WO2018040899A1 - 搜索词纠错方法及装置 - Google Patents
搜索词纠错方法及装置 Download PDFInfo
- Publication number
- WO2018040899A1 WO2018040899A1 PCT/CN2017/097357 CN2017097357W WO2018040899A1 WO 2018040899 A1 WO2018040899 A1 WO 2018040899A1 CN 2017097357 W CN2017097357 W CN 2017097357W WO 2018040899 A1 WO2018040899 A1 WO 2018040899A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- word
- search
- edit distance
- hot
- character
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Ceased
Links
Images



Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/30—Information retrieval; Database structures therefor; File system structures therefor of unstructured textual data
- G06F16/33—Querying
- G06F16/332—Query formulation
- G06F16/3322—Query formulation using system suggestions
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/90—Details of database functions independent of the retrieved data types
- G06F16/903—Querying
- G06F16/9032—Query formulation
- G06F16/90324—Query formulation using system suggestions
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/90—Details of database functions independent of the retrieved data types
- G06F16/95—Retrieval from the web
- G06F16/953—Querying, e.g. by the use of web search engines
- G06F16/9532—Query formulation
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/90—Details of database functions independent of the retrieved data types
- G06F16/95—Retrieval from the web
- G06F16/953—Querying, e.g. by the use of web search engines
- G06F16/9535—Search customisation based on user profiles and personalisation
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/20—Natural language analysis
- G06F40/205—Parsing
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/20—Natural language analysis
- G06F40/232—Orthographic correction, e.g. spell checking or vowelisation
Definitions
- the present application relates to the field of computer technology, and in particular, to a search term error correction method and apparatus.
- the embodiment of the present application provides a search term error correction method and apparatus.
- a search word error correction method including: identifying an erroneous search term; using a weighted edit distance algorithm, calculating a weighted edit distance between the search term and a pre-acquired hot word, wherein
- a weighted edit distance calculation process for the operation of converting from a search word to a hot word, respectively, an insert character operation, a delete character operation, a near-word or a near-word replacement operation, a non-near-word or a near-word
- the replacement operation, the exchange character operation, and the weights of different values are set; according to the weighted edit distance and the hot word heat, a predetermined number of hot words are selected for error correction prompting.
- a weighted edit distance between words comprising: a definition state transition equation for representing a weighted edit distance between the search term and a hot word, wherein two state quantities are defined in the state transition equation for respectively representing the search
- the character corresponding to the position between the word and the hot word; according to the operation of inserting a character, deleting a character, replacing a near-word or near-word, replacing a non-near or near-word, or exchanging a character
- the weights of the different values are used to solve the solution of the state transition equation in the corresponding operation; according to the solution of the state transition equation, the weighted edit distance is obtained.
- the method further includes: determining whether the search term and the hot word are in a near-word or near-word by looking up a preset near-word mapping table or a near-word mapping table.
- the identifying the wrong search term includes: analyzing or calculating a search click rate, a word feature, an appearance probability, a total matching result number, and a total matching ratio of the search word to be identified based on the search log; Identifying the search click rate, the word feature, the appearance probability, the total matching result number, and the total matching ratio of the search term, and determining that the to-be-identified search term is an incorrect search term or a normal search term.
- the determining, according to the weighted edit distance and the hot word heat, selecting a predetermined number of hot words to perform error correction prompting comprising: normalizing the hot word search times; and editing the distance and the hot words according to the weighting The number of search times is normalized, and the recommended comprehensive score is calculated; the predetermined number of hot words whose recommended comprehensive score is the highest and the weighted edit distance is less than the predetermined value is selected as the recommended word for error correction, and the error correction prompt is performed.
- a weighted edit distance calculation method includes: obtaining a source string and a target string; and calculating a weight between the source string and the target string Editing distance, wherein in the weighted edit distance calculation process, weights of different values are respectively set for different operations of converting from the source string to the target character string.
- the calculating a weighted edit distance between the source string and the target string includes: defining a state transition equation for indicating a weight between the source string and the target string Editing distance, wherein two state quantities are defined in the state transition equation for respectively representing characters corresponding to the position between the source string and the target string; and according to the weights of different values set for different operations, the solution The solution of the state transition equation in the corresponding operation; according to the solution of the state transition equation, the weighted edit distance is obtained.
- a search word error correction apparatus including: an error search word recognition unit for identifying an erroneous search word; and a weighted edit distance calculation unit for calculating a distance using a weighted edit distance algorithm a weighted edit distance between the search term and the pre-acquired hot word, wherein in the weighted edit distance calculation process, the operation for converting from the search word to the hot word is respectively inserting a character operation, deleting a character operation, and a shape a replacement operation of a near-word or near-word, a replacement operation of a non-near-word or a near-word, an exchange of character operations, and a weighting of different values; an error correction prompting unit for editing the distance and the heat of the heat according to the weighting, Select a predetermined number of hot words for error correction.
- the weighted edit distance calculation unit includes: a state transition equation definition subunit, configured to define a state transition equation, used to represent a weighted edit distance between the search term and the hot word, wherein, in the state transition equation Two state quantities are defined for respectively representing characters corresponding to the position between the search term and the hot word; the equation solving subunit is used for the replacement operation according to the insertion character operation, the delete character operation, the shape near word or the near word The replacement operation of the non-shaped near-word or near-word, the weight of the different values set by the exchange character operation, and the solution of the state transition equation in the corresponding operation is solved as the weighted edit distance.
- a state transition equation definition subunit configured to define a state transition equation, used to represent a weighted edit distance between the search term and the hot word, wherein, in the state transition equation Two state quantities are defined for respectively representing characters corresponding to the position between the search term and the hot word
- the equation solving subunit is used for the replacement operation according to the insertion character operation, the delete character
- the device further includes: a near-word or near-word determining unit, configured to search a preset near-word mapping table or a near-word mapping table, and determine whether the search word and the hot word are mutually It is a near-word or a near-word.
- a near-word or near-word determining unit configured to search a preset near-word mapping table or a near-word mapping table, and determine whether the search word and the hot word are mutually It is a near-word or a near-word.
- the error search term identifying unit includes: a log searching and calculating subunit, configured to parse or calculate a search click rate, a word feature, an appearance probability, a total matching result number, and a search term of the to-be-identified search word based on the search log. a total matching ratio; a recognition result determining subunit, configured to determine, according to the search click rate, the word feature, the appearance probability, the total matching result number, and the total matching ratio of the search word to be identified
- the search word to be identified is an incorrect search word or a normal search word.
- the error correction prompting unit includes: a normalization processing subunit for normalizing the hot word search times; and a recommended comprehensive score calculation subunit for editing the distance and the hot words according to the weighting
- the search result normalization processing result is calculated, and the recommended comprehensive score is calculated;
- the recommended word determining subunit is configured to select a predetermined number of hot words whose recommended comprehensive score is the highest and the weighted edit distance is less than a predetermined value, as the recommended word for error correction, Error correction tips.
- a weighted edit distance calculation apparatus includes: an acquisition unit for acquiring a source character string and a target character string; and a calculation unit configured to calculate the source character string and the target character string A weighted edit distance between, wherein in the weighted edit distance calculation process, weights of different values are respectively set for different operations of converting from the source string to the target character string.
- the calculating unit includes: a state transition equation defining subunit, configured to define a state transition equation, configured to represent a weighted edit distance between the source string and the target string, wherein, in the state transition Two state quantities are defined in the equation for respectively representing the characters corresponding to the position between the source string and the target string; the state transition equation solving sub-unit is used to solve the weights of different values set for different operations.
- the state transition equation is the solution of the corresponding operation as the weighted edit distance.
- an embodiment of the present application provides a method for correcting search words, including include:
- a predetermined number of hot words are selected from the pre-acquired hot words for error correction prompting.
- the weighting edit distance between the identified search term and the pre-acquired hot word is calculated according to the weight of different values set in advance for each operation of converting from the search term to the hot word, including:
- a state transition equation for representing a weighted edit distance between the identified search term and a pre-acquired hot word, wherein two state quantities are defined in the state transition equation for respectively representing the identified search term a character corresponding to the position between the pre-acquired hot words;
- the weighted edit distance is obtained according to the solution of the state transition equation.
- the state transition equation is:
- Edit(i,j) min ⁇ edit(i-1,j)+1,edit(i,j-1)+1,edit(i-1,j-1)+f(i,j), ⁇ ;
- f(i, j) is the operation cost value
- f(i, j) is based on the replacement operation of the inserted character operation, the delete character operation, the shape near word or the near word.
