WO2022097709A1 - データ拡張方法、学習装置およびプログラム - Google Patents
データ拡張方法、学習装置およびプログラム Download PDFInfo
- Publication number
- WO2022097709A1 WO2022097709A1 PCT/JP2021/040736 JP2021040736W WO2022097709A1 WO 2022097709 A1 WO2022097709 A1 WO 2022097709A1 JP 2021040736 W JP2021040736 W JP 2021040736W WO 2022097709 A1 WO2022097709 A1 WO 2022097709A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- sample
- data set
- label
- data
- expansion
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Ceased
Links
Images












Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V10/00—Arrangements for image or video recognition or understanding
- G06V10/70—Arrangements for image or video recognition or understanding using pattern recognition or machine learning
- G06V10/77—Processing image or video features in feature spaces; using data integration or data reduction, e.g. principal component analysis [PCA] or independent component analysis [ICA] or self-organising maps [SOM]; Blind source separation
- G06V10/774—Generating sets of training patterns; Bootstrap methods, e.g. bagging or boosting
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V10/00—Arrangements for image or video recognition or understanding
- G06V10/70—Arrangements for image or video recognition or understanding using pattern recognition or machine learning
- G06V10/77—Processing image or video features in feature spaces; using data integration or data reduction, e.g. principal component analysis [PCA] or independent component analysis [ICA] or self-organising maps [SOM]; Blind source separation
- G06V10/774—Generating sets of training patterns; Bootstrap methods, e.g. bagging or boosting
- G06V10/7753—Incorporation of unlabelled data, e.g. multiple instance learning [MIL]
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F18/00—Pattern recognition
- G06F18/20—Analysing
- G06F18/21—Design or setup of recognition systems or techniques; Extraction of features in feature space; Blind source separation
- G06F18/214—Generating training patterns; Bootstrap methods, e.g. bagging or boosting
- G06F18/2155—Generating training patterns; Bootstrap methods, e.g. bagging or boosting characterised by the incorporation of unlabelled data, e.g. multiple instance learning [MIL], semi-supervised techniques using expectation-maximisation [EM] or naïve labelling
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F18/00—Pattern recognition
- G06F18/20—Analysing
- G06F18/21—Design or setup of recognition systems or techniques; Extraction of features in feature space; Blind source separation
- G06F18/217—Validation; Performance evaluation; Active pattern learning techniques
- G06F18/2178—Validation; Performance evaluation; Active pattern learning techniques based on feedback of a supervisor
- G06F18/2185—Validation; Performance evaluation; Active pattern learning techniques based on feedback of a supervisor the supervisor being an automated module, e.g. intelligent oracle
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/0464—Convolutional networks [CNN, ConvNet]
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/08—Learning methods
- G06N3/09—Supervised learning
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/08—Learning methods
- G06N3/0985—Hyperparameter optimisation; Meta-learning; Learning-to-learn
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V10/00—Arrangements for image or video recognition or understanding
- G06V10/70—Arrangements for image or video recognition or understanding using pattern recognition or machine learning
- G06V10/77—Processing image or video features in feature spaces; using data integration or data reduction, e.g. principal component analysis [PCA] or independent component analysis [ICA] or self-organising maps [SOM]; Blind source separation
- G06V10/776—Validation; Performance evaluation
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V10/00—Arrangements for image or video recognition or understanding
- G06V10/70—Arrangements for image or video recognition or understanding using pattern recognition or machine learning
- G06V10/82—Arrangements for image or video recognition or understanding using pattern recognition or machine learning using neural networks
Definitions
- the present disclosure relates to a data expansion method, a learning device, and a program of a learning data set used for learning a neural network.
- Data expansion is a method of inflating a sample by performing a conversion process on a sample for learning such as image data, and various data expansions have been proposed (for example, Non-Patent Document 1).
- Non-Patent Document 1 discloses a technique of filling a part of an image with another value to expand the data.
- Non-Patent Document 1 can increase the number of samples for learning, it may not be possible to obtain a highly accurate AI model. In other words, if the training sample is not properly converted, the generation of the discrimination surface (discrimination line) by learning will deviate significantly from the ideal boundary line, and not only will it not contribute to the improvement of prediction accuracy. In some cases, the prediction accuracy may be reduced.
- the present disclosure has been made in view of the above circumstances, and an object of the present disclosure is to provide a data expansion method or the like that can increase the number of samples of a learning data set so that a highly accurate AI model can be acquired.
- the data expansion method is a data expansion method of a training data set used for training a neural network, and is a method of expanding a plurality of parameters including weights in the neural network.
- the first optimization process for optimizing and the second optimization process for optimizing hyperparameters which are variables that define the data conversion process for each sample used when performing data expansion processing, alternate.
- the first sample included in the training data set is subjected to the data expansion process to acquire the first expansion sample, and the neural network is subjected to the first.
- the error function is calculated, the plurality of parameters are updated based on the calculated first error function, and the second optimization process is similar to the distribution of the test data set for evaluating the performance of the neural network.
- a second sample is acquired from the evaluation data set, which is a data set of the distributed distribution, and the neural network in which the plurality of parameters are updated is made to predict the second label from the second sample, and the second label is predicted.
- the second error function for evaluating the error from the second correct answer label indicating the correct answer of the second sample included in the evaluation data set, and the calculated second error function is used as the hyper parameter.
- the hyperparameters are updated based on the gradient obtained by partial differentiation with respect to.
- a recording medium such as a system, method, integrated circuit, computer program or computer-readable CD-ROM, and the system, method, integrated circuit, computer. It may be realized by any combination of a program and a recording medium.
- the number of samples of the learning data set can be increased so that a highly accurate AI model can be acquired.
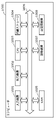
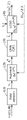
- FIG. 1 is a block diagram showing an example of the configuration of the learning device according to the embodiment.
- FIG. 2 is a diagram showing an example of a hardware configuration of a computer that realizes the function of the learning device according to the embodiment by software.
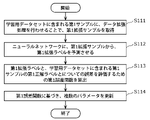
- FIG. 3 is a flowchart showing an operation outline of the learning device according to the embodiment.
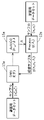
- FIG. 4 is a flowchart showing the detailed operation of the first optimization process shown in FIG.
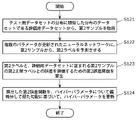
- FIG. 5 is a flowchart showing the detailed operation of the second optimization process shown in FIG.
- FIG. 6 is a diagram for conceptually explaining a processing example in which the first optimization processing and the second optimization processing according to the first embodiment are alternately performed.
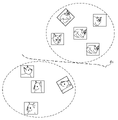
- FIG. 7A is a diagram showing an example of the evaluation data set according to the first embodiment.
- FIG. 7B is a diagram showing an example of a learning data set according to the first embodiment.
- FIG. 8A is a diagram for conceptually explaining a functional example for performing the first optimization process according to the first embodiment.
- FIG. 8B is a diagram for explaining a specific function of the LOSS function shown in FIG. 8A.
- FIG. 9 is a diagram showing a pseudo code of algorithm 1 showing an example of an optimization processing procedure in which the first optimization processing and the second optimization processing according to the first embodiment are alternately performed.
- FIG. 10 is a diagram for explaining problems in the case of data expansion using hyperparameters shared among all the data according to the comparative example.
- FIG. 11 is a diagram for conceptually explaining the generation of the discrimination surface by the learning process.
- FIG. 12A is a diagram for conceptually explaining the data expansion process.
- FIG. 12B is a diagram for conceptually explaining the problem of generation of the discrimination surface by the learning process when the number of data included in the learning data set is small.
- FIG. 12C is a diagram for conceptually explaining an example of generation of an identification surface by a learning process using a learning data set whose data has been expanded by the data expansion process.
- FIG. 13 is a diagram for explaining a problem in the data expansion process according to the comparative example.
- FIG. 14 is a diagram for conceptually explaining the identification surface generated by using the learning data set whose data has been expanded by the data expansion process according to the present disclosure.
- FIG. 15 is a diagram showing a verification result in which an error rate is evaluated using a test data set after learning using the learning data set according to an experimental example.
- FIG. 16 is a diagram showing an accuracy learning curve when learning is performed using the learning data set according to the experimental example.
- the data expansion method is a data expansion method for a training dataset used for training a neural network, and is a first method for optimizing a plurality of parameters including weights in the neural network.
- the optimization process and the second optimization process for optimizing the hyper parameter which is a variable that defines the data conversion process for each sample used when performing the data expansion process, are alternately performed, and the first optimization process is performed.
- the first expansion sample is obtained by causing the first sample included in the training data set to perform the data expansion processing, and the neural network is subjected to the first expansion label from the first expansion sample.
- a first error function for evaluating an error between the first extended label and the first correct answer label indicating the correct answer of the first sample included in the training data set was calculated and calculated.
- the plurality of parameters are updated, and in the second optimization process, evaluation is a data set having a distribution similar to the distribution of the test data set for evaluating the performance of the neural network.
- a second sample is acquired from the data set for use, and the neural network with the plurality of parameters updated predicts the second label from the second sample, and the second label and the evaluation data set are used.
- the hyper parameter is updated based on.
- the number of samples of the training data set can be increased so that a highly accurate AI model can be acquired.
- a data-expanded training data set is used using the gradient obtained by partially differentiating the hyperparameters of each sample.
- the deviation of the distribution between the test and the test data set can be minimized. Therefore, even if the neural network is trained using the training data expanded by the data expansion process, the generation of the discriminant surface by learning can be brought closer to the ideal discriminant surface.
- the number of samples can be increased. In this way, the number of samples of the training data set can be increased so that a highly accurate AI model can be obtained.
- the hyperparameters for each sample can be optimized together with the learning of the multiple parameters of the neural network. Therefore, it is possible to suppress the calculation cost required for optimizing a plurality of parameters of the neural network and optimizing the hyperparameters for each sample.
- the hyperparameters when updating the hyperparameters, the distribution of the training data set after the data expansion obtained by performing the data expansion processing on the training data set and the distribution of the evaluation data set.
- the hyperparameters are updated based on the gradient to reduce the deviation.
- the hyperparameter may be made an implicit function in the function indicating the data expansion process, and the neural network may be a function that is completely differentiable.
- the error between the first correct answer soft label obtained by soft-labeling the correct answer value indicated by the first correct answer label and the first extended label is calbback libler divergence.
- the first error function to be evaluated may be calculated using.
- the hyperparameters for each sample are set so as to minimize the deviation of the distribution between the data-expanded training data set and the test data set. Can be optimized.
- the first error function may be further weighted for each sample.
- the hyperparameters for each sample are set so as to minimize the deviation of the distribution between the data-expanded training data set and the test data set. Can be optimized.
- the learning device is a learning device for performing a data expansion method of a learning data set used for learning a neural network, and includes a processor and a memory, and the processor is the above-mentioned. It is a variable that defines the first optimization process for optimizing a plurality of parameters including weights in the neural network and the data conversion process for each sample used when performing the data expansion process using the memory. The second optimization process for optimizing the hyper parameters is alternately performed, and in the first optimization process, the first sample included in the training data set is subjected to the data expansion process.
- the first extended sample is acquired, the neural network is made to predict the first extended label from the first extended sample, and the first extended label and the correct answer of the first sample included in the training data set are obtained.
- a first error function for evaluating an error with respect to the first correct answer label indicating the above is calculated, the plurality of parameters are updated based on the calculated first error function, and in the second optimization process, the said A second sample is obtained from the evaluation data set, which is a data set having a distribution similar to the distribution of the test data set for evaluating the performance of the neural network, and the neural network in which the plurality of parameters are updated is used.
- the function is calculated, and the calculated hyper parameter is updated based on the gradient obtained by partially differentiating the calculated second error function with respect to the hyper parameter.
- a recording medium such as a system, method, integrated circuit, computer program or computer-readable CD-ROM, and the system, method, integrated circuit, computer. It may be realized by any combination of a program and a recording medium.
- FIG. 1 is a block diagram showing an example of the configuration of the learning device 10 according to the embodiment.
- the learning device 10 is a device for learning a neural network and for performing a data expansion method of a learning data set used for learning a neural network.
- the learning device 10 is a variable that defines the first optimization process for optimizing a plurality of parameters including weights in the neural network and the data conversion process for each sample used when performing the data expansion process.
- the second optimization process for optimizing the parameters is performed alternately.
- the learning device 10 includes an acquisition unit 11, a data expansion processing unit 12, a DNN 13, an error calculation unit 14, and an optimization unit 15.
- the acquisition unit 11 acquires the first sample from the learning data set and inputs it to the data expansion processing unit 12.
- the training data set consists of a plurality of samples such as image data and their correct labels.
- the sample is not limited to the case of image data.
- the acquisition unit 11 acquires the first correct answer label indicating the correct answer of the first sample from the learning data set and inputs it to the error calculation unit 14.
- the acquisition unit 11 acquires a second sample from the evaluation data set and inputs it to the DNN 13.
- the evaluation data set is a data set having a distribution similar to the distribution of the test data set for evaluating the performance of the trained DNN 13.
- the evaluation data set and the test data set are different.
- the evaluation data set can be generated by dividing the test data set of the existing data set.
- the acquisition unit 11 acquires the second correct answer label indicating the correct answer of the second sample from the evaluation data set and inputs it to the error calculation unit 14.
- the acquisition unit 11 may acquire a third sample from the learning data set and input it to the data expansion processing unit 12.
- the acquisition unit 11 may acquire a third correct answer label indicating the correct answer of the third sample from the learning data set and input it to the error calculation unit 14.
- the third sample may be different or the same as the first sample.
- the data expansion processing unit 12 performs data expansion processing on the first sample included in the learning data set, and outputs the first expansion sample. More specifically, in the first optimization process, the data expansion processing unit 12 performs data expansion processing on the first sample by using hyperparameters which are variables that define the data conversion processing for each sample. Hyperparameters are variables that specify data conversion processing such as rotation processing, zoom processing, translation processing, and color conversion processing, and are specified for each sample.
- the data expansion processing unit 12 performs the data expansion processing by applying a function indicating the data expansion processing to the sample acquired from the training data set.
- the hyperparameters are made implicit in the function indicating the data expansion process.
- the data expansion processing unit 12 can perform the data expansion processing of the first sample by causing g ( ⁇ 1 ) to act on the first sample in the first optimization processing, and can perform the data expansion processing of the first sample. Can be output. Therefore, in the first optimization process, when the hyperparameter for the i-th (i is a natural number) sample is ⁇ i , the data expansion processing unit 12 causes g ( ⁇ i ) to act on the i-th sample. Data expansion processing of isample can be performed.
- the data expansion processing unit 12 may perform the data expansion processing on the third sample and output the third expansion sample.
- the data expansion processing unit 12 causes the third sample to act on g ( ⁇ 3 ) having the hyperparameters ⁇ 3 for the third sample, thereby performing the data expansion processing of the third sample. Is possible, so that the third extended sample can be output.
- the DNN 13 is composed of a neural network having a plurality of parameters such as a CNN. In the first optimization process, the DNN 13 predicts the first expansion label from the first expansion sample input by the acquisition unit 11.
