WO2022221441A2 - Products and compositions - Google Patents
Products and compositions Download PDFInfo
- Publication number
- WO2022221441A2 WO2022221441A2 PCT/US2022/024672 US2022024672W WO2022221441A2 WO 2022221441 A2 WO2022221441 A2 WO 2022221441A2 US 2022024672 W US2022024672 W US 2022024672W WO 2022221441 A2 WO2022221441 A2 WO 2022221441A2
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- oligomeric compound
- compound according
- region
- nucleoside
- nos
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Ceased
Links
Classifications
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/11—DNA or RNA fragments; Modified forms thereof; Non-coding nucleic acids having a biological activity
- C12N15/113—Non-coding nucleic acids modulating the expression of genes, e.g. antisense oligonucleotides; Antisense DNA or RNA; Triplex- forming oligonucleotides; Catalytic nucleic acids, e.g. ribozymes; Nucleic acids used in co-suppression or gene silencing
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K38/00—Medicinal preparations containing peptides
- A61K38/16—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- A61K38/17—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans
- A61K38/36—Blood coagulation or fibrinolysis factors
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P7/00—Drugs for disorders of the blood or the extracellular fluid
- A61P7/02—Antithrombotic agents; Anticoagulants; Platelet aggregation inhibitors
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K14/00—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N9/00—Enzymes; Proenzymes; Compositions thereof; Processes for preparing, activating, inhibiting, separating or purifying enzymes
- C12N9/14—Hydrolases (3)
- C12N9/48—Hydrolases (3) acting on peptide bonds (3.4)
- C12N9/50—Proteinases, e.g. Endopeptidases (3.4.21-3.4.25)
- C12N9/64—Proteinases, e.g. Endopeptidases (3.4.21-3.4.25) derived from animal tissue
- C12N9/6421—Proteinases, e.g. Endopeptidases (3.4.21-3.4.25) derived from animal tissue from mammals
- C12N9/6424—Serine endopeptidases (3.4.21)
- C12N9/6443—Coagulation factor XIa (3.4.21.27)
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2310/00—Structure or type of the nucleic acid
- C12N2310/10—Type of nucleic acid
- C12N2310/11—Antisense
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2310/00—Structure or type of the nucleic acid
- C12N2310/30—Chemical structure
- C12N2310/31—Chemical structure of the backbone
- C12N2310/312—Phosphonates
- C12N2310/3125—Methylphosphonates
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2310/00—Structure or type of the nucleic acid
- C12N2310/30—Chemical structure
- C12N2310/31—Chemical structure of the backbone
- C12N2310/315—Phosphorothioates
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2310/00—Structure or type of the nucleic acid
- C12N2310/30—Chemical structure
- C12N2310/32—Chemical structure of the sugar
- C12N2310/321—2'-O-R Modification
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2310/00—Structure or type of the nucleic acid
- C12N2310/30—Chemical structure
- C12N2310/32—Chemical structure of the sugar
- C12N2310/322—2'-R Modification
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2310/00—Structure or type of the nucleic acid
- C12N2310/30—Chemical structure
- C12N2310/35—Nature of the modification
- C12N2310/351—Conjugate
- C12N2310/3515—Lipophilic moiety, e.g. cholesterol
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2310/00—Structure or type of the nucleic acid
- C12N2310/30—Chemical structure
- C12N2310/35—Nature of the modification
- C12N2310/352—Nature of the modification linked to the nucleic acid via a carbon atom
- C12N2310/3521—Methyl
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2310/00—Structure or type of the nucleic acid
- C12N2310/30—Chemical structure
- C12N2310/35—Nature of the modification
- C12N2310/353—Nature of the modification linked to the nucleic acid via an atom other than carbon
- C12N2310/3533—Halogen
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Y—ENZYMES
- C12Y304/00—Hydrolases acting on peptide bonds, i.e. peptidases (3.4)
- C12Y304/21—Serine endopeptidases (3.4.21)
- C12Y304/21027—Coagulation factor XIa (3.4.21.27)
Definitions
- FXI Factor XI
- Methods, compounds, and compositions are provided for reducing expression of FXI mRNA and protein in an animal. Such methods, compounds, and compositions are useful to treat, prevent, or ameliorate thromboembolic diseases, such as deep vein thrombosis, venous or arterial thrombosis, pulmonary embolism, myocardial infarction, stroke, thrombosis associated with chronic kidney disease or end-stage renal disease (ESRD), including thrombosis associated with dialysis, or other procoagulant condition.
- thromboembolic diseases such as deep vein thrombosis, venous or arterial thrombosis, pulmonary embolism, myocardial infarction, stroke, thrombosis associated with chronic kidney disease or end-stage renal disease (ESRD), including thrombosis associated with dialysis, or other procoagulant condition.
- thromboembolic diseases such as deep vein thrombosis, venous or arterial thrombosis,
- coagulation comprises a cascade of reactions culminating in the conversion of soluble fibrinogen to an insoluble fibrin gel.
- the steps of the cascade involve the conversion of an inactive zymogen to an activated enzyme.
- the active enzyme then catalyzes the next step in the cascade.
- Coagulation Cascade The coagulation cascade may be initiated through two branches, the tissue factor pathway (also “extrinsic pathway”), which is the primary pathway, and the contact activation pathway (also “intrinsic pathway”).
- TF cell surface receptor tissue factor
- extravascular cells pericytes, cardiomyocytes, smooth muscle cells, and keratinocytes
- vascular monocytes and endothelial cells upon induction by inflammatory cytokines or endotoxin.
- TF is the high affinity cellular receptor for coagulation Factor VIIa, a serine protease.
- VIIa In the absence of TF, VIIa has very low catalytic activity, and binding to TF is necessary to render VIIa functional through an allosteric mechanism (Drake et al., Am J Pathol 1989, 134: 1087-1097).
- the TF-VIIa complex activates Factor X to Xa.
- Xa in turn associates with its co-factor Factor Va into a prothrombinase complex which in turn activates prothrombin, (also known as Factor II or Factor 2) to thrombin (also known as Factor Ila, or Factor 2a).
- Thrombin activates platelets, converts fibrinogen to fibrin and promotes fibrin cross-linking by activating Factor XIII, thus forming a stable plug at sites where TF is exposed on extravascular cells.
- thrombin reinforces the coagulation cascade response by activating Factors V and VIII.
- the contact activation pathway is triggered by activation of Factor XII to Xlla.
- Factor Xlla converts XI to XIa
- XIa converts IX to IXa.
- IXa associates with its cofactor VIIIa to convert X to Xa.
- Factor Xa associates with Factor Va to activate prothrombin (Factor II) to thrombin (Factor Ila).
- Factor XI enhances both the formation and stability of clots in vitro, but is not thought to be involved in the initiation of clotting. Rather, Factor XI is important in the propagation phase of clot growth (von de Borne, et al., Blood Coagulation and Fibrinolysis, 2006, 17:251-257).
- TAFI thrombin activatable fibrinolysis inhibitor
- Inhibition of coagulation At least three mechanisms keep the coagulation cascade in check, namely the action of activated protein C, antithrombin, and tissue factor pathway inhibitor.
- Activated protein C is a serine protease that degrades cofactors Va and VIIIa. Protein C is activated by thrombin with thrombomodulin, and requires coenzyme Protein S to function.
- Antithrombin is a serine protease inhibitor (serpin) that inhibits serine proteases: thrombin, Xa, Xlla, XIa and IXa. Tissue factor pathway inhibitor inhibits the action of Xa and the TF-VIIa complex.
- serpin serine protease inhibitor
- thrombin serine protease inhibitor
- Xa Xa
- Xlla XIa
- IXa Tissue factor pathway inhibitor inhibits the action of Xa and the TF-VIIa complex.
- Disease Thrombosis is the pathological development of blood clots, and an embolism occurs when a blood clot migrates to another part of the body and interferes with organ function. Thromboembolism may cause conditions such as deep vein thrombosis, pulmonary embolism, myocardial infarction, and stroke.
- Warfarin is typically used to treat patients suffering from atrial fibrillation.
- the drug interacts with vitamin K-dependent coagulation factors which include Factors II, VII, IX and X.
- Anticoagulant proteins C and S are also inhibited by warfarin. Drug therapy using warfarin is further complicated by the fact that warfarin interacts with other medications, including drugs used to treat atrial fibrillation, such as amiodarone. Because therapy with warfarin is difficult to predict, patients must be carefully monitored in order to detect any signs of anomalous bleeding. Heparin functions by activating antithrombin which inhibits both thrombin and Factor X (Bjork I, Lindahl U. Mol Cell Biochem.198248: 161-182). Treatment with heparin may cause an immunological reaction that makes platelets aggregate within blood vessels that can lead to thrombosis.
- HIT heparin-induced thrombocytopenia
- LMWH can also inhibit Factor II, but to a lesser degree than unfractioned heparin (UFH).
- UHF unfractioned heparin
- LMWH has been implicated in the development of HIT.
- Several direct oral anticoagulants have been FDA-approved for the treatment of thrombotic disease, including four Factor Xa inhibitors Betrixaban, Apixaban, Rivaroxaban and Edoxaban and one direct thrombin inhibitor Dabigatran. (Smith, M., Surg Clin N Am 201898:219-238).
- Double-stranded RNA (dsRNA) able to complementarily bind expressed mRNA has been shown to be able to block gene expression (Fire et a.l, 1998, Nature.1998 Feb 19;391 (6669):806-11 and Elbashir et at., 2001 , Nature.2001 May 24;411 (6836):494-88) by a mechanism that has been termed RNA interference (RNAi).
- RNAi RNA interference
- RNAi is mediated by the RNA-induced silencing complex (RISC), a sequence-specific, multi-component nuclease that destroys messenger RNAs homologous to the silencing trigger loaded into the RISC complex.
- RISC RNA-induced silencing complex
- Interfering RNA (iRNA) such as siRNAs, antisense RNA, and micro-RNA are oligonucleotides that prevent the formation of proteins by gene-silencing i.e. inhibiting gene translation of the protein through degradation of mRNA molecules. Gene-silencing agents are becoming increasingly important for therapeutic applications in medicine.
- An aim is to, therefore, provide compounds, methods, and pharmaceutical compositions for the treatment of thromboembolic diseases as described herein, which comprise oligomeric compounds that modulate and inhibit, gene expression by RNAi.
- Summary Nucleic acid products are provided that modulate, interfere with, or inhibit, Factor XI (FXI) gene expression, and associated therapeutic uses. Specific oligomeric compounds and sequences are described herein. This summary is not intended to identify key features or essential features of the subject matter as described herein, nor is it intended to be used to determine the scope of that subject matter. Detailed Description and Embodiments The embodiments described below are exemplary but the skilled artisan will recognize that additional embodiments may be achieved.
- Figures 3 to 12 show the screening results for FXI gene expression as a percentage of gene expression in non-treated cells for oligomeric compounds including oligonucleotides of Table 1a / 1b of Example 1.
