WO2019176939A1 - 一塩基多型検出用オリゴヌクレオチドプローブ、及びシス型-トランス型判別方法 - Google Patents
一塩基多型検出用オリゴヌクレオチドプローブ、及びシス型-トランス型判別方法 Download PDFInfo
- Publication number
- WO2019176939A1 WO2019176939A1 PCT/JP2019/010012 JP2019010012W WO2019176939A1 WO 2019176939 A1 WO2019176939 A1 WO 2019176939A1 JP 2019010012 W JP2019010012 W JP 2019010012W WO 2019176939 A1 WO2019176939 A1 WO 2019176939A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- single nucleotide
- nucleotide polymorphism
- base sequence
- region
- probe
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Ceased
Links
Images




Classifications
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Q—MEASURING OR TESTING PROCESSES INVOLVING ENZYMES, NUCLEIC ACIDS OR MICROORGANISMS; COMPOSITIONS OR TEST PAPERS THEREFOR; PROCESSES OF PREPARING SUCH COMPOSITIONS; CONDITION-RESPONSIVE CONTROL IN MICROBIOLOGICAL OR ENZYMOLOGICAL PROCESSES
- C12Q1/00—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions
- C12Q1/68—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions involving nucleic acids
- C12Q1/6813—Hybridisation assays
- C12Q1/6827—Hybridisation assays for detection of mutation or polymorphism
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Q—MEASURING OR TESTING PROCESSES INVOLVING ENZYMES, NUCLEIC ACIDS OR MICROORGANISMS; COMPOSITIONS OR TEST PAPERS THEREFOR; PROCESSES OF PREPARING SUCH COMPOSITIONS; CONDITION-RESPONSIVE CONTROL IN MICROBIOLOGICAL OR ENZYMOLOGICAL PROCESSES
- C12Q1/00—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions
- C12Q1/68—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions involving nucleic acids
- C12Q1/6876—Nucleic acid products used in the analysis of nucleic acids, e.g. primers or probes
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Q—MEASURING OR TESTING PROCESSES INVOLVING ENZYMES, NUCLEIC ACIDS OR MICROORGANISMS; COMPOSITIONS OR TEST PAPERS THEREFOR; PROCESSES OF PREPARING SUCH COMPOSITIONS; CONDITION-RESPONSIVE CONTROL IN MICROBIOLOGICAL OR ENZYMOLOGICAL PROCESSES
- C12Q1/00—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions
- C12Q1/68—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions involving nucleic acids
- C12Q1/6876—Nucleic acid products used in the analysis of nucleic acids, e.g. primers or probes
- C12Q1/6883—Nucleic acid products used in the analysis of nucleic acids, e.g. primers or probes for diseases caused by alterations of genetic material
- C12Q1/6886—Nucleic acid products used in the analysis of nucleic acids, e.g. primers or probes for diseases caused by alterations of genetic material for cancer
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Q—MEASURING OR TESTING PROCESSES INVOLVING ENZYMES, NUCLEIC ACIDS OR MICROORGANISMS; COMPOSITIONS OR TEST PAPERS THEREFOR; PROCESSES OF PREPARING SUCH COMPOSITIONS; CONDITION-RESPONSIVE CONTROL IN MICROBIOLOGICAL OR ENZYMOLOGICAL PROCESSES
- C12Q2600/00—Oligonucleotides characterized by their use
- C12Q2600/156—Polymorphic or mutational markers
Definitions
- the present invention relates to an oligonucleotide probe for detecting a single nucleotide polymorphism and a method for discriminating whether two kinds of single nucleotide polymorphisms exist in a cis form or a trans form.
- Epidermal growth factor receptor (EGFR: Epidermal Growth Factor Receptor) is a transmembrane receptor tyrosine kinase and is known as a factor involved in the control of cell proliferation and growth. Since EGFR is overexpressed in many cancers including lung cancer as an oncogene, it has attracted attention as a molecular target for cancer therapy, and cancer therapeutic drugs such as EGFR tyrosine kinase inhibitor (EGFR-TKI) have been developed.
- EGFR-TKI EGFR tyrosine kinase inhibitor
- EGFR tyrosine kinase inhibitors such as gefitinib, erlotinib, and afatinib are known to develop resistance and re-exacerbate in about one year.
- About half of the cause of this resistance acquisition is a mutation (T790M) in which threonine (T), which is the 790th amino acid of EGFR, is substituted with methionine (M). Therefore, a probe for enabling detection of this T790M has been developed, and polymorphism detection probes designed to hybridize to the sequence of the EGFR gene containing T790M have been reported (Patent Documents 1 and 2). ).
- osmeltinib an EGFR tyrosine kinase inhibitor effective for T790M, has been developed and used as a therapeutic agent for lung cancer.
- SNP Single Nucleotide Polymorphism
- the polymorphism detection probe is simple and inexpensive to synthesize and can accurately detect the presence of the polymorphism.
- a probe has a reporter region that detects a single nucleotide polymorphism, an anchor region that binds to a target nucleotide sequence regardless of the presence or absence of the single nucleotide polymorphism, and a linker region that links the reporter region and the anchor region.
- An oligonucleotide probe for detecting a single nucleotide polymorphism which is a probe capable of detecting the presence or absence of a single nucleotide polymorphism based on the fluorescence intensity with a fluorescent dye possessed by a reporter region has been developed (Patent Document 3).
- the first single nucleotide polymorphism and the second single nucleotide polymorphism are present in cis form. It is an object of the present invention to provide an oligonucleotide probe for detecting a single nucleotide polymorphism for discriminating whether or not it exists in a trans form. The present invention also provides a method for discriminating whether the first single nucleotide polymorphism and the second single nucleotide polymorphism are present in cis form or in trans form using the oligonucleotide probe. With the goal.
- the first single nucleotide polymorphism and the second single nucleotide polymorphism are present in cis form.
- An oligonucleotide probe for detecting a single nucleotide polymorphism for discriminating whether or not it exists in trans form
- the target nucleic acid includes a first target base sequence in which the first single nucleotide polymorphism exists, and a second target base sequence in which the second single nucleotide polymorphism exists
- the probe includes a reporter region for detecting the first single nucleotide polymorphism, an anchor region for detecting the second single nucleotide polymorphism, and a linker region,
- Have The anchor region has an oligonucleotide having a base sequence that perfectly matches the second target base sequence,
- the linker region connects the reporter region and the anchor region, and the first single nucleotide polymorphism and the second single nucleot
- An oligonucleotide having a non-complementary base sequence with respect to the base sequence between the target base sequence and the second target base sequence Provided is a probe wherein the length of the reporter region oligonucleotide is shorter than the length of the anchor region oligonucleotide.
- the probe of the present invention has an anchor region for detecting the second single nucleotide polymorphism separately from the reporter region for detecting the first single nucleotide polymorphism, and both regions are linked by a linker region.
- the length of the reporter region oligonucleotide is shorter than the length of the anchor region oligonucleotide. Therefore, when the binding property of the probe is ensured by hybridizing the anchor region to the second target base sequence, the first single nucleotide polymorphism of the first single nucleotide polymorphism is linked by the reporter region having a fluorescent dye linked by the linker region. Presence or absence can be detected with high sensitivity.
- the first single nucleotide polymorphism and the second Whether a single nucleotide polymorphism exists in a cis form or a trans form can be discriminated with good accuracy and detection sensitivity.
- the linker region is preferably an oligonucleotide having a base sequence that does not contain a universal base. By not using a universal base in the linker region, a probe can be synthesized at a lower cost.
- the linker region is preferably an oligonucleotide consisting of only one base selected from adenine, guanine, cytosine, and thymine. This reduces the possibility of binding to the target nucleic acid in the linker region of the probe, thereby increasing the degree of freedom of the reporter region and improving the detectability of the first single nucleotide polymorphism and the second single nucleotide polymorphism. Can do. Moreover, a probe can be synthesized at a lower cost by constituting the linker region only with the above base.
- the linker region is preferably an oligonucleotide composed of 3 to 11 nucleotides.
- the present invention is also a method for discriminating whether the first single nucleotide polymorphism and the second single nucleotide polymorphism are present in the cis form or in the trans form.
- the first single nucleotide polymorphism and the second single nucleotide polymorphism exist in cis form or in trans form based on the fluorescence intensity. It can be determined whether it exists.
- the first single nucleotide polymorphism and the second single nucleotide polymorphism are cis-type. It is possible to easily determine whether it exists in a trans form or in a trans form without using a complicated process.
- FIG. 1 is a schematic diagram of a mechanism for detecting T790M and C797S existing in a cis form by the probe of this embodiment.
- the enclosed part indicates a SNP or a part corresponding to the SNP.
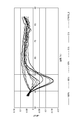
- FIG. 2 shows the results of thermal melting curve analysis when the C797S detection probe was used. 100% indicates that the template DNA is DNA having an EGFR gene sequence including C797S_1, and 50% to 5% indicates that the ratio of DNA having the EGFR gene sequence including C797S_1 in the template DNA is 50% to 5%, respectively.
- FIG. 3 is a schematic diagram of the synthetic oligonucleotide in which the three probes (1) to (3) designed in Example 3 and a sequence recognizing T790M and a sequence recognizing C797S are linked by a linker.
- the encircled portion indicates SNP or a portion corresponding to SNP, and the circle bonded to the end opposite to the linker region of each probe indicates QProbe.
- FIG. 3 is a schematic diagram of the synthetic oligonucleotide in which the three probes (1) to (3) designed in Example 3 and a sequence recognizing T790M and a sequence recognizing C797S are linked by a linker.
- the encircled portion indicates SNP or a portion corresponding to SNP, and the circle bonded to the end opposite to the linker region of each probe indicates QProbe.
- FIG. 3 is a schematic diagram of the synthetic oligonucleotide in which the three probes (1) to (3) designed in Example 3 and a sequence recognizing T790M and
- FIG. 4 shows the results of thermal melting curve analysis using the synthetic oligonucleotide shown in FIG. 3 in which a sequence recognizing T790M and a sequence recognizing C797S are linked by a linker.
- FIG. 5 shows the results of thermal melting curve analysis when using a cis-type detection linker probe.
- “Cis (T790M / C797S + wt)” is a template DNA comprising a DNA having an EGFR gene sequence containing T790M and C797S in a cis form (T790M / C797S), and a wild type EGFR gene sequence not containing the mutation as an allele thereof. The case where it has DNA (wt) is shown.
- cis 50% and cis 25% are: a template DNA containing 50% and 25% of T790M / C797S, respectively (otherwise, DNA having a wild-type EGFR gene sequence), and a wild-type that does not contain the mutation as an allele thereof
- DNA (wt) having the EGFR gene sequence is included is shown. Therefore, the mutation abundance rate of T790M / C797S in the whole of cis 50% and cis 25% is 25% and 12.5%, respectively.
- Trans (T790M + C797S) indicates that the template DNA is DNA having an EGFR gene sequence including T790M and C797S in trans form, and wt is the case where the template DNA is all DNA having a wild type EGFR gene sequence.
- T790M shows the case where the template DNA is a DNA having an EGFR gene sequence containing only T790M
- C797S shows the case where the template DNA is a DNA having an EGFR gene sequence containing only C797S.
- the present embodiment a mode for carrying out the present invention (hereinafter referred to as “the present embodiment”) will be described in detail.
- this invention is not limited to the following embodiment.
- single nucleotide polymorphism refers to a polymorphism caused by substitution of a single base on a base sequence.
- the “target nucleic acid” is a nucleic acid that is a target for confirming the presence or absence of SNP using the probe of the present embodiment.
- the target nucleic acid includes a first target base sequence that is a region where the first single nucleotide polymorphism exists, and a second target base sequence that is a region where the second single nucleotide polymorphism exists.
- the first target base sequence and the second target base sequence can be determined in advance from the base sequence of a nucleic acid whose SNP is known.
- the first single nucleotide polymorphism and the second single nucleotide polymorphism exist in either a cis-type or trans-type positional relationship.
- the cis type means that the first single nucleotide polymorphism and the second single nucleotide polymorphism are located on the same chromosome
- the trans type means the first single nucleotide polymorphism and the second single nucleotide polymorphism. It means that the polymorphism is located on different chromosomes.
- the cis type is the same as the first single nucleotide polymorphism and the second single nucleotide polymorphism. It means to be located on the allele, and the trans type means that the first single nucleotide polymorphism and the second single nucleotide polymorphism are located on different alleles.
- first single nucleotide polymorphism and the second single nucleotide polymorphism may exist on the same allele
- the first single nucleotide polymorphism is C797S
- the second single nucleotide polymorphism is C790M.
- the first target base sequence is a region consisting of 3 to 6 nucleotides containing a base that can contain the SNP (first single nucleotide polymorphism) to be detected in the base sequence of a nucleic acid known to have SNP.
- the first target base sequence is more preferably a region consisting of 3 to 5 nucleotides, and further preferably a region consisting of 4 or 5 nucleotides.
- the position of the base into which the SNP can enter is not particularly limited, but is preferably near the center of the first target base sequence.
- the second target base sequence does not overlap with the first target base sequence, and in the base sequence of the nucleic acid in which the presence of SNP is known, the base that can contain the SNP (second single nucleotide polymorphism) to be detected A region consisting of 8 to 20 nucleotides including is preferred.
- the second target base sequence is more preferably a region consisting of 10 to 18 nucleotides, more preferably a region consisting of 11 to 15 nucleotides, and particularly preferably a region consisting of 14 or 15 nucleotides.
- the position of the base where the SNP can enter is not particularly limited, but is preferably near the center of the second target base sequence.
- the second target nucleotide sequence is located on the 3 ′ side or 5 ′ side of the first target nucleotide sequence.
- the number of nucleotides from the 3 ′ end of the first target base sequence to the 5 ′ end of the second target base sequence Is preferably 0 to 15, more preferably 3 to 12, and still more preferably 4 to 10.
- the interval between the first target base sequence and the second target base sequence By setting the interval between the first target base sequence and the second target base sequence within the above range, an appropriate distance can be maintained between the reporter region and the anchor region in the probe of the present embodiment. There is a tendency to improve the detection ability.
- the length of the linker region can be set according to the interval between the first target base sequence and the second target base sequence, it is not necessary to synthesize extra nucleotides and tends to be economically superior. It is in.
- the second target base sequence is located on the 5 ′ side of the first target base sequence, the number of nucleotides from the 5 ′ end of the first target base sequence to the 3 ′ end of the second target base sequence is calculated.
- the above range can be set.
- the target nucleic acid in this embodiment includes DNA or RNA, but is preferably DNA.
- the origin of the target nucleic acid is not particularly limited as long as it contains DNA or RNA, and examples thereof include animals, plants, fungi, microorganisms, viruses and the like.
- the method for preparing the target nucleic acid is not particularly limited, and may be prepared directly from an organism or virus, may be prepared from a specific tissue, or artificially cloned from a template nucleic acid. It may be prepared, or an amplification product by PCR method or LAMP method may be used.
- the term “perfect match” means that the first target base sequence and the reporter region have a sequence that is completely complementary to the first target base sequence in the target nucleic acid. And hybridize.
- a “mismatch” has a different base sequence in the reporter region with respect to the base sequence in the target nucleic acid, even if only one base is present. Is difficult to hybridize.
- the probe of the present embodiment includes a reporter region that detects the first single nucleotide polymorphism, an anchor region that detects the second single nucleotide polymorphism, and a linker region.
- the positional relationship between the reporter region and the anchor region is the first when the first single nucleotide polymorphism and the second single nucleotide polymorphism are present in a cis-type positional relationship in the target nucleic acid. It can be set as appropriate according to the positional relationship between the target base sequence and the second target base sequence. For example, when the second target base sequence is located on the 3 ′ side of the first target base sequence, the anchor region is arranged on the 5 ′ side of the reporter region.
- the probe of this embodiment includes an anchor region that binds to a target base sequence for detecting the second single nucleotide polymorphism, in addition to the reporter region for detecting the first single nucleotide polymorphism.
- the reporter region oligonucleotide is shorter than the anchor region oligonucleotide. Therefore, when the anchor region hybridizes to the second target nucleotide sequence and the binding property of the probe is ensured, the reporter region linked by the linker region accurately detects the presence or absence of the first single nucleotide polymorphism. Can be detected well.
- the method for producing the probe of the present embodiment is not particularly limited, and examples thereof include a normal oligonucleotide synthesis method using a chemical synthesis method. Since the probe of this embodiment is composed of ordinary oligonucleotides, it does not require a complicated synthesis method and can be produced simply and inexpensively.
- the reporter region is a region for detecting the first single nucleotide polymorphism.
- the oligonucleotide of the reporter region is a nucleotide consisting of a base sequence complementary to the first target base sequence in which the first single nucleotide polymorphism exists.
- the reporter region perfectly matches the first target base sequence in which the first single nucleotide polymorphism is present, and is a sequence other than the first target base sequence (other than the absence of the first single base polymorphism, (Including a sequence identical to the target base sequence of 1) is an oligonucleotide having a base sequence that is mismatched.
- the reporter region has a fluorescent dye that is quenched when the first target base sequence and the reporter region are hybridized.
- the reporter region has such a fluorescent dye, the single nucleotide polymorphism can be easily detected by measuring the fluorescence intensity.
- fluorescent dyes having such characteristics include the QProbe series (manufactured by Nippon Steel & Sumikin Environment Co., Ltd.). In QProbe, when guanine is present in the vicinity of a base complementary to a base modified with a fluorescent dye when hybridized, fluorescence resonance energy transfer occurs and the fluorescence is quenched.
- fluorescent dyes possessed by QProbe include Pacific Blue, ATTO465, BODIPY-FL, Rhodamine 6G, TAMRA, and ATTO655.
- the fluorescent dye is preferably bound to the end opposite to the linker region in the reporter region.
- the length of the oligonucleotide in the reporter region is preferably 3 to 6 nucleotides, more preferably 3 to 5 nucleotides, and 4 or 5 nucleotides. More preferred are nucleotides.
- the length of the oligonucleotide of the reporter region is shorter than the length of the oligonucleotide of the anchor region from the viewpoint of improving the detectability of cis-type SNP.
- the oligonucleotide of the reporter region has guanine in the first target base sequence within 1 to 3 sites from the binding site of the fluorescent dye. It is preferably designed to exist.
- the anchor region is a region for detecting the second single nucleotide polymorphism.
- the oligonucleotide in the anchor region is a nucleotide having a base sequence complementary to the second target base sequence in which the second single nucleotide polymorphism exists.
- the anchor region perfectly matches the second target nucleotide sequence in which the second single nucleotide polymorphism exists, and other than the second target nucleotide sequence (the first one except that the second single nucleotide polymorphism does not exist) (Including a sequence identical to the target base sequence of 2) is an oligonucleotide having a base sequence that is mismatched.
- the length of the oligonucleotide in the anchor region is preferably 8 to 20 nucleotides, more preferably 10 to 18 nucleotides, and 11 to 15 More preferred are 14 nucleotides, especially 14 or 15 nucleotides.
- the linker region is a region for increasing the degree of freedom of the probe.
- the linker region connects the reporter region and the anchor region.
- the linker region is relative to the base sequence between the first target base sequence and the second target base sequence in the target nucleic acid when the first single nucleotide polymorphism and the second single nucleotide polymorphism exist in cis form. And an oligonucleotide having a non-complementary base sequence.
- the linker region preferably does not contain a universal base.
- Universal bases include universal bases that are bases other than adenine, guanine, cytosine, thymine, and uracil, or analogs thereof.
- Examples of universal bases or analogs thereof include 5-nitroindole, deoxyriboside, 3-nitropyrrole deoxyriboside, 4-nitrobenzimidazole deoxyriboside, deoxynebulaline, deoxyinosine, 2′-OMe inosine, 2′-OMe5 -Nitroindole riboside, 2'-OMe3-nitropyrrole riboside, 2'-F inosine riboside, 2'-F nebulaline, 2'-F5-nitroindole riboside, 2'-F4-nitrobenzimidazole riboside 2'-F3-nitropyrrole riboside, PNA-5-nitroindole, PNA-nebulaline, PNA-inosine, PNA-4-nitrobenzimidazole, PNA-3-nitropyrrole, morpholino-5-nitroindole
- the linker region is preferably an oligonucleotide consisting of only one base of adenine, guanine, cytosine, or thymine.
- the length of the oligonucleotide in the linker region is preferably 3 to 11 nucleotides, more preferably 3 to 9 nucleotides, and particularly preferably 7.
- the length of the oligonucleotide in the linker region is determined from the first target base sequence and the second target in terms of obtaining a degree of freedom in steric structure. Is preferably ⁇ 5 to +5, and more preferably ⁇ 3 to +3.
- the probe of this embodiment has a fluorescent dye in the reporter region for detecting the first single nucleotide polymorphism, the presence or absence of the first single nucleotide polymorphism in the target nucleic acid can be detected based on the fluorescence intensity. it can.
- the probe of the present embodiment and the first one Based on the measured fluorescence intensity, a step of mixing target nucleic acids present at different positions of the nucleotide polymorphism and the second single nucleotide polymorphism, preparing a mixture, a step of measuring the fluorescence intensity of the mixture, And a step of determining whether the first single nucleotide polymorphism and the second single nucleotide polymorphism are present in a cis form or in a trans form.
- FIG. 1 schematically shows the state of the probe of this embodiment and a target nucleic acid when they are mixed when the first single nucleotide polymorphism is C797S and the second single nucleotide polymorphism is T790M.
- FIG. 1 In the anchor region having a sequence complementary to the second target base sequence in which T790M is present, the probe hybridizes with the target nucleic acid (FIGS. 1 (a) and (b-1)).
- the reporter region further hybridizes with the first target base sequence in which C797S is present, the fluorescence of the fluorescent dye is quenched (FIG. 1 (a)). In this case, it can be determined that C797S and T790M exist in a cis form.
- the reporter region when the reporter region is mismatched, the fluorescence of the fluorescent dye continues to be emitted because the reporter region cannot hybridize (FIG. 1 (b-1)). In this case, it can be determined that C797S and T790M exist in a trans form.
- the nucleotide length of the reporter region is shorter than the nucleotide length of the anchor region, and the binding property of the probe is ensured by the anchor region. Therefore, if the anchor region is mismatched, the reporter region cannot hybridize to the first target base sequence even if the first target base sequence in which C797S exists is present. The fluorescence continues to be emitted (FIG. 1 (b-2)). Also in this case, it can be determined that C797S and T790M exist in a trans form.
- the probe of this embodiment emits fluorescence when the reporter region does not hybridize with the first target base sequence in the target nucleic acid.
- the first single nucleotide polymorphism and the second single nucleotide polymorphism exist in cis form. It can be determined.
- the probe and target nucleic acid are mixed and the fluorescence intensity of the mixture is maintained or increased compared to before mixing, the first single nucleotide polymorphism and the second single nucleotide polymorphism are trans It can be determined that it exists as a type.
- the first single nucleotide polymorphism and the second single nucleotide polymorphism exist in cis form or trans form. Can be efficiently determined.
- Tm analysis can be performed by a method commonly used by those skilled in the art.
- Tm analysis include a method in which a probe and a target nucleic acid are mixed and the fluorescence intensity of the mixed solution at that time is measured while changing the temperature of the mixed solution.
- the reporter region is mismatched, the thermal stability of the probe and target nucleic acid complex is lower than when the reporter region is completely matched, so the reporter region binds to the target nucleic acid at a lower temperature, and fluorescence quenching is measured. The This temperature is called the quenching start temperature.
- the reporter region when the reporter region is a perfect match, the probe and target nucleic acid complex is more thermally stable than the mismatch, so that the reporter region binds to the target nucleic acid even at a higher temperature, and fluorescence quenching occurs. Measured. Therefore, for example, the quenching start temperature of the target nucleic acid when the reporter region is mismatched is measured, and when the quenching start temperature is higher than this value, the target nucleic acid used for the measurement has the first single nucleotide It can be determined that the type and the second single nucleotide polymorphism exist in the cis form.
- the quenching start temperature of the target nucleic acid when the anchor region becomes a mismatch is measured, and the quenching start is higher than this value.
- the temperature is high, it can be determined that the first single nucleotide polymorphism and the second single nucleotide polymorphism exist in cis form in the target nucleic acid used for the measurement.
- the method for determining whether the first single nucleotide polymorphism and the second single nucleotide polymorphism of the present embodiment are present in the cis form or in the trans form includes the probe, the first single nucleotide polymorphism and the first single nucleotide polymorphism.
- a competing oligonucleotide can be further mixed.
- the competing oligonucleotide may be an oligonucleotide having a sequence that is completely complementary to the wild-type base sequence for the first target base sequence, and a sequence that is completely complementary to the wild-type base sequence for the second target base sequence. It may be an oligonucleotide having a combination thereof, or a combination thereof, but is preferably an oligonucleotide having a sequence that is completely complementary to a wild-type base sequence for the second target base sequence.
- the nucleotide length of the reporter region for detecting the first single nucleotide polymorphism is extremely shortened. Can do. Therefore, the specificity of the reporter region is increased, and the reporter region is less likely to hybridize to the mismatched sequence even under a low temperature such as room temperature. As a result, the fluorescence intensity of the liquid mixture near room temperature at the time of mismatch does not decrease significantly even when compared with the fluorescence intensity at the quenching start temperature. On the other hand, when the reporter region completely matches, the reporter region hybridizes with the target nucleic acid through the first target base sequence near room temperature.
- the fluorescence intensity of the liquid mixture near room temperature at the time of perfect match is significantly reduced compared to the fluorescence intensity at the quenching start temperature, and is about 60% or less. Therefore, for example, in the SNP detection method using Tm analysis, when the fluorescence intensity of the mixture near room temperature is 60% or less of the fluorescence intensity at the quenching start temperature, the target nucleic acid used for the measurement is It can be determined that one single nucleotide polymorphism and the second single nucleotide polymorphism exist in cis form.
- an amplification product amplified by a method such as a PCR method or a LAMP method may be used as the target nucleic acid.
- the first single nucleotide polymorphism and the second single nucleotide polymorphism are present in a different positional relationship from the cis type or the trans type, so that the disease symptoms change. It is possible to provide an index for selecting a diagnosis, an appropriate therapeutic agent / treatment method, and the like for a patient having a disease.
- the first single nucleotide polymorphism and the second single nucleotide polymorphism are present in a positional relationship different from that of the cis type or trans type, so that it is appropriate for a patient having a disease whose response to a therapeutic drug is changed.
- the first single nucleotide polymorphism and the second single nucleotide polymorphism that cause resistance to the therapeutic drug are present in a positional relationship different from that of the cis-type or trans-type, thereby allowing resistance to the therapeutic drug.
- the strength of the drug is different, it is possible to provide an index for selection of the response to the resistance and development of a therapeutic agent / treatment method for overcoming the resistance.
- Example 1 Design of probe and primer for LAMP method
- EGFR Homo sapiens epidermal growth factor receptor
- LRG_304 RefSeqGene on chromosome 7
- Mutations in the EGFR gene are as follows.
- T790M and C797S were targeted.
- a probe and competing oligo sequence for detecting T790M, a probe and competing oligo sequence for detecting C797S alone, and a probe and competing oligo sequence for detecting when T790M and C797S are present in cis form, 2 was designed.
- C797S is known to have two mutations, 2389T> A and 2390G> C.
- a probe for detecting C797S was designed based on 2389T> A, which has a high detection frequency.
- C797S caused by mutation of 2389T> A is also referred to as C797S_2 due to mutation of C797S_1, 2390G> C.
- Example 2 Detection of C797S_1 using the LAMP method
- the detectability of C797S with a probe (C797S detection probe in Table 2) for detecting C797S_1 (2389T> A) designed in Example 1 alone was measured using the LAMP method.
- Template DNA DNA having an EGFR gene sequence including C797S_1 (2389T> A), DNA having an EGFR gene sequence including C797S_2 (2390G> C), DNA having a wild-type EGFR gene sequence.
- the template DNA is used alone or in combination.
- QProbe binding probe a probe in which QProbe is bound to DNA having the base sequence of SEQ ID NO: 5 (C797S detection probe).
- LAMP primer a primer having any one of the nucleotide sequences of SEQ ID NOS: 7 to 10.
- a reaction solution was prepared by adding 5 ⁇ l of template DNA (template amount 10000 cps) denatured by heating to 20 ⁇ l of LAMP master mix. Incubate the reaction solution at 65 ° C for 90 minutes with a real-time fluorescence spectrometer LC480 (Roche), heat denature the amplified product at 95 ° C for 5 minutes, and then hybridize the amplified product and the QProbe binding probe at 37 ° C for 5 minutes. Made soy. After the reaction, the temperature of the reaction solution was gradually increased from 37 ° C. to 80 ° C. (acquisition 7 / ° C.), the fluorescence intensity was measured, and the thermal melting curve analysis was performed. The fluorescence intensity was measured at 465/510 (nm) when QProbe had BodipyFL, and was measured at 533/580 (nm) when QProbe had TAMRA.
- FIG. 2 shows the change in fluorescence intensity when the thermal melting curve analysis is performed.
- the mutation content means the ratio of the template DNA containing the mutation in the entire template DNA.
- Example 3 Screening of cis-type linker probe using LAMP method
- TAMRA QProbe
- a synthetic oligonucleotide was designed in which a sequence recognizing T790M and a sequence recognizing C797S were linked by a linker.
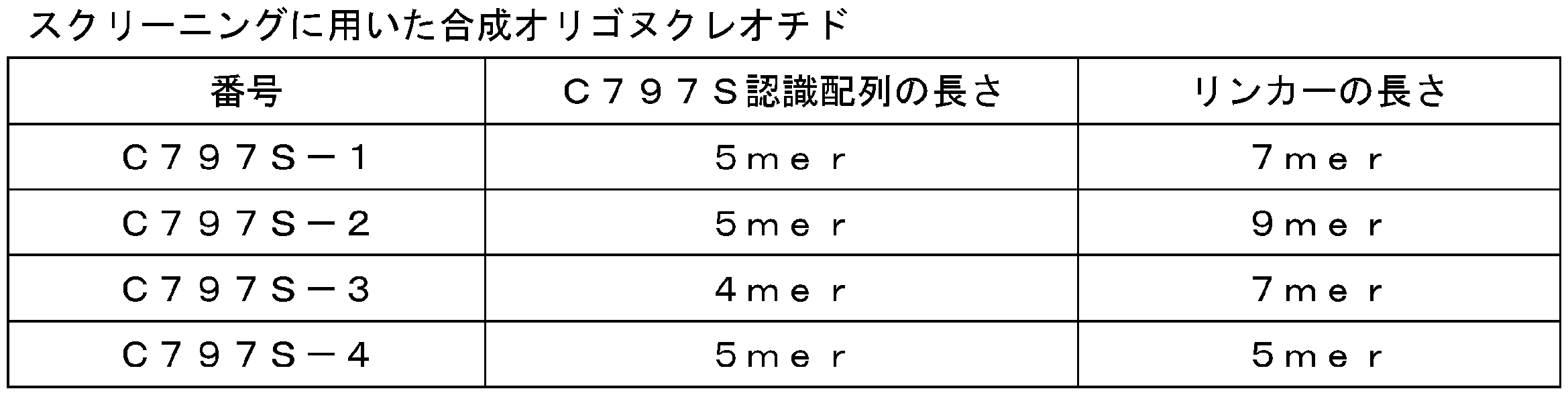
- the sequence recognizing C797S and the length of the linker were changed without changing the sequence recognizing T790M, and four types of synthetic oligonucleotides were designed as shown in Table 4.
- the synthetic oligonucleotides in Table 4 were used as template DNAs, and probes (1) to (3) in FIG. 3 were used as QProbe binding probes, respectively, and hybridized with the following reagent composition.
- a master mix for screening (30 mM KCl, 10 mM Tris-HCl (pH 8.0), 0.1% Tween, 1.6 ⁇ M synthetic oligonucleotide, 0.05 ⁇ M probe)
- a real-time fluorescence analyzer LC480 (Roche)
- the temperature of the reaction solution was gradually increased from 37 to 80 ° C. (acquisition 7 / ° C.), the fluorescence intensity was measured, and the thermal melting curve analysis was performed.
- FIG. 4 shows the results of thermal melting curve analysis when a synthetic oligonucleotide in which the sequence recognizing T790M and the sequence recognizing C797S described in FIG. 3 are linked by a linker (TTTTTTTT) is used.
- Example 4 Detection of cis-type mutation using LAMP method
- a C797S-1 synthetic oligonucleotide SEQ ID NO: 3
- SEQ ID NO: 3 which was able to efficiently detect only a sequence containing cis-type T790M and C797S, was converted into a probe, and a cis-type linker probe for detection was used.
- an EGFR gene sequence containing cis-type T790M and C797S, an EGFR gene sequence containing trans-type T790M and C797S, an EGFR gene sequence containing only T790M, and An EGFR gene sequence containing only C797S was designed to produce an artificial gene.
- Hybridization was carried out by the LAMP method in the same manner as in Example 2 using genomic DNAs having the artificial gene and wild type EGFR gene sequences as template DNAs and using the cis-type detection linker probe as a QProbe binding probe. .
- a competitive oligo (SEQ ID NO: 2) that completely complements the wild type at the T790M sequence site to eliminate the slight observed quenching when using an oligonucleotide having an artificial gene sequence containing only C797S, and to further increase sensitivity was added at 1.2 ⁇ M.
- FIG. 5 shows the results of analyzing the thermal melting curve by measuring the fluorescence intensity of the LAMP product in the same manner as in Example 2.
- the mutation content means the ratio of the template DNA containing the mutation in the entire template DNA.
Landscapes
- Chemical & Material Sciences (AREA)
- Life Sciences & Earth Sciences (AREA)
- Organic Chemistry (AREA)
- Proteomics, Peptides & Aminoacids (AREA)
- Zoology (AREA)
- Health & Medical Sciences (AREA)
- Engineering & Computer Science (AREA)
- Wood Science & Technology (AREA)
- Analytical Chemistry (AREA)
- Microbiology (AREA)
- Physics & Mathematics (AREA)
- Molecular Biology (AREA)
- Immunology (AREA)
- Biotechnology (AREA)
- Biophysics (AREA)
- Biochemistry (AREA)
- Bioinformatics & Cheminformatics (AREA)
- General Engineering & Computer Science (AREA)
- General Health & Medical Sciences (AREA)
- Genetics & Genomics (AREA)
- Measuring Or Testing Involving Enzymes Or Micro-Organisms (AREA)
Abstract
Description
上記標的核酸が、上記第1の一塩基多型が存在する第1の標的塩基配列と、上記第2の一塩基多型が存在する第2の標的塩基配列と、を含み、
上記プローブが、上記第1の一塩基多型を検出するレポーター領域と、上記第2の一塩基多型を検出するアンカー領域と、リンカー領域と、を含み、
上記レポーター領域が、上記第1の標的塩基配列に対して完全マッチする塩基配列からなるオリゴヌクレオチドと、上記第1の標的塩基配列及び上記レポーター領域がハイブリダイズしたときに消光する蛍光色素と、を有し、
上記アンカー領域が、上記第2の標的塩基配列に対して完全マッチする塩基配列からなるオリゴヌクレオチドを有し、
上記リンカー領域が、上記レポーター領域及び上記アンカー領域を連結しており、上記第1の一塩基多型及び第2の一塩基多型がシス型で存在する場合の上記標的核酸における上記第1の標的塩基配列及び上記第2の標的塩基配列の間の塩基配列に対して、非相補的な塩基配列からなるオリゴヌクレオチドを有し、
上記レポーター領域のオリゴヌクレオチドの長さが、上記アンカー領域のオリゴヌクレオチドの長さよりも短い、プローブを提供する。
本実施形態のプローブは、第1の一塩基多型を検出するレポーター領域と、第2の一塩基多型を検出するアンカー領域と、リンカー領域と、を含む。本実施形態のプローブにおいて、レポーター領域及びアンカー領域の位置関係は、標的核酸において第1の一塩基多型及び第2の一塩基多型がシス型の位置関係で存在するときの、第1の標的塩基配列及び第2の標的塩基配列の位置関係に応じて、適宜設定することができる。例えば、第2の標的塩基配列が第1の標的塩基配列の3’側に位置するときは、アンカー領域はレポーター領域の5’側に配置される。
レポーター領域は、第1の一塩基多型を検出するための領域である。レポーター領域のオリゴヌクレオチドは、第1の一塩基多型が存在する第1の標的塩基配列と相補的な塩基配列からなるヌクレオチドである。レポーター領域は、第1の一塩基多型が存在する第1の標的塩基配列に対して完全マッチし、第1の標的塩基配列以外の配列(第1の一塩基多型が存在しない以外は第1の標的塩基配列と同一である配列を含む)のときにはミスマッチとなる塩基配列からなるオリゴヌクレオチドである。
アンカー領域は、第2の一塩基多型を検出するための領域である。アンカー領域のオリゴヌクレオチドは、第2の一塩基多型が存在する第2の標的塩基配列と相補的な塩基配列からなるヌクレオチドである。アンカー領域は、第2の一塩基多型が存在する第2の標的塩基配列に対して完全マッチし、第2の標的塩基配列以外のとき(第2の一塩基多型が存在しない以外は第2の標的塩基配列と同一である配列を含む)にはミスマッチとなる塩基配列からなるオリゴヌクレオチドである。第2の標的塩基配列に対して良好な結合性を得る観点から、アンカー領域のオリゴヌクレオチドの長さは、8~20個のヌクレオチドが好ましく、10~18個のヌクレオチドでより好ましく、11~15個のヌクレオチドが更に好ましく、14又は15個のヌクレオチドが特に好ましい。
リンカー領域は、プローブの自由度を増加させるための領域である。リンカー領域は、レポーター領域及びアンカー領域を連結している。リンカー領域は、第1の一塩基多型及び第2の一塩基多型がシス型で存在する場合の標的核酸における第1の標的塩基配列及び第2の標的塩基配列の間の塩基配列に対して、非相補的な塩基配列からなるオリゴヌクレオチドを有する。
本実施形態のプローブは、第1の一塩基多型を検出するレポーター領域に蛍光色素を有するため、その蛍光強度に基づいて、標的核酸における第1の一塩基多型の有無を検出することができる。
リファレンス配列として、Homo sapiens epidermal growth factor receptor (EGFR), RefSeqGene(LRG_304) on chromosome 7(NCBIアクセッション番号:NG_007726)の配列を用いた。EGFR遺伝子における変異は以下の通りである。



実施例1で設計したC797S_1(2389T>A)を単独で検出するためのプローブ(表2のC797S検出用プローブ)による、C797Sの検出能を、LAMP法を用いて測定した。
鋳型DNA:C797S_1(2389T>A)を含むEGFR遺伝子配列を有するDNA、C797S_2(2390G>C)を含むEGFR遺伝子配列を有するDNA、野生型のEGFR遺伝子配列を有するDNA。鋳型DNAは、上記DNAを単独又は混合して用いる。
QProbe結合プローブ:配列番号5の塩基配列を有するDNAにQProbeを結合させたもの(C797S検出用プローブ)。
LAMP用プライマー:配列番号7~10のいずれかの塩基配列を有するプライマー。
LAMP用マスターミックス:30mM KCl、1.8% Dextran、14mM Tricine、0.1% n-heptyl、0.5% Tween、0.3% FCP、1mM DTT、1.7mM each dNTPs、8mM MgSO4、1.6μM Forward inner primer(FIP、配列番号9)、Backward inner primer(BIP、配列番号10)、0.8μM Loop primer(LP、配列番号11)、0.2μM F3(配列番号7)、0.2μM B3(配列番号8)、1.2μM 競合オリゴ、0.04μM probe、0.0375× intercalator (gel green)、19.7U Bst DNA polymerase(以上は、濃度は25μL時の最終濃度)。
LAMP用マスターミックス20μlに対して加熱変性させた鋳型DNA5μl(鋳型量10000cps)を添加し反応液を調製した。リアルタイム蛍光測定器LC480(Roche社製)にて、反応液を65℃90分インキュベートし、増幅産物を95℃5分で熱変性させてから、37℃5分で増幅産物とQProbe結合プローブをハイブリダイズさせた。反応後、反応液の温度を37℃~80℃まで徐々に上昇(acquisition 7/℃)させ、蛍光強度を測定して熱融解曲線解析を行った。蛍光強度は、QProbeがBodipyFLを有するときには、465/510(nm)にて測定し、QProbeがTAMRAを有するときには、533/580(nm)にて測定した。
熱融解曲線解析を行った際の蛍光強度の変化を図2に示す。実施例1で設計したC797S検出用プローブを用いることにより、鋳型量が10000cpsのとき、C797S_1の変異含有率5%まで検出できることが示された。ここで、変異含有率とは、鋳型DNA全体における変異を含む鋳型DNAの割合を意味する。
図3のように、長さが同じ3つのプローブ(1)~(3)を作成した。各プローブには、QProbe(TAMRA)が結合されている。
(1)T790M及びC797Sを含む配列からなるプローブ(配列番号12)
(2)T790Mを含む配列及び野生型の配列からなるプローブ(配列番号13)
(3)野生型の配列及びC797Sを含む配列からなるプローブ(配列番号14)
実施例3において、効率よくシス型のT790M及びC797Sを含む配列のみを検出することができたC797S-1の合成オリゴヌクレオチド(配列番号3)をプローブへと変換し、シス型検出用リンカープローブを作製した。
Claims (5)
- 第1の一塩基多型及び第2の一塩基多型が異なる位置に存在する標的核酸において、前記第1の一塩基多型及び第2の一塩基多型がシス型で存在するか又はトランス型で存在するかを判別するための一塩基多型検出用オリゴヌクレオチドプローブであって、
前記標的核酸が、前記第1の一塩基多型が存在する第1の標的塩基配列と、前記第2の一塩基多型が存在する第2の標的塩基配列と、を含み、
前記プローブが、前記第1の一塩基多型を検出するレポーター領域と、前記第2の一塩基多型を検出するアンカー領域と、リンカー領域と、を含み、
前記レポーター領域が、前記第1の標的塩基配列に対して完全マッチする塩基配列からなるオリゴヌクレオチドと、前記第1の標的塩基配列及び前記レポーター領域がハイブリダイズしたときに消光する蛍光色素と、を有し、
前記アンカー領域が、前記第2の標的塩基配列に対して完全マッチする塩基配列からなるオリゴヌクレオチドを有し、
前記リンカー領域が、前記レポーター領域及び前記アンカー領域を連結しており、前記第1の一塩基多型及び第2の一塩基多型がシス型で存在する場合の前記標的核酸における前記第1の標的塩基配列及び前記第2の標的塩基配列の間の塩基配列に対して、非相補的な塩基配列からなるオリゴヌクレオチドを有し、
前記レポーター領域のオリゴヌクレオチドの長さが、前記アンカー領域のオリゴヌクレオチドの長さよりも短い、プローブ。 - 前記リンカー領域が、ユニバーサル塩基を含まない塩基配列からなるオリゴヌクレオチドである、請求項1に記載のプローブ。
- 前記リンカー領域が、アデニン、グアニン、シトシン、又はチミンのいずれか1種の塩基のみからなるオリゴヌクレオチドである、請求項1又は2に記載のプローブ。
- 前記リンカー領域が、3~11個のヌクレオチドからなるオリゴヌクレオチドである、請求項1~3のいずれか一項に記載のプローブ。
- 第1の一塩基多型及び第2の一塩基多型がシス型で存在するか又はトランス型で存在するかを判別する方法であって、
請求項1~4のいずれか一項に記載のプローブ並びに第1の一塩基多型及び第2の一塩基多型が異なる位置に存在する標的核酸を混合し、混合液を調製する工程と、
前記混合液の蛍光強度を測定する工程と、
前記蛍光強度に基づき、前記第1の一塩基多型及び第2の一塩基多型がシス型で存在するか又はトランス型で存在するかを判別する工程と、を備える方法。
Priority Applications (4)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US16/980,367 US11851701B2 (en) | 2018-03-15 | 2019-03-12 | Oligonucleotide probe for detecting single nucleotide polymorphisms, and method for determining cis-trans configuration |
| CN201980009100.1A CN111615561B (zh) | 2018-03-15 | 2019-03-12 | 单核苷酸多态性检测用寡核苷酸探针和顺式-反式判别方法 |
| JP2020506557A JP6933768B2 (ja) | 2018-03-15 | 2019-03-12 | 一塩基多型検出用オリゴヌクレオチドプローブ、及びシス型−トランス型判別方法 |
| EP19767893.1A EP3766992A4 (en) | 2018-03-15 | 2019-03-12 | OLIGONUCLEOTIDE PROBE FOR DETECTION OF MONONUCLEOTIDIC POLYMORPHISM, AND PROCESS FOR DIFFERENTIATION OF CIS FORM AND TRANS FORM |
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2018047582 | 2018-03-15 | ||
| JP2018-047582 | 2018-03-15 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2019176939A1 true WO2019176939A1 (ja) | 2019-09-19 |
Family
ID=67906713
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2019/010012 Ceased WO2019176939A1 (ja) | 2018-03-15 | 2019-03-12 | 一塩基多型検出用オリゴヌクレオチドプローブ、及びシス型-トランス型判別方法 |
Country Status (5)
| Country | Link |
|---|---|
| US (1) | US11851701B2 (ja) |
| EP (1) | EP3766992A4 (ja) |
| JP (1) | JP6933768B2 (ja) |
| CN (1) | CN111615561B (ja) |
| WO (1) | WO2019176939A1 (ja) |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2024023510A1 (en) * | 2022-07-26 | 2024-02-01 | Mast Group Limited | Method and kit for detecting single nucleotide polymorphisms (snp) by loop-mediated isothermal amplification (lamp) |
Citations (9)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2001286300A (ja) * | 1999-04-20 | 2001-10-16 | Japan Bioindustry Association | 核酸の測定方法、それに用いる核酸プローブ及びその方法によって得られるデータを解析する方法 |
| WO2004000995A2 (en) * | 2002-05-22 | 2003-12-31 | Marshall University | Methods, probes, and accessory molecules for detecting single nucleotide polymorphisms |
| WO2006086777A2 (en) | 2005-02-11 | 2006-08-17 | Memorial Sloan Kettering Cancer Center | Methods and compositions for detecting a drug resistant egfr mutant |
| JP2009517054A (ja) * | 2005-12-02 | 2009-04-30 | サイモンズ ハプロミクス リミテッド | 遺伝子マッピング及びハプロタイプ決定の方法 |
| WO2011052754A1 (ja) | 2009-10-30 | 2011-05-05 | アークレイ株式会社 | Egfr遺伝子多型検出用プローブおよびその用途 |
| JP2012523821A (ja) * | 2009-03-27 | 2012-10-11 | ライフ テクノロジーズ コーポレーション | 対立遺伝子変種を検出するための方法、組成物、およびキット |
| WO2013145939A1 (ja) * | 2012-03-28 | 2013-10-03 | 日本電気株式会社 | 標的物質の検出方法、検査キット、および検出装置 |
| JP2014526257A (ja) * | 2011-09-19 | 2014-10-06 | エピスタム リミテッド | 複数の標的領域特異性および三部分的特性を有するプローブ |
| WO2016098595A1 (ja) | 2014-12-19 | 2016-06-23 | 栄研化学株式会社 | 一塩基多型検出用オリゴヌクレオチドプローブ及び一塩基多型検出方法 |
Family Cites Families (14)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| EP1430150B1 (en) * | 2001-09-24 | 2015-08-19 | One Lambda, Inc. | Diagnostic probe detection system |
| WO2005010201A2 (en) | 2003-01-29 | 2005-02-03 | Naxcor, Inc. | Methods and compositions for detecting nucleic acid sequences |
| CN103898207B (zh) * | 2003-08-01 | 2016-09-14 | 戴诺生物技术有限公司 | 自杂交多重靶核酸探针及其使用方法 |
| US8673564B2 (en) | 2007-06-07 | 2014-03-18 | Haplomic Technologies Pty Ltd | In situ methods for gene mapping and haplotyping |
| US7989465B2 (en) * | 2007-10-19 | 2011-08-02 | Avila Therapeutics, Inc. | 4,6-disubstituted pyrimidines useful as kinase inhibitors |
| US20110207736A1 (en) * | 2009-12-23 | 2011-08-25 | Gatekeeper Pharmaceuticals, Inc. | Compounds that modulate egfr activity and methods for treating or preventing conditions therewith |
| US9328382B2 (en) | 2013-03-15 | 2016-05-03 | Complete Genomics, Inc. | Multiple tagging of individual long DNA fragments |
| WO2015071552A1 (en) | 2013-11-18 | 2015-05-21 | Teknologian Tutkimuskeskus Vtt | Multi-unit probes with high specificity and a method of designing the same |
| US20160281166A1 (en) * | 2015-03-23 | 2016-09-29 | Parabase Genomics, Inc. | Methods and systems for screening diseases in subjects |
| JP7511326B2 (ja) | 2015-10-09 | 2024-07-05 | ウェイブ ライフ サイエンシズ リミテッド | オリゴヌクレオチド組成物およびその方法 |
| CN107083438A (zh) * | 2017-06-12 | 2017-08-22 | 上海捷易生物科技有限公司 | 检测egfr基因20外显子t790m和c797s突变的引物、探针及方法 |
| CN107488710B (zh) | 2017-07-14 | 2020-09-22 | 上海吐露港生物科技有限公司 | 一种Cas蛋白的用途及靶标核酸分子的检测方法和试剂盒 |
| CN109504777B (zh) * | 2018-12-29 | 2020-05-12 | 江苏先声医学诊断有限公司 | 用于检测t790m和c797s顺反式突变类型的探针组、试剂盒、反应体系及系统 |
| CN109554444A (zh) * | 2018-12-31 | 2019-04-02 | 新羿制造科技(北京)有限公司 | 一种检测核酸突变顺反式结构的方法及其试剂盒 |
-
2019
- 2019-03-12 JP JP2020506557A patent/JP6933768B2/ja active Active
- 2019-03-12 US US16/980,367 patent/US11851701B2/en active Active
- 2019-03-12 EP EP19767893.1A patent/EP3766992A4/en active Pending
- 2019-03-12 WO PCT/JP2019/010012 patent/WO2019176939A1/ja not_active Ceased
- 2019-03-12 CN CN201980009100.1A patent/CN111615561B/zh active Active
Patent Citations (9)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2001286300A (ja) * | 1999-04-20 | 2001-10-16 | Japan Bioindustry Association | 核酸の測定方法、それに用いる核酸プローブ及びその方法によって得られるデータを解析する方法 |
| WO2004000995A2 (en) * | 2002-05-22 | 2003-12-31 | Marshall University | Methods, probes, and accessory molecules for detecting single nucleotide polymorphisms |
| WO2006086777A2 (en) | 2005-02-11 | 2006-08-17 | Memorial Sloan Kettering Cancer Center | Methods and compositions for detecting a drug resistant egfr mutant |
| JP2009517054A (ja) * | 2005-12-02 | 2009-04-30 | サイモンズ ハプロミクス リミテッド | 遺伝子マッピング及びハプロタイプ決定の方法 |
| JP2012523821A (ja) * | 2009-03-27 | 2012-10-11 | ライフ テクノロジーズ コーポレーション | 対立遺伝子変種を検出するための方法、組成物、およびキット |
| WO2011052754A1 (ja) | 2009-10-30 | 2011-05-05 | アークレイ株式会社 | Egfr遺伝子多型検出用プローブおよびその用途 |
| JP2014526257A (ja) * | 2011-09-19 | 2014-10-06 | エピスタム リミテッド | 複数の標的領域特異性および三部分的特性を有するプローブ |
| WO2013145939A1 (ja) * | 2012-03-28 | 2013-10-03 | 日本電気株式会社 | 標的物質の検出方法、検査キット、および検出装置 |
| WO2016098595A1 (ja) | 2014-12-19 | 2016-06-23 | 栄研化学株式会社 | 一塩基多型検出用オリゴヌクレオチドプローブ及び一塩基多型検出方法 |
Non-Patent Citations (2)
| Title |
|---|
| K. UCHIBORI ET AL.: "Brigatinib combined with anti-EGFR antibody overcomes osimertinib resistance in EGFR-mutated non-small-cell lung cancer", NATURE COMMUNICATIONS, 2017 |
| See also references of EP3766992A4 |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2024023510A1 (en) * | 2022-07-26 | 2024-02-01 | Mast Group Limited | Method and kit for detecting single nucleotide polymorphisms (snp) by loop-mediated isothermal amplification (lamp) |
Also Published As
| Publication number | Publication date |
|---|---|
| JP6933768B2 (ja) | 2021-09-08 |
| CN111615561A (zh) | 2020-09-01 |
| EP3766992A1 (en) | 2021-01-20 |
| US20210040544A1 (en) | 2021-02-11 |
| US11851701B2 (en) | 2023-12-26 |
| JPWO2019176939A1 (ja) | 2021-02-04 |
| CN111615561B (zh) | 2024-06-04 |
| EP3766992A4 (en) | 2021-12-01 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN111511925B (zh) | 用于扩增靶核酸的方法及用于扩张靶核酸的组合物 | |
| Vargas et al. | Multiplex real-time PCR assays that measure the abundance of extremely rare mutations associated with cancer | |
| US11306350B2 (en) | Primers, compositions, and methods for nucleic acid sequence variation detection | |
| US20130078631A1 (en) | Probe, and polymorphism detection method using the same | |
| KR20140010093A (ko) | 혼합 집단 중 표적 dna의 서열분석을 위한 키트 및 방법 | |
| WO2016167317A1 (ja) | 遺伝子変異の検出方法 | |
| JP6933768B2 (ja) | 一塩基多型検出用オリゴヌクレオチドプローブ、及びシス型−トランス型判別方法 | |
| US11512343B2 (en) | Oligonucleotide probe for detecting single nucleotide polymorphism, and method for detecting single nucleotide polymorphism | |
| JP6755857B2 (ja) | 遺伝子変異の検出方法 | |
| US20240035074A1 (en) | Target nucleic acid amplification method with high specificity and target nucleic acid amplifying composition using same | |
| JP2008161165A (ja) | 競合オリゴヌクレオチドを用いた遺伝子検出法 | |
| US9121051B2 (en) | Method of determining the abundance of a target nucleotide sequence of a gene of interest | |
| WO2016103727A1 (ja) | 特異的核酸配列の増幅促進方法 | |
| US20250236917A1 (en) | Rapid and accurate single-nucleotide polymorphism detection by fluorophore-nucleic acid interaction | |
| US20060084068A1 (en) | Process for detecting a nucleic acid target | |
| JP2021533769A (ja) | 核酸の増幅のための試薬、混合物、キット、および方法 | |
| JP2007075052A (ja) | 単一蛍光標識オリゴヌクレオチドを用いた核酸の検出法 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 19767893 Country of ref document: EP Kind code of ref document: A1 |
|
| ENP | Entry into the national phase |
Ref document number: 2020506557 Country of ref document: JP Kind code of ref document: A |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 2019767893 Country of ref document: EP |
|
| ENP | Entry into the national phase |
Ref document number: 2019767893 Country of ref document: EP Effective date: 20201015 |