WO2015016133A1 - 情報管理装置及び情報管理方法 - Google Patents
情報管理装置及び情報管理方法 Download PDFInfo
- Publication number
- WO2015016133A1 WO2015016133A1 PCT/JP2014/069571 JP2014069571W WO2015016133A1 WO 2015016133 A1 WO2015016133 A1 WO 2015016133A1 JP 2014069571 W JP2014069571 W JP 2014069571W WO 2015016133 A1 WO2015016133 A1 WO 2015016133A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- document data
- unit
- field
- information management
- management apparatus
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Ceased
Links
Images








Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/90—Details of database functions independent of the retrieved data types
- G06F16/93—Document management systems
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/30—Information retrieval; Database structures therefor; File system structures therefor of unstructured textual data
- G06F16/35—Clustering; Classification
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/30—Information retrieval; Database structures therefor; File system structures therefor of unstructured textual data
- G06F16/35—Clustering; Classification
- G06F16/353—Clustering; Classification into predefined classes
Definitions
- the present invention relates to an information management apparatus and an information management method.
- search engines have been provided as means for searching document data related to a specific word (keyword) for a large number of unspecified documents on the Internet.
- a search engine receives input of a keyword, searches for document data related to the keyword, and outputs the document data.
- Patent Document 1 A technique for automatically extracting only main contents from document data searched by a search engine in this way is known (for example, see Patent Document 1). Further, a technique for classifying a plurality of document data on the Internet to be searched into similar contents is known (for example, see Patent Document 2).
- JP 2010-117941 A Japanese Patent No. 4125951
- the conventional technology has a problem that document data cannot be properly searched when the document data of the genre desired by the user is smaller than the total amount of document data. For example, when trying to search for an article with a low topic, such as an article about security, it was difficult to appropriately search for similar articles and related articles.
- an object of the present invention is to appropriately search for document data even when the document data of the genre desired by the user is smaller than the total amount of document data.
- the information management apparatus uses a collection unit that collects a plurality of document data on a network, and words included in each document data collected by the collection unit, The document data is classified for each predetermined field, tagging unit corresponding to the field is provided for each document data, a receiving unit that receives designation of a field of document data to be searched, and the receiving unit And a search unit for searching for document data to which tag information corresponding to the field accepted by is attached.
- the information management method is an information management method executed by the information management apparatus, and includes a collection step of collecting a plurality of document data on a network, and a word included in each document data collected by the collection step. And using the step of classifying each document data for each predetermined field and adding tag information corresponding to the field for each document data, and receiving the designation of the field of the document data to be searched, And a search step of searching for document data to which tag information corresponding to the field received by the receiving step is given.
- the information management apparatus and the information management method disclosed in the present application are, for example, the case where document data of a genre desired by the user is small compared to the total amount of document data, for example, search data is missing or irrelevant document data is mixed. It is possible to search document data appropriately.
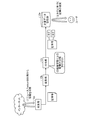
- FIG. 1 is a diagram illustrating an example of the configuration of the information management apparatus according to the first embodiment.
- FIG. 2 is a diagram illustrating an example of information stored by the document data storage unit according to the first embodiment.
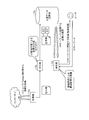
- FIG. 3 is a diagram for explaining a series of processes for assigning a tag to a collected article and performing a search based on the tag in the information management apparatus according to the first embodiment.
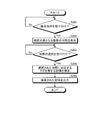
- FIG. 4 is a flowchart for explaining the flow of the tag assignment process in the information management apparatus according to the first embodiment.
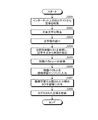
- FIG. 5 is a flowchart for explaining the flow of information search processing in the information management apparatus according to the first embodiment.
- FIG. 6 is a diagram illustrating an example of the configuration of the information management apparatus according to the second embodiment.
- FIG. 7 is a diagram illustrating an example of information stored by the field-specific word list storage unit according to the second embodiment.
- FIG. 8 is a diagram for explaining a series of processes for assigning a tag to an article with reference to a field word list and performing a search based on the tag in the information management apparatus according to the second embodiment.
- FIG. 9 is a flowchart for explaining the flow of tag assignment processing in the information management apparatus according to the second embodiment.
- FIG. 10 is a diagram illustrating a series of processes for assigning a tag to an article and searching for an article related to the keyword in the information management apparatus according to the third embodiment.
- FIG. 11 is a flowchart for explaining the flow of the information search process in the information management apparatus according to the third embodiment.
- FIG. 12 is a diagram illustrating a computer that executes an information management program.
- FIG. 1 is a diagram for explaining the configuration of the information management apparatus 10 according to the first embodiment.
- the information management apparatus 10 includes a communication processing unit 11, a function unit 12, a storage unit 13, and a control unit 14.
- the information management apparatus 10 is connected to the Internet.
- the communication processing unit 11 controls communication related to various information exchanged with devices on the Internet. For example, the communication processing unit 11 requests document data including articles and the like from a server on the Internet, and receives the document data.
- the storage unit 13 includes a document data storage unit 13a.
- the storage unit 13 is, for example, a semiconductor memory element such as a RAM (Random Access Memory) or a flash memory, or a storage device such as a hard disk or an optical disk.
- RAM Random Access Memory
- flash memory a storage device such as a hard disk or an optical disk.