- Figure 13 provides dose response curves for the 26 FXI lead compounds as identified in Example 2.
- Figure 14 provides dose response curves for the 5 FXI lead compounds as identified further to the results of Figure 13.
- Figures 15 to 17 show the overall sequences for oligomeric compounds F11-91, F11-46, F11-152.
- Figure 18 shows compounds which have been selected for medicinal chemistry.
- Figure 19 shows performance of the compounds shown in Figure 18.
- Figure 20 show compounds which have been designed on the basis of the results shown in Figure 19.
- Figure 21 shows data for the compounds displayed in Figure 20.
- Figure 22 shows the structure of compounds tested in humanized mice.
- Figure 23 shows the data obtained from testing in humanized mice.
- Figure 24 shows the design of an in vivo study with compound 91-Conv-31.
- Figure 25 shows performance of a compound in an in vivo study in terms of Factor XI activity knock- down.
- Figure 26 shows the molecular mechanism underlying the tests for targeting specificity as performed in the course of an in vivo study.
- Figure 27 shows the read-out of the tests illustrated in Figure 26.
- Figure 28 presents data demonstrating a lack of side effects. Definitions Unless specific definitions are provided, the nomenclature used in connection with, and the procedures and techniques of, analytical chemistry, synthetic organic chemistry, and medicinal and pharmaceutical chemistry described herein are those well known and commonly used in the art.
- Standard techniques may be used for chemical synthesis, and chemical analysis. Certain such techniques and procedures may be found for example in "Carbohydrate Modifications in Antisense Research” Edited by Sangvi and Cook, American Chemical Society , Washington D.C., 1994; “Remington's Pharmaceutical Sciences,” Mack Publishing Co., Easton, Pa., 21 st edition, 2005; and “Antisense Drug Technology, Principles, Strategies, and Applications” Edited by Stanley T. Crooke, CRC Press, Boca Raton, Florida; and Sambrook et al., "Molecular Cloning, A laboratory Manual,” 2 nd Edition, Cold Spring Harbor Laboratory Press, 1989, which are hereby incorporated by reference for any purpose.
- excipient means any compound or mixture of compounds that is added to a composition as provided herein that is suitable for delivery of an oligomeric compound.
- nucleoside means a compound comprising a nucleobase moiety and a sugar moiety. Nucleosides include, but are not limited to, naturally occurring nucleosides (as found in DNA and RNA) and modified nucleosides.
- Nucleosides may be linked to a phosphate moiety, phosphate- linked nucleosides also being referred to as “nucleotides”.
- “chemical modification” or “chemically modified” means a chemical difference in a compound when compared to a naturally occurring counterpart. Chemical modifications of oligonucleotides include nucleoside modifications (including sugar moiety modifications and nucleobase modifications) and internucleoside linkage modifications. In reference to an oligonucleotide, chemical modification does not include differences only in nucleobase sequence.
- furanosyl means a structure comprising a 5-membered ring comprising four carbon atoms and one oxygen atom.
- naturally occurring sugar moiety means a ribofuranosyl as found in naturally occurring RNA or a deoxyribofuranosyl as found in naturally occurring DNA.
- a “naturally occurring sugar moiety” as referred to herein is also termed as an "unmodified sugar moiety".
- such a “naturally occurring sugar moiety” or an “unmodified sugar moiety” as referred to herein has a -H (DNA sugar moiety) or –OH (RNA sugar moiety) at the 2'-position of the sugar moiety, especially a -H (DNA sugar moiety) at the 2'-position of the sugar moiety.
- sugar moiety means a naturally occurring sugar moiety or a modified sugar moiety of a nucleoside.
- modified sugar moiety means a substituted sugar moiety or a sugar surrogate.
- substituted sugar moiety means a furanosyl that has been substituted.
- Substituted sugar moieties include, but are not limited to furanosyls comprising substituents at the 2'-position, the 3'-position, the 5'-position and / or the 4'-position. Certain substituted sugar moieties are bicyclic sugar moieties.
- 2'-substituted sugar moiety means a furanosyl comprising a substituent at the 2'- position other than H or OH. Unless otherwise indicated, a 2'-substituted sugar moiety is not a bicyclic sugar moiety (i.e., the 2' -substituent of a 2'-substituted sugar moiety does not form a bridge to another atom of the furanosyl ring).
- MOE means -OCH2CH2OCH3.
- 2'-F nucleoside refers to a nucleoside comprising a sugar comprising fluorine at the 2' position.
- the fluorine in a 2'-F nucleoside is in the ribo position (replacing the OH of a natural ribose).
- Duplexes of uniformly modified 2′-fluorinated (ribo) oligonucleotides hybridized to RNA strands are not RNase H substrates while the ara analogs retain RNase H activity.
- sucrose surrogate means a structure that does not comprise a furanosyl and that is capable of replacing the naturally occurring sugar moiety of a nucleoside, such that the resulting nucleoside sub-units are capable of linking together and / or linking to other nucleosides to form an oligomeric compound which is capable of hybridizing to a complementary oligomeric compound.
- Such structures include rings comprising a different number of atoms than furanosyl (e.g., 4, 6, or 7-membered rings); replacement of the oxygen of a furanosyl with a non-oxygen atom (e.g., carbon, sulfur, or nitrogen); or both a change in the number of atoms and a replacement of the oxygen.
- Such structures may also comprise substitutions corresponding to those described for substituted sugar moieties (e.g., 6-membered carbocyclic bicyclic sugar surrogates optionally comprising additional substituents).
- Sugar surrogates also include more complex sugar replacements (e.g., the non-ring systems of peptide nucleic acid).
- Sugar surrogates include without limitation morpholinos, cyclohexenyls and cyclohexitols.
- "bicyclic sugar moiety” means a modified sugar moiety comprising a 4 to 7 membered ring (including but not limited to a furanosyl) comprising a bridge connecting two atoms of the 4 to 7 membered ring to form a second ring, resulting in a bicyclic structure.
- the 4 to 7 membered ring is a sugar ring.
- the 4 to 7 membered ring is a furanosyl.
- the bridge connects the 2 '-carbon and the 4 '-carbon of the furanosyl.
- nucleotide means a nucleoside further comprising a phosphate linking group.
- linked nucleosides may or may not be linked by phosphate linkages and thus includes, but is not limited to “linked nucleotides.”
- linked nucleosides are nucleosides that are connected in a continuous sequence (i.e. no additional nucleosides are present between those that are linked).
- nucleobase means a group of atoms that can be linked to a sugar moiety to create a nucleoside that is capable of incorporation into an oligonucleotide, and wherein the group of atoms is capable of bonding with a complementary naturally occurring nucleobase of another oligonucleotide or nucleic acid. Nucleobases may be naturally occurring or may be modified.
- unmodified nucleobase or “naturally occurring nucleobase” means the naturally occurring heterocyclic nucleobases of RNA or DNA: the purine bases adenine (A) and guanine (G), and the pyrimidine bases thymine (T), cytosine (C) (including 5-methyl C), and uracil (U).
- modified nucleobase means any nucleobase that is not a naturally occurring nucleobase.
- modified nucleoside means a nucleoside comprising at least one chemical modification compared to naturally occurring RNA or DNA nucleosides.
- Modified nucleosides can comprise a modified sugar moiety and / or a modified nucleobase.
- bicyclic nucleoside or “BNA” means a nucleoside comprising a bicyclic sugar moiety.
- locked nucleic acid nucleoside or “LNA” means a nucleoside comprising a bicyclic sugar moiety comprising a 4'-CH2-O-2'bridge.
- 2 '-substituted nucleoside means a nucleoside comprising a substituent at the 2'- position of the sugar moiety other than H or OH.
- a 2 '-substituted nucleoside is not a bicyclic nucleoside.
- deoxynucleoside means a nucleoside comprising 2'-H furanosyl sugar moiety, as found in naturally occurring deoxyribonucleosides (DNA).
- a 2'- deoxynucleoside may comprise a modified nucleobase or may comprise an RNA nucleobase (e.g., uracil).
- oligonucleotide means a compound comprising a plurality of linked nucleosides.
- an oligonucleotide comprises one or more unmodified ribonucleosides (RNA) and / or unmodified deoxyribonucleosides (DNA) and / or one or more modified nucleosides.
- modified oligonucleotide means an oligonucleotide comprising at least one modified nucleoside and / or at least one modified internucleoside linkage.
- linkage or “linking group” means a group of atoms that link together two or more other groups of atoms.
- internucleoside linkage means a covalent linkage between adjacent nucleosides in an oligonucleotide.
- naturally occurring internucleoside linkage means a 3' to 5' phosphodiester linkage.
- modified internucleoside linkage means any internucleoside linkage other than a naturally occurring internucleoside linkage.
- a "modified internucleoside linkage" as referred to herein can include a modified phosphorous linking group such as a phosphorothioate or phosphorodithioate internucleoside linkage.
- terminal internucleoside linkage means the linkage between the last two nucleosides of an oligonucleotide or defined region thereof.
- phosphorus linking group means a linking group comprising a phosphorus atom and can include naturally occurring phosphorous linking groups as present in naturally occurring RNA or DNA, such as phosphodiester linking groups, or modified phosphorous linking groups that are not generally present in naturally occurring RNA or DNA, such as phosphorothioate or phosphorodithioate linking groups.
- Phosphorus linking groups can therefore include without limitation, phosphodiester, phosphorothioate, phosphorodithioate, phosphonate, methylphosphonate, phosphoramidate, phosphorothioamidate, thionoalkylphosphonate, phosphotriesters, thionoalkylphosphotriester and boranophosphate.
- internucleoside phosphorus linking group means a phosphorus linking group that directly links two nucleosides.
- "oligomeric compound” means a polymeric structure comprising two or more substructures. In certain embodiments, an oligomeric compound comprises an oligonucleotide, such as a modified oligonucletide.
- an oligomeric compound further comprises one or more conjugate groups and / or terminal groups and / or ligands.
- an oligomeric compound consists of an oligonucleotide.
- an oligomeric compound comprises a backbone of one or more linked monomeric sugar moieties, where each linked monomeric sugar moiety is directly or indirectly attached to a heterocyclic base moiety.
- oligomeric compounds may also include monomeric sugar moieties that are not linked to a heterocyclic base moiety, thereby providing abasic sites.
- Oligomeric compounds may be defined in terms of a nucleobase sequence only, i.e., by specifying the sequence of A, G, C, U (or T).
- the structure of the sugar-phosphate backbone is not partictularly limited and may or may not comprise modified sugars and/or modified phosphates.
- oligomeric compounds may be more comprehensively defined, i.e, by specifying not only the nucleobase sequence, but also the structure of the backbone, in particular the modification status of the sugars (unmodified, 2'-OMe modified, 2'-F modified etc.) and/or of the phosphates.
- terminal group means one or more atom attached to either, or both, the 3 ' end or the 5' end of an oligonucleotide. In certain embodiments, a terminal group comprises one or more terminal group nucleosides.
