WO2016117549A1 - モグロシドの調製方法 - Google Patents
モグロシドの調製方法 Download PDFInfo
- Publication number
- WO2016117549A1 WO2016117549A1 PCT/JP2016/051416 JP2016051416W WO2016117549A1 WO 2016117549 A1 WO2016117549 A1 WO 2016117549A1 JP 2016051416 W JP2016051416 W JP 2016051416W WO 2016117549 A1 WO2016117549 A1 WO 2016117549A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- seq
- mogroside
- polynucleotide
- glucoside bond
- amino acid
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Ceased
Links
Images






Classifications
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12P—FERMENTATION OR ENZYME-USING PROCESSES TO SYNTHESISE A DESIRED CHEMICAL COMPOUND OR COMPOSITION OR TO SEPARATE OPTICAL ISOMERS FROM A RACEMIC MIXTURE
- C12P19/00—Preparation of compounds containing saccharide radicals
- C12P19/44—Preparation of O-glycosides, e.g. glucosides
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P3/00—Drugs for disorders of the metabolism
- A61P3/08—Drugs for disorders of the metabolism for glucose homeostasis
- A61P3/10—Drugs for disorders of the metabolism for glucose homeostasis for hyperglycaemia, e.g. antidiabetics
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N9/00—Enzymes; Proenzymes; Compositions thereof; Processes for preparing, activating, inhibiting, separating or purifying enzymes
- C12N9/14—Hydrolases (3)
- C12N9/24—Hydrolases (3) acting on glycosyl compounds (3.2)
- C12N9/2402—Hydrolases (3) acting on glycosyl compounds (3.2) hydrolysing O- and S- glycosyl compounds (3.2.1)
- C12N9/2405—Glucanases
- C12N9/2434—Glucanases acting on beta-1,4-glucosidic bonds
- C12N9/2445—Beta-glucosidase (3.2.1.21)
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2319/00—Fusion polypeptide
- C07K2319/01—Fusion polypeptide containing a localisation/targetting motif
- C07K2319/02—Fusion polypeptide containing a localisation/targetting motif containing a signal sequence
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N9/00—Enzymes; Proenzymes; Compositions thereof; Processes for preparing, activating, inhibiting, separating or purifying enzymes
- C12N9/14—Hydrolases (3)
- C12N9/24—Hydrolases (3) acting on glycosyl compounds (3.2)
Definitions
- the present invention relates to a method for preparing mogroside.
- Lacanka (Siraitia grosvenorii) is a plant of the Cucurbitaceae that originated in Guangxi, China.
- Lacanca fruit exhibits strong sweetness, and its extract is used as an artificial sweetener.
- dried lakanka fruit is also used as a herbal medicine.
- Lacanca fruit is known to contain mogrosides as a sweetening ingredient.
- Mogroside is a glycoside in which glucose is bound to mogrol, which is an aglycone. Mogrosides are classified into various mogrosides based on differences in glucose binding positions and numbers. The mogrosides contained in the fruits of Lacanca are mogroside V, mogroside IV, siamenoside I and 11-oxomogroside.
- mogroside, mogroside I, mogroside IVA, mogroside III, mogroside IIIA 1, mogroside IIIA 2, mogroside IIIE, mogroside IIA, mogroside IIA 1, mogroside IIA 2, mogroside IIB, mogroside IIE, mogroside IA 1, mogroside IE 1 is known.
- Non-Patent Document 1 Yao Xue Xue Bao, 2009, 44, 1252-1257. Further, there is a report that mogroside III exhibits intestinal maltase inhibitory activity and suppresses an increase in blood glucose level (Non-patent Document 2: J. Agric. Food Chem. 2005, 53, 2941-2946).
- Such mogrosides can be prepared by purifying the extract of Lacanca fruit, but several other preparation methods are known. For example, a method for preparing various mogrosides by glycosylation of mogrol using UDP-glucose transferase has been disclosed (Patent Document 1: WO2013 / 0756577). Furthermore, a method for preparing various mogrol glycosides from a Lacanca extract using pectinase derived from Aspergillus niger has been disclosed (Patent Document 1: WO2013 / 0756577).
- yeast Sacharomyces cerevisiae
- EXG1 GH5 family, ⁇ -1,3 glucanase
- Neisseria gonorrhoeae is known as an organism that secretes various hydrolases, and genome information is also known. There are approximately 40 genes thought to encode ⁇ -glucosidase-like proteins, but there is little information about the substrate specificity of the proteins encoded by each gene.
- a glycoside hydrolase (GH) 3 family ⁇ -glucosidase encoded by the AO090009000356 gene of Aspergillus oryzae has been reported to hydrolyze a disaccharide having a ⁇ -glucoside bond (Non-patent Document 4: Biosci. Biotech. Biochem. 1764). 972-978 (2006)).
- laminaribiose having a ⁇ -1,3 bond ⁇ -gentiobiose having a ⁇ -1,6 bond, cellobiose having a ⁇ -1,4 bond, and sophorose having a ⁇ -1,2 bond in this order. Specificity of hydrolysis is high.
- the present inventors have found that the gonococcal glycoside hydrolases ASBGL2, AOBGL2, AOBGL1 and ASBGL1 have the activity of cleaving the ⁇ -1,6 glucoside bond of mogroside V. As a result, the present invention has been completed.
- the present invention is as follows. [1] Reacting a protein selected from the group consisting of the following (a) to (c) with a mogroside having at least one ⁇ 1,6-glucoside bond to cleave the ⁇ 1,6-glucoside bond: A method for preparing mogrosides without ⁇ 1,6-glucoside bonds.
- A a protein comprising an amino acid sequence selected from the group consisting of SEQ ID NO: 4, SEQ ID NO: 8, SEQ ID NO: 12 and SEQ ID NO: 16;
- B an amino acid in which 1 to 84 amino acids are deleted, substituted, inserted and / or added in an amino acid sequence selected from the group consisting of SEQ ID NO: 4, SEQ ID NO: 8, SEQ ID NO: 12 and SEQ ID NO: 16 A protein comprising a sequence and having an activity of cleaving the ⁇ -1,6-glucoside bond of mogroside;
- C an amino acid sequence having 90% or more sequence identity to an amino acid sequence selected from the group consisting of SEQ ID NO: 4, SEQ ID NO: 8, SEQ ID NO: 12 and SEQ ID NO: 16, and ⁇ of mogroside A protein having an activity of cleaving a 1,6-glucoside bond [2]
- the method according to [1] above, wherein the protein selected from the group consisting of (a) to (c) further comprises a secretory
- a polynucleotide comprising a nucleotide sequence selected from the group consisting of 2586, 58th to 2891 of SEQ ID NO: 10, 58th to 2586th of SEQ ID NO: 13, and 58th to 2892 of SEQ ID NO: 14;
- B a polynucleotide encoding a protein consisting of an amino acid sequence selected from the group consisting of SEQ ID NO: 4, SEQ ID NO: 8, SEQ ID NO: 12, and SEQ ID NO: 16;
- C In the amino acid sequence selected from the group consisting of SEQ ID NO: 4, SEQ ID NO: 8, SEQ ID NO: 12, and SEQ ID NO: 16, 1 to 84 amino acids have been
- a polynucleotide comprising a base sequence encoding the secretory signal peptide is represented by SEQ ID NO: 1 from 1 to 60, SEQ ID NO: 5 from 1 to 60, SEQ ID NO: 9 from 1 to 57, SEQ ID NO: 13
- a polynucleotide comprising a polynucleotide consisting of a base sequence encoding the secretory signal peptide is SEQ ID NO: 1, SEQ ID NO: 2, SEQ ID NO: 5, SEQ ID NO: 6, SEQ ID NO: 9, SEQ ID NO: 10, SEQ ID NO: 13, SEQ ID NO: 14.
- the method according to [8] above comprising the base sequence set forth in any of SEQ ID NO: 17 to SEQ ID NO: 25.
- a polynucleotide comprising a nucleotide sequence selected from the group consisting of 2586, 58th to 2891 of SEQ ID NO: 10, 58th to 2586th of SEQ ID NO: 13, and 58th to 2892 of SEQ ID NO: 14;
- B a polynucleotide encoding a protein consisting of an amino acid sequence selected from the group consisting of SEQ ID NO: 4, SEQ ID NO: 8, SEQ ID NO: 12, and SEQ ID NO: 16;
- C In the amino acid sequence selected from the group consisting of SEQ ID NO: 4, SEQ ID NO: 8, SEQ ID NO: 12, and SEQ ID NO: 16, 1 to 84 amino acids have been
- a polynucleotide comprising a base sequence encoding the secretory signal peptide is represented by SEQ ID NO: 1 from 1 to 60, SEQ ID NO: 5 from 1 to 60, SEQ ID NO: 9 from 1 to 57, SEQ ID NO: 13
- a polynucleotide comprising a polynucleotide consisting of a base sequence encoding the secretory signal peptide is SEQ ID NO: 1, SEQ ID NO: 2, SEQ ID NO: 5, SEQ ID NO: 6, SEQ ID NO: 9, SEQ ID NO: 10, SEQ ID NO: 13, SEQ ID NO: 14.
- the method according to [14] above comprising the nucleotide sequence set forth in any of SEQ ID NO: 17 to SEQ ID NO: 25.
- the method of the present invention provides a new method for preparing mogrosides.
- the transformant of the present invention can produce mogrosides without ⁇ -1,6 glucoside bond. Since the transformant of the present invention has a high content of mogroside without ⁇ -1,6 glucoside bond, it is possible to efficiently extract and purify mogroside without ⁇ -1,6 glucoside bond from these transformants. Can do.
- the secretory signal peptide sequence (DNA sequence and amino acid sequence) of the secreted protein of yeast is shown.
- A is MF (ALPHA) 1 (YPL187W).
- B is PHO5 (YBR093C).
- C is SUC2 (YIL162W).
- the result of LC analysis of the reaction product obtained by reacting mogroside V with an enzyme solution is shown.
- A is the result with the enzyme solution ASBGL2
- B is the result with the enzyme solution AOBGL1
- C is the control.
- (1) is mogroside V and (2) is mogroside IIIE.
- the result of LC analysis of the reaction product obtained by reacting mogroside IIIE with an enzyme solution is shown.
- A is the result with the enzyme solution AOBGL1, and B is a control.
- (1) is mogroside IIIE, and (2) is a mogrol glycoside (disaccharide).
- A is the result with the enzyme solution AOBGL1, and B is a control.
- (1) is mogroside IIIE, (2) is a mogrol glycoside (disaccharide), and (3) is a mogrol glycoside (monosaccharide).
- the alignment of the amino acid sequences of AOBGL1 protein (AOBGL1p), ASBGL1 protein (ASBGL1p), AOBGL2 protein (AOBGL2p) and ASBGL2 (ASBGL2p) protein is shown.
- the double underlined part is the putative secretory signal sequence. This is a continuation of FIG.
- ASBGL2 is ⁇ -glucosidase derived from Aspergillus oryzae.
- the cDNA sequence, genomic DNA sequence, amino acid sequence, and mature protein amino acid sequence are SEQ ID NO: 1, SEQ ID NO: 2, SEQ ID NO: 3, and SEQ ID NO: 4 shows.
- AOBGL2 is a ⁇ -glucosidase derived from Aspergillus oryzae.
- the cDNA sequence, genomic DNA sequence, amino acid sequence, and mature protein amino acid sequence are SEQ ID NO: 5, SEQ ID NO: 6, SEQ ID NO: 7, and SEQ ID NO: It is shown in FIG.
- AOBGL1 is a ⁇ -glucosidase derived from Aspergillus oryzae.
- the cDNA sequence, genomic DNA sequence, amino acid sequence, and mature protein amino acid sequence are SEQ ID NO: 9, SEQ ID NO: 10, SEQ ID NO: 11, and SEQ ID NO: 12, respectively.
- Shown in “ASBGL1” is ⁇ -glucosidase derived from Aspergillus oryzae.
- the cDNA sequence, genomic DNA sequence, amino acid sequence, and mature protein amino acid sequence are SEQ ID NO: 13, SEQ ID NO: 14, SEQ ID NO: 15, and SEQ ID NO: 16.
- the present invention relates to a protein selected from the group consisting of the following (a) to (c) (hereinafter referred to as “protein of the present invention”), and mogroside having at least one ⁇ 1,6-glucoside bond To prepare a mogroside having no ⁇ 1,6-glucoside bond, which comprises the step of cleaving the ⁇ 1,6-glucoside bond.
- a protein comprising an amino acid sequence selected from the group consisting of SEQ ID NO: 4, SEQ ID NO: 8, SEQ ID NO: 12 and SEQ ID NO: 16;
- B an amino acid in which 1 to 84 amino acids are deleted, substituted, inserted and / or added in an amino acid sequence selected from the group consisting of SEQ ID NO: 4, SEQ ID NO: 8, SEQ ID NO: 12 and SEQ ID NO: 16 A protein comprising a sequence and having an activity of cleaving the ⁇ -1,6-glucoside bond of mogroside;
- C an amino acid sequence having 90% or more sequence identity to an amino acid sequence selected from the group consisting of SEQ ID NO: 4, SEQ ID NO: 8, SEQ ID NO: 12 and SEQ ID NO: 16, and ⁇ of mogroside
- the protein described in (b) or (c) above is typically a variant of a protein comprising an amino acid sequence selected from the group consisting of SEQ ID NO: 4, SEQ ID NO: 8, SEQ ID NO: 12 and SEQ ID NO: 16.
- SEQ ID NO: 4 amino acid sequence selected from the group consisting of SEQ ID NO: 4, SEQ ID NO: 8, SEQ ID NO: 12 and SEQ ID NO: 16.
- 6 proteins having an activity of cleaving a glucoside bond include an amino acid sequence selected from the group consisting of SEQ ID NO: 4, SEQ ID NO: 8, SEQ ID NO: 12 and SEQ ID NO: 16 and 90% or more, 91% or more, 92% Or more, 93% or more, 94% or more, 95% or more, 96% or more, 97% or more, 98% or more, 99% or more, 99.1% or more, 99.2% or more, 99.3% or more, 99.
- “activity for cleaving ⁇ -1,6 glucoside bond of mogroside” means ⁇ -1,6, which is formed by glucose in mogroside in mogroside which is a glycoside obtained by binding glucose to mogrol which is aglycone. It means the activity of cleaving a 6-glucoside bond.
- the protein of the present invention may have an activity of cleaving a ⁇ -1,2 glucoside bond in mogroside. Even in this case, the protein of the present invention is compared with the ⁇ -1,2 glucoside bond. , Preferentially cleave the ⁇ -1,6 glucoside bond.