- the document data storage unit 13a stores articles and posted document data collected from news sites on the Internet, BBS (Bulletin Board System), Twitter (registered trademark), and the like. Further, the document data storage unit 13a stores tag information indicating the genre (field) of the document data in association with the document data.
- the document data storage unit 13a may use a general database (MySQL, PostgreSQL, etc.), and may be stored in any form such as a table format or a text format.
- the document data storage unit 13 a stores “article body” indicating the content of the document data and “tag” indicating the genre of the article body in association with each other.
- the number of “tags” may be one or plural for one article.
- the article text “Vulnerability of virus infection found on smartphone via charging device” and tag “security, mobile phone” are stored in association with each other as shown in FIG. Has been.
- the function unit 12 includes a collection unit 12a, a conversion unit 12b, a grant unit 12c, a reception unit 12d, and a search unit 12e.
- the functional unit 12 is responsible for each process, and is actually realized as software (one component thereof) or middleware.
- the control unit 14 controls operations of the communication processing unit 11, the function unit 12, and the storage unit 13 to control the operation of the information management apparatus 10.
- the control unit 14 is a CPU (Central Processing Unit) or MPU (Micro Processing Unit). Unit).
- the collecting unit 12a collects a plurality of document data on the network. For example, the collection unit 12a collects articles from news sites on the Internet, BBS, Twitter, and the like. Here, for the news site and BBS, the collection unit 12a accesses the site and collects articles based on a collection destination list determined in advance by the user.
- the collection unit 12a uses a streaming API or a search API, for example, to acquire a part from all tweets, or based on a keyword or Twitter user ID determined in advance by a user, get.
- the collection unit 12a shapes the collected articles so that they can be used for analysis. Specifically, for news and BBS, unnecessary HTML tags, scripts, or advertisements unrelated to articles are removed.
- the conversion unit 12b converts the document data into feature vectors based on the words included in each document data collected by the collection unit 12a. Specifically, the conversion unit 12b performs unnecessary character removal and character type unification on the collected article data, and then performs feature vector conversion for applying the article data to the machine learning engine.
- the conversion unit 12b deletes, for example, unnecessary blanks or URLs that obstruct language processing from the article data. Further, for example, the conversion unit 12b unifies English uppercase and lowercase letters and so-called half-width full-width characters for characters used in article data as unification of character types.
- the conversion unit 12b can use, for example, one based on morphological analysis, one based on n-gram, or one based on a delimiter for conversion into a feature vector.
- the conversion unit 12b divides the article data by parts of speech when using the morphological analysis, and converts them into feature vectors.
- a library such as an open source Mecab can be used.
- the conversion unit 12b uses morphological analysis when the article data is a sentence “I don't know how to use Twitter yet,” and “Twitter // How to use / / Well / I do n’t know / n / ”.
- the conversion unit 12b divides the article data by a delimiter character (space or comma “,”, etc.) separately defined, and converts them into feature vectors.
- a delimiter character space or comma “,”, etc.
- morphological analysis is often applied to Japanese sentences, and blank separators are applied to English.
- the conversion unit 12b uses the delimiter when the article data is a sentence “I don't know how to use Twitter yet,” and the comma “,” is used as the delimiter. / Still / I don't know well. "
- the conversion unit 12b converts the article data divided into elements in this way into feature vectors.
- a feature vector conversion method for example, a method in which the number of appearances of each element is directly used as a feature vector, a method in which whether or not to appear regardless of the number of times corresponds to 1 or 0, and a weight considering the number of appearances of the entire sentence There is a method of attaching. Any of these may be used as long as it is a method included in the machine learning library to be used.
- the assigning unit 12c classifies each document data for each predetermined field using words included in each document data collected by the collecting unit 12a, and assigns tag information corresponding to the field for each document data. Specifically, the assigning unit 12c classifies each document data for each predetermined field using the feature vector converted by the converting unit 12b, and assigns tag information corresponding to the field for each document data.
- the assigning unit 12c gives the feature vector converted by the converting unit 12b to the machine learning engine, and classifies it into a predetermined category.
- the categories given in advance are, for example, fields that are of interest to the user, such as “security”, “programming”, and “mobile”.
- the machine learning engine used here is not limited to any kind, but, for example, open source Jubatus or the like can be used.
- the assigning unit 12c assigns the tag of the category classified by machine learning to the article data, and stores the article and the tag together in the document data storage unit 13a.
- the accepting unit 12d accepts designation of the field of document data to be searched. Specifically, the accepting unit 12d displays candidates for the field of the document data to be searched, and accepts designation of the field from the displayed candidates for the field.
- the accepting unit 12d when accepting a search instruction to start a search, displays words indicating fields such as “security”, “programming”, and “mobile” as candidates for the field of document data to be searched. In addition, a check box is displayed near each word. Then, the accepting unit 12d accepts a word having a check symbol in the check box as the designated field. Note that the number of fields in which the receiving unit 12d receives the designation may be one or plural.
- the search unit 12e searches for document data to which tag information corresponding to the field received by the receiving unit 12d is assigned. For example, when receiving a search instruction for the field “security”, the search unit 12e searches the document data storage unit 13a for document data to which a tag “security” is attached. Then, the search unit 12e displays the searched document data.
