WO2021009990A1 - オーキシンデグロンシステムのキット、及びその使用 - Google Patents
オーキシンデグロンシステムのキット、及びその使用 Download PDFInfo
- Publication number
- WO2021009990A1 WO2021009990A1 PCT/JP2020/018237 JP2020018237W WO2021009990A1 WO 2021009990 A1 WO2021009990 A1 WO 2021009990A1 JP 2020018237 W JP2020018237 W JP 2020018237W WO 2021009990 A1 WO2021009990 A1 WO 2021009990A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- nucleic acid
- group
- auxin
- protein
- ostir1
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Ceased
Links
- 0 *c(cc1)cc2c1[n]cc2CC(O)=O Chemical compound *c(cc1)cc2c1[n]cc2CC(O)=O 0.000 description 1
- YHZAHWMLGPVMOB-UHFFFAOYSA-N Cc(c(C)c1)ccc1-c(cc1)cc2c1[nH]cc2CC(O)=O Chemical compound Cc(c(C)c1)ccc1-c(cc1)cc2c1[nH]cc2CC(O)=O YHZAHWMLGPVMOB-UHFFFAOYSA-N 0.000 description 1
- OCFCYCJFVMQJMG-UHFFFAOYSA-N OC(Cc(c1c2)c[nH]c1ccc2-c1cccc(Cl)c1)=O Chemical compound OC(Cc(c1c2)c[nH]c1ccc2-c1cccc(Cl)c1)=O OCFCYCJFVMQJMG-UHFFFAOYSA-N 0.000 description 1
Images

















Classifications
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/63—Introduction of foreign genetic material using vectors; Vectors; Use of hosts therefor; Regulation of expression
- C12N15/635—Externally inducible repressor mediated regulation of gene expression, e.g. tetR inducible by tetracyline
-
- A—HUMAN NECESSITIES
- A01—AGRICULTURE; FORESTRY; ANIMAL HUSBANDRY; HUNTING; TRAPPING; FISHING
- A01K—ANIMAL HUSBANDRY; AVICULTURE; APICULTURE; PISCICULTURE; FISHING; REARING OR BREEDING ANIMALS, NOT OTHERWISE PROVIDED FOR; NEW BREEDS OF ANIMALS
- A01K67/00—Rearing or breeding animals, not otherwise provided for; New or modified breeds of animals
- A01K67/027—New or modified breeds of vertebrates
- A01K67/0275—Genetically modified vertebrates, e.g. transgenic
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/87—Introduction of foreign genetic material using processes not otherwise provided for, e.g. co-transformation
- C12N15/90—Stable introduction of foreign DNA into chromosome
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N9/00—Enzymes; Proenzymes; Compositions thereof; Processes for preparing, activating, inhibiting, separating or purifying enzymes
- C12N9/10—Transferases (2.)
- C12N9/1025—Acyltransferases (2.3)
- C12N9/104—Aminoacyltransferases (2.3.2)
-
- A—HUMAN NECESSITIES
- A01—AGRICULTURE; FORESTRY; ANIMAL HUSBANDRY; HUNTING; TRAPPING; FISHING
- A01K—ANIMAL HUSBANDRY; AVICULTURE; APICULTURE; PISCICULTURE; FISHING; REARING OR BREEDING ANIMALS, NOT OTHERWISE PROVIDED FOR; NEW BREEDS OF ANIMALS
- A01K2217/00—Genetically modified animals
- A01K2217/05—Animals comprising random inserted nucleic acids (transgenic)
- A01K2217/052—Animals comprising random inserted nucleic acids (transgenic) inducing gain of function
-
- A—HUMAN NECESSITIES
- A01—AGRICULTURE; FORESTRY; ANIMAL HUSBANDRY; HUNTING; TRAPPING; FISHING
- A01K—ANIMAL HUSBANDRY; AVICULTURE; APICULTURE; PISCICULTURE; FISHING; REARING OR BREEDING ANIMALS, NOT OTHERWISE PROVIDED FOR; NEW BREEDS OF ANIMALS
- A01K2217/00—Genetically modified animals
- A01K2217/20—Animal model comprising regulated expression system
- A01K2217/203—Animal model comprising inducible/conditional expression system, e.g. hormones, tet
-
- A—HUMAN NECESSITIES
- A01—AGRICULTURE; FORESTRY; ANIMAL HUSBANDRY; HUNTING; TRAPPING; FISHING
- A01K—ANIMAL HUSBANDRY; AVICULTURE; APICULTURE; PISCICULTURE; FISHING; REARING OR BREEDING ANIMALS, NOT OTHERWISE PROVIDED FOR; NEW BREEDS OF ANIMALS
- A01K2227/00—Animals characterised by species
- A01K2227/10—Mammal
- A01K2227/105—Murine
-
- A—HUMAN NECESSITIES
- A01—AGRICULTURE; FORESTRY; ANIMAL HUSBANDRY; HUNTING; TRAPPING; FISHING
- A01K—ANIMAL HUSBANDRY; AVICULTURE; APICULTURE; PISCICULTURE; FISHING; REARING OR BREEDING ANIMALS, NOT OTHERWISE PROVIDED FOR; NEW BREEDS OF ANIMALS
- A01K2267/00—Animals characterised by purpose
- A01K2267/03—Animal model, e.g. for test or diseases
-
- A—HUMAN NECESSITIES
- A01—AGRICULTURE; FORESTRY; ANIMAL HUSBANDRY; HUNTING; TRAPPING; FISHING
- A01K—ANIMAL HUSBANDRY; AVICULTURE; APICULTURE; PISCICULTURE; FISHING; REARING OR BREEDING ANIMALS, NOT OTHERWISE PROVIDED FOR; NEW BREEDS OF ANIMALS
- A01K2267/00—Animals characterised by purpose
- A01K2267/03—Animal model, e.g. for test or diseases
- A01K2267/0393—Animal model comprising a reporter system for screening tests
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2319/00—Fusion polypeptide
- C07K2319/60—Fusion polypeptide containing spectroscopic/fluorescent detection, e.g. green fluorescent protein [GFP]
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2319/00—Fusion polypeptide
- C07K2319/95—Fusion polypeptide containing a motif/fusion for degradation (ubiquitin fusions, PEST sequence)
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2310/00—Structure or type of the nucleic acid
- C12N2310/10—Type of nucleic acid
- C12N2310/20—Type of nucleic acid involving clustered regularly interspaced short palindromic repeats [CRISPR]
Definitions
- the present invention relates to a kit of the auxin degron system and its use. Specifically, the present invention relates to a kit of an auxin degron system, a method for degrading a target protein, a target proteolysis inducer, and a cell.
- the present application claims priority based on Japanese Patent Application No. 2019-131464 filed in Japan on July 16, 2019, the contents of which are incorporated herein by reference.
- TIR1 which constitutes an auxin-responsive ubiquitin ligase
- TIR1 is introduced into cells derived from eukaryotes such as yeast and animal cells, and the presence or absence and timing of addition of auxin are adjusted to cause a degradation tag (plant-derived aux).
- IAA family protein or a partial protein thereof; also referred to as degron controls the degradation of the target protein.
- the method for controlling the degradation of target proteins (also referred to as the auxin degron method) developed by the present inventors has already been widely used in cell biology research, and is a model organism such as yeast, nematode, Drosophila, and zebrafish. It is also being used for.
- auxin makes it possible to rapidly degrade the target protein to which a degradation tag (degron) has been added.
- degron a degradation tag
- it is difficult to strictly control the expression because the target protein is weakly decomposed even when auxin is not added.
- a relatively high concentration of auxin of 100 ⁇ M or more is used for inducing degradation, and there has been concern about the toxic effect of auxin itself, especially in multicellular animals.
- the present invention has been made in view of the above circumstances, and is a kit of an auxin degron system capable of strictly and freely controlling protein degradation, a target protein degradation method, a target proteolysis inducer, cells, and a compound. I will provide a.
- the present invention includes the following aspects.
- the present invention includes the following aspects.
- a kit of the auxin degron system that controls the degradation of target proteins in non-plant-derived eukaryotic cells, and the first nucleic acid encoding a mutant TIR1 family protein having a mutation in the auxin binding site.
- a degradation tag comprising an auxin analog having an affinity for the mutant TIR1 family protein and at least a portion of the Aux / IAA family protein and having an affinity for the mutant TIR1 family protein-the auxin analog complex.
- a kit comprising two nucleic acids.
- the kit according to [1] further comprising a third nucleic acid encoding a target protein linked upstream or downstream of the second nucleic acid.
- the mutant TIR1 family protein is a rice-derived protein.
- the mutant TIR1 family protein is a protein in which the 74th F of OsTIR1 is mutated to A, G, or S. ..
- the auxin analog is a compound represented by the following general formula (I) or an ester thereof.
- R 10 may have a substituent, or a cyclic aliphatic hydrocarbon group in which a part of the carbon atom constituting the ring may be substituted with a hetero atom, or , It is an aromatic hydrocarbon group which may have a substituent and may have a part of carbon atoms constituting the ring substituted with a heteroatom.
- a fourth encoding a linker for controlling a plurality of genes linked between the first nucleic acid and the second nucleic acid and the third nucleic acid with one promoter.
- the kit according to any one of [2] to [5], which comprises the nucleic acid of.
- a target proteolysis inducer used in the auxin degron system that controls the degradation of target proteins in non-plant-derived eukaryotic cells is a compound represented by the following general formula (I) or an ester thereof.
- a target proteolytic inducer containing the body is a compound represented by the following general formula (I) or an ester thereof.
- R 10 may have a substituent, or a cyclic aliphatic hydrocarbon group in which a part of the carbon atom constituting the ring may be substituted with a hetero atom, or , It is an aromatic hydrocarbon group which may have a substituent and may have a part of carbon atoms constituting the ring substituted with a heteroatom.
- mutant TIR1 family protein is a rice-derived protein.
- mutant TIR1 family protein is a protein in which the 74th F of OsTIR1 is mutated to A, G, or S.
- R 30 represents a hydrogen atom, an alkyl group having 1 to 6 carbon atoms, or a halogen atom
- R 31 represents a hydrogen atom or an alkyl group having 1 to 6 carbon atoms.
- R 30 is a hydrogen atom or an alkyl group having 1 to 6 carbon atoms
- R 31 is an alkyl group having 1 to 6 carbon atoms.
- auxin degron system kit of the present invention protein degradation control can be performed strictly and freely.
- Example 3 This is the result of examining the degradation of the target protein in OsTIR1 (F74G) / mAID-EGFP-NLS expressing cells in Example 1. This is the result of examining the degradation of the target protein in OsTIR1 (F74G) / mAID-EGFP-NLS-expressing cells by adding a plurality of kinds of auxin analogs in Example 2. It is the result of the colony forming test in Example 3.
- A is a microscopic image of OsTIR1 (F74G) / DHC1-mAID-Clover expressing cells supplemented with 5-Ph-IAA.
- B 5-Ph-IAA-dependent degradation of DHC1 was confirmed by Western blotting.
- FIG. 1 It is a conceptual diagram of a target proteolytic system.
- A 5-Ph-IAA-dependent degradation of CENPH was confirmed by Western blotting.
- B 5-Ph-IAA-dependent degradation of POLD1 was confirmed by Western blotting.
- A It is a result of examining the degradation of the target protein in OsTIR1 (WT) / mAID-EGFP-NLS expressing cells and OsTIR1 (F74G) / mAID-EGFP-NLS expressing cells.
- FIG. 5 is a graph showing the results of inducing mAID-EGFP-NLS reporter degradation in OsTIR1 (WT) and OsTIR1 (F74G) using different doses of IAA (auxin) and 5-Ph-IAA, respectively.
- B It is a graph which shows the result of having induced the reporter decomposition with time in OsTIR1 (WT) and OsTIR1 (F74G). This is the result of examining the recovery of mAID-EGFP-NLS reporter expression after removal of 5-Ph-IAA in OsTIR1 (F74G).
- (A) It is a figure which shows the outline of the experiment in Example 5.
- (B) It is a photograph which showed the degree of colony formation on a plate in each yeast strain.
- (A) It is a photograph which investigated the degradation of the reporter containing RAD21 in the RAD21-mAID-Clover (RAD21-mAC) cell expressing OsTIR1 (WT) or OsTIR1 (F74G).
- (B) It is a graph which shows the result of inducing the degradation of the RAD21 reporter with time in the RAD21-mAID-Clover (RAD21-mAC) cell expressing OsTIR1 (WT) or OsTIR1 (F74G).
- FIG. 1 It is a photograph showing the presence or absence of colonization in OsTIR1 (WT or F74G) or AtAFB2-expressing cells for which genome editing was attempted using mini-IAA7 (mIAA7).
- C This is the result of FACS analysis of the degradation of the reporter when the degradation of mIAA7 or mAID-tagged DHC1 was induced in the cells expressing AtAFB2 or OsTIR1 (F74G). It is a result of examining the degradation of SMC2, CTCF, and POLR2A to which mAID was added by addition of 5-Ph-IAA in HCT116 which constitutively expresses OsTIR1 (F74G).
- the kit of the present invention is a kit of the auxin degron system that controls the degradation of target proteins in non-plant-derived eukaryotic cells, and is the first kit encoding a mutant TIR1 family protein having a mutation in the auxin binding site.
- the "auxin degron system” is a protein degradation control technology developed by the present inventors, and the plant-specific proteolytic system introduced by the plant hormone auxin is applied to non-plant-derived eukaryotic cells. It is a system (see, for example, Patent Documents 1 to 3). Specifically, this system consists of a plant-derived TIR1 family protein as an F-box protein, which is a subunit of the E3 ubiquitinating enzyme complex (SCF complex), and a plant-derived Aux / IAA family protein or a partial sequence thereof.
- SCF complex E3 ubiquitinating enzyme complex
- the TIR1 family protein which is an auxin receptor, produces a peptide consisting of the Aux / IAA family protein or a subunit thereof in an auxin-dependent manner. It is a system that recognizes and degrades target proteins using the ubiquitin / proteasome degradation system in non-plant-derived eukaryotic cells.
- the present inventors have found a problem that the target protein is degraded in an auxin-independent manner in such a system.
- the present inventors have a mutant TIR1 family protein having a mutation in the auxin binding site, an auxin analog having an affinity for the mutant TIR1 family protein, and at least a part of the Aux / IAA family proteins.
- the present inventors have found that a low concentration of auxin analog can induce degradation of a target protein. According to the present invention, it is possible to provide an auxin degron system in which the degradation of the target protein hardly occurs when auxin is not added, and the degradation efficiency of the target protein is very high when auxin is added.
- the first nucleic acid encodes a mutant TIR1 family protein having a mutation in the auxin binding site.
- the TIR1 family protein is an F-box protein which is one of the subunits forming an E3 ubiquitinating enzyme complex (SCF complex) in ubiquitin / proteasome system proteolysis, and is a plant-specific protein. It is known that the TIR1 family protein is a receptor for the growth hormone auxin, and by accepting auxin, it recognizes the auxin signal transduction system inhibitor Aux / IAA family protein and degrades the target protein. Has been done.
- the type of the gene encoding the TIR1 family protein is not limited as long as it is a gene encoding a plant-derived TIR1 family protein.
- the type of plant from which it is derived is not limited, and examples thereof include Arabidopsis thaliana, rice, zinnia, pine, fern, and Physcomitrella patens.
- Specific examples of the gene encoding the TIR1 family protein include TIR1 gene, AFB1 gene, AFB2 gene, AFB3 gene, FBX14 gene, AFB5 gene and the like. Of these, the OsTIR1 gene, which is a TIR1 gene derived from rice, is preferable.
- Examples of the gene include the genes of accession numbers NM_001059194 (GeneID: 4335966) and Os04g0395600 or accession numbers EAY9333 and OsI_15707 registered in NCBI, and more specifically, the base sequence represented by SEQ ID NO: 1. Examples include genes consisting of. Further, a gene consisting of the base sequence represented by SEQ ID NO: 2 whose codon is optimized for human cells is preferable.
- the mutant TIR1 family protein has a mutation in the auxin binding site.
- the mutant protein is not particularly limited as long as it has an affinity for the auxin analog described later, but it is preferable that the 74th F of OsTIR1 is mutated to A, G, or S, and the mutated protein is mutated to G. What is more preferable.
- the mutant TIR1 family protein consists of a sequence containing any one of the following amino acid sequences (a) to (c), and binds to a degradation tag via a complex with an auxin analog. Proteins that lead to degradation of the target protein are particularly preferred.
- A An amino acid sequence in which the amino acid number 74 of the amino acid sequence represented by SEQ ID NO: 3 is glycine
- B An amino acid sequence in which one to several amino acids have been deleted, inserted, substituted or added at a site other than the 74th amino acid number in (a) above.
- C An amino acid sequence having 80% or more identity at a site other than the 74th amino acid number in (a) above.
- the number of amino acids deleted, inserted, substituted or added in (b) is preferably 1 to 120, more preferably 1 to 60, further preferably 1 to 20, and particularly preferably 1 to 10. Most preferably, 1 to 5 pieces.
- it has 80% or more identity. As for the identity, 85% or more is more preferable, 90% or more is further preferable, 95% or more is particularly preferable, and 99% or more is most preferable.
- Examples of the OsTIR1 F74A protein include those consisting of the amino acid sequence represented by SEQ ID NO: 4, and examples of the gene encoding the OsTIR1 F74A protein include a gene consisting of the base sequence represented by SEQ ID NO: 5.
- Examples of the OsTIR1 F74G protein include those consisting of the amino acid sequence represented by SEQ ID NO: 6, and examples of the gene encoding the OsTIR1 F74G protein include a gene consisting of the base sequence represented by SEQ ID NO: 7.
- the first nucleic acid encoding the mutant TIR1 family protein may be a DNA containing an exon and an intron, or a cDNA composed of an exon.
- the first nucleic acid encoding the mutant TIR1 family protein may be, for example, a full-length sequence in genomic DNA or a full-length sequence in cDNA.
- the first nucleic acid encoding the mutant TIR1 family protein may be a partial sequence in genomic DNA or a partial sequence in cDNA as long as the expressed protein functions as TIR1.
- TIR1 family protein means, for example, recognizing a degradation tag (full-length or partial protein of Aux / IAA family protein) in the presence of an auxin analog. This is because if the TIR1 family protein can recognize the degradation tag, the target protein labeled with the degradation tag can be degraded.
- a promoter sequence that controls transcription of the first nucleic acid is operably linked to the 5'end of the first nucleic acid encoding the TIR1 family protein.
- the TIR1 family protein can be expressed more reliably.
- operably linked means between a gene expression control sequence (eg, a promoter or a series of transcription factor binding sites) and a gene to be expressed (the first nucleic acid encoding a TIR1 family protein).
- a gene expression control sequence eg, a promoter or a series of transcription factor binding sites
- the expression control sequence means a sequence that directs the transcription of the gene to be expressed (the first nucleic acid encoding the TIR1 family protein).
- the promoter is not particularly limited and can be appropriately determined depending on, for example, the type of cell. Specific examples of the promoter include CMV promoter, SV40 promoter, EF1a promoter, RSV promoter and the like.
- the first nucleic acid encoding the TIR1 family protein and the promoter sequence operably linked upstream may be in the form inserted into a vector.
- the vector is preferably an expression vector.
- the expression vector is not particularly limited, and an expression vector suitable for the host cell can be used.
- the vector may have a polyadenylation signal, NLS, a marker gene for a fluorescent protein, or the like operably linked to the 5'end or 3'end of the first nucleic acid encoding the TIR1 family protein.
- the kit of the present invention may include non-plant-derived eukaryotic cells having the first nucleic acid on the chromosome. Such cells preferably have the first nucleic acid in the safe harbor locus.
- the "safe harbor locus” is a gene region that is constitutively and stably expressed, and sustains life even when the gene originally encoded in the region is deleted or modified. Means the area where When inserting foreign DNA (in this embodiment, the gene encoding TIR1) into the safe harbor locus using the CRISPR system, it is preferable to have a PAM sequence in the vicinity.
- the safe harbor locus include GTP-binding protein 10 locus, Rosa26 locus, beta-actin locus, AAVS1 (the AAV integration site 1) locus and the like. Above all, in the case of human-derived cells, it is preferable to insert foreign DNA into the AAVS1 locus.
- the cell is not particularly limited as long as it is a non-plant-derived eukaryotic cell, and examples thereof include cells of animals, fungi, prokaryotes, and the like.
- animals include mammals such as humans, mice, rats and rabbits, fish and amphibians such as zebrafish and Xenopus laevis, and invertebrates such as C. elegans and Drosophila.
- eukaryotic-derived cells, ES cells, and iPS cells that have been established can also be mentioned.
- eukaryotic cells for example, strained human-derived cells, strained mouse-derived cells, strained chicken-derived cells, human ES cells, mouse ES cells, human iPS cells, mouse iPS cells.
- fungi include budding yeast, fission yeast and the like.
- the auxin analog is not particularly limited as long as it has an affinity for the mutant TIR1 family protein, and is preferably a compound represented by the following general formula (I) or an ester thereof.
- R 10 may have a substituent, or a cyclic aliphatic hydrocarbon group in which a part of the carbon atom constituting the ring may be substituted with a hetero atom, or , It is an aromatic hydrocarbon group which may have a substituent and may have a part of carbon atoms constituting the ring substituted with a heteroatom.
- the cyclic aliphatic hydrocarbon group in R 10 may be a monocyclic group or a polycyclic group.
- Examples of the monocyclic aliphatic hydrocarbon include a cyclopropyl group, a cyclobutyl group, a cyclopentyl group, a cyclohexyl group, a methylcyclohexyl group, a dimethylcyclohexyl group, a cycloheptyl group, a cyclooctyl group, a cyclononyl group and a cyclodecyl group.
- Examples of the polycyclic alicyclic hydrocarbon group include a decahydronaphthyl group, an adamantyl group, a 2-alkyladamantan-2-yl group, a 1- (adamantan-1-yl) alkane-1-yl group, and a norbornyl group. Examples thereof include a methylnorbornyl group and an isobornyl group.
- a part of carbon atoms constituting the ring may be replaced with a hetero atom.
- the hetero atom include an oxygen atom, a sulfur atom, a nitrogen atom and the like.
- heterocycles include pyrrolidine, tetrahydrofuran, tetrahydrothiophene, piperidine, tetrahydropyran, tetrahydrothiopyran, dioxane, dioxolane and the like.
- substituents examples include an alkyl group having 1 to 6 carbon atoms, an alkoxy group having 1 to 6 carbon atoms, a halogen atom, and an aryl group having 6 to 30 carbon atoms.
- alkyl group examples include a methyl group, an ethyl group, an n-propyl group, an isopropyl group, a cyclopropyl group, an n-butyl group, an isobutyl group, a sec-butyl group, a tert-butyl group, a cyclobutyl group, and an n-pentyl group.
- examples thereof include a group, a cyclohexyl group, a 2-methylpentyl group, a 3-methylpentyl group, a 1,1,2-trimethylpropyl group, a 3,3-dimethylbutyl group and the like.
- alkoxy group examples include those in which the R portion of ⁇ OR is the same as the above-mentioned alkyl group having 1 to 6 carbon atoms. Among them, the carbon number alkoxy group is preferably a methoxy group or an ethoxy group.
- the halogen atom examples include a fluorine atom, a chlorine atom, a bromine atom, an iodine atom and the like. Among them, as the halogen atom, a fluorine atom or a chlorine atom is preferable.
- aryl group examples include a phenyl group, a naphthyl group, a benzyl group, a phenethyl group, a biphenyl group, a pentarenyl group, an indenyl group, an anthranyl group, a tetrasenyl group, a pentasenyl group, a pyrenyl group, a perylenel group, a fluorenyl group and a phenanthryl group.
- Examples of the aromatic hydrocarbon group in R 10 include the above-mentioned aryl group having 6 to 30 carbon atoms. In the aromatic hydrocarbon group, a part of the carbon atom constituting the ring may be substituted with a hetero atom.
- Examples of the hetero atom include an oxygen atom, a sulfur atom, a nitrogen atom and the like. Examples of such heterocycles include pyrrole, furan, thiophene, pyridine, imidazole, pyrazole, oxazole, thiazole, pyridazine, pyrimidine, indol, benzimidazole, quinoline, isoquinoline, chromene, isochromene and the like.
- substituents examples include those similar to those listed in [Cyclic aliphatic hydrocarbon group].
- the ester of the compound represented by the general formula (I) is one in which the hydrogen atom in -COOH of the general formula (I) is substituted with a hydrocarbon group, and the ester compound is preferably substituted with an alkyl group.
- the alkyl group an alkyl group having 1 to 6 carbon atoms is preferable, and a methyl group, an ethyl group, an n-propyl group, an isopropyl group, a cyclopropyl group, an n-butyl group, an isobutyl group, a sec-butyl group, and a tert- Butyl group, cyclobutyl group, n-pentyl group, isopentyl group, sec-pentyl group, neopentyl group, tert-pentyl group, cyclopentyl group, 2,3-dimethylpropyl group, 1-ethylpropyl group, 1-methylbutyl group, 2
- R 10 is an aromatic hydrocarbon group.
- R 1 is an alkyl group having 1 to 6 carbon atoms, an alkoxy group having 1 to 6 carbon atoms, a halogen atom, or an aryl group having 6 to 30 carbon atoms.
- N is 0. it is an integer of 1-5, and when n is an integer of 2 to 5, n pieces of R 1 may be the same or different from each other.
- halogen atom of R 1 examples include a fluorine atom, a chlorine atom, a bromine atom, an iodine atom and the like. Among them, as the halogen atom, a fluorine atom or a chlorine atom is preferable.
- alkyl group of R 1 examples include methyl group, ethyl group, n-propyl group, isopropyl group, cyclopropyl group, n-butyl group, isobutyl group, sec-butyl group, tert-butyl group, cyclobutyl group and n.
- -Pentyl group isopentyl group, sec-pentyl group, neopentyl group, tert-pentyl group, cyclopentyl group, 2,3-dimethylpropyl group, 1-ethylpropyl group, 1-methylbutyl group, 2-methylbutyl group, n-hexyl
- examples thereof include a group, an isohexyl group, a cyclohexyl group, a 2-methylpentyl group, a 3-methylpentyl group, a 1,1,2-trimethylpropyl group and a 3,3-dimethylbutyl group.
- the alkyl group having 1 to 6 carbon atoms is preferably a methyl group or an ethyl group.
- Examples of the alkoxy group of R 1 include those in which the R portion of ⁇ OR is the same as the above-mentioned alkyl group having 1 to 6 carbon atoms. Among them, the carbon number alkoxy group is preferably a methoxy group or an ethoxy group.
- Examples of the aryl group of R 1 include a phenyl group, a naphthyl group, a benzyl group, a phenethyl group, a biphenyl group, a pentarenyl group, an indenyl group, an anthranyl group, a tetrasenyl group, a pentasenyl group, a pyrenyl group, a perylenel group, a fluorenyl group and a phenanthryl group. Can be mentioned.
- N of R 1 is an integer of 0 to 5, preferably 0 to 3.
- the compound represented by the general formula (I-1) has a plurality of R 1 , the following compounds or esters thereof can be mentioned.
- R 1 to R 3 are independently alkyl groups having 1 to 6 carbon atoms and alkoxy groups having 1 to 6 carbon atoms, respectively. It is a halogen atom or an aryl group having 6 to 30 carbon atoms.
- R 1 ⁇ R 3 are the same as R 1 in the general formula (I-1).
- a compound represented by the following formula (I-1-4) also referred to as 5- (3-MeOPh) -IAA).
- a compound represented by the following formula (I-1-5) also referred to as 5-Ph-IAA).
- a compound represented by the following formula (I-1-6) also referred to as 5- (3,4-diMePh) -IAA).
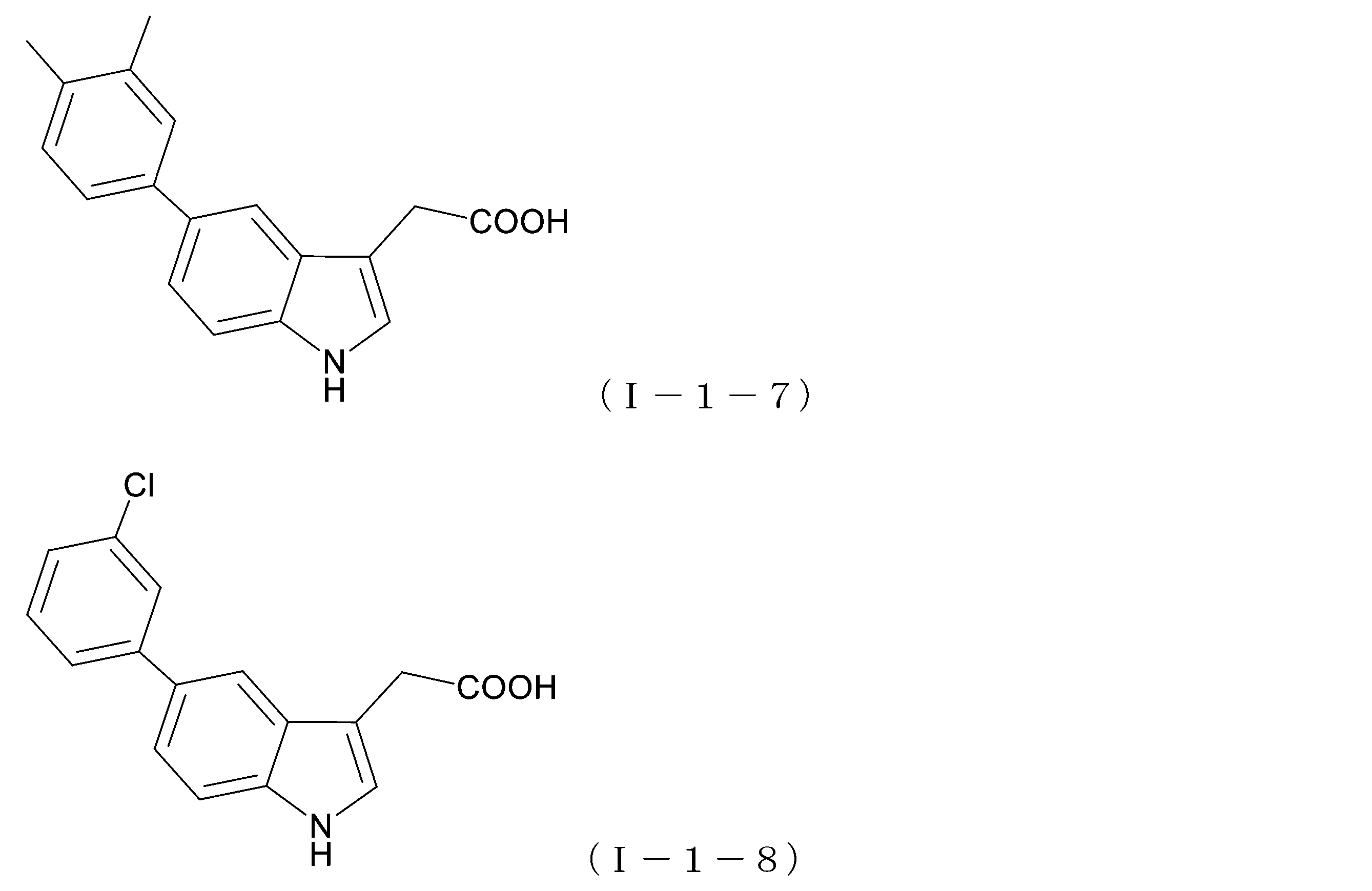
- a compound represented by the following formula (I-1-7) also referred to as 5- (3-MePh) -IAA).
- a compound represented by the following formula (I-1-8) also referred to as 5- (3-ClPh) -IAA).
- R 10 is an aromatic hydrocarbon group
- compounds represented by the following formulas (I-2) to (I-5) or esters thereof are also preferable.
- R 10 is a cyclic aliphatic hydrocarbon group, a compound represented by the following general formula (I-6), or an ester thereof.
- R 1 is an alkyl group having 1 to 6 carbon atoms, an alkoxy group having 1 to 6 carbon atoms, a halogen atom, or an aryl group having 6 to 30 carbon atoms.
- M is 0. is an integer from to 11, when m is an integer of 2 to 11, m pieces of R 1 may be the same or different from each other.
- R 1 is the same as that given in the general formula (I-1). m is preferably 0 to 6, more preferably 0 to 3.
- R 10 is a cyclic aliphatic hydrocarbon group
- a compound represented by the following formula (I-7) or an ester thereof is also preferable.
- the second nucleic acid comprises at least a portion of the Aux / IAA family protein and encodes a degradation tag having an affinity for the mutant TIR1 family protein-the auxin analog complex.
- the gene encoding the Aux / IAA family protein is not particularly limited as long as it is a plant-derived Aux / IAA family gene.
- genes encoding the Aux / IAA family proteins include, for example, IAA1 gene, IAA2 gene, IAA3 gene, IAA4 gene, IAA5 gene, IAA6 gene, IAA7 gene, IAA8 gene, IAA9 gene, IAA10 gene, IAA11 gene, IAA12 gene, IAA13 gene, IAA14 gene, IAA15 gene, IAA16 gene, IAA17 gene, IAA18 gene, IAA19 gene, IAA20 gene, IAA26 gene, IAA27 gene, IAA28 gene, IAA29 gene, IAA30 gene, IAA31 gene, IAA32 gene , IAA34 gene and the like.
- the kit of the present invention may have a full-length or partial sequence of a gene encoding any one of the Aux / IAA family proteins, or may have two or more of them.
- the sequence of the Aux / IAA family gene derived from Arabidopsis thaliana is registered in TAIR (the Arabidopsis Information Resource), and the accession number of each gene is as follows.
- IAA1 gene (AT4G14560), IAA2 gene (AT3G23030), IAA3 gene (AT1G04240), IAA4 gene (AT5G43700), IAA5 gene (AT1G15580), IAA6 gene (AT1G52830), IAA7 gene (AT3G23050), IAA7 gene (AT3G23050) (AT5G65670), IAA10 gene (AT1G04100), IAA11 gene (AT4G28640), IAA12 gene (AT1G04550), IAA13 gene (AT2G33310), IAA14 gene (AT4G14550), IAA15 gene (AT1G80390), IAA16 gene (AT1G80390), IAA16 gene ), IAA18 gene (AT1G51950), IAA19 gene (AT3G15540), IAA20 gene (AT2G46990), IAA26 gene (AT3G16500), IAA27 gene (AT4G29080), IAA28 gene (AT5G25890), IAA29 gene (
- the degradation tag is not particularly limited as long as it binds to the mutant TIR1 family protein-auxin analog complex and leads to degradation of the target protein, and is an Aux / IAA family protein containing the full-length or partial protein of mAID. Is preferable.
- MAID is an abbreviation for "Mini-auxin-inducible degron” and is a protein consisting of a partial sequence of Arabidopsis thaliana IAA17, which is one of the Aux / IAA family proteins. This partial sequence is a sequence consisting of a region containing at least two Lys residues on the N-terminal side and the C-terminal side of the domain II region of the Aux / IAA family protein, or a sequence in which two or more of the sequences are linked. Is an array.
- This mAID can be a degradation tag that labels the target protein.
- the amino acid sequence of mAID is represented by SEQ ID NO: 8.
- a third nucleic acid encoding the target protein linked upstream or downstream of the second nucleic acid may be provided.
- the second nucleic acid may be placed adjacent to either the 5'side or the 3'side of the third nucleic acid.
- the fusion nucleic acid composed of the second nucleic acid and the third nucleic acid preferably has a promoter sequence operably linked, and may be integrated into an expression vector.
- first nucleic acid and the second nucleic acid, or the fusion nucleic acid consisting of the second nucleic acid and the third nucleic acid may be incorporated into the expression vector, respectively, but the kit of the present invention is , Equipped with a fourth nucleic acid encoding a linker for controlling multiple genes with one promoter, linked between a first nucleic acid and a fusion nucleic acid consisting of a second nucleic acid and a third nucleic acid. It may be.
- the fourth nucleic acid include nucleic acids encoding read-through linkers and nucleic acids encoding non-read-through linkers.
- nucleic acid encoding the read-through linker examples include a nucleic acid encoding a cleavage sequence by an endogenous enzyme, which encodes a nucleic acid encoding a T2A peptide, a nucleic acid encoding a P2A peptide, a nucleic acid encoding an F2A peptide, and an E2A peptide. Nucleic acid can be mentioned. Nucleic acids encoding non-read-through linkers include IRES.
- the kit of the present invention may include a transposon vector containing a first nucleic acid and / or a fusion nucleic acid consisting of a second nucleic acid and the third nucleic acid.
- the kit of the present invention comprises a vector having transposon elements at both ends of a first nucleic acid and / or a fusion nucleic acid to which a promoter sequence is operably linked, and a nucleic acid encoding transposase. It is preferable to include a vector.
- the first nucleic acid and the fusion nucleic acid may be contained in individual vectors, but when they are contained in one vector, the vector preferably contains the fourth nucleic acid.
- Transposons require an enzyme that catalyzes the transposition reaction (transposes) and DNA that is recognized and transferred by the transposes (transposons element).
- the kit of the present invention preferably contains these.
- the transposon DNA when introduced into the cell, self-transposes. It can be expressed and transferred.
- Such autonomous transposons can migrate from one location to another. Therefore, in order to more stably introduce the target gene into the chromosome, it is preferable that the kit of the present invention incorporates the DNA encoding the transposase and the transposon element into separate expression systems.
- the transposon is not particularly limited, and examples thereof include Sleeping Beauty, piggyBac, and Tol2.
- the kit of the invention preferably comprises a target genomic DNA cleaving enzyme encoding an endogenous target protein or a fifth nucleic acid encoding said enzyme.
- the system used for double-strand breakage of the target genomic DNA include a CRISPR-Cas9 system, a Transcriction activator-like effector nucleoase (TALEN) system, and a Zn finger nuclease system.
- the method for introducing these systems into cells is not particularly limited, and the target genomic DNA cleaving enzyme itself may be introduced into cells, and a target genomic DNA cleaving enzyme expression vector containing a fifth nucleic acid is introduced into cells.
- You may.
- a method of introducing a Cas9 expression vector and an expression vector encoding a guide RNA that induces Cas9 at a site to be cleaved into cells, a recombinant Cas9 protein whose expression has been purified, and a guide RNA. can be mentioned.
- the guide RNA may be divided into two, tracrRNA and crRNA, or may be sgRNA connected to one.
- the method for degrading the target protein of the present invention is the method using the above-mentioned kit of the present invention.
- the above-mentioned kit in the auxin degron system it is possible to strictly and freely control the degradation of the target protein.
- the target protein labeled with the degradation tag and the TIR1 family protein are expressed in the cell. It is preferable that the target protein labeled with the degradation tag and the TIR1 family protein are constantly expressed.
- the concentration of the auxin analog contained in the medium is not limited, and is preferably 1 ⁇ M or more and less than 0.1 mM, and preferably 10 nM or more and 50 ⁇ M or less.
- the combination of the compound represented by the general formula (I) and OsTIR1 (F74G) can sufficiently induce the decomposition of the target protein at a concentration of 50 nM.
- Addition of a predetermined concentration of auxin analog forms a mutant TIR1 family protein-auxin analog complex, which recognizes the target protein labeled by the degradation tag and induces degradation of the target protein.
- degradation of a target protein can be induced specifically for an auxin analog.
- the compound of the present invention is a compound represented by the following general formula (II).
- R 30 represents a hydrogen atom, an alkyl group having 1 to 6 carbon atoms, or a halogen atom
- R 31 represents a hydrogen atom or an alkyl group having 1 to 6 carbon atoms.
- R 30 is a hydrogen atom or an alkyl group having 1 to 6 carbon atoms
- R 31 is an alkyl group having 1 to 6 carbon atoms.
- halogen atom of R 30 examples include a fluorine atom, a chlorine atom, a bromine atom, an iodine atom and the like. Among them, as the halogen atom, a fluorine atom or a chlorine atom is preferable.
- alkyl groups of R 30 and R 31 include methyl group, ethyl group, n-propyl group, isopropyl group, cyclopropyl group, n-butyl group, isobutyl group, sec-butyl group and tert, respectively.
- the alkyl group having 1 to 6 carbon atoms is preferably a methyl group or an ethyl group.
- the cells of the present invention are non-plant-derived eukaryotic cells used in the auxin degron system that controls the degradation of target proteins, and are the first nucleic acids encoding mutant TIR1 family proteins having mutations in the auxin binding site. Has a chromosome containing.
- the cells of the invention preferably have the first nucleic acid in the safe harbor locus.
- the cells are the same as those described in ⁇ Auxin Deglon System Kit >>.
- the eukaryotic cells derived from non-plants are not particularly limited, and examples thereof include cells of animals, fungi, prokaryotes and the like.
- the OsTIR1 protein which is the same as that described in ⁇ Kit of auxin degron system >> and is a TIR1 protein derived from rice, is preferable.
- the mutant TIR1 family protein is the same as that described in ⁇ Kit of auxin degron system >>, and it is preferable that the 74th F of OsTIR1 is mutated to A, G, or S, and it is mutated to G. What is more preferable.
- the mutant TIR1 family protein is the same as that described in ⁇ Kit of auxin degron system >>, and consists of a sequence containing any one of the amino acid sequences (a) to (c) described above.
- a protein that binds to a degradation tag via a complex with an auxin analog and leads to degradation of a target protein is particularly preferable.
- the cells of the present invention further include a second nucleic acid comprising at least some Aux / IAA family proteins and encoding a degradation tag having an affinity for the mutant TIR1 family protein-auxin analog complex, and the second nucleic acid described above. It preferably has a chromosome containing a third nucleic acid encoding a target protein linked upstream or downstream of the nucleic acid.
- the method for introducing the first nucleic acid, the second nucleic acid, and the third nucleic acid into the chromosome is not particularly limited, and as described in ⁇ Kit of auxindegron system >>, genome editing technology such as CRISPR system is used. It may be introduced using a transposon vector.
- HCT116 cells human colon adenocarcinoma-derived cells
- OsTIR1 (WT) / mAID-EGFP-NLS-expressing cells or "OsTIR1 (F74G) / mAID-EGFP-NLS-expressing cells”
- WT human colon adenocarcinoma-derived cells
- F74G mAID-EGFP-NLS-expressing cells
- OsTIR1 (WT) / mAID-EGFP-NLS-expressing cells were prepared (hereinafter referred to as "OsTIR1 (WT) / mAID-EGFP-NLS-expressing cells”). See FIG. 1).
- auxin analog concentration in medium: 0,200 ⁇ M
- OsTIR1 F74G
- mAID-EGFP-NLS expressing cells culture for 24 hours.
- auxin analog concentration in medium: 0,200 ⁇ M
- WT OsTIR1
- mAID-EGFP-NLS expressing cells were also prepared.
- OsTIR1 (WT) / mAID-EGFP-NLS-expressing cells 100 ⁇ M auxin was added to OsTIR1 (WT) / mAID-EGFP-NLS-expressing cells, and 1 ⁇ M5-Ph-IAA was added to OsTIR1 (F74G) / mAID-EGFP-NLS-expressing cells for 4 hours. The cells were later collected and FACS analysis was performed. The results are shown in FIG. 7 (A). Comparing OsTIR1 (WT) and OsTIR1 (F74G) against a homogeneous genetic background, OsTIR1 (WT) had a low mAID-EGFP-NLS reporter level and a wide signal peak in the absence of auxin. It showed that there was basal decomposition.
- OsTIR1 (F74A) / mAID-EGFP-NLS expressing cells were also used and similar experiments were performed with three clones. The results are shown in FIG. 7 (B). As shown in FIG. 7 (B), the three cell lines expressing OsTIR1 (WT) showed broader peaks at low expression levels, suggesting that there was basal degradation without auxin. On the other hand, clones expressing OsTIR1 (F74G) and OsTIR1 (F74A) showed stronger expression levels of the reporter in the absence of 5-Ph-IAA, suggesting that basal degradation was suppressed.
- clones expressing OsTIR1 showed sharper degradation of the mAID-EGFP-NLS reporter compared to clones expressing OsTIR1 (F74A) by 5-Ph-IAA treatment. In all cases, the signal peak shifted to the left after 5-Ph-IAA treatment, indicating that degradation was induced.
- 5-Phenyl-indole 3-acetic acid methyl ester (124 mg, 0.47 mmol) was placed in a 10 mL round bottom flask, and 1 mL of methanol and 1 mL of tetrahydrofuran were added. An aqueous solution of lithium hydroxide (23 mg, 0.96 mmol dissolved in 1 mL of water) was added dropwise thereto. The reaction was hydrolyzed by stirring at room temperature for 2 hours. 5 mL of 1 M dilute hydrochloric acid and 5 mL of ethyl acetate were added to the reaction mixture, and the product was extracted from the ethyl acetate layer.
- HCT116 cells in which a plasmid containing the OsTIR1 (WT) gene or OsTIR1 (F74G) gene has been introduced and the mAID-EGFP (green fluorescent protein) -NLS (nuclear translocation signal) gene has been inserted on the chromosome ( Human colon adenocarcinoma-derived cells) (hereinafter referred to as "OsTIR1 (WT) / mAID-EGFP-NLS-expressing cells" or "OsTIR1 (F74G) / mAID-EGFP-NLS-expressing cells”) were prepared (see FIG. 1). ).
- auxin analog concentration in medium: 0, 50 nM, 100 nM, 500 nM, 1 ⁇ M was added and cultured for 24 hours.
- auxin analog concentration in medium: 0, 50 nM, 100 nM, 500 nM, 1 ⁇ M was added and cultured for 24 hours.
- WT OsTIR1
- mAID-EGFP-NLS expressing cells were also prepared.
- auxin-supplemented OsTIR1 F74G
- mAID-EGFP-NLS-expressing cells degraded GFP at a lower concentration than auxin-supplemented OsTIR1 (WT) / mAID-EGFP-NLS-expressing cells.
- OsTIR1 (F74G) / mAID-EGFP-NLS expressing cells were treated with low concentrations of each auxin analog.
- the results are shown in FIG.
- 5-Ph-IAA showed a stronger effect of inducing degradation of the mAID-EGFP-NLS reporter at 1 nM and 10 nM than other compounds.
- Example 3 1. Cell preparation In HCT116 cells, the OsTIR1 (WT) gene or OsTIR1 (F74G) gene is introduced into the AAVS1 locus at the safe harbor locus using the CRISPR / Cas system, and OsTIR1 (WT) -expressing HCT116 cells or OsTIR1 (F74G) expressed HCT116 cells were constructed.
- WT OsTIR1
- F74G OsTIR1
- OsTIR1 (F74G) -expressing HCT116 cells hereinafter referred to as "OsTIR1 (F74G) / DHC1-mAID-Clover expressing cells" that had undergone homologous recombination in 2 above.
- the test was conducted.
- a compound represented by the formula (I-2) also referred to as 5-Ph-IAA was added to OsTIR1 (F74G) / DHC1-mAID-Clover expressing cells, and the state of the cells after 24 hours was observed (FIG. 4 (A)).
- FIG. 4 (A) the addition of 5-Ph-IAA resulted in the degradation of the DHC1-mAID-Clover fusion protein, and the accumulation of cells during mitosis was observed. Furthermore, the decomposition of DHC1 was confirmed by Western blotting (FIG. 4 (B)). As shown in FIG. 4B, degradation of DHC1 and mAID was confirmed in all of clones # 1 to 3 prepared by homologous recombination in a 5-Ph-IAA-dependent manner.
- Example 4 There are three drawbacks to constructing an intrinsic target proteolytic system. (1) Since many cultured cells are polyploid, there are two or more copies of allele of the target gene. Therefore, it is difficult to construct this degradation system in various cultured cell lines. (2) It is necessary to create a parent strain into which OsTIR1 (F74G) has been introduced in advance. (3) It takes time and effort to construct a large number of decomposition systems and create a library.
- a new target proteolytic system shown in FIG. 5 was constructed.
- (1) the OsTIR1 (F74G) gene and the mAID-target gene are linked to a transposon vector with a P2A linker gene, and (2) to knock out an endogenous target gene including a gRNA and a Cas9 gene.
- the transposon vector integrates the OsTIR1 (F74G) gene and the mAID-target gene into the genome, while the CRISPR-KO vector knocks out the endogenous target gene.
- the OsTIR1 (F74G) gene and the mAID-EGFP-CENPH or mAID-EGFP-POLD1 target gene are linked to create a transposon vector linked by the P2A linker gene, and this vector is used as a target for the endogenous CENPH or POLD1 gene. It was introduced into HeLa cells together with the vector. 5-Ph-IAA was added to the cells, and the degradation of the target protein was confirmed by Western blotting (Fig. 6).
- FIG. 6A shows the results of Western blotting using an anti-CENPH antibody. It was confirmed that the endogenous CENPH gene was knocked out, and that mAID-EGFP-CENPH was degraded in a 5-Ph-IAA-dependent manner.
- FIG. 6B shows the results of Western blotting using the anti-POLD1 antibody.
- clones # 1 to 3 it was confirmed that the endogenous POLD1 gene was knocked out, and that mAID-EGFP-POLD1 was degraded in a 5-Ph-IAA-dependent manner.
- OsTIR1 WT, F74G, or F74A
- MCM10 essential replication initiators
- SLD3, or CDC45 essential replication initiators
- yeast strains expressing OsTIR1 show slow growth and higher basal degradation in yeast, as shown in OsTIR1 ON, no ligand, cdc45-mAID, etc. in FIG. 12 (B). Suggested that there is.
- OsTIR1 WT and F74A showed growth inhibition of these mAID-introduced strains at 500 ⁇ MIAA, suggesting that OsTIR1 (F74A) remains reactive to IAA.
- strains expressing OsTIR1 F74G or F74A showed strong growth inhibition on plates containing 5 ⁇ M5-Ph-IAA.
- OsTIR1 F74G or F74A
- the growth of the mcm10-mAID strain and the sld3-mAID strain is strongly inhibited, so that the AID2 system can produce a mutant having a higher degradation ability and a strong phenotype. Is shown.
- Example 6 Using human HCT116 cells that constitutively express OsTIR1 (F74G) as a material, RAD21-mAID-Clover (RAD21-mAC) cells were prepared by genome editing, and the effect of adding 5-Ph-IAA was confirmed. As shown in FIGS. 13 (A) and 13 (B), the expression level of RAD21-mAC expressed OsTIR1 (F74G) more than the cells expressing OsTIR1 (WT) at 0 minutes before addition. The cells are higher, indicating basal degradation in the conventional AID system. RAD21-mAC disappeared rapidly after addition of the ligand in both OsTIR1 (WT) and OsTIR1 (F74G).
- T1 / 2 was 26.5 minutes and 11.7 minutes for OsTIR1 (WT) and OsTIR1 (F74G), respectively, indicating that RAD21-mAC was degraded faster by the AID2 system.
- WT OsTIR1
- F74G OsTIR1
- Example 7 In view of the fact that OsTIR1 (F74G) showed less basal degradation, it was examined whether DHC1-mAID-Clover (DHC1-mAC) could be produced in HCT116 cells that constitutively express OsTIR1 (F74G).
- a parental cell line constitutively expressing OsTIR1 WT or F74G was transfected with a CRISPR plasmid for adding the degron tag and two donors with neomycin or hygromycin resistance markers, respectively (see Figure 14).
- OsTIR1 (F74G) -expressing cells colonies were formed in the presence of G418 and hygromycin, and the DHC1 gene in both alleles was tagged (see FIG.
- FIG. 16B colonization was confirmed under all conditions. However, the number of colonies was smaller in the cells expressing OsTIR1 (WT) and AtAFB2 than in the cells expressing OsTIR1 (F74G). In cells expressing AtAFB2 or OsTIR1 (F74G), degradation of mIAA7 or mAID-tagged DHC1 was induced (see FIG. 16C). In FIG. 16C, it was confirmed that the combination of OsTIR1 (F74G) and the mAID tag was the most efficient. This is because, as shown in FIG.
- the length of mIAA7 is short and / or the number of lysine residues required for ubiquitination of mIAA7 is small, so that the efficiency of formation of the three-component complex by IAA is reduced. It is thought that this is the reason.
- Example 8 It was difficult to generate an AID cell line using HCT116 cells that constitutively express OsTIR1 (WT). Condensin complex subunit SMC2, insulator protein CTCF, and RNA polymerase 2 largest subunit. Regarding (POLR2A), it was examined whether a cell line could be prepared from cells constitutively expressing OsTIR1 (F74G). As shown in FIG. 17, it was confirmed that tags can be added to both alleles of endogenous SMC2, CTCF, and POLR2A in HCT116 that constitutively express OsTIR1 (F74G). In these cell lines, the addition of 1 ⁇ M5-Ph-IAA rapidly degraded the mAID fusion target. From these results, it was confirmed that the AID2 system using cells constitutively expressing OsTIR1 (F74G) can be produced even for genes for which it is impossible to generate a cell line using the original AID system. Was done.
- auxin-independent degradation of the target protein can be inhibited, so that the degradation of the target protein can be strictly and freely controlled.
Landscapes
- Life Sciences & Earth Sciences (AREA)
- Health & Medical Sciences (AREA)
- Genetics & Genomics (AREA)
- Engineering & Computer Science (AREA)
- Chemical & Material Sciences (AREA)
- Zoology (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Organic Chemistry (AREA)
- Biotechnology (AREA)
- Wood Science & Technology (AREA)
- Molecular Biology (AREA)
- Biomedical Technology (AREA)
- General Engineering & Computer Science (AREA)
- General Health & Medical Sciences (AREA)
- Biochemistry (AREA)
- Microbiology (AREA)
- Environmental Sciences (AREA)
- Biophysics (AREA)
- Plant Pathology (AREA)
- Physics & Mathematics (AREA)
- Veterinary Medicine (AREA)
- Biodiversity & Conservation Biology (AREA)
- Animal Husbandry (AREA)
- Animal Behavior & Ethology (AREA)
- Medicinal Chemistry (AREA)
- Mycology (AREA)
- Peptides Or Proteins (AREA)
- Micro-Organisms Or Cultivation Processes Thereof (AREA)
- Measuring Or Testing Involving Enzymes Or Micro-Organisms (AREA)
Abstract
Description
本願は、2019年7月16日に、日本に出願された特願2019-131464号に基づき優先権を主張し、その内容をここに援用する。
[1]非植物由来の真核細胞中の目的タンパク質の分解を制御するオーキシンデグロンシステムのキットであって、オーキシン結合部位に変異を有する変異型TIR1ファミリータンパク質をコードする第一の核酸と、前記変異型TIR1ファミリータンパク質に親和性を有するオーキシンアナログと、少なくとも一部のAux/IAAファミリータンパク質を含み、前記変異型TIR1ファミリータンパク質-前記オーキシンアナログ複合体に親和性を有する分解タグをコードする第二の核酸と、を備える、キット。
[2]更に、前記第二の核酸の上流又は下流に連結された標的タンパク質をコードする第三の核酸を備える、[1]に記載のキット。
[3]前記変異型TIR1ファミリータンパク質は、イネ由来タンパク質である、[1]又は[2]に記載のキット。
[4]前記変異型TIR1ファミリータンパク質は、OsTIR1の74番目のFが、A、G、又はSに変異しているタンパク質である、[1]~[3]のいずれか一つに記載のキット。
[5]前記オーキシンアナログは、下記一般式(I)で表される化合物、又はそのエステル体である、[1]~[4]のいずれか一つに記載のキット。
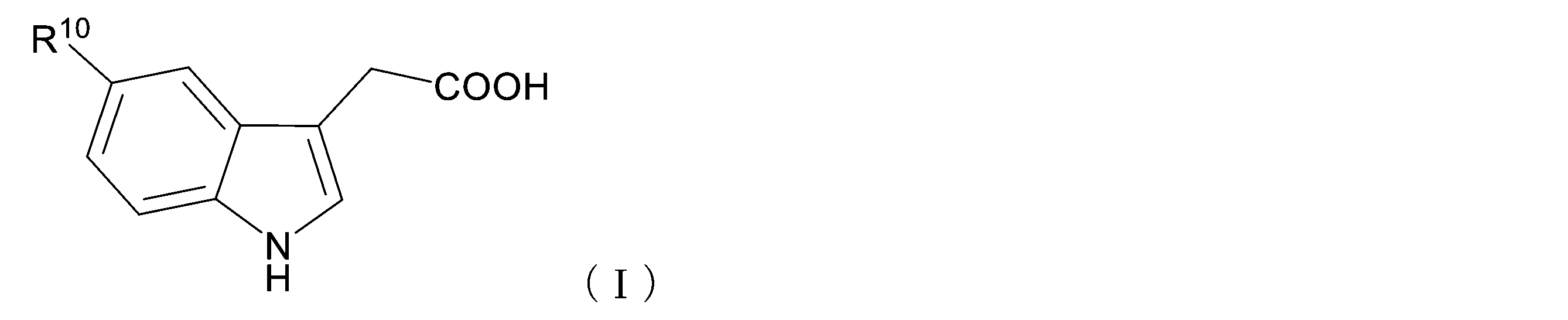
[6]更に、前記第一の核酸と、前記第二の核酸及び前記第三の核酸との間に、連結された、複数の遺伝子を1つのプロモーターで制御するためのリンカーをコードする第四の核酸を備える、[2]~[5]のいずれか一つに記載のキット。
[7]更に、前記第一の核酸、並びに/又は、前記第二の核酸及び前記第三の核酸を含むトランスポゾンベクターを備える、[2]~[6]のいずれか一つに記載のキット。
[8]更に、内在性の目的タンパク質をコードする標的ゲノムDNA切断酵素又は前記酵素をコードする第五の核酸を含有する、[1]~[7]のいずれか一つに記載のキット。
[9]更に、前記第一の核酸を染色体上に有する非植物由来の真核細胞を備える、請求項[1]~[8]のいずれか一つに記載のキット。
[10][1]~[9]のいずれか一つに記載のキットを用いる、標的タンパク質の分解方法。
[11]非植物由来の真核細胞中の標的タンパク質の分解を制御するオーキシンデグロンシステムに用いられる標的タンパク質分解誘導剤であって、下記一般式(I)で表される化合物、又はそのエステル体を含有する、標的タンパク質分解誘導剤。

[12]標的タンパク質の分解を制御するオーキシンデグロンシステムに用いられる非植物由来の真核細胞であって、オーキシン結合部位に変異を有する変異型TIR1ファミリータンパク質をコードする第一の核酸を含む染色体を有する、細胞。
[13]前記変異型TIR1ファミリータンパク質は、イネ由来タンパク質である、[12]に記載の細胞。
[14]前記変異型TIR1ファミリータンパク質は、OsTIR1の74番目のFが、A、G、又はSに変異しているタンパク質である、[12]又は[13]に記載の細胞。
[15]下記一般式(II)で表される化合物。

本発明のキットは、非植物由来の真核細胞中の標的タンパク質の分解を制御するオーキシンデグロンシステムのキットであって、オーキシン結合部位に変異を有する変異型TIR1ファミリータンパク質をコードする第一の核酸と、前記変異型TIR1ファミリータンパク質に親和性を有するオーキシンアナログと、少なくとも一部のAux/IAAファミリータンパク質を含み、前記変異型TIR1ファミリータンパク質-前記オーキシンアナログ複合体に親和性を有する分解タグをコードする第二の核酸と、を備える。
具体的に、このシステムは、E3ユビキチン化酵素複合体(SCF複合体)のサブユニットであるF-boxタンパク質としての植物由来TIR1ファミリータンパク質と、植物由来Aux/IAAファミリータンパク質又はその部分配列からなるペプチドで標識された標的タンパク質とを非植物由来の真核細胞に導入することにより、オーキシン受容体であるTIR1ファミリータンパク質が、オーキシン依存的に、Aux/IAAファミリータンパク質又はその部分配列からなるペプチドを認識し、非植物由来の真核細胞におけるユビキチン/プロテアソーム分解系を利用して、標的タンパク質を分解するシステムである。
また、本発明者らは、低濃度のオーキシンアナログで、標的タンパク質を分解誘導できることを見出した。
本発明によれば、オーキシン非添加時には、標的タンパク質の分解はほとんど起こらず、オーキシン添加時には、標的タンパク質の分解効率が非常に高いオーキシンデグロンシステムを提供できる。
本発明において、第一の核酸は、オーキシン結合部位に変異を有する変異型TIR1ファミリータンパク質をコードする。
TIR1ファミリータンパク質とは、ユビキチン/プロテアソーム系のタンパク質分解において、E3ユビキチン化酵素複合体(SCF複合体)を形成するサブユニットの一つであるF-boxタンパク質であり、植物特有のタンパク質である。TIR1ファミリータンパク質は、成長ホルモンであるオーキシンの受容体となっており、オーキシンを受容することによって、オーキシン情報伝達系の抑制因子Aux/IAAファミリータンパク質を認識して、標的タンパク質を分解することが知られている。
中でも、イネ由来のTIR1遺伝子である、OsTIR1遺伝子が好ましい。係る遺伝子としては、NCBIに登録されているアクセッション番号NM_001059194(GeneID:4335696)、Os04g0395600又はアクセッション番号EAY93933、OsI_15707の遺伝子が挙げられ、より具体的には、配列番号1で表される塩基配列からなる遺伝子が挙げられる。更に、ヒト細胞用にコドンを最適化した配列番号2で表される塩基配列からなる遺伝子が好ましい。
(a)配列番号3で表されるアミノ酸配列のアミノ酸番号74位がグリシンであるアミノ酸配列、
(b)前記(a)のアミノ酸番号74位以外の部位において、1~数個のアミノ酸が欠失、挿入、置換若しくは付加されたアミノ酸配列、
(c)前記(a)のアミノ酸番号74位以外の部位において、80%以上の同一性を有するアミノ酸配列
(a)のアミノ酸配列を含む配列からなるタンパク質と機能的に同等であるためには80%以上の同一性を有する。係る同一性としては、85%以上がより好ましく、90%以上が更に好ましく、95%以上が特に好ましく、99%以上が最も好ましい。
OsTIR1のF74Gタンパク質としては、配列番号6で表されるアミノ酸配列からなるものが挙げられ、OsTIR1のF74Gタンパク質をコードする遺伝子としては、配列番号7で表される塩基配列からなる遺伝子が挙げられる。
「セーフハーバー座位」とは、恒常的且つ安定的に発現が行われている遺伝子領域であり、かつ当該領域に本来コードされている遺伝子が欠損又は改変された場合であっても、生命の維持が可能な領域を意味する。CRISPRシステムを用いて、外来DNA(本実施形態においては、TIR1をコードする遺伝子)をセーフハーバー座位に挿入する場合には、近傍にPAM配列を有することが好ましい。セーフハーバー座位としては、例えば、GTP-binding protein 10遺伝子座、Rosa26遺伝子座、beta-Actin遺伝子座、AAVS1(the AAV integration site 1)遺伝子座等が挙げられる。中でも、ヒト由来細胞の場合は外来DNAをAAVS1遺伝子座に挿入することが好ましい。
また、株化された真核動物由来細胞やES細胞、iPS細胞も挙げられる。真核細胞として具体的には、例えば、株化されたヒト由来細胞、株化されたマウス由来細胞、株化されたニワトリ由来細胞、ヒトES細胞、マウスES細胞、ヒトiPS細胞、マウスiPS細胞等が挙げられる。具体的には、ヒトHCT116細胞、ヒトHT1080細胞、ヒトNALM6細胞、ヒトES細胞、ヒトiPS細胞、マウスES細胞、マウスiPS細胞、ニワトリDT40細胞等が挙げられる。
また、菌類としては、例えば、出芽酵母、分裂酵母等が挙げられる。
本発明において、オーキシンアナログは、前記変異型TIR1ファミリータンパク質に親和性を有するものであれば特に限定されず、下記一般式(I)で表される化合物、又はそのエステル体であることが好ましい。