- the activity of cleaving the ⁇ -1,6 glucoside bond of mogroside is obtained by reacting the protein of the present invention with mogroside having at least one ⁇ -1,6 glucoside bond, and purifying the resulting reaction product. It can confirm by analyzing what was done by well-known methods, such as a liquid chromatography (Liquid Chromatography: LC).
- LC Liquid Chromatography
- a mogroside having a ⁇ -1,2 glucoside bond is used for the reaction with the protein of the present invention, so that ⁇ It can also be confirmed whether the 1,6-glucoside bond is preferentially cleaved.
- amino acid residues that can be substituted with each other are shown below. Amino acid residues contained in the same group can be substituted for each other.
- Group A leucine, isoleucine, norleucine, valine, norvaline, alanine, 2-aminobutanoic acid, methionine, o-methylserine, t-butylglycine, t-butylalanine, cyclohexylalanine;
- Group B aspartic acid, glutamic acid, isoaspartic acid, isoglutamic acid, 2-aminoadipic acid, 2-aminosuberic acid;
- Group C asparagine, glutamine;
- Group D lysine, arginine, ornithine, 2,4-diaminobutanoic acid, 2,3-diaminopropionic acid;
- Group E proline, 3-hydroxyproline, 4-hydroxyproline;
- Group F serine, threonine, homoserine;
- Group G phenylalanine, tyrosine.
- the secretory signal peptide is cleaved and does not contain the secretory signal peptide. Some other proteins of the invention leave the secretory signal peptide uncut and thus may additionally contain a secretory signal peptide.
- a secretory signal peptide is included, preferably the secretory signal peptide is included at the N-terminus of the protein of the present invention.
- the secretory signal peptide means a peptide region responsible for secreting the protein bound to the secretory signal peptide to the outside of the cell. The amino acid sequences of such secretory signal peptides and the polynucleotide sequences encoding them are well known and reported in the art.
- the protein of the present invention can be obtained by, for example, expressing a polynucleotide encoding the same (see “polynucleotide of the present invention” described later) in an appropriate host cell.
- the Fmoc method fluorenylmethyl
- the Fmoc method can also be produced by chemical synthesis methods such as the oxycarbonyl method) and the tBoc method (t-butyloxycarbonyl method).
- AAPPPec LLC Perkin Elmer Inc. Manufactured by Protein Technologies Inc. Chemical synthesis can also be carried out using a peptide synthesizer such as manufactured by PerSeptive Biosystems, Applied Biosystems, or SHIMADZU CORPORATION.
- mogroside is a glycoside in which glucose is bound to mogrol, which is an aglycon. Examples of mogrol and mogroside are shown below.
- Glc6-Glc- indicates that it contains a ⁇ 1,6-glucoside bond.
- Glc2-Glc- indicates that it contains a ⁇ 1,2-glucoside bond.
- (Glc6Glc2 (Glc)- indicates that a ⁇ 1,6-glucoside bond and a ⁇ 1,2-glucoside bond are included.
- mogrosides having at least one (eg, 1 or 2) ⁇ 1,6-glucoside bond are, for example, mogroside V, siamenoside I, mogroside IV, mogroside IVA, mogroside III, mogroside IIIA 1 , mogroside IIIA 2 , Mogroside IIA 1 , and mogroside IIA 2 .
- the mogroside having at least one ⁇ 1,6-glucoside bond preferably further has a mogroside having at least one (eg, one) ⁇ 1,2-glucoside bond.
- the mogroside having at least one ⁇ 1,6-glucoside bond and at least one ⁇ 1,2-glucoside bond is, for example, a mogroside selected from mogroside V, siamenoside I, mogroside IV, and mogroside IIIA 1 , preferably Mogroside V.
- a ⁇ 1,6-glucoside bond is cleaved to obtain a mogroside without a ⁇ 1,6-glucoside bond (hereinafter referred to as “mogroside of the present invention”).
- the mogroside without ⁇ 1,6-glucoside bond varies as follows depending on the starting material “mogroside having ⁇ 1,6-glucoside bond”. An example is shown below.
- the mogroside having at least one ⁇ 1,6 glucoside bond as a starting material can be obtained by extraction from the fruits of Lacanca and purification, or a known method ( For example, you may prepare by the method according to patent document 1, or the method according to it.
- the starting mogroside having at least one ⁇ 1,6 glucoside bond may be commercially available.
- the ⁇ 1,6-glucoside bond of a mogroside selected from mogroside V, siamenoside I, mogroside IV, and mogroside IIIA 1 is cleaved to obtain a mogroside selected from mogroside IIIE and mogroside IIA It is done.
- the ⁇ 1,6-glucoside bond of mogroside V is cleaved to obtain mogroside IIIE.
- the protein of the present invention may further have an activity of cleaving a ⁇ -1,2 glucoside bond in mogroside.
- the mogroside of the present invention may include a mogroside having neither ⁇ 1,6-glucoside bond nor ⁇ -1,2-glucoside bond.
- the mogrosides having neither ⁇ 1,6-glucoside bond nor ⁇ -1,2 glucoside bond are, for example, mogroside IIB, mogroside IIE, mogroside IA 1 , and mogroside IE 1 , and preferably mogroside IIE.
- mogroside IIB mogroside IIE
- mogroside IA 1 mogroside IA 1
- mogroside IIE 1 is obtained.
- the method for preparing mogroside according to the present invention includes a step of reacting the protein of the present invention with mogroside having at least one ⁇ 1,6-glucoside bond to cleave the ⁇ 1,6-glucoside bond.
- the method of the present invention may further include a step of purifying the mogroside having no ⁇ 1,6-glucoside bond produced in the above step.
- Mogrosides without ⁇ 1,6-glucoside bond are extracted with an appropriate solvent (aqueous solvent such as water, or organic solvent such as alcohol, ether or acetone), ethyl acetate or other organic solvent: water gradient, high performance liquid chromatography.
- the mogroside of the present invention comprises a mogroside having no ⁇ 1,6-glucoside bond but having at least one ⁇ -1,2 glucoside bond, and a mogroside having neither ⁇ 1,6-glucoside bond nor ⁇ -1,2 glucoside bond In this case, these mogrosides may be separated and purified by a known method, if necessary.
- Mogrosides without a ⁇ 1,6-glucoside bond but having at least one ⁇ -1,2 glucoside bond are, for example, mogroside IIIE and mogroside IIA.
- the mogrosides having neither ⁇ 1,6-glucoside bond nor ⁇ -1,2glucoside bond are as described above.
- the protein of the present invention is a secreted enzyme derived from Aspergillus or a variant thereof, and may have high activity in the extracellular environment as in Aspergillus. Be expected.
- a polynucleotide encoding the protein of the present invention (see “polynucleotide of the present invention” described later) is introduced into host cells derived from bacteria, fungi, plants, insects, mammals other than humans, and the like. Then, the protein of the present invention is expressed extracellularly, and the mogroside of the present invention can be produced by reacting the protein of the present invention with mogroside having a ⁇ 1,6-glucoside bond. Alternatively, depending on the host, the protein of the present invention can be expressed in a host cell to produce the mogroside of the present invention.
- the present invention provides a host selected from the group consisting of the following (a) to (e) (hereinafter referred to as “polynucleotide of the present invention”) to a host that produces a mogroside having at least one ⁇ 1,6-glucoside bond.
- a method for producing a mogroside having no ⁇ 1,6-glucoside bond which comprises culturing a non-human transformant introduced with a “nucleotide” (hereinafter referred to as “transformant of the present invention”).
- a polynucleotide comprising a nucleotide sequence selected from the group consisting of 2586, 58th to 2891 of SEQ ID NO: 10, 58th to 2586th of SEQ ID NO: 13, and 58th to 2892 of SEQ ID NO: 14;
- B a polynucleotide encoding a protein consisting of an amino acid sequence selected from the group consisting of SEQ ID NO: 4, SEQ ID NO: 8, SEQ ID NO: 12, and SEQ ID NO: 16;
- C In the amino acid sequence selected from the group consisting of SEQ ID NO: 4, SEQ ID NO: 8, SEQ ID NO: 12, and SEQ ID NO: 16, 1 to 84 amino acids have been
- polynucleotide means DNA or RNA.
- Examples of the polynucleotide encoding the protein consisting of the amino acid sequence of SEQ ID NO: 4 include a polynucleotide consisting of the 61st to 2601th base sequences of SEQ ID NO: 1.
- Examples of the polynucleotide encoding the protein consisting of the amino acid sequence of SEQ ID NO: 8 include a polynucleotide consisting of the 61st to 2601st base sequences of SEQ ID NO: 5.
- Examples of the polynucleotide encoding the protein consisting of the amino acid sequence of SEQ ID NO: 12 include a polynucleotide consisting of the 58th to 2586th base sequences of SEQ ID NO: 9.
- Examples of the polynucleotide encoding the protein consisting of the amino acid sequence of SEQ ID NO: 16 include the polynucleotide consisting of the 58th to 2586th base sequences of SEQ ID NO: 13.
- amino acid sequence selected from the group consisting of SEQ ID NO: 4, SEQ ID NO: 8, SEQ ID NO: 12, and SEQ ID NO: 16 an amino acid sequence in which 1 to 84 amino acids have been deleted, substituted, inserted and / or added.
- protein having activity for cleaving the ⁇ -1,6 glucoside bond of mogroside include those described above.
- Having an amino acid sequence having 90% or more sequence identity to an amino acid sequence selected from the group consisting of SEQ ID NO: 4, SEQ ID NO: 8, SEQ ID NO: 12 and SEQ ID NO: 16, and ⁇ -1 of mogroside , 6 "includes a protein having an activity of cleaving a glucoside bond.
- polynucleotide hybridizing under highly stringent conditions means, for example, 61st to 2601st of SEQ ID NO: 1, 61st to 2707th of SEQ ID NO: 2, 61st of SEQ ID NO: 5 ⁇ 2601; 61th to 2708th of SEQ ID NO: 6; 58th to 2586th of SEQ ID NO: 9; 58th to 2891th of SEQ ID NO: 10; 58th to 2586th of SEQ ID NO: 13; and 58 of SEQ ID NO: 14
- a polynucleotide consisting of a base sequence complementary to a base sequence selected from the group consisting of th to 2892 th, or an amino acid sequence selected from the group consisting of SEQ ID NO: 4, SEQ ID NO: 8, SEQ ID NO: 12, and SEQ ID NO: 16 A colony using as a probe all or part of a polynucleotide comprising a nucleotide sequence complementary to the nucleot
- hybridization methods include, for example, “Sambrook & Russell, Molecular Cloning: A Laboratory Manual Vol. 4, Cold Spring Harbor, Laboratory Pressure 2012,” Ausubel, Current Protocol. Can be used.
- “high stringent conditions” means, for example, 5 ⁇ SSC, 5 ⁇ Denhardt's solution, 0.5% SDS, 50% formamide, 50 ° C., or 0.2 ⁇ SSC, 0.1% SDS, The conditions are 60 ° C., 0.2 ⁇ SSC, 0.1% SDS, 62 ° C., or 0.2 ⁇ SSC, 0.1% SDS, 65 ° C., but are not limited thereto. Under these conditions, it can be expected that DNA having high sequence identity can be efficiently obtained as the temperature is increased.
- factors affecting the stringency of hybridization include multiple factors such as temperature, probe concentration, probe length, ionic strength, time, and salt concentration, and those skilled in the art can select these factors as appropriate. By doing so, it is possible to achieve the same stringency.
- Alkphos Direct Labeling and Detection System (GE Healthcare) can be used, for example.
- the membrane was subjected to a primary wash containing 0.1% (w / v) SDS at 55-60 ° C. After washing with a buffer, the hybridized DNA can be detected.
- 61 to 2601 of SEQ ID NO: 1, 61 to 2707 of SEQ ID NO: 2, 61 to 2601 of SEQ ID NO: 5, 61 to 2708 of SEQ ID NO: 6, 58 to 2586 of SEQ ID NO: 9 The nucleotide sequence complementary to the nucleotide sequence selected from the group consisting of the 58th to 2891th of SEQ ID NO: 10, the 58th to 2586th of SEQ ID NO: 13 and the 58th to 2892th of SEQ ID NO: 14, or a sequence
- the probe is digoxigenin (D When G) label is capable of detecting the hybridization using DIG nucleic
- the 61st to 2601st positions of SEQ ID NO: 1 and the 61st to 2707th positions of SEQ ID NO: 2 are calculated using BLAST homology search software using default parameters.
- a DNA of a base sequence selected from the group consisting of 58th to 2892th of SEQ ID NO: 14, or an amino acid sequence selected from the group consisting of SEQ ID NO: 4, SEQ ID NO: 8, SEQ ID NO: 12, and SEQ ID NO: 16 60% or more, 61% or more, 62% or more, 63% or more, 64% or more 5% or more, 66% or more, 67% or more, 68% or more, 69% or more, 70% or more, 71% or more, 72% or more, 73% or more, 74% or more, 75% or more, 76% or more, 77% 78% or more, 79% or more, 80% or more, 81% or more, 82% or more, 83% or more, 84% or more, 85% or more, 86% or more
- sequence identity of the amino acid sequence and the base sequence is the algorithm BLAST (Basic Local Alignment Search Tool) (Proc. Natl. Acad. Sci. USA 87262264-2268, 1990; Proc Natl Acad SciUSA90 by Carlin and Arthur. 5873, 1993).
- BLAST Basic Local Alignment Search Tool
- the default parameters of each program are used.
- the polynucleotide of the present invention may further include a polynucleotide consisting of a base sequence encoding a secretory signal peptide.
- a polynucleotide consisting of a base sequence encoding a secretory signal peptide is included at the 5 'end of the polynucleotide of the present invention.
- the secretory signal peptide is as described above. Such a secretory signal peptide can be appropriately selected according to the host into which the polynucleotide of the present invention is introduced.
- a secretory signal peptide derived from yeast for example, MF (ALPHA) 1 signal peptide, PHO5 signal peptide, and SUC2 signal peptide
- MF (ALPHA) 1 signal peptide for example, MF (ALPHA) 1 signal peptide, PHO5 signal peptide, and SUC2 signal peptide
- polynucleotide encoding the MF (ALPHA) 1 signal peptide, PHO5 signal peptide, and SUC2 signal peptide include polynucleotides consisting of the nucleotide sequences of SEQ ID NO: 43, SEQ ID NO: 45, and SEQ ID NO: 47, respectively.
- amino acid sequences of MF (ALPHA) 1 signal peptide, PHO5 signal peptide, and SUC2 signal peptide are the amino acid sequences of SEQ ID NO: 44, SEQ ID NO: 46, and SEQ ID NO: 48, respectively.
