WO2015132914A1 - データ圧縮装置およびデータ圧縮方法 - Google Patents
データ圧縮装置およびデータ圧縮方法 Download PDFInfo
- Publication number
- WO2015132914A1 WO2015132914A1 PCT/JP2014/055671 JP2014055671W WO2015132914A1 WO 2015132914 A1 WO2015132914 A1 WO 2015132914A1 JP 2014055671 W JP2014055671 W JP 2014055671W WO 2015132914 A1 WO2015132914 A1 WO 2015132914A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- data
- check matrix
- compression
- error correction
- data compression
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Ceased
Links
Images


Classifications
-
- H—ELECTRICITY
- H03—ELECTRONIC CIRCUITRY
- H03M—CODING; DECODING; CODE CONVERSION IN GENERAL
- H03M7/00—Conversion of a code where information is represented by a given sequence or number of digits to a code where the same, similar or subset of information is represented by a different sequence or number of digits
- H03M7/30—Compression; Expansion; Suppression of unnecessary data, e.g. redundancy reduction
- H03M7/60—General implementation details not specific to a particular type of compression
- H03M7/6017—Methods or arrangements to increase the throughput
-
- H—ELECTRICITY
- H03—ELECTRONIC CIRCUITRY
- H03M—CODING; DECODING; CODE CONVERSION IN GENERAL
- H03M7/00—Conversion of a code where information is represented by a given sequence or number of digits to a code where the same, similar or subset of information is represented by a different sequence or number of digits
- H03M7/30—Compression; Expansion; Suppression of unnecessary data, e.g. redundancy reduction
-
- H—ELECTRICITY
- H03—ELECTRONIC CIRCUITRY
- H03M—CODING; DECODING; CODE CONVERSION IN GENERAL
- H03M13/00—Coding, decoding or code conversion, for error detection or error correction; Coding theory basic assumptions; Coding bounds; Error probability evaluation methods; Channel models; Simulation or testing of codes
- H03M13/03—Error detection or forward error correction by redundancy in data representation, i.e. code words containing more digits than the source words
- H03M13/05—Error detection or forward error correction by redundancy in data representation, i.e. code words containing more digits than the source words using block codes, i.e. a predetermined number of check bits joined to a predetermined number of information bits
- H03M13/11—Error detection or forward error correction by redundancy in data representation, i.e. code words containing more digits than the source words using block codes, i.e. a predetermined number of check bits joined to a predetermined number of information bits using multiple parity bits
- H03M13/1102—Codes on graphs and decoding on graphs, e.g. low-density parity check [LDPC] codes
- H03M13/1148—Structural properties of the code parity-check or generator matrix
- H03M13/116—Quasi-cyclic LDPC [QC-LDPC] codes, i.e. the parity-check matrix being composed of permutation or circulant sub-matrices
- H03M13/1162—Array based LDPC codes, e.g. array codes
-
- H—ELECTRICITY
- H03—ELECTRONIC CIRCUITRY
- H03M—CODING; DECODING; CODE CONVERSION IN GENERAL
- H03M13/00—Coding, decoding or code conversion, for error detection or error correction; Coding theory basic assumptions; Coding bounds; Error probability evaluation methods; Channel models; Simulation or testing of codes
- H03M13/03—Error detection or forward error correction by redundancy in data representation, i.e. code words containing more digits than the source words
- H03M13/05—Error detection or forward error correction by redundancy in data representation, i.e. code words containing more digits than the source words using block codes, i.e. a predetermined number of check bits joined to a predetermined number of information bits
- H03M13/13—Linear codes
- H03M13/15—Cyclic codes, i.e. cyclic shifts of codewords produce other codewords, e.g. codes defined by a generator polynomial, Bose-Chaudhuri-Hocquenghem [BCH] codes
- H03M13/151—Cyclic codes, i.e. cyclic shifts of codewords produce other codewords, e.g. codes defined by a generator polynomial, Bose-Chaudhuri-Hocquenghem [BCH] codes using error location or error correction polynomials
- H03M13/1515—Reed-Solomon codes
-
- H—ELECTRICITY
- H03—ELECTRONIC CIRCUITRY
- H03M—CODING; DECODING; CODE CONVERSION IN GENERAL
- H03M13/00—Coding, decoding or code conversion, for error detection or error correction; Coding theory basic assumptions; Coding bounds; Error probability evaluation methods; Channel models; Simulation or testing of codes
- H03M13/03—Error detection or forward error correction by redundancy in data representation, i.e. code words containing more digits than the source words
- H03M13/05—Error detection or forward error correction by redundancy in data representation, i.e. code words containing more digits than the source words using block codes, i.e. a predetermined number of check bits joined to a predetermined number of information bits
- H03M13/13—Linear codes
- H03M13/15—Cyclic codes, i.e. cyclic shifts of codewords produce other codewords, e.g. codes defined by a generator polynomial, Bose-Chaudhuri-Hocquenghem [BCH] codes
- H03M13/151—Cyclic codes, i.e. cyclic shifts of codewords produce other codewords, e.g. codes defined by a generator polynomial, Bose-Chaudhuri-Hocquenghem [BCH] codes using error location or error correction polynomials
- H03M13/152—Bose-Chaudhuri-Hocquenghem [BCH] codes
-
- H—ELECTRICITY
- H03—ELECTRONIC CIRCUITRY
- H03M—CODING; DECODING; CODE CONVERSION IN GENERAL