- the search unit 12e may search the document data storage unit 13a for document data to which tags corresponding to all the fields are assigned. You may make it search all the document data to which the tag corresponding to one of the fields was provided.
- FIG. 3 is a diagram for explaining a series of processes for assigning a tag to a collected article and performing a search based on the tag in the information management apparatus according to the first embodiment.
- the collection unit 12a of the information management apparatus 10 collects information such as articles from news sites, Twitter, BBS, etc. on the Internet (see (1) in FIG. 3).
- the conversion unit 12b converts the article into a feature vector based on the words included in each article collected by the collection unit 12a.
- the assigning unit 12c gives the feature vector converted by the converting unit 12b to the machine learning engine, classifies it into a previously given category, and gives a tag corresponding to the category to an article or the like (FIG. 3 ( 2)).
- the search unit 12e searches for document data to which tag information corresponding to the field designated by the user is assigned (see (3) in FIG. 3).
- FIG. 4 is a flowchart for explaining the flow of the tag assignment process in the information management apparatus according to the first embodiment.
- FIG. 5 is a flowchart for explaining the flow of information search processing in the information management apparatus according to the first embodiment.
- the collection unit 12a of the information management apparatus 10 collects articles from websites on the Internet (news sites, BBS, Twitter, blogs, etc.) (step S101).
- the conversion unit 12b removes unnecessary characters from the collected articles (step S102). For example, the conversion unit 12b deletes unnecessary blanks or URLs that obstruct language processing, etc., from article data as unnecessary characters.
- the conversion unit 12b unifies character types for the collected articles (step S103).
- the conversion unit 12b performs unification of uppercase and lowercase letters and so-called half-width and full-width characters for characters used in article data as unification of character types.
- the conversion unit 12b removes unnecessary characters and unifies character types for the collected articles, and then performs feature vector conversion to be applied to the machine learning engine (step S104). For example, the conversion unit 12b converts the feature vector by dividing the article using one of morphological analysis, n-gram, and delimiter for conversion to a feature vector.
- the assigning unit 12c gives the feature vector converted by the converting unit 12b to the machine learning engine, and classifies it into a predetermined category (step S105). Then, the assigning unit 12c assigns the category tags classified by machine learning to the article data (step S106). Thereafter, the assigning unit 12c stores the collected articles and the assigned categories in the document data storage unit 13a (step S107).
- step S201 when the receiving unit 12d of the information management apparatus 10 receives a search instruction for starting a search (Yes in step S201), the receiving unit 12d displays candidates of a plurality of fields that can be search targets (step S202).
- the accepting unit 12d when accepting a search instruction to start a search, displays words indicating fields such as “security”, “programming”, and “mobile” as candidates for the field of document data to be searched. In addition, a check box is displayed near each word. Then, the accepting unit 12d accepts a word having a check symbol in the check box as the designated field. Note that the number of fields in which the receiving unit 12d receives the designation may be one or plural.
- the receiving unit 12d determines whether or not the designation of the field is accepted from the displayed field candidates (step S203).
- step S203 determines whether or not the designation of the field is accepted from the displayed field candidates.
- an article having a tag corresponding to the selected field is searched (step S204). For example, when receiving a search instruction for the field “security”, the search unit 12e searches the document data storage unit 13a for document data to which a tag “security” is attached. Then, the search unit 12e outputs the searched article (step S205).
- the information management apparatus 10 collects a plurality of document data on the network, and uses the words included in each collected document data to predetermine each document data. And tag information corresponding to each field is assigned to each document data. Then, the information management apparatus 10 accepts designation of the field of document data to be searched, and retrieves document data to which tag information corresponding to the accepted field is given. Even if the document data of the genre desired by the user is smaller than the total amount of document data, it is possible to search the document data appropriately.
- the information management apparatus 10 collects articles from websites on the Internet (news, Twitter, BBS, blog, etc.), classifies and tags these articles by machine learning, and stores the articles and tags. And since the article that the user wants can be searched based on the tag attached to the article, even if the article of the genre that the user wants is less than the total amount of the article, based on the tag information, You can search for articles you want from many articles.
- the information management apparatus 10 converts the document data into feature vectors based on the words included in each collected document data. Then, the information management apparatus 10 classifies each document data for each predetermined field using the converted feature vector, and assigns tag information corresponding to the field for each document data. For this reason, it is possible to attach a tag appropriately to document data.
- the information management apparatus 10 displays candidates for the field of the document data to be searched, and accepts designation of the field from the displayed candidates for the field. For this reason, when the user does not know the search keyword, for example, even an article related to a new topic can be searched.
- the information management apparatus may store a word list related to a predetermined field, refer to the word list, and add tag information corresponding to the field for each document data. Therefore, in the following, using FIG. 6 to FIG. 9, a word list relating to a predetermined field is stored, a word is extracted from each document data by referring to the word list, and the document data is extracted based on the word. A case of converting to a feature vector will be described. In addition, description is abbreviate
- FIG. 6 is a diagram illustrating an example of the configuration of the information management apparatus according to the second embodiment.
- the information management apparatus 10A according to the second embodiment is different from the information management apparatus 10 according to the first embodiment shown in FIG. 1 in that a field-specific word list storage unit 13b is newly provided. To do.
- the field-specific word list storage unit 13b stores a field-specific word list related to a predetermined field.
