WO2023007544A1 - 情報処理装置、情報処理方法、およびプログラム - Google Patents
情報処理装置、情報処理方法、およびプログラム Download PDFInfo
- Publication number
- WO2023007544A1 WO2023007544A1 PCT/JP2021/027527 JP2021027527W WO2023007544A1 WO 2023007544 A1 WO2023007544 A1 WO 2023007544A1 JP 2021027527 W JP2021027527 W JP 2021027527W WO 2023007544 A1 WO2023007544 A1 WO 2023007544A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- modalities
- feature values
- learning model
- information processing
- feature
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Ceased
Links
Images






Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/0464—Convolutional networks [CNN, ConvNet]
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/08—Learning methods
- G06N3/0895—Weakly supervised learning, e.g. semi-supervised or self-supervised learning
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/045—Combinations of networks
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/08—Learning methods
- G06N3/09—Supervised learning
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06Q—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR ADMINISTRATIVE, COMMERCIAL, FINANCIAL, MANAGERIAL OR SUPERVISORY PURPOSES; SYSTEMS OR METHODS SPECIALLY ADAPTED FOR ADMINISTRATIVE, COMMERCIAL, FINANCIAL, MANAGERIAL OR SUPERVISORY PURPOSES, NOT OTHERWISE PROVIDED FOR
- G06Q30/00—Commerce
- G06Q30/06—Buying, selling or leasing transactions
- G06Q30/0601—Electronic shopping [e-shopping]
- G06Q30/0623—Electronic shopping [e-shopping] by investigating goods or services
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06Q—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR ADMINISTRATIVE, COMMERCIAL, FINANCIAL, MANAGERIAL OR SUPERVISORY PURPOSES; SYSTEMS OR METHODS SPECIALLY ADAPTED FOR ADMINISTRATIVE, COMMERCIAL, FINANCIAL, MANAGERIAL OR SUPERVISORY PURPOSES, NOT OTHERWISE PROVIDED FOR
- G06Q30/00—Commerce
- G06Q30/06—Buying, selling or leasing transactions
- G06Q30/0601—Electronic shopping [e-shopping]
- G06Q30/0631—Recommending goods or services
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/048—Activation functions
Definitions
- the present invention relates to an information processing device, an information processing method, and a program, and more particularly to a technology for predicting attributes of a given object from multiple pieces of information related to the object.
- Machine learning including deep learning
- deep learning is known as a method for achieving complex identification and estimation with high accuracy.
- multimodal deep learning that identifies arbitrary events/attributes by combining multiple modalities such as images, text, voice, and sensor values is attracting attention.
- E-commerce/e-commerce electronic commerce
- EC Electronic Commerce
- Many are built in EC sites are often constructed using the languages of countries around the world, enabling users (consumers) living in many countries to purchase products.
- PC Personal Computer
- a mobile terminal such as a smartphone
- users can select and purchase desired products without going to the actual store and regardless of time. It's becoming For the purpose of increasing the user's willingness to buy, on the EC site, the user browses products that have the same attributes as the products that the user has purchased in the past (information specific to the product) as recommended products.
- Non-Patent Document 1 discloses a method of using multimodal deep learning to treat product-related information as modalities, and to predict and identify product attributes from multiple modalities.
- two modalities, an image of the product and a text describing the product are input as information related to the product, and from the results of combining and linking the two modalities, the color and part of the product are determined as attributes of the product. Identifies a typical shape.
- Non-Patent Document 1 by combining two modalities, which are the image of the product and the text describing the product, the attribute of the product can be improved compared to the case where only the text describing the product is used. The effect of increasing the prediction accuracy is obtained.
- modalities which are the image of the product and the text describing the product.
- the present invention has been made to solve the above problems, and an object of the present invention is to provide an information processing apparatus and an information processing apparatus capable of appropriately identifying attributes of an object such as a product from a plurality of pieces of information related to the object.
- the object is to provide a method and a program.
- one aspect of the information processing apparatus includes acquisition means for acquiring a plurality of modalities related to an object and information identifying the object; feature generation means for generating; derivation means for deriving weights corresponding to each of the plurality of modalities based on the feature values of each of the plurality of modalities and information identifying the object; and feature values of each of the plurality of modalities are weighted by the corresponding weights and concatenated to predict the attribute of the object.
- the derivation means from the plurality of feature values and the information identifying the object, assigns attention weights indicating the degree of importance of each of the plurality of modalities to prediction of the attribute as weights corresponding to each of the plurality of feature values. can be derived.
- the attention weights of the plurality of modalities may be 1 in total.
- One aspect of an information processing apparatus is an acquisition unit configured to acquire a plurality of modalities related to an object and information identifying the object; feature generating means for generating a plurality of feature values for each of the modalities; and applying the feature values of each of the plurality of modalities and the information identifying the object to a second learning model to correspond to each of the plurality of feature values. and a deriving means for deriving a weight to predict the attribute of the object by applying a concatenated value obtained by weighting and concatenating the feature values of the plurality of modalities with the corresponding weight to a third learning model. and prediction means, wherein the second learning model is a learning model that outputs different weights for each of the objects.
- the second learning model receives as input the plurality of feature values and information identifying the object, and assigns an attention weight indicating importance of each of the plurality of modalities to prediction of the attribute to each of the plurality of feature values. It can be a learning model that outputs as corresponding weights.
- the attention weights of the plurality of modalities may be 1 in total.
- the first learning model may be a learning model that takes the plurality of modalities as input, maps the plurality of modalities to a latent space common to the plurality of modalities, and outputs feature values of the plurality of modalities.
- the third learning model may be a learning model that receives the concatenated value as an input and outputs a prediction result of the attribute.
- the acquisition means may acquire the plurality of modalities from the website on which the object is posted.
- the object is a product
- the plurality of modalities may include two or more of image data representing the product, text data describing the product, and audio data describing the product.
- the attributes of the object may include color information of the product.
- One aspect of an information processing method includes an acquisition step of acquiring a plurality of modalities related to an object and information identifying the object; a feature generation step of generating a feature value for each of the plurality of modalities; a derivation step of deriving a weight corresponding to each of the plurality of modalities based on the feature value of each of the plurality of modalities and the information identifying the object; and weighting the feature value of each of the plurality of modalities with the corresponding weight. and a prediction step of predicting attributes of the object from the concatenated values concatenated with the attributes.
- One aspect of an information processing method is an acquisition step of acquiring a plurality of modalities related to an object and information identifying the object; and applying the feature values of each of the plurality of modalities and the information identifying the object to a second learning model, corresponding to each of the plurality of feature values a deriving step of deriving a weight; and a prediction of predicting an attribute of the object by applying a concatenated value obtained by weighting and concatenating the feature values of each of the plurality of modalities with the corresponding weight to a third learning model.
- the second learning model is a learning model that outputs different weights for each of the objects.
- One aspect of an information processing program is an information processing program for causing a computer to execute information processing, the program providing the computer with a plurality of modalities related to an object and information identifying the object.
- a feature generation process for generating feature values for each of the plurality of modalities; and corresponding to each of the plurality of modalities based on the feature values for each of the plurality of modalities and the information identifying the object.
- One aspect of an information processing program is an information processing program for causing a computer to execute information processing, the program providing the computer with a plurality of modalities related to an object and information identifying the object.
- a feature generation process for generating a plurality of feature values for the plurality of modalities by applying the plurality of modalities to a first learning model; and a feature value for each of the plurality of modalities and the object a derivation process for deriving weights corresponding to each of the plurality of feature values by applying information identifying the modalities to the second learning model; and weighting the feature values of each of the plurality of modalities with the corresponding weights.
- a prediction process of predicting the attribute of the object by applying the concatenated value concatenated by the third learning model to the third learning model, the second learning model being different for each object It is a learning model that outputs weights.
- FIG. 1 is a block diagram showing an example of the functional configuration of a classification device according to an embodiment of the invention.
- FIG. 2 is a block diagram showing an example of the hardware configuration of the classification device according to the embodiment of the present invention.
- FIG. 3 is a conceptual diagram illustrating processing by the feature generation unit, attention unit, and classification unit according to the embodiment of the present invention.
- FIG. 4A shows an example of attention weight distribution.
- FIG. 4B shows another example of attention weight distribution.
- FIG. 5 shows an example of attention weight distribution for image data and text data.
- FIG. 6 is a flow chart showing an example of a processing procedure of classification processing executed by the classification device according to the embodiment of the present invention.
- FIG. 7 shows an example of a web page screen on the EC site.
- FIG. 8 shows another example of a web page screen on the EC site.
- FIG. 9 shows a performance comparison of attribute prediction according to the prior art and embodiments of the present invention.
- a classifier acquires a plurality of modalities associated with a given object and information identifying the object, generates feature values for each of the plurality of modalities, and identifies the feature values and the object. Weights corresponding to each of the plurality of modalities are derived based on the information, and attributes of the object are predicted from concatenated values obtained by weighting and concatenating the feature values with the corresponding weights.
- modality indicates information related to an object, and is synonymous with modality information, modality item, and modality value, and may be referred to as such.
- An example of an object is a product distributed in electronic commerce.
- An example of a plurality of modalities, which are information related to an object is image data representing an image of a product (hereinafter simply referred to as image data) and text data describing the product (hereinafter simply referred to as text data).
- image data an image of a product
- text data describing the product
- An example of an attribute of an object is color information of the product when the object is a product. It should be noted that the following only describes a non-limiting example of the sorting device, and the object is not limited to goods, but may be any service that can be provided to the user.
- the plurality of pieces of information related to the object are not limited to image and text data, and any information related to the object such as voice data may be used.
- the attribute of an object can be any information specific to an object, not just color information.
- FIG. 1 shows an example of the functional configuration of a classification device 1 according to this embodiment.
- the learning model storage unit 16 stores a first learning model 17, a second learning model 18, and a third learning model 19, which are pre-learned models.
- the acquisition unit 11 acquires a plurality of modalities (modalities 10-i to 10-n (n is an integer equal to or greater than 2)).
- the acquisition unit 11 may acquire a plurality of modalities by an input operation through the input unit 25 (FIG. 2) by the user (operator) who operates the classification device 1, or may be acquired by the storage unit (FIG. 2) by the user's operation. may be acquired from the ROM 22 or RAM 23).
- the acquisition unit 11 may acquire a plurality of modalities received from an external device via the communication I/F 27 (FIG. 2).