- H03M13/00—Coding, decoding or code conversion, for error detection or error correction; Coding theory basic assumptions; Coding bounds; Error probability evaluation methods; Channel models; Simulation or testing of codes
- H03M13/63—Joint error correction and other techniques
- H03M13/6312—Error control coding in combination with data compression
-
- H—ELECTRICITY
- H03—ELECTRONIC CIRCUITRY
- H03M—CODING; DECODING; CODE CONVERSION IN GENERAL
- H03M7/00—Conversion of a code where information is represented by a given sequence or number of digits to a code where the same, similar or subset of information is represented by a different sequence or number of digits
- H03M7/30—Compression; Expansion; Suppression of unnecessary data, e.g. redundancy reduction
- H03M7/3082—Vector coding
-
- H—ELECTRICITY
- H03—ELECTRONIC CIRCUITRY
- H03M—CODING; DECODING; CODE CONVERSION IN GENERAL
- H03M7/00—Conversion of a code where information is represented by a given sequence or number of digits to a code where the same, similar or subset of information is represented by a different sequence or number of digits
- H03M7/30—Compression; Expansion; Suppression of unnecessary data, e.g. redundancy reduction
- H03M7/55—Compression Theory, e.g. compression of random number, repeated compression
-
- H—ELECTRICITY
- H03—ELECTRONIC CIRCUITRY
- H03M—CODING; DECODING; CODE CONVERSION IN GENERAL
- H03M7/00—Conversion of a code where information is represented by a given sequence or number of digits to a code where the same, similar or subset of information is represented by a different sequence or number of digits
- H03M7/30—Compression; Expansion; Suppression of unnecessary data, e.g. redundancy reduction
- H03M7/60—General implementation details not specific to a particular type of compression
- H03M7/6041—Compression optimized for errors
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V10/00—Arrangements for image or video recognition or understanding
- G06V10/40—Extraction of image or video features
- G06V10/46—Descriptors for shape, contour or point-related descriptors, e.g. scale invariant feature transform [SIFT] or bags of words [BoW]; Salient regional features
- G06V10/462—Salient features, e.g. scale invariant feature transforms [SIFT]
-
- H—ELECTRICITY
- H03—ELECTRONIC CIRCUITRY
- H03M—CODING; DECODING; CODE CONVERSION IN GENERAL
- H03M13/00—Coding, decoding or code conversion, for error detection or error correction; Coding theory basic assumptions; Coding bounds; Error probability evaluation methods; Channel models; Simulation or testing of codes
- H03M13/03—Error detection or forward error correction by redundancy in data representation, i.e. code words containing more digits than the source words
- H03M13/05—Error detection or forward error correction by redundancy in data representation, i.e. code words containing more digits than the source words using block codes, i.e. a predetermined number of check bits joined to a predetermined number of information bits
- H03M13/11—Error detection or forward error correction by redundancy in data representation, i.e. code words containing more digits than the source words using block codes, i.e. a predetermined number of check bits joined to a predetermined number of information bits using multiple parity bits
- H03M13/1102—Codes on graphs and decoding on graphs, e.g. low-density parity check [LDPC] codes
Definitions
- the present invention relates to a data compression apparatus and a data compression method for compressing data shortly.
- Compressed data was generated by multiplying data such as images, sound, and sensors themselves, or feature values extracted from the data with a matrix having random numbers as elements.
- the number of data elements related to dimension compression is called the number of dimensions.
- an element of an m ⁇ n matrix is set to a real value, and a randomly selected value is used as an element to form the matrix.
- n is the number of dimensions of the original data
- m is the number of dimensions of the compressed data. Further, n ⁇ m.
- the amount of data processing related to search, recognition, prediction, etc. is reduced, speeding up, and one operation in a short time Can be processed, or more work or more complex work can be performed in a certain time.
- a number of sample images stored in an image database (hereinafter referred to as DB) 201 of the server device 200 are images close to a photograph (search image 101) taken by the terminal device 100. Search from within.
- the feature amount extraction unit 102 of the terminal device 100 extracts a feature amount from the search image 101.
- SIFT Scale-Invariant Feature Transform
- a plurality generally several tens to several hundreds
- 128-byte / piece feature quantity vectors are extracted per image.
- the conventional dimension compressing unit 103 performs dimension compression on the feature amount using a random mapping matrix.
- the random mapping matrix used here follows the equation (1), and the elements a (r, c) of the random mapping matrix follow a normal distribution with a mean of 0 and variance 1 of a (r, c) to N (0, 1).
- Non-Patent Document 1 characterized the elements y k of the vector y are discussed with respect to method for reducing the quantization size, such as the above-mentioned 1-5 bits up to 23 bits the size of the elements y k in the example after compression This shows a method of compressing to the extent. In this method, dimensional compression is performed under the condition of maintaining the distance between feature amounts.
