WO2022244892A1 - 企業評価装置及び企業評価方法 - Google Patents
企業評価装置及び企業評価方法 Download PDFInfo
- Publication number
- WO2022244892A1 WO2022244892A1 PCT/JP2022/022254 JP2022022254W WO2022244892A1 WO 2022244892 A1 WO2022244892 A1 WO 2022244892A1 JP 2022022254 W JP2022022254 W JP 2022022254W WO 2022244892 A1 WO2022244892 A1 WO 2022244892A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- coefficient
- company
- evaluation
- processing means
- classification
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Ceased
Links
Images















Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06Q—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR ADMINISTRATIVE, COMMERCIAL, FINANCIAL, MANAGERIAL OR SUPERVISORY PURPOSES; SYSTEMS OR METHODS SPECIALLY ADAPTED FOR ADMINISTRATIVE, COMMERCIAL, FINANCIAL, MANAGERIAL OR SUPERVISORY PURPOSES, NOT OTHERWISE PROVIDED FOR
- G06Q50/00—Information and communication technology [ICT] specially adapted for implementation of business processes of specific business sectors, e.g. utilities or tourism
- G06Q50/10—Services
- G06Q50/18—Legal services
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06Q—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR ADMINISTRATIVE, COMMERCIAL, FINANCIAL, MANAGERIAL OR SUPERVISORY PURPOSES; SYSTEMS OR METHODS SPECIALLY ADAPTED FOR ADMINISTRATIVE, COMMERCIAL, FINANCIAL, MANAGERIAL OR SUPERVISORY PURPOSES, NOT OTHERWISE PROVIDED FOR
- G06Q10/00—Administration; Management
- G06Q10/06—Resources, workflows, human or project management; Enterprise or organisation planning; Enterprise or organisation modelling
- G06Q10/063—Operations research, analysis or management
- G06Q10/0639—Performance analysis of employees; Performance analysis of enterprise or organisation operations
- G06Q10/06393—Score-carding, benchmarking or key performance indicator [KPI] analysis
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06Q—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR ADMINISTRATIVE, COMMERCIAL, FINANCIAL, MANAGERIAL OR SUPERVISORY PURPOSES; SYSTEMS OR METHODS SPECIALLY ADAPTED FOR ADMINISTRATIVE, COMMERCIAL, FINANCIAL, MANAGERIAL OR SUPERVISORY PURPOSES, NOT OTHERWISE PROVIDED FOR
- G06Q10/00—Administration; Management
- G06Q10/06—Resources, workflows, human or project management; Enterprise or organisation planning; Enterprise or organisation modelling
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06Q—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR ADMINISTRATIVE, COMMERCIAL, FINANCIAL, MANAGERIAL OR SUPERVISORY PURPOSES; SYSTEMS OR METHODS SPECIALLY ADAPTED FOR ADMINISTRATIVE, COMMERCIAL, FINANCIAL, MANAGERIAL OR SUPERVISORY PURPOSES, NOT OTHERWISE PROVIDED FOR
- G06Q10/00—Administration; Management
- G06Q10/06—Resources, workflows, human or project management; Enterprise or organisation planning; Enterprise or organisation modelling
- G06Q10/063—Operations research, analysis or management
- G06Q10/0639—Performance analysis of employees; Performance analysis of enterprise or organisation operations
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06Q—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR ADMINISTRATIVE, COMMERCIAL, FINANCIAL, MANAGERIAL OR SUPERVISORY PURPOSES; SYSTEMS OR METHODS SPECIALLY ADAPTED FOR ADMINISTRATIVE, COMMERCIAL, FINANCIAL, MANAGERIAL OR SUPERVISORY PURPOSES, NOT OTHERWISE PROVIDED FOR
- G06Q40/00—Finance; Insurance; Tax strategies; Processing of corporate or income taxes
Definitions
- the present invention relates to a company evaluation device and a company evaluation method that objectively evaluate companies.
- ESG ESG
- SDG Sustainable Development Goals
- Patent Document 1 evaluates companies from an ESG perspective based on news articles collected on the Internet.
- the multiple rating agencies do not have common criteria for evaluating companies from the perspective of management indicators, and the reality is that each rating agency uses its own method to rate companies. Therefore, there is a risk that the evaluation results of companies may contain the subjectivity and sense of values of each rating agency, and there is a problem that it is difficult to obtain a sense of fairness. Therefore, there is a demand for a method that enhances objectivity and reliability when evaluating companies from the viewpoint of management indicators.
- the present invention has been made to solve the above-mentioned problems, and provides a company evaluation device and a company evaluation method that objectively evaluates companies from the viewpoint of management indicators and derives highly reliable evaluation results. intended to provide
- a corporate evaluation apparatus provides a weight for reflecting the degree of relevance of information on one or more industrial property rights linked to a company to a management index incorporated in the management policy of the company in corporate evaluation. It has an evaluation processing means for obtaining the evaluation result of the enterprise from the viewpoint of the management index by using the information.
- a corporate evaluation method is a weighting that reflects the degree of relevance of information on one or more industrial property rights linked to a company to management indicators incorporated in the management policy of the company in corporate evaluation. It employs a method of obtaining evaluation results of companies from the viewpoint of management indicators using information.
- the present invention uses weighting information to reflect the degree of relevance of information on one or more industrial property rights tied to a company to a management index incorporated in the management policy of the company in the evaluation of the company. Ask for Therefore, it is possible to incorporate the viewpoint of industrial property rights into the evaluation of companies from the viewpoint of management indicators.
- industrial property rights are examined by the patent offices of each country, the objective utility of registered rights is recognized.
- applicants when acquiring industrial property rights, applicants usually prepare application documents in order to ensure objective usefulness on the premise that examination will be conducted. Therefore, evaluation results based on information on industrial property rights are naturally highly objective information. Therefore, according to the present invention, it is possible to objectively evaluate companies from the viewpoint of management indicators and derive highly reliable evaluation results.
- FIG. 2 is a block diagram illustrating the functional configuration of the company evaluation device in FIG. 1;
- FIG. 3 is an explanatory diagram schematically showing an example of a target list created by name identification processing means of FIG. 2;
- FIG. 3 is an explanatory diagram exemplifying the relationship between weight information stored in the storage unit of FIG. 2 and information on industrial property rights;
- 3 is an explanatory diagram illustrating an outline of a publication coefficient obtained by the publication processing means of FIG. 2;
- FIG. 3 is an explanatory diagram illustrating an outline of classification information extracted and collected by the classification processing means of FIG. 2;
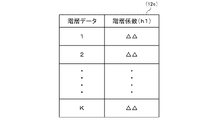
- FIG. 3 is an explanatory diagram schematically illustrating a hierarchy table stored in a storage unit in FIG. 2;
- FIG. FIG. 3 is an explanatory diagram schematically exemplifying a word table stored in a storage unit in FIG. 2;
- FIG. 3 is an explanatory diagram schematically illustrating an extraction number table stored in the storage unit of FIG. 2;
- FIG. 3 is an explanatory diagram of a classification score obtained by the classification processing means of FIG. 2; It is the flowchart which illustrated the flow of the whole process of the enterprise evaluation method in this Embodiment.
- FIG. 4 is a flowchart showing an operation example related to derivation of a related score in a word processing step in the company evaluation method of the present embodiment
- 2 is a flowchart showing an operation example related to derivation of a publication coefficient in a publication processing step in a company evaluation method according to the present embodiment
- 4 is a flow chart showing an operation example in a classification processing step in the company evaluation method of the present embodiment.
- FIG. 11 is an explanatory diagram illustrating a classification table according to a modification of the embodiment
- FIG. 11 is a flow chart showing an operation example of a method for creating a classification table according to a modification of the present embodiment
- FIG. FIG. 10 is a flow chart showing an operation example in a classification processing step in a company evaluation method according to a modified example of the present embodiment
- the company evaluation device 10 uses an algorithm that analyzes the degree of relevance of information on one or more industrial property rights linked to the company to be evaluated to the management index incorporated in the company's management policy, and evaluates the company. It is evaluated from the viewpoint of management indicators.
- the company evaluation device 10 has a function of evaluating companies from the viewpoint of management indicators by a technique using machine learning. Management indicators are indicators that take environmental and social aspects into consideration, and are particularly incorporated into medium- to long-term corporate management policies.
- the company evaluation device 10 is connected to external devices such as a management terminal 50, one or more information terminals 80, a rating server group 100, and an information providing server group 300 via a network N such as the Internet so as to be able to communicate with each other. be done.
- the enterprise evaluation device 10 is configured by an on-premise physical server, a cloud server based on cloud computing, or a system combining these.
- industrial property rights refer to patent rights, utility model rights, design rights, and trademark rights among intellectual property rights.
- information on industrial property rights includes publications (patent publications, patent publication publications, publications concerning utility models, etc.), information on applicants, right holders, inventors, inventors, etc., as well as information on the prosecution process, examination etc. is included.