- the acquisition unit 11 may acquire a plurality of modalities directly, or may acquire the plurality of modalities after performing extraction processing on the data. For example, if the data input via the input unit 25 is data containing a mixture of multiple modalities, the acquiring unit 11 may extract and acquire the multiple modalities from the data. As a specific example, when the object is a product, the multiple modalities are image data and text data, and the input data is a web page on which the product is posted on an EC site, the acquisition unit 11 retrieves the product from the web page. , image data and text data can be extracted and obtained.
- a plurality of modalities may be associated with information identifying an object associated with the modality, and the obtaining unit 11 is configured to obtain information identifying an object by obtaining a plurality of modalities.
- the acquisition unit 11 may acquire information for identifying objects related to modalities separately from a plurality of modalities.
- Acquisition unit 11 outputs the acquired modalities to feature generation unit 12 .
- the acquisition unit 11 may output the information to the attention unit 13 when information for identifying an object is acquired separately from a plurality of modalities.
- the acquisition unit 11 may also encode each of the acquired modalities and output the encoded modalities to the attention unit 13 .
- the feature generation unit 12 acquires a plurality of modalities (which may be encoded multiple modalities; the same applies hereinafter) output from the acquisition unit 11, and generates a feature value for each modality.
- the feature generation unit 12 applies the plurality of modalities to the first learning model 17 stored in the learning model storage unit 16 to generate feature values (characteristic expressions) for each modality.
- the feature generation unit 12 uses the first learning model 17 to project (map) a plurality of modalities onto a latent space common to all modalities of the plurality of modalities, thereby condensing information indicating features. Feature values can be obtained.
- the latent space refers to a space in which different modalities, that is, modalities with different dimensions are projected by compressing the dimensions, and feature amounts/feature values of the different modalities are expressed in this common space.
- the feature generation unit 12 reduces the amount of information for each modality by compressing the dimensions of the input data of a plurality of modalities, that is, generates a latent space representation (feature value) that is a low-dimensional space after compression. can do.
- the first learning model 17 is, for example, a model constructed by a neural network of FCN (Fully Connected Network).
- FCN is a type of CNN (Convolutional Neural Network), and is a network in which a fully connected layer of the CNN is replaced with an upsampled convolutional layer. SegNet or the like can also be used as a neural network model.
- the feature generation unit 12 outputs the generated feature value of each modality to the attention unit 13 and the classification unit 14 .
- the attention unit 13 acquires the feature value of each modality from the feature generation unit 12, and generates an attention weight for each modality from the feature value and information identifying the object.
- the attention unit 13 applies the feature value of each modality and the information identifying the object to the second learning model 18 stored in the learning model storage unit 16, thereby determining the attention weight for each modality.
- the attention weight indicates the degree of importance of each of a plurality of modalities in predicting the attribute of the object.
- the second learning model 18 is, for example, a model constructed by a neural network (attention network) that acquires attention information.
- the attention weight for each modality is generated according to the objects associated with the multiple modalities acquired by the acquisition unit 11 .
- the attention weights generated for each modality may vary between when the object is product A and when it is product B (product B is different from product A).
- the attention weights for the plurality of modalities acquired by the acquisition unit 11 are, for example, 1 in total.
- the attention weight generated by the attention unit 13 will be described later with reference to FIGS. 3 to 5.
- FIG. The attention unit 13 outputs the generated attention weight for each modality to the classification unit 14 .
- the classification unit 14 acquires the feature value of each modality from the feature generation unit 12, acquires the attention weight for each modality from the attention unit 13, and predicts the attribute of the object from these pieces of information.
- the classification unit 14 uses the third learning model 19 stored in the learning model storage unit 16 to predict attributes of objects. Specifically, the classification unit 14 first applies (for example, multiplies) each feature value (feature value of each modality) to the attention weight for each feature value to generate a weighted feature value, Concatenate (integrate) the weighted feature values to obtain a concatenated value.
- the classification unit 14 applies the concatenated value to the third learning model 19 to predict and classify the attribute class label (correct data).
- the classification unit 14 generates and outputs classification result information according to the classification.
- the classification unit 14 outputs the color information of the object obtained by applying the third learning model 19 from the concatenated value as the classification result (prediction result).
- the classification result may be the color information itself, or may be an index (R@P95) or the like indicating the recall rate (Recall) that the matching rate (Precision) with the correct data is 95%.
- the classification unit 14 may output the classification result to an external device (not shown) via, for example, the communication I/F 27 (FIG. 2), or may display the classification result on the display unit 26 (FIG. 2).
- the third learning model 19 is, for example, a model constructed by a multi-layer neural network having an input layer, an intermediate layer (hidden layer), and an output layer consisting of multiple nodes.
- the multilayer neural network can be, for example, DNN (Deep Neural Network), CNN, RNN (Recurrent Neural Network), LSTM (Long Short-Term Memory).
- the learning unit 15 learns the first learning model 17, the second learning model 18, and the third learning model 19, respectively. Update various parameters of .
- a sufficient number of samples input to the learning unit 15 in advance, correct data for a plurality of modalities (that is, information indicating attributes of objects to which the plurality of modalities are related) are used. can be performed using
- the learning unit 15 can update various parameters for the neural network according to, for example, a gradient descent optimization procedure, based on a comparison between the classification results of the classification unit 14 for a plurality of modalities acquired by the acquisition unit 11 and the correct data. .
- the first learning model 17 , the second learning model 18 , and the third learning model 19 that have been learned by the learning unit 15 and have their parameters updated are stored in the learning model storage unit 16 .
- the configuration shown in FIG. 1 is an example of the functional configuration of the classification device 1, and does not mean that the classification device 1 according to this embodiment is implemented in a single device.
- the functional configuration shown in FIG. 1 may be implemented, for example, in a plurality of devices such as servers interconnected by a network, and each unit and storage unit of the classification device 1 shown in FIG. 1 may be implemented in the same device. , may be implemented in different devices from each other.
- the feature generation unit 12 and the attention unit 13 of the classification device 1 may be implemented in different devices.
- the learning model storage unit 16 may be configured outside the classification device 1 .
- FIG. 2 is a block diagram showing an example of the hardware configuration of the classification device 1 according to this embodiment.
- the classifier 1 according to this embodiment can be implemented on any computer, mobile device or any other processing platform, single or multiple. With reference to FIG. 2, an example in which the classification device 1 is implemented in a single computer is shown, but the classification device 1 according to this embodiment may be implemented in a computer system including a plurality of computers. A plurality of computers may be interconnectably connected by a wired or wireless network.
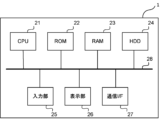
- the classification device 1 may include a CPU 21 , a ROM 22 , a RAM 23 , an HDD 24 , an input section 25 , a display section 26 , a communication I/F 27 and a system bus 28 .
- the classification device 1 may also comprise an external memory.
- a CPU (Central Processing Unit) 21 comprehensively controls the operation of the classification apparatus 1, and controls each component (22 to 27) via a system bus 28, which is a data transmission line.
- a ROM (Read Only Memory) 22 is a non-volatile memory that stores control programs and the like necessary for the CPU 21 to execute processing.
- the program may be stored in a non-volatile memory such as HDD (Hard Disk Drive) 24 or SSD (Solid State Drive) or external memory such as a removable storage medium (not shown).
- a RAM (Random Access Memory) 23 is a volatile memory and functions as a main memory of the CPU 81, a work area, and the like. That is, the CPU 21 loads necessary programs and the like from the ROM 22 to the RAM 23 when executing processing, and executes the programs and the like to realize various functional operations.
- the HDD 24 stores, for example, various data and information necessary for the CPU 21 to perform processing using programs. Further, the HDD 24 stores various data, various information, and the like obtained by the CPU 21 performing processing using programs and the like, for example.
- the input unit 25 is composed of a pointing device such as a keyboard and a mouse.
- the display unit 26 is configured by a monitor such as a liquid crystal display (LCD).
- the display unit 26 displays a GUI (Graphical User Interface), which is a user interface for inputting instructions to the classification device 1, such as various parameters used in keyword identification processing and communication parameters used in communication with other devices. may provide.
- GUI Graphic User Interface
- the communication I/F 27 is an interface that controls communication between the classification device 1 and an external device.
- a communication I/F 27 provides an interface with a network and executes communication with an external device via the network.
- Various data, various parameters, etc. are transmitted/received to/from an external device via the communication I/F 27 .
- the communication I/F 27 may perform communication via a wired LAN (Local Area Network) conforming to a communication standard such as Ethernet (registered trademark) or a dedicated line.
- the network that can be used in this embodiment is not limited to this, and may be configured as a wireless network.
- This wireless network includes a wireless PAN (Personal Area Network) such as Bluetooth (registered trademark), ZigBee (registered trademark), and UWB (Ultra Wide Band). It also includes a wireless LAN (Local Area Network) such as Wi-Fi (Wireless Fidelity) (registered trademark) and a wireless MAN (Metropolitan Area Network) such as WiMAX (registered trademark). Furthermore, wireless WANs (Wide Area Networks) such as LTE/3G, 4G, and 5G are included. It should be noted that the network connects each device so as to be able to communicate with each other, and the communication standard, scale, and configuration are not limited to those described above.
- At least some of the functions of the elements of the classification device 1 shown in FIG. 1 can be realized by the CPU 21 executing a program. However, at least some of the functions of the elements of the classification device 1 shown in FIG. 1 may operate as dedicated hardware. In this case, the dedicated hardware operates under the control of the CPU 21 .
- FIG. 3 is a conceptual diagram illustrating processing by the feature generation unit 12, the attention unit 13, and the classification unit 14 of the classification device 1.
- the feature generation unit 12 uses the first learning model 17 constructed by the FCN neural network
- the attention unit 12 uses the second learning model 18 constructed by the attention network.
- the classification unit 14 uses a third learning model 19 constructed by a DNN neural network.
- the multiple modalities acquired by the acquisition unit 11 are image data and text data related to a product, which is an object.
- image data (Image data) is expressed as m i (j)
- text data (Text data) is expressed as m t (j)
- j is a parameter (information) for identifying a product.
- the feature generation unit 12 applies an FCN neural network to each of the image data h i (j) and the text data h t (j) , and from the output layer, the image data h i Obtain the feature value f ⁇ (h i (j) ) of (j) and the feature value f ⁇ (h t (j) ) of the text data h t (j) .
- f ⁇ (.) is the FCN neural network parameterized by ⁇ .
