WO2020246567A1 - プロテアーゼ基質、及びプロテアーゼ切断配列を含むポリペプチド - Google Patents
プロテアーゼ基質、及びプロテアーゼ切断配列を含むポリペプチド Download PDFInfo
- Publication number
- WO2020246567A1 WO2020246567A1 PCT/JP2020/022226 JP2020022226W WO2020246567A1 WO 2020246567 A1 WO2020246567 A1 WO 2020246567A1 JP 2020022226 W JP2020022226 W JP 2020022226W WO 2020246567 A1 WO2020246567 A1 WO 2020246567A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- amino acid
- sequence
- seq
- terminal
- antibody
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Ceased
Links
Images




















Classifications
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N9/00—Enzymes; Proenzymes; Compositions thereof; Processes for preparing, activating, inhibiting, separating or purifying enzymes
- C12N9/14—Hydrolases (3)
- C12N9/48—Hydrolases (3) acting on peptide bonds (3.4)
- C12N9/50—Proteinases, e.g. Endopeptidases (3.4.21-3.4.25)
- C12N9/64—Proteinases, e.g. Endopeptidases (3.4.21-3.4.25) derived from animal tissue
- C12N9/6421—Proteinases, e.g. Endopeptidases (3.4.21-3.4.25) derived from animal tissue from mammals
- C12N9/6424—Serine endopeptidases (3.4.21)
- C12N9/6456—Plasminogen activators
- C12N9/6462—Plasminogen activators u-Plasminogen activator (3.4.21.73), i.e. urokinase
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P43/00—Drugs for specific purposes, not provided for in groups A61P1/00-A61P41/00
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K38/00—Medicinal preparations containing peptides
- A61K38/16—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- A61K38/17—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans
- A61K38/19—Cytokines; Lymphokines; Interferons
- A61K38/20—Interleukins [IL]
- A61K38/204—IL-6
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K38/00—Medicinal preparations containing peptides
- A61K38/16—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- A61K38/43—Enzymes; Proenzymes; Derivatives thereof
- A61K38/46—Hydrolases (3)
- A61K38/48—Hydrolases (3) acting on peptide bonds (3.4)
- A61K38/482—Serine endopeptidases (3.4.21)
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K39/395—Antibodies; Immunoglobulins; Immune serum, e.g. antilymphocytic serum
- A61K39/39533—Antibodies; Immunoglobulins; Immune serum, e.g. antilymphocytic serum against materials from animals
- A61K39/3955—Antibodies; Immunoglobulins; Immune serum, e.g. antilymphocytic serum against materials from animals against proteinaceous materials, e.g. enzymes, hormones, lymphokines
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K39/395—Antibodies; Immunoglobulins; Immune serum, e.g. antilymphocytic serum
- A61K39/44—Antibodies bound to carriers
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K47/00—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient
- A61K47/50—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates
- A61K47/51—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent
- A61K47/62—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent the modifying agent being a protein, peptide or polyamino acid
- A61K47/64—Drug-peptide, drug-protein or drug-polyamino acid conjugates, i.e. the modifying agent being a peptide, protein or polyamino acid which is covalently bonded or complexed to a therapeutically active agent
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K14/00—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- C07K14/435—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans
- C07K14/52—Cytokines; Lymphokines; Interferons
- C07K14/54—Interleukins [IL]
- C07K14/5412—IL-6
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IG], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IG], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/28—Immunoglobulins [IG], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants
- C07K16/2803—Immunoglobulins [IG], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants against the immunoglobulin superfamily
- C07K16/2818—Immunoglobulins [IG], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants against the immunoglobulin superfamily against CD28 or CD152
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IG], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IG], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/28—Immunoglobulins [IG], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants
- C07K16/2866—Immunoglobulins [IG], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants against receptors for cytokines, lymphokines, interferons
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K7/00—Peptides having 5 to 20 amino acids in a fully defined sequence; Derivatives thereof
- C07K7/04—Linear peptides containing only normal peptide links
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K7/00—Peptides having 5 to 20 amino acids in a fully defined sequence; Derivatives thereof
- C07K7/04—Linear peptides containing only normal peptide links
- C07K7/08—Linear peptides containing only normal peptide links having 12 to 20 amino acids
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/63—Introduction of foreign genetic material using vectors; Vectors; Use of hosts therefor; Regulation of expression
- C12N15/79—Vectors or expression systems specially adapted for eukaryotic hosts
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/63—Introduction of foreign genetic material using vectors; Vectors; Use of hosts therefor; Regulation of expression
- C12N15/79—Vectors or expression systems specially adapted for eukaryotic hosts
- C12N15/85—Vectors or expression systems specially adapted for eukaryotic hosts for animal cells
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N9/00—Enzymes; Proenzymes; Compositions thereof; Processes for preparing, activating, inhibiting, separating or purifying enzymes
- C12N9/14—Hydrolases (3)
- C12N9/48—Hydrolases (3) acting on peptide bonds (3.4)
- C12N9/50—Proteinases, e.g. Endopeptidases (3.4.21-3.4.25)
- C12N9/64—Proteinases, e.g. Endopeptidases (3.4.21-3.4.25) derived from animal tissue
- C12N9/6421—Proteinases, e.g. Endopeptidases (3.4.21-3.4.25) derived from animal tissue from mammals
- C12N9/6424—Serine endopeptidases (3.4.21)
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Y—ENZYMES
- C12Y304/00—Hydrolases acting on peptide bonds, i.e. peptidases (3.4)
- C12Y304/21—Serine endopeptidases (3.4.21)
- C12Y304/21073—Serine endopeptidases (3.4.21) u-Plasminogen activator (3.4.21.73), i.e. urokinase
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Y—ENZYMES
- C12Y304/00—Hydrolases acting on peptide bonds, i.e. peptidases (3.4)
- C12Y304/21—Serine endopeptidases (3.4.21)
- C12Y304/21109—Matriptase (3.4.21.109)
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K2039/505—Medicinal preparations containing antigens or antibodies comprising antibodies
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K38/00—Medicinal preparations containing peptides
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/50—Immunoglobulins specific features characterized by immunoglobulin fragments
- C07K2317/56—Immunoglobulins specific features characterized by immunoglobulin fragments variable (Fv) region, i.e. VH and/or VL
- C07K2317/569—Single domain, e.g. dAb, sdAb, VHH, VNAR or nanobody®
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2319/00—Fusion polypeptide
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2319/00—Fusion polypeptide
- C07K2319/50—Fusion polypeptide containing protease site
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2800/00—Nucleic acids vectors
- C12N2800/10—Plasmid DNA
- C12N2800/106—Plasmid DNA for vertebrates
- C12N2800/107—Plasmid DNA for vertebrates for mammalian
Definitions
- the present disclosure includes a protease substrate, a peptide sequence that can be cleaved by a protease, a polypeptide containing a protease cleavage sequence and a method for producing the same, a pharmaceutical composition containing a polypeptide containing the protease cleavage sequence, and a protease cleavage sequence contained in the polypeptide.
- a method of releasing an antigen-binding domain or ligand by being cleaved is provided.
- Protease is an enzyme that cleaves peptide bonds between amino acid residues. Some proteases are known to disrupt specific peptide bonds based on the presence of specific amino acid sequences within the protein. Proteases occur naturally in all living organisms and are involved in a variety of physiological responses, from simple degradation to highly regulated pathways. However, many pathological conditions are associated with deviant protease expression and / or activity. Thus, inadequate proteolysis is associated with the development and progression of cancer and cardiovascular, inflammatory, neurodegenerative, eukaryotic, bacterial, viral, and parasitic diseases. May play a major role.
- the present disclosure has been made in view of such circumstances, and one of the purposes thereof is a protease substrate, a peptide sequence that can be cleaved by a protease, a polypeptide containing a protease cleavage sequence, a method for producing the same, and a protease. It is an object of the present invention to provide a pharmaceutical composition containing a polypeptide containing a cleavage sequence, a method for releasing an antigen-binding domain or a ligand by cleavage of a protease cleavage sequence contained in the polypeptide.
- a compound that can be used as a protease substrate particularly a peptide sequence that can be used as a protease substrate / can be cleaved by a protease. It is useful for the treatment of diseases including administration of a polypeptide containing a peptide sequence that can be cleaved by a protease (protease cleaved sequence for short), and includes the protease cleaved sequence in the manufacture of a drug for treating the disease.
- protease protease
- the inventors of the present disclosure have completed the present disclosure by creating a polypeptide containing the protease cleavage sequence and a method for producing the same.
- the protease substrate according to [1] which has a higher cleavage rate by human uPA than a protease substrate containing any one of SEQ ID NOs: 1, 2, and 3.
- protease according to any one of [1] to [4], which has a higher cleavage rate by mouse MT-SP1 than a protease substrate containing any one of SEQ ID NOs: 1, 2, and 3. Substrate.
- Any one of [1] to [5] which has a higher ratio of cleavage rate by human uPA to cleavage rate by human serum than a protease substrate containing any one of SEQ ID NOs: 1, 2, and 3.
- the ratio of the cleavage rate by mouse MT-SP1 to the cleavage rate by human serum is higher than that of the protease substrate containing any one of SEQ ID NOs: 1, 2, and 3.
- the protease substrate according to any one is higher than that of the protease substrate containing any one of SEQ ID NOs: 1, 2, and 3.
- the protease substrate according to any one is higher than that of the protease substrate containing any one of SEQ ID NOs: 1, 2, and 3.
- the protease substrate according to any one is not cleaved by human serum.
- Protease substrate containing at least one sequence selected from the following: SEQ ID NO: Sequences from the N-terminal 4th to 15th amino acids of the sequence selected from 5 to 17201, N-terminal 4th to 13th amino acids of the sequence selected from SEQ ID NOs: 5 to 17201 Sequence, SEQ ID NO: 5 to 17201 N-terminal sequence from 6th amino acid to 13th amino acid, SEQ ID NO: 17202 to 17993 N-terminal 1st to 12th amino acid Sequences up to, SEQ ID NO: 17202 to 17993, sequences from the N-terminal 3rd amino acid to the 12th amino acid, SEQ ID NO: 17202 to 17993, N-terminal 3rd to 11th amino acids From the N-terminal 3rd amino acid of the sequence selected from SEQ ID NO: 17202 to 17993, the sequence from the N-terminal 3rd amino acid to the 10th amino acid of the sequence selected from SEQ ID NO: 17202 to 17993, Sequence up
- protease substrate according to any one of [12] to [14] which has a higher cleavage rate by the protease than a protease substrate containing any one of the sequences of SEQ ID NO: 1, 2, and 3.
- the protease substrate according to any one of [12] to [17] which has a higher cleavage rate by mouse uPA than a protease substrate containing any one of the sequences of SEQ ID NO: 1, 2, and 3.
- protease according to any one of [12] to [18], which has a higher cleavage rate by mouse MT-SP1 than a protease substrate containing any one of the sequences of SEQ ID NO: 1, 2, and 3. Substrate. [20] Any of [12] to [19], wherein the ratio of the cleavage rate by human uPA to the cleavage rate by human serum is higher than that of the protease substrate containing any one of SEQ ID NOs: 1, 2, and 3. The protease substrate according to one.
- the ratio of the cleavage rate by mouse MT-SP1 to the cleavage rate by human serum is higher than that of the protease substrate containing any one of SEQ ID NOs: 1, 2, and 3.
- the protease substrate according to any one is not cleaved by human serum.
- a polypeptide comprising at least one sequence selected from the following: SEQ ID NO: Sequences from the N-terminal 4th to 15th amino acids of the sequence selected from 5 to 17201, N-terminal 4th to 13th amino acids of the sequence selected from SEQ ID NOs: 5 to 17201 Sequence, SEQ ID NO: 5 to 17201 N-terminal sequence from 6th amino acid to 13th amino acid, SEQ ID NO: 17202 to 17993 N-terminal 1st to 12th amino acid Sequences up to, SEQ ID NO: 17202 to 17993, sequences from the N-terminal 3rd amino acid to the 12th amino acid, SEQ ID NO: 17202 to 17993, N-terminal 3rd to 11th amino acids From the N-terminal 3rd amino acid of the sequence selected from SEQ ID NO: 17202 to 17991, the sequence from the N-terminal 3rd amino acid to the 10th amino acid of the sequence selected from SEQ ID NO: 17202 to 17993, Sequence up
- Sequence number N-terminal of sequence selected from 5 to 17201 Sequences from 4th amino acid to 15th amino acid, SEQ ID NO: 13th from N-terminal 4th amino acid of sequence selected from 5 to 17201 Sequences up to amino acids, sequences from the 6th to 13th amino acids at the N end of the sequence selected from SEQ ID NOs: 5 to 17201, sequences from the 1st amino acid at the N end of the sequences selected from SEQ ID NOs: 17202 to 17993 Sequence up to the second amino acid, N-terminal sequence of the sequence selected from SEQ ID NO: 17202 to 17993 Sequence from the third amino acid to the twelfth amino acid, N-terminal third amino acid of the sequence selected from SEQ ID NO: 17202 to 17993 Sequences from to 11th amino acid, SEQ ID NO: 17202 to 17993, N-terminal sequence from 3rd amino acid to 10th amino acid, N-terminal 3rd sequence selected from SEQ ID NO: 17994-
- [A-2] Inhibition of the inhibitory domain against the antigen-binding activity of the antigen-binding domain in a state in which the protease-cleaving sequence is cleaved by a protease is the antigen-binding of the inhibitory domain in a state in which the protease-cleaving sequence is uncut.
- the polypeptide according to [A-1] which is weaker than the inhibition of the antigen-binding activity of the domain.
- [A-3] The polypeptide according to [A-1] or [A-2], wherein the antigen-binding domain has a shorter half-life in blood than the uncleaved polypeptide.
- [A-4] The polypeptide according to any one of [A-1] to [A-3], wherein the antigen-binding domain has a shorter half-life in blood than the transport portion.
- [A-5] The polypeptide according to any one of [A-1] to [A-4], wherein the molecular weight of the antigen-binding domain is smaller than the molecular weight of the transport portion.
- [A-6] The polypeptide according to any one of [A-1] to [A-5], wherein the antigen-binding domain has a molecular weight of 60 kDa or less.
- the transport moiety has FcRn-binding activity, and the antigen-binding domain has no FcRn-binding activity or has a weaker FcRn-binding activity than the transport moiety, [A-1] to [A-6]. ].
- the polypeptide according to any one of. [A-8] The antigen-binding domain can be released from the polypeptide, and the antigen-binding activity under the state where the antigen-binding domain is released from the polypeptide is not released from the polypeptide.
- the polypeptide according to any one of [A-1] to [A-7] which is higher than the antigen-binding activity below.
- One of the polypeptides. [A-10] The polypeptide according to [A-8], wherein the antigen-binding domain can be released from the polypeptide by cleaving the protease cleavage sequence with a protease.
- [A-12] The polypeptide according to any one of [A-1] to [A-11], wherein the protease is matriptase and / or urokinase.
- the protease is any one of [A-1] to [A-11], which is at least one protease selected from human MT-SP1, mouse MT-SP1, human uPA, and mouse uPA.
- One of the polypeptides is.
- [A-14] The polypeptide according to any one of [A-1] to [A-13], wherein a first mobile linker is further added to one end of the protease cleavage sequence.
- [A-15] The polypeptide according to [A-14], wherein the first mobile linker is a mobile linker composed of a glycine-serine polymer.
- [A-16] The polypeptide according to [A-14] or [A-15], wherein a second mobile linker is further added to the other end of the protease cleavage sequence.
- [A-17] The polypeptide according to [A-16], wherein the second mobile linker is a mobile linker composed of a glycine-serine polymer.
- the antigen-binding domain contains a monodomain antibody or is a monodomain antibody, and the inhibitory domain of the transport portion suppresses the antigen-binding activity of the monodomain antibody, [A-1] to [ A-17]
- the antigen-binding domain comprises a monodomain antibody, the inhibitory domain of the transport portion is VHH, or antibody VH, or antibody VL, and the monodomain antibody is the VHH, or antibody VH, or antibody.
- the antigen-binding domain comprises a monodomain antibody, the inhibitory domain of the transport portion is VHH, or antibody VH, or antibody VL, and the monodomain antibody is the VHH, or antibody VH, or antibody.
- the monodomain antibody is VHH, or VH having antigen-binding activity in a single domain
- the inhibitory domain of the transport portion is antibody VL, and VHH or VH having antigen-binding activity in a single domain.
- the monodomain antibody is a VHH, which is amino acid substituted at at least one position selected from amino acids 37, 44, 45, or 47 (all Kabat numbering).
- the monodomain antibody is VHH, which comprises at least one amino acid selected from 37V, 44G, 45L, or 47W (all Kabat numbered) amino acids, from [A-18] to [A]. -22] The polypeptide according to any one of.
- the monodomain antibody is VHH, which is selected from amino acid substitutions of F37V, Y37V, E44G, Q44G, R45L, H45L, G47W, F47W, L47W, T47W, or S47W (all Kabat numbering).
- the monodomain antibody is VHH, and the VHH is 37/44, 37/45, 37/47, 44/45, 44/47, 45 /.
- the monodomain antibody is VHH, and the VHH is 37V / 44G, 37V / 45L, 37V / 47W, 44G / 45L, 44G / 47W, 45L / 47W, 37V / 44G / 45L, 37V / 44G.
- the polypeptide according to any one.
- the monodomain antibody is a VHH, which comprises at least one set of amino acid substitutions selected from F37V / R45L, F37V / G47W, R45L / G47W, F37V / R45L / G47W (all Kabat numbering). , [A-18] to [A-22].
- the monodomain antibody is a VL having an antigen-binding activity in a single domain
- the inhibitory domain of the transport portion is an antibody VH
- the VL having an antigen-binding activity in the monodomain is the antibody VH.
- [A-30] The polypeptide according to any one of [A-1] to [A-29], wherein the transport portion has an FcRn binding region.
- [A-31] The polypeptide according to any one of [A-1] to [A-30], wherein the transport portion contains an antibody constant region.
- [A-32] The polypeptide according to [A-31], wherein the antibody constant region of the transport portion and the antigen-binding domain are fused with or without a linker.
- the transport portion comprises an antibody heavy chain constant region, and the antibody heavy chain constant region and the antigen binding domain are fused with or without a linker [A-31]. ].
- the polypeptide described in. [A-34] The transport portion comprises an antibody light chain constant region, and the antibody light chain constant region and the antigen binding domain are fused with or without a linker [A-31]. ].
- [A-35] In the polypeptide, the N-terminal of the antibody heavy chain constant region of the transport portion and the C-terminal of the antigen-binding domain are fused with or without a linker, and the protease cleavage sequence is obtained.
- [A-36] In the polypeptide, the N-terminal of the antibody light chain constant region of the transport portion and the C-terminal of the antigen-binding domain are fused with or without a linker, and the protease cleavage sequence is obtained.
- polypeptide according to [A-34] which is located in the sequence of the antigen-binding domain or on the side of the antigen-binding domain from the amino acid No. 113 (Kabat numbering) of the light chain antibody constant region.
- the N-terminal of the antibody constant region of the transport portion and the C-terminal of the antigen-binding domain are fused with or without a linker, and the antigen-binding domain is derived from VH. It is a prepared monodomain antibody or VHH, and the protease cleavage sequence is located in the sequence of the antibody constant region or on the side of the antibody constant region from amino acid No.
- the polypeptide according to [A-32] which is located near the boundary between the antigen-binding domain and the antibody constant region.
- the N-terminal of the antibody heavy chain constant region of the transport portion and the C-terminal of the antigen-binding domain are fused with or without a linker, and the protease cleavage sequence is obtained.
- the polypeptide according to [A-33] located near the boundary between the antigen-binding domain and the antibody heavy chain constant region.
- the N-terminal of the antibody light chain constant region of the transport portion and the C-terminal of the antigen-binding domain are fused with or without a linker, and the protease cleavage sequence is obtained.
- the antigen-binding domain is a monodomain antibody or VHH prepared from VH, and the protease cleavage sequence is the amino acid No. 109 (Kabat numbering) of the monodomain antibody of the antigen-binding domain and the antibody weight.
- the antigen-binding domain is a monodomain antibody or VHH prepared from VH, and the protease cleavage sequence is the amino acid No.
- the antigen-binding domain is a monodomain antibody prepared from VL, and the protease cleavage sequence is the amino acid No. 104 (Kabat numbering) of the monodomain antibody of the antigen-binding domain and the antibody heavy chain constant.
- the antigen-binding domain is a monodomain antibody prepared from VL, and the protease cleavage sequence is the amino acid No. 109 (Kabat numbering) of the monodomain antibody of the antigen-binding domain and the antibody light chain constant.
- [A-45] The polypeptide according to any one of [A-31] to [A-44], wherein the antibody constant region of the polypeptide is an IgG antibody constant region.
- A-46 The polypeptide according to any one of [A-1] to [A-45], wherein the polypeptide is an IgG antibody-like molecule.
- [A-47] When the measurement is performed using the BLI (Bio-Layer Interferometry) method (Octet) in a state where the antigen-binding domain is not free, no antigen-binding domain-antigen binding is observed, [A-47]. 1] The polypeptide according to any one of [A-46]. [A-48] The polypeptide according to any one of [A-1] to [A-47], wherein a second antigen-binding domain is further linked to the antigen-binding domain. [A-49] The polypeptide according to [A-48], wherein the second antigen-binding domain has an antigen-binding specificity different from that of the antigen-binding domain.
- BLI Bio-Layer Interferometry
- [A-50] The polypeptide according to [A-48] or [A-49], wherein the second antigen binding domain comprises a second monodomain antibody.
- the antigen-binding domain is a monodomain antibody
- the second antigen-binding domain is a second monodomain antibody
- the antigen-binding domain and the second antigen-binding domain are derived from the polypeptide.
- the monodomain antibody and the second monodomain antibody form a bispecific antigen-binding molecule.
- the polypeptide further has an antigen-binding domain different from the antigen-binding domain, and the other antigen-binding domain is also linked to the carrying portion of the polypeptide to suppress the antigen-binding activity.
- [A-53] The polypeptide according to [A-52], which has an antigen-binding specificity different from that of the other antigen-binding domain and the antigen-binding domain.
- a pharmaceutical composition containing the polypeptide according to any one of [A-1] to [A-53].
- [A-55] The method for producing the polypeptide according to any one of [A-1] to [A-53].
- [A-56] A polynucleotide encoding the polypeptide according to any one of [A-1] to [A-53].
- [A-57] A vector containing the polynucleotide according to [A-56].
- [A-58] A host cell containing the polynucleotide according to [A-56] or the vector according to [A-57].
- [A-59] A method for producing the polypeptide according to any one of [A-1] to [A-53], which comprises the step of culturing the host cell according to [A-58].
- [A-60] The method for producing a polypeptide according to [A-59], which comprises the step of isolating the polypeptide from the culture supernatant.
- [A-62] The method according to [A-61], wherein the polypeptide further comprises a transport moiety, which has an inhibitory domain that suppresses the antigen binding activity of the antigen binding domain.
- [A-63] Inhibition of the inhibitory domain against the antigen-binding activity of the antigen-binding domain in a state in which the protease-cleaving sequence is cleaved by a protease is the antigen-binding of the inhibitory domain in a state in which the protease-cleaving sequence is uncut.
- the method according to [A-62] which is weaker than the inhibition of the antigen-binding activity of the domain.
- [A-64] The method according to [A-62] or [A-63], wherein the antigen-binding domain has a shorter half-life in blood than the uncleaved polypeptide.
- [A-65] The method according to any one of [A-62] to [A-64], wherein the antigen-binding domain has a shorter half-life in blood than the transport portion.
- [A-66] The method according to any one of [A-62] to [A-65], wherein the molecular weight of the antigen-binding domain is smaller than the molecular weight of the transport portion.
- [A-67] The method according to any one of [A-62] to [A-66], wherein the antigen-binding domain has a molecular weight of 60 kDa or less.
- the transport moiety has FcRn-binding activity, and the antigen-binding domain has no FcRn-binding activity or has a weaker FcRn-binding activity than the transport moiety, [A-62] to [A-67].
- the protease is any one of [A-62] to [A-71], which is at least one type of protease selected from human MT-SP1, mouse MT-SP1, human uPA, and mouse uPA.
- [A-74] The method according to any one of [A-62] to [A-73], wherein the first movable linker is further added to one end of the protease cleavage sequence.
- [A-75] The method according to [A-74], wherein the first movable linker is a movable linker composed of a glycine-serine polymer.
- [A-76] The method according to [A-74] or [A-75], wherein a second movable linker is further added to the other end of the protease cleavage sequence.
- [A-77] The method according to [A-76], wherein the second movable linker is a movable linker composed of a glycine-serine polymer.
- the antigen-binding domain comprises a monodomain antibody or is a monodomain antibody, and the inhibitory domain of the transport portion suppresses the antigen-binding activity of the monodomain antibody, from [A-62] to [A-62].
- [A-79] The method according to [A-78], wherein the monodomain antibody is a VHH, or a VH having a single domain antigen-binding activity, or a VL having a single domain antigen-binding activity.
- the antigen-binding domain comprises a monodomain antibody, the inhibitory domain of the transport portion is VHH, or antibody VH, or antibody VL, and the monodomain antibody is the VHH, or antibody VH, or antibody.
- the antigen-binding domain comprises a monodomain antibody
- the inhibitory domain of the transport portion is VHH, or antibody VH, or antibody VL
- the monodomain antibody is the VHH, or antibody VH, or antibody.
- the monodomain antibody is VHH, or VH having antigen-binding activity in a single domain
- the inhibitory domain of the transport portion is antibody VL, and VHH or VH having antigen-binding activity in a single domain.
- the monodomain antibody is a VHH, which is amino acid substituted at at least one position selected from amino acids 37, 44, 45, or 47 (all Kabat numbering).
- the monodomain antibody is VHH, which comprises at least one amino acid selected from 37V, 44G, 45L, or 47W (all Kabat numbered) amino acids, from [A-78] to [A].
- the monodomain antibody is VHH, which VHH is selected from amino acid substitutions of F37V, Y37V, E44G, Q44G, R45L, H45L, G47W, F47W, L47W, T47W, or S47W (all Kabat numbering).
- the method according to any one of [A-78] to [A-82], which comprises at least one amino acid substitution.
- the monodomain antibody is VHH, and the VHH is 37/44, 37/45, 37/47, 44/45, 44/47, 45 /.
- the monodomain antibody is VHH, and the VHH is 37V / 44G, 37V / 45L, 37V / 47W, 44G / 45L, 44G / 47W, 45L / 47W, 37V / 44G / 45L, 37V / 44G.
- the monodomain antibody is a VHH, which comprises at least one set of amino acid substitutions selected from F37V / R45L, F37V / G47W, R45L / G47W, F37V / R45L / G47W (all Kabat numbering). , [A-78] to [A-82].
- the monodomain antibody is a VL having an antigen-binding activity in a single domain
- the inhibitory domain of the transport portion is an antibody VH
- the VL having an antigen-binding activity in the monodomain is the antibody VH.
- [A-90] The method according to any one of [A-62] to [A-89], wherein the transport portion has an FcRn binding region.
- [A-91] The method according to any one of [A-62] to [A-90], wherein the transport portion contains an antibody constant region.
- [A-92] The method according to [A-91], wherein the antibody constant region of the transport portion and the antigen binding domain are fused with or without a linker.
- the transport portion comprises an antibody heavy chain constant region, and the antibody heavy chain constant region and the antigen binding domain are fused with or without a linker [A-91]. ]
- the method described in. [A-94]
- the transport portion comprises an antibody light chain constant region, and the antibody light chain constant region and the antigen binding domain are fused with or without a linker [A-91]. ] The method described in.
- [A-95] In the polypeptide, the N-terminal of the antibody heavy chain constant region of the transport portion and the C-terminal of the antigen-binding domain are fused with or without a linker, and the protease cleavage sequence is obtained.
- [A-96] In the polypeptide, the N-terminal of the antibody light chain constant region of the transport portion and the C-terminal of the antigen-binding domain are fused with or without a linker, and the protease cleavage sequence is obtained.
- the antigen-binding domain is a monodomain antibody or VHH prepared from VH, and the protease cleavage sequence is the amino acid No. 109 (Kabat numbering) of the monodomain antibody of the antigen-binding domain and the antibody weight.
- the antigen-binding domain is a monodomain antibody or VHH prepared from VH, and the protease cleavage sequence is the amino acid No.
- the antigen-binding domain is a monodomain antibody prepared from VL, and the protease cleavage sequence is the amino acid No. 104 (Kabat numbering) of the monodomain antibody of the antigen-binding domain and the antibody heavy chain constant.
- the antigen-binding domain is a monodomain antibody prepared from VL, and the protease cleavage sequence is the amino acid No. 109 (Kabat numbering) of the monodomain antibody of the antigen-binding domain and the antibody light chain constant.
- [A-105] The method according to any one of [A-91] to [A-104], wherein the antibody constant region of the polypeptide is an IgG antibody constant region.
- A-106 The method according to any one of [A-62] to [A-105], wherein the polypeptide is an IgG antibody-like molecule.
- [A-107] When the measurement is performed using the BLI (Bio-Layer Interferometry) method (Octet) in a state where the antigen-binding domain is not free, no antigen-binding domain-antigen binding is observed, [A-107]. 62] to any one of [A-106]. [A-108] The method according to any one of [A-62] to [A-107], wherein a second antigen-binding domain is further linked to the antigen-binding domain. [A-109] The method according to [A-108], wherein the second antigen-binding domain has an antigen-binding specificity different from that of the antigen-binding domain.
- BLI Bio-Layer Interferometry
- [A-110] The method according to [A-108] or [A-109], wherein the second antigen binding domain comprises a second monodomain antibody.
- the antigen-binding domain is a monodomain antibody
- the second antigen-binding domain is a second monodomain antibody
- the antigen-binding domain and the second antigen-binding domain are derived from the polypeptide.
- the monodomain antibody and the second monodomain antibody form a bispecific antigen-binding molecule.
- the polypeptide further has an antigen-binding domain different from the antigen-binding domain, and the other antigen-binding domain is also linked to the transport portion of the polypeptide to suppress the antigen-binding activity.
- [A-113] The method according to [A-112], which has an antigen-binding specificity different from that of the other antigen-binding domain and the antigen-binding domain.
- [B-3] The ligand-binding molecule according to any one of [B-1] to [B-2], wherein the protease is matriptase and / or urokinase.
- the protease is any one of [B-1] to [B-3], which is at least one type of protease selected from human MT-SP1, mouse MT-SP1, human uPA, and mouse uPA.
- [B-5] The ligand-binding molecule according to any one of [B-1] to [B-4], wherein a first mobile linker is further added to one end of the protease cleavage sequence.
- [B-6] The ligand-binding molecule according to [B-5], wherein the first mobile linker is a mobile linker composed of a glycine-serine polymer.
- [B-7] The ligand-binding molecule according to [B-5] or [B-6], wherein a second mobile linker is further added to the other end of the protease cleavage sequence.
- [B-8] The ligand-binding molecule according to [B-7], wherein the second mobile linker is a mobile linker composed of a glycine-serine polymer.
- [B-9] The ligand-binding molecule according to any one of [B-1] to [B-8], wherein the ligand-binding molecule contains an antibody VH, an antibody VL, and an antibody constant region.
- the protease cleavage sequence or the protease cleavage sequence and the first mobile linker, or the protease cleavage sequence and the first mobile linker and the second mobile linker are located in the antibody constant region [B-9].
- protease cleavage sequence or the protease cleavage sequence and the first mobile linker, or the protease cleavage sequence and the first mobile linker and the second mobile linker are countered from amino acid 118 (EU numbering) in the antibody heavy chain constant region.
- the ligand-binding molecule according to [B-10] which is introduced at an arbitrary position in the sequence up to amino acid 140 (EU numbering) in the constant region of the body weight chain.
- the protease cleavage sequence or the protease cleavage sequence and the first mobile linker, or the protease cleavage sequence and the first movable linker and the second movable linker are antibodies from amino acid 108 (Kabat numbering) of the antibody light chain constant region.
- the ligand-binding molecule according to [B-10] which is introduced at an arbitrary position in the sequence up to amino acid 131 (Kabat numbering) in the light chain constant region.
- protease cleavage sequence, or the protease cleavage sequence and the first mobile linker, or the protease cleavage sequence and the first and second mobile linkers are located in the antibody VH or in the antibody VL, [ B-9].
- the protease cleavage sequence, or the protease cleavage sequence and the first mobile linker, or the protease cleavage sequence and the first movable linker and the second movable linker are amino acids VH 7th amino acid (Kabat numbering) to 16th amino acid (Kabat).
- protease cleavage sequence or the protease cleavage sequence and the first movable linker, or the protease cleavage sequence and the first movable linker and the second movable linker are prepared from the antibody VL7 amino acid (Kabat numbering) to the 19th amino acid (Kabat).
- the protease cleavage sequence or the protease cleavage sequence and the first mobile linker, or the protease cleavage sequence and the first mobile linker and the second mobile linker are located near the boundary between the antibody constant region and the antibody VH, and /.
- the ligand-binding molecule according to [B-9] which is located near the boundary between the antibody constant region and the antibody VL.
- the protease cleavage sequence, or the protease cleavage sequence and the first mobile linker, or the protease cleavage sequence and the first movable linker and the second mobile linker are antibody heavy chain constants from amino acid VH109 (Kabat numbering).
- the ligand-binding molecule according to [B-17] which is introduced at an arbitrary position in the sequence up to the amino acid (EU numbering) of region 122.
- the protease cleavage sequence or the protease cleavage sequence and the first mobile linker, or the protease cleavage sequence and the first movable linker and the second movable linker are antibody light chain constants from amino acid VL104 (Kabat numbering).
- the ligand-binding molecule according to [B-16] which is introduced at an arbitrary position in the sequence up to the amino acid (Kabat numbering) of region 113.
- the antibody VL and the antibody VH in the ligand-binding molecule are associated, and the association is resolved by cleaving the protease cleavage sequence with a protease, from [B-9] to [B-9].
- the ligand-binding molecule according to any one of B-18].
- the ligands are ligands selected from interleukins, interferons, hematopoietic factors, TNF superfamily, chemokines, cell growth factors, and TGF- ⁇ families, [B-1] to [B-20].
- the ligand-binding molecule according to any one of the above.
- [B-25] The ligand-binding molecule according to any one of [B-1] to [B-23] fused to the ligand.
- [B-26] The ligand-binding molecule according to [B-25], wherein the ligand-binding molecule does not bind to another ligand when the ligand-binding molecule is fused with the ligand.
- [B-27] The ligand-binding molecule according to [B-25] or [B-26], wherein the ligand-binding molecule is fused to the ligand via a linker.
- [B-28] The ligand-binding molecule according to [B-27], wherein the linker does not contain a protease cleavage sequence.
- [B-29] A complex formed by the ligand and the ligand-binding molecule according to any one of [B-1] to [B-23] bound to the ligand.
- [B-30] A fusion protein in which the ligand and the ligand-binding molecule according to any one of [B-1] to [B-23] are fused.
- the fusion protein according to [B-30] wherein the ligand-binding molecule does not bind to another ligand when the ligand is fused to the ligand.
- [B-32] The fusion protein according to [B-30] or [B-31], wherein the ligand-binding molecule is fused to the ligand via a linker.
- [B-33] The fusion protein according to [B-32], wherein the linker does not contain a protease cleavage sequence.
- [B-34] The fusion protein according to [B-32] or [B-33], wherein the linker is a linker composed of a glycine-serine polymer.
- [B-35] A pharmaceutical composition comprising the ligand-binding molecule according to any one of [B-1] to [B-28].
- [B-36] A pharmaceutical composition comprising the ligand-binding molecule and the ligand according to any one of [B-1] to [B-24].
- [B-37] A pharmaceutical composition comprising the complex according to [B-29].
- [B-38] A pharmaceutical composition comprising the fusion protein according to any one of [B-30] to [B-34].
- [B-39] The method for producing a ligand-binding molecule according to any one of [B-1] to [B-28].
- [B-40] The production method according to [B-39], which comprises introducing a protease cleavage sequence into a molecule capable of binding to a ligand.
- [B-41] The method for producing a fusion protein according to any one of [B-30] to [B-34], which comprises fusing a ligand-binding molecule having a protease cleavage sequence and the ligand thereof.
- [B-42] A polynucleotide encoding the ligand-binding molecule according to any one of [B-1] to [B-28].
- [B-43] A vector containing the polynucleotide according to [B-42].
- [B-44] A host cell containing the polynucleotide described in [B-42] or the vector described in [B-43].
- [B-45] The method for producing a ligand-binding molecule according to any one of [B-1] to [B-28], which comprises the step of culturing the host cell according to [B-44].
- [B-46] The method for producing a ligand-binding molecule according to [B-45], which comprises the step of isolating the polypeptide from the culture supernatant.
- [B-47] A polynucleotide encoding the fusion protein according to any one of [B-30] to [B-34].
- [B-48] A vector containing the polynucleotide according to [B-46].
- [B-49] A host cell containing the polynucleotide described in [B-46] or the vector described in [B-48].
- [B-50] The method for producing the fusion protein according to any one of [B-30] to [B-34], which comprises the step of culturing the host cell according to [B-49].
- [B-51] The method for producing a fusion protein according to [B-50], which comprises the step of isolating the polypeptide from the culture supernatant.
- [B-52] A sequence from the 4th amino acid to the 15th amino acid at the N-terminal of a sequence selected from SEQ ID NO: 5 to 17201, which is contained in a ligand-binding molecule capable of binding to a ligand, from SEQ ID NO: 5 to 17201.
- Sequences from the 4th to 13th amino acids at the N-terminal of the selected sequence SEQ ID NOs: 5 to 17201, sequences from the 6th to 13th amino acids at the N-terminal of the selected sequence, SEQ ID NOs: 17202 to Sequence from the N-terminal 1st amino acid to the 12th amino acid of the sequence selected from 17993, SEQ ID NO:: Sequence from the N-terminal 3rd amino acid to the 12th amino acid of the sequence selected from 17202 to 17993, SEQ ID NO:: Sequence from the N-terminal 3rd amino acid to the 11th amino acid of the sequence selected from 17202 to 17993, sequence from the N-terminal 3rd amino acid to the 10th amino acid of the sequence selected from SEQ ID NO: 17202 to 17993.
- a method of releasing the ligand bound to the ligand-binding molecule which comprises cleaving the ligand by a protease.
- Sequence from the N-terminal 4th to 13th amino acids of the sequence selected from 5 to 17201 SEQ ID NO: Sequence from the N-terminal 6th to 13th amino acids of the sequence selected from 5 to 17201, Sequence numbers from the N-terminal 1st to 12th amino acids of the sequence selected from SEQ ID NO: 17202 to 17993, N-terminal from the 3rd to 12th amino acids of the sequence selected from SEQ ID NOs: 17202 to 17993 Sequence, SEQ ID NO: 17202 to 17993, N-terminal 3rd to 11th amino acids, SEQ ID NO: 17202 to 17993, N-terminal, 3rd to 10th amino acids Sequence number: 17994-18003 N-terminal sequence from 3rd to 14th amino acid, SEQ ID NO: 17994-18003 N-terminal 5th amino acid to 12th Sequence number up to amino acid, SEQ ID NO: 17994-18003 N-terminal sequence from 5th amino acid to 10th amino
- [B-54] The method of [B-53], wherein the ligand-binding molecule is fused to the ligand via a linker.
- [B-55] The method according to [B-54], wherein the linker does not contain a protease cleavage sequence.
- [B-56] The method according to [B-54] or [B-55], wherein the linker is a linker composed of a glycine-serine polymer.
- [B-57] The method according to any one of [B-53] to [B-56], wherein the ligand-binding molecule does not bind to another ligand in a fused state with the ligand.
- [B-58] The binding of the ligand-binding molecule to the ligand in the state where the protease-cleaving sequence is cleaved is weaker than the binding of the ligand-binding molecule to the ligand in the state where the protease-cleaving sequence is uncut, [B-52]. ] To [B-57]. [B-59] The method according to any one of [B-52] to [B-58], wherein the protease is matliptase and / or urokinase.
- the protease is any one of [B-52] to [B-59], which is at least one protease selected from human MT-SP1, mouse MT-SP1, human uPA, and mouse uPA.
- [B-61] The method according to any one of [B-52] to [B-60], wherein a first movable linker is further added to one end of the protease cleavage sequence.
- the first movable linker is a movable linker composed of a glycine-serine polymer.
- [B-63] The method according to [B-61] or [B-62], wherein a second movable linker is further added to the other end of the protease cleavage sequence.
- [B-64] The method according to [B-63], wherein the second movable linker is a movable linker composed of a glycine-serine polymer.
- [B-65] The method according to any one of [B-52] to [B-64], wherein the ligand-binding molecule comprises an antibody VH, an antibody VL, and an antibody constant region.
- protease cleavage sequence, or the protease cleavage sequence and the first mobile linker, or the protease cleavage sequence and the first and second mobile linkers are located within the antibody constant region [B-65].
- the method described in. [B-67] The protease cleavage sequence, or the protease cleavage sequence and the first mobile linker, or the protease cleavage sequence and the first mobile linker and the second mobile linker are countered from amino acid 118 (EU numbering) in the antibody heavy chain constant region.
- the method according to [B-66] which is introduced at an arbitrary position in the sequence up to amino acid 140 (EU numbering) in the constant region of the body weight chain.
- the protease cleavage sequence, or the protease cleavage sequence and the first mobile linker, or the protease cleavage sequence and the first movable linker and the second mobile linker are antibodies from amino acid 108 (Kabat numbering) of the antibody light chain constant region.
- protease cleavage sequence, or the protease cleavage sequence and the first mobile linker, or the protease cleavage sequence and the first and second mobile linkers are located in the antibody VH or in the antibody VL, [ B-65].
- the protease cleavage sequence, or the protease cleavage sequence and the first movable linker, or the protease cleavage sequence and the first movable linker and the second movable linker are prepared from the antibody VH amino acid VH7 (Kabat numbering) to amino acid 16 (Kabat).
- the protease cleavage sequence, or the protease cleavage sequence and the first movable linker, or the protease cleavage sequence and the first movable linker and the second movable linker are prepared from the antibody VL7 amino acid (Kabat numbering) to the 19th amino acid (Kabat).
- the method according to [B-65] which is located near the boundary between the antibody constant region and the antibody VL.
- the protease cleavage sequence, or the protease cleavage sequence and the first mobile linker, or the protease cleavage sequence and the first mobile linker and the second mobile linker are antibody heavy chain constants from the amino acid (Kabat numbering) of antibody VH109.
- the method according to [B-73] which is introduced at an arbitrary position in the sequence up to the amino acid (EU numbering) of region 122.
- protease cleavage sequence, or the protease cleavage sequence and the first mobile linker, or the protease cleavage sequence and the first movable linker and the second movable linker are obtained from the amino acid (Kabat numbering) of antibody VL104 to the antibody light chain constant.
- [B-75] The antibody VL and the antibody VH in the ligand-binding molecule are associated with each other, and the association is resolved by cleaving the protease cleavage sequence with a protease, from [B-65] to [B-65].
- B-74] according to any one of the methods.
- [B-76] Any of [B-52] to [B-75], wherein the ligand is a molecule having biological activity, and the ligand-binding molecule inhibits the biological activity of the ligand by binding to the ligand. The method described in one.
- [B-77] The method according to any one of [B-52] to [B-76], wherein the ligand is a cytokine or chemokine.
- the ligand is a ligand selected from interleukin, interferon, hematopoietic factor, TNF superfamily, chemokine, cell growth factor, and TGF- ⁇ family, [B-52] to [B-76].
- the method described in any one of. [B-79] The method according to any one of [B-52] to [B-78], wherein the ligand-binding molecule is an IgG antibody.
- [C-2] The ligand-binding molecule according to [C-1], wherein the ligand is released from the ligand-binding molecule when the protease cleavage sequence is cleaved.
- [C-3] The ligand-binding molecule according to [C-1] or [C-2], wherein the protease is matriptase and / or urokinase.
- the protease is any one of [C-1] to [C-3], which is at least one protease selected from human MT-SP1, mouse MT-SP1, human uPA, and mouse uPA.
- [C-5] The ligand-binding molecule according to any one of [C-1] to [C-4], wherein a first mobile linker is further added to one end of the protease cleavage sequence.
- [C-6] The ligand-binding molecule according to [C-5], wherein the first mobile linker is a mobile linker composed of a glycine-serine polymer.
- [C-7] The ligand-binding molecule according to [C-5] or [C-6], wherein a second mobile linker is further added to the other end of the protease cleavage sequence.
- [C-8] The ligand-binding molecule according to [C-7], wherein the second mobile linker is a mobile linker composed of a glycine-serine polymer.
- the second mobile linker is a mobile linker composed of a glycine-serine polymer.
- the monodomain antibody is a VHH or monodomain VH antibody, and the cleavage site, or the protease cleavage sequence, or the protease cleavage sequence and the first mobile linker, or the protease cleavage sequence and the first movable linker and the first.
- the monodomain antibody is a monodomain VL antibody, and the cleavage site, or the protease cleavage sequence, or the protease cleavage sequence and the first mobile linker, or the protease cleavage sequence and the first movable linker and the second movable linker.
- the ligand-binding molecule according to any one of [C-1] to [C-14], wherein the ligand-binding molecule further contains an antibody Fc region.
- the ligand-binding molecule is any one of [C-1] to [C-15], which comprises a series of peptide chains consisting of a monodomain antibody-antibody Fc region from the N-terminal to the C-terminal.
- the ligand-binding molecule is a dimer containing two series of peptide chains consisting of a monodomain antibody-antibody hinge region-antibody Fc region, from [C-1] to [C-15].
- the antibody Fc region is an Fc region containing one sequence selected from the amino acid sequences set forth in SEQ ID NO: 18004 to 18007, or an Fc region variant obtained by modifying these Fc regions.
- the ligand-binding molecule according to [C-15] to [C-17].
- the ligand is a ligand selected from interleukin, interferon, hematopoietic factor, TNF superfamily, chemokine, cell growth factor, and TGF- ⁇ family, [C-1] to [C-19].
- [C-24] The ligand-binding molecule according to [C-22] or [C-23], wherein the ligand-binding molecule is fused to the ligand via a linker.
- [C-25] The ligand-binding molecule according to [C-24], wherein the linker does not contain a protease cleavage sequence.
- [C-26] A complex formed by the ligand and the ligand-binding molecule according to any one of [C-1] to [C-20].
- [C-27] A fusion protein in which the ligand and the ligand-binding molecule according to any one of [C-1] to [C-20] are fused.
- [C-28] The fusion protein according to [C-27], wherein the monodomain antibody does not bind to yet another ligand when the ligand-binding molecule is fused to the ligand.
- [C-29] The fusion protein according to [C-27] or [C-28], wherein the ligand-binding molecule is fused to the ligand via a linker.
- [C-30] The fusion protein according to [C-29], wherein the linker does not contain a protease cleavage sequence.
- [C-31] The fusion protein according to [C-29] or [C-30], which is fused in the order of a ligand-linker-ligand binding molecule from the N-terminal to the C-terminal.
- [C-32] A pharmaceutical composition comprising the ligand-binding molecule according to any one of [C-1] to [C-22].
- [C-33] A pharmaceutical composition comprising the ligand-binding molecule and the ligand according to any one of [C-1] to [C-21].
- [C-34] A pharmaceutical composition comprising the complex according to [C-26].
- [C-35] A pharmaceutical composition comprising the fusion protein according to any one of [C-27] to [C-31].
- [C-36] The method for producing a ligand-binding molecule according to any one of [C-1] to [C-20].
- [C-37] The production method according to [C-36], which comprises introducing a protease cleavage sequence into a monodomain antibody in a ligand-binding molecule containing a monodomain antibody.
- the method for producing a fusion protein according to one of the above.
- [C-39] A polynucleotide encoding the ligand-binding molecule according to any one of [C-1] to [C-20].
- [C-40] A vector containing the polynucleotide according to [C-39].
- [C-41] A host cell containing the polynucleotide described in [C-39] or the vector described in [C-40].
- [C-42] A method for producing a ligand-binding molecule according to any one of [C-1] to [C-20], which comprises the step of culturing the host cell according to [C-41].
- [C-43] The method for producing a ligand-binding molecule according to [C-42], which comprises the step of isolating the polypeptide from the culture supernatant.
- [C-44] A polynucleotide encoding the fusion protein according to any one of [C-27] to [C-31].
- [C-45] A vector containing the polynucleotide according to [C-43].
- [C-46] A host cell containing the polynucleotide described in [C-43] or the vector described in [C-45].
- [C-47] The method for producing the fusion protein according to any one of [C-27] to [C-31], which comprises the step of culturing the host cell according to [C-46].
- [C-48] The method for producing a ligand-binding molecule according to [C-47], which comprises the step of isolating the polypeptide from the culture supernatant.
- Sequence from the 4th to 13th amino acids at the N-terminal of the sequence selected from 5 to 17201 SEQ ID NO: Sequence from the 6th to 13th amino acids at the N-terminal of the sequence selected from 5 to 17201, Sequences from the N-terminal 1st amino acid to the 12th amino acid of the sequence selected from SEQ ID NO: 17202 to 17993, N-terminal from the N-terminal 3rd amino acid to the 12th amino acid of the sequence selected from SEQ ID NO: 17202 to 17993 Sequence, SEQ ID NO: 17202 to 17993 N-terminal sequence from 3rd amino acid to 11th amino acid, SEQ ID NO: 17202 to 17993 N-terminal 3rd to 10th amino acid Sequence number: 17994-18003 N-terminal sequence from 3rd amino acid to 14th amino acid, SEQ ID NO: 17994-18003 N-terminal 5th amino acid to 12th amino acid The sequence from the 5th amino acid to the 10th amino acid at
- Sequence from the 4th to 13th amino acids at the N-terminal of the sequence selected from 5 to 17201 SEQ ID NO: Sequence from the 6th to 13th amino acids at the N-terminal of the sequence selected from 5 to 17201, Sequences from the N-terminal 1st amino acid to the 12th amino acid of the sequence selected from SEQ ID NO: 17202 to 17993, N-terminal from the N-terminal 3rd amino acid to the 12th amino acid of the sequence selected from SEQ ID NO: 17202 to 17993 Sequence, SEQ ID NO: 17202 to 17993 N-terminal sequence from 3rd amino acid to 11th amino acid, SEQ ID NO: 17202 to 17993 N-terminal 3rd to 10th amino acid Sequence number: 17994-18003 N-terminal sequence from 3rd amino acid to 14th amino acid, SEQ ID NO: 17994-18003 N-terminal 5th amino acid to 12th amino acid Sequence number up to amino acid, SEQ ID NO: 179
- a method for releasing a ligand from a fusion protein of the ligand and the ligand-binding molecule which comprises cleaving a site having one sequence by a protease.
- [C-51] The method according to [C-50], wherein the ligand-binding molecule is fused to the ligand via a linker.
- [C-52] The method according to [C-51], wherein the linker does not contain a protease cleavage sequence.
- [C-53] The method according to [C-51] or [C-52], wherein the linker is a linker composed of a glycine-serine polymer.
- [C-54] The method according to any one of [C-50] to [C-53], wherein the ligand-binding molecule does not bind to another ligand in a fused state with the ligand.
- [C-55] The binding of the ligand-binding molecule to the ligand when the protease cleavage sequence is cleaved is attenuated as compared with the binding of the ligand-binding molecule to the ligand when the protease cleavage sequence is uncleaved.
- [C-56] The method according to [C-55], wherein when the protease cleavage sequence is cleaved, the ligand is released from the ligand-binding molecule.
- [C-57] The method according to [C-55] or [C-56], wherein the protease is matriptase and / or urokinase.
- the protease is any one of [C-55] to [C-57], which is at least one protease selected from human MT-SP1, mouse MT-SP1, human uPA, and mouse uPA. The method described in one.
- [C-59] The method according to any one of [C-55] to [C-58], wherein the first movable linker is further added to one end of the protease cleavage sequence.
- [C-60] The method according to [C-59], wherein the first movable linker is a movable linker composed of a glycine-serine polymer.
- [C-61] The method according to [C-59] or [C-60], wherein a second movable linker is further added to the other end of the protease cleavage sequence.
- [C-62] The method according to [C-61], wherein the second movable linker is a movable linker composed of a glycine-serine polymer.
- [C-63] The method according to any one of [C-55] to [C-62], wherein the monodomain antibody is a VHH, a monodomain VH antibody, or a monodomain VL antibody.
- the monodomain antibody is a VHH or monodomain VH antibody and is the cleavage site, or the protease cleavage sequence, or the protease cleavage sequence and the first mobile linker, or the protease cleavage sequence and the first mobile linker and the first.
- the method according to [C-63] wherein the bimovable linker is introduced at one or more positions contained in one or more sequences selected from the following sequences of the monodomain antibody: monodomain antibody # 7.
- the monodomain antibody is a monodomain VL antibody and is the cleavage site, or the protease cleavage sequence, or the protease cleavage sequence and the first mobile linker, or the protease cleavage sequence and the first movable linker and the second mobile.
- [C-67] The method according to any one of [C-55] to [C-66], wherein the ligand is a molecule having biological activity and the monodomain antibody has neutralizing activity against the ligand. ..
- [C-69] The method according to any one of [C-55] to [C-68], wherein the ligand-binding molecule further comprises an antibody Fc region.
- [C-70] Any one of [C-55] to [C-69], wherein the ligand-binding molecule comprises a series of peptide chains consisting of a monodomain antibody-antibody Fc region from the N-terminus to the C-terminus.
- the method described in. [C-71] The ligand-binding molecule is a dimer containing two series of peptide chains consisting of a monodomain antibody-antibody hinge region-antibody Fc region, from [C-55] to [C-69]. The method described.
- the antibody Fc region is an Fc region containing one sequence selected from the amino acid sequences set forth in SEQ ID NO: 18004 to 18007, or an Fc region variant obtained by modifying these Fc regions.
- [C-73] The method according to any one of [C-55] to [C-72], wherein the ligand is a cytokine or chemokine.
- the ligand is a ligand selected from interleukin, interferon, hematopoietic factor, TNF superfamily, chemokine, cell growth factor, and TGF- ⁇ family, [C-55] to [C-73].
- the polypeptide comprises an antigen binding domain and a carrier portion.
- a polypeptide in which the antigen-binding domain and the transport portion are linked has a long half-life and does not bind to the antigen.
- the polypeptide of interest is an IgG antibody-like molecule.
- A Obtain a monodomain antibody that binds to the target antigen.
- B The monodomain antibody is associated with VL in place of the VH of the IgG antibody so that the antigen binding activity of the monodomain antibody is suppressed.
- C A protease cleavage sequence is introduced into an IgG antibody-like molecular precursor into which a monodomain antibody has been introduced. It is a figure which shows an example of the polypeptide containing the protease cleavage sequence of this disclosure.
- the polypeptide is an IgG antibody-like molecule, and an antigen-binding domain is provided in each of the portions corresponding to the two variable regions of the IgG antibody.
- the two antigen-binding domains may have similar antigen-binding specificities or may have different antigen-binding specificities. It is a figure which shows an example of the polypeptide containing the protease cleavage sequence of this disclosure. Here, the conjugated antigen-binding domain and the second antigen-binding domain are included in the polypeptide. In this example, the liberated antigen-binding domain and the second antigen-binding domain form a bispecific antigen-binding molecule. (A) It is a figure which shows the polypeptide in the unfree state. The antigen-binding activity of the antigen-binding domain is suppressed.
- (B) It is a figure which shows the release of the bispecific antigen-binding molecule formed by the antigen-binding domain and the second antigen-binding domain.
- (C) As an example of the bispecific antigen-binding molecule after liberation, for example, it is a figure which shows the bispecific antigen-binding molecule for T cell surface antigen and cancer cell surface antigen. It is a figure which shows an example of the polypeptide containing the protease cleavage sequence of this disclosure.
- the polypeptide is a fusion protein of a ligand and an anti-ligand antibody.
- the protease cleavage sequence is contained in the anti-ligand antibody, and in the state where the protease cleavage sequence is not cleaved, the ligand is bound to the anti-ligand antibody.
- B When the protease cleavage sequence is cleaved, a part of the ligand and the anti-ligand antibody is released from the polypeptide, and the ligand can bind to the receptor. It is a figure which shows an example of the polypeptide containing the protease cleavage sequence of this disclosure. Here, the polypeptide is an anti-ligand antibody.
- the protease cleavage sequence is contained in the anti-ligand antibody, and when the protease cleavage sequence is not cleaved, the anti-ligand antibody can bind to the ligand.
- B When the protease cleavage sequence is cleaved, the ligand-binding activity of the anti-ligand antibody is weakened, the ligand dissociates from the anti-ligand antibody, and the ligand can bind to the receptor.
- the polypeptide is a monodomain antibody comprising a protease cleavage sequence.
- the monodomain antibody When the protease cleavage sequence contained in the monodomain antibody is uncut, the monodomain antibody can bind to the ligand, and when the protease cleavage sequence is cleaved, the monodomain antibody is cleaved and binds to the ligand. No, the ligand is released.
- the polypeptide is a fusion protein of a monodomain antibody comprising a ligand and a protease cleavage sequence.
- the monodomain antibody in the fusion protein can bind to the ligand in the fusion protein, and in the state where the protease cleavage sequence is cleaved, the monodomain antibody It is cleaved and unable to bind to the ligand, releasing some of the fusion proteins containing the ligand.
- the polypeptide is a dimeric protein containing a monodomain antibody-antibody hinge region-antibody Fc region containing a protease cleavage sequence.
- the polypeptide is a fusion protein of a ligand and a dimeric protein containing a monodomain antibody-antibody hinge region-antibody Fc region containing a protease cleavage sequence. It is a figure which shows the result of SDS-PAGE of a protease-treated ligand-binding molecule and a protease-untreated ligand-binding molecule.
- Control molecules that do not contain protease cleavage sequences have bands at the same position regardless of whether they are protease-treated or untreated, whereas ligand-binding molecules into which each protease cleavage sequence is introduced are only after protease treatment. It was shown that there was a new band resulting, i.e., the single domain antibody-containing ligand-binding molecule into which each protease cleavage sequence was introduced was cleaved by protease treatment. It is a real-time binding graph which evaluated the binding to IL-6R of a protease-treated ligand-binding molecule and a protease-untreated ligand-binding molecule.
- each figure is the name of the measurement sample, the vertical axis shows the relative binding between the ligand-binding molecule and IL-6R, and the horizontal axis shows the time (s).
- the gray line shows the data of the protease untreated sample, and the black line shows the data of the protease treated sample. It is a figure which shows the result of SDS-PAGE of a protease-treated fusion protein and a protease-untreated fusion protein.
- each fusion protein containing the single-domain antibody-containing ligand-binding molecule into which the protease cleavage sequence is introduced is after protease treatment. It was shown that there was a new band that only occurred, i.e., each fusion protein containing a monodomain antibody-containing ligand-binding molecule into which each protease cleavage sequence was introduced was cleaved by protease treatment. It is a figure which shows the continuation of FIG. It is a figure which shows the continuation of FIG. It is a figure which shows the continuation of FIG. It is a figure which shows the continuation of FIG.
- FIG. 5 is a real-time graph showing binding of free human PD-1 present in a protease-treated fusion protein and a protease-untreated fusion protein solution to a biotinylated anti-PD-1 monodomain antibody-containing molecule (PD1-bio).
- the title of each figure is the name of the measurement sample, the vertical axis shows the relative binding between PD-1 and PD1-bio, and the horizontal axis shows the time (s).
- the gray line shows the data of the protease untreated sample, and the black line shows the data of the protease treated sample.
- Amino Acids In the present specification, for example, Ala / A, Leu / L, Arg / R, Lys / K, Asn / N, Met / M, Asp / D, Phe / F, Cys / C, Pro / P, Gln / Amino acids are single-letter codes or as represented by Q, Ser / S, Glu / E, Thr / T, Gly / G, Trp / W, His / H, Tyr / Y, Ile / I, Val / V. It is written in 3-character code or both.
- Natural Amino Acids The term "natural amino acids" as used herein refers to 20 types of amino acids contained in proteins. Specifically, it refers to Gly, Ala, Ser, Thr, Val, Leu, Ile, Phe, Tyr, Trp, His, Glu, Asp, Gln, Asn, Cys, Met, Lys, Arg, and Pro.
- peptide refers to a compound in which two or more amino acid molecules are bound by removing one molecule of water from one amino group and the other carboxyl group.
- the number of amino acids contained in a peptide is not limited. Therefore, both oligopeptides and polypeptides are included in the peptides.
- polypeptides in the present disclosure usually refer to peptides and proteins having a length of about 10 amino acids or more.
- a chain of amino acids connected by a peptide bond from the N-terminal to the C-terminal is a series of peptide chains
- a plurality of series of peptide chains interact with each other such as SS bond, hydrophobic interaction, and ionic bond. It may be a complex protein formed by.
- the polypeptide in the present disclosure is usually a polypeptide consisting of an artificially designed sequence, but is not particularly limited, and may be, for example, a synthetic polypeptide, a recombinant polypeptide, or the like.
- fragments of the above polypeptides are also included in the polypeptides of the present disclosure.
- polypeptides of the present disclosure can refer to isolated polypeptides.
- An "isolated" polypeptide is one that has been separated from its original environmental components.
- the polypeptide is, for example, electrophoresis (eg, SDS-PAGE, isoelectric focusing (IEF), capillary electrophoresis) or chromatograph (eg, ion exchange or reverse phase HPLC). Purified to a purity greater than 95% or 99% as measured by. If the polypeptide is an antibody, see, for example, Flatman et al., J. Chromatogr. B 848: 79-87 (2007) for a review of methods for assessing antibody purity.
- Protease refers to an enzyme such as endopeptidase or exopeptidase that hydrolyzes a peptide bond, usually endopeptidase.
- protease types include cysteine proteases (including catepsin families B, L, S, etc.), aspartyl proteases (catepsin D, E, K, O, etc.), Serin Protease (Matryptase (including MT-SP1), Catepsin A and G, Trombin, Plasmin, Urokinase (uPA), Tissue Plasminogen Activator (tPA), Elastase, Proteinase 3, Trombin, Caliclein, Tryptase, Kimase (Including), metalloproteases (metalloproteases (MMP1-28) containing both membrane-bound (MMP14-17 and MMP24-25) and secretory types (MMP1-13 and MMP18-23 and MMP26-28)), proteases A disintegrate and metalloprotease (ADAM), A disintegrate or metalloprotease with a thrombospondin motif (ADAMTS), mepurin (
- proteases of the present disclosure can be proteases that are closely associated with diseased tissue. For example (1) Proteases expressed at higher levels in diseased tissues than in normal tissues, (2) Proteases having higher activity in diseased tissues than in normal tissues, (3) Proteases expressed at higher levels in cells in diseased tissues than in normal cells, (4) Proteases having higher activity in target cells in diseased tissues than normal cells, Can be pointed to either.
- diseased tissues are cancerous tissues and inflamed tissues.
- cancer tissue means a tissue containing at least one cancer cell. Thus, it refers to all cell types that contribute to the formation of tumor masses, including cancer cells and endothelial cells, such as cancer tissue containing cancer cells and blood vessels.
- a mass means a tumor tissue lesion (a foci of tumor tissue).
- tumor is commonly used to mean benign or malignant neoplasms.
- the "inflamed tissue” is exemplified as follows. ⁇ Joints in rheumatoid arthritis and osteoarthritis ⁇ Lungs (alveoli) in bronchial asthma and COPD ⁇ Digestive organs in inflammatory bowel disease, Crohn's disease and ulcerative colitis ⁇ Fibrotic tissue in fibrosis in liver, kidney and lung ⁇ Tissue with rejection in organ transplantation ⁇ Vascular and heart in arteriosclerosis and heart failure (Myocardium) ⁇ Visceral fat in metabolic syndrome ⁇ Skin tissue in atopic dermatitis and other dermatitis ⁇ Spinal nerve in disc herniation and chronic low back pain
- Urokinase Urokinase (uPA) Urokinase (uPA), also called urokinase-type plasminogen activator, is a type of extracellular serine protease.
- the terms urokinase, urokinase-type plasminogen activator and uPA are used interchangeably herein and are naturally occurring and endogenous as long as they have serine protease activity and can be derived from any suitable organism. Includes any uPA produced and / or recombinant form.
- uPA is a double-stranded active form (tc-uPA).
- Urokinase is further derived from human uPA or primates (eg, chimpanzees, cynomolgus monkeys or rhesus monkeys); rodents (such as mice or rats), rabbits (such as rabbits) or cloven-hoofed animals (such as cows, sheep, pigs or camels).
- uPA from other species such as mammalian-derived uPA such as uPA.
- the terms urokinase-type plasminogen activator and uPA further include recombinantly produced uPA. This includes any uPA "produced by recombinant genetic engineering", including but not limited to proteins expressed in mammalian cell lines or bacteria or yeasts.
- Urokinase (uPA) is said to be highly associated with cancer tissues, and peptide sequences that can be cleaved by urokinase (uPA) are more cleaved in cancer tissues than in normal tissues.
- Matliptase Matliptase is a type of serine protease.
- the matliptase of the present disclosure includes any naturally occurring, endogenously produced and / or recombinant form of matliptase that can be derived from any suitable organism as long as it has serine protease activity.
- Matliptase derived from human matriptase or primates eg chimpanzees, cynomolgus monkeys or rhesus monkeys); rodents (mouse or rat etc.), rabbits (rabbits etc.) or cloven-hoofed animals (cattle, sheep, pigs or camels etc.)
- matriptase from other species such as mammalian-derived matriptase such as matliptase.
- Matliptase further includes recombinantly produced matriptase. This includes any matliptase "produced by recombinant genetic engineering", including but not limited to proteins expressed in mammalian cell lines or bacteria or yeasts.
- Matliptase contains MT-SP1, which is a naturally occurring, endogenously produced and / or recombinant form that can be derived from any suitable organism as long as it has serine protease activity.
- MT-SP1 contains human MT-SP1 or primates (eg chimpanzees, cynomolgus monkeys or rhesus monkeys); rodents (mouse or rat, etc.), rabbits (rabbits, etc.) or cloven-hoofed animals (cows, sheep, pigs or camels, etc.) )
- MT-SP1 from other species such as mammalian-derived MT-SP1.
- MT-SP1 further includes MT-SP1 produced by recombination.
- matriptase including MT-SP1
- matriptase including MT-SP1
- MT-SP1 is highly associated with cancer tissues, and the peptide sequence that can be cleaved by matriptase (including MT-SP1) is higher than that in normal tissues. More disconnected in the tissue. Since the sequences of human MT-SP1 and mouse MT-SP1 are quite similar, the enzyme activity for the same substrate seems to be similar.
- the type and concentration of protease used for evaluation, treatment temperature and treatment time can be appropriately selected.
- PBS containing 1000 nM human uPA, PBS containing 1000 nM mouse uPA, and 500 nM Using PBS containing human MT-SP1 or PBS containing 500 nM mouse MT-SP1, treatment can be performed at 37 ° C for 1 hour.
- the peptide array is treated with serum (including human serum and mouse serum), and the cleavage rate is calculated as follows using the fluorescence value measured from the chip.
- serum including human serum and mouse serum
- the type and concentration of serum used for evaluation, the treatment temperature, and the treatment time can be appropriately selected.
- human serum diluted to 80% concentration is used as the treatment solution, and the temperature is 37 ° C. overnight. Processing can be performed.
- "not cleaved by serum” means that the cleavage rate by serum measured and calculated by the above method is 1.5 or less, or that the above method is compared with the peptide shown in SEQ ID NO: 4. It can be pointed out that the cleavage rate by serum measured and calculated in is low.
- a solution containing the polypeptide containing the protease cleavage sequence was subjected to SDS-PAGE (polyacrylamide gel electrophoresis). It can be confirmed by measuring the molecular weight of the fragment. It can also be confirmed by comparing the molecular weights of the protease-untreated polypeptide and the protease-treated polypeptide.
- the term “cleaved” refers to a state in which a polypeptide is disrupted after modification of a protease cleavage sequence by a protease and / or reduction of a cysteine-cysteine disulfide bond in the protease cleavage sequence.
- the term “uncleaved” refers to a protease in a polypeptide in the absence of cleavage of a protease cleavage sequence by a protease and / or reduction of a cysteine-cysteine disulfide bond in a protease cleavage sequence. A state in which the parts on both sides of the cut array are connected.
- an antibody variant into which a protease cleavage sequence has been introduced can be used as a recombinant human u-Plasminogen Activator / Urokinase (human uPA, huPA) (R & D Systems; 1310-SE-010) or a recombinant human Matriptase / ST14 Catalyst Domain (human MT-SP1, hMT).
- -SP1 R & D Systems; 3946-SE-010
- -SP1 is used to evaluate the cleavage rate under the conditions of huPA 40 nM or hMT-SP1 3 nM, antibody variant 100 ⁇ g / mL, PBS, 37 ° C for 1 hour.
- capillary electrophoresis immunoassay After the reaction, it is subjected to a capillary electrophoresis immunoassay.
- Wes Protein Simple
- Wes can be used for the capillary electrophoresis immunoassay, but the method is not limited to this, and as an alternative method to the capillary electrophoresis immunoassay, it may be detected by the Western Blotting method after separation by SDS-PAGE or the like. It is not limited to the method of.
- An anti-human lambda chain HRP-labeled antibody (abcam; ab9007) can be used to detect the light chain before and after cleavage, but any antibody that can detect the cleaved fragment can be used.
- the cleavage rate (%) of the antibody variant can be calculated (cleaved light chain peak area) * 100. It can be calculated by the formula / (cut light chain peak area + uncut light chain peak area).
- the cleavage rate can be calculated if the protein fragment before and after the protease treatment can be detected, and the cleavage rate of the molecule into which the protease cleavage sequence is introduced can be calculated not only for the antibody variant but also for various proteins.
- the cleavage rate in vivo can be calculated by detecting the administered molecule in a blood sample.
- a blood sample For example, after administering an antibody variant into which a protease cleavage sequence has been introduced to mice, plasma is collected from a blood sample, and the antibody is purified by a method known to those skilled in the art using Dynabeads Protein A (Thermo; 10001D), and is used for capillary electrophoresis immunoassay. By providing this, it is possible to evaluate the protease cleavage rate of the antibody variant.
- Dynabeads Protein A Thermo; 10001D
- Wes can be used for the capillary electrophoresis immunoassay, but the method is not limited to this, and as an alternative method to the capillary electrophoresis immunoassay, it may be detected by the Western Blotting method after separation by SDS-PAGE or the like. It is not limited to the method of.
- An anti-human lambda chain HRP-labeled antibody (abcam; ab9007) can be used to detect the light chain of the antibody variant recovered from the mouse, but any antibody that can detect the cleaved fragment can be used.
- the area of each peak obtained by the capillary electrophoresis immunoassay is output by Wes-dedicated software (Compass for SW; Protein Simple), and the light chain residual ratio (light chain peak area) / (heavy chain peak area) is calculated. Therefore, it is possible to calculate the ratio of the full-length light chain that remains uncut in the mouse body. It is possible to calculate the cleavage efficiency in the living body if the protein fragment recovered from the living body can be detected, and the cleavage rate of the molecule into which the protease cleavage sequence is introduced can be calculated not only in the antibody variant but also in various proteins. Is.
- cleavage rate By calculating the cleavage rate using the method described above, for example, it is possible to compare the cleavage rates of antibody variants into which different cleavage sequences have been introduced in vivo, and to determine the cleavage rates of the same antibody variants. It is also possible to compare between different animal models such as normal mouse models and tumor transplanted mouse models.
- protease substrate refers to a peptide or polypeptide having an amino acid sequence that is hydrolyzed by the action of a protease.
- the protease substrate is a peptide of amino acids about 5-15 in length.
- the protease substrates of the present disclosure are approximately 0.001-1500 ⁇ 10 4 M -1 S -1 or at least 0.001, 0.005, 0.01, 0.05, 0.1, 0.5.
- the protease substrates of the present disclosure have a higher rate of cleavage by a protease than a protease substrate containing any one of SEQ ID NOs: 1, 2, or 3. In certain embodiments, the protease substrates of the present disclosure have a higher cleavage rate by human uPA than a protease substrate containing any one of SEQ ID NOs: 1, 2, or 3. In certain embodiments, the cleavage rates of the protease substrates of the present disclosure by human uPA are 1.5 or higher, 1.6 or higher, 1.8 or higher, 2 or higher, 2.2 or higher, 2.4 or higher, 2.6 or higher.
- the protease substrates of the present disclosure have a higher cleavage rate by human MT-SP1 than a protease substrate containing any one of SEQ ID NOs: 1, 2, or 3.
- the cleavage rates of the protease substrates of the present disclosure by human MT-SP1 are 1.5 or higher, 1.6 or higher, 1.8 or higher, 2 or higher, 2.2 or higher, 2.4 or higher, 2.
- the protease substrates of the present disclosure have a higher cleavage rate by mouse uPA than a protease substrate containing any one of SEQ ID NOs: 1, 2, or 3.
- the cleavage rates of the protease substrates of the present disclosure by mouse uPA are 1 or higher, 1.1 or higher, 1.2 or higher, 1.3 or higher, 1.4 or higher, 1.5 or higher, 1.6 or higher.
- the protease substrates of the present disclosure have a higher cleavage rate by mouse MT-SP1 than a protease substrate containing any one of SEQ ID NOs: 1, 2, or 3.
- the cleavage rates of the protease substrates of the present disclosure by mouse MT-SP1 are 1.5 or higher, 1.6 or higher, 1.8 or higher, 2 or higher, 2.2 or higher, 2.4 or higher, 2.
- the protease substrates of the present disclosure have a higher ratio of cleavage rate by human uPA to cleavage rate by human serum than a protease substrate containing any one of SEQ ID NOs: 1, 2, and 3.
- the ratio of the cleavage rate of the protease substrate of the present disclosure by human uPA to the cleavage rate by human serum is 0.9 or higher, 0.95 or higher, 1 or higher, 1.2 or higher, 1.4 or higher, 1 6.6 or more, 1.8 or more, 2 or more, 2.2 or more, 2.4 or more, 2.6 or more, 2.8 or more, 3 or more, 3.2 or more, 3.4 or more, 3.6 or more, 3.8 or more, or 4 or more.
- the cleavage rate by human serum is 1 or less, it can be converted to 1 and used for calculation of the ratio of the cleavage rate by human uPA to the cleavage rate by human serum.
- the protease substrates of the present disclosure have a higher ratio of cleavage rate by human MT-SP1 to cleavage rate by human serum than a protease substrate containing any one of SEQ ID NOs: 1, 2, and 3. ..
- the ratio of cleavage rate of the protease substrate of the present disclosure by human MT-SP1 to cleavage rate by human serum is 0.7 or greater, 0.8 or greater, 0.9 or greater, 0.95 or greater, 1 or greater. , 1.2 or more, 1.4 or more, 1.6 or more, 1.8 or more, 2 or more, 2.2 or more, 2.4 or more, 2.5 or more, or 2.6 or more.
- the protease substrates of the present disclosure have a higher ratio of cleavage rate by mouse uPA to cleavage rate by human serum than a protease substrate containing any one of SEQ ID NOs: 1, 2, and 3.
- the ratio of cleavage rate of the protease substrate of the present disclosure by mouse uPA to cleavage rate by human serum is 0.6 or greater, 0.7 or greater, 0.8 or greater, 0.9 or greater, 0.95 or greater.
- the protease substrates of the present disclosure have a higher ratio of cleavage rate by mouse MT-SP1 to cleavage rate by human serum than a protease substrate containing any one of SEQ ID NOs: 1, 2, and 3. ..
- the ratio of cleavage rate of the protease substrate of the present disclosure by mouse MT-SP1 to cleavage rate by human serum is 0.7 or greater, 0.8 or greater, 0.9 or greater, 0.95 or greater, 1 or greater. , 1.2 or more, 1.4 or more, 1.6 or more, 1.8 or more, 2 or more, 2.2 or more, 2.4 or more, 2.5 or more, or 2.6 or more.
- the cleavage rate by human serum is 1 or less, it can be converted to 1 and then used to calculate the ratio of the cleavage rate by mouse MT-SP1 to the cleavage rate by human serum.
- the protease substrates of the present disclosure are not cleaved by human serum.
- the cleavage rate of the protease substrate of the present disclosure by human serum is 1.5 or less.
- the cleavage rate of the protease substrate of the present disclosure by human serum is lower than the cleavage rate of the peptide shown in SEQ ID NO: 4 by human serum.
- sequence from the 4th amino acid to the 15th amino acid at the N-terminal of the sequence selected from SEQ ID NO: 5 to 17201 and the 4th N-terminal of the sequence selected from SEQ ID NO: 5 to 17201.
- a peptide represented by a sequence composed of the N-terminal in the order of "sequence selected from the following group A-sequence selected from the following group B" is also hydrolyzed by the action of protease.
- SEQ ID NO: Sequence from the 1st amino acid to the 9th amino acid at the N-terminal of the sequence selected from 5 to 17201
- SEQ ID NO: Sequence from the 5th amino acid to the 9th amino acid at the N-terminal of the sequence selected from 5 to 17201
- SEQ ID NO: Sequence from the 5th amino acid to the 9th amino acid at the N-terminal of the sequence selected from 5 to 17201
- SEQ ID NO: Sequence from the 6th amino acid to the 9th amino acid at the N-terminal of the sequence selected from 5 to 17201
- the protease substrate of the present disclosure can be utilized as a library for selecting a substrate having properties according to a purpose, for example, when incorporating it into a polypeptide.
- the protease sensitivity can be evaluated in order to selectively cleave the polypeptide by a protease localized in the lesion. After being administered to a living body, a polypeptide may reach a lesion through contact with various proteases. Therefore, it is desirable to have sensitivity to proteases localized in the lesion while having resistance to other proteases as high as possible.
- Protease resistance can be known by comprehensively analyzing the susceptibility of each protease substrate to various proteases in advance in order to select a desirable protease substrate according to the purpose.
- protease substrate with the required sensitivity and resistance can be found.
- the polypeptide incorporating the protease substrate reaches the lesion not only through the enzymatic action of the protease but also through various environmental loads such as pH change, temperature, and redox stress. Even with respect to such external factors, it is possible to select a protease substrate having desirable properties according to the purpose based on the information comparing the resistance of each protease substrate.
- protease cleavage sequence is a specific amino acid sequence that is specifically recognized by a protease when the polypeptide is hydrolyzed by the protease in aqueous solution.
- a protease cleavage sequence may be referred to as a peptide sequence that can be cleaved by a protease.
- protease cleavage sequences of the present disclosure are approximately 0.001-1500 ⁇ 10 4 M -1 S -1 or at least 0.001, 0.005, 0.01, 0.05, 0.1, 0. 5, 1, 2.5, 5, 7.5, 10, 15, 20, 25, 50, 75, 100, 125, 150, 200, 250, 500, 750, 1000, 1250, or 1500 x 10 4 M It can be specifically modified (cut) at a rate of -1 S -1 .
- sequence from the N-terminal 4th amino acid to the 15th amino acid of the sequence selected from SEQ ID NO: 5 to 17201 and the N-terminal 4th to 13th amino acid of the sequence selected from SEQ ID NO: 5 to 17201.
- the present disclosure also relates to the use of these sequences as protease cleavage sequences.
- any of the sequences composed in the order of "sequence selected from the following group A-sequence selected from the following group B" from the N-terminal is useful as a protease cleavage sequence.
- SEQ ID NO: Sequence from the 1st amino acid to the 9th amino acid at the N-terminal of the sequence selected from 5 to 17201
- SEQ ID NO: Sequence from the 4th amino acid to the 9th amino acid at the N-terminal of the sequence selected from 5 to 17201
- SEQ ID NO: Sequence from the 5th amino acid to the 9th amino acid at the N-terminal of the sequence selected from 5 to 17201
- SEQ ID NO: Sequence from the 5th amino acid to the 9th amino acid at the N-terminal of the sequence selected from 5 to 17201
- SEQ ID NO: Sequence from the 6th amino acid to the 9th amino acid at the N-terminal of the sequence selected from 5 to 17201
- the protease cleavage sequence is ligated to or otherwise attached to the antibody.
- a protease cleavage sequence is one or more to an antibody that binds to a given target such that when exposed to a protease, ie matliptase and / or uPA, the protease cleavage sequence is cleaved and the agent is released from the antibody. Used to link multiple agents.
- the protease cleavage sequences of the present disclosure have a higher rate of cleavage by a protease than a protease substrate comprising any one of SEQ ID NOs: 1, 2, or 3. In certain embodiments, the protease cleavage sequences of the present disclosure have a higher cleavage rate by human uPA than a protease substrate comprising any one of SEQ ID NOs: 1, 2, and 3. In certain embodiments, the cleavage rate of the protease cleavage sequences of the present disclosure by human uPA is 1.5 or higher, 1.6 or higher, 1.8 or higher, 2 or higher, 2.2 or higher, 2.4 or higher, 2.6 or higher.
- the protease cleavage sequences of the present disclosure have a higher cleavage rate by human MT-SP1 than a protease substrate containing any one of SEQ ID NOs: 1, 2, and 3.
- the cleavage rate of the protease cleavage sequences of the present disclosure by human MT-SP1 is 1.5 or greater, 1.6 or higher, 1.8 or higher, 2 or higher, 2.2 or higher, 2.4 or higher, 2 6.6 or more, 2.8 or more, 3 or more, 3.2 or more, 3.4 or more, 3.6 or more, 3.8 or more, 3.9 or more, or 4 or more.
- the protease cleavage sequences of the present disclosure have a higher cleavage rate by mouse uPA than a protease substrate comprising any one of SEQ ID NOs: 1, 2, and 3.
- the cleavage rates of the protease cleavage sequences of the present disclosure by mouse uPA are such that, in some embodiments, the cleavage rates of the protease substrates of the present disclosure by mouse uPA are 1 or greater, 1.1 or greater, 1.2 or greater. 1.3 or more, 1.4 or more, 1.5 or more, 1.6 or more, 1.7 or more, 1.8 or more, 1.9 or more, 2 or more, 2.5 or more, 3 or more, 3.5 or more , Or 4 or more.
- the protease cleavage sequences of the present disclosure have a higher cleavage rate by mouse MT-SP1 than a protease substrate containing any one of SEQ ID NOs: 1, 2, and 3.
- the cleavage rate of the protease cleavage sequences of the present disclosure by mouse MT-SP1 is 1.5 or higher, 1.6 or higher, 1.8 or higher, 2 or higher, 2.2 or higher, 2.4 or higher, 2 6.6 or more, 2.8 or more, 3 or more, 3.2 or more, 3.4 or more, 3.6 or more, 3.8 or more, 3.9 or more, or 4 or more.
- the protease cleavage sequences of the present disclosure have a higher ratio of cleavage rate by human uPA to cleavage rate by human serum than a protease substrate containing any one of SEQ ID NOs: 1, 2, and 3.
- the ratio of cleavage rate by human uPA to cleavage rate by human serum of the protease cleavage sequences of the present disclosure is 0.9 or greater, 0.95 or greater, 1 or greater, 1.2 or greater, 1.4 or greater.
- the protease cleavage sequences of the present disclosure have a ratio of cleavage rate by human MT-SP1 to cleavage rate by human serum as compared to a protease substrate containing any one of SEQ ID NOs: 1, 2, and 3. high.
- the ratio of cleavage rate by human MT-SP1 to cleavage rate by human serum of the protease cleavage sequences of the present disclosure is 0.7 or greater, 0.8 or greater, 0.9 or greater, 0.95 or greater, 1 1.2 or more, 1.4 or more, 1.6 or more, 1.8 or more, 2 or more, 2.2 or more, 2.4 or more, 2.5 or more, or 2.6 or more.
- the cleavage rate by human serum is 1 or less, it can be converted to 1 and then used for calculating the ratio of the cleavage rate by human MT-SP1 to the cleavage rate by human serum.
- the protease cleavage sequences of the present disclosure have a higher ratio of cleavage rate by mouse uPA to cleavage rate by human serum than a protease substrate containing any one of SEQ ID NOs: 1, 2, and 3.
- the ratio of cleavage rate by mouse uPA to cleavage rate by human serum of the protease cleavage sequences of the present disclosure is 0.6 or greater, 0.7 or greater, 0.8 or greater, 0.9 or greater, 0.95. 1 or more, 1.1 or more, 1.2 or more, 1.3 or more, 1.4 or more, 1.5 or more, 1.6 or more, 1.7 or more, 1.8 or more, 1.9 or more, Or 2 or more.
- the protease cleavage sequences of the present disclosure have a ratio of cleavage rate by mouse MT-SP1 to cleavage rate by human serum as compared to a protease substrate containing any one of SEQ ID NOs: 1, 2, and 3. high.
- the ratio of cleavage rate by mouse MT-SP1 to cleavage rate by human serum of the protease cleavage sequences of the present disclosure is 0.7 or greater, 0.8 or greater, 0.9 or greater, 0.95 or greater, 1 1.2 or more, 1.4 or more, 1.6 or more, 1.8 or more, 2 or more, 2.2 or more, 2.4 or more, 2.5 or more, or 2.6 or more.
- the cleavage rate by human serum is 1 or less, it can be converted to 1 and then used to calculate the ratio of the cleavage rate by mouse MT-SP1 to the cleavage rate by human serum.
- the protease cleavage compounds of the present disclosure are not cleaved by human serum.
- the cleavage rate of the protease cleavage sequence of the present disclosure by human serum is 1.5 or less.
- the cleavage rate of the protease substrate of the present disclosure by human serum is lower than the cleavage rate of the peptide shown in SEQ ID NO: 4 by human serum.
- the protease cleavage sequence of the present disclosure can be utilized as a library for selecting a sequence having properties according to a purpose, for example, when incorporating into a polypeptide.
- the protease sensitivity can be evaluated in order to selectively cleave the polypeptide by a protease localized in the lesion. After being administered to a living body, a polypeptide may reach a lesion through contact with various proteases. Therefore, it is desirable to have sensitivity to proteases localized in the lesion while having resistance to other proteases as high as possible.
- Protease resistance can be known by comprehensively analyzing the susceptibility of each protease cleavage sequence to various proteases in advance in order to select a desirable protease cleavage sequence according to the purpose. Based on the obtained protease resistance spectrum, a protease cleavage sequence having the required sensitivity and resistance can be found. Alternatively, the polypeptide incorporating the protease cleavage sequence reaches the lesion not only through enzymatic action by the protease but also through various environmental loads such as pH change, temperature, and redox stress. Even for such external factors, a protease cleavage sequence having desirable properties according to the purpose can be selected based on the information comparing the resistance of each protease cleavage sequence.
- the protease cleavage sequence is at least cleaved by matliptase. In some embodiments, the protease cleavage sequence is cleaved by at least MT-SP1. In some embodiments, the protease cleavage sequence is at least cleaved by uPA. In some embodiments, the protease cleavage sequence is cleaved by at least matliptase and uPA. In some embodiments, the protease cleavage sequence is cleaved by at least MT-SP1 and uPA.
- the protease cleavage sequence is a substrate for matriptase and / or uPA, at least already resistant to cleavage by other proteases. In some embodiments, the protease cleavage sequence is a substrate for matliptase and / or uPA and is at least a substrate resistant to cleavage by plasmin. In some embodiments, the protease cleavage sequence is a substrate for matliptase and / or uPA and is at least a substrate resistant to cleavage by tissue plasminogen activator (tPA). In some embodiments, the protease cleavage sequence is a substrate for matliptase and / or uPA and is at least a substrate resistant to cleavage by human serum.
- tPA tissue plasminogen activator
- a cell-free translation system (Clover Direct (Protein Express)) containing a tRNA in which an unnatural amino acid is bound to a complementary amber suppressor tRNA of a UAG codon (amber codon), which is one of the stop codons, is also preferable. Used.
- the meaning of the terms “and / or” used to describe the site of modification of an amino acid includes any combination of “and” and “or” as appropriate.
- “the amino acids 37, 45, and / or 47 have been replaced” includes the following variations of amino acid modifications; (a) 37th, (b) 45th, (c) 47th, (d) 37th and 45th, (e) 37th and 47th, (f) 45th and 47th, (g) 37th And 45 and 47.
- an expression indicating the modification of an amino acid an expression in which the one-character code or the three-character code of the amino acid before and after the modification is written before and after the number indicating a specific position can be appropriately used.
- the modification F37V or Phe37Val used when substituting the amino acid contained in the antibody variable region represents the substitution of Phe at position 37 with Val, which is represented by Kabat numbering. That is, the number represents the position of the amino acid represented by Kabat numbering, the one-letter code or three-letter code of the amino acid described before it is the amino acid before replacement, and the one-letter code or 3 of the amino acid described after that.
- the character code represents the amino acid after replacement.
- the modification P238A or Pro238Ala used when substituting an amino acid for the Fc region contained in the antibody constant region represents the substitution of Pro at position 238 with Ala represented by EU numbering. That is, the number represents the position of the amino acid represented by the EU numbering, the one-letter code or three-letter code of the amino acid described before it is the amino acid before replacement, and the one-letter code or 3 of the amino acid described after it.
- the character code represents the amino acid after replacement.
- amino acid sequence A into amino acid sequence B means to divide amino acid sequence B into two parts without deleting it, and to connect the two parts with amino acid sequence A (that is, "the first half of amino acid sequence B-". Amino acid sequence A-Amino acid sequence B latter half "to create a new amino acid sequence).
- To "introduce” amino acid sequence A into amino acid sequence B means to divide amino acid sequence B into two parts and connect the two parts with amino acid sequence A, and to connect the amino acid sequence A into amino acid sequence B.
- one or more amino acid residues including the amino acid residue of amino acid sequence B adjacent to amino acid sequence A are deleted, and then the two parts are connected by amino acid sequence A ( That is, it is also possible to replace a part of the amino acid sequence B with the amino acid sequence A).
- the term “near the boundary between the A part and the B part” refers to the secondary structure of the A part and / or the B part before and after the site where the A part and the B part are connected in the polypeptide. The part that does not significantly affect.
- antibody is used herein in the broadest sense and is not limited to, but is not limited to, monoclonal antibodies, polyclonal antibodies, multispecificity, as long as they exhibit the desired antigen-binding activity. Includes a variety of antibody structures, including antibodies (eg, bispecific antibodies) and antibody fragments.
- Antibody fragment refers to a molecule other than the complete antibody, which contains a part of the complete antibody that binds to the antigen to which the complete antibody binds.
- Examples of antibody fragments are, but are not limited to, Fv, Fab, Fab', Fab'-SH, F (ab') 2, diabodies, linear antibodies, single chain antibody molecules (eg, scFv). , And multispecific antibodies formed from antibody fragments.
- full-length antibody “complete antibody,” and “whole antibody” are used interchangeably herein and have a structure substantially similar to that of a native antibody, or are defined herein.
- a protease cleavage sequence is contained in the antibody, but it can be expressed as an "antibody” regardless of whether or not the protease cleavage sequence is contained.
- variable region refers to the heavy or light chain domain of an antibody that is involved in binding the antibody to an antigen.
- the variable domains of the heavy and light chains of an antibody typically have similar structures, each domain containing four conserved framework regions (FRs) and three complementarity determining regions (CDRs). Have. (See, for example, Kindt et al. Kuby Immunology, 6th ed., WH Freeman and Co., page 91 (2007).)
- One VH or VL domain may be sufficient to confer antigen binding specificity.
- CDR complementarity determining regions
- CDRs are hypervariable in sequence and / or form structurally defined loops ("supervariable loops") and / or antigens.
- Contact residues (“antigen contacts”), variable domain or monodomain antibody regions of an antibody.
- the antibody contains 6 CDRs: 3 for VH (H1, H2, H3) and 3 for VL (L1, L2, L3).
- the exemplary antibody CDRs herein include: (a) At amino acid residues 26-32 (L1), 50-52 (L2), 91-96 (L3), 26-32 (H1), 53-55 (H2), and 96-101 (H3).
- the resulting hypervariable loop (Chothia and Lesk, J.
- Single domain antibodies usually contain three CDRs: CDR1, CDR2, CDR3.
- the CDRs of the monodomain antibody typically include: (a) Hypervariable loops occurring at amino acid residues 26-32 (CDR1), 53-55 (CDR2), and 96-101 (CDR3) (Chothia and Lesk, J. Mol. Biol. 196: 901-917 ( 1987)); (b) CDRs (Kabat et al., Sequences of Proteins of Immunological Interest, 5th Ed. Public Health Service) occurring at amino acid residues 31-35b (CDR1), 50-65 (CDR2), and 95-102 (CDR3).
- the CDRs of the monodomain antibody typically include: (a) Hypervariable loops occurring at amino acid residues 26-32 (CDR1), 50-52 (CDR2), and 91-96 (CDR3) (Chothia and Lesk, J. Mol. Biol. 196: 901-917 ( 1987)); (b) CDRs (Kabat et al., Sequences of Proteins of Immunological Interest, 5th Ed. Public Health Service) occurring at amino acid residues 24-34 (CDR1), 50-56 (CDR2), and 89-97 (CDR3).
- CDR residues and other residues in the variable domain are numbered herein according to Kabat et al., Supra.
- FR “Framework” or “FR” refers to variable domain residues or monodomain antibody residues other than complementarity determining region (CDR) residues.
- the FR of a variable domain or monodomain antibody usually consists of four FR domains: FR1, FR2, FR3, and FR4.
- the CDR and FR sequences usually appear in VH (or VL) in the following order: FR1-H1 (L1) -FR2-H2 (L2) -FR3-H3 (L3) -FR4.
- the CDR and FR sequences usually appear in the following order: FR1-CDR1-FR2-CDR2-FR3-CDR3-FR4.
- the "human consensus framework” is a framework that shows the most commonly occurring amino acid residues in the selection group of human immunoglobulin VL or VH framework sequences.
- the selection of human immunoglobulin VL or VH sequences is from a subgroup of variable domain sequences.
- the subgroups of the array are the subgroups in Kabat et al., Sequences of Proteins of Immunological Interest, Fifth Edition, NIH Publication 91-3242, Bethesda MD (1991), vols. 1-3.
- the subgroup is the subgroup ⁇ I by Kabat et al. Above.
- the subgroup is Subgroup III by Kabat et al. Above.
- Constant Region refers to a portion of an antibody other than the variable region.
- an IgG antibody is a heterotetraglycoprotein of approximately 150,000 daltons composed of two identical disulfide-bonded light chains and two identical heavy chains, from the N-terminus to the C-terminus.
- Each heavy chain has a variable region (VH), also called a variable heavy chain domain or a heavy chain variable domain, followed by a heavy chain constant region (CH) containing the CH1 domain, hinge region, CH2 domain, and CH3 domain.
- VH variable region
- CH heavy chain constant region
- each light chain has a variable region (VL), also called the variable light chain domain or light chain variable domain, followed by the constant light chain (CL) domain.
- VL variable region
- CL constant light chain
- the light chain of a native antibody may be attributed to one of two types, called kappa ( ⁇ ) and lambda ( ⁇ ), based on the amino acid sequence of its constant domain.
- ⁇ kappa
- ⁇ lambda
- the term "contains a constant region” may include the entire constant region or a portion of the constant region.
- the numbering of amino acid residues in the antibody variable region and the antibody light chain heavy chain constant region is referred to as Kabat et al., Sequences of Proteins of Immunological Interest, 5th Ed. Public Health Service, National. follow the Kabat numbering system described in Institutes of Health, Bethesda, MD 1991.
- the "class" of an antibody refers to the type of constant domain or constant region provided in the heavy chain of an antibody.
- Heavy chain constant domains corresponding to different classes of immunoglobulins are referred to as ⁇ , ⁇ , ⁇ , ⁇ , and ⁇ , respectively.
- Fc region is used herein to define the C-terminal region of an immunoglobulin heavy chain that contains at least a portion of the constant region.
- the term includes the Fc region of a native sequence and the mutant Fc region.
- the heavy chain Fc region extends from Cys226 or from Pro230 to the carboxyl end of the heavy chain.
- the C-terminal lysine (Lys447) or glycine-lysine (Gly446-Lys447) in the Fc region may or may not be present.
- the numbering of amino acid residues in the Fc region or antibody heavy chain constant region is Kabat et al., Sequences of Proteins of Immunological Interest, 5th Ed. Public Health Service, National Institutes of Health. , Bethesda, MD 1991, according to the EU numbering system (also known as the EU index).
- Hinge Region or “antibody hinge region” can refer to a region of the antibody heavy chain consisting of the 216th to 230th amino acids of EU numbering, or a portion thereof.
- Monodomain antibody is an antibody capable of exerting antigen-binding activity in its domain alone.
- the structure of a monodomain antibody is not limited as long as the domain alone can exert antigen-binding activity.
- Normal antibodies such as IgG antibodies show antigen-binding activity when a variable region is formed by pairing VH and VL, whereas monodomain antibodies do not pair with other domains. It is known that the domain structure of the monodomain antibody itself can exert antigen-binding activity alone.
- Monodomain antibodies usually have a relatively low molecular weight and are present in monomeric form. In some embodiments, the morphology of the monodomain antibody is similar to the antibody heavy chain variable region or antibody light chain variable region.
- single domain antibodies but not limited to, for example, a variable region (VHH) of the camelid heavy chain antibodies, such as shark V NAR, antigen binding molecule lacking congenitally light chain or antibody
- VHH variable region
- Examples of monodomain antibodies that are antibody fragments that include all or part of the VH / VL domain of an antibody are, but are not limited to, human antibodies VH or human antibodies as described in, for example, US Pat. No. 6,248,516 B1. Examples thereof include monodomain antibodies (hereinafter, monodomain VH antibodies and monodomain VL antibodies) artificially produced starting from VL.
- the monodomain antibody can be obtained from an animal capable of producing a monodomain antibody or by immunizing an animal capable of producing a monodomain antibody.
- animals capable of producing a monodomain antibody include, but are not limited to, camelids and transgenic animals into which a gene capable of producing a monodomain antibody has been introduced.
- Camelids include camels, llamas, alpaca, dromedaries and guanaco.
- transgenic animals into which a gene capable of producing a monodomain antibody has been introduced include, but are not limited to, the transgenic animals described in WO2015 / 143414 and US Patent Publication US2011 / 0123527 A1.
- a humanized monodomain antibody can also be obtained by setting the framework sequence of the monodomain antibody obtained from an animal to a human germline sequence or a sequence similar thereto.
- a humanized single domain antibody eg, humanized VHH is also an aspect of the single domain antibody herein.
- the monodomain antibody can be obtained from a polypeptide library containing the monodomain antibody by ELISA, panning, or the like.
- polypeptide libraries containing monodomain antibodies include, but are not limited to, naive antibody libraries obtained from various animals or humans (eg Methods in Molecular Biology 2012 911 (65-78), Biochimica et Biophysica Acta-Proteins. and Proteomics 2006 1764: 8 (1307-1319)), antibody libraries obtained by immunizing various animals (eg Journal of Applied Microbiology 2014 117: 2 (528-536)), or antibody genes of various animals or humans. Synthetic antibody libraries created from (Example: Journal of Biological Screening 2016 21: 1 (35-43), Journal of Biological Chemistry 2016 291: 24 (12641-12657), AIDS 2016 30:11 (1691-1701)) Be done.
- a protease cleavage sequence is contained in the monodomain antibody, but it can be expressed as a "monodomain antibody" regardless of whether or not the protease cleavage sequence is contained.
- Monodomain antibodies herein are generally expressed in some forms.
- Amino acid sequence consisting of 4 framework regions / sequences with 3 complementarity determination regions / sequences inserted in between (Amino acid residue at position 11 by Kabat numbering consists of L, M, S, V, W) (Preferably L) selected from) and / or
- Amino acid sequence consisting of four framework regions / sequences with three complement determination regions / sequences inserted in between (amino acid at position 37 by Kabat numbering).
- Residues are selected from the group consisting of F, Y, H, I, L, V, preferably F or Y), and / or c) three complementarity determination regions / sequences inserted in between.
- Amino acid sequence consisting of 4 framework regions / sequences (Amino acid residue at position 44 according to Kabat numbering is selected from the group consisting of G, E, A, D, Q, R, S, L, preferably G, E Or Q, more preferably G or E), and / or d) Amino acid sequence consisting of four framework regions / sequences with three complement determination regions / sequences inserted in between (45 by Kabat numbering).
- the amino acid residue at the position is selected from the group consisting of L, R, C, I, L, P, Q, V, preferably L or R), and / or e) three complementarity determining regions / Amino acid sequence consisting of 4 framework regions / sequences with a sequence inserted between them (Amino acid residue at position 47 according to Kabat numbering is W, L, F, A, G, I, M, R, S, V, Y Selected from the group consisting of (preferably W, L, F or R), and / or f) Amino acids consisting of four framework regions / sequences with three complementarizing regions / sequences inserted in between.
- amino acid residue at position 83 is selected from the group consisting of R, K, N, E, G, I, M, Q, T, preferably K or R, more preferably K.
- Amino acid sequence consisting of 4 framework regions / sequences with 3 complementar determination regions / sequences inserted in between is P, A, L, Selected from the group consisting of R, S, T, D, V, preferably P), and / or h) 4 framework regions / sequences with three complementarity determination regions / sequences inserted in between.
- Amino acid sequence consisting of (the amino acid residue at position 103 according to Kabat numbering is selected from the group consisting of W, P, R, S, which is W), and / or i).
- An amino acid sequence consisting of four framework regions / sequences interspersed with three complementarity determining regions / sequences (the amino acid residue at position 104 by Kabat numbering is G or D, preferably G), and / Or j)
- Amino acid sequence consisting of 4 framework regions / sequences with 3 complementarity determining regions / sequences inserted (Amino acid residue at position 108 by Kabat numbering is selected from the group consisting of Q, L, R) , Preferably Q or L), can be defined as a polypeptide.
- monodomain antibodies include any one of the amino acid sequences consisting of four framework regions / sequences with the following three complementarity determining regions / sequences inserted in between.
- Chimeric antibody is one in which a portion of the heavy and / or light chain is derived from a particular source or species, while the rest of the heavy and / or light chain is from a different source or species. Derived antibody. "Chimeric monodomain antibody” refers to a monodomain antibody in which part of the monodomain antibody is derived from a particular source or species, while the rest of the monodomain antibody is derived from a different source or species. ..
- Humanized Antibodies A "humanized” antibody is a chimeric antibody that comprises an amino acid residue from a non-human CDR and an amino acid residue from a human FR.
- the humanized antibody comprises substantially all of at least one, typically two, variable domains, in which all or substantially all CDRs are those of a non-human antibody. And all or virtually all FRs correspond to those of human antibodies.
- “Humanized monodomain antibody” refers to a chimeric monodomain antibody that comprises an amino acid residue from a non-human CDR and an amino acid residue from a human FR.
- a humanized monodomain antibody corresponds to all or substantially all CDRs of a non-human antibody, and all or substantially all FRs correspond to those of a human antibody.
- substantially all FRs are considered as an example corresponding to those of the human antibody.
- the humanized antibody may optionally include at least a portion of the antibody constant region derived from the human antibody.
- the "humanized form" of an antibody eg, a non-human antibody refers to an antibody that has undergone humanization.
- association can be rephrased as referring to, for example, a state in which two or more polypeptide regions interact with each other.
- hydrophobic bonds, hydrogen bonds, ionic bonds and the like are formed between the target polypeptide regions to form aggregates.
- VH heavy chain variable region
- VL light chain variable region
- Dissolution of the association can be rephrased as, for example, the dissolution of all or part of the interaction state of two or more polypeptide regions.
- the cancellation of the VH-VL association may mean that the VH-VL interaction may be completely eliminated or a part of the VH-VL interaction may be eliminated.
- FcRn binding region refers to a region having binding to FcRn, and any structure can be used as long as it has binding to FcRn. Molecules containing the FcRn binding region can be taken up into cells by the FcRn salvage pathway and then returned to plasma. For example, the plasma retention of IgG molecules is relatively long (slow disappearance) because FcRn, which is known as a salvage receptor for IgG molecules, is functioning. IgG molecules incorporated into endosomes by pinocytosis bind to FcRn expressed in endosomes under acidic conditions within endosomes.
- the FcRn binding region is preferably a region that directly binds to FcRn.
- a preferred example of the FcRn binding region is the Fc region of an antibody.
- the FcRn-binding region in the present disclosure May be a region that binds to a polypeptide capable of binding to such FcRn.
- the binding activity of the FcRn binding region in the present disclosure to FcRn, particularly human FcRn, can be measured by a method known to those skilled in the art as described in the section on binding activity, and the conditions can be measured by those skilled in the art. Can be determined as appropriate.
- the binding activity to human FcRn is KD (Dissociation constant: dissociation constant), apparent KD (Apparent dissociation constant: apparent dissociation constant), dissociation rate kd (Dissociation rate), or apparent kd (Apparent). It can be evaluated as dissociation (apparent dissociation rate) and the like. These can be measured by methods known to those skilled in the art. For example, Biacore (GE healthcare), Scatchard plot, flow cytometer, etc. can be used.
- the conditions for measuring the FcRn-binding activity of the FcRn-binding region can be appropriately selected by those skilled in the art, and are not particularly limited. For example, it can be measured in MES buffer, 37 ° C. conditions as described in WO2009 / 125825.
- the binding activity of the FcRn binding region of the present disclosure to FcRn can be measured by a method known to those skilled in the art, and can be measured using, for example, Biacore (GE Healthcare).
- a molecule containing FcRn or FcRn binding region or FcRn binding region is flowed as an analyst to a transport portion containing FcRn binding region or FcRn binding region or a chip on which FcRn is immobilized. Can be evaluated by
- the binding affinity between the FcRn binding region and FcRn may be evaluated at any pH of pH 4.0 to pH 6.5.
- a pH of pH 5.8 to pH 6.0 which is close to the pH in the early endosomes in vivo, is used to determine the binding affinity between the FcRn binding region and human FcRn.
- the binding affinity between the FcRn binding region and FcRn may be evaluated at any temperature of 10 ° C to 50 ° C.
- a temperature of 15 ° C to 40 ° C is used to determine the binding affinity between the FcRn binding region and human FcRn.
- any temperature of is similarly used to determine the binding affinity between the FcRn binding region and FcRn.
- the temperature of 25 ° C. is a non-limiting example of aspects of the present disclosure.
- the FcRn binding region is, but is not limited to, the IgG antibody Fc region.
- the type is not limited, and it is possible to use an Fc region such as IgG1, IgG2, IgG3, or IgG4.
- a modified Fc region in which one or more amino acids are substituted can be used as long as it has FcRn binding property.
- EU numbering 237th, 238th, 239th, 248th, 250th, 252nd, 254th, 255th, 256th, 257th, 258th, 265th, 270th, 286th in the IgG antibody Fc region can be used as long as it has FcRn binding property.
- an amino acid substitution that replaces Gly at position 237 of the EU numbering in the IgG antibody Fc region with Met Amino acid substitution that replaces Pro at position 238 with Ala
- Amino acid substitution that replaces Ser at position 239 with Lys Amino acid substitution that replaces Lys at position 248 with Ile
- Amino acid substitution that replaces Thr 250 with Ala Phe, Ile, Met, Gln, Ser, Val, Trp, or Tyr
- Amino acid substitution that replaces Met at position 252 with Phe, Trp, or Tyr Amino acid substitution that replaces Ser at position 254 with Thr
- Amino acid substitution that replaces Arg at position 255 with Glu Amino acid substitution that replaces Thr 256 with Asp, Glu, or Gln
- Amino acid substitution that replaces the 257th Pro with Ala, Gly, Ile, Leu, Met, Asn, Ser, Thr, or Val Amino acid substitution that replaces the 257th Pro with Al
- Amino acid substitution that replaces the 308th Val with Ala, Phe, Ile, Leu, Met, Pro, Gln, or Thr Amino acid substitution that replaces Leu or Val at position 309 with Ala, Asp, Glu, Pro, or Arg
- Amino acid substitution that replaces the 311th Gln with Ala, His, or Ile Amino acid substitution that replaces the 312th Asp with Ala or His
- Amino acid substitution that replaces Leu at position 314 with Lys or Arg Amino acid substitution that replaces Asn at position 315 with Ala or His
- Amino acid substitution that replaces the 317th Lys with Ala Amino acid substitution that replaces Asn at position 325 with Gly
- Amino acid substitution that replaces Ile at position 332 with Val Amino acid substitution that replaces the 334th Lys with Leu
- Amino acid substitution that replaces the 360th Lys with His Amino acid substitution that replaces the 376th
- Amino acid substitution that replaces His at position 433 with Lys Modifications comprising at least one amino acid substitution selected from an amino acid substitution that replaces Asn at position 434 with Ala, Phe, His, Ser, Trp, or Tyr, and an amino acid substitution that replaces Tyr or Phe at position 436 with His. It is possible to use the Fc region.
- Affinity refers to the total intensity of non-covalent interactions between a molecule (eg, an antibody) binding site and a molecule's binding partner (eg, an antigen).
- binding affinity refers to a unique binding affinity that reflects a 1: 1 interaction between members of a binding pair (eg, antibody and antigen).
- the affinity of the molecule X for its partner Y can generally be expressed by the dissociation constant (Kd). Affinity can be measured by conventional methods known in the art, including those described herein. Specific examples and exemplary embodiments for measuring binding affinity are described below.
- monoclonal antibody refers to an antibody obtained from a substantially homogeneous population of antibodies. That is, the individual antibodies that make up the population are possible mutant antibodies (eg, mutant antibodies that contain naturally occurring mutations, or mutant antibodies that occur during the production of monoclonal antibody preparations, such variants are usually slightly present. Except for the amount present), it binds to the same and / or the same epitope.
- Each monoclonal antibody in a monoclonal antibody preparation is for a single determinant on an antigen, as opposed to a polyclonal antibody preparation that typically comprises different antibodies against different determinants (epitopes).
- the modifier "monoclonal” should not be construed as requiring the production of an antibody by any particular method, indicating the characteristic of the antibody that it is obtained from a substantially homogeneous population of antibodies.
- the monoclonal antibodies used in accordance with the present disclosure are, but are not limited to, hybridoma methods, recombinant DNA methods, phage display methods, transgenic animals containing all or part of the human immunoglobulin locus. It may be made by a variety of methods, including methods that utilize, such methods and other exemplary methods for making monoclonal antibodies are described herein.
- a method for producing an antibody having a desired binding activity is known to those skilled in the art.
- the method for producing an antibody that binds to IL-6R is exemplified below.
- Antibodies that bind to antigens other than IL-6R can also be appropriately prepared according to the following examples.
- the anti-IL-6R antibody can be obtained as a polyclonal or monoclonal antibody using known means.
- a monoclonal antibody derived from a mammal can be preferably produced.
- Monoclonal antibodies derived from mammals include those produced by hybridomas, those produced by host cells transformed with an expression vector containing an antibody gene by a genetic engineering technique, and the like.
- Antibodies referred to in the present application include "humanized antibodies" and "chimeric antibodies”.
- the monoclonal antibody-producing hybridoma can be produced, for example, as follows by using a known technique. That is, the IL-6R protein is used as a sensitizing antigen to immunize mammals according to conventional immunization methods. The resulting immune cells are fused with known parent cells by conventional cell fusion methods. Hybridomas that produce anti-IL-6R antibodies can then be selected by screening monoclonal antibody-producing cells by conventional screening methods.
- the production of the monoclonal antibody is carried out as shown below, for example.
- the IL-6R protein used as a sensitizing antigen for antibody acquisition can be obtained. That is, an appropriate host cell is transformed by inserting the gene sequence encoding IL-6R into a known expression vector.
- the desired human IL-6R protein is purified from the host cell or culture supernatant by a known method.
- the soluble IL-6R as described by Mullberg et al. (J. Immunol. (1994) 152 (10), 4958-4968) IL-6R is expressed.
- Purified natural IL-6R protein can also be used as a sensitizing antigen as well.
- the purified IL-6R protein can be used as a sensitizing antigen used for immunization against mammals. Partial peptides of IL-6R can also be used as sensitizing antigens. At this time, the partial peptide can also be obtained by chemical synthesis from the amino acid sequence of human IL-6R. It can also be obtained by incorporating a part of the IL-6R gene into an expression vector and expressing it. Furthermore, it can be obtained by degrading the IL-6R protein using a proteolytic enzyme, but the region and size of the IL-6R peptide used as a partial peptide are not particularly limited to special embodiments.
- the number of amino acids constituting the peptide to be the sensitizing antigen is preferably at least 5, for example, 6 or more, or 7 or more. More specifically, peptides of 8 to 50, preferably 10 to 30 residues can be used as sensitizing antigens.
- a desired partial polypeptide of IL-6R protein or a fusion protein obtained by fusing a peptide with a different polypeptide can be used as a sensitizing antigen.
- fusion proteins used as sensitizing antigens for example, Fc fragments of antibodies, peptide tags and the like can be preferably utilized.
- a vector expressing a fusion protein can be prepared by in-frame fusion of genes encoding two or more desired polypeptide fragments and inserting the fusion gene into the expression vector as described above. The method for producing the fusion protein is described in Molecular Cloning 2nd ed.
- the mammal immunized with the sensitizing antigen is not limited to a specific animal, but is preferably selected in consideration of compatibility with the parent cell used for cell fusion. Generally, rodent animals such as mice, rats, hamsters, rabbits, monkeys and the like are preferably used. When obtaining a monodomain antibody, a camelid or a transgenic animal into which a gene capable of producing a monodomain antibody has been introduced is preferably used.
- the above animals are immunized with the sensitizing antigen according to a known method.
- immunization is performed by administering the sensitizing antigen intraperitoneally or subcutaneously in a mammal.
- a sensitizing antigen diluted with PBS (Phosphate-Buffered Saline), physiological saline, or the like at an appropriate dilution ratio is optionally mixed with a usual adjuvant, for example, Freund's complete adjuvant, and emulsified.
- the sensitizing antigen is administered to the mammal several times every 4 to 21 days.
- suitable carriers may be used during immunization of the sensitizing antigen.
- a partial peptide having a small molecular weight when used as a sensitizing antigen, it may be desirable to immunize the sensitizing antigen peptide bound to a carrier protein such as albumin or keyhole limpet hemocyanin.
- a carrier protein such as albumin or keyhole limpet hemocyanin.
- Hybridomas that produce the desired antibody can also be made using DNA immunity as follows.
- DNA immunization means that a sensitized antigen is expressed in the living body of the immune animal to which the vector DNA constructed in such a manner that the gene encoding the antigen protein can be expressed in the immune animal is administered. It is an immune method in which an immune stimulus is given by being performed. Compared with the general immunization method in which a protein antigen is administered to an immunized animal, DNA immunization is expected to have the following advantages. -Immune stimulation can be given by maintaining the structure of membrane proteins such as IL-6R-No need to purify immune antigens
- DNA expressing the IL-6R protein is administered to an immunized animal.
- the DNA encoding IL-6R can be synthesized by known methods such as PCR.
- the obtained DNA is inserted into an appropriate expression vector and administered to an immune animal.
- a commercially available expression vector such as pcDNA3.1 can be preferably used.
- a method for administering the vector to a living body a commonly used method can be used.
- DNA immunization is performed by introducing gold particles adsorbed by an expression vector into the cells of an immune animal individual with a gene gun.
- the production of an antibody that recognizes IL-6R can also be produced by using the method described in WO 2003/104453.
- immune cells are collected from the mammal and subjected to cell fusion.
- splenocytes in particular can be used.
- Mammalian myeloma cells are used as cells fused with the immune cells.
- Myeloma cells preferably include a suitable selectable marker for screening.
- Selectable markers refer to traits that can (or cannot) survive under specific culture conditions.
- Known selectable markers include hypoxanthine-guanine-phosphoribosyl transferase deficiency (hereinafter abbreviated as HGPRT deficiency) or thymidine kinase deficiency (hereinafter abbreviated as TK deficiency).
- HGPRT deficiency hypoxanthine-guanine-phosphoribosyl transferase deficiency
- TK deficiency thymidine kinase deficiency
- Cells with HGPRT or TK deficiency have hypoxanthine-aminopterin-thymidine sensitivity (hereinafter abbreviated as HAT sensitivity).
- HAT-sensitive cells die because
- HGPRT-deficient and TK-deficient cells can be selected in a medium containing 6 thioguanine, 8 azaguanine (hereinafter abbreviated as 8AG), or 5'bromodeoxyuridine, respectively.
- 8AG 8 azaguanine
- 5'bromodeoxyuridine normal cells that incorporate these pyrimidine analogs into their DNA die.
- cells deficient in these enzymes that cannot uptake these pyrimidine analogs can survive in selective medium.
- G418 resistance confer resistance to 2-deoxystreptamine antibiotics (gentamicin analogs) by the neomycin resistance gene.
- gentamicin analogs gentamicin analogs
- myeloma cells suitable for cell fusion are known.
- Such myeloma cells include, for example, P3 (P3x63Ag8.653) (J.Immunol. (1979) 123 (4), 1548-1550), P3x63Ag8U.1 (Current Topics in Microbiology and Immunology (1978) 81,1- 7), NS-1 (C.Eur.J.Immunol. (1976) 6 (7), 511-519), MPC-11 (Cell (1976) 8 (3), 405-415), SP2 / 0 ( Nature (1978) 276 (5685), 269-270), FO (J. Immunol. Methods (1980) 35 (1-2), 1-21), S194 / 5.XX0.BU.1 (J. Exp. Med. (1978) 148 (1), 313-323), R210 (Nature (1979) 277 (5692), 131-133) and the like can be preferably used.
- P3 P3x63Ag8.653
- cell fusion of the immune cells and myeloma cells is performed according to a known method, for example, the method of Koehler and Milstain et al. (Methods Enzymol. (1981) 73, 3-46). More specifically, the cell fusion can be performed, for example, in the presence of a cell fusion promoter in a normal nutrient culture medium.
- a cell fusion promoter for example, polyethylene glycol (PEG), Sendai virus (HVJ) and the like are used, and an auxiliary agent such as dimethyl sulfoxide is optionally added and used in order to further increase the fusion efficiency.
- the usage ratio of immune cells and myeloma cells can be set arbitrarily. For example, it is preferable to increase the number of immune cells by 1 to 10 times that of myeloma cells.
- the culture medium used for the cell fusion for example, RPMI1640 culture medium suitable for the growth of the myeloma cell line, MEM culture medium, and other ordinary culture mediums used for this type of cell culture are used, and further, cattle. Serum supplements such as fetal bovine serum (FCS) can be suitably added.
- FCS fetal bovine serum
- a predetermined amount of the immune cells and myeloma cells are well mixed in the culture medium, and a PEG solution preheated to about 37 ° C. (for example, an average molecular weight of about 1000 to 6000) is usually 30 to 60%. It is added at a concentration of (w / v).
- the desired fusion cells are formed by gently mixing the mixed solution. Then, the appropriate culture solution mentioned above is sequentially added, and by repeating the operation of centrifuging and removing the supernatant, a cell fusion agent or the like that is unfavorable for the growth of hybridoma can be removed.
- the hybridoma thus obtained can be selected by culturing in a normal selective culture medium, for example, a HAT culture medium (a culture medium containing hypoxanthine, aminopterin and thymidine). Culture using the above HAT culture medium can be continued for a sufficient time (usually, such a sufficient time is several days to several weeks) for cells other than the desired hybridoma (non-fusion cells) to die.
- a HAT culture medium a culture medium containing hypoxanthine, aminopterin and thymidine.
- Culture using the above HAT culture medium can be continued for a sufficient time (usually, such a sufficient time is several days to several weeks) for cells other than the desired hybridoma (non-fusion cells) to die.
- the hybridomas that produce the desired antibody are then screened and single cloned by conventional limiting dilution methods.
- the hybridoma thus obtained can be selected by using a selective culture solution according to the selectable marker possessed by the myeloma used for cell fusion.
- cells deficient in HGPRT or TK can be selected by culturing in HAT culture medium (culture medium containing hypoxanthine, aminopterin and thymidine). That is, when HAT-sensitive myeloma cells are used for cell fusion, cells that have succeeded in cell fusion with normal cells can selectively proliferate in the HAT culture medium. Culture using the above-mentioned HAT culture medium is continued for a sufficient time for cells other than the desired hybridoma (non-fusion cells) to die.
- the desired hybridoma can be selected by culturing for several days to several weeks. Screening and single cloning of hybridomas producing the desired antibody can then be performed by conventional limiting dilution methods.
- Screening and single cloning of the desired antibody can be suitably performed by a screening method based on a known antigen-antibody reaction.
- a monoclonal antibody that binds to IL-6R can bind to IL-6R expressed on the cell surface.
- Such monoclonal antibodies can be screened, for example, by FACS (fluorescence activated cell sorting).
- FACS fluorescence activated cell sorting
- FACS is a system that makes it possible to measure the binding of an antibody to the cell surface by analyzing the cells in contact with a fluorescent antibody with laser light and measuring the fluorescence emitted by each cell.
- cells expressing IL-6R are prepared.
- Preferred cells for screening are mammalian cells that have been forced to express IL-6R.
- the binding activity of the antibody to IL-6R on the cell surface can be selectively detected. That is, a hybridoma that produces an IL-6R monoclonal antibody can be obtained by selecting a hybridoma that produces an antibody that does not bind to a host cell but binds to an IL-6R forced expression cell.
- the binding activity of the antibody to immobilized IL-6R-expressing cells can be evaluated based on the principle of ELISA.
- IL-6R-expressing cells are immobilized in wells of an ELISA plate.
- the hybridoma culture supernatant is brought into contact with the immobilized cells in the well, and an antibody that binds to the immobilized cells is detected.
- the monoclonal antibody is of mouse origin, the antibody bound to the cell can be detected by an anti-mouse immunoglobulin antibody.
- the hybridoma that produces the desired antibody having the ability to bind to the antigen selected by these screenings can be cloned by a limiting dilution method or the like.
- the hybridoma producing the monoclonal antibody thus produced can be subcultured in a normal culture medium.
- the hybridoma can be stored in liquid nitrogen for a long period of time.
- the hybridoma can be cultured according to a usual method, and a desired monoclonal antibody can be obtained from the culture supernatant.
- a hybridoma can be administered to a compatible mammal to proliferate and a monoclonal antibody can be obtained from the ascites.
- the former method is suitable for obtaining a high-purity antibody.
- An antibody encoded by an antibody gene cloned from an antibody-producing cell such as the hybridoma can also be preferably used.
- the cloned antibody gene By incorporating the cloned antibody gene into an appropriate vector and introducing it into the host, the antibody encoded by the gene is expressed.
- Methods for isolation of antibody genes, introduction into vectors, and transformation of host cells have already been established, for example, by Vandamme et al. (Eur. J. Biochem. (1990) 192 (3), 767- 775). Methods for producing recombinant antibodies are also known, as described below.
- a cDNA encoding the variable region (V region) of an anti-IL-6R antibody is obtained from a hybridoma cell that produces an anti-IL-6R antibody.
- the total RNA is usually first extracted from the hybridoma.
- the following method can be used. -Guanidine ultracentrifugation (Biochemistry (1979) 18 (24), 5294-5299) -AGPC method (Anal. Biochem. (1987) 162 (1), 156-159)
- the extracted mRNA can be purified using mRNA Purification Kit (manufactured by GE Healthcare Bioscience) or the like.
- kits for extracting total mRNA directly from cells such as QuickPrep mRNA Purification Kit (manufactured by GE Healthcare Bioscience) are also commercially available.
- mRNA can be obtained from hybridomas.
- a cDNA encoding the antibody V region can be synthesized from the obtained mRNA using reverse transcriptase.
- the cDNA can be synthesized by AMV Reverse Transcriptase First-strand cDNA Synthesis Kit (manufactured by Seikagaku Corporation) or the like.
- the desired cDNA fragment is purified from the obtained PCR product and then ligated with the vector DNA.
- a desired recombinant vector can be prepared from the Escherichia coli that formed the colony. Then, whether or not the recombinant vector has the base sequence of the target cDNA is confirmed by a known method, for example, the dideoxynucleotide chain illumination method or the like.
- cDNA is synthesized using RNA extracted from hybridoma cells as a template, and a 5'-RACE cDNA library is obtained.
- kits such as SMART RACE cDNA amplification kits are appropriately used for the synthesis of the 5'-RACE cDNA library.
- the antibody gene is amplified by the PCR method.
- Primers for mouse antibody gene amplification can be designed based on known antibody gene sequences. These primers have different base sequences for each subclass of immunoglobulin. Therefore, it is desirable to determine the subclass in advance using a commercially available kit such as the IsoStrip mouse monoclonal antibody isotyping kit (Roche Diagnostics).
- a primer capable of amplifying a gene encoding ⁇ 1, ⁇ 2a, ⁇ 2b, ⁇ 3 as a heavy chain and a gene encoding a ⁇ chain and a ⁇ chain as a light chain is used.
- a primer that anneals to a portion corresponding to a constant region close to the variable region is generally used as a primer on the 3'side.
- the primer attached to the 5'RACE cDNA library preparation kit is used as the primer on the 5'RACE cDNA library preparation kit.
- the PCR product thus amplified can be used to reconstitute an immunoglobulin consisting of a combination of heavy and light chains.
- the desired antibody can be screened using the binding activity of the reconstituted immunoglobulin to IL-6R as an index. For example, when the purpose is to obtain an antibody against IL-6R, it is more preferable that the binding of the antibody to IL-6R is specific.
- Antibodies that bind to IL-6R can be screened, for example, as follows; (1) A step of contacting an IL-6R-expressing cell with an antibody containing a V region encoded by cDNA obtained from a hybridoma. (2) A step of detecting the binding between IL-6R-expressing cells and an antibody, and (3) a step of selecting an antibody that binds to IL-6R-expressing cells.
- a method for detecting the binding between an antibody (including a monodomain antibody) and IL-6R-expressing cells is known. Specifically, the binding between the antibody and IL-6R-expressing cells can be detected by a method such as FACS described above. Fixed specimens of IL-6R-expressing cells can be appropriately utilized to assess antibody binding activity.
- a panning method using a phage vector is also preferably used. Even when screening a single domain antibody, it can be appropriately screened according to the following examples.
- an antibody gene is obtained as a library of heavy chain and light chain subclasses from a polyclonal antibody-expressing cell group, a screening method using a phage vector is advantageous.
- Genes encoding the variable regions of the heavy and light chains can form a single chain Fv (scFv) by linking with the appropriate linker sequence. By inserting a gene encoding scFv into a phage vector, phage expressing scFv on the surface can be obtained.
- the DNA encoding scFv having the desired binding activity can be recovered. By repeating this operation as necessary, scFv having the desired binding activity can be concentrated.
- the cDNA is digested by a restriction enzyme that recognizes the restriction enzyme sites inserted at both ends of the cDNA.
- Preferred restriction enzymes recognize and digest base sequences that rarely appear in the base sequences that make up an antibody gene. Further, in order to insert one copy of the digested fragment into the vector in the correct direction, it is preferable to insert a restriction enzyme that gives an attachment end.
- An antibody expression vector can be obtained by inserting the cDNA encoding the V region of the anti-IL-6R antibody digested as described above into an appropriate expression vector.
- a chimeric antibody is obtained.
- the chimeric antibody means that the origins of the constant region and the variable region are different. Therefore, in addition to heterologous chimeric antibodies such as mouse-human, human-human allogeneic chimeric antibodies are also included in the chimeric antibodies of the present disclosure.
- a chimeric antibody expression vector can be constructed by inserting the V region gene into an expression vector having a constant region in advance.
- a restriction enzyme recognition sequence of a restriction enzyme that digests the V region gene can be appropriately arranged on the 5'side of an expression vector holding a DNA encoding a desired antibody constant region (C region). ..
- a chimeric antibody expression vector is constructed by in-frame fusion of both digested with the same combination of restriction enzymes.
- the antibody gene is incorporated into an expression vector so that it is expressed under the control of an expression control region.
- the expression control region for expressing an antibody includes, for example, an enhancer and a promoter.
- an appropriate signal sequence can be added to the amino terminus so that the expressed antibody is secreted extracellularly.
- a signal sequence a peptide having the amino acid sequence MGWSCIILFLVATATGVHS (SEQ ID NO: 18008) can be used, but a suitable signal sequence is added in addition to this.
- the expressed polypeptide is cleaved at the carboxyl-terminal portion of the above sequence, and the cleaved polypeptide can be secreted extracellularly as a mature polypeptide.
- a suitable host cell is then transformed with this expression vector to obtain a recombinant cell expressing the DNA encoding the anti-IL-6R antibody.
- Polynucleotide refers to a polymer of nucleotides of any length, including DNA and RNA.
- Nucleotides can be deoxyribonucleotides, ribonucleotides, modified nucleotides or bases, and / or analogs thereof, or any substance that can be incorporated into a polymer by DNA or RNA polymerase or by a synthetic reaction.
- Polynucleotides can include modified nucleotides such as methylated nucleotides and analogs thereof.
- a non-nucleotide component may interrupt the nucleotide sequence.
- Polynucleotides can include modifications made after synthesis, such as conjugation to a label.
- modifications include, for example, "caps", substitutions of one or more naturally occurring nucleotides and analogs, internucleotide modifications, such as uncharged linkages (eg, methylphosphonate, phosphotriester, phosphoramic acid).
- any hydroxyl group normally present in sugars can be replaced, for example, with a phosphonate group, a phosphate group, protected by standard protecting groups, or activated to generate additional linkages to additional nucleotides.
- Or can be conjugated to a solid or semi-solid support.
- OH at the 5'and 3'ends can be phosphorylated or substituted with amines or organic cap group moieties of 1-20 carbon atoms.
- Other hydroxyls can also be derivatized to standard protecting groups.
- Polynucleotides may also include similar forms of ribose or deoxyribose sugars commonly known in the art, including, for example: 2'-O-methyl-, 2'-O-allyl-, 2'-fluoro- or 2'-azido-ribose, carbocyclic sugar analogs, ⁇ -anomeric sugars, arabinose or epimer sugars such as xylose or lyxose, pyranose sugars, furanose sugars, sedoheptulose, acyclic analogs, and methylribosides Basic lyxose analogs such as.
- One or more phosphodiester bonds can be replaced by alternative linking groups.
- linking groups include, but are not limited to, embodiments in which the phosphate is replaced by: P (O) S (“thioate”), P (S) S (“”. Dithioate “), (O) NR2 ("Amidate “), P (O) R, P (O) OR', CO, or CH2 (" Holm Acetal "), where each R or R'is independent. H, or optionally an ether (-O-) linkage, aryl, alkenyl, cycloalkyl, cycloalkenyl, or substituted or unsubstituted alkyl (1-20C) containing arargyl. Not all linkages in the polynucleotide need be the same. The above description applies to all polynucleotides referred to herein, including RNA and DNA.
- vector refers to a nucleic acid molecule to which it can augment another nucleic acid to which it is linked.
- the term includes a vector as a self-replicating nucleic acid structure and a vector that is incorporated into the genome of the host cell into which it has been introduced. Certain vectors can result in the expression of nucleic acids to which they are operably linked. Such vectors are also referred to herein as "expression vectors.”
- Host cell and other terms "host cell,””host cell line,” and “host cell culture” are used interchangeably in cells into which foreign nucleic acids have been introduced, including progeny of such cells. Say that. Host cells include “transformants” and “transformants”, which include primary transformants and progeny derived from those cells regardless of the number of passages. Offspring do not have to be exactly identical in content to the parent cell and nucleic acid and may contain mutations. Variant progeny with the same function or biological activity as those used when the original transformed cells were screened or selected are also included herein.
- polypeptides Containing Protease Cleavage Sequences One aspect of the present disclosure relates to polypeptides comprising protease cleavage sequences. Another aspect of the present disclosure is also the sequence from the N-terminal 4th amino acid to the 15th amino acid of the sequence selected from SEQ ID NO: 5 to 17201, the N-terminal 4th of the sequence selected from SEQ ID NO: 5 to 17201.
- the present invention
- polypeptide comprising any of the sequences composed from the N-terminus in the order "sequences selected from Group A below-sequences selected from Group B below": (Group A) SEQ ID NO:: Sequence from the 1st amino acid to the 9th amino acid at the N-terminal of the sequence selected from 5 to 17201, SEQ ID NO:: Sequence from the 2nd amino acid to the 9th amino acid at the N-terminal of the sequence selected from 5 to 17201, SEQ ID NO:: Sequence from the 3rd amino acid to the 9th amino acid at the N-terminal of the sequence selected from 5 to 17201, SEQ ID NO:: Sequence from the 4th amino acid to the 9th amino acid at the N-terminal of the sequence selected from 5 to 17201, SEQ ID NO:: Sequence from the 5th amino acid to the 9th amino acid at the N-terminal of the sequence selected from 5 to 17201, SEQ ID NO: The sequence from the 6th amino acid to
- the N-terminal of a sequence selected from SEQ ID NO: 5 to 17201 the sequence from the 4th to 15th amino acids, and the N-terminal of the sequence selected from SEQ ID NO: 5 to 17201.
- the polypeptide also comprises one of the sequences composed from the N-terminus in the order of "sequence selected from group A below-sequence selected from group B below".
- the sequence in the polypeptide is cleaveable by the protease, i.e., the sequence functions as a protease cleavage sequence in the polypeptide: (Group A) SEQ ID NO:: Sequence from the 1st amino acid to the 9th amino acid at the N-terminal of the sequence selected from 5 to 17201, SEQ ID NO:: Sequence from the 2nd amino acid to the 9th amino acid at the N-terminal of the sequence selected from 5 to 17201, SEQ ID NO:: Sequence from the 3rd amino acid to the 9th amino acid at the N-terminal of the sequence selected from 5 to 17201, SEQ ID NO:: Sequence from the 4th amino acid to the 9th amino acid at the N-terminal of the sequence selected from 5 to 17201,
- a mobile linker is further added to either one end or both ends of the protease cleavage sequence.
- the movable linker at one end of the protease cleavage sequence can be referred to as the first movable linker, and the movable linker at the other end can be referred to as the second movable linker.
- the protease cleavage sequence and the mobile linker include one of the following formulas: (Protease cleavage sequence) (First movable linker)-(Protease cleavage sequence) (Protease cleavage sequence)-(Second movable linker) (First mobile linker)-(Protease cleavage sequence)-(Second mobile linker)
- the movable linker in this embodiment is preferably a peptide linker.
- the first mobile linker and the second mobile linker are independent and optional, and are the same or different mobile linkers containing at least one flexible amino acid (such as Gly).
- a sufficient number of residues (Arg, Ile, Gln, Glu, Cys, Tyr, Trp, Thr, Val, His, Phe, Pro, Met, Lys) for the protease cleavage sequence to obtain the desired protease accessibility.
- residues Arg, Ile, Gln, Glu, Cys, Tyr, Trp, Thr, Val, His, Phe, Pro, Met, Lys
- Gly, Ser, Asp, Asn, Ala and the like optionally selected amino acids, especially Gly, Ser, Asp, Asn, Ala, especially Gly and Ser, especially Gly and the like.
- a mobile linker suitable for use at both ends of a protease cleavage sequence usually improves the access of the protease to the protease cleavage sequence and increases the efficiency of protease cleavage.
- Suitable mobile linkers are readily selectable, from 1 amino acid (such as Gly) to 20 amino acids, 2 amino acids to 15 amino acids, 4 amino acids to 10 amino acids, 5 amino acids to 9 amino acids, 6 amino acids to 8 amino acids or 7 amino acids. Suitable ones can be selected from different lengths such as 8 amino acids and 3 to 12 amino acids.
- the mobile linker is a 1 to 7 amino acid peptide linker.
- mobile linkers include, but are not limited to, glycine polymer (G) n, glycine-serine polymer (eg, (GS) n, (GSGGS: SEQ ID NO: 18018) n and (GGGS: SEQ ID NO: 1809)).
- G glycine polymer
- glycine-serine polymer eg, (GS) n, (GSGGS: SEQ ID NO: 18018) n and (GGGS: SEQ ID NO: 1809).
- n is an integer of at least 1
- glycine-alanine polymers glycine-alanine polymers
- alanine-serine polymers alanine-serine polymers
- other mobile linkers known in the art.
- glycine and glycine-serine polymers are attracting attention, because these amino acids are relatively unstructured and easily function as neutral tethers between the components.
- Examples of mobile linkers consisting of glycine-serine polymers include, but are not limited to, eg. Ser Gly ⁇ Ser (GS) Ser ⁇ Gly (SG) Gly / Gly / Ser (GGS) Gly / Ser / Gly (GSG) Ser / Gly / Gly (SGG) Gly / Ser / Ser (GSS) Ser / Ser / Gly (SSG) Ser / Gly / Ser (SGS) Gly, Gly, Gly, Ser (GGGS, SEQ ID NO: 1809) Gly / Gly / Ser / Gly (GGSG, SEQ ID NO: 18010) Gly / Ser / Gly / Gly (GSGG, SEQ ID NO: 18011) Ser / Gly / Gly / Gly (SGGG, SEQ ID NO: 18012) Gly / Ser / Ser / Gly (GSSG, SEQ ID NO: 18013) Gly, Gly, Gly, Gly, Ser
- the polypeptide containing the protease cleavage sequence of the present disclosure is a sequence from the N-terminal 4th amino acid to the 15th amino acid of the sequence selected from SEQ ID NO: 5 to 17201, and N of the sequence selected from SEQ ID NO: 5 to 17201.
- polypeptide containing the protease cleavage sequence of the present disclosure also contains any of the sequences composed in the order of "sequence selected from the following group A-sequence selected from the following group B" from the N-terminal.
- SEQ ID NO: Sequence from the 1st amino acid to the 9th amino acid at the N-terminal of the sequence selected from 5 to 17201
- SEQ ID NO: Sequence from the 5th amino acid to the 9th amino acid at the N-terminal of the sequence selected from 5 to 17201
- SEQ ID NO: Sequence from the 5th amino acid to the 9th amino acid at the N-terminal of the sequence selected from 5 to 17201
- SEQ ID NO: The sequence from the 6th amino acid to the 9th amino acid at the N-terminal of the sequence selected from 5 to 17201
- the polypeptide containing the protease cleavage sequence of the present disclosure may be an activable antibody.
- activable antibodies include: (i) antibodies that specifically bind to a target; (ii) inhibit antibody binding to a target when the protease cleavage sequence is present in an uncleaved state. The masking moiety; and the (iii) cleavable moiety coupled to the antibody, where the cleavable moiety is at least one sequence selected from the protease cleavage sequences of the present disclosure.
- polypeptides Containing Antigen-Binding Domain and Carrying Part the polypeptide comprises an antigen-binding domain and a transporting portion, which transport suppresses the antigen-binding activity of the antigen-binding domain. Has an inhibitory domain.
- the present disclosure also relates to a method of releasing an antigen-binding domain from a polypeptide, which comprises cleaving a protease cleavage sequence in the polypeptide comprising the antigen-binding domain and transport portion described herein.
- the "antigen binding domain” is limited only by binding to the target antigen.
- a domain having any structure can be used as long as it binds to the antigen of interest.
- Examples of such domains include, but are not limited to, the heavy chain variable region (VH) of an amino acid and the light chain variable region (VL) of an amino acid, a monodomain antibody (sdAb), which are present in vivo.
- a module called A domain of about 35 amino acids contained in Avimer which is a cell membrane protein (international publication WO2004 / 044011, WO2005 / 040229), and 10Fn3 domain, which is a domain that binds to a protein in fibronectin, which is a sugar protein expressed in cell membrane.
- Adnectin International Publication WO2002 / 032925
- Affibody International Publication WO1995 / 001937
- whose scaffold is the IgG binding domain constituting three helix bundles consisting of 58 amino acids of Protein A, Turn containing 33 amino acid residues DARPins (Designed Ankyrin Repeat proteins)
- DARPins Designed Ankyrin Repeat proteins
- International Publication WO2002 / 020565 which is a region exposed on the molecular surface of ankyrin repeat (AR), which has a structure in which two antiparallel helix and loop subsystems are repeatedly stacked.
- Anticalin a four-loop region in which eight highly conserved antiparallel strands in lipocalin molecules such as neutrophil gelatinase-associated lipocalin (NGAL) support one side of a centrally twisted barrel structure.
- Etc. International Publication WO 2003/029462
- Acquired of jawless species such as Yatsume eel and Nuta eel Rich in leucine residues of variable lymphocyte receptor (VLR) that does not have immunoglobulin structure as an immune system
- VLR variable lymphocyte receptor
- An example is a recessed area of a parallel sheet structure inside a horse-shaped structure in which repeat (leucine-rich-repeat (LRR)) modules are repeatedly stacked (International Publication WO2008 / 016854).
- an antigen-binding domain capable of exerting an antigen-binding function with a molecule composed only of the antigen-binding domain, and an antigen-binding function alone after being released from other linked peptides.
- antigen-binding domains that can be exerted.
- antigen-binding domains include, but are not limited to, single-chain antibodies, scFv, Fv, Fab, Fab', F (ab') 2, and the like.
- One of the preferred examples of the antigen-binding domain of the present disclosure is an antigen-binding domain having a molecular weight of 60 kDa or less.
- antigen-binding domains include, but are not limited to, single domain antibodies, scFv, Fab, Fab'.
- Antigen-binding domains with a molecular weight of 60 kDa or less are usually likely to cause renal clearance when present in the blood as monomers (J Biol Chem. 1988 Oct 15; 263 (29): 15064-70 reference).
- one of the preferred examples of the antigen-binding domain of the present disclosure is an antigen-binding domain having a half-life in blood of 12 hours or less. Examples of such antigen-binding domains include, but are not limited to, single domain antibodies, scFv, Fab, Fab'and the like.
- a monodomain antibody (sdAb) is mentioned as one of the preferable examples of the antigen-binding domain of the present disclosure.
- antigen is limited only to include an epitope to which an antigen-binding domain binds.
- Suitable examples of antigens include, but are not limited to, animal or human derived peptides, polypeptides, and proteins.
- Preferable examples of antigens include, but are not limited to, molecules expressed on the surface of target cells (eg, cancer cells, inflammatory cells), molecules expressed on the surface of other cells in tissues containing the target cells, targets. Examples thereof include molecules expressed on the surface of cells having an immunological role for cells and tissues containing target cells, large molecules existing in the stroma of tissues containing target cells, and the like.
- the following molecules are used as antigens: 17-IA, 4-1BB, 4Dc, 6-keto-PGF1a, 8-iso-PGF2a, 8-oxo-dG, A1 adenosine receptor, A33, ACE, ACE-2, Activin, Activin A, Activin AB, Activin B, Activin C, Activin RIA, Activin RIA ALK-2, Activin RIB ALK-4, Activin RIIA, Activin RIIB, ADAM, ADAM10, ADAM12, ADAM15, ADAM17 / TACE, ADAM8, ADAM9 , ADAMTS, ADAMTS4, ADAMTS5, addressin, aFGF, ALCAM, ALK, ALK-1, ALK-7, alpha-1-antitrypsin, alpha-V / beta-1 antagonist, ANG, Ang, APAF-1, APE, APJ , APP, APRIL, AR, ARC
- Receptors are also described in the above-mentioned examples of antigens, but even when these receptors are present in a soluble form in a biological fluid, they can be used as an antigen to which the antigen-binding domain of the present disclosure binds.
- antigens examples include membrane-type molecules expressed on cell membranes and soluble-type molecules secreted extracellularly from cells.
- the antigen-binding domain of the present disclosure binds to a soluble molecule secreted from a cell, it is preferable that the antigen-binding domain has a neutralizing activity.
- the soluble molecule can be present in a biological fluid, that is, any liquid that fills between a vessel or a tissue / cell in the living body.
- the soluble molecule to which the antigen-binding domain of the present disclosure binds can be present in extracellular fluid.
- extracellular fluid is a component in bone and cartilage such as plasma, intertissue fluid, lymph, tight connective tissue, cerebrospinal fluid, cerebrospinal fluid, puncture fluid, or joint fluid, and alveolar fluid (bronchial lung).
- Cell permeate fluid plasma lavage fluid
- ascites pleural fluid
- cerebrospinal fluid cyst fluid
- aqueous humor aqueous humor
- the term "transporting portion” refers to a portion of a polypeptide other than the antigen-binding domain.
- the transport portion of the present disclosure is usually a peptide or polypeptide composed of amino acids, and as a specific embodiment, the transport portion in the polypeptide is linked to an antigen binding domain via a protease cleavage sequence.
- the transport portion of the present disclosure may be a series of peptides or polypeptides linked by amide bonds, and the plurality of peptides or polypeptides may be covalent bonds such as disulfide bonds or non-covalent bonds such as hydrogen bonds and hydrophobic interactions. It may be a complex formed by binding.
- the transport portion of the present disclosure has an inhibitory domain that suppresses the antigen-binding activity of the antigen-binding domain.
- the term "suppressive domain” is limited only by suppressing the antigen-binding activity of the antigen-binding domain.
- the inhibitory domain a domain having any structure can be used as long as the antigen-binding activity of the antigen-binding domain can be suppressed. Examples of such inhibitory domains include, but are not limited to, heavy chain variable regions (VHs) of antibodies, light chain variable regions (VL) of antibodies, pre-B cell receptors, and monodomain antibodies. Be done.
- the suppression domain may be composed of the entire transport portion or a portion of the transport portion.
- inhibition of the antigen-binding domain's antigen-binding activity of the inhibitory domain in a state in which the protease cleavage sequence is cleaved by the protease is the protease.
- the cleavage sequence is weaker than the inhibition of the antigen-binding domain of the antigen-binding domain in the uncleaved state.
- the antigen-binding domain has a shorter half-life in blood than an uncleaved polypeptide.
- the polypeptides of the present disclosure contain an antigen-binding domain and a carrier, in certain embodiments, the antigen-binding domain has a shorter half-life in blood than the carrier.
- the molecular weight of the antigen-binding domain is smaller than the molecular weight of the transport portion. In certain embodiments, the molecular weight of the antigen binding domain can be 60 kDa or less.
- the transport moiety has FcRn-binding activity and the antigen-binding domain has no or weaker FcRn-binding activity than the transport moiety.
- the polypeptide containing the antigen-binding domain and carrier has a longer half-life in blood than the antigen-binding domain present alone.
- the carrier is designed to have a longer half-life in blood. .. Examples of embodiments that extend the half-life of the transport portion in blood are, but are not limited to, a large molecular weight of the transport portion, or the transport portion having FcRn binding property, or the transport portion having albumin binding property.
- the transport portion is PEGylated.
- the polypeptide of the present disclosure comprises an antigen-binding domain and a carrier
- the carrier has a longer half-life in blood than the antigen-binding domain (in other words, the antigen-binding domain has a shorter half-life in blood than the carrier. Period).
- mice eg., normal mice, human antigen-expressing transgenic mice, human FcRn-expressing transgenic mice, etc.
- monkeys eg, cynomolgus monkeys, etc.
- the blood half-life in humans can be predicted based on the blood half-life in humans.
- One embodiment of extending the half-life of the transport portion in blood is that the transport portion has a large molecular weight.
- One embodiment in which the half-life in blood of the transport portion is longer than the half-life in blood of the antigen-binding domain is to make the molecular weight of the transport portion larger than the molecular weight of the antigen-binding domain.
- One embodiment of extending the half-life of the transport portion in blood is to make the transport portion have FcRn binding property.
- In order to give the transport portion an FcRn binding property there is usually a method of providing an FcRn binding region in the transport portion.
- Having the transport part have FcRn binding does not mean that the antigen-binding domain does not have FcRn binding.
- the half-life of the transport portion is made longer than the half-life of the antigen-binding domain in blood, the antigen-binding domain does not have FcRn-binding property, and the antigen-binding domain has FcRn-binding property.
- the carrier comprises an antibody Fc region.
- the transport portion comprises the CH2 and CH3 domains of a human IgG antibody.
- the transport portion comprises a portion extending from the human IgG1 antibody heavy chain Cys226 or from Pro230 to the carboxyl end of the heavy chain.
- the C-terminal lysine (Lys447) or glycine-lysine (Gly446-Lys447) in the Fc region may or may not be present.
- the transport moiety comprises an antibody constant region.
- the transport portion comprises an IgG antibody constant region.
- the transport portion comprises a human IgG antibody constant region.
- the transport moiety is a region having a structure substantially similar to the antibody heavy chain constant region and a covalent bond such as a disulfide bond to the region.
- the transport moiety includes a region having a structure similar to that of an antibody light chain, which is bound by a non-covalent bond such as a hydrogen bond or a hydrophobic interaction.
- the antigen-binding domain is free from the polypeptide and the antigen-binding domain is free from the polypeptide.
- the activity is higher than the antigen-binding activity in the state where it is not released from the polypeptide.
- the protease cleavage sequence is cleaved by a protease to allow the antigen-binding domain to be released from the polypeptide.
- the release of the antigen-binding domain from the polypeptide results in higher antigen-binding activity than before release.
- the antigen-binding domain is not released from the polypeptide, its antigen-binding activity is suppressed by the inhibitory domain.
- FACS fluorescence activated cell sorting
- ELISA Enzyme-Linked ImmunoSorbent Assay
- ECL electrogenerated chemiluminescence
- SPR as a method for confirming that the antigen-binding activity of the antigen-binding domain is suppressed by the inhibitory domain.
- the antigen-binding domain is released from the polypeptide as compared to the binding activity in which the antigen-binding domain is not released from the polypeptide.
- the pre-release antigen-binding domain measures the antigen-binding activity of the antigen-binding domain by one method selected from the above methods. When, no binding between the antigen-binding domain and the antigen is seen.
- the polypeptide of the present disclosure comprises an antigen-binding domain and a transport portion
- cleavage of the protease cleavage sequence allows the antigen-binding domain to be released from the polypeptide, and thus antigen binding in such an embodiment.
- the activity can be compared by comparing the antigen-binding activity before and after cleavage of the polypeptide. That is, the antigen-binding activity measured using the cleaved polypeptide is 2-fold, 3-fold, 4-fold, 5-fold, 6-fold, and 7-fold compared to the antigen-binding activity measured using the uncleaved polypeptide.
- the uncleaved polypeptide does not show binding of the antigen-binding domain to the antigen when the antigen-binding activity is measured by one method selected from the above methods. ..
- the polypeptide of the present disclosure comprises an antigen-binding domain and a carrier
- the protease cleavage sequence is cleaved by the protease, so a comparison of antigen-binding activity in such embodiments is made before and after protease treatment of the polypeptide. It can be done by comparing the antigen-binding activities of. That is, the antigen-binding activity measured using the protease-treated polypeptide was 2-fold, 3-fold, 4-fold, 5-fold, as compared with the antigen-binding activity measured using the polypeptide not treated with protease.
- protease-untreated polypeptides show binding of the antigen-binding domain to the antigen when the antigen-binding activity is measured by one method selected from the above methods. Absent.
- the antigen-binding activity of the antigen-binding domain is suppressed by the association of the antigen-binding domain with the inhibitory domain of the transport portion.
- the protease cleavage sequence is cleaved by a protease to eliminate the association between the antigen-binding domain and the inhibitory domain of the transport portion.
- the antigen-binding domain comprises a monodomain antibody or is a monodomain antibody
- the inhibitory domain of the transport portion is of the monodomain antibody. Suppresses antigen-binding activity.
- the monodomain antibody may be VHH, VH having antigen-binding activity in a single domain, or VL having antigen-binding activity in a single domain.
- the inhibitory domain of the carrier associates with the antigen binding domain.
- the suppression domain may be part of the transport portion or the entire transport portion. From another point of view, the part of the transport part that associates with the antigen-binding domain can be paraphrased as the inhibitory domain.
- the antigen binding domain which is a monodomain antibody
- the inhibitory domain which is VL or VH or VHH, form an association such as antibody VH and antibody VL.
- the antigen-binding domain which is a monodomain antibody and the inhibitory domain which is VL or VH or VHH form an association such as antibody VH and antibody VL and the association is formed.
- the inhibitory domain stereoscopically inhibits the binding of the antigen to the antigen-binding domain, or the three-dimensional structure of the antigen-binding site of the antigen-binding domain is changed, so that the antigen-binding activity of the monodomain antibody becomes the VL or Suppressed by VH or VHH.
- VHH is used as a single domain antibody
- CDR3 which is the main antigen binding site of VHH, or a site in the vicinity thereof is present at the interface where the inhibitory domain is associated
- the binding of VHH and the antigen is three-dimensionally structured by the inhibitory domain. It is thought that it is hindered by.
- the association between the inhibitory domain and the antigen-binding domain can be resolved by, for example, cleaving the cleavage site. Resolving the association can be rephrased as, for example, resolving the interaction state of two or more polypeptide regions. The interaction between the two or more polypeptide regions may be completely eliminated, or a part of the interaction between the two or more polypeptide regions may be eliminated.
- the term "interface” usually refers to an association surface at the time of association (interaction), and the amino acid residue forming the interface is usually contained in the polypeptide region provided for the association. Alternatively, it refers to a plurality of amino acid residues, more preferably amino acid residues that approach and participate in an interaction at the time of association. Specifically, the interaction includes non-covalent bonds such as hydrogen bonds, electrostatic interactions, and salt bridges between amino acid residues that approach each other at the time of association.
- amino acid residue forming an interface in the present specification specifically refers to an amino acid residue contained in the polypeptide region constituting the interface.
- the polypeptide region constituting the interface for example, refers to a polypeptide region having an intramolecular or intermolecular selective binding in an antibody, a ligand, a receptor, a substrate, or the like.
- a heavy chain variable region, a light chain variable region, and the like can be exemplified, and when the polypeptide of the present disclosure contains an antigen-binding domain and a transport portion, in some embodiments, the antigen-binding domain.
- the inhibitory domain can be exemplified.
- amino acid residues forming an interface include, but are not limited to, amino acid residues that approach at the time of association.
- Amino acid residues approaching at the time of association can be found, for example, by analyzing the three-dimensional structure of the polypeptide and examining the amino acid sequence of the polypeptide region forming the interface at the time of association of the polypeptide.
- Amino acid residues involved in association within the domain can be modified.
- the amino acid residue forming the interface with the inhibitory domain in the antigen-binding domain or the amino acid residue forming the interface with the antigen-binding domain in the inhibitory domain can be modified. ..
- modification of the amino acid residue forming the interface is a method of introducing a mutation in the amino acid residue into the interface so that two or more amino acid residues forming the interface have different charges.
- Modification of amino acid residues to result in heterogeneous charges is modification from positively charged amino acid residues to negatively charged amino acid residues or uncharged amino acid residues, negatively charged amino acid residues. It includes modification from a group to a positively charged or uncharged amino acid residue, and from an uncharged amino acid residue to a positively or negatively charged amino acid residue.
- Such amino acid modification is for promoting association, and the position of amino acid modification and the type of amino acid are not limited as long as the purpose of promoting association can be achieved. Modifications include, but are not limited to, substitutions.
- the antigen-binding domain VHH is associated with the inhibitory domain VL.
- amino acid residues involved in association with VL in VHH the amino acid residues forming the interface between VHH and VL can be pointed out.
- amino acid residues involved in association with VL in VHH include, but are not limited to, amino acid residues at positions 37, 44, 45, and 47 (J. Mol. Biol. (2005) 350, 112-125.).
- amino acid residues involved in association with VHH include, but are not limited to, amino acid residues at positions 37, 44, 45, and 47 (J. Mol. Biol. (2005) 350, 112-125.).
- amino acid residues forming the interface between VHH and VL can be pointed out.
- Amino acid residues involved in VL association in VHH can be modified to facilitate VHH-VL association.
- amino acid substitutions include, but are not limited to, F37V, Y37V, E44G, Q44G, R45L, H45L, G47W, F47W, L47W, T47W, or / and S47W.
- VHHs having 37V, 44G, 45L, or / and 47W amino acid residues from the beginning can be used without modification for each residue in VHH.
- VHH is used as the antigen-binding domain and VH or VHH is used as the inhibitory domain to associate the antigen-binding domain with the inhibitory domain.
- VHH is used as the antigen-binding domain
- VH or VHH is used as the inhibitory domain to associate the antigen-binding domain with the inhibitory domain.
- the amino acid residues involved in the association with the inhibitory domain VH or VHH in the antigen-binding domain VHH They can be identified and their amino acid residues can be modified.
- amino acid residues involved in association with VHH, which is an antigen-binding domain, in VH or VHH, which is an inhibitory domain can be identified, and those amino acid residues can be modified.
- the transport moiety and the antigen-binding domain are fused via a linker.
- the transport moiety and the antigen binding domain are fused via a linker containing a protease cleavage sequence.
- the transport moiety and the antigen-binding domain are fused via a linker, and the fusion protein after fusion contains a protease cleavage sequence.
- the transport moiety and the antigen-binding domain are fused without a linker.
- an amino bond is formed between the N-terminal amino acid of the transport portion and the C-terminal amino acid of the antigen-binding domain to form a fusion protein.
- the fusion protein formed contains a protease cleavage sequence.
- the N-terminus of the transport moiety to a few amino acids or / and the C-terminus of the antigen-binding domain C-terminus to a few amino acids are modified to fuse the N-terminus of the transport moiety with the C-terminus of the antigen binding domain.
- LSGRSDNH SEQ ID NO: 18031
- the four amino acids at the C-terminal of the antigen-binding domain are made into the LSGR sequence, and the four amino acids at the N-terminal of the transport portion are SDNH. It can be sequenced to form a protease cleaved sequence.
- the protease cleavage sequence releases the antigen-binding domain when the protease is cleaved, and loses the antigen-binding activity of the antigen-binding domain after release. As long as it does not exist, it may be placed in any part of the polypeptide.
- the transport moiety comprises an antibody constant region, with the N-terminus of the antibody constant region and the C-terminus of the antigen binding domain via a linker or. It is fused without going through a linker.
- the protease cleavage sequence is located within the antibody constant region contained in the transport moiety. In this case, the protease cleavage sequence may be located within the antibody constant region so that the antigen-binding domain can be released when the protease is cleaved.
- the protease cleavage sequence is located within the antibody heavy chain constant region contained in the transport moiety, and more specifically, the antigen binding domain from amino acid No. 140 (EU numbering) in the antibody heavy chain constant region. It is located on the side or on the antigen-binding domain side of amino acid No. 122 (EU numbering) in the antibody heavy chain constant region.
- the protease cleavage sequence is located within the antibody light chain constant region contained in the transport moiety, and more specifically, the antigen from the 130th (Kabat numbering) amino acid in the antibody light chain constant region. It is located on the binding domain side or on the antigen binding domain side of amino acid No. 113 (Kabat numbering) in the antibody light chain constant region.
- the antigen-binding domain is a monodomain antibody, with the C-terminus of the monodomain antibody and the N-terminus of the transport portion via a linker or It is fused without going through a linker.
- the protease cleavage sequence is located within a monodomain antibody.
- the monodomain antibody is a monodomain antibody or VHH made from VH, and the protease cleavage sequence is on the transport portion side of the 35b (Kabat numbering) amino acid of the monodomain antibody, or the single domain antibody.
- the monodomain antibody is a monodomain antibody prepared from VL, and the protease cleavage sequence is on the transport portion side of the 32nd (Kabat numbering) amino acid of the monodomain antibody, or the monodomain. It is located on the transport portion side of the 91st (Kabat numbering) amino acid of the antibody, or on the transport portion side of the 104th (Kabat numbering) amino acid of the monodomain antibody.
- the carrier comprises an antibody constant region
- the antigen-binding domain is a monodomain antibody
- the antibody constant region and the monodomain antibody It is fused with or without a linker.
- the N-terminus of the antibody constant region and the C-terminus of the monodomain antibody are fused with or without a linker.
- the C-terminus of the antibody constant region and the N-terminus of the monodomain antibody are fused with or without a linker.
- the protease cleavage sequence is located within the antibody constant region contained in the transport moiety.
- the protease cleavage sequence is located on the monodomain antibody side of amino acid 140 (EU numbering) in the antibody heavy chain constant region, or from amino acid 122 (EU numbering) in the antibody heavy chain constant region. It is located on the monodomain antibody side.
- the protease cleavage sequence is located on the antigen-binding domain side of the 130 (Kabat numbering) amino acid in the antibody light chain constant region, or from the 113 (Kabat numbering) amino acid in the antibody light chain constant region. It is located on the antigen-binding domain side.
- the protease cleavage sequence is located within a monodomain antibody.
- the monodomain antibody is a monodomain antibody or VHH prepared from VH, and the protease cleavage sequence is on the antibody constant region side of the 35b (Kabat numbering) amino acid of the monodomain antibody, or said. It is located on the antibody constant region side of the 95th (Kabat numbering) amino acid of the monodomain antibody, or on the antibody constant region side of the 109th (Kabat numbering) amino acid of the single domain antibody.
- the monodomain antibody is a monodomain antibody prepared from VL, and the protease cleavage sequence is on the antibody constant region side of the 32nd (Kabat numbering) amino acid of the monodomain antibody, or the single domain antibody.
- the protease cleavage sequence is located near the boundary between the antigen binding domain and the transport portion.
- the vicinity of the boundary between the antigen-binding domain and the transport portion refers to a portion before and after the site where the antigen-binding domain and the transport portion are connected, which does not significantly affect the secondary structure of the antigen-binding domain.
- the antigen binding domain is linked to the antibody constant region contained in the transport portion and the protease cleavage sequence is located near the boundary between the antigen binding domain and the antibody constant region.
- the vicinity of the boundary between the antigen-binding domain and the antibody constant region can refer to the vicinity of the boundary between the antigen-binding domain and the antibody heavy chain constant region, or the vicinity of the boundary between the antigen-binding domain and the antibody light chain constant region.
- the antigen-binding domain is a monodomain antibody or VHH prepared from VH and is linked to the antibody heavy chain constant region
- the vicinity of the boundary between the antigen-binding domain and the antibody constant region is monodomain antibody No. 101 (Kabat numbering).
- the antigen-binding domain is a monodomain antibody or VHH prepared from VH and is linked to the antibody light chain constant region, the vicinity of the boundary between the antigen-binding domain and the antibody light chain constant region is monodomain antibody No. 101 ( It can point between the amino acids of Kabat numbering) to the antibody light chain constant region 130 (Kabat numbering), or from the amino acid of monodomain antibody 109 (Kabat numbering) to antibody light chain constant region 113 (Kabat numbering). ) Can be pointed between amino acids.
- the antigen-binding domain is a monodomain antibody prepared from VL
- the vicinity of the boundary between the antigen-binding domain and the antibody constant region is from monodomain antibody No. 96 (Kabat numbering) or from monodomain antibody No. 104 (Kabat numbering). Is.
- the polypeptide of the present disclosure comprises an antigen binding domain and a carrier
- the polypeptide is an IgG antibody-like molecule.
- examples of such embodiments include, but are not limited to, for example, a monodomain antibody in which the transport portion comprises an IgG antibody constant region and is an antigen-binding domain replaces the VH of the IgG antibody, and VL increases the antigen-binding activity.
- An embodiment in which the antigen-binding activity is suppressed by VH in which the suppressed embodiment or the transport portion contains an IgG antibody constant region and a monodomain antibody which is an antigen-binding domain replaces the VL of the IgG antibody.
- Is an IgG antibody constant region a monodomain antibody that is an antigen-binding domain replaces one of the VH / VL of the IgG antibody, and another monodomain antibody that suppresses the antigen-binding activity of the antigen-binding domain is the VH of the IgG antibody. Examples include embodiments that replace the other of / VL.
- IgG antibody-like molecule refers to a moiety that is substantially similar to the structure of a constant domain or constant region, such as an IgG antibody, and the structure and substance of a variable domain or variable region, such as an IgG antibody. It is used to define a molecule that has a substantially similar moiety and has a three-dimensional structure substantially similar to that of an IgG antibody.
- Antibodies CH1 and CL-like domains in IgG antibody-like molecules can be used interchangeably with each other, i.e., both domains have an IgG antibody CH1 and CL-like interaction. As long as the domain linked to the portion similar to the antibody hinge region is the antibody CH1 domain or the antibody CL domain.
- the "IgG antibody-like molecule” in the present specification is not limited to exhibiting antigen-binding activity while maintaining a structure similar to that of an IgG antibody.
- the polypeptide of the present disclosure contains an antigen-binding domain and a transport portion
- the polypeptide may contain one or more antigen-binding domains.
- the number of inhibitory domains that suppress the antigen-binding activity of the plurality of antigen-binding domains may be one or plural.
- a plurality of antigen-binding domains may each form an association with an inhibitory domain.
- a plurality of antigen-binding domains may be fused with the transport portion. It may be possible for each of the plurality of antigen-binding domains to be released from the polypeptide.
- the protease cleavage sequence for releasing a plurality of antigen-binding domains may be plural corresponding to each antigen-binding domain.
- the polypeptide is an IgG antibody-like molecule
- an embodiment in which an antigen-binding domain is provided in each of the portions corresponding to the two variable regions of the IgG antibody as shown in FIG. 3 is a person skilled in the art mentioned in the present disclosure. It would be an understandable embodiment. An embodiment in which a person skilled in the art who has touched the present disclosure can understand whether the antigen-binding domain incorporated in both arms has the same antigen-binding specificity or different antigen-binding specificity. It is clear that this does not deviate from the scope of this disclosure.
- the antigen-binding domain is further linked to a second antigen-binding domain.
- a module called A domain of about 35 amino acids contained in a monodomain antibody, an antibody fragment, and Avimer which is a cell membrane protein existing in the living body, is not limited to that (International Publication WO2004).
- Adnectin containing the 10Fn3 domain which is a domain that binds to a protein in fibronectin, which is a sugar protein expressed on the cell membrane
- Adnectin containing the 10Fn3 domain which is a domain that binds to a protein in fibronectin, which is a sugar protein expressed on the cell membrane
- Affibody International Publication WO1995 / 001937 with the IgG binding domain constituting (bundle) as scaffold, ankyrin repeat having a structure in which a turn containing 33 amino acid residues and two antiparallel helix and loop subsystems are repeatedly stacked.
- lipocalin molecules such as DARPins (Designed Ankyrin Repeat proteins) (International Publication WO2002 / 020565), which are regions exposed on the molecular surface of ankyrin repeat: AR), and neutrophil gelatinase-associated lipocalin (NGAL).
- DARPins Designed Ankyrin Repeat proteins
- NGAL neutrophil gelatinase-associated lipocalin
- Anticalin et al. International Publication WO2003 / 029462
- LRR leucine-rich-repeat
- VLR variable lymphocyte receptor
- the recessed area of the parallel sheet structure inside International Publication WO2008 / 016854
- the second antigen binding domain has different antigen binding specificity than the antigen binding domain.
- the molecular weight of the linked antigen-binding domain and the second antigen-binding domain is 60 kDa or less.
- the antigen binding domain and the second antigen binding domain are monodomain antibodies having different antigen binding specificities, and the linked antigen binding domain and the second antigen binding domain are It can be released from the polypeptide, and the antigen-binding domain after release and the second antigen-binding domain form a bispecific antigen-binding molecule.
- bispecific antigen-binding molecules are, but are not limited to, for example, an antigen-binding domain specifically binds to a target cell surface antigen, and a second antigen-binding domain is specific to an immune cell surface antigen.
- a bispecific antigen-binding molecule that binds to a bispecific antigen-binding molecule in which the antigen-binding domain and the second antigen-binding domain bind to different subunits of the same antigen, an antigen-binding domain and a second antigen-binding domain
- bispecific antigen-binding molecules that bind to different epitopes in the same antigen.
- Such bispecific antigen-binding molecules are considered to be useful in the treatment of diseases caused by target cells because they can recruit immune cells to the vicinity of the target cells.
- the antigen-binding activity of the second antigen-binding domain may or may not be suppressed by the transport portion.
- the second antigen-binding domain may or may not form an association with a partial structure of the transport portion.
- the antigen-binding domain and the second antigen-binding domain have different antigen-binding specificities, for example, as shown in FIG. 4, even if the antigen-binding activity of the second antigen-binding domain is not suppressed, Even if the second antigen-binding domain does not form an association with a part of the structure of the transport portion, the antigen-binding activity of the antigen-binding domain cannot be exerted in a state where the antigen-binding domain is not released, and the antigen-binding domain cannot be exerted.
- FIG. 4 illustrates an embodiment in which an antigen-binding domain is further linked to a second antigen-binding domain.
- the term "specificity" refers to the property that one molecule of a molecule that specifically binds does not substantially bind to a molecule other than the one or more of the other molecule to which it binds. It is also used when the antigen-binding domain has specificity for an epitope contained in a specific antigen. It is also used when the antigen-binding domain has specificity for a specific epitope among a plurality of epitopes contained in a certain antigen.
- a sequence composed in the order of "sequence selected from the following group A-sequence selected from the following group B" from the N-terminal can also be used as a protease cleavage site in the polypeptide exemplified in FIG. 1.
- SEQ ID NO: Sequence from the 1st amino acid to the 9th amino acid at the N-terminal of the sequence selected from 5 to 17201, SEQ ID NO:: Sequence from the 2nd amino acid to the 9th amino acid at the N-terminal of the sequence selected from 5 to 17201, SEQ ID NO:: Sequence from the 3rd amino acid to the 9th amino acid at the N-terminal of the sequence selected from 5 to 17201, SEQ ID NO:: Sequence from the 4th amino acid to the 9th amino acid at the N-terminal of the sequence selected from 5 to 17201, SEQ ID NO:: Sequence from the 5th amino acid to the 9th amino acid at the N-terminal of the sequence selected from 5 to 17201, SEQ ID NO: The sequence from the 6th amino acid to the 9th amino acid at the N-terminal of the sequence selected from 5 to 17201, SEQ ID NO: The sequence from the 7th amino acid to the 9th amino acid at the N-terminal of the sequence selected from 5 to 17201
- the polypeptide in which the antigen-binding domain and the transport portion are linked has a long half-life, the antigen-binding activity of the antigen-binding domain is suppressed, and the polypeptide does not bind to the antigen (A). After the antigen-binding domain is released, the antigen-binding activity is restored and the half-life is short (B).
- the polypeptide shown in FIG. 1 has various variations, but when an IgG antibody-like molecule is used, it can be produced by a production method as exemplified in FIG.
- a single domain antibody eg, VH or VHH
- the obtained monodomain antibody is replaced with one of VH and VL of an IgG antibody having a germline sequence and associated with the other of VH and VL to form an IgG antibody-like molecule (B).
- B Introduce a protease cleavage sequence into an IgG antibody-like molecule (C).
- An example of the introduction position is near the boundary between the introduced single domain antibody (VH or VHH) and the constant region (CH1 or CL).
- Monodomain antibodies have antigen-binding activity when present in a single domain, but lose their antigen-binding activity when forming a variable region with VL / VH / VHH or the like. Since VL / VH is a natural human antibody sequence having a germline sequence, the risk of immunogenicity is low, and it is extremely unlikely that an anti-drug antibody that recognizes the VL / VH will be induced. Also, when VHHs are used to form variable regions with monodomain antibodies, humanization of VHHs can reduce the risk of immunogenicity and induce anti-drug antibodies that recognize the humanized VHHs. The sex can be reduced.
- the single domain antibody is released by cleaving the protease cleavage sequence inserted into the IgG antibody-like molecule with protease.
- the released monodomain antibody has antigen-binding activity.
- the IgG antibody-like molecule before cleavage by protease has a long blood retention because it has a structure similar to that of a general IgG molecule, whereas the monodomain antibody released by cleavage by protease has an Fc region.
- the molecular weight is about 13 kDa, it disappears rapidly by renal excretion. In fact, the half-life of full-length IgG is about 2 to 3 weeks (Blood.
- the antigen-binding molecule activated by protease has a short half-life in blood and is less likely to bind to an antigen in normal tissue. If the monodomain antibody is VL, a similar concept can be achieved by introducing a protease cleavage sequence, for example, near the boundary between VL and CL.
- the present disclosure also relates to a method for producing a polypeptide when the polypeptide contains a transport portion having an inhibitory domain and an antigen binding domain.
- a method for producing a polypeptide containing a transport portion having an inhibitory domain and an antigen-binding domain of the present disclosure an antigen-binding domain having an antigen-binding activity is obtained, and the antigen-binding activity of the antigen-binding domain is determined by the inhibitory domain.
- the antigen-binding domain and the transport portion are linked to form a polypeptide precursor so as to be suppressed, and a protease cleavage sequence is further inserted into the polypeptide precursor, or a part of the polypeptide precursor is a protease cleavage sequence.
- protease cleavage sequence can be introduced into the polypeptide precursor, and the method for introducing the protease cleavage sequence may be either insertion of the protease cleavage sequence or modification of a part of the polypeptide precursor. Furthermore, it will be apparent to those skilled in the art who have touched this specification that a protease cleavage sequence can be introduced into a polypeptide precursor by combining both means, without departing from the scope of the present disclosure. There will be.
- an antigen-binding domain having an antigen-binding activity is obtained, and the antigen-binding activity of the antigen-binding domain is suppressed.
- the protease cleavage sequence may be sandwiched between the antigen-binding domain and the transport portion, and a part of the antigen-binding domain and / or a part of the transport portion. May be modified and used as part of the protease cleavage sequence.
- a method for producing a polypeptide comprising a transport moiety having an inhibitory domain and an antigen binding domain is described in the following steps: (a) Step of obtaining a monodomain antibody that binds to a target antigen; (b) A step of linking the monodomain antibody with the transport portion to form a polypeptide precursor so that the antigen-binding activity of the monodomain antibody obtained in step (a) is suppressed by the inhibitory domain of the transport portion. ; (c) Step of introducing a protease cleavage sequence into the polypeptide precursor; It is a manufacturing method including.
- a method for producing a polypeptide comprising a transport moiety having an inhibitory domain and an antigen binding domain is described in the following steps: (a) Step of obtaining a monodomain antibody that binds to a target antigen; (b) A step of linking the monodomain antibody with the transport portion to form a polypeptide precursor so that the antigen-binding activity of the monodomain antibody obtained in step (a) is suppressed by the inhibitory domain of the transport portion. ; (c) A step of introducing a protease cleavage sequence near the boundary between the monodomain antibody and the transport portion; It is a manufacturing method including.
- a method for producing a polypeptide comprising a transport moiety having an inhibitory domain and an antigen binding domain is described in the following steps: (a) Step of obtaining a monodomain antibody that binds to a target antigen; (b) The monodomain antibody is linked to the transport portion via a protease cleavage sequence so that the antigen-binding activity of the monodomain antibody obtained in step (a) is suppressed by the suppressor domain of the transport portion. Steps to form peptides; It is a manufacturing method including.
- the method for producing a polypeptide comprising a transport moiety having an inhibitory domain and an antigen binding domain further comprises the following steps: (d) A step of confirming that the binding activity of the monodomain antibody incorporated in the polypeptide or the polypeptide precursor to the target antigen is weakened or lost; It is a manufacturing method including.
- "weakened binding activity” means that the binding activity to the target antigen is reduced as compared with that before ligation, and the degree of reduction is not limited.
- the method for producing a polypeptide comprising a transport moiety having an inhibitory domain and an antigen binding domain further comprises the following steps: (e) A step of releasing the monodomain antibody by cleaving the protease cleavage sequence with a protease and confirming that the free monodomain antibody binds to an antigen; It is a manufacturing method including.
- a method for producing a polypeptide which is an IgG antibody-like molecule containing a transport portion having an inhibitory domain and an antigen-binding domain is described in the following steps: (a) Step of obtaining a monodomain antibody that binds to a target antigen; (b) The monodomain antibody is associated with VL instead of the VH of the IgG antibody so that the antigen-binding activity of the monodomain antibody obtained in step (a) is suppressed, or the monodomain antibody is associated with the IgG antibody.
- a method for producing a polypeptide which is an IgG antibody-like molecule containing a transport portion having an inhibitory domain and an antigen binding domain is described in the following steps: (a) Step of obtaining a monodomain antibody that binds to a target antigen; (b) The monodomain antibody is associated with VL instead of the VH of the IgG antibody so that the antigen-binding activity of the monodomain antibody obtained in step (a) is suppressed, or the monodomain antibody is associated with the IgG antibody.
- a method for producing a polypeptide which is an IgG antibody-like molecule containing a transport portion having an inhibitory domain and an antigen binding domain is described in the following steps: (a) Step of obtaining a monodomain antibody that binds to a target antigen; (b) Instead of IgG antibody VH or VL, the single domain antibody is used as a heavy chain constant of IgG antibody via a protease cleavage sequence so that the antigen-binding activity of the monodomain antibody obtained in step (a) is suppressed.
- a method for producing a polypeptide which is an IgG antibody-like molecule containing a transport moiety having an inhibitory domain and an antigen binding domain is further described by (d) A step of confirming that the binding activity of the monodomain antibody introduced into the IgG antibody-like molecule or the IgG antibody-like molecular precursor to the target antigen is weakened or lost; It is a manufacturing method including.
- "weakened binding activity” means that the binding activity to the target antigen is reduced as compared with that before association or before ligation, and the degree of reduction is not limited.
- a method for producing a polypeptide which is an IgG antibody-like molecule containing a transport moiety having an inhibitory domain and an antigen binding domain is further described by (e) A step of releasing the monodomain antibody by cleaving the protease cleavage sequence with a protease and confirming that the free monodomain antibody binds to the target antigen; It is a manufacturing method including.
- VH / VL / VHH When VH / VL / VHH is used as the inhibitory domain, there is a method of associating the single domain antibody with VH / VL / VHH as a method of suppressing the antigen-binding activity of the monodomain antibody in the inhibitory domain of the transport portion.
- VH / VL / VHH that suppresses the antigen-binding activity of the prepared monodomain antibody is obtained by associating a known VH / VL / VHH with the monodomain antibody and comparing the antigen-binding activity of the monodomain antibody before and after the association. Can be screened.
- a method for producing an IgG antibody-like molecular polypeptide containing a transport moiety having an inhibitory domain and an antigen binding domain is described in the following steps: (a) Substituting an amino acid residue involved in association with antibody VH in a monodomain antibody, or substituting an amino acid residue involved in association with antibody VL in a monodomain antibody, the monodomain antibody. A step of producing a modified monodomain antibody that retains the binding activity to the target antigen of (b) By associating the modified monodomain antibody with antibody VH or associating the modified monodomain antibody with antibody VL so as to suppress the antigen-binding activity of the modified monodomain antibody prepared in step (a).
- a step of forming an IgG antibody-like molecular precursor into which the modified monodomain antibody has been introduced (c) A step of introducing a protease cleavage sequence into an IgG antibody-like molecular precursor into which the modified monodomain antibody has been introduced; It is a manufacturing method including.
- a method for producing a polypeptide which is an IgG antibody-like molecule containing a transport portion having an inhibitory domain and an antigen binding domain is described in the following steps: (a) Substituting an amino acid residue involved in association with antibody VH in a monodomain antibody, or substituting an amino acid residue involved in association with antibody VL in a monodomain antibody, the monodomain antibody. A step of producing a modified monodomain antibody that retains the binding activity to the target antigen of (b) By associating the modified monodomain antibody with antibody VH or associating the modified monodomain antibody with antibody VL so as to suppress the antigen-binding activity of the modified monodomain antibody prepared in step (a).
- a step of forming an IgG antibody-like molecular precursor into which the modified monodomain antibody has been introduced (c) A step of introducing a protease cleavage sequence near the boundary between the modified monodomain antibody and the constant region of the IgG antibody-like molecular precursor; It is a manufacturing method including.
- a method for producing a polypeptide which is an IgG antibody-like molecule containing a transport portion having an inhibitory domain and an antigen binding domain is described in the following steps: (a) Substituting an amino acid residue involved in association with antibody VH in a monodomain antibody, or substituting an amino acid residue involved in association with antibody VL in a monodomain antibody, the monodomain antibody.
- a step of producing a modified monodomain antibody that retains the binding activity to the target antigen of (b) The modified monodomain antibody is linked to the heavy chain constant region of the IgG antibody via a protease cleavage sequence or modified so as to suppress the antigen-binding activity of the modified monodomain antibody prepared in step (a).
- a method for producing a polypeptide which is an IgG antibody-like molecule containing a transport moiety having an inhibitory domain and an antigen binding domain is further described by (d) A step of confirming that the binding activity of the modified monodomain antibody introduced into the IgG antibody-like molecule or the IgG antibody-like molecular precursor to the target antigen is weakened or lost; It is a manufacturing method including.
- "weakened binding activity” means that the binding activity to the target antigen is reduced as compared with that before association or before ligation, and the degree of reduction is not limited.
- a method for producing a polypeptide which is an IgG antibody-like molecule containing a transport moiety having an inhibitory domain and an antigen binding domain is further described by (e) A step of releasing the modified monodomain antibody by cleaving the protease cleavage sequence with a protease and confirming that the free modified monodomain antibody binds to the target antigen; It is a manufacturing method including.
- the polypeptide is a ligand-binding molecule capable of binding to a ligand, and the binding of the ligand-binding molecule to the ligand in a state in which the protease cleavage sequence is cleaved is a protease.
- the cleaved sequence is weaker than the binding of the ligand-binding molecule to the ligand in the uncleaved state.
- the present disclosure also relates to a method for releasing a ligand bound to a ligand-binding molecule, which comprises cleaving a protease cleavage sequence contained in the ligand-binding molecule described herein by a protease.
- the present disclosure also relates to a method of releasing a ligand from a ligand-binding molecule-ligand fusion protein, comprising cleaving the protease cleavage sequence contained in the ligand-binding molecule described herein by a protease.
- ligand-binding molecule is a molecule that can bind to a ligand, particularly a molecule that can bind to a ligand in an uncleaved state.
- the "bond” here usually refers to a bond due to an interaction mainly consisting of a non-covalent bond such as an electrostatic force, a van der Waals force, or a hydrogen bond.
- Preferable examples of the ligand-binding embodiment of the ligand-binding molecule of the present disclosure include, but are not limited to, an antigen-antibody reaction in which an antigen-binding region, an antigen-binding molecule, an antibody, an antibody fragment, or the like bind to an antigen. ..
- being able to bind to a ligand means that the ligand-binding molecule can bind to the ligand even if the ligand-binding molecule and the ligand are different molecules, and it means that the ligand-binding molecule and the ligand are linked by a covalent bond. do not do.
- the fact that a ligand and a ligand-binding molecule are covalently bonded via a linker does not mean that the ligand can be bound to the ligand. Attenuating binding to a ligand means diminishing the ability to bind.
- the ligand-binding molecule may be linked to the ligand via a linker or the like as long as the ligand-binding molecule can bind to the ligand.
- the ligand-binding molecule of the present disclosure is limited only by binding to the ligand in the uncut state, and a molecule having any structure can be used as long as it can bind to the target ligand in the uncut state.
- ligand-binding molecules include, but are not limited to, heavy chain variable regions (VHs) of antibodies, light chain variable regions (VL) of antibodies, monodomain antibodies (sdAb), and cell membrane proteins present in vivo.
- a module containing about 35 amino acids called A domain (international publication WO2004 / 044011, WO2005 / 040229) contained in Avimer, and Adnectin (international) containing 10Fn3 domain, which is a domain that binds to a protein in fibronectin, which is a sugar protein expressed on the cell membrane.
- Adnectin international
- 10Fn3 domain which is a domain that binds to a protein in fibronectin, which is a sugar protein expressed on the cell membrane.
- DARPins Designed Ankyrin Repeat proteins
- neutrophil geratinase which is a region exposed on the molecular surface of ankyrin repeat (AR) having a structure in which parallel helix and loop subsystems are repeatedly stacked.
- NGAL neutrophil gelatinase-associated lipocalin
- VLR variable lymphocyte receptor
- LRR rich-repeat
- the protease cleavage sequence may be placed at any position in the polypeptide as long as the cleavage of the sequence can attenuate the binding of the ligand-binding molecule to the ligand. good. Further, the protease cleavage sequence contained in the polypeptide may be one or a plurality.
- the polypeptide of the present disclosure is a ligand-binding molecule
- the ligand binding in the cleaved state is weaker (that is, attenuated) than in the uncleaved state of the ligand-binding molecule. ..
- the binding of the ligand binding molecule to the ligand is an antigen-antibody reaction
- the attenuation of the ligand binding can be assessed by the ligand binding activity of the ligand binding molecule.
- the evaluation of the binding activity between the ligand-binding molecule and the ligand is performed by FACS, ELISA format, BIACORE method using ALPHA screen (Amplified Luminescent Proximity Homogeneous Assay), surface plasmon resonance (SPR) phenomenon, and BLI (Bio-Layer Interferometry) method (Octet). ) Etc., can be confirmed by a well-known method (Proc. Natl. Acad. Sci. USA (2006) 103 (11), 4005-4010).
- the ALPHA screen is implemented on the following principle by ALPHA technology, which uses two beads, a donor and an acceptor.
- the luminescent signal is detected only when the molecule bound to the donor bead interacts with the molecule bound to the acceptor bead and the two beads are in close proximity.
- the photosensitizer in the donor beads excited by the laser converts the surrounding oxygen into excited singlet oxygen.
- Singlet oxygen diffuses around the donor beads, and when it reaches the nearby acceptor beads, it causes a chemiluminescent reaction inside the beads, eventually emitting light.
- the chemiluminescent reaction does not occur because the singlet oxygen produced by the donor bead does not reach the acceptor bead.
- a biotin-labeled ligand-binding molecule is bound to the donor beads, and a ligand tagged with glutathione S transferase (GST) is bound to the acceptor beads.
- GST glutathione S transferase
- the ligand-binding molecule and the ligand interact to produce a signal of 520-620 nm.
- the untagged ligand-binding molecule competes with the interaction between the tagged ligand-binding molecule and the ligand.
- Relative binding affinity can be determined by quantifying the decrease in fluorescence that results from competition.
- a ligand-binding molecule such as an antibody is biotinylated using Sulfo-NHS-biotin or the like.
- a GST fusion ligand is expressed in a cell or the like carrying a vector capable of expressing a fusion gene in which a polynucleotide encoding a ligand and a polynucleotide encoding GST are fused in frame.
- a method of purification using a glutathione column or the like can be appropriately adopted.
- the obtained signal is preferably analyzed by adapting it to a one-site competition model using non-linear regression analysis using software such as GRAPHPAD PRISM (GraphPad, San Diego).
- the Biacore system takes the above-mentioned shift amount, that is, the change in mass on the surface of the sensor chip on the vertical axis, and displays the change in mass over time as measurement data (sensorgram).
- Kinetics The binding rate constant (ka) and the dissociation rate constant (kd) are obtained from the curve of the sensorgram, and the dissociation constant (KD) is obtained from the ratio of the constants.
- the inhibition measurement method and the equilibrium value analysis method are also preferably used.
- An example of the inhibition measurement method is described in Proc. Natl. Acad. Sci. USA (2006) 103 (11), 4005-4010, and an example of the equilibrium value analysis method is described in Methods Enzymol. 2000; 323: 325-40. There is.
- the ability of a ligand-binding molecule to bind to a ligand is attenuated, for example, based on the above-mentioned measurement method, the amount of ligand-binding per test ligand-binding molecule is 50% as compared with the control ligand-binding molecule.
- the amount of ligand-binding per test ligand-binding molecule is 50% as compared with the control ligand-binding molecule.
- 45% or less 40% or less, 35% or less, 30% or less, 20% or less, 15% or less, particularly preferably 10% or less, 9% or less, 8% or less, 7% or less, 6% or less.
- a desired index may be appropriately used as the index of the binding activity, and for example, the dissociation constant (KD) may be used.
- the dissociation constant (KD) is used as an evaluation index of the binding activity
- the dissociation constant (KD) of the test ligand-binding molecule to the ligand is larger than the dissociation constant (KD) of the control ligand-binding molecule to the ligand. It is shown that the binding activity of the test ligand-binding molecule to the ligand is weaker than that of the control ligand-binding molecule.
- the diminished function of binding to a ligand means that, for example, the dissociation constant (KD) of a test ligand-binding molecule to a ligand is more than twice the dissociation constant (KD) of a control ligand-binding molecule to a ligand. It means that it is preferably 5 times or more, 10 times or more, and particularly preferably 100 times or more.
- Control ligand-binding molecules include, for example, uncleaved ligand-binding molecules.
- ligand is a molecule having biological activity. Molecules with biological activity usually function by interacting with receptors on the cell surface, thereby biologically stimulating, inhibiting, or otherwise modulating them, which usually carry said receptors. It appears to be involved in intracellular signal transduction pathways.
- the ligand includes a desired molecule that exerts biological activity by interacting with a biomolecule.
- a ligand not only means a molecule that interacts with a receptor, but also a molecule that exerts biological activity by interacting with the molecule is also a ligand, for example, a receptor that interacts with the molecule or a receptor thereof.
- Bound fragments and the like are also included in the ligand.
- a protein including a ligand binding site of a protein known as a receptor and a site where the receptor interacts with another molecule is included in the ligand in the present disclosure.
- soluble receptors, soluble fragments of receptors, extracellular domains of transmembrane receptors, and polypeptides containing them are included in the ligands in the present disclosure.
- the ligands of the present disclosure can usually exert the desired biological activity by binding to one or more binding partners.
- the binding partner of the ligand can be an extracellular, intracellular, or transmembrane protein.
- the binding partner of the ligand is an extracellular protein, eg, a soluble receptor.
- the binding partner of the ligand is a membrane-bound receptor.
- the ligands of the present disclosure have 10 ⁇ M, 1 ⁇ M, 100 nM, 50 nM, 10 nM, 5 nM, 1 nM, 500 pM, 400 pM, 350 pM, 300 pM, 250 pM, 200 pM, 150 pM, 100 pM, 50 pM, 25 pM, 10 pM, 5 pM, 1 pM, as their binding partners. It can specifically bind with a dissociation constant (KD) of 0.5 pM or less.
- KD dissociation constant
- molecules having biological activity include, but are not limited to, cytokines, chemokines, polypeptide hormones, growth factors, apoptosis-inducing factors, PAMPs, DAMPs, nucleic acids, or fragments thereof.
- interleukins, interferons, hematopoietic factors, TNF superfamily, chemokines, cell growth factors, TGF- ⁇ families, myokines, adipokines, or neurotrophic factors can be used as ligands.
- the ligands are CXCL10, IL-2, IL-7, IL-12, IL-15, IL-18, IL-21, IFN- ⁇ , IFN- ⁇ , IFN-g, MIG.
- I-TAC I-TAC
- RANTES MIP-1a
- MIP-1b MIP-1b
- IL-1R1 Interleukin-1 receptor, type I
- IL-1R2 Interleukin-1 receptor, type II
- IL-1RAcP Interleukin-1 receptor accessory protein
- IL-1Ra protein accession No. NP_776214, mRNA accession No. NM_173842.2
- Chemokines are a family of homogeneous serum proteins between 7 and 16 kDa and were originally characterized by their ability to induce leukocyte migration. Most chemokines have four characteristic cysteines (Cys) and are classified into CXC, or alpha, CC or beta, C or gamma and CX3C or delta chemokine classes by the motif represented by the first two cysteines. Has been done. Two disulfide bonds are formed between the first and third cysteines and between the second and fourth cysteines.
- Disulfide bridges are generally considered necessary, and Clark-Lewis and co-workers have reported that disulfide bonds, at least for CXCL10, are critical to chemokine activity (Clark-Lewis et al., J). Biol. Chem. 269: 16075-16081, 1994).
- the only exception to having four cysteines is phosphotactin, which has only two cysteine residues. Therefore, phosphotactin manages to retain its functional structure with only one disulfide bond.
- ELR-CXC chemokines Glu-Leu-Arg
- non-ELR-CXC chemokines eg, ELR-CXC chemokines
- the ligand is a cytokine.
- Cytokines are a family of secretory cell signaling proteins involved in immunomodulatory and inflammatory processes, which are secreted by glial cells of the neural system and by numerous cells of the immune system. Cytokines can be classified as proteins, peptides or glycoproteins and include a large and diverse family of regulators. Cytokines bind to cell surface receptors and induce intracellular signal transduction, which can lead to regulation of enzyme activity, up-regulation or down-regulation of some genes and their transcription factors, or inhibition of feedback.
- the cytokines of the disclosure include immunomodulators such as interleukins (IL) and interferons (IFNs).
- IL interleukins
- IFNs interferons
- Suitable cytokines can include proteins from one or more of the following types: four ⁇ -helix bundle families, which include the IL-2 subfamily, IFN subfamily and IL-10 subfamily; The IL-1 family (which includes IL-1 and IL-8), as well as the IL-17 family.
- Cytokines are type 1 cytokines that enhance the cell-mediated immune response (eg, IFN- ⁇ , TGF- ⁇ , etc.) or type 2 cytokines that favor the antibody response (eg, IL-4, IL-10, IL-13, etc.) ) Can also be included.
- the ligand is a chemokine.
- Chemokines generally act as chemical attractants that mobilize immune effector cells to chemokine expression sites. This may be beneficial for the expression of specific chemokine genes, such as cytokine genes, for the purpose of mobilizing other immune system components to the therapeutic site.
- chemokines include CXCL10, RANTES, MCAF, MIP1- ⁇ , MIP1- ⁇ .
- cytokines are also known to have chemoattractive effects and can be classified by the term chemokine.
- polypeptide of the present disclosure is a ligand-binding molecule
- variants such as cytokines, chemokines and the like (eg, Annu Rev Immunol. 2015; 33: 139-67.) And fusion proteins containing them (eg, Annu Rev Immunol. 2015; 33: 139-67.)
- fusion proteins containing them eg, Annu Rev Immunol. 2015; 33: 139-67.
- the ligands are from CXCL10, PD-1, IL-12, IL-6R, IL-1R1, IL-1R2, IL-1RAcP, IL-1Ra. To be elected.
- the CXCL10, PD-1, IL-12, IL-6R, IL-1R1, IL-1R2, IL-1RAcP, and IL-1Ra are naturally occurring CXCL10, PD-1, IL-12, IL-6R, It may have the same sequence as IL-1R1, IL-1R2, IL-1RAcP, IL-1Ra, and naturally exists CXCL10, PD-1, IL-12, IL-6R, IL-1R1, IL- It may be a variant having a different sequence from 1R2, IL-1RAcP, and IL-1Ra but having a corresponding natural ligand and retaining physiological activity.
- the ligand sequence may be artificially modified for various purposes, and the variant of the ligand is preferably modified by making a modification that is not subject to protease cleavage (protease resistant). get.
- the ligand-binding molecule releases the ligand from the ligand-binding molecule by cleaving the cleavage site.
- the linker does not have a protease cleavage sequence, the ligand is released while being linked to the portion of the ligand-binding molecule via the linker. (See, for example, FIG. 5).
- the ligand is released from the ligand-binding molecule as long as it is released from the majority of the ligand-binding molecule.
- a method for detecting that a ligand is released from a ligand-binding molecule by cleavage of a cleavage site there is a method for detecting a ligand with a ligand detection antibody or the like that recognizes the ligand.
- the ligand-binding molecule is an antibody fragment
- the ligand-detecting antibody preferably binds to an epitope similar to that of the ligand-binding molecule.
- Ligand detection using an antibody for ligand detection is performed by FACS, ELISA format, BIACORE method using ALPHA screen (Amplified Luminescent Proximity Homogeneous Assay), surface plasmon resonance (SPR) phenomenon, and BLI (Bio-Layer Interferometry) method (Octet). Etc., can be confirmed by a well-known method (Proc. Natl. Acad. Sci. USA (2006) 103 (11), 4005-4010).
- the ligand detection antibody that recognizes the ligand is biotinylated, contacted with a biosensor, and then the binding to the ligand in the sample is measured to measure the release of the ligand.
- the amount of the ligand is measured using a ligand detection antibody, and the amount of the ligand detected in the sample before and after the protease treatment is measured.
- Ligand release can be detected by comparison.
- the amount of ligand was measured using a ligand detection antibody for a sample containing a protease, a ligand-binding molecule and a ligand, and a sample containing a ligand-binding molecule and a ligand without a protease, and a sample with or without a ligand.
- Ligand release can be detected by comparing the amount of ligand detected in the substance. More specifically, the release of the ligand can be detected by the method in the examples of the present application.
- the amount of the ligand is measured using a ligand detection antibody on a sample containing the fusion protein before or after the protease treatment, and the ligand treatment is performed.
- Ligand release can be detected by comparing the amount of ligand detected in the samples before and after.
- the amount of ligand detected in the sample containing the protease and the fusion protein and the sample containing the fusion protein without the protease were measured using the ligand detection antibody, and the amount of the ligand detected in the sample with and without the protease was measured.
- Ligand release can be detected by comparison. More specifically, the release of the ligand can be detected by the method in the examples of the present application.
- the release of the ligand is performed by measuring the physiological activity of the ligand in the sample. Can be detected. Specifically, the release of the ligand can be detected by measuring and comparing the physiological activity of the ligand with respect to the sample containing the ligand-binding molecule and the ligand before or after the protease treatment.
- the release of the ligand can be detected by measuring and comparing the physiological activity of the ligand with respect to the sample containing the protease, the ligand-binding molecule and the ligand, and the sample containing the ligand-binding molecule and the ligand without the protease.
- the release of the ligand is released by measuring and comparing the physiological activity of the ligand with respect to the sample containing the protease and the fusion protein and the sample containing the fusion protein without the protease.
- the ligand-binding molecule comprises an Fc region.
- the Fc region of an IgG antibody the type is not limited, and it is possible to use an Fc region such as IgG1, IgG2, IgG3, or IgG4.
- the ligand binding molecule comprises an antibody constant region.
- the ligand-binding molecule is an antibody.
- binding to the ligand is achieved by a variable region.
- the ligand binding molecule is an IgG antibody.
- the type is not limited, and IgG1, IgG2, IgG3, IgG4 and the like can be used. Even when an IgG antibody is used as the ligand-binding molecule, the binding to the ligand is realized by the variable region, and the binding to the ligand can be realized by either one or both of the two variable regions of the IgG antibody.
- the protease cleavage sequence in the ligand-binding molecule is cleaved to disrupt the domain having ligand-binding activity in the ligand-binding molecule into a ligand. Bonds are weakened.
- an IgG antibody is used as a ligand-binding molecule
- a protease cleavage sequence is provided in the antibody variable region, and in the cleavage state, a complete antibody variable region cannot be formed, and the binding to the ligand is attenuated. Can be mentioned.
- the ligand binds to an uncleaved ligand-binding molecule to inhibit its biological activity.
- the biological activity of the ligand is inhibited are not limited, but as an example, for example, binding of an uncleaved ligand-binding molecule to a ligand substantially or significantly interferes with or competes with the binding of the ligand to its binding partner. Examples thereof include.
- the biological activity of the ligand can be inhibited by exerting the neutralizing activity of the ligand-binding molecule bound to the ligand.
- the uncleaved ligand-binding molecule preferably can sufficiently neutralize the biological activity of the ligand by binding to the ligand. That is, it is preferable that the biological activity of the ligand bound to the uncleaved ligand-binding molecule is lower than the biological activity of the ligand not bound to the uncleaved ligand-binding molecule.
- the bioactivity of a ligand bound to an uncleaved ligand-binding molecule is 90%, but not limited to, compared to the bioactivity of a ligand unbound to an uncleaved ligand-binding molecule.
- the method of the present disclosure comprises contacting a ligand to neutralize biological activity with a ligand-binding molecule of the present disclosure and recovering the binding product of both. Cleavage of the ligand-binding molecule of the recovered binding product can restore the biological activity of the ligand neutralized thereby. That is, the method for neutralizing the biological activity of the ligand of the present disclosure further restores the biological activity of the ligand by cleaving the ligand-binding molecule of the binding product consisting of the ligand-ligand-binding molecule (that is, the ligand-binding property). It can include a step of releasing the neutralizing action of the molecule).
- the binding activity of the cleaved ligand-binding molecule to the ligand is that of a naturally occurring binding partner to the ligand (eg, a natural receptor to the ligand). It is preferably lower than the binding activity to the ligand.
- the binding activity of the cleaved ligand-binding molecule and the ligand is 90% or less compared to the binding amount (per unit binding partner) of the natural binding partner and the ligand in vivo.
- the index of the binding activity a desired index may be used as appropriate, and for example, the dissociation constant (KD) may be used.
- the dissociation constant (KD) of the cleaved ligand-binding molecule to the ligand is compared with the dissociation constant (KD) of the natural binding partner in vivo. Larger indicates that the binding activity of the cleaved ligand-binding molecule to the ligand is weaker than that of the natural binding partner in vivo.
- the dissociation constant (KD) of the cleaved ligand-binding molecule for the ligand is, for example, 1.1 times or more, preferably 1.5 times or more, as compared with the dissociation constant (KD) for the ligand of the natural binding partner in vivo.
- the biological activity of the suppressed ligand is restored after the ligand-binding molecule is cleaved. It is desirable that the binding of the cleaved ligand-binding molecule to the ligand is attenuated, so that the ligand biological activity inhibitory function of the ligand-binding molecule is also attenuated.
- One of ordinary skill in the art can confirm the biological activity of a ligand by a known method, for example, by detecting the binding of the ligand to its binding partner.
- the polypeptide of the present disclosure is a ligand-binding molecule
- the uncleaved ligand-binding molecule forms a complex with the ligand by antigen-antibody binding.
- the complex of the ligand-binding molecule and the ligand is formed by a non-covalent bond between the ligand-binding molecule and the ligand, for example, an antigen-antibody binding.
- the uncleaved ligand-binding molecule is fused with a ligand to form a fusion protein, and then the ligand-binding molecule portion and the ligand portion in the fusion protein. Are further interacting by antigen-antibody binding.
- the ligand-binding molecule and the ligand can be fused with or without a linker. Even when the ligand-binding molecule and the ligand in the fusion protein are fused with or without a linker, there is still a non-covalent bond between the ligand-binding molecule portion and the ligand portion.
- the non-covalent bond between the ligand-binding molecule moiety and the ligand moiety is similar to the embodiment in which the ligand-binding molecule and the ligand are not fused. Cleavage of the ligand-binding molecule attenuates its non-covalent bond. That is, the binding between the ligand-binding molecule and the ligand is attenuated.
- the polypeptide of the present disclosure is a ligand-binding molecule
- the ligand-binding molecule and the ligand are fused via a linker.
- a linker used when fusing a ligand-binding molecule and a ligand it is disclosed in any peptide linker that can be introduced by genetic engineering, or a synthetic compound linker (see, for example, Protein Engineering, 9 (3), 299-305, 1996). Although a linker or the like can be used, a peptide linker is preferable in this embodiment.
- the length of the peptide linker is not particularly limited and can be appropriately selected by those skilled in the art depending on the intended purpose. Examples include, but are not limited to, peptide linkers from glycine-serine polymers. However, those skilled in the art can appropriately select the length and sequence of the peptide linker according to the purpose.
- Synthetic compound linkers are commonly used cross-linking agents for cross-linking peptides, such as N-hydroxysuccinimide (NHS), dysuccinimidyl svelate (DSS), bis (sulfosuccinimidyl) svelate.
- BS3 dithiobis (succinimidyl propionate) (DSP), dithiobis (sulfosuccinimidyl propionate) (DTSSP), ethylene glycol bis (succinimidyl succinate) (EGS), ethylene glycol Bis (sulfosuccinimidyl succinate) (sulfo-EGS), dissuccinimidyl tartrate (DST), disulfosuccinimidyl tartrate (sulfo-DST), bis [2- (succinimideoxycarbonyloxy) Ethyl] sulfone (BSOCOES), bis [2- (sulfosuccinimideoxycarbonyloxy) ethyl] sulfone (sulfo-BSOCOES), etc., and these cross-linking agents are commercially available.
- a ligand-binding molecule-ligand fusion protein is a fusion protein in which the N-terminus of the ligand-binding molecule and the C-terminus of the ligand are fused via or without a linker.
- the ligand may be a fusion protein obtained by fusing to the N-terminal or C-terminal of any peptide chain in the ligand-binding molecule with or without a linker.
- the ligand-binding molecule is an IgG antibody
- the ligand may be fused to the N-terminus of VH or the N-terminus of VL with or without a linker.
- the ligand-binding molecule of the present disclosure comprises a monodomain antibody
- some aspects of the structure of the ligand-binding molecule-ligand fusion protein are listed below. The following embodiments are described in the order of N-terminal to C-terminal. It will be obvious to those skilled in the art who have referred to this disclosure that these fusion proteins may be monomeric or multimeric (including dimers).
- Ligand-Single Domain Antibody Ligand-Linker-Single Domain Antibody Ligand-Single Domain Antibody-Antibody constant region (or fragment thereof) Ligand-Linker-Single domain antibody-Antibody constant region (or fragment thereof) Ligand-monodomain antibody-antibody hinge region-antibody CH2-antibody CH3 Ligand-Linker-Single domain antibody-Antibody hinge region-Antibody CH2-Antibody CH3
- the ligand-binding molecule comprises antibody VH and antibody VL.
- ligand-binding molecules containing VH and VL include, but are not limited to, Fv, scFv, Fab, Fab', Fab'-SH, F (ab') 2, complete antibody and the like.
- the polypeptide of the present disclosure is a ligand-binding molecule
- VH and VL contained in the ligand-binding molecule are associated.
- the association between antibody VH and antibody VL can be resolved by, for example, cleavage of the protease cleavage sequence.
- the ligand-binding molecule of the present disclosure includes a ligand-binding molecule in which the association between antibody VL or a part thereof and antibody VH or a part thereof in the ligand-binding molecule is eliminated by cleaving the protease cleavage sequence with protease. Included.
- the polypeptide of the present disclosure is a ligand-binding molecule
- the ligand-binding molecule comprises antibody VH and antibody VL
- the protease cleavage sequence of the ligand-binding molecule is not cleaved.
- Antibody VH and antibody VL are associated, and cleavage of the protease cleavage sequence resolves the association between antibody VH and antibody VL in the ligand-binding molecule.
- the protease cleavage sequence in the ligand-binding molecule may be located at any position in the ligand-binding molecule as long as it can attenuate the binding of the ligand-binding molecule to the ligand by cleavage.
- the ligand-binding molecule comprises antibody VH, antibody VL, and antibody constant region.
- Antibodies VH and VL, CH and CL are mediated by many amino acid side chains between domains as described by Rothlisberger et al. (J Mol Biol. 2005 Apr 8; 347 (4): 773-89.). It is known to interact. It is known that VH-CH1 and VL-CL can form a stable structure as a Fab domain, but as reported, the amino acid side chain between VH and VL is generally 10 -5. They interact with dissociation constants in the range of M to 10-8 M, and it is considered that the rate of forming an association state is small when only the VH domain and the VL domain are present.
- the ligand-binding molecule containing antibody VH and antibody VL is provided with a rotease cleavage sequence, and prior to cleavage, heavy chain-light chain mutual in the Fab structure.
- the protease cleavage sequence is cleaved, between the peptide containing VH (or part of VH) and the peptide containing VL (or part of VL), whereas all of the action is between the two peptides.
- a ligand-binding molecule is designed in which the interaction is attenuated and the association between VH and VL is eliminated.
- the protease cleavage sequence is located within the antibody constant region.
- the protease cleavage sequence is more variable than amino acid 140 (EU numbering) in the antibody heavy chain constant region, or more variable than amino acid 122 (EU numbering) in the antibody heavy chain constant region.
- the protease cleavage sequence is introduced at any position in the sequence from the antibody heavy chain constant region amino acid 118 (EU numbering) to the antibody heavy chain constant region amino acid 140 (EU numbering).
- the protease cleavage sequence is located on the variable region side of the 130 (Kabat numbering) amino acid in the antibody light chain constant region, or the 113 (Kabat numbering) amino acid in the antibody light chain constant region. It is located on the variable region side, on the variable region side of the 112th (Kabat numbering) amino acid in the antibody light chain constant region. In some specific embodiments, the protease cleavage sequence is introduced at any position in the sequence from the antibody light chain constant region amino acid 108 (Kabat numbering) to the antibody light chain constant region 131 amino acid (Kabat numbering). To.
- the protease cleavage sequence is located within antibody VH or within antibody VL.
- the protease cleavage sequence is on the antibody constant region side of antibody VH No. 7 (Kabat numbering) amino acid, or on the antibody constant region side of antibody VH No. 40 (Kabat numbering) amino acid, or antibody VH. From the 101st (Kabat numbering) amino acid to the antibody constant region side, or from the 109th (Kabat numbering) amino acid of the antibody VH to the antibody constant region side, and from the 111th (Kabat numbering) amino acid of the antibody VH to the antibody constant region side.
- the cleavage site / protease cleavage sequence is on the antibody constant region side of antibody VL No. 7 (Kabat numbering) amino acid, or on the antibody constant region side of antibody VL No. 39 (Kabat numbering) amino acid, or , Antibody constant region side from antibody VL 96 (Kabat numbering) amino acid, or antibody constant region side from antibody VL 104 (Kabat numbering) amino acid, antibody constant region side from antibody VL 105 (Kabat numbering) amino acid Located in.
- the protease cleavage sequence is introduced at the position of a loop-forming or near-loop-structured residue in antibody VH or antibody VL.
- the loop structure in antibody VH or antibody VL refers to a portion of antibody VH or antibody VL that does not form a secondary structure such as ⁇ -helix or ⁇ -sheet.
- the positions of the residues forming the loop structure and the residues close to the loop structure are specifically: antibody VH from amino acid 7 (Kabat numbering) to amino acid 16 (Kabat numbering), from amino acid 40 (Kabat numbering).
- Amino acid 47 (Kabat numbering), amino acid 55 (Kabat numbering) to amino acid 69 (Kabat numbering), amino acid 73 (Kabat numbering) to amino acid 79 (Kabat numbering), amino acid 83 (Kabat numbering) To amino acid 89 (Kabat numbering), amino acid 95 (Kabat numbering) to amino acid 99 (Kabat numbering), amino acid 101 (Kabat numbering) to amino acid 113 (Kabat numbering), antibody VL7 amino acid (Kabat) From (numbering) to 19th amino acid (Kabat numbering), from 39th amino acid (Kabat numbering) to 46th amino acid (Kabat numbering), from 49th amino acid (Kabat numbering) to 62nd amino acid (Kabat numbering), 96th amino acid (Kabat numbering) It can refer to the range from (Kabat numbering) to amino acid 107 (Kabat numbering).
- the protease cleavage sequence is from antibody VH amino acid VH 7 (Kabat numbering) to amino acid 16 (Kabat numbering), amino acid 40 (Kabat numbering) to 47. From amino acid No.
- Kabat numbering from amino acid 55 (Kabat numbering) to amino acid 69 (Kabat numbering), from amino acid 73 (Kabat numbering) to amino acid 79 (Kabat numbering), from amino acid 83 (Kabat numbering) Introduced at any position in the sequence from amino acid 89 (Kabat numbering), amino acid 95 (Kabat numbering) to amino acid 99 (Kabat numbering), and amino acid 101 (Kabat numbering) to amino acid 113 (Kabat numbering). Will be done.
- the protease cleavage sequence is from amino acid VL7 (Kabat numbering) to amino acid 19 (Kabat numbering) and from amino acid 39 (Kabat numbering) to 46. Introduced at arbitrary positions in the sequence from amino acid No. 49 (Kabat numbering), amino acid 49 (Kabat numbering) to amino acid 62 (Kabat numbering), and amino acid 96 (Kabat numbering) to amino acid 107 (Kabat numbering). To.
- the protease cleavage sequence is located near the boundary between antibody VH and antibody constant region.
- Near the boundary between the antibody VH and the antibody heavy chain constant region can refer to the amino acid between the amino acid 101 (Kabat numbering) of the antibody VH and the amino acid 140 (EU numbering) of the antibody heavy chain constant region, or the antibody VH.
- the vicinity of the boundary between the antibody VH and the antibody light chain constant region is from the amino acid No. 101 (Kabat numbering) of the antibody VH to the antibody light chain constant region No. 130.
- the protease cleavage sequence is located near the boundary between antibody VL and antibody constant region.
- Near the boundary between antibody VL and antibody light chain constant region can be between the amino acid of antibody VL 96 (Kabat numbering) to the amino acid of antibody light chain constant region 130 (Kabat numbering), or antibody VL.
- the vicinity of the boundary between the antibody VL and the antibody heavy chain constant region is from the amino acid No. 96 (Kabat numbering) of the antibody VL to the antibody heavy chain constant region No. 140 (EU).
- Multiple protease cleavage sequences can be provided in the ligand-binding molecule, for example, in the antibody constant region, in the antibody VH, in the antibody VL, near the boundary between the antibody VH and the antibody constant region, and the boundary between the antibody VL and the antibody constant region. It can be installed in multiple locations selected from the vicinity. Further, a person skilled in the art who has touched the present disclosure can change the shape of the molecule containing the antibody VH, the antibody VL, and the antibody constant region, such as by exchanging the antibody VH and the antibody VL. Do not deviate from the scope of disclosure.
- the ligand-binding molecules comprise a monodomain antibody.
- the protease cleavage sequence in the ligand-binding molecule may be located at any position in the ligand-binding molecule as long as it can attenuate the binding of the ligand-binding molecule to the ligand by cleavage.
- the protease cleavage sequence is introduced into the monodomain antibody in the ligand-binding molecule.
- the protease cleavage sequence is introduced at the positions of the residues forming the loop structure and the residues close to the loop structure in the monodomain antibody.
- the loop structure in a monodomain antibody refers to a portion of a monodomain antibody that does not form a secondary structure such as ⁇ -helix or ⁇ -sheet.
- the polypeptide of the present disclosure is a ligand-binding molecule containing a monodomain antibody
- the monodomain antibody is a VHH or a monodomain VH antibody
- residues forming a loop structure and residues close to the loop structure The positions are specifically: Monodomain antibody Amino acid 7 (Kabat numbering) to amino acid 17 (Kabat numbering), amino acid 12 (Kabat numbering) to amino acid 17 (Kabat numbering), amino acid 31 (Kabat numbering).
- the protease cleavage sequence is one selected from the following sequences of the monodomain antibody or Introduced to one or more positions in multiple sequences: Single domain antibody sequence from amino acid 7 (Kabat numbering) to amino acid 17 (Kabat numbering), single domain antibody sequence from amino acid 12 (Kabat numbering) to amino acid 17 (Kabat numbering), single domain antibody amino acid 31 Sequence from (Kabat numbering) to amino acid 35b (Kabat numbering), sequence from amino acid 40 (Kabat numbering) to amino acid 47 (Kabat numbering), monodomain antibody amino acid 50 (Kabat numbering) to 65 Sequence up to amino acid number (Kabat numbering), sequence from amino acid 55 (Kabat numbering) to amino acid 69 (Kabat numbering), single domain antibody amino acid 73 (Kabat numbering
- the positions of the residues forming the loop structure and the residues close to the loop structure are , Specifically: Single domain antibody From amino acid 7 (Kabat numbering) to amino acid 19 (Kabat numbering), from amino acid 24 (Kabat numbering) to amino acid 34 (Kabat numbering), from amino acid 39 (Kabat numbering) Amino acid 46 (Kabat numbering), amino acid 49 (Kabat numbering) to amino acid 62 (Kabat numbering), amino acid 50 (Kabat numbering) to amino acid 56 (Kabat numbering), amino acid 89 (Kabat numbering) It can refer to the range from amino acid No. 97 (Kabat numbering) to amino acid 96 (Kabat numbering) to amino acid 107 (Kabat numbering).
- the polypeptide of the present disclosure is a ligand-binding molecule comprising a monodomain antibody
- the monodomain antibody is a monodomain VL antibody
- the protease cleavage sequence is one or more selected from the following sequences of the monodomain antibody.
- a plurality of protease cleavage sequences can be provided in the ligand-binding molecule, for example, a plurality of protease cleavage sequences can be provided in the monodomain antibody in the ligand-binding molecule.
- the uncleaved ligand-binding molecule has a longer half-life than the monodomain antibody alone.
- the molecular weight of the ligand-binding molecule is increased, or FcRn binding to the monodomain antibody is not limited to that. Fusing with a moiety having an albumin, or fusing with a moiety having albumin binding with a monodomain antibody, or fusing with a moiety that has been PEGylated with a monodomain antibody.
- the polypeptide of the present disclosure is a ligand-binding molecule containing a monodomain antibody
- the blood half-life in humans can be predicted based on the blood half-life in humans.
- the polypeptide of the present disclosure is a ligand-binding molecule containing a monodomain antibody
- one embodiment in which the blood half-life of the ligand-binding molecule is longer than the blood half-life of a single-domain antibody alone is to increase the molecular weight of the ligand-binding molecule.
- the molecular weight of the ligand-binding molecule is 60 kDa or more. Molecules with a molecular weight of 60 kDa or more are usually less likely to cause renal clearance and have a longer half-life in the blood when present in the blood (J Biol Chem. 1988 Oct 15; 263 (29). ): See 15064-70).
- the polypeptide of the present disclosure is a ligand-binding molecule containing a monodomain antibody
- the blood half-life of the ligand-binding molecule is longer than the blood half-life of the monodomain antibody alone, the monodomain antibody and the FcRn-binding region Is to be fused with.
- the polypeptide of the present disclosure is a ligand-binding molecule containing a monodomain antibody
- the blood half-life of the ligand-binding molecule is longer than the blood half-life of a single domain antibody alone
- the single domain antibody and albumin binding property There is a method of fusing with the part having.
- Albumin does not undergo renal excretion and has FcRn binding, so it has a long half-life in blood of 17 to 19 days (J Clin Invest. 1953 Aug; 32 (8): 746-768.). Therefore, it has been reported that the protein bound to albumin becomes bulky and can indirectly bind to FcRn, resulting in an increase in the half-life in blood (Antibodies 2015, 4 (3), 141-156).
- the half-life of the ligand-binding molecule is longer than the half-life of the single domain antibody alone
- Examples of methods for introducing a protease cleavage sequence into a molecule capable of binding to a ligand include a method for inserting a protease cleavage sequence into the amino acid sequence of a polypeptide capable of binding to a ligand, and an amino acid sequence of a polypeptide capable of binding to a ligand.
- a method of replacing a part of the above with a protease cleavage sequence and the like can be mentioned.
- An example of a method for obtaining a molecule capable of binding to a ligand is a method for obtaining a ligand-binding region having the ability to bind to a ligand.
- the ligand binding region can be obtained, for example, by a method using a known method for producing an antibody.
- the antibody obtained by the production method may be used as it is in the ligand binding region, or only the Fv region of the obtained antibody may be used, and the Fv region is single-strand (also referred to as “sc”). If the antigen can be recognized in, only the single strand may be used. Further, a Fab region including an Fv region may be used.
- a molecule in which a protease cleavage sequence is introduced into a molecule capable of binding to a ligand becomes a disclosed ligand-binding molecule. It can be optionally confirmed whether the ligand-binding molecule is cleaved by the treatment of the protease corresponding to the protease cleavage sequence. For example, was the protease cleavage sequence cleaved by contacting a molecule in which a protease cleavage sequence was introduced into a molecule capable of binding to a ligand with a protease and confirming the molecular weight of the product after protease treatment by electrophoresis such as SDS-PAGE? It can be confirmed whether or not.
- a method for producing a ligand-ligand-binding molecule is also provided.
- a method for producing a ligand-ligand-binding molecule complex is also provided, which comprises a step of bringing the ligand-binding molecule into contact with the ligand and a step of recovering the complex composed of the ligand-binding molecule and the ligand.
- Such a complex can be made into a pharmaceutical composition, for example, by blending with a pharmaceutically acceptable carrier.
- the present disclosure also relates to a method for producing a ligand-binding molecule whose binding to a ligand is attenuated in a cleaved state, or a fusion protein in which the ligand-binding molecule and a ligand are fused.
- a method for producing a ligand-binding molecule or fusion protein comprising introducing a protease cleavage sequence into a molecule capable of binding to a ligand is provided.
- the disclosure also relates to polynucleotides that encode polypeptides containing protease substrates or protease cleavage sequences.
- the polynucleotide in the present disclosure is usually carried (inserted) into a suitable vector and introduced into a host cell.
- the vector is not particularly limited as long as it stably holds the inserted nucleic acid.
- Escherichia coli when Escherichia coli is used as the host, a pBluescript vector (manufactured by Stratagene) is preferable as the cloning vector, but it is commercially available.
- a pBluescript vector manufactured by Stratagene
- Expression vectors are particularly useful when vectors are used for the purposes of producing the polypeptides of the present disclosure.
- the expression vector is not particularly limited as long as it is a vector that expresses a polypeptide in vitro, in Escherichia coli, in cultured cells, or in an individual organism.
- pBEST vector manufactured by Promega
- Escherichia coli If it is a pET vector (manufactured by Invitrogen), if it is a cultured cell, it is a pME18S-FL3 vector (GenBank Accession No. AB009864), if it is an individual organism, it is a pME18S vector (Mol Cell Biol. 8: 466-472 (1988)), etc.
- the DNA of the present disclosure can be inserted into the vector by a conventional method, for example, by a ligase reaction using a restriction enzyme site (Current protocols in Molecular Biology edit. Ausubel et al. (1987) Publish. John Wiley & Sons. Section 11.4-11.11).
- the host cell is not particularly limited, and various host cells are used depending on the purpose.
- Examples of cells for expressing a polypeptide include bacterial cells (eg, Streptococcus, Staphylococcus, Escherichia coli, Streptomyces, Bacillus subtilis), fungal cells (eg, yeast, Aspergillus), and insect cells (eg, Drosophylla S2). , Spodoptera SF9), animal cells (eg, CHO, COS, HeLa, C127, 3T3, BHK, HEK293, Bowes melanoma cells) and plant cells can be exemplified.
- bacterial cells eg, Streptococcus, Staphylococcus, Escherichia coli, Streptomyces, Bacillus subtilis
- fungal cells eg, yeast, Aspergillus
- insect cells eg, Drosophylla S2
- Spodoptera SF9 animal cells
- animal cells
- Vector introduction into host cells includes, for example, calcium phosphate precipitation method, electric pulse perforation method (Current protocols in Molecular Biology edit. Ausubel et al. (1987) Publish. John Wiley & Sons. Section 9.1-9.9), lipofectamine method (GIBCO). -It can be performed by a known method such as BRL) or microinjection method.
- An appropriate secretory signal can be incorporated into the target polypeptide in order to secrete the polypeptide expressed in the host cell into the endoplasmic reticulum lumen, the pericellular cavity, or the extracellular environment. These signals may be endogenous or heterologous to the polypeptide of interest.
- the medium is recovered.
- the polypeptide of the present disclosure is produced intracellularly, the cell is first lysed and then the polypeptide is recovered.
- ammonium sulfate or ethanol precipitation acid extraction, anion or cation exchange chromatography, phosphocellulose chromatography, hydrophobic interaction chromatography, affinity chromatography, Known methods can be used, including hydroxylapatite chromatography and lectin chromatography.
- treatment and its grammatical derivatives such as “treat”, “treat”, etc.) as used herein are clinically intended to alter the natural course of the individual being treated. It means intervention and can be performed both for prevention and during the course of the clinical condition.
- desired effects of treatment are, but are not limited to, prevention of the onset or recurrence of the disease, alleviation of symptoms, reduction of any direct or indirect pathological effects of the disease, prevention of metastasis, progression of the disease. Includes reduced rate, recovery or alleviation of disease state, and ameliorated or improved prognosis.
- the polypeptides comprising the protease cleavage sequences of the present disclosure are used to delay the onset of the disease or slow the progression of the disease.
- compositions Also disclosed in the present disclosure are pharmaceutical compositions (drugs) containing protease-cleaving sequences and pharmaceutically acceptable carriers, polypeptides and ligands containing protease-cleaving sequences and pharmaceutically acceptable carriers. It also relates to a pharmaceutical composition (drug) comprising, a fusion protein in which a polypeptide containing a protease cleavage sequence and a ligand are fused, and a pharmaceutical composition (drug) comprising a pharmaceutically acceptable carrier.
- the pharmaceutical composition usually refers to a drug for treating or preventing a disease, or for testing / diagnosis.
- pharmaceutical composition containing a polypeptide containing a protease cleavage sequence is paraphrased as "a therapeutic method for a disease including administration of a polypeptide containing a protease cleavage sequence to a therapeutic subject”.
- the term "pharmaceutical composition containing a polypeptide and a ligand containing a protease cleavage sequence” refers to "a method for treating a disease including administering a polypeptide and a ligand containing a protease cleavage sequence to a therapeutic subject". It can be paraphrased as "use of a polypeptide and a ligand containing a protease cleavage sequence to treat a disease", or "protease cleavage in the manufacture of a drug for treating a disease”. It can also be rephrased as "use of a polypeptide containing a sequence and a ligand”.
- the term "pharmaceutical composition containing a fusion protein” can be rephrased as "a method for treating a disease including administration of the fusion protein to a therapeutic subject", and “treating a disease”. It can be paraphrased as "use of fusion protein for treatment” or "use of fusion protein in the manufacture of a drug for treating a disease”.
- the pharmaceutical composition of the present disclosure can be formulated using a method known to those skilled in the art.
- it can be used parenterally in the form of sterile solutions with water or other pharmaceutically acceptable liquids, or injectable suspensions.
- pharmacologically acceptable carriers or vehicles specifically sterile water or saline, vegetable oils, emulsifiers, suspensions, surfactants, stabilizers, flavors, excipients, vehicles, preservatives.
- Aseptic compositions for injection can be formulated according to routine formulation practices using vehicles such as distilled water for injection.
- Aqueous solutions for injection include, for example, saline, isotonic solutions containing glucose and other adjuvants (eg, D-sorbitol, D-mannose, D-mannitol, sodium chloride).
- Suitable solubilizers such as alcohols (ethanol, etc.), polyalcohols (propylene glycol, polyethylene glycol, etc.), nonionic surfactants (polysorbate 80 (TM), HCO-50, etc.) can be used in combination.
- oily liquid examples include sesame oil and soybean oil, and benzyl benzoate and / or benzyl alcohol can also be used as a solubilizing agent. It can also be blended with buffers (eg, phosphate buffers and sodium acetate buffers), soothing agents (eg, procaine hydrochloride), stabilizers (eg, benzyl alcohol and phenol), antioxidants.
- buffers eg, phosphate buffers and sodium acetate buffers
- soothing agents eg, procaine hydrochloride
- stabilizers eg, benzyl alcohol and phenol
- antioxidants antioxidants.
- the prepared injection solution is usually filled in a suitable ampoule.
- the pharmaceutical composition of the present disclosure is preferably administered by parenteral administration.
- parenteral administration for example, an injection type, a nasal administration type, a pulmonary administration type, and a transdermal administration type composition are administered.
- it can be administered systemically or locally by intravenous injection, intramuscular injection, intraperitoneal injection, subcutaneous injection, or the like.
- the administration method can be appropriately selected depending on the patient's age and symptoms.
- the dose of the pharmaceutical composition of the present disclosure can be set, for example, in the range of 0.0001 mg to 1000 mg per kg of body weight at a time. Alternatively, for example, a dose of 0.001 to 100,000 mg per patient can be set, but the disclosure is not necessarily limited to these numbers.
- the dose and administration method vary depending on the weight, age, symptoms, etc. of the patient, but those skilled in the art can set an appropriate dose and administration method in consideration of these conditions.
- a composition containing the ligand-binding molecule can be administered to an individual.
- the ligand-binding molecule administered to the individual binds to the ligand originally existing in the individual in the individual, for example, in blood, tissue, etc., and is further transported in the living body while being bound to the ligand.
- the ligand-binding molecule transported to the diseased tissue is cleaved in the diseased tissue, the binding to the ligand is weakened, and the ligand bound in the diseased tissue can be released.
- the released ligand exerts biological activity in the diseased tissue and can treat the disease caused by the diseased tissue.
- the biological activity of the ligand is suppressed when the ligand-binding molecule is bound to the ligand and the ligand-binding molecule is cleaved specifically for the disease tissue, the biological activity of the ligand during transport is not exerted. Only after being cleaved in the diseased tissue can the biological activity of the ligand be exerted, the disease can be treated, and systemic side effects can be suppressed.
- the composition containing the ligand-binding molecule and the composition containing the ligand can be administered to the individual separately or simultaneously.
- a composition containing both a ligand-binding molecule and a ligand can be administered to an individual.
- the ligand-binding molecule and the ligand in the composition may form a complex.
- the ligand-binding molecule When both the ligand-binding molecule and the ligand are administered to the individual, the ligand-binding molecule binds to the ligand administered to the individual and is transported in vivo with the ligand bound.
- the ligand-binding molecule transported to the diseased tissue is cleaved in the diseased tissue, the binding to the ligand is weakened, and the ligand bound in the diseased tissue can be released.
- the released ligand exerts biological activity in the diseased tissue and can treat the disease caused by the diseased tissue.
- the biological activity of the ligand is suppressed when the ligand-binding molecule is bound to the ligand and the ligand-binding molecule is cleaved specifically for the disease tissue
- the biological activity of the ligand during transport is not exerted. Only after being cleaved in the diseased tissue can the biological activity of the ligand be exerted, the disease can be treated, and systemic side effects can be suppressed.
- the ligand-binding molecule administered to the individual can bind not only to the ligand administered to the individual but also to the ligand originally present in the individual, and the ligand originally present in the individual or the ligand administered to the individual can be used. It can be transported in vivo while bound.
- a fusion protein in which the ligand-binding molecule and the ligand are fused can be administered to an individual.
- the ligand binding molecule and the ligand in the fusion protein form the fusion protein with or without a linker, but the non-covalent bond between the ligand binding molecule portion and the ligand moiety remains.
- the fusion protein When an individual is administered with a fusion protein in which a ligand-binding molecule and a ligand are fused, the fusion protein is transported in vivo, and the ligand-binding molecular portion in the fusion protein is cleaved in the diseased tissue, whereby the ligand of the ligand-binding molecular portion is cleaved.
- the non-covalent bond to is attenuated and the ligand and some of the ligand-binding molecules are released from the fusion protein.
- Some of the released ligands and ligand-binding molecules can exert the biological activity of the ligand in the diseased tissue and treat the disease caused by the diseased tissue.
- the ligand-binding molecule suppresses the biological activity of the ligand when it is bound to the ligand and the ligand-binding molecule is cleaved specifically for the disease tissue
- the biological activity of the ligand in the fusion protein during transport is exhibited.
- the biological activity of the ligand can be exerted only after being cleaved in the diseased tissue, the disease can be treated, and systemic side effects can be suppressed.
- protease cleavage sequence contained in the polypeptide of the present disclosure is cleaved by matliptase and / or urokinase, it is expected to be cleaved in cancer tissue, and cancer can be treated while suppressing systemic side effects.
- Example 1 Search for protease cleavage sequence using peptide array 1-1 Design and preparation of peptide library A 15-amino acid peptide library was designed based on the sequence TSTSGRSANPRG (SEQ ID NO: 1) that can be cleaved by uPA and MP-SP1. Gly, Ser, or both are added to the N-terminal and / or C-terminal of the sequence shown by SEQ ID NO: 1, and some of the amino acids in the sequence shown by SEQ ID NO: 1 are C, R, K.
- each peptide array is composed of recombinant human u-Plasminogen Activator / Urokinase (human uPA, huPA) (R & D Systems; 1310-SE-010), recombinant human Mattriptase / ST14 Catalytic Domain (human MT-SP1, It was treated by hMT-SP1) (R & D Systems; 3946-SE-010) and recombinant mouse u-Plasminogen Activator / Urokinase (mouse uPA, muPA) (abcam; ab92641).
- Each peptide array was also treated with human serum (hserum) (Valley Biomedical; HS1004C) to assess serum cleavage of the peptides.
- the processing conditions are shown in Tables 1 and 2.
- GGSTSTSGRSANPRG SEQ ID NO: 2
- TSTSGRSANPRGGS SEQ ID NO: 3
- GGGSGGGSGGGSGGG SEQ ID NO: 4
- the cleavage rate (Proteolytic Activity Ratio, PAR for short) was calculated as (fluorescence (RFU) when treated with PBS alone) / (fluorescence (RFU) when treated with protease).
- FIGS. 5 and 6 show an example of a molecule using an antibody as a ligand-binding molecule when the polypeptide is a ligand-binding molecule.
- a protease cleavage sequence is introduced near the boundary between the variable region (VH or VL) and the constant region (CH1 or CL) of the anti-ligand neutralizing antibody. It is confirmed that the anti-ligand antibody retains the ligand binding activity even after the introduction of the protease cleavage sequence.
- VH or VL alone cannot bind to the ligand (both VH and VL are required to bind to the ligand), the ligand is deneutralized and can exert a biological effect on the tumor tissue. Is.
- the VH molecule of this released ligand-linker-anti-ligand antibody does not have an Fc region and has a small molecular weight, so it has a very short half-life and disappears rapidly from the whole body. It is possible to minimize sexual side effects.
- the ligand and the anti-ligand antibody are not fused with a linker as shown in FIG.
- the anti-ligand antibody and the ligand having a protease cleavage sequence introduced near the boundary between VH and CH1 are mixed and administered. .. If the affinity of the anti-ligand antibody for the ligand is sufficiently strong and the anti-ligand antibody is sufficient for the ligand concentration, the biological activity of the ligand is sufficiently inhibited. Even if this ligand-anti-ligand antibody complex is systemically administered, the ligand is neutralized and therefore does not exert its biological activity, and the ligand-anti-ligand antibody complex has an Fc region and therefore has a long half-life. Have.
- the VH molecule of the anti-ligand antibody is released when the protease cleavage sequence near the boundary between VH and CH1 is cleaved by a protease highly expressed in the tumor tissue. Since VH or VL alone cannot bind to the ligand (both VH and VL are required to bind to the ligand), the ligand is deneutralized and can exert a biological effect on the tumor tissue. Is. In addition, this released ligand molecule does not have an Fc region and has a small molecular weight, so it has a very short half-life and disappears rapidly from the whole body, thus minimizing the systemic side effects caused by the ligand.
- Example 3 Example of a ligand-binding molecule containing a monodomain antibody into which a protease-cleaving sequence has been introduced
- FIGS. 7 to 10 when the polypeptide is a ligand-binding molecule containing a monodomain antibody, the protease-cleaving sequence has been introduced.
- An example of a ligand-binding molecule containing a domain antibody is shown.
- FIG. 7 shows an example of a ligand-binding molecule containing only a monodomain antibody into which a protease cleavage sequence has been introduced.
- the monodomain antibody can bind to the ligand, and if the affinity of the monodomain antibody for the ligand is sufficiently strong, the biological activity of the ligand is sufficiently inhibited. Even if the ligand-binding molecule and the ligand are systemically administered, the ligand in the ligand-binding molecule-ligand complex is neutralized and does not exert its biological activity, and the ligand-ligand-binding molecule complex is not exhibited. Has a longer half-life than the ligand alone.
- the systemically administered ligand-binding molecule and the ligand-formed complex cannot bind to the ligand, and the ligand cannot be bound to the ligand.
- the neutralization of the antibody is released, and it is possible to exert a biological effect on the tumor tissue.
- FIG. 8 shows an example of a fusion polypeptide in which a ligand is fused with a ligand-binding molecule containing only a single domain antibody into which a protease cleavage sequence has been introduced.
- the monodomain antibody in the fusion polypeptide can bind to the ligand, and if the affinity of the monodomain antibody for the ligand is sufficiently strong, the biological activity of the ligand is sufficiently inhibited. Has been done.
- the ligand in the fusion polypeptide is neutralized and therefore does not exert its biological activity, and the fusion polypeptide has a longer half-life than the ligand alone.
- a systemically administered fusion polypeptide when the protease cleavage sequence in the monodomain antibody is cleaved by a protease highly expressed in the tumor tissue, the monodomain antibody in the fusion polypeptide cannot bind to the ligand, and the ligand is neutralized. Is released and part of the fusion polypeptide containing the ligand is released, allowing it to exert a biological effect on the tumor tissue.
- FIGS. 9 and 10 show examples of a single domain antibody into which a protease cleavage sequence has been introduced, a ligand-binding molecule containing an antibody hinge region and an antibody Fc region, and a fusion polypeptide of the ligand-binding molecule and a ligand. is there. Similar to the aspects of FIGS. 7 and 8, the ligand can be neutralized by the monodomain antibody in the uncleaved state, and the ligand can be released in the cleaved state to exert a biological effect. is there. Further, in the examples of FIGS. 9 and 10, since the antibody Fc region is contained in the complex or fusion polypeptide in the uncut state, the half-life of the uncut state is further longer than that of the examples of FIGS. 7 and 8. Is expected.
- Example 4 Anti-human IL-6R monodomain antibody-containing ligand-binding molecule into which a protease cleavage sequence has been introduced. 4-1 Preparation of a ligand-binding molecule by introducing a protease cleavage sequence into a polypeptide containing an anti-human IL-6R monodomain antibody.
- the protease cleavage sequence was inserted into the monodomain antibody in the polypeptide IL6R90-G1T3dCHdC (SEQ ID NO: 18030) in which the antibody hinge region shown in 18029 and the N-terminal of the antibody Fc region sequence were fused, and the protease cleavage sequence was introduced.
- a domain antibody-containing ligand-binding molecule was prepared.
- a sequence containing a peptide sequence (LSGRSDNH, SEQ ID NO: 18031) reported to be cleaved by MT-SP1 expressed specifically for cancer was inserted into the polypeptide IL6R90-G1T3dCHdC and shown in Table 3.
- a ligand-binding molecule was prepared, expressed by transient expression using Expi293 (Life Technologies), and purified by a method known to those skilled in the art using protein A.
- IL6R90-G1T3dCHdC was expressed and purified as a control molecule containing no protease cleavage sequence.
- the prepared ligand-binding molecule and control molecule are dimeric proteins as shown in FIG.
- control molecules (Lane 12, 13) containing no protease cleavage sequence have bands at the same position regardless of whether they are protease-treated or untreated, whereas each protease cleavage sequence is introduced into a ligand binding.
- the molecule had a new band that occurred only after protease treatment, that is, the single domain antibody-containing ligand-binding molecule into which each protease cleavage sequence was introduced was cleaved by protease treatment.
- a Protein G sensor (ForteBio, 18-0022) was hydrated with PBS and measured with Octet RED 384 at a setting of 25 degrees. Baseline measurements were performed in wells containing PBS for 30 seconds, after which the antibody was bound to the Protein G sensor for 200 seconds. Baseline measurements were performed again in the wells containing PBS for 30 seconds, then binding was measured in wells containing human 500 nM IL-6R for 180 seconds, and dissociation was measured in wells containing PBS for 180 seconds. A real-time join graph showing the state of join is shown in FIG. As shown in FIG.
- Example 5 Preparation and evaluation of an anti-human IL-6R monodomain antibody-containing ligand-binding molecule into which a protease cleavage sequence has been introduced and a human IL-6R fusion protein (ligand-binding molecule-IL-6R fusion protein). 5-1. Preparation of fusion protein of anti-human IL-6R single domain antibody-containing ligand-binding molecule and human IL-6R into which a protease cleavage sequence was introduced Glycin at the N-terminus of the ligand-binding molecule prepared in Example 4-1.
- a ligand-binding molecule-IL-6R fusion protein was prepared by fusing with the C-terminus of human IL-6R (SEQ ID NO: 18037) via various linkers consisting of and serine (Table 4). These fusion proteins were expressed by transient expression using Expi293 (Life Technologies) by a method known to those skilled in the art, and were purified by a method known to those skilled in the art using protein A. Each of the produced fusion proteins is a dimeric protein having two peptide chains having the sequences shown in Table 4.
- a control molecule containing no protease cleavage sequence As a control molecule containing no protease cleavage sequence, a molecule (Table 5) in which the N-terminal of IL6R90-G1T3dCHdC (SEQ ID NO: 18030) was fused with the C-terminal of IL-6R via a linker was prepared, and expressed and purified. Was done. Each of the prepared control molecules is also a dimeric protein having two peptide chains having the sequences shown in Table 5.
- each fusion protein containing a molecule has a new band that occurs only after protease treatment, that is, each fusion protein containing a monodomain antibody-containing ligand-binding molecule into which each protease cleavage sequence has been introduced has been cleaved by protease treatment.
- biotinylated anti-IL-6R monodomain antibody-containing molecule As a method for detecting the release of IL-6R fused to a ligand-binding molecule, biotin is added to the monodomain antibody-containing molecule that recognizes IL-6R. A method was used to detect the binding of free IL-6R to a molecule containing an anti-IL-6R monodomain antibody that had been imparted and ionized.
- the biotinylated anti-IL-6R monodomain antibody-containing molecule was prepared as follows.
- An anti-IL-6R monodomain antibody-containing molecule having the same monodomain antibody partial sequence as IL6R90-G1T3dCH1dC (SEQ ID NO: 18030) was prepared, and a biotin addition sequence (AviTag sequence, SEQ ID NO: 18068) was added to the C-terminal.
- IL6R90-FcBAPdC (SEQ ID NO: 18069) was prepared.
- a gene fragment encoding IL6R90-FcBAPdC was prepared and introduced into an animal cell expression vector by a method known to those skilled in the art. At this time, a gene expressing EBNA1 and a gene expressing biotin ligase were simultaneously introduced, and biotin was added for the purpose of biotin labeling.
- the cells into which the gene was introduced were cultured at 37 ° C. and 8% CO2, and the target biotinylated anti-IL-6R monodomain antibody-containing molecule (IL6R90-bio) was secreted into the culture supernatant.
- IL6R90-bio was purified from the culture supernatant by a method known to those skilled in the art.
- Example 5-2-3 Biotinylated anti-IL-6R monodomain antibody-containing molecule ( It was evaluated by the biolayer interference method (BLI method) using IL6R90-bio).
- protease-treated fusion protein, protease-untreated fusion protein, and IL6R90-bio prepared in Example 5-2-1 were dispensed into different wells of Tilted bottom (TW384) Micro plates (ForteBio, 18-5076), respectively.
- a Streptavidin biosensor (ForteBio, 18-5021) was hydrated using PBS and measured with Octet RED 384 at a setting of 27 ° C. Baseline measurements were performed in wells containing PBS for 30 seconds, after which IL6R90-bio was coupled to the Streptavidin sensor for 200 seconds.
- FIGS. 17 and 18 Real-time join graphs showing the state of join are shown in FIGS. 17 and 18.
- FIGS. 17 and 18 in the case of the single domain antibody-containing ligand-binding molecule-IL-6R fusion protein into which the protease cleavage sequence was introduced, IL6R90-bio was obtained in the case of protease treatment as compared with the case of untreated protease. The amount of human IL-6R bound was increased. That is, the protease treatment attenuated the binding activity of the monodomain antibody in the fusion protein to IL-6R, and IL-6R was released from the fusion protein.
- Example 6 Preparation and evaluation of a fusion protein of an anti-human PD-1 monodomain antibody-containing ligand-binding molecule and human PD-1 into which a protease cleavage sequence has been introduced (ligand-binding molecule-PD-1 fusion protein). 6-1.
- the extracellular domain of human PD-1 (SEQ ID NO: 18072) was transferred to the N-terminus of each via various linkers consisting of glycine and serine. It was fused with the C-terminus to prepare a ligand-binding molecule-PD-1 fusion protein (Table 6). These fusion proteins were expressed by transient expression using Expi293 (Life Technologies) by a method known to those skilled in the art, and were purified by a method known to those skilled in the art using protein A. Each of the fusion proteins produced is a dimeric protein having two peptide chains having the sequences shown in Table 6.
- Example 6-2-2 Confirmation of protease cleavage of anti-PD-1 monodomain antibody-PD-1 fusion protein (SDS-PAGE) It was confirmed by SDS-PAGE whether the ligand-binding molecule-PD-1 fusion protein was cleaved by the protease treatment carried out in Example 6-2-1. 9 ⁇ L of the solution containing the protease-treated fusion protein / protease-untreated fusion protein prepared in Example 6-2-1 was mixed with 3 ⁇ L of sample buffer and kept warm at 95 ° C. for 1 minute.
- each fusion protein containing a monodomain antibody-containing ligand-binding molecule into which each protease cleavage sequence has been introduced has a new band that occurs only after protease treatment, that is, each protease cleavage sequence has been introduced. It was shown that each fusion protein containing a domain antibody-containing ligand-binding molecule was cleaved by protease treatment.
- biotinylated anti-PD-1 monodomain antibody-containing molecule As a method for detecting the release of PD-1 fused to a ligand-binding molecule, biotinate in a monodomain antibody-containing molecule that recognizes PD-1. was applied, and a method of detecting free PD-1 binding to a biotinylated anti-PD-1 monodomain antibody-containing molecule was used.
- the biotinylated anti-PD-1 monodomain antibody-containing molecule was prepared as follows.
- a monodomain antibody-containing molecule having the same monodomain antibody partial sequence as PD102C3-G1T3noCyshinge was prepared, and a biotin addition sequence (AviTag sequence, SEQ ID NO: 18068) was added to the C-terminal to PD102C3-FcBAPdC (SEQ ID NO:). : 18077) was produced.
- an anti-PD-1 monodomain antibody-containing molecule having the same monodomain antibody partial sequence as PD102C12-G1T3noCyshinge was prepared, and a biotin addition sequence (AviTag sequence, SEQ ID NO: 18068) was added to the C-terminal thereof.
- PD102C12-FcBAPdC (SEQ ID NO: 18078) was prepared.
- Gene fragments encoding PD102C3-FcBAPdC and PD102C12-FcBAPdC were prepared, respectively, and introduced into an animal cell expression vector by a method known to those skilled in the art.
- a gene expressing EBNA1 and a gene expressing biotin ligase were simultaneously introduced, and biotin was added for the purpose of biotin labeling.
- the cells into which the gene was introduced were cultured at 37 ° C. at 8% CO2, and the target biotinylated anti-PD-1 monodomain antibody-containing molecule (PD1-bio) was secreted into the culture supernatant.
- PD1-bio was purified from the culture supernatant by a method known to those skilled in the art.
- protease-treated fusion protein, protease-untreated fusion protein, and PD1-bio prepared in Example 6-2-1 were dispensed into different wells of Tilted bottom (TW384) Microplates (ForteBio, 18-5076), respectively.
- TW384 Tilted bottom
- PD102C3-FcBAPdC or PD102C12-FcBAPdC is appropriately selected so as to bind to the same epitope as the monodomain antibody in the measurement sample.
- a Streptavidin biosensor (ForteBio, 18-5021) was hydrated using PBS and measured with Octet RED 384 at a setting of 27 ° C.
- FIG. 20 A real-time join graph showing the state of join is shown in FIG. As shown in FIG. 20, in the case of the single domain antibody-containing ligand-binding molecule-PD-1 fusion protein into which the protease cleavage sequence has been introduced, a human who binds to PD1-bio in the case of protease treatment as compared with the case of no protease treatment. The amount of PD-1 increased. That is, the protease treatment attenuated the binding activity of the monodomain antibody in the fusion protein to PD-1, and PD-1 was released from the fusion protein.
- Example 7 Evaluation of antibody inserted with various protease cleavage sequences 7-1
- G7 heavy chain: G7H-G1T4 (SEQ ID NO: 18079), light chain: G7L-LT0 (SEQ ID NO: 18080), which is an antibody that neutralizes human CXCL10.
- the protease cleavage sequence shown in Table 7 was inserted between the light chain variable region 106a (Kabat numbering) and the light chain constant region 107a (Kabat numbering).
- the antibody variants shown in Table 7, which are a combination of the antibody light chain variants and heavy chains prepared above, are expressed by transient expression using Expi293 cells (Life technologies) by a method known to those skilled in the art, and are proteins. Purified by a method known to those skilled in the art using A.
- each antibody variant is used.
- Recombinant Human u-Plasminogen Activator / Urokinase human uPA, huPA
- Recombinant Human Mattriptase / ST14 Catalytic Domain human MT-SP1, hMT-SP1
- mice u-Plasminogen Activator / Urokinase mouse uPA, muPA
- the antibody variant 100 ⁇ g / mL was reacted with huPA or hMT-SP1 or muPA for 1 hour under the conditions of PBS and 37 ° C., and then evaluated by reduction capillary electrophoresis.
- Wes Protein Simple
- anti-human lambda chain HRP-labeled antibody (abcam; ab9007) was used for detection.
- the peak around 36 kDa disappeared and a new peak was observed around 20 kDa. That is, the peak near 36 kDa was considered to be an uncut light chain, and the peak near 20 kDa was considered to be a truncated light chain.
- the area of each peak obtained after protease treatment is output from Wes-dedicated software (Compass for SW; Protein Simple), and the cleavage rate (%) of the antibody variant is (cleaved light chain peak area) * 100 / (cleaved light). It was obtained by calculating (chain peak area + uncut light chain peak area).
- Tables 8, 9, 10, 11, 12, 13, 14, and 15 summarize the protease concentration and the cleavage rate (%) of the antibody variants used in the huPA treatment, hMT-SP1 treatment, and muPA treatment.
- 71 antibodies including G7L.106a.12aa were subjected to the same protease treatment again. The results are shown in Table 16.
- Table 17 shows antibody variants in which the cleavage rates at huPA, hMT-SP1 and muPA were all equal to or higher than those of G7L.106a.12aa.
- the peptide sequences of the present disclosure are useful as protease substrates, and these substrates are useful in a variety of therapeutic, diagnostic, and prophylactic indications.
- Polypeptides comprising the peptide sequences of the present disclosure as protease cleavage sequences are also useful in a variety of therapeutic, diagnostic, and prophylactic indications.
- the polypeptide of the present disclosure is a polypeptide containing a transport portion having an antigen-binding domain and an inhibitory domain
- the polypeptide and the pharmaceutical composition containing the same are antigen-binding while suppressing the antigen-binding activity of the antigen-binding domain.
- the domain can be carried in the blood.
- the antigen-binding activity of the antigen-binding domain can be specifically exerted at the disease site.
- the half-life is shorter than that during transportation, so that the risk of systemic action is reduced, which is extremely useful for the treatment of diseases.
- the ligand-binding molecule When the polypeptide of the present disclosure is a ligand-binding molecule, the ligand-binding molecule is transported in vivo with the ligand bound, and is cleaved in the diseased tissue to weaken the binding to the ligand, making the ligand specific to the diseased tissue. Since it can be released, the diseased tissue can be specifically exposed to the ligand. In addition, since the ligand-binding molecule suppresses the biological activity of the ligand during transport, the risk of the ligand acting systemically is reduced, and it is extremely useful for the treatment of diseases.
Landscapes
- Health & Medical Sciences (AREA)
- Chemical & Material Sciences (AREA)
- Life Sciences & Earth Sciences (AREA)
- Organic Chemistry (AREA)
- Engineering & Computer Science (AREA)
- Genetics & Genomics (AREA)
- Bioinformatics & Cheminformatics (AREA)
- General Health & Medical Sciences (AREA)
- Medicinal Chemistry (AREA)
- Zoology (AREA)
- Wood Science & Technology (AREA)
- Biochemistry (AREA)
- Molecular Biology (AREA)
- Biomedical Technology (AREA)
- Immunology (AREA)
- General Engineering & Computer Science (AREA)
- Proteomics, Peptides & Aminoacids (AREA)
- Biotechnology (AREA)
- Biophysics (AREA)
- Microbiology (AREA)
- Animal Behavior & Ethology (AREA)
- Pharmacology & Pharmacy (AREA)
- Public Health (AREA)
- Veterinary Medicine (AREA)
- Epidemiology (AREA)
- Gastroenterology & Hepatology (AREA)
- Physics & Mathematics (AREA)
- Plant Pathology (AREA)
- Mycology (AREA)
- Endocrinology (AREA)
- Toxicology (AREA)
- Chemical Kinetics & Catalysis (AREA)
- General Chemical & Material Sciences (AREA)
- Nuclear Medicine, Radiotherapy & Molecular Imaging (AREA)
- Peptides Or Proteins (AREA)
- Micro-Organisms Or Cultivation Processes Thereof (AREA)
- Preparation Of Compounds By Using Micro-Organisms (AREA)
- Medicinal Preparation (AREA)
- Medicines That Contain Protein Lipid Enzymes And Other Medicines (AREA)
Abstract
本出願は、プロテアーゼ基質、プロテアーゼにより切断可能なペプチド配列、プロテアーゼ切断配列を含むポリペプチド及びそれらの製造方法、プロテアーゼ切断配列を含むポリペプチドを含む医薬組成物、ポリペプチドに含まれるプロテアーゼ切断配列が切断されることにより抗原結合ドメインまたはリガンドを遊離させる方法に関する。
Description
本開示は、プロテアーゼ基質、プロテアーゼにより切断可能なペプチド配列、プロテアーゼ切断配列を含むポリペプチド及びそれらの製造方法、プロテアーゼ切断配列を含むポリペプチドを含む医薬組成物、ポリペプチドに含まれるプロテアーゼ切断配列が切断されることにより抗原結合ドメインまたはリガンドを放出する方法を提供する。
プロテアーゼは、アミノ酸残基間のペプチド結合を切断する酵素である。一部のプロテアーゼは、タンパク質内の特定のアミノ酸配列の存在に基づいて特定のペプチド結合を破壊ことが知られている。プロテアーゼは、すべての生物体内で自然に生じ、簡単な分解から高度に調整された経路までさまざまな生理的反応に関与している。しかしながら、多くの病的状態が、調節を逸脱したプロテアーゼの発現及び/又は活性に関連している。このように、不適切なタンパク質分解が、癌、並びに心臓血管疾患、炎症性疾患、神経変性疾患、真核生物性疾患、細菌性疾患、ウイルス性疾患、及び寄生虫性疾患の発生及び進行において主要な役割を担っている可能性がある。
従って、プロテアーゼのための新しい基質を同定する必要性、並びにさまざまな治療的、診断的、及び予防的適応においてこれらの基質を使用する必要性が存在する。
本開示は、このような状況に鑑みて為されたものであり、その目的の一つは、プロテアーゼ基質、プロテアーゼにより切断可能なペプチド配列、プロテアーゼ切断配列を含むポリペプチド及びそれらの製造方法、プロテアーゼ切断配列を含むポリペプチドを含む医薬組成物、ポリペプチドに含まれるプロテアーゼ切断配列が切断されることにより抗原結合ドメインまたはリガンドを放出する方法を提供することにある。
本開示の発明者らは、上記の目的を達成するために鋭意研究を進めたところ、プロテアーゼ基質として使用可能な化合物、特にプロテアーゼ基質として使用可能な/プロテアーゼにより切断可能なペプチド配列を見出すとともに、プロテアーゼにより切断可能なペプチド配列(略してプロテアーゼ切断配列)を含むポリペプチドを投与することを含む疾患の治療に有用であること、及び疾患の治療のための医薬の製造において当該プロテアーゼ切断配列を含むポリペプチドが有用であることを見出した。また、本開示の発明者らは、当該プロテアーゼ切断配列を含むポリペプチド及びそれらの製造方法を創作して本開示を完成させた。
本開示はこのような知見に基づくものであり、具体的には以下に例示的に記載する態様を包含するものである。
[1] 配列番号:1、2、3のいずれか一つの配列を含むプロテアーゼ基質に比べ、プロテアーゼによる切断率が高い、プロテアーゼ基質。
[2] 配列番号:1、2、3のいずれか一つの配列を含むプロテアーゼ基質に比べ、ヒトuPAによる切断率が高い、[1]に記載のプロテアーゼ基質。
[3] 配列番号:1、2、3のいずれか一つの配列を含むプロテアーゼ基質に比べ、ヒトMT-SP1による切断率が高い、[1]から[2]のいずれか一つに記載のプロテアーゼ基質。
[4] 配列番号:1、2、3のいずれか一つの配列を含むプロテアーゼ基質に比べ、マウスuPAによる切断率が高い、[1]から[3]のいずれか一つに記載のプロテアーゼ基質。
[5] 配列番号:1、2、3のいずれか一つの配列を含むプロテアーゼ基質に比べ、マウスMT-SP1による切断率が高い、[1]から[4]のいずれか一つに記載のプロテアーゼ基質。
[6] 配列番号:1、2、3のいずれか一つの配列を含むプロテアーゼ基質に比べ、ヒトuPAによる切断率とヒト血清による切断率の比が高い、[1]から[5]のいずれか一つに記載のプロテアーゼ基質。
[7] 配列番号:1、2、3のいずれか一つの配列を含むプロテアーゼ基質に比べ、ヒトMT-SP1による切断率とヒト血清による切断率の比が高い、[1]から[6]のいずれか一つに記載のプロテアーゼ基質。
[8] 配列番号:1、2、3のいずれか一つの配列を含むプロテアーゼ基質に比べ、マウスuPAによる切断率とヒト血清による切断率の比が高い、[1]から[7]のいずれか一つに記載のプロテアーゼ基質。
[9] 配列番号:1、2、3のいずれか一つの配列を含むプロテアーゼ基質に比べ、マウスMT-SP1による切断率とヒト血清による切断率の比が高い、[1]から[8]のいずれか一つに記載のプロテアーゼ基質。
[10] ヒト血清により切断されない、[1]から[9]のいずれか一つに記載のプロテアーゼ基質。
[11] 下記から選ばれる少なくとも一つの配列を含む、[1]から[10]に記載のプロテアーゼ基質:
配列番号:5~17201から選ばれる配列のN末端4番目のアミノ酸から15番目のアミノ酸までの配列、配列番号:5~17201から選ばれる配列のN末端4番目のアミノ酸から13番目のアミノ酸までの配列、配列番号:5~17201から選ばれる配列のN末端6番目のアミノ酸から13番目のアミノ酸までの配列、配列番号:17202~17993から選ばれる配列のN末端1番目のアミノ酸から12番目のアミノ酸までの配列、配列番号:17202~17993から選ばれる配列のN末端3番目のアミノ酸から12番目のアミノ酸までの配列、配列番号:17202~17993から選ばれる配列のN末端3番目のアミノ酸から11番目のアミノ酸までの配列、配列番号:17202~17993から選ばれる配列のN末端3番目のアミノ酸から10番目のアミノ酸までの配列、配列番号:17994~18003から選ばれる配列のN末端3番目のアミノ酸から14番目のアミノ酸までの配列、配列番号:17994~18003から選ばれる配列のN末端5番目のアミノ酸から12番目のアミノ酸までの配列、配列番号:17994~18003から選ばれる配列のN末端5番目のアミノ酸から10番目のアミノ酸までの配列、配列番号:5~18003のいずれかで示される配列。
[12] 下記から選ばれる少なくとも一つの配列を含む、プロテアーゼ基質:
配列番号:5~17201から選ばれる配列のN末端4番目のアミノ酸から15番目のアミノ酸までの配列、配列番号:5~17201から選ばれる配列のN末端4番目のアミノ酸から13番目のアミノ酸までの配列、配列番号:5~17201から選ばれる配列のN末端6番目のアミノ酸から13番目のアミノ酸までの配列、配列番号:17202~17993から選ばれる配列のN末端1番目のアミノ酸から12番目のアミノ酸までの配列、配列番号:17202~17993から選ばれる配列のN末端3番目のアミノ酸から12番目のアミノ酸までの配列、配列番号:17202~17993から選ばれる配列のN末端3番目のアミノ酸から11番目のアミノ酸までの配列、配列番号:17202~17993から選ばれる配列のN末端3番目のアミノ酸から10番目のアミノ酸までの配列、配列番号:17994~18003から選ばれる配列のN末端3番目のアミノ酸から14番目のアミノ酸までの配列、配列番号:17994~18003から選ばれる配列のN末端5番目のアミノ酸から12番目のアミノ酸までの配列、配列番号:17994~18003から選ばれる配列のN末端5番目のアミノ酸から10番目のアミノ酸までの配列、配列番号:5~18003のいずれかで示される配列。
[13] 前記プロテアーゼはマトリプターゼおよび/またはウロキナーゼである、[12]に記載のプロテアーゼ基質。
[14] 前記プロテアーゼはヒトMT-SP1、マウスMT-SP1、ヒトuPA、マウスuPAから選ばれる少なくとも一種類のプロテアーゼである、[12]から[13]のいずれかに記載のプロテアーゼ基質。
[15] 配列番号:1、2、3のいずれか一つの配列を含むプロテアーゼ基質に比べ、前記プロテアーゼによる切断率が高い、[12]から[14]のいずれか一つに記載のプロテアーゼ基質。
[16] 配列番号:1、2、3のいずれか一つの配列を含むプロテアーゼ基質に比べ、ヒトuPAによる切断率が高い、[12]から[15]のいずれか一つに記載のプロテアーゼ基質。
[17] 配列番号:1、2、3のいずれか一つの配列を含むプロテアーゼ基質に比べ、ヒトMT-SP1による切断率が高い、[12]から[16]のいずれか一つに記載のプロテアーゼ基質。
[18] 配列番号:1、2、3のいずれか一つの配列を含むプロテアーゼ基質に比べ、マウスuPAによる切断率が高い、[12]から[17]のいずれか一つに記載のプロテアーゼ基質。
[19] 配列番号:1、2、3のいずれか一つの配列を含むプロテアーゼ基質に比べ、マウスMT-SP1による切断率が高い、[12]から[18]のいずれか一つに記載のプロテアーゼ基質。
[20] 配列番号:1、2、3のいずれか一つの配列を含むプロテアーゼ基質に比べ、ヒトuPAによる切断率とヒト血清による切断率の比が高い、[12]から[19]のいずれか一つに記載のプロテアーゼ基質。
[21] 配列番号:1、2、3のいずれか一つの配列を含むプロテアーゼ基質に比べ、ヒトMT-SP1による切断率とヒト血清による切断率の比が高い、[12]から[20]のいずれか一つに記載のプロテアーゼ基質。
[22] 配列番号:1、2、3のいずれか一つの配列を含むプロテアーゼ基質に比べ、マウスuPAによる切断率とヒト血清による切断率の比が高い、[12]から[21]のいずれか一つに記載のプロテアーゼ基質。
[23] 配列番号:1、2、3のいずれか一つの配列を含むプロテアーゼ基質に比べ、マウスMT-SP1による切断率とヒト血清による切断率の比が高い、[12]から[22]のいずれか一つに記載のプロテアーゼ基質。
[24] ヒト血清により切断されない、[12]から[23]のいずれか一つに記載のプロテアーゼ基質。
[25] 下記から選ばれる少なくとも一つの配列の、プロテアーゼ切断配列としての使用:
配列番号:5~17201から選ばれる配列のN末端4番目のアミノ酸から15番目のアミノ酸までの配列、配列番号:5~17201から選ばれる配列のN末端4番目のアミノ酸から13番目のアミノ酸までの配列、配列番号:5~17201から選ばれる配列のN末端6番目のアミノ酸から13番目のアミノ酸までの配列、配列番号:17202~17993から選ばれる配列のN末端1番目のアミノ酸から12番目のアミノ酸までの配列、配列番号:17202~17993から選ばれる配列のN末端3番目のアミノ酸から12番目のアミノ酸までの配列、配列番号:17202~17993から選ばれる配列のN末端3番目のアミノ酸から11番目のアミノ酸までの配列、配列番号:17202~17993から選ばれる配列のN末端3番目のアミノ酸から10番目のアミノ酸までの配列、配列番号:17994~18003から選ばれる配列のN末端3番目のアミノ酸から14番目のアミノ酸までの配列、配列番号:17994~18003から選ばれる配列のN末端5番目のアミノ酸から12番目のアミノ酸までの配列、配列番号:17994~18003から選ばれる配列のN末端5番目のアミノ酸から10番目のアミノ酸までの配列、配列番号:5~18003のいずれかで示される配列。
[26] 下記から選ばれる少なくとも一つの配列を含む、ポリペプチド:
配列番号:5~17201から選ばれる配列のN末端4番目のアミノ酸から15番目のアミノ酸までの配列、配列番号:5~17201から選ばれる配列のN末端4番目のアミノ酸から13番目のアミノ酸までの配列、配列番号:5~17201から選ばれる配列のN末端6番目のアミノ酸から13番目のアミノ酸までの配列、配列番号:17202~17993から選ばれる配列のN末端1番目のアミノ酸から12番目のアミノ酸までの配列、配列番号:17202~17993から選ばれる配列のN末端3番目のアミノ酸から12番目のアミノ酸までの配列、配列番号:17202~17993から選ばれる配列のN末端3番目のアミノ酸から11番目のアミノ酸までの配列、配列番号:17202~17993から選ばれる配列のN末端3番目のアミノ酸から10番目のアミノ酸までの配列、配列番号:17994~18003から選ばれる配列のN末端3番目のアミノ酸から14番目のアミノ酸までの配列、配列番号:17994~18003から選ばれる配列のN末端5番目のアミノ酸から12番目のアミノ酸までの配列、配列番号:17994~18003から選ばれる配列のN末端5番目のアミノ酸から10番目のアミノ酸までの配列、配列番号:5~18003のいずれかで示される配列。
[27] 配列番号:5~17201から選ばれる配列のN末端4番目のアミノ酸から15番目のアミノ酸までの配列、配列番号:5~17201から選ばれる配列のN末端4番目のアミノ酸から13番目のアミノ酸までの配列、配列番号:5~17201から選ばれる配列のN末端6番目のアミノ酸から13番目のアミノ酸までの配列、配列番号:17202~17993から選ばれる配列のN末端1番目のアミノ酸から12番目のアミノ酸までの配列、配列番号:17202~17993から選ばれる配列のN末端3番目のアミノ酸から12番目のアミノ酸までの配列、配列番号:17202~17993から選ばれる配列のN末端3番目のアミノ酸から11番目のアミノ酸までの配列、配列番号:17202~17993から選ばれる配列のN末端3番目のアミノ酸から10番目のアミノ酸までの配列、配列番号:17994~18003から選ばれる配列のN末端3番目のアミノ酸から14番目のアミノ酸までの配列、配列番号:17994~18003から選ばれる配列のN末端5番目のアミノ酸から12番目のアミノ酸までの配列、配列番号:17994~18003から選ばれる配列のN末端5番目のアミノ酸から10番目のアミノ酸までの配列、配列番号:5~18003のいずれかで示される配列から選ばれる前記配列はプロテアーゼにより切断可能なプロテアーゼ切断配列である、[26]に記載のポリペプチド。
[28] [26]または[27]に記載のポリペプチドを製造する方法。
[29] [26]または[27]に記載のポリペプチドをエンコードするポリヌクレオチド。
[30] [29]に記載のポリヌクレオチドを含むベクター。
[31] [29]に記載のポリヌクレオチドまたは[30]に記載のベクターを含む宿主細胞。
[32] [31]に記載の宿主細胞を培養する工程を含む、[26]または[27]に記載のポリペプチドを製造する方法。
[33] ポリペプチドを培養上清から単離する工程を含む、[32]に記載のポリペプチドを製造する方法。
[1] 配列番号:1、2、3のいずれか一つの配列を含むプロテアーゼ基質に比べ、プロテアーゼによる切断率が高い、プロテアーゼ基質。
[2] 配列番号:1、2、3のいずれか一つの配列を含むプロテアーゼ基質に比べ、ヒトuPAによる切断率が高い、[1]に記載のプロテアーゼ基質。
[3] 配列番号:1、2、3のいずれか一つの配列を含むプロテアーゼ基質に比べ、ヒトMT-SP1による切断率が高い、[1]から[2]のいずれか一つに記載のプロテアーゼ基質。
[4] 配列番号:1、2、3のいずれか一つの配列を含むプロテアーゼ基質に比べ、マウスuPAによる切断率が高い、[1]から[3]のいずれか一つに記載のプロテアーゼ基質。
[5] 配列番号:1、2、3のいずれか一つの配列を含むプロテアーゼ基質に比べ、マウスMT-SP1による切断率が高い、[1]から[4]のいずれか一つに記載のプロテアーゼ基質。
[6] 配列番号:1、2、3のいずれか一つの配列を含むプロテアーゼ基質に比べ、ヒトuPAによる切断率とヒト血清による切断率の比が高い、[1]から[5]のいずれか一つに記載のプロテアーゼ基質。
[7] 配列番号:1、2、3のいずれか一つの配列を含むプロテアーゼ基質に比べ、ヒトMT-SP1による切断率とヒト血清による切断率の比が高い、[1]から[6]のいずれか一つに記載のプロテアーゼ基質。
[8] 配列番号:1、2、3のいずれか一つの配列を含むプロテアーゼ基質に比べ、マウスuPAによる切断率とヒト血清による切断率の比が高い、[1]から[7]のいずれか一つに記載のプロテアーゼ基質。
[9] 配列番号:1、2、3のいずれか一つの配列を含むプロテアーゼ基質に比べ、マウスMT-SP1による切断率とヒト血清による切断率の比が高い、[1]から[8]のいずれか一つに記載のプロテアーゼ基質。
[10] ヒト血清により切断されない、[1]から[9]のいずれか一つに記載のプロテアーゼ基質。
[11] 下記から選ばれる少なくとも一つの配列を含む、[1]から[10]に記載のプロテアーゼ基質:
配列番号:5~17201から選ばれる配列のN末端4番目のアミノ酸から15番目のアミノ酸までの配列、配列番号:5~17201から選ばれる配列のN末端4番目のアミノ酸から13番目のアミノ酸までの配列、配列番号:5~17201から選ばれる配列のN末端6番目のアミノ酸から13番目のアミノ酸までの配列、配列番号:17202~17993から選ばれる配列のN末端1番目のアミノ酸から12番目のアミノ酸までの配列、配列番号:17202~17993から選ばれる配列のN末端3番目のアミノ酸から12番目のアミノ酸までの配列、配列番号:17202~17993から選ばれる配列のN末端3番目のアミノ酸から11番目のアミノ酸までの配列、配列番号:17202~17993から選ばれる配列のN末端3番目のアミノ酸から10番目のアミノ酸までの配列、配列番号:17994~18003から選ばれる配列のN末端3番目のアミノ酸から14番目のアミノ酸までの配列、配列番号:17994~18003から選ばれる配列のN末端5番目のアミノ酸から12番目のアミノ酸までの配列、配列番号:17994~18003から選ばれる配列のN末端5番目のアミノ酸から10番目のアミノ酸までの配列、配列番号:5~18003のいずれかで示される配列。
[12] 下記から選ばれる少なくとも一つの配列を含む、プロテアーゼ基質:
配列番号:5~17201から選ばれる配列のN末端4番目のアミノ酸から15番目のアミノ酸までの配列、配列番号:5~17201から選ばれる配列のN末端4番目のアミノ酸から13番目のアミノ酸までの配列、配列番号:5~17201から選ばれる配列のN末端6番目のアミノ酸から13番目のアミノ酸までの配列、配列番号:17202~17993から選ばれる配列のN末端1番目のアミノ酸から12番目のアミノ酸までの配列、配列番号:17202~17993から選ばれる配列のN末端3番目のアミノ酸から12番目のアミノ酸までの配列、配列番号:17202~17993から選ばれる配列のN末端3番目のアミノ酸から11番目のアミノ酸までの配列、配列番号:17202~17993から選ばれる配列のN末端3番目のアミノ酸から10番目のアミノ酸までの配列、配列番号:17994~18003から選ばれる配列のN末端3番目のアミノ酸から14番目のアミノ酸までの配列、配列番号:17994~18003から選ばれる配列のN末端5番目のアミノ酸から12番目のアミノ酸までの配列、配列番号:17994~18003から選ばれる配列のN末端5番目のアミノ酸から10番目のアミノ酸までの配列、配列番号:5~18003のいずれかで示される配列。
[13] 前記プロテアーゼはマトリプターゼおよび/またはウロキナーゼである、[12]に記載のプロテアーゼ基質。
[14] 前記プロテアーゼはヒトMT-SP1、マウスMT-SP1、ヒトuPA、マウスuPAから選ばれる少なくとも一種類のプロテアーゼである、[12]から[13]のいずれかに記載のプロテアーゼ基質。
[15] 配列番号:1、2、3のいずれか一つの配列を含むプロテアーゼ基質に比べ、前記プロテアーゼによる切断率が高い、[12]から[14]のいずれか一つに記載のプロテアーゼ基質。
[16] 配列番号:1、2、3のいずれか一つの配列を含むプロテアーゼ基質に比べ、ヒトuPAによる切断率が高い、[12]から[15]のいずれか一つに記載のプロテアーゼ基質。
[17] 配列番号:1、2、3のいずれか一つの配列を含むプロテアーゼ基質に比べ、ヒトMT-SP1による切断率が高い、[12]から[16]のいずれか一つに記載のプロテアーゼ基質。
[18] 配列番号:1、2、3のいずれか一つの配列を含むプロテアーゼ基質に比べ、マウスuPAによる切断率が高い、[12]から[17]のいずれか一つに記載のプロテアーゼ基質。
[19] 配列番号:1、2、3のいずれか一つの配列を含むプロテアーゼ基質に比べ、マウスMT-SP1による切断率が高い、[12]から[18]のいずれか一つに記載のプロテアーゼ基質。
[20] 配列番号:1、2、3のいずれか一つの配列を含むプロテアーゼ基質に比べ、ヒトuPAによる切断率とヒト血清による切断率の比が高い、[12]から[19]のいずれか一つに記載のプロテアーゼ基質。
[21] 配列番号:1、2、3のいずれか一つの配列を含むプロテアーゼ基質に比べ、ヒトMT-SP1による切断率とヒト血清による切断率の比が高い、[12]から[20]のいずれか一つに記載のプロテアーゼ基質。
[22] 配列番号:1、2、3のいずれか一つの配列を含むプロテアーゼ基質に比べ、マウスuPAによる切断率とヒト血清による切断率の比が高い、[12]から[21]のいずれか一つに記載のプロテアーゼ基質。
[23] 配列番号:1、2、3のいずれか一つの配列を含むプロテアーゼ基質に比べ、マウスMT-SP1による切断率とヒト血清による切断率の比が高い、[12]から[22]のいずれか一つに記載のプロテアーゼ基質。
[24] ヒト血清により切断されない、[12]から[23]のいずれか一つに記載のプロテアーゼ基質。
[25] 下記から選ばれる少なくとも一つの配列の、プロテアーゼ切断配列としての使用:
配列番号:5~17201から選ばれる配列のN末端4番目のアミノ酸から15番目のアミノ酸までの配列、配列番号:5~17201から選ばれる配列のN末端4番目のアミノ酸から13番目のアミノ酸までの配列、配列番号:5~17201から選ばれる配列のN末端6番目のアミノ酸から13番目のアミノ酸までの配列、配列番号:17202~17993から選ばれる配列のN末端1番目のアミノ酸から12番目のアミノ酸までの配列、配列番号:17202~17993から選ばれる配列のN末端3番目のアミノ酸から12番目のアミノ酸までの配列、配列番号:17202~17993から選ばれる配列のN末端3番目のアミノ酸から11番目のアミノ酸までの配列、配列番号:17202~17993から選ばれる配列のN末端3番目のアミノ酸から10番目のアミノ酸までの配列、配列番号:17994~18003から選ばれる配列のN末端3番目のアミノ酸から14番目のアミノ酸までの配列、配列番号:17994~18003から選ばれる配列のN末端5番目のアミノ酸から12番目のアミノ酸までの配列、配列番号:17994~18003から選ばれる配列のN末端5番目のアミノ酸から10番目のアミノ酸までの配列、配列番号:5~18003のいずれかで示される配列。
[26] 下記から選ばれる少なくとも一つの配列を含む、ポリペプチド:
配列番号:5~17201から選ばれる配列のN末端4番目のアミノ酸から15番目のアミノ酸までの配列、配列番号:5~17201から選ばれる配列のN末端4番目のアミノ酸から13番目のアミノ酸までの配列、配列番号:5~17201から選ばれる配列のN末端6番目のアミノ酸から13番目のアミノ酸までの配列、配列番号:17202~17993から選ばれる配列のN末端1番目のアミノ酸から12番目のアミノ酸までの配列、配列番号:17202~17993から選ばれる配列のN末端3番目のアミノ酸から12番目のアミノ酸までの配列、配列番号:17202~17993から選ばれる配列のN末端3番目のアミノ酸から11番目のアミノ酸までの配列、配列番号:17202~17993から選ばれる配列のN末端3番目のアミノ酸から10番目のアミノ酸までの配列、配列番号:17994~18003から選ばれる配列のN末端3番目のアミノ酸から14番目のアミノ酸までの配列、配列番号:17994~18003から選ばれる配列のN末端5番目のアミノ酸から12番目のアミノ酸までの配列、配列番号:17994~18003から選ばれる配列のN末端5番目のアミノ酸から10番目のアミノ酸までの配列、配列番号:5~18003のいずれかで示される配列。
[27] 配列番号:5~17201から選ばれる配列のN末端4番目のアミノ酸から15番目のアミノ酸までの配列、配列番号:5~17201から選ばれる配列のN末端4番目のアミノ酸から13番目のアミノ酸までの配列、配列番号:5~17201から選ばれる配列のN末端6番目のアミノ酸から13番目のアミノ酸までの配列、配列番号:17202~17993から選ばれる配列のN末端1番目のアミノ酸から12番目のアミノ酸までの配列、配列番号:17202~17993から選ばれる配列のN末端3番目のアミノ酸から12番目のアミノ酸までの配列、配列番号:17202~17993から選ばれる配列のN末端3番目のアミノ酸から11番目のアミノ酸までの配列、配列番号:17202~17993から選ばれる配列のN末端3番目のアミノ酸から10番目のアミノ酸までの配列、配列番号:17994~18003から選ばれる配列のN末端3番目のアミノ酸から14番目のアミノ酸までの配列、配列番号:17994~18003から選ばれる配列のN末端5番目のアミノ酸から12番目のアミノ酸までの配列、配列番号:17994~18003から選ばれる配列のN末端5番目のアミノ酸から10番目のアミノ酸までの配列、配列番号:5~18003のいずれかで示される配列から選ばれる前記配列はプロテアーゼにより切断可能なプロテアーゼ切断配列である、[26]に記載のポリペプチド。
[28] [26]または[27]に記載のポリペプチドを製造する方法。
[29] [26]または[27]に記載のポリペプチドをエンコードするポリヌクレオチド。
[30] [29]に記載のポリヌクレオチドを含むベクター。
[31] [29]に記載のポリヌクレオチドまたは[30]に記載のベクターを含む宿主細胞。
[32] [31]に記載の宿主細胞を培養する工程を含む、[26]または[27]に記載のポリペプチドを製造する方法。
[33] ポリペプチドを培養上清から単離する工程を含む、[32]に記載のポリペプチドを製造する方法。
[A-1] [27]に記載のポリペプチドであって、当該ポリペプチドは抗原結合ドメインと運搬部分とを含み、当該運搬部分は前記抗原結合ドメインの抗原結合活性を抑制する抑制ドメインを有する、ポリペプチド。
[A-2] 前記プロテアーゼ切断配列がプロテアーゼにより切断された状態における前記抑制ドメインの前記抗原結合ドメインの抗原結合活性に対する抑制は、前記プロテアーゼ切断配列が未切断の状態における前記抑制ドメインの前記抗原結合ドメインの抗原結合活性に対する抑制より弱い、[A-1]に記載のポリペプチド。
[A-3] 前記抗原結合ドメインは前記未切断のポリペプチドより短い血中半減期を有する、[A-1]または[A-2]に記載のポリペプチド。
[A-4] 前記抗原結合ドメインは前記運搬部分より短い血中半減期を有する、[A-1]から[A-3]のいずれか一つに記載のポリペプチド。
[A-5] 前記抗原結合ドメインの分子量は前記運搬部分の分子量より小さい、[A-1]から[A-4]のいずれか一つに記載のポリペプチド。
[A-6] 前記抗原結合ドメインの分子量は60kDa以下である、[A-1]から[A-5]のいずれか一つに記載のポリペプチド。
[A-7] 前記運搬部分はFcRn結合活性を有し、前記抗原結合ドメインはFcRn結合活性を有さないまたは前記運搬部分より弱いFcRn結合活性を有する、[A-1]から[A-6]のいずれか一つに記載のポリペプチド。
[A-8] 前記抗原結合ドメインは前記ポリペプチドから遊離可能であり、前記抗原結合ドメインは、前記ポリペプチドから遊離している状態下における抗原結合活性は、前記ポリペプチドから遊離していない状態下における抗原結合活性より高い、[A-1]から[A-7]のいずれか一つに記載のポリペプチド。
[A-9] 前記抗原結合ドメインと前記運搬部分の前記抑制ドメインが会合することで前記抗原結合ドメインの抗原結合活性が抑制される、[A-1]から[A-8]のいずれか一つに記載のポリペプチド。
[A-10] 前記プロテアーゼ切断配列がプロテアーゼにより切断されることで前記抗原結合ドメインが前記ポリペプチドから遊離可能になる、[A-8]に記載のポリペプチド。
[A-11] 前記プロテアーゼ切断配列がプロテアーゼにより切断されることで前記抗原結合ドメインと前記運搬部分の前記抑制ドメインの会合が解消される、[A-9]に記載のポリペプチド。
[A-12] 前記プロテアーゼは、マトリプターゼおよび/またはウロキナーゼである、[A-1]から[A-11]のいずれか一つに記載のポリペプチド。
[A-13] 前記プロテアーゼは、ヒトMT-SP1、マウスMT-SP1、ヒトuPA、マウスuPAから選ばれる少なくとも一種類のプロテアーゼである、[A-1]から[A-11]のいずれか一つに記載のポリペプチド。
[A-14] 前記プロテアーゼ切断配列の一端に、第一可動リンカーが更に付加されている、[A-1]から[A-13]のいずれか一つに記載のポリペプチド。
[A-15] 前記第一可動リンカーは、グリシン-セリンポリマーからなる可動リンカーである、[A-14]に記載のポリペプチド。
[A-16] 前記プロテアーゼ切断配列の他端に、第二可動リンカーが更に付加されている、[A-14]または[A-15]に記載のポリペプチド。
[A-17] 前記第二可動リンカーは、グリシン-セリンポリマーからなる可動リンカーである、[A-16]に記載のポリペプチド。
[A-18] 前記抗原結合ドメインは単ドメイン抗体を含み、もしくは単ドメイン抗体であり、前記運搬部分の前記抑制ドメインは当該単ドメイン抗体の抗原結合活性を抑制する、[A-1]から[A-17]のいずれか一つに記載のポリペプチド。
[A-19] 前記単ドメイン抗体は、VHH、または単ドメインで抗原結合活性を有するVH、または単ドメインで抗原結合活性を有するVLである、[A-18]に記載のポリペプチド。
[A-20] 前記抗原結合ドメインは単ドメイン抗体を含み、前記運搬部分の前記抑制ドメインはVHH、または抗体VH、または抗体VLであり、前記単ドメイン抗体は当該VHH、または抗体VH、または抗体VLにより抗原結合活性が抑制される、[A-1]から[A-19]のいずれか一つに記載のポリペプチド。
[A-21] 前記抗原結合ドメインは単ドメイン抗体を含み、前記運搬部分の前記抑制ドメインはVHH、または抗体VH、または抗体VLであり、前記単ドメイン抗体は当該VHH、または抗体VH、または抗体VLと会合することにより抗原結合活性が抑制される、[A-1]から[A-20]のいずれか一つに記載のポリペプチド。
[A-22] 前記単ドメイン抗体はVHH、または単ドメインで抗原結合活性を有するVHであり、前記運搬部分の前記抑制ドメインは抗体VLであり、前記VHHまたは単ドメインで抗原結合活性を有するVHは、前記抗体VLと会合することで抗原結合活性が抑制される、[A-18]から[A-21]のいずれか一つに記載のポリペプチド。
[A-23] 前記単ドメイン抗体はVHHであり、当該VHHは37番、44番、45番、または47番(すべてKabatナンバリング)のアミノ酸から選ばれる少なくとも一つのポジションにおいてアミノ酸置換されている、[A-18]から[A-22]のいずれか一つに記載のポリペプチド。
[A-24] 前記単ドメイン抗体はVHHであり、当該VHHは37V、44G、45L、または47W(すべてKabatナンバリング)のアミノ酸から選ばれる少なくとも一つのアミノ酸を含む、[A-18]から[A-22]のいずれか一つに記載のポリペプチド。
[A-25] 前記単ドメイン抗体はVHHであり、当該VHHはF37V、Y37V、E44G、Q44G、R45L、H45L、G47W、F47W、L47W、T47W、またはS47W(すべてKabatナンバリング)のアミノ酸置換から選ばれる少なくとも一つのアミノ酸置換を含む、[A-18]から[A-22]のいずれか一つに記載のポリペプチド。
[A-26] 前記単ドメイン抗体はVHHであり、当該VHHは37番/44番、37番/45番、37番/47番、44番/45番、44番/47番、45番/47番、37番/44番/45番、37番/44番/47番、37番/45番/47番、44番/45番/47番、37番/44番/45番/47番(すべてKabatナンバリング)から選ばれる少なくとも一組のポジションにおいてアミノ酸置換されている、[A-18]から[A-22]のいずれか一つに記載のポリペプチド。
[A-27] 前記単ドメイン抗体はVHHであり、当該VHHは37V/44G、37V/45L、37V/47W、44G/45L、44G/47W、45L/47W、37V/44G/45L、37V/44G/47W、37V/45L/47W、44G/45L/47W、37V/44G/45L/47W(すべてKabatナンバリング)から選ばれる少なくとも一組のアミノ酸を含む、[A-18]から[A-22]のいずれか一つに記載のポリペプチド。
[A-28] 前記単ドメイン抗体はVHHであり、当該VHHはF37V/R45L、F37V/G47W、R45L/G47W、F37V/R45L/G47W(すべてKabatナンバリング)から選ばれる少なくとも一組のアミノ酸置換を含む、[A-18]から[A-22]のいずれか一つに記載のポリペプチド。
[A-29] 前記単ドメイン抗体は単ドメインで抗原結合活性を有するVLであり、前記運搬部分の前記抑制ドメインは抗体VHであり、前記単ドメインで抗原結合活性を有するVLは、前記抗体VHと会合することで抗原結合活性が抑制される、[A-18]から[A-21]のいずれか一つに記載のポリペプチド。
[A-30] 前記運搬部分はFcRn結合領域を有する、[A-1]から[A-29]のいずれか一つに記載のポリペプチド。
[A-31] 前記運搬部分は抗体定常領域を含む、[A-1]から[A-30]のいずれか一つに記載のポリペプチド。
[A-32] 前記運搬部分の抗体定常領域と前記抗原結合ドメインは、リンカーを介して、またはリンカーを介さずに融合されている、[A-31]に記載のポリペプチド。
[A-33] 前記運搬部分は抗体重鎖定常領域を含み、当該抗体重鎖定常領域と前記抗原結合ドメインは、リンカーを介して、またはリンカーを介さずに融合されている、[A-31]に記載のポリペプチド。
[A-34] 前記運搬部分は抗体軽鎖定常領域を含み、当該抗体軽鎖定常領域と前記抗原結合ドメインは、リンカーを介して、またはリンカーを介さずに融合されている、[A-31]に記載のポリペプチド。
[A-35] 前記ポリペプチドは前記運搬部分の抗体重鎖定常領域のN末端と前記抗原結合ドメインのC末端がリンカーを介してまたはリンカーを介さずに融合されており、前記プロテアーゼ切断配列は、前記抗原結合ドメインの配列中、または前記重鎖抗体定常領域の122番(EUナンバリング)のアミノ酸より前記抗原結合ドメイン側に位置する、[A-33]に記載のポリペプチド。
[A-36] 前記ポリペプチドは前記運搬部分の抗体軽鎖定常領域のN末端と前記抗原結合ドメインのC末端がリンカーを介してまたはリンカーを介さずに融合されており、前記プロテアーゼ切断配列は、前記抗原結合ドメインの配列中、または前記軽鎖抗体定常領域の113番(Kabatナンバリング)のアミノ酸より前記抗原結合ドメイン側に位置する、[A-34]に記載のポリペプチド。
[A-37] 前記ポリペプチドは前記運搬部分の抗体定常領域のN末端と前記抗原結合ドメインのC末端がリンカーを介してまたはリンカーを介さずに融合されており、前記抗原結合ドメインはVHから作製された単ドメイン抗体またはVHHであり、前記プロテアーゼ切断配列は、前記抗体定常領域の配列中、または前記抗原結合ドメインの単ドメイン抗体の109番(Kabatナンバリング)のアミノ酸より前記抗体定常領域側に位置する、[A-32]から[A-35]のいずれか一つに記載のポリペプチド。
[A-38] 前記ポリペプチドは前記運搬部分の抗体定常領域のN末端と前記抗原結合ドメインのC末端がリンカーを介してまたはリンカーを介さずに融合されており、前記プロテアーゼ切断配列は、前記抗原結合ドメインと前記抗体定常領域の境界付近に位置する、[A-32]に記載のポリペプチド。
[A-39] 前記ポリペプチドは前記運搬部分の抗体重鎖定常領域のN末端と前記抗原結合ドメインのC末端がリンカーを介してまたはリンカーを介さずに融合されており、前記プロテアーゼ切断配列は、前記抗原結合ドメインと前記抗体重鎖定常領域の境界付近に位置する、[A-33]に記載のポリペプチド。
[A-40] 前記ポリペプチドは前記運搬部分の抗体軽鎖定常領域のN末端と前記抗原結合ドメインのC末端がリンカーを介してまたはリンカーを介さずに融合されており、前記プロテアーゼ切断配列は、前記抗原結合ドメインと前記抗体軽鎖定常領域の境界付近に位置する、[A-34]に記載のポリペプチド。
[A-41] 前記抗原結合ドメインはVHから作製された単ドメイン抗体またはVHHであり、前記プロテアーゼ切断配列は、前記抗原結合ドメインの単ドメイン抗体の109番(Kabatナンバリング)のアミノ酸と前記抗体重鎖定常領域の122番(EUナンバリング)のアミノ酸の間に位置する、[A-39]に記載のポリペプチド。
[A-42] 前記抗原結合ドメインはVHから作製された単ドメイン抗体またはVHHであり、前記プロテアーゼ切断配列は、前記抗原結合ドメインの単ドメイン抗体の109番(Kabatナンバリング)のアミノ酸と前記抗体軽鎖定常領域の113番(Kabatナンバリング)のアミノ酸の間に位置する、[A-40]に記載のポリペプチド。
[A-43] 前記抗原結合ドメインはVLから作製された単ドメイン抗体であり、前記プロテアーゼ切断配列は、前記抗原結合ドメインの単ドメイン抗体の104番(Kabatナンバリング)のアミノ酸と前記抗体重鎖定常領域の122番(EUナンバリング)のアミノ酸の間に位置する、[A-39]に記載のポリペプチド。
[A-44] 前記抗原結合ドメインはVLから作製された単ドメイン抗体であり、前記プロテアーゼ切断配列は、前記抗原結合ドメインの単ドメイン抗体の109番(Kabatナンバリング)のアミノ酸と前記抗体軽鎖定常領域の113番(Kabatナンバリング)のアミノ酸の間に位置する、[A-40]に記載のポリペプチド。
[A-45] 前記ポリペプチドの抗体定常領域はIgG抗体定常領域である、[A-31]から[A-44]のいずれか一つに記載のポリペプチド。
[A-46] 前記ポリペプチドはIgG抗体様分子である、[A-1]から[A-45]のいずれか一つに記載のポリペプチド。
[A-47] 前記抗原結合ドメインが未遊離の状態において、BLI(Bio-Layer Interferometry)法(Octet)を用いて測定を行うとき、抗原結合ドメインと抗原の結合が見られない、[A-1]から[A-46]のいずれか一つに記載のポリペプチド。
[A-48] 前記抗原結合ドメインに更に第2の抗原結合ドメインが連結されている、[A-1]から[A-47]のいずれか一つに記載のポリペプチド。
[A-49] 前記第2の抗原結合ドメインは、前記抗原結合ドメインと異なる抗原結合特異性を有する、[A-48]に記載のポリペプチド。
[A-50] 前記第2の抗原結合ドメインは第2の単ドメイン抗体を含む、[A-48]または[A-49]に記載のポリペプチド。
[A-51] 前記抗原結合ドメインは単ドメイン抗体であり、前記第2の抗原結合ドメインは第2の単ドメイン抗体であり、前記抗原結合ドメインおよび前記第2の抗原結合ドメインは前記ポリペプチドから遊離可能であり、前記抗原結合ドメインおよび前記第2の抗原結合ドメインの遊離状態において、前記単ドメイン抗体と前記第2の単ドメイン抗体とが二重特異的抗原結合分子を形成している、[A-50]に記載のポリペプチド。
[A-52] 前記ポリペプチドは、前記抗原結合ドメインと別の抗原結合ドメインを更に有し、当該別の抗原結合ドメインも前記ポリペプチドの前記運搬部分と連結することにより抗原結合活性が抑制される、[A-1]から[A-51]のいずれか一つに記載のポリペプチド。
[A-53] 前記別の抗原結合ドメインと前記抗原結合ドメインと異なる抗原結合特異性を有する、[A-52]に記載のポリペプチド。
[A-54] [A-1]から[A-53]のいずれか一つに記載のポリペプチドを含む医薬組成物。
[A-55] [A-1]から[A-53]のいずれか一つに記載のポリペプチドを製造する方法。
[A-56] [A-1]から[A-53]のいずれか一つに記載のポリペプチドをエンコードするポリヌクレオチド。
[A-57] [A-56]に記載のポリヌクレオチドを含むベクター。
[A-58] [A-56]に記載のポリヌクレオチドまたは[A-57]に記載のベクターを含む宿主細胞。
[A-59] [A-58]に記載の宿主細胞を培養する工程を含む、[A-1]から[A-53]のいずれか一つに記載のポリペプチドを製造する方法。
[A-60] ポリペプチドを培養上清から単離する工程を含む、[A-59]に記載のポリペプチドを製造する方法。
[A-61] 抗原結合ドメインを含むポリペプチドに含まれる、配列番号:5~17201から選ばれる配列のN末端4番目のアミノ酸から15番目のアミノ酸までの配列、配列番号:5~17201から選ばれる配列のN末端4番目のアミノ酸から13番目のアミノ酸までの配列、配列番号:5~17201から選ばれる配列のN末端6番目のアミノ酸から13番目のアミノ酸までの配列、配列番号:17202~17993から選ばれる配列のN末端1番目のアミノ酸から12番目のアミノ酸までの配列、配列番号:17202~17993から選ばれる配列のN末端3番目のアミノ酸から12番目のアミノ酸までの配列、配列番号:17202~17993から選ばれる配列のN末端3番目のアミノ酸から11番目のアミノ酸までの配列、配列番号:17202~17993から選ばれる配列のN末端3番目のアミノ酸から10番目のアミノ酸までの配列、配列番号:17994~18003から選ばれる配列のN末端3番目のアミノ酸から14番目のアミノ酸までの配列、配列番号:17994~18003から選ばれる配列のN末端5番目のアミノ酸から12番目のアミノ酸までの配列、配列番号:17994~18003から選ばれる配列のN末端5番目のアミノ酸から10番目のアミノ酸までの配列、配列番号:5~18003のいずれかで示される配列から選ばれる少なくとも一つの配列を有する部位がプロテアーゼによって切断されることを含む、前記ポリペプチドから前記抗原結合ドメインを遊離させる方法。
[A-62] 前記ポリペプチドは更に運搬部分を含み、当該運搬部分は前記抗原結合ドメインの抗原結合活性を抑制する抑制ドメインを有する、[A-61]に記載の方法。
[A-63] 前記プロテアーゼ切断配列がプロテアーゼにより切断された状態における前記抑制ドメインの前記抗原結合ドメインの抗原結合活性に対する抑制は、前記プロテアーゼ切断配列が未切断の状態における前記抑制ドメインの前記抗原結合ドメインの抗原結合活性に対する抑制より弱い、[A-62]に記載の方法。
[A-64] 前記抗原結合ドメインは前記未切断のポリペプチドより短い血中半減期を有する、[A-62]または[A-63]に記載の方法。
[A-65] 前記抗原結合ドメインは前記運搬部分より短い血中半減期を有する、[A-62]から[A-64]のいずれか一つに記載の方法。
[A-66] 前記抗原結合ドメインの分子量は前記運搬部分の分子量より小さい、[A-62]から[A-65]のいずれか一つに記載の方法。
[A-67] 前記抗原結合ドメインの分子量は60kDa以下である、[A-62]から[A-66]のいずれか一つに記載の方法。
[A-68] 前記運搬部分はFcRn結合活性を有し、前記抗原結合ドメインはFcRn結合活性を有さないまたは前記運搬部分より弱いFcRn結合活性を有する、[A-62]から[A-67]のいずれか一つに記載の方法。
[A-69] 前記抗原結合ドメインは、前記ポリペプチドから遊離している状態下における抗原結合活性は、前記ポリペプチドから遊離していない状態下における抗原結合活性より高い、[A-62]から[A-68]のいずれか一つに記載の方法。
[A-70] 前記抗原結合ドメインと前記運搬部分の前記抑制ドメインが会合することで前記抗原結合ドメインの抗原結合活性が抑制される、[A-62]から[A-69]のいずれか一つに記載の方法。
[A-71] 前記プロテアーゼ切断配列がプロテアーゼにより切断されることで前記抗原結合ドメインと前記運搬部分の前記抑制ドメインの会合が解消される、[A-70]に記載の方法。
[A-72] 前記プロテアーゼは、マトリプターゼおよび/またはウロキナーゼである、[A-62]から[A-71]のいずれか一つに記載の方法。
[A-73] 前記プロテアーゼは、ヒトMT-SP1、マウスMT-SP1、ヒトuPA、マウスuPAから選ばれる少なくとも一種類のプロテアーゼである、[A-62]から[A-71]のいずれか一つに記載の方法。
[A-74] 前記プロテアーゼ切断配列の一端に、第一可動リンカーが更に付加されている、[A-62]から[A-73]のいずれか一つに記載の方法。
[A-75] 前記第一可動リンカーは、グリシン-セリンポリマーからなる可動リンカーである、[A-74]に記載の方法。
[A-76] 前記プロテアーゼ切断配列の他端に、第二可動リンカーが更に付加されている、[A-74]または[A-75]に記載の方法。
[A-77] 前記第二可動リンカーは、グリシン-セリンポリマーからなる可動リンカーである、[A-76]に記載の方法。
[A-78] 前記抗原結合ドメインは単ドメイン抗体を含み、もしくは単ドメイン抗体であり、前記運搬部分の前記抑制ドメインは当該単ドメイン抗体の抗原結合活性を抑制する、[A-62]から[A-77]のいずれか一つに記載の方法。
[A-79] 前記単ドメイン抗体は、VHH、または単ドメインで抗原結合活性を有するVH、または単ドメインで抗原結合活性を有するVLである、[A-78]に記載の方法。
[A-80] 前記抗原結合ドメインは単ドメイン抗体を含み、前記運搬部分の前記抑制ドメインはVHH、または抗体VH、または抗体VLであり、前記単ドメイン抗体は当該VHH、または抗体VH、または抗体VLにより抗原結合活性が抑制される、[A-62]から[A-79]のいずれか一つに記載の方法。
[A-81] 前記抗原結合ドメインは単ドメイン抗体を含み、前記運搬部分の前記抑制ドメインはVHH、または抗体VH、または抗体VLであり、前記単ドメイン抗体は当該VHH、または抗体VH、または抗体VLと会合することにより抗原結合活性が抑制される、[A-62]から[A-80]のいずれか一つに記載の方法。
[A-82] 前記単ドメイン抗体はVHH、または単ドメインで抗原結合活性を有するVHであり、前記運搬部分の前記抑制ドメインは抗体VLであり、前記VHHまたは単ドメインで抗原結合活性を有するVHは、前記抗体VLと会合することで抗原結合活性が抑制される、[A-78]から[A-81]のいずれか一つに記載の方法。
[A-83] 前記単ドメイン抗体はVHHであり、当該VHHは37番、44番、45番、または47番(すべてKabatナンバリング)のアミノ酸から選ばれる少なくとも一つのポジションにおいてアミノ酸置換されている、[A-78]から[A-82]のいずれか一つに記載の方法。
[A-84] 前記単ドメイン抗体はVHHであり、当該VHHは37V、44G、45L、または47W(すべてKabatナンバリング)のアミノ酸から選ばれる少なくとも一つのアミノ酸を含む、[A-78]から[A-82]のいずれか一つに記載の方法。
[A-85] 前記単ドメイン抗体はVHHであり、当該VHHはF37V、Y37V、E44G、Q44G、R45L、H45L、G47W、F47W、L47W、T47W、またはS47W(すべてKabatナンバリング)のアミノ酸置換から選ばれる少なくとも一つのアミノ酸置換を含む、[A-78]から[A-82]のいずれか一つに記載の方法。
[A-86] 前記単ドメイン抗体はVHHであり、当該VHHは37番/44番、37番/45番、37番/47番、44番/45番、44番/47番、45番/47番、37番/44番/45番、37番/44番/47番、37番/45番/47番、44番/45番/47番、37番/44番/45番/47番(すべてKabatナンバリング)から選ばれる少なくとも一組のポジションにおいてアミノ酸置換されている、[A-78]から[A-82]のいずれか一つに記載の方法。
[A-87] 前記単ドメイン抗体はVHHであり、当該VHHは37V/44G、37V/45L、37V/47W、44G/45L、44G/47W、45L/47W、37V/44G/45L、37V/44G/47W、37V/45L/47W、44G/45L/47W、37V/44G/45L/47W(すべてKabatナンバリング)から選ばれる少なくとも一組のアミノ酸を含む、[A-78]から[A-82]のいずれか一つに記載の方法。
[A-88] 前記単ドメイン抗体はVHHであり、当該VHHはF37V/R45L、F37V/G47W、R45L/G47W、F37V/R45L/G47W(すべてKabatナンバリング)から選ばれる少なくとも一組のアミノ酸置換を含む、[A-78]から[A-82]のいずれか一つに記載の方法。
[A-89] 前記単ドメイン抗体は単ドメインで抗原結合活性を有するVLであり、前記運搬部分の前記抑制ドメインは抗体VHであり、前記単ドメインで抗原結合活性を有するVLは、前記抗体VHと会合することで抗原結合活性が抑制される、[A-78]から[A-81]のいずれか一つに記載の方法。
[A-90] 前記運搬部分はFcRn結合領域を有する、[A-62]から[A-89]のいずれか一つに記載の方法。
[A-91] 前記運搬部分は抗体定常領域を含む、[A-62]から[A-90]のいずれか一つに記載の方法。
[A-92] 前記運搬部分の抗体定常領域と前記抗原結合ドメインは、リンカーを介して、またはリンカーを介さずに融合されている、[A-91]に記載の方法。
[A-93] 前記運搬部分は抗体重鎖定常領域を含み、当該抗体重鎖定常領域と前記抗原結合ドメインは、リンカーを介して、またはリンカーを介さずに融合されている、[A-91]に記載の方法。
[A-94] 前記運搬部分は抗体軽鎖定常領域を含み、当該抗体軽鎖定常領域と前記抗原結合ドメインは、リンカーを介して、またはリンカーを介さずに融合されている、[A-91]に記載の方法。
[A-95] 前記ポリペプチドは前記運搬部分の抗体重鎖定常領域のN末端と前記抗原結合ドメインのC末端がリンカーを介してまたはリンカーを介さずに融合されており、前記プロテアーゼ切断配列は、前記抗原結合ドメインの配列中、または前記重鎖抗体定常領域の122番(EUナンバリング)のアミノ酸より前記抗原結合ドメイン側に位置する、[A-93]に記載の方法。
[A-96] 前記ポリペプチドは前記運搬部分の抗体軽鎖定常領域のN末端と前記抗原結合ドメインのC末端がリンカーを介してまたはリンカーを介さずに融合されており、前記プロテアーゼ切断配列は、前記抗原結合ドメインの配列中、または前記軽鎖抗体定常領域の113番(Kabatナンバリング)のアミノ酸より前記抗原結合ドメイン側に位置する、[A-94]に記載の方法。
[A-97] 前記ポリペプチドは前記運搬部分の抗体定常領域のN末端と前記抗原結合ドメインのC末端がリンカーを介してまたはリンカーを介さずに融合されており、前記抗原結合ドメインはVHから作製された単ドメイン抗体またはVHHであり、前記プロテアーゼ切断配列は、前記抗体定常領域の配列中、または前記抗原結合ドメインの単ドメイン抗体の109番(Kabatナンバリング)のアミノ酸より前記抗体定常領域側に位置する、[A-92]から[A-95]のいずれか一つに記載の方法。
[A-98] 前記ポリペプチドは前記運搬部分の抗体定常領域のN末端と前記抗原結合ドメインのC末端がリンカーを介してまたはリンカーを介さずに融合されており、前記プロテアーゼ切断配列は、前記抗原結合ドメインと前記抗体定常領域の境界付近に位置する、[A-92]に記載の方法。
[A-99] 前記ポリペプチドは前記運搬部分の抗体重鎖定常領域のN末端と前記抗原結合ドメインのC末端がリンカーを介してまたはリンカーを介さずに融合されており、前記プロテアーゼ切断配列は、前記抗原結合ドメインと前記抗体重鎖定常領域の境界付近に位置する、[A-93]に記載のポリペプチド。
[A-100] 前記ポリペプチドは前記運搬部分の抗体軽鎖定常領域のN末端と前記抗原結合ドメインのC末端がリンカーを介してまたはリンカーを介さずに融合されており、前記プロテアーゼ切断配列は、前記抗原結合ドメインと前記抗体軽鎖定常領域の境界付近に位置する、[A-34]に記載の方法。
[A-101] 前記抗原結合ドメインはVHから作製された単ドメイン抗体またはVHHであり、前記プロテアーゼ切断配列は、前記抗原結合ドメインの単ドメイン抗体の109番(Kabatナンバリング)のアミノ酸と前記抗体重鎖定常領域の122番(EUナンバリング)のアミノ酸の間に位置する、[A-99]に記載の方法。
[A-102] 前記抗原結合ドメインはVHから作製された単ドメイン抗体またはVHHであり、前記プロテアーゼ切断配列は、前記抗原結合ドメインの単ドメイン抗体の109番(Kabatナンバリング)のアミノ酸と前記抗体軽鎖定常領域の113番(Kabatナンバリング)のアミノ酸の間に位置する、[A-100]に記載の方法。
[A-103] 前記抗原結合ドメインはVLから作製された単ドメイン抗体であり、前記プロテアーゼ切断配列は、前記抗原結合ドメインの単ドメイン抗体の104番(Kabatナンバリング)のアミノ酸と前記抗体重鎖定常領域の122番(EUナンバリング)のアミノ酸の間に位置する、[A-99]に記載の方法。
[A-104] 前記抗原結合ドメインはVLから作製された単ドメイン抗体であり、前記プロテアーゼ切断配列は、前記抗原結合ドメインの単ドメイン抗体の109番(Kabatナンバリング)のアミノ酸と前記抗体軽鎖定常領域の113番(Kabatナンバリング)のアミノ酸の間に位置する、[A-100]に記載の方法。
[A-105] 前記ポリペプチドの抗体定常領域はIgG抗体定常領域である、[A-91]から[A-104]のいずれか一つに記載の方法。
[A-106] 前記ポリペプチドはIgG抗体様分子である、[A-62]から[A-105]のいずれか一つに記載の方法。
[A-107] 前記抗原結合ドメインが未遊離の状態において、BLI(Bio-Layer Interferometry)法(Octet)を用いて測定を行うとき、抗原結合ドメインと抗原の結合が見られない、[A-62]から[A-106]のいずれか一つに記載の方法。
[A-108] 前記抗原結合ドメインに更に第2の抗原結合ドメインが連結されている、[A-62]から[A-107]のいずれか一つに記載の方法。
[A-109] 前記第2の抗原結合ドメインは、前記抗原結合ドメインと異なる抗原結合特異性を有する、[A-108]に記載の方法。
[A-110] 前記第2の抗原結合ドメインは第2の単ドメイン抗体を含む、[A-108]または[A-109]に記載の方法。
[A-111] 前記抗原結合ドメインは単ドメイン抗体であり、前記第2の抗原結合ドメインは第2の単ドメイン抗体であり、前記抗原結合ドメインおよび前記第2の抗原結合ドメインは前記ポリペプチドから遊離可能であり、前記抗原結合ドメインおよび前記第2の抗原結合ドメインの遊離状態において、前記単ドメイン抗体と前記第2の単ドメイン抗体とが二重特異的抗原結合分子を形成している、[A-110]に記載の方法。
[A-112] 前記ポリペプチドは、前記抗原結合ドメインと別の抗原結合ドメインを更に有し、当該別の抗原結合ドメインも前記ポリペプチドの前記運搬部分と連結することにより抗原結合活性が抑制される、[A-62]から[A-111]のいずれか一つに記載の方法。
[A-113] 前記別の抗原結合ドメインと前記抗原結合ドメインと異なる抗原結合特異性を有する、[A-112]に記載の方法。
[A-2] 前記プロテアーゼ切断配列がプロテアーゼにより切断された状態における前記抑制ドメインの前記抗原結合ドメインの抗原結合活性に対する抑制は、前記プロテアーゼ切断配列が未切断の状態における前記抑制ドメインの前記抗原結合ドメインの抗原結合活性に対する抑制より弱い、[A-1]に記載のポリペプチド。
[A-3] 前記抗原結合ドメインは前記未切断のポリペプチドより短い血中半減期を有する、[A-1]または[A-2]に記載のポリペプチド。
[A-4] 前記抗原結合ドメインは前記運搬部分より短い血中半減期を有する、[A-1]から[A-3]のいずれか一つに記載のポリペプチド。
[A-5] 前記抗原結合ドメインの分子量は前記運搬部分の分子量より小さい、[A-1]から[A-4]のいずれか一つに記載のポリペプチド。
[A-6] 前記抗原結合ドメインの分子量は60kDa以下である、[A-1]から[A-5]のいずれか一つに記載のポリペプチド。
[A-7] 前記運搬部分はFcRn結合活性を有し、前記抗原結合ドメインはFcRn結合活性を有さないまたは前記運搬部分より弱いFcRn結合活性を有する、[A-1]から[A-6]のいずれか一つに記載のポリペプチド。
[A-8] 前記抗原結合ドメインは前記ポリペプチドから遊離可能であり、前記抗原結合ドメインは、前記ポリペプチドから遊離している状態下における抗原結合活性は、前記ポリペプチドから遊離していない状態下における抗原結合活性より高い、[A-1]から[A-7]のいずれか一つに記載のポリペプチド。
[A-9] 前記抗原結合ドメインと前記運搬部分の前記抑制ドメインが会合することで前記抗原結合ドメインの抗原結合活性が抑制される、[A-1]から[A-8]のいずれか一つに記載のポリペプチド。
[A-10] 前記プロテアーゼ切断配列がプロテアーゼにより切断されることで前記抗原結合ドメインが前記ポリペプチドから遊離可能になる、[A-8]に記載のポリペプチド。
[A-11] 前記プロテアーゼ切断配列がプロテアーゼにより切断されることで前記抗原結合ドメインと前記運搬部分の前記抑制ドメインの会合が解消される、[A-9]に記載のポリペプチド。
[A-12] 前記プロテアーゼは、マトリプターゼおよび/またはウロキナーゼである、[A-1]から[A-11]のいずれか一つに記載のポリペプチド。
[A-13] 前記プロテアーゼは、ヒトMT-SP1、マウスMT-SP1、ヒトuPA、マウスuPAから選ばれる少なくとも一種類のプロテアーゼである、[A-1]から[A-11]のいずれか一つに記載のポリペプチド。
[A-14] 前記プロテアーゼ切断配列の一端に、第一可動リンカーが更に付加されている、[A-1]から[A-13]のいずれか一つに記載のポリペプチド。
[A-15] 前記第一可動リンカーは、グリシン-セリンポリマーからなる可動リンカーである、[A-14]に記載のポリペプチド。
[A-16] 前記プロテアーゼ切断配列の他端に、第二可動リンカーが更に付加されている、[A-14]または[A-15]に記載のポリペプチド。
[A-17] 前記第二可動リンカーは、グリシン-セリンポリマーからなる可動リンカーである、[A-16]に記載のポリペプチド。
[A-18] 前記抗原結合ドメインは単ドメイン抗体を含み、もしくは単ドメイン抗体であり、前記運搬部分の前記抑制ドメインは当該単ドメイン抗体の抗原結合活性を抑制する、[A-1]から[A-17]のいずれか一つに記載のポリペプチド。
[A-19] 前記単ドメイン抗体は、VHH、または単ドメインで抗原結合活性を有するVH、または単ドメインで抗原結合活性を有するVLである、[A-18]に記載のポリペプチド。
[A-20] 前記抗原結合ドメインは単ドメイン抗体を含み、前記運搬部分の前記抑制ドメインはVHH、または抗体VH、または抗体VLであり、前記単ドメイン抗体は当該VHH、または抗体VH、または抗体VLにより抗原結合活性が抑制される、[A-1]から[A-19]のいずれか一つに記載のポリペプチド。
[A-21] 前記抗原結合ドメインは単ドメイン抗体を含み、前記運搬部分の前記抑制ドメインはVHH、または抗体VH、または抗体VLであり、前記単ドメイン抗体は当該VHH、または抗体VH、または抗体VLと会合することにより抗原結合活性が抑制される、[A-1]から[A-20]のいずれか一つに記載のポリペプチド。
[A-22] 前記単ドメイン抗体はVHH、または単ドメインで抗原結合活性を有するVHであり、前記運搬部分の前記抑制ドメインは抗体VLであり、前記VHHまたは単ドメインで抗原結合活性を有するVHは、前記抗体VLと会合することで抗原結合活性が抑制される、[A-18]から[A-21]のいずれか一つに記載のポリペプチド。
[A-23] 前記単ドメイン抗体はVHHであり、当該VHHは37番、44番、45番、または47番(すべてKabatナンバリング)のアミノ酸から選ばれる少なくとも一つのポジションにおいてアミノ酸置換されている、[A-18]から[A-22]のいずれか一つに記載のポリペプチド。
[A-24] 前記単ドメイン抗体はVHHであり、当該VHHは37V、44G、45L、または47W(すべてKabatナンバリング)のアミノ酸から選ばれる少なくとも一つのアミノ酸を含む、[A-18]から[A-22]のいずれか一つに記載のポリペプチド。
[A-25] 前記単ドメイン抗体はVHHであり、当該VHHはF37V、Y37V、E44G、Q44G、R45L、H45L、G47W、F47W、L47W、T47W、またはS47W(すべてKabatナンバリング)のアミノ酸置換から選ばれる少なくとも一つのアミノ酸置換を含む、[A-18]から[A-22]のいずれか一つに記載のポリペプチド。
[A-26] 前記単ドメイン抗体はVHHであり、当該VHHは37番/44番、37番/45番、37番/47番、44番/45番、44番/47番、45番/47番、37番/44番/45番、37番/44番/47番、37番/45番/47番、44番/45番/47番、37番/44番/45番/47番(すべてKabatナンバリング)から選ばれる少なくとも一組のポジションにおいてアミノ酸置換されている、[A-18]から[A-22]のいずれか一つに記載のポリペプチド。
[A-27] 前記単ドメイン抗体はVHHであり、当該VHHは37V/44G、37V/45L、37V/47W、44G/45L、44G/47W、45L/47W、37V/44G/45L、37V/44G/47W、37V/45L/47W、44G/45L/47W、37V/44G/45L/47W(すべてKabatナンバリング)から選ばれる少なくとも一組のアミノ酸を含む、[A-18]から[A-22]のいずれか一つに記載のポリペプチド。
[A-28] 前記単ドメイン抗体はVHHであり、当該VHHはF37V/R45L、F37V/G47W、R45L/G47W、F37V/R45L/G47W(すべてKabatナンバリング)から選ばれる少なくとも一組のアミノ酸置換を含む、[A-18]から[A-22]のいずれか一つに記載のポリペプチド。
[A-29] 前記単ドメイン抗体は単ドメインで抗原結合活性を有するVLであり、前記運搬部分の前記抑制ドメインは抗体VHであり、前記単ドメインで抗原結合活性を有するVLは、前記抗体VHと会合することで抗原結合活性が抑制される、[A-18]から[A-21]のいずれか一つに記載のポリペプチド。
[A-30] 前記運搬部分はFcRn結合領域を有する、[A-1]から[A-29]のいずれか一つに記載のポリペプチド。
[A-31] 前記運搬部分は抗体定常領域を含む、[A-1]から[A-30]のいずれか一つに記載のポリペプチド。
[A-32] 前記運搬部分の抗体定常領域と前記抗原結合ドメインは、リンカーを介して、またはリンカーを介さずに融合されている、[A-31]に記載のポリペプチド。
[A-33] 前記運搬部分は抗体重鎖定常領域を含み、当該抗体重鎖定常領域と前記抗原結合ドメインは、リンカーを介して、またはリンカーを介さずに融合されている、[A-31]に記載のポリペプチド。
[A-34] 前記運搬部分は抗体軽鎖定常領域を含み、当該抗体軽鎖定常領域と前記抗原結合ドメインは、リンカーを介して、またはリンカーを介さずに融合されている、[A-31]に記載のポリペプチド。
[A-35] 前記ポリペプチドは前記運搬部分の抗体重鎖定常領域のN末端と前記抗原結合ドメインのC末端がリンカーを介してまたはリンカーを介さずに融合されており、前記プロテアーゼ切断配列は、前記抗原結合ドメインの配列中、または前記重鎖抗体定常領域の122番(EUナンバリング)のアミノ酸より前記抗原結合ドメイン側に位置する、[A-33]に記載のポリペプチド。
[A-36] 前記ポリペプチドは前記運搬部分の抗体軽鎖定常領域のN末端と前記抗原結合ドメインのC末端がリンカーを介してまたはリンカーを介さずに融合されており、前記プロテアーゼ切断配列は、前記抗原結合ドメインの配列中、または前記軽鎖抗体定常領域の113番(Kabatナンバリング)のアミノ酸より前記抗原結合ドメイン側に位置する、[A-34]に記載のポリペプチド。
[A-37] 前記ポリペプチドは前記運搬部分の抗体定常領域のN末端と前記抗原結合ドメインのC末端がリンカーを介してまたはリンカーを介さずに融合されており、前記抗原結合ドメインはVHから作製された単ドメイン抗体またはVHHであり、前記プロテアーゼ切断配列は、前記抗体定常領域の配列中、または前記抗原結合ドメインの単ドメイン抗体の109番(Kabatナンバリング)のアミノ酸より前記抗体定常領域側に位置する、[A-32]から[A-35]のいずれか一つに記載のポリペプチド。
[A-38] 前記ポリペプチドは前記運搬部分の抗体定常領域のN末端と前記抗原結合ドメインのC末端がリンカーを介してまたはリンカーを介さずに融合されており、前記プロテアーゼ切断配列は、前記抗原結合ドメインと前記抗体定常領域の境界付近に位置する、[A-32]に記載のポリペプチド。
[A-39] 前記ポリペプチドは前記運搬部分の抗体重鎖定常領域のN末端と前記抗原結合ドメインのC末端がリンカーを介してまたはリンカーを介さずに融合されており、前記プロテアーゼ切断配列は、前記抗原結合ドメインと前記抗体重鎖定常領域の境界付近に位置する、[A-33]に記載のポリペプチド。
[A-40] 前記ポリペプチドは前記運搬部分の抗体軽鎖定常領域のN末端と前記抗原結合ドメインのC末端がリンカーを介してまたはリンカーを介さずに融合されており、前記プロテアーゼ切断配列は、前記抗原結合ドメインと前記抗体軽鎖定常領域の境界付近に位置する、[A-34]に記載のポリペプチド。
[A-41] 前記抗原結合ドメインはVHから作製された単ドメイン抗体またはVHHであり、前記プロテアーゼ切断配列は、前記抗原結合ドメインの単ドメイン抗体の109番(Kabatナンバリング)のアミノ酸と前記抗体重鎖定常領域の122番(EUナンバリング)のアミノ酸の間に位置する、[A-39]に記載のポリペプチド。
[A-42] 前記抗原結合ドメインはVHから作製された単ドメイン抗体またはVHHであり、前記プロテアーゼ切断配列は、前記抗原結合ドメインの単ドメイン抗体の109番(Kabatナンバリング)のアミノ酸と前記抗体軽鎖定常領域の113番(Kabatナンバリング)のアミノ酸の間に位置する、[A-40]に記載のポリペプチド。
[A-43] 前記抗原結合ドメインはVLから作製された単ドメイン抗体であり、前記プロテアーゼ切断配列は、前記抗原結合ドメインの単ドメイン抗体の104番(Kabatナンバリング)のアミノ酸と前記抗体重鎖定常領域の122番(EUナンバリング)のアミノ酸の間に位置する、[A-39]に記載のポリペプチド。
[A-44] 前記抗原結合ドメインはVLから作製された単ドメイン抗体であり、前記プロテアーゼ切断配列は、前記抗原結合ドメインの単ドメイン抗体の109番(Kabatナンバリング)のアミノ酸と前記抗体軽鎖定常領域の113番(Kabatナンバリング)のアミノ酸の間に位置する、[A-40]に記載のポリペプチド。
[A-45] 前記ポリペプチドの抗体定常領域はIgG抗体定常領域である、[A-31]から[A-44]のいずれか一つに記載のポリペプチド。
[A-46] 前記ポリペプチドはIgG抗体様分子である、[A-1]から[A-45]のいずれか一つに記載のポリペプチド。
[A-47] 前記抗原結合ドメインが未遊離の状態において、BLI(Bio-Layer Interferometry)法(Octet)を用いて測定を行うとき、抗原結合ドメインと抗原の結合が見られない、[A-1]から[A-46]のいずれか一つに記載のポリペプチド。
[A-48] 前記抗原結合ドメインに更に第2の抗原結合ドメインが連結されている、[A-1]から[A-47]のいずれか一つに記載のポリペプチド。
[A-49] 前記第2の抗原結合ドメインは、前記抗原結合ドメインと異なる抗原結合特異性を有する、[A-48]に記載のポリペプチド。
[A-50] 前記第2の抗原結合ドメインは第2の単ドメイン抗体を含む、[A-48]または[A-49]に記載のポリペプチド。
[A-51] 前記抗原結合ドメインは単ドメイン抗体であり、前記第2の抗原結合ドメインは第2の単ドメイン抗体であり、前記抗原結合ドメインおよび前記第2の抗原結合ドメインは前記ポリペプチドから遊離可能であり、前記抗原結合ドメインおよび前記第2の抗原結合ドメインの遊離状態において、前記単ドメイン抗体と前記第2の単ドメイン抗体とが二重特異的抗原結合分子を形成している、[A-50]に記載のポリペプチド。
[A-52] 前記ポリペプチドは、前記抗原結合ドメインと別の抗原結合ドメインを更に有し、当該別の抗原結合ドメインも前記ポリペプチドの前記運搬部分と連結することにより抗原結合活性が抑制される、[A-1]から[A-51]のいずれか一つに記載のポリペプチド。
[A-53] 前記別の抗原結合ドメインと前記抗原結合ドメインと異なる抗原結合特異性を有する、[A-52]に記載のポリペプチド。
[A-54] [A-1]から[A-53]のいずれか一つに記載のポリペプチドを含む医薬組成物。
[A-55] [A-1]から[A-53]のいずれか一つに記載のポリペプチドを製造する方法。
[A-56] [A-1]から[A-53]のいずれか一つに記載のポリペプチドをエンコードするポリヌクレオチド。
[A-57] [A-56]に記載のポリヌクレオチドを含むベクター。
[A-58] [A-56]に記載のポリヌクレオチドまたは[A-57]に記載のベクターを含む宿主細胞。
[A-59] [A-58]に記載の宿主細胞を培養する工程を含む、[A-1]から[A-53]のいずれか一つに記載のポリペプチドを製造する方法。
[A-60] ポリペプチドを培養上清から単離する工程を含む、[A-59]に記載のポリペプチドを製造する方法。
[A-61] 抗原結合ドメインを含むポリペプチドに含まれる、配列番号:5~17201から選ばれる配列のN末端4番目のアミノ酸から15番目のアミノ酸までの配列、配列番号:5~17201から選ばれる配列のN末端4番目のアミノ酸から13番目のアミノ酸までの配列、配列番号:5~17201から選ばれる配列のN末端6番目のアミノ酸から13番目のアミノ酸までの配列、配列番号:17202~17993から選ばれる配列のN末端1番目のアミノ酸から12番目のアミノ酸までの配列、配列番号:17202~17993から選ばれる配列のN末端3番目のアミノ酸から12番目のアミノ酸までの配列、配列番号:17202~17993から選ばれる配列のN末端3番目のアミノ酸から11番目のアミノ酸までの配列、配列番号:17202~17993から選ばれる配列のN末端3番目のアミノ酸から10番目のアミノ酸までの配列、配列番号:17994~18003から選ばれる配列のN末端3番目のアミノ酸から14番目のアミノ酸までの配列、配列番号:17994~18003から選ばれる配列のN末端5番目のアミノ酸から12番目のアミノ酸までの配列、配列番号:17994~18003から選ばれる配列のN末端5番目のアミノ酸から10番目のアミノ酸までの配列、配列番号:5~18003のいずれかで示される配列から選ばれる少なくとも一つの配列を有する部位がプロテアーゼによって切断されることを含む、前記ポリペプチドから前記抗原結合ドメインを遊離させる方法。
