2013-04-30 JP JP2014518252A patent/JP6020561B2/ja active Active
- 2013-04-30 SG SG11201407897YA patent/SG11201407897YA/en unknown
- 2013-04-30 EP EP13797356.6A patent/EP2858012A4/en not_active Withdrawn
- 2013-04-30 WO PCT/JP2013/002900 patent/WO2013179579A1/ja not_active Ceased
Patent Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2009139769A (ja) * | 2007-12-07 | 2009-06-25 | Sony Corp | 信号処理装置、信号処理方法及びプログラム |
| JP2012042664A (ja) * | 2010-08-18 | 2012-03-01 | Nippon Telegr & Teleph Corp <Ntt> | 音源パラメータ推定装置と音源分離装置とそれらの方法と、プログラムと記憶媒体 |
| WO2012128207A1 (ja) * | 2011-03-18 | 2012-09-27 | 日本電気株式会社 | 多変量データの混合モデル推定装置、混合モデル推定方法および混合モデル推定プログラム |
Non-Patent Citations (7)
| Title |
|---|
| BEAL, M. J.: "PhD thesis", 2003, article "Variational Algorithms for Approximate Bayesian Inference" |
| C. BISHOP: "Pattern Recognition and Machine Learning", 2007, SPRINGER, pages: 610 - 629 |
| NAONORI UEDA: "EM Algorithm no Shin Tenkai :Henbun Bayes-ho", IEICE TECHNICAL REPORT 0913-5685, vol. 101, no. 616, 22 January 2002 (2002-01-22), pages 23 - 30, XP008173190 * |
| NAONORI UEDA: "Variational Bayesian Learning for Optimal Model Search", TRANSACTIONS OF THE JAPANESE SOCIETY FOR ARTIFICIAL INTELLIGENCE, vol. 16, 1 November 2001 (2001-11-01), pages 299 - 308, XP055153724 * |
| RYOHEIFUJIMAKI; SATOSHIMORINAGA: "FactorizedAsymptotic Bayesian Inference for Mixture Modeling", PROCEEDINGS OF THE FIFTEENTH INTERNATIONAL CONFERENCE ON ARTIFICIAL INTELLIGENCE AND STATISTICS (AISTATS, 2012 |
| See also references of EP2858012A4 |
| VAN GAEL, J.; SAATCI, Y; TEH, Y.-W.; GHAHRAMANI, Z., BEAM SAMPLING FOR THE INFINITE HIDDEN MARKOV MODEL |
Cited By (10)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2015145978A1 (ja) * | 2014-03-28 | 2015-10-01 | 日本電気株式会社 | エネルギー量推定装置、エネルギー量推定方法、及び、記録媒体 |
| JP2015191667A (ja) * | 2014-03-28 | 2015-11-02 | エヌイーシー(チャイナ)カンパニー, リミテッドNEC(China)Co.,Ltd. | リレーショナルモデル決定用の方法と装置 |
| JPWO2015145978A1 (ja) * | 2014-03-28 | 2017-04-13 | 日本電気株式会社 | エネルギー量推定装置、エネルギー量推定方法、及び、エネルギー量推定プログラム |
| WO2015166637A1 (ja) * | 2014-04-28 | 2015-11-05 | 日本電気株式会社 | メンテナンス時期決定装置、劣化予測システム、劣化予測方法および記録媒体 |
| JPWO2015166637A1 (ja) * | 2014-04-28 | 2017-04-20 | 日本電気株式会社 | メンテナンス時期決定装置、劣化予測システム、劣化予測方法および記録媒体 |
| WO2016009599A1 (ja) * | 2014-07-14 | 2016-01-21 | 日本電気株式会社 | Cm計画支援システムおよび売上予測支援システム |
| JPWO2016009599A1 (ja) * | 2014-07-14 | 2017-04-27 | 日本電気株式会社 | Cm計画支援システムおよび売上予測支援システム |
| US11188946B2 (en) | 2014-07-14 | 2021-11-30 | Nec Corporation | Commercial message planning assistance system and sales prediction assistance system |
| JP2016194913A (ja) * | 2015-03-31 | 2016-11-17 | 日本電気株式会社 | 区分線形モデル生成システム及び生成方法 |
| JP2016194909A (ja) * | 2015-03-31 | 2016-11-17 | 日本電気株式会社 | 区分的線形モデル生成システム及び生成方法 |
Also Published As
| Publication number | Publication date |
|---|---|
| US20130325782A1 (en) | 2013-12-05 |
| JPWO2013179579A1 (ja) | 2016-01-18 |