- the feature amount extraction unit 102 extracts feature amounts from the sample images stored in the image DB 201, and the dimension compression unit 103 and the quantization size reduction unit 104 compress the feature amounts.
- the server device 200 performs feature amount extraction and data compression on each sample image, and the search unit 205 stores the search image 101 sent from the terminal device 100. A comparison is made with the compressed feature quantity, and a sample image close to the search image 101 is searched.
- the present invention has been made to solve the above-described problems, and an object thereof is to reduce the amount of calculation at the time of data compression.
- the data compression apparatus generates compressed data by calculating data or feature quantities and a check matrix of error correction codes when compressing data or feature quantities of data obtained from information communication equipment.
- compressed data when compressing data or a feature amount of data obtained from an information communication device, compressed data is generated by calculating the data or feature amount and a check matrix of an error correction code.
- the error correction code check matrix is used as the random mapping matrix, so that the amount of calculation can be reduced.
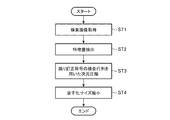
- FIG. 4 is a flowchart showing an operation of an information communication device incorporating the data compression apparatus according to the first embodiment.
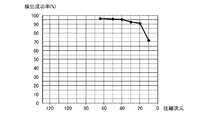
- 6 is a graph for explaining a method of determining a compression dimension of the dimension compression unit according to the first embodiment. It is a block diagram which shows the structure of the image matching system using the conventional data compression method.
- Embodiment 1 FIG.
- data compression is performed using an example of an image matching system configured using an information communication device (terminal device 10 or server device 20) incorporating a data compression device according to the present invention.
- the terminal device 10 is a tablet PC (Personal Computer), a smartphone, a monitoring camera, or the like, and includes a search image acquisition unit 11, a feature amount extraction unit 12, a dimension compression unit 13 (data compression device), and a quantization size reduction unit 14.
- the server device 20 that can communicate with the terminal device 10 includes an image DB 21, a feature amount extraction unit 12, a dimension compression unit 13 (data compression device), a quantization size reduction unit 14, and a search unit 25.
- Each of the terminal device 10 and the server device 20 is configured by a CPU (Central Processing Unit) (not shown), and when the CPU executes a program stored in an internal memory, the feature amount extraction unit 12, dimension compression Functions as the unit 13, the quantization size reduction unit 14, and the search unit 25 are realized.
- the dimension compression unit 13 may be configured with a dedicated arithmetic circuit.
- the image DB 21 is configured by an HDD (Hard Disk Drive) or the like.
- the search image acquisition unit 11 captures an image received from a camera or the like as a search image to be matched, and outputs it to the feature amount extraction unit 12 (step ST1).
- the feature quantity extraction unit 12 extracts the features of the detected image and outputs them to the dimension compression unit 13 (step ST2).
- SIFT as a feature quantity extraction method, but any feature quantity extraction method may be used.
- key points characteristic points
- a 128-byte feature vector is output for each key point.
- the dimension of this 128-byte feature vector is set to 128, and is regarded as a 128-dimensional vector.
- the dimension compression unit 13 performs dimension compression on the feature quantity vector output from the feature quantity extraction unit 12 by using a parity check matrix of an error correction code (step ST3).
- the parity check matrix of the error correction code used here is a matrix having two elements ⁇ 0, 1 ⁇ as elements, and is represented by Expression (11).
- the error correction code check matrix may be configured by a matrix having non-binary elements as in Expression (12). In the following description, it is assumed that a random code parity check matrix having a binary element ⁇ 0, 1 ⁇ as an equation (11) is used as the error correction code parity check matrix.
- p is a natural number other than 2.
- Each element h (r, c) of the parity check matrix H can be expressed by 1 bit, and the element y k of the feature vector y after compression can be calculated by the equation (13).
- the difference from the conventional dimensional compression (dimensional compression unit 103 in FIG. 4) that does not use the error correction code check matrix is the amount of calculation.
- n multiplications and n ⁇ 1 additions are necessary, and this calculation needs to be repeated m times for the feature vector y. In the end, it was necessary to multiply nm times and add (n-1) m times.
- the quantization size reduction unit 14 reduces the quantization size of the element y k of the feature vector y after compression as in Non-Patent Document 1 above, and compresses it from a maximum of 15 bits to about 1 to 5 bits. (Step ST4). At this time, evaluation is performed in advance so that the relative relationship of the relative distances between the feature quantities can be maintained, and a compression dimension that can maintain the relative relationship of the distances is determined.
- a photograph of one of the 200 types of buildings (different from the previous 800 photographs) is prepared as a target.
- k-neighbor method k data closest to the target is taken and a majority vote is taken
- a photograph of the building closest to the target building is detected from among 800 photographs.
- FIG. 3 shows the detection results, where the vertical axis represents the detection success rate and the horizontal axis represents the compression dimension.
- k is set to 10, and the distance between the feature quantity of the target building and the feature quantity of the building in the 800 photos is compared. The case where a large number of cases are occupied is regarded as successful detection.
- 40 can be selected as the dimension after compression.
- the compression dimension determined by such a method or the like is set in the dimension compression unit 13 in advance.