- the field-specific word list storage unit 13b stores a word list related to each field in association with the field, as illustrated in FIG. Referring to the example of FIG. 7, for example, the field-specific word list storage unit 13 b stores the word “vulnerability, virus...” In association with the field “security”.
- FIG. 7 is a diagram illustrating an example of information stored by the field-specific word list storage unit 13b according to the second embodiment. Here, it is assumed that the field-specific word list storage unit 13b stores words of a genre desired by the user as a field-specific word list.
- the conversion unit 12b refers to the word list stored in the field-specific word list storage unit 13b, extracts words from each document data, and converts the document data into feature vectors based on the words.
- the conversion unit 12b removes unnecessary characters and unifies character types for the collected article data, and then, as a field-specific word extraction process, creates a list of each field based on a field-specific word list given in advance.
- the included words are extracted from the article text, and the extracted words are converted into feature vectors.
- the conversion unit 12b displays the word list according to the field illustrated in FIG. Referencing and extracting the words included in the list from the body of the article, as a result, the word “virus” and “vulnerability” in the field “security” and the word “smartphone” in the field “mobile” are extracted. Will be. Then, the conversion unit 12b converts “virus”, “vulnerability”, and “smartphone” into feature vectors.
- the assigning unit 12c gives the feature vector converted by the converting unit 12b to the machine learning engine and classifies it into a predetermined category. Then, the assigning unit 12c assigns a tag to the category classified by machine learning with respect to the article data, and stores the article and the tag together in the document data storage unit 13a.
- the process of converting to a feature vector may be omitted, and the field corresponding to the extracted word may be assigned to the article data as a tag. That is to say, using the above example, for example, the adding unit 12c extracts “virus”, “vulnerability”, and “smartphone” as a result of extraction processing of words included in the list from the article text.
- “security” corresponding to viruses and vulnerabilities and “mobile phone” corresponding to smartphones may be added as tags, or only “security” corresponding to the word with the largest number of words. It may be given as a tag.
- FIG. 8 is a diagram for explaining a series of processes for assigning a tag to an article with reference to a field word list and performing a search based on the tag in the information management apparatus according to the second embodiment.
- the collection unit 12a of the information management apparatus 10A collects information such as articles from news sites, Twitter, BBS, etc. on the Internet (see (1) in FIG. 8).
- the conversion unit 12b refers to the word list stored in the field-specific word list storage unit 13b, extracts words from each document data, and converts the document data into feature vectors based on the words.
- the assigning unit 12c gives the feature vector converted by the converting unit 12b to the machine learning engine, classifies the feature vector in a category given in advance, and gives a tag corresponding to the category to an article or the like (( 2)).
- the search unit 12e searches for document data to which tag information corresponding to the field designated by the user is assigned (see (3) in FIG. 8).
- FIG. 9 is a flowchart for explaining the flow of tag assignment processing in the information management apparatus according to the second embodiment.
- the collection unit 12a of the information management apparatus 10A collects articles from websites on the Internet (news sites, BBS, Twitter, blogs, etc.) (step S301). Then, the conversion unit 12b removes unnecessary characters from the collected articles (step S302). For example, the conversion unit 12b deletes unnecessary blanks or URLs that obstruct language processing, etc., from article data as unnecessary characters.
- the conversion unit 12b unifies the character types for the collected articles (step S303). For example, the conversion unit 12b performs unification of uppercase and lowercase letters and so-called half-width and full-width characters for characters used in article data as unification of character types.
- the conversion unit 12b refers to the word list for each field and extracts words included in the list for each field from the article text (step S304). Then, feature vector conversion for applying to the machine learning engine is performed (step S305). For example, for the conversion to the feature vector, the conversion unit 12b divides the article using any one of the extracted word as it is, the morphological analysis, the n-gram, or the delimiter, Perform feature vector conversion.
- the assigning unit 12c gives the feature vector converted by the converting unit 12b to the machine learning engine, and classifies it into a predetermined category (step S306). Then, the assigning unit 12c assigns a category tag classified by machine learning to the article data (step S307). Thereafter, the assigning unit 12c stores the collected articles and the assigned categories in the document data storage unit 13a (step S308).
- the information management apparatus 10A stores a word list related to a predetermined field. Then, the information management apparatus 10A refers to the word list, extracts words from each document data, and converts the document data into feature vectors based on the words. For this reason, classification into more specific fields is possible by using words in the word list when converting to feature vectors.
- the information management apparatus accepts input of a keyword related to a field as designation of a field of document data to be searched, and searches for document data to which tag information corresponding to the accepted keyword is given. You may do it.
- a case where an article related to a keyword is searched and a similar article is output will be described with reference to FIGS. 10 and 11.
- FIG. 10 is a diagram illustrating a series of processes for assigning a tag to an article and searching for an article related to the keyword in the information management apparatus 10B according to the third embodiment.
- the collection unit 12a of the information management apparatus 10B collects information such as articles from news sites, Twitter, BBS, etc. on the Internet (see (1) in FIG. 10).
- the assigning unit 12c gives the feature vector converted by the converting unit 12b to the machine learning engine, classifies the feature vector into a category given in advance, and gives a tag corresponding to the category to an article or the like (( 2)).
- the reception part 12d receives the input of a keyword from a user (refer (3) of FIG. 10).