- conjugate or “conjugate group” means an atom or group of atoms bound to an oligonucleotide or oligomeric compound. In certain embodiments, a conjugate group links a ligand to a modified oligonucleotide or oligomeric compound.
- conjugate groups can modify one or more properties of the compound to which they are attached, including, but not limited to pharmacodynamic, pharmacokinetic, binding, absorption, cellular distribution, cellular uptake, charge and / or clearance properties.
- conjugate linker or “linker” in the context of a conjugate group means a portion of a conjugate group comprising any atom or group of atoms and which covalently link an oligonucleotide to another portion of the conjugate group.
- the point of attachment on the oligomeric compound is the 3 '-oxygen atom of the 3'-hydroxyl group of the 3' terminal nucleoside of the oligonucleotide.
- the point of attachment on the oligomeric compound is the 5'-oxygen atom of the 5'-hydroxyl group of the 5' terminal nucleoside of the oligonucleotide.
- the bond for forming attachment to the oligomeric compound is a cleavable bond. In certain such embodiments, such cleavable bond constitutes all or part of a cleavable moiety.
- conjugate groups comprise a cleavable moiety (e.g., a cleavable bond or cleavable nucleoside) and ligand portion that can comprise one or more ligands, such as a carbohydrate cluster portion, such as an N-Acetyl-Galactosamine, also referred to as "GalNAc", cluster portion.
- the carbohydrate cluster portion is identified by the number and identity of the ligand.
- the carbohydrate cluster portion comprises 2 GalNAc groups.
- the carbohydrate cluster portion comprises 3 GalNAc groups and this is particularly preferred.
- the carbohydrate cluster portion comprises 4 GalNAc groups.
- Such ligand portions are attached to an oligomeric compound via a cleavable moiety, such as a cleavable bond or cleavable nucleoside.
- a cleavable moiety such as a cleavable bond or cleavable nucleoside.
- the ligands can be arranged in a linear or branched configuration, such as a biantennary or triantennary configurations.
- "cleavable moiety” means a bond or group that is capable of being cleaved under physiological conditions.
- a cleavable moiety is cleaved inside a cell or sub- cellular compartments, such as an endosome or lysosome.
- a cleavable moiety is cleaved by endogenous enzymes, such as nucleases.
- a cleavable moiety comprises a group of atoms having one, two, three, four, or more than four cleavable bonds.
- a cleavable moiety is a phosphodiester linkage.
- cleavable bond means any chemical bond capable of being broken.
- carbohydrate cluster means a compound having one or more carbohydrate residues attached to a linker group.
- modified carbohydrate means any carbohydrate having one or more chemical modifications relative to naturally occurring carbohydrates.
- carbohydrate derivative means any compound which may be synthesized using a carbohydrate as a starting material or intermediate.
- carbohydrate means a naturally occurring carbohydrate, a modified carbohydrate, or a carbohydrate derivative.
- a carbohydrate is a biomolecule including carbon (C), hydrogen (H) and oxygen (O) atoms.
- Carbohydrates can include monosaccharide, disaccharides, trisaccharides, tetrasaccharides, oligosaccharides or polysaccharides, such as one or more galactose moieties, one or more lactose moieties, one or more N-Acetyl-Galactosamine moieties, and / or one or more mannose moieties.
- a particularly preferred carbohydrate is N-Acetyl-Galactosamine moieties.
- "strand” means an oligomeric compound comprising linked nucleosides.
- the linker is not particularly limited, but includes phosphodiesters and variants thereof as disclosed herein.
- a strand may also be viewed as a plurality of linked nucleotides in which case the linker would be a covalent bond.
- the term "construct” means a region of linked nucleosides which is defined in terms of nucleobase sequence and sugar modifications. A construct may coincide with a strand or compound, but may also be part thereof.
- single strand or “single-stranded” means an oligomeric compound comprising linked nucleosides that are connected in a continuous sequence without a break therebetween. Such single strands may include regions of sufficient self-complementarity so as to be capable of forming a stable self-duplex in a hairpin structure.
- hairpin means a single stranded oligomeric compound that includes a duplex formed by base pairing between sequences in the strand that are self-complementary and opposite in directionality.
- hairpin loop means an unpaired loop of linked nucleosides in a hairpin that is created as a result of hybridization of the self-complementary sequences. The resulting structure looks like a loop or a U-shape.
- short hairpin RNA also denoted as shRNA, comprises a duplex region and a loop connecting the regions forming the duplex. The end of the duplex region which does not carry the loop may be blunt-ended or carry (a) 3' and/or (a) 5' overhang(s).
- the construct is blunt-ended.
- Such molecules are also referred to as "mxRNAs".
- mxRNA is in particular understood as defined in WO 2020/044186 A2 which is incorporated by reference herein in its entirety.
- Particularly preferred hairpin RNAs in accordance with the invention are those shown in Tables 6 and 7 and Figures 15 to 18, 20 and 22.
- "directionality" means the end-to-end chemical orientation of an oligonucleotide based on the chemical convention of numbering of carbon atoms in the sugar moiety meaning that there will be a 5′-end defined by the 5′ carbon of the sugar moiety, and a 3′-end defined by the 3' carbon of the sugar moiety.
- duplex In a duplex or double stranded oligonucleotide, the respective strands run in opposite 5' to 3' directions to permit base pairing between them.
- duplex also abbreviated as “dup”, means two or more complementary strand regions, or strands, of an oligonucleotide or oligonucleotides, hybridized together by way of non- covalent, sequence-specific interaction therebetween. Most commonly, the hybridization in the duplex will be between nucleobases adenine (A) and thymine (T), and / or (A) adenine and uracil (U), and / or guanine (G) and cytosine (C).
- A adenine
- T thymine
- U adenine and uracil
- G guanine
- C cytosine
- the duplex may be part of a single stranded structure, wherein self-complementarity leads to hybridization, or as a result of hybridization between respective strands in a double stranded molecule.
- double strand or double stranded means a pair of oligomeric compounds that are hybridized to one another.
- a double-stranded oligomeric compound comprises a first and a second oligomeric compound.
- expression means the process by which a gene ultimately results in a protein. Expression includes, but is not limited to, transcription, post-transcriptional modification (e.g., splicing, polyadenlyation, addition of 5 '-cap), and translation.
- transcription refers to the first of several steps of DNA based gene expression in which a target sequence of DNA is copied into RNA (especially mRNA) by the enzyme RNA polymerase. During transcription, a DNA sequence is read by an RNA polymerase, which produces a complementary, antiparallel RNA sequence called a primary transcript.
- target sequence means a sequence to which an oligomeric compound is intended to hybridize to result in a desired activity with respect to Factor XI expression. Oligonucleotides have sufficient complementarity to their target sequences to allow hybridization under physiological conditions.
- nucleobase complementarity or “complementarity” when in reference to nucleobases means a nucleobase that is capable of base pairing with another nucleobase.
- adenine (A) is complementary to thymine (T).
- adenine (A) is complementary to uracil (U).
- guanine (G) is complementary to cytosine (C).
- complementary nucleobase means a nucleobase of an oligomeric compound that is capable of base pairing with a nucleobase of its target sequence.
- nucleobases at a certain position of an oligomeric compound are capable of hydrogen bonding with a nucleobase at a certain position of a target sequence
- the position of hydrogen bonding between the oligomeric compound and the target sequence is considered to be complementary at that nucleobase pair.
- Nucleobases comprising certain modifications may maintain the ability to pair with a counterpart nucleobase and thus, are still capable of nucleobase complementarity.
- non-complementary in reference to nucleobases means a pair of nucleobases that do not form hydrogen bonds with one another.
- complementary in reference to oligomeric compounds (e.g., linked nucleosides, oligonucleotides) means the capacity of such oligomeric compounds or regions thereof to hybridize to a target sequence, or to a region of the oligomeric compound itself, through nucleobase complementarity.
- Complementary oligomeric compounds need not have nucleobase complementarity at each nucleoside. Rather, some mismatches are tolerated.
- complementary oligomeric compounds or regions are complementary at 70% of the nucleobases (70% complementary).
- complementary oligomeric compounds or regions are 80%> complementary.
- complementary oligomeric compounds or regions are 90%> complementary.
- complementary oligomeric compounds or regions are 95% complementary. In certain embodiments, complementary oligomeric compounds or regions are 100% complementary.
- self-complementarity in reference to oligomeric compounds means a compound that may fold back on itself, creating a duplex as a result of nucleobase hybridization of internal complementary strand regions. Depending on how close together and / or how long the strand regions are, then the compound may form hairpin loops, junctions, bulges or internal loops.
- mismatch means a nucleobase of an oligomeric compound that is not capable of pairing with a nucleobase at a corresponding position of a target sequence, or at a corresponding position of the oligomeric compound itself when the oligomeric compound hybridizes as a result of self-complementarity, when the oligomeric compound and the target sequence and / or self- complementary regions of the oligomeric compound, are aligned.
- hybridization means the pairing of complementary oligomeric compounds (e.g., an oligomeric compound and its target sequence).
- the most common mechanism of pairing involves hydrogen bonding, which may be Watson-Crick, Hoogsteen or reversed Hoogsteen hydrogen bonding, between complementary nucleobases.
- hydrogen bonding which may be Watson-Crick, Hoogsteen or reversed Hoogsteen hydrogen bonding, between complementary nucleobases.
- specifically hybridizes means the ability of an oligomeric compound to hybridize to one nucleic acid site with greater affinity than it hybridizes to another nucleic acid site.
- "fully complementary” in reference to an oligomeric compound or region thereof means that each nucleobase of the oligomeric compound or region thereof is capable of pairing with a nucleobase of a complementary nucleic acid target sequence or a self-complementary region of the oligomeric compound.
- a fully complementary oligomeric compound or region thereof comprises no mismatches or unhybridized nucleobases with respect to its target sequence or a self- complementary region of the oligomeric compound.
- percent complementarity means the percentage of nucleobases of an oligomeric compound that are complementary to an equal-length portion of a target nucleic acid. Percent complementarity is calculated by dividing the number of nucleobases of the oligomeric compound that are complementary to nucleobases at corresponding positions in the target nucleic acid by the total length of the oligomeric compound.
- percent identity means the number of nucleobases in a first nucleic acid that are the same type (independent of chemical modification) as nucleobases at corresponding positions in a second nucleic acid, divided by the total number of nucleobases in the first nucleic acid.
- modulation means a change of amount or quality of a molecule, function, or activity when compared to the amount or quality of a molecule, function, or activity prior to modulation. For example, modulation includes the change, either an increase (stimulation or induction) or a decrease (inhibition or reduction) in gene expression.
- nucleoside having a modification of a first type may be an unmodified nucleoside.
- differentiately modified mean chemical modifications or chemical substituents that are different from one another, including absence of modifications. Thus, for example, a MOE nucleoside and an unmodified naturally occurring RNA nucleoside are “differently modified,” even though the naturally occurring nucleoside is unmodified.
