WO2014206304A1 - 高稳定性的t细胞受体及其制法和应用 - Google Patents
高稳定性的t细胞受体及其制法和应用 Download PDFInfo
- Publication number
- WO2014206304A1 WO2014206304A1 PCT/CN2014/080773 CN2014080773W WO2014206304A1 WO 2014206304 A1 WO2014206304 A1 WO 2014206304A1 CN 2014080773 W CN2014080773 W CN 2014080773W WO 2014206304 A1 WO2014206304 A1 WO 2014206304A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- amino acid
- tcr
- chain variable
- variable domain
- acid sequence
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Ceased
Links
Classifications
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K38/00—Medicinal preparations containing peptides
- A61K38/16—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- A61K38/17—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans
- A61K38/177—Receptors; Cell surface antigens; Cell surface determinants
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K38/00—Medicinal preparations containing peptides
- A61K38/16—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- A61K38/17—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans
- A61K38/177—Receptors; Cell surface antigens; Cell surface determinants
- A61K38/1774—Immunoglobulin superfamily (e.g. CD2, CD4, CD8, ICAM molecules, B7 molecules, Fc-receptors, MHC-molecules)
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K47/00—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient
- A61K47/50—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates
- A61K47/51—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent
- A61K47/62—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent the modifying agent being a protein, peptide or polyamino acid
- A61K47/64—Drug-peptide, drug-protein or drug-polyamino acid conjugates, i.e. the modifying agent being a peptide, protein or polyamino acid which is covalently bonded or complexed to a therapeutically active agent
- A61K47/6425—Drug-peptide, drug-protein or drug-polyamino acid conjugates, i.e. the modifying agent being a peptide, protein or polyamino acid which is covalently bonded or complexed to a therapeutically active agent the peptide or protein in the drug conjugate being a receptor, e.g. CD4, a cell surface antigen, i.e. not a peptide ligand targeting the antigen, or a cell surface determinant, i.e. a part of the surface of a cell
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K49/00—Preparations for testing in vivo
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P31/00—Antiinfectives, i.e. antibiotics, antiseptics, chemotherapeutics
- A61P31/12—Antivirals
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P35/00—Antineoplastic agents
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P37/00—Drugs for immunological or allergic disorders
- A61P37/02—Immunomodulators
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P37/00—Drugs for immunological or allergic disorders
- A61P37/02—Immunomodulators
- A61P37/06—Immunosuppressants, e.g. drugs for graft rejection
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K14/00—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- C07K14/435—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans
- C07K14/705—Receptors; Cell surface antigens; Cell surface determinants
- C07K14/70503—Immunoglobulin superfamily
- C07K14/7051—T-cell receptor (TcR)-CD3 complex
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IG], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IG], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/28—Immunoglobulins [IG], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants
- C07K16/2803—Immunoglobulins [IG], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants against the immunoglobulin superfamily
- C07K16/2809—Immunoglobulins [IG], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants against the immunoglobulin superfamily against the T-cell receptor (TcR)-CD3 complex
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K38/00—Medicinal preparations containing peptides
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/70—Immunoglobulins specific features characterized by effect upon binding to a cell or to an antigen
- C07K2317/76—Antagonist effect on antigen, e.g. neutralization or inhibition of binding
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2319/00—Fusion polypeptide
- C07K2319/30—Non-immunoglobulin-derived peptide or protein having an immunoglobulin constant or Fc region, or a fragment thereof, attached thereto
Definitions
- the present invention relates to the field of biotechnology, and more particularly to a highly stable soluble sputum receptor (TCR) receptor (TCR) in a hydrophobic core region.
- TCR soluble sputum receptor
- the invention also relates to the preparation and use of such receptors. Background technique
- TCR T cell receptor
- TCR is the only receptor for a specific antigenic peptide presented on the major histocompatibility complex (MHC), which may be the only sign of abnormal cell appearance.
- MHC major histocompatibility complex
- APCs antigen presenting cells
- TCR On the T cell membrane, TCR binds to the constant protein CD3 involved in signal transduction to form a complex. TCR exists in many forms and is structurally similar, whereas T cells expressing these TCRs may exist in different anatomical locations and may have different functions.
- the extracellular portion of the TCR consists of two near-membrane constant domains and two distal membrane variable domains with polymorphic loops similar to the complementarity determining regions (CDRs) of the antibody. It is these loops that form the binding site for T cell receptor molecules and determine peptide specificity.
- MHC class I and class II molecular ligands corresponding to TCR are also proteins of the immunoglobulin superfamily but are specific for antigen presentation, and they have polymorphic peptide binding sites that enable them to present a variety of Different short peptide fragments are added to the surface of APC cells.
- TCR Like immunoglobulins (antibodies) as antigen recognition molecules, TCR can also be developed and applied. Diagnosis and treatment. However, it is difficult to prepare such a protein consisting of more than one polypeptide subunit and having a transmembrane region in a (water) soluble form, since, in many cases, such a protein is stabilized by its transmembrane region. . This is the case with TCR, which has been reflected in the scientific literature. The literature describes a truncated form of TCR that contains only extracellular regions or only extracellular and cytoplasmic regions. Such TCRs can be specifically TCR-specific. Antibody recognition (this indicates that the recombinant TCR portion recognized by the antibody has been correctly folded), but the yield is not high, is not stable enough at low concentrations and/or does not recognize the primary histocompatibility complex-peptide complex.
- Soluble TCR has a wide range of uses, not only for studying TCR-pMHC interactions, but also as a diagnostic tool for detecting infections or as a marker for autoimmune diseases.
- soluble TCR can be used to deliver therapeutic agents (such as cytotoxic compounds or immunostimulatory compounds) to cells that present specific antigens, or to inhibit tau cells (such as those that react with autoimmune peptide antigens). T cells).
- therapeutic agents such as cytotoxic compounds or immunostimulatory compounds
- tau cells such as those that react with autoimmune peptide antigens.
- modification of the TCR protein is critical.
- heterologous expression of TCR in prokaryotic or eukaryotic systems is important.
- TCRs can be recognized by TCR-specific antibodies, they only show recognition of natural ligands at relatively high concentrations, suggesting that the recognition is unstable.
- Another object of the present invention is to provide a process and use of the high stability T cell receptor.
- TCR T-cell receptor
- the stability of the TCR is higher than the TCR of its corresponding hydrophobic core being wild type.
- the "mutation" means that the hydrophobic core region of the TCR of the present invention is mutated relative to the corresponding wild-type TCR hydrophobic core region.
- the "stability higher than" indicates that the TCR of the present invention has a stability improvement of at least 5%, preferably at least 30%, more preferably than the corresponding hydrophobic core of the wild type. At least 80%.
- wild-type TCR hydrophobic core refers to a hydrophobic core which is the same as the hydrophobic core amino acid residue (sequence) in the naturally occurring TCR without mutation.
- the phrase "the corresponding hydrophobic core is a wild type TCR” means that the hydrophobic core is wild type, and the other regions are different from the TCR which is mutated in the hydrophobic core region of the present invention. Invented the same TCR for TCR. Additionally or preferably, said "the corresponding hydrophobic core is a wild-type TCR” refers to a naturally occurring wild-type TCR that does not contain any mutation sites, particularly its a-chain variable domain and beta-chain. The variable domain is a wild-type sTv molecule, and representative examples include LC13-WT.
- the CDR region of the TCR is identical to the wild type, or contains an affinity A sudden increase in mutation.
- the affinity refers to the binding affinity between the TCR molecule and its corresponding antigen.
- the T cell receptor variable region framework and the hydrophobic region of the side chain in the constant region position are mutated toward the surface.
- the variable domain backbone of the TCR and the amino acid residues exposed to the surface in the constant domain are mutated.
- the mutated amino acid residue is an amino acid residue exposed to the surface of the a chain and/or the beta chain variable domain of the TCR.
- the amino acid sites exposed to the surface in the variable domain include the 4th, 12th, 16th, 93rd, 97th, and 100th positions of the TCR a chain variable domain amino acid,
- the amino acid position number is numbered according to the position listed in IMGT (International Immunogenetics Information System).
- the T cell receptor variable region framework side chain is directed to the surface (the variable domain is exposed to the surface) and the mutant form of the hydrophobic residue includes, but is not limited to, a chain : I7S, A9S, A10S, V20S, ⁇ 92 ⁇ , A93S, J gene
- the amino acid position of the short peptide from the penultimate position changes from I to ⁇ , ⁇ chain: I 12S, or any combination of the above mutations, where the amino acid position number is listed in IMGT The location number.
- the T cell receptor is soluble.
- the T cell receptor is a membrane protein.
- the T cell receptor comprises (a) all or part of a TCR a chain other than a transmembrane domain; and (b) all or part of a TCR ⁇ chain other than a transmembrane domain;
- the TCR is a single-chain TCR composed of a flexible peptide chain linking the variable domains of the a and ⁇ chains of the TCR.
- the mutation comprises a mutation in at least one hydrophobic core position.
- the T cell receptor has one or more mutations at the position, a and/or ⁇ chain amino acid sequence variable region hydrophobic core position: i.e., variable region amino acid number 11, 13, 19 , 21, 53, 76, 89, 91, 94, and/or ⁇ chain J gene short peptide amino acid position reciprocal number 3, 5, 7 and / or ⁇ chain J gene short peptide amino acid position reciprocal 2, 4, 6 digits, where the amino acid position number is based on top GT (country The location number listed in the Immune Genetics Information System.
- top GT country The location number listed in the Immune Genetics Information System.
- the a-chain variable domain of the TCR is mutated in one or more of the following positions: alpha chain variable region amino acids 11, 13, 19, 21, 53, 76, 89, 91 Or, at position 94, and/or the alpha chain J gene short peptide amino acid reciprocal number 3, the penultimate number 5 or the penultimate number 7, wherein the amino acid position number is in the position listed in IMGT (International Immunogenetics Information System) Numbering.
- IMGT International Immunogenetics Information System
- the TCR is at one or more of the following positions in the alpha chain variable domain set forth in SEQ ID NO: 9 or SEQ ID NO: 29 or SEQ ID NO: 31 or SEQ ID NO: Mutations occur: a chain variable region amino acid 11th, 13th, 19th, 21st, 53th, 76th, 89th, 91th, or 94th, and/or a chain J gene short peptide amino acid reciprocal 3rd, the penultimate 5th Bit 7 or the last 7th digit, where the amino acid position number is numbered according to the position listed in IMGT.
- the ⁇ chain variable domain of the TCR is mutated in one or more of the following positions: ⁇ chain variable region amino acids 11, 13, 19, 21, 53, 76, 89, 91 , or the 94th, and / or ⁇ chain J gene short peptide amino acid reciprocal number 2, the last 4th or the last 6th, wherein the amino acid position number is numbered according to the position listed in IMGT.
- the TCR is at SEQ ID NO: 11 or SEQ ID NO: 30 or SEQ ID NO:
- a mutation occurs in one or more of the following positions of the ⁇ chain variable domain represented by NO: 32 or SEQ ID NO: 34: ⁇ chain variable region amino acids 11, 11, 19, 21, 53, 76, 89, 91, or the 94th, and / or ⁇ chain J gene short peptide amino acid reciprocal number 2, the last 4th or the last 6th, wherein the amino acid position number is numbered according to the position listed in IMGT.
- the a-chain variable domain of the TCR comprises one or more amino acid residues selected from the group consisting of: 11L, 11M or 11E; 13V, 13R or 13K; 19V; 211; 91L or 911; 94V or 941; and/or the beta chain variable domain of the TCR comprises one or more amino acid residues selected from the group consisting of: 11L or 11V; 13V; 19V; 89L; 91F or 911; 94V or 94L;
- the sixth reciprocal of the J gene is the fourth position of the T and ⁇ chain J genes, and the fourth position is M; wherein the amino acid position numbers are numbered according to the positions listed in the IMGT.
- the amino acid residue exposed to the surface of the a chain and/or the ⁇ chain variable domain of the TCR is mutated.
- the TCR comprises one or more of the a chain variable domain amino acid residues 4L selected from the group consisting of: 12N; 16S; 93N or 93R; 97N; 100G; 105S; and a chain J gene reciprocal
- the first position is D
- the TCR comprises one or more ⁇ chain variable domain amino acid residues 41 selected from the group consisting of: 101L; the first position of the ⁇ chain J gene is the reciprocal of the D and ⁇ chain J genes.
- the third digit is E.
- the TCR comprises one of the following alpha chain variable domain amino acid sequences SEQ ID NO: 15, 17, 35, 37, 39, 75, 76, 77, 78, 79, 80, 81, 82 , 83, 84, 85,
- the TCR comprises one of the following ⁇ chain variable domain amino acid sequences SEQ ID NO: 16, 18, 36, 38, 40, 86, 87, 88, 89, 90, 91, 92, 93 , 94, 95, 96,
- the combination of the a-chain variable domain and the beta-chain variable domain of the TCR is selected from one of the following combinations:
- the T cell receptor a chain variable region hydrophobic core has at least one of the following mutations: the 19th amino acid mutation is V, the 21st amino acid mutation is I, and the 91st amino acid mutation is L; And/or the beta chain variable region hydrophobic core has at least one of the following mutations: the amino acid mutation at position 91 is F or the mutation is I; and/or the amino acid at position 4 of the amino acid sequence of the short peptide of the ⁇ chain J gene is mutated to M.
- the mutation is selected from the group consisting of:
- the 19th amino acid mutation of the a chain variable region is V, the 21st amino acid mutation is I, the 91st amino acid mutation is ⁇ chain variable region 91th amino acid mutation is F, ⁇ chain J gene short peptide
- the fourth position of the amino acid sequence is mutated to M; or (ii) the 19th amino acid mutation of the ⁇ chain variable region is V, the amino acid mutation at position 21 is I, and the amino acid mutation at position 91 of the ⁇ chain variable region is I;
- the amino acid mutation at position 19 of the ⁇ chain variable region is V
- the amino acid mutation at position 21 is I
- the amino acid mutation at position 91 is changed to the amino acid at position 91 of the ⁇ chain variable region.
- the ⁇ cell receptor a chain variable region hydrophobic core has at least one of the following mutations: L19V, L21I, I91L; and/or the ⁇ chain variable region hydrophobic core has at least one of the following mutations: V91F or The fourth position of the amino acid sequence of the V91I; and/or ⁇ chain J gene short peptide is mutated from L to M.
- the mutation is selected from the group consisting of:
- the amino acid position number is numbered according to the position listed in the top GT.
- the sputum cell receptor further has a disulfide bond connecting the TCR ⁇ chain constant region and the ⁇ chain constant region.
- the disulfide bond is present in the natural TCR or introduced artificially.
- the artificially introduced disulfide bond is located between the constant domains of TCRcc and the beta strand.
- the artificially introduced cysteine residue forming an interchain disulfide bond replaces an amino acid residue including, but not limited to, at least one of the a and ⁇ chains in the following positions:
- the T cell receptor is screened by phage display technology.
- the tau cell receptor binds (covalently or otherwise) to a conjugate.
- the conjugate is selected from one or more of the group consisting of:
- the detectable label comprises: a fluorescent or luminescent label, a radioactive label, an MRI
- Magnetic resonance imaging or CT (computer tomography) contrast agents, or enzymes capable of producing detectable products.
- the therapeutic agent comprises: a radionuclide, a biotoxin, a cytokine (such as IL-2, etc.), an antibody, an antibody Fc fragment, an antibody scFv fragment, a gold nanoparticle/nanorod, a virus particle, a liposome , nanomagnetic particles, prodrug activating enzymes (for example, DT-diaphorase (DTD) or biphenyl hydrolase-like protein (; BPHL), chemotherapeutic agents (eg, cisplatin;) or any form of nano Particles, etc.
- a radionuclide for example, DT-diaphorase (DTD) or biphenyl hydrolase-like protein (; BPHL), chemotherapeutic agents (eg, cisplatin;) or any form of nano Particles, etc.
- the conjugate is an anti-CD3 antibody linked to the C- or ⁇ -terminus of the a and/or ⁇ chain of the TCR.
- nucleic acid molecule comprising a sputum cell receptor according to any one of the first aspects of the invention, or a complement thereof, is provided.
