WO2022109102A1 - Nav1.7 binders - Google Patents
Nav1.7 binders Download PDFInfo
- Publication number
- WO2022109102A1 WO2022109102A1 PCT/US2021/059842 US2021059842W WO2022109102A1 WO 2022109102 A1 WO2022109102 A1 WO 2022109102A1 US 2021059842 W US2021059842 W US 2021059842W WO 2022109102 A1 WO2022109102 A1 WO 2022109102A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- seq
- amino acid
- acid sequence
- binder
- set forth
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Ceased
Links
Classifications
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IG], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IG], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/28—Immunoglobulins [IG], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P23/00—Anaesthetics
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K2039/505—Medicinal preparations containing antigens or antibodies comprising antibodies
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/30—Immunoglobulins specific features characterized by aspects of specificity or valency
- C07K2317/31—Immunoglobulins specific features characterized by aspects of specificity or valency multispecific
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/30—Immunoglobulins specific features characterized by aspects of specificity or valency
- C07K2317/34—Identification of a linear epitope shorter than 20 amino acid residues or of a conformational epitope defined by amino acid residues
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/50—Immunoglobulins specific features characterized by immunoglobulin fragments
- C07K2317/56—Immunoglobulins specific features characterized by immunoglobulin fragments variable (Fv) region, i.e. VH and/or VL
- C07K2317/565—Complementarity determining region [CDR]
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/50—Immunoglobulins specific features characterized by immunoglobulin fragments
- C07K2317/56—Immunoglobulins specific features characterized by immunoglobulin fragments variable (Fv) region, i.e. VH and/or VL
- C07K2317/569—Single domain, e.g. dAb, sdAb, VHH, VNAR or nanobody®
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/70—Immunoglobulins specific features characterized by effect upon binding to a cell or to an antigen
- C07K2317/76—Antagonist effect on antigen, e.g. neutralization or inhibition of binding
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/90—Immunoglobulins specific features characterized by (pharmaco)kinetic aspects or by stability of the immunoglobulin
- C07K2317/92—Affinity (KD), association rate (Ka), dissociation rate (Kd) or EC50 value
Definitions
- the present invention relates to antibodies and antigen-binding fragments thereof that bind the human voltage-gated sodium channel Nav1.7 ⁇ protein subunit (Nav1.7 binders).
- Nav1.7 binders comprising a heavy-chain immunoglobulin single variable domain (ISVD or VHH).
- Nav1.7 ⁇ subunit belongs to a family of nine voltage-gated sodium channels that play crucial roles in the electrical conductance of skeletal muscles (Nav1.4 ⁇ ), cardiac muscles (Nav1.5 ⁇ ), central (Nav1.1 ⁇ , Nav1.2 ⁇ , Nav1.3 ⁇ and Nav1.6 ⁇ ) and peripheral (Nav1.1 ⁇ , Nav1.6 ⁇ , Nav1.7 ⁇ , Nav1.8 ⁇ and Nav1.9 ⁇ ) neurons.
- Nav1.7 ⁇ is mainly expressed on different types of afferent fibres of the peripheral nervous system and is essential to the firing of action potentials by boosting subthreshold stimuli (Dib-Hajj & Waxman 2015 Pain 156: 2406).
- Each domain has six transmembrane helices (S1 to S6 in bottom panel Fig.1 connected by extracellular loops (ECLs) and intracellular loops (ICLs) (respectively solid and dotted lines in bottom panel Fig.1.
- ECLs extracellular loops
- ICLs intracellular loops
- Two small (S1-S2 and S3-S4) and one larger (S5-S6) ECL per domain make up the limited extracellular surface of the channel accessible to biologicals (cytoplasmic membrane is marked by dotted lines in top right panel in Fig. 1).
- the different domains are connected by ICLs (S6-S1) and both N- and C-terminal ends reside at the cytoplasmic side of the channel (marked respectively by N and C in bottom panel Fig. 1).
- Each domain consists of a voltage sensor domain (VSD; S1-S4) and ion-conducting pore domain (PD; S5-S6) arranged such that the VSD of each domain is closest to the PD of the following domain, in a clockwise orientation.
- VSD voltage sensor domain
- PD ion-conducting pore domain
- the central Na + -conducting pore of the channel (marked by a star in bottom panel 1) is formed by the PDs and their ECLs that line the cavity.
- Fig. 32 is a schematic representation of Navi.7 ⁇ .
- Voltage-gated sodium channels may interact with different Nav ⁇ -subunits (Nav ⁇ 1 to Nav ⁇ 4) that among other things can modulate the channels’ electrophysiological properties and cell surface expression levels (reviewed by Winters & Isom 2016 Current Topics in Membranes 78: 315).
- the bottom panel of Fig.l depicts suggested interaction sites for three different Nav ⁇ -subunits, according to recent findings (Das et al. 2016 eLIFE 5:el0960; Zhu et al. 2017 J Gen Physiol 149: 813; Yan et al. 2017 Cell 170: 470).
- the present invention provides Navi.7 binders, which are immunoglobulin single variable domains (ISVDs) that bind and inhibit Navi.7 ⁇ channels with extraordinar selectivity over other Nav channel paralogs.
- the Navi.7 binders may be useful for preparing formulations for treating chronic pain or pain.
- the present invention provides Navi.7 binders that bind to a human voltage-gated sodium channel Navi.7 ⁇ protein subunit (human NaV1.7 ⁇ subunit) between amino acids 272 and 331 of the human NaV1.7 ⁇ subunit Domain 1 S5-S6 loop, wherein the human NaV1.7 ⁇ subunit comprises the amino acid sequence set forth in SEQ ID NO: 1.
- the Nav 1.7 binder contacts amino acids F276, R277, E281, and V331 of the human NaV1.7 ⁇ subunit, which in particular embodiments, binds to the human NaV1.7 ⁇ subunit with lower affinity than to human NaV1.7 ⁇ subunit lacking such substitutions.
- the Navi.7 binder further is capable of binding a rhesus monkey human NaV1.7 ⁇ subunit with a lower affinity than it binds to the human NaV1.7 ⁇ subunit.
- the Navi.7 binder is an antibody or an antibody fragment, which in specific embodiments is a heavy chain antibody or an ISVD.
- the heavy chain antibody is a camelid antibody and the ISVD is a VHH.
- the Navi.7 binder comprises (a) a complementarity determining region (CDR) 1, CDR1, comprising the amino acid sequence set forth in SEQ ID NO: 247, a CDR2 comprising the amino acid sequence set forth in SEQ ID NO: 248, and a CDR3 comprising the amino acid sequence set forth in SEQ ID NO: 249; or (b) a CDR1 comprising the amino acid sequence set forth in SEQ ID NO: 250, a CDR2 comprising the amino acid sequence set forth in SEQ ID NO: 251, and a CDR3 comprising the amino acid sequence set forth in SEQ ID NO: 252; or (c) a CDR1 comprising the amino acid sequence set forth in SEQ ID NO: 253, a CDR2 comprising the amino acid sequence set forth in SEQ ID NO: 254, and a CDR3 comprising the amino acid sequence SRY; or (d) a CDR1 comprising the amino acid sequence set forth in SEQ ID NO: 256, a CDR2 comprising
- the Navi.7 binder comprises (a) a CDR1 comprising the amino acid sequence set forth in SEQ ID NO: 196 or SEQ ID NO: 197; a CDR2 comprising the amino acid sequence set forth in SEQ ID NO: 198 or SEQ ID NO: 199; and, a CDR3 comprising the amino acid sequence set forth in SEQ ID NO: 200; or (b) a CDR1 comprising the amino acid sequence set forth in SEQ ID NO: 201; a CDR2 comprising the amino acid sequence set forth in SEQ ID NO: 202, SEQ ID NO: 203, SEQ ID NO: 204, or SEQ ID NO: 205; and, a CDR3 comprising the amino acid sequence set forth in SEQ ID NO: 206; or (c) a CDR1 comprising the amino acid sequence set forth in SEQ ID NO: 207, SEQ ID NO: 208, SEQ ID NO: 209, SEQ ID NO: 210, SEQ ID NO: 211, or
- the Navi.7 binder comprises (a) an amino acid sequence selected from the group consisting of SEQ ID NO: 69, SEQ ID NO: 70, SEQ ID NO: 71, SEQ ID NO: 72, SEQ ID NO: 73, SEQ ID NO: 74, SEQ ID NO: 75, SEQ ID NO: 76, SEQ ID NO: 77, SEQ ID NO: 78, SEQ ID NO: 79, SEQ ID NO: 80, and SEQ ID NO: 81; or (b) an amino acid sequence selected from the group consisting of SEQ ID NO: 82, SEQ ID NO: 83, SEQ ID NO: 84, SEQ ID NO: 85, SEQ ID NO: 86, SEQ ID NO: 87, SEQ ID NO: 88, SEQ ID NO: 89, SEQ ID NO: 90, SEQ ID NO: 91, SEQ ID NO: 92, SEQ ID NO: 93, SEQ ID NO: 94, SEQ ID NO: 95, SEQ ID NO:
- the Navi.7 binder comprises a C-terminal alanine residue.
- the Navi.7 binder is conjugated to a half-life extender, which in certain embodiments is a human serum albumin (HSA) binder or the crystallizable fragment (Fc) of an antibody.
- HSA binders include but are not limited ALBI 1002 or ALB00223.
- the Navi.7 binder is conjugated to is polyethylene glycol, which provides half-life extension.
- the present invention further provides for use of a Navi.7 binder disclosed herein for the manufacture of a medicament for the treatment of chronic pain.
- the present invention further provides for use of a Navi.7 binder disclosed herein for the treatment of chronic pain.
- the present invention further provides a method for treating an individual with chronic pain comprising administering to the individual a therapeutically effective amount of a Navi.7 binder disclosed herein to treat the chronic pain.
- the individual may be a human patient in need of pain relief.
- the human patient may be treated in a hospital setting or in an out-patient setting.
- the Navi.7 binder may be administered by syringe, autoinjector, dose-settable delivery device, or the like.
- the present invention further provides a composition comprising a Navi.7 binder disclosed herein and a pharmaceutically acceptable carrier.
- the present invention further provides a nucleic acid molecule encoding the Navi .7 binder disclosed herein.
- the nucleic acid molecule encoding the Navi.7 binder comprises a nucleotide sequence selected from the group consisting of nucleotide sequences set forth in SEQ ID NO: 273-283.
- the nucleic acid molecule encoding the Navi.7 binder comprises a nucleotide sequence selected from the group consisting of nucleotide sequences set forth in SEQ ID NO: 284-421.
- the present invention further provides a vector comprising the nucleic acid molecule encoding aNav.7 binder.
- the present invention further provides a host cell comprising a nucleic acid molecule encoding a Navi.7 binder disclosed herein.
- the present invention further provides a method for producing a Navi.7 binder disclosed herein comprising: (a) providing a host cell comprising a nucleic acid molecule encoding a Navi .7 binder disclosed herein or a vector comprising a nucleic acid molecule encoding the Navi.7 binder disclosed herein; (b) cultivating the host cell in a medium under conditions suitable for expression of the Navi.7 binder by the host cell; and (c) isolating the Navi.7 binder from the medium to provide the Navi.7 binder.
- the present invention further provides aNav ⁇ 1 binder comprising (a) a first immunoglobulin single variable domain (ISVD) comprising three complementarity determining regions (CDRs) wherein CDR1 comprises the amino acid sequence set forth in SEQ ID NO: 425, CDR2 comprises the amino acid sequence set forth in SEQ ID NO: 426, and CDR3 comprises the amino acid sequence set forth in SEQ ID NO: 427; or (b) a second ISVD comprising three CDRs wherein CDR1 comprises the amino acid sequence set forth in SEQ ID NO: 437, CDR2 comprises the amino acid sequence set forth in SEQ ID NO: 438, and CDR3 comprise the amino acid sequence set forth in SEQ ID NO: 439.
- ISVD immunoglobulin single variable domain
- CDR3 comprises the amino acid sequence set forth in SEQ ID NO: 427
- a second ISVD comprising three CDRs wherein CDR1 comprises the amino acid sequence set forth in SEQ ID NO: 437, CDR2 comprises the
- the first ISVD comprises the amino acid sequence set forth in SEQ ID NO: 411 and the second ISVD comprises the amino acid sequence set forth in SEQ ID NO: 415.
- the N-terminal amino acid of the first ISVD or the second ISVD is linked to the C-terminal amino acid of a Navi .7 binder of claim 1 by a peptide or polypeptide linker or the N-terminal amino acid of the Navi.7 binder of claim 1 is linked to the C-terminal amino acid of the first ISVD or the second ISVD by a peptide or polypeptide linker.
- the peptide or polypeptide linker comprises any combination of glycine and serine amino acids up to 40 amino acids.
- the peptide or polypeptide linker comprises an amino acid sequence comprising GGGGS (SEQ ID NO: 246)) n wherein n is 1, 2, 3 ,4, 5, 6, 7, 8, 9 or 10.
- the polypeptide linker comprises the amino acid sequence set forth in SEQ ID NO: 463.
- the present invention further provides a nucleic acid molecule encoding a Nav ⁇ 1 binder disclosed herein.
- the Nav ⁇ 1 binder comprises a nucleotide sequence selected from the group consisting of nucleotide sequences set forth in SEQ ID NO: 456 and 461.
- the present invention further provides a vector comprising the nucleic acid molecule encoding aNav ⁇ 1 binder disclosed herein.
- the present invention further provides a host cell comprising a nucleic acid molecule encoding aNav ⁇ 1 binder disclosed herein.
- the present invention further provides a method for producing a Nav ⁇ 1 binder disclosed herein comprising: (a) providing a host cell comprising a nucleic acid molecule encoding a Nav ⁇ 1 binder disclosed herein or a vector comprising a nucleic acid molecule encoding the Nav ⁇ 1 binder disclosed herein; (b) cultivating the host cell in a medium under conditions suitable for expression of the Nav ⁇ 1 binder by the host cell; and (c) isolating the Nav ⁇ 1 binder from the medium to provide the Nav ⁇ 1 binder.
- the present invention further provides aNav ⁇ 2 binder comprising (a) a first immunoglobulin single variable domain (ISVD) comprising three complementarity determining regions (CDRs) wherein CDR1 comprises the amino acid sequence set forth in SEQ ID NO: 422, a CDR2 comprising the amino acid sequence set forth in SEQ ID NO: 423, and a CDR3 comprising the amino acid sequence set forth in SEQ ID NO: 424; (b) a second ISVD comprising three CDRs wherein CDR1 comprises the amino acid sequence set forth in SEQ ID NO: 428, a CDR2 comprising the amino acid sequence set forth in SEQ ID NO: 429, and a CDR3 comprising the amino acid sequence set forth in SEQ ID NO: 430; (c) a third ISVD comprising three CDRs wherein CDR1 comprises the amino acid sequence set forth in SEQ ID NO: 431, a CDR2 comprising the amino acid sequence set forth in SEQ ID NO: 432, and a CDR
- the first ISVD comprises the amino acid sequence set forth in SEQ ID NO: 410
- the second ISVD comprises the amino acid sequence set forth in SEQ ID NO: 412
- the third ISVD comprises the amino acid sequence set forth in SEQ ID NO: 413
- the fourth ISVD comprises the amino acid sequence set forth in SEQ ID NO: 414.
- the N-terminal amino acid of the first ISVD, the second ISVD, the third ISVD, or the fourth ISVD is linked to the C-terminal amino acid of a Navi.7 binder of claim 1 by a peptide or polypeptide linker or the N-terminal amino acid of the Navi.7 binder of claim 1 is linked to the C-terminal amino acid of the first ISVD, the second ISVD, the third ISVD, or the fourth ISVD by a peptide or polypeptide linker.
- the peptide or polypeptide linker comprises any combination of glycine and serine amino acids up to 40 amino acids.
- the peptide or polypeptide linker comprises an amino acid sequence comprising GGGGS (SEQ ID NO: 246)) n wherein n is 1, 2, 3 ,4, 5, 6, 7, 8, 9 or 10.
- the polypeptide linker comprises the amino acid sequence set forth in SEQ ID NO: 463.
- the present invention further provides a nucleic acid molecule encoding a Nav ⁇ 2 binder disclosed herein.
- the Nav ⁇ 1 binder comprises a nucleotide sequence selected from the group consisting of nucleotide sequences set forth in SEQ ID NO: 456, 458, 459, and 460.
- the present invention further provides a vector comprising the nucleic acid molecule encoding aNav ⁇ 1 binder disclosed herein.
- the present invention further provides a host cell comprising a nucleic acid molecule encoding aNav ⁇ 1 binder disclosed herein.
- the present invention further provides a method for producing aNav ⁇ 1 binder disclosed herein comprising: (a) providing a host cell comprising a nucleic acid molecule encoding a Nav ⁇ 1 binder disclosed herein or a vector comprising a nucleic acid molecule encoding the Nav ⁇ 1 binder disclosed herein; (b) cultivating the host cell in a medium under conditions suitable for expression of the Nav ⁇ 1 binder by the host cell; and (c) isolating the Nav ⁇ 1 binder from the medium to provide the Nav ⁇ 1 binder.
- the present invention further provides aNavl.7-Nav ⁇ bispecific binder comprising a Navi.7 binder as disclosed herein and a Nav ⁇ binder selected from the group consisting of the Nav ⁇ 1 binder or Nav ⁇ 2 binder as disclosed herein.
- the Navi.7 binder comprises: (i) an amino acid sequence selected from the group consisting of SEQ ID NO: 46, SEQ ID NO: 47, SEQ ID NO: 48, SEQ ID NO: 49, SEQ ID NO: 50, SEQ ID NO: 51, SEQ ID NO: 52, SEQ ID NO: 53, SEQ ID NO: 54, and SEQ ID NO: 55; (ii) an amino acid sequence selected from the group consisting of SEQ ID NO: 69, SEQ ID NO: 70, SEQ ID NO: 71, SEQ ID NO: 72, SEQ ID NO: 73, SEQ ID NO: 74, SEQ ID NO: 75, SEQ ID NO: 76, SEQ ID NO: 77, SEQ ID NO: 78, SEQ ID NO: 79, SEQ ID NO: 80, and SEQ ID NO: 81; or (iii) an amino acid sequence selected from the group consisting of SEQ ID NO: 82
- the present invention further provides aNavl.7-Nav ⁇ bispecific binder wherein the Navl.7-Nav ⁇ bispecific binder is linked to a half-life extender.
- the present invention further provides aNavl.7-Nav ⁇ bispecific binder disclosed herein wherein the half-life extender is a human serum albumin (HSA) binder or HC constant domain or crystallizable fragment (Fc domain).
- HSA human serum albumin
- Fc domain crystallizable fragment
- the present invention further provides a Navl.7-Nav ⁇ bispecific binder disclosed herein wherein the Navl.7-Nav ⁇ bispecific binder comprises a C-terminal alanine residue.
- the present invention further provides a composition comprising aNavl.7-Nav ⁇ bispecific binder disclosed herein and a pharmaceutically acceptable carrier.
- the present invention further provides for the use of aNavl.7-Nav ⁇ bispecific binder disclosed herein for the manufacture of a medicament for the treatment of chronic pain.
- the present invention further provides aNavl.7-Nav ⁇ bispecific binder disclosed herein or a composition comprising said Navl.7-Nav ⁇ bispecific binder for the treatment of chronic pain.
- the present invention further provides a method for treating an individual with chronic pain comprising administering to the individual a therapeutically effective amount of the Navl.7-Nav ⁇ bispecific binder disclosed herein or a composition comprising said Navl.7-Nav ⁇ bispecific binder to treat the chronic pain.
- the present invention further provides a nucleic acid molecule encoding a Navl.7-Nav ⁇ bispecific binder comprising anucleic acid molecule encoding aNavl.7 binder disclosed herein and a Nav ⁇ 1 or Nav ⁇ 2 binder disclosed herein.
- the nucleic acid molecule encoding the Navi.7 binder comprises a nucleotide sequence selected from the group consisting of nucleotide sequences set forth in SEQ ID NO: 273-283
- the Nav ⁇ 1 binder comprises a nucleotide sequence selected from the group consisting of nucleotide sequences set forth in SEQ ID NO: 457 and 461
- Nav ⁇ 2 binder comprises a nucleotide sequence selected from the group consisting of nucleotide sequences set forth in SEQ ID NO: 456, 458, 459, and 460.
- the nucleic acid molecule encoding the Navi.7 binder comprises a nucleotide sequence selected from the group consisting of nucleotide sequences set forth in SEQ ID NO: 284-421
- the Nav ⁇ 1 binder comprises a nucleotide sequence selected from the group consisting of nucleotide sequences set forth in SEQ ID NO: 457 and 461
- Nav ⁇ 2 binder comprises a nucleotide sequence selected from the group consisting of nucleotide sequences set forth in SEQ ID NO: 456, 458, 459, and 460.
- the present invention further provides a vector comprising the nucleic acid molecule encoding aNavl.7-Nav ⁇ bispecific binder disclosed herein.
- the present invention further provides a host cell comprising a nucleic acid molecule encoding aNavl.7-Nav ⁇ bispecific binder disclosed herein.
- the present invention further provides a method for producing a Navi ,7-Nav ⁇ bispecific binder disclosed herein comprising: (a) providing a host cell comprising a nucleic acid molecule encoding aNavl.7-Nav ⁇ bispecific binder disclosed herein or a vector comprising a nucleic acid molecule encoding the Navl.7-Nav ⁇ bispecific binder disclosed herein; (b) cultivating the host cell in a medium under conditions suitable for expression of the Navi.7- Nav ⁇ bispecific binder by the host cell; and (c) isolating the Navl.7-Nav ⁇ bispecific binder from the medium to provide the Navl.7-Nav ⁇ bispecific binder.
- the present invention further provides a Navi.7 binder, Nav ⁇ 1 binder, or Nav ⁇ 2 binder comprising an amino acid sequence disclosed in Table 56.
- the present invention further provides a nucleic acid molecule encoding a Navi.7 binder, Nav ⁇ 1 binder, orNav ⁇ 2 binder and comprising a nucleotide sequence having at least 80, 90%, 95%, or 100% identity to a nucleotide sequence disclosed in Table 56 provided the amino acid sequence encoded by the nucleotide sequence is disclosed in Table 56.
- the present invention further provides a Navl.7-Nav ⁇ bispecific binder comprising an amino acid sequence disclosed in Table 56 or comprised of a Navi.7 binder and at least one Nav ⁇ binder selected from Nav ⁇ 1 binder and Nav ⁇ 2 binder, each comprising an amino acid sequence disclosed in Table 56.
- the present invention further provides a nucleic acid molecule comprising a nucleotide sequence encoding aNavl.7-Nav ⁇ bispecific binder wherein the nucleotide sequence has at least 80, 90%, 95%, or 100% identity to a nucleotide sequence disclosed in Table 56 provided the nucleotide sequence encodes an amino acid sequence disclosed in Table 56.
- Fig- 1 shows the proposed structure ofNavl.7 ⁇ .
- Drawing shows ahuNavl.7 ⁇ model viewed from top/ extracellular (top left panel) and side through cytoplasmic membrane (top right panel).
- Navi.7 ⁇ structural topology viewed from extracellular side (bottom panel) shown with pi, P2, and P3 subunits.
- Fig. 2A and Fig. 2B together show sequence comparisons of huNavl.7 ⁇ to paralogs and orthologs (based on sequences listed in the Table 41).
- Fig. 3A shows the binding of ISVDs F103262CO2, F0103265B04, F0103262B06, F0103265A11 to huNavl.7 ⁇ + ⁇ 1- ⁇ 2- ⁇ 3.
- MFI median fluorescence intensity
- IRR irrelevant control ISVD
- a-FLAG is a detection moiety.
- Fig. 3B shows the binding of ISVD F0103362B08 to huNavl.7 ⁇ + ⁇ 1- ⁇ 2- ⁇ 3.
- MFI median fluorescence intensity; a-FLAG is a detection moiety.
- Fig. 3C shows the binding of ISVDs F103262CO2, F0103265B04, F0103262B06, F0103265A11 to huNavl.7 ⁇ +pi.
- MFI median fluorescence intensity
- IRR irrelevant control ISVD
- a-FLAG is a detection moiety.
- Fig. 3D shows the binding of ISVDs F103262CO2, F0103265B04, F0103262B06, F0103265A11 to huNavl.5 ⁇ - ⁇ 1- ⁇ 2- ⁇ 3.
- MFI median fluorescence intensity
- IRR irrelevant control ISVD
- a-FLAG is a detection moiety.
- Fig. 3E shows the binding of ISVDs F0103265B04 and F0103262B08, to huNavl.7 ⁇ + ⁇ 1- ⁇ 2- ⁇ 3.
- MFI median fluorescence intensity
- IRR irrelevant control ISVD
- a- FLAG is a detection moiety.
- Fig. 3F shows the binding of ISVDs F0103265B04 and F0103262B08, to huNavl.5 ⁇ - ⁇ 1- ⁇ 2- ⁇ 3.
- MFI median fluorescence intensity
- IRR irrelevant control ISVD
- a- FLAG is a detection moiety.
- Fig. 3G shows the binding of ISVDs F103262CO2, F0103265B04, F0103262B06, F0103265A11 to huNav157chimeral4- ⁇ 1- ⁇ 2- ⁇ 3.
- MFI median fluorescence intensity
- IRR irrelevant control ISVD
- a-FLAG is a detection moiety.
- Fig. 3H shows the binding of ISVDs F0103265B04 and F0103262B08, to huNavl.7 ⁇ +pi.
- MFI median fluorescence intensity
- IRR irrelevant control ISVD
- a-FLAG is a detection moiety.
- Fig. 31 shows the binding of ISVDs F0103265B04 and F0103262B08, to huNav157chimeral4- ⁇ 1- ⁇ 2- ⁇ 3.
- MFI median fluorescence intensity
- IRR irrelevant control ISVD
- a-FLAG is a detection moiety.
- Fig- 4 shows a sequence alignment of functional Navl.7 ⁇ +selective ISVDs compared to the human VH3-JH consensus sequence (SEQ ID NO: 57). Residues identical to the human VH3-JH consensus are shown by dots. CDRs are highlighted.
- the amino acid sequences for the ISVDs are F0103265B04 (SEQ ID NO: 49); F0103275B05 (SEQ ID NO: 50), F0103387G04 (SEQ ID NO: 52); F0103265A11 (SEQ ID NO: 48); F0103387G05 (SEQ ID NO: 53); F0103362B08 (SEQ ID NO: 51).
- Fig. 5 shows screening of the F0103275B05 (275B05) stage I affinity maturation library in binding fluorescence-activated cell sorting (FACS) on huNavl.7 ⁇ and rhNavl.7 ⁇ .
- FACS fluorescence-activated cell sorting
- Fig. 6 shows screening of the F0103275B05 (275B05) stage II affinity maturation library in binding FACS on huNavl.7 ⁇ and rhNavl.7 ⁇ .
- Fig. 7A shows a schematic for a single pulse electrophysiology protocol.
- Fig. 7B shows a schematic for a two pulse electrophysiology protocol.
- Fig- 8 shows screening of the F0103265A11 (265A11) stage I affinity maturation library in binding FACS on huNavl.7 ⁇ and rhNavl.7 ⁇ .
- Fig. 9 shows screening of the F0103265A11 (265 Al 1) stage II affinity maturation library in binding FACS on huNavl.7 ⁇ and rhNavl.7 ⁇ .
- Fig. 10 shows screening of the F0103265B04 (265B04) stage I affinity maturation library in binding FACS on huNavl.7 ⁇ and rhNavl.7 ⁇ .
- Fig. 11 shows screening of the F0103387G05 (387G05) stage I affinity maturation library in binding FACS on huNavl.7 ⁇ and rhNavl.7 ⁇ .
- Fig. 12 shows screening of the F0103362B08 (362B08) stage I affinity maturation library in binding FACS on huNavl.7 ⁇ and rhNavl.7 ⁇ .
- Fig. 13 shows screening of the F0103464B09 (464B09) stage I affinity maturation library in binding FACS on huNavl.7 ⁇ and rhNavl.7 ⁇ .
- Fig. 14 shows screening of the F0103464B09 (464B09) stage II affinity maturation library in binding FACS on huNavl.7 ⁇ and rhNavl.7 ⁇ .
- Fig. 15A shows competition FACS of extracellular anti-Navl.7 ⁇ ISVDs vs.
- Fig. 15B shows competition FACS of extracellular anti-Navl.7 ⁇ ISVDs vs.
- Fig. 15C shows competition FACS of extracellular anti-Navl.7 ⁇ ISVDs vs.
- Fig. 15D shows competition FACS of extracellular anti-Navl.7 ⁇ ISVDs vs.
- Fig. 16 shows a schematic overview of huNavl.7 ⁇ +huNavl.5a (huNav!57) chimeras.
- Fig. 17A, Fig. 17B, and Fig. 17C together show epitope mapping FACS of extracellular anti-Navl.7 ⁇ ISVDs (1 ⁇ M) on transiently transfected cells expressing huNav157+ ⁇ 1- ⁇ 2- ⁇ 3 chimeras 1, 2, 3, or 4 (huNav157chiml, huNav157chim2, huNav157chim3, or huNav157chim4, respectively) compared to cells expressing huNavl.7 ⁇ + ⁇ 1- ⁇ 2- ⁇ 3.
- Fig. 18A, Fig. 18B, and Fig. 18C together show epitope mapping FACS of extracellular anti-Navl.7 ⁇ ISVDs (1 pM) on transiently transfected cells expressing huNav157+ ⁇ 1- ⁇ 2- ⁇ 3 chimeras 5, 6, 7, or 8 (huNav157chim5, huNav157chim6, huNav157chim7, or huNav157chim8, respectively) compared to cells expressing huNavl.7 ⁇ + ⁇ 1- ⁇ 2- ⁇ 3.
- Fig. 19A and Fig. 19B together show epitope mapping FACS of extracellular anti-Navl.7 ⁇ ISVDs (1 pM) on transiently transfected cells expressing huNav157+ ⁇ 1- ⁇ 2- ⁇ 3 chimeras 9 or 12 (huNav157chim9 or huNav157chim12, respectively) compared to cells expressing huNavl.7 ⁇ + ⁇ 1- ⁇ 2- ⁇ 3.
- Fig. 20A and Fig. 20B together show epitope mapping FACS of extracellular anti-Navl.7 ⁇ ISVDs (1 pM) on transiently transfected cells expressing huNav157+ ⁇ 1- ⁇ 2- ⁇ 3 chimeras 22 or 18 (huNav157chim22 or huNav157chim18, respectively) compared to cells expressing huNavl.7 ⁇ + ⁇ 1- ⁇ 2- ⁇ 3.
- Fig. 21A and Fig. 21B together show shows epitope mapping FACS of extracellular anti-Navl.7 ⁇ ISVDs (1 pM) on transiently transfected cells expressing huNavl.7+ ⁇ 1- ⁇ 2- ⁇ 3, rhNavl.7 ⁇ + ⁇ 1- ⁇ 2- ⁇ 3, or huNavl.7(N146S, V194I, F276V, R277Q, E281V, V331M, E504D, D507E, S508N, N533S)- ⁇ 1- ⁇ 2- ⁇ 3.
- Fig. 22A shows binding FACS of extracellular anti-Navl.7 ⁇ ISVDs on stable huNavl.7 ⁇ -rhNavl.7 ⁇ chimera cell line CHO Flpin huNavl.7 ⁇ + ⁇ 1- ⁇ 2- ⁇ 3.
- Fig. 22B shows binding FACS of extracellular anti-Navl.7 ⁇ ISVDs on stable huNavl.7 ⁇ -rhNavl.7 ⁇ chimera cell line CHO Flpin RhNavl.7 ⁇ + ⁇ 1- ⁇ 2- ⁇ 3.
- Fig. 22C shows binding FACS of extracellular anti-Navl.7 ⁇ ISVDs on stable huNavl.7 ⁇ -rhNavl.7 ⁇ chimera cell line CHO Flpin Navl.7 ⁇ (F276V)+ ⁇ 1- ⁇ 2- ⁇ 3.
- Fig. 22D shows binding FACS of extracellular anti-Navl.7 ⁇ ISVDs on stable huNavl.7 ⁇ -rhNavl.7 ⁇ chimera cell line CHO Flpin Navl.7 ⁇ (R277Q)+ ⁇ 1- ⁇ 2- ⁇ 3.
- Fig. 22E shows binding FACS of extracellular anti-Navl.7 ⁇ ISVDs on stable huNavl.7 ⁇ -rhNavl.7 ⁇ chimera cell line CHO Flpin Navl.7 ⁇ (E281V)+ ⁇ 1- ⁇ 2- ⁇ 3.
- Fig. 22F shows binding FACS of extracellular anti-Navl.7 ⁇ ISVDs on stable huNavl.7 ⁇ -rhNavl.7 ⁇ chimera cell line CHO Flpin Navl.7 ⁇ (V331M)+ ⁇ 1- ⁇ 2- ⁇ 3.
- Fig. 22G shows a schematic representation of the extracellular polymorphisms between huNavl.7 ⁇ and rhNavl.7 ⁇ on an huNavl.7 ⁇ model viewed from the extracellular side.
- Fig. 23A shows a schematic illustrating the lonFlux 16 single pulse protocol.
- Fig. 23B shows a schematic illustrating the lonFlux 16 two pulse protocol.
- Fig. 24A shows an lonFlux 16 dose response titration of F0103265B04, F0103362B08, F0103387G04 and F0103387G05 using the single pulse (Pl) protocol.
- Fig. 24B shows an lonFlux 16 dose response titration of F0103265B04, F0103362B08, F0103387G04 and F0103387G05 using two pulse (P2) protocol.
- Fig. 25A shows an lonFlux 16 single high concentration dose response for F0103265B04, F0103275B05, and F0103262C02 in HEK huNavl.7 ⁇ +pi cells using single pulse (Pl) and two pulse (P2) protocols.
- Fig. 25B shows an lonFlux 16 single high concentration dose response for F0103265B04, F0103275B05, and F0103262C02 in HEK huNavl.7 ⁇ cells using single pulse (Pl) and two pulse (P2) protocols.
- Fig. 25C shows an lonFlux 16 single high concentration dose response for F0103265B04, F0103275B05, and F0103262C02 in CHO Flpin huNavl.7 ⁇ + ⁇ 1- ⁇ 2- ⁇ 3 cells using single pulse (Pl) and two pulse (P2) protocols.
- Fig. 25D shows an lonFlux 16 single high concentration dose response for F0103262B06, F0103265A11, and F0103265B04 in CHO Flpin huNavl.7 ⁇ + ⁇ 1- ⁇ 2- ⁇ 3 cells using single pulse (Pl) and two pulse (P2) protocols.
- Fig. 25E shows an lonFlux 16 single high concentration dose response for F0103262B06, F0103265A11, and F0103265B04 in HEK Flpin huNavl.7 ⁇ + ⁇ 1- ⁇ 2- ⁇ 3 cells using single pulse (Pl) and two pulse (P2) protocols.
- Fig. 26 shows the results of an lonFlux 16 washout experiment using F0103265B04.
- Fig. 27 shows the results of an lonFlux 16 time course experiment using F0103265B04.
- Fig. 28 shows a sequence analysis of F0103275B05 (SEQ ID NO: 50) and F010387G04 (SEQ ID NO: 52) compared to the human VH3-JH consensus sequence (SEQ ID NO: 57), VHH2 consensus sequence (SEQ ID NO: 58), and sequenced optimized F0103387G04 (F0103387G04_SO; SEQ ID NO:59).
- F0103387G05_SO sequenced optimized F0103387G05
- Fig. 30 shows the Tm of F0103387G05 variants in function of pH. Dotted lines mark variants with H37Y substitution (see Table 30).
- Fig. 31 shows a sequence analysis of F0103464B09 (SEQ ID NO: 55) compared to the human VH3-JH consensus sequence (SEQ ID NO: 57), VHH2 consensus sequence (SEQ ID NO: 58), and sequenced optimized F01034647B09 (F01034647B09_SO; SEQ ID NO:61).
- Fig. 32 shows a schematic diagram of huNavl.7 ⁇ .
- VSD voltage sensing domain
- PM pore module
- D domain
- S transmembrane segment.
- Fig. 33 shows results of a binding FACS of anti-Nav ⁇ 2 ISVD F0103240B04 on stable cell lines.
- Fig. 34A shows results of a binding ELISA of the shown anti-Nav ⁇ ISVDs binding to Nav ⁇ 1.
- F0103240B04 is a potent anti-Nav ⁇ 2 binder control and IRR022 is a negative control comprising an irrelevant binder.
- F0103478E09 weakly binds Nav ⁇ 1.
- Fig. 34B shows results of a binding ELISA of the shown anti-Nav ⁇ ISVDs binding to P2.
- F0103240B04 is a potent anti-Nav ⁇ 2 binder control and IRR0022 is a negative control comprising an irrelevant binder.
- F0103492E09, F0103500E03, and F0103505D08 weakly bind P2.
- Fig. 34C shows results of a binding ELISA of the shown anti-Nav ⁇ ISVDs binding to Nav ⁇ 3.
- F0103240B04 is a potent anti-Nav ⁇ 2 binder control and IRR0202 is a negative control comprising an irrelevant binder. None of the ISVDs bind Nav ⁇ 3.
- Fig. 35A, Fig. 35B, Fig. 35C, and Fig. 35D together show results of binding FACS of the shown anti-Nav ⁇ subunit ISVDs (12.3 nM) on transiently transfected cells.
- Positive controls anti-Nav ⁇ 1, anti-Nav ⁇ 2, and anti-Nav ⁇ 3 are rabbit polyclonal antibodies specific for human Nav ⁇ 1, Nav ⁇ 2, and Nav ⁇ 3, respectively.
- Fig. 36A shows results of binding FACS of anti-Nav ⁇ ISVD F0103478E09 on various stable cell lines.
- Fig. 36B shows results of binding FACS of anti-Nav ⁇ ISVD F0103492E09 on various stable cell lines.
- Fig. 36C shows results of binding FACS of anti-Nav ⁇ ISVD F0103500E03 on various stable cell lines.
- Fig. 36D shows results of binding FACS of anti-Nav ⁇ ISVD F0103505D08 on various stable cell lines.
- Fig. 36E shows results of binding FACS of anti-Nav ⁇ ISVD F0103495D09 on various stable cell lines.
- Fig. 37A shows the results of a competition FACS of Navl.7 ⁇ -Nav ⁇ bispecific ISVDs on stable CHO cell lines expressing human Navl.7 ⁇ -Nav ⁇ 1-Nav ⁇ 2-Nav ⁇ 3 (Navl.7-pi- P2-P3).
- Fig. 37B shows the results of a competition FACS ofNavl.7 ⁇ -Nav ⁇ bispecific ISVDs on stable CHO cell lines expressing rhesus Navl.7 ⁇ -Nav ⁇ 1-Nav ⁇ 2-Nav ⁇ 3 (Navl.7-pi- P2-P3).
- Fig. 38A shows the results of a competition FACS of Navl.7 ⁇ -Nav ⁇ bispecific ISVDs on stable HEK cell lines expressing human Navi.7 ⁇ (Navi.7).
- Fig. 38B shows the results of a competition FACS ofNavl.7 ⁇ -Nav ⁇ bispecific ISVDs on stable HEK cell lines human expressing Navl.7 ⁇ -Nav ⁇ 1 (Navl.7-pi).
- Fig. 38C shows the results of a competition FACS of Navl.7 ⁇ -Nav ⁇ bispecific ISVDs on stable HEK cell lines expressing human Navi.7 ⁇ -Nav ⁇ 1-Nav ⁇ 2-Nav ⁇ 3 (Navl.7-pi- P2-P3).
- Fig. 39A shows binding FACS of Navi.7 binder F0103262C02 on stable huNavl.x paralog HEK293T cell lines.
- MFI median fluorescence intensity; a-FLAG is a detection moiety.
- Fig. 39B shows binding FACS of Navi.7 binder F0103265B04 on stable huNavl.x paralog HEK293T cell lines.
- MFI median fluorescence intensity; a-FLAG is a detection moiety.
- Fig. 39C shows binding FACS of Navi.7 binder F0103275B05 on stable huNavl.x paralog HEK293T cell lines.
- MFI median fluorescence intensity; a-FLAG is a detection moiety.
- Fig. 39D shows binding FACS of Navi.7 binder F0103464B09 on stable huNavl.x paralog HEK293T cell lines.
- MFI median fluorescence intensity; a-FLAG is a detection moiety.
- Fig. 39E shows binding FACS of Navi.7 binder F0103387G05 on stable huNavl.x paralog HEK293T cell lines.
- MFI median fluorescence intensity; a-FLAG is a detection moiety.
- Navi.7 binder refers to an antibody, an antibody fragment, an immunoglobulin single variable domain (also referred to as “ISV” or ISVD”) or single domain antibody (also referred to as “sdAb”) that binds to Navi.7 ⁇ .
- ISV immunoglobulin single variable domain
- sdAb single domain antibody
- Nav ⁇ binder refers to an antibody, an antibody fragment, an immunoglobulin single variable domain (also referred to as “ISV” or ISVD”) or single domain antibody (also referred to as “sdAb”) that binds to Navp.
- ISV immunoglobulin single variable domain
- sdAb single domain antibody
- antibody refers to an entire immunoglobulin, including recombinantly produced forms and includes any form of antibody that exhibits the desired biological activity. Thus, it is used in the broadest sense and specifically covers, but is not limited to, monoclonal antibodies (including full length monoclonal antibodies), polyclonal antibodies, multispecific antibodies (e.g, bispecific antibodies), humanized antibodies, fully human antibodies, biparatopic antibodies, and chimeric antibodies.
- Monoclonal antibodies including full length monoclonal antibodies
- polyclonal antibodies include multispecific antibodies (e.g, bispecific antibodies), humanized antibodies, fully human antibodies, biparatopic antibodies, and chimeric antibodies.
- Parental antibodies are antibodies obtained by exposure of an immune system to an antigen prior to modification of the antibodies for an intended use, such as humanization of a non-human antibody for use as a human therapeutic antibody.
- antibody refers, in one embodiment, to a conventional antibody, which is a protein tetramer comprising two heavy chains (HCs) and two light chains (LCs) interconnected by disulfide bonds, or an antigen binding portion thereof, and in another embodiment, to a nonconventional antibody, which is a heavy chain antibody protein dimer comprising two heavy chains inter-connected by disulfide bonds and no light chains, or antigen binding portion thereof.
- each heavy chain is comprised of a heavy chain variable region or domain (abbreviated herein as Vj-[) and a heavy chain constant region or domain.
- the heavy chain constant region is comprised of three domains, C H 1 , C H 2 and C H 3.
- each light chain is comprised of a light chain variable region or domain (abbreviated herein as V L and a light chain constant region or domain.
- the light chain constant region is comprised of one domain, CL.
- the human Vj-[ includes six family members: V H 1. V H 2. V H 3. V H 4. V H 5. and V H 6 and the human V L family includes 16 family members: V K 1, V K 2, V K 3, V K 4, V K 5, V K 6, V ⁇ l, V ⁇ 2. V ⁇ 3. V ⁇ 4. V ⁇ 5. V ⁇ 6, V ⁇ 7, V ⁇ 8, V ⁇ 9, and V ⁇ 10.
- Each of these family members can be further divided into particular subtypes.
- V H and V L regions can be further subdivided into regions of hypervariability, termed complementarity determining regions (CDR), interspersed with regions that are more conserved, termed framework regions (FR).
- CDR complementarity determining regions
- FR framework regions
- Each V H and V L is composed of three CDRs and four FRs, arranged from amino-terminus to carboxy-terminus in the following order: FR1, CDR1, FR2, CDR2, FR3, CDR3, FR4.
- the CDRs form a binding domain that interacts with an antigen.
- the constant regions of the antibodies may mediate the binding of the immunoglobulin to host tissues or factors, including various cells of the immune system (e.g., effector cells) and the first component (Clq) of the classical complement system.
- the constant domains or regions of the antibodies may mediate the binding of the immunoglobulin to host tissues or factors, including various cells of the immune system (e.g., effector cells) and the first component (Clq) of the classical complement system.
- the numbering of the amino acids in the heavy chain constant domain begins with number 118, which is in accordance with the Eu numbering scheme.
- the Eu numbering scheme is based upon the amino acid sequence of human IgG
- variable domains or regions of the heavy and light chains contain a binding domain comprising the CDRs that interacts with an antigen.
- a number of methods are available in the art for defining or predicting the CDR amino acid sequences of antibody variable domains (see Dondelinger et al., Frontiers in Immunol. 9: Article 2278 (2016)).
- the common numbering schemes include the following.
- Kabat numbering scheme is based on sequence variability and is the most commonly used (See Kabat et al. Sequences of Proteins of Immunological Interest, 5th Ed. Public Health Service, National Institutes of Health, Bethesda, Md. (1991) (defining the CDR regions of an antibody by sequence);
- Chothia numbering scheme is based on the location of the structural loop region (See Chothia & Lesk J. Mol. Biol. 196: 901-917 (1987); Al-Lazikani et al., J. Mol. Biol. 273: 927-948 (1997)); • AbM numbering scheme is a compromise between the two used by Oxford Molecular's AbM antibody modelling software (see Karu et al, ILAR Journal 37: 132-141 (1995);
- IMGT (ImMunoGeneTics) numbering scheme is a standardized numbering system for all the protein sequences of the immunoglobulin superfamily, including variable domains from antibody light and heavy chains as well as T cell receptor chains from different species and counts residues continuously from 1 to 128 based on the germ-line V sequence alignment (see Giudicelli et al., Nucleic Acids Res. 25:206-11 (1997); Lefranc, Immunol Today 18:509(1997); Lefranc et al., Dev Comp Immunol. 27:55-77 (2003)).
- the numbering of the entire variable region typically follows the Kabat numbering scheme with the particular CDR numbering scheme imposed thereupon.
- the state of the art recognizes that in many cases, the CDR3 region of the heavy chain is the primary determinant of antibody specificity, and examples of specific antibody generation based on CDR3 of the heavy chain alone are known in the art (e.g., Beiboer et al., J. Mol. Biol. 296: 833-849 (2000); Klimka et al., British J. Cancer 83: 252-260 (2000); Rader et al., Proc. Natl. Acad. Sci. USA 95: 8910-8915 (1998); Xu et al., Immunity 13: 37-45 (2000).
- a conventional antibody tetramer includes two identical pairs of polypeptide chains, each pair having one "light” (about 25 kDa) and one "heavy” chain (about 50-70 kDa).
- the amino-terminal portion of each chain includes a variable region of about 100 to 110 or more amino acids primarily responsible for antigen recognition.
- the carboxy-terminal portion of the heavy chain may define a constant region primarily responsible for effector function.
- human light chains are classified as kappa and lambda light chains.
- human heavy chains are typically classified as mu, delta, gamma, alpha, or epsilon, and define the antibody's isotype as IgM, IgD, IgG, IgA, and IgE, respectively.
- variable and constant regions are joined by a "J" region of about 12 or more amino acids, with the heavy chain also including a "D” region of about 10 more amino acids.
- the heavy chain of a conventional antibody may or may not contain a terminal lysine (K), or a terminal glycine and lysine (GK).
- antibody binding fragment or “antigen binding portion” refers to fragments of antibodies, i.e. antibody fragments that retain the ability to bind specifically to the antigen bound by the full-length antibody, e.g. fragments that retain one or more CDR regions.
- antibody binding fragments include, but are not limited to, Fab, Fab', F(ab')2, and Fv fragments; diabodies; single-chain antibody molecules, e.g., sc-Fv; immunoglobulin single variable domain molecules, and multispecific antibodies formed from antibody fragments.
- immunoglobulin single variable domain also referred to as “ISV” or ISVD”
- single domain antibody also referred to as “sdAb”
- immunoglobulin variable domains which may be heavy chain or light chain domains, including VH, VHH, or V L domains
- VH immunoglobulin variable domain
- VHH single domain antibody
- ISVDs include for example, VHHs, humanized VHHs, and/or a camelized VHs such as camelized human VHs), IgNAR domains, single domain antibodies such as dAbsTM, which are VH domains or are derived from a VH domain or are V L domains or are derived from a V L domain. ISVDs that are based on and/or derived from heavy chain variable domains (such as VH or VHH domains) are generally preferred.
- an ISVD will be a VHH, a humanized VHH, or a camelized VH (such as a camelized human VH) or generally a sequence optimized VHH (e.g., optimized for chemical stability and/or solubility, maximum overlap with known human framework regions and maximum expression).
- Nanobody® molecule is generally as defined in WO 2008/020079 or WO 2009/138519, and thus in a specific aspect denotes an VHH, a humanized VHH, or a camelized VH (such as a camelized human VH) or generally a sequence optimized VHH (such as, e.g., optimized for chemical stability and/or solubility, maximum overlap with known human framework regions and maximum expression).
- VHH a humanized VHH
- camelized VH such as a camelized human VH
- sequence optimized VHH such as, e.g., optimized for chemical stability and/or solubility, maximum overlap with known human framework regions and maximum expression.
- Nanobody® is a registered trademark of Ablynx N.V.
- Navi.7 binder refers to a conventional antibody, heavy chain antibody, antigen binding fragment of an antibody or ISVD that binds to Navi.7 ⁇ .
- a Navi.7 binder may be part of a larger molecule such as a multivalent, bispecific, or multispecific binder that includes one or more Navi.7 binders and may include one or more binders to a target other than Navi.7 ⁇ (e.g., Nav ⁇ binder) and may comprises another functional element, such as, for example, a half-life extender (HLE), an Fc domain of an immunoglobulin, a targeting unit and/or a small molecule such a polyethylene glycol (PEG).
- HLE half-life extender
- Fc domain of an immunoglobulin a targeting unit
- PEG polyethylene glycol
- Nav ⁇ binder refers to a conventional antibody, heavy chain antibody, antigen binding fragment of an antibody or ISVD that binds to Nav ⁇ 1 or Nav ⁇ 2.
- a Nav ⁇ binder may be part of a larger molecule such as a multivalent, bispecific, or multispecific binder that includes one or more Nav ⁇ binders and may include one or more binders to a target other than Nav ⁇ 1 or Nav ⁇ 2 (e.g., a Navi .7 binder) and may comprise another functional element, such as, for example, a half-life extender (HLE), an Fc domain of an immunoglobulin, a targeting unit and/or a small molecule such as a PEG.
- HLE half-life extender
- a monovalent Navi.7 or Nav ⁇ binder e.g., ISVD such as a Nanobody® molecule
- a bivalent or bispecific Navi.7 binder e.g., ISVD such as a Nanobody® molecule
- a multivalent or multispecific Navi.7 binder comprises more than one antigen-binding domain (e.g., 1, 2, 3, 4, 5, 6, or 7).
- a multivalent or multispecific binder comprises only two antigen binding domains it may be referred to as a bispecific or bivalent binder.
- a "Fab fragment” is comprised of one light chain and the C H 1 and variable regions of one heavy chain.
- the heavy chain of a Fab molecule cannot form a disulfide bond with another heavy chain molecule.
- a "Fab fragment” can be the product of papain cleavage of an antibody.
- a "Fab' fragment” contains one light chain and a portion or fragment of one heavy chain that contains the V H domain and the C H 1 domain and also the region between the C H 1 and C H 2 domains, such that an interchain disulfide bond can be formed between the two heavy chains of two Fab' fragments to form a F(ab')2 molecule.
- a "F(ab')2 fragment” contains two light chains and two heavy chains containing the VH domain and a portion of the constant region between the C H 1 and C H 2 domains, such that an interchain disulfide bond is formed between the two heavy chains.
- An F(ab')2 fragment thus is composed of two Fab' fragments that are held together by a disulfide bond between the two heavy chains.
- An "F(ab')2 fragment” can be the product of pepsin cleavage of an antibody.
- an “Fv region” comprises the variable regions from both the heavy and light chains but lacks the constant regions.
- Antigen-binding fragments can be produced by recombinant DNA techniques, or by enzymatic or chemical cleavage of intact immunoglobulins.
- an "Fc domain” or “Fc region” each refer to the fragment crystallizable region of an antibody.
- the Fc domain comprises two heavy chain fragments comprising the C H 1 and C H 2 domains of an antibody.
- the two heavy chain fragments are held together by two or more disulfide bonds and by hydrophobic interactions of the C H 3 domains.
- the Fc domain may be fused at the N-terminus or the C-terminus to a heterologous protein.
- a "diabody” refers to a small antibody fragment with two antigenbinding regions, which fragments comprise a heavy chain variable domain (V H ) connected to a light chain variable domain (V L ) in the same polypeptide chain (VH- V L or V L -V H ).
- V H heavy chain variable domain
- V L light chain variable domain
- isolated antibodies or antigen-binding fragments thereof are at least partially free of other biological molecules from the cells or cell cultures in which they are produced.
- biological molecules include nucleic acids, proteins, lipids, carbohydrates, or other material such as cellular debris and growth medium.
- An isolated antibody or antigen-binding fragment may further be at least partially free of expression system components such as biological molecules from a host cell or of the growth medium thereof.
- isolated is not intended to refer to a complete absence of such biological molecules or to an absence of water, buffers, or salts or to components of a pharmaceutical formulation that includes the antibodies or fragments.
- a “monoclonal antibody” refers to a population of substantially homogeneous antibodies, i.e., the antibody molecules comprising the population are identical in amino acid sequence except for possible naturally occurring mutations that may be present in minor amounts.
- conventional (polyclonal) antibody preparations typically include a multitude of different antibodies having different amino acid sequences in their variable domains that are often specific for different epitopes.
- the modifier "monoclonal” indicates the character of the antibody as being obtained from a substantially homogeneous population of antibodies, and is not to be construed as requiring production of the antibody by any particular method.
- the monoclonal antibodies to be used in accordance with the present invention may be made by the hybridoma method first described by Kohler et al. (1975) Nature 256: 495, or may be made by recombinant DNA methods (see, e.g., U.S. Pat. No. 4,816,567).
- the "monoclonal antibodies” may also be isolated from phage antibody libraries using the techniques described in Clackson et al. (1991) Nature 352: 624-628 and Marks et al. (1991) J. Mol. Biol. 222: 581-597, for example. See also Presta (2005) J. Allergy Clin. Immunol. 116:731.
- a "humanized ISVD” or “humanized antibody” refers to forms of Navi.7 binders that contain sequences from both human and non-human (e.g., llama, murine, rat) antibodies.
- the humanized Navi.7 and Nav ⁇ binders will comprise all of at least one, and typically two, variable domains, in which the hypervariable loops correspond to those of a non-human immunoglobulin, and all or substantially all of the framework (FR) regions are those of a human immunoglobulin sequence.
- the humanized Navi .7 and/or Nav ⁇ binder may optionally comprise at least a portion of a human immunoglobulin constant region (Fc).
- Humanization also called Reshaping or CDR-grafting
- mAbs monoclonal antibodies
- ADCC complement activation, Clq binding
- the engineered mAh is engineered using the techniques of molecular biology, however simple CDR-grafting of the rodent complementaritydetermining regions (CDRs) into human frameworks often results in loss of binding affinity and/or specificity of the original mAh.
- the design of the humanized antibody includes variations such as conservative amino acid substitutions in residues of the CDRs, and back substitution of residues from the rodent mAh into the human framework regions (backmutations).
- the positions can be discerned or identified by sequence comparison for structural analysis or by analysis of a homology model of the variable regions' 3D structure.
- affinity maturation has most recently used phage libraries to vary the amino acids at chosen positions.
- many approaches have been used to choose the most appropriate human frameworks in which to graft the rodent CDRs. As the datasets of known parameters for antibody structures increases, so does the sophistication and refinement of these techniques.
- Consensus or germline sequences from a single antibody or fragments of the framework sequences within each light or heavy chain variable region from several different human mAbs can be used.
- Another approach to humanization is to modify only surface residues of the rodent sequence with the most common residues found in human mAbs and has been termed "resurfacing" or "veneering.”
- Known human Ig sequences are disclosed, e.g., www.ncbi.nlm.nih.gov/entrez/query.fcgi; www.ncbi.nih.gov/igblast; www.atcc.org/phage/hdb.html; www.kabatdatabase.com/top.html; www.antibodyresource.com/onlinecomp.html; www.appliedbiosystems.com; www.biodesign.com; antibody.bath.ac.uk; www.unizh.ch; www.cryst.bbk.ac.uk/.about.ubc
- non-human amino acid sequences with respect to antibodies or immunoglobulins refers to an amino acid sequence that is characteristic of the amino acid sequence of a non-human mammal. The term does not include amino acid sequences of antibodies or immunoglobulins obtained from a fully human antibody library where diversity in the library is generated in silico (See for example, U.S. Patent No. 8,877,688 or 8,691,730).
- effector functions refer to those biological activities attributable to the Fc region of an antibody, which vary with the antibody isotype.
- antibody effector functions include: Clq binding and complement dependent cytotoxicity (CDC); Fc receptor binding; antibody-dependent cell-mediated cytotoxicity (ADCC); phagocytosis; down regulation of cell surface receptors (e.g. B cell receptor); and B cell activation.
- “conservatively modified variants” or “conservative substitution” refers to substitutions of amino acids with other amino acids having similar characteristics (e.g. charge, side-chain size, hydrophobicity /hydrophilicity, backbone conformation and rigidity, etc.), such that the changes can frequently be made without altering the biological activity of the protein.
- conservative substitutions are set forth in the table below.
- epitopes within protein antigens can be formed both from contiguous amino acids (usually a linear epitope) or noncontiguous amino acids juxtaposed by tertiary folding of the protein (usually a conformational epitope). Epitopes formed from contiguous amino acids are typically, but not always, retained on exposure to denaturing solvents, whereas epitopes formed by tertiary folding are typically lost on treatment with denaturing solvents.
- a contiguous linear epitope comprises a peptide domain on an antigen comprising at least 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14 or 15 amino acids.
- a noncontiguous conformational epitope comprises one or more peptide domains or regions on antigen bound by a binder interspersed by one or more amino acids or peptide domains not bound by the binder, each domain independently comprises at least 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14 or 15 amino acids.
- epitope mapping Methods for determining what epitopes are bound by a given binder (i.e., epitope mapping) are well known in the art and include, for example, immunoblotting and immunoprecipitation assays, wherein overlapping or contiguous peptides (e.g., from Navi.7 ⁇ , Nav ⁇ 1, Nav ⁇ 2) are tested for reactivity with a given binder.
- Methods of determining spatial conformation of epitopes include techniques in the art and those described herein, for example, x-ray crystallography, 2-dimensional nuclear magnetic resonance, and HDX-MS (see, e.g., Epitope Mapping Protocols in Methods in Molecular Biology, Vol. 66, G. E. Morris, Ed. (1996)).
- epitopope mapping refers to the process of identification of the molecular determinants on the antigen involved in antibody-antigen recognition.
- binds to the same epitope with reference to two or more binders means that the binders bind to the same segment of amino acid residues on a target, as determined by a given method.
- Techniques for determining whether a particular binder binds to the "same epitope " as the Navi.7 orNav ⁇ binders described herein include, for example, epitope mapping methods, such as, x-ray analyses of crystals of Navl.7 ⁇ :Navl.7 binder or Nav ⁇ :Nav ⁇ binder complexes, which provides atomic resolution of the epitope, and hydrogen/deuterium exchange mass spectrometry (HDX-MS). Other methods that monitor the binding of the antibody to antigen fragments (e.g.
- proteolytic fragments or to mutated variations of the antigen where loss of binding due to a modification of an amino acid residue within the antigen sequence is often considered an indication of an epitope component (e.g. alanine scanning mutagenesis— Cunningham & Wells (1985) Science 244:1081).
- an epitope component e.g. alanine scanning mutagenesis— Cunningham & Wells (1985) Science 244:1081.
- computational combinatorial methods for epitope mapping can also be used. These methods rely on the ability of the binder of interest to affinity isolate specific short peptides from combinatorial phage display peptide libraries.
- Binders that "compete with a binder of the present invention for binding to a target antigen" refer to binders that inhibit (partially or completely) the binding of the Navi.7 binder of the present invention to Navi.7 ⁇ or Nav ⁇ binder to Navp. Whether two binders compete with each other for binding to the target antigen, i.e., whether and to what extent one binder inhibits the binding of the other binder to the target antigen, may be determined using known competition experiments. In certain embodiments, a binder competes with, and inhibits binding of a binder of the present invention to the target antigen by at least 10%, 20%, 30%, 40%, 50%, 60%, 70%, 80%, 90% or 100%.
- the level of inhibition or competition may be different depending on which binder is the "blocking binder" (i.e., the unlabeled binder that is incubated first with the target antigen).
- Competition assays can be conducted as described, for example, in Ed Harlow and David Lane, Cold Spring Harb Protoc; 2006; doi: 10.1101/pdb.prot4277 or in Chapter 11 of "Using Antibodies” by Ed Harlow and David Lane, Cold Spring Harbor Laboratory Press, Cold Spring Harbor, N.Y., USA 1999. Competing Navi.7 binders bind to the same epitope as defined herein.
- bindings refers, with respect to a target antigen, to the preferential association of a binder, in whole or part, with the target antigen and not to other molecules, particularly molecules found in human blood or serum. Binders as shown herein typically bind specifically to the target antigen with high affinity, reflected by a dissociation constant (K D ) of 10 -7 to 10 - 11 M or less. Any K D greater than about 10 -6 M is generally considered to indicate nonspecific binding.
- a binder that "specifically binds" or “binds specifically" to a target antigen refers to a binder that binds to the target antigen with high affinity, which means having a K D of 10 -7 M or less, in particular embodiments a K D of 10 -8 M or less, or 5x 10 -9 M or less, or between 10 -8 M and 10-11 M or less, but does not bind with measurable binding to closely related proteins such as human Navi, la, human Navi.2a, human Navi.3a, humanNavl.4a, human Navi.5a, human Nav 1.6a, or human Navi.8a as determined in a cell ELISA or Surface Plasmon Resonance assay (SPR; Biacore) using 10 pg/mL antibody.
- SPR Surface Plasmon Resonance assay
- an antigen is "substantially identical" to a given antigen if it exhibits a high degree of amino acid sequence identity to the given antigen, for example, if it exhibits at least 80%, at least 90%, at least 95%, at least 97%, or at least 99% or greater amino acid sequence identity to the amino acid sequence of the given antigen.
- an antibody that binds specifically to human Navi.7 ⁇ or Nav ⁇ may also cross-react with Navi.7 ⁇ or Nav ⁇ from certain non-human primate species (e.g., rhesus monkey or cynomolgus monkey). The term specifically excludes human Navi, la, human Navi.2a, human Navi.3a, humanNavl.4a, human Navi.5a, human Nav 1.6a, and human Navi.8a.
- isolated nucleic acid molecule means a DNA or RNA of genomic, mRNA, cDNA, or synthetic origin or some combination thereof which is not associated with all or a portion of a polynucleotide in which the isolated polynucleotide is found in nature, or is linked to a polynucleotide to which it is not linked in nature.
- a nucleic acid molecule comprising a particular nucleotide sequence does not encompass intact chromosomes.
- Isolated nucleic acid molecules "comprising" specified nucleic acid sequences may include, in addition to the specified sequences, coding sequences for up to ten or even up to twenty or more other proteins or portions or fragments thereof, or may include operably linked regulatory sequences that control expression of the coding region of the recited nucleic acid sequences, and/or may include vector sequences.
- treat or “treating” means to administer a therapeutic agent, such as a composition containing any of the Navi.7 and/or Nav ⁇ binders of the present invention, topically, subcutaneously, intramuscular, intradermally, or systemically to an individual experiencing chronic pain.
- a therapeutic agent such as a composition containing any of the Navi.7 and/or Nav ⁇ binders of the present invention
- the amount of a therapeutic agent that is effective to alleviate chronic pain in the individual may vary according to factors such as the injury or disease state, age, and/or weight of the individual, and the ability of the therapeutic agent to elicit a desired response in the individual.
- chronic pain has been alleviated can be assessed by the individual and/or any clinical measurement typically used by physicians or other skilled healthcare providers to assess the severity or progression status of chronic pain.
- the terms denote that a beneficial result has been or will be conferred on a human or animal individual experiencing chronic pain.
- treatment refers to therapeutic treatment, as well as diagnostic applications.
- Treatment as it applies to a human or veterinary individual, encompasses contact of the antibodies or antigen binding fragments of the present invention to a human or animal subject.
- terapéuticaally effective amount refers to a quantity of a specific substance sufficient to achieve a desired effect in an individual being treated. For instance, this may be the amount necessary to inhibit or reduce the severity of chronic pain in an individual.
- effector-silent refers to an antibody, antibody fragment, HC constant domain, or Fc domain thereof that displays (i) no measurable binding to one or more Fc receptors (FcRs) as may be measured in a surface plasmon resonance (SPR) assay (e.g., BiacoreTM assay) wherein an association constant in the micromolar range indicates no measurable binding or (ii) measurable binding to one or more FcRs as may be measured in SPR assay that is reduced compared to the binding that is typical for an antibody, antibody fragment, HC constant domain or Fc domain thereof the same isotype.
- SPR surface plasmon resonance
- the antibody, antibody fragment, HC constant domain, or Fc domain thereof may comprise one or more mutations in the HC constant domain and the Fc domain in particular such that the mutated an antibody, antibody fragment, HC constant domain or Fc domain thereof has reduced or no measurable binding to FcyRIIIa, FcyRIIa, and FcyRI compared to a wild-type antibody of the same isotype as the mutated antibody.
- the affinity or association constant of an effector-silent an antibody, antibody fragment, HC constant domain or Fc domain thereof to one or more of FcyRIIIa, FcyRIIa, and FcyRI is reduced by at least 1000- fold compared to the affinity of the wild-type isotype; reduced by at least 100-fold to 1000-fold compared to the affinity of the wild-type isotype reduced by at least 50-fold to 100-fold compared to the affinity of the wild-type isotype; or at least 10-fold to 50-fold compared to the affinity of the wild-type isotype.
- the effector-silent an antibody, antibody fragment, HC constant domain, or Fc domain thereof has no detectable or measurable binding to one or more of the FcyRIIIa, FcyRIIa, and FcyRI as compared to binding by the wildtype isotype.
- effector-silent an antibody, antibody fragment, HC constant domain, or Fc domain thereof will lack measurable antibody-dependent cell-mediated cytotoxicity (ADCC) activity.
- An ISVD not fused or linked to an effector-silent HC constant domain or Fc domain thereof displays no detectable or measurable binding to one or more of FcyRIIIa, FcyRIIa, or FcyRI.
- SPR assays measure binding of an effector-silent antibody, antibody fragment, HC constant domain or Fc domain thereof, against human FcRs.
- Navi.7 ⁇ channels predominantly expressed in peripheral C-fiber nociceptors are therefore a drug target of great interest for treatment of various pain conditions.
- ISVDs Navi.7 binders
- Functional inhibitory Navi.7 activity of the Navi.7 binders was assessed in automated in vitro patch clamp assays. IC50 values in the nanomolar range have been measured.
- any Navi.7 binder or other binder as set forth herein comprises, where applicable, a substitution of the amino acid at position 11 to the amino acid V and a substitution of the amino acid at position 89 to the amino acid L.
- the Navi.7 binder further includes a substitution of the amino acid at position 110 to the amino acid T, K, or Q.
- the amino acid at position 112 is substituted with the amino acid S, K or Q. In each case wherein the numbering is according to the Kabat numbering scheme.
- the a-subunits of the Navi.7 channel are polypeptide chains of 1977 amino acids that are folded into four homologous (but not identical) domains termed DI-DIV that are linked by three intracellular loops (L1-L3).
- Each domain has six transmembrane segments (S1-S6) with S1-S4 in each domain comprising a voltage sensing domain (VSD), and S5-S6 together with their extracellular linker (including the P-loop) included in the pore domain (PD) (Caterall (2000) Neuron 26:13-25; Guy & Seetharamulu (1986) Proceedings of the National Academy of Sciences of the United States of America 83: 508-512; Noda et al. (1984) Nature 312:121-127).
- VSD voltage sensing domain
- PD pore domain
- each a-subunit has four distinct VSDs and four PDs which assemble to form one sodiumselective pore.
- Sodium is selectivity achieved in the extracellular portion of the pore domain by tight association of the four P-loops that re-enter the membrane between the S5 and S6 segments in DI-DIV and includes several negatively charged residues (aspartic acid and glutamic acid) (Caterall 2000).
- the human Navi.7 ⁇ comprises the amino acid sequence set forth in SEQ ID NO: 1.
- Domain I of the human Navi.7 ⁇ consists of the amino acid sequence shown in SEQ ID NO: 63 and the Domain I S5-S6 loop is shown in SEQ ID NO: 64.
- the amino acid sequence for the rhesus monkey NAVI.7 ⁇ is shown in SEQ ID NO: 2, which has 99% identity with the human Navi ,7 ⁇ .
- a schematic representation of Navi ,7 ⁇ is shown in Fig. 32.
- the present invention provides Navi.7 binders (e.g., ISVDs) that bind to Navi.7 ⁇ and methods of use of the binders for or in the treatment or prevention of disease.
- the Navi.7 binders are antagonistic anti-NaV1.7 ⁇ ISVDs.
- the Navi.7 binder antagonizes the activity of the Navi.7 channel, for example, by blocking the channel, which may be by physically blocking or closing the Navi.7 pore to Na + flux or by conformationally changing the Navi.7 channel to an inactive state.
- the Navi.7 binders include binders that bind to the Domain I S5-S6 loop of the human Navi.7 ⁇ comprising amino acids 276 through 331 thereof (e.g., FRNSLENNETLESIMNTLESEEDFRKYFYYLEGSKDALLCGFSTDSGQCPEGYTCV (SEQ ID NO: 62)), and heteromeric channels in which the Navi.7 ⁇ is complexed with one or more beta subunits such as ⁇ 1, ⁇ 2, ⁇ 3, and/or ⁇ 4.
- the Navi.7 binder contacts one or more of the following Navi.7 ⁇ amino acid residues: F276, R277, E281, and V331 as shown underlined in the amino acid sequence above.
- the Navi.7 binder contacts the following four Navi.7 ⁇ amino acid residues: F276, R277, E281, and V331.
- the Navi.7 binders of the present invention bind to an epitope on Navi.7 ⁇ comprising amino acid residues F276, R277, E281, and V331.
- the epitope consists of amino acid residues F276, R277, E281, and V331.
- the Navi.7 binder binds to Navi.7 ⁇ having one or more mutations at residue F276, R277, E281, and/or V331 with lower affinity than to human Navi.7 ⁇ lacking such mutations.
- the binder binds to human Navi.7 ⁇ comprising one or more mutations at positions Q1530, H1531, and E1534 with a substantially similar affinity to that of human Navi.7 ⁇ lacking said mutations.
- the binder binds to human Navi.7 ⁇ comprising mutations at positions Q1530, H1531, and E1534 with a substantially similar affinity to that of human Navi ,7 ⁇ lacking said mutations.
- the Navi .7 binder does not bind to rhesus monkey Navi.7 ⁇ or binds with a lower affinity than to human Navi.7 ⁇ .
- the Navi.7 binder binds to human Navi.7 ⁇ with substantially similar affinity to human Navi.7 ⁇ lacking one more of loops other than the domain 1 S5-S6 loop.
- the Navi.7 binders of the present invention comprise three complementarity determining regions (CDRs) having amino acid sequences selected from the tables below.
- CDR amino acid sequences shown in Table 2 and Table 3 are set forth according to the AbM numbering scheme for defining CDR amino acid sequences.
- a particular CDR amino acid sequence defined by any one of the other schemes advanced for defining CDR amino acid sequences may have more or less amino acids than shown for CDR amino acid sequences identified according to the AbM numbering scheme but will overlap the CDR amino acid sequences defined according the AbM numbering scheme.
- the CDR amino acid sequences shown herein are not to be construed as limiting and any Navi.7 binder in which the CDR amino acid sequences have been defined by any other numbering scheme will fall within the scope of the Navi.7 binders of the present invention provided the amino acid sequences for such Navi.7 binders comprise the amino acid sequences defined for the three CDR amino acid sequences as shown in Table 2 and Table 3.
- any Navi.7 binder that comprises the three amino acid sequences defined for CDR1, CDR2, and CDR3 for any of the Navi.7 binders shown in Table 2 and Table 3 are Navi.7 binders of the present invention.
- the Navi.7 binders comprise three CDRs and four Frameworks (FR) in the following alignment FR1-CDR1-FR2-CDR2-FR3-CDR3-FR4.
- the Navi.7 binder CDRs may comprise CDRs comprising the following amino acid sequences.
- the Navi.7 binder comprises a CDR1 comprising the amino acid sequence set forth in SEQ ID NO: 247, a CDR2 comprising the amino acid sequence set forth in SEQ ID NO: 248, and a CDR3 comprising the amino acid sequence set forth in SEQ ID NO: 249.
- the Navi.7 binder comprises a CDR1 comprising the amino acid sequence set forth in SEQ ID NO: 250, a CDR2 comprising the amino acid sequence set forth in SEQ ID NO: 251, and a CDR3 comprising the amino acid sequence set forth in SEQ ID NO: 252.
- the Navi.7 binder comprises a CDR1 comprising the amino acid sequence set forth in SEQ ID NO: 253, a CDR2 comprising the amino acid sequence set forth in SEQ ID NO: 254, and a CDR3 comprising the amino acid sequence SRY.
- the Navi.7 binder comprises a CDR1 comprising the amino acid sequence set forth in SEQ ID NO: 256, a CDR2 comprising the amino acid sequence set forth in SEQ ID NO: 257, and a CDR3 comprising the amino acid sequence set forth in SEQ ID NO: 258.
- the Navi.7 binder comprises a CDR1 comprising the amino acid sequence set forth in SEQ ID NO: 259, a CDR2 comprising the amino acid sequence set forth in SEQ ID NO: 260, and a CDR3 comprising the amino acid sequence set forth in SEQ ID NO: 261.
- the Navi.7 binder comprises a CDR1 comprising the amino acid sequence set forth in SEQ ID NO: 262, a CDR2 comprising the amino acid sequence set forth in SEQ ID NO: 263, and a CDR3 comprising the amino acid sequence set forth in SEQ ID NO: 264.
- the Navi.7 binder comprises a CDR1 comprising the amino acid sequence set forth in SEQ ID NO: 196, a CDR2 comprising the amino acid sequence set forth in SEQ ID NO: 198, and a CDR3 comprising the amino acid sequence set forth in SEQ ID NO: 200.
- the Navi.7 binder comprises a CDR1 comprising the amino acid sequence set forth in SEQ ID NO: 201, a CDR2 comprising the amino acid sequence set forth in SEQ ID NO: 202, and a CDR3 comprising the amino acid sequence set forth in SEQ ID NO: 206.
- the Navi .7 binder comprises a CDR1 comprising the amino acid sequence set forth in SEQ ID NO: 207, a CDR2 comprising the amino acid sequence set forth in SEQ ID NO: 213, and a CDR3 comprising the amino acid sequence set forth in SEQ ID NO: 219.
- the Navi.7 binder comprises a CDR1 comprising the amino acid sequence set forth in SEQ ID NO: 221, a CDR2 comprising the amino acid sequence set forth in SEQ ID NO: 223, and a CDR3 comprising the amino acid sequence set forth in SEQ ID NO: 225.
- the Navi.7 binder comprises three CDRs having an amino acid sequence as set forth in Table 3.
- the Navi.7 binder comprises a CDR1 comprising the amino acid sequence set forth in SEQ ID NO: 196 or SEQ ID NO: 197; a CDR2 comprising the amino acid sequence set forth in SEQ ID NO: 198 or SEQ ID NO: 199; and, a CDR3 comprising the amino acid sequence set forth in SEQ ID NO: 200.
- the Navi.7 binder comprises a CDR1 comprising the amino acid sequence set forth in SEQ ID NO: 201; a CDR2 comprising the amino acid sequence set forth in SEQ ID NO: 202, SEQ ID NO: 203, SEQ ID NO: 204, or SEQ ID NO: 205; and, a CDR3 comprising the amino acid sequence set forth in SEQ ID NO: 206.
- the Navi.7 binder comprises a CDR1 comprising the amino acid sequence set forth in SEQ ID NO: 207, SEQ ID NO: 208, SEQ ID NO: 209, SEQ ID NO: 210, SEQ ID NO: 211, or SEQ ID NO: 212; a CDR2 comprising the amino acid sequence set forth in SEQ ID NO: 213, SEQ ID NO: 214, SEQ ID NO: 215, SEQ ID NO: 216, SEQ ID NO: 217, or SEQ ID NO: 218; and a CDR3 comprising the amino acid sequence set forth in SEQ ID NO: 219.
- the Navi.7 binder comprises a CDR1 comprising the amino acid sequence set forth in SEQ ID NO: 201 or SEQ ID NO: 222; a CDR2 comprising the amino acid sequence set forth in SEQ ID NO: 223 or SEQ ID NO: 224; and a CDR3 comprising the amino acid sequence set forth in SEQ ID NO: 225, SEQ ID NO: 226, SEQ ID NO: 227, SEQ ID NO: 228, SEQ ID NO: 229, SEQ ID NO: 230, SEQ ID NO: 231, SEQ ID NO: 232, or SEQ ID NO: 233.
- the Navi.7 binder comprises a CDR1 comprising the amino acid sequence set forth in SEQ ID NO: 201; a CDR2 comprising the amino acid sequence set forth in SEQ ID NO: 205; and, a CDR3 comprising the amino acid sequence set forth in SEQ ID NO: 206.
- the Navi.7 binder comprises a CDR1 comprising the amino acid sequence set forth in SEQ ID NO: 211; a CDR2 comprising the amino acid sequence set forth in SEQ ID NO: 215; and, a CDR3 comprising the amino acid sequence set forth in SEQ ID NO: 219.
- the Navi.7 binder comprises a CDR1 comprising the amino acid sequence set forth in SEQ ID NO: 222; a CDR2 comprising the amino acid sequence set forth in SEQ ID NO: 223; and, a CDR3 comprising the amino acid sequence set forth in SEQ ID NO: 233.
- the Navi.7 binders comprise four frameworks: FR1, FR2, FR3, and FR4 wherein the Navi.7 binder is a single polypeptide having the structure beginning from the N-terminus FR1-CDR1-FR2-CDR2-FR3-CDR3-FR4.
- the numbering of the frameworks may be as shown herein be according to the Kabat numbering scheme and the junction between each framework and a CDR may be defined according to the AbM numbering scheme as shown herein.
- the Navi.7 binders comprise the VHH2-consensus frameworks FR1, FR2, FR3, and FR4, wherein FR1 has the amino acid sequence set forth in SEQ ID NO: 268, FR2 has the amino acid sequence set forth in SEQ ID NO: 269, FR3 has the amino acid sequence set forth in SEQ ID NO: 270, and FR4 has the amino acid sequence set forth in SEQ ID NO: 271.
- each framework may comprise one or more substitutions and or insertions with the proviso that the Navi.7 binder is capable of binding human Navi.7 ⁇ .
- frameworks may comprise one or more of the substitutions and/or insertions shown in Table 4 in any combination.
- FR1 may comprise one or more of the substitutions shown for FR1 in Table 4.
- FR2 may comprise one or more of the substitutions shown for FR2 in Table 4.
- FR3 may comprise one or more of the substitutions shown for FR3 in Table 4.
- FR4 may comprise one of the substitutions shown for FR4 in Table 4.
- each framework comprises at least one amino acid substitution.
- the Navi.7 binder comprises at least one substitution and/or insertion shown in Table 4 for each of FR1, FR2, FR3, and FR4.
- the Navi.7 binder comprises the one substitution or specific substitution and/or insertion combination shown in Table 4 for each of FR1, FR2, FR3, and FR4.
- the ISVD framework comprises one or more substitutions to minimize binding to pre-existing antibodies.
- Pre-existing antibodies are antibodies existing in the body of a patient prior to receipt of an ISVD and are immunoglobulins mainly of the IgG class that are present in varying degrees in up to 50% of the human population and that bind to critical residues clustered at the C-terminal region of ISVDs.
- the ISVDs of the present invention are based, in part, in llama antibodies whose C-terminal constant domains have been removed; thus, exposing the neo-epitopes in the C-terminus of the resulting VHH to preexisting antibody binding.
- Table H of Buyse & Boutton on page 97 showed comparative data for an ISVD with a V89L mutation alone (with or without C-terminal extension) and the same ISVD with a V89L mutation in combination with an LI IV mutation (again, with or without a C-terminal extension). Also, although generated in two separate experiments, the data shown in Table H for the LI 1V/V89L combination as compared to the data given in Table B for an LI IV mutation alone (in the same ISVD) showed that the pre-existing antibody binding reduction that is obtained by the LI 1V/V89L combination was greater than that for the LI IV mutation alone.
- the ISVD comprises at least the LI 1V/V89L substitutions in the framework regions.
- FR1 comprises at least an LI IV substitution and FR3 comprises at least a V89L substitution.
- the Navi.7 binder may comprise one of the 125 specific sets of FR1, FR2, FR3, and FR4 combinations shown in Table 4.
- the FR1 may further comprise a Q1E or a Q1D amino acid substitution.
- the Navi.7 binder comprises an amino acid sequence selected from the group consisting of SEQ ID NO: 46, SEQ ID NO: 47, SEQ ID NO: 48, SEQ ID NO: 49, SEQ ID NO: 50, SEQ ID NO: 51, SEQ ID NO: 52, SEQ ID NO: 53, SEQ ID NO: 54, and SEQ ID NO: 55.
- the Navi.7 binder comprises an amino acid sequence selected from the group consisting of SEQ ID NO: 69, SEQ ID NO: 70, SEQ ID NO: 71, SEQ ID NO: 72, SEQ ID NO: 73, SEQ ID NO: 74, SEQ ID NO: 75, SEQ ID NO: 76, SEQ ID NO: 77, SEQ ID NO: 78, SEQ ID NO: 79, SEQ ID NO: 80, and SEQ ID NO: 81.
- the Navi.7 binder comprises an amino acid sequence selected from the group consisting of SEQ ID NO: 82, SEQ ID NO: 83, SEQ ID NO: 84, SEQ ID NO: 85, SEQ ID NO: 86, SEQ ID NO: 87, SEQ ID NO: 88, SEQ ID NO: 89, SEQ ID NO: 90, SEQ ID NO: 91, SEQ ID NO: 92, SEQ ID NO: 93, SEQ ID NO: 94, SEQ ID NO: 95, SEQ ID NO: 96, and SEQ ID NO: 97.
- the Navi.7 binder comprises an amino acid sequence selected from the group consisting of SEQ ID NO: 98, SEQ ID NO: 99, SEQ ID NO: 100, SEQ ID NO: 102, SEQ ID NO: 103, SEQ ID NO: 104, SEQ ID NO: 105, SEQ ID NO: 106, SEQ ID NO: 107, SEQ ID NO: 108, SEQ ID NO: 109, SEQ ID NO: 110, SEQ ID NO: 111, SEQ ID NO: 112, SEQ ID NO: 113, SEQ ID NO: 114, SEQ ID NO: 115, SEQ ID NO: 116, SEQ ID NO: 117, SEQ ID NO: 118, SEQ ID NO: 119, SEQ ID NO: 120, SEQ ID NO: 121, SEQ ID NO: 122, SEQ ID NO: 123, SEQ ID NO: 124, SEQ ID NO: 125, SEQ ID NO: 126, SEQ ID NO: 127, SEQ ID NO: 120, SEQ
- the Navi.7 binder comprises an amino acid sequence selected from the group consisting of SEQ ID NO: 154, SEQ ID NO: 155, SEQ ID NO: 156, SEQ ID NO: 157, SEQ ID NO: 158, SEQ ID NO: 159, SEQ ID NO: 160, SEQ ID NO: 161, SEQ ID NO: 162, SEQ ID NO: 163, SEQ ID NO: 164, SEQ ID NO: 165, SEQ ID NO: 166, SEQ ID NO: 167, SEQ ID NO: 168, SEQ ID NO: 169, SEQ ID NO: 170, SEQ ID NO: 171, SEQ ID NO: 172, SEQ ID NO: 173, SEQ ID NO: 174, SEQ ID NO: 175, SEQ ID NO: 176, SEQ ID NO: 177, SEQ ID NO: 178, SEQ ID NO: 179, SEQ ID NO: 180, SEQ ID NO: 181, SEQ ID NO: 182, SEQ ID NO: 179, SEQ ID NO: 180
- the Navi.7 binder comprises the amino acid sequence set forth in SEQ ID NO: 96.
- the Navi.7 binder comprises the amino acid sequence set forth in SEQ ID NO: 148.
- the Navi.7 binder comprises the amino acid sequence set forth in SEQ ID NO: 192.
- the N-terminal Glu is substituted with Asp.
- Navi.7 binders of the invention can be fused or linked to one or more other amino acid sequences, chemical entities or moieties by a peptide or non-peptide linker. These other amino acid sequences, chemical entities or moieties can confer one or more desired properties to the resulting Navi.7 binders of the invention, for example, to provide the resulting Navi.7 binders of the invention with affinity against another therapeutically relevant target such that the resulting polypeptide becomes “bispecific” with respect to Navi.7 and that other therapeutically relevant target), or to provide a desired half-life, to provide a cytotoxic effect and/or to serve as a detectable tag or label.
- Some non-limiting examples of such other amino acid sequences, chemical entities or moieties are:
- Suitable peptide or polypeptide linkers such as a 9GS, 15GS or 35GS linker (any combination of 9, 15, 20 or 35 G and S amino acids such as, for example, GGGGSGGGS (9GS linker; SEQ ID NO: 243), GGGGSGGGGSGGGGSGGGGS (20GS linker; SEQ ID NO: 244) or GGGGSGGGGSGGGGS GGGGSGGGGSGGGGSGGGGS (35GS linker; SEQ ID NO: 245)), GGGGSGGGGSGGGGSGGGGSGGGGSGGGGSGGGGGGSGGGGS (50GS linker; SEQ ID NO: 463) or (GGGGS (SEQ ID NO: 246)) n wherein n is 1, 2, 3 ,4, 5, 6, 7, 8, 9 or 10); and/or
- binding moieties directed against a target other than Navi .7 or epitope thereof, for example, against a different epitope ofNavl.7 ⁇ , Navi. la, Navi.2a, Navi.3a , Navi.4a, Navi.5a, Navi.6a, Navi.8a, Navi.9a, Na x alpha subunit, a sodium channel beta subunit (e.g, Nav ⁇ 1, Nav ⁇ 2, Nav ⁇ 3, or Nav ⁇ 4), a calcium channel or a potassium channel); and/or
- binding domains or binding units that provide for an increase in half-life
- a binding domain or binding unit that can bind against a serum protein such as serum albumin, e.g., human serum albumin), e.g., ALBI 1002; See W0200868280;
- a binding domain, binding unit or other chemical entity that allows for the Navi.7 binder e.g, an ISVD such as a Nanobody® ISVD
- a desired cell for example, an internalizing anti-EGFR Nanobody® molecule as described in WO05044858;
- a chemical moiety that improves half-life such as a suitable polyethyleneglycol group (i.e. PEGylation) or an amino acid sequence that provides for increased half-life such as human serum albumin or a suitable fragment thereof (i.e. albumin fusion); and/or
- a payload such as a cytotoxic payload
- a detectable label or tag such as a radiolabel or fluorescent label
- a tag that can help with immobilization, detection and/or purification of the binder e.g. , an ISVD such as a Nanobody® ISVD), such as a HIS n , wherein n is 6 to 18, or FLAG tag or combination thereof (e.g., SEQ ID NO: 56);
- a tag that can be functionalized such as a C-terminal GGC tag
- a C-terminal extension X( n ) (e.g. , -Ala), which may be as further described herein for the Navi.7 binders (e.g., an ISVD such as a Nanobody® ISVD) of the invention and/or as described in WO12175741 or WO2015173325.
- the present invention further provides ISVDs that bind the Nav ⁇ 1 or NavP2 subunits.
- These Nav ⁇ binders comprise three CDRs having amino acid sequences selected from the table below.
- the CDR amino acid sequences shown in Table 5 are set forth according to the AbM numbering scheme for defining CDR amino acid sequences.
- a particular CDR amino acid sequence defined by any one of the other schemes advanced for defining CDR amino acid sequences See Table 1 may have more or less amino acids than shown for CDR amino acid sequences identified according to the AbM numbering scheme but will overlap the CDR amino acid sequences defined according the AbM numbering scheme.
- the CDR amino acid sequences shown herein are not to be construed as limiting and any Nav ⁇ binder in which the CDR amino acid sequences have been defined by any other numbering scheme will fall within the scope of the Nav ⁇ binders of the present invention provided the amino acid sequences for such Nav ⁇ binders comprise the amino acid sequences defined for the three CDR amino acid sequences as shown in Table 5.
- any Navp binder that comprises the three amino acid sequences defined for CDR1, CDR2, and CDR3 for any of the Navp binders shown in Table 5 are Navp binders of the present invention.
- the Navp binders comprise three CDRs and four Frameworks (FR) in the following alignment FR1-CDR1-FR2-CDR2-FR3-CDR3-FR4.
- the Navp binder CDRs may comprise CDRs comprising the following amino acid sequences.
- the Nav ⁇ 1 binder comprises a CDR1 comprising the amino acid sequence set forth in SEQ ID NO: 425, a CDR2 comprising the amino acid sequence set forth in SEQ ID NO: 426, and a CDR3 comprising the amino acid sequence set forth in SEQ ID NO: 427.
- the Nav ⁇ 1 binder comprises a CDR1 comprising the amino acid sequence set forth in SEQ ID NO: 437, a CDR2 comprising the amino acid sequence set forth in SEQ ID NO: 438, and a CDR3 comprising the amino acid sequence set forth in SEQ ID NO: 439.
- the Nav ⁇ 2 binder comprises a CDR1 comprising the amino acid sequence set forth in SEQ ID NO: 422, a CDR2 comprising the amino acid sequence set forth in SEQ ID NO: 423, and a CDR3 comprising the amino acid sequence set forth in SEQ ID NO: 424.
- the Nav ⁇ 2 binder comprises a CDR1 comprising the amino acid sequence set forth in SEQ ID NO: 428, a CDR2 comprising the amino acid sequence set forth in SEQ ID NO: 429, and a CDR3 comprising the amino acid sequence set forth in SEQ ID NO: 430.
- the Nav ⁇ 2 binder comprises a CDR1 comprising the amino acid sequence set forth in SEQ ID NO: 431, a CDR2 comprising the amino acid sequence set forth in SEQ ID NO: 432, and a CDR3 comprising the amino acid sequence set forth in SEQ ID NO: 433.
- the Nav ⁇ 2 binder comprises a CDR1 comprising the amino acid sequence set forth in SEQ ID NO: 434, a CDR2 comprising the amino acid sequence set forth in SEQ ID NO: 435, and a CDR3 comprising the amino acid sequence set forth in SEQ ID NO: 436.
- the Nav ⁇ 1 or Nav ⁇ 2 binders comprise four frameworks: FR1, FR2, FR3, and FR4 wherein the Nav ⁇ 1 or Nav ⁇ 2 binder is a single polypeptide having the structure beginning from the N-terminus FR1-CDR1-FR2-CDR2-FR3-CDR3-FR4.
- the numbering of the frameworks may be as shown herein be according to the Kabat numbering scheme and the junction between each framework and CDR may be determined by the AbM numbering scheme as shown herein.
- the Navi.7 binders comprise the VHH2-consensus frameworks FR1, FR2, FR3, and FR4, wherein FR1 has the amino acid sequence set forth in SEQ ID NO: 268, FR2 has the amino acid sequence set forth in SEQ ID NO: 269, FR3 has the amino acid sequence set forth in SEQ ID NO: 270, and FR4 has the amino acid sequence set forth in SEQ ID NO: 271.
- each framework may comprise one or more substitutions and or insertions with the proviso that the Nav ⁇ 1 or Nav ⁇ 2 binder is capable of binding human Navi.7 ⁇ .
- frameworks may comprise one or more of the substitutions and/or insertions shown in Table 4 in any combination.
- FR1 may comprise one or more of the substitutions shown for FR1 in Table 4.
- FR2 may comprise one or more of the substitutions shown for FR2 in Table 4.
- FR3 may comprise one or more of the substitutions shown for FR3 in Table 4.
- FR4 may comprise one of the substitutions shown for FR4 in Table 4.
- each framework comprises at least one amino acid substitution.
- the Nav ⁇ 1 or Nav ⁇ 2 binder comprises at least one substitution and/or insertion shown in Table 4 for each of FR1, FR2, FR3, and FR4.
- the Nav ⁇ 1 or Nav ⁇ 2 binder comprises the one substitution or specific substitution and/or insertion combination shown in Table 4 for each of FR1, FR2, FR3, and FR4.
- FR1 comprises at least an LI IV substitution and FR3 comprises at least a V89L substitution.
- the Nav ⁇ 1 or Nav ⁇ 2 binder may comprise one of the 125 specific sets of FR1, FR2, FR3, and FR4 combinations shown in Table 4.
- the FR1 may further comprise a Q1E or a Q1D amino acid substitution.
- the Nav ⁇ 1 binder comprises the amino acid sequence set forth in SEQ ID NO: 411.
- the Nav ⁇ 1 binder comprises the amino acid sequence set forth in SEQ ID NO: 415.
- the Nav ⁇ 2 binder comprises the amino acid sequence set forth in SEQ ID NO: 410.
- the Nav ⁇ 2 binder comprises the amino acid sequence set forth in SEQ ID NO: 412.
- the Nav ⁇ 2 binder comprises the amino acid sequence set forth in SEQ ID NO: 413.
- the Nav ⁇ 2 binder comprises the amino acid sequence set forth in SEQ ID NO: 414.
- the Nav ⁇ binders of the invention can be fused or linked to one or more other amino acid sequences, chemical entities or moieties by a peptide or non-peptide linker. These other amino acid sequences, chemical entities or moieties can confer one or more desired properties to the resulting Nav ⁇ binders of the invention, for example, to provide the resulting Nav ⁇ binders of the invention with affinity against another therapeutically relevant target such that the resulting polypeptide becomes “bispecific” with respect to Nav ⁇ and that other therapeutically relevant target), or to provide a desired half-life, to provide a cytotoxic effect and/or to serve as a detectable tag or label.
- Suitable peptide or polypeptide linkers such as a 9GS, 15GS or 35GS linker (any combination of 9, 15, 20 or 35 G and S amino acids such as, for example, GGGGSGGGS (9GS linker; SEQ ID NO: 243), GGGGSGGGGSGGGGSGGGGS (20GS linker; SEQ ID NO: 244) or GGGGSGGGGSGGGGS GGGGSGGGGSGGGGSGGGGS (35GS linker; SEQ ID NO: 245)), GGGGSGGGGSGGGGSGGGGSGGGGSGGGGSGGGGGGSGGGGS (50GS linker; SEQ ID NO: 463), or (GGGGS (SEQ ID NO: 246)) n wherein n is 1, 2, 3 ,4, 5, 6, 7, 8, 9 or 10); and/or
- binding moieties directed against a target other than Nav ⁇ or epitope thereof, for example, against a different epitope ofNav ⁇ , Navi. la, Navi.2a, Navi.3a, Navi.4a, Navi.5a, Navi.6a, Navi.7 ⁇ , Navi.8a, Navi.9a, Na x alpha subunit, a sodium channel beta subunit (e.g, Nav ⁇ 1, Nav ⁇ 2, Nav ⁇ 3, or Nav ⁇ 4), a calcium channel or a potassium channel); and/or
- binding domains or binding units that provide for an increase in half-life
- a binding domain or binding unit that can bind against a serum protein such as serum albumin, e.g, human serum albumin
- serum albumin e.g, human serum albumin
- ALB 11002 See W0200868280; WO2006122787 or W02012175400 and/or
- Nav ⁇ binder e.g. , an ISVD such as a Nanobody® ISVD
- a desired cell for example, an internalizing anti-EGFR Nanobody® molecule as described in WO05044858;
- a chemical moiety that improves half-life such as a suitable polyethyleneglycol group (i.e. PEGylation) or an amino acid sequence that provides for increased half-life such as human serum albumin or a suitable fragment thereof (i.e. albumin fusion); and/or
- a payload such as a cytotoxic payload
- a detectable label or tag such as a radiolabel or fluorescent label
- a tag that can help with immobilization, detection and/or purification of the binder e.g. , an ISVD such as a Nanobody® ISVD, such as a HIS n , wherein n is 6 to 18, or FLAG tag or combination thereof (e.g., SEQ ID NO: 56);
- an ISVD such as a Nanobody® ISVD, such as a HIS n , wherein n is 6 to 18, or FLAG tag or combination thereof (e.g., SEQ ID NO: 56);
- a tag that can be functionalized such as a C-terminal GGC tag
- Navi. 7-Navfl Bispeciflc Binders The present invention further provides Navl.7-Nav ⁇ bispecific binders comprising at least one Navi.7 binder and at least one Nav ⁇ binder linked together by peptide or polypeptide linker.
- Navl.7-Nav ⁇ bispecific binder refers to binders comprising one or more Navi.7 binders linked to one or more Nav ⁇ binders.
- the Navi.7- Nav ⁇ bispecific binders comprise a Navi.7 ISVD linked via a peptide or polypeptide linker at the C-terminus of the Navi .7 ISVD to the N-terminus of a Nav ⁇ ISVD.
- the Navl.7-Nav ⁇ bispecific binders comprise a Nav ⁇ ISVD linked via a peptide or polypeptide linker at the C-terminus of the Nav ⁇ ISVD to the N-terminus of a Navi .7 ISVD.
- the Navi .7- Nav ⁇ bispecific binders are provided as a continuous amino acid sequence.
- the peptide or polypeptide linker comprises repeating Gly (G) and Ser (S) amino acids to provide for example, 9GS, 15GS, or 35GS peptide or polypeptide linkers (any combination of 9, 15, 20 or 35 G and S amino acids such as, for example, GGGGSGGGS (9GS linker; SEQ ID NO: 243), GGGGSGGGGSGGGGSGGGGS (20GS linker; SEQ ID NO: 244) or GGGGSGGGGSGGGGS GGGGSGGGGSGGGGSGGGGS (35GS linker; SEQ ID NO: 245)), GGGGSGGGGSGGGGSGGGGSGGGGGGSGGGGSGGGGGGSGGGGS (50GS linker; SEQ ID NO: 463), or (GGGGS (SEQ ID NO: 246)) n wherein n is 1, 2, 3 ,4, 5, 6, 7, 8, 9 or 10).
- the N-terminal amino acid of the Navl.7-Nav ⁇ bispecific binders is an Asp or Glu amino acid and the C-terminus of the Navl.7-Nav ⁇ bispecific binders comprises a C-terminal extension of one or more Ala amino acids.
- the C-terminal extension consists of one Ala residue.
- the Nav ⁇ binder is a Nav ⁇ 1 binder or a Nav ⁇ 2 binder.
- the Navl.7-Nav ⁇ 1 bispecific binder comprises a Nav ⁇ 1 binder comprising (a) a CDR1 comprising the amino acid sequence set forth in SEQ ID NO: 425, a CDR2 comprising the amino acid sequence set forth in SEQ ID NO: 426, and a CDR3 comprising the amino acid sequence set forth in SEQ ID NO: 427; or (b) a CDR1 comprising the amino acid sequence set forth in SEQ ID NO: 437, a CDR2 comprising the amino acid sequence set forth in SEQ ID NO: 438, and a CDR3 comprising the amino acid sequence set forth in SEQ ID NO: 439.
- the Navl.7-Nav ⁇ 1 bispecific binder comprises aNav ⁇ 1 binder comprising the amino acid sequence set forth in SEQ ID NO: 411 or the amino acid sequence set forth in SEQ ID NO: 415.
- the Navl.7-Nav ⁇ 2 bispecific binder comprises a Nav ⁇ 2 binder comprising (a) a CDR1 comprising the amino acid sequence set forth in SEQ ID NO: 422, a CDR2 comprising the amino acid sequence set forth in SEQ ID NO: 423, and a CDR3 comprising the amino acid sequence set forth in SEQ ID NO: 424; (b) a CDR1 comprising the amino acid sequence set forth in SEQ ID NO: 428, a CDR2 comprising the amino acid sequence set forth in SEQ ID NO: 429, and a CDR3 comprising the amino acid sequence set forth in SEQ ID NO: 430; (c) a CDR1 comprising the amino acid sequence set forth in SEQ ID NO: 431, a CDR2 comprising the amino acid sequence set forth in SEQ ID NO: 432, and a CDR3 comprising the amino acid sequence set forth in SEQ ID NO: 433; or (d) a CDR1 comprising the amino acid sequence set forth
- the Navl.7-Nav ⁇ 1 bispecific binder comprises aNav ⁇ 2 binder comprising the amino acid sequence set forth in SEQ ID NO: 410, the amino acid sequence set forth in SEQ ID NO: 412, the amino acid sequence set forth in SEQ ID NO: 413, or amino acid sequence set forth in SEQ ID NO: 414.
- the Navl.7-Nav ⁇ 1 bispecific binder comprises a Navi.7 binder comprising (a) a CDR1 comprising the amino acid sequence set forth in SEQ ID NO: 196 or SEQ ID NO: 197; a CDR2 comprising the amino acid sequence set forth in SEQ ID NO: 198 or SEQ ID NO: 199; and, a CDR3 comprising the amino acid sequence set forth in SEQ ID NO: 200; (b) a CDR1 comprising the amino acid sequence set forth in SEQ ID NO: 201; a CDR2 comprising the amino acid sequence set forth in SEQ ID NO: 202, SEQ ID NO: 203, SEQ ID NO: 204, or SEQ ID NO: 205; and, a CDR3 comprising the amino acid sequence set forth in SEQ ID NO: 206; (c) a CDR1 comprising the amino acid sequence set forth in SEQ ID NO: 207, SEQ ID NO: 208, SEQ ID NO: 209, SEQ ID
- the Navi.7 binder comprising the Navl.7-Nav ⁇ bispecific binder comprises (a) an amino acid sequence selected from the group consisting of SEQ ID NO: 46, SEQ ID NO: 47, SEQ ID NO: 48, SEQ ID NO: 49, SEQ ID NO: 50, SEQ ID NO: 51, SEQ ID NO: 52, SEQ ID NO: 53, SEQ ID NO: 54, and SEQ ID NO: 55; (b) an amino acid sequence selected from the group consisting of SEQ ID NO: 69, SEQ ID NO: 70, SEQ ID NO: 71, SEQ ID NO: 72, SEQ ID NO: 73, SEQ ID NO: 74, SEQ ID NO: 75, SEQ ID NO: 76, SEQ ID NO: 77, SEQ ID NO: 78, SEQ ID NO: 79, SEQ ID NO: 80, and SEQ ID NO: 81; (c) an amino acid sequence selected from the group consisting of SEQ ID NO: 82,
- the Navi.7 binder comprising the Navl.7-Nav ⁇ bispecific binder comprises the amino acid sequence set forth in SEQ ID NO: 96; the amino acid sequence set forth in SEQ ID NO: 148; or, the amino acid sequence set forth in SEQ ID NO: 192.
- the N-terminal Glu is substituted with Asp.
- the N-terminal ISVD of the Navl.7-Nav ⁇ binder comprises an Asp amino acid residue at the N-terminus.
- the Navi.7 binders, Nav ⁇ binders, and Navl.7-Nav ⁇ bispecific binders of the present invention may further comprise one or more half-life extenders such as one or more anti- HSA (human serum albumin) binders and/or one or more polyethylene glycol (PEG) molecules.
- HSA human serum albumin
- PEG polyethylene glycol
- HSA binders bind to HSA (e.g., an ISVD such as a Nanobody® ISVD) as well as any binder which includes such a molecule that is fused to another binder.
- HSA e.g., an ISVD such as a Nanobody® ISVD
- An individual HSA binder may be referred to as an HSA binding moiety if it is part of a larger molecule, e.g., a multivalent molecule.
- the HSA binders of the invention that are fused to the Navi.7 binder, Nav ⁇ binder, or Navl.7-Nav ⁇ bispecific binder comprise the same combination of CDRs (i. e. , CDR1 , CDR2 and CDR3) as are present in ALB 11002 or comprise the amino acid sequence of ALB 11002 (SEQ ID NO: 234).
- the present invention also includes Navi.7 binders, Nav ⁇ binders, and Navi.7- Nav ⁇ bispecific binders that further include being linked by a peptide or polypeptide linker to one or more HSA binding moieties which are variants of ALBI 1002, e.g., wherein the HSA binder comprises CDR1, CDR2 and CDR3 of said ALBI 1002 variants set forth below in Table
- the ALBI 1002 further lacks the C-terminal Alanine
- the HSA binder comprises the amino acid sequence set forth in SEQ ID NO: 238 but which further comprises an EID, VI IL, and an L93V substitution to provide an HSA binder comprising the amino acid sequence set forth in SEQ ID NO: 240:
- This embodiment may further lack the C-terminal Alanine to provide the amino acid sequence set forth in SEQ ID NO: 239.
- the HLE is ALB11 comprising the amino acid sequence: EVQLVESGGGLVQPGNSLRLSCAASGFTFSSFGMSWVRQAPGKGLEWVSSISGSGSDTL YADSVKGRFTISRDNAKTTLYLQMNSLRPEDTAVYYCTIGGSLSRSSQGTLVTVSSA (SEQ ID NO: 242) and in a further embodiment lacks the C-terminal Alanine (SEQ ID NO:241).
- ALB00233 lacks a C-terminal A as shown in SEQ ID NO: 266.
- the half-life extender is an HSA binder comprising: a CDR1 that comprises the amino acid sequence GFTFSSFGMS (SEQ ID NO: 235) or GFTFRSFGMS (SEQ ID NO: 267); a CDR2 that comprises the amino acid sequence SISGSGSDTL (SEQ ID NO: 236); and a CDR3 that comprises the amino acid sequence GGSLSR (SEQ ID NO: 237).
- the first amino acid of any of the HSA binders is E and in another embodiment of the invention, the first amino acid of any of the HSA binders is D.
- the peptide or polypeptide linker comprises repeating Gly (G) and Ser (S) amino acids to provide for example, 9GS, 15GS, or 35GS peptide or polypeptide linkers (any combination of 9, 15, 20 or 35 G and S amino acids such as, for example, GGGGSGGGS (9GS linker; SEQ ID NO: 243), GGGGSGGGGSGGGGSGGGGS (20GS linker; SEQ ID NO: 244) or GGGGSGGGGSGGGGS GGGGSGGGGSGGGGSGGGGS (35GS linker; SEQ ID NO: 245)), GGGGSGGGGSGGGGSGGGGSGGGGGGSGGGGSGGGGGGSGGGGS (50GS linker; SEQ ID NO: 463), or (GGGGS (SEQ ID NO: 246)) n wherein n is 1, 2, 3 ,4, 5, 6, 7, 8, 9 or 10).
- the half-life extender is a polyethylene glycol (PEG) moiety appended to the Navi.7 binder, Nav ⁇ binder, or Navl.7-Nav ⁇ bispecific binder to provide a PEGylated Navl.7 binder, Nav ⁇ binder, or Navl.7-Nav ⁇ bispecific binder.
- the molecular weight of the polyethylene glycol (PEG) moiety may be about 12,000 daltons or about 20,000 daltons.
- the Navi.7 binder, Nav ⁇ binder, or Navl.7-Nav ⁇ bispecific binder comprises one or more polyethylene glycol molecules covalently attached via a linker (e.g., a C 2-12 alkyl such as -CH 2 CH 2 CH 2 -) to a single amino acid residue of a single subunit of the Navi.7 binder, Nav ⁇ binder, or Navl.7-Nav ⁇ bispecific binder, wherein said amino acid residue is the alpha amino group of the N-terminal amino acid residue or the epsilon amino group of a lysine residue.
- a linker e.g., a C 2-12 alkyl such as -CH 2 CH 2 CH 2 -
- the PEGylated binder is: (PEG)fo-L-NH- [binder]; wherein b is 1-9 and L is a C 2-12 alkyl linker moiety covalently attached to a nitrogen (N) of the single amino acid residue of the binder.
- the PEGylated binder has the formula: [X-O(CH 2 CH 2 O) n ]b-L- NH-[binder], wherein X is H or C 1 -4 alkyl; n is 20 to 2300; b is 1 to 9; and L is a C 1-11 alkyl linker moiety which is covalently attached to the nitrogen (N) of the alpha amino group at the amino terminus of one binder subunit; provided that when b is greater than 1, the total of n does not exceed 2300.
- N nitrogen
- PEGylation is carried out via an acylation reaction or an alkylation reaction with a reactive PEG molecule (or an analogous reactive water-soluble polymer).
- polyethylene glycol is intended to encompass any of the forms of PEG that have been used to derivatize other proteins, such as mono (C 1 -1 10 ) alkoxy- or aryloxy -poly ethylene glycol or polyethylene glycol-mal eimide.
- the binder to be PEGylated is an aglycosylated binder. Methods for PEGylating proteins are known in the art and can be applied to the binder of the invention. See, e.g., EP0154316 and EP0401384, each of which is incorporated herein by reference in its entirety.
- the Navi.7 binder, Nav ⁇ binder, or Navl.7-Nav ⁇ bispecific binder is fused at the C-terminus to an HC constant domain of Fc domain thereof domain.
- the HC domain or Fc domain thereof is of the IgGl, IgG2, IgG3, or IgG4 isotype.
- the amino acid sequences of the IgGl, IgG2, and IgG4 isotype HC constant domains are set forth in SEQ ID NO: 469, SEQ ID NO: 476, and SEQ ID No: 482, respectively.
- the Fc domain may comprise the CH2 and CH3 domains of the HC constant domain.
- the Fc domain may further comprise the hinge region between the CHI and CH2 domains or the hinge region comprising one or amino acid deletions.
- Navi.7 binders, Nav ⁇ binders, or Navl.7-Nav ⁇ bispecific binders are fused to an HC domain or Fc domain thereof of the IgGl, IgG2, or IgG4 isotype.
- the Navi.7 binders, Nav ⁇ binders, or Navi.7- Nav ⁇ bispecific binders are fused to the N-terminus of an HC domain or Fc domain thereof.
- the Navi.7 binders, Nav ⁇ binders, or Navl.7-Nav ⁇ bispecific binders are fused to the C-terminus of an HC domain or Fc domain thereof.
- Navl.7 binders, Nav ⁇ binders, or Navl.7-Nav ⁇ bispecific binders of the present invention further include ISVDs that are fused or linked to an effector-silent HC constant domain or Fc domain thereof.
- the effector-silent HC constant domain or Fc domain has been modified such that it displays no measurable binding to one or more FcRs or displays reduced binding to one or more FcRs compared to that of an unmodified HC constant domain or Fc domain of the same IgG isotype.
- the effector-silent HC constant domain or Fc domain may in further embodiments display no measurable binding to each of FcyRIIIa, FcyRIIa, and FcyRI or display reduced binding to each of FcyRIIIa, FcyRIIa, and FcyRI compared to that of an unmodified antibody of the same IgG isotype.
- the effector-silent HC constant domain or Fc domain is a modified human HC constant domain or Fc domain.
- the effector-silent HC constant domain or Fc domain thereof comprises an Fc domain of an IgGl or IgG2, IgG3, or IgG4 isotype that has been modified to lack /V-glycosylation of the asparagine (Asn) residue at position 297 (Eu numbering system) of the HC constant domain.
- the consensus sequence for /V-glycosylation is Asn-Xaa- Ser/Thr (wherein Xaa at position 298 is any amino acid except Pro); in all four isotypes the N- glycosylation consensus sequence is Asn-Ser-Thr.
- the modification may be achieved by replacing the codon encoding the Asn at position 297 in the nucleic acid molecule encoding the HC constant domain with a codon encoding another amino acid, for example Ala, Asp, Gin, Gly, or Glu, e.g. N297A, N297Q, N297G, N297E, or N297D.
- the codon for Ser at position 298 may be replaced with the codon for Pro or the codon for Thr at position 299 may be replaced with any codon except the codon for Ser.
- each of the amino acids comprising the /V-glycosylation consensus sequence is replaced with another amino acid.
- Such modified IgG molecules have no measurable effector function.
- these mutated HC molecules may further comprise 1, 2, 3, 4, 5, 6, 7, 8, 9, or 10 additional amino acid substitutions, insertions, and/or deletions, wherein said substitutions may be conservative mutations or non-conservative mutations.
- such IgGs modified to lack /V-glycosylation at position 297 may further include one or more additional mutations disclosed herein for eliminating measurable effector function.
- an exemplary IgGl HC constant domain or Fc domain thereof mutated at position 297, which abolishes the N-glycosylation of the HC constant domain is set forth in SEQ ID NO: 474
- an exemplary IgG2 HC constant domain mutated at position 297, which abolishes the /V-glycosylation of the HC constant is set forth in SEQ ID NO: 480
- an exemplary IgG4 HC constant domain mutated at position 297 to abolish /V-glycosylation of the HC constant domain is set forth in SEQ ID NO: 485.
- these mutated HC molecules may further comprise 1, 2, 3, 4, 5, 6, 7, 8, 9, or 10 additional amino acid substitutions, insertions, and/or deletions, wherein said substitutions may be conservative mutations or non-conservative mutations.
- the HC constant domain or Fc domain thereof of the IgGl IgG2, IgG3, or IgG4 HC constant domain is modified to include one or more amino acid substitutions selected from E233P, L234A, L235A, L235E, N297A, N297D, D265S, and P331S (wherein the positions are identified according to Eu numbering) and wherein said HC constant domain is effector-silent.
- the modified IgGl further comprise 1, 2, 3, 4, 5, 6, 7, 8, 9, or 10 additional amino acid substitutions, insertions, and/or deletions, wherein said substitutions may be conservative mutations or non-conservative mutations.
- the HC constant domain or Fc domain thereof comprises L234A, L235A, and D265S substitutions (wherein the positions are identified according to Eu numbering).
- the HC constant domain comprises an amino acid substitution at position Pro329 and at least one further amino acid substitution selected from E233P, L234A, L235A, L235E, N297A, N297D, D265S, and P331S (wherein the positions are identified according to Eu numbering).
- the HC constant domain or Fc domain thereof comprises an L234A/L235A/D265A; L234A/L235A/P329G; L235E; D265A; D265A/N297G; or V234A/G237A/P238S/H268A/V309L/A330S/P331S substitutions, wherein the positions are identified according to Eu numbering.
- the HC molecules further comprise 1, 2, 3, 4, 5, 6, 7, 8, 9, or 10 additional amino acid substitutions, insertions, and/or deletions, wherein said substitutions may be conservative mutations or non- conservative mutations.
- the effector-silent HC constant domain or Fc domain thereof comprises an IgGl isotype, in which the Fc domain of the HC constant domain has been modified to be effector-silent by substituting the amino acids from position 233 to position 236 of the IgGl with the corresponding amino acids of the human IgG2 HC and substituting the amino acids at positions 327, 330, and 331 with the corresponding amino acids of the human IgG4 HC, wherein the positions are identified according to Eu numbering (Armour et al., Eur. J. Immunol. 29(8):2613-24 (1999); Shields et al., J. Biol. Chem. 276(9):6591-604(2001)).
- the modified IgGl further comprise 1, 2, 3, 4, 5, 6, 7, 8, 9, or 10 additional amino acid substitutions, insertions, and/or deletions, wherein said substitutions may be conservative mutations or non-conservative mutations.
- the effector-silent HC constant domain or Fc domain thereof is a hybrid human immunoglobulin HC constant domain, which includes a hinge region, a CH2 domain and a CH3 domain in an N-terminal to C-terminal direction, wherein the hinge region comprises an at least partial amino acid sequence of a human IgD hinge region or a human IgGl hinge region; and the CH2 domain is of a human IgG4 CH2 domain, a portion of which, at its N-terminal region, is replaced by 4-37 amino acid residues of an N-terminal region of a human IgG2 CH2 or human IgD CH2 domain.
- Such hybrid human HC constant domain is disclosed in U.S. Pat. No. 7,867,491, which is incorporated herein by reference in its entirety.
- the effector-silent HC constant domain or Fc domain thereof is an IgG4 HC constant domain in which the serine at position 228 according to the Eu system is substituted with proline, see for example SEQ ID NO: 52.
- This modification prevents formation of a potential inter-chain disulfide bond between the cysteines at positions Cys226 and Cys229 in the EU numbering scheme and which may interfere with proper intra-chain disulfide bond formation. See Angal et al. Mol. Imunol. 30:105 (1993); see also (Schuurman et al., Mol. Immunol. 38: 1-8, (2001)).
- the IgG4 constant domain includes in addition to the S228P substitution, a P239G, D265A, or D265A/N297G amino acid substitution, wherein the positions are identified according to Eu numbering.
- the IgG4 HC constant domain is a human HC constant domain.
- the HC molecules further comprise 1, 2, 3, 4, 5, 6, 7, 8, 9, or 10 additional amino acid substitutions, insertions, and/or deletions, wherein said substitutions may be conservative mutations or non-conservative mutations.
- Exemplary IgGl HC constant domains comprise an amino acid sequence selected from the group consisting of amino acid sequences set forth in SEQ ID NO: 470, SEQ ID NO: 471, SEQ ID NO: 472, SEQ ID NO: 473, SEQ ID NO: 474, and SEQ ID NO: 475.
- Exemplary IgG2 HC constant domains comprise an amino acid sequence selected from the group consisting of amino acid sequences set forth in SEQ ID NO: 477, SEQ ID NO: 478, SEQ ID NO: 479, and SEQ ID NO: 480.
- Exemplary IgG4 HC constant domains comprise an amino acid sequence selected from the group consisting of amino acid sequences set forth in SEQ ID NO: 483, SEQ ID NO: 484, and SEQ ID NO: 485.
- the Navi.7 binder, Nav ⁇ binder, or Navl.7-Nav ⁇ bispecific binder is linked to the HC constant domain or Fc domain thereof by a peptide or polypeptide linker to provide a fusion protein comprising the structure binder-linker-HC constant domain or Fc domain thereof or HC constant domain-linker-binder wherein binder refers to Navi.7 binder, Nav ⁇ binder, or Navl.7-Nav ⁇ bispecific binder.
- the Fc domain thereof as used herein includes embodiments lacking the hinge region and embodiments wherein the Fc comprises one or amino acids of the hinge region.
- the peptide or polypeptide linker comprises repeating Gly (G) and Ser (S) amino acids to provide for example, 9GS, 15GS, or 35GS peptide or polypeptide linkers (any combination of 9, 15, 20 or 35 G and S amino acids such as, for example, GGGGSGGGS (9GS linker; SEQ ID NO: 243), GGGGSGGGGSGGGGSGGGGS (20GS linker; SEQ ID NO: 244) or GGGGSGGGGSGGGGS GGGGSGGGGSGGGGSGGGGS (35GS linker; SEQ ID NO: 245)), GGGGSGGGGSGGGGSGGGGSGGGGGGSGGGGSGGGGGGSGGGGS (50GS linker; SEQ ID NO: 463), or (GGGGS (SEQ ID NO: 246)) n wherein n is 1, 2, 3 ,4, 5, 6, 7, 8, 9 or 10).
- the Navi.7 binders, Nav ⁇ binders, or Navl.7-Nav ⁇ bispecific binders are fused to the N-terminus of an effector-silent HC domain or Fc domain thereof.
- the Navi.7 binders, Nav ⁇ binders, or Navl.7-Nav ⁇ bispecific binders are fused to the C-terminus of an effector-silent HC domain or Fc domain thereof.
- the Navi.7 binders, Nav ⁇ binders, or Navl.7-Nav ⁇ bispecific binders are linked to the N-terminus of an effector-silent HC domain or Fc domain thereof by anon-peptide linker, which in particular embodiments, may be a non-peptide polymer.
- the non-peptide polymer refers to a biocompatible polymer to which at least two repeat units are conjugated, and the repeat units are interconnected by random covalent bonds other than peptide bonds.
- the non-peptide polymer may be selected from the group consisting of polyethylene glycol, polypropylene glycol, a copolymer between ethylene glycol and propylene glycol, poly oxyethylated polyol, polyvinyl alcohol, polysaccharide, dextran, polyvinyl ethyl ether, a biodegradable polymer such as polylactic acid (PLA) and polylactic-glycolic acid (PLGA), lipid polymer, chitins, hyaluronic acid, and a combination thereof, and preferably, polyethylene glycol.
- PLA polylactic acid
- PLGA polylactic-glycolic acid
- lipid polymer chitins, hyaluronic acid, and a combination thereof, and preferably, polyethylene glycol.
- the non-peptide linker comprises polyethylene glycol, which in particular embodiments may be 3,400 daltons.
- Conjugates comprising a heterologous protein conjugated to an Fc domain by a non-peptide linker have been disclosed in U.S. Patent No. 7,636,420; 7,737,260; 7,968,316; 8,029,789; 8,110,665; 8,124,094; 8,822,650; 8,846,874; 9,394, 546; 10,071,171; 10,272,159; and 10,973,881, each of which is incorporated herein by reference in its entirety.
- the HC constant domain or Fc domain conjugates form a homodimer wherein each HC constant domain or Fc domain conjugates comprising the homodimer is fused or conjugated to the same binder selected from Navi.7 binder, Nav ⁇ binder, and Navl.7-Nav ⁇ bispecific binder.
- the HC constant domain or Fc domain conjugates form a heterodimer wherein a HC constant domain or Fc domain conjugate comprising the heterodimer is fused or conjugated to a binder selected from Navi.7 binder, Nav ⁇ binder, and Navl.7-Nav ⁇ bispecific binder and a second HC constant domain or Fc domain conjugate comprising the heterodimer is fused or conjugated to a binder selected from Navi.7 binder, Nav ⁇ binder, and Navl.7-Nav ⁇ bispecific binder that is not fused or conjugated to the first HC constant domain or Fc domain conjugate.
- the HC constant domain or Fc domain conjugate form a heterodimer wherein a first HC constant domain or Fc domain conjugate comprising the heterodimer is fused or conjugated to a binder selected from Navi.7 binder, Nav ⁇ binder, and Navl.7-Nav ⁇ bispecific binder and the second HC constant domain or Fc domain is not fused or conjugated to aNavl.7 binder, Nav ⁇ binder, and Navi.7- Nav ⁇ bispecific binder.
- the second HC constant domain or Fc domain is fused or conjugated to a heterologous protein, which may be the Fab of an antibody or ISVD other than aNavl.7 binder, Nav ⁇ binder, or Navl.7-Nav ⁇ bispecific binder; a heterologous protein, polypeptide, or peptide; or a small molecule.
- HC constant domain and Fc domain heterodimers have been disclosed in WO9627011; WO9850431; WO9929732; W02009089004; W02013055809; W02013063702; WO2014145907; and W02014084607, each of which is incorporated herein by reference in its entirety.
- the HC constant or Fc domains as disclosed herein may comprise a C-terminal lysine or lack either a C-terminal lysine or a C- terminal glycine-lysine dipeptide.
- the present invention further provides Navi.7 binders, Nav ⁇ binders, or Navi.7- Nav ⁇ bispecific binders that comprise a C-terminal extension.
- the present invention provides, for example, C-terminal extensions such as X( n ), wherein X and n can be as follows:
- C-terminal extensions are the following amino acid sequences: A, AA, AAA, G, GG, GGG, AG, GA, AAG, AGG, AGA, GGA, GAA or GAG.
- any C-terminal extension present in a Navi.7 binder, Nav ⁇ binder, or Navl.7-Nav ⁇ bispecific binder does not contain a free cysteine residue (unless said cysteine residue is used or intended for further functionalization, for example for PEGylation).
- the Navi.7 binders, Nav ⁇ binders, or Navl.7-Nav ⁇ bispecific binders disclosed herein may also be conjugated to a chemical moiety.
- a chemical moiety may be, inter alia, a polymer, a radionuclide or a cytotoxic factor.
- the chemical moiety is a polymer that increases the half-life of the Navi.7 binder, Nav ⁇ binder, or Navl.7-Nav ⁇ bispecific binder in the body of a subject.
- Suitable polymers include, but are not limited to, hydrophilic polymers, which include but are not limited to, polyethylene glycol (PEG) (e.g., PEG with a molecular weight of 2kDa, 5 kDa, 10 kDa, 12kDa, 20 kDa, 30kDa or 40kDa), dextran and monomethoxypolyethylene glycol (mPEG).
- PEG polyethylene glycol
- mPEG monomethoxypolyethylene glycol
- the Navi.7 binders, Nav ⁇ binders, or Navl.7-Nav ⁇ bispecific binders disclosed herein may also be conjugated with labels such as "TC, 90 Y, ni In, 32 P, 14 C, 125 1, 3 H, 131 I, 1 'C. 15 O, 13 N, 18 F, 35 S, 51 Cr, 57 TO, 226 Ra, 60 Co, 59 Fe, 57 Se, 152 Eu, 67 CU, 217 Ci, 211 At, 212 Pb, 47 Sc, 109 Pd, 234 Th, and 40 K, 157 Gd, 55 Mn, 52 Tr, and 56 Fe.
- labels such as "TC, 90 Y, ni In, 32 P, 14 C, 125 1, 3 H, 131 I, 1 'C. 15 O, 13 N, 18 F, 35 S, 51 Cr, 57 TO, 226 Ra, 60 Co, 59 Fe, 57 Se, 152 Eu, 67 CU, 217 Ci, 211 At, 212 P
- the Navi.7 binders may also be conjugated with fluorescent or chemiluminescent labels, including fluorophores such as rare earth chelates, fluorescein and its derivatives, rhodamine and its derivatives, isothiocyanate, phycoerythrin, phycocyanin, allophycocyanin, o- phthaladehyde, fluorescamine, 152 Eu, dansyl, umbelliferone, luciferin, luminal label, isoluminal label, an aromatic acridinium ester label, an imidazole label, an acridimium salt label, an oxalate ester label, an aequorin label, 2,3-dihydrophthalazinediones, biotin/avidin, spin labels and stable free radicals.
- fluorophores such as rare earth chelates, fluorescein and its derivatives, rhodamine and its derivatives, isothiocyanate, phycoerythr
- the Navi.7 binder, Nav ⁇ binder, or Navl.7-Nav ⁇ bispecific binder may also be conjugated to a cytotoxic factor such as diptheria toxin, Pseudomonas aeruginosa exotoxin A chain, ricin A chain, abrin A chain, modeccin A chain, alpha-sarcin, Aleurites fordii proteins and compounds (e.g., fatty acids), dianthin proteins, Phytolacca americana proteins PAPI, PAPII, and PAP-S, momordica charantia inhibitor, curcin, crotin, saponaria officinalis inhibitor, mitogellin, restrictocin, phenomycin, and enomycin.
- a cytotoxic factor such as diptheria toxin, Pseudomonas aeruginosa exotoxin A chain, ricin A chain, abrin A chain, modeccin A chain, alpha-sarcin,
- Any method known in the art for conjugating a Navi.7 binder, Nav ⁇ binder, or Navl.7-Nav ⁇ bispecific binder to the various moieties may be employed, including those methods described by Hunter, et al., (1962) Nature 144:945; David, et al., (1974) Biochemistry 13:1014; Pain, et al., (1981) J. Immunol. Meth. 40:219; and Nygren, J., (1982) Histochem. and Cytochem. 30:407. Methods for conjugating binders are conventional and very well known in the art.
- the present invention further provides nucleic acid molecules encoding any one of the Navi.7 binders, Nav ⁇ binders, or Navl.7-Nav ⁇ bispecific binders disclosed herein.
- the nucleic acid molecule encoding the Navi.7 binder comprises a nucleotide sequence selected from the group of nucleotide sequences set forth in SEQ ID NO: 273-283.
- the nucleic acid molecule encoding the Navi.7 binder comprises a nucleotide sequence selected from the group of nucleotide sequences set forth in SEQ ID NO: 284-421.
- the nucleic acid molecule encoding the Nav ⁇ binder comprises a nucleotide sequence selected from the group of nucleotide sequences set forth in SEQ ID NO: 456-461.
- the following examples are intended to promote a further understanding of the present invention.
- the amino acid sequences for the Navi.7 binder, Nav ⁇ binder, or Navi.7- Nav ⁇ bispecific binders and nucleic acid sequences encoding the Navi.7 binder, Nav ⁇ binder, or Navl.7-Nav ⁇ bispecific binders that are disclosed in the following examples are provided in Table 56.
- Various embodiments of the aforementioned binders comprise an amino acid sequence set forth in Table 56.
- amino acid sequences for huNavl.7 ⁇ , rhNavl.7 ⁇ , huNavl.la, huNavl.2a, huNav 1.3a, huNavl.4a, huNavl.5a, huNavl.6a, and huNavl.8a are set forth in SEQ ID NO: 1, SEQ ID NO: 2, SEQ ID NO: 23, SEQ ID NO: 24, SEQ ID NO: 25, SEQ ID NO: 26, SEQ ID NO: 27, and SEQ ID NO: 28, respectively.
- HEK cell lines expressing huNavl.la, huNavl.2a, huNav 1.3 a, huNav 1.4a, huNav 1.5 a, huNav 1.6a, or huNav 1.8 a were constructed.
- the Nav constructs where indicated were fused at the C-terminus via a P2A viral peptide linker (SEQ ID NO: 43) to a single polypeptide encoding sodium channel beta subunits pi (SEQ ID NO: 40), ⁇ 2 (SEQ ID NO: 41), and ⁇ 3 (SEQ ID NO: 42) in tandem in which each ⁇ subunit is separated from the preceding P subunit by a P2A viral peptide linker (referred to herein as ⁇ 1- ⁇ 2- ⁇ 3; See SEQ ID NO:21).
- the P2A peptide linker facilitates a co-translational cleavage event that effectively liberates polypeptides N-terminal and C-terminal to it.
- Plasmid constructs and expression vectors Table 7 gives an overview of all plasmid constructs and expression vectors.
- HEK293T cells were seeded at a concentration of 1.5 x 10 6 per T75 flask and incubated overnight at 37°C in DMEM (Dulbecco’s modified Eagle’s medium; Gibco, catalog # 31966) supplemented with 10% FBS (fetal bovine serum, Sigma. Catalog # F7524). The medium was then replaced by Opti-MEM medium (Gibco, catalog # 31985).
- DMEM Dulbecco’s modified Eagle’s medium
- FBS fetal bovine serum, Sigma. Catalog # F7524
- Binding of the ISVDs to cell-expressed Navi.7 ⁇ was detected via murine antiFlag (Sigma, catalog # Fl 804). Briefly, cells were resuspended in FACS buffer (PBS, 10% FBS, 0.05% NaN3) and transferred to a 96-well V-bottom plate at 1 * 10 ⁇ cells/well. Purified FLAG3-tagged ISVD was diluted in FACS buffer and added to the cells for 30 minutes at 4°C. ISVD binding was detected by resuspending the samples subsequently in 100 pL murine anti- Flag at 1 pg/mL and 100 pL APC-labelled goat anti-mlgG (Jackson ImmunoResearch, catalog # 115-135-164).
- the samples Prior to the read-out, the samples were resuspended in 1 pg/mL propidium iodide (Sigma, catalog # P4170) to exclude dead cells. Between each step, the cells were centrifuged for 5 minutes at 200 grams and washed with 100 pL/well FACS buffer.
- An alternative approach used PE-labelled goat anti-murine IgG (Jackson ImmunoResearch, catalog
- Control antibodies were detected as follows.
- Murine anti-Navl.7 ⁇ mAb S68-6 (Abeam, catalog # ab85015) was detected by PE-conjugated goat anti-murine IgG (Jackson ImmunoResearch, catalog # 115-116-071) after fixation and permabilization of the cells with FIX & PERM kit according to the manufacturer's instructions (ThermoFisher Scientific, catalog
- Rabbit anti-Navl.5a pAb (Alomone Labs, catalog # ASC-013) was detected with PE-conjugated goat anti-rabbit IgG (Jackson ImmunoResearch, catalog # 711-116-152) after fixation and permabilization of the cells with FIX & PERM kit according to the manufacturer’s instructions (ThermoFisher Scientific, catalog # GAS003).
- Rabbit anti-human pL pAb (ThermoFisher Scientific, catalog # PA5-24142) was detected with PE-conjugated goat antirabbit IgG (Jackson ImmunoResearch, catalog # 711-116-152). Immunizations
- PBMCs peripheral blood mononuclear cells
- Ficoll- Hypaque according to the manufacturer’s instructions (Amersham Biosciences, Piscataway, NJ, US).
- RNA was extracted and used as starting material for RT-PCR to amplify the VHH/ISVD-encoding DNA segments, essentially as described in WO05044858.
- phages were prepared according to standard protocols (see for example the prior art and applications filed by Ablynx N.V. cited herein.) and stored after filter sterilization at 4 °C for further use.
- VHH repertoires obtained from all camelids and cloned as phage library were subjected for two or three consecutive selection rounds to proteoliposome (PL) (5pg/mL) or amphipol (amphipathic surfactant for maintaining solubilized membrane proteins in detergent- free solutions, catalog # A835, Anatrace) preparations (5 pg/mL) derived from HEK293 cells recombinantly expressing huNavl.7 ⁇ together with Nav ⁇ 1, Nav ⁇ 2, and Nav ⁇ 3 subunits (P 1 -P2- P3).
- proteoliposome 5pg/mL
- amphipol amphipathic surfactant for maintaining solubilized membrane proteins in detergent- free solutions
- Each selection round was performed in the presence of the following competing agents: 100 pg/mL of in house produced membrane extracts from HEK293 cells and 100 nM each of recombinant Nav ⁇ 1 (Abnova, catalog # H00006324-P01), Nav ⁇ 2 (Sino Biological, catalog # 13859-H02H) and Nav ⁇ 3 (Sino Biological, catalog # 13500-H02H). After antigen incubation of the libraries and extensive washing; bound phage were eluted with trypsin (1 mg/mL) for 15 minutes and then the protease activity was immediately neutralized by applying 0.8 mM protease inhibitor ABSF.
- ISVD- containing DNA fragments obtained by PCR with specific combinations of forward FR1 and reverse FR4 primers each carrying a unique restriction site, were digested with the appropriate restriction enzymes and ligated into the matching cloning cassettes of ISVD expression vectors (described below). The ligation mixtures were then transformed to electrocompetent Escherichia coli TGI (60502, Lucigen, Middleton, WI) cells which were then grown under the appropriate antibiotic selection pressure. Resistant clones were verified by Sanger sequencing of plasmid DNA (LGC Genomics, Berlin, Germany).
- Monovalent ISVDs were expressed in E. coli TGI from a plasmid expression vector containing the lac promoter, a resistance gene for kanamycin, an E. coli replication origin and an ISVD cloning site preceded by the coding sequence for the OmpA signal peptide.
- the vector codes for a C- terminal FLAG3 (or CMYC3) and HIS6 tag.
- the signal peptide directs the expressed ISVDs to the periplasmic compartment of the bacterial host.
- the tested clones herein comprise the ISVD amino acid sequence shown for it in Table 56 further fused at the C-terminus to a FLAG-HIS6 polypeptide (SEQ ID NO: 56) or HIS6.
- the amino acid positions in the ISVDs disclosed herein are numbered according to the Kabat numbering scheme.
- E. coli TG-1 cells containing the ISVD constructs of interest were grown for 2 hours at 37°C followed by 29 hours at 30°C in baffled shaker flasks containing “5052” autoinduction medium (0.5% glycerol, 0.05% glucose, 0.2% lactose + 3 mM MgSOq). Overnight frozen cell pellets from E. coli expression cultures are then dissolved in PBS (1/12.5 th of the original culture volume) and incubated at 4°C for one hour while gently rotating. Finally, the cells were pelleted down once more, and the supernatant containing the proteins secreted into the periplasmic space was stored for further purification.
- HIS6-tagged ISVDs were purified by immobilized metal affinity chromatography (IMAC) on either Ni-Excel (GE Healthcare) or Ni- IDA/NTA (Genscript) resins with Imidazole (for the former) or acidic elution (for the latter) followed by a desalting step (PD columns with Sephadex G25 resin, GE Healthcare) and if necessary, gel filtration chromatography (Superdex column, GE Healthcare) in PBS.
- IMAC immobilized metal affinity chromatography
- amino acid sequences for the ten ISVDs (Navi.7 binders) without the FLAG- HIS6 peptide (SEQ ID NO: 56) are shown in SEQ ID NO: 46, 47, 48, 49, 50, 51, 52, 53, 54, and 55, respectively.
- Affinity maturation was used to further improve the functional potencies of selected ISVDs by means of in vitro affinity maturation.
- the same process was applied to improve the NHP cross-reactivity to enable in vivo proof of concept (POC) studies in rhesus monkeys.
- In vitro affinity maturation of ISVDs is a two-stage process that aims to improve binding-related properties like affinity, species crossreactivity or potency. First, all CDR-based residues are systematically changed to every possible amino acid on a one-by-one basis.
- the resulting libraries of single site substitution variants pooled per CDR are then screened for improvement of the desired property after which the hits are identified by means of Sanger sequencing.
- the beneficial single site substitutions are then combined into a library of combinatorial variants which are evaluated for further improvement of the desired property, followed by Sanger sequencing of hits.
- the generation the DNA fragments encoding the ISVD variants is either outsourced to commercial providers GeneWiz (South Plainfield, NJ) or IDT (Coralville, IA) or performed in house using commonly known molecular biology techniques such as site-directed mutagenesis, overlap extension PCR and oligonucleotide gene assembly (In Vitro Mutagenesis Protocols, 2 nd Edition (2002), Jeff Braman ed., Humana Press, Totowa NJ).
- stage I hits have substitutions in 7/10, 7/9, and 5/15 positions of respectively CDR1, CDR3 and CDR3.
- substitutions in three of these positions (27, 28 and 53) recapitulate some of the differences between F0103275B05 and its rhNavl.7 ⁇ cross-reactive relative F0103387G04 and thus bring additional confidence in the outcome of the stage I screening.
- These three substitutions were included in the design of the stage II combinatorial library (bottom row of Table 8), in which 11 positions were allowed to vary between the parental F0103275B05 and the highest ranked stage I hit residue.
- the top 25% of the hits are enriched for the N93R substitution but display a lower proportion of the N30L, 131W, A35R, G55W and T57W substitutions.
- the bottom 25% of the hits displayed a lower proportion of the 131W and A35R substitutions.
- An analysis of the subset of the top 25% hits that did not carry the N93R mutation revealed that these were enriched for the S33R, S50Y and S56D substitutions and had a lower proportion of A94W, compared to the reference sample.
- a number of combinatorial affinity maturation variants of F0103275B5 were then characterized in detail in binding FACS and electrophysiology (Table 11).
- a pooled single site saturation library of F0103265 Al 1 was constructed and crude periplasmic extracts of 1848 individual clones were prepared and screened in binding FACS on huNavl.7 ⁇ and rhNavl.7 ⁇ . Clones with a single mutation in CDR2, CDR3 or CDR1 residues showed an improved binding to huNavl.7 ⁇ , but not to rhNavl.7 ⁇ (Fig. 12).
- stage I hits have substitutions in 3 of 10, 7 of 11, and 4 of 6 positions of respectively CDR1, CDR3 and CDR3. Of interest, four CDR2 positions (51, 53, 56 and 57) have substitutions to a Trp residue.
- the top 25% of the hits are enriched for the A31R, V60N and S93A substitutions but display a lower proportion of the N30Y, I51W, S53W, T57V and N58T substitutions.
- the bottom 25% of the hits are enriched for the T57V, S93A and L103Q substitutions but display a lower proportion of the N30Y, 151W and S53W substitutions.
- Affinity maturation of F0103265B04 A pooled single site saturation library of F0103265B04 was constructed and crude periplasmic extracts of 2016 individual clones were prepared and screened in binding FACS on huNavl.7 ⁇ and rhNavl.7 ⁇ . No clones with a single mutation in CDR3, CDR2 or CDR1 residues showed an improved binding to huNavl.7 ⁇ or rhNavl.7 ⁇ (Fig. 10). The outliers in the top right quadrant of Fig. 10 was determined to be a contamination with F0103240B04, a ⁇ 2 binding ISVD.
- a pooled single site saturation library of F0103387G05 was constructed and crude periplasmic extracts of 3360 individual clones were prepared and screened in binding FACS on huNavl.7 ⁇ and rhNavl.7 ⁇ . Clones with a single mutation of CDR2, CDR3 or CDR1 residues showed weakly improved binding to huNavl.7 ⁇ , but not to rhNavl.7 ⁇ (Fig. 11).
- a pooled single site saturation library of F0103362B08 was constructed and crude periplasmic extracts of 4032 individual clones were prepared and screened in binding FACS on huNavl.7 ⁇ and rhNavl.7 ⁇ . Clones with a single mutation of CDR2, CDR3 or CDR1 residues showed weakly improved binding to huNavl.7 ⁇ , but not to rhNavl.7 ⁇ (Fig. 12).
- a pooled single site saturation library of F0103464B09 was constructed and crude periplasmic extracts of 3356 individual clones were prepared and screened in binding FACS on huNavl.7 ⁇ and rhNavl.7 ⁇ . Clones with a single mutation of mainly CDR2 residues showed weakly improved binding to rhNavl ,7 ⁇ , but hardly not to huNavl ,7 ⁇ (Fig. 13).
- a combinatorial library was generated with a diversity of 320 different variants, as summarized by Table 17.
- Crude periplasmic of 2880 clones of the stage II combinatorial library were prepared and screened in binding FACS on huNavl.7 ⁇ and rhNavl.7 ⁇ .
- a large fraction of the variants display improved binding to rhNavl.7 ⁇ compared to the parental F0103464B09 (Fig. 14), indicating that the library design successfully captured and improved the promise of the stage I library.
- No outspoken improvements for binding to huNavl.7 ⁇ were observed for stage II, in line with the observations during stage I.
- FACS assays were performed with CMYC3-tagged ISVD F0103265B04 or F0103275B05(N93R) affinity maturation variant on aHEK Flpin huNavl.7 ⁇ + ⁇ 1- ⁇ 2- ⁇ 3 transgenic cell line. Briefly, cells were resuspended in FACS buffer (PBS, 2% FBS, 0.05% NaN 3 ) and 1 x 10 5 cells/well were transferred to 96-well V-bottom plates.
- FACS buffer PBS, 2% FBS, 0.05% NaN 3
- CMYC3-tagged ISVD F0103265B04 at a concentration equivalent to EC30
- Residual binding of CMYC3-tagged ISVD F0103265B04 was detected with 100 ⁇ L murine anti-CMYC (1/250 dilution) (Bio-Rad, catalog # MCA2200) followed by PE-conjugated goat anti-murine (Jackson Immunoresearch, catalog #115-116-071).
- the cells were centrifuged for 5 minutes at 200 g and washed with 100 pL/well FACS buffer. Prior to the read-out, the samples were resuspended in 5nM TOPRO3 (Molecular probes, catalog # T3605) to exclude dead cells.
- F0103262C02, F0103262B06, F0103265A11, F0103265B04, F0103275B05, F0103362B08, and F0103387G04 all compete with F0103265B04 for binding to huNavl.7 ⁇ , in contrast to an irrelevant control ISVD (IRR) (see Table 21 and Fig. 15A, Fig. 15B, Fig. 15C, and Fig. 15D).
- IRR irrelevant control ISVD
- Binding to huNavl.7a-Navl.5 chimeras FACS binding studies (as described above) were performed on HEK293T cells transiently transfected with expression vectors encoding a huNavl.7a or rhNavl.7a fused at the C-terminus via a P2A viral peptide linker to a single polypeptide encoding sodium channel beta subunits Nav01, Nav02, and Nav03 in tandem ( ⁇ 1- ⁇ 2- ⁇ 3; SEQ ID NO:21).
- HEK293T cells transiently transfected with expression vectors encoding chimeric variants of huNavl.7a in which individual domains are replaced by their huNavl.5 ⁇ counterparts (chimeras 1 to 4 in Fig. 16) or with chimeric variants of huNavl.5 in which individual domains are replaced by their huNavl.7a counterparts (chimeras 5 to 8 in Fig. 16) fused at the C-terminus via a P2A viral peptide linker to 01-02-03 as above. See Table 7 for description of the expression vectors encoding the chimeras, Table 21 and Fig. 16).
- FACS binding studies were performed on HEK293T cells transiently transfected with a chimeric variant of huNavl.7 ⁇ in which all the huNavl.7 ⁇ - rhNavl.7 ⁇ polymorphisms of DI are present (N146S, V194I, F276V, R277Q, E281V, V331M, E504D, D507E, S508N, N533S).
- F0103262C02, F0103275B05 and F0103387G05 are more subtly affected in terms of EC50 or Bmax by some of the polymorphisms. None of the individual DI S5-S6 polymorphisms by themselves appear to have an impact on the binding of the two rhNavl.7 ⁇ cross-reactive ISVDs F0103387G04 and F0103464B09. In addition, no effect on binding of the two ISVDs was observed (data not shown) for the three extracellular DIV VSD huNavl.7 ⁇ - rhNavl.7 ⁇ polymorphisms Q1530P, H1531Y and E1534D (Fig. 22G).
- the extracellular solution contained (in mM): 138 NaCl, 4 KC1, 1.8 CaC12, 1 MgC12, 10 HEPES, 5.6 glucose (pH 7.2 with NaOH, and 285 - 290 mOsmolar).
- Intracellular solution contained (in mM): 5 NaCl, 100 CsF, 45 CsCl, 10 HEPES, 5 EGTA (pH 7.45 with CsOH, and 300 - 315 mOsmolar). These solutions were freshly made, filtered and stocked for no longer than 6 months at 4 °C.
- HEK Flp-In and CHO Flp-In cells stably expressing the human Navi.7 ⁇ channel were generated.
- Cells were cultured in T-175 cell culture flasks (Greinerbio-one, catalog # 660160) using standard cell culture conditions.
- CHO Flp-In culture medium consists of F12 nutrient mix (Gibco, catalog # 31765) containing 10 % FBS (Sigma- Aldrich, catalog # F7524), 0.8 mg/mL hygromycin B (Invitrogen, catalog # 10687010).
- HEK Flp-In culture medium consists of DMEM GlutamaxTM (Gibco, catalog # 31966) containing 10 % FBS (Sigma- Aldrich, catalog # F7524), 0.8 mg/mL hygromycin B (Invitrogen, catalog # 10687010), 1% NEAA (Gibco, catalog # 11140) and 1% Na-pyruvate (Gibco, catalog # 11360). Cells were seeded at a density of 1.7 x 1Q4 cells/cm 2 (Hek293 Flp-In) or 5.7 x 1Q3 cells/cm 2 (CHO Flp-In) for 2 days before being used in the lonFlux 16 (Fluxion).
- Optimal cell confluence prior to harvesting never exceeded 80 %.
- the cells were washed twice with d-PBS without Ca2+ and Mg2+ (Gibco, catalog # 14190) and detached with 4 mL Trypsin/EDTA 0.25% (Invitrogen, catalog # 25200- 056) for 5 to 10 min at 37°C.
- Medium containing 10 % FBS is added to inactivate the enzymatic reaction triggered by the trypsin.
- the cells were counted (Casy TT, Roche) and centrifuged at 200 x g during 2 min at RT in 50 mL conical CELLSTAR® tube (Greiner Bio- One, catalog # 227-261) suspended at 1 x 10 6 cells/ml in CHO-S-SFMII (Gibco, catalog # 12052) supplemented with 25 mM Hepes (Gibco, catalog # 15630), transferred to a 25 mL cell culture flask (Greiner Bio-One, catalog # 690190) and gently shaken at RT for approximately 20 min. 1 x 10 7 cells were centrifuged for 2 min at 200 x g.
- the pellet is gently resuspended in 5 mL extracellular buffer and centrifuged a second time for 2 min at 200 x g. Finally, the pellet is resuspended in 2000 pl extracellular buffer and immediately tested on the lonFlux. lonFlux Automated patch clamp procedure
- 250 pL of sterile cell culture grade water is dispensed into every well of the lonFlux 96-well plate except the outlet wells, using an eight channel multi-pipette. Any excess water on the rim of the plate is wiped off before rinsing the plate.
- the designated plate is inserted into the lonFlux system and subsequently rinsed 4 times according to a standard Water Rinse protocol. After rinsing, the plate is emptied. The inlet wells were then manually filled with extracellular buffer, trap wells with intracellular buffer and the diluted ISVDs or selective peptides were distributed into the compounds wells (250 pL/well). Subsequently, the plate is primed before the actual experiment according to the plate specific protocols.
- Whole cell access is achieved by rupturing the patch of the membrane over the hole using the break protocol.
- a different protocol is used for CHO or HEK293 cells.
- a time course protocol is applied to assess the effect of the compounds on sodium currents elicited by a depolarizing pulse protocol.
- cells were clamped at -100 mV for 50 milliseconds then hyperpolarized to -120 mV for 100 milliseconds, and repolarized to -80 mV for 30 milliseconds.
- Two data acquisition protocols were used: single pulse and two pulse.
- Single pulse protocol cells were clamped at a holding potential of -100 mV, stepped to -120 mV for 100 milliseconds to maximize channel availability and then to -30 mV for 50 milliseconds to open the Na + channels.
- the sweep interval was five seconds with a holding potential of -80Mv (Fig. 23 A).
- sodium currents were elicited by a depolarizing step from -80 mV to -30 mV for 1000 millieseconds, followed by 10ms hyperpolarization at -120 mV and a second depolarizing step at -30 mV for 10 milliseconds.
- the sweep interval was 9 seconds with a holding potential of -80mV (Fig. 23B).
- extracellular buffer is continuously perfused for 120 seconds as a negative control, followed by sequential perfusion of different concentrations of ISVDs or selective peptides.
- EXAMPLE 8 Sequence optimization is a process in which parental ISVD sequences are mutated to yield ISVD sequences that are more identical to human and/or llama/alpaca IGHV3- IGHJ germline consensus sequences.
- Specific amino acids with the exception of the so-called hallmark residues, in the FRs that differ between the ISVD and the human IGHV3-IGHJ germline consensus are altered to the human counterpart in such a way that the protein structure, activity and stability are kept intact.
- the amino acids present in the CDRs for which there is experimental evidence that they are sensitive to post-translational modifications (PTMs) are altered in such a way that the PTM site is inactivated while the protein structure, activity and stability are kept intact.
- certain FR residues are altered.
- amino acid residue differences in the CDR regions are not taken into account for sequence optimization. All amino acid differences in the FRs between the ISVD and the human VH3-JH consensus counterparts are identified. Typically, these amino acid residues (numbered according to Kabat) fall into three classes:
- Hallmarks These residues are known to be critical for the stability/activity/affinity of the ISVD (based on literature). Therefore, these positions are usually not included in the process. Only when a hallmark is deviating from its llama germline, it is taken into account to be mutated back to the llama/alpaca germline sequence to evaluate potential improvements in stability/activity/affinity. When taken into account this mutation is investigated on an individual basis.
- a potential PTM site will only be mutated when there is evidence that the particular site is sensitive to modification under accelerated stress conditions. If a particular amino acid position is insensitive, the parental sequence will be left unchanged in the final construct. Assessment of chemical stability by means of accelerated stress studies is performed by CMC.
- the N-terminal Glu residue of the first block of an ISVD construct will always be mutated to an Asp (EID) because experimental evidence has shown that the majority of ISVDs is significantly sensitive to pyroglutamate formation and that the EID mutation has no effect on stability/activity/affinity of the ISVD.
- EID Asp
- Percent amino acid identity in the FRs of the ISVD vs the human VH3-JH consensus sequence wherein the CDRs may be defined by Kabat, IMGT, AbM, Chothia, or the like. In particular embodiments, the calculation is performed in which the CDRs are defined by at least two methods.
- Fig. 28 shows a sequence analysis of F0103275B05/387G04 aligned against the human VH3-J3 consensus sequence and the llama VHH2 consensus sequence.
- the thermal shift assay was performed in a 96-well plate on the LightCycler 480II machine (Roche). Per row, one sample was analyzed according to the following pH range: 3.5 / 4 / 4.5 / 5 / 5.5 / 6 / 6.5 / 7 / 7.5 / 8 / 8.5 / 9. Per well, 5 ⁇ L of sample (0.8 mg/ml in PBS) was added to 5 pL of Sypro Orange (40x in MilliQ water; Invitrogen cat. No. S6551) and 10 pL of buffer (100 mM phosphate, 100 mM borate, 100 mM citrate and 115 mM NaCl with a pH ranging 3.5 to 9).
- the applied temperature gradient (37 to 99°C at a rate of 0.03°C/s) induces unfolding of the ISVDs whereby their hydrophobic patches become exposed.
- the inflection point of the first derivative of the fluorescence intensity curve at pH 7 serves as a measure of the melting temperature (Tm).
- Variant F010302383 was selected as the final sequence optimization variant of F0103387G04 (see F0103387G04_SO in Fig. 28). It boasts a 2- and 20-fold improved binding on huNavl.7 ⁇ and rhNavl.7 ⁇ respectively, as well as comparable aSEC and OD340nm behavior and a slightly reduced thermal stability (Table 31). In vitro electrophysiology experiments confirmed the low nM potency on huNavl.7 ⁇ and rhNavl.7 ⁇ and selectivity over Navi.4, Navi.5 ⁇ and Navi.6a. All PTM liabilities (Table 24) were successfully substituted. Cell-free fermentation expression titers at CMC of the corresponding monovalent tagless variant F01032396 in P. pastoris were 3.6 g/L.
- N73Q substitution resulted in a better binding profile compared to the parental reference (Table 33) and was further evaluated, as well as N73A andN73Y substitutions.
- Variant F010302391 was selected as the final sequence optimization variant of
- F0103387G05 (see F0103387G05_SO in Fig. 29). It boasts a comparable binding on human Navi.7 ⁇ , as well as comparable aSEC and OD340 nm behavior, an improved thermal stability at low pH and a reduced Tagg (Table 36 and Fig. 30).
- Cell-free fermentation expression titers at CMC of the corresponding monovalent tagless variant F010302400 in P. pastoris were 2.5 g/L.
- Variant F010302363 was selected as the final sequence optimization variant of F0103464B09 (see F0103464B09_SO in Fig. 31). It boasts a strongly improved binding on rhesus Navi.7 ⁇ , reduced binding to muNavl.7 ⁇ , as well as comparable aSEC and OD340 nm behavior and an improved thermal stability (Table 41). In vitro electrophysiology experiments confirmed the low nM potency on huNavl.7 ⁇ and rhNavl.7 ⁇ and selectivity over Navi.4a, Navi.5a, and Navi.6a. All PTM liabilities (Table 37) were successfully substituted. Cell-free fermentation expression titers at CMC of the corresponding monovalent tagless variant F01032390 in P. pastoris were 2.0 g/L.
- Table 42 summarizes the screening data of five lead ISVD candidates F0103478E09, F0103492E09, F0103495F09, F0103500E03 and F0103505D08 (for the screening each F0103478E09, F0103492E09, F0103495F09, F0103500E03 and F0103505D08 was linked at the N-terminus to the C-terminus of an F103275B05(N93R)-50GS moiety to form a bivalent ISVD) for which the totality of the data in comparison to a control (bivalent ISVD F010300702 comprising an irrelevant anti-RSV building block linked at the N- terminus to the C-terminus of an F103275B05(N93R)-50GS moiety) suggests that they bind in an avid fashion to Navi.7 ⁇ :
- ISVD F0103240B04 was identified by means of binding ELISA as a candidate Nav ⁇ 2 binder. Binding FACS (Fig. 33) and binding ELISA (Fig. 34B) experiments with purified monovalent protein suggest that F0103240B04 is indeed a potent Nav ⁇ 2 binder.
- F0103495F09 was not evaluated as purified monovalent protein in the binding ELISA or binding FACS experiments using transiently transfected cells because binding FACS experiments using stable cell lines suggest that it recognizes a HEK293-specific cell background marker (See Fig. 36E). Additional competition FACS experiments with Navi.7 ⁇ - Nav ⁇ -subunit bispecific ISVDs; however, classify F103495F09 as a weak Nav ⁇ 1 binder, similar to F0103478E09. Binding ELISA
- HEK huNavl.7 ⁇ -Nav ⁇ 1 (huNavl.7-pi) expressing cells and HEK293T null ME cells were coated in bicarbonate buffer (pH9.6) overnight at 4°C in 384- well HB Spectraplate (catalog # 6007500, Perkin Elmer). Wells were blocked with 4 % Marvel in PBS.
- periplasmic extracts either peri (1/5) or purified ISVD
- 2 % Marvel Premier Foods Group, St Albans, UK
- PBS Periplasmic extracts
- FLAG3-tagged ISVD binding was detected using a mouse anti-Flag-HRP conjugate (catalog # A8592-1MG, Sigma) and a subsequent enzymatic reaction in the presence of the substrate esTMB (3, 3’, 5,5’- tetramentylbenzidine) (catalog # #esTMB, SDT). Plates were read out on a MultiSkan device (ThermoFisher Scientific) at OD450. EC50 values were calculated using four-parameter logistic curves in GraphPad Prism7.
- HEKhuNavl.7 ⁇ -Nav ⁇ 1-Nav ⁇ 2-Nav ⁇ 3 huNavl.7-pi- P2-P3
- cl. 11 PL was used as coated antigen in combination with detection of CMYC3-tagged ISVDs by mouse anti-c-myc biotin conjugate (catalog # MCA2200B Serotec) followed by extravidin-HRP conjugate (catalog # E2886, Sigma-Aldrich).
- Bispecific leads were generated, fusing different anti-Nav ⁇ ISVDs to the C- terminus of the rhesus cross-reactive anti-Navl.7 ⁇ ISVD F103275B05(N93R) by means of a long flexible 50GS linker.
- the bispecifics were evaluated for their ability to compete for binding with the monovalent F0103275B05(N73R) variant to Navi.7 ⁇ in FACS experiments on different cell lines.
- the data shown in Table 43, Figs. 37A-37B, and Figs. 38A-38C reveals 10- to 1000-fold improved competition FACS IC50 values compared to the monovalent F0103275B05(N73R) control (F010300468 in table).
- HLE half-life extension
- huFc fusions were generated with the F0103265B04.
- the huFc moiety is based on hlgGl with LALA and D265S mutations to reduce the interaction with FcyR.
- F0103265B04 is fused to the N-terminus of the huFc separated by a number of linkers with differing flexibilities as described elsewhere (Klein et al. Protein Eng Des Sei. 27:325-30 (2014), which is incorporated herein by reference in its entirety).
- Comparison of the different constructs in binding FACS revealed EC50 values comparable to monovalent F0103265B04 (Table 46), with the exception of 22ARO which suffered from a drop in potency.
- functional characterization using a single pulse electrophysiology protocol (Fig. 7A) revealed potencies highly favorable compared to monovalent F0103265B04 (last column of Table 46). Future experiments should determine whether these improvements are Fc-or linker-mediated.
- Table 50, Table 51, Table 52, Table 53, Table 54, and Table 55 show the results.
- N.E. means “no effect” and ND means “not determined”.
Landscapes
- Health & Medical Sciences (AREA)
- Chemical & Material Sciences (AREA)
- Organic Chemistry (AREA)
- Immunology (AREA)
- Medicinal Chemistry (AREA)
- Life Sciences & Earth Sciences (AREA)
- General Health & Medical Sciences (AREA)
- Proteomics, Peptides & Aminoacids (AREA)
- Genetics & Genomics (AREA)
- Molecular Biology (AREA)
- Biophysics (AREA)
- Biochemistry (AREA)
- General Chemical & Material Sciences (AREA)
- Chemical Kinetics & Catalysis (AREA)
- Anesthesiology (AREA)
- Nuclear Medicine, Radiotherapy & Molecular Imaging (AREA)
- Pharmacology & Pharmacy (AREA)
- Animal Behavior & Ethology (AREA)
- Public Health (AREA)
- Veterinary Medicine (AREA)
- Peptides Or Proteins (AREA)
Abstract
Antibodies and antigen-binding fragments thereof that bind the human voltage-gated sodium channel Nav1.7α protein subunit (Nav1.7 binders) are described. In particular embodiments, the Nav1.7 binders comprise a heavy-chain immunoglobulin single variable domain (ISVD or VHH).
Description
TITLE OF THE INVENTION NAV1.7 BINDERS BACKGROUND OF THE INVENTION Field of the Invention The present invention relates to antibodies and antigen-binding fragments thereof that bind the human voltage-gated sodium channel Nav1.7α protein subunit (Nav1.7 binders). In particular, the present invention relates to Nav1.7 binders comprising a heavy-chain immunoglobulin single variable domain (ISVD or VHH). Description of Related Art Nav1.7α subunit belongs to a family of nine voltage-gated sodium channels that play crucial roles in the electrical conductance of skeletal muscles (Nav1.4α), cardiac muscles (Nav1.5α), central (Nav1.1α, Nav1.2α, Nav1.3α and Nav1.6α) and peripheral (Nav1.1α, Nav1.6α, Nav1.7α, Nav1.8α and Nav1.9α) neurons. Nav1.7α is mainly expressed on different types of afferent fibres of the peripheral nervous system and is essential to the firing of action potentials by boosting subthreshold stimuli (Dib-Hajj & Waxman 2015 Pain 156: 2406). Extensive genetic evidence in mice and men suggests that Nav1.7 is necessary and non- redundant in pain and olfactory pathways (reviewed by Dib-Hajj et al.2013 Nat Rev Neurosci. 14: 49). Interestingly, a large and diverse body of naturally occurring toxins acts on voltage- gated sodium channels, including Nav1.7α (reviewed by Deuis et al., 2017 Neuropharmaco DOI10.1016/j.neuropharm.2017.04.014). Nav1.7α has been one of the most hotly pursued targets in the field of chronic pain where there is a large unmet need (reviewed by de Lera Ruiz & Kraus 2015 J Med Chem 58: 7093). Marketed painkillers like local anaesthetics effectively target voltage-gated sodium channels but suffer from undesired side effects prohibiting widespread use in chronic pain indications. Recent efforts to generate more selective Nav1.7α small molecule inhibitors or modified peptide toxins have failed to deliver a marketed drug so far. Attempts to generate selective anti-Nav1.7α biologicals were not reproducible (Lee et al 2014 Cell 157:1393; Liu et al.2016 F1000Res 5:2764; and many patents). Four consecutive similar domains, DI to DIV (Fig.1), make up the nearly 2,000 amino acids large Nav1.7α channel. Each domain has six transmembrane helices (S1 to S6 in bottom panel Fig.1 connected by extracellular loops (ECLs) and intracellular loops (ICLs) (respectively solid and dotted lines in bottom panel Fig.1. Two small (S1-S2 and S3-S4) and
one larger (S5-S6) ECL per domain make up the limited extracellular surface of the channel accessible to biologicals (cytoplasmic membrane is marked by dotted lines in top right panel in Fig. 1). The different domains are connected by ICLs (S6-S1) and both N- and C-terminal ends reside at the cytoplasmic side of the channel (marked respectively by N and C in bottom panel Fig. 1). Each domain consists of a voltage sensor domain (VSD; S1-S4) and ion-conducting pore domain (PD; S5-S6) arranged such that the VSD of each domain is closest to the PD of the following domain, in a clockwise orientation. The central Na+-conducting pore of the channel (marked by a star in bottom panel 1) is formed by the PDs and their ECLs that line the cavity. Fig. 32 is a schematic representation of Navi.7α.
Voltage-gated sodium channels may interact with different Navβ-subunits (Navβ1 to Navβ4) that among other things can modulate the channels’ electrophysiological properties and cell surface expression levels (reviewed by Winters & Isom 2016 Current Topics in Membranes 78: 315). The bottom panel of Fig.l depicts suggested interaction sites for three different Navβ-subunits, according to recent findings (Das et al. 2016 eLIFE 5:el0960; Zhu et al. 2017 J Gen Physiol 149: 813; Yan et al. 2017 Cell 170: 470).
A detailed sequence comparison of the different ECLs of huNavl.7α to their ortholog and paralog counterparts can be found in Figs. 2A-2B. Different splice variants of Navi.7α exist that through interaction with Navβ1 impact on the electrophysiological properties of the channel (Chatelier et al. 2008 J Neurophysiol 99: 2241; Farmer et al. 2012 PLoS ONE 7: e41750). The major technical drawbacks of Navi.7α as a target for biologicals are its poor cell surface expression level combined with a limited accessibility to the extracellular surface.
BRIEF SUMMARY OF THE INVENTION
The present invention provides Navi.7 binders, which are immunoglobulin single variable domains (ISVDs) that bind and inhibit Navi.7 α channels with exquisite selectivity over other Nav channel paralogs. The Navi.7 binders may be useful for preparing formulations for treating chronic pain or pain.
The present invention provides Navi.7 binders that bind to a human voltage-gated sodium channel Navi.7α protein subunit (human NaV1.7α subunit) between amino acids 272 and 331 of the human NaV1.7α subunit Domain 1 S5-S6 loop, wherein the human NaV1.7α subunit comprises the amino acid sequence set forth in SEQ ID NO: 1. In particular embodiments, the Nav 1.7 binder contacts amino acids F276, R277, E281, and V331 of the human NaV1.7α subunit, which in particular embodiments, binds to the human NaV1.7α subunit
with lower affinity than to human NaV1.7α subunit lacking such substitutions. In certain embodiments, the Navi.7 binder further is capable of binding a rhesus monkey human NaV1.7α subunit with a lower affinity than it binds to the human NaV1.7α subunit.
The Navi.7 binder is an antibody or an antibody fragment, which in specific embodiments is a heavy chain antibody or an ISVD. In particular embodiments, the heavy chain antibody is a camelid antibody and the ISVD is a VHH.
In particular embodiments, the Navi.7 binder comprises (a) a complementarity determining region (CDR) 1, CDR1, comprising the amino acid sequence set forth in SEQ ID NO: 247, a CDR2 comprising the amino acid sequence set forth in SEQ ID NO: 248, and a CDR3 comprising the amino acid sequence set forth in SEQ ID NO: 249; or (b) a CDR1 comprising the amino acid sequence set forth in SEQ ID NO: 250, a CDR2 comprising the amino acid sequence set forth in SEQ ID NO: 251, and a CDR3 comprising the amino acid sequence set forth in SEQ ID NO: 252; or (c) a CDR1 comprising the amino acid sequence set forth in SEQ ID NO: 253, a CDR2 comprising the amino acid sequence set forth in SEQ ID NO: 254, and a CDR3 comprising the amino acid sequence SRY; or (d) a CDR1 comprising the amino acid sequence set forth in SEQ ID NO: 256, a CDR2 comprising the amino acid sequence set forth in SEQ ID NO: 257, and a CDR3 comprising the amino acid sequence set forth in SEQ ID NO: 258; or (e) a CDR1 comprising the amino acid sequence set forth in SEQ ID NO: 259, a CDR2 comprising the amino acid sequence set forth in SEQ ID NO: 260, and a CDR3 comprising the amino acid sequence set forth in SEQ ID NO: 261; or (I) a CDR1 comprising the amino acid sequence set forth in SEQ ID NO: 262, a CDR2 comprising the amino acid sequence set forth in SEQ ID NO: 263, and a CDR3 comprising the amino acid sequence set forth in SEQ ID NO: 264; or (g) a CDR1 comprising the amino acid sequence set forth in SEQ ID NO: 196, a CDR2 comprising the amino acid sequence set forth in SEQ ID NO: 198, and a CDR3 comprising the amino acid sequence set forth in SEQ ID NO: 200; or (h) a CDR1 comprising the amino acid sequence set forth in SEQ ID NO: 201, a CDR2 comprising the amino acid sequence set forth in SEQ ID NO: 202, and a CDR3 comprising the amino acid sequence set forth in SEQ ID NO: 206; or (i) a CDR1 comprising the amino acid sequence set forth in SEQ ID NO: 207, a CDR2 comprising the amino acid sequence set forth in SEQ ID NO: 213, and a CDR3 comprising the amino acid sequence set forth in SEQ ID NO: 219; or (j) a CDR1 comprising the amino acid sequence set forth in SEQ ID NO: 221, a CDR2 comprising the amino acid sequence set forth in SEQ ID NO: 223, and a CDR3 comprising the amino acid sequence set forth in SEQ ID NO: 225.
In a further embodiment, the Navi.7 binder comprises (a) a CDR1 comprising the amino acid sequence set forth in SEQ ID NO: 196 or SEQ ID NO: 197; a CDR2 comprising the amino acid sequence set forth in SEQ ID NO: 198 or SEQ ID NO: 199; and, a CDR3 comprising the amino acid sequence set forth in SEQ ID NO: 200; or (b) a CDR1 comprising the amino acid sequence set forth in SEQ ID NO: 201; a CDR2 comprising the amino acid sequence set forth in SEQ ID NO: 202, SEQ ID NO: 203, SEQ ID NO: 204, or SEQ ID NO: 205; and, a CDR3 comprising the amino acid sequence set forth in SEQ ID NO: 206; or (c) a CDR1 comprising the amino acid sequence set forth in SEQ ID NO: 207, SEQ ID NO: 208, SEQ ID NO: 209, SEQ ID NO: 210, SEQ ID NO: 211, or SEQ ID NO: 212; a CDR2 comprising the amino acid sequence set forth in SEQ ID NO: 213, SEQ ID NO: 214, SEQ ID NO: 215, SEQ ID NO: 216, SEQ ID NO: 217, or SEQ ID NO: 218; and a CDR3 comprising the amino acid sequence set forth in SEQ ID NO: 219; or (d) a CDR1 comprising the amino acid sequence set forth in SEQ ID NO: 201 or SEQ ID NO: 222; a CDR2 comprising the amino acid sequence set forth in SEQ ID NO: 223 or SEQ ID NO: 224; and a CDR3 comprising the amino acid sequence set forth in SEQ ID NO: 225, SEQ ID NO: 226, SEQ ID NO: 227, SEQ ID NO: 228, SEQ ID NO: 229, SEQ ID NO: 230, SEQ ID NO: 231, SEQ ID NO: 232, or SEQ ID NO: 233; or (e) a CDR1 comprising the amino acid sequence set forth in SEQ ID NO: 201; a CDR2 comprising the amino acid sequence set forth in SEQ ID NO: 205; and, a CDR3 comprising the amino acid sequence set forth in SEQ ID NO: 206; or (I) a CDR1 comprising the amino acid sequence set forth in SEQ ID NO: 211; a CDR2 comprising the amino acid sequence set forth in SEQ ID NO: 215; and, a CDR3 comprising the amino acid sequence set forth in SEQ ID NO: 219; or (g) a CDR1 comprising the amino acid sequence set forth in SEQ ID NO: 222; a CDR2 comprising the amino acid sequence set forth in SEQ ID NO: 223; and, a CDR3 comprising the amino acid sequence set forth in SEQ ID NO: 233.
In a further embodiment the Navi.7 binder comprises (a) an amino acid sequence selected from the group consisting of SEQ ID NO: 69, SEQ ID NO: 70, SEQ ID NO: 71, SEQ ID NO: 72, SEQ ID NO: 73, SEQ ID NO: 74, SEQ ID NO: 75, SEQ ID NO: 76, SEQ ID NO: 77, SEQ ID NO: 78, SEQ ID NO: 79, SEQ ID NO: 80, and SEQ ID NO: 81; or (b) an amino acid sequence selected from the group consisting of SEQ ID NO: 82, SEQ ID NO: 83, SEQ ID NO: 84, SEQ ID NO: 85, SEQ ID NO: 86, SEQ ID NO: 87, SEQ ID NO: 88, SEQ ID NO: 89, SEQ ID NO: 90, SEQ ID NO: 91, SEQ ID NO: 92, SEQ ID NO: 93, SEQ ID NO: 94, SEQ ID NO: 95, SEQ ID NO: 96, and SEQ ID NO: 97; or (c) an amino acid sequence selected from the group consisting of SEQ ID NO: 98, SEQ ID NO: 99, SEQ ID NO: 100, SEQ ID NO: 102, SEQ
ID NO: 103, SEQ ID NO: 104, SEQ ID NO: 105, SEQ ID NO: 106, SEQ ID NO: 107, SEQ ID NO: 108, SEQ ID NO: 109, SEQ ID NO: 110, SEQ ID NO: 111, SEQ ID NO: 112, SEQ ID NO: 113, SEQ ID NO: 114, SEQ ID NO: 115, SEQ ID NO: 116, SEQ ID NO: 117, SEQ ID NO: 118, SEQ ID NO: 119, SEQ ID NO: 120, SEQ ID NO: 121, SEQ ID NO: 122, SEQ ID NO: 123, SEQ ID NO: 124, SEQ ID NO: 125, SEQ ID NO: 126, SEQ ID NO: 127, SEQ ID NO: 128, SEQ ID NO: 129, SEQ ID NO: 130, SEQ ID NO: 131, SEQ ID NO: 132, SEQ ID NO: 133, SEQ ID NO: 134, SEQ ID NO: 135, SEQ ID NO: 136, SEQ ID NO: 137, SEQ ID NO: 138, SEQ ID NO: 139, SEQ ID NO: 140, SEQ ID NO: 141, SEQ ID NO: 142, SEQ ID NO: 143, SEQ ID NO: 144, SEQ ID NO: 145, SEQ ID NO: 146, SEQ ID NO: 147, SEQ ID NO: 148, SEQ ID NO: 149, SEQ ID NO: 150, SEQ ID NO: 151, SEQ ID NO: 152, and SEQ ID NO: 153; or (d) an amino acid sequence selected from the group consisting of SEQ ID NO: 154, SEQ ID NO: 155, SEQ ID NO: 156, SEQ ID NO: 157, SEQ ID NO: 158, SEQ ID NO: 159, SEQ ID NO: 160, SEQ ID NO: 161, SEQ ID NO: 162, SEQ ID NO: 163, SEQ ID NO: 164, SEQ ID NO: 165, SEQ ID NO: 166, SEQ ID NO: 167, SEQ ID NO: 168, SEQ ID NO: 169, SEQ ID NO: 170, SEQ ID NO: 171, SEQ ID NO: 172, SEQ ID NO: 173, SEQ ID NO: 174, SEQ ID NO: 175, SEQ ID NO: 176, SEQ ID NO: 177, SEQ ID NO: 178, SEQ ID NO: 179, SEQ ID NO: 180, SEQ ID NO: 181, SEQ ID NO: 182, SEQ ID NO: 183, SEQ ID NO: 184, SEQ ID NO: 185, SEQ ID NO: 186, SEQ ID NO: 187, SEQ ID NO: 188, SEQ ID NO: 189, SEQ ID NO: 190, SEQ ID NO: 191, SEQ ID NO: 192, SEQ ID NO: 193, SEQ ID NO: 194, and SEQ ID NO: 195.
In particular embodiments, the Navi.7 binder comprises a C-terminal alanine residue.
In particular embodiments, the Navi.7 binder is conjugated to a half-life extender, which in certain embodiments is a human serum albumin (HSA) binder or the crystallizable fragment (Fc) of an antibody. HSA binders include but are not limited ALBI 1002 or ALB00223. In particular embodiments, the Navi.7 binder is conjugated to is polyethylene glycol, which provides half-life extension.
The present invention further provides for use of a Navi.7 binder disclosed herein for the manufacture of a medicament for the treatment of chronic pain.
The present invention further provides for use of a Navi.7 binder disclosed herein for the treatment of chronic pain.
The present invention further provides a method for treating an individual with chronic pain comprising administering to the individual a therapeutically effective amount of a Navi.7 binder disclosed herein to treat the chronic pain. The individual may be a human patient
in need of pain relief. The human patient may be treated in a hospital setting or in an out-patient setting. The Navi.7 binder may be administered by syringe, autoinjector, dose-settable delivery device, or the like.
The present invention further provides a composition comprising a Navi.7 binder disclosed herein and a pharmaceutically acceptable carrier.
The present invention further provides a nucleic acid molecule encoding the Navi .7 binder disclosed herein. In a further embodiment the nucleic acid molecule encoding the Navi.7 binder comprises a nucleotide sequence selected from the group consisting of nucleotide sequences set forth in SEQ ID NO: 273-283. In a further embodiment the nucleic acid molecule encoding the Navi.7 binder comprises a nucleotide sequence selected from the group consisting of nucleotide sequences set forth in SEQ ID NO: 284-421.
The present invention further provides a vector comprising the nucleic acid molecule encoding aNav.7 binder. The present invention further provides a host cell comprising a nucleic acid molecule encoding a Navi.7 binder disclosed herein.
The present invention further provides a method for producing a Navi.7 binder disclosed herein comprising: (a) providing a host cell comprising a nucleic acid molecule encoding a Navi .7 binder disclosed herein or a vector comprising a nucleic acid molecule encoding the Navi.7 binder disclosed herein; (b) cultivating the host cell in a medium under conditions suitable for expression of the Navi.7 binder by the host cell; and (c) isolating the Navi.7 binder from the medium to provide the Navi.7 binder.
The present invention further provides aNavβ1 binder comprising (a) a first immunoglobulin single variable domain (ISVD) comprising three complementarity determining regions (CDRs) wherein CDR1 comprises the amino acid sequence set forth in SEQ ID NO: 425, CDR2 comprises the amino acid sequence set forth in SEQ ID NO: 426, and CDR3 comprises the amino acid sequence set forth in SEQ ID NO: 427; or (b) a second ISVD comprising three CDRs wherein CDR1 comprises the amino acid sequence set forth in SEQ ID NO: 437, CDR2 comprises the amino acid sequence set forth in SEQ ID NO: 438, and CDR3 comprise the amino acid sequence set forth in SEQ ID NO: 439.
In a further embodiment of the Navβ1 binder, the first ISVD comprises the amino acid sequence set forth in SEQ ID NO: 411 and the second ISVD comprises the amino acid sequence set forth in SEQ ID NO: 415. In a further embodiment, the N-terminal amino acid of the first ISVD or the second ISVD is linked to the C-terminal amino acid of a Navi .7 binder of claim 1 by a peptide or polypeptide linker or the N-terminal amino acid of the Navi.7 binder of
claim 1 is linked to the C-terminal amino acid of the first ISVD or the second ISVD by a peptide or polypeptide linker.
In further embodiments of the Navβ1 binder, the peptide or polypeptide linker comprises any combination of glycine and serine amino acids up to 40 amino acids. In a further embodiment of the Navβ1 binder, the peptide or polypeptide linker comprises an amino acid sequence comprising GGGGS (SEQ ID NO: 246))n wherein n is 1, 2, 3 ,4, 5, 6, 7, 8, 9 or 10. In a particular embodiment, the polypeptide linker comprises the amino acid sequence set forth in SEQ ID NO: 463.
The present invention further provides a nucleic acid molecule encoding a Navβ1 binder disclosed herein. In a further embodiment, the Navβ1 binder comprises a nucleotide sequence selected from the group consisting of nucleotide sequences set forth in SEQ ID NO: 456 and 461.
The present invention further provides a vector comprising the nucleic acid molecule encoding aNavβ1 binder disclosed herein. The present invention further provides a host cell comprising a nucleic acid molecule encoding aNavβ1 binder disclosed herein.
The present invention further provides a method for producing a Navβ1 binder disclosed herein comprising: (a) providing a host cell comprising a nucleic acid molecule encoding a Navβ1 binder disclosed herein or a vector comprising a nucleic acid molecule encoding the Navβ1 binder disclosed herein; (b) cultivating the host cell in a medium under conditions suitable for expression of the Navβ1 binder by the host cell; and (c) isolating the Navβ1 binder from the medium to provide the Navβ1 binder.
The present invention further provides aNavβ2 binder comprising (a) a first immunoglobulin single variable domain (ISVD) comprising three complementarity determining regions (CDRs) wherein CDR1 comprises the amino acid sequence set forth in SEQ ID NO: 422, a CDR2 comprising the amino acid sequence set forth in SEQ ID NO: 423, and a CDR3 comprising the amino acid sequence set forth in SEQ ID NO: 424; (b) a second ISVD comprising three CDRs wherein CDR1 comprises the amino acid sequence set forth in SEQ ID NO: 428, a CDR2 comprising the amino acid sequence set forth in SEQ ID NO: 429, and a CDR3 comprising the amino acid sequence set forth in SEQ ID NO: 430; (c) a third ISVD comprising three CDRs wherein CDR1 comprises the amino acid sequence set forth in SEQ ID NO: 431, a CDR2 comprising the amino acid sequence set forth in SEQ ID NO: 432, and a CDR3 comprising the amino acid sequence set forth in SEQ ID NO: 433; or (d) a fourth ISVD comprising three CDRs wherein CDR1 comprises the amino acid sequence set forth in SEQ ID
NO: 434, a CDR2 comprising the amino acid sequence set forth in SEQ ID NO: 435, and a CDR3 comprising the amino acid sequence set forth in SEQ ID NO: 436.
In a further embodiment of the Navβ2 binder, the first ISVD comprises the amino acid sequence set forth in SEQ ID NO: 410, the second ISVD comprises the amino acid sequence set forth in SEQ ID NO: 412, the third ISVD comprises the amino acid sequence set forth in SEQ ID NO: 413, and the fourth ISVD comprises the amino acid sequence set forth in SEQ ID NO: 414.
In a further embodiment of the Navβ2 binder, the N-terminal amino acid of the first ISVD, the second ISVD, the third ISVD, or the fourth ISVD is linked to the C-terminal amino acid of a Navi.7 binder of claim 1 by a peptide or polypeptide linker or the N-terminal amino acid of the Navi.7 binder of claim 1 is linked to the C-terminal amino acid of the first ISVD, the second ISVD, the third ISVD, or the fourth ISVD by a peptide or polypeptide linker.
In a further embodiment, the peptide or polypeptide linker comprises any combination of glycine and serine amino acids up to 40 amino acids. In further embodiments, the peptide or polypeptide linker comprises an amino acid sequence comprising GGGGS (SEQ ID NO: 246))n wherein n is 1, 2, 3 ,4, 5, 6, 7, 8, 9 or 10. In particular embodiments, the polypeptide linker comprises the amino acid sequence set forth in SEQ ID NO: 463.
The present invention further provides a nucleic acid molecule encoding a Navβ2 binder disclosed herein. In a further embodiment, the Navβ1 binder comprises a nucleotide sequence selected from the group consisting of nucleotide sequences set forth in SEQ ID NO: 456, 458, 459, and 460.
The present invention further provides a vector comprising the nucleic acid molecule encoding aNavβ1 binder disclosed herein. The present invention further provides a host cell comprising a nucleic acid molecule encoding aNavβ1 binder disclosed herein.
The present invention further provides a method for producing aNavβ1 binder disclosed herein comprising: (a) providing a host cell comprising a nucleic acid molecule encoding a Navβ1 binder disclosed herein or a vector comprising a nucleic acid molecule encoding the Navβ1 binder disclosed herein; (b) cultivating the host cell in a medium under conditions suitable for expression of the Navβ1 binder by the host cell; and (c) isolating the Navβ1 binder from the medium to provide the Navβ1 binder.
The present invention further provides aNavl.7-Navβ bispecific binder comprising a Navi.7 binder as disclosed herein and a Navβ binder selected from the group consisting of the Navβ1 binder or Navβ2 binder as disclosed herein.
In further embodiments of the Navl.7-Navβ bispecific binder, (a) the Navi.7 binder comprises: (i) an amino acid sequence selected from the group consisting of SEQ ID NO: 46, SEQ ID NO: 47, SEQ ID NO: 48, SEQ ID NO: 49, SEQ ID NO: 50, SEQ ID NO: 51, SEQ ID NO: 52, SEQ ID NO: 53, SEQ ID NO: 54, and SEQ ID NO: 55; (ii) an amino acid sequence selected from the group consisting of SEQ ID NO: 69, SEQ ID NO: 70, SEQ ID NO: 71, SEQ ID NO: 72, SEQ ID NO: 73, SEQ ID NO: 74, SEQ ID NO: 75, SEQ ID NO: 76, SEQ ID NO: 77, SEQ ID NO: 78, SEQ ID NO: 79, SEQ ID NO: 80, and SEQ ID NO: 81; or (iii) an amino acid sequence selected from the group consisting of SEQ ID NO: 82, SEQ ID NO: 83, SEQ ID NO: 84, SEQ ID NO: 85, SEQ ID NO: 86, SEQ ID NO: 87, SEQ ID NO: 88, SEQ ID NO: 89, SEQ ID NO: 90, SEQ ID NO: 91, SEQ ID NO: 92, SEQ ID NO: 93, SEQ ID NO: 94, SEQ ID NO: 95, SEQ ID NO: 96, and SEQ ID NO: 97; or (iv) an amino acid sequence selected from the group consisting of SEQ ID NO: 98, SEQ ID NO: 99, SEQ ID NO: 100, SEQ ID NO: 102, SEQ ID NO: 103, SEQ ID NO: 104, SEQ ID NO: 105, SEQ ID NO: 106, SEQ ID NO: 107, SEQ ID NO: 108, SEQ ID NO: 109, SEQ ID NO: 110, SEQ ID NO: 111, SEQ ID NO: 112, SEQ ID NO: 113, SEQ ID NO: 114, SEQ ID NO: 115, SEQ ID NO: 116, SEQ ID NO: 117, SEQ ID NO: 118, SEQ ID NO: 119, SEQ ID NO: 120, SEQ ID NO: 121, SEQ ID NO: 122, SEQ ID NO: 123, SEQ ID NO: 124, SEQ ID NO: 125, SEQ ID NO: 126, SEQ ID NO: 127, SEQ ID NO: 128, SEQ ID NO: 129, SEQ ID NO: 130, SEQ ID NO: 131, SEQ ID NO: 132, SEQ ID NO: 133, SEQ ID NO: 134, SEQ ID NO: 135, SEQ ID NO: 136, SEQ ID NO: 137, SEQ ID NO: 138, SEQ ID NO: 139, SEQ ID NO: 140, SEQ ID NO: 141, SEQ ID NO: 142, SEQ ID NO: 143, SEQ ID NO: 144, SEQ ID NO: 145, SEQ ID NO: 146, SEQ ID NO: 147, SEQ ID NO: 148, SEQ ID NO: 149, SEQ ID NO: 150, SEQ ID NO: 151, SEQ ID NO: 152, and SEQ ID NO: 153; or (v) an amino acid sequence selected from the group consisting of SEQ ID NO: 154, SEQ ID NO: 155, SEQ ID NO: 156, SEQ ID NO: 157, SEQ ID NO: 158, SEQ ID NO: 159, SEQ ID NO: 160, SEQ ID NO: 161, SEQ ID NO: 162, SEQ ID NO: 163, SEQ ID NO: 164, SEQ ID NO: 165, SEQ ID NO: 166, SEQ ID NO: 167, SEQ ID NO: 168, SEQ ID NO: 169, SEQ ID NO: 170, SEQ ID NO: 171, SEQ ID NO: 172, SEQ ID NO: 173, SEQ ID NO: 174, SEQ ID NO: 175, SEQ ID NO: 176, SEQ ID NO: 177, SEQ ID NO: 178, SEQ ID NO: 179, SEQ ID NO: 180, SEQ ID NO: 181, SEQ ID NO: 182, SEQ ID NO: 183, SEQ ID NO: 184, SEQ ID NO: 185, SEQ ID NO: 186, SEQ ID NO: 187, SEQ ID NO: 188, SEQ ID NO: 189, SEQ ID NO: 190, SEQ ID NO: 191, SEQ ID NO: 192, SEQ ID NO: 193, SEQ ID NO: 194, and SEQ ID NO: 195; (b) the Navβ1 binder comprises an amino acid sequence selected from the group consisting of SEQ ID NO: 411 and SEQ ID NO: 415; and, (c)
the Navβ2 binder comprises an amino acid sequence selected from the group consisting of SEQ ID NO: 410, SEQ ID NO: 412, SEQ ID NO: 413, and SEQ ID NO: 414.
The present invention further provides aNavl.7-Navβ bispecific binder wherein the Navl.7-Navβ bispecific binder is linked to a half-life extender.
The present invention further provides aNavl.7-Navβ bispecific binder disclosed herein wherein the half-life extender is a human serum albumin (HSA) binder or HC constant domain or crystallizable fragment (Fc domain). The present invention further provides a Navl.7-Navβ bispecific binder disclosed herein wherein the Navl.7-Navβ bispecific binder comprises a C-terminal alanine residue.
The present invention further provides a composition comprising aNavl.7-Navβ bispecific binder disclosed herein and a pharmaceutically acceptable carrier.
The present invention further provides for the use of aNavl.7-Navβ bispecific binder disclosed herein for the manufacture of a medicament for the treatment of chronic pain.
The present invention further provides aNavl.7-Navβ bispecific binder disclosed herein or a composition comprising said Navl.7-Navβ bispecific binder for the treatment of chronic pain.
The present invention further provides a method for treating an individual with chronic pain comprising administering to the individual a therapeutically effective amount of the Navl.7-Navβ bispecific binder disclosed herein or a composition comprising said Navl.7-Navβ bispecific binder to treat the chronic pain.
The present invention further provides a nucleic acid molecule encoding a Navl.7-Navβ bispecific binder comprising anucleic acid molecule encoding aNavl.7 binder disclosed herein and a Navβ1 or Navβ2 binder disclosed herein. In a further embodiment, the nucleic acid molecule encoding the Navi.7 binder comprises a nucleotide sequence selected from the group consisting of nucleotide sequences set forth in SEQ ID NO: 273-283, the Navβ1 binder comprises a nucleotide sequence selected from the group consisting of nucleotide sequences set forth in SEQ ID NO: 457 and 461, and Navβ2 binder comprises a nucleotide sequence selected from the group consisting of nucleotide sequences set forth in SEQ ID NO: 456, 458, 459, and 460. In a further embodiment, the nucleic acid molecule encoding the Navi.7 binder comprises a nucleotide sequence selected from the group consisting of nucleotide sequences set forth in SEQ ID NO: 284-421, the Navβ1 binder comprises a nucleotide sequence selected from the group consisting of nucleotide sequences set forth in SEQ ID NO: 457 and
461, and Navβ2 binder comprises a nucleotide sequence selected from the group consisting of nucleotide sequences set forth in SEQ ID NO: 456, 458, 459, and 460.
The present invention further provides a vector comprising the nucleic acid molecule encoding aNavl.7-Navβ bispecific binder disclosed herein. The present invention further provides a host cell comprising a nucleic acid molecule encoding aNavl.7-Navβ bispecific binder disclosed herein.
The present invention further provides a method for producing a Navi ,7-Navβ bispecific binder disclosed herein comprising: (a) providing a host cell comprising a nucleic acid molecule encoding aNavl.7-Navβ bispecific binder disclosed herein or a vector comprising a nucleic acid molecule encoding the Navl.7-Navβ bispecific binder disclosed herein; (b) cultivating the host cell in a medium under conditions suitable for expression of the Navi.7- Navβ bispecific binder by the host cell; and (c) isolating the Navl.7-Navβ bispecific binder from the medium to provide the Navl.7-Navβ bispecific binder.
The present invention further provides a Navi.7 binder, Navβ1 binder, or Navβ2 binder comprising an amino acid sequence disclosed in Table 56. The present invention further provides a nucleic acid molecule encoding a Navi.7 binder, Navβ1 binder, orNavβ2 binder and comprising a nucleotide sequence having at least 80, 90%, 95%, or 100% identity to a nucleotide sequence disclosed in Table 56 provided the amino acid sequence encoded by the nucleotide sequence is disclosed in Table 56. The present invention further provides a Navl.7-Navβ bispecific binder comprising an amino acid sequence disclosed in Table 56 or comprised of a Navi.7 binder and at least one Navβ binder selected from Navβ1 binder and Navβ2 binder, each comprising an amino acid sequence disclosed in Table 56. The present invention further provides a nucleic acid molecule comprising a nucleotide sequence encoding aNavl.7-Navβ bispecific binder wherein the nucleotide sequence has at least 80, 90%, 95%, or 100% identity to a nucleotide sequence disclosed in Table 56 provided the nucleotide sequence encodes an amino acid sequence disclosed in Table 56.
BRIEF DESCRIPTION OF THE DRAWINGS
Fig- 1 shows the proposed structure ofNavl.7α. Drawing shows ahuNavl.7α model viewed from top/ extracellular (top left panel) and side through cytoplasmic membrane (top right panel). Navi.7α structural topology viewed from extracellular side (bottom panel) shown with pi, P2, and P3 subunits.
Fig. 2A and Fig. 2B together show sequence comparisons of huNavl.7α to paralogs and orthologs (based on sequences listed in the Table 41).
Fig. 3A shows the binding of ISVDs F103262CO2, F0103265B04, F0103262B06, F0103265A11 to huNavl.7α+β1-β2-β3. MFI = median fluorescence intensity; IRR = irrelevant control ISVD; a-FLAG is a detection moiety.
Fig. 3B shows the binding of ISVD F0103362B08 to huNavl.7α+β1-β2-β3. MFI = median fluorescence intensity; a-FLAG is a detection moiety.
Fig. 3C shows the binding of ISVDs F103262CO2, F0103265B04, F0103262B06, F0103265A11 to huNavl.7α+pi. MFI = median fluorescence intensity; IRR = irrelevant control ISVD; a-FLAG is a detection moiety.
Fig. 3D shows the binding of ISVDs F103262CO2, F0103265B04, F0103262B06, F0103265A11 to huNavl.5α-β1-β2-β3. MFI = median fluorescence intensity; IRR = irrelevant control ISVD; a-FLAG is a detection moiety.
Fig. 3E shows the binding of ISVDs F0103265B04 and F0103262B08, to huNavl.7α+β1-β2-β3. MFI = median fluorescence intensity; IRR = irrelevant control ISVD; a- FLAG is a detection moiety.
Fig. 3F shows the binding of ISVDs F0103265B04 and F0103262B08, to huNavl.5α-β1-β2-β3. MFI = median fluorescence intensity; IRR = irrelevant control ISVD; a- FLAG is a detection moiety.
Fig. 3G shows the binding of ISVDs F103262CO2, F0103265B04, F0103262B06, F0103265A11 to huNav157chimeral4-β1-β2-β3. MFI = median fluorescence intensity; IRR = irrelevant control ISVD; a-FLAG is a detection moiety.
Fig. 3H shows the binding of ISVDs F0103265B04 and F0103262B08, to huNavl.7α+pi. MFI = median fluorescence intensity; IRR = irrelevant control ISVD; a-FLAG is a detection moiety.
Fig. 31 shows the binding of ISVDs F0103265B04 and F0103262B08, to huNav157chimeral4-β1-β2-β3. MFI = median fluorescence intensity; IRR = irrelevant control ISVD; a-FLAG is a detection moiety.
Fig- 4 shows a sequence alignment of functional Navl.7α+selective ISVDs compared to the human VH3-JH consensus sequence (SEQ ID NO: 57). Residues identical to the human VH3-JH consensus are shown by dots. CDRs are highlighted. The amino acid sequences for the ISVDs are F0103265B04 (SEQ ID NO: 49); F0103275B05 (SEQ ID NO: 50),
F0103387G04 (SEQ ID NO: 52); F0103265A11 (SEQ ID NO: 48); F0103387G05 (SEQ ID NO: 53); F0103362B08 (SEQ ID NO: 51).
Fig. 5 shows screening of the F0103275B05 (275B05) stage I affinity maturation library in binding fluorescence-activated cell sorting (FACS) on huNavl.7α and rhNavl.7α.
Fig. 6 shows screening of the F0103275B05 (275B05) stage II affinity maturation library in binding FACS on huNavl.7α and rhNavl.7α.
Fig. 7A shows a schematic for a single pulse electrophysiology protocol.
Fig. 7B shows a schematic for a two pulse electrophysiology protocol.
Fig- 8 shows screening of the F0103265A11 (265A11) stage I affinity maturation library in binding FACS on huNavl.7α and rhNavl.7α.
Fig. 9 shows screening of the F0103265A11 (265 Al 1) stage II affinity maturation library in binding FACS on huNavl.7α and rhNavl.7α.
Fig. 10 shows screening of the F0103265B04 (265B04) stage I affinity maturation library in binding FACS on huNavl.7α and rhNavl.7α.
Fig. 11 shows screening of the F0103387G05 (387G05) stage I affinity maturation library in binding FACS on huNavl.7α and rhNavl.7α.
Fig. 12 shows screening of the F0103362B08 (362B08) stage I affinity maturation library in binding FACS on huNavl.7α and rhNavl.7α.
Fig. 13 shows screening of the F0103464B09 (464B09) stage I affinity maturation library in binding FACS on huNavl.7α and rhNavl.7α.
Fig. 14 shows screening of the F0103464B09 (464B09) stage II affinity maturation library in binding FACS on huNavl.7α and rhNavl.7α.
Fig. 15A shows competition FACS of extracellular anti-Navl.7α ISVDs vs.
F0103265B04 on stable HEK cell lines expressing huNavl.7α+β1-β2-β3.
Fig. 15B shows competition FACS of extracellular anti-Navl.7α ISVDs vs.
F0103265B04 on stable HEK cell lines expressing huNavl.7α+β1-β2-β3.
Fig. 15C shows competition FACS of extracellular anti-Navl.7α ISVDs vs.
F0103275B05(N93R) on stable CHO cell lines expressing huNavl.7α+β1-β2-β3.
Fig. 15D shows competition FACS of extracellular anti-Navl.7α ISVDs vs.
F0103275B05(N93R) on stable CHO cell lines expressing rhNavl.7α+β1-β2-β3.
Fig. 16 shows a schematic overview of huNavl.7α+huNavl.5a (huNav!57) chimeras.
Fig. 17A, Fig. 17B, and Fig. 17C together show epitope mapping FACS of extracellular anti-Navl.7α ISVDs (1 μM) on transiently transfected cells expressing huNav157+β1-β2-β3 chimeras 1, 2, 3, or 4 (huNav157chiml, huNav157chim2, huNav157chim3, or huNav157chim4, respectively) compared to cells expressing huNavl.7α+β1-β2-β3.
Fig. 18A, Fig. 18B, and Fig. 18C together show epitope mapping FACS of extracellular anti-Navl.7α ISVDs (1 pM) on transiently transfected cells expressing huNav157+β1-β2-β3 chimeras 5, 6, 7, or 8 (huNav157chim5, huNav157chim6, huNav157chim7, or huNav157chim8, respectively) compared to cells expressing huNavl.7α+β1-β2-β3.
Fig. 19A and Fig. 19B together show epitope mapping FACS of extracellular anti-Navl.7α ISVDs (1 pM) on transiently transfected cells expressing huNav157+β1-β2-β3 chimeras 9 or 12 (huNav157chim9 or huNav157chim12, respectively) compared to cells expressing huNavl.7α+β1-β2-β3.
Fig. 20A and Fig. 20B together show epitope mapping FACS of extracellular anti-Navl.7α ISVDs (1 pM) on transiently transfected cells expressing huNav157+β1-β2-β3 chimeras 22 or 18 (huNav157chim22 or huNav157chim18, respectively) compared to cells expressing huNavl.7α+β1-β2-β3.
Fig. 21A and Fig. 21B together show shows epitope mapping FACS of extracellular anti-Navl.7α ISVDs (1 pM) on transiently transfected cells expressing huNavl.7+β1-β2-β3, rhNavl.7α+β1-β2-β3, or huNavl.7(N146S, V194I, F276V, R277Q, E281V, V331M, E504D, D507E, S508N, N533S)-β1-β2-β3.
Fig. 22A shows binding FACS of extracellular anti-Navl.7α ISVDs on stable huNavl.7α-rhNavl.7α chimera cell line CHO Flpin huNavl.7α+β1-β2-β3.
Fig. 22B shows binding FACS of extracellular anti-Navl.7α ISVDs on stable huNavl.7α-rhNavl.7α chimera cell line CHO Flpin RhNavl.7α+β1-β2-β3.
Fig. 22C shows binding FACS of extracellular anti-Navl.7α ISVDs on stable huNavl.7α-rhNavl.7α chimera cell line CHO Flpin Navl.7α(F276V)+β1-β2-β3.
Fig. 22D shows binding FACS of extracellular anti-Navl.7α ISVDs on stable huNavl.7α-rhNavl.7α chimera cell line CHO Flpin Navl.7α(R277Q)+β1-β2-β3.
Fig. 22E shows binding FACS of extracellular anti-Navl.7α ISVDs on stable huNavl.7α-rhNavl.7α chimera cell line CHO Flpin Navl.7α(E281V)+β1-β2-β3.
Fig. 22F shows binding FACS of extracellular anti-Navl.7α ISVDs on stable huNavl.7α-rhNavl.7α chimera cell line CHO Flpin Navl.7α(V331M)+β1-β2-β3.
Fig. 22G shows a schematic representation of the extracellular polymorphisms between huNavl.7α and rhNavl.7α on an huNavl.7α model viewed from the extracellular side.
Fig. 23A shows a schematic illustrating the lonFlux 16 single pulse protocol.
Fig. 23B shows a schematic illustrating the lonFlux 16 two pulse protocol.
Fig. 24A shows an lonFlux 16 dose response titration of F0103265B04, F0103362B08, F0103387G04 and F0103387G05 using the single pulse (Pl) protocol.
Fig. 24B shows an lonFlux 16 dose response titration of F0103265B04, F0103362B08, F0103387G04 and F0103387G05 using two pulse (P2) protocol.
Fig. 25A shows an lonFlux 16 single high concentration dose response for F0103265B04, F0103275B05, and F0103262C02 in HEK huNavl.7α+pi cells using single pulse (Pl) and two pulse (P2) protocols.
Fig. 25B shows an lonFlux 16 single high concentration dose response for F0103265B04, F0103275B05, and F0103262C02 in HEK huNavl.7α cells using single pulse (Pl) and two pulse (P2) protocols.
Fig. 25C shows an lonFlux 16 single high concentration dose response for F0103265B04, F0103275B05, and F0103262C02 in CHO Flpin huNavl.7α+β1-β2-β3 cells using single pulse (Pl) and two pulse (P2) protocols.
Fig. 25D shows an lonFlux 16 single high concentration dose response for F0103262B06, F0103265A11, and F0103265B04 in CHO Flpin huNavl.7α+β1-β2-β3 cells using single pulse (Pl) and two pulse (P2) protocols.
Fig. 25E shows an lonFlux 16 single high concentration dose response for F0103262B06, F0103265A11, and F0103265B04 in HEK Flpin huNavl.7α+β1-β2-β3 cells using single pulse (Pl) and two pulse (P2) protocols.
Fig. 26 shows the results of an lonFlux 16 washout experiment using F0103265B04.
Fig. 27 shows the results of an lonFlux 16 time course experiment using F0103265B04.
Fig. 28 shows a sequence analysis of F0103275B05 (SEQ ID NO: 50) and F010387G04 (SEQ ID NO: 52) compared to the human VH3-JH consensus sequence (SEQ ID NO: 57), VHH2 consensus sequence (SEQ ID NO: 58), and sequenced optimized F0103387G04 (F0103387G04_SO; SEQ ID NO:59).
Fig. 29 shows a sequence analysis of F0103387G05 (SEQ ID NO: 53) compared to the human VH3-JH consensus sequence (SEQ ID NO: 57), VHH2 consensus sequence (SEQ ID NO: 58), and sequenced optimized F0103387G05 (F0103387G05_SO; SEQ ID NO:60).
Fig. 30 shows the Tm of F0103387G05 variants in function of pH. Dotted lines mark variants with H37Y substitution (see Table 30).
Fig. 31 shows a sequence analysis of F0103464B09 (SEQ ID NO: 55) compared to the human VH3-JH consensus sequence (SEQ ID NO: 57), VHH2 consensus sequence (SEQ ID NO: 58), and sequenced optimized F01034647B09 (F01034647B09_SO; SEQ ID NO:61).
Fig. 32 shows a schematic diagram of huNavl.7α. VSD = voltage sensing domain; PM = pore module; D =domain; S = transmembrane segment.
Fig. 33 shows results of a binding FACS of anti-Navβ2 ISVD F0103240B04 on stable cell lines.
Fig. 34A shows results of a binding ELISA of the shown anti-Navβ ISVDs binding to Navβ1. F0103240B04 is a potent anti-Navβ2 binder control and IRR022 is a negative control comprising an irrelevant binder. F0103478E09 weakly binds Navβ1.
Fig. 34B shows results of a binding ELISA of the shown anti-Navβ ISVDs binding to P2. F0103240B04 is a potent anti-Navβ2 binder control and IRR0022 is a negative control comprising an irrelevant binder. F0103492E09, F0103500E03, and F0103505D08 weakly bind P2.
Fig. 34C shows results of a binding ELISA of the shown anti-Navβ ISVDs binding to Navβ3. F0103240B04 is a potent anti-Navβ2 binder control and IRR0202 is a negative control comprising an irrelevant binder. None of the ISVDs bind Navβ3.
Fig. 35A, Fig. 35B, Fig. 35C, and Fig. 35D together show results of binding FACS of the shown anti-Navβ subunit ISVDs (12.3 nM) on transiently transfected cells. Positive controls anti-Navβ 1, anti-Navβ2, and anti-Navβ3 are rabbit polyclonal antibodies specific for human Navβ1, Navβ2, and Navβ3, respectively.
Fig. 36A shows results of binding FACS of anti-Navβ ISVD F0103478E09 on various stable cell lines.
Fig. 36B shows results of binding FACS of anti-Navβ ISVD F0103492E09 on various stable cell lines.
Fig. 36C shows results of binding FACS of anti-Navβ ISVD F0103500E03 on various stable cell lines.
Fig. 36D shows results of binding FACS of anti-Navβ ISVD F0103505D08 on various stable cell lines.
Fig. 36E shows results of binding FACS of anti-Navβ ISVD F0103495D09 on various stable cell lines.
Fig. 37A shows the results of a competition FACS of Navl.7α-Navβ bispecific ISVDs on stable CHO cell lines expressing human Navl.7α-Navβ1-Navβ2-Navβ3 (Navl.7-pi- P2-P3).
Fig. 37B shows the results of a competition FACS ofNavl.7α-Navβ bispecific ISVDs on stable CHO cell lines expressing rhesus Navl.7α-Navβ1-Navβ2-Navβ3 (Navl.7-pi- P2-P3).
Fig. 38A shows the results of a competition FACS of Navl.7α-Navβ bispecific ISVDs on stable HEK cell lines expressing human Navi.7α (Navi.7).
Fig. 38B shows the results of a competition FACS ofNavl.7α-Navβ bispecific ISVDs on stable HEK cell lines human expressing Navl.7α-Navβ1 (Navl.7-pi).
Fig. 38C shows the results of a competition FACS of Navl.7α-Navβ bispecific ISVDs on stable HEK cell lines expressing human Navi.7α-Navβ1-Navβ2-Navβ3 (Navl.7-pi- P2-P3).
Fig. 39A shows binding FACS of Navi.7 binder F0103262C02 on stable huNavl.x paralog HEK293T cell lines. MFI = median fluorescence intensity; a-FLAG is a detection moiety.
Fig. 39B shows binding FACS of Navi.7 binder F0103265B04 on stable huNavl.x paralog HEK293T cell lines. MFI = median fluorescence intensity; a-FLAG is a detection moiety.
Fig. 39C shows binding FACS of Navi.7 binder F0103275B05 on stable huNavl.x paralog HEK293T cell lines. MFI = median fluorescence intensity; a-FLAG is a detection moiety.
Fig. 39D shows binding FACS of Navi.7 binder F0103464B09 on stable huNavl.x paralog HEK293T cell lines. MFI = median fluorescence intensity; a-FLAG is a detection moiety.
Fig. 39E shows binding FACS of Navi.7 binder F0103387G05 on stable huNavl.x paralog HEK293T cell lines. MFI = median fluorescence intensity; a-FLAG is a detection moiety.
DETAILED DESCRIPTION OF THE INVENTION
Definitions
As used herein, the term “Navi.7 binder” refers to an antibody, an antibody fragment, an immunoglobulin single variable domain (also referred to as “ISV” or ISVD”) or single domain antibody (also referred to as “sdAb”) that binds to Navi.7α. An example of an ISVD is a Nanobody® molecule.
As used herein, the term “Navβ binder” refers to an antibody, an antibody fragment, an immunoglobulin single variable domain (also referred to as “ISV” or ISVD”) or single domain antibody (also referred to as “sdAb”) that binds to Navp. The term “Navβ” comprises the terms “Navβ1” and “Navβ2”.
As used herein, "antibody" refers to an entire immunoglobulin, including recombinantly produced forms and includes any form of antibody that exhibits the desired biological activity. Thus, it is used in the broadest sense and specifically covers, but is not limited to, monoclonal antibodies (including full length monoclonal antibodies), polyclonal antibodies, multispecific antibodies (e.g, bispecific antibodies), humanized antibodies, fully human antibodies, biparatopic antibodies, and chimeric antibodies. "Parental antibodies" are antibodies obtained by exposure of an immune system to an antigen prior to modification of the antibodies for an intended use, such as humanization of a non-human antibody for use as a human therapeutic antibody.
The term “antibody" refers, in one embodiment, to a conventional antibody, which is a protein tetramer comprising two heavy chains (HCs) and two light chains (LCs) interconnected by disulfide bonds, or an antigen binding portion thereof, and in another embodiment, to a nonconventional antibody, which is a heavy chain antibody protein dimer comprising two heavy chains inter-connected by disulfide bonds and no light chains, or antigen binding portion thereof. In either embodiment, each heavy chain is comprised of a heavy chain variable region or domain (abbreviated herein as Vj-[) and a heavy chain constant region or domain. In certain naturally occurring IgG, IgD and IgA antibodies, the heavy chain constant region is comprised of three domains, CH1 , CH2 and CH3. In certain naturally occurring antibodies, each light chain is comprised of a light chain variable region or domain (abbreviated herein as VL and a light chain constant region or domain. The light chain constant region is comprised of one domain, CL. The human Vj-[ includes six family members: VH 1. VH 2. VH 3. VH 4. VH 5. and VH6 and the human VL family includes 16 family members: VK1, VK2, VK3, VK4, VK5, VK6, Vλl, Vλ2.
Vλ3. Vλ4. Vλ5. Vλ6, Vλ7, Vλ8, Vλ9, and Vλ10. Each of these family members can be further divided into particular subtypes.
The VH and VL regions can be further subdivided into regions of hypervariability, termed complementarity determining regions (CDR), interspersed with regions that are more conserved, termed framework regions (FR). Each VH and VL is composed of three CDRs and four FRs, arranged from amino-terminus to carboxy-terminus in the following order: FR1, CDR1, FR2, CDR2, FR3, CDR3, FR4. The CDRs form a binding domain that interacts with an antigen. The constant regions of the antibodies may mediate the binding of the immunoglobulin to host tissues or factors, including various cells of the immune system (e.g., effector cells) and the first component (Clq) of the classical complement system.
The constant domains or regions of the antibodies may mediate the binding of the immunoglobulin to host tissues or factors, including various cells of the immune system (e.g., effector cells) and the first component (Clq) of the classical complement system. Typically, the numbering of the amino acids in the heavy chain constant domain begins with number 118, which is in accordance with the Eu numbering scheme. The Eu numbering scheme is based upon the amino acid sequence of human IgG | (Eu), which has a constant domain that begins at amino acid position 118 of the amino acid sequence of the IgG | described in Edelman et al., Proc. Natl. Acad. Sci. USA. 63: 78-85 (1969), and is shown for the IgGj, IgG2, IgG3, and IgGq constant domains in Beranger, et al., Ibid.
The variable domains or regions of the heavy and light chains contain a binding domain comprising the CDRs that interacts with an antigen. A number of methods are available in the art for defining or predicting the CDR amino acid sequences of antibody variable domains (see Dondelinger et al., Frontiers in Immunol. 9: Article 2278 (2018)). The common numbering schemes include the following.
• Kabat numbering scheme is based on sequence variability and is the most commonly used (See Kabat et al. Sequences of Proteins of Immunological Interest, 5th Ed. Public Health Service, National Institutes of Health, Bethesda, Md. (1991) (defining the CDR regions of an antibody by sequence);
• Chothia numbering scheme is based on the location of the structural loop region (See Chothia & Lesk J. Mol. Biol. 196: 901-917 (1987); Al-Lazikani et al., J. Mol. Biol. 273: 927-948 (1997));
• AbM numbering scheme is a compromise between the two used by Oxford Molecular's AbM antibody modelling software (see Karu et al, ILAR Journal 37: 132-141 (1995);
• Contact numbering scheme is based on an analysis of the available complex crystal structures (See www.bioinf.org.uk : Prof. Andrew C.R. Martin's Group; Abhinandan & Martin, Mol. Immunol. 45:3832-3839 (2008).
• IMGT (ImMunoGeneTics) numbering scheme is a standardized numbering system for all the protein sequences of the immunoglobulin superfamily, including variable domains from antibody light and heavy chains as well as T cell receptor chains from different species and counts residues continuously from 1 to 128 based on the germ-line V sequence alignment (see Giudicelli et al., Nucleic Acids Res. 25:206-11 (1997); Lefranc, Immunol Today 18:509(1997); Lefranc et al., Dev Comp Immunol. 27:55-77 (2003)).
While there are several different methods for determining the amino acid sequences of the CDRs, the numbering of the entire variable region typically follows the Kabat numbering scheme with the particular CDR numbering scheme imposed thereupon.
The following general rules disclosed in www.bioinf.org.uk : Prof. Andrew C.R. Martin's Group and reproduced in Table 1 below may be used to define or predict the CDRs in an antibody sequence that includes those amino acids that specifically interact with the amino acids comprising the epitope in the antigen to which the antibody binds. There are rare examples where these generally constant features do not occur; however, the Cys residues are the most conserved feature.