- DNA and RNA oligonucleotides are "differently modified," even though both are naturally-occurring unmodified nucleosides.
- Nucleosides that are the same but for comprising different nucleobases are not differently modified.
- a nucleoside comprising a 2'-OMe modified sugar moiety and an unmodified adenine nucleobase and a nucleoside comprising a 2'-OMe modified sugar moiety and an unmodified thymine nucleobase are not differently modified.
- “the same type of modifications” refers to modifications that are the same as one another, including absence of modifications.
- RNA nucleosides having the same type modification may comprise different nucleobases.
- region or regions or “portion” or “portions”, mean a plurality of linked nucleosides that have a function or character as defined herein, in particular with reference to the subject-matter and definitions described herein. Typically such regions or portions comprise at least 10, at least 11, at least 12 or at least 13 linked nucleosides. For example, such regions can comprise 13 to 20 linked nucleosides, such as 13 to 16 or 18 to 20 linked nucleosides.
- first region as defined herein consists essentially of 18 to 20 nucleosides and a second region as defined herein consists essentially of 13 to 16 linked nucleosides.
- pharmaceutically acceptable carrier or diluent means any substance suitable for use in administering to an animal.
- a pharmaceutically acceptable carrier or diluent is sterile saline.
- such sterile saline is pharmaceutical grade saline.
- substituteduent and “substituent group” means an atom or group that replaces the atom or group of a named parent compound.
- a substituent of a modified nucleoside is any atom or group that differs from the atom or group found in a naturally occurring nucleoside (e.g., a modified 2'- substituent is any atom or group at the 2 '-position of a nucleoside other than H or OH).
- Substituent groups can be protected or unprotected.
- compounds of the present disclosure have substituents at one or at more than one position of the parent compound. Substituents may also be further substituted with other substituent groups and may be attached directly or via a linking group such as oxygen or an alkyl or hydrocarbyl group to a parent compound.
- substituents can be present as the modification on the sugar moiety, in particular a substituent present at the 2'-position of the sugar moiety.
- groups amenable for use as substituents include without limitation, one or more of halo, hydroxyl, alkyl, alkenyl, alkynyl, acyl, carboxyl, alkoxy, alkoxyalkylene and amino substituents.
- substituents as described herein can represent modifications directly attached to a ring of a sugar moiety (such as a halo, such as fluoro, directly attached to a sugar ring), or a modification indirectly linked to a ring of a sugar moiety by way of an oxygen linking atom that itself is directly linked to the sugar moiety (such as an alkoxyalkylene, such as methoxyethylene, linked to an oxygen atom, overall providing an MOE substituent as described herein attached to the 2'-position of the sugar moiety).
- alkyl as used herein, means a saturated straight or branched monovalent C 1-6 hydrocarbon radical, with methyl being a most preferred alkyl as a substituent at the 2'-position of the sugar moiety.
- the alkyl group typically attaches to an oxygen linking atom at the 2' position of the sugar, therefore, overall providing an –O-alkyl substituent, such as an -OCH 3 substituent, on a sugar moiety of an oligomeric compound as described herein.
- alkylene means a saturated straight or branched divalent hydrocarbon radical of the general formula -CnH2n- where n is 1-6.
- alkenyl means a straight or branched unsaturated monovalent C 2-6 hydrocarbon radical, with ethenyl or propenyl being most preferred alkenyls as a substituent at the 2'-position of the sugar moiety.
- degree of unsaturation that is present in an alkenyl radical is the presence of at least one carbon to carbon double bond.
- alkynyl means a straight or branched unsaturated C2-6 hydrocarbon radical, with ethynyl being a most preferred alkynyl as a substituent at the 2'-position of the sugar moiety.
- the degree of unsaturation that is present in an alkynyl radical is the presence of at least one carbon to carbon triple bond.
- the alkynyl group typically attaches to an oxygen linking atom at the 2'-position of the sugar, therefore, overall providing a –Oalkynyl substituent on a sugar moiety of an oligomeric compound as described herein.
- carboxyl is a radical having a general formula –CO 2 H.
- acyl means a radical formed by removal of a hydroxyl group from a carboxyl radical as defined herein and has the general Formula -C(O)-X where X is typically C 1-6 alkyl.
- alkoxy means a radical formed between an alkyl group, such as a C 1-6 alkyl group, and an oxygen atom wherein the oxygen atom is used to attach the alkoxy group either to a parent molecule (such as at the 2'-position of a sugar moiety), or to another group such as an alkylene group as defined herein.
- alkoxy groups include without limitation, methoxy, ethoxy, propoxy, isopropoxy, n-butoxy, sec-butoxy and tert-butoxy.
- Alkoxy groups as used herein may optionally include further substituent groups.
- alkoxyalkylene means an alkoxy group as defined herein that is attached to an alkylene group also as defined herein, and wherein the oxygen atom of the alkoxy group attaches to the alkylene group and the alkylene attaches to a parent molecule.
- the alkylene group typically attaches to an oxygen linking atom at the 2'-position of the sugar, therefore, overall providing a – Oalkylenealkoxy substituent, such as an –OCH 2 CH 2 OCH 3 substituent, on a sugar moiety of an oligomeric compound as described herein.
- a – Oalkylenealkoxy substituent such as an –OCH 2 CH 2 OCH 3 substituent
- MOE substituent as defined herein and as known in the art.
- amino includes primary, secondary and tertiary amino groups.
- halo and halogen mean an atom selected from fluorine, chlorine, bromine and iodine.
- oligomeric compounds as described herein may have one or more non- hybridizing nucleosides at one or both ends of one or both strands (overhangs) and / or one or more internal non-hybridizing nucleosides (mismatches) provided there is sufficient complementarity to maintain hybridization under physiologically relevant conditions.
- oligomeric compounds as described herein may be blunt ended at at least one end.
- the term "comprising" is used herein to mean including the method steps or elements identified, but that such steps or elements do not comprise an exclusive list and as such there may be present additional steps or elements.
- each of the constructs of the invention may or may not have a phosphate modification at the 5' end group.
- each of the above constructs may or may not have a "3x GalNAc” coupled to the 3' end group.
- a construct bears a 3x GalNAc ligand, such as a "toothbrush" moiety as disclosed herein.
- Aspect 1 An oligomeric compound capable of modulating, preferably inhibiting, expression of FXI, wherein the compound comprises at least a first region of linked nucleosides having at least a first nucleobase sequence that is at least partially complementary to at least a portion of RNA transcribed from an FXI gene, wherein the first nucleobase sequence is selected from the following sequences, or a portion thereof: SEQ ID NOs 1 to 250, or SEQ ID NOs 1251 to 1500.
- An oligomeric compound according to aspect 1 which further comprises at least a second region of linked nucleosides having at least a second nucleobase sequence that is at least partially complementary to the first nucleobase sequence and is selected from the following sequences, or a portion thereof: SEQ ID NOs 251 to 500, or SEQ ID NOs 1501 to 1750.
- An oligomeric compound according to aspect 1 or 2 wherein the first nucleobase sequence is selected from the following sequences, or a portion thereof: SEQ ID NOs 8, 13, 27, 39, 46, 91, 98, 103, 105, 109, 120, 140, 146, 151, 152, 163, 182, 183, 199, 207, 210, 218, 220, 223, 224, 238, or SEQ ID NOs 1258, 1263, 1277, 1289, 1296, 1341, 1348, 1353, 1355, 1359, 1370, 1390, 1396, 1401, 1402, 1413, 1432, 1433, 1449, 1457, 1460, 1468, 1470, 1473, 1474, 1488.
- Aspect 4 Aspect 4.
- Aspect 5 An oligomeric compound according to any of aspects 1 to 4, wherein the first nucleobase sequence is selected from the following sequences, or a portion thereof: SEQ ID NOs 8, 46, 91, 146, 152, 207, or SEQ ID NOs 1258, 1296, 1341, 1396, 1402, 1457.
- Aspect 6 An oligomeric compound according to aspect 5, wherein the second nucleobase sequence is selected from the following sequences, or a portion thereof: SEQ ID NOs 258, 296, 341, 396, 402, 457, or SEQ ID NOs 1508, 1546, 1591, 1646, 1652, 1707.
- Aspect 7 An oligomeric compound according to any of aspects 1 to 4, wherein the first nucleobase sequence is selected from the following sequences, or a portion thereof: SEQ ID NOs 8, 46, 91, 146, 152, 207, or SEQ ID NOs 1258, 1296, 1341, 1396, 1402, 1457.
- Aspect 6 An
- Aspect 8 An oligomeric compound according to aspect 7, wherein the second nucleobase sequence is selected from the following sequences, or a portion thereof: SEQ ID NOs 296, 341, 402, or SEQ ID NOs 1546, 1591, 1652.
- Aspect 9 An oligomeric compound according to any of aspects 1 to 8, wherein the first nucleobase sequence is at least partially complementary to any of the following sequences, or a portion thereof: SEQ ID NOs 1001 to 1250.
- An oligomeric compound according to aspect 3 and / or 4 wherein the first nucleobase sequence is at least partially complementary to any of the following sequences, or a portion thereof: SEQ ID NOs 1008, 1013, 1027, 1039, 1046, 1091, 1098, 1103, 1105, 1109, 1120, 1140, 1146, 1151, 1152, 1163, 1182, 1183, 1199, 1207, 1210, 1218, 1220, 1223, 1224, 1238.
- Aspect 11 An oligomeric compound according to aspect 5 and / or 6, wherein the first nucleobase sequence is at least partially complementary to any of the following sequences, or a portion thereof: SEQ ID NOs 1008, 1046, 1091, 1146, 1152, 1207.
- Aspect 13 An oligomeric compound capable of modulating, preferably inhibiting, expression of FXI, which compound comprises at least a first region of linked nucleosides having at least a first nucleobase sequence that is at least partially complementary to at least a portion of RNA transcribed from an FXI gene, wherein the RNA is selected from the following sequences, or a portion thereof: SEQ ID NOs 1001 to 1250.
- RNA is selected from the following sequences, or a portion thereof: SEQ ID NOs 1008, 1013, 1027, 1039, 1046, 1091, 1098, 1103, 1105, 1109, 1120, 1140, 1146, 1151, 1152, 1163, 1182, 1183, 1199, 1207, 1210, 1218, 1220, 1223, 1224, 1238.
- Aspect 17 An oligomeric compound according to any of aspects 1 to 16, wherein the first region of linked nucleosides consists essentially of 18 to 20 linked nucleosides.
- Aspect 18 An oligomeric compound according to any of aspects 2 to 17, wherein the second region of linked nucleosides consists essentially of 11 to 16, advantageously 12 to 15 or 13 to 16 linked nucleosides.
- An oligomeric compound according to aspect 20 wherein the 5’ region of the first nucleoside region is directly or indirectly linked to the 3’ region of the second nucleoside region, for example by complementary base pairing, and / or wherein the 3’ region of the first nucleoside region is directly or indirectly linked to the 5’ region of the second nucleoside region.