- a vector comprising the nucleic acid molecule of the second aspect of the invention is provided.
- a host cell or genetically engineered engineered cell comprising the vector of the third aspect of the invention or the chromosome of the second aspect of the invention integrated with exogenous Nucleic acid molecule.
- the host cell is selected from the group consisting of: a prokaryotic cell and a eukaryotic cell, such as Escherichia coli, yeast cells, CH0 cells, and the like.
- a method of preparing a T cell receptor according to the first aspect of the invention comprising the steps of:
- the T cell receptor is isolated or purified.
- the invention provides a T cell receptor complex, characterized in that the complex comprises the T cell receptor according to any one of the first aspects of the invention.
- the complex comprises a complex formed by binding of a tau cell receptor of the present invention to a therapeutic agent, or a complex formed by binding to a detectable label.
- the complex comprises two or more T cell receptor molecules.
- a seventh aspect of the invention there is provided the use of the T cell receptor of the invention described above for use in the manufacture of a medicament for the treatment of a tumor, a viral infection or an autoimmune disease.
- a pharmaceutical composition comprising a pharmaceutically acceptable carrier and a safe and effective amount of the T cell receptor of any one of the first aspects of the invention.
- a method of treating a disease comprising administering a T cell receptor according to any one of the first aspects of the invention, or a T cell according to the sixth aspect, to a subject in need of treatment A receptor complex, or a pharmaceutical composition as described in the eighth aspect.
- the disease comprises: a tumor, an autoimmune disease, and a viral infectious disease.
- a method for the preparation of the T cell receptor of the first aspect of the invention comprising the steps of:
- the screening methods include, but are not limited to, phage display technology.
- step (i i) a T cell receptor which is mutated in the hydrophobic core region is displayed by phage display technology and screened.
- the method further comprises the step of determining the sequence, activity and/or other characteristics of the selected T cell receptor.
- Figure 1 shows a schematic diagram of the variable domain structure of a typical TCR with a cancer antigen MAGE
- Figures 2a and 2b show the TCR a chain variable domain amino acid sequence and nucleotide sequence (SEQ ID NOS: 9 and 10), respectively, after site-directed mutagenesis.
- the amino acid sequence is further optimized for the a-chain variable domain amino acid sequence of the TCR disclosed in the patent document (WO2012/013913), and more specifically, the hydrophobic residue exposed to the surface in the variable domain is further mutated to hydrophilic. Or a polar residue in which the bolded and underlined letter is the mutated amino acid residue.
- Figures 3a and 3b show the TCR i chain variable domain amino acid sequence and nucleotide sequence (SEQ ID NOS: 11 and 12), respectively, after site-directed mutagenesis.
- the amino acid sequence is further optimized for the TCR i chain variable domain amino acid sequence disclosed in the patent document (WO2012/013913), and more specifically, the hydrophobic residue exposed to the surface in the variable domain is further mutated to hydrophilic or A polar residue in which the bolded and underlined letters are the mutated amino acid residues.
- Figure 4 shows the connection of each primer when constructing MAGE-sTv-WT.
- Figures 5a and 5b are the amino acid sequence and nucleotide sequence (SEQ ID NOS: 13 and 14) of the a and ⁇ chain conjugates when constructing the sTv mutant library, respectively.
- Figures 6a and 6b are the a-chain variable domain amino acid sequence and the ⁇ -chain variable domain amino acid sequence (SEQ ID NOS: 15 and 16), respectively, of the sTv mutant MG29, and the mutated residues are in bold relative to MAGE-sTv-WT. Words and underscores are displayed.
- Figures 7a and 7b are the a-chain variable domain amino acid sequence and the ⁇ -chain variable domain amino acid sequence (SEQ ID ⁇ 0: 17 and 18) of the sTv mutant P8F1, respectively, and the mutated residues are in bold relative to MAGE-sTv-WT. Words and underscores are displayed.
- Figures 8a and 8b are the a-chain variable domain amino acid sequence and the ⁇ -chain variable domain amino acid sequence (SEQ ID ⁇ 0: 15 and 18) of the sTv mutant P8F2, respectively, and the mutated residues are in bold relative to MAGE-sTv-WT. Words and underscores are displayed.
- Figure 9 is a ELISA experimental 0D value of different mutant strains and MAGE-sTv-WT against antigen MAGEA3, EBV, Flu, NY-ES0.
- Figure 10a and Figure 10b are the a-chain variable domains (SEQ ID NO: 29) and ⁇ -chain variable domains of LC13-WT, respectively. (SEQ ID NO: 30) amino acid sequence.
- Figure 11a and Figure lib are the amino acid sequences of the ⁇ chain variable domain (SEQ ID NO: 31) and the ⁇ chain variable domain (SEQ ID NO: 32), respectively, of JM22-WT.
- Figure 12a and Figure 12b are the amino acid sequences of the ⁇ G chain variable domain (SEQ ID NO: 33) and the ⁇ chain variable domain (SEQ ID NO: 34), respectively, of 1G4-WT.
- Figure 13a and Figure 13b are the amino acid sequences of the LC13-sTva chain variable domain (SEQ ID NO: 35) and the LC13-sTv beta chain variable domain (SEQ ID NO: 36), respectively.
- Figure 14a and Figure 14b show the amino acid sequences of the JM22-sTva chain variable domain (SEQ ID NO: 37) and the JM22-sTv beta chain variable domain (SEQ ID NO: 38), respectively.
- Figure 15a and Figure 15b are the amino acid sequences of the 1G4-sTv alpha chain variable domain (SEQ ID NO: 39) and the 1G4-sTvP chain variable domain (SEQ ID NO: 40), respectively.
- Figure 16 is the amino acid sequence (SEQ ID NO: 41) of the ligated linker used to construct the sTv single-stranded molecule.
- Figure 17 is an SDS-PAGE gel of the purified protein LC13-WT and LC13-sTv. Lane 1: molecular marker, lane 2: LC13-WT, lane 3: LC13-sTv.
- Figure 18a and Figure 18b show the SEC profiles of the purified proteins LC13-WT and LC13-sTv, respectively.
- Figure 19 is an SDS-PAGE gel of the purified proteins JM22-WT and JM22-sTv.
- Lane 1 molecular weight marker
- lane 2 JM22-WT
- lane 3 JM22-sTv.
- Figure 20a and Figure 20b show the SEC profiles of the purified proteins JM22-WT and JM22-sTv, respectively.
- Figure 21 is an SDS-PAGE gel of the purified protein 1G4-WT and 1G4-STV.
- Lane 1 molecular weight marker
- lane 2 1G4-WT
- Figure 22a and Figure 22b show the SEC profiles of the purified proteins 1G4-WT and 1G4-STV, respectively.
- Figure 23 is the amino acid sequence of 1G4-STV (SEQ ID NO: 42).
- Figure 24 shows the 0D values of the 1G4-STV mutant for different antigens.
- Figure 25 shows the ⁇ chain variable domain amino acid sequence of the 1G4-STV high stability mutant screen (SEQ ID NO: 1G4-STV high stability mutant screen (SEQ ID NO: 1G4-STV high stability mutant screen
- Figure 26 is a ⁇ chain variable domain amino acid sequence (SEQ ID NO: 86-96) of the screened 1G4-STV high stability mutant.
- Figure 27 is a DSC graph of a 1G4-STV high stability mutant.
- Figure 28 is a DSC graph of 1G4-WT.
- Figure 29a and Figure 29b show the amino acid sequences of the highly stable G15a chain variable domain (SEQ ID NO: 97) and the ⁇ chain variable domain (SEQ ID NO: 98), respectively.
- Figure 30 is an SDS-PAGE gel of the purified proteins 1G4-WT, 1G4-sTv, G13, G15, G9.
- Lane 1 molecular weight marker
- lane 2 1G4-WT
- lane 4 lane G13
- lane 5 G15
- lane 6 molecular weight marker
- lane 7 G9.
- Figures 31a, 31b and 31c are SEC profiles of purified proteins G9, G13 and G15, respectively.
- Figure 32a and Figure 32b are the amino acid sequences of the LC13-G9 chain variable domain (SEQ ID NO: 99) and the ⁇ chain variable domain (SEQ ID NO: 100), respectively.
- Figure 33a and Figure 33b are the amino acid sequences of the LC13-G15 alpha chain variable domain (SEQ ID NO: 101) and the beta chain variable domain (SEQ ID NO: 102), respectively.
- Figure 34a and Figure 34b show the amino acid sequences of the JM22-G9a chain variable domain (SEQ ID NO: 103) and the ⁇ chain variable domain (SEQ ID NO: 104), respectively.
- Figure 35a and Figure 35b are the amino acid sequences of the JM22-G15 chain variable domain (SEQ ID NO: 105) and the beta chain variable domain (SEQ ID NO: 106), respectively.
- Figure 36 is a SDS-PAGE gel of the purified proteins LC13-WT, LC13-sTv, LC13-G15, LC13-G9.
- Lane 1 molecular weight marker
- lane 2 LC13-WT
- lane 3 LC13-sTv
- lane 4 LC13-G15
- lane 5 molecular weight marker
- lane 6 LC13-G9o
- Figure 37 is a SEC map of the purified protein LC13-G9.
- Figure 38 is a SEC map of the purified protein LC13-G15.
- Figure 39 is a SDS-PAGE gel of the purified proteins JM22-WT, JM22-sTv, JM22-G15, JM22-G9.
- Lane 1 molecular weight marker
- lane 2 JM22-WT
- lane 3 JM22-sTv
- lane 4 JM22-G15
- lane 5 JM22-G9o
- Figure 40 is a SEC map of the purified protein JM22-G9.
- Figure 41 is a SEC map of the purified protein JM22-G15.
- Figure 42a and Figure 42b show the amino acid sequences of the MAGE-G15 chain variable domain (SEQ ID NO: 107) and the ⁇ chain variable domain (SEQ ID NO: 108), respectively.
- Figure 43 is an SDS-PAGE gel of the purified protein MAGE-G15.
- Lane 1 molecular weight marker
- lane 2 MAGE - G15.
- Figure 44 is a SEC map of the purified protein MAGE-G15.
- Figure 45 is a DSC graph of the purified protein MAGE-G15.
- Figure 46 is a DSC graph of the purified protein G15.
- Figure 47 is a DSC graph of the purified protein LC13-sTv.
- Figures 48a and 48b are DSC plots of purified proteins JM22-WT and JM22-sTv, respectively.
- Figures 49a and 49b are DSC plots of purified proteins LC13-G9 and LC13-G15, respectively.
- the inventors have extensively and intensively studied and found for the first time that a highly stable mutant TCR, particularly soluble TCR, can be unexpectedly obtained by targeted mutation of the hydrophobic core region of a T cell receptor.
- the present invention has been completed on this basis.
- the inventors used an optimized TCR protein structure to construct a highly stable TCR molecule by changing the hydrophobic core of the TCR.
- the present invention constructs a novel single-stranded TCR variable domain, and the optimal hydrophobic core is isolated by directed molecular evolution.
- a TCR fragment having a novel hydrophobic core can be further improved by replacing the hydrophobic residue exposed to the surface in the TCR variable domain with a hydrophilic or polar residue.
- each strand comprises a variable region, a junction region, and a constant region
- the beta strand typically also contains a short polymorphic region between the variable region and the junction region, but the variable region is often considered part of the junction region.
- the three CDRs (complementarity determining regions) of each variable region are chimeric in the framework of the variable region, and the hydrophobic core is also located in the framework of the variable region.
- the alpha chain variable region (V a ) can be divided into several classes, and the ⁇ chain variable region ( ⁇ ⁇ ) can also be classified into several classes.
- the Va type and the ⁇ type are referred to by the unique TRAV number and the TRBV number, respectively, and TRAJ and TRBJ refer to the TCR junction area.
- the ⁇ chain J gene used in the present invention means TRAJ, and the ⁇ chain J gene means TRBJ.
- the a and ⁇ chains of TCR are often treated as having two "domains", namely "variable domains" and “constant domains".
- the variable domain consists of variable and connected regions that are connected together.
- TCR a variable domain refers to TRAV and TRAJ linked together
- TCR i variable domain refers to TRBV and TRBJ joined together.
- the TCR field is widely known and available to obtain the amino acid sequence of the TCR given in the top GT and its variable domain framework including the specific position number of the hydrophobic core position in the IMGT. For example, it can be found in the IMGT public database.
- the TCR amino acid position numbers are numbered according to the positions listed in the IMGT unless otherwise stated. If there is a change in the position number listed in the IMGT in the future, the amino acid sequence position number of the TCR listed in the IMGT version of the January 1, 2013 version shall prevail.
- hydrophobic core which may also be referred to as “hydrophobic core” means that when any protein is dissolved in water, the protein domain typically comprises a core region comprised of a hydrophobic amino acid, typically within its molecular structure.
- the hydrophobic core of the TCR ci chain variable domain is the amino acid positions of the variable region amino acids 1, 1, 13, 19, 21, 53, 76, 89, 91, 94 and the ⁇ chain J gene (TRAJ) short peptide.
- TRAJ ⁇ chain J gene
- the third, fifth, and seventh digits of the reciprocal; the hydrophobic core of the TCR i chain variable domain is the variable region amino acid 1, 1, 13, 19, 21, 53, 76, 89, 91, 94 and the ⁇ chain J gene (TRAJ)
- the amino acid position of the short peptide is in the second, fourth, and sixth positions.
- the above location number uses the location number listed in the top GT.
- Figure 1 is a schematic diagram showing the structure of the variable region of the wild-type TCR having the specificity of the cancer antigen MAGE A3 HLA A1.
- the bold amino acid residues in the lower left and lower right sides of the schematic are respectively a and A hydrophobic core at the position of the ⁇ chain variable region framework.
- the antigen binding site of TCR is in the CDR region, and the CDR region determines the binding affinity between TCR and its corresponding antigen.
- the hydrophobic core is not in the CDR region, and its mutation should not affect the binding and binding affinity of the TCR to its corresponding antigen, but according to the inventors' study, the change of the hydrophobic core will result in the stability of the TCR molecule. influences.
- Tv refers to a single-chain TCR consisting of a variable domain of the a and beta chains of a TCR linked by a flexible peptide chain
- the flexible peptide chain can be any peptide suitable for linking the TCR a to the beta variable domain.
- the chain, the number of amino acid residues of the peptide chain may be 1 to 50, but is not limited to 1 to 50.
- the term "stability" refers to any aspect of protein stability. Compared to the original wild-type protein, the highly stable protein obtained by screening has one or more of the following characteristics: more resistant to unfolding, more resistant to inappropriate or undesired folding, more renaturation, and more expressive ability Strong, protein reproducible yields, increased thermal stability, increased stability in a variety of environments (eg, ra value, salt concentration, presence of detergent, presence of denaturant, etc.).
- the final receptor When a phage display system is used to isolate a receptor, the final receptor is usually screened by two important properties, the first being the binding strength or affinity of the receptor to the ligand, and the second being the receptor on the surface of the phage. Show density.
- the first property is the basis for the evolution of protein affinity, which guides the development of all methodologies that produce high affinity receptors. A brief description is as follows: When a receptor display library is loaded onto a ligand, receptors with higher binding strength bind to the ligand at a faster rate and/or longer retention time and are able to withstand higher Intensive washing. Therefore, these receptors and their coding genes will be Capture and zoom in on subsequent processes.
- the affinity factor does not contribute to the screening, and the display density dominates the evolutionary result.
- the receptor and the coding gene have more opportunities and matches. In vivo binding, more of this receptor should be retained under defined wash conditions, thereby being captured and expanded during subsequent screening.
- more stable proteins can be isolated by using phage display technology or other directed molecular display techniques.
- the inventors have devised a directed evolutionary library of TCR protein hydrophobic cores to isolate more stable proteins or TCRs. Such a hydrophobic core has been shown to have substantially no effect on the binding strength of TCR to its ligand pMHC or pHLA, since TCR binds to pMHC through its complementarity determining region (CDR).
- phage display technology can be used to isolate more stable protein constructs.
- this hypothesis is tested with a TCR (hereinafter referred to as MAGE A3 TCR) extracellular domain specific for the cancer antigen MAGE A3 HLA A1.