In general, the state of the art recognizes that in many cases, the CDR3 region of the heavy chain is the primary determinant of antibody specificity, and examples of specific antibody generation based on CDR3 of the heavy chain alone are known in the art (e.g., Beiboer et al., J. Mol. Biol. 296: 833-849 (2000); Klimka et al., British J. Cancer 83: 252-260 (2000); Rader et al., Proc. Natl. Acad. Sci. USA 95: 8910-8915 (1998); Xu et al., Immunity 13: 37-45 (2000).
A conventional antibody tetramer includes two identical pairs of polypeptide chains, each pair having one "light" (about 25 kDa) and one "heavy" chain (about 50-70 kDa). The amino-terminal portion of each chain includes a variable region of about 100 to 110 or more amino acids primarily responsible for antigen recognition. The carboxy-terminal portion of the heavy chain may define a constant region primarily responsible for effector function. Typically, human light chains are classified as kappa and lambda light chains. Furthermore, human heavy chains are typically classified as mu, delta, gamma, alpha, or epsilon, and define the antibody's isotype as IgM, IgD, IgG, IgA, and IgE, respectively. Within light and heavy chains, the variable and constant regions are joined by a "J" region of about 12 or more amino acids, with the heavy chain also including a "D" region of about 10 more amino acids. See generally, Fundamental Immunology Ch. 7 (Paul, W., ed., 2nd ed. Raven Press, N.Y. (1989).
The heavy chain of a conventional antibody may or may not contain a terminal lysine (K), or a terminal glycine and lysine (GK).
As used herein, "antigen binding fragment" or “antigen binding portion” refers to fragments of antibodies, i.e. antibody fragments that retain the ability to bind specifically to the antigen bound by the full-length antibody, e.g. fragments that retain one or more CDR regions. Examples of antibody binding fragments include, but are not limited to, Fab, Fab', F(ab')2, and Fv fragments; diabodies; single-chain antibody molecules, e.g., sc-Fv; immunoglobulin single variable domain molecules, and multispecific antibodies formed from antibody fragments.
As used herein, the term “immunoglobulin single variable domain” (also referred to as “ISV” or ISVD”) or “single domain antibody (also referred to as “sdAb”) are terms that are used to refer to immunoglobulin variable domains (which may be heavy chain or light chain domains, including VH, VHH, or VL domains) that can form a functional antigen-binding site without interaction with another variable domain (e.g. , without a VH/VL interaction as is required between the VH and VL domains of a conventional four-chain monoclonal antibody). The term “VH” refers to a heavy chain variable domain of a conventional antibody and the term “VHH” refers to the heavy chain variable domain of a non-conventional heavy chain antibody.
Examples of ISVDs include for example, VHHs, humanized VHHs, and/or a camelized VHs such as camelized human VHs), IgNAR domains, single domain antibodies such as dAbs™, which are VH domains or are derived from a VH domain or are VL domains or are derived from a VL domain. ISVDs that are based on and/or derived from heavy chain variable domains (such as VH or VHH domains) are generally preferred. Most preferably, an ISVD will be a VHH, a humanized VHH, or a camelized VH (such as a camelized human VH) or generally a sequence optimized VHH (e.g., optimized for chemical stability and/or solubility, maximum overlap with known human framework regions and maximum expression).
The term “Nanobody® molecule” is generally as defined in WO 2008/020079 or WO 2009/138519, and thus in a specific aspect denotes an VHH, a humanized VHH, or a camelized VH (such as a camelized human VH) or generally a sequence optimized VHH (such as, e.g., optimized for chemical stability and/or solubility, maximum overlap with known human framework regions and maximum expression). The term Nanobody® is a registered trademark of Ablynx N.V.
As used herein, “Navi.7 binder” refers to a conventional antibody, heavy chain antibody, antigen binding fragment of an antibody or ISVD that binds to Navi.7α. A Navi.7 binder may be part of a larger molecule such as a multivalent, bispecific, or multispecific binder
that includes one or more Navi.7 binders and may include one or more binders to a target other than Navi.7α (e.g., Navβ binder) and may comprises another functional element, such as, for example, a half-life extender (HLE), an Fc domain of an immunoglobulin, a targeting unit and/or a small molecule such a polyethylene glycol (PEG).
As used herein, “Navβ binder” refers to a conventional antibody, heavy chain antibody, antigen binding fragment of an antibody or ISVD that binds to Navβ1 or Navβ2. A Navβ binder may be part of a larger molecule such as a multivalent, bispecific, or multispecific binder that includes one or more Navβ binders and may include one or more binders to a target other than Navβ1 or Navβ2 (e.g., a Navi .7 binder) and may comprise another functional element, such as, for example, a half-life extender (HLE), an Fc domain of an immunoglobulin, a targeting unit and/or a small molecule such as a PEG. Monovalent, monospecific and/or biparatopic Navi.7 or Navβ binders are part of the present invention. A monovalent Navi.7 or Navβ binder (e.g., ISVD such as a Nanobody® molecule) is a molecule that comprises a single antigen-binding domain. A bivalent or bispecific Navi.7 binder (e.g., ISVD such as a Nanobody® molecule) comprises two antigen-binding domains, e.g., aNavl.7-Navβ bispecific binder. A multivalent or multispecific Navi .7 binder comprises more than one antigen-binding domain (e.g., 1, 2, 3, 4, 5, 6, or 7). When a multivalent or multispecific binder comprises only two antigen binding domains it may be referred to as a bispecific or bivalent binder.
For a general description of multivalent and multispecific polypeptides containing one or more ISVDs and their preparation, reference is also made to Conrath et al., J. Biol. Chem, Vol. 276, 10. 7346-7350, 2001; Muyldermans, Reviews in Molecular Biotechnology 74 (2001), 277-302; as well as to for example WO 1996/34103, WO 1999/23221, WO 2004/041862, WO 2006/122786, WO 2008/020079, WO 2008/142164 or WO 2009/068627.
As used herein, a "Fab fragment" is comprised of one light chain and the CH1 and variable regions of one heavy chain. The heavy chain of a Fab molecule cannot form a disulfide bond with another heavy chain molecule. A "Fab fragment" can be the product of papain cleavage of an antibody.
As used herein, a "Fab' fragment" contains one light chain and a portion or fragment of one heavy chain that contains the VH domain and the CH1 domain and also the region between the CH1 and CH2 domains, such that an interchain disulfide bond can be formed between the two heavy chains of two Fab' fragments to form a F(ab')2 molecule.
As used herein, a "F(ab')2 fragment" contains two light chains and two heavy chains containing the VH domain and a portion of the constant region between the CH1 and CH2 domains, such that an interchain disulfide bond is formed between the two heavy chains. An F(ab')2 fragment thus is composed of two Fab' fragments that are held together by a disulfide bond between the two heavy chains. An "F(ab')2 fragment" can be the product of pepsin cleavage of an antibody.
As used herein, an "Fv region" comprises the variable regions from both the heavy and light chains but lacks the constant regions.
These and other potential constructs are described at Chan & Carter (2010) Nat. Rev. Immunol. 10:301. These antibody fragments are obtained using conventional techniques known to those with skill in the art, and the fragments are screened for utility in the same manner as are intact antibodies. Antigen-binding fragments can be produced by recombinant DNA techniques, or by enzymatic or chemical cleavage of intact immunoglobulins.
As used herein, an "Fc domain” or “Fc region” each refer to the fragment crystallizable region of an antibody. The Fc domain comprises two heavy chain fragments comprising the CH1 and CH2 domains of an antibody. The two heavy chain fragments are held together by two or more disulfide bonds and by hydrophobic interactions of the CH3 domains. The Fc domain may be fused at the N-terminus or the C-terminus to a heterologous protein.
As used herein, a "diabody" refers to a small antibody fragment with two antigenbinding regions, which fragments comprise a heavy chain variable domain (VH) connected to a light chain variable domain (VL) in the same polypeptide chain (VH- VL or VL-VH). By using a linker that is too short to allow pairing between the two domains on the same chain, the domains are forced to pair with the complementarity domains of another chain and create two antigenbinding regions. Diabodies are described more fully in, e.g, EP 404,097; WO 93/11161; and Holliger et al. (1993) Proc. Natl. Acad. Sci. USA 90: 6444-6448. For a review of engineered antibody variants generally see Holliger and Hudson (2005) Nat. Biotechnol. 23:1126-1136.
As used herein, "isolated” antibodies or antigen-binding fragments thereof (e.g., Navi.7 and Navβ binders) are at least partially free of other biological molecules from the cells or cell cultures in which they are produced. Such biological molecules include nucleic acids, proteins, lipids, carbohydrates, or other material such as cellular debris and growth medium. An isolated antibody or antigen-binding fragment may further be at least partially free of expression system components such as biological molecules from a host cell or of the growth medium
thereof. Generally, the term "isolated" is not intended to refer to a complete absence of such biological molecules or to an absence of water, buffers, or salts or to components of a pharmaceutical formulation that includes the antibodies or fragments.
As used herein, a "monoclonal antibody" refers to a population of substantially homogeneous antibodies, i.e., the antibody molecules comprising the population are identical in amino acid sequence except for possible naturally occurring mutations that may be present in minor amounts. In contrast, conventional (polyclonal) antibody preparations typically include a multitude of different antibodies having different amino acid sequences in their variable domains that are often specific for different epitopes. The modifier "monoclonal" indicates the character of the antibody as being obtained from a substantially homogeneous population of antibodies, and is not to be construed as requiring production of the antibody by any particular method. For example, the monoclonal antibodies to be used in accordance with the present invention may be made by the hybridoma method first described by Kohler et al. (1975) Nature 256: 495, or may be made by recombinant DNA methods (see, e.g., U.S. Pat. No. 4,816,567). The "monoclonal antibodies" may also be isolated from phage antibody libraries using the techniques described in Clackson et al. (1991) Nature 352: 624-628 and Marks et al. (1991) J. Mol. Biol. 222: 581-597, for example. See also Presta (2005) J. Allergy Clin. Immunol. 116:731.
As used herein, a "humanized ISVD" or “humanized antibody” refers to forms of Navi.7 binders that contain sequences from both human and non-human (e.g., llama, murine, rat) antibodies. In general, the humanized Navi.7 and Navβ binders will comprise all of at least one, and typically two, variable domains, in which the hypervariable loops correspond to those of a non-human immunoglobulin, and all or substantially all of the framework (FR) regions are those of a human immunoglobulin sequence. The humanized Navi .7 and/or Navβ binder may optionally comprise at least a portion of a human immunoglobulin constant region (Fc).
"Humanization" (also called Reshaping or CDR-grafting) is now a well- established technique for reducing the immunogenicity of monoclonal antibodies (mAbs) from xenogeneic sources (commonly rodent or camelids) and for improving the effector functions (ADCC, complement activation, Clq binding). The engineered mAh is engineered using the techniques of molecular biology, however simple CDR-grafting of the rodent complementaritydetermining regions (CDRs) into human frameworks often results in loss of binding affinity and/or specificity of the original mAh. In order to humanize an antibody, the design of the humanized antibody includes variations such as conservative amino acid substitutions in residues of the CDRs, and back substitution of residues from the rodent mAh into the human framework
regions (backmutations). The positions can be discerned or identified by sequence comparison for structural analysis or by analysis of a homology model of the variable regions' 3D structure. The process of affinity maturation has most recently used phage libraries to vary the amino acids at chosen positions. Similarly, many approaches have been used to choose the most appropriate human frameworks in which to graft the rodent CDRs. As the datasets of known parameters for antibody structures increases, so does the sophistication and refinement of these techniques. Consensus or germline sequences from a single antibody or fragments of the framework sequences within each light or heavy chain variable region from several different human mAbs can be used. Another approach to humanization is to modify only surface residues of the rodent sequence with the most common residues found in human mAbs and has been termed "resurfacing" or "veneering." Known human Ig sequences are disclosed, e.g., www.ncbi.nlm.nih.gov/entrez/query.fcgi; www.ncbi.nih.gov/igblast; www.atcc.org/phage/hdb.html; www.kabatdatabase.com/top.html; www.antibodyresource.com/onlinecomp.html; www.appliedbiosystems.com; www.biodesign.com; antibody.bath.ac.uk; www.unizh.ch; www.cryst.bbk.ac.uk/.about.ubcg07s; Kabat et al., Sequences of Proteins of Immunological Interest, U.S. Dept. Health (1983), each entirely incorporated herein by reference. Often, the human or humanized antibody is substantially non-immunogenic in humans.
As used herein, “non-human amino acid sequences” with respect to antibodies or immunoglobulins refers to an amino acid sequence that is characteristic of the amino acid sequence of a non-human mammal. The term does not include amino acid sequences of antibodies or immunoglobulins obtained from a fully human antibody library where diversity in the library is generated in silico (See for example, U.S. Patent No. 8,877,688 or 8,691,730).
As used herein, "effector functions" refer to those biological activities attributable to the Fc region of an antibody, which vary with the antibody isotype. Examples of antibody effector functions include: Clq binding and complement dependent cytotoxicity (CDC); Fc receptor binding; antibody-dependent cell-mediated cytotoxicity (ADCC); phagocytosis; down regulation of cell surface receptors (e.g. B cell receptor); and B cell activation.
As used herein, "conservatively modified variants" or "conservative substitution" refers to substitutions of amino acids with other amino acids having similar characteristics (e.g. charge, side-chain size, hydrophobicity /hydrophilicity, backbone conformation and rigidity, etc.), such that the changes can frequently be made without altering the biological activity of the protein. Those of skill in this art recognize that, in general, single amino acid substitutions in
non-essential regions of a polypeptide do not substantially alter biological activity (see, e.g., Watson et al. (1987) Molecular Biology of the Gene, The Benjamin/Cummings Pub. Co., p. 224 (4th Ed.)). In addition, substitutions of structurally or functionally similar amino acids are less likely to disrupt biological activity. Exemplary conservative substitutions are set forth in the table below.