- Aspect 22 An oligomeric compound according to any of aspects 1 to 21, which further comprises one or more ligands.
- An oligomeric compound according to aspect 25, wherein the one or more ligands comprise one or more carbohydrates.
- an oligomeric compound according to aspect 26 wherein the one or more carbohydrates can be a monosaccharide, disaccharide, trisaccharide, tetrasaccharide, oligosaccharide or polysaccharide.
- Aspect 28 An oligomeric compound according to aspect 27, wherein the one or more carbohydrates comprise one or more galactose moieties, one or more lactose moieties, one or more N-Acetyl-Galactosamine moieties, and / or one or more mannose moieties.
- Aspect 29 An oligomeric compound according to aspect 28, wherein the one or more carbohydrates comprise one or more N-Acetyl-Galactosamine moieties.
- Aspect 30 An oligomeric compound according to aspect 26, wherein the one or more carbohydrates can be a monosaccharide, disaccharide, trisaccharide, tetrasaccharide, oligosaccharide or polysaccharide.
- Aspect 28
- Aspect 31. An oligomeric compound according to any of aspects 22 to 30, wherein the one or more ligands are attached to the oligomeric compound, preferably to the second nucleoside region thereof, in a linear configuration, or in a branched configuration. Preferred is that the ligand has the following structure, also referred to as "toothbrush” herein: A particularly preferred embodiment of "GalNAc" (as used herein) is the above structure.
- Aspect 33. An oligomeric compound according to aspect 19, wherein the oligomeric compound comprises a single strand comprising the first and second nucleoside regions, wherein the single strand dimerises whereby at least a portion of the first nucleoside region is directly or indirectly linked to at least a portion of the second nucleoside region so as to form the at least partially complementary duplex region.
- An oligomeric compound according to aspect 33 wherein the first nucleoside region has a greater number of linked nucleosides compared to the second nucleoside region, whereby the additional number of linked nucleosides of the first nucleoside region form a hairpin loop linking the first and second nucleoside regions.
- Aspect 35 An oligomeric compound according to aspect 34, as dependent on aspect 20, whereby the hairpin loop is present at the 3' region of the first nucleoside region.
- Aspect 36 An oligomeric compound according to aspect 34 or 35, wherein the hairpin loop comprises 4 or 5 linked nucleosides.
- Aspect 40 An oligomeric compound according to aspect 39, which comprises 7, 8, 9 or 10 phosphorothioate or phosphorodithioate internucleoside linkages.
- Aspect 41 An oligomeric compound according to any of aspects 38 to 40, as dependent on aspect 20, which comprises one or more phosphorothioate or phosphorodithioate internucleoside linkages at the 5’ region of the first nucleoside region.
- Aspect 42 An oligomeric compound according to any of aspects 38 to 41, as dependent on aspect 20, which comprises one or more phosphorothioate or phosphorodithioate internucleoside linkages at the 5’ region of the second nucleoside region.
- Aspect 43 An oligomeric compound according to any of aspects 38 to 40, as dependent on aspect 20, which comprises one or more phosphorothioate or phosphorodithioate internucleoside linkages at the 5’ region of the second nucleoside region.
- An oligomeric compound according to aspect 43 which comprises a phosphorothioate or phosphorodithioate internucleoside linkage between each adjacent nucleoside that is present in the hairpin loop.
- Aspect 45 An oligomeric compound according to any of aspects 1 to 44, wherein at least one nucleoside comprises a modified sugar.
- modified sugar is selected from 2' modified sugars; conformationally restricted nucleotides (CRN) sugar such as locked nucleic acid (LNA), (S)-constrained ethyl bicyclic nucleic acid, and constrained ethyl (cEt), tricyclo- DNA; morpholino, unlocked nucleic acid (UNA), glycol nucleic acid (GNA), D-hexitol nucleic acid (HNA), and cyclohexene nucleic acid (CeNA), and preferably is a 2'-O-methyl modified sugar.
- CRN conformationally restricted nucleotides
- LNA locked nucleic acid
- S locked nucleic acid
- cEt constrained ethyl
- tricyclo- DNA tricyclo- DNA
- morpholino unlocked nucleic acid
- GNA glycol nucleic acid
- HNA D-hexitol nucleic acid
- CeNA cyclohexene nucleic acid
- 2' modified sugars include 2'-O-alkyl modified sugar, 2'-O-methoxyethyl modified sugar, 2'-O- allyl modified sugar, 2'-C-allyl modified sugar, 2'-deoxy modified sugar such as 2'-deoxy ribose, 2'-F modified sugar, 2'-arabino-fluoro modified sugar, 2'-O-benzyl modified sugar, 2'-amino modified sugar, and 2'-O-methyl-4-pyridine modified sugar.
- Aspect 47 An oligomeric compound according to aspect 45 or 46, wherein the modified sugar is a 2'-F modified sugar.
- Aspect 50 Aspect 50.
- An oligomeric compound according to aspect 48 or 49 wherein sugars of the nucleosides at any of positions 2 and 14 downstream from the first nucleoside of the 5’ region of the first nucleoside region, contain 2'-F modifications.
- Aspect 51 An oligomeric compound according to any of aspects 48 to 50, wherein sugars of the nucleosides of the second nucleoside region, that correspond in position to any of the nucleosides of the first nucleoside region at any of positions 9 to 11 downstream from the first nucleoside of the 5’ region of the first nucleoside region, contain 2'-F modifications.
- An oligomeric compound according to aspect 52 wherein one or more of the odd numbered nucleosides starting from the 3’ region of the second nucleoside region are modified by a modification that is different from the modification of odd numbered nucleosides of the first nucleoside region.
- Aspect 54 An oligomeric compound according to aspect 52 or 53, wherein one or more of the even numbered nucleosides starting from the 3’ region of the second nucleoside region are modified by a modification that is different from the modification of even numbered nucleosides of the first nucleoside region according to aspect 53.
- Aspect 55 is provided.
- An oligomeric compound according to any of aspects 52 to 54 wherein at least one or more of the modified even numbered nucleosides of the first nucleoside region is adjacent to at least one or more of the differently modified odd numbered nucleosides of the first nucleoside region.
- Aspect 56 An oligomeric compound according to any of aspects 52 to 55, wherein at least one or more of the modified even numbered nucleosides of the second nucleoside region is adjacent to at least one or more of the differently modified odd numbered nucleosides of the second nucleoside region.
- An oligomeric compound according to any of aspects 52 to 56 wherein sugars of one or more of the odd numbered nucleosides starting from the 5’ region of the first nucleoside region are 2'-O-methyl modified sugars.
- Aspect 58 An oligomeric compound according to any of aspects 52 to 57, wherein one or more of the even numbered nucleosides starting from the 5’ region of the first nucleoside region are 2'-F modified sugars.
- An oligomeric compound according to any of aspects 52 to 58 wherein sugars of one or more of the odd numbered nucleosides starting from the 3’ region of the second nucleoside region are 2'-F modified sugars.
- Aspect 60 An oligomeric compound according to any of aspects 52 to 56, wherein sugars of one or more of the odd numbered nucleosides starting from the 5’ region of the first nucleoside region are 2'-O-methyl modified sugars.
- Aspect 61. An oligomeric compound according to any of aspects 45 to 60, wherein sugars of a plurality of adjacent nucleosides of the first nucleoside region are modified by a common modification.
- An oligomeric compound according to aspect 65 wherein the plurality of adjacent 2'- O-methyl modified sugars are present in three or four adjacent nucleosides of the hairpin loop.
- Aspect 68. An oligomeric compound according to aspect 45, as dependent on aspect 34, wherein the hairpin loop comprises at least one nucleoside having a modified sugar.
- Aspect 69. An oligomeric compound according to aspect 68, wherein the at least one nucleoside is adjacent a nucleoside with a differently modified sugar.
- Aspect 70 An oligomeric compound according to aspect 69, wherein the modified sugar is a 2'- O-methyl modified sugar, and the differently modifies sugar is a 2'-F modified sugar.
- An oligomeric compound according to any of aspects 1 to 70 which comprises one or more nucleosides having an un-modified sugar moiety.
- Aspect 72 An oligomeric compound according to aspect 71, wherein the unmodified sugar is present in the 5' region of the second nucleoside region.
- Aspect 73 An oligomeric compound according to aspect 71 or 72, as dependent on aspect 34, wherein the unmodified sugar is present in the hairpin loop.
- An oligomeric compound according to any of aspects 1 to 73 wherein one or more nucleosides of the first nucleoside region and / or the second nucleoside region is an inverted nucleoside and is attached to an adjacent nucleoside via the 3' carbon of its sugar and the 3' carbon of the sugar of the adjacent nucleoside, and / or one or more nucleosides of the first nucleoside region and / or the second nucleoside region is an inverted nucleoside and is attached to an adjacent nucleoside via the 5' carbon of its sugar and the 5' carbon of the sugar of the adjacent nucleoside.
- Aspect 75 An oligomeric compound according to any of aspects 1 to 74, which is blunt ended.
- Aspect 77. An oligomeric compound capable of modulating, preferably inhibiting, expression of FXI, wherein the compound comprises at least a first region of linked nucleosides having at least a first nucleobase sequence that is at least partially complementary to at least a portion of RNA transcribed from an FXI gene, wherein the first nucleobase sequence is a modified sequence and is selected from the following sequences, or a portion thereof: construct NOs 501 to 750, or construct NOs 1751 to 2000.
- An oligomeric compound according to aspect 77 which further comprises at least a second region of linked nucleosides having at least a second nucleobase sequence that is at least partially complementary to the first nucleobase sequence, wherein the second nucleobase sequence is a modified sequence and is selected from the following sequences, or a portion thereof: construct NOs 751 to 1000, or construct NOs 2001 to 2250.
- an oligomeric compound according to aspect 77 or 78 wherein the first nucleobase sequence is selected from the following sequences, or a portion thereof: construct NOs 508, 513, 527, 539, 546, 591, 598, 603, 605, 609, 620, 640, 646, 651, 652, 663, 682, 683, 699, 707, 710, 718, 720, 723, 724, 738, or construct NOs 1758, 1763,1777, 1789, 1796, 1841, 1848, 1853, 1855, 1859, 1870, 1890, 1896, 1901, 1902, 1913, 1932, 1933, 1949, 1957, 1960, 1968, 1970, 1973, 1974, 1988.
- Aspect 80 Aspect 80.
- an oligomeric compound according to aspect 79 wherein the second nucleobase sequence is selected from the following sequences, or a portion thereof: construct NOs 758, 763, 777, 789, 796, 841, 848, 853, 855, 859, 870, 890, 896, 901, 902, 913, 932, 933, 949, 957, 960, 968, 970, 973, 974, 988, or construct NOs 2008, 2013, 2027, 2039, 2046, 2091, 2098, 2103, 2105, 2109, 2120, 2140, 2146, 2151, 2152, 2163, 2182, 2183, 2199, 2207, 2210, 2218, 2220, 2223, 2224, 2238.