- the information on examination and the like may include citation information indicating the number of citations (number of citations) of publications relating to industrial property rights in notices of reasons for refusal and the like.
- Information related to examination may include search reports from search companies, and information such as search processing and examination details by examiners.
- information on industrial property rights corresponds to one application, and not only information on applications for which rights have been granted (including those that have been extinguished due to the expiration of the term of validity, etc.), but also information on applications that have not been granted rights, and information on rights It also includes information on applications pending or pending prosecution prior to civilization.
- Applications for which rights have not been granted include applications for which a request for examination has not been filed within the prescribed period and applications for which a decision of refusal has become final and binding.
- information on industrial property rights will also be referred to as “rights-related information”.
- the rights-related information includes at least application number information.
- the rating server 110 performs rating processing for companies from the perspective of management indicators, which are indicators incorporated into company management policies. That is, the rating server 110 is a server or the like used and managed by a rating agency such as MSCI (Morgan Stanley Capital International), FTSE, or Sustainalytics.
- the rating server group 100 assumes one or more rating servers 110 .
- the rating server 110 is configured by a cloud server based on cloud computing, an on-premise physical server, or a system combining these.
- the company evaluation device 10 can build the company evaluation system 200 in cooperation with the rating server 110 .
- the company evaluation device 10 evaluates the company to be evaluated from the viewpoint of management indicators based on the rights-related information of the company to be evaluated, and provides the evaluation results to one or more rating servers 110.
- the rating server 110 can incorporate the viewpoint of industrial property rights into the company's rating process, thereby enhancing the objectivity of information provided to customers.
- the management terminal 50 is for managing information in the company evaluation device 10.
- the management terminal 50 is, for example, a PC (Personal Computer) used by a company that manages software and data in the company evaluation device 10 .
- PCs include tablet PCs, notebook PCs, desktop PCs, and the like.
- the administrator can adjust and change information, programs, and various parameters in the database in the enterprise evaluation device 10 .
- the information providing server group 300 is assumed to be, for example, servers around the world that provide rights-related information through an API (Application Programming Interface).
- rights-related information which is one data set, is linked to a company or the like that is an applicant or a right holder.
- Each server constituting the information providing server group 300 is configured by a cloud server based on cloud computing, an on-premise physical server, or a system combining these.
- the information providing server group 300 stores a database (hereinafter referred to as an intellectual property database) in which one family ID is linked to one or a plurality of name data indicating an applicant or right holder pertaining to one invention or device. Contains a server device. Recently, many companies have filed patent applications for the same invention, etc. in multiple countries, and such a collection of patent applications is called a patent family.
- the family ID is identification information that is commonly given to patent families, and the same family ID is given to the same company no matter how different the notations of the company names are.
- the information terminal 80 accesses the database provided by the company evaluation device 10 or the rating server 110 according to the user's operation, and acquires and displays various information in the database. That is, the information terminal 80 acquires the rating score or the like, which is the result of the objective evaluation of the company, from the company evaluation device 10, and provides the acquired information such as the rating score to the user. The information terminal 80 acquires objective rating scores and the like reflecting objectivity based on industrial property rights from the rating server 110, and provides information such as the acquired objective rating scores to the user.
- the company evaluation device 10 has a communication unit 11, a storage unit 12, a control unit 13, and an evaluation database unit 120.
- the communication unit 11 is an interface through which the control unit 13 performs wired or wireless communication with external devices such as the management terminal 50 , the information terminal 80 , the rating server group 100 , and the information providing server group 300 .
- the storage unit 12 stores the operating program of the control unit 13, such as the company evaluation program P1, as well as various data required for company evaluation.
- the storage unit 12 stores weight information that reflects the degree of relevance (degree of relevance) of one or more pieces of rights-related information linked to a company to a management index in corporate evaluation.
- the weight information includes at least one of the location coefficient, the related coefficient d, the number of searches, the related score U, the publication coefficient e, the citation coefficient f, the classification score H, and the word coefficient D.
- the weight information may include at least one of the hierarchy factor h1 and the explanation factor h2.
- the weight information may include the number of extractions and the extraction factor K.
- Weight information may include a classification factor g.
- the weighting information may include a progression factor based on the filing date, the date of patenting, etc. of the subject information.
- the weight information may include a mitigation factor for mitigating the impact of an unexpected increase in search volume on the company's evaluation results.
- the storage unit 12 stores table information such as related data 12a, target list 12b, relaxation table, related table 12c, publication coefficient table 12d, hierarchy table 12e, word table 12f, extraction number table 12g, and classification table 12h. do.
- the storage unit 12 may store an estimation model M1 for estimating the validity of the contents of publications relating to rights-related information.
- the storage unit 12 can be configured by RAM (Random Access Memory) and ROM (Read Only Memory), PROM (Programmable ROM) such as flash memory, SSD (Solid State Drive), or HDD (Hard Disk Drive). .
- the control unit 13 has collection processing means 13a, name identification processing means 13b, and evaluation processing means 13c.
- the collection processing means 13a periodically collects rights-related information through an API or the like.
- the collection processing unit 13a collects information such as patent publications, patent publication publications, and utility model publications around the world as rights-related information.
- the collection processing means 13a has a function of normalizing the collected rights-related information by arranging the divisions of the information and preparing the file format.
- the collection processing means 13a collects non-patent literature, various technical papers and technical reports, technical standards, websites of companies, research institutes, universities, etc., articles and catalogs on the Web, blogs, SNS (social networking service) all over the world. etc., and such data may be used to derive the publication coefficient e.
- the collection processing means 13a collects a plurality of keywords that are considered to be related to management indicators by rating agencies from the database provided in the rating server group 100, and collects them as related data 12a. Store in the storage unit 12 . Each keyword listed in the related data 12a is hereinafter referred to as a related word W.
- FIG. The related words W collected from the rating server group 100 by the collection processing means 13a can be used when evaluating the degree of relevance between the management index and the rights-related information.
- the collection processing means 13a has a function of accessing an external server capable of searching for peripheral words such as synonyms and suggestion keywords, and extracting peripheral words of related words W collected from the rating server group 100.
- the collection processing unit 13a may store the extracted peripheral words as related words W in the storage unit 12 as well. That is, the collection processing means 13a has a function of expanding the related words W collected from the rating server group 100 to synonyms and the like.
- software such as a thesaurus capable of searching peripheral words may be stored in the storage unit 12 or the like, and the collection processing means 13a may expand the related words W using the software.
- the collection processing means 13a collects peripheral words of the related word W collected from the rating server group 100, peripheral words that have a low relevance to management indicators and are inappropriate for use in company evaluation are extracted. is also assumed. Therefore, the collection processing means 13a has a function of selecting peripheral words associated with the related words W collected from the rating server group 100 based on their relevance to the management index. Natural language processing and machine learning should be incorporated into the peripheral word selection function. For example, the collection processing means 13a converts the related words W collected from the rating server group 100 into distributed representation by Word2Vec (natural language processing technology for vectorizing words), etc., and converts the extracted peripheral words into distributed representation. Then, it is preferable to select peripheral words based on the degree of matching between these vectors.
- Word2Vec natural language processing technology for vectorizing words
- the name identification processing means 13b accesses the intellectual property database of the information providing server group 300, extracts and organizes a plurality of rights-related information to be listed. For example, rights-related information for a specified period such as 10 years or 20 years, rights-related information for a specified area by country or region, or rights-related information for a specified period in a specified area are listed. Targets to be listed can be set from the management terminal 50 or the like, and can be changed as appropriate.
- the name identification processing means 13b extracts each piece of information linked to the rights-related information within the specified period. For example, when the rights-related information of a designated area such as Japan, the United States, China, and Europe is listed, the name identification processing means 13b extracts each piece of information linked to the rights-related information of each country. When rights-related information for a specified period in a certain specified area is to be listed, the name identification processing means 13b extracts each piece of information linked to the rights-related information within the specified period in the specified area.
- the target of listing can be arbitrarily set, and the name identification processing means 13b can list all rights-related information in the intellectual property database.
- the name identification processing means 13b accesses the intellectual property database and extracts the application number included in each of the plurality of target information, and the name data and family ID associated with each of the application numbers. Then, the name identification processing means 13b organizes the application numbers and name data based on the family IDs to create the target list 12b.
- the name identification processing means 13b adds a common name, which is at least one of a common name and common identification information, to a plurality of name data associated with the same family ID.
- a target list 12b is created by associating the data.
- Common data is obtained by collating name data based on family IDs.
- the target list 12b in FIG. 3 is an example of table information in which common data, application numbers, name data, and family IDs are associated with each target information.
- family IDs are abbreviated as F 1 to F N (N is an arbitrary natural number), where N corresponds to the number of target information (target information 1 to N).
- the information associated with the family ID “F 1 ” is surrounded by a thick line, indicating that the information below it is also sorted by family ID.