- a signal peptide derived from Neisseria gonorrhoeae for example, a peptide consisting of the first to 20th amino acid sequence of SEQ ID NO: 3, a peptide consisting of the first to 20th amino acid sequence of SEQ ID NO: 7, Examples thereof include a peptide consisting of the first to 19th amino acid sequence of SEQ ID NO: 11 and a peptide consisting of the first to 19th amino acid sequence of SEQ ID NO: 15.
- the polynucleotide encoding the peptide consisting of the amino acid sequence of No. 1 and the polynucleotide encoding the peptide consisting of the amino acid sequence of No. 1 to 19 of SEQ ID NO: 15 are, for example, the 1st to 60th of SEQ ID NO: 1, respectively.
- a polynucleotide comprising a base sequence selected from the group consisting of SEQ ID NO: 5 from 1st to 60th, SEQ ID NO: 9, 1st to 57th, and SEQ ID NO: 13 from 1st to 57th.
- the polynucleotide of the present invention including a polynucleotide consisting of a base sequence encoding a secretory signal peptide includes, for example, SEQ ID NO: 1, SEQ ID NO: 2, SEQ ID NO: 5, SEQ ID NO: 6, SEQ ID NO: 9, SEQ ID NO: 10, SEQ ID NO: 13. , SEQ ID NO: 14 and a polynucleotide comprising the base sequence set forth in any of SEQ ID NOs: 17 to 25, and preferably a polynucleotide comprising the base sequence set forth in any of SEQ ID NOs: 17 to 25.
- the above-described polynucleotide of the present invention can be obtained by a known genetic engineering technique or a known synthesis technique.
- the polynucleotide of the present invention is preferably introduced into a host while being inserted into an appropriate expression vector.
- Suitable expression vectors are usually (I) a promoter capable of transcription in a host cell; (Ii) a polynucleotide of the present invention linked to the promoter; and (iii) an expression cassette comprising, as a component, a signal that functions in a host cell for transcription termination and polyadenylation of an RNA molecule. .
- the method for producing the expression vector includes, but is not limited to, a method using a plasmid, phage, cosmid or the like.
- the specific type of the vector is not particularly limited, and a vector that can be expressed in the host cell can be appropriately selected. That is, according to the type of the host cell, a promoter sequence is appropriately selected in order to reliably express the polynucleotide of the present invention, and a vector in which this and the polynucleotide of the present invention are incorporated into various plasmids or the like is used as an expression vector. Good.
- the expression vector of the present invention contains an expression control region (for example, a promoter, a terminator and / or a replication origin) depending on the type of host to be introduced.
- an expression control region for example, a promoter, a terminator and / or a replication origin
- Conventional promoters eg, trc promoter, tac promoter, lac promoter, etc.
- yeast promoters include glyceraldehyde 3-phosphate dehydrogenase promoter, PH05 promoter, etc.
- Examples of the promoter for filamentous fungi include amylase and trpC.
- promoters for expressing a target gene in plant cells include the cauliflower mosaic virus 35S RNA promoter, the rd29A gene promoter, the rbcS promoter, and the enhancer sequence of the cauliflower mosaic virus 35S RNA promoter derived from Agrobacterium. And the mac-1 promoter added to the 5 'side of the mannopine synthase promoter sequence.
- animal cell host promoters include viral promoters (eg, SV40 early promoter, SV40 late promoter, etc.).
- the expression vector preferably contains at least one selectable marker.
- auxotrophic markers ura5, niaD
- drug resistance markers hyromycin, zeocin
- geneticin resistance gene G418r
- copper resistance gene CUP1
- cerulenin resistance gene fas2m, PDR4
- the production method (production method) of the transformant of the present invention is not particularly limited, and examples thereof include a method of transforming by introducing an expression vector containing the polynucleotide of the present invention into a host.
- the host used here is not particularly limited as long as it produces a mogroside having at least one ⁇ 1,6-glucoside bond, and a mogroside having at least one ⁇ 1,6-glucoside bond like Lacanca.
- a gene necessary for the production of mogrosides having at least one ⁇ 1,6-glucoside bond is introduced not only in plants that produce glycine but also in cells or organisms that do not naturally produce mogrosides having at least one ⁇ 1,6-glucoside bond Can be used as a host.
- Examples of the “gene required for production of mogroside having at least one ⁇ 1,6-glucoside bond” include, for example, genes having mogrol and mogroside synthesis activity described in WO2013 / 075657 and WO2014 / 086842.
- cells or organisms to be transformed various conventionally known cells or organisms can be suitably used.
- examples of cells to be transformed include bacteria such as Escherichia coli, yeasts (budding yeast Saccharomyces cerevisiae, fission yeast Schizosaccharomyces pombe), filamentous fungi (Aspergillus oryzae plant), Excluding animal cells and the like.
- Appropriate culture media and conditions for the above-described host cells are well known in the art.
- the organism to be transformed is not particularly limited, and examples thereof include various microorganisms exemplified in the host cell, animals other than plants or animals.
- the transformant is preferably a yeast or a plant.
- a host cell transformation method As a host cell transformation method, a commonly known method can be used. For example, electroporation method (Mackenxie, DA et al., Appl. Environ. Microbiol., Vol. 66, p. 4655-4661, 2000), particle delivery method (Japanese Patent Laid-Open No. 2005-287403, “lipid producing bacteria” The method described in the "Breeding Methods", Spheroplast Method (Proc. Natl. Acad. Sci. USA, vol. 75, p. 1929, 1978), Lithium Acetate Method (J. Bacteriology, vol. 153, p. 163, 1983), Methods in yeast genetics, 2000 Edition: Method described in A Cold Spring Harbor Laboratory Manual, etc.) But it is not limited to, et al.
- the transformant When the transformant is yeast, the transformant is obtained by introducing a recombinant vector containing the polynucleotide of the present invention into yeast so that the polypeptide encoded by the polynucleotide can be expressed.
- the yeast transformed with the polynucleotide of the present invention expresses more of the protein of the present invention than the wild type. Therefore, the expressed protein of the present invention reacts with mogroside having at least one ⁇ 1,6-glucoside bond produced in yeast, the ⁇ 1,6-glucoside bond is cleaved, and there is no ⁇ 1,6-glucoside bond
- the mogroside of the present invention is produced in yeast cells or in a culture solution, preferably in a culture solution.
- the transformant When the transformant is a plant, it is obtained by introducing a recombinant vector containing the polynucleotide of the present invention into the plant so that the protein encoded by the polynucleotide can be expressed.
- Plants to be transformed in the present invention include whole plants, plant organs (eg leaves, petals, stems, roots, seeds, etc.), plant tissues (eg epidermis, phloem, soft tissue, xylem, vascular bundle, It means any of a palisade tissue, a spongy tissue, etc.) or a plant culture cell, or various forms of plant cells (eg, suspension culture cells), protoplasts, leaf sections, callus, and the like.
- plant organs eg leaves, petals, stems, roots, seeds, etc.
- plant tissues eg epidermis, phloem, soft tissue, xylem, vascular bundle, It means any of a palisade tissue, a
- a plant that produces a mogroside having at least one ⁇ 1,6-glucoside bond, or a gene that originally does not produce a mogroside having at least one ⁇ 1,6-glucoside bond is introduced.
- any plant belonging to the monocotyledonous plant class or the dicotyledonous plant class may be used.
- transformation methods known to those skilled in the art for example, Agrobacterium method, gene gun method, PEG method, electroporation method, etc. are used.
- a cell or plant tissue into which a gene has been introduced is first selected for drug resistance such as hygromycin resistance, and then regenerated into a plant by a conventional method. Regeneration of a plant body from a transformed cell can be performed by a method known to those skilled in the art depending on the type of plant cell. Whether or not the polynucleotide of the present invention has been introduced into a plant can be confirmed by PCR, Southern hybridization, Northern hybridization, or the like. Once a transformed plant in which the polynucleotide of the present invention has been integrated into the genome is obtained, offspring can be obtained by sexual or asexual reproduction of the plant.
- plants of the present invention contains more of the protein of the present invention than its wild type. Therefore, the protein of the present invention reacts with the mogroside having at least one ⁇ 1,6-glucoside bond produced in the plant of the present invention, the ⁇ 1,6-glucoside bond is cleaved, and the ⁇ 1,6-glucoside bond None of the mogrosides of the invention are produced in plants.
- the transformant of some aspects of the present invention or the culture solution thereof has a higher content of the mogroside of the present invention than its wild type, and the extract or the culture solution contains the mogroside of the present invention at a high concentration. included.
- the extract of the transformant of the present invention can be obtained by crushing the transformant using glass beads, a homogenizer, a sonicator or the like, centrifuging the crushed material, and collecting the supernatant. it can.
- the transformant and the culture supernatant are separated from each other by the usual method (for example, centrifugation, filtration, etc.) after completion of the culture.
- a culture supernatant containing mogroside can be obtained.
- the thus obtained extract or culture supernatant may be further subjected to a purification step.
- Purification of the mogrosides of the present invention can be performed according to conventional separation and purification methods. The specific method is the same as described above.
- Method for preparing mogroside of the present invention using an enzyme agent derived from a non-human transformed cell The polynucleotide of the present invention is introduced into a host cell derived from bacteria, fungi, plants, insects, mammals other than humans, etc.
- an enzyme agent derived from a transformed cell expressing the protein of the present invention that is, at least one enzyme agent derived from a transformed cell expressing the protein of the present invention.
- the mogroside of the present invention can be produced by contacting with a mogroside having a ⁇ 1,6-glucoside bond.
- "Enzyme agent derived from transformed cells” is not limited as long as it is prepared using transformed cells and contains the protein of the present invention.
- the present invention provides at least one ⁇ 1,6 enzyme agent derived from a non-human transformed cell into which a polynucleotide selected from the group consisting of the following (a) to (e) is introduced into a host cell.
- a method for preparing a mogroside having no ⁇ 1,6-glucoside bond comprising a step of cleaving the ⁇ 1,6-glucoside bond by contacting with a mogroside having a glucoside bond.
- a polynucleotide comprising a nucleotide sequence selected from the group consisting of 2586, 58th to 2891 of SEQ ID NO: 10, 58th to 2586th of SEQ ID NO: 13, and 58th to 2892 of SEQ ID NO: 14;
- B a polynucleotide encoding a protein consisting of an amino acid sequence selected from the group consisting of SEQ ID NO: 4, SEQ ID NO: 8, SEQ ID NO: 12, and SEQ ID NO: 16;
- C In the amino acid sequence selected from the group consisting of SEQ ID NO: 4, SEQ ID NO: 8, SEQ ID NO: 12, and SEQ ID NO: 16, 1 to 84 amino acids have been
- the polynucleotide selected from the group consisting of (a) to (e) above is the polynucleotide of the present invention and is the same as described above.
- the polynucleotide of the present invention may further include a polynucleotide consisting of a base sequence encoding a secretory signal peptide.
- a polynucleotide consisting of a base sequence encoding a secretory signal peptide is included at the 5 'end of the polynucleotide of the present invention.
- the polynucleotide from the secretory signal peptide and the base sequence encoding it is the same as described above.
- the polynucleotide of the present invention including a polynucleotide consisting of a base sequence encoding a secretory signal peptide includes, for example, SEQ ID NO: 1, SEQ ID NO: 2, SEQ ID NO: 5, SEQ ID NO: 6, SEQ ID NO: 9, SEQ ID NO: 10, SEQ ID NO: 13. , SEQ ID NO: 14 and a polynucleotide comprising the base sequence set forth in any of SEQ ID NOs: 17 to 25, and preferably a polynucleotide comprising the base sequence set forth in any of SEQ ID NOs: 17 to 25.
- the polynucleotide of the present invention is preferably introduced into a host cell in a state inserted in an appropriate expression vector.
- Suitable expression vectors are as described above.
- the method for producing the transformed cell of the present invention is not particularly limited, and examples thereof include a method for transformation by introducing an expression vector containing the polynucleotide of the present invention into a host cell.
- cells to be transformed conventionally known various cells or organisms can be suitably used.
- cells to be transformed include bacteria such as Escherichia coli, yeast (budding yeast Saccharomyces cerevisiae, fission yeast Schizosaccharomyces pombe), filamentous fungi (Aspergillus oryzae, Excluding animal cells and the like. Appropriate culture media and conditions for the above-described host cells are well known in the art.
- the transformed cell is preferably a bacterium such as Escherichia coli or a yeast.
- the host cell transformation method is as described above.
- the transformed cell of the present invention can be obtained, for example, by introducing a recombinant vector containing the polynucleotide of the present invention into a host cell so that the polypeptide encoded by the polynucleotide can be expressed.
- a host cell transformed with the polynucleotide of the present invention expresses more of the protein of the present invention than the wild type. Therefore, an enzyme agent derived from a transformed cell expressing the protein of the present invention is used, that is, an enzyme agent derived from a transformed cell expressing the protein of the present invention is bound to at least one ⁇ 1,6-glucoside bond.
- the mogroside of the present invention can be produced by contacting with a mogroside having
- Contact means that the enzyme agent derived from the transformed cell of the present invention and mogroside having at least one ⁇ 1,6-glucoside bond are present in the same reaction system or culture system. Adding a mogroside having at least one ⁇ 1,6-glucoside bond to a container containing an enzyme agent derived from the transformed cell of the invention; and an enzyme agent derived from the transformed cell of the present invention and at least one ⁇ 1,6- Mixing with a mogroside having a glucoside bond and adding the enzyme agent derived from the transformed cell of the present invention to a container containing at least one ⁇ 1,6-glucoside bond.
- “Mogroside”, “mogroside having at least one ⁇ 1,6-glucoside bond” and “mogroside having no ⁇ 1,6-glucoside bond” are the same as described above.
- the mogroside having at least one ⁇ 1,6-glucoside bond preferably further has at least one ⁇ 1,2-glucoside bond.
- the mogroside having at least one ⁇ 1,6-glucoside bond and at least one ⁇ 1,2-glucoside bond is the same as described above.
- the mogrosides of the present invention thus obtained can be used in accordance with conventional methods, for example, for applications such as production of foods, sweeteners, fragrances, pharmaceuticals, and industrial raw materials (raw materials such as cosmetics and soaps). .
- foods examples include nutritional supplements, health foods, functional foods, infant foods, and elderly foods.
- food is a general term for solids, fluids, liquids, and mixtures thereof that can be consumed.