- the replacing operation of the near-word or near-word includes:
- Determining whether the search term and the hot word are mutually similar or close to each other by searching a preset near-word mapping table or a sound near-word mapping table.
- the different values set in advance for each operation of converting from a search term to a hot word satisfy the following relationship:
- the identifying the wrong search term includes:
- the search word to be identified is an incorrect search word.
- the determining, according to the weighted edit distance and the hot word heat of the pre-acquired hot word, selecting a predetermined number of hot words from the pre-acquired hot words to perform error correction prompting including:
- a predetermined number of hot words whose recommendation comprehensive score is the highest and the weighted edit distance is less than a predetermined value are selected as the recommended words for error correction, and an error correction prompt is performed.
- an embodiment of the present application provides a weighted edit distance calculation method, including:
- the weighting edit distance between the source string and the target string is calculated according to weights of different values set for different operations, including:
- the weighted edit distance is obtained according to the solution of the state transition equation.
- an embodiment of the present application provides a search term error correction apparatus, including:
- a weighted edit distance calculation unit configured to calculate a weighted edit distance between the recognized search term and the pre-acquired hot word according to weights of different values set in advance for each operation of converting from the search word to the hot word, wherein
- the operations include inserting a character operation, deleting a character operation, replacing a near-word or near-word, replacing a non-near-word or near-word, and exchanging a character operation;
- the error correction prompting unit is configured to select a predetermined number of hot words from the pre-acquired hot words to perform error correction prompts according to the weighted edit distance and the hot word heat of the pre-acquired hot words.
- the weighted edit distance calculation unit includes:
- the state transition equation defines a subunit for defining a state transition equation for representing a weighted edit distance between the identified search term and a pre-acquired hot word, wherein two state quantities are defined in the state transition equation, Characters respectively indicating corresponding positions between the identified search term and the pre-acquired hot word;
- the equation solving subunit is used for different values set by the character operation for inserting a character, deleting a character operation, replacing a near-word or a near-word, replacing a non-near-word or a near-word, or exchanging character operations.
- Weighting solving the solution of the state transition equation in the corresponding operation, and obtaining the weighted edit distance according to the solution of the state transition equation.
- the state transition equation is:
- Edit(i,j) min ⁇ edit(i-1,j)+1,edit(i,j-1)+1,edit(i-1,j-1)+f(i,j), ⁇ ;
- f(0, j) is the operation cost value
- f(i, j) is based on the replacement operation of the inserted character operation, the delete character operation, the shape near word or the near word.
- the replacing operation of the near-word or near-word includes:
- the different values set in advance for each operation of converting from a search term to a hot word satisfy the following relationship:
- the error search term identifying unit includes:
- a log search and calculation sub-unit for parsing or calculating a search click rate, a word feature, an appearance probability, a total matching result number, and a total matching ratio of the search word to be recognized based on the search log;
- a recognition result determining subunit configured to determine the to-be-identified search according to the search click rate, the word feature, the appearance probability, the total matching result number, and the total matching ratio of the search word to be identified The word is the wrong search term.
- the error correction prompting unit includes:
- a normalization processing sub-unit configured to normalize the hot word search times of the pre-acquired hot words
- a comprehensive score calculation sub-unit is configured to calculate a recommended comprehensive score according to the normalized processing result of the weighted edit distance and the hot word search times;
- a recommendation word determining subunit configured to select, from the pre-acquired hot words, a predetermined number of hot words whose recommendation comprehensive score is the highest and the weighted edit distance is less than a predetermined value, as a recommended word for error correction, correcting Wrong prompt.
- an embodiment of the present application provides a weighted edit distance calculation device, where the device includes:
- An obtaining unit for obtaining a source string and a target string An obtaining unit for obtaining a source string and a target string
- a calculating unit configured to separately set weights of different values for different operations of converting from the source string to the target string, and calculating the source string and the weight according to weights of different values set for different operations The weighted edit distance between the target strings.
- the calculating unit may include:
- a state transition equation defining subunit for defining a state transition equation for representing a weighted edit distance between the source string and the target string, wherein two state quantities are defined in the state transition equation for Characters representing the corresponding positions between the source string and the target string, respectively;
- a state transition equation solving subunit for solving a solution of the state transition equation in a corresponding operation according to weights of different values set for different operations, according to the solution of the state transition equation To the weighted edit distance.
- an embodiment of the present application further includes an electronic device, including: a first processor, a first communication interface, a first memory, and a first communication bus, wherein the first processor is first a communication interface, the first memory completes communication with each other through a first communication bus; a first memory is configured to store a computer program; and a first processor is configured to execute a program stored on the first memory to implement the search word error correction Method steps.
- an embodiment of the present application further discloses a computer readable storage medium, where the storage medium stores a computer program, and when the computer program is executed by a processor, the step of performing the search word error correction method is implemented. .
- an embodiment of the present application further discloses an electronic device, including: a second processor, a second communication interface, a second memory, and a second communication bus, wherein the second processor, the second a communication interface, the second memory completes communication with each other through the second communication bus; a second memory is configured to store the computer program; and a second processor is configured to execute the program stored on the second memory to implement the weighted edit distance calculation Method steps.
- an embodiment of the present application further discloses a computer readable storage medium, where the computer includes a computer program, where the computer program is executed by a processor to implement the weighted edit distance calculation method step. .
- the embodiment of the present application provides a method and a device for correcting a search word based on a weighted edit distance, by deleting a character operation, inserting a character operation, forming a near-word or a near-word replacement operation, a non-near-word or a near-word
- the replacement operation and the exchange character operation respectively set different weights, so that in the weighted edit distance calculation process, various operations that may be involved in the process from the search word to the hot word conversion are fully covered, so that the calculation can be performed more quickly and accurately. Improve the accuracy of search word correction from the search distance between the search word and the hot word.
- FIG. 1 is a flowchart of a method for correcting search words according to an embodiment of the present application
- FIG. 2 is a flowchart of a method for calculating a weighted edit distance according to an embodiment of the present application
- FIG. 3 is a schematic structural diagram of a search word error correction apparatus according to an embodiment of the present disclosure
- FIG. 4 is a schematic diagram of a first structure of an electronic device according to an embodiment of the present application.
- FIG. 5 is a schematic diagram of a second structure of an electronic device according to an embodiment of the present disclosure.
- the error correction scheme based on the edit distance in the prior art does not consider the relationship between the replacement characters, such as the near-word, the near-word, and the like, and does not consider the exchange operation between adjacent characters in the string. Therefore, this traditional editing distance effect is not ideal.
- the embodiment of the present application provides a search term error correction method and apparatus based on a weighted edit distance, by deleting a character operation, inserting a character operation, a near-word or a near-word replacement operation, a non-near-word or a near-word replacement operation.
- exchange character operations respectively set different weights, so that in the weighted edit distance calculation process, fully covers the various operations that may be involved in the process from search word to hot word conversion, so that the search can be calculated more quickly and accurately.
- the editing distance between words and hot words improves the accuracy of search words.
- FIG. 1 is a flowchart of a method for correcting a search word according to an embodiment of the present application, where the method includes:
- Error correction of search words is to correct the wrong search words, so it is first necessary to identify the wrong search words.
- the reason why the search words are wrong including many kinds of situations, for example, search words due to homophone selection errors, search words due to pinyin spelling errors, search words due to glyph input errors, which leads to the search results not satisfying the user. Demand.
- the wrong search term can be identified: by the search term click rate, the search result is completely matched. The number of results and the probability of the search term based on the language model can effectively identify the wrong search term.
- Step 1 Based on the search log, parse or calculate the search click rate, word characteristics, appearance probability, total matching result number, and total matching proportion of the search words to be identified.
- the search click rate of the search term to be recognized is calculated. For example, the number of searches for the search term to be recognized by the user and the number of clicks of the search result are obtained from the search log; the number of clicks of the search result is divided by the number of searches to obtain the search click rate.
- word processing is performed on the identified search words to obtain multiple word features.
- the probability of occurrence of the search word to be identified is calculated.
- the total matching result number and the related result number of the search word to be recognized are calculated, wherein the total matching result number is the number of results of all the content including the to-be-identified search word among all the search results for the search word to be recognized, and the related result The number is the number of results of the partial content of the search word to be recognized among all the search results for the search word to be recognized.
- the search word to be recognized is a "remote-controllable camera”
- part of the content of the search word to be recognized is “camera”
- the number of results of the "remote-controllable camera” in the search result is 10, including " The number of results for the camera is 15;
- the number of all matching results is 10, and the number of related results is 15.