[A-62] 前記ポリペプチドは更に運搬部分を含み、当該運搬部分は前記抗原結合ドメインの抗原結合活性を抑制する抑制ドメインを有する、[A-61]に記載の方法。
[A-63] 前記プロテアーゼ切断配列がプロテアーゼにより切断された状態における前記抑制ドメインの前記抗原結合ドメインの抗原結合活性に対する抑制は、前記プロテアーゼ切断配列が未切断の状態における前記抑制ドメインの前記抗原結合ドメインの抗原結合活性に対する抑制より弱い、[A-62]に記載の方法。
[A-64] 前記抗原結合ドメインは前記未切断のポリペプチドより短い血中半減期を有する、[A-62]または[A-63]に記載の方法。
[A-65] 前記抗原結合ドメインは前記運搬部分より短い血中半減期を有する、[A-62]から[A-64]のいずれか一つに記載の方法。
[A-66] 前記抗原結合ドメインの分子量は前記運搬部分の分子量より小さい、[A-62]から[A-65]のいずれか一つに記載の方法。
[A-67] 前記抗原結合ドメインの分子量は60kDa以下である、[A-62]から[A-66]のいずれか一つに記載の方法。
[A-68] 前記運搬部分はFcRn結合活性を有し、前記抗原結合ドメインはFcRn結合活性を有さないまたは前記運搬部分より弱いFcRn結合活性を有する、[A-62]から[A-67]のいずれか一つに記載の方法。
[A-69] 前記抗原結合ドメインは、前記ポリペプチドから遊離している状態下における抗原結合活性は、前記ポリペプチドから遊離していない状態下における抗原結合活性より高い、[A-62]から[A-68]のいずれか一つに記載の方法。
[A-70] 前記抗原結合ドメインと前記運搬部分の前記抑制ドメインが会合することで前記抗原結合ドメインの抗原結合活性が抑制される、[A-62]から[A-69]のいずれか一つに記載の方法。
[A-71] 前記プロテアーゼ切断配列がプロテアーゼにより切断されることで前記抗原結合ドメインと前記運搬部分の前記抑制ドメインの会合が解消される、[A-70]に記載の方法。
[A-72] 前記プロテアーゼは、マトリプターゼおよび/またはウロキナーゼである、[A-62]から[A-71]のいずれか一つに記載の方法。
[A-73] 前記プロテアーゼは、ヒトMT-SP1、マウスMT-SP1、ヒトuPA、マウスuPAから選ばれる少なくとも一種類のプロテアーゼである、[A-62]から[A-71]のいずれか一つに記載の方法。
[A-74] 前記プロテアーゼ切断配列の一端に、第一可動リンカーが更に付加されている、[A-62]から[A-73]のいずれか一つに記載の方法。
[A-75] 前記第一可動リンカーは、グリシン-セリンポリマーからなる可動リンカーである、[A-74]に記載の方法。
[A-76] 前記プロテアーゼ切断配列の他端に、第二可動リンカーが更に付加されている、[A-74]または[A-75]に記載の方法。
[A-77] 前記第二可動リンカーは、グリシン-セリンポリマーからなる可動リンカーである、[A-76]に記載の方法。
[A-78] 前記抗原結合ドメインは単ドメイン抗体を含み、もしくは単ドメイン抗体であり、前記運搬部分の前記抑制ドメインは当該単ドメイン抗体の抗原結合活性を抑制する、[A-62]から[A-77]のいずれか一つに記載の方法。
[A-79] 前記単ドメイン抗体は、VHH、または単ドメインで抗原結合活性を有するVH、または単ドメインで抗原結合活性を有するVLである、[A-78]に記載の方法。
[A-80] 前記抗原結合ドメインは単ドメイン抗体を含み、前記運搬部分の前記抑制ドメインはVHH、または抗体VH、または抗体VLであり、前記単ドメイン抗体は当該VHH、または抗体VH、または抗体VLにより抗原結合活性が抑制される、[A-62]から[A-79]のいずれか一つに記載の方法。
[A-81] 前記抗原結合ドメインは単ドメイン抗体を含み、前記運搬部分の前記抑制ドメインはVHH、または抗体VH、または抗体VLであり、前記単ドメイン抗体は当該VHH、または抗体VH、または抗体VLと会合することにより抗原結合活性が抑制される、[A-62]から[A-80]のいずれか一つに記載の方法。
[A-82] 前記単ドメイン抗体はVHH、または単ドメインで抗原結合活性を有するVHであり、前記運搬部分の前記抑制ドメインは抗体VLであり、前記VHHまたは単ドメインで抗原結合活性を有するVHは、前記抗体VLと会合することで抗原結合活性が抑制される、[A-78]から[A-81]のいずれか一つに記載の方法。
[A-83] 前記単ドメイン抗体はVHHであり、当該VHHは37番、44番、45番、または47番(すべてKabatナンバリング)のアミノ酸から選ばれる少なくとも一つのポジションにおいてアミノ酸置換されている、[A-78]から[A-82]のいずれか一つに記載の方法。
[A-84] 前記単ドメイン抗体はVHHであり、当該VHHは37V、44G、45L、または47W(すべてKabatナンバリング)のアミノ酸から選ばれる少なくとも一つのアミノ酸を含む、[A-78]から[A-82]のいずれか一つに記載の方法。
[A-85] 前記単ドメイン抗体はVHHであり、当該VHHはF37V、Y37V、E44G、Q44G、R45L、H45L、G47W、F47W、L47W、T47W、またはS47W(すべてKabatナンバリング)のアミノ酸置換から選ばれる少なくとも一つのアミノ酸置換を含む、[A-78]から[A-82]のいずれか一つに記載の方法。
[A-86] 前記単ドメイン抗体はVHHであり、当該VHHは37番/44番、37番/45番、37番/47番、44番/45番、44番/47番、45番/47番、37番/44番/45番、37番/44番/47番、37番/45番/47番、44番/45番/47番、37番/44番/45番/47番(すべてKabatナンバリング)から選ばれる少なくとも一組のポジションにおいてアミノ酸置換されている、[A-78]から[A-82]のいずれか一つに記載の方法。
[A-87] 前記単ドメイン抗体はVHHであり、当該VHHは37V/44G、37V/45L、37V/47W、44G/45L、44G/47W、45L/47W、37V/44G/45L、37V/44G/47W、37V/45L/47W、44G/45L/47W、37V/44G/45L/47W(すべてKabatナンバリング)から選ばれる少なくとも一組のアミノ酸を含む、[A-78]から[A-82]のいずれか一つに記載の方法。
[A-88] 前記単ドメイン抗体はVHHであり、当該VHHはF37V/R45L、F37V/G47W、R45L/G47W、F37V/R45L/G47W(すべてKabatナンバリング)から選ばれる少なくとも一組のアミノ酸置換を含む、[A-78]から[A-82]のいずれか一つに記載の方法。
[A-89] 前記単ドメイン抗体は単ドメインで抗原結合活性を有するVLであり、前記運搬部分の前記抑制ドメインは抗体VHであり、前記単ドメインで抗原結合活性を有するVLは、前記抗体VHと会合することで抗原結合活性が抑制される、[A-78]から[A-81]のいずれか一つに記載の方法。
[A-90] 前記運搬部分はFcRn結合領域を有する、[A-62]から[A-89]のいずれか一つに記載の方法。
[A-91] 前記運搬部分は抗体定常領域を含む、[A-62]から[A-90]のいずれか一つに記載の方法。
[A-92] 前記運搬部分の抗体定常領域と前記抗原結合ドメインは、リンカーを介して、またはリンカーを介さずに融合されている、[A-91]に記載の方法。
[A-93] 前記運搬部分は抗体重鎖定常領域を含み、当該抗体重鎖定常領域と前記抗原結合ドメインは、リンカーを介して、またはリンカーを介さずに融合されている、[A-91]に記載の方法。
[A-94] 前記運搬部分は抗体軽鎖定常領域を含み、当該抗体軽鎖定常領域と前記抗原結合ドメインは、リンカーを介して、またはリンカーを介さずに融合されている、[A-91]に記載の方法。
[A-95] 前記ポリペプチドは前記運搬部分の抗体重鎖定常領域のN末端と前記抗原結合ドメインのC末端がリンカーを介してまたはリンカーを介さずに融合されており、前記プロテアーゼ切断配列は、前記抗原結合ドメインの配列中、または前記重鎖抗体定常領域の122番(EUナンバリング)のアミノ酸より前記抗原結合ドメイン側に位置する、[A-93]に記載の方法。
[A-96] 前記ポリペプチドは前記運搬部分の抗体軽鎖定常領域のN末端と前記抗原結合ドメインのC末端がリンカーを介してまたはリンカーを介さずに融合されており、前記プロテアーゼ切断配列は、前記抗原結合ドメインの配列中、または前記軽鎖抗体定常領域の113番(Kabatナンバリング)のアミノ酸より前記抗原結合ドメイン側に位置する、[A-94]に記載の方法。
[A-97] 前記ポリペプチドは前記運搬部分の抗体定常領域のN末端と前記抗原結合ドメインのC末端がリンカーを介してまたはリンカーを介さずに融合されており、前記抗原結合ドメインはVHから作製された単ドメイン抗体またはVHHであり、前記プロテアーゼ切断配列は、前記抗体定常領域の配列中、または前記抗原結合ドメインの単ドメイン抗体の109番(Kabatナンバリング)のアミノ酸より前記抗体定常領域側に位置する、[A-92]から[A-95]のいずれか一つに記載の方法。
[A-98] 前記ポリペプチドは前記運搬部分の抗体定常領域のN末端と前記抗原結合ドメインのC末端がリンカーを介してまたはリンカーを介さずに融合されており、前記プロテアーゼ切断配列は、前記抗原結合ドメインと前記抗体定常領域の境界付近に位置する、[A-92]に記載の方法。
[A-99] 前記ポリペプチドは前記運搬部分の抗体重鎖定常領域のN末端と前記抗原結合ドメインのC末端がリンカーを介してまたはリンカーを介さずに融合されており、前記プロテアーゼ切断配列は、前記抗原結合ドメインと前記抗体重鎖定常領域の境界付近に位置する、[A-93]に記載のポリペプチド。
[A-100] 前記ポリペプチドは前記運搬部分の抗体軽鎖定常領域のN末端と前記抗原結合ドメインのC末端がリンカーを介してまたはリンカーを介さずに融合されており、前記プロテアーゼ切断配列は、前記抗原結合ドメインと前記抗体軽鎖定常領域の境界付近に位置する、[A-34]に記載の方法。
[A-101] 前記抗原結合ドメインはVHから作製された単ドメイン抗体またはVHHであり、前記プロテアーゼ切断配列は、前記抗原結合ドメインの単ドメイン抗体の109番(Kabatナンバリング)のアミノ酸と前記抗体重鎖定常領域の122番(EUナンバリング)のアミノ酸の間に位置する、[A-99]に記載の方法。
[A-102] 前記抗原結合ドメインはVHから作製された単ドメイン抗体またはVHHであり、前記プロテアーゼ切断配列は、前記抗原結合ドメインの単ドメイン抗体の109番(Kabatナンバリング)のアミノ酸と前記抗体軽鎖定常領域の113番(Kabatナンバリング)のアミノ酸の間に位置する、[A-100]に記載の方法。
[A-103] 前記抗原結合ドメインはVLから作製された単ドメイン抗体であり、前記プロテアーゼ切断配列は、前記抗原結合ドメインの単ドメイン抗体の104番(Kabatナンバリング)のアミノ酸と前記抗体重鎖定常領域の122番(EUナンバリング)のアミノ酸の間に位置する、[A-99]に記載の方法。
[A-104] 前記抗原結合ドメインはVLから作製された単ドメイン抗体であり、前記プロテアーゼ切断配列は、前記抗原結合ドメインの単ドメイン抗体の109番(Kabatナンバリング)のアミノ酸と前記抗体軽鎖定常領域の113番(Kabatナンバリング)のアミノ酸の間に位置する、[A-100]に記載の方法。
[A-105] 前記ポリペプチドの抗体定常領域はIgG抗体定常領域である、[A-91]から[A-104]のいずれか一つに記載の方法。
[A-106] 前記ポリペプチドはIgG抗体様分子である、[A-62]から[A-105]のいずれか一つに記載の方法。
[A-107] 前記抗原結合ドメインが未遊離の状態において、BLI(Bio-Layer Interferometry)法(Octet)を用いて測定を行うとき、抗原結合ドメインと抗原の結合が見られない、[A-62]から[A-106]のいずれか一つに記載の方法。
[A-108] 前記抗原結合ドメインに更に第2の抗原結合ドメインが連結されている、[A-62]から[A-107]のいずれか一つに記載の方法。
[A-109] 前記第2の抗原結合ドメインは、前記抗原結合ドメインと異なる抗原結合特異性を有する、[A-108]に記載の方法。
[A-110] 前記第2の抗原結合ドメインは第2の単ドメイン抗体を含む、[A-108]または[A-109]に記載の方法。
[A-111] 前記抗原結合ドメインは単ドメイン抗体であり、前記第2の抗原結合ドメインは第2の単ドメイン抗体であり、前記抗原結合ドメインおよび前記第2の抗原結合ドメインは前記ポリペプチドから遊離可能であり、前記抗原結合ドメインおよび前記第2の抗原結合ドメインの遊離状態において、前記単ドメイン抗体と前記第2の単ドメイン抗体とが二重特異的抗原結合分子を形成している、[A-110]に記載の方法。
[A-112] 前記ポリペプチドは、前記抗原結合ドメインと別の抗原結合ドメインを更に有し、当該別の抗原結合ドメインも前記ポリペプチドの前記運搬部分と連結することにより抗原結合活性が抑制される、[A-62]から[A-111]のいずれか一つに記載の方法。
[A-113] 前記別の抗原結合ドメインと前記抗原結合ドメインと異なる抗原結合特異性を有する、[A-112]に記載の方法。
[B-1] [27]に記載のポリペプチドであって、当該ポリペプチドはリガンドに結合可能なリガンド結合分子であり、前記プロテアーゼ切断配列が切断された状態における当該リガンド結合分子のリガンドに対する結合が、前記プロテアーゼ切断配列が未切断の状態における当該リガンド結合分子のリガンドに対する結合より弱い、リガンド結合分子。
[B-2] 前記プロテアーゼ切断配列が切断された状態では、前記リガンドが前記リガンド結合分子から遊離する、[B-1]に記載のリガンド結合分子。
[B-3] 前記プロテアーゼは、マトリプターゼおよび/またはウロキナーゼである、[B-1]から[B-2]のいずれか一つに記載のリガンド結合分子。
[B-4] 前記プロテアーゼは、ヒトMT-SP1、マウスMT-SP1、ヒトuPA、マウスuPAから選ばれる少なくとも一種類のプロテアーゼである、[B-1]から[B-3]のいずれか一つに記載のリガンド結合分子。
[B-5] 前記プロテアーゼ切断配列の一端に、第一可動リンカーが更に付加されている、[B-1]から[B-4]のいずれか一つに記載のリガンド結合分子。
[B-6] 前記第一可動リンカーは、グリシン-セリンポリマーからなる可動リンカーである、[B-5]に記載のリガンド結合分子。
[B-7] 前記プロテアーゼ切断配列の他端に、第二可動リンカーが更に付加されている、[B-5]または[B-6]に記載のリガンド結合分子。
[B-8] 前記第二可動リンカーは、グリシン-セリンポリマーからなる可動リンカーである、[B-7]に記載のリガンド結合分子。
[B-9] 前記リガンド結合分子は抗体VHと、抗体VLと、抗体定常領域を含む、[B-1]から[B-8]のいずれか一つに記載のリガンド結合分子。
[B-10] 前記プロテアーゼ切断配列、またはプロテアーゼ切断配列と第一可動リンカー、またはプロテアーゼ切断配列と第一可動リンカーと第二可動リンカーは、前記抗体定常領域内に位置する、[B-9]に記載のリガンド結合分子。
[B-11] 前記プロテアーゼ切断配列、またはプロテアーゼ切断配列と第一可動リンカー、またはプロテアーゼ切断配列と第一可動リンカーと第二可動リンカーは、抗体重鎖定常領域118番アミノ酸(EUナンバリング)から抗体重鎖定常領域140番アミノ酸(EUナンバリング)までの配列中の任意の位置に導入される、[B-10]に記載のリガンド結合分子。
[B-12] 前記プロテアーゼ切断配列、またはプロテアーゼ切断配列と第一可動リンカー、またはプロテアーゼ切断配列と第一可動リンカーと第二可動リンカーは、抗体軽鎖定常領域108番アミノ酸(Kabatナンバリング)から抗体軽鎖定常領域131番アミノ酸(Kabatナンバリング)までの配列中の任意の位置に導入される、[B-10]に記載のリガンド結合分子。
[B-13] 前記プロテアーゼ切断配列、またはプロテアーゼ切断配列と第一可動リンカー、またはプロテアーゼ切断配列と第一可動リンカーと第二可動リンカーは、前記抗体VH内もしくは前記抗体VL内に位置する、[B-9]に記載のリガンド結合分子。
[B-14] 前記プロテアーゼ切断配列、またはプロテアーゼ切断配列と第一可動リンカー、またはプロテアーゼ切断配列と第一可動リンカーと第二可動リンカーは、抗体VH7番アミノ酸(Kabatナンバリング)から16番アミノ酸(Kabatナンバリング)まで、40番アミノ酸(Kabatナンバリング)から47番アミノ酸(Kabatナンバリング)まで、55番アミノ酸(Kabatナンバリング)から69番アミノ酸(Kabatナンバリング)まで、73番アミノ酸(Kabatナンバリング)から79番アミノ酸(Kabatナンバリング)まで、83番アミノ酸(Kabatナンバリング)から89番アミノ酸(Kabatナンバリング)まで、95番アミノ酸(Kabatナンバリング)から99番アミノ酸(Kabatナンバリング)まで、および101番アミノ酸(Kabatナンバリング)から113番アミノ酸(Kabatナンバリング)までからなる群より選択される配列中の任意位置に導入される、[B-13]に記載のリガンド結合分子。
[B-15] 前記プロテアーゼ切断配列、またはプロテアーゼ切断配列と第一可動リンカー、またはプロテアーゼ切断配列と第一可動リンカーと第二可動リンカーは、抗体VL7番アミノ酸(Kabatナンバリング)から19番アミノ酸(Kabatナンバリング)まで、39番アミノ酸(Kabatナンバリング)から46番アミノ酸(Kabatナンバリング)まで、49番アミノ酸(Kabatナンバリング)から62番アミノ酸(Kabatナンバリング)まで、および96番アミノ酸(Kabatナンバリング)から107番アミノ酸(Kabatナンバリング)までからなる群より選択される配列中の任意位置に導入される、[B-13]に記載のリガンド結合分子。
[B-16] 前記プロテアーゼ切断配列、またはプロテアーゼ切断配列と第一可動リンカー、またはプロテアーゼ切断配列と第一可動リンカーと第二可動リンカーは、前記抗体定常領域と前記抗体VHの境界付近、および/または前記抗体定常領域と前記抗体VLとの境界付近に位置する、[B-9]に記載のリガンド結合分子。
[B-17] 前記プロテアーゼ切断配列、またはプロテアーゼ切断配列と第一可動リンカー、またはプロテアーゼ切断配列と第一可動リンカーと第二可動リンカーは、抗体VH109番のアミノ酸(Kabatナンバリング)から抗体重鎖定常領域122番のアミノ酸(EUナンバリング)までの配列中の任意位置に導入される、[B-17]に記載のリガンド結合分子。
[B-18] 前記プロテアーゼ切断配列、またはプロテアーゼ切断配列と第一可動リンカー、またはプロテアーゼ切断配列と第一可動リンカーと第二可動リンカーは、抗体VL104番のアミノ酸(Kabatナンバリング)から抗体軽鎖定常領域113番のアミノ酸(Kabatナンバリング)までの配列中の任意位置に導入される、[B-16]に記載のリガンド結合分子。
[B-19] 前記リガンド結合分子中の前記抗体VLと前記抗体VHは会合しており、当該会合は前記プロテアーゼ切断配列がプロテアーゼで切断されることにより解消される、[B-9]から[B-18]のいずれか一つに記載のリガンド結合分子。
[B-20] 前記リガンドは生物活性を有する分子であり、前記リガンド結合分子は前記リガンドとの結合で前記リガンドの生物活性を阻害する、[B-1]から[B-19]のいずれか一つに記載のリガンド結合分子。
[B-21] 前記リガンドはサイトカインまたはケモカインである、[B-1]から[B-20]のいずれか一つに記載のリガンド結合分子。
[B-22] 前記リガンドは、インターロイキン、インターフェロン、造血因子、TNFスーパーファミリー、ケモカイン、細胞増殖因子、及びTGF-βファミリーから選ばれるリガンドである、[B-1]から[B-20]のいずれか一つに記載のリガンド結合分子。
[B-23] 前記リガンド結合分子はIgG抗体である、[B-1]から[B-22]のいずれか一つに記載のリガンド結合分子。
[B-24] 前記リガンドと結合している[B-1]から[B-23]のいずれか一つに記載のリガンド結合分子。
[B-25] 前記リガンドと融合されている[B-1]から[B-23]のいずれか一つに記載のリガンド結合分子。
[B-26] 前記リガンド結合分子がリガンドと融合されている状態では更に別のリガンドと結合しない、[B-25]に記載のリガンド結合分子。
[B-27] 前記リガンド結合分子は、リンカーを介して前記リガンドと融合されている、[B-25]または[B-26]に記載のリガンド結合分子。
[B-28] 前記リンカーはプロテアーゼ切断配列を含まない、[B-27]に記載のリガンド結合分子。
[B-29] 前記リガンドと、前記リガンドと結合している[B-1]から[B-23]のいずれか一つに記載のリガンド結合分子とで形成されている複合体。
[B-30] 前記リガンドと[B-1]から[B-23]のいずれか一つに記載のリガンド結合分子が融合されている融合タンパク質。
[B-31] 前記リガンド結合分子がリガンドと融合されている状態では更に別のリガンドと結合しない、[B-30]に記載の融合タンパク質。
[B-32] 前記リガンド結合分子は、リンカーを介して前記リガンドと融合されている、[B-30]または[B-31]に記載の融合タンパク質。
[B-33] 前記リンカーはプロテアーゼ切断配列を含まない、[B-32]に記載の融合タンパク質。
[B-34] 前記リンカーは、グリシン‐セリンポリマーからなるリンカーである、[B-32]または[B-33]に記載の融合タンパク質。
[B-35] [B-1]から[B-28]のいずれか一つに記載のリガンド結合分子を含む、医薬組成物。
[B-36] [B-1]から[B-24]のいずれか一つに記載のリガンド結合分子とリガンドを含む、医薬組成物。
[B-37] [B-29]に記載の複合体を含む、医薬組成物。
[B-38] [B-30]から[B-34]のいずれか一つに記載の融合タンパク質を含む、医薬組成物。
[B-39] [B-1]から[B-28]のいずれか一つに記載のリガンド結合分子を製造する方法。
[B-40] リガンドに結合可能な分子中に、プロテアーゼ切断配列を導入することを含む、[B-39]に記載の製造方法。
[B-41] プロテアーゼ切断配列を有するリガンド結合分子とそのリガンドを融合させることを含む、[B-30]から[B-34]のいずれか一つに記載の融合タンパク質の製造方法。
[B-42] [B-1]から[B-28]のいずれか一つに記載のリガンド結合分子をコードするポリヌクレオチド。
[B-43] [B-42]に記載のポリヌクレオチドを含むベクター。
[B-44] [B-42]に記載のポリヌクレオチドもしくは[B-43]に記載のベクターを含む宿主細胞。
[B-45] [B-44]に記載の宿主細胞を培養する工程を含む、[B-1]から[B-28]のいずれか一つに記載のリガンド結合分子を製造する方法。
[B-46] ポリペプチドを培養上清から単離する工程を含む、[B-45]に記載のリガンド結合分子を製造する方法。
[B-47] [B-30]から[B-34]のいずれか一つに記載の融合タンパク質をコードするポリヌクレオチド。
[B-48] [B-46]に記載のポリヌクレオチドを含むベクター。
[B-49] [B-46]に記載のポリヌクレオチドもしくは[B-48]に記載のベクターを含む宿主細胞。
[B-50] [B-49]に記載の宿主細胞を培養する工程を含む、[B-30]から[B-34]のいずれか一つに記載の融合タンパク質を製造する方法。
[B-51] ポリペプチドを培養上清から単離する工程を含む、[B-50]に記載の融合タンパク質を製造する方法。
[B-52] リガンドに結合可能なリガンド結合分子に含まれる、配列番号:5~17201から選ばれる配列のN末端4番目のアミノ酸から15番目のアミノ酸までの配列、配列番号:5~17201から選ばれる配列のN末端4番目のアミノ酸から13番目のアミノ酸までの配列、配列番号:5~17201から選ばれる配列のN末端6番目のアミノ酸から13番目のアミノ酸までの配列、配列番号:17202~17993から選ばれる配列のN末端1番目のアミノ酸から12番目のアミノ酸までの配列、配列番号:17202~17993から選ばれる配列のN末端3番目のアミノ酸から12番目のアミノ酸までの配列、配列番号:17202~17993から選ばれる配列のN末端3番目のアミノ酸から11番目のアミノ酸までの配列、配列番号:17202~17993から選ばれる配列のN末端3番目のアミノ酸から10番目のアミノ酸までの配列、配列番号:17994~18003から選ばれる配列のN末端3番目のアミノ酸から14番目のアミノ酸までの配列、配列番号:17994~18003から選ばれる配列のN末端5番目のアミノ酸から12番目のアミノ酸までの配列、配列番号:17994~18003から選ばれる配列のN末端5番目のアミノ酸から10番目のアミノ酸までの配列、配列番号:5~18003のいずれかで示される配列から選ばれる少なくとも一つの配列を有する部位がプロテアーゼによって切断されることを含む、前記リガンド結合分子に結合した前記リガンドを遊離させる方法。
[B-53] リガンドとリガンド結合分子の融合タンパク質中のリガンド結合分子に含まれる、配列番号:5~17201から選ばれる配列のN末端4番目のアミノ酸から15番目のアミノ酸までの配列、配列番号:5~17201から選ばれる配列のN末端4番目のアミノ酸から13番目のアミノ酸までの配列、配列番号:5~17201から選ばれる配列のN末端6番目のアミノ酸から13番目のアミノ酸までの配列、配列番号:17202~17993から選ばれる配列のN末端1番目のアミノ酸から12番目のアミノ酸までの配列、配列番号:17202~17993から選ばれる配列のN末端3番目のアミノ酸から12番目のアミノ酸までの配列、配列番号:17202~17993から選ばれる配列のN末端3番目のアミノ酸から11番目のアミノ酸までの配列、配列番号:17202~17993から選ばれる配列のN末端3番目のアミノ酸から10番目のアミノ酸までの配列、配列番号:17994~18003から選ばれる配列のN末端3番目のアミノ酸から14番目のアミノ酸までの配列、配列番号:17994~18003から選ばれる配列のN末端5番目のアミノ酸から12番目のアミノ酸までの配列、配列番号:17994~18003から選ばれる配列のN末端5番目のアミノ酸から10番目のアミノ酸までの配列、配列番号:5~18003のいずれかで示される配列から選ばれる少なくとも一つの配列を有する部位がプロテアーゼによって切断されることを含む、前記融合タンパク質から前記リガンドを遊離させる方法。
[B-54] 前記リガンド結合分子は、リンカーを介して前記リガンドと融合されている、[B-53]に記載の方法。
[B-55] 前記リンカーはプロテアーゼ切断配列を含まない、[B-54]に記載の方法。
[B-56] 前記リンカーは、グリシン‐セリンポリマーからなるリンカーである、[B-54]または[B-55]に記載の方法。
[B-57] 前記リガンド結合分子がリガンドと融合されている状態では更に別のリガンドと結合しない、[B-53]から[B-56]のいずれか一つに記載の方法。
[B-58] 前記プロテアーゼ切断配列が切断された状態における当該リガンド結合分子のリガンドに対する結合が、前記プロテアーゼ切断配列が未切断の状態における当該リガンド結合分子のリガンドに対する結合より弱い、[B-52]から[B-57]のいずれか一つに記載の方法。
[B-59] 前記プロテアーゼは、マトリプターゼおよび/またはウロキナーゼである、[B-52]から[B-58]のいずれか一つに記載の方法。
[B-60] 前記プロテアーゼは、ヒトMT-SP1、マウスMT-SP1、ヒトuPA、マウスuPAから選ばれる少なくとも一種類のプロテアーゼである、[B-52]から[B-59]のいずれか一つに記載の方法。
[B-61] 前記プロテアーゼ切断配列の一端に、第一可動リンカーが更に付加されている、[B-52]から[B-60]のいずれか一つに記載の方法。
[B-62] 前記第一可動リンカーは、グリシン-セリンポリマーからなる可動リンカーである、[B-61]に記載の方法。
[B-63] 前記プロテアーゼ切断配列の他端に、第二可動リンカーが更に付加されている、[B-61]または[B-62]に記載の方法。
[B-64] 前記第二可動リンカーは、グリシン-セリンポリマーからなる可動リンカーである、[B-63]に記載の方法。
[B-65] 前記リガンド結合分子は抗体VHと、抗体VLと、抗体定常領域を含む、[B-52]から[B-64]のいずれか一つに記載の方法。
[B-66] 前記プロテアーゼ切断配列、またはプロテアーゼ切断配列と第一可動リンカー、またはプロテアーゼ切断配列と第一可動リンカーと第二可動リンカーは、前記抗体定常領域内に位置する、[B-65]に記載の方法。
[B-67] 前記プロテアーゼ切断配列、またはプロテアーゼ切断配列と第一可動リンカー、またはプロテアーゼ切断配列と第一可動リンカーと第二可動リンカーは、抗体重鎖定常領域118番アミノ酸(EUナンバリング)から抗体重鎖定常領域140番アミノ酸(EUナンバリング)までの配列中の任意の位置に導入される、[B-66]に記載の方法。
[B-68] 前記プロテアーゼ切断配列、またはプロテアーゼ切断配列と第一可動リンカー、またはプロテアーゼ切断配列と第一可動リンカーと第二可動リンカーは、抗体軽鎖定常領域108番アミノ酸(Kabatナンバリング)から抗体軽鎖定常領域131番アミノ酸(Kabatナンバリング)までの配列中の任意の位置に導入される、[B-66]に記載の方法。
[B-69] 前記プロテアーゼ切断配列、またはプロテアーゼ切断配列と第一可動リンカー、またはプロテアーゼ切断配列と第一可動リンカーと第二可動リンカーは、前記抗体VH内もしくは前記抗体VL内に位置する、[B-65]に記載の方法。
[B-70] 前記プロテアーゼ切断配列、またはプロテアーゼ切断配列と第一可動リンカー、またはプロテアーゼ切断配列と第一可動リンカーと第二可動リンカーは、抗体VH7番アミノ酸(Kabatナンバリング)から16番アミノ酸(Kabatナンバリング)まで、40番アミノ酸(Kabatナンバリング)から47番アミノ酸(Kabatナンバリング)まで、55番アミノ酸(Kabatナンバリング)から69番アミノ酸(Kabatナンバリング)まで、73番アミノ酸(Kabatナンバリング)から79番アミノ酸(Kabatナンバリング)まで、83番アミノ酸(Kabatナンバリング)から89番アミノ酸(Kabatナンバリング)まで、95番アミノ酸(Kabatナンバリング)から99番アミノ酸(Kabatナンバリング)まで、および101番アミノ酸(Kabatナンバリング)から113番アミノ酸(Kabatナンバリング)までからなる群より選択される配列中の任意位置に導入される、[B-69]に記載の方法。
[B-71] 前記プロテアーゼ切断配列、またはプロテアーゼ切断配列と第一可動リンカー、またはプロテアーゼ切断配列と第一可動リンカーと第二可動リンカーは、抗体VL7番アミノ酸(Kabatナンバリング)から19番アミノ酸(Kabatナンバリング)まで、39番アミノ酸(Kabatナンバリング)から46番アミノ酸(Kabatナンバリング)まで、49番アミノ酸(Kabatナンバリング)から62番アミノ酸(Kabatナンバリング)まで、および96番アミノ酸(Kabatナンバリング)から107番アミノ酸(Kabatナンバリング)までからなる群より選択される配列中の任意位置に導入される、[B-69]に記載の方法。
[B-72] 前記プロテアーゼ切断配列、またはプロテアーゼ切断配列と第一可動リンカー、またはプロテアーゼ切断配列と第一可動リンカーと第二可動リンカーは、前記抗体定常領域と前記抗体VHの境界付近、および/または前記抗体定常領域と前記抗体VLとの境界付近に位置する、[B-65]に記載の方法。
[B-73] 前記プロテアーゼ切断配列、またはプロテアーゼ切断配列と第一可動リンカー、またはプロテアーゼ切断配列と第一可動リンカーと第二可動リンカーは、抗体VH109番のアミノ酸(Kabatナンバリング)から抗体重鎖定常領域122番のアミノ酸(EUナンバリング)までの配列中の任意位置に導入される、[B-73]に記載の方法。
[B-74] 前記プロテアーゼ切断配列、またはプロテアーゼ切断配列と第一可動リンカー、またはプロテアーゼ切断配列と第一可動リンカーと第二可動リンカーは、抗体VL104番のアミノ酸(Kabatナンバリング)から抗体軽鎖定常領域113番のアミノ酸(Kabatナンバリング)までの配列中の任意位置に導入される、[B-72]に記載の方法。
[B-75] 前記リガンド結合分子中の前記抗体VLと前記抗体VHは会合しており、当該会合は前記プロテアーゼ切断配列がプロテアーゼで切断されることにより解消される、[B-65]から[B-74]のいずれか一つに記載のリ方法。
[B-76] 前記リガンドは生物活性を有する分子であり、前記リガンド結合分子は前記リガンドとの結合で前記リガンドの生物活性を阻害する、[B-52]から[B-75]のいずれか一つに記載の方法。
[B-77] 前記リガンドはサイトカインまたはケモカインである、[B-52]から[B-76]のいずれか一つに記載の方法。
[B-78] 前記リガンドは、インターロイキン、インターフェロン、造血因子、TNFスーパーファミリー、ケモカイン、細胞増殖因子、及びTGF-βファミリーから選ばれるリガンドである、[B-52]から[B-76]のいずれか一つに記載の方法。
[B-79] 前記リガンド結合分子はIgG抗体である、[B-52]から[B-78]のいずれか一つに記載の方法。
[B-2] 前記プロテアーゼ切断配列が切断された状態では、前記リガンドが前記リガンド結合分子から遊離する、[B-1]に記載のリガンド結合分子。
[B-3] 前記プロテアーゼは、マトリプターゼおよび/またはウロキナーゼである、[B-1]から[B-2]のいずれか一つに記載のリガンド結合分子。
[B-4] 前記プロテアーゼは、ヒトMT-SP1、マウスMT-SP1、ヒトuPA、マウスuPAから選ばれる少なくとも一種類のプロテアーゼである、[B-1]から[B-3]のいずれか一つに記載のリガンド結合分子。
[B-5] 前記プロテアーゼ切断配列の一端に、第一可動リンカーが更に付加されている、[B-1]から[B-4]のいずれか一つに記載のリガンド結合分子。
[B-6] 前記第一可動リンカーは、グリシン-セリンポリマーからなる可動リンカーである、[B-5]に記載のリガンド結合分子。
[B-7] 前記プロテアーゼ切断配列の他端に、第二可動リンカーが更に付加されている、[B-5]または[B-6]に記載のリガンド結合分子。
[B-8] 前記第二可動リンカーは、グリシン-セリンポリマーからなる可動リンカーである、[B-7]に記載のリガンド結合分子。
[B-9] 前記リガンド結合分子は抗体VHと、抗体VLと、抗体定常領域を含む、[B-1]から[B-8]のいずれか一つに記載のリガンド結合分子。
[B-10] 前記プロテアーゼ切断配列、またはプロテアーゼ切断配列と第一可動リンカー、またはプロテアーゼ切断配列と第一可動リンカーと第二可動リンカーは、前記抗体定常領域内に位置する、[B-9]に記載のリガンド結合分子。
[B-11] 前記プロテアーゼ切断配列、またはプロテアーゼ切断配列と第一可動リンカー、またはプロテアーゼ切断配列と第一可動リンカーと第二可動リンカーは、抗体重鎖定常領域118番アミノ酸(EUナンバリング)から抗体重鎖定常領域140番アミノ酸(EUナンバリング)までの配列中の任意の位置に導入される、[B-10]に記載のリガンド結合分子。
[B-12] 前記プロテアーゼ切断配列、またはプロテアーゼ切断配列と第一可動リンカー、またはプロテアーゼ切断配列と第一可動リンカーと第二可動リンカーは、抗体軽鎖定常領域108番アミノ酸(Kabatナンバリング)から抗体軽鎖定常領域131番アミノ酸(Kabatナンバリング)までの配列中の任意の位置に導入される、[B-10]に記載のリガンド結合分子。
[B-13] 前記プロテアーゼ切断配列、またはプロテアーゼ切断配列と第一可動リンカー、またはプロテアーゼ切断配列と第一可動リンカーと第二可動リンカーは、前記抗体VH内もしくは前記抗体VL内に位置する、[B-9]に記載のリガンド結合分子。
[B-14] 前記プロテアーゼ切断配列、またはプロテアーゼ切断配列と第一可動リンカー、またはプロテアーゼ切断配列と第一可動リンカーと第二可動リンカーは、抗体VH7番アミノ酸(Kabatナンバリング)から16番アミノ酸(Kabatナンバリング)まで、40番アミノ酸(Kabatナンバリング)から47番アミノ酸(Kabatナンバリング)まで、55番アミノ酸(Kabatナンバリング)から69番アミノ酸(Kabatナンバリング)まで、73番アミノ酸(Kabatナンバリング)から79番アミノ酸(Kabatナンバリング)まで、83番アミノ酸(Kabatナンバリング)から89番アミノ酸(Kabatナンバリング)まで、95番アミノ酸(Kabatナンバリング)から99番アミノ酸(Kabatナンバリング)まで、および101番アミノ酸(Kabatナンバリング)から113番アミノ酸(Kabatナンバリング)までからなる群より選択される配列中の任意位置に導入される、[B-13]に記載のリガンド結合分子。
[B-15] 前記プロテアーゼ切断配列、またはプロテアーゼ切断配列と第一可動リンカー、またはプロテアーゼ切断配列と第一可動リンカーと第二可動リンカーは、抗体VL7番アミノ酸(Kabatナンバリング)から19番アミノ酸(Kabatナンバリング)まで、39番アミノ酸(Kabatナンバリング)から46番アミノ酸(Kabatナンバリング)まで、49番アミノ酸(Kabatナンバリング)から62番アミノ酸(Kabatナンバリング)まで、および96番アミノ酸(Kabatナンバリング)から107番アミノ酸(Kabatナンバリング)までからなる群より選択される配列中の任意位置に導入される、[B-13]に記載のリガンド結合分子。
[B-16] 前記プロテアーゼ切断配列、またはプロテアーゼ切断配列と第一可動リンカー、またはプロテアーゼ切断配列と第一可動リンカーと第二可動リンカーは、前記抗体定常領域と前記抗体VHの境界付近、および/または前記抗体定常領域と前記抗体VLとの境界付近に位置する、[B-9]に記載のリガンド結合分子。
[B-17] 前記プロテアーゼ切断配列、またはプロテアーゼ切断配列と第一可動リンカー、またはプロテアーゼ切断配列と第一可動リンカーと第二可動リンカーは、抗体VH109番のアミノ酸(Kabatナンバリング)から抗体重鎖定常領域122番のアミノ酸(EUナンバリング)までの配列中の任意位置に導入される、[B-17]に記載のリガンド結合分子。
[B-18] 前記プロテアーゼ切断配列、またはプロテアーゼ切断配列と第一可動リンカー、またはプロテアーゼ切断配列と第一可動リンカーと第二可動リンカーは、抗体VL104番のアミノ酸(Kabatナンバリング)から抗体軽鎖定常領域113番のアミノ酸(Kabatナンバリング)までの配列中の任意位置に導入される、[B-16]に記載のリガンド結合分子。
[B-19] 前記リガンド結合分子中の前記抗体VLと前記抗体VHは会合しており、当該会合は前記プロテアーゼ切断配列がプロテアーゼで切断されることにより解消される、[B-9]から[B-18]のいずれか一つに記載のリガンド結合分子。
[B-20] 前記リガンドは生物活性を有する分子であり、前記リガンド結合分子は前記リガンドとの結合で前記リガンドの生物活性を阻害する、[B-1]から[B-19]のいずれか一つに記載のリガンド結合分子。
[B-21] 前記リガンドはサイトカインまたはケモカインである、[B-1]から[B-20]のいずれか一つに記載のリガンド結合分子。
[B-22] 前記リガンドは、インターロイキン、インターフェロン、造血因子、TNFスーパーファミリー、ケモカイン、細胞増殖因子、及びTGF-βファミリーから選ばれるリガンドである、[B-1]から[B-20]のいずれか一つに記載のリガンド結合分子。
[B-23] 前記リガンド結合分子はIgG抗体である、[B-1]から[B-22]のいずれか一つに記載のリガンド結合分子。
[B-24] 前記リガンドと結合している[B-1]から[B-23]のいずれか一つに記載のリガンド結合分子。
[B-25] 前記リガンドと融合されている[B-1]から[B-23]のいずれか一つに記載のリガンド結合分子。
[B-26] 前記リガンド結合分子がリガンドと融合されている状態では更に別のリガンドと結合しない、[B-25]に記載のリガンド結合分子。
[B-27] 前記リガンド結合分子は、リンカーを介して前記リガンドと融合されている、[B-25]または[B-26]に記載のリガンド結合分子。
[B-28] 前記リンカーはプロテアーゼ切断配列を含まない、[B-27]に記載のリガンド結合分子。
[B-29] 前記リガンドと、前記リガンドと結合している[B-1]から[B-23]のいずれか一つに記載のリガンド結合分子とで形成されている複合体。
[B-30] 前記リガンドと[B-1]から[B-23]のいずれか一つに記載のリガンド結合分子が融合されている融合タンパク質。
[B-31] 前記リガンド結合分子がリガンドと融合されている状態では更に別のリガンドと結合しない、[B-30]に記載の融合タンパク質。
[B-32] 前記リガンド結合分子は、リンカーを介して前記リガンドと融合されている、[B-30]または[B-31]に記載の融合タンパク質。
[B-33] 前記リンカーはプロテアーゼ切断配列を含まない、[B-32]に記載の融合タンパク質。
[B-34] 前記リンカーは、グリシン‐セリンポリマーからなるリンカーである、[B-32]または[B-33]に記載の融合タンパク質。
[B-35] [B-1]から[B-28]のいずれか一つに記載のリガンド結合分子を含む、医薬組成物。
[B-36] [B-1]から[B-24]のいずれか一つに記載のリガンド結合分子とリガンドを含む、医薬組成物。
[B-37] [B-29]に記載の複合体を含む、医薬組成物。
[B-38] [B-30]から[B-34]のいずれか一つに記載の融合タンパク質を含む、医薬組成物。
[B-39] [B-1]から[B-28]のいずれか一つに記載のリガンド結合分子を製造する方法。
[B-40] リガンドに結合可能な分子中に、プロテアーゼ切断配列を導入することを含む、[B-39]に記載の製造方法。
[B-41] プロテアーゼ切断配列を有するリガンド結合分子とそのリガンドを融合させることを含む、[B-30]から[B-34]のいずれか一つに記載の融合タンパク質の製造方法。
[B-42] [B-1]から[B-28]のいずれか一つに記載のリガンド結合分子をコードするポリヌクレオチド。
[B-43] [B-42]に記載のポリヌクレオチドを含むベクター。
[B-44] [B-42]に記載のポリヌクレオチドもしくは[B-43]に記載のベクターを含む宿主細胞。
[B-45] [B-44]に記載の宿主細胞を培養する工程を含む、[B-1]から[B-28]のいずれか一つに記載のリガンド結合分子を製造する方法。
[B-46] ポリペプチドを培養上清から単離する工程を含む、[B-45]に記載のリガンド結合分子を製造する方法。
[B-47] [B-30]から[B-34]のいずれか一つに記載の融合タンパク質をコードするポリヌクレオチド。
[B-48] [B-46]に記載のポリヌクレオチドを含むベクター。
[B-49] [B-46]に記載のポリヌクレオチドもしくは[B-48]に記載のベクターを含む宿主細胞。
[B-50] [B-49]に記載の宿主細胞を培養する工程を含む、[B-30]から[B-34]のいずれか一つに記載の融合タンパク質を製造する方法。
[B-51] ポリペプチドを培養上清から単離する工程を含む、[B-50]に記載の融合タンパク質を製造する方法。
[B-52] リガンドに結合可能なリガンド結合分子に含まれる、配列番号:5~17201から選ばれる配列のN末端4番目のアミノ酸から15番目のアミノ酸までの配列、配列番号:5~17201から選ばれる配列のN末端4番目のアミノ酸から13番目のアミノ酸までの配列、配列番号:5~17201から選ばれる配列のN末端6番目のアミノ酸から13番目のアミノ酸までの配列、配列番号:17202~17993から選ばれる配列のN末端1番目のアミノ酸から12番目のアミノ酸までの配列、配列番号:17202~17993から選ばれる配列のN末端3番目のアミノ酸から12番目のアミノ酸までの配列、配列番号:17202~17993から選ばれる配列のN末端3番目のアミノ酸から11番目のアミノ酸までの配列、配列番号:17202~17993から選ばれる配列のN末端3番目のアミノ酸から10番目のアミノ酸までの配列、配列番号:17994~18003から選ばれる配列のN末端3番目のアミノ酸から14番目のアミノ酸までの配列、配列番号:17994~18003から選ばれる配列のN末端5番目のアミノ酸から12番目のアミノ酸までの配列、配列番号:17994~18003から選ばれる配列のN末端5番目のアミノ酸から10番目のアミノ酸までの配列、配列番号:5~18003のいずれかで示される配列から選ばれる少なくとも一つの配列を有する部位がプロテアーゼによって切断されることを含む、前記リガンド結合分子に結合した前記リガンドを遊離させる方法。
[B-53] リガンドとリガンド結合分子の融合タンパク質中のリガンド結合分子に含まれる、配列番号:5~17201から選ばれる配列のN末端4番目のアミノ酸から15番目のアミノ酸までの配列、配列番号:5~17201から選ばれる配列のN末端4番目のアミノ酸から13番目のアミノ酸までの配列、配列番号:5~17201から選ばれる配列のN末端6番目のアミノ酸から13番目のアミノ酸までの配列、配列番号:17202~17993から選ばれる配列のN末端1番目のアミノ酸から12番目のアミノ酸までの配列、配列番号:17202~17993から選ばれる配列のN末端3番目のアミノ酸から12番目のアミノ酸までの配列、配列番号:17202~17993から選ばれる配列のN末端3番目のアミノ酸から11番目のアミノ酸までの配列、配列番号:17202~17993から選ばれる配列のN末端3番目のアミノ酸から10番目のアミノ酸までの配列、配列番号:17994~18003から選ばれる配列のN末端3番目のアミノ酸から14番目のアミノ酸までの配列、配列番号:17994~18003から選ばれる配列のN末端5番目のアミノ酸から12番目のアミノ酸までの配列、配列番号:17994~18003から選ばれる配列のN末端5番目のアミノ酸から10番目のアミノ酸までの配列、配列番号:5~18003のいずれかで示される配列から選ばれる少なくとも一つの配列を有する部位がプロテアーゼによって切断されることを含む、前記融合タンパク質から前記リガンドを遊離させる方法。
[B-54] 前記リガンド結合分子は、リンカーを介して前記リガンドと融合されている、[B-53]に記載の方法。
[B-55] 前記リンカーはプロテアーゼ切断配列を含まない、[B-54]に記載の方法。
[B-56] 前記リンカーは、グリシン‐セリンポリマーからなるリンカーである、[B-54]または[B-55]に記載の方法。
[B-57] 前記リガンド結合分子がリガンドと融合されている状態では更に別のリガンドと結合しない、[B-53]から[B-56]のいずれか一つに記載の方法。
[B-58] 前記プロテアーゼ切断配列が切断された状態における当該リガンド結合分子のリガンドに対する結合が、前記プロテアーゼ切断配列が未切断の状態における当該リガンド結合分子のリガンドに対する結合より弱い、[B-52]から[B-57]のいずれか一つに記載の方法。
[B-59] 前記プロテアーゼは、マトリプターゼおよび/またはウロキナーゼである、[B-52]から[B-58]のいずれか一つに記載の方法。
[B-60] 前記プロテアーゼは、ヒトMT-SP1、マウスMT-SP1、ヒトuPA、マウスuPAから選ばれる少なくとも一種類のプロテアーゼである、[B-52]から[B-59]のいずれか一つに記載の方法。
[B-61] 前記プロテアーゼ切断配列の一端に、第一可動リンカーが更に付加されている、[B-52]から[B-60]のいずれか一つに記載の方法。
[B-62] 前記第一可動リンカーは、グリシン-セリンポリマーからなる可動リンカーである、[B-61]に記載の方法。
[B-63] 前記プロテアーゼ切断配列の他端に、第二可動リンカーが更に付加されている、[B-61]または[B-62]に記載の方法。
[B-64] 前記第二可動リンカーは、グリシン-セリンポリマーからなる可動リンカーである、[B-63]に記載の方法。
[B-65] 前記リガンド結合分子は抗体VHと、抗体VLと、抗体定常領域を含む、[B-52]から[B-64]のいずれか一つに記載の方法。
[B-66] 前記プロテアーゼ切断配列、またはプロテアーゼ切断配列と第一可動リンカー、またはプロテアーゼ切断配列と第一可動リンカーと第二可動リンカーは、前記抗体定常領域内に位置する、[B-65]に記載の方法。
[B-67] 前記プロテアーゼ切断配列、またはプロテアーゼ切断配列と第一可動リンカー、またはプロテアーゼ切断配列と第一可動リンカーと第二可動リンカーは、抗体重鎖定常領域118番アミノ酸(EUナンバリング)から抗体重鎖定常領域140番アミノ酸(EUナンバリング)までの配列中の任意の位置に導入される、[B-66]に記載の方法。
[B-68] 前記プロテアーゼ切断配列、またはプロテアーゼ切断配列と第一可動リンカー、またはプロテアーゼ切断配列と第一可動リンカーと第二可動リンカーは、抗体軽鎖定常領域108番アミノ酸(Kabatナンバリング)から抗体軽鎖定常領域131番アミノ酸(Kabatナンバリング)までの配列中の任意の位置に導入される、[B-66]に記載の方法。
[B-69] 前記プロテアーゼ切断配列、またはプロテアーゼ切断配列と第一可動リンカー、またはプロテアーゼ切断配列と第一可動リンカーと第二可動リンカーは、前記抗体VH内もしくは前記抗体VL内に位置する、[B-65]に記載の方法。
[B-70] 前記プロテアーゼ切断配列、またはプロテアーゼ切断配列と第一可動リンカー、またはプロテアーゼ切断配列と第一可動リンカーと第二可動リンカーは、抗体VH7番アミノ酸(Kabatナンバリング)から16番アミノ酸(Kabatナンバリング)まで、40番アミノ酸(Kabatナンバリング)から47番アミノ酸(Kabatナンバリング)まで、55番アミノ酸(Kabatナンバリング)から69番アミノ酸(Kabatナンバリング)まで、73番アミノ酸(Kabatナンバリング)から79番アミノ酸(Kabatナンバリング)まで、83番アミノ酸(Kabatナンバリング)から89番アミノ酸(Kabatナンバリング)まで、95番アミノ酸(Kabatナンバリング)から99番アミノ酸(Kabatナンバリング)まで、および101番アミノ酸(Kabatナンバリング)から113番アミノ酸(Kabatナンバリング)までからなる群より選択される配列中の任意位置に導入される、[B-69]に記載の方法。
[B-71] 前記プロテアーゼ切断配列、またはプロテアーゼ切断配列と第一可動リンカー、またはプロテアーゼ切断配列と第一可動リンカーと第二可動リンカーは、抗体VL7番アミノ酸(Kabatナンバリング)から19番アミノ酸(Kabatナンバリング)まで、39番アミノ酸(Kabatナンバリング)から46番アミノ酸(Kabatナンバリング)まで、49番アミノ酸(Kabatナンバリング)から62番アミノ酸(Kabatナンバリング)まで、および96番アミノ酸(Kabatナンバリング)から107番アミノ酸(Kabatナンバリング)までからなる群より選択される配列中の任意位置に導入される、[B-69]に記載の方法。
[B-72] 前記プロテアーゼ切断配列、またはプロテアーゼ切断配列と第一可動リンカー、またはプロテアーゼ切断配列と第一可動リンカーと第二可動リンカーは、前記抗体定常領域と前記抗体VHの境界付近、および/または前記抗体定常領域と前記抗体VLとの境界付近に位置する、[B-65]に記載の方法。
[B-73] 前記プロテアーゼ切断配列、またはプロテアーゼ切断配列と第一可動リンカー、またはプロテアーゼ切断配列と第一可動リンカーと第二可動リンカーは、抗体VH109番のアミノ酸(Kabatナンバリング)から抗体重鎖定常領域122番のアミノ酸(EUナンバリング)までの配列中の任意位置に導入される、[B-73]に記載の方法。
[B-74] 前記プロテアーゼ切断配列、またはプロテアーゼ切断配列と第一可動リンカー、またはプロテアーゼ切断配列と第一可動リンカーと第二可動リンカーは、抗体VL104番のアミノ酸(Kabatナンバリング)から抗体軽鎖定常領域113番のアミノ酸(Kabatナンバリング)までの配列中の任意位置に導入される、[B-72]に記載の方法。
[B-75] 前記リガンド結合分子中の前記抗体VLと前記抗体VHは会合しており、当該会合は前記プロテアーゼ切断配列がプロテアーゼで切断されることにより解消される、[B-65]から[B-74]のいずれか一つに記載のリ方法。
[B-76] 前記リガンドは生物活性を有する分子であり、前記リガンド結合分子は前記リガンドとの結合で前記リガンドの生物活性を阻害する、[B-52]から[B-75]のいずれか一つに記載の方法。
[B-77] 前記リガンドはサイトカインまたはケモカインである、[B-52]から[B-76]のいずれか一つに記載の方法。
[B-78] 前記リガンドは、インターロイキン、インターフェロン、造血因子、TNFスーパーファミリー、ケモカイン、細胞増殖因子、及びTGF-βファミリーから選ばれるリガンドである、[B-52]から[B-76]のいずれか一つに記載の方法。
[B-79] 前記リガンド結合分子はIgG抗体である、[B-52]から[B-78]のいずれか一つに記載の方法。
[C-1] [27]に記載のポリペプチドであって、当該ポリペプチドはリガンドに結合可能なリガンド結合分子であり、当該リガンド結合分子は単ドメイン抗体を含み、当該単ドメイン抗体はリガンドに結合可能であり且つ少なくとも一つの前記プロテアーゼ切断配列が導入されており、当該プロテアーゼ切断配列が切断された状態での当該リガンド結合分子の前記リガンドに対する結合が、当該プロテアーゼ切断配列が未切断の状態での当該リガンド結合分子の前記リガンドに対する結合より減弱される、リガンド結合分子。
[C-2] 前記プロテアーゼ切断配列が切断された状態では、前記リガンドがリガンド結合分子から遊離する、[C-1]に記載のリガンド結合分子。
[C-3] 前記プロテアーゼは、マトリプターゼおよび/またはウロキナーゼである、[C-1]または[C-2]に記載のリガンド結合分子。
[C-4] 前記プロテアーゼは、ヒトMT-SP1、マウスMT-SP1、ヒトuPA、マウスuPAから選ばれる少なくとも一種類のプロテアーゼである、[C-1]から[C-3]のいずれか一つに記載のリガンド結合分子。
[C-5] 前記プロテアーゼ切断配列の一端に、第一可動リンカーが更に付加されている、[C-1]から[C-4]のいずれか一つに記載のリガンド結合分子。
[C-6] 前記第一可動リンカーは、グリシン-セリンポリマーからなる可動リンカーである、[C-5]に記載のリガンド結合分子。
[C-7] 前記プロテアーゼ切断配列の他端に、第二可動リンカーが更に付加されている、[C-5]また[C-6]に記載のリガンド結合分子。
[C-8] 前記第二可動リンカーは、グリシン-セリンポリマーからなる可動リンカーである、[C-7]に記載のリガンド結合分子。
[C-9] 前記単ドメイン抗体はVHH、または単ドメインVH抗体、また単ドメインVL抗体である、[C-1]から[C-8]のいずれか一つに記載のリガンド結合分子。
[C-10] 前記単ドメイン抗体はVHHまたは単ドメインVH抗体であり、前記切断サイト、または前記プロテアーゼ切断配列、またはプロテアーゼ切断配列と第一可動リンカー、またはプロテアーゼ切断配列と第一可動リンカーと第二可動リンカーは、前記単ドメイン抗体の下記配列から選ばれる一つまたは複数の配列に含まれる一つまたは複数の位置に導入される、[C-9]に記載のリガンド結合分子: 単ドメイン抗体7番アミノ酸(Kabatナンバリング)から17番アミノ酸(Kabatナンバリング)までの配列、単ドメイン抗体12番アミノ酸(Kabatナンバリング)から17番アミノ酸(Kabatナンバリング)までの配列、単ドメイン抗体31番アミノ酸(Kabatナンバリング)から35b番アミノ酸(Kabatナンバリング)までの配列、単ドメイン抗体40番アミノ酸(Kabatナンバリング)から47番アミノ酸(Kabatナンバリング)までの配列、単ドメイン抗体50番アミノ酸(Kabatナンバリング)から65番アミノ酸(Kabatナンバリング)までの配列、単ドメイン抗体55番アミノ酸(Kabatナンバリング)から69番アミノ酸(Kabatナンバリング)までの配列、単ドメイン抗体73番アミノ酸(Kabatナンバリング)から79番アミノ酸(Kabatナンバリング)までの配列、単ドメイン抗体83番アミノ酸(Kabatナンバリング)から89番アミノ酸(Kabatナンバリング)までの配列、単ドメイン抗体95番アミノ酸(Kabatナンバリング)から99番アミノ酸(Kabatナンバリング)までの配列、単ドメイン抗体95番アミノ酸(Kabatナンバリング)から102番アミノ酸(Kabatナンバリング)までの配列、単ドメイン抗体101番アミノ酸(Kabatナンバリング)から113番アミノ酸(Kabatナンバリング)までの配列。
[C-11] 前記単ドメイン抗体は単ドメインVL抗体であり、前記切断サイト、または前記プロテアーゼ切断配列、またはプロテアーゼ切断配列と第一可動リンカー、またはプロテアーゼ切断配列と第一可動リンカーと第二可動リンカーは、前記単ドメイン抗体の下記配列から選ばれる一つまたは複数の配列に含まれる一つまたは複数の位置に導入される、[C-9]に記載のリガンド結合分子: 単ドメイン抗体7番アミノ酸(Kabatナンバリング)から19番アミノ酸(Kabatナンバリング)までの配列、単ドメイン抗体24番アミノ酸(Kabatナンバリング)から34番アミノ酸(Kabatナンバリング)までの配列、単ドメイン抗体39番アミノ酸(Kabatナンバリング)から46番アミノ酸(Kabatナンバリング)までの配列、単ドメイン抗体49番アミノ酸(Kabatナンバリング)から62番アミノ酸(Kabatナンバリング)までの配列、単ドメイン抗体50番アミノ酸(Kabatナンバリング)から56番アミノ酸(Kabatナンバリング)までの配列、単ドメイン抗体89番アミノ酸(Kabatナンバリング)から97番アミノ酸(Kabatナンバリング)までの配列、単ドメイン抗体96番アミノ酸(Kabatナンバリング)から107番アミノ酸(Kabatナンバリング)までの配列。
[C-12] 前記リガンドは生物活性を有する分子であり、前記単ドメイン抗体は前記リガンドと結合することで前記リガンドの生物活性を阻害する、[C-1]から[C-11]のいずれか一つに記載のリガンド結合分子。
[C-13] 前記リガンドは生物活性を有する分子であり、前記単ドメイン抗体は前記リガンドに対する中和活性を有する、[C-1]から[C-12]のいずれか一つに記載のリガンド結合分子。
[C-14] 前記リガンド結合分子は、前記切断サイトまたはプロテアーゼ切断配列を含む単ドメイン抗体のみを含む、[C-1]から[C-13]のいずれか一つに記載のリガンド結合分子。
[C-15] 前記リガンド結合分子は更に抗体Fc領域を含む、[C-1]から[C-14]のいずれか一つに記載のリガンド結合分子。
[C-16] 前記リガンド結合分子はN末端からC末端に向かって単ドメイン抗体-抗体Fc領域からなる一連のペプチド鎖を含む、[C-1]から[C-15]のいずれか一つに記載のリガンド結合分子。
[C-17] 前記リガンド結合分子は、単ドメイン抗体-抗体ヒンジ領域-抗体Fc領域からなる一連のペプチド鎖を二つ含む二量体である、[C-1]から[C-15]に記載のリガンド結合分子。
[C-18] 前記抗体Fc領域は、配列番号:18004~18007で示されるアミノ酸配列から選ばれる一つの配列を含むFc領域、またはこれらのFc領域に改変を加えたFc領域変異体である、[C-15]から[C-17]に記載のリガンド結合分子。
[C-19] 前記リガンドはサイトカインまたはケモカインである、[C-1]から[C-18]のいずれか一つに記載のリガンド結合分子。
[C-20] 前記リガンドは、インターロイキン、インターフェロン、造血因子、TNFスーパーファミリー、ケモカイン、細胞増殖因子、及びTGF-βファミリーから選ばれるリガンドである、[C-1]から[C-19]のいずれか一つに記載のリガンド結合分子。
[C-21] 前記リガンドと結合している、[C-1]から[C-20]のいずれか一つに記載のリガンド結合分子。
[C-22] 前記リガンドと融合されている、[C-1]から[C-20]のいずれか一つに記載のリガンド結合分子。
[C-23] 前記リガンド結合分子がリガンドと融合されている状態では、当該リガンド結合分子に含まれる単ドメイン抗体は更に別のリガンドと結合しない、[C-22]に記載のリガンド結合分子。
[C-24] 前記リガンド結合分子は、リンカーを介して前記リガンドと融合されている、[C-22]または[C-23]に記載のリガンド結合分子。
[C-25] 前記リンカーはプロテアーゼ切断配列を含まない、[C-24]に記載のリガンド結合分子。
[C-26] 前記リガンドと、[C-1]から[C-20]のいずれか一つに記載のリガンド結合分子とで形成されている複合体。
[C-27] 前記リガンドと[C-1]から[C-20]のいずれか一つに記載のリガンド結合分子が融合されている融合タンパク質。
[C-28] 前記リガンド結合分子がリガンドと融合されている状態では、前記単ドメイン抗体は更に別のリガンドと結合しない、[C-27]に記載の融合タンパク質。
[C-29] 前記リガンド結合分子は、リンカーを介して前記リガンドと融合されている、[C-27]または[C-28]に記載の融合タンパク質。
[C-30] 前記リンカーはプロテアーゼ切断配列を含まない、[C-29]に記載の融合タンパク質。
[C-31] N末端からC末端に向かってリガンド-リンカー-リガンド結合分子の順で融合されている、[C-29]または[C-30]に記載の融合タンパク質。
[C-32] [C-1]から[C-22]のいずれか一つに記載のリガンド結合分子を含む、医薬組成物。
[C-33] [C-1]から[C-21]のいずれか一つに記載のリガンド結合分子とリガンドを含む、医薬組成物。
[C-34] [C-26]に記載の複合体を含む、医薬組成物。
[C-35] [C-27]から[C-31]のいずれか一つに記載の融合タンパク質を含む、医薬組成物。
[C-36] [C-1]から[C-20]のいずれか一つに記載のリガンド結合分子を製造する方法。
[C-37] 単ドメイン抗体を含むリガンド結合分子中の単ドメイン抗体に、プロテアーゼ切断配列を導入することを含む、[C-36]に記載の製造方法。
[C-38] プロテアーゼ切断配列が導入された単ドメイン抗体含有リガンド結合分子と、当該単ドメイン抗体と結合可能なリガンドを融合させることを含む、[C-27]から[C-31]のいずれか一つに記載の融合タンパク質の製造方法。
[C-39] [C-1]から[C-20]のいずれか一つに記載のリガンド結合分子をコードするポリヌクレオチド。
[C-40] [C-39]に記載のポリヌクレオチドを含むベクター。
[C-41] [C-39]に記載のポリヌクレオチドもしくは[C-40]に記載のベクターを含む宿主細胞。
[C-42] [C-41]に記載の宿主細胞を培養する工程を含む、[C-1]から[C-20]のいずれか一つに記載のリガンド結合分子を製造する方法。
[C-43] ポリペプチドを培養上清から単離する工程を含む、[C-42]に記載のリガンド結合分子を製造する方法。
[C-44] [C-27]から[C-31]のいずれか一つに記載の融合タンパク質をコードするポリヌクレオチド。
[C-45] [C-43]に記載のポリヌクレオチドを含むベクター。
[C-46] [C-43]に記載のポリヌクレオチドもしくは[C-45]に記載のベクターを含む宿主細胞。
[C-47] [C-46]に記載の宿主細胞を培養する工程を含む、[C-27]から[C-31]のいずれか一つに記載の融合タンパク質を製造する方法。
[C-48] ポリペプチドを培養上清から単離する工程を含む、[C-47]に記載のリガンド結合分子を製造する方法。
[C-49] リガンドに結合可能なリガンド結合分子中の単ドメイン抗体に含まれる、配列番号:5~17201から選ばれる配列のN末端4番目のアミノ酸から15番目のアミノ酸までの配列、配列番号:5~17201から選ばれる配列のN末端4番目のアミノ酸から13番目のアミノ酸までの配列、配列番号:5~17201から選ばれる配列のN末端6番目のアミノ酸から13番目のアミノ酸までの配列、配列番号:17202~17993から選ばれる配列のN末端1番目のアミノ酸から12番目のアミノ酸までの配列、配列番号:17202~17993から選ばれる配列のN末端3番目のアミノ酸から12番目のアミノ酸までの配列、配列番号:17202~17993から選ばれる配列のN末端3番目のアミノ酸から11番目のアミノ酸までの配列、配列番号:17202~17993から選ばれる配列のN末端3番目のアミノ酸から10番目のアミノ酸までの配列、配列番号:17994~18003から選ばれる配列のN末端3番目のアミノ酸から14番目のアミノ酸までの配列、配列番号:17994~18003から選ばれる配列のN末端5番目のアミノ酸から12番目のアミノ酸までの配列、配列番号:17994~18003から選ばれる配列のN末端5番目のアミノ酸から10番目のアミノ酸までの配列、配列番号:5~18003のいずれかで示される配列から選ばれる少なくとも一つの配列を有する部位がプロテアーゼによって切断されることを含む、前記リガンド結合分子に結合した前記リガンドを遊離させる方法。
[C-50] リガンドに結合可能なリガンド結合分子中の単ドメイン抗体に含まれる、配列番号:5~17201から選ばれる配列のN末端4番目のアミノ酸から15番目のアミノ酸までの配列、配列番号:5~17201から選ばれる配列のN末端4番目のアミノ酸から13番目のアミノ酸までの配列、配列番号:5~17201から選ばれる配列のN末端6番目のアミノ酸から13番目のアミノ酸までの配列、配列番号:17202~17993から選ばれる配列のN末端1番目のアミノ酸から12番目のアミノ酸までの配列、配列番号:17202~17993から選ばれる配列のN末端3番目のアミノ酸から12番目のアミノ酸までの配列、配列番号:17202~17993から選ばれる配列のN末端3番目のアミノ酸から11番目のアミノ酸までの配列、配列番号:17202~17993から選ばれる配列のN末端3番目のアミノ酸から10番目のアミノ酸までの配列、配列番号:17994~18003から選ばれる配列のN末端3番目のアミノ酸から14番目のアミノ酸までの配列、配列番号:17994~18003から選ばれる配列のN末端5番目のアミノ酸から12番目のアミノ酸までの配列、配列番号:17994~18003から選ばれる配列のN末端5番目のアミノ酸から10番目のアミノ酸までの配列、配列番号:5~18003のいずれかで示される配列から選ばれる少なくとも一つの配列を有する部位がプロテアーゼによって切断されることを含む、前記リガンドと前記リガンド結合分子の融合タンパク質からリガンドを遊離させる方法。
[C-51] 前記リガンド結合分子は、リンカーを介して前記リガンドと融合されている、[C-50]に記載の方法。
[C-52] 前記リンカーはプロテアーゼ切断配列を含まない、[C-51]に記載の方法。
[C-53] 前記リンカーは、グリシン‐セリンポリマーからなるリンカーである、[C-51]または[C-52]に記載の方法。
[C-54] 前記リガンド結合分子がリガンドと融合されている状態では更に別のリガンドと結合しない、[C-50]から[C-53]のいずれか一つに記載の方法。
[C-55] 当該プロテアーゼ切断配列が切断された状態での当該リガンド結合分子の前記リガンドに対する結合が、当該プロテアーゼ切断配列が未切断の状態での当該リガンド結合分子の前記リガンドに対する結合より減弱される、[C-49]から[C-54]のいずれか一つに記載の方法。
[C-56] 前記プロテアーゼ切断配列が切断された状態では、前記リガンドがリガンド結合分子から遊離する、[C-55]に記載の方法子。
[C-57] 前記プロテアーゼは、マトリプターゼおよび/またはウロキナーゼである、[C-55]または[C-56]に記載の方法。
[C-58] 前記プロテアーゼは、ヒトMT-SP1、マウスMT-SP1、ヒトuPA、マウスuPAから選ばれる少なくとも一種類のプロテアーゼである、[C-55]から[C-57]のいずれか一つに記載の方法。
[C-59] 前記プロテアーゼ切断配列の一端に、第一可動リンカーが更に付加されている、[C-55]から[C-58]のいずれか一つに記載の方法。
[C-60] 前記第一可動リンカーは、グリシン-セリンポリマーからなる可動リンカーである、[C-59]に記載の方法。
[C-61] 前記プロテアーゼ切断配列の他端に、第二可動リンカーが更に付加されている、[C-59]また[C-60]に記載の方法。
[C-62] 前記第二可動リンカーは、グリシン-セリンポリマーからなる可動リンカーである、[C-61]に記載の方法。
[C-63] 前記単ドメイン抗体はVHH、または単ドメインVH抗体、また単ドメインVL抗体である、[C-55]から[C-62]のいずれか一つに記載の方法。
[C-64] 前記単ドメイン抗体はVHHまたは単ドメインVH抗体であり、前記切断サイト、または前記プロテアーゼ切断配列、またはプロテアーゼ切断配列と第一可動リンカー、またはプロテアーゼ切断配列と第一可動リンカーと第二可動リンカーは、前記単ドメイン抗体の下記配列から選ばれる一つまたは複数の配列に含まれる一つまたは複数の位置に導入される、[C-63]に記載の方法: 単ドメイン抗体7番アミノ酸(Kabatナンバリング)から17番アミノ酸(Kabatナンバリング)までの配列、単ドメイン抗体12番アミノ酸(Kabatナンバリング)から17番アミノ酸(Kabatナンバリング)までの配列、単ドメイン抗体31番アミノ酸(Kabatナンバリング)から35b番アミノ酸(Kabatナンバリング)までの配列、単ドメイン抗体40番アミノ酸(Kabatナンバリング)から47番アミノ酸(Kabatナンバリング)までの配列、単ドメイン抗体50番アミノ酸(Kabatナンバリング)から65番アミノ酸(Kabatナンバリング)までの配列、単ドメイン抗体55番アミノ酸(Kabatナンバリング)から69番アミノ酸(Kabatナンバリング)までの配列、単ドメイン抗体73番アミノ酸(Kabatナンバリング)から79番アミノ酸(Kabatナンバリング)までの配列、単ドメイン抗体83番アミノ酸(Kabatナンバリング)から89番アミノ酸(Kabatナンバリング)までの配列、単ドメイン抗体95番アミノ酸(Kabatナンバリング)から99番アミノ酸(Kabatナンバリング)までの配列、単ドメイン抗体95番アミノ酸(Kabatナンバリング)から102番アミノ酸(Kabatナンバリング)までの配列、単ドメイン抗体101番アミノ酸(Kabatナンバリング)から113番アミノ酸(Kabatナンバリング)までの配列。
[C-65] 前記単ドメイン抗体は単ドメインVL抗体であり、前記切断サイト、または前記プロテアーゼ切断配列、またはプロテアーゼ切断配列と第一可動リンカー、またはプロテアーゼ切断配列と第一可動リンカーと第二可動リンカーは、前記単ドメイン抗体の下記配列から選ばれる一つまたは複数の配列に含まれる一つまたは複数の位置に導入される、[C-63]に記載の方法: 単ドメイン抗体7番アミノ酸(Kabatナンバリング)から19番アミノ酸(Kabatナンバリング)までの配列、単ドメイン抗体24番アミノ酸(Kabatナンバリング)から34番アミノ酸(Kabatナンバリング)までの配列、単ドメイン抗体39番アミノ酸(Kabatナンバリング)から46番アミノ酸(Kabatナンバリング)までの配列、単ドメイン抗体49番アミノ酸(Kabatナンバリング)から62番アミノ酸(Kabatナンバリング)までの配列、単ドメイン抗体50番アミノ酸(Kabatナンバリング)から56番アミノ酸(Kabatナンバリング)までの配列、単ドメイン抗体89番アミノ酸(Kabatナンバリング)から97番アミノ酸(Kabatナンバリング)までの配列、単ドメイン抗体96番アミノ酸(Kabatナンバリング)から107番アミノ酸(Kabatナンバリング)までの配列。
[C-66] 前記リガンドは生物活性を有する分子であり、前記単ドメイン抗体は前記リガンドと結合することで前記リガンドの生物活性を阻害する、[C-55]から[C-65]のいずれか一つに記載の方法。
[C-67] 前記リガンドは生物活性を有する分子であり、前記単ドメイン抗体は前記リガンドに対する中和活性を有する、[C-55]から[C-66]のいずれか一つに記載の方法。
[C-68] 前記リガンド結合分子は、前記切断サイトまたはプロテアーゼ切断配列を含む単ドメイン抗体のみを含む、[C-55]から[C-67]のいずれか一つに記載の方法。
[C-69] 前記リガンド結合分子は更に抗体Fc領域を含む、[C-55]から[C-68]のいずれか一つに記載の方法。
[C-70] 前記リガンド結合分子はN末端からC末端に向かって単ドメイン抗体-抗体Fc領域からなる一連のペプチド鎖を含む、[C-55]から[C-69]のいずれか一つに記載の方法。
[C-71] 前記リガンド結合分子は、単ドメイン抗体-抗体ヒンジ領域-抗体Fc領域からなる一連のペプチド鎖を二つ含む二量体である、[C-55]から[C-69]に記載の方法。
[C-72] 前記抗体Fc領域は、配列番号:18004~18007で示されるアミノ酸配列から選ばれる一つの配列を含むFc領域、またはこれらのFc領域に改変を加えたFc領域変異体である、[C-69]から[C-71]に記載の方法。
[C-73] 前記リガンドはサイトカインまたはケモカインである、[C-55]から[C-72]のいずれか一つに記載の方法。
[C-74] 前記リガンドは、インターロイキン、インターフェロン、造血因子、TNFスーパーファミリー、ケモカイン、細胞増殖因子、及びTGF-βファミリーから選ばれるリガンドである、[C-55]から[C-73]のいずれか一つに記載の方法。
[C-2] 前記プロテアーゼ切断配列が切断された状態では、前記リガンドがリガンド結合分子から遊離する、[C-1]に記載のリガンド結合分子。
[C-3] 前記プロテアーゼは、マトリプターゼおよび/またはウロキナーゼである、[C-1]または[C-2]に記載のリガンド結合分子。
[C-4] 前記プロテアーゼは、ヒトMT-SP1、マウスMT-SP1、ヒトuPA、マウスuPAから選ばれる少なくとも一種類のプロテアーゼである、[C-1]から[C-3]のいずれか一つに記載のリガンド結合分子。
[C-5] 前記プロテアーゼ切断配列の一端に、第一可動リンカーが更に付加されている、[C-1]から[C-4]のいずれか一つに記載のリガンド結合分子。
[C-6] 前記第一可動リンカーは、グリシン-セリンポリマーからなる可動リンカーである、[C-5]に記載のリガンド結合分子。
[C-7] 前記プロテアーゼ切断配列の他端に、第二可動リンカーが更に付加されている、[C-5]また[C-6]に記載のリガンド結合分子。
[C-8] 前記第二可動リンカーは、グリシン-セリンポリマーからなる可動リンカーである、[C-7]に記載のリガンド結合分子。
[C-9] 前記単ドメイン抗体はVHH、または単ドメインVH抗体、また単ドメインVL抗体である、[C-1]から[C-8]のいずれか一つに記載のリガンド結合分子。
[C-10] 前記単ドメイン抗体はVHHまたは単ドメインVH抗体であり、前記切断サイト、または前記プロテアーゼ切断配列、またはプロテアーゼ切断配列と第一可動リンカー、またはプロテアーゼ切断配列と第一可動リンカーと第二可動リンカーは、前記単ドメイン抗体の下記配列から選ばれる一つまたは複数の配列に含まれる一つまたは複数の位置に導入される、[C-9]に記載のリガンド結合分子: 単ドメイン抗体7番アミノ酸(Kabatナンバリング)から17番アミノ酸(Kabatナンバリング)までの配列、単ドメイン抗体12番アミノ酸(Kabatナンバリング)から17番アミノ酸(Kabatナンバリング)までの配列、単ドメイン抗体31番アミノ酸(Kabatナンバリング)から35b番アミノ酸(Kabatナンバリング)までの配列、単ドメイン抗体40番アミノ酸(Kabatナンバリング)から47番アミノ酸(Kabatナンバリング)までの配列、単ドメイン抗体50番アミノ酸(Kabatナンバリング)から65番アミノ酸(Kabatナンバリング)までの配列、単ドメイン抗体55番アミノ酸(Kabatナンバリング)から69番アミノ酸(Kabatナンバリング)までの配列、単ドメイン抗体73番アミノ酸(Kabatナンバリング)から79番アミノ酸(Kabatナンバリング)までの配列、単ドメイン抗体83番アミノ酸(Kabatナンバリング)から89番アミノ酸(Kabatナンバリング)までの配列、単ドメイン抗体95番アミノ酸(Kabatナンバリング)から99番アミノ酸(Kabatナンバリング)までの配列、単ドメイン抗体95番アミノ酸(Kabatナンバリング)から102番アミノ酸(Kabatナンバリング)までの配列、単ドメイン抗体101番アミノ酸(Kabatナンバリング)から113番アミノ酸(Kabatナンバリング)までの配列。
[C-11] 前記単ドメイン抗体は単ドメインVL抗体であり、前記切断サイト、または前記プロテアーゼ切断配列、またはプロテアーゼ切断配列と第一可動リンカー、またはプロテアーゼ切断配列と第一可動リンカーと第二可動リンカーは、前記単ドメイン抗体の下記配列から選ばれる一つまたは複数の配列に含まれる一つまたは複数の位置に導入される、[C-9]に記載のリガンド結合分子: 単ドメイン抗体7番アミノ酸(Kabatナンバリング)から19番アミノ酸(Kabatナンバリング)までの配列、単ドメイン抗体24番アミノ酸(Kabatナンバリング)から34番アミノ酸(Kabatナンバリング)までの配列、単ドメイン抗体39番アミノ酸(Kabatナンバリング)から46番アミノ酸(Kabatナンバリング)までの配列、単ドメイン抗体49番アミノ酸(Kabatナンバリング)から62番アミノ酸(Kabatナンバリング)までの配列、単ドメイン抗体50番アミノ酸(Kabatナンバリング)から56番アミノ酸(Kabatナンバリング)までの配列、単ドメイン抗体89番アミノ酸(Kabatナンバリング)から97番アミノ酸(Kabatナンバリング)までの配列、単ドメイン抗体96番アミノ酸(Kabatナンバリング)から107番アミノ酸(Kabatナンバリング)までの配列。
[C-12] 前記リガンドは生物活性を有する分子であり、前記単ドメイン抗体は前記リガンドと結合することで前記リガンドの生物活性を阻害する、[C-1]から[C-11]のいずれか一つに記載のリガンド結合分子。
[C-13] 前記リガンドは生物活性を有する分子であり、前記単ドメイン抗体は前記リガンドに対する中和活性を有する、[C-1]から[C-12]のいずれか一つに記載のリガンド結合分子。
[C-14] 前記リガンド結合分子は、前記切断サイトまたはプロテアーゼ切断配列を含む単ドメイン抗体のみを含む、[C-1]から[C-13]のいずれか一つに記載のリガンド結合分子。
[C-15] 前記リガンド結合分子は更に抗体Fc領域を含む、[C-1]から[C-14]のいずれか一つに記載のリガンド結合分子。
[C-16] 前記リガンド結合分子はN末端からC末端に向かって単ドメイン抗体-抗体Fc領域からなる一連のペプチド鎖を含む、[C-1]から[C-15]のいずれか一つに記載のリガンド結合分子。
[C-17] 前記リガンド結合分子は、単ドメイン抗体-抗体ヒンジ領域-抗体Fc領域からなる一連のペプチド鎖を二つ含む二量体である、[C-1]から[C-15]に記載のリガンド結合分子。
[C-18] 前記抗体Fc領域は、配列番号:18004~18007で示されるアミノ酸配列から選ばれる一つの配列を含むFc領域、またはこれらのFc領域に改変を加えたFc領域変異体である、[C-15]から[C-17]に記載のリガンド結合分子。
[C-19] 前記リガンドはサイトカインまたはケモカインである、[C-1]から[C-18]のいずれか一つに記載のリガンド結合分子。
[C-20] 前記リガンドは、インターロイキン、インターフェロン、造血因子、TNFスーパーファミリー、ケモカイン、細胞増殖因子、及びTGF-βファミリーから選ばれるリガンドである、[C-1]から[C-19]のいずれか一つに記載のリガンド結合分子。
[C-21] 前記リガンドと結合している、[C-1]から[C-20]のいずれか一つに記載のリガンド結合分子。
[C-22] 前記リガンドと融合されている、[C-1]から[C-20]のいずれか一つに記載のリガンド結合分子。
[C-23] 前記リガンド結合分子がリガンドと融合されている状態では、当該リガンド結合分子に含まれる単ドメイン抗体は更に別のリガンドと結合しない、[C-22]に記載のリガンド結合分子。
[C-24] 前記リガンド結合分子は、リンカーを介して前記リガンドと融合されている、[C-22]または[C-23]に記載のリガンド結合分子。
[C-25] 前記リンカーはプロテアーゼ切断配列を含まない、[C-24]に記載のリガンド結合分子。
[C-26] 前記リガンドと、[C-1]から[C-20]のいずれか一つに記載のリガンド結合分子とで形成されている複合体。
[C-27] 前記リガンドと[C-1]から[C-20]のいずれか一つに記載のリガンド結合分子が融合されている融合タンパク質。
[C-28] 前記リガンド結合分子がリガンドと融合されている状態では、前記単ドメイン抗体は更に別のリガンドと結合しない、[C-27]に記載の融合タンパク質。
[C-29] 前記リガンド結合分子は、リンカーを介して前記リガンドと融合されている、[C-27]または[C-28]に記載の融合タンパク質。
[C-30] 前記リンカーはプロテアーゼ切断配列を含まない、[C-29]に記載の融合タンパク質。
[C-31] N末端からC末端に向かってリガンド-リンカー-リガンド結合分子の順で融合されている、[C-29]または[C-30]に記載の融合タンパク質。
[C-32] [C-1]から[C-22]のいずれか一つに記載のリガンド結合分子を含む、医薬組成物。
[C-33] [C-1]から[C-21]のいずれか一つに記載のリガンド結合分子とリガンドを含む、医薬組成物。
[C-34] [C-26]に記載の複合体を含む、医薬組成物。
[C-35] [C-27]から[C-31]のいずれか一つに記載の融合タンパク質を含む、医薬組成物。
[C-36] [C-1]から[C-20]のいずれか一つに記載のリガンド結合分子を製造する方法。
[C-37] 単ドメイン抗体を含むリガンド結合分子中の単ドメイン抗体に、プロテアーゼ切断配列を導入することを含む、[C-36]に記載の製造方法。
[C-38] プロテアーゼ切断配列が導入された単ドメイン抗体含有リガンド結合分子と、当該単ドメイン抗体と結合可能なリガンドを融合させることを含む、[C-27]から[C-31]のいずれか一つに記載の融合タンパク質の製造方法。
[C-39] [C-1]から[C-20]のいずれか一つに記載のリガンド結合分子をコードするポリヌクレオチド。
[C-40] [C-39]に記載のポリヌクレオチドを含むベクター。
[C-41] [C-39]に記載のポリヌクレオチドもしくは[C-40]に記載のベクターを含む宿主細胞。
[C-42] [C-41]に記載の宿主細胞を培養する工程を含む、[C-1]から[C-20]のいずれか一つに記載のリガンド結合分子を製造する方法。
[C-43] ポリペプチドを培養上清から単離する工程を含む、[C-42]に記載のリガンド結合分子を製造する方法。
[C-44] [C-27]から[C-31]のいずれか一つに記載の融合タンパク質をコードするポリヌクレオチド。
[C-45] [C-43]に記載のポリヌクレオチドを含むベクター。
[C-46] [C-43]に記載のポリヌクレオチドもしくは[C-45]に記載のベクターを含む宿主細胞。
[C-47] [C-46]に記載の宿主細胞を培養する工程を含む、[C-27]から[C-31]のいずれか一つに記載の融合タンパク質を製造する方法。
[C-48] ポリペプチドを培養上清から単離する工程を含む、[C-47]に記載のリガンド結合分子を製造する方法。
[C-49] リガンドに結合可能なリガンド結合分子中の単ドメイン抗体に含まれる、配列番号:5~17201から選ばれる配列のN末端4番目のアミノ酸から15番目のアミノ酸までの配列、配列番号:5~17201から選ばれる配列のN末端4番目のアミノ酸から13番目のアミノ酸までの配列、配列番号:5~17201から選ばれる配列のN末端6番目のアミノ酸から13番目のアミノ酸までの配列、配列番号:17202~17993から選ばれる配列のN末端1番目のアミノ酸から12番目のアミノ酸までの配列、配列番号:17202~17993から選ばれる配列のN末端3番目のアミノ酸から12番目のアミノ酸までの配列、配列番号:17202~17993から選ばれる配列のN末端3番目のアミノ酸から11番目のアミノ酸までの配列、配列番号:17202~17993から選ばれる配列のN末端3番目のアミノ酸から10番目のアミノ酸までの配列、配列番号:17994~18003から選ばれる配列のN末端3番目のアミノ酸から14番目のアミノ酸までの配列、配列番号:17994~18003から選ばれる配列のN末端5番目のアミノ酸から12番目のアミノ酸までの配列、配列番号:17994~18003から選ばれる配列のN末端5番目のアミノ酸から10番目のアミノ酸までの配列、配列番号:5~18003のいずれかで示される配列から選ばれる少なくとも一つの配列を有する部位がプロテアーゼによって切断されることを含む、前記リガンド結合分子に結合した前記リガンドを遊離させる方法。
[C-50] リガンドに結合可能なリガンド結合分子中の単ドメイン抗体に含まれる、配列番号:5~17201から選ばれる配列のN末端4番目のアミノ酸から15番目のアミノ酸までの配列、配列番号:5~17201から選ばれる配列のN末端4番目のアミノ酸から13番目のアミノ酸までの配列、配列番号:5~17201から選ばれる配列のN末端6番目のアミノ酸から13番目のアミノ酸までの配列、配列番号:17202~17993から選ばれる配列のN末端1番目のアミノ酸から12番目のアミノ酸までの配列、配列番号:17202~17993から選ばれる配列のN末端3番目のアミノ酸から12番目のアミノ酸までの配列、配列番号:17202~17993から選ばれる配列のN末端3番目のアミノ酸から11番目のアミノ酸までの配列、配列番号:17202~17993から選ばれる配列のN末端3番目のアミノ酸から10番目のアミノ酸までの配列、配列番号:17994~18003から選ばれる配列のN末端3番目のアミノ酸から14番目のアミノ酸までの配列、配列番号:17994~18003から選ばれる配列のN末端5番目のアミノ酸から12番目のアミノ酸までの配列、配列番号:17994~18003から選ばれる配列のN末端5番目のアミノ酸から10番目のアミノ酸までの配列、配列番号:5~18003のいずれかで示される配列から選ばれる少なくとも一つの配列を有する部位がプロテアーゼによって切断されることを含む、前記リガンドと前記リガンド結合分子の融合タンパク質からリガンドを遊離させる方法。
[C-51] 前記リガンド結合分子は、リンカーを介して前記リガンドと融合されている、[C-50]に記載の方法。
[C-52] 前記リンカーはプロテアーゼ切断配列を含まない、[C-51]に記載の方法。
[C-53] 前記リンカーは、グリシン‐セリンポリマーからなるリンカーである、[C-51]または[C-52]に記載の方法。
[C-54] 前記リガンド結合分子がリガンドと融合されている状態では更に別のリガンドと結合しない、[C-50]から[C-53]のいずれか一つに記載の方法。
[C-55] 当該プロテアーゼ切断配列が切断された状態での当該リガンド結合分子の前記リガンドに対する結合が、当該プロテアーゼ切断配列が未切断の状態での当該リガンド結合分子の前記リガンドに対する結合より減弱される、[C-49]から[C-54]のいずれか一つに記載の方法。
[C-56] 前記プロテアーゼ切断配列が切断された状態では、前記リガンドがリガンド結合分子から遊離する、[C-55]に記載の方法子。
[C-57] 前記プロテアーゼは、マトリプターゼおよび/またはウロキナーゼである、[C-55]または[C-56]に記載の方法。
[C-58] 前記プロテアーゼは、ヒトMT-SP1、マウスMT-SP1、ヒトuPA、マウスuPAから選ばれる少なくとも一種類のプロテアーゼである、[C-55]から[C-57]のいずれか一つに記載の方法。
[C-59] 前記プロテアーゼ切断配列の一端に、第一可動リンカーが更に付加されている、[C-55]から[C-58]のいずれか一つに記載の方法。
[C-60] 前記第一可動リンカーは、グリシン-セリンポリマーからなる可動リンカーである、[C-59]に記載の方法。
[C-61] 前記プロテアーゼ切断配列の他端に、第二可動リンカーが更に付加されている、[C-59]また[C-60]に記載の方法。
[C-62] 前記第二可動リンカーは、グリシン-セリンポリマーからなる可動リンカーである、[C-61]に記載の方法。
[C-63] 前記単ドメイン抗体はVHH、または単ドメインVH抗体、また単ドメインVL抗体である、[C-55]から[C-62]のいずれか一つに記載の方法。
[C-64] 前記単ドメイン抗体はVHHまたは単ドメインVH抗体であり、前記切断サイト、または前記プロテアーゼ切断配列、またはプロテアーゼ切断配列と第一可動リンカー、またはプロテアーゼ切断配列と第一可動リンカーと第二可動リンカーは、前記単ドメイン抗体の下記配列から選ばれる一つまたは複数の配列に含まれる一つまたは複数の位置に導入される、[C-63]に記載の方法: 単ドメイン抗体7番アミノ酸(Kabatナンバリング)から17番アミノ酸(Kabatナンバリング)までの配列、単ドメイン抗体12番アミノ酸(Kabatナンバリング)から17番アミノ酸(Kabatナンバリング)までの配列、単ドメイン抗体31番アミノ酸(Kabatナンバリング)から35b番アミノ酸(Kabatナンバリング)までの配列、単ドメイン抗体40番アミノ酸(Kabatナンバリング)から47番アミノ酸(Kabatナンバリング)までの配列、単ドメイン抗体50番アミノ酸(Kabatナンバリング)から65番アミノ酸(Kabatナンバリング)までの配列、単ドメイン抗体55番アミノ酸(Kabatナンバリング)から69番アミノ酸(Kabatナンバリング)までの配列、単ドメイン抗体73番アミノ酸(Kabatナンバリング)から79番アミノ酸(Kabatナンバリング)までの配列、単ドメイン抗体83番アミノ酸(Kabatナンバリング)から89番アミノ酸(Kabatナンバリング)までの配列、単ドメイン抗体95番アミノ酸(Kabatナンバリング)から99番アミノ酸(Kabatナンバリング)までの配列、単ドメイン抗体95番アミノ酸(Kabatナンバリング)から102番アミノ酸(Kabatナンバリング)までの配列、単ドメイン抗体101番アミノ酸(Kabatナンバリング)から113番アミノ酸(Kabatナンバリング)までの配列。
[C-65] 前記単ドメイン抗体は単ドメインVL抗体であり、前記切断サイト、または前記プロテアーゼ切断配列、またはプロテアーゼ切断配列と第一可動リンカー、またはプロテアーゼ切断配列と第一可動リンカーと第二可動リンカーは、前記単ドメイン抗体の下記配列から選ばれる一つまたは複数の配列に含まれる一つまたは複数の位置に導入される、[C-63]に記載の方法: 単ドメイン抗体7番アミノ酸(Kabatナンバリング)から19番アミノ酸(Kabatナンバリング)までの配列、単ドメイン抗体24番アミノ酸(Kabatナンバリング)から34番アミノ酸(Kabatナンバリング)までの配列、単ドメイン抗体39番アミノ酸(Kabatナンバリング)から46番アミノ酸(Kabatナンバリング)までの配列、単ドメイン抗体49番アミノ酸(Kabatナンバリング)から62番アミノ酸(Kabatナンバリング)までの配列、単ドメイン抗体50番アミノ酸(Kabatナンバリング)から56番アミノ酸(Kabatナンバリング)までの配列、単ドメイン抗体89番アミノ酸(Kabatナンバリング)から97番アミノ酸(Kabatナンバリング)までの配列、単ドメイン抗体96番アミノ酸(Kabatナンバリング)から107番アミノ酸(Kabatナンバリング)までの配列。
[C-66] 前記リガンドは生物活性を有する分子であり、前記単ドメイン抗体は前記リガンドと結合することで前記リガンドの生物活性を阻害する、[C-55]から[C-65]のいずれか一つに記載の方法。
[C-67] 前記リガンドは生物活性を有する分子であり、前記単ドメイン抗体は前記リガンドに対する中和活性を有する、[C-55]から[C-66]のいずれか一つに記載の方法。
[C-68] 前記リガンド結合分子は、前記切断サイトまたはプロテアーゼ切断配列を含む単ドメイン抗体のみを含む、[C-55]から[C-67]のいずれか一つに記載の方法。
[C-69] 前記リガンド結合分子は更に抗体Fc領域を含む、[C-55]から[C-68]のいずれか一つに記載の方法。
[C-70] 前記リガンド結合分子はN末端からC末端に向かって単ドメイン抗体-抗体Fc領域からなる一連のペプチド鎖を含む、[C-55]から[C-69]のいずれか一つに記載の方法。
[C-71] 前記リガンド結合分子は、単ドメイン抗体-抗体ヒンジ領域-抗体Fc領域からなる一連のペプチド鎖を二つ含む二量体である、[C-55]から[C-69]に記載の方法。
[C-72] 前記抗体Fc領域は、配列番号:18004~18007で示されるアミノ酸配列から選ばれる一つの配列を含むFc領域、またはこれらのFc領域に改変を加えたFc領域変異体である、[C-69]から[C-71]に記載の方法。
[C-73] 前記リガンドはサイトカインまたはケモカインである、[C-55]から[C-72]のいずれか一つに記載の方法。
[C-74] 前記リガンドは、インターロイキン、インターフェロン、造血因子、TNFスーパーファミリー、ケモカイン、細胞増殖因子、及びTGF-βファミリーから選ばれるリガンドである、[C-55]から[C-73]のいずれか一つに記載の方法。
アミノ酸
本明細書において、たとえば、Ala/A、Leu/L、Arg/R、Lys/K、Asn/N、Met/M、Asp/D、Phe/F、Cys/C、Pro/P、Gln/Q、Ser/S、Glu/E、Thr/T、Gly/G、Trp/W、His/H、Tyr/Y、Ile/I、Val/Vと表されるように、アミノ酸は1文字コードまたは3文字コード、またはその両方で表記されている。
天然アミノ酸
本明細書における「天然アミノ酸」とは、タンパク質に含まれる20種類のアミノ酸を指す。具体的にはGly、Ala、Ser、Thr、Val、Leu、Ile、Phe、Tyr、Trp、His、Glu、Asp、Gln、Asn、Cys、Met、Lys、Arg、Proを指す。
本明細書において、たとえば、Ala/A、Leu/L、Arg/R、Lys/K、Asn/N、Met/M、Asp/D、Phe/F、Cys/C、Pro/P、Gln/Q、Ser/S、Glu/E、Thr/T、Gly/G、Trp/W、His/H、Tyr/Y、Ile/I、Val/Vと表されるように、アミノ酸は1文字コードまたは3文字コード、またはその両方で表記されている。
天然アミノ酸
本明細書における「天然アミノ酸」とは、タンパク質に含まれる20種類のアミノ酸を指す。具体的にはGly、Ala、Ser、Thr、Val、Leu、Ile、Phe、Tyr、Trp、His、Glu、Asp、Gln、Asn、Cys、Met、Lys、Arg、Proを指す。
ペプチド
本明細書における「ペプチド」とは、2個以上のアミノ酸分子が,一方のアミノ基と他方のカルボキシル基とから1分子の水がとれて結合した化合物をいう。ペプチドに含まれるアミノ酸の数は限定されない。従って、オリゴペプチドとポリペプチドの両方のどちらもペプチドに含まれる。
本明細書における「ペプチド」とは、2個以上のアミノ酸分子が,一方のアミノ基と他方のカルボキシル基とから1分子の水がとれて結合した化合物をいう。ペプチドに含まれるアミノ酸の数は限定されない。従って、オリゴペプチドとポリペプチドの両方のどちらもペプチドに含まれる。
ポリペプチド
本開示におけるポリペプチドとは、通常、10アミノ酸程度以上の長さを有するペプチド、およびタンパク質を指す。N末端からC末端までペプチド結合でつながるアミノ酸の連鎖を一連のペプチド鎖とする場合、本開示のポリペプチドは、複数の一連のペプチド鎖がS-S結合、疎水性相互作用、イオン結合等の相互作用により形成された複合体タンパク質であっても良い。また、本開示におけるポリペプチドは通常、人工的に設計された配列からなるポリペプチドであるが、特に限定されず、例えば、合成ポリペプチド、組換えポリペプチド等のいずれであってもよい。さらに、上記のポリペプチドの断片もまた、本開示のポリペプチドに含まれる。
本開示におけるポリペプチドとは、通常、10アミノ酸程度以上の長さを有するペプチド、およびタンパク質を指す。N末端からC末端までペプチド結合でつながるアミノ酸の連鎖を一連のペプチド鎖とする場合、本開示のポリペプチドは、複数の一連のペプチド鎖がS-S結合、疎水性相互作用、イオン結合等の相互作用により形成された複合体タンパク質であっても良い。また、本開示におけるポリペプチドは通常、人工的に設計された配列からなるポリペプチドであるが、特に限定されず、例えば、合成ポリペプチド、組換えポリペプチド等のいずれであってもよい。さらに、上記のポリペプチドの断片もまた、本開示のポリペプチドに含まれる。
単離されたポリペプチド
本開示のポリペプチドは、単離されたポリペプチドを指すことができる。「単離された」ポリペプチドは、そのもともとの環境の成分から分離されたものである。いくつかの態様において、ポリペプチドは、例えば、電気泳動(例えば、SDS-PAGE、等電点分離法 (isoelectric focusing: IEF)、キャピラリー電気泳動)またはクロマトグラフ(例えば、イオン交換または逆相HPLC)で測定して、95%または99%を超える純度まで精製される。ポリペプチドが抗体である場合、抗体の純度の評価のための方法の総説として、例えば、Flatman et al., J. Chromatogr. B 848:79-87 (2007) を参照のこと。
本開示のポリペプチドは、単離されたポリペプチドを指すことができる。「単離された」ポリペプチドは、そのもともとの環境の成分から分離されたものである。いくつかの態様において、ポリペプチドは、例えば、電気泳動(例えば、SDS-PAGE、等電点分離法 (isoelectric focusing: IEF)、キャピラリー電気泳動)またはクロマトグラフ(例えば、イオン交換または逆相HPLC)で測定して、95%または99%を超える純度まで精製される。ポリペプチドが抗体である場合、抗体の純度の評価のための方法の総説として、例えば、Flatman et al., J. Chromatogr. B 848:79-87 (2007) を参照のこと。
プロテアーゼ
本明細書において、用語「プロテアーゼ」は、ペプチド結合を加水分解するエンドペプチダーゼまたはエキソペプチダーゼなどの酵素、通常はエンドペプチダーゼを言う。
本明細書において、用語「プロテアーゼ」は、ペプチド結合を加水分解するエンドペプチダーゼまたはエキソペプチダーゼなどの酵素、通常はエンドペプチダーゼを言う。
限定して解釈されるものではないが、具体的なプロテアーゼの種類としては、システインプロテアーゼ(カテプシンファミリーB、L、Sなどを含む)、アスパルチルプロテアーゼ(カテプシンD、E、K、O等)、セリンプロテアーゼ(マトリプターゼ(MT-SP1を含む)、カテプシンAおよびG、トロンビン、プラスミン、ウロキナーゼ(uPA)、組織プラスミノーゲン活性化因子(tPA)、エラスターゼ、プロテイナーゼ3、トロンビン、カリクレイン、トリプターゼ、キマーゼを含む)、メタロプロテアーゼ(膜結合型(MMP14-17およびMMP24-25)および分泌型(MMP1-13およびMMP18-23およびMMP26-28)の両方を含むメタロプロテアーゼ(MMP1-28))、プロテアーゼのAディスインテグリンおよびメタロプロテアーゼ(ADAM)、Aディスインテグリンまたはトロンボスポンジンモチーフを有するメタロプロテアーゼ(ADAMTS)、メプリン(メプリンα(meprin alpha)、メプリンβ(meprin beta)))、CD10(CALLA)、ならびに前立腺特異的抗原(PSA)、レグマイン、TMPRSS3、TMPRSS4、好中球エラスターゼ(HNE)、ベータセクレターゼ(BACE)、線維芽細胞活性化蛋白質アルファ(FAP)、グランザイムB、 グアニジノベンゾアターゼ(GB)、ヘプシン、ネプリライシン、NS3/4A、HCV-NS3/4、カルパイン、ADAMDEC1、レニン、カテプシンC、カテプシンV/L2、カテプシン X/Z/P、クルジパイン、オツバイン2、カリクレイン関連ペプチダーゼ(KLKs(KLK3、KLK4、KLK5、KLK6、KLK7、KLK8、KLK10、KLK11、KLK13、KLK14))、骨形成タンパク質1(BMP-1)、活性化プロテインC、血液凝固関連プロテアーゼ(Factor VIIa、Factor IXa、Factor Xa、Factor XIa、Factor XIIa)、HtrA1、ラクトフェリン、マラプシン、PACE4、DESC1、ジペプチジルペプチダーゼ4(DPP-4)、TMPRSS2、カテプシンF、カテプシンH、カテプシンL2、カテプシンO、カテプシンS、グランザイムA、Gepsinカルパイン2、グルタミン酸カルボキシペプチダーゼ2、AMSH-Like Proteases、AMSH、ガンマセクレターゼ、抗プラスミン切断酵素(APCE)、Decysin 1、N-Acetylated Alpha-Linked Acidic Dipeptidase-Like 1(NAALADL1)、フーリン(furin)等が挙げられる。
本開示のプロテアーゼは、疾患組織と密に関連するプロテアーゼであり得る。例えば、
(1)疾患組織にて正常組織より高レベルで発現するプロテアーゼ、
(2)疾患組織にて正常組織より高い活性を有するプロテアーゼ、
(3)疾患組織中の細胞にて正常細胞より高レベルで発現するプロテアーゼ、
(4)疾患組織中の標的細胞にて正常細胞より高い活性を有するプロテアーゼ、
のいずれかを指すことができる。疾患組織の例として、癌組織や炎症組織がある。
(1)疾患組織にて正常組織より高レベルで発現するプロテアーゼ、
(2)疾患組織にて正常組織より高い活性を有するプロテアーゼ、
(3)疾患組織中の細胞にて正常細胞より高レベルで発現するプロテアーゼ、
(4)疾患組織中の標的細胞にて正常細胞より高い活性を有するプロテアーゼ、
のいずれかを指すことができる。疾患組織の例として、癌組織や炎症組織がある。
用語「癌組織」とは、少なくとも一つの癌細胞を含む組織を意味する。したがって、例えば癌組織が癌細胞と血管を含んでいるように、癌細胞および内皮細胞を含む腫瘤(tumor mass)の形成に寄与するすべての細胞型をいう。本明細書において、腫瘤とは腫瘍組織巣(a foci of tumor tissue)をいう。「腫瘍」という用語は、一般に、良性新生物または悪性新生物を意味するために用いられる。
本明細書において、「炎症組織」とは、例えば、以下が例示的に挙げられる。
・関節リウマチや変形性関節症における関節
・気管支喘息やCOPDにおける肺(肺胞)
・炎症性腸疾患やクローン病や潰瘍性大腸炎における消化器官
・肝臓、腎臓、肺における線維化症における線維化組織
・臓器移植における拒絶反応が起こっている組織
・動脈硬化や心不全における血管、心臓(心筋)
・メタボリック症候群における内臓脂肪
・アトピー性皮膚炎その他皮膚炎における皮膚組織
・椎間板ヘルニアや慢性腰痛における脊髄神経
・関節リウマチや変形性関節症における関節
・気管支喘息やCOPDにおける肺(肺胞)
・炎症性腸疾患やクローン病や潰瘍性大腸炎における消化器官
・肝臓、腎臓、肺における線維化症における線維化組織
・臓器移植における拒絶反応が起こっている組織
・動脈硬化や心不全における血管、心臓(心筋)
・メタボリック症候群における内臓脂肪
・アトピー性皮膚炎その他皮膚炎における皮膚組織
・椎間板ヘルニアや慢性腰痛における脊髄神経
ウロキナーゼ(uPA)
ウロキナーゼ(uPA)は、ウロキナーゼ型プラスミノーゲン活性化因子とも称され、細胞外セリンプロテアーゼの一種である。ウロキナーゼ、ウロキナーゼ型プラスミノーゲン活性化因子及びuPAという用語は本明細書において互換的に使用され、セリンプロテアーゼ活性を有する限り、任意の好適な生物に由来し得る、天然に存在する、内因的に産生された及び/又は組換え形態の任意のuPAを包含する。例えば本開示の一態様では、uPAは2本鎖活性形態(tc-uPA)である。ウロキナーゼは更に、ヒトuPA又は、霊長類(例えばチンパンジー、カニクイザル又はアカゲザル);げっ歯類(マウス又はラットなど)、ウサギ類(ウサギなど)又は偶蹄類(ウシ、ヒツジ、ブタ若しくはラクダなど)由来のuPAなどの哺乳動物由来uPAなどの別の種由来のuPAを包含する。ウロキナーゼ型プラスミノーゲン活性化因子及びuPAという用語は更に、組換えによって生成されたuPAを包含する。これは、これだけに限らないが哺乳動物細胞系又は細菌又は酵母において発現されたタンパク質を含む「組換え遺伝子技術によって生成された」任意のuPAを含む。
ウロキナーゼ(uPA)は、がん組織との関連が高いと言われており、ウロキナーゼ(uPA)により切断可能なペプチド配列は、正常組織中に比べ、癌組織中でより切断される。
ウロキナーゼ(uPA)は、ウロキナーゼ型プラスミノーゲン活性化因子とも称され、細胞外セリンプロテアーゼの一種である。ウロキナーゼ、ウロキナーゼ型プラスミノーゲン活性化因子及びuPAという用語は本明細書において互換的に使用され、セリンプロテアーゼ活性を有する限り、任意の好適な生物に由来し得る、天然に存在する、内因的に産生された及び/又は組換え形態の任意のuPAを包含する。例えば本開示の一態様では、uPAは2本鎖活性形態(tc-uPA)である。ウロキナーゼは更に、ヒトuPA又は、霊長類(例えばチンパンジー、カニクイザル又はアカゲザル);げっ歯類(マウス又はラットなど)、ウサギ類(ウサギなど)又は偶蹄類(ウシ、ヒツジ、ブタ若しくはラクダなど)由来のuPAなどの哺乳動物由来uPAなどの別の種由来のuPAを包含する。ウロキナーゼ型プラスミノーゲン活性化因子及びuPAという用語は更に、組換えによって生成されたuPAを包含する。これは、これだけに限らないが哺乳動物細胞系又は細菌又は酵母において発現されたタンパク質を含む「組換え遺伝子技術によって生成された」任意のuPAを含む。
ウロキナーゼ(uPA)は、がん組織との関連が高いと言われており、ウロキナーゼ(uPA)により切断可能なペプチド配列は、正常組織中に比べ、癌組織中でより切断される。
マトリプターゼ
マトリプターゼは、セリンプロテアーゼの一種である。本開示のマトリプターゼは、セリンプロテアーゼ活性を有する限り、任意の好適な生物に由来し得る、天然に存在する、内因的に産生された及び/又は組換え形態の任意のマトリプターゼを包含する。マトリプターゼに、ヒトマトリプターゼ又は、霊長類(例えばチンパンジー、カニクイザル又はアカゲザル);げっ歯類(マウス又はラットなど)、ウサギ類(ウサギなど)又は偶蹄類(ウシ、ヒツジ、ブタ若しくはラクダなど)由来のマトリプターゼなどの哺乳動物由来マトリプターゼなどの別の種由来のマトリプターゼを包含する。マトリプターゼは更に、組換えによって生成されたマトリプターゼを包含する。これは、これだけに限らないが哺乳動物細胞系又は細菌又は酵母において発現されたタンパク質を含む「組換え遺伝子技術によって生成された」任意のマトリプターゼを含む。
マトリプターゼにはMT-SP1が含まれ、MT-SP1は、セリンプロテアーゼ活性を有する限り、任意の好適な生物に由来し得る、天然に存在する、内因的に産生された及び/又は組換え形態の任意のMT-SP1を包含する。MT-SP1に、ヒトMT-SP1又は、霊長類(例えばチンパンジー、カニクイザル又はアカゲザル);げっ歯類(マウス又はラットなど)、ウサギ類(ウサギなど)又は偶蹄類(ウシ、ヒツジ、ブタ若しくはラクダなど)由来のMT-SP1などの哺乳動物由来MT-SP1などの別の種由来のMT-SP1を包含する。MT-SP1は更に、組換えによって生成されたMT-SP1を包含する。これは、これだけに限らないが哺乳動物細胞系又は細菌又は酵母において発現されたタンパク質を含む「組換え遺伝子技術によって生成された」任意のMT-SP1を含む。
マトリプターゼ(MT-SP1を含む)は、がん組織との関連が高いと言われており、マトリプターゼ(MT-SP1を含む))により切断可能なペプチド配列は、正常組織中に比べ、癌組織中でより切断される。
ヒトMT-SP1とマウスMT-SP1の配列が相当類似しているため、同じ基質に対する酵素活性は類似すると思われる。
マトリプターゼは、セリンプロテアーゼの一種である。本開示のマトリプターゼは、セリンプロテアーゼ活性を有する限り、任意の好適な生物に由来し得る、天然に存在する、内因的に産生された及び/又は組換え形態の任意のマトリプターゼを包含する。マトリプターゼに、ヒトマトリプターゼ又は、霊長類(例えばチンパンジー、カニクイザル又はアカゲザル);げっ歯類(マウス又はラットなど)、ウサギ類(ウサギなど)又は偶蹄類(ウシ、ヒツジ、ブタ若しくはラクダなど)由来のマトリプターゼなどの哺乳動物由来マトリプターゼなどの別の種由来のマトリプターゼを包含する。マトリプターゼは更に、組換えによって生成されたマトリプターゼを包含する。これは、これだけに限らないが哺乳動物細胞系又は細菌又は酵母において発現されたタンパク質を含む「組換え遺伝子技術によって生成された」任意のマトリプターゼを含む。
マトリプターゼにはMT-SP1が含まれ、MT-SP1は、セリンプロテアーゼ活性を有する限り、任意の好適な生物に由来し得る、天然に存在する、内因的に産生された及び/又は組換え形態の任意のMT-SP1を包含する。MT-SP1に、ヒトMT-SP1又は、霊長類(例えばチンパンジー、カニクイザル又はアカゲザル);げっ歯類(マウス又はラットなど)、ウサギ類(ウサギなど)又は偶蹄類(ウシ、ヒツジ、ブタ若しくはラクダなど)由来のMT-SP1などの哺乳動物由来MT-SP1などの別の種由来のMT-SP1を包含する。MT-SP1は更に、組換えによって生成されたMT-SP1を包含する。これは、これだけに限らないが哺乳動物細胞系又は細菌又は酵母において発現されたタンパク質を含む「組換え遺伝子技術によって生成された」任意のMT-SP1を含む。
マトリプターゼ(MT-SP1を含む)は、がん組織との関連が高いと言われており、マトリプターゼ(MT-SP1を含む))により切断可能なペプチド配列は、正常組織中に比べ、癌組織中でより切断される。
ヒトMT-SP1とマウスMT-SP1の配列が相当類似しているため、同じ基質に対する酵素活性は類似すると思われる。
プロテアーゼによる切断を確認する方法
本明細書に記載のプロテアーゼ基質またはプロテアーゼ切断配列のプロテアーゼによる切断を評価する方法として、Mol Cell Proteomics. 2014 Jun;13(6):1585-97. doi: 10.1074/mcp.M113.033308. Epub 2014 Apr 4.に記載の方法が例示される。
評価対象となるプロテアーゼ基質またはプロテアーゼ切断配列をペプチドアレイ上に固定し、評価対象のプロテアーゼが含まれる溶液を用いてペプチドアレイを処理し、チップから測定される蛍光値を使用して切断率を下記のように算出することが出来る:
 評価に使用するプロテアーゼの種類や濃度、処理温度や処理時間は適宜選択することが可能であり、例示的に、1000 nMのヒトuPAを含むPBS、1000 nMのマウスuPAを含むPBS、500 nMのヒトMT-SP1を含むPBS、または500 nMのマウスMT-SP1を含むPBSを使用し、37℃で1時間処理を行うことが出来る。
評価に使用するプロテアーゼの種類や濃度、処理温度や処理時間は適宜選択することが可能であり、例示的に、1000 nMのヒトuPAを含むPBS、1000 nMのマウスuPAを含むPBS、500 nMのヒトMT-SP1を含むPBS、または500 nMのマウスMT-SP1を含むPBSを使用し、37℃で1時間処理を行うことが出来る。
本明細書に記載のプロテアーゼ基質またはプロテアーゼ切断配列のプロテアーゼによる切断を評価する方法として、Mol Cell Proteomics. 2014 Jun;13(6):1585-97. doi: 10.1074/mcp.M113.033308. Epub 2014 Apr 4.に記載の方法が例示される。
評価対象となるプロテアーゼ基質またはプロテアーゼ切断配列をペプチドアレイ上に固定し、評価対象のプロテアーゼが含まれる溶液を用いてペプチドアレイを処理し、チップから測定される蛍光値を使用して切断率を下記のように算出することが出来る:
また、プロテアーゼ含有溶液を使用する代わりに、血清(ヒト血清、マウス血清を含む)を用いてペプチドアレイを処理し、チップから測定される蛍光値を使用して切断率を下記のように算出することが出来る:
 評価に使用する血清の種類や濃度、処理温度や処理時間は適宜選択することが可能であり、例示的に、80%濃度に希釈されたヒト血清を処理液として使用し、37℃で一晩処理を行うことが出来る。本明細書における「血清により切断されない」とは、上記方法で測定され計算された血清による切断率はが1.5以下であること、または、配列番号:4で示すペプチドと比べて、上記方法で測定され計算された血清による切断率が低いこと、を指すことが出来る。
評価に使用する血清の種類や濃度、処理温度や処理時間は適宜選択することが可能であり、例示的に、80%濃度に希釈されたヒト血清を処理液として使用し、37℃で一晩処理を行うことが出来る。本明細書における「血清により切断されない」とは、上記方法で測定され計算された血清による切断率はが1.5以下であること、または、配列番号:4で示すペプチドと比べて、上記方法で測定され計算された血清による切断率が低いこと、を指すことが出来る。
ポリペプチド中に含まれるプロテアーゼ切断配列がプロテアーゼにより切断されたか否かを定性的に確認する方法として、プロテアーゼ切断配列を含むポリペプチドを含む溶液をSDS-PAGE(ポリアクリルアミドゲル電気泳動)に供し、断片の分子量を測定することにより確認することができる。また、プロテアーゼ未処理のポリペプチドとプロテアーゼ処理後のポリペプチドの分子量を比較することにより確認することができる。
本明細書において、用語「切断された」は、プロテアーゼによるプロテアーゼ切断配列の改変および/またはプロテアーゼ切断配列のシステイン-システインジスルフィド結合の還元後の、ポリペプチドが分断された状態をいう。本明細書において、用語「切断されていない」は、プロテアーゼによるプロテアーゼ切断配列の切断の非存在下および/またはプロテアーゼ切断配列のシステイン-システインジスルフィド結合の還元の非存在下における、ポリペプチド中のプロテアーゼ切断配列の両サイドの部分が連結されている状態をいう。
また、SDS-PAGE等の電気泳動法により分離したプロテアーゼ処理後の切断断片量を定量することにより、プロテアーゼ切断配列の評価、およびプロテアーゼ切断配列を導入した分子の切断率の評価が可能である。プロテアーゼ切断配列を導入した分子の切断率を評価する方法の非限定な一態様として以下の方法が挙げられる。例えばプロテアーゼ切断配列を導入した抗体改変体をリコンビナントヒトu-Plasminogen Activator/Urokinase(human uPA, huPA)(R&D Systems;1310-SE-010)もしくはリコンビナントヒトMatriptase/ST14 Catalytic Domain (human MT-SP1, hMT-SP1) (R&D Systems; 3946-SE-010)を用いて切断率を評価する場合、huPA 40 nMもしくはhMT-SP1 3 nM、抗体改変体 100μg/mL、PBS、37℃の条件下で1時間反応させたのちに、キャピラリー電気泳動イムノアッセイに供する。キャピラリー電気泳動イムノアッセイにはWes (Protein Simple) が使用可能であるが、これに限定されずキャピラリー電気泳動イムノアッセイに代わる方法としてSDS-PAGE等により分離後にWestern Blotting法で検出してもよいし、これらの方法に限定されるものではない。切断前後の軽鎖の検出には抗ヒトlambda鎖HRP標識抗体 (abcam; ab9007) が使用可能であるが、切断断片を検出できる抗体はいずれの抗体も使用可能である。プロテアーゼ処理後に得られた各ピークの面積をWes専用のソフトウェア (Compass for SW; Protein Simple) を用いて出力することで、抗体改変体の切断率 (%) を(切断軽鎖ピーク面積)*100/(切断軽鎖ピーク面積+未切断軽鎖ピーク面積)の式により算出できる。切断率の算出は、プロテアーゼ処理前後のタンパク質断片が検出できれば可能であり、プロテアーゼ切断配列を導入した分子は抗体改変体に限らず様々なタンパク質において切断率を算出することが可能である。
プロテアーゼ切断配列を導入した分子を動物に投与した後、血液サンプル中の投与分子を検出することにより、生体内における切断率の算出が可能である。例えばプロテアーゼ切断配列を導入した抗体改変体をマウスに投与後、血液サンプルから血漿を回収しDynabeads Protein A (Thermo; 10001D) を用いて当業者公知の方法で抗体を精製し、キャピラリー電気泳動イムノアッセイに供することで抗体改変体のプロテアーゼ切断率の評価が可能である。キャピラリー電気泳動イムノアッセイにはWes (Protein Simple) が使用可能であるが、これに限定されずキャピラリー電気泳動イムノアッセイに代わる方法としてSDS-PAGE等により分離後にWestern Blotting法で検出してもよいし、これらの方法に限定されるものではない。マウスから回収された抗体改変体の軽鎖の検出には抗ヒトlambda鎖HRP標識抗体 (abcam; ab9007) が使用可能であるが、切断断片を検出できる抗体はいずれの抗体も使用可能である。キャピラリー電気泳動イムノアッセイにより得られた各ピークの面積をWes専用のソフトウェア (Compass for SW; Protein Simple) で出力し、軽鎖残存比として(軽鎖ピーク面積)/(重鎖ピーク面積)を計算することで、マウス体内で切断されずに残った全長軽鎖の割合の算出が可能である。生体内における切断効率の算出には、生体から回収されたタンパク質断片が検出できれば可能であり、プロテアーゼ切断配列を導入した分子は抗体改変体に限らず様々なタンパク質において切断率を算出することが可能である。上述した方法を用いて切断率を算出することにより、例えば異なる切断配列を導入した抗体改変体の生体内における切断率を比較することが可能であるし、また同一の抗体改変体の切断率を正常マウスモデルや腫瘍移植マウスモデルなどの異なる動物モデル間で比較することも可能である。
プロテアーゼ基質
本開示の一側面は、プロテアーゼ基質に関する。一態様では、プロテアーゼ基質は、プロテアーゼの作用によって加水分解されるアミノ酸配列を有するペプチドまたはポリペプチドを指す。また別の態様では、プロテアーゼ基質は長さが約5~15個のアミノ酸のペプチドである。
本開示のプロテアーゼ基質は、プロテアーゼによって、約0.001~1500×104M-1S-1または少なくとも0.001、0.005、0.01、0.05、0.1、0.5、1、2.5、5、7.5、10、15、20、25、50、75、100、125、150、200、250、500、750、1000、1250、もしくは1500×104M-1S-1の速度で特異的に修飾(切断)されることができる。
本開示の一側面は、プロテアーゼ基質に関する。一態様では、プロテアーゼ基質は、プロテアーゼの作用によって加水分解されるアミノ酸配列を有するペプチドまたはポリペプチドを指す。また別の態様では、プロテアーゼ基質は長さが約5~15個のアミノ酸のペプチドである。
本開示のプロテアーゼ基質は、プロテアーゼによって、約0.001~1500×104M-1S-1または少なくとも0.001、0.005、0.01、0.05、0.1、0.5、1、2.5、5、7.5、10、15、20、25、50、75、100、125、150、200、250、500、750、1000、1250、もしくは1500×104M-1S-1の速度で特異的に修飾(切断)されることができる。
ある実施態様では、本開示のプロテアーゼ基質は、配列番号:1、2、3のいずれか一つの配列を含むプロテアーゼ基質に比べ、プロテアーゼによる切断率が高い。
ある実施態様では、本開示のプロテアーゼ基質は、配列番号:1、2、3のいずれか一つの配列を含むプロテアーゼ基質に比べ、ヒトuPAによる切断率が高い。ある実施態様では、本開示のプロテアーゼ基質のヒトuPAによる切断率は、1.5以上、1.6以上、1.8以上、2以上、2.2以上、2.4以上、2.6以上、2.8以上、3以上、3.2以上、3.4以上、3.6以上、3.8以上、3.9以上、または4以上である。
ある実施態様では、本開示のプロテアーゼ基質は、配列番号:1、2、3のいずれか一つの配列を含むプロテアーゼ基質に比べ、ヒトMT-SP1による切断率が高い。ある実施態様では、本開示のプロテアーゼ基質のヒトMT-SP1による切断率は、1.5以上、1.6以上、1.8以上、2以上、2.2以上、2.4以上、2.6以上、2.8以上、3以上、3.2以上、3.4以上、3.6以上、3.8以上、3.9以上、または4以上である。
ある実施態様では、本開示のプロテアーゼ基質は、配列番号:1、2、3のいずれか一つの配列を含むプロテアーゼ基質に比べ、マウスuPAによる切断率が高い。ある実施態様では、本開示のプロテアーゼ基質のマウスuPAによる切断率は、1以上、1.1以上、1.2以上、1.3以上、1.4以上、1.5以上、1.6以上、1.7以上、1.8以上、1.9以上、2以上、2.5以上、3以上、3.5以上、または4以上である。
ある実施態様では、本開示のプロテアーゼ基質は、配列番号:1、2、3のいずれか一つの配列を含むプロテアーゼ基質に比べ、マウスMT-SP1による切断率が高い。ある実施態様では、本開示のプロテアーゼ基質のマウスMT-SP1による切断率は、1.5以上、1.6以上、1.8以上、2以上、2.2以上、2.4以上、2.6以上、2.8以上、3以上、3.2以上、3.4以上、3.6以上、3.8以上、3.9以上、または4以上である。
ある実施態様では、本開示のプロテアーゼ基質は、配列番号:1、2、3のいずれか一つの配列を含むプロテアーゼ基質に比べ、ヒトuPAによる切断率とヒト血清による切断率の比が高い。ある実施態様では、本開示のプロテアーゼ基質のヒトuPAによる切断率とヒト血清による切断率の比は、0.9以上、0.95以上、1以上、1.2以上、1.4以上、1.6以上、1.8以上、2以上、2.2以上、2.4以上、2.6以上、2.8以上、3以上、3.2以上、3.4以上、3.6以上、3.8以上、または4以上である。ここで、ヒト血清による切断率が1以下である場合、1に変換した上でヒトuPAによる切断率とヒト血清による切断率の比の計算に使用することが可能である。
ある実施態様では、本開示のプロテアーゼ基質は、配列番号:1、2、3のいずれか一つの配列を含むプロテアーゼ基質に比べ、ヒトMT-SP1による切断率とヒト血清による切断率の比が高い。ある実施態様では、本開示のプロテアーゼ基質のヒトMT-SP1による切断率とヒト血清による切断率の比は、0.7以上、0.8以上、0.9以上、0.95以上、1以上、1.2以上、1.4以上、1.6以上、1.8以上、2以上、2.2以上、2.4以上、2.5以上、または2.6以上である。ここで、ヒト血清による切断率が1以下である場合、1に変換した上でヒトMT-SP1による切断率とヒト血清による切断率の比の計算に使用することが可能である。
ある実施態様では、本開示のプロテアーゼ基質は、配列番号:1、2、3のいずれか一つの配列を含むプロテアーゼ基質に比べ、マウスuPAによる切断率とヒト血清による切断率の比が高い。ある実施態様では、本開示のプロテアーゼ基質のマウスuPAによる切断率とヒト血清による切断率の比は、0.6以上、0.7以上、0.8以上、0.9以上、0.95以上、1以上、1.1以上、1.2以上、1.3以上、1.4以上、1.5以上、1.6以上、1.7以上、1.8以上、1.9以上、または2以上である。ここで、ヒト血清による切断率が1以下である場合、1に変換した上でマウスuPAによる切断率とヒト血清による切断率の比の計算に使用することが可能である。
ある実施態様では、本開示のプロテアーゼ基質は、配列番号:1、2、3のいずれか一つの配列を含むプロテアーゼ基質に比べ、マウスMT-SP1による切断率とヒト血清による切断率の比が高い。ある実施態様では、本開示のプロテアーゼ基質のマウスMT-SP1による切断率とヒト血清による切断率の比は、0.7以上、0.8以上、0.9以上、0.95以上、1以上、1.2以上、1.4以上、1.6以上、1.8以上、2以上、2.2以上、2.4以上、2.5以上、または2.6以上である。ここで、ヒト血清による切断率が1以下である場合、1に変換した上でマウスMT-SP1による切断率とヒト血清による切断率の比の計算に使用することが可能である。
ある実施態様では、本開示のプロテアーゼ基質は、ヒト血清により切断されない。具体的な一例として、本開示のプロテアーゼ基質のヒト血清による切断率は1.5以下である。別の具体的な一例として、本開示のプロテアーゼ基質のヒト血清による切断率は、配列番号:4で示すペプチドのヒト血清による切断率より低い。
ある実施態様では、本開示のプロテアーゼ基質は、配列番号:1、2、3のいずれか一つの配列を含むプロテアーゼ基質に比べ、ヒトuPAによる切断率が高い。ある実施態様では、本開示のプロテアーゼ基質のヒトuPAによる切断率は、1.5以上、1.6以上、1.8以上、2以上、2.2以上、2.4以上、2.6以上、2.8以上、3以上、3.2以上、3.4以上、3.6以上、3.8以上、3.9以上、または4以上である。
ある実施態様では、本開示のプロテアーゼ基質は、配列番号:1、2、3のいずれか一つの配列を含むプロテアーゼ基質に比べ、ヒトMT-SP1による切断率が高い。ある実施態様では、本開示のプロテアーゼ基質のヒトMT-SP1による切断率は、1.5以上、1.6以上、1.8以上、2以上、2.2以上、2.4以上、2.6以上、2.8以上、3以上、3.2以上、3.4以上、3.6以上、3.8以上、3.9以上、または4以上である。
ある実施態様では、本開示のプロテアーゼ基質は、配列番号:1、2、3のいずれか一つの配列を含むプロテアーゼ基質に比べ、マウスuPAによる切断率が高い。ある実施態様では、本開示のプロテアーゼ基質のマウスuPAによる切断率は、1以上、1.1以上、1.2以上、1.3以上、1.4以上、1.5以上、1.6以上、1.7以上、1.8以上、1.9以上、2以上、2.5以上、3以上、3.5以上、または4以上である。
ある実施態様では、本開示のプロテアーゼ基質は、配列番号:1、2、3のいずれか一つの配列を含むプロテアーゼ基質に比べ、マウスMT-SP1による切断率が高い。ある実施態様では、本開示のプロテアーゼ基質のマウスMT-SP1による切断率は、1.5以上、1.6以上、1.8以上、2以上、2.2以上、2.4以上、2.6以上、2.8以上、3以上、3.2以上、3.4以上、3.6以上、3.8以上、3.9以上、または4以上である。
ある実施態様では、本開示のプロテアーゼ基質は、配列番号:1、2、3のいずれか一つの配列を含むプロテアーゼ基質に比べ、ヒトuPAによる切断率とヒト血清による切断率の比が高い。ある実施態様では、本開示のプロテアーゼ基質のヒトuPAによる切断率とヒト血清による切断率の比は、0.9以上、0.95以上、1以上、1.2以上、1.4以上、1.6以上、1.8以上、2以上、2.2以上、2.4以上、2.6以上、2.8以上、3以上、3.2以上、3.4以上、3.6以上、3.8以上、または4以上である。ここで、ヒト血清による切断率が1以下である場合、1に変換した上でヒトuPAによる切断率とヒト血清による切断率の比の計算に使用することが可能である。
ある実施態様では、本開示のプロテアーゼ基質は、配列番号:1、2、3のいずれか一つの配列を含むプロテアーゼ基質に比べ、ヒトMT-SP1による切断率とヒト血清による切断率の比が高い。ある実施態様では、本開示のプロテアーゼ基質のヒトMT-SP1による切断率とヒト血清による切断率の比は、0.7以上、0.8以上、0.9以上、0.95以上、1以上、1.2以上、1.4以上、1.6以上、1.8以上、2以上、2.2以上、2.4以上、2.5以上、または2.6以上である。ここで、ヒト血清による切断率が1以下である場合、1に変換した上でヒトMT-SP1による切断率とヒト血清による切断率の比の計算に使用することが可能である。
ある実施態様では、本開示のプロテアーゼ基質は、配列番号:1、2、3のいずれか一つの配列を含むプロテアーゼ基質に比べ、マウスuPAによる切断率とヒト血清による切断率の比が高い。ある実施態様では、本開示のプロテアーゼ基質のマウスuPAによる切断率とヒト血清による切断率の比は、0.6以上、0.7以上、0.8以上、0.9以上、0.95以上、1以上、1.1以上、1.2以上、1.3以上、1.4以上、1.5以上、1.6以上、1.7以上、1.8以上、1.9以上、または2以上である。ここで、ヒト血清による切断率が1以下である場合、1に変換した上でマウスuPAによる切断率とヒト血清による切断率の比の計算に使用することが可能である。
ある実施態様では、本開示のプロテアーゼ基質は、配列番号:1、2、3のいずれか一つの配列を含むプロテアーゼ基質に比べ、マウスMT-SP1による切断率とヒト血清による切断率の比が高い。ある実施態様では、本開示のプロテアーゼ基質のマウスMT-SP1による切断率とヒト血清による切断率の比は、0.7以上、0.8以上、0.9以上、0.95以上、1以上、1.2以上、1.4以上、1.6以上、1.8以上、2以上、2.2以上、2.4以上、2.5以上、または2.6以上である。ここで、ヒト血清による切断率が1以下である場合、1に変換した上でマウスMT-SP1による切断率とヒト血清による切断率の比の計算に使用することが可能である。
ある実施態様では、本開示のプロテアーゼ基質は、ヒト血清により切断されない。具体的な一例として、本開示のプロテアーゼ基質のヒト血清による切断率は1.5以下である。別の具体的な一例として、本開示のプロテアーゼ基質のヒト血清による切断率は、配列番号:4で示すペプチドのヒト血清による切断率より低い。
更に具体的な例として、例えば、配列番号:5~17201から選ばれる配列のN末端4番目のアミノ酸から15番目のアミノ酸までの配列、配列番号:5~17201から選ばれる配列のN末端4番目のアミノ酸から13番目のアミノ酸までの配列、配列番号:5~17201から選ばれる配列のN末端6番目のアミノ酸から13番目のアミノ酸までの配列、配列番号:17202~17993から選ばれる配列のN末端1番目のアミノ酸から12番目のアミノ酸までの配列、配列番号:17202~17993から選ばれる配列のN末端3番目のアミノ酸から12番目のアミノ酸までの配列、配列番号:17202~17993から選ばれる配列のN末端3番目のアミノ酸から11番目のアミノ酸までの配列、配列番号:17202~17993から選ばれる配列のN末端3番目のアミノ酸から10番目のアミノ酸までの配列、配列番号:17994~18003から選ばれる配列のN末端3番目のアミノ酸から14番目のアミノ酸までの配列、配列番号:17994~18003から選ばれる配列のN末端5番目のアミノ酸から12番目のアミノ酸までの配列、配列番号:17994~18003から選ばれる配列のN末端5番目のアミノ酸から10番目のアミノ酸までの配列、配列番号:5~18003で示される配列のいずれかで示すペプチドは、プロテアーゼの作用によって加水分解されるプロテアーゼ基質として有用である。
別の具体的な例として、例えば、N末端から「下記グループAから選ばれる配列-下記グループBから選ばれる配列」の順で構成された配列で示すペプチドも、プロテアーゼの作用によって加水分解されるプロテアーゼ基質として有用である:
(グループA)
配列番号:5~17201から選ばれる配列のN末端1番目のアミノ酸から9番目のアミノ酸までの配列、
配列番号:5~17201から選ばれる配列のN末端2番目のアミノ酸から9番目のアミノ酸までの配列、
配列番号:5~17201から選ばれる配列のN末端3番目のアミノ酸から9番目のアミノ酸までの配列、
配列番号:5~17201から選ばれる配列のN末端4番目のアミノ酸から9番目のアミノ酸までの配列、
配列番号:5~17201から選ばれる配列のN末端5番目のアミノ酸から9番目のアミノ酸までの配列、
配列番号:5~17201から選ばれる配列のN末端6番目のアミノ酸から9番目のアミノ酸までの配列、
配列番号:5~17201から選ばれる配列のN末端7番目のアミノ酸から9番目のアミノ酸までの配列、
配列番号:5~17201から選ばれる配列のN末端8番目のアミノ酸から9番目のアミノ酸までの配列、
配列番号:17202~17993から選ばれる配列のN末端1番目のアミノ酸から6番目のアミノ酸までの配列、
配列番号:17202~17993から選ばれる配列のN末端2番目のアミノ酸から6番目のアミノ酸までの配列、
配列番号:17202~17993から選ばれる配列のN末端3番目のアミノ酸から6番目のアミノ酸までの配列、
配列番号:17202~17993から選ばれる配列のN末端4番目のアミノ酸から6番目のアミノ酸までの配列、
配列番号:17202~17993から選ばれる配列のN末端5番目のアミノ酸から6番目のアミノ酸までの配列、
配列番号:17994~18003から選ばれる配列のN末端1番目のアミノ酸から8番目のアミノ酸までの配列、
配列番号:17994~18003から選ばれる配列のN末端2番目のアミノ酸から8番目のアミノ酸までの配列、
配列番号:17994~18003から選ばれる配列のN末端3番目のアミノ酸から8番目のアミノ酸までの配列、
配列番号:17994~18003から選ばれる配列のN末端4番目のアミノ酸から8番目のアミノ酸までの配列、
配列番号:17994~18003から選ばれる配列のN末端5番目のアミノ酸から8番目のアミノ酸までの配列、
配列番号:17994~18003から選ばれる配列のN末端6番目のアミノ酸から8番目のアミノ酸までの配列、
配列番号:17994~18003から選ばれる配列のN末端7番目のアミノ酸から8番目のアミノ酸までの配列;
(グループB)
配列番号:5~17201から選ばれる配列のN末端10番目のアミノ酸から15番目のアミノ酸までの配列、
配列番号:5~17201から選ばれる配列のN末端10番目のアミノ酸から14番目のアミノ酸までの配列、
配列番号:5~17201から選ばれる配列のN末端10番目のアミノ酸から13番目のアミノ酸までの配列、
配列番号:5~17201から選ばれる配列のN末端10番目のアミノ酸から12番目のアミノ酸までの配列、
配列番号:5~17201から選ばれる配列のN末端10番目のアミノ酸から11番目のアミノ酸までの配列、
配列番号:17202~17993から選ばれる配列のN末端7番目のアミノ酸から15番目のアミノ酸までの配列、
配列番号:17202~17993から選ばれる配列のN末端7番目のアミノ酸から14番目のアミノ酸までの配列、
配列番号:17202~17993から選ばれる配列のN末端7番目のアミノ酸から13番目のアミノ酸までの配列、
配列番号:17202~17993から選ばれる配列のN末端7番目のアミノ酸から12番目のアミノ酸までの配列、
配列番号:17202~17993から選ばれる配列のN末端7番目のアミノ酸から11番目のアミノ酸までの配列、
配列番号:17202~17993から選ばれる配列のN末端7番目のアミノ酸から10番目のアミノ酸までの配列、
配列番号:17202~17993から選ばれる配列のN末端7番目のアミノ酸から9番目のアミノ酸までの配列、
配列番号:17202~17993から選ばれる配列のN末端7番目のアミノ酸から8番目のアミノ酸までの配列、
配列番号:17994~18003から選ばれる配列のN末端9番目のアミノ酸から15番目のアミノ酸までの配列、
配列番号:17994~18003から選ばれる配列のN末端9番目のアミノ酸から14番目のアミノ酸までの配列、
配列番号:17994~18003から選ばれる配列のN末端9番目のアミノ酸から13番目のアミノ酸までの配列、
配列番号:17994~18003から選ばれる配列のN末端9番目のアミノ酸から12番目のアミノ酸までの配列、
配列番号:17994~18003から選ばれる配列のN末端9番目のアミノ酸から11番目のアミノ酸までの配列、
配列番号:17994~18003から選ばれる配列のN末端9番目のアミノ酸から10番目のアミノ酸までの配列。
別の具体的な例として、例えば、N末端から「下記グループAから選ばれる配列-下記グループBから選ばれる配列」の順で構成された配列で示すペプチドも、プロテアーゼの作用によって加水分解されるプロテアーゼ基質として有用である:
(グループA)
配列番号:5~17201から選ばれる配列のN末端1番目のアミノ酸から9番目のアミノ酸までの配列、
配列番号:5~17201から選ばれる配列のN末端2番目のアミノ酸から9番目のアミノ酸までの配列、
配列番号:5~17201から選ばれる配列のN末端3番目のアミノ酸から9番目のアミノ酸までの配列、
配列番号:5~17201から選ばれる配列のN末端4番目のアミノ酸から9番目のアミノ酸までの配列、
配列番号:5~17201から選ばれる配列のN末端5番目のアミノ酸から9番目のアミノ酸までの配列、
配列番号:5~17201から選ばれる配列のN末端6番目のアミノ酸から9番目のアミノ酸までの配列、
配列番号:5~17201から選ばれる配列のN末端7番目のアミノ酸から9番目のアミノ酸までの配列、
配列番号:5~17201から選ばれる配列のN末端8番目のアミノ酸から9番目のアミノ酸までの配列、
配列番号:17202~17993から選ばれる配列のN末端1番目のアミノ酸から6番目のアミノ酸までの配列、
配列番号:17202~17993から選ばれる配列のN末端2番目のアミノ酸から6番目のアミノ酸までの配列、
配列番号:17202~17993から選ばれる配列のN末端3番目のアミノ酸から6番目のアミノ酸までの配列、
配列番号:17202~17993から選ばれる配列のN末端4番目のアミノ酸から6番目のアミノ酸までの配列、
配列番号:17202~17993から選ばれる配列のN末端5番目のアミノ酸から6番目のアミノ酸までの配列、
配列番号:17994~18003から選ばれる配列のN末端1番目のアミノ酸から8番目のアミノ酸までの配列、
配列番号:17994~18003から選ばれる配列のN末端2番目のアミノ酸から8番目のアミノ酸までの配列、
配列番号:17994~18003から選ばれる配列のN末端3番目のアミノ酸から8番目のアミノ酸までの配列、
配列番号:17994~18003から選ばれる配列のN末端4番目のアミノ酸から8番目のアミノ酸までの配列、
配列番号:17994~18003から選ばれる配列のN末端5番目のアミノ酸から8番目のアミノ酸までの配列、
配列番号:17994~18003から選ばれる配列のN末端6番目のアミノ酸から8番目のアミノ酸までの配列、
配列番号:17994~18003から選ばれる配列のN末端7番目のアミノ酸から8番目のアミノ酸までの配列;
(グループB)
配列番号:5~17201から選ばれる配列のN末端10番目のアミノ酸から15番目のアミノ酸までの配列、
配列番号:5~17201から選ばれる配列のN末端10番目のアミノ酸から14番目のアミノ酸までの配列、
配列番号:5~17201から選ばれる配列のN末端10番目のアミノ酸から13番目のアミノ酸までの配列、
配列番号:5~17201から選ばれる配列のN末端10番目のアミノ酸から12番目のアミノ酸までの配列、
配列番号:5~17201から選ばれる配列のN末端10番目のアミノ酸から11番目のアミノ酸までの配列、
配列番号:17202~17993から選ばれる配列のN末端7番目のアミノ酸から15番目のアミノ酸までの配列、
配列番号:17202~17993から選ばれる配列のN末端7番目のアミノ酸から14番目のアミノ酸までの配列、
配列番号:17202~17993から選ばれる配列のN末端7番目のアミノ酸から13番目のアミノ酸までの配列、
配列番号:17202~17993から選ばれる配列のN末端7番目のアミノ酸から12番目のアミノ酸までの配列、
配列番号:17202~17993から選ばれる配列のN末端7番目のアミノ酸から11番目のアミノ酸までの配列、
配列番号:17202~17993から選ばれる配列のN末端7番目のアミノ酸から10番目のアミノ酸までの配列、
配列番号:17202~17993から選ばれる配列のN末端7番目のアミノ酸から9番目のアミノ酸までの配列、
配列番号:17202~17993から選ばれる配列のN末端7番目のアミノ酸から8番目のアミノ酸までの配列、
配列番号:17994~18003から選ばれる配列のN末端9番目のアミノ酸から15番目のアミノ酸までの配列、
配列番号:17994~18003から選ばれる配列のN末端9番目のアミノ酸から14番目のアミノ酸までの配列、
配列番号:17994~18003から選ばれる配列のN末端9番目のアミノ酸から13番目のアミノ酸までの配列、
配列番号:17994~18003から選ばれる配列のN末端9番目のアミノ酸から12番目のアミノ酸までの配列、
配列番号:17994~18003から選ばれる配列のN末端9番目のアミノ酸から11番目のアミノ酸までの配列、
配列番号:17994~18003から選ばれる配列のN末端9番目のアミノ酸から10番目のアミノ酸までの配列。
本開示のプロテアーゼ基質は、たとえばポリペプチドへの組み込みに当たって、目的に応じた性状を備えたものを選択するためのライブラリとして活用することができる。具体的には、ポリペプチドを病巣に局在するプロテアーゼによって選択的に切断するために、そのプロテアーゼ感受性を評価することができる。ポリペプチドは、生体に投与された後に、様々なプロテアーゼとの接触を経て、病巣に到達する可能性が有る。したがって、病巣に局在するプロテアーゼには感受性を持ちながら、それ以外のプロテアーゼにはできるだけ高い耐性を持つことが望ましい。目的に応じて、望ましいプロテアーゼ基質を選ぶために、予め、各プロテアーゼ基質について、種々のプロテアーゼによる感受性を網羅的に解析すれば、プロテアーゼ耐性を知ることができる。得られたプロテアーゼ耐性スペクトルに基づいて、必要な感受性と耐性を備えたプロテアーゼ基質を見出すことができる。
あるいは、プロテアーゼ基質を組み込まれたポリペプチドは、プロテアーゼによる酵素的な作用のみならず、pHの変化、温度、酸化還元ストレス等の様々な環境負荷を経て病巣に到達する。このような外部要因に対しても、各プロテアーゼ基質の耐性を比較した情報に基づいて、目的に応じた望ましい性状を備えたプロテアーゼ基質を選択することもできる。
あるいは、プロテアーゼ基質を組み込まれたポリペプチドは、プロテアーゼによる酵素的な作用のみならず、pHの変化、温度、酸化還元ストレス等の様々な環境負荷を経て病巣に到達する。このような外部要因に対しても、各プロテアーゼ基質の耐性を比較した情報に基づいて、目的に応じた望ましい性状を備えたプロテアーゼ基質を選択することもできる。
プロテアーゼ切断配列
本開示の一側面は、プロテアーゼ切断配列に関する。プロテアーゼ切断配列は、水溶液中でポリペプチドがプロテアーゼによって加水分解を受ける際に、該プロテアーゼにより特異的に認識される特定のアミノ酸配列である。本開示において、プロテアーゼ切断配列をプロテアーゼにより切断可能なペプチド配列と称する場合がある。
本開示の一側面は、プロテアーゼ切断配列に関する。プロテアーゼ切断配列は、水溶液中でポリペプチドがプロテアーゼによって加水分解を受ける際に、該プロテアーゼにより特異的に認識される特定のアミノ酸配列である。本開示において、プロテアーゼ切断配列をプロテアーゼにより切断可能なペプチド配列と称する場合がある。
本開示のプロテアーゼ切断配列は、プロテアーゼによって、約0.001~1500×104M-1S-1または少なくとも0.001、0.005、0.01、0.05、0.1、0.5、1、2.5、5、7.5、10、15、20、25、50、75、100、125、150、200、250、500、750、1000、1250、もしくは1500×104M-1S-1の速度で特異的に修飾される(切断)ことができる。
たとえば、配列番号:5~17201から選ばれる配列のN末端4番目のアミノ酸から15番目のアミノ酸までの配列、配列番号:5~17201から選ばれる配列のN末端4番目のアミノ酸から13番目のアミノ酸までの配列、配列番号:5~17201から選ばれる配列のN末端6番目のアミノ酸から13番目のアミノ酸までの配列、配列番号:17202~17993から選ばれる配列のN末端1番目のアミノ酸から12番目のアミノ酸までの配列、配列番号:17202~17993から選ばれる配列のN末端3番目のアミノ酸から12番目のアミノ酸までの配列、配列番号:17202~17993から選ばれる配列のN末端3番目のアミノ酸から11番目のアミノ酸までの配列、配列番号:17202~17993から選ばれる配列のN末端3番目のアミノ酸から10番目のアミノ酸までの配列、配列番号:17994~18003から選ばれる配列のN末端3番目のアミノ酸から14番目のアミノ酸までの配列、配列番号:17994~18003から選ばれる配列のN末端5番目のアミノ酸から12番目のアミノ酸までの配列、配列番号:17994~18003から選ばれる配列のN末端5番目のアミノ酸から10番目のアミノ酸までの配列、配列番号:5~18003で示される配列のいずれも、プロテアーゼ切断配列として有用である。本開示はまた、これらの配列のプロテアーゼ切断配列としての使用に関する。
たとえば、N末端から「下記グループAから選ばれる配列-下記グループBから選ばれる配列」の順で構成された配列のいずれも、プロテアーゼ切断配列として有用である。本開示はまた、これらの配列のプロテアーゼ切断配列としての使用に関する:
(グループA)
配列番号:5~17201から選ばれる配列のN末端1番目のアミノ酸から9番目のアミノ酸までの配列、
配列番号:5~17201から選ばれる配列のN末端2番目のアミノ酸から9番目のアミノ酸までの配列、
配列番号:5~17201から選ばれる配列のN末端3番目のアミノ酸から9番目のアミノ酸までの配列、
配列番号:5~17201から選ばれる配列のN末端4番目のアミノ酸から9番目のアミノ酸までの配列、
配列番号:5~17201から選ばれる配列のN末端5番目のアミノ酸から9番目のアミノ酸までの配列、
配列番号:5~17201から選ばれる配列のN末端6番目のアミノ酸から9番目のアミノ酸までの配列、
配列番号:5~17201から選ばれる配列のN末端7番目のアミノ酸から9番目のアミノ酸までの配列、
配列番号:5~17201から選ばれる配列のN末端8番目のアミノ酸から9番目のアミノ酸までの配列、
配列番号:17202~17993から選ばれる配列のN末端1番目のアミノ酸から6番目のアミノ酸までの配列、
配列番号:17202~17993から選ばれる配列のN末端2番目のアミノ酸から6番目のアミノ酸までの配列、
配列番号:17202~17993から選ばれる配列のN末端3番目のアミノ酸から6番目のアミノ酸までの配列、
配列番号:17202~17993から選ばれる配列のN末端4番目のアミノ酸から6番目のアミノ酸までの配列、
配列番号:17202~17993から選ばれる配列のN末端5番目のアミノ酸から6番目のアミノ酸までの配列、
配列番号:17994~18003から選ばれる配列のN末端1番目のアミノ酸から8番目のアミノ酸までの配列、
配列番号:17994~18003から選ばれる配列のN末端2番目のアミノ酸から8番目のアミノ酸までの配列、
配列番号:17994~18003から選ばれる配列のN末端3番目のアミノ酸から8番目のアミノ酸までの配列、
配列番号:17994~18003から選ばれる配列のN末端4番目のアミノ酸から8番目のアミノ酸までの配列、
配列番号:17994~18003から選ばれる配列のN末端5番目のアミノ酸から8番目のアミノ酸までの配列、
配列番号:17994~18003から選ばれる配列のN末端6番目のアミノ酸から8番目のアミノ酸までの配列、
配列番号:17994~18003から選ばれる配列のN末端7番目のアミノ酸から8番目のアミノ酸までの配列;
(グループB)
配列番号:5~17201から選ばれる配列のN末端10番目のアミノ酸から15番目のアミノ酸までの配列、
配列番号:5~17201から選ばれる配列のN末端10番目のアミノ酸から14番目のアミノ酸までの配列、
配列番号:5~17201から選ばれる配列のN末端10番目のアミノ酸から13番目のアミノ酸までの配列、
配列番号:5~17201から選ばれる配列のN末端10番目のアミノ酸から12番目のアミノ酸までの配列、
配列番号:5~17201から選ばれる配列のN末端10番目のアミノ酸から11番目のアミノ酸までの配列、
配列番号:17202~17993から選ばれる配列のN末端7番目のアミノ酸から15番目のアミノ酸までの配列、
配列番号:17202~17993から選ばれる配列のN末端7番目のアミノ酸から14番目のアミノ酸までの配列、
配列番号:17202~17993から選ばれる配列のN末端7番目のアミノ酸から13番目のアミノ酸までの配列、
配列番号:17202~17993から選ばれる配列のN末端7番目のアミノ酸から12番目のアミノ酸までの配列、
配列番号:17202~17993から選ばれる配列のN末端7番目のアミノ酸から11番目のアミノ酸までの配列、
配列番号:17202~17993から選ばれる配列のN末端7番目のアミノ酸から10番目のアミノ酸までの配列、
配列番号:17202~17993から選ばれる配列のN末端7番目のアミノ酸から9番目のアミノ酸までの配列、
配列番号:17202~17993から選ばれる配列のN末端7番目のアミノ酸から8番目のアミノ酸までの配列、
配列番号:17994~18003から選ばれる配列のN末端9番目のアミノ酸から15番目のアミノ酸までの配列、
配列番号:17994~18003から選ばれる配列のN末端9番目のアミノ酸から14番目のアミノ酸までの配列、
配列番号:17994~18003から選ばれる配列のN末端9番目のアミノ酸から13番目のアミノ酸までの配列、
配列番号:17994~18003から選ばれる配列のN末端9番目のアミノ酸から12番目のアミノ酸までの配列、
配列番号:17994~18003から選ばれる配列のN末端9番目のアミノ酸から11番目のアミノ酸までの配列、
配列番号:17994~18003から選ばれる配列のN末端9番目のアミノ酸から10番目のアミノ酸までの配列。
たとえば、N末端から「下記グループAから選ばれる配列-下記グループBから選ばれる配列」の順で構成された配列のいずれも、プロテアーゼ切断配列として有用である。本開示はまた、これらの配列のプロテアーゼ切断配列としての使用に関する:
(グループA)
配列番号:5~17201から選ばれる配列のN末端1番目のアミノ酸から9番目のアミノ酸までの配列、
配列番号:5~17201から選ばれる配列のN末端2番目のアミノ酸から9番目のアミノ酸までの配列、
配列番号:5~17201から選ばれる配列のN末端3番目のアミノ酸から9番目のアミノ酸までの配列、
配列番号:5~17201から選ばれる配列のN末端4番目のアミノ酸から9番目のアミノ酸までの配列、
配列番号:5~17201から選ばれる配列のN末端5番目のアミノ酸から9番目のアミノ酸までの配列、
配列番号:5~17201から選ばれる配列のN末端6番目のアミノ酸から9番目のアミノ酸までの配列、
配列番号:5~17201から選ばれる配列のN末端7番目のアミノ酸から9番目のアミノ酸までの配列、
配列番号:5~17201から選ばれる配列のN末端8番目のアミノ酸から9番目のアミノ酸までの配列、
配列番号:17202~17993から選ばれる配列のN末端1番目のアミノ酸から6番目のアミノ酸までの配列、
配列番号:17202~17993から選ばれる配列のN末端2番目のアミノ酸から6番目のアミノ酸までの配列、
配列番号:17202~17993から選ばれる配列のN末端3番目のアミノ酸から6番目のアミノ酸までの配列、
配列番号:17202~17993から選ばれる配列のN末端4番目のアミノ酸から6番目のアミノ酸までの配列、
配列番号:17202~17993から選ばれる配列のN末端5番目のアミノ酸から6番目のアミノ酸までの配列、
配列番号:17994~18003から選ばれる配列のN末端1番目のアミノ酸から8番目のアミノ酸までの配列、
配列番号:17994~18003から選ばれる配列のN末端2番目のアミノ酸から8番目のアミノ酸までの配列、
配列番号:17994~18003から選ばれる配列のN末端3番目のアミノ酸から8番目のアミノ酸までの配列、
配列番号:17994~18003から選ばれる配列のN末端4番目のアミノ酸から8番目のアミノ酸までの配列、
配列番号:17994~18003から選ばれる配列のN末端5番目のアミノ酸から8番目のアミノ酸までの配列、
配列番号:17994~18003から選ばれる配列のN末端6番目のアミノ酸から8番目のアミノ酸までの配列、
配列番号:17994~18003から選ばれる配列のN末端7番目のアミノ酸から8番目のアミノ酸までの配列;
(グループB)
配列番号:5~17201から選ばれる配列のN末端10番目のアミノ酸から15番目のアミノ酸までの配列、
配列番号:5~17201から選ばれる配列のN末端10番目のアミノ酸から14番目のアミノ酸までの配列、
配列番号:5~17201から選ばれる配列のN末端10番目のアミノ酸から13番目のアミノ酸までの配列、
配列番号:5~17201から選ばれる配列のN末端10番目のアミノ酸から12番目のアミノ酸までの配列、
配列番号:5~17201から選ばれる配列のN末端10番目のアミノ酸から11番目のアミノ酸までの配列、
配列番号:17202~17993から選ばれる配列のN末端7番目のアミノ酸から15番目のアミノ酸までの配列、
配列番号:17202~17993から選ばれる配列のN末端7番目のアミノ酸から14番目のアミノ酸までの配列、
配列番号:17202~17993から選ばれる配列のN末端7番目のアミノ酸から13番目のアミノ酸までの配列、
配列番号:17202~17993から選ばれる配列のN末端7番目のアミノ酸から12番目のアミノ酸までの配列、
配列番号:17202~17993から選ばれる配列のN末端7番目のアミノ酸から11番目のアミノ酸までの配列、
配列番号:17202~17993から選ばれる配列のN末端7番目のアミノ酸から10番目のアミノ酸までの配列、
配列番号:17202~17993から選ばれる配列のN末端7番目のアミノ酸から9番目のアミノ酸までの配列、
配列番号:17202~17993から選ばれる配列のN末端7番目のアミノ酸から8番目のアミノ酸までの配列、
配列番号:17994~18003から選ばれる配列のN末端9番目のアミノ酸から15番目のアミノ酸までの配列、
配列番号:17994~18003から選ばれる配列のN末端9番目のアミノ酸から14番目のアミノ酸までの配列、
配列番号:17994~18003から選ばれる配列のN末端9番目のアミノ酸から13番目のアミノ酸までの配列、
配列番号:17994~18003から選ばれる配列のN末端9番目のアミノ酸から12番目のアミノ酸までの配列、
配列番号:17994~18003から選ばれる配列のN末端9番目のアミノ酸から11番目のアミノ酸までの配列、
配列番号:17994~18003から選ばれる配列のN末端9番目のアミノ酸から10番目のアミノ酸までの配列。
ある実施態様において、プロテアーゼ切断配列は、抗体に連結されているか又は別の方法で取り付けられている。例えば、プロテアーゼ切断配列は、プロテアーゼ、すなわち、マトリプターゼ及び/又はuPAに晒されると、プロテアーゼ切断配列が切断され、そして剤が抗体から放出されるように、所定の標的に結合する抗体に1若しくは複数の剤を連結するのに使用される。
ある実施態様では、本開示のプロテアーゼ切断配列は、配列番号:1、2、3のいずれか一つの配列を含むプロテアーゼ基質に比べ、プロテアーゼによる切断率が高い。
ある実施態様では、本開示のプロテアーゼ切断配は、配列番号:1、2、3のいずれか一つの配列を含むプロテアーゼ基質に比べ、ヒトuPAによる切断率が高い。ある実施態様では、本開示のプロテアーゼ切断配列のヒトuPAによる切断率は、1.5以上、1.6以上、1.8以上、2以上、2.2以上、2.4以上、2.6以上、2.8以上、3以上、3.2以上、3.4以上、3.6以上、3.8以上、3.9以上、または4以上である。
ある実施態様では、本開示のプロテアーゼ切断配は、配列番号:1、2、3のいずれか一つの配列を含むプロテアーゼ基質に比べ、ヒトMT-SP1による切断率が高い。ある実施態様では、本開示のプロテアーゼ切断配列のヒトMT-SP1による切断率は、1.5以上、1.6以上、1.8以上、2以上、2.2以上、2.4以上、2.6以上、2.8以上、3以上、3.2以上、3.4以上、3.6以上、3.8以上、3.9以上、または4以上である。
ある実施態様では、本開示のプロテアーゼ切断配は、配列番号:1、2、3のいずれか一つの配列を含むプロテアーゼ基質に比べ、マウスuPAによる切断率が高い。ある実施態様では、本開示のプロテアーゼ切断配列のマウスuPAによる切断率は、ある実施態様では、本開示のプロテアーゼ基質のマウスuPAによる切断率は、1以上、1.1以上、1.2以上、1.3以上、1.4以上、1.5以上、1.6以上、1.7以上、1.8以上、1.9以上、2以上、2.5以上、3以上、3.5以上、または4以上である。
ある実施態様では、本開示のプロテアーゼ切断配は、配列番号:1、2、3のいずれか一つの配列を含むプロテアーゼ基質に比べ、マウスMT-SP1による切断率が高い。ある実施態様では、本開示のプロテアーゼ切断配列のマウスMT-SP1による切断率は、1.5以上、1.6以上、1.8以上、2以上、2.2以上、2.4以上、2.6以上、2.8以上、3以上、3.2以上、3.4以上、3.6以上、3.8以上、3.9以上、または4以上である。ある実施態様では、本開示のプロテアーゼ切断配は、配列番号:1、2、3のいずれか一つの配列を含むプロテアーゼ基質に比べ、ヒトuPAによる切断率とヒト血清による切断率の比が高い。ある実施態様では、本開示のプロテアーゼ切断配列のヒトuPAによる切断率とヒト血清による切断率の比は、0.9以上、0.95以上、1以上、1.2以上、1.4以上、1.6以上、1.8以上、2以上、2.2以上、2.4以上、2.6以上、2.8以上、3以上、3.2以上、3.4以上、3.6以上、3.8以上、または4以上である。ここで、ヒト血清による切断率が1以下である場合、1に変換した上でヒトuPAによる切断率とヒト血清による切断率の比の計算に使用することが可能である。
ある実施態様では、本開示のプロテアーゼ切断配は、配列番号:1、2、3のいずれか一つの配列を含むプロテアーゼ基質に比べ、ヒトMT-SP1による切断率とヒト血清による切断率の比が高い。ある実施態様では、本開示のプロテアーゼ切断配列のヒトMT-SP1による切断率とヒト血清による切断率の比は、0.7以上、0.8以上、0.9以上、0.95以上、1以上、1.2以上、1.4以上、1.6以上、1.8以上、2以上、2.2以上、2.4以上、2.5以上、または2.6以上である。ここで、ヒト血清による切断率が1以下である場合、1に変換した上でヒトMT-SP1による切断率とヒト血清による切断率の比の計算に使用することが可能である。
ある実施態様では、本開示のプロテアーゼ切断配は、配列番号:1、2、3のいずれか一つの配列を含むプロテアーゼ基質に比べ、マウスuPAによる切断率とヒト血清による切断率の比が高い。ある実施態様では、本開示のプロテアーゼ切断配列のマウスuPAによる切断率とヒト血清による切断率の比は、0.6以上、0.7以上、0.8以上、0.9以上、0.95以上、1以上、1.1以上、1.2以上、1.3以上、1.4以上、1.5以上、1.6以上、1.7以上、1.8以上、1.9以上、または2以上である。ここで、ヒト血清による切断率が1以下である場合、1に変換した上でマウスuPAによる切断率とヒト血清による切断率の比の計算に使用することが可能である。
ある実施態様では、本開示のプロテアーゼ切断配は、配列番号:1、2、3のいずれか一つの配列を含むプロテアーゼ基質に比べ、マウスMT-SP1による切断率とヒト血清による切断率の比が高い。ある実施態様では、本開示のプロテアーゼ切断配列のマウスMT-SP1による切断率とヒト血清による切断率の比は、0.7以上、0.8以上、0.9以上、0.95以上、1以上、1.2以上、1.4以上、1.6以上、1.8以上、2以上、2.2以上、2.4以上、2.5以上、または2.6以上である。ここで、ヒト血清による切断率が1以下である場合、1に変換した上でマウスMT-SP1による切断率とヒト血清による切断率の比の計算に使用することが可能である。
ある実施態様では、本開示のプロテアーゼ切断配は、ヒト血清により切断されない。具体的な一例として、本開示のプロテアーゼ切断配列のヒト血清による切断率は1.5以下である。別の具体的な一例として、本開示のプロテアーゼ基質のヒト血清による切断率は、配列番号:4で示すペプチドのヒト血清による切断率より低い。
ある実施態様では、本開示のプロテアーゼ切断配は、配列番号:1、2、3のいずれか一つの配列を含むプロテアーゼ基質に比べ、ヒトuPAによる切断率が高い。ある実施態様では、本開示のプロテアーゼ切断配列のヒトuPAによる切断率は、1.5以上、1.6以上、1.8以上、2以上、2.2以上、2.4以上、2.6以上、2.8以上、3以上、3.2以上、3.4以上、3.6以上、3.8以上、3.9以上、または4以上である。
ある実施態様では、本開示のプロテアーゼ切断配は、配列番号:1、2、3のいずれか一つの配列を含むプロテアーゼ基質に比べ、ヒトMT-SP1による切断率が高い。ある実施態様では、本開示のプロテアーゼ切断配列のヒトMT-SP1による切断率は、1.5以上、1.6以上、1.8以上、2以上、2.2以上、2.4以上、2.6以上、2.8以上、3以上、3.2以上、3.4以上、3.6以上、3.8以上、3.9以上、または4以上である。
ある実施態様では、本開示のプロテアーゼ切断配は、配列番号:1、2、3のいずれか一つの配列を含むプロテアーゼ基質に比べ、マウスuPAによる切断率が高い。ある実施態様では、本開示のプロテアーゼ切断配列のマウスuPAによる切断率は、ある実施態様では、本開示のプロテアーゼ基質のマウスuPAによる切断率は、1以上、1.1以上、1.2以上、1.3以上、1.4以上、1.5以上、1.6以上、1.7以上、1.8以上、1.9以上、2以上、2.5以上、3以上、3.5以上、または4以上である。
ある実施態様では、本開示のプロテアーゼ切断配は、配列番号:1、2、3のいずれか一つの配列を含むプロテアーゼ基質に比べ、マウスMT-SP1による切断率が高い。ある実施態様では、本開示のプロテアーゼ切断配列のマウスMT-SP1による切断率は、1.5以上、1.6以上、1.8以上、2以上、2.2以上、2.4以上、2.6以上、2.8以上、3以上、3.2以上、3.4以上、3.6以上、3.8以上、3.9以上、または4以上である。ある実施態様では、本開示のプロテアーゼ切断配は、配列番号:1、2、3のいずれか一つの配列を含むプロテアーゼ基質に比べ、ヒトuPAによる切断率とヒト血清による切断率の比が高い。ある実施態様では、本開示のプロテアーゼ切断配列のヒトuPAによる切断率とヒト血清による切断率の比は、0.9以上、0.95以上、1以上、1.2以上、1.4以上、1.6以上、1.8以上、2以上、2.2以上、2.4以上、2.6以上、2.8以上、3以上、3.2以上、3.4以上、3.6以上、3.8以上、または4以上である。ここで、ヒト血清による切断率が1以下である場合、1に変換した上でヒトuPAによる切断率とヒト血清による切断率の比の計算に使用することが可能である。
ある実施態様では、本開示のプロテアーゼ切断配は、配列番号:1、2、3のいずれか一つの配列を含むプロテアーゼ基質に比べ、ヒトMT-SP1による切断率とヒト血清による切断率の比が高い。ある実施態様では、本開示のプロテアーゼ切断配列のヒトMT-SP1による切断率とヒト血清による切断率の比は、0.7以上、0.8以上、0.9以上、0.95以上、1以上、1.2以上、1.4以上、1.6以上、1.8以上、2以上、2.2以上、2.4以上、2.5以上、または2.6以上である。ここで、ヒト血清による切断率が1以下である場合、1に変換した上でヒトMT-SP1による切断率とヒト血清による切断率の比の計算に使用することが可能である。
ある実施態様では、本開示のプロテアーゼ切断配は、配列番号:1、2、3のいずれか一つの配列を含むプロテアーゼ基質に比べ、マウスuPAによる切断率とヒト血清による切断率の比が高い。ある実施態様では、本開示のプロテアーゼ切断配列のマウスuPAによる切断率とヒト血清による切断率の比は、0.6以上、0.7以上、0.8以上、0.9以上、0.95以上、1以上、1.1以上、1.2以上、1.3以上、1.4以上、1.5以上、1.6以上、1.7以上、1.8以上、1.9以上、または2以上である。ここで、ヒト血清による切断率が1以下である場合、1に変換した上でマウスuPAによる切断率とヒト血清による切断率の比の計算に使用することが可能である。
ある実施態様では、本開示のプロテアーゼ切断配は、配列番号:1、2、3のいずれか一つの配列を含むプロテアーゼ基質に比べ、マウスMT-SP1による切断率とヒト血清による切断率の比が高い。ある実施態様では、本開示のプロテアーゼ切断配列のマウスMT-SP1による切断率とヒト血清による切断率の比は、0.7以上、0.8以上、0.9以上、0.95以上、1以上、1.2以上、1.4以上、1.6以上、1.8以上、2以上、2.2以上、2.4以上、2.5以上、または2.6以上である。ここで、ヒト血清による切断率が1以下である場合、1に変換した上でマウスMT-SP1による切断率とヒト血清による切断率の比の計算に使用することが可能である。
ある実施態様では、本開示のプロテアーゼ切断配は、ヒト血清により切断されない。具体的な一例として、本開示のプロテアーゼ切断配列のヒト血清による切断率は1.5以下である。別の具体的な一例として、本開示のプロテアーゼ基質のヒト血清による切断率は、配列番号:4で示すペプチドのヒト血清による切断率より低い。
本開示のプロテアーゼ切断配列は、たとえばポリペプチドへの組み込みに当たって、目的に応じた性状を備えたものを選択するためのライブラリとして活用することができる。具体的には、ポリペプチドを病巣に局在するプロテアーゼによって選択的に切断するために、そのプロテアーゼ感受性を評価することができる。ポリペプチドは、生体に投与された後に、様々なプロテアーゼとの接触を経て、病巣に到達する可能性が有る。したがって、病巣に局在するプロテアーゼには感受性を持ちながら、それ以外のプロテアーゼにはできるだけ高い耐性を持つことが望ましい。目的に応じて、望ましいプロテアーゼ切断配列を選ぶために、予め、各プロテアーゼ切断配列について、種々のプロテアーゼによる感受性を網羅的に解析すれば、プロテアーゼ耐性を知ることができる。得られたプロテアーゼ耐性スペクトルに基づいて、必要な感受性と耐性を備えたプロテアーゼ切断配列を見出すことができる。
あるいは、プロテアーゼ切断配列を組み込まれたポリペプチドは、プロテアーゼによる酵素的な作用のみならず、pHの変化、温度、酸化還元ストレス等の様々な環境負荷を経て病巣に到達する。このような外部要因に対しても、各プロテアーゼ切断配列の耐性を比較した情報に基づいて、目的に応じた望ましい性状を備えたプロテアーゼ切断配列を選択することもできる。
あるいは、プロテアーゼ切断配列を組み込まれたポリペプチドは、プロテアーゼによる酵素的な作用のみならず、pHの変化、温度、酸化還元ストレス等の様々な環境負荷を経て病巣に到達する。このような外部要因に対しても、各プロテアーゼ切断配列の耐性を比較した情報に基づいて、目的に応じた望ましい性状を備えたプロテアーゼ切断配列を選択することもできる。
いくつかの実施形態において、プロテアーゼ切断配列は少なくともマトリプターゼにより切断可能である。いくつかの実施形態において、プロテアーゼ切断配列は少なくともMT-SP1により切断可能である。いくつかの実施形態において、プロテアーゼ切断配列は少なくともuPAにより切断可能である。いくつかの実施形態において、プロテアーゼ切断配列は少なくともマトリプターゼ及びuPAにより切断可能である。いくつかの実施形態において、プロテアーゼ切断配列は少なくともMT-SP1及びuPAにより切断可能である。
いくつかの実施形態において、プロテアーゼ切断配列はマトリプターゼ及び/又はuPAのための基質であり、少なくとももう他のプロテアーゼによる切断に対して抵抗性の基質である。いくつかの実施形態において、プロテアーゼ切断配列はマトリプターゼ及び/又はuPAのための基質であり、少なくともプラスミンによる切断に対して抵抗性の基質である。いくつかの実施形態において、プロテアーゼ切断配列はマトリプターゼ及び/又はuPAのための基質であり、少なくとも組織プラスミノーゲン活性化因子(tPA)による切断に対して抵抗性の基質である。いくつかの実施形態において、プロテアーゼ切断配列はマトリプターゼ及び/又はuPAのための基質であり、少なくともヒト血清による切断に対して抵抗性の基質である。
アミノ酸改変
ポリペプチドのアミノ酸配列中のアミノ酸の改変のためには、部位特異的変異誘発法(Kunkelら(Proc. Natl. Acad. Sci. USA (1985) 82, 488-492))やOverlap extension PCR等の公知の方法が適宜採用され得る。また、天然のアミノ酸以外のアミノ酸に置換するアミノ酸の改変方法として、複数の公知の方法もまた採用され得る(Annu. Rev. Biophys. Biomol. Struct. (2006) 35, 225-249、Proc. Natl. Acad. Sci. U.S.A. (2003) 100 (11), 6353-6357)。例えば、終止コドンの1つであるUAGコドン(アンバーコドン)の相補的アンバーサプレッサーtRNAに非天然アミノ酸が結合されたtRNAが含まれる無細胞翻訳系システム(Clover Direct(Protein Express))等も好適に用いられる。
ポリペプチドのアミノ酸配列中のアミノ酸の改変のためには、部位特異的変異誘発法(Kunkelら(Proc. Natl. Acad. Sci. USA (1985) 82, 488-492))やOverlap extension PCR等の公知の方法が適宜採用され得る。また、天然のアミノ酸以外のアミノ酸に置換するアミノ酸の改変方法として、複数の公知の方法もまた採用され得る(Annu. Rev. Biophys. Biomol. Struct. (2006) 35, 225-249、Proc. Natl. Acad. Sci. U.S.A. (2003) 100 (11), 6353-6357)。例えば、終止コドンの1つであるUAGコドン(アンバーコドン)の相補的アンバーサプレッサーtRNAに非天然アミノ酸が結合されたtRNAが含まれる無細胞翻訳系システム(Clover Direct(Protein Express))等も好適に用いられる。
本明細書において、アミノ酸の改変部位を表す際に用いられる「および/または」の用語の意義は、「および」と「または」が適宜組み合わされたあらゆる組合せを含む。具体的には、例えば「37番、45番、および/または47番のアミノ酸が置換されている」とは以下のアミノ酸の改変のバリエーションが含まれる;
(a) 37番、(b)45番、(c)47番、(d) 37番および45番、(e) 37番および47番、(f) 45番および47番、(g) 37番および45番および47番。
(a) 37番、(b)45番、(c)47番、(d) 37番および45番、(e) 37番および47番、(f) 45番および47番、(g) 37番および45番および47番。
本明細書において、また、アミノ酸の改変を表す表現として、特定の位置を表す数字の前後に改変前と改変後のアミノ酸の1文字コードまたは3文字コードを併記した表現が適宜使用され得る。例えば、抗体可変領域に含まれるアミノ酸の置換を加える際に用いられるF37VまたはPhe37Valという改変は、Kabatナンバリングで表される37位のPheのValへの置換を表す。すなわち、数字はKabatナンバリングで表されるアミノ酸の位置を表し、その前に記載されるアミノ酸の1文字コード又は3文字コードは置換前のアミノ酸、そのあとに記載されるアミノ酸の1文字コードまたは3文字コードは置換後のアミノ酸を表す。同様に、抗体定常領域に含まれるFc領域にアミノ酸の置換を加える際に用いられるP238AまたはPro238Alaという改変は、EUナンバリングで表される238位のProのAlaへの置換を表す。すなわち、数字はEUナンバリングで表されるアミノ酸の位置を表し、その前に記載されるアミノ酸の1文字コードまたは3文字コードは置換前のアミノ酸、そのあとに記載されるアミノ酸の1文字コードまたは3文字コードは置換後のアミノ酸を表す。
アミノ酸配列Aをアミノ酸配列B中に「挿入」することは、アミノ酸配列Bを欠損させず二つの部分に分け、二つの部分の間をアミノ酸配列Aで繋げること(即ち、「アミノ酸配列B前半-アミノ酸配列A-アミノ酸配列B後半」のようなアミノ酸配列を新たに作ること)を指す。アミノ酸配列Aをアミノ酸配列B中に「導入」することは、アミノ酸配列Bを二つの部分に分け、二つの部分の間をアミノ酸配列Aで繋げることを指し、前記アミノ酸配列Aをアミノ酸配列B中に「挿入」すること以外に、アミノ酸配列Aと隣接するアミノ酸配列Bのアミノ酸残基を始めとする一つまたは複数のアミノ酸残基を欠損させてからアミノ酸配列Aで二つの部分を繋げること(即ち、アミノ酸配列Bの一部をアミノ酸配列Aに置き換えること)も可能である。
また、本明細書で用語「A部分とB部分の境界付近」とは、ポリペプチド中のA部分とB部分が連結されている部位の前後で、A部分および/またはB部分の二次構造に大きく影響しない部分を言う。
また、本明細書で用語「A部分とB部分の境界付近」とは、ポリペプチド中のA部分とB部分が連結されている部位の前後で、A部分および/またはB部分の二次構造に大きく影響しない部分を言う。
抗体及び抗体断片
本明細書で用語「抗体」は、最も広い意味で使用され、所望の抗原結合活性を示す限りは、これらに限定されるものではないが、モノクローナル抗体、ポリクローナル抗体、多重特異性抗体(例えば、二重特異性抗体)および抗体断片を含む、種々の抗体構造を包含する。
本明細書で用語「抗体」は、最も広い意味で使用され、所望の抗原結合活性を示す限りは、これらに限定されるものではないが、モノクローナル抗体、ポリクローナル抗体、多重特異性抗体(例えば、二重特異性抗体)および抗体断片を含む、種々の抗体構造を包含する。
「抗体断片」は、完全抗体が結合する抗原に結合する当該完全抗体の一部分を含む、当該完全抗体以外の分子のことをいう。抗体断片の例は、それだけに限定されるものではないが、Fv、Fab、Fab'、Fab’-SH、F(ab')2、ダイアボディ、線状抗体、単鎖抗体分子(例えば、scFv)、および抗体断片から形成された多重特異性抗体を含む。
用語「全長抗体」、「完全抗体」、および「全部抗体」は、本明細書では相互に交換可能に用いられ、天然型抗体構造に実質的に類似した構造を有する、または本明細書で定義するFc領域を含む重鎖を有する抗体のことをいう。
本明細書において、抗体中にプロテアーゼ切断配列が含まれる態様があるが、プロテアーゼ切断配列が含まれるか否かに関わらず、「抗体」として表現できる。
可変領域
用語「可変領域」または「可変ドメイン」は、抗体を抗原へと結合させることに関与する、抗体の重鎖または軽鎖のドメインのことをいう。抗体の重鎖および軽鎖の可変ドメイン(それぞれVHおよびVL)は、通常、各ドメインが4つの保存されたフレームワーク領域 (FR) および3つの相補性決定領域 (CDR) を含む、類似の構造を有する。(例えば、Kindt et al. Kuby Immunology, 6th ed., W.H. Freeman and Co., page 91 (2007) 参照。)1つのVHまたはVLドメインで、抗原結合特異性を与えるに充分であろう。
用語「可変領域」または「可変ドメイン」は、抗体を抗原へと結合させることに関与する、抗体の重鎖または軽鎖のドメインのことをいう。抗体の重鎖および軽鎖の可変ドメイン(それぞれVHおよびVL)は、通常、各ドメインが4つの保存されたフレームワーク領域 (FR) および3つの相補性決定領域 (CDR) を含む、類似の構造を有する。(例えば、Kindt et al. Kuby Immunology, 6th ed., W.H. Freeman and Co., page 91 (2007) 参照。)1つのVHまたはVLドメインで、抗原結合特異性を与えるに充分であろう。
CDR
本明細書で用いられる用語「相補性決定領域」または「CDR」は、配列において超可変であり、および/または構造的に定まったループ(「超可変ループ」)を形成し、および/または抗原接触残基(「抗原接触」)、抗体の可変ドメインまたは単ドメイン抗体の各領域のことをいう。
通常、抗体は6つのCDRを含む:VHに3つ(H1、H2、H3)、およびVLに3つ(L1、L2、L3)である。本明細書での例示的な抗体CDRは、以下のものを含む:
(a) アミノ酸残基26-32 (L1)、50-52 (L2)、91-96 (L3)、26-32 (H1)、53-55 (H2)、および96-101 (H3)のところで生じる超可変ループ (Chothia and Lesk, J. Mol. Biol. 196:901-917 (1987));
(b) アミノ酸残基24-34 (L1)、50-56 (L2)、89-97 (L3)、31-35b (H1)、50-65 (H2)、 および95-102 (H3)のところで生じるCDR (Kabat et al., Sequences of Proteins of Immunological Interest, 5th Ed. Public Health Service, National Institutes of Health, Bethesda, MD (1991));
(c) アミノ酸残基27c-36 (L1)、46-55 (L2)、89-96 (L3)、30-35b (H1)、47-58 (H2)、および93-101 (H3) のところで生じる抗原接触 (MacCallum et al. J. Mol. Biol. 262: 732-745 (1996));ならびに、
(d) CDRアミノ酸残基46-56 (L2)、47-56 (L2)、48-56 (L2)、49-56 (L2)、26-35 (H1)、26-35b (H1)、49-65 (H2)、93-102 (H3)、または94-102 (H3)を含む、(a)、(b)、および/または(c)の組合せ。
本明細書で用いられる用語「相補性決定領域」または「CDR」は、配列において超可変であり、および/または構造的に定まったループ(「超可変ループ」)を形成し、および/または抗原接触残基(「抗原接触」)、抗体の可変ドメインまたは単ドメイン抗体の各領域のことをいう。
通常、抗体は6つのCDRを含む:VHに3つ(H1、H2、H3)、およびVLに3つ(L1、L2、L3)である。本明細書での例示的な抗体CDRは、以下のものを含む:
(a) アミノ酸残基26-32 (L1)、50-52 (L2)、91-96 (L3)、26-32 (H1)、53-55 (H2)、および96-101 (H3)のところで生じる超可変ループ (Chothia and Lesk, J. Mol. Biol. 196:901-917 (1987));
(b) アミノ酸残基24-34 (L1)、50-56 (L2)、89-97 (L3)、31-35b (H1)、50-65 (H2)、 および95-102 (H3)のところで生じるCDR (Kabat et al., Sequences of Proteins of Immunological Interest, 5th Ed. Public Health Service, National Institutes of Health, Bethesda, MD (1991));
(c) アミノ酸残基27c-36 (L1)、46-55 (L2)、89-96 (L3)、30-35b (H1)、47-58 (H2)、および93-101 (H3) のところで生じる抗原接触 (MacCallum et al. J. Mol. Biol. 262: 732-745 (1996));ならびに、
(d) CDRアミノ酸残基46-56 (L2)、47-56 (L2)、48-56 (L2)、49-56 (L2)、26-35 (H1)、26-35b (H1)、49-65 (H2)、93-102 (H3)、または94-102 (H3)を含む、(a)、(b)、および/または(c)の組合せ。
通常、単ドメイン抗体は3つのCDRを含む:CDR1、CDR2、CDR3。単ドメイン抗体がVHHまたは単ドメインVH抗体の場合、単ドメイン抗体のCDRは、例示的に以下のものを含む:
(a) アミノ酸残基26-32 (CDR1)、53-55 (CDR2)、および96-101 (CDR3)のところで生じる超可変ループ (Chothia and Lesk, J. Mol. Biol. 196:901-917 (1987));
(b) アミノ酸残基31-35b (CDR1)、50-65 (CDR2)、 および95-102 (CDR3)のところで生じるCDR (Kabat et al., Sequences of Proteins of Immunological Interest, 5th Ed. Public Health Service, National Institutes of Health, Bethesda, MD (1991));
(c) アミノ酸残基30-35b (CDR1)、47-58 (CDR2)、および93-101 (CDR3) のところで生じる抗原接触 (MacCallum et al. J. Mol. Biol. 262: 732-745 (1996));ならびに、
(d) CDRアミノ酸残基26-35 (CDR1)、26-35b (CDR1)、49-65 (CDR2)、93-102 (CDR3)、または94-102 (CDR3)を含む、(a)、(b)、および/または(c)の組合せ。
(a) アミノ酸残基26-32 (CDR1)、53-55 (CDR2)、および96-101 (CDR3)のところで生じる超可変ループ (Chothia and Lesk, J. Mol. Biol. 196:901-917 (1987));
(b) アミノ酸残基31-35b (CDR1)、50-65 (CDR2)、 および95-102 (CDR3)のところで生じるCDR (Kabat et al., Sequences of Proteins of Immunological Interest, 5th Ed. Public Health Service, National Institutes of Health, Bethesda, MD (1991));
(c) アミノ酸残基30-35b (CDR1)、47-58 (CDR2)、および93-101 (CDR3) のところで生じる抗原接触 (MacCallum et al. J. Mol. Biol. 262: 732-745 (1996));ならびに、
(d) CDRアミノ酸残基26-35 (CDR1)、26-35b (CDR1)、49-65 (CDR2)、93-102 (CDR3)、または94-102 (CDR3)を含む、(a)、(b)、および/または(c)の組合せ。
単ドメイン抗体が単ドメインVL抗体の場合、単ドメイン抗体のCDRは、例示的に以下のものを含む:
(a) アミノ酸残基26-32 (CDR1)、50-52 (CDR2)、および91-96 (CDR3)のところで生じる超可変ループ (Chothia and Lesk, J. Mol. Biol. 196:901-917 (1987));
(b) アミノ酸残基24-34 (CDR1)、50-56 (CDR2)、および89-97 (CDR3)のところで生じるCDR (Kabat et al., Sequences of Proteins of Immunological Interest, 5th Ed. Public Health Service, National Institutes of Health, Bethesda, MD (1991));
(c) アミノ酸残基27c-36 (CDR1)、46-55 (CDR2)、および89-96 (CDR3)のところで生じる抗原接触 (MacCallum et al. J. Mol. Biol. 262: 732-745 (1996));ならびに、
(d) CDRアミノ酸残基46-56 (CDR2)、47-56 (CDR2)、48-56 (CDR2)、または49-56 (CDR2)を含む、(a)、(b)、および/または(c)の組合せ。
(a) アミノ酸残基26-32 (CDR1)、50-52 (CDR2)、および91-96 (CDR3)のところで生じる超可変ループ (Chothia and Lesk, J. Mol. Biol. 196:901-917 (1987));
(b) アミノ酸残基24-34 (CDR1)、50-56 (CDR2)、および89-97 (CDR3)のところで生じるCDR (Kabat et al., Sequences of Proteins of Immunological Interest, 5th Ed. Public Health Service, National Institutes of Health, Bethesda, MD (1991));
(c) アミノ酸残基27c-36 (CDR1)、46-55 (CDR2)、および89-96 (CDR3)のところで生じる抗原接触 (MacCallum et al. J. Mol. Biol. 262: 732-745 (1996));ならびに、
(d) CDRアミノ酸残基46-56 (CDR2)、47-56 (CDR2)、48-56 (CDR2)、または49-56 (CDR2)を含む、(a)、(b)、および/または(c)の組合せ。
別段示さない限り、CDR残基および可変ドメイン中の他の残基(例えば、FR残基)は、本明細書では上記のKabatらにしたがって番号付けされる。
FR
「フレームワーク」または「FR」は、相補性決定領域 (CDR) 残基以外の、可変ドメイン残基または単ドメイン抗体残基のことをいう。可変ドメインまたは単ドメイン抗体のFRは、通常4つのFRドメイン:FR1、FR2、FR3、およびFR4からなる。それに応じて、CDRおよびFRの配列は、通常次の順序でVH(またはVL)に現れる:FR1-H1(L1)-FR2-H2(L2)-FR3-H3(L3)-FR4。単ドメイン抗体においては、CDRおよびFRの配列は、通常次の順序で現れる:FR1-CDR1-FR2-CDR2-FR3-CDR3-FR4。
「フレームワーク」または「FR」は、相補性決定領域 (CDR) 残基以外の、可変ドメイン残基または単ドメイン抗体残基のことをいう。可変ドメインまたは単ドメイン抗体のFRは、通常4つのFRドメイン:FR1、FR2、FR3、およびFR4からなる。それに応じて、CDRおよびFRの配列は、通常次の順序でVH(またはVL)に現れる:FR1-H1(L1)-FR2-H2(L2)-FR3-H3(L3)-FR4。単ドメイン抗体においては、CDRおよびFRの配列は、通常次の順序で現れる:FR1-CDR1-FR2-CDR2-FR3-CDR3-FR4。
「ヒトコンセンサスフレームワーク」は、ヒト免疫グロブリンVLまたはVHフレームワーク配列の選択群において最も共通して生じるアミノ酸残基を示すフレームワークである。通常、ヒト免疫グロブリンVLまたはVH配列の選択は、可変ドメイン配列のサブグループからである。通常、配列のサブグループは、Kabat et al., Sequences of Proteins of Immunological Interest, Fifth Edition, NIH Publication 91-3242, Bethesda MD (1991), vols. 1-3におけるサブグループである。一態様において、VLについて、サブグループは上記のKabatらによるサブグループκIである。一態様において、VHについて、サブグループは上記のKabatらによるサブグループIIIである。
定常領域
本明細書で用語「定常領域」または「定常ドメイン」は、抗体の可変領域以外の部分を言う。例えば、IgG抗体は、ジスルフィド結合している2つの同一の軽鎖と2つの同一の重鎖から構成される約150,000ダルトンのヘテロ四量体糖タンパク質であり、N末端からC末端に向かって、各重鎖は、可変重鎖ドメインまたは重鎖可変ドメインとも呼ばれる可変領域 (VH) を有し、CH1ドメイン、ヒンジ領域、CH2ドメイン、CH3ドメインを含む重鎖定常領域(CH)が続く。同様に、N末端からC末端に向かって、各軽鎖は、可変軽鎖ドメインまたは軽鎖可変ドメインとも呼ばれる可変領域 (VL) を有し、それに定常軽鎖 (CL) ドメインが続く。天然型抗体の軽鎖は、その定常ドメインのアミノ酸配列に基づいて、カッパ(κ)およびラムダ(λ)と呼ばれる、2つのタイプの1つに帰属させられてよい。「定常領域を含む」との用語は、定常領域の全部を含んでも良く、定常領域の一部を含んでも良い。
本明細書で用語「定常領域」または「定常ドメイン」は、抗体の可変領域以外の部分を言う。例えば、IgG抗体は、ジスルフィド結合している2つの同一の軽鎖と2つの同一の重鎖から構成される約150,000ダルトンのヘテロ四量体糖タンパク質であり、N末端からC末端に向かって、各重鎖は、可変重鎖ドメインまたは重鎖可変ドメインとも呼ばれる可変領域 (VH) を有し、CH1ドメイン、ヒンジ領域、CH2ドメイン、CH3ドメインを含む重鎖定常領域(CH)が続く。同様に、N末端からC末端に向かって、各軽鎖は、可変軽鎖ドメインまたは軽鎖可変ドメインとも呼ばれる可変領域 (VL) を有し、それに定常軽鎖 (CL) ドメインが続く。天然型抗体の軽鎖は、その定常ドメインのアミノ酸配列に基づいて、カッパ(κ)およびラムダ(λ)と呼ばれる、2つのタイプの1つに帰属させられてよい。「定常領域を含む」との用語は、定常領域の全部を含んでも良く、定常領域の一部を含んでも良い。
本明細書では別段特定しない限り、抗体可変領域および抗体軽鎖重鎖定常領域中のアミノ酸残基の番号付けは、Kabat et al., Sequences of Proteins of Immunological Interest, 5th Ed. Public Health Service, National Institutes of Health, Bethesda, MD 1991 に記載の、Kabatナンバリングシステムにしたがう。
抗体の「クラス」は、抗体の重鎖に備わる定常ドメインまたは定常領域のタイプのことをいう。抗体には5つの主要なクラスがある:IgA、IgD、IgE、IgG、およびIgMである。そして、このうちいくつかはさらにサブクラス(アイソタイプ)に分けられてもよい。例えば、IgG1、IgG2、IgG3、IgG4、IgA1、およびIgA2である。異なるクラスの免疫グロブリンに対応する重鎖定常ドメインを、それぞれ、α、δ、ε、γ、およびμと呼ぶ。
Fc領域
本明細書で用語「Fc領域」は、少なくとも定常領域の一部分を含む免疫グロブリン重鎖のC末端領域を定義するために用いられる。この用語は、天然型配列のFc領域および変異体Fc領域を含む。一態様において、ヒトIgG1の場合、重鎖Fc領域はCys226から、またはPro230から、重鎖のカルボキシル末端まで延びる。ただし、Fc領域のC末端のリジン (Lys447) またはグリシン‐リジン(Gly446-Lys447)は、存在していてもしていなくてもよい。本明細書では別段特定しない限り、Fc領域または抗体重鎖定常領域中のアミノ酸残基の番号付けは、Kabat et al., Sequences of Proteins of Immunological Interest, 5th Ed. Public Health Service, National Institutes of Health, Bethesda, MD 1991 に記載の、EUナンバリングシステム(EUインデックスとも呼ばれる)にしたがう。
本明細書で用語「Fc領域」は、少なくとも定常領域の一部分を含む免疫グロブリン重鎖のC末端領域を定義するために用いられる。この用語は、天然型配列のFc領域および変異体Fc領域を含む。一態様において、ヒトIgG1の場合、重鎖Fc領域はCys226から、またはPro230から、重鎖のカルボキシル末端まで延びる。ただし、Fc領域のC末端のリジン (Lys447) またはグリシン‐リジン(Gly446-Lys447)は、存在していてもしていなくてもよい。本明細書では別段特定しない限り、Fc領域または抗体重鎖定常領域中のアミノ酸残基の番号付けは、Kabat et al., Sequences of Proteins of Immunological Interest, 5th Ed. Public Health Service, National Institutes of Health, Bethesda, MD 1991 に記載の、EUナンバリングシステム(EUインデックスとも呼ばれる)にしたがう。
ヒンジ領域
「ヒンジ領域」あるいは「抗体ヒンジ領域」なる用語は、抗体重鎖におけるEUナンバリング216番目から230番目のアミノ酸で構成される領域、またはその中の一部分を指すことが出来る。
「ヒンジ領域」あるいは「抗体ヒンジ領域」なる用語は、抗体重鎖におけるEUナンバリング216番目から230番目のアミノ酸で構成される領域、またはその中の一部分を指すことが出来る。
単ドメイン抗体
本明細書で用語「単ドメイン抗体」は、そのドメイン単独で抗原結合活性を発揮できる抗体である。単ドメイン抗体は、そのドメイン単独で抗原結合活性を発揮できるかぎりその構造は限定されない。IgG抗体等で例示される通常の抗体は、VHとVLのペアリングにより可変領域を形成された状態では抗原結合活性を示すのに対し、単ドメイン抗体は他のドメインとペアリングすることなく、単ドメイン抗体自身のドメイン構造単独で抗原結合活性を発揮できると知られている。単ドメイン抗体は通常比較的に低分子量を有し、単量体の形態で存在する。いくつかの実施形態では、単ドメイン抗体の形態は、抗体重鎖可変領域もしくは抗体軽鎖可変領域と類似する。
単ドメイン抗体の例として、それだけに限定されないが、例えば、ラクダ科の動物重鎖抗体の可変領域(VHH)、サメのVNARのような、先天的に軽鎖を欠如する抗原結合分子、または抗体のVHドメインのすべてもしくは一部分またはVLドメインのすべてもしくは一部分を含む抗体断片が挙げられる。抗体のVH/VLドメインのすべてもしくは一部分を含む抗体断片である単ドメイン抗体の例として、それだけに限定されないが、例えば、米国特許第6,248,516号B1等に記載されているようなヒト抗体VHまたはヒト抗体VLから出発して人工的に作製された単ドメイン抗体(以下、単ドメインVH抗体、単ドメインVL抗体)が挙げられる。
本明細書で用語「単ドメイン抗体」は、そのドメイン単独で抗原結合活性を発揮できる抗体である。単ドメイン抗体は、そのドメイン単独で抗原結合活性を発揮できるかぎりその構造は限定されない。IgG抗体等で例示される通常の抗体は、VHとVLのペアリングにより可変領域を形成された状態では抗原結合活性を示すのに対し、単ドメイン抗体は他のドメインとペアリングすることなく、単ドメイン抗体自身のドメイン構造単独で抗原結合活性を発揮できると知られている。単ドメイン抗体は通常比較的に低分子量を有し、単量体の形態で存在する。いくつかの実施形態では、単ドメイン抗体の形態は、抗体重鎖可変領域もしくは抗体軽鎖可変領域と類似する。
単ドメイン抗体の例として、それだけに限定されないが、例えば、ラクダ科の動物重鎖抗体の可変領域(VHH)、サメのVNARのような、先天的に軽鎖を欠如する抗原結合分子、または抗体のVHドメインのすべてもしくは一部分またはVLドメインのすべてもしくは一部分を含む抗体断片が挙げられる。抗体のVH/VLドメインのすべてもしくは一部分を含む抗体断片である単ドメイン抗体の例として、それだけに限定されないが、例えば、米国特許第6,248,516号B1等に記載されているようなヒト抗体VHまたはヒト抗体VLから出発して人工的に作製された単ドメイン抗体(以下、単ドメインVH抗体、単ドメインVL抗体)が挙げられる。
単ドメイン抗体は、単ドメイン抗体を産生できる動物から、または単ドメイン抗体を産生できる動物を免疫することにより取得し得る。単ドメイン抗体を産生できる動物の例として、それだけに限定されないが、例えば、ラクダ科動物、単ドメイン抗体を産生できる遺伝子が導入された遺伝子導入動物(transgenic animals)が挙げられる。ラクダ科動物はラクダ、ラマ、アルパカ、ヒトコブラクダおよびグアナコ等を含む。単ドメイン抗体を産生できる遺伝子が導入された遺伝子導入動物の例として、それだけに限定されないが、国際公開WO2015/143414号、米国特許公開US2011/0123527号A1に記載の遺伝子導入動物が挙げられる。動物から取得した単ドメイン抗体のフレームワーク配列をヒトジャームライン配列あるいはそれに類似した配列とすることで、ヒト化した単ドメイン抗体を取得することも出来る。ヒト化した単ドメイン抗体(例えば、ヒト化VHH)はまた、本明細書の単ドメイン抗体の一態様である。
また、単ドメイン抗体は、単ドメイン抗体を含むポリペプチドライブラリから、ELISA、パニング等により取得し得る。単ドメイン抗体を含むポリペプチドライブラリの例として、それだけに限定されないが、例えば、各種動物若しくはヒトから取得したナイーブ抗体ライブラリ(例:Methods in Molecular Biology 2012 911 (65-78)、Biochimica et Biophysica Acta - Proteins and Proteomics 2006 1764:8 (1307-1319))、各種動物を免疫することで取得した抗体ライブラリ(例:Journal of Applied Microbiology 2014 117:2 (528-536))、または各種動物若しくはヒトの抗体遺伝子より作成した合成抗体ライブラリ(例:Journal of Biomolecular Screening 2016 21:1 (35-43)、Journal of Biological Chemistry 2016 291:24 (12641-12657)、AIDS 2016 30:11 (1691-1701))が挙げられる。
本開示において、単ドメイン抗体中にプロテアーゼ切断配列が含まれる態様があるが、プロテアーゼ切断配列が含まれるか否かに関わらず、「単ドメイン抗体」として表現できる。
本明細書の単ドメイン抗体は、いくつかの形態において、概して、
a)3つの相補性決定領域/配列が間に挿入された4つのフレームワーク領域/配列から成るアミノ酸配列(Kabatナンバリングによる11位のアミノ酸残基はL、M、S、V、Wからなる群から選択される、好ましくはLである)、及び/又は
b)3つの相補性決定領域/配列が間に挿入された4つのフレームワーク領域/配列から成るアミノ酸配列(Kabatナンバリングによる37位のアミノ酸残基はF、Y、H、I、L、Vからなる群から選択される、好ましくはFまたはYである)、及び/又は
c)3つの相補性決定領域/配列が間に挿入された4つのフレームワーク領域/配列から成るアミノ酸配列(Kabatナンバリングによる44位のアミノ酸残基はG、E、A、D、Q、R、S、Lからなる群から選択される、好ましくはG、EまたはQである、より好ましくはGまたはEである)、及び/又は
d)3つの相補性決定領域/配列が間に挿入された4つのフレームワーク領域/配列から成るアミノ酸配列(Kabatナンバリングによる45位のアミノ酸残基はL、R、C、I、L、P、Q、Vからなる群から選択される、好ましくはLまたはRである)、及び/又は
e)3つの相補性決定領域/配列が間に挿入された4つのフレームワーク領域/配列から成るアミノ酸配列(Kabatナンバリングによる47位のアミノ酸残基はW、L、F、A、G、I、M、R、S、V、Yからなる群から選択される、好ましくはW、L、FまたはRである)、及び/又は
f)3つの相補性決定領域/配列が間に挿入された4つのフレームワーク領域/配列から成るアミノ酸配列(Kabatナンバリングによる83位のアミノ酸残基はR、K、N、E、G、I、M、Q、Tからなる群から選択される、好ましくはKまたはRである、より好ましくはKである)、及び/又は
g)3つの相補性決定領域/配列が間に挿入された4つのフレームワーク領域/配列から成るアミノ酸配列(Kabatナンバリングによる84位のアミノ酸残基はP、A、L、R、S、T、D、Vからなる群から選択される、好ましくはPである)、及び/又は
h)3つの相補性決定領域/配列が間に挿入された4つのフレームワーク領域/配列から成るアミノ酸配列(Kabatナンバリングによる103位のアミノ酸残基はW、P、R、Sからなる群から選択される、このましくはWである)、及び/又は
i)3つの相補性決定領域/配列が間に挿入された4つのフレームワーク領域/配列から成るアミノ酸配列(Kabatナンバリングによる104位のアミノ酸残基はGまたはDである、好ましくはGである)、及び/又は
j)3つの相補性決定領域/配列が間に挿入された4つのフレームワーク領域/配列から成るアミノ酸配列(Kabatナンバリングによる108位のアミノ酸残基はQ、L、Rからなる群から選択される、好ましくはQまたはLである)を含む、ポリペプチドと定義することができる。
a)3つの相補性決定領域/配列が間に挿入された4つのフレームワーク領域/配列から成るアミノ酸配列(Kabatナンバリングによる11位のアミノ酸残基はL、M、S、V、Wからなる群から選択される、好ましくはLである)、及び/又は
b)3つの相補性決定領域/配列が間に挿入された4つのフレームワーク領域/配列から成るアミノ酸配列(Kabatナンバリングによる37位のアミノ酸残基はF、Y、H、I、L、Vからなる群から選択される、好ましくはFまたはYである)、及び/又は
c)3つの相補性決定領域/配列が間に挿入された4つのフレームワーク領域/配列から成るアミノ酸配列(Kabatナンバリングによる44位のアミノ酸残基はG、E、A、D、Q、R、S、Lからなる群から選択される、好ましくはG、EまたはQである、より好ましくはGまたはEである)、及び/又は
d)3つの相補性決定領域/配列が間に挿入された4つのフレームワーク領域/配列から成るアミノ酸配列(Kabatナンバリングによる45位のアミノ酸残基はL、R、C、I、L、P、Q、Vからなる群から選択される、好ましくはLまたはRである)、及び/又は
e)3つの相補性決定領域/配列が間に挿入された4つのフレームワーク領域/配列から成るアミノ酸配列(Kabatナンバリングによる47位のアミノ酸残基はW、L、F、A、G、I、M、R、S、V、Yからなる群から選択される、好ましくはW、L、FまたはRである)、及び/又は
f)3つの相補性決定領域/配列が間に挿入された4つのフレームワーク領域/配列から成るアミノ酸配列(Kabatナンバリングによる83位のアミノ酸残基はR、K、N、E、G、I、M、Q、Tからなる群から選択される、好ましくはKまたはRである、より好ましくはKである)、及び/又は
g)3つの相補性決定領域/配列が間に挿入された4つのフレームワーク領域/配列から成るアミノ酸配列(Kabatナンバリングによる84位のアミノ酸残基はP、A、L、R、S、T、D、Vからなる群から選択される、好ましくはPである)、及び/又は
h)3つの相補性決定領域/配列が間に挿入された4つのフレームワーク領域/配列から成るアミノ酸配列(Kabatナンバリングによる103位のアミノ酸残基はW、P、R、Sからなる群から選択される、このましくはWである)、及び/又は
i)3つの相補性決定領域/配列が間に挿入された4つのフレームワーク領域/配列から成るアミノ酸配列(Kabatナンバリングによる104位のアミノ酸残基はGまたはDである、好ましくはGである)、及び/又は
j)3つの相補性決定領域/配列が間に挿入された4つのフレームワーク領域/配列から成るアミノ酸配列(Kabatナンバリングによる108位のアミノ酸残基はQ、L、Rからなる群から選択される、好ましくはQまたはLである)を含む、ポリペプチドと定義することができる。
より具体的に、排他的ではないが、単ドメイン抗体は下記の3つの相補性決定領域/配列が間に挿入された4つのフレームワーク領域/配列から成るアミノ酸配列のいずれか一つの配列を含むポリペプチドと定義することができる:
k)Kabatナンバリングによる43位~46位のアミノ酸残基はKEREまたはKQREであるアミノ酸配列;
l)Kabatナンバリングによる44位~47位のアミノ酸残基はGLEWであるアミノ酸配列;
m)Kabatナンバリングによる83位~84位のアミノ酸残基はKPまたはEPであるアミノ酸配列。
k)Kabatナンバリングによる43位~46位のアミノ酸残基はKEREまたはKQREであるアミノ酸配列;
l)Kabatナンバリングによる44位~47位のアミノ酸残基はGLEWであるアミノ酸配列;
m)Kabatナンバリングによる83位~84位のアミノ酸残基はKPまたはEPであるアミノ酸配列。
キメラ抗体
用語「キメラ」抗体は、重鎖および/または軽鎖の一部分が特定の供給源または種に由来する一方で、重鎖および/または軽鎖の残りの部分が異なった供給源または種に由来する抗体のことをいう。「キメラ単ドメイン抗体」は、単ドメイン抗体の一部分が特定の供給源または種に由来する一方で、単ドメイン抗体の残りの部分が異なった供給源または種に由来する単ドメイン抗体のことをいう。
用語「キメラ」抗体は、重鎖および/または軽鎖の一部分が特定の供給源または種に由来する一方で、重鎖および/または軽鎖の残りの部分が異なった供給源または種に由来する抗体のことをいう。「キメラ単ドメイン抗体」は、単ドメイン抗体の一部分が特定の供給源または種に由来する一方で、単ドメイン抗体の残りの部分が異なった供給源または種に由来する単ドメイン抗体のことをいう。
ヒト化抗体
「ヒト化」抗体は、非ヒトCDRからのアミノ酸残基およびヒトFRからのアミノ酸残基を含む、キメラ抗体のことをいう。ある態様では、ヒト化抗体は、少なくとも1つ、典型的には2つの可変ドメインの実質的にすべてを含み、当該可変領域においては、すべてのもしくは実質的にすべてのCDRは非ヒト抗体のものに対応し、かつ、すべてのもしくは実質的にすべてのFRはヒト抗体のものに対応する。「ヒト化単ドメイン抗体」は、非ヒトCDRからのアミノ酸残基およびヒトFRからのアミノ酸残基を含む、キメラ単ドメイン抗体のことをいう。ある態様では、ヒト化単ドメイン抗体は、すべてのもしくは実質的にすべてのCDRは非ヒト抗体のものに対応し、かつ、すべてのもしくは実質的にすべてのFRはヒト抗体のものに対応する。ヒト化抗体において、FR中の残基の一部がヒト抗体のものと対応しない場合も、実質的にすべてのFRはヒト抗体のものに対応する一例として考えられる。たとえば、単ドメイン抗体の一態様であるVHHをヒト化する場合、FR中の残基の一部をヒト抗体のものと対応しない残基にする必要がある(C Vinckeら、The Journal of Biological Chemistry 284, 3273-3284.)。
ヒト化抗体は、任意で、ヒト抗体に由来する抗体定常領域の少なくとも一部分を含んでもよい。抗体(例えば、非ヒト抗体)の「ヒト化された形態」は、ヒト化を経た抗体のことをいう。
「ヒト化」抗体は、非ヒトCDRからのアミノ酸残基およびヒトFRからのアミノ酸残基を含む、キメラ抗体のことをいう。ある態様では、ヒト化抗体は、少なくとも1つ、典型的には2つの可変ドメインの実質的にすべてを含み、当該可変領域においては、すべてのもしくは実質的にすべてのCDRは非ヒト抗体のものに対応し、かつ、すべてのもしくは実質的にすべてのFRはヒト抗体のものに対応する。「ヒト化単ドメイン抗体」は、非ヒトCDRからのアミノ酸残基およびヒトFRからのアミノ酸残基を含む、キメラ単ドメイン抗体のことをいう。ある態様では、ヒト化単ドメイン抗体は、すべてのもしくは実質的にすべてのCDRは非ヒト抗体のものに対応し、かつ、すべてのもしくは実質的にすべてのFRはヒト抗体のものに対応する。ヒト化抗体において、FR中の残基の一部がヒト抗体のものと対応しない場合も、実質的にすべてのFRはヒト抗体のものに対応する一例として考えられる。たとえば、単ドメイン抗体の一態様であるVHHをヒト化する場合、FR中の残基の一部をヒト抗体のものと対応しない残基にする必要がある(C Vinckeら、The Journal of Biological Chemistry 284, 3273-3284.)。
ヒト化抗体は、任意で、ヒト抗体に由来する抗体定常領域の少なくとも一部分を含んでもよい。抗体(例えば、非ヒト抗体)の「ヒト化された形態」は、ヒト化を経た抗体のことをいう。
会合
本明細書における「会合」とは、例えば、2以上のポリペプチド領域が相互作用する状態を指すものと換言することができる。一般的に、対象となるポリペプチド領域の間に、疎水結合、水素結合、イオン結合等が作られ会合体が形成される。よく見る会合の一つの例として、天然型抗体を代表とする抗体においては、重鎖可変領域(VH)と軽鎖可変領域(VL)が両者間の非共有結合等によりペアリング構造を保持することが知られている。
会合の解消とは、例えば、2以上のポリペプチド領域の相互作用状態の全部もしくは一部が解消されると換言することができる。VHとVLの会合の解消とは、VHとVLの相互作用が全部解消されても、VHとVLの相互作用の中の一部が解消されても良い。
本明細書における「会合」とは、例えば、2以上のポリペプチド領域が相互作用する状態を指すものと換言することができる。一般的に、対象となるポリペプチド領域の間に、疎水結合、水素結合、イオン結合等が作られ会合体が形成される。よく見る会合の一つの例として、天然型抗体を代表とする抗体においては、重鎖可変領域(VH)と軽鎖可変領域(VL)が両者間の非共有結合等によりペアリング構造を保持することが知られている。
会合の解消とは、例えば、2以上のポリペプチド領域の相互作用状態の全部もしくは一部が解消されると換言することができる。VHとVLの会合の解消とは、VHとVLの相互作用が全部解消されても、VHとVLの相互作用の中の一部が解消されても良い。
FcRn結合領域
本明細書における「FcRn結合領域」とは、FcRnへ結合性を持つ領域を言い、FcRnへの結合性を持つ限りどんな構造でも使用可能である。
FcRn結合領域を含む分子は、FcRnのサルベージ経路により細胞内に取り込まれた後に再び血漿中に戻ることが可能である。例えば、IgG分子の血漿中滞留性が比較的長い(消失が遅い)のは、IgG分子のサルベージレセプターとして知られているFcRnが機能しているためである。ピノサイトーシスによってエンドソームに取り込まれたIgG分子は、エンドソーム内の酸性条件下においてエンドソーム内に発現しているFcRnに結合する。FcRnに結合できなかったIgG分子はライソソームへと進みそこで分解されるが、FcRnへ結合したIgG分子は細胞表面へ移行し血漿中の中性条件下においてFcRnから解離することで再び血漿中に戻る。
FcRn結合領域は、直接FcRnと結合する領域であることが好ましい。FcRn結合領域の好ましい例として、抗体のFc領域を挙げることができる。しかしながら、アルブミンやIgGなどのFcRnとの結合能を有するポリペプチドに結合可能な領域は、アルブミンやIgGなどを介して間接的にFcRnと結合することが可能であるので、本開示におけるFcRn結合領域はそのようなFcRnとの結合能を有するポリペプチドに結合する領域であってもよい。
本明細書における「FcRn結合領域」とは、FcRnへ結合性を持つ領域を言い、FcRnへの結合性を持つ限りどんな構造でも使用可能である。
FcRn結合領域を含む分子は、FcRnのサルベージ経路により細胞内に取り込まれた後に再び血漿中に戻ることが可能である。例えば、IgG分子の血漿中滞留性が比較的長い(消失が遅い)のは、IgG分子のサルベージレセプターとして知られているFcRnが機能しているためである。ピノサイトーシスによってエンドソームに取り込まれたIgG分子は、エンドソーム内の酸性条件下においてエンドソーム内に発現しているFcRnに結合する。FcRnに結合できなかったIgG分子はライソソームへと進みそこで分解されるが、FcRnへ結合したIgG分子は細胞表面へ移行し血漿中の中性条件下においてFcRnから解離することで再び血漿中に戻る。
FcRn結合領域は、直接FcRnと結合する領域であることが好ましい。FcRn結合領域の好ましい例として、抗体のFc領域を挙げることができる。しかしながら、アルブミンやIgGなどのFcRnとの結合能を有するポリペプチドに結合可能な領域は、アルブミンやIgGなどを介して間接的にFcRnと結合することが可能であるので、本開示におけるFcRn結合領域はそのようなFcRnとの結合能を有するポリペプチドに結合する領域であってもよい。
本開示におけるFcRn結合領域のFcRn、特にヒトFcRnに対する結合活性は、前記結合活性の項で述べられているように、当業者に公知の方法により測定することが可能であり、条件については当業者が適宜決定することが可能である。ヒトFcRnへの結合活性は、KD(Dissociation constant:解離定数)、見かけのKD(Apparent dissociation constant:見かけの解離定数)、解離速度であるkd(Dissociation rate:解離速度)、又は見かけのkd(Apparent dissociation:見かけの解離速度)等として評価され得る。これらは当業者公知の方法で測定され得る。例えばBiacore(GE healthcare)、スキャッチャードプロット、フローサイトメーター等を使用され得る。
FcRn結合領域のFcRnに対する結合活性を測定する際の条件は当業者が適宜選択することが可能であり、特に限定されない。例えば、WO2009/125825に記載されているようにMESバッファー、37℃の条件において測定され得る。また、本開示のFcRn結合領域のFcRnに対する結合活性の測定は当業者公知の方法により行うことが可能であり、例えば、Biacore(GE Healthcare)などを用いて測定され得る。FcRn結合領域とFcRnの結合活性の測定は、FcRn結合領域またはFcRn結合領域を含む運搬部分あるいはFcRnを固定化したチップへ、それぞれFcRnあるいはFcRn結合領域またはFcRn結合領域を含む分子をアナライトとして流すことによって評価され得る。
測定条件に使用されるpHとして、FcRn結合領域とFcRnとの結合アフィニティは、pH4.0~pH6.5の任意のpHで評価してもよい。好ましくは、FcRn結合領域とヒトFcRnとの結合アフィニティを決定するために、生体内の早期エンドソーム内のpHに近いpH5.8~pH6.0のpHが使用される。測定条件に使用される温度として、FcRn結合領域とFcRnとの結合アフィニティは、10℃~50℃の任意の温度で評価してもよい。好ましくは、FcRn結合領域とヒトFcRnとの結合アフィニティを決定するために、15℃~40℃の温度が使用される。より好ましくは、20、21、22、23、24、25、26、27、28、29、30、31、32、33、34、および35℃のいずれか1つのような20℃から35℃までの任意の温度も同様に、FcRn結合領域とFcRnとの結合アフィニティを決定するために使用される。25℃という温度は本開示の態様の非限定な一例である。
FcRn結合領域の一つの例として、それだけに限定されないが、例えば、IgG抗体Fc領域が挙げられる。IgG抗体のFc領域を用いる場合、その種類は限定されず、IgG1、IgG2、IgG3、IgG4などのFc領域を用いることが可能である。例えば、配列番号:18004、18005、18006、18007で示されるアミノ酸配列から選ばれる一つの配列を含むFc領域を用いることが可能である。
また、天然型IgG抗体のFc領域はもちろん、FcRn結合性を有する限り、一つまたはそれ以上のアミノ酸が置換された改変Fc領域も使用可能である。
例えば、IgG抗体Fc領域におけるEUナンバリング237番目、238番目、239番目、248番目、250番目、252番目、254番目、255番目、256番目、257番目、258番目、265番目、270番目、286番目、289番目、297番目、298番目、303番目、305番目、307番目、308番目、309番目、311番目、312番目、314番目、315番目、317番目、325番目、332番目、334番目、360番目、376番目、380番目、382番目、384番目、385番目、386番目、387番目、389番目、424番目、428番目、433番目、434番目および436番目から選択される少なくとも1つのアミノ酸を他のアミノ酸に置換したアミノ酸配列を含む改変Fc領域を使用ことは可能である。
例えば、IgG抗体Fc領域におけるEUナンバリング237番目、238番目、239番目、248番目、250番目、252番目、254番目、255番目、256番目、257番目、258番目、265番目、270番目、286番目、289番目、297番目、298番目、303番目、305番目、307番目、308番目、309番目、311番目、312番目、314番目、315番目、317番目、325番目、332番目、334番目、360番目、376番目、380番目、382番目、384番目、385番目、386番目、387番目、389番目、424番目、428番目、433番目、434番目および436番目から選択される少なくとも1つのアミノ酸を他のアミノ酸に置換したアミノ酸配列を含む改変Fc領域を使用ことは可能である。
より具体的には、FcRn結合領域として、IgG抗体Fc領域におけるEUナンバリング
237番目のGlyをMetに置換するアミノ酸置換、
238番目のProをAlaに置換するアミノ酸置換、
239番目のSerをLysに置換するアミノ酸置換、
248番目のLysをIleに置換するアミノ酸置換、
250番目のThrをAla、Phe、Ile、Met、Gln、Ser、Val、Trp、またはTyrに置換するアミノ酸置換、
252番目のMetをPhe、Trp、またはTyrに置換するアミノ酸置換、
254番目のSerをThrに置換するアミノ酸置換、
255番目のArgをGluに置換するアミノ酸置換、
256番目のThrをAsp、Glu、またはGlnに置換するアミノ酸置換、
257番目のProをAla、Gly、Ile、Leu、Met、Asn、Ser、Thr、またはValに置換するアミノ酸置換、
258番目のGluをHisに置換するアミノ酸置換、
265番目のAspをAlaに置換するアミノ酸置換、
270番目のAspをPheに置換するアミノ酸置換、
286番目のAsnをAlaまたはGluに置換するアミノ酸置換、
289番目のThrをHisに置換するアミノ酸置換、
297番目のAsnをAlaに置換するアミノ酸置換、
298番目のSerをGlyに置換するアミノ酸置換、
303番目のValをAlaに置換するアミノ酸置換、
305番目のValをAlaに置換するアミノ酸置換、
307番目のThrをAla、Asp、Phe、Gly、His、Ile、Lys、Leu、Met、Asn、Pro、Gln、Arg、Ser、Val、Trp、またはTyrに置換するアミノ酸置換、
308番目のValをAla、Phe、Ile、Leu、Met、Pro、Gln、またはThrに置換するアミノ酸置換、
309番目のLeuまたはValをAla、Asp、Glu、Pro、またはArgに置換するアミノ酸置換、
311番目のGlnをAla、His、またはIleに置換するアミノ酸置換、
312番目のAspをAlaまたはHisに置換するアミノ酸置換、
314番目のLeuをLysまたはArgに置換するアミノ酸置換、
315番目のAsnをAlaまたはHisに置換するアミノ酸置換、
317番目のLysをAlaに置換するアミノ酸置換、
325番目のAsnをGlyに置換するアミノ酸置換、
332番目のIleをValに置換するアミノ酸置換、
334番目のLysをLeuに置換するアミノ酸置換、
360番目のLysをHisに置換するアミノ酸置換、
376番目のAspをAlaに置換するアミノ酸置換、
380番目のGluをAlaに置換するアミノ酸置換、
382番目のGluをAlaに置換するアミノ酸置換、
384番目のAsnまたはSerをAlaに置換するアミノ酸置換、
385番目のGlyをAspまたはHisに置換するアミノ酸置換、
386番目のGlnをProに置換するアミノ酸置換、
387番目のProをGluに置換するアミノ酸置換、
389番目のAsnをAlaまたはSerに置換するアミノ酸置換、
424番目のSerをAlaに置換するアミノ酸置換、
428番目のMetをAla、Asp、Phe、Gly、His、Ile、Lys、Leu、Asn、Pro、Gln、Ser、Thr、Val、Trp、またはTyrに置換するアミノ酸置換、
433番目のHisをLysに置換するアミノ酸置換、
434番目のAsnをAla、Phe、His、Ser、Trp、またはTyrに置換するアミノ酸置換、および
436番目のTyrまたはPheをHisに置換するアミノ酸置換
から選択される少なくとも1つのアミノ酸置換を含む、改変Fc領域を使用することは可能である。
237番目のGlyをMetに置換するアミノ酸置換、
238番目のProをAlaに置換するアミノ酸置換、
239番目のSerをLysに置換するアミノ酸置換、
248番目のLysをIleに置換するアミノ酸置換、
250番目のThrをAla、Phe、Ile、Met、Gln、Ser、Val、Trp、またはTyrに置換するアミノ酸置換、
252番目のMetをPhe、Trp、またはTyrに置換するアミノ酸置換、
254番目のSerをThrに置換するアミノ酸置換、
255番目のArgをGluに置換するアミノ酸置換、
256番目のThrをAsp、Glu、またはGlnに置換するアミノ酸置換、
257番目のProをAla、Gly、Ile、Leu、Met、Asn、Ser、Thr、またはValに置換するアミノ酸置換、
258番目のGluをHisに置換するアミノ酸置換、
265番目のAspをAlaに置換するアミノ酸置換、
270番目のAspをPheに置換するアミノ酸置換、
286番目のAsnをAlaまたはGluに置換するアミノ酸置換、
289番目のThrをHisに置換するアミノ酸置換、
297番目のAsnをAlaに置換するアミノ酸置換、
298番目のSerをGlyに置換するアミノ酸置換、
303番目のValをAlaに置換するアミノ酸置換、
305番目のValをAlaに置換するアミノ酸置換、
307番目のThrをAla、Asp、Phe、Gly、His、Ile、Lys、Leu、Met、Asn、Pro、Gln、Arg、Ser、Val、Trp、またはTyrに置換するアミノ酸置換、
308番目のValをAla、Phe、Ile、Leu、Met、Pro、Gln、またはThrに置換するアミノ酸置換、
309番目のLeuまたはValをAla、Asp、Glu、Pro、またはArgに置換するアミノ酸置換、
311番目のGlnをAla、His、またはIleに置換するアミノ酸置換、
312番目のAspをAlaまたはHisに置換するアミノ酸置換、
314番目のLeuをLysまたはArgに置換するアミノ酸置換、
315番目のAsnをAlaまたはHisに置換するアミノ酸置換、
317番目のLysをAlaに置換するアミノ酸置換、
325番目のAsnをGlyに置換するアミノ酸置換、
332番目のIleをValに置換するアミノ酸置換、
334番目のLysをLeuに置換するアミノ酸置換、
360番目のLysをHisに置換するアミノ酸置換、
376番目のAspをAlaに置換するアミノ酸置換、
380番目のGluをAlaに置換するアミノ酸置換、
382番目のGluをAlaに置換するアミノ酸置換、
384番目のAsnまたはSerをAlaに置換するアミノ酸置換、
385番目のGlyをAspまたはHisに置換するアミノ酸置換、
386番目のGlnをProに置換するアミノ酸置換、
387番目のProをGluに置換するアミノ酸置換、
389番目のAsnをAlaまたはSerに置換するアミノ酸置換、
424番目のSerをAlaに置換するアミノ酸置換、
428番目のMetをAla、Asp、Phe、Gly、His、Ile、Lys、Leu、Asn、Pro、Gln、Ser、Thr、Val、Trp、またはTyrに置換するアミノ酸置換、
433番目のHisをLysに置換するアミノ酸置換、
434番目のAsnをAla、Phe、His、Ser、Trp、またはTyrに置換するアミノ酸置換、および
436番目のTyrまたはPheをHisに置換するアミノ酸置換
から選択される少なくとも1つのアミノ酸置換を含む、改変Fc領域を使用することは可能である。
別の面から見れば、FcRn結合領域として、IgG抗体Fc領域における、EUナンバリング
237番目のアミノ酸におけるMet、
238番目のアミノ酸におけるAla、
239番目のアミノ酸におけるLys、
248番目のアミノ酸におけるIle、
250番目のアミノ酸におけるAla、Phe、Ile、Met、Gln、Ser、Val、Trp、またはTyr、
252番目のアミノ酸におけるPhe、Trp、またはTyr、
254番目のアミノ酸におけるThr、
255番目のアミノ酸におけるGlu、
256番目のアミノ酸におけるAsp、Glu、またはGln、
257番目のアミノ酸におけるAla、Gly、Ile、Leu、Met、Asn、Ser、Thr、またはVal、
258番目のアミノ酸におけるHis、
265番目のアミノ酸におけるAla、
270番目のアミノ酸におけるPhe、
286番目のアミノ酸におけるAlaまたはGlu、
289番目のアミノ酸におけるHis、
297番目のアミノ酸におけるAla、
298番目のアミノ酸におけるGly、
303番目のアミノ酸におけるAla、
305番目のアミノ酸におけるAla、
307番目のアミノ酸におけるAla、Asp、Phe、Gly、His、Ile、Lys、Leu、Met、Asn、Pro、Gln、Arg、Ser、Val、Trp、またはTyr、
308番目のアミノ酸におけるAla、Phe、Ile、Leu、Met、Pro、Gln、またはThr、
309番目のアミノ酸におけるAla、Asp、Glu、Pro、またはArg、
311番目のアミノ酸におけるAla、His、またはIle、
312番目のアミノ酸におけるAlaまたはHis、
314番目のアミノ酸におけるLysまたはArg、
315番目のアミノ酸におけるAlaまたはHis、
317番目のアミノ酸におけるAla、
325番目のアミノ酸におけるGly、
332番目のアミノ酸におけるVal、
334番目のアミノ酸におけるLeu、
360番目のアミノ酸におけるHis、
376番目のアミノ酸におけるAla、
380番目のアミノ酸におけるAla、
382番目のアミノ酸におけるAla、
384番目のアミノ酸におけるAla、
385番目のアミノ酸におけるAspまたはHis、
386番目のアミノ酸におけるPro、
387番目のアミノ酸におけるGlu、
389番目のアミノ酸におけるAlaまたはSer、
424番目のアミノ酸におけるAla、
428番目のアミノ酸におけるAla、Asp、Phe、Gly、His、Ile、Lys、Leu、Asn、Pro、Gln、Ser、Thr、Val、Trp、またはTyr、
433番目のアミノ酸におけるLys、
434番目のアミノ酸におけるAla、Phe、His、Ser、Trp、またはTyr、および
436番目のアミノ酸におけるHis
から選択される少なくとも1つのアミノ酸を含むFc領域を使用することは可能である。
237番目のアミノ酸におけるMet、
238番目のアミノ酸におけるAla、
239番目のアミノ酸におけるLys、
248番目のアミノ酸におけるIle、
250番目のアミノ酸におけるAla、Phe、Ile、Met、Gln、Ser、Val、Trp、またはTyr、
252番目のアミノ酸におけるPhe、Trp、またはTyr、
254番目のアミノ酸におけるThr、
255番目のアミノ酸におけるGlu、
256番目のアミノ酸におけるAsp、Glu、またはGln、
257番目のアミノ酸におけるAla、Gly、Ile、Leu、Met、Asn、Ser、Thr、またはVal、
258番目のアミノ酸におけるHis、
265番目のアミノ酸におけるAla、
270番目のアミノ酸におけるPhe、
286番目のアミノ酸におけるAlaまたはGlu、
289番目のアミノ酸におけるHis、
297番目のアミノ酸におけるAla、
298番目のアミノ酸におけるGly、
303番目のアミノ酸におけるAla、
305番目のアミノ酸におけるAla、
307番目のアミノ酸におけるAla、Asp、Phe、Gly、His、Ile、Lys、Leu、Met、Asn、Pro、Gln、Arg、Ser、Val、Trp、またはTyr、
308番目のアミノ酸におけるAla、Phe、Ile、Leu、Met、Pro、Gln、またはThr、
309番目のアミノ酸におけるAla、Asp、Glu、Pro、またはArg、
311番目のアミノ酸におけるAla、His、またはIle、
312番目のアミノ酸におけるAlaまたはHis、
314番目のアミノ酸におけるLysまたはArg、
315番目のアミノ酸におけるAlaまたはHis、
317番目のアミノ酸におけるAla、
325番目のアミノ酸におけるGly、
332番目のアミノ酸におけるVal、
334番目のアミノ酸におけるLeu、
360番目のアミノ酸におけるHis、
376番目のアミノ酸におけるAla、
380番目のアミノ酸におけるAla、
382番目のアミノ酸におけるAla、
384番目のアミノ酸におけるAla、
385番目のアミノ酸におけるAspまたはHis、
386番目のアミノ酸におけるPro、
387番目のアミノ酸におけるGlu、
389番目のアミノ酸におけるAlaまたはSer、
424番目のアミノ酸におけるAla、
428番目のアミノ酸におけるAla、Asp、Phe、Gly、His、Ile、Lys、Leu、Asn、Pro、Gln、Ser、Thr、Val、Trp、またはTyr、
433番目のアミノ酸におけるLys、
434番目のアミノ酸におけるAla、Phe、His、Ser、Trp、またはTyr、および
436番目のアミノ酸におけるHis
から選択される少なくとも1つのアミノ酸を含むFc領域を使用することは可能である。
アフィニティ
「アフィニティ」は、分子(例えば、抗体)の結合部位1個と、分子の結合パートナー(例えば、抗原)との間の、非共有結合的な相互作用の合計の強度のことをいう。別段示さない限り、本明細書で用いられる「結合アフィニティ」は、ある結合対のメンバー(例えば、抗体と抗原)の間の1:1相互作用を反映する、固有の結合アフィニティのことをいう。分子XのそのパートナーYに対するアフィニティは、一般的に、解離定数 (Kd) により表すことができる。アフィニティは、本明細書に記載のものを含む、当該技術分野において知られた通常の方法によって測定され得る。結合アフィニティを測定するための具体的な実例となるおよび例示的な態様については、下で述べる。
「アフィニティ」は、分子(例えば、抗体)の結合部位1個と、分子の結合パートナー(例えば、抗原)との間の、非共有結合的な相互作用の合計の強度のことをいう。別段示さない限り、本明細書で用いられる「結合アフィニティ」は、ある結合対のメンバー(例えば、抗体と抗原)の間の1:1相互作用を反映する、固有の結合アフィニティのことをいう。分子XのそのパートナーYに対するアフィニティは、一般的に、解離定数 (Kd) により表すことができる。アフィニティは、本明細書に記載のものを含む、当該技術分野において知られた通常の方法によって測定され得る。結合アフィニティを測定するための具体的な実例となるおよび例示的な態様については、下で述べる。
モノクローナル抗体
本明細書でいう用語「モノクローナル抗体」は、実質的に均一な抗体の集団から得られる抗体のことをいう。すなわち、その集団を構成する個々の抗体は、生じ得る変異抗体(例えば、自然に生じる変異を含む変異抗体、またはモノクローナル抗体調製物の製造中に発生する変異抗体。そのような変異体は通常若干量存在している。)を除いて、同一でありおよび/または同じエピトープに結合する。異なる決定基(エピトープ)に対する異なる抗体を典型的に含むポリクローナル抗体調製物とは対照的に、モノクローナル抗体調製物の各モノクローナル抗体は、抗原上の単一の決定基に対するものである。したがって、修飾語「モノクローナル」は、実質的に均一な抗体の集団から得られるものである、という抗体の特徴を示し、何らかの特定の方法による抗体の製造を求めるものと解釈されるべきではない。例えば、本開示にしたがって用いられるモノクローナル抗体は、これらに限定されるものではないが、ハイブリドーマ法、組換えDNA法、ファージディスプレイ法、ヒト免疫グロブリン遺伝子座の全部または一部を含んだトランスジェニック動物を利用する方法を含む、様々な手法によって作成されてよく、モノクローナル抗体を作製するためのそのような方法および他の例示的な方法は、本明細書に記載されている。
本明細書でいう用語「モノクローナル抗体」は、実質的に均一な抗体の集団から得られる抗体のことをいう。すなわち、その集団を構成する個々の抗体は、生じ得る変異抗体(例えば、自然に生じる変異を含む変異抗体、またはモノクローナル抗体調製物の製造中に発生する変異抗体。そのような変異体は通常若干量存在している。)を除いて、同一でありおよび/または同じエピトープに結合する。異なる決定基(エピトープ)に対する異なる抗体を典型的に含むポリクローナル抗体調製物とは対照的に、モノクローナル抗体調製物の各モノクローナル抗体は、抗原上の単一の決定基に対するものである。したがって、修飾語「モノクローナル」は、実質的に均一な抗体の集団から得られるものである、という抗体の特徴を示し、何らかの特定の方法による抗体の製造を求めるものと解釈されるべきではない。例えば、本開示にしたがって用いられるモノクローナル抗体は、これらに限定されるものではないが、ハイブリドーマ法、組換えDNA法、ファージディスプレイ法、ヒト免疫グロブリン遺伝子座の全部または一部を含んだトランスジェニック動物を利用する方法を含む、様々な手法によって作成されてよく、モノクローナル抗体を作製するためのそのような方法および他の例示的な方法は、本明細書に記載されている。
抗体の作製方法
所望の結合活性を有する抗体を作製する方法は当業者において公知である。以下に、IL-6Rに結合する抗体(抗IL-6R抗体)を作製する方法が例示される。IL-6R以外の抗原に結合する抗体も下記の例示に準じて適宜作製され得る。単ドメイン抗体を作製する場合、免疫動物の違い等はあるが、下記の例示に準じて適宜作製され得る。
所望の結合活性を有する抗体を作製する方法は当業者において公知である。以下に、IL-6Rに結合する抗体(抗IL-6R抗体)を作製する方法が例示される。IL-6R以外の抗原に結合する抗体も下記の例示に準じて適宜作製され得る。単ドメイン抗体を作製する場合、免疫動物の違い等はあるが、下記の例示に準じて適宜作製され得る。
抗IL-6R抗体は、公知の手段を用いてポリクローナルまたはモノクローナル抗体として取得され得る。抗IL-6R抗体としては、哺乳動物由来のモノクローナル抗体が好適に作製され得る。哺乳動物由来のモノクローナル抗体には、ハイブリドーマにより産生されるもの、および遺伝子工学的手法により抗体遺伝子を含む発現ベクターで形質転換した宿主細胞によって産生されるもの等が含まれる。本願中に言及される抗体には、「ヒト化抗体」や「キメラ抗体」が含まれる。
モノクローナル抗体産生ハイブリドーマは、公知技術を使用することによって、例えば以下のように作製され得る。すなわち、IL-6Rタンパク質を感作抗原として使用して、通常の免疫方法にしたがって哺乳動物が免疫される。得られる免疫細胞が通常の細胞融合法によって公知の親細胞と融合される。次に、通常のスクリーニング法によって、モノクローナルな抗体産生細胞をスクリーニングすることによって抗IL-6R抗体を産生するハイブリドーマが選択され得る。
具体的には、モノクローナル抗体の作製は例えば以下に示すように行われる。まず、IL-6R遺伝子を発現することによって、抗体取得の感作抗原として使用されるIL-6Rタンパク質が取得され得る。すなわち、IL-6Rをコードする遺伝子配列を公知の発現ベクターに挿入することによって適当な宿主細胞が形質転換される。当該宿主細胞中または培養上清中から所望のヒトIL-6Rタンパク質が公知の方法で精製される。培養上清中から可溶型のIL-6Rを取得するためには、例えば、Mullbergら(J. Immunol. (1994) 152 (10), 4958-4968)によって記載されているような可溶型IL-6Rが発現される。また、精製した天然のIL-6Rタンパク質もまた同様に感作抗原として使用され得る。
哺乳動物に対する免疫に使用する感作抗原として当該精製IL-6Rタンパク質が使用できる。IL-6Rの部分ペプチドもまた感作抗原として使用できる。この際、当該部分ペプチドはヒトIL-6Rのアミノ酸配列より化学合成によっても取得され得る。また、IL-6R遺伝子の一部を発現ベクターに組込んで発現させることによっても取得され得る。さらにはタンパク質分解酵素を用いてIL-6Rタンパク質を分解することによっても取得され得るが、部分ペプチドとして用いるIL-6Rペプチドの領域および大きさは特に特別の態様に限定されない。感作抗原とするペプチドを構成するアミノ酸の数は少なくとも5以上、例えば6以上、或いは7以上であることが好ましい。より具体的には8~50、好ましくは10~30残基のペプチドが感作抗原として使用され得る。
また、IL-6Rタンパク質の所望の部分ポリペプチドやペプチドを異なるポリペプチドと融合した融合タンパク質が感作抗原として利用され得る。感作抗原として使用される融合タンパク質を製造するために、例えば、抗体のFc断片やペプチドタグなどが好適に利用され得る。融合タンパク質を発現するベクターは、所望の二種類又はそれ以上のポリペプチド断片をコードする遺伝子がインフレームで融合され、当該融合遺伝子が前記のように発現ベクターに挿入されることにより作製され得る。融合タンパク質の作製方法はMolecular Cloning 2nd ed. (Sambrook,J et al., Molecular Cloning 2nd ed., 9.47-9.58(1989)Cold Spring Harbor Lab. press)に記載されている。感作抗原として用いられるIL-6Rの取得方法及びそれを用いた免疫方法は、WO2003/000883、WO2004/022754、WO2006/006693等にも具体的に記載されている。
当該感作抗原で免疫される哺乳動物としては、特定の動物に限定されるものではないが、細胞融合に使用する親細胞との適合性を考慮して選択するのが好ましい。一般的にはげっ歯類の動物、例えば、マウス、ラット、ハムスター、あるいはウサギ、サル等が好適に使用される。単ドメイン抗体を取得する場合、ラクダ科動物または単ドメイン抗体を産生できる遺伝子が導入された遺伝子導入動物が好適に使用される。
公知の方法にしたがって上記の動物が感作抗原により免疫される。例えば、一般的な方法として、感作抗原が哺乳動物の腹腔内または皮下に投与によって投与されることにより免疫が実施される。具体的には、PBS(Phosphate-Buffered Saline)や生理食塩水等で適当な希釈倍率で希釈された感作抗原が、所望により通常のアジュバント、例えばフロイント完全アジュバントと混合され、乳化された後に、該感作抗原が哺乳動物に4から21日毎に数回投与される。また、感作抗原の免疫時には適当な担体が使用され得る。特に分子量の小さい部分ペプチドが感作抗原として用いられる場合には、アルブミン、キーホールリンペットヘモシアニン等の担体タンパク質と結合した該感作抗原ペプチドを免疫することが望ましい場合もある。
また、所望の抗体を産生するハイブリドーマは、DNA免疫を使用し、以下のようにしても作製され得る。DNA免疫とは、免疫動物中で抗原タンパク質をコードする遺伝子が発現され得るような態様で構築されたベクターDNAが投与された当該免疫動物中で、感作抗原が当該免疫動物の生体内で発現されることによって、免疫刺激が与えられる免疫方法である。蛋白質抗原が免疫動物に投与される一般的な免疫方法と比べて、DNA免疫には、次のような優位性が期待される。
-IL-6Rのような膜蛋白質の構造を維持して免疫刺激が与えられ得る
-免疫抗原を精製する必要が無い
-IL-6Rのような膜蛋白質の構造を維持して免疫刺激が与えられ得る
-免疫抗原を精製する必要が無い
DNA免疫によって本開示のモノクローナル抗体を得るために、まず、IL-6Rタンパク質を発現するDNAが免疫動物に投与される。IL-6RをコードするDNAは、PCRなどの公知の方法によって合成され得る。得られたDNAが適当な発現ベクターに挿入され、免疫動物に投与される。発現ベクターとしては、たとえばpcDNA3.1などの市販の発現ベクターが好適に利用され得る。ベクターを生体に投与する方法として、一般的に用いられている方法が利用され得る。たとえば、発現ベクターが吸着した金粒子が、gene gunで免疫動物個体の細胞内に導入されることによってDNA免疫が行われる。さらに、IL-6Rを認識する抗体の作製は国際公開WO 2003/104453に記載された方法を用いても作製され得る。
このように哺乳動物が免疫され、血清中におけるIL-6Rに結合する抗体力価の上昇が確認された後に、哺乳動物から免疫細胞が採取され、細胞融合に供される。好ましい免疫細胞としては、特に脾細胞が使用され得る。
前記免疫細胞と融合される細胞として、哺乳動物のミエローマ細胞が用いられる。ミエローマ細胞は、スクリーニングのための適当な選択マーカーを備えていることが好ましい。選択マーカーとは、特定の培養条件の下で生存できる(あるいはできない)形質を指す。選択マーカーには、ヒポキサンチン-グアニン-ホスホリボシルトランスフェラーゼ欠損(以下HGPRT欠損と省略する)、あるいはチミジンキナーゼ欠損(以下TK欠損と省略する)などが公知である。HGPRTやTKの欠損を有する細胞は、ヒポキサンチン-アミノプテリン-チミジン感受性(以下HAT感受性と省略する)を有する。HAT感受性の細胞はHAT選択培地中でDNA合成を行うことができず死滅するが、正常な細胞と融合すると正常細胞のサルベージ回路を利用してDNAの合成を継続することができるためHAT選択培地中でも増殖するようになる。
HGPRT欠損やTK欠損の細胞は、それぞれ6チオグアニン、8アザグアニン(以下8AGと省略する)、あるいは5'ブロモデオキシウリジンを含む培地で選択され得る。これらのピリミジンアナログをDNA中に取り込む正常な細胞は死滅する。他方、これらのピリミジンアナログを取り込めないこれらの酵素を欠損した細胞は、選択培地の中で生存することができる。この他G418耐性と呼ばれる選択マーカーは、ネオマイシン耐性遺伝子によって2-デオキシストレプタミン系抗生物質(ゲンタマイシン類似体)に対する耐性を与える。細胞融合に好適な種々のミエローマ細胞が公知である。
このようなミエローマ細胞として、例えば、P3(P3x63Ag8.653)(J. Immunol.(1979)123 (4), 1548-1550)、P3x63Ag8U.1(Current Topics in Microbiology and Immunology(1978)81, 1-7)、NS-1(C. Eur. J. Immunol.(1976)6 (7), 511-519)、MPC-11(Cell(1976)8 (3), 405-415)、SP2/0(Nature(1978)276 (5685), 269-270)、FO(J. Immunol. Methods(1980)35 (1-2), 1-21)、S194/5.XX0.BU.1(J. Exp. Med.(1978)148 (1), 313-323)、R210(Nature(1979)277 (5692), 131-133)等が好適に使用され得る。
基本的には公知の方法、たとえば、ケーラーとミルステインらの方法(Methods Enzymol.(1981)73, 3-46)等に準じて、前記免疫細胞とミエローマ細胞との細胞融合が行われる。
より具体的には、例えば細胞融合促進剤の存在下で通常の栄養培養液中で、前記細胞融合が実施され得る。融合促進剤としては、例えばポリエチレングリコール(PEG)、センダイウイルス(HVJ)等が使用され、更に融合効率を高めるために所望によりジメチルスルホキシド等の補助剤が添加されて使用される。
より具体的には、例えば細胞融合促進剤の存在下で通常の栄養培養液中で、前記細胞融合が実施され得る。融合促進剤としては、例えばポリエチレングリコール(PEG)、センダイウイルス(HVJ)等が使用され、更に融合効率を高めるために所望によりジメチルスルホキシド等の補助剤が添加されて使用される。
免疫細胞とミエローマ細胞との使用割合は任意に設定され得る。例えば、ミエローマ細胞に対して免疫細胞を1から10倍とするのが好ましい。前記細胞融合に用いる培養液としては、例えば、前記ミエローマ細胞株の増殖に好適なRPMI1640培養液、MEM培養液、その他、この種の細胞培養に用いられる通常の培養液が使用され、さらに、牛胎児血清(FCS)等の血清補液が好適に添加され得る。
細胞融合は、前記免疫細胞とミエローマ細胞との所定量を前記培養液中でよく混合し、予め37℃程度に加温されたPEG溶液(例えば平均分子量1000から6000程度)が通常30から60%(w/v)の濃度で添加される。混合液が緩やかに混合されることによって所望の融合細胞(ハイブリドーマ)が形成される。次いで、上記に挙げた適当な培養液が逐次添加され、遠心して上清を除去する操作を繰り返すことによりハイブリドーマの生育に好ましくない細胞融合剤等が除去され得る。
このようにして得られたハイブリドーマは、通常の選択培養液、例えばHAT培養液(ヒポキサンチン、アミノプテリンおよびチミジンを含む培養液)で培養することにより選択され得る。所望のハイブリドーマ以外の細胞(非融合細胞)が死滅するのに十分な時間(通常、係る十分な時間は数日から数週間である)上記HAT培養液を用いた培養が継続され得る。次いで、通常の限界希釈法によって、所望の抗体を産生するハイブリドーマのスクリーニングおよび単一クローニングが実施される。
このようにして得られたハイブリドーマは、細胞融合に用いられたミエローマが有する選択マーカーに応じた選択培養液を利用することによって選択され得る。例えばHGPRTやTKの欠損を有する細胞は、HAT培養液(ヒポキサンチン、アミノプテリンおよびチミジンを含む培養液)で培養することにより選択され得る。すなわち、HAT感受性のミエローマ細胞を細胞融合に用いた場合、HAT培養液中で、正常細胞との細胞融合に成功した細胞が選択的に増殖し得る。所望のハイブリドーマ以外の細胞(非融合細胞)が死滅するのに十分な時間、上記HAT培養液を用いた培養が継続される。具体的には、一般に、数日から数週間の培養によって、所望のハイブリドーマが選択され得る。次いで、通常の限界希釈法によって、所望の抗体を産生するハイブリドーマのスクリーニングおよび単一クローニングが実施され得る。
所望の抗体のスクリーニングおよび単一クローニングが、公知の抗原抗体反応に基づくスクリーニング方法によって好適に実施され得る。例えば、IL-6Rに結合するモノクローナル抗体は、細胞表面に発現したIL-6Rに結合することができる。このようなモノクローナル抗体は、たとえば、FACS(fluorescence activated cell sorting)によってスクリーニングされ得る。FACSは、蛍光抗体と接触させた細胞をレーザー光で解析し、個々の細胞が発する蛍光を測定することによって細胞表面に対する抗体の結合を測定することを可能にするシステムである。
FACSによって本開示のモノクローナル抗体を産生するハイブリドーマをスクリーニングするためには、まずIL-6Rを発現する細胞を調製する。スクリーニングのための好ましい細胞は、IL-6Rを強制発現させた哺乳動物細胞である。宿主細胞として使用した形質転換されていない哺乳動物細胞を対照として用いることによって、細胞表面のIL-6Rに対する抗体の結合活性が選択的に検出され得る。すなわち、宿主細胞に結合せず、IL-6R強制発現細胞に結合する抗体を産生するハイブリドーマを選択することによって、IL-6Rモノクローナル抗体を産生するハイブリドーマが取得され得る。
あるいは固定化したIL-6R発現細胞に対する抗体の結合活性がELISAの原理に基づいて評価され得る。たとえば、ELISAプレートのウェルにIL-6R発現細胞が固定化される。ハイブリドーマの培養上清をウェル内の固定化細胞に接触させ、固定化細胞に結合する抗体が検出される。モノクローナル抗体がマウス由来の場合、細胞に結合した抗体は、抗マウスイムノグロブリン抗体によって検出され得る。これらのスクリーニングによって選択された、抗原に対する結合能を有する所望の抗体を産生するハイブリドーマは、限界希釈法等によりクローニングされ得る。
このようにして作製されるモノクローナル抗体を産生するハイブリドーマは通常の培養液中で継代培養され得る。また、該ハイブリドーマは液体窒素中で長期にわたって保存され得る。
当該ハイブリドーマを通常の方法に従い培養し、その培養上清から所望のモノクローナル抗体が取得され得る。あるいはハイブリドーマをこれと適合性がある哺乳動物に投与して増殖せしめ、その腹水からモノクローナル抗体が取得され得る。前者の方法は、高純度の抗体を得るのに好適なものである。
当該ハイブリドーマ等の抗体産生細胞からクローニングされる抗体遺伝子によってコードされる抗体も好適に利用され得る。クローニングした抗体遺伝子を適当なベクターに組み込んで宿主に導入することによって、当該遺伝子によってコードされる抗体が発現する。抗体遺伝子の単離と、ベクターへの導入、そして宿主細胞の形質転換のための方法は例えば、Vandammeらによって既に確立されている(Eur.J. Biochem.(1990)192 (3), 767-775)。下記に述べるように組換え抗体の製造方法もまた公知である。
たとえば、抗IL-6R抗体を産生するハイブリドーマ細胞から、抗IL-6R抗体の可変領域(V領域)をコードするcDNAが取得される。そのために、通常、まずハイブリドーマから全RNAが抽出される。細胞からmRNAを抽出するための方法として、たとえば次のような方法を利用することができる。
-グアニジン超遠心法(Biochemistry (1979) 18 (24), 5294-5299)
-AGPC法(Anal. Biochem. (1987) 162 (1), 156-159)
-グアニジン超遠心法(Biochemistry (1979) 18 (24), 5294-5299)
-AGPC法(Anal. Biochem. (1987) 162 (1), 156-159)
抽出されたmRNAは、mRNA Purification Kit (GEヘルスケアバイオサイエンス製)等を使用して精製され得る。あるいは、QuickPrep mRNA Purification Kit (GEヘルスケアバイオサイエンス製)などのように、細胞から直接全mRNAを抽出するためのキットも市販されている。このようなキットを用いて、ハイブリドーマからmRNAが取得され得る。得られたmRNAから逆転写酵素を用いて抗体V領域をコードするcDNAが合成され得る。cDNAは、AMV Reverse Transcriptase First-strand cDNA Synthesis Kit(生化学工業社製)等によって合成され得る。また、cDNAの合成および増幅のために、SMART RACE cDNA 増幅キット(Clontech製)およびPCRを用いた5’-RACE法(Proc. Natl. Acad. Sci. USA (1988) 85 (23), 8998-9002、Nucleic Acids Res. (1989) 17 (8), 2919-2932)が適宜利用され得る。更にこうしたcDNAの合成の過程においてcDNAの両末端に後述する適切な制限酵素サイトが導入され得る。
得られたPCR産物から目的とするcDNA断片が精製され、次いでベクターDNAと連結される。このように組換えベクターが作製され、大腸菌等に導入されコロニーが選択された後に、該コロニーを形成した大腸菌から所望の組換えベクターが調製され得る。そして、該組換えベクターが目的とするcDNAの塩基配列を有しているか否かについて、公知の方法、例えば、ジデオキシヌクレオチドチェインターミネーション法等により確認される。
可変領域をコードする遺伝子を取得するためには、可変領域遺伝子増幅用のプライマーを使った5’-RACE法を利用するのが簡便である。まずハイブリドーマ細胞より抽出されたRNAを鋳型としてcDNAが合成され、5’-RACE cDNAライブラリが得られる。5’-RACE cDNAライブラリの合成にはSMART RACE cDNA 増幅キットなど市販のキットが適宜用いられる。
得られた5’-RACE cDNAライブラリを鋳型として、PCR法によって抗体遺伝子が増幅される。公知の抗体遺伝子配列をもとにマウス抗体遺伝子増幅用のプライマーがデザインされ得る。これらのプライマーは、イムノグロブリンのサブクラスごとに異なる塩基配列である。したがって、サブクラスは予めIso Stripマウスモノクローナル抗体アイソタイピングキット(ロシュ・ダイアグノスティックス)などの市販キットを用いて決定しておくことが望ましい。
具体的には、たとえばマウスIgGをコードする遺伝子の取得を目的とするときには、重鎖としてγ1、γ2a、γ2b、γ3、軽鎖としてκ鎖とλ鎖をコードする遺伝子の増幅が可能なプライマーが利用され得る。IgGの可変領域遺伝子を増幅するためには、一般に3'側のプライマーには可変領域に近い定常領域に相当する部分にアニールするプライマーが利用される。一方5'側のプライマーには、5’ RACE cDNAライブラリ作製キットに付属するプライマーが利用される。
こうして増幅されたPCR産物を利用して、重鎖と軽鎖の組み合せからなるイムノグロブリンが再構成され得る。再構成されたイムノグロブリンの、IL-6Rに対する結合活性を指標として、所望の抗体がスクリーニングされ得る。たとえばIL-6Rに対する抗体の取得を目的とするとき、抗体のIL-6Rに対する結合は、特異的であることがさらに好ましい。IL-6Rに結合する抗体は、たとえば次のようにしてスクリーニングされ得る;
(1)ハイブリドーマから得られたcDNAによってコードされるV領域を含む抗体をIL-6R発現細胞に接触させる工程、
(2)IL-6R発現細胞と抗体との結合を検出する工程、および
(3)IL-6R発現細胞に結合する抗体を選択する工程。
(1)ハイブリドーマから得られたcDNAによってコードされるV領域を含む抗体をIL-6R発現細胞に接触させる工程、
(2)IL-6R発現細胞と抗体との結合を検出する工程、および
(3)IL-6R発現細胞に結合する抗体を選択する工程。
抗体(単ドメイン抗体を含む)とIL-6R発現細胞との結合を検出する方法は公知である。具体的には、先に述べたFACSなどの手法によって、抗体とIL-6R発現細胞との結合が検出され得る。抗体の結合活性を評価するためにIL-6R発現細胞の固定標本が適宜利用され得る。
結合活性を指標とする抗体のスクリーニング方法として、ファージベクターを利用したパニング法も好適に用いられる。単ドメイン抗体をスクリーニングする場合でも、下記例示に準じて適宜スクリーニングされ得る。
ポリクローナルな抗体発現細胞群より抗体遺伝子を重鎖と軽鎖のサブクラスのライブラリとして取得した場合には、ファージベクターを利用したスクリーニング方法が有利である。重鎖と軽鎖の可変領域をコードする遺伝子は、適当なリンカー配列で連結することによってシングルチェインFv(scFv)を形成することができる。scFvをコードする遺伝子をファージベクターに挿入することにより、scFvを表面に発現するファージが取得され得る。このファージと所望の抗原との接触の後に、抗原に結合したファージを回収することによって、目的の結合活性を有するscFvをコードするDNAが回収され得る。この操作を必要に応じて繰り返すことにより、所望の結合活性を有するscFvが濃縮され得る。
ポリクローナルな抗体発現細胞群より抗体遺伝子を重鎖と軽鎖のサブクラスのライブラリとして取得した場合には、ファージベクターを利用したスクリーニング方法が有利である。重鎖と軽鎖の可変領域をコードする遺伝子は、適当なリンカー配列で連結することによってシングルチェインFv(scFv)を形成することができる。scFvをコードする遺伝子をファージベクターに挿入することにより、scFvを表面に発現するファージが取得され得る。このファージと所望の抗原との接触の後に、抗原に結合したファージを回収することによって、目的の結合活性を有するscFvをコードするDNAが回収され得る。この操作を必要に応じて繰り返すことにより、所望の結合活性を有するscFvが濃縮され得る。
目的とする抗IL-6R抗体のV領域をコードするcDNAが得られた後に、当該cDNAの両末端に挿入した制限酵素サイトを認識する制限酵素によって該cDNAが消化される。好ましい制限酵素は、抗体遺伝子を構成する塩基配列に出現する頻度が低い塩基配列を認識して消化する。更に1コピーの消化断片をベクターに正しい方向で挿入するためには、付着末端を与える制限酵素の挿入が好ましい。上記のように消化された抗IL-6R抗体のV領域をコードするcDNAを適当な発現ベクターに挿入することによって、抗体発現ベクターが取得され得る。このとき、抗体定常領域(C領域)をコードする遺伝子と、前記V領域をコードする遺伝子とがインフレームで融合されれば、キメラ抗体が取得される。ここで、キメラ抗体とは、定常領域と可変領域の由来が異なることをいう。したがって、マウス-ヒトなどの異種キメラ抗体に加え、ヒト-ヒト同種キメラ抗体も、本開示におけるキメラ抗体に含まれる。予め定常領域を有する発現ベクターに、前記V領域遺伝子を挿入することによって、キメラ抗体発現ベクターが構築され得る。具体的には、たとえば、所望の抗体定常領域(C領域)をコードするDNAを保持した発現ベクターの5’側に、前記V領域遺伝子を消化する制限酵素の制限酵素認識配列が適宜配置され得る。同じ組み合わせの制限酵素で消化された両者がインフレームで融合されることによって、キメラ抗体発現ベクターが構築される。
抗IL-6Rモノクローナル抗体を製造するために、抗体遺伝子が発現制御領域による制御の下で発現するように発現ベクターに組み込まれる。抗体を発現するための発現制御領域とは、例えば、エンハンサーやプロモーターを含む。また、発現した抗体が細胞外に分泌されるように、適切なシグナル配列がアミノ末端に付加され得る。例えば、シグナル配列として、アミノ酸配列MGWSCIILFLVATATGVHS(配列番号:18008)を有するペプチドが使用され得るが、これ以外にも適したシグナル配列が付加される。発現されたポリペプチドは上記配列のカルボキシル末端部分で切断され、切断されたポリペプチドが成熟ポリペプチドとして細胞外に分泌され得る。次いで、この発現ベクターによって適当な宿主細胞が形質転換されることによって、抗IL-6R抗体をコードするDNAを発現する組換え細胞が取得され得る。
ポリヌクレオチド(核酸)
本明細書でいい換え可能に使用される「ポリヌクレオチド」または「核酸」は、任意の長さのヌクレオチドのポリマーのことをいい、DNAおよびRNAを含む。ヌクレオチドは、デオキシリボヌクレオチド、リボヌクレオチド、修飾ヌクレオチドもしくは塩基、および/またはそれらのアナログ、またはDNAもしくはRNAポリメラーゼによってまたは合成反応によってポリマーに組み込まれ得る任意の物質であり得る。ポリヌクレオチドは、メチル化ヌクレオチドおよびそれらのアナログなどの修飾ヌクレオチドを含み得る。ヌクレオチドの配列に、非ヌクレオチド成分が割り込んでいてもよい。ポリヌクレオチドは、標識へのコンジュゲーションなどの、合成後になされる修飾を含み得る。他のタイプの修飾は、例えば、「キャップ」、1つまたは複数の天然に存在するヌクレオチドとアナログとの置換、ヌクレオチド間修飾、例えば、非荷電連結(例えば、メチルホスホネート、ホスホトリエステル、ホスホロアミド酸、カルバメート等)および荷電連結(例えば、ホスホロチオエート、ホスホロジチオエート等)を伴うもの、例えばタンパク質(例えば、ヌクレアーゼ、毒素、抗体、シグナルペプチド、ポリ-L-リジン等)などのペンダント部分を含むもの、インターカレート剤(例えば、アクリジン、ソラレン等)を伴うもの、キレート剤(例えば、金属、放射性金属、ホウ素、酸化金属等)を含むもの、アルキル化剤を含むもの、修飾連結(例えば、アルファアノマー核酸等)や非修飾形態のポリヌクレオチドを伴うものを含む。さらに、通常糖に存在する任意のヒドロキシル基は、例えば、ホスホネート基、ホスフェート基によって置換され得、標準的な保護基によって保護され得、もしくはさらなるヌクレオチドへのさらなる連結を生成するよう活性化され得、または固体もしくは半固体支持体にコンジュゲートされ得る。5’および3’末端のOHは、リン酸化またはアミンもしくは1~20炭素原子の有機キャップ基部分で置換され得る。他のヒドロキシルもまた、標準的な保護基に誘導体化され得る。ポリヌクレオチドはまた、例えば以下のものを含む、当技術分野で一般に公知となっているリボースまたはデオキシリボース糖の類似形態を含み得る:2'-O-メチル-、2'-O-アリル-、2'-フルオロ-、または2'-アジド-リボース、炭素環式糖アナログ、α-アノマー糖、アラビノースまたはキシロースまたはリキソースなどのエピマー糖、ピラノース糖、フラノース糖、セドヘプツロース、非環式アナログ、およびメチルリボシドなどの塩基性ヌクレオシドアナログ。1つまたは複数のホスホジエステル結合は、代替の連結基によって置き換えられ得る。これらの代替の連結基は、これらに限定されるものではないが、ホスフェートが以下のものによって置き換えられている態様を含む:P(O)S(「チオエート」)、P(S)S(「ジチオエート」)、(O)NR2(「アミデート」)、P(O)R、P(O)OR'、CO、またはCH2(「ホルムアセタール」)、ここで、各RまたはR'は独立してH、または、任意でエーテル(-O-)連結、アリール、アルケニル、シクロアルキル、シクロアルケニル、もしくはアラルジルを含む置換もしくは非置換アルキル(1~20C)である。ポリヌクレオチド中のすべての連結が同一である必要はない。上記の説明は、RNAおよびDNAを含む本明細書で言及されるすべてのポリヌクレオチドに適用される。
本明細書でいい換え可能に使用される「ポリヌクレオチド」または「核酸」は、任意の長さのヌクレオチドのポリマーのことをいい、DNAおよびRNAを含む。ヌクレオチドは、デオキシリボヌクレオチド、リボヌクレオチド、修飾ヌクレオチドもしくは塩基、および/またはそれらのアナログ、またはDNAもしくはRNAポリメラーゼによってまたは合成反応によってポリマーに組み込まれ得る任意の物質であり得る。ポリヌクレオチドは、メチル化ヌクレオチドおよびそれらのアナログなどの修飾ヌクレオチドを含み得る。ヌクレオチドの配列に、非ヌクレオチド成分が割り込んでいてもよい。ポリヌクレオチドは、標識へのコンジュゲーションなどの、合成後になされる修飾を含み得る。他のタイプの修飾は、例えば、「キャップ」、1つまたは複数の天然に存在するヌクレオチドとアナログとの置換、ヌクレオチド間修飾、例えば、非荷電連結(例えば、メチルホスホネート、ホスホトリエステル、ホスホロアミド酸、カルバメート等)および荷電連結(例えば、ホスホロチオエート、ホスホロジチオエート等)を伴うもの、例えばタンパク質(例えば、ヌクレアーゼ、毒素、抗体、シグナルペプチド、ポリ-L-リジン等)などのペンダント部分を含むもの、インターカレート剤(例えば、アクリジン、ソラレン等)を伴うもの、キレート剤(例えば、金属、放射性金属、ホウ素、酸化金属等)を含むもの、アルキル化剤を含むもの、修飾連結(例えば、アルファアノマー核酸等)や非修飾形態のポリヌクレオチドを伴うものを含む。さらに、通常糖に存在する任意のヒドロキシル基は、例えば、ホスホネート基、ホスフェート基によって置換され得、標準的な保護基によって保護され得、もしくはさらなるヌクレオチドへのさらなる連結を生成するよう活性化され得、または固体もしくは半固体支持体にコンジュゲートされ得る。5’および3’末端のOHは、リン酸化またはアミンもしくは1~20炭素原子の有機キャップ基部分で置換され得る。他のヒドロキシルもまた、標準的な保護基に誘導体化され得る。ポリヌクレオチドはまた、例えば以下のものを含む、当技術分野で一般に公知となっているリボースまたはデオキシリボース糖の類似形態を含み得る:2'-O-メチル-、2'-O-アリル-、2'-フルオロ-、または2'-アジド-リボース、炭素環式糖アナログ、α-アノマー糖、アラビノースまたはキシロースまたはリキソースなどのエピマー糖、ピラノース糖、フラノース糖、セドヘプツロース、非環式アナログ、およびメチルリボシドなどの塩基性ヌクレオシドアナログ。1つまたは複数のホスホジエステル結合は、代替の連結基によって置き換えられ得る。これらの代替の連結基は、これらに限定されるものではないが、ホスフェートが以下のものによって置き換えられている態様を含む:P(O)S(「チオエート」)、P(S)S(「ジチオエート」)、(O)NR2(「アミデート」)、P(O)R、P(O)OR'、CO、またはCH2(「ホルムアセタール」)、ここで、各RまたはR'は独立してH、または、任意でエーテル(-O-)連結、アリール、アルケニル、シクロアルキル、シクロアルケニル、もしくはアラルジルを含む置換もしくは非置換アルキル(1~20C)である。ポリヌクレオチド中のすべての連結が同一である必要はない。上記の説明は、RNAおよびDNAを含む本明細書で言及されるすべてのポリヌクレオチドに適用される。
ベクター
本明細書で用いられる用語「ベクター」は、それが連結されたもう1つの核酸を増やすことができる、核酸分子のことをいう。この用語は、自己複製核酸構造としてのベクター、および、それが導入された宿主細胞のゲノム中に組み入れられるベクターを含む。あるベクターは、自身が動作的に連結された核酸の、発現をもたらすことができる。そのようなベクターは、本明細書では「発現ベクター」とも称される。
本明細書で用いられる用語「ベクター」は、それが連結されたもう1つの核酸を増やすことができる、核酸分子のことをいう。この用語は、自己複製核酸構造としてのベクター、および、それが導入された宿主細胞のゲノム中に組み入れられるベクターを含む。あるベクターは、自身が動作的に連結された核酸の、発現をもたらすことができる。そのようなベクターは、本明細書では「発現ベクター」とも称される。
宿主細胞等
用語「宿主細胞」、「宿主細胞株」、および「宿主細胞培養物」は、相互に交換可能に用いられ、外来核酸を導入された細胞(そのような細胞の子孫を含む)のことをいう。宿主細胞は「形質転換体」および「形質転換細胞」を含み、これには初代の形質転換細胞および継代数によらずその細胞に由来する子孫を含む。子孫は、親細胞と核酸の内容において完全に同一でなくてもよく、変異を含んでいてもよい。オリジナルの形質転換細胞がスクリーニングされたまたは選択された際に用いられたものと同じ機能または生物学的活性を有する変異体子孫も、本明細書では含まれる。
用語「宿主細胞」、「宿主細胞株」、および「宿主細胞培養物」は、相互に交換可能に用いられ、外来核酸を導入された細胞(そのような細胞の子孫を含む)のことをいう。宿主細胞は「形質転換体」および「形質転換細胞」を含み、これには初代の形質転換細胞および継代数によらずその細胞に由来する子孫を含む。子孫は、親細胞と核酸の内容において完全に同一でなくてもよく、変異を含んでいてもよい。オリジナルの形質転換細胞がスクリーニングされたまたは選択された際に用いられたものと同じ機能または生物学的活性を有する変異体子孫も、本明細書では含まれる。
プロテアーゼ切断配列を含むポリペプチド
本開示の一側面は、プロテアーゼ切断配列を含むポリペプチドに関する。
本開示の別の側面はまた、配列番号:5~17201から選ばれる配列のN末端4番目のアミノ酸から15番目のアミノ酸までの配列、配列番号:5~17201から選ばれる配列のN末端4番目のアミノ酸から13番目のアミノ酸までの配列、配列番号:5~17201から選ばれる配列のN末端6番目のアミノ酸から13番目のアミノ酸までの配列、配列番号:17202~17993から選ばれる配列のN末端1番目のアミノ酸から12番目のアミノ酸までの配列、配列番号:17202~17993から選ばれる配列のN末端3番目のアミノ酸から12番目のアミノ酸までの配列、配列番号:17202~17993から選ばれる配列のN末端3番目のアミノ酸から11番目のアミノ酸までの配列、配列番号:17202~17993から選ばれる配列のN末端3番目のアミノ酸から10番目のアミノ酸までの配列、配列番号:17994~18003から選ばれる配列のN末端3番目のアミノ酸から14番目のアミノ酸までの配列、配列番号:17994~18003から選ばれる配列のN末端5番目のアミノ酸から12番目のアミノ酸までの配列、配列番号:17994~18003から選ばれる配列のN末端5番目のアミノ酸から10番目のアミノ酸までの配列、配列番号:5~18003のいずれかで示される配列から選ばれる少なくとも一つの配列を含むポリペプチドに関する。
本開示の別の側面はまた、N末端から「下記グループAから選ばれる配列-下記グループBから選ばれる配列」の順で構成された配列のいずれかを含むポリペプチドに関する:
(グループA)
配列番号:5~17201から選ばれる配列のN末端1番目のアミノ酸から9番目のアミノ酸までの配列、
配列番号:5~17201から選ばれる配列のN末端2番目のアミノ酸から9番目のアミノ酸までの配列、
配列番号:5~17201から選ばれる配列のN末端3番目のアミノ酸から9番目のアミノ酸までの配列、
配列番号:5~17201から選ばれる配列のN末端4番目のアミノ酸から9番目のアミノ酸までの配列、
配列番号:5~17201から選ばれる配列のN末端5番目のアミノ酸から9番目のアミノ酸までの配列、
配列番号:5~17201から選ばれる配列のN末端6番目のアミノ酸から9番目のアミノ酸までの配列、
配列番号:5~17201から選ばれる配列のN末端7番目のアミノ酸から9番目のアミノ酸までの配列、
配列番号:5~17201から選ばれる配列のN末端8番目のアミノ酸から9番目のアミノ酸までの配列、
配列番号:17202~17993から選ばれる配列のN末端1番目のアミノ酸から6番目のアミノ酸までの配列、
配列番号:17202~17993から選ばれる配列のN末端2番目のアミノ酸から6番目のアミノ酸までの配列、
配列番号:17202~17993から選ばれる配列のN末端3番目のアミノ酸から6番目のアミノ酸までの配列、
配列番号:17202~17993から選ばれる配列のN末端4番目のアミノ酸から6番目のアミノ酸までの配列、
配列番号:17202~17993から選ばれる配列のN末端5番目のアミノ酸から6番目のアミノ酸までの配列、
配列番号:17994~18003から選ばれる配列のN末端1番目のアミノ酸から8番目のアミノ酸までの配列、
配列番号:17994~18003から選ばれる配列のN末端2番目のアミノ酸から8番目のアミノ酸までの配列、
配列番号:17994~18003から選ばれる配列のN末端3番目のアミノ酸から8番目のアミノ酸までの配列、
配列番号:17994~18003から選ばれる配列のN末端4番目のアミノ酸から8番目のアミノ酸までの配列、
配列番号:17994~18003から選ばれる配列のN末端5番目のアミノ酸から8番目のアミノ酸までの配列、
配列番号:17994~18003から選ばれる配列のN末端6番目のアミノ酸から8番目のアミノ酸までの配列、
配列番号:17994~18003から選ばれる配列のN末端7番目のアミノ酸から8番目のアミノ酸までの配列;
(グループB)
配列番号:5~17201から選ばれる配列のN末端10番目のアミノ酸から15番目のアミノ酸までの配列、
配列番号:5~17201から選ばれる配列のN末端10番目のアミノ酸から14番目のアミノ酸までの配列、
配列番号:5~17201から選ばれる配列のN末端10番目のアミノ酸から13番目のアミノ酸までの配列、
配列番号:5~17201から選ばれる配列のN末端10番目のアミノ酸から12番目のアミノ酸までの配列、
配列番号:5~17201から選ばれる配列のN末端10番目のアミノ酸から11番目のアミノ酸までの配列、
配列番号:17202~17993から選ばれる配列のN末端7番目のアミノ酸から15番目のアミノ酸までの配列、
配列番号:17202~17993から選ばれる配列のN末端7番目のアミノ酸から14番目のアミノ酸までの配列、
配列番号:17202~17993から選ばれる配列のN末端7番目のアミノ酸から13番目のアミノ酸までの配列、
配列番号:17202~17993から選ばれる配列のN末端7番目のアミノ酸から12番目のアミノ酸までの配列、
配列番号:17202~17993から選ばれる配列のN末端7番目のアミノ酸から11番目のアミノ酸までの配列、
配列番号:17202~17993から選ばれる配列のN末端7番目のアミノ酸から10番目のアミノ酸までの配列、
配列番号:17202~17993から選ばれる配列のN末端7番目のアミノ酸から9番目のアミノ酸までの配列、
配列番号:17202~17993から選ばれる配列のN末端7番目のアミノ酸から8番目のアミノ酸までの配列、
配列番号:17994~18003から選ばれる配列のN末端9番目のアミノ酸から15番目のアミノ酸までの配列、
配列番号:17994~18003から選ばれる配列のN末端9番目のアミノ酸から14番目のアミノ酸までの配列、
配列番号:17994~18003から選ばれる配列のN末端9番目のアミノ酸から13番目のアミノ酸までの配列、
配列番号:17994~18003から選ばれる配列のN末端9番目のアミノ酸から12番目のアミノ酸までの配列、
配列番号:17994~18003から選ばれる配列のN末端9番目のアミノ酸から11番目のアミノ酸までの配列、
配列番号:17994~18003から選ばれる配列のN末端9番目のアミノ酸から10番目のアミノ酸までの配列。
本開示の一側面は、プロテアーゼ切断配列を含むポリペプチドに関する。
本開示の別の側面はまた、配列番号:5~17201から選ばれる配列のN末端4番目のアミノ酸から15番目のアミノ酸までの配列、配列番号:5~17201から選ばれる配列のN末端4番目のアミノ酸から13番目のアミノ酸までの配列、配列番号:5~17201から選ばれる配列のN末端6番目のアミノ酸から13番目のアミノ酸までの配列、配列番号:17202~17993から選ばれる配列のN末端1番目のアミノ酸から12番目のアミノ酸までの配列、配列番号:17202~17993から選ばれる配列のN末端3番目のアミノ酸から12番目のアミノ酸までの配列、配列番号:17202~17993から選ばれる配列のN末端3番目のアミノ酸から11番目のアミノ酸までの配列、配列番号:17202~17993から選ばれる配列のN末端3番目のアミノ酸から10番目のアミノ酸までの配列、配列番号:17994~18003から選ばれる配列のN末端3番目のアミノ酸から14番目のアミノ酸までの配列、配列番号:17994~18003から選ばれる配列のN末端5番目のアミノ酸から12番目のアミノ酸までの配列、配列番号:17994~18003から選ばれる配列のN末端5番目のアミノ酸から10番目のアミノ酸までの配列、配列番号:5~18003のいずれかで示される配列から選ばれる少なくとも一つの配列を含むポリペプチドに関する。
本開示の別の側面はまた、N末端から「下記グループAから選ばれる配列-下記グループBから選ばれる配列」の順で構成された配列のいずれかを含むポリペプチドに関する:
(グループA)
配列番号:5~17201から選ばれる配列のN末端1番目のアミノ酸から9番目のアミノ酸までの配列、
配列番号:5~17201から選ばれる配列のN末端2番目のアミノ酸から9番目のアミノ酸までの配列、
配列番号:5~17201から選ばれる配列のN末端3番目のアミノ酸から9番目のアミノ酸までの配列、
配列番号:5~17201から選ばれる配列のN末端4番目のアミノ酸から9番目のアミノ酸までの配列、
配列番号:5~17201から選ばれる配列のN末端5番目のアミノ酸から9番目のアミノ酸までの配列、
配列番号:5~17201から選ばれる配列のN末端6番目のアミノ酸から9番目のアミノ酸までの配列、
配列番号:5~17201から選ばれる配列のN末端7番目のアミノ酸から9番目のアミノ酸までの配列、
配列番号:5~17201から選ばれる配列のN末端8番目のアミノ酸から9番目のアミノ酸までの配列、
配列番号:17202~17993から選ばれる配列のN末端1番目のアミノ酸から6番目のアミノ酸までの配列、
配列番号:17202~17993から選ばれる配列のN末端2番目のアミノ酸から6番目のアミノ酸までの配列、
配列番号:17202~17993から選ばれる配列のN末端3番目のアミノ酸から6番目のアミノ酸までの配列、
配列番号:17202~17993から選ばれる配列のN末端4番目のアミノ酸から6番目のアミノ酸までの配列、
配列番号:17202~17993から選ばれる配列のN末端5番目のアミノ酸から6番目のアミノ酸までの配列、
配列番号:17994~18003から選ばれる配列のN末端1番目のアミノ酸から8番目のアミノ酸までの配列、
配列番号:17994~18003から選ばれる配列のN末端2番目のアミノ酸から8番目のアミノ酸までの配列、
配列番号:17994~18003から選ばれる配列のN末端3番目のアミノ酸から8番目のアミノ酸までの配列、
配列番号:17994~18003から選ばれる配列のN末端4番目のアミノ酸から8番目のアミノ酸までの配列、
配列番号:17994~18003から選ばれる配列のN末端5番目のアミノ酸から8番目のアミノ酸までの配列、
配列番号:17994~18003から選ばれる配列のN末端6番目のアミノ酸から8番目のアミノ酸までの配列、
配列番号:17994~18003から選ばれる配列のN末端7番目のアミノ酸から8番目のアミノ酸までの配列;
(グループB)
配列番号:5~17201から選ばれる配列のN末端10番目のアミノ酸から15番目のアミノ酸までの配列、
配列番号:5~17201から選ばれる配列のN末端10番目のアミノ酸から14番目のアミノ酸までの配列、
配列番号:5~17201から選ばれる配列のN末端10番目のアミノ酸から13番目のアミノ酸までの配列、
配列番号:5~17201から選ばれる配列のN末端10番目のアミノ酸から12番目のアミノ酸までの配列、
配列番号:5~17201から選ばれる配列のN末端10番目のアミノ酸から11番目のアミノ酸までの配列、
配列番号:17202~17993から選ばれる配列のN末端7番目のアミノ酸から15番目のアミノ酸までの配列、
配列番号:17202~17993から選ばれる配列のN末端7番目のアミノ酸から14番目のアミノ酸までの配列、
配列番号:17202~17993から選ばれる配列のN末端7番目のアミノ酸から13番目のアミノ酸までの配列、
配列番号:17202~17993から選ばれる配列のN末端7番目のアミノ酸から12番目のアミノ酸までの配列、
配列番号:17202~17993から選ばれる配列のN末端7番目のアミノ酸から11番目のアミノ酸までの配列、
配列番号:17202~17993から選ばれる配列のN末端7番目のアミノ酸から10番目のアミノ酸までの配列、
配列番号:17202~17993から選ばれる配列のN末端7番目のアミノ酸から9番目のアミノ酸までの配列、
配列番号:17202~17993から選ばれる配列のN末端7番目のアミノ酸から8番目のアミノ酸までの配列、
配列番号:17994~18003から選ばれる配列のN末端9番目のアミノ酸から15番目のアミノ酸までの配列、
配列番号:17994~18003から選ばれる配列のN末端9番目のアミノ酸から14番目のアミノ酸までの配列、
配列番号:17994~18003から選ばれる配列のN末端9番目のアミノ酸から13番目のアミノ酸までの配列、
配列番号:17994~18003から選ばれる配列のN末端9番目のアミノ酸から12番目のアミノ酸までの配列、
配列番号:17994~18003から選ばれる配列のN末端9番目のアミノ酸から11番目のアミノ酸までの配列、
配列番号:17994~18003から選ばれる配列のN末端9番目のアミノ酸から10番目のアミノ酸までの配列。
本開示のポリペプチドのある実施態様では、配列番号:5~17201から選ばれる配列のN末端4番目のアミノ酸から15番目のアミノ酸までの配列、配列番号:5~17201から選ばれる配列のN末端4番目のアミノ酸から13番目のアミノ酸までの配列、配列番号:5~17201から選ばれる配列のN末端6番目のアミノ酸から13番目のアミノ酸までの配列、配列番号:17202~17993から選ばれる配列のN末端1番目のアミノ酸から12番目のアミノ酸までの配列、配列番号:17202~17993から選ばれる配列のN末端3番目のアミノ酸から12番目のアミノ酸までの配列、配列番号:17202~17993から選ばれる配列のN末端3番目のアミノ酸から11番目のアミノ酸までの配列、配列番号:17202~17993から選ばれる配列のN末端3番目のアミノ酸から10番目のアミノ酸までの配列、配列番号:17994~18003から選ばれる配列のN末端3番目のアミノ酸から14番目のアミノ酸までの配列、配列番号:17994~18003から選ばれる配列のN末端5番目のアミノ酸から12番目のアミノ酸までの配列、配列番号:17994~18003から選ばれる配列のN末端5番目のアミノ酸から10番目のアミノ酸までの配列、配列番号:5~18003のいずれかで示される配列から選ばれる少なくとも一つの配列がポリペプチドに含まれ、当該ポリペプチド中の前記配列は、プロテアーゼにより切断可能である、即ち、前記配列はポリペプチド中にてプロテアーゼ切断配列として機能する。
本開示のポリペプチドのある実施態様ではまた、N末端から「下記グループAから選ばれる配列-下記グループBから選ばれる配列」の順で構成された配列のいずれかがポリペプチドに含まれ、当該ポリペプチド中の前記配列は、プロテアーゼにより切断可能である、即ち、前記配列はポリペプチド中にてプロテアーゼ切断配列として機能する:
(グループA)
配列番号:5~17201から選ばれる配列のN末端1番目のアミノ酸から9番目のアミノ酸までの配列、
配列番号:5~17201から選ばれる配列のN末端2番目のアミノ酸から9番目のアミノ酸までの配列、
配列番号:5~17201から選ばれる配列のN末端3番目のアミノ酸から9番目のアミノ酸までの配列、
配列番号:5~17201から選ばれる配列のN末端4番目のアミノ酸から9番目のアミノ酸までの配列、
配列番号:5~17201から選ばれる配列のN末端5番目のアミノ酸から9番目のアミノ酸までの配列、
配列番号:5~17201から選ばれる配列のN末端6番目のアミノ酸から9番目のアミノ酸までの配列、
配列番号:5~17201から選ばれる配列のN末端7番目のアミノ酸から9番目のアミノ酸までの配列、
配列番号:5~17201から選ばれる配列のN末端8番目のアミノ酸から9番目のアミノ酸までの配列、
配列番号:17202~17993から選ばれる配列のN末端1番目のアミノ酸から6番目のアミノ酸までの配列、
配列番号:17202~17993から選ばれる配列のN末端2番目のアミノ酸から6番目のアミノ酸までの配列、
配列番号:17202~17993から選ばれる配列のN末端3番目のアミノ酸から6番目のアミノ酸までの配列、
配列番号:17202~17993から選ばれる配列のN末端4番目のアミノ酸から6番目のアミノ酸までの配列、
配列番号:17202~17993から選ばれる配列のN末端5番目のアミノ酸から6番目のアミノ酸までの配列、
配列番号:17994~18003から選ばれる配列のN末端1番目のアミノ酸から8番目のアミノ酸までの配列、
配列番号:17994~18003から選ばれる配列のN末端2番目のアミノ酸から8番目のアミノ酸までの配列、
配列番号:17994~18003から選ばれる配列のN末端3番目のアミノ酸から8番目のアミノ酸までの配列、
配列番号:17994~18003から選ばれる配列のN末端4番目のアミノ酸から8番目のアミノ酸までの配列、
配列番号:17994~18003から選ばれる配列のN末端5番目のアミノ酸から8番目のアミノ酸までの配列、
配列番号:17994~18003から選ばれる配列のN末端6番目のアミノ酸から8番目のアミノ酸までの配列、
配列番号:17994~18003から選ばれる配列のN末端7番目のアミノ酸から8番目のアミノ酸までの配列;
(グループB)
配列番号:5~17201から選ばれる配列のN末端10番目のアミノ酸から15番目のアミノ酸までの配列、
配列番号:5~17201から選ばれる配列のN末端10番目のアミノ酸から14番目のアミノ酸までの配列、
配列番号:5~17201から選ばれる配列のN末端10番目のアミノ酸から13番目のアミノ酸までの配列、
配列番号:5~17201から選ばれる配列のN末端10番目のアミノ酸から12番目のアミノ酸までの配列、
配列番号:5~17201から選ばれる配列のN末端10番目のアミノ酸から11番目のアミノ酸までの配列、
配列番号:17202~17993から選ばれる配列のN末端7番目のアミノ酸から15番目のアミノ酸までの配列、
配列番号:17202~17993から選ばれる配列のN末端7番目のアミノ酸から14番目のアミノ酸までの配列、
配列番号:17202~17993から選ばれる配列のN末端7番目のアミノ酸から13番目のアミノ酸までの配列、
配列番号:17202~17993から選ばれる配列のN末端7番目のアミノ酸から12番目のアミノ酸までの配列、
配列番号:17202~17993から選ばれる配列のN末端7番目のアミノ酸から11番目のアミノ酸までの配列、
配列番号:17202~17993から選ばれる配列のN末端7番目のアミノ酸から10番目のアミノ酸までの配列、
配列番号:17202~17993から選ばれる配列のN末端7番目のアミノ酸から9番目のアミノ酸までの配列、
配列番号:17202~17993から選ばれる配列のN末端7番目のアミノ酸から8番目のアミノ酸までの配列、
配列番号:17994~18003から選ばれる配列のN末端9番目のアミノ酸から15番目のアミノ酸までの配列、
配列番号:17994~18003から選ばれる配列のN末端9番目のアミノ酸から14番目のアミノ酸までの配列、
配列番号:17994~18003から選ばれる配列のN末端9番目のアミノ酸から13番目のアミノ酸までの配列、
配列番号:17994~18003から選ばれる配列のN末端9番目のアミノ酸から12番目のアミノ酸までの配列、
配列番号:17994~18003から選ばれる配列のN末端9番目のアミノ酸から11番目のアミノ酸までの配列、
配列番号:17994~18003から選ばれる配列のN末端9番目のアミノ酸から10番目のアミノ酸までの配列。
本開示のポリペプチドのある実施態様ではまた、N末端から「下記グループAから選ばれる配列-下記グループBから選ばれる配列」の順で構成された配列のいずれかがポリペプチドに含まれ、当該ポリペプチド中の前記配列は、プロテアーゼにより切断可能である、即ち、前記配列はポリペプチド中にてプロテアーゼ切断配列として機能する:
(グループA)
配列番号:5~17201から選ばれる配列のN末端1番目のアミノ酸から9番目のアミノ酸までの配列、
配列番号:5~17201から選ばれる配列のN末端2番目のアミノ酸から9番目のアミノ酸までの配列、
配列番号:5~17201から選ばれる配列のN末端3番目のアミノ酸から9番目のアミノ酸までの配列、
配列番号:5~17201から選ばれる配列のN末端4番目のアミノ酸から9番目のアミノ酸までの配列、
配列番号:5~17201から選ばれる配列のN末端5番目のアミノ酸から9番目のアミノ酸までの配列、
配列番号:5~17201から選ばれる配列のN末端6番目のアミノ酸から9番目のアミノ酸までの配列、
配列番号:5~17201から選ばれる配列のN末端7番目のアミノ酸から9番目のアミノ酸までの配列、
配列番号:5~17201から選ばれる配列のN末端8番目のアミノ酸から9番目のアミノ酸までの配列、
配列番号:17202~17993から選ばれる配列のN末端1番目のアミノ酸から6番目のアミノ酸までの配列、
配列番号:17202~17993から選ばれる配列のN末端2番目のアミノ酸から6番目のアミノ酸までの配列、
配列番号:17202~17993から選ばれる配列のN末端3番目のアミノ酸から6番目のアミノ酸までの配列、
配列番号:17202~17993から選ばれる配列のN末端4番目のアミノ酸から6番目のアミノ酸までの配列、
配列番号:17202~17993から選ばれる配列のN末端5番目のアミノ酸から6番目のアミノ酸までの配列、
配列番号:17994~18003から選ばれる配列のN末端1番目のアミノ酸から8番目のアミノ酸までの配列、
配列番号:17994~18003から選ばれる配列のN末端2番目のアミノ酸から8番目のアミノ酸までの配列、
配列番号:17994~18003から選ばれる配列のN末端3番目のアミノ酸から8番目のアミノ酸までの配列、
配列番号:17994~18003から選ばれる配列のN末端4番目のアミノ酸から8番目のアミノ酸までの配列、
配列番号:17994~18003から選ばれる配列のN末端5番目のアミノ酸から8番目のアミノ酸までの配列、
配列番号:17994~18003から選ばれる配列のN末端6番目のアミノ酸から8番目のアミノ酸までの配列、
配列番号:17994~18003から選ばれる配列のN末端7番目のアミノ酸から8番目のアミノ酸までの配列;
(グループB)
配列番号:5~17201から選ばれる配列のN末端10番目のアミノ酸から15番目のアミノ酸までの配列、
配列番号:5~17201から選ばれる配列のN末端10番目のアミノ酸から14番目のアミノ酸までの配列、
配列番号:5~17201から選ばれる配列のN末端10番目のアミノ酸から13番目のアミノ酸までの配列、
配列番号:5~17201から選ばれる配列のN末端10番目のアミノ酸から12番目のアミノ酸までの配列、
配列番号:5~17201から選ばれる配列のN末端10番目のアミノ酸から11番目のアミノ酸までの配列、
配列番号:17202~17993から選ばれる配列のN末端7番目のアミノ酸から15番目のアミノ酸までの配列、
配列番号:17202~17993から選ばれる配列のN末端7番目のアミノ酸から14番目のアミノ酸までの配列、
配列番号:17202~17993から選ばれる配列のN末端7番目のアミノ酸から13番目のアミノ酸までの配列、
配列番号:17202~17993から選ばれる配列のN末端7番目のアミノ酸から12番目のアミノ酸までの配列、
配列番号:17202~17993から選ばれる配列のN末端7番目のアミノ酸から11番目のアミノ酸までの配列、
配列番号:17202~17993から選ばれる配列のN末端7番目のアミノ酸から10番目のアミノ酸までの配列、
配列番号:17202~17993から選ばれる配列のN末端7番目のアミノ酸から9番目のアミノ酸までの配列、
配列番号:17202~17993から選ばれる配列のN末端7番目のアミノ酸から8番目のアミノ酸までの配列、
配列番号:17994~18003から選ばれる配列のN末端9番目のアミノ酸から15番目のアミノ酸までの配列、
配列番号:17994~18003から選ばれる配列のN末端9番目のアミノ酸から14番目のアミノ酸までの配列、
配列番号:17994~18003から選ばれる配列のN末端9番目のアミノ酸から13番目のアミノ酸までの配列、
配列番号:17994~18003から選ばれる配列のN末端9番目のアミノ酸から12番目のアミノ酸までの配列、
配列番号:17994~18003から選ばれる配列のN末端9番目のアミノ酸から11番目のアミノ酸までの配列、
配列番号:17994~18003から選ばれる配列のN末端9番目のアミノ酸から10番目のアミノ酸までの配列。
本開示のポリペプチドのある態様において、プロテアーゼ切断配列のどちらか一端または両端に、可動リンカーを更に付加している。プロテアーゼ切断配列の一端の可動リンカーを第一可動リンカーと呼称することが出来、他端の可動リンカーを第二可動リンカーと呼称することが出来る。特定の実施形態では、プロテアーゼ切断配列と可動リンカーは以下の式のうちの一つを含む。
(プロテアーゼ切断配列)
(第一可動リンカー)-(プロテアーゼ切断配列)
(プロテアーゼ切断配列)-(第二可動リンカー)
(第一可動リンカー)-(プロテアーゼ切断配列)-(第二可動リンカー)
本実施態様における可動リンカーはペプチドリンカーが好ましい。第一可動リンカーと第二可動リンカーは、それぞれ独立かつ任意的に存在し、少なくとも1つのフレキシブルアミノ酸(Glyなど)を含む同一または異なる可動リンカーである。例えば、プロテアーゼ切断配列が所望のプロテアーゼアクセス性を得られるほどの十分な数の残基(Arg、Ile、Gln、Glu、Cys、Tyr、Trp、Thr、Val、His、Phe、Pro、Met、Lys、Gly、Ser、Asp、Asn、Alaなどから任意に選択されるアミノ酸、特にGly、Ser、Asp、Asn、Ala、ことさらGlyおよびSer、特にGlyなど)が含まれる。
(プロテアーゼ切断配列)
(第一可動リンカー)-(プロテアーゼ切断配列)
(プロテアーゼ切断配列)-(第二可動リンカー)
(第一可動リンカー)-(プロテアーゼ切断配列)-(第二可動リンカー)
本実施態様における可動リンカーはペプチドリンカーが好ましい。第一可動リンカーと第二可動リンカーは、それぞれ独立かつ任意的に存在し、少なくとも1つのフレキシブルアミノ酸(Glyなど)を含む同一または異なる可動リンカーである。例えば、プロテアーゼ切断配列が所望のプロテアーゼアクセス性を得られるほどの十分な数の残基(Arg、Ile、Gln、Glu、Cys、Tyr、Trp、Thr、Val、His、Phe、Pro、Met、Lys、Gly、Ser、Asp、Asn、Alaなどから任意に選択されるアミノ酸、特にGly、Ser、Asp、Asn、Ala、ことさらGlyおよびSer、特にGlyなど)が含まれる。
プロテアーゼ切断配列の両端で使用するのに適した可動リンカーは通常、プロテアーゼ切断配列へのプロテアーゼのアクセスを向上し、プロテアーゼの切断効率を上昇させるものである。好適な可動リンカーは容易に選択可能であり、1アミノ酸(Glyなど)から20アミノ酸、2アミノ酸から15アミノ酸あるいは、4アミノ酸から10アミノ酸、5アミノ酸から9アミノ酸、6アミノ酸から8アミノ酸または7アミノ酸から8アミノ酸をはじめとして3アミノ酸から12アミノ酸など、異なる長さのうちからの好適なものを選択できる。本開示のいくつかの実施態様においては、可動リンカーは1から7アミノ酸のペプチドリンカーである。
可動リンカーの例として、それだけに限定されないが、例えば、グリシンポリマー(G)n、グリシン-セリンポリマー(例えば、(GS)n、(GSGGS:配列番号:18018)nおよび(GGGS:配列番号:18009)nを含み、nは少なくとも1の整数である)、グリシン-アラニンポリマー、アラニン-セリンポリマー、従来技術において周知の他の可動リンカーが挙げられる。
このうちグリシンおよびグリシン-セリンポリマーが注目されているが、これらのアミノ酸が比較的構造化されておらず、成分間の中性テザーとして機能しやすいことがその理由である。
グリシン-セリンポリマーからなる可動リンカーの例として、それだけに限定されないが、例えば、
Ser
Gly・Ser(GS)
Ser・Gly(SG)
Gly・Gly・Ser(GGS)
Gly・Ser・Gly(GSG)
Ser・Gly・Gly(SGG)
Gly・Ser・Ser(GSS)
Ser・Ser・Gly(SSG)
Ser・Gly・Ser(SGS)
Gly・Gly・Gly・Ser(GGGS、配列番号:18009)
Gly・Gly・Ser・Gly(GGSG、配列番号:18010)
Gly・Ser・Gly・Gly(GSGG、配列番号:18011)
Ser・Gly・Gly・Gly(SGGG、配列番号:18012)
Gly・Ser・Ser・Gly(GSSG、配列番号:18013)
Gly・Gly・Gly・Gly・Ser(GGGGS、配列番号:18014)
Gly・Gly・Gly・Ser・Gly(GGGSG、配列番号:18015)
Gly・Gly・Ser・Gly・Gly(GGSGG、配列番号:18016)
Gly・Ser・Gly・Gly・Gly(GSGGG、配列番号:18017)
Gly・Ser・Gly・Gly・Ser(GSGGS、配列番号:18018)
Ser・Gly・Gly・Gly・Gly(SGGGG、配列番号:18019)
Gly・Ser・Ser・Gly・Gly(GSSGG、配列番号:18020)
Gly・Ser・Gly・Ser・Gly(GSGSG、配列番号:18021)
Ser・Gly・Gly・Ser・Gly(SGGSG、配列番号:18022)
Gly・Ser・Ser・Ser・Gly(GSSSG、配列番号:18023)
Gly・Gly・Gly・Gly・Gly・Ser(GGGGGS、配列番号:18024)
Ser・Gly・Gly・Gly・Gly・Gly(SGGGGG、配列番号:18025)
Gly・Gly・Gly・Gly・Gly・Gly・Ser(GGGGGGS、配列番号:18026)
Ser・Gly・Gly・Gly・Gly・Gly・Gly(SGGGGGG、配列番号:18027)
(Gly・Gly・Gly・Gly・Ser(GGGGS、配列番号:18014))n
(Ser・Gly・Gly・Gly・Gly(SGGGG、配列番号:18019))n
[nは1以上の整数である]等を挙げることができる。但し、ペプチドリンカーの長さや配列は目的に応じて当業者が適宜選択することができる。
このうちグリシンおよびグリシン-セリンポリマーが注目されているが、これらのアミノ酸が比較的構造化されておらず、成分間の中性テザーとして機能しやすいことがその理由である。
グリシン-セリンポリマーからなる可動リンカーの例として、それだけに限定されないが、例えば、
Ser
Gly・Ser(GS)
Ser・Gly(SG)
Gly・Gly・Ser(GGS)
Gly・Ser・Gly(GSG)
Ser・Gly・Gly(SGG)
Gly・Ser・Ser(GSS)
Ser・Ser・Gly(SSG)
Ser・Gly・Ser(SGS)
Gly・Gly・Gly・Ser(GGGS、配列番号:18009)
Gly・Gly・Ser・Gly(GGSG、配列番号:18010)
Gly・Ser・Gly・Gly(GSGG、配列番号:18011)
Ser・Gly・Gly・Gly(SGGG、配列番号:18012)
Gly・Ser・Ser・Gly(GSSG、配列番号:18013)
Gly・Gly・Gly・Gly・Ser(GGGGS、配列番号:18014)
Gly・Gly・Gly・Ser・Gly(GGGSG、配列番号:18015)
Gly・Gly・Ser・Gly・Gly(GGSGG、配列番号:18016)
Gly・Ser・Gly・Gly・Gly(GSGGG、配列番号:18017)
Gly・Ser・Gly・Gly・Ser(GSGGS、配列番号:18018)
Ser・Gly・Gly・Gly・Gly(SGGGG、配列番号:18019)
Gly・Ser・Ser・Gly・Gly(GSSGG、配列番号:18020)
Gly・Ser・Gly・Ser・Gly(GSGSG、配列番号:18021)
Ser・Gly・Gly・Ser・Gly(SGGSG、配列番号:18022)
Gly・Ser・Ser・Ser・Gly(GSSSG、配列番号:18023)
Gly・Gly・Gly・Gly・Gly・Ser(GGGGGS、配列番号:18024)
Ser・Gly・Gly・Gly・Gly・Gly(SGGGGG、配列番号:18025)
Gly・Gly・Gly・Gly・Gly・Gly・Ser(GGGGGGS、配列番号:18026)
Ser・Gly・Gly・Gly・Gly・Gly・Gly(SGGGGGG、配列番号:18027)
(Gly・Gly・Gly・Gly・Ser(GGGGS、配列番号:18014))n
(Ser・Gly・Gly・Gly・Gly(SGGGG、配列番号:18019))n
[nは1以上の整数である]等を挙げることができる。但し、ペプチドリンカーの長さや配列は目的に応じて当業者が適宜選択することができる。
本開示のプロテアーゼ切断配列を含むポリペプチドは、配列番号:5~17201から選ばれる配列のN末端4番目のアミノ酸から15番目のアミノ酸までの配列、配列番号:5~17201から選ばれる配列のN末端4番目のアミノ酸から13番目のアミノ酸までの配列、配列番号:5~17201から選ばれる配列のN末端6番目のアミノ酸から13番目のアミノ酸までの配列、配列番号:17202~17993から選ばれる配列のN末端1番目のアミノ酸から12番目のアミノ酸までの配列、配列番号:17202~17993から選ばれる配列のN末端3番目のアミノ酸から12番目のアミノ酸までの配列、配列番号:17202~17993から選ばれる配列のN末端3番目のアミノ酸から11番目のアミノ酸までの配列、配列番号:17202~17993から選ばれる配列のN末端3番目のアミノ酸から10番目のアミノ酸までの配列、配列番号:17994~18003から選ばれる配列のN末端3番目のアミノ酸から14番目のアミノ酸までの配列、配列番号:17994~18003から選ばれる配列のN末端5番目のアミノ酸から12番目のアミノ酸までの配列、配列番号:17994~18003から選ばれる配列のN末端5番目のアミノ酸から10番目のアミノ酸までの配列、配列番号:5~18003のいずれかで示される配列から選ばれる少なくとも一つの配列を含んでいる限り、その他の構成は問わない。
本開示のプロテアーゼ切断配列を含むポリペプチドはまた、N末端から「下記グループAから選ばれる配列-下記グループBから選ばれる配列」の順で構成された配列のいずれかを含んでいる限り、その他の構成は問わない:
(グループA)
配列番号:5~17201から選ばれる配列のN末端1番目のアミノ酸から9番目のアミノ酸までの配列、
配列番号:5~17201から選ばれる配列のN末端2番目のアミノ酸から9番目のアミノ酸までの配列、
配列番号:5~17201から選ばれる配列のN末端3番目のアミノ酸から9番目のアミノ酸までの配列、
配列番号:5~17201から選ばれる配列のN末端4番目のアミノ酸から9番目のアミノ酸までの配列、
配列番号:5~17201から選ばれる配列のN末端5番目のアミノ酸から9番目のアミノ酸までの配列、
配列番号:5~17201から選ばれる配列のN末端6番目のアミノ酸から9番目のアミノ酸までの配列、
配列番号:5~17201から選ばれる配列のN末端7番目のアミノ酸から9番目のアミノ酸までの配列、
配列番号:5~17201から選ばれる配列のN末端8番目のアミノ酸から9番目のアミノ酸までの配列、
配列番号:17202~17993から選ばれる配列のN末端1番目のアミノ酸から6番目のアミノ酸までの配列、
配列番号:17202~17993から選ばれる配列のN末端2番目のアミノ酸から6番目のアミノ酸までの配列、
配列番号:17202~17993から選ばれる配列のN末端3番目のアミノ酸から6番目のアミノ酸までの配列、
配列番号:17202~17993から選ばれる配列のN末端4番目のアミノ酸から6番目のアミノ酸までの配列、
配列番号:17202~17993から選ばれる配列のN末端5番目のアミノ酸から6番目のアミノ酸までの配列、
配列番号:17994~18003から選ばれる配列のN末端1番目のアミノ酸から8番目のアミノ酸までの配列、
配列番号:17994~18003から選ばれる配列のN末端2番目のアミノ酸から8番目のアミノ酸までの配列、
配列番号:17994~18003から選ばれる配列のN末端3番目のアミノ酸から8番目のアミノ酸までの配列、
配列番号:17994~18003から選ばれる配列のN末端4番目のアミノ酸から8番目のアミノ酸までの配列、
配列番号:17994~18003から選ばれる配列のN末端5番目のアミノ酸から8番目のアミノ酸までの配列、
配列番号:17994~18003から選ばれる配列のN末端6番目のアミノ酸から8番目のアミノ酸までの配列、
配列番号:17994~18003から選ばれる配列のN末端7番目のアミノ酸から8番目のアミノ酸までの配列;
(グループB)
配列番号:5~17201から選ばれる配列のN末端10番目のアミノ酸から15番目のアミノ酸までの配列、
配列番号:5~17201から選ばれる配列のN末端10番目のアミノ酸から14番目のアミノ酸までの配列、
配列番号:5~17201から選ばれる配列のN末端10番目のアミノ酸から13番目のアミノ酸までの配列、
配列番号:5~17201から選ばれる配列のN末端10番目のアミノ酸から12番目のアミノ酸までの配列、
配列番号:5~17201から選ばれる配列のN末端10番目のアミノ酸から11番目のアミノ酸までの配列、
配列番号:17202~17993から選ばれる配列のN末端7番目のアミノ酸から15番目のアミノ酸までの配列、
配列番号:17202~17993から選ばれる配列のN末端7番目のアミノ酸から14番目のアミノ酸までの配列、
配列番号:17202~17993から選ばれる配列のN末端7番目のアミノ酸から13番目のアミノ酸までの配列、
配列番号:17202~17993から選ばれる配列のN末端7番目のアミノ酸から12番目のアミノ酸までの配列、
配列番号:17202~17993から選ばれる配列のN末端7番目のアミノ酸から11番目のアミノ酸までの配列、
配列番号:17202~17993から選ばれる配列のN末端7番目のアミノ酸から10番目のアミノ酸までの配列、
配列番号:17202~17993から選ばれる配列のN末端7番目のアミノ酸から9番目のアミノ酸までの配列、
配列番号:17202~17993から選ばれる配列のN末端7番目のアミノ酸から8番目のアミノ酸までの配列、
配列番号:17994~18003から選ばれる配列のN末端9番目のアミノ酸から15番目のアミノ酸までの配列、
配列番号:17994~18003から選ばれる配列のN末端9番目のアミノ酸から14番目のアミノ酸までの配列、
配列番号:17994~18003から選ばれる配列のN末端9番目のアミノ酸から13番目のアミノ酸までの配列、
配列番号:17994~18003から選ばれる配列のN末端9番目のアミノ酸から12番目のアミノ酸までの配列、
配列番号:17994~18003から選ばれる配列のN末端9番目のアミノ酸から11番目のアミノ酸までの配列、
配列番号:17994~18003から選ばれる配列のN末端9番目のアミノ酸から10番目のアミノ酸までの配列。
本開示のプロテアーゼ切断配列を含むポリペプチドはまた、N末端から「下記グループAから選ばれる配列-下記グループBから選ばれる配列」の順で構成された配列のいずれかを含んでいる限り、その他の構成は問わない:
(グループA)
配列番号:5~17201から選ばれる配列のN末端1番目のアミノ酸から9番目のアミノ酸までの配列、
配列番号:5~17201から選ばれる配列のN末端2番目のアミノ酸から9番目のアミノ酸までの配列、
配列番号:5~17201から選ばれる配列のN末端3番目のアミノ酸から9番目のアミノ酸までの配列、
配列番号:5~17201から選ばれる配列のN末端4番目のアミノ酸から9番目のアミノ酸までの配列、
配列番号:5~17201から選ばれる配列のN末端5番目のアミノ酸から9番目のアミノ酸までの配列、
配列番号:5~17201から選ばれる配列のN末端6番目のアミノ酸から9番目のアミノ酸までの配列、
配列番号:5~17201から選ばれる配列のN末端7番目のアミノ酸から9番目のアミノ酸までの配列、
配列番号:5~17201から選ばれる配列のN末端8番目のアミノ酸から9番目のアミノ酸までの配列、
配列番号:17202~17993から選ばれる配列のN末端1番目のアミノ酸から6番目のアミノ酸までの配列、
配列番号:17202~17993から選ばれる配列のN末端2番目のアミノ酸から6番目のアミノ酸までの配列、
配列番号:17202~17993から選ばれる配列のN末端3番目のアミノ酸から6番目のアミノ酸までの配列、
配列番号:17202~17993から選ばれる配列のN末端4番目のアミノ酸から6番目のアミノ酸までの配列、
配列番号:17202~17993から選ばれる配列のN末端5番目のアミノ酸から6番目のアミノ酸までの配列、
配列番号:17994~18003から選ばれる配列のN末端1番目のアミノ酸から8番目のアミノ酸までの配列、
配列番号:17994~18003から選ばれる配列のN末端2番目のアミノ酸から8番目のアミノ酸までの配列、
配列番号:17994~18003から選ばれる配列のN末端3番目のアミノ酸から8番目のアミノ酸までの配列、
配列番号:17994~18003から選ばれる配列のN末端4番目のアミノ酸から8番目のアミノ酸までの配列、
配列番号:17994~18003から選ばれる配列のN末端5番目のアミノ酸から8番目のアミノ酸までの配列、
配列番号:17994~18003から選ばれる配列のN末端6番目のアミノ酸から8番目のアミノ酸までの配列、
配列番号:17994~18003から選ばれる配列のN末端7番目のアミノ酸から8番目のアミノ酸までの配列;
(グループB)
配列番号:5~17201から選ばれる配列のN末端10番目のアミノ酸から15番目のアミノ酸までの配列、
配列番号:5~17201から選ばれる配列のN末端10番目のアミノ酸から14番目のアミノ酸までの配列、
配列番号:5~17201から選ばれる配列のN末端10番目のアミノ酸から13番目のアミノ酸までの配列、
配列番号:5~17201から選ばれる配列のN末端10番目のアミノ酸から12番目のアミノ酸までの配列、
配列番号:5~17201から選ばれる配列のN末端10番目のアミノ酸から11番目のアミノ酸までの配列、
配列番号:17202~17993から選ばれる配列のN末端7番目のアミノ酸から15番目のアミノ酸までの配列、
配列番号:17202~17993から選ばれる配列のN末端7番目のアミノ酸から14番目のアミノ酸までの配列、
配列番号:17202~17993から選ばれる配列のN末端7番目のアミノ酸から13番目のアミノ酸までの配列、
配列番号:17202~17993から選ばれる配列のN末端7番目のアミノ酸から12番目のアミノ酸までの配列、
配列番号:17202~17993から選ばれる配列のN末端7番目のアミノ酸から11番目のアミノ酸までの配列、
配列番号:17202~17993から選ばれる配列のN末端7番目のアミノ酸から10番目のアミノ酸までの配列、
配列番号:17202~17993から選ばれる配列のN末端7番目のアミノ酸から9番目のアミノ酸までの配列、
配列番号:17202~17993から選ばれる配列のN末端7番目のアミノ酸から8番目のアミノ酸までの配列、
配列番号:17994~18003から選ばれる配列のN末端9番目のアミノ酸から15番目のアミノ酸までの配列、
配列番号:17994~18003から選ばれる配列のN末端9番目のアミノ酸から14番目のアミノ酸までの配列、
配列番号:17994~18003から選ばれる配列のN末端9番目のアミノ酸から13番目のアミノ酸までの配列、
配列番号:17994~18003から選ばれる配列のN末端9番目のアミノ酸から12番目のアミノ酸までの配列、
配列番号:17994~18003から選ばれる配列のN末端9番目のアミノ酸から11番目のアミノ酸までの配列、
配列番号:17994~18003から選ばれる配列のN末端9番目のアミノ酸から10番目のアミノ酸までの配列。
本開示のプロテアーゼ切断配列を含むポリペプチドは、活性化可能抗体であってもよい。例えば、活性化可能抗体は次のものを含む:(i)標的に対して特異的に結合する抗体;(ii)プロテアーゼ切断配列が未切断状態で存在する場合、標的に対する抗体の結合を阻害するマスキング部分;及び(iii)抗体にカップリングされる切断可能部分、ここで切断可能部分は本開示のプロテアーゼ切断配列から選ばれる少なくとも1つの配列である。
抗原結合ドメインと運搬部分を含むポリペプチド
本開示のポリペプチドの一つの実施態様では、当該ポリペプチドは抗原結合ドメインと運搬部分とを含み、当該運搬部分は前記抗原結合ドメインの抗原結合活性を抑制する抑制ドメインを有する。
本開示はまた、明細書に記載された抗原結合ドメインと運搬部分を含むポリペプチド中のプロテアーゼ切断配列がプロテアーゼにより切断されることを含む、ポリペプチドから抗原結合ドメインを遊離させる方法に関する。
本開示のポリペプチドの一つの実施態様では、当該ポリペプチドは抗原結合ドメインと運搬部分とを含み、当該運搬部分は前記抗原結合ドメインの抗原結合活性を抑制する抑制ドメインを有する。
本開示はまた、明細書に記載された抗原結合ドメインと運搬部分を含むポリペプチド中のプロテアーゼ切断配列がプロテアーゼにより切断されることを含む、ポリペプチドから抗原結合ドメインを遊離させる方法に関する。
本明細書において、「抗原結合ドメイン」は目的とする抗原に結合することのみで制限される。抗原結合ドメインは、目的とする抗原に結合するかぎりどのような構造のドメインも使用され得る。そのようなドメインの例として、それだけに限定するものではないが、例えば、抗体の重鎖可変領域(VH)および抗体の軽鎖可変領域(VL)、単ドメイン抗体(sdAb)、生体内に存在する細胞膜タンパクであるAvimerに含まれる35アミノ酸程度のAドメインと呼ばれるモジュール(国際公開WO2004/044011、WO2005/040229)、細胞膜に発現する糖たんぱく質であるfibronectin中のタンパク質に結合するドメインである10Fn3ドメインを含むAdnectin(国際公開WO2002/032925)、ProteinAの58アミノ酸からなる3つのヘリックスの束(bundle)を構成するIgG結合ドメインをscaffoldとするAffibody(国際公開WO1995/001937)、33アミノ酸残基を含むターンと2つの逆並行ヘリックスおよびループのサブユニットが繰り返し積み重なった構造を有するアンキリン反復(ankyrin repeat:AR)の分子表面に露出する領域であるDARPins(Designed Ankyrin Repeat proteins)(国際公開WO2002/020565)、好中球ゲラチナーゼ結合リポカリン(neutrophil gelatinase-associated lipocalin(NGAL))等のリポカリン分子において高度に保存された8つの逆並行ストランドが中央方向にねじれたバレル構造の片側を支える4つのループ領域であるAnticalin等(国際公開WO2003/029462)、ヤツメウナギ、ヌタウナギなど無顎類の獲得免疫システムとしてイムノグロブリンの構造を有さない可変性リンパ球受容体(variable lymphocyte receptor(VLR))のロイシン残基に富んだリピート(leucine-rich-repeat(LRR))モジュールが繰り返し積み重なった馬てい形の構造の内部の並行型シート構造のくぼんだ領域(国際公開WO2008/016854)が挙げられる。
本開示の抗原結合ドメインの好適な例として、当該抗原結合ドメインのみで構成される分子で抗原結合機能を発揮出来る抗原結合ドメイン、連結されている他のペプチドから遊離した後に単独で抗原結合機能を発揮できる抗原結合ドメイン等が挙げられる。そのような抗原結合ドメインの例として、それだけに限定されないが、単ドメイン抗体、scFv、Fv、Fab、Fab'、F(ab')2等が挙げられる。
本開示の抗原結合ドメインの好適な例の一つとして、分子量60kDa以下の抗原結合ドメインが挙げられる。そのような抗原結合ドメインの例として、それだけに限定されないが、単ドメイン抗体、scFv、Fab、Fab'が挙げられる。分子量が60kDa以下である抗原結合ドメインは通常、単量体として血中に存在する時、腎臓によるクリアランスが発生する可能性が高い(J Biol Chem. 1988 Oct 15;263(29):15064-70参照)。
別の面から見て、本開示の抗原結合ドメインの好適な例の一つとして、血中半減期が12時間以下の抗原結合ドメインが挙げられる。そのような抗原結合ドメインの例として、それだけに限定されないが、単ドメイン抗体、scFv、Fab、Fab'等が挙げられる。
別の面から見て、本開示の抗原結合ドメインの好適な例の一つとして、血中半減期が12時間以下の抗原結合ドメインが挙げられる。そのような抗原結合ドメインの例として、それだけに限定されないが、単ドメイン抗体、scFv、Fab、Fab'等が挙げられる。
本開示の抗原結合ドメインの好適な例の一つとして、単ドメイン抗体(sdAb)が挙げられる。
本明細書において、「抗原」は抗原結合ドメインが結合するエピトープを含むことのみで制限される。抗原の好適な例として、それだけに限定されないが、例えば、動物またはヒト由来のペプチド、ポリペプチド、タンパク質が挙げられる。抗原の好適な例として、それだけに限定されないが、例えば、標的細胞(例:癌細胞、炎症細胞)の表面に発現する分子や、標的細胞を含む組織中の他の細胞表面に発現する分子、標的細胞と標的細胞を含む組織に対して免疫学的役割を持つ細胞の表面に発現する分子、標的細胞を含む組織の間質中に存在する大分子等が挙げられる。
抗原としては下記のような分子:17-IA、4-1BB、4Dc、6-ケト-PGF1a、8-イソ-PGF2a、8-オキソ-dG、A1 アデノシン受容体、A33、ACE、ACE-2、アクチビン、アクチビンA、アクチビンAB、アクチビンB、アクチビンC、アクチビンRIA、アクチビンRIA ALK-2、アクチビンRIB ALK-4、アクチビンRIIA、アクチビンRIIB、ADAM、ADAM10、ADAM12、ADAM15、ADAM17/TACE、ADAM8、ADAM9、ADAMTS、ADAMTS4、ADAMTS5、アドレシン、aFGF、ALCAM、ALK、ALK-1、ALK-7、アルファ-1-アンチトリプシン、アルファ-V/ベータ-1アンタゴニスト、ANG、Ang、APAF-1、APE、APJ、APP、APRIL、AR、ARC、ART、アルテミン、抗Id、ASPARTIC、心房性ナトリウム利尿因子、av/b3インテグリン、Axl、b2M、B7-1、B7-2、B7-H、B-リンパ球刺激因子(BlyS)、BACE、BACE-1、Bad、BAFF、BAFF-R、Bag-1、BAK、Bax、BCA-1、BCAM、Bcl、BCMA、BDNF、b-ECGF、bFGF、BID、Bik、BIM、BLC、BL-CAM、BLK、BMP、BMP-2 BMP-2a、BMP-3 オステオゲニン(Osteogenin)、BMP-4 BMP-2b、BMP-5、BMP-6 Vgr-1、BMP-7(OP-1)、BMP-8(BMP-8a、OP-2)、BMPR、BMPR-IA(ALK-3)、BMPR-IB(ALK-6)、BRK-2、RPK-1、BMPR-II(BRK-3)、BMP、b-NGF、BOK、ボンベシン、骨由来神経栄養因子、BPDE、BPDE-DNA、BTC、補体因子3(C3)、C3a、C4、C5、C5a、C10、CA125、CAD-8、カルシトニン、cAMP、癌胎児性抗原(CEA)、癌関連抗原、カテプシンA、カテプシンB、カテプシンC/DPPI、カテプシンD、カテプシンE、カテプシンH、カテプシンL、カテプシンO、カテプシンS、カテプシンV、カテプシンX/Z/P、CBL、CCI、CCK2、CCL、CCL1、CCL11、CCL12、CCL13、CCL14、CCL15、CCL16、CCL17、CCL18、CCL19、CCL2、CCL20、CCL21、CCL22、CCL23、CCL24、CCL25、CCL26、CCL27、CCL28、CCL3、CCL4、CCL5、CCL6、CCL7、CCL8、CCL9/10、CCR、CCR1、CCR10、CCR10、CCR2、CCR3、CCR4、CCR5、CCR6、CCR7、CCR8、CCR9、CD1、CD2、CD3、CD3E、CD4、CD5、CD6、CD7、CD8、CD10、CD11a、CD11b、CD11c、CD13、CD14、CD15、CD16、CD18、CD19、CD20、CD21、CD22、CD23、CD25、CD27L、CD28、CD29、CD30、CD30L、CD32、CD33(p67タンパク質)、CD34、CD38、CD40、CD40L、CD44、CD45、CD46、CD49a、CD52、CD54、CD55、CD56、CD61、CD64、CD66e、CD74、CD80(B7-1)、CD89、CD95、CD123、CD137、CD138、CD140a、CD146、CD147、CD148、CD152、CD164、CEACAM5、CFTR、cGMP、CINC、ボツリヌス菌毒素、ウェルシュ菌毒素、CKb8-1、CLC、CMV、CMV UL、CNTF、CNTN-1、COX、C-Ret、CRG-2、CT-1、CTACK、CTGF、CTLA-4、PD-1、PD-L1、LAG3、TIM3、galectin-9、CX3CL1、CX3CR1、CXCL、CXCL1、CXCL2、CXCL3、CXCL4、CXCL5、CXCL6、CXCL7、CXCL8、CXCL9、CXCL10、CXCL11、CXCL12、CXCL13、CXCL14、CXCL15、CXCL16、CXCR、CXCR1、CXCR2、CXCR3、CXCR4、CXCR5、CXCR6、サイトケラチン腫瘍関連抗原、DAN、DCC、DcR3、DC-SIGN、補体制御因子(Decay accelerating factor)、des(1-3)-IGF-I(脳IGF-1)、Dhh、ジゴキシン、DNAM-1、Dnase、Dpp、DPPIV/CD26、Dtk、ECAD、EDA、EDA-A1、EDA-A2、EDAR、EGF、EGFR(ErbB-1)、EMA、EMMPRIN、ENA、エンドセリン受容体、エンケファリナーゼ、eNOS、Eot、エオタキシン1、EpCAM、エフリンB2/EphB4、EPO、ERCC、E-セレクチン、ET-1、ファクターIIa、ファクターVII、ファクターVIIIc、ファクターIX、線維芽細胞活性化タンパク質(FAP)、Fas、FcR1、FEN-1、フェリチン、FGF、FGF-19、FGF-2、FGF3、FGF-8、FGFR、FGFR-3、フィブリン、FL、FLIP、Flt-3、Flt-4、卵胞刺激ホルモン、フラクタルカイン、FZD1、FZD2、FZD3、FZD4、FZD5、FZD6、FZD7、FZD8、FZD9、FZD10、G250、Gas6、GCP-2、GCSF、GD2、GD3、GDF、GDF-1、GDF-3(Vgr-2)、GDF-5(BMP-14、CDMP-1)、GDF-6(BMP-13、CDMP-2)、GDF-7(BMP-12、CDMP-3)、GDF-8(ミオスタチン)、GDF-9、GDF-15(MIC-1)、GDNF、GDNF、GFAP、GFRa-1、GFR-アルファ1、GFR-アルファ2、GFR-アルファ3、GITR、グルカゴン、Glut4、糖タンパク質IIb/IIIa(GPIIb/IIIa)、GM-CSF、gp130、gp72、GRO、成長ホルモン放出因子、ハプテン(NP-capまたはNIP-cap)、HB-EGF、HCC、HCMV gBエンベロープ糖タンパク質、HCMV gHエンベロープ糖タンパク質、HCMV UL、造血成長因子(HGF)、Hep B gp120、ヘパラナーゼ、Her2、Her2/neu(ErbB-2)、Her3(ErbB-3)、Her4(ErbB-4)、単純ヘルペスウイルス(HSV) gB糖タンパク質、HSV gD糖タンパク質、HGFA、高分子量黒色腫関連抗原(HMW-MAA)、HIV gp120、HIV IIIB gp 120 V3ループ、HLA、HLA-DR、HM1.24、HMFG PEM、HRG、Hrk、ヒト心臓ミオシン、ヒトサイトメガロウイルス(HCMV)、ヒト成長ホルモン(HGH)、HVEM、I-309、IAP、ICAM、ICAM-1、ICAM-3、ICE、ICOS、IFNg、Ig、IgA受容体、IgE、IGF、IGF結合タンパク質、IGF-1R、IGFBP、IGF-I、IGF-II、IL、IL-1、IL-1R、IL-2、IL-2R、IL-4、IL-4R、IL-5、IL-5R、IL-6、IL-6R、IL-8、IL-9、IL-10、IL-12、IL-13、IL-15、IL-18、IL-18R、IL-21、IL-23、IL-27、インターフェロン(INF)-アルファ、INF-ベータ、INF-ガンマ、インヒビン、iNOS、インスリンA鎖、インスリンB鎖、インスリン様増殖因子1、インテグリンアルファ2、インテグリンアルファ3、インテグリンアルファ4、インテグリンアルファ4/ベータ1、インテグリンアルファ4/ベータ7、インテグリンアルファ5(アルファV)、インテグリンアルファ5/ベータ1、インテグリンアルファ5/ベータ3、インテグリンアルファ6、インテグリンベータ1、インテグリンベータ2、インターフェロンガンマ、IP-10、I-TAC、JE、カリクレイン2、カリクレイン5、カリクレイン6、カリクレイン11、カリクレイン12、カリクレイン14、カリクレイン15、カリクレインL1、カリクレインL2、カリクレインL3、カリクレインL4、KC、KDR、ケラチノサイト増殖因子(KGF)、ラミニン5、LAMP、LAP、LAP(TGF-1)、潜在的TGF-1、潜在的TGF-1 bp1、LBP、LDGF、LECT2、レフティ、ルイス-Y抗原、ルイス-Y関連抗原、LFA-1、LFA-3、Lfo、LIF、LIGHT、リポタンパク質、LIX、LKN、Lptn、L-セレクチン、LT-a、LT-b、LTB4、LTBP-1、肺表面、黄体形成ホルモン、リンホトキシンベータ受容体、Mac-1、MAdCAM、MAG、MAP2、MARC、MCAM、MCAM、MCK-2、MCP、M-CSF、MDC、Mer、METALLOPROTEASES、MGDF受容体、MGMT、MHC(HLA-DR)、MIF、MIG、MIP、MIP-1-アルファ、MK、MMAC1、MMP、MMP-1、MMP-10、MMP-11、MMP-12、MMP-13、MMP-14、MMP-15、MMP-2、MMP-24、MMP-3、MMP-7、MMP-8、MMP-9、MPIF、Mpo、MSK、MSP、ムチン(Muc1)、MUC18、ミュラー管抑制物質、Mug、MuSK、NAIP、NAP、NCAD、N-Cアドヘリン、NCA 90、NCAM、NCAM、ネプリライシン、ニューロトロフィン-3、-4、または-6、ニュールツリン、神経成長因子(NGF)、NGFR、NGF-ベータ、nNOS、NO、NOS、Npn、NRG-3、NT、NTN、OB、OGG1、OPG、OPN、OSM、OX40L、OX40R、p150、p95、PADPr、副甲状腺ホルモン、PARC、PARP、PBR、PBSF、PCAD、P-カドヘリン、PCNA、PDGF、PDGF、PDK-1、PECAM、PEM、PF4、PGE、PGF、PGI2、PGJ2、PIN、PLA2、胎盤性アルカリホスファターゼ(PLAP)、PlGF、PLP、PP14、プロインスリン、プロレラキシン、プロテインC、PS、PSA、PSCA、前立腺特異的膜抗原(PSMA)、PTEN、PTHrp、Ptk、PTN、R51、RANK、RANKL、RANTES、RANTES、レラキシンA鎖、レラキシンB鎖、レニン、呼吸器多核体ウイルス(RSV)F、RSV Fgp、Ret、リウマイド因子、RLIP76、RPA2、RSK、S100、SCF/KL、SDF-1、SERINE、血清アルブミン、sFRP-3、Shh、SIGIRR、SK-1、SLAM、SLPI、SMAC、SMDF、SMOH、SOD、SPARC、Stat、STEAP、STEAP-II、TACE、TACI、TAG-72(腫瘍関連糖タンパク質-72)、TARC、TCA-3、T細胞受容体(例えば、T細胞受容体アルファ/ベータ)、TdT、TECK、TEM1、TEM5、TEM7、TEM8、TERT、睾丸PLAP様アルカリホスファターゼ、TfR、TGF、TGF-アルファ、TGF-ベータ、TGF-ベータ Pan Specific、TGF-ベータRI(ALK-5)、TGF-ベータRII、TGF-ベータRIIb、TGF-ベータRIII、TGF-ベータ1、TGF-ベータ2、TGF-ベータ3、TGF-ベータ4、TGF-ベータ5、トロンビン、胸腺Ck-1、甲状腺刺激ホルモン、Tie、TIMP、TIQ、組織因子、TMEFF2、Tmpo、TMPRSS2、TNF、TNF-アルファ、TNF-アルファベータ、TNF-ベータ2、TNFc、TNF-RI、TNF-RII、TNFRSF10A(TRAIL R1 Apo-2、DR4)、TNFRSF10B(TRAIL R2 DR5、KILLER、TRICK-2A、TRICK-B)、TNFRSF10C(TRAIL R3 DcR1、LIT、TRID)、TNFRSF10D(TRAIL R4 DcR2、TRUNDD)、TNFRSF11A(RANK ODF R、TRANCE R)、TNFRSF11B(OPG OCIF、TR1)、TNFRSF12(TWEAK R FN14)、TNFRSF13B(TACI)、TNFRSF13C(BAFF R)、TNFRSF14(HVEM ATAR、HveA、LIGHT R、TR2)、TNFRSF16(NGFR p75NTR)、TNFRSF17(BCMA)、TNFRSF18(GITR AITR)、TNFRSF19(TROY TAJ、TRADE)、TNFRSF19L(RELT)、TNFRSF1A(TNF RI CD120a、p55-60)、TNFRSF1B(TNF RII CD120b、p75-80)、TNFRSF26(TNFRH3)、TNFRSF3(LTbR TNF RIII、TNFC R)、TNFRSF4(OX40 ACT35、TXGP1 R)、TNFRSF5(CD40 p50)、TNFRSF6(Fas Apo-1、APT1、CD95)、TNFRSF6B(DcR3 M68、TR6)、TNFRSF7(CD27)、TNFRSF8(CD30)、TNFRSF9(4-1BB CD137、ILA)、TNFRSF21(DR6)、TNFRSF22(DcTRAIL R2 TNFRH2)、TNFRST23(DcTRAIL R1 TNFRH1)、TNFRSF25(DR3 Apo-3、LARD、TR-3、TRAMP、WSL-1)、TNFSF10(TRAIL Apo-2リガンド、TL2)、TNFSF11(TRANCE/RANKリガンド ODF、OPGリガンド)、TNFSF12(TWEAK Apo-3リガンド、DR3リガンド)、TNFSF13(APRIL TALL2)、TNFSF13B(BAFF BLYS、TALL1、THANK、TNFSF20)、TNFSF14(LIGHT HVEMリガンド、LTg)、TNFSF15(TL1A/VEGI)、TNFSF18(GITRリガンド AITRリガンド、TL6)、TNFSF1A(TNF-a コネクチン(Conectin)、DIF、TNFSF2)、TNFSF1B(TNF-b LTa、TNFSF1)、TNFSF3(LTb TNFC、p33)、TNFSF4(OX40リガンド gp34、TXGP1)、TNFSF5(CD40リガンド CD154、gp39、HIGM1、IMD3、TRAP)、TNFSF6(Fasリガンド Apo-1リガンド、APT1リガンド)、TNFSF7(CD27リガンド CD70)、TNFSF8(CD30リガンド CD153)、TNFSF9(4-1BBリガンド CD137リガンド)、TP-1、t-PA、Tpo、TRAIL、TRAIL R、TRAIL-R1、TRAIL-R2、TRANCE、トランスフェリン受容体、TRF、Trk、TROP-2、TLR(Toll-like receptor)1、TLR2、TLR3、TLR4、TLR5、TLR6、TLR7、TLR8、TLR9、TLR10、TSG、TSLP、腫瘍関連抗原CA125、腫瘍関連抗原発現ルイスY関連炭水化物、TWEAK、TXB2、Ung、uPAR、uPAR-1、ウロキナーゼ、VCAM、VCAM-1、VECAD、VE-Cadherin、VE-cadherin-2、VEFGR-1(flt-1)、VEGF、VEGFR、VEGFR-3(flt-4)、VEGI、VIM、ウイルス抗原、VLA、VLA-1、VLA-4、VNRインテグリン、フォン・ヴィレブランド因子、WIF-1、WNT1、WNT2、WNT2B/13、WNT3、WNT3A、WNT4、WNT5A、WNT5B、WNT6、WNT7A、WNT7B、WNT8A、WNT8B、WNT9A、WNT9A、WNT9B、WNT10A、WNT10B、WNT11、WNT16、XCL1、XCL2、XCR1、XCR1、XEDAR、XIAP、XPD、HMGB1、IgA、Aβ、CD81, CD97, CD98, DDR1, DKK1, EREG、Hsp90, IL-17/IL-17R、IL-20/IL-20R、酸化LDL, PCSK9, prekallikrein , RON, TMEM16F、SOD1, Chromogranin A, Chromogranin B、tau, VAP1、高分子キニノーゲン、IL-31、IL-31R、Nav1.1、Nav1.2、Nav1.3、Nav1.4、Nav1.5、Nav1.6、Nav1.7、Nav1.8、Nav1.9、EPCR、C1, C1q, C1r, C1s, C2, C2a, C2b, C3, C3a, C3b, C4, C4a, C4b, C5, C5a, C5b, C6, C7, C8, C9, factor B, factor D, factor H, properdin、sclerostin、fibrinogen, fibrin, prothrombin, thrombin, 組織因子, factor V, factor Va, factor VII, factor VIIa, factor VIII, factor VIIIa, factor IX, factor IXa, factor X, factor Xa, factor XI, factor XIa, factor XII, factor XIIa, factor XIII, factor XIIIa, TFPI, antithrombin III, EPCR, トロンボモデュリン、TAPI, tPA, plasminogen, plasmin, PAI-1, PAI-2、GPC3、Syndecan-1、Syndecan-2、Syndecan-3、Syndecan-4、LPA、S1Pならびにホルモンおよび成長因子のための受容体が例示され得る。
上記の抗原の例示には受容体も記載されるが、これらの受容体が生体液中に可溶型で存在する場合にも、本開示の抗原結合ドメインが結合する抗原として使用され得る。
上記の抗原の例示には、細胞膜に発現する膜型分子、および細胞から細胞外に分泌される可溶型分子が含まれる。本開示の抗原結合ドメインが細胞から分泌された可溶型分子に結合する場合、当該抗原結合ドメインとしては中和活性を有していることが好適である。
可溶型分子が存在する溶液に限定はなく生体液、すなわち生体内の脈管又は組織・細胞の間を満たす全ての液体に本可溶型分子は存在し得る。非限定な一態様では、本開示の抗原結合ドメインが結合する可溶型分子は、細胞外液に存在することができる。細胞外液とは、脊椎動物では血漿、組織間液、リンパ液、密な結合組織、脳脊髄液、髄液、穿刺液、または関節液等の骨および軟骨中の成分、肺胞液(気管支肺胞洗浄液)、腹水、胸水、心嚢水、嚢胞液、または眼房水(房水)等の細胞透過液(細胞の能動輸送・分泌活動の結果生じた各種腺腔内の液、および消化管腔その他の体腔内液)の総称をいう。
本明細書で用語「運搬部分」は、ポリペプチド中の抗原結合ドメイン以外の部分を言う。本開示の運搬部分は通常、アミノ酸により構成されたペプチドまたはポリペプチドであり、具体的な一実施態様として、ポリペプチド中の運搬部分はプロテアーゼ切断配列を介して抗原結合ドメインと連結されている。本開示の運搬部分は、アミド結合により繋がれた一連のペプチドもしくはポリペプチドであっても良く、複数のペプチドもしくはポリペプチドがジスルフィド結合等の共有結合もしくは水素結合、疎水性相互作用等の非共有結合により形成された複合体であっても良い。
本開示の運搬部分は、抗原結合ドメインの抗原結合活性を抑制する抑制ドメインを有する。本明細書において用語「抑制ドメイン」は、抗原結合ドメインの抗原結合活性を抑制することのみで制限される。抑制ドメインは、抗原結合ドメインの抗原結合活性を抑制できるかぎりどのような構造のドメインも使用され得る。そのような抑制ドメインの例として、それだけに限定するものではないが、例えば、抗体の重鎖可変領域(VH)、抗体の軽鎖可変領域(VL)、プレB細胞レセプター、および単ドメイン抗体が挙げられる。抑制ドメインは、運搬部分の全部により構成されても、運搬部分の一部により構成されても良い。
本開示のポリペプチドが抗原結合ドメインと運搬部分を含む場合、ある実施態様では、プロテアーゼ切断配列がプロテアーゼにより切断された状態における前記抑制ドメインの前記抗原結合ドメインの抗原結合活性に対する抑制は、前記プロテアーゼ切断配列が未切断の状態における前記抑制ドメインの前記抗原結合ドメインの抗原結合活性に対する抑制より弱い。
本開示のポリペプチドが抗原結合ドメインと運搬部分を含む場合、ある実施態様では、抗原結合ドメインは未切断のポリペプチドより短い血中半減期を有する。本開示のポリペプチドが抗原結合ドメインと運搬部分を含む場合、ある実施態様では、抗原結合ドメインは運搬部分よりも短い血中半減期を有する。
本開示のポリペプチドが抗原結合ドメインと運搬部分を含む場合、ある実施態様では、抗原結合ドメインの分子量は運搬部分の分子量より小さい。ある実施態様では、抗原結合ドメインの分子量は60kDa以下であり得る。
本開示のポリペプチドが抗原結合ドメインと運搬部分を含む場合、ある実施態様では、運搬部分はFcRn結合活性を有し、抗原結合ドメインはFcRn結合活性を有さないまたは運搬部分より弱いFcRn結合活性を有する。
本開示のポリペプチドが抗原結合ドメインと運搬部分を含む場合、ある実施態様では、単独で存在している抗原結合ドメインに比べ、抗原結合ドメインと運搬部分を含むポリペプチドはより長い血中半減期を有する。ポリペプチドの半減期をより長くするために、本開示のポリペプチドが抗原結合ドメインと運搬部分を含む場合、ある実施態様では、運搬部分はより長い血中半減期を有するように設計されている。運搬部分の血中半減期を延長する実施態様の例として、それだけに限定されないが、運搬部分の分子量が大きいこと、または運搬部分がFcRn結合性を有すること、または運搬部分がアルブミン結合性を有すること、または運搬部分がPEG化されていることが挙げられる。また、本開示のポリペプチドが抗原結合ドメインと運搬部分を含む場合、ある実施態様では、運搬部分は抗原結合ドメインより長い血中半減期(言い換えれば、抗原結合ドメインは運搬部分より短い血中半減期)を有する。
本開示においては、抗原結合ドメイン単独とポリペプチドの半減期比較、または抗原結合ドメインと運搬部分の血中半減期比較は、ヒトにおける血中半減期で比較することが好ましい。ヒトでの血中半減期を測定することが困難である場合には、マウス(例えば、正常マウス、ヒト抗原発現トランスジェニックマウス、ヒトFcRn発現トランスジェニックマウス、等)またはサル(例えば、カニクイザルなど)での血中半減期をもとに、ヒトでの血中半減期を予測することができる。
運搬部分の血中半減期を延長する一実施態様として、運搬部分の分子量が大きいことが挙げられる。運搬部分の血中半減期を抗原結合ドメインの血中半減期より長くする一実施態様として、運搬部分の分子量を抗原結合ドメインの分子量より大きくすることが挙げられる。
運搬部分の血中半減期を延長する一実施態様として、運搬部分にFcRn結合性を有させることが挙げられる。運搬部分にFcRn結合性を有させるには、通常、運搬部分中にFcRn結合領域を設ける方法がある。
運搬部分にFcRn結合性を有させることは、抗原結合ドメインにFcRn結合性を有させないことを意味するものではない。運搬部分の血中半減期を抗原結合ドメインの血中半減期より長くする実施態様として、抗原結合ドメインがFcRn結合性を有さないことはもちろん、抗原結合ドメインがFcRn結合性を有していても、運搬部分より弱いFcRn結合性を有すればよい。
また、運搬部分の血中半減期を延長する一実施態様として、運搬部分とアルブミンを結合させる方法がある。アルブミンは腎排泄を受けず、かつFcRn結合性を有するため、血中半減期が17~19日と長い(J Clin Invest. 1953 Aug; 32(8): 746-768.)。そのためアルブミンと結合しているタンパク質は嵩高くなり、かつ間接的にFcRnと結合することが可能となるため、血中半減期が増加することが報告されている(Antibodies 2015, 4(3), 141-156)。
更に、運搬部分の血中半減期を延長する一実施態様として、運搬部分をPEG化する方法がある。タンパク質をPEG化することでタンパク質を嵩高くし、同時に血中のプロテアーゼによる分解を抑えることで、タンパク質の血中半減期が延長すると考えられている(J Pharm Sci. 2008 Oct;97(10):4167-83.)。
本開示のポリペプチドが抗原結合ドメインと運搬部分を含む場合、ある実施態様では、運搬部分は抗体Fc領域を含む。具体的な一実施態様として、運搬部分はヒトIgG抗体のCH2ドメイン及びCH3ドメインを含む。具体的な一実施態様として、運搬部分は、ヒトIgG1抗体重鎖Cys226から、またはPro230から、重鎖のカルボキシル末端まで伸びる部分を含む。ただし、Fc領域のC末端のリジン (Lys447) またはグリシン‐リジン(Gly446-Lys447)は、存在していてもしていなくてもよい。
本開示のポリペプチドが抗原結合ドメインと運搬部分を含む場合、ある実施態様では、運搬部分は抗体定常領域を含む。より好ましい実施態様において、運搬部分はIgG抗体定常領域を含む。より好ましい実施態様において、運搬部分はヒトIgG抗体定常領域を含む。
本開示のポリペプチドが抗原結合ドメインと運搬部分を含む場合、ある実施態様では、運搬部分は抗体重鎖定常領域と実質的に類似する構造を有する領域と、当該領域とジスルフィド結合等の共有結合または水素結合、疎水性相互作用等の非共有結合により結合されている、抗体軽鎖と実質に類似する構造を有する領域とを含む。
本開示のポリペプチドが抗原結合ドメインと運搬部分を含む場合、ある実施態様では、抗原結合ドメインはポリペプチドから遊離可能であり、抗原結合ドメインは、ポリペプチドから遊離している状態下における抗原結合活性は、ポリペプチドから遊離していない状態下における抗原結合活性より高い。
本開示のポリペプチドが抗原結合ドメインと運搬部分を含む場合、ある実施態様では、プロテアーゼ切断配列がプロテアーゼにより切断されることで前記抗原結合ドメインが前記ポリペプチドから遊離可能になる。
本開示のポリペプチドが抗原結合ドメインと運搬部分を含む場合、ある実施態様では、抗原結合ドメインがポリペプチドから遊離することで、抗原結合活性が遊離前より高くなる。言い換えれば、抗原結合ドメインがポリペプチドから遊離していない状態では、その抗原結合活性は抑制ドメインにより抑制された状態にある。抗原結合ドメインの抗原結合活性が抑制ドメインにより抑制されることを確認する方法として、FACS(fluorescence activated cell sorting)、ELISA(Enzyme-Linked ImmunoSorbent Assay)、ECL(electrogenerated chemiluminescence、電気化学発光法)、SPR(Surface Plasmon Resonance、表面プラズモン共鳴)法(Biacore)、BLI(Bio-Layer Interferometry)法(Octet)等の方法がある。本開示のポリペプチドが抗原結合ドメインと運搬部分を含む場合、ある実施態様では、抗原結合ドメインがポリペプチドから遊離していない状態における結合活性に比べて、抗原結合ドメインがポリペプチドから遊離した状態における抗原結合活性は、2倍、3倍、4倍、5倍、6倍、7倍、8倍、9倍、10倍、20倍、30倍、40倍、50倍、60倍、70倍、80倍、90倍、100倍、200倍、300倍、400倍、500倍、600倍、700倍、800倍、900倍、1000倍、2000倍、または3000倍以上の値となる。本開示のポリペプチドが抗原結合ドメインと運搬部分を含む場合、ある実施態様では、遊離前の抗原結合ドメインは、前記方法中から選ばれる一つの方法で抗原結合ドメインの抗原結合活性の測定を行うとき、抗原結合ドメインと抗原との結合が見られない。
本開示のポリペプチドが抗原結合ドメインと運搬部分を含む場合、ある実施態様では、プロテアーゼ切断配列が切断されることによって抗原結合ドメインがポリペプチドから遊離可能になるので、このような態様における抗原結合活性の比較は、ポリペプチドの切断前後の抗原結合活性を比較することにより行うことができる。即ち、未切断のポリペプチドを用いて測定した抗原結合活性に比べて、切断後のポリペプチドを用いて測定した抗原結合活性は、2倍、3倍、4倍、5倍、6倍、7倍、8倍、9倍、10倍、20倍、30倍、40倍、50倍、60倍、70倍、80倍、90倍、100倍、200倍、300倍、400倍、500倍、600倍、700倍、800倍、900倍、1000倍、2000倍、または3000倍以上の値となる。より具体的ないくつかの実施態様においては、未切断のポリペプチドは、前記方法中から選ばれる一つの方法で抗原結合活性の測定を行うとき、抗原結合ドメインと抗原との結合が見られない。
本開示のポリペプチドが抗原結合ドメインと運搬部分を含む場合、ある実施態様では、プロテアーゼ切断配列はプロテアーゼにより切断されるので、このような態様における抗原結合活性の比較は、ポリペプチドのプロテアーゼ処理前後の抗原結合活性を比較することにより行うことができる。即ち、プロテアーゼ処理を行っていないポリペプチドを用いて測定した抗原結合活性に比べて、プロテアーゼ処理後のポリペプチドを用いて測定した抗原結合活性は、2倍、3倍、4倍、5倍、6倍、7倍、8倍、9倍、10倍、20倍、30倍、40倍、50倍、60倍、70倍、80倍、90倍、100倍、200倍、300倍、400倍、500倍、600倍、700倍、800倍、900倍、1000倍、2000倍、または3000倍以上の値となる。より具体的ないくつかの実施態様においては、プロテアーゼ未処理のポリペプチドは、前記方法中から選ばれる一つの方法で抗原結合活性の測定を行うとき、抗原結合ドメインと抗原との結合が見られない。
本開示のポリペプチドが抗原結合ドメインと運搬部分を含む場合、ある実施態様では、プロテアーゼ切断配列が切断されることによって抗原結合ドメインがポリペプチドから遊離可能になるので、このような態様における抗原結合活性の比較は、ポリペプチドの切断前後の抗原結合活性を比較することにより行うことができる。即ち、未切断のポリペプチドを用いて測定した抗原結合活性に比べて、切断後のポリペプチドを用いて測定した抗原結合活性は、2倍、3倍、4倍、5倍、6倍、7倍、8倍、9倍、10倍、20倍、30倍、40倍、50倍、60倍、70倍、80倍、90倍、100倍、200倍、300倍、400倍、500倍、600倍、700倍、800倍、900倍、1000倍、2000倍、または3000倍以上の値となる。より具体的ないくつかの実施態様においては、未切断のポリペプチドは、前記方法中から選ばれる一つの方法で抗原結合活性の測定を行うとき、抗原結合ドメインと抗原との結合が見られない。
本開示のポリペプチドが抗原結合ドメインと運搬部分を含む場合、ある実施態様では、プロテアーゼ切断配列はプロテアーゼにより切断されるので、このような態様における抗原結合活性の比較は、ポリペプチドのプロテアーゼ処理前後の抗原結合活性を比較することにより行うことができる。即ち、プロテアーゼ処理を行っていないポリペプチドを用いて測定した抗原結合活性に比べて、プロテアーゼ処理後のポリペプチドを用いて測定した抗原結合活性は、2倍、3倍、4倍、5倍、6倍、7倍、8倍、9倍、10倍、20倍、30倍、40倍、50倍、60倍、70倍、80倍、90倍、100倍、200倍、300倍、400倍、500倍、600倍、700倍、800倍、900倍、1000倍、2000倍、または3000倍以上の値となる。より具体的ないくつかの実施態様においては、プロテアーゼ未処理のポリペプチドは、前記方法中から選ばれる一つの方法で抗原結合活性の測定を行うとき、抗原結合ドメインと抗原との結合が見られない。
本開示のポリペプチドが抗原結合ドメインと運搬部分を含む場合、ある実施態様では、抗原結合ドメインと前記運搬部分の抑制ドメインが会合することで前記抗原結合ドメインの抗原結合活性が抑制される。
本開示のポリペプチドが抗原結合ドメインと運搬部分を含む場合、ある実施態様では、プロテアーゼ切断配列がプロテアーゼにより切断されることで抗原結合ドメインと運搬部分の前記抑制ドメインの会合が解消される。
本開示のポリペプチドが抗原結合ドメインと運搬部分を含む場合、ある実施態様では、抗原結合ドメインは単ドメイン抗体を含み、もしくは単ドメイン抗体であり、運搬部分の前記抑制ドメインは当該単ドメイン抗体の抗原結合活性を抑制する。単ドメイン抗体は、VHHであってもよく、単ドメインで抗原結合活性を有するVH、または単ドメインで抗原結合活性を有するVLであっても良い。
本開示のポリペプチドが抗原結合ドメインと運搬部分を含む場合、ある実施態様では、運搬部分の抑制ドメインは抗原結合ドメインと会合する。抑制ドメインは運搬部分の一部であっても、運搬部分の全部であっても良い。別の視点から、運搬部分中の、抗原結合ドメインと会合する部分を抑制ドメインと言い換えることも出来る。
より具体的な実施態様として、単ドメイン抗体である抗原結合ドメインと、VLもしくはVHもしくはVHHである抑制ドメインが、抗体VHと抗体VLのような会合を形成する。更に具体的な実施態様として、単ドメイン抗体である抗原結合ドメインとVLもしくはVHもしくはVHHである抑制ドメインが、抗体VHと抗体VLのような会合を形成し、当該会合が形成された状態においては、抑制ドメインが、抗原結合ドメインと抗原の結合を立体構造的に阻害すること、または抗原結合ドメインの抗原結合部位の立体構造を変化させることで、当該単ドメイン抗体の抗原結合活性が当該VLもしくはVHもしくはVHHにより抑制される。単ドメイン抗体としてVHHを利用する実施態様においては、VHHの主たる抗原結合部位であるCDR3またはその近傍の部位が抑制ドメインと会合する界面に存在すると、抑制ドメインによりVHHと抗原の結合が立体構造的に阻害されると考えられる。
また、抑制ドメインと抗原結合ドメインの会合は、例えば切断サイトを切断することにより解消可能である。会合の解消とは、例えば、2以上のポリペプチド領域の相互作用状態が解消されると換言することができる。2以上のポリペプチド領域の相互作用が全部解消されても、2以上のポリペプチド領域の相互作用の中の一部が解消されても良い。
より具体的な実施態様として、単ドメイン抗体である抗原結合ドメインと、VLもしくはVHもしくはVHHである抑制ドメインが、抗体VHと抗体VLのような会合を形成する。更に具体的な実施態様として、単ドメイン抗体である抗原結合ドメインとVLもしくはVHもしくはVHHである抑制ドメインが、抗体VHと抗体VLのような会合を形成し、当該会合が形成された状態においては、抑制ドメインが、抗原結合ドメインと抗原の結合を立体構造的に阻害すること、または抗原結合ドメインの抗原結合部位の立体構造を変化させることで、当該単ドメイン抗体の抗原結合活性が当該VLもしくはVHもしくはVHHにより抑制される。単ドメイン抗体としてVHHを利用する実施態様においては、VHHの主たる抗原結合部位であるCDR3またはその近傍の部位が抑制ドメインと会合する界面に存在すると、抑制ドメインによりVHHと抗原の結合が立体構造的に阻害されると考えられる。
また、抑制ドメインと抗原結合ドメインの会合は、例えば切断サイトを切断することにより解消可能である。会合の解消とは、例えば、2以上のポリペプチド領域の相互作用状態が解消されると換言することができる。2以上のポリペプチド領域の相互作用が全部解消されても、2以上のポリペプチド領域の相互作用の中の一部が解消されても良い。
本明細書における「界面」とは、通常、会合(相互作用)する際の会合面を指し、界面を形成するアミノ酸残基とは、通常、その会合に供されるポリペプチド領域に含まれる1または複数のアミノ酸残基であって、より好ましくは、会合の際に接近し相互作用に関与するアミノ酸残基を言う。該相互作用には、具体的には、会合の際に接近するアミノ酸残基同士が水素結合、静電的相互作用、塩橋を形成している場合等の非共有結合が含まれる。
本明細書における「界面を形成するアミノ酸残基」とは、詳述すれば、界面を構成するポリペプチド領域において、該ポリペプチド領域に含まれるアミノ酸残基を言う。界面を構成するポリペプチド領域とは、一例を示せば、抗体、リガンド、レセプター、基質等において、その分子内、または分子間において選択的な結合を担うポリペプチド領域を指す。具体的には、抗体においては、重鎖可変領域、軽鎖可変領域等を例示することができ、本開示のポリペプチドが抗原結合ドメインと運搬部分を含む場合、ある実施態様では、抗原結合ドメインと抑制ドメインを例示することができる。
界面を形成するアミノ酸残基の例として、それだけに限定されないが、例えば、会合の際に接近するアミノ酸残基が挙げられる。会合の際に接近するアミノ酸残基は、例えば、ポリペプチドの立体構造を解析し、該ポリペプチドの会合の際に界面を形成するポリペプチド領域のアミノ酸配列を調べることにより見出すことができる。
界面を形成するアミノ酸残基の例として、それだけに限定されないが、例えば、会合の際に接近するアミノ酸残基が挙げられる。会合の際に接近するアミノ酸残基は、例えば、ポリペプチドの立体構造を解析し、該ポリペプチドの会合の際に界面を形成するポリペプチド領域のアミノ酸配列を調べることにより見出すことができる。
本開示のポリペプチドが抗原結合ドメインと運搬部分を含む場合、ある実施態様では、抗原結合ドメインと抑制ドメインの会合を促進するために、抗原結合ドメイン中の会合に関与するアミノ酸残基、または抑制ドメイン中の会合に関与するアミノ酸残基を改変することが出来る。更に具体的な実施態様として、抗原結合ドメイン中の、抑制ドメインとの界面を形成するアミノ酸残基、または抑制ドメイン中の、抗原結合ドメインとの界面を形成するアミノ酸残基を改変することが出来る。好ましい実施態様において、界面を形成するアミノ酸残基の改変が、界面を形成する2残基以上のアミノ酸残基が異種の電荷となるように該界面にアミノ酸残基の変異を導入する方法である。異種の電荷となるようなアミノ酸残基の改変は、正の電荷を有するアミノ酸残基から負の電荷を有するアミノ酸残基または電荷を有しないアミノ酸残基への改変、負の電荷を有するアミノ酸残基から正の電荷を有するアミノ酸残基または電荷を有しないアミノ酸残基への改変、および電荷を有しないアミノ酸残基から正または負の電荷を有するアミノ酸残基への改変を含む。そのようなアミノ酸改変は、会合を促進させるためであり、会合促進の目的が達成できる限りアミノ酸改変の位置やアミノ酸の種類は限定されない。改変としては置換が挙げられるがこれに限定されない。
本開示のポリペプチドが抗原結合ドメインと運搬部分を含む場合、ある実施態様では、抗原結合ドメインであるVHHが抑制ドメインであるVLと会合している。VHH中の、VLとの会合に関与するアミノ酸残基の例として、VHHとVLの界面を形成するアミノ酸残基を指すことが出来る。また、VHH中の、VLとの会合に関与するアミノ酸残基の例として、それだけに限定されないが、例えば、37位、44位、45位、47位のアミノ酸残基が挙げられる(J. Mol. Biol. (2005) 350, 112-125.)。VHHとVLの会合が促進されることにより、VHHの活性が抑制される。同時に、VL中の、VHHとの会合に関与するアミノ酸残基の例として、VHHとVLの界面を形成するアミノ酸残基を指すことが出来る。
VHHとVLの会合を促進するために、VHH中のVLとの会合に関与するアミノ酸残基を改変することが出来る。このようなアミノ酸置換の例として、それだけに限定されないが、F37V、Y37V、E44G、Q44G、R45L、H45L、G47W、F47W、L47W、T47W、または/およびS47Wが挙げられる。更に、VHH中の各残基に対して改変をせず、最初から37V、44G、45L、または/および47Wのアミノ酸残基を有するVHHを使用することも出来る。
更に、VHHとVLの会合を促進する目的が達成できる限り、VHH中のアミノ酸ではなく、VL中のVHHとの会合に関与するアミノ酸残基を改変することが可能であり、更にVHHとVLの両方にアミノ酸改変を導入することも可能である。
更に、VHHとVLの会合を促進する目的が達成できる限り、VHH中のアミノ酸ではなく、VL中のVHHとの会合に関与するアミノ酸残基を改変することが可能であり、更にVHHとVLの両方にアミノ酸改変を導入することも可能である。
本開示のポリペプチドが抗原結合ドメインと運搬部分を含む場合、ある実施態様では、抗原結合ドメインとしてVHHを使用し、抑制ドメインとしてVHまたはVHHを使用し、抗原結合ドメインと抑制ドメインを会合させることが出来る。抗原結合ドメインであるVHHと、抑制ドメインであるVHまたはVHHとの会合を促進するために、抗原結合ドメインであるVHH中の、抑制ドメインであるVHまたはVHHとの会合に関与するアミノ酸残基を特定し、それらのアミノ酸残基を改変することができる。また、抑制ドメインであるVHまたはVHH中の、抗原結合ドメインであるVHH中との会合に関与するアミノ酸残基を特定し、それらのアミノ酸残基を改変することができる。
また、抗原結合ドメインとしてVHH以外の単ドメイン抗体を使用する時も、同じように抗原結合ドメイン若しくは抑制ドメイン中の、会合に関与するアミノ酸残基を特定して、それらのアミノ酸残基に対して改変することが出来る。
本開示のポリペプチドが抗原結合ドメインと運搬部分を含む場合、ある実施態様では、運搬部分と抗原結合ドメインはリンカーを介して融合されている。より具体的な実施態様としては、運搬部分と抗原結合ドメインは、プロテアーゼ切断配列を含むリンカーを介して融合されている。別の具体的な実施態様としては、運搬部分と抗原結合ドメインは、リンカーを介して融合されており、融合後の融合タンパク質にはプロテアーゼ切断配列が含まれている。
本開示のポリペプチドが抗原結合ドメインと運搬部分を含む場合、ある実施態様では、運搬部分と抗原結合ドメインはリンカーを介さず融合されている。より具体的な実施態様としては、運搬部分のN末端アミノ酸と抗原結合ドメインのC末端アミノ酸の間でアミノ結合を形成させ、融合タンパク質を形成させている。形成された融合タンパク質にはプロテアーゼ切断配列が含まれている。特定の実施態様においては、運搬部分のN末端の1アミノ酸~数アミノ酸または/および抗原結合ドメインC末端の1アミノ酸~数アミノ酸を改変し、運搬部分のN末端と抗原結合ドメインのC末端を融合させることで、融合位置附近にプロテアーゼ切断配列を形成させる。より具体的に、例えば、LSGRSDNH(配列番号:18031)をプロテアーゼ切断配列として使用する場合、抗原結合ドメインC末端の4個のアミノ酸をLSGR配列にし、運搬部分のN末端の4個のアミノ酸をSDNH配列にしてプロテアーゼ切断配列を形成させることが出来る。
本開示のポリペプチドが抗原結合ドメインと運搬部分を含む場合、プロテアーゼ切断配列は、プロテアーゼの切断を受けたとき、抗原結合ドメインを遊離させ、且つ遊離後の抗原結合ドメインの抗原結合活性を失わせない限り、ポリペプチドのどの部分に配置しても良い。
本開示のポリペプチドが抗原結合ドメインと運搬部分を含む場合、ある実施態様では、運搬部分は抗体定常領域を含み、当該抗体定常領域のN末端と抗原結合ドメインのC末端がリンカーを介してまたはリンカーを介さずに融合されている。
特定の実施態様において、プロテアーゼ切断配列は運搬部分に含まれる抗体定常領域内に位置する。この場合、プロテアーゼ切断配列は、プロテアーゼの切断を受けたとき、抗原結合ドメインを遊離させられるように抗体定常領域内に位置すれば良い。具体的な実施態様において、プロテアーゼ切断配列は運搬部分に含まれる抗体重鎖定常領域内に位置し、より具体的には、抗体重鎖定常領域中の140番(EUナンバリング)アミノ酸より抗原結合ドメイン側、または、抗体重鎖定常領域中の122番(EUナンバリング)アミノ酸より抗原結合ドメイン側に位置する。別の具体的な実施態様において、プロテアーゼ切断配列は運搬部分に含まれる抗体軽鎖定常領域内に位置し、より具体的には、抗体軽鎖定常領域中の130番(Kabatナンバリング)アミノ酸より抗原結合ドメイン側、または、抗体軽鎖定常領域中の113番(Kabatナンバリング)アミノ酸より抗原結合ドメイン側に位置する。
特定の実施態様において、プロテアーゼ切断配列は運搬部分に含まれる抗体定常領域内に位置する。この場合、プロテアーゼ切断配列は、プロテアーゼの切断を受けたとき、抗原結合ドメインを遊離させられるように抗体定常領域内に位置すれば良い。具体的な実施態様において、プロテアーゼ切断配列は運搬部分に含まれる抗体重鎖定常領域内に位置し、より具体的には、抗体重鎖定常領域中の140番(EUナンバリング)アミノ酸より抗原結合ドメイン側、または、抗体重鎖定常領域中の122番(EUナンバリング)アミノ酸より抗原結合ドメイン側に位置する。別の具体的な実施態様において、プロテアーゼ切断配列は運搬部分に含まれる抗体軽鎖定常領域内に位置し、より具体的には、抗体軽鎖定常領域中の130番(Kabatナンバリング)アミノ酸より抗原結合ドメイン側、または、抗体軽鎖定常領域中の113番(Kabatナンバリング)アミノ酸より抗原結合ドメイン側に位置する。
本開示のポリペプチドが抗原結合ドメインと運搬部分を含む場合、ある実施態様では、抗原結合ドメインは単ドメイン抗体であり、当該単ドメイン抗体のC末端と運搬部分のN末端がリンカーを介してまたはリンカーを介さずに融合されている。
特定の実施態様において、プロテアーゼ切断配列は単ドメイン抗体内に位置する。より具体的な実施態様において、単ドメイン抗体はVHから作製された単ドメイン抗体またはVHHであり、プロテアーゼ切断配列は当該単ドメイン抗体の35b番(Kabatナンバリング)アミノ酸より運搬部分側、または、当該単ドメイン抗体の95番(Kabatナンバリング)アミノ酸より運搬部分側、または、当該単ドメイン抗体の109番(Kabatナンバリング)アミノ酸より運搬部分側に位置する。別の具体的な実施態様において、単ドメイン抗体はVLから作製された単ドメイン抗体であり、プロテアーゼ切断配列は当該単ドメイン抗体の32番(Kabatナンバリング)アミノ酸より運搬部分側、または、当該単ドメイン抗体の91番(Kabatナンバリング)アミノ酸より運搬部分側、または、当該単ドメイン抗体の104番(Kabatナンバリング)アミノ酸より運搬部分側に位置する。
特定の実施態様において、プロテアーゼ切断配列は単ドメイン抗体内に位置する。より具体的な実施態様において、単ドメイン抗体はVHから作製された単ドメイン抗体またはVHHであり、プロテアーゼ切断配列は当該単ドメイン抗体の35b番(Kabatナンバリング)アミノ酸より運搬部分側、または、当該単ドメイン抗体の95番(Kabatナンバリング)アミノ酸より運搬部分側、または、当該単ドメイン抗体の109番(Kabatナンバリング)アミノ酸より運搬部分側に位置する。別の具体的な実施態様において、単ドメイン抗体はVLから作製された単ドメイン抗体であり、プロテアーゼ切断配列は当該単ドメイン抗体の32番(Kabatナンバリング)アミノ酸より運搬部分側、または、当該単ドメイン抗体の91番(Kabatナンバリング)アミノ酸より運搬部分側、または、当該単ドメイン抗体の104番(Kabatナンバリング)アミノ酸より運搬部分側に位置する。
本開示のポリペプチドが抗原結合ドメインと運搬部分を含む場合、ある実施態様では、運搬部分は抗体定常領域を含み、抗原結合ドメインは単ドメイン抗体であり、当該抗体定常領域と当該単ドメイン抗体がリンカーを介してまたはリンカーを介さずに融合されている。より具体的な一実施態様において、抗体定常領域のN末端と当該単ドメイン抗体のC末端がリンカーを介してまたはリンカーを介さずに融合されている。別の具体的な一実施態様において、抗体定常領域のC末端と当該単ドメイン抗体のN末端がリンカーを介してまたはリンカーを介さずに融合されている。
特定の実施態様において、プロテアーゼ切断配列は運搬部分に含まれる抗体定常領域内に位置する。より具体的な実施態様において、プロテアーゼ切断配列は、抗体重鎖定常領域中の140番(EUナンバリング)アミノ酸より単ドメイン抗体側、または、抗体重鎖定常領域中の122番(EUナンバリング)アミノ酸より単ドメイン抗体側に位置する。別の具体的な実施態様において、プロテアーゼ切断配列は抗体軽鎖定常領域中の130番(Kabatナンバリング)アミノ酸より抗原結合ドメイン側、または、抗体軽鎖定常領域中の113番(Kabatナンバリング)アミノ酸より抗原結合ドメイン側に位置する。
特定の実施態様において、プロテアーゼ切断配列は単ドメイン抗体内に位置する。より具体的な実施態様において、単ドメイン抗体はVHから作製された単ドメイン抗体またはVHHであり、プロテアーゼ切断配列は当該単ドメイン抗体の35b番(Kabatナンバリング)アミノ酸より抗体定常領域側、または、当該単ドメイン抗体の95番(Kabatナンバリング)アミノ酸より抗体定常領域側、または、当該単ドメイン抗体の109番(Kabatナンバリング)アミノ酸より抗体定常領域側に位置する。別の具体的な実施態様において、単ドメイン抗体はVLから作製された単ドメイン抗体であり、プロテアーゼ切断配列は当該単ドメイン抗体の32番(Kabatナンバリング)アミノ酸より抗体定常領域側、または、当該単ドメイン抗体の91番(Kabatナンバリング)アミノ酸より抗体定常領域側、または、当該単ドメイン抗体の104番(Kabatナンバリング)アミノ酸より抗体定常領域側に位置する。
特定の実施態様において、プロテアーゼ切断配列は抗原結合ドメインと運搬部分の境界付近に位置する。抗原結合ドメインと運搬部分の境界付近とは、抗原結合ドメインと運搬部分が連結されている部位の前後で、抗原結合ドメインの二次構造に大きく影響しない部分を言う。
より具体的な実施態様において、抗原結合ドメインは運搬部分中に含まれている抗体定常領域と連結されており、プロテアーゼ切断配列は抗原結合ドメインと抗体定常領域の境界付近に位置する。抗原結合ドメインと抗体定常領域の境界付近は、抗原結合ドメインと抗体重鎖定常領域の境界付近、または抗原結合ドメインと抗体軽鎖定常領域の境界付近を指すことができる。抗原結合ドメインがVHから作製された単ドメイン抗体またはVHHであり、抗体重鎖定常領域と繋がれている場合、抗原結合ドメインと抗体定常領域の境界付近とは、単ドメイン抗体101番(Kabatナンバリング)のアミノ酸から抗体重鎖定常領域140番(EUナンバリング)のアミノ酸の間を指すことができ、または単ドメイン抗体109番(Kabatナンバリング)のアミノ酸から抗体重鎖定常領域122番(EUナンバリング)のアミノ酸の間を指すことが出来る。抗原結合ドメインがVHから作製された単ドメイン抗体またはVHHであり、抗体軽鎖定常領域と繋がれている場合、抗原結合ドメインと抗体軽鎖定常領域の境界付近とは、単ドメイン抗体101番(Kabatナンバリング)のアミノ酸から抗体軽鎖定常領域130番(Kabatナンバリング)のアミノ酸の間を指すことができ、または単ドメイン抗体109番(Kabatナンバリング)のアミノ酸から抗体軽鎖定常領域113番(Kabatナンバリング)のアミノ酸の間を指すことが出来る。抗原結合ドメインがVLから作製された単ドメイン抗体の場合、抗原結合ドメインと抗体定常領域の境界付近とは、単ドメイン抗体96番(Kabatナンバリング)から、または単ドメイン抗体104番(Kabatナンバリング)からである。
特定の実施態様において、プロテアーゼ切断配列は運搬部分に含まれる抗体定常領域内に位置する。より具体的な実施態様において、プロテアーゼ切断配列は、抗体重鎖定常領域中の140番(EUナンバリング)アミノ酸より単ドメイン抗体側、または、抗体重鎖定常領域中の122番(EUナンバリング)アミノ酸より単ドメイン抗体側に位置する。別の具体的な実施態様において、プロテアーゼ切断配列は抗体軽鎖定常領域中の130番(Kabatナンバリング)アミノ酸より抗原結合ドメイン側、または、抗体軽鎖定常領域中の113番(Kabatナンバリング)アミノ酸より抗原結合ドメイン側に位置する。
特定の実施態様において、プロテアーゼ切断配列は単ドメイン抗体内に位置する。より具体的な実施態様において、単ドメイン抗体はVHから作製された単ドメイン抗体またはVHHであり、プロテアーゼ切断配列は当該単ドメイン抗体の35b番(Kabatナンバリング)アミノ酸より抗体定常領域側、または、当該単ドメイン抗体の95番(Kabatナンバリング)アミノ酸より抗体定常領域側、または、当該単ドメイン抗体の109番(Kabatナンバリング)アミノ酸より抗体定常領域側に位置する。別の具体的な実施態様において、単ドメイン抗体はVLから作製された単ドメイン抗体であり、プロテアーゼ切断配列は当該単ドメイン抗体の32番(Kabatナンバリング)アミノ酸より抗体定常領域側、または、当該単ドメイン抗体の91番(Kabatナンバリング)アミノ酸より抗体定常領域側、または、当該単ドメイン抗体の104番(Kabatナンバリング)アミノ酸より抗体定常領域側に位置する。
特定の実施態様において、プロテアーゼ切断配列は抗原結合ドメインと運搬部分の境界付近に位置する。抗原結合ドメインと運搬部分の境界付近とは、抗原結合ドメインと運搬部分が連結されている部位の前後で、抗原結合ドメインの二次構造に大きく影響しない部分を言う。
より具体的な実施態様において、抗原結合ドメインは運搬部分中に含まれている抗体定常領域と連結されており、プロテアーゼ切断配列は抗原結合ドメインと抗体定常領域の境界付近に位置する。抗原結合ドメインと抗体定常領域の境界付近は、抗原結合ドメインと抗体重鎖定常領域の境界付近、または抗原結合ドメインと抗体軽鎖定常領域の境界付近を指すことができる。抗原結合ドメインがVHから作製された単ドメイン抗体またはVHHであり、抗体重鎖定常領域と繋がれている場合、抗原結合ドメインと抗体定常領域の境界付近とは、単ドメイン抗体101番(Kabatナンバリング)のアミノ酸から抗体重鎖定常領域140番(EUナンバリング)のアミノ酸の間を指すことができ、または単ドメイン抗体109番(Kabatナンバリング)のアミノ酸から抗体重鎖定常領域122番(EUナンバリング)のアミノ酸の間を指すことが出来る。抗原結合ドメインがVHから作製された単ドメイン抗体またはVHHであり、抗体軽鎖定常領域と繋がれている場合、抗原結合ドメインと抗体軽鎖定常領域の境界付近とは、単ドメイン抗体101番(Kabatナンバリング)のアミノ酸から抗体軽鎖定常領域130番(Kabatナンバリング)のアミノ酸の間を指すことができ、または単ドメイン抗体109番(Kabatナンバリング)のアミノ酸から抗体軽鎖定常領域113番(Kabatナンバリング)のアミノ酸の間を指すことが出来る。抗原結合ドメインがVLから作製された単ドメイン抗体の場合、抗原結合ドメインと抗体定常領域の境界付近とは、単ドメイン抗体96番(Kabatナンバリング)から、または単ドメイン抗体104番(Kabatナンバリング)からである。
本開示のポリペプチドが抗原結合ドメインと運搬部分を含む場合、ある実施態様では、ポリペプチドはIgG抗体様分子である。このような実施態様の例として、それだけに限定されないが、例えば、運搬部分がIgG抗体定常領域を含み、抗原結合ドメインである単ドメイン抗体がIgG抗体のVHを取って代わり、VLにより抗原結合活性が抑制される実施態様、または運搬部分がIgG抗体定常領域を含み、抗原結合ドメインである単ドメイン抗体がIgG抗体のVLを取って代わり、VHにより抗原結合活性が抑制される実施態様、または運搬部分がIgG抗体定常領域を含み、抗原結合ドメインである単ドメイン抗体がIgG抗体のVH/VLの一方を取って代わり、抗原結合ドメインの抗原結合活性を抑制する別の単ドメイン抗体がIgG抗体のVH/VLの他方を取って代わる実施態様等が挙げられる。
本明細書で用いられる用語「IgG抗体様分子」は、IgG抗体のような定常ドメインまたは定常領域の構造と実質的に類似する部分と、IgG抗体のような可変ドメインまたは可変領域の構造と実質的に類似する部分を有し、IgG抗体と実質的に類似した立体構造を持つ分子を定義するために用いられる。IgG抗体様分子中の抗体CH1に類似したドメインとCLに類似したドメインは、お互いに互換的に使用することができ、即ち、両ドメイン間はIgG抗体のCH1とCLのような相互作用を持つ限り、抗体ヒンジ領域に類似した部分と連結されているドメインは抗体CH1ドメインであっても抗体CLドメインであっても良い。ただし、本明細書の「IgG抗体様分子」は、IgG抗体と類似する構造を保持したまま抗原結合活性を発揮することに限定されない。
本開示のポリペプチドが抗原結合ドメインと運搬部分を含む場合、ポリペプチド中に含まれる抗原結合ドメインは、一つであっても複数であっても良い。複数の抗原結合ドメインの抗原結合活性をそれぞれ抑制する抑制ドメインも、一つであっても複数であっても良い。複数の抗原結合ドメインがそれぞれ抑制ドメインと会合を形成していても良い。複数の抗原結合ドメインがそれぞれ運搬部分と融合していても良い。複数の抗原結合ドメインがそれぞれポリペプチドから遊離することが可能であっても良い。複数の抗原結合ドメインを遊離させるためのプロテアーゼ切断配列は、各抗原結合ドメインと対応して複数であっても良い。
ポリペプチドがIgG抗体様分子である場合、図3に示されたような、IgG抗体の二つの可変領域に相当する部分にそれぞれ抗原結合ドメインを設ける実施態様は、本開示に触れた当業者であれば理解できる実施態様であろう。その両腕に組み込まれた抗原結合ドメインは、同様の抗原結合特異性を持っていても、異なる抗原結合特異性を持っていても、本開示に触れた当業者であれば当然理解できる実施態様であり、本開示の範囲に逸脱していないことは明らかである。
本開示のポリペプチドが抗原結合ドメインと運搬部分を含む場合、ある実施態様では、抗原結合ドメインが更に第2の抗原結合ドメインと連結されている。第2の抗原結合ドメインの例として、それだけに限定されないが、例えば、単ドメイン抗体、抗体断片、生体内に存在する細胞膜タンパクであるAvimerに含まれる35アミノ酸程度のAドメインと呼ばれるモジュール(国際公開WO2004/044011、WO2005/040229)、細胞膜に発現する糖たんぱく質であるfibronectin中のタンパク質に結合するドメインである10Fn3ドメインを含むAdnectin(国際公開WO2002/032925)、ProteinAの58アミノ酸からなる3つのヘリックスの束(bundle)を構成するIgG結合ドメインをscaffoldとするAffibody(国際公開WO1995/001937)、33アミノ酸残基を含むターンと2つの逆並行ヘリックスおよびループのサブユニットが繰り返し積み重なった構造を有するアンキリン反復(ankyrin repeat:AR)の分子表面に露出する領域であるDARPins(Designed Ankyrin Repeat proteins)(国際公開WO2002/020565)、好中球ゲラチナーゼ結合リポカリン(neutrophil gelatinase-associated lipocalin(NGAL))等のリポカリン分子において高度に保存された8つの逆並行ストランドが中央方向にねじれたバレル構造の片側を支える4つのループ領域であるAnticalin等(国際公開WO2003/029462)、ヤツメウナギ、ヌタウナギなど無顎類の獲得免疫システムとしてイムノグロブリンの構造を有さない可変性リンパ球受容体(variable lymphocyte receptor(VLR))のロイシン残基に富んだリピート(leucine-rich-repeat(LRR))モジュールが繰り返し積み重なった馬てい形の構造の内部の並行型シート構造のくぼんだ領域(国際公開WO2008/016854)等が挙げられる。好ましい実施態様においては、第2の抗原結合ドメインは、抗原結合ドメインと異なる抗原結合特異性を有する。好ましい実施態様においては、連結された抗原結合ドメインと第2の抗原結合ドメインの分子量は60kDa以下である。
より具体的ないくつかの実施態様において、抗原結合ドメインと第2の抗原結合ドメインはそれぞれ異なる抗原結合特異性を有する単ドメイン抗体であり、連結された抗原結合ドメインと第2の抗原結合ドメインはポリペプチドから遊離可能であり、遊離後の抗原結合ドメインと第2の抗原結合ドメインが二重特異的抗原結合分子を形成している。このような二重特異的抗原結合分子の例として、それだけに限定されないが、例えば、抗原結合ドメインが標的細胞表面抗原に特異的に結合し、第2の抗原結合ドメインは免疫細胞表面抗原に特異的に結合する二重特異的抗原結合分子、抗原結合ドメインと第2の抗原結合ドメインが同じ抗原の異なるサブユニットに結合する二重特異的抗原結合分子、抗原結合ドメインと第2の抗原結合ドメインが同じ抗原中の異なるエピトープに結合する二重特異的抗原結合分子等が挙げられる。このような二重特異的抗原結合分子は、標的細胞に起因する疾患の治療において、免疫細胞を標的細胞の近傍までにリクルーティングすることができ、有用であると考えられる。
第2の抗原結合ドメインの抗原結合活性は、運搬部分により抑制されていても、運搬部分により抑制されていなくても良い。また、第2の抗原結合ドメインは、運搬部分の一部構造と会合を形成していても、形成していなくても良い。特に、抗原結合ドメインと第2の抗原結合ドメインが異なる抗原結合特異性を有する場合、例えば、図4に示すように、第2の抗原結合ドメインの抗原結合活性が抑制されていなくても、また第2の抗原結合ドメインが運搬部分の一部構造と会合を形成していなくても、抗原結合ドメインが遊離しない状態において、抗原結合ドメインの抗原結合活性を発揮することが出来ず、抗原結合ドメインと第2の抗原結合ドメインが連結されている二重特異的抗原結合分子は、二重特異的に2種類の抗原に結合する機能を発揮できない。
図4において、抗原結合ドメインが更に第2の抗原結合ドメインと連結されている一態様を例示している。
より具体的ないくつかの実施態様において、抗原結合ドメインと第2の抗原結合ドメインはそれぞれ異なる抗原結合特異性を有する単ドメイン抗体であり、連結された抗原結合ドメインと第2の抗原結合ドメインはポリペプチドから遊離可能であり、遊離後の抗原結合ドメインと第2の抗原結合ドメインが二重特異的抗原結合分子を形成している。このような二重特異的抗原結合分子の例として、それだけに限定されないが、例えば、抗原結合ドメインが標的細胞表面抗原に特異的に結合し、第2の抗原結合ドメインは免疫細胞表面抗原に特異的に結合する二重特異的抗原結合分子、抗原結合ドメインと第2の抗原結合ドメインが同じ抗原の異なるサブユニットに結合する二重特異的抗原結合分子、抗原結合ドメインと第2の抗原結合ドメインが同じ抗原中の異なるエピトープに結合する二重特異的抗原結合分子等が挙げられる。このような二重特異的抗原結合分子は、標的細胞に起因する疾患の治療において、免疫細胞を標的細胞の近傍までにリクルーティングすることができ、有用であると考えられる。
第2の抗原結合ドメインの抗原結合活性は、運搬部分により抑制されていても、運搬部分により抑制されていなくても良い。また、第2の抗原結合ドメインは、運搬部分の一部構造と会合を形成していても、形成していなくても良い。特に、抗原結合ドメインと第2の抗原結合ドメインが異なる抗原結合特異性を有する場合、例えば、図4に示すように、第2の抗原結合ドメインの抗原結合活性が抑制されていなくても、また第2の抗原結合ドメインが運搬部分の一部構造と会合を形成していなくても、抗原結合ドメインが遊離しない状態において、抗原結合ドメインの抗原結合活性を発揮することが出来ず、抗原結合ドメインと第2の抗原結合ドメインが連結されている二重特異的抗原結合分子は、二重特異的に2種類の抗原に結合する機能を発揮できない。
図4において、抗原結合ドメインが更に第2の抗原結合ドメインと連結されている一態様を例示している。
本明細書において、用語「特異性」とは、特異的に結合する分子の一方の分子がその一または複数の結合する相手方の分子以外の分子に対しては実質的に結合しない性質をいう。抗原結合ドメインが特定の抗原中に含まれるエピトープに特異性を有する場合にも用いられる。また、抗原結合ドメインがある抗原中に含まれる複数のエピトープのうち特定のエピトープに対して特異性を有する場合にも用いられる。ここで、実質的に結合しないとは結合活性の項で記載される方法に準じて決定され、前記相手方以外の分子に対する特異的結合分子の結合活性が、前記相手方の分子に対する結合活性の80%以下、通常50%以下、好ましくは30%以下、特に好ましくは15%以下の結合活性を示すことをいう。
配列番号:5~18003のいずれかで示される配列、またはそれらの配列中に含まれるプロテアーゼ切断配列として使用可能な部分配列(配列番号:5~17201から選ばれる配列のN末端4番目のアミノ酸から15番目のアミノ酸までの配列、配列番号:5~17201から選ばれる配列のN末端4番目のアミノ酸から13番目のアミノ酸までの配列、配列番号:5~17201から選ばれる配列のN末端6番目のアミノ酸から13番目のアミノ酸までの配列、配列番号:17202~17993から選ばれる配列のN末端1番目のアミノ酸から12番目のアミノ酸までの配列、配列番号:17202~17993から選ばれる配列のN末端3番目のアミノ酸から12番目のアミノ酸までの配列、配列番号:17202~17993から選ばれる配列のN末端3番目のアミノ酸から11番目のアミノ酸までの配列、配列番号:17202~17993から選ばれる配列のN末端3番目のアミノ酸から10番目のアミノ酸までの配列、配列番号:17994~18003から選ばれる配列のN末端3番目のアミノ酸から14番目のアミノ酸までの配列、配列番号:17994~18003から選ばれる配列のN末端5番目のアミノ酸から12番目のアミノ酸までの配列、配列番号:17994~18003から選ばれる配列のN末端5番目のアミノ酸から10番目のアミノ酸までの配列)は、図1で例示されるポリペプチド中のプロテアーゼ切断部位として使用可能である。
N末端から「下記グループAから選ばれる配列-下記グループBから選ばれる配列」の順で構成された配列もまた、図1で例示されるポリペプチド中のプロテアーゼ切断部位として使用可能である:
(グループA)
配列番号:5~17201から選ばれる配列のN末端1番目のアミノ酸から9番目のアミノ酸までの配列、
配列番号:5~17201から選ばれる配列のN末端2番目のアミノ酸から9番目のアミノ酸までの配列、
配列番号:5~17201から選ばれる配列のN末端3番目のアミノ酸から9番目のアミノ酸までの配列、
配列番号:5~17201から選ばれる配列のN末端4番目のアミノ酸から9番目のアミノ酸までの配列、
配列番号:5~17201から選ばれる配列のN末端5番目のアミノ酸から9番目のアミノ酸までの配列、
配列番号:5~17201から選ばれる配列のN末端6番目のアミノ酸から9番目のアミノ酸までの配列、
配列番号:5~17201から選ばれる配列のN末端7番目のアミノ酸から9番目のアミノ酸までの配列、
配列番号:5~17201から選ばれる配列のN末端8番目のアミノ酸から9番目のアミノ酸までの配列、
配列番号:17202~17993から選ばれる配列のN末端1番目のアミノ酸から6番目のアミノ酸までの配列、
配列番号:17202~17993から選ばれる配列のN末端2番目のアミノ酸から6番目のアミノ酸までの配列、
配列番号:17202~17993から選ばれる配列のN末端3番目のアミノ酸から6番目のアミノ酸までの配列、
配列番号:17202~17993から選ばれる配列のN末端4番目のアミノ酸から6番目のアミノ酸までの配列、
配列番号:17202~17993から選ばれる配列のN末端5番目のアミノ酸から6番目のアミノ酸までの配列、
配列番号:17994~18003から選ばれる配列のN末端1番目のアミノ酸から8番目のアミノ酸までの配列、
配列番号:17994~18003から選ばれる配列のN末端2番目のアミノ酸から8番目のアミノ酸までの配列、
配列番号:17994~18003から選ばれる配列のN末端3番目のアミノ酸から8番目のアミノ酸までの配列、
配列番号:17994~18003から選ばれる配列のN末端4番目のアミノ酸から8番目のアミノ酸までの配列、
配列番号:17994~18003から選ばれる配列のN末端5番目のアミノ酸から8番目のアミノ酸までの配列、
配列番号:17994~18003から選ばれる配列のN末端6番目のアミノ酸から8番目のアミノ酸までの配列、
配列番号:17994~18003から選ばれる配列のN末端7番目のアミノ酸から8番目のアミノ酸までの配列;
(グループB)
配列番号:5~17201から選ばれる配列のN末端10番目のアミノ酸から15番目のアミノ酸までの配列、
配列番号:5~17201から選ばれる配列のN末端10番目のアミノ酸から14番目のアミノ酸までの配列、
配列番号:5~17201から選ばれる配列のN末端10番目のアミノ酸から13番目のアミノ酸までの配列、
配列番号:5~17201から選ばれる配列のN末端10番目のアミノ酸から12番目のアミノ酸までの配列、
配列番号:5~17201から選ばれる配列のN末端10番目のアミノ酸から11番目のアミノ酸までの配列、
配列番号:17202~17993から選ばれる配列のN末端7番目のアミノ酸から15番目のアミノ酸までの配列、
配列番号:17202~17993から選ばれる配列のN末端7番目のアミノ酸から14番目のアミノ酸までの配列、
配列番号:17202~17993から選ばれる配列のN末端7番目のアミノ酸から13番目のアミノ酸までの配列、
配列番号:17202~17993から選ばれる配列のN末端7番目のアミノ酸から12番目のアミノ酸までの配列、
配列番号:17202~17993から選ばれる配列のN末端7番目のアミノ酸から11番目のアミノ酸までの配列、
配列番号:17202~17993から選ばれる配列のN末端7番目のアミノ酸から10番目のアミノ酸までの配列、
配列番号:17202~17993から選ばれる配列のN末端7番目のアミノ酸から9番目のアミノ酸までの配列、
配列番号:17202~17993から選ばれる配列のN末端7番目のアミノ酸から8番目のアミノ酸までの配列、
配列番号:17994~18003から選ばれる配列のN末端9番目のアミノ酸から15番目のアミノ酸までの配列、
配列番号:17994~18003から選ばれる配列のN末端9番目のアミノ酸から14番目のアミノ酸までの配列、
配列番号:17994~18003から選ばれる配列のN末端9番目のアミノ酸から13番目のアミノ酸までの配列、
配列番号:17994~18003から選ばれる配列のN末端9番目のアミノ酸から12番目のアミノ酸までの配列、
配列番号:17994~18003から選ばれる配列のN末端9番目のアミノ酸から11番目のアミノ酸までの配列、
配列番号:17994~18003から選ばれる配列のN末端9番目のアミノ酸から10番目のアミノ酸までの配列。
図1に示す分子は、抗原結合ドメインと運搬部分が連結された状態のポリペプチドは長い半減期を有し、抗原結合ドメインの抗原結合活性が抑制されており、抗原に結合しない(A)。抗原結合ドメインが遊離後、抗原結合活性が回復し、半減期も短い(B)。
N末端から「下記グループAから選ばれる配列-下記グループBから選ばれる配列」の順で構成された配列もまた、図1で例示されるポリペプチド中のプロテアーゼ切断部位として使用可能である:
(グループA)
配列番号:5~17201から選ばれる配列のN末端1番目のアミノ酸から9番目のアミノ酸までの配列、
配列番号:5~17201から選ばれる配列のN末端2番目のアミノ酸から9番目のアミノ酸までの配列、
配列番号:5~17201から選ばれる配列のN末端3番目のアミノ酸から9番目のアミノ酸までの配列、
配列番号:5~17201から選ばれる配列のN末端4番目のアミノ酸から9番目のアミノ酸までの配列、
配列番号:5~17201から選ばれる配列のN末端5番目のアミノ酸から9番目のアミノ酸までの配列、
配列番号:5~17201から選ばれる配列のN末端6番目のアミノ酸から9番目のアミノ酸までの配列、
配列番号:5~17201から選ばれる配列のN末端7番目のアミノ酸から9番目のアミノ酸までの配列、
配列番号:5~17201から選ばれる配列のN末端8番目のアミノ酸から9番目のアミノ酸までの配列、
配列番号:17202~17993から選ばれる配列のN末端1番目のアミノ酸から6番目のアミノ酸までの配列、
配列番号:17202~17993から選ばれる配列のN末端2番目のアミノ酸から6番目のアミノ酸までの配列、
配列番号:17202~17993から選ばれる配列のN末端3番目のアミノ酸から6番目のアミノ酸までの配列、
配列番号:17202~17993から選ばれる配列のN末端4番目のアミノ酸から6番目のアミノ酸までの配列、
配列番号:17202~17993から選ばれる配列のN末端5番目のアミノ酸から6番目のアミノ酸までの配列、
配列番号:17994~18003から選ばれる配列のN末端1番目のアミノ酸から8番目のアミノ酸までの配列、
配列番号:17994~18003から選ばれる配列のN末端2番目のアミノ酸から8番目のアミノ酸までの配列、
配列番号:17994~18003から選ばれる配列のN末端3番目のアミノ酸から8番目のアミノ酸までの配列、
配列番号:17994~18003から選ばれる配列のN末端4番目のアミノ酸から8番目のアミノ酸までの配列、
配列番号:17994~18003から選ばれる配列のN末端5番目のアミノ酸から8番目のアミノ酸までの配列、
配列番号:17994~18003から選ばれる配列のN末端6番目のアミノ酸から8番目のアミノ酸までの配列、
配列番号:17994~18003から選ばれる配列のN末端7番目のアミノ酸から8番目のアミノ酸までの配列;
(グループB)
配列番号:5~17201から選ばれる配列のN末端10番目のアミノ酸から15番目のアミノ酸までの配列、
配列番号:5~17201から選ばれる配列のN末端10番目のアミノ酸から14番目のアミノ酸までの配列、
配列番号:5~17201から選ばれる配列のN末端10番目のアミノ酸から13番目のアミノ酸までの配列、
配列番号:5~17201から選ばれる配列のN末端10番目のアミノ酸から12番目のアミノ酸までの配列、
配列番号:5~17201から選ばれる配列のN末端10番目のアミノ酸から11番目のアミノ酸までの配列、
配列番号:17202~17993から選ばれる配列のN末端7番目のアミノ酸から15番目のアミノ酸までの配列、
配列番号:17202~17993から選ばれる配列のN末端7番目のアミノ酸から14番目のアミノ酸までの配列、
配列番号:17202~17993から選ばれる配列のN末端7番目のアミノ酸から13番目のアミノ酸までの配列、
配列番号:17202~17993から選ばれる配列のN末端7番目のアミノ酸から12番目のアミノ酸までの配列、
配列番号:17202~17993から選ばれる配列のN末端7番目のアミノ酸から11番目のアミノ酸までの配列、
配列番号:17202~17993から選ばれる配列のN末端7番目のアミノ酸から10番目のアミノ酸までの配列、
配列番号:17202~17993から選ばれる配列のN末端7番目のアミノ酸から9番目のアミノ酸までの配列、
配列番号:17202~17993から選ばれる配列のN末端7番目のアミノ酸から8番目のアミノ酸までの配列、
配列番号:17994~18003から選ばれる配列のN末端9番目のアミノ酸から15番目のアミノ酸までの配列、
配列番号:17994~18003から選ばれる配列のN末端9番目のアミノ酸から14番目のアミノ酸までの配列、
配列番号:17994~18003から選ばれる配列のN末端9番目のアミノ酸から13番目のアミノ酸までの配列、
配列番号:17994~18003から選ばれる配列のN末端9番目のアミノ酸から12番目のアミノ酸までの配列、
配列番号:17994~18003から選ばれる配列のN末端9番目のアミノ酸から11番目のアミノ酸までの配列、
配列番号:17994~18003から選ばれる配列のN末端9番目のアミノ酸から10番目のアミノ酸までの配列。
図1に示す分子は、抗原結合ドメインと運搬部分が連結された状態のポリペプチドは長い半減期を有し、抗原結合ドメインの抗原結合活性が抑制されており、抗原に結合しない(A)。抗原結合ドメインが遊離後、抗原結合活性が回復し、半減期も短い(B)。
図1に示すポリペプチドは様々なバリエーションを有するが、IgG抗体様分子を使用する場合、図2に例示されるような製造方法で製造することが可能である。まず標的の抗原に結合する単ドメイン抗体(例:VHあるいはVHH)を取得する(A)。得られた単ドメイン抗体を、ジャームライン配列を有するIgG抗体のVHとVLの一方と入れ替えて、VHとVLの他方と会合させ、IgG抗体様分子を形成させる(B)。IgG抗体様分子中にプロテアーゼ切断配列を導入する(C)。導入位置の例として、導入した単ドメイン抗体(VHあるいはVHH)と定常領域(CH1またはCL)との境界付近が挙げられる。
単ドメイン抗体は単ドメインで存在する場合において抗原結合活性を有するが、VL/VH/VHH等と可変領域を形成すると抗原結合活性を失う。VL/VHはジャームライン配列を有する天然のヒト抗体配列であることから免疫原性のリスクは低く、同VL/VHを認識する抗薬物抗体が誘導される可能性は極めて低い。また、VHHを使用して単ドメイン抗体と可変領域を形成する場合、VHHをヒト化することによって、免疫原性のリスクを低減し、同ヒト化VHHを認識する抗薬物抗体が誘導される可能性を低下させられる。IgG抗体様分子に挿入されたプロテアーゼ切断配列がプロテアーゼで切断されることによって、単ドメイン抗体が遊離する。遊離した単ドメイン抗体は抗原結合活性を有する。プロテアーゼによる切断前のIgG抗体様分子は一般的なIgG分子と類似する構造であることから長い血中滞留性を有するのに対して、プロテアーゼによる切断で遊離した単ドメイン抗体は、Fc領域を保有せず、分子量が約13kDa程度であることから腎排泄により速やかに消失する。実際、全長IgGの半減期は2~3週間程度であるのに対して(Blood. 2016 Mar 31;127(13):1633-41.)、単ドメイン抗体の半減期は約2時間である(Antibodies 2015, 4(3), 141-156)。そのためプロテアーゼにより活性化された抗原結合分子は血中半減期が短く、正常組織の抗原に結合する可能性は低くなる。
単ドメイン抗体がVLの場合は、プロテアーゼ切断配列を、例えばVLとCLの境界付近に導入することで同様のコンセプトを達成可能である。
単ドメイン抗体は単ドメインで存在する場合において抗原結合活性を有するが、VL/VH/VHH等と可変領域を形成すると抗原結合活性を失う。VL/VHはジャームライン配列を有する天然のヒト抗体配列であることから免疫原性のリスクは低く、同VL/VHを認識する抗薬物抗体が誘導される可能性は極めて低い。また、VHHを使用して単ドメイン抗体と可変領域を形成する場合、VHHをヒト化することによって、免疫原性のリスクを低減し、同ヒト化VHHを認識する抗薬物抗体が誘導される可能性を低下させられる。IgG抗体様分子に挿入されたプロテアーゼ切断配列がプロテアーゼで切断されることによって、単ドメイン抗体が遊離する。遊離した単ドメイン抗体は抗原結合活性を有する。プロテアーゼによる切断前のIgG抗体様分子は一般的なIgG分子と類似する構造であることから長い血中滞留性を有するのに対して、プロテアーゼによる切断で遊離した単ドメイン抗体は、Fc領域を保有せず、分子量が約13kDa程度であることから腎排泄により速やかに消失する。実際、全長IgGの半減期は2~3週間程度であるのに対して(Blood. 2016 Mar 31;127(13):1633-41.)、単ドメイン抗体の半減期は約2時間である(Antibodies 2015, 4(3), 141-156)。そのためプロテアーゼにより活性化された抗原結合分子は血中半減期が短く、正常組織の抗原に結合する可能性は低くなる。
単ドメイン抗体がVLの場合は、プロテアーゼ切断配列を、例えばVLとCLの境界付近に導入することで同様のコンセプトを達成可能である。
また、本開示は、ポリペプチドが抑制ドメインを有する運搬部分と抗原結合ドメインとを含む場合、当該ポリペプチドを製造する方法にも関する。
本開示の抑制ドメインを有する運搬部分と抗原結合ドメインとを含むポリペプチドを製造する一つの方法として、抗原結合活性を有する抗原結合ドメインを取得し、当該抗原結合ドメインの抗原結合活性が抑制ドメインにより抑制されるように、抗原結合ドメインと運搬部分を連結させてポリペプチド前駆体を形成させ、当該ポリペプチド前駆体に更にプロテアーゼ切断配列を挿入、もしくは当該ポリペプチド前駆体の一部をプロテアーゼ切断配列に改変する方法がある。ポリペプチド前駆体にプロテアーゼ切断配列を導入できれば良く、プロテアーゼ切断配列トの導入方法は、プロテアーゼ切断配列の挿入とポリペプチド前駆体の一部の改変のどちらでも良い。更に、両方の手段を合わせて、ポリペプチド前駆体にプロテアーゼ切断配列を導入することも出来ることについては、本明細書に触れた当業者であれば明らかであり、本開示の範囲を逸脱しないであろう。
また、本開示の抑制ドメインを有する運搬部分と抗原結合ドメインとを含むポリペプチドを製造する他の方法として、抗原結合活性を有する抗原結合ドメインを取得し、当該抗原結合ドメインの抗原結合活性が抑制ドメインにより抑制されるように、抗原結合ドメインと運搬部分をプロテアーゼ切断配列を介して連結させてポリペプチドを形成させる方法もある。抗原結合ドメインと運搬部分をプロテアーゼ切断配列を介して連結させるとき、抗原結合ドメインと運搬部分の間にプロテアーゼ切断配列が挟まれる形でも良く、抗原結合ドメインの一部または/および運搬部分の一部を改変してプロテアーゼ切断配列の一部として使用する形でも良い。
本開示の抑制ドメインを有する運搬部分と抗原結合ドメインとを含むポリペプチドを製造する一つの方法として、抗原結合活性を有する抗原結合ドメインを取得し、当該抗原結合ドメインの抗原結合活性が抑制ドメインにより抑制されるように、抗原結合ドメインと運搬部分を連結させてポリペプチド前駆体を形成させ、当該ポリペプチド前駆体に更にプロテアーゼ切断配列を挿入、もしくは当該ポリペプチド前駆体の一部をプロテアーゼ切断配列に改変する方法がある。ポリペプチド前駆体にプロテアーゼ切断配列を導入できれば良く、プロテアーゼ切断配列トの導入方法は、プロテアーゼ切断配列の挿入とポリペプチド前駆体の一部の改変のどちらでも良い。更に、両方の手段を合わせて、ポリペプチド前駆体にプロテアーゼ切断配列を導入することも出来ることについては、本明細書に触れた当業者であれば明らかであり、本開示の範囲を逸脱しないであろう。
また、本開示の抑制ドメインを有する運搬部分と抗原結合ドメインとを含むポリペプチドを製造する他の方法として、抗原結合活性を有する抗原結合ドメインを取得し、当該抗原結合ドメインの抗原結合活性が抑制ドメインにより抑制されるように、抗原結合ドメインと運搬部分をプロテアーゼ切断配列を介して連結させてポリペプチドを形成させる方法もある。抗原結合ドメインと運搬部分をプロテアーゼ切断配列を介して連結させるとき、抗原結合ドメインと運搬部分の間にプロテアーゼ切断配列が挟まれる形でも良く、抗原結合ドメインの一部または/および運搬部分の一部を改変してプロテアーゼ切断配列の一部として使用する形でも良い。
抗原結合ドメインとして単ドメイン抗体を使用する実施態様について、以下の抑制ドメインを有する運搬部分と抗原結合ドメインとを含むポリペプチドの製造方法を記載する。
本開示の一実施態様において、抑制ドメインを有する運搬部分と抗原結合ドメインを含むポリペプチドの製造方法は、以下の工程:
(a) 標的抗原に結合する単ドメイン抗体を取得する工程;
(b) (a)工程で取得した単ドメイン抗体の抗原結合活性が運搬部分の抑制ドメインに抑制されるように、当該単ドメイン抗体と当該運搬部分を連結させてポリペプチド前駆体を形成させる工程;
(c) 前記ポリペプチド前駆体にプロテアーゼ切断配列を導入する工程;
を含む製造方法である。
(a) 標的抗原に結合する単ドメイン抗体を取得する工程;
(b) (a)工程で取得した単ドメイン抗体の抗原結合活性が運搬部分の抑制ドメインに抑制されるように、当該単ドメイン抗体と当該運搬部分を連結させてポリペプチド前駆体を形成させる工程;
(c) 前記ポリペプチド前駆体にプロテアーゼ切断配列を導入する工程;
を含む製造方法である。
本発開示の一実施態様において、抑制ドメインを有する運搬部分と抗原結合ドメインを含むポリペプチドの製造方法は、以下の工程:
(a) 標的抗原に結合する単ドメイン抗体を取得する工程;
(b) (a)工程で取得した単ドメイン抗体の抗原結合活性が運搬部分の抑制ドメインに抑制されるように、当該単ドメイン抗体と当該運搬部分を連結させてポリペプチド前駆体を形成させる工程;
(c) 前記単ドメイン抗体と前記運搬部分との境界付近にプロテアーゼ切断配列を導入する工程;
を含む製造方法である。
(a) 標的抗原に結合する単ドメイン抗体を取得する工程;
(b) (a)工程で取得した単ドメイン抗体の抗原結合活性が運搬部分の抑制ドメインに抑制されるように、当該単ドメイン抗体と当該運搬部分を連結させてポリペプチド前駆体を形成させる工程;
(c) 前記単ドメイン抗体と前記運搬部分との境界付近にプロテアーゼ切断配列を導入する工程;
を含む製造方法である。
本開示の一実施態様において、抑制ドメインを有する運搬部分と抗原結合ドメインを含むポリペプチドの製造方法は、以下の工程:
(a) 標的抗原に結合する単ドメイン抗体を取得する工程;
(b) (a)工程で取得した単ドメイン抗体の抗原結合活性が運搬部分の抑制ドメインに抑制されるように、当該単ドメイン抗体を、プロテアーゼ切断配列を介して当該運搬部分と連結させてポリペプチドを形成させる工程;
を含む製造方法である。
(a) 標的抗原に結合する単ドメイン抗体を取得する工程;
(b) (a)工程で取得した単ドメイン抗体の抗原結合活性が運搬部分の抑制ドメインに抑制されるように、当該単ドメイン抗体を、プロテアーゼ切断配列を介して当該運搬部分と連結させてポリペプチドを形成させる工程;
を含む製造方法である。
特定の実施態様において、抑制ドメインを有する運搬部分と抗原結合ドメインを含むポリペプチドの製造方法は、更に以下の工程:
(d) 前記ポリペプチドまたは前記ポリペプチド前駆体中に組み込まれた前記単ドメイン抗体の前記標的抗原に対する結合活性が弱められ、もしくは失われていることを確認する工程;
を含む製造方法である。本開示において「結合活性が弱められ」ているとは、連結前と比較して標的抗原に対する結合活性が減少していることを意味し、減少の程度は問わない。
(d) 前記ポリペプチドまたは前記ポリペプチド前駆体中に組み込まれた前記単ドメイン抗体の前記標的抗原に対する結合活性が弱められ、もしくは失われていることを確認する工程;
を含む製造方法である。本開示において「結合活性が弱められ」ているとは、連結前と比較して標的抗原に対する結合活性が減少していることを意味し、減少の程度は問わない。
特定の実施態様において、抑制ドメインを有する運搬部分と抗原結合ドメインを含むポリペプチドの製造方法は、更に以下の工程:
(e) 前記プロテアーゼ切断配列をプロテアーゼで切断することで前記単ドメイン抗体を遊離させ、遊離の単ドメイン抗体が抗原に結合することを確認する工程;
を含む製造方法である。
(e) 前記プロテアーゼ切断配列をプロテアーゼで切断することで前記単ドメイン抗体を遊離させ、遊離の単ドメイン抗体が抗原に結合することを確認する工程;
を含む製造方法である。
本開示一実施態様において、抑制ドメインを有する運搬部分と抗原結合ドメインを含みIgG抗体様分子であるポリペプチドの製造方法は、以下の工程:
(a) 標的抗原に結合する単ドメイン抗体を取得する工程;
(b) (a)工程で取得した単ドメイン抗体の抗原結合活性が抑制されるように、当該単ドメイン抗体をIgG抗体のVHの代わりとしてVLと会合させ 、または当該単ドメイン抗体をIgG抗体のVLの代わりとしてVHと会合させることによって、前記単ドメイン抗体が導入されたIgG抗体様分子前駆体を形成させる工程;
(c) 前記単ドメイン抗体が導入されたIgG抗体様分子前駆体にプロテアーゼ切断配列を導入する工程;
を含む製造方法である。
(a) 標的抗原に結合する単ドメイン抗体を取得する工程;
(b) (a)工程で取得した単ドメイン抗体の抗原結合活性が抑制されるように、当該単ドメイン抗体をIgG抗体のVHの代わりとしてVLと会合させ 、または当該単ドメイン抗体をIgG抗体のVLの代わりとしてVHと会合させることによって、前記単ドメイン抗体が導入されたIgG抗体様分子前駆体を形成させる工程;
(c) 前記単ドメイン抗体が導入されたIgG抗体様分子前駆体にプロテアーゼ切断配列を導入する工程;
を含む製造方法である。
本開示の一実施態様において、抑制ドメインを有する運搬部分と抗原結合ドメインを含みIgG抗体様分子であるポリペプチドの製造方法は、以下の工程:
(a) 標的抗原に結合する単ドメイン抗体を取得する工程;
(b) (a)工程で取得した単ドメイン抗体の抗原結合活性が抑制されるように、当該単ドメイン抗体をIgG抗体のVHの代わりとしてVLと会合させ 、または当該単ドメイン抗体をIgG抗体のVLの代わりとしてVHと会合させることによって、前記単ドメイン抗体が導入されたIgG抗体様分子前駆体を形成させる工程;
(c) 前記単ドメイン抗体と前記IgG抗体様分子前駆体中の抗体定常領域との境界付近にプロテアーゼ切断配列を導入する工程;
を含む製造方法である。
(a) 標的抗原に結合する単ドメイン抗体を取得する工程;
(b) (a)工程で取得した単ドメイン抗体の抗原結合活性が抑制されるように、当該単ドメイン抗体をIgG抗体のVHの代わりとしてVLと会合させ 、または当該単ドメイン抗体をIgG抗体のVLの代わりとしてVHと会合させることによって、前記単ドメイン抗体が導入されたIgG抗体様分子前駆体を形成させる工程;
(c) 前記単ドメイン抗体と前記IgG抗体様分子前駆体中の抗体定常領域との境界付近にプロテアーゼ切断配列を導入する工程;
を含む製造方法である。
本開示の一実施態様において、抑制ドメインを有する運搬部分と抗原結合ドメインを含みIgG抗体様分子であるポリペプチドの製造方法は、以下の工程:
(a) 標的抗原に結合する単ドメイン抗体を取得する工程;
(b) (a)工程で取得した単ドメイン抗体の抗原結合活性が抑制されるように、当該単ドメイン抗体をIgG抗体VHまたはVLの代わりとして、プロテアーゼ切断配列を介してIgG抗体の重鎖定常領域または軽鎖定常領域と連結させ、前記単ドメイン抗体が導入されたIgG抗体様分子を形成させる工程;
を含む製造方法である。
(a) 標的抗原に結合する単ドメイン抗体を取得する工程;
(b) (a)工程で取得した単ドメイン抗体の抗原結合活性が抑制されるように、当該単ドメイン抗体をIgG抗体VHまたはVLの代わりとして、プロテアーゼ切断配列を介してIgG抗体の重鎖定常領域または軽鎖定常領域と連結させ、前記単ドメイン抗体が導入されたIgG抗体様分子を形成させる工程;
を含む製造方法である。
特定の実施態様において、抑制ドメインを有する運搬部分と抗原結合ドメインを含みIgG抗体様分子であるポリペプチドの製造方法は、更に以下の工程:
(d) 前記IgG抗体様分子または前記IgG抗体様分子前駆体に導入された前記単ドメイン抗体の前記標的抗原に対する結合活性が弱められ、もしくは失われていることを確認する工程;
を含む製造方法である。本開示において「結合活性が弱められ」ているとは、会合前または連結前と比較して標的抗原に対する結合活性が減少していることを意味し、減少の程度は問わない。
(d) 前記IgG抗体様分子または前記IgG抗体様分子前駆体に導入された前記単ドメイン抗体の前記標的抗原に対する結合活性が弱められ、もしくは失われていることを確認する工程;
を含む製造方法である。本開示において「結合活性が弱められ」ているとは、会合前または連結前と比較して標的抗原に対する結合活性が減少していることを意味し、減少の程度は問わない。
特定の実施態様において、抑制ドメインを有する運搬部分と抗原結合ドメインを含みIgG抗体様分子であるポリペプチドの製造方法は、更に以下の工程:
(e) 前記プロテアーゼ切断配列をプロテアーゼで切断することで前記単ドメイン抗体を遊離させ、遊離の単ドメイン抗体が前記標的抗原に結合することを確認する工程;
を含む製造方法である。
(e) 前記プロテアーゼ切断配列をプロテアーゼで切断することで前記単ドメイン抗体を遊離させ、遊離の単ドメイン抗体が前記標的抗原に結合することを確認する工程;
を含む製造方法である。
抑制ドメインとしてVH/VL/VHHを使用する場合、単ドメイン抗体の抗原結合活性を運搬部分の抑制ドメインで抑制させる方法として、単ドメイン抗体とVH/VL/VHHを会合させる方法がある。用意した単ドメイン抗体の抗原結合活性を抑制するVH/VL/VHHは、既知のVH/VL/VHHを当該単ドメイン抗体と会合させ、会合前後の単ドメイン抗体の抗原結合活性を比較することでスクリーニングできる。
また、単ドメイン抗体の抗原結合活性を特定のVH/VL/VHHで抑制させる別の方法として、単ドメイン抗体中の、VH/VL/VHHとの会合に関与しているアミノ酸残基を置換して会合を促進すること、もしくはそれらのアミノ酸残基が最初から会合を促進できるアミノ酸である単ドメイン抗体を使用することにより、会合前後の抗原結合活性の差が所望のレベルにある単ドメイン抗体/抑制ドメインペアを用意することもできる。
また、単ドメイン抗体の抗原結合活性を特定のVH/VL/VHHで抑制させる別の方法として、単ドメイン抗体中の、VH/VL/VHHとの会合に関与しているアミノ酸残基を置換して会合を促進すること、もしくはそれらのアミノ酸残基が最初から会合を促進できるアミノ酸である単ドメイン抗体を使用することにより、会合前後の抗原結合活性の差が所望のレベルにある単ドメイン抗体/抑制ドメインペアを用意することもできる。
本開示の一実施態様において、抑制ドメインを有する運搬部分と抗原結合ドメインを含むIgG抗体様分子ポリペプチドの製造方法は、以下の工程:
(a) 単ドメイン抗体中の、抗体VHとの会合に関与するアミノ酸残基を置換し、または単ドメイン抗体中の、抗体VLとの会合に関与するアミノ酸残基を置換し、当該単ドメイン抗体の標的抗原に対する結合活性を保持する改変単ドメイン抗体を作製する工程;
(b) (a)工程で作製した改変単ドメイン抗体の抗原結合活性を抑制するように、当該改変単ドメイン抗体を抗体VHと会合させ、または当該改変単ドメイン抗体を抗体VLと会合させることによって、当該改変単ドメイン抗体が導入されたIgG抗体様分子前駆体を形成させる工程;
(c) 前記改変単ドメイン抗体が導入されたIgG抗体様分子前駆体にプロテアーゼ切断配列を導入する工程;
を含む製造方法である。
(a) 単ドメイン抗体中の、抗体VHとの会合に関与するアミノ酸残基を置換し、または単ドメイン抗体中の、抗体VLとの会合に関与するアミノ酸残基を置換し、当該単ドメイン抗体の標的抗原に対する結合活性を保持する改変単ドメイン抗体を作製する工程;
(b) (a)工程で作製した改変単ドメイン抗体の抗原結合活性を抑制するように、当該改変単ドメイン抗体を抗体VHと会合させ、または当該改変単ドメイン抗体を抗体VLと会合させることによって、当該改変単ドメイン抗体が導入されたIgG抗体様分子前駆体を形成させる工程;
(c) 前記改変単ドメイン抗体が導入されたIgG抗体様分子前駆体にプロテアーゼ切断配列を導入する工程;
を含む製造方法である。
本開示の一実施態様において、抑制ドメインを有する運搬部分と抗原結合ドメインを含みIgG抗体様分子であるポリペプチドの製造方法は、以下の工程:
(a) 単ドメイン抗体中の、抗体VHとの会合に関与するアミノ酸残基を置換し、または単ドメイン抗体中の、抗体VLとの会合に関与するアミノ酸残基を置換し、当該単ドメイン抗体の標的抗原に対する結合活性を保持する改変単ドメイン抗体を作製する工程;
(b) (a)工程で作製した改変単ドメイン抗体の抗原結合活性を抑制するように、当該改変単ドメイン抗体を抗体VHと会合させ、または当該改変単ドメイン抗体を抗体VLと会合させることによって、当該改変単ドメイン抗体が導入されたIgG抗体様分子前駆体を形成させる工程;
(c) 前記改変単ドメイン抗体と前記IgG抗体様分子前駆体の定常領域との境界付近にプロテアーゼ切断配列を導入する工程;
を含む製造方法である。
(a) 単ドメイン抗体中の、抗体VHとの会合に関与するアミノ酸残基を置換し、または単ドメイン抗体中の、抗体VLとの会合に関与するアミノ酸残基を置換し、当該単ドメイン抗体の標的抗原に対する結合活性を保持する改変単ドメイン抗体を作製する工程;
(b) (a)工程で作製した改変単ドメイン抗体の抗原結合活性を抑制するように、当該改変単ドメイン抗体を抗体VHと会合させ、または当該改変単ドメイン抗体を抗体VLと会合させることによって、当該改変単ドメイン抗体が導入されたIgG抗体様分子前駆体を形成させる工程;
(c) 前記改変単ドメイン抗体と前記IgG抗体様分子前駆体の定常領域との境界付近にプロテアーゼ切断配列を導入する工程;
を含む製造方法である。
本開示の一実施態様において、抑制ドメインを有する運搬部分と抗原結合ドメインを含みIgG抗体様分子であるポリペプチドの製造方法は、以下の工程:
(a) 単ドメイン抗体中の、抗体VHとの会合に関与するアミノ酸残基を置換し、または単ドメイン抗体中の、抗体VLとの会合に関与するアミノ酸残基を置換し、当該単ドメイン抗体の標的抗原に対する結合活性を保持する改変単ドメイン抗体を作製する工程;
(b) (a)工程で作製した改変単ドメイン抗体の抗原結合活性を抑制するように、当該改変単ドメイン抗体をプロテアーゼ切断配列を介してIgG抗体の重鎖定常領域と連結させ、または当該改変単ドメイン抗体をプロテアーゼ切断配列を介してIgG抗体の軽鎖定常領域と連結させ、当該改変単ドメイン抗体が導入されたIgG抗体様分子を形成させる工程;
を含む製造方法である。
(a) 単ドメイン抗体中の、抗体VHとの会合に関与するアミノ酸残基を置換し、または単ドメイン抗体中の、抗体VLとの会合に関与するアミノ酸残基を置換し、当該単ドメイン抗体の標的抗原に対する結合活性を保持する改変単ドメイン抗体を作製する工程;
(b) (a)工程で作製した改変単ドメイン抗体の抗原結合活性を抑制するように、当該改変単ドメイン抗体をプロテアーゼ切断配列を介してIgG抗体の重鎖定常領域と連結させ、または当該改変単ドメイン抗体をプロテアーゼ切断配列を介してIgG抗体の軽鎖定常領域と連結させ、当該改変単ドメイン抗体が導入されたIgG抗体様分子を形成させる工程;
を含む製造方法である。
特定の実施態様において、抑制ドメインを有する運搬部分と抗原結合ドメインを含みIgG抗体様分子であるポリペプチドの製造方法は、更に以下の工程:
(d) 前記IgG抗体様分子または前記IgG抗体様分子前駆体に導入された前記改変単ドメイン抗体の前記標的抗原に対する結合活性が弱められ、もしくは失われていることを確認する工程;
を含む製造方法である。本開示において「結合活性が弱められ」ているとは、会合前または連結前と比較して標的抗原に対する結合活性が減少していることを意味し、減少の程度は問わない。
(d) 前記IgG抗体様分子または前記IgG抗体様分子前駆体に導入された前記改変単ドメイン抗体の前記標的抗原に対する結合活性が弱められ、もしくは失われていることを確認する工程;
を含む製造方法である。本開示において「結合活性が弱められ」ているとは、会合前または連結前と比較して標的抗原に対する結合活性が減少していることを意味し、減少の程度は問わない。
特定の実施態様において、抑制ドメインを有する運搬部分と抗原結合ドメインを含みIgG抗体様分子であるポリペプチドの製造方法は、更に以下の工程:
(e) 前記プロテアーゼ切断配列をプロテアーゼで切断することで前記改変単ドメイン抗体を遊離させ、遊離の改変単ドメイン抗体が前記標的抗原に結合することを確認する工程;
を含む製造方法である。
(e) 前記プロテアーゼ切断配列をプロテアーゼで切断することで前記改変単ドメイン抗体を遊離させ、遊離の改変単ドメイン抗体が前記標的抗原に結合することを確認する工程;
を含む製造方法である。
リガンド結合分子
本開示のポリペプチドの一つの実施態様では、当該ポリペプチドはリガンドに結合可能なリガンド結合分子であり、プロテアーゼ切断配列が切断された状態における当該リガンド結合分子のリガンドに対する結合が、プロテアーゼ切断配列が未切断の状態における当該リガンド結合分子のリガンドに対する結合より弱い。
本開示はまた、明細書に記載されたリガンド結合分子に含まれるプロテアーゼ切断配列がプロテアーゼにより切断されることを含む、リガンド結合分子に結合したリガンドを遊離させる方法に関する。
本開示はまた、明細書に記載されたリガンド結合分子に含まれるプロテアーゼ切断配列がプロテアーゼにより切断されることを含む、リガンド結合分子とリガンドの融合タンパク質からリガンドを遊離させる方法に関する。
本開示のポリペプチドの一つの実施態様では、当該ポリペプチドはリガンドに結合可能なリガンド結合分子であり、プロテアーゼ切断配列が切断された状態における当該リガンド結合分子のリガンドに対する結合が、プロテアーゼ切断配列が未切断の状態における当該リガンド結合分子のリガンドに対する結合より弱い。
本開示はまた、明細書に記載されたリガンド結合分子に含まれるプロテアーゼ切断配列がプロテアーゼにより切断されることを含む、リガンド結合分子に結合したリガンドを遊離させる方法に関する。
本開示はまた、明細書に記載されたリガンド結合分子に含まれるプロテアーゼ切断配列がプロテアーゼにより切断されることを含む、リガンド結合分子とリガンドの融合タンパク質からリガンドを遊離させる方法に関する。
本明細書における用語「リガンド結合分子」は、リガンドに結合可能な分子、特に未切断の状態においてリガンドに結合可能な分子である。ここの「結合」は通常、静電力、ファンデルワールス力、水素結合等の非共有結合を主とした相互作用による結合をいう。本開示のリガンド結合分子のリガンド結合態様の好適な例として、それだけに限定されないが、例えば、抗原結合領域、抗原結合分子、抗体、および抗体断片等が抗原に結合するような抗原抗体反応が挙げられる。
なおリガンドに結合可能とは、リガンド結合分子とリガンドがたとえ別分子であっても、リガンド結合分子はリガンドに結合可能であることを意味し、共有結合によりリガンド結合分子とリガンドを繋ぐことを意味しない。例えばリガンドとリガンド結合分子がリンカーを介して共有結合されていることをもって、リガンドに結合可能とは言わない。またリガンドとの結合が減弱されるとは、前記結合可能である能力が減弱されることを言う。例えばリガンドとリガンド結合分子がリンカーを介して共有結合されている場合に、そのリンカーが切断されることをもってリガンドとの結合が減弱されるとはみなせない。なお本開示においては、リガンド結合分子がリガンドに結合可能である限り、リガンド結合分子はリンカー等を介してリガンドとつながっていてもよい。
本開示のリガンド結合分子は、未切断の状態でリガンドに結合することのみで制限され、未切断の状態で目的とするリガンドに結合できる限りどのような構造の分子も使用され得る。リガンド結合分子の例として、それだけに限定されないが、例えば、抗体の重鎖可変領域(VH)および抗体の軽鎖可変領域(VL)、単ドメイン抗体(sdAb)、生体内に存在する細胞膜タンパクであるAvimerに含まれる35アミノ酸程度のAドメインと呼ばれるモジュール(国際公開WO2004/044011、WO2005/040229)、細胞膜に発現する糖たんぱく質であるfibronectin中のタンパク質に結合するドメインである10Fn3ドメインを含むAdnectin(国際公開WO2002/032925)、ProteinAの58アミノ酸からなる3つのヘリックスの束(bundle)を構成するIgG結合ドメインをscaffoldとするAffibody(国際公開WO1995/001937)、33アミノ酸残基を含むターンと2つの逆並行ヘリックスおよびループのサブユニットが繰り返し積み重なった構造を有するアンキリン反復(ankyrin repeat:AR)の分子表面に露出する領域であるDARPins(Designed Ankyrin Repeat proteins)(国際公開WO2002/020565)、好中球ゲラチナーゼ結合リポカリン(neutrophil gelatinase-associated lipocalin(NGAL))等のリポカリン分子において高度に保存された8つの逆並行ストランドが中央方向にねじれたバレル構造の片側を支える4つのループ領域であるAnticalin等(国際公開WO2003/029462)、ヤツメウナギ、ヌタウナギなど無顎類の獲得免疫システムとしてイムノグロブリンの構造を有さない可変性リンパ球受容体(variable lymphocyte receptor(VLR))のロイシン残基に富んだリピート(leucine-rich-repeat(LRR))モジュールが繰り返し積み重なった馬てい形の構造の内部の並行型シート構造のくぼんだ領域(国際公開WO2008/016854)が挙げられる。
本開示のポリペプチドがリガンド結合分子である場合、プロテアーゼ切断配列は、当該配列が切断されることによってリガンド結合分子のリガンドへの結合を減弱できる限り、ポリペプチド中のどの位置に配置されても良い。また、ポリペプチド中に含まれるプロテアーゼ切断配列は、一つであっても複数であっても良い。
また、本開示のポリペプチドがリガンド結合分子である場合、ある実施態様では、当該リガンド結合分子の未切断状態と比べて、切断された状態でのリガンド結合が弱い(即ち、減弱されている)。リガンド結合分子とリガンドの結合が抗原抗体反応である実施態様において、リガンド結合の減弱はリガンド結合分子のリガンド結合活性により評価され得る。
リガンド結合分子とリガンドの結合活性の評価は、FACS、ELISAフォーマット、ALPHAスクリーン(Amplified Luminescent Proximity Homogeneous Assay)や表面プラズモン共鳴(SPR)現象を利用したBIACORE法、BLI(Bio-Layer Interferometry)法(Octet)等、周知の方法によって確認することができる(Proc. Natl. Acad. Sci. USA (2006) 103 (11), 4005-4010)。
ALPHAスクリーンは、ドナーとアクセプターの2つのビーズを使用するALPHAテクノロジーによって下記の原理に基づいて実施される。ドナービーズに結合した分子が、アクセプタービーズに結合した分子と相互作用し、2つのビーズが近接した状態の時にのみ、発光シグナルが検出される。レーザーによって励起されたドナービーズ内のフォトセンシタイザーは、周辺の酸素を励起状態の一重項酸素に変換する。一重項酸素はドナービーズ周辺に拡散し、近接しているアクセプタービーズに到達するとビーズ内の化学発光反応を引き起こし、最終的に光が放出される。ドナービーズに結合した分子とアクセプタービーズに結合した分子が相互作用しないときは、ドナービーズの産生する一重項酸素がアクセプタービーズに到達しないため、化学発光反応は起きない。
ALPHAスクリーンは、ドナーとアクセプターの2つのビーズを使用するALPHAテクノロジーによって下記の原理に基づいて実施される。ドナービーズに結合した分子が、アクセプタービーズに結合した分子と相互作用し、2つのビーズが近接した状態の時にのみ、発光シグナルが検出される。レーザーによって励起されたドナービーズ内のフォトセンシタイザーは、周辺の酸素を励起状態の一重項酸素に変換する。一重項酸素はドナービーズ周辺に拡散し、近接しているアクセプタービーズに到達するとビーズ内の化学発光反応を引き起こし、最終的に光が放出される。ドナービーズに結合した分子とアクセプタービーズに結合した分子が相互作用しないときは、ドナービーズの産生する一重項酸素がアクセプタービーズに到達しないため、化学発光反応は起きない。
例えば、ドナービーズにビオチン標識されたリガンド結合分子が結合され、アクセプタービーズにはグルタチオンSトランスフェラーゼ(GST)でタグ化されたリガンドが結合される。競合するタグ化されていないリガンド結合分子の非存在下では、リガンド結合分子とリガンドは相互作用し520-620 nmのシグナルを生ずる。タグ化されていないリガンド結合分子は、タグ化されたリガンド結合分子とリガンド間の相互作用と競合する。競合の結果表れる蛍光の減少を定量することによって相対的な結合親和性が決定され得る。抗体等のリガンド結合分子をSulfo-NHS-ビオチン等を用いてビオチン化することは公知である。リガンドをGSTでタグ化する方法としては、リガンドをコードするポリヌクレオチドとGSTをコードするポリヌクレオチドをインフレームで融合した融合遺伝子を発現可能なベクターを保持した細胞等においてGST融合リガンドを発現し、グルタチオンカラムを用いて精製する方法等が適宜採用され得る。得られたシグナルは例えばGRAPHPAD PRISM(GraphPad社、San Diego)等のソフトウェアを用いて非線形回帰解析を利用する一部位競合(one-site competition)モデルに適合させることにより好適に解析される。
相互作用を観察する物質の一方(リガンド)をセンサーチップの金薄膜上に固定し、センサーチップの裏側から金薄膜とガラスの境界面で全反射するように光を当てると、反射光の一部に反射強度が低下した部分(SPRシグナル)が形成される。相互作用を観察する物質の他方(アナライト)をセンサーチップの表面に流しリガンドとアナライトが結合すると、固定化されているリガンド分子の質量が増加し、センサーチップ表面の溶媒の屈折率が変化する。この屈折率の変化により、SPRシグナルの位置がシフトする(逆に結合が解離するとシグナルの位置は戻る)。Biacoreシステムは上記のシフトする量、すなわちセンサーチップ表面での質量変化を縦軸にとり、質量の時間変化を測定データとして表示する(センサーグラム)。センサーグラムのカーブからカイネティクス:結合速度定数(ka)と解離速度定数(kd)が、当該定数の比から解離定数(KD)が求められる。BIACORE法では阻害測定法や平衡値解析法も好適に用いられる。阻害測定法の例はProc. Natl. Acad. Sci. USA (2006) 103 (11), 4005-4010において、平衡値解析法の例はMethods Enzymol. 2000;323:325-40.において記載されている。
リガンド結合分子がリガンドと結合する機能が減弱されているとは、例えば、上記の測定方法に基づいて、被験リガンド結合分子あたりのリガンド結合量が、対照のリガンド結合分子に比較して、50%以下、好ましくは45%以下、40%以下、35%以下、30%以下、20%以下、15%以下、特に好ましくは10%以下、9%以下、8%以下、7%以下、6%以下、5%以下、4%以下、3%以下、2%以下、または1%以下の結合量を示すことをいう。結合活性の指標は適宜所望の指標を用いてよいが、例えば解離定数(KD)を用いてよい。結合活性の評価指標として解離定数(KD)を用いる場合、被験リガンド結合分子のリガンドに対する解離定数(KD)が、対照のリガンド結合分子のリガンドに対する解離定数(KD)に比較して大きいことが、被験リガンド結合分子のリガンドに対する結合活性が対照のリガンド結合分子に比較して弱いことを示す。リガンドと結合する機能が減弱されているとは、例えば、被験リガンド結合分子のリガンドに対する解離定数(KD)が、対照のリガンド結合分子のリガンドに対する解離定数(KD)に比較して、2倍以上、好ましくは5倍以上、10倍以上、特に好ましくは100倍以上であることをいう。
対照のリガンド結合分子としては、例えば、未切断型のリガンド結合分子が挙げられる。
対照のリガンド結合分子としては、例えば、未切断型のリガンド結合分子が挙げられる。
本明細書において、用語「リガンド」は生物活性を有する分子である。生物活性を有する分子は通常、細胞表面の受容体と相互作用し、それにより生物学的に刺激、阻害、または他の様式で変調することによって機能し、これらは通常は前記受容体を保有する細胞内のシグナル伝達経路に関与すると思われる。
本明細書においてリガンドには、生体分子と相互作用することにより生物活性を発揮する所望の分子が包含される。例えばリガンドは、受容体に相互作用する分子を意味するだけでなく、当該分子に相互作用することにより生物活性を発揮する分子もリガンドであって、例えば当該分子に相互作用する受容体や、その結合断片などもリガンドに含まれる。例えば、受容体として知られるタンパク質のリガンド結合部位や、当該受容体が他の分子と相互作用する部位を含むタンパク質は、本開示においてリガンドに含まれる。具体的には、可溶性受容体、受容体の可溶性断片、膜貫通型受容体の細胞外ドメイン、およびそれらを含むポリペプチドなどは、本開示においてリガンドに含まれる。
本開示のリガンドは通常、一つまたは複数の結合パートナーに結合することで、望ましい生物活性を発揮することが出来る。リガンドの結合パートナーは、細胞外、細胞内、または膜貫通タンパク質であることができる。一つの実施形態において、リガンドのその結合パートナーは、細胞外タンパク質、たとえば可溶性受容体である。別の実施形態において、リガンドの結合パートナーは、膜結合型受容体である。
本開示のリガンドは、その結合パートナーに10μM、1μM、100nM、50nM、10nM、5nM、1nM、500pM、400pM、350pM、300pM、250pM、200pM、150pM、100pM、50pM、25pM、10pM、5pM、1pM、0.5pM、または0.1pM以下の解離定数(KD)で特異的に結合することができる。
本開示のリガンドは、その結合パートナーに10μM、1μM、100nM、50nM、10nM、5nM、1nM、500pM、400pM、350pM、300pM、250pM、200pM、150pM、100pM、50pM、25pM、10pM、5pM、1pM、0.5pM、または0.1pM以下の解離定数(KD)で特異的に結合することができる。
生物活性を有する分子の例として、それだけに限定されないが、例えば、サイトカイン、ケモカイン、ポリペプチドホルモン、成長因子、アポトーシス誘導因子、PAMPs、DAMPs、核酸、またはそれらのフラグメントが挙げられる。詳細な実施形態においては、リガンドとして、インターロイキン、インターフェロン、造血因子、TNFスーパーファミリー、ケモカイン、細胞増殖因子、TGF-βファミリー、マイオカイン、アディポカイン、または神経栄養因子が使用され得る。より詳細な実施形態においては、リガンドとして、CXCL10、IL-2、IL-7、IL-12、IL-15、IL-18、IL-21、IFN-α、IFN-β、IFN-g、MIG、I-TAC、RANTES、MIP-1a、MIP-1b、IL-1R1(Interleukin-1 receptor, type I)、IL-1R2(Interleukin-1 receptor, type II)、IL-1RAcP(Interleukin-1 receptor accessory protein)、またはIL-1Ra(タンパク質アクセッションNo. NP_776214、mRNAアクセッションNo. NM_173842.2)が使用され得る。
ケモカインは、7~16kDaの間の均質な血清タンパク質のファミリーであり、元来、白血球の遊走を誘導するその能力を特徴とした。ほとんどのケモカインは、4つの特徴的なシステイン(Cys)を有し、最初の2つのシステインによって示されるモチーフによって、CXC、又はアルファ、CC又はベータ、C又はガンマ及びCX3C又はデルタのケモカインクラスに分類されている。2つのジスルフィド結合は、第1と第3のシステインの間、及び第2と第4のシステインの間に形成される。一般に、ジスルフィド架橋は必要であると考えられ、Clark-Lewisと共同研究者らは、少なくともCXCL10についてはジスルフィド結合は、ケモカイン活性に決定的であることを報告した(Clark-Lewis et al., J. Biol. Chem. 269:16075-16081, 1994)。4つのシステインを有することに対する唯一の例外は、リンホタクチンであり、システイン残基を2つしか有さない。従って、リンホタクチンは、1つだけのジスルフィド結合によって機能的構造をなんとか保持する。
さらに、CXC又はアルファのサブファミリーは、第1のシステインに先行するELRモチーフ(Glu-Leu-Arg)の存在によって2つの群:ELR-CXCケモカイン及び非ELR-CXCケモカインに分類されている(たとえば、Clark-Lewis, 上記、 及びBelperio et al., "CXC Chemokines in Angiogenesis(脈管形成におけるCXCケモカイン)," J. Leukoc. Biol. 68:1-8, 2000を参照)。
さらに、CXC又はアルファのサブファミリーは、第1のシステインに先行するELRモチーフ(Glu-Leu-Arg)の存在によって2つの群:ELR-CXCケモカイン及び非ELR-CXCケモカインに分類されている(たとえば、Clark-Lewis, 上記、 及びBelperio et al., "CXC Chemokines in Angiogenesis(脈管形成におけるCXCケモカイン)," J. Leukoc. Biol. 68:1-8, 2000を参照)。
本開示のポリペプチドがリガンド結合分子である場合、ある実施態様では、リガンドはサイトカインである。
サイトカインは、免疫調節性および炎症性の過程に関与する分泌型細胞シグナル伝達タンパク質のファミリーであり、これは神経システムのグリア細胞によっておよび免疫システムの多数の細胞によって分泌される。サイトカインは、タンパク質、ペプチドまたは糖タンパク質に分類することができ、大きくて多様な調節因子ファミリーを包含する。サイトカインは細胞表面受容体に結合して細胞内シグナル伝達を誘発し、これによって酵素の活性調節、いくつかの遺伝子およびその転写因子の上方制御もしくは下方制御、またはフィードバック阻害等が起こりうる。
本開示のポリペプチドがリガンド結合分子である場合、ある実施態様では、本開示のサイトカインは、インターロイキン(IL)およびインターフェロン(IFN)などの免疫調節因子を含む。適したサイトカインは以下のタイプの1つまたは複数由来のタンパク質を含むことができる:4つのα-ヘリックスバンドルファミリー(これはIL-2サブファミリー、IFNサブファミリーおよびIL-10サブファミリーを含む); IL-1ファミリー(これはIL-1およびIL-8を含む)、ならびにIL-17ファミリー。サイトカインは、細胞免疫反応を増強する1型サイトカイン(例えば、IFN-γ、TGF-βなど)、または抗体反応に有利に働く2型サイトカイン(例えば、IL-4、IL-10、IL-13など)に分類されるものを含むこともできる。
サイトカインは、免疫調節性および炎症性の過程に関与する分泌型細胞シグナル伝達タンパク質のファミリーであり、これは神経システムのグリア細胞によっておよび免疫システムの多数の細胞によって分泌される。サイトカインは、タンパク質、ペプチドまたは糖タンパク質に分類することができ、大きくて多様な調節因子ファミリーを包含する。サイトカインは細胞表面受容体に結合して細胞内シグナル伝達を誘発し、これによって酵素の活性調節、いくつかの遺伝子およびその転写因子の上方制御もしくは下方制御、またはフィードバック阻害等が起こりうる。
本開示のポリペプチドがリガンド結合分子である場合、ある実施態様では、本開示のサイトカインは、インターロイキン(IL)およびインターフェロン(IFN)などの免疫調節因子を含む。適したサイトカインは以下のタイプの1つまたは複数由来のタンパク質を含むことができる:4つのα-ヘリックスバンドルファミリー(これはIL-2サブファミリー、IFNサブファミリーおよびIL-10サブファミリーを含む); IL-1ファミリー(これはIL-1およびIL-8を含む)、ならびにIL-17ファミリー。サイトカインは、細胞免疫反応を増強する1型サイトカイン(例えば、IFN-γ、TGF-βなど)、または抗体反応に有利に働く2型サイトカイン(例えば、IL-4、IL-10、IL-13など)に分類されるものを含むこともできる。
本開示のポリペプチドがリガンド結合分子である場合、ある実施態様では、リガンドはケモカインである。ケモカインは一般に、免疫エフェクター細胞をケモカイン発現部位に動員させる化学誘引物質として作用する。これは、他の免疫系成分を治療部位に動員させる目的で、特定のケモカイン遺伝子を例えばサイトカイン遺伝子とともに発現させるためには有益と考えられる。このようなケモカインには、CXCL10、RANTES、MCAF、MIP1-α、MIP1-βが含まれる。当業者には、ある種のサイトカインも化学誘引作用を有することが知られていて、それらをケモカインという用語で分類しうることを認識していると考えられる。
本開示のポリペプチドがリガンド結合分子である場合、ある実施態様では、リガンドとしてサイトカイン、ケモカイン等の改変体(例:Annu Rev Immunol. 2015;33:139-67.)やそれらを含む融合タンパク質(例:Stem Cells Transl Med. 2015 Jan; 4(1): 66-73.)を使用することができる。
本開示のポリペプチドがリガンド結合分子である場合、ある実施態様では、リガンドはCXCL10、PD-1、IL-12、IL-6R、IL-1R1、IL-1R2、IL-1RAcP 、IL-1Raから選ばれる。前記CXCL10、PD-1、IL-12、IL-6R、IL-1R1、IL-1R2、IL-1RAcP 、IL-1Raは、天然に存在するCXCL10、PD-1、IL-12、IL-6R、IL-1R1、IL-1R2、IL-1RAcP 、IL-1Raと同じ配列を有していても良く、天然に存在するCXCL10、PD-1、IL-12、IL-6R、IL-1R1、IL-1R2、IL-1RAcP 、IL-1Raと配列が異なるが対応する天然のリガンドを有する生理的活性を保持している改変体であってもよい。リガンドの改変体を取得するには、様々な目的で人為的にリガンド配列に改変を加えてもよく、好ましくはプロテアーゼ切断を受けない(プロテアーゼ抵抗性の)改変を加えることでリガンドの改変体を取得する。
本開示のポリペプチドがリガンド結合分子である場合、ある実施態様では、リガンド結合分子は、切断サイトが切断されることにより、リガンド結合分子からリガンドが遊離する。ここで、リガンドがリンカーを介してリガンド結合分子の一部分と結合しており、該リンカーにプロテアーゼ切断配列がない場合は、リガンドは、リガンド結合分子の該一部分とリンカーを介してつながったまま遊離することになる(例えば図5を参照)。このように、リガンドがリガンド結合分子の一部と共に遊離する場合であっても、リガンド結合分子の過半から遊離する限り、リガンド結合分子からリガンドが遊離したと言える。
リガンド結合分子からリガンドが切断サイトの切断により遊離することを検出する方法として、リガンドを認識するリガンド検出用抗体等でリガンドを検出する方法がある。リガンド結合分子が抗体断片である場合、リガンド検出用抗体はリガンド結合分子と同様なエピトープに結合することが好ましい。リガンド検出用抗体を用いるリガンドの検出は、FACS、ELISAフォーマット、ALPHAスクリーン(Amplified Luminescent Proximity Homogeneous Assay)や表面プラズモン共鳴(SPR)現象を利用したBIACORE法、BLI(Bio-Layer Interferometry)法(Octet)等、周知の方法によって確認することができる(Proc. Natl. Acad. Sci. USA (2006) 103 (11), 4005-4010)。
例えば、Octetを用いてリガンドの遊離を検出する場合、リガンドを認識するリガンド検出用抗体をビオチン化し、バイオセンサーと接触させたのちに、サンプル中のリガンドに対する結合を測定することで、リガンドの遊離を検出することができる。具体的には、プロテアーゼ処理前またはプロテアーゼ処理後のリガンド結合分子とリガンドが含まれるサンプルに対して、リガンド検出抗体を用いてリガンドの量を測定し、プロテアーゼ処理前後のサンプル中のリガンド検出量を比較することでリガンドの遊離を検出することができる。また、プロテアーゼとリガンド結合分子とリガンドが含まれるサンプル及び、プロテアーゼを含まないでリガンド結合分子とリガンドが含まれるサンプルに対して、リガンド検出抗体を用いてリガンドの量を測定し、プロテアーゼ有無のサンプル中のリガンド検出量を比較することでリガンドの遊離を検出することができる。より具体的に、本願実施例中の方法によりリガンドの遊離を検出できる。リガンド結合分子がリガンドと融合され融合タンパク質を形成している場合、プロテアーゼ処理前またはプロテアーゼ処理後の融合タンパク質が含まれるサンプルに対して、リガンド検出抗体を用いてリガンドの量を測定し、プロテアーゼ処理前後のサンプル中のリガンド検出量を比較することでリガンドの遊離を検出することができる。また、プロテアーゼと融合タンパク質が含まれるサンプル及び、プロテアーゼを含まないで融合タンパク質が含まれるサンプルに対して、リガンド検出抗体を用いてリガンドの量を測定し、プロテアーゼ有無のサンプル中のリガンド検出量を比較することでリガンドの遊離を検出することができる。より具体的に、本願実施例中の方法によりリガンドの遊離を検出できる。
例えば、Octetを用いてリガンドの遊離を検出する場合、リガンドを認識するリガンド検出用抗体をビオチン化し、バイオセンサーと接触させたのちに、サンプル中のリガンドに対する結合を測定することで、リガンドの遊離を検出することができる。具体的には、プロテアーゼ処理前またはプロテアーゼ処理後のリガンド結合分子とリガンドが含まれるサンプルに対して、リガンド検出抗体を用いてリガンドの量を測定し、プロテアーゼ処理前後のサンプル中のリガンド検出量を比較することでリガンドの遊離を検出することができる。また、プロテアーゼとリガンド結合分子とリガンドが含まれるサンプル及び、プロテアーゼを含まないでリガンド結合分子とリガンドが含まれるサンプルに対して、リガンド検出抗体を用いてリガンドの量を測定し、プロテアーゼ有無のサンプル中のリガンド検出量を比較することでリガンドの遊離を検出することができる。より具体的に、本願実施例中の方法によりリガンドの遊離を検出できる。リガンド結合分子がリガンドと融合され融合タンパク質を形成している場合、プロテアーゼ処理前またはプロテアーゼ処理後の融合タンパク質が含まれるサンプルに対して、リガンド検出抗体を用いてリガンドの量を測定し、プロテアーゼ処理前後のサンプル中のリガンド検出量を比較することでリガンドの遊離を検出することができる。また、プロテアーゼと融合タンパク質が含まれるサンプル及び、プロテアーゼを含まないで融合タンパク質が含まれるサンプルに対して、リガンド検出抗体を用いてリガンドの量を測定し、プロテアーゼ有無のサンプル中のリガンド検出量を比較することでリガンドの遊離を検出することができる。より具体的に、本願実施例中の方法によりリガンドの遊離を検出できる。
また、リガンド結合分子と結合するときにリガンドの生理活性が阻害される実施態様において、リガンド結合分子から遊離することを検出する方法として、サンプル中のリガンドの生理活性を測定することによりリガンドの遊離を検出できる。具体的には、プロテアーゼ処理前またはプロテアーゼ処理後のリガンド結合分子とリガンドが含まれるサンプルに対して、リガンドの生理活性を測定し比較することによりリガンドの遊離を検出できる。また、プロテアーゼとリガンド結合分子とリガンドが含まれるサンプル及び、プロテアーゼを含まないでリガンド結合分子とリガンドが含まれるサンプル対して、リガンドの生理活性を測定し比較することによりリガンドの遊離を検出できる。リガンド結合分子がリガンドと融合され融合タンパク質を形成している場合、プロテアーゼ処理前またはプロテアーゼ処理後の融合タンパク質が含まれるサンプルに対して、リガンドの生理活性を測定し比較することによりリガンドの遊離を検出できる。また、プロテアーゼと融合タンパク質が含まれるサンプル及び、プロテアーゼを含まないで融合タンパク質が含まれるサンプル対して、リガンドの生理活性を測定し比較することによりリガンドの遊離を検出できる。
本開示のポリペプチドがリガンド結合分子である場合、ある実施態様では、リガンド結合分子はFc領域を含む。IgG抗体のFc領域を用いる場合、その種類は限定されず、IgG1、IgG2、IgG3、IgG4などのFc領域を用いることが可能である。例えば、配列番号:18004、18005、18006、18007で示されるアミノ酸配列から選ばれる一つの配列を含むFc領域、またはこれらのFc領域に改変を加えたFc領域変異体を用いることが可能である。また、本開示のいくつかの実施態様において、リガンド結合分子は抗体定常領域を含む。
本開示のポリペプチドがリガンド結合分子である場合、ある実施態様では、リガンド結合分子は抗体である。リガンド結合分子として抗体を使用する場合、リガンドへの結合は可変領域により実現される。更に具体的ないくつかの実施態様において、リガンド結合分子はIgG抗体である。リガンド結合分子としてIgG抗体を使用する場合、その種類は限定されず、IgG1、IgG2、IgG3、IgG4などを使用することが出来る。リガンド結合分子としてIgG抗体を使用する場合でも、リガンドへの結合は可変領域により実現され、IgG抗体の二つの可変領域の片方でも両方でも、リガンドへの結合を実現できる。
本開示のポリペプチドがリガンド結合分子である場合、ある実施態様では、リガンド結合分子中のプロテアーゼ切断配列が切断されることで、リガンド結合分子中のリガンド結合活性を有するドメインが分断され、リガンドへの結合が減弱される。例えば、リガンド結合分子としてIgG抗体を使用する場合、抗体可変領域中にプロテアーゼ切断配列を設け、切断状態においては、完全なる抗体可変領域を形成できなくなり、リガンドへの結合が減弱される実施態様が挙げられる。
本開示のポリペプチドがリガンド結合分子である場合、ある実施態様では、リガンドは未切断のリガンド結合分子と結合することでその生物活性が阻害される。リガンドの生物活性が阻害される実施態様は限定されないが、その例として、例えば、未切断のリガンド結合分子とリガンドの結合は、リガンドとその結合パートナーの結合を実質的または有意的に妨害または競合する実施態様が挙げられる。リガンド結合分子としてリガンド中和活性を有する抗体またはその断片を使用する場合、リガンドと結合したリガンド結合分子がその中和活性を発揮することでリガンドの生物活性が阻害されることが可能である。
本開示のポリペプチドがリガンド結合分子である場合、ある実施態様では、未切断のリガンド結合分子は、リガンドと結合することによりリガンドの生物活性を十分に中和できることが好ましい。即ち、未切断のリガンド結合分子と結合しているリガンドの生物活性が、未切断のリガンド結合分子と結合していないリガンドの生物活性より低いことが好ましい。これに限定されるものではないが、例えば未切断のリガンド結合分子と結合しているリガンドの生物活性が、未切断のリガンド結合分子と結合していないリガンドの生物活性に比較して、90%以下、好ましくは80%以下、70%以下、60%以下、50%以下、40%以下、30%以下、特に好ましくは20%以下、10%以下、9%以下、8%以下、7%以下、6%以下、5%以下、4%以下、3%以下、2%以下、または1%以下であってよい。リガンドの生物活性を十分に中和することにより、リガンド結合分子を投与した場合、疾患組織に到達前にリガンドが生物活性を発揮してしまうことを防ぐことが期待できる。
あるいは、本開示によって、リガンドの生物活性を中和する方法が提供される。本開示の方法は、生物活性を中和すべきリガンドと本開示のリガンド結合性分子を接触させ、両者の結合生成物を回収する工程を含む。回収された結合生成物のリガンド結合性分子の切断によって、それによって中和されたリガンドの生物活性を復元することができる。つまり本開示のリガンドの生物活性の中和方法は、さらに付加的に、リガンド-リガンド結合性分子からなる結合生成物のリガンド結合性分子を切断してリガンドの生物活性を復元(すなわちリガンド結合性分子の中和作用を解除)する工程を含むことができる。
あるいは、本開示によって、リガンドの生物活性を中和する方法が提供される。本開示の方法は、生物活性を中和すべきリガンドと本開示のリガンド結合性分子を接触させ、両者の結合生成物を回収する工程を含む。回収された結合生成物のリガンド結合性分子の切断によって、それによって中和されたリガンドの生物活性を復元することができる。つまり本開示のリガンドの生物活性の中和方法は、さらに付加的に、リガンド-リガンド結合性分子からなる結合生成物のリガンド結合性分子を切断してリガンドの生物活性を復元(すなわちリガンド結合性分子の中和作用を解除)する工程を含むことができる。
本開示のポリペプチドがリガンド結合分子である場合、ある実施態様では、切断されたリガンド結合分子のリガンドに対する結合活性は、リガンドに対する生体内の天然の結合パートナー(例えばリガンドに対する天然の受容体)のリガンドに対する結合活性よりも低いことが好ましい。これに限定されるものではないが、例えば切断されたリガンド結合分子とリガンドの結合活性は、生体内における天然の結合パートナーとリガンドの結合量(単位結合パートナーあたり)に比較して、90%以下、好ましくは80%以下、70%以下、60%以下、50%以下、40%以下、30%以下、特に好ましくは20%以下、10%以下、9%以下、8%以下、7%以下、6%以下、5%以下、4%以下、3%以下、2%以下、または1%以下の結合量を示す。結合活性の指標は適宜所望の指標を用いてよいが、例えば解離定数(KD)を用いてよい。結合活性の評価指標として解離定数(KD)を用いる場合、切断されたリガンド結合分子のリガンドに対する解離定数(KD)が、生体内における天然の結合パートナーのリガンドに対する解離定数(KD)に比較して大きいことが、切断されたリガンド結合分子のリガンドに対する結合活性が生体内における天然の結合パートナーに比較して弱いことを示す。切断されたリガンド結合分子のリガンドに対する解離定数(KD)は、生体内における天然の結合パートナーのリガンドに対する解離定数(KD)に比較して、例えば1.1倍以上、好ましくは1.5倍以上、2倍以上、5倍以上、10倍以上、特に好ましくは100倍以上である。切断後のリガンド結合分子がリガンドに対して低い結合活性しか持たない、もしくはリガンドに対して結合活性をほぼ持たないことにより、リガンド結合分子が切断された後リガンドを遊離させることを保証し、また別のリガンド分子と再度結合してしまうことを防ぐことが期待できる。
リガンド結合分子が切断された後、抑制されたリガンドの生物活性が回復することが望ましい。切断されたリガンド結合分子のリガンドへの結合が減弱されることで、リガンド結合分子のリガンド生物活性阻害機能も減弱されることが望ましい。当業者は、リガンドの生物活性を既知の方法、例えば、リガンドとその結合パートナーとの結合を検出する方法で確認することが出来る。
本開示のポリペプチドがリガンド結合分子である場合、ある実施態様では、未切断状態のリガンド結合分子は、抗原抗体結合によりリガンドと複合体を形成する。より具体的な実施態様において、リガンド結合分子とリガンドとの複合体は、リガンド結合分子とリガンドの非共有結合、例えば抗原抗体結合により形成されている。
本開示のポリペプチドがリガンド結合分子である場合、ある実施態様では、未切断状態のリガンド結合分子はリガンドと融合され、融合タンパク質を形成した上、当該融合タンパク質内のリガンド結合分子部分とリガンド部分が更に抗原抗体結合により相互作用している。リガンド結合分子とリガンドは、リンカーを介してまたはリンカーを介さずに融合され得る。融合タンパク質中のリガンド結合分子とリガンドはリンカーを介してまたは介さずに融合されている場合でも、リガンド結合分子部分とリガンド部分の間の非共有結合は依然として存在する。言い換えれば、リガンド結合分子がリガンドと融合されている実施態様においても、リガンド結合分子部分とリガンド部分の間の非共有結合は、リガンド結合分子とリガンドが融合されていない実施態様と類似する。リガンド結合分子が切断されることにより、その非共有結合が減弱する。すなわち、リガンド結合分子とリガンドとの結合は減弱することになる。
本開示のポリペプチドがリガンド結合分子である場合、ある実施態様では、リガンド結合分子とリガンドをリンカーを介して融合させる。リガンド結合分子とリガンドを融合させるとき用いられるリンカーとして、遺伝子工学により導入し得る任意のペプチドリンカー、または合成化合物リンカー(例えば、Protein Engineering, 9 (3), 299-305, 1996参照)に開示されるリンカー等を用いることができるが、本実施態様においてはペプチドリンカーが好ましい。ペプチドリンカーの長さは特に限定されず、目的に応じて当業者が適宜選択することが可能である。例として、それだけに限定されないが、例えば、ペプチドリンカーの場合、グリシン‐セリンポリマーからリンカーを挙げることができる。但し、ペプチドリンカーの長さや配列は目的に応じて当業者が適宜選択することができる。
本開示のポリペプチドがリガンド結合分子である場合、ある実施態様では、リガンド結合分子とリガンドをリンカーを介して融合させる。リガンド結合分子とリガンドを融合させるとき用いられるリンカーとして、遺伝子工学により導入し得る任意のペプチドリンカー、または合成化合物リンカー(例えば、Protein Engineering, 9 (3), 299-305, 1996参照)に開示されるリンカー等を用いることができるが、本実施態様においてはペプチドリンカーが好ましい。ペプチドリンカーの長さは特に限定されず、目的に応じて当業者が適宜選択することが可能である。例として、それだけに限定されないが、例えば、ペプチドリンカーの場合、グリシン‐セリンポリマーからリンカーを挙げることができる。但し、ペプチドリンカーの長さや配列は目的に応じて当業者が適宜選択することができる。
合成化合物リンカー(化学架橋剤)は、ペプチドの架橋に通常用いられている架橋剤、例えばN-ヒドロキシスクシンイミド(NHS)、ジスクシンイミジルスベレート(DSS)、ビス(スルホスクシンイミジル)スベレート(BS3)、ジチオビス(スクシンイミジルプロピオネート)(DSP)、ジチオビス(スルホスクシンイミジルプロピオネート)(DTSSP)、エチレングリコールビス(スクシンイミジルスクシネート)(EGS)、エチレングリコールビス(スルホスクシンイミジルスクシネート)(スルホ-EGS)、ジスクシンイミジル酒石酸塩(DST)、ジスルホスクシンイミジル酒石酸塩(スルホ-DST)、ビス[2-(スクシンイミドオキシカルボニルオキシ)エチル]スルホン(BSOCOES)、ビス[2-(スルホスクシンイミドオキシカルボニルオキシ)エチル]スルホン(スルホ-BSOCOES)などであり、これらの架橋剤は市販されている。
本開示のいくつかの実施態様において、リガンド結合分子とリガンドの融合タンパク質はリガンド結合分子のN末端とリガンドのC末端がリンカーを介してまたはリンカーを介さず融合されてなる融合タンパク質である。
本開示のリガンド結合分子が多量体である場合、リガンドはリガンド結合分子中の任意ペプチド鎖のN末端またはC末端にリンカーを介してまたはリンカーを介さず融合されてなる融合タンパク質であって良い。一例として、リガンド結合分子がIgG抗体の場合、リガンドはVHのN末端またはVLのN末端にリンカーを介してまたはリンカーを介さず融合されても良い。
本開示のリガンド結合分子が単ドメイン抗体を含む場合、リガンド結合分子とリガンドの融合タンパク質の構造のいくつかの態様を下記に羅列する。下記態様はN末端からC末端の順に記載する。これらの融合タンパク質は、単量体でも多量体(二量体を含む)でも良いことは、本開示に触れた当業者にとって自明であろう。
リガンド - 単ドメイン抗体
リガンド - リンカー - 単ドメイン抗体
リガンド - 単ドメイン抗体 - 抗体定常領域(またはその断片)
リガンド - リンカー - 単ドメイン抗体 - 抗体定常領域(またはその断片)
リガンド - 単ドメイン抗体 - 抗体ヒンジ領域 - 抗体CH2 - 抗体CH3
リガンド - リンカー - 単ドメイン抗体 - 抗体ヒンジ領域 - 抗体CH2 - 抗体CH3
リガンド - 単ドメイン抗体
リガンド - リンカー - 単ドメイン抗体
リガンド - 単ドメイン抗体 - 抗体定常領域(またはその断片)
リガンド - リンカー - 単ドメイン抗体 - 抗体定常領域(またはその断片)
リガンド - 単ドメイン抗体 - 抗体ヒンジ領域 - 抗体CH2 - 抗体CH3
リガンド - リンカー - 単ドメイン抗体 - 抗体ヒンジ領域 - 抗体CH2 - 抗体CH3
VHとVLを含むリガンド結合分子
本開示のポリペプチドがリガンド結合分子である場合、ある実施態様では、リガンド結合分子は抗体VHと抗体VLを含む。VHとVLを含むリガンド結合分子の例として、それだけに限定されないが、例えば、Fv、scFv、Fab、Fab'、Fab’-SH、F(ab')2、完全抗体等が挙げられる。
本開示のポリペプチドがリガンド結合分子である場合、ある実施態様では、リガンド結合分子は抗体VHと抗体VLを含む。VHとVLを含むリガンド結合分子の例として、それだけに限定されないが、例えば、Fv、scFv、Fab、Fab'、Fab’-SH、F(ab')2、完全抗体等が挙げられる。
本開示のポリペプチドがリガンド結合分子である場合、ある実施態様では、リガンド結合分子に含まれるVHとVLは会合する。また、抗体VHと抗体VLの会合は、例えばプロテアーゼ切断配列の切断により解消可能である。
本開示のリガンド結合分子には、リガンド結合分子中の抗体VLもしくはその一部と抗体VHもしくはその一部との会合が、プロテアーゼ切断配列がプロテアーゼで切断されることにより解消されるリガンド結合分子が包含される。
本開示のリガンド結合分子には、リガンド結合分子中の抗体VLもしくはその一部と抗体VHもしくはその一部との会合が、プロテアーゼ切断配列がプロテアーゼで切断されることにより解消されるリガンド結合分子が包含される。
本開示のポリペプチドがリガンド結合分子である場合、ある実施態様では、リガンド結合分子が抗体VHと抗体VLを含み、リガンド結合分子のプロテアーゼ切断配列が切断されてない状態において、リガンド結合分子中の抗体VHと抗体VLは会合しており、プロテアーゼ切断配列の切断により、リガンド結合分子中の抗体VHと抗体VLの会合が解消される。リガンド結合分子中のプロテアーゼ切断配列は、切断されることによってリガンド結合分子のリガンドへの結合を減弱できる限り、リガンド結合分子中のどの位置に配置されても良い。
本開示のポリペプチドがリガンド結合分子である場合、ある実施態様では、リガンド結合分子は抗体VHと抗体VLと抗体定常領域を含む。
抗体のVHとVL、CHとCLは、Rothlisbergerら(J Mol Biol. 2005 Apr 8;347(4):773-89.)により述べられているようにドメイン間で多くのアミノ酸側鎖を介して相互作用していることが知られている。VH-CH1とVL-CLはFabドメインとして安定した構造を形成することが出来ることが知られているが、報告されている通りVHとVLの間のアミノ酸側鎖は一般的には10-5Mから10-8M範囲の解離定数で相互作用しており、VHドメインとVLドメインのみが存在する場合では会合状態を形成している割合は少ないと考えられる。
抗体のVHとVL、CHとCLは、Rothlisbergerら(J Mol Biol. 2005 Apr 8;347(4):773-89.)により述べられているようにドメイン間で多くのアミノ酸側鎖を介して相互作用していることが知られている。VH-CH1とVL-CLはFabドメインとして安定した構造を形成することが出来ることが知られているが、報告されている通りVHとVLの間のアミノ酸側鎖は一般的には10-5Mから10-8M範囲の解離定数で相互作用しており、VHドメインとVLドメインのみが存在する場合では会合状態を形成している割合は少ないと考えられる。
本開示のポリペプチドがリガンド結合分子である場合、ある実施態様では、抗体VHと抗体VLを含むリガンド結合分子にロテアーゼ切断配列が設けられ、切断前には、Fab構造において重鎖-軽鎖相互作用のすべてが二つのペプチド間で存在することに対し、プロテアーゼ切断配列を切断した際、VH(またはVHの一部)を含むペプチドとVL(またはVLの一部)を含むペプチドとの間の相互作用が減弱され、VHとVLの会合は解消されるリガンド結合分子が設計される。
本開示のポリペプチドがリガンド結合分子である場合、ある実施態様では、プロテアーゼ切断配列は抗体定常領域内に位置する。より具体的な実施態様において、プロテアーゼ切断配列は、抗体重鎖定常領域中の140番(EUナンバリング)アミノ酸より可変領域側、または、抗体重鎖定常領域中の122番(EUナンバリング)アミノ酸より可変領域側に位置する。いくつか具体的な実施態様において、プロテアーゼ切断配列は、抗体重鎖定常領域118番アミノ酸(EUナンバリング)から抗体重鎖定常領域140番アミノ酸(EUナンバリング)までの配列中の任意の位置に導入される。別のより具体的な実施態様において、プロテアーゼ切断配列は、抗体軽鎖定常領域中の130番(Kabatナンバリング)アミノ酸より可変領域側、または、抗体軽鎖定常領域中の113番(Kabatナンバリング)アミノ酸より可変領域側、抗体軽鎖定常領域中の112番(Kabatナンバリング)アミノ酸より可変領域側に位置する。いつくか具体的な実施態様において、プロテアーゼ切断配列は、抗体軽鎖定常領域108番アミノ酸(Kabatナンバリング)から抗体軽鎖定常領域131番アミノ酸(Kabatナンバリング)までの配列中の任意の位置に導入される。
本開示のポリペプチドがリガンド結合分子である場合、ある実施態様では、プロテアーゼ切断配列は抗体VH内または抗体VL内に位置する。より具体的な実施態様において、プロテアーゼ切断配列は抗体VHの7番(Kabatナンバリング)アミノ酸より抗体定常領域側、または、抗体VHの40番(Kabatナンバリング)アミノ酸より抗体定常領域側、または、抗体VHの101番(Kabatナンバリング)アミノ酸より抗体定常領域側に、または、抗体VHの109番(Kabatナンバリング)アミノ酸より抗体定常領域側に、抗体VHの111番(Kabatナンバリング)アミノ酸より抗体定常領域側に位置する。より具体的な実施態様において、切断サイト/プロテアーゼ切断配列は抗体VLの7番(Kabatナンバリング)アミノ酸より抗体定常領域側、または、抗体VLの39番(Kabatナンバリング)アミノ酸より抗体定常領域側、または、抗体VLの96番(Kabatナンバリング)アミノ酸より抗体定常領域側、または、抗体VLの104番(Kabatナンバリング)アミノ酸より抗体定常領域側、抗体VLの105番(Kabatナンバリング)アミノ酸より抗体定常領域側に位置する。
本開示のポリペプチドがリガンド結合分子である場合、ある実施態様では、プロテアーゼ切断配列は抗体VHまたは抗体VL中のループ構造を形成している残基及びループ構造に近い残基の位置に導入される。抗体VHまたは抗体VL中のループ構造とは、抗体VHまたは抗体VLの中で、α-へリックス、β-シート等の二次的構造を形成しない部分を言う。ループ構造を形成している残基及びループ構造に近い残基の位置は、具体的に:抗体VH7番アミノ酸(Kabatナンバリング)から16番アミノ酸(Kabatナンバリング)まで、40番アミノ酸(Kabatナンバリング)から47番アミノ酸(Kabatナンバリング)まで、55番アミノ酸(Kabatナンバリング)から69番アミノ酸(Kabatナンバリング)まで、73番アミノ酸(Kabatナンバリング)から79番アミノ酸(Kabatナンバリング)まで、83番アミノ酸(Kabatナンバリング)から89番アミノ酸(Kabatナンバリング)まで、95番アミノ酸(Kabatナンバリング)から99番アミノ酸(Kabatナンバリング)まで、101番アミノ酸(Kabatナンバリング)から113番アミノ酸(Kabatナンバリング)まで、抗体VL7番アミノ酸(Kabatナンバリング)から19番アミノ酸(Kabatナンバリング)まで、39番アミノ酸(Kabatナンバリング)から46番アミノ酸(Kabatナンバリング)まで、49番アミノ酸(Kabatナンバリング)から62番アミノ酸(Kabatナンバリング)まで、96番アミノ酸(Kabatナンバリング)から107番アミノ酸(Kabatナンバリング)までの範囲を指すことができる。
本開示のポリペプチドがリガンド結合分子である場合、ある実施態様では、プロテアーゼ切断配列は、抗体VH7番アミノ酸(Kabatナンバリング)から16番アミノ酸(Kabatナンバリング)まで、40番アミノ酸(Kabatナンバリング)から47番アミノ酸(Kabatナンバリング)まで、55番アミノ酸(Kabatナンバリング)から69番アミノ酸(Kabatナンバリング)まで、73番アミノ酸(Kabatナンバリング)から79番アミノ酸(Kabatナンバリング)まで、83番アミノ酸(Kabatナンバリング)から89番アミノ酸(Kabatナンバリング)まで、95番アミノ酸(Kabatナンバリング)から99番アミノ酸(Kabatナンバリング)まで、101番アミノ酸(Kabatナンバリング)から113番アミノ酸(Kabatナンバリング)までの配列中の任意位置に導入される。
本開示のポリペプチドがリガンド結合分子である場合、ある実施態様では、プロテアーゼ切断配列は、抗体VL7番アミノ酸(Kabatナンバリング)から19番アミノ酸(Kabatナンバリング)まで、39番アミノ酸(Kabatナンバリング)から46番アミノ酸(Kabatナンバリング)まで、49番アミノ酸(Kabatナンバリング)から62番アミノ酸(Kabatナンバリング)まで、96番アミノ酸(Kabatナンバリング)から107番アミノ酸(Kabatナンバリング)までの配列中の任意位置に導入される。
本開示のポリペプチドがリガンド結合分子である場合、ある実施態様では、プロテアーゼ切断配列は抗体VHまたは抗体VL中のループ構造を形成している残基及びループ構造に近い残基の位置に導入される。抗体VHまたは抗体VL中のループ構造とは、抗体VHまたは抗体VLの中で、α-へリックス、β-シート等の二次的構造を形成しない部分を言う。ループ構造を形成している残基及びループ構造に近い残基の位置は、具体的に:抗体VH7番アミノ酸(Kabatナンバリング)から16番アミノ酸(Kabatナンバリング)まで、40番アミノ酸(Kabatナンバリング)から47番アミノ酸(Kabatナンバリング)まで、55番アミノ酸(Kabatナンバリング)から69番アミノ酸(Kabatナンバリング)まで、73番アミノ酸(Kabatナンバリング)から79番アミノ酸(Kabatナンバリング)まで、83番アミノ酸(Kabatナンバリング)から89番アミノ酸(Kabatナンバリング)まで、95番アミノ酸(Kabatナンバリング)から99番アミノ酸(Kabatナンバリング)まで、101番アミノ酸(Kabatナンバリング)から113番アミノ酸(Kabatナンバリング)まで、抗体VL7番アミノ酸(Kabatナンバリング)から19番アミノ酸(Kabatナンバリング)まで、39番アミノ酸(Kabatナンバリング)から46番アミノ酸(Kabatナンバリング)まで、49番アミノ酸(Kabatナンバリング)から62番アミノ酸(Kabatナンバリング)まで、96番アミノ酸(Kabatナンバリング)から107番アミノ酸(Kabatナンバリング)までの範囲を指すことができる。
本開示のポリペプチドがリガンド結合分子である場合、ある実施態様では、プロテアーゼ切断配列は、抗体VH7番アミノ酸(Kabatナンバリング)から16番アミノ酸(Kabatナンバリング)まで、40番アミノ酸(Kabatナンバリング)から47番アミノ酸(Kabatナンバリング)まで、55番アミノ酸(Kabatナンバリング)から69番アミノ酸(Kabatナンバリング)まで、73番アミノ酸(Kabatナンバリング)から79番アミノ酸(Kabatナンバリング)まで、83番アミノ酸(Kabatナンバリング)から89番アミノ酸(Kabatナンバリング)まで、95番アミノ酸(Kabatナンバリング)から99番アミノ酸(Kabatナンバリング)まで、101番アミノ酸(Kabatナンバリング)から113番アミノ酸(Kabatナンバリング)までの配列中の任意位置に導入される。
本開示のポリペプチドがリガンド結合分子である場合、ある実施態様では、プロテアーゼ切断配列は、抗体VL7番アミノ酸(Kabatナンバリング)から19番アミノ酸(Kabatナンバリング)まで、39番アミノ酸(Kabatナンバリング)から46番アミノ酸(Kabatナンバリング)まで、49番アミノ酸(Kabatナンバリング)から62番アミノ酸(Kabatナンバリング)まで、96番アミノ酸(Kabatナンバリング)から107番アミノ酸(Kabatナンバリング)までの配列中の任意位置に導入される。
本開示のポリペプチドがリガンド結合分子である場合、ある実施態様では、プロテアーゼ切断配列は抗体VHと抗体定常領域の境界付近に位置する。抗体VHと抗体重鎖定常領域の境界付近とは、抗体VHの101番(Kabatナンバリング)のアミノ酸から抗体重鎖定常領域140番(EUナンバリング)のアミノ酸の間を指すことができ、または抗体VHの109番(Kabatナンバリング)のアミノ酸から抗体重鎖定常領域122番(EUナンバリング)のアミノ酸の間を指すことができ、または抗体VHの111番(Kabatナンバリング)のアミノ酸から抗体重鎖定常領域122番(EUナンバリング)のアミノ酸の間を指すことが出来る。また、抗体VHと抗体軽鎖定常領域を連結している場合、抗体VHと抗体軽鎖定常領域の境界付近とは、抗体VHの101番(Kabatナンバリング)のアミノ酸から抗体軽鎖定常領域130番(Kabatナンバリング)のアミノ酸の間を指すことができ、または抗体VHの109番(Kabatナンバリング)のアミノ酸から抗体軽鎖定常領域113番(Kabatナンバリング)のアミノ酸の間を指すことができ、または抗体VHの111番(Kabatナンバリング)のアミノ酸から抗体軽鎖定常領域112番(Kabatナンバリング)のアミノ酸の間を指すことが出来る。
本開示のポリペプチドがリガンド結合分子である場合、ある実施態様では、プロテアーゼ切断配列は抗体VLと抗体定常領域の境界付近に位置する。抗体VLと抗体軽鎖定常領域の境界付近とは、抗体VLの96番(Kabatナンバリング)のアミノ酸から抗体軽鎖定常領域130番(Kabatナンバリング)のアミノ酸の間を指すことができ、または抗体VLの104番(Kabatナンバリング)のアミノ酸から抗体軽鎖定常領域113番(Kabatナンバリング)のアミノ酸の間を指すことができ、または抗体VLの105番(Kabatナンバリング)のアミノ酸から抗体軽鎖定常領域112番(Kabatナンバリング)のアミノ酸の間を指すことが出来る。抗体VLと抗体重鎖定常領域を連結している場合、抗体VLと抗体重鎖定常領域の境界付近とは、抗体VLの96番(Kabatナンバリング)のアミノ酸から抗体重鎖定常領域140番(EUナンバリング)のアミノ酸の間を指すことができ、または抗体VLの104番(Kabatナンバリング)のアミノ酸から抗体重鎖定常領域122番(EUナンバリング)のアミノ酸の間を指すことができ、または抗体VLの105番(Kabatナンバリング)のアミノ酸から抗体重鎖定常領域122番(EUナンバリング)のアミノ酸の間を指すことが出来る。
プロテアーゼ切断配列は、リガンド結合分子中に複数設けられることが出来、例えば、抗体定常領域内、抗体VH内、抗体VL内、抗体VHと抗体定常領域の境界付近、抗体VLと抗体定常領域の境界付近から選ばれる複数個所に設けることが出来る。また、本開示に触れた当業者であれば、抗体VHと抗体VLを入れ替える等、抗体VHと抗体VLと抗体定常領域を含む分子の形を変更することは可能であり、当該分子形は本開示の範囲から逸脱しない。
単ドメイン抗体を含むリガンド結合分子
本開示のポリペプチドがリガンド結合分子である場合、ある実施態様では、リガンド結合分子は単ドメイン抗体を含む。リガンド結合分子中のプロテアーゼ切断配列は、切断されることによってリガンド結合分子のリガンドへの結合を減弱できる限り、リガンド結合分子中のどの位置に配置されても良い。
本開示のポリペプチドがリガンド結合分子である場合、ある実施態様では、リガンド結合分子は単ドメイン抗体を含む。リガンド結合分子中のプロテアーゼ切断配列は、切断されることによってリガンド結合分子のリガンドへの結合を減弱できる限り、リガンド結合分子中のどの位置に配置されても良い。
本開示のポリペプチドが単ドメイン抗体を含むリガンド結合分子の場合、ある実施態様において、プロテアーゼ切断配列はリガンド結合分子中の単ドメイン抗体内に導入される。いくつかのより具体的な実施態様において、プロテアーゼ切断配列は単ドメイン抗体中のループ構造を形成している残基及びループ構造に近い残基の位置に導入される。単ドメイン抗体中のループ構造とは、単ドメイン抗体の中で、α-へリックス、β-シート等の二次的構造を形成しない部分を言う。
本開示のポリペプチドが単ドメイン抗体を含むリガンド結合分子の場合、単ドメイン抗体がVHHまたは単ドメインVH抗体である実施態様において、ループ構造を形成している残基及びループ構造に近い残基の位置は、具体的に:単ドメイン抗体7番アミノ酸(Kabatナンバリング)から17番アミノ酸(Kabatナンバリング)まで、12番アミノ酸(Kabatナンバリング)から17番アミノ酸(Kabatナンバリング)まで、31番アミノ酸(Kabatナンバリング)から35b番アミノ酸(Kabatナンバリング)まで、40番アミノ酸(Kabatナンバリング)から47番アミノ酸(Kabatナンバリング)まで、50番アミノ酸(Kabatナンバリング)から65番アミノ酸(Kabatナンバリング)まで、55番アミノ酸(Kabatナンバリング)から69番アミノ酸(Kabatナンバリング)まで、73番アミノ酸(Kabatナンバリング)から79番アミノ酸(Kabatナンバリング)まで、83番アミノ酸(Kabatナンバリング)から89番アミノ酸(Kabatナンバリング)まで、95番アミノ酸(Kabatナンバリング)から99番アミノ酸(Kabatナンバリング)まで、95番アミノ酸(Kabatナンバリング)から102番アミノ酸(Kabatナンバリング)まで、101番アミノ酸(Kabatナンバリング)から113番アミノ酸(Kabatナンバリング)までの範囲を指すことが出来る。
本開示のポリペプチドが単ドメイン抗体を含むリガンド結合分子の場合、単ドメイン抗体がVHHまたは単ドメインVH抗体である実施態様において、プロテアーゼ切断配列は、単ドメイン抗体の下記配列から選ばれる一つまたは複数の配列に含まれる一つまたは複数の位置に導入される:
単ドメイン抗体7番アミノ酸(Kabatナンバリング)から17番アミノ酸(Kabatナンバリング)までの配列、単ドメイン抗体12番アミノ酸(Kabatナンバリング)から17番アミノ酸(Kabatナンバリング)までの配列、単ドメイン抗体31番アミノ酸(Kabatナンバリング)から35b番アミノ酸(Kabatナンバリング)までの配列、単ドメイン抗体40番アミノ酸(Kabatナンバリング)から47番アミノ酸(Kabatナンバリング)までの配列、単ドメイン抗体50番アミノ酸(Kabatナンバリング)から65番アミノ酸(Kabatナンバリング)までの配列、単ドメイン抗体55番アミノ酸(Kabatナンバリング)から69番アミノ酸(Kabatナンバリング)までの配列、単ドメイン抗体73番アミノ酸(Kabatナンバリング)から79番アミノ酸(Kabatナンバリング)までの配列、単ドメイン抗体83番アミノ酸(Kabatナンバリング)から89番アミノ酸(Kabatナンバリング)までの配列、単ドメイン抗体95番アミノ酸(Kabatナンバリング)から99番アミノ酸(Kabatナンバリング)までの配列、単ドメイン抗体95番アミノ酸(Kabatナンバリング)から102番アミノ酸(Kabatナンバリング)までの配列、単ドメイン抗体101番アミノ酸(Kabatナンバリング)から113番アミノ酸(Kabatナンバリング)までの配列。
単ドメイン抗体7番アミノ酸(Kabatナンバリング)から17番アミノ酸(Kabatナンバリング)までの配列、単ドメイン抗体12番アミノ酸(Kabatナンバリング)から17番アミノ酸(Kabatナンバリング)までの配列、単ドメイン抗体31番アミノ酸(Kabatナンバリング)から35b番アミノ酸(Kabatナンバリング)までの配列、単ドメイン抗体40番アミノ酸(Kabatナンバリング)から47番アミノ酸(Kabatナンバリング)までの配列、単ドメイン抗体50番アミノ酸(Kabatナンバリング)から65番アミノ酸(Kabatナンバリング)までの配列、単ドメイン抗体55番アミノ酸(Kabatナンバリング)から69番アミノ酸(Kabatナンバリング)までの配列、単ドメイン抗体73番アミノ酸(Kabatナンバリング)から79番アミノ酸(Kabatナンバリング)までの配列、単ドメイン抗体83番アミノ酸(Kabatナンバリング)から89番アミノ酸(Kabatナンバリング)までの配列、単ドメイン抗体95番アミノ酸(Kabatナンバリング)から99番アミノ酸(Kabatナンバリング)までの配列、単ドメイン抗体95番アミノ酸(Kabatナンバリング)から102番アミノ酸(Kabatナンバリング)までの配列、単ドメイン抗体101番アミノ酸(Kabatナンバリング)から113番アミノ酸(Kabatナンバリング)までの配列。
本開示のポリペプチドが単ドメイン抗体を含むリガンド結合分子の場合、単ドメイン抗体が単ドメインVL抗体である実施態様において、ループ構造を形成している残基及びループ構造に近い残基の位置は、具体的に:単ドメイン抗体7番アミノ酸(Kabatナンバリング)から19番アミノ酸(Kabatナンバリング)まで、24番アミノ酸(Kabatナンバリング)から34番アミノ酸(Kabatナンバリング)まで、39番アミノ酸(Kabatナンバリング)から46番アミノ酸(Kabatナンバリング)まで、49番アミノ酸(Kabatナンバリング)から62番アミノ酸(Kabatナンバリング)まで、50番アミノ酸(Kabatナンバリング)から56番アミノ酸(Kabatナンバリング)まで、89番アミノ酸(Kabatナンバリング)から97番アミノ酸(Kabatナンバリング)まで、96番アミノ酸(Kabatナンバリング)から107番アミノ酸(Kabatナンバリング)までの範囲を指すことができる。
本開示のポリペプチドが単ドメイン抗体を含むリガンド結合分子の場合、単ドメイン抗体が単ドメインVL抗体である実施態様において、プロテアーゼ切断配列は、単ドメイン抗体の下記配列から選ばれる一つまたは複数の配列に含まれる一つまたは複数の位置に導入される:
単ドメイン抗体7番アミノ酸(Kabatナンバリング)から19番アミノ酸(Kabatナンバリング)までの配列、単ドメイン抗体24番アミノ酸(Kabatナンバリング)から34番アミノ酸(Kabatナンバリング)までの配列、単ドメイン抗体39番アミノ酸(Kabatナンバリング)から46番アミノ酸(Kabatナンバリング)までの配列、単ドメイン抗体49番アミノ酸(Kabatナンバリング)から62番アミノ酸(Kabatナンバリング)までの配列、単ドメイン抗体50番アミノ酸(Kabatナンバリング)から56番アミノ酸(Kabatナンバリング)までの配列、単ドメイン抗体89番アミノ酸(Kabatナンバリング)から97番アミノ酸(Kabatナンバリング)までの配列、単ドメイン抗体96番アミノ酸(Kabatナンバリング)から107番アミノ酸(Kabatナンバリング)までの配列。