- ⁇ -glucosidase homologue was searched from the gonococcal genome data (PRJNA28175). As a result, 5 genes encoding amino acid sequences having a GH2 family motif, 28 genes encoding amino acid sequences having a GH3 family motif, and 7 genes encoding amino acid sequences having a GH5 family motif were found. Among them, AO090001000544 and AO090009000356 are among sequences encoding a protein having a GH3 family motif and having a secretion signal, and these were cloned.
- Neisseria gonorrhoeae cDNA Neisseria gonorrhoeae Aspergillus oryzae var. Bruneus (IFO30102) or Aspergillus sojae (NBRC4239) was inoculated into GY plates (2% glucose, 0.5% yeast extract, 2% agar) and cultured at 25 ° C. for 3 days. The grown cells were collected from the GY plate, and total RNA was extracted with RNeasy (QIAGEN). CDNA was synthesized by SuperScript Double-Stranded cDNA Synthesis Kit (Life Technologies).
- AOBGL2-1 5'-GCGGCCGCATGGCTGCCTTCCCGGCCTA (SEQ ID NO: 26)
- AOBGL2-2 5′-GTCGACCTACAAAGTAGAACATCCCTCTCCAACC (SEQ ID NO: 27)
- ASBGL2-1 5′- GCGGCCGC ATGGCTGCCTTTCCGGCCTAC (underlined part is restriction enzyme BglII site) (SEQ ID NO: 28)
- ASBGL2-2 5′- GTCGAC CTATAAAGTAGAACATCCCTCCCCTACT (SEQ ID NO: 29)
- the following primers were designed based on the DNA sequence of AO090009000356.
- AOBGL1-1 5′- AGATCT ATGAAGCTTGGTTGGATCGAGGT (underlined part is restriction enzyme BglII site) (SEQ ID NO: 30)
- AOBGL1-2 5′- GTCGAC TTACTGGGCCTTAGGCAGCGA (underlined part is restriction enzyme SalI site) (SEQ ID NO: 31)
- plasmids were designated as pCR-AOBGL2, pCR-ASBGL2, pCR-AOBGL1, or pCR-ASBGL1, respectively.
- FIGS. 5-1 and 5-2 show alignments of amino acid sequences of AOBGL2 protein (AOBGL2p), ASBGL2 protein (ASBGL2p), AOBGL1 protein (AOBGL1p), and ASBGL1 protein (ASBGL1p).
- Yeast Expression Vector A DNA fragment obtained by digesting the yeast expression vector pYE22m (Biosci. Biotech. Biochem., 59, 1221-1228, 1995) with the restriction enzymes BamHI and SalI, and pCR-ASBGL2, pCR- A DNA fragment of about 2.6 kbp obtained by digesting AOBGL1 or pCR-ASBGL1 with restriction enzymes BglII and SalI was prepared by using DNA Ligation Kit Ver. 1 (Takara Bio) was used for ligation, and the resulting plasmid was designated as pYE-ASBGL2, pYE-AOBGL1, or pYE-ASBGL1.
- EH13-15 strain was transformed by the lithium acetate method using plasmids pYE22m (control), pYE-ASBGL2 (for ASBGL2 expression), pYE-AOBGL1 (for AOBGL1 expression), and pYE-ASBGL1 (for ASBGL1 expression), respectively.
- the transformed strain was SC-Trp (per 1 L, Yeast nitrogen base w / o amino acids (DIFCO) 6.7 g, glucose 20 g, and amino acid powder (adenine sulfate 1.25 g, arginine 0.6 g, aspartic acid 3 g, Glutamic acid 3 g, histidine 0.6 g, leucine 1.8 g, lysine 0.9 g, methionine 0.6 g, phenylalanine 1.5 g, serine 11.25 g, tyrosine 0.9 g, valine 4.5 g, threonine 6 g, uracil 0.6 g 1) containing 1.3 g) and those growing on an agar medium (2% agar) were selected.
- SC-Trp per 1 L, Yeast nitrogen base w / o amino acids (DIFCO) 6.7 g, glucose 20 g, and amino acid powder (adenine sulfate 1.25 g,
- the selected strain was applied to an SC-Trp agar medium containing 0.004% X- ⁇ -Glc and cultured at 30 ° C. for 3 days.
- the plasmid was transformed with any plasmid of pYE-ASBGL2, pYE-AOBGL1p, and pYE-ASBGL1.
- Neither the transformed strain nor the strain transformed with pYE22m as a control showed a blue color, and the X- ⁇ -Glc degradation activity could not be confirmed.
- the selected strain was inoculated with 1 platinum ear in 10 mL of SC-Trp liquid medium supplemented with 1/10 amount of 1M potassium phosphate buffer, and cultured with shaking at 30 ° C. and 125 rpm for 2 days.
- the obtained culture was separated into a culture supernatant and cells by centrifugation.
- the cells are suspended in 50 mM sodium phosphate buffer (pH 7.0) and 0.1% CHAPS solution, the cells are crushed with glass beads, and the supernatant obtained by centrifugation is used as the cell lysate. It was.
- the pNP- ⁇ -Glc activity of the obtained culture supernatant or bacterial cell disruption solution was examined.
- both the culture supernatant and the bacterial cell disruption liquid of any transformant including the control had pNP- ⁇ -Glc degrading activity, and there was no significant difference in activity between the two.
- Substitution of secretory signal sequence The 20 amino acids at the N-terminus of AOBGL2p and ASBGL2p are presumed to be secretory signal sequences, and the 19 amino acids at the N-terminus of AOBGL1p and ASBGL1p are presumed to be secretory signal sequences.
- the double underlined portions in FIG. 5A are putative secretory signal sequences of AOBGL1, ASBGL1, AOBGL2, and ASBGL2.
- oligo DNA was synthesized and annealed, and then inserted into the EcoRI site of the vector pYE22m to prepare pYE-PacNhe.
- PacI-NheI-F 5′-AATTAATTAAGAGCTAGCG-3 ′
- PacI-NheI-R 5′-TTAATTCTCGATCGCTTAA-3 ′
- PCR was performed with the following primer Sac-ASBGL2-F and primer Sal-ASBGL2-R using KOD-Plus (Toyobo).
- a DNA fragment of about 2.6 kbp obtained by digesting a DNA fragment amplified by PCR with restriction enzymes SacI and SalI is inserted into vector pYE-PacNhe into restriction enzyme SacI and SalI sites, and plasmid pYE-PN-ASBGL2 is inserted. It was constructed.
- Sac-ASBGL2-F 5′-AAGAGCTCGAGTCTCTGACATCAAGAGCCTCTACAGA-3 ′
- Sal-ASBGL2-R 5′-GGGTCGACCTATAAAGTAGAACATCCCTCCCCTACTACAC-3 ′
- SEQ ID NO: 35
- PCR was performed with the following primers Bgl2-AOBGL1-F and primer AOBGL1-2 using KOD-Plus (Toyobo).
- a DNA fragment of about 2.5 kbp obtained by digesting a DNA fragment amplified by PCR with restriction enzymes BglII and SalI is inserted into vector pYE-PacNhe into restriction enzyme BamHI and SalI sites, and plasmid pYE-PN-AOBGL1 or pYE-PN-ASBGL1 was constructed.
- Bgl2-AOBGL1-F 5′-TAAGATCTAAGGATGATCTCGCGTACTCCCC-3 ′ (SEQ ID NO: 36)
- AOBGL1-2 5′-GTCGACTTACTGGGCCTTAGGCAGCGA-3 ′ (SEQ ID NO: 31)
- a putative secretory signal sequence of ASBGL2p, AOBGL2p, AOBGL1p or ASBGL1p (1 to 20th sequence of SEQ ID NO: 3, 1 to 20th sequence of SEQ ID NO: 7, 1 to 19th sequence of SEQ ID NO: 11, or sequence, respectively
- the secretory signal sequence of yeast secretory protein MF (ALPHA) 1 (YPL187W) (1st to 19th sequence of the amino acid sequence shown in FIG. 1A), PHO5 (YBR093C) (Fig. 15)
- APHA yeast secretory protein MF
- YPL187W (1st to 19th sequence of the amino acid sequence shown in FIG. 1A
- PHO5 YBR093C
- Fig. 15 In order to construct a plasmid for expressing a protein replaced with SUC2 (YIL162W) (1-19th sequence of the amino acid sequence shown in FIG. 1C), SUC2 (YIL162W sequence of the amino acid sequence described in 1B), The following
- the DNA sequence and amino acid sequence of the secretion signal sequence MF (ALPHA) 1 (YPL187W) are shown in SEQ ID NO: 43 and SEQ ID NO: 44, respectively.
- the DNA sequence and amino acid sequence of the secretory signal sequence PHO5 (YBR093C) are shown in SEQ ID NO: 45 and SEQ ID NO: 46, respectively.
- the DNA sequence and amino acid sequence of the secretory signal sequence SUC2 (YIL162W) are shown in SEQ ID NO: 47 and SEQ ID NO: 48, respectively.
- ScPHO5-F 5′-TAAATGTTTAAATCTGTTGTTTATTCAATTTTAGCCGCTTCTTTGGCCAATGCAG-3 ′
- ScPHO5-R 5′-CTAGCTGCATTGGCCAAAGAAGCGGCTAAAATTGAATAAACAACAGATTTAAACATTTAAT-3 ′
- ScSUC2-F 5′-TAAATGCTTTTGCAAGCTTTCCTTTTTTCCTTTTTTGGCTGGTTTTTTGCAGCCAAAATATCTGCAG-3 ′
- ScSUC2-R 5′-TAAATGAGATTTCCTTCAATTTTTACTGCAGTTTTATTCGCAGCATCCTCCGCATTAGCTG-3 ′
- ScMF1-F 5′-TAAATGAGATTTCCTTCAATTTTTACTGCAGTTTTATTCGCAGCATCCTCCGCATTAGCTG-3 ′
- ScMF1-F 5′-TAAATGAGATTTCCTTCAATTTTTACTGCAGTTTTATTCGCAGCATCCTCCGCATTAGCTG-3
- pYE-PHO5s-ASBGL2 (for expression of PHO5s-AOBGL2) pYE-SUC2s-ASBGL2 (for SUC2s-AOBGL2 expression) pYE-MF1s-ASBGL2 (for MF1s-AOBGL2 expression) pYE-PHO5s-AOBGL1 (for expression of PHO5s-AOBGL1) pYE-SUC2s-AOBGL1 (for SUC2s-AOBGL1 expression) pYE-MF1s-AOBGL1 (for MF1s-AOBGL1 expression) pYE-PHO5s-ASBGL1 (for expression of PHO5s-ASBGL1) pYE-SUC2s-ASBGL1 (for SUC2s-ASBGL1 expression) pYE-MF1s-ASBGL1 (for MF1s-ASBGL1 expression)
- DNA sequences of PHO5s-ASBGL2, SUC2s-ASBGL2, and MF1s-ASBGL2 are shown in SEQ ID NO: 17, SEQ ID NO: 18, and SEQ ID NO: 19. Further, the DNA sequences of PHO5s-AOBGL1, SUC2s-AOBGL1, and MF1s-AOBGL1 are SEQ ID NO: 20, SEQ ID NO: 21, and SEQ ID NO: 22, and the DNA sequences of PHO5s-ASBGL1, SUC2s-ASBGL1, and MF1s-ASBGL1 are SEQ ID NO: 23 No. 24 and SEQ ID No. 25.
- EXG1 YLR300w
- EXG2 YDR261c gene
- ⁇ exg1 strain ⁇ exg1: KanMX MATapha his3 ⁇ 1 leu2 ⁇ 0 lys2 ⁇ 0 ura3 ⁇ 0, clone ID15210, Open Bio Systems
- Each bacterial cell was scraped with a platinum loop, and SC-Met, Lys (per 1 L, yeast nitrogen base w / o amino acids (DIFCO) 6.7 g, glucose 20 g, and amino acid powder (adenine sulfate 1.25 g, arginine 0 .6 g, aspartic acid 3 g, glutamic acid 3 g, histidine 0.6 g, leucine 1.8 g, phenylalanine 1.5 g, serine 11.25 g, tyrosine 0.9 g, valine 4.5 g, threonine 6 g, tryptophan 1.2 g, uracil 0
- the mixture was mixed on an agar medium (2% agar) containing 1.3 g, and cultured at 30 ° C.
- the growing strain was considered to be a heterodiploid in which the two strains were crossed.
- the obtained strain was applied to a YPD agar medium and cultured at 30 ° C. for 2 days, the cells were scraped with a platinum loop and applied to a 0.5% potassium acetate agar medium (2% agar), and at room temperature. After culturing for 5 days, spores were formed. Tetramolecular separation was performed to isolate a haploid strain.
- the genotype of the obtained strain was confirmed by PCR, and a strain which was ⁇ exg1 ⁇ exg2-1 strain ( ⁇ exg1: KanMX ⁇ exg2: KanMX his3 ⁇ 1 leu2 ⁇ 0 lys2 ⁇ 0 ura3 ⁇ 0) was selected.
- PCR was performed using KOD-Plus (Toyobo) with the following primers TRP1-F and TRP1-R using the genomic DNA of yeast S288C strain as a template.
- the amplified DNA fragment of about 2.7 kbp was cloned using Zero Blunt TOPO PCR cloning Kit (Life Technologies) to obtain plasmid pCR-TRP1.
- TRP1-F TACTATTAGCTGAATTGCCACTGCTATCG (SEQ ID NO: 49)
- TRP1-R TCTACAACCGCTAAATGTTTTTGTTCG (SEQ ID NO: 50)
- PCR was performed with primers TRP1-F and TRP1-R using KOD-Plus (Toyobo), and the obtained 4.4 kbp DNA fragment was used to transform ⁇ exg1 ⁇ exg2-1 into lithium acetate.
- SC-Ura per 1L, Yeast nitrogen base w / o amino acids (DIFCO) 6.7 g, glucose 20 g, and amino acid powder (adenine sulfate 1.25 g, arginine 0.6 g, aspartic acid 3 g) , Glutamic acid 3 g, histidine 0.6 g, leucine 1.8 g, lysine 0.9 g, methionine 0.6 g, phenylalanine 1.5 g, serine 11.25 g, tyrosine 0.9 g, valine 4.5 g, threonine 6 g, tryptophan 1.
- DIFCO Yeast nitrogen base w / o amino acids
- ⁇ exg1 ⁇ exg2-2 strains were transformed into plasmids pYE-PHO5s-ASBGL2, pYE-SUC2s-ASBGL2, pYE-MF1s-ASBGL2, pYE-PHO5s-AOBGL1, pYE-SB1GY1S-AOBGL1PB -Transformation with SUC2s-ASBGL1 by the lithium acetate method, and growth on SC-Trp agar medium were selected as transformants.