As used herein, the term "epitope" or "antigenic determinant" refers to a site on an antigen (e.g., Navi.7α, Navβ1, Navβ2) to which a binder specifically binds. Epitopes within protein antigens can be formed both from contiguous amino acids (usually a linear epitope) or noncontiguous amino acids juxtaposed by tertiary folding of the protein (usually a conformational epitope). Epitopes formed from contiguous amino acids are typically, but not always, retained on exposure to denaturing solvents, whereas epitopes formed by tertiary folding are typically lost on treatment with denaturing solvents. A contiguous linear epitope comprises a peptide domain on an antigen comprising at least 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14 or 15 amino acids. A noncontiguous conformational epitope comprises one or more peptide domains or regions on antigen bound by a binder interspersed by one or more amino acids or peptide domains not bound by the binder, each domain independently comprises at least 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14 or 15 amino acids. Methods for determining what epitopes are bound by a given binder (i.e., epitope mapping) are well known in the art and include, for example, immunoblotting and immunoprecipitation assays, wherein overlapping or contiguous peptides (e.g., from Navi.7α, Navβ1, Navβ2) are tested for reactivity with a given binder. Methods of determining spatial conformation of epitopes include techniques in the art and those described
herein, for example, x-ray crystallography, 2-dimensional nuclear magnetic resonance, and HDX-MS (see, e.g., Epitope Mapping Protocols in Methods in Molecular Biology, Vol. 66, G. E. Morris, Ed. (1996)).
The term "epitope mapping" refers to the process of identification of the molecular determinants on the antigen involved in antibody-antigen recognition.
The term "binds to the same epitope" with reference to two or more binders means that the binders bind to the same segment of amino acid residues on a target, as determined by a given method. Techniques for determining whether a particular binder binds to the "same epitope " as the Navi.7 orNavβ binders described herein include, for example, epitope mapping methods, such as, x-ray analyses of crystals of Navl.7α:Navl.7 binder or Navβ:Navβ binder complexes, which provides atomic resolution of the epitope, and hydrogen/deuterium exchange mass spectrometry (HDX-MS). Other methods that monitor the binding of the antibody to antigen fragments (e.g. proteolytic fragments) or to mutated variations of the antigen where loss of binding due to a modification of an amino acid residue within the antigen sequence is often considered an indication of an epitope component (e.g. alanine scanning mutagenesis— Cunningham & Wells (1985) Science 244:1081). In addition, computational combinatorial methods for epitope mapping can also be used. These methods rely on the ability of the binder of interest to affinity isolate specific short peptides from combinatorial phage display peptide libraries.
Binders that "compete with a binder of the present invention for binding to a target antigen" refer to binders that inhibit (partially or completely) the binding of the Navi.7 binder of the present invention to Navi.7α or Navβ binder to Navp. Whether two binders compete with each other for binding to the target antigen, i.e., whether and to what extent one binder inhibits the binding of the other binder to the target antigen, may be determined using known competition experiments. In certain embodiments, a binder competes with, and inhibits binding of a binder of the present invention to the target antigen by at least 10%, 20%, 30%, 40%, 50%, 60%, 70%, 80%, 90% or 100%. The level of inhibition or competition may be different depending on which binder is the "blocking binder" (i.e., the unlabeled binder that is incubated first with the target antigen). Competition assays can be conducted as described, for example, in Ed Harlow and David Lane, Cold Spring Harb Protoc; 2006; doi: 10.1101/pdb.prot4277 or in Chapter 11 of "Using Antibodies" by Ed Harlow and David Lane, Cold Spring Harbor Laboratory Press, Cold Spring Harbor, N.Y., USA 1999. Competing Navi.7 binders bind to the same epitope as defined herein.
Other competitive binding assays include: solid phase direct or indirect radioimmunoassay (RIA), solid phase direct or indirect enzyme immunoassay (EIA), sandwich competition assay (see Stahli et al., Methods in Enzymology 9:242 (1983)); solid phase direct biotin-avidin EIA (see Kirkland et al., J. Immunol. 137:3614 (1986)); solid phase direct labeled assay, solid phase direct labeled sandwich assay (see Harlow and Lane, Antibodies: A Laboratory Manual, Cold Spring Harbor Press (1988)); solid phase direct label RIA using 1-125 label (see Morel et al., Mol. Immunol. 25(1):7 (1988)); solid phase direct biotin-avidin EIA (Cheung et al., Virology 176:546 (1990)); and direct labeled RIA. (Moldenhauer et al., Scand. J. Immunol. 32:77 (1990)).
As used herein, “specifically binds" refers, with respect to a target antigen, to the preferential association of a binder, in whole or part, with the target antigen and not to other molecules, particularly molecules found in human blood or serum. Binders as shown herein typically bind specifically to the target antigen with high affinity, reflected by a dissociation constant (KD) of 10-7 to 10- 11 M or less. Any KD greater than about 10-6 M is generally considered to indicate nonspecific binding. As used herein, a binder that "specifically binds" or "binds specifically" to a target antigen refers to a binder that binds to the target antigen with high affinity, which means having a KD of 10-7 M or less, in particular embodiments a KD of 10-8 M or less, or 5x 10-9 M or less, or between 10-8 M and 10-11 M or less, but does not bind with measurable binding to closely related proteins such as human Navi, la, human Navi.2a, human Navi.3a, humanNavl.4a, human Navi.5a, human Nav 1.6a, or human Navi.8a as determined in a cell ELISA or Surface Plasmon Resonance assay (SPR; Biacore) using 10 pg/mL antibody.
As used herein, an antigen is "substantially identical" to a given antigen if it exhibits a high degree of amino acid sequence identity to the given antigen, for example, if it exhibits at least 80%, at least 90%, at least 95%, at least 97%, or at least 99% or greater amino acid sequence identity to the amino acid sequence of the given antigen. By way of example, an antibody that binds specifically to human Navi.7α or Navβ may also cross-react with Navi.7α or Navβ from certain non-human primate species (e.g., rhesus monkey or cynomolgus monkey). The term specifically excludes human Navi, la, human Navi.2a, human Navi.3a, humanNavl.4a, human Navi.5a, human Nav 1.6a, and human Navi.8a.
As used herein, "isolated nucleic acid molecule" means a DNA or RNA of genomic, mRNA, cDNA, or synthetic origin or some combination thereof which is not associated with all or a portion of a polynucleotide in which the isolated polynucleotide is found
in nature, or is linked to a polynucleotide to which it is not linked in nature. For purposes of this disclosure, it should be understood that "a nucleic acid molecule comprising" a particular nucleotide sequence does not encompass intact chromosomes. Isolated nucleic acid molecules "comprising" specified nucleic acid sequences may include, in addition to the specified sequences, coding sequences for up to ten or even up to twenty or more other proteins or portions or fragments thereof, or may include operably linked regulatory sequences that control expression of the coding region of the recited nucleic acid sequences, and/or may include vector sequences.
As used herein, "treat" or "treating" means to administer a therapeutic agent, such as a composition containing any of the Navi.7 and/or Navβ binders of the present invention, topically, subcutaneously, intramuscular, intradermally, or systemically to an individual experiencing chronic pain. The amount of a therapeutic agent that is effective to alleviate chronic pain in the individual may vary according to factors such as the injury or disease state, age, and/or weight of the individual, and the ability of the therapeutic agent to elicit a desired response in the individual. Whether chronic pain has been alleviated can be assessed by the individual and/or any clinical measurement typically used by physicians or other skilled healthcare providers to assess the severity or progression status of chronic pain. Thus, the terms denote that a beneficial result has been or will be conferred on a human or animal individual experiencing chronic pain.
As used herein, "treatment," as it applies to a human or veterinary individual, refers to therapeutic treatment, as well as diagnostic applications. "Treatment" as it applies to a human or veterinary individual, encompasses contact of the antibodies or antigen binding fragments of the present invention to a human or animal subject.
As used herein, “therapeutically effective amount” refers to a quantity of a specific substance sufficient to achieve a desired effect in an individual being treated. For instance, this may be the amount necessary to inhibit or reduce the severity of chronic pain in an individual.
As used herein, the term “effector-silent” as used herein refers to an antibody, antibody fragment, HC constant domain, or Fc domain thereof that displays (i) no measurable binding to one or more Fc receptors (FcRs) as may be measured in a surface plasmon resonance (SPR) assay (e.g., Biacore™ assay) wherein an association constant in the micromolar range indicates no measurable binding or (ii) measurable binding to one or more FcRs as may be measured in SPR assay that is reduced compared to the binding that is typical for an antibody,
antibody fragment, HC constant domain or Fc domain thereof the same isotype. In particular embodiments, the antibody, antibody fragment, HC constant domain, or Fc domain thereof may comprise one or more mutations in the HC constant domain and the Fc domain in particular such that the mutated an antibody, antibody fragment, HC constant domain or Fc domain thereof has reduced or no measurable binding to FcyRIIIa, FcyRIIa, and FcyRI compared to a wild-type antibody of the same isotype as the mutated antibody. In particular embodiments, the affinity or association constant of an effector-silent an antibody, antibody fragment, HC constant domain or Fc domain thereof to one or more of FcyRIIIa, FcyRIIa, and FcyRI is reduced by at least 1000- fold compared to the affinity of the wild-type isotype; reduced by at least 100-fold to 1000-fold compared to the affinity of the wild-type isotype reduced by at least 50-fold to 100-fold compared to the affinity of the wild-type isotype; or at least 10-fold to 50-fold compared to the affinity of the wild-type isotype. In particular embodiments, the effector-silent an antibody, antibody fragment, HC constant domain, or Fc domain thereof has no detectable or measurable binding to one or more of the FcyRIIIa, FcyRIIa, and FcyRI as compared to binding by the wildtype isotype. In general, effector-silent an antibody, antibody fragment, HC constant domain, or Fc domain thereof will lack measurable antibody-dependent cell-mediated cytotoxicity (ADCC) activity. An ISVD not fused or linked to an effector-silent HC constant domain or Fc domain thereof displays no detectable or measurable binding to one or more of FcyRIIIa, FcyRIIa, or FcyRI. SPR assays measure binding of an effector-silent antibody, antibody fragment, HC constant domain or Fc domain thereof, against human FcRs.
Introduction
Patients with loss of function mutations in the gene encoding the Navi.7α channel (SCN9A) show profound insensitivity to pain from birth on. In contrast, gain of function mutations can result in chronic pain disorders. Navi.7α channels predominantly expressed in peripheral C-fiber nociceptors are therefore a drug target of great interest for treatment of various pain conditions. We have identified ISVDs (Navi.7 binders) that inhibit Navi.7α channels with exquisite selectivity over other Nav channel paralogs. Functional inhibitory Navi.7 activity of the Navi.7 binders was assessed in automated in vitro patch clamp assays. IC50 values in the nanomolar range have been measured. In vivo target modulation in the tissue of interest (peripheral C-fiber nociceptors) was demonstrated in Rhesus microneurography assays. The potential advantages of injectable Navi.7 binders for the treatment of chronic pain syndromes, such as painful diabetic peripheral neuropathy and osteoarthritis pain, are specificity and
extended half-life. Clinical differentiation will be based on improved or comparable efficacy with beter side effect profile versus standard of care.
In an embodiment of the invention, any Navi.7 binder or other binder as set forth herein comprises, where applicable, a substitution of the amino acid at position 11 to the amino acid V and a substitution of the amino acid at position 89 to the amino acid L. In further embodiments, the Navi.7 binder further includes a substitution of the amino acid at position 110 to the amino acid T, K, or Q. In further embodiments, the amino acid at position 112 is substituted with the amino acid S, K or Q. In each case wherein the numbering is according to the Kabat numbering scheme.
Navi. 7 Sodium Ion Channel
The a-subunits of the Navi.7 channel are polypeptide chains of 1977 amino acids that are folded into four homologous (but not identical) domains termed DI-DIV that are linked by three intracellular loops (L1-L3). Each domain has six transmembrane segments (S1-S6) with S1-S4 in each domain comprising a voltage sensing domain (VSD), and S5-S6 together with their extracellular linker (including the P-loop) included in the pore domain (PD) (Caterall (2000) Neuron 26:13-25; Guy & Seetharamulu (1986) Proceedings of the National Academy of Sciences of the United States of America 83: 508-512; Noda et al. (1984) Nature 312:121-127). Thus, each a-subunit has four distinct VSDs and four PDs which assemble to form one sodiumselective pore. Sodium is selectivity achieved in the extracellular portion of the pore domain by tight association of the four P-loops that re-enter the membrane between the S5 and S6 segments in DI-DIV and includes several negatively charged residues (aspartic acid and glutamic acid) (Caterall 2000). The human Navi.7α comprises the amino acid sequence set forth in SEQ ID NO: 1. Domain I of the human Navi.7α consists of the amino acid sequence shown in SEQ ID NO: 63 and the Domain I S5-S6 loop is shown in SEQ ID NO: 64. The amino acid sequence for the rhesus monkey NAVI.7α is shown in SEQ ID NO: 2, which has 99% identity with the human Navi ,7α. A schematic representation of Navi ,7α is shown in Fig. 32.
Navi. 7 Binders
The present invention provides Navi.7 binders (e.g., ISVDs) that bind to Navi.7α and methods of use of the binders for or in the treatment or prevention of disease. In an embodiment of the Navi.7 binders, the Navi.7 binders are antagonistic anti-NaV1.7α ISVDs. In further embodiments, the Navi.7 binder antagonizes the activity of the Navi.7 channel, for
example, by blocking the channel, which may be by physically blocking or closing the Navi.7 pore to Na+ flux or by conformationally changing the Navi.7 channel to an inactive state.
The Navi.7 binders include binders that bind to the Domain I S5-S6 loop of the human Navi.7α comprising amino acids 276 through 331 thereof (e.g., FRNSLENNETLESIMNTLESEEDFRKYFYYLEGSKDALLCGFSTDSGQCPEGYTCV (SEQ ID NO: 62)), and heteromeric channels in which the Navi.7α is complexed with one or more beta subunits such as β1, β2, β3, and/or β4. In an embodiment of the invention, the Navi.7 binder contacts one or more of the following Navi.7α amino acid residues: F276, R277, E281, and V331 as shown underlined in the amino acid sequence above. In a further embodiment, the Navi.7 binder contacts the following four Navi.7α amino acid residues: F276, R277, E281, and V331. Thus, in particular embodiments, the Navi.7 binders of the present invention bind to an epitope on Navi.7α comprising amino acid residues F276, R277, E281, and V331. In a further embodiment, the epitope consists of amino acid residues F276, R277, E281, and V331.
In particular embodiments of the invention, the Navi.7 binder binds to Navi.7α having one or more mutations at residue F276, R277, E281, and/or V331 with lower affinity than to human Navi.7α lacking such mutations. In particular embodiments of the invention, the binder binds to human Navi.7α comprising one or more mutations at positions Q1530, H1531, and E1534 with a substantially similar affinity to that of human Navi.7α lacking said mutations. In particular embodiments of the invention, the binder binds to human Navi.7α comprising mutations at positions Q1530, H1531, and E1534 with a substantially similar affinity to that of human Navi ,7α lacking said mutations. In further embodiments of the invention, the Navi .7 binder does not bind to rhesus monkey Navi.7α or binds with a lower affinity than to human Navi.7α.
In an embodiment of the invention, the Navi.7 binder binds to human Navi.7α with substantially similar affinity to human Navi.7α lacking one more of loops other than the domain 1 S5-S6 loop.
The Navi.7 binders of the present invention comprise three complementarity determining regions (CDRs) having amino acid sequences selected from the tables below. The CDR amino acid sequences shown in Table 2 and Table 3 are set forth according to the AbM numbering scheme for defining CDR amino acid sequences. A particular CDR amino acid sequence defined by any one of the other schemes advanced for defining CDR amino acid sequences (See Table 1) may have more or less amino acids than shown for CDR amino acid sequences identified according to the AbM numbering scheme but will overlap the CDR amino
acid sequences defined according the AbM numbering scheme. Thus, the CDR amino acid sequences shown herein are not to be construed as limiting and any Navi.7 binder in which the CDR amino acid sequences have been defined by any other numbering scheme will fall within the scope of the Navi.7 binders of the present invention provided the amino acid sequences for such Navi.7 binders comprise the amino acid sequences defined for the three CDR amino acid sequences as shown in Table 2 and Table 3. Thus, regardless of the method used to define the CDRs of aNavl.7 binder (e.g., Kabat, AbM, Clothia, IMGT, Contact, etc.), any Navi.7 binder that comprises the three amino acid sequences defined for CDR1, CDR2, and CDR3 for any of the Navi.7 binders shown in Table 2 and Table 3 are Navi.7 binders of the present invention.
The Navi.7 binders comprise three CDRs and four Frameworks (FR) in the following alignment FR1-CDR1-FR2-CDR2-FR3-CDR3-FR4. The Navi.7 binder CDRs may comprise CDRs comprising the following amino acid sequences.
 In particular embodiments of the invention, the Navi.7 binder comprises a CDR1 comprising the amino acid sequence set forth in SEQ ID NO: 247, a CDR2 comprising the amino acid sequence set forth in SEQ ID NO: 248, and a CDR3 comprising the amino acid sequence set forth in SEQ ID NO: 249.
In particular embodiments of the invention, the Navi.7 binder comprises a CDR1 comprising the amino acid sequence set forth in SEQ ID NO: 247, a CDR2 comprising the amino acid sequence set forth in SEQ ID NO: 248, and a CDR3 comprising the amino acid sequence set forth in SEQ ID NO: 249.
In particular embodiments of the invention, the Navi.7 binder comprises a CDR1 comprising the amino acid sequence set forth in SEQ ID NO: 250, a CDR2 comprising the amino acid sequence set forth in SEQ ID NO: 251, and a CDR3 comprising the amino acid sequence set forth in SEQ ID NO: 252.
In particular embodiments of the invention, the Navi.7 binder comprises a CDR1 comprising the amino acid sequence set forth in SEQ ID NO: 253, a CDR2 comprising the amino acid sequence set forth in SEQ ID NO: 254, and a CDR3 comprising the amino acid sequence SRY.
In particular embodiments of the invention, the Navi.7 binder comprises a CDR1 comprising the amino acid sequence set forth in SEQ ID NO: 256, a CDR2 comprising the amino acid sequence set forth in SEQ ID NO: 257, and a CDR3 comprising the amino acid sequence set forth in SEQ ID NO: 258.
In particular embodiments of the invention, the Navi.7 binder comprises a CDR1 comprising the amino acid sequence set forth in SEQ ID NO: 259, a CDR2 comprising the amino acid sequence set forth in SEQ ID NO: 260, and a CDR3 comprising the amino acid sequence set forth in SEQ ID NO: 261.
In particular embodiments of the invention, the Navi.7 binder comprises a CDR1 comprising the amino acid sequence set forth in SEQ ID NO: 262, a CDR2 comprising the amino acid sequence set forth in SEQ ID NO: 263, and a CDR3 comprising the amino acid sequence set forth in SEQ ID NO: 264.
In particular embodiments of the invention, the Navi.7 binder comprises a CDR1 comprising the amino acid sequence set forth in SEQ ID NO: 196, a CDR2 comprising the amino acid sequence set forth in SEQ ID NO: 198, and a CDR3 comprising the amino acid sequence set forth in SEQ ID NO: 200.
In particular embodiments of the invention, the Navi.7 binder comprises a CDR1 comprising the amino acid sequence set forth in SEQ ID NO: 201, a CDR2 comprising the amino acid sequence set forth in SEQ ID NO: 202, and a CDR3 comprising the amino acid sequence set forth in SEQ ID NO: 206.
In particular embodiments of the invention, the Navi .7 binder comprises a CDR1 comprising the amino acid sequence set forth in SEQ ID NO: 207, a CDR2 comprising the amino acid sequence set forth in SEQ ID NO: 213, and a CDR3 comprising the amino acid sequence set forth in SEQ ID NO: 219.
In particular embodiments of the invention, the Navi.7 binder comprises a CDR1 comprising the amino acid sequence set forth in SEQ ID NO: 221, a CDR2 comprising the amino acid sequence set forth in SEQ ID NO: 223, and a CDR3 comprising the amino acid sequence set forth in SEQ ID NO: 225.
In a further embodiments of the invention, the Navi.7 binder comprises three CDRs having an amino acid sequence as set forth in Table 3.


