WO2018235380A1 - 音声評価プログラム、音声評価方法および音声評価装置 - Google Patents
音声評価プログラム、音声評価方法および音声評価装置 Download PDFInfo
- Publication number
- WO2018235380A1 WO2018235380A1 PCT/JP2018/013867 JP2018013867W WO2018235380A1 WO 2018235380 A1 WO2018235380 A1 WO 2018235380A1 JP 2018013867 W JP2018013867 W JP 2018013867W WO 2018235380 A1 WO2018235380 A1 WO 2018235380A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- evaluation
- voice
- distribution
- unit
- pitch
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Ceased
Links
Images














Classifications
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L25/00—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00
- G10L25/90—Pitch determination of speech signals
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/22—Procedures used during a speech recognition process, e.g. man-machine dialogue
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L25/00—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00
- G10L25/48—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00 specially adapted for particular use
- G10L25/51—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00 specially adapted for particular use for comparison or discrimination
- G10L25/60—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00 specially adapted for particular use for comparison or discrimination for measuring the quality of voice signals
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L25/00—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00
- G10L25/48—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00 specially adapted for particular use
- G10L25/51—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00 specially adapted for particular use for comparison or discrimination
- G10L25/63—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00 specially adapted for particular use for comparison or discrimination for estimating an emotional state
Definitions
- the present invention relates to a voice evaluation program and the like.
- FIG. 15 is a diagram for explaining the prior art.
- the horizontal axis of the graph 5 of FIG. 15 is an axis showing time, and the vertical axis is an axis showing frequency.
- a pitch frequency with a large vertical width is clear (bright), and a pitch frequency with a small vertical width is determined as unclear (dark).
- the upper and lower width of the pitch frequency is the difference between the maximum value and the minimum value of the pitch frequency in a certain period.
- the half pitch or the double pitch may be erroneously calculated due to the characteristics. For this reason, as in the prior art, it may not be possible to accurately evaluate the voice if it is determined that the voice is clear or indistinct simply by the size of the upper and lower width of the pitch frequency.
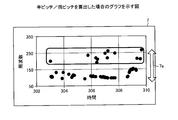
- FIG. 16 is a diagram showing a graph in the case where an accurate pitch frequency is calculated.
- the horizontal axis of the graph 6 of FIG. 16 is an axis showing time, and the vertical axis is an axis showing frequency.
- the graph 6 shows the case where the accurate pitch frequency is calculated. In graph 6, since the pitch frequency upper and lower width 6a is small, it can be determined that the voice is unclear.
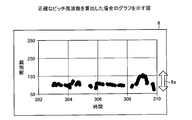
- FIG. 17 is a diagram showing a graph when half pitch / double pitch is calculated.
- the horizontal axis of the graph 7 of FIG. 17 is an axis showing time, and the vertical axis is an axis showing frequency.
- the graph 7 shows the case where the half pitch / double pitch is calculated by mistake.
- the upper and lower width 7a of the pitch frequency becomes large, and it is actually determined that the voice is clear although the voice is unclear.
- the present invention aims to provide a voice evaluation program, a voice evaluation method and a voice evaluation device capable of accurately evaluating speech.
- the computer is made to execute the following processing.
- the computer analyzes the audio signal to detect pitch frequency.
- the computer selects an evaluation target area to be evaluated among the detected pitch frequencies based on the detected distribution of the detected pitch frequency.
- the computer evaluates the voice based on the distribution of the detection frequency and the selected evaluation target area.
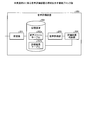
- FIG. 1 is a functional block diagram showing the configuration of the speech evaluation apparatus according to the first embodiment.
- FIG. 2 is a functional block diagram showing the configuration of the speech evaluation unit according to the first embodiment.
- FIG. 3 is a diagram showing an example of a histogram.
- FIG. 4 is a flowchart of the processing procedure of the speech evaluation unit according to the first embodiment.
- FIG. 5 is a diagram for explaining other processing of the voice evaluation device.
- FIG. 6 is a diagram showing the configuration of the voice evaluation system according to the second embodiment.
- FIG. 7 is a functional block diagram showing the configuration of the speech evaluation apparatus according to the second embodiment.
- FIG. 8 is a functional block diagram showing the configuration of the speech evaluation unit according to the second embodiment.
- FIG. 9 is a view showing an example of the data structure of the normal distribution table according to the second embodiment.
- FIG. 10 is a diagram showing the configuration of the voice evaluation system according to the third embodiment.
- FIG. 11 is a functional block diagram of the configuration of the recording device according to the third embodiment.
- FIG. 12 is a functional block diagram of the speech evaluation apparatus according to the third embodiment.
- FIG. 13 is a functional block diagram showing the configuration of the speech evaluation unit according to the third embodiment.
- FIG. 14 is a diagram illustrating an example of a hardware configuration of a computer that implements the same function as the voice evaluation device.
- FIG. 15 is a diagram for explaining the prior art.
- FIG. 16 is a diagram showing a graph in the case where an accurate pitch frequency is calculated.
- FIG. 17 is a diagram showing a graph when half pitch / double pitch is calculated.
- FIG. 1 is a functional block diagram showing the configuration of the speech evaluation apparatus according to the first embodiment.
- this voice evaluation device 100 is connected to a microphone 10 for collecting the voice of a speaker (not shown).
- the microphone 10 outputs the collected voice signal to the voice evaluation device 100.
- the signal of the sound collected by the microphone 10 will be referred to as "sound signal”.
- the voice evaluation device 100 includes an AD (Analog-to-Digital) conversion unit 101, a voice filing unit 102, a voice evaluation unit 103, an evaluation result storage unit 104, a storage device 105, and an output unit 106.
- AD Analog-to-Digital
- the AD conversion unit 101 is a processing unit that receives an audio signal from the microphone 10 and performs AD conversion. Specifically, the AD conversion unit 101 converts an audio signal (analog signal) into an audio signal (digital signal). The AD conversion unit 101 outputs the audio signal (digital signal) to the audio file conversion unit 102 and the audio evaluation unit 103. In the following description, the audio signal (digital signal) output from the AD conversion unit 101 is simply referred to as an audio signal.
- the audio file conversion unit 102 is a processing unit that converts an audio signal into an audio file according to a predetermined audio file format.
- the audio file includes information in which each time is associated with the strength of the audio signal.
- the audio file conversion unit 102 stores the audio file in the audio file table 105 a of the storage unit 105. In the following description, for convenience, the information on the relationship between the time included in the audio file and the strength of the audio signal will be simply described as the audio signal.
- the voice filing unit 102 obtains speaker information from an input device (not shown) and attaches the speaker information to a voice file.
- the speaker information is information that uniquely identifies a speaker.
- the voice evaluation unit 103 is a processing unit that evaluates the impression of the speaker's voice based on the voice signal. For example, the evaluation result of the speaker's voice impression is either "good", "normal” or "poor".
- the voice evaluation unit 103 outputs the speaker information and the information of the evaluation result to the evaluation result storage unit 104.
- the evaluation result storage unit 104 is a processing unit that stores speaker information and an evaluation result in the evaluation result table 105 b of the storage device 105 in association with each other.
- the storage device 105 stores an audio file table 105a and an evaluation result table 105b.
- the storage device 105 includes a random access memory (RAM) and a read only memory (ROM).
- the memory corresponds to a semiconductor memory device such as a flash memory and a storage device such as a hard disk drive (HDD).
- the audio file table 105 a is a table for storing audio files output from the audio file conversion unit 102.
- the evaluation result table 105 b is a table in which the speaker information stored by the evaluation result storage unit 104 is associated with the evaluation result.
- the output unit 106 is a processing unit that displays the evaluation result by outputting the evaluation result table 105 b stored in the storage device 105 to the display device.
- the output unit 106 may output the audio file stored in the audio file table 105 a to another external device.
- the AD conversion unit 101, the audio file conversion unit 102, the audio evaluation unit 103, the evaluation result storage unit 104, and the output unit 106 shown in FIG. 1 correspond to predetermined control units (not shown).
- the control unit can be realized by a central processing unit (CPU) or a micro processing unit (MPU).
- the control unit can also be realized by hard wired logic such as an application specific integrated circuit (ASIC) or a field programmable gate array (FPGA).
- ASIC application specific integrated circuit
- FPGA field programmable gate array
- FIG. 2 is a functional block diagram showing the configuration of the speech evaluation unit according to the first embodiment.
- the voice evaluation unit 103 includes a pitch detection unit 110, a distribution calculation unit 111, a spread calculation unit 112, a storage unit 113, an estimation unit 114, and an evaluation unit 115.
- the pitch detection unit 110 is a processing unit that detects a pitch frequency by analyzing the frequency of the audio signal of the audio file.
- the pitch frequency corresponds to the fundamental frequency of the audio signal.
- the pitch detection unit 110 outputs information on the pitch frequency to the distribution calculation unit 111.
- the pitch detection unit 110 may detect a speech section from the speech signal of the speech file, and may detect the pitch frequency based on the speech signal of the speech section. For example, the pitch detection unit 110 sets the time when the strength of the voice signal is equal to or more than the threshold as the start time of the utterance period. After the start time, the pitch detection unit 110 sets the time when the strength of the voice signal is less than the threshold as the end time of the utterance period. The pitch detection unit 110 sets a section from the start time to the end time as a speech section.
- the pitch detection unit 110 divides the speech signal of the speech section into a plurality of sections having a predetermined time width, and analyzes the frequency of the speech signal of each section to detect the pitch frequency of each section.
- the pitch detection unit 110 outputs, to the distribution calculation unit 111, pitch frequencies for each of a plurality of sections included in the utterance section.
- the pitch detection unit 110 is described in the literature (D. Talkin, “A Robust Algorithm for Pitch Tracking (RAPT),“ in Speech Coding & Synthesis, WBKlejn and KKPailwal (Eds.), Elsevier, pp. 495-518, 1995).
- the pitch frequency may be detected based on
- the distribution calculation unit 111 is a processing unit that calculates a histogram based on a plurality of pitch frequencies in a predetermined section.
- FIG. 3 is a diagram showing an example of a histogram.
- the horizontal axis of the histogram 20 shown in FIG. 3 is an axis corresponding to the pitch frequency, and the vertical axis is an axis corresponding to the detection frequency.
- the histogram 20 corresponds to the distribution of the pitch frequency detection frequency.
- the distribution calculating unit 111 identifies the center and the bottom of the histogram 20 by executing the following process.
- the distribution calculation unit 111 calculates an average ⁇ of each pitch frequency in a predetermined section.
- the distribution calculation unit 111 calculates the standard deviation ⁇ of each pitch frequency in a predetermined section. For example, the distribution calculating unit 111 sets the central portion of the histogram 20 as “ ⁇ to ⁇ + ⁇ ”.
- the distribution calculating unit 111 sets the bottom of the histogram 20 to “( ⁇ ) / 2 to ( ⁇ + ⁇ ) / 2” and “2 ⁇ ( ⁇ ) / 2 to 2 ⁇ ( ⁇ + ⁇ )”.
- the range A of the pitch frequency is at the center, and the ranges B1 and B2 are at the foot.
- the distribution calculating unit 111 may calculate the center and the bottom of the histogram 20 by processing other than the above.
- the distribution calculation unit 111 may identify the range between the start point and the end point of the central mountain from the outline of the histogram 20 as the central part, and may specify the range other than the central part as the foot.
- the distribution calculating unit 111 outputs, to the spread calculating unit 112, information on a plurality of pitch frequencies in the predetermined section or information on the histogram 20, information on the central portion, and information on the foot.
- the spread calculation unit 112 is a processing unit that calculates the spread of the histogram 20 after correcting the histogram 20. As described below, the spread of the corrected histogram 20 corresponds to the standard deviation based on the corrected pitch frequency.
- the spread calculation unit 112 classifies a plurality of pitch frequencies in a predetermined section into a pitch frequency corresponding to the center and a pitch frequency corresponding to the bottom.
- the spread calculation unit 112 corrects each pitch frequency in the central portion by multiplying each pitch frequency corresponding to the central portion with the weight “ ⁇ ”.
- ⁇ is set to “1”, for example, the administrator may change it as appropriate.
- the spread calculation unit 112 corrects each pitch frequency of the skirt by multiplying each pitch frequency corresponding to the skirt with the weight “ ⁇ ”. Although the value of ⁇ is, for example, “0.1”, the manager may change it as appropriate.
- the spread calculation unit 112 calculates the standard deviation of the pitch frequency on the basis of the corrected pitch frequency at the central portion and the bottom portion. As described above, the standard deviation of the pitch frequency calculated based on the corrected pitch frequency of the central portion and the foot portion corresponds to the spread of the corrected histogram 20. The spread calculation unit 112 outputs information of the standard deviation corresponding to the spread of the corrected histogram 20 to the estimation unit 114 and the evaluation unit 115.
- the storage unit 113 has a normal distribution table 113a.
- the storage unit 113 corresponds to a storage device such as a semiconductor memory device such as a RAM, a ROM, or a flash memory, or an HDD.
- the normal distribution table 113a is a table for holding information on the spread of the histogram of the speaker in normal time. For example, the normal distribution table 113a associates speaker information with a standard deviation. The standard deviation of the normal distribution table 113a is estimated by the estimation unit 114 described later.
- the estimation unit 114 is a processing unit that estimates the standard deviation of the speaker in normal times.
- the estimation unit 114 associates the speaker information with the standard deviation in normal and stores the information in the normal distribution table 113a.
- the estimation unit 114 acquires the speaker information attached to the audio file.
- the estimation unit 114 acquires speaker information, and performs “initial operation” when the standard deviation corresponding to the speaker information is not stored in the normal distribution table 113 a. On the other hand, when the standard deviation corresponding to the speaker information is stored in the normal distribution table 113a, the estimation unit 114 performs the "update operation". Hereinafter, the initial operation and the update operation will be described in order.
- the estimation unit 114 sets a section from a start time of the speech section to a predetermined time later (one minute later) as an initial section, and acquires the standard deviation in the initial section from the spread calculation section 112.
- the standard deviation in the initial section is the standard deviation calculated after correcting the pitch frequency by the weights ⁇ and ⁇ as described above.
- the estimation unit 114 may calculate the standard deviation in the initial section. That is, the estimation unit 114 classifies the plurality of pitch frequencies in the initial section into the pitch frequency corresponding to the central portion and the pitch frequency corresponding to the skirt portion. The estimation unit 114 corrects each pitch frequency in the central portion by multiplying each pitch frequency corresponding to the central portion with the weight “ ⁇ ”. The estimation unit 114 corrects each pitch frequency of the skirt by multiplying each pitch frequency corresponding to the skirt with the weight “ ⁇ ”. The estimation unit 114 calculates the standard deviation of the pitch frequency on the basis of the corrected pitch frequency at the central portion and the skirt portion.
- the estimation unit 114 performs the initial operation as described above, associates the speaker information with the standard deviation of the initial section, and registers the information in the normal distribution table 113a.
- movement which the estimation part 114 performs is demonstrated.
- the estimation unit 114 acquires the standard deviation corresponding to the speaker information from the normal distribution table 113a. Further, the estimation unit 114 obtains, from the spread calculation unit 112, the standard deviation within the predetermined section.
- the standard deviation acquired from the normal distribution table 113a is referred to as "normal standard deviation”
- the standard deviation acquired from the spread calculation unit 112 is referred to as "evaluation standard deviation”.
- the estimation unit 114 calculates a new normal standard deviation based on the equation (1), and updates the normal standard deviation of the normal distribution table 113a with the calculated normal standard deviation.
- Normal standard deviation 0.8 ⁇ normal standard deviation + 0.2 ⁇ evaluation standard deviation ... (1)
- the estimation unit 114 Each time the estimation unit 114 receives the standard deviation (evaluation standard deviation) in the predetermined section from the spread calculation unit 112, the estimation unit 114 repeatedly executes the above process to update the normal distribution table 113a.
- the estimation unit 114 acquires speaker information from the evaluation unit 115 and receives a request for a standard deviation at normal times, the normal unit deviation corresponding to the speaker information is acquired from the normal distribution table 113a. The standard deviation is output to the evaluation unit 115 at all times.
- the evaluation unit 115 is a processing unit that evaluates the voice impression of the speaker based on the standard deviation and the evaluation standard deviation at normal times. For example, the evaluation unit 115 outputs the speaker information attached to the audio file to the estimation unit 114, and acquires the standard deviation at normal times. The evaluation unit 115 acquires the evaluation standard deviation from the spread calculation unit 112.
- Evaluation part 115 evaluates that an impression is good, when evaluation standard deviation is usually larger than standard deviation.
- the evaluation unit 115 determines that the impression is normal if the evaluation standard deviation is equal to the standard deviation at all times.
- the evaluation unit 115 determines that the impression is good when the evaluation standard deviation is usually smaller than the standard deviation.
- the evaluation unit 115 may perform the evaluation as follows. For example, the evaluation unit 115 evaluates that the impression is good when the evaluation standard deviation is larger than the standard deviation normally and the difference between the evaluation standard deviation and the standard deviation is larger than the threshold. The evaluation unit 115 evaluates that the impression is normal when the difference between the evaluation standard deviation and the standard deviation is less than a threshold. The evaluation unit 115 evaluates that the impression is bad when the evaluation standard deviation is smaller than the standard deviation normally and the difference between the evaluation standard deviation and the standard deviation is larger than the threshold.
- the evaluation unit 115 outputs the speaker information and the information of the evaluation result to the evaluation result storage unit 104.
- FIG. 4 is a flowchart of the processing procedure of the speech evaluation unit according to the first embodiment.