- the transformed strain obtained was inoculated with 1 platinum ear in a liquid medium in which 10 mL of SD-Trp liquid medium and 1 mL of 1M potassium phosphate buffer were mixed, and cultured with shaking at 30 ° C. for 2 days. . The culture was separated into cells and culture supernatant by centrifugation.
- the culture supernatant was concentrated to about 500 ⁇ L with Amicon Ultra-15 50k (Merck) by ultrafiltration, and the buffer was replaced with 50 mM sodium phosphate buffer (pH 7.0) containing 0.1% CHAPS. It was. 50 ⁇ L of the enzyme enzyme solution, 50 ⁇ L of 0.2 M sodium citrate buffer, 50 ⁇ L of 20 mM pNP- ⁇ Glc aqueous solution and 50 ⁇ L of water were mixed and reacted at 37 ° C., and the change in absorbance at 405 nm was examined. The results are shown in Table 5 below.
- the active mogroside V against mogroside V was 50 ⁇ g / mL, 50 mM sodium citrate buffer (pH 5.0), 20 ⁇ L of the enzyme solution to make a total volume of 100 ⁇ L, and reacted at 50 ° C. for 4 hours.
- the reaction solution was subjected to SepPakC18 500 mg (Waters) washed with methanol and equilibrated with water. After washing with 40% methanol, elution was performed with 80% methanol, followed by drying at a speed bag. Dissolved in 100 ⁇ L of water and subjected to HPLC.
- the conditions of HPLC are as follows.
- AOBGL1 enzyme solution was allowed to react with mogroside IIIE under the same conditions as described above, with a reaction time of 16 hours. As a result, AOBGL1 was also detected to hydrolyze mogroside IIIE into mogrol disaccharide glycoside and mogrol monosaccharide glycoside (Fig. 3A, Fig. 4A). In the control, AOBGL1 was newly generated from mogroside IIIE. (FIG. 3B, FIG. 4B).
- [SEQ ID NO: 3] is an amino acid sequence of ASBGL2.
- [SEQ ID NO: 4] Amino acid sequence of ASBGL2 mature protein.
- [SEQ ID NO: 5] is a cDNA sequence of AOBGL2.
- [SEQ ID NO: 6] Genomic DNA sequence of AOBGL2.
- [SEQ ID NO: 7] is the amino acid sequence of AOBGL2.
- [SEQ ID NO: 9] cDNA sequence of AOBGL1.
- [SEQ ID NO: 10] Genomic DNA sequence of AOBGL1.
- [SEQ ID NO: 12] is an amino acid sequence of AOBGL1 mature protein.
- [SEQ ID NO: 13] is the cDNA sequence of ASBGL1.
- [SEQ ID NO: 14] This is the genomic DNA sequence of ASBGL1.
- [SEQ ID NO: 16] Amino acid sequence of ASBGL1 mature protein.
- [SEQ ID NO: 17] is the DNA sequence of PHO5s-ASBGL2.
- [SEQ ID NO: 18] This is the DNA sequence of SUC2s-ASBGL2.
- [SEQ ID NO: 19] This is the DNA sequence of MF1s-ASBGL2.
- [SEQ ID NO: 20] is the DNA sequence of PHO5s-AOBGL1.
- [SEQ ID NO: 21] This is the DNA sequence of SUC2s-AOBGL1.
- [SEQ ID NO: 22] This is the DNA sequence of MF1s-AOBGL1.
- [SEQ ID NO: 23] is the DNA sequence of PHO5s-ASBGL1.
- [SEQ ID NO: 24] This is the DNA sequence of SUC2s-ASBGL1.
- [SEQ ID NO: 25] is the DNA sequence of MF1s-ASBGL1.
- [SEQ ID NO: 26] Primer used in the examples (AOBGL2-1).
- [SEQ ID NO: 27] Primer used in the examples (AOBGL2-2).
- [SEQ ID NO: 43] is a DNA sequence of secretory signal sequence MF (ALPHA) 1 (YPL187W).
- [SEQ ID NO: 44] is an amino acid sequence of secretory signal sequence MF (ALPHA) 1 (YPL187W).
- [SEQ ID NO: 45] is a DNA sequence of secretory signal sequence PHO5 (YBR093C).
- [SEQ ID NO: 46] is an amino acid sequence of secretory signal sequence PHO5 (YBR093C).
- [SEQ ID NO: 47] is a DNA sequence of secretory signal sequence SUC2 (YIL162W).
- [SEQ ID NO: 48] is an amino acid sequence of secretory signal sequence SUC2 (YIL162W).
- [SEQ ID NO: 49] Primer used in the examples (TRP1-F).
- [SEQ ID NO: 50] Primer used in the examples (TRP1-R).
Landscapes
- Health & Medical Sciences (AREA)
- Chemical & Material Sciences (AREA)
- Life Sciences & Earth Sciences (AREA)
- Organic Chemistry (AREA)
- Engineering & Computer Science (AREA)
- Wood Science & Technology (AREA)
- Zoology (AREA)
- Genetics & Genomics (AREA)
- Bioinformatics & Cheminformatics (AREA)
- General Engineering & Computer Science (AREA)
- Biotechnology (AREA)
- General Health & Medical Sciences (AREA)
- Microbiology (AREA)
- Biochemistry (AREA)
- Biomedical Technology (AREA)
- Molecular Biology (AREA)
- General Chemical & Material Sciences (AREA)
- Medicinal Chemistry (AREA)
- Chemical Kinetics & Catalysis (AREA)
- Diabetes (AREA)
- Biophysics (AREA)
- Plant Pathology (AREA)
- Physics & Mathematics (AREA)
- Animal Behavior & Ethology (AREA)
- Public Health (AREA)
- Hematology (AREA)
- Endocrinology (AREA)
- Nuclear Medicine, Radiotherapy & Molecular Imaging (AREA)
- Pharmacology & Pharmacy (AREA)
- Emergency Medicine (AREA)
- Obesity (AREA)
- Veterinary Medicine (AREA)
- Preparation Of Compounds By Using Micro-Organisms (AREA)
- Micro-Organisms Or Cultivation Processes Thereof (AREA)
- Peptides Or Proteins (AREA)
- Enzymes And Modification Thereof (AREA)
- Pharmaceuticals Containing Other Organic And Inorganic Compounds (AREA)
- Medicines Containing Plant Substances (AREA)
- Steroid Compounds (AREA)
Abstract
Description
[1]
以下の(a)~(c)からなる群から選択されるタンパク質と、少なくとも1つのβ1,6-グルコシド結合を有するモグロシドを反応させて、前記β1,6-グルコシド結合を切断する工程を含む、β1,6-グルコシド結合のないモグロシドの調製方法。
(a)配列番号4、配列番号8、配列番号12および配列番号16からなる群から選択されるアミノ酸配列からなるタンパク質;
(b)配列番号4、配列番号8、配列番号12および配列番号16からなる群から選択されるアミノ酸配列において、1~84個のアミノ酸が欠失、置換、挿入、および/または付加されたアミノ酸配列からなり、かつモグロシドのβ-1,6グルコシド結合を切断する活性を有するタンパク質;
(c)配列番号4、配列番号8、配列番号12および配列番号16からなる群から選択されるアミノ酸配列に対して、90%以上の配列同一性を有するアミノ酸配列を有し、かつモグロシドのβ-1,6グルコシド結合を切断する活性を有するタンパク質
[2]
前記(a)~(c)からなる群から選択されるタンパク質が、さらに、分泌シグナルペプチドを含む、前記[1]に記載の方法。
[3]
前記少なくとも1つのβ1,6-グルコシド結合を有するモグロシドが、さらに、少なくとも1つのβ1,2-グルコシド結合を有する、前記[1]または[2]に記載の方法。
[4]
前記少なくとも1つのβ1,6-グルコシド結合および少なくとも1つのβ1,2-グルコシド結合を有するモグロシドが、モグロシドV、シアメノシドI、モグロシドIV、およびモグロシドIIIA1から選択される、前記[3]に記載の方法。
[5]
前記β1,6-グルコシド結合のないモグロシドが、モグロシドIIIEおよびモグロシドIIAから選択される、前記[4]に記載の方法。
[6]
少なくとも1つのβ1,6-グルコシド結合を有するモグロシドを生成する宿主に、以下の(a)~(e)からなる群から選択されるポリヌクレオチドが導入された非ヒト形質転換体を培養することを含む、β1,6-グルコシド結合のないモグロシドの生産方法。
(a)配列番号1の61番目~2601番目、配列番号2の61番目~2707番目、配列番号5の61番目~2601番目、配列番号6の61番目~2708番目、配列番号9の58番目~2586番目、配列番号10の58番目~2891番目、配列番号13の58番目~2586番目、および配列番号14の58番目~2892番目からなる群から選択される塩基配列からなるポリヌクレオチド;
(b)配列番号4、配列番号8、配列番号12、および配列番号16からなる群から選択されるアミノ酸配列からなるタンパク質をコードするポリヌクレオチド;
(c)配列番号4、配列番号8、配列番号12、および配列番号16からなる群から選択されるアミノ酸配列において、1~84個のアミノ酸が欠失、置換、挿入、および/または付加されたアミノ酸配列からなり、かつモグロシドのβ-1,6グルコシド結合を切断する活性を有するタンパク質をコードするポリヌクレオチド;
(d)配列番号4、配列番号8、配列番号12、および配列番号16からなる群から選択されるアミノ酸配列に対して、90%以上の配列同一性を有するアミノ酸配列を有し、かつモグロシドのβ-1,6グルコシド結合を切断する活性を有するタンパク質をコードするポリヌクレオチド;
(e)配列番号1の61番目~2601番目、配列番号2の61番目~2707番目、配列番号5の61番目~2601番目、配列番号6の61番目~2708番目、配列番号9の58番目~2586番目、配列番号10の58番目~2891番目、配列番号13の58番目~2586番目、および配列番号14の58番目~2892番目からなる群から選択される塩基配列と相補的な塩基配列からなるポリヌクレオチドと高ストリンジェントな条件下でハイブリダイズするポリヌクレオチドであって、かつモグロシドのβ-1,6グルコシド結合を切断する活性を有するタンパク質をコードするポリヌクレオチド
[7]
前記(a)~(e)からなる群から選択されるポリヌクレオチドが、さらに、分泌シグナルペプチドをコードする塩基配列からなるポリヌクレオチド含む、前記[6]に記載の方法。
[8]
前記分泌シグナルペプチドをコードする塩基配列からなるポリヌクレオチドが、配列番号1の1番目~60番目、配列番号5の1番目~60番目、配列番号9の1番目~57番目、配列番号13の1番目~57番目、配列番号43、配列番号45および配列番号47のいずれかに記載の塩基配列からなるポリヌクレオチドである、前記[7]に記載の方法。
[9]
前記分泌シグナルペプチドをコードする塩基配列からなるポリヌクレオチドを含むポリヌクレオチドが、配列番号1、配列番号2、配列番号5、配列番号6、配列番号9、配列番号10、配列番号13、配列番号14、および配列番号17~配列番号25のいずれかに記載の塩基配列からなる、前記[8]に記載の方法。
[10]
前記ポリヌクレオチドが、発現ベクターに挿入されたものである、前記[6]~[9]のいずれか1項に記載の方法。
[11]
前記形質転換体が、形質転換酵母または形質転換植物である、前記[6]~[10]のいずれか1項に記載の方法。
[12]
宿主細胞に、以下の(a)~(e)からなる群から選択されるポリヌクレオチドが導入された非ヒト形質転換細胞に由来する酵素剤を、少なくとも1つのβ1,6-グルコシド結合を有するモグロシドと接触させて、前記β1,6-グルコシド結合を切断する工程を含む、β1,6-グルコシド結合のないモグロシドの調製方法。
(a)配列番号1の61番目~2601番目、配列番号2の61番目~2707番目、配列番号5の61番目~2601番目、配列番号6の61番目~2708番目、配列番号9の58番目~2586番目、配列番号10の58番目~2891番目、配列番号13の58番目~2586番目、および配列番号14の58番目~2892番目からなる群から選択される塩基配列からなるポリヌクレオチド;
(b)配列番号4、配列番号8、配列番号12、および配列番号16からなる群から選択されるアミノ酸配列からなるタンパク質をコードするポリヌクレオチド;