In particular embodiments of the invention, the Navi.7 binder comprises a CDR1 comprising the amino acid sequence set forth in SEQ ID NO: 196 or SEQ ID NO: 197; a CDR2 comprising the amino acid sequence set forth in SEQ ID NO: 198 or SEQ ID NO: 199; and, a CDR3 comprising the amino acid sequence set forth in SEQ ID NO: 200.
In particular embodiments of the invention, the Navi.7 binder comprises a CDR1 comprising the amino acid sequence set forth in SEQ ID NO: 201; a CDR2 comprising the amino acid sequence set forth in SEQ ID NO: 202, SEQ ID NO: 203, SEQ ID NO: 204, or SEQ ID NO: 205; and, a CDR3 comprising the amino acid sequence set forth in SEQ ID NO: 206.
In particular embodiments of the invention, the Navi.7 binder comprises a CDR1 comprising the amino acid sequence set forth in SEQ ID NO: 207, SEQ ID NO: 208, SEQ ID NO: 209, SEQ ID NO: 210, SEQ ID NO: 211, or SEQ ID NO: 212; a CDR2 comprising the amino acid sequence set forth in SEQ ID NO: 213, SEQ ID NO: 214, SEQ ID NO: 215, SEQ ID NO: 216, SEQ ID NO: 217, or SEQ ID NO: 218; and a CDR3 comprising the amino acid sequence set forth in SEQ ID NO: 219.
In particular embodiments of the invention, the Navi.7 binder comprises a CDR1 comprising the amino acid sequence set forth in SEQ ID NO: 201 or SEQ ID NO: 222; a CDR2 comprising the amino acid sequence set forth in SEQ ID NO: 223 or SEQ ID NO: 224; and a CDR3 comprising the amino acid sequence set forth in SEQ ID NO: 225, SEQ ID NO: 226, SEQ
ID NO: 227, SEQ ID NO: 228, SEQ ID NO: 229, SEQ ID NO: 230, SEQ ID NO: 231, SEQ ID NO: 232, or SEQ ID NO: 233.
In a further embodiment of the invention, the Navi.7 binder comprises a CDR1 comprising the amino acid sequence set forth in SEQ ID NO: 201; a CDR2 comprising the amino acid sequence set forth in SEQ ID NO: 205; and, a CDR3 comprising the amino acid sequence set forth in SEQ ID NO: 206.
In particular embodiments of the invention, the Navi.7 binder comprises a CDR1 comprising the amino acid sequence set forth in SEQ ID NO: 211; a CDR2 comprising the amino acid sequence set forth in SEQ ID NO: 215; and, a CDR3 comprising the amino acid sequence set forth in SEQ ID NO: 219.
In particular embodiments of the invention, the Navi.7 binder comprises a CDR1 comprising the amino acid sequence set forth in SEQ ID NO: 222; a CDR2 comprising the amino acid sequence set forth in SEQ ID NO: 223; and, a CDR3 comprising the amino acid sequence set forth in SEQ ID NO: 233.
As recited above, the Navi.7 binders comprise four frameworks: FR1, FR2, FR3, and FR4 wherein the Navi.7 binder is a single polypeptide having the structure beginning from the N-terminus FR1-CDR1-FR2-CDR2-FR3-CDR3-FR4. The numbering of the frameworks may be as shown herein be according to the Kabat numbering scheme and the junction between each framework and a CDR may be defined according to the AbM numbering scheme as shown herein. In particular embodiments, the Navi.7 binders comprise the VHH2-consensus frameworks FR1, FR2, FR3, and FR4, wherein FR1 has the amino acid sequence set forth in SEQ ID NO: 268, FR2 has the amino acid sequence set forth in SEQ ID NO: 269, FR3 has the amino acid sequence set forth in SEQ ID NO: 270, and FR4 has the amino acid sequence set forth in SEQ ID NO: 271. In further embodiments, each framework may comprise one or more substitutions and or insertions with the proviso that the Navi.7 binder is capable of binding human Navi.7α. In further embodiments, frameworks may comprise one or more of the substitutions and/or insertions shown in Table 4 in any combination. In further embodiments, FR1 may comprise one or more of the substitutions shown for FR1 in Table 4. In further embodiments, FR2 may comprise one or more of the substitutions shown for FR2 in Table 4. In further embodiments, FR3 may comprise one or more of the substitutions shown for FR3 in Table 4. In further embodiments, FR4 may comprise one of the substitutions shown for FR4 in Table 4. In a further embodiment, each framework comprises at least one amino acid substitution. In a further embodiment, the Navi.7 binder comprises at least one substitution
and/or insertion shown in Table 4 for each of FR1, FR2, FR3, and FR4. In a further embodiment, the Navi.7 binder comprises the one substitution or specific substitution and/or insertion combination shown in Table 4 for each of FR1, FR2, FR3, and FR4.
In particular embodiments, the ISVD framework comprises one or more substitutions to minimize binding to pre-existing antibodies. Pre-existing antibodies are antibodies existing in the body of a patient prior to receipt of an ISVD and are immunoglobulins mainly of the IgG class that are present in varying degrees in up to 50% of the human population and that bind to critical residues clustered at the C-terminal region of ISVDs. The ISVDs of the present invention are based, in part, in llama antibodies whose C-terminal constant domains have been removed; thus, exposing the neo-epitopes in the C-terminus of the resulting VHH to preexisting antibody binding. It has been discovered that the combination of mutations of residues 11 and 89 (e.g., LI IV and I89L or V89L) led to a surprising lack of pre-existing antibody binding. Mutations in residue 112 have also been shown to remarkably reduce pre-existing antibody binding. Buyse & Boutton (WO2015/173325) included data showing that the combination of an LI IV and V89L mutation provided a remarkable improvement in reducing pre-existing antibody binding compared to an LI IV mutation alone or a V89L mutation alone. For example, Table H of Buyse & Boutton on page 97 showed comparative data for an ISVD with a V89L mutation alone (with or without C-terminal extension) and the same ISVD with a V89L mutation in combination with an LI IV mutation (again, with or without a C-terminal extension). Also, although generated in two separate experiments, the data shown in Table H for the LI 1V/V89L combination as compared to the data given in Table B for an LI IV mutation alone (in the same ISVD) showed that the pre-existing antibody binding reduction that is obtained by the LI 1V/V89L combination was greater than that for the LI IV mutation alone. Since the llama antibody scaffold structure is known to be very highly conserved, the effect of the mutations at positions 11 and 89 is very likely to exist for any ISVD. Thus, in embodiments herein, the ISVD comprises at least the LI 1V/V89L substitutions in the framework regions.
In a further embodiment, FR1 comprises at least an LI IV substitution and FR3 comprises at least a V89L substitution. In a further still embodiment, the Navi.7 binder may comprise one of the 125 specific sets of FR1, FR2, FR3, and FR4 combinations shown in Table 4. In any one of the above embodiments, the FR1 may further comprise a Q1E or a Q1D amino acid substitution.