- the pitch detection unit 110 of the voice evaluation unit 103 receives a voice signal (step S101).
- the pitch detection unit 110 analyzes the voice signal to calculate a pitch frequency (step S102).
- the distribution calculation unit 111 of the voice evaluation unit 103 calculates the distribution of pitch frequency (step S103).
- the process of calculating the distribution of pitch frequencies corresponds to the process of calculating the center and bottom of the histogram 20 based on each pitch frequency as described above.
- the spread calculation unit 112 of the voice evaluation unit 103 calculates the spread of the distribution (step S104).
- the process of calculating the spread of the distribution in step S104 corresponds to the process of calculating the evaluation standard deviation described above.
- the estimation unit 114 of the speech evaluation unit 103 calculates the spread of the normal distribution (step S1). 05).
- the process of calculating the spread of the normal distribution corresponds to the above-described process of calculating the standard deviation.
- the evaluation unit 115 of the speech evaluation unit 103 usually evaluates the speech based on the standard deviation and the evaluation standard deviation (step S106).
- the voice evaluation unit 103 ends the processing in the case of voice termination (step S107, Yes). On the other hand, when the voice evaluation unit 103 does not end the voice (Step S107, No), the voice evaluation unit 103 updates the analysis start position (Step S108), and proceeds to Step S102.
- the voice evaluation device 100 analyzes the voice signal to create a distribution of detection frequency of pitch frequency, performs correction to suppress the tail portion of the distribution, and performs voice evaluation based on the corrected distribution. Therefore, even if half pitch or double pitch is calculated by the process of detecting the pitch frequency, these pitches are classified into the pitch frequency of the skirt portion, and the voice is evaluated after the influence is suppressed.
- the voice can be evaluated accurately. For example, even though the voice is actually a bright voice, it is possible to suppress the evaluation as a dark voice even if a half pitch or a double pitch is incorrectly calculated.
- the voice evaluation device 100 executes processing for correcting the distribution by multiplying the pitch frequency corresponding to the central portion of the distribution (histogram) by the weight ⁇ and multiplying the pitch frequency corresponding to the tail portion of the distribution by the weight ⁇ Therefore, it is possible to suppress the error determination due to the influence of half pitch or double pitch.
- the estimation unit 114 of the speech evaluation apparatus 100 estimates the spread of the normal distribution of the speaker, and the evaluation unit 115 compares the spread of the normal distribution with the spread of the current distribution to obtain an impression of voice. Evaluate For this reason, it is possible to evaluate speech based on the spread of the distribution of the speaker's own normal.
- the estimation unit of the voice evaluation device 114 performs the "update operation". This makes it possible to correct the normal distribution on the speaker more appropriately.
- speech evaluation apparatus 100 multiplies the pitch frequency corresponding to the center of the distribution (histogram) by weight ⁇ , and multiplies the pitch frequency corresponding to the bottom of distribution by weight ⁇ to obtain the distribution.
- This processing selects the central pitch frequency included in the distribution in that the effect of the pitch frequency of the tail included in the distribution is removed, and the speech is evaluated based on the standard deviation of the selected pitch frequency. It can be said that
- the pitch detection unit 110 of the speech evaluation apparatus 100 divides the speech signal of the speech section into a plurality of sections having a predetermined time width, and analyzes the frequency of the speech signal of each section to detect the pitch frequency of each section.
- the pitch detection unit 110 may output an average value of each pitch frequency detected from a predetermined number of sections as the pitch frequency to the distribution calculation unit 111.
- the pitch detection unit 110 may output the upper limit value of each pitch frequency detected from a predetermined number of sections to the distribution calculation unit 111 as a pitch frequency.
- the pitch detection unit 110 may output the lower limit value of each pitch frequency detected from a predetermined number of sections to the distribution calculation unit 111 as a pitch frequency.
- the pitch frequency can be used according to the speaker and the environment.
- the spread calculation unit 112 of the voice evaluation device 100 calculates the standard deviation of each pitch frequency included in the utterance section as the spread of the distribution
- the present invention is not limited to this.
- the spread calculation unit 112 may calculate any of the dispersion, range, sum of squares, and quartile range of each pitch frequency included in the speech section as the spread of the distribution.
- the speech evaluation apparatus 100 may evaluate the speech of the speaker based on the outline of the histogram of the speech section as described below.
- FIG. 5 is a diagram for explaining other processing of the voice evaluation device. As shown in FIG. 5, the speech evaluation apparatus 100 calculates a histogram 25 based on a plurality of pitch frequencies of the speech section. The horizontal axis of the histogram 25 is an axis corresponding to the pitch frequency, and the vertical axis is an axis corresponding to the detection frequency.
- the voice evaluation device 100 performs pattern matching and the like to specify the central portion C and the foot portions D1 and D2 in the outline of the histogram 25.
- the voice evaluation device 100 corrects the histogram 25 by multiplying the detection frequency of the central portion C by the weight ⁇ and multiplying the detection frequency of the foot portions D1 and D2 by the weight ⁇ .
- the corrected histogram is described as a histogram 26. For example, assume that heavy ⁇ is “1” and weight ⁇ is “0.1”.
- the speech evaluation apparatus 100 determines the impression of the speech of the speaker based on the size of the spread of the histogram 26 after correction. For example, the voice evaluation device 100 specifies a range in which the detection frequency of the histogram 26 is equal to or higher than a predetermined frequency as the spread of the histogram 26. When the spread of the histogram 26 is equal to or greater than a predetermined threshold, the voice evaluation device 100 evaluates that the speaker's impression is bright. On the other hand, when the spread of the histogram 26 is equal to or larger than a predetermined threshold, the voice evaluation device 100 evaluates that the speaker's impression is dark.
- the weight of the bottom is decreased, the weight of the center is increased, and the histogram 25 is corrected by mistake. It is possible to deter evaluation.
- FIG. 6 is a diagram showing the configuration of the voice evaluation system according to the second embodiment.
- this voice evaluation system has a portable terminal 2a, a terminal device 2b, a branch connector 3, a recording device 150, and a cloud 160.
- the portable terminal 2a is connected to the branch connector 3 via the telephone network 15a.
- the terminal device 2 b is connected to the branch connector 3.
- the branch connector 3 is connected to the recording device 150.
- the recording device 150 is connected to the cloud 160 via the Internet network 15 b.
- the cloud 160 includes the voice evaluation device 200.
- the voice evaluation device 200 may be configured by a plurality of servers.
- the portable terminal 2a and the terminal device 2b are connected to a microphone (not shown).
- the voice of the speaker 1a is collected by the microphone of the portable terminal 2a, and the collected voice signal is transmitted to the recording device 150 via the branch connector 3.
- the voice signal of the speaker 1a will be referred to as "first voice signal”.
- the portable terminal 2a adds the attribute information of the speaker 1a to the first voice signal.
- the attribute information includes gender information and voice height information.
- the gender uniquely identifies the gender of the speaker.
- Voice height or information is information indicating whether the speaker's voice is high or low.
- the speaker 1a registers his / her attribute information in the portable terminal 2a.
- the voice of the speaker 1 b is collected by the microphone of the terminal device 2 b, and the collected voice signal is transmitted to the recording device 150 via the branch connector 3.
- the voice signal of the speaker 1 b is referred to as “second voice signal”.
- the terminal device 2b adds attribute information of the speaker 1b to the second voice signal.
- the speaker 1b registers his / her attribute information in the terminal device 2b.
- the explanation of the attribute information of the speaker 1 b is the same as the explanation of the attribute information of the speaker 1 a.
- the recording device 150 is a device for recording the first audio signal and the second audio signal. For example, when the recording device 150 receives the first audio signal, the recording device 150 converts the first audio signal into an audio file according to a predetermined audio file format, and transmits the audio file of the first audio signal to the audio evaluation device 200 .
- the voice file of the first voice signal includes attribute information of the speaker 1a.
- the audio file of the first audio signal will be referred to as the "first audio file" as appropriate.
- the recording device 150 converts the second audio signal into an audio file according to a predetermined audio file format, and transmits the audio file of the second audio signal to the audio evaluation device 200.
- the voice file of the second voice signal includes attribute information of the speaker 1b.
- the audio file of the second audio signal will be referred to as the "second audio file" as appropriate.
- the voice evaluation device 200 evaluates the voice impression of the speaker 1 a based on the first voice signal of the first voice file.
- the voice evaluation device 200 evaluates the voice impression of the speaker 1 b based on the second voice signal of the second voice file. Then, the voice evaluation device 200 calculates the score of the entire conversation between the speakers 1a and 1b based on the evaluation result of the impression of the voice of the speaker 1a and the evaluation result of the impression of the voice of the speaker 2a.
- FIG. 7 is a functional block diagram showing the configuration of the speech evaluation apparatus according to the second embodiment.
- the voice evaluation device 200 includes a reception unit 201, a storage device 202, a voice evaluation unit 203, and an evaluation result storage unit 204.
- the receiving unit 201 is a processing unit that receives the first audio file and the second audio file from the recording device 150.
- the receiving unit 201 registers the received first audio file and second audio file in the audio file table 202 a of the storage unit 202.
- the receiving unit 201 corresponds to a communication device.
- the storage device 202 includes an audio file table 202a and an evaluation result table 202b.
- the storage device 202 corresponds to a storage device such as a RAM, a ROM, a semiconductor memory element such as a flash memory, or an HDD.
- the audio file table 202a is a table for storing the first audio file and the second audio file.
- the evaluation result table 202 b is a table for storing the evaluation result.
- the evaluation result table 202b stores the evaluation result of the speaker 1a, the evaluation result of the speaker 1b, and the score of the entire conversation between the speakers 1a and 1b.
- the voice evaluation unit 203 evaluates the impression of the voices of the speakers 1a and 1b based on the first voice file and the second voice file. Then, the voice evaluation unit 203 calculates the score of the entire conversation between the speakers 1 a and 1 b based on the evaluation result of the impression of the voice of the speakers 1 a and 1. The voice evaluation unit 203 outputs the evaluation results of the impressions of the voices of the speakers 1a and 1b and the score of the entire conversation to the evaluation result storage unit 204.
- the evaluation result storage unit 204 is a processing unit that stores the evaluation results of the impressions of the voices of the speakers 1a and 1 and the score of the entire conversation in the evaluation result table 202b.
- the voice evaluation unit 203 and the evaluation result storage unit 204 illustrated in FIG. 7 correspond to predetermined control units (not shown).
- the control unit can be realized by a CPU, an MPU, or the like.
- the control unit can also be realized by hard wired logic such as ASIC or FPGA.
- FIG. 8 is a functional block diagram showing the configuration of the speech evaluation unit according to the second embodiment.
- the voice evaluation unit 203 includes a pitch detection unit 210, a distribution calculation unit 211, a spread calculation unit 212, a storage unit 213, an estimation unit 114, and an evaluation unit 115.
- the pitch detection unit 210 is a processing unit that detects a pitch frequency in each predetermined section by performing frequency analysis on the audio signal of the audio file. For example, the pitch detection unit 210 detects the first pitch frequency of the first audio signal by analyzing the frequency of the first audio signal of the first audio file. Also, the pitch detection unit 210 detects the second pitch frequency of the second audio signal by analyzing the frequency of the second audio signal of the second audio file. The process in which the pitch detection unit 210 detects the pitch frequency from the audio signal is the same as the process in which the pitch detection unit 110 illustrated in FIG. 2 detects the pitch frequency from the audio signal.
- the pitch detection unit 210 outputs the attribute information of the speaker 1a and the plurality of first pitch frequencies to the distribution calculation unit 211. Further, the pitch detection unit 210 outputs the attribute information of the speaker 1 b and the plurality of second pitch frequencies to the distribution calculation unit 211.
- the distribution calculating unit 211 is a processing unit that calculates a histogram based on a plurality of pitch frequencies in a predetermined section. For example, the distribution calculating unit 211 calculates the first histogram based on the plurality of first pitch frequencies in the predetermined section. The distribution calculating unit 211 calculates a second histogram based on the plurality of second pitch frequencies in the predetermined section. The process in which the distribution calculating unit 211 calculates a histogram is the same as the process in which the distribution calculating unit 111 illustrated in FIG. 2 calculates a histogram.
- the distribution calculating unit 211 outputs the information of the first histogram calculated based on the plurality of first pitch frequencies to the spread calculating unit 212.
- the information on the first histogram includes information on the center of the first histogram and information on the tail of the first histogram.
- the distribution calculating unit 211 outputs the information of the second histogram calculated based on the plurality of second pitch frequencies to the spread calculating unit 212.
- the information on the second histogram includes information on the center of the second histogram and information on the tail of the second histogram.
- the spread calculation unit 212 is a processing unit that calculates the spread of the histogram after correcting the histogram. For example, the spread calculation unit 212 corrects the first histogram and then calculates the spread of the first histogram. The spread calculation unit 212 corrects the second histogram and then calculates the spread of the second histogram. The process in which the spread calculation unit 212 calculates the spread of the histogram is the same as the process in which the spread calculation unit 112 illustrated in FIG. 2 calculates the spread of the histogram. For example, the spread of the corrected histogram corresponds to the standard deviation based on the corrected pitch frequency (first pitch frequency, second pitch frequency).
- the spread calculation unit 212 outputs information of the standard deviation corresponding to the corrected spread of the histogram to the estimation unit 214 and the evaluation unit 215 in association with the attribute information. For example, the spread calculation unit 212 outputs information on the standard deviation corresponding to the corrected spread of the first histogram to the estimation unit 214 and the evaluation unit 215 in association with the attribute information of the speaker 1a. The spread calculation unit 212 outputs information of the standard deviation corresponding to the spread of the corrected second histogram to the estimation unit 214 and the evaluation unit 215 in association with the attribute information of the speaker 1 b.
- the storage unit 213 has a normal distribution table 213a.
- the storage unit 213 corresponds to a semiconductor memory device such as a RAM, a ROM, or a flash memory, or a storage device such as an HDD.
- the normal distribution table 213a is a table for holding information on the spread of the histogram in the normal time of the speaker corresponding to the attribute information. For example, the normal distribution table 213a associates attribute information with a standard deviation. The standard deviation of the normal distribution table 213a is estimated by the estimation unit 214 described later.
- FIG. 9 is a view showing an example of the data structure of the normal distribution table according to the second embodiment.
- the normal distribution table 213a associates attribute information with a standard deviation.
- the attribute information associates gender information with voice height information.
- the estimation unit 214 is a processing unit that estimates the standard deviation of the speaker in normal times for each piece of attribute information.
- the estimation unit 214 associates the attribute information with the standard deviation in normal and stores the result in the normal distribution table 213a.
- the estimation unit 214 acquires attribute information attached to the audio file (first audio file and second audio file).
- the estimation unit 214 acquires attribute information, and performs “initial operation” when the standard deviation corresponding to the attribute information is not stored in the normal distribution table 213a. On the other hand, when the standard deviation corresponding to the attribute information is stored in the normal distribution table 213a, the estimation unit 214 performs the "update operation".
- the description of the initial operation and the update operation by the estimation unit 214 is the same as the description of the initial operation and the update operation of the estimation unit 114 except that the process is performed for each attribute information.
- first normal standard deviation the standard deviation acquired from the normal distribution table 213a corresponding to the attribute information of the speaker 1a
- first evaluation standard deviation the standard deviation acquired from the spread calculation unit 212, which corresponds to the attribute information of the speaker 1a.
- the standard deviation obtained from the normal distribution table 213a, which corresponds to the attribute information of the speaker 1b, is referred to as “the second normal standard deviation”.
- the standard deviation acquired from the spread calculation unit 212 corresponding to the attribute information of the speaker 1 b is referred to as “second evaluation standard deviation”.
- the estimation unit 214 acquires attribute information of the speaker 1a from the evaluation unit 215, and when receiving a request for the first standard deviation, acquires the first standard deviation from the normal distribution table 213a. And outputs the first normal standard deviation to the evaluation unit 215.
- the estimation unit 214 acquires the attribute information of the speaker 1b from the evaluation unit 215, and when receiving a request for the second standard deviation, acquires the second standard deviation from the normal distribution table 213a, The second normal standard deviation is output to the evaluation unit 215.
- the evaluation unit 215 is a processing unit that evaluates the voice impressions of the speakers 1a and 1b based on the standard deviations. Further, the evaluation unit 215 calculates the score of the entire conversation between the speakers 1a and 1b based on the evaluation result of the impression of the voices of the speakers 1a and 1b.
- the evaluation unit 215 evaluates the voice impression of the speaker 1a based on the first normal standard deviation and the first evaluation standard deviation. In addition, the evaluation unit 215 may set the second normal standard deviation and the second normal deviation. The voice impression of the speaker 1b is evaluated based on the evaluation standard deviation. The process in which the evaluation unit 215 evaluates the impression of the voices of the speakers 1a and 1b based on each standard deviation is the same as the process in which the evaluation unit 115 evaluates voices.
- the evaluation unit 215 specifies the evaluation result of the speaker 1 a and the evaluation result of the speaker 1 b for each predetermined section by repeatedly executing the above process.
- the evaluation unit 215 calculates the score of the entire conversation based on the equation (2).
- Score of the entire conversation (number of sections evaluated as having good impression of speaker 1a + number of sections evaluated as having good impression of speaker 1b) / (total number of sections ⁇ 2) ⁇ 100 (2) )
- the evaluation unit 215 outputs the evaluation results of the impressions of the voices of the speakers 1a and 1b and the score of the entire conversation to the evaluation result storage unit 204.