- the above is the method of data compression by the terminal device 10.
- the example in which the feature amount of the search image is compressed is shown, but the search image itself may be compressed.
- the feature amount extraction unit 12 extracts feature amounts from the sample image stored in the image DB 21 by the same method as described above, and the dimension compression unit 13 performs the same method as described above. Dimensional compression using an error correction code check matrix is performed, and the quantization size reduction unit 14 reduces the quantization size by the same method as described above. At this time, also on the server device 20 side, the same amount of calculation as that on the terminal device 10 side can be reduced in the calculation of dimension compression.
- the feature amount extraction unit 12, the dimension compression unit 13, and the quantization size reduction unit 14 perform feature amount extraction and data compression on each sample image, and compress the features.
- the amount is output to the search unit 25.
- the search unit 25 compares the compressed feature amount of the search image sent from the terminal device 10 with the compressed feature amount of each sample image input from the quantization size reduction unit 14, and is close to the search image. Search for sample images.
- the search unit 25 extracts the k-nearest neighbor method (k data closest to the target). By using a technique such as taking a majority vote, it is possible to determine which of the sample images stored in the image DB 21 is close to the search image of the terminal device 10. As a result, there is a feature that deterioration of the accuracy rate due to compression can be suppressed. In this case, since the search target of the k-neighbor method is a compressed feature amount, the processing time can be reduced to 15.6% by a simple comparison search.
- the dimension compressing unit 13 generates the compressed data by multiplying the data or the feature quantity extracted from the data with the parity check matrix of the error correction code.
- the amount can be reduced.
- the amount of calculation for compression can be reduced when a conventional random mapping matrix is used. It can be reduced from the multiplication of nm times and the addition of (n ⁇ 1) m times to the addition of (n / 2-1) m times.
- Embodiment 2 The data compression apparatus according to the second embodiment will be described with the aid of the image matching system shown in FIG.
- the error correction code check matrix used by the dimension compression unit 13 (data compression apparatus) for dimension compression is composed of binary ⁇ 0, 1 ⁇ elements as shown in the above equation (11).
- a parity check matrix of LDPC (Low-Density Parity-Check) code is used.
- LDPC Low-Density Parity-Check
- a parity check matrix of an LDPC code composed of non-binary elements as in the above equation (12) may be used.
- LDPC codes generally have an average column weight of 4 and an average row weight of (average column weight) ⁇ n / m.
- the column weight is the number of 1 included in one column of the matrix.
- the LDPC code is characterized in that the weights of these columns and rows do not change even when n or m increases.
- the number of 1s in a column is an average n / 2 and the number of 1s in a row is an average m / 2, which is proportional to the LDPC code check matrix. Since the number of 1s increases in both the column and the row, and the total number of 1s in the matrix is squared, this total number also increases. On the other hand, in the case of an LDPC code parity check matrix, the number of 1s is always constant and sparse, so the total number of 1s is overwhelmingly smaller than that of a random code parity check matrix.
- each element h (r, c) of the parity check matrix H of the LDPC code can be expressed by 1 bit, and the element y k of the feature vector y after compression is expressed by the above equation (13). Can be calculated. Since it is only necessary to delete the calculation when the element of the parity check matrix H of the LDPC code is 0 and add x i only to the position where 1 stands, the element 1 byte of the feature vector x before compression is equal to 8 bits.
- the dimension compression unit 13 significantly reduces the amount of calculation by using a sparse LDPC code check matrix when compressing data or a feature amount extracted from the data. it can.
- the LDPC code check matrix has regular elements, it can be expected to suppress the variation in compression performance.
- the LDPC code parity check matrix has a higher compression efficiency as the dimension number n of the feature quantity before compression is larger, it is particularly effective when handling long feature quantities of several hundred or more.
- a matrix composed of binary ⁇ 0, 1 ⁇ elements has been exemplified as a check matrix.
- a matrix composed of three elements ⁇ -1, 0, 1 ⁇ can also be used.
- 0 may be left as it is, and the matrix of the following formula (15) in which the portion of 1 is assigned to ⁇ 1 or 1 may be used.
- the dimension compression unit 13 adds the values corresponding to locations where the element of the parity check matrix is 1 or ⁇ 1 in the data or the feature quantity extracted from the data, or Subtract to generate compressed data. There is no great difference in the amount of calculation itself between whether the check matrix elements are binary ⁇ 0, 1 ⁇ or three elements ⁇ -1, 0, 1 ⁇ . Should be selected.
- the present invention can be freely combined with each embodiment, modified any component of each embodiment, or omitted any component in each embodiment. Is possible.
- the data compression apparatus since the data compression apparatus according to the present invention compresses data with a small amount of calculation using the parity check matrix of the error correction code, search and recognition is performed based on data such as images, sounds, and sensors. It is suitable for use in an apparatus that executes processing such as prediction at high speed.
- 10,100 terminal device 11 search image acquisition unit, 12,102 feature quantity extraction unit, 13,103 dimension compression unit (data compression device), 14,104 quantization size reduction unit, 20,200 server device, 21,201 Image DB, 25, 205 Search unit, 101 Search image.
