WO2022074796A1 - 評価方法、評価装置、および評価プログラム - Google Patents
評価方法、評価装置、および評価プログラム Download PDFInfo
- Publication number
- WO2022074796A1 WO2022074796A1 PCT/JP2020/038178 JP2020038178W WO2022074796A1 WO 2022074796 A1 WO2022074796 A1 WO 2022074796A1 JP 2020038178 W JP2020038178 W JP 2020038178W WO 2022074796 A1 WO2022074796 A1 WO 2022074796A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- machine learning
- training data
- learning model
- data
- trained
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Ceased
Links
Images




Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N20/00—Machine learning
Definitions
- the present invention relates to an evaluation method, an evaluation device, and an evaluation program.
- Poisoning attack which is one of the security problems peculiar to machine learning, is an attack that intentionally modifies the machine learning model by mixing abnormal data into the training data of the machine learning model, and significantly reduces the inference accuracy. ..
- the evaluation method that actually launches a poisoning attack requires repeated training of a machine learning model using a large amount of abnormal data and evaluation of the degree of deterioration of inference accuracy, which causes a problem that a huge amount of time is required.
- the evaluation method using the influence function it is necessary to specifically prepare training data for evaluating the degree of influence, but there is a problem that it becomes difficult to prepare the data especially when the data input space is wide.
- One aspect is to provide an evaluation method, an evaluation device, and an evaluation program capable of more efficiently evaluating the resistance of a machine learning model to training data that lowers the inference accuracy of the machine learning model.
- the computer In the first plan, the computer generates the second training data that reduces the inference accuracy based on the information indicating the degree of the decrease in the inference accuracy of the machine learning model with respect to the change in the first training data, and the second.
- the machine learning model is trained using the training data of, and the process of evaluating the trained machine learning model is executed.
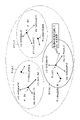
- FIG. 1 is a functional block diagram showing a functional configuration of the evaluation device 10 according to the first embodiment.
- FIG. 2 is a diagram showing an example of the training data space according to the first embodiment.
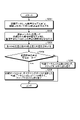
- FIG. 3 is a flowchart showing the flow of the resistance evaluation process of the machine learning model according to the first embodiment.
- FIG. 4 is a flowchart showing the flow of the training data update process according to the first embodiment.
- FIG. 5 is a flowchart showing the flow of the resistance evaluation process of the machine learning model according to the second embodiment.
- FIG. 6 is a diagram illustrating a hardware configuration example of the evaluation device 10.
- FIG. 1 is a functional block diagram showing a functional configuration of the evaluation device 10 according to the first embodiment.
- the evaluation device 10 includes a communication unit 20, a storage unit 30, and a control unit 40.
- the communication unit 20 is a processing unit that controls communication with other devices, and is, for example, a communication interface.
- the storage unit 30 is an example of a storage device that stores various data and a program executed by the control unit 40, and is, for example, a memory or a hard disk.
- the storage unit 30 can also store, for example, model parameters for constructing a machine learning model and training data for a machine learning model.
- various data can be stored in the storage unit 30.
- the control unit 40 is a processing unit that controls the entire evaluation device 10, and is, for example, a processor.
- the control unit 40 has a generation unit 41, a training unit 42, an evaluation unit 43, and a calculation unit 44.
- Each processing unit is an example of an electronic circuit possessed by the processor and an example of a process executed by the processor.
- the generation unit 41 generates training data for reducing the inference accuracy in order to evaluate the resistance of the machine learning model to the poisoning data based on the information indicating the degree of deterioration of the inference accuracy of the machine learning model with respect to the change of the training data. do.
- poisoning data that lowers the inference accuracy of the machine learning model is generated for the training data used for training the machine learning model, and the poisoning data is added to the training data used for training. Generated by adding.
- FIG. 2 is a diagram showing an example of the training data space according to the first embodiment.
- the training data space has three labels, labels 1 to 3.
- the generation unit 41 randomly selects data as an initial point from a cluster of all labels of the training data used for training the machine learning model.
- (data A, label 1), (data B, label 2), and (data C, label 3) are randomly selected as initial points from the clusters of labels 1 to 3, respectively.
- the initial point is, for example, a combination of data and labels that are the basis for searching for data having a higher degree of contamination using the gradient ascending method.
- the combination of the data and the label searched based on the initial point finally becomes the poisoning data.
- the generation unit 41 adds one or more labels different from the original label to each of the data selected from each cluster to the initial point.
- the original label of the data A is the label 1
- data to which the label 2 or the label 3 which is a label different from the original label is added to the data A is added to the initial point. do.
- the initial point of the point will be completed.
- the generation unit 41 adds data in which data having different labels are paired with each other to the initial point.
- the pairing is a data conversion, which is a conversion in which two data are used to generate one data. For example, if the training data includes data x_1 and x_2 and the labels are y_1 and y_2, respectively, the pairing of the data (x_1, y_1) and (x_2, y_2) can be calculated by the following equation. By pairing, two data can be generated from a set of data having different labels.
- Pairing data can be generated. Therefore, a total of 6 points, 3 combinations of different labels and 2 points of pairing data, are added as initial points by pairing.
- the initial points generated as described above are updated to data with a higher degree of pollution by, for example, the calculation unit 44 using the gradient ascending method. Then, the data is repeatedly updated until a predetermined condition is satisfied, and poisoning data that further lowers the inference accuracy of the machine learning model is calculated. The poisoning data is calculated for each of the initial points, and the generation unit 41 adds a plurality of training data that reduce the inference accuracy to the training data used for training the machine learning model. Generate.
- the training unit 42 trains the machine learning model using the training data generated by the generation unit 41 that reduces the inference accuracy in order to evaluate the resistance of the machine learning model to the poisoning data.
- a plurality of training data are generated by the generation unit 41, and in order to evaluate the inference accuracy of the machine learning model when training using each training data, each of the plurality of training data is used. Use to train machine learning models. That is, multiple trained machine learning models will be created.
- the evaluation unit 43 evaluates the resistance of the machine learning model trained by the training unit 42 to the poisoning data using the training data that reduces the inference accuracy.
- the evaluation is also performed on each of the multiple trained machine learning models. Further, in the evaluation, the inference accuracy between the machine learning model trained using the training data for evaluation and the machine learning model trained by the training unit 42 using the training data generated in advance for evaluation is performed. It is done by calculating the accuracy difference using a loss function. That is, how much the inference accuracy of the machine learning model trained by the training unit 42 using the training data that reduces the inference accuracy is reduced with respect to the machine learning model trained using the training data for evaluation. Calculate and evaluate as an accuracy difference.
- the calculation unit 44 updates the initial points generated by the generation unit 41 using the gradient ascending method, and calculates poisoning data that further lowers the inference accuracy of the machine learning model.
- the function used in the gradient ascending method is also calculated by the calculation unit 44.
- the function can be calculated by using existing technology or by performing training, and calculates the gradient of the change amount ⁇ of the loss function when (data x, label y) is added to the training data X_t.
- X_v is "training data generated in advance for evaluation" in the explanation of the evaluation unit 43, and is for evaluating how much the inference accuracy of the machine learning model is lowered with respect to the poisoning data.
- This is the standard data.
- the change amount ⁇ of the loss function is the machine learning model trained using the training data X_t for evaluation and the training data X_t ⁇ ⁇ (x, y) in which (data x, label y) is added to the training data X_t. ) ⁇ Is the accuracy difference of the inference accuracy from the machine learning model trained using.
- the machine learning model trained using the training data X_t for evaluation is M
- the machine learning model trained using the training data X_t ⁇ ⁇ (x, y) ⁇ is M'
- the loss function is L
- calculation unit 44 calculates the accuracy difference of the inference accuracy of the machine learning model before and after the training using the training data that lowers the inference accuracy.
