WO2021018183A1 - 一种资源分配方法和资源借调方法 - Google Patents
一种资源分配方法和资源借调方法 Download PDFInfo
- Publication number
- WO2021018183A1 WO2021018183A1 PCT/CN2020/105476 CN2020105476W WO2021018183A1 WO 2021018183 A1 WO2021018183 A1 WO 2021018183A1 CN 2020105476 W CN2020105476 W CN 2020105476W WO 2021018183 A1 WO2021018183 A1 WO 2021018183A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- cluster
- node
- hash
- resource
- target
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Ceased
Links
Images



















Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/46—Multiprogramming arrangements
- G06F9/50—Allocation of resources, e.g. of the central processing unit [CPU]
- G06F9/5005—Allocation of resources, e.g. of the central processing unit [CPU] to service a request
- G06F9/5027—Allocation of resources, e.g. of the central processing unit [CPU] to service a request the resource being a machine, e.g. CPUs, Servers, Terminals
- G06F9/505—Allocation of resources, e.g. of the central processing unit [CPU] to service a request the resource being a machine, e.g. CPUs, Servers, Terminals considering the load
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/46—Multiprogramming arrangements
- G06F9/50—Allocation of resources, e.g. of the central processing unit [CPU]
- G06F9/5061—Partitioning or combining of resources
- G06F9/5072—Grid computing
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/46—Multiprogramming arrangements
- G06F9/48—Program initiating; Program switching, e.g. by interrupt
- G06F9/4806—Task transfer initiation or dispatching
- G06F9/4843—Task transfer initiation or dispatching by program, e.g. task dispatcher, supervisor, operating system
- G06F9/4881—Scheduling strategies for dispatcher, e.g. round robin, multi-level priority queues
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/46—Multiprogramming arrangements
- G06F9/50—Allocation of resources, e.g. of the central processing unit [CPU]
- G06F9/5005—Allocation of resources, e.g. of the central processing unit [CPU] to service a request
- G06F9/5027—Allocation of resources, e.g. of the central processing unit [CPU] to service a request the resource being a machine, e.g. CPUs, Servers, Terminals
- G06F9/5038—Allocation of resources, e.g. of the central processing unit [CPU] to service a request the resource being a machine, e.g. CPUs, Servers, Terminals considering the execution order of a plurality of tasks, e.g. taking priority or time dependency constraints into consideration
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/46—Multiprogramming arrangements
- G06F9/50—Allocation of resources, e.g. of the central processing unit [CPU]
- G06F9/5083—Techniques for rebalancing the load in a distributed system
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F2209/00—Indexing scheme relating to G06F9/00
- G06F2209/50—Indexing scheme relating to G06F9/50
- G06F2209/505—Clust
Definitions
- This application relates to the field of distributed systems, and in particular, to a resource allocation method and a resource secondment method.
- the resource mutual assistance scenarios between devices are mainly divided into two categories.
- One is the resource mutual assistance of hierarchical heterogeneous devices, such as the collaboration of devices with different computing capabilities between edge devices, edge servers, and central cloud processors; the other is the same
- the resource coordination between layer devices that is, when the edge device resources are insufficient, resources can be borrowed from other edge devices.
- the master node in the busy cluster needs to send a resource query request to a randomly selected idle cluster, and after receiving the return, perform resource secondment.
- secondment conflicts may occur.
- the embodiment of the present application provides a resource allocation method and a resource secondment method, and there is no secondment conflict caused by multiple busy clusters concurrently seconding resources to the same idle cluster.
- this application provides a resource allocation method, including:
- the first node determines the hash value corresponding to the first cluster; the first node obtains a hash ring, the hash ring includes at least one hash value interval, and each hash value interval corresponds to a second cluster; the The first node determines the corresponding target second cluster according to the hash value corresponding to the first cluster, wherein the hash value corresponding to the first cluster belongs to a target hash interval, and the target hash interval is the at least A hash value interval in a hash value interval, and the target hash interval corresponds to the target second cluster; the first node establishes an association relationship between the first cluster and the target second cluster, wherein The target second cluster in which the first cluster has established an association relationship is allowed to apply for resources from the first cluster.
- the correspondence of resource secondment is determined based on the correspondence between the hash value of the first cluster on the hash ring generated based on the second cluster, the correspondence is unique, so the first cluster can only be The corresponding second cluster on the Greek ring seconded resources, so there will be no secondment conflicts caused by multiple clusters concurrently seconding resources to the same cluster.
- the first node can determine the target second cluster corresponding to the first cluster through the distribution of the hash value corresponding to the first cluster on the hash ring (generated according to the hash value corresponding to the second cluster), and establish the target
- the association relationship between the second cluster and the first cluster is determined by the distribution of the hash value corresponding to the first cluster and the hash node corresponding to the second cluster on the hash ring based on the consistent hash algorithm. Only fixed clusters are allowed to second. Therefore, when the target second cluster needs to second the idle resources of the first cluster, there is no need to randomly send a resource query request to a certain cluster, and after receiving the return, perform resource secondment. Directly borrow resources to a specific first cluster, reducing the delay overhead of a round trip of information.
- the first cluster is an idle cluster containing multiple idle nodes
- the second cluster is a busy cluster containing multiple busy nodes.
- the idle nodes and busy nodes are determined according to the load of the nodes. For example, nodes whose load is higher than a certain threshold are busy nodes, and nodes whose load is not higher than a certain threshold are idle nodes.
- the first cluster is a fat cluster containing multiple fat nodes
- the second cluster is a thin cluster containing multiple thin nodes.
- the fat nodes and thin nodes are based on the resources of the nodes. Or distinguished by ability, for example, nodes with limited resources or weak capabilities are thin nodes, nodes with rich resources, and nodes with strong processing capabilities are fat nodes.
- the hash ring includes a first hash node and a second hash node, the first hash node corresponds to the target second cluster, and the first hash node
- the hope node is the adjacent successor node of the second hash node on the hash ring
- the target hash interval is the hash value of the first hash node and the hash value of the second hash node.
- the method further includes: the first node divides an idle cluster including multiple computing nodes to obtain multiple sub-clusters, and the first cluster is the multiple sub-clusters. One of the clusters.
- the multiple sub-clusters include a third sub-cluster and a fourth sub-cluster
- the third sub-cluster is the sub-cluster with the largest amount of resource idleness among the multiple sub-clusters
- the fourth sub-cluster is the cluster with the smallest amount of idle resources among the plurality of sub-clusters, and the absolute value of the difference between the idle amount of resources of the third sub-cluster and the idle amount of resources of the fourth sub-cluster is less than a first threshold .
- the first node can divide the multiple computing nodes of the idle cluster, so that the difference in the amount of free resources between the first clusters in the multiple sub-clusters obtained after the division will not be too large.
- the absolute value of the difference between the idle amount of resources of each sub-cluster of the plurality of sub-clusters and the idle amount of preset resources is less than or equal to the second threshold, and the preset resource The amount of idleness is related to the amount of historical resource requests.
- the first node divides the multiple computing nodes of the idle cluster based on the historical resource request, so that the amount of idle resources of each sub-cluster after division is close to the amount of historical resource requests.
- the number of the multiple sub-clusters and the number of the second clusters are less than a third threshold.
- the method further includes: the first node receives a first resource secondment request sent by the target second cluster, where the first resource secondment request includes task data and An identifier of a cluster; the first node sends the task data to the first cluster according to the identifier of the first cluster.
- the method further includes: the first node receives a first resource secondment request sent by the target second cluster, where the first resource secondment request includes task data; The first node sends the task data to the first cluster.
- the sending of the task data by the first node to the first cluster includes: the first node sends the task data to the first cluster based on the association relationship between the first cluster and the target second cluster.
- the first cluster sends the task data.
- the hash ring includes Y hash nodes, each second cluster corresponds to at least one hash node, and the corresponding hash values of the Y hash nodes
- the hash value corresponding to the first cluster is generated according to the same hash algorithm, and the Y is a positive integer.
- the hash value corresponding to the hash node on the hash ring and the hash value corresponding to the first cluster are generated based on the same hash algorithm, so that the hash value and the hash value corresponding to the first cluster do not appear.
- the coincidence of hash nodes on the ring is
- the method further includes: the first node determines Y hash values corresponding to the X second clusters, wherein each second cluster corresponds to at least one hash value ,
- the X is a positive integer
- the Y is a positive integer greater than or equal to X
- the first node generates the hash ring according to the Y hash values, wherein the hash ring includes Y hash values
- each second cluster corresponds to at least one hash node
- the Y hash nodes divide the hash ring into Y hash value intervals
- each hash node corresponds to a hash value interval. In this way, the first node can generate a hash ring by itself.
- the method further includes: the first node receiving the hash ring sent by the second cluster.
- the method further includes: the first node sends the resource idle amount of the first cluster to the target second cluster.
- the present application provides a resource secondment method, the method includes: a second node determines a first cluster that has an association relationship with a target second cluster, wherein the second node belongs to the target second cluster
- the target second cluster corresponds to the target hash value interval in the hash ring, and the hash value corresponding to the first cluster belongs to the target hash value interval
- the second node receives task data
- the The second node sends a first resource secondment request to the first node, where the first secondment request is used to instruct the first node to allocate the task data to the first cluster for processing.
- each idle cluster is only allowed to be seconded by a fixed empty cluster Therefore, when the target second cluster needs to second the idle resources of the first cluster, it does not need to randomly send a resource query request to the selected idle cluster, and after receiving the return, perform the resource secondment, which can be directly seconded to the first cluster Resources, reducing the delay overhead of a round trip of information.
- the method further includes: the second node determines that the first cluster is in a resource non-borable state based on sending the first resource secondment request to the first node. In this way, after the second node sends the first resource secondment request to the first node, it is equivalent to occupying the idle resources of the first cluster, and it can be determined that the first cluster is in a resource unavailable state.
- the second node may mark the resource loan status of the first cluster as the resource unavailable status in the mapping table.
- the first node may also determine that the first cluster is in a resource non-secondable state, that is, determine that the first cluster cannot provide available resources for other busy clusters, thereby ensuring resource locking and realizing conflict-free scheduling of resources across clusters.
- the second node determining the first cluster having an association relationship with the target second cluster includes: The second node determines that one of the multiple clusters having an association relationship with the target second cluster is the first cluster.
- the second node determining that one of the multiple clusters having an association relationship with the target second cluster is the first cluster includes: the second node determining and Among the resource vacancies of the plurality of clusters in which the target second cluster has an association relationship, the cluster corresponding to the resource vacancy with the smallest difference in resource demand of the task data is the first cluster. In this way, the second node determines that among the resource vacancies of the multiple clusters associated with the target second cluster, the cluster corresponding to the resource vacancy with the smallest difference in the resource demand of the task data is the The first cluster improves resource utilization during resource secondment.
- the method further includes: the second node receives the resource demand of the task data sent by the third node; based on the resource of the first cluster The idle amount is greater than or equal to the resource demand, and the second node sends the identifier of the first cluster and the idle amount of resources of the first cluster to the third node.
- the receiving task data by the second node includes: receiving, by the second node, a second resource loan request sent by the third node, and the second resource loan request includes all The task data, the second secondment request is used to instruct the second node to allocate the task data to the first cluster for processing.
- the present application provides a resource secondment method, including: a second node receives resource demand of task data sent by a third node; the second node determines a first cluster that has an association relationship with a target second cluster , Wherein the second node belongs to the target second cluster, the target second cluster corresponds to the target hash value interval in the hash ring, and the hash value corresponding to the first cluster belongs to the target hash value. Hope range; based on the resource idle amount of the first cluster being greater than or equal to the resource demand, the second node sends a third resource secondment request to the third node, and the third resource secondment request is used for Indicate that the third node is allowed to apply for resources from the first cluster.
- the first node can determine the target second cluster corresponding to the first cluster through the distribution of the hash value corresponding to the first cluster on the hash ring (generated according to the hash value corresponding to the second cluster), and establish the target
- the relationship between the second cluster and the first cluster is determined by the distribution of the hash value corresponding to the first cluster and the hash node corresponding to the second cluster on the hash ring based on the consistent hash algorithm, and each idle The cluster is only allowed to be seconded by a fixed empty cluster. Therefore, when the third node needs to borrow resources from the second node, the second node does not need to randomly send resource query requests to the selected idle cluster, and then proceed after receiving the return. For resource secondment, it is directly possible to determine the first cluster where resources can be seconded, reducing the delay overhead of a round trip of information.
- the second node determining the first cluster having an association relationship with the target second cluster includes: The second node determines that one of the multiple clusters having an association relationship with the target second cluster is the first cluster.
- the present application provides a resource secondment method, including: a third node receives task data; the third node sends the resource demand of the task data to the second node; and the third node receives the A third resource secondment request sent by the second node, where the third resource secondment request is used to indicate that the third node is allowed to apply for resources from the first cluster, where the second node belongs to the target second cluster, and The target second cluster corresponds to the target hash value interval in the hash ring, the hash value corresponding to the first cluster belongs to the target hash value interval, and the resource idle amount of the first cluster is greater than or equal to all The resource demand; the third node sends a first resource secondment request to the first node, where the first secondment request is used to instruct the first node to allocate the task data to the first cluster for processing.
- the second node does not need to randomly send resource query requests to the selected idle cluster, and after receiving the return, perform the resource secondment, but can directly determine the first cluster that can second the resources, reducing Delay overhead of a round trip of information.
- the third node sending the resource demand of the task data to the second node includes: the resource demand of the third node sending the task data to multiple nodes
- the second node is one of the multiple nodes
- the third node receiving a third resource loan request sent by the second node includes: the third node receiving the third resource loan request sent by the multiple nodes
- the third resource secondment request is used to indicate that the third node is allowed to apply for resources from multiple sub-clusters, and the first cluster is one of the multiple sub-clusters.
- the method further includes: the third node determines the resource with the smallest difference from the resource demand of the task data among the resource idle amounts of the multiple sub-clusters The sub-cluster corresponding to the idle amount is the first cluster.
- the present application provides a first management node, where the first management node includes:
- the processing module is configured to determine the hash value corresponding to the first cluster; obtain a hash ring, the hash ring includes at least one hash value interval, and each hash value interval corresponds to a second cluster;
- the hash value corresponding to the cluster determines the corresponding target second cluster, wherein the hash value corresponding to the first cluster belongs to a target hash interval, and the target hash interval is one of the at least one hash value interval A hash value interval, where the target hash interval corresponds to the target second cluster;
- the transceiver module is configured to establish an association relationship between a first cluster and a target second cluster, wherein the target second cluster that has established an association relationship with the first cluster is allowed to apply for resources from the first cluster.
- the hash ring includes a first hash node and a second hash node, the first hash node corresponds to the target second cluster, and the first hash node
- the hope node is the adjacent successor node of the second hash node on the hash ring
- the target hash interval is the hash value of the first hash node and the hash value of the second hash node. The hash interval between the Greek values.
- the processing module is further configured to divide an idle cluster including multiple computing nodes to obtain multiple sub-clusters, and the first cluster is one of the multiple sub-clusters One.
- the multiple sub-clusters include a third sub-cluster and a fourth sub-cluster
- the third sub-cluster is the sub-cluster with the largest amount of resource idleness among the multiple sub-clusters
- the fourth sub-cluster is the cluster with the smallest amount of idle resources among the plurality of sub-clusters, and the absolute value of the difference between the idle amount of resources of the third sub-cluster and the idle amount of resources of the fourth sub-cluster is less than a first threshold .
- the absolute value of the difference between the idle amount of resources of each sub-cluster in the plurality of sub-clusters and the idle amount of the preset resources is less than or equal to the second threshold, and the preset resource The amount of idleness is related to the amount of historical resource requests.
- the number of the plurality of sub-clusters and the number of the second clusters are less than a third threshold.
- the transceiver module is further used for:
- the transceiver module is further used for:
- the transceiver module is specifically configured to send the task data to the first cluster based on the association relationship between the first cluster and the target second cluster.
- the hash ring includes Y hash nodes, each second cluster corresponds to at least one hash node, and the corresponding hash values of the Y hash nodes
- the hash value corresponding to the first cluster is generated according to the same hash algorithm, and the Y is a positive integer.
- the processing module is further configured to determine Y hash values corresponding to X second clusters, wherein each second cluster corresponds to at least one hash value, and X is a positive integer, and the Y is a positive integer greater than or equal to X; the hash ring is generated according to the Y hash values, wherein the hash ring includes Y hash nodes, and each second cluster Corresponding to at least one hash node, the Y hash nodes divide the hash ring into Y hash value intervals, and each hash node corresponds to a hash value interval.
- the transceiver module is further configured to receive the hash ring sent by the second cluster.
- the transceiver module is further configured to send the resource idle amount of the first cluster to the target second cluster.
- this application provides a second management node, wherein the second management node includes:
- a processing module configured to determine a first cluster having an association relationship with a target second cluster, wherein the second node belongs to the target second cluster, and the target second cluster corresponds to the target hash in the hash ring Value interval, the hash value corresponding to the first cluster belongs to the target hash value interval;
- the transceiver module is configured to receive task data; and send a first resource secondment request to the first node, where the first secondment request is used to instruct the first node to allocate the task data to the first cluster for processing.
- the processing module is further configured to send a resource secondment request to the first node based on the transceiver module to determine that the first cluster is in a resource non-secondable state.
- the processing module is specifically configured to determine multiple clusters that have an association relationship with the target second cluster.
- One of the clusters is the first cluster.
- the processing module is specifically configured to determine the resource idle amount of the multiple clusters associated with the target second cluster, and the resource demand amount of the task data The cluster corresponding to the resource idle amount with the smallest difference is the first cluster.
- the transceiver module is further configured to receive the resource demand of the task data sent by the third node, and based on the resource idle amount of the first cluster being greater than or equal to all The resource demand, sending the identifier of the first cluster and the resource idle amount of the first cluster to the third node.
- the transceiver module is specifically configured to receive a second resource loan request sent by the third node, where the second resource loan request includes the task data, and the second resource loan request The second secondment request is used to instruct the second node to allocate the task data to the first cluster for processing.
- the present application provides a second management node, wherein the second management node includes:
- the transceiver module is used to receive the resource demand of task data sent by the third node;
- a processing module configured to determine a first cluster having an association relationship with a target second cluster, wherein the second node belongs to the target second cluster, and the target second cluster corresponds to the target hash in the hash ring Value interval, the hash value corresponding to the first cluster belongs to the target hash value interval;
- the transceiver module is further configured to send a third resource loan request to the third node based on the resource idle amount of the first cluster being greater than or equal to the resource demand amount, and the third resource loan request is used to indicate The third node is allowed to apply for resources from the first cluster.
- the processing module is specifically configured to determine multiple clusters that have an association relationship with the target second cluster.
- One of the clusters is the first cluster.
- the present application provides a third management node, wherein the third management node includes:
- the transceiver module is configured to receive task data, send the resource demand of the task data to the second node, and receive a third resource secondment request sent by the second node, where the third resource secondment request is used to instruct the second node
- Three nodes are allowed to apply for resources from the first cluster, where the second node belongs to the target second cluster, the target second cluster corresponds to the target hash value interval in the hash ring, and the first cluster corresponds to If the hash value belongs to the target hash value interval, and the resource idle amount of the first cluster is greater than or equal to the resource demand, a first resource secondment request is sent to the first node, and the first secondment request is used for Instruct the first node to allocate the task data to the first cluster for processing.
- the transceiver module is specifically configured to send the resource demand of the task data to multiple nodes, and the second node is one of the multiple nodes, and receives A third resource secondment request sent by the multiple nodes, where the third resource secondment request is used to indicate that the third node is allowed to apply for resources from multiple sub-clusters, and the first cluster is one of the multiple sub-clusters One.
- the third management node further includes:
- the processing module is configured to determine that among the resource idle amounts of the plurality of sub-clusters, the sub-cluster corresponding to the resource idle amount with the smallest difference between the resource requirements of the task data is the first cluster.
- the present application provides a cluster, the cluster includes multiple computing nodes, the computing nodes provide task data with required resources to execute the task data, and the cluster further includes: The first management node described in one aspect.
- the present application provides a cluster, the cluster includes a plurality of computing nodes, the computing nodes provide task data with required resources to execute the task data, and the cluster further includes: The second management node described in one aspect.
- the present application provides a cluster, the cluster includes a plurality of computing nodes, the computing nodes provide task data with required resources to execute the task data, and the cluster further includes: the above The third management node of any aspect.
- this application provides a distributed system, wherein the distributed system includes the cluster described in the ninth aspect and the cluster described in the tenth aspect.
- this application provides a distributed system, characterized in that the distributed system includes the cluster described in the ninth aspect, the cluster described in the tenth aspect, and the cluster described in the eleventh aspect.
- this application provides a computer storage medium for storing computer software instructions used by the above-mentioned first management node, which contains the program designed for executing the above-mentioned aspect.
- this application provides a computer storage medium for storing computer software instructions used by the above-mentioned second management node, which contains the program designed for executing the above-mentioned aspect.
- this application provides a computer storage medium for storing computer software instructions used by the above-mentioned third management node, which contains the program designed for executing the above-mentioned aspect.
- the first node determines the hash value corresponding to the first cluster; the first node obtains the hash ring, the hash ring includes at least one hash value interval, and each hash value interval corresponds to a second cluster; The first node determines the corresponding target second cluster according to the hash value corresponding to the first cluster, where the hash value corresponding to the first cluster belongs to the target hash interval, and the target hash interval is one of at least one hash value interval The hash value interval, the target hash interval corresponds to the target second cluster; the first node establishes an association relationship between the first cluster and the target second cluster, wherein the target second cluster that has established an association relationship with the first cluster Is allowed to apply for resources from the first cluster.
- the first node can determine the target second cluster corresponding to the first cluster through the distribution of the hash value corresponding to the first cluster on the hash ring (generated according to the hash value corresponding to the second cluster), Establish the association relationship between the target second cluster and the first cluster. Since the distribution of the hash value corresponding to the first cluster and the hash node corresponding to the second cluster on the hash ring based on the consistent hash algorithm is determined, An idle cluster is only allowed to be seconded by a fixed empty cluster.
- the target second cluster needs to second the idle resources of the first cluster, there is no need to randomly send a resource query request to the selected idle cluster, and after receiving the return, For resource secondment, resources can be directly seconded to the first cluster, which reduces the delay overhead of a round trip of information.
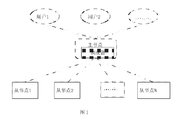
- Figure 1 is a schematic diagram of a centralized distributed system architecture with a one-tier architecture
- Figure 2 is a schematic diagram of the architecture of a resource secondment scenario
- FIG. 3a is a schematic diagram of an embodiment of a resource allocation method provided by an embodiment of this application.
- Figure 3b is a schematic diagram of a cluster idle and busy state distribution
- Figure 3c is a schematic diagram of a cluster idle and busy state distribution
- Figure 3d is a schematic diagram of a packing result in an embodiment of the application.
- 4a is a schematic structural diagram of a hash ring provided by an embodiment of this application.
- FIG. 4b is a schematic structural diagram of a hash ring provided by an embodiment of this application.
- FIG. 4c is a schematic structural diagram of a hash ring provided by an embodiment of this application.
- 4d is a schematic structural diagram of a hash ring provided by an embodiment of this application.
- FIG. 5 is a schematic diagram of an embodiment of a resource secondment method provided by an embodiment of this application.
- FIG. 6 is a schematic diagram of an embodiment of a resource loan method provided by an embodiment of the application.
- FIG. 7 is a schematic structural diagram of a first management node provided by an embodiment of this application.
- FIG. 8 is a schematic structural diagram of a second management node provided by an embodiment of this application.
- FIG. 9 is a schematic structural diagram of a third management node provided by an embodiment of this application.
- FIG. 10 is an example of a system of a management node applicable to an embodiment of the present invention.
- FIG. 11 is a schematic structural diagram of a cluster provided by an embodiment of this application.
- FIG. 12 is a schematic structural diagram of a cluster provided by an embodiment of this application.
- FIG. 13 is a schematic structural diagram of a cluster provided by an embodiment of this application.
- FIG. 14 is a schematic structural diagram of a distributed system provided by an embodiment of this application.
- FIG. 15 is a schematic structural diagram of a distributed system provided by an embodiment of this application.
- FIG. 1 is a schematic diagram of a centralized distributed system with a one-tier architecture.
- users user1, user2,(7) can submit task data to the master node of the node cluster.
- the master node schedules and distributes task data through the scheduler, and allocates all the task data.
- the required resources are allocated to the slave nodes (slave1, slave2,...slaveN) that meet the required resources of the task.
- master node in this application can also be understood as a management node
- slave node can be understood as a computing node
- the scheduler may be a hardware device integrated on the relevant node, or it may be implemented by software through the general hardware of the node.
- the specific manner in which the management node implements the scheduler function is not limited.
- the resource scheduling described in the embodiment of the present invention refers to allocating the resources of the computing nodes in the distribution to task data.
- a computing node refers to a collection of resources as a resource scheduling unit in a distributed system.
- a computing node is based on a server or a physical computer. of.
- computing nodes can be divided according to different division units. For example, when the CPU is used as the monitored resource, the processor or processing core can be used as the division unit, and each processor or processing core in the distributed system is used as a computing node, and a server may contain multiple computing nodes.
- data shards can be used as the dividing unit of computing nodes. Then a data shard in a distributed database serves as a computing node, and a server may contain multiple data shards , Which contains multiple computing nodes.
- the resource mutual assistance scenarios between devices are mainly divided into two categories.
- One is the resource mutual assistance of hierarchical heterogeneous devices, such as the collaboration of devices with different computing capabilities between edge devices, edge servers, and central cloud processors; the other is the same
- the resource coordination between layer devices that is, when the edge device resources are insufficient, resources can be borrowed from other edge devices.
- Figure 2 is a schematic diagram of the architecture of a resource secondment scenario, as shown in Figure 2, including cluster 201, cluster 202, cluster 203, and cluster 204, where cluster 201, cluster 202, and cluster 203 are resources An idle cluster with more idle capacity, cluster 204 is a busy cluster with less idle resources, cluster 201 includes management node 2011 and multiple computing nodes 2012, cluster 202 includes management node 2021 and multiple computing nodes 2022, cluster 203 includes management The node 2031 and multiple computing nodes 2032, and the cluster 204 includes a management node 2041 and multiple computing nodes 2042.
- cross-cluster resource loaning may be performed according to the following strategy:
- the management node 2041 sorts the cluster 201, the cluster 202, and the cluster 203 from large to small according to the amount of free resources, and obtains the first cluster list.
- the first cluster list is ⁇ cluster 201, cluster 203, cluster 202 ⁇ .
- the management node 2041 receives the task data, and determines that the available resource idle amount of the multiple computing nodes 2042 is less than the resource requirement of the task data.
- the management node 2041 selects clusters whose idle amount of resources meets the resource requirements of the task data, and obtains the second cluster list.
- the second cluster list is ⁇ cluster 201, cluster 203, cluster 202 ⁇ .
- the management node 2041 randomly selects two clusters from the second cluster list, and sends resource query requests to the selected two clusters.
- the management node 2041 selects the cluster 201 and the cluster 203. At this time, the management node 2041 may send resource query requests to the management node 2011 and the management node 2021.
- the management node 2041 selects the first cluster that returns the secondment result and meets the resource requirements of the task data to perform cross-cluster resource secondment.
- the management node can send the task data to the management node 2011, so that the management node 2011 schedules multiple computing nodes to process the task data.
- resource secondment is performed at the granularity of clusters.
- the probability of secondment conflicts is relatively high, that is, for the same idle cluster, there may be multiple busy clusters for resource secondment .
- a resource secondment conflict will occur between cluster 201 and cluster 203, resulting in no cluster returning the secondment result.
- FIG. 3a is a schematic diagram of an embodiment of a resource allocation method provided by an embodiment of this application. As shown in FIG. 3a, this The resource allocation methods provided by the application include:
- the first node determines a hash value corresponding to the first cluster.
- the first node may be a management node of an idle cluster, where the idle cluster includes the first node and multiple computing nodes, and the first cluster may be composed of all or some of the multiple computing nodes
- the node cluster, the first cluster may also include the first node, which is not limited here.
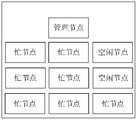
- the first node may first determine the busy and idle state of the cluster where it is located.
- the first node may evaluate the busy/idle state of the node based on the occupancy rate of the dominant resource of the computing node in the cluster where it is located, and based on the number of busy nodes and the number of idle nodes in the cluster where it is located. Evaluate the busy and busy status of the cluster.
- the first node may define the free/idle state of the computing node according to the following formula:
- i represents the i-th resource
- Use(i) represents the resource occupation of the i-th resource in use
- Total(i) represents the total resource amount of the i-th resource
- a is a preset threshold
- max ⁇ P i ⁇ represents the largest occupancy rate of i resources.
- the first node when the maximum resource occupancy rate in the computing node is greater than or equal to the threshold a, the first node can determine that the computing node is a busy node, and when the maximum resource occupancy rate in the computing node is less than the threshold a, the first node The node can determine that the computing node is an idle node.
- threshold a can be adjusted in real time according to requirements, and can be configured according to different scenarios, which is not limited in this application.
- the first node may define the free/busy state of the cluster where it is located in the following manner:
- the number of busy nodes is n, and the number of idle nodes is m;
- the first node can determine that the cluster where it is located is a busy cluster
- b is the preset threshold.
- threshold b can be adjusted in real time according to requirements, and can be configured according to different scenarios, which is not limited in this application.
- the cluster shown in FIG. 3b is an idle cluster, which can provide idle resources.
- the first node may determine the hash value corresponding to the first cluster when it determines that the idle/busy state of the cluster where it is located is idle.
- the idle cluster where the first node is located includes multiple computing nodes, and the first node may divide the multiple computing nodes of the idle cluster to obtain multiple sub-clusters.
- the idle cluster where the first node is located includes multiple idle nodes, and the first node may divide the multiple idle nodes of the idle cluster to obtain multiple sub-clusters.
- the plurality of sub-clusters includes a third cluster and a fourth cluster
- the third cluster is the cluster with the largest amount of idle resources among the plurality of sub-clusters
- the fourth cluster is the cluster with the smallest amount of idle resources among the plurality of sub-clusters.
- the absolute value of the difference between the idle amount of resources of the three clusters and the idle amount of resources of the fourth cluster is smaller than the first threshold.
- the first node may divide the multiple computing nodes of the idle cluster, so that the difference in the amount of free resources between the first clusters in the multiple sub-clusters obtained after the division will not be too large (The absolute value of the difference between the largest amount of free resources and the smallest amount of free resources is smaller than the first threshold).
- the first node may randomly select a part of idle nodes or all idle nodes from the multiple idle nodes in the idle cluster as reserved resources, and provide resources for the local busy nodes in the idle cluster;
- the first node may determine the remaining idle nodes other than the reserved resources among the idle nodes as borrowable resources, and group them.
- the first node may determine that the remaining idle nodes in the idle nodes other than reserved resources include: ⁇ node 1, node 2, node 3, node 4, node 5, node 6, node 7, node 8, node 9 , Node 10, node 11, node 12 ⁇ , where each node has been sorted in descending order of idle rate (that is, node 1 has the highest idle rate and node 12 has the lowest idle rate).
- Figure 3d which is one of the embodiments of this application.
- a schematic diagram of the packing result where when the number of groups j is determined to be 5, the "S"-shaped packing result diagram is shown in Fig. 3d. In Fig. 3d, 5 sub-clusters are obtained after division.
- the absolute value of the difference between the free amount of resources of each sub-cluster in the plurality of sub-clusters and the free amount of preset resources is less than or equal to the second threshold, and the preset amount of free resources is compared with the history Related to the amount of resource requests.
- the idle amount of resources may include the idle amount of CPU resources and the idle amount of memory resources
- the preset idle amount of resources may include the preset idle amount of CPU resources and the preset idle amount of memory resources, where the preset idle amount of resources and historical resource requests
- the preset idle amount of CPU resources is related to the historical CPU resource request amount
- the preset memory resource idle amount is related to the historical memory resource request amount
- the absolute value of the difference between the idle amount of CPU resources of each of the plurality of sub-clusters and the preset amount of idle CPU resources is less than or equal to the third threshold, and each of the plurality of sub-clusters
- the absolute value of the difference between the idle amount of the memory resources of the cluster and the idle amount of the preset memory resources is less than or equal to the fourth threshold.
- the preset idle amount of CPU resources and the preset idle amount of memory resources in the embodiments of the present application may be determined according to the amount of resource requests in the historical loan request.
- the first node may record the idle cluster where it is located in the last k cycles.
- the first node may first calculate and average the CPU resource request amount and memory resource request amount in k cycles according to the historical resource request table to obtain the historical average CPU request amount of each idle resource group in a single cycle. And memory historical average request
- i represents a CPU in the CPU resource request amount of the i th cycle
- s i represents the number of idle resource groups within the i th cycle
- MEM i represents the memory resources within the i th cycle request amount.
- the first node can determine the historical average CPU request To preset the idle amount of CPU resources, the average historical memory request amount It is the preset amount of memory resources.
- the first node can be with As an indicator, the available resources are grouped so that the free amount of CPU resources and the free amount of memory resources in each sub-cluster after grouping are close to with
- the first node can calculate the contribution rate of each idle node And according to the contribution rate, the idle nodes are sorted in descending order, and the borrowable resources are divided into N groups, Carry out "S" boxing of all borrowable nodes to obtain multiple sub-clusters.
- idle_c i represents the amount of free CPU and idle_m i represents the amount of free memory
- ⁇ and ⁇ represent the weight parameters of CPU and memory
- sum_cpu represents the total amount of free CPU that can be borrowed in the idle cluster
- sum_mem represents the total amount of free memory that can be borrowed in the idle cluster .
- the management nodes in the cluster can determine the idle and busy status of the cluster where they are located.
- the management nodes in the idle cluster may be All or part of the idle nodes are divided to obtain multiple sub-clusters.
- the management node determines that the set it is in is a busy cluster, it can broadcast its busy/idle status (busy status) to other management nodes.
- the first node may determine the hash value corresponding to the first cluster. Specifically, the first node may determine the hash value corresponding to each of the multiple sub-clusters. It should be understood that there are many One of sub-clusters.
- the first cluster may uniquely correspond to an identifier, for example, the first cluster may be uniquely identified by IP and ID, where IP is the identifier of the idle cluster where the first node is located, and the ID is the identifier of the grouping.
- IP can be the IP address of the server where the idle cluster is located, and the IP address can include the server's IP address and port number.
- calculating the hash value corresponding to the first cluster may be based on the IP address of the server where it is located, the port number information, and the ID used to identify the group, and the hash value corresponding to the first cluster is calculated based on a preset hash algorithm. value.
- the first node may calculate the hash value corresponding to each sub-cluster based on the preset hash algorithm. Specifically, the first node may calculate the hash value of the identifier of each sub-cluster based on the preset hash algorithm. If the identifiers of are not repeated, the corresponding hash values are also different.
- the first node obtains a hash ring, where the hash ring includes at least one hash value interval, and each hash value interval corresponds to a second cluster.
- the hash ring can be understood as a data structure including the hash values of multiple hash nodes and the hash value interval between two adjacent hash nodes.
- the data structure may be a list or The form of an array. This application does not limit the specific form of the hash value, as long as it is a data structure that can reflect the distribution characteristics of at least one second cluster, it should fall within the protection scope of this application.
- the first node may construct a hash ring based on a preset hash algorithm.
- clusters can be distributed on a logical ring of numerical space according to their respective hash values, called a hash ring.
- the hash ring is generally generated and saved by the management node.
- a data range on the hash ring (for example, the hash value range of 1000 to 20000 on the hash ring) is called a hash value interval.
- the management node when the management node determines that the cluster it is in is a busy cluster, it can broadcast its own busy status (busy status) to other management nodes.
- the first node can determine the busy cluster (at least one busy cluster) included in the distributed system. The second cluster).
- the first node can calculate the hash value corresponding to each second cluster based on a preset hash algorithm.
- a preset hash algorithm can be a jhash hash algorithm or other types of hash algorithms The embodiments of this application do not specifically limit this.
- the first node can select a suitable hash algorithm according to the needs of the system, as long as calculating the hash value of the first cluster and calculating the hash value of the second cluster use the same hash algorithm.
- the first node can generate a hash ring according to the hash value corresponding to each second cluster.
- FIG. 4a is a schematic structural diagram of a hash ring provided by an embodiment of the application.
- the data range of the hash ring is 0
- each large circle in the hash ring is a hash value calculated according to the identifier of the second cluster, and represents a second cluster.
- the second clusters are distributed in different positions on the hash ring according to their corresponding hash values.
- the hash value corresponding to the second cluster divides the entire hash ring into the same number of hash value intervals as the second cluster, and a hash value interval is a piece of hash value data on the hash ring range.
- the hash ring includes a first hash node and a second hash node, the first hash node corresponds to the target second cluster, and the first hash node is the second hash node on the hash ring.
- the target hash interval is the hash interval between the first hash node and the second hash node.
- each hash value interval on the hash ring corresponds to a second cluster.
- a search is started from the hash value interval along the first direction, and the first second cluster found is determined as the hash value interval.
- the second cluster corresponding to the Greek value interval.
- the first direction is the positive direction of the Hash ring, and it may be clockwise or counterclockwise, which is not specifically limited in the embodiment of the present application.
- the clockwise direction is selected as the first direction in FIG. 4a.
- the first node can determine Y hash values corresponding to X second clusters, where each second cluster corresponds to at least one hash value, X is a positive integer, and Y is a positive value greater than or equal to X. Integer.
- Y is greater than X, that is, there is a second cluster, and the second cluster corresponds to multiple hash values.
- FIG. 4b which is a schematic structural diagram of a hash ring provided by an embodiment of this application.
- the second cluster can be corresponding to multiple nodes on the hash ring, that is, virtual nodes can be introduced.
- Fig. 4c is a schematic structural diagram of a hash ring provided by an embodiment of the application. As shown in Fig. 4c, the target second cluster can correspond to two hash nodes on the hash ring.
- the second cluster can correspond to multiple nodes on the hash ring, and the distribution of the second cluster on the hash ring is not too sparse.
- the second cluster corresponding to multiple nodes on the hash ring by introducing virtual nodes refer to the implementation in the existing solution, which is not repeated here.
- the first node generates a hash ring based on Y hash values, where the hash ring includes Y hash nodes, and each second cluster corresponds to at least one hash node, and the Y hash nodes are
- the hash ring is divided into Y hash value intervals, each hash node corresponds to a hash value interval, that is, each hash node corresponds to a second cluster, and a second cluster can correspond to multiple hash values Hash node.
- the first node may periodically receive the idle/busy status broadcasted by other clusters, and periodically update the hash ring according to the idle/busy status broadcasted by other clusters.
- the first node may receive the hash table sent by the second cluster.
- the management node (for example, the second node) in the second cluster can receive the idle/busy status broadcasted by other clusters, and construct a hash ring based on the idle/busy status broadcasted by other clusters.
- the management node for example, the second node
- construct a hash ring based on the idle/busy status broadcasted by other clusters.
- the first node determines the corresponding target second cluster according to the hash value corresponding to the first cluster, where the hash value corresponding to the first cluster belongs to the target hash interval, and the target hash interval is in at least one hash value interval A hash value interval of, the target hash interval corresponds to the target second cluster.
- the first node determines the hash value corresponding to the first cluster and obtains the hash ring generated based on the hash value of the second cluster, it can obtain the hash value from the hash value corresponding to the first cluster. Determine the corresponding target second cluster in Xihuan.
- the first node can determine the hash value interval to which the hash value corresponding to the first cluster belongs on the hash ring Is the target hash interval, and the second cluster corresponding to the target hash interval is determined to be the target second cluster.
- Fig. 4d is a schematic structural diagram of a hash ring provided by an embodiment of the application.
- the hash ring includes: six hash nodes ⁇ hash node 1, hash node 3.
- Hash node 4, hash node 6, hash node 8, hash node 10 ⁇ where hash node 3 and hash node 8 correspond to the second cluster 1, and hash node 1 and hash node 4 correspond The second cluster 2, the hash node 6 and the hash node 10 correspond to the second cluster 3.
- the hash value interval between hash node 1 and hash node 3 corresponds to second cluster 1
- the hash value interval between hash node 3 and hash node 4 corresponds to second cluster 2
- hash node 4 The hash value interval between hash node 6 and hash node 6 corresponds to second cluster 3
- the hash value interval between hash node 6 and hash node 8 corresponds to second cluster 1
- the hash value interval between 10 corresponds to the second cluster 3
- the hash value interval between the hash node 10 and the hash node 1 corresponds to the second cluster 2.
- the idle cluster a includes two sub-clusters ⁇ first cluster a1, first cluster a2 ⁇
- the idle cluster b includes two sub-clusters ⁇ first cluster b1, first cluster b2 ⁇ .
- each first cluster ⁇ first cluster a1, first cluster a2, first cluster b1, first cluster b2 ⁇ on the hash ring is shown in Figure 4, where the first cluster a1 corresponds to the The Greek value belongs to the hash value interval between hash node 8 and hash node 6, and the hash value corresponding to the first cluster a2 belongs to the hash value interval between hash node 4 and hash node 10.
- the first cluster The hash value corresponding to b1 belongs to the hash value interval between hash node 1 and hash node 3, and the hash value corresponding to the first cluster b2 belongs to the hash value interval between hash node 4 and hash node 10. .
- the first node in the idle cluster a can determine that the first cluster a1 corresponds to the second cluster 6, and the first node in the idle cluster a can determine that the first cluster a2 corresponds to
- the first node in the idle cluster b may determine that the first cluster b1 corresponds to the second cluster 3
- the first node in the idle cluster b may determine that the first cluster b2 corresponds to the second cluster 4.
- the first node establishes an association relationship between a first cluster and a target second cluster, wherein the target second cluster that has established an association relationship with the first cluster is allowed to apply for resources from the first cluster.
- the first node may send the identification of the first cluster to the target second cluster.
- a resource allocation instruction may be sent to the management node (second node) in the target second cluster.
- the resource allocation instruction includes the identifier of the first cluster, and the resource allocation instruction may Indicates that the target second node is allowed to apply for resources from the first cluster.
- the first node may also send the resource idle amount of the first cluster to the target second cluster.
- the first node may also send the idle amount of CPU resources and the idle amount of memory resources of the first cluster to the target second cluster.
- the first node can determine the target second cluster corresponding to the first cluster through the distribution of the hash value corresponding to the first cluster on the hash ring (generated according to the hash value corresponding to the second cluster), and establish The relationship between the target second cluster and the first cluster is determined by the distribution of the hash value corresponding to the first cluster and the hash node corresponding to the second cluster on the hash ring based on the consistent hash algorithm.
- Idle clusters are only allowed to be seconded by fixed empty clusters. Therefore, when the target second cluster needs to second the idle resources of the first cluster, there is no need to randomly send a resource query request to the selected idle cluster, and proceed after receiving the return. Resource secondment can directly borrow resources from the first cluster, reducing the delay overhead of a round trip of information.
- the corresponding relationship of resource secondment is determined based on the corresponding relationship of the hash value of the first cluster on the hash ring generated based on the busy cluster, the corresponding relationship is unique, so the idle cluster can only be Since the corresponding busy cluster on the Greek ring seconded resources, there will be no secondment conflicts caused by multiple busy clusters concurrently seconding resources to the same idle cluster.
- the first node divides the multiple computing nodes of the idle cluster to obtain multiple sub-clusters, and then can use the sub-cluster as a unit to borrow resources for other busy clusters, so that the idle resources in the idle cluster can be relatively balanced Seconded.
- the second cluster (for example, the target second cluster) can be assigned to multiple nodes on the hash ring , That is, the introduction of virtual nodes, so that because the second cluster is too sparsely distributed on the hash ring, one second cluster will correspond to multiple first clusters, which increases the balance of resource allocation.
- the first node determines the hash value corresponding to the first cluster; the first node obtains the hash ring, the hash ring includes at least one hash value interval, and each hash value interval corresponds to a second cluster; The first node determines the corresponding target second cluster according to the hash value corresponding to the first cluster, where the hash value corresponding to the first cluster belongs to the target hash interval, and the target hash interval is one of at least one hash value interval The hash value interval, the target hash interval corresponds to the target second cluster; the first node establishes an association relationship between the first cluster and the target second cluster, wherein the target second cluster that has established an association relationship with the first cluster Is allowed to apply for resources from the first cluster.
- the first node can determine the target first cluster corresponding to the first cluster through the distribution of the hash value corresponding to the first cluster on the hash ring (generated according to the hash value corresponding to the second cluster)
- the second cluster is to establish the association relationship between the target second cluster and the first cluster, because the distribution of the hash value corresponding to the first cluster on the hash ring based on the consistent hash algorithm and the hash node corresponding to the second cluster is determined Yes, each idle cluster is only allowed to be seconded by a fixed empty cluster.
- the target second cluster when the target second cluster needs to second the idle resources of the first cluster, it does not need to randomly send a resource query request to the selected idle cluster, and return it after receiving After that, resources are seconded again, and resources can be directly seconded to the first cluster, which reduces the delay overhead of a round trip of information.
- the correspondence relationship of resource secondment is determined based on the correspondence relationship between the hash value of the first cluster on the hash ring generated based on the busy cluster, the correspondence relationship is unique, so the idle cluster can only be hashed
- the corresponding busy cluster borrows resources on the corresponding busy cluster, therefore, there will be no secondment conflicts caused by multiple busy clusters concurrently seconding resources to the same idle cluster.
- the first node may not determine the corresponding target second cluster based on the distribution of the hash value corresponding to the first cluster on the hash ring, but through random allocation. Or a sequential allocation method determines the corresponding target second cluster.
- the first node may randomly select a second cluster from the multiple second clusters in the distributed system as the target second cluster.
- At least one second cluster can be sorted, and multiple sub-clusters (including the first cluster) can be sequentially mounted to the corresponding second cluster in a preset order (ie, each sub-cluster and the second cluster are established Relationship). Then, the first node may also determine the corresponding target second cluster in the foregoing manner.
- the actual application may not be limited to the above implementation methods, as long as the distributed system determines a fixed resource allocation relationship (the first node establishes an association relationship with a certain target second cluster) when the resource secondment relationship is allocated, it can be implemented.
- the busy cluster performs resource secondment, it does not need to randomly send resource query requests to the selected idle cluster, and after receiving the return, the resource secondment will be performed, and resources can be directly seconded to the first cluster, reducing the delay of one information round trip Overhead.
- the correspondence relationship of resource secondment is determined based on the correspondence relationship between the hash value of the first cluster on the hash ring generated based on the busy cluster, the correspondence relationship is unique, so the idle cluster can only be hashed
- the corresponding busy cluster borrows resources on the corresponding busy cluster, therefore, there will be no secondment conflicts caused by multiple busy clusters concurrently seconding resources to the same idle cluster.
- FIG. 5 is a schematic diagram of an embodiment of a resource secondment method provided by an embodiment of this application.
- the resource secondment method provided by this application includes:
- a second node determines a first cluster having an association relationship with a target second cluster, where the second node belongs to the target second cluster, and the target second cluster corresponds to the target hash in the hash ring Value interval, the hash value corresponding to the first cluster belongs to the target hash value interval.
- the second node belongs to the target second cluster, and the target second cluster is a busy cluster.
- the second node may receive the resource allocation instruction sent by the first node, the resource allocation instruction includes the identifier of the first cluster, and the resource allocation instruction may indicate that the second node can second the idle resources of the first cluster. How the node sends the identifier of the first cluster to the target second cluster can refer to the foregoing embodiment, which will not be repeated here.
- the second node may receive the identifiers of multiple sub-clusters, that is, there are multiple clusters that have an association relationship with the target second cluster.
- the second node may determine that one of the multiple clusters having an association relationship with the target second cluster is the first cluster.
- the second node may also receive the resource idle amount of each of the multiple sub-clusters.
- the second node receives task data.
- the second node may receive task data.
- the second node after the second node receives the task data, it can determine the resource demand of the received task data, and determine the resources of the idle nodes in the busy cluster (target second cluster). Idle amount, if the resource idle amount of the idle node in the busy cluster to which it belongs is greater than or equal to the resource requirement of the task data, it is equivalent to that the second node can determine that the local cluster has sufficient resource idle amount to process the task data. If the resource idle amount of the idle node in the busy cluster to which it belongs is less than the resource demand amount of the task data, it is equivalent to that the second node can determine that the local cluster does not have enough resource idle amount to process the task data.
- the second node can determine that the local cluster has enough free resources to process the task data. If the CPU resource idle amount of the idle node in the busy cluster to which it belongs is less than the CPU resource demand of task data, and the memory resource idle amount of the idle node in the busy cluster to which it belongs is less than the memory resource demand of task data, it is equivalent to the second The node can determine that the local cluster does not have enough free resources to process the task data.
- the second node sends a first resource secondment request to the first node, where the first secondment request is used to instruct the first node to allocate the task data to the first cluster for processing.
- the second node determines that the local cluster does not have enough free resources to process the task data, it needs to borrow resources from other clusters to execute the task data.
- the second node may send a first resource secondment request to the first node.
- the first secondment request may include task data and the identifier of the first cluster. Accordingly, after the first node receives the first resource secondment request , The task data included in it can be assigned to the first cluster for processing.
- the second node may receive the identifiers of the multiple sub-clusters and the resource idle amount of the multiple sub-clusters. At this time, the second node needs to determine a cluster from among them as the object of resource loaning. Next, discuss the second node How to determine the first cluster to be the target of resource secondment from multiple sub-clusters.
- the second node may maintain a mapping table in which the identities of multiple sub-clusters and the corresponding free resources of multiple sub-clusters are stored in the mapping table.
- the second node may look up the free resources of multiple sub-clusters in the mapping table.
- the cluster set that is greater than or equal to the resource demand of the task data obtains the sub-cluster set ⁇ slices 1, slices 2, ..., slices n ⁇ that meets the resource demand, where slices n represents the identifier of the nth sub-cluster.
- the second node After the second node obtains the sub-cluster set ⁇ slices 1, slices 2, ising, slices n ⁇ , it can prioritize multiple sub-clusters in the sub-cluster set, where the index of priority ranking is the resource of the sub-cluster The closeness between the idle amount and the resource demand of the task data, the closer the corresponding sub-cluster priority is, the second node can select the sub-cluster with the highest priority to initiate the first secondment request.
- the second node may maintain the following mapping table:
- the second node receives the task data and determines that the CPU resource demand corresponding to the task data is 0.6 and the memory resource demand is 0.65.
- the second node may search the mapping table for a plurality of cluster sets in the first cluster where the resource idle amount is greater than or equal to the resource demand of the task data, and obtain the first cluster set ⁇ slices6, slices7 ⁇ that meets the resource demand.
- the second node can determine the first cluster that is closest to the resource demand of the task data according to the following formula:
- ⁇ represents the weight parameter of the CPU
- ⁇ represents the weight parameter of the memory
- ⁇ is 0.6 and ⁇ is 0.4.
- the second node can determine that the resource idle amount of the first cluster corresponding to slices 6 is closest to the resource demand of the task data, and initiate a first secondment request to the first cluster corresponding to slices 6.
- the second node determines that among the resource idle amounts of the multiple clusters having an association relationship with the target second cluster, the cluster corresponding to the resource idle amount with the smallest difference in the resource demand of the task data is
- the first cluster improves resource utilization during resource secondment.
- the second node may determine that the first cluster is in a resource loanable state based on receiving the identifier of the first cluster sent by the first node.
- the second node may determine that the first cluster is in a resource non-secondable state based on sending a resource secondment request to the first node.
- the second node after the second node sends a resource secondment request to the first node, it is equivalent to occupying the idle resources of the first cluster, and it can be determined that the first cluster is in a resource unavailable state.
- the second node may mark the resource loan status of the first cluster as the resource unavailable status in the mapping table.
- the first node may also determine that the first cluster is in a resource non-secondable state, that is, determine that the first cluster cannot provide available resources for other busy clusters, thereby ensuring resource locking and realizing conflict-free scheduling of resources across clusters.
- the first cluster after the first cluster has processed the task data, it may return the processing result to the first node, and the first node sends the processing result to the second node.
- the second node determines the first cluster that has an association relationship with the target second cluster, where the second node belongs to the target second cluster, and the target second cluster corresponds to the hash ring
- the target hash value interval of the first cluster the hash value corresponding to the first cluster belongs to the target hash value interval
- the second node receives task data
- the second node sends a first resource secondment request to the first node
- the first secondment request is used to instruct the first node to allocate the task data to the first cluster for processing.
- Distribution to determine the target second cluster corresponding to the first cluster, and indicate that the target second cluster can second the idle resources of the first cluster, because the hash value corresponding to the first cluster on the hash ring based on the consistent hash algorithm
- the distribution of hash nodes corresponding to the second cluster is determined and relatively balanced. Therefore, when the target second cluster needs to second the idle resources of the first cluster, there is no need to randomly send resource query requests to the selected idle cluster, and After receiving the return, the resource secondment is performed, but the first cluster that needs to second the resource is directly determined, and the first resource secondment request is sent to the first node, which reduces the delay overhead of a round trip of information.
- the correspondence relationship of resource secondment is determined based on the correspondence relationship between the hash value of the first cluster on the hash ring generated based on the busy cluster, the correspondence relationship is unique, so the idle cluster can only be hashed
- the corresponding busy cluster borrows resources on the corresponding busy cluster, therefore, there will be no secondment conflicts caused by multiple busy clusters concurrently seconding resources to the same idle cluster.
- FIG. 6 is a schematic diagram of an embodiment of a resource secondment method provided by an embodiment of the application.
- the resource secondment method provided by the present application includes:
- the second node determines a first cluster that has an association relationship with a target second cluster, where the second node belongs to the target second cluster, and the target second cluster corresponds to the target hash in the hash ring Value interval, the hash value corresponding to the first cluster belongs to the target hash value interval.
- step 601 For the specific description of step 601, refer to the specific description of step 501 in the embodiment corresponding to FIG. 5, which will not be repeated here.
- the second node receives the resource demand of the task data sent by the third node.
- the third node after the third node receives the task data, it can determine the resource demand of the received task data, and determine the resource idle amount of the idle node in the busy cluster to which it belongs.
- the resource idle amount of the node is less than the resource requirement of the task data, that is, the third node determines that the local cluster does not have enough idle resources to process the task data.
- the third node can traverse the mapping table storing the identifiers of multiple sub-clusters and the corresponding resource idle amount, and search the mapping table for the cluster set with the resource idle amount of the multiple sub-clusters greater than or equal to the resource demand of the task data, If the third node determines that the resource idle amount of each sub-cluster in the multiple sub-clusters is less than the resource demand of the task data, or determines that the multiple sub-clusters are in a resource unavailable state, the third node needs to borrow resources from other busy clusters.
- the third node may determine the adjacent subsequent node of the hash node corresponding to the third node from the maintained Hash ring along the first direction, and the adjacent subsequent node corresponds to the second cluster.
- the third node may send the resource demand of task data to the management node (second node) of the second cluster.
- the third node may send the resource demand of task data to the second node.
- the third node may determine multiple subsequent nodes of the hash node corresponding to the third node from the maintained hash ring along the first direction, and the multiple subsequent nodes correspond to multiple The second cluster.
- the third node may send the resource demand of task data to multiple management nodes (second nodes) of the second cluster.
- the second node can receive the resource demand of the task data sent by the third node.
- the second node Based on the resource idle amount of the first cluster being greater than or equal to the resource requirement, the second node sends a third resource loan request to the third node, where the third resource loan request is used to indicate that the third node is allowed Apply for resources from the first cluster.
- the second node after the second node receives the resource demand, it can look up the mapping table it maintains, and determine the first cluster with the resource free amount greater than or equal to the resource demand, and send a third resource secondment to the third node Request, the third resource secondment request includes an identifier of the first cluster, and the third resource secondment request is used to indicate that the third node is allowed to apply for resources from the first cluster.
- the second node may determine that the resource idle amount of the multiple sub-clusters is greater than or equal to the resource demand, and the second node may send the determined identifiers of the multiple sub-clusters to the third node.
- a cluster is one of multiple sub-clusters.
- the second node may determine that the resource idle amount of the multiple sub-clusters is greater than or equal to the resource demand, and randomly select a part of the sub-clusters from the determined multiple sub-clusters, and send to the third node Part of the sub-cluster ID.
- the second node may receive a second resource loan request sent by the third node, where the second resource loan request includes the task data, and the second loan request is used to indicate The second node allocates the task data to the first cluster for processing.
- the third node after the third node receives the identifier of the first cluster sent by the second node, it is equivalent to acquiring the identifier of the first cluster that can perform resource secondment from the second node.
- the third node may receive the identities of multiple sub-clusters sent by multiple second nodes, or the third node may receive the identities of multiple sub-clusters sent by one second node. , It is necessary to determine one of the multiple sub-clusters as the resource secondment object. Regarding how the third node determines one of the multiple first clusters as the resource secondment object, refer to the above-mentioned embodiment, how the second node The description of determining the first cluster among the multiple sub-clusters as the resource secondment object will not be repeated here.
- the second node may receive a second resource secondment request sent by the third node, where the second resource secondment request includes the task data and The identifier of the first cluster, and the second secondment request is used to instruct the second node to allocate the task data to the first cluster for processing.
- the second node may send task data and the identification of the first cluster to the first node.
- the first node may allocate the task data to the first cluster for processing.
- the third node may not send a second resource loan request to the second node to indicate the The second node allocates the task data to the first cluster for processing, but directly sends a first resource secondment request to the first node, and the first secondment request is used to instruct the first node to transfer the task data Allocating to the first cluster processing reduces the forwarding overhead of one step of information.
- FIG. 7 is a schematic structural diagram of a first management node 700 according to an embodiment of the application. As shown in FIG. 7, the first management node 700 includes:
- the processing module 701 is configured to determine the hash value corresponding to the first cluster; obtain a hash ring, where the hash ring includes at least one hash value interval, and each hash value interval corresponds to a second cluster; A hash value corresponding to a cluster determines a corresponding target second cluster, wherein the hash value corresponding to the first cluster belongs to a target hash interval, and the target hash interval is one of the at least one hash value interval A hash value interval, and the target hash interval corresponds to the target second cluster;
- the transceiver module 702 is configured to establish an association relationship between a first cluster and a target second cluster, wherein the target second cluster that has established an association relationship with the first cluster is allowed to apply for resources from the first cluster.
- the hash ring includes a first hash node and a second hash node
- the first hash node corresponds to the target second cluster
- the first hash node A node is an adjacent successor node of the second hash node on the hash ring
- the target hash interval is the hash value of the first hash node and the hash value of the second hash node The hash interval between values.
- the processing module 701 is further configured to divide an idle cluster including multiple computing nodes to obtain multiple sub-clusters, and the first cluster is one of the multiple sub-clusters One.
- the multiple sub-clusters include a third sub-cluster and a fourth sub-cluster
- the third sub-cluster is the sub-cluster with the largest amount of free resources among the multiple sub-clusters.
- the fourth sub-cluster is the cluster with the smallest amount of idle resources among the plurality of sub-clusters, and the absolute value of the difference between the idle amount of resources of the third sub-cluster and the idle amount of resources of the fourth sub-cluster is smaller than the first threshold.
- the absolute value of the difference between the amount of free resources of each sub-cluster of the plurality of sub-clusters and the amount of free resources of a preset is less than or equal to a second threshold, and the preset resource is idle
- the amount is related to the historical resource request amount.
- the transceiver module 702 is further configured to:
- the hash ring includes Y hash nodes, each second cluster corresponds to at least one hash node, and the corresponding hash values of the Y hash nodes are sum
- the hash value corresponding to the first cluster is generated according to the same hash algorithm, and the Y is a positive integer.
- the processing module 701 is further configured to determine Y hash values corresponding to X second clusters, where each second cluster corresponds to at least one hash value, and X is a positive integer, and the Y is a positive integer greater than or equal to X; the hash ring is generated according to the Y hash values, wherein the hash ring includes Y hash nodes, and each second cluster Corresponding to at least one hash node, the Y hash nodes divide the hash ring into Y hash value intervals, and each hash node corresponds to a hash value interval.
- the transceiver module 702 is further configured to receive the hash ring sent by the second cluster.
- the transceiver module 702 is further configured to send the resource idle amount of the first cluster to the target second cluster.
- FIG. 8 is a schematic structural diagram of a second management node 800 provided by an embodiment of the application. As shown in FIG. 8, the second management node 800 includes:
- the processing module 801 is configured to determine a first cluster having an association relationship with a target second cluster, where the second node belongs to the target second cluster, and the target second cluster corresponds to the target hash ring. A rare value interval, the hash value corresponding to the first cluster belongs to the target hash value interval;
- the transceiver module 802 is configured to receive task data; and send a first resource secondment request to the first node, where the first secondment request is used to instruct the first node to allocate the task data to the first cluster for processing.
- the processing module 801 is further configured to send a resource secondment request to the first node based on the transceiver module to determine that the first cluster is in a resource non-secondable state.
- the processing module 801 is specifically configured to determine multiple clusters that have an association relationship with the target second cluster.
- One of the clusters is the first cluster.
- the processing module 801 is specifically configured to determine the resource idle amount of the multiple clusters associated with the target second cluster, and the resource demand amount of the task data The cluster corresponding to the resource idle amount with the smallest difference is the first cluster.
- the transceiver module 802 is further configured to receive the resource demand of the task data sent by the third node, and based on the resource idle amount of the first cluster being greater than or equal to The resource demand, sending the identifier of the first cluster and the resource idle amount of the first cluster to the third node.
- the transceiver module 802 is specifically configured to receive a second resource loan request sent by the third node, where the second resource loan request includes the task data, and the second resource loan The second secondment request is used to instruct the second node to allocate the task data to the first cluster for processing.
- FIG. 8 is a schematic structural diagram of a second management node 800 provided by an embodiment of the application. As shown in FIG. 8, the second management node 800 includes:
- the transceiver module 802 is configured to receive the resource demand of task data sent by the third node;
- the processing module 801 is configured to determine a first cluster having an association relationship with a target second cluster, where the second node belongs to the target second cluster, and the target second cluster corresponds to the target hash ring. A rare value interval, the hash value corresponding to the first cluster belongs to the target hash value interval;
- the transceiver module 802 is further configured to send a third resource secondment request to the third node based on that the resource idle amount of the first cluster is greater than or equal to the resource demand, and the third resource secondment request is used for Indicate that the third node is allowed to apply for resources from the first cluster.
- the processing module is specifically configured to determine multiple clusters that have an association relationship with the target second cluster One of the clusters is the first cluster.
- FIG. 9 is a schematic structural diagram of a third management node 900 according to an embodiment of the application. As shown in FIG. 9, the third management node 900 includes:
- the transceiver module 901 is configured to receive task data, send the resource demand of the task data to a second node, and receive a third resource secondment request sent by the second node, where the third resource secondment request is used to indicate the
- the third node is allowed to apply for resources from the first cluster, where the second node belongs to the target second cluster, the target second cluster corresponds to the target hash value interval in the hash ring, and the first cluster corresponds to The hash value of which belongs to the target hash value interval, and the resource idle amount of the first cluster is greater than or equal to the resource demand, a first resource secondment request is sent to the first node, and the first secondment request is used Instructing the first node to allocate the task data to the first cluster for processing.
- the transceiver module 901 is specifically configured to send resource requirements of the task data to multiple nodes, and the second node is one of the multiple nodes, and A third resource secondment request sent by the multiple nodes, where the third resource secondment request is used to indicate that the third node is allowed to apply for resources from multiple sub-clusters, and the first cluster is one of the multiple sub-clusters One.
- the third management node 900 further includes:
- the processing module 902 is configured to determine that, among the resource idle amounts of the multiple sub-clusters, the sub-cluster corresponding to the resource idle amount with the smallest difference in the resource demand of the task data is the first cluster.
- Figure 10 illustrates a system example of a management node applicable to an embodiment of the present invention, where the management node may be any one of the first management node, the second management node, and the third management node described in the above embodiment .
- the functions of each logic module of the management node in the previous embodiment can be realized.
- This embodiment is only an example applicable to the present invention, and does not attempt to suggest any restriction on the function and structure of the management node provided by the present invention.
- the embodiment of the present invention uses a general computer system environment as an example to describe the management node. As we all know, it is applicable to the management node and other hardware architectures can also be used to achieve similar functions. Including but not limited to, personal computers, service computers, multi-processor systems, microprocessor-based systems, programmable consumer appliances, network PCs, small computers, large computers, and distributed computing environments including any of the above systems or equipment ,and many more.
- the exemplified system for implementing the present invention includes a general-purpose computing device in the form of a management node 1000.
- the management node described in this embodiment may be the execution subject of the embodiment of the present invention described in the foregoing scenario and architecture.
- it can be a master node, a management node, or any node in a decentralized architecture.
- the components of the management node 1000 may include, but are not limited to, a processing unit 1020, a system memory 1030, and a system bus 1010.
- the system bus couples various system elements including a system memory with the processing unit 1020.
- the system bus 1010 may be any one of several types of bus structures. These buses may include a memory bus or a memory controller, a peripheral bus, and a local bus using one bus structure.
- the bus structure may include an industry standard architecture (ISA) bus, a microchannel architecture (MCA) bus, an extended ISA (EISA) bus, a video electronics standards association (VESA) local bus, and a peripheral device interconnect (PCI) bus.
- ISA industry standard architecture
- MCA microchannel architecture
- EISA extended ISA
- VESA video electronics standards association
- PCI peripheral device interconnect
- the management node 1000 generally includes a variety of management node-readable media.
- the management node readable medium may be any medium that can be effectively accessed by the management node 1000, and includes volatile or nonvolatile media, and detachable or non-detachable media.
- the management node readable medium may include a management node storage medium and a communication medium. It is implemented by any method or technology that manages the readable instructions, data structures, program modules or other data information of the management node.
- the storage medium of the management node includes, but is not limited to, RAM, ROM, EEPROM, flash memory or other storage technologies, or hard disk storage, solid state hard disk storage, optical disk storage, disk cartridges, disk storage or other storage devices, or any other
- Communication media generally include embedded computer-readable instructions, data structures, program modules, or other data in modular data signals (for example, carrier waves or other transmission mechanisms), and also include any information transfer media.
- modular data signal refers to a signal that has one or more signal characteristic groups or is changed by encoding information in the signal.
- communication media include wired media such as wired networks or direct wired connections, and wireless media such as acoustic, RF infrared, and other wireless media. Any combination of the above should also be included in the scope of the management node readable medium.
- the system memory 1030 includes a management node storage medium, which can be volatile and non-volatile memory, for example, read only memory (ROM) 1031 and random access memory (RAM) 1032.
- the basic input/output system 1033 (BIOS) is generally stored in the ROM 1031 and contains basic routines, which facilitates the transmission of information between various components in the management node 1010.
- the RAM 1032 generally contains data and/or program modules, which can be accessed and/or operated immediately by the processing unit 1020.
- FIG. 10 illustrates an operating system 1034, application programs 1035, other program modules 1036, and program data 1037.
- the management node 1000 may also include other detachable/non-detachable, volatile/non-volatile management node storage media.
- Figure 10 illustrates the hard disk storage 1041, which can be a non-removable and non-volatile readable and writable magnetic medium; the external storage 1051, which can be various types of removable and non-volatile external storage, such as Optical disk, magnetic disk, flash memory or mobile hard disk, etc.; the hard disk memory 1041 is generally connected to the system bus 1010 through a non-removable storage interface (for example, interface 1040), and the external memory is generally connected to the system bus through a removable storage interface (for example, the interface 1060) 1010 is connected.
- a non-removable storage interface for example, interface 1040
- the external memory is generally connected to the system bus through a removable storage interface (for example, the interface 1060) 1010 is connected.
- the drive discussed above and shown in FIG. 10 and its related management node storage medium provide storage of management node readable instructions, data structures, program modules, and other data of the management node 1000.
- the hard disk drive 1041 is illustrated for storing the operating system 1042, application programs 1043, other application programs 1044, and program data 1045. It should be noted that these components may be the same as or different from the operating system 1034, application programs 1035, other program modules 1036, and program data 1037.
- the method in the foregoing embodiment or the function of the logic module in the previous embodiment can be stored in the management node storage medium through code or readable instructions, and the processing unit 1020 can read the code or The instructions are readable to perform the method.
- the user can input commands and information through the management node 1000 through various input devices 1061.
- Various input devices are often connected to the processing unit 1020 through the user input interface 1060, which is coupled to the system bus, but can also be connected through other interfaces and bus structures, such as parallel interfaces or universal serial Interface (USB).
- the display device 1091 may also be connected to the system bus 1010 through an interface (for example, a video interface 1090).
- the computing device 1000 may also include various peripheral output devices 1020, and the output devices may be connected through the output interface 10100 or the like.
- the management node 1000 may be logically connected to one or more computing devices, for example, a remote computer 1071.
- the remote computing nodes include management nodes, computing nodes, servers, routers, network PCs, equivalent devices or other general network nodes, and generally include many or all of the above-discussed elements related to the management node 1000.
- the remote computing node may be a slave node, a computing node, or other management nodes.
- the logical connection illustrated in FIG. 10 includes a local area network (LAN) and a wide area network (WAN), and may also include other networks. Through logical connection, the management node can realize the interaction with other subjects in the present invention with other nodes.
- the task information and data can be transmitted through the logical link with the user to obtain the user's task data; the logical link with the computing node can be used for the transmission of resource data and the transmission of task allocation commands, so as to realize the resource information of each node The acquisition and distribution of task data.
- FIG. 11 is a schematic structural diagram of a cluster 1100 provided by an embodiment of the application.
- the cluster 1100 includes a plurality of computing nodes 1101, and the computing nodes 1101 provide task data.
- the resources required to execute the task data, and the cluster 1100 further includes: the first management node 700 described in the embodiment corresponding to FIG. 7.
- FIG. 12 is a schematic structural diagram of a cluster provided by an embodiment of the application.
- the cluster 1200 includes a plurality of computing nodes 1201, and the computing nodes 1201 provide data for tasks.
- the resources required to execute the task data, and the cluster 1200 further includes: the second management node 800 described in the embodiment corresponding to FIG. 8.
- FIG. 13 is a schematic structural diagram of a cluster provided by an embodiment of the application.
- the cluster 1300 includes a plurality of computing nodes 1301, and the computing nodes 1301 provide task data.
- the required resources to execute the task data, and the cluster 1300 further includes: the third management node 900 described in the embodiment corresponding to FIG. 9.
- FIG. 14 is a schematic structural diagram of a distributed system 1400 provided by an embodiment of the application.
- the distributed system 1400 includes the cluster 1100 described in the embodiment corresponding to FIG. And the cluster 1200 described in the embodiment corresponding to FIG. 12.
- FIG. 15 is a schematic structural diagram of a distributed system provided by an embodiment of the application.
- the distributed system 1500 includes the cluster 1100, which is described in the embodiment corresponding to FIG.
- the computer program product includes one or more computer instructions.
- the computer may be a general-purpose computer, a special-purpose computer, a computer network, or other programmable devices.
- the computer instructions may be stored in a computer-readable storage medium or transmitted from one computer-readable storage medium to another computer-readable storage medium.
- the computer instructions may be transmitted from a website, computer, server, or data center. Transmission to another website, computer, server, or data center via wired (for example, coaxial cable, optical fiber, Digital Subscriber Line (DSL)) or wireless (for example, infrared, wireless, microwave, etc.).
- wired for example, coaxial cable, optical fiber, Digital Subscriber Line (DSL)
- wireless for example, infrared, wireless, microwave, etc.
- the computer-readable storage medium may be any available medium that can be stored by a computer or a data storage device such as a server or data center integrated with one or more available media.
- the usable medium may be a magnetic medium (for example, a floppy disk, a hard disk, a magnetic tape), an optical medium (for example, a DVD), or a semiconductor medium (for example, a solid state disk (SSD)).
- the disclosed system, device, and method may be implemented in other ways.
- the device embodiments described above are only illustrative.
- the division of the units is only a logical function division, and there may be other divisions in actual implementation, for example, multiple units or components can be combined or It can be integrated into another system, or some features can be ignored or not implemented.
- the displayed or discussed mutual coupling or direct coupling or communication connection may be indirect coupling or communication connection through some interfaces, devices or units, and may be in electrical, mechanical or other forms.
- the units described as separate components may or may not be physically separated, and the components displayed as units may or may not be physical units, that is, they may be located in one place, or they may be distributed on multiple network units. Some or all of the units may be selected according to actual needs to achieve the objectives of the solutions of the embodiments.
- each unit in each embodiment of the present application may be integrated into one processing unit, or each unit may exist alone physically, or two or more units may be integrated into one unit.
- the above-mentioned integrated unit can be implemented in the form of hardware or software functional unit.
- the integrated unit is implemented in the form of a software functional unit and sold or used as an independent product, it can be stored in a computer readable storage medium.
- the technical solution of this application essentially or the part that contributes to the existing technology or all or part of the technical solution can be embodied in the form of a software product, and the computer software product is stored in a storage medium , Including several instructions to make a computer device (which can be a personal computer, a server, or a network device, etc.) execute all or part of the steps of the method described in each embodiment of the present application.
- the aforementioned storage media include: U disk, mobile hard disk, read-only memory (ROM, Read-Only Memory), random access memory (RAM, Random Access Memory), magnetic disk or optical disk and other media that can store program code .
Landscapes
- Engineering & Computer Science (AREA)
- Software Systems (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Mathematical Physics (AREA)
- Mobile Radio Communication Systems (AREA)
- Data Exchanges In Wide-Area Networks (AREA)
Abstract
一种资源分配方法,不会出现由于多个忙集群向同一个空闲集群并发借调资源而导致的借调冲突。其中,资源分配方法包括:第一节点确定第一集群对应的哈希值;第一节点获取哈希环;第一节点建立第一集群和目标第二集群的关联关系(304),其中,与第一集群建立了关联关系的目标第二集群被允许从第一集群申请资源。
Description
本申请要求于2019年07月31日提交中国国家知识产权局、申请号为201910704756.7、发明名称为“一种资源分配方法和资源借调方法”的中国专利申请的优先权,其全部内容通过引用结合在本申请中。
本申请涉及分布式系统领域,尤其涉及一种资源分配方法和资源借调方法。
随着人工智能(artificial intelligence,AI)和物联网(internet of things,IoT)的发展,许多新兴计算密集型和延迟敏感型终端应用,如虚拟现实(virtual reality,VR)、增强现实(augmented reality,AR)以及高清视频图片处理等正在迅速兴起,低延时、高带宽和强计算等应用需求日益增长。云计算技术受网络链路容量限制等因素影响,容易导致数据传输速率过慢以及响应延迟过高等问题,难以满足应用服务需求。利用靠近数据源的边缘设备进行计算以提高服务响应性能逐渐成为一种趋势。然而单个边缘设备算力小,仅使用单个边缘设备执行任务难以胜任大规模任务需求。因此,将多边缘设备的计算能力加以组合使用,通过多边缘设备资源共享互助,协同完成复杂任务的数据处理,从而可以有效保障服务质量。
设备间的资源互助场景主要分为两类,一类是层次化的异构设备的资源互助,如边缘设备和边缘服务器、中央云处理器之间不同运算能力设备的协同;另一类是同层设备间的资源协同,即当边缘设备资源不足时,可以向其他边缘设备借调资源。
现有技术中,当资源不足的忙集群需要向其他空闲集群借调资源时,需要忙集群中的主节点向随机选择的空闲集群发送资源查询请求,并在接收到返回后,再进行资源借调,在多个忙集群向同一个空闲集群并发借调资源时,会出现借调冲突的情况。
发明内容
本申请实施例提供了一种资源分配方法和资源借调方法,不会出现由于多个忙集群向同一个空闲集群并发借调资源而导致的借调冲突。
第一方面,本申请提供了一种资源分配方法,包括:
第一节点确定第一集群对应的哈希值;所述第一节点获取哈希环,所述哈希环包括至少一个哈希值区间,每个哈希值区间对应一个第二集群;所述第一节点根据所述第一集群对应的哈希值确定对应的目标第二集群,其中,所述第一集群对应的哈希值属于目标哈希区间,所述目标哈希区间为所述至少一个哈希值区间中的一个哈希值区间,所述目标哈希区间对应所述目标第二集群;所述第一节点建立第一集群和目标第二集群的关联关系,其中,与所述第一集群建立了关联关系的所述目标第二集群被允许从所述第一集群申请资源。且,由于资源借调的对应关系是基于将第一集群的哈希值在基于第二集群生成的哈希环上的对应关系确定的,该对应关系是唯一的,因此第一集群仅能被哈希环上对应的第二集群 借调资源,因此,不会出现由于多个集群向同一个集群并发借调资源而导致的借调冲突。
这样,第一节点可以通过第一集群对应的哈希值在哈希环(根据第二集群对应的哈希值生成的)上的分布,来确定第一集群对应的目标第二集群,建立目标第二集群和第一集群的关联关系,由于基于一致性哈希算法的哈希环上的第一集群对应的哈希值和第二集群对应的哈希节点的分布是确定的,每个集群只允许被固定的集群借调,因此,当目标第二集群需要借调第一集群的空闲资源时,不需要随机向某个集群发送资源查询请求,并在接收到返回后,再进行资源借调,可以直接向特定的第一集群借调资源,减少了一次信息往返的时延开销。
在第一方面的一种可选设计中,第一集群为包含多个空闲节点的空闲集群,第二集群为包含多个忙节点的忙集群,其中空闲节点和忙节点是根据节点的负载来区分的,比如负载高于特定阈值的节点为忙节点,负载不高于特定阈值的节点为空闲节点。
在第一方面的一种可选设计中,第一集群为包含多个胖节点的胖集群,第二集群为包含多个瘦节点的瘦集群,其中胖节点和瘦节点是根据节点具有的资源或能力来区分的,比如资源受限或能力偏弱的节点为瘦节点,资源丰富,处理能力强节点为胖节点。在第一方面的一种可选设计中,所述哈希环包括第一哈希节点和第二哈希节点,所述第一哈希节点对应所述目标第二集群,所述第一哈希节点为所述哈希环上所述第二哈希节点的相邻后继节点,所述目标哈希区间为所述第一哈希节点的哈希值与所述第二哈希节点的哈希值之间的哈希区间。
在第一方面的一种可选设计中,所述方法还包括:所述第一节点对包括多个计算节点的空闲集群进行划分,得到多个子集群,所述第一集群为所述多个子集群中的一个。
在第一方面的一种可选设计中,所述多个子集群包括第三子集群和第四子集群,所述第三子集群为所述多个子集群中资源空闲量最大的子集群,所述第四子集群为所述多个子集群中资源空闲量最小的集群,所述第三子集群的资源空闲量与所述第四子集群的资源空闲量的差值的绝对值小于第一阈值。这样,第一节点可以对空闲集群的多个计算节点进行划分,以使得划分后得到的多个子集群中的各个第一集群之间的资源空闲量的差异不会过大。
在第一方面的一种可选设计中,所述多个子集群中的每个子集群的资源空闲量与预设资源空闲量的差值的绝对值小于或等于第二阈值,所述预设资源空闲量与历史资源请求量相关。这样,第一节点基于历史资源请求在对空闲集群的多个计算节点进行划分,使得划分后的每个子集群的空闲资源量接近于历史资源请求量。
在第一方面的一种可选设计中,所述多个子集群的数量与所述第二集群的数量小于第三阈值。
在第一方面的一种可选设计中,所述方法还包括:所述第一节点接收所述目标第二集群发送的第一资源借调请求,所述第一资源借调请求包括任务数据和第一集群的标识;所述第一节点根据所述第一集群的标识向所述第一集群发送所述任务数据。
在第一方面的一种可选设计中,所述方法还包括:所述第一节点接收所述目标第二集群发送的第一资源借调请求,所述第一资源借调请求包括任务数据;所述第一节点向所述 第一集群发送所述任务数据。
在第一方面的一种可选设计中,所述第一节点向所述第一集群发送所述任务数据,包括:第一节点基于所述第一集群和目标第二集群的关联关系向所述第一集群发送所述任务数据。
在第一方面的一种可选设计中,所述哈希环包括Y个哈希节点,每个第二集群对应至少一个哈希节点,且所述Y个哈希节点的对应的哈希值和所述第一集群对应的哈希值为根据相同的哈希算法生成的,所述Y为正整数。这样,哈希环上的哈希节点的对应的哈希值和所述第一集群对应的哈希值基于相同的哈希算法生成,使得不会出现第一集群对应的哈希值与哈希环上的哈希节点重合的情况。
在第一方面的一种可选设计中,所述方法还包括:所述第一节点确定X个第二集群对应的Y个哈希值,其中,每个第二集群对应至少一个哈希值,所述X正整数,所述Y为大于或等于X的正整数;所述第一节点根据所述Y个哈希值生成所述哈希环,其中,所述哈希环包括Y个哈希节点,每个第二集群对应至少一个哈希节点,所述Y个哈希节点将所述哈希环划分为Y个哈希值区间,每个哈希节点对应一个哈希值区间。这样,第一节点可以自己生成哈希环。
在第一方面的一种可选设计中,所述方法还包括:所述第一节点接收所述第二集群发送的所述哈希环。
在第一方面的一种可选设计中,所述方法还包括:所述第一节点向所述目标第二集群发送所述第一集群的资源空闲量。
第二方面,本申请提供了一种资源借调方法,所述方法包括:第二节点确定与目标第二集群具有关联关系的第一集群,其中,所述第二节点属于所述目标第二集群,所述目标第二集群对应于哈希环中的目标哈希值区间,所述第一集群对应的哈希值属于所述目标哈希值区间;所述第二节点接收任务数据;所述第二节点向第一节点发送第一资源借调请求,所述第一借调请求用于指示所述第一节点将所述任务数据分配给所述第一集群处理。
这样,由于基于一致性哈希算法的哈希环上的第一集群对应的哈希值和第二集群对应的哈希节点的分布是确定的,每个空闲集群只允许被固定的空集群借调,因此,当目标第二集群需要借调第一集群的空闲资源时,不需要随机向选择的空闲集群发送资源查询请求,并在接收到返回后,再进行资源借调,可以直接向第一集群借调资源,减少了一次信息往返的时延开销。
在第二方面的一种可选设计中,所述方法还包括:所述第二节点基于向第一节点发送所述第一资源借调请求,确定所述第一集群处于资源不可借调状态。这样,第二节点向第一节点发送第一资源借调请求之后,相当于已经占用了第一集群的空闲资源,则可以确定第一集群处于资源不可借调状态。可选地,第二节点可以在映射表中标注第一集群的资源借调状态为资源不可借状态。相应的,第一节点也可以确定第一集群处于资源不可借调状态,即确定第一集群不能为其他忙集群提供可用资源,从而确保了资源锁定,实现了跨集群资源的无冲突调度。
在第二方面的一种可选设计中,与所述目标第二集群具有关联关系的集群有多个,所 述第二节点确定与目标第二集群具有关联关系的第一集群,包括:所述第二节点确定与所述目标第二集群具有关联关系的多个集群中的一个集群为第一集群。
在第二方面的一种可选设计中,所述第二节点确定与所述目标第二集群具有关联关系的多个集群中的一个集群为第一集群,包括:所述第二节点确定与所述目标第二集群具有关联关系的多个集群的资源空闲量中,与所述任务数据的资源需求量差值最小的资源空闲量对应的集群为所述第一集群。这样,所述第二节点确定与所述目标第二集群具有关联关系的多个集群的资源空闲量中,与所述任务数据的资源需求量差值最小的资源空闲量对应的集群为所述第一集群,提高了资源借调时的资源利用率。
在第二方面的一种可选设计中,其特征在于,所述方法还包括:所述第二节点接收第三节点发送的所述任务数据的资源需求量;基于所述第一集群的资源空闲量大于或等于所述资源需求量,所述第二节点向所述第三节点发送所述第一集群的标识和第一集群的资源空闲量。
在第二方面的一种可选设计中,所述第二节点接收任务数据包括:所述第二节点接收所述第三节点发送的第二资源借调请求,所述第二资源借调请求包括所述任务数据,所述第二借调请求用于指示所述第二节点将所述任务数据分配给所述第一集群处理。
第三方面,本申请提供了一种资源借调方法,包括:第二节点接收第三节点发送的任务数据的资源需求量;所述第二节点确定与目标第二集群具有关联关系的第一集群,其中,所述第二节点属于所述目标第二集群,所述目标第二集群对应于哈希环中的目标哈希值区间,所述第一集群对应的哈希值属于所述目标哈希值区间;基于所述第一集群的资源空闲量大于或等于所述资源需求量,所述第二节点向所述第三节点发送第三资源借调请求,所述第三资源借调请求用于指示所述第三节点被允许从所述第一集群申请资源。
这样,第一节点可以通过第一集群对应的哈希值在哈希环(根据第二集群对应的哈希值生成的)上的分布,来确定第一集群对应的目标第二集群,建立目标第二集群和第一集群的关联关系,由于基于一致性哈希算法的哈希环上的第一集群对应的哈希值和第二集群对应的哈希节点的分布是确定的,每个空闲集群只允许被固定的空集群借调,因此,当第三节点需要向第二节点借调资源时,第二节点不需要随机向选择的空闲集群发送资源查询请求,并在接收到返回后,再进行资源借调,而是直接可以确定可以借调资源的第一集群,减少了一次信息往返的时延开销。
在第三方面的一种可选设计中,与所述目标第二集群具有关联关系的集群有多个,所述第二节点确定与目标第二集群具有关联关系的第一集群,包括:所述第二节点确定与所述目标第二集群具有关联关系的多个集群中的一个集群为第一集群。
第四方面,本申请提供了一种资源借调方法,包括:第三节点接收任务数据;所述第三节点向第二节点发送所述任务数据的资源需求量;所述第三节点接收所述第二节点发送的第三资源借调请求,所述第三资源借调请求用于指示所述第三节点被允许从第一集群申请资源,其中,所述第二节点属于目标第二集群,所述目标第二集群对应于哈希环中的目标哈希值区间,所述第一集群对应的哈希值属于所述目标哈希值区间,且所述第一集群的资源空闲量大于或等于所述资源需求量;所述第三节点向第一节点发送第一资源借调请求, 所述第一借调请求用于指示所述第一节点将所述任务数据分配给所述第一集群处理。
这样,由于基于一致性哈希算法的哈希环上的第一集群对应的哈希值和第二集群对应的哈希节点的分布是确定的,且相对均衡,因此,当第三节点需要向第二节点借调资源时,第二节点不需要随机向选择的空闲集群发送资源查询请求,并在接收到返回后,再进行资源借调,而是直接可以确定可以借调资源的第一集群,减少了一次信息往返的时延开销。
在第四方面的一种可选设计中,所述第三节点向第二节点发送所述任务数据的资源需求量,包括:所述第三节点向多个节点发送所述任务数据的资源需求量,所述第二节点为所述多个节点中的一个;所述第三节点接收所述第二节点发送的第三资源借调请求,包括:所述第三节点接收所述多个节点发送的第三资源借调请求,所述第三资源借调请求用于指示所述第三节点被允许从多个子集群申请资源,所述第一集群为所述多个子集群中的一个。
在第四方面的一种可选设计中,所述方法还包括:所述第三节点确定所述多个子集群的资源空闲量中,与所述任务数据的资源需求量的差值最小的资源空闲量对应的子集群为所述第一集群。
第五方面,本申请提供了一种第一管理节点,所述第一管理节点包括:
处理模块,用于确定第一集群对应的哈希值;获取哈希环,所述哈希环包括至少一个哈希值区间,每个哈希值区间对应一个第二集群;根据所述第一集群对应的哈希值确定对应的目标第二集群,其中,所述第一集群对应的哈希值属于目标哈希区间,所述目标哈希区间为所述至少一个哈希值区间中的一个哈希值区间,所述目标哈希区间对应所述目标第二集群;
收发模块,用于建立第一集群和目标第二集群的关联关系,其中,与所述第一集群建立了关联关系的所述目标第二集群被允许从所述第一集群申请资源。
在第五方面的一种可选设计中,所述哈希环包括第一哈希节点和第二哈希节点,所述第一哈希节点对应所述目标第二集群,所述第一哈希节点为所述哈希环上所述第二哈希节点的相邻后继节点,所述目标哈希区间为所述第一哈希节点的哈希值与所述第二哈希节点的哈希值之间的哈希区间。
在第五方面的一种可选设计中,所述处理模块,还用于对包括多个计算节点的空闲集群进行划分,得到多个子集群,所述第一集群为所述多个子集群中的一个。
在第五方面的一种可选设计中,所述多个子集群包括第三子集群和第四子集群,所述第三子集群为所述多个子集群中资源空闲量最大的子集群,所述第四子集群为所述多个子集群中资源空闲量最小的集群,所述第三子集群的资源空闲量与所述第四子集群的资源空闲量的差值的绝对值小于第一阈值。
在第五方面的一种可选设计中,所述多个子集群中的每个子集群的资源空闲量与预设资源空闲量的差值的绝对值小于或等于第二阈值,所述预设资源空闲量与历史资源请求量相关。
在第五方面的一种可选设计中,所述多个子集群的数量与所述第二集群的数量小于第三阈值。
在第五方面的一种可选设计中,所述收发模块还用于:
接收所述目标第二集群发送的第一资源借调请求,所述第一资源借调请求包括任务数据和第一集群的标识;
根据所述第一集群的标识向所述第一集群发送所述任务数据。
在第五方面的一种可选设计中,所述收发模块还用于:
接收所述目标第二集群发送的第一资源借调请求,所述第一资源借调请求包括任务数据,向所述第一集群发送所述任务数据。
在第五方面的一种可选设计中,所述收发模块具体用于:基于所述第一集群和目标第二集群的关联关系向所述第一集群发送所述任务数据。
在第五方面的一种可选设计中,所述哈希环包括Y个哈希节点,每个第二集群对应至少一个哈希节点,且所述Y个哈希节点的对应的哈希值和所述第一集群对应的哈希值为根据相同的哈希算法生成的,所述Y为正整数。
在第五方面的一种可选设计中,所述处理模块,还用于确定X个第二集群对应的Y个哈希值,其中,每个第二集群对应至少一个哈希值,所述X正整数,所述Y为大于或等于X的正整数;根据所述Y个哈希值生成所述哈希环,其中,所述哈希环包括Y个哈希节点,每个第二集群对应至少一个哈希节点,所述Y个哈希节点将所述哈希环划分为Y个哈希值区间,每个哈希节点对应一个哈希值区间。
在第五方面的一种可选设计中,所述收发模块,还用于接收所述第二集群发送的所述哈希环。
在第五方面的一种可选设计中,所述收发模块,还用于向所述目标第二集群发送所述第一集群的资源空闲量。
第六方面,本申请提供了一种第二管理节点,其特征在于,所述第二管理节点包括:
处理模块,用于确定与目标第二集群具有关联关系的第一集群,其中,所述第二节点属于所述目标第二集群,所述目标第二集群对应于哈希环中的目标哈希值区间,所述第一集群对应的哈希值属于所述目标哈希值区间;
收发模块,用于接收任务数据;并向第一节点发送第一资源借调请求,所述第一借调请求用于指示所述第一节点将所述任务数据分配给所述第一集群处理。
在第六方面的一种可选设计中,所述处理模块,还用于基于收发模块向第一节点发送资源借调请求,确定所述第一集群处于资源不可借调状态。
在第六方面的一种可选设计中,与所述目标第二集群具有关联关系的集群有多个,所述处理模块,具体用于确定与所述目标第二集群具有关联关系的多个集群中的一个集群为第一集群。
在第六方面的一种可选设计中,所述处理模块,具体用于确定与所述目标第二集群具有关联关系的多个集群的资源空闲量中,与所述任务数据的资源需求量差值最小的资源空闲量对应的集群为所述第一集群。
在第六方面的一种可选设计中,所述收发模块,还用于接收第三节点发送的所述任务数据的资源需求量,并基于所述第一集群的资源空闲量大于或等于所述资源需求量,向所述第三节点发送所述第一集群的标识和第一集群的资源空闲量。
在第六方面的一种可选设计中,所述收发模块,具体用于接收所述第三节点发送的第二资源借调请求,所述第二资源借调请求包括所述任务数据,所述第二借调请求用于指示所述第二节点将所述任务数据分配给所述第一集群处理。
第七方面,本申请提供了一种第二管理节点,其特征在于,所述第二管理节点包括:
收发模块,用于接收第三节点发送的任务数据的资源需求量;
处理模块,用于确定与目标第二集群具有关联关系的第一集群,其中,所述第二节点属于所述目标第二集群,所述目标第二集群对应于哈希环中的目标哈希值区间,所述第一集群对应的哈希值属于所述目标哈希值区间;
所述收发模块,还用于基于所述第一集群的资源空闲量大于或等于所述资源需求量,向所述第三节点发送第三资源借调请求,所述第三资源借调请求用于指示所述第三节点被允许从所述第一集群申请资源。
在第七方面的一种可选设计中,与所述目标第二集群具有关联关系的集群有多个,所述处理模块,具体用于确定与所述目标第二集群具有关联关系的多个集群中的一个集群为第一集群。
第八方面,本申请提供了一种第三管理节点,其特征在于,所述第三管理节点包括:
收发模块,用于接收任务数据,向第二节点发送所述任务数据的资源需求量,接收所述第二节点发送的第三资源借调请求,所述第三资源借调请求用于指示所述第三节点被允许从第一集群申请资源,其中,所述第二节点属于目标第二集群,所述目标第二集群对应于哈希环中的目标哈希值区间,所述第一集群对应的哈希值属于所述目标哈希值区间,且所述第一集群的资源空闲量大于或等于所述资源需求量,向第一节点发送第一资源借调请求,所述第一借调请求用于指示所述第一节点将所述任务数据分配给所述第一集群处理。
在第八方面的一种可选设计中,所述收发模块,具体用于向多个节点发送所述任务数据的资源需求量,所述第二节点为所述多个节点中的一个,接收所述多个节点发送的第三资源借调请求,所述第三资源借调请求用于指示所述第三节点被允许从多个子集群申请资源,所述第一集群为所述多个子集群中的一个。
在第八方面的一种可选设计中,所述第三管理节点还包括:
处理模块,用于确定所述多个子集群的资源空闲量中,与所述任务数据的资源需求量的差值最小的资源空闲量对应的子集群为所述第一集群。
第九方面,本申请提供了一种集群,所述集群包括多个计算节点,所述计算节点为任务数据提供所需的资源以执行所述任务数据,以及,所述集群还包括:上述任一方面所述的第一管理节点。
第十方面,本申请提供了一种集群,所述集群包括多个计算节点,所述计算节点为任务数据提供所需的资源以执行所述任务数据,以及,所述集群还包括:上述任一方面所述的第二管理节点。
第十一方面,本申请提供了一种集群,所述集群包括多个计算节点,所述计算节点为任务数据提供所需的资源以执行所述任务数据,以及,所述集群还包括:上述任一方面所述的第三管理节点。
第十二方面,本申请提供了一种分布式系统,其特征在于,所述分布式系统包括上述第九方面描述的集群以及上述第十方面描述的集群。
第十三方面,本申请提供了一种分布式系统,其特征在于,所述分布式系统包括上述第九方面描述的集群、上述第十方面描述的集群以及上述第十一方面描述的集群。
第十四方面,本申请提供了一种计算机存储介质,用于储存为上述第一管理节点所用的计算机软件指令,其包含用于执行上述方面所设计的程序。
第十五方面,本申请提供了一种计算机存储介质,用于储存为上述第二管理节点所用的计算机软件指令,其包含用于执行上述方面所设计的程序。
第十六方面,本申请提供了一种计算机存储介质,用于储存为上述第三管理节点所用的计算机软件指令,其包含用于执行上述方面所设计的程序。
本申请实施例中,第一节点确定第一集群对应的哈希值;第一节点获取哈希环,哈希环包括至少一个哈希值区间,每个哈希值区间对应一个第二集群;第一节点根据第一集群对应的哈希值确定对应的目标第二集群,其中,第一集群对应的哈希值属于目标哈希区间,目标哈希区间为至少一个哈希值区间中的一个哈希值区间,目标哈希区间对应目标第二集群;第一节点建立第一集群和目标第二集群的关联关系,其中,与所述第一集群建立了关联关系的所述目标第二集群被允许从所述第一集群申请资源。通过上述方式,第一节点可以通过第一集群对应的哈希值在哈希环(根据第二集群对应的哈希值生成的)上的分布,来确定第一集群对应的目标第二集群,建立目标第二集群和第一集群的关联关系,由于基于一致性哈希算法的哈希环上的第一集群对应的哈希值和第二集群对应的哈希节点的分布是确定的,每个空闲集群只允许被固定的空集群借调,因此,当目标第二集群需要借调第一集群的空闲资源时,不需要随机向选择的空闲集群发送资源查询请求,并在接收到返回后,再进行资源借调,可以直接向第一集群借调资源,减少了一次信息往返的时延开销。
图1为一种一层架构的中心化分布式系统架构示意图;
图2为一种资源借调场景的架构示意图;
图3a为本申请实施例提供的一种资源分配方法的实施例的示意图;
图3b为一种集群闲忙状态分布示意图;
图3c为一种集群闲忙状态分布示意图;
图3d为本申请实施例中的一种装箱结果示意图;
图4a为本申请实施例提供的一种哈希环的结构示意图;
图4b为本申请实施例提供的一种哈希环的结构示意图;
图4c为本申请实施例提供的一种哈希环的结构示意图;
图4d为本申请实施例提供的一种哈希环的结构示意图;
图5为本申请实施例提供的一种资源借调方法的实施例的示意图;
图6为本申请实施例提供的一种资源借调方法的实施例的示意图;
图7为本申请实施例提供的一种第一管理节点的结构示意图;
图8为本申请实施例提供的一种第二管理节点的结构示意图;
图9为本申请实施例提供的一种第三管理节点的结构示意图;
图10为适用于本发明实施例的一种管理节点的系统实例;
图11为本申请实施例提供的一种集群的结构示意图;
图12为本申请实施例提供的一种集群的结构示意图;
图13为本申请实施例提供的一种集群的结构示意图;
图14为本申请实施例提供的一种分布式系统的结构示意图;
图15为本申请实施例提供的一种分布式系统的结构示意图。
本申请的说明书和权利要求书及上述附图中的术语“第一”、“第二”、“第三”、“第四”等(如果存在)是用于区别类似的对象,而不必用于描述特定的顺序或先后次序。应该理解这样使用的数据在适当情况下可以互换,以便这里描述的本申请的实施例例如能够以除了在这里图示或描述的那些以外的顺序实施。此外,术语“包括”和“具有”以及他们的任何变形,意图在于覆盖不排他的包括,例如,包括了一系列步骤或单元的过程、方法、系统、产品或设备不必限于清楚地列出的那些步骤或单元,而是可包括没有清楚地列出的或对于这些过程、方法、产品或设备固有的其它步骤或单元。
为使本发明的目的、技术方案和优点更加清楚,下面将结合附图对本发明实施方式作进一步地详细描述。
下面通过图1示例性的说明本发明实施例应用的的分布式系统的系统架构。
如图1所示的是一种一层架构的中心化分布式系统架构示意图。在该架构下,用户(user1、user2、……)可以将任务数据提交到节点集群的主节点(master)上,主节点通过调度器(scheduler)对任务数据进行调度分配,为任务数据分配所需要的资源,从而把任务分配到满足任务所需资源的从节点(slave1、slave2、……slaveN)上。
需要说明的是,本申请中的主节点(master)也可以被理解为管理节点,从节点(slave)可以被理解为计算节点。
在前述的多种架构中,调度器(scheduler)可以是集成在相关节点上的硬件设备,也可以通过节点的通用硬件通过软件实现。在本发明实施例中,不限制管理节点实施所述调度器功能的具体方式。
本发明实施例中所述的资源调度,是指将分布式中的计算节点的资源分配给任务数据。应当注意的是,在本发明的各类实施例中,计算节点指的是分布式系统中作为资源调度单位的一个资源集合,一般而言,计算节点是以一台服务器或者一个物理计算机为单位的。但是,在一些场景下,针对不同的资源类型,可以按照不同的划分单位来划分计算节点。例如,当以CPU作为被监测资源时,可以按照处理器或者处理核作为划分单位,分布式系统中每个处理器或者处理核作为一个计算节点,一个服务器中可能包含多个计算节点。又例如,当仅以存储资源作为被监测资源时,可以按照数据分片作为计算节点的划分单位,则分布式数据库中一个数据分片作为一个计算节点,一个服务器中可能包含多个数据分片, 即包含多个计算节点。
随着人工智能(artificial intelligence,AI)和物联网(internet of things,IoT)的发展,许多新兴计算密集型和延迟敏感型终端应用,如虚拟现实(virtual reality,VR)、增强现实(augmented reality,AR)以及高清视频图片处理等正在迅速兴起,低延时、高带宽和强计算等应用需求日益增长。云计算技术受网络链路容量限制等因素影响,容易导致数据传输速率过慢以及响应延迟过高等问题,难以满足应用服务需求。利用靠近数据源的边缘设备进行计算以提高服务响应性能逐渐成为一种趋势。然而单个边缘设备算力小,仅使用单个边缘设备执行任务难以胜任大规模任务需求。因此,将多边缘设备的计算能力加以组合使用,通过多边缘设备资源共享互助,协同完成复杂任务的数据处理,从而可以有效保障服务质量。
设备间的资源互助场景主要分为两类,一类是层次化的异构设备的资源互助,如边缘设备和边缘服务器、中央云处理器之间不同运算能力设备的协同;另一类是同层设备间的资源协同,即当边缘设备资源不足时,可以向其他边缘设备借调资源。
参照图2,图2为一种资源借调场景的架构示意图,如图2中示出的那样,包括集群201、集群202、集群203和集群204,其中,集群201、集群202、集群203为资源空闲量较多的空闲集群,集群204为资源空闲量较少的忙集群,集群201包括管理节点2011和多个计算节点2012,集群202包括管理节点2021和多个计算节点2022,集群203包括管理节点2031和多个计算节点2032,集群204包括管理节点2041和多个计算节点2042。
在一种实施例中,以集群204的空闲资源不足为例,可以按照如下策略进行跨集群的资源借调:
管理节点2041对集群201、集群202、集群203按照资源空闲量的大小进行从大到小进行排序,得到第一集群列表。
例如,第一集群列表是{集群201,集群203,集群202}。
管理节点2041接收任务数据,并确定多个计算节点2042可用的资源空闲量小于任务数据的资源需求量。
管理节点2041在第一集群列表中,选择资源空闲量满足任务数据的资源需求的集群,得到第二集群列表。
例如,若集群201、集群202、集群203的资源空闲量都满足任务数据的资源需求,则第二集群列表是{集群201,集群203,集群202}。
管理节点2041从第二集群列表中随机选择2个集群,向选择的2个集群发送资源查询请求。
例如,管理节点2041选择了集群201和集群203,此时,管理节点2041可以向管理节点2011和管理节点2021发送资源查询请求。
管理节点2041选择第一个返回借调结果且满足任务数据的资源需求的集群,进行跨集群的资源借调。
例如,集群201为第一个返回借调结果且满足任务数据的资源需求的集群,则管理节 点可以将任务数据发送给管理节点2011,使得管理节点2011调度多个计算节点处理任务数据。
然而,在上述设计中,由于管理节点2041在进行跨级群的资源借调时,需要向随机选择的k个集群发送资源查询请求,并在接收到返回借调结果后,再进行资源借调,因此,资源借调前需要一次信息往返的时延开销,增加了时延。
同时,以集群为粒度进行资源借调,对于集群数小、但集群中节点多的场景,并发借调时,借调冲突概率比较大,即针对于同一个空闲集群,可能存在多个忙集群进行资源借调。例如,以上述实施例为例,若集群201和集群203都正在被其他忙集群借调资源,则集群201和集群203上会发生资源借调冲突,导致没有一个集群返回借调结果。
为解决上述技术问题,本申请提供了一种资源分配方法,参照图3a,图3a为本申请实施例提供的一种资源分配方法的实施例的示意图,如图3a中示出的那样,本申请提供的资源分配方法包括:
301、第一节点确定第一集群对应的哈希值。
本申请实施例中,第一节点可以是空闲集群的管理节点,其中,空闲集群包括第一节点和多个计算节点,第一集群可以是由多个计算节点中的全部节点或部分节点组成的节点集群,第一集群也可以包括第一节点,这里并不限定。
本申请实施例中,第一节点在确定第一集群对应的哈希值之前,可以先确定所在的集群的忙闲状态。
可选地,在一种实施例中,第一节点可以根据所在的集群下计算节点的主导资源的占用率评估节点的忙闲状态,并根据所在的集群中忙节点个数和闲节点的个数评估集群的忙闲状态。
示例性的,第一节点可以按照如下公式定义计算节点的忙闲状态:

其中,i表示第i种资源,Use(i)表示正在使用的第i种资源的资源占用量,Total(i)表示第i种资源的总资源量;

其中,a为预设的阈值,max{P
i}表示i个资源占用率中最大的。
本申请实施例中,当计算节点中最大的资源占用率大于或等于阈值a时,第一节点可以确定该计算节点为忙节点,当计算节点中最大的资源占用率小于阈值a时,第一节点可以确定该计算节点为空闲节点。
需要说明的是,上述阈值a可以根据需求实时调整,可根据不同场景进行配置,本申请并不限定。
示例性的,第一节点可以按照如下方式定义所在的集群的忙闲状态:
第一节点所在的集群中,忙节点数量为n,闲节点数量为m;
当m=1时:即第一节点所在的集群内只有一个空闲节点时,第一节点可以确定所在的集群为忙集群;
当m≠1时:计算

其中,b为预设的阈值。
需要说明的是,上述阈值b可以根据需求实时调整,可根据不同场景进行配置,本申请并不限定。
参照图3b和图3c,图3b和图3c是一种集群闲忙状态分布示意图,如图3b和图3c所示,在图3b中,集群内有4个忙节点,5个空闲节点,即n=4,m=5;
则p=1.25,若确定阈值b为0.3,由于1.25>0.3,则图3b示出的集群为闲集群,可以提供空闲资源。
同理,图3c所示的集群内有7个忙节点,2个空闲节点,即n=7,m=2;
则p=0.286,由于0.286<0.3,则图3c示出的集群为忙集群。
本申请实施例中,第一节点在确定所在的集群的闲忙状态为闲时,可以确定第一集群对应的哈希值。
可选的,第一节点在所在的空闲集群包括多个计算节点,第一节点可以对空闲集群的多个计算节点进行划分,得到多个子集群。
进一步的,第一节点在所在的空闲集群包括多个空闲节点,第一节点可以对空闲集群的多个空闲节点进行划分,得到多个子集群。
在一种实施例中,多个子集群包括第三集群和第四集群,第三集群为多个子集群中资源空闲量最大的集群,第四集群为多个子集群中资源空闲量最小的集群,第三集群的资源空闲量与第四集群的资源空闲量的差值的绝对值小于第一阈值。
即,本申请实施例中,第一节点可以对空闲集群的多个计算节点进行划分,以使得划分后得到的多个子集群中的各个第一集群之间的资源空闲量的差异不会过大(最大的资源空闲量与最小的资源空闲量的差值的绝对值小于第一阈值)。
示例性的,第一节点可以在空闲集群的多个闲节点中随机选取一部分空闲节点或全部空闲节点作为预留资源,为空闲集群本地的忙节点提供资源;
本申请实施例中,第一节点可以确定空闲节点中除了作为预留资源之外的剩余空闲节点作为可借资源,并对其进行分组。
具体的,第一节点可以首先计算可借资源中的每个空闲节点的资源空闲率r
i=α×c
i+β×m
i,并根据资源空闲率将节点进行降序排序,其中,c
i表示CPU资源空闲率,m
i表示内存资源空闲率,α和β表示CPU资源空闲率和内存资源空闲率的权重参数。
第一节点将可借资源分为j组,并将所有可借节点进行“s”型装箱操作,同时计算每个空闲资源组的总空闲率
 以及σ
j=max{R
j}-min{R
j},迭代到σ
j大于σ
j-1时,算法终止,将j-1组作为分组结果,其中,n表示可借节点个数,需要说明的是,j为一个可配置参数,实际应用中可按照需求选择,这里并不限定。
以及σ
j=max{R
j}-min{R
j},迭代到σ
j大于σ
j-1时,算法终止,将j-1组作为分组结果,其中,n表示可借节点个数,需要说明的是,j为一个可配置参数,实际应用中可按照需求选择,这里并不限定。
例如,第一节点可以确定空闲节点中除了作为预留资源之外的剩余空闲节点包括:{节点1,节点2,节点3,节点4,节点5,节点6,节点7,节点8,节点9,节点10,节点11,节点12},其中每个节点已经按照空闲率降序排序(即节点1空闲率最高,节点12空闲率最低),参照图3d,图3d为本申请实施例中的一种装箱结果示意图,其中,当确定分组数量j为5时,“S”型装箱结果示意图如图3d所示,在图3d中,划分后得到了5个子集群。
在另一种实施例中,所述多个子集群中的每个子集群的资源空闲量与预设资源空闲量的差值的绝对值小于或等于第二阈值,所述预设资源空闲量与历史资源请求量相关。
具体的,资源空闲量可以包括CPU资源空闲量和内存资源空闲量,预设资源空闲量可以包括预设CPU资源空闲量和预设内存资源空闲量,其中,预设资源空闲量与历史资源请求量相关,相应的,预设CPU资源空闲量与历史CPU资源请求量相关,预设内存资源空闲量与历史内存资源请求量相关。
本申请实施例中,所述多个子集群中的每个子集群的CPU资源空闲量与预设CPU资源空闲量的差值的绝对值小于或等于第三阈值,所述多个子集群中的每个子集群的内存资源空闲量与预设内存资源空闲量的差值的绝对值小于或等于第四阈值。
本申请实施例中预设CPU资源空闲量和预设内存资源空闲量可以根据历史借调请求中的资源请求量来确定,示例性的,第一节点可以记录所在的空闲集群最近k个周期内被请求的资源信息,其中k为可调参数。
可选的,第一节点可以首先根据历史资源请求表,分别对k个周期内的CPU资源请求量和内存资源请求量进行统计平均,得到单个周期内每个空闲资源组CPU历史平均请求量
 和内存历史平均请求量
和内存历史平均请求量



其中,CPU
i表示第i个周期内的CPU资源请求总量,s
i表示第i个周期内的空闲资源组个数,MEM
i表示第i个周期内的内存资源请求总量。
第一节点可以确定CPU历史平均请求量
 为预设CPU资源空闲量,内存历史平均请求量
为预设CPU资源空闲量,内存历史平均请求量
 为预设内存资源量。
为预设内存资源量。
第一节点可以以
 和
和
 为指标,对可借资源进行分组,使得分组后的每个子集 群内的CPU资源空闲量和内存资源空闲量都接近于
为指标,对可借资源进行分组,使得分组后的每个子集 群内的CPU资源空闲量和内存资源空闲量都接近于
 和
和

第一节点可以计算每个空闲节点的贡献率
 并根据贡献率将空闲节点进行降序排序,将可借资源分为N组,
并根据贡献率将空闲节点进行降序排序,将可借资源分为N组,
 将所有可借节点进行“S”型装箱,得到多个子集群。
将所有可借节点进行“S”型装箱,得到多个子集群。
其中,idle_c
i表示CPU空闲量和idle_m
i表示内存空闲量,α和β表示CPU和内存的权重参数,sum_cpu表示空闲集群内可借空闲CPU总量,sum_mem表示空闲集群内可借空闲内存总量。
关于第一节点如何将所有空闲节点进行“S”型装箱,得到多个子集群,可以参照上述实施例中的描述,这里不再赘述。
本申请实施例中,每隔预设的时间,集群内的管理节点可以确定各自所在的集群的闲忙状态,当管理节点确定所在的集为空闲集群时,可以按照上述方式对空闲集群中的全部或部分空闲节点进行划分,得到多个子集群。当管理节点确定所在的集为忙集群时,可以向其他管理节点广播自己的忙闲状态(忙状态)。
本申请实施例中,第一节点可以确定第一集群对应的哈希值,具体的,第一节点可以确定多个子集群中的每个子集群对应的哈希值,应当理解,第一集群中多个子集群中的一个。
具体的,第一集群可以唯一对应一个标识,例如可以用IP和ID来唯一标识第一集群,其中,IP为第一节点所在的空闲集群的标识,ID为分组的标识,本申请实施例中,IP可以为空闲集群所在的服务器的IP地址,IP地址可以包含服务器的IP地址和端口号两项信息。举例来说,计算第一集群对应的哈希值可以是根据所在的服务器的IP地址、端口号信息以及用于标识分组的ID,基于预设的哈希算法计算得到第一集群对应的哈希值。
第一节点可以基于预设的哈希算法计算每个子集群对应的哈希值,具体的,第一节点可以基于预设的哈希算法计算每个子集群的标识的哈希值,由于多个子集群的标识彼此不重复,则对应的哈希值也是不同的。
302、第一节点获取哈希环,所述哈希环包括至少一个哈希值区间,每个哈希值区间对应一个第二集群。
本申请实施例中,哈希环可以理解为包括多个哈希节点的哈希值以及相邻两个哈希节点之间的哈希值区间的数据结构,该数据结构可以为列表,或者是数组的形式。本申请并不限定哈希值的具体形式,只要是可以反映至少一个第二集群的分布特征的数据结构都应落入本申请的保护范围。
在一种实施例中,第一节点可以基于预设的哈希算法构建哈希环。
其中,在基于一致性哈希(hash)算法的分布式系统中,集群可以根据其分别对应的哈 希值而分布于一个数值空间逻辑环上,称为哈希环。该哈希环一般由管理节点生成并保存。在所述哈希环上的一段数据范围(如哈希环上1000~20000的hash值范围)称为一个哈希值区间。
具体的,当管理节点确定所在的集为忙集群时,可以向其他管理节点广播自己的忙闲状态(忙状态),相应的,第一节点可以确定分布式系统中包括的忙集群(至少一个第二集群)。
第一节点可以基于预设的哈希算法计算各个第二集群对应的哈希值,需要说明的是,上述预设的哈希算法可以为jhash哈希算法,也可以为其它类型的哈希算法,本申请实施例对此不作具体限定。第一节点可根据系统需要选择合适的哈希算法,只要计算第一集群的哈希值与计算第二集群的哈希值采用相同的哈希算法即可。
第一节点可以根据各个第二集群对应的哈希值生成哈希环,参照图4a,图4a为本申请实施例提供的一种哈希环的结构示意图,该哈希环的数据范围从0到232,哈希环中的每个大圆圈为根据第二集群的标识计算得到的哈希值,代表一个第二集群。第二集群根据各自对应的哈希值而分布在哈希环上的不同位置。如图4a所示,第二集群对应的哈希值将整个哈希环划分为与第二集群相同数量的哈希值区间,一个哈希值区间是哈希环上的一段哈希值的数据范围。
可选的,在一种实施例中,哈希环包括第一哈希节点和第二哈希节点,第一哈希节点对应目标第二集群,第一哈希节点为哈希环上第二哈希节点的相邻后继节点,目标哈希区间为第一哈希节点与第二哈希节点之间的哈希区间。
本申请实施例中,哈希环上的每个哈希值区间与一个第二集群对应。在一种可能的实现方式中,针对组成哈希环的任一哈希值区间,沿着第一方向从该哈希值区间开始查找,将查找到的第一个第二集群确定为该哈希值区间对应的第二集群。换句话说,若第二集群的哈希值为该哈希值区间在第一方向上的边界哈希值,则可认为该第二集群与该哈希值区间对应。其中,第一方向为哈希环的正方向,它可以是顺时针方向,也可以是逆时针方向,本申请实施例不作具体限定。示例性地,图4a中选取了顺时针方向为第一方向。
本申请实施例中,第一节点可以确定X个第二集群对应的Y个哈希值,其中,每个第二集群对应至少一个哈希值,X正整数,Y为大于或等于X的正整数。
在一种实施例中,Y大于X,即存在第二集群,该第二集群对应多个哈希值。
本申请实施例中,当第二集群的数量过少时,在哈希环上第二集群的分布会过于稀疏,参照图4b,图4b为本申请实施例提供的一种哈希环的结构示意图,当第二集群的数量过少时,第二集群在哈希环上的分布会过于稀疏,因此,可以将第二集群对应哈希环上的多个节点,即引入虚拟节点,参照图4c,图4c为本申请实施例提供的一种哈希环的结构示意图,如图4c中示出的那样,目标第二集群可以对应于哈希环上的两个哈希节点,通过引入虚拟节点,使得第二集群可以对应哈希环上的多个节点,进而第二集群在哈希环上的分布不会过于稀疏。关于如何通过引入虚拟节点来实现将第二集群对应哈希环上的多个节点可以参照现有方案中的实现,这里不再赘述。
本申请实施例中,第一节点根据Y个哈希值生成哈希环,其中,哈希环包括Y个哈希 节点,每个第二集群对应至少一个哈希节点,Y个哈希节点将哈希环划分为Y个哈希值区间,每个哈希节点对应一个哈希值区间,即每个哈希节点对应一个第二集群,而一个第二集群可以对应哈希环上的多个哈希节点。
本申请实施例中,第一节点可以周期性的接收到其他集群广播的闲忙状态,并根据其他集群广播的闲忙状态周期性的更新哈希环。
可选的,在另一种实施例中,第一节点可以接收第二集群发送的哈希表。
本申请实施例中,第二集群中的管理节点(例如第二节点)可以接收到其他集群广播的闲忙状态,并根据其他集群广播的闲忙状态构建哈希环,关于第二集群如何根据其他集群广播的闲忙状态构建哈希环可以参照上述实施例中的描述,这里不再赘述。
303、第一节点根据第一集群对应的哈希值确定对应的目标第二集群,其中,第一集群对应的哈希值属于目标哈希区间,目标哈希区间为至少一个哈希值区间中的一个哈希值区间,目标哈希区间对应目标第二集群。
本申请实施例中,第一节点在确定第一集群对应的哈希值,以及获取到基于第二集群的哈希值生成的哈希环之后,可以根据第一集群对应的哈希值从哈希环中确定对应的目标第二集群。
本申请实施例中,由于哈希环上的每个哈希值区间对应一个第二集群,因此,第一节点可以确定第一集群对应的哈希值在哈希环上属于的哈希值区间为目标哈希区间,并确定该目标哈希区间对应的第二集群为目标第二集群。
参照图4d,图4d为本申请实施例提供的一种哈希环的结构示意图,如图4d中示出的那样,哈希环包括:六个哈希节点{哈希节点1,哈希节点3,哈希节点4,哈希节点6,哈希节点8,哈希节点10},其中,哈希节点3和哈希节点8对应第二集群1,哈希节点1和哈希节点4对应第二集群2,哈希节点6和哈希节点10对应第二集群3。
哈希节点1与哈希节点3之间的哈希值区间对应于第二集群1,哈希节点3与哈希节点4之间的哈希值区间对应于第二集群2,哈希节点4与哈希节点6之间的哈希值区间对应于第二集群3,哈希节点6与哈希节点8之间的哈希值区间对应于第二集群1,哈希节点8与哈希节点10之间的哈希值区间对应于第二集群3,哈希节点10与哈希节点1之间的哈希值区间对应于第二集群2。
空闲集群a包括两个子集群{第一集群a1,第一集群a2},空闲集群b包括两个子集群{第一集群b1,第一集群b2}。
各个第一集群{第一集群a1,第一集群a2,第一集群b1,第一集群b2}在哈希环上的分布如图4中示出的那样,其中,第一集群a1对应的哈希值属于哈希节点8与哈希节点6之间的哈希值区间,第一集群a2对应的哈希值属于哈希节点4与哈希节点10之间的哈希值区间,第一集群b1对应的哈希值属于哈希节点1与哈希节点3之间的哈希值区间,第一集群b2对应的哈希值属于哈希节点4与哈希节点10之间的哈希值区间。
结合上述各个第一集群在哈希环中的分布,空闲集群a中的第一节点可以确定第一集群a1对应于第二集群6,空闲集群a中的第一节点可以确定第一集群a2对应于第二集群4,空闲集群b中的第一节点可以确定第一集群b1对应于第二集群3,空闲集群b中的第一节 点可以确定第一集群b2对应于第二集群4。
304、所述第一节点建立第一集群和目标第二集群的关联关系,其中,与所述第一集群建立了关联关系的所述目标第二集群被允许从所述第一集群申请资源。
本申请实施例中,第一节点根据第一集群对应的哈希值确定对应的目标第二集群之后,可以向目标第二集群发送第一集群的标识,具体的,第一节点根据第一集群对应的哈希值确定对应的目标第二集群之后,可以向目标第二集群中的管理节点(第二节点)发送资源分配指示,该资源分配指示包括第一集群的标识,该资源分配指示可以指示目标第二节点被允许从所述第一集群申请资源。
可选的,在一种实施例中,第一节点还可以向目标第二集群发送第一集群的资源空闲量。
具体的,第一节点还可以向目标第二集群发送第一集群的CPU资源空闲量和内存资源空闲量。
一方面,第一节点可以通过第一集群对应的哈希值在哈希环(根据第二集群对应的哈希值生成的)上的分布,来确定第一集群对应的目标第二集群,建立目标第二集群和第一集群的关联关系,由于基于一致性哈希算法的哈希环上的第一集群对应的哈希值和第二集群对应的哈希节点的分布是确定的,每个空闲集群只允许被固定的空集群借调,因此,当目标第二集群需要借调第一集群的空闲资源时,不需要随机向选择的空闲集群发送资源查询请求,并在接收到返回后,再进行资源借调,可以直接向第一集群借调资源,减少了一次信息往返的时延开销。
另一方面,由于资源借调的对应关系是基于将第一集群的哈希值在基于忙集群生成的哈希环上的对应关系确定的,该对应关系是唯一的,因此空闲集群仅能被哈希环上对应的忙集群借调资源,因此,不会出现由于多个忙集群向同一个空闲集群并发借调资源而导致的借调冲突。
另一方面,第一节点通过对空闲集群的多个计算节点进行划分,得到多个子集群,之后可以以子集群为单位为其他忙集群借调资源,使得空闲集群中的空闲资源可以实现相对均衡的借调。
另一方面,当第二集群的数量过少时,第二集群在哈希环上的分布会过于稀疏,因此,可以将第二集群(例如目标第二集群)对应哈希环上的多个节点,即引入虚拟节点,使得不会出现由于第二集群在哈希环上分布过于稀疏,而导致一个第二集群会对应多个第一集群的情况,增加了资源分配的均衡性。
本申请实施例中,第一节点确定第一集群对应的哈希值;第一节点获取哈希环,哈希环包括至少一个哈希值区间,每个哈希值区间对应一个第二集群;第一节点根据第一集群对应的哈希值确定对应的目标第二集群,其中,第一集群对应的哈希值属于目标哈希区间,目标哈希区间为至少一个哈希值区间中的一个哈希值区间,目标哈希区间对应目标第二集群;第一节点建立第一集群和目标第二集群的关联关系,其中,与所述第一集群建立了关联关系的所述目标第二集群被允许从所述第一集群申请资源。通过上述方式,一方面,第一节点可以通过第一集群对应的哈希值在哈希环(根据第二集群对应的哈希值生成的)上 的分布,来确定第一集群对应的目标第二集群,建立目标第二集群和第一集群的关联关系,由于基于一致性哈希算法的哈希环上的第一集群对应的哈希值和第二集群对应的哈希节点的分布是确定的,每个空闲集群只允许被固定的空集群借调,因此,当目标第二集群需要借调第一集群的空闲资源时,不需要随机向选择的空闲集群发送资源查询请求,并在接收到返回后,再进行资源借调,可以直接向第一集群借调资源,减少了一次信息往返的时延开销。且,由于资源借调的对应关系是基于将第一集群的哈希值在基于忙集群生成的哈希环上的对应关系确定的,该对应关系是唯一的,因此空闲集群仅能被哈希环上对应的忙集群借调资源,因此,不会出现由于多个忙集群向同一个空闲集群并发借调资源而导致的借调冲突。
需要说明的是,在另一种实施例中,第一节点可以不基于第一集群对应的哈希值在哈希环上的分布确定对应的目标第二集群,而是通过随机分配的方式,或者顺序分配的方式确定对应的目标第二集群。
具体的,第一节点可以从分布式系统中的多个第二集群中随机选择一个第二集群作为目标第二集群。
具体的,可以对至少一个第二集群进行排序,并按照预设的顺序将多个子集群(包括第一集群)顺次挂载到相应的第二集群上(即建立各个子集群与第二集群的关联关系)。则,第一节点也可以通过上述方式确定对应的目标第二集群。
应当理解,实际应用中可以不限于上述实现方式,只要在资源借调关系分配时,分布式系统确定固定的资源分配关系(第一节点与某一个目标第二集群建立关联关系),都可以实现,忙集群在进行资源借调时,不需要随机向选择的空闲集群发送资源查询请求,并在接收到返回后,再进行资源借调,可以直接向第一集群借调资源,减少了一次信息往返的时延开销。且,由于资源借调的对应关系是基于将第一集群的哈希值在基于忙集群生成的哈希环上的对应关系确定的,该对应关系是唯一的,因此空闲集群仅能被哈希环上对应的忙集群借调资源,因此,不会出现由于多个忙集群向同一个空闲集群并发借调资源而导致的借调冲突。
参照图5,图5为本申请实施例提供的一种资源借调方法的实施例的示意图,如图5中示出的那样,本申请提供的资源借调方法包括:
501、第二节点确定与目标第二集群具有关联关系的第一集群,其中,所述第二节点属于所述目标第二集群,所述目标第二集群对应于哈希环中的目标哈希值区间,所述第一集群对应的哈希值属于所述目标哈希值区间。
本申请实施例中,第二节点属于目标第二集群,其中,目标第二集群为忙集群。具体的,第二节点可以接收到第一节点发送的资源分配指示,该资源分配指示包括第一集群的标识,该资源分配指示可以指示第二节点可以借调第一集群的空闲资源,关于第一节点如何向目标第二集群发送第一集群的标识可参照上述实施例,这里不再赘述。
本申请实施例中,第二节点可以接收到多个子集群的标识,即,与所述目标第二集群具有关联关系的集群有多个。
本实施例中,所述第二节点可以确定与所述目标第二集群具有关联关系的多个集群中的一个集群为第一集群。
可选的,在一种实施例中,第二节点还可以接收到多个子集群中每个子集群的资源空闲量。
502、第二节点接收任务数据。
本申请实施例中,第二节点可以接收到任务数据。
可选的,在一种实施例中,第二节点接收到任务数据之后,可以确定接收到的任务数据的资源需求量,并判断所在的忙集群(目标第二集群)中的空闲节点的资源空闲量,若所属的忙集群中的空闲节点的资源空闲量大于或等于任务数据的资源需求量,相当于第二节点可以确定本地的集群有足够的资源空闲量来处理该任务数据。若所属的忙集群中的空闲节点的资源空闲量小于任务数据的资源需求量,相当于第二节点可以确定本地的集群没有足够的资源空闲量来处理该任务数据。
具体的,若所属的忙集群中的空闲节点的CPU资源空闲量大于或等于任务数据的CPU资源需求量,且所属的忙集群中的空闲节点的内存资源空闲量大于或等于任务数据的内存资源需求量,相当于第二节点可以确定本地的集群有足够的资源空闲量来处理该任务数据。若所属的忙集群中的空闲节点的CPU资源空闲量小于任务数据的CPU资源需求量,且所属的忙集群中的空闲节点的内存资源空闲量小于任务数据的内存资源需求量,相当于第二节点可以确定本地的集群没有足够的资源空闲量来处理该任务数据。
503、第二节点向第一节点发送第一资源借调请求,所述第一借调请求用于指示所述第一节点将所述任务数据分配给所述第一集群处理。
若第二节点确定本地集群没有足够的资源空闲量来处理该任务数据,则需要向其他集群借调资源来执行该任务数据。
本申请实施例中,第二节点可以向第一节点发送第一资源借调请求,第一借调请求可以包括任务数据和第一集群的标识,相应的,第一节点接收到第一资源借调请求之后,可以将其中包括的任务数据分配给第一集群来处理。
在一种实施例中,第二节点可以接收到多个子集群的标识以及多个子集群的资源空闲量,此时第二节点需要从其中确定一个集群作为资源借调的对象,接下来论述第二节点如何从多个子集群中确定作为资源借调对象的第一集群。
本申请实施例中,第二节点可以维护一个映射表,该映射表中存储了多个子集群的标识,以及对应的资源空闲量,第二节点可以在映射表中查找多个子集群中资源空闲量大于或等于任务数据的资源需求量的集群集合,得到满足资源需求量的子集群集合{slices 1,slices 2,……,slices n},其中,slices n表示第n个子集群的标识。
第二节点在得到子集群集合{slices 1,slices 2,……,slices n}之后,可以对子集群集合中的多个子集群进行优先级排序,其中,优先级排序的指标为子集群的资源空闲量与任务数据的资源需求量的接近程度,越接近则对应的子集群的优先级越高,第二节点可以选择优先级最高的子集群发起第一借调请求。
示例性的,第二节点可以维护如下的映射表:

第二节点接收到任务数据,并确定该任务数据对应的CPU资源需求量为0.6,内存资源需求量为0.65。
第二节点可以在映射表中查找多个第一集群中资源空闲量大于或等于任务数据的资源需求量的集群集合,得到满足资源需求量的第一集群集合{slices6,slices7}。
第二节点可以根据如下公式来确定与任务数据的资源需求量最接近的第一集群:

其中,α表示CPU的权重参数,β表示内存的权重参数,
 表示注册在第二集群j上的第一集群i的CPU资源空闲量,
表示注册在第二集群j上的第一集群i的CPU资源空闲量,
 表示第二集群j中确定的任务数据需要的CPU资源空闲量,
表示第二集群j中确定的任务数据需要的CPU资源空闲量,
 表示注册在第二集群j上的第一集群i的空闲内存资源量,
表示注册在第二集群j上的第一集群i的空闲内存资源量,
 表示第二集群j中确定的任务数据需要的空闲内存资源量。示例性的,α为0.6,β为0.4。
表示第二集群j中确定的任务数据需要的空闲内存资源量。示例性的,α为0.6,β为0.4。
slices 6与任务数据资源请求量的接近程度为:
(0.65-0.6)*0.6+(0.75-0.65)*0.4=0.07
slices 7与任务数据资源请求量的接近程度为:
(0.74-0.6)*0.6+(0.7-0.65)*0.4=0.104
则第二节点可以确定slices 6对应的第一集群的资源空闲量最接近任务数据的资源需求量,并向slices 6对应的第一集群发起第一借调请求。
需要说明的是,上述描述仅为一种示意,其中具体的参数选择仅为一种示意,本申请 并不限定。
通过上述方式,所述第二节点确定与所述目标第二集群具有关联关系的多个集群的资源空闲量中,与所述任务数据的资源需求量差值最小的资源空闲量对应的集群为所述第一集群,提高了资源借调时的资源利用率。
可选地,在一种实施例中,第二节点可以基于接收到第一节点发送的第一集群的标识,确定该第一集群处于资源可借调状态。
第二节点可以基于向第一节点发送资源借调请求,确定第一集群处于资源不可借调状态。
本申请实施例中,第二节点向第一节点发送资源借调请求之后,相当于已经占用了第一集群的空闲资源,则可以确定第一集群处于资源不可借调状态。可选地,第二节点可以在映射表中标注第一集群的资源借调状态为资源不可借状态。相应的,第一节点也可以确定第一集群处于资源不可借调状态,即确定第一集群不能为其他忙集群提供可用资源,从而确保了资源锁定,实现了跨集群资源的无冲突调度。
本申请实施例中,第一集群在处理完任务数据之后,可以将处理结果返回第一节点,第一节点将处理结果发送到第二节点。
本申请实施例中,第二节点确定与目标第二集群具有关联关系的第一集群,其中,所述第二节点属于所述目标第二集群,所述目标第二集群对应于哈希环中的目标哈希值区间,所述第一集群对应的哈希值属于所述目标哈希值区间;所述第二节点接收任务数据;所述第二节点向第一节点发送第一资源借调请求,所述第一借调请求用于指示所述第一节点将所述任务数据分配给所述第一集群处理。通过上述方式,一方面,当分布式系统中存在多个第一集群时,各个第一节点通过第一集群对应的哈希值在根据第二集群对应的哈希值生成的哈希环上的分布,来确定第一集群对应的目标第二集群,并指示目标第二集群可以借调第一集群的空闲资源,由于基于一致性哈希算法的哈希环上的第一集群对应的哈希值和第二集群对应的哈希节点的分布是确定的,且相对均衡,因此,当目标第二集群需要借调第一集群的空闲资源时,不需要随机向选择的空闲集群发送资源查询请求,并在接收到返回后,再进行资源借调,而是直接确定需要借调资源的第一集群,并向第一节点发送第一资源借调请求,减少了一次信息往返的时延开销。且,由于资源借调的对应关系是基于将第一集群的哈希值在基于忙集群生成的哈希环上的对应关系确定的,该对应关系是唯一的,因此空闲集群仅能被哈希环上对应的忙集群借调资源,因此,不会出现由于多个忙集群向同一个空闲集群并发借调资源而导致的借调冲突。
参照图6,图6为本申请实施例提供的一种资源借调方法的实施例的示意图,如图5中示出的那样,本申请提供的资源借调方法包括:
601、第二节点确定与目标第二集群具有关联关系的第一集群,其中,所述第二节点属于所述目标第二集群,所述目标第二集群对应于哈希环中的目标哈希值区间,所述第一集群对应的哈希值属于所述目标哈希值区间。
步骤601的具体描述可参照图5对应的实施例中步骤501的具体描述,这里不再赘述。
602、第二节点接收第三节点发送的任务数据的资源需求量。
本申请实施例中,第三节点接收到任务数据之后,可以确定接收到的任务数据的资源需求量,并判断所属的忙集群中的空闲节点的资源空闲量,若所属的忙集群中的空闲节点的资源空闲量小于任务数据的资源需求量,即第三节点确定本地的集群没有足够的资源空闲量来处理该任务数据。
则第三节点可以遍历存储了多个子集群的标识,以及对应的资源空闲量的映射表,并在映射表中查找多个子集群中资源空闲量大于或等于任务数据的资源需求量的集群集合,若第三节点确定多个子集群中的每个子集群的资源空闲量都小于任务数据的资源需求量,或者确定多个子集群都为资源不可借调状态,则第三节点需要向其他忙集群借调资源。
具体的,第三节点可以从维护的哈希环中沿着第一方向确定第三节点对应的哈希节点的相邻后续节点,该相邻后续节点对应于第二集群。第三节点可以向第二集群的管理节点(第二节点)发送任务数据的资源需求量,具体的,第三节点可以向第二节点发送任务数据的资源需求量。
可选地,在一种实施例中,第三节点可以从维护的哈希环中沿着第一方向确定第三节点对应的哈希节点的多个后续节点,多个后续节点对应于多个第二集群。第三节点可以向多个第二集群的管理节点(第二节点)发送任务数据的资源需求量。
相应的,第二节点可以接收到第三节点发送的任务数据的资源需求量。
603、基于第一集群的资源空闲量大于或等于资源需求量,所述第二节点向第三节点发送第三资源借调请求,所述第三资源借调请求用于指示所述第三节点被允许从所述第一集群申请资源。
本申请实施例中,第二节点接收到资源需求量之后,可以查找自己维护的映射表,并确定资源空闲量大于或等于资源需求量的第一集群,并向第三节点发送第三资源借调请求,第三资源借调请求包括第一集群的标识,所述第三资源借调请求用于指示所述第三节点被允许从第一集群申请资源。
可选地,在一种实施例中,第二节点可以确定多个子集群的资源空闲量大于或等于资源需求量,则第二节点可以向第三节点发送确定的多个子集群的标识,其中第一集群为多个子集群中的一个。
可选地,在一种实施例中,第二节点可以确定多个子集群的资源空闲量大于或等于资源需求量,并从确定的多个子集群中随机选择一部分子集群,并向第三节点发送一部分子集群的标识。
可选地,在一种实施例中,第二节点可以接收到第三节点发送的第二资源借调请求,所述第二资源借调请求包括所述任务数据,所述第二借调请求用于指示所述第二节点将所述任务数据分配给所述第一集群处理。
本申请实施例中,第三节点接收到第二节点发送的第一集群的标识之后,相当于从第二节点获取到了可以进行资源借调的第一集群的标识。
可选地,在一种实施例中,第三节点可以接收到多个第二节点发送的多个子集群的标识,或者,第三节点可以接收到一个第二节点发送的多个子集群的标识之后,需要确定出 多个子集群中的一个集群作为资源借调对象,关于第三节点如何确定出多个第一集群中的一个第一集群作为资源借调对象,可以参照上述实施例中,第二节点如何确定出多个子集群中的第一集群作为资源借调对象的描述,这里不再赘述。
若第三节点确定多个子集群中的第一集群为资源借调对象,相应的,第二节点可以接收第三节点发送的第二资源借调请求,所述第二资源借调请求包括所述任务数据和第一集群的标识,所述第二借调请求用于指示所述第二节点将所述任务数据分配给所述第一集群处理。
本申请实施例中,第二节点可以向第一节点发送任务数据和第一集群的标识。
第一节点可以将所述任务数据分配给所述第一集群处理。
可选地,在另一种实施例中,所述第三节点在接收所述第二节点发送的第三资源借调请求之后,可以不向第二节点发送第二资源借调请求,来指示所述第二节点将所述任务数据分配给所述第一集群处理,而是直接向第一节点发送第一资源借调请求,所述第一借调请求用于指示所述第一节点将所述任务数据分配给所述第一集群处理,减少了一步信息的转发开销。
参照图7,图7为本申请实施例提供的一种第一管理节点700的结构示意图,如图7中示出的那样,所述第一管理节点700包括:
处理模块701,用于确定第一集群对应的哈希值;获取哈希环,所述哈希环包括至少一个哈希值区间,每个哈希值区间对应一个第二集群;根据所述第一集群对应的哈希值确定对应的目标第二集群,其中,所述第一集群对应的哈希值属于目标哈希区间,所述目标哈希区间为所述至少一个哈希值区间中的一个哈希值区间,所述目标哈希区间对应所述目标第二集群;
收发模块702,用于建立第一集群和目标第二集群的关联关系,其中,与所述第一集群建立了关联关系的所述目标第二集群被允许从所述第一集群申请资源。
可选地,在一种实施例中,所述哈希环包括第一哈希节点和第二哈希节点,所述第一哈希节点对应所述目标第二集群,所述第一哈希节点为所述哈希环上所述第二哈希节点的相邻后继节点,所述目标哈希区间为所述第一哈希节点的哈希值与所述第二哈希节点的哈希值之间的哈希区间。
可选地,在一种实施例中,所述处理模块701,还用于对包括多个计算节点的空闲集群进行划分,得到多个子集群,所述第一集群为所述多个子集群中的一个。
可选地,在一种实施例中,所述多个子集群包括第三子集群和第四子集群,所述第三子集群为所述多个子集群中资源空闲量最大的子集群,所述第四子集群为所述多个子集群中资源空闲量最小的集群,所述第三子集群的资源空闲量与所述第四子集群的资源空闲量的差值的绝对值小于第一阈值。
可选地,在一种实施例中,所述多个子集群中的每个子集群的资源空闲量与预设资源空闲量的差值的绝对值小于或等于第二阈值,所述预设资源空闲量与历史资源请求量相关。
可选地,在一种实施例中,所述收发模块702还用于:
接收所述目标第二集群发送的资源借调请求,所述资源借调请求包括任务数据和第一集群的标识;
根据所述第一集群的标识向所述第一集群发送所述任务数据。
可选地,在一种实施例中,所述哈希环包括Y个哈希节点,每个第二集群对应至少一个哈希节点,且所述Y个哈希节点的对应的哈希值和所述第一集群对应的哈希值为根据相同的哈希算法生成的,所述Y为正整数。
可选地,在一种实施例中,所述处理模块701,还用于确定X个第二集群对应的Y个哈希值,其中,每个第二集群对应至少一个哈希值,所述X正整数,所述Y为大于或等于X的正整数;根据所述Y个哈希值生成所述哈希环,其中,所述哈希环包括Y个哈希节点,每个第二集群对应至少一个哈希节点,所述Y个哈希节点将所述哈希环划分为Y个哈希值区间,每个哈希节点对应一个哈希值区间。
可选地,在一种实施例中,所述收发模块702,还用于接收所述第二集群发送的所述哈希环。
可选地,在一种实施例中,所述收发模块702,还用于向所述目标第二集群发送所述第一集群的资源空闲量。
参照图8,图8为本申请实施例提供的一种第二管理节点800的结构示意图,如图8中示出的那样,所述第二管理节点800包括:
处理模块801,用于确定与目标第二集群具有关联关系的第一集群,其中,所述第二节点属于所述目标第二集群,所述目标第二集群对应于哈希环中的目标哈希值区间,所述第一集群对应的哈希值属于所述目标哈希值区间;
收发模块802,用于接收任务数据;并向第一节点发送第一资源借调请求,所述第一借调请求用于指示所述第一节点将所述任务数据分配给所述第一集群处理。
可选地,在一种实施例中,所述处理模块801,还用于基于收发模块向第一节点发送资源借调请求,确定所述第一集群处于资源不可借调状态。
可选地,在一种实施例中,与所述目标第二集群具有关联关系的集群有多个,所述处理模块801,具体用于确定与所述目标第二集群具有关联关系的多个集群中的一个集群为第一集群。
可选地,在一种实施例中,所述处理模块801,具体用于确定与所述目标第二集群具有关联关系的多个集群的资源空闲量中,与所述任务数据的资源需求量差值最小的资源空闲量对应的集群为所述第一集群。
可选地,在一种实施例中,所述收发模块802,还用于接收第三节点发送的所述任务数据的资源需求量,并基于所述第一集群的资源空闲量大于或等于所述资源需求量,向所述第三节点发送所述第一集群的标识和第一集群的资源空闲量。
可选地,在一种实施例中,所述收发模块802,具体用于接收所述第三节点发送的第二资源借调请求,所述第二资源借调请求包括所述任务数据,所述第二借调请求用于指示所述第二节点将所述任务数据分配给所述第一集群处理。
参照图8,图8为本申请实施例提供的一种第二管理节点800的结构示意图,如图8中示出的那样,所述第二管理节点800包括:
收发模块802,用于接收第三节点发送的任务数据的资源需求量;
处理模块801,用于确定与目标第二集群具有关联关系的第一集群,其中,所述第二节点属于所述目标第二集群,所述目标第二集群对应于哈希环中的目标哈希值区间,所述第一集群对应的哈希值属于所述目标哈希值区间;
所述收发模块802,还用于基于所述第一集群的资源空闲量大于或等于所述资源需求量,向所述第三节点发送第三资源借调请求,所述第三资源借调请求用于指示所述第三节点被允许从所述第一集群申请资源。
可选地,在一种实施例中,与所述目标第二集群具有关联关系的集群有多个,所述处理模块,具体用于确定与所述目标第二集群具有关联关系的多个集群中的一个集群为第一集群。
参照图9,图9为本申请实施例提供的一种第三管理节点900的结构示意图,如图9中示出的那样,所述第三管理节点900包括:
收发模块901,用于接收任务数据,向第二节点发送所述任务数据的资源需求量,接收所述第二节点发送的第三资源借调请求,所述第三资源借调请求用于指示所述第三节点被允许从第一集群申请资源,其中,所述第二节点属于目标第二集群,所述目标第二集群对应于哈希环中的目标哈希值区间,所述第一集群对应的哈希值属于所述目标哈希值区间,且所述第一集群的资源空闲量大于或等于所述资源需求量,向第一节点发送第一资源借调请求,所述第一借调请求用于指示所述第一节点将所述任务数据分配给所述第一集群处理。
可选地,在一种实施例中,所述收发模块901,具体用于向多个节点发送所述任务数据的资源需求量,所述第二节点为所述多个节点中的一个,接收所述多个节点发送的第三资源借调请求,所述第三资源借调请求用于指示所述第三节点被允许从多个子集群申请资源,所述第一集群为所述多个子集群中的一个。
可选地,在一种实施例中,所述第三管理节点900还包括:
处理模块902,用于确定所述多个子集群的资源空闲量中,与所述任务数据的资源需求量的差值最小的资源空闲量对应的子集群为所述第一集群。
图10说明了适用于本发明实施例的一种管理节点的系统实例,其中该管理节点可以为上述实施例中描述的第一管理节点、第二管理节点和第三管理节点中的任意一种。基于该实施例中的系统环境可以实现上一实施例中管理节点的各个逻辑模块的功能。该实施例只是一个适用于本发明的实例,并不试图建议对本发明所提供的管理节点的功能和结构构成任何限制。
本发明实施例以一种通用计算机系统环境作为示例来对管理节点进行说明。众所周知的,可适用于该管理节点还可以采用其他的硬件架构来实现类似的功能。包括并不限制于,个人计算机,服务计算机,多处理器系统,基于微处理器的系统,可编程消费电器,网路 PC,小型计算机,大型计算机,包括任何上述系统或设备的分布式计算环境,等等。
参照图10,实现本发明所举例的系统包括管理节点1000形式的通用计算设备。结合前述所述的系统场景及架构,本实施例所述的管理节点可以为前述场景及架构中所说明的本发明实施例的执行主体。例如,可以为主节点、管理节点或者去中心化架构中的任一节点。
管理节点1000的元件可以包括,但并不限制于,处理单元1020,系统存储器1030,和系统总线1010。系统总线将包括系统存储器的各种系统元件与处理单元1020相耦合。系统总线1010可以是几种类型总线结构中的任意一种总线,这些总线可以包括存储器总线或存储器控制器,外围总线,和使用一种总线结构的局部总线。总线结构可以包括工业标准结构(ISA)总线,微通道结构(MCA)总线,扩展ISA(EISA)总线,视频电子标准协会(VESA)局域总线,以及外围器件互联(PCI)总线。
管理节点1000一般包括多种管理节点可读媒介。管理节点可读媒介可以是任何管理节点1000可有效访问的媒介,并包括易失性或非易失性媒介,以及可拆卸或非拆卸的媒介。例如,但并不限制于,管理节点可读媒介可以包括管理节点存储媒介和通讯媒介。管理管理节点可读指令,数据结构,程序模块或其他数据的信息的任何方法或技术来实现。管理节点存储媒介包括,但并不限制于,RAM,ROM,EEPROM,闪存存储器或其他存储器技术,或者硬盘存储、固态硬盘存储、光盘存储,磁盘盒,磁盘存储或其它存储设备,或任何其它可以存储所要求信息和能够被管理节点1000访问的媒介。通讯媒介一般包括嵌入的计算机可读指令,数据结构,程序模块或在模块化数据信号(例如,载波或其他传输机制)中的其他数据,并且还包括任何信息传递的媒介。术语“模块化数据信号”是指具有一个或多个信号特征组或采用对信号中的信息进行编码的方式来改变的信号。例如,但并不限制,通讯媒介包括诸如有线网络或直接有线连接的有线媒介,和诸如声,RF红外和其它无线媒介的无线媒介。上述任何组合也应该包括在管理节点可读媒介的范围内。
系统存储器1030包括管理节点存储媒介,它可以是易失性和非易失性存储器,例如,只读存储器(ROM)1031和随即存取存储器(RAM)1032。基本输入/输出系统1033(BIOS)一般存储于ROM1031中,包含着基本的例行程序,它有助于在管理节点1010中各元件之间的信息传输。RAM 1032一般包含着数据和/或程序模块,它可以被处理单元1020即时访问和/或立即操作。例如,但并不限制于,图10说明了操作系统1034,应用程序1035,其他程序模块1036和程序数据1037。
管理节点1000也可以包括其他可拆卸/非拆卸,易失性/非易失性的管理节点存储媒介。仅仅是一个实例,图10说明了硬盘存储器1041,它可以是非拆卸和非易失性的可读写磁媒介;外部存储器1051,它可以是可拆卸和非易失性的各类外部存储器,例如光盘、磁盘、闪存或者移动硬盘等;硬盘存储器1041一般是通过非拆卸存储接口(例如,接口1040)与系统总线1010相连接,外部存储器一般通过可拆卸存储接口(例如,接口1060)与系统总线1010相连接。上述所讨论的以及图10所示的驱动器和它相关的管理节点存储媒介提供了管理节点可读指令,数据结构,程序模块和管理节点1000的其它数据的存储。例如,硬盘驱动器1041说明了用于存储操作系统1042,应用程序1043,其它应用程序1044以及程序数据1045。值得注意的是,这些元件可以与操作系统1034,应用程序1035,其他程序模块1036,以及 程序数据1037是相同的或者是不同的。
在本实施例中,前述实施例中的方法或者上一实施例中逻辑模块的功能可以通过存储在管理节点存储媒介中的代码或者可读指令,并由处理单元1020读取所述的代码或者可读指令从而执行所述方法。
用户可以通过各类输入设备1061管理节点1000输入命令和信息。各种输入设备经常都是通过用户输入接口1060与处理单元1020相连接,用户输入接口1060与系统总线相耦合,但也可以通过其他接口和总线结构相连接,例如,并行接口,或通用串行接口(USB)。显示设备1091也可以通过接口(例如,视频接口1090)与系统总线1010相连接。此外,诸如计算设备1000也可以包括各类外围输出设备1020,输出设备可以通过输出接口10100等来连接。管理节点1000可以在使用逻辑连接着一个或多个计算设备,例如,远程计算机1071。远程计算节点包括管理节点,计算节点,服务器,路由器,网络PC,等同的设备或其它通用的网络结点,并且一般包括许多或所有与管理节点1000有关的上述所讨论的元件。结合前述图1所描述的架构中,远程计算节点可以是从节点、计算节点或者其他管理节点。在图10中所说明的逻辑连接包括局域网(LAN)和广域网(WAN),也可以包括其它网络。通过逻辑连接,管理节点可以与其他节点实现本发明中与其他主题之间的交互。例如,可以通过与用户的逻辑链接进行任务信息和数据的传输,从而获取用户的任务数据;通过和计算节点的逻辑链接进行资源数据的传输以及任务分配命令的传输,从而实现各个节点的资源信息的获取以及任务数据的分配。
参照图11,图11为本申请实施例提供的一种集群1100的结构示意图,如图11中示出的那样,所述集群1100包括多个计算节点1101,所述计算节点1101为任务数据提供所需的资源以执行所述任务数据,以及,所述集群1100还包括:图7对应的实施例中描述的第一管理节点700。
参照图12,图12为本申请实施例提供的一种集群的结构示意图,如图12中示出的那样,所述集群1200包括多个计算节点1201,所述计算节点1201为任务数据提供所需的资源以执行所述任务数据,以及,所述集群1200还包括:图8对应的实施例中描述的第二管理节点800。
参照图13,图13为本申请实施例提供的一种集群的结构示意图,如图13中示出的那样,所述集群1300包括多个计算节点1301,所述计算节点1301为任务数据提供所需的资源以执行所述任务数据,以及,所述集群1300还包括:图9对应的实施例中描述的第三管理节点900。
参照图14,图14为本申请实施例提供的一种分布式系统1400的结构示意图,如图14中示出的那样,所述分布式系统1400包括图11对应的实施例中描述的集群1100以及图12对应的实施例中描述的集群1200。
参照图15,图15为本申请实施例提供的一种分布式系统的结构示意图,如图12中示出的那样,所述分布式系统1500包括图11对应的实施例中描述的集群1100、图12对应的实施例中描述的集群1200以及图13对应的实施例中描述的集群1300。
在上述实施例中,可以全部或部分地通过软件、硬件、固件或者其任意组合来实现。当使用软件实现时,可以全部或部分地以计算机程序产品的形式实现。
所述计算机程序产品包括一个或多个计算机指令。在计算机上加载和执行所述计算机程序指令时,全部或部分地产生按照本发明实施例所述的流程或功能。所述计算机可以是通用计算机、专用计算机、计算机网络、或者其他可编程装置。所述计算机指令可以存储在计算机可读存储介质中,或者从一个计算机可读存储介质向另一计算机可读存储介质传输,例如,所述计算机指令可以从一个网站站点、计算机、服务器或数据中心通过有线(例如同轴电缆、光纤、数字用户线(Digital Subscriber Line,DSL))或无线(例如红外、无线、微波等)方式向另一个网站站点、计算机、服务器或数据中心进行传输。所述计算机可读存储介质可以是计算机能够存储的任何可用介质或者是包含一个或多个可用介质集成的服务器、数据中心等数据存储设备。所述可用介质可以是磁性介质,(例如,软盘、硬盘、磁带)、光介质(例如,DVD)、或者半导体介质(例如固态硬盘Solid State Disk(SSD))等。
所属领域的技术人员可以清楚地了解到,为描述的方便和简洁,上述描述的系统,装置和单元的具体工作过程,可以参考前述方法实施例中的对应过程,在此不再赘述。
在本申请所提供的几个实施例中,应该理解到,所揭露的系统,装置和方法,可以通过其它的方式实现。例如,以上所描述的装置实施例仅仅是示意性的,例如,所述单元的划分,仅仅为一种逻辑功能划分,实际实现时可以有另外的划分方式,例如多个单元或组件可以结合或者可以集成到另一个系统,或一些特征可以忽略,或不执行。另一点,所显示或讨论的相互之间的耦合或直接耦合或通信连接可以是通过一些接口,装置或单元的间接耦合或通信连接,可以是电性,机械或其它的形式。
所述作为分离部件说明的单元可以是或者也可以不是物理上分开的,作为单元显示的部件可以是或者也可以不是物理单元,即可以位于一个地方,或者也可以分布到多个网络单元上。可以根据实际的需要选择其中的部分或者全部单元来实现本实施例方案的目的。
另外,在本申请各个实施例中的各功能单元可以集成在一个处理单元中,也可以是各个单元单独物理存在,也可以两个或两个以上单元集成在一个单元中。上述集成的单元既可以采用硬件的形式实现,也可以采用软件功能单元的形式实现。
所述集成的单元如果以软件功能单元的形式实现并作为独立的产品销售或使用时,可以存储在一个计算机可读取存储介质中。基于这样的理解,本申请的技术方案本质上或者说对现有技术做出贡献的部分或者该技术方案的全部或部分可以以软件产品的形式体现出来,该计算机软件产品存储在一个存储介质中,包括若干指令用以使得一台计算机设备(可以是个人计算机,服务器,或者网络设备等)执行本申请各个实施例所述方法的全部或部分步骤。而前述的存储介质包括:U盘、移动硬盘、只读存储器(ROM,Read-Only Memory)、随机存取存储器(RAM,Random Access Memory)、磁碟或者光盘等各种可以存储程序代码的介质。
以上所述,以上实施例仅用以说明本申请的技术方案,而非对其限制;尽管参照前述实施例对本申请进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本申请各实施例技术方案的精神和范围。
Claims (48)
- 一种资源分配方法,其特征在于,所述方法包括:第一节点确定第一集群对应的哈希值;所述第一节点获取哈希环,所述哈希环包括至少一个哈希值区间,每个哈希值区间对应一个第二集群;所述第一节点根据所述第一集群对应的哈希值确定对应的目标第二集群,其中,所述第一集群对应的哈希值属于目标哈希区间,所述目标哈希区间为所述至少一个哈希值区间中的一个哈希值区间,所述目标哈希区间对应所述目标第二集群;所述第一节点建立第一集群和目标第二集群的关联关系,其中,与所述第一集群建立了关联关系的所述目标第二集群被允许从所述第一集群申请资源。
- 根据权利要求1所述的方法,其特征在于,所述哈希环包括第一哈希节点和第二哈希节点,所述第一哈希节点对应所述目标第二集群,所述第一哈希节点为所述哈希环上所述第二哈希节点的相邻后继节点,所述目标哈希区间为所述第一哈希节点的哈希值与所述第二哈希节点的哈希值之间的哈希区间。
- 根据权利要求1或2所述的方法,其特征在于,所述方法还包括:所述第一节点对包括多个计算节点的空闲集群进行划分,得到多个子集群,所述第一集群为所述多个子集群中的一个。
- 根据权利要求3所述的方法,其特征在于,所述多个子集群包括第三子集群和第四子集群,所述第三子集群为所述多个子集群中资源空闲量最大的子集群,所述第四子集群为所述多个子集群中资源空闲量最小的集群,所述第三子集群的资源空闲量与所述第四子集群的资源空闲量的差值的绝对值小于第一阈值。
- 根据权利要求3所述的方法,其特征在于,所述多个子集群中的每个子集群的资源空闲量与预设资源空闲量的差值的绝对值小于或等于第二阈值,所述预设资源空闲量与历史资源请求量相关。
- 根据权利要求1至5任一所述的方法,其特征在于,所述方法还包括:所述第一节点接收所述目标第二集群发送的第一资源借调请求,所述第一资源借调请求包括任务数据和第一集群的标识;所述第一节点根据所述第一集群的标识向所述第一集群发送所述任务数据。
- 根据权利要求1至6任一所述的方法,其特征在于,所述哈希环包括Y个哈希节点,每个第二集群对应至少一个哈希节点,且所述Y个哈希节点的对应的哈希值和所述第一集群对应的哈希值为根据相同的哈希算法生成的,所述Y为正整数。
- 根据权利要求1至7任一所述的方法,其特征在于,所述第一节点获取哈希环,包括:所述第一节点确定X个第二集群对应的Y个哈希值,其中,每个第二集群对应至少一个哈希值,所述X正整数,所述Y为大于或等于X的正整数;所述第一节点根据所述Y个哈希值生成所述哈希环,其中,所述哈希环包括Y个哈希节点,每个第二集群对应至少一个哈希节点,所述Y个哈希节点将所述哈希环划分为Y个 哈希值区间,每个哈希节点对应一个哈希值区间。
- 根据权利要求1至7任一所述的方法,其特征在于,所述第一节点获取哈希环,包括:所述第一节点接收所述第二集群发送的所述哈希环。
- 根据权利要求1至9任一所述的方法,其特征在于,所述方法还包括:所述第一节点向所述目标第二集群发送所述第一集群的资源空闲量。
- 一种资源借调方法,其特征在于,所述方法包括:第二节点确定与目标第二集群具有关联关系的第一集群,其中,所述第二节点属于所述目标第二集群,所述目标第二集群对应于哈希环中的目标哈希值区间,所述第一集群对应的哈希值属于所述目标哈希值区间;所述第二节点接收任务数据;所述第二节点向第一节点发送第一资源借调请求,所述第一资源借调请求用于指示所述第一节点将所述任务数据分配给所述第一集群处理。
- 根据权利要求11所述的方法,其特征在于,所述方法还包括:所述第二节点基于向第一节点发送第一资源借调请求,确定所述第一集群处于资源不可借调状态。
- 根据权利要求12所述的方法,其特征在于,所述方法还包括:所述第二节点接收第一节点发送的第一集群的资源空闲量。
- 根据权利要求11至13任一所述的方法,其特征在于,与所述目标第二集群具有关联关系的集群有多个,所述第二节点确定与目标第二集群具有关联关系的第一集群,包括:所述第二节点确定与所述目标第二集群具有关联关系的多个集群中的一个集群为第一集群。
- 根据权利要求14所述的方法,其特征在于,所述第二节点确定与所述目标第二集群具有关联关系的多个集群中的一个集群为第一集群,包括:所述第二节点确定与所述目标第二集群具有关联关系的多个集群的资源空闲量中,与所述任务数据的资源需求量差值最小的资源空闲量对应的集群为所述第一集群。
- 根据权利要求11至15任一所述的方法,其特征在于,所述方法还包括:所述第二节点接收第三节点发送的所述任务数据的资源需求量;基于所述第一集群的资源空闲量大于或等于所述资源需求量,所述第二节点向所述第三节点发送所述第一集群的标识和第一集群的资源空闲量。
- 根据权利要求16所述的方法,其特征在于,所述第二节点接收任务数据包括:所述第二节点接收所述第三节点发送的第二资源借调请求,所述第二资源借调请求包括所述任务数据,所述第二借调请求用于指示所述第二节点将所述任务数据分配给所述第一集群处理。
- 一种资源借调方法,其特征在于,包括:第二节点接收第三节点发送的任务数据的资源需求量;所述第二节点确定与目标第二集群具有关联关系的第一集群,其中,所述第二节点属于所述目标第二集群,所述目标第二集群对应于哈希环中的目标哈希值区间,所述第一集群对应的哈希值属于所述目标哈希值区间;基于所述第一集群的资源空闲量大于或等于所述资源需求量,所述第二节点向所述第三节点发送第三资源借调请求,所述第三资源借调请求用于指示所述第三节点被允许从所述第一集群申请资源。
- 根据权利要求18所述的方法,其特征在于,与所述目标第二集群具有关联关系的集群有多个,所述第二节点确定与目标第二集群具有关联关系的第一集群,包括:所述第二节点确定与所述目标第二集群具有关联关系的多个集群中的一个集群为第一集群。
- 一种资源借调方法,其特征在于,包括:第三节点接收任务数据;所述第三节点向第二节点发送所述任务数据的资源需求量;所述第三节点接收所述第二节点发送的第三资源借调请求,所述第三资源借调请求用于指示所述第三节点被允许从第一集群申请资源,其中,所述第二节点属于目标第二集群,所述目标第二集群对应于哈希环中的目标哈希值区间,所述第一集群对应的哈希值属于所述目标哈希值区间,且所述第一集群的资源空闲量大于或等于所述资源需求量;所述第三节点向第一节点发送第一资源借调请求,所述第一借调请求用于指示所述第一节点将所述任务数据分配给所述第一集群处理。
- 根据权利要求20所述的方法,其特征在于,所述第三节点向第二节点发送所述任务数据的资源需求量,包括:所述第三节点向多个节点发送所述任务数据的资源需求量,所述第二节点为所述多个节点中的一个;所述第三节点接收所述第二节点发送的第三资源借调请求,包括:所述第三节点接收所述多个节点发送的第三资源借调请求,所述第三资源借调请求用于指示所述第三节点被允许从多个子集群申请资源,所述第一集群为所述多个子集群中的一个。
- 根据权利要求21所述的方法,其特征在于,所述方法还包括:所述第三节点确定所述多个子集群的资源空闲量中,与所述任务数据的资源需求量的差值最小的资源空闲量对应的子集群为所述第一集群。
- 一种第一管理节点,其特征在于,所述第一管理节点包括:处理模块,用于确定第一集群对应的哈希值;获取哈希环,所述哈希环包括至少一个哈希值区间,每个哈希值区间对应一个第二集群;根据所述第一集群对应的哈希值确定对应的目标第二集群,其中,所述第一集群对应的哈希值属于目标哈希区间,所述目标哈希区间为所述至少一个哈希值区间中的一个哈希值区间,所述目标哈希区间对应所述目标第二集群;收发模块,用于建立第一集群和目标第二集群的关联关系,其中,与所述第一集群建 立了关联关系的所述目标第二集群被允许从所述第一集群申请资源。
- 根据权利要求23所述的第一管理节点,其特征在于,所述哈希环包括第一哈希节点和第二哈希节点,所述第一哈希节点对应所述目标第二集群,所述第一哈希节点为所述哈希环上所述第二哈希节点的相邻后继节点,所述目标哈希区间为所述第一哈希节点的哈希值与所述第二哈希节点的哈希值之间的哈希区间。
- 根据权利要求23或24所述的第一管理节点,其特征在于,所述处理模块,还用于对包括多个计算节点的空闲集群进行划分,得到多个子集群,所述第一集群为所述多个子集群中的一个。
- 根据权利要求25所述的第一管理节点,其特征在于,所述多个子集群包括第三子集群和第四子集群,所述第三子集群为所述多个子集群中资源空闲量最大的子集群,所述第四子集群为所述多个子集群中资源空闲量最小的集群,所述第三子集群的资源空闲量与所述第四子集群的资源空闲量的差值的绝对值小于第一阈值。
- 根据权利要求25所述的第一管理节点,其特征在于,所述多个子集群中的每个子集群的资源空闲量与预设资源空闲量的差值的绝对值小于或等于第二阈值,所述预设资源空闲量与历史资源请求量相关。
- 根据权利要求23至27任一所述的第一管理节点,其特征在于,所述收发模块还用于:接收所述目标第二集群发送的第一资源借调请求,所述第一资源借调请求包括任务数据和第一集群的标识;根据所述第一集群的标识向所述第一集群发送所述任务数据。
- 根据权利要求23至28任一所述的第一管理节点,其特征在于,所述哈希环包括Y个哈希节点,每个第二集群对应至少一个哈希节点,且所述Y个哈希节点的对应的哈希值和所述第一集群对应的哈希值为根据相同的哈希算法生成的,所述Y为正整数。
- 根据权利要求23至29任一所述的第一管理节点,其特征在于,所述处理模块,还用于确定X个第二集群对应的Y个哈希值,其中,每个第二集群对应至少一个哈希值,所述X正整数,所述Y为大于或等于X的正整数;根据所述Y个哈希值生成所述哈希环,其中,所述哈希环包括Y个哈希节点,每个第二集群对应至少一个哈希节点,所述Y个哈希节点将所述哈希环划分为Y个哈希值区间,每个哈希节点对应一个哈希值区间。
- 根据权利要求23至29任一所述的第一管理节点,其特征在于,所述收发模块,还用于接收所述第二集群发送的所述哈希环。
- 根据权利要求23至31任一所述的第一管理节点,其特征在于,所述收发模块,还用于向所述目标第二集群发送所述第一集群的资源空闲量。
- 一种第二管理节点,其特征在于,所述第二管理节点包括:处理模块,用于确定与目标第二集群具有关联关系的第一集群,其中,所述第二节点属于所述目标第二集群,所述目标第二集群对应于哈希环中的目标哈希值区间,所述第一集群对应的哈希值属于所述目标哈希值区间;收发模块,用于接收任务数据,并向第一节点发送第一资源借调请求,所述第一借调 请求用于指示所述第一节点将所述任务数据分配给所述第一集群处理。
- 根据权利要求33所述的第二管理节点,其特征在于,所述处理模块,还用于基于收发模块向第一节点发送第一资源借调请求,确定所述第一集群处于资源不可借调状态。
- 根据权利要求33或34所述的第二管理节点,其特征在于,与所述目标第二集群具有关联关系的集群有多个,所述处理模块,具体用于确定与所述目标第二集群具有关联关系的多个集群中的一个集群为第一集群。