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- Mathematical Physics (AREA)
- Probability & Statistics with Applications (AREA)
- General Physics & Mathematics (AREA)
- Algebra (AREA)
- Pure & Applied Mathematics (AREA)
- Compression, Expansion, Code Conversion, And Decoders (AREA)
- Compression Of Band Width Or Redundancy In Fax (AREA)
- Image Analysis (AREA)
- Image Processing (AREA)
- Compression Or Coding Systems Of Tv Signals (AREA)
Abstract
Description

量子化サイズ縮小部104が上記非特許文献1の方法を用いて特徴量の量子化サイズを圧縮した場合、一つの特徴量が128×8=1024ビットであったデータ量を、m=40、量子化サイズ4ビットに圧縮すると、圧縮後のデータ量は128×40/128×4=160ビットであり、160/1024=15.6%までデータ量が圧縮される。
実施の形態1.
実施の形態1では、図1に示すように、この発明に係るデータ圧縮装置を組み込んだ情報通信機器(端末装置10、サーバ装置20)を用いて構成した画像マッチングシステムを例にして、データ圧縮方法を説明する。端末装置10は、タブレットPC(Personal Computer)、スマートフォン、監視カメラ等であり、検索画像取得部11、特徴量抽出部12、次元圧縮部13(データ圧縮装置)、量子化サイズ縮小部14を備えている。この端末装置10との間で通信可能なサーバ装置20は、画像DB21、特徴量抽出部12、次元圧縮部13(データ圧縮装置)、量子化サイズ縮小部14、検索部25を備えている。
画像DB21は、HDD(Hard Disk Drive)等によって構成されている。
端末装置10において、検索画像取得部11は、カメラ等から受像した画像を、マッチング対象の検索画像として取り込み、特徴量抽出部12へ出力する(ステップST1)。
以下の説明では、誤り訂正符号の検査行列として、式(11)のように2元{0,1}を要素に持つ、ランダム符号の検査行列を用いるものとする。
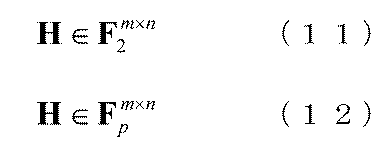
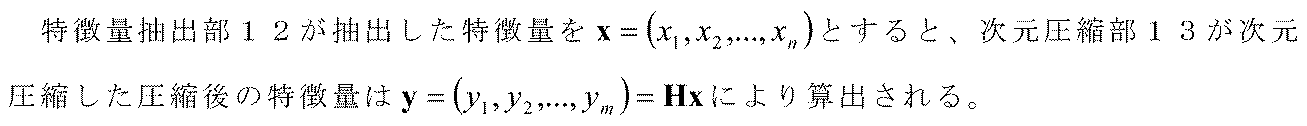
従来例では、圧縮後の特徴量ベクトルyの要素ykを一個求めるためにn回の掛け算とn-1回の加算が必要であり、この計算を特徴量ベクトルyの長さm回分繰り返す必要があるため、最終的に、nm回の掛け算と(n-1)m回の加算が必要であった。
一方、実施の形態1では、ランダム符号化の場合、検査行列Hの各要素が1である確率と0である確率は共に1/2であるため、要素ykを一個求めるために平均n/2-1回の加算でよく、この計算を特徴量ベクトルyの長さm回分繰り返しても、最終的に、平均(n/2-1)m回の加算で十分となる。
なお、上記説明では検索画像の特徴量を圧縮する例を示したが、検索画像そのものを圧縮してもよい。
検索部25は、端末装置10から送られてくる検索画像の圧縮された特徴量と、量子化サイズ縮小部14から入力される各サンプル画像の圧縮された特徴量を比較し、検索画像と近いサンプル画像を検索する。
特に、誤り訂正符号の検査行列に、0と1の2元の要素から構成されるランダム符号の検査行列を用いることにより、圧縮のための計算量を、従来のランダム写像行列を用いた場合のnm回の掛け算と(n-1)m回の足し算から、(n/2-1)m回の足し算のみに削減できる。
図1に示した画像マッチングシステムを援用して、実施の形態2に係るデータ圧縮装置を説明する。
この実施の形態2では、次元圧縮部13(データ圧縮装置)が次元圧縮に用いる誤り訂正符号の検査行列として、上式(11)のように2元{0,1}の要素で構成される、LDPC(Low-Density Parity-Check)符号の検査行列を用いるものとする。
なお、説明は省略するが、上式(12)のように非2元の要素で構成される、LDPC符号の検査行列を用いてもよい。
ここで一例として、n=28、m=21のLDPC符号の検査行列Hを、式(14)に示す。

LDPC符号の検査行列Hの要素が0の箇所は計算を削除し、1が立った箇所のみxiを加算すればよいので、圧縮前の特徴量ベクトルxの要素1バイト=8ビットに対して、行重み分の(列の平均重み)×n/m=12.8個分として必要な2進数表現24の4ビットが加算されることになり、最大8+4=12ビットが圧縮後の特徴量ベクトルyの要素ykの量子化サイズとなる。また、圧縮後の特徴量ベクトルyの長さはm次元のベクトルとして表現でき、次元をm=40とした場合に圧縮前の128から40に圧縮できる。
検査行列の要素を2元{0,1}にするか3つの要素{-1,0,1}にするかは、計算量自体あまり大きな差は無い為、性能評価により良好な性能を示す方を選択すればよい。

Claims (9)
- 情報通信機器から入手したデータまたは前記データの特徴量を圧縮するデータ圧縮装置であって、
前記データまたは前記特徴量と誤り訂正符号の検査行列との演算により圧縮データを生成することを特徴とするデータ圧縮装置。 - 前記誤り訂正符号の検査行列に、0と1の2元の要素から構成される検査行列を用い、前記データまたは前記特徴量において前記検査行列の要素が1の箇所に対応する値を行単位で足し算して、圧縮データを生成することを特徴とする請求項1記載のデータ圧縮装置。
- 前記誤り訂正符号の検査行列に、0と1と-1の3つの要素から構成される検査行列を用い、前記データまたは前記特徴量において前記検査行列の要素が1または-1の箇所に対応する値を行単位で足し算または引き算して、圧縮データを生成することを特徴とする請求項1記載のデータ圧縮装置。
- 前記誤り訂正符号の検査行列に、ランダム符号の検査行列を用いることを特徴とする請求項2記載のデータ圧縮装置。
- 前記誤り訂正符号の検査行列に、LDPC符号の検査行列を用いることを特徴とする請求項2記載のデータ圧縮装置。
- 前記誤り訂正符号の検査行列に、BCH符号の検査行列を用いることを特徴とする請求項2記載のデータ圧縮装置。
- 前記誤り訂正符号の検査行列に、リードソロモン符号の検査行列を用いることを特徴とする請求項2記載のデータ圧縮装置。
- 前記誤り訂正符号の検査行列に、巡回符号の検査行列を用いることを特徴とする請求項2記載のデータ圧縮装置。
- 情報通信機器から入手したデータまたは前記データの特徴量を圧縮するデータ圧縮方法であって、