- FIG. 3 is a flowchart showing the flow of the resistance evaluation process of the machine learning model according to the first embodiment.
- training data X_v for evaluation which is a reference for evaluating how much the inference accuracy of the machine learning model has deteriorated with respect to the poisoning data, is generated in advance. Further, the inference accuracy of the target machine learning model may be calculated in advance using the evaluation data X_v using the loss function.
- the evaluation device 10 calculates the function d ⁇ / dx (X_v, y) using the training data X_t and the evaluation data X_v (step S101).
- the evaluation device 10 selects data as an initial point from the clusters of all labels of the training data X_t (step S102).
- Data selection from each cluster is, for example, random.
- the evaluation device 10 adds data to the data selected in step S102 with a label different from the original label to the initial point (step S103). It should be noted that the addition of different labels may be performed on all labels that are different from the original label, or may be performed on some different labels.
- the evaluation device 10 adds data in which data having different labels are paired to the initial point (step S104).
- the pairing data is generated for the number of combinations of different labels at the maximum ⁇ 2 points, and is added as an initial point.
- the execution order of steps S103 and S104 may be reversed.
- the evaluation device 10 updates each of the initial points generated in steps S102 to S104 by using the function d ⁇ / dx (X_v, y) when the label is fixed, and calculates a plurality of poisoning data.
- x 0 indicates the data of the initial point.
- ⁇ is a parameter called the learning rate, which indicates the amount of movement of the data x, and for example, a small positive number is set.
- the evaluation device 10 trains the machine learning model using the training data X_t to which the poisoning data calculated in step S105 is added (step S106). Since a plurality of poisoning data are calculated in step S105, the machine learning model is trained using each of the calculated poisoning data, and a plurality of trained machine learning models are generated.
- the evaluation device 10 evaluates the machine learning model trained using the training data X_t to which the poisoning data is added in step S106 (step S107).
- step S106 since a plurality of trained machine learning models are generated, evaluation is performed for each of the trained machine learning models. Specifically, the accuracy difference in inference accuracy between each of the trained machine learning models generated in step S106 and the machine learning model trained using the evaluation data X_v is calculated using the loss function. Evaluates the target machine learning model. The larger the calculated accuracy difference, the more contaminated the machine learning model of interest is with the poisoning data, and the less resistant it is to the poisoning data. After the execution of S107, the resistance evaluation process of the machine learning model shown in FIG. 3 ends.
- FIG. 4 is a flowchart showing the flow of the training data update process according to the first embodiment.
- this process in order to approximate the influence of multiple poisoning data well, every time the accuracy difference of the inference accuracy of the machine learning model before and after training using the poisoning data becomes more than a certain level, the function d ⁇ / using the poisoning data.
- the evaluation device 10 uses the evaluation data X_v, the machine learning model M'trained using the training data X_t to which the poisoning data is added, and the function ⁇ for calculating the change amount of the loss function.
- the first accuracy difference is calculated using (step S201).
- the first accuracy difference is ⁇ (X_t), where ⁇ is the training data including poisoning data, where ⁇ is the function representing the amount of change from the value of the loss function in the evaluation data X_v for the training data not including poisoning data.
- X_v can be calculated.
- the evaluation device 10 has a second machine learning model M trained using the training data X_t and a machine learning model M'trained using the training data X_t to which poisoning data is added in step S106.
- the accuracy difference of is calculated (step S202). Similar to the first accuracy difference, the second accuracy difference can be calculated by the formula L (M', X_v) -L (M, X_v) using the loss function L.
- the evaluation device 10 calculates the difference between the first accuracy difference calculated in step S201 and the second accuracy difference calculated in step S202 (step S203).
- the difference between the two accuracy differences is equal to or greater than a predetermined threshold value (step S204: Yes)
- the evaluation device 10 replaces the training data X_t with the training data X_t ⁇ ⁇ (x, y) ⁇ to which poisoning data is added, and steps are taken. The process is repeated from S101 (step S205).
- step S204 when the difference between the two accuracy differences is not equal to or more than a predetermined threshold value (step S204: No), the evaluation device 10 does not update the training data X_t and repeats the process from step S102 (step S206). After the execution of S205 or S206, the training data update process shown in FIG. 4 ends.
- FIG. 5 is a flowchart showing the flow of the resistance evaluation process of the machine learning model according to the second embodiment.
- the gradient with respect to the amount of change ⁇ of the loss is performed not only for the data x but also for the label y.
- both the data and the label are further updated by the gradient ascending method, and the data x is further updated by the gradient ascending method for the optimized data and the label to calculate the poisoning data. do.
- the evaluation device 10 uses the training data X_t and the evaluation data X_v with respect to x and y of the change amount ⁇ of the loss function when (data x, label y) is added to X_t.
- the functions d ⁇ / dx (X_v) and d ⁇ / dy (X_v) for calculating the gradient are calculated (step S301).
- the function d ⁇ / dy (X_v) for calculating the gradient with respect to y is a function for measuring the gradient of the data y with respect to the change amount ⁇ of the loss function L, and how to update the data y to infer the machine learning model. It is possible to measure whether the accuracy is good or bad.
- the function d ⁇ / dy (X_v) can be calculated using the existing technology as well as the function d ⁇ / dx (X_v).
- Steps S302 to S304 are the same as steps S102 to S104 of the first embodiment. However, when the data with different labels is added to the initial point in step S303, it is performed not for all the labels different from the original label but for some different labels.
- the evaluation device 10 updates each of the initial points generated in steps S302 to S304 using the functions d ⁇ / dx (X_v) and d ⁇ / dy (X_v) (step S305).
- the update of the initial point is performed, for example, by using the gradient ascending method.
- the data before the update is (data x i , label y i ) and the data after the update is (data x i + 1 , label y i + 1 )
- .. i is a numerical value that is counted up every time it is updated with 0 as the initial value. Therefore, x 0 and y 0 indicate the initial point data.
- ⁇ is a parameter called the learning rate, which indicates the amount of movement of the data x, and for example, a small positive number is set.
- the predetermined conditions are, for example, that the number of executions of the update process has reached a predetermined threshold value, the difference between the data before and after the update has disappeared, the update has stopped, and the data after the update is separated from the data at the initial point by a certain amount or more.
- the calculated label y may be a decimal value, in which case it is converted to an integer value.
- the evaluation device 10 updates and fixes y to the value of the label closest to the value of y for the updated label y, and then generates it in steps S302 to S304 using the function d ⁇ / dx (X_v).
- Each of the initial points is updated, and a plurality of poisoning data are calculated (step S306).
- the update of the initial point in step S306 is also repeated as in step S105 until a predetermined condition is satisfied by using, for example, a gradient ascending method.
- Steps S307 and S308 are the same as steps S106 and S107 of the first embodiment. After the execution of S308, the resistance evaluation process of the machine learning model shown in FIG. 5 ends.
- the evaluation device 10 generates the second training data that reduces the inference accuracy based on the information indicating the degree of the decrease in the inference accuracy of the machine learning model with respect to the change in the first training data, and the second training data is generated.
- the machine learning model is trained using the training data of No. 2, and the trained machine learning model is evaluated.
- poisoning data with a higher degree of contamination is searched for and generated for the target machine learning model, and the machine learning model is trained using the generated poisoning data to evaluate the resistance of the machine learning model to the poisoning data. It can be performed. Therefore, it is possible to more efficiently evaluate the resistance of the machine learning model to the training data that lowers the inference accuracy of the machine learning model.
- data is randomly selected as an initial point from the clusters of all the labels of the first training data, and each of the selected data is selected.
- the data with one or more labels different from the original label is added to the initial point, the data in which the data with different labels are paired is added to the initial point, and the second training is based on the initial point.
- the process of generating the second training data executed by the evaluation device 10 includes a process of generating a plurality of second training data based on a plurality of initial points, and is a process of training the machine learning model. Includes the process of training a machine learning model using each of the plurality of second training data, and the process of evaluating the trained machine learning model is trained using each of the plurality of second training data. Includes processing to evaluate each of the multiple trained machine learning models.