- the search unit 12e searches for an article with a tag corresponding to the keyword (see (4) in FIG. 10). For example, when “vulnerability” is given as a keyword, an article with a tag “security” corresponding to “vulnerability” is searched. And the search part 12e outputs the article relevant to a keyword to a user by making the searched result into a recommendation result (refer (5) of FIG. 10).
- FIG. 11 is a flowchart for explaining the flow of the information search process in the information management apparatus according to the third embodiment.
- the receiving unit 12d of the information management apparatus 10B receives a search instruction to start a search (Yes at Step S401), the receiving unit 12d determines whether an input of a keyword has been received (Step S402).
- the receiving unit 12d searches for an article having a tag corresponding to the keyword (Step S403). For example, when “vulnerability” is assigned as a keyword, the search unit 12e searches for an article provided with a tag “security” corresponding to “vulnerability”. Then, the search unit 12e outputs the searched article (step S404).
- the information management apparatus 10B As described above, in the information management apparatus 10B according to the third embodiment, as the specification of the field of the document data to be searched, the input of the keyword related to the field is accepted and the tag information corresponding to the accepted keyword is given. Search for document data. For this reason, in the information management apparatus 10B, it is possible to search document data appropriately based on the keyword input by the user.
- each component of each illustrated apparatus is functionally conceptual, and does not necessarily need to be physically configured as illustrated.
- the specific form of distribution / integration of each device is not limited to that shown in the figure, and all or a part thereof may be functionally or physically distributed or arbitrarily distributed in arbitrary units according to various loads or usage conditions. Can be integrated and configured.
- the conversion unit 12b and the grant unit 12c may be integrated.
- all or any part of each processing function performed in each device may be realized by a CPU and a program analyzed and executed by the CPU, or may be realized as hardware by wired logic.
- FIG. 12 is a diagram illustrating a computer 1000 that executes an information management program.
- the computer 1000 includes, for example, a memory 1010, a CPU 1020, a hard disk drive interface 1030, a disk drive interface 1040, a serial port interface 1050, a video adapter 1060, and a network interface 1070. These units are connected by a bus 1080.
- the memory 1010 includes a ROM (Read Only Memory) 1011 and a RAM 1012 as illustrated in FIG.
- the ROM 1011 stores a boot program such as BIOS (Basic Input Output System).
- BIOS Basic Input Output System
- the hard disk drive interface 1030 is connected to the hard disk drive 1031 as illustrated in FIG.
- the disk drive interface 1040 is connected to the disk drive 1041 as illustrated in FIG.
- a removable storage medium such as a magnetic disk or an optical disk is inserted into the disk drive 1041.
- the serial port interface 1050 is connected to, for example, a mouse 1051 and a keyboard 1052 as illustrated in FIG.
- the video adapter 1060 is connected to a display 1061, for example, as illustrated in FIG.
- the hard disk drive 1031 stores, for example, an OS 1091, an application program 1092, a program module 1093, and program data 1094. That is, the information management program is stored in, for example, the hard disk drive 1031 as a program module in which a command executed by the computer 1000 is described.
- various data described in the above embodiment is stored as program data in, for example, the memory 1010 or the hard disk drive 1031.
- the CPU 1020 reads the program module 1093 and the program data 1094 stored in the memory 1010 and the hard disk drive 1031 to the RAM 1012 as necessary, and executes various processing procedures.
- program module 1093 and the program data 1094 related to the information management program are not limited to being stored in the hard disk drive 1031, but are stored in, for example, a removable storage medium and read out by the CPU 1020 via the disk drive or the like. Also good. Alternatively, the program module 1093 and the program data 1094 related to the information management program are stored in another computer connected via a network (LAN (Local Area Network), WAN (Wide Area Network), etc.), and the network interface 1070 is stored. Via the CPU 1020.