- MAGE A3 TCR TCR
- the extracellular domain is synthesized according to the sequence in the patent literature.
- ELI SA enzyme-linked immunosorbent assay
- the A and ⁇ chains of the TCR displayed by the phage are detected by ELI SA.
- No binding function was found in the single-chain TCR form (sTv) composed of the variable domains.
- the library of restriction-random mutations of the single-chain TCR (sTv) variable domain hydrophobic core was cloned into the phage display vector and after several rounds of screening, some highly stable clones were unexpectedly obtained, and then detected by ELISA. These clones can be found to bind to the corresponding pMHC.
- TCR T cell receptor
- polypeptides of the invention may also include other mutations outside of the hydrophobic core region, particularly those that increase affinity and mutations in amino acid residues that are exposed to the surface in the TCR variable domain.
- hydrophobic core regions include, but are not limited to: 1-6 (usually 1-5, preferably 1-3, more preferably 1-2, optimally 1) Amino acid deletions, insertions and/or substitutions, one or several (usually 5 or less, preferably 3 or less, more preferably 2 or less) amino acids are added to the C-terminus and/or the N-terminus.
- 1-6 usually 1-5, preferably 1-3, more preferably 1-2, optimally 1
- Amino acid deletions, insertions and/or substitutions one or several (usually 5 or less, preferably 3 or less, more preferably 2 or less) amino acids are added to the C-terminus and/or the N-terminus.
- amino acids when substituted with amino acids of similar or similar properties, the function of the protein is generally not altered. Add one or both at the C-terminus and / or N-terminus Several amino acids usually do not alter the structure and function of the protein.
- the term also encompasses polypeptides of the invention in both monomeric and multimeric forms
- amino acid names in this article are identified by the internationally accepted single letter, and the corresponding amino acid names are abbreviated as: Ala (A), Arg (R), Asn (N), Asp (D), Cys (C), Gin (Q), Glu (E), Gly (G), Hi s (H), l ie (1), Leu (L), Lys (K), Met (M), Phe (F) , Pro (P), Ser (S), Thr (T), Trp (W), Tyr (Y), Val (V).
- amino acid substitution is written in such a way that L19V represents the substitution of V (valine) at the 19th position of the position number given in the top GT, and the meaning of other identical amino acid substitutions is referred to this example. .
- the invention also encompasses active fragments, derivatives and analogs of the polypeptides of the invention.
- fragment refers to a polypeptide that binds to a ligand molecule.
- a polypeptide fragment, derivative or analog of the invention may be (i) a polypeptide having one or more conservative or non-conservative amino acid residues (preferably conservative amino acid residues) substituted, or (ii) at one or more a polypeptide having a substituent group in one amino acid residue, or (iii) a polypeptide formed by fusing a TCR of the present invention with another compound (such as a compound which prolongs the half-life of the polypeptide, such as polyethylene glycol), or (iv) an additional amino acid.
- a polypeptide formed by the fusion of the polypeptide sequence a fusion protein formed by fusion with a leader sequence, a secretory sequence or a tag sequence such as 6His).
- a preferred class of reactive derivatives means having up to 5, preferably up to 3, more preferably up to 2, and optimally 1 amino acid is replaced by an amino acid of similar or similar nature to form a polypeptide.
- These conservation variant polypeptides are preferably produced by amino acid substitutions according to Table A.
- the invention also provides analogs of the TCR of the invention.
- the difference between these analogs and the pro-TCR polypeptide of the present invention may be a difference in amino acid sequence, a difference in the modification form which does not affect the sequence, or a combination thereof.
- Analogs also include analogs having residues other than the native L-amino acid (e.g., D-amino acids), as well as analogs having non-naturally occurring or synthetic amino acids (e.g., beta, ⁇ -amino acids). It is to be understood that the polypeptide of the present invention is not limited to the representative polypeptides exemplified above.
- Modifications include: chemically derivatized forms of the polypeptide, such as acetylation or carboxylation, in vivo or in vitro. Modifications also include glycosylation, such as those produced by glycosylation modifications in the synthesis and processing of the polypeptide or in further processing steps. Such modification can be accomplished by exposing the polypeptide to an enzyme that performs glycosylation, such as a mammalian glycosylation enzyme or a deglycosylation enzyme. Modified forms also include sequences having phosphorylated amino acid residues such as phosphotyrosine, phosphoserine, phosphothreonine. Also included are polypeptides modified to increase their resistance to proteolytic properties or to optimize solubility properties.
- the polypeptides of the invention may also be used in the form of a salt derived from a pharmaceutically or physiologically acceptable acid or base.
- These salts include, but are not limited to, salts formed with: hydrochloric acid, hydrobromic acid, sulfuric acid, citric acid, tartaric acid, phosphoric acid, lactic acid, pyruvic acid, acetic acid, succinic acid, oxalic acid, fumaric acid, malay Acid, oxaloacetic acid, methanesulfonic acid, ethanesulfonic acid, benzenesulfonic acid, or isethionic acid.
- Other salts include: salts with alkali or alkaline earth metals such as sodium, potassium, calcium or magnesium, as well as esters, carbamates or other conventional The form of "prodrugs".
- the polypeptides of the invention may be provided in the form of a multivalent complex.
- the multivalent TCR complex of the present invention comprises two, three, four or more T cell receptor molecules linked to another molecule. Coding sequence
- the invention also relates to polynucleotides encoding the TCRs of the invention.
- the polynucleotide of the present invention may be in the form of DNA or RNA. ⁇ can be a coded chain or a non-coded chain.
- the coding region sequence encoding the mature polypeptide may be the same as the coding region sequence shown in SEQ ID NO: 10 or a degenerate variant.
- degenerate variant in the present invention refers to a nucleic acid sequence which encodes a protein having SEQ ID NO: 9, but differs from the corresponding coding region sequence in SEQ ID NO: 10.
- the full-length nucleotide sequence of the present invention or a fragment thereof can be usually obtained by, but not limited to, PCR amplification, recombinant methods or synthetic methods.
- DNA sequences encoding the polypeptides of the present invention (or fragments thereof, or derivatives thereof) have been obtained by chemical synthesis.
- the DNA sequence can then be introduced into various existing Sa molecules (e.g., vectors) and cells known in the art.
- the invention also relates to vectors comprising the polynucleotides of the invention, and to host cells genetically engineered using the vectors or coding sequences of the invention.
- the invention also encompasses polyclonal and monoclonal antibodies, particularly monoclonal antibodies, that are specific for a TCR polypeptide of the invention.
- One method of producing the TCR of the present invention is to select a highly stable TCR from a diverse library of phage particles displaying such TCR.
- Mutations can be carried out by any suitable method, including but not limited to those based on polymerase chain reaction (PCR), restriction enzyme-based cloning or linkage-independent cloning (LIC) methods. Many standard molecular biology textbooks detail these methods. Further details of polymerase chain reaction (PCR) mutagenesis and cloning based on restriction enzymes can be found in Sambrook and Russell, (2001) Molecular Cloning-A Laboratory Manual (Third Edition). CSHL Press. More information on the LIC method can be found (Rashtchian, (1995) Curr Opin Bi otechnol 6 (1): 30-6).
- PCR polymerase chain reaction
- LIC linkage-independent cloning
- the polypeptide of the invention may be a recombinant polypeptide or a synthetic polypeptide.
- the polypeptides of the invention may be chemically synthesized, or recombinant. Accordingly, the polypeptide of the present invention can be artificially synthesized by a conventional method or can be produced by a recombinant method.
- the polynucleotide of the present invention can be utilized to express or produce a recombinant polypeptide of the present invention by conventional recombinant DNA techniques. Generally there are the following steps:
- TCR polypeptide of the present invention is isolated and purified from a culture medium or a cell.
- the recombinant polypeptide can be expressed intracellularly, or on the cell membrane, or secreted extracellularly. If desired, the recombinant protein can be isolated and purified by various separation methods using its physical, chemical, and other properties. These methods are well known to those skilled in the art. Examples of such methods include, but are not limited to: conventional renaturation treatment, treatment with a protein precipitant (salting method), centrifugation, osmotic sterilizing, ultra-treatment, ultra-centrifugation, molecular sieve chromatography (gel filtration), adsorption layer Analysis, ion exchange chromatography, high performance liquid chromatography (HPLC) and various other liquid chromatography techniques and combinations of these methods.
- Pharmaceutical composition and method of administration include, but are not limited to: conventional renaturation treatment, treatment with a protein precipitant (salting method), centrifugation, osmotic sterilizing, ultra-treatment, ultra-centrifugation, molecular sieve chromatography (gel filtration
- the TCR of the invention and the TCR transfected T cells of the invention can be provided in a pharmaceutical composition together with a pharmaceutically acceptable carrier.
- the TCRs, multivalent TCR complexes and cells of the invention are typically provided as part of a sterile pharmaceutical composition, which typically comprises a pharmaceutically acceptable carrier.
- the pharmaceutical composition can be in any suitable form (depending on the method desired for administration to the patient). It can be provided in unit dosage form, usually in a sealed container, and can be provided as part of a kit. Such kits (but not required) include instructions for use. It can include a plurality of said unit dosage forms.
- polypeptides of the invention may be used alone or in combination or in combination with other therapeutic agents (e.g., formulated in the same pharmaceutical composition).
- Therapeutic agents that can be combined or coupled to the TCRs of the invention include, but are not limited to: 1. Radionuclides (Koppe et al, 2005, Cancer metastas is reviews 24, 539); 2. Biotoxins (Chaudhary et al, 1989, Nature 339, 394; Epel et al., 2002, Cancer Immunology and Immunotherapy 51, 565); 3. Cytokines (Gi llies et al., 1992, Proceedings of the National Academy of Sciences) (PNAS) 89, 1428; Card et al, 2004, Cancer Immunology and Immunotherapy 53 , 345; Hal in et al, 2003, Cancer Research 63, 3202); 4.
- Antibody Fc Fragments (Mosquera et al, 2005, The Journal Of Immunology 174, 4381); 5. Antibody scFv fragments (Zhu et al, 1995, International Journal of Cancer 62, 319); 6. Gold nanoparticles/nanorods (Lapotko et al., 2005, Cancer letters 239, 36; Huang et al., 2006, Journal of the American Chemical Society 128, 2115); 7. Viral particles (Peng et al, 2004, Gene therapy 1 1, 1234); 8. Liposomes (Mamot et al, 2005, Cancer research 65, 11631); 9. Nanomagnetic particles; 10. A prodrug activating enzyme (for example, DT-diaphorase (DTD) or biphenyl hydrolase-like protein (BraD); 1 1. a chemotherapeutic agent (for example, cisplatin) or the like.
- DTD DT-diaphorase
- BrainD biphenyl hydrolase-like protein
- the pharmaceutical composition may also contain a pharmaceutically acceptable carrier.
- pharmaceutically acceptable carrier refers to a carrier for the administration of a therapeutic agent.
- pharmaceutical carriers which do not themselves induce the production of antibodies harmful to the individual receiving the composition and which are not excessively toxic after administration. These vectors are well known to those of ordinary skill in the art. A full discussion of pharmaceutically acceptable excipients can be found in Remington's Pharmaceutical Sciences (Mack Pub. Co., N. J. 1991).
- Such carriers include, but are not limited to, saline, buffer, dextrose, water, glycerol, ethanol, adjuvants, and combinations thereof.
- the pharmaceutically acceptable carrier in the therapeutic composition may contain a liquid such as water, saline, glycerol and ethanol.
- auxiliary substances such as wetting or emulsifying agents, pH buffering substances and the like may also be present in these carriers.
- the therapeutic compositions may be in the form of injectables, such as liquid solutions or suspensions; solid forms such as liquid carriers, which may be formulated in solution or suspension prior to injection.
- composition of the invention can be administered by conventional routes including, but not limited to, intraocular, intramuscular, intravenous, subcutaneous, intradermal, or topical administration.
- the object to be prevented or treated may be an animal; especially a human.
- composition of the present invention When used for actual treatment, a pharmaceutical composition of various different dosage forms may be employed depending on the use.
- a pharmaceutical composition of various different dosage forms may be employed depending on the use.
- an injection, an oral preparation, or the like can be exemplified.
- compositions can be formulated by mixing, diluting or dissolving according to conventional methods, and occasionally adding suitable pharmaceutical additives such as excipients, disintegrating agents, binders, lubricants, diluents, buffers, isotonicity (i sotonic i ties preservatives, wetting agents, emulsifiers, dispersants, stabilizers and co-solvents, and the formulation process can be carried out in a customary manner depending on the dosage form.
- suitable pharmaceutical additives such as excipients, disintegrating agents, binders, lubricants, diluents, buffers, isotonicity (i sotonic i ties preservatives, wetting agents, emulsifiers, dispersants, stabilizers and co-solvents, and the formulation process can be carried out in a customary manner depending on the dosage form.
- compositions of the invention may also be administered in the form of sustained release agents.
- the polypeptide of the present invention can be incorporated into a pill or microcapsule in which the sustained release polymer is used as a carrier, and then the pill or microcapsule is surgically implanted into the tissue to be treated.
- the sustained-release polymer an ethylene-vinyl acetate copolymer, polyhydroxymethacrylate (polyhydrometaacrylate polyacrylamide, polyvinylpyrrolidone, or the like) may be mentioned.
- Methylcellulose, lactic acid polymer, lactic acid-glycolic acid copolymer and the like are preferably exemplified by biodegradable polymers such as lactic acid polymers and lactic acid-glycolic acid copolymers.
- the dose of the polypeptide of the present invention or a pharmaceutically acceptable salt thereof as an active ingredient may be based on the weight, age, sex, and degree of symptoms of each patient to be treated. Determine it reasonably.
- the TCR of the present invention can be used as a pharmaceutical or diagnostic reagent. Modifications or other modifications may be made to obtain features that are more suitable for use as a drug or diagnostic agent.
- the medicament or diagnostic reagent can be used to treat or diagnose a variety of different diseases including, but not limited to: cancer (eg, kidney cancer, ovarian cancer, head and neck cancer, testicular cancer, lung cancer, stomach cancer, cervical cancer, bladder) Cancer, prostate cancer or melanoma, etc., autoimmune diseases, viral infectious diseases, transplant rejection and graft versus host disease.
- Drug localization or targeted administration can be achieved by the specificity of the TCR of the present invention, thereby improving the therapeutic or diagnostic effects of various diseases.
- targeting tumors or metastatic cancer can increase the effects of toxins or immune stimuli.
- an autoimmune disease it is possible to specifically inhibit an immune response to normal cells or tissues, or to slowly release an immunosuppressive drug, so that it produces more local effects over a longer period of time, thereby The impact of immunity is minimized.
- the role of immunosuppression can be optimized in the same way in preventing transplant rejection.
- viral diseases in which a drug already exists such as HIV, SIV, EBV, CMV, HCV, HBV, it is also beneficial that the drug releases or exerts an activating function in the vicinity of the infected cell region.
- the TCR of the present invention can be used to modulate T cell activation, and the TCR of the present invention inhibits T cell activation by binding to specific pMHC.
- Autoimmune diseases involving T cell-mediated inflammation and/or tissue damage may be suitable for this method, such as type I diabetes.
- the TCR of the present invention can also be used for the purpose of delivering cytotoxic agents to cancer cells, or can be used to transfect T cells, thereby enabling them to destroy tumor cells presenting HLA complexes, in a process known as adoptive immunotherapy. Give the patient.
- the TCR of the present invention can also be used as a diagnostic reagent.
- the TCR of the present invention is labeled with a detectable label, such as a label for diagnostic purposes, to detect binding between the MHC-peptide and the MHC-peptide specific TCR of the invention.
- a detectable label such as a label for diagnostic purposes
- Fluorescently labeled TCR multimers are suitable for FACS analysis and can be used to detect antigen presenting cells carrying TCR-specific peptides.
- TCR of the invention that binds to a conjugate, including but not limited to an anti-CD3 antibody
- the T cells are redirected to target cells that present a particular antigen, such as tumor cells.
- the highly stable sputum cell receptor of the present invention can be used for the purpose of studying the interaction between TCR and pMHC (peptide-major histocompatibility complex) and the diagnosis and treatment of diseases.