- the speech evaluation device 200 learns the standard deviation normally according to the speaker's attribute information, and at the time of evaluation, uses the normal standard deviation according to the speaker's attribute information to calculate the speaker's speech. evaluate. Therefore, voice evaluation can be performed based on speaker attribute information, and the accuracy of the evaluation can be improved.
- the speech evaluation device 200 calculates the score of the entire conversation based on the evaluation result of the speech of each speaker 1a, 1b, the administrator etc. grasps the goodness or badness of the whole conversation by referring to the score can do. For example, it can be said that, as the score of the entire conversation calculated by equation (2) is larger, the conversation content is better.
- FIG. 10 is a diagram showing the configuration of the voice evaluation system according to the third embodiment.
- this voice evaluation system includes microphones 30A, 30B, and 30C, a recording device 300, and a cloud 170.
- the microphones 30A to 30C are connected to the recording device 300.
- the recording device 300 is connected to the cloud 170 via the Internet network 15 b.
- the cloud 170 includes the voice evaluation device 400.
- the voice evaluation device 400 may be configured by a plurality of servers.
- the voice of the speaker 1A is collected by the microphone 30a, and the collected voice signal is output to the recording device 300.
- the voice of the speaker 1 B is collected by the microphone 30 b, and the collected voice signal is output to the recording device 300.
- the voice of the speaker 1C is collected by the microphone 30c, and the collected voice signal is output to the recording device 300.
- the voice signal of the speaker 1A is referred to as "first voice signal”.
- the voice signal of the speaker 1B is referred to as "second voice signal”.
- the voice signal of the speaker 1C is referred to as "third voice signal”.
- the speaker information of the speaker 1A is added to the first voice signal.
- Speaker information is information that uniquely identifies a speaker.
- the speaker information of the speaker 1B is added to the second voice signal.
- the speaker information of the speaker 1C is attached to the third voice signal.
- the recording device 300 is a device for recording the first audio signal, the second audio signal, and the third audio signal. Also, the recording device 300 executes a process of detecting the pitch frequency of each audio signal. The recording device 300 associates the speaker information with the pitch frequency for each predetermined section, and transmits it to the voice evaluation device 400.
- the voice evaluation device 400 is a processing unit that evaluates the voice of each speaker based on the pitch frequency of each speaker information received from the recording device 300. Further, the voice evaluation device 400 evaluates the impression of the conversations of the speakers 1A to 1C based on the evaluation results of the voices of the speakers.
- FIG. 11 is a functional block diagram of the configuration of the recording device according to the third embodiment.
- the recording device 300 includes AD conversion units 310a to 310b, a pitch detection unit 320, a filing unit 330, and a transmission unit 340.
- the AD conversion unit 310a is a processing unit that receives the first audio signal from the microphone 30a and performs AD conversion. Specifically, the AD conversion unit 310a converts the first audio signal (analog signal) into a first audio signal (digital signal). The AD conversion unit 310 a outputs the first audio signal (digital signal) to the pitch detection unit 320. In the following description, the first audio signal (digital signal) output from the AD conversion unit 310a is simply referred to as a first audio signal.
- the AD conversion unit 310 b is a processing unit that receives the second audio signal from the microphone 30 b and performs AD conversion. Specifically, the AD conversion unit 310 b converts the second audio signal (analog signal) into a second audio signal (digital signal). The AD conversion unit 310 b outputs the second audio signal (digital signal) to the pitch detection unit 320. In the following description, the second audio signal (digital signal) output from the AD conversion unit 310b is simply referred to as a second audio signal.
- the AD conversion unit 310c is a processing unit that receives the third audio signal from the microphone 30c and performs AD conversion. Specifically, the AD conversion unit 310 c converts the third audio signal (analog signal) into a third audio signal (digital signal). The AD conversion unit 310 c outputs the third audio signal (digital signal) to the pitch detection unit 320. In the following description, the third audio signal (digital signal) output from the AD conversion unit 310c is simply referred to as a third audio signal.
- the pitch detection unit 320 is a processing unit that calculates a pitch frequency for each predetermined section by analyzing the frequency of the audio signal. For example, the pitch detection unit 320 detects the first pitch frequency of the first audio signal by analyzing the frequency of the first audio signal. The pitch detection unit 320 detects the second pitch frequency of the second audio signal by analyzing the frequency of the second audio signal. The pitch detection unit 320 detects the third pitch frequency of the third audio signal by analyzing the frequency of the third audio signal.
- the pitch detection unit 320 associates the speaker information of the speaker 1A with the first pitch frequency for each predetermined section, and outputs the result to the filing unit 330.
- the pitch detection unit 320 associates the speaker information of the speaker 1B with the second pitch frequency for each predetermined section, and outputs the result to the filing unit 330.
- the pitch detection unit 320 associates the speaker information of the speaker 1C with the third pitch frequency for each predetermined section, and outputs the result to the filing unit 330.
- the filing unit 330 is a processing unit that generates “voice file information” by filing information received from the pitch detection unit 320.
- the voice file information includes information in which the speaker information and the pitch frequency for each predetermined section are associated with each other. Specifically, the voice file information includes information in which the speaker information of the speaker 1A is associated with the first pitch frequency for each predetermined section.
- the voice file information includes information in which the speaker information of the speaker 1B is associated with the second pitch frequency in each predetermined section.
- the voice file information includes information in which the speaker information of the speaker 1C is associated with the third pitch frequency in each predetermined section.
- the file conversion unit 330 outputs the audio file information to the transmission unit 340.
- the transmission unit 340 acquires audio file information from the file conversion unit 330, and transmits the acquired audio file information to the audio evaluation device 400.
- FIG. 12 is a functional block diagram of the speech evaluation apparatus according to the third embodiment.
- the voice evaluation device 400 includes a reception unit 401, a storage device 402, a voice evaluation unit 403, and an evaluation result storage unit 404.
- the receiving unit 401 is a processing unit that receives audio file information from the recording device 300.
- the receiving unit 401 registers the received audio file information in the audio file table 402 a of the storage unit 402.
- the receiving unit 401 corresponds to a communication device.
- the storage device 402 includes an audio file table 402 a and an evaluation result table 402 b.
- the storage device 402 corresponds to a storage device such as a semiconductor memory device such as a RAM, a ROM, or a flash memory, or an HDD.
- the audio file table 402a is a table for storing audio file information.
- the voice file information includes information in which the speaker information of the speaker 1A is associated with the first pitch frequency for each predetermined section.
- the voice file information includes information in which the speaker information of the speaker 1B is associated with the second pitch frequency in each predetermined section.
- the voice file information includes information in which the speaker information of the speaker 1C is associated with the third pitch frequency in each predetermined section.
- the evaluation result table 402 b is a table for storing the evaluation result.
- the evaluation result table 402b stores evaluation results of the entire conversation between the speakers 1A to 1C and evaluation results of the speakers 1A to 1C.
- the speech evaluation unit 403 evaluates the impression of the speech of the speakers 1A to 1C based on the speech file information. Then, based on the evaluation results of the impressions of the voices of the speakers 1A to 1C, the voice evaluation unit 403 evaluates the entire conversation between the speakers 1A to 1C. The voice evaluation unit 403 outputs the evaluation results of the impressions of the voices of the speakers 1A to 1C and the evaluation result of the entire conversation to the evaluation result storage unit 404.
- the evaluation result storage unit 404 is a processing unit that stores the evaluation results of the impressions of the voices of the speakers 1A to 1C and the evaluation results of the entire conversation in the evaluation result table 402b.
- the voice evaluation unit 403 and the evaluation result storage unit 404 shown in FIG. 12 correspond to predetermined control units (not shown).
- the control unit can be realized by a CPU, an MPU, or the like.
- the control unit can also be realized by hard wired logic such as ASIC or FPGA.
- FIG. 13 is a functional block diagram showing the configuration of the speech evaluation unit according to the third embodiment.
- the voice evaluation unit 403 includes a pitch acquisition unit 410, a distribution calculation unit 411, a spread calculation unit 412, a storage unit 413, an estimation unit 414, and an evaluation unit 415.
- the pitch acquisition unit 410 is a processing unit that acquires audio file information from the audio file table 402a.
- the pitch acquisition unit 410 outputs the audio file information to the distribution calculation unit 411.
- the distribution calculating unit 411 is a processing unit that calculates a histogram based on a plurality of pitch frequencies in a predetermined section. For example, the distribution calculating unit 411 calculates the first histogram based on the plurality of first pitch frequencies in the predetermined section. The distribution calculating unit 411 calculates a second histogram based on the plurality of second pitch frequencies in the predetermined section. The distribution calculating unit 411 calculates a third histogram based on the plurality of third pitch frequencies in the predetermined section.
- the process in which the distribution calculation unit 411 calculates a histogram is the same as the process in which the distribution calculation unit 111 illustrated in FIG. 2 calculates a histogram.
- the distribution calculating unit 411 outputs the information of the first histogram calculated based on the plurality of first pitch frequencies to the spread calculating unit 412.
- the information on the first histogram includes information on the center of the first histogram and information on the tail of the first histogram.
- the distribution calculating unit 411 outputs the information of the second histogram calculated based on the plurality of second pitch frequencies to the spread calculating unit 412.
- the information on the second histogram includes information on the center of the second histogram and information on the tail of the second histogram.
- the distribution calculating unit 411 outputs the information of the third histogram calculated based on the plurality of third pitch frequencies to the spread calculating unit 412.
- the information on the second histogram includes information on the center of the third histogram and information on the tail of the third histogram.
- the spread calculation unit 412 is a processing unit that calculates the spread of the histogram after correcting the histogram. For example, the spread calculation unit 412 corrects the first histogram and then calculates the spread of the first histogram. The spread calculation unit 412 corrects the second histogram, and then calculates the spread of the second histogram. The spread calculation unit 412 corrects the third histogram and then calculates the spread of the third histogram.
- the process in which the spread calculating unit 412 calculates the spread of the histogram is the same as the process in which the spread calculating unit 112 illustrated in FIG. 2 calculates the spread of the histogram.
- the spread of the corrected histogram corresponds to the standard deviation based on the corrected pitch frequency (first pitch frequency, second pitch frequency, third pitch frequency).
- the spread calculation unit 412 outputs information of the standard deviation corresponding to the corrected spread of the histogram to the estimation unit 414 and the evaluation unit 415 in association with the speaker information. For example, the spread calculation unit 412 outputs information of the standard deviation corresponding to the corrected spread of the first histogram to the estimation unit 414 and the evaluation unit 415 in association with the speaker information of the speaker 1A. The spread calculation unit 412 outputs information on the standard deviation corresponding to the corrected spread of the second histogram to the estimation unit 414 and the evaluation unit 415 in association with the speaker information of the speaker 1B. The spread calculation unit 412 outputs information of the standard deviation corresponding to the corrected spread of the second histogram to the estimation unit 414 and the evaluation unit 415 in association with the speaker information of the speaker 1C.
- the storage unit 413 has a normal distribution table 413a.
- the storage unit 413 corresponds to a semiconductor memory element such as a RAM, a ROM, or a flash memory, or a storage device such as an HDD.
- the normal distribution table 413a is a table for holding information on the spread of the histogram in the normal time of the speaker corresponding to the speaker information. For example, the normal distribution table 413a associates speaker information with a standard deviation. The standard deviation of the normal distribution table 413a is estimated by the estimation unit 414 described later.
- the estimation unit 414 is a processing unit that estimates the standard deviation of the speaker in normal times for each of the speaker information.
- the estimation unit 414 associates the speaker information with the standard deviation in normal, and stores the information in the normal distribution table 413a.
- the estimation unit 414 acquires the speaker information attached to the audio file information.
- the estimation unit 414 acquires speaker information, and performs “initial operation” when the standard deviation corresponding to the speaker information is not stored in the normal distribution table 413 a. On the other hand, when the standard deviation corresponding to the speaker information is stored in the normal distribution table 413a, the estimation unit 414 performs the "update operation".
- the description of the initial operation and the update operation by the estimation unit 414 is the same as the description of the initial operation and the update operation of the estimation unit 114 illustrated in FIG. 2.
- first normal standard deviation the standard deviation acquired from the normal distribution table 413a corresponding to the speaker information of the speaker 1A
- first evaluation standard deviation The standard deviation acquired from the spread calculation unit 412 corresponding to the speaker information of the speaker 1A is referred to as “first evaluation standard deviation”.
- the standard deviation acquired from the normal distribution table 413a corresponding to the speaker information of the speaker 1B is denoted as “second normal standard deviation”.
- the standard deviation acquired from the spread calculation unit 412 corresponding to the speaker information of the speaker 1B is referred to as “second evaluation standard deviation”.
- the standard deviation acquired from the normal distribution table 413a corresponding to the speaker information of the speaker 1C is denoted as "third normal standard deviation”.
- the standard deviation acquired from the spread calculation unit 412 corresponding to the speaker information of the speaker 1C is referred to as “third evaluation standard deviation”.
- the estimation unit 414 acquires the speaker information of the speaker 1A from the evaluation unit 415, and receives the request for the first standard deviation from the first normal standard deviation from the normal distribution table 413a. The first normal standard deviation is acquired and output to the evaluation unit 415.
- the estimation unit 414 acquires the speaker information of the speaker 1B from the evaluation unit 415, and when receiving a request for the second standard deviation, acquires the second standard deviation from the normal distribution table 413a.
- the second normal standard deviation is output to the evaluation unit 415.
- the estimation unit 414 acquires the speaker information of the speaker 1C from the evaluation unit 415, and when receiving a request for the third normal deviation, acquires the third normal deviation from the normal distribution table 413a. And the third normal standard deviation to the evaluation unit 415.
- the evaluation unit 415 is a processing unit that evaluates the voice impressions of the speakers 1A to 1C based on the standard deviations. Further, the evaluation unit 415 evaluates the entire conversations of the speakers 1A to 1C based on the evaluation results of the impressions of the voices of the speakers 1A to 1C.
- the evaluation unit 415 evaluates the voice impression of the speaker 1A based on the first normal standard deviation and the first evaluation standard deviation.
- the evaluation unit 415 evaluates the voice impression of the speaker 1B based on the second normal standard deviation and the second evaluation standard deviation.
- the evaluation unit 415 evaluates the voice impression of the speaker 1C based on the third normal standard deviation and the third evaluation standard deviation.
- the process in which the evaluation unit 415 evaluates the impression of the voices of the speakers 1A to 1C based on each standard deviation is the same as the process in which the evaluation unit 115 evaluates voices.
- the evaluation unit 415 specifies the evaluation result of the speaker 1A, the evaluation result of the speaker 1B, and the evaluation result of the speaker 1C for each predetermined section by repeatedly executing the above process.
- the evaluation unit 415 evaluates the entire conversation after specifying the evaluation results of the speakers 1A to 1C. For example, the evaluation unit 415 specifies, for each speaker, an average evaluation result among the evaluation results “good, normal, bad” in a predetermined frame. For example, the evaluation unit 415 sets the most frequent evaluation result as the average evaluation result among the evaluation results in a predetermined frame.
- the evaluation unit 415 determines that the conversation is good when the evaluation results of the averages of the speakers 1A to 1C are very close. If the evaluation results of the averages of the speakers 1A to 1C are different, the evaluation unit 415 determines that the conversation is a bad conversation.
- the evaluation unit 415 compares the evaluation results of the averages of the speakers 1A to 1C, and determines that the conversation is good when the evaluation results of two or more averages match. On the other hand, the evaluation unit 415 compares the evaluation results of the averages of the speakers 1A to 1C, and determines that the conversation is a bad conversation if the evaluation results of two or more averages do not match.
- the evaluation unit 415 outputs the evaluation results of the impressions of the voices of the speakers 1A to 1C and the evaluation results of the entire conversation to the evaluation result storage unit 404.
- the speech evaluation device 400 learns the standard deviation at normal time in accordance with the speaker information of the speaker, and at the time of evaluation, the normal standard deviation corresponding to the speaker information of the speaker is used to Evaluate the voice. Therefore, voice evaluation can be performed based on the speaker information, and the accuracy of the evaluation can be improved.
- the voice evaluation device 400 evaluates the entire conversation based on the evaluation results of the voices of the respective speakers 1A to 1C, the manager or the like can grasp the goodness or badness of the entire conversation.
- the voice evaluation device 400 when evaluating the entire conversation, may calculate the score of the entire conversation based on Expression (3).
- Score of whole conversation (number of sections evaluated as having good impression of speaker 1A + number of sections evaluated as having good impression of speaker 1B + number of sections evaluated as having good impression of speaker 1C) / ( Total number of sections x 3) x 100 (3)
- FIG. 14 is a diagram illustrating an example of a hardware configuration of a computer that implements the same function as the voice evaluation device.
- the computer 500 includes a CPU 501 that executes various arithmetic processing, an input device 502 that receives input of data from a user, and a display 503.
- the computer 500 also includes a reading device 504 that reads a program or the like from a storage medium, and an interface device 505 that exchanges data with a recording device or the like via a wired or wireless network.
- the computer 500 also has a RAM 506 for temporarily storing various information, and a hard disk device 507.
- the devices 501 to 507 are connected to the bus 508.
- the hard disk drive 507 has a pitch detection program 507a, a distribution calculation program 507b, a spread calculation program 507c, an estimation program 507d, and an evaluation program 507e.
- the CPU 501 reads the pitch detection program 507 a, the distribution calculation program 507 b, the spread calculation program 507 c, the estimation program 507 d, and the evaluation program 507 d, and develops the read program on the RAM 506.
- the pitch detection program 507a functions as a pitch detection process 506a.
- the distribution calculation program 507 b functions as a distribution calculation process 506 b.