R10における環状の脂肪族炭化水素基としては、単環式基でも多環式基でもよい。
単環式の脂肪族炭化水素としては、シクロプロピル基、シクロブチル基、シクロペンチル基、シクロヘキシル基、メチルシクロヘキシル基、ジメチルシクロヘキシル基、シクロヘプチル基、シクロオクチル基、シクロノニル基、シクロデシル基が挙げられる。
多環式の脂環式炭化水素基としては、デカヒドロナフチル基、アダマンチル基、2-アルキルアダマンタン-2-イル基、1-(アダマンタン-1-イル)アルカン-1-イル基、ノルボルニル基、メチルノルボルニル基、イソボルニル基等が挙げられる。
ハロゲン原子としては、例えば、フッ素原子、塩素原子、臭素原子、ヨウ素原子等が挙げられる。中でも、ハロゲン原子としては、フッ素原子又は塩素原子が好ましい。
R10における芳香族炭化水素基としては、上述した炭素数6~30のアリール基が挙げられる。
芳香族炭化水素基は、環を構成する炭素原子の一部がヘテロ原子で置換されていてもよい。ヘテロ原子としては、酸素原子、硫黄原子、窒素原子等が挙げられる。係る複素環としては、ピロール、フラン、チオフェン、ピリジン、イミダゾール、ピラゾール、オキサゾール、チアゾール、ピリダジン、ピリミジン、インドール、ベンゾイミダゾール、キノリン、イソキノリン、クロメン、イソクロメン等が挙げられる。
係るアルキル基としては、炭素数1~6のアルキル基が好ましく、メチル基、エチル基、n-プロピル基、イソプロピル基、シクロプロピル基、n-ブチル基、イソブチル基、sec-ブチル基、tert-ブチル基、シクロブチル基、n-ペンチル基、イソペンチル基、sec-ペンチル基、ネオペンチル基、tert-ペンチル基、シクロペンチル基、2,3-ジメチルプロピル基、1-エチルプロピル基、1-メチルブチル基、2-メチルブチル基、n-ヘキシル基、イソヘキシル基、シクロヘキシル基、2-メチルペンチル基、3-メチルペンチル基、1,1,2-トリメチルプロピル基、3,3-ジメチルブチル基等が挙げられる。
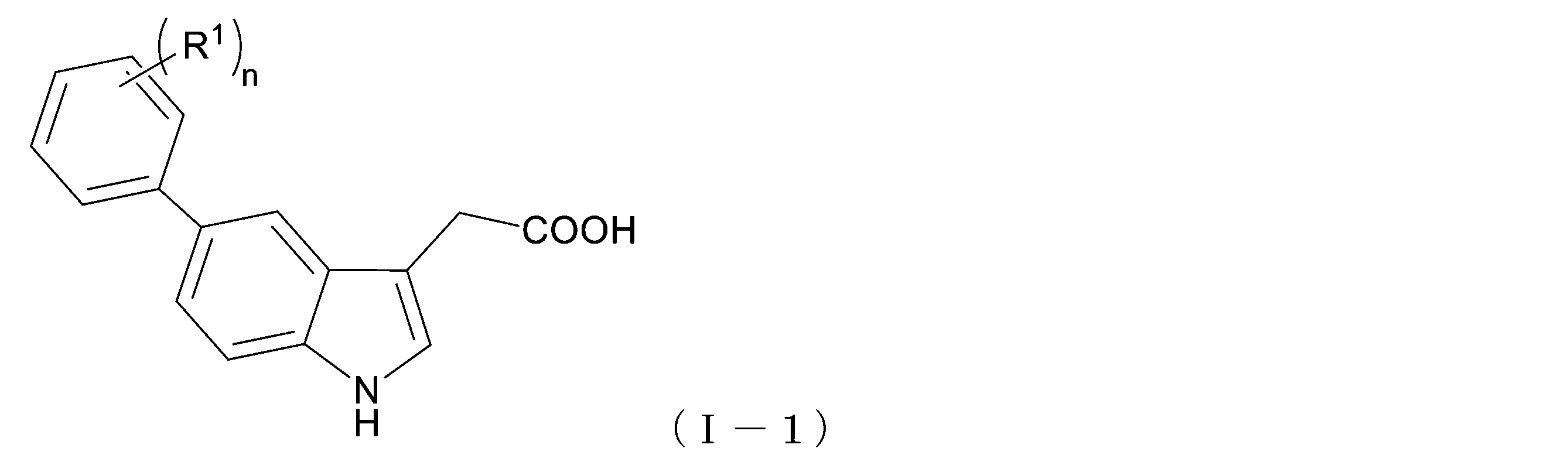

下記式(I-1-4)で示される化合物(5-(3-MeOPh)-IAAともいう。)。
下記式(I-1-5)で示される化合物(5-Ph-IAAともいう。)。
下記式(I-1-6)で示される化合物(5-(3,4-diMePh)-IAAともいう。)。
下記式(I-1-7)で示される化合物(5-(3-MePh)-IAAともいう。)。
下記式(I-1-8)で示される化合物(5-(3-ClPh)-IAAともいう。)。



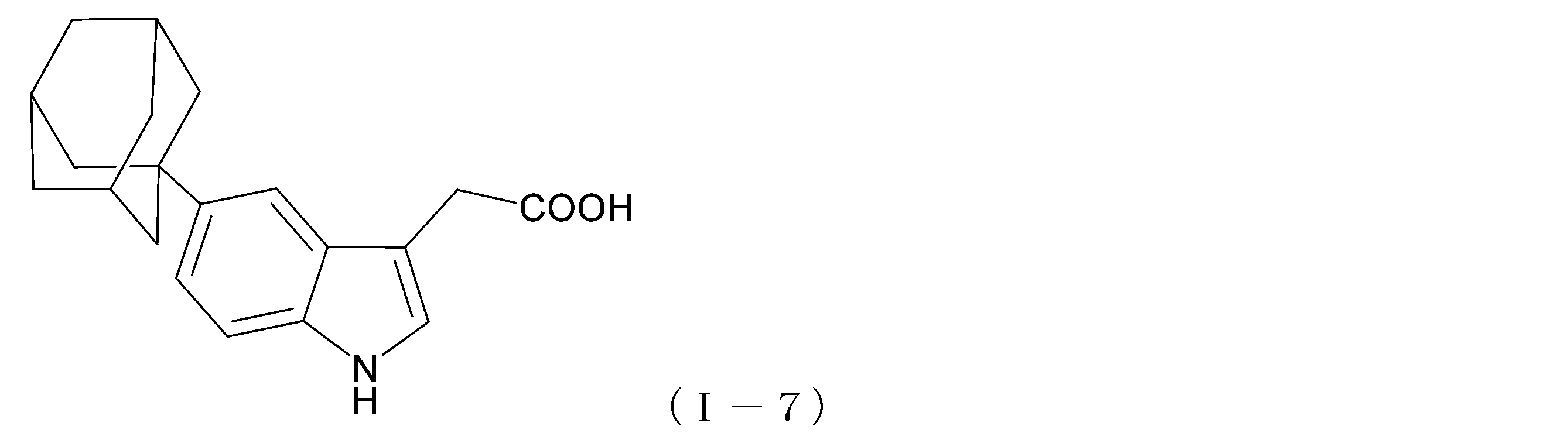
本発明において、第二の核酸は、少なくとも一部のAux/IAAファミリータンパク質を含み、変異型TIR1ファミリータンパク質-前記オーキシンアナログ複合体に親和性を有する分解タグをコードする。
Aux/IAAファミリータンパク質をコードする遺伝子としては、植物由来のAux/IAAファミリー遺伝子であれば、その種類について特別な限定はない。Aux/IAAファミリータンパク質をコードする遺伝子の具体例としては、例えば、IAA1遺伝子、IAA2遺伝子、IAA3遺伝子、IAA4遺伝子、IAA5遺伝子、IAA6遺伝子、IAA7遺伝子、IAA8遺伝子、IAA9遺伝子、IAA10遺伝子、IAA11遺伝子、IAA12遺伝子、IAA13遺伝子、IAA14遺伝子、IAA15遺伝子、IAA16遺伝子、IAA17遺伝子、IAA18遺伝子、IAA19遺伝子、IAA20遺伝子、IAA26遺伝子、IAA27遺伝子、IAA28遺伝子、IAA29遺伝子、IAA30遺伝子、IAA31遺伝子、IAA32遺伝子、IAA33遺伝子、IAA34遺伝子等が挙げられる。
これらの中でも、シロイヌナズナIAA17遺伝子が好ましい。
本発明のキットにおいて、標的タンパク質が定まっている場合には、第二の核酸の上流又は下流に連結された標的タンパク質をコードする第三の核酸を備えていてもよい。第二の核酸は、第三の核酸の5’側又は3’側のどちらに隣接されて配置されてもよい。
第二の核酸と第三の核酸からなる融合核酸は、第一の核酸と同様に、プロモーター配列が作動可能に連結されていることが好ましく、発現ベクターに組み込まれたものであってもよい。
上記、第一の核酸、及び、第二の核酸、又は第二の核酸と第三の核酸からなる融合核酸は、それぞれ発現ベクターに組み込まれたものであってもよいが、本発明のキットは、第一の核酸と、第二の核酸と第三の核酸からなる融合核酸との間に連結された、複数の遺伝子を1つのプロモーターで制御するためのリンカーをコードする第四の核酸を備えていてもよい。
第四の核酸としては、リードスルーリンカーをコードする核酸、非リードスルーリンカーをコードする核酸が挙げられる。
リードスルーリンカーをコードする核酸としては、内在性酵素による切断配列をコードする核酸が挙げられ、T2Aペプチドをコードする核酸、P2Aペプチドをコードする核酸、F2Aペプチドをコードする核酸、E2Aペプチドをコードする核酸が挙げられる。
非リードスルーリンカーをコードする核酸としては、IRESが挙げられる。
本発明のキットは、第一の核酸、並びに/又は、第二の核酸及び前記第三の核酸からなる融合核酸を含むトランスポゾンベクターを備えていてもよい。
具体的には、本発明のキットは、プロモーター配列が作動可能に連結された、第一の核酸、及び/又は、融合核酸の両端にトランスポゾンエレメントを備えたベクターと、トランスポゼースをコードする核酸を備えたベクターを含むことが好ましい。
第一の核酸及び融合核酸は、それぞれ個別のベクターに含まれていてもよいが、一つのベクターに含まれる場合には、係るベクターは、上記第四の核酸を含むことが好ましい。
本発明のキットにおいて、トランスポゼースをコードするDNA及びトランスポゾンエレメントが、トランスポゾンDNAとして、連結して一つの発現系に組み込まれている場合には、トランスポゾンDNAは、一度細胞内に導入すると、自らトランスポゼースを発現して転移し得る。
このような自律性トランスポゾンは、転移した位置から別の位置へ転移する可能性がある。そのため、より安定して染色体内に目的遺伝子を導入するためには、本発明のキットは、トランスポゼースをコードするDNA及びトランスポゾンエレメントが、それぞれ別個の発現系に組み込まれていることが好ましい。
第二の核酸と第三の核酸からなる融合核酸は、相同組換えにより内在性の第三の核酸と入れ替えられてもよいが、係る融合核酸がトランスポゾン等により、任意の染色体に組み込まれている場合には、本発明のキットは、内在性の標的タンパク質をコードする標的ゲノムDNA切断酵素又は前記酵素をコードする第五の核酸を含むことが好ましい。標的ゲノムDNAの二重鎖切断に用いるシステムとしては、CRISPR-Cas9システム、Transcription activator-like effector nuclease(TALEN)システム、及びZnフィンガーヌクレアーゼシステム等が挙げられる。これらのシステムの細胞への導入方法としては、特に限定されず、標的ゲノムDNA切断酵素自体を細胞に導入してもよく、第五の核酸を含む標的ゲノムDNA切断酵素発現ベクターを細胞に導入してもよい。
例えば、CRISPR-Cas9システムにおいては、Cas9発現ベクターと、切断したい箇所にCas9を誘導するガイドRNAをコードする発現ベクターと、を細胞に導入する方法や、発現精製した組み換えCas9タンパク質と、ガイドRNAと、を細胞に導入する方法等が挙げられる。ガイドRNAはtracrRNAとcrRNAの2つに分かれていてもよく、1本につながっているsgRNAであってもよい。
本発明の標的タンパク質の分解方法は、上述した本発明のキットを用いる方法である。オーキシンデグロンシステムにおいて、上述のキットを用いることで、厳密かつ自在に標的タンパク質の分解制御が可能である。
まず、細胞内において、分解タグで標識された標的タンパク質、及びTIR1ファミリータンパク質を発現させる。分解タグで標識された標的タンパク質、及びTIR1ファミリータンパク質は、定常的に発現していることが好ましい。
本発明の化合物は、下記一般式(II)で表される化合物である。

本発明の細胞は、標的タンパク質の分解を制御するオーキシンデグロンシステムに用いられる非植物由来の真核細胞であって、オーキシン結合部位に変異を有する変異型TIR1ファミリータンパク質をコードする第一の核酸を含む染色体を有する。
本発明の細胞は、第一の核酸をセーフハーバー座位に有することが好ましい。
非植物由来の真核細胞であれば特に限定されず、動物、菌類、原生生物等の細胞があげられる。
1.オーキシンアナログの合成
式(I-2)で示される化合物(5-Ph-IAAともいう。)を合成した。
OsTIR1(WT)遺伝子又はOsTIR1(F74G)遺伝子とmAID-EGFP(緑色蛍光タンパク質)-NLS(核移行シグナル)遺伝子がP2A配列を介してコードされるDNAがトランスポゾンにより染色体上に挿入されているHCT116細胞(ヒト結腸腺癌由来細胞)(以下、「OsTIR1(WT)/mAID-EGFP-NLS発現細胞」又は「OsTIR1(F74G)/mAID-EGFP-NLS発現細胞」と称する)を準備した(図1参照。)。
OsTIR1(F74G)/mAID-EGFP-NLS発現細胞にオーキシンアナログ(培地中の濃度:0、200μM)を添加して、24時間培養した。また、対照として、OsTIR1(WT)/mAID-EGFP-NLS発現細胞にオーキシンを添加した細胞も準備した。
オーキシンアナログの添加から24時間後に細胞を回収し、FACS解析を行った。結果を図1に示す。
同質遺伝的背景で、OsTIR1(WT)とOsTIR1(F74G)を比較したところ、OsTIR1(WT)においては、オーキシン未添加の状態で、mAID-EGFP-NLSレポーターレベルが低く、そのシグナルピークが広く、基底分解があることを示していた。OsTIR1(WT)に100μMオーキシンを添加することにより、シグナルピークが左にシフトし、レポーターが分解したことを示した。
対照的に、OsTIR1(F74G)を発現している細胞では、mAID-EGFP-NLSレポーターの発現レベルが高く、そのシグナルピークがよりシャープであり、これらの細胞では基底分解が、低いことが示された。更に、1μM5-Ph-IAAを4時間添加すると、レポーターはOsTIR1(F74G)を発現する細胞で効率的に分解された。
図7(B)に示す様に、OsTIR1(WT)を発現する3つの細胞株は、低発現レベルでより広いピークを示し、オーキシン無しでも基底分解があることを示唆した。
一方、OsTIR1(F74G)及びOsTIR1(F74A)を発現するクローンは、5-Ph-IAAを添加しない状態で、レポーターのより強い発現レベルを示し、基底分解が抑制されたことを示唆している。
更に、OsTIR1(F74G)を発現するクローンは、5-Ph-IAA処理によりOsTIR1(F74A)を発現するクローンと比較して、よりシャープなmAID-EGFP-NLSレポーターの分解を示した。 すべての場合において、シグナルピークは、5-Ph-IAA処理後に左にシフトし、分解が誘発されたことを示した。
一方、従来のシステムは、半減期147.1±12.5分で効率が低下していた。OsTIR1(F74G)を使用したAID2システムは、標的タンパク質の基底分解が少なく、新しい活性化リガンドである5-Ph-IAAの濃度が大幅に低くて済み、ターゲットの分解速度が速くなることが確認された。
1.オーキシンアナログの合成
式(I-1-5)で示される化合物(5-Ph-IAAともいう。)、式(I-1-6)で示される化合物(5-(3,4-diMePh)-IAAともいう。)、式(I-1-7)で示される化合物(5-(3-MePh)-IAAともいう。)、式(I-1-8)で示される化合物(5-(3-ClPh)-IAAともいう。)を合成した。式(I-1-4)で示される化合物(5-(3-MeOPh)-IAAともいう。)は、東京化成工業株式会社から購入した。
以下に、合成した化合物の合成方法を示す。

得られた化合物の1H-NMR、及び13C-NMRによる分析結果を以下に示す。
1H-NMR (400 MHz, CDCl3) δ 8.17 (s, 1H), 7.73 (d, J = 1.8 Hz, 1H), 7.28 (dd, J = 7.6, 5.7 Hz, 1H), 7.20 (dd, J = 13.5, 4.8 Hz, 1H), 7.16-7.10 (m, 1H), 3.75-3.70 (m, 2H), 3.71 (s, 3H),13C-NMR (100MHz, CDCl3) δC 172.33, 134.80, 129.06, 125.21, 124.42, 121.59, 113.12, 112.730, 108.24, 52.18, 30.98.
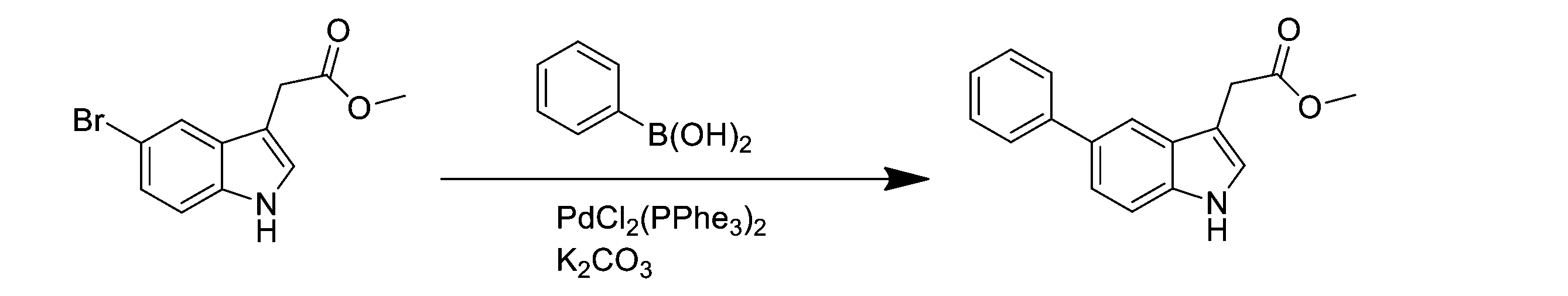
得られた化合物の1H-NMR、及び13C-NMRによる分析結果を以下に示す。
1H-NMR (400 MHz, CDCl3) δ 8.14 (s, 1H), 7.82 (s, 1H), 7.69-7.61 (m, 2H), 7.43 (t, J = 7.8 Hz, 3H), 7.40-7.34 (m, 1H), 7.34-7.28 (m, 1H), 7.16 (d, J = 10.1 Hz, 1H), 4.17 (qd, J = 7.1, 4.0 Hz, 2H), 3.81 (s, 3H),13C-NMR (100MHz, CDCl3) δC 172.19, 142.64, 135.74, 133.37, 128.74, 127.52, 126.44, 123.88, 122.18, 117.53, 111.52, 109.04, 60.95, 31.50.

得られた化合物の1H-NMR、及び13C-NMRによる分析結果を以下に示す。
1H-NMR (400 MHz, acetone-d6) δ10.61 (s, 1H), 10.17 (s, 1H), 7.89 (s, 1H), 7.68-7.65 (m, 2H), 7.48-7.46 (m, 1H), 7.44-7.40 (m, 3H), 7.34 (d, J = 2.3 Hz, 1H), 7.26 (tt, J = 7.3, 1.4 Hz, 1H), 3.82 (s, 2H), 13C-NMR (100 MHz, acetone-d6) δ 173.20, 143.65, 137.15, 133.06, 129.51, 129.15, 127.86, 126.96, 125.39, 121.85, 118.07, 112.54, 109.65, 31.39

得られた化合物の1H-NMR、及び13C-NMRによる分析結果を以下に示す。
1H-NMR (400 MHz, CDCl3) δ 8.23 (s, 1H), 7.73 (s, 1H), 7.24 (dd, J = 8.5, 2.1 Hz, 1H), 7.15 (d, J = 8.7 Hz, 1H), 7.07 (s, 1H), 4.18 (q, J = 7.2 Hz, 2H), 3.71 (s, 2H), 1.28 (t, J = 7.3 Hz, 3H), 13C-NMR (100 MHz, CDCl3) δ 172.07, 134.82, 129.05, 125.08, 124.49, 121.64, 112.99, 112.77, 108.21, 61.11, 31.31, 14.32.
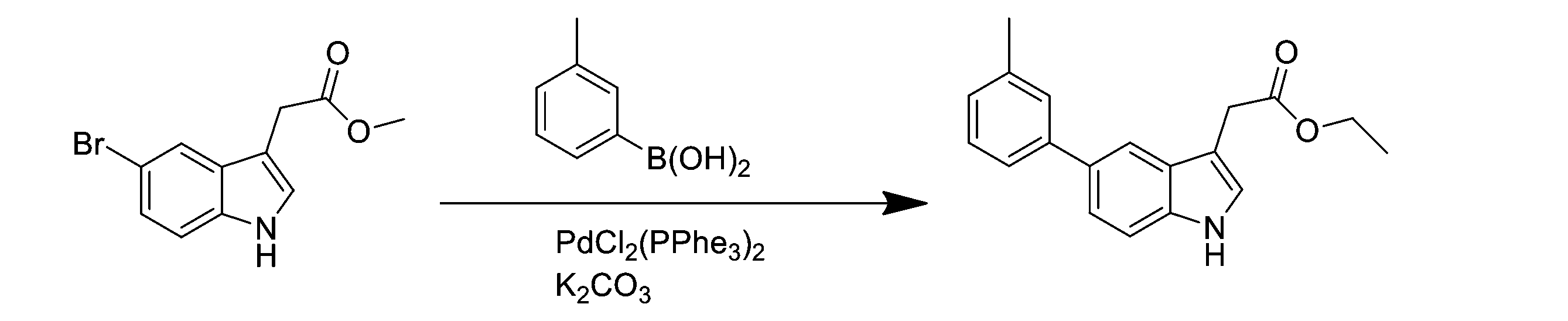
得られた化合物の1H-NMR、及び13C-NMRによる分析結果を以下に示す。
1H-NMR (400 MHz, CDCl3) δ 8.10 (s, 1H), 7.81 (s, 1H), 7.49-7.42 (m, 3H), 7.39 (d, J = 8.2 Hz, 1H), 7.32 (t, J=7.8, 1H), 7.19 (d, J = 1.1 Hz, 1H), 7.16-7.11 (m, 1H), 4.18 (q, J=7.6, 2H), 3.82 (s, 2H), 2.41 (s, 3H), 1.27 (t, J = 7.1 Hz, 3H), 13C-NMR (100MHz, CDCl3) δC 172.12, 142.59, 138.23, 135.68, 133.51, 128.62, 128.32, 127.84, 127.19, 124.61, 123.74, 122.24, 117.51, 111.39, 109.13, 60.91, 31.49, 21.67, 14.34.

1H-NMR (400 MHz, CDCl3) δ 8.05 (s, 1H), 7.77 (d, J = 1.4 Hz, 1H), 7.48-7.40 (m, 3H), 7.36 (d, J=8.7Hz, 1H), 7.30 (t, J=7.3Hz,1H), 7.16-7.09 (m, 2H), 3.82 (s, 2H), 2.41 (s, 3H), 13C-NMR (100MHz, CDCl3) δC 177.84, 142.51, 138.29, 135.63, 133.70, 128.67, 128.36, 127.69, 127.27, 124.68, 124.04, 122.41, 117.34, 111.53, 108.22, 31.07, 21.68.

得られた化合物の1H-NMR、及び13C-NMRによる分析結果を以下に示す。
1H-NMR (400 MHz, CDCl3) δ 8.10 (s, 1H), 7.79 (d, J = 0.9 Hz, 1H), 7.44 (m, 2H), 7.38 (m, 2H), 7.22-7.14 (m, 2H), 4.17 (q, J = 7.0 Hz, 2H), 3.80 (s, 2H), 2.35 (s, 3H), 2.31 (s,3H), 1.25 (t, J = 7.0 Hz, 3H), 13C-NMR (100MHz CDCl3) δC 172.17, 140.24, 136.80, 135.55, 134.75, 133.44, 130.30, 128.80, 127.83, 124.85, 123.70, 122.15, 117.23, 111.37, 109.04, 60.89, 31.49, 20.04, 19.46, 14.35

得られた化合物の1H-NMR、及び13C-NMRによる分析結果を以下に示す。
1H-NMR (400 MHz, CDCl3) δ 8.06 (s, 1H), 7.76 (s, 1H), 7.46-7.40 (m, 2H), 7.37 (d, J = 8.2 Hz, 2H), 7.22-7.14 (m, 2H), 3.84 (s, 2H), 2.33 (s, 3H), 2.30 (s, 3H),13C-NMR (100MHz, CDCl3) δC 177.32, 140.13, 136.83, 135.50, 134.83, 133.67, 130.05, 128.83, 127.69, 124.89, 123.91, 122.34, 117.10, 111.45, 108.23, 30.99, 20.03, 19.46.
得られた化合物の1H-NMR、及び13C-NMRによる分析結果を以下に示す。
1H-NMR (400 MHz, CDCl3) δ 8.14 (s, 1H),7.80 (s, 1H), 7.63 (t, J = 1.8 Hz, 1H), 7.53 (dt, J = 8.0, 1.4 Hz, 1H), 7.42 (d, J = 1.4 Hz, 2H), 7.36 (t, J = 8.0 Hz, 1H), 7.30-7.24 (m, 1H), 7.23 (d, J = 2.3 Hz, 1H), 4.18 (q, J = 7.2 Hz, 2H), 3.81 (s, 2H), 1.27 (t, 7.2 Hz, 3H), 13C-NMR (100MHz, CDCl3) δC 171.99, 144.48, 135.96, 134.54, 131.96, 129.90, 127.98, 127.52, 126.38, 125.59, 123.99, 121.98, 117.68, 111.61, 109.29, 60.95, 31.45, 14.34.