- the plurality of parameters are, for example, weights, but are not limited to weights.
- the DNN 13 predicts the first extended label as the correct answer of the first extended sample by applying a function indicating the prediction process by the neural network to the first extended sample in the first optimization process.
- Perform prediction processing the function showing the prediction processing by the neural network is a completely differentiable function.
- a plurality of parameters are implicitly converted into a function indicating prediction processing by a neural network.
- DNN13 causes f ( ⁇ ) to act on the first extended sample in the first optimization processing.
- the first extended label can be predicted.
- the DNN 13 predicts the second label from the second sample included in the evaluation data set input by the acquisition unit 11 after the plurality of parameters are updated by the first optimization process.
- the DNN 13 causes the second sample to have f ( ⁇ ) whose plurality of parameters have been updated by the first optimization process, thereby displaying the second label. Predict.
- the DNN 13 predicts the third expansion label as the correct answer of the third expansion sample from the third expansion sample when the third expansion sample is input by the data expansion processing unit 12 in the second optimization processing. good.
- the error calculation unit 14 is a first error function for evaluating an error between the first extended label and the first correct answer label indicating the correct answer of the first sample included in the training data set in the first optimization process. Is calculated.
- the first error function here is a loss function called Kullback-Leibler divergence (KL divergence).
- the first error function may be a cross entropy error function.
- Kullback-Leibler divergence can be used as a measure of the difference between two probability distributions in probability theory and information theory.
- the Kullback-Leibler divergence is a loss function that can evaluate how similar the probability distribution, which is the correct answer distribution, and the probability distribution, which is the estimated distribution, are.
- the error calculation unit 14 uses KL divergence to determine the error between the first correct answer soft label obtained by soft labeling the correct answer value indicated by the first correct answer label and the first extended label.
- the first error function to be evaluated may be calculated.
- the soft label means that the similarity between the first extended sample and the correct label is expressed not as a discrete value (hard label) but as a ratio.
- the soft label Gumbel-softmax or softmax can be used. As a result, it is possible to suppress the noise of the correct label for the sample included after the data expansion.
- the error calculation unit 14 may further weight the calculated first error function for each sample.
- the error calculation unit 14 evaluates the error between the second label and the second correct answer label indicating the correct answer of the second sample included in the evaluation data set in the second optimization process. Is calculated.
- the second error function may be a loss function called KL divergence or a cross entropy error function, as in the first error function.
- the DNN 13 predicts the third extended label from the third extended sample
- the third extended label and the third sample included in the training data set are used by using the first error function. It suffices to evaluate the error with respect to the third correct answer label which shows the correct answer of.
- the optimization unit 15 updates a plurality of parameters in the first optimization process based on the first error function calculated by the error calculation unit 14. As a result, the optimization unit 15 can perform the first optimization process for optimizing a plurality of parameters in the neural network.
- the optimization unit 15 updates the hyperparameters based on the gradient obtained by partially differentiating the second error function calculated by the error calculation unit 14 with respect to the hyperparameters. Since the hyperparameters are made into an implicit function, the partial differential of the hyperparameters can be calculated by using the implicit differentiation method of the implicit function.
- the optimization unit 15 makes a gradient so as to reduce the deviation between the distribution of the training data set after the data expansion obtained by performing the data expansion processing on the training data set and the distribution of the evaluation data set. Update hyperparameters based on. As a result, the optimization unit 15 can optimize the hyperparameters, which are variables that define the data conversion process for each sample used when performing the data expansion process in the second optimization process.
- the learning device 10 configured as described above alternately performs the first optimization process for a plurality of parameters in the neural network and the second optimization process for the hyperparameters for each sample used when performing the data expansion process. ..
- the distribution of the training data set that has undergone data expansion processing can be matched to the distribution of the test data set, so the number of samples of the training data set can be increased so that a highly accurate AI model can be obtained. Can be done.
- the generation of the discrimination surface by learning becomes the ideal discrimination surface. You can increase the number of samples in the training dataset so that you can get closer. In this way, the number of samples of the training data set can be increased so that a highly accurate AI model can be obtained.
- FIG. 2 is a diagram showing an example of a hardware configuration of a computer 1000 that realizes the function of the learning device 10 according to the embodiment by software.
- the computer 1000 is a computer including an input device 1001, an output device 1002, a CPU 1003, an internal storage 1004, a RAM 1005, a reading device 1007, a transmission / reception device 1008, and a bus 1009.
- the input device 1001, the output device 1002, the CPU 1003, the built-in storage 1004, the RAM 1005, the reading device 1007, and the transmission / reception device 1008 are connected by the bus 1009.
- the input device 1001 is a device that serves as a user interface such as an input button, a touch pad, and a touch panel display, and accepts user operations.
- the input device 1001 may be configured to accept a user's contact operation, a voice operation, a remote control, or the like.
- the output device 1002 is also used as an input device 1001, and is configured by a touch pad, a touch panel display, or the like, and notifies the user of information to be notified.
- the built-in storage 1004 is a flash memory or the like. Further, the built-in storage 1004 stores in advance a program for realizing the function of the learning device 10, a neural network having a plurality of parameters, a function f indicating prediction processing by the neural network, a function g indicating data expansion processing, and the like. You may.
- RAM1005 is a random access memory (RandomAccessMemory), which is used to store data or the like when executing a program or application.
- RandomAccessMemory Random AccessMemory
- the reading device 1007 reads information from a recording medium such as a USB (Universal Serial Bus) memory.
- the reading device 1007 reads the program or application from the recording medium in which the program or application as described above is recorded, and stores the program or application in the built-in storage 1004.
- the transmission / reception device 1008 is a communication circuit for wirelessly or wired communication.
- the transmission / reception device 1008 may communicate with, for example, a server device or a cloud connected to a network, download a program or application as described above from the server device or the cloud, and store the program or application in the built-in storage 1004.
- the CPU 1003 is a central processing unit (Central Processing Unit), copies programs and applications stored in the built-in storage 1004 to RAM 1005, and sequentially reads and executes instructions included in the programs and applications from RAM 1005. It may be executed directly from the built-in storage 1004.
- Central Processing Unit Central Processing Unit
- FIG. 3 is a flowchart showing an operation outline of the learning device 10 according to the embodiment.
- the learning device 10 performs a first optimization process for optimizing a plurality of parameters in the neural network (S11). Next, the learning device 10 performs a second optimization process for optimizing the hyperparameters for each sample used when performing the data expansion process (S12). Next, the learning device 10 determines whether to end the process (S13). For example, when the first optimization process and the second optimization process are performed a predetermined number of times (the number of epochs), the learning device 10 determines that the process is terminated (Yes in S13), and terminates this operation.
- the learning device 10 determines that the process is not terminated (No in S13), and the process in step S11. Repeat from.
- FIG. 4 is a flowchart showing the detailed operation of the first optimization process shown in FIG.
- the learning device 10 performs a data expansion process on the first sample included in the learning data set, and acquires the first expansion sample (S111).
- the learning device 10 performs data expansion processing on the first sample by using hyperparameters which are variables that define data conversion processing for each sample. For example, assuming that the function indicating the data expansion process is g and the hyperparameter for the first sample is ⁇ 1 , the learning device 10 causes g ( ⁇ 1 ) to act on the first sample for the first sample. Obtain the first expansion sample that has undergone data expansion processing.
- the learning device 10 causes the neural network to predict the first expansion label from the first expansion sample acquired in step S111 (S112). For example, assuming that the function indicating the prediction processing by the neural network is f and the plurality of parameters including the weights are ⁇ , the learning device 10 causes the neural network to be the first by applying f ( ⁇ ) to the first expansion sample. 1 Predict the expansion label.
- the learning device 10 calculates a first error function for evaluating an error between the first extended label predicted in step S112 and the first correct label of the first sample included in the training data set.
- the first error function is, for example, a loss function called KL divergence.
- the learning device 10 evaluates the error between the first correct answer soft label obtained by soft-labeling the correct answer value indicated by the first correct answer label and the first extended label by using KL divergence. 1
- the error function may be calculated.
- the learning device 10 may further perform weighting calculated for each sample on the calculated first error function.
- the learning device 10 updates a plurality of parameters based on the first error function calculated in step S113 (S114).
- the learning device 10 optimizes a plurality of parameters such as weights in the neural network by using the learning data set inflated by the data expansion processing after the initial or second optimization processing. It is possible to perform the conversion process.
- FIG. 5 is a flowchart showing the detailed operation of the second optimization process shown in FIG.
- the learning device 10 acquires a second sample from the evaluation data set, which is a data set having a distribution similar to the distribution of the test data set (S121).
- the learning device 10 causes the neural network in which a plurality of parameters are updated in the first optimization process to predict the second label from the second sample (S122). For example, assuming that the function indicating the prediction processing by the neural network is f and the plurality of parameters including the weights are ⁇ , the learning device 10 causes the neural network to receive a second sample by applying f ( ⁇ ) to the second sample. Make the label predict.
- the learning device 10 calculates a second error function for evaluating the error between the second label predicted in step S122 and the second correct label of the second sample included in the evaluation data set (). S123).
- the second error function is, for example, a loss function called KL divergence, but it may be a cross entropy error function.
- the learning device 10 updates the hyperparameters based on the gradient obtained by partially differentiating the second error function calculated in step S123 with respect to the hyperparameters (S124).
- the learning device 10 is based on a gradient so as to reduce the deviation between the distribution of the training data set after the data expansion obtained by performing the data expansion processing on the training data set and the distribution of the evaluation data set. And update the hyperparameters.
- the learning device 10 can perform the second optimization process for optimizing the hyperparameters for each sample used when performing the data expansion process using the evaluation data set.
- FIG. 6 is a diagram for conceptually explaining a processing example in which the first optimization processing and the second optimization processing according to the first embodiment are alternately performed.
- Process 12a shows the data expansion processing function performed by the data expansion processing unit 12, and g ( ⁇ i ) indicates a function indicating the data expansion processing and the hyperparameter ⁇ i is an implicit function.
- Process 12a acquires a sample (x i , y i ) from the training data set and expands the data with the hyperparameter ⁇ i for the sample (x i ). Perform processing. Then, Process 12a outputs the expanded sample g ( xi , y i , ⁇ i ) obtained by the data expansion process to DNN 13a.
- DNN13a indicates a neural network having a plurality of parameters ⁇ of DNN13, and f ( ⁇ ) indicates a function indicating prediction processing by the neural network.
- f ( ⁇ ) indicates a function indicating prediction processing by the neural network.
- the neural network of DNN13a is learned by using the extended sample g (x i , y i , ⁇ i ) output from Process 12a in the first optimization process. ..
- a sample (x iv , y iv ) is acquired from the evaluation data set, and the sample (x iv ) is input to the DNN 13a .
- the DNN13a performs a prediction process by applying a function f ( ⁇ ) to the sample ( xiv ). Then, the DNN 13a outputs a correct label for the sample ( xiv ) obtained by the prediction process.
- AutoDO15a shows the second optimization processing function performed by the optimization unit 15, and ⁇ L v / ⁇ is differential (partial differential) with respect to the hyperparameter ⁇ of the error function Lv calculated based on the result of the prediction processing of DNN13a.
- the gradient obtained by the above is shown. More specifically, in the second optimization process, the correct label for the sample (x iv ) obtained by the prediction process and the correct label ( y iv ) for the sample (x iv ) obtained from the evaluation data set .
- the error function Lv for is calculated.
- AutoDO15a optimizes the hyperparameter ⁇ by updating ⁇ i based on the gradient obtained by partially differentiating the calculated error function L v with respect to ⁇ i .
- FIG. 7A is a diagram showing an example of the evaluation data set according to the first embodiment.
- FIG. 7B is a diagram showing an example of a learning data set according to the first embodiment.
- the sample of the evaluation data set shown in FIG. 7A is image data having 1, 6, 7, and 9 digits.
- FIG. 7A illustrates a sample dataset with a distribution similar to that of the test dataset for evaluating the performance of the trained DNN13a.
- the sample of the learning data set shown in FIG. 7B is image data having a number of digits of 0, 0, 1, 2, 6, 9, and the like.
- FIG. 7B illustrates a sample containing a bias and noise (label noise) in the correct label for the sample.
- FIG. 8A is a diagram for conceptually explaining a functional example for performing the first optimization process according to the first embodiment.
- FIG. 8B is a diagram for explaining a specific function of LOSS 14b shown in FIG. 8A.
- the Data Sampler 11b shows the acquisition processing function performed by the acquisition unit 11 in the first optimization process, and acquires the sample x i from the learning data set represented by i to U (1, N).
- Augment12b indicates the data expansion processing function performed by the data expansion processing unit 12 in the first optimization processing
- g A ( ⁇ A ) is a function indicating the data expansion processing
- the hyperparameter ⁇ A is an implicit function. The function is shown.
- the hyperparameters ⁇ A of g A ( ⁇ A ) in Augment 12b are updated by the gradient ⁇ L v / ⁇ in the second optimization process.
- Augment12b performs data expansion processing by applying gA ( ⁇ A ) to the sample xi acquired by Data Sampler 11b. Then, the Data Sampler 11b outputs the extended sample x iA obtained by the data expansion process to the DNN 13b.
- DNN13b indicates a neural network having a plurality of parameters ⁇ of DNN13, and f ( ⁇ ) indicates a function indicating prediction processing by the neural network.
- the DNN 13b applies f ( ⁇ ) to the extended sample x i A output from the Augment 12 b to perform the data prediction process.
- DNN13b is a correct label for the extended sample x iA obtained by the prediction process. Is output.
- LOSS14b shows a processing function for calculating an error function (first error function) in the first optimization processing.
- g s, w ( ⁇ s, w ) is a first optimization process using a weight for each sample (loss weight) for capturing the bias of the sample and a soft label for dealing with a noisy correct label.
- the error function (first error function) in. ⁇ s and w indicate the loss weight and the hyperparameters of the soft label, and are implicit functions.
- the hyperparameters ⁇ s and w are updated by the gradient ⁇ L v / ⁇ in the second optimization process.
- LOSS14b has the functions of Soft-label 141, Weight KL Div 142, and Reweight 143, as shown in FIG. 8B.
- the Soft-label 141 soft-labels the correct answer value indicated by the input correct answer label by using, for example, Gumbel Softmax or Softmax, and outputs the soft-label.
- g s ( ⁇ s ) indicates a function to be soft-labeled in order to correspond to a correct label with a lot of noise, and the hyperparameter ⁇ s is implicitly converted.
- the Soft-label 141 is input with the correct label y i for the sample x i from the training data set represented by i to U (1, N), and the input correct label y i is used. Make it a soft label.
- the Soft-label 141 outputs the soft-labeled soft-label y is to the Weight KL Div 142.
- ⁇ i S is a hyperparameter of the soft label for each sample and is made into an implicit function.
- Weight KL Div 142 calculates an error function (first error function) in the first optimization process using the weight for each sample (loss weight) and the soft label for corresponding to the correct label with a lot of noise. More specifically, the Weight KL Div 142 has a soft label y is output by Soft-label 141 and a correct label output by DNN 13b.