- the attention unit 12 passes the feature value f ⁇ (h i (j) ) of the image data h i (j) and the feature value f ⁇ (h t ( j) ) of the text data h t (j) to the attention network. Then, by inputting the vector of the output layer into a sigmoid function ( ⁇ ), the attention weights for the image data h i (j) and the text data h t (j) are derived. In this example, the sum of both attention weights is 1, and the attention weight a (j ) for the image data hi(j) is derived. Note that it may be configured to derive a weight for the text data h t (j) . Also, although the sigmoid function ( ⁇ ) is used in FIG. 3, other activation functions such as the softmax function may be used.
- the attention weight a (j ) for the image data h i (j) for the product j is represented by Equation (1).
- W[f ⁇ (h i (j) ), f ⁇ (h t (j) )] is a weighting factor obtained from the feature value f ⁇ (h i (j) ) of the image data h i (j ). and a concatenated value applied to the feature value f ⁇ (h t (j) ) of the text data h t (j) .
- b (a value of 0 or more) represents a bias.
- Arbitrary initial values are given to the weighting factors and bias values, and the learning unit 15 It is a value variably determined by the learning process by
- the attention weight a (j ) for the image data hi(j) has a different value for each product j.
- the attention weight for text data h t (j) is derived as (1 ⁇ a (j) ).
- the attention weight a (j) for image data h i (j) and the attention weight (1 ⁇ a (j) ) for text data h t (j) after learning are shown in FIG. This will be described later with reference to FIG. 4B.
- the classification unit 14 classifies the image data h i (j ) and the feature value f ⁇ (h t ( j ) ) of the text data h t (j) are weighted and connected.
- the value after weighting and concatenation is expressed as in Equation (2).
- the classification unit 14 applies the DNN to the concatenated value represented by Equation (2), and class labels of attributes for product j related to image data h i (j) and text data h t (j) (Color information of product j) Predict and classify c (h i (j) ,h t (j) ).
- Each node in the output layer of the DNN corresponds to an attribute class that product j can take (color type that product j can take if the attribute is color information).
- the number of nodes is the number of types of attribute classes that product j can have (the number of color types that product j can have). Classification (discrimination) of all classes is performed by using DNN.
- the post-learning distributions of the attention weight a (j) for image data and the attention weight (1 ⁇ a (j) ) for text data for product j will be described with reference to FIGS. 4A and 4B.
- the learning is performed using a large number of sets of multiple modalities (image data and text data, or encoded data for each of the modalities) and product attribute information (color information) as correct data for the modalities. 15.
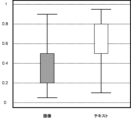
- FIG. 4A is a diagram showing the post-learning distribution of the attention weight a (j) for image data and the attention weight (1 ⁇ a (j) ) for text data for each genre to which products, which are objects, belong.
- general EC sites handle a huge number of products, and multiple products belonging to the same genre tend to have similar weight distribution characteristics. It shows the distribution for each
- FIG. 4A shows the distribution of attention weights for image data and attention weights for text data for three genres.
- a genre 41 indicates “bag/accessory”
- a genre 42 indicates “smartphone/tablet PC”
- a genre 43 indicates "men's fashion”.
- the range between the maximum and minimum values is represented by a line
- the distribution close to the average value for each data is represented by a box. Boxes with hatching indicate the distribution of attention weights for image data
- boxes without hatching indicate the distribution of attention weights for text data.
- the attention weight for text data is distributed at a higher value than the attention weight for image data.
- genre 43 men's fashion
- genre 41 bags/accessories
- FIG. 4A shows three genres
- FIG. 4B shows the distribution of attention weights obtained by performing the same learning for a plurality of genres 41-49.
- the genres 41 to 43 are the same as in FIG. 4A.
- Genre 44 is "Ladies fashion”
- Genre 45 is “Shoes”
- Genre 46 is “Healthcare/Medical supplies”
- Genre 47 is “Kids/Baby/Maternity”
- Genre 48 is “Watches”
- Genre 49 is "Cars/ "Motorcycle Equipment”.
- the attention weight for image data is distributed with a higher value than the attention weight for text data.
- the attention weights for text data are distributed over higher values than the attention weights for image data. From the results shown in FIG. 4B, it can be seen that the color information is often directly represented by the description (text data) about the product, and the attention weight for the text data tends to be higher than the attention weight for the image data. It turns out that there is
- FIG. 5 shows the results obtained by summarizing the results of FIGS. 4A and 4B for each image data and text data.
- the maximum and minimum range is represented by a line
- the distribution close to the mean for each data is represented by a box. Boxes with hatching indicate the distribution of attention weights for image data
- boxes without hatching indicate the distribution of attention weights for text data. It can be seen from FIG. 5 that the distribution of attention weights for text data has lower values than the distribution of attention weights for image data. This indicates that, in general, as described above, text data often directly includes color information about products.
- FIG. 6 is a flow chart showing an example of the processing procedure of the classification process executed by the classification device 1 according to this embodiment.
- Each step in FIG. 6 is realized by the CPU reading and executing a program stored in the storage unit of the classification device 1 .
- at least part of the flowchart shown in FIG. 6 may be realized by hardware.
- a dedicated circuit may be automatically generated on an FPGA (Field Programmable Gate Array) from a program for implementing each step, for example, by using a predetermined compiler.
- a Gate Array circuit may be formed in the same manner as the FPGA and implemented as hardware.
- it may be realized by an ASIC (Application Specific Integrated Circuit).
- FIGS. 7 and 8. Application Specific Integrated Circuit
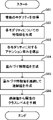
- the acquisition unit 11 acquires a plurality of modalities.
- the modalities may be coded modalities.
- the acquisition unit 11 acquires image data and text data (which may be encoded data of each of the data) via the input unit 25 as a plurality of modalities.
- the acquisition unit 11 extracts and acquires the image part as image data, and the product description part as text data. can be extracted as
- FIG. 7 shows an example of a web page screen on which products are posted on an EC site.
- a screen 70 of a web page on which one or more products (clothes) included in the genre of men's fashion are described is shown.
- an area 71 indicates a plurality of attributes for each product.
- the attributes for each product include size 71a, color 71b, season 71c, taste 71d, style (neck) 71e, pattern 71f, material 71g, length (sleeves) 71h, and brand 71i. It has become.
- the attributes for each product have the following meanings.
- the size 71a represents the standardized clothing size, and includes SS to 3L.
- Color 71b represents the color of the clothing, here five colors are identified.
- Season 71c represents a season type suitable for wearing clothes.
- the taste 71d represents the type of atmosphere and characteristics of clothes.
- the style (neck) 71e represents the design type of the collar portion of the clothes.
- the pattern 71f represents the pattern type of the fabric of the clothes.
- the material 71g represents the type of fabric of the clothing.
- the length (sleeve) 71h represents the type of sleeve length of the garment.
- the brand 71i represents the name of the company/service that indicates the manufacturer/designer of the clothes.
- each type is displayed in size 71a and color 71b.
- the season 71c, taste 71d, style (neck) 71e, pattern 71f, material 71g, length (sleeves) 71h, and brand 71i are displayed in a pull-down (not shown). Note that the display (presentation) form is not limited to this.
- Area 72 shows information about each product.
- the information about each product includes an image representing at least part of the product, a description of the product, and a price, and all products have the same layout. Note that this is just an example, and the layout of information about each product can be arbitrary.
- the user selects the area 73 . The selection is made with a pointing device such as a mouse.
- FIG. 8 shows an example of a screen of a web page that is displayed when the user selects area 73 .
- FIG. 8 shows an example web page screen for the product shown in area 72 of FIG.
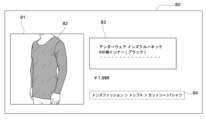
- image data 81 represents image data of the product 82
- text data 83 represents text data describing the product 82
- an area 84 shows the relationship between subdivided genres (right) from all genres (left) of products handled by the EC site until the screen 80 is displayed by the user's operation.
- Acquisition unit 11 acquires image data 81 and text data 83 and outputs them to feature generation unit 12 .
- the acquisition unit 11 can acquire the image data 81 and the text data 82 according to the layout positions.
- the acquisition unit 11 may acquire the image data 81 and the text data 82 using an image processing technique capable of distinguishing between the image data 81 and the text data 82 .
- the image data 81 and the text data 83 are associated with the information of the product 82 in advance, and the acquisition unit 11 can acquire the information of the product 82 by acquiring the image data 81 and the text data 82 .
- the acquisition unit 11 may acquire the most subdivided genre (“T-shirt” in the example of FIG. 8) of the genres shown in the area 84 as the information on the product 82 .
- the feature generation unit 12 generates a feature value for each modality of the plurality of modalities acquired by the acquisition unit 11.
- the feature generator 12 acquires the image data 81 and the text data 83 from the acquirer 11 and generates feature values (characteristic expressions) of the image data 81 and the text data 83.
- the feature generator 12 applies the first learning model 17 to the image data 81 and the text data 83, and projects the image data 81 and the text data 83 into a latent space common to all modalities of the plurality of modalities. generate feature values for
- the attention unit 13 derives the attention weight for the feature value of each modality. 7 and 8, the attention unit 13 acquires feature values of the image data 81 and the text data 83 generated by the feature generation unit 12, derives attention weights for each, and creates an attention distribution (attention map). to generate The attention weight is as described with reference to FIG.
- the classifier 14 applies the feature value of each modality to the corresponding attention weight to generate multiple weighted feature values. 7 and 8, the classification unit 14 applies the feature values of the image data 81 and the text data 83 generated by the feature generation unit 12 to the corresponding attention weights derived by the attention unit 13 to obtain a plurality of generate weighted feature values for
- the classifying unit 14 concatenates the multiple weighted feature values generated in S64. Referring to FIGS. 7 and 8, the classification unit 14 concatenates the weighted feature values of the image data 81 and the text data 83 to generate a concatenated value. In subsequent S66, the classification unit 14 applies the third learning model to the generated concatenated value to predict the attribute of the object. Using the screen examples of FIGS. 7 and 8, the classifier 14 predicts the class labels of the attributes of the product 82 . When the attribute is color information, the classification unit 14 predicts the color information of the product 82 . For example, the classification unit 14 predicts which type of color 71b in the screen 70 in FIG. 7 the product 82 in the screen 80 in FIG.
- the attribute may be any attribute included in the area 71.
- the classifying unit 14 may be one of the attributes of sizes 71a to 71i as the attribute of the product 82. It can also be configured to predict the type of
- FIG. 9 shows a performance comparison between the conventional attribute prediction method and the attribute prediction method according to this embodiment. represents a comparison result.
- the object is the product.
- Graph 9a represents the results of object attribute prediction using image data as a single modality.