- Aspect 81 An oligomeric compound according to any of aspects 77 to 80, wherein the first nucleobase sequence is selected from the following sequences, or a portion thereof: construct NOs 508, 546, 591, 646, 652, 707, or construct NOs 1758, 1796, 1841, 1896, 1902, 1957.
- Aspect 82 An oligomeric compound according to aspect 81, wherein the second nucleobase sequence is selected from the following sequences, or a portion thereof: construct NOs 758, 796, 841, 896, 902, 957, or construct NOs 2008, 2046, 2091, 2146, 2152, 2207.
- Aspect 83 An oligomeric compound according to any of aspects 77 to 80, wherein the first nucleobase sequence is selected from the following sequences, or a portion thereof: construct NOs 508, 546, 591, 646, 652, 707, or construct NOs 1758, 1796, 1841, 1896, 1902, 1957.
- Aspect 82 An
- An oligomeric compound capable of modulating, preferably inhibiting, expression of FXI which is selected from the following sequences: SEQ ID NOs 2251 to 2253, or SEQ ID NOs 2284 to 2288, preferably SEQ ID NO: 2287.
- An oligomeric compound capable of modulating, preferably inhibiting, expression of FXI which is selected from the following sequences: construct NOs 2254 to 2283.
- An oligomeric compound according to aspect 88 wherein the one or more ligands are conjugated at the 3 ' region of the sequences, preferably at the 3' terminal nucleoside.
- Aspect 90 An oligomeric compound according to aspect 88, wherein the one or more ligands are conjugated at non-terminal positions.
- Aspect 91 An oligomeric compound according to any of aspects 88 to 90, wherein the one or more ligands are any cell directing moiety, such as lipids, carbohydrates, aptamers, vitamins and / or peptides that bind cellular membrane or a specific target on cellular surface.
- Aspect 92 Aspect 92.
- Aspect 95 An oligomeric compound according to aspect 94, wherein the one or more carbohydrates comprise one or more N-Acetyl-Galactosamine moieties.
- Aspect 96 An oligomeric compound according to aspect 95, which comprises two or three N-Acetyl- Galactosamine moieties, preferably three.
- Aspect 97 An oligomeric compound according to any of aspects 88 to 96, wherein the one or more ligands are attached to the oligomeric compound in a linear configuration, or in a branched configuration.
- Aspect 98 An oligomeric compound according to any of aspects 88 to 96, wherein the one or more ligands are attached to the oligomeric compound in a linear configuration, or in a branched configuration.
- An oligomeric compound according to aspect 97 wherein the one or more ligands are attached to the oligomeric compound as a biantennary or triantennary configuration.
- Aspect 99 An oligomeric compound according to any of aspects 86 to aspect 98, wherein the sequences self dimerise so as to form an at least partially complementary duplex region.
- Aspect 100 An oligomeric compound according to aspect 99, having a nucleobase sequence and structure as shown in any of Figures 15 to 17 or 18 to 20, construct NOs: 2290 to 2292 being preferred, construct NO: 2290 being particularly preferred.
- Aspect 101 A composition comprising an oligomeric compound according to any of aspects 1 to 100, and a physiologically acceptable excipient.
- Aspect 102 A composition comprising an oligomeric compound according to any of aspects 1 to 100, and a physiologically acceptable excipient.
- An oligomeric compound according to any of aspects 1 to 100 for use in therapy.
- Aspect 103 An oligomeric compound according to any of aspects 1 to 100, for use in the treatment of a disease or disorder.
- Aspect 104. A method of treating a disease or disorder comprising administration of an oligomeric compound according to any of aspects 1 to 100, to an individual in need of treatment.
- Aspect 105. A method according to aspect 104, wherein the oligomeric compound is administered subcutaneously or intravenously to the individual.
- thromboembolic disease is selected from the group consisting of deep vein thrombosis, venous or arterial thrombosis, pulmonary embolism, myocardial infarction, stroke, thrombosis associated with chronic kidney disease or end- stage renal disease (ESRD), including thrombosis associated with dialysis, or other procoagulant condition.
- ESRD end-stage renal disease
- Aspect 109 Use or method according to aspect 108, wherein the thromboembolic disease is deep vein thrombosis, pulmonary embolism, or a combination thereof.
- Aspect 110 is a combination thereof.
- oligomeric compound according to any of items 1 to 100 in the manufacture of a medicament for a treatment of a disease or disorder.
- the diseases and disorders are advantageously the same as set forth herein above.
- the molecules disclosed herein, including, but not limited to, the hairpin RNAs as shown in Tables 6 and 7 and Figures 15 to 18, 20 and 22 are characterized by surprisingly outstanding performance, including in an in vivo setting; see, for example, the evidence shown in Figures 24 and 25. These data show a long-lasting down-regulation of Factor XI in response to administration of constructs as described herein. Further evidence of surprising performance of a plurality of constructs can be seen in the in vitro data provided in the Examples, including the data shown in Figure 19.
- the syntheses of the RNAi constructs disclosed herein may be carried out using synthesis methods known to the person skilled in the art, such as synthesis methods disclosed in https://en.wikipedia.org/wiki/Oligonucleotide_synthesis ⁇ retrieved on 16 February 2022 ⁇ , wherein the methods disclosed on this website are incorporated by reference herein in their entirety .
- Table 1a A represents adenine; U represents uracil; C represents cytosine; G represents guanine.
- Table 1b Summary sequence table for active nucleobase sequences with chemical modifications:
- Table 1b A represents adenine; U represents uracil; C represents cytosine; G represents guanine; P represents a terminal phosphate group; m represents a methyl modification at the 2' position of the sugar of the underlying nucleoside; f represents a fluoro modification at the 2' position of the sugar of the underlying nucleoside.
- Table 1c Summary sequence table for the nucleobases of the target gene: In above Table 1c: A represents adenine; U represents uracil; C represents cytosine; G represents guanine.
- the scope of the present embodiments extends to sequences that correspond to those in Table 1a or Table 1b, and wherein the 5' nucleoside of the antisense (guide) strand (first region as defined herein) can include any nucleobase that can be present in an RNA molecule, in other words can be any of adenine (A), uracil (U), guanine or cytosine (C).
- A adenine
- U uracil
- C cytosine
- the scope of the present embodiments extends to sequences that correspond to those in Table 1a or Table 1b, and wherein the 3' nucleoside of the sense (passenger) strand (second region as defined herein) can include any nucleobase that can be present in an RNA molecule, in other words can be any of adenine (A), uracil (U), guanine or cytosine (C), preferably however a nucleobase that is complementary to the 5' nucleobase of the antisense (guide) strand (first region as defined herein).
- A adenine
- U uracil
- C cytosine
- N and N' respectively represent any RNA nucleobase that can be present in the 5' terminal position of the antisense (guide) strand (first region as defined herein) and in the 3' terminal position of the sense (passenger) strand (second region as defined herein).
- Table 1d Summary sequence table for active nucleobase sequences:
- Table 1e Summary sequence table for active nucleobase sequences with chemical modifications:
- Example 2 Oligonucleotides as set out in Tables 1a / 1b above that target FXI mRNA in human hepatoma cells were screened as follows.
- Example 3 Dose response curves for the 26 FXI lead compounds as identified in Example 2 are shown in Figure 13. Dose response curves for the 5 FXI lead compounds are shown in Figure 14.
- Example 4 IC50 values are shown for the 26 FXI lead compounds as identified in Example 2 in following Table 4. Table 4:
- Example 5 Species cross-reactivity of the 26 FXI lead compounds as identified in Example 2 are shown in following Table 5. Table 5:
- Example 6 Further to the data as provided in Examples 3 to 5, oligonucleotides F11-46 / SEQ ID NO: 46, F11-91 / SEQ ID NO: 91 and F11-152 / SEQ ID NO: 152 have been identified as particularly preferred antisense oligonucleotide sequences to be used in oligomeric compounds as described herein. On this basis, these sequences have been incorporated into overall oligomeric compounds as described herein of the following sequences SEQ ID NOs 2251 to 2253 as set out in following Table 6. Furthermore, selected modifications have been applied to SEQ ID NOs 2251 to 2253 as shown in SEQ ID NOs 2254 to 2286 in following Table 6. All sequences as provided below in Table 6 are set out in the 5' to 3' directionality. Table 6:
- a ligand such as a galnac ligand, is preferably attached at the 3' end of the sequence.
- Galnac can represent any arrangement of Galnac attachment, preferably however a triantennary galnac attachment:
- the ligand, preferably Galnac, attachment can be to an internal non-terminal nucleoside, such as attachment to the nucleosides in the above sequences where the nucleobase is not shown as modified.
- Example 7 This Example describes a structure-function relationship study of constructs comprising the nucleobase sequence of SEQ ID NO: 91.
- Figure 18 shows the constructs comprising the nucleobase sequence of SEQ ID NO: 91 which have been tested. Tests have been performed in primary hepatocytes.
- Human plateable 5 donor hepatocytes (Sekisui XenoTech, HPCH05+) are thawed in 45 mL of Human OptiThaw Hepatocyte media (Sekisui Xenotech, K8000), spun down at 200g for 5 minutes, and resuspended in 2x WEM complete (5% FBS, 2uM Dexamethasone, Pen/Strep, 8 ug/mL human insulin, 4 mM GlutaMAX, 30 mM HEPES pH 7.4).
- 2x WEM complete consists of WEM (Gibco, A1217601) and 2x the Hepatocyte Plating Supplement Pack (Gibco, CM3000) with only 1x FBS.
- the hepatocytes are then plated on 6 well Collagen 1 coated plates (Gibco, A1142803) at 25,000 cell/well at 50 uL per well and allowed to recover and adhere for 4 hours at 37C. After 4 hours, GalNac conjugated complexes are diluted to 2 uM in basal WEM and used to make a 2x, 7 step, 5 fold dilution series. 50 uL of each dilution is added to corresponding wells of the plated hepatocytes to make a final dilution series of 1 - 0.000064 uM in 1x WEM complete.
- Example 19 The cells are allowed to culture for 72 hours at 37 degrees without disruption before harvest and RNA isolation using the PureLink Pro 96 total RNA Purification Kit (Invitrogen, 12173011A) according to the manufacturer's protocol. Results are shown in Figure 19. Based on these results, 7 molecules have been designed which are to be subjected to further analysis (see following Examples). These molecules are shown in Figure 20. Performance data in primary hepatocytes are shown in Figure 21. Based on these data, three molecules have been tested in humanized mice; see Example 8 below. Example 8: This Examples describes testing of the three molecules identified in Example 7 in humanized mice. Table 7 below shows nucleobase sequences (SEQ ID NOs) and full modification information (construct NOs) of these three molecules.
- Figure 22 also shows the structures of these molecules.
- Figure 23 shows performance of these molecules 5 days after administration.