- the initial point is updated by the gradient ascending method, and the second training is performed based on the updated initial point. Includes processing to generate data.
- the process of generating the second training data based on the initial point which is executed by the evaluation device 10
- the label given to the initial point is updated by the gradient ascending method, and the updated initial point and the label are updated. Based on this, it includes a process of generating a second training data.
- the process of evaluating the trained machine learning model executed by the evaluation device 10 uses a function for calculating the amount of change in the loss function, and the machine learning model trained using the second training data. And, the first accuracy difference of the inference accuracy from the machine learning model trained using the first training data for evaluating the machine learning model was calculated, and the training was performed based on the first accuracy difference. Includes processing to evaluate machine learning models.
- the evaluation device 10 uses a loss function to obtain a second inference accuracy between a machine learning model trained using the first training data and a machine learning model trained using the second training data. If the difference between the first accuracy difference and the second accuracy difference is equal to or greater than a predetermined threshold value, the first training data is replaced with the second training data to reduce the inference accuracy.
- the process of generating the training data of No. 4, training the machine learning model using the fourth training data, and evaluating the trained machine learning model using the fourth training data is further executed.
- each component of each device shown in the figure is a functional concept, and does not necessarily have to be physically configured as shown in the figure. That is, the specific form of distribution or integration of each device is not limited to the one shown in the figure. That is, all or part of them can be functionally or physically distributed / integrated in any unit according to various loads and usage conditions.
- the generation unit 41 and the calculation unit 44 of the evaluation device 10 can be integrated.
- each processing function performed by each device may be realized by a CPU and a program analyzed and executed by the CPU, or may be realized as hardware by wired logic.
- FIG. 6 is a diagram showing a hardware configuration example of the evaluation device 10.
- the evaluation device 10 includes a communication unit 10a, an HDD (Hard Disk Drive) 10b, a memory 10c, and a processor 10d. Further, the parts shown in FIG. 6 are connected to each other by a bus or the like.
- HDD Hard Disk Drive
- the communication unit 10a is a network interface card or the like, and communicates with other servers.
- the HDD 10b stores programs and data for operating the functions shown in FIG.
- the processor 10d reads a program that executes the same processing as each processing unit shown in FIG. 1 from the HDD 10b or the like and expands the program into the memory 10c to operate a process that executes each function described in FIG. For example, this process performs the same function as each processing unit of the evaluation device 10.
- the processor 10d reads a program having the same functions as the generation unit 41, the training unit 42, and the like from the HDD 10b and the like. Then, the processor 10d executes a process of executing the same processing as the generation unit 41, the training unit 42, and the like.
- the evaluation device 10 operates as an information processing device that executes each process by reading and executing the program. Further, the evaluation device 10 can realize the same function as that of the above-described embodiment by reading the program from the recording medium by the medium reader and executing the read program.
- the program referred to in the other examples is not limited to being executed by the evaluation device 10.
- the present invention can be similarly applied when other computers or servers execute programs, or when they execute programs in cooperation with each other.
- This program can be distributed via networks such as the Internet.
- this program is recorded on a computer-readable recording medium such as a hard disk, flexible disk (FD), CD-ROM, MO (Magnet-Optical disk), DVD (Digital Versaille Disc), and is recorded from the recording medium by the computer. It can be executed by being read.
- Evaluation device 10a Communication unit 10b HDD 10c memory 10d processor 20 communication unit 30 storage unit 40 control unit 41 generation unit 42 training unit 43 evaluation unit 44 calculation unit