- Graph 9b represents the results of object attribute prediction using text data as a single modality.
- a graph 9c represents a result of performing attribute prediction by connecting image data and text data as a plurality of modalities without attention weighting.
- Graph 9d represents the results of attribute prediction by connecting image data and text data as a plurality of modalities using attention weights according to objects, as in the present embodiment.
- the vertical axis (R@P95) indicates the recall rate (Recall) of 95% matching rate (Precision) with correct data as an index of performance evaluation.
- the classifier acquires a plurality of modalities related to an object as inputs, generates feature values for the plurality of modalities, and then weights them with attention weights according to the object. Attributes of the object are identified from the concatenated values. By such processing, it is possible to predict and identify the attribute of an object with higher accuracy than when using a single modality or when using multiple modalities without weighting according to the object. It becomes possible. Thereby, even if the attribute of an object is not defined, the attribute can be predicted from multiple modalities related to the object.
- this embodiment when this embodiment is applied to products (objects), image data, and text data (multiple modalities) on an EC site, an improvement in user's shopping experience can be expected, leading to an increase in sales.
- the user side/product provider side it becomes easier to filter product items, which contributes to the improvement of convenience for users and the improvement of marketing analysis.
- 1 classification device, 10-i to n: modality, 11: acquisition unit, 12: feature generation unit, 13: attention unit, 14: classification unit, 15: learning unit, 16: learning model storage unit, 17: first learning model, 18: second learning model, 19: third learning model
Landscapes
- Engineering & Computer Science (AREA)
- Physics & Mathematics (AREA)
- Theoretical Computer Science (AREA)
- Business, Economics & Management (AREA)
- General Physics & Mathematics (AREA)
- Accounting & Taxation (AREA)
- Finance (AREA)
- Artificial Intelligence (AREA)
- Data Mining & Analysis (AREA)
- Software Systems (AREA)
- Mathematical Physics (AREA)
- General Engineering & Computer Science (AREA)
- Health & Medical Sciences (AREA)
- Life Sciences & Earth Sciences (AREA)
- Computing Systems (AREA)
- Biomedical Technology (AREA)
- Biophysics (AREA)
- Computational Linguistics (AREA)
- Molecular Biology (AREA)
- Evolutionary Computation (AREA)
- General Health & Medical Sciences (AREA)
- General Business, Economics & Management (AREA)
- Development Economics (AREA)
- Economics (AREA)
- Marketing (AREA)
- Strategic Management (AREA)
- Image Analysis (AREA)
- Management, Administration, Business Operations System, And Electronic Commerce (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
Abstract
分類装置(1)は、オブジェクトに関連する複数のモダリティと前記オブジェクトを識別する情報とを取得する取得手段(11)と、前記複数のモダリティそれぞれの特徴値を生成する特徴生成手段(12)と、前記複数のモダリティそれぞれの特徴値と前記オブジェクトを識別する情報に基づいて、前記複数のモダリティそれぞれに対応する重みを導出する導出手段(13)と、前記複数のモダリティそれぞれの特徴値を、前記対応する重みで重みづけして連結した連結値から、前記オブジェクトの属性を予測する予測手段(14)と、を有する。
Description
本発明は、情報処理装置、情報処理方法、およびプログラムに関し、特に、所与のオブジェクトに関連する複数の情報から、当該オブジェクトの属性を予測する技術に関する。
深層学習をはじめとする機械学習は、複雑な識別や推定を高精度に実現する手法として知られている。また、機械学習の分野において、画像、テキスト、音声、およびセンサ値等である、複数のモダリティを組み合わせて、任意の事象/属性を識別するマルチモーダル深層学習の利用が注目されている。
一方、近年、インターネットを使って商品の販売を行う電子商取引(E-commerce/eコマース)が盛んに実施されており、そのような電子商取引の実施のためのEC(Electronic Commerce)サイトがウェブ上に多く構築されている。ECサイトは、世界中の各国の言語を用いて構築されることも多く、多くの国に在住するユーザ(消費者)が商品を購入することを可能にしている。ユーザは、PC(Personal Computer)や、スマートフォンといった携帯端末からECサイトにアクセスすることで、実際の店舗に赴くことなく、また時間に関係なく、所望の商品の選択や購入を行うことが可能となっている。
ECサイトでは、ユーザによる購買意欲を増進させることを目的に、過去にユーザが購入した商品の属性(商品に特有な情報)と同様の属性を有する商品を、レコメンデーションする商品として、ユーザが閲覧している画面において合わせて表示することがある。また、ユーザも、所望の商品を購入する場合に、購入しようとする商品の属性から検索する場合がある。このようなことから、電子商取引では、商品の属性を識別することが、サイト運営側や商品提供側にとって共通の課題となっている。
ECサイトでは、ユーザによる購買意欲を増進させることを目的に、過去にユーザが購入した商品の属性(商品に特有な情報)と同様の属性を有する商品を、レコメンデーションする商品として、ユーザが閲覧している画面において合わせて表示することがある。また、ユーザも、所望の商品を購入する場合に、購入しようとする商品の属性から検索する場合がある。このようなことから、電子商取引では、商品の属性を識別することが、サイト運営側や商品提供側にとって共通の課題となっている。
マルチモーダル深層学習を用いて、商品に関連する情報をモダリティとして扱い、複数のモダリティから商品の属性を予測・識別する手法が、非特許文献1に開示されている。当該文献では、商品に関連する情報として、商品の画像と商品を説明するテキストである2つのモダリティを入力して、両モダリティを組み合わせて連結した結果から、商品の属性として、商品の色や部分的な形状を識別している。
Tiangang Zhu, et.at., "Multimodal Joint Attribute Prediction and Value Extraction for E-commerce Product", Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pp.2129-2139, November, 2020.
非特許文献1に開示される手法によれば、商品の画像と商品を説明するテキストである2つのモダリティを組み合わせることにより、商品を説明するテキストのみを用いる場合と比較して、商品の属性の予測精度が高くなるという効果が得られている。
しかしながら、ECサイトで販売される商品は多岐にわたり、各商品について、商品に関連する情報(モダリティ)も異なることから、すべての商品について同様な方法で単に複数のモダリティを連結するのでは、各商品の属性を精度よく識別できない可能性がある。
しかしながら、ECサイトで販売される商品は多岐にわたり、各商品について、商品に関連する情報(モダリティ)も異なることから、すべての商品について同様な方法で単に複数のモダリティを連結するのでは、各商品の属性を精度よく識別できない可能性がある。
本発明は上記課題を解決するためになされたものであり、その目的は、商品といったオブジェクトに関連する複数の情報から当該オブジェクトの属性を適切に識別することが可能な、情報処理装置、情報処理方法、およびプログラムを提供することにある。
上記課題を解決するために、本発明による情報処理装置の一態様は、オブジェクトに関連する複数のモダリティと前記オブジェクトを識別する情報とを取得する取得手段と、前記複数のモダリティそれぞれの特徴値を生成する特徴生成手段と、前記複数のモダリティそれぞれの特徴値と前記オブジェクトを識別する情報に基づいて、前記複数のモダリティそれぞれに対応する重みを導出する導出手段と、前記複数のモダリティそれぞれの特徴値を、前記対応する重みで重みづけして連結した連結値から、前記オブジェクトの属性を予測する予測手段と、を有する。