- Step 2 determining, according to the search click rate, the word feature, the appearance probability, the total matching result number, and the total matching ratio of the search word to be identified, the search word to be identified is an incorrect search word or a normal search word.
- the multi-dimensional feature of the search term to be identified may be merged; for example, the multi-dimensional feature of the search term to be identified may include the following: search click rate, each of the word features, probability of occurrence of the search word to be recognized, and full match The number of results and the total match ratio.
- identifying the search words according to the multi-dimensional feature can reduce the difficulty of identifying the search words to be recognized, thereby improving the recognition ability of the search words to be recognized, and is useful for identifying whether the search words to be identified are incorrect search words.
- S102 Calculating a weighted edit distance between the search term and the pre-acquired hot word by using a weighted edit distance algorithm, wherein in the weighted edit distance calculation process, the operation for converting from the search word to the hot word is respectively an insert character operation , deleting a character operation, a near-word or a near-word replacement operation, The substitution operation of a non-near-word or near-word, the exchange of character operations, and the weighting of different values.
- a hot word refers to a network or a commonly used or popular word.
- a number of hot words can be determined by a click rate to form a hot vocabulary.
- the user is provided with a better experience by correcting the wrong search words into hot words with similar editing distances.
- Edit Distance also known as the Levenshtein distance
- Levenshtein distance refers to the minimum number of editing operations required between two strings to be converted from one to another.
- Traditional editing operations include replacing one character with another, inserting one character, and deleting one character.
- the smaller the edit distance the greater the similarity between the two strings.
- the traditional editing distance operation includes: replacing one character with another character, inserting one character, and deleting one character, and each operation corresponds to a distance of one. These operations do not include the exchange operations between adjacent characters in a string, nor the particularity of the near-word or near-word replacement operations.
- the swap operation can be implemented by two replacement operations, such as CD->DD->DC, according to the traditional edit distance algorithm, the corresponding distance is 2. Considering that in the actual search process, the probability that the user inputs two characters into the wrong position is very high, and the distance of the exchange operation is 2 is unreasonable. In addition, the probability of a search word input error caused by the user's near-word or near-word is also high. If there is no special treatment for this special replacement operation, setting the distance to 1 is obviously unreasonable.
- a weighted edit distance calculation method which includes the following five operations, and different weights are respectively set.
- each operation weight it is necessary to satisfy w1 ⁇ w2 ⁇ 1.
- a weighted edit distance calculation method provided in the embodiment of the present application may include:
- a weighted edit distance between the source string and the target string is calculated, wherein in the weighted edit distance calculation process, weights of different values are respectively set for different operations from the source string to the target string.
- Weighted edit distances can set different weights for different operations to solve the above problems.
- the idea is to describe the state of the operation and solve it with a state transition equation.
- the source string str1 (the search term in this embodiment) and the target string str2 (the hot word in this embodiment) are involved, and it is obvious that a state quantity cannot describe such a calculation from the source string.
- the weighted edit distance is converted to the binary relationship of the target string, so the two state quantities i, j are used to describe a state in the edit distance from the source string to the target string.
- the optimal edit distance for 1->j from 1->i of the source string str1 to the target string str2 is represented by edit(i,j), where 1->i indicates that the source string length is i.
- Substring, 1->j represents a substring whose target string length is j
- the transfer from the source string to the target string needs to pass a state transition equation, ie how to derive these substates from ti ⁇ i, tj ⁇ j Transfer to state i, j, where the substate is the state of the source string and the target string before calculating the edit distance.
- ti ⁇ i indicates the state of the source string when the source string is not converted to the target string.
- tj ⁇ j represents the state of the target character string when the source character string is not converted into the target character string
- the states i and j represent the state of the source character string and the target character string after the edit distance is calculated.
- FIG. 2 is a flowchart of a weighted edit distance calculation method provided by an embodiment of the present application, including:
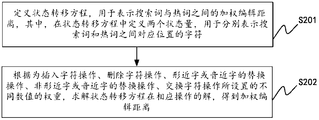
- S201 defining a state transition equation for representing a weighted edit distance between the search term and the hot word, Wherein, two state quantities are defined in the state transition equation for respectively representing characters corresponding to positions between the search term and the hot word.
- the similarity between the hot words and the erroneous search words is implemented by a weighted editing algorithm.
- a weighted editing algorithm For the embodiment of the present application, the similarity between the hot words and the erroneous search words is implemented by a weighted editing algorithm.
- str1(i) represents the first The i+1th character of the string
- str2(j) represents the j+1th character of the second string.
- edit(i,j) min ⁇ edit(i-1,j)+1,edit(i,j-1)+1,edit(i-1,j-1) +f(i,j) ⁇ , where:
- steps A, B, and C initialize the function edit(i, j)
- step D1 indicates that the character str1(i-1) is the same as the character str2(j-1)
- step D2 represents the character str1(i-1) and the character str2.
- f(i, j) is Operational value
- f(i,j) is set according to the operation of inserting a character, deleting a character, replacing a near-word or a near-word, replacing a non-near-word or a near-word, or changing a character operation
- the weight of the value is the value of the generation corresponding to each weight. This allows the edit distance between the erroneous search term and the hot word to be calculated.
- the replacement operation of the near-word or near-word may include:
- the sound near word mapping table or the near word mapping table is used to determine whether the search word and the hot word are mutually close to each other or near the word.
- the sound near word mapping table may first extract the pinyin of the Chinese character, and then find all the Chinese characters included in the pinyin, thereby establishing a sound near word mapping table.
- a mapping table can be established in a similar manner.
- S103 Select a predetermined number of hot words from the pre-acquired hot words for error correction according to the weighted edit distance and the hot word heat of the pre-acquired hot words.
- the selected predetermined number of hot words for performing the error correction prompt is the recommended word
- the selecting the recommended word may be completed by the following steps: 1. normalizing the hot word search times of the hot words obtained in advance; Calculating the recommended comprehensive score according to the normalized processing result of the weighted edit distance and the hot word search times of the hot words acquired in advance; 3. selecting the predetermined number of recommended hot scores from the pre-acquired hot words and the weighted edit distance is less than the predetermined value.
- the hot word as the recommended word for error correction.
- the logarithmic formula is used to normalize the number of hot word searches to 0-1.
- the normalization formula is:
- Hot_index min(log(impression_count+1)/20,1)
- final_score represents the comprehensive score
- hot_index represents the result of normalizing the number of hot word searches to 0-1.
- the k hot words with the highest recommended comprehensive score and the weighted edit distance less than the predetermined value are selected as the recommended words of the error correction prompt, and the error correction prompt is performed.
- search word error correction method provided by the embodiment of the present application is described in detail from another angle:
- a predetermined number of hot words are selected from the pre-acquired hot words for error correction prompting.
- the calculating the weight between the search term and the pre-acquired hot word according to the weight of different values set in advance for each operation of converting from the search word to the hot word Weighted edit distance including:
- a state transition equation for representing a weighted edit distance between the identified search term and a pre-acquired hot word, wherein two state quantities are defined in the state transition equation for respectively representing the identified search term a character corresponding to the position between the pre-acquired hot words;
- the weighted edit distance is obtained according to the solution of the state transition equation.
- the state transition equation may be:
- Edit(i,j) min ⁇ edit(i-1,j)+1,edit(i,j-1)+1,edit(i-1,j-1)+f(i,j), ⁇ ;
- f(i, j) is the operation cost value
- f(i, j) is based on the replacement operation of the inserted character operation, the delete character operation, the shape near word or the near word.
- the replacing operation of the near-word or near-word may include:
- Determining whether the search term and the hot word are mutually similar or close to each other by searching a preset near-word mapping table or a sound near-word mapping table.
- the weights of the different values set in advance for each operation of converting from the search term to the hot word satisfy the following relationship:
- the identifying the wrong search term may include:
- the search word to be identified is an incorrect search word.
- the predetermined number of hot words are selected from the pre-acquired hot words according to the weighted edit distance and the hot word heat of the pre-acquired hot words.
- Wrong tips including:
- a predetermined number of hot words whose recommendation comprehensive score is the highest and the weighted edit distance is less than a predetermined value are selected as the recommended words for error correction, and an error correction prompt is performed.
- different weights are set respectively for deleting a character operation, inserting a character operation, a near-word or a near-word replacement operation, a non-shaped near-word or a near-word replacement operation, and exchanging character operations, thereby respectively weighting
- the process of editing distance calculation it fully covers the various operations that may be involved in the process from search word to hot word conversion, so that the editing distance from search words to hot words can be calculated more quickly and accurately, and the search word correction can be improved. Wrong accuracy.