- the first error function L which is the KL divergence for evaluating the error with the above, is calculated.
- Weight KL Div 142 is a weighted first error function by multiplying by the weight wi (scalar amount) calculated by the calculated Reweight 143. Is calculated.
- Reweight 143 uses an activation function such as softplus to calculate the weight wi for each sample to capture the bias of the sample.
- g w ( ⁇ w ) indicates a function for calculating the weight (loss weight) for each sample weighted by the error function L for capturing the bias of the sample.
- ⁇ i W is a hyperparameter of the weight (loss weight) for each sample and is made into an implicit function.
- the weighted first error function calculated as described above. Can be used to update a plurality of parameters ⁇ of DNN13b.
- FIG. 9 is a diagram showing a pseudo code of algorithm 1 showing an example of an optimization processing procedure in which the first optimization processing and the second optimization processing according to the first embodiment are alternately performed.
- the variables such as ⁇ and the functions such as f ( ⁇ ) shown in FIG. 9 are as described with reference to FIGS. 8A and 8B.
- the sample of the training data set described above is represented as data.
- Algorithm 1 shown in FIG. 9 is performed by, for example, the processor of the learning device 10.
- the second line stipulates that the procedures of the third to 19th lines, that is, the first optimization process and the second optimization process are repeated up to the number of epochs.
- the third line stipulates that the procedure of the fourth to ninth lines, that is, the first optimization process is repeated up to the number of batches.
- the fourth line stipulates that batches are sampled from the training dataset D train .
- the batch corresponds to the data (sample in the above) included in the subset when the training data set is divided into several subsets.
- the fifth line stipulates that the sampled data x is processed for data expansion.
- the soft label of the correct label obtained from the training data set D train which is the correct label for the data x sampled from the training data set D train , is generated in the 4th line. ing.
- the eighth line stipulates that the weighted error function is calculated by KL divergence and differentiated by the parameter ⁇ ( ⁇ ⁇ ).
- the 10th line stipulates that if the number of epochs exceeds the E number, the processing from the 11th line onward is performed.
- the 11th line stipulates that the procedure of the 12th to 19th lines, that is, the second optimization process is repeated up to the number of batches.
- Line 12 stipulates that batches are sampled from the training dataset D train .
- Line 13 stipulates that batches are sampled from the evaluation dataset D val .
- the correct label is predicted from the data XA obtained by data expansion processing of the data of the training data set D train sampled in the 12th line.
- the soft label of the correct label obtained from the training data set D train which is the correct label for the data x sampled from the training data set D train , is generated in the 12th line. ing.
- the error function L v and the error function L shown in the 18th line are calculated, and the error function L v is differentiated ( ⁇ ⁇ ) by the hyperparameter ⁇ . ..
- the error function Lv is an error function that evaluates the error between the data of the evaluation data set D val and the correct answer label predicted in the 14th line.
- the error function L is a weighted error function that evaluates the error between the soft label generated in the 16th line and the correct label of the data expanded data XA predicted in the 15th line. ..
- the 18th line stipulates that the hyperparameter ⁇ is updated.
- HO shown on the 19th line is an abbreviation for hyperparameter optimization.
- the first optimization process and the second optimization process can be performed alternately.
- hyperparameters can be optimized, so that the number of samples of the training data set should be increased so that a highly accurate AI model can be obtained. Can be done.
- a data-expanded training data set is used using the gradient obtained by partially differentiating the hyperparameters of each sample.
- the deviation of the distribution between the test and the test data set can be minimized. Therefore, even if the neural network is trained using the training data expanded by the data expansion process, the generation of the discriminant surface by learning can be brought closer to the ideal discriminant surface.
- the number of samples can be increased. In this way, the number of samples of the training data set can be increased so that a highly accurate AI model can be obtained.
- the learning device 10 and the data expansion method according to the present embodiment by alternately optimizing a plurality of parameters of the neural network and hyperparameters of the data expansion processing for each sample, the samples are sampled. Hyperparameters for each can be optimized along with learning multiple parameters of the neural network. Therefore, there is also an effect that the calculation cost required for optimizing a plurality of parameters of the neural network and optimizing the hyperparameters for each sample can be suppressed.
- the distribution of the training data set after the data expansion obtained by performing the data expansion processing on the training data set and the distribution of the evaluation data set Update hyperparameters based on the gradient to reduce deviations from.
- the hyperparameters are implicitly converted into at least a function indicating the data expansion process, and the neural network is a completely differentiable function. This makes it possible to calculate the partial differential for hyperparameters by using the implicit differentiation method.
- the first error function in the first optimization process using the soft label for dealing with the noisy correct label is calculated.
- the hyperparameters for each sample are set so as to minimize the deviation of the distribution between the data-expanded training data set and the test data set. Can be optimized.
- the calculated first error function is weighted by using the weight for each sample for capturing the bias of the sample.
- the hyperparameters for each sample are set so as to minimize the deviation of the distribution between the data-expanded training data set and the test data set. Can be optimized.
- FIG. 10 is a diagram for explaining problems when data expansion is performed using hyperparameters shared among all the data related to the comparative example.
- the plane (identification line) is shown.
- the smallest solid circle in the region above and below the identification surface of the central dotted square conceptually shows the distribution of the training data.
- the dotted circles in the upper region and the lower region conceptually show the distribution of the training data set whose data has been expanded by the data expansion process g ( ⁇ ).
- the large solid circle in the dotted square conceptually shows the distribution of the test dataset.
- FIG. 11 is a diagram for conceptually explaining the generation of the discrimination surface by the learning process.
- the AI in the classification problem, when the AI is subjected to the learning process using the learning data set consisting of images of various dogs or cats and their correct answer labels, the AI is characterized by extracting features and identifying surface d1 .
- the generation of the identification surface d1 conceptually corresponds to drawing a boundary line for distinguishing a dog from a cat.
- FIG. 12A is a diagram for conceptually explaining the data expansion process.
- the data expansion processing of the training data set is performed by performing conversion processing such as rotation processing, zoom processing, translation processing, and color conversion processing on the data of the training data set. This is a process to artificially increase and inflate the data that make up the set.
- FIG. 12B is a diagram for conceptually explaining the problem of generation of the identification surface by the learning process when the number of data included in the learning data set is small.
- FIG. 12C is a diagram for conceptually explaining an example of generation of an identification surface by a learning process using a learning data set whose data has been expanded by the data expansion process.
- the gap shown in FIG. 12B can be pseudo - filled with the data expanded data, so that the AI has the identification surface d1. As shown by, it is easier to draw a line that distinguishes dogs from cats.
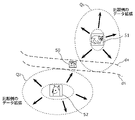
- FIG. 13 is a diagram for explaining a problem in the data expansion process according to the comparative example.
- FIG. 13 shows that the position of the discriminant plane generated by learning deviates from the ideal discriminant plane if the data expansion is not successful.
- the distribution of the learning data set regarding the data of the cat after the data expansion is the distribution Q1 .
- the distribution of the learning data set regarding the dog data after the data expansion becomes the distribution Q2 .
- AI learns the training data set after data expansion to generate the identification surface d5 at a position deviated from the position on the ideal identification surface d4. Then, if the dog image 50, which is the test data set, is located outside the distribution Q2 of the training data set regarding the dog data after data expansion, the AI is the dog image 50, which is the test data set. Will be identified as a cat.
- FIG. 14 is a diagram for conceptually explaining the identification surface generated by using the learning data set whose data has been expanded by the data expansion process according to the present disclosure.
- the training data set is data-expanded so as to match the distribution of the test data set. More specifically, by expanding the data of the cat data 51 so as to match the distribution Q t1 of the test data set for the cat, the distribution Q of the training data set regarding the data of the cat after the data expansion can be obtained. It can be set to 3 . Similarly, by expanding the data of the dog data 52 so as to match the distribution Q t2 of the test data set for the cat, the distribution of the training data set regarding the dog data after the data expansion becomes the distribution Q 4 . Can be done.
- the AI can generate the identification surface d6 at a position close to the position on the ideal identification surface d4.
- FIG. 15 is a diagram showing a verification result in which an error rate is evaluated using a test data set after learning using the learning data set according to the experimental example.
- the SVHN dataset contains a large amount of labeled data such as images with more than 600,000 digits.
- the SVHN data set consists of a 73,257-digit training data set and a 26,032-digit test data set.
- a slightly less difficult sample of 531 and 131 that can be used as additional learning data is added to the SVHN dataset.
- a training data set a training data set without data bias and label noise and a training data set with data bias or label noise were used for verification.
- the presence / absence of data bias and the presence / absence of label noise are shown by the class imbalance ratio (IR) and the label noise ratio (NR), which indicate the bias of the data.
- the training data set of the SVHN data set corresponds to the training data set without data bias and label noise.
- IR-NR 100%-0.1
- NR 0.1
- the number of image data indicating ⁇ 0 to 4 ⁇ is 100 times the number of image data indicating ⁇ 5 to 9 ⁇ , which means that the number of sample samples in the class is non-uniform, that is, the data is biased. do.
- the training data set having an IR-NR of "1-0.0" corresponds to the training data set without data bias and label noise.
- a training data set having an IR-NR of "100-0.0" corresponds to a training data set having data bias but no label noise.
- a training data set having an IR-NR of "1-0.1” corresponds to a training data set having label noise, although the data is not biased.
- a training data set having an IR-NR of "100-0.1" corresponds to a training data set having data bias and label noise.
- ⁇ A (ours), ⁇ A, W (ours), ⁇ A, W, S (ours) indicate the data expansion method of the present disclosure.
- a learning process that is, a first optimization process and a second optimization process were performed using the algorithm 1 shown in FIG. The second optimization process started after the 50th epoch.
- ⁇ A is optimized only for the hyperparameter ⁇ A , which is a variable that defines the data conversion process for each sample used when performing the data expansion process. ..
- ⁇ A, W, S indicate that they are optimized for data expansion processing, loss weights, and softlabel hyperparameters.
- ⁇ A and W (ours) indicate that they are optimized for the hyperparameters of data expansion processing and loss weights.
- FIG. 15 shows the verification result of ⁇ SHA (ours) as a comparative example.
- ⁇ ASHA (ours) is shown to be optimized for the hyperparameter ⁇ ASHA shared between all data, not per data.
- FIG. 15 also shows the verification results of Baseline and FAA as a comparative example. More specifically, Baseline shows the verification results in the case of performing data expansion processing using only the method described in Non-Patent Document 1, that is, standard conversion processing such as random cropping, horizontal inversion, and erasing. .. FAA (Fast AutoAugment) shows the verification result in the case of performing data expansion processing by the method described in Non-Patent Document 2.
- ⁇ A (ours) and ⁇ A, W (ours) are compared with the verification results of ⁇ AHA , Baseline, and FA A.
- the verification results have achieved an error rate of about the same level or less (top 1 error rate).
- the verification results of ⁇ AHA , Baseline, and FAA are improved regardless of whether the training data set has data bias or label noise.
- the error rate top 1 error rate
- FIG. 16 is a diagram showing an accuracy learning curve when learning is performed using the learning data set according to the experimental example.
- FIG. 16 shows an accuracy learning curve (c) when training is performed using a training data set having an IR-NR of “1-0.0”.
- the above-mentioned optimization process for ⁇ A, W, S (ours) corresponds to AutoDO
- the above-mentioned optimization process for ⁇ A, W, S (ours) data expansion method of the present disclosure.
- the start of the second optimization process is indicated as AutoDO start.
- AutoDO start is started after the 50th epoch.
- FIG. 16 also shows, as a comparative example, the accuracy learning curves (a) and (b) when the above Baseline and FAA are trained using the training data set according to the experimental example.
- the data expansion method of the present disclosure does not improve the performance unless AutoDO, that is, the second optimization process is started. Further, it can be seen that the data expansion method of the present disclosure can effectively optimize the hyperparameters ⁇ A, W, S by performing AutoDO, that is, the second optimization process, and the performance is sharply improved.
- the subject and the device in which each process is performed are not particularly limited. It may be processed by a processor built in a specific device located locally. It may also be processed by a cloud server or the like located at a location different from the local device.
- this disclosure also includes the following cases.
- the above-mentioned device is a computer system composed of a microprocessor, ROM, RAM, a hard disk unit, a display unit, a keyboard, a mouse, and the like.
- a computer program is stored in the RAM or the hard disk unit.
- the microprocessor operates according to the computer program, each device achieves its function.
- a computer program is configured by combining a plurality of instruction codes indicating commands to a computer in order to achieve a predetermined function.
- a part or all of the components constituting the above device may be composed of one system LSI (Large Scale Integration).
- a system LSI is a super-multifunctional LSI manufactured by integrating a plurality of components on one chip, and specifically, is a computer system including a microprocessor, ROM, RAM, and the like. ..
- a computer program is stored in the RAM. When the microprocessor operates according to the computer program, the system LSI achieves its function.
- Some or all of the components constituting the above device may be composed of an IC card or a single module that can be attached to and detached from each device.
- the IC card or the module is a computer system composed of a microprocessor, a ROM, a RAM, and the like.
- the IC card or the module may include the above-mentioned super multifunctional LSI.
- the microprocessor operates according to a computer program, the IC card or the module achieves its function. This IC card or this module may have tamper resistance.
- the present disclosure may be the method shown above. Further, it may be a computer program that realizes these methods by a computer, or it may be a digital signal composed of the computer program.
- the computer program or a recording medium capable of reading the digital signal by a computer for example, a flexible disk, a hard disk, a CD-ROM, MO, DVD, DVD-ROM, DVD-RAM, BD ( It may be recorded on a Blu-ray (registered trademark) Disc), a semiconductor memory, or the like. Further, it may be the digital signal recorded on these recording media.
- the computer program or the digital signal may be transmitted via a telecommunication line, a wireless or wired communication line, a network typified by the Internet, data broadcasting, or the like.
- the present disclosure is a computer system including a microprocessor and a memory, and the memory may store the computer program, and the microprocessor may operate according to the computer program.
- the present disclosure can be used for data expansion methods, learning devices and programs of training datasets used for training neural networks, and particularly suppresses calculation costs to train neural networks and optimize hyperparameters for each sample. It can be used for data expansion methods, learning devices and programs that can be used.