単ドメイン抗体7番アミノ酸(Kabatナンバリング)から19番アミノ酸(Kabatナンバリング)までの配列、単ドメイン抗体24番アミノ酸(Kabatナンバリング)から34番アミノ酸(Kabatナンバリング)までの配列、単ドメイン抗体39番アミノ酸(Kabatナンバリング)から46番アミノ酸(Kabatナンバリング)までの配列、単ドメイン抗体49番アミノ酸(Kabatナンバリング)から62番アミノ酸(Kabatナンバリング)までの配列、単ドメイン抗体50番アミノ酸(Kabatナンバリング)から56番アミノ酸(Kabatナンバリング)までの配列、単ドメイン抗体89番アミノ酸(Kabatナンバリング)から97番アミノ酸(Kabatナンバリング)までの配列、単ドメイン抗体96番アミノ酸(Kabatナンバリング)から107番アミノ酸(Kabatナンバリング)までの配列。
プロテアーゼ切断配列は、リガンド結合分子中に複数設けられることが出来、例えば、リガンド結合分子中の単ドメイン抗体内の複数個所に設けることが出来る。
本開示のポリペプチドが単ドメイン抗体を含むリガンド結合分子の場合、ある実施態様では、未切断のリガンド結合分子が単ドメイン抗体単体より長い半減期を有する。リガンド結合分子の血中半減期を単ドメイン抗体単体の血中半減期より長くする実施態様の例として、それだけに限定されないが、リガンド結合分子の分子量を大きくすること、または単ドメイン抗体とFcRn結合性を有する部分と融合させること、または単ドメイン抗体とアルブミン結合性を有する部分と融合させること、または単ドメイン抗体とPEG化されている部分と融合させることが挙げられる。
本開示のポリペプチドが単ドメイン抗体を含むリガンド結合分子の場合、単ドメイン抗体単体とリガンド結合分子の半減期比較は、ヒトにおける血中半減期で比較することが好ましい。ヒトでの血中半減期を測定することが困難である場合には、マウス(例えば、正常マウス、ヒト抗原発現トランスジェニックマウス、ヒトFcRn発現トランスジェニックマウス、等)またはサル(例えば、カニクイザルなど)での血中半減期をもとに、ヒトでの血中半減期を予測することができる。
本開示のポリペプチドが単ドメイン抗体を含むリガンド結合分子の場合、リガンド結合分子の血中半減期を単ドメイン抗体単体の血中半減期より長くする一実施態様として、リガンド結合分子の分子量を大きくすることが挙げられる。好ましい実施態様として、リガンド結合分子の分子量が60kDa以上である。分子量が60kDa以上である分子は通常、血中に存在するとき、腎臓によるクリアランスが発生する可能性が低く、血中半減期が長い可能性が高い(J Biol Chem. 1988 Oct 15;263(29):15064-70参照)。
本開示のポリペプチドが単ドメイン抗体を含むリガンド結合分子の場合、リガンド結合分子の血中半減期を単ドメイン抗体単体の血中半減期より長くする一実施態様として、単ドメイン抗体とFcRn結合領域と融合させることが挙げられる。
本開示のポリペプチドが単ドメイン抗体を含むリガンド結合分子の場合、リガンド結合分子の血中半減期を単ドメイン抗体単体の血中半減期より長くする一実施態様として、単ドメイン抗体とアルブミン結合性を有する部分と融合させる方法がある。アルブミンは腎排泄を受けず、かつFcRn結合性を有するため、血中半減期が17~19日と長い(J Clin Invest. 1953 Aug; 32(8): 746-768.)。そのためアルブミンと結合しているタンパク質は嵩高くなり、かつ間接的にFcRnと結合することが可能となるため、血中半減期が増加することが報告されている(Antibodies 2015, 4(3), 141-156)。
更に、リガンド結合分子の血中半減期を単ドメイン抗体単体の血中半減期より長くする一実施態様として、単ドメイン抗体とPEG化されている部分と融合させる方法がある。タンパク質をPEG化することでタンパク質を嵩高くし、同時に血中のプロテアーゼによる分解を抑えることで、タンパク質の血中半減期が延長すると考えられている(J Pharm Sci. 2008 Oct;97(10):4167-83.)。
リガンドに結合可能な分子中にプロテアーゼ切断配列を導入する方法の例として、リガンドに結合可能なポリペプチドのアミノ酸配列中にプロテアーゼ切断配列を挿入する方法や、リガンドに結合可能なポリペプチドのアミノ酸配列の一部をプロテアーゼ切断配列に置き換える方法等が挙げられる。
リガンドに結合可能な分子を取得する方法の例として、リガンドに結合する能力を有するリガンド結合領域を取得する方法が挙げられる。リガンド結合領域は、例えば、公知の抗体の作製方法を用いた方法により得られる。
該作製方法により得られた抗体は、そのままリガンド結合領域に用いてもよく、得られた抗体のうちFv領域のみを用いてもよく、該Fv領域が一本鎖(「sc」とも称する。)で抗原を認識し得る場合には、該一本鎖のみを用いてもよい。また、Fv領域を含むFab領域を用いてもよい。
該作製方法により得られた抗体は、そのままリガンド結合領域に用いてもよく、得られた抗体のうちFv領域のみを用いてもよく、該Fv領域が一本鎖(「sc」とも称する。)で抗原を認識し得る場合には、該一本鎖のみを用いてもよい。また、Fv領域を含むFab領域を用いてもよい。
リガンドに結合可能な分子にプロテアーゼ切断配列を導入した分子は、開示のリガンド結合分子になる。リガンド結合分子に対して、任意的に、当該プロテアーゼ切断配列に対応するプロテアーゼの処理によりリガンド結合分子が切断されるかを確認することが出来る。例えば、リガンドに結合可能な分子にプロテアーゼ切断配列を導入した分子をプロテアーゼと接触させ、プロテアーゼ処理後産物の分子量をSDS-PAGE等の電気泳動法で確認することにより、プロテアーゼ切断配列が切断されたか否かを確認することができる。
本開示のポリペプチドがリガンド結合分子の場合、ある実施形態では、リガンド-リガンド結合分子の製造方法も提供する。例えば、リガンド結合分子とリガンドを接触させる工程と、当該リガンド結合分子とリガンドからなる複合体を回収する工程を含む、リガンド-リガンド結合分子複合体の製造方法も提供する。このような複合体は、例えば薬学的に許容される担体と配合することによって、医薬組成物とすることができる。
本開示はまた、切断された状態でリガンドへの結合が減弱されるリガンド結合分子、または当該リガンド結合分子とリガンドを融合させた融合タンパク質を製造する方法にも関する。本開示のポリペプチドがリガンド結合分子である場合、ある実施態様では、リガンドに結合可能な分子中に、プロテアーゼ切断配列を導入することを含むリガンド結合分子または融合タンパク質の製造方法が提供される。
ポリペプチドの製造方法
また、本開示は、プロテアーゼ基質またはプロテアーゼ切断配列を含むポリペプチドをエンコードするポリヌクレオチドにも関する。
また、本開示は、プロテアーゼ基質またはプロテアーゼ切断配列を含むポリペプチドをエンコードするポリヌクレオチドにも関する。
本開示におけるポリヌクレオチドは、通常、適当なベクターへ担持(挿入)され、宿主細胞へ導入される。該ベクターとしては、挿入した核酸を安定に保持するものであれば特に制限されず、例えば宿主に大腸菌を用いるのであれば、クローニング用ベクターとしてはpBluescriptベクター(Stratagene社製)などが好ましいが、市販の種々のベクターを利用することができる。本開示のポリペプチドを生産する目的においてベクターを用いる場合には、特に発現ベクターが有用である。発現ベクターとしては、試験管内、大腸菌内、培養細胞内、生物個体内でポリペプチドを発現するベクターであれば特に制限されないが、例えば、試験管内発現であればpBESTベクター(プロメガ社製)、大腸菌であればpETベクター(Invitrogen社製)、培養細胞であればpME18S-FL3ベクター(GenBank Accession No. AB009864)、生物個体であればpME18Sベクター(Mol Cell Biol. 8:466-472(1988))などが好ましい。ベクターへの本開示のDNAの挿入は、常法により、例えば、制限酵素サイトを用いたリガーゼ反応により行うことができる(Current protocols in Molecular Biology edit. Ausubel et al. (1987) Publish. John Wiley & Sons.Section 11.4-11.11)。
上記宿主細胞としては特に制限はなく、目的に応じて種々の宿主細胞が用いられる。ポリペプチドを発現させるための細胞としては、例えば、細菌細胞(例:ストレプトコッカス、スタフィロコッカス、大腸菌、ストレプトミセス、枯草菌)、真菌細胞(例:酵母、アスペルギルス)、昆虫細胞(例:ドロソフィラS2、スポドプテラSF9)、動物細胞(例:CHO、COS、HeLa、C127、3T3、BHK、HEK293、Bowes メラノーマ細胞)および植物細胞を例示することができる。宿主細胞へのベクター導入は、例えば、リン酸カルシウム沈殿法、電気パルス穿孔法(Current protocols in Molecular Biology edit. Ausubel et al. (1987) Publish. John Wiley & Sons.Section 9.1-9.9)、リポフェクタミン法(GIBCO-BRL社製)、マイクロインジェクション法などの公知の方法で行うことが可能である。
宿主細胞において発現したポリペプチドを小胞体の内腔に、細胞周辺腔に、または細胞外の環境に分泌させるために、適当な分泌シグナルを目的のポリペプチドに組み込むことができる。これらのシグナルは目的のポリペプチドに対して内因性であっても、異種シグナルであってもよい。
上記製造方法におけるポリペプチドの回収は、本開示のポリペプチドが培地に分泌される場合は、培地を回収する。本開示のポリペプチドが細胞内に産生される場合は、その細胞をまず溶解し、その後にポリペプチドを回収する。
組換え細胞培養物から本開示のポリペプチドを回収し精製するには、硫酸アンモニウムまたはエタノール沈殿、酸抽出、アニオンまたはカチオン交換クロマトグラフィー、ホスホセルロースクロマトグラフィー、疎水性相互作用クロマトグラフィー、アフィニティクロマトグラフィー、ヒドロキシルアパタイトクロマトグラフィーおよびレクチンクロマトグラフィーを含めた公知の方法を用いることができる。
治療
本明細書で用いられる「治療」(および、その文法上の派生語、例えば「治療する」、「治療すること」など)は、治療される個体の自然経過を改変することを企図した臨床的介入を意味し、予防のためにも、臨床的病態の経過の間にも実施され得る。治療の望ましい効果は、それだけに限定されるものではないが、疾患の発生または再発の防止、症状の軽減、疾患による任意の直接的または間接的な病理的影響の減弱、転移の防止、疾患の進行速度の低減、疾患状態の回復または緩和、および寛解または改善された予後を含む。いくつかの実施態様において、本開示のプロテアーゼ切断配列を含むポリペプチドは、疾患の発症を遅らせる、または疾患の進行を遅くするために用いられる。
本明細書で用いられる「治療」(および、その文法上の派生語、例えば「治療する」、「治療すること」など)は、治療される個体の自然経過を改変することを企図した臨床的介入を意味し、予防のためにも、臨床的病態の経過の間にも実施され得る。治療の望ましい効果は、それだけに限定されるものではないが、疾患の発生または再発の防止、症状の軽減、疾患による任意の直接的または間接的な病理的影響の減弱、転移の防止、疾患の進行速度の低減、疾患状態の回復または緩和、および寛解または改善された予後を含む。いくつかの実施態様において、本開示のプロテアーゼ切断配列を含むポリペプチドは、疾患の発症を遅らせる、または疾患の進行を遅くするために用いられる。
医薬組成物
また本開示は、プロテアーゼ切断配列を含むポリペプチドおよび医薬的に許容される担体を含む医薬組成物(薬剤)、プロテアーゼ切断配列を含むポリペプチドとリガンドおよび医薬的に許容される担体を含む医薬組成物(薬剤)、プロテアーゼ切断配列を含むポリペプチドとリガンドが融合されている融合タンパク質および医薬的に許容される担体を含む医薬組成物(薬剤)にも関する。
また本開示は、プロテアーゼ切断配列を含むポリペプチドおよび医薬的に許容される担体を含む医薬組成物(薬剤)、プロテアーゼ切断配列を含むポリペプチドとリガンドおよび医薬的に許容される担体を含む医薬組成物(薬剤)、プロテアーゼ切断配列を含むポリペプチドとリガンドが融合されている融合タンパク質および医薬的に許容される担体を含む医薬組成物(薬剤)にも関する。
本開示において医薬組成物とは、通常、疾患の治療もしくは予防、あるいは検査・診断のための薬剤をいう。
また、本開示において、「プロテアーゼ切断配列を含むポリペプチドを含む医薬組成物」との用語は、「プロテアーゼ切断配列を含むポリペプチドを治療対象に投与することを含む疾患の治療方法」と言い換えることが可能であり、「疾患を治療するためのプロテアーゼ切断配列を含むポリペプチドの使用」と言い換えることも可能であるし、「疾患を治療するための医薬の製造におけるプロテアーゼ切断配列を含むポリペプチドの使用」と言い換えることも可能である。
また、本開示において、「プロテアーゼ切断配列を含むポリペプチドとリガンドを含む医薬組成物」との用語は、「プロテアーゼ切断配列を含むポリペプチドとリガンドを治療対象に投与することを含む疾患の治療方法」と言い換えることが可能であり、「疾患を治療するためのプロテアーゼ切断配列を含むポリペプチドとリガンドの使用」と言い換えることも可能であるし、「疾患を治療するための医薬の製造におけるプロテアーゼ切断配列を含むポリペプチドとリガンドの使用」と言い換えることも可能である。
また、本開示において、「融合タンパク質を含む医薬組成物」との用語は、「融合タンパク質を治療対象に投与することを含む疾患の治療方法」と言い換えることが可能であり、「疾患を治療するための融合タンパク質の使用」と言い換えることも可能であるし、「疾患を治療するための医薬の製造における融合タンパク質の使用」と言い換えることも可能である。
また、本開示において、「プロテアーゼ切断配列を含むポリペプチドを含む医薬組成物」との用語は、「プロテアーゼ切断配列を含むポリペプチドを治療対象に投与することを含む疾患の治療方法」と言い換えることが可能であり、「疾患を治療するためのプロテアーゼ切断配列を含むポリペプチドの使用」と言い換えることも可能であるし、「疾患を治療するための医薬の製造におけるプロテアーゼ切断配列を含むポリペプチドの使用」と言い換えることも可能である。
また、本開示において、「プロテアーゼ切断配列を含むポリペプチドとリガンドを含む医薬組成物」との用語は、「プロテアーゼ切断配列を含むポリペプチドとリガンドを治療対象に投与することを含む疾患の治療方法」と言い換えることが可能であり、「疾患を治療するためのプロテアーゼ切断配列を含むポリペプチドとリガンドの使用」と言い換えることも可能であるし、「疾患を治療するための医薬の製造におけるプロテアーゼ切断配列を含むポリペプチドとリガンドの使用」と言い換えることも可能である。
また、本開示において、「融合タンパク質を含む医薬組成物」との用語は、「融合タンパク質を治療対象に投与することを含む疾患の治療方法」と言い換えることが可能であり、「疾患を治療するための融合タンパク質の使用」と言い換えることも可能であるし、「疾患を治療するための医薬の製造における融合タンパク質の使用」と言い換えることも可能である。
本開示の医薬組成物は、当業者に公知の方法を用いて製剤化され得る。例えば、水もしくはそれ以外の薬学的に許容し得る液との無菌性溶液、又は懸濁液剤の注射剤の形で非経口的に使用され得る。例えば、薬理学上許容される担体もしくは媒体、具体的には、滅菌水や生理食塩水、植物油、乳化剤、懸濁剤、界面活性剤、安定剤、香味剤、賦形剤、ベヒクル、防腐剤、結合剤等と適宜組み合わせて、一般に認められた製薬実施に要求される単位用量形態で混和することによって製剤化され得る。これら製剤における有効成分量は、指示された範囲の適当な容量が得られるように設定される。
注射のための無菌組成物は注射用蒸留水のようなベヒクルを用いて通常の製剤実施にしたがって処方され得る。注射用の水溶液としては、例えば生理食塩水、ブドウ糖やその他の補助薬(例えばD-ソルビトール、D-マンノース、D-マンニトール、塩化ナトリウム)を含む等張液が挙げられる。適切な溶解補助剤、例えばアルコール(エタノール等)、ポリアルコール(プロピレングリコール、ポリエチレングリコール等)、非イオン性界面活性剤(ポリソルベート80(TM)、HCO-50等)が併用され得る。
油性液としてはゴマ油、大豆油が挙げられ、溶解補助剤として安息香酸ベンジル及び/またはベンジルアルコールも併用され得る。また、緩衝剤(例えば、リン酸塩緩衝液及び酢酸ナトリウム緩衝液)、無痛化剤(例えば、塩酸プロカイン)、安定剤(例えば、ベンジルアルコール及びフェノール)、酸化防止剤と配合され得る。調製された注射液は通常、適切なアンプルに充填される。
本開示の医薬組成物は、好ましくは非経口投与により投与される。例えば、注射剤型、経鼻投与剤型、経肺投与剤型、経皮投与型の組成物が投与される。例えば、静脈内注射、筋肉内注射、腹腔内注射、皮下注射などにより全身または局部的に投与され得る。
投与方法は、患者の年齢、症状により適宜選択され得る。本開示の医薬組成物の投与量は、例えば、一回につき体重1 kgあたり0.0001 mgから1000 mgの範囲に設定され得る。または、例えば、患者あたり0.001~100000 mgの投与量が設定され得るが、本開示はこれらの数値に必ずしも制限されるものではない。投与量及び投与方法は、患者の体重、年齢、症状などにより変動するが、当業者であればそれらの条件を考慮し適当な投与量及び投与方法を設定することが可能である。
本開示のポリペプチドがリガンド結合分子の場合、ある実施態様では、リガンド結合分子を含む組成物を個体に投与することが出来る。個体に投与されたリガンド結合分子は、個体内、例えば、血中、組織中等で、個体内に元々存在しているリガンドと結合し、リガンドと結合したまま更に生体内で運搬される。疾患組織に運搬されたリガンド結合分子は、疾患組織にて切断され、リガンドに対する結合が減弱し、疾患組織にて結合しているリガンドをリリースすることが出来る。リリースされたリガンドは、疾患組織にて生物活性を発揮し、疾患組織に起因する疾患を治療することが出来る。リガンド結合分子がリガンドと結合している時リガンドの生物活性を抑制し、かつリガンド結合分子が疾患組織特異的に切断される実施態様においては、運搬時のリガンドの生物活性を発揮させることなく、疾患組織にて切断されて初めてリガンドの生物活性を発揮させ、疾患を治療することが出来、全身副作用を抑えることが出来る。
本開示のポリペプチドがリガンド結合分子の場合、ある実施態様では、リガンド結合分子を含む組成物と、リガンドを含む組成物を別々にまたは同時に個体に投与することが出来る。また、リガンド結合分子とリガンドの両方を含む組成物を個体に投与するもできる。リガンド結合分子とリガンドの両方を含む組成物を個体に投与する場合、当該組成物中のリガンド結合分子とリガンドは複合体を形成していても良い。リガンド結合分子とリガンドの両方を個体に投与した場合、リガンド結合分子は、個体に投与されたリガンドと結合し、リガンドを結合したまま生体内で運搬される。疾患組織に運搬されたリガンド結合分子は、疾患組織にて切断され、リガンドに対する結合が減弱し、疾患組織にて結合しているリガンドをリリースすることが出来る。リリースされたリガンドは、疾患組織にて生物活性を発揮し、疾患組織に起因する疾患を治療することが出来る。リガンド結合分子がリガンドと結合している時リガンドの生物活性を抑制し、かつリガンド結合分子が疾患組織特異的に切断される実施態様においては、運搬時のリガンドの生物活性を発揮させることなく、疾患組織にて切断されて初めてリガンドの生物活性を発揮させ、疾患を治療することが出来、全身副作用を抑えることが出来る。個体に投与されたリガンド結合分子は、個体に投与されたリガンド以外に、個体内に元々存在するリガンドとも結合することも可能であり、個体内に元々存在するリガンドまたは個体に投与されたリガンドを結合したまま生体内で運搬することが出来る。
本開示のポリペプチドがリガンド結合分子の場合、ある実施態様では、リガンド結合分子とリガンドを融合した融合タンパク質を個体に投与することが出来る。当該いくつかの実施態様において、融合タンパク質中のリガンド結合分子とリガンドはリンカーを介してまたは介さずに融合タンパク質を形成しているが、リガンド結合分子部分とリガンド部分の間の非共有結合は依然として存在する。リガンド結合分子とリガンドを融合した融合タンパク質を個体に投与した場合、融合タンパク質は生体内で運搬され、疾患組織で融合タンパク質中のリガンド結合分子部分が切断されることにより、リガンド結合分子部分のリガンドに対する非共有結合が減弱され、リガンド及びリガンド結合分子の一部が融合タンパク質からリリースされる。リリースされたリガンド及びリガンド結合分子の一部は、疾患組織にてリガンドの生物活性を発揮し、疾患組織に起因する疾患を治療することが出来る。リガンド結合分子がリガンドと結合している時リガンドの生物活性を抑制し、かつリガンド結合分子が疾患組織特異的に切断される実施態様においては、運搬時の融合タンパク質中のリガンドの生物活性を発揮させることなく、疾患組織にて切断されて初めてリガンドの生物活性を発揮させ、疾患を治療することが出来、全身副作用を抑えることが出来る。
本開示のポリペプチドに含まれるプロテアーゼ切断配列は、マトリプターゼおよび/またはウロキナーゼにより切断されるため、癌組織にて切断されることが予想され、全身副作用を抑えながら癌を治療することが出来る。
本明細書に記載の1又は複数の実施態様を任意に組み合わせたものも、当業者の技術常識に基づいて技術的に矛盾しない限り、本開示に含まれることが当業者には当然に理解される。また、本明細書に記載の1又は複数の実施態様を任意に組み合わせたものを本開示から除外した発明も、当業者の技術常識に基づいて技術的に矛盾しない限り、本明細書において意図され、記載された発明とみなされるべきものである。
以下は、本開示の方法および組成物の実施例である。上述の一般的な記載に照らし、種々の他の態様が実施され得ることが、理解されるであろう。
実施例1 ペプチドアレイを用いたプロテアーゼ切断配列の探索
1-1 ペプチドライブラリの設計と作製
uPAおよびMP-SP1により切断可能な配列TSTSGRSANPRG(配列番号:1)を基にした15アミノ酸のペプチドライブラリが設計された。配列番号:1で示す配列のN末端、またC末端、またはその両方にGly、Ser、またはその両方を付加し、更に配列番号:1で示す配列中のアミノ酸の一部をC、R、K以外の天然アミノ酸のいずれかになるように、Library 1:GGSXXXXXRSANPRG(配列番号:18079)、Library 2:TSTSGRXXXXXGGGS(配列番号:18080)、Library 3:GGGSXXXRXXGGGSG(配列番号:18081)となるようにライブラリが設計された(XはC、R、K以外の17種類の天然アミノ酸のいずれかを指す)。Mol Cell Proteomics. 2014 Jun;13(6):1585-97. doi: 10.1074/mcp.M113.033308. Epub 2014 Apr 4.に記載の方法でLibrary 1、Library 2、Library 3のペプチドライブラリが合成され、これらペプチドライブラリが固定されたペプチドアレイが作製された。
1-1 ペプチドライブラリの設計と作製
uPAおよびMP-SP1により切断可能な配列TSTSGRSANPRG(配列番号:1)を基にした15アミノ酸のペプチドライブラリが設計された。配列番号:1で示す配列のN末端、またC末端、またはその両方にGly、Ser、またはその両方を付加し、更に配列番号:1で示す配列中のアミノ酸の一部をC、R、K以外の天然アミノ酸のいずれかになるように、Library 1:GGSXXXXXRSANPRG(配列番号:18079)、Library 2:TSTSGRXXXXXGGGS(配列番号:18080)、Library 3:GGGSXXXRXXGGGSG(配列番号:18081)となるようにライブラリが設計された(XはC、R、K以外の17種類の天然アミノ酸のいずれかを指す)。Mol Cell Proteomics. 2014 Jun;13(6):1585-97. doi: 10.1074/mcp.M113.033308. Epub 2014 Apr 4.に記載の方法でLibrary 1、Library 2、Library 3のペプチドライブラリが合成され、これらペプチドライブラリが固定されたペプチドアレイが作製された。
1-2 ペプチドの切断とデータ解析
プロテアーゼによるアレイ上のペプチドの切断評価は、Mol Cell Proteomics. 2014 Jun;13(6):1585-97. doi: 10.1074/mcp.M113.033308. Epub 2014 Apr 4.に記載の方法に従って実施された。
プロテアーゼによるアレイ上のペプチドの切断評価は、Mol Cell Proteomics. 2014 Jun;13(6):1585-97. doi: 10.1074/mcp.M113.033308. Epub 2014 Apr 4.に記載の方法に従って実施された。
プロテアーゼによる切断を評価するため、各ペプチドアレイはリコンビナントヒトu-Plasminogen Activator/Urokinase(human uPA, huPA) (R&D Systems; 1310-SE-010) 、リコンビナントヒトMatriptase/ST14 Catalytic Domain (human MT-SP1, hMT-SP1) (R&D Systems; 3946-SE-010)、リコンビナントマウスu-Plasminogen Activator/Urokinase(mouse uPA, muPA) (abcam; ab92641)のそれぞれにより処理された。またペプチドの血清中切断を評価するため、各ペプチドアレイはヒト血清(human serum, hserum)(Valley Biomedical; HS1004C)により処理された。処理条件を表1、表2に示す。プロテアーゼ切断のコントロール(ポジティブコントロール)として、Library 1ではGGSTSTSGRSANPRG(配列番号:2)を、Library 2,3ではTSTSGRSANPRGGS(配列番号:3)が用いられた。また非特異的切断のコントロール(ネガティブコントロール)として、GGGSGGGSGGGSGGG(配列番号:4)が用いられた。
切断率(Proteolytic Activity Ratio、略してPAR)は、(PBSのみで処理した際の蛍光(RFU))/(プロテアーゼで処理した際の蛍光(RFU))として算出された。
切断率(Proteolytic Activity Ratio、略してPAR)は、(PBSのみで処理した際の蛍光(RFU))/(プロテアーゼで処理した際の蛍光(RFU))として算出された。


Library 1において、human uPA, human MT-SP1での切断率が共に配列番号:2で示す配列よりも高かったものは17,197配列あった(配列番号:5~17201)。また、human uPA, human MT-SP1, mouse uPAでの切断率が全て配列番号:2で示す配列よりも高かったものは3,200配列あった(配列番号:5~3204)。そのうち、human serumでの切断率が配列番号:4で示す配列よりも低かったものは452配列あった(配列番号:5~456)。また、human uPA, human MT-SP1での切断率が共に配列番号:2で示す配列よりも高かった17,197配列のうち、human serumでの切断率が1未満の場合は1に変換した上で、human uPA, human MT-SP1, mouse uPAでの切断率をhuman serumでの切断率で割った値が全て配列番号:2で示す配列よりも高く、さらにhuman uPA, human MT-SP1での切断率が共に配列番号:2で示す配列よりも高かったものは7,567配列あった(配列番号:5~1811、3205~8964)。
Library 2において、human uPA, human MT-SP1での切断率が共に配列番号:3で示す配列よりも高かったものは792配列あった(配列番号:17202~17993)。そのうち、mouse uPAでの切断率も配列番号:3で示す配列より高かったものは2配列あった(配列番号:17202、17203)。また、human uPA, human MT-SP1での切断率が共に配列番号:3で示す配列よりも高かった792配列のうち、human serumでの切断率が配列番号:4で示す配列よりも低かったものは175配列あった(配列番号:17204~17378)。
Library 3において、human uPA, human MT-SP1での切断率が共に配列番号:3で示す配列よりも高かったものは10配列あった(配列番号:17994~18003)。そのうち、mouse uPAでの切断率も配列番号:3で示す配列より高かったものは6配列あった(配列番号:17994~17999)。また、human uPA, human MT-SP1での切断率が共に配列番号:3で示す配列よりも高かった10配列のうち、human serumでの切断率が配列番号:4で示す配列よりも低かったものは7配列あった(配列番号:17994~17996、18000~18003)。
実施例2 プロテアーゼ切断配列を導入したリガンド結合分子の例
図5、図6ではポリペプチドがリガンド結合分子の場合、リガンド結合分子として抗体を用いた分子の例を示している。これらの例では、まずリガンドに対する中和抗体を取得する。続いて、抗リガンド中和抗体の可変領域(VHあるいはVL)と定常領域(CH1あるいはCL)の境界付近にプロテアーゼ切断配列を導入する。当該抗リガンド抗体がプロテアーゼ切断配列導入後においてもリガンド結合活性が保持されていることを確認する。リガンドが抗リガンド中和抗体に結合した状態で、プロテアーゼで切断することにより、リガンドが解離することを確認する。解離したリガンドが生物活性を発揮することを確認する。
図5において、リガンドのC末端と抗リガンド抗体のVHのN末端がリンカーを介して融合されており、VHとCH1の境界付近にプロテアーゼ切断配列が導入されている。抗リガンド抗体のリガンドに対する親和性が十分に強ければ、リガンドの生物活性は十分に阻害されている。このリガンド-抗リガンド抗体融合体を全身投与してもリガンドは中和されているためその生物活性を発揮することは無く、またリガンド-抗リガンド抗体融合体はFc領域を有するため長い半減期を有する。全身投与されたリガンド-抗リガンド抗体融合体は、腫瘍組織で高発現するプロテアーゼによってVHとCH1の境界付近のプロテアーゼ切断配列が切断されると、リガンド-リンカー-抗リガンド抗体のVH分子が遊離する。VHあるいはVL単独ではリガンドに結合することができないため(リガンドへ結合するためにはVHとVL両方が必要)、リガンドの中和は解除され、腫瘍組織において生物学的作用を発揮することが可能である。また、このリリースされたリガンド-リンカー-抗リガンド抗体のVH分子は、Fc領域を有さず、分子量が小さいため、非常に短い半減期を有し、速やかに全身から消失するため、リガンドによる全身性の副作用を最小化することが可能である。
図6においては、リガンドと抗リガンド抗体は図5のようにリンカーで融合されておらず、VHとCH1の境界付近にプロテアーゼ切断配列が導入された抗リガンド抗体とリガンドが混合して投与される。抗リガンド抗体のリガンドに対する親和性が十分に強く、リガンド濃度に対して抗リガンド抗体が十分あれば、リガンドの生物活性は十分に阻害されている。このリガンド-抗リガンド抗体複合体を全身投与してもリガンドは中和されているためその生物活性を発揮することは無く、またリガンド-抗リガンド抗体複合体はFc領域を有するため長い半減期を有する。全身投与されたリガンド‐抗リガンド抗体複合体は、腫瘍組織で高発現するプロテアーゼによってVHとCH1の境界付近のプロテアーゼ切断配列が切断されると、抗リガンド抗体のVH分子が遊離する。VHあるいはVL単独ではリガンドに結合することができないため(リガンドへ結合するためにはVHとVL両方が必要)、リガンドの中和は解除され、腫瘍組織において生物学的作用を発揮することが可能である。また、このリリースされたリガンド分子は、Fc領域を有さず、分子量が小さいため、非常に短い半減期を有し、速やかに全身から消失するため、リガンドによる全身性の副作用を最小化することが可能である。
このようにVHとCH1の境界付近にプロテアーゼ切断配列が導入された抗リガンド抗体を用いることで、リガンドをプロテアーゼが発現する組織で選択的にリリースし、その生物学的作用を発揮させることが可能となる。リガンドがサイトカインであれば、サイトカインをプロテアーゼが発現する組織で選択的に作用させることができる。リガンドがケモカインであれば、プロテアーゼが発現する組織でケモカインが高濃度で存在し、末梢血でケモカイン濃度が低くなるため、ケモカイン受容体を発現する細胞をプロテアーゼが発現する組織に遊走させることができる。
図5、図6ではポリペプチドがリガンド結合分子の場合、リガンド結合分子として抗体を用いた分子の例を示している。これらの例では、まずリガンドに対する中和抗体を取得する。続いて、抗リガンド中和抗体の可変領域(VHあるいはVL)と定常領域(CH1あるいはCL)の境界付近にプロテアーゼ切断配列を導入する。当該抗リガンド抗体がプロテアーゼ切断配列導入後においてもリガンド結合活性が保持されていることを確認する。リガンドが抗リガンド中和抗体に結合した状態で、プロテアーゼで切断することにより、リガンドが解離することを確認する。解離したリガンドが生物活性を発揮することを確認する。
図5において、リガンドのC末端と抗リガンド抗体のVHのN末端がリンカーを介して融合されており、VHとCH1の境界付近にプロテアーゼ切断配列が導入されている。抗リガンド抗体のリガンドに対する親和性が十分に強ければ、リガンドの生物活性は十分に阻害されている。このリガンド-抗リガンド抗体融合体を全身投与してもリガンドは中和されているためその生物活性を発揮することは無く、またリガンド-抗リガンド抗体融合体はFc領域を有するため長い半減期を有する。全身投与されたリガンド-抗リガンド抗体融合体は、腫瘍組織で高発現するプロテアーゼによってVHとCH1の境界付近のプロテアーゼ切断配列が切断されると、リガンド-リンカー-抗リガンド抗体のVH分子が遊離する。VHあるいはVL単独ではリガンドに結合することができないため(リガンドへ結合するためにはVHとVL両方が必要)、リガンドの中和は解除され、腫瘍組織において生物学的作用を発揮することが可能である。また、このリリースされたリガンド-リンカー-抗リガンド抗体のVH分子は、Fc領域を有さず、分子量が小さいため、非常に短い半減期を有し、速やかに全身から消失するため、リガンドによる全身性の副作用を最小化することが可能である。
図6においては、リガンドと抗リガンド抗体は図5のようにリンカーで融合されておらず、VHとCH1の境界付近にプロテアーゼ切断配列が導入された抗リガンド抗体とリガンドが混合して投与される。抗リガンド抗体のリガンドに対する親和性が十分に強く、リガンド濃度に対して抗リガンド抗体が十分あれば、リガンドの生物活性は十分に阻害されている。このリガンド-抗リガンド抗体複合体を全身投与してもリガンドは中和されているためその生物活性を発揮することは無く、またリガンド-抗リガンド抗体複合体はFc領域を有するため長い半減期を有する。全身投与されたリガンド‐抗リガンド抗体複合体は、腫瘍組織で高発現するプロテアーゼによってVHとCH1の境界付近のプロテアーゼ切断配列が切断されると、抗リガンド抗体のVH分子が遊離する。VHあるいはVL単独ではリガンドに結合することができないため(リガンドへ結合するためにはVHとVL両方が必要)、リガンドの中和は解除され、腫瘍組織において生物学的作用を発揮することが可能である。また、このリリースされたリガンド分子は、Fc領域を有さず、分子量が小さいため、非常に短い半減期を有し、速やかに全身から消失するため、リガンドによる全身性の副作用を最小化することが可能である。
このようにVHとCH1の境界付近にプロテアーゼ切断配列が導入された抗リガンド抗体を用いることで、リガンドをプロテアーゼが発現する組織で選択的にリリースし、その生物学的作用を発揮させることが可能となる。リガンドがサイトカインであれば、サイトカインをプロテアーゼが発現する組織で選択的に作用させることができる。リガンドがケモカインであれば、プロテアーゼが発現する組織でケモカインが高濃度で存在し、末梢血でケモカイン濃度が低くなるため、ケモカイン受容体を発現する細胞をプロテアーゼが発現する組織に遊走させることができる。
実施例3 プロテアーゼ切断配列が導入された単ドメイン抗体を含有するリガンド結合分子の例
図7~図10では、ポリペプチドが単ドメイン抗体を含むリガンド結合分子の場合、プロテアーゼ切断配列が導入された単ドメイン抗体を含有するリガンド結合分子の例を示している。
図7で示しているのは、プロテアーゼ切断配列が導入された単ドメイン抗体のみを含有するリガンド結合分子の例である。プロテアーゼ切断配列が切断されていない状態において、当該単ドメイン抗体はリガンドに結合可能であり、単ドメイン抗体のリガンドに対する親和性が十分に強ければ、リガンドの生物活性は十分に阻害されている。このリガンド結合分子とリガンドを全身投与しても、リガンド結合分子とリガンドの複合体中のリガンドは中和されているためその生物活性を発揮することは無く、またリガンド-リガンド結合分子の複合体はリガンド単体より長い半減期を有する。全身投与されたリガンド結合分子とリガンドが形成された複合体は、腫瘍組織で高発現するプロテアーゼによって単ドメイン抗体中のプロテアーゼ切断配列が切断されると、単ドメイン抗体がリガンドへ結合できなくなり、リガンドの中和は解除され、腫瘍組織において生物学的作用を発揮することが可能である。
図7~図10では、ポリペプチドが単ドメイン抗体を含むリガンド結合分子の場合、プロテアーゼ切断配列が導入された単ドメイン抗体を含有するリガンド結合分子の例を示している。
図7で示しているのは、プロテアーゼ切断配列が導入された単ドメイン抗体のみを含有するリガンド結合分子の例である。プロテアーゼ切断配列が切断されていない状態において、当該単ドメイン抗体はリガンドに結合可能であり、単ドメイン抗体のリガンドに対する親和性が十分に強ければ、リガンドの生物活性は十分に阻害されている。このリガンド結合分子とリガンドを全身投与しても、リガンド結合分子とリガンドの複合体中のリガンドは中和されているためその生物活性を発揮することは無く、またリガンド-リガンド結合分子の複合体はリガンド単体より長い半減期を有する。全身投与されたリガンド結合分子とリガンドが形成された複合体は、腫瘍組織で高発現するプロテアーゼによって単ドメイン抗体中のプロテアーゼ切断配列が切断されると、単ドメイン抗体がリガンドへ結合できなくなり、リガンドの中和は解除され、腫瘍組織において生物学的作用を発揮することが可能である。
図8で示しているのは、プロテアーゼ切断配列が導入された単ドメイン抗体のみを含有するリガンド結合分子とリガンドを融合させた融合ポリペプチドの例である。プロテアーゼ切断配列が切断されていない状態において、当該融合ポリペプチド中の単ドメイン抗体はリガンドに結合可能であり、単ドメイン抗体のリガンドに対する親和性が十分に強ければ、リガンドの生物活性は十分に阻害されている。この融合ポリペプチドを全身投与しても、融合ポリペプチド中のリガンドは中和されているためその生物活性を発揮することは無く、また融合ポリペプチドはリガンド単体より長い半減期を有する。全身投与された融合ポリペプチドは、腫瘍組織で高発現するプロテアーゼによって単ドメイン抗体中のプロテアーゼ切断配列が切断されると、融合ポリペプチド中の単ドメイン抗体がリガンドへ結合できなくなり、リガンドの中和は解除され、リガンドを含む融合ポリペプチドの一部が放出され、腫瘍組織において生物学的作用を発揮することが可能である。
図9、図10で示しているのは、プロテアーゼ切断配列が導入された単ドメイン抗体と抗体ヒンジ領域と抗体Fc領域を含むリガンド結合分子、及び当該リガンド結合分子とリガンドの融合ポリペプチドの例である。図7、図8の態様と同じように、未切断の状態においてリガンドが単ドメイン抗体により中和されることが可能で、切断状態においてリガンドが放出され生物学的作用を発揮することが可能である。また、図9、図10の例では、未切断状態の複合体もしくは融合ポリペプチドに抗体Fc領域が含まれているため、未切断状態の半減期が図7、図8の例より更に長いことが予想される。
実施例4 プロテアーゼ切断配列が導入された抗ヒトIL-6R単ドメイン抗体含有リガンド結合分子
4-1 抗ヒトIL-6R単ドメイン抗体を含むポリペプチドへのプロテアーゼ切断配列の導入によるリガンド結合分子の作製
ヒトIL-6Rに対する単ドメイン抗体(配列番号:18028)のC末端にと配列番号:18029で示す抗体ヒンジ領域と抗体Fc領域配列のN末端を融合させたポリペプチドIL6R90-G1T3dCHdC(配列番号:18030)中の単ドメイン抗体にプロテアーゼ切断配列を挿入し、プロテアーゼ切断配列が導入された単ドメイン抗体含有リガンド結合分子を作製した。まず、癌特異的に発現しているMT-SP1で切断されることが報告されているペプチド配列(LSGRSDNH、配列番号:18031)を含む配列をポリペプチドIL6R90-G1T3dCHdCに挿入し、表3に示すリガンド結合分子を作製し、Expi293 (Life Technologies)を用いた一過性発現により発現し、プロテインAを用いた当業者公知の方法により精製を行った。なおプロテアーゼ切断配列を含まない対照分子としてIL6R90-G1T3dCHdCを発現および精製した。作製されたリガンド結合分子及び対照分子は図9で示すような二量体タンパク質である。
4-1 抗ヒトIL-6R単ドメイン抗体を含むポリペプチドへのプロテアーゼ切断配列の導入によるリガンド結合分子の作製
ヒトIL-6Rに対する単ドメイン抗体(配列番号:18028)のC末端にと配列番号:18029で示す抗体ヒンジ領域と抗体Fc領域配列のN末端を融合させたポリペプチドIL6R90-G1T3dCHdC(配列番号:18030)中の単ドメイン抗体にプロテアーゼ切断配列を挿入し、プロテアーゼ切断配列が導入された単ドメイン抗体含有リガンド結合分子を作製した。まず、癌特異的に発現しているMT-SP1で切断されることが報告されているペプチド配列(LSGRSDNH、配列番号:18031)を含む配列をポリペプチドIL6R90-G1T3dCHdCに挿入し、表3に示すリガンド結合分子を作製し、Expi293 (Life Technologies)を用いた一過性発現により発現し、プロテインAを用いた当業者公知の方法により精製を行った。なおプロテアーゼ切断配列を含まない対照分子としてIL6R90-G1T3dCHdCを発現および精製した。作製されたリガンド結合分子及び対照分子は図9で示すような二量体タンパク質である。
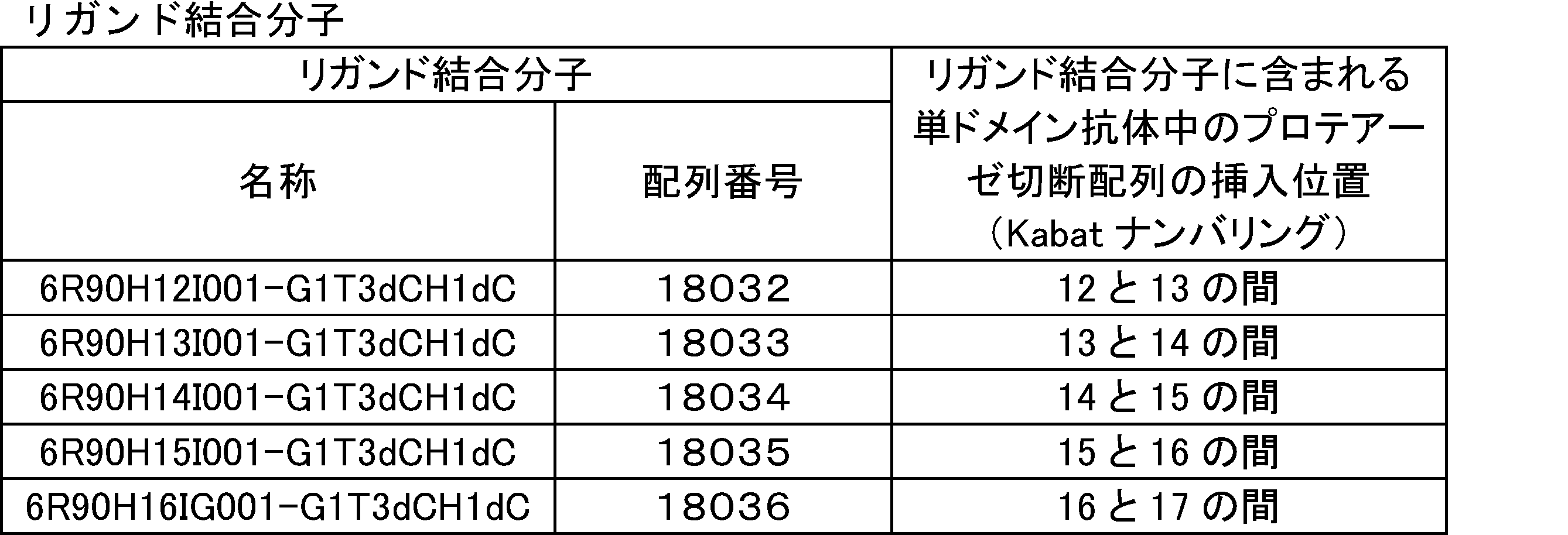
4-2 プロテアーゼ切断配列が導入された抗ヒトIL-6R単ドメイン抗体含有リガンド結合分子のヒトIL-6Rに対する結合評価
4-2-1 プロテアーゼ処理
実施例4-1で調製されたリガンド結合分子0.1mg/mLに対して、終濃度25nMとなるようにRecombinant Human Matriptase/ST14 Catalytic Domain (hMT-SP1, R&D systemsm 3946-SE-010)を添加し、37度で一晩保温し、プロテアーゼ処理リガンド結合分子を含む溶液とした。プロテアーゼ未処理リガンド結合分子を含む溶液の作製の条件は、プロテアーゼの代わりにPBSを同体積で加え、同じ条件で保存した条件である。
4-2-1 プロテアーゼ処理
実施例4-1で調製されたリガンド結合分子0.1mg/mLに対して、終濃度25nMとなるようにRecombinant Human Matriptase/ST14 Catalytic Domain (hMT-SP1, R&D systemsm 3946-SE-010)を添加し、37度で一晩保温し、プロテアーゼ処理リガンド結合分子を含む溶液とした。プロテアーゼ未処理リガンド結合分子を含む溶液の作製の条件は、プロテアーゼの代わりにPBSを同体積で加え、同じ条件で保存した条件である。
4-2-2 リガンド結合分子のプロテアーゼ切断確認(SDS-PAGE)
実施例4-2-1で実施されたプロテアーゼ処理でリガンド結合分子が切断されているかSDS-PAGEで確認した。実施例4-2-1で調製されたプロテアーゼ処理リガンド結合分子/プロテアーゼ未処理リガンド結合分子を含む溶液9μLを3μLのサンプルバッファーと混合し、95℃で1分間保温した。次にMini-PROTEAN TGX gel (4-20% 15well) (Bio-Rad #456-1096)を用いて電気泳動を行い、Sample Blue Safe Stain (novex, LC6065)でタンパク質を染色した。その結果を図11に示す。図11に示すように、プロテアーゼ切断配列を含まない対照分子(Lane 12、13)がプロテアーゼ処理/未処理関係なく、バンドが同じ位置にあるのに対し、各プロテアーゼ切断配列が導入されたリガンド結合分子はプロテアーゼ処理後のみに生じる新しいバンドがあり、即ち、各プロテアーゼ切断配列が導入された単ドメイン抗体含有リガンド結合分子はプロテアーゼ処理で切断されたことが示された。
実施例4-2-1で実施されたプロテアーゼ処理でリガンド結合分子が切断されているかSDS-PAGEで確認した。実施例4-2-1で調製されたプロテアーゼ処理リガンド結合分子/プロテアーゼ未処理リガンド結合分子を含む溶液9μLを3μLのサンプルバッファーと混合し、95℃で1分間保温した。次にMini-PROTEAN TGX gel (4-20% 15well) (Bio-Rad #456-1096)を用いて電気泳動を行い、Sample Blue Safe Stain (novex, LC6065)でタンパク質を染色した。その結果を図11に示す。図11に示すように、プロテアーゼ切断配列を含まない対照分子(Lane 12、13)がプロテアーゼ処理/未処理関係なく、バンドが同じ位置にあるのに対し、各プロテアーゼ切断配列が導入されたリガンド結合分子はプロテアーゼ処理後のみに生じる新しいバンドがあり、即ち、各プロテアーゼ切断配列が導入された単ドメイン抗体含有リガンド結合分子はプロテアーゼ処理で切断されたことが示された。
4-2-3 プロテアーゼ処理リガンド結合分子/プロテアーゼ未処理リガンド結合分子のヒトIL-6Rに対する結合評価
実施例4-2-1で調製されたプロテアーゼ処理リガンド結合分子/プロテアーゼ未処理リガンド結合分子を含む溶液20μLに対し、PBS60μLを加えてIL-6R結合評価サンプルとした。サンプルのIL-6R結合評価はバイオレイヤー干渉法(BLI法)で測定した。IL-6R結合評価サンプルとIL-6RをTilted bottom (TW384) Microplate (Forte bio, 18-5076)に分注した。Protein Gセンサー(ForteBio, 18-0022)をPBSで水和し、25度の設定でOctet RED 384で測定を実施した。PBSが入ったウェルで30秒間ベースライン測定を実施し、その後200秒間抗体をProtein Gセンサーに結合させた。再度PBSが入ったウェルで30秒間ベースライン測定を実施し、その後ヒト500nM IL-6Rが入ったウェルで180秒間結合を測定し、PBSが入ったウェルで180秒間解離を測定した。結合の様子を示すリアルタイム結合グラフを図12に示す。図12に示す通り、プロテアーゼ切断配列が導入された各リガンド結合分子を使用する場合、プロテアーゼ未処理リガンド結合分子を使用する場合に比べて、ヒトIL-6R結合量が減少した。
実施例4-2-1で調製されたプロテアーゼ処理リガンド結合分子/プロテアーゼ未処理リガンド結合分子を含む溶液20μLに対し、PBS60μLを加えてIL-6R結合評価サンプルとした。サンプルのIL-6R結合評価はバイオレイヤー干渉法(BLI法)で測定した。IL-6R結合評価サンプルとIL-6RをTilted bottom (TW384) Microplate (Forte bio, 18-5076)に分注した。Protein Gセンサー(ForteBio, 18-0022)をPBSで水和し、25度の設定でOctet RED 384で測定を実施した。PBSが入ったウェルで30秒間ベースライン測定を実施し、その後200秒間抗体をProtein Gセンサーに結合させた。再度PBSが入ったウェルで30秒間ベースライン測定を実施し、その後ヒト500nM IL-6Rが入ったウェルで180秒間結合を測定し、PBSが入ったウェルで180秒間解離を測定した。結合の様子を示すリアルタイム結合グラフを図12に示す。図12に示す通り、プロテアーゼ切断配列が導入された各リガンド結合分子を使用する場合、プロテアーゼ未処理リガンド結合分子を使用する場合に比べて、ヒトIL-6R結合量が減少した。
実施例5 プロテアーゼ切断配列が導入された抗ヒトIL-6R単ドメイン抗体含有リガンド結合分子とヒトIL-6Rの融合タンパク質(リガンド結合分子‐IL-6R融合タンパク質)の作製及び評価
5-1 .プロテアーゼ切断配列が導入された抗ヒトIL-6R単ドメイン抗体含有リガンド結合分子とヒトIL-6Rの融合タンパク質の作製
実施例4-1で作製されたリガンド結合分子のN末端にグリシンとセリンからなる様々なリンカーを介してヒトIL-6R(配列番号:18037)のC末端と融合し、リガンド結合分子-IL-6R融合タンパク質を作製した(表4)。これらの融合タンパク質は、当業者公知の方法でExpi293 (Life Technologies)を用いた一過性発現により発現し、プロテインAを用いた当業者公知の方法により精製を行った。作製された融合タンパク質はそれぞれ、表4で示す配列のペプチド鎖を二つ有する二量体タンパク質である。
5-1 .プロテアーゼ切断配列が導入された抗ヒトIL-6R単ドメイン抗体含有リガンド結合分子とヒトIL-6Rの融合タンパク質の作製
実施例4-1で作製されたリガンド結合分子のN末端にグリシンとセリンからなる様々なリンカーを介してヒトIL-6R(配列番号:18037)のC末端と融合し、リガンド結合分子-IL-6R融合タンパク質を作製した(表4)。これらの融合タンパク質は、当業者公知の方法でExpi293 (Life Technologies)を用いた一過性発現により発現し、プロテインAを用いた当業者公知の方法により精製を行った。作製された融合タンパク質はそれぞれ、表4で示す配列のペプチド鎖を二つ有する二量体タンパク質である。

なお、プロテアーゼ切断配列を含まない対照分子として、IL6R90-G1T3dCHdC(配列番号:18030)のN末端をリンカー介してIL-6RのC末端と融合させた分子(表5)を作製し、発現および精製を行った。作製された対照分子もそれぞれ、表5で示す配列のペプチド鎖を二つ有する二量体タンパク質である。

5-2 リガンド結合分子‐IL-6R融合タンパク質のプロテアーゼによる切断評価
5-2-1 プロテアーゼ処理
実施例5-1で調製されたリガンド結合分子-IL-6R融合タンパク質0.1mg/mLに対して、終濃度25nMとなるようにRecombinant Human Matriptase/ST14 Catalytic Domain(hMT-SP1, R&D systemsm 3946-SE-010)を添加し、37度で一晩保温し、プロテアーゼ処理融合タンパク質を含む溶液とした。プロテアーゼ未処理融合タンパク質を含む溶液の作製条件は、プロテアーゼの代わりにPBSを同体積で加え、同じ条件で保存した条件である。
5-2-1 プロテアーゼ処理
実施例5-1で調製されたリガンド結合分子-IL-6R融合タンパク質0.1mg/mLに対して、終濃度25nMとなるようにRecombinant Human Matriptase/ST14 Catalytic Domain(hMT-SP1, R&D systemsm 3946-SE-010)を添加し、37度で一晩保温し、プロテアーゼ処理融合タンパク質を含む溶液とした。プロテアーゼ未処理融合タンパク質を含む溶液の作製条件は、プロテアーゼの代わりにPBSを同体積で加え、同じ条件で保存した条件である。
5-2-2 抗IL-6R単ドメイン抗体‐IL-6R融合タンパク質のプロテアーゼ切断確認(SDS-PAGE)
実施例5-2-1で実施されたプロテアーゼ処理でリガンド結合分子‐IL-6R融合タンパク質が切断されているかSDS-PAGEで確認した。実施例5-2-1で調製されたプロテアーゼ処理融合タンパク質/プロテアーゼ未処理融合タンパク質を含む溶液9μLを3μLのサンプルバッファーと混合し、95℃で1分間保温した。次にMini-PROTEAN TGX gel (4-20% 15well) (Bio-Rad #456-1096)を用いて電気泳動を行い、Sample Blue Safe Stain (novex, LC6065)でタンパク質を染色した。その結果を図13~図16に示す。図13~図16に示すように、プロテアーゼ切断配列を含まない対照分子がプロテアーゼ処理/未処理関係なく、バンドが同じ位置にあるのに対し、プロテアーゼ切断配列が導入された単ドメイン抗体含有リガンド結合分子を含む各融合タンパク質はプロテアーゼ処理後のみに生じる新しいバンドがあり、即ち、各プロテアーゼ切断配列が導入された単ドメイン抗体含有リガンド結合分子を含む各融合タンパク質はプロテアーゼ処理で切断されたことが示された。
実施例5-2-1で実施されたプロテアーゼ処理でリガンド結合分子‐IL-6R融合タンパク質が切断されているかSDS-PAGEで確認した。実施例5-2-1で調製されたプロテアーゼ処理融合タンパク質/プロテアーゼ未処理融合タンパク質を含む溶液9μLを3μLのサンプルバッファーと混合し、95℃で1分間保温した。次にMini-PROTEAN TGX gel (4-20% 15well) (Bio-Rad #456-1096)を用いて電気泳動を行い、Sample Blue Safe Stain (novex, LC6065)でタンパク質を染色した。その結果を図13~図16に示す。図13~図16に示すように、プロテアーゼ切断配列を含まない対照分子がプロテアーゼ処理/未処理関係なく、バンドが同じ位置にあるのに対し、プロテアーゼ切断配列が導入された単ドメイン抗体含有リガンド結合分子を含む各融合タンパク質はプロテアーゼ処理後のみに生じる新しいバンドがあり、即ち、各プロテアーゼ切断配列が導入された単ドメイン抗体含有リガンド結合分子を含む各融合タンパク質はプロテアーゼ処理で切断されたことが示された。
5-2-3 ビオチン化抗IL-6R単ドメイン抗体含有分子の作製
リガンド結合分子に融合されたIL-6Rの遊離を検出する方法として、IL-6Rを認識する単ドメイン抗体含有分子にビオチンを付与し、ビオチン化された抗IL-6R単ドメイン抗体含有分子に対して遊離IL-6Rの結合を検出する方法を用いた。ビオチン化抗IL-6R単ドメイン抗体含有分子は以下のように作製された。 IL6R90-G1T3dCH1dC(配列番号:18030)と同じ単ドメイン抗体部分配列を有している抗IL-6R単ドメイン抗体含有分子を調製し、そのC末端にビオチン付加配列(AviTag配列、配列番号:18068)を付加したIL6R90-FcBAPdC(配列番号:18069)を作製した。IL6R90-FcBAPdCをコードする遺伝子断片を作製し、当業者公知の方法で動物細胞発現用ベクターに導入した。このときEBNA1を発現する遺伝子およびビオチンリガーゼを発現する遺伝子を同時に導入し、ビオチン標識する目的でビオチンを添加した。遺伝子が導入された細胞を37℃、8% CO2で培養し、目的のビオチン化抗IL-6R単ドメイン抗体含有分子(IL6R90-bio)を培養上清中に分泌させた。培養上清から当業者公知の方法でIL6R90-bioを精製した。
リガンド結合分子に融合されたIL-6Rの遊離を検出する方法として、IL-6Rを認識する単ドメイン抗体含有分子にビオチンを付与し、ビオチン化された抗IL-6R単ドメイン抗体含有分子に対して遊離IL-6Rの結合を検出する方法を用いた。ビオチン化抗IL-6R単ドメイン抗体含有分子は以下のように作製された。 IL6R90-G1T3dCH1dC(配列番号:18030)と同じ単ドメイン抗体部分配列を有している抗IL-6R単ドメイン抗体含有分子を調製し、そのC末端にビオチン付加配列(AviTag配列、配列番号:18068)を付加したIL6R90-FcBAPdC(配列番号:18069)を作製した。IL6R90-FcBAPdCをコードする遺伝子断片を作製し、当業者公知の方法で動物細胞発現用ベクターに導入した。このときEBNA1を発現する遺伝子およびビオチンリガーゼを発現する遺伝子を同時に導入し、ビオチン標識する目的でビオチンを添加した。遺伝子が導入された細胞を37℃、8% CO2で培養し、目的のビオチン化抗IL-6R単ドメイン抗体含有分子(IL6R90-bio)を培養上清中に分泌させた。培養上清から当業者公知の方法でIL6R90-bioを精製した。
5-2-4 プロテアーゼ処理による融合タンパク質からのIL-6R遊離評価
融合タンパク質のプロテアーゼ処理によるIL-6R遊離を実施例5-2-3で調製したビオチン化抗IL-6R単ドメイン抗体含有分子(IL6R90-bio) を用いてバイオレイヤー干渉法(BLI法)で評価した。
融合タンパク質のプロテアーゼ処理によるIL-6R遊離を実施例5-2-3で調製したビオチン化抗IL-6R単ドメイン抗体含有分子(IL6R90-bio) を用いてバイオレイヤー干渉法(BLI法)で評価した。
実施例5-2-1で調製したプロテアーゼ処理融合タンパク質、プロテアーゼ未処理融合タンパク質、IL6R90-bioをそれぞれTilted bottom (TW384) Micro plates(ForteBio、18-5076)の異なるウェルに分注した。Streptavidinバイオセンサー(ForteBio, 18-5021)をPBSを用いて水和し、27℃の設定でOctet RED 384で測定が行われた。PBSが入ったウェルで30秒間ベースライン測定を実施し、その後200秒間IL6R90-bioをStreptavidinセンサーに結合させた。再度PBSが入ったウェルで30秒間ベースライン測定を実施し、その後プロテアーゼ処理融合タンパク質またはプロテアーゼ未処理融合タンパク質が入ったウェルで180秒間結合を測定し、PBSが入ったウェルで180秒間解離を測定した。結合の様子を示すリアルタイム結合グラフを図17、図18に示す。図17、図18に示す通り、プロテアーゼ切断配列が導入された単ドメイン抗体含有リガンド結合分子-IL-6R融合タンパク質の場合、プロテアーゼ未処理の場合に比べて、プロテアーゼ処理の場合ではIL6R90-bioに結合するヒトIL-6Rの量が増加した。即ち、プロテアーゼ処理により融合タンパク質中の単ドメイン抗体のIL-6Rに対する結合活性が減弱し、IL-6Rが融合タンパク質から遊離した。
実施例6 プロテアーゼ切断配列が導入された抗ヒトPD-1単ドメイン抗体含有リガンド結合分子とヒトPD-1の融合タンパク質(リガンド結合分子‐PD-1融合タンパク質)の作製及び評価
6-1. プロテアーゼ切断配列が導入された抗ヒトPD-1単ドメイン抗体含有リガンド結合分子とヒトPD-1の融合タンパク質の作製
ヒトPD-1に結合する単ドメイン抗体にヒト抗体定常領域を融合したPD102C3-G1T3noCyshinge(配列番号:18070), PD102C12-G1T3noCyshinge(配列番号:18071)を当業者公知の方法で作製した。次に、PD102C3-G1T3noCyshingeと PD102C12-G1T3noCyshingeにプロテアーゼ切断配列を導入したのち、それぞれのN末端をグリシンとセリンからなる様々なリンカーを介してヒトPD-1の細胞外ドメイン(配列番号:18072)のC末端と融合し、リガンド結合分子-PD-1融合タンパク質を作製した(表6)。これらの融合タンパク質は、当業者公知の方法でExpi293 (Life Technologies)を用いた一過性発現により発現し、プロテインAを用いた当業者公知の方法により精製を行った。作製された融合タンパク質はそれぞれ、表6で示す配列のペプチド鎖を二つ有する二量体タンパク質である。
6-1. プロテアーゼ切断配列が導入された抗ヒトPD-1単ドメイン抗体含有リガンド結合分子とヒトPD-1の融合タンパク質の作製
ヒトPD-1に結合する単ドメイン抗体にヒト抗体定常領域を融合したPD102C3-G1T3noCyshinge(配列番号:18070), PD102C12-G1T3noCyshinge(配列番号:18071)を当業者公知の方法で作製した。次に、PD102C3-G1T3noCyshingeと PD102C12-G1T3noCyshingeにプロテアーゼ切断配列を導入したのち、それぞれのN末端をグリシンとセリンからなる様々なリンカーを介してヒトPD-1の細胞外ドメイン(配列番号:18072)のC末端と融合し、リガンド結合分子-PD-1融合タンパク質を作製した(表6)。これらの融合タンパク質は、当業者公知の方法でExpi293 (Life Technologies)を用いた一過性発現により発現し、プロテインAを用いた当業者公知の方法により精製を行った。作製された融合タンパク質はそれぞれ、表6で示す配列のペプチド鎖を二つ有する二量体タンパク質である。

6-2. リガンド結合分子‐PD-1融合タンパク質のプロテアーゼによる切断評価
6-2-1. プロテアーゼ処理
実施例6-1で調製されたリガンド結合分子-PD-1融合タンパク質0.1mg/mLに対して、終濃度25nMとなるようにRecombinant Human Matriptase/ST14 Catalytic Domain (hMT-SP1, R&D systemsm 3946-SE-010) を添加し、37度で一晩保温し、プロテアーゼ処理融合タンパク質を含む溶液とした。プロテアーゼ未処理融合タンパク質を含む溶液の作製条件は、プロテアーゼの代わりにPBSを同体積で加え、同じ条件で保存した条件である。
6-2-1. プロテアーゼ処理
実施例6-1で調製されたリガンド結合分子-PD-1融合タンパク質0.1mg/mLに対して、終濃度25nMとなるようにRecombinant Human Matriptase/ST14 Catalytic Domain (hMT-SP1, R&D systemsm 3946-SE-010) を添加し、37度で一晩保温し、プロテアーゼ処理融合タンパク質を含む溶液とした。プロテアーゼ未処理融合タンパク質を含む溶液の作製条件は、プロテアーゼの代わりにPBSを同体積で加え、同じ条件で保存した条件である。
6-2-2. 抗PD-1単ドメイン抗体‐PD-1融合タンパク質のプロテアーゼ切断確認(SDS-PAGE)
実施例6-2-1で実施されたプロテアーゼ処理でリガンド結合分子‐PD-1融合タンパク質が切断されているかSDS-PAGEで確認した。実施例6-2-1で調製されたプロテアーゼ処理融合タンパク質/プロテアーゼ未処理融合タンパク質を含む溶液9μLを3μLのサンプルバッファーと混合し、95℃で1分間保温した。次にMini-PROTEAN TGX gel (4-20% 15well) (Bio-Rad #456-1096)を用いて電気泳動を行い、Sample Blue Safe Stain (novex, LC6065)でタンパク質を染色した。その結果を図19に示す。図19に示すように、各プロテアーゼ切断配列が導入された単ドメイン抗体含有リガンド結合分子を含む各融合タンパク質はプロテアーゼ処理後のみに生じる新しいバンドがあり、即ち、各プロテアーゼ切断配列が導入された単ドメイン抗体含有リガンド結合分子を含む各融合タンパク質体はプロテアーゼ処理で切断されたことが示された。
実施例6-2-1で実施されたプロテアーゼ処理でリガンド結合分子‐PD-1融合タンパク質が切断されているかSDS-PAGEで確認した。実施例6-2-1で調製されたプロテアーゼ処理融合タンパク質/プロテアーゼ未処理融合タンパク質を含む溶液9μLを3μLのサンプルバッファーと混合し、95℃で1分間保温した。次にMini-PROTEAN TGX gel (4-20% 15well) (Bio-Rad #456-1096)を用いて電気泳動を行い、Sample Blue Safe Stain (novex, LC6065)でタンパク質を染色した。その結果を図19に示す。図19に示すように、各プロテアーゼ切断配列が導入された単ドメイン抗体含有リガンド結合分子を含む各融合タンパク質はプロテアーゼ処理後のみに生じる新しいバンドがあり、即ち、各プロテアーゼ切断配列が導入された単ドメイン抗体含有リガンド結合分子を含む各融合タンパク質体はプロテアーゼ処理で切断されたことが示された。
6-2-3. ビオチン化抗PD-1単ドメイン抗体含有分子の作製
リガンド結合分子に融合されたPD-1の遊離を検出する方法として、PD-1を認識する単ドメイン抗体含有分子にビオチンを付与し、ビオチン化された抗PD-1単ドメイン抗体含有分子に対して遊離PD-1の結合を検出する方法を用いた。ビオチン化抗PD-1単ドメイン抗体含有分子は以下のように作製された。PD102C3-G1T3noCyshingeと同じ単ドメイン抗体部分配列を有している単ドメイン抗体含有分子を調製し、そのC末端にビオチン付加配列(AviTag配列、配列番号:18068)を付加し、PD102C3-FcBAPdC(配列番号:18077)を作製した。 また、PD102C12-G1T3noCyshingeと同じ単ドメイン抗体部分配列を有している抗PD-1単ドメイン抗体含有分子を調製し、そのC末端にビオチン付加配列(AviTag配列、配列番号:18068)を付加し、PD102C12-FcBAPdC(配列番号:18078)を作製した。PD102C3-FcBAPdC及びPD102C12-FcBAPdCをそれぞれコードする遺伝子断片を作製し、当業者公知の方法で動物細胞発現用ベクターに導入した。このときEBNA1を発現する遺伝子およびビオチンリガーゼを発現する遺伝子を同時に導入し、ビオチン標識する目的でビオチンを添加した。遺伝子が導入された細胞を37℃、8% CO2で培養し、目的のビオチン化抗PD-1単ドメイン抗体含有分子(PD1-bio)を培養上清中に分泌させた。培養上清から当業者公知の方法でPD1-bioを精製した。
リガンド結合分子に融合されたPD-1の遊離を検出する方法として、PD-1を認識する単ドメイン抗体含有分子にビオチンを付与し、ビオチン化された抗PD-1単ドメイン抗体含有分子に対して遊離PD-1の結合を検出する方法を用いた。ビオチン化抗PD-1単ドメイン抗体含有分子は以下のように作製された。PD102C3-G1T3noCyshingeと同じ単ドメイン抗体部分配列を有している単ドメイン抗体含有分子を調製し、そのC末端にビオチン付加配列(AviTag配列、配列番号:18068)を付加し、PD102C3-FcBAPdC(配列番号:18077)を作製した。 また、PD102C12-G1T3noCyshingeと同じ単ドメイン抗体部分配列を有している抗PD-1単ドメイン抗体含有分子を調製し、そのC末端にビオチン付加配列(AviTag配列、配列番号:18068)を付加し、PD102C12-FcBAPdC(配列番号:18078)を作製した。PD102C3-FcBAPdC及びPD102C12-FcBAPdCをそれぞれコードする遺伝子断片を作製し、当業者公知の方法で動物細胞発現用ベクターに導入した。このときEBNA1を発現する遺伝子およびビオチンリガーゼを発現する遺伝子を同時に導入し、ビオチン標識する目的でビオチンを添加した。遺伝子が導入された細胞を37℃、8% CO2で培養し、目的のビオチン化抗PD-1単ドメイン抗体含有分子(PD1-bio)を培養上清中に分泌させた。培養上清から当業者公知の方法でPD1-bioを精製した。
6-2-4 プロテアーゼ処理による融合タンパク質からのPD-1遊離評価
融合タンパク質のプロテアーゼ処理によるPD-1遊離を実施例6-2-3で調製したビオチン化抗PD-1単ドメイン抗体含有分子(PD1-bio) を用いてバイオレイヤー干渉法(BLI法)で評価した。
融合タンパク質のプロテアーゼ処理によるPD-1遊離を実施例6-2-3で調製したビオチン化抗PD-1単ドメイン抗体含有分子(PD1-bio) を用いてバイオレイヤー干渉法(BLI法)で評価した。
実施例6-2-1で調製したプロテアーゼ処理融合タンパク質、プロテアーゼ未処理融合タンパク質、PD1-bioをそれぞれTilted bottom (TW384) Micro plates(ForteBio、18-5076)の異なるウェルに分注した。PD1-Bioは、測定サンプル中の単ドメイン抗体と同じエピトープに結合するように、適宜PD102C3-FcBAPdCまたはPD102C12-FcBAPdCが選択される。Streptavidinバイオセンサー(ForteBio, 18-5021)をPBSを用いて水和し、27℃の設定でOctet RED 384で測定が行われた。PBSが入ったウェルで30秒間ベースライン測定を実施し、その後200秒間PD1-bioをStreptavidinセンサーに結合させた。再度PBSが入ったウェルで30秒間ベースライン測定を実施し、その後プロテアーゼ処理融合タンパク質またはプロテアーゼ未処理融合タンパク質が入ったウェルで180秒間結合を測定し、PBSが入ったウェルで180秒間解離を測定した。結合の様子を示すリアルタイム結合グラフを図20に示す。図20に示す通り、プロテアーゼ切断配列が導入された単ドメイン抗体含有リガンド結合分子-PD-1融合タンパク質の場合、プロテアーゼ未処理の場合に比べて、プロテアーゼ処理の場合ではPD1-bioに結合するヒトPD-1の量が増加した。即ち、プロテアーゼ処理により融合タンパク質中の単ドメイン抗体のPD-1に対する結合活性が減弱し、PD-1が融合タンパク質から遊離した。
前述の発明は、明確な理解を助ける目的のもと、実例および例示を用いて詳細に記載したが、本明細書における記載および例示は、本開示の範囲を限定するものと解釈されるべきではない。本明細書で引用したすべての特許文献および科学文献の開示は、その全体にわたって、参照により明示的に本明細書に組み入れられる。
実施例7 各種プロテアーゼ切断配列を挿入された抗体の評価
7-1 プロテアーゼ切断配列を挿入された抗体改変体の作製
ヒトCXCL10を中和する抗体であるG7(重鎖:G7H-G1T4(配列番号:18079)、軽鎖:G7L-LT0(配列番号:18080))の軽鎖可変領域106a位(Kabatナンバリング)と軽鎖定常領域107a位(Kabatナンバリング)の間に、表7中に示すプロテアーゼ切断配列が挿入された。
上記で作製された抗体軽鎖改変体と重鎖が組み合わされた表7に示す抗体改変体が、当業者公知の方法でExpi293細胞 (Life technologies)を用いた一過性発現により発現され、プロテインAを用いた当業者公知の方法により精製された。
7-1 プロテアーゼ切断配列を挿入された抗体改変体の作製
ヒトCXCL10を中和する抗体であるG7(重鎖:G7H-G1T4(配列番号:18079)、軽鎖:G7L-LT0(配列番号:18080))の軽鎖可変領域106a位(Kabatナンバリング)と軽鎖定常領域107a位(Kabatナンバリング)の間に、表7中に示すプロテアーゼ切断配列が挿入された。
上記で作製された抗体軽鎖改変体と重鎖が組み合わされた表7に示す抗体改変体が、当業者公知の方法でExpi293細胞 (Life technologies)を用いた一過性発現により発現され、プロテインAを用いた当業者公知の方法により精製された。






7-2 プロテアーゼ切断配列を挿入された抗体改変体のプロテアーゼによる切断の評価
実施例7-1で調製された抗体改変体がプロテアーゼ処理により切断されるかどうかを評価するため、各抗体改変体はリコンビナントヒトu-Plasminogen Activator/Urokinase(human uPA, huPA) (R&D Systems; 1310-SE-010) 、リコンビナントヒトMatriptase/ST14 Catalytic Domain (human MT-SP1, hMT-SP1) (R&D Systems; 3946-SEB-010)、リコンビナントマウスu-Plasminogen Activator/Urokinase(mouse uPA, muPA) (abcam; ab92641)のそれぞれにより処理された。抗体改変体 100μg/mLを、PBS、37℃の条件下でhuPAもしくはhMT-SP1もしくはmuPA と1時間反応させたのちに、還元キャピラリー電気泳動で評価された。キャピラリー電気泳動にはWes (Protein Simple) が使用され、検出には抗ヒトlambda鎖HRP標識抗体 (abcam; ab9007) が使用された。その結果、プロテアーゼ処理後の抗体改変体では、36kDa付近のピークが消失して20kDa付近に新たにピークが観察された。すなわち、36kDa付近のピークが未切断軽鎖、20kDa付近のピークが切断軽鎖と考えられた。プロテアーゼ処理後に得られた各ピークの面積がWes専用のソフトウェア (Compass for SW; Protein Simple) から出力され、抗体改変体の切断率 (%) は(切断軽鎖ピーク面積)*100/(切断軽鎖ピーク面積+未切断軽鎖ピーク面積)を計算することで求められた。huPA処理、hMT-SP1処理、muPA処理に用いたプロテアーゼ濃度と抗体改変体の切断率 (%) をまとめたものを表8、9、10、11、12、13、14、15に示す。切断率が評価された抗体改変体のうち、G7L.106a.12aaを含む71抗体に対し再度同様にプロテアーゼ処理が行われた。その結果を表16に示す。それらの中で、G7L.106a.12aaと比較して、huPA、hMT-SP1、muPAでの切断率が全て同等以上だった抗体改変体を表17に示す。
実施例7-1で調製された抗体改変体がプロテアーゼ処理により切断されるかどうかを評価するため、各抗体改変体はリコンビナントヒトu-Plasminogen Activator/Urokinase(human uPA, huPA) (R&D Systems; 1310-SE-010) 、リコンビナントヒトMatriptase/ST14 Catalytic Domain (human MT-SP1, hMT-SP1) (R&D Systems; 3946-SEB-010)、リコンビナントマウスu-Plasminogen Activator/Urokinase(mouse uPA, muPA) (abcam; ab92641)のそれぞれにより処理された。抗体改変体 100μg/mLを、PBS、37℃の条件下でhuPAもしくはhMT-SP1もしくはmuPA と1時間反応させたのちに、還元キャピラリー電気泳動で評価された。キャピラリー電気泳動にはWes (Protein Simple) が使用され、検出には抗ヒトlambda鎖HRP標識抗体 (abcam; ab9007) が使用された。その結果、プロテアーゼ処理後の抗体改変体では、36kDa付近のピークが消失して20kDa付近に新たにピークが観察された。すなわち、36kDa付近のピークが未切断軽鎖、20kDa付近のピークが切断軽鎖と考えられた。プロテアーゼ処理後に得られた各ピークの面積がWes専用のソフトウェア (Compass for SW; Protein Simple) から出力され、抗体改変体の切断率 (%) は(切断軽鎖ピーク面積)*100/(切断軽鎖ピーク面積+未切断軽鎖ピーク面積)を計算することで求められた。huPA処理、hMT-SP1処理、muPA処理に用いたプロテアーゼ濃度と抗体改変体の切断率 (%) をまとめたものを表8、9、10、11、12、13、14、15に示す。切断率が評価された抗体改変体のうち、G7L.106a.12aaを含む71抗体に対し再度同様にプロテアーゼ処理が行われた。その結果を表16に示す。それらの中で、G7L.106a.12aaと比較して、huPA、hMT-SP1、muPAでの切断率が全て同等以上だった抗体改変体を表17に示す。
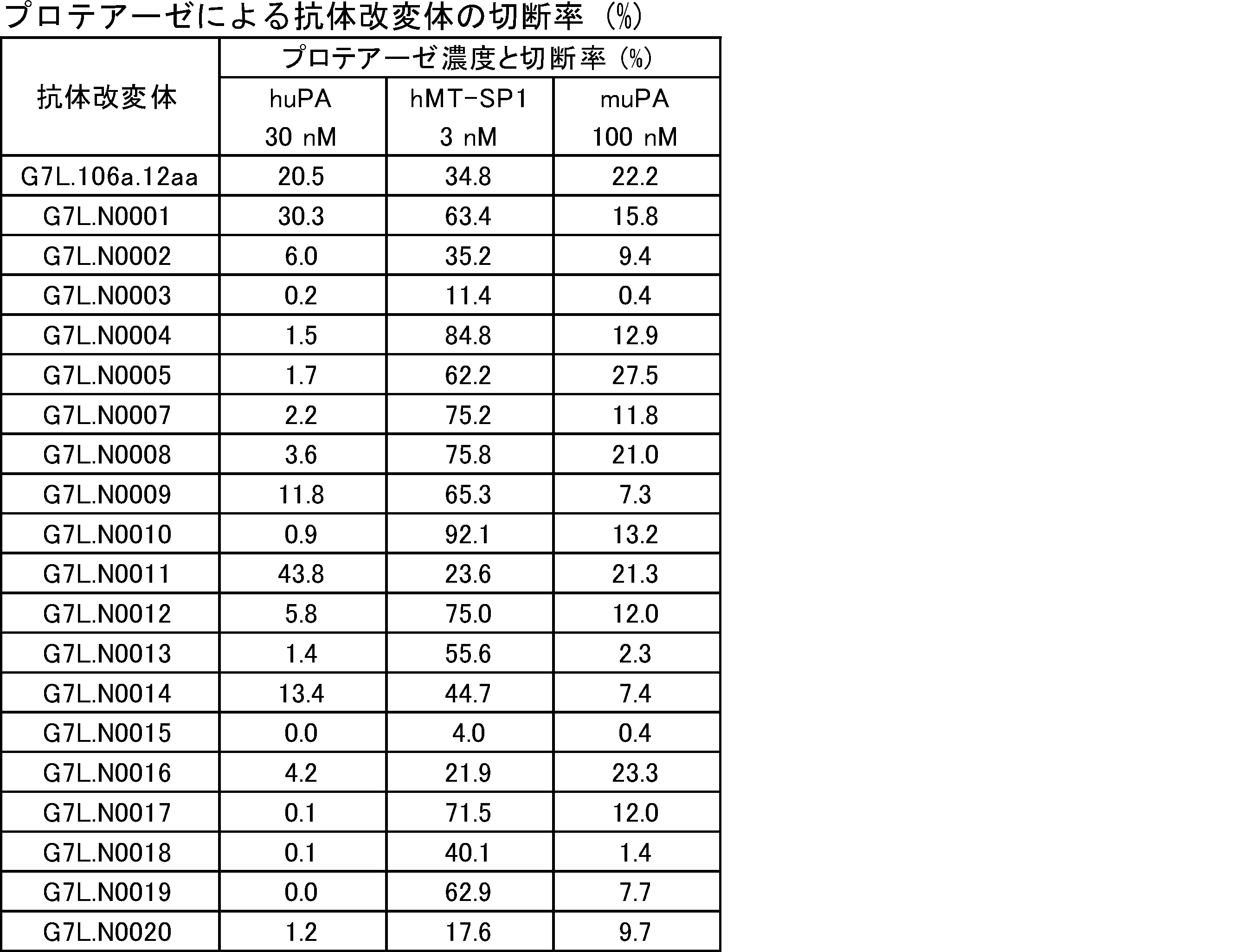









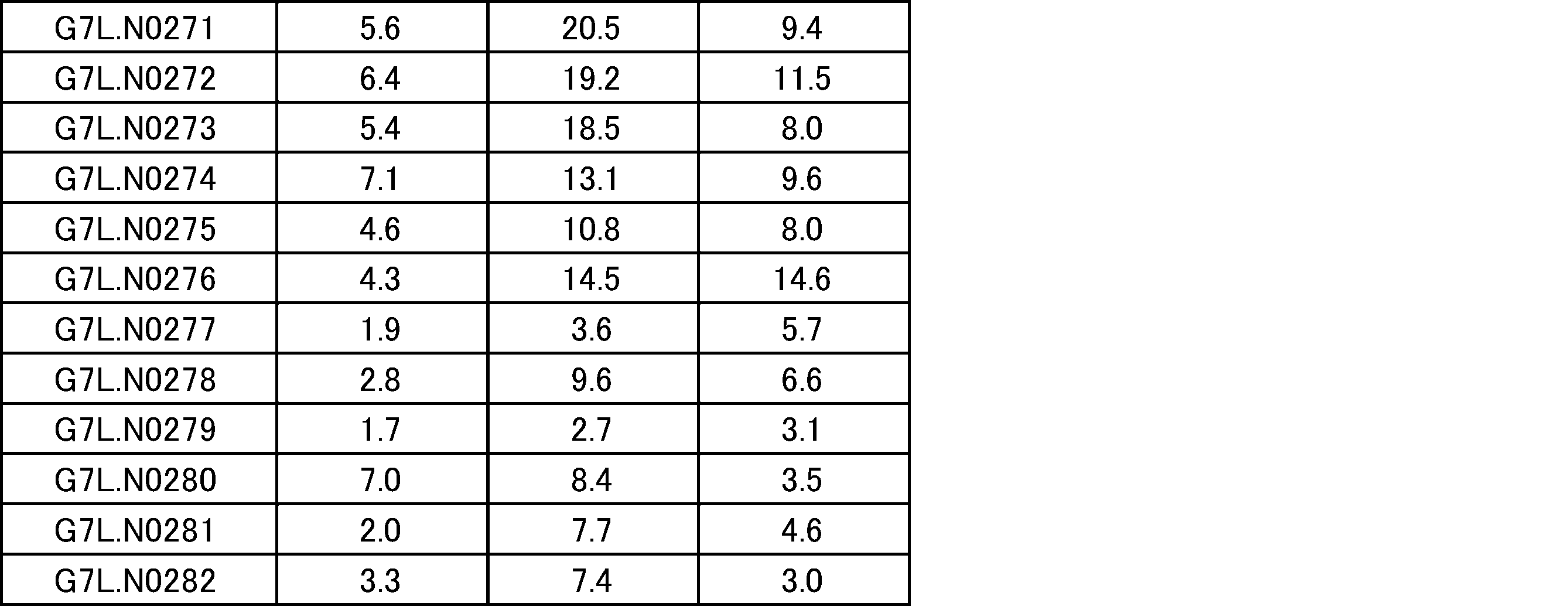
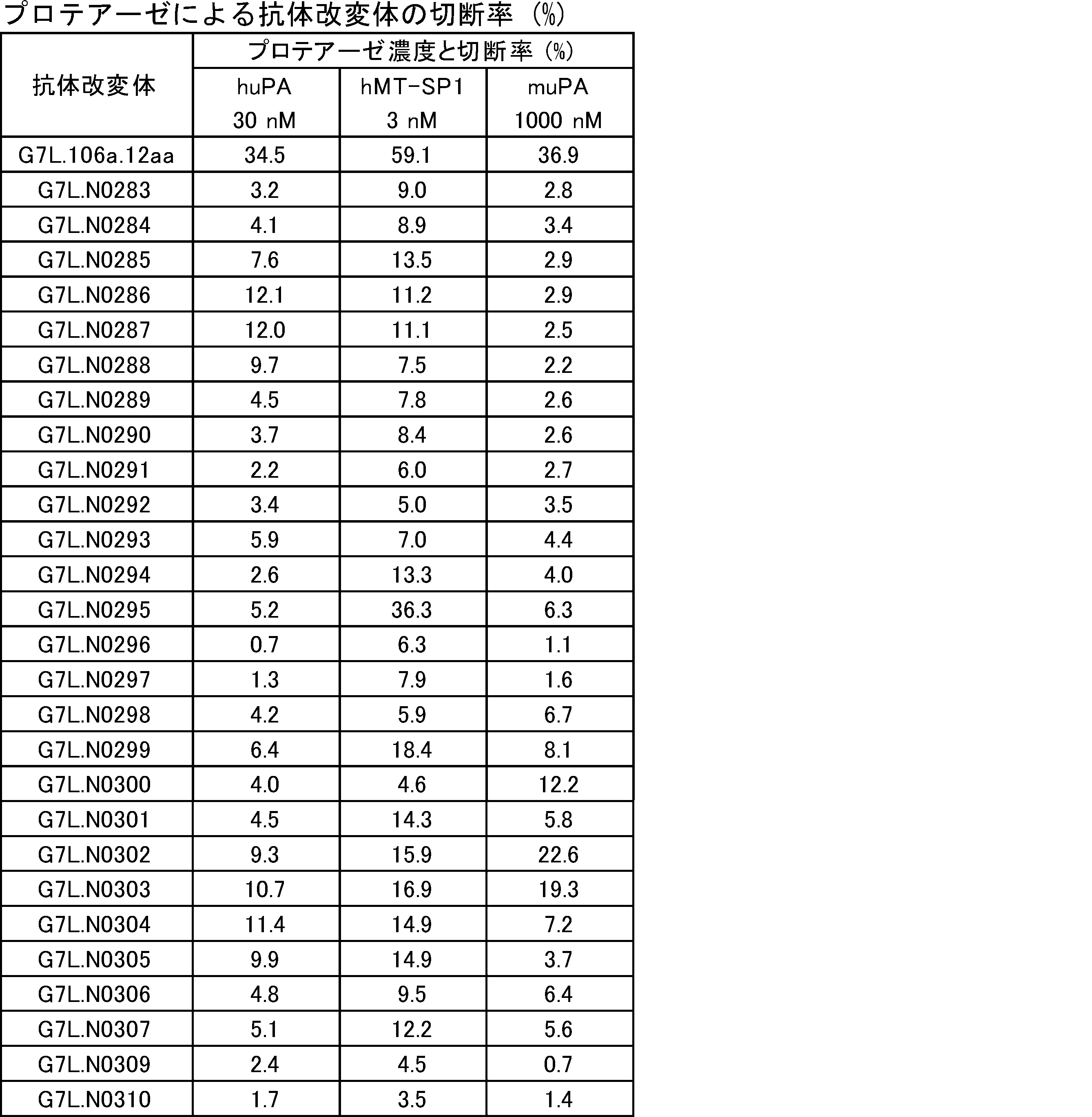


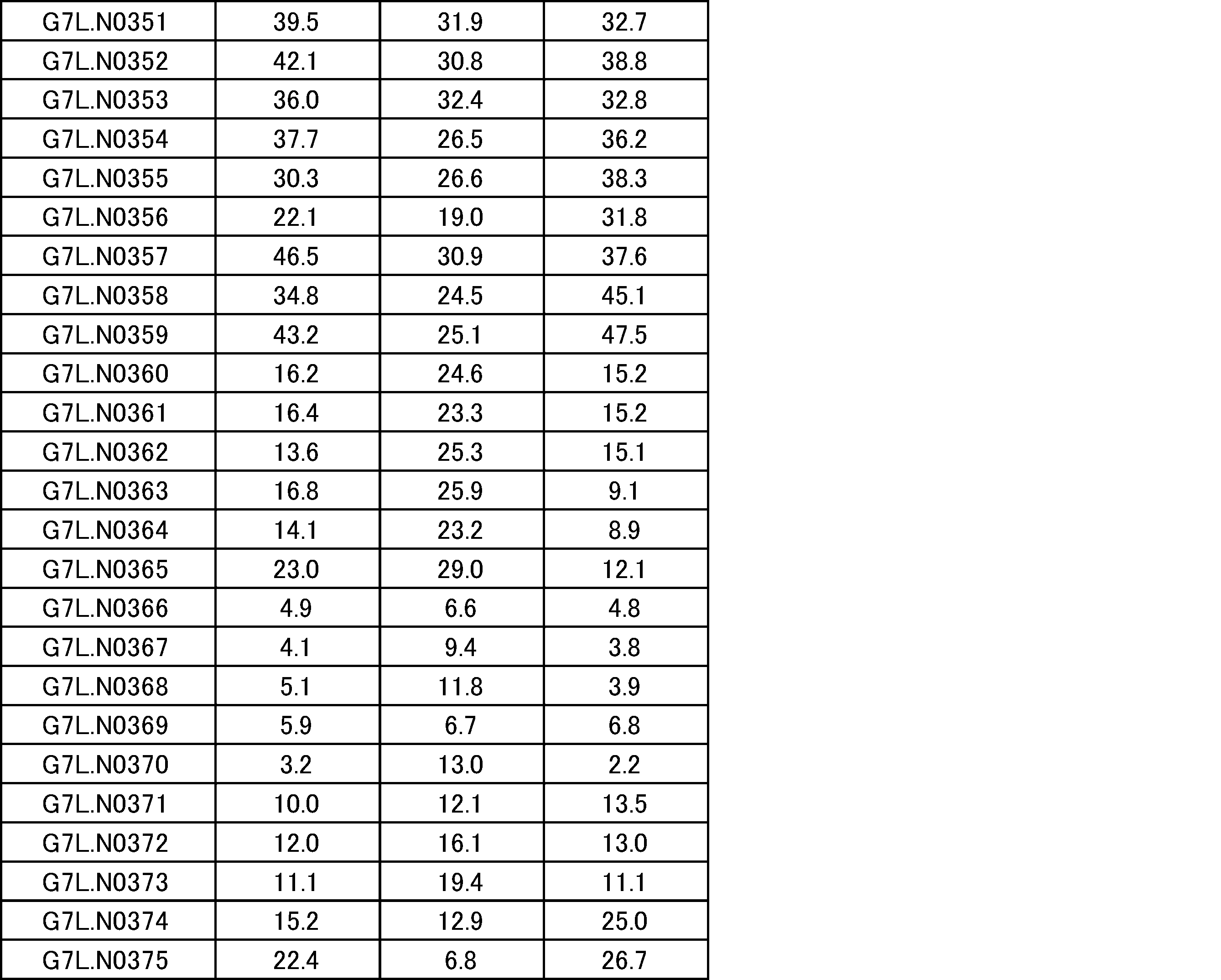
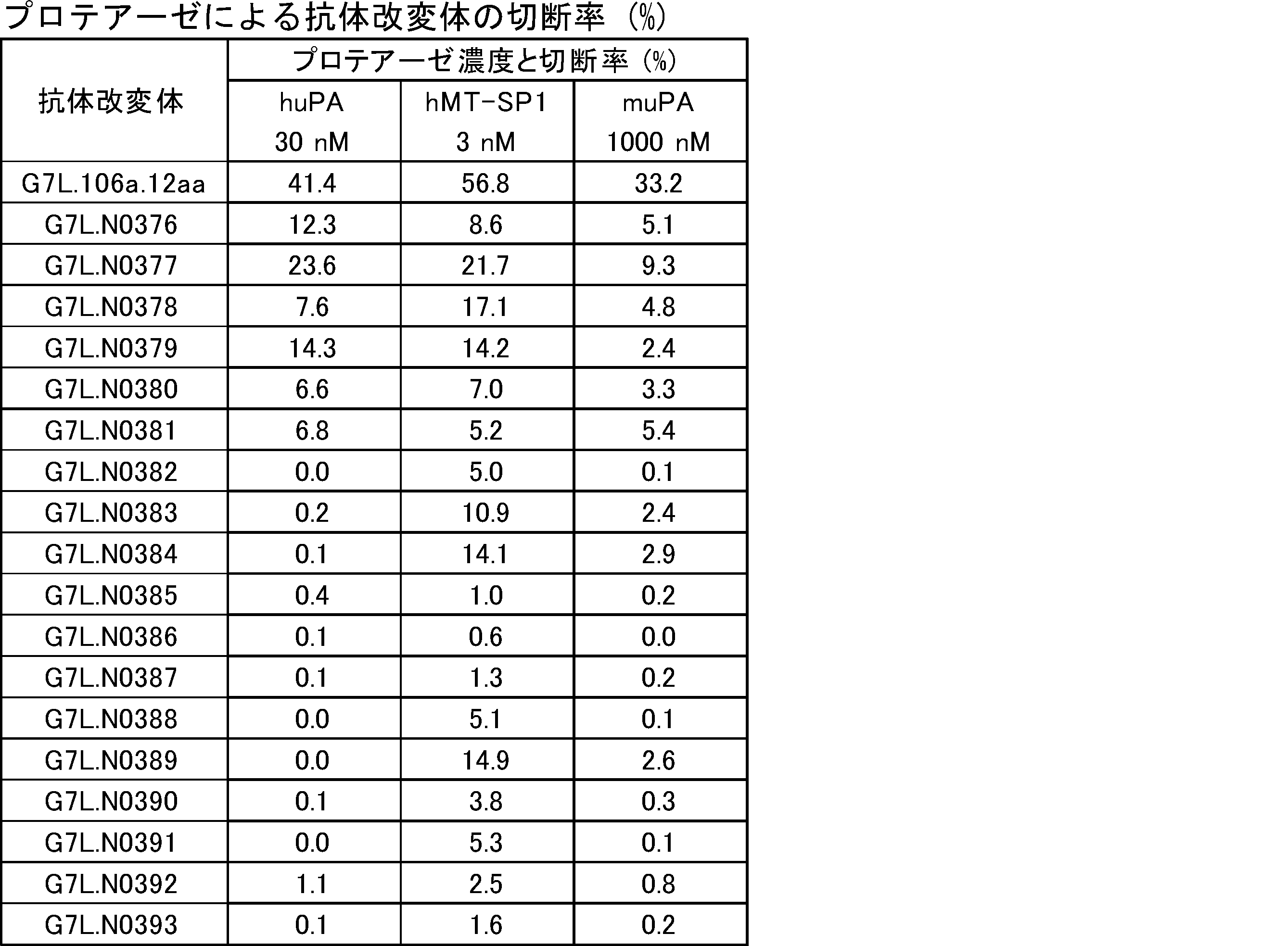



本開示のペプチド配列は、プロテアーゼ基質として有用であり、これらの基質はさまざまな治療的、診断的、及び予防的適応において有用である。また、本開示のペプチド配列をプロテアーゼ切断配列として含むポリペプチドもまた、さまざまな治療的、診断的、及び予防的適応において有用である。
本開示のポリペプチドが抗原結合ドメインと抑制ドメインを有する運搬部分を含むポリペプチドである場合、当該ポリペプチドならびにこれを含む医薬組成物は、抗原結合ドメインの抗原結合活性を抑制したまま、抗原結合ドメインを血中で運搬できる。また、当該ポリペプチドを使用することで、抗原結合ドメインの抗原結合活性を疾患部位で特異的に発揮させることが出来る。さらに、抗原結合活性を発揮時は、運搬時より短い半減期を有するので、全身的に作用してしまう恐れが減少し、疾患の治療に極めて有用である。
本開示のポリペプチドがリガンド結合分子である場合、当該リガンド結合分子は、リガンドを結合したまま生体内で運搬され、疾患組織において切断されてリガンドへの結合が弱まり、リガンドを疾患組織特異的にリリースできるので、疾患組織を特異的にリガンドに暴露することができる。また、当該リガンド結合分子は運搬時にリガンドの生物活性を抑制していることから、リガンドが全身的に作用してしまう恐れが減少し、疾患の治療に極めて有用である。
Claims (15)
- 配列番号:1、2、3のいずれか一つの配列を含むプロテアーゼ基質に比べ、プロテアーゼによる切断率が高い、プロテアーゼ基質。
- ヒト血清により切断されない、請求項1に記載のプロテアーゼ基質。
- 下記から選ばれる少なくとも一つの配列を含む、請求項1または請求項2に記載のプロテアーゼ基質:
配列番号:5~17201から選ばれる配列のN末端4番目のアミノ酸から15番目のアミノ酸までの配列、配列番号:5~17201から選ばれる配列のN末端4番目のアミノ酸から13番目のアミノ酸までの配列、配列番号:5~17201から選ばれる配列のN末端6番目のアミノ酸から13番目のアミノ酸までの配列、配列番号:17202~17993から選ばれる配列のN末端1番目のアミノ酸から12番目のアミノ酸までの配列、配列番号:17202~17993から選ばれる配列のN末端3番目のアミノ酸から12番目のアミノ酸までの配列、配列番号:17202~17993から選ばれる配列のN末端3番目のアミノ酸から11番目のアミノ酸までの配列、配列番号:17202~17993から選ばれる配列のN末端3番目のアミノ酸から10番目のアミノ酸までの配列、配列番号:17994~18003から選ばれる配列のN末端3番目のアミノ酸から14番目のアミノ酸までの配列、配列番号:17994~18003から選ばれる配列のN末端5番目のアミノ酸から12番目のアミノ酸までの配列、配列番号:17994~18003から選ばれる配列のN末端5番目のアミノ酸から10番目のアミノ酸までの配列、配列番号:5~18003のいずれかで示される配列。 - 前記プロテアーゼはマトリプターゼおよび/またはウロキナーゼである、請求項1から請求項3のいずれか一つに記載のプロテアーゼ基質。
- 前記プロテアーゼはヒトMT-SP1、マウスMT-SP1、ヒトuPA、マウスuPAから選ばれる少なくとも一種類のプロテアーゼである、請求項1から請求項4のいずれかに記載のプロテアーゼ基質。
- 下記から選ばれる少なくとも一つの配列の、プロテアーゼ切断配列としての使用:
配列番号:5~17201から選ばれる配列のN末端4番目のアミノ酸から15番目のアミノ酸までの配列、配列番号:5~17201から選ばれる配列のN末端4番目のアミノ酸から13番目のアミノ酸までの配列、配列番号:5~17201から選ばれる配列のN末端6番目のアミノ酸から13番目のアミノ酸までの配列、配列番号:17202~17993から選ばれる配列のN末端1番目のアミノ酸から12番目のアミノ酸までの配列、配列番号:17202~17993から選ばれる配列のN末端3番目のアミノ酸から12番目のアミノ酸までの配列、配列番号:17202~17993から選ばれる配列のN末端3番目のアミノ酸から11番目のアミノ酸までの配列、配列番号:17202~17993から選ばれる配列のN末端3番目のアミノ酸から10番目のアミノ酸までの配列、配列番号:17994~18003から選ばれる配列のN末端3番目のアミノ酸から14番目のアミノ酸までの配列、配列番号:17994~18003から選ばれる配列のN末端5番目のアミノ酸から12番目のアミノ酸までの配列、配列番号:17994~18003から選ばれる配列のN末端5番目のアミノ酸から10番目のアミノ酸までの配列、配列番号:5~18003のいずれかで示される配列。 - 下記から選ばれる少なくとも一つのプロテアーゼ切断配列を含む、ポリペプチド:
配列番号:5~17201から選ばれる配列のN末端4番目のアミノ酸から15番目のアミノ酸までの配列、配列番号:5~17201から選ばれる配列のN末端4番目のアミノ酸から13番目のアミノ酸までの配列、配列番号:5~17201から選ばれる配列のN末端6番目のアミノ酸から13番目のアミノ酸までの配列、配列番号:17202~17993から選ばれる配列のN末端1番目のアミノ酸から12番目のアミノ酸までの配列、配列番号:17202~17993から選ばれる配列のN末端3番目のアミノ酸から12番目のアミノ酸までの配列、配列番号:17202~17993から選ばれる配列のN末端3番目のアミノ酸から11番目のアミノ酸までの配列、配列番号:17202~17993から選ばれる配列のN末端3番目のアミノ酸から10番目のアミノ酸までの配列、配列番号:17994~18003から選ばれる配列のN末端3番目のアミノ酸から14番目のアミノ酸までの配列、配列番号:17994~18003から選ばれる配列のN末端5番目のアミノ酸から12番目のアミノ酸までの配列、配列番号:17994~18003から選ばれる配列のN末端5番目のアミノ酸から10番目のアミノ酸までの配列、配列番号:5~18003のいずれかで示される配列。 - 請求項7に記載のポリペプチドであって、当該ポリペプチドは抗原結合ドメインと運搬部分とを含み、当該運搬部分は前記抗原結合ドメインの抗原結合活性を抑制する抑制ドメインを有する、ポリペプチド。
- 請求項7に記載のポリペプチドであって、当該ポリペプチドはリガンドに結合可能なリガンド結合分子であり、前記プロテアーゼ切断配列が切断された状態における当該リガンド結合分子のリガンドに対する結合が、前記プロテアーゼ切断配列が未切断の状態における当該リガンド結合分子のリガンドに対する結合より弱い、ポリペプチド。
- 請求項7に記載のポリペプチドであって、当該ポリペプチドはリガンドに結合可能なリガンド結合分子であり、当該リガンド結合分子は単ドメイン抗体を含み、当該単ドメイン抗体はリガンドに結合可能であり且つ少なくとも一つの前記プロテアーゼ切断配列が導入されており、当該プロテアーゼ切断配列が切断された状態での当該リガンド結合分子の前記リガンドに対する結合が、当該プロテアーゼ切断配列が未切断の状態での当該リガンド結合分子の前記リガンドに対する結合より減弱される、ポリペプチド。
- 前記リガンドと、請求項9または請求項10に記載のポリペプチドが融合されている融合タンパク質。
- 請求項7から請求項10に記載のポリペプチド、または請求項11に記載の融合タンパク質を含む医薬組成物。
- 請求項9または請求項10に記載のポリペプチドおよび前記リガンドを含む医薬組成物。
- 請求項7から請求項10に記載のポリペプチド、または請求項11に記載の融合タンパク質をコードするポリヌクレオチド。
- 請求項7から請求項10に記載のポリペプチド、または請求項11に記載の融合タンパク質を製造する方法。
Priority Applications (5)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US17/615,633 US20220315909A1 (en) | 2019-06-05 | 2020-06-05 | Protease substrate, and polypeptide including protease cleavage sequence |
| EP20818589.2A EP3981428A4 (en) | 2019-06-05 | 2020-06-05 | Protease substrate, and polypeptide including protease cleavage sequence |
| CN202080049137.XA CN114127277A (zh) | 2019-06-05 | 2020-06-05 | 蛋白酶底物和包含蛋白酶切割序列的多肽 |
| JP2021524912A JP7716979B2 (ja) | 2019-06-05 | 2020-06-05 | プロテアーゼ基質、及びプロテアーゼ切断配列を含むポリペプチド |
| JP2025099946A JP2025134810A (ja) | 2019-06-05 | 2025-06-16 | プロテアーゼ基質、及びプロテアーゼ切断配列を含むポリペプチド |
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2019105464 | 2019-06-05 | ||
| JP2019-105464 | 2019-06-05 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2020246567A1 true WO2020246567A1 (ja) | 2020-12-10 |
Family
ID=73652780
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2020/022226 Ceased WO2020246567A1 (ja) | 2019-06-05 | 2020-06-05 | プロテアーゼ基質、及びプロテアーゼ切断配列を含むポリペプチド |
Country Status (5)
| Country | Link |
|---|---|
| US (1) | US20220315909A1 (ja) |
| EP (1) | EP3981428A4 (ja) |
| JP (2) | JP7716979B2 (ja) |
| CN (1) | CN114127277A (ja) |
| WO (1) | WO2020246567A1 (ja) |
Cited By (8)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US11365233B2 (en) | 2020-04-10 | 2022-06-21 | Cytomx Therapeutics, Inc. | Activatable cytokine constructs and related compositions and methods |
| WO2023002952A1 (en) * | 2021-07-19 | 2023-01-26 | Chugai Seiyaku Kabushiki Kaisha | Protease-mediated target specific cytokine delivery using fusion polypeptide |
| US11667687B2 (en) | 2021-03-16 | 2023-06-06 | Cytomx Therapeutics, Inc. | Masked activatable interferon constructs |
| US11932697B2 (en) | 2016-11-28 | 2024-03-19 | Chugai Seiyaku Kabushiki Kaisha | Antigen-binding domain, and polypeptide including conveying section |
| US12030955B2 (en) | 2017-11-28 | 2024-07-09 | Chugai Seiyaku Kabushiki Kaisha | Polypeptide including antigen-binding domain and carrying section |
| US12060654B2 (en) | 2016-11-28 | 2024-08-13 | Chugai Seiyaku Kabushiki Kaisha | Ligand-binding molecule having adjustable ligand binding activity |
| US12077577B2 (en) | 2018-05-30 | 2024-09-03 | Chugai Seiyaku Kabushiki Kaisha | Polypeptide comprising aggrecan binding domain and carrying moiety |
| US12195528B2 (en) | 2017-11-28 | 2025-01-14 | Chugai Seiyaku Kabushiki Kaisha | Ligand-binding molecule having adjustable ligand-binding activity |
Families Citing this family (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2024150172A1 (en) * | 2023-01-11 | 2024-07-18 | Bright Peak Therapeutics Ag | Cleavable peptides and methods of use thereof |
| WO2025030217A1 (en) * | 2023-08-10 | 2025-02-13 | The University Of Adelaide | Separation of minerals using short peptides or mimetics thereof |
Citations (18)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO1995001937A1 (fr) | 1993-07-09 | 1995-01-19 | Association Gradient | Procede de traitement de residus de combustion et installation de mise en ×uvre dudit procede |
| US6248516B1 (en) | 1988-11-11 | 2001-06-19 | Medical Research Council | Single domain ligands, receptors comprising said ligands methods for their production, and use of said ligands and receptors |
| WO2002020565A2 (en) | 2000-09-08 | 2002-03-14 | Universität Zürich | Collections of repeat proteins comprising repeat modules |
| WO2002032925A2 (en) | 2000-10-16 | 2002-04-25 | Phylos, Inc. | Protein scaffolds for antibody mimics and other binding proteins |
| WO2003000883A1 (fr) | 2001-06-22 | 2003-01-03 | Chugai Seiyaku Kabushiki Kaisha | Inhibiteurs de proliferation cellulaire renfermant un anticorps anti-glypicane 3 |
| WO2003029462A1 (en) | 2001-09-27 | 2003-04-10 | Pieris Proteolab Ag | Muteins of human neutrophil gelatinase-associated lipocalin and related proteins |
| WO2003104453A1 (ja) | 2002-06-05 | 2003-12-18 | 中外製薬株式会社 | 抗体作製方法 |
| WO2004022754A1 (ja) | 2002-09-04 | 2004-03-18 | Chugai Seiyaku Kabushiki Kaisha | MRL/lprマウスを用いた抗体の作製 |
| WO2004044011A2 (en) | 2002-11-06 | 2004-05-27 | Avidia Research Institute | Combinatorial libraries of monomer domains |
| WO2005040229A2 (en) | 2003-10-24 | 2005-05-06 | Avidia, Inc. | Ldl receptor class a and egf domain monomers and multimers |
| WO2006006693A1 (ja) | 2004-07-09 | 2006-01-19 | Chugai Seiyaku Kabushiki Kaisha | 抗グリピカン3抗体 |
| WO2007027935A2 (en) * | 2005-08-31 | 2007-03-08 | The Regents Of The University Of California | Cellular libraries of peptide sequences (clips) and methods of using the same |
| WO2008016854A2 (en) | 2006-08-02 | 2008-02-07 | The Uab Research Foundation | Methods and compositions related to soluble monoclonal variable lymphocyte receptors of defined antigen specificity |
| WO2009125825A1 (ja) | 2008-04-11 | 2009-10-15 | 中外製薬株式会社 | 複数分子の抗原に繰り返し結合する抗原結合分子 |
| US20110123527A1 (en) | 2008-05-23 | 2011-05-26 | Hiroaki Shizuya | Method of generating single vl domain antibodies in transgenic animals |
| WO2015143414A2 (en) | 2014-03-21 | 2015-09-24 | Regeneron Pharmaceuticals, Inc. | Non-human animals that make single domain binding proteins |
| CN107602706A (zh) * | 2017-10-16 | 2018-01-19 | 湖北大学 | 一种切割效率增强的hrv3c蛋白酶底物突变体及其应用 |
| WO2018097307A1 (ja) * | 2016-11-28 | 2018-05-31 | 中外製薬株式会社 | 抗原結合ドメインおよび運搬部分を含むポリペプチド |
Family Cites Families (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| AU2003234775A1 (en) * | 2002-04-30 | 2003-11-17 | Dnavec Research Inc. | Vector with modified protease-dependent tropism |
| DK1735439T3 (da) * | 2004-04-12 | 2012-02-06 | Catalyst Biosciences Inc | Spaltning af VEGF og VEGF receptor ved hjælp af vild-type og mutant MT-SP1 |
| KR101778174B1 (ko) * | 2006-07-05 | 2017-09-13 | 카탈리스트 바이오사이언시즈, 인코포레이티드 | 프로테아제 스크리닝 방법 및 이에 의해 확인된 프로테아제 |
| WO2018097308A1 (ja) * | 2016-11-28 | 2018-05-31 | 中外製薬株式会社 | リガンド結合活性が調整可能なリガンド結合分子 |
| US20190038935A1 (en) * | 2017-08-07 | 2019-02-07 | Timofey Ignatyev | Exercise game and apparatus employing color-changing base locations |
| WO2019032472A1 (en) | 2017-08-08 | 2019-02-14 | The Board Of Trustees Of The Leland Stanford Junior University | HIGH AFFINITY MODIFIED MATRIX INHIBITOR |
| WO2020132574A1 (en) * | 2018-12-21 | 2020-06-25 | CentryMed Pharmaceutical Inc. | Protease cleavable bispecific antibodies and uses thereof |
-
2020
- 2020-06-05 CN CN202080049137.XA patent/CN114127277A/zh active Pending
- 2020-06-05 WO PCT/JP2020/022226 patent/WO2020246567A1/ja not_active Ceased
- 2020-06-05 JP JP2021524912A patent/JP7716979B2/ja active Active
- 2020-06-05 US US17/615,633 patent/US20220315909A1/en active Pending
- 2020-06-05 EP EP20818589.2A patent/EP3981428A4/en active Pending
-
2025
- 2025-06-16 JP JP2025099946A patent/JP2025134810A/ja active Pending
Patent Citations (18)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US6248516B1 (en) | 1988-11-11 | 2001-06-19 | Medical Research Council | Single domain ligands, receptors comprising said ligands methods for their production, and use of said ligands and receptors |
| WO1995001937A1 (fr) | 1993-07-09 | 1995-01-19 | Association Gradient | Procede de traitement de residus de combustion et installation de mise en ×uvre dudit procede |
| WO2002020565A2 (en) | 2000-09-08 | 2002-03-14 | Universität Zürich | Collections of repeat proteins comprising repeat modules |
| WO2002032925A2 (en) | 2000-10-16 | 2002-04-25 | Phylos, Inc. | Protein scaffolds for antibody mimics and other binding proteins |
| WO2003000883A1 (fr) | 2001-06-22 | 2003-01-03 | Chugai Seiyaku Kabushiki Kaisha | Inhibiteurs de proliferation cellulaire renfermant un anticorps anti-glypicane 3 |
| WO2003029462A1 (en) | 2001-09-27 | 2003-04-10 | Pieris Proteolab Ag | Muteins of human neutrophil gelatinase-associated lipocalin and related proteins |
| WO2003104453A1 (ja) | 2002-06-05 | 2003-12-18 | 中外製薬株式会社 | 抗体作製方法 |
| WO2004022754A1 (ja) | 2002-09-04 | 2004-03-18 | Chugai Seiyaku Kabushiki Kaisha | MRL/lprマウスを用いた抗体の作製 |
| WO2004044011A2 (en) | 2002-11-06 | 2004-05-27 | Avidia Research Institute | Combinatorial libraries of monomer domains |
| WO2005040229A2 (en) | 2003-10-24 | 2005-05-06 | Avidia, Inc. | Ldl receptor class a and egf domain monomers and multimers |
| WO2006006693A1 (ja) | 2004-07-09 | 2006-01-19 | Chugai Seiyaku Kabushiki Kaisha | 抗グリピカン3抗体 |
| WO2007027935A2 (en) * | 2005-08-31 | 2007-03-08 | The Regents Of The University Of California | Cellular libraries of peptide sequences (clips) and methods of using the same |
| WO2008016854A2 (en) | 2006-08-02 | 2008-02-07 | The Uab Research Foundation | Methods and compositions related to soluble monoclonal variable lymphocyte receptors of defined antigen specificity |
| WO2009125825A1 (ja) | 2008-04-11 | 2009-10-15 | 中外製薬株式会社 | 複数分子の抗原に繰り返し結合する抗原結合分子 |
| US20110123527A1 (en) | 2008-05-23 | 2011-05-26 | Hiroaki Shizuya | Method of generating single vl domain antibodies in transgenic animals |
| WO2015143414A2 (en) | 2014-03-21 | 2015-09-24 | Regeneron Pharmaceuticals, Inc. | Non-human animals that make single domain binding proteins |
| WO2018097307A1 (ja) * | 2016-11-28 | 2018-05-31 | 中外製薬株式会社 | 抗原結合ドメインおよび運搬部分を含むポリペプチド |
| CN107602706A (zh) * | 2017-10-16 | 2018-01-19 | 湖北大学 | 一种切割效率增强的hrv3c蛋白酶底物突变体及其应用 |
Non-Patent Citations (50)
| Title |
|---|
| "Current protocols in Molecular Biology", 1987, JOHN WILEY & SONS |
| "GenBank", Database accession no. AB009864 |
| ANAL. BIOCHEM., vol. 162, no. 1, 1987, pages 156 - 159 |
| ANNU REV IMMUNOL., vol. 33, 2015, pages 139 - 67 |
| ANNU. REV. BIOPHYS. BIOMOL. STRUCT., vol. 35, 2006, pages 225 - 249 |
| ANTIBODIES, vol. 4, no. 3, 2015, pages 141 - 156 |
| BELPERIO ET AL.: "CXC Chemokines in Angiogenesis", J. LEUKOC. BIOL., vol. 68, 2000, pages 1 - 8, XP002440747 |
| BIOCHEMISTRY, vol. 18, no. 24, 1979, pages 5294 - 5299 |
| BIOCHIMICA ET BIOPHYSICA ACTA - PROTEINS AND PROTEOMICS, vol. 1764, no. 8, 2006, pages 1307 - 1319 |
| BLOOD, vol. 127, no. 13, 31 March 2016 (2016-03-31), pages 1633 - 41 |
| C VINCKE ET AL., JOURNAL OF BIOLOGICAL CHEMISTRY, vol. 284, pages 3273 - 3284 |
| C. EUR. J. IMMUNOL., vol. 6, no. 7, 1976, pages 511 - 519 |
| CELL, vol. 8, no. 3, 1976, pages 405 - 415 |
| CHOTHIALESK, J. MOL. BIOL., vol. 196, 1987, pages 901 - 917 |
| CLARK-LEWIS ET AL., J. BIOL. CHEM., vol. 269, 1994, pages 16075 - 16081 |
| CURRENT TOPICS IN MICROBIOLOGY AND IMMUNOLOGY, vol. 81, 1978, pages 1 - 7 |
| FLATMAN ET AL., J. CHROMATOGR. B, vol. 848, 2007, pages 79 - 87 |
| J BIOL CHEM., vol. 263, no. 29, 15 October 1988 (1988-10-15), pages 15064 - 70 |
| J CLIN INVEST, vol. 32, no. 8, August 1953 (1953-08-01), pages 746 - 768 |
| J CLIN INVEST., vol. 32, no. 8, August 1953 (1953-08-01), pages 746 - 768 |
| J PHARM SCI, vol. 97, no. 10, October 2008 (2008-10-01), pages 4167 - 83 |
| J. EXP. MED., vol. 148, no. 1, 1978, pages 313 - 323 |
| J. IMMUNOL. METHODS, vol. 35, no. 1-2, 1980, pages 1 - 21 |
| J. IMMUNOL., vol. 123, no. 4, 1979, pages 1548 - 1550 |
| J. MOL. BIOL., vol. 350, 2005, pages 112 - 125 |
| JOURNAL OF APPLIED MICROBIOLOGY, vol. 117, no. 2, 2014, pages 528 - 536 |
| JOURNAL OF BIOLOGICAL CHEMISTRY, vol. 291, no. 24, 2016, pages 12641 - 12657 |
| JOURNAL OF BIOMOLECULAR SCREENING, vol. 21, no. 1, 2016, pages 35 - 43 |
| KABAT ET AL.: "Sequences of Proteins of Immunological Interest", vol. 1-3, 1991, PUBLIC HEALTH SERVICE |
| KINDT ET AL.: "Kuby Immunology", 2007, W.H. FREEMAN AND CO., pages: 91 |
| KUNKEL ET AL., PROC. NATL. ACAD. SCI. USA, vol. 82, 1985, pages 488 - 492 |
| MACCALLUM ET AL., J. MOL. BIOL., vol. 262, 1996, pages 732 - 745 |
| METHODS ENZYMOL., vol. 323, 2000, pages 325 - 40 |
| METHODS IN MOLECULAR BIOLOGY, vol. 911, no. 65-78, 2012 |
| MILSTEIN, METHODS ENZYMOL., vol. 73, 1981, pages 3 - 46 |
| MOL CELL BIOL, vol. 8, 1988, pages 466 - 472 |
| MOL CELL PROTEOMICS, vol. 13, no. 6, 4 April 2014 (2014-04-04), pages 1585 - 97 |
| MULLBERG ET AL., J. IMMUNOL., vol. 152, no. 10, 1994, pages 4958 - 4968 |
| NATURE, vol. 276, no. 5685, 1978, pages 269 - 270 |
| NATURE, vol. 277, no. 5692, 1979, pages 131 - 133 |
| NUCLEIC ACIDS RES., vol. 47-58, no. 8, 1989, pages 2919 - 2932 |
| PROC. NATL. ACAD. SCI. U.S.A., vol. 100, no. 11, 2003, pages 6353 - 6357 |
| PROC. NATL. ACAD. SCI. USA, vol. 103, no. 11, 2006, pages 4005 - 4010 |
| PROC. NATL. ACAD. SCI. USA, vol. 85, no. 23, 1988, pages 8998 - 9002 |
| PROTEIN ENGINEERING, vol. 9, no. 3, 1996, pages 299 - 305 |
| ROTHLISBERGER ET AL., J MOL BIOL., vol. 347, no. 4, 8 April 2005 (2005-04-08), pages 773 - 89 |
| See also references of EP3981428A4 |
| STEM CELLS TRANSL MED, vol. 4, no. 1, January 2015 (2015-01-01), pages 66 - 73 |
| THOMAS, D. A. ET AL.: "A broad-spectrum fluorescence-based peptide library for the rapid identification of protease substrates", PROTEOMICS, vol. 6, 2006, pages 2112 - 2120, XP007912813, DOI: 10.1002/pmic.200500153 * |
| VANDAMME ET AL., EUR. J. BIOCHEM., vol. 192, no. 3, 1990, pages 767 - 775 |
Cited By (9)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US11932697B2 (en) | 2016-11-28 | 2024-03-19 | Chugai Seiyaku Kabushiki Kaisha | Antigen-binding domain, and polypeptide including conveying section |
| US12060654B2 (en) | 2016-11-28 | 2024-08-13 | Chugai Seiyaku Kabushiki Kaisha | Ligand-binding molecule having adjustable ligand binding activity |
| US12030955B2 (en) | 2017-11-28 | 2024-07-09 | Chugai Seiyaku Kabushiki Kaisha | Polypeptide including antigen-binding domain and carrying section |
| US12195528B2 (en) | 2017-11-28 | 2025-01-14 | Chugai Seiyaku Kabushiki Kaisha | Ligand-binding molecule having adjustable ligand-binding activity |
| US12077577B2 (en) | 2018-05-30 | 2024-09-03 | Chugai Seiyaku Kabushiki Kaisha | Polypeptide comprising aggrecan binding domain and carrying moiety |
| US11365233B2 (en) | 2020-04-10 | 2022-06-21 | Cytomx Therapeutics, Inc. | Activatable cytokine constructs and related compositions and methods |
| US12091442B2 (en) | 2020-04-10 | 2024-09-17 | Cytomx Therapeutics, Inc. | Activatable cytokine constructs and related compositions and methods |
| US11667687B2 (en) | 2021-03-16 | 2023-06-06 | Cytomx Therapeutics, Inc. | Masked activatable interferon constructs |
| WO2023002952A1 (en) * | 2021-07-19 | 2023-01-26 | Chugai Seiyaku Kabushiki Kaisha | Protease-mediated target specific cytokine delivery using fusion polypeptide |
Also Published As
| Publication number | Publication date |
|---|---|
| CN114127277A (zh) | 2022-03-01 |
| EP3981428A1 (en) | 2022-04-13 |
| JP7716979B2 (ja) | 2025-08-01 |
| US20220315909A1 (en) | 2022-10-06 |
| JPWO2020246567A1 (ja) | 2020-12-10 |
| EP3981428A4 (en) | 2023-07-12 |
| JP2025134810A (ja) | 2025-09-17 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP7432575B2 (ja) | 抗原結合ドメインおよび運搬部分を含むポリペプチド | |
| JP7716979B2 (ja) | プロテアーゼ基質、及びプロテアーゼ切断配列を含むポリペプチド | |
| TWI700292B (zh) | 多胜肽異種多聚體之製造方法 | |
| JP6774164B2 (ja) | マウスFcγRII特異的Fc抗体 | |
| US20250026852A1 (en) | Polypeptide including antigen-binding domain and carrying section | |
| JP2021525065A (ja) | Il−1r1結合ドメインおよび運搬部分を含むポリペプチド | |
| RU2815452C2 (ru) | Полипептид, включающий антигенсвязывающий домен и транспортирующий сегмент | |
| RU2827545C2 (ru) | Полипептид, содержащий антигенсвязывающий домен и транспортирующий сегмент | |
| RU2827545C9 (ru) | Полипептид, содержащий антигенсвязывающий домен и транспортирующий сегмент | |
| WO2025169945A1 (ja) | 安定性が改善されたcd3標的抗原結合分子 | |
| HK40064164A (en) | Protease substrate, and polypeptide including protease cleavage sequence |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 20818589 Country of ref document: EP Kind code of ref document: A1 |
|
| ENP | Entry into the national phase |
Ref document number: 2021524912 Country of ref document: JP Kind code of ref document: A |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| ENP | Entry into the national phase |
Ref document number: 2020818589 Country of ref document: EP Effective date: 20220105 |