- Example 9 This Example describes a Pharmacodynamics Study of construct designated "91-Conv-31" (structure displayed in Figure 22) Following Single/Repeat Subcutaneous Injection to Cynomolgus Monkeys. Material and Methods For an overview of the study protocol, see Figure 24. A more detailed account is given below. STUDY PROTOCOL Table 8. Study Design
- Test Article and Vehicle Information 2.1 Test Article Compounds as specified further above. Desiccate at room temperature, protected from light Storage Conditions: Handling Standard laboratory precautions as defined in WuXi SOPs Instructions: Doses will be prepared according to instructions provided by the Dose Preparation: sponsor. A copy of the instructions, as well as details of preparation, will be maintained in the study records. Dose Solution Analysis Samples: Disposition of Remaining Remaining formulations will be stored at 4°C. Test Article Formulations: Disposition of
- Remaining Remaining test article will be shipped back to sponsor or discarded
- Test Article dry 6 months after the final report is signed or at approval of Sponsor, powder or solid: Test System Identification
- the number of animals in each group is the minimum
- the room(s) will be controlled and monitored for relative humidity (targeted mean range 40% to 70%, and any excursion from this range for more than 3 hours will be documented as a deviation) and temperature (targeted mean range 18°C to 26°C, and any excursion from this range will be documented as a deviation) with 10 to 20 air changes/hour.
- the room will be on a 12-hour light/dark cycle except when interruptions are necessitated by study activities.
- Animals will be pair-housed in cages that are in accordance with applicable animal welfare laws and regulations during acclimation period. The monkeys will be housed individually in cages during experiment. Diet and Feeding
- RO Reverse osmosis
- Dose Administration The dose formulations will be administered per facility SOPs.
- SC ADMINISTRATION SC injection site will be along the dorsal area of the animals’ thoracic regions. For multiple or large doses, different sites will be used. When the injection site is altered, the location must be documented in the record.
- 4.1 Observations and Examinations 4.1.1 Clinical Observations Twice daily (approximately 9:30 a.m. and 4:00 p.m.), cage-side observations for general health and appearance will be conducted. Animals will be given physical examinations prior to study initiation to confirm animals’ health. On dosing days, the animals will be observed at 2, 4 and 6- hours post-dosing.
- a blood smear will be prepared from each hematology sample. Blood smears will be labeled, stained, and stored. Blood smears may be read to investigate results of the hematology analyses. If additional examination of blood smears is deemed necessary, the smears may be subsequently evaluated and this evaluation will be described in a study plan amendment.
- Blood All blood samples will be collected from a peripheral vessel from restrained, non-sedated animals.
- Protocol and SOP deviations that could impact data interpretation will be included in the final report. 6 Archiving of Materials Test article preparation, test article tracking, in-life data, protocol, protocol amendments (if applicable), and the original final report generated as a result of this study will be archived. 7 STATISTICAL ANALYSIS The following section does not apply to data recorded on unscheduled occasions. Such data will be reported on an individual basis. All numerical data will be subjected to calculation of group means and standard deviations by using Microsoft Excel software, unless otherwise stated hereafter. These descriptive statistics will be presented for each dataset of interest, as determined by the variable to be analyzed and the dataset classification variables (for example: sex, measurement occasion, and any other relevant variable that can be used to specify on which subdivision the descriptive statistics have to be reported).
- Dunnett’s test When significant differences among the means are indicated by ANOVA test (p ⁇ 0.05), Dunnett’s test will be used to perform the group mean comparisons between the control group and each treated group. If Levene’s test indicates heterogeneous group variances (p ⁇ 0.05) and the data set contains just positive values, log transformation will be performed. If transformed data still fail the test for homogeneity of variance (p ⁇ 0.05) or where the data contain zero and/or negative values, then the non-parametric Kruskal-Wallis test will be used to compare all considered groups. When Kruskal-Wallis test is significant (p ⁇ 0.05), Dunnett’ s test on ranks will be used to perform the pairwise group comparisons of interest.
- Levene’s test will be performed as described above but a two-sample t-test will replace the one-way ANOVA, a Wilcoxon rank-sum test will be performed instead of the Kruskal-Wallis and, no Dunnett’s tests or Dunnett’s tests on ranks will be performed.
- Figure 25 shows performance of construct designated "91-Conv-31" (structure displayed in Figure 22) in an in vivo study in terms of Factor XI activity knock-down. The effect of different dosages (expressed in mg/kg) and of single or multiple dosing at the beginning are shown and compared to a negative control (saline).
- Figure 26 shows the molecular mechanism underlying the tests for targeting specificity as performed in the course of an in vivo study.
- APTT activated partial thromboplastin time. It measures the activity of intrinsic pathway of clotting that is impacted by factors like FXI.
- PT stands for prothrombin time which evaluates the integrity of extrinsic pathway of clotting that looks at the presence of factors like VII, V, X, prothrombin and fibrinogen.
- Figure 27 shows the read-out of the tests illustrated in Figure 26.
- Figure 28 presents data demonstrating a lack of side effects.
- a panel liver function and hematology parameters have been assessed. In particular, no elevated levels of liver enzymes and no changes in hematology parameters could be found.
Landscapes
- Health & Medical Sciences (AREA)
- Life Sciences & Earth Sciences (AREA)
- Engineering & Computer Science (AREA)
- Chemical & Material Sciences (AREA)
- Genetics & Genomics (AREA)
- Organic Chemistry (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Biomedical Technology (AREA)
- Zoology (AREA)
- General Health & Medical Sciences (AREA)
- Wood Science & Technology (AREA)
- Molecular Biology (AREA)
- General Engineering & Computer Science (AREA)
- Medicinal Chemistry (AREA)
- Biotechnology (AREA)
- Biochemistry (AREA)
- Animal Behavior & Ethology (AREA)
- Microbiology (AREA)
- Veterinary Medicine (AREA)
- Hematology (AREA)
- Public Health (AREA)
- Pharmacology & Pharmacy (AREA)
- Biophysics (AREA)
- Gastroenterology & Hepatology (AREA)
- Proteomics, Peptides & Aminoacids (AREA)
- General Chemical & Material Sciences (AREA)
- Physics & Mathematics (AREA)
- Diabetes (AREA)
- Chemical Kinetics & Catalysis (AREA)
- Plant Pathology (AREA)
- Nuclear Medicine, Radiotherapy & Molecular Imaging (AREA)
- Epidemiology (AREA)
- Immunology (AREA)
- Pharmaceuticals Containing Other Organic And Inorganic Compounds (AREA)
- Saccharide Compounds (AREA)
- Medicinal Preparation (AREA)
- Medicines That Contain Protein Lipid Enzymes And Other Medicines (AREA)
- Compositions Of Macromolecular Compounds (AREA)
Abstract
Description

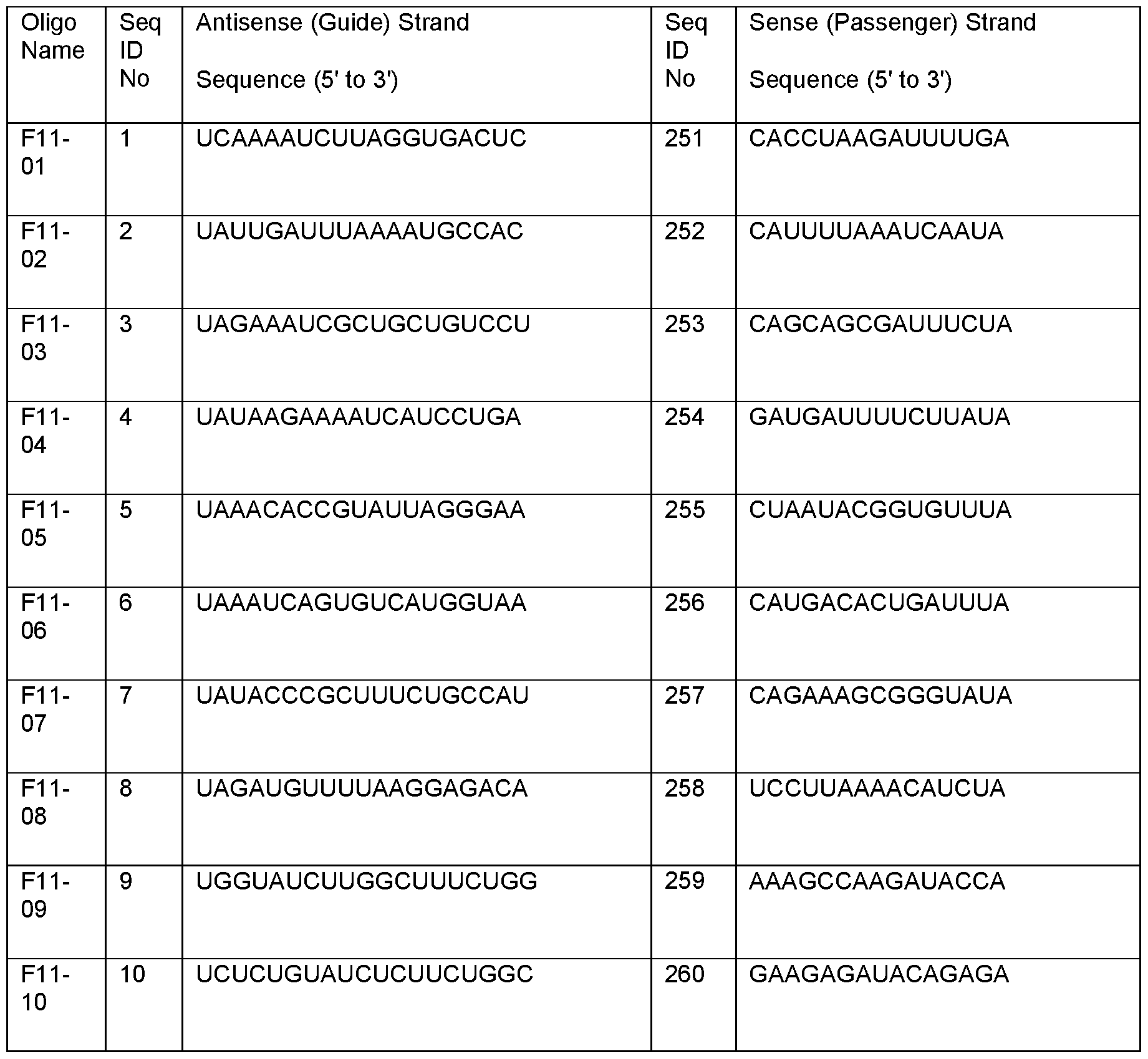
























































































Claims
Priority Applications (7)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| IL307655A IL307655A (en) | 2021-04-13 | 2022-04-13 | Factor XI suppressors, preparations containing them and their uses |
| CA3215347A CA3215347A1 (en) | 2021-04-13 | 2022-04-13 | Products and compositions |
| BR112023021231A BR112023021231A2 (en) | 2021-04-13 | 2022-04-13 | PRODUCTS AND COMPOSITIONS |
| EP22788875.7A EP4323523A4 (en) | 2021-04-13 | 2022-04-13 | Products and compositions |
| AU2022258464A AU2022258464A1 (en) | 2021-04-13 | 2022-04-13 | Products and compositions |
| CN202280040778.8A CN117500926A (en) | 2021-04-13 | 2022-04-13 | products and compositions |
| JP2023562925A JP2024514887A (en) | 2021-04-13 | 2022-04-13 | Products and Compositions |
Applications Claiming Priority (4)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US202163174533P | 2021-04-13 | 2021-04-13 | |
| US63/174,533 | 2021-04-13 | ||
| US202163253040P | 2021-10-06 | 2021-10-06 | |
| US63/253,040 | 2021-10-06 |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| WO2022221441A2 true WO2022221441A2 (en) | 2022-10-20 |
| WO2022221441A3 WO2022221441A3 (en) | 2022-11-24 |
Family
ID=83639715