前記導出手段は、前記複数の特徴値と前記オブジェクトを識別する情報から、前記複数のモダリティそれぞれの、前記属性の予測に対する重要度を示すアテンション重みを、前記複数の特徴値それぞれに対応する重みとして導出してよい。
前記複数のモダリティのアテンション重みは、合計で1でありうる。
本発明による情報処理装置の一態様は、オブジェクトに関連する複数のモダリティと前記オブジェクトを識別する情報とを取得する取得手段と、前記複数のモダリティを第1学習モデルに適用することにより、前記複数のモダリティに対する複数の特徴値を生成する特徴生成手段と、前記複数のモダリティそれぞれの特徴値と前記オブジェクトを識別する情報とを第2学習モデルに適用することにより、前記複数の特徴値それぞれに対応する重みを導出する導出手段と、前記複数のモダリティそれぞれの特徴値を、前記対応する重みで重みづけして連結した連結値を第3学習モデルに適用することにより、前記オブジェクトの属性を予測する予測手段と、を有し、前記第2学習モデルは前記オブジェクト毎に異なる重みを出力する学習モデルである。
前記第2学習モデルは、前記複数の特徴値と前記オブジェクトを識別する情報を入力として、前記複数のモダリティそれぞれの、前記属性の予測に対する重要度を示すアテンション重みを、前記複数の特徴値それぞれに対応する重みとして出力する学習モデルでありうる。
前記複数のモダリティのアテンション重みは、合計で1でありうる。
前記第1学習モデルは、前記複数のモダリティを入力として、前記複数のモダリティを前記複数のモダリティ共通の潜在空間にマッピングすることにより当該複数のモダリティの特徴値を出力する学習モデルでありうる。
前記第3学習モデルは、前記連結値を入力として、前記属性の予測結果を出力する学習モデルでありうる。
前記取得手段は、前記複数のモダリティを、前記オブジェクトが掲載されているウェブサイトから取得しうる。
前記オブジェクトは商品であり、前記複数のモダリティは、前記商品を表す画像のデータ、前記商品を説明するテキストのデータ、前記商品を説明する音声のデータ、のうちの2つ以上を含みうる。
前記オブジェクトの属性は、前記商品の色情報を含みうる。
本発明による情報処理方法の一態様は、オブジェクトに関連する複数のモダリティと前記オブジェクトを識別する情報とを取得する取得工程と、前記複数のモダリティそれぞれの特徴値を生成する特徴生成工程と、前記複数のモダリティそれぞれの特徴値と前記オブジェクトを識別する情報に基づいて、前記複数のモダリティそれぞれに対応する重みを導出する導出工程と、前記複数のモダリティそれぞれの特徴値を、前記対応する重みで重みづけして連結した連結値から、前記オブジェクトの属性を予測する予測工程と、を有する。
本発明による情報処理方法の一態様は、オブジェクトに関連する複数のモダリティと前記オブジェクトを識別する情報とを取得する取得工程と、前記複数のモダリティを第1学習モデルに適用することにより、前記複数のモダリティに対する複数の特徴値を生成する特徴生成工程と、前記複数のモダリティそれぞれの特徴値と前記オブジェクトを識別する情報を第2学習モデルに適用することにより、前記複数の特徴値それぞれに対応する重みを導出する導出工程と、前記複数のモダリティそれぞれの特徴値を、前記対応する重みで重みづけして連結した連結値を第3学習モデルに適用することにより、前記オブジェクトの属性を予測する予測工程と、を有し、前記第2学習モデルは前記オブジェクト毎に異なる重みを出力する学習モデルである。
本発明による情報処理プログラムの一態様は、情報処理をコンピュータに実行させるための情報処理プログラムであって、該プログラムは、前記コンピュータに、オブジェクトに関連する複数のモダリティと前記オブジェクトを識別する情報とを取得する取得処理と、前記複数のモダリティそれぞれの特徴値を生成する特徴生成処理と、前記複数のモダリティそれぞれの特徴値と前記オブジェクトを識別する情報に基づいて、前記複数のモダリティそれぞれに対応する重みを導出する導出処理と、前記複数のモダリティそれぞれの特徴値を、前記対応する重みで重みづけして連結した連結値から、前記オブジェクトの属性を予測する予測処理と、を含む処理を実行させるためのものである。
本発明による情報処理プログラムの一態様は、情報処理をコンピュータに実行させるための情報処理プログラムであって、該プログラムは、前記コンピュータに、オブジェクトに関連する複数のモダリティと前記オブジェクトを識別する情報とを取得する取得処理と、前記複数のモダリティを第1学習モデルに適用することにより、前記複数のモダリティに対する複数の特徴値を生成する特徴生成処理と、前記複数のモダリティそれぞれの特徴値と前記オブジェクトを識別する情報を第2学習モデルに適用することにより、前記複数の特徴値それぞれに対応する重みを導出する導出処理と、前記複数のモダリティそれぞれの特徴値を、前記対応する重みで重みづけして連結した連結値を第3学習モデルに適用することにより、前記オブジェクトの属性を予測する予測処理と、を含む処理を実行させるためのものであり、前記第2学習モデルは前記オブジェクト毎に異なる重みを出力する学習モデルである。
本発明によれば、オブジェクトに関連する複数の情報から当該オブジェクトの属性を適切に識別することが可能となる。
上記した本発明の目的、態様及び効果並びに上記されなかった本発明の目的、態様及び効果は、当業者であれば添付図面及び請求の範囲の記載を参照することにより下記の発明を実施するための形態から理解できるであろう。
上記した本発明の目的、態様及び効果並びに上記されなかった本発明の目的、態様及び効果は、当業者であれば添付図面及び請求の範囲の記載を参照することにより下記の発明を実施するための形態から理解できるであろう。
以下、添付図面を参照して、本発明を実施するための実施形態について詳細に説明する。以下に開示される構成要素のうち、同一機能を有するものには同一の符号を付し、その説明を省略する。なお、以下に開示される実施形態は、本発明の実現手段としての一例であり、本発明が適用される装置の構成や各種条件によって適宜修正または変更されるべきものであり、本発明は以下の実施形態に限定されるものではない。また、本実施形態で説明されている特徴の組み合わせの全てが本発明の解決手段に必須のものとは限らない。
本実施形態による分類装置は、所与のオブジェクトに関連する複数のモダリティと、当該オブジェクトを識別する情報を取得し、該複数のモダリティそれぞれの特徴値を生成し、該特徴値と該オブジェクトを識別する情報に基づいて、該複数のモダリティそれぞれに対応する重みを導出し、該特徴値を該対応する重みで重みづけして連結した連結値から、該オブジェクトの属性を予測するように構成される。ここで、モダリティは、オブジェクトに関連する情報を示し、モダリティ情報、モダリティアイテム、モダリティ値と同義であり、そのように称されてもよい。
オブジェクトの一例は、電子商取引で流通される商品である。また、オブジェクトに関連する情報である複数のモダリティの一例は、商品の画像を示す画像データ(以下、単に画像データと称する)と、商品を説明するテキストデータ(以下、単にテキストデータと称する)である。また、オブジェクトの属性の一例は、オブジェクトが商品である場合は、当該商品の色情報である。
なお、以下では、分類装置の非限定的な例を説明するにすぎず、オブジェクトは商品に限定されず、ユーザに提供可能な任意のサービスであってもよい。また、オブジェクトに関する複数の情報として、画像とテキストデータに限らず、音声データ等、オブジェクトに関連するあらゆる情報を用いてもよい。また、オブジェクトの属性は、色情報だけでなく、オブジェクトに特有なあらゆる情報でありうる。
オブジェクトの一例は、電子商取引で流通される商品である。また、オブジェクトに関連する情報である複数のモダリティの一例は、商品の画像を示す画像データ(以下、単に画像データと称する)と、商品を説明するテキストデータ(以下、単にテキストデータと称する)である。また、オブジェクトの属性の一例は、オブジェクトが商品である場合は、当該商品の色情報である。
なお、以下では、分類装置の非限定的な例を説明するにすぎず、オブジェクトは商品に限定されず、ユーザに提供可能な任意のサービスであってもよい。また、オブジェクトに関する複数の情報として、画像とテキストデータに限らず、音声データ等、オブジェクトに関連するあらゆる情報を用いてもよい。また、オブジェクトの属性は、色情報だけでなく、オブジェクトに特有なあらゆる情報でありうる。
<分類装置の機能構成>
図1は、本実施形態による分類装置1の機能構成の一例を示す。
図1に示す分類装置1は、取得部11、特徴生成部12、アテンション部13、分類部14、学習部15、学習モデル記憶部16を有して構成される。学習モデル記憶部16は、あらかじめ学習された学習済みモデルである、第1学習モデル17、第2学習モデル18、および第3学習モデル19を保存している。
図1は、本実施形態による分類装置1の機能構成の一例を示す。
図1に示す分類装置1は、取得部11、特徴生成部12、アテンション部13、分類部14、学習部15、学習モデル記憶部16を有して構成される。学習モデル記憶部16は、あらかじめ学習された学習済みモデルである、第1学習モデル17、第2学習モデル18、および第3学習モデル19を保存している。
取得部11は、複数のモダリティ(モダリティ10-i~10-n(nは2以上の整数))を取得する。取得部11は、複数のモダリティを、分類装置1を操作するユーザ(オペレータ)による入力部25(図2)を介した入力操作によって取得してもよいし、ユーザの操作により記憶部(図2のROM22やRAM23)から取得してもよい。また、取得部11は、通信I/F27(図2)を介して外部装置から受信した複数のモダリティを取得してもよい。
取得部11は、直接的に複数のモダリティを取得してもよいし、データに対する抽出処理を行ってから当該複数のモダリティを取得してもよい。例えば、入力部25を介して入力されたデータが、複数のモダリティを混合的に含むデータである場合、取得部11は、当該データから、複数のモダリティを抽出して取得してもよい。具体例として、オブジェクトが商品であり、複数のモダリティが画像データとテキストデータであり、入力されたデータがECサイトにおいて当該商品を掲載するウェブページである場合、取得部11は、当該ウェブページから、画像データとテキストデータとを抽出して取得することができる。
複数のモダリティには、当該モダリティが関連するオブジェクトを識別する情報が関連付けられていてもよく、取得部11は、複数のモダリティを取得することで、オブジェクトを識別する情報を取得するように構成されてもよい。あるいは、取得部11は、複数のモダリティと別に、当該モダリティに関連するオブジェクトを識別する情報を取得してもよい。
取得部11は、取得した複数のモダリティを特徴生成部12へ出力する。取得部11は、複数のモダリティと別にオブジェクトを識別する情報を取得した場合は当該情報をアテンション部13に出力してもよい。
また、取得部11は、取得した複数のモダリティそれぞれを符号化して、符号化された複数のモダリティをアテンション部13に出力してもよい。
取得部11は、取得した複数のモダリティを特徴生成部12へ出力する。取得部11は、複数のモダリティと別にオブジェクトを識別する情報を取得した場合は当該情報をアテンション部13に出力してもよい。
また、取得部11は、取得した複数のモダリティそれぞれを符号化して、符号化された複数のモダリティをアテンション部13に出力してもよい。
特徴生成部12は、取得部11から出力された複数のモダリティ(符号化された複数のモダリティでありうる。以下同様。)を取得し、各モダリティの特徴値を生成する。本実施形態では、特徴生成部12は、当該複数のモダリティを、学習モデル記憶部16に保存されている第1学習モデル17に適用して、各モダリティの特徴値(特徴的表現)を生成する。例えば、特徴生成部12は、複数のモダリティを、第1学習モデル17を用いて、当該複数のモダリティの全モダリティ共通の潜在空間に投影(マッピング)することにより、特徴を示す情報に凝縮して特徴値を得ることができる。