得られた化合物の1H-NMR、及び13C-NMRによる分析結果を以下に示す。
1H-NMR (400 MHz, CDCl3) δ 8.13 (s, 1H), 7.76 (s, 1H), 7.61 (t, J = 1.8 Hz, 1H), 7.49 (dt, J = 7.8, 1.4 Hz, 1H), 7.40 (s, 2H), 7.34 (t, J = 7.8 Hz, 1H), 7.26-7.28 (m, 1H), 7.20 (d, J = 2.3 Hz, 1H), 3.82 (s, 2H), 13C-NMR (100MHz, CDCl3) δC 177.42, 144.36, 135.92, 134.54, 132.15, 129.94, 127.74, 127.54, 126.45, 125.66, 124.26, 122.15, 117.51, 111.73, 108.39, 30.98.
OsTIR1(WT)遺伝子又はOsTIR1(F74G)遺伝子を含むプラスミドが導入されており、mAID-EGFP(緑色蛍光タンパク質)-NLS(核移行シグナル)遺伝子が染色体上に挿入されているHCT116細胞(ヒト結腸腺癌由来細胞)(以下、「OsTIR1(WT)/mAID-EGFP-NLS発現細胞」又は「OsTIR1(F74G)/mAID-EGFP-NLS発現細胞」と称する)を準備した(図1参照。)。
OsTIR1(F74G)/mAID-EGFP-NLS発現細胞にオーキシンアナログ(培地中の濃度:0、50nM、100nM、500nM、1μM)を添加して、24時間培養した。また、対照として、OsTIR1(WT)/mAID-EGFP-NLS発現細胞にオーキシンを添加した細胞も準備した。
各オーキシンアナログの添加から24時間後に細胞を回収し、FACS解析を行った。結果を図2に示す。図2において、「Control」とは、オーキシンアナログ溶媒であるDMSOのみを添加した細胞を示す。
5-Ph-IAAは、1nMおよび10nMで他の化合物よりより強いmAID-EGFP-NLSレポーターの分解誘導の効果を示した。
1.細胞の準備
HCT116細胞において、セーフハーバー座位であるAAVS1遺伝子座に、CRISPR/Casシステムを用いて、OsTIR1(WT)遺伝子又はOsTIR1(F74G)遺伝子を導入し、OsTIR1(WT)発現HCT116細胞、又はOsTIR1(F74G)発現HCT116細胞を構築した。
mAIDとCloverとネオマイシン耐性遺伝子を有し、mAIDとネオマイシン耐性遺伝子とを挟むように、DHC1遺伝子に対して相同な配列を有するプラスミドベクターを、CRISPR/Cas9システムを用いて、OsTIR1(WT)発現HCT116細胞、又はOsTIR1(F74G)発現HCT116細胞に導入し、内在性のDHC1遺伝子と相同組換えを行った。次いで、G418によるセレクションの後、形成されたコロニーを、クリスタルバイオレットを用いて染色した。尚、「DHC1」とはdynein heavy chain1の略称であり、ダイニン重鎖1を意味する。結果を図3に示す。
上記2にて相同組換えを行った、OsTIR1(F74G)発現HCT116細胞(以下、「OsTIR1(F74G)/DHC1-mAID-Clover発現細胞」と称する。)を用いて、DHC1の分解誘導試験を行った。
OsTIR1(F74G)/DHC1-mAID-Clover発現細胞に、式(I-2)で示される化合物(5-Ph-IAAともいう。)を添加し、24時間後の細胞の様子を観察した(図4(A))。
更に、DHC1の分解をウエスタンブロッティングにより確認した(図4(B))。図4(B)に示すように、相同組換えを行って作製したクローン#1~3の全てにおいて、5-Ph-IAA依存的に、DHC1及びmAIDの分解が確認された。
内在性の標的タンパク質分解系を構築するには、以下3点の難点がある。(1)多くの培養細胞は多倍体化しているため、標的遺伝子のアリルが2コピー以上ある。そのため、様々な培養細胞株でこの分解系を構築することが難しい。(2)OsTIR1(F74G)があらかじめ導入された親株を作成する必要がある。(3)多数の分解系を構築してライブラリー化するには手間がかかる。
この分解系では、トランスポゾンベクターにより、ゲノム中にOsTIR1(F74G)遺伝子とmAID-標的遺伝子をインテグレートさせる一方で、CRISPR-KOベクターにより、内在性の標的遺伝子をノックアウトする。
図6(A)に抗CENPH抗体を用いたウエスタンブロッティングの結果を示す。内在性のCENPH遺伝子がノックアウトされていることが確認され、かつ5-Ph-IAA依存的にmAID-EGFP-CENPHの分解が確認された。
図6(B)に抗POLD1抗体を用いたウエスタンブロッティングの結果を示す。クローン#1~3において、内在性のPOLD1遺伝子がノックアウトされていることが確認され、かつ5-Ph-IAA依存的にmAID-EGFP-POLD1の分解が確認された。
AID2システムが酵母でも機能することを確認するために、GAL1-10プロモーターの制御下で、URA3遺伝子座に、OsTIR1(WT、F74G、又はF74A)を導入した(図12(A)参照。)。その後、必須の複製イニシエーターである、MCM10、SLD3、又はCDC45をコードする遺伝子にmAIDタグを付けた。
例えば、図12(B)のOsTIR1 ON、リガンドなし、cdc45-mAID等に示されるように、OsTIR1(WT又はF74A)を発現している酵母株は、遅い増殖を示し、酵母でより高い基底分解があることを示唆した。
更に、OsTIR1(WT及びF74A)は、500μMIAAでこれらmAID導入株の増殖抑制がみられたこのことは、OsTIR1(F74A)がIAAに対する反応性を残していることを示唆している。
すべての場合において、OsTIR1(F74G又はF74A)を発現する株は、5μM5-Ph-IAAを含むプレート上で、強い増殖阻害を示した。OsTIR1(F74G又はF74A)が発現された場合、mcm10-mAID株及びsld3-mAID株の増殖が強く阻害されることから、AID2システムがより分解能力が高く、強い表現型を示す変異体を製造できることを示している。
OsTIR1(F74G)を恒常的に発現するヒトHCT116細胞を材料に、ゲノム編集によりRAD21-mAID-Clover(RAD21-mAC)細胞を作製し、5-Ph-IAA添加による効果を確認した。図13(A)及び(B)に示されるように、 RAD21-mACの発現レベルは、添加前の0分でOsTIR1(WT)を発現している細胞よりも、OsTIR1(F74G)を発現している細胞の方が高く、従来のAIDシステムのにおける基底分解を示している。
RAD21-mACは、OsTIR1(WT)とOsTIR1(F74G)両方の場合に、リガンドの添加後に急速に消失した。但し、T1/2は、OsTIR1(WT)とOsTIR1(F74G)でそれぞれ26.5分と11.7分であり、RAD21-mACがAID2システムによってより速く分解されたことを示している。これらの結果は、AID2システムが、従来のAIDシステムよりもRAD21-mACをより迅速に制御できることを示している。
OsTIR1(F74G)がより少ない基底分解を示したことに鑑みて、OsTIR1(F74G)を恒常的に発現するHCT116細胞で、DHC1-mAID-Clover(DHC1-mAC)を作製できるかどうか検討した。 OsTIR1(WT又はF74G)を構成的に発現する親細胞株に、デグロンタグを付加するためのCRISPRプラスミドと、それぞれネオマイシンまたはハイグロマイシン耐性マーカーを持つ二つのドナーをトランスフェクトした(図14参照。)。OsTIR1(F74G)発現細胞において、G418及びハイグロマイシンの存在下で、コロニーは形成され、両アリルでのDHC1遺伝子にタグが付加された(図15(A)参照。)。 OsTIR1(WT)を発現する細胞では、コロニーは形成されなかった。OsTIR1(F74G)を発現するクローンでは、DHC1-mACは1μM 5-Ph-IAAの添加により効率的に分解した(図15(B)参照。)。 これらの細胞は有糸分裂で停止し(図15C参照。)、有糸分裂紡錘体形成に強い欠陥を示した(図15(D)参照。)。これは、DHC1が有糸分裂時に形成される紡錘体形成に必須であることと一致している。
AtAFB2又はOsTIR1(F74G)を発現している細胞で、mIAA7又はmAIDタグ付きDHC1の分解を誘導した(図16(C)参照)。図16(C)において、OsTIR1(F74G)とmAIDタグの組み合わせが、最も効率的であることが確認された。これは、図16(A)に示す様に、mIAA7の長さが短いため、及び/又はmIAA7のユビキチン化に必要なリジン残基が少ないために、IAAによる3成分複合体の形成効率が落ちるためと考えられる。
OsTIR1(WT)を恒常的に発現するHCT116細胞を使用しては、AID細胞株を作製することが困難であった、コンデンシン複合体のサブユニットSMC2、インシュレータータンパク質CTCF、及びRNA ポリメラーゼ 2 最大サブユニット(POLR2A)について、OsTIR1(F74G)を構成的に発現する細胞で、細胞株を作製できるか検討した。図17に示すように、OsTIR1(F74G)を構成的に発現しているHCT116内の内因性SMC2、CTCF、及びPOLR2Aの両アリルにタグを付加できることが確認された。これらの細胞株では、1μM5-Ph-IAAの添加によりmAID融合ターゲットが急速に分解された。これらの結果により、OsTIR1(F74G)を構成的に発現する細胞を使用するAID2システムが、元のAIDシステムを使用して細胞株を作製することが不可能な遺伝子に対しても作製できることが確認された。
Claims (15)
- 非植物由来の真核細胞中の標的タンパク質の分解を制御するオーキシンデグロンシステムのキットであって、
オーキシン結合部位に変異を有する変異型TIR1ファミリータンパク質をコードする第一の核酸と、
前記変異型TIR1ファミリータンパク質に親和性を有するオーキシンアナログと、
少なくとも一部のAux/IAAファミリータンパク質を含み、前記変異型TIR1ファミリータンパク質-前記オーキシンアナログ複合体に親和性を有する分解タグをコードする第二の核酸と、
を備える、キット。 - 更に、前記第二の核酸の上流又は下流に連結された標的タンパク質をコードする第三の核酸を備える、請求項1に記載のキット。
- 前記変異型TIR1ファミリータンパク質は、イネ由来タンパク質である、請求項1又は2に記載のキット。
- 前記変異型TIR1ファミリータンパク質は、OsTIR1の74番目のFが、A、G、又はSに変異しているタンパク質である、請求項1~3のいずれか一項に記載のキット。
- 前記オーキシンアナログは、下記一般式(I)で表される化合物、又はそのエステル体である、請求項1~4のいずれか一項に記載のキット。