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/US2022/024672 Ceased WO2022221441A2 (en) | 2021-04-13 | 2022-04-13 | Products and compositions |
Country Status (8)
| Country | Link |
|---|---|
| US (1) | US12378552B2 (en) |
| EP (1) | EP4323523A4 (en) |
| JP (1) | JP2024514887A (en) |
| AU (1) | AU2022258464A1 (en) |
| BR (1) | BR112023021231A2 (en) |
| CA (1) | CA3215347A1 (en) |
| IL (1) | IL307655A (en) |
| WO (1) | WO2022221441A2 (en) |
Cited By (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2024140986A1 (en) * | 2022-12-30 | 2024-07-04 | 北京福元医药股份有限公司 | Double-stranded ribonucleic acid, double-stranded ribonucleic acid modifier, and double-stranded ribonucleic acid conjugate and use thereof in inhibiting expression of blood coagulation factor xi gene |
| WO2024240058A1 (en) * | 2023-05-19 | 2024-11-28 | Shanghai Argo Biopharmaceutical Co., Ltd. | Compositions and methods for inhibiting expression of coagulation factor xi (fxi) |
| WO2025252255A1 (en) * | 2024-06-06 | 2025-12-11 | 北京福元医药股份有限公司 | Sirna for inhibiting fxi gene expression, and conjugate, pharmaceutical composition and use thereof |
Families Citing this family (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN121729496A (en) * | 2023-08-31 | 2026-03-24 | 正大天晴药业集团股份有限公司 | Double-stranded RNA targeting coagulation factor XI |
| WO2026002238A1 (en) * | 2024-06-28 | 2026-01-02 | 成都新泽利医药科技有限公司 | Sirna capable of inhibiting expression of coagulation factor xi and use thereof |
Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2010045509A2 (en) | 2008-10-15 | 2010-04-22 | Isis Pharmaceuticals, Inc. | Modulation of factor 11 expression |
| WO2019217527A1 (en) | 2018-05-09 | 2019-11-14 | Ionis Pharmaceuticals, Inc. | Compounds and methods for reducing fxi expression |
| EP3974532A1 (en) | 2019-05-22 | 2022-03-30 | Suzhou Ribo Life Science Co., Ltd. | Nucleic acid, pharmaceutical composition, conjugate, preparation method, and use |
Family Cites Families (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US9181551B2 (en) * | 2002-02-20 | 2015-11-10 | Sirna Therapeutics, Inc. | RNA interference mediated inhibition of gene expression using chemically modified short interfering nucleic acid (siNA) |
| US9150606B2 (en) * | 2002-11-05 | 2015-10-06 | Isis Pharmaceuticals, Inc. | Compositions comprising alternating 2'-modified nucleosides for use in gene modulation |
| MX2011010930A (en) * | 2009-04-15 | 2012-04-30 | Isis Pharmaceuticals Inc | Modulation of inflammatory responses by factor xi. |
| WO2022028457A1 (en) * | 2020-08-04 | 2022-02-10 | 上海拓界生物医药科技有限公司 | Sirna for inhibiting expression of blood coagulation factor xi, and composition and medical use thereof |
-
2022
- 2022-04-13 JP JP2023562925A patent/JP2024514887A/en active Pending
- 2022-04-13 US US17/720,129 patent/US12378552B2/en active Active
- 2022-04-13 AU AU2022258464A patent/AU2022258464A1/en not_active Abandoned
- 2022-04-13 IL IL307655A patent/IL307655A/en unknown
- 2022-04-13 BR BR112023021231A patent/BR112023021231A2/en not_active Application Discontinuation
- 2022-04-13 EP EP22788875.7A patent/EP4323523A4/en active Pending
- 2022-04-13 WO PCT/US2022/024672 patent/WO2022221441A2/en not_active Ceased
- 2022-04-13 CA CA3215347A patent/CA3215347A1/en active Pending
Patent Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2010045509A2 (en) | 2008-10-15 | 2010-04-22 | Isis Pharmaceuticals, Inc. | Modulation of factor 11 expression |
| WO2019217527A1 (en) | 2018-05-09 | 2019-11-14 | Ionis Pharmaceuticals, Inc. | Compounds and methods for reducing fxi expression |
| EP3974532A1 (en) | 2019-05-22 | 2022-03-30 | Suzhou Ribo Life Science Co., Ltd. | Nucleic acid, pharmaceutical composition, conjugate, preparation method, and use |
Non-Patent Citations (1)
| Title |
|---|
| See also references of EP4323523A4 |
Cited By (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2024140986A1 (en) * | 2022-12-30 | 2024-07-04 | 北京福元医药股份有限公司 | Double-stranded ribonucleic acid, double-stranded ribonucleic acid modifier, and double-stranded ribonucleic acid conjugate and use thereof in inhibiting expression of blood coagulation factor xi gene |
| WO2024240058A1 (en) * | 2023-05-19 | 2024-11-28 | Shanghai Argo Biopharmaceutical Co., Ltd. | Compositions and methods for inhibiting expression of coagulation factor xi (fxi) |
| WO2025252255A1 (en) * | 2024-06-06 | 2025-12-11 | 北京福元医药股份有限公司 | Sirna for inhibiting fxi gene expression, and conjugate, pharmaceutical composition and use thereof |
Also Published As
| Publication number | Publication date |
|---|---|
| WO2022221441A3 (en) | 2022-11-24 |
| US12378552B2 (en) | 2025-08-05 |
| EP4323523A4 (en) | 2025-06-11 |
| AU2022258464A1 (en) | 2023-10-26 |
| IL307655A (en) | 2023-12-01 |
| EP4323523A2 (en) | 2024-02-21 |
| BR112023021231A2 (en) | 2024-01-09 |
| US20220364087A1 (en) | 2022-11-17 |
| JP2024514887A (en) | 2024-04-03 |
| CA3215347A1 (en) | 2022-10-20 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| WO2022221441A2 (en) | Products and compositions | |
| AU2009200036B2 (en) | Modulators of pharmacological agents | |
| AU2001296305B2 (en) | RNA aptamers and methods for identifying the same | |
| JP4718541B2 (en) | Improved coagulation factor regulator | |
| KR20230046319A (en) | RNAi constructs and methods for inhibiting MARC1 expression | |
| CN114703184A (en) | LPA inhibitor and use thereof | |
| AU2002312059A1 (en) | Modulators of pharmacological agents | |
| US12600967B2 (en) | SiRNA compound that inhibits complement factor B (CFB) | |
| JP2022513111A (en) | Novel RNA Compositions and Methods for Inhibiting ANGPTL8 | |
| JP2026510791A (en) | Compositions and methods for inhibiting the expression of the inhibin subunit beta E (INHBE) gene | |
| CN111212909A (en) | RNAi agents and compositions for inhibiting expression of asialoglycoprotein receptor 1 | |
| TW202345869A (en) | Rnai constructs for inhibiting pnpla3 expression and methods of use thereof | |
| CN117500926A (en) | products and compositions | |
| WO2022266486A2 (en) | Products and compositions | |
| TW202500168A (en) | Nucleic acid targeting angiotensinogen and its use | |
| AU2012244176B2 (en) | Modulators of pharmacological agents | |
| WO2024216267A2 (en) | Products and compositions | |
| WO2025201156A1 (en) | Nucleic acid targeting coagulation factor xi and use thereof | |
| WO2026092650A1 (en) | Rnai preparation for inhibiting lpa gene expression and use thereof | |
| CN121511305A (en) | An RNAi agent that inhibits PCSK9 gene expression and its application | |
| KR20250119645A (en) | RNAI constructs for suppressing TTR expression and methods of using the same |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 22788875 Country of ref document: EP Kind code of ref document: A2 |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 307655 Country of ref document: IL |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 3215347 Country of ref document: CA Ref document number: 2022258464 Country of ref document: AU Ref document number: AU2022258464 Country of ref document: AU |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 2023562925 Country of ref document: JP |
|
| REG | Reference to national code |
Ref country code: BR Ref legal event code: B01A Ref document number: 112023021231 Country of ref document: BR |
|
| ENP | Entry into the national phase |
Ref document number: 2022258464 Country of ref document: AU Date of ref document: 20220413 Kind code of ref document: A |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 2022788875 Country of ref document: EP |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| ENP | Entry into the national phase |
Ref document number: 2022788875 Country of ref document: EP Effective date: 20231113 |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 202280040778.8 Country of ref document: CN |
|
| REG | Reference to national code |
Ref country code: BR Ref legal event code: B01E Ref document number: 112023021231 Country of ref document: BR Free format text: EFETUAR, EM ATE 60 (SESSENTA) DIAS, O PAGAMENTO DE GRU CODIGO DE SERVICO 260 PARA A REGULARIZACAO DO PEDIDO, CONFORME ART. 2O 1O DA RESOLUCAO/INPI/NO 189/2017 E NOTA DE ESCLARECIMENTO PUBLICADA NA RPI 2421 DE 30/05/2017, UMA VEZ QUE A PETICAO NO 870230102165 DE 21/11/2023 APRESENTA DOCUMENTOS REFERENTES A 2 SERVICOS DIVERSOS (TRADUCAO DOS DOCUMENTOS APRESENTADOS NO DEPOSITO E MODIFICACOES NO QUADRO REIVINDICATORIO) TENDO SIDO PAGA SOMENTE 1 RETRIBUICAO. DEVERA SER PAGA MAIS 1 (UMA) GRU CODIGO DE SERVICO 260 E A GRU CODIGO DE SERVICO 207 REFERENTE A RESPOSTA DESTA EXIGENCIA. |
|
| ENP | Entry into the national phase |
Ref document number: 112023021231 Country of ref document: BR Kind code of ref document: A2 Effective date: 20231011 |
|
| WWW | Wipo information: withdrawn in national office |
Ref document number: 307655 Country of ref document: IL |