潜在空間とは、異なるモダリティ、すなわち、次元の異なるモダリティが、次元を圧縮して投影される空間を示し、この共通の空間において、当該異なるモダリティの特徴量/特徴値が表される。特徴生成部12は、入力される複数のモダリティのデータの次元を圧縮することで、各モダリティの情報量を削減した、すなわち、圧縮後の低次元空間である潜在空間表現(特徴値)を生成することができる。
潜在空間とは、異なるモダリティ、すなわち、次元の異なるモダリティが、次元を圧縮して投影される空間を示し、この共通の空間において、当該異なるモダリティの特徴量/特徴値が表される。特徴生成部12は、入力される複数のモダリティのデータの次元を圧縮することで、各モダリティの情報量を削減した、すなわち、圧縮後の低次元空間である潜在空間表現(特徴値)を生成することができる。
第1学習モデル17は、例えば、FCN(Fully Connected Network)のニューラルネットワークにより構築されるモデルである。FCNは、CNN(Convolutional Neural Network)の一種であり、CNNの全結合層をアップサンプリングした畳み込み層に置き換えたネットワークである。また、ニューラルネットワークのモデルとして、SegNet等を用いることもできる。
特徴生成部12は、生成した各モダリティの特徴値をアテンション部13と分類部14に出力する。
特徴生成部12は、生成した各モダリティの特徴値をアテンション部13と分類部14に出力する。
アテンション部13は、特徴生成部12から各モダリティの特徴値を取得し、当該特徴値およびオブジェクトを識別する情報から、各モダリティに対するアテンション重みを生成する。本実施形態では、アテンション部13は、各モダリティの特徴値およびオブジェクトを識別する情報を、学習モデル記憶部16に保存されている第2学習モデル18に適用することにより、各モダリティに対するアテンション重みを生成する。アテンション重みは、複数のモダリティそれぞれの、オブジェクトの属性の予測に対する重要度を示す。
第2学習モデル18は、例えば、アテンション情報を取得するニューラルネットワーク(アテンションネットワーク)により構築されるモデルである。各モダリティに対するアテンション重みは、取得部11により取得された複数のモダリティに関連付けられたオブジェクトに応じて生成される。例えば、オブジェクトが商品Aである場合と商品B(商品Bは商品Aと異なる)である場合で、各モダリティに対して生成されるアテンション重みは変化しうる。取得部11により取得された複数のモダリティに対するアテンション重みは、例えば合計で1である。アテンション部13により生成されるアテンション重みについては、図3~図5を参照して後述する。
アテンション部13は、生成した各モダリティに対するアテンション重みを分類部14に出力する。
アテンション部13は、生成した各モダリティに対するアテンション重みを分類部14に出力する。
分類部14は、特徴生成部12から各モダリティの特徴値を取得し、また、アテンション部13から各モダリティに対するアテンション重みを取得し、これらの情報から、オブジェクトの属性を予測する。本実施形態では、分類部14は、学習モデル記憶部16に保存されている第3学習モデル19を用いて、オブジェクトの属性を予測する。
具体的には、分類部14はまず、各特徴値(各モダリティの特徴値)を、各特徴値に対するアテンション重みに適用して(例えば乗算して)、重みづけ特徴値を生成し、すべての重みづけ特徴値を連結(統合)して連結値を得る。
具体的には、分類部14はまず、各特徴値(各モダリティの特徴値)を、各特徴値に対するアテンション重みに適用して(例えば乗算して)、重みづけ特徴値を生成し、すべての重みづけ特徴値を連結(統合)して連結値を得る。
続いて、分類部14は、当該連結値を、第3学習モデル19に適用することにより、属性のクラスラベル(正解データ)を予測して分類する。分類部14は、当該分類にしたがって分類結果の情報を生成し、出力する。属性が商品(オブジェクト)の色情報である場合、分類部14は、連結値から、第3学習モデル19を適用して得られたオブジェクトの色情報を、分類結果(予測結果)として出力する。
分類結果は、色情報そのものであってもよいし、正解データとの適合率(Precision)が95%であることの再現率(Recall)を示す指標(R@P95)等であってもよい。
分類部14は、不図示の外部装置に例えば通信I/F27(図2)を介して分類結果を出力してもよいし、表示部26(図2)に分類結果を表示してもよい。
分類結果は、色情報そのものであってもよいし、正解データとの適合率(Precision)が95%であることの再現率(Recall)を示す指標(R@P95)等であってもよい。
分類部14は、不図示の外部装置に例えば通信I/F27(図2)を介して分類結果を出力してもよいし、表示部26(図2)に分類結果を表示してもよい。
第3学習モデル19は、例えば、複数のノードからなる入力層、中間層(隠れ層)、および出力層を有する多層のニューラルネットワークにより構築されるモデルである。多層のニューラルネットワークは、例えば、DNN(Deep Neural Network)、CNN、RNN(Recurrent Neural Network)、LSTM(Long Short-Term Memory)でありうる。
学習部15は、第1学習モデル17、第2学習モデル18、第3学習モデル19をそれぞれ学習し、学習済みのモデルで第1学習モデル17、第2学習モデル18、第3学習モデル19についての各種パラメータをそれぞれ更新する。当該各種パラメータの更新処理は、あらかじめ学習部15に入力されている、十分な数のサンプル数の、複数のモダリティに対する正解データ(すなわち、当該複数のモダリティが関連するオブジェクトの属性を示す情報)を用いて行うことができる。学習部15は、取得部11により取得される複数のモダリティに対する分類部14による分類結果と、正解データとの比較から、例えば勾配降下最適化手順に従って、ニューラルネットワークに対する各種パラメータを更新することができる。
学習部15により学習してパラメータ更新された第1学習モデル17、第2学習モデル18、第3学習モデル19は、学習モデル記憶部16に保存される。
学習部15により学習してパラメータ更新された第1学習モデル17、第2学習モデル18、第3学習モデル19は、学習モデル記憶部16に保存される。
なお、図1に示す構成は、分類装置1の機能的な構成を例示的に示すものであり、本実施形態による分類装置1が単一の装置に実装されることを意味するものではない。図1に示す機能構成は、例えば、ネットワークで相互接続される複数のサーバ等の装置に実装されてもよく、図1に示す分類装置1の各部、記憶部が同一の装置に実装されても、互いに異なる装置に実装されてもよい。例えば、分類装置1の特徴生成部12とアテンション部13とが、互いに異なる装置に実装されてもよい。また、学習モデル記憶部16が分類装置1の外部に構成されてもよい。
<分類装置のハードウェア構成>
図2は、本実施形態による分類装置1のハードウェア構成の一例を示すブロック図である。
本実施形態による分類装置1は、単一または複数の、あらゆるコンピュータ、モバイルデバイス、または他のいかなる処理プラットフォーム上にも実装することができる。
図2を参照して、分類装置1は、単一のコンピュータに実装される例が示されているが、本実施形態による分類装置1は、複数のコンピュータを含むコンピュータシステムに実装されてよい。複数のコンピュータは、有線または無線のネットワークにより相互通信可能に接続されてよい。
図2は、本実施形態による分類装置1のハードウェア構成の一例を示すブロック図である。
本実施形態による分類装置1は、単一または複数の、あらゆるコンピュータ、モバイルデバイス、または他のいかなる処理プラットフォーム上にも実装することができる。
図2を参照して、分類装置1は、単一のコンピュータに実装される例が示されているが、本実施形態による分類装置1は、複数のコンピュータを含むコンピュータシステムに実装されてよい。複数のコンピュータは、有線または無線のネットワークにより相互通信可能に接続されてよい。
図2に示すように、分類装置1は、CPU21と、ROM22と、RAM23と、HDD24と、入力部25と、表示部26と、通信I/F27と、システムバス28とを備えてよい。分類装置1はまた、外部メモリを備えてよい。
CPU(Central Processing Unit)21は、分類装置1における動作を統括的に制御するものであり、データ伝送路であるシステムバス28を介して、各構成部(22~27)を制御する。
CPU(Central Processing Unit)21は、分類装置1における動作を統括的に制御するものであり、データ伝送路であるシステムバス28を介して、各構成部(22~27)を制御する。
ROM(Read Only Memory)22は、CPU21が処理を実行するために必要な制御プログラム等を記憶する不揮発性メモリである。なお、当該プログラムは、HDD(Hard Disk Drive)24、SSD(Solid State Drive)等の不揮発性メモリや着脱可能な記憶媒体(不図示)等の外部メモリに記憶されていてもよい。
RAM(Random Access Memory)23は、揮発性メモリであり、CPU81の主メモリ、ワークエリア等として機能する。すなわち、CPU21は、処理の実行に際してROM22から必要なプログラム等をRAM23にロードし、当該プログラム等を実行することで各種の機能動作を実現する。
RAM(Random Access Memory)23は、揮発性メモリであり、CPU81の主メモリ、ワークエリア等として機能する。すなわち、CPU21は、処理の実行に際してROM22から必要なプログラム等をRAM23にロードし、当該プログラム等を実行することで各種の機能動作を実現する。
HDD24は、例えば、CPU21がプログラムを用いた処理を行う際に必要な各種データや各種情報等を記憶している。また、HDD24には、例えば、CPU21がプログラム等を用いた処理を行うことにより得られた各種データや各種情報等が記憶される。
入力部25は、キーボードやマウス等のポインティングデバイスにより構成される。
表示部26は、液晶ディスプレイ(LCD)等のモニターにより構成される。表示部26は、キーワード特定処理で使用される各種パラメータや、他の装置との通信で使用される通信パラメータ等を分類装置1へ指示入力するためのユーザインタフェースであるGUI(Graphical User Interface)を提供してよい。
入力部25は、キーボードやマウス等のポインティングデバイスにより構成される。
表示部26は、液晶ディスプレイ(LCD)等のモニターにより構成される。表示部26は、キーワード特定処理で使用される各種パラメータや、他の装置との通信で使用される通信パラメータ等を分類装置1へ指示入力するためのユーザインタフェースであるGUI(Graphical User Interface)を提供してよい。
通信I/F27は、分類装置1と外部装置との通信を制御するインタフェースである。
通信I/F27は、ネットワークとのインタフェースを提供し、ネットワークを介して、外部装置との通信を実行する。通信I/F27を介して、外部装置との間で各種データや各種パラメータ等が送受信される。本実施形態では、通信I/F27は、イーサネット(登録商標)等の通信規格に準拠する有線LAN(Local Area Network)や専用線を介した通信を実行してよい。ただし、本実施形態で利用可能なネットワークはこれに限定されず、無線ネットワークで構成されてもよい。この無線ネットワークは、Bluetooth(登録商標)、ZigBee(登録商標)、UWB(Ultra Wide Band)等の無線PAN(Personal Area Network)を含む。また、Wi-Fi(Wireless Fidelity)(登録商標)等の無線LAN(Local Area Network)や、WiMAX(登録商標)等の無線MAN(Metropolitan Area Network)を含む。さらに、LTE/3G、4G、5G等の無線WAN(Wide Area Network)を含む。なお、ネットワークは、各機器を相互に通信可能に接続し、通信が可能であればよく、通信の規格、規模、構成は上記に限定されない。