In a further embodiment of the invention, the Navi.7 binder comprises an amino acid sequence selected from the group consisting of SEQ ID NO: 46, SEQ ID NO: 47, SEQ ID
NO: 48, SEQ ID NO: 49, SEQ ID NO: 50, SEQ ID NO: 51, SEQ ID NO: 52, SEQ ID NO: 53, SEQ ID NO: 54, and SEQ ID NO: 55.
In a further embodiment of the invention, the Navi.7 binder comprises an amino acid sequence selected from the group consisting of SEQ ID NO: 69, SEQ ID NO: 70, SEQ ID NO: 71, SEQ ID NO: 72, SEQ ID NO: 73, SEQ ID NO: 74, SEQ ID NO: 75, SEQ ID NO: 76, SEQ ID NO: 77, SEQ ID NO: 78, SEQ ID NO: 79, SEQ ID NO: 80, and SEQ ID NO: 81.
In a further embodiment of the invention, the Navi.7 binder comprises an amino acid sequence selected from the group consisting of SEQ ID NO: 82, SEQ ID NO: 83, SEQ ID NO: 84, SEQ ID NO: 85, SEQ ID NO: 86, SEQ ID NO: 87, SEQ ID NO: 88, SEQ ID NO: 89, SEQ ID NO: 90, SEQ ID NO: 91, SEQ ID NO: 92, SEQ ID NO: 93, SEQ ID NO: 94, SEQ ID NO: 95, SEQ ID NO: 96, and SEQ ID NO: 97.
In a further embodiment of the invention, the Navi.7 binder comprises an amino acid sequence selected from the group consisting of SEQ ID NO: 98, SEQ ID NO: 99, SEQ ID NO: 100, SEQ ID NO: 102, SEQ ID NO: 103, SEQ ID NO: 104, SEQ ID NO: 105, SEQ ID NO: 106, SEQ ID NO: 107, SEQ ID NO: 108, SEQ ID NO: 109, SEQ ID NO: 110, SEQ ID NO: 111, SEQ ID NO: 112, SEQ ID NO: 113, SEQ ID NO: 114, SEQ ID NO: 115, SEQ ID NO: 116, SEQ ID NO: 117, SEQ ID NO: 118, SEQ ID NO: 119, SEQ ID NO: 120, SEQ ID NO: 121, SEQ ID NO: 122, SEQ ID NO: 123, SEQ ID NO: 124, SEQ ID NO: 125, SEQ ID NO: 126, SEQ ID NO: 127, SEQ ID NO: 128, SEQ ID NO: 129, SEQ ID NO: 130, SEQ ID NO: 131, SEQ ID NO: 132, SEQ ID NO: 133, SEQ ID NO: 134, SEQ ID NO: 135, SEQ ID NO: 136, SEQ ID NO: 137, SEQ ID NO: 138, SEQ ID NO: 139, SEQ ID NO: 140, SEQ ID NO: 141, SEQ ID NO: 142, SEQ ID NO: 143, SEQ ID NO: 144, SEQ ID NO: 145, SEQ ID NO: 146, SEQ ID NO: 147, SEQ ID NO: 148, SEQ ID NO: 149, SEQ ID NO: 150, SEQ ID NO: 151, SEQ ID NO: 152, and SEQ ID NO: 153.
In a further embodiment of the invention, the Navi.7 binder comprises an amino acid sequence selected from the group consisting of SEQ ID NO: 154, SEQ ID NO: 155, SEQ ID NO: 156, SEQ ID NO: 157, SEQ ID NO: 158, SEQ ID NO: 159, SEQ ID NO: 160, SEQ ID NO: 161, SEQ ID NO: 162, SEQ ID NO: 163, SEQ ID NO: 164, SEQ ID NO: 165, SEQ ID NO: 166, SEQ ID NO: 167, SEQ ID NO: 168, SEQ ID NO: 169, SEQ ID NO: 170, SEQ ID NO: 171, SEQ ID NO: 172, SEQ ID NO: 173, SEQ ID NO: 174, SEQ ID NO: 175, SEQ ID NO: 176, SEQ ID NO: 177, SEQ ID NO: 178, SEQ ID NO: 179, SEQ ID NO: 180, SEQ ID NO: 181, SEQ ID NO: 182, SEQ ID NO: 183, SEQ ID NO: 184, SEQ ID NO: 185, SEQ ID NO: 186, SEQ ID NO: 187,
SEQ ID NO: 188, SEQ ID NO: 189, SEQ ID NO: 190, SEQ ID NO: 191, SEQ ID NO: 192, SEQ ID NO: 193, SEQ ID NO: 194, and SEQ ID NO: 195.
In a further embodiment of the invention, the Navi.7 binder comprises the amino acid sequence set forth in SEQ ID NO: 96.
In a further embodiment of the invention, the Navi.7 binder comprises the amino acid sequence set forth in SEQ ID NO: 148.
In a further embodiment of the invention, the Navi.7 binder comprises the amino acid sequence set forth in SEQ ID NO: 192.
In particular embodiments of the Navi.7 binders, the N-terminal Glu is substituted with Asp.
Navi.7 binders of the invention can be fused or linked to one or more other amino acid sequences, chemical entities or moieties by a peptide or non-peptide linker. These other amino acid sequences, chemical entities or moieties can confer one or more desired properties to the resulting Navi.7 binders of the invention, for example, to provide the resulting Navi.7 binders of the invention with affinity against another therapeutically relevant target such that the resulting polypeptide becomes “bispecific” with respect to Navi.7 and that other therapeutically relevant target), or to provide a desired half-life, to provide a cytotoxic effect and/or to serve as a detectable tag or label. Some non-limiting examples of such other amino acid sequences, chemical entities or moieties are:
• one or more suitable peptide or polypeptide linkers (such as a 9GS, 15GS or 35GS linker (any combination of 9, 15, 20 or 35 G and S amino acids such as, for example, GGGGSGGGS (9GS linker; SEQ ID NO: 243), GGGGSGGGGSGGGGSGGGGS (20GS linker; SEQ ID NO: 244) or GGGGSGGGGSGGGGS GGGGSGGGGSGGGGSGGGGS (35GS linker; SEQ ID NO: 245)), GGGGSGGGGSGGGGSGGGGSGGGGSGGGGSGGGGSGGGGSGGGGSGGGGS (50GS linker; SEQ ID NO: 463) or (GGGGS (SEQ ID NO: 246))n wherein n is 1, 2, 3 ,4, 5, 6, 7, 8, 9 or 10); and/or
• one or more binding moieties, directed against a target other than Navi .7 or epitope thereof, for example, against a different epitope ofNavl.7α, Navi. la, Navi.2a, Navi.3a , Navi.4a, Navi.5a, Navi.6a, Navi.8a, Navi.9a, Nax alpha subunit, a sodium channel beta subunit (e.g, Navβ1, Navβ2, Navβ3, or Navβ4), a calcium channel or a potassium channel); and/or
• one or more binding domains or binding units that provide for an increase in half-life (for example, a binding domain or binding unit that can bind against a serum protein such as
serum albumin, e.g., human serum albumin), e.g., ALBI 1002; See W0200868280;
WO2006122787 or W02012175400 and/or
• a binding domain, binding unit or other chemical entity that allows for the Navi.7 binder (e.g, an ISVD such as a Nanobody® ISVD) to be internalized into a desired cell (for example, an internalizing anti-EGFR Nanobody® molecule as described in WO05044858); and/or
• a chemical moiety that improves half-life such as a suitable polyethyleneglycol group (i.e. PEGylation) or an amino acid sequence that provides for increased half-life such as human serum albumin or a suitable fragment thereof (i.e. albumin fusion); and/or
• a payload such as a cytotoxic payload; and/or
• a detectable label or tag, such as a radiolabel or fluorescent label; and/or
• a tag that can help with immobilization, detection and/or purification of the binder (e.g. , an ISVD such as a Nanobody® ISVD), such as a HISn, wherein n is 6 to 18, or FLAG tag or combination thereof (e.g., SEQ ID NO: 56);
• a tag that can be functionalized, such as a C-terminal GGC tag; and/or
• a C-terminal extension X(n) (e.g. , -Ala), which may be as further described herein for the Navi.7 binders (e.g., an ISVD such as a Nanobody® ISVD) of the invention and/or as described in WO12175741 or WO2015173325.
Sodium Channel Beta Subunit (Navβ) Binders
The present invention further provides ISVDs that bind the Navβ1 or NavP2 subunits. These Navβ binders comprise three CDRs having amino acid sequences selected from the table below. The CDR amino acid sequences shown in Table 5 are set forth according to the AbM numbering scheme for defining CDR amino acid sequences. A particular CDR amino acid sequence defined by any one of the other schemes advanced for defining CDR amino acid sequences (See Table 1) may have more or less amino acids than shown for CDR amino acid sequences identified according to the AbM numbering scheme but will overlap the CDR amino acid sequences defined according the AbM numbering scheme. Thus, the CDR amino acid sequences shown herein are not to be construed as limiting and any Navβ binder in which the CDR amino acid sequences have been defined by any other numbering scheme will fall within the scope of the Navβ binders of the present invention provided the amino acid sequences for such Navβ binders comprise the amino acid sequences defined for the three CDR amino acid
sequences as shown in Table 5. Thus, regardless of the method used to define the CDRs of a Navp binder (e.g., Kabat, AbM, Clothia, IMGT, Contact, etc.), any Navp binder that comprises the three amino acid sequences defined for CDR1, CDR2, and CDR3 for any of the Navp binders shown in Table 5 are Navp binders of the present invention.
The Navp binders comprise three CDRs and four Frameworks (FR) in the following alignment FR1-CDR1-FR2-CDR2-FR3-CDR3-FR4. The Navp binder CDRs may comprise CDRs comprising the following amino acid sequences.
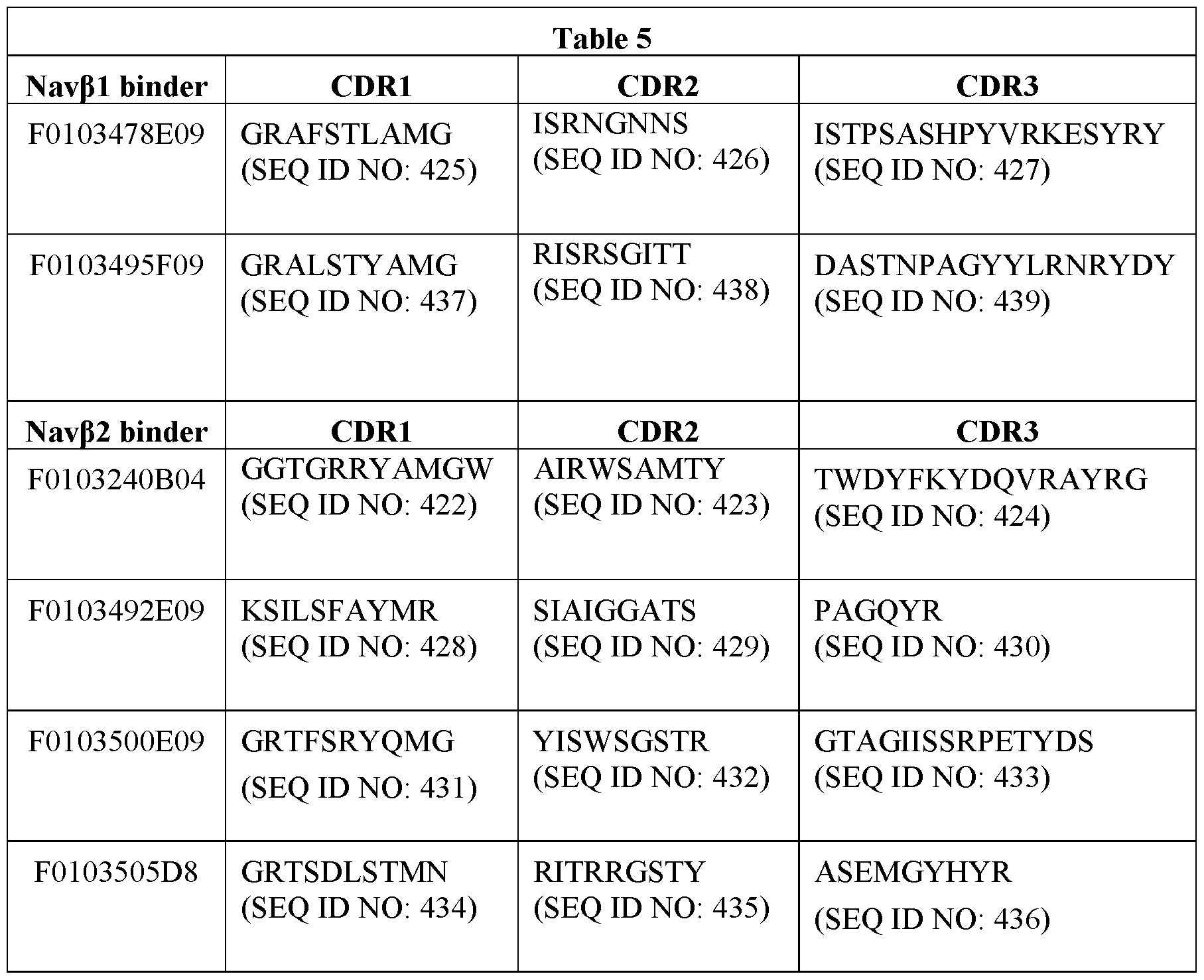
In particular embodiments of the invention, the Navβ1 binder comprises a CDR1 comprising the amino acid sequence set forth in SEQ ID NO: 425, a CDR2 comprising the amino acid sequence set forth in SEQ ID NO: 426, and a CDR3 comprising the amino acid sequence set forth in SEQ ID NO: 427.
In particular embodiments of the invention, the Navβ1 binder comprises a CDR1 comprising the amino acid sequence set forth in SEQ ID NO: 437, a CDR2 comprising the amino
acid sequence set forth in SEQ ID NO: 438, and a CDR3 comprising the amino acid sequence set forth in SEQ ID NO: 439.
In particular embodiments of the invention, the Navβ2 binder comprises a CDR1 comprising the amino acid sequence set forth in SEQ ID NO: 422, a CDR2 comprising the amino acid sequence set forth in SEQ ID NO: 423, and a CDR3 comprising the amino acid sequence set forth in SEQ ID NO: 424.
In particular embodiments of the invention, the Navβ2 binder comprises a CDR1 comprising the amino acid sequence set forth in SEQ ID NO: 428, a CDR2 comprising the amino acid sequence set forth in SEQ ID NO: 429, and a CDR3 comprising the amino acid sequence set forth in SEQ ID NO: 430.
In particular embodiments of the invention, the Navβ2 binder comprises a CDR1 comprising the amino acid sequence set forth in SEQ ID NO: 431, a CDR2 comprising the amino acid sequence set forth in SEQ ID NO: 432, and a CDR3 comprising the amino acid sequence set forth in SEQ ID NO: 433.
In particular embodiments of the invention, the Navβ2 binder comprises a CDR1 comprising the amino acid sequence set forth in SEQ ID NO: 434, a CDR2 comprising the amino acid sequence set forth in SEQ ID NO: 435, and a CDR3 comprising the amino acid sequence set forth in SEQ ID NO: 436.
As recited above, the Navβ1 or Navβ2 binders comprise four frameworks: FR1, FR2, FR3, and FR4 wherein the Navβ1 or Navβ2 binder is a single polypeptide having the structure beginning from the N-terminus FR1-CDR1-FR2-CDR2-FR3-CDR3-FR4. The numbering of the frameworks may be as shown herein be according to the Kabat numbering scheme and the junction between each framework and CDR may be determined by the AbM numbering scheme as shown herein. In particular embodiments, the Navi.7 binders comprise the VHH2-consensus frameworks FR1, FR2, FR3, and FR4, wherein FR1 has the amino acid sequence set forth in SEQ ID NO: 268, FR2 has the amino acid sequence set forth in SEQ ID NO: 269, FR3 has the amino acid sequence set forth in SEQ ID NO: 270, and FR4 has the amino acid sequence set forth in SEQ ID NO: 271. In further embodiments, each framework may comprise one or more substitutions and or insertions with the proviso that the Navβ1 or Navβ2 binder is capable of binding human Navi.7α. In further embodiments, frameworks may comprise one or more of the substitutions and/or insertions shown in Table 4 in any combination. In further embodiments, FR1 may comprise one or more of the substitutions shown for FR1 in Table 4. In further embodiments, FR2 may comprise one or more of the
substitutions shown for FR2 in Table 4. In further embodiments, FR3 may comprise one or more of the substitutions shown for FR3 in Table 4. In further embodiments, FR4 may comprise one of the substitutions shown for FR4 in Table 4. In a further embodiment, each framework comprises at least one amino acid substitution. In a further embodiment, the Navβ1 or Navβ2 binder comprises at least one substitution and/or insertion shown in Table 4 for each of FR1, FR2, FR3, and FR4. In a further embodiment, the Navβ1 or Navβ2 binder comprises the one substitution or specific substitution and/or insertion combination shown in Table 4 for each of FR1, FR2, FR3, and FR4. In a further embodiment, FR1 comprises at least an LI IV substitution and FR3 comprises at least a V89L substitution. In a further still embodiment, the Navβ1 or Navβ2 binder may comprise one of the 125 specific sets of FR1, FR2, FR3, and FR4 combinations shown in Table 4. In any one of the above embodiments, the FR1 may further comprise a Q1E or a Q1D amino acid substitution.
In particular embodiments of the invention, the Navβ1 binder comprises the amino acid sequence set forth in SEQ ID NO: 411.
In particular embodiments of the invention, the Navβ1 binder comprises the amino acid sequence set forth in SEQ ID NO: 415.
In particular embodiments of the invention, the Navβ2 binder comprises the amino acid sequence set forth in SEQ ID NO: 410.
In particular embodiments of the invention, the Navβ2 binder comprises the amino acid sequence set forth in SEQ ID NO: 412.
In particular embodiments of the invention, the Navβ2 binder comprises the amino acid sequence set forth in SEQ ID NO: 413.
In particular embodiments of the invention, the Navβ2 binder comprises the amino acid sequence set forth in SEQ ID NO: 414.
The Navβ binders of the invention can be fused or linked to one or more other amino acid sequences, chemical entities or moieties by a peptide or non-peptide linker. These other amino acid sequences, chemical entities or moieties can confer one or more desired properties to the resulting Navβ binders of the invention, for example, to provide the resulting Navβ binders of the invention with affinity against another therapeutically relevant target such that the resulting polypeptide becomes “bispecific” with respect to Navβ and that other therapeutically relevant target), or to provide a desired half-life, to provide a cytotoxic effect and/or to serve as a detectable tag or label. Some non-limiting examples of such other amino acid sequences, chemical entities or moieties are:
• one or more suitable peptide or polypeptide linkers (such as a 9GS, 15GS or 35GS linker (any combination of 9, 15, 20 or 35 G and S amino acids such as, for example, GGGGSGGGS (9GS linker; SEQ ID NO: 243), GGGGSGGGGSGGGGSGGGGS (20GS linker; SEQ ID NO: 244) or GGGGSGGGGSGGGGS GGGGSGGGGSGGGGSGGGGS (35GS linker; SEQ ID NO: 245)), GGGGSGGGGSGGGGSGGGGSGGGGSGGGGSGGGGSGGGGSGGGGSGGGGS (50GS linker; SEQ ID NO: 463), or (GGGGS (SEQ ID NO: 246))n wherein n is 1, 2, 3 ,4, 5, 6, 7, 8, 9 or 10); and/or
• one or more binding moieties, directed against a target other than Navβ or epitope thereof, for example, against a different epitope ofNavβ, Navi. la, Navi.2a, Navi.3a, Navi.4a, Navi.5a, Navi.6a, Navi.7α, Navi.8a, Navi.9a, Nax alpha subunit, a sodium channel beta subunit (e.g, Navβ1, Navβ2, Navβ3, or Navβ4), a calcium channel or a potassium channel); and/or
• one or more binding domains or binding units that provide for an increase in half-life (for example, a binding domain or binding unit that can bind against a serum protein such as serum albumin, e.g, human serum albumin), e.g, ALB 11002; See W0200868280; WO2006122787 or W02012175400 and/or
• a binding domain, binding unit or other chemical entity that allows for the Navβ binder (e.g. , an ISVD such as a Nanobody® ISVD) to be internalized into a desired cell (for example, an internalizing anti-EGFR Nanobody® molecule as described in WO05044858); and/or
• a chemical moiety that improves half-life such as a suitable polyethyleneglycol group (i.e. PEGylation) or an amino acid sequence that provides for increased half-life such as human serum albumin or a suitable fragment thereof (i.e. albumin fusion); and/or
• a payload such as a cytotoxic payload; and/or
• a detectable label or tag, such as a radiolabel or fluorescent label; and/or
• a tag that can help with immobilization, detection and/or purification of the binder (e.g. , an ISVD such as a Nanobody® ISVD, such as a HISn, wherein n is 6 to 18, or FLAG tag or combination thereof (e.g., SEQ ID NO: 56);
• a tag that can be functionalized, such as a C-terminal GGC tag; and/or
• a C-terminal extension X(n) (e.g, -Ala), which may be as further described herein.
Navi. 7-Navfl Bispeciflc Binders
The present invention further provides Navl.7-Navβ bispecific binders comprising at least one Navi.7 binder and at least one Navβ binder linked together by peptide or polypeptide linker. As used herein, Navl.7-Navβ bispecific binder refers to binders comprising one or more Navi.7 binders linked to one or more Navβ binders. In an embodiment, the Navi.7- Navβ bispecific binders comprise a Navi.7 ISVD linked via a peptide or polypeptide linker at the C-terminus of the Navi .7 ISVD to the N-terminus of a Navβ ISVD. In another embodiment, the Navl.7-Navβ bispecific binders comprise a Navβ ISVD linked via a peptide or polypeptide linker at the C-terminus of the Navβ ISVD to the N-terminus of a Navi .7 ISVD. The Navi .7- Navβ bispecific binders are provided as a continuous amino acid sequence.
In particular embodiments, the peptide or polypeptide linker comprises repeating Gly (G) and Ser (S) amino acids to provide for example, 9GS, 15GS, or 35GS peptide or polypeptide linkers (any combination of 9, 15, 20 or 35 G and S amino acids such as, for example, GGGGSGGGS (9GS linker; SEQ ID NO: 243), GGGGSGGGGSGGGGSGGGGS (20GS linker; SEQ ID NO: 244) or GGGGSGGGGSGGGGS GGGGSGGGGSGGGGSGGGGS (35GS linker; SEQ ID NO: 245)), GGGGSGGGGSGGGGSGGGGSGGGGSGGGGSGGGGSGGGGSGGGGSGGGGS (50GS linker; SEQ ID NO: 463), or (GGGGS (SEQ ID NO: 246))n wherein n is 1, 2, 3 ,4, 5, 6, 7, 8, 9 or 10).
In particular embodiments, the N-terminal amino acid of the Navl.7-Navβ bispecific binders is an Asp or Glu amino acid and the C-terminus of the Navl.7-Navβ bispecific binders comprises a C-terminal extension of one or more Ala amino acids. In particular embodiments, the C-terminal extension consists of one Ala residue.
In particular embodiments of the Navl.7-Navβ1 bispecific binder, the Navβ binder is a Navβ1 binder or a Navβ2 binder.
In particular embodiments, the Navl.7-Navβ1 bispecific binder comprises a Navβ1 binder comprising (a) a CDR1 comprising the amino acid sequence set forth in SEQ ID NO: 425, a CDR2 comprising the amino acid sequence set forth in SEQ ID NO: 426, and a CDR3 comprising the amino acid sequence set forth in SEQ ID NO: 427; or (b) a CDR1 comprising the amino acid sequence set forth in SEQ ID NO: 437, a CDR2 comprising the amino acid sequence set forth in SEQ ID NO: 438, and a CDR3 comprising the amino acid sequence set forth in SEQ ID NO: 439.
In a further embodiment, the Navl.7-Navβ1 bispecific binder comprises aNavβ1 binder comprising the amino acid sequence set forth in SEQ ID NO: 411 or the amino acid sequence set forth in SEQ ID NO: 415.
In particular embodiments, the Navl.7-Navβ2 bispecific binder comprises a Navβ2 binder comprising (a) a CDR1 comprising the amino acid sequence set forth in SEQ ID NO: 422, a CDR2 comprising the amino acid sequence set forth in SEQ ID NO: 423, and a CDR3 comprising the amino acid sequence set forth in SEQ ID NO: 424; (b) a CDR1 comprising the amino acid sequence set forth in SEQ ID NO: 428, a CDR2 comprising the amino acid sequence set forth in SEQ ID NO: 429, and a CDR3 comprising the amino acid sequence set forth in SEQ ID NO: 430; (c) a CDR1 comprising the amino acid sequence set forth in SEQ ID NO: 431, a CDR2 comprising the amino acid sequence set forth in SEQ ID NO: 432, and a CDR3 comprising the amino acid sequence set forth in SEQ ID NO: 433; or (d) a CDR1 comprising the amino acid sequence set forth in SEQ ID NO: 434, a CDR2 comprising the amino acid sequence set forth in SEQ ID NO: 435, and a CDR3 comprising the amino acid sequence set forth in SEQ ID NO: 436.
In a further embodiment, the Navl.7-Navβ1 bispecific binder comprises aNavβ2 binder comprising the amino acid sequence set forth in SEQ ID NO: 410, the amino acid sequence set forth in SEQ ID NO: 412, the amino acid sequence set forth in SEQ ID NO: 413, or amino acid sequence set forth in SEQ ID NO: 414.
In particular embodiments, the Navl.7-Navβ1 bispecific binder comprises a Navi.7 binder comprising (a) a CDR1 comprising the amino acid sequence set forth in SEQ ID NO: 196 or SEQ ID NO: 197; a CDR2 comprising the amino acid sequence set forth in SEQ ID NO: 198 or SEQ ID NO: 199; and, a CDR3 comprising the amino acid sequence set forth in SEQ ID NO: 200; (b) a CDR1 comprising the amino acid sequence set forth in SEQ ID NO: 201; a CDR2 comprising the amino acid sequence set forth in SEQ ID NO: 202, SEQ ID NO: 203, SEQ ID NO: 204, or SEQ ID NO: 205; and, a CDR3 comprising the amino acid sequence set forth in SEQ ID NO: 206; (c) a CDR1 comprising the amino acid sequence set forth in SEQ ID NO: 207, SEQ ID NO: 208, SEQ ID NO: 209, SEQ ID NO: 210, SEQ ID NO: 211, or SEQ ID NO: 212; a CDR2 comprising the amino acid sequence set forth in SEQ ID NO: 213, SEQ ID NO: 214, SEQ ID NO: 215, SEQ ID NO: 216, SEQ ID NO: 217, or SEQ ID NO: 218; and a CDR3 comprising the amino acid sequence set forth in SEQ ID NO: 219; (d) a CDR1 comprising the amino acid sequence set forth in SEQ ID NO: 201 or SEQ ID NO: 222; a CDR2 comprising the amino acid sequence set forth in SEQ ID NO: 223 or SEQ ID NO: 224; and a CDR3 comprising the amino
acid sequence set forth in SEQ ID NO: 225, SEQ ID NO: 226, SEQ ID NO: 227, SEQ ID NO: 228, SEQ ID NO: 229, SEQ ID NO: 230, SEQ ID NO: 231, SEQ ID NO: 232, or SEQ ID NO: 233; (e) a CDR1 comprising the amino acid sequence set forth in SEQ ID NO: 201; a CDR2 comprising the amino acid sequence set forth in SEQ ID NO: 205; and, a CDR3 comprising the amino acid sequence set forth in SEQ ID NO: 206; (I) a CDR1 comprising the amino acid sequence set forth in SEQ ID NO: 211; a CDR2 comprising the amino acid sequence set forth in SEQ ID NO: 215; and, a CDR3 comprising the amino acid sequence set forth in SEQ ID NO: 219; or (g) a CDR1 comprising the amino acid sequence set forth in SEQ ID NO: 222; a CDR2 comprising the amino acid sequence set forth in SEQ ID NO: 223; and, a CDR3 comprising the amino acid sequence set forth in SEQ ID NO: 233.
In any one of the foregoing embodiments, the Navi.7 binder comprising the Navl.7-Navβ bispecific binder comprises (a) an amino acid sequence selected from the group consisting of SEQ ID NO: 46, SEQ ID NO: 47, SEQ ID NO: 48, SEQ ID NO: 49, SEQ ID NO: 50, SEQ ID NO: 51, SEQ ID NO: 52, SEQ ID NO: 53, SEQ ID NO: 54, and SEQ ID NO: 55; (b) an amino acid sequence selected from the group consisting of SEQ ID NO: 69, SEQ ID NO: 70, SEQ ID NO: 71, SEQ ID NO: 72, SEQ ID NO: 73, SEQ ID NO: 74, SEQ ID NO: 75, SEQ ID NO: 76, SEQ ID NO: 77, SEQ ID NO: 78, SEQ ID NO: 79, SEQ ID NO: 80, and SEQ ID NO: 81; (c) an amino acid sequence selected from the group consisting of SEQ ID NO: 82, SEQ ID NO: 83, SEQ ID NO: 84, SEQ ID NO: 85, SEQ ID NO: 86, SEQ ID NO: 87, SEQ ID NO: 88, SEQ ID NO: 89, SEQ ID NO: 90, SEQ ID NO: 91, SEQ ID NO: 92, SEQ ID NO: 93, SEQ ID NO: 94, SEQ ID NO: 95, SEQ ID NO: 96, and SEQ ID NO: 97; (d) an amino acid sequence selected from the group consisting of SEQ ID NO: 98, SEQ ID NO: 99, SEQ ID NO: 100, SEQ ID NO: 102, SEQ ID NO: 103, SEQ ID NO: 104, SEQ ID NO: 105, SEQ ID NO: 106, SEQ ID NO: 107, SEQ ID NO: 108, SEQ ID NO: 109, SEQ ID NO: 110, SEQ ID NO: 111, SEQ ID NO: 112, SEQ ID NO: 113, SEQ ID NO: 114, SEQ ID NO: 115, SEQ ID NO: 116, SEQ ID NO: 117, SEQ ID NO: 118, SEQ ID NO: 119, SEQ ID NO: 120, SEQ ID NO: 121, SEQ ID NO: 122, SEQ ID NO: 123, SEQ ID NO: 124, SEQ ID NO: 125, SEQ ID NO: 126, SEQ ID NO: 127, SEQ ID NO: 128, SEQ ID NO: 129, SEQ ID NO: 130, SEQ ID NO: 131, SEQ ID NO: 132, SEQ ID NO: 133, SEQ ID NO: 134, SEQ ID NO: 135, SEQ ID NO: 136, SEQ ID NO: 137, SEQ ID NO: 138, SEQ ID NO: 139, SEQ ID NO: 140, SEQ ID NO: 141, SEQ ID NO: 142, SEQ ID NO: 143, SEQ ID NO: 144, SEQ ID NO: 145, SEQ ID NO: 146, SEQ ID NO: 147, SEQ ID NO: 148, SEQ ID NO: 149, SEQ ID NO: 150, SEQ ID NO: 151, SEQ ID NO: 152, and SEQ ID NO: 153; (e) an amino acid sequence selected from the group consisting of SEQ ID NO: 154, SEQ ID NO: 155,
SEQ ID NO: 156, SEQ ID NO: 157, SEQ ID NO: 158, SEQ ID NO: 159, SEQ ID NO: 160, SEQ ID NO: 161, SEQ ID NO: 162, SEQ ID NO: 163, SEQ ID NO: 164, SEQ ID NO: 165, SEQ ID NO: 166, SEQ ID NO: 167, SEQ ID NO: 168, SEQ ID NO: 169, SEQ ID NO: 170, SEQ ID NO: 171, SEQ ID NO: 172, SEQ ID NO: 173, SEQ ID NO: 174, SEQ ID NO: 175, SEQ ID NO: 176, SEQ ID NO: 177, SEQ ID NO: 178, SEQ ID NO: 179, SEQ ID NO: 180, SEQ ID NO: 181, SEQ ID NO: 182, SEQ ID NO: 183, SEQ ID NO: 184, SEQ ID NO: 185, SEQ ID NO: 186, SEQ ID NO: 187, SEQ ID NO: 188, SEQ ID NO: 189, SEQ ID NO: 190, SEQ ID NO: 191, SEQ ID NO: 192, SEQ ID NO: 193, SEQ ID NO: 194, and SEQ ID NO: 195.
In particular embodiments, the Navi.7 binder comprising the Navl.7-Navβ bispecific binder comprises the amino acid sequence set forth in SEQ ID NO: 96; the amino acid sequence set forth in SEQ ID NO: 148; or, the amino acid sequence set forth in SEQ ID NO: 192.
In particular embodiments of the Navi.7 binders or Navβ binders comprising the Navl.7-Navβ bispecific binder, the N-terminal Glu is substituted with Asp. In particular embodiments, the N-terminal ISVD of the Navl.7-Navβ binder comprises an Asp amino acid residue at the N-terminus.
Half-Life Extenders (HLE)
The Navi.7 binders, Navβ binders, and Navl.7-Navβ bispecific binders of the present invention, may further comprise one or more half-life extenders such as one or more anti- HSA (human serum albumin) binders and/or one or more polyethylene glycol (PEG) molecules.
As discussed herein, the “HSA binders” of the present invention bind to HSA (e.g., an ISVD such as a Nanobody® ISVD) as well as any binder which includes such a molecule that is fused to another binder. An individual HSA binder may be referred to as an HSA binding moiety if it is part of a larger molecule, e.g., a multivalent molecule.
As further described herein, the HSA binders of the invention that are fused to the Navi.7 binder, Navβ binder, or Navl.7-Navβ bispecific binder comprise the same combination of CDRs (i. e. , CDR1 , CDR2 and CDR3) as are present in ALB 11002 or comprise the amino acid sequence of ALB 11002 (SEQ ID NO: 234).
The present invention also includes Navi.7 binders, Navβ binders, and Navi.7- Navβ bispecific binders that further include being linked by a peptide or polypeptide linker to one or more HSA binding moieties which are variants of ALBI 1002, e.g., wherein the HSA
binder comprises CDR1, CDR2 and CDR3 of said ALBI 1002 variants set forth below in Table
6