(c)配列番号4、配列番号8、配列番号12、および配列番号16からなる群から選択されるアミノ酸配列において、1~84個のアミノ酸が欠失、置換、挿入、および/または付加されたアミノ酸配列からなり、かつモグロシドのβ-1,6グルコシド結合を切断する活性を有するタンパク質をコードするポリヌクレオチド;
(d)配列番号4、配列番号8、配列番号12、および配列番号16からなる群から選択されるアミノ酸配列に対して、90%以上の配列同一性を有するアミノ酸配列を有し、かつモグロシドのβ-1,6グルコシド結合を切断する活性を有するタンパク質をコードするポリヌクレオチド;
(e)配列番号1の61番目~2601番目、配列番号2の61番目~2707番目、配列番号5の61番目~2601番目、配列番号6の61番目~2708番目、配列番号9の58番目~2586番目、配列番号10の58番目~2891番目、配列番号13の58番目~2586番目、および配列番号14の58番目~2892番目からなる群から選択される塩基配列と相補的な塩基配列からなるポリヌクレオチドと高ストリンジェントな条件下でハイブリダイズするポリヌクレオチドであって、かつモグロシドのβ-1,6グルコシド結合を切断する活性を有するタンパク質をコードするポリヌクレオチド
[13]
前記(a)~(e)からなる群から選択されるポリヌクレオチドが、さらに、分泌シグナルペプチドをコードする塩基配列からなるポリヌクレオチド含む、上記[12]に記載の方法。
[14]
前記分泌シグナルペプチドをコードする塩基配列からなるポリヌクレオチドが、配列番号1の1番目~60番目、配列番号5の1番目~60番目、配列番号9の1番目~57番目、配列番号13の1番目~57番目、配列番号43、配列番号45および配列番号47のいずれかに記載の塩基配列からなるポリヌクレオチドである、上記[13]に記載の方法。
[15]
前記分泌シグナルペプチドをコードする塩基配列からなるポリヌクレオチドを含むポリヌクレオチドが、配列番号1、配列番号2、配列番号5、配列番号6、配列番号9、配列番号10、配列番号13、配列番号14、および配列番号17~配列番号25のいずれかに記載の塩基配列からなる、上記[14]に記載の方法。
[16]
前記ポリヌクレオチドが、発現ベクターに挿入されたものである、上記[12]~[15]のいずれか1項に記載の方法。
[17]
前記形質転換細胞が、形質転換細菌または形質転換酵母である、上記[12]~[16]のいずれか1項に記載の方法。
[18]
前記少なくとも1つのβ1,6-グルコシド結合を有するモグロシドが、さらに、少なくとも1つのβ1,2-グルコシド結合を有する、上記[12]~[17]に記載の方法。
[19]
前記少なくとも1つのβ1,6-グルコシド結合および少なくとも1つのβ1,2-グルコシド結合を有するモグロシドが、モグロシドV、シアメノシドI、モグロシドIV、およびモグロシドIIIA1から選択される、上記[18]に記載の方法。
[20]
前記β1,6-グルコシド結合のないモグロシドが、モグロシドIIIEおよびモグロシドIIAから選択される、上記[19]に記載の方法。
なお、本明細書において引用した全ての文献、および公開公報、特許公報その他の特許文献は、参照として本明細書に組み込むものとする。また、本明細書は、2015年1月20日に出願された本願優先権主張の基礎となる日本国特許出願(特願2015-008508号)の明細書及び図面に記載の内容を包含する。
「AOBGL2」は、麹菌由来のβ-グルコシダーゼであり、そのcDNA配列、ゲノムDNA配列、アミノ酸配列、および成熟タンパク質のアミノ酸配列は、それぞれ、配列番号5、配列番号6、配列番号7、および配列番号8に示される。
「AOBGL1」は、麹菌由来のβ-グルコシダーゼあり、そのcDNA配列、ゲノムDNA配列、アミノ酸配列、および成熟タンパク質のアミノ酸配列は、それぞれ、配列番号9、配列番号10、配列番号11、および配列番号12に示される。
「ASBGL1」は、麹菌由来のβ-グルコシダーゼであり、そのcDNA配列、ゲノムDNA配列、アミノ酸配列、および成熟タンパク質のアミノ酸配列は、それぞれ、配列番号13、配列番号14、配列番号15、および配列番号16に示される。
これらのポリヌクレオチドおよび酵素は、後述の実施例に記載した手法、公知の遺伝子工学的手法、公知の合成手法等によって取得することが可能である。
本発明は、以下の(a)~(c)からなる群から選択されるタンパク質(以下、「本発明のタンパク質」という)と、少なくとも1つのβ1,6-グルコシド結合を有するモグロシドを反応させて、前記β1,6-グルコシド結合を切断する工程を含む、β1,6-グルコシド結合のないモグロシドの調製方法を提供する。
(b)配列番号4、配列番号8、配列番号12および配列番号16からなる群から選択されるアミノ酸配列において、1~84個のアミノ酸が欠失、置換、挿入、および/または付加されたアミノ酸配列からなり、かつモグロシドのβ-1,6グルコシド結合を切断する活性を有するタンパク質;
(c)配列番号4、配列番号8、配列番号12および配列番号16からなる群から選択されるアミノ酸配列に対して、90%以上の配列同一性を有するアミノ酸配列を有し、かつモグロシドのβ-1,6グルコシド結合を切断する活性を有するタンパク質
B群:アスパラギン酸、グルタミン酸、イソアスパラギン酸、イソグルタミン酸、2-アミノアジピン酸、2-アミノスベリン酸;
C群:アスパラギン、グルタミン;
D群:リジン、アルギニン、オルニチン、2,4-ジアミノブタン酸、2,3-ジアミノプロピオン酸;
E群:プロリン、3-ヒドロキシプロリン、4-ヒドロキシプロリン;
F群:セリン、スレオニン、ホモセリン;
G群:フェニルアラニン、チロシン。



本発明のいくつかの態様では、モグロシドV、シアメノシドI、モグロシドIV、およびモグロシドIIIA1から選択されるモグロシドのβ1,6-グルコシド結合が切断され、モグロシドIIIEおよびモグロシドIIAから選択されるモグロシドが得られる。本発明の最も好ましい態様では、モグロシドVのβ1,6-グルコシド結合が切断され、モグロシドIIIEが得られる。
β1,6-グルコシド結合のないモグロシドは、適切な溶媒(水等の水性溶媒、またはアルコール、エーテル、アセトン等の有機溶媒)による抽出、酢酸エチルその他の有機溶媒:水の勾配、高速液体クロマトグラフィー(High Performance Liquid Chromatography:HPLC)、ガスクロマトグラフィー、飛行時間型質量分析(Time-of-Flight mass spectrometry:TOF-MS)、超高性能液体クロマトグラフィー(Ultra (High) Performance Liquid chromatography:UPLC)等の公知の方法によって精製することができる。
本発明のタンパク質は、麹菌に由来する分泌型の酵素またはその変異体であり、麹菌と同様に細胞外環境において高い活性を有することが期待される。この場合、本発明のタンパク質をコードするポリヌクレオチド(後述する「本発明のポリヌクレオチド」を参照)を、細菌、真菌類、植物、昆虫、ヒトを除く哺乳動物などに由来する宿主細胞に導入して本発明のタンパク質を細胞外に発現させ、本発明のタンパク質と、β1,6-グルコシド結合を有するモグロシドとを反応させることにより本発明のモグロシドを生成することができる。あるいは、宿主によっては、本発明のタンパク質を宿主細胞内で発現させ、本発明のモグロシドを生成することもできる。
(b)配列番号4、配列番号8、配列番号12、および配列番号16からなる群から選択されるアミノ酸配列からなるタンパク質をコードするポリヌクレオチド;
(c)配列番号4、配列番号8、配列番号12、および配列番号16からなる群から選択されるアミノ酸配列において、1~84個のアミノ酸が欠失、置換、挿入、および/または付加されたアミノ酸配列からなり、かつモグロシドのβ-1,6グルコシド結合を切断する活性を有するタンパク質をコードするポリヌクレオチド;
(d)配列番号4、配列番号8、配列番号12、および配列番号16からなる群から選択されるアミノ酸配列に対して、90%以上の配列同一性を有するアミノ酸配列を有し、かつモグロシドのβ-1,6グルコシド結合を切断する活性を有するタンパク質をコードするポリヌクレオチド;
(e)配列番号1の61番目~2601番目、配列番号2の61番目~2707番目、配列番号5の61番目~2601番目、配列番号6の61番目~2708番目、配列番号9の58番目~2586番目、配列番号10の58番目~2891番目、配列番号13の58番目~2586番目、および配列番号14の58番目~2892番目からなる群から選択される塩基配列と相補的な塩基配列からなるポリヌクレオチドと高ストリンジェントな条件下でハイブリダイズするポリヌクレオチドであって、かつモグロシドのβ-1,6グルコシド結合を切断する活性を有するタンパク質をコードするポリヌクレオチド
本明細書中、「高ストリンジェントな条件」とは、例えば、5×SSC、5×デンハルト溶液、0.5%SDS、50%ホルムアミド、50℃、または0.2xSSC、0.1%SDS、60℃、または0.2xSSC、0.1%SDS、62℃、または0.2xSSC、0.1%SDS、65℃の条件であるが、これに限定されるものではない。これらの条件において、温度を上げるほど高い配列同一性を有するDNAが効率的に得られることが期待できる。ただし、ハイブリダイゼーションのストリンジェンシーに影響する要素としては温度、プローブ濃度、プローブの長さ、イオン強度、時間、塩濃度等の複数の要素が考えられ、当業者であればこれらの要素を適宜選択することで同様のストリンジェンシーを実現することが可能である。
(i)宿主細胞内で転写可能なプロモーター;
(ii)該プロモーターに結合した、本発明のポリヌクレオチド;および
(iii)RNA分子の転写終結およびポリアデニル化に関し、宿主細胞内で機能するシグナルを構成要素として含む発現カセット
を含むように構成される。
本発明のポリヌクレオチドを、細菌、真菌類、植物、昆虫、ヒトを除く哺乳動物などに由来する宿主細胞に導入して本発明のタンパク質を発現させ、本発明のタンパク質を発現する形質転換細胞に由来する酵素剤を用いること、すなわち、本発明のタンパク質を発現する形質転換細胞に由来する酵素剤を、少なくとも1つのβ1,6-グルコシド結合を有するモグロシドと接触させることにより本発明のモグロシドを生成することができる。「形質転換細胞に由来する酵素剤」は、形質転換細胞を用いて調製され、本発明のタンパク質を含むものであれば限定されないが、例えば、形質転換細胞自体、形質転換細胞の粉砕物自体、形質転換細胞の培養上清自体、およびこれらの精製物である。 そこで、本発明は、宿主細胞に、以下の(a)~(e)からなる群から選択されるポリヌクレオチドが導入された非ヒト形質転換細胞に由来する酵素剤を、少なくとも1つのβ1,6-グルコシド結合を有するモグロシドと接触させて、前記β1,6-グルコシド結合を切断する工程を含む、β1,6-グルコシド結合のないモグロシドの調製方法を提供する。
(a)配列番号1の61番目~2601番目、配列番号2の61番目~2707番目、配列番号5の61番目~2601番目、配列番号6の61番目~2708番目、配列番号9の58番目~2586番目、配列番号10の58番目~2891番目、配列番号13の58番目~2586番目、および配列番号14の58番目~2892番目からなる群から選択される塩基配列からなるポリヌクレオチド;
(b)配列番号4、配列番号8、配列番号12、および配列番号16からなる群から選択されるアミノ酸配列からなるタンパク質をコードするポリヌクレオチド;
(c)配列番号4、配列番号8、配列番号12、および配列番号16からなる群から選択されるアミノ酸配列において、1~84個のアミノ酸が欠失、置換、挿入、および/または付加されたアミノ酸配列からなり、かつモグロシドのβ-1,6グルコシド結合を切断する活性を有するタンパク質をコードするポリヌクレオチド;
(d)配列番号4、配列番号8、配列番号12、および配列番号16からなる群から選択されるアミノ酸配列に対して、90%以上の配列同一性を有するアミノ酸配列を有し、かつモグロシドのβ-1,6グルコシド結合を切断する活性を有するタンパク質をコードするポリヌクレオチド;
(e)配列番号1の61番目~2601番目、配列番号2の61番目~2707番目、配列番号5の61番目~2601番目、配列番号6の61番目~2708番目、配列番号9の58番目~2586番目、配列番号10の58番目~2891番目、配列番号13の58番目~2586番目、および配列番号14の58番目~2892番目からなる群から選択される塩基配列と相補的な塩基配列からなるポリヌクレオチドと高ストリンジェントな条件下でハイブリダイズするポリヌクレオチドであって、かつモグロシドのβ-1,6グルコシド結合を切断する活性を有するタンパク質をコードするポリヌクレオチド
宿主細胞の形質転換方法は、前述の通りである。
以下の実施例において、5-Bromo-4-chloro-3-indlyl β-D-glucopyranoside(以下、X-β-Glc)、および4-Nitrophenyl β-D-glucopyranoside(以下、pNP-β-Glc)は、SIGMA-Aldrich Corporationから入手したものを用いた。
麹菌ゲノムデータ(PRJNA28175)より、β-グルコシダーゼホモログを探索した。その結果、GH2ファミリーモチーフを有するアミノ酸配列をコードする遺伝子が5個、GH3ファミリーモチーフを有するアミノ酸配列をコードする遺伝子が28個、GH5ファミリーモチーフを有するアミノ酸配列をコードする遺伝子が7つ見つかった。その中で、GH3ファミリーモチーフを有し、分泌シグナルを有するタンパク質をコードする配列の中に、AO090001000544とAO090009000356があり、これらをクローン化した。
麹菌Aspergillus oryzae var.brunneus(IFO30102)またはAspergillus sojae(NBRC4239)をGYプレート(2%グルコース、0.5%酵母エキス、2% アガー)に植菌し、25℃で3日間培養した。生育した菌体をGYプレートから回収し、RNeasy(QIAGEN)でトータルRNAを抽出した。SuperScript Double-Stranded cDNA Synthesis Kit(ライフテクノロジーズ)により、cDNAを合成した。
AOBGL2-2:5’-GTCGACCTACAAAGTAGAACATCCCTCTCCAACC(配列番号27)
Aspergillus sojaeのAO090001000544のホモログをクローン化するために、Aspergillus sojaeのゲノムデータ(DNA Res.18(3),165-176(2011)参照)から、BLAST検索により該当する配列を抽出した(配列番号2)。このDNA配列をもとに、以下のプライマーを設計した。
ASBGL2-2:5’-GTCGACCTATAAAGTAGAACATCCCTCCCCTACT(配列番号29)
AOBGL1-2:5’-GTCGACTTACTGGGCCTTAGGCAGCGA(下線部は制限酵素SalIサイトである)(配列番号31)




酵母用発現ベクターpYE22m(Biosci.Biotech.Biochem.,59,1221-1228,1995)を制限酵素BamHIとSalIで消化して得られたDNA断片と、pCR-ASBGL2、pCR-AOBGL1、またはpCR-ASBGL1を制限酵素BglIIとSalIで消化して得られた約2.6kbpのDNA断片を、DNA Ligation Kit Ver.1(タカラバイオ)を用いて、連結し、得られたプラスミドをpYE-ASBGL2、pYE-AOBGL1、またはpYE-ASBGL1とした。
形質転換の親株として、S.cerevisiaeのEH13-15株(trp1,MATα)(Appl.Microbiol.Biotechnol.,30,515-520,1989)を用いた。
AOBGL2pやASBGL2pのN末端の20アミノ酸は分泌シグナル配列であると推定され、また、AOBGL1pやASBGL1pのN末端の19アミノ酸は、分泌シグナル配列であると推定される。ここで、図5-1中の二重下線部分が、AOBGL1、ASBGL1、AOBGL2、ASBGL2の推定分泌シグナル配列である。
PacI-NheI-R:5’-TTAATTCTCGATCGCTTAA-3’(配列番号33)
Sal-ASBGL2-R:5’-GGGTCGACCTATAAAGTAGAACATCCCTCCCCTACTACAC-3’(配列番号35)
AOBGL1-2:5’-GTCGACTTACTGGGCCTTAGGCAGCGA-3’(配列番号31)
ScPHO5-R:5’-CTAGCTGCATTGGCCAAAGAAGCGGCTAAAATTGAATAAACAACAGATTTAAACATTTAAT-3’(配列番号38)
ScSUC2-F:5’-TAAATGCTTTTGCAAGCTTTCCTTTTCCTTTTGGCTGGTTTTGCAGCCAAAATATCTGCAG-3’(配列番号39)