通信I/F27は、ネットワークとのインタフェースを提供し、ネットワークを介して、外部装置との通信を実行する。通信I/F27を介して、外部装置との間で各種データや各種パラメータ等が送受信される。本実施形態では、通信I/F27は、イーサネット(登録商標)等の通信規格に準拠する有線LAN(Local Area Network)や専用線を介した通信を実行してよい。ただし、本実施形態で利用可能なネットワークはこれに限定されず、無線ネットワークで構成されてもよい。この無線ネットワークは、Bluetooth(登録商標)、ZigBee(登録商標)、UWB(Ultra Wide Band)等の無線PAN(Personal Area Network)を含む。また、Wi-Fi(Wireless Fidelity)(登録商標)等の無線LAN(Local Area Network)や、WiMAX(登録商標)等の無線MAN(Metropolitan Area Network)を含む。さらに、LTE/3G、4G、5G等の無線WAN(Wide Area Network)を含む。なお、ネットワークは、各機器を相互に通信可能に接続し、通信が可能であればよく、通信の規格、規模、構成は上記に限定されない。
図1に示す分類装置1の各要素のうち少なくとも一部の機能は、CPU21がプログラムを実行することで実現することができる。ただし、図1に示す分類装置1の各要素のうち少なくとも一部の機能が専用のハードウェアとして動作するようにしてもよい。この場合、専用のハードウェアは、CPU21の制御に基づいて動作する。
<特徴生成部12、アテンション部13、分類部14による処理の具体例>
図3は、分類装置1の特徴生成部12、アテンション部13、および分類部14による処理を説明する概念図である。本例では、特徴生成部12はFCNのニューラルネットワークにより構築された第1学習モデル17を使用し、アテンション部12はアテンションネットワークにより構築された第2学習モデル18を使用するものとする。また、分類部14はDNNのニューラルネットワークにより構築された第3学習モデル19を使用するものとする。
図3は、分類装置1の特徴生成部12、アテンション部13、および分類部14による処理を説明する概念図である。本例では、特徴生成部12はFCNのニューラルネットワークにより構築された第1学習モデル17を使用し、アテンション部12はアテンションネットワークにより構築された第2学習モデル18を使用するものとする。また、分類部14はDNNのニューラルネットワークにより構築された第3学習モデル19を使用するものとする。
図3では、取得部11により取得される複数のモダリティが、オブジェクトである商品に関連する、画像データとテキストデータであるとして説明する。ここで、画像データ(Image data)をmi
(j)と表し、テキストデータ(Text data)をmt
(j)と表し、ここで、jは商品を識別するパラメータ(情報)とする。
取得部11はさらに、画像データmi (j)を符号化して符号化した画像データhi (j)(=I(mi (j)))、および、テキストデータmt (j)を符号化して符号化したテキストデータht (j)(=T(mt (j)))を得る。ここで、I(.)とT(.)はそれぞれ、画像データとテキストデータを符号化するための符号化関数を示す。
特徴生成部12は、画像データhi (j)とテキストデータht (j)それぞれに対してFCNのニューラルネットワークを適用し、出力層から、潜在空間表現(特徴値)として、画像データhi (j)の特徴値fθ(hi (j))と、テキストデータht (j)の特徴値fθ(ht (j))とを得る。ここで、fθ(.)は、θでパラメータ化されたFCNのニューラルネットワークである。
取得部11はさらに、画像データmi (j)を符号化して符号化した画像データhi (j)(=I(mi (j)))、および、テキストデータmt (j)を符号化して符号化したテキストデータht (j)(=T(mt (j)))を得る。ここで、I(.)とT(.)はそれぞれ、画像データとテキストデータを符号化するための符号化関数を示す。
特徴生成部12は、画像データhi (j)とテキストデータht (j)それぞれに対してFCNのニューラルネットワークを適用し、出力層から、潜在空間表現(特徴値)として、画像データhi (j)の特徴値fθ(hi (j))と、テキストデータht (j)の特徴値fθ(ht (j))とを得る。ここで、fθ(.)は、θでパラメータ化されたFCNのニューラルネットワークである。
アテンション部12は、画像データhi
(j)の特徴値fθ (hi
(j))と、テキストデータht
(j)の特徴値fθ(ht
(j))とをアテンションネットワークに適用し、出力層のベクトルをシグモイド関数(σ)に入力することで、画像データhi
(j)とテキストデータht
(j)に対するアテンション重み(アテンションウェイト)を導出する。本例では、両アテンション重みの合計が1であり、画像データhi
(j) に対するアテンション重みa(j)を導出するものとする。なお、テキストデータht
(j)に対する重みを導出するように構成されてもよい。
また、図3ではシグモイド関数(σ)を用いているが、softmax関数などの他の活性化関数を用いてもよい。
また、図3ではシグモイド関数(σ)を用いているが、softmax関数などの他の活性化関数を用いてもよい。
商品jについての、画像データhi
(j)に対するアテンション重みa(j)は、式(1)のように表される。

ここで、W[fθ(hi
(j)), fθ(ht
(j))]は、重み係数を、画像データhi
(j)の特徴値fθ(hi
(j))と、テキストデータht
(j)の特徴値fθ(ht
(j))に適用して連結した値を表す。また、b(0以上の値)はバイアスを表す。当該重み係数およびバイアスの値は、任意の初期値が与えられ、複数のモダリティ(画像データとテキストデータ)と当該モダリティに対する正解データ(商品の属性情報)の多数のセットを用いて、学習部15による学習過程によって可変に決定される値である。画像データhi
(j) に対するアテンション重みa(j)は商品jごとに異なる値になる。
テキストデータht (j) に対するアテンション重みは、(1-a(j))として導出される。
商品jについての、画像データhi (j) のに対するアテンション重みa(j)とテキストデータht (j)に対するアテンション重み(1-a(j))の学習後の分布については、図4Aと図4Bを参照して後述する。
テキストデータht (j) に対するアテンション重みは、(1-a(j))として導出される。
商品jについての、画像データhi (j) のに対するアテンション重みa(j)とテキストデータht (j)に対するアテンション重み(1-a(j))の学習後の分布については、図4Aと図4Bを参照して後述する。
画像データhi
(j) に対するアテンション重みa(j)とテキストデータht
(j)に対するアテンション重み(1-a(j))が導出されると、分類部14により、画像データhi
(j)の特徴値fθ(mi
(j))と、テキストデータht
(j)の特徴値fθ(ht
(j))に対する重みづけおよび連結処理が行われる。
重みづけおよび連結後の値は式(2)のように表される。
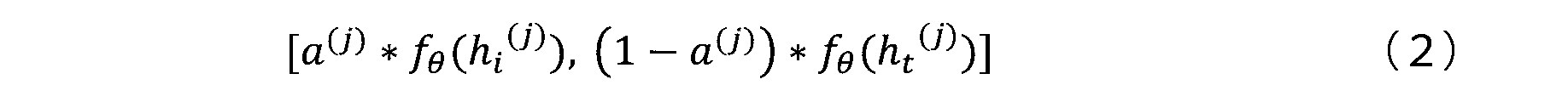
重みづけおよび連結後の値は式(2)のように表される。
分類部14は、式(2)のように表される連結値に対してDNNを適用し、画像データhi
(j)とテキストデータht
(j)に関連する商品jに対する属性のクラスラベル(商品jの色情報)c (hi
(j),ht
(j))を予測して分類する。DNNにおける出力層の各ノードは、商品jが取りうる属性のクラス(属性が色情報の場合は商品jが取りうる色のタイプ)に相当する。なお、ノードの数は、商品jが取りうる属性のクラスの種類の数(商品jが取りうる色のタイプの数)となる。DNNを用いることにより、全クラスの分類(識別)が行われる。
次に、商品jに対する画像データに対するアテンション重みa(j)とテキストデータに対するアテンション重み(1-a(j))の学習後の分布について、図4Aと図4Bを参照して説明する。当該学習は、複数のモダリティ(画像データとテキストデータ、または当該データそれぞれの符号化データ)と、当該モダリティに対する正解データとしての商品の属性情報(色情報)との多数のセットを用いて、学習部15により行われる。
図4Aは、オブジェクトである商品が属するジャンルごとの、画像データに対するアテンション重みa(j)とテキストデータに対するアテンション重み(1-a(j))の学習後の分布を示す図である。一般に、総合ECサイトでは、膨大な数の商品が扱われ、同一のジャンルに属する複数の商品は、同様の重み分布の特徴を有する傾向があることから、図4Aでは、複数の商品が属するジャンルごとの分布を示している。
図4Aでは、3つのジャンルについての、画像データに対するアテンション重みとテキストデータに対するアテンション重みの分布が表されている。ジャンル41は「バック/アクセサリ」を示し、ジャンル42は「スマートフォン/タブレットPC」を示し、ジャンル43は「メンズファッション」を示す。画像データに対するアテンション重みとテキストデータに対するアテンション重みの分布のそれぞれにおいて、最大値と最小値の範囲が線で表され、各データに対して平均値に近い分布がボックスで表されている。斜線ありのボックスは画像データに対するアテンション重みの分布を示し、斜線なしのボックスはテキストデータに対するアテンション重みの分布を示す。
ジャンル41(バック/アクセサリ)の分布では、テキストデータに対するアテンション重みが、画像データに対するアテンション重みより高い値で分布していることがわかる。これは例えば、テキストデータ、すなわち、バック/アクセサリのジャンルに含まれる商品を説明する説明文が、当該商品の色情報を直接的に含む傾向が高いことを意味する。バック/アクセサリは、形、色、ブランドで好みが分かれる傾向の強いジャンルの商品である。色については、画像データよりもテキストデータの方が曖昧さなく、情報として信頼度が高いため、テキストデータのアテンション重みが高くなったと考えられる。
ジャンル42(スマートフォン/タブレットPC)の分布では、画像データとテキストデータに関して、ジャンル41(バック/アクセサリ)の分布と逆の特性が表れていることがわかる。すなわち、画像データに対するアテンション重みが、テキストデータに対するアテンション重みより高い値で分布していることがわかる。これは例えば、スマートフォン/タブレットPCのジャンルに含まれる商品を説明する説明文(テキストデータ)が、スマートフォン/タブレットPCの機能に関する記載が多く、画像データが色情報そのものを表す傾向が高いことを意味する。
ジャンル43(メンズファッション)の分布では、ジャンル41(バック/アクセサリ)の分布と同様の特性が表れていることがわかる。これは、ジャンル41(バック/アクセサリ)と同様に、メンズファッション商品のジャンルに含まれる商品を説明する説明文(テキストデータ)が、当該商品の色情報を直接的に含む傾向が高いことを意味する。
図4Aでは3つのジャンルについて示したが、複数のジャンル41~49について同様の学習を行ったアテンション重みの分布を図4Bに示す。ジャンル41~43については図4Aと同様である。ジャンル44は「レディースファッション」、ジャンル45は「靴」、ジャンル46は「ヘルスケア/医療用品」、ジャンル47は「キッズ/ベビー/マタニティ」、ジャンル48は「時計」、ジャンル49は「車/バイク用品」を示す。
図4Bでは、ジャンル42(スマートフォン/タブレットPC)とジャンル49(車/バイク用品)において、画像データに対するアテンション重みが、テキストデータに対するアテンション重みより高い値で分布しているが、他のジャンル41、43~48では、テキストデータに対するアテンション重みが、画像データに対するアテンション重みより高い値に分布していることがわかる。