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Software Systems (AREA)
- Data Mining & Analysis (AREA)
- Evolutionary Computation (AREA)
- Medical Informatics (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Physics & Mathematics (AREA)
- Computing Systems (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Mathematical Physics (AREA)
- Artificial Intelligence (AREA)
- Management, Administration, Business Operations System, And Electronic Commerce (AREA)
- Debugging And Monitoring (AREA)
Abstract
ポイズニング攻撃に対する機械学習モデルの従来の耐性評価方法には、評価に膨大な時間を要するという問題やデータの準備が困難となる問題がある。コンピュータが、第1の訓練データの変化に対する機械学習モデルの推論精度の低下の度合いを示す情報に基づいて、推論精度を低下させる第2の訓練データを生成し、第2の訓練データを用いて機械学習モデルを訓練し、訓練された機械学習モデルの評価を行う処理を実行する。これにより、一つの側面では、機械学習モデルの推論精度を低下させる訓練データに対する機械学習モデルの耐性評価をより効率的に行うことができる。
Description
本発明は、評価方法、評価装置、および評価プログラムに関する。
機械学習固有のセキュリティ問題の1つであるポイズニング攻撃は、機械学習モデルの訓練データに異常データを混入させることにより、機械学習モデルを意図的に改変し、その推論精度を著しく低下させる攻撃である。
そのため、機械学習モデルがポイズニング攻撃によりどの程度汚染され、推論精度が低下するかを予め評価することが重要とされている。ポイズニング攻撃に対する機械学習モデルの耐性評価として、例えば、実際に、機械学習モデルにポイズニング攻撃をしかけて、推論精度を低下させ、その度合いを評価する方法がある。また、別の評価方法として、個々の訓練データが機械学習モデルの推論に与える影響を定量化する影響関数を用いて、ポイズニング攻撃による異常データの影響度合いを評価する方法がある。
"Towards Poisoning of Deep Learning Algorithms with Backgradient Optimization",L. Munoz-Gonzalez, B. Biggio, A. Demontis, A. Paudice, V. Wongrassamee, E.C. Lupu, and F. Roli
"Understanding Black-box Predictions via Influence Functions", K. W. Pang, L. Percy
しかしながら、ポイズニング攻撃を実際にしかける評価方法は、大量の異常データを用いて機械学習モデルの訓練と、推論精度の低下度合いの評価とを繰り返す必要があり、膨大な時間を要するという問題がある。また、影響関数を用いる評価方法は、影響度合いを評価するための訓練データを具体的に準備する必要があるが、データの入力空間が広い場合は特にデータの準備が困難となる問題がある。
一つの側面では、機械学習モデルの推論精度を低下させる訓練データに対する機械学習モデルの耐性評価をより効率的に行うことができる評価方法、評価装置、および評価プログラムを提供することを目的とする。
第1の案では、コンピュータが、第1の訓練データの変化に対する機械学習モデルの推論精度の低下の度合いを示す情報に基づいて、推論精度を低下させる第2の訓練データを生成し、第2の訓練データを用いて機械学習モデルを訓練し、訓練された機械学習モデルの評価を行う処理を実行する。
一つの側面では、機械学習モデルの推論精度を低下させる訓練データに対する機械学習モデルの耐性評価をより効率的に行うことができる。
以下に、本願の開示する評価方法、評価装置、および評価プログラムの実施例を図面に基づいて詳細に説明する。なお、この実施例によりこの発明が限定されるものではない。また、各実施例は、矛盾のない範囲内で適宜組み合わせることができる。
[評価装置10の機能構成]
まず、本願の開示する評価方法の実行主体となる評価装置10の機能構成について説明する。図1は、実施例1にかかる評価装置10の機能構成を示す機能ブロック図である。図1に示すように、評価装置10は、通信部20、記憶部30、および制御部40を有する。
まず、本願の開示する評価方法の実行主体となる評価装置10の機能構成について説明する。図1は、実施例1にかかる評価装置10の機能構成を示す機能ブロック図である。図1に示すように、評価装置10は、通信部20、記憶部30、および制御部40を有する。
通信部20は、他の装置との間の通信を制御する処理部であり、例えば、通信インタフェースである。
記憶部30は、各種データや、制御部40が実行するプログラムを記憶する記憶装置の一例であり、例えば、メモリやハードディスクなどである。記憶部30は、例えば、機械学習モデルを構築するためのモデルパラメータや、機械学習モデルのための訓練データも記憶できる。なお、記憶部30には、上記具体例以外にも様々なデータを記憶できる。
制御部40は、評価装置10全体を司る処理部であり、例えば、プロセッサなどである。制御部40は、生成部41、訓練部42、評価部43、および算出部44を有する。なお、各処理部は、プロセッサが有する電子回路の一例やプロセッサが実行するプロセスの一例である。
生成部41は、訓練データの変化に対する機械学習モデルの推論精度の低下の度合いを示す情報に基づいて、機械学習モデルのポイズニングデータに対する耐性評価を行うために、推論精度を低下させる訓練データを生成する。推論精度を低下させる訓練データは、機械学習モデルの訓練に用いた訓練データに対して、機械学習モデルの推論精度を低下させるようなポイズニングデータを生成し、訓練に用いた訓練データにポイズニングデータを追加することで生成される。
ポイズニングデータ生成について説明する。図2は、実施例1にかかる訓練データ空間の例を示す図である。図2の例では、訓練データ空間に、ラベル1~3の3つのラベルがあるものとして説明する。まず、生成部41は、機械学習モデルの訓練に用いた訓練データの全てのラベルのクラスタからデータを初期点としてランダムに選択する。図2の例では、(データA,ラベル1)、(データB,ラベル2)、(データC,ラベル3)が、それぞれ、ラベル1~3のクラスタからの初期点としてランダムに選択される。なお、初期点は、例えば、勾配上昇法を用いて汚染度のより高いデータを探索するための基となるデータおよびラベルの組み合わせである。初期点に基づいて探索されたデータおよびラベルの組み合わせが、最終的にポイズニングデータとなる。
また、生成部41は、各クラスタから選択されたデータの各々に対し元のラベルと異なるラベルを1つまたは複数付与したデータを初期点に追加する。図2を用いて説明すると、例えば、データAの元のラベルはラベル1であるので、データAに対し、元のラベルと異なるラベルであるラベル2やラベル3を付与したデータを初期点に追加する。図2の例では、元のラベルを付与したデータの3点に対し、異なるラベルを付与したデータが、3点×異なるラベル分の2点の計6点あるため、この時点では、最多で9点の初期点ができあがることになる。
さらに、生成部41は、ラベルの異なるデータ同士を対合させたデータを初期点に追加する。ここで、対合とは、データ変換であり、2つのデータを用いて1つのデータを生成する変換である。例えば、訓練データにデータx_1、x_2があり、それぞれのラベルがy_1、y_2であった場合、データ(x_1,y_1)と(x_2,y_2)との対合は、次の式によって算出できる。なお、対合によって、ラベルの異なる1組のデータから2つのデータを生成できる。1つ目の対合は、データx_1およびx_2が数値として、ないしベクトル値であってそれぞれの数値がa~bの範囲をとり、λを0~1の実数として、対合1=(λ(b-x_1)+(1-λ)(x_2-a),y_1)、2つ目の対合は、対合2=(λ(x_1-a)+(1-λ)(b-x_2),y_2)を用いて算出できる。また、図2の例では、ラベルが3つあるため、異なるラベルの組み合わせは、ラベル1-ラベル2、ラベル2-ラベル3、ラベル3-ラベル1の3つあり、それぞれに対して、2点の対合データが生成できる。そのため、対合により、異なるラベルの組み合わせ3つ×対合データ2点の計6点がさらに初期点として追加される。
以上のようにして生成された初期点は、例えば、算出部44によって勾配上昇法を用いて汚染度のより高いデータに更新される。そして、所定条件を満たすまでデータの更新が繰り返され、機械学習モデルの推論精度をより低下させるポイズニングデータが算出される。なお、ポイズニングデータは初期点の各々に対して算出され、生成部41は、機械学習モデルの訓練に用いた訓練データに各ポイズニングデータを追加することで、推論精度を低下させる複数の訓練データを生成する。
訓練部42は、機械学習モデルのポイズニングデータに対する耐性評価を行うために、生成部41によって生成された推論精度を低下させる訓練データを用いて機械学習モデルを訓練する。なお、上述したように、生成部41によって複数の訓練データが生成されるが、各々の訓練データを用いて訓練した場合の機械学習モデルの推論精度を評価するため、複数の訓練データの各々を用いて機械学習モデルを訓練する。すなわち、複数の訓練済み機械学習モデルができあがることになる。
評価部43は、推論精度を低下させる訓練データを用いて訓練部42によって訓練された機械学習モデルのポイズニングデータに対する耐性評価を行う。当該評価も、複数の訓練済み機械学習モデルの各々に対して行われる。また、当該評価は、予め評価用に生成された訓練データを用いて、評価用の訓練データを用いて訓練された機械学習モデルと、訓練部42によって訓練された機械学習モデルとの推論精度の精度差を、損失関数を用いて算出することにより行われる。すなわち、評価用の訓練データを用いて訓練された機械学習モデルに対して、推論精度を低下させる訓練データを用いて訓練部42によって訓練された機械学習モデルの推論精度がどれだけ低下したかを精度差として算出し、評価する。
算出部44は、生成部41によって生成された初期点を、勾配上昇法を用いて更新し、機械学習モデルの推論精度をより低下させるポイズニングデータを算出する。なお、勾配上昇法で用いる関数も算出部44によって算出される。当該関数は、既存技術を用いる、または訓練を実施することにより算出でき、訓練データX_tに、(データx,ラベルy)を追加した際の損失関数の変化量Δのデータxに関する勾配を計算するための関数dΔ/dx(X_v,y)である。
ここで、X_vは、評価部43の説明の際の“予め評価用に生成された訓練データ”であり、ポイズニングデータに対して機械学習モデルの推論精度がどれだけ低下したかを評価するための基準となるデータである。また、損失関数の変化量Δは、評価用の訓練データX_tを用いて訓練された機械学習モデルと、訓練データX_tに(データx,ラベルy)を追加した訓練データX_t∪{(x,y)}を用いて訓練された機械学習モデルとの推論精度の精度差である。評価用の訓練データX_tを用いて訓練された機械学習モデルをM、訓練データX_t∪{(x,y)}を用いて訓練された機械学習モデルをM´、損失関数をLとすると、算出部44は、損失関数Lの変化量Δを、Δ=L(M´,X_v)-L(M,X_v)の式で算出できる。すなわち、関数dΔ/dx(X_v,y)は、損失関数Lの変化量Δに対するデータxの勾配を測る関数であり、これにより、ラベルyに対してデータxをどのように更新すれば、機械学習モデルの推論精度が良く、または悪くなるかを測ることができる。
また、詳細については図4を用いて後述するが、算出部44は、推論精度を低下させる訓練データを用いた訓練前後の機械学習モデルの推論精度の精度差を算出する。
[処理の流れ]
次に、機械学習モデルの耐性評価処理について、処理の流れに沿って説明する。図3は、実施例1にかかる機械学習モデルの耐性評価処理の流れを示すフローチャートである。耐性評価処理を実行するにあたり、ポイズニングデータに対して機械学習モデルの推論精度がどれだけ低下したかを評価するための基準となる評価用の訓練データX_vを予め生成しておく。また、評価データX_vを用いて、対象となる機械学習モデルの推論精度を、損失関数を用いて予め算出しておいてもよい。
次に、機械学習モデルの耐性評価処理について、処理の流れに沿って説明する。図3は、実施例1にかかる機械学習モデルの耐性評価処理の流れを示すフローチャートである。耐性評価処理を実行するにあたり、ポイズニングデータに対して機械学習モデルの推論精度がどれだけ低下したかを評価するための基準となる評価用の訓練データX_vを予め生成しておく。また、評価データX_vを用いて、対象となる機械学習モデルの推論精度を、損失関数を用いて予め算出しておいてもよい。
まず、図3に示すように、評価装置10は、訓練データX_tおよび評価データX_vを用いて関数dΔ/dx(X_v,y)を算出する(ステップS101)。
次に、評価装置10は、訓練データX_tの全ラベルのクラスタからデータを初期点として選択する(ステップS102)。各クラスタからのデータ選択は、例えば、ランダムに行われる。
次に、評価装置10は、ステップS102で選択されたデータに元のラベルと異なるラベルを付与したデータを初期点に追加する(ステップS103)。なお、異なるラベルの付与は、元のラベルに対して異なる全てのラベルに対して行われてもよいし、異なる一部のラベルに対して行われてもよい。
次に、評価装置10は、ラベルの異なるデータ同士を対合させたデータを初期点に追加する(ステップS104)。対合データは、上述したように、最大で異なるラベルの組み合わせの数×2点分生成され、初期点として追加される。なお、ステップS103およびS104の実行順序は逆であってもよい。
次に、評価装置10は、ラベルが固定された時の関数dΔ/dx(X_v,y)を用いて、ステップS102~S104で生成した初期点の各々を更新し、複数のポイズニングデータを算出する(ステップS105)。初期点の更新は、例えば、勾配上昇法を用いて行われる。より具体的には、例えば、更新前のデータを(データxi,ラベルy)、更新後のデータを(データxi+1,ラベルy)とすると、更新後のデータxi+1は、xi+1=xi+εdΔ/dx(X_v,y)の式で算出できる。ラベルyは固定であるため、変更はない。iは、0を初期値として更新の度にカウントアップされる数値である。そのため、x0が初期点のデータを示す。また、εは、学習率と呼ばれる、データxを動かす量を示すパラメータで、例えば、小さい正の数が設定される。このような式を用いて、初期点の各データの更新を、ラベルを固定したまま所定条件を満たすまで繰り返すことで、汚染度のより高いポイズニングデータを算出する。ここで、所定条件とは、例えば、更新処理の実行回数が所定の閾値に達した、更新前後のデータの差が無くなり更新が止まった、更新後のデータが初期点のデータから一定以上離れた、などである。
次に、評価装置10は、ステップS105で算出されたポイズニングデータを追加した訓練データX_tを用いて、機械学習モデルを訓練する(ステップS106)。なお、ステップS105では複数のポイズニングデータが算出されるため、算出されたポイズニングデータの各々を用いて機械学習モデルが訓練され、複数の訓練済みの機械学習モデルが生成されることになる。
そして、評価装置10は、ステップS106で、ポイズニングデータを追加した訓練データX_tを用いて訓練された機械学習モデルを評価する(ステップS107)。ここでも、ステップS106では、複数の訓練済みの機械学習モデルが生成されるため、訓練済みの機械学習モデルの各々に対して評価が行われる。具体的には、ステップS106で生成された訓練済みの機械学習モデルの各々と、評価データX_vを用いて訓練された機械学習モデルとの推論精度の精度差を、損失関数を用いて算出することにより、対象の機械学習モデルを評価する。算出された精度差が大きいほど、対象の機械学習モデルはポイズニングデータによってより汚染されていることを示し、ポイズニングデータに対する耐性が低いことになる。S107の実行後、図3に示す機械学習モデルの耐性評価処理は終了する。
次に、訓練データの更新処理について、処理の流れに沿って説明する。図4は、実施例1にかかる訓練データの更新処理の流れを示すフローチャートである。本処理では、複数のポイズニングデータの影響をよく近似させるために、ポイズニングデータを用いた訓練前後の機械学習モデルの推論精度の精度差が一定以上になる度に、ポイズニングデータを用いて関数dΔ/dx(X_v,y)を更新し、図3の耐性評価処理を繰り返す。そのため、本処理は、図3に示す機械学習モデルの耐性評価処理のステップS106の実行後に実行される。
まず、図4に示すように、評価装置10は、評価データX_vと、ポイズニングデータを追加した訓練データX_tを用いて訓練した機械学習モデルM´と、損失関数の変化量を算出する関数Δを用いて第1の精度差を算出する(ステップS201)。第1の精度差はポイズニングデータを含まない訓練データに対する評価データX_vにおける損失関数の値との変化量を表す関数をΔとした場合に、ポイズングデータを含む訓練データをX_tとして、Δ(X_t,X_v)の式で算出できる。
次に、評価装置10は、訓練データX_tを用いて訓練された機械学習モデルMと、ステップS106で、ポイズニングデータを追加した訓練データX_tを用いて訓練された機械学習モデルM´との第2の精度差を算出する(ステップS202)。第1の精度差と同様に、第2の精度差も損失関数Lを用いて、L(M´,X_v)-L(M,X_v)の式で算出できる。
次に、評価装置10は、ステップS201で算出された第1の精度差と、ステップS202で算出された第2の精度差との差を算出する(ステップS203)。両精度差の差が所定の閾値以上である場合(ステップS204:Yes)、評価装置10は、訓練データX_tを、ポイズニングデータを追加した訓練データX_t∪{(x,y)}に置き換え、ステップS101から処理を繰り返す(ステップS205)。
一方、両精度差の差が所定の閾値以上でない場合(ステップS204:No)、評価装置10は、訓練データX_tの更新は行わず、ステップS102から処理を繰り返す(ステップS206)。S205またはS206の実行後、図4に示す訓練データの更新処理は終了する。
また、機械学習モデルの耐性評価処理は、図3を用いて説明した実施例1の他、実施例2として示す以下のような処理を採用できる。図5は、実施例2にかかる機械学習モデルの耐性評価処理の流れを示すフローチャートである。実施例2にかかる耐性評価処理では、実施例1にかかる耐性評価処理と異なり、損失の変化量Δに対しての勾配をデータxに対してのみでなくラベルyに対しても行う。そして、実施例2にかかる耐性評価処理ではさらに、データおよびラベルの両方を勾配上昇法によって更新し、最適化されたデータおよびラベルについて、さらにデータxを勾配上昇法によって更新してポイズニングデータを算出する。
まず、図5に示すように、評価装置10は、訓練データX_tおよび評価データX_vを用いて、X_tに(データx,ラベルy)を追加した際の損失関数の変化量Δのxとyに関する勾配を計算するための関数dΔ/dx(X_v)およびdΔ/dy(X_v)を算出する(ステップS301)。yに関する勾配を計算するための関数dΔ/dy(X_v)は、損失関数Lの変化量Δに対するデータyの勾配を測る関数であり、データyをどのように更新すれば、機械学習モデルの推論精度が良く、または悪くなるかを測ることができる。関数dΔ/dy(X_v)も、関数dΔ/dx(X_v)同様、既存技術を用いて算出できる。
ステップS302~S304は、実施例1のステップS102~S104と同様である。しかしながら、ステップS303にて異なるラベルを付与したデータを初期点に追加する際は、元のラベルと異なる全てのラベルに対してではなく、異なる一部のラベルに対して行われる。
次に、評価装置10は、関数dΔ/dx(X_v)およびdΔ/dy(X_v)を用いて、ステップS302~S304で生成した初期点の各々を更新する(ステップS305)。初期点の更新は、例えば、勾配上昇法を用いて行われる。より具体的には、例えば、更新前のデータを(データxi,ラベルyi)、更新後のデータを(データxi+1,ラベルyi+1)とすると、更新後のデータxi+1は、xi+1=xi+εdΔ/dx(X_v)の式、更新後のデータyi+1は、yi+1=xi+εdΔ/dy(X_v)の式で算出できる。iは、0を初期値として更新の度にカウントアップされる数値である。そのため、x0およびy0が初期点のデータを示す。また、εは、学習率と呼ばれる、データxを動かす量を示すパラメータで、例えば、小さい正の数が設定される。このような式を用いて、初期点の各データの更新を、所定条件を満たすまで繰り返す。ここで、所定条件とは、例えば、更新処理の実行回数が所定の閾値に達した、更新前後のデータの差が無くなり更新が止まった、更新後のデータが初期点のデータから一定以上離れた、などである。なお、算出されるラベルyは小数値である場合があり、その場合は、整数値に変換される。
次に、評価装置10は、更新されたラベルyについてyの値に一番近しいラベルの値にyを更新し固定した上で関数dΔ/dx(X_v)を用いて、ステップS302~S304で生成した初期点の各々を更新し、複数のポイズニングデータを算出する(ステップS306)。ステップS306の初期点の更新も、ステップS105同様、例えば、勾配上昇法を用いて所定条件を満たすまで繰り返される。
ステップS307およびS308は、実施例1のステップS106およびS107と同様である。S308の実行後、図5に示す機械学習モデルの耐性評価処理は終了する。
[効果]
上述したように、評価装置10は、第1の訓練データの変化に対する機械学習モデルの推論精度の低下の度合いを示す情報に基づいて、推論精度を低下させる第2の訓練データを生成し、第2の訓練データを用いて機械学習モデルを訓練し、訓練された機械学習モデルの評価を行う。
上述したように、評価装置10は、第1の訓練データの変化に対する機械学習モデルの推論精度の低下の度合いを示す情報に基づいて、推論精度を低下させる第2の訓練データを生成し、第2の訓練データを用いて機械学習モデルを訓練し、訓練された機械学習モデルの評価を行う。
これにより、対象の機械学習モデルに対してより汚染度の高いポイズニングデータを探索および生成し、生成されたポイズニングデータを用いて機械学習モデルを訓練することにより、ポイズニングデータに対する機械学習モデルの耐性評価を行うことができる。したがって、機械学習モデルの推論精度を低下させる訓練データに対する機械学習モデルの耐性評価をより効率的に行うことができる。
また、評価装置10によって実行される、第2の訓練データを生成する処理は、第1の訓練データの全てのラベルのクラスタからデータを初期点としてランダムに選択し、選択されたデータの各々に対し元のラベルと異なるラベルを1つまたは複数付与したデータを初期点に追加し、ラベルの異なるデータ同士を対合させたデータを初期点に追加し、初期点に基づいて、第2の訓練データを生成する処理を含む。
これにより、より汚染度の高いポイズニングデータを生成できる。
また、評価装置10によって実行される、第2の訓練データを生成する処理は、複数の初期点に基づいて、複数の第2の訓練データを生成する処理を含み、機械学習モデルを訓練する処理は、複数の第2の訓練データの各々を用いて機械学習モデルを訓練する処理を含み、訓練された機械学習モデルの評価を行う処理は、複数の第2の訓練データの各々を用いて訓練された複数の訓練された機械学習モデルの各々の評価を行う処理を含む。
これにより、より汚染度の高いポイズニングデータを効率的に生成できる。
また、評価装置10によって実行される、初期点に基づいて、第2の訓練データを生成する処理は、初期点を勾配上昇法によって更新し、更新された初期点に基づいて、第2の訓練データを生成する処理を含む。
これにより、より汚染度の高いポイズニングデータを生成できる。
また、評価装置10によって実行される、初期点に基づいて、第2の訓練データを生成する処理は、初期点に付与されたラベルを勾配上昇法によって更新し、更新された初期点およびラベルに基づいて、第2の訓練データを生成する処理を含む。
これにより、より汚染度の高いポイズニングデータを生成できる。
また、評価装置10によって実行される、訓練された機械学習モデルの評価を行う処理は、損失関数の変化量を算出する関数を用いて、第2の訓練データを用いて訓練された機械学習モデルと、機械学習モデルを評価するための第1の訓練データを用いて訓練された機械学習モデルとの推論精度の第1の精度差を算出し、第1の精度差に基づいて、訓練された機械学習モデルの評価を行う処理を含む。
これにより、ポイズニングデータに対する機械学習モデルの耐性評価をより効率的に行うことができる。
また、評価装置10は、損失関数を用いて、第1の訓練データを用いて訓練された機械学習モデルと、第2の訓練データを用いて訓練された機械学習モデルとの推論精度の第2の精度差を算出し、第1の精度差と第2の精度差との差が所定の閾値以上の場合、第1の訓練データを第2の訓練データに置き換えて、推論精度を低下させる第4の訓練データを生成し、第4の訓練データを用いて機械学習モデルを訓練し、第4の訓練データを用いて訓練された機械学習モデルの評価を行う処理をさらに実行する。
これにより、複数のポイズニングデータの影響をよく近似させることができる。
さて、これまで本発明の実施例1および2について説明したが、本発明は上述した実施例以外にも、種々の異なる形態にて実施されてよいものである。
[システム]
上記文書中や図面中で示した処理手順、制御手順、具体的名称、各種のデータやパラメータを含む情報については、特記する場合を除いて任意に変更できる。また、実施例で説明した具体例、分布、数値などは、あくまで一例であり、任意に変更できる。
上記文書中や図面中で示した処理手順、制御手順、具体的名称、各種のデータやパラメータを含む情報については、特記する場合を除いて任意に変更できる。また、実施例で説明した具体例、分布、数値などは、あくまで一例であり、任意に変更できる。
また、図示した各装置の各構成要素は機能概念的なものであり、必ずしも物理的に図示の如く構成されていることを要しない。すなわち、各装置の分散や統合の具体的形態は図示のものに限られない。つまり、その全部または一部を、各種の負荷や使用状況などに応じて、任意の単位で機能的または物理的に分散・統合して構成できる。例えば、評価装置10の生成部41と算出部44とを統合できる。
さらに、各装置にて行なわれる各処理機能は、その全部または任意の一部が、CPUおよび当該CPUにて解析実行されるプログラムにて実現され、あるいは、ワイヤードロジックによるハードウェアとして実現され得る。
[ハードウェア]
上述した評価装置10のハードウェア構成を説明する。図6は、評価装置10のハードウェア構成例を示す図である。図6に示すように、評価装置10は、通信部10a、HDD(Hard Disk Drive)10b、メモリ10c、およびプロセッサ10dを有する。また、図6に示した各部は、バスなどで相互に接続される。
上述した評価装置10のハードウェア構成を説明する。図6は、評価装置10のハードウェア構成例を示す図である。図6に示すように、評価装置10は、通信部10a、HDD(Hard Disk Drive)10b、メモリ10c、およびプロセッサ10dを有する。また、図6に示した各部は、バスなどで相互に接続される。
通信部10aは、ネットワークインタフェースカードなどであり、他のサーバとの通信を行う。HDD10bは、図1に示した機能を動作させるプログラムやデータを記憶する。
プロセッサ10dは、図1に示した各処理部と同様の処理を実行するプログラムをHDD10bなどから読み出してメモリ10cに展開することで、図1で説明した各機能を実行するプロセスを動作させる。例えば、このプロセスは、評価装置10が有する各処理部と同様の機能を実行する。具体的には、例えば、プロセッサ10dは、生成部41や訓練部42などと同様の機能を有するプログラムをHDD10bなどから読み出す。そして、プロセッサ10dは、生成部41や訓練部42などと同様の処理を実行するプロセスを実行する。
このように、評価装置10は、プログラムを読み出して実行することで各処理を実行する情報処理装置として動作する。また、評価装置10は、媒体読取装置によって記録媒体から上記プログラムを読み出し、読み出された上記プログラムを実行することで上記した実施例と同様の機能を実現することもできる。なお、この他の実施例でいうプログラムは、評価装置10によって実行されることに限定されるものではない。例えば、他のコンピュータまたはサーバがプログラムを実行する場合や、これらが協働してプログラムを実行するような場合にも、本発明を同様に適用できる。
なお、このプログラムは、インターネットなどのネットワークを介して配布できる。また、このプログラムは、ハードディスク、フレキシブルディスク(FD)、CD-ROM、MO(Magneto-Optical disk)、DVD(Digital Versatile Disc)などのコンピュータで読み取り可能な記録媒体に記録され、コンピュータによって記録媒体から読み出されることによって実行できる。
10 評価装置
10a 通信部
10b HDD
10c メモリ
10d プロセッサ
20 通信部
30 記憶部
40 制御部
41 生成部
42 訓練部
43 評価部
44 算出部
10a 通信部
10b HDD
10c メモリ
10d プロセッサ
20 通信部
30 記憶部
40 制御部
41 生成部
42 訓練部
43 評価部
44 算出部
Claims (9)
- コンピュータが、
第1の訓練データの変化に対する機械学習モデルの推論精度の低下の度合いを示す情報に基づいて、前記推論精度を低下させる第2の訓練データを生成し、
前記第2の訓練データを用いて前記機械学習モデルを訓練し、
訓練された前記機械学習モデルの評価を行う
処理を実行することを特徴とする評価方法。 - 前記第2の訓練データを生成する処理は、
前記第1の訓練データの全てのラベルのクラスタからデータを初期点としてランダムに選択し、
前記選択されたデータの各々に対し元のラベルと異なるラベルを1つまたは複数付与したデータを前記初期点に追加し、
前記ラベルの異なるデータ同士を対合させたデータを前記初期点に追加し、
前記初期点に基づいて、前記第2の訓練データを生成する
処理を含むことを特徴とする請求項1に記載の評価方法。 - 前記第2の訓練データを生成する処理は、複数の前記初期点に基づいて、複数の前記第2の訓練データを生成する処理を含み、
前記機械学習モデルを訓練する処理は、前記複数の第2の訓練データの各々を用いて前記機械学習モデルを訓練する処理を含み、
前記訓練された機械学習モデルの評価を行う処理は、前記複数の第2の訓練データの各々を用いて訓練された複数の前記訓練された機械学習モデルの各々の評価を行う処理を含むことを特徴とする請求項2に記載の評価方法。 - 前記初期点に基づいて、前記第2の訓練データを生成する処理は、
前記初期点を勾配上昇法によって更新し、
前記更新された初期点に基づいて、前記第2の訓練データを生成する
処理を含むことを特徴とする請求項2または3に記載の評価方法。 - 前記初期点に基づいて、前記第2の訓練データを生成する処理は、
前記初期点に付与されたラベルを前記勾配上昇法によって更新し、
前記更新された初期点およびラベルに基づいて、前記第2の訓練データを生成する
処理を含むことを特徴とする請求項4に記載の評価方法。 - 前記訓練された機械学習モデルの評価を行う処理は、
損失関数の変化量を算出する関数を用いて、前記第2の訓練データを用いて訓練された前記機械学習モデルと、前記第1の訓練データを用いて訓練された前記機械学習モデルとの前記推論精度の第1の精度差を算出し、
前記第1の精度差に基づいて、前記訓練された機械学習モデルの評価を行う
処理を含むことを特徴とする請求項1に記載の評価方法。 - 前記コンピュータが、
前記損失関数を用いて、前記第1の訓練データを用いて訓練された前記機械学習モデルと、前記第2の訓練データを用いて訓練された前記機械学習モデルとの前記推論精度の第2の精度差を算出し、
前記第1の精度差と前記第2の精度差との差が所定の閾値以上の場合、前記第1の訓練データを前記第2の訓練データに置き換えて、前記推論精度を低下させる第4の訓練データを生成し、
前記第4の訓練データを用いて前記機械学習モデルを訓練し、
前記第4の訓練データを用いて訓練された前記機械学習モデルの評価を行う
処理をさらに実行することを特徴とする請求項6に記載の評価方法。 - 第1の訓練データの変化に対する機械学習モデルの推論精度の低下の度合いを示す情報に基づいて、前記推論精度を低下させる第2の訓練データを生成する生成部と、
前記第2の訓練データを用いて前記機械学習モデルを訓練する訓練部と、
訓練された前記機械学習モデルの評価を行う評価部と
を有することを特徴とする評価装置。 - コンピュータに、
第1の訓練データの変化に対する機械学習モデルの推論精度の低下の度合いを示す情報に基づいて、前記推論精度を低下させる第2の訓練データを生成し、
前記第2の訓練データを用いて前記機械学習モデルを訓練し、
訓練された前記機械学習モデルの評価を行う
処理を実行させることを特徴とする評価プログラム。
Priority Applications (5)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| PCT/JP2020/038178 WO2022074796A1 (ja) | 2020-10-08 | 2020-10-08 | 評価方法、評価装置、および評価プログラム |
| JP2022555205A JP7517448B2 (ja) | 2020-10-08 | 2020-10-08 | 生成方法、評価方法、生成装置、評価装置、生成プログラム、および評価プログラム |
| CN202080105036.XA CN116097285A (zh) | 2020-10-08 | 2020-10-08 | 评价方法、评价装置、以及评价程序 |
| EP20956743.7A EP4227864A4 (en) | 2020-10-08 | 2020-10-08 | ASSESSMENT METHOD, ASSESSMENT APPARATUS AND ASSESSMENT PROGRAM |
| US18/174,973 US20230222385A1 (en) | 2020-10-08 | 2023-02-27 | Evaluation method, evaluation apparatus, and non-transitory computer-readable recording medium storing evaluation program |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| PCT/JP2020/038178 WO2022074796A1 (ja) | 2020-10-08 | 2020-10-08 | 評価方法、評価装置、および評価プログラム |
Related Child Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| US18/174,973 Continuation US20230222385A1 (en) | 2020-10-08 | 2023-02-27 | Evaluation method, evaluation apparatus, and non-transitory computer-readable recording medium storing evaluation program |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2022074796A1 true WO2022074796A1 (ja) | 2022-04-14 |
Family
ID=81126373
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2020/038178 Ceased WO2022074796A1 (ja) | 2020-10-08 | 2020-10-08 | 評価方法、評価装置、および評価プログラム |
Country Status (5)
| Country | Link |
|---|---|
| US (1) | US20230222385A1 (ja) |
| EP (1) | EP4227864A4 (ja) |
| JP (1) | JP7517448B2 (ja) |
| CN (1) | CN116097285A (ja) |
| WO (1) | WO2022074796A1 (ja) |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2024029644A (ja) * | 2022-08-22 | 2024-03-06 | Kddi株式会社 | 評価用データ出力装置、評価用データ出力方法及び評価用データ出力プログラム |
Families Citing this family (9)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US12306935B2 (en) | 2022-12-29 | 2025-05-20 | Dell Products L.P. | System and method for detecting malicious attacks targeting artificial intelligence models |
| US12462018B2 (en) | 2022-12-29 | 2025-11-04 | Dell Products L.P. | System and method for detecting poisoned training data based on characteristics of updated artificial intelligence models |
| US12481793B2 (en) | 2022-12-29 | 2025-11-25 | Dell Products L.P. | System and method for proactively identifying poisoned training data used to train artificial intelligence models |
| US12536338B2 (en) | 2022-12-29 | 2026-01-27 | Dell Products L.P. | System and method for managing AI models based on downstream use of inferences |
| US12321498B2 (en) | 2022-12-29 | 2025-06-03 | Dell Products L.P. | System and method for managing AI models using anomaly detection |
| US12572650B2 (en) * | 2022-12-29 | 2026-03-10 | Dell Products L.P. | System and method for managing AI models using view level analysis |
| US11797672B1 (en) * | 2023-06-01 | 2023-10-24 | HiddenLayer, Inc. | Machine learning-based technique for model provenance |
| US11921903B1 (en) | 2023-06-01 | 2024-03-05 | HiddenLayer, Inc. | Machine learning model fingerprinting |
| US12596965B2 (en) | 2024-07-11 | 2026-04-07 | HiddenLayer, Inc. | Cross-model format comparison |
Citations (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2019207770A1 (ja) * | 2018-04-27 | 2019-10-31 | 日本電気株式会社 | 学習済みモデル更新装置、学習済みモデル更新方法、プログラム |
Family Cites Families (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US11295119B2 (en) * | 2017-06-30 | 2022-04-05 | The Johns Hopkins University | Systems and method for action recognition using micro-doppler signatures and recurrent neural networks |
| US10630793B2 (en) * | 2017-10-19 | 2020-04-21 | Reflektion, Inc. | Browser fingerprinting |
| CN108021931A (zh) * | 2017-11-20 | 2018-05-11 | 阿里巴巴集团控股有限公司 | 一种数据样本标签处理方法及装置 |
| US11443178B2 (en) * | 2017-12-15 | 2022-09-13 | Interntional Business Machines Corporation | Deep neural network hardening framework |
| CN109086814B (zh) * | 2018-07-23 | 2021-05-14 | 腾讯科技(深圳)有限公司 | 一种数据处理方法、装置及网络设备 |
| US10810513B2 (en) * | 2018-10-25 | 2020-10-20 | The Boeing Company | Iterative clustering for machine learning model building |
| JP7268402B2 (ja) * | 2019-02-28 | 2023-05-08 | 富士通株式会社 | 抽出プログラム、抽出方法及び抽出装置 |
-
2020
- 2020-10-08 EP EP20956743.7A patent/EP4227864A4/en active Pending
- 2020-10-08 JP JP2022555205A patent/JP7517448B2/ja active Active