- the spread calculation program 507 c functions as a spread calculation process 506 c.
- the estimation program 507d functions as an estimation process 506d.
- the evaluation program 507 e functions as an evaluation process 506 e.
- the processing of the pitch detection process 506a corresponds to the processing of the pitch detection units 110, 210, and 320.
- the distribution calculation process 506 b corresponds to the processing of the distribution calculation units 111, 211 and 411.
- the processing of the spread calculation process 506 c corresponds to the processing of the spread calculation units 112, 212, and 412.
- the estimation process 506 d corresponds to the processing of the estimation units 114, 214, and 414.
- the respective programs 507 a to 507 e may not necessarily be stored in the hard disk device 507 from the beginning.
- each program is stored in a “portable physical medium” such as a flexible disk (FD), a CD-ROM, a DVD disk, a magneto-optical disk, an IC card or the like inserted into the computer 500.
- the computer 500 may read and execute the programs 507a to 507e.
- An audio signal is analyzed to detect a pitch frequency
- An evaluation target area to be evaluated is selected from the detected pitch frequencies based on the detected distribution of the detected pitch frequency
- a voice evaluation program characterized by making a computer execute a process of evaluating voice based on the distribution of the detection frequency and the selected evaluation target area.
- a pitch frequency corresponding to the central portion of the distribution is multiplied by a first weight, and a pitch frequency corresponding to a tail portion of the distribution is multiplied by a second weight smaller than the first weight.
- the process of correcting the distribution is further executed, and the process of evaluating evaluates the impression of voice in the utterance section based on the spread of the corrected distribution.
- Voice evaluation program
- the process of detecting the pitch frequency is characterized in that any one of the pitch frequency at each time and the average pitch frequency, the upper limit pitch frequency, and the lower limit pitch frequency within a fixed time is detected.
- the speech evaluation program according to 1 or 2.
- the process of evaluating calculates a statistic of any of variance, standard deviation, range, sum of squares, and interquartile range related to a plurality of pitch frequencies, and based on the statistic, speech is used.
- the speech evaluation program according to any one of appendices 1, 2 or 3, characterized by evaluating an impression.
- the processing to be evaluated is characterized as evaluating that the impression of voice is good when the spread of the distribution is large, and evaluating that the impression of voice is bad when the spread of the distribution is small.
- a voice evaluation method executed by a computer Analyze the voice signal to detect pitch frequency, An evaluation target area to be evaluated is selected from the detected pitch frequencies based on the detected distribution of the detected pitch frequency, A voice evaluation method comprising: causing a computer to execute a process of evaluating a voice based on the distribution of the detection frequency and the selected evaluation target area.
- a pitch frequency corresponding to the central portion of the distribution is multiplied by a first weight, and a pitch frequency corresponding to a bottom portion of the distribution is multiplied by a second weight smaller than the first weight. Further, the process of correcting the distribution is further executed, and the process of evaluating evaluates the impression of the voice in the utterance section based on the spread of the corrected distribution. Voice evaluation method.
- the process of detecting the pitch frequency is characterized in that any one of the pitch frequency at each time and the average pitch frequency, the upper limit pitch frequency, and the lower limit pitch frequency within a fixed time is detected.
- the voice evaluation method according to 12 or 13.
- the process of estimating the reference distribution corresponds to the designated speaker information stored in the storage device when the reference distribution corresponding to the designated speaker information is stored in the storage device.
- the speech evaluation method according to appendix 17, wherein the reference distribution to be set is set to an initial value for estimating the reference distribution.
- the evaluation process is characterized as evaluating that the impression of voice is good when the spread of the distribution is large, and evaluating that the impression of voice is bad when the spread of the distribution is small.
- the voice evaluation method as described in 14 or 15.
- a pitch detection unit that analyzes a voice signal to detect a pitch frequency, An evaluation target area to be evaluated among the detected pitch frequencies is selected based on the detected detection frequency of the pitch frequency, and a voice is selected based on the detection frequency distribution and the selected evaluation target area.
- Evaluation department to evaluate A voice evaluation device characterized by having.
- the evaluation unit further includes a spread calculation unit that corrects the distribution, and the evaluation unit evaluates the impression of the voice in the utterance section based on the spread of the corrected distribution.
- the supplementary note 23 or 24 characterized in that the pitch detection unit detects any one of the pitch frequency at each time and the average pitch frequency, the upper limit pitch frequency, and the lower limit pitch frequency within a fixed time.
- the spread calculation unit calculates a statistic of any of variance, standard deviation, range, sum of squares, and quartile range, for a plurality of pitch frequencies, and the evaluation unit calculates the statistic based on the statistic.
- the speech evaluation apparatus according to appendix 24 or 25, characterized by evaluating an impression of speech.
- the information processing apparatus further includes an estimation unit for estimating a reference distribution of detection frequency of the user in normal times based on a pitch frequency obtained by analyzing a voice signal in a predetermined predetermined section, and the evaluation unit 24.
- the speech evaluation apparatus according to appendix 24, wherein the impression of speech is evaluated based on the reference distribution and the corrected distribution.
- the estimation unit stores the reference distribution and the speaker information in association with each other in the storage device, and the evaluation unit selects the reference distribution corresponding to the speaker information, and selects the selected reference distribution.
- the speech evaluation apparatus according to appendix 27, wherein the impression of speech is evaluated based on the spread and the spread of the corrected distribution.
- the estimation unit determines the reference distribution corresponding to the designated speaker information stored in the storage device. 28.
- the supplementary note 24 wherein the evaluation unit evaluates that the impression of the voice is good when the spread of the distribution is large, and evaluates that the impression of the voice is bad when the spread of the distribution is small.
- the voice evaluation device according to 25 or 26.
Landscapes
- Engineering & Computer Science (AREA)
- Computational Linguistics (AREA)
- Health & Medical Sciences (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Human Computer Interaction (AREA)
- Physics & Mathematics (AREA)
- Acoustics & Sound (AREA)
- Multimedia (AREA)
- Signal Processing (AREA)
- Quality & Reliability (AREA)
- Telephonic Communication Services (AREA)
- Measurement Of Mechanical Vibrations Or Ultrasonic Waves (AREA)
Abstract
【課題】音声を正確に評価すること。 【解決手段】音声評価装置100は、音声信号を解析してピッチ周波数を検出する。音声評価装置100は、検出したピッチ周波数の検出頻度の分布に基づいて、検出したピッチ周波数のうち評価対象とする評価対象領域を選択する。音声評価装置100は、検出頻度の分布と選択した評価対象領域に基づいて、音声を評価する。
Description
本発明は、音声評価プログラム等に関する。
近年、多くの企業が顧客満足度を重視する傾向にあり、対応者と顧客との会話における、応対者の印象や顧客の感情を把握したいというニーズが高まっている。応対者の印象や、顧客の感情は、音声に現れることが多い。
たとえば、従来技術には、通話中の音声のピッチ周波数の上下幅に基づいて、音声の印象を判定するものがある。図15は、従来技術を説明するための図である。図15のグラフ5の横軸は時間を示す軸であり、縦軸は周波数を示す軸である。
従来技術では、ピッチ周波数の上下幅が大きいものを明瞭(明るい)と判定し、ピッチ周波数の上下幅が小さいものを不明瞭(暗い)と判定する。ピッチ周波数の上下幅は、ある期間中のピッチ周波数の最大値と最小値との差である。
たとえば、従来技術は、グラフ5の期間T1において、上下幅5aが大きいため、音声の印象が明瞭であると判定する。従来技術は、グラフ5の期間T2において、上下幅5bが小さいため、音声の印象が不明瞭であると判定する。
しかしながら、上述した従来技術では、音声を正確に評価することができないという問題がある。
ピッチ周波数を検出する処理では、特性上、半ピッチや倍ピッチを誤って算出する場合がある。このため、従来技術のように、単純に、ピッチ周波数の上下幅の大小により、音声の明瞭・不明瞭を判定すると、音声を正確に評価できない場合がある。
図16は、正確なピッチ周波数を算出した場合のグラフを示す図である。図16のグラフ6の横軸は時間を示す軸であり、縦軸は周波数を示す軸である。グラフ6は、正確なピッチ周波数を算出した場合を示すものである。グラフ6では、ピッチ周波数の上下幅6aが小さいため、音声が不明瞭であると判定できる。
図17は、半ピッチ/倍ピッチを算出した場合のグラフを示す図である。図17のグラフ7の横軸は時間を示す軸であり、縦軸は周波数を示す軸である。グラフ7は、誤って、半ピッチ/倍ピッチを算出した場合を示すものである。グラフ7では、ピッチ周波数の上下幅7aが大きくなってしまい、実際には、音声が不明瞭であるにも関わらず、音声が明瞭であると判定してしまう。
1つの側面では、本発明は、音声を正確に評価することができる音声評価プログラム、音声評価方法および音声評価装置を提供することを目的とする。
第1の案では、コンピュータに下記の処理を実行させる。コンピュータは、音声信号を解析してピッチ周波数を検出する。コンピュータは、検出したピッチ周波数の検出頻度の分布に基づいて、検出したピッチ周波数のうち評価対象とする評価対象領域を選択する。コンピュータは、検出頻度の分布と選択した評価対象領域に基づいて、音声を評価する。
音声を正確に評価することができる。
以下に、本願の開示する音声評価プログラム、音声評価方法および音声評価装置の実施例を図面に基づいて詳細に説明する。なお、この実施例によりこの発明が限定されるものではない。
図1は、本実施例1に係る音声評価装置の構成を示す機能ブロック図である。図1に示すように、この音声評価装置100は、話者(図示略)の音声を集音するマイク10に接続される。マイク10は、集音した音声の信号を、音声評価装置100に出力する。以下の説明では、マイク10が集音した音声の信号を「音声信号」と表記する。
音声評価装置100は、AD(Analog-to-Digital)変換部101、音声ファイル化部
102、音声評価部103、評価結果格納部104、記憶装置105、出力部106を有
する。
102、音声評価部103、評価結果格納部104、記憶装置105、出力部106を有
する。
AD変換部101は、マイク10から音声信号を受信し、AD変換を実行する処理部である。具体的には、AD変換部101は、音声信号(アナログ信号)を、音声信号(デジタル信号)に変換する。AD変換部101は、音声信号(デジタル信号)を、音声ファイル化部102、音声評価部103に出力する。以下の説明では、AD変換部101から出力される音声信号(デジタル信号)を単に音声信号と表記する。
音声ファイル化部102は、音声信号を所定の音声ファイルフォーマットにより、音声ファイルに変換する処理部である。たとえば、音声ファイルは、各時刻と、音声信号の強さとをそれぞれ対応づけた情報を含む。音声ファイル化部102は、音声ファイルを、記憶部105の音声ファイルテーブル105aに格納する。以下の説明では、便宜上、音声ファイルに含まれる時刻と音声信号の強さとの関係の情報を単に、音声信号と記載する。
なお、音声ファイル化部102は、入力装置(図示略)から話者情報を取得し、話者情報を音声ファイルに添付する。たとえば、話者情報は、話者を一意に識別する情報である。
音声評価部103は、音声信号を基にして、話者の音声の印象を評価する処理部である。たとえば、話者の音声の印象の評価結果は「印象が良い」、「普通」、「印象が悪い」のいずれかとなる。音声評価部103は、話者情報と、評価結果の情報とを、評価結果格納部104に出力する。
評価結果格納部104は、話者情報と、評価結果とを対応づけて、記憶装置105の評価結果テーブル105bに格納する処理部である。
記憶装置105は、音声ファイルテーブル105aおよび評価結果テーブル105bを記憶する。記憶装置105は、RAM(Random Access Memory)、ROM(Read Only
Memory)、フラッシュメモリ(Flash Memory)などの半導体メモリ素子や、HDD(Hard Disk Drive)などの記憶装置に対応する。
Memory)、フラッシュメモリ(Flash Memory)などの半導体メモリ素子や、HDD(Hard Disk Drive)などの記憶装置に対応する。
音声ファイルテーブル105aは、音声ファイル化部102から出力される音声ファイルを格納するテーブルである。評価結果テーブル105bは、評価結果格納部104により格納される話者情報と、評価結果とを対応づけたテーブルである。
出力部106は、記憶装置105に格納された評価結果テーブル105bを、表示装置に出力することで、評価結果を表示させる処理部である。また、出力部106は、音声ファイルテーブル105aに格納された音声ファイルを他の外部装置に出力してもよい。
ここで、図1に示したAD変換部101、音声ファイル化部102、音声評価部103、評価結果格納部104、出力部106は、所定の制御部(図示略)に対応する。たとえば、制御部は、CPU(Central Processing Unit)やMPU(Micro Processing Unit)などによって実現できる。また、制御部は、ASIC(Application Specific Integrated Circuit)やFPGA(Field Programmable Gate Array)などのハードワイヤードロジックによっても実現できる。
続いて、図1に示した音声評価部103の構成について説明する。図2は、本実施例1に係る音声評価部の構成を示す機能ブロック図である。図2に示すように、この音声評価部103は、ピッチ検出部110、分布算出部111、広がり算出部112、記憶部113、推定部114、評価部115を有する。
ピッチ検出部110は、音声ファイルの音声信号を周波数解析することで、ピッチ周波数を検出する処理部である。ピッチ周波数は、音声信号の基本周波数に対応するものである。ピッチ検出部110は、ピッチ周波数の情報を、分布算出部111に出力する。
ピッチ検出部110は、音声ファイルの音声信号から、発話区間を検出し、発話区間の音声信号に基づいて、ピッチ周波数を検出しても良い。たとえば、ピッチ検出部110は、音声信号の強さが閾値以上となる時刻を発話区間の開始時刻とする。ピッチ検出部110は、開始時刻以降において、音声信号の強さが閾値未満となる時刻を発話区間の終了時刻とする。ピッチ検出部110は、開始時刻から終了時刻までの区間を、発話区間とする。
ピッチ検出部110は、発話区間の音声信号を、所定の時間幅となる複数の区間に分割し、区間毎の音声信号を周波数解析することで、区間毎のピッチ周波数を検出する。ピッチ検出部110は、発話区間に含まれる複数の区間毎のピッチ周波数を、分布算出部111に出力する。
たとえば、ピッチ検出部110は、文献(D.Talkin,"A Robust Algorithm for Pitch Tracking (RAPT),"in Speech Coding & Synthesis, W.B.Kleijn and K.K.Pailwal (Eds.), Elsevier,pp.495-518,1995)に基づいて、ピッチ周波数を検出しても
良い。
良い。
分布算出部111は、所定区間内の複数のピッチ周波数を基にして、ヒストグラムを算出する処理部である。図3は、ヒストグラムの一例を示す図である。図3に示すヒストグラム20の横軸は、ピッチ周波数に対応する軸であり、縦軸は検出頻度に対応する軸である。このヒストグラム20は、ピッチ周波数の検出頻度の分布に対応するものである。
分布算出部111は、下記の処理を実行することで、ヒストグラム20の中心部と裾部とを特定する。分布算出部111は、所定区間内の各ピッチ周波数の平均μを算出する。分布算出部111は、所定区間内の各ピッチ周波数の標準偏差σを算出する。たとえば、分布算出部111は、ヒストグラム20の中心部を「μ-σ~μ+σ」とする。分布算出部111は、ヒストグラム20の裾部を「(μ-σ)/2~(μ+σ)/2」、「2×(μ-σ)/2~2×(μ+σ)」とする。
たとえば、図3において、ピッチ周波数の範囲Aが中心部となり、範囲B1,B2が裾部となる。なお、分布算出部111は、上記以外の処理により、ヒストグラム20の中心部および裾部を算出してもよい。分布算出部111は、ヒストグラム20の概形から中心の山の始点と終点との間を中心部として特定し、この中心部以外の範囲を裾部として特定してもよい。
分布算出部111は、所定区間内の複数のピッチ周波数の情報あるいはヒストグラム20の情報と、中心部の情報と、裾部の情報とを、広がり算出部112に出力する。
広がり算出部112は、ヒストグラム20を補正した上で、ヒストグラム20の広がりを算出する処理部である。下記に説明するように、補正したヒストグラム20の広がりは、補正したピッチ周波数に基づく標準偏差に対応する。
たとえば、広がり算出部112は、所定区間内の複数のピッチ周波数を、中心部に対応するピッチ周波数と、裾部に対応するピッチ周波数に分類する。広がり算出部112は、中央部に対応する各ピッチ周波数に重み「α」をそれぞれ乗算することで、中心部の各ピ
ッチ周波数を補正する。αの値をたとえば「1」とするが、管理者が適宜変更してもよい。
ッチ周波数を補正する。αの値をたとえば「1」とするが、管理者が適宜変更してもよい。
広がり算出部112は、裾部に対応する各ピッチ周波数に重み「β」をそれぞれ乗算することで、裾部の各ピッチ周波数を補正する。βの値をたとえば「0.1」とするが、管理者が適宜変更してもよい。
広がり算出部112は、補正した中央部および裾部の各ピッチ周波数を基にして、ピッチ周波数の標準偏差を算出する。このように、補正した中央部および裾部の各ピッチ周波数を基にして算出されるピッチ周波数の標準偏差が、補正したヒストグラム20の広がりに対応するものとなる。広がり算出部112は、補正したヒストグラム20の広がりに対応する標準偏差の情報を、推定部114および評価部115に出力する。
記憶部113は、平常時分布テーブル113aを有する。記憶部113は、RAM、ROM、フラッシュメモリなどの半導体メモリ素子や、HDDなどの記憶装置に対応する。
平常時分布テーブル113aは、平常時における話者のヒストグラムの広がりの情報を保持するテーブルである。たとえば、平常時分布テーブル113aは、話者情報と、標準偏差とを対応づける。平常時分布テーブル113aの標準偏差は、後述する推定部114によって推定される。
推定部114は、話者の平常時における標準偏差を推定する処理部である。推定部114は、話者情報と、平常時における標準偏差とを対応づけて、平常時分布テーブル113aに格納する。推定部114は、音声ファイルに添付されている話者情報を取得する。
推定部114は、話者情報を取得し、話者情報に対応する標準偏差が平常時分布テーブル113aに格納されていない場合には、「初期動作」を行う。一方、推定部114は、話者情報に対応する標準偏差が、平常時分布テーブル113aに格納されている場合には、「更新動作」を行う。以下において、初期動作、更新動作について順に説明する。
推定部114が実行する初期動作について説明する。推定部114は、発話区間の開始時刻から、所定時間後(1分後)までの区間を初期区間とし、初期区間における標準偏差を、広がり算出部112から取得する。初期区間における標準偏差は、上記のように、重みα、βにより、ピッチ周波数を補正した後に、算出される標準偏差である。
なお、推定部114が、初期区間おける標準偏差を算出しても良い。すなわち、推定部114は、初期区間内の複数のピッチ周波数を、中心部に対応するピッチ周波数と、裾部に対応するピッチ周波数に分類する。推定部114は、中央部に対応する各ピッチ周波数に重み「α」をそれぞれ乗算することで、中心部の各ピッチ周波数を補正する。推定部114は、裾部に対応する各ピッチ周波数に重み「β」をそれぞれ乗算することで、裾部の各ピッチ周波数を補正する。推定部114は、補正した中央部および裾部の各ピッチ周波数を基にして、ピッチ周波数の標準偏差を算出する。
推定部114は、上記のように初期動作を行い、話者情報と、初期区間の標準偏差とを対応づけて、平常時分布テーブル113aに登録する。
推定部114が実行する更新動作について説明する。推定部114は、平常時分布テーブル113aから、話者情報に対応する標準偏差を取得する。また、推定部114は、広がり算出部112から、所定区間内の標準偏差を取得する。以下の説明では、平常時分布テーブル113aから取得した、標準偏差を「平常時標準偏差」と表記し、広がり算出部
112から取得した標準偏差を「評価標準偏差」と表記する。
112から取得した標準偏差を「評価標準偏差」と表記する。
推定部114は、式(1)に基づいて、新たな平常時標準偏差を算出し、算出した平常時標準偏差により、平常時分布テーブル113aの平常時標準偏差を更新する。
平常時標準偏差=0.8×平常時標準偏差+0.2×評価標準偏差・・・(1)
推定部114は、広がり算出部112から、所定区間内の標準偏差(評価標準偏差)を受信する度に、上記処理を繰り返し実行し、平常時分布テーブル113aを更新する。
なお、推定部114は、評価部115から、話者情報を取得し、平常時標準偏差の要求を受け付けた場合に、話者情報に対応する平常時標準偏差を平常時分布テーブル113aから取得し、平常時標準偏差を、評価部115に出力する。
評価部115は、平常時標準偏差と、評価標準偏差とを基にして、話者の音声の印象を評価する処理部である。たとえば、評価部115は、音声ファイルに添付された話者情報を、推定部114に出力して、平常時標準偏差を取得する。評価部115は、評価標準偏差を、広がり算出部112から取得する。
評価部115は、評価標準偏差が平常時標準偏差よりも大きい場合には、印象が良いと評価する。評価部115は、評価標準偏差が平常時標準偏差と同等である場合には、印象が普通であると判定する。評価部115は、評価標準偏差が平常時標準偏差より小さい場合には、印象がよいと判定する。
また、評価部115は、下記の様に評価を行ってもよい。たとえば、評価部115は、評価標準偏差が平常時標準偏差よりも大きく、評価標準偏差が平常時標準偏差との差が閾値以上である場合に、印象が良いと評価する。評価部115は、評価標準偏差が平常時標準偏差との差が閾値未満である場合に、印象が普通であると評価する。評価部115は、評価標準偏差が平常時標準偏差よりも小さく、評価標準偏差が平常時標準偏差との差が閾値以上である場合に、印象が悪いと評価する。
評価部115は、話者情報と、評価結果の情報とを、評価結果格納部104に出力する。
次に、本実施例1に係る音声評価装置100の音声評価部103の処理手順について説明する。図4は、本実施例1に係る音声評価部の処理手順を示すフローチャートである。図4に示すように、この音声評価部103のピッチ検出部110は、音声信号を受信する(ステップS101)。
ピッチ検出部110は、音声信号を解析して、ピッチ周波数を算出する(ステップS102)。音声評価部103の分布算出部111は、ピッチ周波数の分布を算出する(ステップS103)。ステップS103において、分布算出部111は、ピッチ周波数の分布を算出する処理は、上記のように、各ピッチ周波数に基づいて、ヒストグラム20の中心部および裾部を算出する処理に対応する。
音声評価部103の広がり算出部112は、分布の広がりを算出する(ステップS104)。ステップS104において、分布の広がりを算出する処理は、上記の評価標準偏差を算出する処理に対応する。
音声評価部103の推定部114は、平常時の分布の広がりを算出する(ステップS1
05)。平常時の分布の広がりを算出する処理は、上記の平常時標準偏差を算出する処理に対応する。
05)。平常時の分布の広がりを算出する処理は、上記の平常時標準偏差を算出する処理に対応する。
音声評価部103の評価部115は、平常時標準偏差と評価標準偏差とを基にして、音声を評価する(ステップS106)。
音声評価部103は、音声終了の場合には(ステップS107,Yes)、処理を終了する。一方、音声評価部103は、音声終了でない場合には(ステップS107,No)、分析開始位置を更新し(ステップS108)、ステップS102に移行する。
次に、本実施例1に係る音声評価装置100の効果について説明する。音声評価装置100は、音声信号を解析して、ピッチ周波数の検出頻度の分布を作成し、分布の裾部分を抑える補正を行い、補正後の分布に基づき、音声の評価を行う。このため、ピッチ周波数を検出する処理により、仮に、半ピッチや倍ピッチを算出した場合にでも、これらのピッチは、裾部のピッチ周波数に分類され、影響を抑えた後に、音声の評価を行うことができ、音声を正確に評価することができる。たとえば、実際に明るい声であるにもかかわらず、半ピッチや倍ピッチが誤って算出された場合でも、暗い声と評価することを抑止することができる。
音声評価装置100は、分布(ヒストグラム)の中心部に対応するピッチ周波数に重みαを乗算し、分布の裾部分に対応するピッチ周波数に重みβを乗算することで、分布を補正する処理を実行するため、半ピッチや倍ピッチの影響による誤り判定を抑止することができる。
音声評価装置100の推定部114は、話者の平常時の分布の広がりを推定し、評価部115が、平常時の分布の広がりと、現在の分布の広がりとを比較して、音声の印象を評価する。このため、話者自身の平常時の分布の広がりに基づいた音声の評価を行うことができる。
音声評価装置114の推定部は、話者情報に対応する平常時の分布の広がり(標準偏差)が、平常時分布テーブル113aに格納されている場合には、「更新動作」を行う。これにより、話者に関する平常時の分布をより適切なものに補正することができる。
なお、音声評価装置100は、一例として、分布(ヒストグラム)の中心部に対応するピッチ周波数に重みαを乗算し、分布の裾部分に対応するピッチ周波数に重みβを乗算することで、分布を補正する場合について説明した。この処理は、分布に含まれる裾部のピッチ周波数の影響を取り除くという点において、分布に含まれる中央部のピッチ周波数を選択し、選択したピッチ周波数の標準偏差を基にして、音声を評価しているとも言える。
音声評価装置100のピッチ検出部110は、発話区間の音声信号を、所定の時間幅となる複数の区間に分割し、区間毎の音声信号を周波数解析することで、区間毎のピッチ周波数を検出していたが、これに限定されるものではない。たとえば、ピッチ検出部110は、所定数の区間から検出した各ピッチ周波数の平均値を、ピッチ周波数として分布算出部111に出力してもよい。ピッチ検出部110は、所定数の区間から検出した各ピッチ周波数の上限値を、ピッチ周波数として分布算出部111に出力してもよい。ピッチ検出部110は、所定数の区間から検出した各ピッチ周波数の下限値を、ピッチ周波数として分布算出部111に出力してもよい。これにより、話者や環境に合わせて、ピッチ周波数を利用することができる。
音声評価装置100の広がり算出部112は、発話区間に含まれる各ピッチ周波数の標
準偏差を分布の広がりとして算出していたが、これに限定されるものではない。たとえば、広がり算出部112は、発話区間に含まれる各ピッチ周波数の分散、範囲、平方和、四分位範囲のいずれかを、分布の広がりとして算出してもよい。
準偏差を分布の広がりとして算出していたが、これに限定されるものではない。たとえば、広がり算出部112は、発話区間に含まれる各ピッチ周波数の分散、範囲、平方和、四分位範囲のいずれかを、分布の広がりとして算出してもよい。
ところで、本実施例1に係る音声評価装置100は、以下に説明するように、発話区間のヒストグラムの概形を基にして、話者の音声を評価してもよい。図5は、音声評価装置のその他の処理を説明するための図である。図5に示すように、音声評価装置100は、発話区間の複数のピッチ周波数を基にして、ヒストグラム25を算出する。ヒストグラム25の横軸は、ピッチ周波数に対応する軸であり、縦軸は検出頻度に対応する軸である。
音声評価装置100は、パターンマッチングなどを行って、ヒストグラム25の概形のおける中心部Cと、裾部D1,D2とを特定する。音声評価装置100は、中心部Cの検出頻度に重みαを乗算し、裾部D1,D2の検出頻度に重みβを乗算することで、ヒストグラム25を補正する。補正後のヒスヒストグラムをヒストグラム26と表記する。たとえば、重いαを「1」とし、重みβを「0.1」とする。
音声評価装置100は、補正後のヒストグラム26の広がりの大きさを基にして、話者の音声の印象を判定する。たとえば、音声評価装置100は、ヒストグラム26の検出頻度が所定頻度以上となる範囲を、ヒストグラム26の広がりとして特定する。音声評価装置100は、ヒストグラム26の広がりが、所定の閾値以上である場合には、話者の印象が明るいと評価する。一方、音声評価装置100は、ヒストグラム26の広がりが、所定の閾値以上である場合には、話者の印象が暗いと評価する。
たとえば、半ピッチ/倍ピッチは分布(ヒストグラム25)の裾部に存在しているため、裾部の重みを小さくし、中心部の重みを大きくして、ヒストグラム25を補正することで、誤って評価することを抑止することができる。
図6は、本実施例2に係る音声評価システムの構成を示す図である。図6に示すように、この音声評価システムは、携帯端末2a、端末装置2b、分岐コネクタ3、収録機器150、クラウド160を有する。携帯端末2aは、電話網15aを介して、分岐コネクタ3に接続される。端末装置2bは、分岐コネクタ3に接続される。分岐コネクタ3は、収録機器150に接続される。収録機器150は、インターネット網15bを介して、クラウド160に接続される。たとえば、クラウド160には、音声評価装置200が含まれる。図示を省略するが、音声評価装置200は、複数のサーバによって構成されていてもよい。携帯端末2aおよび端末装置2bは、マイク(図示略)に接続される。
話者1aによる音声は、携帯端末2aのマイクにより集音され、集音された音声信号は、分岐コネクタ3を介して、収録機器150に送信される。以下の説明では、話者1aの音声信号を、「第1音声信号」と表記する。
携帯端末2aは、第1音声信号に、話者1aの属性情報を付与する。たとえば、属性情報は、性別情報と、声の高さ情報とを含む。性別は、話者の性別を一意に識別するものである。声の高さか情報は、話者の声が高いか低いかを示す情報である。たとえば、話者1aは、自身の属性情報を、携帯端末2aに登録しておく。
話者1bによる音声は、端末装置2bのマイクにより集音され、集音された音声信号は、分岐コネクタ3を介して、収録機器150に送信される。以下の説明では、話者1bの音声信号を、「第2音声信号」と表記する。
端末装置2bは、第2音声信号に、話者1bの属性情報を付与する。たとえば、話者1bは、自身の属性情報を、端末装置2bに登録しておく。話者1bの属性情報に関する説明は、話者1aの属性情報に関する説明と同様である。
収録機器150は、第1音声信号および第2音声信号を収録する装置である。たとえば、収録機器150は、第1音声信号を受信すると、第1音声信号を、所定の音声ファイルフォーマットにより、音声ファイルに変換し、第1音声信号の音声ファイルを、音声評価装置200に送信する。第1音声信号の音声ファイルには、話者1aの属性情報が含まれる。以下の説明では、適宜、第1音声信号の音声ファイルを「第1音声ファイル」と表記する。
収録機器150は、第2音声信号を受信すると、第2音声信号を、所定の音声ファイルフォーマットにより、音声ファイルに変換し、第2音声信号の音声ファイルを、音声評価装置200に送信する。第2音声信号の音声ファイルには、話者1bの属性情報が含まれる。以下の説明では、適宜、第2音声信号の音声ファイルを「第2音声ファイル」と表記する。