- LAN Local Area Network
- WAN Wide Area Network
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Databases & Information Systems (AREA)
- Data Mining & Analysis (AREA)
- Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Business, Economics & Management (AREA)
- General Business, Economics & Management (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
Abstract
Description
以下の実施形態では、第一の実施形態に係る情報管理装置及び情報管理方法による処理の流れを順に説明し、最後に第一の実施形態による効果を説明する。
図1に示した情報管理装置10の構成を説明する。図1は、第一の実施形態に係る情報管理装置10の構成を説明するための図である。図1に示すように、情報管理装置10は、通信処理部11、機能部12、記憶部13および制御部14を有する。また、情報管理装置10は、インターネットに接続されている。
次に、図4、5を用いて、第一の実施形態に係る情報管理装置10による処理を説明する。図4は、第一の実施形態に係る情報管理装置におけるタグ付与処理の流れを説明するためのフローチャートである。図5は、第一の実施形態に係る情報管理装置における情報検索処理の流れを説明するためのフローチャートである。
上述してきたように、第一の実施形態にかかる情報管理装置10では、ネットワーク上における複数の文書データを収集し、収集された各文書データに含まれる単語を用いて、前記各文書データを所定の分野ごとに分類し、該分野に対応するタグ情報を文書データごとに付与する。そして、情報管理装置10では、検索対象とする文書データの分野の指定を受け付け、受け付けられた分野に対応するタグ情報が付与された文書データを検索する。利用者が望むジャンルの文書データが全体の文書データの量に比べて少ない場合であっても、適切に文書データを検索することが可能である。
第二の実施形態において、情報管理装置が、所定の分野に関する単語リストを記憶し、単語リストを参照して、分野に対応するタグ情報を文書データごとに付与するようにしてもよい。そこで、以下では、図6~図9を用いて、所定の分野に関する単語リストを記憶し、単語リストを参照して、各文書データから単語を抽出し、該単語に基づいて、該文書データを特徴ベクトルに変換する場合について説明する。なお、第一の実施形態と共通する構成および処理については、説明を省略する。
第三の実施形態では、情報管理装置が、検索対象とする文書データの分野の指定として、分野に関するキーワードの入力を受け付け、受け付けられたキーワードに対応するタグ情報が付与された文書データを検索するようにしてもよい。そこで、以下では、図10および図11を用いて、キーワードに関連する記事の検索を行い、類似した記事を出力する場合について説明する。なお、第一の実施形態と共通する構成および処理については、説明を省略する。
また、図示した各装置の各構成要素は機能概念的なものであり、必ずしも物理的に図示の如く構成されていることを要しない。すなわち、各装置の分散・統合の具体的形態は図示のものに限られず、その全部または一部を、各種の負荷や使用状況などに応じて、任意の単位で機能的または物理的に分散・統合して構成することができる。例えば、変換部12bと付与部12cとを統合してもよい。さらに、各装置にて行なわれる各処理機能は、その全部または任意の一部が、CPUおよび当該CPUにて解析実行されるプログラムにて実現され、あるいは、ワイヤードロジックによるハードウェアとして実現され得る。
また、上記実施形態において説明した情報管理装置10が実行する処理をコンピュータが実行可能な言語で記述したプログラムを作成することもできる。例えば、第一の実施形態に係る情報管理装置10が実行する処理をコンピュータが実行可能な言語で記述した情報管理プログラムを作成することもできる。この場合、コンピュータが情報管理プログラムを実行することにより、上記実施形態と同様の効果を得ることができる。さらに、かかる情報管理プログラムをコンピュータ読み取り可能な記録媒体に記録して、この記録媒体に記録された情報管理プログラムをコンピュータに読み込ませて実行することにより上記第一の実施形態と同様の処理を実現してもよい。以下に、図1に示した情報管理装置10と同様の機能を実現する情報管理プログラムを実行するコンピュータの一例を説明する。
11 通信処理部
12 機能部
12a 収集部
12b 変換部
12c 付与部
12d 受付部
12e 検索部
13 記憶部
13a 文書データ記憶部
13b 分野別単語リスト記憶部
14 制御部
Claims (6)
- ネットワーク上における複数の文書データを収集する収集部と、
前記収集部によって収集された各文書データに含まれる単語を用いて、前記各文書データを所定の分野ごとに分類し、該分野に対応するタグ情報を文書データごとに付与する付与部と、
検索対象とする文書データの分野の指定を受け付ける受付部と、
前記受付部によって受け付けられた分野に対応するタグ情報が付与された文書データを検索する検索部と、
を有することを特徴とする情報管理装置。 - 前記収集部によって収集された各文書データに含まれる単語に基づいて、該文書データを特徴ベクトルに変換する変換部をさらに有し、
前記付与部は、前記変換部によって変換された特徴ベクトルを用いて、前記各文書データを所定の分野ごとに分類し、該分野に対応するタグ情報を文書データごとに付与することを特徴とする請求項1に記載の情報管理装置。 - 所定の分野に関する単語リストを記憶する記憶部をさらに有し、
前記変換部は、前記記憶部に記憶された単語リストを参照して、前記各文書データから単語を抽出し、該単語に基づいて、該文書データを特徴ベクトルに変換することを特徴とする請求項2に記載の情報管理装置。 - 前記受付部は、検索対象となる文書データの分野の候補を表示し、表示した分野の候補のなかから分野の指定を受け付けることを特徴とする請求項1~3のいずれか一つに記載の情報管理装置。
- 前記受付部は、検索対象とする文書データの分野の指定として、分野に関するキーワードの入力を受け付け、
前記検索部は、前記受付部によって受け付けられたキーワードに対応するタグ情報が付与された文書データを検索することを特徴とする請求項1~3のいずれか一つに記載の情報管理装置。 - 情報管理装置によって実行される情報管理方法であって、
ネットワーク上における複数の文書データを収集する収集工程と、
前記収集工程によって収集された各文書データに含まれる単語を用いて、前記各文書データを所定の分野ごとに分類し、該分野に対応するタグ情報を文書データごとに付与する付与工程と、
検索対象とする文書データの分野の指定を受け付ける受付工程と、
前記受付工程によって受け付けられた分野に対応するタグ情報が付与された文書データを検索する検索工程と、
を含んだことを特徴とする情報管理方法。
Priority Applications (4)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2015529543A JPWO2015016133A1 (ja) | 2013-07-30 | 2014-07-24 | 情報管理装置及び情報管理方法 |
| CN201480041608.7A CN105408896A (zh) | 2013-07-30 | 2014-07-24 | 信息管理装置和信息管理方法 |
| EP14832339.7A EP3012748A4 (en) | 2013-07-30 | 2014-07-24 | Information management device, and information management method |
| US14/908,267 US20160170983A1 (en) | 2013-07-30 | 2014-07-24 | Information management apparatus and information management method |
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2013-158200 | 2013-07-30 | ||
| JP2013158200 | 2013-07-30 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2015016133A1 true WO2015016133A1 (ja) | 2015-02-05 |