- 更に、前記第一の核酸と、前記第二の核酸及び前記第三の核酸との間に、連結された、複数の遺伝子を1つのプロモーターで制御するためのリンカーをコードする第四の核酸を備える、請求項2~5のいずれか一項に記載のキット。
- 更に、前記第一の核酸、並びに/又は、前記第二の核酸及び前記第三の核酸を含むトランスポゾンベクターを備える、請求項2~6のいずれか一項に記載のキット。
- 更に、内在性の標的タンパク質をコードする標的ゲノムDNA切断酵素又は前記酵素をコードする第五の核酸を含有する、請求項1~7のいずれか一項に記載のキット。
- 更に、前記第一の核酸を染色体上に有する非植物由来の真核細胞を備える、請求項1~8のいずれか一項に記載のキット。
- 請求項1~9のいずれか一項に記載のキットを用いる、標的タンパク質の分解方法。
- 非植物由来の真核細胞中の標的タンパク質の分解を制御するオーキシンデグロンシステムに用いられる標的タンパク質分解誘導剤であって、
下記一般式(I)で表される化合物、又はそのエステル体を含有する、標的タンパク質分解誘導剤。
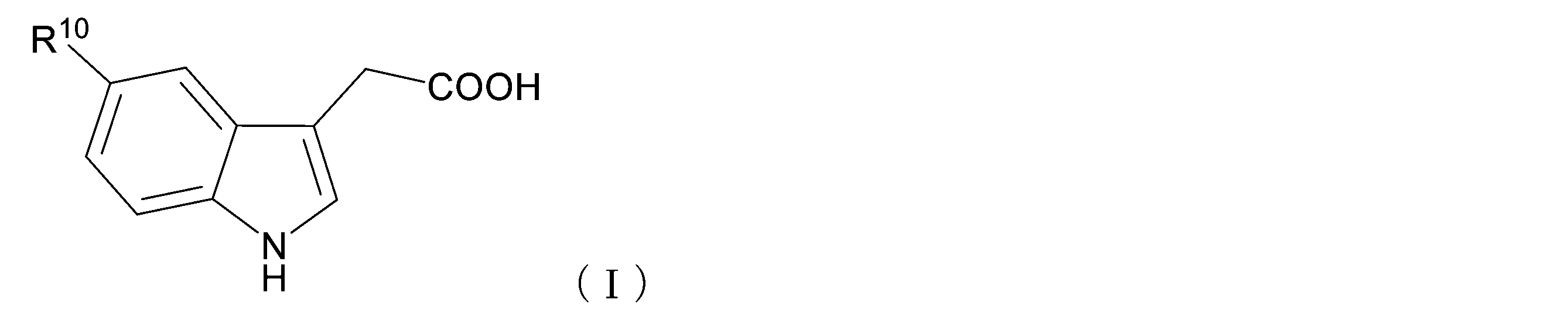
- 標的タンパク質の分解を制御するオーキシンデグロンシステムに用いられる非植物由来の真核細胞であって、
オーキシン結合部位に変異を有する変異型TIR1ファミリータンパク質をコードする第一の核酸を含む染色体を有する、細胞。 - 前記変異型TIR1ファミリータンパク質は、イネ由来タンパク質である、請求項12に記載の細胞。
- 前記変異型TIR1ファミリータンパク質は、OsTIR1の74番目のFが、A、G、又はSに変異しているタンパク質である、請求項12又は13に記載の細胞。
- 下記式(II)で表される化合物。
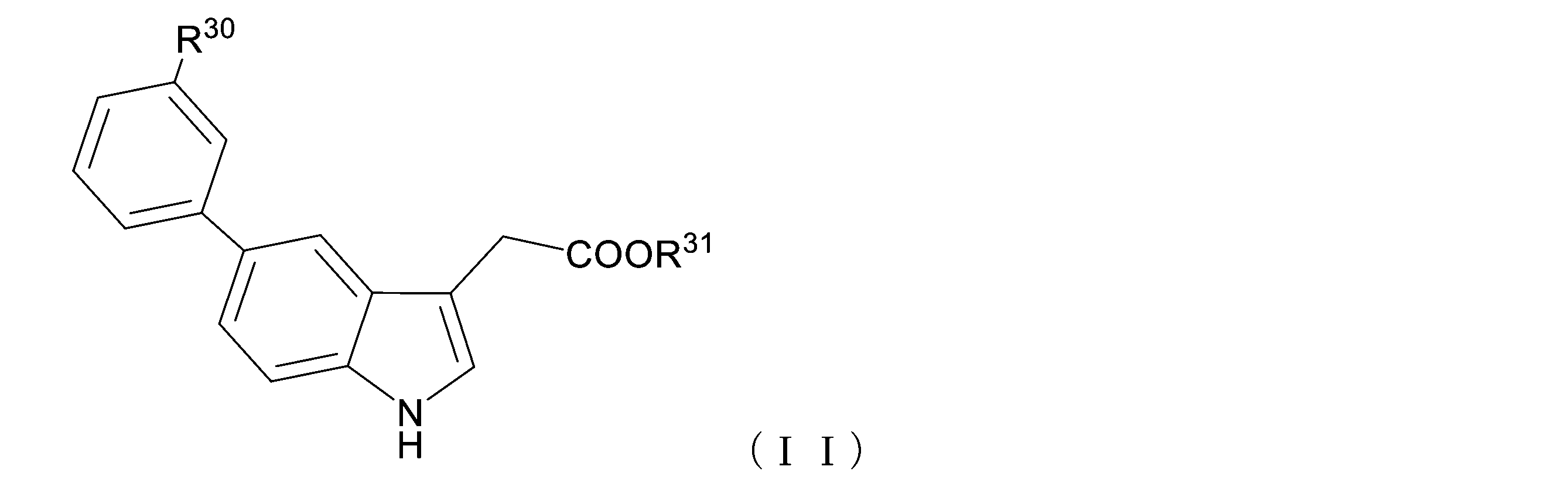
Priority Applications (5)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| EP20840241.2A EP4026828A4 (en) | 2019-07-16 | 2020-04-30 | Auxin-inducible degron system kit and use thereof |
| US17/620,977 US12553055B2 (en) | 2019-07-16 | 2020-04-30 | Auxin-inducible degron system kit and use thereof |
| JP2021532685A JPWO2021009990A1 (ja) | 2019-07-16 | 2020-04-30 | |
| CN202080050923.1A CN114144400A (zh) | 2019-07-16 | 2020-04-30 | 生长素降解决定子系统的试剂盒及其用途 |
| JP2024086613A JP2024103589A (ja) | 2019-07-16 | 2024-05-28 | オーキシンデグロンシステムのキット、及びその使用 |
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2019-131464 | 2019-07-16 | ||
| JP2019131464 | 2019-07-16 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2021009990A1 true WO2021009990A1 (ja) | 2021-01-21 |
Family
ID=74210401
Family Applications (2)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2020/018310 Ceased WO2021009993A1 (ja) | 2019-07-16 | 2020-04-30 | 非ヒト動物、及びその使用 |
| PCT/JP2020/018237 Ceased WO2021009990A1 (ja) | 2019-07-16 | 2020-04-30 | オーキシンデグロンシステムのキット、及びその使用 |
Family Applications Before (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2020/018310 Ceased WO2021009993A1 (ja) | 2019-07-16 | 2020-04-30 | 非ヒト動物、及びその使用 |
Country Status (5)
| Country | Link |
|---|---|
| US (2) | US12522836B2 (ja) |
| EP (2) | EP4026828A4 (ja) |
| JP (3) | JP7458615B2 (ja) |
| CN (2) | CN114127294A (ja) |
| WO (2) | WO2021009993A1 (ja) |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2023026824A1 (ja) * | 2021-08-23 | 2023-03-02 | 大学共同利用機関法人情報・システム研究機構 | オーキシンデグロンシステムのキット、及びその使用 |
Families Citing this family (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2021009993A1 (ja) | 2019-07-16 | 2021-01-21 | 大学共同利用機関法人情報・システム研究機構 | 非ヒト動物、及びその使用 |
| WO2024185847A1 (ja) * | 2023-03-09 | 2024-09-12 | 国立研究開発法人理化学研究所 | 遺伝子改変マウス |
Citations (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2008187958A (ja) | 2007-02-05 | 2008-08-21 | Osaka Univ | タンパク質分解誘導性細胞、その製造方法、および、タンパク質分解の制御方法 |
| WO2010125620A1 (ja) | 2009-04-30 | 2010-11-04 | 国立大学法人大阪大学 | 哺乳類細胞におけるタンパク質分解誘導方法 |
| WO2013073653A1 (ja) | 2011-11-18 | 2013-05-23 | 大学共同利用機関法人情報・システム研究機構 | 真核細胞におけるタンパク質分解誘導方法 |
| WO2017029833A1 (ja) * | 2015-08-20 | 2017-02-23 | 大学共同利用機関法人情報・システム研究機構 | 動物細胞ゲノム部位特異的外来dna挿入方法及び前記挿入方法を用いて得られる細胞 |
| WO2018164214A1 (ja) * | 2017-03-08 | 2018-09-13 | 国立大学法人名古屋大学 | 植物成長調整剤 |
| JP2019131464A (ja) | 2015-12-18 | 2019-08-08 | 富士電機株式会社 | 炭化珪素半導体基板、炭化珪素半導体基板の製造方法、半導体装置および半導体装置の製造方法 |
Family Cites Families (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN102676545B (zh) | 2012-05-29 | 2013-05-29 | 南京农业大学 | 菊花生长素响应蛋白Aux/IAA 编码基因CmIAA1 及其植物表达载体和构建方法 |
| WO2020193867A1 (en) | 2019-03-27 | 2020-10-01 | Helsingin Yliopisto | Polynucleotide and uses thereof |
| WO2021009993A1 (ja) | 2019-07-16 | 2021-01-21 | 大学共同利用機関法人情報・システム研究機構 | 非ヒト動物、及びその使用 |
-
2020
- 2020-04-30 WO PCT/JP2020/018310 patent/WO2021009993A1/ja not_active Ceased
- 2020-04-30 JP JP2021532687A patent/JP7458615B2/ja active Active
- 2020-04-30 WO PCT/JP2020/018237 patent/WO2021009990A1/ja not_active Ceased
- 2020-04-30 EP EP20840241.2A patent/EP4026828A4/en active Pending
- 2020-04-30 CN CN202080050921.2A patent/CN114127294A/zh active Pending
- 2020-04-30 EP EP20840243.8A patent/EP4001414A4/en not_active Withdrawn
- 2020-04-30 JP JP2021532685A patent/JPWO2021009990A1/ja active Pending
- 2020-04-30 US US17/620,993 patent/US12522836B2/en active Active
- 2020-04-30 US US17/620,977 patent/US12553055B2/en active Active
- 2020-04-30 CN CN202080050923.1A patent/CN114144400A/zh active Pending
-
2024
- 2024-05-28 JP JP2024086613A patent/JP2024103589A/ja active Pending
Patent Citations (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2008187958A (ja) | 2007-02-05 | 2008-08-21 | Osaka Univ | タンパク質分解誘導性細胞、その製造方法、および、タンパク質分解の制御方法 |
| WO2010125620A1 (ja) | 2009-04-30 | 2010-11-04 | 国立大学法人大阪大学 | 哺乳類細胞におけるタンパク質分解誘導方法 |
| WO2013073653A1 (ja) | 2011-11-18 | 2013-05-23 | 大学共同利用機関法人情報・システム研究機構 | 真核細胞におけるタンパク質分解誘導方法 |
| WO2017029833A1 (ja) * | 2015-08-20 | 2017-02-23 | 大学共同利用機関法人情報・システム研究機構 | 動物細胞ゲノム部位特異的外来dna挿入方法及び前記挿入方法を用いて得られる細胞 |
| JP2019131464A (ja) | 2015-12-18 | 2019-08-08 | 富士電機株式会社 | 炭化珪素半導体基板、炭化珪素半導体基板の製造方法、半導体装置および半導体装置の製造方法 |
| WO2018164214A1 (ja) * | 2017-03-08 | 2018-09-13 | 国立大学法人名古屋大学 | 植物成長調整剤 |
Non-Patent Citations (8)
| Title |
|---|
| AISHA YESBOLATOVA, TOYOAKI NATSUME, KENICHIRO HAYASHI, MASATO KANEMAKI: "Chemical and Genetical Improvement of Auxin- Inducible Degron (AID) Technology", ANNUAL MEETING OF THE MOLECULAR BIOLOGY SOCIETY OF JAPAN PROGRAM • ABSTRACTS; NOVEMBER 28-30, 2018, vol. 41, 2018, pages 1P-0747, XP009526233 * |
| DATABASE Database CHEMICATS [online] 1 March 2019 (2019-03-01), Database accession no. 0998366508 * |
| NAOYUKI UCHIDA, TAKAHASHI KOJI, IWASAKI RIE, YAMADA RYOTARO, YOSHIMURA MASAHIKO, ENDO TAKAHO A, KIMURA SEISUKE, ZHANG HUA, NOMOTO : "Chemical hijacking of auxin signaling with an engineered auxinâÃÂÃÂTIR1 pair", NATURE CHEMICAL BIOLOGY, NATURE PUB. GROUP, NEW YORK, vol. 14, no. 3, New York, pages 299 - 305, XP055555203, ISSN: 1552-4450, DOI: 10.1038/nchembio.2555 * |
| NIKKEI BP INC: "piggyBac transposon method", 12 February 2018 (2018-02-12), JP, XP009526232, Retrieved from the Internet <URL:https://bio.nikkeibp.co.jp/atcl/report/16/011900001/18/02/08/00159/> * |
| NISHIMURA KOHEI; FUKAGAWA TATSUO: "An efficient method to generate conditional knockout cell lines for essential genes by combination of auxin-inducible degron tag and CRISPR/Cas9", CHROMOSOME RESEARCH, KLUWER ACADEMIC PUBLISHERS, NL, vol. 25, no. 3, 6 June 2017 (2017-06-06), NL, pages 253 - 260, XP036350642, ISSN: 0967-3849, DOI: 10.1007/s10577-017-9559-7 * |
| See also references of EP4026828A4 |
| TOYOAKI NATSUME, TOMOMI KIYOMITSU, YUMIKO SAGA, MASATOïÿýT. KANEMAKI: "Rapid Protein Depletion in Human Cells by Auxin-Inducible Degron Tagging with Short Homology Donors", CELL REPORTS, ELSEVIER INC, US, vol. 15, no. 1, 1 April 2016 (2016-04-01), US, pages 210 - 218, XP055373129, ISSN: 2211-1247, DOI: 10.1016/j.celrep.2016.03.001 * |
| YESBOLATOVA AISHA, SAITO YUICHIRO, KANEMAKI MASATO T.: "Constructing Auxin-Inducible Degron Mutants Using an All-in-One Vector", PHARMACEUTICALS, vol. 13, no. 5, pages 103, XP055783487, DOI: 10.3390/ph13050103 * |
Cited By (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2023026824A1 (ja) * | 2021-08-23 | 2023-03-02 | 大学共同利用機関法人情報・システム研究機構 | オーキシンデグロンシステムのキット、及びその使用 |
| JP2023030479A (ja) * | 2021-08-23 | 2023-03-08 | 大学共同利用機関法人情報・システム研究機構 | オーキシンデグロンシステムのキット、及びその使用 |
| JP7760117B2 (ja) | 2021-08-23 | 2025-10-27 | 大学共同利用機関法人情報・システム研究機構 | オーキシンデグロンシステムのキット、及びその使用 |
Also Published As
| Publication number | Publication date |
|---|---|
| JPWO2021009993A1 (ja) | 2021-01-21 |
| US12553055B2 (en) | 2026-02-17 |
| CN114144400A (zh) | 2022-03-04 |
| CN114127294A (zh) | 2022-03-01 |
| JP2024103589A (ja) | 2024-08-01 |
| EP4001414A1 (en) | 2022-05-25 |
| EP4001414A4 (en) | 2023-06-28 |
| US12522836B2 (en) | 2026-01-13 |
| US20220380782A1 (en) | 2022-12-01 |
| WO2021009993A1 (ja) | 2021-01-21 |
| JPWO2021009990A1 (ja) | 2021-01-21 |
| US20220378024A1 (en) | 2022-12-01 |
| EP4026828A4 (en) | 2023-09-13 |
| JP7458615B2 (ja) | 2024-04-01 |
| EP4026828A1 (en) | 2022-07-13 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| Ling et al. | Ubiquitin-dependent chloroplast-associated protein degradation in plants | |
| JP2024103589A (ja) | オーキシンデグロンシステムのキット、及びその使用 | |
| He et al. | A versatile vector toolkit for functional analysis of rice genes | |
| Igarashi et al. | 14-3-3 proteins regulate intracellular localization of the bZIP transcriptional activator RSG | |
| Eklund et al. | The Arabidopsis thaliana STYLISH1 protein acts as a transcriptional activator regulating auxin biosynthesis | |
| Gong et al. | ROS1, a repressor of transcriptional gene silencing in Arabidopsis, encodes a DNA glycosylase/lyase | |
| Dickinson et al. | Engineering the Caenorhabditis elegans genome using Cas9-triggered homologous recombination | |
| Kumar et al. | Functional conservation in the SIAMESE-RELATED family of cyclin-dependent kinase inhibitors in land plants | |
| Zhang et al. | Arabidopsis DDB1-CUL4 ASSOCIATED FACTOR1 forms a nuclear E3 ubiquitin ligase with DDB1 and CUL4 that is involved in multiple plant developmental processes | |
| Yin et al. | Epigenetic regulation, somatic homologous recombination, and abscisic acid signaling are influenced by DNA polymerase ϵ mutation in Arabidopsis | |
| Kwan et al. | The Tol2kit: a multisite gateway‐based construction kit for Tol2 transposon transgenesis constructs | |
| Muchardt et al. | The mammalian SWI/SNF complex and the control of cell growth | |
| Yoshizumi et al. | Increased level of polyploidy1, a conserved repressor of CYCLINA2 transcription, controls endoreduplication in Arabidopsis | |
| JP2017518758A5 (ja) | ||
| Liu et al. | DNA replication factor C1 mediates genomic stability and transcriptional gene silencing in Arabidopsis | |
| WO2010125620A1 (ja) | 哺乳類細胞におけるタンパク質分解誘導方法 | |
| Lin et al. | Discrete and essential roles of the multiple domains of Arabidopsis FHY3 in mediating phytochrome A signal transduction | |
| Zhou et al. | A domesticated Harbinger transposase forms a complex with HDA6 and promotes histone H3 deacetylation at genes but not TEs in Arabidopsis | |
| Zhao et al. | AtMCM10 promotes DNA replication‐coupled nucleosome assembly in Arabidopsis | |
| Lee et al. | Cloning of two splice variants of the rice PTS1 receptor, OsPex5pL and OsPex5pS, and their functional characterization using pex5‐deficient yeast and Arabidopsis | |
| Andersson et al. | The FLX gene of Arabidopsis is required for FRI-dependent activation of FLC expression | |
| Lu et al. | Involvement of MEM1 in DNA demethylation in Arabidopsis | |
| WO2023026824A1 (ja) | オーキシンデグロンシステムのキット、及びその使用 | |
| Park et al. | Generation of knockout mouse models of cyclin-dependent kinase inhibitors by engineered nuclease-mediated genome editing | |
| Zhu et al. | Subcellular localizations of AS1 and AS2 suggest their common and distinct roles in plant development |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 20840241 Country of ref document: EP Kind code of ref document: A1 |
|
| ENP | Entry into the national phase |
Ref document number: 2021532685 Country of ref document: JP Kind code of ref document: A |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| ENP | Entry into the national phase |
Ref document number: 2020840241 Country of ref document: EP Effective date: 20220216 |
|
| WWG | Wipo information: grant in national office |
Ref document number: 17620977 Country of ref document: US |