前記データまたは前記特徴量と誤り訂正符号の検査行列との演算により圧縮データを生成することを特徴とするデータ圧縮方法。
Priority Applications (6)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2016506007A JP6192804B2 (ja) | 2014-03-05 | 2014-03-05 | データ圧縮装置およびデータ圧縮方法 |
| EP14884812.0A EP3116132A4 (en) | 2014-03-05 | 2014-03-05 | Data compression apparatus and data compression method |
| KR1020167027376A KR101800571B1 (ko) | 2014-03-05 | 2014-03-05 | 데이터 압축 장치 및 데이터 압축 방법 |
| US15/119,155 US9735803B2 (en) | 2014-03-05 | 2014-03-05 | Data compression device and data compression method |
| CN201480076704.5A CN106063133B (zh) | 2014-03-05 | 2014-03-05 | 数据压缩装置和数据压缩方法 |
| PCT/JP2014/055671 WO2015132914A1 (ja) | 2014-03-05 | 2014-03-05 | データ圧縮装置およびデータ圧縮方法 |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| PCT/JP2014/055671 WO2015132914A1 (ja) | 2014-03-05 | 2014-03-05 | データ圧縮装置およびデータ圧縮方法 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2015132914A1 true WO2015132914A1 (ja) | 2015-09-11 |
Family
ID=54054751
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2014/055671 Ceased WO2015132914A1 (ja) | 2014-03-05 | 2014-03-05 | データ圧縮装置およびデータ圧縮方法 |
Country Status (6)
| Country | Link |
|---|---|
| US (1) | US9735803B2 (ja) |
| EP (1) | EP3116132A4 (ja) |
| JP (1) | JP6192804B2 (ja) |
| KR (1) | KR101800571B1 (ja) |
| CN (1) | CN106063133B (ja) |
| WO (1) | WO2015132914A1 (ja) |
Cited By (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN106209312A (zh) * | 2016-07-06 | 2016-12-07 | 重庆邮电大学 | 一种利用软判决的循环码参数盲识别算法 |
| JP2019133659A (ja) * | 2018-01-29 | 2019-08-08 | 光禾感知科技股▲ふん▼有限公司Osense Technology Co., Ltd. | 分散型室内位置決めシステム及びその方法 |
| JP2022543085A (ja) * | 2019-08-06 | 2022-10-07 | マイクロソフト テクノロジー ライセンシング,エルエルシー | 量子計算装置のためのシンドローム・データ圧縮 |
Families Citing this family (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN107767331A (zh) * | 2017-10-18 | 2018-03-06 | 中国电建集团中南勘测设计研究院有限公司 | 一种激光扫描地形数据压缩方法及地形图成图方法 |
| CN109586733B (zh) * | 2018-11-23 | 2021-06-25 | 清华大学 | 一种基于图形处理器的ldpc-bch译码方法 |
| US12476655B2 (en) * | 2023-10-04 | 2025-11-18 | Realtek Singapore Private Limited | Low-density parity check decoder |
| TWI880719B (zh) | 2024-04-22 | 2025-04-11 | 慧榮科技股份有限公司 | 快閃記憶體控制器及快閃記憶體的存取方法 |
Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2003204316A (ja) * | 2002-01-08 | 2003-07-18 | Nec Corp | 通信システム及び通信方法 |
| JP2006217363A (ja) * | 2005-02-04 | 2006-08-17 | Japan Aerospace Exploration Agency | 動画像圧縮符号化装置、圧縮データ伸長装置、動画像圧縮符号化及び/又は圧縮データ伸長プログラム、動画像圧縮符号化方法、及び、圧縮データ伸長方法 |
| JP2011077958A (ja) * | 2009-09-30 | 2011-04-14 | Chiba Univ | 次元圧縮装置、次元圧縮方法及び次元圧縮プログラム |
Family Cites Families (21)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US5490258A (en) * | 1991-07-29 | 1996-02-06 | Fenner; Peter R. | Associative memory for very large key spaces |
| US5635932A (en) * | 1994-10-17 | 1997-06-03 | Fujitsu Limited | Lempel-ziv compression with expulsion of dictionary buffer matches |
| JPH08221113A (ja) | 1995-02-16 | 1996-08-30 | Hitachi Ltd | 時系列データ記憶装置およびプロセス異常診断装置 |
| JP3720412B2 (ja) | 1995-05-01 | 2005-11-30 | キヤノン株式会社 | 情報処理方法及び装置 |