- TCR polypeptide of the invention has high stability
- TCR polypeptides with high stability and high affinity can be further screened.
- the primers designed as shown in Table 1 were subjected to directed point mutation of the chemically synthesized TCR ci chain and the ⁇ chain variable domain amino acid sequence (refer to Patent Document W02012/013913, respectively). These mutations cause the hydrophobic residues exposed to the surface in the TCR alpha and beta chain variable domains to become hydrophilic or polar residues for use in making templates for hydrophobic core mutant libraries.
- the process of mutating the surface hydrophobic residue V at position 20 of the a chain to the hydrophilic residue S is accomplished by site-directed mutagenesis when constructing a hydrophobic core mutant library.
- YW800, YW80U YW802, YW803, YW804 are primers designed for site-directed mutagenesis ⁇ chain variable domain
- YW806 and YW807 are primers designed to direct the mutant ⁇ chain variable domain
- YW805 is a ligation primer for introducing flexible peptide chains.
- the sTv was constructed by PCR according to the primer connection method shown in Fig. 4.
- the sTv was named MAGE-sTv-WT.
- the first step PCR uses the following primer pairs for YW801/YW803 (a chain), YW802/YW804 (a chain), YW806/YW807 ( ⁇ chain) for PCR.
- the reaction procedure was: denaturation at 98 °C for 30 seconds, repeated cycles of 25 cycles of 94 ° C for 5 seconds, 55 ° C for 10 seconds, and 72 ° C for 20 seconds.
- the second step PCR uses the first step PCR purified product and the chemically synthesized flexible peptide single-stranded DNA as a template, and YW800/YW807 as a primer for the second step PCR.
- the reaction procedure was: denaturation at 98 ° C for 30 seconds, repeated cycles of 30 cycles of 94 ° C for 5 seconds, 55 ° C for 10 seconds, 72 ° C for 30 seconds, and once for 72 ° C for 5 minutes.
- the purified PCR product of the second step is digested and ligated into the phage display vector.
- Ncol and Notll-cleaved DNA sequence encoding MAGE-sTv-WT was ligated into the pET-28a vector (Novagen) cleaved with Ncol and Notll.
- the ligated plasmid was transformed into a conventional competent E. coli ( ⁇ cAer ⁇ ac ⁇ ) strain BL21
- Figures 2a and 3a show the alpha-chain variable domain and the beta-chain variable domain amino acid sequence of MAGE-sTv-WT, respectively.
- FIGS. 9 and 11 the optimized amino acid positions are shown in bold and underlined.
- Figures 2b and 3b show the alpha-chain variable domain and beta-chain variable domain nucleotide sequences of MAGE-sTv-WT, respectively (SEQ ID NOS: 10 and 12).
- Example 3 Expression, renaturation and purification of MAGE-sTv-WT
- the expression plasmid containing MAGE-sTv-WT obtained in Example 2 was transformed into a medium plate of Escherichia coli strain Rosetta (DE3) (Merck), cultured at 37 ° C overnight, and the single colony was contained at 37 ° C.
- the natamycin medium was cultured to 0D 6 . .
- protein expression was then induced with 0.5 mM IPTG for 4 hours, and cells were harvested by centrifugation at 5,000 rpm for 15 minutes using a Fisher Thermo Sovall R6+ centrifuge. Cell pellets were lysed with Bugbuster MasterMix (Merck).
- the inclusion body pellet was recovered by centrifugation at 6,000 g for 15 minutes using a FisherThermo Sovall X1R centrifuge. The inclusion bodies were then washed three times with a 10-fold diluted Bugbuster solution to remove cell debris and membrane components. The inclusion bodies were then dissolved using the following buffer: 20 mM Tris, pH 9.0, 8 M urea. After quantification by BCA method, the fraction was 10 mg per tube and frozen at -80 °C.
- the dialyzed renaturation MAGE-sTv-WT was centrifuged and the anion exchange column Q HP 5 ml (GE) was washed with a linear gradient of 0-1 M NaCl prepared with 20 mM Tris pH 9.0 using an AKTA Purifier (GE).
- the debound protein was 10 column volumes, and the elution peak (relative molecular mass of approximately 28 kD) was collected and analyzed by SDS-PAGE (Bio-Rad).
- the fraction containing MAGE-sTv-WT was concentrated and further purified by a gel filtration column (Superdex 75 10/300, GE Healthcare).
- the target component is run on SDS-PAGE gel and analyzed, and then the target component is stored at 4 °C.
- the target peak fractions were combined and concentrated and replaced with 10 mM HEPES buffer pH 7.4.
- the eluted fraction was further tested for purity by gel filtration.
- the conditions are: Column Agilent Bio SEC-3 (300 ⁇ , ⁇ 7.8 ⁇ 300 mm), mobile phase 150 mM phosphate buffer, flow rate 0.5 mL/min, column temperature 25 ° C, UV detection wavelength 214 nm.
- a library of MAGE-sTv-WT hydrophobic core variants was generated using phage display technology to screen and identify highly stable mutants.
- the hydrophobic core mutant library was constructed by mutagenesis of the hydrophobic core site of MAGE-sTv-WT, and the library was panned and screened.
- TCR phage library differs in the design of hydrophobic core mutant library.
- Primers are designed based on the hydrophobic core sites of the template strand, while the high affinity TCR library is constructed by designing primers based on the CDR regions of the template strand.
- the designed primers are shown in Table 2 below.
- the hydrophobic core of the highly stable sTv mutant strain screened by the above method was mutated.
- the highly stable mutant strains screened were named MG29, P8F1 and P8F2.
- the amino acid of one or more of the following hydrophobic core positions of the ⁇ chain variable domain is mutated: 19th, 21st, 91st; and/or its ⁇ chain variable domain
- the amino acid of one or more of the following hydrophobic core positions is mutated: position 91, the fourth strand of the amino acid sequence of the ⁇ chain J gene short peptide. More specifically, according to the position number in the top GT, it has one or more of the following alpha chain variable domain amino acid residues 19V, 211, 91L and/or one or more of the following beta chain variable domain amino acid residues 91F or
- the specific a-chain variable domain amino acid sequences are SEQ ID NOs: 15 and 17; the ⁇ -chain variable domain amino acid sequences are SEQ ID NO: 16 and 18.
- the amino acid sequences of the ⁇ and ⁇ chain variable domains constituting the mutant strain MG29 are SEQ ID NOs: 15 and 16, respectively, as shown in Figures 6a and 6b.
- amino acid sequences of the ⁇ and ⁇ chain variable domains of the mutant strain P8F1 are SEQ ID NOs: 17 and 18, respectively, as shown in Figures 7a and 7b; the amino acid sequences of the a and ⁇ chain variable domains of the mutant P8F2 SEQ ID NO: 15 and 18, respectively, as shown in Figures 8a and 8b;
- the high-stability mutants MG29, P8F1, P8F2 with high 0D values and the MAGE-sTv-WT with no hydrophobic mutations were compared for their 0D values, and the specificity of the mutants was verified.
- the supernatant of the overnight culture was collected by centrifugation, and the phage in the supernatant was precipitated with 1/4 volume ratio of PEG/NaCl, placed on ice for 1 h, and the pellet was collected by centrifugation and resuspended in 3 mL of PBS.
- Hydrophobic core-optimized clones can display sTv to varying degrees and specifically bind to their original ligand MAGE A3 pHLA-Al antigen, but have no junction with other unrelated antigens such as EBV, influenza and NY-ES0-1 antigen. Hehe.
- the binding of the sTv of the hydrophobic core mutation detected by phage display to MG29, P8F1 and P8F2 and the specific antigen should not be due to the fact that its affinity is stronger than that of the wild TCR, which was proved in Example 15.
- the partially hydrophobic core of the high stability variant screened in Example 4 was introduced into several other TCR molecules according to a site-directed mutagenesis method well known to those skilled in the art to construct a highly stable sTv molecule.
- variable domains of the alpha and beta chains of the wild-type TCR molecule of the specific antigen were constructed into single-stranded forms of the above several molecules, respectively, and designated as LC13-WT, JM22-WT and 1G4-WT, respectively.
- amino acid sequences of the ⁇ 13 and ⁇ chain variable domains of LC13-WT are SEQ ID NO: 29 and SEQ ID NO: 30, respectively, as shown in Figures 10a and 10b; the ⁇ -chain and ⁇ -chain variable domains of JM22-WT
- the amino acid sequences are SEQ ID NO: 31 and SEQ ID NO: 32, respectively, as shown in Figures 11a and lib; the amino acid sequences of the ⁇ G and ⁇ chain variable domains of 1G4-WT are SEQ ID NO: 33 and SEQ ID NO, respectively. : 34, as shown in Figures 12a and 12b.
- the partial hydrophobic core of the high stability variant screened in Example 4 was separately introduced into the LC13-WT, JM22-WT and 1G4-WT molecules by site-directed mutagenesis well known to those skilled in the art, and the mutation was introduced.
- the molecules are designated LC13-sTv, JM22-sTv, and 1G4-STV, respectively, and the introduced hydrophobic core is indicated by an underlined bold letter.
- amino acid sequences of the a chain and the ⁇ chain variable domain of LC13-sTv are SEQ ID ⁇ 0:35 and SEQ ID ⁇ 0:36, respectively, as shown in Figures 13a and 13b, wherein the hydrophobic core introduced in the ⁇ chain variable domain is 11L, 13V, 211 and 911, the hydrophobic core introduced in the ⁇ chain variable domain is 94L; the amino acid sequences of the ⁇ chain and ⁇ chain variable domains of JM22-sTv are SEQ ID NO: 37 and SEQ ID NO: 38, respectively.
- the hydrophobic core introduced in the ⁇ chain variable domain is 19V and 211, and the hydrophobic core introduced in the ⁇ chain variable domain is 911 and 94L;
- the ⁇ chain and ⁇ chain of 1G4-STV can be
- the variable domain amino acid sequences are SEQ ID NO: 39 and SEQ ID NO: 40, respectively, as shown in Figures 15a and 15b, and the hydrophobic core introduced in the ⁇ chain variable domain is 19V and 211, and the ⁇ chain variable domain thereof
- the hydrophobic core introduced in the 19V, 911, 94L and the sixth of the J gene are the T.
- the above location numbers are based on the location numbers listed in IMGT.
- the linker for constructing the above single-stranded molecule may be any suitable sequence, and the preferred amino acid sequence of the present invention is SEQ ID NO: 41, as shown in FIG.
- Expression, renaturation, and protein LC13-WT and LC13-sTv were expressed by the method described in Example 3. After purification, the gel filtration column was purified and run SDS-PAGE gel, and the SEC map of the two proteins was made by gel filtration, and the expression amount, the amount of protein obtained after purification and the protein refolding yield were calculated. Among them, the expression amount was 1 L of E. coli induced expression and purification of the inclusion body. The amount of protein obtained after purification was 1 L of E. coli induced expression and purification, and the obtained inclusion body was renatured and purified to obtain the amount of protein.
- Protein refolding yield (%) 100 * The amount of protein obtained after purification (mg) / the amount of inclusion body used for renaturation (mg).
- the expression amount and protein refolding yield referred to in the present invention are calculated according to the above calculation methods, unless otherwise specified.
- the Tm values of the purified proteins LC13-WT and LC13-sTv were determined by a differential scanning calorimeter (Nano DSC) of TA (waters), USA.
- the scanning range is 10-9CTC
- the heating rate is 1 °C /min
- the loading is 90 ( ⁇ L.
- the Tm value is obtained by fitting the two-dimensional scaled fitting model of the analysis software Nanoanalyze.
- Table 3 below lists the expression levels of LC13-WT and LC13-sTv, the amount of protein obtained after purification, and the refolding yield of the protein.
- Figure 17 is a SDS-PAGE gel of the protein LC13-WT and LC13-sTv obtained after purification through a gel filtration column (Superdex 75 10/300, GE Healthcare) as described in Example 3.
- the gel map shows that the bands formed by the LC13-WT protein after purification are not uniform, and the LC13-sTv can form a single band with high purity.
- the renaturation of LC13-sTv is much better than that of LC13-WT.
- Figures 18a and 18b show the SEC profiles of the proteins LC13-WT and LC13-sTv, respectively. From the map, the purified protein LC13-WT has no peak, and LC13-sTv can form a single and symmetric elution peak. The renaturation of LC13-sTv was significantly better than LC13-WT.
- LC13-WT After refolding, LC13-WT showed minimal protein content in the correct conformation, no obvious protein unfolding endothermic peak, and the Tm value of LC13-sTv after hydrophobic core mutation was not obtained by the analysis software Nanoanalyze.
- the temperature is 43. 6 ° C, and its DSC curve is shown in Figure 47. This indicates that LC13-sTv is more versatile, more resistant to unfolding, more resistant to inappropriate or undesirable folding, and has a significantly improved thermal stability compared to LC13-WT.
- LC13-sTv modified by hydrophobic core
- the unmodified LC13-WT is more renaturation, more resistant to unfolding, more resistant to inappropriate or undesirable folding, higher yield of protein refolding, and a significant increase in thermal stability. Therefore, LC13-sTv has a significant improvement over LC 13-WT stability.
- the amount of stability improvement was calculated from the data of protein refolding yield, and the stability of LC13-sTv was 35 times higher than that of LC13-WT in the present invention.
- the proteins JM22-WT and JM22-sTv were expressed, renatured and purified by the method described in Example 3.
- the gel filtration column was purified and run SDS-PAGE gel, and the SEC pattern of the two proteins was determined by gel filtration.
- the expression amount, the amount of protein obtained after purification, and the protein refolding yield were calculated, and the Tm value was determined by the method described in Example 6.
- Table 4 lists the expression levels of JM22-WT and JM22-sTv, the amount of protein obtained after purification, and the protein refolding yield.
- Figure 19 is an SDS-PAGE gel of proteins JM22-WT and JM22-sTv obtained after purification through a gel filtration column (Superdex 75 10/300, GE Healthcare) as described in Example 3.
- the glue map shows that the monomer bands formed by the renaturation of JM22-WT are not uniform, and there are three bands, and JM22-sTv can form a single band of monomers with high purity.
- the renaturation of JM22-sTv is much better than that of JM22-WT.
- Figures 20a and 20b show the SEC profiles of the proteins JM22-WT and JM22-sTv, respectively. From the map, the purified protein JM22-WT forms a single elution peak with a low signal, and the purified JM22-sTv can A single and symmetric elution peak is formed, indicating that the renaturation of JM22-sTv is significantly better than JM22-WT.
- Figures 48a and 48b are DSC plots of proteins JM22-WT and JM22-sTv, respectively. Due to the minimal protein content of the correct conformation of JM22- WT, there is no obvious protein unfolding endothermic peak. The Tm value is not obtained by the analysis software Nanoanalyze, and the Tm of JM22-sTv after the hydrophobic core mutation. The value is 43. 7 °C. From the above DSC curve, JM22-sTv is more versatile than JM22-WT. Stronger, more resistant to unfolding, more resistant to improper or undesirable folding and a significant increase in thermal stability.
- the hydrophobic core modified JM22-sTv Compared with the hydrophobic core, the unmodified JM22-WT has stronger renaturation ability, more anti-folding, more resistance to inappropriate or undesired folding and thermal stability, and a significant increase in protein refolding yield. Therefore, the JM22-sTv of the present invention has a significantly improved stability compared to JM22-WT.
- the amount of stability improvement was calculated from the data of the refolding yield of the protein. In the present invention, the stability of JM22-sTv was improved by 4200% with respect to JM22-WT.
- the proteins 1G4-WT and 1G4-STV were expressed, renatured and purified by the method described in Example 3.
- the gel filtration column was purified and run SDS-PAGE gel, and the SEC pattern of the two proteins was determined by gel filtration. At the same time, the expression amount, the amount of protein obtained after purification, and the yield were calculated.
- Table 5 below lists the expression levels of 1G4-WT and 1G4-STV, the amount of protein obtained after purification, and the protein reproducibility yield.
- the 1G4-STV protein introduced into the hydrophobic core was increased by 2.6 times compared with the 1G4-WT protein in which the hydrophobic core was not mutated.