In particular embodiments, the ALBI 1002 further lacks the C-terminal Alanine
(SEQ ID NO: 234). In a further embodiment, the HSA binder comprises the amino acid sequence set forth in SEQ ID NO: 238 but which further comprises an EID, VI IL, and an L93V substitution to provide an HSA binder comprising the amino acid sequence set forth in SEQ ID NO: 240:
EVQLVESGGGVVQPGNSLRLSCAASGFTFSSFGMSWVRQAPGKGLEWVSSISGSGSDTL YADSVKGRFTISRDNAKTTLYLQMNSLRPEDTALYYCTIGGSLSRSSQGTLVTVSSA. This embodiment may further lack the C-terminal Alanine to provide the amino acid sequence set forth in SEQ ID NO: 239.
In an embodiment of the invention, the HLE is ALB11 comprising the amino acid sequence:
EVQLVESGGGLVQPGNSLRLSCAASGFTFSSFGMSWVRQAPGKGLEWVSSISGSGSDTL YADSVKGRFTISRDNAKTTLYLQMNSLRPEDTAVYYCTIGGSLSRSSQGTLVTVSSA (SEQ ID NO: 242) and in a further embodiment lacks the C-terminal Alanine (SEQ ID NO:241).
In particular embodiments ALB00233 lacks a C-terminal A as shown in SEQ ID NO: 266.
In an embodiment of the invention, the half-life extender is an HSA binder comprising: a CDR1 that comprises the amino acid sequence GFTFSSFGMS (SEQ ID NO: 235) or GFTFRSFGMS (SEQ ID NO: 267); a CDR2 that comprises the amino acid sequence SISGSGSDTL (SEQ ID NO: 236); and a CDR3 that comprises the amino acid sequence GGSLSR (SEQ ID NO: 237).
In an embodiment of the invention, the first amino acid of any of the HSA binders is E and in another embodiment of the invention, the first amino acid of any of the HSA binders is D.
In particular embodiments, the peptide or polypeptide linker comprises repeating Gly (G) and Ser (S) amino acids to provide for example, 9GS, 15GS, or 35GS peptide or polypeptide linkers (any combination of 9, 15, 20 or 35 G and S amino acids such as, for example, GGGGSGGGS (9GS linker; SEQ ID NO: 243), GGGGSGGGGSGGGGSGGGGS (20GS linker; SEQ ID NO: 244) or GGGGSGGGGSGGGGS GGGGSGGGGSGGGGSGGGGS (35GS linker; SEQ ID NO: 245)), GGGGSGGGGSGGGGSGGGGSGGGGSGGGGSGGGGSGGGGSGGGGSGGGGS (50GS linker; SEQ ID NO: 463), or (GGGGS (SEQ ID NO: 246))n wherein n is 1, 2, 3 ,4, 5, 6, 7, 8, 9 or 10).
In another embodiment of the invention, the half-life extender is a polyethylene glycol (PEG) moiety appended to the Navi.7 binder, Navβ binder, or Navl.7-Navβ bispecific binder to provide a PEGylated Navl.7 binder, Navβ binder, or Navl.7-Navβ bispecific binder. The molecular weight of the polyethylene glycol (PEG) moiety may be about 12,000 daltons or about 20,000 daltons. In an embodiment of the invention, the Navi.7 binder, Navβ binder, or Navl.7-Navβ bispecific binder comprises one or more polyethylene glycol molecules covalently attached via a linker (e.g., a C2-12 alkyl such as -CH2CH2CH2-) to a single amino acid residue of a single subunit of the Navi.7 binder, Navβ binder, or Navl.7-Navβ bispecific binder, wherein said amino acid residue is the alpha amino group of the N-terminal amino acid residue or the epsilon amino group of a lysine residue. In an embodiment of the invention, the PEGylated binder is: (PEG)fo-L-NH- [binder]; wherein b is 1-9 and L is a C2-12 alkyl linker
moiety covalently attached to a nitrogen (N) of the single amino acid residue of the binder. In an embodiment of the invention, the PEGylated binder has the formula: [X-O(CH2CH2O)n]b-L- NH-[binder], wherein X is H or C1 -4 alkyl; n is 20 to 2300; b is 1 to 9; and L is a C1-11 alkyl linker moiety which is covalently attached to the nitrogen (N) of the alpha amino group at the amino terminus of one binder subunit; provided that when b is greater than 1, the total of n does not exceed 2300. See, for example, US. Patent No. 7,052,686, which is incorporated herein by reference in its entirety.
To PEGylate a Navi.7 binder, Navβ binder, or Navl.7-Navβ bispecific binder, typically the binder is reacted with a reactive form of polyethylene glycol (PEG), such as a reactive ester or aldehyde derivative of PEG, under conditions in which one or more PEG groups become attached to the binder. In particular embodiments, the PEGylation is carried out via an acylation reaction or an alkylation reaction with a reactive PEG molecule (or an analogous reactive water-soluble polymer). As used herein, the term "polyethylene glycol" is intended to encompass any of the forms of PEG that have been used to derivatize other proteins, such as mono (C1 -110) alkoxy- or aryloxy -poly ethylene glycol or polyethylene glycol-mal eimide. In certain embodiments, the binder to be PEGylated is an aglycosylated binder. Methods for PEGylating proteins are known in the art and can be applied to the binder of the invention. See, e.g., EP0154316 and EP0401384, each of which is incorporated herein by reference in its entirety.
In certain embodiments, the Navi.7 binder, Navβ binder, or Navl.7-Navβ bispecific binder is fused at the C-terminus to an HC constant domain of Fc domain thereof domain. In a particular embodiment, the HC domain or Fc domain thereof is of the IgGl, IgG2, IgG3, or IgG4 isotype. The amino acid sequences of the IgGl, IgG2, and IgG4 isotype HC constant domains are set forth in SEQ ID NO: 469, SEQ ID NO: 476, and SEQ ID No: 482, respectively. In the embodiments herein, the Fc domain may comprise the CH2 and CH3 domains of the HC constant domain. In particular embodiments, the Fc domain may further comprise the hinge region between the CHI and CH2 domains or the hinge region comprising one or amino acid deletions. In exemplary embodiments, Navi.7 binders, Navβ binders, or Navl.7-Navβ bispecific binders are fused to an HC domain or Fc domain thereof of the IgGl, IgG2, or IgG4 isotype. In particular embodiments, the Navi.7 binders, Navβ binders, or Navi.7- Navβ bispecific binders are fused to the N-terminus of an HC domain or Fc domain thereof. In particular embodiments, the Navi.7 binders, Navβ binders, or Navl.7-Navβ bispecific binders are fused to the C-terminus of an HC domain or Fc domain thereof.
Navl.7 binders, Navβ binders, or Navl.7-Navβ bispecific binders of the present invention further include ISVDs that are fused or linked to an effector-silent HC constant domain or Fc domain thereof. The effector-silent HC constant domain or Fc domain has been modified such that it displays no measurable binding to one or more FcRs or displays reduced binding to one or more FcRs compared to that of an unmodified HC constant domain or Fc domain of the same IgG isotype. The effector-silent HC constant domain or Fc domain may in further embodiments display no measurable binding to each of FcyRIIIa, FcyRIIa, and FcyRI or display reduced binding to each of FcyRIIIa, FcyRIIa, and FcyRI compared to that of an unmodified antibody of the same IgG isotype. In particular embodiments, the effector-silent HC constant domain or Fc domain is a modified human HC constant domain or Fc domain.
In particular embodiments, the effector-silent HC constant domain or Fc domain thereof comprises an Fc domain of an IgGl or IgG2, IgG3, or IgG4 isotype that has been modified to lack /V-glycosylation of the asparagine (Asn) residue at position 297 (Eu numbering system) of the HC constant domain. The consensus sequence for /V-glycosylation is Asn-Xaa- Ser/Thr (wherein Xaa at position 298 is any amino acid except Pro); in all four isotypes the N- glycosylation consensus sequence is Asn-Ser-Thr. The modification may be achieved by replacing the codon encoding the Asn at position 297 in the nucleic acid molecule encoding the HC constant domain with a codon encoding another amino acid, for example Ala, Asp, Gin, Gly, or Glu, e.g. N297A, N297Q, N297G, N297E, or N297D. Alternatively, the codon for Ser at position 298 may be replaced with the codon for Pro or the codon for Thr at position 299 may be replaced with any codon except the codon for Ser. In a further alternative each of the amino acids comprising the /V-glycosylation consensus sequence is replaced with another amino acid. Such modified IgG molecules have no measurable effector function. In particular embodiments, these mutated HC molecules may further comprise 1, 2, 3, 4, 5, 6, 7, 8, 9, or 10 additional amino acid substitutions, insertions, and/or deletions, wherein said substitutions may be conservative mutations or non-conservative mutations. In further embodiments, such IgGs modified to lack /V-glycosylation at position 297 may further include one or more additional mutations disclosed herein for eliminating measurable effector function.
An exemplary IgGl HC constant domain or Fc domain thereof mutated at position 297, which abolishes the N-glycosylation of the HC constant domain, is set forth in SEQ ID NO: 474, an exemplary IgG2 HC constant domain mutated at position 297, which abolishes the /V-glycosylation of the HC constant, is set forth in SEQ ID NO: 480, and an exemplary IgG4 HC constant domain mutated at position 297 to abolish /V-glycosylation of the HC constant
domain is set forth in SEQ ID NO: 485. In particular embodiments, these mutated HC molecules may further comprise 1, 2, 3, 4, 5, 6, 7, 8, 9, or 10 additional amino acid substitutions, insertions, and/or deletions, wherein said substitutions may be conservative mutations or non-conservative mutations.
In particular embodiments, the HC constant domain or Fc domain thereof of the IgGl IgG2, IgG3, or IgG4 HC constant domain is modified to include one or more amino acid substitutions selected from E233P, L234A, L235A, L235E, N297A, N297D, D265S, and P331S (wherein the positions are identified according to Eu numbering) and wherein said HC constant domain is effector-silent. In particular embodiments, the modified IgGl further comprise 1, 2, 3, 4, 5, 6, 7, 8, 9, or 10 additional amino acid substitutions, insertions, and/or deletions, wherein said substitutions may be conservative mutations or non-conservative mutations.
In particular embodiments, the HC constant domain or Fc domain thereof comprises L234A, L235A, and D265S substitutions (wherein the positions are identified according to Eu numbering). In particular embodiments, the HC constant domain comprises an amino acid substitution at position Pro329 and at least one further amino acid substitution selected from E233P, L234A, L235A, L235E, N297A, N297D, D265S, and P331S (wherein the positions are identified according to Eu numbering). These and other substitutions are disclosed in WO9428027; W02004099249; W020121300831, U.S. Pat. Nos. 9,708,406; 8,969,526; 9,296,815; Sondermann et al. Nature 406, 267-273 (2000), each of which is incorporated herein by reference in its entirety).
In particular embodiments of the above, the HC constant domain or Fc domain thereof comprises an L234A/L235A/D265A; L234A/L235A/P329G; L235E; D265A; D265A/N297G; or V234A/G237A/P238S/H268A/V309L/A330S/P331S substitutions, wherein the positions are identified according to Eu numbering. In particular embodiments, the HC molecules further comprise 1, 2, 3, 4, 5, 6, 7, 8, 9, or 10 additional amino acid substitutions, insertions, and/or deletions, wherein said substitutions may be conservative mutations or non- conservative mutations.
In particular embodiments, the effector-silent HC constant domain or Fc domain thereof comprises an IgGl isotype, in which the Fc domain of the HC constant domain has been modified to be effector-silent by substituting the amino acids from position 233 to position 236 of the IgGl with the corresponding amino acids of the human IgG2 HC and substituting the amino acids at positions 327, 330, and 331 with the corresponding amino acids of the human IgG4 HC, wherein the positions are identified according to Eu numbering (Armour et al., Eur. J.
Immunol. 29(8):2613-24 (1999); Shields et al., J. Biol. Chem. 276(9):6591-604(2001)). In particular embodiments, the modified IgGl further comprise 1, 2, 3, 4, 5, 6, 7, 8, 9, or 10 additional amino acid substitutions, insertions, and/or deletions, wherein said substitutions may be conservative mutations or non-conservative mutations.
In particular embodiments, the effector-silent HC constant domain or Fc domain thereof is a hybrid human immunoglobulin HC constant domain, which includes a hinge region, a CH2 domain and a CH3 domain in an N-terminal to C-terminal direction, wherein the hinge region comprises an at least partial amino acid sequence of a human IgD hinge region or a human IgGl hinge region; and the CH2 domain is of a human IgG4 CH2 domain, a portion of which, at its N-terminal region, is replaced by 4-37 amino acid residues of an N-terminal region of a human IgG2 CH2 or human IgD CH2 domain. Such hybrid human HC constant domain is disclosed in U.S. Pat. No. 7,867,491, which is incorporated herein by reference in its entirety.
In particular embodiments, the effector-silent HC constant domain or Fc domain thereof is an IgG4 HC constant domain in which the serine at position 228 according to the Eu system is substituted with proline, see for example SEQ ID NO: 52. This modification prevents formation of a potential inter-chain disulfide bond between the cysteines at positions Cys226 and Cys229 in the EU numbering scheme and which may interfere with proper intra-chain disulfide bond formation. See Angal et al. Mol. Imunol. 30:105 (1993); see also (Schuurman et al., Mol. Immunol. 38: 1-8, (2001)). In further embodiments, the IgG4 constant domain includes in addition to the S228P substitution, a P239G, D265A, or D265A/N297G amino acid substitution, wherein the positions are identified according to Eu numbering. In particular embodiments of the above, the IgG4 HC constant domain is a human HC constant domain. In particular embodiments, the HC molecules further comprise 1, 2, 3, 4, 5, 6, 7, 8, 9, or 10 additional amino acid substitutions, insertions, and/or deletions, wherein said substitutions may be conservative mutations or non-conservative mutations.
Exemplary IgGl HC constant domains comprise an amino acid sequence selected from the group consisting of amino acid sequences set forth in SEQ ID NO: 470, SEQ ID NO: 471, SEQ ID NO: 472, SEQ ID NO: 473, SEQ ID NO: 474, and SEQ ID NO: 475.
Exemplary IgG2 HC constant domains comprise an amino acid sequence selected from the group consisting of amino acid sequences set forth in SEQ ID NO: 477, SEQ ID NO: 478, SEQ ID NO: 479, and SEQ ID NO: 480.
Exemplary IgG4 HC constant domains comprise an amino acid sequence selected from the group consisting of amino acid sequences set forth in SEQ ID NO: 483, SEQ ID NO: 484, and SEQ ID NO: 485.
The particular embodiments, the Navi.7 binder, Navβ binder, or Navl.7-Navβ bispecific binder is linked to the HC constant domain or Fc domain thereof by a peptide or polypeptide linker to provide a fusion protein comprising the structure binder-linker-HC constant domain or Fc domain thereof or HC constant domain-linker-binder wherein binder refers to Navi.7 binder, Navβ binder, or Navl.7-Navβ bispecific binder. The Fc domain thereof as used herein includes embodiments lacking the hinge region and embodiments wherein the Fc comprises one or amino acids of the hinge region.
In particular embodiments, the peptide or polypeptide linker comprises repeating Gly (G) and Ser (S) amino acids to provide for example, 9GS, 15GS, or 35GS peptide or polypeptide linkers (any combination of 9, 15, 20 or 35 G and S amino acids such as, for example, GGGGSGGGS (9GS linker; SEQ ID NO: 243), GGGGSGGGGSGGGGSGGGGS (20GS linker; SEQ ID NO: 244) or GGGGSGGGGSGGGGS GGGGSGGGGSGGGGSGGGGS (35GS linker; SEQ ID NO: 245)), GGGGSGGGGSGGGGSGGGGSGGGGSGGGGSGGGGSGGGGSGGGGSGGGGS (50GS linker; SEQ ID NO: 463), or (GGGGS (SEQ ID NO: 246))n wherein n is 1, 2, 3 ,4, 5, 6, 7, 8, 9 or 10).
In particular embodiments, the Navi.7 binders, Navβ binders, or Navl.7-Navβ bispecific binders are fused to the N-terminus of an effector-silent HC domain or Fc domain thereof. In particular embodiments, the Navi.7 binders, Navβ binders, or Navl.7-Navβ bispecific binders are fused to the C-terminus of an effector-silent HC domain or Fc domain thereof.
In particular embodiments, the Navi.7 binders, Navβ binders, or Navl.7-Navβ bispecific binders are linked to the N-terminus of an effector-silent HC domain or Fc domain thereof by anon-peptide linker, which in particular embodiments, may be a non-peptide polymer. The non-peptide polymer refers to a biocompatible polymer to which at least two repeat units are conjugated, and the repeat units are interconnected by random covalent bonds other than peptide bonds. The non-peptide polymer may be selected from the group consisting of polyethylene glycol, polypropylene glycol, a copolymer between ethylene glycol and propylene glycol, poly oxyethylated polyol, polyvinyl alcohol, polysaccharide, dextran, polyvinyl ethyl ether, a biodegradable polymer such as polylactic acid (PLA) and polylactic-glycolic acid
(PLGA), lipid polymer, chitins, hyaluronic acid, and a combination thereof, and preferably, polyethylene glycol. The derivatives known in the art and the derivatives that can easily be prepared using the technology in the art are also included in the scope of the present invention. In particular embodiments, the non-peptide linker comprises polyethylene glycol, which in particular embodiments may be 3,400 daltons. Conjugates comprising a heterologous protein conjugated to an Fc domain by a non-peptide linker have been disclosed in U.S. Patent No. 7,636,420; 7,737,260; 7,968,316; 8,029,789; 8,110,665; 8,124,094; 8,822,650; 8,846,874; 9,394, 546; 10,071,171; 10,272,159; and 10,973,881, each of which is incorporated herein by reference in its entirety.
In particular embodiments, the HC constant domain or Fc domain conjugates form a homodimer wherein each HC constant domain or Fc domain conjugates comprising the homodimer is fused or conjugated to the same binder selected from Navi.7 binder, Navβ binder, and Navl.7-Navβ bispecific binder. In particular embodiments, the HC constant domain or Fc domain conjugates form a heterodimer wherein a HC constant domain or Fc domain conjugate comprising the heterodimer is fused or conjugated to a binder selected from Navi.7 binder, Navβ binder, and Navl.7-Navβ bispecific binder and a second HC constant domain or Fc domain conjugate comprising the heterodimer is fused or conjugated to a binder selected from Navi.7 binder, Navβ binder, and Navl.7-Navβ bispecific binder that is not fused or conjugated to the first HC constant domain or Fc domain conjugate. In particular embodiments, the HC constant domain or Fc domain conjugate form a heterodimer wherein a first HC constant domain or Fc domain conjugate comprising the heterodimer is fused or conjugated to a binder selected from Navi.7 binder, Navβ binder, and Navl.7-Navβ bispecific binder and the second HC constant domain or Fc domain is not fused or conjugated to aNavl.7 binder, Navβ binder, and Navi.7- Navβ bispecific binder. In particular embodiments, the second HC constant domain or Fc domain is fused or conjugated to a heterologous protein, which may be the Fab of an antibody or ISVD other than aNavl.7 binder, Navβ binder, or Navl.7-Navβ bispecific binder; a heterologous protein, polypeptide, or peptide; or a small molecule. HC constant domain and Fc domain heterodimers have been disclosed in WO9627011; WO9850431; WO9929732; W02009089004; W02013055809; W02013063702; WO2014145907; and W02014084607, each of which is incorporated herein by reference in its entirety.
In particular embodiments of the invention, the HC constant or Fc domains as disclosed herein may comprise a C-terminal lysine or lack either a C-terminal lysine or a C- terminal glycine-lysine dipeptide.
C-terminal Extensions
The present invention further provides Navi.7 binders, Navβ binders, or Navi.7- Navβ bispecific binders that comprise a C-terminal extension. The present invention provides, for example, C-terminal extensions such as X(n), wherein X and n can be as follows:
(a) n = 1 and X = Ala;
(b) n = 2 and each X = Ala;
(c) n = 3 and each X = Ala;
(d) n = 2 and at least one X = Ala (with the remaining amino acid residue(s) X being independently chosen from any naturally occurring amino acid but preferably being independently chosen from Vai, Leu and/or Ile);
(e) n = 3 and at least one X = Ala (with the remaining amino acid residue(s) X being independently chosen from any naturally occurring amino acid but preferably being independently chosen from Vai, Leu and/or Ile);
(f) n = 3 and at least two X = Ala (with the remaining amino acid residue(s) X being independently chosen from any naturally occurring amino acid but preferably being independently chosen from Vai, Leu and/or Ile);
(g) n = 1 and X = Gly;
(h) n = 2 and each X = Gly;
(i) n = 3 and each X = Gly;
(j) n = 2 and at least one X = Gly (with the remaining amino acid residue(s) X being independently chosen from any naturally occurring amino acid but preferably being independently chosen from Vai, Leu and/or Ile);
(k) n = 3 and at least one X = Gly (with the remaining amino acid residue(s) X being independently chosen from any naturally occurring amino acid but preferably being independently chosen from Vai, Leu and/or Ile);
(l) n = 3 and at least two X = Gly (with the remaining amino acid residue(s) X being independently chosen from any naturally occurring amino acid but preferably being independently chosen from Vai, Leu and/or Ile);
(m) n = 2 and each X = Ala or Gly;
(n) n = 3 and each X = Ala or Gly;
(o) n = 3 and at least one X = Ala or Gly (with the remaining amino acid residue(s) X being independently chosen from any naturally occurring amino acid but preferably being independently chosen from Vai, Leu and/or Ile); or
(p) n = 3 and at least two X = Ala or Gly (with the remaining amino acid residue(s) X being independently chosen from any naturally occurring amino acid but preferably being independently chosen from Vai, Leu and/or Ile); with aspects (a), (b), (c), (g), (h), (i), (m) and (n) being preferred, with aspects in which n =1 or 2 being preferred and aspects in which n = 1 being preferred.
Some specific, but non-limiting examples of useful C-terminal extensions are the following amino acid sequences: A, AA, AAA, G, GG, GGG, AG, GA, AAG, AGG, AGA, GGA, GAA or GAG.
In an embodiment of the invention, any C-terminal extension present in a Navi.7 binder, Navβ binder, or Navl.7-Navβ bispecific binder does not contain a free cysteine residue (unless said cysteine residue is used or intended for further functionalization, for example for PEGylation).
Conjugates
The Navi.7 binders, Navβ binders, or Navl.7-Navβ bispecific binders disclosed herein may also be conjugated to a chemical moiety. Such conjugated binders are an embodiment of the present invention. The chemical moiety may be, inter alia, a polymer, a radionuclide or a cytotoxic factor. In particular embodiments, the chemical moiety is a polymer that increases the half-life of the Navi.7 binder, Navβ binder, or Navl.7-Navβ bispecific binder in the body of a subject. Suitable polymers include, but are not limited to, hydrophilic polymers, which include but are not limited to, polyethylene glycol (PEG) (e.g., PEG with a molecular weight of 2kDa, 5 kDa, 10 kDa, 12kDa, 20 kDa, 30kDa or 40kDa), dextran and monomethoxypolyethylene glycol (mPEG). Lee, et al., (1999) (Bioconj. Chem. 10:973-981) discloses PEG conjugated single-chain antibodies. Wen, et al., (2001) (Bioconj. Chem. 12:545- 553) disclose conjugating antibodies with PEG which is attached to a radiometal chelator (diethylenetriaminpentaacetic acid (DTP A)).
The Navi.7 binders, Navβ binders, or Navl.7-Navβ bispecific binders disclosed herein may also be conjugated with labels such as "TC,90Y, niIn, 32P, 14C, 1251, 3H, 131I, 1 'C. 15O, 13N, 18F, 35S, 51Cr, 57TO, 226Ra, 60Co, 59Fe, 57Se, 152Eu, 67CU, 217Ci, 211At, 212Pb, 47Sc, 109Pd, 234Th, and 40K, 157Gd, 55Mn, 52Tr, and 56Fe.
The Navi.7 binders may also be conjugated with fluorescent or chemiluminescent labels, including fluorophores such as rare earth chelates, fluorescein and its derivatives, rhodamine and its derivatives, isothiocyanate, phycoerythrin, phycocyanin, allophycocyanin, o- phthaladehyde, fluorescamine, 152Eu, dansyl, umbelliferone, luciferin, luminal label, isoluminal label, an aromatic acridinium ester label, an imidazole label, an acridimium salt label, an oxalate ester label, an aequorin label, 2,3-dihydrophthalazinediones, biotin/avidin, spin labels and stable free radicals.
The Navi.7 binder, Navβ binder, or Navl.7-Navβ bispecific binder may also be conjugated to a cytotoxic factor such as diptheria toxin, Pseudomonas aeruginosa exotoxin A chain, ricin A chain, abrin A chain, modeccin A chain, alpha-sarcin, Aleurites fordii proteins and compounds (e.g., fatty acids), dianthin proteins, Phytolacca americana proteins PAPI, PAPII, and PAP-S, momordica charantia inhibitor, curcin, crotin, saponaria officinalis inhibitor, mitogellin, restrictocin, phenomycin, and enomycin.
Any method known in the art for conjugating a Navi.7 binder, Navβ binder, or Navl.7-Navβ bispecific binder to the various moieties may be employed, including those methods described by Hunter, et al., (1962) Nature 144:945; David, et al., (1974) Biochemistry 13:1014; Pain, et al., (1981) J. Immunol. Meth. 40:219; and Nygren, J., (1982) Histochem. and Cytochem. 30:407. Methods for conjugating binders are conventional and very well known in the art.
The present invention further provides nucleic acid molecules encoding any one of the Navi.7 binders, Navβ binders, or Navl.7-Navβ bispecific binders disclosed herein. In particular embodiments, the nucleic acid molecule encoding the Navi.7 binder comprises a nucleotide sequence selected from the group of nucleotide sequences set forth in SEQ ID NO: 273-283. In particular embodiments, the nucleic acid molecule encoding the Navi.7 binder comprises a nucleotide sequence selected from the group of nucleotide sequences set forth in SEQ ID NO: 284-421. In particular embodiments, the nucleic acid molecule encoding the Navβ binder comprises a nucleotide sequence selected from the group of nucleotide sequences set forth in SEQ ID NO: 456-461.
The following examples are intended to promote a further understanding of the present invention. The amino acid sequences for the Navi.7 binder, Navβ binder, or Navi.7- Navβ bispecific binders and nucleic acid sequences encoding the Navi.7 binder, Navβ binder, or Navl.7-Navβ bispecific binders that are disclosed in the following examples are provided in
Table 56. Various embodiments of the aforementioned binders comprise an amino acid sequence set forth in Table 56.
EXAMPLE 1
Generation of stable recombinant huNavl.7a cell lines
Different stable CHO Flpin (ThermoFisher Scientific, catalog # R758-07) or HEK Flpin (ThermoFisher Scientific, catalog # R750-07) transgenic cell lines were generated according to the manufacturer's instructions. To this purpose, different Navi.7α constructs (human or rhesus) were cloned into pcDNA5/FRT (ThermoFisher Scientific, catalog # V601020). The amino acid sequences for huNavl.7α, rhNavl.7α, huNavl.la, huNavl.2a, huNav 1.3a, huNavl.4a, huNavl.5a, huNavl.6a, and huNavl.8a are set forth in SEQ ID NO: 1, SEQ ID NO: 2, SEQ ID NO: 23, SEQ ID NO: 24, SEQ ID NO: 25, SEQ ID NO: 26, SEQ ID NO: 27, and SEQ ID NO: 28, respectively. The generation of HEK293 cell lines stably expressing huNavl.7α with and without the human P subunit is detailed elsewhere (Schmalhofer et al. Mol Pharmacol 74:1476-1484, 2008). HEK cell lines expressing huNavl.la, huNavl.2a, huNav 1.3 a, huNav 1.4a, huNav 1.5 a, huNav 1.6a, or huNav 1.8 a were constructed.
A detailed sequence comparison of the different extra-cellular loops (ECLs) of huNavl.7α to their ortholog and paralog counterparts is shown in Figs. 2A-2B. Different splice variants of Navi.7α exist that through interaction with pi impact on the electrophysiological properties of the channel (Chatelier et al. 2008 J Neurophysiol 99: 2241; Farmer et al. 2012 PLoS ONE 7: e41750). The 5N11S variant of huNav 1.7α (Fig. 32) was used consistently throughout the examples. The major technical drawbacks of Navi ,7α as a target for biologicals are its poor cell surface expression level combined with a limited accessibility to the extracellular surface.
For various experiments set forth in the examples, the Nav constructs where indicated were fused at the C-terminus via a P2A viral peptide linker (SEQ ID NO: 43) to a single polypeptide encoding sodium channel beta subunits pi (SEQ ID NO: 40), β2 (SEQ ID NO: 41), and β3 (SEQ ID NO: 42) in tandem in which each β subunit is separated from the preceding P subunit by a P2A viral peptide linker (referred to herein as β1-β2-β3; See SEQ ID NO:21). The P2A peptide linker facilitates a co-translational cleavage event that effectively liberates polypeptides N-terminal and C-terminal to it.
Plasmid constructs and expression vectors
Table 7 gives an overview of all plasmid constructs and expression vectors.




Generation ofHEK293T cells, transiently transfected with different huNavl.7a constructs
To this purpose, different Navi.7α constructs were cloned into pcDNA3.1 (ThermoFisher Scientific, catalog # V79020) and plasmid DNA was prepared from Escherichia coli TOPIO cells. HEK293T cells were seeded at a concentration of 1.5 x 106 per T75 flask and incubated overnight at 37°C in DMEM (Dulbecco’s modified Eagle’s medium; Gibco, catalog # 31966) supplemented with 10% FBS (fetal bovine serum, Sigma. Catalog # F7524). The
medium was then replaced by Opti-MEM medium (Gibco, catalog # 31985). A mixture of 9 pg plasmid DNA, 27 pL Fugene 6 (Promega, catalog # E2691) in a final volume of 1 mL Opti- MEM was incubated for 15 min at room temperature and then added to the cells. After 3 hours incubation at 37°C, 10 mL of DMEM supplemented with 20% FBS was added and incubation continued. After 48 hours, cells were washed with phosphate buffered saline (PBS) and resuspended with 4 mL of trypsin EDTA (Gibco, catalog # 25200-056) followed by addition of 6 mL DMEM medium supplemented with 10% FBS.
Membrane Preparations
On Day 1, suspend pellet in 3 mL HB (250 mM Sucrose, 25 mM HEPES, pH 7.5) + 30 pL Mammalian Protease Inhibitor cocktail + 30 pL Benzonase/Nuclease-Dnase (25 U/pL) PER 1 billion cells; dounce homogenize with 5 strokes of a Type B/tight fit pestle (glass homogenizer); transfer homogenized cells to Nalgene 3119-0050 Oak Ridge centrifuge tubes and centrifuge at 5k x g (6,025 rpm) for 30 minutes at 4°C. Collect supernatant fraction (and store on ice (pellet Pl). Suspend pellet in 2 mL HB. Repeat dounce homogenization and transfer homogenized cells to fresh 50 mL falcon tubes. Increase the volume to 50mL with HB. Centrifuge at 2k xg (3,161 rpm) in for 15 minutes at 4°C; collect the supernatant fraction, and pool with supernatant fraction collected above (Pl). Suspend pellet in 2 mL HB. Repeat dounce homogenization. Increase volume to 50 mL with HB. Repeat 2K xg centrifugation. Collect the supernatant fraction and pool with the supernatant fraction collected above (Pl). Transfer pooled supernatant fraction to fresh Nalgene tubes. Fill to fill line with HB. (Pl) Suspend remaining pellet and transfer to fresh Nalgene tube. Fill to fill-line with HB to produce pellet 2 (P2).
Centrifuge Pl & P2 at 39,800 xg (17k rpm) for 45 minutes at 4°C. Keep 1 mL of supernatants (sla + s2a). Store in -80°C and decant remainder of supernatant fractions. Suspend pellets (Pl + P2) in 0.1 M FB (100 mM NaCl, 25 mM Tris-HCl pH7.5). Repeat centrifugation at 39.8k xg for 45 minutes at 4°C. Keep 1 mL of supernatants (sib + s2b). Store at -80°C. Decant remainder of supernatants. Store pellets (Pl + P2) on ice in 4°C overnight.
On Day 2, suspend pellets in 1.5 M FB (1.5 M NaCl, 25 mM Tris-HCl pH7.5); dounce homogenize with 5 strokes of a Type B/ tight fit pestle (glass homogenizer); transfer pellet to Nalgene 3119-0050 tube(s) and fill to fill line with 1.5 M FB; centrifuge at 39.8k xg for 45 min at 4C; remove supernatant fraction and store pellets at -80°C (SA).
Pool like pellets in 5-10mL 1.5 M FB; dounce homogenize with 5 strokes of a Type B/ tight fit pestle (glass homogenizer); return membrane to Nalgene tube and again fill to
fill line with 1.5 M FB; repeat centrifuge at 39,800 xg (17k rpm) for 45 minutes at 4°C. Remove supernatant fraction and store pellets at -80°C (SB).
Suspend pellets in 5-10mL 0.1 M FB; repeat dounce homogenization; return membrane to Nalgene tube and fill to fill line with 0.1 M FB; Centrifuge a 3rd time at 39,800 xg (17k rpm) for 45 minutes at 4°C. Remove supernatant fraction and store pellet at -80°C (SC).
Suspend pellets in 0.1 M FB; dounce homogenize with 5 strokes of a Type B/ tight fit pestle (glass homogenizer); determine protein concentrations via Bradford assay; if desired, adjust concentration with 0.1 M FB; aliquot mem preparations, freeze on dry ice and store at 80°C.
Binding FACS
Binding of the ISVDs to cell-expressed Navi.7α was detected via murine antiFlag (Sigma, catalog # Fl 804). Briefly, cells were resuspended in FACS buffer (PBS, 10% FBS, 0.05% NaN3) and transferred to a 96-well V-bottom plate at 1 * 10^ cells/well. Purified FLAG3-tagged ISVD was diluted in FACS buffer and added to the cells for 30 minutes at 4°C. ISVD binding was detected by resuspending the samples subsequently in 100 pL murine anti- Flag at 1 pg/mL and 100 pL APC-labelled goat anti-mlgG (Jackson ImmunoResearch, catalog # 115-135-164). Prior to the read-out, the samples were resuspended in 1 pg/mL propidium iodide (Sigma, catalog # P4170) to exclude dead cells. Between each step, the cells were centrifuged for 5 minutes at 200 grams and washed with 100 pL/well FACS buffer. An alternative approach used PE-labelled goat anti-murine IgG (Jackson ImmunoResearch, catalog
# 115-116-071) as detection antibody and 5 nM TOPRO3 (Molecular probes, catalog # T3605) as dead dye.
Control antibodies were detected as follows. Murine anti-Navl.7α mAb S68-6 (Abeam, catalog # ab85015) was detected by PE-conjugated goat anti-murine IgG (Jackson ImmunoResearch, catalog # 115-116-071) after fixation and permabilization of the cells with FIX & PERM kit according to the manufacturer's instructions (ThermoFisher Scientific, catalog
# GAS003). Rabbit anti-Navl.5a pAb (Alomone Labs, catalog # ASC-013) was detected with PE-conjugated goat anti-rabbit IgG (Jackson ImmunoResearch, catalog # 711-116-152) after fixation and permabilization of the cells with FIX & PERM kit according to the manufacturer’s instructions (ThermoFisher Scientific, catalog # GAS003). Rabbit anti-human pL pAb (ThermoFisher Scientific, catalog # PA5-24142) was detected with PE-conjugated goat antirabbit IgG (Jackson ImmunoResearch, catalog # 711-116-152).
Immunizations
After approval of the Ethical Committee of the faculty of Veterinary Medicine (University Ghent, Belgium) or the Ethical Committee of the Ablynx Camelid Facility (LAI 400575), 3 camelids were immunized with a CMV-promoter based DNA vector encoding codon optimized huNavl.7α, followed by codon optimized huNav157 chimera 14 DNA and membrane extracts prepared from recombinant HEK293 cells expressing huNavl.7α together with Navβ1, Navβ2 and Navβ3 (as described above).
Cloning of heavy chain-only antibody fragment repertoires and preparation of phage
Following the final immunogen injection, blood samples were collected. From these blood samples, peripheral blood mononuclear cells (PBMCs) were prepared using Ficoll- Hypaque according to the manufacturer’s instructions (Amersham Biosciences, Piscataway, NJ, US). From the PBMCs, total RNA was extracted and used as starting material for RT-PCR to amplify the VHH/ISVD-encoding DNA segments, essentially as described in WO05044858. Subsequently, phages were prepared according to standard protocols (see for example the prior art and applications filed by Ablynx N.V. cited herein.) and stored after filter sterilization at 4 °C for further use.
Selection of Navi. 7a specific ISVDs via phage display
VHH repertoires obtained from all camelids and cloned as phage library were subjected for two or three consecutive selection rounds to proteoliposome (PL) (5pg/mL) or amphipol (amphipathic surfactant for maintaining solubilized membrane proteins in detergent- free solutions, catalog # A835, Anatrace) preparations (5 pg/mL) derived from HEK293 cells recombinantly expressing huNavl.7α together with Navβ1, Navβ2, and Navβ3 subunits (P 1 -P2- P3). Each selection round was performed in the presence of the following competing agents: 100 pg/mL of in house produced membrane extracts from HEK293 cells and 100 nM each of recombinant Navβ1 (Abnova, catalog # H00006324-P01), Navβ2 (Sino Biological, catalog # 13859-H02H) and Navβ3 (Sino Biological, catalog # 13500-H02H). After antigen incubation of the libraries and extensive washing; bound phage were eluted with trypsin (1 mg/mL) for 15 minutes and then the protease activity was immediately neutralized by applying 0.8 mM protease inhibitor ABSF. As a control, selections with in-house produced membrane extracts from HEK293 cells or without antigen were performed in parallel. Phage outputs were used to infect E. coli TGI for analysis of individual VHH clones. Periplasmic extracts were prepared
according to standard protocols (see for example WO03035694, W004041865, W004041863, W004062551).
Generation ofISVD expression constructs
Sequence analysis of ISVDs from phage display selection outputs was done according to commonly known procedures (Pardon et al., Nat Protoc 9: 674 (2014)). ISVD- containing DNA fragments, obtained by PCR with specific combinations of forward FR1 and reverse FR4 primers each carrying a unique restriction site, were digested with the appropriate restriction enzymes and ligated into the matching cloning cassettes of ISVD expression vectors (described below). The ligation mixtures were then transformed to electrocompetent Escherichia coli TGI (60502, Lucigen, Middleton, WI) cells which were then grown under the appropriate antibiotic selection pressure. Resistant clones were verified by Sanger sequencing of plasmid DNA (LGC Genomics, Berlin, Germany). Monovalent ISVDs were expressed in E. coli TGI from a plasmid expression vector containing the lac promoter, a resistance gene for kanamycin, an E. coli replication origin and an ISVD cloning site preceded by the coding sequence for the OmpA signal peptide. In frame with the ISVD coding sequence, the vector codes for a C- terminal FLAG3 (or CMYC3) and HIS6 tag. The signal peptide directs the expressed ISVDs to the periplasmic compartment of the bacterial host.
Unless specified otherwise, the tested clones herein comprise the ISVD amino acid sequence shown for it in Table 56 further fused at the C-terminus to a FLAG-HIS6 polypeptide (SEQ ID NO: 56) or HIS6. The amino acid positions in the ISVDs disclosed herein are numbered according to the Kabat numbering scheme.
Generic expression and purification of ISVDs
E. coli TG-1 cells containing the ISVD constructs of interest were grown for 2 hours at 37°C followed by 29 hours at 30°C in baffled shaker flasks containing “5052” autoinduction medium (0.5% glycerol, 0.05% glucose, 0.2% lactose + 3 mM MgSOq). Overnight frozen cell pellets from E. coli expression cultures are then dissolved in PBS (1/12.5th of the original culture volume) and incubated at 4°C for one hour while gently rotating. Finally, the cells were pelleted down once more, and the supernatant containing the proteins secreted into the periplasmic space was stored for further purification. HIS6-tagged ISVDs were purified by immobilized metal affinity chromatography (IMAC) on either Ni-Excel (GE Healthcare) or Ni- IDA/NTA (Genscript) resins with Imidazole (for the former) or acidic elution (for the latter)
followed by a desalting step (PD columns with Sephadex G25 resin, GE Healthcare) and if necessary, gel filtration chromatography (Superdex column, GE Healthcare) in PBS.
EXAMPLE 2
Selective Binding to huNavl.7a.
Crude periplasmic extracts containing ISVDs from phage display selections (as described above) were screened in FACS for binding to huNavl.7α but not to huNavl.5a. Confirmatory binding FACS experiments with purified FLAG3-HIS6 tagged ISVD proteins revealed that the ISVDs all bind selectively to different stable cell lines expressing huNavl.7α and huNav157 chimera 14 (extracellular and transmembrane sequences of huNavl.7α, combined with intracellular sequences of huNavl.7α and huNavl.8a and the Navβ1, Navβ2, and Navβ3 subunits (see Table 8; Fig. 3A - Fig. 31)), but not to cell lines expressing rhNavl.7α, huNavl.la, huNavl.2a, huNavl.3a, huNavl.4a, huNavl.5a, huNavl.6a or huNavl.8a. For example, Figs. 39A-39E show that F0103262C02, F0103265B04, F0103275B05, F0103464B09, and F0103387G05 are specific for huNavl.7α with no binding to huNavl.la, huNavl.2a, huNavl.3a, huNavl.4a, huNavl.5a, huNavl.6a or huNavl.8a. As used in Table 8, the drawings, and throughout the description, Navβ1, Navβ2, and Navβ3 are human homologs unless specifically identified otherwise.


The amino acid sequences for the ten ISVDs (Navi.7 binders) without the FLAG- HIS6 peptide (SEQ ID NO: 56) are shown in SEQ ID NO: 46, 47, 48, 49, 50, 51, 52, 53, 54, and 55, respectively.
EXAMPLE 3
Affinity maturation was used to further improve the functional potencies of selected ISVDs by means of in vitro affinity maturation. In addition, as none of the selected ISVDs is cross-reactive to rhNavl.7α (with the exception of the weakly cross-reactive ISVD F0103387G04), the same process was applied to improve the NHP cross-reactivity to enable in vivo proof of concept (POC) studies in rhesus monkeys. In vitro affinity maturation of ISVDs is a two-stage process that aims to improve binding-related properties like affinity, species crossreactivity or potency. First, all CDR-based residues are systematically changed to every possible amino acid on a one-by-one basis. The resulting libraries of single site substitution variants pooled per CDR are then screened for improvement of the desired property after which the hits are identified by means of Sanger sequencing. The beneficial single site substitutions are then combined into a library of combinatorial variants which are evaluated for further improvement of
the desired property, followed by Sanger sequencing of hits. The generation the DNA fragments encoding the ISVD variants is either outsourced to commercial providers GeneWiz (South Plainfield, NJ) or IDT (Coralville, IA) or performed in house using commonly known molecular biology techniques such as site-directed mutagenesis, overlap extension PCR and oligonucleotide gene assembly (In Vitro Mutagenesis Protocols, 2nd Edition (2002), Jeff Braman ed., Humana Press, Totowa NJ).
Affinity maturation of F0103275B05 & F0103 387G04
As ISVD F0103275B05 and rhNavl.7α cross-reactive F0103387G04 appear to be related ISVDs with highly similar CDRs (Fig. 4), it was decided to pursue these two ISVDs for affinity maturation in one and the same effort. A pooled single site saturation stage I library of F0103275B05 was constructed and crude periplasmic extracts of 2100 individual clones were prepared and screened in binding FACS to huNavl.7α and rhNavl.7α. Clones with a single mutation in CDR3, CDR2 or CDR1 residues showed an improved binding to rhNavl.7α, but much less so to huNavl.7α (Fig. 5).
The sequence analysis of 384 hits is summarized in Table 9. The stage I hits have substitutions in 7/10, 7/9, and 5/15 positions of respectively CDR1, CDR3 and CDR3. Interestingly, the substitutions in three of these positions (27, 28 and 53) recapitulate some of the differences between F0103275B05 and its rhNavl.7α cross-reactive relative F0103387G04 and thus bring additional confidence in the outcome of the stage I screening. These three substitutions were included in the design of the stage II combinatorial library (bottom row of Table 8), in which 11 positions were allowed to vary between the parental F0103275B05 and the highest ranked stage I hit residue. The stage II library thus captures 2^ = 2048 different combinatorial variants.

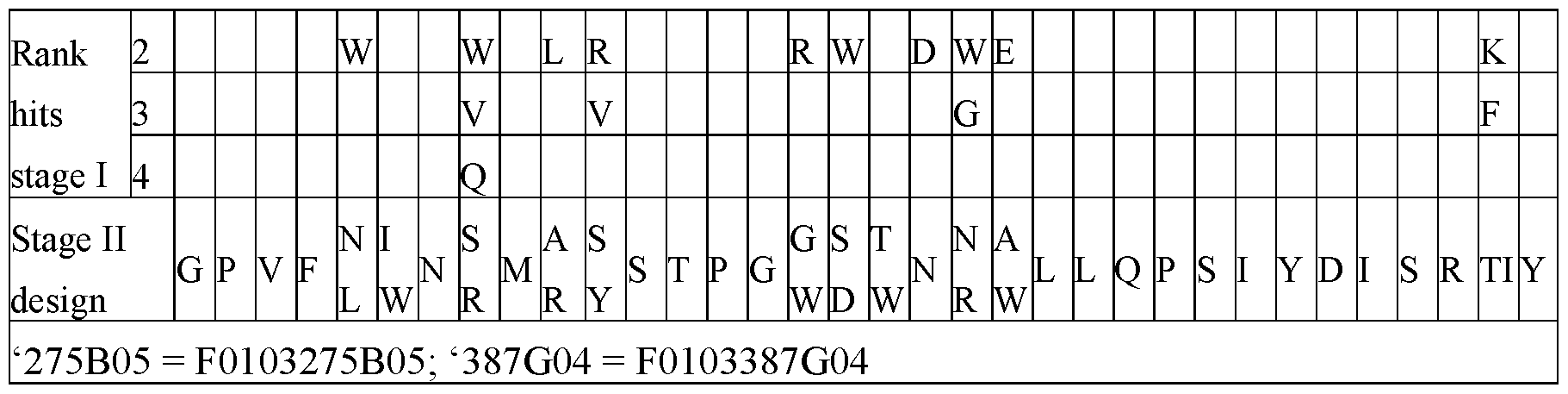
Crude periplasmic of 2100 clones of the stage II combinatorial library were prepared and screened in binding FACS on huNavl.7α and rhNavl.7α. A large fraction of the variants displayed improved binding to rhNavl.7α compared to the huNavl.7α-selective parental F0103275B05 (Fig. 6), indicating that the library design successfully captured and improved the promise of the stage I library. No improvements for binding to huNavl.7α were observed for stage II, in line with the observations during stage I. The sequence analysis of 300 hits is summarized in Table 10. Compared to a randomly picked reference sample, the top 25% of the hits are enriched for the N93R substitution but display a lower proportion of the N30L, 131W, A35R, G55W and T57W substitutions. Compared to a randomly picked reference sample, the bottom 25% of the hits displayed a lower proportion of the 131W and A35R substitutions. An analysis of the subset of the top 25% hits that did not carry the N93R mutation revealed that these were enriched for the S33R, S50Y and S56D substitutions and had a lower proportion of A94W, compared to the reference sample.
 A number of combinatorial affinity maturation variants of F0103275B5 were then characterized in detail in binding FACS and electrophysiology (Table 11). All variants bound rhNavl.7α, many with greater affinity than F01033387G04. This was confirmed for most of them in 2-pulse (Fig. 7B) and single pulse (Fig. 7A) electrophysiology experiments. A subset of variants is equipotent on huNavl.7α and rhNavl.7α, with binding EC50 values of ±20 nM. The minimal number of mutations to a achieve this is four (S33R, S50Y, S56D and N93R) as exemplified by F010301461. F0103387G04 remains the best binder to huNavl.7α, most likely due to differences compared to F0103275B05 in other CDR positions. Variant F010300659 was the first variant with good rhNavl.7α cross-reactivity to be characterized, and as such was selected for in vivo assessment.
A number of combinatorial affinity maturation variants of F0103275B5 were then characterized in detail in binding FACS and electrophysiology (Table 11). All variants bound rhNavl.7α, many with greater affinity than F01033387G04. This was confirmed for most of them in 2-pulse (Fig. 7B) and single pulse (Fig. 7A) electrophysiology experiments. A subset of variants is equipotent on huNavl.7α and rhNavl.7α, with binding EC50 values of ±20 nM. The minimal number of mutations to a achieve this is four (S33R, S50Y, S56D and N93R) as exemplified by F010301461. F0103387G04 remains the best binder to huNavl.7α, most likely due to differences compared to F0103275B05 in other CDR positions. Variant F010300659 was the first variant with good rhNavl.7α cross-reactivity to be characterized, and as such was selected for in vivo assessment.
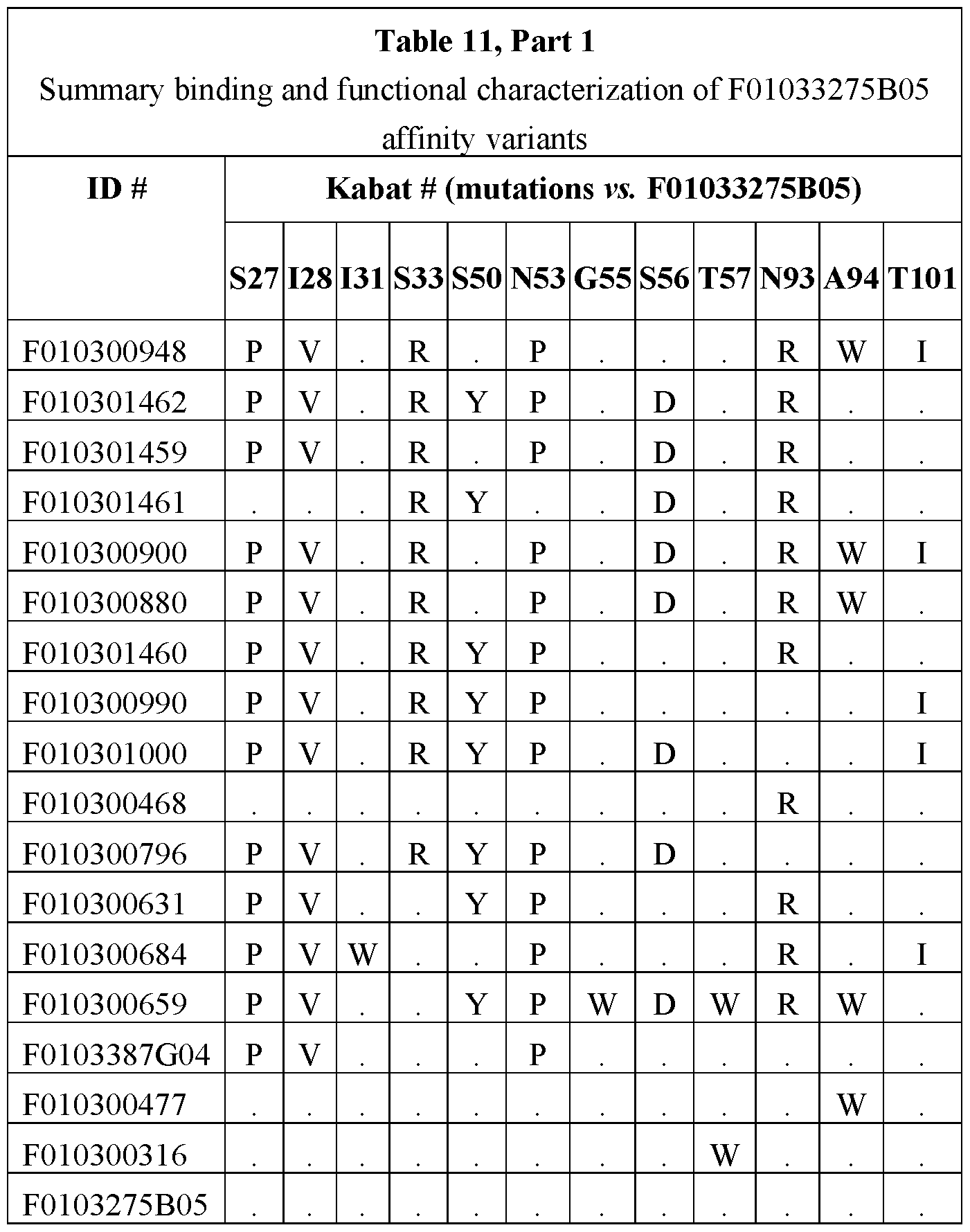




Affinity maturation of F01033265All
A pooled single site saturation library of F0103265 Al 1 was constructed and crude periplasmic extracts of 1848 individual clones were prepared and screened in binding FACS on huNavl.7α and rhNavl.7α. Clones with a single mutation in CDR2, CDR3 or CDR1 residues showed an improved binding to huNavl.7α, but not to rhNavl.7α (Fig. 12).
The sequence analysis of 288 hits is summarized in Table 12. The stage I hits have substitutions in 3 of 10, 7 of 11, and 4 of 6 positions of respectively CDR1, CDR3 and CDR3. Of interest, four CDR2 positions (51, 53, 56 and 57) have substitutions to a Trp residue. The stage II library design captures 2^ 1 = 2048 different combinatorial variants.
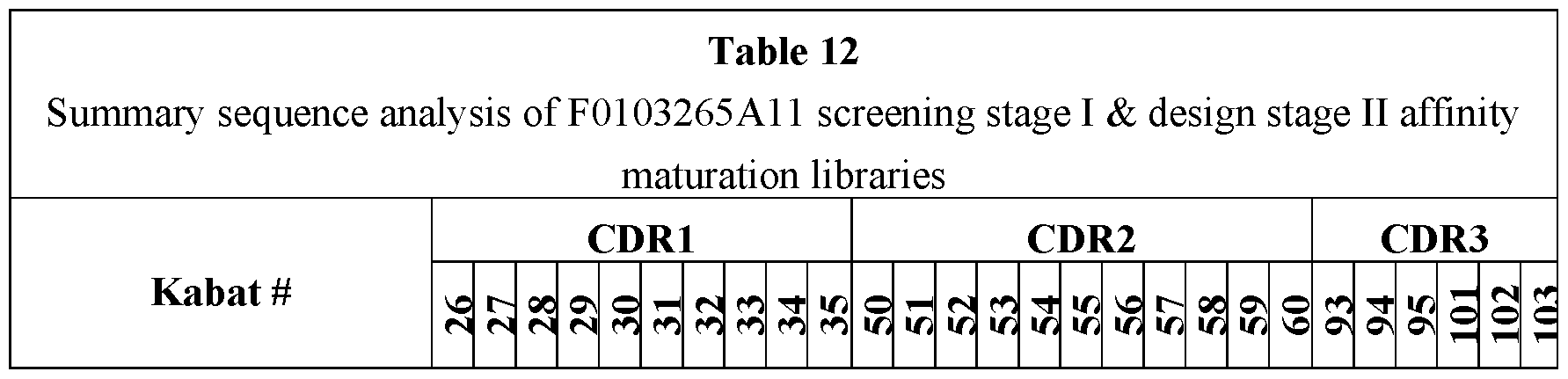

Crude periplasmic of 2016 clones of the stage II combinatorial library were prepared and screened in binding FACS on huNavl.7α and rhNavl.7α. A large fraction of the variants displayed improved binding to huNavl.7α compared to the parental F0103265 Al 1 (Fig. 9), indicating that the library design successfully captured and improved the promise of the stage I library. No improvements for binding to rhNavl ,7α were observed for stage II, in line with the observations during stage I. The sequence analysis of 288 hits is summarized in Table 13. Compared to a randomly picked reference sample, the top 25% of the hits are enriched for the A31R, V60N and S93A substitutions but display a lower proportion of the N30Y, I51W, S53W, T57V and N58T substitutions. Compared to a randomly picked reference sample, the bottom 25% of the hits are enriched for the T57V, S93A and L103Q substitutions but display a lower proportion of the N30Y, 151W and S53W substitutions.
 A number of combinatorial affinity maturation variants of F0103265 All were then characterized in detail in binding FACS and electrophysiology (Table 14). Most variants displayed clear improvements in binding EC50 and Bmax values on huNavl.7α, compared to parental F0103265A11. This became even more pronounced when huNavl ,7α was expressed in the absence of Navβ-subunits: no binding was observed for parental 265 Al 1, whereas many affinity maturation variants showed clear binding curves to the HEKa-only line. The previously observed β-subunit dependency of F0103265 All was improved by the affinity maturation process. Clear improvements in functional inhibition of the ion channel were observed (last column of Table 14), compared to the marginal functional inhibition observed in the past for parental F0103265A11.
A number of combinatorial affinity maturation variants of F0103265 All were then characterized in detail in binding FACS and electrophysiology (Table 14). Most variants displayed clear improvements in binding EC50 and Bmax values on huNavl.7α, compared to parental F0103265A11. This became even more pronounced when huNavl ,7α was expressed in the absence of Navβ-subunits: no binding was observed for parental 265 Al 1, whereas many affinity maturation variants showed clear binding curves to the HEKa-only line. The previously observed β-subunit dependency of F0103265 All was improved by the affinity maturation process. Clear improvements in functional inhibition of the ion channel were observed (last column of Table 14), compared to the marginal functional inhibition observed in the past for parental F0103265A11.