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- Evolutionary Computation (AREA)
- Artificial Intelligence (AREA)
- General Physics & Mathematics (AREA)
- Software Systems (AREA)
- General Health & Medical Sciences (AREA)
- Computing Systems (AREA)
- Health & Medical Sciences (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Databases & Information Systems (AREA)
- Data Mining & Analysis (AREA)
- Medical Informatics (AREA)
- Multimedia (AREA)
- Life Sciences & Earth Sciences (AREA)
- General Engineering & Computer Science (AREA)
- Biophysics (AREA)
- Computational Linguistics (AREA)
- Biomedical Technology (AREA)
- Molecular Biology (AREA)
- Mathematical Physics (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Bioinformatics & Computational Biology (AREA)
- Evolutionary Biology (AREA)
- Management, Administration, Business Operations System, And Electronic Commerce (AREA)
- Complex Calculations (AREA)
- Image Analysis (AREA)
Abstract
DNNの複数のパラメータの最適化を行う第1最適化処理(S11)と、データ拡張処理のためのサンプル毎のハイパーパラメータの最適化を行う第2最適化処理(S12)とを交互に行う。第1最適化処理では、学習用データセットに含まれる第1サンプルにデータ拡張処理を行った第1拡張サンプルから、第1拡張ラベルをDNNに予測させ、第1拡張ラベルと、第1サンプルの第1正解ラベルとについての第1誤差関数を算出し、第1誤差関数に基づき、複数のパラメータを更新する。第2最適化処理では、テスト用データセットの分布に類似する評価用データセットから、第2サンプルを取得し、複数のパラメータが更新されたDNNに、第2サンプルから第2ラベルを予測させ、第2ラベルと、第2サンプルの第2正解ラベルとの第2誤差関数を算出し、第2誤差関数をハイパーパラメータについて微分して得た勾配に基づいて、ハイパーパラメータを更新する。
Description
本開示は、ニューラルネットワークの学習に用いる学習用データセットのデータ拡張方法、学習装置およびプログラムに関する。
画像認識を応用したシステムの開発において、高精度なAIモデルを獲得するために、学習用の画像データを多く集める必要がある。
人物など汎用的な対象については画像データなどのサンプルを大規模に集めやすい一方で、ベビーカーなど汎用的でない対象についてサンプルを大規模には集められない。また、特定の製品、異常サンプルなどそもそも少量しか存在しない対象もサンプルを大規模に集められない。
これに対して、学習用のサンプル数が少ない場合でも、サンプル数を増加させることができるデータ拡張という手法がある。データ拡張は、画像データなどの学習用のサンプルに対して変換処理を行うことでサンプルを水増しする手法であるが、種々のデータ拡張が提案されている(例えば非特許文献1)。
非特許文献1には、画像の一部を別の値で塗りつぶしてデータ拡張する技術が開示されている。
Ekin D Cubuk, Barret Zoph, Dandelion Mane, Vijay Vasudevan,and Quoc V Le. AutoAugment: Learning augmentation policies from data. arXiv:1805.09501, 2018.
Sungbin Lim, Ildoo Kim, Taesup Kim, Chiheon Kim, and Sungwoong Kim. Fast AutoAugment. In Advances in Neural Information Processing Systems, 2019.
しかしながら、非特許文献1で開示された技術では、学習用のサンプル数を増やすことができるものの、高精度なAIモデルを獲得できない場合がある。換言すると、学習用のサンプルに対して適切に変換処理を行わないと、学習による識別面(識別線)の生成が理想的な境界線から大きく外れてしまい、予測精度の向上に寄与しないばかりか予測精度を低下させてしまう場合も生じる。
本開示は、上述の事情を鑑みてなされたもので、高精度なAIモデルを獲得できるように学習用データセットのサンプル数を増やすことができるデータ拡張方法等を提供することを目的とする。
上記課題を解決するために、本開示の一形態に係るデータ拡張方法は、ニューラルネットワークの学習に用いる学習用データセットのデータ拡張方法であって、前記ニューラルネットワークにおける、重みを含む複数のパラメータの最適化を行うための第1最適化処理と、データ拡張処理を行う際に用いるサンプル毎のデータ変換処理を規定する変数であるハイパーパラメータの最適化を行うための第2最適化処理とを交互に行い、前記第1最適化処理では、前記学習用データセットに含まれる第1サンプルに、前記データ拡張処理を行わせることで、第1拡張サンプルを取得し、前記ニューラルネットワークに、前記第1拡張サンプルから、第1拡張ラベルを予測させ、前記第1拡張ラベルと、前記学習用データセットに含まれる前記第1サンプルの正解を示す第1正解ラベルとについての誤差を評価するための第1誤差関数を算出し、算出した前記第1誤差関数に基づき、前記複数のパラメータを更新し、前記第2最適化処理では、前記ニューラルネットワークの性能を評価するためのテスト用データセットの分布に類似した分布のデータセットである評価用データセットから、第2サンプルを取得し、前記複数のパラメータが更新された前記ニューラルネットワークに、前記第2サンプルから、第2ラベルを予測させ、前記第2ラベルと、前記評価用データセットに含まれる前記第2サンプルの正解を示す第2正解ラベルとの誤差を評価するための第2誤差関数を算出し、算出した前記第2誤差関数を、前記ハイパーパラメータについて偏微分して得た勾配に基づいて、前記ハイパーパラメータを更新する。
なお、これらの全般的または具体的な態様は、システム、方法、集積回路、コンピュータプログラムまたはコンピュータで読み取り可能なCD-ROMなどの記録媒体で実現されてもよく、システム、方法、集積回路、コンピュータプログラムおよび記録媒体の任意な組み合わせで実現されてもよい。
本開示のデータ拡張方法等によれば、高精度なAIモデルを獲得できるように学習用データセットのサンプル数を増やすことができる。
本開示の一形態に係るデータ拡張方法は、ニューラルネットワークの学習に用いる学習用データセットのデータ拡張方法であって、前記ニューラルネットワークにおける、重みを含む複数のパラメータの最適化を行うための第1最適化処理と、データ拡張処理を行う際に用いるサンプル毎のデータ変換処理を規定する変数であるハイパーパラメータの最適化を行うための第2最適化処理とを交互に行い、前記第1最適化処理では、前記学習用データセットに含まれる第1サンプルに、前記データ拡張処理を行わせることで、第1拡張サンプルを取得し、前記ニューラルネットワークに、前記第1拡張サンプルから、第1拡張ラベルを予測させ、前記第1拡張ラベルと、前記学習用データセットに含まれる前記第1サンプルの正解を示す第1正解ラベルとについての誤差を評価するための第1誤差関数を算出し、算出した前記第1誤差関数に基づき、前記複数のパラメータを更新し、前記第2最適化処理では、前記ニューラルネットワークの性能を評価するためのテスト用データセットの分布に類似した分布のデータセットである評価用データセットから、第2サンプルを取得し、前記複数のパラメータが更新された前記ニューラルネットワークに、前記第2サンプルから、第2ラベルを予測させ、前記第2ラベルと、前記評価用データセットに含まれる前記第2サンプルの正解を示す第2正解ラベルとの誤差を評価するための第2誤差関数を算出し、算出した前記第2誤差関数を、前記ハイパーパラメータについて偏微分して得た勾配に基づいて、前記ハイパーパラメータを更新する。
これによれば、ハイパーパラメータを最適化できるので、高精度なAIモデルを獲得できるように学習用データセットのサンプル数を増やすことができる。
より具体的には、ニューラルネットワークの複数のパラメータの最適化を行うニューラルネットワークの学習の過程で、サンプル毎のハイパーパラメータについて偏微分して得た勾配を用いて、データ拡張された学習用データセットとテスト用データセットとの分布のずれを最小化することができる。よって、データ拡張処理によりデータ拡張された学習用データを用いて、ニューラルネットワークを学習させても、学習による識別面の生成を理想的な識別面に近づけることができるように、学習用データセットのサンプル数を増やすことができる。このようにして、高精度なAIモデルを獲得できるように学習用データセットのサンプル数を増やすことができる。
さらに、サンプル毎に、ニューラルネットワークの複数のパラメータとデータ拡張処理のハイパーパラメータを交互に最適化を行うことで、サンプル毎のハイパーパラメータの最適化をニューラルネットワークの複数のパラメータの学習とともに行える。よって、ニューラルネットワークの複数のパラメータの最適化とサンプル毎のハイパーパラメータの最適化に要する計算コストを抑制できる。
ここで、例えば、前記ハイパーパラメータを更新する際、前記学習用データセットに前記データ拡張処理を行うことで得られるデータ拡張後の学習用データセットの分布と、前記評価用データセットの分布とのずれを減らすよう、前記勾配に基づいて前記ハイパーパラメータを更新する。
これにより、データ拡張された学習用データセットとテスト用データセットとの分布のずれを最小化するように、ハイパーパラメータを更新できる。よって、データ拡張処理によりデータ拡張された学習用データを用いて、ニューラルネットワークを学習させても、学習による識別面の生成を理想的な識別面に近づけることができる。
また、例えば、前記ハイパーパラメータは、前記データ拡張処理を示す関数において陰関数化され、前記ニューラルネットワークは、完全微分可能な関数であるとしてもよい。
これにより、陰関数の微分手法を用いることで、ハイパーパラメータについての偏微分を計算することができる。
また、例えば、前記第1誤差関数を算出する際、前記第1正解ラベルが示す正解値をソフトラベル化して得た第1正解ソフトラベルと、前記第1拡張ラベルとの誤差をカルバックライブラーダイバージェンスを用いて評価する前記第1誤差関数を算出してもよい。
これにより、データ拡張後に含まれるサンプルに対する正解ラベルのノイズを抑制することができる。よって、サンプル毎のハイパーパラメータについて偏微分して得た勾配を用いて、データ拡張された学習用データセットとテスト用データセットとの分布のずれを最小化するように、サンプル毎のハイパーパラメータを最適化できる。
また、例えば、前記第1誤差関数を算出する際、前記第1誤差関数に対して、さらに、サンプル毎に算出される重みづけを行ってもよい。
これにより、サンプルのバイアスを捉えて抑制することができる。よって、サンプル毎のハイパーパラメータについて偏微分して得た勾配を用いて、データ拡張された学習用データセットとテスト用データセットとの分布のずれを最小化するように、サンプル毎のハイパーパラメータを最適化できる。
また、本開示の一形態に係る学習装置は、ニューラルネットワークの学習に用いる学習用データセットのデータ拡張方法を行うための学習装置であって、プロセッサと、メモリとを備え、前記プロセッサは、前記メモリを用いて、前記ニューラルネットワークにおける、重みを含む複数のパラメータの最適化を行うための第1最適化処理と、データ拡張処理を行う際に用いるサンプル毎のデータ変換処理を規定する変数であるハイパーパラメータの最適化を行うための第2最適化処理とを交互に行い、前記第1最適化処理では、前記学習用データセットに含まれる第1サンプルに、前記データ拡張処理を行わせることで、第1拡張サンプルを取得し、前記ニューラルネットワークに、前記第1拡張サンプルから、第1拡張ラベルを予測させ、前記第1拡張ラベルと、前記学習用データセットに含まれる前記第1サンプルの正解を示す第1正解ラベルとについての誤差を評価するための第1誤差関数を算出し、算出した前記第1誤差関数に基づき、前記複数のパラメータを更新し、前記第2最適化処理では、前記ニューラルネットワークの性能を評価するためのテスト用データセットの分布に類似した分布のデータセットである評価用データセットから、第2サンプルを取得し、前記複数のパラメータが更新された前記ニューラルネットワークに、前記第2サンプルから、第2ラベルを予測させ、前記第2ラベルと、前記評価用データセットに含まれる前記第2サンプルの正解を示す第2正解ラベルとの誤差を評価するための第2誤差関数を算出し、算出した前記第2誤差関数を、前記ハイパーパラメータについて偏微分して得た勾配に基づいて、前記ハイパーパラメータを更新する。
なお、これらの包括的または具体的な態様は、システム、方法、集積回路、コンピュータプログラムまたはコンピュータで読み取り可能なCD-ROMなどの記録媒体で実現されてもよく、システム、方法、集積回路、コンピュータプログラムおよび記録媒体の任意な組み合わせで実現されてもよい。
以下で説明する実施の形態は、いずれも本開示の一具体例を示すものである。以下の実施の形態で示される数値、形状、構成要素、ステップ、ステップの順序などは、一例であり、本開示を限定する主旨ではない。また、以下の実施の形態における構成要素のうち、最上位概念を示す独立請求項に記載されていない構成要素については、任意の構成要素として説明される。また全ての実施の形態において、各々の内容を組み合わせることもできる。
(実施の形態)
以下では、図面を参照しながら、実施の形態に係る学習装置10の情報処理方法等の説明を行う。
以下では、図面を参照しながら、実施の形態に係る学習装置10の情報処理方法等の説明を行う。
[1.1 学習装置10の構成]
図1は、実施の形態に係る学習装置10の構成の一例を示すブロック図である。
図1は、実施の形態に係る学習装置10の構成の一例を示すブロック図である。
学習装置10は、ニューラルネットワークの学習を行うとともに、ニューラルネットワークの学習に用いる学習用データセットのデータ拡張方法を行うための装置である。学習装置10は、ニューラルネットワークにおける、重みを含む複数のパラメータの最適化を行うための第1最適化処理と、データ拡張処理を行う際に用いるサンプル毎のデータ変換処理を規定する変数であるハイパーパラメータの最適化を行うための第2最適化処理とを交互に行う。
本実施の形態では、学習装置10は、図1に示すように取得部11と、データ拡張処理部12と、DNN13と、誤差算出部14と、最適化部15とで構成されている。
[1.1.1 取得部11]
取得部11は、第1最適化処理において、学習用データセットから、第1サンプルを取得し、データ拡張処理部12に入力する。ここで、学習用データセットは、例えば画像データなどの複数のサンプルとそれらの正解ラベルとからなる。なお、サンプルは、画像データである場合に限らない。
取得部11は、第1最適化処理において、学習用データセットから、第1サンプルを取得し、データ拡張処理部12に入力する。ここで、学習用データセットは、例えば画像データなどの複数のサンプルとそれらの正解ラベルとからなる。なお、サンプルは、画像データである場合に限らない。
また、取得部11は、第1最適化処理において、学習用データセットから、第1サンプルの正解を示す第1正解ラベルを取得し、誤差算出部14に入力する。
また、取得部11は、第2最適化処理において、評価用データセットから、第2サンプルを取得し、DNN13に入力する。ここで、評価用データセットは、学習済のDNN13の性能を評価するためのテスト用データセットの分布に類似した分布のデータセットである。なお、評価用データセットと、テスト用データセットとは異なる。評価用データセットは、既存のデータセットのテスト用データセットを分割することで生成することができる。
また、取得部11は、第2最適化処理において、評価用データセットから、第2サンプルの正解を示す第2正解ラベルを取得し、誤差算出部14に入力する。
なお、第2最適化処理において、取得部11は、学習用データセットから、第3サンプルを取得し、データ拡張処理部12に入力してもよい。この場合、取得部11は、学習用データセットから、第3サンプルの正解を示す第3正解ラベルを取得し、誤差算出部14に入力すればよい。第3サンプルは、第1サンプルと異なっていてもよいし同じであってもよい。
[1.1.2 データ拡張処理部12]
データ拡張処理部12は、第1最適化処理において、学習用データセットに含まれる第1サンプルに、データ拡張処理を行い、第1拡張サンプルを出力する。より具体的には、第1最適化処理において、データ拡張処理部12は、サンプル毎のデータ変換処理を規定する変数であるハイパーパラメータを用いて、第1サンプルに、データ拡張処理を行う。ハイパーパラメータは、例えば回転処理、ズーム処理、並進処理、色変換処理といったデータの変換処理を規定する変数であり、サンプル毎に規定される。
データ拡張処理部12は、第1最適化処理において、学習用データセットに含まれる第1サンプルに、データ拡張処理を行い、第1拡張サンプルを出力する。より具体的には、第1最適化処理において、データ拡張処理部12は、サンプル毎のデータ変換処理を規定する変数であるハイパーパラメータを用いて、第1サンプルに、データ拡張処理を行う。ハイパーパラメータは、例えば回転処理、ズーム処理、並進処理、色変換処理といったデータの変換処理を規定する変数であり、サンプル毎に規定される。
本実施の形態では、データ拡張処理部12は、データ拡張処理を示す関数を、学習用データセットから取得されたサンプルに作用させることで、データ拡張処理を行う。ここで、ハイパーパラメータは、データ拡張処理を示す関数において陰関数化されている。
ここで、データ拡張処理を示す関数をgとし、第1サンプルに対するハイパーパラメータをλ1とする。この場合、データ拡張処理部12は、第1最適化処理において、g(λ1)を第1サンプルに作用させることで、第1サンプルのデータ拡張処理を行うことができ、第1拡張サンプルを出力することができる。したがって、データ拡張処理部12は、第1最適化処理において、第i(iは自然数)サンプルに対するハイパーパラメータをλiとする場合、g(λi)を第iサンプルに作用させることで、第iサンプルのデータ拡張処理を行うことができる。
なお、第2最適化処理において、データ拡張処理部12は、取得部11により第3サンプルが入力される場合、第3サンプルに、データ拡張処理を行い、第3拡張サンプルを出力すればよい。この場合、データ拡張処理部12は、第2最適化処理において、第3サンプルに対するハイパーパラメータをλ3とするg(λ3)を第3サンプルに作用させることで、第3サンプルのデータ拡張処理を行うことができるので、第3拡張サンプルを出力することができる。
[1.1.3 DNN13]
DNN13は、CNNなど、複数のパラメータを有するニューラルネットワークにより構成される。DNN13は、第1最適化処理において、取得部11により入力された第1拡張サンプルから、第1拡張ラベルを予測する。複数のパラメータは、例えば重みであるが、重みに限らない。
DNN13は、CNNなど、複数のパラメータを有するニューラルネットワークにより構成される。DNN13は、第1最適化処理において、取得部11により入力された第1拡張サンプルから、第1拡張ラベルを予測する。複数のパラメータは、例えば重みであるが、重みに限らない。
本実施の形態では、DNN13は、第1最適化処理において、ニューラルネットワークによる予測処理を示す関数を、第1拡張サンプルに作用させることで、第1拡張サンプルの正解としての第1拡張ラベルを予測する予測処理を行う。ここで、ニューラルネットワークによる予測処理を示す関数は、完全微分可能な関数である。また、複数のパラメータは、ニューラルネットワークによる予測処理を示す関数において陰関数化されている。
ここで、ニューラルネットワークによる予測処理を示す関数をfとし、重みを含む複数のパラメータをθとすると、DNN13は、第1最適化処理において、f(θ)を第1拡張サンプルに作用させることで、第1拡張ラベルを予測することができる。
また、DNN13は、第1最適化処理により複数のパラメータが更新された後、取得部11により入力された、評価用データセットに含まれる第2サンプルから、第2ラベルを予測する。換言すると、本実施の形態では、第2最適化処理において、DNN13は、第1最適化処理により複数のパラメータが更新されたf(θ)を第2サンプルに作用させることで、第2ラベルを予測する。
なお、DNN13は、第2最適化処理において、データ拡張処理部12により第3拡張サンプルが入力された場合、第3拡張サンプルから、第3拡張サンプルの正解としての第3拡張ラベルを予測すればよい。
[1.1.4 誤差算出部14]
誤差算出部14は、第1最適化処理において、第1拡張ラベルと、学習用データセットに含まれる第1サンプルの正解を示す第1正解ラベルとについての誤差を評価するための第1誤差関数を算出する。ここでの第1誤差関数は、カルバック・ライブラー・ダイバージェンス(KLダイバージェンス)というロス関数である。第1誤差関数は、クロスエントロピー誤差関数であってもよい。
誤差算出部14は、第1最適化処理において、第1拡張ラベルと、学習用データセットに含まれる第1サンプルの正解を示す第1正解ラベルとについての誤差を評価するための第1誤差関数を算出する。ここでの第1誤差関数は、カルバック・ライブラー・ダイバージェンス(KLダイバージェンス)というロス関数である。第1誤差関数は、クロスエントロピー誤差関数であってもよい。
なお、カルバック・ライブラー・ダイバージェンスは、確率論と情報理論とにおける2つの確率分布の差異を計る尺度として用いることができる。つまり、カルバック・ライブラー・ダイバージェンスは、正解分布である確率分布と推定分布である確率分布とがどのくらい似ているかを評価できるロス関数である。
また、誤差算出部14は、第1最適化処理において、第1正解ラベルが示す正解値をソフトラベル化して得た第1正解ソフトラベルと、第1拡張ラベルとの誤差をKLダイバージェンスを用いて評価する第1誤差関数を算出してもよい。ここで、ソフトラベルは、第1拡張サンプルと正解ラベルの類似度を離散値(ハードラベル)ではなく、割合で表すことを意味する。例えば、ソフトラベルとしては、ガンベルソフトマックス(gumbel-softmax)またはソフトマックス(softmax)を用いることができる。これにより、データ拡張後に含まれるサンプルに対する正解ラベルのノイズを抑制することができる。
さらに、第1最適化処理では、誤差算出部14は、算出した第1誤差関数に対して、さらに、サンプル毎に算出される重みづけを行ってもよい。
また、誤差算出部14は、第2最適化処理において、第2ラベルと、評価用データセットに含まれる第2サンプルの正解を示す第2正解ラベルとの誤差を評価するための第2誤差関数を算出する。ここで、第2誤差関数は、第1誤差関数と同様に、KLダイバージェンスというロス関数であってもよいし、クロスエントロピー誤差関数であってもよい。
なお、第2最適化処理において、DNN13が、第3拡張サンプルから第3拡張ラベルを予測する場合、第1誤差関数を用いて、第3拡張ラベルと、学習用データセットに含まれる第3サンプルの正解を示す第3正解ラベルとについての誤差を評価すればよい。
[1.1.5 最適化部15]
最適化部15は、第1最適化処理において、誤差算出部14により算出された第1誤差関数に基づき、複数のパラメータを更新する。これにより、最適化部15は、ニューラルネットワークにおける複数のパラメータの最適化を行う第1最適化処理を行うことができる。
最適化部15は、第1最適化処理において、誤差算出部14により算出された第1誤差関数に基づき、複数のパラメータを更新する。これにより、最適化部15は、ニューラルネットワークにおける複数のパラメータの最適化を行う第1最適化処理を行うことができる。
また、最適化部15は、第2最適化処理において、誤差算出部14により算出された第2誤差関数を、ハイパーパラメータについて偏微分して得た勾配に基づいて、ハイパーパラメータを更新する。なお、ハイパーパラメータは、陰関数化されているので、陰関数の微分手法を用いることで、ハイパーパラメータについての偏微分を計算することができる。ここで、最適化部15は、学習用データセットにデータ拡張処理を行うことで得られるデータ拡張後の学習用データセットの分布と、評価用データセットの分布とのずれを減らすよう、勾配に基づいてハイパーパラメータを更新する。これにより、最適化部15は、第2最適化処理において、データ拡張処理を行う際に用いるサンプル毎のデータ変換処理を規定する変数であるハイパーパラメータの最適化を行うことができる。
以上のように構成された学習装置10は、ニューラルネットワークにおける複数のパラメータに対する第1最適化処理と、データ拡張処理を行う際に用いるサンプル毎のハイパーパラメータに対する第2最適化処理とを交互に行う。これにより、データ拡張処理がされた学習用データセットの分布を、テスト用データセットの分布に合わせることができるので、高精度なAIモデルを獲得できるように学習用データセットのサンプル数を増やすことができる。
より具体的には、上記のようにしてデータ拡張処理がされたサンプル数が増えた学習用データを用いて、ニューラルネットワークを学習させても、学習による識別面の生成を理想的な識別面に近づけることができるように、学習用データセットのサンプル数を増やすことができる。このようにして、高精度なAIモデルを獲得できるように学習用データセットのサンプル数を増やすことができる。
[1.2 学習装置10のハードウェア構成]
図2は、実施の形態に係る学習装置10の機能をソフトウェアにより実現するコンピュータ1000のハードウェア構成の一例を示す図である。
図2は、実施の形態に係る学習装置10の機能をソフトウェアにより実現するコンピュータ1000のハードウェア構成の一例を示す図である。
コンピュータ1000は、図2に示すように、入力装置1001、出力装置1002、CPU1003、内蔵ストレージ1004、RAM1005、読取装置1007、送受信装置1008およびバス1009を備えるコンピュータである。入力装置1001、出力装置1002、CPU1003、内蔵ストレージ1004、RAM1005、読取装置1007および送受信装置1008は、バス1009により接続される。
入力装置1001は、入力ボタン、タッチパッド、タッチパネルディスプレイなどといったユーザインタフェースとなる装置であり、ユーザの操作を受け付ける。なお、入力装置1001は、ユーザの接触操作を受け付ける他、音声での操作、リモコン等での遠隔操作を受け付ける構成であってもよい。
出力装置1002は、入力装置1001と兼用されており、タッチパッドまたはタッチパネルディスプレイなどによって構成され、ユーザに知らすべき情報を通知する。
内蔵ストレージ1004は、フラッシュメモリなどである。また、内蔵ストレージ1004は、学習装置10の機能を実現するためのプログラム、複数のパラメータを有するニューラルネットワーク、ニューラルネットワークによる予測処理を示す関数f及びデータ拡張処理を示す関数gなどが予め記憶されていてもよい。
RAM1005は、ランダムアクセスメモリ(Random Access Memory)であり、プログラム又はアプリケーションの実行に際してデータ等の記憶に利用される。
読取装置1007は、USB(Universal Serial Bus)メモリなどの記録媒体から情報を読み取る。読取装置1007は、上記のようなプログラムやアプリケーションが記録された記録媒体からそのプログラム、アプリケーションを読み取り、内蔵ストレージ1004に記憶させる。
送受信装置1008は、無線又は有線で通信を行うための通信回路である。送受信装置1008は、例えばネットワークに接続されたサーバ装置またはクラウドと通信を行い、サーバ装置またはクラウドから上記のようなプログラム、アプリケーションをダウンロードして内蔵ストレージ1004に記憶させてもよい。
CPU1003は、中央演算処理装置(Central Processing Unit)であり、内蔵ストレージ1004に記憶されたプログラム、アプリケーションをRAM1005にコピーし、そのプログラムやアプリケーションに含まれる命令をRAM1005から順次読み出して実行する。なお、内蔵ストレージ1004から直接実行しても良い。
[1.3 学習装置10の動作]
次に、上記のように構成された学習装置10の動作について説明する。
次に、上記のように構成された学習装置10の動作について説明する。
図3は、実施の形態に係る学習装置10の動作概要を示すフローチャートである。
まず、学習装置10は、ニューラルネットワークにおける複数のパラメータの最適化を行う第1最適化処理を行う(S11)。次に、学習装置10は、データ拡張処理を行う際に用いるサンプル毎のハイパーパラメータの最適化を行う第2最適化処理を行う(S12)。次に、学習装置10は、処理を終了させるかを判定する(S13)。学習装置10は、例えば既定の回数(エポック回数)だけ第1最適化処理及び第2最適化処理を行った場合、処理を終了させると判定し(S13でYes)、本動作を終了させる。一方、学習装置10は、例えば既定の回数(エポック回数)まで第1最適化処理及び第2最適化処理を行っていない場合、処理を終了させないと判定し(S13でNo)、ステップS11の処理から繰り返す。
図4は、図3に示す第1最適化処理の詳細動作を示すフローチャートである。
第1最適化処理において、まず、学習装置10は、学習用データセットに含まれる第1サンプルに、データ拡張処理を行い、第1拡張サンプルを取得する(S111)。ここで、学習装置10は、サンプル毎のデータ変換処理を規定する変数であるハイパーパラメータを用いて、第1サンプルに、データ拡張処理を行う。例えば、データ拡張処理を示す関数をgとし、第1サンプルに対するハイパーパラメータをλ1とすると、学習装置10は、g(λ1)を第1サンプルに作用させることで、第1サンプルに対してデータ拡張処理を行った第1拡張サンプルを取得する。
次に、学習装置10は、ニューラルネットワークに、ステップS111で取得した第1拡張サンプルから、第1拡張ラベルを予測させる(S112)。例えば、ニューラルネットワークによる予測処理を示す関数をfとし、重みを含む複数のパラメータをθとすると、学習装置10は、f(θ)を第1拡張サンプルに作用させることで、ニューラルネットワークに、第1拡張ラベルを予測させる。
次に、学習装置10は、ステップS112で予測させた第1拡張ラベルと、学習用データセットに含まれる第1サンプルの第1正解ラベルとについての誤差を評価するための第1誤差関数を算出する(S113)。ここで、第1誤差関数は、例えばKLダイバージェンスというロス関数である。なお、上述したように、学習装置10は、第1正解ラベルが示す正解値をソフトラベル化して得た第1正解ソフトラベルと、第1拡張ラベルとの誤差をKLダイバージェンスを用いて評価する第1誤差関数を算出してもよい。学習装置10は、さらに、算出した第1誤差関数に対して、さらに、サンプル毎に算出される重みづけを行ってもよい。
次に、学習装置10は、ステップS113で算出した第1誤差関数に基づき、複数のパラメータを更新する(S114)。
このようにして、学習装置10は、初期または第2最適処理後のデータ拡張処理により水増しされた学習用データセットを用いて、ニューラルネットワークにおける重みなどの複数のパラメータの最適化を行う第1最適化処理を行うことができる。
図5は、図3に示す第2最適化処理の詳細動作を示すフローチャートである。
第2最適化処理において、まず、学習装置10は、テスト用データセットの分布に類似した分布のデータセットである評価用データセットから、第2サンプルを取得する(S121)。
次に、学習装置10は、第1最適化処理において複数のパラメータが更新されたニューラルネットワークに、第2サンプルから、第2ラベルを予測させる(S122)。例えば、ニューラルネットワークによる予測処理を示す関数をfとし、重みを含む複数のパラメータをθとすると、学習装置10は、f(θ)を第2サンプルに作用させることで、ニューラルネットワークに、第2ラベルを予測させる。
次に、学習装置10は、ステップS122で予測させた第2ラベルと、評価用データセットに含まれる第2サンプルの第2正解ラベルとの誤差を評価するための第2誤差関数を算出する(S123)。ここで、第2誤差関数は、例えばKLダイバージェンスというロス関数であるが、クロスエントロピー誤差関数であってもよい。
次に、学習装置10は、ステップS123で算出した第2誤差関数を、ハイパーパラメータについて偏微分して得た勾配に基づいて、ハイパーパラメータを更新する(S124)。ここで、学習装置10は、学習用データセットにデータ拡張処理を行うことで得られるデータ拡張後の学習用データセットの分布と、評価用データセットの分布とのずれを減らすよう、勾配に基づいてハイパーパラメータを更新する。
このようにして、学習装置10は、評価用データセットを用いて、データ拡張処理を行う際に用いるサンプル毎のハイパーパラメータの最適化を行う第2最適化処理を行うことができる。
(実施例1)
以下、本実施の形態の実施例1について説明する。
以下、本実施の形態の実施例1について説明する。
図6は、実施例1に係る第1最適化処理及び第2最適化処理を交互に行う処理例を概念的に説明するための図である。
Process12aは、データ拡張処理部12が行うデータ拡張処理機能を示し、g(λi)は、当該データ拡張処理を示す関数であってハイパーパラメータλiが陰関数化された関数を示している。図6に示す例では、第1最適化処理において、Process12aは、学習用データセットからサンプル(xi、yi)を取得し、サンプル(xi)に対して、ハイパーパラメータλiでデータ拡張処理を行う。そして、Process12aは、データ拡張処理により得た拡張サンプルg(xi、yi、λi)をDNN13aに出力する。
DNN13aは、DNN13の複数のパラメータθを有するニューラルネットワークを示し、f(θ)は、当該ニューラルネットワークによる予測処理を示す関数を示している。図6に示す例では、第1最適化処理において、Process12aから出力された拡張サンプルg(xi、yi、λi)を用いて、DNN13aのニューラルネットワークが学習されることが示されている。
また、図6に示す例では、第2最適化処理において、評価用データセットからサンプル(xi
v、yi
v)を取得し、サンプル(xi
v)をDNN13aに入力する。DNN13aは、サンプル(xi
v)に対して、関数f(θ)を作用させて、予測処理を行う。そして、DNN13aは、予測処理により得たサンプル(xi
v)に対する正解ラベルを出力する。
AutoDO15aは、最適化部15が行う第2最適化処理機能を示し、∂Lv/∂λは、DNN13aの予測処理の結果に基づき算出した誤差関数Lvのハイパーパラメータλについて微分(偏微分)して得た勾配を示す。より具体的には、第2最適化処理では、予測処理により得たサンプル(xi
v)に対する正解ラベルと評価用データセットから取得したサンプル(xi
v)の正解ラベル(yi
v)とについての誤差関数Lvを算出する。そして、AutoDO15aは、算出した誤差関数Lvを、λiについて偏微分して得た勾配に基づいて、λiを更新することで、ハイパーパラメータλを最適化する。
図7Aは、実施例1に係る評価用データセットの一例を示す図である。図7Bは、実施例1に係る学習用データセットの一例を示す図である。
図7Aに示す評価用データセットのサンプルは、桁数1,6,7,9の画像データである。図7Aには、学習済のDNN13aの性能を評価するためのテスト用データセットの分布に類似した分布のデータセットのサンプルが例示されている。
一方、図7Bに示す学習用データセットのサンプルは、桁数0,0,1,2、6、9等の画像データである。図7Bには、バイアスが含まれたサンプルと、サンプルに対する正解ラベルにノイズ(ラベルノイズ)が含まれていることが例示されている。
図8Aは、実施例1に係る第1最適化処理を行うための機能例を概念的に説明するための図である。図8Bは、図8Aに示すLOSS14bの具体的な機能を説明するための図である。
Data Sampler11bは、第1最適化処理において取得部11が行う取得処理機能を示し、i~U(1、N)で示される学習用データセットから、サンプルxiを取得する。
Augment12bは、第1最適化処理においてデータ拡張処理部12が行うデータ拡張処理機能を示し、gA(λA)は、当該データ拡張処理を示す関数であってハイパーパラメータλAが陰関数化された関数を示している。図8Aに示す例では、Augment12bにおけるgA(λA)は、第2最適化処理において勾配∂Lv/∂λによりハイパーパラメータλAが更新されている。
Augment12bは、Data Sampler11bにより取得されたサンプルxiに対して、gA(λA)を作用させてデータ拡張処理を行う。そして、Data Sampler11bは、データ拡張処理により得た拡張サンプルxi
AをDNN13bに出力する。
DNN13bは、DNN13の複数のパラメータθを有するニューラルネットワークを示し、f(θ)は、当該ニューラルネットワークによる予測処理を示す関数を示している。図8Aに示す例では、第1最適化処理において、DNN13bは、Augment12bから出力された拡張サンプルxi
Aに対して、f(θ)を作用させてデータ予測処理を行う。そして、DNN13bは、予測処理により得た拡張サンプルxi
Aに対する正解ラベル

を出力する。
LOSS14bは、第1最適化処理における誤差関数(第1誤差関数)を算出する処理機能を示す。gs,w(λs,w)は、サンプルのバイアスを捉えるためのサンプル毎の重み(損失重み)と、ノイズの多い正解ラベルに対応するためのソフトラベルとを用いた第1最適化処理における誤差関数(第1誤差関数)を示す。λs、wは、損失重みとソフトラベルのハイパーパラメータを示し、陰関数化されている。
なお、ハイパーパラメータλs、wは、第2最適化処理において勾配∂Lv/∂λにより更新されている。
より詳細には、LOSS14bは、図8Bに示すように、Soft-label141と、Weight KL Div142と、Reweight143との機能を有する。
Soft-label141は、例えば、ガンベルソフトマックスまたはソフトマックスを用いて、入力された正解ラベルが示す正解値をソフトラベル化して、出力する。gs(λs)は、ノイズの多い正解ラベルに対応するためのソフトラベル化処理する関数を示し、ハイパーパラメータλsが陰関数化されている。
図8Bに示す例では、Soft-label141は、i~U(1、N)で示される学習用データセットから、サンプルxiに対する正解ラベルyiが入力され、入力された示す正解ラベルyiをソフトラベル化する。Soft-label141は、ソフトラベル化したソフトラベルyi
sをWeight KL Div142に出力する。ここで、例えば、Soft-label141は、yi
s
=gs(yi、λi
s)=softmax(λi
S)の式を用いて正解ラベルyiからサンプル毎のソフトラベルyi
sを算出する。ここで、λi
Sは、サンプル毎のソフトラベルのハイパーパラメータであり、陰関数化されている。
Weight KL Div142は、サンプル毎の重み(損失重み)と、ノイズの多い正解ラベルに対応するためのソフトラベルとを用いた第1最適化処理における誤差関数(第1誤差関数)を算出する。より具体的には、Weight KL Div142は、Soft-label141により出力されたソフトラベルyi
sとDNN13bにより出力された正解ラベル

との誤差を評価するKLダイバージェンスである第1誤差関数Lを算出する。そして、Weight KL Div142は、算出したReweight143により算出された重みwi(スカラ量)でかけることで、重み付けされた第1誤差関数

を算出する。
Reweight143は、softplusなどの活性化関数を用いて、サンプルのバイアスを捉えるためのサンプル毎の重みwiを算出する。gw(λw)は、サンプルのバイアスを捉えるための誤差関数Lに重み付けされるサンプル毎の重み(損失重み)を算出する関数を示す。
図8Bに示す例では、Reweight143は、gw(Li、λi
w)=wiLiの式における重みwiを算出し、Weight KL Div142に出力する。例えばReweight143は、wi=1.44×softplus(λi
W)の式を用いてサンプル毎の重みwiを算出する。ここで、λi
Wは、サンプル毎の重み(損失重み)のハイパーパラメータであり、陰関数化されている。
第1最適化処理において、上記のように算出された重み付けされた第1誤差関数

を用いて、DNN13bの複数のパラメータθを更新することができる。
続いて、図9を用いて、実施例1に係る第1最適化処理及び第2最適化処理を交互に行う最適化処理手順について説明する。
図9は、実施例1に係る第1最適化処理及び第2最適化処理を交互に行う最適化処理手順の一例を示すアルゴリズム1の擬似コードを示す図である。なお、図9に示されるλなどの変数、f(θ)などの関数は、図8A及び図8Bで説明した通りである。図9では、上記における学習用データセットのサンプルをデータと称して表現されている。
図9に示すアルゴリズム1は、例えば学習装置10のプロセッサにより行われる。
図9に示すように、1行目の手順では、パラメータθとハイパーパラメータλとの初期化が行われることが規定されている。
2行目では、3行目~19行目の手順すなわち第1最適化処理及び第2最適化処理がエポック回数まで繰り返されることが規定されている。
3行目では、4行目~9行目の手順すなわち第1最適化処理がバッチ個数まで繰り返されることが規定されている。
4行目では、学習用データセットDtrainからバッチがサンプリングされることが規定されている。なおバッチとは、学習用データセットを幾つかのサブセットに分けたときのサブセットに含まれるデータ(上記でのサンプル)に該当する。
5行目では、サンプリングされたデータxがデータ拡張処理されることが規定されている。
6行目では、5行目においてデータ拡張処理されたデータxAから正解ラベルが予測されることが規定されている。
7行目では、4行目で学習用データセットDtrainからサンプリングされたデータxに対する正解ラベルであって学習用データセットDtrainから取得された正解ラベルのソフトラベルが生成されることが規定されている。
8行目では、重み付き誤差関数がKLダイバージェンスで計算され、パラメータθで微分(∇θ)されることが規定されている。
9行目では、ニューラルネットワークによる予測処理を示す関数f(θ)のパラメータθが更新されることが規定されている。
10行目では、エポック回数がE回数を超えていたら、11行目以降の処理を行われることが規定されている。
11行目では、12行目~19行目の手順すなわち第2最適化処理がバッチ個数まで繰り返されることが規定されている。
12行目では、学習用データセットDtrainからバッチがサンプリングされることが規定されている。
13行目では、評価用データセットDvalからバッチがサンプリングされることが規定されている。
14行目では、13行目でサンプリングされた評価用データセットDvalのデータXvから正解ラベルが予測されることが規定されている。
15行目では、12行目でサンプリングされた学習用データセットDtrainのデータがデータ拡張処理されたデータXAから正解ラベルが予測されることが規定されている。
16行目では、12行目で学習用データセットDtrainからサンプリングされたデータxに対する正解ラベルであって学習用データセットDtrainから取得された正解ラベルのソフトラベルが生成されることが規定されている。
17行目及び18行目では、18行目に示される誤差関数Lvと誤差関数Lとが計算され、誤差関数Lvをハイパーパラメータλで微分(∇λ)されることが規定されている。ここで、誤差関数Lvは、評価用データセットDvalのデータと14行目で予測されたその正解ラベルとの誤差を評価する誤差関数である。誤差関数Lは、16行目において生成されたソフトラベルと15行目において予測されたデータ拡張処理されたデータXAの正解ラベルとの誤差を評価する誤差関数に重みが付されたものである。
18行目では、ハイパーパラメータλが更新されることが規定されている。なお、19行目に示されるHOは、hyperparameter optimizationの略語である。
このように規定されるアルゴリズム1を実行することで、第1最適化処理及び第2最適化処理を交互に行うことができる。
[1.4 効果等]
以上のように、本実施の形態に係る学習装置10及びデータ拡張方法によれば、ハイパーパラメータを最適化できるので、高精度なAIモデルを獲得できるように学習用データセットのサンプル数を増やすことができる。
以上のように、本実施の形態に係る学習装置10及びデータ拡張方法によれば、ハイパーパラメータを最適化できるので、高精度なAIモデルを獲得できるように学習用データセットのサンプル数を増やすことができる。
より具体的には、ニューラルネットワークの複数のパラメータの最適化を行うニューラルネットワークの学習の過程で、サンプル毎のハイパーパラメータについて偏微分して得た勾配を用いて、データ拡張された学習用データセットとテスト用データセットとの分布のずれを最小化することができる。よって、データ拡張処理によりデータ拡張された学習用データを用いて、ニューラルネットワークを学習させても、学習による識別面の生成を理想的な識別面に近づけることができるように、学習用データセットのサンプル数を増やすことができる。このようにして、高精度なAIモデルを獲得できるように学習用データセットのサンプル数を増やすことができる。
ところで、従来、データ拡張処理を行うためには学習用データセットの変換方法を定める大規模なハイパーパラメータを調整する必要があった。また、データの分布の偏り及び正解ラベルの不正確さを含む不完全な学習用データセットを用いて、ニューラルネットワークの複数のパラメータを学習させても、高精度なAIモデルを獲得できないという問題もある。したがって、ニューラルネットワークの学習のための計算と、データ拡張処理を行うために学習用データセットの大規模なハイパーパラメータを最適化する計算といった2重の最適化計算が必要になる。このため、多大な計算コストを要しないとハイパーパラメータを最適化できなかった。
これに対して、本実施の形態に係る学習装置10及びデータ拡張方法によれば、サンプル毎に、ニューラルネットワークの複数のパラメータとデータ拡張処理のハイパーパラメータを交互に最適化を行うことで、サンプル毎のハイパーパラメータの最適化をニューラルネットワークの複数のパラメータの学習とともに行える。よって、ニューラルネットワークの複数のパラメータの最適化とサンプル毎のハイパーパラメータの最適化に要する計算コストを抑制できるという効果も奏する。
ここで、本実施の形態に係る学習装置10及びデータ拡張方法では、学習用データセットにデータ拡張処理を行うことで得られるデータ拡張後の学習用データセットの分布と、評価用データセットの分布とのずれを減らすよう、勾配に基づいてハイパーパラメータを更新する。
これにより、データ拡張された学習用データセットとテスト用データセットとの分布のずれを最小化するように、ハイパーパラメータを更新できる。よって、データ拡張処理によりデータ拡張された学習用データを用いて、ニューラルネットワークを学習させても、学習による識別面の生成を理想的な識別面に近づけることができる。
また、本実施の形態に係る学習装置10及びデータ拡張方法では、ハイパーパラメータは、少なくともデータ拡張処理を示す関数において陰関数化され、ニューラルネットワークは、完全微分可能な関数である。これにより、陰関数の微分手法を用いることで、ハイパーパラメータについての偏微分を計算することができる。
また、本実施の形態に係る学習装置10及びデータ拡張方法では、ノイズの多い正解ラベルに対応するためのソフトラベルを用いた第1最適化処理における第1誤差関数を算出する。これにより、データ拡張後に含まれるサンプルに対する正解ラベルのノイズを抑制することができる。よって、サンプル毎のハイパーパラメータについて偏微分して得た勾配を用いて、データ拡張された学習用データセットとテスト用データセットとの分布のずれを最小化するように、サンプル毎のハイパーパラメータを最適化できる。
また、本実施の形態に係る学習装置10及びデータ拡張方法では、算出した第1誤差関数に対して、サンプルのバイアスを捉えるためのサンプル毎の重みを用いて重み付けする。
これにより、サンプルのバイアスを捉えて抑制することができる。よって、サンプル毎のハイパーパラメータについて偏微分して得た勾配を用いて、データ拡張された学習用データセットとテスト用データセットとの分布のずれを最小化するように、サンプル毎のハイパーパラメータを最適化できる。
(比較例)
以下、比較例に係るデータ拡張方法とその問題点について説明する。
以下、比較例に係るデータ拡張方法とその問題点について説明する。
図10は、比較例に係るすべてのデータ間で共有するハイパーパラメータを用いてデータ拡張を行った場合の問題点を説明するための図である。
図10では、すべてのデータ間で共有するハイパーパラメータλを用いたデータ拡張処理g(λ)でデータ拡張された学習用データセットを用いて、ニューラルネットワークf(θ)を学習させたときの識別面(識別線)が示されている。また、図10では、中心の点線四角の識別面より上方領域及び下方領域での一番小さい実線の円は、学習用データの分布を概念的に示している。また、上方領域及び下方領域での点線の円は、データ拡張処理g(λ)でデータ拡張された学習用データセットの分布を概念的に示している。点線四角における大きい実線の円は、テスト用データセットの分布を概念的に示している。
図10に示す比較例に係るデータ拡張処理g(λ)でデータ拡張された場合、学習用データセットのすべてのデータすなわち数字の分布が均等に増加される。このようにデータ拡張された学習用データセットを用いて学習されて得た識別面は、テスト用データセットの一部を横切っているため、テスト用データセットを正しく識別できないという問題がある。
つまり、比較例に係るデータ拡張方法では、学習による識別面の生成が理想的な境界線から大きく外れてしまうという問題がある。なお、この問題は、学習用データセットの分布に応じてデータ拡張されるための生じていると考えられる。
以下、比較例に係るデータ拡張の問題について具体的に説明する。
図11は、学習処理による識別面の生成を概念的に説明するための図である。図11に示すように、分類問題において、AIは、種々の犬または猫の画像とそれらの正解ラベルからなる学習用データセットを用いて学習処理が行われると、特徴抽出して識別面d1を生成する。識別面d1の生成は、図11からわかるように、概念的には犬と猫とを見分ける境界線を引くことに該当する。
図12Aは、データ拡張処理を概念的に説明するための図である。
図12Aに示すように、学習用データセットのデータ拡張処理は、学習用データセットのデータに対して回転処理、ズーム処理、並進処理、色変換処理などの変換処理を行うことで、学習用データセットを構成するデータを擬似的に増加、水増しさせる処理である。
図12Bは、学習用データセットに含まれるデータ数が少ない場合における学習処理による識別面の生成の問題点を概念的に説明するための図である。図12Cは、データ拡張処理によりデータ拡張された学習用データセットを用いた学習処理による識別面の生成の一例を概念的に説明するための図である。
図12Bに示すように、学習用データセットに含まれるデータ数が少ない場合には、犬と猫のデータ間の隙間が大きいため、AIは、識別面d1、d2、d3で示されるように、犬と猫とを見分ける境界線をどこに引けばわからない。
一方、図12Cに示すように、データ拡張処理により適切にデータ拡張された場合、図12Bに示される隙間をデータ拡張されたデータを擬似的に埋めることができるため、AIは、識別面d1で示されるように、犬と猫とを見分ける境界線が引きやすくなる。
続いて、データ拡張処理における課題について説明する。
図13は、比較例に係るデータ拡張処理における問題点を説明するための図である。図13には、データ拡張をうまくしないと学習により生成される識別面の位置が理想的な識別面からずれてしまうことが示されている。