- Figure 21 is an SDS-PAGE gel of Protein 1G4-WT and lG4-sTv obtained after purification through a gel filtration column (Superdex 75 10/300, GE Healthcare) as described in Example 3.
- the gel image shows that the bands formed by the 1G4-WT protein after purification are not uniform, forming two bands, and 1G4-STV can form a single band of monomers with high purity.
- the renaturation of 1G4-STV is much better than that of 1G4-WT.
- Figures 22a and 22b show the SEC profiles of the proteins 1G4-WT and 1G4-STV, respectively. From the map, the purified protein 1G4-WT has a single elution peak and a lower signal, while the purified 1G4-STV can A single and symmetric elution peak is formed, indicating that the renaturation of 1G4-STV is significantly better than that of 1G4-WT.
- 1G4-STV modified by hydrophobic core is more hydrophobic than 1G4-STV.
- the core unmodified 1G4-WT has stronger renaturation ability, higher expression level, and higher protein refolding yield. Therefore, the 1G4-STV of the present invention has a significantly improved stability compared to 1G4-WT. Take The data of protein refolding yield was calculated for the amount of stability improvement. In the present invention, the stability of 1G4-STV was increased by 260% relative to 1G4-WT.
- the surface amino acid residues of the hydrophobic core and the variable domain were mutated by using 1G4-STV as a template to construct a library and screen for highly stable molecules.
- the hydrophobic core site to be mutated has been indicated in bold underlined in SEQ ID NO: 42 and the surface amino acid residues that need to be mutated are shown in bold, as shown in Figure 23.
- Example 4 The basic method employed in library construction has been described in Example 4.
- three libraries were constructed for sites that required mutation, and the hydrophobic core sites required for mutation were all in library 1, and libraries 2 and 3 were constructed for surface amino acid residues.
- the 1G4-STV plasmid was used as a template, and the mutated DNA fragment was obtained by overlapping PCR with the designed mutant primer, and then the fragment was cloned into the pUC19-based phage plasmid vector pLitmus28 by Ncol/Notl digestion. (NEB).
- the ligated DNA was electroporated into TGI competent cells (lucigen), and a total of three phage plasmid vector libraries were obtained, and the storage capacity was about 1 X 10 9 -3 X 10 9 in terms of colony number.
- the lawns grown from the three libraries were scraped off and added to a final concentration of 20% glycerol and stored at -80 °C.
- Table 8, Table 9, and Table 10 below are primers designed for Library 1, Library 2, and Library 3, respectively.
- Primer name Primer sequence (5' -3') SEQ ID NO :
- the phage grown in the library is concentrated after precipitation.
- Example 10 Stability verification of clones screened in Example 9
- Example 9 The 11 clones screened in Example 9 were examined by the ELISA test procedure described in Example 4. The 0D value was measured and the antigen specificity was verified, and the results are shown in Fig. 24. This result shows that 11 clones have high 0D values and can specifically bind to their original ligand antigen HLA-A2/SLL ⁇ ITQC (NY-ES0-1 tumor-specific antigen), and have no binding to other unrelated antigens. The binding of these sTvs detected by phage display to the antigen HLA-A2/SLLMWITQC should not be due to their affinity being stronger than wild TCR, as demonstrated in Example 11.
- the above 11 mutants are mutated at one or more of the following hydrophobic core positions: the 11th, 13th or 94th and/or ⁇ chain of the alpha chain variable region
- the 11th, 13th or 94th position of the variable zone comprises one or more of the following alpha chain variable region hydrophobic core amino acid residues 11M, 11E, 13R, 13K, 94V or 941 and/or beta chain variable region hydrophobic core amino acid residues 11L, 11V, 13V or 94V.
- the clones we screened also contain one or more of the following alpha chain variable region amino acid residues 4L, 12N, 16S, 93N, 93R, 97N, 100G, 105S or ⁇ chain J gene reciprocal first D and/or ⁇ chain variable region amino acid residues 41, 101 ⁇ chain J gene reciprocal first position is D or the third last digit is E.
- the selected 11 clones were ligated, expressed, renatured and purified by the methods described in Example 2 and Example 3.
- the Tm values of the above 11 clones were determined using a differential scanning calorimeter (Nano DSC) of TA (waters), USA. The scanning range is 10-90 ° C, the heating rate is rC /min, and the loading is 90 ( ⁇ L.
- the Tm value is obtained by fitting the two-statescaled fitting model of the analysis software Nanoanalyze. The results are shown in Fig. 27 and As shown in Table 9, the Tm value is not less than 37. 9 ° C, and has a distinct protein unfolding endothermic peak.
- the 1G4-WT is identical to the expression, renaturation, purification process and DSC experimental conditions of the above clones.
- the DSC results are shown in Figure 28. As can be seen from the figure, there is no obvious endothermic peak of protein unfolding, indicating that the protein content of the correct conformation is extremely small. Compare the DSC map of the above 11 clones with the 1G4-WT The DSC map results showed that the clones screened were more resistant to unfolding than 1G4-WT, more resistant to inappropriate or undesirable folding, more renaturation and a significant increase in thermal stability. Therefore, we screened clones. The stability is much higher than that of the hydrophobic core without mutation 1G4 - WT.
- the mutant strains G9 G13 and G15 described in Example 10 were expressed, renatured and purified by the method described in Example 3. After purification by gel filtration column, SDS-PAGE gel was run, and gel filtration was used. The SEC profile of the protein was simultaneously calculated for its expression, the amount of protein obtained after purification, and the refolding yield of the protein, and compared with 1G4-WT.
- Table 10 lists the expression levels of 1G4-WT G9 G13 and G15, the amount of protein obtained after purification, and the reproducibility yield of the protein.
- Figure 30 is an SDS-PAGE gel of Protein 1G4-WT, G9, G13 and G15 obtained after purification through a gel filtration column (Superdex 75 10/300, GE Healthcare) as described in Example 3.
- the gel map shows that the bands formed by the 1G4-WT protein after purification are not uniform, and the modified G9, G13 and G15 are capable of forming a single band of monomers with high purity. Note that the renaturation of G9, G13 and G15 is better than 1G4-WT.
- Figures 31a, 31b, and 31c show the SEC profiles of proteins G9, G13, and G15, respectively. From the SEC profile of 1G4-WT in Figure 22a, the purified protein 1G4O L
- the elution peak formed by OO LWT is not single and the signal is low, and the purified G9, G13 and G15 can form a single OG-OL and symmetric elution peak, indicating that the renaturation of G9, G13 and G15 is significant. Better than 1G4-WT.
- the Tm value of G15 was determined by the method described in Example 10 to be 46. 6 ° C, and the DSC chart is shown in Fig. 46. According to the results of the measurement in Example 10, the Tm values of the mutant strains G9 and G13 were also relatively high, being 49.55 ° C and 49. 63 ° C, respectively.
- the BIAcore T200 real-time analysis system was used to detect the binding of proteins G9, G13 and G15 to their ligands.
- the results showed that the affinity of the three sTv proteins to the antigen HLA-A2/SLLMWITQC was not superior to that of the wild-type 1G4 TCR.
- the dissociation equilibrium constant of the 1G4TCR binding antigen HLA-A2/SLLMWITQC is 32 ⁇ (Refer to Li et al.
- a highly stable sTv molecule was constructed from the hydrophobic core of the high stability variant screened in Example 9 and the surface amino acid residue of the variable region backbone.
- amino acid sequences of the ⁇ chain and the ⁇ chain variable domain of LC13-G9 are SEQ ID NO: 99 and
- the hydrophobic core introduced in the alpha chain variable domain is 13V, 211, 911 and 941.
- the hydrophobic core introduced in the ⁇ chain variable domain is 11V, 13V and 94V.
- the amino acid sequences of the ⁇ chain and ⁇ chain variable domains of LC13-G15 are SEQ ID NO: 101 and SEQ ID NO: 102, respectively, as shown in Figures 33a and 33b, and the hydrophobic core introduced in the ⁇ chain variable domain is 11L.
- the hydrophobic core introduced in the ⁇ chain variable domain is 11L, 13V and 94V;
- the amino acid sequences of the ⁇ chain and ⁇ chain variable domain of JM22-G9 are SEQ ID NO: 103 and SEQ, respectively ID NO: 104, as shown in Figures 34a and 34b, the hydrophobic cores introduced in the ⁇ chain variable domain are 11M, 13V, 19V, 211 and 941, and the hydrophobic core introduced in the ⁇ chain variable domain is 11V, 13V.
- the amino acid sequences of the alpha and beta chain variable domains of JM22-G15 are SEQ ID NO: 105 and SEQ ID NO: 106, respectively, as shown in Figures 35a and 35b, introduced in the alpha chain variable domain
- the hydrophobic cores are 13V, 19V, 211 and 941, and the hydrophobic cores introduced in the ⁇ -chain variable domains are 13V, 911 and 94V;
- the ⁇ -chain and ⁇ -chain of MAGE-G15 can be
- the amino acid sequence of the domain is SEQ ID ⁇ 0: 107 and SEQ ID NO: 108, respectively, as shown in Figures 42a and 42b, the hydrophobic core introduced in the ⁇ chain variable domain is 19V, 211 and 941, and the ⁇ chain variable domain thereof
- the hydrophobic cores introduced are 13V, 89L, 911 and 94V.
- the above location number uses the location number listed in the top GT.
- the ligated linker used to construct the above single-stranded molecule may be any suitable sequence, and the preferred amino acid sequence of the present invention is SEQ ID NO: 41, as shown in FIG.
- the proteins LC13-G9 and LC13-G15 were expressed, renatured and purified by the method described in Example 3.
- the gel filtration column was purified and run SDS-PAGE gel, and the SEC map of the two proteins was made by gel filtration.
- the expression amount, the amount of protein obtained after purification, and the protein refolding yield were calculated.
- Table 11 lists the expression levels of LC13-G9 and LC13-G15, the amount of protein obtained after purification, and the refolding yield of the protein. The data of LC13-WT are also listed for analysis.
- Protein name Expression amount (mg/L) Protein amount after purification (mg/L) Yield (%)
- the revival yield of the 1G4-WT protein was 5.4% higher than that of the 1G4-WT protein, which was not mutated by the hydrophobic core, respectively. And 57. 9 times.
- Figure 36 is an SDS-PAGE gel of proteins LC 13-G9 and LC13-G15 obtained after purification through a gel filtration column (Superdex 75 10/300, GE Healthcare) as described in Example 3.
- the gel map shows that the bands formed by LC 13-WT are not uniform, and the modified LC13-G9 and LC13-G15 are capable of forming a single band of monomers with high purity. Note The renaturation of LC13-G9 and LC13-G15 is much better than that of LX13-WT.
- Figure 37 and ⁇ 38 are the SEC spectra of the proteins LC13-G9 and LC13-G15, respectively.
- the SEC map of LC 13-WT shows no peak, while the proteins LC 13-G9 and LC13-G15 can form a single and symmetrical
- the elution peak indicated that the renaturation of LC13-G9 and LC13-G15 was significantly better than that of LC13-WT.
- Tm values of the proteins LC13-G O9 and LC13-G15 were determined by the method described in Example 10.
- Figures 49a and 49b are DSC curves of the proteins LC13-G9 and LC13-G15, respectively, with Tm values of 43 °C. And 50. 5 °C.
- LC13-WT has a low protein content in the correct conformation after renaturation, and there is no obvious protein unfolding endothermic peak, and its Tm value cannot be obtained.
- the thermal stability of LC13-G9 and LC13-G15 of the present invention is at least double that of LC13-WT.
- the LC13-G9 of the present invention is more resistant to unfolding, more resistant to inappropriate or undesirable folding and renaturation than LC 13-WT.
- the LC 13-G9 of the present invention has a markedly improved stability compared to LC 13-WT compared to LC13-G15.
- the stability of the LC13-G9 and the LC13-G15 were increased by 5.4% and 57.9 times, respectively, with respect to the LC13-WT, respectively.
- the proteins JM22-G9 and JM22-G15 were expressed, renatured and purified by the method described in Example 3.
- the gel filtration column was purified and run SDS-PAGE gel, and the SEC pattern of the two proteins was determined by gel filtration. At the same time, the expression amount, the amount of protein obtained after purification, and the protein refolding yield were calculated.
- Table 12 lists the expression levels of JM22-G9 and JM22-G15, the amount of protein obtained after purification, and protein. The data of the renaturation yield, together with the relevant data of JM22-WT, for analysis.
- Figure 39 is a gel filtration column as described in Example 3 (Superdex 75 10/300, GE
- Heal thcare was purified to obtain SDS-PAGE gel images of proteins JM22-G9 and JM22-G15.
- the glue map shows that the monomer bands formed by the renaturation of JM22-WT are not uniform, and there are three bands, and the modified JM22-G9 and JM22-G15 can form a single band of monomers with high purity. Note The renaturation of JM22-G9 and JM22-G15 is much better than JM22-WT.
- Figure 40 and ⁇ 41 are the SEC spectra of proteins JM22-G9 and JM22-G15, respectively.
- the SEC map of JM22-WT shows that the elution peaks formed are not single and the signal is very low, while the proteins JM22-G9 and JM22-G15 can basically A single and symmetric elution peak was formed, further indicating that the renaturation of JM22-G9 and JM22-G15 was significantly better than JM22-WT.
- JM22-G9 and JM22-G15 have stronger renaturation ability, higher expression amount and protein refolding yield than the hydrophobic core unmodified JM22-WT. Therefore, the JM22-G9 of the present invention has a significant improvement in stability compared to JM22-G15 compared to JM22-WT.
- the stability of the protein was calculated by the data of the protein refolding yield. In the present invention, the stability of JM22-G9 and JM22-G15 relative to JM22-WT was increased by 28. 5 times and 127.2 times, respectively.
- the protein MAGE-G15 was expressed, renatured and purified by the method described in Example 3. After purification by gel filtration column, SDS-PAGE gel was run, and the SEC spectrum of the protein was determined by gel filtration, and the expression amount was calculated. , the amount of protein obtained after purification and protein refolding yield.
- Table 13 lists the expression levels of MAGE-sTv-WT and MAGE-G15, the amount of protein obtained after purification, and the refolding yield of protein.
- the SDS-PAGE gel of the protein obtained after purification of the hydrophobic core-modified MAGE-G15 via a gel filtration column is shown in Fig. 43.
- the gel image shows that MAGE-G15 is able to form a single band with high purity, indicating that the refolding ability of protein MAGE-G15 is much stronger than MAGE-sTv-WT.
- the SEC map of MAGE-G15 shown in Figure 44 has a single and symmetric elution peak, which also indicates that the refolding ability of protein MAGE-G15 is much stronger than that of MAGE-sTv-WT.
- Figure 45 is a DSC curve of the protein MAGE-G15, which was obtained by fitting the two-dimensional scaled model of the analysis software Nanoanalyze to obtain a Tm value of 46. 7 °C.
- the BIAcore T200 real-time analysis system was used to detect the binding of the protein MAGE-G15 to its ligand.
- the results showed that the affinity of the protein MAGE-G15 to its ligand was not superior to its corresponding wild-type TCR, and its K D value was 30. 4 ⁇ . Hey.
- the amount of stability improvement was calculated from the data of protein refolding yield. As can be seen from Table 13, the MAGE-G15 of the present invention has an infinite-fold improvement (at least 10,000 times) compared to the MAGE-sTv-WT stability. ).
- the protein we constructed was purified by a gel filtration column (Superdex 75 10/300, GE Heal thcare) and its molecular weight was determined by mass spectrometry. The molecular weight of the mass spectrometry was determined to be consistent with its theoretical molecular weight. Whether the protein sequence is identical to the original design sequence.
- the full protein molecular weight of the sample was determined using a mass spectrometer (Eks igent nano LC (nanflex) - Triple T0F 5600 LC/MS system) from AB SCIEX, USA.
- the sample was diluted with 10% acetonitrile (Fi sherA955-4), 1% formic acid (Fi sher A11750) and water (Si gma39253-1 L-R) and analyzed by mass spectrometry.
- the system analysis conditions are as follows:
- the Triple T0F 5600 with Nanospray source analyzes the eluent in the column
- the collected mass spectrometry data was deconvoluted by Bioanalyst software to obtain the complete protein molecular weight information of the sample.