Affinity maturation of F0103265B04
A pooled single site saturation library of F0103265B04 was constructed and crude periplasmic extracts of 2016 individual clones were prepared and screened in binding FACS on huNavl.7α and rhNavl.7α. No clones with a single mutation in CDR3, CDR2 or CDR1 residues showed an improved binding to huNavl.7α or rhNavl.7α (Fig. 10). The outliers in the top right quadrant of Fig. 10 was determined to be a contamination with F0103240B04, a β2 binding ISVD.
Affinity maturation of F0103387G05
A pooled single site saturation library of F0103387G05 was constructed and crude periplasmic extracts of 3360 individual clones were prepared and screened in binding FACS on huNavl.7α and rhNavl.7α. Clones with a single mutation of CDR2, CDR3 or CDR1 residues showed weakly improved binding to huNavl.7α, but not to rhNavl.7α (Fig. 11).
Sequence analysis of 384 hits revealed an enrichment for certain positions and mutations, but as there were no outspoken improvements in binding observed, it was decided to first characterize a number of stage I variants rather than combining these in a stage II combinatorial library. Binding FACS experiments (Table 15) revealed that most of the tested variants were comparable to parental F0103387G05. Interestingly, a number of CDR1- and CDR2-based (Kabat positions 23, 53, 54 and 58) mutations, all substitutions of Asp with Gly, displayed subtle improvements compared to parental F0103387G05. Combinations of these substitutions further improved the binding in a subtle way (Table 15) Combinations of these substitutions further improved the binding in a subtle way with D23A and D58G substitutions contributing the most (Table 15), resulting in the selection of F0103301563 as the preferred variant.

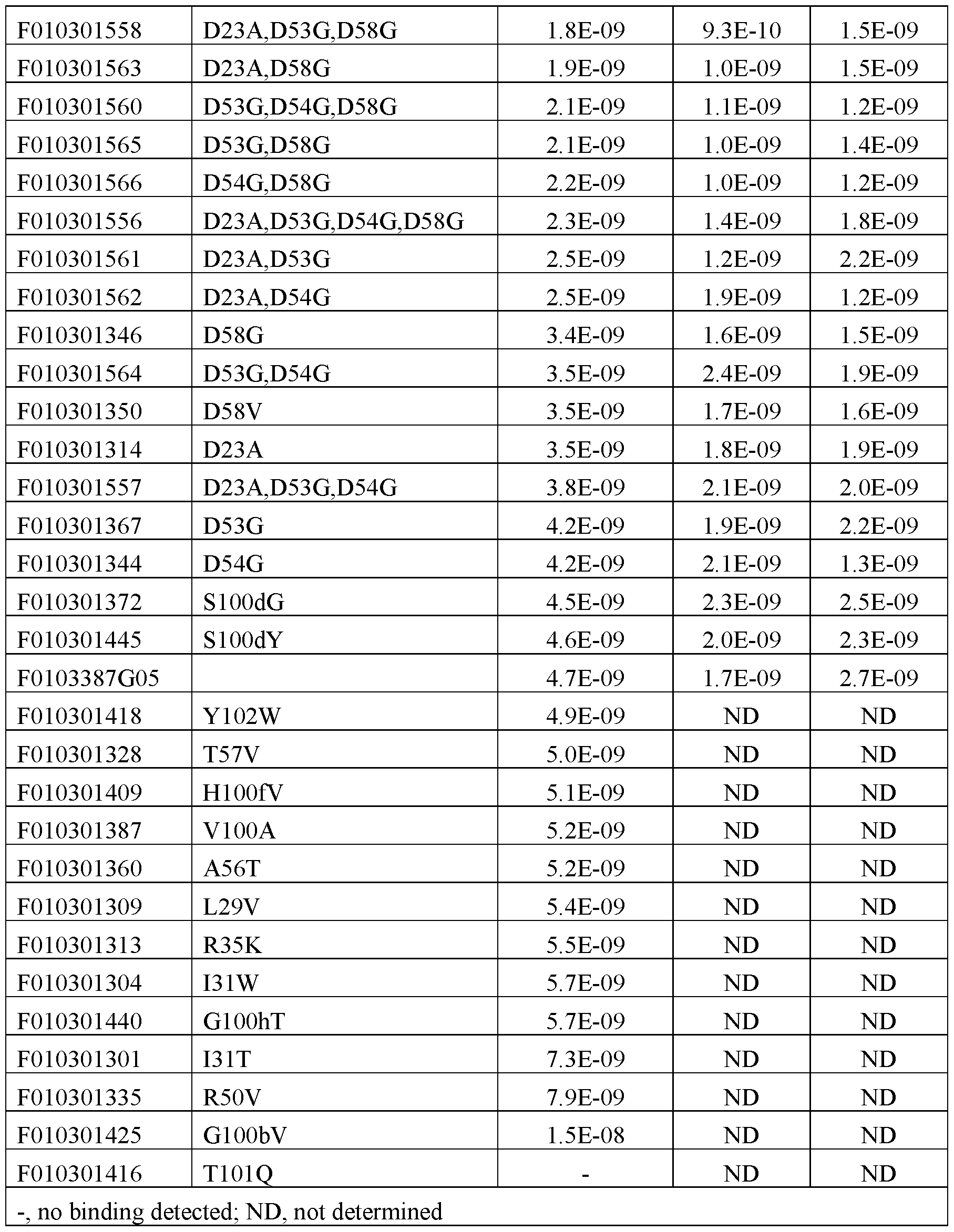
Affinity maturation of F0103362B08
A pooled single site saturation library of F0103362B08 was constructed and crude periplasmic extracts of 4032 individual clones were prepared and screened in binding FACS on
huNavl.7α and rhNavl.7α. Clones with a single mutation of CDR2, CDR3 or CDR1 residues showed weakly improved binding to huNavl.7α, but not to rhNavl.7α (Fig. 12).
Sequence analysis of 326 hits revealed an enrichment for certain positions and mutations, but as there were no outspoken improvements in binding observed, it was decided to first characterize a number of stage I variants rather than combining these in a stage II combinatorial library. Binding FACS experiments (Table 16) revealed that most of the tested variants were comparable to parental F0103362B8. A number of mutations (Kabat positions 50, 97, 99 and 1001), consistently displayed subtle improvements compared to parental 362B08 across two different huNavl.7α cell lines.


Affinity maturation of F0103464B09
A pooled single site saturation library of F0103464B09 was constructed and crude periplasmic extracts of 3356 individual clones were prepared and screened in binding FACS on huNavl.7α and rhNavl.7α. Clones with a single mutation of mainly CDR2 residues showed weakly improved binding to rhNavl ,7α, but hardly not to huNavl ,7α (Fig. 13).
Sequence analysis of 186 hits revealed an enrichment for certain positions and mutations, particularly in CDR1 and CDR2. It was decided to first characterize a number of stage I variants based on their sequence enrichment in the hits and/or improved binding vs. parental controls (Table 17). Compared to parental F0103464B09, a number of the tested
substitutions clearly improved binding to rhNavl.7α in terms of Bmax while being neutral for binding to huNavl.7α.

Based on these observations, a combinatorial library was generated with a diversity of 320 different variants, as summarized by Table 17. Crude periplasmic of 2880 clones of the stage II combinatorial library were prepared and screened in binding FACS on huNavl.7α and rhNavl.7α. A large fraction of the variants display improved binding to rhNavl.7α compared to the parental F0103464B09 (Fig. 14), indicating that the library design successfully captured and improved the promise of the stage I library. No outspoken improvements for binding to huNavl.7α were observed for stage II, in line with the observations during stage I.
The sequence analysis of 273 hits (per 96-well plate, each time top three hits on huNavl.7α and top seven hits on rhNavl.7α) is summarized in Table 18. Compared to a randomly picked reference sample, the V33L, G54W and S95A substitutions are underrepresented in the top three hits on huNavl.7α and rhNavl.7α. As such, the variants with these substitutions were excluded from further analysis. Furthermore, 38/96 (40%) of the top 3 hits on huNavl.7α matched the parental F0103464B09 sequence, again suggesting that no major improvements on huNavl.7α could be expected from this library. As no outspoken sequence enrichments could be observed from Table 18, the following criteria were applied to further narrow down the number of variants for detailed characterization:
• sequenced multiple times and at least once present in both top 2 hits on huNavl.7α and rhNavl.7α;
• no deamidation motif on position 53;
• less than 5 mutations compared to parental F0103464B09.
The resulting combinatorial variants (Table 19) were supplemented with one variant carrying V33L substitution, as this is one of the most promising single substitutions (Table 17). These variants were combined with a two variable sequence optimization substitutions R39Q and A63V in a background containing a large number of sequence optimization substitutions (LI IV, T24A, T25S, V40A, E44Q, F62S, S68T, M77T, T79Y, R81Q, S82aN, N82bS, K83R, G88A, V89L, N99S).



In the course of the F0103464B09 sequence optimization process subtle drops in binding to rhNavl.7α were observed for the following substitutions: R39Q, A63V, T79Y, R81Q, and N99S. R39Q substitution also resulted in a subtle drop in binding to huNavl.7α. The combination of these, as present in the background in which the combinatorial variation was introduced, resulted in the complete abolishment of binding to rhNavl.7α for the controls that do not carry any of the affinity maturation substitutions (F010302365, F010302366 and F010302368 in Table 20) and the same was observed for the variants combining the A28Q G54E substitutions. Less outspoken, none of the variants combining the A28Q G54E N58Q, S26H A28Q G54E N58Q, or A28Q N53E G54S N58Q substitutions reached maximum binding levels to rhNavl.7α (Table 20) A similar observation was made for the variants combining the S26H V33L N53E G54S substitutions, which also resulted in a drop in binding EC50 to huNavl.7α. The three remaining combinations S26H N53E N58Q, S26H N53E G54S N58Q and S26H A28Q N53E N58Q were highly comparable for their binding to huNavl.7α and rhNavl.7α (Table 20) The S26H N53E N58Q combination was then selected as it achieves the same binding improvements with one mutation less than the two others.
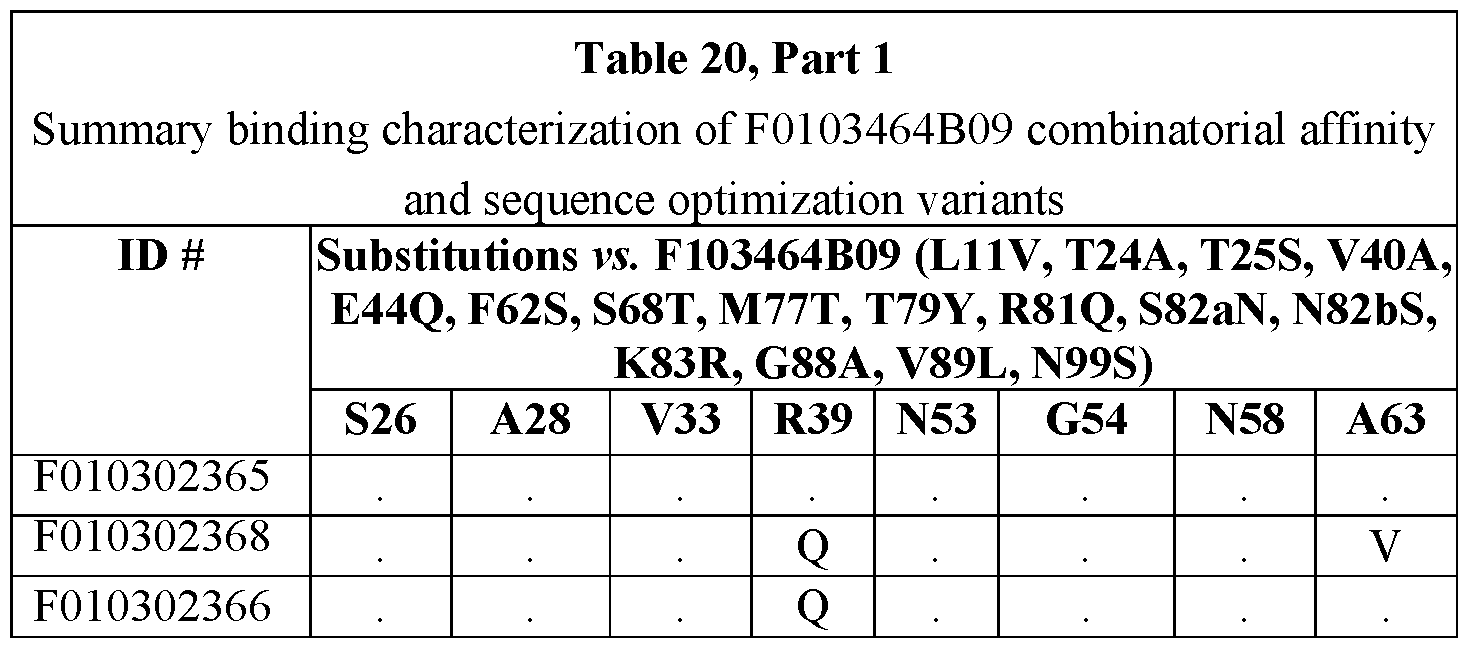



EXAMPLE 4
Competitive binding to huNavl.7a
Competition FACS assays were performed with CMYC3-tagged ISVD F0103265B04 or F0103275B05(N93R) affinity maturation variant on aHEK Flpin huNavl.7α+β1-β2-β3 transgenic cell line. Briefly, cells were resuspended in FACS buffer (PBS, 2% FBS, 0.05% NaN3) and 1 x 105 cells/well were transferred to 96-well V-bottom plates.
Cells were subsequently resuspended in a 100 pL mixture of purified ISVD (dilution series) and
CMYC3-tagged ISVD F0103265B04 (at a concentration equivalent to EC30) followed by incubation for 1.5 hours at 4°C. Residual binding of CMYC3-tagged ISVD F0103265B04 was detected with 100μL murine anti-CMYC (1/250 dilution) (Bio-Rad, catalog # MCA2200) followed by PE-conjugated goat anti-murine (Jackson Immunoresearch, catalog #115-116-071). Between each step, the cells were centrifuged for 5 minutes at 200 g and washed with 100 pL/well FACS buffer. Prior to the read-out, the samples were resuspended in 5nM TOPRO3 (Molecular probes, catalog # T3605) to exclude dead cells. F0103262C02, F0103262B06, F0103265A11, F0103265B04, F0103275B05, F0103362B08, and F0103387G04 all compete with F0103265B04 for binding to huNavl.7α, in contrast to an irrelevant control ISVD (IRR) (see Table 21 and Fig. 15A, Fig. 15B, Fig. 15C, and Fig. 15D). The data shown in the figures and summarized in Table 20 suggests that all extracellular anti-Navl.7α leads bind to an overlapping footprint.

EXAMPLE 5
Binding to huNavl.7a-Navl.5 chimeras
FACS binding studies (as described above) were performed on HEK293T cells transiently transfected with expression vectors encoding a huNavl.7a or rhNavl.7a fused at the C-terminus via a P2A viral peptide linker to a single polypeptide encoding sodium channel beta subunits Nav01, Nav02, and Nav03 in tandem (β1-β2-β3; SEQ ID NO:21). Similarly, HEK293T cells transiently transfected with expression vectors encoding chimeric variants of huNavl.7a in which individual domains are replaced by their huNavl.5α counterparts (chimeras 1 to 4 in Fig. 16) or with chimeric variants of huNavl.5 in which individual domains are replaced by their huNavl.7a counterparts (chimeras 5 to 8 in Fig. 16) fused at the C-terminus via a P2A viral peptide linker to 01-02-03 as above. See Table 7 for description of the expression vectors encoding the chimeras, Table 21 and Fig. 16).
From experiments summarized in Table 22 and shown in Fig. 17 A - Fig. 17C and Fig. 18A-18C, it could be concluded that DI of huNavl.7a is necessary and sufficient for the binding of F0103262C02, F0103262B06, F0103265B04, F0103275B05, and F0103265A11 (see Fig. 16). From a separate experiment (Table 22 and Figs. 19A-19B) with a chimeric variant of huNavl.7a in which the DI S5-S6 sequence is replaced by the huNavl.5 counterpart (chimera 12 in Fig. 16), it could be concluded that DI S5-S6 is necessary for the binding of F0103262C02, F0103262B06, F0103265B04, F0103275B05, and F0103265Allto huNavl.7a. In addition, F0103275B05 appears to also interact with the adjoining DIV VSD (Table 22, Figs. 17A-17C, Figs. 18A-18C, and Figs. 20A-20B). Control antibodies murine anti-Navl.7a mAh S68-6 (Abeam, catalog # ab85015) and rabbit anti-Navl.5a pAb (Alomone Labs, catalog # ASC-013) recognize an epitope at the intracellular C -terminal part of their respective channel.
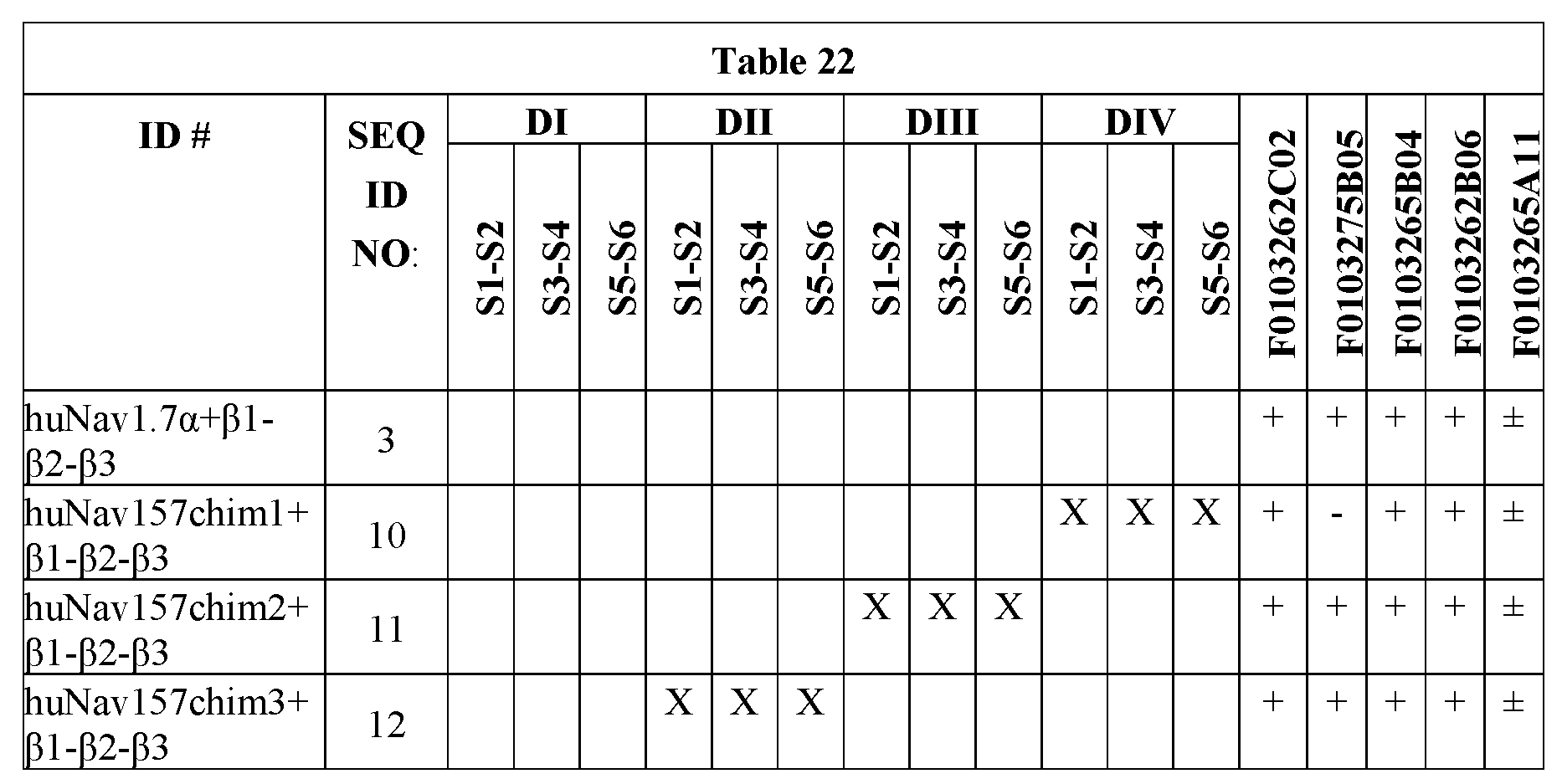

EXAMPLE 6
Binding to huNavl.7a-rhNavl.7a chimeras
FACS binding studies (as described above) were performed on HEK293T cells transiently transfected with a chimeric variant of huNavl.7α in which all the huNavl.7α- rhNavl.7α polymorphisms of DI are present (N146S, V194I, F276V, R277Q, E281V, V331M, E504D, D507E, S508N, N533S). Replacing the huNavl.7α DI sequence for that of rhNavl.7α is sufficient to abolish the binding of F0103262C02, F0103265B04, F0103262B06, and F0103265A11 to huNavl.7α, recapitulating the absence of binding on rhNavl.7α (see Figs. 21A- 2 IB).
Based on the huNavl.7α model (as described above) the following huNavl.7α- rhNavl.7α polymorphisms can be allocated to the extracellular part of DI: N146S, F276V, R277Q, E281V and V331M. The first of the residues is in DI S1-S2 whereas the latter four residues belong to DI S5-S6. FACS binding studies (as described above) were performed to stable CHO Flpin cell lines expressing different variants of huNavl.7α+β1-β2-β3, each including one of the four possible extracellular huNavl.7α-rhNavl.7α polymorphisms in the DI S5-S6 region: F276V, R277Q, E281V and V331M (Table 23 and Figs. 22A-22F). Individual polymorphisms were each sufficient to abolish the binding of F0103265B04, F0103362B08, F010301080, and F0103262B06 to huNavl.7α, recapitulating the absence of binding on rhNavl.7α. F0103262C02, F0103275B05 and F0103387G05 are more subtly affected in terms
of EC50 or Bmax by some of the polymorphisms. None of the individual DI S5-S6 polymorphisms by themselves appear to have an impact on the binding of the two rhNavl.7α cross-reactive ISVDs F0103387G04 and F0103464B09. In addition, no effect on binding of the two ISVDs was observed (data not shown) for the three extracellular DIV VSD huNavl.7α- rhNavl.7α polymorphisms Q1530P, H1531Y and E1534D (Fig. 22G).
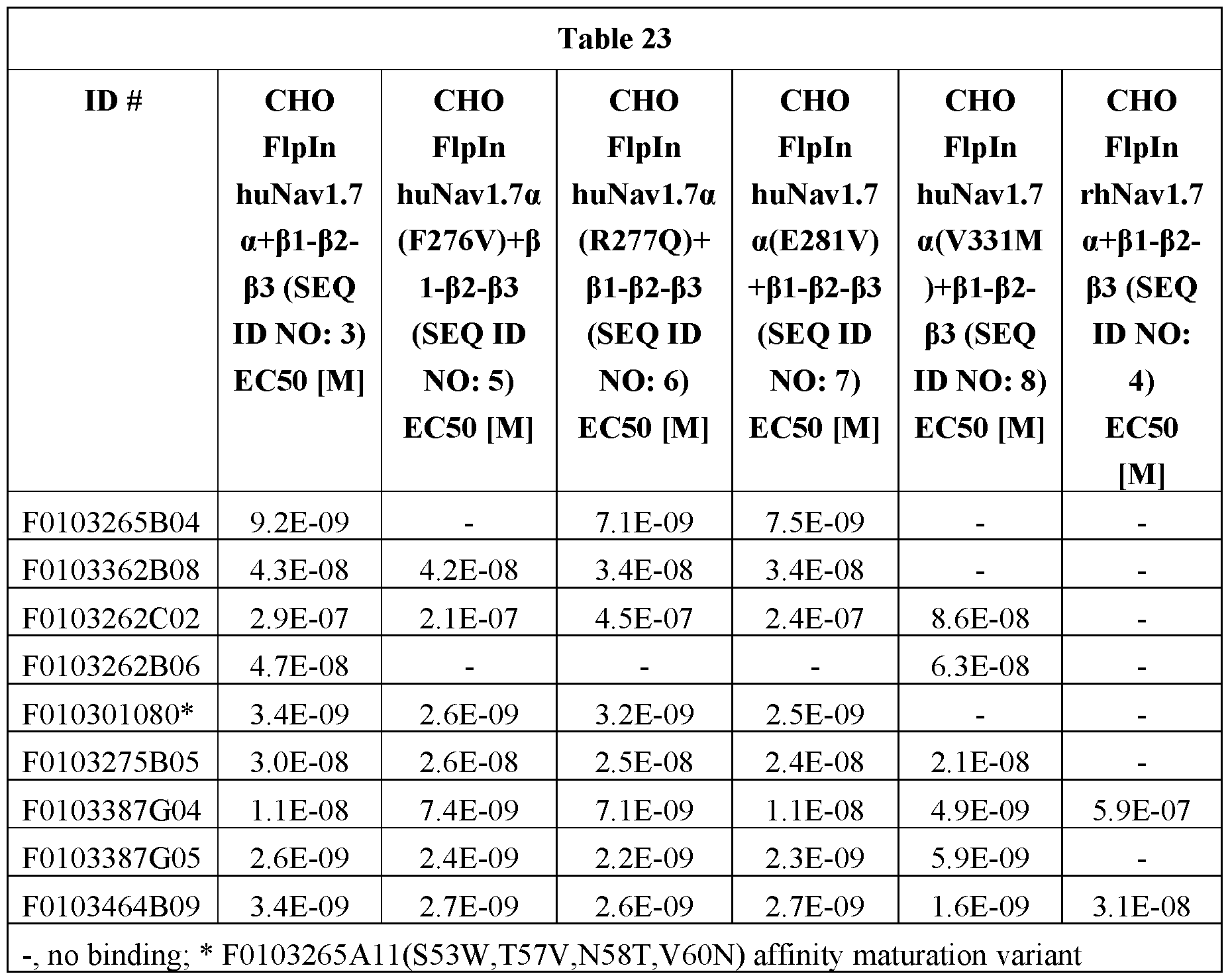
Summary epitope mapping
The combined data of the binding studies on the huNav157 chimeras and the huNavl.7α-rhNavl.7α chimeras, together with the competition binding data suggests that the ISVDs recognize an overlapping epitope on the DI S5-S6 part of huNavl.7α, which can be further delineated by the extracellular human-rhesus polymorphisms in that part which can be further dissected out by the extracellular huNavl.7α-rhNavl.7α polymorphisms in that area or by additional contacts with the adjoining DIV VSD in the case of F0103275B05.
EXAMPLE 7
Electrophysiological characterization of Navi.7α selective ISVDs on lonFlux 16 automated patch clamp system (Fluxion Biosciences, Inc., Alameda, CA).
Solutions and ISVDs handling
The extracellular solution contained (in mM): 138 NaCl, 4 KC1, 1.8 CaC12, 1 MgC12, 10 HEPES, 5.6 glucose (pH 7.2 with NaOH, and 285 - 290 mOsmolar). Intracellular solution contained (in mM): 5 NaCl, 100 CsF, 45 CsCl, 10 HEPES, 5 EGTA (pH 7.45 with CsOH, and 300 - 315 mOsmolar). These solutions were freshly made, filtered and stocked for no longer than 6 months at 4 °C.
Cell preparation
HEK Flp-In and CHO Flp-In cells stably expressing the human Navi.7α channel were generated. Cells were cultured in T-175 cell culture flasks (Greinerbio-one, catalog # 660160) using standard cell culture conditions. CHO Flp-In culture medium consists of F12 nutrient mix (Gibco, catalog # 31765) containing 10 % FBS (Sigma- Aldrich, catalog # F7524), 0.8 mg/mL hygromycin B (Invitrogen, catalog # 10687010). HEK Flp-In culture medium consists of DMEM Glutamax™ (Gibco, catalog # 31966) containing 10 % FBS (Sigma- Aldrich, catalog # F7524), 0.8 mg/mL hygromycin B (Invitrogen, catalog # 10687010), 1% NEAA (Gibco, catalog # 11140) and 1% Na-pyruvate (Gibco, catalog # 11360). Cells were seeded at a density of 1.7 x 1Q4 cells/cm2 (Hek293 Flp-In) or 5.7 x 1Q3 cells/cm2 (CHO Flp-In) for 2 days before being used in the lonFlux 16 (Fluxion). Optimal cell confluence prior to harvesting never exceeded 80 %. The cells were washed twice with d-PBS without Ca2+ and Mg2+ (Gibco, catalog # 14190) and detached with 4 mL Trypsin/EDTA 0.25% (Invitrogen, catalog # 25200- 056) for 5 to 10 min at 37°C. Medium containing 10 % FBS is added to inactivate the enzymatic reaction triggered by the trypsin. Subsequently, the cells were counted (Casy TT, Roche) and centrifuged at 200 x g during 2 min at RT in 50 mL conical CELLSTAR® tube (Greiner Bio- One, catalog # 227-261) suspended at 1 x 106 cells/ml in CHO-S-SFMII (Gibco, catalog # 12052) supplemented with 25 mM Hepes (Gibco, catalog # 15630), transferred to a 25 mL cell culture flask (Greiner Bio-One, catalog # 690190) and gently shaken at RT for approximately 20 min. 1 x 107 cells were centrifuged for 2 min at 200 x g. The pellet is gently resuspended in 5 mL extracellular buffer and centrifuged a second time for 2 min at 200 x g. Finally, the pellet is resuspended in 2000 pl extracellular buffer and immediately tested on the lonFlux.
lonFlux Automated patch clamp procedure
250 pL of sterile cell culture grade water is dispensed into every well of the lonFlux 96-well plate except the outlet wells, using an eight channel multi-pipette. Any excess water on the rim of the plate is wiped off before rinsing the plate. The designated plate is inserted into the lonFlux system and subsequently rinsed 4 times according to a standard Water Rinse protocol. After rinsing, the plate is emptied. The inlet wells were then manually filled with extracellular buffer, trap wells with intracellular buffer and the diluted ISVDs or selective peptides were distributed into the compounds wells (250 pL/well). Subsequently, the plate is primed before the actual experiment according to the plate specific protocols. For population plates (Molecular Devices, catalog # 910-0098): 1) traps and compounds at 5 psi for t= 0 - 160 s and 2 psi for t= 160 - 175 s, 2) traps but not compounds at two psi for t= 175 - 180 s, and 3) main channel at 1 psi for t= 0 - 160 s and 0.3 psi for t= 162 - 180 s. For single cell plates (Molecular Devices, # 910-0100): 1) traps but not compounds at eleven psi for t= 0 - 350 s and 1.5 psi for t= 625 - 6302) traps and compounds at five psi for t= 350 - 600 s and 1.5 psi for t= 600 - 625 s, and 3) main channel at 0.5 psi for t= 0 - 350 s and one psi for t= 350 - 600 s, and 0.3 psi for t= 600 - 627 s. After priming, the outlet and inlet wells were emptied and 250 pL of the prepared cell suspension (i.e. approximately one million cells) is distributed into the inlet wells of the designated plate. After introduction of the cells, the plate is reprimed: 1) traps and compounds at five psi for t= 0 - 20 seconds and two psi for t= 25 - 50 seconds, 2) traps not with compounds at two psi for t= 50 - 55 seconds, and 3) main channel at one for t= 0 - 30 seconds and 0.4 psi for t= 30 - 55 seconds. Then, cells were introduced to the main channel and trapped at lateral trapping sites with the trapping protocol: 1) trapping vacuum of 7 mmHg for t= 0 to 85 seconds, 2) main channel pressure of 0.2 psi for t= 0 - 2 seconds, followed by 15 repeated square pulses of 0 - 0.2 psi with baseline duration of 4.2 seconds and pulse duration of 0.8 seconds, followed by 0.2 psi for 8 seconds. Whole cell access is achieved by rupturing the patch of the membrane over the hole using the break protocol. A different protocol is used for CHO or HEK293 cells. Breaking protocol for HEK293 cells: 1) breaking vacuum of seven mmHg for t= 0 - 5 seconds, followed by a square pulse of 18 mmHg with a pulse duration of 15 seconds, and followed by 6 mmHg for five seconds, and 2) main channel pressure at 0.15 psi for t= 0 - 25 seconds. Breaking protocol for CHO cells: 1) breaking vacuum of seven mmHg for t= 0 - 10 seconds, followed by a square pulse of 25 mmHg with a pulse duration of five seconds, followed by 6 mmHg for 6 seconds, and a second pulse of 25 mmHg with a pulse duration of five seconds,
followed by 6 mmHg for 80 seconds, and 2) main channel pressure at 0.15 psi for t= 0 - 120 seconds. After whole cell configuration, the vacuum pressure is held at 5 mmHg and the main channel pressure at 0.1 psi until the end of the experiment. Cells were first allowed to dialyze for 300 seconds, before compounds were tested. A time course protocol is applied to assess the effect of the compounds on sodium currents elicited by a depolarizing pulse protocol. In order to be able to perform an off-line linear leak subtraction, cells were clamped at -100 mV for 50 milliseconds then hyperpolarized to -120 mV for 100 milliseconds, and repolarized to -80 mV for 30 milliseconds.
Two data acquisition protocols were used: single pulse and two pulse. Single pulse protocol: cells were clamped at a holding potential of -100 mV, stepped to -120 mV for 100 milliseconds to maximize channel availability and then to -30 mV for 50 milliseconds to open the Na+ channels. The sweep interval was five seconds with a holding potential of -80Mv (Fig. 23 A). For the two pulse protocol sodium currents were elicited by a depolarizing step from -80 mV to -30 mV for 1000 millieseconds, followed by 10ms hyperpolarization at -120 mV and a second depolarizing step at -30 mV for 10 milliseconds. The sweep interval was 9 seconds with a holding potential of -80mV (Fig. 23B).
After the stabilizing period, extracellular buffer is continuously perfused for 120 seconds as a negative control, followed by sequential perfusion of different concentrations of ISVDs or selective peptides. The inhibitory responses were recorded at room temperature (21 °C - 24°C) with a minimum of n= 2 for each compound. lonFlux data inclusion criteria and data analysis
Data points were accepted when:
(0) Automated Population Patch a. Individual membrane resistance quality and stability is greater than 3 MQ during data acquisition b. Current amplitude quality and stability is greater than 2 nA at -30 mV after negative control c. Run-up/run-down less than 10% during data acquisition d. IC50 value for reference compounds within anticipated range
(B) Automated Single cell patch a. Individual membrane resistance quality and stability is greater than 500 MΩ during data acquisition
b. Current amplitude quality and stability is greater than 200 pA at -30 mV after negative control c. Run-up/run-down less than 10% during data acquisition d. IC50 value for reference compounds within anticipated range
Currents were measured using lonFlux software (Fluxion Biosciences) and monitored continuously during the exposure to the compounds. Measured currents were normalized by the mean ISustained corrected amplitude prior to compound addition . Current inhibition is estimated by the residual response after 120 seconds of each compound application. Data analysis was performed with lonFlux software (Fluxion Biosciences), Microsoft Excel (Microsoft) and Prism 6 (GraphPad Software).
Electrophysiology experiments
A series of experiments was performed, using the two pulse protocol shown in Fig. 23B and a single concentration (IpM) of F0103265B04, F0103265A11, F0103275B05, F0103362B08, F0103387G04, F0103387G05, F0103262C02, and F0103262B06 applied for 5 minutes to CHO Flpin huNavl.7α+Navβ1-PNav2-Navβ3 cells, HEK293 huNavl.7α+Navβ1 cells, HEK293 huNavl.7α cells and HEK Flpin huNavl.7α+Navβ1-Navβ2-Navβ3 cells (see Figs. 25A-25E). In another experiment, a concentration range (1 μM to 1 nM) of F0103265B04 and F0103362B08 was applied to HEK Flpin huNavl.7α+Navβ1-Navβ2-Navβ3 cells, using the same protocol (see Fig. 24). From these experiments it could be concluded that F0103265B04, F0103265A11, F0103275B05, F0103362B08, F0103387G04 and F0103387G05 but not F0103262C02 or F0103262B06, functionally inhibit huNavl.7α currents in a dose-dependent manner.
After the application of F0103265B04 to the cells was stopped and the compound was allowed to wash out by application of buffer, the cells were continued to be monitored on the patch clamp. The inhibitory effect of F0103265B04 did not wash out in the time frame (11 minutes) of the experiment (see Fig 26).
A time course experiment with F0103265B04 using the single pulse protocol (see Fig. 25A) revealed that it takes greater than two minutes at 1 pM and greater than eight minutes for F0103265B04 at 10 nM and 100 nM to fully block of the huNavl.7α currents (see Fig. 27).
EXAMPLE 8
Sequence optimization is a process in which parental ISVD sequences are mutated to yield ISVD sequences that are more identical to human and/or llama/alpaca IGHV3- IGHJ germline consensus sequences. Specific amino acids, with the exception of the so-called hallmark residues, in the FRs that differ between the ISVD and the human IGHV3-IGHJ germline consensus are altered to the human counterpart in such a way that the protein structure, activity and stability are kept intact. In addition, the amino acids present in the CDRs for which there is experimental evidence that they are sensitive to post-translational modifications (PTMs) are altered in such a way that the PTM site is inactivated while the protein structure, activity and stability are kept intact. Furthermore, in order to reduce the binding of pre-existing antibodies to the ISVDs, certain FR residues are altered.
Amino acid residue differences in the CDR regions are not taken into account for sequence optimization. All amino acid differences in the FRs between the ISVD and the human VH3-JH consensus counterparts are identified. Typically, these amino acid residues (numbered according to Kabat) fall into three classes:
1. Hallmarks: These residues are known to be critical for the stability/activity/affinity of the ISVD (based on literature). Therefore, these positions are usually not included in the process. Only when a hallmark is deviating from its llama germline, it is taken into account to be mutated back to the llama/alpaca germline sequence to evaluate potential improvements in stability/activity/affinity. When taken into account this mutation is investigated on an individual basis.
2. Standard: Sequence optimization of these positions is not expected to dramatically change the stability/activity/affinity of the ISVD (based on previous sequence optimization efforts) and they are therefore altered all at once, yielding a basic variant.
3. Unique: It is not known if sequence optimization of these positions affects the stability/activity/affinity of the ISVD and therefore they are investigated on an individual basis on top of the basic variant. These positions typically differ from ISVD to ISVD.
A potential PTM site will only be mutated when there is evidence that the particular site is sensitive to modification under accelerated stress conditions. If a particular amino acid position is insensitive, the parental sequence will be left unchanged in the final construct. Assessment of chemical stability by means of accelerated stress studies is performed by CMC. The N-terminal Glu residue of the first block of an ISVD construct will always be mutated to an Asp (EID) because experimental evidence has shown that the majority of ISVDs
is significantly sensitive to pyroglutamate formation and that the EID mutation has no effect on stability/activity/affinity of the ISVD. The El residues of all other building blocks in the construct are not mutated.
In order to reduce the binding of pre-existing antibodies to the ISVDs, LI IV and V89L substitutions are introduced to the FRs and an Ala residue is added to the very C-terminus of the ISVD construct. Exceptionally, the T110K mutation may be introduced as well. The “humanness” of a sequence optimized ISVD may be defined as:
Percent amino acid identity in the FRs of the ISVD vs the human VH3-JH consensus sequence wherein the CDRs may be defined by Kabat, IMGT, AbM, Chothia, or the like. In particular embodiments, the calculation is performed in which the CDRs are defined by at least two methods.
Sequence Optimization of F0103275B05/F0103387G04
Several PTM substitution libraries were generated based on the accelerated stress data summarized in Table 24 and screened as crude periplasmic extracts in binding FACS on human and rhesus Navi.7α. Fig. 28 shows a sequence analysis of F0103275B05/387G04 aligned against the human VH3-J3 consensus sequence and the llama VHH2 consensus sequence.



Screening of F0103275B05/387G04 PTM substitution libraries
Several PTM substitution libraries were generated based on the accelerated stress data summarized in Table 24 and screened as crude periplasmic extracts in binding FACS on human and rhesus Navi.7α.
• N73G substitution resulted in a comparable or slightly improved binding profile compared to the parental reference F0103275B05 (Table 25) and was retained as this was also the naturally occurring residue on this position in F0103387G04 (Fig. 28).
• Both D72G and D72Q substitutions resulted in a comparable or slightly improved binding profile compared to the parental reference (Table 27) and were further evaluated, as well G73A and G73R substitutions.
• D99S, D99R and D99N substitutions resulted in a comparable or slightly improved binding profile compared to the parental reference (Table 26) and were further evaluated, as well as S100R and S100V substitutions; S99 is the naturally occurring residue on this position in F0103275B05 (Fig. 28).
• N1 OOcI and N 1 OOcG (Kabat position 100c) substitutions resulted in a comparable or slightly improved binding profile compared to the parental reference (Table 27) and were further evaluated; Il 00c is the naturally occurring residue on this position in F0103275B05 (Fig. 28)







Characterization of F0103275B05/387G04 variants
Sequence optimization was initiated on F0103275B05 (Table 29) but later on continued on the related and improved F0103387G04 (Table 30). Likewise, affinity maturation
substitutions identified for F0103275B05 were successfully transferred to F0103387G04. The variants were compared in binding FACS on human and rhesus Navi.7α, in aSEC for possible multimerization, in OD340 for insoluble aggregate formation and in the thermal shift assay for Tm.
The thermal shift assay (TSA) was performed in a 96-well plate on the LightCycler 480II machine (Roche). Per row, one sample was analyzed according to the following pH range: 3.5 / 4 / 4.5 / 5 / 5.5 / 6 / 6.5 / 7 / 7.5 / 8 / 8.5 / 9. Per well, 5 μL of sample (0.8 mg/ml in PBS) was added to 5 pL of Sypro Orange (40x in MilliQ water; Invitrogen cat. No. S6551) and 10 pL of buffer (100 mM phosphate, 100 mM borate, 100 mM citrate and 115 mM NaCl with a pH ranging 3.5 to 9). The applied temperature gradient (37 to 99°C at a rate of 0.03°C/s) induces unfolding of the ISVDs whereby their hydrophobic patches become exposed. Sypro Orange binds to those hydrophobic patches, resulting in an increase in fluorescence intensity (Ex/Em = 465/580 nm). The inflection point of the first derivative of the fluorescence intensity curve at pH 7 serves as a measure of the melting temperature (Tm).
Table 28 summarizes the effects of the explored substitutions.






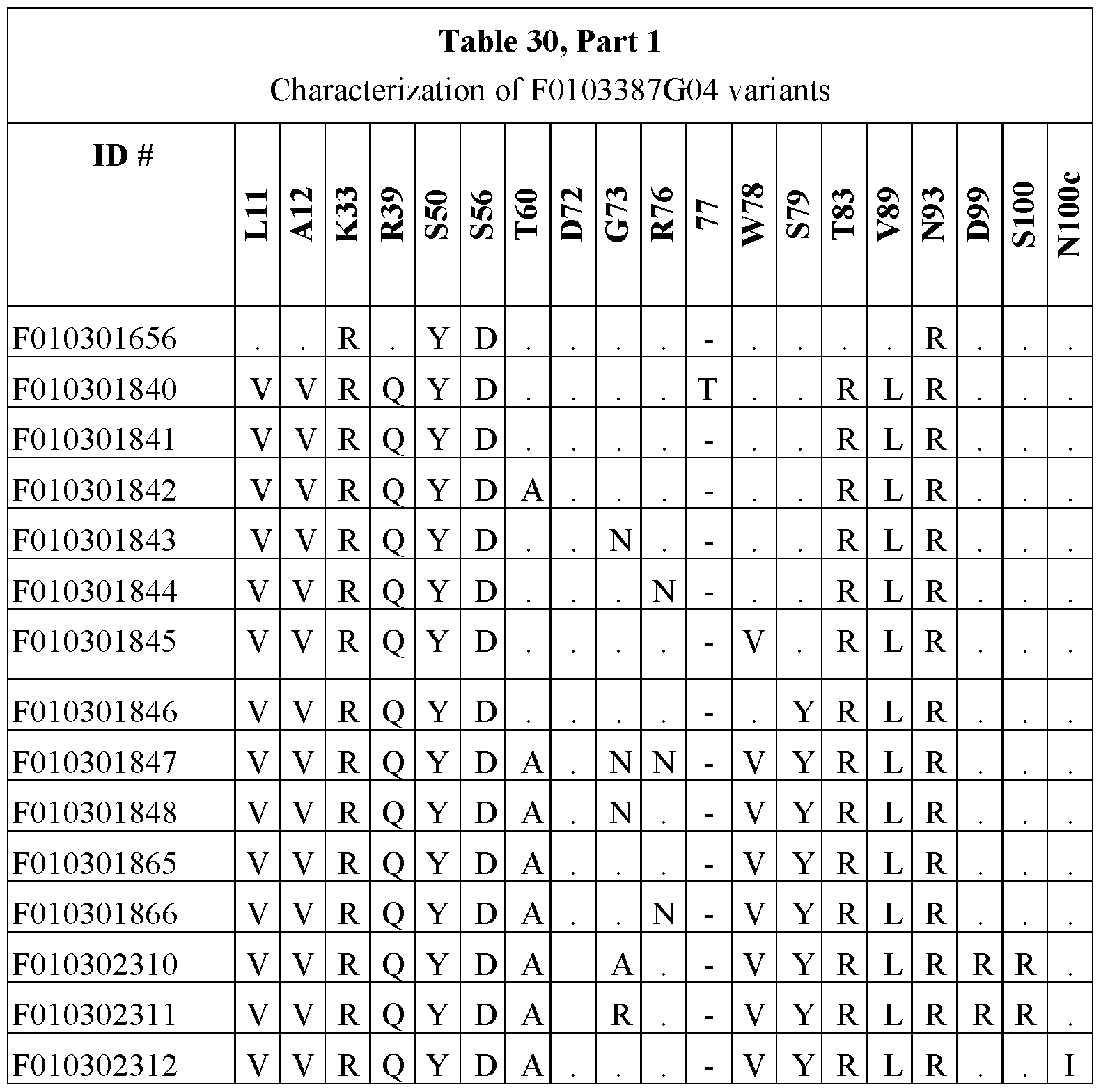




Selection of an F0103387G04 sequence optimization variant
Variant F010302383 was selected as the final sequence optimization variant of F0103387G04 (see F0103387G04_SO in Fig. 28). It boasts a 2- and 20-fold improved binding on huNavl.7α and rhNavl.7α respectively, as well as comparable aSEC and OD340nm behavior and a slightly reduced thermal stability (Table 31). In vitro electrophysiology experiments confirmed the low nM potency on huNavl.7α and rhNavl.7α and selectivity over Navi.4, Navi.5α and Navi.6a. All PTM liabilities (Table 24) were successfully substituted. Cell-free fermentation expression titers at CMC of the corresponding monovalent tagless variant F01032396 in P. pastoris were 3.6 g/L.
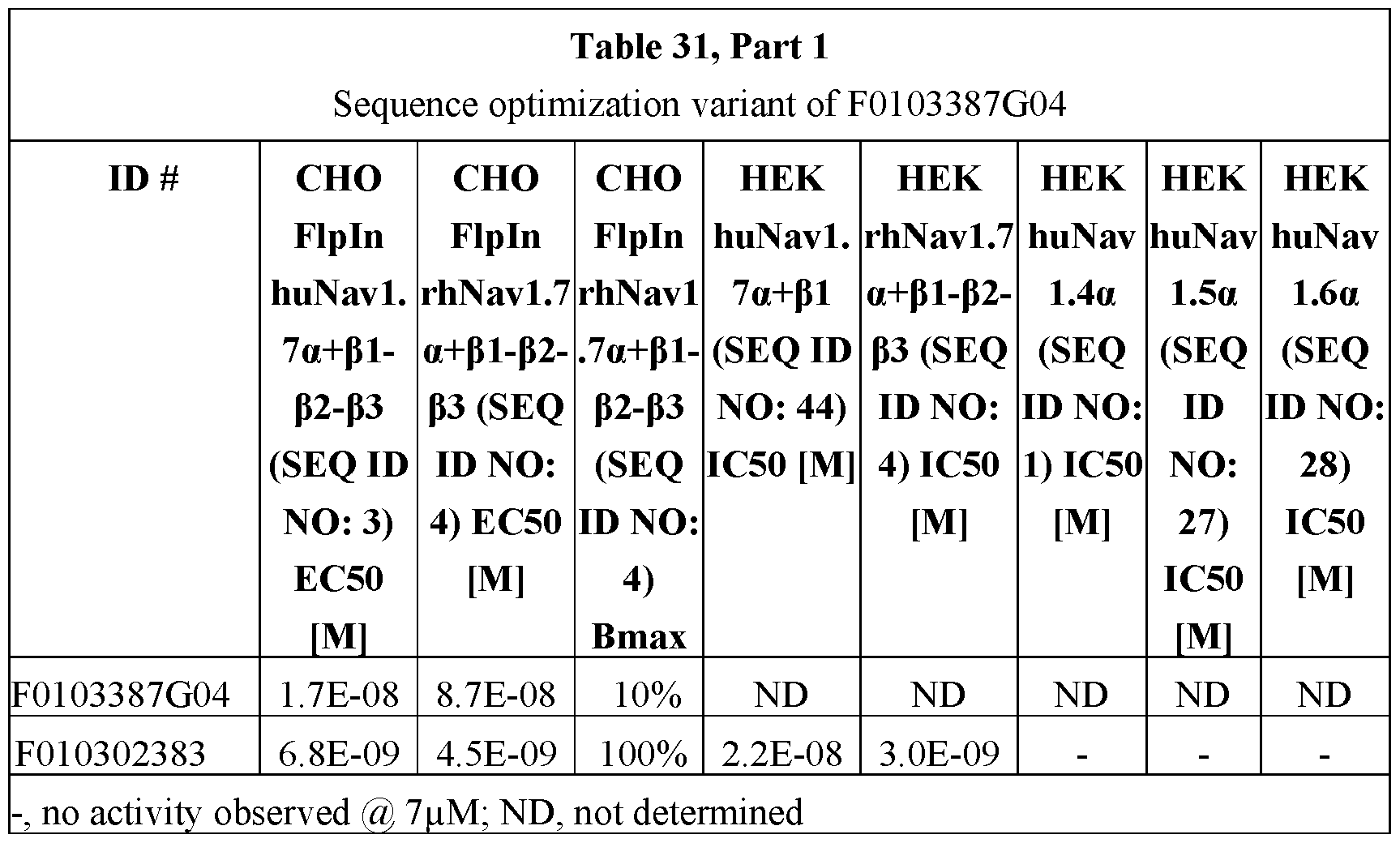

EXAMPLE 9
Sequence Optimization of F0103387G05
Several PTM substitution libraries were generated based on the accelerated stress data summarized in Table 32 and screened as crude periplasmic extracts in binding FACS on human Navi.7α.


• N73Q substitution resulted in a better binding profile compared to the parental reference (Table 33) and was further evaluated, as well as N73A andN73Y substitutions.
• Because of the available choices to substitute N73, no mutations for A74 were further evaluated.






Characterization of F0103387G05 variants
Affinity maturation substitutions that improved the binding of F0103387G05 were transferred to the sequence optimized variants. These variants were compared (Table 35) in binding FACS on human Navi.7α, in aSEC for possible multimerization, in OD340 for insoluble aggregate formation and in the thermal shift assay for Tm. Table 34 summarizes the effects of the explored substitutions.




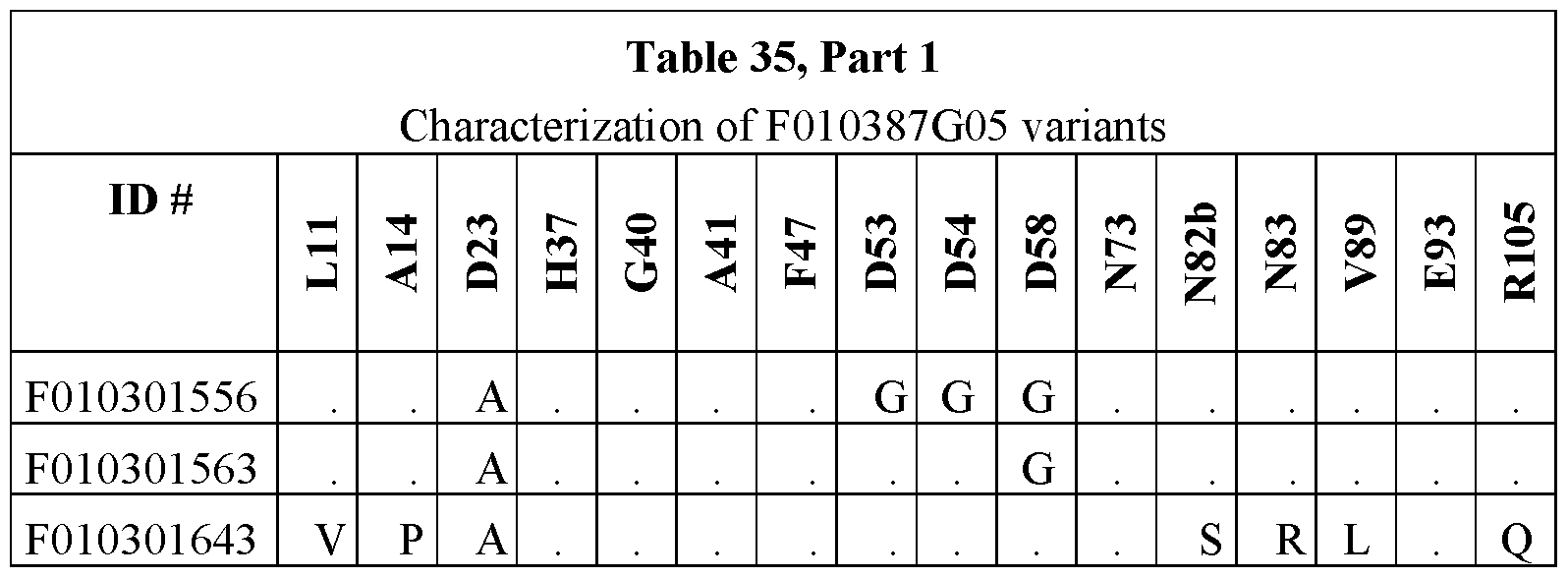




Selection of an F0103387G05 sequence optimization variant
Variant F010302391 was selected as the final sequence optimization variant of
F0103387G05 (see F0103387G05_SO in Fig. 29). It boasts a comparable binding on human
Navi.7α, as well as comparable aSEC and OD340 nm behavior, an improved thermal stability at low pH and a reduced Tagg (Table 36 and Fig. 30). In vitro electrophysiology experiments confirmed the low nM potency on huNavl.7α and selectivity over Navi.4a, Navi.5a, and Navi.6a. All PTM liabilities (Table 32) were substituted with the exception of N73. Cell-free fermentation expression titers at CMC of the corresponding monovalent tagless variant F010302400 in P. pastoris were 2.5 g/L.


 EXAMPLE 10
EXAMPLE 10
Sequence optimization of F0103464B09
Several PTM substitution libraries were generated based on the accelerated stress data summarized in Table 37 and screened as crude periplasmic extracts in binding FACS on human, rhesus and murine Navi.7α. No substitution libraries were generated for M77 and N53 substitutions.

N99S substitution resulted in a comparable or slightly improved binding profile compared to the parental reference F0103464B09 (Table 38) and was retained.

 Characterization of F0103464B09 variants
Characterization of F0103464B09 variants
In the first round, a large number of sequence optimization substitutions were explored. In the second round, eight different affinity maturation combinations (see Example 3) were explored for improved binding to rhesus Navi.7α, combined with the remaining sequence optimization substitutions. The variants were compared in binding FACS on human, rhesus and murine Navi.7α (muNavl.7α), in aSEC for possible for possible multimerization, in OD340 for insoluble aggregate formation, and in the thermal shift assay for Tm (Table 40). Table 35 summarizes the effects of the explored substitutions.
In the course of the sequence optimization process, subtle drops in binding to rhesus Navi.7α were observed for the following substitutions: R39Q, A63V, T79Y, R81Q and N99S (Table 39). R39Q substitution also resulted in a subtle drop in binding to human Navi.7α (Table 39) The combination of these, as present in the background in which the combinatorial affinity maturation substitutions were introduced, resulted in the complete abolishment of binding to rhesus Navi.7α for the controls that do not carry any of the affinity maturation substitutions (variants F010302365, F010302366 and F010302368 in Table 40) and the same was observed for the variants combining the A28Q G54E substitutions. Less outspoken, none of the variants combining the A28Q G54E N58Q, S26H A28Q G54E N58Q or A28Q N53E G54S N58Q substitutions reached maximum binding levels to rhesus Navi.7α (Table 40). A similar observation was made for the variants combining the S26H V33L N53E G54S substitutions, which also resulted in a drop in binding EC50 to human Navi.7α. The three remaining combinations S26H N53E N58Q, S26H N53E G54S N58Q and S26H A28Q N53E N58Q were highly comparable for their binding to human and rhesus Navi.7α (Table 40). The S26H N53E N58Q combination was then selected as it achieves the same binding improvements with one mutation less than the two others.











Selection of an F0103464B09 sequence optimization variant
Variant F010302363 was selected as the final sequence optimization variant of F0103464B09 (see F0103464B09_SO in Fig. 31). It boasts a strongly improved binding on rhesus Navi.7α, reduced binding to muNavl.7α, as well as comparable aSEC and OD340 nm behavior and an improved thermal stability (Table 41). In vitro electrophysiology experiments confirmed the low nM potency on huNavl.7α and rhNavl.7α and selectivity over Navi.4a, Navi.5a, and Navi.6a. All PTM liabilities (Table 37) were successfully substituted. Cell-free fermentation expression titers at CMC of the corresponding monovalent tagless variant F01032390 in P. pastoris were 2.0 g/L.