- the source string may be the identified wrong search word, and the target string may be pre-acquired. hot word.
- the weight of the value, the weighted edit distance between the source string and the target string may include:
- the weighted edit distance is obtained according to the solution of the state transition equation.
- the weighted edit distance is applied to the error correction, and the similarity between the strings is calculated, and the precision is higher.
- FIG. 3 is a schematic structural diagram of a search term error correction apparatus according to an embodiment of the present application.
- the device includes:
- An incorrect search word identifying unit 301 configured to identify an erroneous search term
- Error correction of search words is to correct the wrong search words, so it is first necessary to identify the wrong search words.
- the erroneous search term can be identified based on the search log: the search term is searched, the number of results of the search result is completely matched, and the search term probability based on the language model can effectively identify the wrong search term.
- the weighted edit distance calculation unit 302 is configured to calculate, by using a weighted edit distance algorithm, a weighted edit distance between the search term and a pre-acquired hot word, wherein, in the weighted edit distance calculation process,
- the operations to the hot words are respectively inserting a character operation, deleting a character operation, replacing a near-word or a near-word, replacing a non-near-word or a near-word, exchanging character operations, and setting weights of different values;
- Hot words are words that are commonly used or popular in the network or in the current operation. Determine a number of hot words to form a hot vocabulary. In the process of generating the hot vocabulary, it is necessary to filter out words with low click rate and few search results to ensure the accuracy of the hot words. In the embodiment of the present application, the user is provided with a better experience by correcting the wrong search words into hot words with similar editing distances.
- Edit Distance also known as the Levenshtein distance
- Levenshtein distance refers to the minimum number of editing operations required between two strings to be converted from one to another.
- Traditional editing operations include replacing one character with another, inserting one character, and deleting one character.
- the smaller the edit distance the greater the similarity between the two strings.
- the traditional editing distance operation includes: replacing one character with another character, inserting one character, and deleting one character, and each operation corresponds to a distance of one. These operations do not include the exchange operations between adjacent characters in a string, nor the particularity of the near-word or near-word replacement operations.
- the swap operation can be implemented by two replacement operations, such as CD->DD->DC, according to the traditional edit distance algorithm, the corresponding distance is 2. Considering that in the actual search process, the probability that the user inputs two characters into the wrong position is very high, and the distance of the exchange operation is 2 is unreasonable. In addition, the probability of a search word input error caused by the user's near-word or near-word is also high. If there is no special treatment for this special replacement operation, setting the distance to 1 is obviously unreasonable.
- a weighted edit distance calculation device including:
- An obtaining unit for obtaining a source string and a target string An obtaining unit for obtaining a source string and a target string
- a calculating unit configured to calculate a weighted edit distance between the source string and the target string, wherein, in the weighted edit distance calculation process, converting from the source string to the target string Different operations set the weights of different values.
- the computing unit may include:
- a state transition equation defining subunit for defining a state transition equation for representing a weighted edit distance between the source string and the target string, wherein two state quantities are defined in the state transition equation for Characters representing the corresponding positions between the source string and the target string, respectively;
- the state transition equation solving subunit is configured to solve the solution of the state transition equation in the corresponding operation according to the weights of different values set for different operations, and obtain the weighted edit distance according to the solution of the state transition equation.
- the above different operations include the following five operations, and different weights are set separately.
- the error correction prompting unit 303 is configured to select a predetermined number of hot words from the pre-acquired hot words to perform error correction prompting according to the weighted edit distance and the hot word heat of the pre-acquired hot words.
- the weighted edit distance calculation unit 302 includes:
- the state transition equation defining subunit 3021 is configured to define a state transition equation for representing a weighted edit distance between the search term and the hot word, wherein two state quantities are defined in the state transition equation for respectively representing the search a character corresponding to the position between the word and the hot word;
- the equation solving sub-unit 3022 is configured to perform different operations according to the insertion of a character operation, a delete character operation, a near-word or near-word replacement operation, a non-near-word or near-word replacement operation, and a different value set by an exchange character operation. Weighting, solving the solution of the state transition equation in the corresponding operation, and obtaining the weighted edit distance according to the solution of the state transition equation.
- the state transition equation is:
- Edit(i,j) min ⁇ edit(i-1,j)+1,edit(i,j-1)+1,edit(i-1,j-1)+f(i,j), ⁇ ;
- f(i, j) is the operation cost value
- f(i, j) is based on the replacement operation of the inserted character operation, the delete character operation, the shape near word or the near word.
- the replacing operation of the near-word or near-word includes:
- the device further includes:
- the operation weight setting unit 305 is configured to set each operation weight to satisfy the following relationship:
- w1 and w2 need special attention. In general, it is necessary to satisfy w1 ⁇ w2 ⁇ 1.
- the error search term identifying unit 301 includes:
- the log search and calculation sub-unit 3011 is configured to parse or calculate a search click rate, a word feature, an appearance probability, a total matching result number, and a total matching ratio of the search word to be identified based on the search log;
- calculating a search click rate of the search word to be recognized for example, obtaining a search count of the user for the search word to be recognized and a number of click search results from the search log; dividing the number of click search results by the number of search times to obtain a search click Rate; secondly, the word processing is performed on the identified search words to obtain multiple word features; then, using the statistical language model and each word feature, the probability of occurrence of the search word to be recognized is calculated; and then, the total matching result of the search word to be recognized is calculated.
- the total matching result number is the number of results of all the search results including the search word to be recognized in all the search results for the search word to be recognized
- the related result number is all the search results for the search word to be recognized.
- the recognition result determining subunit 3012 is configured to determine the to-be-identified according to the search click rate, the word feature, the appearance probability, the total matching result number, and the total matching ratio of the search word to be identified.
- the search term is an incorrect search term or a normal search term.
- the identification is performed, which reduces the difficulty of identifying the search words to be recognized, thereby improving the recognition ability of the search words to be recognized, and is useful for identifying whether the search words to be recognized are incorrect search words.
- the error correction prompting unit 303 includes:
- a normalization processing sub-unit 3031 configured to normalize the hot word search times of the pre-acquired hot words
- the recommended comprehensive score calculation sub-unit 3032 is configured to calculate a recommended comprehensive score according to the weighted edit distance and the hot word search number normalization processing result;
- a recommendation word determining sub-unit 3033 configured to select, from the pre-acquired hot words, a predetermined number of hot words whose recommendation comprehensive score is the highest and the weighted edit distance is less than a predetermined value, as a recommended word for error correction Error correction tips.
- search term error correction device provided by the embodiment of the present application is described in detail from another angle:
- a search term error correction device provided by the embodiment of the present application, the device may include:
- a weighted edit distance calculation unit configured to calculate a weighted edit distance between the recognized search term and the pre-acquired hot word according to weights of different values set in advance for each operation of converting from the search word to the hot word, wherein
- the operations include inserting a character operation, deleting a character operation, replacing a near-word or near-word, replacing a non-near-word or near-word, and exchanging a character operation;
- the error correction prompting unit is configured to select a predetermined number of hot words from the pre-acquired hot words to perform error correction prompts according to the weighted edit distance and the hot word heat of the pre-acquired hot words.
- the weighted edit distance calculation unit includes:
- the state transition equation defines a subunit for defining a state transition equation for representing a weighted edit distance between the identified search term and a pre-acquired hot word, wherein two state quantities are defined in the state transition equation, Characters respectively indicating corresponding positions between the identified search term and the pre-acquired hot word;
- the equation solving subunit is used for different values set by the character operation for inserting a character, deleting a character operation, replacing a near-word or a near-word, replacing a non-near-word or a near-word, or exchanging character operations.
- Weighting solving the solution of the state transition equation in the corresponding operation, and obtaining the weighted edit distance according to the solution of the state transition equation.
- the state transition equation may be:
- Edit(i,j) min ⁇ edit(i-1,j)+1,edit(i,j-1)+1,edit(i-1,j-1)+f(i,j), ⁇ ;
- f(i, j) is the operation cost value
- f(i, j) is based on the replacement operation of the inserted character operation, the delete character operation, the shape near word or the near word.
- the replacing operation of the near-word or near-word includes:
- the weights of the different values set in advance for each operation of converting from the search term to the hot word satisfy the following relationship:
- the error search term identifying unit includes:
- a log search and calculation sub-unit for parsing or calculating a search click rate, a word feature, an appearance probability, a total matching result number, and a total matching ratio of the search word to be recognized based on the search log;
- a recognition result determining subunit configured to determine the to-be-identified search according to the search click rate, the word feature, the appearance probability, the total matching result number, and the total matching ratio of the search word to be identified The word is the wrong search term.