- the molecular weight of the whole protein determined by mass spectrometry is consistent with its theoretical molecular weight, indicating that the purified protein sequence is identical to the original design protein sequence.
- the hydrophobic core screened by the present invention can significantly improve the stability of TCR molecules.
- the above examples demonstrate that the introduction of the hydrophobic core screened by the present invention into other TCR molecules also serves to enhance stability.
Landscapes
- Health & Medical Sciences (AREA)
- Life Sciences & Earth Sciences (AREA)
- Immunology (AREA)
- Chemical & Material Sciences (AREA)
- General Health & Medical Sciences (AREA)
- Medicinal Chemistry (AREA)
- Engineering & Computer Science (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Organic Chemistry (AREA)
- Proteomics, Peptides & Aminoacids (AREA)
- Animal Behavior & Ethology (AREA)
- Public Health (AREA)
- Veterinary Medicine (AREA)
- Pharmacology & Pharmacy (AREA)
- Cell Biology (AREA)
- Epidemiology (AREA)
- Molecular Biology (AREA)
- Zoology (AREA)
- Gastroenterology & Hepatology (AREA)
- Biochemistry (AREA)
- Biophysics (AREA)
- Genetics & Genomics (AREA)
- Chemical Kinetics & Catalysis (AREA)
- General Chemical & Material Sciences (AREA)
- Nuclear Medicine, Radiotherapy & Molecular Imaging (AREA)
- Toxicology (AREA)
- Virology (AREA)
- Communicable Diseases (AREA)
- Oncology (AREA)
- Transplantation (AREA)
- Peptides Or Proteins (AREA)
- Micro-Organisms Or Cultivation Processes Thereof (AREA)
- Preparation Of Compounds By Using Micro-Organisms (AREA)
- Medicines Containing Material From Animals Or Micro-Organisms (AREA)
- Medicines That Contain Protein Lipid Enzymes And Other Medicines (AREA)
Abstract
Description







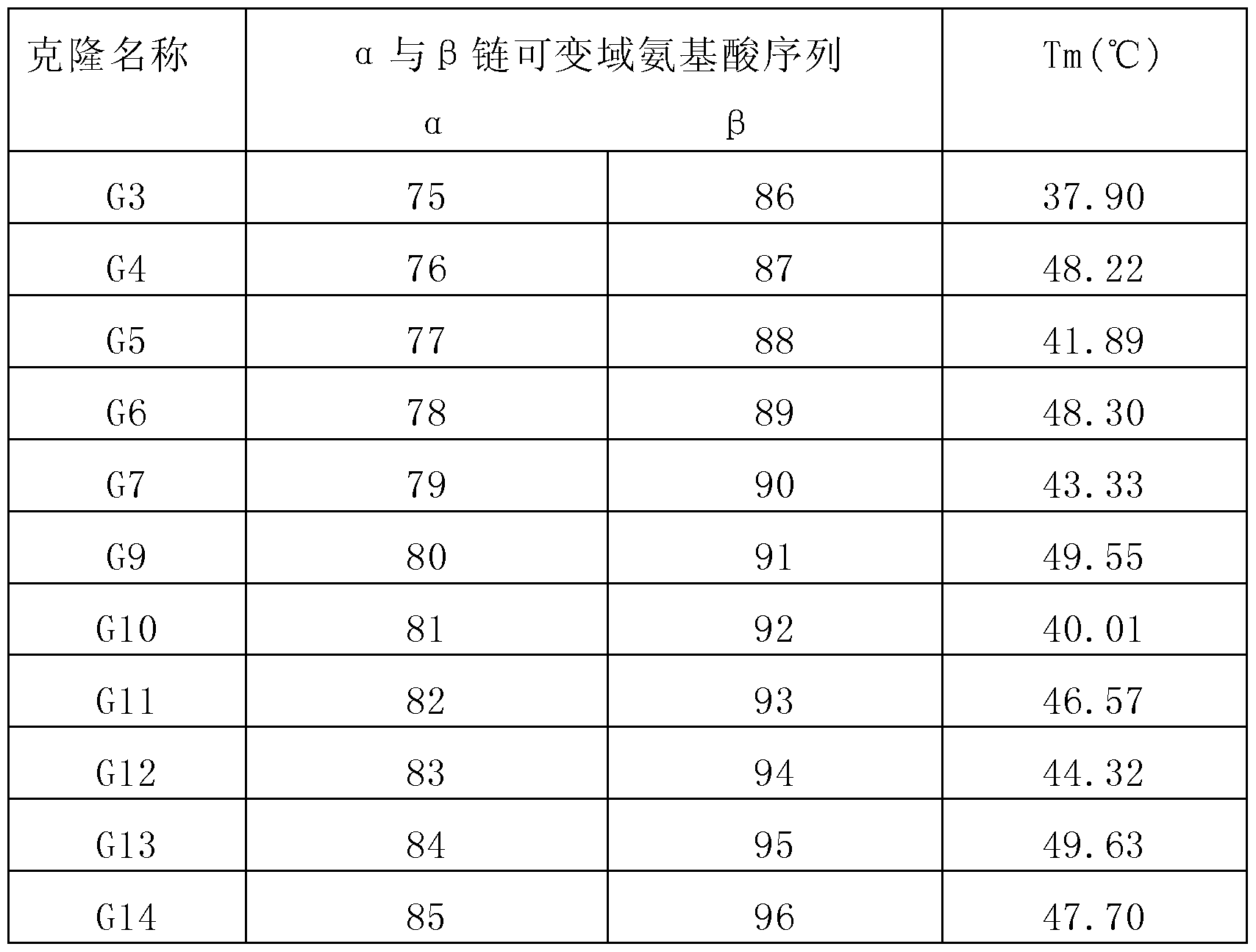


Claims
Priority Applications (12)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2016522222A JP6549564B2 (ja) | 2013-06-26 | 2014-06-25 | 高安定性のt細胞受容体およびその製法と使用 |
| CN201480036288.6A CN105683215B (zh) | 2013-06-26 | 2014-06-25 | 高稳定性的t细胞受体及其制法和应用 |
| EP14817065.7A EP3015477B1 (en) | 2013-06-26 | 2014-06-25 | High-stability t-cell receptor and preparation method and application thereof |
| AU2014301777A AU2014301777B2 (en) | 2013-06-26 | 2014-06-25 | High-stability T-cell receptor and preparation method and application thereof |
| US14/901,344 US10654906B2 (en) | 2013-06-26 | 2014-06-25 | High-stability T-cell receptor and preparation method and application thereof |
| RU2016101711A RU2645256C2 (ru) | 2013-06-26 | 2014-06-25 | Высокостабильный т-клеточный рецептор и способ его получения и применения |
| MX2016000231A MX375056B (es) | 2013-06-26 | 2014-06-25 | Receptor de celulas t de alta estabilidad y metodo de preparacion y aplicacion del mismo. |
| CA2916960A CA2916960C (en) | 2013-06-26 | 2014-06-25 | High-stability t-cell receptor and preparation method and application thereof |
| NZ715815A NZ715815A (en) | 2013-06-26 | 2014-06-25 | High-stability t-cell receptor and preparation method and application thereof |
| KR1020167002293A KR101904385B1 (ko) | 2013-06-26 | 2014-06-25 | 고안정성의 t 세포 수용체 및 이의 제조방법과 응용 |
| IL243365A IL243365B (en) | 2013-06-26 | 2015-12-27 | T-cells with high stability and a method for their preparation |
| AU2017204047A AU2017204047B2 (en) | 2013-06-26 | 2017-06-15 | High-stability T-cell receptor and preparation method and application thereof |
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN201310263384 | 2013-06-26 | ||
| CN201310263384.1 | 2013-06-26 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2014206304A1 true WO2014206304A1 (zh) | 2014-12-31 |
Family
ID=52141082
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/CN2014/080773 Ceased WO2014206304A1 (zh) | 2013-06-26 | 2014-06-25 | 高稳定性的t细胞受体及其制法和应用 |
Country Status (12)
| Country | Link |
|---|---|
| US (1) | US10654906B2 (zh) |
| EP (1) | EP3015477B1 (zh) |
| JP (1) | JP6549564B2 (zh) |
| KR (1) | KR101904385B1 (zh) |
| CN (1) | CN105683215B (zh) |
| AU (2) | AU2014301777B2 (zh) |
| CA (1) | CA2916960C (zh) |
| IL (1) | IL243365B (zh) |
| MX (1) | MX375056B (zh) |
| NZ (1) | NZ715815A (zh) |
| RU (1) | RU2645256C2 (zh) |
| WO (1) | WO2014206304A1 (zh) |
Cited By (57)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2016095783A1 (zh) * | 2014-12-17 | 2016-06-23 | 中国科学院广州生物医药与健康研究院 | 识别eb病毒短肽的t细胞受体 |
| WO2016124142A1 (zh) * | 2015-02-06 | 2016-08-11 | 广州市香雪制药股份有限公司 | 高亲和力ny-eso t细胞受体 |
| WO2016170320A1 (en) * | 2015-04-20 | 2016-10-27 | Ucl Business Plc | T cell receptor |
| CN106336457A (zh) * | 2015-10-30 | 2017-01-18 | 广州市香雪制药股份有限公司 | 识别mage-a3抗原短肽的t细胞受体 |
| CN106432475A (zh) * | 2015-10-19 | 2017-02-22 | 广州市香雪制药股份有限公司 | 高亲和力 ny‑eso t 细胞受体 |
| CN106478809A (zh) * | 2015-11-06 | 2017-03-08 | 广州市香雪制药股份有限公司 | 识别prame抗原短肽的tcr |
| CN106478808A (zh) * | 2015-11-02 | 2017-03-08 | 广州市香雪制药股份有限公司 | 识别ny-eso-1抗原短肽的t细胞受体 |
| CN106478807A (zh) * | 2015-10-30 | 2017-03-08 | 广州市香雪制药股份有限公司 | 识别mage-a3 的t 细胞受体 |
| CN106519019A (zh) * | 2015-11-06 | 2017-03-22 | 广州市香雪制药股份有限公司 | 识别prame抗原的tcr |
| CN106632658A (zh) * | 2015-11-04 | 2017-05-10 | 广州市香雪制药股份有限公司 | 识别ny-eso-1抗原短肽的tcr |
| CN106699874A (zh) * | 2016-03-29 | 2017-05-24 | 广州市香雪制药股份有限公司 | 识别prame抗原短肽的t细胞受体 |
| CN106749620A (zh) * | 2016-03-29 | 2017-05-31 | 广州市香雪制药股份有限公司 | 识别mage‑a1抗原短肽的t细胞受体 |
| CN106831978A (zh) * | 2015-12-04 | 2017-06-13 | 中国科学院广州生物医药与健康研究院 | 识别prame抗原的t细胞受体 |
| WO2018077242A1 (zh) * | 2016-10-27 | 2018-05-03 | 中国科学院广州生物医药与健康研究院 | 识别sage1抗原短肽的t细胞受体 |
| CN108117596A (zh) * | 2016-11-29 | 2018-06-05 | 广东香雪精准医疗技术有限公司 | 针对ny-eso的高亲和力tcr |
| CN108264550A (zh) * | 2017-01-04 | 2018-07-10 | 广东香雪精准医疗技术有限公司 | 一种识别源自于prame抗原短肽的tcr |
| JP2018522061A (ja) * | 2015-05-20 | 2018-08-09 | ▲広▼▲東▼香雪精准医▲療▼技▲術▼有限公司Guangdong Xiangxue Life Sciences, Ltd. | 安定した可溶性ヘテロ二量体tcr |
| CN110016074A (zh) * | 2018-01-08 | 2019-07-16 | 中国科学院广州生物医药与健康研究院 | Mage-a3人源化t细胞受体 |
| WO2020024915A1 (zh) | 2018-07-30 | 2020-02-06 | 广东香雪精准医疗技术有限公司 | 一种识别afp抗原的t细胞受体 |
| WO2020057619A1 (zh) | 2018-09-21 | 2020-03-26 | 广东香雪精准医疗技术有限公司 | 一种识别afp抗原的高亲和力t细胞受体 |
| WO2020063488A1 (zh) | 2018-09-26 | 2020-04-02 | 广东香雪精准医疗技术有限公司 | 一种识别ssx2抗原的t细胞受体 |
| US10654906B2 (en) | 2013-06-26 | 2020-05-19 | Guangdong Xiangxue Life Sciences, Ltd. | High-stability T-cell receptor and preparation method and application thereof |
| WO2020098717A1 (zh) | 2018-11-14 | 2020-05-22 | 广东香雪精准医疗技术有限公司 | 一种识别afp的高亲和力tcr |
| EP3554514A4 (en) * | 2016-12-16 | 2020-08-05 | Twist Bioscience Corporation | BANKS OF VARIANTS OF IMMUNOLOGICAL SYNAPSE AND THEIR SYNTHESIS |
| WO2020182082A1 (zh) | 2019-03-08 | 2020-09-17 | 广东香雪精准医疗技术有限公司 | 一种识别afp抗原的高亲和力tcr |
| US10894959B2 (en) | 2017-03-15 | 2021-01-19 | Twist Bioscience Corporation | Variant libraries of the immunological synapse and synthesis thereof |
| US10894242B2 (en) | 2017-10-20 | 2021-01-19 | Twist Bioscience Corporation | Heated nanowells for polynucleotide synthesis |
| WO2021016887A1 (zh) | 2019-07-30 | 2021-02-04 | 广东香雪精准医疗技术有限公司 | 识别ssx2抗原短肽的t细胞受体 |
| WO2021023116A1 (zh) | 2019-08-02 | 2021-02-11 | 广东香雪精准医疗技术有限公司 | 识别ny-eso-1抗原的高亲和力t细胞受体 |
| EP3773908A1 (en) * | 2018-04-05 | 2021-02-17 | Juno Therapeutics, Inc. | T cell receptors and engineered cells expressing same |
| US10936953B2 (en) | 2018-01-04 | 2021-03-02 | Twist Bioscience Corporation | DNA-based digital information storage with sidewall electrodes |
| WO2021036924A1 (zh) | 2019-08-23 | 2021-03-04 | 广东香雪精准医疗技术有限公司 | 一种识别ssx2抗原的高亲和力tcr |
| WO2021043284A1 (zh) | 2019-09-05 | 2021-03-11 | 广东香雪精准医疗技术有限公司 | 一种识别ssx2的高亲和力t细胞受体 |
| US10975372B2 (en) | 2016-08-22 | 2021-04-13 | Twist Bioscience Corporation | De novo synthesized nucleic acid libraries |
| WO2021068938A1 (zh) | 2019-10-10 | 2021-04-15 | 香雪生命科学技术(广东)有限公司 | 一种识别kras突变的t细胞受体及其编码序列 |
| WO2021185368A1 (zh) | 2020-03-20 | 2021-09-23 | 香雪生命科学技术(广东)有限公司 | 识别afp抗原的高亲和力tcr |
| US11185837B2 (en) | 2013-08-05 | 2021-11-30 | Twist Bioscience Corporation | De novo synthesized gene libraries |
| WO2021254458A1 (zh) * | 2020-06-17 | 2021-12-23 | 香雪生命科学技术(广东)有限公司 | 一种识别hpv抗原的高亲和力t细胞受体 |
| US11263354B2 (en) | 2016-09-21 | 2022-03-01 | Twist Bioscience Corporation | Nucleic acid based data storage |
| US11332740B2 (en) | 2017-06-12 | 2022-05-17 | Twist Bioscience Corporation | Methods for seamless nucleic acid assembly |
| US11332738B2 (en) | 2019-06-21 | 2022-05-17 | Twist Bioscience Corporation | Barcode-based nucleic acid sequence assembly |
| WO2022111475A1 (zh) | 2020-11-26 | 2022-06-02 | 香雪生命科学技术(广东)有限公司 | 一种识别hpv抗原的tcr |
| US11377676B2 (en) | 2017-06-12 | 2022-07-05 | Twist Bioscience Corporation | Methods for seamless nucleic acid assembly |
| US11407837B2 (en) | 2017-09-11 | 2022-08-09 | Twist Bioscience Corporation | GPCR binding proteins and synthesis thereof |
| US11492728B2 (en) | 2019-02-26 | 2022-11-08 | Twist Bioscience Corporation | Variant nucleic acid libraries for antibody optimization |
| US11492665B2 (en) | 2018-05-18 | 2022-11-08 | Twist Bioscience Corporation | Polynucleotides, reagents, and methods for nucleic acid hybridization |
| US11512347B2 (en) | 2015-09-22 | 2022-11-29 | Twist Bioscience Corporation | Flexible substrates for nucleic acid synthesis |
| US11550939B2 (en) | 2017-02-22 | 2023-01-10 | Twist Bioscience Corporation | Nucleic acid based data storage using enzymatic bioencryption |
| US11643451B2 (en) | 2016-10-19 | 2023-05-09 | Ucl Business Ltd | T cell receptor |
| US11691118B2 (en) | 2015-04-21 | 2023-07-04 | Twist Bioscience Corporation | Devices and methods for oligonucleic acid library synthesis |
| WO2023179768A1 (zh) | 2022-03-24 | 2023-09-28 | 香雪生命科学技术(广东)有限公司 | 一种识别mage-a4抗原的高亲和力tcr及其序列和应用 |
| US11807956B2 (en) | 2015-09-18 | 2023-11-07 | Twist Bioscience Corporation | Oligonucleic acid variant libraries and synthesis thereof |
| US12091777B2 (en) | 2019-09-23 | 2024-09-17 | Twist Bioscience Corporation | Variant nucleic acid libraries for CRTH2 |
| US12173282B2 (en) | 2019-09-23 | 2024-12-24 | Twist Bioscience, Inc. | Antibodies that bind CD3 epsilon |
| US12331427B2 (en) | 2019-02-26 | 2025-06-17 | Twist Bioscience Corporation | Antibodies that bind GLP1R |
| US12357959B2 (en) | 2018-12-26 | 2025-07-15 | Twist Bioscience Corporation | Highly accurate de novo polynucleotide synthesis |