ScSUC2-R:5’-TAAATGAGATTTCCTTCAATTTTTACTGCAGTTTTATTCGCAGCATCCTCCGCATTAGCTG-3’(配列番号40)
ScMF1-F:5’-TAAATGAGATTTCCTTCAATTTTTACTGCAGTTTTATTCGCAGCATCCTCCGCATTAGCTG-3’(配列番号41)
ScMF1-R:5’-CTAGCAGCTAATGCGGAGGATGCTGCGAATAAAACTGCAGTAAAAATTGAAGGAAATCTCATTTAAT-3’(配列番号42)
pYE-SUC2s-ASBGL2(SUC2s-AOBGL2発現用)
pYE-MF1s-ASBGL2(MF1s-AOBGL2発現用)
pYE-PHO5s-AOBGL1(PHO5s-AOBGL1発現用)
pYE-SUC2s-AOBGL1(SUC2s-AOBGL1発現用)
pYE-MF1s-AOBGL1(MF1s-AOBGL1発現用)
pYE-PHO5s-ASBGL1(PHO5s-ASBGL1発現用)
pYE-SUC2s-ASBGL1(SUC2s-ASBGL1発現用)
pYE-MF1s-ASBGL1(MF1s-ASBGL1発現用)
形質転換の宿主株としては、酵母の菌体外β-グルコシダーゼ活性の大半を担っていると考えられているEXG1(YLR300w)遺伝子とそのホモログであるEXG2(YDR261c)遺伝子を欠損させた株を使用することとし、以下のとおり作成した。
Δexg1株(Δexg1:KanMX MATalpha his3Δ1 leu2Δ0 lys2Δ0 ura3Δ0,クローンID15210、Open Bio Systems)と、Δexg2株(Δexg2:KanMX MATa his3Δ1 leu2Δ0 met15Δ0 ura3Δ0,クローンID3620、Open Bio Systems)をそれぞれYPD寒天培地に塗布し、30℃で2日間培養した。それぞれの菌体を白金耳でかきとり、SC-Met,Lys(1Lあたり、Yeast nitrogen base w/o amino acids(DIFCO)6.7g、グルコース20g、およびアミノ酸パウダー(アデニン硫酸塩1.25g、アルギニン0.6g、アスパラギン酸3g、グルタミン酸3g、ヒスチジン0.6g、ロイシン1.8g、フェニルアラニン1.5g、セリン11.25g、チロシン0.9g、バリン4.5g、スレオニン6g、トリプトファン1.2g、ウラシル0.6gを混合したもの)1.3gを含む)寒天培地(2%アガー)上で混合し、30℃で2日間培養した。生育してくる株は、2つの株が掛け合わされたヘテロ二倍体であると考えられた。得られた株をYPD寒天培地に塗布し、30℃で2日間培養した後、菌体を白金耳でかきとって、0.5% 酢酸カリウム寒天培地(2%アガー)に塗布し、室温で5日間培養し、胞子を形成させた。四分子分離を行い、一倍体株を分離した。得られた株の遺伝子型をPCRにより確認し、Δexg1 Δexg2-1株(Δexg1:KanMX Δexg2:KanMX his3Δ1 leu2Δ0 lys2Δ0 ura3Δ0)であるものを選抜した。
TRP1-R:TCTACAACCGCTAAATGTTTTTGTTCG(配列番号50)
得られた形質転換株を0.004%X-β-Glcを含むSD-Trp寒天培地に塗布し、30℃で3日間培養したところ、pYE-PHO5s-AOBGL1、pYE-SUC2s-AOBGL1、pYE-MF1s-AOBGL1、pYE-PHO5s-ASBGL1、pYE-SUC2s-ASBGL1、pYE-MF1s-ASBGL1で形質転換した株は、菌体およびその周りが青く染まり、X-β-Glcを加水分解する活性を有することが示唆された。
得られた形質転換株をSD-Trp 液体培地10mLと1Mリン酸カリウムバッファー1mLを混合した液体培地に1白金耳植菌し、30℃で2日間振とう培養した。培養物を遠心分離により菌体と培養上清に分離した。
結果を以下の表5に示す。

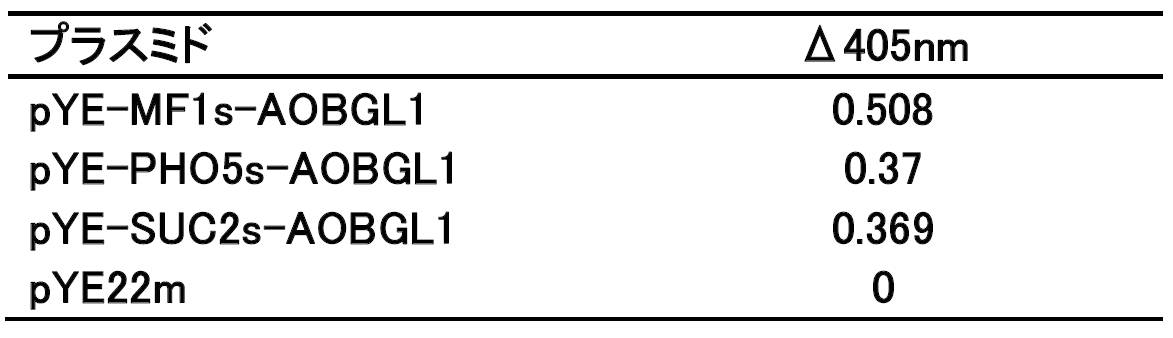
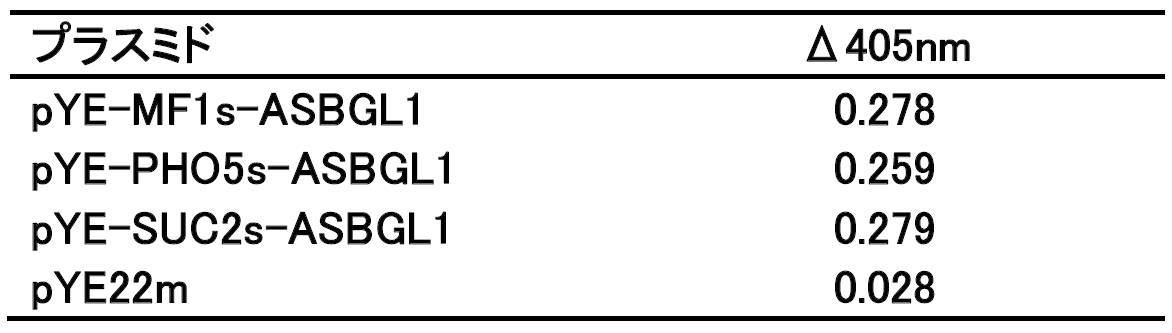
pYE-SUC2s-ASBGL2導入株、pYE-MF1s-AOBGL1導入株とコントロールベクターpYE22m導入株を、SC-Trp液体培地に1Mリン酸カリウムバッファー(pH6.0)を1/10量加えた液体培地で、それぞれ30℃で3日間振とう培養した。得られた培養物(200ml)を遠心分離し、培養上清を得た。培養上清を硫酸アンモニウム80%飽和にし、10000xgにて遠心分離した。上清を捨て、得られた沈澱を0.1%CHAPSを含む50mMリン酸ナトリウムバッファー(pH7.0)15mLに溶解した。アミコン ウルトラ-15 100kDaで脱塩、濃縮を行い、最終的に約500μLのサンプルを得た。
モグロシドVを50μg/mL、50mMクエン酸ナトリウムバッファー(pH5.0)、上記酵素液20μLで、全量100μLとし、50℃で、4時間反応させた。反応液を、メタノールで洗浄し水で平衡化したSepPakC18 500mg(Waters)に供した。40%メタノールで洗浄後、80%メタノールで溶出し、スピードバックで乾固した。100μLの水に溶解し、HPLCに供した。
HPLCの条件は、以下の通りである。
移動相:A;アセトニトリル、B;水
B conc.90%→30% 60分 linear gradient
流速:1ml/分
温度:40℃
検出:UV 203nm
AOBGL1酵素液を、モグロシドIIIEと反応時間を16時間にして、上記と同様の条件で作用させた。その結果、AOBGL1はモグロシドIIIEをモグロール2糖配糖体、モグロール1糖配糖体に加水分解する活性も検出されたが(図3A、図4A)、コントロールでは、モグロシドIIIEから新たに生成したものはなかった(図3B、図4B)。
[配列番号2]ASBGL2のゲノムDNA配列である。
[配列番号3]ASBGL2のアミノ酸配列である。
[配列番号4]ASBGL2成熟タンパク質のアミノ酸配列である。
[配列番号5]AOBGL2のcDNA配列である。
[配列番号6]AOBGL2のゲノムDNA配列である。
[配列番号7]AOBGL2のアミノ酸配列である。
[配列番号8]AOBGL2成熟タンパク質のアミノ酸配列である。
[配列番号9]AOBGL1のcDNA配列である。
[配列番号10]AOBGL1のゲノムDNA配列である。
[配列番号11]AOBGL1のアミノ酸配列である。
[配列番号12]AOBGL1成熟タンパク質のアミノ酸配列である。
[配列番号13]ASBGL1のcDNA配列である。
[配列番号14]ASBGL1のゲノムDNA配列である。
[配列番号15]ASBGL1のアミノ酸配列である。
[配列番号16]ASBGL1成熟タンパク質のアミノ酸配列である。
[配列番号17]PHO5s-ASBGL2のDNA配列である。
[配列番号18]SUC2s-ASBGL2のDNA配列である。
[配列番号19]MF1s-ASBGL2のDNA配列である。
[配列番号20]PHO5s-AOBGL1のDNA配列である。
[配列番号21]SUC2s-AOBGL1のDNA配列である。
[配列番号22]MF1s-AOBGL1のDNA配列である。
[配列番号23]PHO5s-ASBGL1のDNA配列である。
[配列番号24]SUC2s-ASBGL1のDNA配列である。
[配列番号25]MF1s-ASBGL1のDNA配列である。
[配列番号26]実施例で用いたプライマーである(AOBGL2-1)。
[配列番号27]実施例で用いたプライマーである(AOBGL2-2)。
[配列番号28]実施例で用いたプライマーである(ASBGL2-1)。
[配列番号29]実施例で用いたプライマーである(ASBGL2-2)。
[配列番号30]実施例で用いたプライマーである(AOBGL1-1)。
[配列番号31]実施例で用いたプライマーである(AOBGL1-2)。
[配列番号32]実施例で用いたオリゴDNAである(PacI-NheI-F)。
[配列番号33]実施例で用いたオリゴDNAである(PacI-NheI-R)。
[配列番号34]実施例で用いたオリゴDNAである(Sac-ASBGL2-F)。
[配列番号35]実施例で用いたオリゴDNAである(Sal-ASBGL2-R)。
[配列番号36]実施例で用いたプライマーである(Bgl2-AOBGL1-F)。
[配列番号37]実施例で用いたプライマーである(ScPHO5-F)。
[配列番号38]実施例で用いたプライマーである(ScPHO5-R)。
[配列番号39]実施例で用いたプライマーである(ScSUC2-F)。
[配列番号40]実施例で用いたプライマーである(ScSUC2-R)。
[配列番号41]実施例で用いたプライマーである(ScMF1-F)。
[配列番号42]実施例で用いたプライマーである(ScMF1-R)。
[配列番号43]分泌シグナル配列MF(ALPHA)1(YPL187W)のDNA配列である。
[配列番号44]分泌シグナル配列MF(ALPHA)1(YPL187W)のアミノ酸配列である。
[配列番号45]分泌シグナル配列PHO5(YBR093C)のDNA配列である。
[配列番号46]分泌シグナル配列PHO5(YBR093C)のアミノ酸配列である。
[配列番号47]分泌シグナル配列SUC2(YIL162W)のDNA配列である。
[配列番号48]分泌シグナル配列SUC2(YIL162W)のアミノ酸配列である。
[配列番号49]実施例で用いたプライマーである(TRP1-F)。
[配列番号50]実施例で用いたプライマーである(TRP1-R)。
Claims (20)
- 以下の(a)~(c)からなる群から選択されるタンパク質と、少なくとも1つのβ1,6-グルコシド結合を有するモグロシドを反応させて、前記β1,6-グルコシド結合を切断する工程を含む、β1,6-グルコシド結合のないモグロシドの調製方法。
(a)配列番号4、配列番号8、配列番号12および配列番号16からなる群から選択されるアミノ酸配列からなるタンパク質;
(b)配列番号4、配列番号8、配列番号12および配列番号16からなる群から選択されるアミノ酸配列において、1~84個のアミノ酸が欠失、置換、挿入、および/または付加されたアミノ酸配列からなり、かつモグロシドのβ-1,6グルコシド結合を切断する活性を有するタンパク質;
(c)配列番号4、配列番号8、配列番号12および配列番号16からなる群から選択されるアミノ酸配列に対して、90%以上の配列同一性を有するアミノ酸配列を有し、かつモグロシドのβ-1,6グルコシド結合を切断する活性を有するタンパク質 - 前記(a)~(c)からなる群から選択されるタンパク質が、さらに、分泌シグナルペプチドを含む、請求項1に記載の方法。
- 前記少なくとも1つのβ1,6-グルコシド結合を有するモグロシドが、さらに、少なくとも1つのβ1,2-グルコシド結合を有する、請求項1または2に記載の方法。
- 前記少なくとも1つのβ1,6-グルコシド結合および少なくとも1つのβ1,2-グルコシド結合を有するモグロシドが、モグロシドV、シアメノシドI、モグロシドIV、およびモグロシドIIIA1から選択される、請求項3に記載の方法。
- 前記β1,6-グルコシド結合のないモグロシドが、モグロシドIIIEおよびモグロシドIIAから選択される、請求項4に記載の方法。
- 少なくとも1つのβ1,6-グルコシド結合を有するモグロシドを生成する宿主に、以下の(a)~(e)からなる群から選択されるポリヌクレオチドが導入された非ヒト形質転換体を培養することを含む、β1,6-グルコシド結合のないモグロシドの生産方法。
(a)配列番号1の61番目~2601番目、配列番号2の61番目~2707番目、配列番号5の61番目~2601番目、配列番号6の61番目~2708番目、配列番号9の58番目~2586番目、配列番号10の58番目~2891番目、配列番号13の58番目~2586番目、および配列番号14の58番目~2892番目からなる群から選択される塩基配列からなるポリヌクレオチド;
(b)配列番号4、配列番号8、配列番号12、および配列番号16からなる群から選択されるアミノ酸配列からなるタンパク質をコードするポリヌクレオチド;
(c)配列番号4、配列番号8、配列番号12、および配列番号16からなる群から選択されるアミノ酸配列において、1~84個のアミノ酸が欠失、置換、挿入、および/または付加されたアミノ酸配列からなり、かつモグロシドのβ-1,6グルコシド結合を切断する活性を有するタンパク質をコードするポリヌクレオチド;
(d)配列番号4、配列番号8、配列番号12、および配列番号16からなる群から選択されるアミノ酸配列に対して、90%以上の配列同一性を有するアミノ酸配列を有し、かつモグロシドのβ-1,6グルコシド結合を切断する活性を有するタンパク質をコードするポリヌクレオチド;
(e)配列番号1の61番目~2601番目、配列番号2の61番目~2707番目、配列番号5の61番目~2601番目、配列番号6の61番目~2708番目、配列番号9の58番目~2586番目、配列番号10の58番目~2891番目、配列番号13の58番目~2586番目、および配列番号14の58番目~2892番目からなる群から選択される塩基配列と相補的な塩基配列からなるポリヌクレオチドと高ストリンジェントな条件下でハイブリダイズするポリヌクレオチドであって、かつモグロシドのβ-1,6グルコシド結合を切断する活性を有するタンパク質をコードするポリヌクレオチド - 前記(a)~(e)からなる群から選択されるポリヌクレオチドが、さらに、分泌シグナルペプチドをコードする塩基配列からなるポリヌクレオチド含む、請求項6に記載の方法。
- 前記分泌シグナルペプチドをコードする塩基配列からなるポリヌクレオチドが、配列番号1の1番目~60番目、配列番号5の1番目~60番目、配列番号9の1番目~57番目、配列番号13の1番目~57番目、配列番号43、配列番号45および配列番号47のいずれかに記載の塩基配列からなるポリヌクレオチドである、請求項7に記載の方法。
- 前記分泌シグナルペプチドをコードする塩基配列からなるポリヌクレオチドを含むポリヌクレオチドが、配列番号1、配列番号2、配列番号5、配列番号6、配列番号9、配列番号10、配列番号13、配列番号14、および配列番号17~配列番号25のいずれかに記載の塩基配列からなる、請求項8に記載の方法。
- 前記ポリヌクレオチドが、発現ベクターに挿入されたものである、請求項6~9のいずれか1項に記載の方法。
- 前記形質転換体が、形質転換酵母または形質転換植物である、請求項6~10のいずれか1項に記載の方法。
- 宿主細胞に、以下の(a)~(e)からなる群から選択されるポリヌクレオチドが導入された非ヒト形質転換細胞に由来する酵素剤を、少なくとも1つのβ1,6-グルコシド結合を有するモグロシドと接触させて、前記β1,6-グルコシド結合を切断する工程を含む、β1,6-グルコシド結合のないモグロシドの調製方法。
(a)配列番号1の61番目~2601番目、配列番号2の61番目~2707番目、配列番号5の61番目~2601番目、配列番号6の61番目~2708番目、配列番号9の58番目~2586番目、配列番号10の58番目~2891番目、配列番号13の58番目~2586番目、および配列番号14の58番目~2892番目からなる群から選択される塩基配列からなるポリヌクレオチド;
(b)配列番号4、配列番号8、配列番号12、および配列番号16からなる群から選択されるアミノ酸配列からなるタンパク質をコードするポリヌクレオチド;
(c)配列番号4、配列番号8、配列番号12、および配列番号16からなる群から選択されるアミノ酸配列において、1~84個のアミノ酸が欠失、置換、挿入、および/または付加されたアミノ酸配列からなり、かつモグロシドのβ-1,6グルコシド結合を切断する活性を有するタンパク質をコードするポリヌクレオチド;
(d)配列番号4、配列番号8、配列番号12、および配列番号16からなる群から選択されるアミノ酸配列に対して、90%以上の配列同一性を有するアミノ酸配列を有し、かつモグロシドのβ-1,6グルコシド結合を切断する活性を有するタンパク質をコードするポリヌクレオチド;
(e)配列番号1の61番目~2601番目、配列番号2の61番目~2707番目、配列番号5の61番目~2601番目、配列番号6の61番目~2708番目、配列番号9の58番目~2586番目、配列番号10の58番目~2891番目、配列番号13の58番目~2586番目、および配列番号14の58番目~2892番目からなる群から選択される塩基配列と相補的な塩基配列からなるポリヌクレオチドと高ストリンジェントな条件下でハイブリダイズするポリヌクレオチドであって、かつモグロシドのβ-1,6グルコシド結合を切断する活性を有するタンパク質をコードするポリヌクレオチド - 前記(a)~(e)からなる群から選択されるポリヌクレオチドが、さらに、分泌シグナルペプチドをコードする塩基配列からなるポリヌクレオチド含む、請求項12に記載の方法。
- 前記分泌シグナルペプチドをコードする塩基配列からなるポリヌクレオチドが、配列番号1の1番目~60番目、配列番号5の1番目~60番目、配列番号9の1番目~57番目、配列番号13の1番目~57番目、配列番号43、配列番号45および配列番号47のいずれかに記載の塩基配列からなるポリヌクレオチドである、請求項13に記載の方法。
- 前記分泌シグナルペプチドをコードする塩基配列からなるポリヌクレオチドを含むポリヌクレオチドが、配列番号1、配列番号2、配列番号5、配列番号6、配列番号9、配列番号10、配列番号13、配列番号14、および配列番号17~配列番号25のいずれかに記載の塩基配列からなる、請求項14に記載の方法。
- 前記ポリヌクレオチドが、発現ベクターに挿入されたものである、請求項12~15のいずれか1項に記載の方法。
- 前記形質転換細胞が、形質転換細菌または形質転換酵母である、請求項12~16のいずれか1項に記載の方法。
- 前記少なくとも1つのβ1,6-グルコシド結合を有するモグロシドが、さらに、少なくとも1つのβ1,2-グルコシド結合を有する、請求項12~17に記載の方法。
- 前記少なくとも1つのβ1,6-グルコシド結合および少なくとも1つのβ1,2-グルコシド結合を有するモグロシドが、モグロシドV、シアメノシドI、モグロシドIV、およびモグロシドIIIA1から選択される、請求項18に記載の方法。
- 前記β1,6-グルコシド結合のないモグロシドが、モグロシドIIIEおよびモグロシドIIAから選択される、請求項19に記載の方法。
Priority Applications (4)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CA2974185A CA2974185C (en) | 2015-01-20 | 2016-01-19 | Method for preparing mogroside |
| US15/544,316 US10626430B2 (en) | 2015-01-20 | 2016-01-19 | Method for preparing mogroside having no β-1,6-glucoside bond |
| JP2016570649A JP6850130B2 (ja) | 2015-01-20 | 2016-01-19 | モグロシドの調製方法 |
| EP16740156.1A EP3249044A4 (en) | 2015-01-20 | 2016-01-19 | Method for preparing mogroside |
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2015008508 | 2015-01-20 | ||
| JP2015-008508 | 2015-01-20 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2016117549A1 true WO2016117549A1 (ja) | 2016-07-28 |
Family
ID=56417090
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2016/051416 Ceased WO2016117549A1 (ja) | 2015-01-20 | 2016-01-19 | モグロシドの調製方法 |
Country Status (4)
| Country | Link |
|---|---|
| US (1) | US10626430B2 (ja) |
| EP (1) | EP3249044A4 (ja) |
| JP (1) | JP6850130B2 (ja) |
| WO (1) | WO2016117549A1 (ja) |
Cited By (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2018016483A1 (ja) * | 2016-07-19 | 2018-01-25 | サントリーホールディングス株式会社 | モグロールまたはモグロール配糖体の生産方法 |
| WO2018229283A1 (en) * | 2017-06-15 | 2018-12-20 | Evolva Sa | Production of mogroside compounds in recombinant hosts |
| WO2023225459A2 (en) | 2022-05-14 | 2023-11-23 | Novozymes A/S | Compositions and methods for preventing, treating, supressing and/or eliminating phytopathogenic infestations and infections |
Families Citing this family (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN112334012A (zh) * | 2018-04-23 | 2021-02-05 | 可口可乐公司 | 新型罗汉果苷、获得新型罗汉果苷的方法及用途 |
| CN109055474A (zh) * | 2018-10-31 | 2018-12-21 | 大闽食品(漳州)有限公司 | 一种提高罗汉果甜苷甜度的方法 |
Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2004099228A2 (en) * | 2003-05-02 | 2004-11-18 | Novozymes Inc. | Variants of beta-glucosidases |
| JP2007167062A (ja) * | 2005-11-24 | 2007-07-05 | National Institute Of Advanced Industrial & Technology | 高効率分泌シグナルペプチド及びそれらを利用したタンパク質発現系 |
| WO2011046768A2 (en) * | 2009-10-12 | 2011-04-21 | Board Of Supervisors Of Louisiana State University And Agricultural And Mechanical College | Masking bitter flavors |
| WO2014150127A1 (en) * | 2013-03-15 | 2014-09-25 | Tate & Lyle Ingredients Americas, LLC | Redistribution of mogrol glycoside content |
Family Cites Families (8)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US4084010A (en) | 1976-01-01 | 1978-04-11 | Tsunematsu Takemoto | Glycosides having sweetness |
| JP3699103B2 (ja) | 2004-01-30 | 2005-09-28 | 日本製紙株式会社 | インクジェット記録媒体 |
| JP2007028912A (ja) * | 2005-07-22 | 2007-02-08 | Gekkeikan Sake Co Ltd | 新規β−グルコシダーゼ、及びその利用 |
| US8772010B2 (en) | 2009-06-16 | 2014-07-08 | Codexis, Inc. | β-Glucosidase variants |
| CN102477455B (zh) * | 2010-11-26 | 2014-03-26 | 成都普瑞法科技开发有限公司 | 制备罗汉果苷ⅳ的方法 |
| AR087433A1 (es) | 2011-08-08 | 2014-03-26 | Merck Sharp & Dohme | Analogos de insulina n-glicosilados |
| BR112014012543A2 (pt) | 2011-11-23 | 2017-06-13 | Evolva Sa | métodos e materiais para síntese enzimática de compostos de mogrosídeo |
| CA2905033C (en) * | 2013-03-15 | 2023-06-27 | Lallemand Hungary Liquidity Management Llc | Expression of beta-glucosidases for hydrolysis of lignocellulose and associated oligomers |
-
2016
- 2016-01-19 JP JP2016570649A patent/JP6850130B2/ja active Active
- 2016-01-19 EP EP16740156.1A patent/EP3249044A4/en not_active Withdrawn
- 2016-01-19 US US15/544,316 patent/US10626430B2/en active Active
- 2016-01-19 WO PCT/JP2016/051416 patent/WO2016117549A1/ja not_active Ceased
Patent Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2004099228A2 (en) * | 2003-05-02 | 2004-11-18 | Novozymes Inc. | Variants of beta-glucosidases |
| JP2007167062A (ja) * | 2005-11-24 | 2007-07-05 | National Institute Of Advanced Industrial & Technology | 高効率分泌シグナルペプチド及びそれらを利用したタンパク質発現系 |
| WO2011046768A2 (en) * | 2009-10-12 | 2011-04-21 | Board Of Supervisors Of Louisiana State University And Agricultural And Mechanical College | Masking bitter flavors |
| WO2014150127A1 (en) * | 2013-03-15 | 2014-09-25 | Tate & Lyle Ingredients Americas, LLC | Redistribution of mogrol glycoside content |
Non-Patent Citations (5)
| Title |
|---|
| DATABASE GenBank [o] 18 June 2012 (2012-06-18), XP055467943, Database accession no. EIT73097 * |
| DATABASE GenBank [o] 19 January 2010 (2010-01-19), XP055467951, Database accession no. XP_002382041 * |
| DATABASE GenBank [o] 3 March 2011 (2011-03-03), XP055467926, Database accession no. XP_001819055 * |
| LANGSTON J. ET AL.: "Substrate specificity of Aspergillus oryzae family 3 beta-glucosidase", BIOCHIM. BIOPHYS. ACTA, vol. 1764, no. 5, 2006, pages 972 - 978, XP025123101 * |
| See also references of EP3249044A4 * |
Cited By (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2018016483A1 (ja) * | 2016-07-19 | 2018-01-25 | サントリーホールディングス株式会社 | モグロールまたはモグロール配糖体の生産方法 |
| US11008600B2 (en) | 2016-07-19 | 2021-05-18 | Suntory Holdings Limited | Method for producing mogrol or mogrol glycoside |
| WO2018229283A1 (en) * | 2017-06-15 | 2018-12-20 | Evolva Sa | Production of mogroside compounds in recombinant hosts |
| US11248248B2 (en) | 2017-06-15 | 2022-02-15 | Evolva Sa | Production of mogroside compounds in recombinant hosts |
| WO2023225459A2 (en) | 2022-05-14 | 2023-11-23 | Novozymes A/S | Compositions and methods for preventing, treating, supressing and/or eliminating phytopathogenic infestations and infections |
Also Published As
| Publication number | Publication date |
|---|---|
| CA2974185A1 (en) | 2016-07-28 |
| JP6850130B2 (ja) | 2021-03-31 |
| US10626430B2 (en) | 2020-04-21 |
| EP3249044A4 (en) | 2018-11-07 |
| EP3249044A1 (en) | 2017-11-29 |
| US20180010160A1 (en) | 2018-01-11 |
| JPWO2016117549A1 (ja) | 2017-10-26 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP6845244B2 (ja) | モグロールまたはモグロール配糖体の生産方法 | |
| JP6850130B2 (ja) | モグロシドの調製方法 | |
| JP6824975B2 (ja) | Aobgl11ホモログを用いたステビオールおよびステビオール配糖体の製造方法 | |
| JP6778208B2 (ja) | Aobgl1ホモログを用いたステビオール配糖体およびステビオールの製造方法 | |
| JP6778207B2 (ja) | Aobgl3ホモログを用いたステビオール配糖体およびステビオールの製造方法 | |
| JP6916801B2 (ja) | セサミノールまたはセサミノール配糖体の生産方法 | |
| CA2974185C (en) | Method for preparing mogroside | |
| WO2018190378A1 (ja) | ステビア由来ラムノース合成酵素及び遺伝子 | |
| HK40003005A (en) | Method for producing sesaminol or sesaminol glycoside | |
| HK40003005B (en) | Method for producing sesaminol or sesaminol glycoside |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 16740156 Country of ref document: EP Kind code of ref document: A1 |
|
| ENP | Entry into the national phase |
Ref document number: 2016570649 Country of ref document: JP Kind code of ref document: A |
|
| ENP | Entry into the national phase |
Ref document number: 2974185 Country of ref document: CA |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 15544316 Country of ref document: US |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| REEP | Request for entry into the european phase |
Ref document number: 2016740156 Country of ref document: EP |