- the error correction prompting unit includes:
- a normalization processing sub-unit configured to normalize the hot word search times of the pre-acquired hot words
- a comprehensive score calculation sub-unit is configured to calculate a recommended comprehensive score according to the normalized processing result of the weighted edit distance and the hot word search times;
- a recommendation word determining subunit configured to select, from the pre-acquired hot words, a predetermined number of hot words whose recommendation comprehensive score is the highest and the weighted edit distance is less than a predetermined value, as a recommended word for error correction, correcting Wrong prompt.
- different weights are set respectively for deleting a character operation, inserting a character operation, a near-word or a near-word replacement operation, a non-shaped near-word or a near-word replacement operation, and exchanging character operations, thereby respectively weighting
- the process of editing distance calculation it fully covers the various operations that may be involved in the process from search word to hot word conversion, so that the editing distance from search words to hot words can be calculated more quickly and accurately, and the search word correction can be improved. Wrong accuracy.
- weighted edit distance calculation device For a clearer understanding of the weighted edit distance calculation device, the weighted edit distance calculation device provided by the embodiment of the present application is described in detail from another angle:
- a weighted edit distance calculation device provided by the embodiment of the present application, the device may include:
- An obtaining unit for obtaining a source string and a target string An obtaining unit for obtaining a source string and a target string
- a calculating unit configured to separately set weights of different values for different operations of converting from the source string to the target string, and calculating the source string and the weight according to weights of different values set for different operations The weighted edit distance between the target strings.
- the calculating unit may include:
- a state transition equation defining subunit for defining a state transition equation for representing a weighted edit distance between the source string and the target string, wherein two state quantities are defined in the state transition equation for Characters representing the corresponding positions between the source string and the target string, respectively;
- the state transition equation solving subunit is configured to solve a solution of the state transition equation in a corresponding operation according to weights of different values set for different operations, and obtain the weighted edit distance according to the solution of the state transition equation.
- the weighted edit distance is applied to the error correction, and the similarity between the strings is calculated, and the precision is higher.
- the embodiment of the present application further provides an electronic device, as shown in FIG. 4, including: a first processor 401, a first communication interface 402, a first memory 403, and a first communication bus 404, wherein the first processor 401
- the first communication interface 402, the first memory 403 completes communication with each other through the first communication bus 404;
- the first memory 403 is configured to store a computer program;
- the first processor 401 is configured to execute the storage on the first memory 403.
- the program implements the above steps of the search word error correction method, and the method includes:
- a predetermined number of hot words are selected from the pre-acquired hot words for error correction prompting.
- different weights are set respectively for deleting a character operation, inserting a character operation, a near-word or a near-word replacement operation, a non-shaped near-word or a near-word replacement operation, and exchanging character operations, thereby respectively weighting
- the process of editing distance calculation it fully covers the various operations that may be involved in the process from search word to hot word conversion, so that the editing distance from search words to hot words can be calculated more quickly and accurately, and the search word correction can be improved. Wrong accuracy.
- the weighting between the identified search term and the pre-acquired hot word is calculated according to the weight of different values set in advance for each operation of converting from the search term to the hot word.
- Edit distance including:
- a state transition equation for representing a weighted edit distance between the identified search term and a pre-acquired hot word, wherein two state quantities are defined in the state transition equation for respectively representing the identified search term a character corresponding to the position between the pre-acquired hot words;
- the weighted edit distance is obtained according to the solution of the state transition equation.
- the state transition equation is:
- Edit(i,j) min ⁇ edit(i-1,j)+1,edit(i,j-1)+1,edit(i-1,j-1)+f(i,j), ⁇ ;
- f(i, j) is the operation cost value
- f(i, j) is based on the replacement operation of the inserted character operation, the delete character operation, the shape near word or the near word.
- the replacing operation of the near-word or near-word includes:
- Determining whether the search term and the hot word are mutually similar or close to each other by searching a preset near-word mapping table or a sound near-word mapping table.
- the weights of the different values set in advance for each operation of converting from the search term to the hot word satisfy the following relationship:
- the identifying the wrong search term includes:
- the search word to be identified is an incorrect search word.
- the predetermined number of hot words are selected from the pre-acquired hot words for error correction according to the weighted edit distance and the hot word heat of the pre-acquired hot words.
- a predetermined number of hot words whose recommendation comprehensive score is the highest and the weighted edit distance is less than a predetermined value are selected as the recommended words for error correction, and an error correction prompt is performed.
- the embodiment of the present application further provides a computer readable storage medium, where the computer program stores a computer program, and when the computer program is executed by the processor, the method for correcting the search word is implemented.
- the method includes:
- a predetermined number of hot words are selected from the pre-acquired hot words for error correction prompting.
- different weights are set respectively for deleting a character operation, inserting a character operation, a near-word or a near-word replacement operation, a non-shaped near-word or a near-word replacement operation, and exchanging character operations, thereby respectively weighting
- the process of editing distance calculation it fully covers the various operations that may be involved in the process from search word to hot word conversion, so that the editing distance from search words to hot words can be calculated more quickly and accurately, and the search word correction can be improved. Wrong accuracy.
- the according to the foregoing is to convert from a search term to a hot word.
- Calculating the weighted edit distance between the identified search term and the pre-acquired hot word including:
- a state transition equation for representing a weighted edit distance between the identified search term and a pre-acquired hot word, wherein two state quantities are defined in the state transition equation for respectively representing the identified search term a character corresponding to the position between the pre-acquired hot words;
- the weighted edit distance is obtained according to the solution of the state transition equation.
- the state transition equation is:
- Edit(i,j) min ⁇ edit(i-1,j)+1,edit(i,j-1)+1,edit(i-1,j-1)+f(i,j), ⁇ ;
- f(i, j) is the operation cost value
- f(i, j) is based on the replacement operation of the inserted character operation, the delete character operation, the shape near word or the near word.
- the replacing operation of the near-word or near-word includes:
- Determining whether the search term and the hot word are mutually similar or close to each other by searching a preset near-word mapping table or a sound near-word mapping table.
- the weights of the different values set in advance for each operation of converting from the search term to the hot word satisfy the following relationship:
- the identifying the wrong search term includes:
- the search word to be identified is an incorrect search word.
- the weighting edit distance and the pre-acquisition according to the weighting Taking the hot word heat of the hot word, selecting a predetermined number of hot words from the pre-acquired hot words for error correction prompting, including:
- a predetermined number of hot words whose recommendation comprehensive score is the highest and the weighted edit distance is less than a predetermined value are selected as the recommended words for error correction, and an error correction prompt is performed.
- the embodiment of the present application further provides an electronic device, as shown in FIG. 5, including: a second processor 501, a second communication interface 502, a second memory 503, and a second communication bus 504, wherein the second processor 501
- the second communication interface 502, the second memory 503 completes communication with each other through the second communication bus 504;
- the second memory 503 is configured to store a computer program;
- the second processor 501 is configured to execute the second memory 503.
- the program implements the above weighting edit distance calculation method steps, and the method includes:
- the weighted edit distance is applied to the error correction, and the similarity between the strings is calculated, and the precision is higher.
- the weighting edit distance between the source string and the target string is calculated according to weights of different values set for different operations, including:
- the weighted edit distance is obtained according to the solution of the state transition equation.
- the embodiment of the present application further provides a computer readable storage medium, where the computer program stores a computer program, and when the computer program is executed by the processor, the weighting edit distance calculation method step is implemented.
- the method includes:
- the weighted edit distance is applied to the error correction, and the similarity between the strings is calculated, and the precision is higher.
- the weighting edit distance between the source string and the target string is calculated according to weights of different values set for different operations, including:
- the weighted edit distance is obtained according to the solution of the state transition equation.
- the description is relatively simple, and the relevant parts can be referred to the description of the method embodiment.
- embodiments of the embodiments of the present application can be provided as a method, apparatus, or computer program product. Therefore, the embodiments of the present application may take the form of an entirely hardware embodiment, an entirely software embodiment, or an embodiment combining software and hardware. Moreover, embodiments of the present application may employ a computer program embodied on one or more computer usable storage media (including but not limited to disk storage, CD-ROM, optical storage, etc.) having computer usable program code embodied therein. The form of the product.
- computer usable storage media including but not limited to disk storage, CD-ROM, optical storage, etc.
- Embodiments of the present application are described with reference to flowcharts and/or block diagrams of methods, terminal devices (systems), and computer program products according to embodiments of the present application. It will be understood that each flow and/or block of the flowchart illustrations and/or FIG.