| CN104160412A (zh) | 2014-11-19 |
| MX2014013721A (es) | 2015-02-10 |
| MX338266B (es) | 2016-04-11 |
| CN104160412B (zh) | 2017-08-11 |
| SG11201407897YA (en) | 2015-01-29 |
| JP6020561B2 (ja) | 2016-11-02 |
| US9043261B2 (en) | 2015-05-26 |
| EP2858012A4 (en) | 2017-02-15 |
| EP2858012A1 (en) | 2015-04-08 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP6020561B2 (ja) | 隠れ変数モデル推定装置および方法 | |
| CN103221945B (zh) | 多变量数据混合模型估计装置、混合模型估计方法 | |
| Zhu et al. | A dynamic discretization method for reliability inference in Dynamic Bayesian Networks | |
| EP3008528B1 (en) | A method and system of dynamic model identification for monitoring and control of dynamic machines with variable structure or variable operation conditions | |
| US8909582B2 (en) | Hierarchical latent variable model estimation device, hierarchical latent variable model estimation method, and recording medium | |
| WO2020149971A2 (en) | Robust and data-efficient blackbox optimization | |
| Akhare et al. | Diffhybrid-uq: uncertainty quantification for differentiable hybrid neural modeling | |
| EP2261816A2 (en) | Split variational inference | |
| KR20110116563A (ko) | 주성분 분석과 마르코프 연쇄 몬테카를로 기법을 결합한 퍼지 군집화 방법 | |
| JP6380404B2 (ja) | モデル推定装置、モデル推定方法およびモデル推定プログラム | |
| Venkatesh et al. | Heteroscedastic calibration of uncertainty estimators in deep learning | |
| Yao et al. | Adaptive path sampling in metastable posterior distributions | |
| JP2016520220A (ja) | 隠れ属性モデル推定装置、方法およびプログラム | |
| Song | Efficient sampling-based RBDO by using virtual support vector machine and improving the accuracy of the Kriging method | |
| JP2010170424A (ja) | 分布推定装置、クラスタリング装置、分布推定装置の推定方法及びプログラム | |
| US20240403386A1 (en) | Anomaly detection method and system | |
| Xu et al. | An adaptive Gaussian process method for multi-modal Bayesian inverse problems | |
| Maidstone | Efficient analysis of complex changepoint problems | |
| Daniušis | Feature extraction via dependence structure optimization | |
| Boots et al. | Hilbert space embeddings of PSRs | |
| Callut et al. | Learning partially observable markov models from first passage times | |
| Balesdent et al. | 8.1 Sensitivity analysis | |
| Bajer et al. | Model Guided Sampling Optimization for Low-dimensional Problems | |
| Repický et al. | Traditional Gaussian Process Surrogates in the BBOB Framework. | |
| Chatelain et al. | Surgical Gesture Modeling using Switching Linear Dynamical Systems |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 13797356 Country of ref document: EP Kind code of ref document: A1 |
|
| ENP | Entry into the national phase |
Ref document number: 2014518252 Country of ref document: JP Kind code of ref document: A |
|
| WWE | Wipo information: entry into national phase |
Ref document number: MX/A/2014/013721 Country of ref document: MX |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |