WO2021066167A1 - ヘパリン様物質の製造方法、組換え細胞及びその製造方法 - Google Patents
ヘパリン様物質の製造方法、組換え細胞及びその製造方法 Download PDFInfo
- Publication number
- WO2021066167A1 WO2021066167A1 PCT/JP2020/037626 JP2020037626W WO2021066167A1 WO 2021066167 A1 WO2021066167 A1 WO 2021066167A1 JP 2020037626 W JP2020037626 W JP 2020037626W WO 2021066167 A1 WO2021066167 A1 WO 2021066167A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- amino acid
- seq
- acid sequence
- heparin
- sequence
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Ceased
Links
Images









Classifications
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12P—FERMENTATION OR ENZYME-USING PROCESSES TO SYNTHESISE A DESIRED CHEMICAL COMPOUND OR COMPOSITION OR TO SEPARATE OPTICAL ISOMERS FROM A RACEMIC MIXTURE
- C12P19/00—Preparation of compounds containing saccharide radicals
- C12P19/26—Preparation of nitrogen-containing carbohydrates
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K14/00—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- C07K14/435—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans
- C07K14/705—Receptors; Cell surface antigens; Cell surface determinants
-
- C—CHEMISTRY; METALLURGY
- C08—ORGANIC MACROMOLECULAR COMPOUNDS; THEIR PREPARATION OR CHEMICAL WORKING-UP; COMPOSITIONS BASED THEREON
- C08B—POLYSACCHARIDES; DERIVATIVES THEREOF
- C08B37/00—Preparation of polysaccharides not provided for in groups C08B1/00 - C08B35/00; Derivatives thereof
- C08B37/006—Heteroglycans, i.e. polysaccharides having more than one sugar residue in the main chain in either alternating or less regular sequence; Gellans; Succinoglycans; Arabinogalactans; Tragacanth or gum tragacanth or traganth from Astragalus; Gum Karaya from Sterculia urens; Gum Ghatti from Anogeissus latifolia; Derivatives thereof
- C08B37/0063—Glycosaminoglycans or mucopolysaccharides, e.g. keratan sulfate; Derivatives thereof, e.g. fucoidan
- C08B37/0075—Heparin; Heparan sulfate; Derivatives thereof, e.g. heparosan; Purification or extraction methods thereof
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K14/00—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- C07K14/435—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans
- C07K14/46—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans from vertebrates
- C07K14/47—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans from vertebrates from mammals
- C07K14/4701—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans from vertebrates from mammals not used
- C07K14/4725—Proteoglycans, e.g. aggreccan
-
- C—CHEMISTRY; METALLURGY
- C08—ORGANIC MACROMOLECULAR COMPOUNDS; THEIR PREPARATION OR CHEMICAL WORKING-UP; COMPOSITIONS BASED THEREON
- C08L—COMPOSITIONS OF MACROMOLECULAR COMPOUNDS
- C08L5/00—Compositions of polysaccharides or of their derivatives not provided for in groups C08L1/00 or C08L3/00
- C08L5/10—Heparin; Derivatives thereof
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/63—Introduction of foreign genetic material using vectors; Vectors; Use of hosts therefor; Regulation of expression
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/63—Introduction of foreign genetic material using vectors; Vectors; Use of hosts therefor; Regulation of expression
- C12N15/79—Vectors or expression systems specially adapted for eukaryotic hosts
- C12N15/85—Vectors or expression systems specially adapted for eukaryotic hosts for animal cells
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N5/00—Undifferentiated human, animal or plant cells, e.g. cell lines; Tissues; Cultivation or maintenance thereof; Culture media therefor
- C12N5/06—Animal cells or tissues; Human cells or tissues
- C12N5/0602—Vertebrate cells
- C12N5/0681—Cells of the genital tract; Non-germinal cells from gonads
- C12N5/0682—Cells of the female genital tract, e.g. endometrium; Non-germinal cells from ovaries, e.g. ovarian follicle cells
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N5/00—Undifferentiated human, animal or plant cells, e.g. cell lines; Tissues; Cultivation or maintenance thereof; Culture media therefor
- C12N5/10—Cells modified by introduction of foreign genetic material
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N9/00—Enzymes; Proenzymes; Compositions thereof; Processes for preparing, activating, inhibiting, separating or purifying enzymes
- C12N9/10—Transferases (2.)
- C12N9/13—Transferases (2.) transferring sulfur containing groups (2.8)
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Y—ENZYMES
- C12Y208/00—Transferases transferring sulfur-containing groups (2.8)
- C12Y208/02—Sulfotransferases (2.8.2)
- C12Y208/02008—[Heparan sulfate]-glucosamine N-sulfotransferase (2.8.2.8)
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2510/00—Genetically modified cells
- C12N2510/02—Cells for production
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2800/00—Nucleic acids vectors
- C12N2800/10—Plasmid DNA
- C12N2800/106—Plasmid DNA for vertebrates
- C12N2800/107—Plasmid DNA for vertebrates for mammalian
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2800/00—Nucleic acids vectors
- C12N2800/90—Vectors containing a transposable element
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2840/00—Vectors comprising a special translation-regulating system
- C12N2840/20—Vectors comprising a special translation-regulating system translation of more than one cistron
- C12N2840/203—Vectors comprising a special translation-regulating system translation of more than one cistron having an IRES
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Y—ENZYMES
- C12Y208/00—Transferases transferring sulfur-containing groups (2.8)
- C12Y208/02—Sulfotransferases (2.8.2)
- C12Y208/02023—[Heparan sulfate]-glucosamine 3-sulfotransferase 1 (2.8.2.23)
Definitions
- the present invention relates to a method for producing a heparin-like substance, recombinant cells, and a method for producing the same.
- Heparin is an indispensable drug used in medical settings such as dialysis and extracorporeal circulation as an anticoagulant. Heparin is used in an injectable form, for example as a prophylactic or therapeutic agent for thromboembolism. Heparin is also used to form anticoagulant surfaces on various experimental and medical devices, such as renal dialysis machines.
- Heparin is a polysaccharide that is one of the four major subfamilies of glycosaminoglycans (hereinafter, also abbreviated as GAG).
- GAG is a long polysaccharide consisting of repetitive disaccharide units.
- GAG is mainly (1) heparan sulfate (hereinafter, also abbreviated as HS) / heparin, (2) keratan sulfate (KS), (3) chondroitin / dermatan sulfate (CS / DS), (4) hyaluronic acid or hyaluronan. It is classified into four subfamilies of (HA).
- the GAG subfamilies differ from each other in monosaccharide components, glycosylation, and the position and degree of sugar. With the exception of HA, GAG is covalently bound to the core protein, and GAG covalently bound to the core protein is known as a proteoglycan.
- Heparin and HS are heterogeneous compounds of acidic mucopolysaccharides, and heparin is a type of HS.
- Heparin / HS consists of disaccharides of uronic acid ( ⁇ -D-glucuronic acid and ⁇ -L-iduronic acid) and glucosamine (DN-acetylglucosamine and DN-glucosamine sulfate) as one unit. Is a linear polysaccharide in which ⁇ or ⁇ -1,4 bonds are repeated tens to hundreds of times. The molecular weight varies from 3 to 30 kDa depending on the difference in chain length, and averages 12 to 15 kDa.
- Modifications to heparin / HS include, for example, O-sulfation of the 2-position of uronic acid, O-sulfation of the 3- and 6-positions of glucosamine, and N-sulfation of the amino group at the 2-position.
- HS regulates cell growth and development by regulating growth factors such as fibroblast growth factor (FGF) family, platelet-derived growth factor (PDGF), and vascular endothelial growth factor (VEGF).
- FGF fibroblast growth factor
- PDGF platelet-derived growth factor
- VEGF vascular endothelial growth factor
- heparin is mainly produced by mast cells.
- Heparin used in pharmaceutical products is mainly extracted and purified from the small intestine of pigs or the lungs of cattle.
- heparin obtained from these sources is associated with some adverse events due to contamination with persulfated chondroitin sulfate (Non-Patent Document 1).
- the isolation of heparin from animal tissues carries the risk of transmitting disease pathogens such as viruses, bacteria and infectious spongiform encephalopathy from animals to humans. Therefore, it is desired to develop a new production technique for heparin that does not use animal-derived tissues.
- heparin can be synthesized by chemical or chemoenzymatic methods, it is difficult to produce heterogeneous populations present in animal-derived heparin.
- Cindecane is a family of four proteoglycans on the cell surface with retained plasma membrane domain and cytoplasmic domain. Covalently bound glycosaminoglycan chains are present in the extracellular domain. They are mainly heparan sulfate (HS) and also include chondroitin sulfate (CS) (Non-Patent Document 2).
- HS heparan sulfate
- CS chondroitin sulfate
- an object of the present invention is to provide a production method for efficiently producing a heparinoid substance without using an animal-derived tissue.
- the present inventors have found that the above-mentioned problems can be solved by introducing a gene encoding the extracellular domain of Cindecane into mammalian cells producing a heparinoid substance, and have completed the present invention.
- the present invention is as follows. 1.
- a method for producing a heparinoid substance which comprises the following steps (1) to (3).
- An extracellular domain of Cindecane (hereinafter abbreviated as SDC) is added to a mammalian cell that produces a heparin-like substance prepared in step (1).
- Steps of preparing recombinant cells into which the gene encoding the above is introduced (3) Steps of culturing the recombinant cells prepared in step (2) in a medium and recovering a heparin-like substance from the obtained culture supernatant.
- the mammalian cells that produce the heparin-like substance include a gene encoding bifunctional heparan sulfate N-deacetylase / N-sulfate transferase (hereinafter abbreviated as NDST2) and heparan sulfate glucosamine 3 sulfate transfer.
- NDST2 bifunctional heparan sulfate N-deacetylase / N-sulfate transferase
- Hs3st1 heparan sulfate glucosamine 3 sulfate transfer.
- NDST2 is a protein containing the amino acid sequence of any one of (1a) to (1c) below and having the function of NDST2.
- Hs3st1 is a protein containing the amino acid sequence of any one of (2a) to (2c) below and having the function of Hs3st1.
- Nucleotide sequence complementary to the base sequence and base sequence that hybridizes under stringent conditions (2D) Base sequence having 80% or more homology with the base sequence shown in SEQ ID NO: 5.
- the gene encoding the extracellular domain of SDC is the base sequence of any one of (3A) to (3D) below, and the base sequence encoding the amino acid sequence of the protein having the function of the extracellular domain of SDC.
- the production method according to any one of 1 to 9 above, which comprises.
- Nucleotide sequence complementary to the base sequence and base sequence that hybridizes under stringent conditions (3D) Base sequence having 80% or more homology with the base sequence shown in SEQ ID NO: 6. Recombinant cells in which a gene encoding the extracellular domain of SDC is introduced into mammalian cells that produce heparinoids. 12. 11.
- the recombinant cell according to 11 above wherein the mammalian cell producing the heparin-like substance is a cell into which at least one of a gene encoding NDST2 and a gene encoding Hs3st1 has been introduced. 13.
- the recombinant cell according to 11 or 12 wherein the mammalian cell is a CHO cell.
- a method for producing a cell that secretes and produces a heparin-like substance which comprises a step of introducing a recombinant expression vector containing a gene encoding the extracellular domain of SDC into a mammalian cell that produces a heparin-like substance.
- a gene encoding the extracellular domain of Cindecane is introduced into a mammalian cell producing a heparin-like substance to secrete and produce the heparin-like substance in a culture supernatant.
- the heparin-like substance can be recovered from the culture supernatant.
- FIG. 1 is a diagram showing the results of measuring the amount of sGAG in the culture supernatant of CHO / NH-SRGN cells and CHO / NH-SDC cells by the sGAG assay.
- FIG. 2 is a diagram showing the results of measuring the amount of sGAG in the culture supernatant of CHO / NH-SRGN cells and CHO / NH-SDC cells by HPLC.
- 3A and 3B are diagrams showing the results of analysis of the sugar chain structure of heparin in the culture supernatants of CHO / NH-SRGN cells and CHO / NH-SDC cells using HPLC.
- FIG. 3 (A) shows the results of quantifying the heparin-like sugar chain concentration
- FIG. 3 (A) shows the results of quantifying the heparin-like sugar chain concentration
- FIG. 3 (B) shows the results of quantifying the ratio to sulfate.
- FIG. 4 is a diagram showing the results of measuring the amount of sGAG after serum-free acclimation.
- FIG. 5 is a diagram showing the results of calculating the production rate of sGAG after serum-free acclimation.
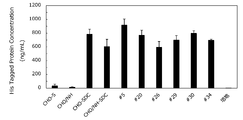
- FIG. 6 is a diagram showing the results of measuring the expression level of the target protein by ELISA.
- 7 (A) to 7 (C) are the results of measuring the expression level of the introduced gene by qRT-PCR.
- FIG. 7 (A) shows the expression level of the NDST2 gene
- FIG. 7 (B) shows the expression level of the Hs3st1 gene
- FIG. 7 (C) shows the expression level of the SDC gene.
- FIG. 7 (A) shows the expression level of the NDST2 gene
- FIG. 7 (B) shows the expression level of the Hs3st1 gene
- FIG. 7 (C) shows the expression level of the SDC gene
- FIG. 8 shows the results of quantifying the sGAG of the sample used for the analysis of the sugar chain structure by HPLC.
- FIG. 9 shows a standard heparin-derived unsaturated disaccharide (HS-standard) and a chromatogram obtained by HPLC obtained from each sample.
- 10 (A) and 10 (B) are diagrams showing the results of analysis of the sugar chain structure of heparin in the culture supernatant of each cell using HPLC.
- FIG. 10 (A) shows the results of quantifying the heparin-like sugar chain concentration
- FIG. 10 (B) shows the results of quantifying the ratio to sulfate.
- FIG. 11 shows a calibration curve used for evaluating the anticoagulant activity.
- the method for producing a heparin-like substance of the present invention is characterized by including the following steps (1) to (3).
- Step of preparing a mammalian cell that produces a heparin-like substance (2) A set in which a gene encoding the extracellular domain of Cindecane is introduced into a mammalian cell that produces a heparin-like substance prepared in step (1).
- Steps for preparing replacement cells (3) Steps for culturing the recombinant cells prepared in step (2) in a medium and recovering a heparin-like substance from the obtained culture supernatant The following steps will be described.
- Step (1) Preparation of mammalian cells that produce heparin-like substances
- heparin is introduced by introducing a gene encoding a protein required for heparin biosynthesis into a host mammalian cell. This is the step of preparing mammalian cells that produce similar substances.
- the "heparin-like substance" refers to a mixture of heparin and HS.
- mammalian cells examples include Chinese hamster ovary cell CHO cells [Journal of Experimental Medicine, 108, 945 (1958); Proc. Natl. Acad. Sci. USA, 60, 1275 (1968); Genetics, 55, 513. (1968); Chromosoma, 41, 129 (1973); Methods in Cell Science, 18, 115 (1996); Radiation Research, 148, 260 (1997); Proc. Natl. Acad. Sci. USA, 77, 4216 (1980) ); Proc. Natl. Acad. Sci., 60, 1275 (1968); Cell, 6, 121 (1975); Molecular Cell Genetics, Appendix I, II (pp.
- CHO / DG44 cells Defective CHO cells (CHO / DG44 cells) [Proc.Natl.Acad.Sci.USA,77,4216 (1980)], CHO-K1 (ATCC CCL-61), DUkXB11 (ATCC CCL-9096), Pro-5 (ATCC CCL-1781), CHO-S (Life Technologies, Cat # 11619), Pro-3, human umbilical vein endothelial cells (HUVEC), human umbilical artery endothelial cells (HUAEC), human lung microvascular endothelial cells (HLMVEC) , Human aortic endothelial cells (HAoEC), human coronary endothelial cells (HCAEC), human pulmonary artery endothelial cells (HPAEC), human fetal kidney (HEK), rat myeloma cells YB2 / 3HL.
- HAVEC human umbilical vein endothelial cells
- HAAEC human umbilical artery
- G11.16Ag. 20 also referred to as YB2 / 0
- monkey cell COS cell mouse myeloma cell NSO
- mouse myeloma cell SP2 / 0-Ag14
- Syrian hamster cell BHK or HBT5637 Japanese Patent Laid-Open No. 63-000299
- CHO cells CHO / DG44 cells or CHO-K1 (ATCC CCL-61) are preferable, and CHO cells are more preferable.
- proteins required for heparan biosynthesis include bifunctional heparan sulfate N-deacetylase / N-sulfate transferase (hereinafter abbreviated as NDST2), heparan sulfate glucosamine 3 sulfate transferase 1 (hereinafter abbreviated). , Hs3st1), heparan sulfate 2-O-sulfate transferase, C5-epimerase, heparan sulfate 6-O-sulfate transferase, and the like.
- NDST2 and Hs3st1 are preferable.
- These proteins may be variants of the protein as long as they have the activity required for heparin biosynthesis.
- These proteins are preferably of mammalian origin, more preferably of mouse or human origin.
- Examples of the protein required for heparin biosynthesis include proteins that are not expressed in wild-type mammalian cells.
- the mammalian cell is a CHO cell
- CHO cells that produce heparin-like substances can be obtained (Bail JY et al., Metab Eng 14: 81-90, 2012).
- NDST2 examples include proteins containing the amino acid sequence of any one of (1-a) to (1-c) below and having the function of NDST2.
- Hs3st1 include proteins containing the amino acid sequence of any one of (2-a) to (2-c) below and having the function of Hs3st1.
- (2-a) Amino acid sequence shown in SEQ ID NO: 3 or the amino acid sequence of NCBI accession number NP_034604.1
- (2-b) In the amino acid sequence shown in SEQ ID NO: 3 or the amino acid sequence of NCBI accession number NP_034604.1.
- more preferably 90% or more most preferably 95% or more amino acid sequence having homology
- a polypeptide having an amino acid sequence in which one to several amino acids are deleted, substituted or added in the target amino acid sequence is a site-specific mutagenesis method [Molecular Cloning, A Laboratory Manual, Second Edition, Cold Spring Harbor Laboratory. Press (1989), Current Protocols in Molecular Biology, John Wiley & Sons (1987-1997), Nucleic Acids Research, 10, 6487 (1982), Proc. Natl. Acad. Sci. USA, 79, 6409 (1982), Gene , 34, 315 (1985), Molecular Acids Research, 13, 4431 (1985), Proc. Natl. Acad. Sci. USA, 82, 488 (1985)], for example, amino acid sequences of SEQ ID NOs: 1 to 3. It can be obtained by introducing a site-specific mutation into a DNA encoding a polypeptide containing.
- the range of "1 to several” in “deletion, substitution, addition of 1 to several amino acids” of the amino acid sequence is not particularly limited. 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19 or 20, preferably 1, 2 per unit It means about 3, 4, 5, 6, 7, 8, 9 or 10, more preferably about 1, 2, 3, 4 or 5.
- amino acid deletion means missing or eliminating an amino acid residue in the sequence
- amino acid substitution means that an amino acid residue in the sequence has been replaced with another amino acid residue.
- Additional of amino acids means that new amino acid residues have been added to the sequence for insertion.
- substitution, substitution, addition of 1 to several amino acids there is an embodiment in which 1 to several amino acids are replaced with another chemically similar amino acid.
- a case where one hydrophobic amino acid is replaced with another hydrophobic amino acid, a case where a certain polar amino acid is replaced with another polar amino acid having the same charge, and the like can be mentioned.
- Such chemically similar amino acids are known in the art for each amino acid.
- non-polar (hydrophobic) amino acids such as alanine, valine, glycine, isoleucine, leucine, proline, tryptophan, phenylalanine, and methionine.
- polar (neutral) amino acids include serine, threonine, tyrosine, glutamine, asparagine, and cysteine.
- positively charged basic amino acids include arginine, histidine, and lysine.
- negatively charged acidic amino acids include aspartic acid and glutamic acid.
- the amino acid sequence having deletions, substitutions, additions, etc. of one to several amino acids includes an amino acid sequence having a certain degree of sequence identity with the amino acid sequence of the target protein.
- the amino acid sequence of the protein of interest is 60% or more, preferably 65% or more, preferably 70% or more, preferably 75% or more, preferably 80% or more, preferably 85% or more, more preferably.
- Examples include amino acid sequences having 90% or more, more preferably 95% or more sequence identity.
- the gene encoding NDST2 is a gene having the base sequence of any one of (1-A) to (1-D) below and containing the base sequence encoding the amino acid sequence of the protein having the function of NDST2. Can be mentioned.
- (1-A) The nucleotide sequence shown in SEQ ID NO: 4 or the nucleotide sequence of NCBI Accession No. NM_003635.3
- (1-B) In the nucleotide sequence shown in SEQ ID NO: 4 or the nucleotide sequence of NCBI Accession No. NM_003635.3. Nucleotide sequence and stringent complementary to the nucleotide sequence shown in SEQ ID NO: 4 or the nucleotide sequence of NCBI Accession No.
- NM_003635.3 in which 1 to several bases are deleted, substituted or added.
- Nucleotide sequence (1-D) that hybridizes under various conditions A nucleotide sequence having at least 60% or more homology with the nucleotide sequence of SEQ ID NO: 4 or the nucleotide sequence of NCBI Accession No. NM_003635.3, preferably 80%.
- the gene encoding Hs3st1 is a gene having the base sequence of any one of (2-A) to (2-D) below and containing the base sequence encoding the amino acid sequence of the protein having the function of Hs3st1. Can be mentioned.
- NM_010474.2 in which 1 to several nucleotides are deleted, substituted or added.
- Nucleotide sequence (2-D) that hybridizes under various conditions A nucleotide sequence having at least 60% or more homology with the nucleotide sequence of SEQ ID NO: 5 or the nucleotide sequence of NCBI Accession No. NM_010474.2, preferably 80%.
- a colony hybridization method As the base sequence that hybridizes under stringent conditions, a colony hybridization method, a plaque hybridization method, a Southern blot hybridization method, or a DNA microarray method using a DNA containing the target base sequence as a probe. It refers to the base sequence of hybridizable DNA obtained by the above.
- 0.7 to 1.0 mol / L sodium chloride is present using a filter or slide glass on which DNA derived from hybridized colonies or plaques, or PCR product or oligo DNA having the sequence is immobilized.
- Hybridization method at 65 ° C. [Molecular Cloning, A Laboratory Manual, Second Edition, Cold Spring Harbor Laboratory Press (1989), Current Protocols in Molecular Biology, John Wiley & Sons (1987-1997), DNA Cloning 1: CoreTech , A Practical Approach, Second Edition, Oxford University, (1995)]
- 0.1 to 2 times the concentration of SSC solution the composition of the 1 times concentration of SSC solution is 150 mmol / L sodium chloride, 15 mmol / L.
- the base sequence of DNA that can be identified by washing the filter or slide glass under 65 ° C. conditions using (consisting of sodium chloride) can be mentioned.
- DNA containing a base sequence that hybridizes under stringent conditions examples include DNA having a certain degree of sequence identity with the base sequence of DNA having the base sequence of the gene to be used as a probe. For example, DNA having at least 60% or more homology with the target base sequence, preferably DNA having 80% or more homology, and more preferably 95% or more homology. Further, for example, assuming that the number of bases in the base sequence is 100 as one unit, in the base sequence of the target gene, 1 to several, preferably 1 to 40, preferably 1 to 35 per unit.
- a DNA containing a base sequence having a deletion, substitution, addition, etc. of 10, more preferably 1, 2, 3, 4 or 5 bases can be mentioned.
- Base deletion means that a base in the sequence is missing or missing
- base substitution means that the base in the sequence has been replaced with another base
- base replacement means that a new base has been added to insert.
- Gene polymorphisms are often found in the base sequences of genes encoding eukaryotic proteins.
- the gene used in the present invention also contains a gene in which a small mutation has occurred in the base sequence due to such a polymorphism.
- the default parameters are 5 when G (Cost to open gap) is a base sequence, 11 when it is an amino acid sequence, 2 when -E (Cost to extend gap) is a base sequence, and 1 when it is an amino acid sequence.
- -Q (Penalty for nucleotide mismatch) is -3
- -r (reward for nucleotide match) is 1
- -e (expect value) is 10
- -W (wordsize) is 11 residues
- amino acid sequence In the case of, 3 residues
- -y [Dropoff (X) for blast extensions in bits] is 20, if it is blastn 7, 7 in programs other than blastn
- -X (X dropoff value for gapped sequences in bits) is 15 and-
- Z final X dropoff value for gapped alignment in bits) is blastn, it is 50, and for programs other than blastn, it is 25 (https://blast.ncbi.nlm.nih.gov/Blast.cg
- Mammalian cells producing heparin-like substances are obtained by introducing a recombinant vector containing a cDNA encoding the full length or a partial length of a protein required for heparin biosynthesis into a mammalian cell as a host cell. be able to.
- any one that can autonomously replicate in the host cell to be used or integrate into the chromosome and contains an appropriate promoter at a position where the DNA encoding the polypeptide can be transcribed is used. be able to.
- the transcription termination sequence is not always necessary for the recombinant vector, but it is preferable to place the transcription termination sequence directly under the structural gene.
- the recombinant vector may contain a gene that controls a promoter.
- the recombinant vector it is preferable to use a plasmid in which the Kozak sequence, which is a ribosome-binding sequence, is appropriately arranged around the start codon.
- the base in the base sequence of DNA, can be replaced so as to be the optimum codon for expression in the host, thereby improving the production rates of the target NDST2 and Hs3st1.
- any one that can exert its function in animal cells can be used.
- any promoter that can exert its function in animal cells can be used.
- a promoter of the cytomegalovirus (CMV) immediate early (IE) gene an initial promoter of SV40, and a promoter of retrovirus.
- an enhancer of the IE gene of human CMV may be used together with a promoter.
- the recombinant vector may contain a selectable marker.
- a "selectable marker” is a gene that allows the selection of cells containing the gene. "Positive selection” refers to the process by which positive selection occurs and the cells containing the selectable marker are selected.
- An example of a selectable marker with positive drug resistance is that cells containing the marker survive in the drug-containing culture medium and cells without the marker die.
- Selectable markers include drug resistance genes such as neo, which confer G418 resistance; hygr, which confer hygromycin resistance; and puro, which confer puromycin resistance.
- Other positive selectable marker genes include genes that allow identification or screening of cells containing the marker.
- genes include, among others, surface markers such as the fluorescent protein (GFP and GFP-like chromophore, luciferase) gene, the lacZ gene, the alkaline phosphatase gene, and CD8.
- surface markers such as the fluorescent protein (GFP and GFP-like chromophore, luciferase) gene, the lacZ gene, the alkaline phosphatase gene, and CD8.
- Negative selection refers to the process of killing cells containing a negative selectable marker by exposure to the appropriate negative selectable agent.
- HSV-tk herpes simplex virus thymidine kinase
- GANC drug ganciclovir
- the gpt gene makes cells 6-thioxanthine sensitive.
- any method for introducing DNA into an animal cell can be used.
- the electroporation method [Cytotechnology, 3, 133 (1990)]
- the calcium phosphate method Japanese Patent Laid-Open No. 02-227075
- the lipofection method [Proc. Natl. Acad. Sci. USA, 84, 7413 (1987). )] And so on.
- Step (2) A step of preparing a recombinant cell in which a gene encoding the extracellular domain of Cindecane is introduced into a mammalian cell producing a heparin-like substance prepared in Step (1).
- Step (2) is a step of preparing a recombinant cell of Cindecane. This is a step of preparing a recombinant cell in which a recombinant vector containing a gene encoding an extracellular domain is introduced into a mammalian cell producing a heparin-like substance prepared in step (1).
- Cindecane consists of an extracellular domain, a transmembrane domain and a cytoplasmic domain.
- the extracellular domain of Cindecane contains the glycosaminoglycan binding site. It is preferable to have at least a glycosaminoglycan binding site as the extracellular domain of Cindecane.
- the extracellular domain of Cindecane is preferably of mammalian origin, more preferably of mouse or human origin.
- Examples of the extracellular domain of Cindecane include proteins containing the amino acid sequence of any one of (3-a) to (3-c) below and having the function of the extracellular domain of Cindecane.
- the added amino acid sequence (3-c) is an amino acid sequence having 60% or more, preferably 80% or more, more preferably 90% or more, most preferably 95% or more homology with the amino acid sequence shown in SEQ ID NO: 1.
- amino acid sequence shown in SEQ ID NO: 1 is the 1st to 229th amino acid sequence from the N-terminal of the amino acid sequence (total length 310 amino acids) of NCBI accession number NP_001006947.1.
- the gene encoding the extracellular domain of Cindecane is the amino acid sequence of a protein having the base sequence of any one of (3-A) to (3-D) below and having the function of the extracellular domain of Cindecane. Examples include genes containing a base sequence encoding.
- NM_001006946.1 in which 1 to several nucleotides are deleted, substituted or added.
- Nucleotide sequence (3-D) that hybridizes under various conditions A nucleotide sequence having at least 60% or more homology with the nucleotide sequence of SEQ ID NO: 6 or the nucleotide sequence of NCBI Accession No. NM_001006946.1, preferably 80%.
- a heparin-like substance prepared in step (1) is produced by preparing a recombinant vector containing a gene encoding the extracellular domain of Cindecane and cDNA encoding the total length or a partial length of the extracellular domain of Cindecane.
- a recombinant cell capable of secreting a heparin-like substance into a culture supernatant is obtained.
- the method for introducing the recombinant vector and the recombinant vector into the host cell is the same as in step (1).
- step (3) A step of culturing the recombinant cells prepared in step (2) in a medium and recovering a heparin-like substance from the obtained culture supernatant.
- step (3) the recombinant cells prepared in step (2) are used. This is a step of secreting and producing a heparin-like substance in a medium by culturing in a medium, and recovering the heparin-like substance from the obtained culture supernatant.
- the recombinant cells are preferably cultured under conditions that promote the production of heparin-like substances. Specifically, for example, it is preferable to culture the recombinant cells in a medium that enables the production of heparin-like substances in the recombinant cells and promotes the secretion of the heparin-like substances from the recombinant cells to the culture supernatant. ..
- the medium contains at least sufficient carbon, nitrogen, oxygen and other nutrients, growth factors, buffers, cofactors and any other substance to maintain cell viability and allow the expression of heparin-like substances. It is preferable to contain it.
- the medium may further comprise an inducer.
- the medium examples include RPMI or DMEM supplemented with 10% fetal bovine serum (FCS), and tissue culture medium supplemented with factors such as antibacterial agents, growth factors, and other cytokines (for example, Cell Biology (eg, Cell Biology). Third Edition) A Laboratory Handbook, vol. 1, 2006, Elsevier Inc.). Specific examples thereof include medium preparations known to those skilled in the art, such as RPMI, IMDM, DMEM, DMEM / F12, serum-free or low-serum EMEM. These media may contain additional dietary supplements such as antibiotics, lipids, transferrin, insulin, amino acids, and optionally cofactors.
- FCS fetal bovine serum
- tissue culture medium supplemented with factors such as antibacterial agents, growth factors, and other cytokines (for example, Cell Biology (eg, Cell Biology). Third Edition) A Laboratory Handbook, vol. 1, 2006, Elsevier Inc.). Specific examples thereof include medium preparations known to those skilled in the art, such as RPMI,
- the medium preferably contains at least one selected from glucose, sulfate and phosphoric acid.
- concentration of glucose in the medium is usually preferably 5 to 75 mM, more preferably 10 to 60 mM, still more preferably 15 to 35 mM.
- concentration of sulfate in the medium is usually preferably 0.5 to 50 mM, more preferably 10 to 50 mM, and even more preferably 30 to 50 mM.
- concentration of phosphate in the medium is usually preferably 0.5 to 50 mM, more preferably 1 to 50 mM, still more preferably 10 to 50 mM.
- a heparin-like substance can be produced by producing and accumulating a heparin-like substance in the culture supernatant and collecting it from the culture supernatant.
- the method of culturing the recombinant cells in the medium can be carried out according to a usual method. Culturing is usually carried out for 1 to 7 days under conditions such as pH 6 to 8, 30 to 40 ° C. and the presence of 5% CO 2.
- the secretory production of heparin-like substances from recombinant cells is for unsaturated disaccharide analysis after enzyme treatment by adding an enzyme solution containing heparin lyases I, II, and III to the culture supernatant, as described later in Examples. It can be confirmed by quantifying by HPLC. Specifically, 2SNS6, glucuronic acid in which the amino group of glucosamine and 3 sulfate groups are bonded to the 6-position in the culture supernatant of recombinant cells as compared with the culture supernatant of control (wild type) cells.
- the amount of at least one selected from 2SNS in which a sulfate group is bonded to the 2-position and the glucosamine amino group, NS6S in which the amino group of glucosamine and two sulfates are bonded to the 6-position, and NS in which the sulfate group is bonded to glucosamine N increases. If so, it is assumed that a heparin-like substance is secreted and produced in the culture supernatant from the recombinant cells. The secretory production of heparinoids from recombinant cells can also be confirmed by measuring the amount of sGAG (sulfated GAG) in the culture supernatant, as will be described later in the examples.
- sGAG sulfated GAG
- proteoglycan which is a glycoprotein containing a core protein bound to a heparin-like substance that is GAG, is secreted from the recombinant cells into the culture supernatant. Isolation of the protein from the culture supernatant is carried out by a method conventionally known in the art.
- tags that facilitate the isolation of heparinoids such as affinity tags, may be used.
- Tags include, for example, polyhistidine (His6 tag), nickel matrix, chitin binding protein (CBP), maltose binding protein (MBP), glutathione-S-transferase (GST), FLAG tag or epitope tag.
- Isolation of heparinoids from core proteins is performed by methods conventionally known in the art. For example, enzymatic digestion using heparinase, treatment with sodium hydroxide or boron borohydride can be mentioned.
- the isolated heparinoid substance preferably contains 50% or more, more preferably 60% or more, further preferably 70% or more, and particularly preferably 80% or more of sulfated disaccharides.
- the isolated heparinoids include, for example, the following (1) to (20). (1) 10 to 50% trisulfated disaccharide, 30 to 50% disulfated disaccharide and 10 to 30% monosulfated disaccharide. (2) 10-40% trisulfated disaccharide, 35-45% disulfated disaccharide and 10-25% monosulfated disaccharide. (3) 15-40% trisulfated disaccharide, 35-45% disulfated disaccharide and 10-25% monosulfated disaccharide. (4) 5 to 25% trisulfated disaccharide, 30 to 50% disulfated disaccharide and 10 to 20% monosulfated disaccharide.
- Heparinoids can contain repeating structures of disaccharide units of various lengths. Heparin-like substances are UA-GlcNAc (6S), UA (2S) -GlcNAc, UA- (2S) -GlcNAc (6S), UA-GlcNS, UA-GlcNS (6S), UA (2S) -GlcNS, UA ( It preferably contains any of 2S) -GlcNS (6S), which may be present in the heparin-like substance in any order.
- UA is a uronic acid residue (ie, glucuronic acid or iduronic acid)
- Ac is acetyl
- GlcNAc is N-acetylglucosamine
- GlcNS is glucosamine-N-sulfate
- 2S is 2-O-sulfate
- 6S is 6. -O-sulfate.
- One aspect of the present invention is a recombinant cell in which a gene encoding the extracellular domain of SDC is introduced into a mammalian cell producing a heparin-like substance.
- the recombinant cell prepares a mammalian cell that produces a heparin-like substance in the same manner as described above in the steps (1) and (2) of the section ⁇ Method for producing a heparin-like substance>, and prepares the mammalian cell. It can be prepared by introducing a gene encoding the extracellular domain of Cindecane into a cell.
- a method for producing a cell secreting and producing a heparin-like substance which comprises a step of introducing a recombinant expression vector containing a gene encoding the extracellular domain of SDC into a mammalian cell producing a heparin-like substance.
- a mammalian cell producing a heparin-like substance is prepared in the same manner as described above in the steps (1) and (2) of the section ⁇ Method for producing a heparin-like substance>, and the mammalian cell is prepared. It can be carried out by introducing a gene encoding the extracellular domain of Cindecane into.
- ⁇ Pharmaceutical composition> is a pharmaceutical composition containing a heparin-like substance or a fragment thereof produced by the method described in the present specification.
- the heparinoid or fragment thereof may be bound to the core protein.
- the pharmaceutical composition may contain other therapeutic agents.
- Pharmaceutical compositions can also be formulated using, for example, conventional vehicles or diluents, as well as pharmaceutical additives of the type suitable for the desired method of administration (eg, excipients, binders, preservatives).
- Examples of the form of the pharmaceutical composition include sterile aqueous agents for injection.
- Aqueous sterile injectables can be formulated according to known techniques using suitable dispersants or wetting and suspending agents.
- the sterile injectable aqueous agent may be a sterile injectable solution or suspension in a non-toxic parenterally acceptable diluent or solvent, such as a solution in 1,3-butanediol.
- Acceptable vehicles and solvents that can be used are water, Ringer's solution and isotonic saline.
- the dosage form of the pharmaceutical composition is not particularly limited, and a wide variety of dosage forms can be used.
- Examples of the dosage form for administering the pharmaceutical composition include tablets, capsules, sachets, lozenges, pills, powders, granules, elixirs, tinctures, solutions, suspensions, etc.
- Examples include administration in the form of elixirs, syrups, ointments, creams, intravenous administration or injection, pastes, emulsions or solutions.
- transdermal administration by a patch mechanism or an ointment can be mentioned. Any of these may be modified to sustained release and / or sustained release formulations.
- Pharmaceutically acceptable carriers include vehicles, adjuvants, surfactants, suspensions, emulsifiers, inert fillers, diluents, excipients, wetting agents, binders, lubricants, buffers, disintegration agents. Includes, but is not limited to, agents and carriers.
- the pharmaceutically acceptable carrier is chemically inert to the active compound and has no adverse side effects or toxicity under conditions of use. The properties of the pharmaceutically acceptable carrier may vary depending on the particular dosage form and other characteristics of the composition used.
- One aspect of the invention involves or by blood coagulation in a subject in need thereof, comprising administering a heparin-like substance or fragment thereof produced by the methods described herein. Examples include methods of treating or preventing the condition that is caused.
- the heparinoid or fragment thereof may be bound to the core protein.
- Conditions associated with or caused by blood coagulation or blood coagulation include, for example, acute coronary syndrome, atrial fibrillation, deep vein thrombosis or pulmonary embolism.
- Mammals include, for example, humans, primates, domestic animals (eg, sheep, cows, horses, donkeys, pigs), companion animals (eg, dogs, cats), laboratory test animals (eg, mice, rabbits, rats). , Guinea pigs, hamsters), captured wild animals (eg, foxes, deer). Mammals are typically humans or primates, and more typically humans.
- the dose and timing are preferably doses and timings that provide therapeutic benefits in the treatment, prevention or management of blood coagulation or conditions associated with blood coagulation.
- the specific effective dose and timing of administration may vary depending on factors such as the subject's condition, medical history, physique, body weight, and age.
- the vector PB513B-1_SRGN-IRES-EGFP used for the production of CHO / NH-SRGN cells is based on PiggyBac Transposon Vector PB513B-1 and has a Chinese hamster EF1 ⁇ promoter, an IRES element, and a mycHis tag sequence at the C-terminal. Is.
- the DNA encoding hSRGN (the base sequence represented by SEQ ID NO: 7) is co-expressed with the screening markers EGFP gene and puromycin resistance gene. Introduced to do.
- CHO / NH-SRGN cells in which DNA encoding human seriglycin (SRGN) (base sequence represented by SEQ ID NO: 7) was introduced into CHO / NH # 3 cells using the vector PB513B-1_SRGN-IRES-EGFP, and CHO / NH-SRGN cells.
- CHO / NH-SDC cells were prepared by introducing the DNA of the extracellular domain of human syndecane (SDC) (the nucleotide sequence represented by SEQ ID NO: 6) using the vector PB513B-1_SDC-IRES-EGFP.
- the vector PB513B-1_SDC-IRES-EGFP used to prepare CHO / NH-SDC cells is based on PiggyBac Transposon Vector PB513B-1 and has a Chinese hamster EF1 ⁇ promoter, an IRES element, and a mycHis tag sequence at the C-terminus. It is a vector.
- the DNA encoding SRGN (the base sequence represented by SEQ ID NO: 7) is co-expressed with the screening markers EGFP gene and puromycin resistance gene. Introduced to do.
- the culture supernatant of each cell prepared as described above was analyzed to evaluate the heparin-producing ability.
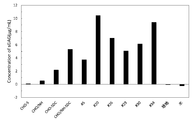
- sGAG assay refers to an assay in which the total amount of sGAG in a solution is colorimetrically quantified using a dye (1,9-dimethylmethylene blue) that specifically binds to a sulfated sugar chain. The results are shown in FIG.
- heparin To confirm the production of heparin, first take 20 ⁇ L of the sample solution directly, add 10 ⁇ L of a buffer solution and 10 ⁇ L of an enzyme solution containing 10 mU of each of heparin liase I, II, and III, and perform enzyme treatment at 37 ° C. for 3 hours to complete the reaction. After that, the enzyme was inactivated at 100 ° C. for 5 minutes, and after freeze-drying, 20 ⁇ L of water was added and quantified by HPLC for unsaturated disaccharide analysis. The results are shown in FIGS. 3 (A) and 3 (B).
- WT is a wild-type CHO cell
- # 3 is a CHO-NH # 3 cell
- SRGN is a DNA encoding SRGN (base sequence represented by SEQ ID NO: 7) in the CHO cell.
- CHO-SRGN cells introduced using the vector PB513B-1_SRGN-IRES-EGFP
- # 3SRGN is CHO / NH-SRGN cells
- SDC is CHO cells with DNA of the extracellular domain of SDC (base sequence represented by SEQ ID NO: 6).
- Is introduced using the vector PB513B-1_SDC-IRES-EGFP.
- CHO-SDC cells are shown.
- CHO / NH-SDC cells were cultured in a serum-containing medium to form an adhesive state, and cloning was performed on a collagen-coated 96-well plate by the limiting dilution method. At this time, since the cells were cultured from one cell, the cells were cultured without adding a drug in consideration of toxicity to the cells.
- the collagen coat was scaled up to a 24- or 6-well plate, and a plurality of clones were cultured to establish 36 clones.
- each cell was seeded on a normal 6-well plate at 0.6 ⁇ 10 6 cells / well, and the amount of sGAG in the culture supernatant was measured using the culture supernatant collected 3 days later without medium exchange as a sample.
- Top 6 clones (# 5, # 20, # 26, # 29, # 30, # 34) were subjected to serum-free acclimation.
- the evaluated 6 clones have the same or higher SDC secretion-producing ability as those of CHO / NH-SDC cells, and # 5 is 1. of CHO / NH-SDC cells. It was 5 times or more and showed the highest expression level.
- FIG. 7 (A) shows the expression level of the NDST2 gene
- FIG. 7 (B) shows the expression level of the Hs3st1 gene
- FIG. 7 (C) shows the expression level of the SDC gene.
- ⁇ Analysis conditions> As a pretreatment of the sample, 400 ⁇ L of two-stage distilled water (Double Distilled Water, DDW) was added to the upper layer obtained by centrifuging 400 ⁇ L of the culture supernatant of various CHO cells at 10,000 rpm for 10 minutes, and freeze-dried. Then, 20 ⁇ L was separated from the 40 ⁇ L sample and treated with Heparin lyase I, II and III, 80 ⁇ L of DDW was added, and 20 ⁇ L was subjected to HPLC.
- DDW Double Distilled Water
- the treatment with the specific degrading enzyme was as follows. Acetic acid buffer [0.1MCH 3 COONa, 10 mM (CH 3 COO) 2Ca (pH 7.0)] 20 ⁇ L, 0.5 mU / ⁇ L Heparinase 5 ⁇ L, 0.5 mU / ⁇ L Heparitinase I 5 ⁇ L, 0.5 mU / ⁇ L Heparitinase II 5 ⁇ L at the same time.
- heparin-like sugar chains were decomposed into unsaturated disaccharides by incubating at 37 ° C. for 16 hours. The enzyme was inactivated by heating in a boiling water bath for 3 minutes, lyophilized, dissolved in water, and subjected to unsaturated disaccharide analysis by HPLC.
- FIG. 8 The result of quantifying sGAG in the sample used for the analysis by HPLC is shown in FIG. 8, and the standard heparin-derived unsaturated disaccharide (HS-Standards) and the chromatogram obtained from the sample are shown in FIG.
- FIGS. 10 (A) and 10 (B) The results of quantifying the content of heparin-like sugar chains and the ratio of each sugar chain to sulfate by HPLC are shown in FIGS. 10 (A) and 10 (B), respectively.
- Table 1 shows the concentration of sulfated sugar chains (HS) and the ratio of sulfated sugar chains in the detected heparin-like substance.
- Antithrombin III agent Antithrombin III (human origin) 3.
- Factor Xa agent Factor Xa (derived from bovine) 4.
- Buffer solution 2-amino-2-hydroxymethyl-1,3-propanediol buffer solution 5.
- Normal plasma agent Human normal plasma
- anticoagulant activity was determined using the calibration curve shown in FIG. The results are shown in Table 2.
Landscapes
- Health & Medical Sciences (AREA)
- Chemical & Material Sciences (AREA)
- Life Sciences & Earth Sciences (AREA)
- Organic Chemistry (AREA)
- Engineering & Computer Science (AREA)
- Genetics & Genomics (AREA)
- Zoology (AREA)
- Wood Science & Technology (AREA)
- Bioinformatics & Cheminformatics (AREA)
- General Health & Medical Sciences (AREA)
- Biochemistry (AREA)
- Biomedical Technology (AREA)
- Biotechnology (AREA)
- General Engineering & Computer Science (AREA)
- Molecular Biology (AREA)
- Microbiology (AREA)
- Medicinal Chemistry (AREA)
- Chemical Kinetics & Catalysis (AREA)
- Biophysics (AREA)
- Cell Biology (AREA)
- Physics & Mathematics (AREA)
- Plant Pathology (AREA)
- Polymers & Plastics (AREA)
- Reproductive Health (AREA)
- Materials Engineering (AREA)
- General Chemical & Material Sciences (AREA)
- Toxicology (AREA)
- Gastroenterology & Hepatology (AREA)
- Proteomics, Peptides & Aminoacids (AREA)
- Immunology (AREA)
- Preparation Of Compounds By Using Micro-Organisms (AREA)
- Micro-Organisms Or Cultivation Processes Thereof (AREA)
- Peptides Or Proteins (AREA)
Abstract
本発明は、動物由来組織を用いずに、ヘパリン様物質を効率的に生産する製造方法を提供することを目的とする。本発明は、(1)ヘパリン様物質を産生する哺乳動物細胞を調製する工程、(2)工程(1)で調製したヘパリン様物質を産生する哺乳動物細胞に、シンデカンの細胞外ドメインをコードする遺伝子を導入した組換え細胞を調製する工程、(3)工程(2)で調製した組換え細胞を培地中で培養し、得られる培養上清からヘパリン様物質を回収する工程を含むヘパリン様物質の製造方法等に関する。
Description
本発明は、ヘパリン様物質の製造方法、組換え細胞及びその製造方法に関する。
ヘパリンは抗血液凝固薬として、人工透析や体外循環などの医療現場で使用されている必要不可欠な薬剤である。ヘパリンは、例えば血栓塞栓症の予防又は治療薬として、注射可能な形態で使用される。ヘパリンはまた、例えば腎臓透析機などの様々な実験用および医療用装置上に抗凝固剤表面を形成するためにも使用される。
ヘパリンは、グリコサミノグリカン(以下、GAGとも略す。)の4つの主要なサブファミリーの1つである多糖類である。GAGは、反復二糖単位からなる長い多糖である。GAGは主に、(1)ヘパラン硫酸(以下、HSとも略す。)/ヘパリン、(2)ケラタン硫酸(KS)、(3)コンドロイチン/デルマタン硫酸(CS/DS)、(4)ヒアルロン酸またはヒアルロナン(HA)の4つのサブファミリーに分類される。
GAGのサブファミリーは、単糖成分、グリコシル結合、並びに糖の位置及び程度が互いに異なる。HAを除いて、GAGはコアタンパク質に共有結合しており、GAGがコアタンパク質と共有結合したものは、プロテオグリカンとして知られている。
ヘパリン及びHSは酸性ムコ多糖類の不均一な混成物であり、ヘパリンはHSの一種である。ヘパリン/HSは、ウロン酸(β-D-グルクロン酸およびα-L-イズロン酸)とグルコサミン(D-N-アセチルグルコサミンおよびD-N-硫酸グルコサミン)の二糖が1単位となって、それらがα又はβ-1,4結合を数十から数百回繰り返した直鎖状の多糖である。分子量は鎖長の違いによって3から30kDaと様々であり、平均12~15kDaである。ヘパリン/HSに対する修飾としては、例えば、ウロン酸の2位のO-硫酸化、グルコサミンの3位及び6位のO-硫酸化、2位のアミノ基のN-硫酸化が挙げられる。
ほとんどすべての哺乳動物細胞は、細胞外マトリックスに存在する細胞関連糖鎖中のプロテオグリカンに組み込まれて組織形態および機能を規定するGAGを産生する。HSは、線維芽細胞増殖因子(FGF)ファミリー、血小板由来増殖因子(PDGF)、および血管内皮細胞増殖因子(VEGF)などの増殖因子を調節することによって細胞の増殖および発生を調節する。一方、ヘパリンは主に肥満細胞で産生される。
医薬品等に用いられるヘパリンは、主にブタの小腸又はウシの肺から抽出、精製されている。しかしながら、これらの供給源から得られたヘパリンは、過硫酸化コンドロイチン硫酸の混入によるいくつかの有害事象と関連している(非特許文献1)。また、動物組織からのヘパリンの単離は、動物からヒトへ、例えばウイルス、バクテリアおよび伝染性海綿状脳症(Transmissible Spongiform Encephalopathy)のような疾病病原体が伝播する危険性がある。したがって、動物由来組織を用いないヘパリンの新しい生産技術の開発が望まれている。ヘパリンを化学的又は化学酵素的な手法により合成することも可能であるが、動物由来のヘパリンに存在する不均一な構造の集団を製造することは困難である。
一方、シンデカンは、保持された原形質膜ドメインと細胞質ドメインを持った細胞表面の4種のプロテオグリカンファミリーである。細胞外ドメインには、共有結合したグリコサミノグリカン鎖が存在している。それらは主としてヘパラン硫酸(HS)であり、コンドロイチン硫酸(CS)も含まれる(非特許文献2)。
Guerrini et al, Nat. Biotechnol., 2008, 26, pp.669-675
Trends in Glycoscience and Glycotechnology, 1993, Vol.5, No.22, pp.107-120
上述したように、動物由来組織を用いないヘパリンの新しい生産技術の開発が望まれている。本発明者らは、ヘパリン様物質を産生する哺乳動物細胞を用いたヘパリン様物質の産生を試みたところ、該哺乳動物細胞から生産されるヘパリン様物質を含有するプロテオグリカンが細胞膜に付着し、培養上清中に分泌されにくいことを見出した。そのため、複雑な精製工程が必要となり、ヘパリン様物質の工業生産化にあたり大きな課題となる。したがって、本発明は、動物由来組織を用いずに、ヘパリン様物質を効率的に生産する製造方法を提供することを目的とする。
本発明者らは、ヘパリン様物質を産生する哺乳動物細胞に、シンデカンの細胞外ドメインをコードする遺伝子を導入することにより、上記課題を解決できることを見出し、本発明を完成させた。
本発明は、以下の通りである。
1.以下の工程(1)~(3)を含むヘパリン様物質の製造方法。
(1)ヘパリン様物質を産生する哺乳動物細胞を調製する工程
(2)工程(1)で調製したヘパリン様物質を産生する哺乳動物細胞に、シンデカン(以下、SDCと略す。)の細胞外ドメインをコードする遺伝子を導入した組換え細胞を調製する工程
(3)工程(2)で調製した組換え細胞を培地中で培養し、得られる培養上清からヘパリン様物質を回収する工程
2.前記へパリン様物質を産生する哺乳動物細胞は、両機能性ヘパラン硫酸エステルN-脱アセチラーゼ/N-硫酸転移酵素(以下、NDST2と略す。)をコードする遺伝子及びへパラン硫酸エステルグルコサミン3 硫酸転移酵素1(以下、Hs3st1と略す。)をコードする遺伝子の少なくとも一方が導入された細胞である、前記1に記載の製造方法。
3.前記哺乳動物細胞はチャイニーズ・ハムスター由来卵巣(以下、CHOと略す。)細胞である、前記1又は2に記載の製造方法。
4.NDST2が以下の(1a)~(1c)のいずれか1のアミノ酸配列を含み、かつNDST2の機能を有するタンパク質である、前記2又は3に記載の製造方法。
(1a)配列番号2に記載のアミノ酸配列
(1b)配列番号2に記載のアミノ酸配列において、1から数個のアミノ酸が欠失、置換又は付加されたアミノ酸配列
(1c)配列番号2に記載のアミノ酸配列と80%以上の相同性を有するアミノ酸配列
5.Hs3st1が以下の(2a)~(2c)のいずれか1のアミノ酸配列を含み、かつHs3st1の機能を有するタンパク質である、前記2~4のいずれか1に記載の製造方法。
(2a)配列番号3に記載のアミノ酸配列
(2b)配列番号3に記載のアミノ酸配列において、1から数個のアミノ酸が欠失、置換又は付加されたアミノ酸配列
(2c)配列番号3に記載のアミノ酸配列と80%以上の相同性を有するアミノ酸配列
6.SDCの細胞外ドメインが以下の(3a)~(3c)のいずれか1のアミノ酸配列を含み、かつSDCの細胞外ドメインの機能を有するタンパク質である、前記1~5のいずれか1に記載の製造方法。
(3a)配列番号1に記載のアミノ酸配列
(3b)配列番号1に記載のアミノ酸配列において、1から数個のアミノ酸が欠失、置換又は付加されたアミノ酸配列
(3c)配列番号1に記載のアミノ酸配列と80%以上の相同性を有するアミノ酸配列
7.NDST2及びHs3st1がマウス又はヒト由来である、前記2~6のいずれか1に記載の製造方法。
8.NDST2をコードする遺伝子が、以下の(1A)~(1D)のいずれか1の塩基配列であって、かつNDST2の機能を有するタンパク質のアミノ酸配列をコードする塩基配列を含む、前記2~7のいずれか1に記載の製造方法。
(1A)配列番号4に記載の塩基配列
(1B)配列番号4に記載の塩基配列において、1から数個の塩基が欠失、置換又は付加された塩基配列
(1C)配列番号4に記載の塩基配列に相補的な塩基配列とストリンジェントな条件下でハイブリダイズする塩基配列
(1D)配列番号4に記載の塩基配列と80%以上の相同性を有する塩基配列
9.Hs3st1をコードする遺伝子が、以下の(2A)~(2D)のいずれか1の塩基配列であって、かつHs3st1の機能を有するタンパク質のアミノ酸配列をコードする塩基配列を含む、前記2~8のいずれか1に記載の製造方法。
(2A)配列番号5に記載の塩基配列
(2B)配列番号5に記載の塩基配列において、1から数個の塩基が欠失、置換又は付加された塩基配列
(2C)配列番号5に記載の塩基配列に相補的な塩基配列とストリンジェントな条件下でハイブリダイズする塩基配列
(2D)配列番号5に記載の塩基配列と80%以上の相同性を有する塩基配列
10.SDCの細胞外ドメインをコードする遺伝子が、以下の(3A)~(3D)のいずれか1の塩基配列であって、かつSDCの細胞外ドメインの機能を有するタンパク質のアミノ酸配列をコードする塩基配列を含む、前記1~9のいずれか1に記載の製造方法。
(3A)配列番号6に記載の塩基配列
(3B)配列番号6に記載の塩基配列において、1から数個の塩基が欠失、置換又は付加された塩基配列
(3C)配列番号6に記載の塩基配列に相補的な塩基配列とストリンジェントな条件下でハイブリダイズする塩基配列
(3D)配列番号6に記載の塩基配列と80%以上の相同性を有する塩基配列
11.ヘパリン様物質を産生する哺乳動物細胞に、SDCの細胞外ドメインをコードする遺伝子が導入された組換え細胞。
12.前記へパリン様物質を産生する哺乳動物細胞は、NDST2をコードする遺伝子及びHs3st1をコードする遺伝子の少なくとも一方が導入された細胞である、前記11に記載の組換え細胞。
13.前記哺乳動物細胞はCHO細胞である、前記11又は12に記載の組換え細胞。
14.ヘパリン様物質を産生する哺乳動物細胞に、SDCの細胞外ドメインをコードする遺伝子を含む組換え発現ベクターを導入する工程を含む、ヘパリン様物質を分泌産生する細胞の製造方法。
1.以下の工程(1)~(3)を含むヘパリン様物質の製造方法。
(1)ヘパリン様物質を産生する哺乳動物細胞を調製する工程
(2)工程(1)で調製したヘパリン様物質を産生する哺乳動物細胞に、シンデカン(以下、SDCと略す。)の細胞外ドメインをコードする遺伝子を導入した組換え細胞を調製する工程
(3)工程(2)で調製した組換え細胞を培地中で培養し、得られる培養上清からヘパリン様物質を回収する工程
2.前記へパリン様物質を産生する哺乳動物細胞は、両機能性ヘパラン硫酸エステルN-脱アセチラーゼ/N-硫酸転移酵素(以下、NDST2と略す。)をコードする遺伝子及びへパラン硫酸エステルグルコサミン3 硫酸転移酵素1(以下、Hs3st1と略す。)をコードする遺伝子の少なくとも一方が導入された細胞である、前記1に記載の製造方法。
3.前記哺乳動物細胞はチャイニーズ・ハムスター由来卵巣(以下、CHOと略す。)細胞である、前記1又は2に記載の製造方法。
4.NDST2が以下の(1a)~(1c)のいずれか1のアミノ酸配列を含み、かつNDST2の機能を有するタンパク質である、前記2又は3に記載の製造方法。
(1a)配列番号2に記載のアミノ酸配列
(1b)配列番号2に記載のアミノ酸配列において、1から数個のアミノ酸が欠失、置換又は付加されたアミノ酸配列
(1c)配列番号2に記載のアミノ酸配列と80%以上の相同性を有するアミノ酸配列
5.Hs3st1が以下の(2a)~(2c)のいずれか1のアミノ酸配列を含み、かつHs3st1の機能を有するタンパク質である、前記2~4のいずれか1に記載の製造方法。
(2a)配列番号3に記載のアミノ酸配列
(2b)配列番号3に記載のアミノ酸配列において、1から数個のアミノ酸が欠失、置換又は付加されたアミノ酸配列
(2c)配列番号3に記載のアミノ酸配列と80%以上の相同性を有するアミノ酸配列
6.SDCの細胞外ドメインが以下の(3a)~(3c)のいずれか1のアミノ酸配列を含み、かつSDCの細胞外ドメインの機能を有するタンパク質である、前記1~5のいずれか1に記載の製造方法。
(3a)配列番号1に記載のアミノ酸配列
(3b)配列番号1に記載のアミノ酸配列において、1から数個のアミノ酸が欠失、置換又は付加されたアミノ酸配列
(3c)配列番号1に記載のアミノ酸配列と80%以上の相同性を有するアミノ酸配列
7.NDST2及びHs3st1がマウス又はヒト由来である、前記2~6のいずれか1に記載の製造方法。
8.NDST2をコードする遺伝子が、以下の(1A)~(1D)のいずれか1の塩基配列であって、かつNDST2の機能を有するタンパク質のアミノ酸配列をコードする塩基配列を含む、前記2~7のいずれか1に記載の製造方法。
(1A)配列番号4に記載の塩基配列
(1B)配列番号4に記載の塩基配列において、1から数個の塩基が欠失、置換又は付加された塩基配列
(1C)配列番号4に記載の塩基配列に相補的な塩基配列とストリンジェントな条件下でハイブリダイズする塩基配列
(1D)配列番号4に記載の塩基配列と80%以上の相同性を有する塩基配列
9.Hs3st1をコードする遺伝子が、以下の(2A)~(2D)のいずれか1の塩基配列であって、かつHs3st1の機能を有するタンパク質のアミノ酸配列をコードする塩基配列を含む、前記2~8のいずれか1に記載の製造方法。
(2A)配列番号5に記載の塩基配列
(2B)配列番号5に記載の塩基配列において、1から数個の塩基が欠失、置換又は付加された塩基配列
(2C)配列番号5に記載の塩基配列に相補的な塩基配列とストリンジェントな条件下でハイブリダイズする塩基配列
(2D)配列番号5に記載の塩基配列と80%以上の相同性を有する塩基配列
10.SDCの細胞外ドメインをコードする遺伝子が、以下の(3A)~(3D)のいずれか1の塩基配列であって、かつSDCの細胞外ドメインの機能を有するタンパク質のアミノ酸配列をコードする塩基配列を含む、前記1~9のいずれか1に記載の製造方法。
(3A)配列番号6に記載の塩基配列
(3B)配列番号6に記載の塩基配列において、1から数個の塩基が欠失、置換又は付加された塩基配列
(3C)配列番号6に記載の塩基配列に相補的な塩基配列とストリンジェントな条件下でハイブリダイズする塩基配列
(3D)配列番号6に記載の塩基配列と80%以上の相同性を有する塩基配列
11.ヘパリン様物質を産生する哺乳動物細胞に、SDCの細胞外ドメインをコードする遺伝子が導入された組換え細胞。
12.前記へパリン様物質を産生する哺乳動物細胞は、NDST2をコードする遺伝子及びHs3st1をコードする遺伝子の少なくとも一方が導入された細胞である、前記11に記載の組換え細胞。
13.前記哺乳動物細胞はCHO細胞である、前記11又は12に記載の組換え細胞。
14.ヘパリン様物質を産生する哺乳動物細胞に、SDCの細胞外ドメインをコードする遺伝子を含む組換え発現ベクターを導入する工程を含む、ヘパリン様物質を分泌産生する細胞の製造方法。
本発明のヘパリン様物質の製造方法によれば、ヘパリン様物質を産生する哺乳動物細胞に、シンデカンの細胞外ドメインをコードする遺伝子を導入することにより、ヘパリン様物質を培養上清に分泌生産させて、該培養上清からヘパリン様物質を回収することができる。このことにより、生産物であるヘパリン様物質が細胞膜に付着するという問題点を解決し、複雑な精製工程を要しない。したがって、本発明の製造方法によれば、動物由来組織を用いずに、ヘパリン様物質を効率的に生産することができる。
以下、本明細書において使用される用語は特に言及しない限り、当該分野で通常用いられる意味を有する。
<ヘパリン様物質の製造方法>
本発明のヘパリン様物質の製造方法は、以下の工程(1)~(3)を含むことを特徴とする。
(1)ヘパリン様物質を産生する哺乳動物細胞を調製する工程
(2)工程(1)で調製したヘパリン様物質を産生する哺乳動物細胞に、シンデカンの細胞外ドメインをコードする遺伝子を導入した組換え細胞を調製する工程
(3)工程(2)で調製した組換え細胞を培地中で培養し、得られる培養上清からヘパリン様物質を回収する工程
以下各工程について説明する。
本発明のヘパリン様物質の製造方法は、以下の工程(1)~(3)を含むことを特徴とする。
(1)ヘパリン様物質を産生する哺乳動物細胞を調製する工程
(2)工程(1)で調製したヘパリン様物質を産生する哺乳動物細胞に、シンデカンの細胞外ドメインをコードする遺伝子を導入した組換え細胞を調製する工程