- These computer program instructions can be provided to a processor of a general purpose computer, special purpose computer, embedded processor or other programmable data processing terminal device to produce a machine such that instructions are executed by a processor of a computer or other programmable data processing terminal device
- Means are provided for implementing the functions specified in one or more of the flow or in one or more blocks of the flow chart.
- the computer program instructions can also be stored in a computer readable memory that can direct a computer or other programmable data processing terminal device to operate in a particular manner, such that the instructions stored in the computer readable memory produce an article of manufacture comprising the instruction device.
- the instruction device implements the functions specified in one or more blocks of the flowchart or in a flow or block of the flowchart.
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- Databases & Information Systems (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Computational Linguistics (AREA)
- Data Mining & Analysis (AREA)
- Audiology, Speech & Language Pathology (AREA)
- General Health & Medical Sciences (AREA)
- Health & Medical Sciences (AREA)
- Artificial Intelligence (AREA)
- Mathematical Physics (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
- Machine Translation (AREA)
Abstract
Description
Claims (22)
- 一种搜索词纠错方法,其特征在于,包括:识别出错误的搜索词;利用加权编辑距离算法,计算所述搜索词与预先获取的热词之间的加权编辑距离,其中,在所述加权编辑距离计算过程中,针对从搜索词转换到热词的操作,分别为插入字符操作、删除字符操作、形近字或音近字的替换操作、非形近字或音近字的替换操作、交换字符操作,设置不同数值的权重;根据所述加权编辑距离和热词热度,选取预定数目的热词进行纠错提示。
- 根据权利要求1所述的方法,其特征在于,所述利用加权编辑距离算法,计算所述搜索词与预先获取的热词之间的加权编辑距离,包括:定义状态转移方程,用于表示所述搜索词与热词之间的加权编辑距离,其中,在状态转移方程中定义两个状态量,用于分别表示搜索词和热词之间对应位置的字符;根据为插入字符操作、删除字符操作、形近字或音近字的替换操作、非形近字或音近字的替换操作、交换字符操作所设置的不同数值的权重,求解所述状态转移方程在相应操作的解;根据所述状态转移方程的解,得到所述加权编辑距离。
- 根据权利要求2所述的方法,其特征在于,所述状态转移方程为:edit(i,j)=min{edit(i-1,j)+1,edit(i,j-1)+1,edit(i-1,j-1)+f(i,j),};其中,i、j为所述两个状态量,f(i,j)为操作代价值,f(i,j)根据为插入字符操作、删除字符操作、形近字或音近字的替换操作、非形近字或音近字的替换操作、交换字符操作所设置的不同数值的权重,得到各权重对应的代价值。
- 根据权利要求1-3任一项所述的方法,其特征在于,还包括:通过查找预先设置的形近字映射表或音近字映射表,确定所述搜索词与所述热词是否互为形近字或音近字。
- 根据权利要求1-3任一项所述的方法,其特征在于,还包括:设置各操作权重满足如下关系:形近字或音近字的替换操作权重<交换字符操作权重<插入字符操作权重=删除字符操作权重=非形近字或音近字的替换操作权重。
- 根据权利要求1-3任一项所述的方法,其特征在于,所述识别出错误的搜索词,包括:基于搜索日志,解析或计算出待识别搜索词的搜索点击率、词特征、出现概率、全匹配结果数和全匹配占比;根据待识别搜索词的所述搜索点击率、所述词特征、所述出现概率、所述全匹配结果数和所述全匹配占比,确定所述待识别搜索词为错误搜索词或正常搜索词。
- 根据权利要求1-3任一项所述的方法,其特征在于,所述根据所述加权编辑距离和热词热度,选取预定数目的热词进行纠错提示,包括:将热词搜索次数进行归一化处理;根据所述加权编辑距离与热词搜索次数归一化处理结果,计算推荐综合得分;选择推荐综合得分最高且所述加权编辑距离小于预定值的预定数目的热词,作为纠错的推荐词,进行纠错提示。
- 一种加权编辑距离计算方法,其特征在于,包括:获取源字符串和目标字符串;计算所述源字符串和所述目标字符串之间的加权编辑距离,其中,在所述加权编辑距离计算过程中,针对从所述源字符串转换到所述目标字符串的不同操作分别设置不同数值的权重。
- 根据权利要求8所述的方法,其特征在于,所述计算所述源字符串和所述目标字符串之间的加权编辑距离,包括:定义状态转移方程,用于表示所述源字符串和所述目标字符串之间的加权编辑距离,其中,在状态转移方程中定义两个状态量,用于分别表示源字符串和所述目标字符串之间对应位置的字符;根据为不同操作所设置的不同数值的权重,求解所述状态转移方程在相应操作的解;根据所述状态转移方程的解,得到所述加权编辑距离。
- 一种搜索词纠错装置,其特征在于,包括:错误搜索词识别单元,用于识别出错误的搜索词;加权编辑距离计算单元,用于利用加权编辑距离算法,计算所述搜索词与预先获取的热词之间的加权编辑距离,其中,在所述加权编辑距离计算过程中,针对从搜索词转换到热词的操作,分别为插入字符操作、删除字符操作、形近字或音近字的替换操作、非形近字或音近字的替换操作、交换字符操作,设置不同数值的权重;纠错提示单元,用于根据所述加权编辑距离和热词热度,选取预定数目的热词进行纠错提示。
- 根据权利要求10所述的装置,其特征在于,所述加权编辑距离计算单元包括:状态转移方程定义子单元,用于定义状态转移方程,用于表示所述搜索词与热词之间的加权编辑距离,其中,在状态转移方程中定义两个状态量,用于分别表示搜索词和热词之间对应位置的字符;方程求解子单元,用于根据为插入字符操作、删除字符操作、形近字或音近字的替换操作、非形近字或音近字的替换操作、交换字符操作所设置的不同数值的权重,求解所述状态转移方程在相应操作的解,作为所述加权编辑距离。
- 根据权利要求11所述的装置,其特征在于,所述状态转移方程为:edit(i,j)=min{edit(i-1,j)+1,edit(i,j-1)+1,edit(i-1,j-1)+f(i,j),};其中,i、j为所述两个状态量,f(i,j)为操作代价值,f(i,j)根据为插入字符操作、删除字符操作、形近字或音近字的替换操作、非形近字或音近字的替换操作、交换字符操作所设置的不同数值的权重,得到各权重对应的代价值。
- 根据权利要求10-12任一项所述的装置,其特征在于,还包括:形近字或音近字确定单元,用于查找预先设置的形近字映射表或音近字映射表,确定所述搜索词与所述热词是否互为形近字或音近字。
- 根据权利要求10-12任一项所述的装置,其特征在于,还包括:操作权重设置单元,用于设置各操作权重满足如下关系:形近字或音近字的替换操作权重<交换字符操作权重<插入字符操作权重=删除字符操作权重=非形近字或音近字的替换操作权重。
- 根据权利要求10-12任一项所述的装置,其特征在于,所述错误搜索词识别单元包括:日志查找及计算子单元,用于基于搜索日志,解析或计算出待识别搜索词的搜索点击率、词特征、出现概率、全匹配结果数和全匹配占比;识别结果确定子单元,用于根据待识别搜索词的所述搜索点击率、所述词特征、所述出现概率、所述全匹配结果数和所述全匹配占比,确定所述待识别搜索词为错误搜索词或正常搜索词。
- 根据权利要求10-12任一项所述的装置,其特征在于,所述纠错提示单元包括:归一化处理子单元,用于将热词搜索次数进行归一化处理;推荐综合得分计算子单元,用于根据所述加权编辑距离与热词搜索次数归一化处理结果,计算推荐综合得分;推荐词确定子单元,用于选择推荐综合得分最高且所述加权编辑距离小于预定值的预定数目的热词,作为纠错的推荐词,进行纠错提示。
- 一种加权编辑距离计算装置,其特征在于,包括:获取单元,用于获取源字符串和目标字符串;计算单元,用于计算所述源字符串和所述目标字符串之间的加权编辑距离,其中,在所述加权编辑距离计算过程中,针对从所述源字符串转换到所述目标字符串的不同操作分别设置不同数值的权重。
- 根据权利要求17所述的装置,其特征在于,所述计算单元包括:状态转移方程定义子单元,用于定义状态转移方程,用于表示所述源字符串和所述目标字符串之间的加权编辑距离,其中,在状态转移方程中定义两个状态量,用于分别表示源字符串和所述目标字符串之间对应位置的字符;状态转移方程求解子单元,用于根据为不同操作所设置的不同数值的权重,求解所述状态转移方程在相应操作的解,作为所述加权编辑距离。
- 一种电子设备,其特征在于,包括第一处理器、第一通信接口、第 一存储器和第一通信总线,其中,第一处理器,第一通信接口,第一存储器通过第一通信总线完成相互间的通信;第一存储器,用于存放计算机程序;第一处理器,用于执行第一存储器上所存放的程序时,实现权利要求1-7任一所述的方法步骤。
- 一种计算机可读存储介质,其特征在于,所述存储介质内存储有计算机程序,所述计算机程序被处理器执行时实现权利要求1-7任一所述的方法步骤。
- 一种电子设备,其特征在于,包括第二处理器、第二通信接口、第二存储器和第二通信总线,其中,第二处理器,第二通信接口,第二存储器通过第二通信总线完成相互间的通信;第二存储器,用于存放计算机程序;第二处理器,用于执行第二存储器上所存放的程序时,实现权利要求8-9任一所述的方法步骤。
- 一种计算机可读存储介质,其特征在于,所述存储介质内存储有计算机程序,所述计算机程序被处理器执行时实现权利要求8-9任一所述的方法步骤。
Priority Applications (8)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CA3029588A CA3029588C (en) | 2016-08-31 | 2017-08-14 | Error correction method and device for search term |
| US16/315,193 US11574012B2 (en) | 2016-08-31 | 2017-08-14 | Error correction method and device for search term |