Family
ID=52431669
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2014/069571 Ceased WO2015016133A1 (ja) | 2013-07-30 | 2014-07-24 | 情報管理装置及び情報管理方法 |
Country Status (5)
| Country | Link |
|---|---|
| US (1) | US20160170983A1 (ja) |
| EP (1) | EP3012748A4 (ja) |
| JP (1) | JPWO2015016133A1 (ja) |
| CN (1) | CN105408896A (ja) |
| WO (1) | WO2015016133A1 (ja) |
Families Citing this family (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP6235082B1 (ja) * | 2016-07-13 | 2017-11-22 | ヤフー株式会社 | データ分類装置、データ分類方法、およびプログラム |
| US11220916B2 (en) | 2020-01-22 | 2022-01-11 | General Electric Company | Turbine rotor blade with platform with non-linear cooling passages by additive manufacture |
| US11492908B2 (en) | 2020-01-22 | 2022-11-08 | General Electric Company | Turbine rotor blade root with hollow mount with lattice support structure by additive manufacture |
Citations (8)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH10143537A (ja) * | 1996-11-12 | 1998-05-29 | Ricoh Co Ltd | 文書検索処理方法 |
| JP4125951B2 (ja) | 2002-12-25 | 2008-07-30 | 日本電信電話株式会社 | テキスト自動分類方法及び装置並びにプログラム及び記録媒体 |
| JP2008217157A (ja) * | 2007-02-28 | 2008-09-18 | Nippon Telegr & Teleph Corp <Ntt> | 操作履歴を利用した自動情報整理装置、方法、およびプログラム |
| JP2008276344A (ja) * | 2007-04-26 | 2008-11-13 | Just Syst Corp | 多重トピック分類装置、多重トピック分類方法、および多重トピック分類プログラム |
| JP2009259248A (ja) * | 2008-04-11 | 2009-11-05 | Nhn Corp | ウェブページに含まれるイメージに対してタグ付けを実行し、その結果を利用してウェブ検索サービスを提供するための方法、装置及びコンピュータ読み取り可能な記録媒体 |
| JP2010026923A (ja) * | 2008-07-23 | 2010-02-04 | Omron Corp | 文書分類方法、文書分類装置、文書分類プログラム、および、コンピュータ読取り可能記録媒体 |
| JP2010117941A (ja) | 2008-11-13 | 2010-05-27 | Nippon Telegr & Teleph Corp <Ntt> | Web文書主要コンテンツ抽出装置及びプログラム |
| JP2012164018A (ja) * | 2011-02-03 | 2012-08-30 | Nifty Corp | タグ推薦装置 |
Family Cites Families (15)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US6505150B2 (en) * | 1997-07-02 | 2003-01-07 | Xerox Corporation | Article and method of automatically filtering information retrieval results using test genre |
| US6711585B1 (en) * | 1999-06-15 | 2004-03-23 | Kanisa Inc. | System and method for implementing a knowledge management system |
| JP4363868B2 (ja) * | 2002-08-23 | 2009-11-11 | 株式会社東芝 | 検索キーワード分析プログラム及びシステム並びに方法 |
| JP4581520B2 (ja) * | 2004-07-09 | 2010-11-17 | 富士ゼロックス株式会社 | ドキュメント管理プログラム、ドキュメント管理方法、及びドキュメント管理装置 |
| US7761078B2 (en) * | 2006-07-28 | 2010-07-20 | Qualcomm Incorporated | Dual inductor circuit for multi-band wireless communication device |
| US7711668B2 (en) * | 2007-02-26 | 2010-05-04 | Siemens Corporation | Online document clustering using TFIDF and predefined time windows |
| JP5079019B2 (ja) * | 2008-01-08 | 2012-11-21 | 三菱電機株式会社 | 情報フィルタリングシステム、情報フィルタリング方法および情報フィルタリングプログラム |
| EP2260373A4 (en) * | 2008-02-25 | 2016-08-03 | Atigeo Llc | DETERMINATION OF RELEVANT INFORMATION FOR INTERESTS |
| US8566349B2 (en) * | 2009-09-28 | 2013-10-22 | Xerox Corporation | Handwritten document categorizer and method of training |
| CN102640152B (zh) * | 2009-12-09 | 2014-10-15 | 国际商业机器公司 | 根据检索关键词检索文档数据的方法及其计算机系统 |
| US8725739B2 (en) * | 2010-11-01 | 2014-05-13 | Evri, Inc. | Category-based content recommendation |
| CN103299304B (zh) * | 2011-01-13 | 2016-09-28 | 三菱电机株式会社 | 分类规则生成装置和分类规则生成方法 |
| CN102737057B (zh) * | 2011-04-14 | 2015-04-01 | 阿里巴巴集团控股有限公司 | 一种商品类目信息的确定方法及装置 |
| US9292505B1 (en) * | 2012-06-12 | 2016-03-22 | Firstrain, Inc. | Graphical user interface for recurring searches |
| US9235812B2 (en) * | 2012-12-04 | 2016-01-12 | Msc Intellectual Properties B.V. | System and method for automatic document classification in ediscovery, compliance and legacy information clean-up |
-
2014
- 2014-07-24 US US14/908,267 patent/US20160170983A1/en not_active Abandoned
- 2014-07-24 EP EP14832339.7A patent/EP3012748A4/en not_active Withdrawn
- 2014-07-24 JP JP2015529543A patent/JPWO2015016133A1/ja active Pending