- the target list 12b may be configured to include registration numbers and the like.
- the name identification processing means 13b may use one of a plurality of name data having a common family ID as common data, or may use characters and the like common to these as common data.
- the name identification processing means 13b may separately generate common data.
- 1 to N are associated with the common data and used for convenience.
- the name identification processing means 13b can perform highly accurate name identification processing by uniform processing using family IDs even if there is no sense of unity in a plurality of name data corresponding to one company.
- the name identification processing means 13b groups a plurality of name data groups each composed of one family ID and one or more name data linked thereto for each company, and assigns unique common data to each group. have a function. That is, the name identification processing means 13b groups the name data groups (family IDs) for each company based on the commonality and similarity of the name data constituting each of the plurality of name data groups, and performs A target list 12b is created by adding unique common data to each name data in the group. As a result, since the same common data is associated with the application number and name data of the same company, it is possible to accurately evaluate each company.
- the evaluation processing means 13c uses weight information that reflects the degree of relevance of one or more pieces of rights-related information linked to the company to the management index in the evaluation of the company from the viewpoint of the management index. is a request.
- the evaluation processing means 13c searches for a plurality of related words W related to the management index from one or a plurality of rights-related information linked to the company, and uses the weight information linked to the searched related word W to It has a function to obtain the evaluation result of
- the weight information associated with the related word W is set according to the related coefficient d set to at least one of the plurality of related words W, the number of searches for the related word W, and the location of the related word W. and a location coefficient.
- the evaluation processing means 13c obtains an evaluation score Ts and a rating score as the company evaluation results.
- the evaluation processing means 13c may search for a word that completely matches the related word W, but from the viewpoint of ensuring search accuracy, a semantic match with the related word W is performed by natural language processing such as Word2Vec or Doc2Vec. Do a degree-based word search. For example, the evaluation processing means 13c performs morphological analysis on at least a part of the rights-related information and decomposes the morphemes into morphemes with part-of-speech information. ). Then, the evaluation processing unit 13c preferably compares the vector in which the related word W is expressed in distributed representation with each element vector, and searches for an element vector with a certain degree of matching or more. In other words, the evaluation processing means 13c may be configured to perform a similarity search for the related word W. FIG.
- FIG. 4 exemplifies one target information
- the weight information is set for all the target information.
- FIG. 4 it is assumed that n related words W1 to Wn (n is an arbitrary natural number) are set, and related coefficients d 1 to d n is exemplified.
- the association coefficients d 1 to d n need not all be different values and may have some overlap.
- FIG. 4 shows an example in which the related coefficient d is set to all of the plurality of related words W, the related coefficient d may be set to only some of the plurality of related words W. may be That is, the related coefficient d may be set to at least one of the multiple related words W.
- FIG. 4 shows an example in which the related coefficient d is set to all of the plurality of related words W, the related coefficient d may be set to only some of the plurality of related words W. may be That is, the related coefficient d may be set to at least one of the multiple related words W.
- the location is information indicating where the related word W exists in the rights-related information.
- the location coefficients are a specification coefficient a, which is a weighting coefficient when the related word W exists in the description, and a summary, which is a weighting coefficient when the related word W exists in the abstract.
- the location coefficient includes a detail coefficient a corresponding to the specification, a summary coefficient b corresponding to the abstract, and a claim coefficient c corresponding to the scope of claims.
- the summary coefficient b is preferably set larger than the detail coefficient a
- the claim coefficient c is preferably set larger than the summary coefficient b.
- the detailed coefficient a, the summary coefficient b, and the claim coefficient c are set so that the relationship "a ⁇ b ⁇ c" is established, such as the detailed coefficient a is 1, the summary coefficient b is 3, and the claim coefficient c is 5.
- the specification also describes content that has little relevance to the scope of rights.
- the publication coefficient e is a weighting coefficient that is set according to the degree of effectiveness of the contents of the publication, and is based on the premise that the industrial property right is a patent right or a utility model right.
- the publication coefficient e may be set step by step according to preset conditions, or may be obtained individually for each target information by analysis processing based on terms and the like included in the target information.
- the citation coefficient f is a weighting coefficient set according to the number of citations of the publication.
- the classification coefficient g is a weighting coefficient for adjusting the balance between the association score U and the classification score H. If the calculation itself of the association score U and the classification score H adjusts the balance, the classification coefficient g is unnecessary. becomes.
- the classification score H is set for each classification code in the patent classification on the premise that the industrial property rights are patent rights or utility model rights.
- a patent classification is, for example, CPC or IPC.
- multiple classification codes are arranged in a hierarchical structure, and each classification code is associated with an explanation. That is, each classification code is associated with hierarchy data, which is information about the hierarchy of the classification code, and explanation data, which is information about the description of the classification code.
- hierarchy data which is information about the hierarchy of the classification code
- explanation data which is information about the description of the classification code.
- the classification score H can be obtained by calculation using a hierarchy coefficient h1 associated with hierarchical data and an explanation coefficient h2 associated with explanation data.
- the evaluation processing means 13c has word processing means 131, publication processing means 132, classification processing means 133, and rating processing means 134.
- the word processing means 131 obtains a related score U for each object information for each object processing means by a calculation such as the following formula (1).
- the word processing means 131 searches for each related word W from the target information, and obtains the location of the related word W and the number of searches.
- the word processing means 131 has a function of performing a similarity search for related words W based on natural language processing. Then, the word processing means 131 obtains the location coefficients (a to c), the relation coefficients d k , and the number of searches (X k to Z k ) for all the related words W, and sums the products of these to obtain the related words. Find the score U.
- the word processing means 131 associates the obtained related score U with the target information and stores it in the storage unit 12 . For example, the word processing means 131 creates a relation table 12c in which the target information and the relation score U are associated with each other.
- related words W including similar words
- component names, etc. that can be used frequently in the specification, etc.
- the number of searches increases more than expected, and the related score U decreases. Reliability may decrease. Therefore, for example, an upper limit of the number of searches may be set, and when the number of searches exceeds the upper limit, the word processing unit 131 may replace the number of searches used for calculation of the related score U with the upper limit.
- a mitigation coefficient that mitigates the effect of an increase in the number of searches on the related score U is set in advance and stored in the storage unit 12.
- a relaxation table that associates the number of searches with the relaxation coefficient is stored in the storage unit 12, and the word processing unit 131 compares the calculated number of searches with the relaxation table to obtain the relaxation coefficient.
- the word processing unit 131 preferably calculates the association score U using, instead of the number of searches, a value obtained by multiplying the number of searches by a relaxation coefficient.
- the word processing unit 131 may be configured to use both the method using the upper limit of the number of searches and the method using the relaxation coefficient.
- the calculation of the related score U may reflect only whether or not the related word W has been retrieved.
- the word processing unit 131 may treat the case where the number of searches is 1 and the case where the number of searches is plural in the calculation of the association score U in the same way.
- the publication processing means 132 obtains the publication coefficient e for each target information.
- FIG. 5 is an explanatory diagram illustrating an outline of the publication coefficient e.
- the publication coefficient e can be configured to include publication coefficient e1, publication coefficient e2, publication coefficient e3, and publication coefficient e4 .
- the publication coefficient e1 corresponds to the patent publication.
- the publication coefficient e2 corresponds to the patent publications considered to be relatively effective among the publications.
- the publication coefficient e3 corresponds to those of patent publications considered to be relatively less effective or those of utility model publications considered to be relatively less effective.
- the publication coefficient e4 corresponds to publications of patent publications that are considered to be of very low validity or publications relating to utility models that are of relatively low validity.
- the publication coefficient e2 should be set smaller than the publication coefficient e1
- the publication coefficient e3 should be set smaller than the publication coefficient e2
- the publication coefficient e4 should be set smaller than the publication coefficient e3.
- the discrimination process between the publication coefficient e 1 and the publication coefficients e 2 to e 4 can be uniformly performed by the type of publication, that is, the code attached to each publication.
- the discrimination between the publication coefficient e2 , the publication coefficient e3 , and the publication coefficient e4 is more accurate by adopting analysis processing based on machine learning or the like than by using only the publication type. Therefore, the publication processing means 132 has a function of performing a predetermined analysis process for each target information to obtain the publication coefficient e.
- the publication processing means 132 preferably creates a publication coefficient table 12d in which the target information and the publication coefficient e are associated with each other.
- the publication processing means 132 obtains the publication coefficient e using the estimated model M1 stored in the storage unit 12 or an external storage device.
- the estimation model M1 is a trained model that outputs a publication coefficient e that indicates the effectiveness of the content of the publication.
- the content of the publication includes at least one of the claims and the specification, and may include an abstract and drawings.
- the validity of the contents of the gazette is analyzed from the perspective of novelty and inventive step, that is, the possibility of invalidation, etc., and information on examination, etc. is also analyzed.
- the estimation model M1 may be configured to output information from which the publication coefficient e was derived together with the publication coefficient e.