- 2020-10-08 WO PCT/JP2020/038178 patent/WO2022074796A1/ja not_active Ceased
- 2020-10-08 CN CN202080105036.XA patent/CN116097285A/zh active Pending
-
2023
- 2023-02-27 US US18/174,973 patent/US20230222385A1/en active Pending
Patent Citations (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2019207770A1 (ja) * | 2018-04-27 | 2019-10-31 | 日本電気株式会社 | 学習済みモデル更新装置、学習済みモデル更新方法、プログラム |
Non-Patent Citations (6)
| Title |
|---|
| "Computer vision - ECCV 2020 : 16th European conference, Glasgow, UK, August 23-28, 2020 : proceedings", vol. 10, 1 January 1900, SPRINGER INTERNATIONAL PUBLISHING, Cham, ISBN: 978-3-030-58594-5, article SOLANS DAVID; BIGGIO BATTISTA; CASTILLO CARLOS: "Poisoning Attacks on Algorithmic Fairness", pages: 162 - 177, XP047582841, DOI: 10.1007/978-3-030-67658-2_10 * |
| K. W. PANGL. PERCY, UNDERSTANDING BLACK-BOX PREDICTIONS VIA INFLUENCE FUNCTIONS |
| L. MUNOZ-GONZALEZB. BIGGIOA. DEMONTISA. PAUDICEV. WONGRASSAMEEE. C. LUPUF. ROLI, TOWARDS POISONING OF DEEP LEARNING ALGORITHMS WITH BACKGRADIENT OPTIMIZATION |
| LUIS MU\~NOZ-GONZ\'ALEZ; BATTISTA BIGGIO; AMBRA DEMONTIS; ANDREA PAUDICE; VASIN WONGRASSAMEE; EMIL C. LUPU; FABIO ROLI: "Towards Poisoning of Deep Learning Algorithms with Back-gradient Optimization", ARXIV.ORG, CORNELL UNIVERSITY LIBRARY, 201 OLIN LIBRARY CORNELL UNIVERSITY ITHACA, NY 14853, 29 August 2017 (2017-08-29), 201 Olin Library Cornell University Ithaca, NY 14853 , XP080954979 * |
| PANG WEI KOH; PERCY LIANG: "Understanding Black-box Predictions via Influence Functions", ARXIV.ORG, CORNELL UNIVERSITY LIBRARY, 201 OLIN LIBRARY CORNELL UNIVERSITY ITHACA, NY 14853, 14 March 2017 (2017-03-14), 201 Olin Library Cornell University Ithaca, NY 14853 , XP080756783 * |
| See also references of EP4227864A4 |
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2024029644A (ja) * | 2022-08-22 | 2024-03-06 | Kddi株式会社 | 評価用データ出力装置、評価用データ出力方法及び評価用データ出力プログラム |
| JP7688610B2 (ja) | 2022-08-22 | 2025-06-04 | Kddi株式会社 | 評価用データ出力装置、評価用データ出力方法及び評価用データ出力プログラム |
Also Published As
| Publication number | Publication date |
|---|---|
| EP4227864A4 (en) | 2023-11-22 |
| CN116097285A (zh) | 2023-05-09 |
| JP7517448B2 (ja) | 2024-07-17 |
| JPWO2022074796A1 (ja) | 2022-04-14 |
| US20230222385A1 (en) | 2023-07-13 |
| EP4227864A1 (en) | 2023-08-16 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| WO2022074796A1 (ja) | 評価方法、評価装置、および評価プログラム | |
| EP4116853B1 (en) | Computer-readable recording medium storing evaluation program, evaluation method, and information processing device | |
| JP7119820B2 (ja) | 予測プログラム、予測方法および学習装置 | |
| KR102038703B1 (ko) | 동적 전이 앙상블 모형을 통한 실시간 다변량 시계열 예측방법 및 그 시스템 | |
| WO2018143019A1 (ja) | 情報処理装置、情報処理方法およびプログラム記録媒体 | |
| Liu et al. | Improving the estimation of the Boyce index using statistical smoothing methods for evaluating species distribution models with presence‐only data | |
| Pekalp et al. | An integral equation for the second moment function of a geometric process and its numerical solution | |
| Alfaro et al. | Proposal of Two Measures of Complexity Based on Lempel‐Ziv for Dynamic Systems: An Application for Manufacturing Systems | |
| CN113469377B (zh) | 联邦学习审计方法和装置 | |
| JPWO2018135515A1 (ja) | 情報処理装置、ニューラルネットワークの設計方法及びプログラム | |
| CN118740419A (zh) | 网络环境的测试方法、设备及存储介质 | |
| Lee et al. | Evaluating the lifetime performance index based on the bayesian estimation for the rayleigh lifetime products with the upper record values | |
| CN102262693A (zh) | 分布式模型识别 | |
| CN113269325B (zh) | 基于指令重排的量子程序执行方法及装置 | |
| CN114553710B (zh) | 变电站信息传输网络流量仿真方法、装置、设备和介质 | |
| Ibrahim Rauf et al. | Robustness test of selected estimators of linear regression with autocorrelated error term: a monte-carlo simulation study | |
| WO2024180746A1 (ja) | 因果探索プログラム、因果探索方法および情報処理装置 | |
| WO2011131248A1 (en) | Method and apparatus for losslessly compressing/decompressing data | |
| JP7180520B2 (ja) | 更新プログラム、更新方法および情報処理装置 | |
| JP2023077904A (ja) | 計算機システム及びデータ解析方法 | |
| Peter et al. | Quantum-Enhanced Reinforcement Learning for Power Grid Security Assessment | |
| Wang et al. | Model checking optimal infinite-horizon control for probabilistic gene regulatory networks | |
| CN120579066B (zh) | 基础设施系统安全评估方法、装置、电子设备及存储介质 | |
| Samadidana | The effects of information stagnancy on distributed problem solving | |
| Almutairi et al. | Performance Modelling of Attack Graphs |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 20956743 Country of ref document: EP Kind code of ref document: A1 |
|
| ENP | Entry into the national phase |
Ref document number: 2022555205 Country of ref document: JP Kind code of ref document: A |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| ENP | Entry into the national phase |
Ref document number: 2020956743 Country of ref document: EP Effective date: 20230508 |