EXAMPLE 11
Identification of anti-Navf subunit ISVDs The aim of this campaign was to identify lead candidates that bind to different, non-overlapping epitopes compared to previously identified extracellular Navi.7α binders (see
previous examples). To this end, a selection and screening strategy was designed to identify lead candidates that would be able to bind in an avid fashion, when combined with a previously identified extracellular Navi.7α binding ISVD.
Different immune repertoires were cloned downstream of an anchor building block [(F103275B05(N93R), a rhNavl.7α cross-reactive variant] separated by a long 50GS linker, resulting in bivalent phage display libraries.
Selections using high quality proteoliposome (PL) preparations or cell lines as antigen were performed on bivalent libraries derived from immunization schedules in which the animals first were repeatedly administered with different forms of full-length DNA, followed by up to four administrations with PL or membrane extract (ME), followed again by multiple administrations with different forms of full-length DNA. Crude periplasmic extracts containing bivalent ISVDs enriched by the selection process, were screened in binding FACS and competition FACS on different cell lines. Table 42 summarizes the screening data of five lead ISVD candidates F0103478E09, F0103492E09, F0103495F09, F0103500E03 and F0103505D08 (for the screening each F0103478E09, F0103492E09, F0103495F09, F0103500E03 and F0103505D08 was linked at the N-terminus to the C-terminus of an F103275B05(N93R)-50GS moiety to form a bivalent ISVD) for which the totality of the data in comparison to a control (bivalent ISVD F010300702 comprising an irrelevant anti-RSV building block linked at the N- terminus to the C-terminus of an F103275B05(N93R)-50GS moiety) suggests that they bind in an avid fashion to Navi.7α:
• selective binding on hu & rhNavl ,7α in HEK & CHO at higher levels than the average of control F010300702
• remaining binding after competition with anchor building block at higher levels than the average of control F010300702
Sequence analysis revealed that these lead candidates are unrelated and belong to different ISVD families (last column of (Table 42). Most of these lead candidates and/or related family members with high sequence similarity were identified multiple times throughout different selection and screening campaigns. Further characterization revealed that these lead candidates did not bind to Navi ,7α but instead were Navβ1 or Navβ2 binders.



Binding characterization monovalent fi-subunit binders
ISVD F0103240B04 was identified by means of binding ELISA as a candidate Navβ2 binder. Binding FACS (Fig. 33) and binding ELISA (Fig. 34B) experiments with purified monovalent protein suggest that F0103240B04 is indeed a potent Navβ2 binder.
Five ISVDs, F0103478E09, F0103492E09, F0103495F09, F0103500E03 and F0103505D08, identified by binding and competition FACS (Table 42) were further characterized as purified monovalent protein. The combined data from the binding ELISA (Figs. 34A-34C) and binding FACS experiments (Figs. 35A-35D and Figs. 36A-36E) suggest that F0103478E09 is a weak Navβ1 binder and that F0103492E09, F0103500E03, and F0103505D08 are weak Navβ2 binders. F0103495F09 was not evaluated as purified monovalent protein in the binding ELISA or binding FACS experiments using transiently transfected cells because binding FACS experiments using stable cell lines suggest that it recognizes a HEK293-specific cell background marker (See Fig. 36E). Additional competition FACS experiments with Navi.7α- Navβ-subunit bispecific ISVDs; however, classify F103495F09 as a weak Navβ1 binder, similar to F0103478E09.
Binding ELISA
In general, 10 pg/mL ofHEK huNavl.7α-Navβ1 (huNavl.7-pi) expressing cells and HEK293T null ME cells were coated in bicarbonate buffer (pH9.6) overnight at 4°C in 384- well HB Spectraplate (catalog # 6007500, Perkin Elmer). Wells were blocked with 4 % Marvel in PBS. After addition of periplasmic extracts (either peri (1/5) or purified ISVD) diluted in 2 % Marvel (Premier Foods Group, St Albans, UK) in PBS, FLAG3-tagged ISVD binding was detected using a mouse anti-Flag-HRP conjugate (catalog # A8592-1MG, Sigma) and a subsequent enzymatic reaction in the presence of the substrate esTMB (3, 3’, 5,5’- tetramentylbenzidine) (catalog # #esTMB, SDT). Plates were read out on a MultiSkan device (ThermoFisher Scientific) at OD450. EC50 values were calculated using four-parameter logistic curves in GraphPad Prism7.
Alternatively, 3 pg/mL of HEKhuNavl.7α-Navβ1-Navβ2-Navβ3 (huNavl.7-pi- P2-P3) cl. 11 PL was used as coated antigen in combination with detection of CMYC3-tagged ISVDs by mouse anti-c-myc biotin conjugate (catalog # MCA2200B Serotec) followed by extravidin-HRP conjugate (catalog # E2886, Sigma-Aldrich).
EXAMPLE 12
Navi. 7a-Navβ bispecific ISVDs
Bispecific leads were generated, fusing different anti-Navβ ISVDs to the C- terminus of the rhesus cross-reactive anti-Navl.7α ISVD F103275B05(N93R) by means of a long flexible 50GS linker. The bispecifics were evaluated for their ability to compete for binding with the monovalent F0103275B05(N73R) variant to Navi.7α in FACS experiments on different cell lines. The data shown in Table 43, Figs. 37A-37B, and Figs. 38A-38C reveals 10- to 1000-fold improved competition FACS IC50 values compared to the monovalent F0103275B05(N73R) control (F010300468 in table). This holds true for both Navβ1binders and Navβ2 binders on cell lines expressing the relevant counterparts. Also, stronger Navβ binders bring about greater IC50 improvements to the respective bispecifics. The monovalent Navβ binders were not able to displace F0103275B05(N73R) from Navi.7α by themselves (Figs. 38A- 38C).


 EXAMPLE 13
EXAMPLE 13
This example shows that in vivo performance may be enhanced by half-life extension (HLE), which may be particularly useful in therapeutic formats for chronic pain indications. Two types of HLE formats were evaluated: fusion to (i) the anti-SA building block ALB23002 or to (ii) huFc.
A number of pilot experiments were performed with the rhesus cross-reactive affinity maturation variant F010300659 of F0103275B05. The addition of ALB23002 to the C- terminus of F010300659 separated by a flexible GlySer linker resulted in a two- to five-fold drop in binding competition (Table 44) and functional (Table 45 and Fig. 7 A) potency. In the presence of a saturating concentration of human SA, an additional two- to ten-fold reduction in potency was observed which appeared to be more pronounced for the shorter 9GS compared to the longer 35GS linker construct.




A number of huFc fusions were generated with the F0103265B04. The huFc moiety is based on hlgGl with LALA and D265S mutations to reduce the interaction with FcyR. F0103265B04 is fused to the N-terminus of the huFc separated by a number of linkers with differing flexibilities as described elsewhere (Klein et al. Protein Eng Des Sei. 27:325-30 (2014), which is incorporated herein by reference in its entirety). Comparison of the different constructs in binding FACS revealed EC50 values comparable to monovalent F0103265B04 (Table 46), with the exception of 22ARO which suffered from a drop in potency. Interestingly, functional characterization using a single pulse electrophysiology protocol (Fig. 7A) revealed potencies highly favorable compared to monovalent F0103265B04 (last column of Table 46). Future experiments should determine whether these improvements are Fc-or linker-mediated.

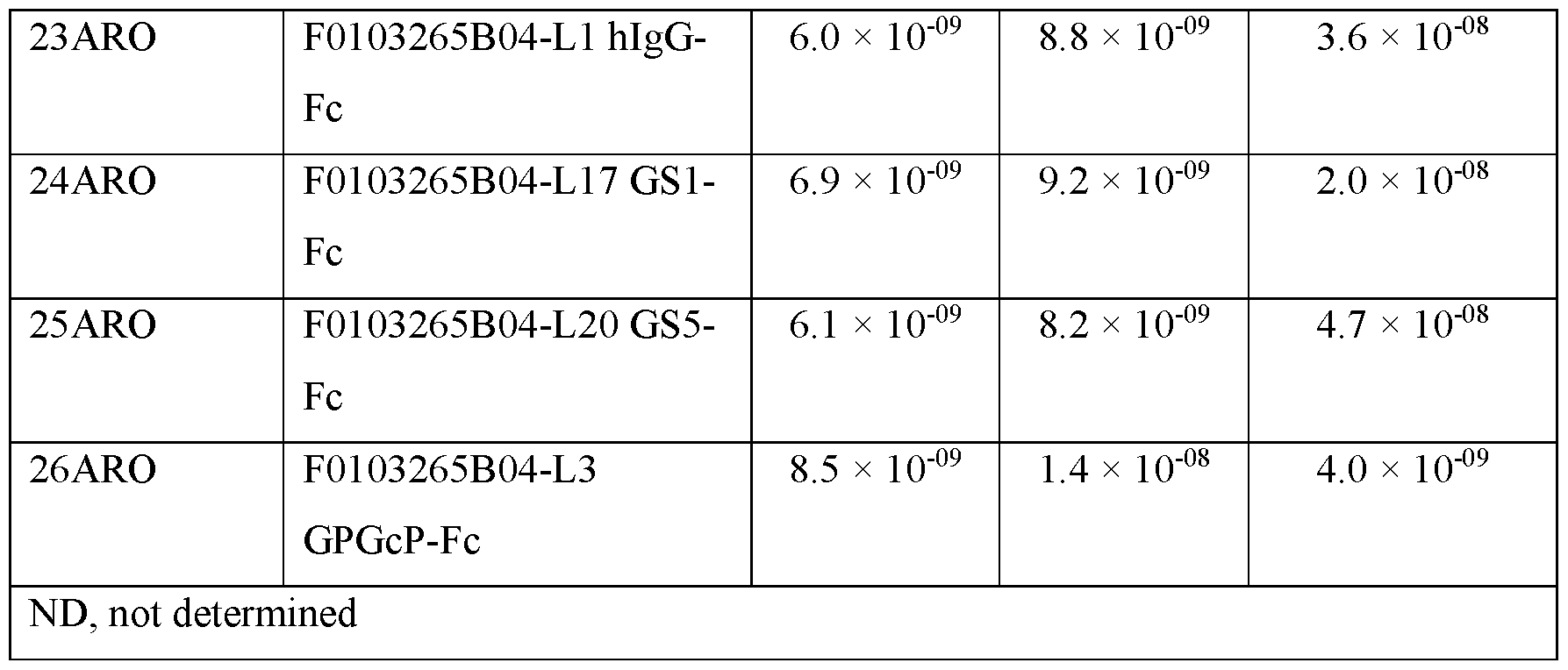
Another set of Navi.7 binder-Fc fusion proteins was generated, this time with a 5GS linker separating the two moieties, and tested for binding and electrophysiology (Table 47) following the protocol depicted in Fig. 7A. Here, affinity maturation variants F010300659 (derived from F0103275B05) and F010301656 (derived from F0103387G04) were compared to parental F0103275B05. Addition of the Fc moiety does not appear to have a major impact on the functional potency.


In a last experiment, the potencies of different HLE versions of the F0103387G04 affinity maturation variant F010301656 were compared in competition FACS and electrophysiology on huNavl.7 and rhNavl.7 (Table 48 and Table 49). As described above, the addition of an ALB23002 or Fc moiety as HLE has no outspoken effect on the potency. The presence of a saturating concentration of human SA results in a ±5-fold drop in the potency of the ALB23002 fusion.



EXAMPLE 14
Electrophysiological characterization of Navi. 7a selective ISVDs on the automated patch clamp system QPatch.
Whole-cell currents were measured from cells stably expressing human, rhesus, or rat Navi.7α, 1.6a, 1.5a, 1.4a channels using the QPatch HT™ (Sophion Bioscience). Cells were grown to 60-70% confluence in T175 cell culture flasks. Cells were lifted with Accutase™ and single cell suspensions generated with two million cells/mL.
Experiments were performed at room temperature (25-29 °C). Human and rhesus Navi.7α currents were measured holding cells -85 mV and applying 30 ms test pulses to -20 mV at a frequency 0.1Hz. Rat Navi.7α currents were measured holding cells at -75 mV applying 30 ms test pulses to -20 mV at a frequency 0.1Hz. Human and rhesus Navi ,6a, Navi . 5a, and Navi.4a were held at -85 mV, -95 mV and -80 mV, respectively. The following solutions were used: Internal Solution (in mM): 30 CsCl, 5 HEPES, 10 EGTA, 120 CsF, 5 NaF, 2 MgCl2, pH=7.3 with CsOH; External solutions (in mM) for human and rhesus Navi.7α: 40 NaCl, 120 NMDG, 1 KC1, 0.5 MgCl2, 5 HEPES, 2.7 CaCl2, pH to 7.3 with NaOH; for rat Navi.7α: 150 NaCl, 5 KC1, 2 CaCl2, 1 MgCl2, 10 HEPES, 12 Dextrose, pH 7.3 with NaOH. Sodium currents were monitored for at least five minutes in vehicle before addition of test articles. Double additions of test article were made to QPlate™ wells to achieve equilibrium. Current inhibition was measured after 60 pulses in test article. ProTX-II was used as positive control.
IC50 values, based on three concentrations, were calculated using a built-in four parameter logistic function (Hill equation): f(x) = Imin + (Imax-Imin)/(1+(IC50/[x])h); Imin = minimal current (fixed to 0); Imax = maximal current (fixed to a value of 100); IC50 = half maximal inhibitory concentration; h = Hill coefficient.
Table 50, Table 51, Table 52, Table 53, Table 54, and Table 55 show the results. In Tables 50-55, N.E. means “no effect” and ND means “not determined”.




















































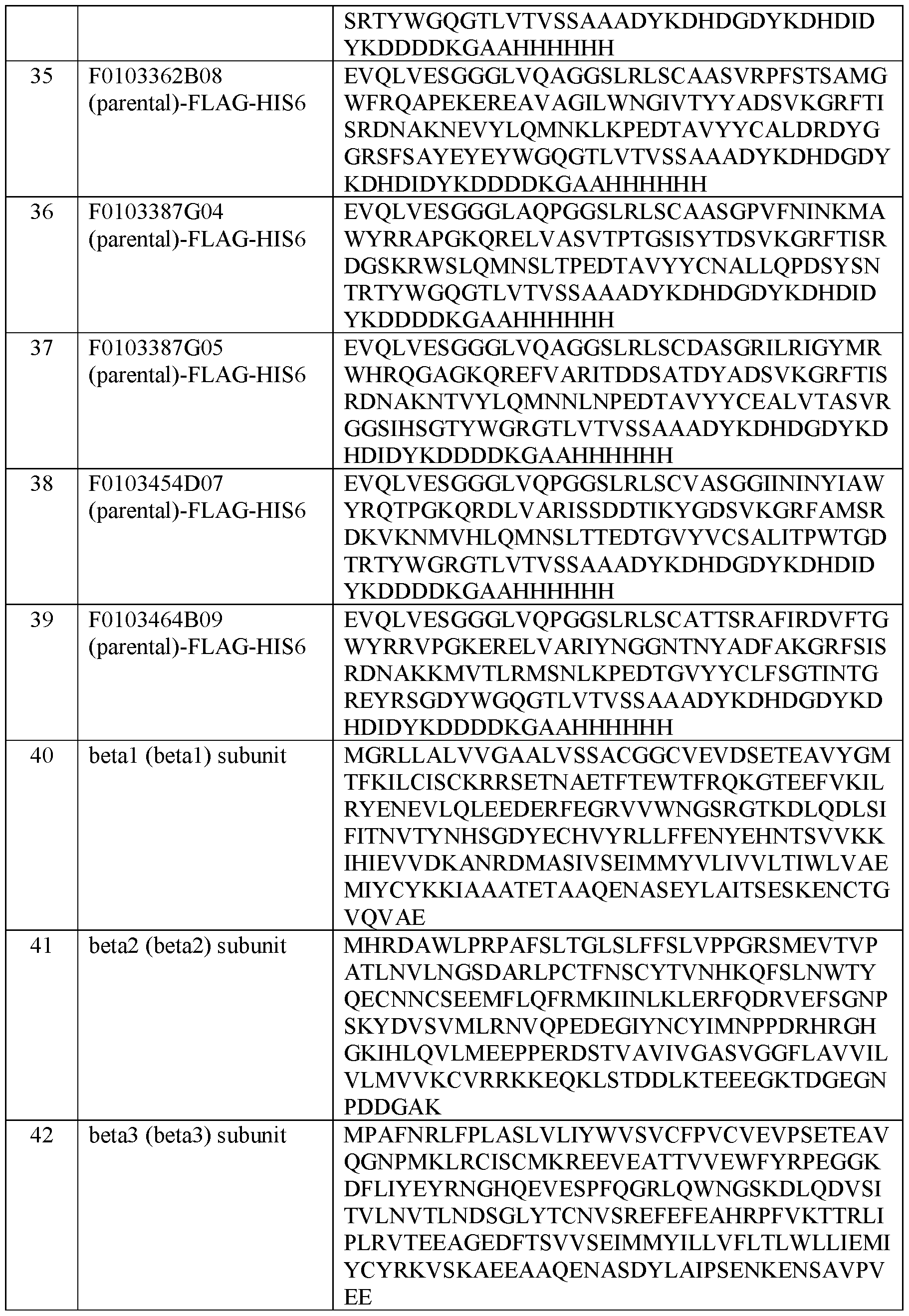






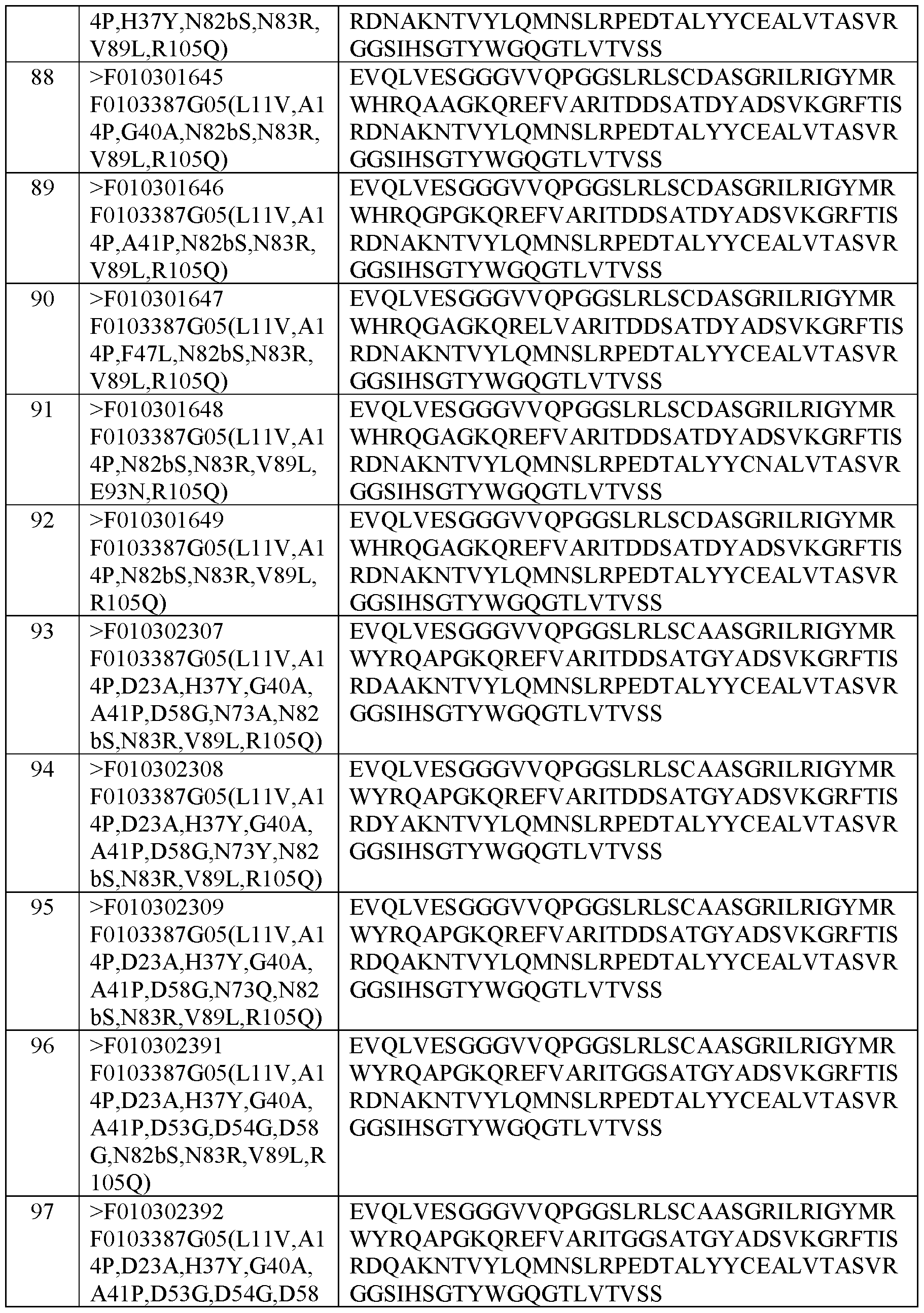




























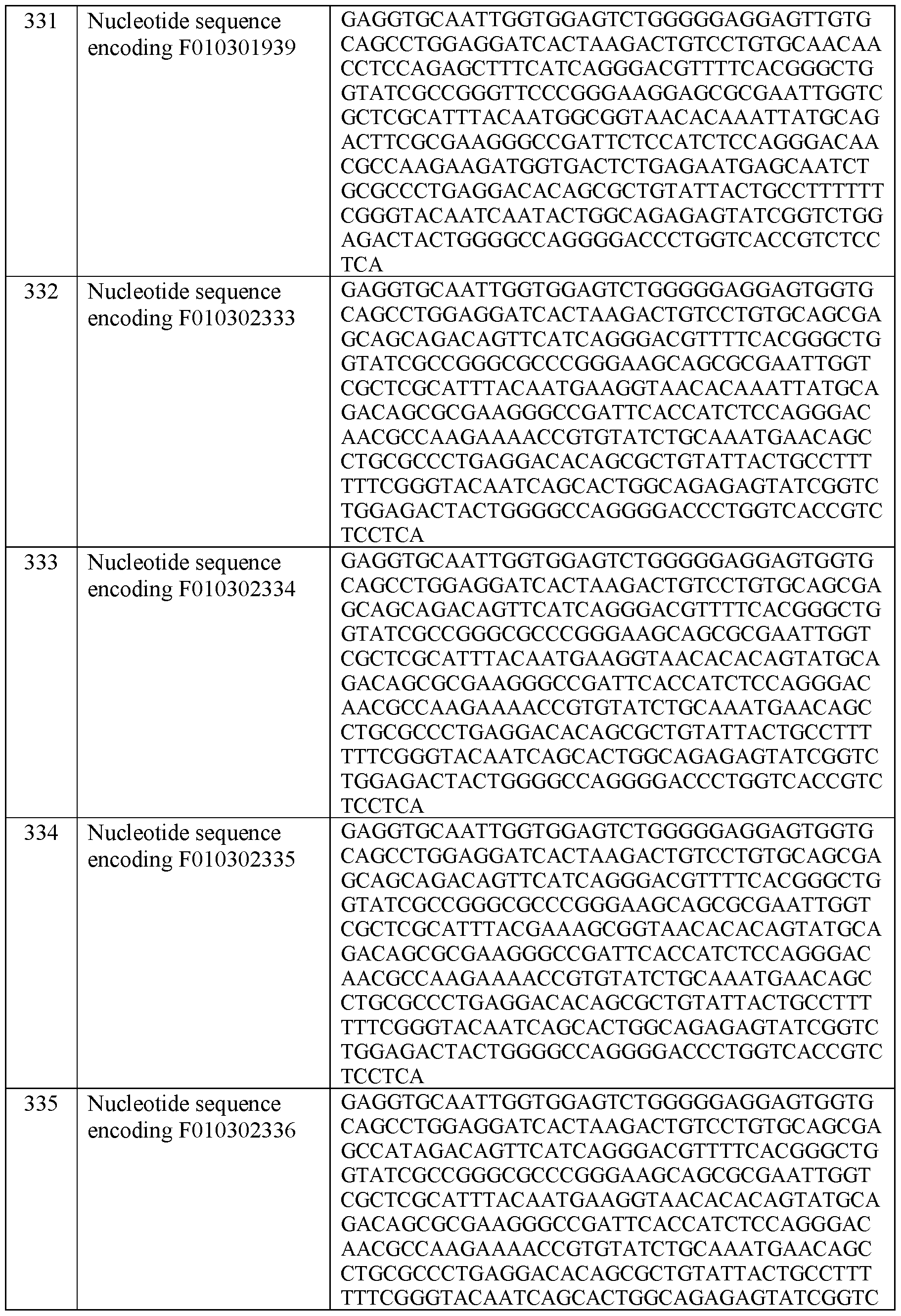


















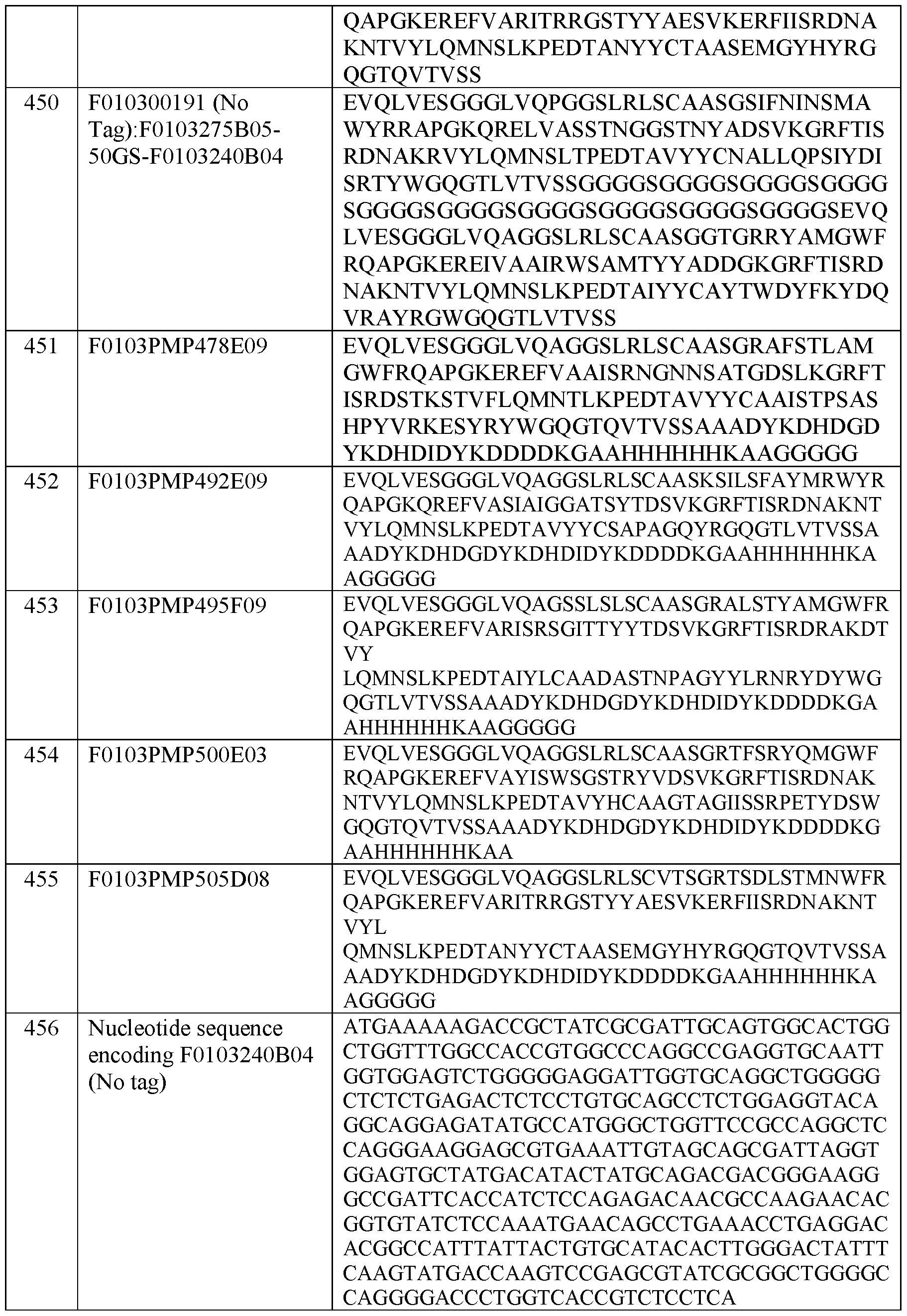



















While the present invention is described herein with reference to illustrated embodiments, it should be understood that the invention is not limited hereto. Those having ordinary skill in the art and access to the teachings herein will recognize additional modifications
and embodiments within the scope thereof. Therefore, the present invention is limited only by the claims attached herein.
Claims
1. A Nav 1.7 binder that binds to a human voltage-gated sodium channel Navi.7α protein subunit (human NaV1.7α subunit) between amino acids 272 and 331 of the human NaV1.7α subunit Domain 1 S5-S6 loop, wherein the human NaV1.7α subunit comprises the amino acid sequence set forth in SEQ ID NO: 1.
2. The Navi.7 binder of claim 1, wherein the Navi.7 binder contacts amino acids F276, R277, E281, and V331 of the human NaVl.7α subunit.
3. The Navi .7 binder of claim 2, wherein Navi .7 binder binds to the human NaV1.7α subunit comprising one or more mutations at residue F276, R277, E281 and/or V331 with lower affinity than to human NaV1.7 alpha subunit lacking such mutations.
4. The Navi.7 binder of claim 1, wherein the Navi.7 binder further is capable of binding a rhesus monkey human NaV1.7α subunit with a lower affinity than it binds to the human NaV1.7α subunit.
5. The Navi.7 binder of claim 1, wherein the Navi.7 binder is an antigenbinding fragment of either an antibody or a heavy chain antibody.
6. The Navi.7 binder of claim 1, wherein the Navi.7 binder is an immunoglobulin single variable domain (ISVD).
7. The Navi .7 binder of claim 6, wherein the Navi .7 binder comprises:
(a) a complementarity determining region (CDR) 1 comprising the amino acid sequence set forth in SEQ ID NO: 247, a CDR2 comprising the amino acid sequence set forth in SEQ ID NO: 248, and a CDR3 comprising the amino acid sequence set forth in SEQ ID NO: 249; or
(b) a CDR1 comprising the amino acid sequence set forth in SEQ ID NO: 250, a CDR2 comprising the amino acid sequence set forth in SEQ ID NO: 251, and a CDR3 comprising the amino acid sequence set forth in SEQ ID NO: 252; or
(c) a CDR1 comprising the amino acid sequence set forth in SEQ ID NO: 253, a CDR2 comprising the amino acid sequence set forth in SEQ ID NO: 254, and a CDR3 comprising the amino acid sequence SRY; or
(d) a CDR1 comprising the amino acid sequence set forth in SEQ ID NO: 256, a CDR2 comprising the amino acid sequence set forth in SEQ ID NO: 257, and a CDR3 comprising the amino acid sequence set forth in SEQ ID NO: 258; or
(e) a CDR1 comprising the amino acid sequence set forth in SEQ ID NO: 259, a CDR2 comprising the amino acid sequence set forth in SEQ ID NO: 260, and a CDR3 comprising the amino acid sequence set forth in SEQ ID NO: 261; or
(I) a CDR1 comprising the amino acid sequence set forth in SEQ ID NO: 262, a CDR2 comprising the amino acid sequence set forth in SEQ ID NO: 263, and a CDR3 comprising the amino acid sequence set forth in SEQ ID NO: 264; or
(g) a CDR1 comprising the amino acid sequence set forth in SEQ ID NO: 196, a CDR2 comprising the amino acid sequence set forth in SEQ ID NO: 198, and a CDR3 comprising the amino acid sequence set forth in SEQ ID NO: 200; or
(h) a CDR1 comprising the amino acid sequence set forth in SEQ ID NO: 201, a CDR2 comprising the amino acid sequence set forth in SEQ ID NO: 202, and a CDR3 comprising the amino acid sequence set forth in SEQ ID NO: 206; or
(i) a CDR1 comprising the amino acid sequence set forth in SEQ ID NO: 207, a CDR2 comprising the amino acid sequence set forth in SEQ ID NO: 213, and a CDR3 comprising the amino acid sequence set forth in SEQ ID NO: 219; or
(j) a CDR1 comprising the amino acid sequence set forth in SEQ ID NO: 221, a CDR2 comprising the amino acid sequence set forth in SEQ ID NO: 223, and a CDR3 comprising the amino acid sequence set forth in SEQ ID NO: 225.
8. The Navi .7 binder of claim 6, wherein the Navi .7 binder comprises:
(a) a CDR1 comprising the amino acid sequence set forth in SEQ ID NO: 196 or SEQ ID NO: 197; a CDR2 comprising the amino acid sequence set forth in SEQ ID NO: 198 or SEQ ID NO: 199; and, a CDR3 comprising the amino acid sequence set forth in SEQ ID NO: 200; or
(b) a CDR1 comprising the amino acid sequence set forth in SEQ ID NO: 201; a CDR2 comprising the amino acid sequence set forth in SEQ ID NO: 202, SEQ ID NO:
203, SEQ ID NO: 204, or SEQ ID NO: 205; and, a CDR3 comprising the amino acid sequence set forth in SEQ ID NO: 206; or
(c) a CDR1 comprising the amino acid sequence set forth in SEQ ID NO: 207, SEQ ID NO: 208, SEQ ID NO: 209, SEQ ID NO: 210, SEQ ID NO: 211, or SEQ ID NO: 212; a CDR2 comprising the amino acid sequence set forth in SEQ ID NO: 213, SEQ ID NO: 214, SEQ ID NO: 215, SEQ ID NO: 216, SEQ ID NO: 217, or SEQ ID NO: 218; and a CDR3 comprising the amino acid sequence set forth in SEQ ID NO: 219; or
(d) a CDR1 comprising the amino acid sequence set forth in SEQ ID NO: 201 or SEQ ID NO: 222; a CDR2 comprising the amino acid sequence set forth in SEQ ID NO: 223 or SEQ ID NO: 224; and a CDR3 comprising the amino acid sequence set forth in SEQ ID NO: 225, SEQ ID NO: 226, SEQ ID NO: 227, SEQ ID NO: 228, SEQ ID NO: 229, SEQ ID NO: 230, SEQ ID NO: 231, SEQ ID NO: 232, or SEQ ID NO: 233; or
(e) a CDR1 comprising the amino acid sequence set forth in SEQ ID NO: 201; a CDR2 comprising the amino acid sequence set forth in SEQ ID NO: 205; and, a CDR3 comprising the amino acid sequence set forth in SEQ ID NO: 206; or
(I) a CDR1 comprising the amino acid sequence set forth in SEQ ID NO: 211; a CDR2 comprising the amino acid sequence set forth in SEQ ID NO: 215; and, a CDR3 comprising the amino acid sequence set forth in SEQ ID NO: 219; or
(g) a CDR1 comprising the amino acid sequence set forth in SEQ ID NO: 222; a CDR2 comprising the amino acid sequence set forth in SEQ ID NO: 223; and, a CDR3 comprising the amino acid sequence set forth in SEQ ID NO: 233.
9. The Navi.7 binder of claim 6, wherein the Navi.7 binder comprises:
(a) an amino acid sequence selected from the group consisting of SEQ ID NO: 46, SEQ ID NO: 47, SEQ ID NO: 48, SEQ ID NO: 49, SEQ ID NO: 50, SEQ ID NO: 51, SEQ ID NO: 52, SEQ ID NO: 53, SEQ ID NO: 54, and SEQ ID NO: 55;
(b) an amino acid sequence selected from the group consisting of SEQ ID NO: 69, SEQ ID NO: 70, SEQ ID NO: 71, SEQ ID NO: 72, SEQ ID NO: 73, SEQ ID NO: 74, SEQ ID NO: 75, SEQ ID NO: 76, SEQ ID NO: 77, SEQ ID NO: 78, SEQ ID NO: 79, SEQ ID NO: 80, and SEQ ID NO: 81; or
(c) an amino acid sequence selected from the group consisting of SEQ ID NO: 82, SEQ ID NO: 83, SEQ ID NO: 84, SEQ ID NO: 85, SEQ ID NO: 86, SEQ ID NO: 87,
SEQ ID NO: 88, SEQ ID NO: 89, SEQ ID NO: 90, SEQ ID NO: 91, SEQ ID NO: 92, SEQ ID NO: 93, SEQ ID NO: 94, SEQ ID NO: 95, SEQ ID NO: 96, and SEQ ID NO: 97; or
(d) an amino acid sequence selected from the group consisting of SEQ ID NO: 98, SEQ ID NO: 99, SEQ ID NO: 100, SEQ ID NO: 102, SEQ ID NO: 103, SEQ ID NO: 104, SEQ ID NO: 105, SEQ ID NO: 106, SEQ ID NO: 107, SEQ ID NO: 108, SEQ ID NO: 109, SEQ ID NO: 110, SEQ ID NO: 111, SEQ ID NO: 112, SEQ ID NO: 113, SEQ ID NO: 114, SEQ ID NO: 115, SEQ ID NO: 116, SEQ ID NO: 117, SEQ ID NO: 118, SEQ ID NO: 119, SEQ ID NO: 120, SEQ ID NO: 121, SEQ ID NO: 122, SEQ ID NO: 123, SEQ ID NO: 124, SEQ ID NO: 125, SEQ ID NO: 126, SEQ ID NO: 127, SEQ ID NO: 128, SEQ ID NO: 129, SEQ ID NO: 130, SEQ ID NO: 131, SEQ ID NO: 132, SEQ ID NO: 133, SEQ ID NO: 134, SEQ ID NO: 135, SEQ ID NO: 136, SEQ ID NO: 137, SEQ ID NO: 138, SEQ ID NO: 139, SEQ ID NO: 140, SEQ ID NO: 141, SEQ ID NO: 142, SEQ ID NO: 143, SEQ ID NO: 144, SEQ ID NO: 145, SEQ ID NO: 146, SEQ ID NO: 147, SEQ ID NO: 148, SEQ ID NO: 149, SEQ ID NO: 150, SEQ ID NO: 151, SEQ ID NO: 152, and SEQ ID NO: 153; or
(e) an amino acid sequence selected from the group consisting of SEQ ID NO: 154, SEQ ID NO: 155, SEQ ID NO: 156, SEQ ID NO: 157, SEQ ID NO: 158, SEQ ID NO: 159, SEQ ID NO: 160, SEQ ID NO: 161, SEQ ID NO: 162, SEQ ID NO: 163, SEQ ID NO: 164, SEQ ID NO: 165, SEQ ID NO: 166, SEQ ID NO: 167, SEQ ID NO: 168, SEQ ID NO: 169, SEQ ID NO: 170, SEQ ID NO: 171, SEQ ID NO: 172, SEQ ID NO: 173, SEQ ID NO: 174, SEQ ID NO: 175, SEQ ID NO: 176, SEQ ID NO: 177, SEQ ID NO: 178, SEQ ID NO: 179, SEQ ID NO: 180, SEQ ID NO: 181, SEQ ID NO: 182, SEQ ID NO: 183, SEQ ID NO: 184, SEQ ID NO: 185, SEQ ID NO: 186, SEQ ID NO: 187, SEQ ID NO: 188, SEQ ID NO: 189, SEQ ID NO: 190, SEQ ID NO: 191, SEQ ID NO: 192, SEQ ID NO: 193, SEQ ID NO: 194, and SEQ ID NO: 195.
10. The Navi .7 binder of claim 6, wherein the Navi .7 binder comprises a C- terminal alanine residue.
11. The Navi .7 binder of claim 6, wherein the Navi .7 binder is linked to a half-life extender.
12. The Navi .7 binder of claim 11, wherein the half-life extender is a human serum albumin (HSA) binder, heavy chain (HC) constant domain, or the crystallizable fragment (Fc) domain thereof.
13. The Navi.7 binder of claim 12, wherein the HSA binder is ALB11002 or ALB00223.
14. The Navi .7 binder of claim 11, wherein the half-life extender is a heavy chain (HC) constant domain or the crystallizable fragment (Fc) domain thereof .
15. Use of a Navi.7 binder of any one of claims 1-14 for the manufacture of a medicament for the treatment of chronic pain.
16. Use of aNavl.7 binder of any one of claims 1-14 for the treatment of chronic pain.
17. A composition comprising a Navi.7 binder of any one of claims 1-14 and a pharmaceutically acceptable carrier.
18. A method for treating an individual with chronic pain comprising: administering to the individual a therapeutically effective amount of the Navi.7 binder of any one of claims 1-13 or the composition of claim 17 to treat the chronic pain.
19. A nucleic acid molecule encoding the Navi .7 binder of any one of claims 1-14.
20. A vector comprising the nucleic acid molecule of claim 19.
21. A host cell comprising the nucleic acid molecule of claim 19 or the vector of claim 19.
22. A method for producing the Navi.7 binder of any one of claims 1-14 comprising:
(a) providing the host cell of claim 21 ;
(b) cultivating the host cell in a medium under conditions suitable for expression of the Navi.7 binder by the host cell; and
(c) isolating the Navi .7 binder from the medium to provide the Navi .7 binder.
23. The nucleic acid molecule of claim 19, wherein the nucleic acid molecule comprises a nucleotide sequence selected from the group consisting of nucleotide sequences set forth in SEQ ID NO: 273-283.
24. The nucleic acid molecule of claim 18, wherein the nucleic acid molecule comprises a nucleotide sequence selected from the group consisting of nucleotide sequences set forth in SEQ ID NO: 284-421.
25. A Navβ1 binder comprising:
(a) a first immunoglobulin single variable domain (ISVD) comprising three complementarity determining regions (CDRs) wherein CDR1 comprises the amino acid sequence set forth in SEQ ID NO: 425, CDR2 comprises the amino acid sequence set forth in SEQ ID NO: 426, and CDR3 comprises the amino acid sequence set forth in SEQ ID NO: 427; or,
(b) a second ISVD comprising three CDRs wherein CDR1 comprises the amino acid sequence set forth in SEQ ID NO: 437, CDR2 comprises the amino acid sequence set forth in SEQ ID NO: 438, and CDR3 comprise the amino acid sequence set forth in SEQ ID NO: 439.
26. The Navβ1 binder of claim 25, wherein the first ISVD comprises the amino acid sequence set forth in SEQ ID NO: 411 and the second ISVD comprises the amino acid sequence set forth in SEQ ID NO: 415.
27. The Navβ1 binder of claim 25, wherein the N-terminal amino acid of the first ISVD or the second ISVD is linked to the C-terminal amino acid of a Navi .7 binder of claim 1 by a peptide or polypeptide linker or the N-terminal amino acid of the Navi.7 binder of
claim 1 is linked to the C-terminal amino acid of the first ISVD or the second ISVD by a peptide or polypeptide linker.
28. The Navβ1 binder of claim 27, wherein the peptide or polypeptide linker comprises any combination of glycine and serine amino acids up to 40 amino acids.
29. The Navβ1 binder of claim 28, wherein the peptide or polypeptide linker comprises an amino acid sequence comprising GGGGS (SEQ ID NO: 246))n wherein n is 1, 2, 3 ,4, 5, 6, 7, 8, 9 or 10.
30. The Navβ1 binder of claim 28, wherein the polypeptide linker comprises the amino acid sequence set forth in SEQ ID NO: 463.
31. A Navβ2 binder comprising:
(a) a first immunoglobulin single variable domain (ISVD) comprising three complementarity determining regions (CDRs) wherein CDR1 comprises the amino acid sequence set forth in SEQ ID NO: 422, a CDR2 comprising the amino acid sequence set forth in SEQ ID NO: 423, and a CDR3 comprising the amino acid sequence set forth in SEQ ID NO: 424;
(b) a second ISVD comprising three CDRs wherein CDR1 comprises the amino acid sequence set forth in SEQ ID NO: 428, a CDR2 comprising the amino acid sequence set forth in SEQ ID NO: 429, and a CDR3 comprising the amino acid sequence set forth in SEQ ID NO: 430;
(c) a third ISVD comprising three CDRs wherein CDR1 comprises the amino acid sequence set forth in SEQ ID NO: 431, a CDR2 comprising the amino acid sequence set forth in SEQ ID NO: 432, and a CDR3 comprising the amino acid sequence set forth in SEQ ID NO: 433; or
(d) a fourth ISVD comprising three CDRs wherein CDR1 comprises the amino acid sequence set forth in SEQ ID NO: 434, a CDR2 comprising the amino acid sequence set forth in SEQ ID NO: 435, and a CDR3 comprising the amino acid sequence set forth in SEQ ID NO: 436.
32. The Navβ2 binder of claim 31, wherein the first ISVD comprises the amino acid sequence set forth in SEQ ID NO: 410, the second ISVD comprises the amino acid sequence set forth in SEQ ID NO: 412, the third ISVD comprises the amino acid sequence set forth in SEQ ID NO: 413, and the fourth ISVD comprises the amino acid sequence set forth in SEQ ID NO: 414.
33. The Navβ2 binder of claim 31, wherein the N-terminal amino acid of the first ISVD, the second ISVD, the third ISVD, or the fourth ISVD is linked to the C-terminal amino acid of a Navi.7 binder of claim 1 by a peptide or polypeptide linker or the N-terminal amino acid of the Navi.7 binder of claim 1 is linked to the C-terminal amino acid of the first ISVD, the second ISVD, the third ISVD, or the fourth ISVD by a peptide or polypeptide linker.
34. The Navβ2 binder of claim 33, wherein the peptide or polypeptide linker comprises any combination of glycine and serine amino acids up to 40 amino acids.
35. The Navβ2 binder of claim 34, wherein the peptide or polypeptide linker comprises an amino acid sequence comprising GGGGS (SEQ ID NO: 246))n wherein n is 1, 2, 3 ,4, 5, 6, 7, 8, 9 or 10.
36. The Navβ2 binder of claim 35, wherein the polypeptide linker comprises the amino acid sequence set forth in SEQ ID NO: 463.
37. ANavl.7-Navβ bispecific binder comprising aNavl.7 binder of any one of claims 1 to 14 and aNavβ binder selected from the group consisting of the Navβ1 binder of any one of claims 25 to 30 and the Navβ2 binder of any one of claims 31 to 36.
38. A Navl.7-Navβ bispecific binder of claim 37, wherein
(a) the Navi .7 binder comprises:
(i) an amino acid sequence selected from the group consisting of SEQ ID NO: 46, SEQ ID NO: 47, SEQ ID NO: 48, SEQ ID NO: 49, SEQ ID NO: 50, SEQ ID NO: 51, SEQ ID NO: 52, SEQ ID NO: 53, SEQ ID NO: 54, and SEQ ID NO: 55;
(ii) an amino acid sequence selected from the group consisting of SEQ ID NO: 69, SEQ ID NO: 70, SEQ ID NO: 71, SEQ ID NO: 72, SEQ ID NO: 73, SEQ ID NO: 74, SEQ ID NO: 75, SEQ ID NO: 76, SEQ ID NO: 77, SEQ ID NO: 78, SEQ ID NO: 79, SEQ ID NO: 80, and SEQ ID NO: 81; or
(iii) an amino acid sequence selected from the group consisting of SEQ ID NO: 82, SEQ ID NO: 83, SEQ ID NO: 84, SEQ ID NO: 85, SEQ ID NO: 86, SEQ ID NO: 87, SEQ ID NO: 88, SEQ ID NO: 89, SEQ ID NO: 90, SEQ ID NO: 91, SEQ ID NO: 92, SEQ ID NO: 93, SEQ ID NO: 94, SEQ ID NO: 95, SEQ ID NO: 96, and SEQ ID NO: 97; or
(iv) an amino acid sequence selected from the group consisting of SEQ ID NO: 98, SEQ ID NO: 99, SEQ ID NO: 100, SEQ ID NO: 102, SEQ ID NO: 103, SEQ ID NO: 104, SEQ ID NO: 105, SEQ ID NO: 106, SEQ ID NO: 107, SEQ ID NO: 108, SEQ ID NO: 109, SEQ ID NO: 110, SEQ ID NO: 111, SEQ ID NO: 112, SEQ ID NO: 113, SEQ ID NO: 114, SEQ ID NO: 115, SEQ ID NO: 116, SEQ ID NO: 117, SEQ ID NO: 118, SEQ ID NO: 119, SEQ ID NO: 120, SEQ ID NO: 121, SEQ ID NO: 122, SEQ ID NO: 123, SEQ ID NO: 124, SEQ ID NO: 125, SEQ ID NO: 126, SEQ ID NO: 127, SEQ ID NO: 128, SEQ ID NO: 129, SEQ ID NO: 130, SEQ ID NO: 131, SEQ ID NO: 132, SEQ ID NO: 133, SEQ ID NO: 134, SEQ ID NO: 135, SEQ ID NO: 136, SEQ ID NO: 137, SEQ ID NO: 138, SEQ ID NO: 139, SEQ ID NO: 140, SEQ ID NO: 141, SEQ ID NO: 142, SEQ ID NO: 143, SEQ ID NO: 144, SEQ ID NO: 145, SEQ ID NO: 146, SEQ ID NO: 147, SEQ ID NO: 148, SEQ ID NO: 149, SEQ ID NO: 150, SEQ ID NO: 151, SEQ ID NO: 152, and SEQ ID NO: 153; or
(v) an amino acid sequence selected from the group consisting of SEQ
ID NO: 154, SEQ ID NO: 155, SEQ ID NO: 156, SEQ ID NO: 157, SEQ ID NO: 158, SEQ ID NO: 159, SEQ ID NO: 160, SEQ ID NO: 161, SEQ ID NO: 162, SEQ ID NO: 163, SEQ ID NO:
164, SEQ ID NO: 165, SEQ ID NO: 166, SEQ ID NO: 167, SEQ ID NO: 168, SEQ ID NO: 169,
SEQ ID NO: 170, SEQ ID NO: 171, SEQ ID NO: 172, SEQ ID NO: 173, SEQ ID NO: 174, SEQ
ID NO: 175, SEQ ID NO: 176, SEQ ID NO: 177, SEQ ID NO: 178, SEQ ID NO: 179, SEQ ID NO: 180, SEQ ID NO: 181, SEQ ID NO: 182, SEQ ID NO: 183, SEQ ID NO: 184, SEQ ID NO:
185, SEQ ID NO: 186, SEQ ID NO: 187, SEQ ID NO: 188, SEQ ID NO: 189, SEQ ID NO: 190,
SEQ ID NO: 191, SEQ ID NO: 192, SEQ ID NO: 193, SEQ ID NO: 194, and SEQ ID NO: 195;
(b) the Navβ1 binder comprises an amino acid sequence selected from the group consisting of SEQ ID NO: 411 and SEQ ID NO: 415; and,
(c) the Navβ2 binder comprises an amino acid sequence selected from the group consisting of SEQ ID NO: 410, SEQ ID NO: 412, SEQ ID NO: 413, and SEQ ID NO: 414.
39. The Navi.7-Navβ bispecific binder of claim 37 or 38, wherein the Navl.7-Navβ bispecific binder is linked to a half-life extender.
40. The Navi .7-Navβ bispecific binder of claim 39, wherein the half-life extender is a human serum albumin (HSA) binder, HC constant domain, or the crystallizable fragment (Fc) thereof.
41. The Navi.7-Navβ bispecific binder of any one of claims 37 to 40, wherein the Navi.7-Navβ bispecific binder comprises a C-terminal alanine residue.
42. A composition comprising a Navi .7-Navβ bispecific binder of any one of claim 37 to 41 and a pharmaceutically acceptable carrier.
43. Use of a Navi.7-Navβ bispecific binder of any one of claims 37 to 41 for the manufacture of a medicament for the treatment of chronic pain.
44. A Navi.7-Navβ bispecific binder of any one of claims 37 to 41 or the composition of claim 42 for the treatment of chronic pain.
45. A method for treating an individual with chronic pain comprising: administering to the individual a therapeutically effective amount of the Navi.7- Navβ bispecific binder any one of claims 37 to 41 or the composition of claim 42 to treat the chronic pain.
Priority Applications (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| EP21895562.3A EP4247418A4 (en) | 2020-11-19 | 2021-11-18 | NAV1.7 BINDERS |
| US18/252,428 US20240002497A1 (en) | 2020-11-19 | 2021-11-18 | Nav1.7 binders |
Applications Claiming Priority (4)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US202063115878P | 2020-11-19 | 2020-11-19 | |
| US63/115,878 | 2020-11-19 | ||
| US202163271963P | 2021-10-26 | 2021-10-26 | |
| US63/271,963 | 2021-10-26 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2022109102A1 true WO2022109102A1 (en) | 2022-05-27 |
Family
ID=81709766
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/US2021/059842 Ceased WO2022109102A1 (en) | 2020-11-19 | 2021-11-18 | Nav1.7 binders |
Country Status (3)
| Country | Link |
|---|---|
| US (1) | US20240002497A1 (en) |
| EP (1) | EP4247418A4 (en) |
| WO (1) | WO2022109102A1 (en) |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2023074888A1 (en) | 2021-11-01 | 2023-05-04 | 塩野義製薬株式会社 | NOVEL Nav1.7 MONOCLONAL ANTIBODY |
Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20150010546A1 (en) * | 2012-01-23 | 2015-01-08 | Ablynx N.V. | Sequences directed against hepatocyte growth factor (hfg) and polypeptides comprising the same for the treatment of cancers and/or tumors |
| US20160024208A1 (en) * | 2013-03-14 | 2016-01-28 | Regeneron Pharmaceuticals, Inc. | Human antibodies to nav1.7 |
| US20160222107A1 (en) * | 2009-10-27 | 2016-08-04 | Ucb Biopharma Sprl | METHODS OF TREATING PAIN USING FUNCTION MODIFYING NAv1.7 ANTIBODIES |
| US20170306013A1 (en) * | 2014-10-21 | 2017-10-26 | Kymab Limited | Selective nav protein binders |
| US20190202908A1 (en) * | 2014-04-15 | 2019-07-04 | President And Fellows Of Harvard College | Bi-specific agents |
Family Cites Families (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US9234037B2 (en) * | 2009-10-27 | 2016-01-12 | Ucb Biopharma Sprl | Method to generate antibodies to ion channels |
| GB2517953A (en) * | 2013-09-05 | 2015-03-11 | Argen X Bv | Antibodies to complex targets |
| JPWO2019230856A1 (en) * | 2018-05-31 | 2021-06-24 | 塩野義製薬株式会社 | Nav1.7 monoclonal antibody |
-
2021
- 2021-11-18 US US18/252,428 patent/US20240002497A1/en active Pending
- 2021-11-18 WO PCT/US2021/059842 patent/WO2022109102A1/en not_active Ceased
- 2021-11-18 EP EP21895562.3A patent/EP4247418A4/en active Pending
Patent Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20160222107A1 (en) * | 2009-10-27 | 2016-08-04 | Ucb Biopharma Sprl | METHODS OF TREATING PAIN USING FUNCTION MODIFYING NAv1.7 ANTIBODIES |
| US20150010546A1 (en) * | 2012-01-23 | 2015-01-08 | Ablynx N.V. | Sequences directed against hepatocyte growth factor (hfg) and polypeptides comprising the same for the treatment of cancers and/or tumors |
| US20160024208A1 (en) * | 2013-03-14 | 2016-01-28 | Regeneron Pharmaceuticals, Inc. | Human antibodies to nav1.7 |
| US20190202908A1 (en) * | 2014-04-15 | 2019-07-04 | President And Fellows Of Harvard College | Bi-specific agents |
| US20170306013A1 (en) * | 2014-10-21 | 2017-10-26 | Kymab Limited | Selective nav protein binders |
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2023074888A1 (en) | 2021-11-01 | 2023-05-04 | 塩野義製薬株式会社 | NOVEL Nav1.7 MONOCLONAL ANTIBODY |
| KR20240099394A (en) | 2021-11-01 | 2024-06-28 | 시오노기세이야쿠가부시키가이샤 | Novel Nav1.7 monoclonal antibody |
Also Published As
| Publication number | Publication date |
|---|---|
| EP4247418A1 (en) | 2023-09-27 |
| EP4247418A4 (en) | 2024-12-18 |
| US20240002497A1 (en) | 2024-01-04 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US20250074996A1 (en) | ANTI-GPRC5DxBCMAxCD3 TRISPECIFIC ANTIBODY AND USE THEREOF | |
| AU2019326635B2 (en) | Anti-PD-L1/anti-LAG3 bispecific antibodies and uses thereof | |
| US9441040B2 (en) | Antagonist antibodies and their fab fragments against GPVI and uses thereof | |
| US11919954B2 (en) | Anti-TREM-1 antibodies and uses thereof | |
| US20210347908A1 (en) | Novel anti-sirpa antibodies | |
| JP2021502100A (en) | Bispecific and monospecific antibodies using novel anti-PD-1 sequences | |
| CA3004804A1 (en) | Pd-l1 antibody, antigen-binding fragment thereof and medical application thereof | |
| EP3189081A1 (en) | Cd123 binding agents and uses thereof | |
| US20250163157A1 (en) | Bispecific antibodies against cd277 and a tumor-antigen | |
| US20240182592A1 (en) | Multi-specific antibody targeting bcma | |
| TW202202529A (en) | Bispecific antibody and use thereof | |
| CA3227854A1 (en) | Novel anti-sirpa antibodies | |
| US20250136688A1 (en) | Stabilized cd3 antigen binding agents and methods of use thereof | |
| JP7808306B2 (en) | anti-CD3 humanized antibody | |
| WO2022109102A1 (en) | Nav1.7 binders | |
| US20250163182A1 (en) | Enpp3 and cd3 binding agents and methods of use thereof | |
| US20250026842A1 (en) | Modified protein or polypeptide | |
| US20230374148A1 (en) | Binding molecules that multimerise cd45 | |
| WO2025077834A1 (en) | Anti-il-4ra antibodies and uses thereof | |
| US20240166737A1 (en) | Msln and cd3 binding agents and methods of use thereof | |
| US20250002593A1 (en) | Novel anti-il-36r antibodies | |
| WO2026044000A1 (en) | Multispecific antibodies and methods of use thereof | |
| TW202523697A (en) | Anti-tslp antibody constructs and uses thereof | |
| TW202542184A (en) | Novel antibodies that bind to cd3 and lilrb4, and uses thereof | |
| EA051514B1 (en) | Polypeptide constructs that selectively bind to CLDN6 and CD3 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 21895562 Country of ref document: EP Kind code of ref document: A1 |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 18252428 Country of ref document: US |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| ENP | Entry into the national phase |
Ref document number: 2021895562 Country of ref document: EP Effective date: 20230619 |