(3)工程(2)で調製した組換え細胞を培地中で培養し、得られる培養上清からヘパリン様物質を回収する工程
以下各工程について説明する。
工程(1):ヘパリン様物質を産生する哺乳動物細胞を調製する工程
工程(1)は、ヘパリン生合成に必要となるタンパク質をコードする遺伝子を宿主となる哺乳動物細胞に導入することにより、ヘパリン様物質を産生する哺乳動物細胞を調製する工程である。
工程(1)は、ヘパリン生合成に必要となるタンパク質をコードする遺伝子を宿主となる哺乳動物細胞に導入することにより、ヘパリン様物質を産生する哺乳動物細胞を調製する工程である。
本発明において、「ヘパリン様物質」とは、ヘパリン及びHSの混合物をいう。
哺乳動物細胞としては、例えば、チャイニーズ・ハムスター卵巣細胞CHO細胞[Journal of Experimental Medicine, 108, 945 (1958); Proc. Natl. Acad. Sci. USA, 60 , 1275 (1968); Genetics, 55, 513 (1968); Chromosoma, 41, 129 (1973); Methods in Cell Science, 18, 115 (1996); Radiation Research, 148, 260 (1997); Proc. Natl. Acad. Sci. USA, 77, 4216 (1980); Proc. Natl. Acad. Sci., 60, 1275 (1968); Cell, 6, 121 (1975); Molecular Cell Genetics, Appendix I, II (pp. 883-900)]、ジヒドロ葉酸還元酵素遺伝子が欠損したCHO細胞(CHO/DG44細胞)[Proc.Natl.Acad.Sci.USA,77,4216(1980)]、CHO-K1(ATCC CCL-61)、DUkXB11(ATCC CCL-9096)、Pro-5(ATCC CCL-1781)、CHO-S(Life Technologies、Cat#11619)、Pro-3、ヒト臍帯静脈内皮細胞(HUVEC)、ヒト臍帯動脈内皮細胞(HUAEC)、ヒト肺微小血管内皮細胞(HLMVEC)、ヒト大動脈内皮細胞(HAoEC)、ヒト冠状動脈内皮細胞(HCAEC)、ヒト肺動脈内皮細胞(HPAEC)、ヒト胎児腎臓(HEK)、ラットミエローマ細胞YB2/3HL.P2.G11.16Ag.20(またはYB2/0ともいう)、サル細胞COS細胞、マウスミエローマ細胞NSO、マウスミエローマ細胞SP2/0-Ag14、シリアンハムスター細胞BHKまたはHBT5637(日本国特開昭63-000299号公報)などが挙げられる。生産効率の点から、これらの中でも、CHO細胞、CHO/DG44細胞又はCHO-K1(ATCC CCL-61)は好ましく、CHO細胞がより好ましい。
ヘパリン生合成に必要となるタンパク質としては、例えば、両機能性ヘパラン硫酸エステルN-脱アセチラーゼ/N-硫酸転移酵素(以下、NDST2と略す。)、へパラン硫酸エステルグルコサミン3 硫酸転移酵素1(以下、Hs3st1と略す。)、ヘパラン硫酸2-O-硫酸転移酵素、C5-エピメラーゼ、ヘパラン硫酸6-O-硫酸転移酵素などが挙げられる。これらの中でもNDST2及びHs3st1が好ましい。これらのタンパク質は、ヘパリン生合成に必要となる活性を有していれば、変種のタンパク質であってもよい。これらのタンパク質は、哺乳動物由来であることが好ましく、マウス又はヒト由来であることがより好ましい。
前記ヘパリン生合成に必要なタンパク質としては、野生型の哺乳動物細胞においては発現がみられないタンパク質が挙げられる。具体的には、例えば、哺乳動物細胞がCHO細胞である場合、ヘパリン生合成に必要であり、CHO細胞では発現がみられない、NDST2及びHs3st1をコードする遺伝子の少なくとも一方を導入することにより、ヘパリン様物質を産生するCHO細胞を得ることができる(Bail JY et al., Metab Eng14:81-90, 2012)。
NDST2としては、以下の(1-a)~(1-c)のいずれか1のアミノ酸配列を含み、かつNDST2の機能を有するタンパク質が挙げられる。
(1-a)配列番号2に記載のアミノ酸配列又はNCBIアクセッション番号NP_003626.1のアミノ酸配列
(1-b)配列番号2に記載のアミノ酸配列又はNCBIアクセッション番号NP_003626.1のアミノ酸配列において、1から数個のアミノ酸が欠失、置換又は付加されたアミノ酸配列
(1-c)配列番号2に記載のアミノ酸配列又はNCBIアクセッション番号NP_003626.1のアミノ酸配列と60%以上、好ましくは80%以上、さらに好ましくは90%以上、最も好ましくは95%以上の相同性を有するアミノ酸配列
(1-a)配列番号2に記載のアミノ酸配列又はNCBIアクセッション番号NP_003626.1のアミノ酸配列
(1-b)配列番号2に記載のアミノ酸配列又はNCBIアクセッション番号NP_003626.1のアミノ酸配列において、1から数個のアミノ酸が欠失、置換又は付加されたアミノ酸配列
(1-c)配列番号2に記載のアミノ酸配列又はNCBIアクセッション番号NP_003626.1のアミノ酸配列と60%以上、好ましくは80%以上、さらに好ましくは90%以上、最も好ましくは95%以上の相同性を有するアミノ酸配列
Hs3st1としては、以下の(2-a)~(2-c)のいずれか1のアミノ酸配列を含み、かつHs3st1の機能を有するタンパク質が挙げられる。
(2-a)配列番号3に記載のアミノ酸配列又はNCBIアクセッション番号NP_034604.1のアミノ酸配列
(2-b)配列番号3に記載のアミノ酸配列又はNCBIアクセッション番号NP_034604.1のアミノ酸配列において、1から数個のアミノ酸が欠失、置換又は付加されたアミノ酸配列
(2-c)配列番号3に記載のアミノ酸配列又はNCBIアクセッション番号NP_034604.1のアミノ酸配列と60%以上、好ましくは80%以上、さらに好ましくは90%以上、最も好ましくは95%以上の相同性を有するアミノ酸配列
(2-a)配列番号3に記載のアミノ酸配列又はNCBIアクセッション番号NP_034604.1のアミノ酸配列
(2-b)配列番号3に記載のアミノ酸配列又はNCBIアクセッション番号NP_034604.1のアミノ酸配列において、1から数個のアミノ酸が欠失、置換又は付加されたアミノ酸配列
(2-c)配列番号3に記載のアミノ酸配列又はNCBIアクセッション番号NP_034604.1のアミノ酸配列と60%以上、好ましくは80%以上、さらに好ましくは90%以上、最も好ましくは95%以上の相同性を有するアミノ酸配列
目的とするアミノ酸配列において1から数個のアミノ酸が欠失、置換または付加されたアミノ酸配列を有するポリペプチドは、部位特異的変異導入法[Molecular Cloning, A Laboratory Manual, Second Edition, Cold Spring Harbor Laboratory Press (1989)、Current Protocols in Molecular Biology, John Wiley & Sons (1987-1997)、Nucleic Acids Research, 10, 6487 (1982)、Proc. Natl. Acad. Sci. USA, 79, 6409 (1982)、Gene, 34, 315 (1985)、Nucleic Acids Research, 13, 4431 (1985)、Proc. Natl. Acad. Sci. USA, 82, 488 (1985)]などを用いて、例えば配列番号1~3のアミノ酸配列を含むポリペプチドをコードするDNAに、部位特異的変異を導入することにより得ることができる。
アミノ酸配列の「1から数個のアミノ酸の欠失、置換、付加」における「1から数個」の範囲は特に限定されないが、例えば、アミノ酸配列におけるアミノ酸数100個を一単位とすれば、該一単位あたり、1、2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19又は20個、好ましくは1、2、3、4、5、6、7、8、9又は10個程度、より好ましくは1、2、3、4又は5個程度を意味する。
「アミノ酸の欠失」とは配列中のアミノ酸残基の欠落又は消失を意味し、「アミノ酸の置換」は配列中のアミノ酸残基が別のアミノ酸残基に置き換えられていることを意味し、「アミノ酸の付加」とは配列中に新たなアミノ酸残基が挿入するように付け加えられていることを意味する。
「1から数個のアミノ酸の欠失、置換、付加」の具体的な態様としては、1から数個のアミノ酸が別の化学的に類似したアミノ酸で置き換えられた態様がある。例えば、ある疎水性アミノ酸を別の疎水性アミノ酸に置換する場合、ある極性アミノ酸を同じ電荷を有する別の極性アミノ酸に置換する場合などを挙げることができる。このような化学的に類似したアミノ酸は、アミノ酸毎に当該技術分野において知られている。
具体例を挙げると、非極性(疎水性)アミノ酸としては、アラニン、バリン、グリシン、イソロイシン、ロイシン、プロリン、トリプトファン、フェニルアラニン、メチオニンなどが挙げられる。極性(中性)アミノ酸としては、セリン、スレオニン、チロシン、グルタミン、アスパラギン、システインなどが挙げられる。陽電荷をもつ塩基性アミノ酸としては、アルギニン、ヒスチジン、リジンなどが挙げられる。また、負電荷をもつ酸性アミノ酸としては、アスパラギン酸、グルタミン酸などが挙げられる。
対象となるタンパク質が有するアミノ酸配列において1から数個のアミノ酸の欠失、置換、付加などを有するアミノ酸配列としては、対象となるタンパク質が有するアミノ酸配列と一定以上の配列同一性を有するアミノ酸配列が挙げられ、例えば、対象となるタンパク質が有するアミノ酸配列と60%以上、好ましくは65%以上、好ましくは70%以上、好ましくは75%以上、好ましくは80%以上、好ましくは85%以上、より好ましくは90%以上、さらに好ましくは95%以上の配列同一性を有するアミノ酸配列が挙げられる。
NDST2をコードする遺伝子としては、以下の(1-A)~(1-D)のいずれか1の塩基配列であって、かつNDST2の機能を有するタンパク質のアミノ酸配列をコードする塩基配列を含む遺伝子が挙げられる。
(1-A)配列番号4に記載の塩基配列又はNCBIアクセッション番号NM_003635.3の塩基配列
(1-B)配列番号4に記載の塩基配列又はNCBIアクセッション番号NM_003635.3の塩基配列において、1から数個の塩基が欠失、置換又は付加された塩基配列
(1-C)配列番号4に記載の塩基配列又はNCBIアクセッション番号NM_003635.3の塩基配列に相補的な塩基配列とストリンジェントな条件下でハイブリダイズする塩基配列
(1-D)配列番号4に記載の塩基配列又はNCBIアクセッション番号NM_003635.3の塩基配列と少なくとも60%以上の相同性を有する塩基配列、好ましくは80%以上の相同性を有する塩基配列、さらに好ましくは95%以上の相同性を有する塩基配列
(1-A)配列番号4に記載の塩基配列又はNCBIアクセッション番号NM_003635.3の塩基配列
(1-B)配列番号4に記載の塩基配列又はNCBIアクセッション番号NM_003635.3の塩基配列において、1から数個の塩基が欠失、置換又は付加された塩基配列
(1-C)配列番号4に記載の塩基配列又はNCBIアクセッション番号NM_003635.3の塩基配列に相補的な塩基配列とストリンジェントな条件下でハイブリダイズする塩基配列
(1-D)配列番号4に記載の塩基配列又はNCBIアクセッション番号NM_003635.3の塩基配列と少なくとも60%以上の相同性を有する塩基配列、好ましくは80%以上の相同性を有する塩基配列、さらに好ましくは95%以上の相同性を有する塩基配列
Hs3st1をコードする遺伝子としては、以下の(2-A)~(2-D)のいずれか1の塩基配列であって、かつHs3st1の機能を有するタンパク質のアミノ酸配列をコードする塩基配列を含む遺伝子が挙げられる。
(2-A)配列番号5に記載の塩基配列又はNCBIアクセッション番号NM_010474.2の塩基配列
(2-B)配列番号5に記載の塩基配列又はNCBIアクセッション番号NM_010474.2の塩基配列において、1から数個の塩基が欠失、置換又は付加された塩基配列
(2-C)配列番号5に記載の塩基配列又はNCBIアクセッション番号NM_010474.2の塩基配列に相補的な塩基配列とストリンジェントな条件下でハイブリダイズする塩基配列
(2-D)配列番号5に記載の塩基配列又はNCBIアクセッション番号NM_010474.2の塩基配列と少なくとも60%以上の相同性を有する塩基配列、好ましくは80%以上の相同性を有する塩基配列、さらに好ましくは95%以上の相同性を有する塩基配列
(2-A)配列番号5に記載の塩基配列又はNCBIアクセッション番号NM_010474.2の塩基配列
(2-B)配列番号5に記載の塩基配列又はNCBIアクセッション番号NM_010474.2の塩基配列において、1から数個の塩基が欠失、置換又は付加された塩基配列
(2-C)配列番号5に記載の塩基配列又はNCBIアクセッション番号NM_010474.2の塩基配列に相補的な塩基配列とストリンジェントな条件下でハイブリダイズする塩基配列
(2-D)配列番号5に記載の塩基配列又はNCBIアクセッション番号NM_010474.2の塩基配列と少なくとも60%以上の相同性を有する塩基配列、好ましくは80%以上の相同性を有する塩基配列、さらに好ましくは95%以上の相同性を有する塩基配列
ストリンジェントな条件下でハイブリダイズする塩基配列としては、対象となる塩基配列を含むDNAをプローブに用いた、コロニー・ハイブリダイゼーション法、プラーク・ハイブリダイゼーション法、サザンブロット・ハイブリダイゼーション法またはDNAマイクロアレイ法などにより得られるハイブリダイズ可能なDNAの塩基配列のことをいう。
具体的には、ハイブリダイズしたコロニーあるいはプラーク由来のDNA、または該配列を有するPCR産物若しくはオリゴDNAを固定化したフィルター若しくはスライドガラスを用いて、0.7~1.0mol/Lの塩化ナトリウム存在下、65℃でハイブリダイゼーション法[Molecular Cloning, A Laboratory Manual, Second Edition, Cold Spring Harbor Laboratory Press (1989)、Current Protocols in Molecular Biology, John Wiley & Sons (1987-1997)、DNA Cloning 1: Core Techniques, A Practical Approach, Second Edition, Oxford University, (1995)]を行った後、0.1~2倍濃度のSSC溶液(1倍濃度のSSC溶液の組成は、150mmol/L塩化ナトリウム、15mmol/Lクエン酸ナトリウムよりなる)を用い、65℃条件下でフィルターまたはスライドガラスを洗浄することにより同定できるDNAの塩基配列を挙げることができる。
ストリンジェントな条件下でハイブリダイズする塩基配列を含むDNAとしては、プローブとして使用する対象となる遺伝子の塩基配列を有するDNAの塩基配列と一定以上の配列同一性を有するDNAが挙げられる。例えば、対象となる塩基配列と少なくとも60%以上の相同性を有するDNA、好ましくは80%以上の相同性を有するDNA、さらに好ましくは95%以上の相同性を有するDNAが挙げられる。また、例えば、塩基配列における塩基数100個を一単位とすれば、対象となる遺伝子の塩基配列において、該一単位あたり、1から数個、好ましくは1~40個、好ましくは1~35個、好ましくは1~30個、好ましくは1~25個、好ましくは1~20個、より好ましくは1~15個、さらに好ましくは1、2、3、4、5、6、7、8、9又は10個、なおさらに好ましくは1、2、3、4又は5個の塩基の欠失、置換、付加などを有する塩基配列を含むDNAが挙げられる。
「塩基の欠失」とは配列中の塩基に欠落又は消失があることを意味し、「塩基の置換」は配列中の塩基が別の塩基に置き換えられていることを意味し、「塩基の付加」とは新たな塩基が挿入するように付け加えられていることを意味する。
真核生物のタンパク質をコードする遺伝子の塩基配列には、しばしば遺伝子の多型が認められる。本発明において用いられる遺伝子に、このような多型によって塩基配列に小規模な変異を生じた遺伝子も該遺伝子に含有される。
本発明における相同性の数値は、特に明示した場合を除き、当業者に公知の相同性検索プログラムを用いて算出される数値であってよいが、塩基配列については、BLAST[J. Mol. Biol., 215, 403 (1990)]においてデフォルトのパラメータを用いて算出される数値など、アミノ酸配列については、BLAST2[Nucleic Acids Res.,25, 3389 (1997),Genome Res., 7, 649 (1997), https://blast.ncbi.nlm.nih.gov/Blast.cgi?PAGE_TYPE=BlastSearch&BLAST_SPEC=blast2seq&LINK_LOC=align2seq]においてデフォルトのパラメータを用いて算出される数値などが挙げられる。
デフォルトのパラメータとしては、G(Cost to open gap)が塩基配列の場合は5、アミノ酸配列の場合は11、-E(Cost to extend gap)が塩基配列の場合は2、アミノ酸配列の場合は1、-q(Penalty for nucleotide mismatch)が-3、-r(reward for nucleotide match)が1、-e(expect value)が10、-W(wordsize)が塩基配列の場合は11残基、アミノ酸配列の場合は3残基、-y[Dropoff(X)for blast extensions in bits]がblastnの場合は20、blastn以外のプログラムでは7、-X(X dropoff value for gapped alignment in bits)が15および-Z(final X dropoff value for gapped alignment in bits)がblastnの場合は50、blastn以外のプログラムでは25である(https://blast.ncbi.nlm.nih.gov/Blast.cgi?PAGE_TYPE=BlastSearch)。
ヘパリン様物質を産生する哺乳動物細胞は、ヘパリン生合成に必要となるタンパク質の全長又はその部分長をコードするcDNAを含む組換えベクターを、宿主細胞となる哺乳動物細胞に導入することにより、得ることができる。
組換えベクターとしては、使用する宿主細胞における自律複製又は染色体中への組込みが可能で、ポリペプチドをコードするDNAを転写できる位置に、適当なプロモーターを含有しているものであればいずれも用いることができる。
組換えベクターには、転写終結配列は必ずしも必要ではないが、構造遺伝子の直下に転写終結配列を配置することが好ましい。さらに、該組換えベクターには、プロモーターを制御する遺伝子を含んでいてもよい。
組換えベクターとしては、リボソーム結合配列であるコザック配列を開始コドン周辺に適当に配置したプラスミドを用いることが好ましい。
DNAの塩基配列において、宿主内での発現に最適なコドンとなるように塩基を置換することができ、これにより目的とするNDST2およびHs3st1の生産率を向上させることができる。
組換えベクターとしては、動物細胞中で機能を発揮できるものであればいずれも用いることができ、例えば、pcDNA I、pcDM8(フナコシ社)、pAGE107[日本国特開平03-22979号公報; Cytotechnology, 3, 133 (1990)]、pAS3-3(日本国特開平02-227075号公報)、pcDM8[Nature, 329, 840 (1987)]、pcDNA I/Amp(インビトロジェン社)、pcDNA3.1(インビトロジェン社)、pREP4(インビトロジェン社)、pAGE103[J. Biochemistry, 101, 1307 (1987)]、pAGE210、pME18SFL3、pKANTEX93(国際公開第97/10354号)、N5KG1val(米国特許第6001358号明細書)、INPEP4(Biogen-IDEC社)およびトランスポゾンベクター(国際公開第2010/143698号)などが挙げられる。
プロモーターとしては、動物細胞中で機能を発揮できるものであればいずれも用いることができ、例えば、サイトメガロウイルス(CMV)のimmediate early(IE)遺伝子のプロモーター、SV40の初期プロモーター、レトロウイルスのプロモーター、メタロチオネインプロモーター、ヒートショックプロモーター、SRαプロモーター、又はモロニーマウス白血病ウイルスのプロモーター若しくはエンハンサーが挙げられる。また、ヒトCMVのIE遺伝子のエンハンサーをプロモーターと共に用いてもよい。
組換えベクターは選択マーカーを含む場合がある。「選択マーカー」は、遺伝子を含有する細胞の選択を可能にする遺伝子である。「正の選択」とは、正の選択が起こって、選択マーカーを含有する細胞を選択するプロセスを指す。薬剤耐性が正の選択マーカーの一例であり、マーカーを含有する細胞は薬剤含有培養培地中で生存し、マーカーのない細胞は死滅する。選択マーカーとしては、G418耐性を与えるneo;ハイグロマイシン耐性を与えるhygr;およびピューロマイシン耐性を与えるpuroなどの薬剤耐性遺伝子が挙げられる。他の正の選択マーカー遺伝子には、マーカーを含有する細胞の同定またはスクリーニングを可能にする遺伝子が含まれる。これらの遺伝子としては、とりわけ、蛍光タンパク質(GFPおよびGFP様発色団、ルシフェラーゼ)遺伝子、lacZ遺伝子、アルカリ性ホスファターゼ遺伝子、およびCD8などの表面マーカーが挙げられる。「負の選択」とは、適切な負の選択薬剤に曝露して、負の選択マーカーを含有する細胞を死滅させるプロセスを指す。例えば、単純ヘルペスウイルスチミジンキナーゼ(HSV-tk)遺伝子を含有する細胞[Wigler et al, Cell 11:223 (1977)]は薬剤ガンシクロビル(GANC)に対して感受性である。同様に、gpt遺伝子は細胞を6-チオキサンチン感受性にする。
宿主細胞への組換えベクターの導入方法としては、動物細胞にDNAを導入する方法であればいずれも用いることができる。例えば、エレクトロポレーション法[Cytotechnology、3、133(1990)]、リン酸カルシウム法(日本国特開平02-227075号公報)、又はリポフェクション法[Proc. Natl. Acad. Sci. USA, 84, 7413 (1987)]などが挙げられる。
工程(2):工程(1)で調製したヘパリン様物質を産生する哺乳動物細胞に、シンデカンの細胞外ドメインをコードする遺伝子を導入した組換え細胞を調製する工程
工程(2)は、シンデカンの細胞外ドメインをコードする遺伝子を含有する組換えベクターを、工程(1)で調製したヘパリン様物質を産生する哺乳動物細胞に導入した組換え細胞を調製する工程である。
工程(2)は、シンデカンの細胞外ドメインをコードする遺伝子を含有する組換えベクターを、工程(1)で調製したヘパリン様物質を産生する哺乳動物細胞に導入した組換え細胞を調製する工程である。
シンデカンの構造は、細胞外ドメイン、膜貫通ドメインおよび細胞質ドメインからなる。このうち、シンデカンの細胞外ドメインはグリコサミノグリカン結合部位を含んでいる。シンデカンの細胞外ドメインとして、少なくともグリコサミノグリカン結合部位を有することが好ましい。シンデカンの細胞外ドメインは、哺乳動物由来であることが好ましく、マウス又はヒト由来であることがより好ましい。
シンデカンの細胞外ドメインとしては、以下の(3-a)~(3-c)のいずれか1のアミノ酸配列を含み、かつシンデカンの細胞外ドメインの機能を有するタンパク質が挙げられる。
(3-a)配列番号1に記載のアミノ酸配列又はNCBIアクセッション番号NP_001006947.1のアミノ酸配列
(3-b)配列番号1に記載のアミノ酸配列において、1から数個のアミノ酸が欠失、置換又は付加されたアミノ酸配列
(3-c)配列番号1に記載のアミノ酸配列と60%以上、好ましくは80%以上、さらに好ましくは90%以上、最も好ましくは95%以上の相同性を有するアミノ酸配列
(3-a)配列番号1に記載のアミノ酸配列又はNCBIアクセッション番号NP_001006947.1のアミノ酸配列
(3-b)配列番号1に記載のアミノ酸配列において、1から数個のアミノ酸が欠失、置換又は付加されたアミノ酸配列
(3-c)配列番号1に記載のアミノ酸配列と60%以上、好ましくは80%以上、さらに好ましくは90%以上、最も好ましくは95%以上の相同性を有するアミノ酸配列
配列番号1に記載のアミノ酸配列はNCBIアクセッション番号NP_001006947.1のアミノ酸配列(全長310アミノ酸)のN末端から第1~229番目のアミノ酸配列である。
シンデカンの細胞外ドメインをコードする遺伝子としては、以下の(3-A)~(3-D)のいずれか1の塩基配列であって、かつシンデカンの細胞外ドメインの機能を有するタンパク質のアミノ酸配列をコードする塩基配列を含む遺伝子が挙げられる。
(3-A)配列番号6に記載の塩基配列又はNCBIアクセッション番号NM_001006946.1の塩基配列
(3-B)配列番号6に記載の塩基配列又はNCBIアクセッション番号NM_001006946.1の塩基配列において、1から数個の塩基が欠失、置換又は付加された塩基配列
(3-C)配列番号6に記載の塩基配列又はNCBIアクセッション番号NM_001006946.1の塩基配列に相補的な塩基配列とストリンジェントな条件下でハイブリダイズする塩基配列
(3-D)配列番号6に記載の塩基配列又はNCBIアクセッション番号NM_001006946.1の塩基配列と少なくとも60%以上の相同性を有する塩基配列、好ましくは80%以上の相同性を有する塩基配列、さらに好ましくは95%以上の相同性を有する塩基配列
(3-A)配列番号6に記載の塩基配列又はNCBIアクセッション番号NM_001006946.1の塩基配列
(3-B)配列番号6に記載の塩基配列又はNCBIアクセッション番号NM_001006946.1の塩基配列において、1から数個の塩基が欠失、置換又は付加された塩基配列
(3-C)配列番号6に記載の塩基配列又はNCBIアクセッション番号NM_001006946.1の塩基配列に相補的な塩基配列とストリンジェントな条件下でハイブリダイズする塩基配列
(3-D)配列番号6に記載の塩基配列又はNCBIアクセッション番号NM_001006946.1の塩基配列と少なくとも60%以上の相同性を有する塩基配列、好ましくは80%以上の相同性を有する塩基配列、さらに好ましくは95%以上の相同性を有する塩基配列
工程(2)においては、シンデカンの細胞外ドメインをコードする遺伝子をシンデカンの細胞外ドメインの全長又はその部分長をコードするcDNAを含む組換えベクターを工程(1)で調製したヘパリン様物質を産生する哺乳動物細胞に導入することにより、ヘパリン様物質を培養上清中に分泌し得る組換え細胞を得る。
組換えベクター及び宿主細胞への組換えベクターの導入方法としては、工程(1)と同様とする。
(3)工程(2)で調製した組換え細胞を培地中で培養し、得られる培養上清からヘパリン様物質を回収する工程
工程(3)は、工程(2)で調製した組換え細胞を培地中で培養することにより、組換え細胞にヘパリン様物質を培地中に分泌生産させて、得られる培養上清からヘパリン様物質を回収する工程である。
工程(3)は、工程(2)で調製した組換え細胞を培地中で培養することにより、組換え細胞にヘパリン様物質を培地中に分泌生産させて、得られる培養上清からヘパリン様物質を回収する工程である。
工程(3)においては、組換え細胞は、ヘパリン様物質の産生を促進する条件下で培養することが好ましい。具体的には例えば、組換え細胞のへパリン様物質の産生を可能にし、かつ組換え細胞から培養上清へのヘパリン様物質の分泌を促進する培地中で組換え細胞を培養することが好ましい。
培地は、少なくとも細胞の生存率を維持し、ヘパリン様物質の発現を可能にするために十分な炭素、窒素、酸素および他の栄養素、成長因子、緩衝剤、補因子および他の任意の物質を含有することが好ましい。ヘパリン様物質をコードする遺伝子が誘導性プロモーターの制御下にあるか、または誘導性プロモーターを含む実施形態では、培地はさらにインデューサーを含んでもよい。
培地としては、例えば、10%ウシ胎児血清(FCS)を添加したRPMIまたはDMEM、並びに抗菌剤、増殖因子、他のサイトカインなどの因子を添加した組織培養培地中が挙げられる(例えば、Cell Biology (Third Edition) A Laboratory Handbook, vol. 1, 2006, Elsevier Inc.)。具体的には例えば、当業者に公知の培地製剤、例えば、RPMI、IMDM、DMEM、DMEM/F12、無血清または低血清のEMEMが挙げられる。これらの培地は、抗生物質、脂質、トランスフェリン、インスリン、アミノ酸などの追加の栄養補助食品、および必要に応じて補因子を含んでもよい。
ヘパリン様物質の産生を促進する観点から、培地は、グルコース、硫酸塩及びリン酸から選ばれる少なくとも1を含有することが好ましい。培地におけるグルコースの濃度は、通常5~75mMであることが好ましく、より好ましくは10~60mM、さらに好ましくは15~35mMである。培地における硫酸塩の濃度は、通常0.5~50mMであることが好ましく、より好ましくは10~50mM、さらに好ましくは30~50mMである。培地におけるリン酸塩の濃度は、通常0.5~50mMであることが好ましく、より好ましくは1~50mM、さらに好ましくは10~50mMである。
培養上清中にヘパリン様物質を生成蓄積させ、培養上清から採取することにより、ヘパリン様物質を製造することができる。組換え細胞を培地中で培養する方法は、通常の方法に従って行うことができる。培養は、通常pH6~8、30~40℃、5%CO2存在下などの条件下で1~7日間行う。
組換え細胞からのヘパリン様物質の分泌生産は、実施例において後述するように、培養上清にヘパリンリアーゼI、II、IIIを含む酵素溶液を添加して酵素処理後、不飽和二糖分析用HPLCで定量することにより確認できる。具体的には、コントロール(野生型)の細胞の培養上清と比較して、組換え細胞の培養上清における、グルコサミンのアミノ基と6位に3個の硫酸基が結合した2SNS6、グルクロン酸2位とグルコサミンアミノ基に硫酸基が結合した2SNS、グルコサミンのアミノ基と6位に2個の硫酸が結合したNS6S、グルコサミンNに硫酸基が結合したNSから選ばれる少なくとも1の量が増加している場合に、組換え細胞から培養上清中にヘパリン様物質が分泌生産されているとする。組換え細胞からのヘパリン様物質の分泌生産は、実施例において後述するように、培養上清中におけるsGAG(硫酸化されたGAG)量を測定することによっても確認できる。
工程(3)においては、組換え細胞から培養上清中に、GAGであるヘパリン様物質に結合したコアタンパク質を含む糖タンパク質であるプロテオグリカンが分泌される。培養上清からのタンパク質の単離は、当該分野で従来公知の方法により行う。例えば、アフィニティータグのようなヘパリン様物質の単離を容易にするタグを用いてもよい。タグとしては、例えば、ポリヒスチジン(His6タグ)、ニッケルマトリックス、キチン結合タンパク質(CBP)、マルトース結合タンパク質(MBP)、グルタチオン-S-トランスフェラーゼ(GST)、FLAGタグ又はエピトープタグが挙げられる。
コアタンパク質からのヘパリン様物質の単離は、当該技術分野において従来公知の方法により行う。例えば、ヘパリナーゼを用いた酵素消化法、水酸化ナトリウム又はアルカリ水素化ホウ素による処理が挙げられる。
単離されるヘパリン様物質は、好ましくは50%以上、より好ましくは60%以上、さらに好ましくは70%以上、特に好ましくは80%以上が硫酸化された二糖類を含むことが好ましい。
単離されるヘパリン様物質は、例えば、以下の(1)~(20)を含む。
(1)10~50%の三硫酸化二糖、30~50%の二硫酸化二糖及び10~30%の一硫酸化二糖。
(2)10~40%の三硫酸化二糖、35~45%の二硫酸化二糖及び10~25%の一硫酸化二糖。
(3)15~40%の三硫酸化二糖、35~45%の二硫酸化二糖及び10~25%の一硫酸化二糖。
(4)5~25%の三硫酸化二糖、30~50%の二硫酸化二糖及び10~20%の一硫酸化二糖。
(5)1~30%の三硫酸化二糖、25~55%の二硫酸化二糖、および5~40%の一硫酸化二糖。
(6)15~40%の三硫酸化二糖類。
(7)35~45%の二硫酸化二糖類。
(8)10~25%の一硫酸化二糖類。
(9)10~50%の三硫酸化二糖類。
(10)30~50%の二硫酸化二糖類。
(11)10~30%の一硫酸化二糖類。
(12)15~30%の三硫酸化二糖類。
(13)40~45%の二硫酸化二糖類。
(14)10~15%の一硫酸化二糖類。
(15)5~25%の三硫酸化二糖類。
(16)1~30%の三硫酸化二糖類。
(17)30~50%二硫酸化二糖類。
(18)25~55%の二硫酸化二糖類。
(19)10~20%の一硫酸化二糖類。
(20)5~40%の一硫酸化二糖類。
(1)10~50%の三硫酸化二糖、30~50%の二硫酸化二糖及び10~30%の一硫酸化二糖。
(2)10~40%の三硫酸化二糖、35~45%の二硫酸化二糖及び10~25%の一硫酸化二糖。
(3)15~40%の三硫酸化二糖、35~45%の二硫酸化二糖及び10~25%の一硫酸化二糖。
(4)5~25%の三硫酸化二糖、30~50%の二硫酸化二糖及び10~20%の一硫酸化二糖。
(5)1~30%の三硫酸化二糖、25~55%の二硫酸化二糖、および5~40%の一硫酸化二糖。
(6)15~40%の三硫酸化二糖類。
(7)35~45%の二硫酸化二糖類。
(8)10~25%の一硫酸化二糖類。
(9)10~50%の三硫酸化二糖類。
(10)30~50%の二硫酸化二糖類。
(11)10~30%の一硫酸化二糖類。
(12)15~30%の三硫酸化二糖類。
(13)40~45%の二硫酸化二糖類。
(14)10~15%の一硫酸化二糖類。
(15)5~25%の三硫酸化二糖類。
(16)1~30%の三硫酸化二糖類。
(17)30~50%二硫酸化二糖類。
(18)25~55%の二硫酸化二糖類。
(19)10~20%の一硫酸化二糖類。
(20)5~40%の一硫酸化二糖類。
ヘパリン様物質は、様々な長さの二糖単位の繰り返し構造を含み得る。ヘパリン様物質は、UA-GlcNAc(6S)、UA(2S)-GlcNAc、UA-(2S)-GlcNAc(6S)、UA-GlcNS、UA-GlcNS(6S)、UA(2S)-GlcNS、UA(2S)-GlcNS(6S)のいずれかを含むことが好ましく、これらはヘパリン様物質中に任意の順序で存在してもよい。
上記において、UAはウロン酸残基(すなわち、グルクロン酸またはイズロン酸)、Acはアセチル、GlcNAcはN-アセチルグルコサミン、GlcNSはグルコサミン-N-硫酸、2Sは2-O-硫酸塩、6Sは6-O-硫酸塩である。
<組換え細胞>
本発明の一態様として、ヘパリン様物質を産生する哺乳動物細胞に、SDCの細胞外ドメインをコードする遺伝子が導入された組換え細胞が挙げられる。該組換え細胞は、<ヘパリン様物質の製造方法>の項の工程(1)及び工程(2)において上述したのと同様に、ヘパリン様物質を産生する哺乳動物細胞を調製し、該哺乳動物細胞にシンデカンの細胞外ドメインをコードする遺伝子を導入することにより作製できる。
本発明の一態様として、ヘパリン様物質を産生する哺乳動物細胞に、SDCの細胞外ドメインをコードする遺伝子が導入された組換え細胞が挙げられる。該組換え細胞は、<ヘパリン様物質の製造方法>の項の工程(1)及び工程(2)において上述したのと同様に、ヘパリン様物質を産生する哺乳動物細胞を調製し、該哺乳動物細胞にシンデカンの細胞外ドメインをコードする遺伝子を導入することにより作製できる。
<ヘパリン様物質を分泌産生する細胞の製造方法>
本発明の一態様として、ヘパリン様物質を産生する哺乳動物細胞に、SDCの細胞外ドメインをコードする遺伝子を含む組換え発現ベクターを導入する工程を含むヘパリン様物質を分泌産生する細胞の製造方法が挙げられる。該製造方法は、<ヘパリン様物質の製造方法>の項の工程(1)及び工程(2)において上述したのと同様に、ヘパリン様物質を産生する哺乳動物細胞を調製し、該哺乳動物細胞にシンデカンの細胞外ドメインをコードする遺伝子を導入することにより実施することができる。
本発明の一態様として、ヘパリン様物質を産生する哺乳動物細胞に、SDCの細胞外ドメインをコードする遺伝子を含む組換え発現ベクターを導入する工程を含むヘパリン様物質を分泌産生する細胞の製造方法が挙げられる。該製造方法は、<ヘパリン様物質の製造方法>の項の工程(1)及び工程(2)において上述したのと同様に、ヘパリン様物質を産生する哺乳動物細胞を調製し、該哺乳動物細胞にシンデカンの細胞外ドメインをコードする遺伝子を導入することにより実施することができる。
<医薬組成物>
本発明の一態様として、本明細書に記載の方法により製造されたヘパリン様物質又はその断片を含む医薬組成物が挙げられる。本態様において、ヘパリン様物質又はその断片は、コアタンパク質に結合していてもよい。医薬組成物は他の治療薬を含有してもよい。また、医薬組成物は、例えば、慣用のビヒクルまたは希釈剤、ならびに所望の投与方法に適したタイプの医薬添加剤(例えば賦形剤、結合剤、保存剤)を使用することにより処方され得る。
本発明の一態様として、本明細書に記載の方法により製造されたヘパリン様物質又はその断片を含む医薬組成物が挙げられる。本態様において、ヘパリン様物質又はその断片は、コアタンパク質に結合していてもよい。医薬組成物は他の治療薬を含有してもよい。また、医薬組成物は、例えば、慣用のビヒクルまたは希釈剤、ならびに所望の投与方法に適したタイプの医薬添加剤(例えば賦形剤、結合剤、保存剤)を使用することにより処方され得る。
医薬組成物の形態としては、例えば、滅菌注射用水性剤が挙げられる。滅菌注射用水性剤は、適切な分散剤または湿潤剤および懸濁剤を使用して、既知の技術に従って処方することができる。滅菌注射用水性剤は、例えば1,3-ブタンジオール中の溶液のような、無毒の非経口的に許容される希釈剤または溶媒中の滅菌注射用溶液または懸濁液であってもよい。使用可能な許容されるビヒクルおよび溶媒は、水、リンゲル液および等張食塩水である。
医薬組成物の剤型は特に限定されず、多種多様な剤型とすることができる。医薬組成物を投与するための剤型としては、例えば、組成物は、錠剤、カプセル剤、サシェ剤、トローチ剤、丸剤、散剤、顆粒剤、エリキシル剤、チンキ剤、液剤、懸濁剤、エリキシル剤、シロップ剤、軟膏剤、クリーム剤などの形態での投与、静脈内投与若しくは注射、ペースト、エマルジョンまたは溶液が挙げられる。また、例えば、パッチメカニズムまたは軟膏による経皮投与が挙げられる。これらのいずれも、徐放および/または持続放出製剤に改変してもよい。
薬学的に許容される担体には、ビヒクル、アジュバント、界面活性剤、懸濁剤、乳化剤、不活性充填剤、希釈剤、賦形剤、湿潤剤、結合剤、滑沢剤、緩衝剤、崩壊剤および担体が含まれるがこれらに限定されない。典型的には、薬学的に許容される担体は活性化合物に対して化学的に不活性であり、そして使用条件下で有害な副作用または毒性を有さない。薬学的に許容される担体の性質は、使用される特定の剤形および組成物の他の特徴に応じて異なり得る。
<治療方法及び予防方法>
本発明の一態様として、本明細書に記載の方法により製造されたヘパリン様物質又はその断片を投与することを含む、それを必要とする被験体における血液凝固または血液凝固に関連するまたはそれによって引き起こされる状態を治療または予防する方法が挙げられる。本態様において、ヘパリン様物質又はその断片は、コアタンパク質に結合していてもよい。血液凝固または血液凝固に関連するまたはそれによって引き起こされる状態としては、例えば、急性冠症候群、心房細動、深部静脈血栓症または肺塞栓症が挙げられる。
本発明の一態様として、本明細書に記載の方法により製造されたヘパリン様物質又はその断片を投与することを含む、それを必要とする被験体における血液凝固または血液凝固に関連するまたはそれによって引き起こされる状態を治療または予防する方法が挙げられる。本態様において、ヘパリン様物質又はその断片は、コアタンパク質に結合していてもよい。血液凝固または血液凝固に関連するまたはそれによって引き起こされる状態としては、例えば、急性冠症候群、心房細動、深部静脈血栓症または肺塞栓症が挙げられる。
前記被験体は哺乳動物をいう。哺乳動物としては、例えば、ヒト、霊長類、家畜動物(例えば、ヒツジ、ウシ、ウマ、ロバ、ブタ)、コンパニオンアニマル(例えば、イヌ、ネコ)、実験室試験動物(例えば、マウス、ウサギ、ラット、モルモット、ハムスター)、捕獲野生動物(例えば、キツネ、シカ)が挙げられる。哺乳動物は、典型的にはヒトまたは霊長類であり、より典型的にはヒトである。
投与量及び投与時期は、血液凝固または血液凝固に関連する状態の治療、予防または管理において治療上の利益を提供する投与量及び時期であることが好ましい。有効である具体的な投与量及び投与時期は、被験体の状態、病歴、体格、体重、年齢などの要因に応じて変動し得る。
以下に実施例を示すが、本発明は下記実施例に限定されるものではない。
1.CHO/NH-SRGN細胞およびCHO/NH-SDC細胞におけるヘパリン生産能の評価
<CHO/NH-SRGN細胞及びCHO/NH-SDC細胞の作製>
Bail JY et al., Metab Eng14:81-90, 2012に基づき、NDST2をコードするDNA(配列番号4で表される塩基配列)およびHs3st1コードするDNA(配列番号5で表される塩基配列)を共導入してCHO/NH細胞のクローン#3(CHO-NH#3細胞)を得た。
<CHO/NH-SRGN細胞及びCHO/NH-SDC細胞の作製>
Bail JY et al., Metab Eng14:81-90, 2012に基づき、NDST2をコードするDNA(配列番号4で表される塩基配列)およびHs3st1コードするDNA(配列番号5で表される塩基配列)を共導入してCHO/NH細胞のクローン#3(CHO-NH#3細胞)を得た。
CHO/NH-SRGN細胞の作製に用いた、ベクターPB513B-1_SRGN-IRES-EGFPはPiggyBac Transposon Vector PB513B-1をベースとして、チャイニーズ・ハムスターのEF1αプロモーター、IRESエレメント、C末端におけるmycHisタグ配列を有するベクターである。ベクターPB513B-1_SRGN-IRES-EGFPにおいては、EF1αプロモーターの制御下に、hSRGNをコードするDNA(配列番号7で表される塩基配列)を、スクリーニングマーカーであるEGFP遺伝子及びピューロマイシン耐性遺伝子と共発現するように導入した。
CHO/NH#3細胞にヒトセリグリシン(SRGN)をコードするDNA(配列番号7で表される塩基配列)をベクターPB513B-1_SRGN-IRES-EGFPを用いて導入したCHO/NH-SRGN細胞、及びヒトシンデカン(SDC)の細胞外ドメインのDNA(配列番号6で表される塩基配列)をベクターPB513B-1_SDC-IRES-EGFPを用いて導入したCHO/NH-SDC細胞を作製した。
CHO/NH-SDC細胞の作製に用いた、ベクターPB513B-1_SDC-IRES-EGFPは、PiggyBac Transposon Vector PB513B-1をベースとして、チャイニーズ・ハムスターのEF1αプロモーター、IRESエレメント、C末端におけるmycHisタグ配列を有するベクターである。ベクターPB513B-1_SDC-IRES-EGFPにおいては、EF1αプロモーターの制御下に、SRGNをコードするDNA(配列番号7で表される塩基配列)を、スクリーニングマーカーであるEGFP遺伝子及びピューロマイシン耐性遺伝子と共発現するように導入した。
上記のようにして作製した各細胞の培養上清を解析しヘパリン生産能の評価を行った。
<CHO/NH-SRGN細胞及びCHO/NH-SDC細胞の培養上清におけるsGAG量の測定>
各細胞を増殖性のよい状態で培養した後、6ウェルプレートに0.6×106cells/wellで播種し、培地交換を行わず3日後に回収した培養上清を試料として、sGAG量をsGAGアッセイにより測定した。sGAGアッセイとは、硫酸化糖鎖に特異的に結合する色素(1,9-ジメチルメチレンブルー)を用いて溶液中の全sGAG量を比色定量するアッセイをいう。結果を図1に示す。
各細胞を増殖性のよい状態で培養した後、6ウェルプレートに0.6×106cells/wellで播種し、培地交換を行わず3日後に回収した培養上清を試料として、sGAG量をsGAGアッセイにより測定した。sGAGアッセイとは、硫酸化糖鎖に特異的に結合する色素(1,9-ジメチルメチレンブルー)を用いて溶液中の全sGAG量を比色定量するアッセイをいう。結果を図1に示す。
<HPLCによる糖鎖構造の解析結果>
sGAGアッセイによって培養上清中へのヘパリン産生が示唆されたことから、同サンプルについて、HPLCによる糖鎖構造の解析をした。解析に使用したサンプルのsGAG定量結果を図2に示す。なお、CHO/NH-SDC細胞のサンプルについては濃度が低く解析に十分な糖鎖があるか確認できなかったことから、スピンカラムによる濃縮操作を行った。
sGAGアッセイによって培養上清中へのヘパリン産生が示唆されたことから、同サンプルについて、HPLCによる糖鎖構造の解析をした。解析に使用したサンプルのsGAG定量結果を図2に示す。なお、CHO/NH-SDC細胞のサンプルについては濃度が低く解析に十分な糖鎖があるか確認できなかったことから、スピンカラムによる濃縮操作を行った。
ヘパリンの産生の確認については、まず試料溶液を直接20μLとり、緩衝液10μL、各10mUのヘパリンリアーゼI、II、IIIを含む酵素溶液10μLを添加して3時間37℃で酵素処理し、反応終了後100℃、5分間で酵素を失活、凍結乾燥後20μLの水を加えて不飽和二糖分析用HPLCで定量した。結果を図3(A)及び(B)に示す。
図3(A)及び(B)において、WTは野生型CHO細胞、#3はCHO-NH#3細胞、SRGNはCHO細胞にSRGNをコードするDNA(配列番号7で表される塩基配列)をベクターPB513B-1_SRGN-IRES-EGFPを用いて導入したCHO-SRGN細胞、#3SRGNはCHO/NH-SRGN細胞、SDCはCHO細胞にSDCの細胞外ドメインのDNA(配列番号6で表される塩基配列)をベクターPB513B-1_SDC-IRES-EGFPを用いて導入したCHO-SDC細胞を示す。
図3(A)及び(B)に示すように、SRGN導入細胞(SRGN、#3SRGN)の培養上清において、WT又は#3と比較して、ヘパリン様物質の検出の増加は検出されなかった。一方で、SDC導入細胞(SDC、#3SDC)の培養上清においては、ヘパリン様物質の産生がWT又は#3と比較して、増加していた。以上の結果より、CHO/NH-SDC細胞がよりヘパリン様物質の産生に適した細胞であると考え、クローニング及び各クローンにおける解析を実施した。
2.無血清馴化後におけるGAG量の測定結果
ヘパリンに特徴的な糖鎖構造が見られたことからCHO/NH-SDC細胞のクローニングと各クローンにおける解析を実施した。
ヘパリンに特徴的な糖鎖構造が見られたことからCHO/NH-SDC細胞のクローニングと各クローンにおける解析を実施した。
<クローニングおよび無血清馴化>
血清入り培地を用いてCHO/NH-SDC細胞を培養して接着状態にし、限界希釈法によってコラーゲンコート96ウェルプレートでクローニングを行った。この際、1細胞からの培養のため、細胞への毒性を考慮して、薬剤添加は行わずに培養した。コラーゲンコート24、6ウェルプレートとスケールアップし、複数のクローンを培養させ、36個のクローンを樹立した。その後、各細胞をノーマル6ウェルプレートに0.6×106cells/wellで播種し、培地交換を行わず3日後に回収した培養上清を試料として、培養上清中のsGAG量を測定し、上位6クローン(#5、#20、#26、#29、#30、#34)について無血清馴化を行った。
血清入り培地を用いてCHO/NH-SDC細胞を培養して接着状態にし、限界希釈法によってコラーゲンコート96ウェルプレートでクローニングを行った。この際、1細胞からの培養のため、細胞への毒性を考慮して、薬剤添加は行わずに培養した。コラーゲンコート24、6ウェルプレートとスケールアップし、複数のクローンを培養させ、36個のクローンを樹立した。その後、各細胞をノーマル6ウェルプレートに0.6×106cells/wellで播種し、培地交換を行わず3日後に回収した培養上清を試料として、培養上清中のsGAG量を測定し、上位6クローン(#5、#20、#26、#29、#30、#34)について無血清馴化を行った。
<無血清馴化後におけるsGAG量、sGAG産生速度、SDC量の測定>
無血清馴化後、各細胞をノーマル6ウェルプレートに0.6×106cells/wellで播種し、培地交換を行わず3日後に回収した培養上清を試料として、培養上清中のsGAG量を測定した。結果を図4に示す。また、sGAGの産生速度を計算した結果を図5に、ELISAにより培養上清中のSDC量を定量した結果を図6にそれぞれ示す。
無血清馴化後、各細胞をノーマル6ウェルプレートに0.6×106cells/wellで播種し、培地交換を行わず3日後に回収した培養上清を試料として、培養上清中のsGAG量を測定した。結果を図4に示す。また、sGAGの産生速度を計算した結果を図5に、ELISAにより培養上清中のSDC量を定量した結果を図6にそれぞれ示す。
図6に示すように、評価した6クローンは、CHO/NH-SDC細胞と比較して、同等以上のSDCの分泌産生能を有しており、#5がCHO/NH-SDC細胞の1.5倍以上であり最も高い発現量を示した。
<qRT-PCRによる導入遺伝子発現量の解析>
各細胞を6ウェルプレートに0.6×106cells/wellで播種し、培地交換を行わず3日間培養した細胞からRNAの抽出及びcDNAの作製を行い、qRT-PCRにより導入遺伝子(NDST2、Hs3st1及びSDC)の発現量を定量した。図7(A)はNDST2遺伝子、図7(B)はHs3st1遺伝子、図7(C)はSDC遺伝子の発現量をそれぞれ示す。
各細胞を6ウェルプレートに0.6×106cells/wellで播種し、培地交換を行わず3日間培養した細胞からRNAの抽出及びcDNAの作製を行い、qRT-PCRにより導入遺伝子(NDST2、Hs3st1及びSDC)の発現量を定量した。図7(A)はNDST2遺伝子、図7(B)はHs3st1遺伝子、図7(C)はSDC遺伝子の発現量をそれぞれ示す。
図7(A)~(C)に示すように、#5において各遺伝子の高い発現レベルが確認できた一方で、#26では発現が認められなかった。#26は抗凝固活性においても他のクローンと比較して低い活性を示しており、NDST2およびHs3st1によってATIII認識特異配列が形成されていることが示唆された。
3.HPLCによる糖鎖構造の解析
各種CHO細胞により産生されたヘパリン様物質の糖鎖構造をHPLCにより解析した。
各種CHO細胞により産生されたヘパリン様物質の糖鎖構造をHPLCにより解析した。
<分析条件>
試料の前処理として、各種CHO細胞の培養上清400μLを10,000rpmにて10分間遠心分離した上層に400μLの二段蒸留水(Double Distilled Water、DDW)を加え、凍結乾燥させた。その後、40μLのサンプルから20μLを分取し、Heparin lyase I、II及びIII処理をした後、80μLのDDWを加え、20μLをHPLCに供した。
試料の前処理として、各種CHO細胞の培養上清400μLを10,000rpmにて10分間遠心分離した上層に400μLの二段蒸留水(Double Distilled Water、DDW)を加え、凍結乾燥させた。その後、40μLのサンプルから20μLを分取し、Heparin lyase I、II及びIII処理をした後、80μLのDDWを加え、20μLをHPLCに供した。
特異的分解酵素による処理は、次の通りとした。酢酸緩衝液[0.1MCH3COONa、10mM(CH3COO)2Ca(pH7.0)]20μL、0.5mU/μL Heparinase 5μL、0.5mU/μL HeparitinaseI 5μL、0.5mU/μL HeparitinaseII 5μLを同時に加え、37℃にて16時間インキュベーションすることでヘパリン様糖鎖を不飽和二糖に分解した。沸騰水浴中3分間加熱して酵素を失活させ、凍結乾燥した後水に溶解しHPLCによる不飽和二糖分析に供した。
<HS及びCSの二糖組成分析>
下記に示す装置及び解析ソフトを用いてHS及びCSの二糖組成分析を行った。
溶離液のポンプ:島津製作所製LIQUID CHROMATOGRAPHY LC-10Ai
検出器:JASCO製Intelligent Fluorescence Detector FP-920S
ポスト反応用ポンプ:日本精密科学株式会社製MINICHEMI PUMP NP-FX(II)-1U
インテグレーター:日立製作所製Chromato Integrator D-2500
インジェクター:Reodyne社製sample injector(model 7725)
カラム:センシュー科学製Senshu Pak DOCOSIL(4.6mm i.d.x150mm)
カラムオーブン:日立製作所製 L-7300
ドライ反応槽:島村計器製作所製Dry Reaction Bath DB-5
解析ソフト:株式会社ランタイムインスツルメンツ製Chromato-PRO
下記に示す装置及び解析ソフトを用いてHS及びCSの二糖組成分析を行った。
溶離液のポンプ:島津製作所製LIQUID CHROMATOGRAPHY LC-10Ai
検出器:JASCO製Intelligent Fluorescence Detector FP-920S
ポスト反応用ポンプ:日本精密科学株式会社製MINICHEMI PUMP NP-FX(II)-1U
インテグレーター:日立製作所製Chromato Integrator D-2500
インジェクター:Reodyne社製sample injector(model 7725)
カラム:センシュー科学製Senshu Pak DOCOSIL(4.6mm i.d.x150mm)
カラムオーブン:日立製作所製 L-7300
ドライ反応槽:島村計器製作所製Dry Reaction Bath DB-5
解析ソフト:株式会社ランタイムインスツルメンツ製Chromato-PRO
解析に用いた試料中のsGAGをHPLCにより定量した結果を図8に、標準ヘパリン由来不飽和二糖(HS-Standards)及び試料から得られたクロマトグラムを図9に示す。また、ヘパリン様糖鎖の含有量、硫酸化に占める各糖鎖の割合をHPLCにより定量した結果をそれぞれ図10(A)及び(B)に示す。表1に検出されたヘパリン様物質中硫酸化糖鎖(HS)の濃度及び硫酸化糖鎖の比率を示す。

表1に示すように、作製したクローン(#5、#20、#26、#29、#30、#34)から得られたサンプルから検出された糖鎖の硫酸化度はヘパリンと同程度であり、ヘパリン様糖鎖の産生がコントロール(CHO-S、SDC)と比較して、顕著に増加していた。
<抗ファクターXa活性の測定>
積水メディカル株式会社製テストチームヘパリンS測定キット(http://www.info.pmda.go.jp/tgo/pack/13A2X00197218081_A_01_10/)を用いて測定した。標準品ヘパリンは医療用ヘパリン(101IU/mg)を用いて調製した。測定原理の概要は以下の通りとした。
構成試薬名、成分:
1.基質剤:N-ベンゾイル-L-イソロイシル-L-グルタミル(γ-OR)-グリシル-L-アルギニル-p-ニトロアニリド・塩酸塩(S-2222)
2.アンチトロンビンIII剤:アンチトロンビンIII(ヒト由来)
3.ファクターXa剤:ファクターXa(ウシ由来)
4.緩衝液:2-アミノ-2-ヒドロキシメチル-1,3-プロパンジオール緩衝液
5.正常血漿剤:ヒト正常血漿
積水メディカル株式会社製テストチームヘパリンS測定キット(http://www.info.pmda.go.jp/tgo/pack/13A2X00197218081_A_01_10/)を用いて測定した。標準品ヘパリンは医療用ヘパリン(101IU/mg)を用いて調製した。測定原理の概要は以下の通りとした。
構成試薬名、成分:
1.基質剤:N-ベンゾイル-L-イソロイシル-L-グルタミル(γ-OR)-グリシル-L-アルギニル-p-ニトロアニリド・塩酸塩(S-2222)
2.アンチトロンビンIII剤:アンチトロンビンIII(ヒト由来)
3.ファクターXa剤:ファクターXa(ウシ由来)
4.緩衝液:2-アミノ-2-ヒドロキシメチル-1,3-プロパンジオール緩衝液
5.正常血漿剤:ヒト正常血漿
抗凝固能の検証
上記HPLC結果において硫酸化度が高いクローン(#20、#26、#29、#30、#34)について図11に示す検量線を用いて抗凝固活性(抗FXa活性9を調べた。結果を表2に示す。
上記HPLC結果において硫酸化度が高いクローン(#20、#26、#29、#30、#34)について図11に示す検量線を用いて抗凝固活性(抗FXa活性9を調べた。結果を表2に示す。

表2に示すように、#20、#29、#30、#34から得られた試料において、培地1mLあたりおよそ0.1IUの抗FXa活性が確認できた。この結果から、NDST2およびHs3st1の導入によってアンチトロンビン結合性配列が培養上清中のヘパリン様糖鎖に含まれていることが示唆された。
本発明を特定の態様を用いて詳細に説明したが、本発明の意図と範囲を離れることなく様々な変更および変形が可能であることは、当業者にとって明らかである。なお、本出願は、2019年10月2日付けで出願された日本特許出願(特願2019-182467)に基づいており、その全体が引用により援用される。
Claims (14)
- 以下の工程(1)~(3)を含むヘパリン様物質の製造方法。
(1)ヘパリン様物質を産生する哺乳動物細胞を調製する工程
(2)工程(1)で調製したヘパリン様物質を産生する哺乳動物細胞に、シンデカン(以下、SDCと略す。)の細胞外ドメインをコードする遺伝子を導入した組換え細胞を調製する工程
(3)工程(2)で調製した組換え細胞を培地中で培養し、得られる培養上清からヘパリン様物質を回収する工程 - 前記へパリン様物質を産生する哺乳動物細胞は、両機能性ヘパラン硫酸エステルN-脱アセチラーゼ/N-硫酸転移酵素(以下、NDST2と略す。)をコードする遺伝子及びへパラン硫酸エステルグルコサミン3 硫酸転移酵素1(以下、Hs3st1と略す。)をコードする遺伝子の少なくとも一方が導入された細胞である、請求項1に記載の製造方法。
- 前記哺乳動物細胞はチャイニーズ・ハムスター由来卵巣(以下、CHOと略す。)細胞である、請求項1又は2に記載の製造方法。
- NDST2が以下の(1a)~(1c)のいずれか1のアミノ酸配列を含み、かつNDST2の機能を有するタンパク質である、請求項2又は3に記載の製造方法。
(1a)配列番号2に記載のアミノ酸配列
(1b)配列番号2に記載のアミノ酸配列において、1から数個のアミノ酸が欠失、置換又は付加されたアミノ酸配列
(1c)配列番号2に記載のアミノ酸配列と80%以上の相同性を有するアミノ酸配列 - Hs3st1が以下の(2a)~(2c)のいずれか1のアミノ酸配列を含み、かつHs3st1の機能を有するタンパク質である、請求項2~4のいずれか1項に記載の製造方法。
(2a)配列番号3に記載のアミノ酸配列
(2b)配列番号3に記載のアミノ酸配列において、1から数個のアミノ酸が欠失、置換又は付加されたアミノ酸配列
(2c)配列番号3に記載のアミノ酸配列と80%以上の相同性を有するアミノ酸配列 - SDCの細胞外ドメインが以下の(3a)~(3c)のいずれか1のアミノ酸配列を含み、かつSDCの細胞外ドメインの機能を有するタンパク質である、請求項1~5のいずれか1項に記載の製造方法。
(3a)配列番号1に記載のアミノ酸配列
(3b)配列番号1に記載のアミノ酸配列において、1から数個のアミノ酸が欠失、置換又は付加されたアミノ酸配列
(3c)配列番号1に記載のアミノ酸配列と80%以上の相同性を有するアミノ酸配列 - NDST2及びHs3st1がマウス又はヒト由来である、請求項2~6のいずれか1項に記載の製造方法。
- NDST2をコードする遺伝子が、以下の(1A)~(1D)のいずれか1の塩基配列であって、かつNDST2の機能を有するタンパク質のアミノ酸配列をコードする塩基配列を含む、請求項2~7のいずれか1項に記載の製造方法。
(1A)配列番号4に記載の塩基配列
(1B)配列番号4に記載の塩基配列において、1から数個の塩基が欠失、置換又は付加された塩基配列
(1C)配列番号4に記載の塩基配列に相補的な塩基配列とストリンジェントな条件下でハイブリダイズする塩基配列
(1D)配列番号4に記載の塩基配列と80%以上の相同性を有する塩基配列 - Hs3st1をコードする遺伝子が、以下の(2A)~(2D)のいずれか1の塩基配列であって、かつHs3st1の機能を有するタンパク質のアミノ酸配列をコードする塩基配列を含む、請求項2~8のいずれか1項に記載の製造方法。
(2A)配列番号5に記載の塩基配列
(2B)配列番号5に記載の塩基配列において、1から数個の塩基が欠失、置換又は付加された塩基配列
(2C)配列番号5に記載の塩基配列に相補的な塩基配列とストリンジェントな条件下でハイブリダイズする塩基配列
(2D)配列番号5に記載の塩基配列と80%以上の相同性を有する塩基配列 - SDCの細胞外ドメインをコードする遺伝子が、以下の(3A)~(3D)のいずれか1の塩基配列であって、かつSDCの細胞外ドメインの機能を有するタンパク質のアミノ酸配列をコードする塩基配列を含む、請求項1~9のいずれか1項に記載の製造方法。
(3A)配列番号6に記載の塩基配列
(3B)配列番号6に記載の塩基配列において、1から数個の塩基が欠失、置換又は付加された塩基配列
(3C)配列番号6に記載の塩基配列に相補的な塩基配列とストリンジェントな条件下でハイブリダイズする塩基配列
(3D)配列番号6に記載の塩基配列と80%以上の相同性を有する塩基配列 - ヘパリン様物質を産生する哺乳動物細胞に、SDCの細胞外ドメインをコードする遺伝子が導入された組換え細胞。
- 前記へパリン様物質を産生する哺乳動物細胞は、NDST2をコードする遺伝子及びHs3st1をコードする遺伝子の少なくとも一方が導入された細胞である、請求項11に記載の組換え細胞。
- 前記哺乳動物細胞はCHO細胞である、請求項11又は12に記載の組換え細胞。
- ヘパリン様物質を産生する哺乳動物細胞に、SDCの細胞外ドメインをコードする遺伝子を含む組換え発現ベクターを導入する工程を含む、ヘパリン様物質を分泌産生する細胞の製造方法。
Priority Applications (4)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202080069050.9A CN114502739A (zh) | 2019-10-02 | 2020-10-02 | 肝素样物质的制造方法、重组细胞及其制造方法 |
| EP20872500.2A EP4039814A4 (en) | 2019-10-02 | 2020-10-02 | METHOD FOR PRODUCING HEPARIN-LIKE SUBSTANCES, RECOMBINANT CELLS AND METHOD FOR THE PRODUCTION THEREOF |
| JP2021551617A JP7715392B2 (ja) | 2019-10-02 | 2020-10-02 | ヘパリン様物質の製造方法、組換え細胞及びその製造方法 |