- FIG. 2 shows an example in which the estimation model M1 is stored in the storage unit 12. As shown in FIG.
- the target information includes core data that is the source of the estimation data that is input to the estimation model M1, and auxiliary data that is auxiliary or incidental data. If the target information is related to patents or utility models, the core data includes claim information, rejection notices, search company search reports, and the like. That is, the publication processing means 132 inputs the estimation data generated for each target information to the estimation model M1, and creates the publication coefficient table 12d by associating the publication coefficient e output from the estimation model M1 with the target information.
- the publication processing means 132 has a preprocessing function that generates estimation data by performing analysis processing on the core data of the target information.
- the data for estimation is data to be input to the estimation model M1 in order to estimate the effectiveness of the contents of the publication.
- the publication processing means 132 has a function of performing natural language processing such as morphological analysis on the core data. Morphological analysis is the process of dividing core data written in a natural language into morphemes, which are the smallest units of language, and determining the parts of speech and variations of each morpheme.
- the publication processing means 132 generates estimation data by adding part-of-speech information such as verbs, nouns, and adjectives to each of the morphemes divided from the core data and converting them into distributed expressions.
- the gazette processing means 132 has a function of deleting particles, auxiliary verbs, etc. when generating data for estimation.
- the gazette processing means 132 may extract key information that is the key to machine learning when performing conversion processing on each morpheme, and further performs processing such as weighting on the extracted key information. good too.
- the publication processing means 132 may generate estimation data by performing relatively simple analysis processing such as deleting unnecessary data from the core data by the preprocessing function.
- Unnecessary data refers to characters such as numerical values, line feeds, or symbols that are of low importance for training of the estimation model M1 and calculations using the model.
- the publication processing means 132 may have a learning processing function that generates the estimation model M1 by machine learning based on core data.
- the publication processing means 132 may perform the update processing of the estimation model M1 every arbitrary period such as one day by the learning processing function.
- the publication processing means 132 preferably generates the estimation model M1 by supervised learning using a DNN (Deep Neural Network), for example.
- the publication processing means 132 may generate the estimation model M1 by unsupervised learning or semi-supervised learning.
- the publication processing means 132 may generate the estimation model M1 by machine learning using GBDT (Gradient Boosting Decision Tree).
- the publication processing means 132 may generate the estimated model M1 by a regression method such as linear regression, logistic regression, or decision tree.
- the publication processing means 132 may generate the estimation model M1 by a classification method such as random forest or support vector machine.
- the publication processing means 132 may generate the estimation model M1 by a technique combining a plurality of machine learnings described above.
- the publication processing means 132 may have a translation processing function that unifies the core data into a preset common language. In this case, the publication processing means 132 extracts core data for each target information, and if the extracted core data is configured in a language other than the common language, translates the core data into the common language to generate translated data. do. Even if the core data contains a common language, if a part of the core data contains a language other than the common language, the publication processing means 132 performs partial translation processing on the core data to translate. Generate data.
- the publication processing means 132 When the publication processing means 132 has a translation processing function, it uses the preprocessing function to apply analysis processing to the translation data to generate estimation data to be input to the estimation model M1. When the publication processing means 132 has the translation processing function and the learning processing function, it generates the estimation model M1 by machine learning based on the translation data. The publication processing means 132 inputs the estimation data generated for each target information to the estimation model M1, associates the publication coefficient e output from the estimation model M1 with the target information, and creates the publication coefficient table 12d.
- the classification processing means 133 extracts classification information configured as illustrated in FIG. In FIG. 6, the classification codes are indicated as P 1 to P N in association with the target information 1 to N for convenience, but overlapping classification codes may exist.
- the notation of hierarchical data in FIG. 6 is merely an example.
- FIG. 7 is a table schematically exemplifying the hierarchy table 12e in which the hierarchy data and the hierarchy coefficient h1 are associated.
- the classification processing means 133 compares the extracted hierarchical data with the hierarchical table 12e for each target information to obtain the hierarchical coefficient h1.
- all the hierarchy coefficients h1 are set to " ⁇ ", but in the hierarchy table 12e, different hierarchy coefficients h1 are set for each hierarchy data.
- the same hierarchy coefficient h1 may be set for several different hierarchy data.
- the hierarchical coefficient h1 is preferably set stepwise so that the hierarchical data of the lower layer is larger than the hierarchical data of the upper layer.
- FIG. 8 is a table schematically illustrating a word table 12f in which related words W1 to Wn and word coefficients D are associated.
- all the word coefficients D are set to " ⁇ " for the sake of convenience, but different word coefficients D are set for several different related words W in the word table 12f.
- the word table 12f may be set with the same word coefficient D for several different related words W.
- the word coefficient D may be set to the same value as the related coefficient d, may be set to a different value, or may be partially set to the same value as the related coefficient d.
- FIG. 9 is a table schematically exemplifying the extraction number table 12g in which the extraction number and the extraction coefficient K are associated.
- the number of extractions is the number of related words W extracted from the description data (the number of related words W included in the description data).
- the extraction coefficient K is for absorbing the influence on the classification score H due to an unexpected increase in the number of extractions.
- all the extraction coefficients K are represented by " ⁇ ", but in the extraction number table 12g, different extraction coefficients K are set for several different extraction numbers. However, in the extraction number table 12g, the same extraction coefficient K may be set for several different extraction numbers.
- the classification processing means 133 compares the extracted explanation data with each related word W of the related data 12a for each target information, obtains the explanation coefficient h2 using the result of the comparison, and stores the obtained explanation coefficient h2 in the storage unit 12. be memorized. More specifically, the classification processing means 133 first extracts the related words W from the description data, and obtains the description coefficient h2 based on the type and the number of extractions of the related words W extracted.
- the classification processing means 133 may extract words based on the degree of semantic matching with the related word W by natural language processing such as Word2Vec or Doc2Vec. For example, the classification processing means 133 performs morphological analysis on the explanation data and decomposes it into morphemes with part-of-speech information. It is preferable to extract those with a certain degree of matching or more.
- the classification processing means 133 extracts the word coefficient D from the related word W extracted from the description data by comparing the related word W with the word table 12f, and stores it in the storage unit 12 as the description coefficient h2.
- the classification processing means 133 checks the related words W against the word table 12f to obtain the word coefficient D, and the number of the related words W extracted.
- the extraction coefficient K is obtained by referring to the extraction number table 12g. Then, the classification processing means 133 uses the obtained word coefficient D and extraction coefficient K to obtain the explanation coefficient h2.
- the classification processing means 133 sets the product of the word coefficient D and the extraction coefficient K as the explanation coefficient h2.
- the classification processing means 133 calculates An explanation element coefficient is derived, and if the number of extractions is plural, the explanation element coefficient is derived by the calculation for obtaining the explanation coefficient h2 in the multiple word extraction process described above. Then, the classification processing means 133 uses the explanatory element coefficients of each related word W to obtain the explanatory coefficient h2.
- the classification processing means 133 has a function of excluding target information having explanatory data from which no related word W has been extracted from the calculation target of the classification score H.
- the classification processing means 133 may exclude target information having explanatory data in which only related words W with relatively low relevance to the management index are extracted from the classification score H calculation targets. In other words, there is some target information for which no classification score H is generated.
- an extraction word for the explanation extraction process may be provided. In this case, overlaps may occur between the extracted word and the related word W.
- FIG. 10 is an explanatory diagram exemplifying the classification codes Q 1 to Q M , the hierarchy coefficient h1, the explanation coefficient h2, and the classification score H.
- the classification codes Q 1 to Q M are the classification codes P 1 to P N with some of them removed, or the classification codes P 1 to P N themselves. That is, M is any natural number that satisfies the relationship "M ⁇ N". Similar to the classification codes P 1 to PN , the classification codes Q 1 to QM may overlap.
- the classification processing means 133 obtains the classification score H for each of the classification codes Q 1 to Q M using the hierarchy coefficient h1 and the explanation coefficient h2, associates the obtained classification score H with the target information, and stores it in the storage unit 12. Memorize.
- the classification processing means 133 sets the classification score H as the product of the hierarchy coefficient h1 and the explanation coefficient h2, for example. When a plurality of classification codes are assigned to the target information, the classification score H for one representative classification code may be obtained. A score H may be obtained.
- the classification processing means 133 stores a classification table 12h in which a plurality of classification codes and classification scores H are associated with each other in the storage unit 12.
- FIG. The classification score H is used when the rating processing means 134 obtains the target score T.
- the rating processing means 134 obtains the target score T for each target information by, for example, calculation such as the following formula (2). That is, the rating processing means 134 is configured to obtain the target score T for each target information using the related score U, the classification score H, the classification coefficient g, the publication coefficient e, and the citation coefficient f. be able to. For target information for which no classification score H has been generated, the rating processing means 134 obtains the target score T by setting H in the following equation (2) to 0, for example.