- 根据权利要求35所述的第二管理节点,其特征在于,所述处理模块,具体用于确定与所述目标第二集群具有关联关系的多个集群的资源空闲量中,与所述任务数据的资源需求量差值最小的资源空闲量对应的集群为所述第一集群。
- 根据权利要求33至36任一所述的第二管理节点,其特征在于,所述收发模块,还用于接收第三节点发送的所述任务数据的资源需求量,并基于所述第一集群的资源空闲量大于或等于所述资源需求量,向所述第三节点发送所述第一集群的标识和第一集群的资源空闲量。
- 根据权利要求37所述的第二管理节点,其特征在于,所述收发模块,具体用于接收所述第三节点发送的第二资源借调请求,所述第二资源借调请求包括所述任务数据,所述第二借调请求用于指示所述第二节点将所述任务数据分配给所述第一集群处理。
- 一种第二管理节点,其特征在于,所述第二管理节点包括:收发模块,用于接收第三节点发送的任务数据的资源需求量;处理模块,用于确定与目标第二集群具有关联关系的第一集群,其中,所述第二节点属于所述目标第二集群,所述目标第二集群对应于哈希环中的目标哈希值区间,所述第一集群对应的哈希值属于所述目标哈希值区间;所述收发模块,还用于基于所述第一集群的资源空闲量大于或等于所述资源需求量,向所述第三节点发送第三资源借调请求,所述第三资源借调请求用于指示所述第三节点被允许从所述第一集群申请资源。
- 根据权利要求39所述的第二管理节点,其特征在于,与所述目标第二集群具有关联关系的集群有多个,所述处理模块,具体用于确定与所述目标第二集群具有关联关系的多个集群中的一个集群为第一集群。
- 一种第三管理节点,其特征在于,所述第三管理节点包括:收发模块,用于接收任务数据,向第二节点发送所述任务数据的资源需求量,接收所述第二节点发送的第三资源借调请求,所述第三资源借调请求用于指示所述第三节点被允许从第一集群申请资源,其中,所述第二节点属于目标第二集群,所述目标第二集群对应于哈希环中的目标哈希值区间,所述第一集群对应的哈希值属于所述目标哈希值区间,且所述第一集群的资源空闲量大于或等于所述资源需求量,向第一节点发送第一资源借调请求,所述第一借调请求用于指示所述第一节点将所述任务数据分配给所述第一集群处理。
- 根据权利要求41所述的第三管理节点,其特征在于,所述收发模块,具体用于向多个节点发送所述任务数据的资源需求量,所述第二节点为所述多个节点中的一个,接收所述多个节点发送的第三资源借调请求,所述第三资源借调请求用于指示所述第三节点被 允许从多个子集群申请资源,所述第一集群为所述多个子集群中的一个。
- 根据权利要求42所述的第三管理节点,其特征在于,所述第三管理节点还包括:处理模块,用于确定所述多个子集群的资源空闲量中,与所述任务数据的资源需求量的差值最小的资源空闲量对应的子集群为所述第一集群。
- 一种集群,其特征在于,所述集群包括多个计算节点,所述计算节点为任务数据提供所需的资源以执行所述任务数据,以及,所述集群还包括:如权利要求23-32中任意一项权利要求所述的第一管理节点。
- 一种集群,其特征在于,所述集群包括多个计算节点,所述计算节点为任务数据提供所需的资源以执行所述任务数据,以及,所述集群还包括:如权利要求33-40中任意一项权利要求所述的第二管理节点。
- 一种集群,其特征在于,所述集群包括多个计算节点,所述计算节点为任务数据提供所需的资源以执行所述任务数据,以及,所述集群还包括:如权利要求41至43中任意一项权利要求所述的第三管理节点。
- 一种分布式系统,其特征在于,所述分布式系统包括如权利要求44所述的集群和权利要求45所述的集群。
- 一种分布式系统,其特征在于,所述分布式系统包括如权利要求44所述的集群、权利要求45所述的集群以及如权利要求46所述的集群。
Priority Applications (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| EP20846626.8A EP4002115A4 (en) | 2019-07-31 | 2020-07-29 | Resource allocation method and resource offloading method |
| US17/588,983 US12386671B2 (en) | 2019-07-31 | 2022-01-31 | Resource allocation method and resource borrowing method |
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN201910704756.7 | 2019-07-31 | ||
| CN201910704756.7A CN112306651B (zh) | 2019-07-31 | 2019-07-31 | 一种资源分配方法和资源借调方法 |
Related Child Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| US17/588,983 Continuation US12386671B2 (en) | 2019-07-31 | 2022-01-31 | Resource allocation method and resource borrowing method |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2021018183A1 true WO2021018183A1 (zh) | 2021-02-04 |
Family
ID=74229226
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/CN2020/105476 Ceased WO2021018183A1 (zh) | 2019-07-31 | 2020-07-29 | 一种资源分配方法和资源借调方法 |
Country Status (4)
| Country | Link |
|---|---|
| US (1) | US12386671B2 (zh) |
| EP (1) | EP4002115A4 (zh) |
| CN (1) | CN112306651B (zh) |
| WO (1) | WO2021018183A1 (zh) |
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2023005317A1 (zh) * | 2021-07-27 | 2023-02-02 | 华为技术有限公司 | 通信系统、方法及装置 |
| WO2024082692A1 (zh) * | 2022-10-21 | 2024-04-25 | 华为技术有限公司 | 执行任务的方法和异构服务器 |
Families Citing this family (12)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US11847503B2 (en) * | 2020-01-28 | 2023-12-19 | Hewlett Packard Enterprise Development Lp | Execution of functions by clusters of computing nodes |
| CN113473488B (zh) * | 2021-07-02 | 2024-01-30 | 福建晶一科技有限公司 | 一种基于容器的cu与mec共平台部署方法 |
| CN114185661B (zh) * | 2021-12-10 | 2026-01-13 | 北京百度网讯科技有限公司 | 一种任务处理方法、装置、设备以及存储介质 |
| CN115001969B (zh) * | 2022-05-24 | 2024-06-14 | 北京金玖银玖数字科技有限公司 | 一种数据存储节点部署方法、数据存储方法、装置及设备 |
| US20230419327A1 (en) * | 2022-06-22 | 2023-12-28 | AnChain.ai, Inc. | Secure and scalable blockchain smart contract-based digital asset platform |
| US12524720B1 (en) * | 2022-06-30 | 2026-01-13 | Amazon Technologies, Inc. | Resource sharing between vehicles |
| US20240012664A1 (en) * | 2022-07-07 | 2024-01-11 | Vmware, Inc. | Cross-cluster service resource discovery |
| CN114979282B (zh) * | 2022-07-28 | 2023-01-20 | 北京金山云网络技术有限公司 | 任务调度方法、装置、存储介质以及电子设备 |
| CN115562853B (zh) * | 2022-09-16 | 2025-07-15 | 华中科技大学 | 一种面向混合负载的资源动态管理方法及管理系统 |
| CN115941660A (zh) * | 2022-11-23 | 2023-04-07 | 内蒙古欣荣惠信息技术有限公司 | 未成年人保护系统及方法 |
| CN117195054B (zh) * | 2023-09-15 | 2024-03-26 | 苏州优鲜生网络科技有限公司 | 基于集群的跨节点数据识别方法与系统 |
| US12463918B2 (en) * | 2024-03-18 | 2025-11-04 | Cisco Technology, Inc. | Decentralized approach to identify objects across a federation in a network |
Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN102130938A (zh) * | 2010-12-03 | 2011-07-20 | 中国科学院软件研究所 | 一种面向Web应用宿主平台的资源供给方法 |
| US20170070567A1 (en) * | 2015-09-07 | 2017-03-09 | Electronics And Telecommunications Research Institute | Load balancing apparatus and load balancing method |
| CN108132830A (zh) * | 2016-12-01 | 2018-06-08 | 北京金山云网络技术有限公司 | 一种任务调度方法、装置及系统 |
| CN108173937A (zh) * | 2017-12-28 | 2018-06-15 | 北京中电普华信息技术有限公司 | 访问控制方法和装置 |
Family Cites Families (29)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US5612865A (en) * | 1995-06-01 | 1997-03-18 | Ncr Corporation | Dynamic hashing method for optimal distribution of locks within a clustered system |
| US7779415B2 (en) * | 2003-11-21 | 2010-08-17 | International Business Machines Corporation | Adaptive load distribution in managing dynamic and transient data for distributed applications |
| GB2417580A (en) * | 2004-08-26 | 2006-03-01 | Hewlett Packard Development Co | Method for executing a bag of tasks application on a cluster by loading a slave process onto an idle node in the cluster |
| JP4961833B2 (ja) * | 2006-05-19 | 2012-06-27 | 日本電気株式会社 | クラスタシステム、負荷分散方法、最適化クライアントプログラム、及び調停サーバプログラム |
| JP2007325235A (ja) * | 2006-06-05 | 2007-12-13 | Ricoh Co Ltd | 電子機器 |
| US8244846B2 (en) * | 2007-12-26 | 2012-08-14 | Symantec Corporation | Balanced consistent hashing for distributed resource management |
| US8484354B2 (en) | 2009-11-02 | 2013-07-09 | Beaumaris Networks, Inc. | Distributed resource management |
| US20110153826A1 (en) | 2009-12-22 | 2011-06-23 | Microsoft Corporation | Fault tolerant and scalable load distribution of resources |
| US8510267B2 (en) * | 2011-03-08 | 2013-08-13 | Rackspace Us, Inc. | Synchronization of structured information repositories |
| US8949308B2 (en) * | 2012-01-23 | 2015-02-03 | Microsoft Corporation | Building large scale infrastructure using hybrid clusters |
| US9448966B2 (en) * | 2013-04-26 | 2016-09-20 | Futurewei Technologies, Inc. | System and method for creating highly scalable high availability cluster in a massively parallel processing cluster of machines in a network |
| US9871855B2 (en) * | 2014-09-19 | 2018-01-16 | Facebook, Inc. | Balancing load across cache servers in a distributed data store |
| US20160105323A1 (en) * | 2014-10-14 | 2016-04-14 | Microsoft Corporation | Node identification using clusters |
| CN104461740B (zh) | 2014-12-12 | 2018-03-20 | 国家电网公司 | 一种跨域集群计算资源聚合和分配的方法 |
| US9619391B2 (en) * | 2015-05-28 | 2017-04-11 | International Business Machines Corporation | In-memory caching with on-demand migration |
| US20160378846A1 (en) * | 2015-06-26 | 2016-12-29 | Intel Corporation | Object based storage cluster with multiple selectable data handling policies |
| CN106991008B (zh) * | 2016-01-20 | 2020-12-18 | 华为技术有限公司 | 一种资源锁管理方法、相关设备及系统 |
| CN108009016B (zh) * | 2016-10-31 | 2021-10-22 | 华为技术有限公司 | 一种资源负载均衡控制方法及集群调度器 |
| US10346191B2 (en) * | 2016-12-02 | 2019-07-09 | Wmware, Inc. | System and method for managing size of clusters in a computing environment |
| CN107197035A (zh) * | 2017-06-21 | 2017-09-22 | 中国民航大学 | 一种基于一致性哈希算法的亲和性动态负载均衡方法 |
| CN107801086B (zh) * | 2017-10-20 | 2019-01-04 | 广东省南方数字电视无线传播有限公司 | 多缓存服务器的调度方法和系统 |
| CN110022337A (zh) * | 2018-01-09 | 2019-07-16 | 阿里巴巴集团控股有限公司 | 资源调度方法、装置、设备和系统 |
| US11294601B2 (en) * | 2018-07-10 | 2022-04-05 | Here Data Technology | Method of distributed data redundancy storage using consistent hashing |
| CN109040212B (zh) * | 2018-07-24 | 2021-09-21 | 苏州科达科技股份有限公司 | 设备接入服务器集群方法、系统、设备及存储介质 |
| CN109347917A (zh) * | 2018-09-14 | 2019-02-15 | 北京沃杰知识产权有限公司 | 区块链数据共识处理方法、系统、存储介质和电子设备 |
| CN110071978B (zh) * | 2019-04-28 | 2022-04-22 | 新华三信息安全技术有限公司 | 一种集群管理的方法及装置 |
| CN112019581B (zh) | 2019-05-30 | 2022-02-25 | 华为技术有限公司 | 一种调度任务处理实体的方法及装置 |
| CN110489059B (zh) * | 2019-07-11 | 2022-04-12 | 平安科技(深圳)有限公司 | 数据集群存储的方法、装置及计算机设备 |
| US11023145B2 (en) * | 2019-07-30 | 2021-06-01 | EMC IP Holding Company LLC | Hybrid mapped clusters for data storage |
-
2019
- 2019-07-31 CN CN201910704756.7A patent/CN112306651B/zh active Active
-
2020
- 2020-07-29 WO PCT/CN2020/105476 patent/WO2021018183A1/zh not_active Ceased
- 2020-07-29 EP EP20846626.8A patent/EP4002115A4/en active Pending
-
2022
- 2022-01-31 US US17/588,983 patent/US12386671B2/en active Active
Patent Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN102130938A (zh) * | 2010-12-03 | 2011-07-20 | 中国科学院软件研究所 | 一种面向Web应用宿主平台的资源供给方法 |
| US20170070567A1 (en) * | 2015-09-07 | 2017-03-09 | Electronics And Telecommunications Research Institute | Load balancing apparatus and load balancing method |
| CN108132830A (zh) * | 2016-12-01 | 2018-06-08 | 北京金山云网络技术有限公司 | 一种任务调度方法、装置及系统 |
| CN108173937A (zh) * | 2017-12-28 | 2018-06-15 | 北京中电普华信息技术有限公司 | 访问控制方法和装置 |
Non-Patent Citations (1)
| Title |
|---|
| See also references of EP4002115A4 |
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2023005317A1 (zh) * | 2021-07-27 | 2023-02-02 | 华为技术有限公司 | 通信系统、方法及装置 |
| WO2024082692A1 (zh) * | 2022-10-21 | 2024-04-25 | 华为技术有限公司 | 执行任务的方法和异构服务器 |
Also Published As
| Publication number | Publication date |
|---|---|
| EP4002115A1 (en) | 2022-05-25 |
| CN112306651B (zh) | 2024-09-06 |
| US20220156115A1 (en) | 2022-05-19 |
| EP4002115A4 (en) | 2022-12-07 |
| US12386671B2 (en) | 2025-08-12 |
| CN112306651A (zh) | 2021-02-02 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| WO2021018183A1 (zh) | 一种资源分配方法和资源借调方法 | |
| CN109564528B (zh) | 分布式计算中计算资源分配的系统和方法 | |
| CN104580396B (zh) | 一种任务调度方法、节点及系统 | |
| EP2919116B1 (en) | Global memory sharing method and device and communication system | |
| CN103327072B (zh) | 一种集群负载均衡的方法及其系统 | |
| CN107688492B (zh) | 资源的控制方法、装置和集群资源管理系统 | |
| CN110221920B (zh) | 部署方法、装置、存储介质及系统 | |
| CN102387173B (zh) | 一种MapReduce系统及其调度任务的方法和装置 | |
| CN108268318A (zh) | 一种分布式系统任务分配的方法和装置 | |
| CN112817728B (zh) | 任务调度方法、网络设备和存储介质 | |
| CN104166597B (zh) | 一种分配远程内存的方法及装置 | |
| US8627325B2 (en) | Scheduling memory usage of a workload | |
| CN115629865B (zh) | 一种基于边缘计算的深度学习推理任务调度方法 | |
| CN112506821B (zh) | 一种系统总线接口请求仲裁方法及相关组件 | |
| US11947534B2 (en) | Connection pools for parallel processing applications accessing distributed databases | |
| CN106131244A (zh) | 一种报文传送方法及装置 | |
| CN118210629A (zh) | 内存分配方法及电子设备 | |
| CN118631847A (zh) | 电力物联业务分布式动态调度方法、装置、设备及介质 | |
| WO2026051571A1 (zh) | 数据的处理方法、系统、电子设备和存储介质 | |
| CN105607955A (zh) | 一种计算任务分配的方法及装置 | |
| CN117056064A (zh) | 资源分配方法、装置、服务器、存储介质和程序产品 | |
| CN104301944A (zh) | 资源能力分配方法和设备 | |
| CN109298949B (zh) | 一种分布式文件系统的资源调度系统 | |
| CN116225612B (zh) | 一种容器调度方法、装置和系统 | |
| CN113472591B (zh) | 一种业务性能的确定方法及装置 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 20846626 Country of ref document: EP Kind code of ref document: A1 |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| ENP | Entry into the national phase |
Ref document number: 2020846626 Country of ref document: EP Effective date: 20220218 |