| US12570750B2 (en) | 2019-12-09 | 2026-03-10 | Twist Bioscience Corporation | Antibodies that bind adenosine A2A receptors and methods of use thereof to treat cancer and neurological diseases |
Families Citing this family (20)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| GB201604458D0 (en) | 2016-03-16 | 2016-04-27 | Immatics Biotechnologies Gmbh | Peptides and combination of peptides for use in immunotherapy against cancers |
| GB201617716D0 (en) * | 2016-10-19 | 2016-11-30 | Ucl Business Plc | Cell |
| CN107964041B (zh) * | 2016-10-20 | 2023-08-01 | 中国科学院广州生物医药与健康研究院 | 高稳定性和高亲和力的dmic及其制法 |
| CN109251243B (zh) * | 2017-07-13 | 2021-10-19 | 中国科学院广州生物医药与健康研究院 | 一种识别sage1抗原的t细胞受体及编码该受体的核酸 |
| CA3073055A1 (en) | 2017-09-04 | 2019-03-07 | Agenus Inc. | T cell receptors that bind to mixed lineage leukemia (mll)-specific phosphopeptides and methods of use thereof |
| CN109836490A (zh) * | 2017-11-25 | 2019-06-04 | 深圳宾德生物技术有限公司 | 一种靶向mage-a3的t细胞受体、t细胞受体基因修饰t细胞及其制备方法和应用 |
| CN109837248A (zh) * | 2017-11-25 | 2019-06-04 | 深圳宾德生物技术有限公司 | 一种tcr敲除的靶向mage-a3的t细胞受体基因修饰t细胞及其制备方法和应用 |
| WO2019133443A1 (en) * | 2017-12-28 | 2019-07-04 | Janux Therapeutics, Inc. | Modified t cell receptors |
| TWI822726B (zh) * | 2018-02-26 | 2023-11-21 | 德商梅迪基因免疫治療公司 | Nyeso t細胞受體 |
| WO2020086647A1 (en) * | 2018-10-23 | 2020-04-30 | Regeneron Pharmaceuticals, Inc. | Ny-eso-1 t cell receptors and methods of use thereof |
| TWI852977B (zh) | 2019-01-10 | 2024-08-21 | 美商健生生物科技公司 | 前列腺新抗原及其用途 |
| DE102019121007A1 (de) | 2019-08-02 | 2021-02-04 | Immatics Biotechnologies Gmbh | Antigenbindende Proteine, die spezifisch an MAGE-A binden |
| EP4025598A1 (en) * | 2019-09-06 | 2022-07-13 | Eli Lilly and Company | Proteins comprising t-cell receptor constant domains |
| CR20220220A (es) | 2019-11-18 | 2022-09-20 | Janssen Biotech Inc | Vacunas basadas en calr y jak2 mutantes y sus usos |
| TW202144388A (zh) | 2020-02-14 | 2021-12-01 | 美商健生生物科技公司 | 在卵巢癌中表現之新抗原及其用途 |
| TW202144389A (zh) | 2020-02-14 | 2021-12-01 | 美商健生生物科技公司 | 在多發性骨髓瘤中表現之新抗原及其用途 |
| EP4175664A2 (en) | 2020-07-06 | 2023-05-10 | Janssen Biotech, Inc. | Prostate neoantigens and their uses |
| US12275766B2 (en) | 2020-12-23 | 2025-04-15 | Janssen Biotech, Inc. | Neoantigen peptide mimics |
| CN115490773A (zh) * | 2021-06-18 | 2022-12-20 | 香雪生命科学技术(广东)有限公司 | 一种针对afp抗原的高亲和力t细胞受体 |
| CN117304301A (zh) * | 2022-06-17 | 2023-12-29 | 香雪生命科学技术(广东)有限公司 | 一种结合ssx2抗原的tcr分子及其应用 |
Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US6080840A (en) | 1992-01-17 | 2000-06-27 | Slanetz; Alfred E. | Soluble T cell receptors |
| WO2012013913A1 (en) | 2010-07-28 | 2012-02-02 | Immunocore Ltd | T cell receptors |
| CN102574906A (zh) * | 2009-07-03 | 2012-07-11 | 英美偌科有限公司 | T细胞受体 |
Family Cites Families (11)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| RU2355703C2 (ru) * | 2002-10-09 | 2009-05-20 | Медиджен Лимитед | Одноцепочечные рекомбинантные т-клеточные рецепторы |
| ATE417065T1 (de) | 2004-05-19 | 2008-12-15 | Medigene Ltd | Hochaffiner ny-eso-t-zellen-rezeptor |
| ATE430164T1 (de) * | 2004-05-26 | 2009-05-15 | Immunocore Ltd | Hochaffine telomerase-t-zellen-rezeptoren |
| JP2008514685A (ja) * | 2004-10-01 | 2008-05-08 | メディジーン リミテッド | 治療剤に連結した、非天然型ジスルフィド鎖間結合を含有するt細胞レセプター |
| WO2007034490A2 (en) * | 2005-09-22 | 2007-03-29 | Yeda Research And Development Co. Ltd., At The Weizmann Institute Of Science | Diastereomeric peptides for modulating t cell immunity |
| US20110245153A1 (en) * | 2006-03-15 | 2011-10-06 | National Institutes of Health (NIH), U. S. Dept. of Health and Human Resources (DHHS) U. S. Govt. | Neutralizing Agents for Bacterial Toxins |
| DK2352756T3 (da) * | 2008-11-24 | 2012-12-03 | Helmholtz Zentrum Muenchen | Højaffin T-cellereceptor og anvendelse af denne |
| CN102654994B (zh) | 2011-07-07 | 2014-08-06 | 京东方科技集团股份有限公司 | 双视显示器显示方法和双视显示器 |
| WO2013041865A1 (en) * | 2011-09-22 | 2013-03-28 | Immunocore Limited | T cell receptors |
| BR112014010532A2 (pt) | 2011-11-03 | 2017-04-18 | Tolera Therapeutics Inc | anticorpo e métodos para inibição seletiva de respostas de célula-t |
| AU2014301777B2 (en) | 2013-06-26 | 2017-03-30 | Xlifesc, Ltd. | High-stability T-cell receptor and preparation method and application thereof |
-
2014
- 2014-06-25 AU AU2014301777A patent/AU2014301777B2/en not_active Ceased
- 2014-06-25 US US14/901,344 patent/US10654906B2/en not_active Expired - Fee Related
- 2014-06-25 MX MX2016000231A patent/MX375056B/es active IP Right Grant
- 2014-06-25 CA CA2916960A patent/CA2916960C/en active Active
- 2014-06-25 EP EP14817065.7A patent/EP3015477B1/en not_active Revoked
- 2014-06-25 JP JP2016522222A patent/JP6549564B2/ja not_active Expired - Fee Related
- 2014-06-25 RU RU2016101711A patent/RU2645256C2/ru active
- 2014-06-25 CN CN201480036288.6A patent/CN105683215B/zh active Active
- 2014-06-25 NZ NZ715815A patent/NZ715815A/en not_active IP Right Cessation
- 2014-06-25 WO PCT/CN2014/080773 patent/WO2014206304A1/zh not_active Ceased
- 2014-06-25 KR KR1020167002293A patent/KR101904385B1/ko not_active Expired - Fee Related
-
2015
- 2015-12-27 IL IL243365A patent/IL243365B/en active IP Right Grant
-
2017
- 2017-06-15 AU AU2017204047A patent/AU2017204047B2/en not_active Ceased
Patent Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US6080840A (en) | 1992-01-17 | 2000-06-27 | Slanetz; Alfred E. | Soluble T cell receptors |
| CN102574906A (zh) * | 2009-07-03 | 2012-07-11 | 英美偌科有限公司 | T细胞受体 |
| WO2012013913A1 (en) | 2010-07-28 | 2012-02-02 | Immunocore Ltd | T cell receptors |
| CN103097407A (zh) * | 2010-07-28 | 2013-05-08 | 英美偌科有限公司 | T细胞受体 |
Non-Patent Citations (29)
| Title |
|---|
| "Remington's Pharmaceutical Sciences", 1991, MACK PUB. CO. |
| BOULTER ET AL., PROTEIN ENGINEERING, vol. 16, 2003, pages 707 - 711 |
| CARD ET AL., CANCER IMMUNOLOGY AND IMMUNOTHERAPY, vol. 53, 2004, pages 345 |
| CHANG ET AL., PNAS USA, vol. 91, 1994, pages 11408 - 11412 |
| CHAUDHARY ET AL., NATURE, vol. 339, 1989, pages 394 |
| DAVODEAU ET AL., J. BIOL. CHEM., vol. 268, no. 21, 1993, pages 15455 - 15460 |
| EPEL ET AL., CANCER IMMUNOLOGY AND IMMUNOTHERAPY, vol. 51, 2002, pages 565 |
| GARBOCZI ET AL., J LMMUNOL, vol. 157, no. 12, 1996, pages 5403 - 5410 |
| GARBOCZI ET AL., NATURE, vol. 384, no. 6605, 1996, pages 134 - 41 |
| GARCIAL ET AL., SCIENCE, vol. 274, 1996, pages 209 - 219 |
| GILLIES ET AL., PNAS, vol. 89, 1992, pages 1428 |
| GOLDEN ET AL., J. IMM. METH., vol. 206, 1997, pages 163 - 169 |
| HALIN ET AL., CANCER RESEARCH, vol. 63, 2003, pages 3202 |
| HUANG ET AL., JOURNAL OF THE AMERICAN CHEMICAL SOCIETY, vol. 128, 2006, pages 2115 |
| JONATHAN M.BOULTER ET AL., PROTEIN ENGINEERING, vol. 16, no. 9, 2003, pages 707 - 711 |
| KOPPE ET AL., CANCER METASTASIS REVIEWS, vol. 24, 2005, pages 539 |
| LAPOTKO ET AL., CANCER LETTERS, vol. 239, 2005, pages 36 |
| LI E, NATURE BIOTECHNOLOGY, vol. 34, 2005, pages 349 - 354 |
| LI ET AL., NATURE BIOTECH, vol. 23, no. 3, 2005, pages 349 - 354 |
| LIDDY ET AL., NATURE MEDICINE, vol. 18, 2012, pages 980 - 987 |
| MAMOT ET AL., CANCER RESEARCH, vol. 65, 2005, pages 11631 |
| MOSQUERA ET AL., THE JOURNAL OF IMMUNOLOGY, vol. 174, 2005, pages 4381 |
| PENG ET AL., GENE THERAPY, vol. 11, 2004, pages 1234 |
| RASHTCHIAN, CURR OPIN BIOTEEHHOL, vol. 6, no. 1, 1995, pages 30 - 6 |
| SAMBROOK; RUSSELL ET AL.: "Molecular Cloning-A Laboratory Manual", CSHL PRESS |
| SAMBROOK; RUSSELL: "Molecular Cloning- A laboratory Manual", 2001, CSHL PRESS |
| See also references of EP3015477A4 |
| SHUSTA ET AL., NATURE BIOTECHNOLOGY, vol. 18, 2000, pages 754 - 759 |
| ZHU ET AL., INTERNATIONAL JOURNAL OF CANCER, vol. 62, 1995, pages 319 |
Cited By (91)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US10654906B2 (en) | 2013-06-26 | 2020-05-19 | Guangdong Xiangxue Life Sciences, Ltd. | High-stability T-cell receptor and preparation method and application thereof |
| US12569822B2 (en) | 2013-08-05 | 2026-03-10 | Twist Bioscience Corporation | De novo synthesized gene libraries |
| US11559778B2 (en) | 2013-08-05 | 2023-01-24 | Twist Bioscience Corporation | De novo synthesized gene libraries |
| US11452980B2 (en) | 2013-08-05 | 2022-09-27 | Twist Bioscience Corporation | De novo synthesized gene libraries |
| US11185837B2 (en) | 2013-08-05 | 2021-11-30 | Twist Bioscience Corporation | De novo synthesized gene libraries |
| WO2016095783A1 (zh) * | 2014-12-17 | 2016-06-23 | 中国科学院广州生物医药与健康研究院 | 识别eb病毒短肽的t细胞受体 |
| CN106459177A (zh) * | 2015-02-06 | 2017-02-22 | 广州市香雪制药股份有限公司 | 高亲和力ny‑eso t细胞受体 |
| CN106459177B (zh) * | 2015-02-06 | 2018-07-06 | 广东香雪精准医疗技术有限公司 | 高亲和力ny-eso t细胞受体 |
| WO2016124142A1 (zh) * | 2015-02-06 | 2016-08-11 | 广州市香雪制药股份有限公司 | 高亲和力ny-eso t细胞受体 |
| JP7125264B2 (ja) | 2015-04-20 | 2022-08-24 | ユーシーエル ビジネス リミテッド | T細胞受容体 |
| US12378298B2 (en) | 2015-04-20 | 2025-08-05 | Ucl Buseness Ltd | T cell receptor |
| AU2016251395B2 (en) * | 2015-04-20 | 2020-09-10 | Ucl Business Plc | T cell receptor |
| WO2016170320A1 (en) * | 2015-04-20 | 2016-10-27 | Ucl Business Plc | T cell receptor |
| CN108055847A (zh) * | 2015-04-20 | 2018-05-18 | Ucl商务股份有限公司 | T细胞受体 |
| US11691118B2 (en) | 2015-04-21 | 2023-07-04 | Twist Bioscience Corporation | Devices and methods for oligonucleic acid library synthesis |
| JP2018522061A (ja) * | 2015-05-20 | 2018-08-09 | ▲広▼▲東▼香雪精准医▲療▼技▲術▼有限公司Guangdong Xiangxue Life Sciences, Ltd. | 安定した可溶性ヘテロ二量体tcr |
| US11807956B2 (en) | 2015-09-18 | 2023-11-07 | Twist Bioscience Corporation | Oligonucleic acid variant libraries and synthesis thereof |
| US11512347B2 (en) | 2015-09-22 | 2022-11-29 | Twist Bioscience Corporation | Flexible substrates for nucleic acid synthesis |
| CN106432475B (zh) * | 2015-10-19 | 2018-06-01 | 广东香雪精准医疗技术有限公司 | 高亲和力ny-eso t细胞受体 |
| CN106432475A (zh) * | 2015-10-19 | 2017-02-22 | 广州市香雪制药股份有限公司 | 高亲和力 ny‑eso t 细胞受体 |
| CN106336457A (zh) * | 2015-10-30 | 2017-01-18 | 广州市香雪制药股份有限公司 | 识别mage-a3抗原短肽的t细胞受体 |
| CN106478807B (zh) * | 2015-10-30 | 2018-06-01 | 广东香雪精准医疗技术有限公司 | 识别mage-a3的t细胞受体 |
| CN106336457B (zh) * | 2015-10-30 | 2018-03-06 | 广东香雪精准医疗技术有限公司 | 识别mage‑a3抗原短肽的t细胞受体 |
| CN106478807A (zh) * | 2015-10-30 | 2017-03-08 | 广州市香雪制药股份有限公司 | 识别mage-a3 的t 细胞受体 |
| CN106478808B (zh) * | 2015-11-02 | 2018-06-01 | 广东香雪精准医疗技术有限公司 | 识别ny-eso-1抗原短肽的t细胞受体 |