| SG11201900084PA SG11201900084PA (en) | 2016-08-31 | 2017-08-14 | Error correction method and device for search term |
| EP17845201.7A EP3508992A4 (en) | 2016-08-31 | 2017-08-14 | ERROR CORRECTION AND DEVICE FOR SEARCH TERM |
| MYPI2019000264A MY193919A (en) | 2016-08-31 | 2017-08-14 | Error correction method and device for search term |
| AU2017317878A AU2017317878B2 (en) | 2016-08-31 | 2017-08-14 | Error correction method and device for search term |
| JP2019526358A JP6997781B2 (ja) | 2016-08-31 | 2017-08-14 | 検索語句の誤り訂正方法および装置 |
| KR1020197001982A KR102204971B1 (ko) | 2016-08-31 | 2017-08-14 | 검색어를 위한 오류 정정 방법 및 기기 |
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN201610799830.4A CN106326484A (zh) | 2016-08-31 | 2016-08-31 | 搜索词纠错方法及装置 |
| CN201610799830.4 | 2016-08-31 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2018040899A1 true WO2018040899A1 (zh) | 2018-03-08 |
Family
ID=57786348
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/CN2017/097357 Ceased WO2018040899A1 (zh) | 2016-08-31 | 2017-08-14 | 搜索词纠错方法及装置 |
Country Status (11)
| Country | Link |
|---|---|
| US (1) | US11574012B2 (zh) |
| EP (1) | EP3508992A4 (zh) |
| JP (1) | JP6997781B2 (zh) |
| KR (1) | KR102204971B1 (zh) |
| CN (1) | CN106326484A (zh) |
| AU (1) | AU2017317878B2 (zh) |
| CA (1) | CA3029588C (zh) |
| MY (1) | MY193919A (zh) |
| SG (1) | SG11201900084PA (zh) |
| TW (1) | TWI664540B (zh) |
| WO (1) | WO2018040899A1 (zh) |
Families Citing this family (26)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US11742079B2 (en) * | 2016-07-25 | 2023-08-29 | Siemens Healthcare Diagnostics Inc. | Methods and apparatus for troubleshooting instrument malfunctions |
| CN106326484A (zh) * | 2016-08-31 | 2017-01-11 | 北京奇艺世纪科技有限公司 | 搜索词纠错方法及装置 |
| RU2684578C2 (ru) * | 2017-07-17 | 2019-04-09 | Общество с ограниченной ответственностью "Лаборатория ИнфоВотч" | Языконезависимая технология исправления опечаток, с возможностью верификации результата |
| CN107423444B (zh) * | 2017-08-10 | 2020-05-19 | 世纪龙信息网络有限责任公司 | 热词词组提取方法和系统 |
| CN107766327A (zh) * | 2017-10-23 | 2018-03-06 | 武汉楚鼎信息技术有限公司 | 一种命名实体识别过程中纠错的方法及系统 |
| CN108062373A (zh) * | 2017-12-12 | 2018-05-22 | 焦点科技股份有限公司 | 一种具有纠错功能的关键词下拉联想的方法 |
| CN109992749A (zh) * | 2017-12-29 | 2019-07-09 | 珠海金山办公软件有限公司 | 一种文字显示方法、装置、电子设备及可读存储介质 |
| CN110196833B (zh) * | 2018-03-22 | 2023-06-09 | 腾讯科技(深圳)有限公司 | 应用程序的搜索方法、装置、终端及存储介质 |
| JP6660974B2 (ja) * | 2018-03-30 | 2020-03-11 | 本田技研工業株式会社 | 情報提供装置、情報提供方法、およびプログラム |
| US10963717B1 (en) * | 2018-12-21 | 2021-03-30 | Automation Anywhere, Inc. | Auto-correction of pattern defined strings |
| CN109711412A (zh) * | 2018-12-27 | 2019-05-03 | 信雅达系统工程股份有限公司 | 一种基于字典的光学字符识别纠错方法 |
| CN110163498B (zh) * | 2019-05-15 | 2021-08-03 | 广州视源电子科技股份有限公司 | 课件原创度评分方法、装置、存储介质及处理器 |
| CN110415705B (zh) * | 2019-08-01 | 2022-03-01 | 苏州奇梦者网络科技有限公司 | 一种热词识别方法、系统、装置及存储介质 |
| CN110795617A (zh) * | 2019-08-12 | 2020-02-14 | 腾讯科技(深圳)有限公司 | 一种搜索词的纠错方法及相关装置 |
| CN110909535B (zh) * | 2019-12-06 | 2023-04-07 | 北京百分点科技集团股份有限公司 | 命名实体校对方法、装置、可读存储介质及电子设备 |
| CN113095066A (zh) * | 2019-12-23 | 2021-07-09 | 华为技术有限公司 | 文本处理方法及装置 |
| CN111310442B (zh) * | 2020-02-06 | 2021-12-28 | 北京字节跳动网络技术有限公司 | 形近字纠错语料挖掘方法、纠错方法、设备及存储介质 |
| WO2021227059A1 (zh) * | 2020-05-15 | 2021-11-18 | 深圳市世强元件网络有限公司 | 一种基于多叉树的搜索词推荐方法及系统 |
| CN112131461A (zh) * | 2020-09-09 | 2020-12-25 | 重庆易宠科技有限公司 | 一种商品搜索方法、系统、终端及计算机可读存储介质 |
| CN112069374B (zh) * | 2020-09-18 | 2024-04-30 | 中国工商银行股份有限公司 | 一种银行多个客户编号的识别方法及装置 |
| CN112613522B (zh) * | 2021-01-04 | 2023-03-14 | 重庆邮电大学 | 一种基于融合字形信息的服药单识别结果纠错方法 |
| CN112929131B (zh) * | 2021-02-22 | 2022-05-27 | 天津师范大学 | 一种基于加权编辑距离的标记码传输方法 |
| CN112560452B (zh) * | 2021-02-25 | 2021-05-18 | 智者四海(北京)技术有限公司 | 一种自动生成纠错语料的方法和系统 |
| CN113705202A (zh) * | 2021-08-31 | 2021-11-26 | 北京金堤科技有限公司 | 搜索输入信息纠错方法、装置以及电子设备、存储介质 |
| CN114943966A (zh) * | 2022-04-27 | 2022-08-26 | 联宝(合肥)电子科技有限公司 | 字符串相似度的确定方法、装置、存储介质及电子设备 |
| CN121478764B (zh) * | 2026-01-08 | 2026-03-31 | 中国电子科技集团公司第二十八研究所 | 基于大模型的人员信息纠错方法、系统和存储介质 |
Citations (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN101777042A (zh) * | 2010-01-21 | 2010-07-14 | 西南科技大学 | 基于神经网络和标签库的语句相似度算法 |
| CN102063508A (zh) * | 2011-01-10 | 2011-05-18 | 浙江大学 | 基于广义后缀树的中文搜索引擎模糊自动补全方法 |
| CN102831177A (zh) * | 2012-07-31 | 2012-12-19 | 聚熵信息技术(上海)有限公司 | 语句纠错方法及其系统 |
| CN103399907A (zh) * | 2013-07-31 | 2013-11-20 | 深圳市华傲数据技术有限公司 | 一种基于编辑距离计算中文字符串相似度的方法及装置 |
| CN103927329A (zh) * | 2014-03-19 | 2014-07-16 | 北京奇虎科技有限公司 | 一种即时搜索方法和系统 |
| CN106326484A (zh) * | 2016-08-31 | 2017-01-11 | 北京奇艺世纪科技有限公司 | 搜索词纠错方法及装置 |
Family Cites Families (15)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP4283898B2 (ja) | 1995-10-20 | 2009-06-24 | 富士通株式会社 | 文章校正装置 |
| US6073099A (en) * | 1997-11-04 | 2000-06-06 | Nortel Networks Corporation | Predicting auditory confusions using a weighted Levinstein distance |
| WO2000036530A1 (en) * | 1998-12-15 | 2000-06-22 | Matsushita Electric Industrial Co., Ltd. | Searching method, searching device, and recorded medium |
| US7617202B2 (en) * | 2003-06-16 | 2009-11-10 | Microsoft Corporation | Systems and methods that employ a distributional analysis on a query log to improve search results |