- the association score U is obtained by the word processing means 131 and stored in the word table 12f.
- the classification score H is obtained by the classification processing means 133 and stored in the classification table 12h.
- the publication coefficient e is obtained by the publication processing means 132 and stored in the publication coefficient table 12d.
- the citation coefficient f is stored in advance in the storage unit 12 in the form of, for example, a citation table (not shown) that associates the number of citations with the citation coefficient f.
- the rating processing unit 134 compares the citation information collected by the collection processing unit 13a with the citation table to obtain the citation coefficient f.
- the rating processing means 134 finds the evaluation score Ts for each company by averaging the target scores T for each target information, for example, as in the following equation (3).
- "m" in the formula (3) is the number of target information corresponding to one company, and may be 1 or 2 in some cases.
- the rating processing means 134 compares the evaluation score Ts of each company with a plurality of threshold values set for rating, and obtains a rating score by converting the evaluation score Ts into a graded expression.
- the rating score is expressed using codes such as "AAA”, “AA”, “A”, “BBB”, “BB”, “B”, “CCC”, “CC”, “C”, and "D”.
- the rating processing means 134 builds an evaluation database 120a in which the company information related to the target information, the evaluation score Ts, and the rating score are arranged in association with each other in the evaluation database unit 120.
- the evaluation database unit 120 is a storage device that stores the evaluation database 120a.
- the rating processing unit 134 may store table information in which the target score T is associated with each target information in the evaluation database 120a.
- the evaluation database unit 120 provides the information in the evaluation database 120a to an external device such as the information terminal 80 or the rating server 110.
- the evaluation database unit 120 is composed of RAM, ROM, PROM such as flash memory, SSD, HDD, or the like. However, the evaluation database unit 120 may be provided outside the company evaluation device 10 .
- the control unit 13 can be configured by an arithmetic device such as a CPU (Central Processing Unit) or a GPU (Graphics Processing Unit), and a company evaluation program P1 that cooperates with such an arithmetic device to realize the various functions described above.
- the company evaluation program P1 is a program for causing the control unit 13 and the storage unit 12 as computers to function as collection processing means 13a, name identification processing means 13b, and evaluation processing means 13c.
- the storage unit 12 corresponds to a computer-readable recording medium recording a company evaluation program.
- some of the various functions described above may be implemented by hardware.
- step S103 corresponds to the flowchart of FIG. 12
- step S104 corresponds to the process of FIG. 13
- step S105 corresponds to the flowchart of FIG.
- the name identification processing unit 13b extracts the application number included in each of a plurality of pieces of target information, and the name data and family ID associated with each of the application numbers (step S101).
- the name identification processing means 13b creates a list of application numbers and name data based on the extracted family ID, and associates one or more name data corresponding to the same company with unique common data to create a target list 12b. create (step S102).
- the word processing means 131 retrieves a plurality of related words W from each target information, and obtains weight information associated with the related word W for each target information. Then, the word processing means 131 obtains a related score U for each target information based on the number of searches for each related word W and weight information. The word processing means 131 also creates a relation table 12c in which the target information and the relation score U are associated (step S103).
- the publication processing means 132 generates estimation data for each target information from the core data included in each target information. Further, the publication processing means 132 uses the generated estimation data as an input to the estimation model M1 to obtain the publication coefficient e for each piece of target information. Then, the publication processing means 132 creates the publication coefficient table 12d in which the target information and the publication coefficient e are associated (step S104).
- the classification processing means 133 extracts classification information from each piece of target information and the information providing server group 300, etc., and obtains a classification score H for each piece of target information based on the classification information. Then, the classification processing means 133 creates a classification table 12h in which the target information and the classification score H are associated (step S105).
- the rating processing means 134 reads out the relation score U from the relation table 12c, the publication coefficient e from the publication coefficient table 12d, the classification score H from the classification table 12h, and the classification from the storage unit 12 for each target information. Read the coefficient g and the cited coefficient f. Then, the rating processing means 134 uses each piece of information that has been read out to obtain the target score T by, for example, calculation such as Equation (2) (step S106).
- the rating processing means 134 refers to the target list 12b in which each company is organized based on the family ID, and organizes the target score T for each company. Then, the rating processing means 134 obtains the evaluation score Ts for each company, for example, by calculation such as Equation (3) (step S107). The rating processing means 134 discriminates the evaluation score Ts step by step, and obtains the rating score for each company (step S108). Then, the rating processing unit 134 constructs the evaluation database 120a in which the company information related to the target information, the evaluation score Ts, and the rating score are arranged in association with each other (Step S109).
- Steps S103 to S105 need not be performed in the order of the step numbers. In other words, the order of the processes in steps S103 to S105 may be changed as appropriate, and the processes may be executed in parallel.
- the word processing means 131 searches for one related word W from the target information (step S201). If the related word W is not retrieved (step S202/No), the word processing means 131 starts retrieval processing of other unretrieved related words W (step S201).
- step S202/Yes When the related word W is retrieved (step S202/Yes), if the number of retrievals is plural (step S203/No), the word processing means 131 compares the number of retrievals with a relaxation table to obtain a relaxation coefficient (step S204). Then, the word processing unit 131 obtains a word score by multiplying the location coefficient, the relation coefficient d, and the product of the number of searches and the relaxation coefficient, for example (step S205). On the other hand, if the number of searches is 1 (step S203/Yes), the word processing unit 131 obtains a word score by multiplying the location coefficient by the association coefficient d (step S205).
- the word processing means 131 repeats the series of processes of steps S201 to S206.
- the word processing means 131 calculates the related score U by integrating all the word scores obtained (step S207).
- the word processing means 131 executes a series of processes of steps S201 to S207 for all target information.
- the publication processing means 132 extracts core data from the target information (step S301).
- the publication processing means 132 translates the core data into a common language to generate translation data (step S302).
- the publication processing means 132 performs analysis processing such as natural language processing on the translation data to generate estimation data (step S303).
- the publication processing means 132 obtains the publication coefficient e, which is the output value of the estimation model M1, by inputting the estimation data to the estimation model M1 (step S304).
- the classification processing means 133 extracts classification information from the target information, and acquires hierarchical data and description data linked to the extracted classification information from the information providing server group 300 and the like. Hierarchical data may be derived from the organization of classification information (step S401).
- the classification processing means 133 extracts a plurality of related words W from the acquired explanation data (step S402). If all the related words W do not exist in the explanation data (step S403/No), the classification processing means 133 ends the processing for the target information without obtaining the classification score H.
- the classification processing means 133 obtains the description coefficient h2 based on the type of related word W and the number of extractions. That is, the classification processing means 133 compares the extracted related word W with the word table 12f, extracts the word coefficient D, and stores it as the description coefficient h2. stored in the unit 12; For a plurality of related words W present in the explanation data, the classification processing means 133 compares the related words W with the word table 12f to obtain the word coefficient D, and stores the extracted number of the related words W in the extracted number table 12g. The extraction coefficient K is determined by light. Then, the classification processing means 133 obtains an explanation coefficient h2 by, for example, multiplying the word coefficient D by the extraction coefficient K (step S404).
- the classification processing means 133 compares the acquired hierarchical data with the hierarchical table 12e to determine the hierarchical coefficient h1 (step S405). When only one type of related word W is extracted, the classification processing means 133 obtains the classification score H using the hierarchical coefficient h1 and the explanatory coefficient h2 of the related word W. When a plurality of types of related words W are extracted, the classification processing means 133 obtains the hierarchical coefficient h1 and the explanation coefficient h2 of each related word W, and uses these to obtain the classification score H (step S406).
- the enterprise evaluation device 10 uses weight information that reflects the degree of relevance of one or more rights-related information linked to a enterprise to a management index in enterprise evaluation. Obtain the evaluation result of Therefore, it is possible to incorporate the viewpoint of industrial property rights into the evaluation of companies.
- industrial property rights are examined by the patent offices of each country, the objective utility of registered rights is recognized.
- applicants normally prepare application documents with an objective perspective and an awareness of ensuring usefulness, on the premise that examination will be conducted. Therefore, evaluation results based on information on industrial property rights are naturally highly objective information. Therefore, according to the company evaluation device 10, it is possible to objectively evaluate a company from the viewpoint of management indicators and derive highly reliable evaluation results.
- the company evaluation device 10 can provide the evaluation result of the company to the rating agency.
- the company's evaluation results may be downloaded to the rating server 110, or may be printed out on a paper medium and provided.
- the company evaluation device 10 may provide company evaluation results in the form of data files such as MICROSOFT EXCEL (registered trademark) XLS files, CSV (Comma-Separated Values) files, and text files.
- the rating agency can enhance the objectivity and reliability of the company evaluation by incorporating the evaluation result of the company by the company evaluation device 10 into its own analysis result.