| CN106478808A (zh) * | 2015-11-02 | 2017-03-08 | 广州市香雪制药股份有限公司 | 识别ny-eso-1抗原短肽的t细胞受体 |
| CN106632658A (zh) * | 2015-11-04 | 2017-05-10 | 广州市香雪制药股份有限公司 | 识别ny-eso-1抗原短肽的tcr |
| CN106632658B (zh) * | 2015-11-04 | 2020-10-27 | 广东香雪精准医疗技术有限公司 | 识别ny-eso-1抗原短肽的tcr |
| CN106519019B (zh) * | 2015-11-06 | 2018-07-03 | 广东香雪精准医疗技术有限公司 | 识别prame抗原的tcr |
| CN106519019A (zh) * | 2015-11-06 | 2017-03-22 | 广州市香雪制药股份有限公司 | 识别prame抗原的tcr |
| CN106478809A (zh) * | 2015-11-06 | 2017-03-08 | 广州市香雪制药股份有限公司 | 识别prame抗原短肽的tcr |
| CN106831978A (zh) * | 2015-12-04 | 2017-06-13 | 中国科学院广州生物医药与健康研究院 | 识别prame抗原的t细胞受体 |
| CN106699874A (zh) * | 2016-03-29 | 2017-05-24 | 广州市香雪制药股份有限公司 | 识别prame抗原短肽的t细胞受体 |
| CN106749620A (zh) * | 2016-03-29 | 2017-05-31 | 广州市香雪制药股份有限公司 | 识别mage‑a1抗原短肽的t细胞受体 |
| CN106699874B (zh) * | 2016-03-29 | 2018-06-05 | 广东香雪精准医疗技术有限公司 | 识别prame抗原短肽的t细胞受体 |
| CN106749620B (zh) * | 2016-03-29 | 2020-09-25 | 广东香雪精准医疗技术有限公司 | 识别mage-a1抗原短肽的t细胞受体 |
| US10975372B2 (en) | 2016-08-22 | 2021-04-13 | Twist Bioscience Corporation | De novo synthesized nucleic acid libraries |
| US11562103B2 (en) | 2016-09-21 | 2023-01-24 | Twist Bioscience Corporation | Nucleic acid based data storage |
| US12056264B2 (en) | 2016-09-21 | 2024-08-06 | Twist Bioscience Corporation | Nucleic acid based data storage |
| US11263354B2 (en) | 2016-09-21 | 2022-03-01 | Twist Bioscience Corporation | Nucleic acid based data storage |
| US11643451B2 (en) | 2016-10-19 | 2023-05-09 | Ucl Business Ltd | T cell receptor |
| WO2018077242A1 (zh) * | 2016-10-27 | 2018-05-03 | 中国科学院广州生物医药与健康研究院 | 识别sage1抗原短肽的t细胞受体 |
| CN108117596A (zh) * | 2016-11-29 | 2018-06-05 | 广东香雪精准医疗技术有限公司 | 针对ny-eso的高亲和力tcr |
| EP4335514A2 (en) | 2016-11-29 | 2024-03-13 | XLifeSc, Ltd. | High-affinity tcr for ny-eso |
| WO2018099402A1 (zh) | 2016-11-29 | 2018-06-07 | 广东香雪精准医疗技术有限公司 | 针对ny-eso的高亲和力tcr |
| CN108117596B (zh) * | 2016-11-29 | 2023-08-29 | 香雪生命科学技术(广东)有限公司 | 针对ny-eso的高亲和力tcr |
| US10907274B2 (en) | 2016-12-16 | 2021-02-02 | Twist Bioscience Corporation | Variant libraries of the immunological synapse and synthesis thereof |
| EP3554514A4 (en) * | 2016-12-16 | 2020-08-05 | Twist Bioscience Corporation | BANKS OF VARIANTS OF IMMUNOLOGICAL SYNAPSE AND THEIR SYNTHESIS |
| CN108264550A (zh) * | 2017-01-04 | 2018-07-10 | 广东香雪精准医疗技术有限公司 | 一种识别源自于prame抗原短肽的tcr |
| CN108264550B (zh) * | 2017-01-04 | 2021-04-23 | 香雪生命科学技术(广东)有限公司 | 一种识别源自于prame抗原短肽的tcr |
| US11550939B2 (en) | 2017-02-22 | 2023-01-10 | Twist Bioscience Corporation | Nucleic acid based data storage using enzymatic bioencryption |
| US10894959B2 (en) | 2017-03-15 | 2021-01-19 | Twist Bioscience Corporation | Variant libraries of the immunological synapse and synthesis thereof |
| US11377676B2 (en) | 2017-06-12 | 2022-07-05 | Twist Bioscience Corporation | Methods for seamless nucleic acid assembly |
| US12270028B2 (en) | 2017-06-12 | 2025-04-08 | Twist Bioscience Corporation | Methods for seamless nucleic acid assembly |
| US11332740B2 (en) | 2017-06-12 | 2022-05-17 | Twist Bioscience Corporation | Methods for seamless nucleic acid assembly |
| US11407837B2 (en) | 2017-09-11 | 2022-08-09 | Twist Bioscience Corporation | GPCR binding proteins and synthesis thereof |
| US10894242B2 (en) | 2017-10-20 | 2021-01-19 | Twist Bioscience Corporation | Heated nanowells for polynucleotide synthesis |
| US11745159B2 (en) | 2017-10-20 | 2023-09-05 | Twist Bioscience Corporation | Heated nanowells for polynucleotide synthesis |
| US10936953B2 (en) | 2018-01-04 | 2021-03-02 | Twist Bioscience Corporation | DNA-based digital information storage with sidewall electrodes |
| US12086722B2 (en) | 2018-01-04 | 2024-09-10 | Twist Bioscience Corporation | DNA-based digital information storage with sidewall electrodes |
| CN110016074B (zh) * | 2018-01-08 | 2021-03-30 | 中国科学院广州生物医药与健康研究院 | Mage-a3人源化t细胞受体 |
| CN110016074A (zh) * | 2018-01-08 | 2019-07-16 | 中国科学院广州生物医药与健康研究院 | Mage-a3人源化t细胞受体 |
| EP3773908A1 (en) * | 2018-04-05 | 2021-02-17 | Juno Therapeutics, Inc. | T cell receptors and engineered cells expressing same |
| US12522868B2 (en) | 2018-05-18 | 2026-01-13 | Twist Bioscience Corporation | Polynucleotides, reagents, and methods for nucleic acid hybridization |
| US11492665B2 (en) | 2018-05-18 | 2022-11-08 | Twist Bioscience Corporation | Polynucleotides, reagents, and methods for nucleic acid hybridization |
| US11732294B2 (en) | 2018-05-18 | 2023-08-22 | Twist Bioscience Corporation | Polynucleotides, reagents, and methods for nucleic acid hybridization |
| CN110776562A (zh) * | 2018-07-30 | 2020-02-11 | 广东香雪精准医疗技术有限公司 | 一种识别afp抗原的t细胞受体 |
| US12152065B2 (en) | 2018-07-30 | 2024-11-26 | Xlifesc, Ltd. | T cell receptor for identifying AFP antigen |
| WO2020024915A1 (zh) | 2018-07-30 | 2020-02-06 | 广东香雪精准医疗技术有限公司 | 一种识别afp抗原的t细胞受体 |
| WO2020057619A1 (zh) | 2018-09-21 | 2020-03-26 | 广东香雪精准医疗技术有限公司 | 一种识别afp抗原的高亲和力t细胞受体 |
| WO2020063488A1 (zh) | 2018-09-26 | 2020-04-02 | 广东香雪精准医疗技术有限公司 | 一种识别ssx2抗原的t细胞受体 |
| WO2020098717A1 (zh) | 2018-11-14 | 2020-05-22 | 广东香雪精准医疗技术有限公司 | 一种识别afp的高亲和力tcr |
| US12357959B2 (en) | 2018-12-26 | 2025-07-15 | Twist Bioscience Corporation | Highly accurate de novo polynucleotide synthesis |
| US12565715B2 (en) | 2019-02-26 | 2026-03-03 | Twist Bioscience Corporation | Variant nucleic acid libraries for antibody optimization |
| US12331427B2 (en) | 2019-02-26 | 2025-06-17 | Twist Bioscience Corporation | Antibodies that bind GLP1R |
| US11492728B2 (en) | 2019-02-26 | 2022-11-08 | Twist Bioscience Corporation | Variant nucleic acid libraries for antibody optimization |
| US12570713B2 (en) | 2019-03-08 | 2026-03-10 | Xlifesc, Ltd. | High-affinity TCR for recognizing AFP antigen |
| WO2020182082A1 (zh) | 2019-03-08 | 2020-09-17 | 广东香雪精准医疗技术有限公司 | 一种识别afp抗原的高亲和力tcr |
| US11332738B2 (en) | 2019-06-21 | 2022-05-17 | Twist Bioscience Corporation | Barcode-based nucleic acid sequence assembly |
| WO2021016887A1 (zh) | 2019-07-30 | 2021-02-04 | 广东香雪精准医疗技术有限公司 | 识别ssx2抗原短肽的t细胞受体 |
| WO2021023116A1 (zh) | 2019-08-02 | 2021-02-11 | 广东香雪精准医疗技术有限公司 | 识别ny-eso-1抗原的高亲和力t细胞受体 |
| WO2021036924A1 (zh) | 2019-08-23 | 2021-03-04 | 广东香雪精准医疗技术有限公司 | 一种识别ssx2抗原的高亲和力tcr |
| WO2021043284A1 (zh) | 2019-09-05 | 2021-03-11 | 广东香雪精准医疗技术有限公司 | 一种识别ssx2的高亲和力t细胞受体 |
| US12173282B2 (en) | 2019-09-23 | 2024-12-24 | Twist Bioscience, Inc. | Antibodies that bind CD3 epsilon |
| US12091777B2 (en) | 2019-09-23 | 2024-09-17 | Twist Bioscience Corporation | Variant nucleic acid libraries for CRTH2 |
| WO2021068938A1 (zh) | 2019-10-10 | 2021-04-15 | 香雪生命科学技术(广东)有限公司 | 一种识别kras突变的t细胞受体及其编码序列 |
| US12570750B2 (en) | 2019-12-09 | 2026-03-10 | Twist Bioscience Corporation | Antibodies that bind adenosine A2A receptors and methods of use thereof to treat cancer and neurological diseases |
| WO2021185368A1 (zh) | 2020-03-20 | 2021-09-23 | 香雪生命科学技术(广东)有限公司 | 识别afp抗原的高亲和力tcr |
| WO2021254458A1 (zh) * | 2020-06-17 | 2021-12-23 | 香雪生命科学技术(广东)有限公司 | 一种识别hpv抗原的高亲和力t细胞受体 |
| WO2022111475A1 (zh) | 2020-11-26 | 2022-06-02 | 香雪生命科学技术(广东)有限公司 | 一种识别hpv抗原的tcr |
| WO2023179768A1 (zh) | 2022-03-24 | 2023-09-28 | 香雪生命科学技术(广东)有限公司 | 一种识别mage-a4抗原的高亲和力tcr及其序列和应用 |
Also Published As
| Publication number | Publication date |
|---|---|
| US20160130319A1 (en) | 2016-05-12 |
| JP6549564B2 (ja) | 2019-07-24 |
| AU2014301777A1 (en) | 2016-02-04 |
| EP3015477A1 (en) | 2016-05-04 |
| MX375056B (es) | 2025-03-06 |
| JP2016523268A (ja) | 2016-08-08 |
| AU2014301777B2 (en) | 2017-03-30 |
| AU2017204047B2 (en) | 2019-02-21 |
| CA2916960A1 (en) | 2014-12-31 |
| AU2017204047A1 (en) | 2017-07-06 |
| US10654906B2 (en) | 2020-05-19 |
| EP3015477A4 (en) | 2017-01-11 |
| RU2016101711A (ru) | 2017-07-31 |
| EP3015477B1 (en) | 2021-08-18 |
| CN105683215A (zh) | 2016-06-15 |
| IL243365B (en) | 2020-07-30 |
| CA2916960C (en) | 2022-12-06 |
| IL243365A0 (en) | 2016-03-31 |
| NZ715815A (en) | 2017-02-24 |
| RU2645256C2 (ru) | 2018-02-19 |
| MX2016000231A (es) | 2016-10-05 |
| KR20160058085A (ko) | 2016-05-24 |
| CN105683215B (zh) | 2021-04-23 |
| KR101904385B1 (ko) | 2018-10-05 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| WO2014206304A1 (zh) | 高稳定性的t细胞受体及其制法和应用 | |
| WO2019109821A1 (zh) | 针对prame的高亲和力t细胞受体 | |
| CN112759641B (zh) | 一种识别Kras G12V的高亲和力TCR | |
| JP6640994B2 (ja) | 安定した可溶性ヘテロ二量体tcr | |
| CN106459177B (zh) | 高亲和力ny-eso t细胞受体 | |
| WO2021170115A1 (zh) | 一种识别hpv的t细胞受体 | |
| CN106336457B (zh) | 识别mage‑a3抗原短肽的t细胞受体 | |
| CN106478808B (zh) | 识别ny-eso-1抗原短肽的t细胞受体 | |
| JP6415716B2 (ja) | 可溶性のヘテロ二量体t細胞受容体およびその製法と使用 | |
| WO2021170117A1 (zh) | 一种识别afp抗原短肽的t细胞受体及其编码序列 | |
| WO2021170116A1 (zh) | 一种识别afp的t细胞受体 | |
| CN109890837B (zh) | 高稳定性和高亲和力的dmic及其制法 | |
| WO2021032020A1 (zh) | 一种识别afp的高亲和力t细胞受体 | |
| WO2019158084A1 (zh) | 高亲和力HBs T细胞受体 | |
| WO2023221959A1 (zh) | 一种识别mage的高亲和力t细胞受体及其应用 | |
| CN117659163A (zh) | 一种识别afp的高亲和力t细胞受体及其应用 | |
| CN116836261A (zh) | 一种识别mage-a4抗原的高亲和力tcr及其序列和应用 | |
| CN115819555A (zh) | 一种识别ssx2的高亲和力tcr |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 14817065 Country of ref document: EP Kind code of ref document: A1 |
|
| ENP | Entry into the national phase |
Ref document number: 2016522222 Country of ref document: JP Kind code of ref document: A |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 243365 Country of ref document: IL |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 14901344 Country of ref document: US |
|
| ENP | Entry into the national phase |
Ref document number: 2916960 Country of ref document: CA |
|
| WWE | Wipo information: entry into national phase |
Ref document number: MX/A/2016/000231 Country of ref document: MX |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 2014817065 Country of ref document: EP |
|
| ENP | Entry into the national phase |
Ref document number: 2016101711 Country of ref document: RU Kind code of ref document: A Ref document number: 20167002293 Country of ref document: KR Kind code of ref document: A |
|
| ENP | Entry into the national phase |
Ref document number: 2014301777 Country of ref document: AU Date of ref document: 20140625 Kind code of ref document: A |
|
| WWW | Wipo information: withdrawn in national office |
Ref document number: 2014817065 Country of ref document: EP |