音声評価装置200は、第1音声ファイルの第1音声信号を基にして、話者1aの音声の印象を評価する。音声評価装置200は、第2音声ファイルの第2音声信号を基にして、話者1bの音声の印象を評価する。そして、音声評価装置200は、話者1aの音声の印象の評価結果および話者2aの音声の印象の評価結果を基にして、話者1a、1b間の会話全体のスコアを算出する。
図7は、本実施例2に係る音声評価装置の構成を示す機能ブロック図である。図7に示すように、この音声評価装置200は、受信部201、記憶装置202、音声評価部203、評価結果格納部204を有する。
受信部201は、収録機器150から、第1音声ファイルおよび第2音声ファイルを受信する処理部である。受信部201は、受信した第1音声ファイルおよび第2音声ファイルを、記憶部202の音声ファイルテーブル202aに登録する。受信部201は、通信装置に対応する。
記憶装置202は、音声ファイルテーブル202aと、評価結果テーブル202bを有する。記憶装置202は、RAM、ROM、フラッシュメモリなどの半導体メモリ素子や、HDDなどの記憶装置に対応する。
音声ファイルテーブル202aは、第1音声ファイルおよび第2音声ファイルを格納するテーブルである。
評価結果テーブル202bは、評価結果を格納するテーブルである。たとえば、評価結果テーブル202bは、話者1aの評価結果、話者1bの評価結果、話者1a、1b間の会話全体のスコアを格納する。
音声評価部203は、第1音声ファイルおよび第2音声ファイルを基にして、話者1a、1bの音声の印象を評価する。そして、音声評価部203は、話者1a、1の音声の印象の評価結果を基にして、話者1a、1b間の会話全体のスコアを算出する。音声評価部203は、話者1a、1bの音声の印象の評価結果および会話全体のスコアを、評価結果格納部204に出力する。
評価結果格納部204は、話者1a、1の音声の印象の評価結果および会話全体のスコ
アを、評価結果テーブル202bに格納する処理部である。
アを、評価結果テーブル202bに格納する処理部である。
ここで、図7に示した音声評価部203、評価結果格納部204は、所定の制御部(図示略)に対応する。たとえば、制御部は、CPUやMPUなどによって実現できる。また、制御部は、ASICやFPGAなどのハードワイヤードロジックによっても実現できる。
続いて、図7に示した音声評価部203の構成について説明する。図8は、本実施例2に係る音声評価部の構成を示す機能ブロック図である。図8に示すように、この音声評価部203は、ピッチ検出部210、分布算出部211、広がり算出部212、記憶部213、推定部114、評価部115を有する。
ピッチ検出部210は、音声ファイルの音声信号を周波数解析することで、所定区間毎のピッチ周波数を検出する処理部である。たとえば、ピッチ検出部210は、第1音声ファイルの第1音声信号を周波数解析することで、第1音声信号の第1ピッチ周波数を検出する。また、ピッチ検出部210は、第2音声ファイルの第2音声信号を周波数解析することで、第2音声信号の第2ピッチ周波数を検出する。ピッチ検出部210が、音声信号からピッチ周波数を検出する処理は、図2に示したピッチ検出部110が、音声信号からピッチ周波数を検出する処理と同様である。
ピッチ検出部210は、話者1aの属性情報と、複数の第1ピッチ周波数とを分布算出部211に出力する。また、ピッチ検出部210は、話者1bの属性情報と、複数の第2ピッチ周波数とを分布算出部211に出力する。
分布算出部211は、所定区間内の複数のピッチ周波数を基にして、ヒストグラムを算出する処理部である。たとえば、分布算出部211は、所定区間内の複数の第1ピッチ周波数を基にして、第1ヒストグラムを算出する。分布算出部211は、所定区間内の複数の第2ピッチ周波数を基にして、第2ヒストグラムを算出する。分布算出部211が、ヒストグラムを算出する処理は、図2に示した分布算出部111が、ヒストグラムを算出する処理と同様である。
分布算出部211は、複数の第1ピッチ周波数を基にして算出した、第1ヒストグラムの情報を、広がり算出部212に出力する。第1ヒストグラムの情報は、第1ヒストグラムの中心部の情報、第1ヒストグラムの裾部の情報を含む。
分布算出部211は、複数の第2ピッチ周波数を基にして算出した、第2ヒストグラムの情報を、広がり算出部212に出力する。第2ヒストグラムの情報は、第2ヒストグラムの中心部の情報、第2ヒストグラムの裾部の情報を含む。
広がり算出部212は、ヒストグラムを補正した上で、ヒストグラムの広がりを算出する処理部である。たとえば、広がり算出部212は、第1ヒストグラムを補正した上で、第1ヒストグラムの広がりを算出する。広がり算出部212は、第2ヒストグラムを補正した上で、第2ヒストグラムの広がりを算出する。広がり算出部212が、ヒストグラムの広がりを算出する処理は、図2に示した広がり算出部112が、ヒストグラムの広がりを算出する処理と同様である。たとえば、補正したヒストグラムの広がりは、補正したピッチ周波数(第1ピッチ周波数、第2ピッチ周波数)に基づく標準偏差に対応する。
広がり算出部212は、属性情報と対応づけて、補正したヒストグラムの広がりに対応する標準偏差の情報を、推定部214および評価部215に出力する。たとえば、広がり算出部212は、話者1aの属性情報と対応づけて、補正した第1ヒストグラムの広がり
に対応する標準偏差の情報を、推定部214および評価部215に出力する。広がり算出部212は、話者1bの属性情報と対応づけて、補正した第2ヒストグラムの広がりに対応する標準偏差の情報を、推定部214および評価部215に出力する。
に対応する標準偏差の情報を、推定部214および評価部215に出力する。広がり算出部212は、話者1bの属性情報と対応づけて、補正した第2ヒストグラムの広がりに対応する標準偏差の情報を、推定部214および評価部215に出力する。
記憶部213は、平常時分布テーブル213aを有する。記憶部213は、RAM、ROM、フラッシュメモリなどの半導体メモリ素子や、HDDなどの記憶装置に対応する。
平常時分布テーブル213aは、属性情報に対応する話者の平常時における、ヒストグラムの広がりの情報を保持するテーブルである。たとえば、平常時分布テーブル213aは、属性情報と、標準偏差とを対応づける。平常時分布テーブル213aの標準偏差は、後述する推定部214によって推定される。
図9は、本実施例2に係る平常時分布テーブルのデータ構造の一例を示す図である。図9に示すように、この平常時分布テーブル213aは、属性情報と、標準偏差とを対応づける。属性情報は、性別情報と、声の高さ情報とを対応づける。
推定部214は、属性情報毎に、話者の平常時における標準偏差を推定する処理部である。推定部214は、属性情報と、平常時における標準偏差とを対応づけて、平常時分布テーブル213aに格納する。推定部214は、音声ファイル(第1音声ファイルおよび第2音声ファイル)に添付されている属性情報を取得する。
推定部214は、属性情報を取得し、属性情報に対応する標準偏差が平常時分布テーブル213aに格納されていない場合には、「初期動作」を行う。一方、推定部214は、属性情報に対応する標準偏差が、平常時分布テーブル213aに格納されている場合には、「更新動作」を行う。推定部214による、初期動作、更新動作に関する説明は、属性情報毎に、実行される点を除いて、推定部114の初期動作、更新動作に関する説明と同様である。
以下の説明では、話者1aの属性情報に対応する、平常時分布テーブル213aから取得した、標準偏差を「第1平常時標準偏差」と表記する。話者1aの属性情報に対応する、広がり算出部212から取得した標準偏差を「第1評価標準偏差」と表記する。
話者1bの属性情報に対応する、平常時分布テーブル213aから取得した、標準偏差を「第2平常時標準偏差」と表記する。話者1bの属性情報に対応する、広がり算出部212から取得した標準偏差を「第2評価標準偏差」と表記する。
なお、推定部214は、評価部215から、話者1aの属性情報を取得し、第1平常時標準偏差の要求を受け付けた場合に、第1平常時標準偏差を平常時分布テーブル213aから取得し、第1平常時標準偏差を、評価部215に出力する。
推定部214は、評価部215から、話者1bの属性情報を取得し、第2平常時標準偏差の要求を受け付けた場合に、第2平常時標準偏差を平常時分布テーブル213aから取得し、第2平常時標準偏差を、評価部215に出力する。
評価部215は、各標準偏差を基にして、話者1a,1bの音声の印象を評価する処理部である。また、評価部215は、話者1a,1bの音声の印象の評価結果を基にして、話者1a、1b間の会話全体のスコアを算出する。
具体的に、評価部215は、第1平常時標準偏差と、第1評価標準偏差とを基にして、話者1aの音声の印象を評価する。また、評価部215は、第2平常時標準偏差と、第2
評価標準偏差とを基にして、話者1bの音声の印象を評価する。評価部215が、各標準偏差を基にして、話者1a,1bの音声の印象を評価する処理は、評価部115が、音声を評価する処理と同様である。
評価標準偏差とを基にして、話者1bの音声の印象を評価する。評価部215が、各標準偏差を基にして、話者1a,1bの音声の印象を評価する処理は、評価部115が、音声を評価する処理と同様である。
評価部215は、上記処理を繰り返し実行することで、所定区間毎に、話者1aの評価結果および話者1bの評価結果を特定する。
続いて、評価部215は、話者1aの評価結果および話者1bの評価結果を特定した後に、式(2)に基づいて、会話全体のスコアを算出する。
会話全体のスコア=(話者1aの印象が良いと評価された区間数+話者1bの印象が良いと評価された区間数)/(全体の区間数×2)×100・・・(2)
評価部215は、話者1a、1bの音声の印象の評価結果および会話全体のスコアを、評価結果格納部204に出力する。
次に、本実施例2に係る音声評価装置200の効果について説明する。音声評価装置200は、話者の属性情報に合わせて、平常時標準偏差を学習しておき、評価時において、話者の属性情報に応じた平常時標準偏差を用いて、話者の音声を評価する。このため、話者の属性情報に基づく、音声の評価を行うことができ、評価の正確性を向上させることができる。
また、音声評価装置200は、各話者1a,1bの音声の評価結果に基づいて、会話全体のスコアを算出するため、管理者などが係るスコアを参照することで、会話全体の善し悪しを把握することができる。たとえば、式(2)により算出される会話全体のスコアは、値が大きいほど、会話内容が良かったと言える。
図10は、本実施例3に係る音声評価システムの構成を示す図である。図10に示すように、この音声評価システムは、マイク30A,30B,30C、収録機器300、クラウド170を有する。マイク30A~30Cは、収録機器300に接続される。収録機器300は、インターネット網15bを介して、クラウド170に接続される。たとえば、クラウド170には、音声評価装置400が含まれる。図示を省略するが、音声評価装置400は、複数のサーバによって構成されていてもよい。
話者1Aによる音声は、マイク30aにより集音され、集音された音声信号は、収録機器300に出力される。話者1Bによる音声は、マイク30bにより集音され、集音された音声信号は、収録機器300に出力される。話者1Cによる音声は、マイク30cにより集音され、集音された音声信号は、収録機器300に出力される。
以下の説明では、話者1Aの音声信号を、「第1音声信号」と表記する。話者1Bの音声信号を、「第2音声信号」と表記する。話者1Cの音声信号を、「第3音声信号」と表記する。
なお、第1音声信号には、話者1Aの話者情報が付与される。話者情報は、話者を一意に識別する情報である。第2音声信号には、話者1Bの話者情報が付与される。第3音声信号には、話者1Cの話者情報が付与される。
収録機器300は、第1音声信号、第2音声信号、第3音声信号を収録する装置である。また、収録装置300は、各音声信号のピッチ周波数を検出する処理を実行する。収録
装置300は、話者情報と、所定区間毎のピッチ周波数とを対応づけて、音声評価装置400に送信する。
装置300は、話者情報と、所定区間毎のピッチ周波数とを対応づけて、音声評価装置400に送信する。
音声評価装置400は、収録機器300から受信する各話者情報のピッチ周波数を基にして、各話者の音声を評価する処理部である。また、音声評価装置400は、各話者の音声の評価結果を基にして、話者1A~1Cの会話の印象を評価する。
図11は、本実施例3に係る収録機器の構成を示す機能ブロック図である。図11に示すように、この収録機器300は、AD変換部310a~310bと、ピッチ検出部320と、ファイル化部330と、送信部340とを有する。
AD変換部310aは、マイク30aから第1音声信号を受信し、AD変換を実行する処理部である。具体的には、AD変換部310aは、第1音声信号(アナログ信号)を、第1音声信号(デジタル信号)に変換する。AD変換部310aは、第1音声信号(デジタル信号)を、ピッチ検出部320に出力する。以下の説明では、AD変換部310aから出力される第1音声信号(デジタル信号)を単に第1音声信号と表記する。
AD変換部310bは、マイク30bから第2音声信号を受信し、AD変換を実行する処理部である。具体的には、AD変換部310bは、第2音声信号(アナログ信号)を、第2音声信号(デジタル信号)に変換する。AD変換部310bは、第2音声信号(デジタル信号)を、ピッチ検出部320に出力する。以下の説明では、AD変換部310bから出力される第2音声信号(デジタル信号)を単に第2音声信号と表記する。
AD変換部310cは、マイク30cから第3音声信号を受信し、AD変換を実行する処理部である。具体的には、AD変換部310cは、第3音声信号(アナログ信号)を、第3音声信号(デジタル信号)に変換する。AD変換部310cは、第3音声信号(デジタル信号)を、ピッチ検出部320に出力する。以下の説明では、AD変換部310cから出力される第3音声信号(デジタル信号)を単に第3音声信号と表記する。
ピッチ検出部320は、音声信号を周波数解析することで、所定区間毎のピッチ周波数を算出する処理部である。たとえば、ピッチ検出部320は、第1音声信号を周波数解析することで、第1音声信号の第1ピッチ周波数を検出する。ピッチ検出部320は、第2音声信号を周波数解析することで、第2音声信号の第2ピッチ周波数を検出する。ピッチ検出部320は、第3音声信号を周波数解析することで、第3音声信号の第3ピッチ周波数を検出する。
ピッチ検出部320は、話者1Aの話者情報と、所定区間毎の第1ピッチ周波数とを対応づけて、ファイル化部330に出力する。ピッチ検出部320は、話者1Bの話者情報と、所定区間毎の第2ピッチ周波数とを対応づけて、ファイル化部330に出力する。ピッチ検出部320は、話者1Cの話者情報と、所定区間毎の第3ピッチ周波数とを対応づけて、ファイル化部330に出力する。
ファイル化部330は、ピッチ検出部320から受け付ける情報をファイル化することで、「音声ファイル情報」を生成する処理部である。この音声ファイル情報には、話者情報と、所定区間毎のピッチ周波数とを対応づけた情報を含む。具体的に、音声ファイル情報は、話者1Aの話者情報と、所定区間毎の第1ピッチ周波数とを対応づけた情報を含む。音声ファイル情報は、話者1Bの話者情報と、所定区間毎の第2ピッチ周波数とを対応づけた情報を含む。音声ファイル情報は、話者1Cの話者情報と、所定区間毎の第3ピッチ周波数とを対応づけた情報を含む。ファイル化部330は、音声ファイル情報を、送信部340に出力する。
送信部340は、ファイル化部330から音声ファイル情報を取得し、取得した音声ファイル情報を、音声評価装置400に送信する。
図12は、本実施例3に係る音声評価装置の構成を示す機能ブロック図である。図12に示すように、この音声評価装置400は、受信部401、記憶装置402、音声評価部403、評価結果格納部404を有する。
受信部401は、収録機器300から、音声ファイル情報を受信する処理部である。受信部401は、受信した音声ファイル情報を、記憶部402の音声ファイルテーブル402aに登録する。受信部401は、通信装置に対応する。
記憶装置402は、音声ファイルテーブル402aと、評価結果テーブル402bを有する。記憶装置402は、RAM、ROM、フラッシュメモリなどの半導体メモリ素子や、HDDなどの記憶装置に対応する。
音声ファイルテーブル402aは、音声ファイル情報を格納するテーブルである。音声ファイル情報は、話者1Aの話者情報と、所定区間毎の第1ピッチ周波数とを対応づけた情報を含む。音声ファイル情報は、話者1Bの話者情報と、所定区間毎の第2ピッチ周波数とを対応づけた情報を含む。音声ファイル情報は、話者1Cの話者情報と、所定区間毎の第3ピッチ周波数とを対応づけた情報を含む。
評価結果テーブル402bは、評価結果を格納するテーブルである。たとえば、評価結果テーブル402bは、話者1A~1Cの評価結果、話者1A~1C間の会話全体の評価結果を格納する。
音声評価部403は、音声ファイル情報を基にして、話者1A~1Cの音声の印象を評価する。そして、音声評価部403は、話者1A~1Cの音声の印象の評価結果を基にして、話者1A~1C間の会話全体を評価する。音声評価部403は、話者1A~1Cの音声の印象の評価結果および会話全体の評価結果を、評価結果格納部404に出力する。
評価結果格納部404は、話者1A~1Cの音声の印象の評価結果および会話全体の評価結果を、評価結果テーブル402bに格納する処理部である。
ここで、図12に示した音声評価部403、評価結果格納部404は、所定の制御部(図示略)に対応する。たとえば、制御部は、CPUやMPUなどによって実現できる。また、制御部は、ASICやFPGAなどのハードワイヤードロジックによっても実現できる。
続いて、図13に示した音声評価部403の構成について説明する。図13は、本実施例3に係る音声評価部の構成を示す機能ブロック図である。図13に示すように、この音声評価部403は、ピッチ取得部410、分布算出部411、広がり算出部412、記憶部413、推定部414、評価部415を有する。
ピッチ取得部410は、音声ファイルテーブル402aから音声ファイル情報を取得する処理部である。ピッチ取得部410は、音声ファイル情報を、分布算出部411に出力する。
分布算出部411は、所定区間内の複数のピッチ周波数を基にして、ヒストグラムを算出する処理部である。たとえば、分布算出部411は、所定区間内の複数の第1ピッチ周
波数を基にして、第1ヒストグラムを算出する。分布算出部411は、所定区間内の複数の第2ピッチ周波数を基にして、第2ヒストグラムを算出する。分布算出部411は、所定区間内の複数の第3ピッチ周波数を基にして、第3ヒストグラムを算出する。分布算出部411が、ヒストグラムを算出する処理は、図2に示した分布算出部111が、ヒストグラムを算出する処理と同様である。
波数を基にして、第1ヒストグラムを算出する。分布算出部411は、所定区間内の複数の第2ピッチ周波数を基にして、第2ヒストグラムを算出する。分布算出部411は、所定区間内の複数の第3ピッチ周波数を基にして、第3ヒストグラムを算出する。分布算出部411が、ヒストグラムを算出する処理は、図2に示した分布算出部111が、ヒストグラムを算出する処理と同様である。
分布算出部411は、複数の第1ピッチ周波数を基にして算出した、第1ヒストグラムの情報を、広がり算出部412に出力する。第1ヒストグラムの情報は、第1ヒストグラムの中心部の情報、第1ヒストグラムの裾部の情報を含む。
分布算出部411は、複数の第2ピッチ周波数を基にして算出した、第2ヒストグラムの情報を、広がり算出部412に出力する。第2ヒストグラムの情報は、第2ヒストグラムの中心部の情報、第2ヒストグラムの裾部の情報を含む。
分布算出部411は、複数の第3ピッチ周波数を基にして算出した、第3ヒストグラムの情報を、広がり算出部412に出力する。第2ヒストグラムの情報は、第3ヒストグラムの中心部の情報、第3ヒストグラムの裾部の情報を含む。
広がり算出部412は、ヒストグラムを補正した上で、ヒストグラムの広がりを算出する処理部である。たとえば、広がり算出部412は、第1ヒストグラムを補正した上で、第1ヒストグラムの広がりを算出する。広がり算出部412は、第2ヒストグラムを補正した上で、第2ヒストグラムの広がりを算出する。広がり算出部412は、第3ヒストグラムを補正した上で、第3ヒストグラムの広がりを算出する。広がり算出部412が、ヒストグラムの広がりを算出する処理は、図2に示した広がり算出部112が、ヒストグラムの広がりを算出する処理と同様である。たとえば、補正したヒストグラムの広がりは、補正したピッチ周波数(第1ピッチ周波数、第2ピッチ周波数、第3ピッチ周波数)に基づく標準偏差に対応する。
広がり算出部412は、話者情報と対応づけて、補正したヒストグラムの広がりに対応する標準偏差の情報を、推定部414および評価部415に出力する。たとえば、広がり算出部412は、話者1Aの話者情報と対応づけて、補正した第1ヒストグラムの広がりに対応する標準偏差の情報を、推定部414および評価部415に出力する。広がり算出部412は、話者1Bの話者情報と対応づけて、補正した第2ヒストグラムの広がりに対応する標準偏差の情報を、推定部414および評価部415に出力する。広がり算出部412は、話者1Cの話者情報と対応づけて、補正した第2ヒストグラムの広がりに対応する標準偏差の情報を、推定部414および評価部415に出力する。