- the evaluation result by the enterprise evaluation device 10 reflects the content of information on industrial property rights that is intervened by legal institutions such as the patent offices of each country, and creativity is also required to acquire industrial property rights. be. Moreover, transparency is ensured in examinations, etc., at the patent offices of each country, and there is no room for embellishment. That is, the evaluation result by the enterprise evaluation device 10 is information based on the reliability of the application documents and the like related to industrial property rights and the examination agency thereof, so that the conventional problems as described above can be solved.
- the evaluation processing means 13c searches for a plurality of related words W related to the management index from one or a plurality of rights-related information linked to the company, and uses the weight information linked to the searched related word W to evaluation results can be obtained.
- the evaluation processing unit 13c may use a related coefficient d set to at least one of the plurality of related words W as weight information associated with the related words W.
- the related coefficient d may be set individually for all related words W.
- the evaluation processing means 13c may use the number of searches for the related word W as weight information associated with the related word W.
- the evaluation processing means 13c may use the number of searches as it is to calculate the target score T or the like. may be used to calculate the target score T or the like. As a result, it is possible to prevent the reliability of the evaluation result from declining due to an unexpected increase in the number of searches.
- the evaluation processing means 13c may use a location coefficient set according to the location of the related word W as weight information associated with the related word W.
- the location coefficient is a detail coefficient a corresponding to the specification, a summary coefficient b corresponding to the abstract and set to be greater than the detail coefficient a, and a claim corresponding to the scope of claim set to be greater than the summary coefficient b. and a billing factor c.
- the evaluation processing means 13c may obtain the evaluation result of the company using the publication coefficient e that is set according to the degree of effectiveness of the contents of the publication. By doing so, the objective effectiveness of the contents of the publication relating to the target information can be reflected in the evaluation results, so that the objectivity of the evaluation results can be further enhanced.
- the evaluation processing means 13c may obtain the evaluation result of the company using the classification score H set for each classification code. In this way, the degree of relevance to the management index latent in the classification code can be included in the evaluation result of the company, so that the evaluation of the company can be performed with higher accuracy from the viewpoint of the management index.
- the classification score H may have a hierarchical coefficient h1 that is set in stages so that the lower layer is higher than the upper layer for each layer of the classification code. In this way, the weight of the lower layer linked to the more essential content of the application documents is relatively strengthened, so the reliability of the evaluation result can be enhanced.
- the classification score H may have an explanation coefficient h2 based on the content of the explanation of the classification code as an element. In this way, the presence or absence of terms related to the management index in the explanation can be taken into account in the evaluation result of the company, so that the evaluation accuracy can be improved.
- the evaluation processing means 13c may obtain the explanation coefficient h2 by machine learning using analysis processing, similar to the method of obtaining the publication coefficient e.
- the enterprise evaluation device 10 accesses the intellectual property database, applies the application number included in each of the plurality of rights-related information to be listed, and the name data and family ID associated with each application number. It has name identification processing means 13b for extracting .
- the name identification processing means 13b organizes the application number and name data based on the extracted family ID to create the target list 12b. More specifically, the name identification processing means 13b groups the name data groups for each company based on the commonality and similarity of the name data that constitute each of the plurality of name data groups, and for each name data in the group: A target list 12b is created by assigning unique common data.
- the family ID is identification information commonly given to patent families, and the same family ID is given to the same company no matter how different the notations of the company names are. Therefore, according to the company evaluation device 10, highly accurate name identification processing can be realized regardless of the degree of similarity between company names, so that each company can be accurately categorized.
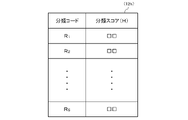
- the storage unit 12 may store in advance a classification table 12h in which classification codes including related words W or extracted words in descriptions are associated with classification scores H.
- FIG. 15 shows the correspondence between classification codes R 1 to R S (S is an arbitrary natural number) containing related words W or extracted words in explanations and classification scores H obtained by the classification processing means 133 in the same manner as described above.
- 12h is an example of the classification table 12h. Other configurations are the same as those described above, and therefore are omitted.
- the classification processing means 133 acquires a plurality of classification information from the information providing server group 300 (step S501). Next, the classification processing means 133 extracts a plurality of related words W from the explanation data included in arbitrary classification information (step S402). If at least one related word W exists in the explanation data (step S403/Yes), the classification processing means 133 obtains an explanation coefficient h2 based on the type and number of extractions of the related word W (step S404).
- the classification processing means 133 compares the acquired hierarchical data with the hierarchical table 12e to obtain the hierarchical coefficient h1 (step S405). Then, the classification processing means 133 obtains the classification score H using the hierarchical coefficient h1 and the explanation coefficient h2 of the extracted related word W, associates the obtained classification score H with the classification code, and stores it in the storage unit 12 (step S406). The classification processing unit 133 determines whether or not there is classification information that has not been subjected to extraction processing (step S502).
- the classification processing means 133 does not obtain the classification score H for the classification information associated with the description data, It is determined whether or not there is classification information that has not been subjected to extraction processing (step S502).
- the classification processing means 133 executes a series of processes of steps S402 to S406 as long as there is classification information that has not been subjected to extraction processing (step S502/Yes), builds a database related to the classification table 12h, and updates it. do.
- the classification processing means 133 ends the generation processing of the classification table 12h when the extraction processing of all the classification information ends (step S502/No).
- the classification processing means 133 extracts the classification code from the target information (step S601).
- the classification processing means 133 compares the extracted classification code with the classification table 12h to obtain a classification score H.
- the classification processing means 133 may determine the classification score H by referring to the classification table 12h for one classification code having a preset high priority.
- the classification processing means 133 compares a plurality of classification codes with high priority set in advance to the classification table 12h, obtains each classification score H, and performs a predetermined calculation using these to classify the target information.
- a score H may be obtained.
- the classification processing means 133 compares all the extracted classification codes with the classification table 12h, obtains the respective classification scores H, and obtains the classification scores H for the target information by a predetermined calculation using these. may
- the classification table 12h in which the classification code and the classification score H are associated is stored in the storage unit 12 in advance. Therefore, the classification processing means 133 can quickly determine whether or not there is a classification score H by referring to the classification code against the classification table 12h, and extract the classification score H stored. Therefore, it is possible to speed up the arithmetic processing related to the company's evaluation result.
- the classification table 12h may be provided to a PC, server, or the like via the network N. FIG.
- the classification table 12h may be provided as a data file such as a MICROSOFT EXCEL (registered trademark) XLS file, a CSV (Comma-Separated Values) file, or a text file.
- the classification table 12h may be printed out on a paper medium and provided.
- the above-described embodiments are specific examples of the company evaluation device, company evaluation program, recording medium, and company evaluation method, and the technical scope of the present invention is not limited to these aspects.
- the above formula (1) is merely an example of an arithmetic formula for obtaining the related score U, and various modifications are possible, and the structure of the company evaluation program is changed accordingly.
- the word processing means 131 may use one or two of the location coefficient, the relation coefficient d k , and the number of searches to calculate the relation score U. That is, the weight information may include at least one of the location coefficient, the related coefficient d k , and the number of searches.
- the classification processing means 133 may obtain the classification score H without using the extraction coefficient K. That is, the weight information may be configured without including the extraction coefficient K.
- the classification score H includes both the hierarchical coefficient h1 and the explanatory coefficient h2 as elements, but the present invention is not limited to this.
- the classification processing means 133 may use the hierarchical coefficient h1 as the classification score H as it is, or may use the explanation coefficient h2 as the classification score H as it is. That is, the weight information may be configured to include at least one of the hierarchical coefficient h1 and the explanatory coefficient h2. Note that the classification processing unit 133 does not need to acquire hierarchical data when the hierarchical coefficient h1 is not used, and does not need to acquire description data when the explanatory coefficient h2 is not used.
- the rating processing means 134 may obtain the target score T without using the classification coefficient g. That is, the weight information may be configured without including the classification coefficient g.
- the rating processing means 134 may obtain the target score T without using the citation coefficient f. That is, the weight information may be configured without including the citation coefficient f.
- the rating processing means 134 may obtain the target score T without using the publication coefficient e. In other words, the weight information may be constructed without including the publication coefficient e, in which case the publication processing means 132 is not required.
- the rating processing means 134 may obtain the target score T without using the classification score H.
- the weight information may be configured without including the classification score H, in which case the classification processing means 133 is not required.
- the rating processing means 134 may obtain the target score T without using the related score U.
- the weight information may be constructed without including the related score U, in which case the word processing means 131 is not required.
- 10 company evaluation device 11 communication unit, 12 storage unit, 12a related data, 12b target list, 12c related table, 12d publication coefficient table, 12e hierarchy table, 12f word table, 12g extraction number table, 12h classification table, 13 control unit , 13a collection processing means, 13b processing means, 13c evaluation processing means, 40 information terminal, 50 management terminal, 80 information terminal, 100 rating server group, 110 rating server, 120 evaluation database section, 120a evaluation database, 131 word processing means, 132 publication processing means, 133 classification processing means, 134 rating processing means, 200 company evaluation system, 300 information providing server group, D word coefficient, H classification score, K extraction coefficient, M1 estimation model, N network, P1 company evaluation program, T target score, Ts evaluation score, U related score, W related word, a detail coefficient, b summary coefficient, c claim coefficient, d related coefficient, e publication coefficient, f citation coefficient, g classification coefficient, h1 hierarchy coefficient, h2 Explanation factor.