- 2014-07-24 WO PCT/JP2014/069571 patent/WO2015016133A1/ja not_active Ceased
- 2014-07-24 CN CN201480041608.7A patent/CN105408896A/zh active Pending
Patent Citations (8)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH10143537A (ja) * | 1996-11-12 | 1998-05-29 | Ricoh Co Ltd | 文書検索処理方法 |
| JP4125951B2 (ja) | 2002-12-25 | 2008-07-30 | 日本電信電話株式会社 | テキスト自動分類方法及び装置並びにプログラム及び記録媒体 |
| JP2008217157A (ja) * | 2007-02-28 | 2008-09-18 | Nippon Telegr & Teleph Corp <Ntt> | 操作履歴を利用した自動情報整理装置、方法、およびプログラム |
| JP2008276344A (ja) * | 2007-04-26 | 2008-11-13 | Just Syst Corp | 多重トピック分類装置、多重トピック分類方法、および多重トピック分類プログラム |
| JP2009259248A (ja) * | 2008-04-11 | 2009-11-05 | Nhn Corp | ウェブページに含まれるイメージに対してタグ付けを実行し、その結果を利用してウェブ検索サービスを提供するための方法、装置及びコンピュータ読み取り可能な記録媒体 |
| JP2010026923A (ja) * | 2008-07-23 | 2010-02-04 | Omron Corp | 文書分類方法、文書分類装置、文書分類プログラム、および、コンピュータ読取り可能記録媒体 |
| JP2010117941A (ja) | 2008-11-13 | 2010-05-27 | Nippon Telegr & Teleph Corp <Ntt> | Web文書主要コンテンツ抽出装置及びプログラム |
| JP2012164018A (ja) * | 2011-02-03 | 2012-08-30 | Nifty Corp | タグ推薦装置 |
Non-Patent Citations (1)
| Title |
|---|
| See also references of EP3012748A4 |
Also Published As
| Publication number | Publication date |
|---|---|
| US20160170983A1 (en) | 2016-06-16 |
| JPWO2015016133A1 (ja) | 2017-03-02 |
| CN105408896A (zh) | 2016-03-16 |
| EP3012748A4 (en) | 2017-05-10 |
| EP3012748A1 (en) | 2016-04-27 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US20160342578A1 (en) | Systems, Methods, and Media for Generating Structured Documents | |
| US9626622B2 (en) | Training a question/answer system using answer keys based on forum content | |
| EP3051432A1 (en) | Semantic information acquisition method, keyword expansion method thereof, and search method and system | |
| US9582486B2 (en) | Apparatus and method for classifying and analyzing documents including text | |
| US10565520B2 (en) | Feature extraction for machine learning | |
| EP3683695A1 (en) | Synonym dictionary creation device, synonym dictionary creation program, and synonym dictionary creation method | |
| US20120290575A1 (en) | Mining intent of queries from search log data | |
| US10083398B2 (en) | Framework for annotated-text search using indexed parallel fields | |
| US20120179709A1 (en) | Apparatus, method and program product for searching document | |
| US11150871B2 (en) | Information density of documents | |
| JP2016532210A (ja) | サーチ方法、装置、設備および不揮発性計算機メモリ | |
| US20150347406A1 (en) | Corpus Generation Based Upon Document Attributes | |
| US20180089335A1 (en) | Indication of search result | |
| CN108829854B (zh) | 用于生成文章的方法、装置、设备和计算机可读存储介质 | |
| CN107735792A (zh) | 软件分析系统、软件分析方法和软件分析程序 | |
| KR20120047622A (ko) | 디지털 콘텐츠 관리 시스템 및 방법 | |
| US8856152B2 (en) | Apparatus and method for visualizing data | |
| JP2021120905A (ja) | 情報処理装置、サーバ装置、ユーザ端末、方法及びプログラム | |
| WO2015016133A1 (ja) | 情報管理装置及び情報管理方法 | |
| JP2016045552A (ja) | 特徴抽出プログラム、特徴抽出方法、および特徴抽出装置 | |
| JP2014074942A (ja) | 情報収集プログラム、情報収集方法および情報処理装置 | |
| CN103218130B (zh) | 一种用于对待选对象执行选择操作的方法和装置 | |
| JP6154072B2 (ja) | 情報分析システム、情報分析方法及び情報分析プログラム | |
| US20180046706A1 (en) | Search system, search method and search program | |
| US11669555B2 (en) | System and method of creating index |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| WWE | Wipo information: entry into national phase |
Ref document number: 201480041608.7 Country of ref document: CN |
|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 14832339 Country of ref document: EP Kind code of ref document: A1 |
|
| ENP | Entry into the national phase |
Ref document number: 2015529543 Country of ref document: JP Kind code of ref document: A |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 2014832339 Country of ref document: EP |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 14908267 Country of ref document: US |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |