WO2020100361A1 - ゲノム編集された細胞を製造する方法 - Google Patents
ゲノム編集された細胞を製造する方法 Download PDFInfo
- Publication number
- WO2020100361A1 WO2020100361A1 PCT/JP2019/031117 JP2019031117W WO2020100361A1 WO 2020100361 A1 WO2020100361 A1 WO 2020100361A1 JP 2019031117 W JP2019031117 W JP 2019031117W WO 2020100361 A1 WO2020100361 A1 WO 2020100361A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- site
- cells
- dna
- tscer2
- chromosome
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Ceased
Links
Images

























Classifications
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/10—Processes for the isolation, preparation or purification of DNA or RNA
- C12N15/102—Mutagenizing nucleic acids
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/11—DNA or RNA fragments; Modified forms thereof; Non-coding nucleic acids having a biological activity
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/87—Introduction of foreign genetic material using processes not otherwise provided for, e.g. co-transformation
- C12N15/90—Stable introduction of foreign DNA into chromosome
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/87—Introduction of foreign genetic material using processes not otherwise provided for, e.g. co-transformation
- C12N15/90—Stable introduction of foreign DNA into chromosome
- C12N15/902—Stable introduction of foreign DNA into chromosome using homologous recombination
- C12N15/907—Stable introduction of foreign DNA into chromosome using homologous recombination in mammalian cells
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N9/00—Enzymes; Proenzymes; Compositions thereof; Processes for preparing, activating, inhibiting, separating or purifying enzymes
- C12N9/14—Hydrolases (3)
- C12N9/16—Hydrolases (3) acting on ester bonds (3.1)
- C12N9/22—Ribonucleases [RNase]; Deoxyribonucleases [DNase]
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2310/00—Structure or type of the nucleic acid
- C12N2310/10—Type of nucleic acid
- C12N2310/20—Type of nucleic acid involving clustered regularly interspaced short palindromic repeats [CRISPR]
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2800/00—Nucleic acids vectors
- C12N2800/80—Vectors containing sites for inducing double-stranded breaks, e.g. meganuclease restriction sites
Definitions
- the present invention relates to a method for producing a genome-edited cell, and mainly to a method for producing a cell in which a hetero mutation is replaced with a normal sequence by homologous recombination between homologous chromosomes.
- TALENs a genome-editing technology of a generation ago
- TALE a fusion protein of a TALE protein that targets DNA and a nuclease that cleaves DNA (mainly FokI), but like the CRISPR-Cas system, it targets on the genome.
- a double-strand break in the DNA occurs at the site.
- nucleotide insertion or deletion (insertion / deletion: indel) occurs, and gene knockout can be performed by frame shift or the like.
- gene knock-in can be performed by homologous recombination between the genome and the donor DNA. In this gene knock-in, not only insertion of DNA but also substitution or deletion of 1 to several nucleotides can be caused.
- Non-Patent Document 1 Non-Patent Document 1
- the present inventors have further developed this method, and put one nick in the target genome and one nick in the donor plasmid containing the repair template.
- the SNGD method (a combination of single nickels in the Target gene and donor plasmids were also developed (Patent Document 1).
- the present invention has been made in view of the problems of the above-mentioned conventional techniques, and an object thereof is to perform genome editing by homologous recombination specifically and highly efficiently without using a foreign donor DNA. To provide a method.
- the present inventors first performed genome editing using a homologous chromosome originally present in the cell as a repair template, rather than introducing the donor DNA from outside the cell. , was conceived to avoid the problem of random integration of donor DNA.
- the gene mutation existing in one allele (this is referred to as "allyl A”) is ”)) Does not exist.
- the mutation of allyl A can be restored to a normal sequence using allyl B as a repair template, or conversely, allyl A can be used as a template. It is possible to introduce mutations into the normal sequence of allyl B. In this case, the foreign donor DNA (artificially synthesized DNA chain, plasmid, etc.) used as a template in the existing method becomes unnecessary.
- repair of homologous recombination occurs between sister chromatids, and homologous recombination between homologous chromosomes is extremely unlikely.
- the present inventors tried to induce homologous recombination between homologous chromosomes by introducing a DNA break around the target site of the homologous chromosomes.
- nicks were generated at multiple sites in the DNA region near the nucleotide to be modified on the recipient chromosome, and on the donor chromosome, nicks were generated on the recipient chromosome.
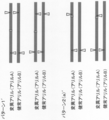
- By creating a nick in at least one of the sites corresponding to the site of growth it was possible to significantly suppress non-homologous end joining and specifically induce recombination between homologous chromosomes at the target site ( An example of the introduction of a nick is shown in Figures 1A-H).
- the present invention relates to genome editing utilizing homologous recombination between homologous chromosomes, and more specifically provides the following.
- a method for producing a genome-edited cell which comprises: A cell having a different base between homologous chromosomes at a specific site of a homologous chromosome is introduced with a combination of site-specific nickases that single-strand breaks in a DNA region near the specific site, and one of the homologous chromosomes is used as a recipient.
- a kit for use in the method according to any one of (1) to (3) In a cell having different bases between homologous chromosomes at a specific site of a homologous chromosome, including a combination of site-specific nickases that single-strand breaks in a DNA region in the vicinity of the specific site, The combination of the site-specific nickase, in the recipient chromosome, single-strand breaks at multiple sites in the DNA region in the vicinity of the specific site, in the donor chromosome, single-stranded in the recipient chromosome A kit for cutting a single strand at least at one position corresponding to the position to be cut.
- the present invention it is possible to perform specific and highly efficient genome editing by homologous recombination between homologous chromosomes while significantly suppressing the occurrence of unintended mutations due to non-homologous end joining.
- genome editing can be performed with high safety even when medical applications such as gene therapy are performed. it can.
- FIG. 1A shows an example of a pattern of single-strand breaks of homologous chromosomes by a site-specific nickase in the method of the present invention.
- FIG. 1B is a continuation of FIG. 1A.
- FIG. 1B is a continuation of FIG. 1B.
- FIG. 1C is a continuation of FIG. 1C.
- FIG. 1C is a continuation of FIG. 1D.
- FIG. 1C is a continuation of FIG. 1E.
- FIG. 1C is a continuation of FIG. 1F.
- FIG. 1C is a continuation of FIG. 1G.
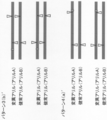
- FIG. 1A shows an example of a pattern of single-strand breaks of homologous chromosomes by a site-specific nickase in the method of the present invention.
- FIG. 1B is a continuation of FIG. 1A.
- FIG. 1B is a continuation of FIG. 1B.
- FIG. 1C is a continuation of FIG. 1C.
- FIG. 2A shows the target site of the crRNA (corresponding to the 5'side region of sgRNA) designed in this example in the thymidine kinase 1 gene of the chromosome that served as the donor for homologous recombination.
- Uppercase letters indicate exons and lowercase letters indicate introns.
- the nucleotide sequence surrounded by a square is the PAM sequence (the same applies to FIGS. 2B to 2H below).
- Underlines indicate the target sites of TSCER2_TK1 (ex4) -322s, TSCER2_TK1 (ex4) 21s, and TSCER2_TK1 (ex4) 29s in order from the top.
- FIG. 2B shows the target site of the crRNA (corresponding to the 5'side region of sgRNA) designed in this example in the thymidine kinase 1 gene of the chromosome that was the recipient of homologous recombination.
- the underlines indicate the target sites of TSCER2_TK1 (ex4) -322s, TSCER2_TK1 (ex4) 21s, TSCER2_TK1 (ex4) 20s, and TSCER2_TK1 (ex4) 29s in order from the top.
- FIG. 2C shows the target site of the crRNA (corresponding to the 5'side region of sgRNA) designed in this example in the thymidine kinase 1 gene of the chromosome that was the recipient of homologous recombination.
- the underlines indicate the target sites of the TSCER2_TK1 (ex4) -S1 (upper diagram) and TSCER2_TK1 (ex4) -S2 (lower diagram) crRNA, respectively.
- FIG. 2D shows the target site of crRNA (corresponding to the 5'side region of sgRNA) designed in this example in the thymidine kinase 1 gene of the chromosome that was the recipient of homologous recombination.
- FIG. 2E shows the target site of the crRNA (corresponding to the 5'side region of sgRNA) designed in this example in the thymidine kinase 1 gene of the chromosome as the recipient of homologous recombination.
- Underlines indicate the target sites of the TSCER2_TK1 (ex4) -S5 (top panel) and TSCER2_TK1 (ex4) -S6 (bottom panel) crRNAs, respectively.
- FIG. 2F shows the target site of the crRNA (corresponding to the 5'side region of sgRNA) designed in this example in the thymidine kinase 1 gene of the chromosome as the recipient of homologous recombination.
- Underlines indicate the target sites of the TSCER2_TK1 (ex4) -S7 (upper diagram) and TSCER2_TK1 (ex4) -S8 (lower diagram) crRNA, respectively.
- FIG. 2G shows the target site of the crRNA (corresponding to the 5'side region of sgRNA) designed in this example in the thymidine kinase 1 gene of the chromosome that was the recipient of homologous recombination.
- FIG. 2H shows the target site of the crRNA (corresponding to the 5'side region of sgRNA) designed in this example in the thymidine kinase 1 gene of the chromosome as the recipient of homologous recombination.
- Underlines indicate the target sites of the TSCER2_TK1 (ex4) -S11 (upper diagram) and TSCER2_TK1 (ex4) -S12 (lower diagram) crRNA, respectively.
- FIG. 2I shows single-strand breaks at the target site when a combination of TSCER2_TK1 (ex4) -322s and TSCER2_TK1 (ex4) 20s was used as crRNA.
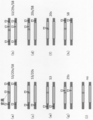
- FIG. 3 shows the positions where single-strand breaks or double-strand breaks of DNA occur in each sample of this example.
- FIG. 4A shows the result of detecting cells in which genome editing occurred in the sample of this example shown in FIG. 3 with the recovery of thymidine kinase activity as an index. The lower part of the figure is an enlarged graph of the samples # 1 to 6 in the figure.
- FIG. 4B shows the result of detection of cells in which genome editing occurred in the sample of this example shown in FIG. 3 with the recovery of thymidine kinase activity as an index.
- FIG. 5 shows the results of analysis of the base sequence of the target site after genome editing in the samples # 2 and # 7 of this example shown in FIGS. 3 and 4.
- FIG. 6 shows the results of detection of cells in which genome editing occurred in the sample of the present example shown in FIG. 7 at the position where DNA single-strand breaks entered (upper figure) and recovery of thymidine kinase activity as an index. (Bottom of figure).
- FIG. 7 shows the positions where single-strand breaks of DNA occur in each sample of this example.
- FIG. 8 shows the results of analyzing the base sequence of the target site after genome editing in the samples S3 / 20s and S12 / 20s of this example shown in FIGS. 6 and 7.
- FIG. 9 shows the positions of DNA single-strand breaks (in the figure) in each sample of the present example shown in FIG. 10 and the cells in which genome editing occurred with the recovery of thymidine kinase activity as an index. The results (bottom of the figure) are shown.
- FIG. 10 shows the positions where single-strand breaks of DNA are introduced in each sample of this example.
- FIG. 11 shows the position of DNA single-strand break (in the figure) in each sample of the present example shown in FIG. 12 and the cells in which genome editing occurred with the recovery of thymidine kinase activity as an index. The results (bottom of the figure) are shown.
- FIG. 12 shows the positions where single-strand breaks of DNA occur in each sample of this example.
- the method for producing a genome-edited cell according to the present invention utilizes homologous recombination between homologous chromosomes induced by single-strand breaks by site-specific nickases, whereby different bases between homologous chromosomes are either The principle is to unify the bases.
- a cell having a different base between homologous chromosomes at a specific site of the homologous chromosome is introduced with a combination of site-specific nickases that single-strand breaks in the DNA region near the specific site, and the homologous chromosome Homologous recombination with one of the recipients as the recipient and the other as the donor is induced to replace the recipient's base at the specific site with the donor's base.
- the “cell” targeted for genome editing in the present invention is not particularly limited as long as it has a homologous chromosome, and various eukaryotic cells can be targeted.
- eukaryotic cell include animal cells, plant cells, algal cells, and fungal cells.
- animal cells include mammalian cells, as well as fish, bird, reptile, amphibian and insect cells.
- Animal cells include, for example, cells that make up individual animals, cells that make up organs / tissues extracted from animals, and cultured cells derived from animal tissues. Specifically, for example, embryo cells of each stage embryo (eg, 1-cell stage embryo, 2-cell stage embryo, 4-cell stage embryo, 8-cell stage embryo, 16-cell stage embryo, morula stage embryo, etc.); induction Stem cells such as pluripotent stem (iPS) cells, embryonic stem (ES) cells, hematopoietic stem cells; fibroblasts, hematopoietic cells, neurons, muscle cells, osteocytes, hepatocytes, pancreatic cells, brain cells, kidney cells, etc. Somatic cells and the like.
- iPS pluripotent stem
- ES embryonic stem
- fibroblasts hematopoietic stem cells
- neurons e.g, muscle cells, osteocytes, hepatocytes, pancreatic cells, brain cells, kidney cells, etc. Somatic cells and the like.
- An oocyte after fertilization that is, a fertilized egg can be used to create a genome-edited animal.
- the fertilized egg is of a pronuclear stage embryo.
- a frozen-preserved oocyte can be thawed and used.
- the term “mammal” is a concept that includes humans and non-human mammals.
- non-human mammals are artiodactyls such as cows, boars, pigs, sheep and goats, perissodactyla such as horses, rodents such as mice, rats, guinea pigs, hamsters and squirrels, and Lagomorpha such as rabbits. , Meats such as dogs, cats and ferrets.
- the non-human mammals described above may be domestic animals or companion animals (pet animals), or may be wild animals.
- Plant cells include, for example, cells of cereals, oil crops, feed crops, fruits and vegetables.
- Plant cells include, for example, cells that form individual plants, cells that form organs and tissues separated from plants, and cultured cells derived from plant tissues. Examples of plant organs and tissues include leaves, stems, shoot tips (growing points), roots, tubers, tubers, seeds, and callus. Examples of plants include rice, corn, banana, peanut, sunflower, tomato, rape, tobacco, wheat, barley, potato, soybean, cotton, carnation and the like.
- a base that differs between homologous chromosomes at a specific site of a homologous chromosome may be a single base or a plurality of bases (base sequence). Further, it may be a mutation or a polymorphism. Examples of the mutation include substitution, deletion, insertion, or a combination thereof, and examples of the polymorphism include single nucleotide polymorphism and microsatellite polymorphism.
- a chromosome having a mutation or polymorphism at a specific site can be a recipient for homologous recombination or a donor. That is, by the genome editing in the present invention, both bases of specific sites of two chromosomes constituting homologous chromosomes can be made into a normal sequence, or both can be made into a specific mutant sequence or polymorphic sequence. it can.
- HLA HLA of a heterozygote can also be made into a homozygous HLA.
- a typical embodiment of the present invention from the viewpoint of medical utility is to restore a mutation in a human cell to a normal sequence in order to treat or prevent a human disease caused by a heterozygous mutation.
- a disease caused by a heterozygous mutation refers to a disease (dominant genetic disease) directly caused by the heterozygous mutation, as well as a disease (recessive recession) caused by a combination of two different mutations (complex heterozygote). (Genetic disease).
- the target disease includes, for example, a disease caused by an autosomal heterozygous mutation having an autosomal dominant inheritance pattern such as OAS1 abnormality in congenital immunodeficiency, and an autosomal recessive inheritance pattern such as ADA deficiency.
- the diseases include, but are not limited to, diseases that develop in an X-linked sex-linked genetic form in women, such as hemophilia with a female factor VIII / factor IX deficiency.
- the “site-specific nickase” used in the present invention is not limited as long as it can site-specifically cleave single-stranded DNA on the genome, but the CRISPR-Cas system having a nickase-type Cas protein as a component is preferable.
- Cas proteins usually contain a domain involved in cleavage of the target strand (RuvC domain) and a domain involved in cleavage of the non-target strand (HNH domain), whereas nickase-type Cas proteins typically Mutation of one of the domains results in loss of its cleavage activity.
- RuvC domain a domain involved in cleavage of the target strand
- HNH domain a domain involved in cleavage of the non-target strand
- nickase-type Cas proteins typically Mutation of one of the domains results in loss of its cleavage activity.
- spCas9 protein Cas9 protein derived from S.
- pyogenes for example, mutation of the 10th amino acid from the N-terminus (aspartic acid) to alanine (mutation in D10A: RuvC domain) , N-terminal 840th amino acid (histidine) mutation to alanine (H840A: mutation in HNH domain), N-terminal 863rd amino acid (asparagine) mutation to alanine (N863A: HNH domain mutation) , Mutation of the 762nd amino acid (glutamic acid) from the N terminus to alanine (E762A: mutation in RuvCII domain), mutation of 986th amino acid from the N terminus (aspartic acid) to alanine (D986A: mutation in RuvCIII domain) ) Is mentioned.
- Cas9 proteins of various origins are known (for example, WO2014 / 131833), and their nickase types can be used.
- the amino acid sequence and base sequence of Cas9 protein are registered in a public database, for example, GenBank (http://www.ncbi.nlm.nih.gov) (for example, accession number: Q99ZW2.1). ), These can be utilized in the present invention.
- Cas proteins other than Cas9 for example, Cpf1 (Cas12a), Cas12b, CasX (Cas12e), Cas14 and the like can be used.
- the mutation in the nickase Cpf1 protein include a mutation in AsCpf1 (Cas12) from the N-terminal to the 1226th amino acid (arginine) to alanine (R1226A: mutation in Nuc domain).
- the amino acid sequence of Cpf1 is registered in a public database, for example, GenBank (http://www.ncbi.nlm.nih.gov) (for example, accession numbers: WP_0217373622, WP_035635884).
- a protein that constitutes the CRISPR-Cas system a protein to which a nuclear localization signal is added may be used.
- the nickase-type Cas protein binds to the guide RNA to form a complex, which is targeted by the target DNA sequence to cut the single-stranded DNA.
- the guide RNA includes crRNA and tracrRNA, but in the CRISPR-Cpf1 system, the tracrRNA is unnecessary.
- the guide RNA in the CRISPR-Cas9 system may be a single-molecule guide RNA containing crRNA and tracrRNA or a double-molecule guide RNA consisting of a crRNA fragment and a tracrRNA fragment.
- the CrRNA contains a base sequence complementary to the target DNA sequence.
- the target DNA sequence is usually a base sequence consisting of 12 to 50 bases, preferably 17 to 30 bases, and more preferably 17 to 25 bases, and is selected from a region adjacent to the PAM (proto-spacer adjuvant motif) sequence.
- PAM proto-spacer adjuvant motif
- site-specific cleavage of DNA occurs at a position determined by both the base pairing complementarity between the crRNA and the target DNA sequence and the PAM that is adjacent to it.
- crRNA further contains a base sequence capable of interacting (hybridizing) with a tracrRNA fragment on the 3'side.
- tracrRNA contains a base sequence capable of interacting (hybridizing) with a part of the base sequence of crRNA on the 5'side. Due to the interaction of these base sequences, crRNA / tracrRNA (one molecule or two molecules) forms a double-stranded RNA, and the formed double-stranded RNA interacts with the Cas protein.
- PAM differs depending on the type and origin of Cas protein.
- a typical PAM sequence is, for example, S.
- the Cas9 protein (type II) derived from P. pyogenes is "5'-NGG", and S.
- the Cas9 protein (type I-A1) derived from S. solfataricus is "5'-CCN", and S.
- the Cas9 protein (type I-A2) derived from S. sofataricus is "5'-TCN", and H.
- Cas9 protein (type IB) derived from walsbyl it is "5'-TTC", and E.
- the Cas9 protein (IE type) derived from E. coli is "5'-AWG",
- the Cas9 protein (type I-F) derived from Aeruginosa it is "5'-CC”.
- the Cas9 protein (Type II-A) derived from Thermophilus is "5'-NNAGAA”, and S.
- the Cas9 protein (type II-A) derived from Agalactiae is "5'-NGG”, and S.
- the Cas9 protein derived from Aureus it is "5'-NGRRT" or "5'-NGRRN”.
- the Cas9 protein derived from Meningitidis is "5'-NNNNGATT", and T.
- the Cas9 protein derived from denticola it is "5'-NAAAC”.
- Cpf1 it is typically "5'-TTN” or “5'-TTTN”. It is also possible to modify PAM recognition by modifying the protein (for example, introducing a mutation) (Benjamin, P. et al., Nature 523, 481-485 (2015), Hirano, S. et al., Molecular). Cell 61, 886-894 (2016)).
- a site-specific nickase other than the CRISPR-Cas system can also be used.
- a site-specific nickase include an artificial nuclease fused with an enzyme having nickase activity.
- the artificial nuclease for example, TALE (transcription activator-like effector), ZF (zinc finger), and PPR (pentatriceptide repeat) can be used.
- An example of an enzyme capable of exerting a nickase activity by fusion with these artificial nucleases is TevI (Nat Commun. 2013; 4: 1762. Doi: 10.1038 / ncomms2782).
- These artificial nucleases are targeted to a target DNA sequence by a DNA binding domain constructed by linking a module (peptide) that recognizes a specific base (or a specific base sequence), and are fused to the DNA binding domain.
- the nickase cleaves the DNA into single strands.
- An appropriate spacer peptide may be introduced between the DNA binding domain and nickase in the artificial nuclease.
- single-strand breaks are made at multiple sites in the DNA region in the vicinity of the specific site (bases that differ between homologous chromosomes).
- a combination of site-specific nickases that single-strand breaks at at least one of the positions corresponding to the sites where double-strand breaks are used.
- nearby DNA region is usually within 100,000 bases, within 10000 bases, within 5000 bases, within 2000 bases, and preferably within 1000 bases (eg, within 500 bases, within 400 bases, 300 bases) from a specific site. Within bases, within 200 bases, within 100 bases, within 50 bases, within 20 bases, within 10 bases).
- the "plurality of neighboring DNA regions” may be in the same DNA chain or on different DNA chains.
- one site is provided in each of the 5′-side DNA region and the 3′-side DNA region of the specific site (pattern 1 and pattern 2 in FIG. 1A and patterns 1 ′ and 2 (in FIG. 1C).
- pattern 1 and pattern 2 in FIG. 1A and patterns 1 ′ and 2 in FIG. 1C.
- a) ′, pattern 2 (b) ′ in FIG. 1D), and two locations in the DNA region near the 5 ′ side of the specific site pattern 3 (a) in FIG. 1B, pattern 4 (a), pattern 3 in FIG. 1D.
- pattern 4 (a) ′ in FIG. 1E two locations in the DNA region near the 3 ′ side of the specific site (pattern 3 (b) in FIG. 1B, pattern 4 (b), pattern in FIG. 1E).
- a mode in which all single-strand breaks in the donor chromosome and the recipient chromosome correspond (pattern 1 in FIG. 1A, pattern 3 in FIG. 1B, pattern 1 ′ in FIG. 1C, pattern 3 in FIG. 1D ( a) ′, pattern 3 (b) ′ in FIG. 1E, pattern 6 in FIG. 1G, pattern 7 (d) in FIG. 1H),
- the site-specific nickase that binds to the target DNA sequence of the recipient chromosome is It may be designed so that it also binds to the corresponding DNA sequence of the chromosome.
- the target DNA sequence of the recipient's chromosome and the corresponding DNA sequence of the donor's chromosome are typically the same DNA sequence.
- a mode in which part of the single-strand break in the donor chromosome and the recipient chromosome does not correspond (Pattern 2 in FIG. 1A, Pattern 4 in FIG. 1B, Pattern 2 (a) ′ in FIG. 1C, In the pattern 2 (b) ′ of FIG. 1D, the pattern 4 (a) ′ of FIG. 1E, the pattern 4 (b) ′ of FIG. 1F, the pattern 5 of FIG. 1G, and the patterns 7 (a) to (c) of FIG. 1H)
- the target DNA sequence of the recipient's chromosome and the corresponding DNA sequence of the donor's chromosome are different DNA sequences.
- the target DNA sequence of the site-specific nickase is set so as to include bases that are replaced by genome editing (bases that differ between homologous chromosomes)
- the target DNA sequence of the recipient chromosome and the corresponding DNA of the donor chromosome The sequences will be different DNA sequences.
- the site-specific nickase is the CRISPR-Cas system
- the guide RNA may be designed so that it has binding specificity to the target DNA sequence of the recipient.
- the DNA binding domain may be designed so that it has binding specificity to the target DNA sequence of the recipient.
- the site to be single-stranded is usually within about 100 bases, more preferably within 50 bases from the above-mentioned specific site (bases that differ between homologous chromosomes). (For example, within 40 bases, within 30 bases, within 20 bases, within 10 bases).
- the distance between single-strand breaks on different DNA strands is usually 100 bases or more, preferably 200 bases or more, and usually 2000 bases or less, preferably 1000 bases or less, more preferably 500 bases.
- site-specific nickases is introduced into cells.
- site-specific nickase is introduced into cells as messenger RNA translated into guide RNA and Cas protein, even in the form of a combination of guide RNA and Cas protein. Or a combination of vectors expressing them.
- the guide RNA may be modified (such as chemically modified) to suppress degradation.
- an artificial nuclease fused with an enzyme having nickase activity for example, it may be in the form of a protein, messenger RNA translated into the protein, or a vector expressing the protein. May be.
- operably linked means that the DNA is expressibly linked to a regulatory element.
- regulatory elements include promoters, enhancers, internal ribosome entry sites (IRES), and other expression control elements (eg, transcription termination signals, such as polyadenylation signals and polyU sequences).
- promoter examples include polIII promoter (for example, U6 and H1 promoter), polII promoter (for example, retrovirus Rous sarcoma virus (RSV) LTR promoter, cytomegalovirus (CMV) promoter, SV40 promoter, dihydrofolate reductase promoter, ⁇ -actin promoter, phosphoglycerol kinase (PGK) promoter, and EF1 ⁇ promoter), polI promoter, or a combination thereof.
- polIII promoter for example, U6 and H1 promoter
- polII promoter for example, retrovirus Rous sarcoma virus (RSV) LTR promoter, cytomegalovirus (CMV) promoter, SV40 promoter, dihydrofolate reductase promoter, ⁇ -actin promoter, phosphoglycerol kinase (PGK) promoter, and EF1 ⁇ promoter
- PGK phosphoglycerol kina
- the site-specific nickase can be introduced into cells by known methods such as electroporation, microinjection, DEAE-dextran method, lipofection method, nanoparticle-mediated transfection method, and virus-mediated nucleic acid delivery method. You can
- a combination of site-specific nickases, in the recipient chromosome, single-strand breaks at multiple sites in the DNA region near the target base, in the donor chromosome, single-stranded in the recipient chromosome Single-strand breaks at at least one of the locations corresponding to the location to be cut. This markedly suppressed the occurrence of unintended mutations due to non-homologous end joining, while inducing homologous recombination between homologous chromosomes, specifically and efficiently replacing the target base with the corresponding base in the donor.
- the occurrence of unintended mutations due to non-homologous end joining is suppressed by 90% or more, preferably 95% or more (for example, 96% or more, 97% or more, 98% or more, 99% or more, 100%). can do.
- the present invention also provides a kit for use in the method of the present invention, which comprises a combination of the above site-specific nickases.
- the kit may further include one or more additional reagents, and examples of the additional reagent include a dilution buffer, a reconstitution solution, a washing buffer, a nucleic acid introduction reagent, a protein introduction reagent, and a control reagent. (For example, a control guide RNA), but is not limited thereto.
- the kit may include instructions for carrying out the methods of the invention.
- TSCER2 cells Cells derived from lymphoblast TK6 cells (one nucleotide inserted into exon 4; frameshift) having a heterozygous mutation of the Thymidine Kinase 1 gene (TK1). Insertion of 31 base pairs into healthy allele intoron 4 (which is not related to loss of TK1 gene function per se) and mutation in exon 5 to change to complex heterozygous mutation, resulting in loss of TK1 gene function. There is.
- thymidine kinase-dependent DNA synthesis salvage pathway does not function, if the DNA de novo synthesis pathway is blocked by aminopterin, the cells cannot proliferate even if 2-deoxycytidine, hypoxanthine, and thymidine are supplied.
- CHAT medium (10 ⁇ M 2-deoxycytidine [Sigma], 200 ⁇ M hypoxanthine [Sigma], 100 nM aminopterin [Sigma], and even 17.5 ⁇ M thymidine] cell proliferation is possible [Sigma]. .
- FIG. 2A A wild-type target region (sequence of TK1 Intron3 to Exon4 to Intron4) serving as a donor is shown in FIG. 2A (SEQ ID NO: 1). Uppercase letters indicate exons and lowercase letters indicate introns. The base sequence surrounded by a square is the PAM sequence. Underlines indicate the target site of TSCER2_TK1 (ex4) -322s, the target site of TSCER2_TK1 (ex4) 21s, and the target site of TSCER2_TK1 (ex4) 29s in order from the top.
- mutant target region that serves as the recipient is shown in FIG. 2B (SEQ ID NO: 2).
- Uppercase letters indicate exons and lowercase letters indicate introns.
- the base sequence surrounded by a square is the PAM sequence.
- the underlines indicate the target sites of TSCER2_TK1 (ex4) -322s, TSCER2_TK1 (ex4) 21s, TSCER2_TK1 (ex4) 20s, and TSCER2_TK1 (ex4) 29s in order from the top.
- FIGS. 2C to 2H SEQ ID NOs: 3 to 14
- Uppercase letters indicate exons
- lowercase letters indicate other sequences.
- the base sequence surrounded by a square is the PAM sequence.
- Target sequence sites are underlined.
- TSCER2_TK1 (ex4) 20s CGTCTCGGAGCAGCGCAGGCG GGG (SEQ ID NO: 15) TSCER2_TK1 (ex4) 21s ACGTCTCGGAGCAGGCAGGC GGG (SEQ ID NO: 16) TSCER2_TK1 (ex4) -322s CCTCAGCCACAAAGAGTAGCT GGG (SEQ ID NO: 17) TSCER2_TK1 (ex4) 29s CCTGGGCCACGTCTCGGAGC AGG (SEQ ID NO: 18) TSCER2_TK1_S1 ACCTCTAGACCATGGATCG AGG (SEQ ID NO: 19) TSCER2_TK1_S2 CTGACAAAGAGCCTCTCAC TGG (SEQ ID NO: 20) TSCER2_TK1_S3 ATTCAAGGGAGGGAGCACCCC AGG (SEQ ID NO: 21) TSCER2_TK1_S3 ATTCAAGGGAGGGAGCACCCC AGG (SEQ ID NO: 21) T
- TSCER2_TK1 (ex4) 29s is used between [CCTGCT] and [CCGAGACTGGGCCCAGG]
- TSCER2_TK1_S is used when TSCER2_TK is used.
- TSCER2_TK1_S2 is used between [CCTCAG] and [ATCCATGGTCTAGAGGT]
- [CCAGTG] and [AAGGAGCTCTTTTGTCAG] and when TSCER2_TK1_S3 [CCTGGG] and CCTGCT of [CCTGGG] and [GTCTCT].
- TSCER2_TK1_S4 When TSCER2_TK1_S4 is used, between [CCTGTC] and [CAGTGGAAAAATCACAAG]; when TSCER2_TK1_S5 is used, between [CCAGCT] and [GTTGGAAGTACAACTTC]; When using TSCER2_TK1_S7 between [GAAGTTTGGCCCTAGTCTG] and [CCCTCG] and [CTGAACTTGGAAGTTTATC], when using TSCER2_TK1_S8 between [CCAGGA] and [GGTATAGATGG_T1 using SCCER2_TK1_S8] and [CCAGGA] and [GGTAGATGTGATKS] are used.
- [CCC C GCCTGCCTGCTCCGAGACG] sequences on mutant alleles is a wild-type sequence of healthy allyl modified by homologous chromosomes Hazama recombination as a template, if it is corrected with [CCCGCCTGCCTGCTCCGAGACG], rhino The midine kinase activity is restored.
- Cas9 and sgRNA were expressed using a vector that expresses both Cas9 and sgRNA.
- the vectors used are shown below.
- EGFP-positive cells (cells that were successfully transfected with the PX461 or PX458 vector) were sorted using FACSAriaII or FACSAriaIII.
- the sorted cells were cultured in 10% horse serum / RPMI1640 medium for 1 day and 5% horse serum / RPMI1640 medium for 5 days.
- CHAT medium 10 ⁇ M 2-deoxycytidine [Sigma], 200 ⁇ M hypoxanthine [Sigma], 100 nM aminopterin [Sigma], and 17.5 ⁇ M thymidine [Sigma]).
- the plate was dispensed at 10, 20, 100, or 200 cells per well, and the culture was continued. Further, in order to measure the plating efficiency, cells in 5% horse serum-RPMI1640 medium were dispensed to 96 plates at 0.5 or 1 cell per well, and cultured. Two weeks later, the percentage of wells that formed colonies was measured.
- FIG. 5A the DNA sequence result in a cell corrected by homologous inter-chromosomal recombination is shown in FIG. 5B, and an example of a DNA sequence with a nucleotide deletion is shown in FIGS. 5C and D.
- the percentage of cells in which the mutant allele was corrected to wild type was 100% (111 clones / 111 clones) in sample # 2 (Table 1).
- VN1 PX461 (Cas9D10A-P2A-GFP) -TSCER2_TK1 (ex4) 20s
- VN2 PX462 (Cas9D10A-P2A-PuroR) -TSCER2_TK1 (ex4) 20s
- VN5 PX462 (Cas9D10A-P2A-PuroR) -empty
- VS1 PX462 (Cas9D10A-P2A-PuroR) -TSCER2_TK1-S1 VS2: PX462 (Cas9D10A-P2A-PuroR) -TSCER2_TK
- FIG. 7 the positions where the nicks enter in each sample are shown in FIG. In each sample, the expected distance between nicks (distance between site A and site B in FIG. 7) and cutting pattern (see FIGS. 1A to 1H) are as follows. -322s / 20s: 341nt, pattern 2 (a) S1 / 20s: 8173nt, pattern 2 (a) S2 / 20s: 5678nt, pattern 2 (a) S3 / 20s: 3964nt, pattern 2 (a) S4 / 20s: 2369nt, pattern 2 (a) S5 / 20s: 1367nt, pattern 2 (a) S6 / 20s: 608nt, pattern 2 (a) S7 / 20s: 136nt, pattern 4 (b) S8 / 20s: 1004nt, pattern 4 (b) S9 / 20s: 2353nt, pattern 4 (b) S10 / 20s: 4041nt, pattern 4 (b) S
- the sorted cells were cultured in 10% horse serum / RPMI1640 medium for 1 day and then in 5% horse serum / RPMI1640 medium. 1-2 weeks after electroporation, a part of the cells was transferred to CHAT medium (10 ⁇ M 2-deoxycytidine [Sigma], 200 ⁇ M hypoxanthine [Sigma], 100 nM aminopterin [Sigma], and 17.5 ⁇ M thymidine [Sigma]]. , 96 plates were dispensed at 40 or 100 cells per well, and the culture was continued. Further, in order to measure the plating efficiency, cells in 5% horse serum-RPMI1640 medium were dispensed into 96 plates at 1 cell per well and cultured. After 2-3 weeks, the percentage of wells that formed colonies was measured.
- a direct PCR of the DNA fragment in the Intron3 to Intron4 region and the DNA fragment in the Intron4 to Intron5 region of the TK1 gene in the cells forming the colony, or PCR using the extracted genomic DNA as a template was amplified by.
- the Kaneka simple DNA extraction kit Version 2 (Kaneka) was used for genomic DNA extraction.
- Direct PCR includes MightyAmp DNA Polymerase Ver. 2 (Takara Bio) was used.
- KOD plus neo (TOYOBO) was used for PCR using the genomic DNA as a template.
- the PCR fragment of the Intron3 to Intron4 region was subjected to DNA sequence analysis by the Sanger sequencing method using [TGAACACTGAGCCTGCTT (SEQ ID NO: 33)], and the PCR fragment of the Intron4 to Intron5 region was [TAACCCTGTGGTGGGCTGA (SEQ ID NO: 36)]. ..
- the DNA sequence results before editing the Intron4 to Intron5 regions are shown in FIG. 8 (a), and the DNA sequence results in cells in which both alleles became wild type by homologous interchromosomal recombination are shown in FIG. 8 (b).
- the cutting patterns (see FIGS. 1A to 1H) in each sample are as follows.
- Each plasmid in the amount shown in the above list was mixed with 150 ⁇ 10 4 TSCER2 cells in 30 ⁇ L of R buffer (Invitrogen Neon Transfection Kit), and 10 ⁇ L of these was mixed with 1300 V for 20 ms twice. Electroporation was performed using the Transfection System (electroporation condition 2). After overnight culture in 10% horse serum / RPMI1640 medium at 37 ° C. and 5% CO2, EGFP-positive cells (cells that were successfully transfected with the PX461 vector) were sorted using FACSAriaII or FACSAriaIII.
- the sorted cells were cultured in 10% horse serum / RPMI1640 medium for 1 day and then in 5% horse serum / RPMI1640 medium for 5 days. 1-2 weeks after electroporation, a part of the cells was transferred to CHAT medium (10 ⁇ M 2-deoxycytidine [Sigma], 200 ⁇ M hypoxanthine [Sigma], 100 nM aminopterin [Sigma], and 17.5 ⁇ M thymidine [Sigma]]. , 96 plates were dispensed at 20 or 200 cells per well, and the culture was continued. Further, in order to measure the plating efficiency, cells in 5% horse serum-RPMI1640 medium were dispensed into 96 plates at 1 cell per well and cultured. After 2-3 weeks, the percentage of wells that formed colonies was measured.
- the proportion of cells that recover thymidine kinase activity in sample S3 / 20s / S11 is also higher than that in samples S3 / 20s / emp and sample 20s / S11 / emp, and cells that recover thymidine kinase activity in sample S6 / 20s / S8 Of sample S6 / 20s / emp and sample 20s / S8 / emp, and the ratio of cells recovering thymidine kinase activity in sample S6 / 20s / S11 was also sample S6 / 20s / emp and sample 20s / It was shown to be higher than S11 / emp.
- Example 4 Verification of genome editing efficiency by multiple nick method without using exogenous DNA A.
- Materials sgRNAs targeting the regions (S3, 20s, 29s, S8) shown in FIG. 11 or sgRNAs (no) having no target sequence in the human genome were combined as follows and introduced into TSCER2 cells together with Cas9D10A mRNA. ..
- sgRNA was added in the amounts shown in the above list, Cas9 mRNA (500 ng / ⁇ L) was added in 1.8 ⁇ L, and R buffer (Invitrogen Neon Transfection Kit) was added to 70 ⁇ 10 4 TSCER2 cells to give a total amount of 14 ⁇ L. .. 10 ⁇ L of this was electroporated by the Neon Transfection System under the condition of 1500 V 10 ms 3 times (electroporation condition 3). Overnight culture was performed in 10% horse serum / RPMI1640 medium at 37 ° C. and 5% CO2, and then, interculturing was performed in 5% horse serum / RPMI1640 medium.
- CHAT medium (10 ⁇ M 2-deoxycytidine [Sigma], 200 ⁇ M hypoxanthine [Sigma], 100 nM aminopterin [Sigma], and 17.5 ⁇ M thymidine [Sigma]).
- the plate was dispensed at 10, 30, 100, or 200 cells per well, and the culture was continued. Further, in order to measure the plating efficiency, cells in 5% horse serum-RPMI1640 medium were dispensed into 96 plates at 1 cell per well and cultured. After 2-3 weeks, the percentage of wells that formed colonies was measured.
- Recipient allele has 1 spot and donor allele has 1 spot Nick sample S3 (0.133 ⁇ 0.026%), 29s (0.844 ⁇ 0.305%), S8 (0.773 ⁇ 0.221%) ,
- the thymidine kinase activity was recovered with higher efficiency than the sample 20s (0.147 ⁇ 0.022%) in which the recipient allele was introduced at one site and the donor allele was not nicked.
- the present invention by utilizing homologous recombination between homologous chromosomes induced by single-strand breaks by site-specific nickase, different bases between homologous chromosomes can be either bases. It is possible to unify.
- the present invention which does not use a foreign donor DNA, can greatly contribute to gene therapy of diseases caused by hetero mutations in particular because of its high safety.
Landscapes
- Health & Medical Sciences (AREA)
- Life Sciences & Earth Sciences (AREA)
- Genetics & Genomics (AREA)
- Engineering & Computer Science (AREA)
- Chemical & Material Sciences (AREA)
- Biomedical Technology (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Zoology (AREA)
- Organic Chemistry (AREA)
- Wood Science & Technology (AREA)
- Molecular Biology (AREA)
- Biotechnology (AREA)
- General Engineering & Computer Science (AREA)
- General Health & Medical Sciences (AREA)
- Microbiology (AREA)
- Biochemistry (AREA)
- Plant Pathology (AREA)
- Biophysics (AREA)
- Physics & Mathematics (AREA)
- Mycology (AREA)
- Cell Biology (AREA)
- Medicinal Chemistry (AREA)
- Crystallography & Structural Chemistry (AREA)
- Micro-Organisms Or Cultivation Processes Thereof (AREA)
- Enzymes And Modification Thereof (AREA)
- Measuring Or Testing Involving Enzymes Or Micro-Organisms (AREA)
Abstract
Description
相同染色体の特定の部位に相同染色体間で異なる塩基を有する細胞に、当該特定の部位の近傍DNA領域で一本鎖切断する部位特異的ニッカーゼの組み合わせを導入し、当該相同染色体の一方をレシピエントとし、他方をドナーとした相同組換えを誘導して、当該特定の部位におけるレシピエントの塩基をドナーの塩基に置換することを含み、
当該部位特異的ニッカーゼの組み合わせが、当該レシピエントの染色体においては、当該特定の部位の近傍DNA領域の複数箇所で一本鎖切断し、当該ドナーの染色体においては、レシピエントの染色体において一本鎖切断される箇所に対応する箇所の少なくとも1箇所で一本鎖切断する方法。
相同染色体の特定の部位に相同染色体間で異なる塩基を有する細胞において、当該特定の部位の近傍DNA領域で一本鎖切断する部位特異的ニッカーゼの組み合わせを含み、
当該部位特異的ニッカーゼの組み合わせが、当該レシピエントの染色体においては、当該特定の部位の近傍DNA領域の複数箇所で一本鎖切断し、当該ドナーの染色体においては、レシピエントの染色体において一本鎖切断される箇所に対応する箇所の少なくとも1箇所で一本鎖切断するキット。
A.材料
(1)TSCER2細胞
Thymidine Kinase 1遺伝子(TK1)のヘテロ接合体変異をもつlymphoblastTK6細胞(exon 4に1ヌクレオチド挿入。フレームシフト)由来細胞である。健常アリルのintoron 4に31塩基対の挿入(これ自体はTK1遺伝子機能の喪失とは関係ない)とexon 5に変異を入れ、複合ヘテロ接合体変異に改変し、TK1遺伝子の機能を喪失させている。サイミジンキナーゼに依存したDNA合成salvage経路が機能しないため、aminopterinによりDNA de novo合成経路を遮断すると、2-deoxycytidine、hypoxanthine、及びthymidineを供給しても細胞増殖することができない。ゲノム編集によりサイミジンキナーゼ活性が回復した場合、CHAT培地(10μM 2-deoxycytidine[Sigma]、200μM hypoxanthine[Sigma], 100nM aminopterin[Sigma]、及び17.5μM thymidine[Sigma])中でも細胞増殖可能となる。
ドナーとなる野生型の標的領域(TK1 Intron3~Exon4~Intron4の配列)を図2A(配列番号:1)に示す。大文字がエクソンを、小文字がイントロンを示す。四角で囲んだ塩基配列はPAM配列である。アンダーラインは、上から順に、TSCER2_TK1(ex4)-322sの標的部位、TSCER2_TK1(ex4)21sの標的部位、TSCER2_TK1(ex4)29sの標的部位を示す。
TSCER2_TK1(ex4)20s
CGTCTCGGAGCAGGCAGGCGGGG(配列番号:15)
TSCER2_TK1(ex4)21s
ACGTCTCGGAGCAGGCAGGCGGG(配列番号:16)
TSCER2_TK1(ex4)-322s
CCTCAGCCACAAGAGTAGCTGGG(配列番号:17)
TSCER2_TK1(ex4)29s
CCTGGGCCACGTCTCGGAGCAGG(配列番号:18)
TSCER2_TK1_S1
ACCTCTAGACCATGGATCTGAGG(配列番号:19)
TSCER2_TK1_S2
CTGACAAAGAGCTCCTTCACTGG(配列番号:20)
TSCER2_TK1_S3
ATTCAAGGGAGGAGCACCCCAGG(配列番号:21)
TSCER2_TK1_S4
CTTGTGATTTTCCACTGGACAGG(配列番号:22)
TSCER2_TK1_S5
GAAGTTGTACTTCCAACAGCTGG(配列番号:23)
TSCER2_TK1_S6
CAGACTAGGCCAACTTCATCAGG(配列番号:24)
TSCER2_TK1_S7
GATAACTTCCAAGTCAGCGAGGG(配列番号:25)
TSCER2_TK1_S8
AGCTTCCCATCTATACCTCCTGG(配列番号:26)
TSCER2_TK1_S9
CAACCGGCCTGGAACCACGTAGG(配列番号:27)
TSCER2_TK1_S10
GATCTAGAACTGCTTGCAATGGG(配列番号:28)
TSCER2_TK1_S11
TCAATCATATCACTCTTAGCTGG(配列番号:29)
TSCER2_TK1_S12
GGAGCTGTCCATGAGACCCAGGG(配列番号:30)
TSCER2_TK1(ex4)20sを用いた場合は、[CCCCGC]と[CTGCCTGCTCCGAGACG]との間に、TSCER2_TK1(ex4)21sを用いた場合は、[CCCGCC]と[TGCCTGCTCCGAGACGT]との間に、TSCER2_TK1(ex4)-322sを用いた場合は、[cccagc]と[tactcttgtggctgagg]との間に、TSCER2_TK1(ex4)29sを用いた場合は、[CCTGCT]と[CCGAGACGTGGCCCAGG]との間に、TSCER2_TK1_S1を用いた場合は、[CCTCAG]と[ATCCATGGTCTAGAGGT]との間に、TSCER2_TK1_S2を用いた場合は、[CCAGTG]と[AAGGAGCTCTTTGTCAG]との間に、TSCER2_TK1_S3を用いた場合は、[CCTGGG]と[GTGCTCCTCCCTTGAAT]との間に、TSCER2_TK1_S4を用いた場合は、[CCTGTC]と[CAGTGGAAAATCACAAG]との間に、TSCER2_TK1_S5を用いた場合は、[CCAGCT]と[GTTGGAAGTACAACTTC]との間に、TSCER2_TK1_S6を用いた場合は、[CCTGAT]と[GAAGTTGGCCTAGTCTG]との間に、TSCER2_TK1_S7を用いた場合は、[CCCTCG]と[CTGACTTGGAAGTTATC]との間に、TSCER2_TK1_S8を用いた場合は、[CCAGGA]と[GGTATAGATGGGAAGCT]との間に、TSCER2_TK1_S9を用いた場合は、[CCTACG]と[TGGTTCCAGGCCGGTTG]との間に、TSCER2_TK1_S10を用いた場合は、[CCCATT]と[GCAAGCAGTTCTAGATC]との間に、TSCER2_TK1_S11を用いた場合は、[CCAGCT]と[AAGAGTGATATGATTGA]との間に、TSCER2_TK1_S12を用いた場合は、[CCCTGG]と[GTCTCATGGACAGCTCC]との間に、それぞれDNA二本鎖切断あるいはニックが生じると予想されている(図2A~H及び配列番号:1~14を参照のこと)。
V1: PX461(Cas9D10A-P2A-GFP)-TSCER2_TK1(ex4)20s
V2: PX461(Cas9D10A-P2A-GFP)-TSCER2_TK1(ex4)21s
V3: PX461(Cas9D10A-P2A-GFP)-empty
V4: PX462(Cas9D10A-P2A-PuroR)-TSCER2_TK1(ex4)-322s
V5: PX462(Cas9D10A-P2A-PuroR)-empty
V6: PX462(Cas9D10A-P2A-PuroR)-empty
V7: PX458(Cas9-P2A-GFP)-TSCER2_TK1(ex4)20s
V8: PX458(Cas9-P2A-GFP)-empty
V9: PX459(Cas9-P2A-PuroR)-empty
上記のベクターを、以下の通り、組み合わせ、TSCER2細胞に導入した。
サンプル#1: V1+V5
サンプル#2: V1+V4
サンプル#3: V2+V5
サンプル#4: V2+V4
サンプル#5: V3+V4
サンプル#6: V3+V5
サンプル#7: V7+V9
サンプル#8: V8+V9
各サンプルにおいてニックあるいはDNA二本鎖切断が入る位置を図3に示した。
2種類のプラスミドをそれぞれ8μg、600x104個のTSCER2細胞を120μLのR buffer(Invitrogen Neon Transfection Kit)中で混合し、このうちの100μLを1350V 10ms 3回の条件でNeon Transfection Systemによりエレクトロポレーションを行った(エレクトロポレーション条件1)。別の方法として、細胞濃度及びプラスミド濃度は維持したまま、10μLを1300V 20ms 2回の条件でNeon Transfection Systemによりエレクトロポレーションを行った(エレクトロポレーション条件2)。10% 馬血清/RPMI1640培地中で37℃ 5%CO2にてオーバーナイト培養し、その後、EGFP陽性細胞(PX461もしくはPX458ベクターのトランスフェクションに成功した細胞)をFACSAriaIIもしくはFACSAriaIIIを用いてソートした。ソート後の細胞は10% 馬血清/RPMI1640培地中で1日、5% 馬血清/RPMI1640培地中で5日間培養した。エレクトロポレーションから1週間後、細胞の一部をCHAT培地(10μM 2-deoxycytidine[Sigma]、200μM hypoxanthine[Sigma]、100nM aminopterin[Sigma]、及び17.5μM thymidine[Sigma]))に移し、96プレートに1 wellあたり10、20、100、又は200細胞となるように分注し、培養を続けた。また、プレーティング効率測定のため、5% 馬血清-RPMI1640培地中の細胞を、96プレートに1 wellあたり0.5、又は1細胞となるように分注し、培養した。2週間後、コロニーを形成したwellの割合を測定した。
(B/A)/(D/C)x100 (%)
結果を図4A(エレクトロポレーション条件1)及び図4B(エレクトロポレーション条件2)に示す。標的遺伝子をCas9もしくはCas9ニッカーゼにより認識させない場合、ゲノム編集は起こらなかった(図3,4A,4B、サンプル#6,#8)。修正対象とするヌクレオチド付近にDNA二本鎖切断を発生させた場合、サイミジンキナーゼ活性を回復する細胞の割合は、5.43±0.77%に達するが、このうち相同染色体間組換えによるものは3.66%にとどまり、96.3%はヌクレオチド欠失が原因となっていた(図3,4A、サンプル#7及び表1)。

A.材料
本実施例で利用したベクターを以下に示す。
VN1: PX461(Cas9D10A-P2A-GFP)-TSCER2_TK1(ex4)20s
VN2: PX462(Cas9D10A-P2A-PuroR)-TSCER2_TK1(ex4)20s
VN3: PX462(Cas9D10A-P2A-PuroR)-TSCER2_TK1(ex4)-322s
VN4: PX461(Cas9D10A-P2A-GFP)-empty
VN5: PX462(Cas9D10A-P2A-PuroR)-empty
VS1: PX462(Cas9D10A-P2A-PuroR)-TSCER2_TK1-S1
VS2: PX462(Cas9D10A-P2A-PuroR)-TSCER2_TK1-S2
VS3: PX462(Cas9D10A-P2A-PuroR)-TSCER2_TK1-S3
VS4: PX462(Cas9D10A-P2A-PuroR)-TSCER2_TK1-S4
VS5: PX462(Cas9D10A-P2A-PuroR)-TSCER2_TK1-S5
VS6: PX462(Cas9D10A-P2A-PuroR)-TSCER2_TK1-S6
VS7: PX462(Cas9D10A-P2A-PuroR)-TSCER2_TK1-S7
VS8: PX462(Cas9D10A-P2A-PuroR)-TSCER2_TK1-S8
VS9: PX462(Cas9D10A-P2A-PuroR)-TSCER2_TK1-S9
VS10: PX462(Cas9D10A-P2A-PuroR)-TSCER2_TK1-S10
VS11: PX462(Cas9D10A-P2A-PuroR)-TSCER2_TK1-S11
VS12: PX462(Cas9D10A-P2A-PuroR)-TSCER2_TK1-S12
上記のベクターを、以下の通り、組み合わせ、TSCER2細胞に導入した。
-322s/20s:VN1(1.5μg)+VN2(1.5μg)+VN3(3.0μg)
S1/20s:VN1(1.5μg)+VN2(1.5μg)+VS1(3.0μg)
S2/20s:VN1(1.5μg)+VN2(1.5μg)+VS2(3.0μg)
S3/20s:VN1(1.5μg)+VN2(1.5μg)+VS3(3.0μg)
S4/20s:VN1(1.5μg)+VN2(1.5μg)+VS4(3.0μg)
S5/20s:VN1(1.5μg)+VN2(1.5μg)+VS5(3.0μg)
S6/20s:VN1(1.5μg)+VN2(1.5μg)+VS6(3.0μg)
S7/20s:VN1(1.5μg)+VN2(1.5μg)+VS7(3.0μg)
S8/20s:VN1(1.5μg)+VN2(1.5μg)+VS8(3.0μg)
S9/20s:VN1(1.5μg)+VN2(1.5μg)+VS9(3.0μg)
S10/20s:VN1(1.5μg)+VN2(1.5μg)+VS10(3.0μg)
S11/20s:VN1(1.5μg)+VN2(1.5μg)+VS11(3.0μg)
S12/20s:VN1(1.5μg)+VN2(1.5μg)+VS12(3.0μg)
20s/emp:VN1(1.5μg)+VN2(1.5μg)+VN5(3.0μg)
emp/emp:VN4(1.5μg)+VN5(4.5μg)
なお、各ベクター由来のガイドRNA(gRNA)が標的とするゲノム上の位置を図6に示した。また、各サンプルにおいてニックが入る位置を図7に示した。各サンプルにおいて、予想されるニック間の距離(図7における部位Aと部位Bとの間の距離)及び切断パターン(図1A~H参照)は以下の通りである。
-322s/20s:341nt、パターン2(a)
S1/20s:8173nt、パターン2(a)
S2/20s:5678nt、パターン2(a)
S3/20s:3964nt、パターン2(a)
S4/20s:2369nt、パターン2(a)
S5/20s:1367nt、パターン2(a)
S6/20s:608nt、パターン2(a)
S7/20s:136nt、パターン4(b)
S8/20s:1004nt、パターン4(b)
S9/20s:2353nt、パターン4(b)
S10/20s:4041nt、パターン4(b)
S11/20s:6333nt、パターン4(b)
S12/20s:8612nt、パターン4(b)、パターン7(a)
20s/emp.:ニックは一箇所のみ
emp./emp.:ニックは発生しない
B.方法と結果
上記リスト中に示した量の各プラスミドと、150x104個のTSCER2細胞を30μLのR buffer(Invitrogen Neon Transfection Kit)中で混合し、このうちの10μLを1300V 20ms 2回の条件でNeon Transfection Systemによりエレクトロポレーションを行った(エレクトロポレーション条件2)。10% 馬血清/RPMI1640培地中で37℃ 5%CO2にてオーバーナイト培養し、その後、EGFP陽性細胞(PX461ベクターのトランスフェクションに成功した細胞)をFACSAriaIIもしくはFACSAriaIIIを用いてソートした。ソート後の細胞は10% 馬血清/RPMI1640培地中で1日、その後、5% 馬血清/RPMI1640培地中で培養した。エレクトロポレーションから1-2週間後、細胞の一部をCHAT培地(10μM 2-deoxycytidine[Sigma]、200μM hypoxanthine[Sigma]、100nM aminopterin[Sigma]、及び17.5μM thymidine[Sigma]))に移し、96プレートに1 wellあたり40、又は100細胞となるように分注し、培養を続けた。また、プレーティング効率測定のため、5% 馬血清-RPMI1640培地中の細胞を、96プレートに1 wellあたり1細胞となるように分注し、培養した。2-3週間後、コロニーを形成したwellの割合を測定した。

A.材料
本実施例で利用したベクターを以下に示す。本実施例では、ベクターを、以下の通り、組み合わせ、TSCER2細胞に導入した。
S3/20s/S8:VN1(1.5μg)+VN2(1.5μg)+VS3(3.0μg)+VS8(3.0μg)
S3/20s/S11:VN1(1.5μg)+VN2(1.5μg)+VS3(3.0μg)+VS11(3.0μg)
S6/20s/S8:VN1(1.5μg)+VN2(1.5μg)+VS6(3.0μg)+VS8(3.0μg)
S6/20s/S11:VN1(1.5μg)+VN2(1.5μg)+VS6(3.0μg)+VS11(3.0μg)
S3/20s/emp:VN1(1.5μg)+VN2(1.5μg)+VS3(3.0μg)+VN5(3.0μg)
S6/20s/emp:VN1(1.5μg)+VN2(1.5μg)+VS6(3.0μg)+VN5(3.0μg)
20s/S8/emp:VN1(1.5μg)+VN2(1.5μg)+VS8(3.0μg)+VN5(3.0μg)
20s/S11/emp:VN1(1.5μg)+VN2(1.5μg)+VS11(3.0μg)+VN5(3.0μg)
20s/emp/emp:VN1(1.5μg)+VN2(1.5μg)+VN5(6.0μg)
emp/emp/emp:VN4(1.5μg)+VN5(7.5μg)
なお、各ベクター由来のガイドRNA(gRNA)が標的とするゲノム上の位置を図9に示した。また、各サンプルにおいてニックが入る位置を図10に示した。各サンプルにおける切断パターン(図1A~H参照)は以下の通りである。
S3/20s/S8:パターン5
S3/20s/S11:パターン5
S6/20s/S8:パターン5
S6/20s/S11:パターン5
S3/20s/emp:パターン2(a)
S6/20s/emp:パターン2(a)
20s/S8/emp:パターン4(b)
20s/S11/emp:パターン4(b)
20s/emp/emp:ニックが一箇所のみ
emp/emp/emp:ニックが発生しない
B.方法と結果
上記リスト中に示した量の各プラスミドと、150x104個のTSCER2細胞を30μLのR buffer(Invitrogen Neon Transfection Kit)中で混合し、このうちの10μLを1300V 20ms 2回の条件でNeon Transfection Systemによりエレクトロポレーションを行った(エレクトロポレーション条件2)。10% 馬血清/RPMI1640培地中で37℃ 5%CO2にてオーバーナイト培養し、その後、EGFP陽性細胞(PX461ベクターのトランスフェクションに成功した細胞)をFACSAriaIIもしくはFACSAriaIIIを用いてソートした。ソート後の細胞は10% 馬血清/RPMI1640培地中で1日、その後、5% 馬血清/RPMI1640培地中で5日間培養した。エレクトロポレーションから1-2週間後、細胞の一部をCHAT培地(10μM 2-deoxycytidine[Sigma]、200μM hypoxanthine[Sigma]、100nM aminopterin[Sigma]、及び17.5μM thymidine[Sigma]))に移し、96プレートに1 wellあたり20、又は200細胞となるように分注し、培養を続けた。また、プレーティング効率測定のため、5% 馬血清-RPMI1640培地中の細胞を、96プレートに1 wellあたり1細胞となるように分注し、培養した。2-3週間後、コロニーを形成したwellの割合を測定した。
A.材料
図11に示した領域(S3、20s、29s、S8)を標的とするsgRNAもしくはヒトゲノム中には標的配列が存在しないsgRNA(no)を、以下の通り組み合わせ、Cas9D10A mRNAとともにTSCER2細胞に導入した。
S3/20s/S8:それぞれ100μMを0.3μLずつ
S3/29s/S8:それぞれ100μMを0.3μLずつ
S3/20s:それぞれ100μMを0.45μLずつ
20s/S8:それぞれ100μMを0.45μLずつ
S3/S8:それぞれ100μMを0.45μLずつ
S3:100μMを0.9μL
20s:100μMを0.9μL
29s:100μMを0.9μL
S8:100μMを0.9μL
no:100μMを0.9μL
また、各サンプルにおいてニックが入る位置を図12に示した。各サンプルにおける切断パターン(図1A~H参照)は以下の通りである。
S3/20s/S8: パターン5
S3/29s/S8: パターン6
S3/20s: パターン2(a)
20s/S8: パターン4(b)
S3/S8: パターン1
S3:ニックは、ドナーアリルの塩基とレシピエントアリルの対応塩基に各一か所
20s: ニックは一か所のみ
29s: ニックは、ドナーアリルの塩基とレシピエントアリルの対応塩基に各一か所
S8:ニックは、ドナーアリルの塩基とレシピエントアリルの対応塩基に各一か所
no: ニックは発生しない
B.方法と結果
sgRNAをそれぞれ上記リスト中に示した量、Cas9 mRNA(500ng/μL)を1.8μL、70x104個のTSCER2細胞にR buffer(Invitrogen Neon Transfection Kit)を加え、全体量を14μLとした。このうちの10μLを1500V 10ms 3回の条件でNeon Transfection Systemによりエレクトロポレーションを行った(エレクトロポレーション条件3)。10% 馬血清/RPMI1640培地中で37℃ 5%CO2にてオーバーナイト培養し、その後、5% 馬血清/RPMI1640培地中で間培養した。エレクトロポレーションから1週間後、細胞の一部をCHAT培地(10μM 2-deoxycytidine[Sigma]、200μM hypoxanthine[Sigma]、100nM aminopterin[Sigma]、及び17.5μM thymidine[Sigma]))に移し、96プレートに1 wellあたり10、30、100又は200細胞となるように分注し、培養を続けた。また、プレーティング効率測定のため、5% 馬血清-RPMI1640培地中の細胞を、96プレートに1 wellあたり1細胞となるように分注し、培養した。2-3週間後、コロニーを形成したwellの割合を測定した。
・人工的な配列
Claims (4)
- ゲノム編集された細胞を製造する方法であって、
相同染色体の特定の部位に相同染色体間で異なる塩基を有する細胞に、当該特定の部位の近傍DNA領域で一本鎖切断する部位特異的ニッカーゼの組み合わせを導入し、当該相同染色体の一方をレシピエントとし、他方をドナーとした相同組換えを誘導して、当該特定の部位におけるレシピエントの塩基をドナーの塩基に置換することを含み、
当該部位特異的ニッカーゼの組み合わせが、当該レシピエントの染色体においては、当該特定の部位の近傍DNA領域の複数箇所で一本鎖切断し、当該ドナーの染色体においては、レシピエントの染色体において一本鎖切断される箇所に対応する少なくとも1箇所で一本鎖切断する方法。 - 置換されるレシピエントの塩基が変異塩基であり、ドナーの塩基が正常塩基である、請求項1に記載の方法。
- 部位特異的ニッカーゼがCRISPR-Cas系である、請求項1又は2に記載の方法。
- 請求項1から3のいずれかに記載の方法に用いるためのキットであって、
相同染色体の特定の部位に相同染色体間で異なる塩基を有する細胞において、当該特定の部位の近傍DNA領域で一本鎖切断する部位特異的ニッカーゼの組み合わせを含み、
当該部位特異的ニッカーゼの組み合わせが、当該レシピエントの染色体においては、当該特定の部位の近傍DNA領域の複数箇所で一本鎖切断し、当該ドナーの染色体においては、レシピエントの染色体において一本鎖切断される箇所に対応する少なくとも1箇所で一本鎖切断するキット。
Priority Applications (4)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN201980075266.3A CN113015799A (zh) | 2018-11-16 | 2019-08-07 | 经基因组编辑的细胞的制造方法 |
| US17/294,165 US12365923B2 (en) | 2018-11-16 | 2019-08-07 | Method for producing genome-edited cell |
| JP2020556604A JP7426101B2 (ja) | 2018-11-16 | 2019-08-07 | ゲノム編集された細胞を製造する方法 |
| EP19885454.9A EP3882347A4 (en) | 2018-11-16 | 2019-08-07 | METHODS FOR GENERATING GENOMEEDIT CELLS |
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2018-215588 | 2018-11-16 | ||
| JP2018215588 | 2018-11-16 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2020100361A1 true WO2020100361A1 (ja) | 2020-05-22 |
Family
ID=70730219
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2019/031117 Ceased WO2020100361A1 (ja) | 2018-11-16 | 2019-08-07 | ゲノム編集された細胞を製造する方法 |
Country Status (5)
| Country | Link |
|---|---|
| US (1) | US12365923B2 (ja) |
| EP (1) | EP3882347A4 (ja) |
| JP (1) | JP7426101B2 (ja) |
| CN (1) | CN113015799A (ja) |
| WO (1) | WO2020100361A1 (ja) |
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPWO2023054573A1 (ja) * | 2021-09-30 | 2023-04-06 | ||
| WO2023120530A1 (ja) | 2021-12-24 | 2023-06-29 | 国立大学法人大阪大学 | 相同組換えを利用したゲノム編集細胞の製造方法 |
Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2014131833A1 (en) | 2013-02-27 | 2014-09-04 | Helmholtz Zentrum München Deutsches Forschungszentrum Für Gesundheit Und Umwelt (Gmbh) | Gene editing in the oocyte by cas9 nucleases |
| JP2018011525A (ja) | 2016-07-19 | 2018-01-25 | 国立大学法人大阪大学 | ゲノム編集方法 |
Family Cites Families (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| EP4357457B1 (en) | 2012-10-23 | 2024-10-16 | Toolgen Incorporated | Composition for cleaving a target dna comprising a guide rna specific for the target dna and cas protein-encoding nucleic acid or cas protein, and use thereof |
| MX2015017312A (es) | 2013-06-17 | 2017-04-10 | Broad Inst Inc | Suministro y uso de composiciones, vectores y sistemas crispr-cas para la modificación dirigida y terapia hepáticas. |
| WO2017044419A1 (en) | 2015-09-08 | 2017-03-16 | University Of Massachusetts | Dnase h activity of neisseria meningitidis cas9 |
| WO2019148166A1 (en) * | 2018-01-29 | 2019-08-01 | Massachusetts Institute Of Technology | Methods of enhancing chromosomal homologous recombination |
-
2019
- 2019-08-07 JP JP2020556604A patent/JP7426101B2/ja active Active
- 2019-08-07 EP EP19885454.9A patent/EP3882347A4/en not_active Withdrawn
- 2019-08-07 WO PCT/JP2019/031117 patent/WO2020100361A1/ja not_active Ceased
- 2019-08-07 US US17/294,165 patent/US12365923B2/en active Active
- 2019-08-07 CN CN201980075266.3A patent/CN113015799A/zh active Pending
Patent Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2014131833A1 (en) | 2013-02-27 | 2014-09-04 | Helmholtz Zentrum München Deutsches Forschungszentrum Für Gesundheit Und Umwelt (Gmbh) | Gene editing in the oocyte by cas9 nucleases |
| JP2018011525A (ja) | 2016-07-19 | 2018-01-25 | 国立大学法人大阪大学 | ゲノム編集方法 |
Non-Patent Citations (6)
| Title |
|---|
| BENJAMIN, P. ET AL., NATURE, vol. 523, 2015, pages 481 - 485 |
| HIRANO, S. ET AL., MOLECULAR CELL, vol. 61, 2016, pages 886 - 894 |
| NAKAJIMA K ET AL., GENOME RES., vol. 28, 2018, pages 223 - 230 |
| NAT COMMUN., vol. 4, 2013, pages 1762 |
| See also references of EP3882347A4 |
| WU, Y. ET AL.: "Correction of a Genetic Disease in Mouse via Use of CRISPR-Cas9", CELL STEM CELL, vol. 13, 5 December 2013 (2013-12-05), pages 659 - 662, XP055196555, DOI: 10.1016/j.stem.2013.10.016 * |
Cited By (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPWO2023054573A1 (ja) * | 2021-09-30 | 2023-04-06 | ||
| WO2023054573A1 (ja) | 2021-09-30 | 2023-04-06 | 国立大学法人大阪大学 | 相同染色体の一方に特異的なdna欠失を有する細胞を製造する方法 |
| JP7672012B2 (ja) | 2021-09-30 | 2025-05-07 | 国立大学法人大阪大学 | 相同染色体の一方に特異的なdna欠失を有する細胞を製造する方法 |
| WO2023120530A1 (ja) | 2021-12-24 | 2023-06-29 | 国立大学法人大阪大学 | 相同組換えを利用したゲノム編集細胞の製造方法 |
Also Published As
| Publication number | Publication date |
|---|---|
| EP3882347A4 (en) | 2022-03-02 |
| JP7426101B2 (ja) | 2024-02-01 |
| JPWO2020100361A1 (ja) | 2021-10-07 |
| EP3882347A1 (en) | 2021-09-22 |
| EP3882347A9 (en) | 2022-11-02 |
| CN113015799A (zh) | 2021-06-22 |
| US12365923B2 (en) | 2025-07-22 |
| US20210324420A1 (en) | 2021-10-21 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US20220256822A1 (en) | Genetic modification non-human organism, egg cells, fertilized eggs, and method for modifying target genes | |
| Bhowmik et al. | Targeted mutagenesis in wheat microspores using CRISPR/Cas9 | |
| Hall et al. | Genome editing in mice using CRISPR/Cas9 technology | |
| Wefers et al. | Gene editing in mouse zygotes using the CRISPR/Cas9 system | |
| Koller et al. | Toward an animal model of cystic fibrosis: targeted interruption of exon 10 of the cystic fibrosis transmembrane regulator gene in embryonic stem cells. | |
| JP6958917B2 (ja) | 遺伝子ノックイン細胞の作製方法 | |
| Zhang et al. | Crispr/Cas9‐mediated cleavages facilitate homologous recombination during genetic engineering of a large chromosomal region | |
| Horii et al. | Generation of floxed mice by sequential electroporation | |
| Wefers et al. | Gene editing in mouse zygotes using the CRISPR/Cas9 system | |
| JP7426101B2 (ja) | ゲノム編集された細胞を製造する方法 | |
| Shola et al. | Generation of mouse model (KI and CKO) via Easi-CRISPR | |
| Chan et al. | Efficient mutagenesis of the rhodopsin gene in rod photoreceptor neurons in mice | |
| US20250129390A1 (en) | Method for producing cell having dna deletion specific to one of homologous chromosomes | |
| EP4455282A1 (en) | Method for producing genome-edited cells utilizing homologous recombination | |
| AU2021238926A1 (en) | Optimised methods for cleavage of target sequences | |
| Mangerich et al. | A caveat in mouse genetic engineering: ectopic gene targeting in ES cells by bidirectional extension of the homology arms of a gene replacement vector carrying human PARP-1 | |
| US20220323609A1 (en) | Gene editing to correct aneuploidies and frame shift mutations | |
| EP1451295B1 (en) | Methods for mutating genes in cells and animals using insertional mutagenesis | |
| WO2024204215A1 (ja) | 相同染色体の一方のCol7a遺伝子に特異的なDNA欠失を有する細胞を製造する方法 | |
| Hu et al. | Enhance genome editing efficiency and specificity by a quick CRISPR/Cas9 system | |
| FKKT et al. | One-step generation of mice carrying mutations in multiple genes by CRISPR/Cas-mediated genome engineering (2013) | |
| HK1065824B (en) | Methods for mutating genes in cells and animals using insertional mutagenesis |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 19885454 Country of ref document: EP Kind code of ref document: A1 |
|
| ENP | Entry into the national phase |
Ref document number: 2020556604 Country of ref document: JP Kind code of ref document: A |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| ENP | Entry into the national phase |
Ref document number: 2019885454 Country of ref document: EP Effective date: 20210616 |
|
| WWW | Wipo information: withdrawn in national office |
Ref document number: 2019885454 Country of ref document: EP |
|
| WWG | Wipo information: grant in national office |
Ref document number: 17294165 Country of ref document: US |