Landscapes
- Business, Economics & Management (AREA)
- Engineering & Computer Science (AREA)
- Human Resources & Organizations (AREA)
- Strategic Management (AREA)
- Economics (AREA)
- Development Economics (AREA)
- Entrepreneurship & Innovation (AREA)
- Educational Administration (AREA)
- Tourism & Hospitality (AREA)
- Marketing (AREA)
- Physics & Mathematics (AREA)
- General Business, Economics & Management (AREA)
- General Physics & Mathematics (AREA)
- Theoretical Computer Science (AREA)
- Operations Research (AREA)
- Quality & Reliability (AREA)
- Game Theory and Decision Science (AREA)
- Technology Law (AREA)
- Health & Medical Sciences (AREA)
- General Health & Medical Sciences (AREA)
- Primary Health Care (AREA)
- Accounting & Taxation (AREA)
- Finance (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
- Management, Administration, Business Operations System, And Electronic Commerce (AREA)
Abstract
Description
図1を参照して、本実施の形態における企業評価装置10及びその周辺環境に係る構成例について説明する。企業評価装置10は、評価対象の企業に紐付けられた1又は複数の産業財産権に関する情報の、企業の経営方針に組み込まれる経営指標に対する関連性の度合いを解析するアルゴリズムを用いて、企業を経営指標の観点から評価するものである。企業評価装置10は、機械学習を用いた手法により、企業を経営指標の観点から評価する機能を有している。経営指標は、環境面や社会的側面にも配慮した指標であり、特に中長期的な企業の経営方針に組み込まれるものである。

分類処理手段133は、説明データから1つだけ抽出された関連ワードWについては、該関連ワードWをワードテーブル12fに照らしてワード係数Dを抽出し、これを説明係数h2として記憶部12に記憶させる。
分類処理手段133は、説明データから複数の同じ関連ワードWが抽出された場合、該関連ワードWをワードテーブル12fに照らしてワード係数Dを求めると共に、該関連ワードWが抽出された数である抽出数を抽出数テーブル12gに照らして抽出係数Kを求める。そして、分類処理手段133は、求めたワード係数D及び抽出係数Kを用いて説明係数h2を求める。分類処理手段133は、例えば、ワード係数Dと抽出係数Kとの積を説明係数h2とする。

まず、名寄せ処理手段13bは、複数の対象情報のそれぞれに含まれる出願番号と、該各出願番号のそれぞれに紐付く名称データ及びファミリーIDを抽出する(ステップS101)。名寄せ処理手段13bは、抽出したファミリーIDに基づいて出願番号及び名称データをリスト化すると共に、同一の企業等に対応する1又は複数の名称データに固有の共通データを対応づけて対象リスト12bを作成する(ステップS102)。
(ワード処理工程)
ワード処理手段131は、各対象情報から複数の関連ワードWを検索し、対象情報ごとに、関連ワードWに紐付く重み情報を求める。そして、ワード処理手段131は、各関連ワードWの検索数及び重み情報に基づいて、対象情報ごとの関連スコアUを求める。また、ワード処理手段131は、対象情報と関連スコアUとを対応づけた関連テーブル12cを作成する(ステップS103)。
公報処理手段132は、各対象情報に含まれるコアデータから、対象情報ごとに推定用データを生成する。また、公報処理手段132は、生成した推定用データを推定モデルM1の入力として、各対象情報それぞれの公報係数eを求める。そして、公報処理手段132は、対象情報と公報係数eとを対応づけた公報係数テーブル12dを作成する(ステップS104)。
分類処理手段133は、各対象情報及び情報提供サーバ群300等から分類情報を抽出し、分類情報に基づいて、対象情報ごとの分類スコアHを求める。そして、分類処理手段133は、対象情報と分類スコアHとを対応づけた分類テーブル12hを作成する(ステップS105)。
次いで、格付処理手段134は、各対象情報について、関連テーブル12cから関連スコアUを読み出し、公報係数テーブル12dから公報係数eを読み出し、分類テーブル12hから分類スコアHを読み出すと共に、記憶部12から分類係数g及び被引用係数fを読み出す。そして、格付処理手段134は、読み出した各情報を用いて、例えば式(2)のような演算により、対象スコアTを求める(ステップS106)。
上記においては、分類処理手段133が、対象スコアTを求める際に分類スコアHを都度求める例を説明したが、これに限定されない。例えば、記憶部12には、説明文に関連ワードWもしくは抽出ワードが含まれる分類コードと、分類スコアHとを対応づけた分類テーブル12hを予め格納しておいてもよい。
Claims (11)
- 企業に紐付けられた1又は複数の産業財産権に関する情報の、企業の経営方針に組み込まれる経営指標に対する関連性の度合いを企業評価に反映させる重み情報を用いて、前記経営指標の観点での企業の評価結果を求める評価処理手段を有する、企業評価装置。
- 前記評価処理手段は、
企業に紐付けられた1又は複数の前記産業財産権に関する情報から、前記経営指標に関連する複数の関連ワードを検索し、検索された前記関連ワードに紐付く前記重み情報を用いて前記評価結果を求めるものである、請求項1に記載の企業評価装置。 - 前記評価処理手段は、
前記関連ワードに紐付く前記重み情報として、
複数の前記関連ワードのうちの少なくとも1つに設定される関連係数を用いるものである、請求項2に記載の企業評価装置。 - 前記評価処理手段は、
前記関連ワードに紐付く前記重み情報として、
前記関連ワードの検索数を用いるものである、請求項2又は3に記載の企業評価装置。 - 前記評価処理手段は、
前記関連ワードに紐付く前記重み情報として、
前記関連ワードの所在に応じて設定される所在係数を用いるものである、請求項2~4の何れか一項に記載の企業評価装置。 - 前記産業財産権は、特許権又は実用新案権であり、
前記所在係数は、
明細書に対応する明細係数と、
要約書に対応し、前記明細係数よりも大きく設定される要約係数と、
請求の範囲に対応し、前記要約係数よりも大きく設定される請求係数と、を含む、請求項5に記載の企業評価装置。 - 前記産業財産権は、特許権又は実用新案権であり、
前記評価処理手段は、
公報の内容の有効性の程度に応じて設定される公報係数を用いて前記評価結果を求めるものである、請求項1~6の何れか一項に記載の企業評価装置。 - 前記産業財産権は、特許権又は実用新案権であり、
前記評価処理手段は、
前記重み情報として、複数の分類コードが階層構造により整理された特許分類における、前記分類コードごとに設定された分類スコアを用いて前記評価結果を求めるものである、請求項1~7の何れか一項に記載の企業評価装置。 - 前記分類スコアは、
前記分類コードの階層ごとに、上位層よりも下位層の方が大きくなるよう段階的に設定された階層係数を要素とするものである、請求項8に記載の企業評価装置。 - 前記分類コードには説明文が紐付けられており、
前記分類スコアは、
前記説明文の内容に基づく説明係数を要素とするものである、請求項8又は9に記載の企業評価装置。 - 企業に紐付けられた1又は複数の産業財産権に関する情報の、企業の経営方針に組み込まれる経営指標に対する関連性の度合いを企業評価に反映させる重み情報を用いて、前記経営指標の観点での企業の評価結果を求める、企業評価方法。
Priority Applications (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| EP22804799.9A EP4339874A4 (en) | 2021-05-15 | 2022-06-01 | COMPANY VALUATION DEVICE AND COMPANY VALUATION PROCEDURE |
| US18/558,350 US20240220905A1 (en) | 2021-05-15 | 2022-06-01 | Company evaluation device and company evaluation method |
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2021082843A JP2022176388A (ja) | 2021-05-15 | 2021-05-15 | 企業評価装置及び企業評価方法 |
| JP2021-082843 | 2021-05-15 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2022244892A1 true WO2022244892A1 (ja) | 2022-11-24 |
Family
ID=84141756
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2022/022254 Ceased WO2022244892A1 (ja) | 2021-05-15 | 2022-06-01 | 企業評価装置及び企業評価方法 |
Country Status (4)
| Country | Link |
|---|---|
| US (1) | US20240220905A1 (ja) |
| EP (1) | EP4339874A4 (ja) |
| JP (1) | JP2022176388A (ja) |
| WO (1) | WO2022244892A1 (ja) |
Families Citing this family (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2024065118A (ja) * | 2021-01-15 | 2024-05-15 | IPDefine株式会社 | データ提供装置、データ管理システム、データ提供システム、データ提供プログラム、データ分析プログラム、記録媒体、データ提供方法、及びデータ管理方法 |
| KR102936744B1 (ko) * | 2023-05-26 | 2026-03-09 | 강원대학교산학협력단 | 기업별 esg 보고서를 이용한 esg 점수 산출 방법 및 이를 기록한 기록매체 |
Citations (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2005041096A1 (ja) * | 2003-10-23 | 2005-05-06 | Intellectual Property Bank Corp. | 企業評価装置並びに企業評価プログラム |
| JP2005326897A (ja) * | 2003-10-21 | 2005-11-24 | Ipb:Kk | 技術・知財評価装置及び技術・知財評価方法 |
| WO2006004132A1 (ja) * | 2004-07-05 | 2006-01-12 | Intellectual Property Bank Corp. | 企業評価寄与因子及び/又は指標特定装置、特定プログラム並びに特定方法 |
| KR20110068277A (ko) * | 2009-12-15 | 2011-06-22 | 한국발명진흥회 | 특허 자동 평가 시스템 및 상기 시스템에서의 평가 요소 정보 처리 방법 |
| CN109447699A (zh) * | 2018-10-23 | 2019-03-08 | 国网江苏省电力有限公司 | 一种专利价值评估系统 |
| JP2021504789A (ja) | 2017-11-23 | 2021-02-15 | アイエスディー インコーポレーテッド | Esg基盤の企業評価遂行装置及びその作動方法 |
| JP2021033365A (ja) * | 2019-08-15 | 2021-03-01 | 株式会社カネカ | 指標算出装置および指標算出プログラム |
Family Cites Families (15)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US6963920B1 (en) * | 1993-11-19 | 2005-11-08 | Rose Blush Software Llc | Intellectual asset protocol for defining data exchange rules and formats for universal intellectual asset documents, and systems, methods, and computer program products related to same |