記憶部413は、平常時分布テーブル413aを有する。記憶部413は、RAM、ROM、フラッシュメモリなどの半導体メモリ素子や、HDDなどの記憶装置に対応する。
平常時分布テーブル413aは、話者情報に対応する話者の平常時における、ヒストグラムの広がりの情報を保持するテーブルである。たとえば、平常時分布テーブル413aは、話者情報と、標準偏差とを対応づける。平常時分布テーブル413aの標準偏差は、後述する推定部414によって推定される。
推定部414は、話者情報毎に、話者の平常時における標準偏差を推定する処理部である。推定部414は、話者情報と、平常時における標準偏差とを対応づけて、平常時分布テーブル413aに格納する。推定部414は、音声ファイル情報に添付されている話者情報を取得する。
推定部414は、話者情報を取得し、話者情報に対応する標準偏差が平常時分布テーブル413aに格納されていない場合には、「初期動作」を行う。一方、推定部414は、話者情報に対応する標準偏差が、平常時分布テーブル413aに格納されている場合には、「更新動作」を行う。推定部414による、初期動作、更新動作に関する説明は、図2に示した推定部114の初期動作、更新動作に関する説明と同様である。
以下の説明では、話者1Aの話者情報に対応する、平常時分布テーブル413aから取得した、標準偏差を「第1平常時標準偏差」と表記する。話者1Aの話者情報に対応する、広がり算出部412から取得した標準偏差を「第1評価標準偏差」と表記する。
話者1Bの話者情報に対応する、平常時分布テーブル413aから取得した、標準偏差を「第2平常時標準偏差」と表記する。話者1Bの話者情報に対応する、広がり算出部412から取得した標準偏差を「第2評価標準偏差」と表記する。
話者1Cの話者情報に対応する、平常時分布テーブル413aから取得した、標準偏差を「第3平常時標準偏差」と表記する。話者1Cの話者情報に対応する、広がり算出部412から取得した標準偏差を「第3評価標準偏差」と表記する。
なお、推定部414は、評価部415から、話者1Aの話者情報を取得し、第1平常時標準偏差の要求を受け付けた場合に、第1平常時標準偏差を平常時分布テーブル413aから取得し、第1平常時標準偏差を、評価部415に出力する。
推定部414は、評価部415から、話者1Bの話者情報を取得し、第2平常時標準偏差の要求を受け付けた場合に、第2平常時標準偏差を平常時分布テーブル413aから取得し、第2平常時標準偏差を、評価部415に出力する。
推定部414は、評価部415から、話者1Cの話者情報を取得し、第3平常時標準偏差の要求を受け付けた場合に、第3平常時標準偏差を平常時分布テーブル413aから取得し、第3平常時標準偏差を、評価部415に出力する。
評価部415は、各標準偏差を基にして、話者1A~1Cの音声の印象を評価する処理部である。また、評価部415は、話者1A~1Cの音声の印象の評価結果を基にして、話者1A~1Cの会話全体の評価を行う。
具体的に、評価部415は、第1平常時標準偏差と、第1評価標準偏差とを基にして、話者1Aの音声の印象を評価する。評価部415は、第2平常時標準偏差と、第2評価標準偏差とを基にして、話者1Bの音声の印象を評価する。評価部415は、第3平常時標準偏差と、第3評価標準偏差とを基にして、話者1Cの音声の印象を評価する。評価部415が、各標準偏差を基にして、話者1A~1Cの音声の印象を評価する処理は、評価部115が、音声を評価する処理と同様である。
評価部415は、上記処理を繰り返し実行することで、所定区間毎に、話者1Aの評価結果、話者1Bの評価結果、話者1Cの評価結果を特定する。
続いて、評価部415は、話者1A~1Cの評価結果を特定した後に、会話全体の評価を行う。たとえば、評価部415は、話者毎に、所定フレーム間の各評価結果「良い、普通、悪い」のうち、平均の評価結果を特定する。たとえば、評価部415は、所定フレーム間の各評価結果のうち、もっとも多い評価結果を、平均の評価結果とする。
評価部415は、各話者1A~1Cの平均の評価結果が非常に近い場合には、良い会話
であると判定する。評価部415は、各話者1A~1Cの平均の評価結果が異なる場合には、悪い会話であると判定する。
であると判定する。評価部415は、各話者1A~1Cの平均の評価結果が異なる場合には、悪い会話であると判定する。
たとえば、評価部415は、各話者1A~1Cの平均の評価結果を比較し、2以上の平均の評価結果が一致した場合には、良い会話であると判定する。一方、評価部415は、各話者1A~1Cの平均の評価結果を比較し、2以上の平均の評価結果が一致しない場合には、悪い会話であると判定する。
評価部415は、話者1A~1Cの音声の印象の評価結果および会話全体の評価結果を、評価結果格納部404に出力する。
次に、本実施例3に係る音声評価装置400の効果について説明する。音声評価装置400は、話者の話者情報に合わせて、平常時標準偏差を学習しておき、評価時において、話者の話者情報に応じた平常時標準偏差を用いて、話者の音声を評価する。このため、話者情報に基づく、音声の評価を行うことができ、評価の正確性を向上させることができる。
また、音声評価装置400は、各話者1A~1Cの音声の評価結果に基づいて、会話全体を評価するため、管理者などが会話全体の善し悪しを把握することができる。
また、本実施例3に係る音声評価装置400は、会話全体を評価する場合に、式(3)に基づいて、会話全体のスコアを算出しても良い。
会話全体のスコア=(話者1Aの印象が良いと評価された区間数+話者1Bの印象が良いと評価された区間数+話者1Cの印象が良いと評価された区間数)/(全体の区間数×3)×100・・・(3)
次に、上記実施例に示した音声評価装置100,200,400と同様の機能を実現するコンピュータのハードウェア構成の一例について説明する。図14は、音声評価装置と同様の機能を実現するコンピュータのハードウェア構成の一例を示す図である。
図14に示すように、コンピュータ500は、各種演算処理を実行するCPU501と、ユーザからのデータの入力を受け付ける入力装置502と、ディスプレイ503とを有する。また、コンピュータ500は、記憶媒体からプログラム等を読み取る読み取り装置504と、有線または無線ネットワークを介して収録機器等との間でデータの授受を行うインターフェース装置505とを有する。また、コンピュータ500は、各種情報を一時記憶するRAM506と、ハードディスク装置507とを有する。そして、各装置501~507は、バス508に接続される。
ハードディスク装置507は、ピッチ検出プログラム507a、分布算出プログラム507b、広がり算出プログラム507c、推定プログラム507d、評価プログラム507eを有する。CPU501は、ピッチ検出プログラム507a、分布算出プログラム507b、広がり算出プログラム507c、推定プログラム507d、評価プログラム507dを読み出してRAM506に展開する。
ピッチ検出プログラム507aは、ピッチ検出プロセス506aとして機能する。分布算出プログラム507bは、分布算出プロセス506bとして機能する。広がり算出プログラム507cは、広がり算出プロセス506cとして機能する。推定プログラム507dは、推定プロセス506dとして機能する。評価プログラム507eは、評価プロセス506eとして機能する。
ピッチ検出プロセス506aの処理は、ピッチ検出部110,210,320の処理に対応する。分布算出プロセス506bは、分布算出部111、211,411の処理に対応する。広がり算出プロセス506cの処理は、広がり算出部112,212,412の処理に対応する。推定プロセス506dは、推定部114,214,414の処理に対応する。
なお、各プログラム507a~507eについては、必ずしも最初からハードディスク装置507に記憶させておかなくても良い。例えば、コンピュータ500に挿入されるフレキシブルディスク(FD)、CD-ROM、DVDディスク、光磁気ディスク、ICカードなどの「可搬用の物理媒体」に各プログラムを記憶させておく。そして、コンピュータ500が各プログラム507a~507eを読み出して実行するようにしても良い。
以上の各実施例を含む実施形態に関し、さらに以下の付記を開示する。
(付記1)音声信号を解析してピッチ周波数を検出し、
検出した前記ピッチ周波数の検出頻度の分布に基づいて、検出した前記ピッチ周波数のうち評価対象とする評価対象領域を選択し、
前記検出頻度の分布と選択した前記評価対象領域に基づいて、音声を評価する
処理をコンピュータに実行させることを特徴とする音声評価プログラム。
検出した前記ピッチ周波数の検出頻度の分布に基づいて、検出した前記ピッチ周波数のうち評価対象とする評価対象領域を選択し、
前記検出頻度の分布と選択した前記評価対象領域に基づいて、音声を評価する
処理をコンピュータに実行させることを特徴とする音声評価プログラム。
(付記2)前記分布の中心部に対応するピッチ周波数に第1の重みを乗算し、前記分布の裾部分に対応するピッチ周波数に前記第1の重みよりも小さい第2の重みを乗算することで、前記分布を補正する処理を更に実行させ、前記評価する処理は、補正した分布の広がりを基にして、前記発話区間内の音声の印象を評価することを特徴とする付記1に記載の音声評価プログラム。
(付記3)前記ピッチ周波数を検出する処理は、各時刻のピッチ周波数と、一定時間内における平均のピッチ周波数、上限のピッチ周波数、下限のピッチ周波数のいずれかを検出することを特徴とする付記1または2に記載の音声評価プログラム。
(付記4)前記評価する処理は、複数のピッチ周波数に関する、分散、標準偏差、範囲、平方和、四分位範囲のいずれかの統計量を算出し、前記統計量を基にして、音声の印象を評価することを特徴とする付記1、2または3に記載の音声評価プログラム。
(付記5)予め定めた所定区間内の音声信号を解析して得られるピッチ周波数を基にして、ユーザの平常時の検出頻度の基準分布を推定する処理を更に実行させ、前記評価する処理は、前記基準分布と、補正された分布とを基にして、音声の印象を評価することを特徴とする付記2に記載の音声評価プログラム。
(付記6)前記基準分布と、話者情報とを対応づけて記憶装置に記憶する処理を更に実行させ、前記評価する処理は、話者情報に対応する基準分布を選択し、選択した基準分布の広がりと、補正された分布の広がりとを基にして、音声の印象を評価することを特徴とする付記5に記載の音声評価プログラム。
(付記7)前記基準分布を推定する処理は、指定された話者情報に対応する基準分布が前記記憶装置に記憶されている場合に、記憶装置に記憶された指定された話者情報に対応する基準分布を、前記基準分布を推定する場合の初期値に設定することを特徴とする付記6に記載の音声評価プログラム。
(付記8)前記分布を補正する処理は、予め定められた所定区間における複数のピッチ周波数を基にして、前記分布の中心部および前記分布の裾部を特定することを特徴とする付記2に記載の音声評価プログラム。
(付記9)前記評価する処理は、異なる話者情報毎に音声を評価し、複数話者による会話全体を評価することを特徴とする付記1に記載の音声評価プログラム。
(付記10)前記評価する処理は、各時刻における音声の印象をそれぞれ評価し、各評価結果に関するスコアを算出することを特徴とする付記1に記載の音声評価プログラム。
(付記11)前記評価する処理は、前記分布の広がりが大きい場合は声の印象が良いと評価し、前記分布の広がりが小さい場合は声の印象が悪いと評価することを特徴とする付記2、3または4に記載の音声評価プログラム。
(付記12)コンピュータが実行する音声評価方法であって、
音声信号を解析してピッチ周波数を検出し、
検出した前記ピッチ周波数の検出頻度の分布に基づいて、検出した前記ピッチ周波数のうち評価対象とする評価対象領域を選択し、
前記検出頻度の分布と選択した前記評価対象領域に基づいて、音声を評価する
処理をコンピュータに実行させることを特徴とする音声評価方法。
音声信号を解析してピッチ周波数を検出し、
検出した前記ピッチ周波数の検出頻度の分布に基づいて、検出した前記ピッチ周波数のうち評価対象とする評価対象領域を選択し、
前記検出頻度の分布と選択した前記評価対象領域に基づいて、音声を評価する
処理をコンピュータに実行させることを特徴とする音声評価方法。
(付記13)前記分布の中心部に対応するピッチ周波数に第1の重みを乗算し、前記分布の裾部分に対応するピッチ周波数に前記第1の重みよりも小さい第2の重みを乗算することで、前記分布を補正する処理を更に実行させ、前記評価する処理は、補正した分布の広がりを基にして、前記発話区間内の音声の印象を評価することを特徴とする付記12に記載の音声評価方法。
(付記14)前記ピッチ周波数を検出する処理は、各時刻のピッチ周波数と、一定時間内における平均のピッチ周波数、上限のピッチ周波数、下限のピッチ周波数のいずれかを検出することを特徴とする付記12または13に記載の音声評価方法。
(付記15)前記評価する処理は、複数のピッチ周波数に関する、分散、標準偏差、範囲、平方和、四分位範囲のいずれかの統計量を算出し、前記統計量を基にして、音声の印象を評価することを特徴とする付記12、13または14に記載の音声評価方法。
(付記16)予め定めた所定区間内の音声信号を解析して得られるピッチ周波数を基にして、ユーザの平常時の検出頻度の基準分布を推定する処理を更に実行させ、前記評価する処理は、前記基準分布と、補正された分布とを基にして、音声の印象を評価することを特徴とする付記13に記載の音声評価方法。
(付記17)前記基準分布と、話者情報とを対応づけて記憶装置に記憶する処理を更に実行させ、前記評価する処理は、話者情報に対応する基準分布を選択し、選択した基準分布の広がりと、補正された分布の広がりとを基にして、音声の印象を評価することを特徴とする付記16に記載の音声評価方法。
(付記18)前記基準分布を推定する処理は、指定された話者情報に対応する基準分布が前記記憶装置に記憶されている場合に、記憶装置に記憶された指定された話者情報に対応する基準分布を、前記基準分布を推定する場合の初期値に設定することを特徴とする付記17に記載の音声評価方法。
(付記19)前記分布を補正する処理は、予め定められた所定区間における複数のピッチ周波数を基にして、前記分布の中心部および前記分布の裾部を特定することを特徴とする付記13に記載の音声評価方法。
(付記20)前記評価する処理は、異なる話者情報毎に音声を評価し、複数話者による会話全体を評価することを特徴とする付記12に記載の音声評価方法。
(付記21)前記評価する処理は、各時刻における音声の印象をそれぞれ評価し、各評価結果に関するスコアを算出することを特徴とする付記12に記載の音声評価方法。
(付記22)前記評価する処理は、前記分布の広がりが大きい場合は声の印象が良いと評価し、前記分布の広がりが小さい場合は声の印象が悪いと評価することを特徴とする付記13、14または15に記載の音声評価方法。
(付記23)音声信号を解析してピッチ周波数を検出するピッチ検出部と、
検出した前記ピッチ周波数の検出頻度の分布に基づいて、検出した前記ピッチ周波数のうち評価対象とする評価対象領域を選択し、前記検出頻度の分布と選択した前記評価対象領域に基づいて、音声を評価する評価部と、
を有することを特徴とする音声評価装置。
検出した前記ピッチ周波数の検出頻度の分布に基づいて、検出した前記ピッチ周波数のうち評価対象とする評価対象領域を選択し、前記検出頻度の分布と選択した前記評価対象領域に基づいて、音声を評価する評価部と、
を有することを特徴とする音声評価装置。
(付記24)前記分布の中心部に対応するピッチ周波数に第1の重みを乗算し、前記分布の裾部分に対応するピッチ周波数に前記第1の重みよりも小さい第2の重みを乗算することで、前記分布を補正する広がり算出部を更に有し、前記評価部は、補正した分布の広がりを基にして、前記発話区間内の音声の印象を評価することを特徴とする付記23に記載の音声評価装置。
(付記25)前記ピッチ検出部は、各時刻のピッチ周波数と、一定時間内における平均のピッチ周波数、上限のピッチ周波数、下限のピッチ周波数のいずれかを検出することを特徴とする付記23または24に記載の音声評価装置。
(付記26)前記広がり算出部は、複数のピッチ周波数に関する、分散、標準偏差、範囲、平方和、四分位範囲のいずれかの統計量を算出し、前記評価部は、前記統計量を基にして、音声の印象を評価することを特徴とする付記24または25に記載の音声評価装置。
(付記27)予め定めた所定区間内の音声信号を解析して得られるピッチ周波数を基にして、ユーザの平常時の検出頻度の基準分布を推定する推定部を更に有し、前記評価部は、前記基準分布と、補正された分布とを基にして、音声の印象を評価することを特徴とする付記24に記載の音声評価装置。
(付記28)前記推定部は、前記基準分布と、話者情報とを対応づけて記憶装置に記憶し、前記評価部は、話者情報に対応する基準分布を選択し、選択した基準分布の広がりと、補正された分布の広がりとを基にして、音声の印象を評価することを特徴とする付記27に記載の音声評価装置。
(付記29)前記推定部は、指定された話者情報に対応する基準分布が前記記憶装置に記憶されている場合に、記憶装置に記憶された指定された話者情報に対応する基準分布を、前記基準分布を推定する場合の初期値に設定することを特徴とする付記28に記載の音声評価装置。
(付記30)前記広がり算出部は、予め定められた所定区間における複数のピッチ周波数
を基にして、前記分布の中心部および前記分布の裾部を特定することを特徴とする付記24に記載の音声評価装置。
を基にして、前記分布の中心部および前記分布の裾部を特定することを特徴とする付記24に記載の音声評価装置。
(付記31)前記評価部は、異なる話者情報毎に音声を評価し、複数話者の会話全体を評価することを特徴とする付記23に記載の音声評価装置。
(付記32)前記評価部は、異なる発話区間の音声をそれぞれ評価し、各評価結果に関するスコアを算出することを特徴とする付記23に記載の音声評価装置。
(付記33)前記評価部は、前記分布の広がりが大きい場合は声の印象が良いと評価し、前記分布の広がりが小さい場合は声の印象が悪いと評価することを特徴とする付記24、25または26に記載の音声評価装置。
100,200,400 音声評価装置
150,300 収録機器
150,300 収録機器
Claims (33)
- 音声信号を解析してピッチ周波数を検出し、
検出した前記ピッチ周波数の検出頻度の分布に基づいて、検出した前記ピッチ周波数のうち評価対象とする評価対象領域を選択し、
前記検出頻度の分布と選択した前記評価対象領域に基づいて、音声を評価する
処理をコンピュータに実行させることを特徴とする音声評価プログラム。 - 前記分布の中心部に対応するピッチ周波数に第1の重みを乗算し、前記分布の裾部分に対応するピッチ周波数に前記第1の重みよりも小さい第2の重みを乗算することで、前記分布を補正する処理を更に実行させ、前記評価する処理は、補正した分布の広がりを基にして、前記発話区間内の音声の印象を評価することを特徴とする請求項1に記載の音声評価プログラム。
- 前記ピッチ周波数を検出する処理は、各時刻のピッチ周波数と、一定時間内における平均のピッチ周波数、上限のピッチ周波数、下限のピッチ周波数のいずれかを検出することを特徴とする請求項1または2に記載の音声評価プログラム。
- 前記評価する処理は、複数のピッチ周波数に関する、分散、標準偏差、範囲、平方和、四分位範囲のいずれかの統計量を算出し、前記統計量を基にして、音声の印象を評価することを特徴とする請求項1、2または3に記載の音声評価プログラム。
- 予め定めた所定区間内の音声信号を解析して得られるピッチ周波数を基にして、ユーザの平常時の検出頻度の基準分布を推定する処理を更に実行させ、前記評価する処理は、前記基準分布と、補正された分布とを基にして、音声の印象を評価することを特徴とする請求項2に記載の音声評価プログラム。
- 前記基準分布と、話者情報とを対応づけて記憶装置に記憶する処理を更に実行させ、前記評価する処理は、話者情報に対応する基準分布を選択し、選択した基準分布の広がりと、補正された分布の広がりとを基にして、音声の印象を評価することを特徴とする請求項5に記載の音声評価プログラム。
- 前記基準分布を推定する処理は、指定された話者情報に対応する基準分布が前記記憶装置に記憶されている場合に、記憶装置に記憶された指定された話者情報に対応する基準分布を、前記基準分布を推定する場合の初期値に設定することを特徴とする請求項6に記載の音声評価プログラム。
- 前記分布を補正する処理は、予め定められた所定区間における複数のピッチ周波数を基にして、前記分布の中心部および前記分布の裾部を特定することを特徴とする請求項2に記載の音声評価プログラム。
- 前記評価する処理は、異なる話者情報毎に音声を評価し、複数話者による会話全体を評価することを特徴とする請求項1に記載の音声評価プログラム。
- 前記評価する処理は、各時刻における音声の印象をそれぞれ評価し、各評価結果に関するスコアを算出することを特徴とする請求項1に記載の音声評価プログラム。
- 前記評価する処理は、前記分布の広がりが大きい場合は声の印象が良いと評価し、前記分布の広がりが小さい場合は声の印象が悪いと評価することを特徴とする請求項2、3または4に記載の音声評価プログラム。
- コンピュータが実行する音声評価方法であって、
音声信号を解析してピッチ周波数を検出し、
検出した前記ピッチ周波数の検出頻度の分布に基づいて、検出した前記ピッチ周波数のうち評価対象とする評価対象領域を選択し、
前記検出頻度の分布と選択した前記評価対象領域に基づいて、音声を評価する