すなわち、図13では、猫のデータ51をデータ拡張することで、データ拡張後の猫のデータに関する学習用データセットの分布が分布Q1となっている。同様に、犬のデータ52をデータ拡張することで、データ拡張後の犬のデータに関する学習用データセットの分布が分布Q2となっている。このような場合、AIは、データ拡張後の学習用データセットを学習することで、理想的な識別面d4での位置からずれた位置の識別面d5を生成してしまう。すると、テスト用データセットである犬の画像50がデータ拡張後の犬のデータに関する学習用データセットの分布Q2から外れた位置にある場合、AIは、テスト用データセットである犬の画像50に対しては、猫と識別してしまうことになる。
このように、学習用データセットの分布に応じてデータ拡張する場合、学習により生成される識別面の位置が理想的な識別面からずれてしまう場合がある。
図14は、本開示に係るデータ拡張処理によりデータ拡張された学習用データセットを用いて生成した識別面を概念的に説明するための図である。
本開示では、テスト用データセットの分布に合わせるように、学習用データセットをデータ拡張処理する。より具体的には、猫のデータ51を猫についてのテスト用データセットの分布Qt1に合わせるようにデータ拡張することで、データ拡張後の猫のデータに関する学習用データセットの分布を、分布Q3となるようにすることができる。同様に、犬のデータ52を猫についてのテスト用データセットの分布Qt2に合わせるようにデータ拡張することで、データ拡張後の犬のデータに関する学習用データセットの分布を、分布Q4となるようにすることができる。
これにより、AIは、理想的な識別面d4での位置に近い位置の識別面d6を生成することができる。
(実験例)
本開示のデータ拡張方法の効果について、The Street View House Numbers (SVHN) Datasetを用いて検証を行ったので、その検証結果を実験例として説明する。
本開示のデータ拡張方法の効果について、The Street View House Numbers (SVHN) Datasetを用いて検証を行ったので、その検証結果を実験例として説明する。
図15は、実験例に係る学習用データセットを用いて学習後に、テスト用データセットでエラー率を評価した検証結果を示す図である。
SVHNデータセットには、600,000桁を超える画像といった大量のラベル付きデータが組み込まれている。SVHNデータセットは、73,257桁の学習用データセットと、26,032桁のテスト用データセットとで構成されている。また、SVHNデータセットには、追加の学習用データとして使用できる531,131のやや難易度の低いサンプルが追加されている。
なお、本実験例では、SVHNデータセットの学習用データセットの32%を分割して評価用データセットとした。
また、本実験例では、学習用データセットとして、データの偏り及びラベルノイズのない学習用データセットと、データの偏りまたはラベルノイズのある学習用データセットを用いて検証した。図15では、データの偏りを示すクラスインバランス比(IR)とラベルノイズ比(NR)とにより、データの偏りの有無、ラベルノイズの有無を示している。なお、SVHNデータセットの学習用データセットは、データの偏り及びラベルノイズのない学習用データセットに該当する。
例えば、IR-NRが「100-0.1」である場合、全画像データのうちのランダムな10%(NR=0.1)の画像データがランダムに反転され、ラベルノイズがあることを意味する。また、例えば{0~4}を示す画像データの数が{5~9}を示す画像データの数の100倍となっており、クラスのサンプル数が不均一すなわちデータに偏りがあることを意味する。
したがって、図15において、IR-NRが「1-0.0」である学習用データセットは、データの偏り及びラベルノイズのない学習用データセットに該当する。IR-NRが「100-0.0」である学習用データセットは、データの偏りはあるがラベルノイズのない学習用データセットに該当する。同様に、IR-NRが「1-0.1」である学習用データセットは、データの偏りはないが、ラベルノイズがある学習用データセットに該当する。IR-NRが「100-0.1」である学習用データセットは、データの偏り及びラベルノイズのある学習用データセットに該当する。
また、図15において、λA(ours)、λA、W(ours)、λA、W、S(ours)は、本開示のデータ拡張方法を示す。本開示のデータ拡張方法としては、図9に示すアルゴリズム1を用いて学習処理すなわち第1最適化処理及び第2最適化処理が行われた。第2最適化処理は、50回目のエポックの後に開始した。
また、図15において、λA(ours)は、データ拡張処理を行う際に用いるサンプル毎のデータ変換処理を規定する変数であるハイパーパラメータλAのみに対して最適化されたことを示している。また、λA、W、S(ours)は、データ拡張処理と損失重みとソフトラベルのハイパーパラメータに対して最適化されたことを示している。λA、W(ours)は、データ拡張処理と損失重みとのハイパーパラメータに対して最適化されたことを示している。これらの最適化処理は、図9に示すアルゴリズム1を用いて行った。
なお、図15では、比較例としてのλASHA(ours)の検証結果が示されている。図15において、λASHA(ours)は、データ毎ではなくすべてのデータ間で共有するハイパーパラメータλASHAに対して最適化されたことを示している。
さらに、図15では、比較例としてBaselineとFAAとの検証結果も示されている。より具体的には、Baselineは、非特許文献1に記載される方法すなわちランダムクロッピング、水平反転、消去などの標準的な変換処理のみを用いてデータ拡張処理をする場合の検証結果を示している。FAA(Fast AutoAugment)は、非特許文献2に記載される方法でデータ拡張処理をする場合の検証結果を示している。
図15からわかるように、データの偏りまたはラベルノイズのある学習用データセットを用いる場合、λASHA、Baseline、FAAの検証結果と比較すると、λA(ours)及びλA、W(ours)の検証結果は同等程度かそれ以下のエラー率(トップ1エラー率)を達成している。
さらに、λASHA、Baseline、FAAの検証結果と比較すると、λA、W、S(ours)の検証結果は、学習用データセットにデータの偏りの有無、ラベルノイズの有無に関わらず、改善されたエラー率(トップ1エラー率)を達成している。
以上から、ハイパーパラメータλA、W、S(ours)に対して最適化だけでなくハイパーパラメータλA(ours)に対して最適化も有効であることがわかる。
図16は、実験例に係る学習用データセットを用いて学習させたときの精度学習曲線を示す図である。図16では、IR-NRが「1-0.0」である学習用データセットを用いて学習させたときの精度学習曲線(c)が示されている。なお、図16において、上記のλA、W、S(ours)に対する最適化処理がAutoDOに該当し、上記のλA、W、S(ours)に対する最適化処理(本開示のデータ拡張方法)のうち、第2最適化処理の開始がAutoDO startとして示されている。また、AutoDO startは、50回目のエポックの後に開始されている。
なお、図16では、比較例として、上記のBaselineとFAAとを実験例に係る学習用データセットを用いて学習させたときの精度学習曲線(a)、(b)も示されている。
図16からわかるように、本開示のデータ拡張方法は、AutoDOすなわち第2最適化処理を開始しないと性能向上しないのがわかる。また、本開示のデータ拡張方法は、AutoDOすなわち第2最適化処理を行うことにより、ハイパーパラメータλA、W、Sを有効に最適化でき、性能が急激に向上することがわかる。
(他の実施態様の可能性)
以上、実施の形態において本開示のデータ拡張方法及び学習装置について説明したが、各処理が実施される主体や装置に関しては特に限定しない。ローカルに配置された特定の装置内に組み込まれたプロセッサなどによって処理されてもよい。またローカルの装置と異なる場所に配置されているクラウドサーバなどによって処理されてもよい。
以上、実施の形態において本開示のデータ拡張方法及び学習装置について説明したが、各処理が実施される主体や装置に関しては特に限定しない。ローカルに配置された特定の装置内に組み込まれたプロセッサなどによって処理されてもよい。またローカルの装置と異なる場所に配置されているクラウドサーバなどによって処理されてもよい。
なお、本開示は、上記実施の形態に限定されるものではない。例えば、本明細書において記載した構成要素を任意に組み合わせて、また、構成要素のいくつかを除外して実現される別の実施の形態を本開示の実施の形態としてもよい。また、上記実施の形態に対して本開示の主旨、すなわち、請求の範囲に記載される文言が示す意味を逸脱しない範囲で当業者が思いつく各種変形を施して得られる変形例も本開示に含まれる。
また、本開示は、さらに、以下のような場合も含まれる。
(1)上記の装置は、具体的には、マイクロプロセッサ、ROM、RAM、ハードディスクユニット、ディスプレイユニット、キーボード、マウスなどから構成されるコンピュータシステムである。前記RAMまたはハードディスクユニットには、コンピュータプログラムが記憶されている。前記マイクロプロセッサが、前記コンピュータプログラムに従って動作することにより、各装置は、その機能を達成する。ここでコンピュータプログラムは、所定の機能を達成するために、コンピュータに対する指令を示す命令コードが複数個組み合わされて構成されたものである。
(2)上記の装置を構成する構成要素の一部または全部は、1個のシステムLSI(Large Scale Integration:大規模集積回路)から構成されているとしてもよい。システムLSIは、複数の構成部を1個のチップ上に集積して製造された超多機能LSIであり、具体的には、マイクロプロセッサ、ROM、RAMなどを含んで構成されるコンピュータシステムである。前記RAMには、コンピュータプログラムが記憶されている。前記マイクロプロセッサが、前記コンピュータプログラムに従って動作することにより、システムLSIは、その機能を達成する。
(3)上記の装置を構成する構成要素の一部または全部は、各装置に脱着可能なICカードまたは単体のモジュールから構成されているとしてもよい。前記ICカードまたは前記モジュールは、マイクロプロセッサ、ROM、RAMなどから構成されるコンピュータシステムである。前記ICカードまたは前記モジュールは、上記の超多機能LSIを含むとしてもよい。マイクロプロセッサが、コンピュータプログラムに従って動作することにより、前記ICカードまたは前記モジュールは、その機能を達成する。このICカードまたはこのモジュールは、耐タンパ性を有するとしてもよい。
(4)また、本開示は、上記に示す方法であるとしてもよい。また、これらの方法をコンピュータにより実現するコンピュータプログラムであるとしてもよいし、前記コンピュータプログラムからなるデジタル信号であるとしてもよい。
(5)また、本開示は、前記コンピュータプログラムまたは前記デジタル信号をコンピュータで読み取り可能な記録媒体、例えば、フレキシブルディスク、ハードディスク、CD-ROM、MO、DVD、DVD-ROM、DVD-RAM、BD(Blu-ray(登録商標) Disc)、半導体メモリなどに記録したものとしてもよい。また、これらの記録媒体に記録されている前記デジタル信号であるとしてもよい。
また、本開示は、前記コンピュータプログラムまたは前記デジタル信号を、電気通信回線、無線または有線通信回線、インターネットを代表とするネットワーク、データ放送等を経由して伝送するものとしてもよい。
また、本開示は、マイクロプロセッサとメモリを備えたコンピュータシステムであって、前記メモリは、上記コンピュータプログラムを記憶しており、前記マイクロプロセッサは、前記コンピュータプログラムに従って動作するとしてもよい。
また、前記プログラムまたは前記デジタル信号を前記記録媒体に記録して移送することにより、または前記プログラムまたは前記デジタル信号を、前記ネットワーク等を経由して移送することにより、独立した他のコンピュータシステムにより実施するとしてもよい。
本開示は、ニューラルネットワークの学習に用いる学習用データセットのデータ拡張方法、学習装置およびプログラムに利用でき、特に計算コストを抑制してニューラルネットワークの学習とサンプル毎のハイパーパラメータの最適化とを行うことができるデータ拡張方法、学習装置およびプログラムに利用できる。
10 学習装置
11 取得部
11b Data Sampler
12 データ拡張処理部
12a Process
12b Augment
14 誤差算出部
15 最適化部
15a AutoDO
141 Soft-label
142 Weight KL Div
143 Reweight
1000 コンピュータ
1001 入力装置
1002 出力装置
1004 内蔵ストレージ
1007 読取装置
1008 送受信装置
1009 バス
11 取得部
11b Data Sampler
12 データ拡張処理部
12a Process
12b Augment
14 誤差算出部
15 最適化部
15a AutoDO
141 Soft-label
142 Weight KL Div
143 Reweight
1000 コンピュータ
1001 入力装置
1002 出力装置
1004 内蔵ストレージ
1007 読取装置
1008 送受信装置
1009 バス
Claims (7)
- ニューラルネットワークの学習に用いる学習用データセットのデータ拡張方法であって、
前記ニューラルネットワークにおける、重みを含む複数のパラメータの最適化を行うための第1最適化処理と、データ拡張処理を行う際に用いるサンプル毎のデータ変換処理を規定する変数であるハイパーパラメータの最適化を行うための第2最適化処理とを交互に行い、
前記第1最適化処理では、
前記学習用データセットに含まれる第1サンプルに、前記データ拡張処理を行わせることで、第1拡張サンプルを取得し、
前記ニューラルネットワークに、前記第1拡張サンプルから、第1拡張ラベルを予測させ、
前記第1拡張ラベルと、前記学習用データセットに含まれる前記第1サンプルの正解を示す第1正解ラベルとについての誤差を評価するための第1誤差関数を算出し、
算出した前記第1誤差関数に基づき、前記複数のパラメータを更新し、
前記第2最適化処理では、
前記ニューラルネットワークの性能を評価するためのテスト用データセットの分布に類似した分布のデータセットである評価用データセットから、第2サンプルを取得し、
前記複数のパラメータが更新された前記ニューラルネットワークに、前記第2サンプルから、第2ラベルを予測させ、
前記第2ラベルと、前記評価用データセットに含まれる前記第2サンプルの正解を示す第2正解ラベルとの誤差を評価するための第2誤差関数を算出し、
算出した前記第2誤差関数を、前記ハイパーパラメータについて偏微分して得た勾配に基づいて、前記ハイパーパラメータを更新する、
データ拡張方法。 - 前記ハイパーパラメータを更新する際、
前記学習用データセットに前記データ拡張処理を行うことで得られるデータ拡張後の学習用データセットの分布と、前記評価用データセットの分布とのずれを減らすよう、前記勾配に基づいて前記ハイパーパラメータを更新する、
請求項1に記載のデータ拡張方法。 - 前記ハイパーパラメータは、前記データ拡張処理を示す関数において陰関数化され、
前記ニューラルネットワークは、完全微分可能な関数である、
請求項1または2に記載のデータ拡張方法。 - 前記第1誤差関数を算出する際、前記第1正解ラベルが示す正解値をソフトラベル化して得た第1正解ソフトラベルと、前記第1拡張ラベルとの誤差をカルバックライブラーダイバージェンスを用いて評価する前記第1誤差関数を算出する、
請求項1~3のいずれか1項に記載のデータ拡張方法。 - 前記第1誤差関数を算出する際、前記第1誤差関数に対して、さらに、サンプル毎に算出される重みづけを行う、
請求項1~4のいずれか1項に記載のデータ拡張方法。 - ニューラルネットワークの学習に用いる学習用データセットのデータ拡張方法を行うための学習装置であって、
プロセッサと、メモリとを備え、
前記プロセッサは、前記メモリを用いて、
前記ニューラルネットワークにおける、重みを含む複数のパラメータの最適化を行うための第1最適化処理と、データ拡張処理を行う際に用いるサンプル毎のデータ変換処理を規定する変数であるハイパーパラメータの最適化を行うための第2最適化処理とを交互に行い、
前記第1最適化処理では、
前記学習用データセットに含まれる第1サンプルに、前記データ拡張処理を行わせることで、第1拡張サンプルを取得し、
前記ニューラルネットワークに、前記第1拡張サンプルから、第1拡張ラベルを予測させ、
前記第1拡張ラベルと、前記学習用データセットに含まれる前記第1サンプルの正解を示す第1正解ラベルとについての誤差を評価するための第1誤差関数を算出し、
算出した前記第1誤差関数に基づき、前記複数のパラメータを更新し、
前記第2最適化処理では、
前記ニューラルネットワークの性能を評価するためのテスト用データセットの分布に類似した分布のデータセットである評価用データセットから、第2サンプルを取得し、
前記複数のパラメータが更新された前記ニューラルネットワークに、前記第2サンプルから、第2ラベルを予測させ、
前記第2ラベルと、前記評価用データセットに含まれる前記第2サンプルの正解を示す第2正解ラベルとの誤差を評価するための第2誤差関数を算出し、
算出した前記第2誤差関数を、前記ハイパーパラメータについて偏微分して得た勾配に基づいて、前記ハイパーパラメータを更新する、
学習装置。 - ニューラルネットワークの学習に用いる学習用データセットのデータ拡張方法をコンピュータに実行させるプログラムであって、
前記ニューラルネットワーク、重みを含む複数のパラメータの最適化を行うための第1最適化処理と、データ拡張処理を行う際に用いるサンプル毎のデータ変換処理を規定する変数であるハイパーパラメータの最適化を行うための第2最適化処理とを交互に行い、
前記第1最適化処理では、
前記学習用データセットに含まれる第1サンプルに、前記データ拡張処理を行わせることで、第1拡張サンプルを取得し、
前記ニューラルネットワークに、前記第1拡張サンプルから、第1拡張ラベルを予測させ、
前記第1拡張ラベルと、前記学習用データセットに含まれる前記第1サンプルの正解を示す第1正解ラベルとについての誤差を評価するための第1誤差関数を算出し、
算出した前記第1誤差関数に基づき、前記複数のパラメータを更新し、
前記第2最適化処理では、
前記ニューラルネットワークの性能を評価するためのテスト用データセットの分布に類似した分布のデータセットである評価用データセットから、第2サンプルを取得し、
前記複数のパラメータが更新された前記ニューラルネットワークに、前記第2サンプルから、第2ラベルを予測させ、
前記第2ラベルと、前記評価用データセットに含まれる前記第2サンプルの正解を示す第2正解ラベルとの誤差を評価するための第2誤差関数を算出し、
算出した前記第2誤差関数を、前記ハイパーパラメータについて偏微分して得た勾配に基づいて、前記ハイパーパラメータを更新することを、
コンピュータに実行させるプログラム。
Priority Applications (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| EP21889261.0A EP4242928A4 (en) | 2020-11-06 | 2021-11-05 | DATA AMPLIFICATION METHOD, LEARNING APPARATUS AND PROGRAM |
| JP2022560820A JP7744923B2 (ja) | 2020-11-06 | 2021-11-05 | データ拡張方法、学習装置およびプログラム |
| US18/141,603 US12412374B2 (en) | 2020-11-06 | 2023-05-01 | Data augmentation method, learning device, and recording medium |
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US202063110570P | 2020-11-06 | 2020-11-06 | |
| US63/110,570 | 2020-11-06 |
Related Child Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| US18/141,603 Continuation US12412374B2 (en) | 2020-11-06 | 2023-05-01 | Data augmentation method, learning device, and recording medium |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2022097709A1 true WO2022097709A1 (ja) | 2022-05-12 |
Family
ID=81458317
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2021/040736 Ceased WO2022097709A1 (ja) | 2020-11-06 | 2021-11-05 | データ拡張方法、学習装置およびプログラム |
Country Status (4)
| Country | Link |
|---|---|
| US (1) | US12412374B2 (ja) |
| EP (1) | EP4242928A4 (ja) |
| JP (1) | JP7744923B2 (ja) |
| WO (1) | WO2022097709A1 (ja) |
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN116226383A (zh) * | 2023-03-06 | 2023-06-06 | 马上消费金融股份有限公司 | 数据增强方法及装置、目标文本分类模型的训练方法 |
| WO2024252575A1 (ja) * | 2023-06-07 | 2024-12-12 | コニカミノルタ株式会社 | 学習制御装置、学習制御方法及びプログラム |
Families Citing this family (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20220319689A1 (en) * | 2021-03-30 | 2022-10-06 | REHABILITATION INSTITUTE OF CHICAGO d/b/a Shirley Ryan AbilityLab | Systems and methods for improved interface noise tolerance of myoelectric pattern recognition controllers using deep learning and data augmentation |
| US20230186075A1 (en) * | 2021-12-09 | 2023-06-15 | Nutanix, Inc. | Anomaly detection with model hyperparameter selection |
| KR102895093B1 (ko) * | 2022-09-14 | 2025-12-03 | 서울여자대학교 산학협력단 | 테스트 시간 증강 교차 엔트로피 및 노이즈혼합 기반 노이즈 라벨 학습 방법, 장치 및 프로그램 |
| EP4575845A1 (en) * | 2023-12-19 | 2025-06-25 | Helsing GmbH | Dataset augmentation |
| CN117874639B (zh) * | 2024-03-12 | 2024-06-18 | 山东能源数智云科技有限公司 | 基于人工智能的机械设备寿命预测方法及装置 |
| CN121365697A (zh) * | 2024-07-19 | 2026-01-20 | 华为技术有限公司 | 一种生成数据的方法及通信装置 |
Citations (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20190205748A1 (en) * | 2018-01-02 | 2019-07-04 | International Business Machines Corporation | Soft label generation for knowledge distillation |
Family Cites Families (9)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US11301733B2 (en) * | 2018-05-18 | 2022-04-12 | Google Llc | Learning data augmentation strategies for object detection |
| US11631151B2 (en) * | 2018-09-30 | 2023-04-18 | Strong Force Tp Portfolio 2022, Llc | Intelligent transportation systems |
| WO2020069517A2 (en) * | 2018-09-30 | 2020-04-02 | Strong Force Intellectual Capital, Llc | Intelligent transportation systems |
| US11610098B2 (en) * | 2018-12-27 | 2023-03-21 | Paypal, Inc. | Data augmentation in transaction classification using a neural network |
| CN111986069B (zh) * | 2019-05-22 | 2025-08-05 | 三星电子株式会社 | 图像处理装置及其图像处理方法 |
| US11307570B2 (en) * | 2019-05-31 | 2022-04-19 | Panasonic Intellectual Property Management Co., Ltd. | Machine learning based predictive maintenance of equipment |
| US11100643B2 (en) * | 2019-09-11 | 2021-08-24 | Nvidia Corporation | Training strategy search using reinforcement learning |
| US11205099B2 (en) * | 2019-10-01 | 2021-12-21 | Google Llc | Training neural networks using data augmentation policies |
| US11232328B2 (en) * | 2020-01-31 | 2022-01-25 | Element Ai Inc. | Method of and system for joint data augmentation and classification learning |
-
2021
- 2021-11-05 JP JP2022560820A patent/JP7744923B2/ja active Active
- 2021-11-05 EP EP21889261.0A patent/EP4242928A4/en active Pending
- 2021-11-05 WO PCT/JP2021/040736 patent/WO2022097709A1/ja not_active Ceased
-
2023
- 2023-05-01 US US18/141,603 patent/US12412374B2/en active Active
Patent Citations (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20190205748A1 (en) * | 2018-01-02 | 2019-07-04 | International Business Machines Corporation | Soft label generation for knowledge distillation |
Non-Patent Citations (2)
| Title |
|---|
| RYUICHIRO HATAYA; JAN ZDENEK; KAZUKI YOSHIZOE; HIDEKI NAKAYAMA: "Meta Approach to Data Augmentation Optimization", ARXIV.ORG, CORNELL UNIVERSITY LIBRARY, 201 OLIN LIBRARY CORNELL UNIVERSITY ITHACA, NY 14853, 14 June 2020 (2020-06-14), 201 Olin Library Cornell University Ithaca, NY 14853 , XP081701043 * |
| See also references of EP4242928A4 * |
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN116226383A (zh) * | 2023-03-06 | 2023-06-06 | 马上消费金融股份有限公司 | 数据增强方法及装置、目标文本分类模型的训练方法 |
| WO2024252575A1 (ja) * | 2023-06-07 | 2024-12-12 | コニカミノルタ株式会社 | 学習制御装置、学習制御方法及びプログラム |
Also Published As
| Publication number | Publication date |
|---|---|
| US12412374B2 (en) | 2025-09-09 |
| EP4242928A4 (en) | 2024-03-27 |
| JP7744923B2 (ja) | 2025-09-26 |
| JPWO2022097709A1 (ja) | 2022-05-12 |
| US20230267713A1 (en) | 2023-08-24 |
| EP4242928A1 (en) | 2023-09-13 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| WO2022097709A1 (ja) | データ拡張方法、学習装置およびプログラム | |
| EP4042320B1 (en) | Adversarial network for transforming handwritten text | |
| US11580363B2 (en) | Systems and methods for assessing item compatibility | |
| CN110033018B (zh) | 图形相似度判断方法、装置及计算机可读存储介质 | |
| JP2019008778A (ja) | 画像の領域のキャプション付加 | |
| CN109948735B (zh) | 一种多标签分类方法、系统、装置及存储介质 | |
| US20180082215A1 (en) | Information processing apparatus and information processing method | |
| US20180330275A1 (en) | Resource-efficient machine learning | |
| JP2021532453A (ja) | フィードフォワード畳み込みニューラルネットワークを使用した高速且つ堅牢な皮膚紋理の印のマニューシャの抽出 | |
| CN108846077A (zh) | 问答文本的语义匹配方法、装置、介质及电子设备 | |
| CN113869398B (zh) | 一种不平衡文本分类方法、装置、设备及存储介质 | |
| CN112651467B (zh) | 卷积神经网络的训练方法和系统以及预测方法和系统 | |
| US20230110719A1 (en) | Systems and methods for few-shot protein fitness prediction with generative models | |
| CN111310930A (zh) | 优化装置、优化方法和非暂态计算机可读存储介质 | |
| CN114842515A (zh) | 指纹识别方法、装置、存储介质及计算机设备 | |
| CN119862524A (zh) | 一种基于Transformer的在线大规模异常轨迹检测方法、系统及介质 | |
| Kim et al. | COVID-19 outbreak prediction using Seq2Seq+ Attention and Word2Vec keyword time series data | |
| CN115757844B (zh) | 一种医学图像检索网络训练方法、应用方法及电子设备 | |
| US20220405640A1 (en) | Learning apparatus, classification apparatus, learning method, classification method and program | |
| CN118675006B (zh) | 动作特征获取方法、装置、电子设备及存储介质 | |
| KR20230030437A (ko) | 디바이스 구조 예측 모델 생성 방법 및 시뮬레이션 장치 | |
| CN111832572A (zh) | 用于分类模型的经计算机实现的分析的方法 | |
| US20210263923A1 (en) | Information processing device, similarity calculation method, and computer-recording medium recording similarity calculation program | |
| JP2022135701A (ja) | 学習装置、方法およびプログラム | |
| Zhu et al. | Active Transfer Prototypical Network: An Efficient Labeling Algorithm for Time-Series Data |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 21889261 Country of ref document: EP Kind code of ref document: A1 |
|
| ENP | Entry into the national phase |
Ref document number: 2022560820 Country of ref document: JP Kind code of ref document: A |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| ENP | Entry into the national phase |
Ref document number: 2021889261 Country of ref document: EP Effective date: 20230606 |