| US17/765,507 US20220380489A1 (en) | 2019-10-02 | 2020-10-02 | Method for producing heparin-like substance, recombinant cell, and method for producing the same |
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2019182467 | 2019-10-02 | ||
| JP2019-182467 | 2019-10-02 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2021066167A1 true WO2021066167A1 (ja) | 2021-04-08 |
Family
ID=75337030
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2020/037626 Ceased WO2021066167A1 (ja) | 2019-10-02 | 2020-10-02 | ヘパリン様物質の製造方法、組換え細胞及びその製造方法 |
Country Status (5)
| Country | Link |
|---|---|
| US (1) | US20220380489A1 (ja) |
| EP (1) | EP4039814A4 (ja) |
| JP (1) | JP7715392B2 (ja) |
| CN (1) | CN114502739A (ja) |
| WO (1) | WO2021066167A1 (ja) |
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2023157899A1 (ja) * | 2022-02-17 | 2023-08-24 | 国立大学法人九州大学 | 組換えヘパリン様物質、及びその製造方法 |
| WO2026009803A1 (ja) * | 2024-07-05 | 2026-01-08 | 国立大学法人九州大学 | ヘパリン様物質を製造する方法 |
Citations (10)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPS63299A (ja) | 1986-04-22 | 1988-01-05 | イミユネツクス・コ−ポレ−シヨン | ヒトg−csfタンパク質の発現 |
| JPH02227075A (ja) | 1988-09-29 | 1990-09-10 | Kyowa Hakko Kogyo Co Ltd | 新規ポリペプチド |
| JPH0322979A (ja) | 1989-06-19 | 1991-01-31 | Kyowa Hakko Kogyo Co Ltd | 新規プラスミノーゲン活性化因子 |
| WO1997010354A1 (fr) | 1995-09-11 | 1997-03-20 | Kyowa Hakko Kogyo Co., Ltd. | Anticorps de la chaine alpha du recepteur de l'interleukine 5 humaine |
| US6001358A (en) | 1995-11-07 | 1999-12-14 | Idec Pharmaceuticals Corporation | Humanized antibodies to human gp39, compositions containing thereof |
| WO2001040267A2 (en) * | 1999-12-05 | 2001-06-07 | Yeda Research And Development Co. Ltd. | Proteoglycans and pharmaceutical compositions comprising them |
| US20040043447A1 (en) * | 2002-06-21 | 2004-03-04 | Sami Saribas | Production of sulfated polysaccharides using glycosaminoglycan-specific sulfotransferases |
| JP2008515417A (ja) * | 2004-10-12 | 2008-05-15 | アバンテイス・フアルマ・エス・アー | ヘパリン型分子を産生するブタ肥満細胞株 |
| WO2010143698A1 (ja) | 2009-06-11 | 2010-12-16 | 大学共同利用機関法人情報・システム研究機構 | タンパク質の生産方法 |
| JP2019182467A (ja) | 2018-04-06 | 2019-10-24 | セッツカートン株式会社 | 段ボール箱 |
Family Cites Families (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US5486599A (en) * | 1989-03-29 | 1996-01-23 | The Board Of Trustees Of The Leland Stanford Junior University | Construction and use of synthetic constructs encoding syndecan |
| JP6555687B2 (ja) * | 2013-11-20 | 2019-08-07 | 国立大学法人北海道大学 | 免疫制御剤 |
| AU2016256600A1 (en) * | 2015-04-30 | 2017-11-16 | Newsouth Innovations Pty Limited | Method for production of heparin and heparan sulfate |
| AU2017378500A1 (en) * | 2016-12-16 | 2019-07-04 | Tega Therapeutics, Inc. | In vitro heparin and heparan sulfate compositions and methods of making and using |
-
2020
- 2020-10-02 JP JP2021551617A patent/JP7715392B2/ja active Active
- 2020-10-02 CN CN202080069050.9A patent/CN114502739A/zh active Pending
- 2020-10-02 US US17/765,507 patent/US20220380489A1/en active Pending
- 2020-10-02 WO PCT/JP2020/037626 patent/WO2021066167A1/ja not_active Ceased
- 2020-10-02 EP EP20872500.2A patent/EP4039814A4/en not_active Withdrawn
Patent Citations (10)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPS63299A (ja) | 1986-04-22 | 1988-01-05 | イミユネツクス・コ−ポレ−シヨン | ヒトg−csfタンパク質の発現 |
| JPH02227075A (ja) | 1988-09-29 | 1990-09-10 | Kyowa Hakko Kogyo Co Ltd | 新規ポリペプチド |
| JPH0322979A (ja) | 1989-06-19 | 1991-01-31 | Kyowa Hakko Kogyo Co Ltd | 新規プラスミノーゲン活性化因子 |
| WO1997010354A1 (fr) | 1995-09-11 | 1997-03-20 | Kyowa Hakko Kogyo Co., Ltd. | Anticorps de la chaine alpha du recepteur de l'interleukine 5 humaine |
| US6001358A (en) | 1995-11-07 | 1999-12-14 | Idec Pharmaceuticals Corporation | Humanized antibodies to human gp39, compositions containing thereof |
| WO2001040267A2 (en) * | 1999-12-05 | 2001-06-07 | Yeda Research And Development Co. Ltd. | Proteoglycans and pharmaceutical compositions comprising them |
| US20040043447A1 (en) * | 2002-06-21 | 2004-03-04 | Sami Saribas | Production of sulfated polysaccharides using glycosaminoglycan-specific sulfotransferases |
| JP2008515417A (ja) * | 2004-10-12 | 2008-05-15 | アバンテイス・フアルマ・エス・アー | ヘパリン型分子を産生するブタ肥満細胞株 |
| WO2010143698A1 (ja) | 2009-06-11 | 2010-12-16 | 大学共同利用機関法人情報・システム研究機構 | タンパク質の生産方法 |
| JP2019182467A (ja) | 2018-04-06 | 2019-10-24 | セッツカートン株式会社 | 段ボール箱 |
Non-Patent Citations (35)
| Title |
|---|
| "Cell Biology (Third Edition) A Laboratory Handbook", vol. 1, 2006, ELSEVIER INC. |
| "DNA Cloning 1: Core Techniques, A Practical Approach", 1995, OXFORD UNIVERSITY |
| "Molecular Cloning, A Laboratory Manual", 1989, COLD SPRING HARBOR LABORATORY PRESS |
| "NCBI", Database accession no. NM _001006946.1 |
| BAIK, J. Y. ET AL.: "Metabolic engineering of Chinese hamster ovary cells: Towards a bioengineered heparin", METABOLIC ENGINEERING, vol. 14, 2012, pages 81 - 90, XP028466088, ISSN: 1096-7176, DOI: 10.1016/j.ymben.2012.01.008 * |
| BAIL JY ET AL., METAB ENG, vol. 14, 2012, pages 81 - 90 |
| BAIL JY ET AL., METAB ENGL, vol. 4, 2012, pages 81 - 90 |
| CELL, vol. 6, 1975, pages 121 |
| CHROMOSOMA, vol. 41, 1973, pages 129 |
| CYTOTECHNOLOGY, vol. 3, 1990, pages 133 |
| GENE, vol. 34, 1985, pages 315 |
| GENETICS, vol. 55, 1968, pages 513 |
| GENOME RES., vol. 7, 1997, pages 649, Retrieved from the Internet <URL:https://blast.ncbi.nlm.nih.gov/Blast.cgi?PAGE_TYPE=BlastSearch&BLAST_SPEC=blast2seq&LINK_LOC=align2seq> |
| GUERRINI ET AL., NAT. BIOTECHNOL., vol. 26, 2008, pages 669 - 675 |
| J. BIOCHEMISTRY, vol. 101, 1987, pages 1307 |
| J. MOL. BIOL., vol. 215, 1990, pages 403 |
| JALKANEN, MARKKU, ELENIUS KLAUS, RAPRAEGER ALAN: "Syndecan: Regulator of cell morphology and growth factor action at the cell-matrix interface", TRENDS IN GLYCOSCIENCE AND GLYCOTECHNOLOGY, vol. 5, no. 22, 1993, pages 107 - 120, XP055811043, ISSN: 0915-7352, DOI: 10.4052/tigg.5.107 * |
| JOURNAL OF EXPERIMENTAL MEDICINE, vol. 108, 1958, pages 945 |
| METHODS IN CELL SCIENCE, vol. 18, 1996, pages 115 |
| MOLECULAR CELL GENETICS, pages 883 - 900 |
| NATURE, vol. 329, 1987, pages 840 |
| NUCLEIC ACIDS RES., vol. 25, 1997, pages 3389 |
| NUCLEIC ACIDS RESEARCH, vol. 10, 1982, pages 6487 |
| NUCLEIC ACIDS RESEARCH, vol. 13, 1985, pages 4431 |
| PROC. NATL. ACAD. SCI. USA, vol. 60, 1968, pages 1275 |
| PROC. NATL. ACAD. SCI. USA, vol. 77, 1980, pages 4216 |
| PROC. NATL. ACAD. SCI. USA, vol. 79, 1982, pages 6409 |
| PROC. NATL. ACAD. SCI. USA, vol. 82, 1985, pages 488 |
| PROC. NATL. ACAD. SCI. USA, vol. 84, 1987, pages 7413 |
| PROC. NATL. ACAD. SCI., vol. 60, 1968, pages 1275 |
| RADIATION RESEARCH, vol. 148, 1997, pages 260 |
| See also references of EP4039814A4 |
| TRENDS IN GLYCOSCIENCE AND GLYCOTECHNOLOGY, vol. 5, no. 22, 1993, pages 107 - 120 |
| WIGLER ET AL., CELL, vol. 11, 1977, pages 223 |
| YANG, YANG, YACCOBY SHMUEL, LIU WEI, LANGFORD J. KEVIN, PUMPHREY CARLA Y., THEUS ALLISON, EPSTEIN JOSHUA, SANDERSON RALPH D.: "Soluble syndecan-1 promotes growth of myeloma tumors in vivo", BLOOD, vol. 100, no. 2, 2002, pages 610 - 617, XP055811048, ISSN: 0006-4971, DOI: 10.1182/blood.V100.2.610 * |
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2023157899A1 (ja) * | 2022-02-17 | 2023-08-24 | 国立大学法人九州大学 | 組換えヘパリン様物質、及びその製造方法 |
| WO2026009803A1 (ja) * | 2024-07-05 | 2026-01-08 | 国立大学法人九州大学 | ヘパリン様物質を製造する方法 |
Also Published As
| Publication number | Publication date |
|---|---|
| EP4039814A1 (en) | 2022-08-10 |
| JPWO2021066167A1 (ja) | 2021-04-08 |
| CN114502739A (zh) | 2022-05-13 |
| JP7715392B2 (ja) | 2025-07-30 |
| EP4039814A4 (en) | 2023-10-11 |
| US20220380489A1 (en) | 2022-12-01 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP6670235B2 (ja) | 可逆的ヘパリン分子、その製法及びその使用方法 | |
| US11203772B2 (en) | Chemoenzymatic synthesis of structurally homogeneous ultra-low molecular weight heparins | |
| KR102560632B1 (ko) | 생합성 헤파린 | |
| US20090035787A1 (en) | Enzymatic synthesis of sulfated polysaccharides without iduronic acid residues | |
| JP7715392B2 (ja) | ヘパリン様物質の製造方法、組換え細胞及びその製造方法 | |
| US11542534B2 (en) | Methods for synthesizing anticoagulant polysaccharides | |
| Lord et al. | Bioengineered human heparin with anticoagulant activity | |
| US20040191870A1 (en) | Methods of 6-0 sulfating polysaccharides and 6-0 sulfated polysaccharide preparations | |
| US10385143B2 (en) | Method for production of heparin and heparan sulfate | |
| US20250154290A1 (en) | Recombinant heparin-like substance and method for producing the same | |
| US20090214513A1 (en) | Mammalian expression systems | |
| JP5977949B2 (ja) | コンドロイチンまたはコンドロイチン硫酸を分解する分解方法、高硫酸化オリゴ糖の製造方法、ならびに組成物 | |
| US20250154476A1 (en) | Improved heparan sulfate and methods of making the same | |
| US20050233453A1 (en) | 6-O-sulfated N-acetylheparosan and hematopoietic stem cell growth auxiliary agent | |
| WO2026009803A1 (ja) | ヘパリン様物質を製造する方法 | |
| Mulatero | Investigating Glycosaminoglycan Binding to the N Terminal Region of Thrombospondin-1 | |
| Busse | EXT Proteins in Heparan Sulfate Biosynthesis |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 20872500 Country of ref document: EP Kind code of ref document: A1 |
|
| ENP | Entry into the national phase |
Ref document number: 2021551617 Country of ref document: JP Kind code of ref document: A |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| ENP | Entry into the national phase |
Ref document number: 2020872500 Country of ref document: EP Effective date: 20220502 |