| US5729223A (en) * | 1996-03-20 | 1998-03-17 | Motorola Inc. | Method and apparatus for data compression and restoration |
| JP4214562B2 (ja) * | 1998-06-26 | 2009-01-28 | ソニー株式会社 | 復号装置 |
| JP2002077637A (ja) * | 2000-08-31 | 2002-03-15 | Canon Inc | 画像符号化装置及び画像符号化方法 |
| JP3971135B2 (ja) * | 2001-07-11 | 2007-09-05 | 株式会社テクノマセマティカル | Dct行列分解方法及びdct装置 |
| JP3709158B2 (ja) | 2001-10-15 | 2005-10-19 | 独立行政法人科学技術振興機構 | 部分選択変換装置、部分選択変換方法及び部分選択変換プログラム |
| US7840072B2 (en) * | 2003-03-13 | 2010-11-23 | Hewlett-Packard Development Company, L.P. | Method and system for pattern matching |
| JP4257145B2 (ja) * | 2003-04-15 | 2009-04-22 | オリンパス株式会社 | 画像圧縮装置及び画像処理システム |
| JP2008276695A (ja) | 2007-05-07 | 2008-11-13 | Yamaha Motor Co Ltd | 客層認識装置 |
| CN101448156B (zh) * | 2008-12-31 | 2010-06-30 | 无锡紫芯集成电路系统有限公司 | 图像分析的方波正交函数体系选取及其软硬件实现方法 |
| CN101504760A (zh) * | 2009-02-27 | 2009-08-12 | 上海师范大学 | 一种数字图像隐密信息检测与定位的方法 |
| JP4735729B2 (ja) | 2009-03-12 | 2011-07-27 | 沖電気工業株式会社 | 近似計算処理装置、近似ウェーブレット係数計算処理装置、及び近似ウェーブレット係数計算処理方法 |
| TWI419481B (zh) * | 2009-12-31 | 2013-12-11 | Nat Univ Tsing Hua | 低密度奇偶檢查碼編解碼器及其方法 |
| JP5709417B2 (ja) | 2010-06-29 | 2015-04-30 | キヤノン株式会社 | 画像処理装置及びその制御方法並びにプログラム |
| US9432298B1 (en) * | 2011-12-09 | 2016-08-30 | P4tents1, LLC | System, method, and computer program product for improving memory systems |
| KR20140003690A (ko) * | 2012-06-22 | 2014-01-10 | 삼성디스플레이 주식회사 | 화소 데이터 압축 장치 |
| CN103248371B (zh) * | 2012-12-18 | 2016-12-28 | 中国农业大学 | 一种基于无标度复杂网络ldpc码的压缩感知方法 |
| US9756340B2 (en) * | 2014-02-03 | 2017-09-05 | Mitsubishi Electric Corporation | Video encoding device and video encoding method |
-
2014
- 2014-03-05 KR KR1020167027376A patent/KR101800571B1/ko not_active Expired - Fee Related
- 2014-03-05 CN CN201480076704.5A patent/CN106063133B/zh active Active
- 2014-03-05 WO PCT/JP2014/055671 patent/WO2015132914A1/ja not_active Ceased
- 2014-03-05 JP JP2016506007A patent/JP6192804B2/ja active Active
- 2014-03-05 US US15/119,155 patent/US9735803B2/en active Active
- 2014-03-05 EP EP14884812.0A patent/EP3116132A4/en active Pending
Patent Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2003204316A (ja) * | 2002-01-08 | 2003-07-18 | Nec Corp | 通信システム及び通信方法 |
| JP2006217363A (ja) * | 2005-02-04 | 2006-08-17 | Japan Aerospace Exploration Agency | 動画像圧縮符号化装置、圧縮データ伸長装置、動画像圧縮符号化及び/又は圧縮データ伸長プログラム、動画像圧縮符号化方法、及び、圧縮データ伸長方法 |
| JP2011077958A (ja) * | 2009-09-30 | 2011-04-14 | Chiba Univ | 次元圧縮装置、次元圧縮方法及び次元圧縮プログラム |
Non-Patent Citations (1)
| Title |
|---|
| See also references of EP3116132A4 * |
Cited By (8)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN106209312A (zh) * | 2016-07-06 | 2016-12-07 | 重庆邮电大学 | 一种利用软判决的循环码参数盲识别算法 |
| CN106209312B (zh) * | 2016-07-06 | 2019-10-01 | 重庆邮电大学 | 一种利用软判决的循环码参数盲识别方法 |
| JP2019133659A (ja) * | 2018-01-29 | 2019-08-08 | 光禾感知科技股▲ふん▼有限公司Osense Technology Co., Ltd. | 分散型室内位置決めシステム及びその方法 |
| US10921129B2 (en) | 2018-01-29 | 2021-02-16 | Osense Technology Co., Ltd. | Distributed indoor positioning system and method thereof |