処理をコンピュータに実行させることを特徴とする音声評価方法。 - 前記分布の中心部に対応するピッチ周波数に第1の重みを乗算し、前記分布の裾部分に対応するピッチ周波数に前記第1の重みよりも小さい第2の重みを乗算することで、前記分布を補正する処理を更に実行させ、前記評価する処理は、補正した分布の広がりを基にして、前記発話区間内の音声の印象を評価することを特徴とする請求項12に記載の音声評価方法。
- 前記ピッチ周波数を検出する処理は、各時刻のピッチ周波数と、一定時間内における平均のピッチ周波数、上限のピッチ周波数、下限のピッチ周波数のいずれかを検出することを特徴とする請求項12または13に記載の音声評価方法。
- 前記評価する処理は、複数のピッチ周波数に関する、分散、標準偏差、範囲、平方和、四分位範囲のいずれかの統計量を算出し、前記統計量を基にして、音声の印象を評価することを特徴とする請求項12、13または14に記載の音声評価方法。
- 予め定めた所定区間内の音声信号を解析して得られるピッチ周波数を基にして、ユーザの平常時の検出頻度の基準分布を推定する処理を更に実行させ、前記評価する処理は、前記基準分布と、補正された分布とを基にして、音声の印象を評価することを特徴とする請求項13に記載の音声評価方法。
- 前記基準分布と、話者情報とを対応づけて記憶装置に記憶する処理を更に実行させ、前記評価する処理は、話者情報に対応する基準分布を選択し、選択した基準分布の広がりと、補正された分布の広がりとを基にして、音声の印象を評価することを特徴とする請求項16に記載の音声評価方法。
- 前記基準分布を推定する処理は、指定された話者情報に対応する基準分布が前記記憶装置に記憶されている場合に、記憶装置に記憶された指定された話者情報に対応する基準分布を、前記基準分布を推定する場合の初期値に設定することを特徴とする請求項17に記載の音声評価方法。
- 前記分布を補正する処理は、予め定められた所定区間における複数のピッチ周波数を基にして、前記分布の中心部および前記分布の裾部を特定することを特徴とする請求項13に記載の音声評価方法。
- 前記評価する処理は、異なる話者情報毎に音声を評価し、複数話者による会話全体を評価することを特徴とする請求項12に記載の音声評価方法。
- 前記評価する処理は、各時刻における音声の印象をそれぞれ評価し、各評価結果に関するスコアを算出することを特徴とする請求項12に記載の音声評価方法。
- 前記評価する処理は、前記分布の広がりが大きい場合は声の印象が良いと評価し、前記分布の広がりが小さい場合は声の印象が悪いと評価することを特徴とする請求項13、14または15に記載の音声評価方法。
- 音声信号を解析してピッチ周波数を検出するピッチ検出部と、
検出した前記ピッチ周波数の検出頻度の分布に基づいて、検出した前記ピッチ周波数のうち評価対象とする評価対象領域を選択し、前記検出頻度の分布と選択した前記評価対象領域に基づいて、音声を評価する評価部と、
を有することを特徴とする音声評価装置。 - 前記分布の中心部に対応するピッチ周波数に第1の重みを乗算し、前記分布の裾部分に対応するピッチ周波数に前記第1の重みよりも小さい第2の重みを乗算することで、前記分布を補正する広がり算出部を更に有し、前記評価部は、補正した分布の広がりを基にして、前記発話区間内の音声の印象を評価することを特徴とする請求項23に記載の音声評価装置。
- 前記ピッチ検出部は、各時刻のピッチ周波数と、一定時間内における平均のピッチ周波数、上限のピッチ周波数、下限のピッチ周波数のいずれかを検出することを特徴とする請求項23または24に記載の音声評価装置。
- 前記広がり算出部は、複数のピッチ周波数に関する、分散、標準偏差、範囲、平方和、四分位範囲のいずれかの統計量を算出し、前記評価部は、前記統計量を基にして、音声の印象を評価することを特徴とする請求項24または25に記載の音声評価装置。
- 予め定めた所定区間内の音声信号を解析して得られるピッチ周波数を基にして、ユーザの平常時の検出頻度の基準分布を推定する推定部を更に有し、前記評価部は、前記基準分布と、補正された分布とを基にして、音声の印象を評価することを特徴とする請求項24に記載の音声評価装置。
- 前記推定部は、前記基準分布と、話者情報とを対応づけて記憶装置に記憶し、前記評価部は、話者情報に対応する基準分布を選択し、選択した基準分布の広がりと、補正された分布の広がりとを基にして、音声の印象を評価することを特徴とする請求項27に記載の音声評価装置。
- 前記推定部は、指定された話者情報に対応する基準分布が前記記憶装置に記憶されている場合に、記憶装置に記憶された指定された話者情報に対応する基準分布を、前記基準分布を推定する場合の初期値に設定することを特徴とする請求項28に記載の音声評価装置。
- 前記広がり算出部は、予め定められた所定区間における複数のピッチ周波数
を基にして、前記分布の中心部および前記分布の裾部を特定することを特徴とする請求項24に記載の音声評価装置。 - 前記評価部は、異なる話者情報毎に音声を評価し、複数話者の会話全体を評価することを特徴とする請求項23に記載の音声評価装置。
- 前記評価部は、異なる発話区間の音声をそれぞれ評価し、各評価結果に関するスコアを算出することを特徴とする請求項23に記載の音声評価装置。
- 前記評価部は、前記分布の広がりが大きい場合は声の印象が良いと評価し、前記分布の広がりが小さい場合は声の印象が悪いと評価することを特徴とする請求項24、25または26に記載の音声評価装置。
Priority Applications (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| EP18821009.0A EP3644316A4 (en) | 2017-06-23 | 2018-03-30 | PROGRAM FOR LANGUAGE ASSESSMENT, METHOD FOR LANGUAGE ASSESSMENT AND DEVICE FOR LANGUAGE ASSESSMENT |
| CN201880003613.7A CN109791774B (zh) | 2017-06-23 | 2018-03-30 | 记录介质、声音评价方法以及声音评价装置 |
| US16/354,260 US11232810B2 (en) | 2017-06-23 | 2019-03-15 | Voice evaluation method, voice evaluation apparatus, and recording medium for evaluating an impression correlated to pitch |
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2017123588A JP6891662B2 (ja) | 2017-06-23 | 2017-06-23 | 音声評価プログラム、音声評価方法および音声評価装置 |
| JP2017-123588 | 2017-06-23 |
Related Child Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| US16/354,260 Continuation US11232810B2 (en) | 2017-06-23 | 2019-03-15 | Voice evaluation method, voice evaluation apparatus, and recording medium for evaluating an impression correlated to pitch |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2018235380A1 true WO2018235380A1 (ja) | 2018-12-27 |
Family
ID=64736984
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2018/013867 Ceased WO2018235380A1 (ja) | 2017-06-23 | 2018-03-30 | 音声評価プログラム、音声評価方法および音声評価装置 |
Country Status (5)
| Country | Link |
|---|---|
| US (1) | US11232810B2 (ja) |
| EP (1) | EP3644316A4 (ja) |
| JP (1) | JP6891662B2 (ja) |
| CN (1) | CN109791774B (ja) |
| WO (1) | WO2018235380A1 (ja) |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPWO2017168663A1 (ja) * | 2016-03-30 | 2018-10-11 | 富士通株式会社 | 発話印象判定プログラム、発話印象判定方法及び発話印象判定装置 |
Families Citing this family (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US12236798B2 (en) * | 2018-10-03 | 2025-02-25 | Bongo Learn, Inc. | Presentation assessment and valuation system |
| EP3931826B1 (en) * | 2019-08-13 | 2025-06-11 | Samsung Electronics Co., Ltd. | Server that supports speech recognition of device, and operation method of the server |
| CN113658581B (zh) * | 2021-08-18 | 2024-03-01 | 北京百度网讯科技有限公司 | 声学模型的训练、语音处理方法、装置、设备及存储介质 |
Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2006267464A (ja) * | 2005-03-23 | 2006-10-05 | Tokyo Electric Power Co Inc:The | 感情解析装置、感情解析プログラム、プログラム格納媒体 |
| JP2006267465A (ja) * | 2005-03-23 | 2006-10-05 | Tokyo Electric Power Co Inc:The | 発話状態評価装置、発話状態評価プログラム、プログラム格納媒体 |
| JP2013072979A (ja) * | 2011-09-27 | 2013-04-22 | Fuji Xerox Co Ltd | 音声解析システムおよび音声解析装置 |
Family Cites Families (8)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP3747492B2 (ja) * | 1995-06-20 | 2006-02-22 | ソニー株式会社 | 音声信号の再生方法及び再生装置 |
| JP3447221B2 (ja) * | 1998-06-17 | 2003-09-16 | ヤマハ株式会社 | 音声変換装置、音声変換方法、および音声変換プログラムを記録した記録媒体 |
| FR2926786B1 (fr) * | 2008-01-30 | 2010-02-19 | Eurocopter France | Procede d'optimisation d'un rotor anti-couple carene a gene acoustique minimale pour un giravion, notamment un helicoptere, et rotor anti-couple carene ainsi obtenu |
| JP5293018B2 (ja) * | 2008-09-09 | 2013-09-18 | ソニー株式会社 | 音楽情報処理装置、音楽情報処理方法およびコンピュータプログラム |
| US8818806B2 (en) * | 2010-11-30 | 2014-08-26 | JVC Kenwood Corporation | Speech processing apparatus and speech processing method |
| JP2015087557A (ja) | 2013-10-31 | 2015-05-07 | 三菱電機株式会社 | 発話様式検出装置および発話様式検出方法 |
| US20160162807A1 (en) * | 2014-12-04 | 2016-06-09 | Carnegie Mellon University, A Pennsylvania Non-Profit Corporation | Emotion Recognition System and Method for Modulating the Behavior of Intelligent Systems |
| JP6759560B2 (ja) * | 2015-11-10 | 2020-09-23 | ヤマハ株式会社 | 調律推定装置及び調律推定方法 |
-
2017
- 2017-06-23 JP JP2017123588A patent/JP6891662B2/ja not_active Expired - Fee Related
-
2018
- 2018-03-30 EP EP18821009.0A patent/EP3644316A4/en not_active Withdrawn
- 2018-03-30 CN CN201880003613.7A patent/CN109791774B/zh not_active Expired - Fee Related
- 2018-03-30 WO PCT/JP2018/013867 patent/WO2018235380A1/ja not_active Ceased
-
2019
- 2019-03-15 US US16/354,260 patent/US11232810B2/en not_active Expired - Fee Related
Patent Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2006267464A (ja) * | 2005-03-23 | 2006-10-05 | Tokyo Electric Power Co Inc:The | 感情解析装置、感情解析プログラム、プログラム格納媒体 |
| JP2006267465A (ja) * | 2005-03-23 | 2006-10-05 | Tokyo Electric Power Co Inc:The | 発話状態評価装置、発話状態評価プログラム、プログラム格納媒体 |
| JP2013072979A (ja) * | 2011-09-27 | 2013-04-22 | Fuji Xerox Co Ltd | 音声解析システムおよび音声解析装置 |
Non-Patent Citations (1)
| Title |
|---|
| See also references of EP3644316A4 * |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPWO2017168663A1 (ja) * | 2016-03-30 | 2018-10-11 | 富士通株式会社 | 発話印象判定プログラム、発話印象判定方法及び発話印象判定装置 |
Also Published As
| Publication number | Publication date |
|---|---|
| JP6891662B2 (ja) | 2021-06-18 |
| EP3644316A4 (en) | 2020-06-24 |
| CN109791774A (zh) | 2019-05-21 |
| JP2019008130A (ja) | 2019-01-17 |
| US20190214039A1 (en) | 2019-07-11 |
| US11232810B2 (en) | 2022-01-25 |
| EP3644316A1 (en) | 2020-04-29 |
| CN109791774B (zh) | 2023-03-10 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| KR102070965B1 (ko) | 소리 신호를 강화하는 소리 신호 처리 장치 및 방법 | |
| US11232810B2 (en) | Voice evaluation method, voice evaluation apparatus, and recording medium for evaluating an impression correlated to pitch | |
| CN102549657B (zh) | 用于确定音频系统的感知质量的方法和系统 | |
| KR20180063282A (ko) | 음성 검측 방법, 장치 및 기억 매체 | |
| CN102576535B (zh) | 用于确定音频系统的感知质量的方法和系统 | |
| CN106558308B (zh) | 一种互联网音频数据质量自动打分系统及方法 | |
| US9431024B1 (en) | Method and apparatus for detecting noise of audio signals | |
| CN104221018A (zh) | 声音检测装置、声音检测方法、声音特征值检测装置、声音特征值检测方法、声音区间检测装置、声音区间检测方法及程序 | |
| JP4816711B2 (ja) | 通話音声処理装置および通話音声処理方法 | |
| JP2014122939A (ja) | 音声処理装置および方法、並びにプログラム | |
| CN115604621A (zh) | 耳机测试方法、装置、设备及计算机可读存储介质 | |
| CN109997186A (zh) | 一种用于分类声环境的设备和方法 | |
| CN116884429B (zh) | 一种基于信号增强的音频处理方法 | |
| US10636438B2 (en) | Method, information processing apparatus for processing speech, and non-transitory computer-readable storage medium | |
| JP5772591B2 (ja) | 音声信号処理装置 | |
| JP6314475B2 (ja) | 音声信号処理装置及びプログラム | |
| CN112509597A (zh) | 录音数据识别方法和装置、录音设备 | |
| US10861477B2 (en) | Recording medium recording utterance impression determination program by changing fundamental frequency of voice signal, utterance impression determination method by changing fundamental frequency of voice signal, and information processing apparatus for utterance impression determination by changing fundamental frequency of voice signal | |
| JP7000757B2 (ja) | 音声処理プログラム、音声処理方法および音声処理装置 | |
| US10258260B2 (en) | Method of testing hearing and a hearing test system | |
| CN117727311B (zh) | 音频处理方法及装置、电子设备及计算机可读存储介质 | |
| US20190096432A1 (en) | Speech processing method, speech processing apparatus, and non-transitory computer-readable storage medium for storing speech processing computer program | |
| JP6907859B2 (ja) | 音声処理プログラム、音声処理方法および音声処理装置 | |
| CN113516965B (zh) | 一种语音测试方法、计算机设备及可读存储介质 | |
| JP2011205324A (ja) | 音声処理装置、音声処理方法およびプログラム |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 18821009 Country of ref document: EP Kind code of ref document: A1 |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 2018821009 Country of ref document: EP |
|
| ENP | Entry into the national phase |
Ref document number: 2018821009 Country of ref document: EP Effective date: 20200123 |