| US20060178963A1 (en) * | 2003-03-17 | 2006-08-10 | Hiroaki Masuyama | Enterprise value evaluation device and enterprise value evaluation program |
| KR20060108614A (ko) * | 2003-10-23 | 2006-10-18 | 가부시키가이샤 아이.피.비. | 기업 평가 장치 및 기업 평가 프로그램 |
| US7716226B2 (en) * | 2005-09-27 | 2010-05-11 | Patentratings, Llc | Method and system for probabilistically quantifying and visualizing relevance between two or more citationally or contextually related data objects |
| US10534820B2 (en) * | 2006-01-27 | 2020-01-14 | Richard A. Heggem | Enhanced buyer-oriented search results |
| US20200349512A1 (en) * | 2007-06-22 | 2020-11-05 | Ichiro Kudo | Patent power calculating device and method for operating patent power calculating device |
| US9898767B2 (en) * | 2007-11-14 | 2018-02-20 | Panjiva, Inc. | Transaction facilitating marketplace platform |
| US8447702B2 (en) * | 2010-02-19 | 2013-05-21 | Go Daddy Operating Company, LLC | Domain appraisal algorithm |
| US9223852B2 (en) * | 2010-06-11 | 2015-12-29 | Salesforce.Com, Inc. | Methods and systems for analyzing search terms in a multi-tenant database system environment |
| US20120191619A1 (en) * | 2011-01-20 | 2012-07-26 | John Nicholas Gross | System & Method For Locating & Assessing Intellectual Property Assets |
| US10891701B2 (en) * | 2011-04-15 | 2021-01-12 | Rowan TELS Corp. | Method and system for evaluating intellectual property |
| US20120278244A1 (en) * | 2011-04-15 | 2012-11-01 | IP Street | Evaluating Intellectual Property |
| US11314753B2 (en) * | 2016-09-26 | 2022-04-26 | Splunk Inc. | Execution of a query received from a data intake and query system |
| KR101932352B1 (ko) * | 2017-10-27 | 2018-12-24 | 석 영 정 | 국가직무능력표준 기반의 도급 거래 매칭 서비스 방법 및 그를 이용하는 시스템 |
| KR20180051380A (ko) * | 2017-10-27 | 2018-05-16 | 석 영 정 | 국가직무능력표준 기반의 유틸리티 매칭 서비스 방법 및 그를 이용하는 시스템 |
-
2021
- 2021-05-15 JP JP2021082843A patent/JP2022176388A/ja active Pending
-
2022
- 2022-06-01 US US18/558,350 patent/US20240220905A1/en active Pending
- 2022-06-01 EP EP22804799.9A patent/EP4339874A4/en not_active Withdrawn
- 2022-06-01 WO PCT/JP2022/022254 patent/WO2022244892A1/ja not_active Ceased
Patent Citations (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2005326897A (ja) * | 2003-10-21 | 2005-11-24 | Ipb:Kk | 技術・知財評価装置及び技術・知財評価方法 |
| WO2005041096A1 (ja) * | 2003-10-23 | 2005-05-06 | Intellectual Property Bank Corp. | 企業評価装置並びに企業評価プログラム |
| WO2006004132A1 (ja) * | 2004-07-05 | 2006-01-12 | Intellectual Property Bank Corp. | 企業評価寄与因子及び/又は指標特定装置、特定プログラム並びに特定方法 |
| KR20110068277A (ko) * | 2009-12-15 | 2011-06-22 | 한국발명진흥회 | 특허 자동 평가 시스템 및 상기 시스템에서의 평가 요소 정보 처리 방법 |
| JP2021504789A (ja) | 2017-11-23 | 2021-02-15 | アイエスディー インコーポレーテッド | Esg基盤の企業評価遂行装置及びその作動方法 |
| CN109447699A (zh) * | 2018-10-23 | 2019-03-08 | 国网江苏省电力有限公司 | 一种专利价值评估系统 |
| JP2021033365A (ja) * | 2019-08-15 | 2021-03-01 | 株式会社カネカ | 指標算出装置および指標算出プログラム |
Non-Patent Citations (1)
| Title |
|---|
| See also references of EP4339874A4 |
Also Published As
| Publication number | Publication date |
|---|---|
| US20240220905A1 (en) | 2024-07-04 |
| JP2022176388A (ja) | 2022-11-28 |
| EP4339874A1 (en) | 2024-03-20 |
| EP4339874A4 (en) | 2024-11-06 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US8983963B2 (en) | Techniques for comparing and clustering documents | |
| US9201866B2 (en) | Computer-implemented systems and methods for mood state determination | |
| CN102770857B (zh) | 关系信息扩展装置、关系信息扩展方法以及程序 | |
| JP5817531B2 (ja) | 文書クラスタリングシステム、文書クラスタリング方法およびプログラム | |
| Stokes et al. | Exploring criteria for successful query expansion in the genomic domain | |
| Bhat et al. | Sumitup: A hybrid single-document text summarizer | |
| Merola et al. | Reconstructing context: Evaluating advanced chunking strategies for retrieval-augmented generation | |
| CN111630518A (zh) | 基于esg的企业评价执行装置及其运转方法 | |
| Gkotsis et al. | It's all in the content: state of the art best answer prediction based on discretisation of shallow linguistic features | |
| US20160364428A1 (en) | Database update and analytics system | |
| Khan et al. | Multi-objective model selection (MOMS)-based semi-supervised framework for sentiment analysis | |
| JP5836893B2 (ja) | ファイル管理装置、ファイル管理方法、及びプログラム | |
| Alotaibi et al. | A cognitive inspired unsupervised language-independent text stemmer for Information retrieval | |
| WO2022244892A1 (ja) | 企業評価装置及び企業評価方法 | |
| Nasr | Building sentiment analysis model using Graphlab | |
| Balaguer et al. | CatSent: a Catalan sentiment analysis website | |
| Verma et al. | Extraction based text summarization methods on user’s review data: A comparative study | |
| Hussain et al. | A technique for perceiving abusive bangla comments | |
| Kim et al. | Opinion Mining‐Based Term Extraction Sentiment Classification Modeling | |
| Gözükara et al. | Türkçe ve ingilizce yorumların duygu analizinde doküman vektörü hesaplama yöntemleri için bir deneysel inceleme | |
| Wrzalik et al. | Balanced word clusters for interpretable document representation | |
| Lee et al. | Knowledge structure of Korean medical informatics: A social network analysis of articles in journal and proceedings | |
| Rybiński et al. | DomESA: a novel approach for extending domain-oriented lexical relatedness calculations with domain-specific semantics | |
| McCarthy et al. | Text Analytics: Using Qualitative Data to Support Quantitative Results | |
| Gupta et al. | Suicidal tendency on social media by using text mining |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 22804799 Country of ref document: EP Kind code of ref document: A1 |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 18558350 Country of ref document: US |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 2022804799 Country of ref document: EP |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| ENP | Entry into the national phase |
Ref document number: 2022804799 Country of ref document: EP Effective date: 20231215 |
|
| WWW | Wipo information: withdrawn in national office |
Ref document number: 2022804799 Country of ref document: EP |