| US7321892B2 (en) * | 2005-08-11 | 2008-01-22 | Amazon Technologies, Inc. | Identifying alternative spellings of search strings by analyzing self-corrective searching behaviors of users |
| US7590626B2 (en) * | 2006-10-30 | 2009-09-15 | Microsoft Corporation | Distributional similarity-based models for query correction |
| US7644075B2 (en) | 2007-06-01 | 2010-01-05 | Microsoft Corporation | Keyword usage score based on frequency impulse and frequency weight |
| US20090083255A1 (en) | 2007-09-24 | 2009-03-26 | Microsoft Corporation | Query spelling correction |
| JP5308786B2 (ja) * | 2008-11-20 | 2013-10-09 | Kddi株式会社 | 文書データ検索装置 |
| CN101916263B (zh) | 2010-07-27 | 2012-10-31 | 武汉大学 | 基于加权编辑距离的模糊关键字查询方法及系统 |
| CN102915314B (zh) | 2011-08-05 | 2018-07-31 | 深圳市世纪光速信息技术有限公司 | 一种纠错对自动生成方法及系统 |
| US10176168B2 (en) * | 2011-11-15 | 2019-01-08 | Microsoft Technology Licensing, Llc | Statistical machine translation based search query spelling correction |
| KR101483433B1 (ko) * | 2013-03-28 | 2015-01-16 | (주)이스트소프트 | 오타 교정 시스템 및 오타 교정 방법 |
| WO2015040793A1 (ja) | 2013-09-20 | 2015-03-26 | 三菱電機株式会社 | 文字列検索装置 |
| GB2535439A (en) * | 2015-01-06 | 2016-08-24 | What3Words Ltd | A method for suggesting candidate words as replacements for an input string received at an electronic device |
-
2016
- 2016-08-31 CN CN201610799830.4A patent/CN106326484A/zh active Pending
-
2017
- 2017-08-14 MY MYPI2019000264A patent/MY193919A/en unknown
- 2017-08-14 JP JP2019526358A patent/JP6997781B2/ja active Active
- 2017-08-14 WO PCT/CN2017/097357 patent/WO2018040899A1/zh not_active Ceased
- 2017-08-14 US US16/315,193 patent/US11574012B2/en active Active
- 2017-08-14 EP EP17845201.7A patent/EP3508992A4/en not_active Ceased
- 2017-08-14 CA CA3029588A patent/CA3029588C/en active Active
- 2017-08-14 KR KR1020197001982A patent/KR102204971B1/ko active Active
- 2017-08-14 SG SG11201900084PA patent/SG11201900084PA/en unknown
- 2017-08-14 AU AU2017317878A patent/AU2017317878B2/en active Active
- 2017-08-25 TW TW106129000A patent/TWI664540B/zh active
Patent Citations (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN101777042A (zh) * | 2010-01-21 | 2010-07-14 | 西南科技大学 | 基于神经网络和标签库的语句相似度算法 |
| CN102063508A (zh) * | 2011-01-10 | 2011-05-18 | 浙江大学 | 基于广义后缀树的中文搜索引擎模糊自动补全方法 |
| CN102831177A (zh) * | 2012-07-31 | 2012-12-19 | 聚熵信息技术(上海)有限公司 | 语句纠错方法及其系统 |
| CN103399907A (zh) * | 2013-07-31 | 2013-11-20 | 深圳市华傲数据技术有限公司 | 一种基于编辑距离计算中文字符串相似度的方法及装置 |
| CN103927329A (zh) * | 2014-03-19 | 2014-07-16 | 北京奇虎科技有限公司 | 一种即时搜索方法和系统 |
| CN106326484A (zh) * | 2016-08-31 | 2017-01-11 | 北京奇艺世纪科技有限公司 | 搜索词纠错方法及装置 |
Also Published As
| Publication number | Publication date |
|---|---|
| KR102204971B1 (ko) | 2021-01-20 |
| CN106326484A (zh) | 2017-01-11 |
| US20190179855A1 (en) | 2019-06-13 |
| SG11201900084PA (en) | 2019-03-28 |
| EP3508992A1 (en) | 2019-07-10 |
| CA3029588A1 (en) | 2018-03-08 |
| JP6997781B2 (ja) | 2022-01-18 |
| TWI664540B (zh) | 2019-07-01 |
| CA3029588C (en) | 2023-07-11 |
| KR20190020119A (ko) | 2019-02-27 |
| AU2017317878A1 (en) | 2019-01-31 |
| EP3508992A4 (en) | 2019-09-04 |
| JP2019526142A (ja) | 2019-09-12 |
| TW201812619A (zh) | 2018-04-01 |
| AU2017317878B2 (en) | 2020-11-19 |
| US11574012B2 (en) | 2023-02-07 |
| MY193919A (en) | 2022-11-01 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| WO2018040899A1 (zh) | 搜索词纠错方法及装置 | |
| CN114547274B (zh) | 多轮问答的方法、装置及设备 | |
| CN106202153B (zh) | 一种es搜索引擎的拼写纠错方法及系统 | |
| CN111625635A (zh) | 问答处理、语言模型的训练方法、装置、设备及存储介质 | |
| CN118170894A (zh) | 一种知识图谱问答方法、装置及存储介质 | |
| WO2015176518A1 (zh) | 一种回复信息推荐方法及装置 | |
| CN104142915A (zh) | 一种添加标点的方法和系统 | |
| CN105068997B (zh) | 平行语料的构建方法及装置 | |
| CN107229627B (zh) | 一种文本处理方法、装置及计算设备 | |
| CN103226606A (zh) | 查询选取方法及系统 | |
| CN111554295B (zh) | 文本纠错方法、相关设备及可读存储介质 | |
| WO2018086519A1 (zh) | 一种特定文本信息的识别方法及装置 | |
| CN112800239B (zh) | 意图识别模型训练方法、意图识别方法及装置 | |
| CN104866498A (zh) | 一种信息处理方法及装置 | |
| CN113435188B (zh) | 基于语义相似的过敏文本样本生成方法、装置及相关设备 | |
| WO2025242036A1 (zh) | 基于图文模态融合的文档信息抽取方法、装置及存储介质 | |
| CN113033204A (zh) | 信息实体抽取方法、装置、电子设备和存储介质 | |
| CN103678271A (zh) | 一种文本校正方法及用户设备 | |
| CN109522397B (zh) | 信息处理方法及装置 | |
| CN108664464B (zh) | 一种语义相关度的确定方法及确定装置 | |
| CN116628185A (zh) | 文本摘要生成方法、计算机设备及计算机存储介质 | |
| CN102955770A (zh) | 一种拼音自动识别方法及系统 | |
| CN107066533B (zh) | 搜索查询纠错系统及方法 | |
| CN109727591B (zh) | 一种语音搜索的方法及装置 | |
| HK1233355A (zh) | 搜索詞糾錯方法及裝置 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 17845201 Country of ref document: EP Kind code of ref document: A1 |
|
| ENP | Entry into the national phase |
Ref document number: 3029588 Country of ref document: CA |
|
| ENP | Entry into the national phase |
Ref document number: 20197001982 Country of ref document: KR Kind code of ref document: A |
|
| ENP | Entry into the national phase |
Ref document number: 2019526358 Country of ref document: JP Kind code of ref document: A |
|
| ENP | Entry into the national phase |
Ref document number: 2017317878 Country of ref document: AU Date of ref document: 20170814 Kind code of ref document: A |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| ENP | Entry into the national phase |
Ref document number: 2017845201 Country of ref document: EP Effective date: 20190401 |