| JP2022543085A (ja) * | 2019-08-06 | 2022-10-07 | マイクロソフト テクノロジー ライセンシング,エルエルシー | 量子計算装置のためのシンドローム・データ圧縮 |
| US12073287B2 (en) | 2019-08-06 | 2024-08-27 | Microsoft Technology Licensing, Llc | Systems for coupling decoders to quantum registers |
| US12093784B2 (en) | 2019-08-06 | 2024-09-17 | Microsoft Technology Licensing, Llc | Geometry-based compression for quantum computing devices |
| JP7571119B2 (ja) | 2019-08-06 | 2024-10-22 | マイクロソフト テクノロジー ライセンシング,エルエルシー | 量子計算装置のためのシンドローム・データ圧縮 |
Also Published As
| Publication number | Publication date |
|---|---|
| JP6192804B2 (ja) | 2017-09-06 |
| KR20160130441A (ko) | 2016-11-11 |
| JPWO2015132914A1 (ja) | 2017-03-30 |
| US20170019125A1 (en) | 2017-01-19 |
| KR101800571B1 (ko) | 2017-11-22 |
| EP3116132A4 (en) | 2017-12-06 |
| CN106063133A (zh) | 2016-10-26 |
| CN106063133B (zh) | 2019-06-14 |
| US9735803B2 (en) | 2017-08-15 |
| EP3116132A1 (en) | 2017-01-11 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP6192804B2 (ja) | データ圧縮装置およびデータ圧縮方法 | |
| CN111831844B (zh) | 图像检索方法、图像检索装置、图像检索设备及介质 | |
| CN106663195B (zh) | 用于指纹匹配和相机识别的改进的方法、设备和系统 | |
| JP6891379B2 (ja) | 画像のサーチのための方法およびデバイス | |
| CN104169946B (zh) | 用于视觉搜索的可扩展查询 | |
| CN115630236B (zh) | 无源遥感影像的全球快速检索定位方法、存储介质及设备 | |
| CN104115189A (zh) | 局部特征量提取装置、用于提取局部特征量的方法和程序 | |
| US10839006B2 (en) | Mobile visual search using deep variant coding | |
| CN103649955A (zh) | 用于视觉搜索的图像拓扑编码 | |
| US9239850B2 (en) | Feature descriptor encoding apparatus, feature descriptor encoding method, and program | |
| CN104392207B (zh) | 一种用于数字图像内容识别的特征编码方法 | |
| CN103930903A (zh) | 用于移动视觉搜索的方法和设备 | |
| JP6035173B2 (ja) | 画像検索システム及び画像検索方法 | |
| CN114692085A (zh) | 特征提取方法、装置、存储介质及电子设备 | |
| US10162832B1 (en) | Data aware deduplication | |
| CN112054805B (zh) | 一种模型数据压缩方法、系统及相关设备 | |
| CN116109976B (zh) | 视频清晰度的检测方法、装置、设备及可读存储介质 | |
| CN114998600B (zh) | 图像处理方法、模型的训练方法、装置、设备及介质 | |
| CN107223259A (zh) | 基于树的图像存储系统 | |
| WO2016004006A1 (en) | Methods, systems, and computer readable for performing image compression | |
| CN112911303B (zh) | 图像编码方法、解码方法、装置、电子设备及存储介质 | |
| CN107730447A (zh) | 一种高光谱图像处理方法、装置及系统 | |
| CN114329007A (zh) | 一种哈希特征压缩方法及相关装置 | |
| CN119559270A (zh) | 图像处理方法及计算机程序产品、设备 | |
| HK40071030B (zh) | 一种哈希特徵压缩方法及相关装置 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 14884812 Country of ref document: EP Kind code of ref document: A1 |
|
| ENP | Entry into the national phase |
Ref document number: 2016506007 Country of ref document: JP Kind code of ref document: A |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 15119155 Country of ref document: US |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| REEP | Request for entry into the european phase |
Ref document number: 2014884812 Country of ref document: EP |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 2014884812 Country of ref document: EP |
|
| ENP | Entry into the national phase |
Ref document number: 20167027376 Country of ref document: KR Kind code of ref document: A |