図4Bに示す結果から、商品についての説明文(テキストデータ)により、色情報が直接的に表されることが多く、テキストデータに対するアテンション重みが、画像データに対するアテンション重みより高い値に分布する傾向があることがわかる。
図4Bに示す結果から、商品についての説明文(テキストデータ)により、色情報が直接的に表されることが多く、テキストデータに対するアテンション重みが、画像データに対するアテンション重みより高い値に分布する傾向があることがわかる。
図5に、図4A~図4Bの結果を画像データとテキストデータごとにまとめた結果を表す。図4A~図4Bと同様に、最大値と最小値の範囲が線で表され、各データに対して平均値に近い分布がボックスで表されている。斜線ありのボックスは画像データに対するアテンション重みの分布を示し、斜線なしのボックスはテキストデータに対するアテンション重みの分布を示す。
図5から、テキストデータに対するアテンション重みの分布が、画像データに対するアテンション重みの分布より値が低くなっていることがわかる。これは、一般的に、上記のように、テキストデータは、商品に関する色情報を直接的に含むことが多いことを示している。
図5から、テキストデータに対するアテンション重みの分布が、画像データに対するアテンション重みの分布より値が低くなっていることがわかる。これは、一般的に、上記のように、テキストデータは、商品に関する色情報を直接的に含むことが多いことを示している。
<処理の流れ>
図6に、本実施形態による分類装置1により実行される分類処理の処理手順の一例を示すフローチャートである。
なお、図6の各ステップは、分類装置1の記憶部に記憶されたプログラムをCPUが読み出し、実行することで実現される。また、図6に示すフローチャートの少なくとも一部をハードウェアにより実現してもよい。ハードウェアにより実現する場合、例えば、所定のコンパイラを用いることで、各ステップを実現するためのプログラムからFPGA(Field Programmable Gate Array)上に自動的に専用回路を生成すればよい。また、FPGAと同様にしてGate Array回路を形成し、ハードウェアとして実現するようにしてもよい。また、ASIC(Application Specific Integrated Circuit)により実現するようにしてもよい。
図6の説明に関し、図7と図8を参照する。
図6に、本実施形態による分類装置1により実行される分類処理の処理手順の一例を示すフローチャートである。
なお、図6の各ステップは、分類装置1の記憶部に記憶されたプログラムをCPUが読み出し、実行することで実現される。また、図6に示すフローチャートの少なくとも一部をハードウェアにより実現してもよい。ハードウェアにより実現する場合、例えば、所定のコンパイラを用いることで、各ステップを実現するためのプログラムからFPGA(Field Programmable Gate Array)上に自動的に専用回路を生成すればよい。また、FPGAと同様にしてGate Array回路を形成し、ハードウェアとして実現するようにしてもよい。また、ASIC(Application Specific Integrated Circuit)により実現するようにしてもよい。
図6の説明に関し、図7と図8を参照する。
S61で、取得部11は、複数のモダリティを取得する。なお、上述のように、当該複数のモダリティは、符号化された複数のモダリティでありうる。本実施形態では、取得部11は、複数のモダリティとして、入力部25を介して画像データとテキストデータ(当該データそれぞれの符号化データでありうる)を取得する。ここで、入力部25に入力されたデータが、ECサイトにおけるウェブページの画面データである場合は、取得部11は、画像データとして画像部分を抽出して取得し、商品の説明部分をテキストデータとして抽出してもよい。
図7に、ECサイトにおける、商品が掲載されたウェブページ画面の一例を示す。ここでは、メンズファッションのジャンルに含まれる1つ以上の商品(服)が記載されたウェブページの画面70を示す。
図7の画面70において、領域71は、各商品に対する複数の属性(Attribute)を示している。図7の例では、各商品に対する属性は、サイズ71a、カラー71b、シーズン71c、テイスト71d、スタイル(首もと)71e、柄71f、素材71g、長さ(袖)71h、ブランド71iを含むものとなっている。
図7の画面70において、領域71は、各商品に対する複数の属性(Attribute)を示している。図7の例では、各商品に対する属性は、サイズ71a、カラー71b、シーズン71c、テイスト71d、スタイル(首もと)71e、柄71f、素材71g、長さ(袖)71h、ブランド71iを含むものとなっている。
一例として、各商品に対する属性は以下の意味を有する。
サイズ71aは、規格化された服のサイズを表し、SS~3Lまでを含むものとなっている。カラー71bは、服の色を表し、ここでは5色が識別されている。シーズン71cは、服の装着にふさわしい季節タイプを表す。テイスト71dは、服の雰囲気や持ち味のタイプを表す。スタイル(首もと)71eは、服の襟部分のデザインのタイプを表す。柄71fは、服の生地の柄のタイプを表す。素材71gは、服の生地のタイプを表す。長さ(袖)71hは、服の袖の長さのタイプを表す。ブランド71iは、服の製造元/デザイン制作側を示す会社/サービスの名前を表す。
一例として、図7の領域71に表される各属性において、サイズ71aとカラー71bでは、それぞれのタイプが表示されている。シーズン71c、テイスト71d、スタイル(首もと)71e、柄71f、素材71g、長さ(袖)71h、ブランド71iでは、プルダウンでそれぞれのタイプが表示されるようになっている(不図示)。なお、表示(提示)形態は、これに限定されない。
サイズ71aは、規格化された服のサイズを表し、SS~3Lまでを含むものとなっている。カラー71bは、服の色を表し、ここでは5色が識別されている。シーズン71cは、服の装着にふさわしい季節タイプを表す。テイスト71dは、服の雰囲気や持ち味のタイプを表す。スタイル(首もと)71eは、服の襟部分のデザインのタイプを表す。柄71fは、服の生地の柄のタイプを表す。素材71gは、服の生地のタイプを表す。長さ(袖)71hは、服の袖の長さのタイプを表す。ブランド71iは、服の製造元/デザイン制作側を示す会社/サービスの名前を表す。
一例として、図7の領域71に表される各属性において、サイズ71aとカラー71bでは、それぞれのタイプが表示されている。シーズン71c、テイスト71d、スタイル(首もと)71e、柄71f、素材71g、長さ(袖)71h、ブランド71iでは、プルダウンでそれぞれのタイプが表示されるようになっている(不図示)。なお、表示(提示)形態は、これに限定されない。
領域72は、各商品についての情報を示している。
図7の例では、各商品についての情報は、商品の少なくとも一部を表す画像と、商品に関する説明と、値段を含むものとなっており、すべての商品について同様のレイアウトとなっている。なお、これは一例であり、各商品についての情報のレイアウトは任意なものでありうる。
ここで、領域73がユーザ(オペレータ)選択されたとする。当該選択は、例えばマウスといったポインティングデバイスで行われる。ユーザが領域73を選択した場合に移行するウェブページの画面例を、図8に示す。
図7の例では、各商品についての情報は、商品の少なくとも一部を表す画像と、商品に関する説明と、値段を含むものとなっており、すべての商品について同様のレイアウトとなっている。なお、これは一例であり、各商品についての情報のレイアウトは任意なものでありうる。
ここで、領域73がユーザ(オペレータ)選択されたとする。当該選択は、例えばマウスといったポインティングデバイスで行われる。ユーザが領域73を選択した場合に移行するウェブページの画面例を、図8に示す。
図8は、図7の領域72に示される商品に対するウェブページ画面の一例を示す。
図8の画面80において、画像データ81は商品82の画像データを表し、テキストデータ83は、商品82を説明するテキストデータを表す。また、領域84は、ユーザの操作により画面80が表示されるまでの、ECサイトが商品として扱う商品の全ジャンル(左)から細分化したジャンル(右)の関係を示す。
図8の画面80において、画像データ81は商品82の画像データを表し、テキストデータ83は、商品82を説明するテキストデータを表す。また、領域84は、ユーザの操作により画面80が表示されるまでの、ECサイトが商品として扱う商品の全ジャンル(左)から細分化したジャンル(右)の関係を示す。
取得部11は、画像データ81とテキストデータ83とを取得し、特徴生成部12へ出力する。ここで、取得部11は、画像データ81とテキストデータ83のレイアウト位置が入力(設定)されている場合は、当該レイアウト位置に従って、画像データ81とテキストデータ82を取得することができる。また、取得部11は、画像データ81とテキストデータ82を識別可能な画像処理技術を用いて、画像データ81とテキストデータ82をそれぞれ取得してもよい。
また、画像データ81とテキストデータ83には、あらかじめ商品82の情報が関連付けられ、取得部11が、画像データ81とテキストデータ82を取得することで、商品82の情報を取得することができる。あるいは、取得部11は、領域84に示されるジャンルの最も細分化されたジャンル(図8の例では、「Tシャツ」)を、商品82の情報として取得してもよい。
また、画像データ81とテキストデータ83には、あらかじめ商品82の情報が関連付けられ、取得部11が、画像データ81とテキストデータ82を取得することで、商品82の情報を取得することができる。あるいは、取得部11は、領域84に示されるジャンルの最も細分化されたジャンル(図8の例では、「Tシャツ」)を、商品82の情報として取得してもよい。
図6の説明に戻り、S62において、特徴生成部12は、取得部11により取得された複数のモダリティの各モダリティの特徴値を生成する。図7と図8を参照すると、特徴生成部12は、取得部11から画像データ81とテキストデータ83を取得し、画像データ81とテキストデータ83の特徴値(特徴的表現)を生成する。例えば、特徴生成部12は、画像データ81とテキストデータ83に第1学習モデル17を適用して、当該複数のモダリティの全モダリティ共通の潜在空間に投影することにより、画像データ81とテキストデータ83の特徴値を生成する。
S63において、アテンション部13は、各モダリティの特徴値に対するアテンション重みを導出する。図7と図8を参照すると、アテンション部13は、特徴生成部12により生成された画像データ81とテキストデータ83の特徴値を取得し、それぞれに対するアテンション重みを導出し、アテンション分布(アテンションマップ)を生成する。アテンション重みについては、図3を参照して説明した通りである。
S64において、分類部14は、各モダリティの特徴値を、対応するアテンション重みに適用し、複数の重みづけ特徴値を生成する。図7と図8を参照すると、分類部14は、特徴生成部12により生成された画像データ81とテキストデータ83の特徴値を、アテンション部13により導出された対応するアテンション重みに適用し、複数の重みづけ特徴値を生成する。
S65において、分類部14は、S64で生成された複数の重みづけ特徴値を連結する。図7と図8を参照すると、分類部14は、画像データ81とテキストデータ83の、重みづけ特徴値を連結して、連結値を生成する。続くS66において、分類部14は生成した連結値に第3学習モデルを適用して、オブジェクトの属性を予測する。図7と図8の画面例を用いると、分類部14は、商品82の属性のクラスラベルを予測する。属性が色情報の場合、分類部14は、商品82の色情報を予測する。
例えば、分類部14は、図8の画面80における商品82が、図7の画面70におけるカラー71bのいずれかのタイプに該当するかを予測する。図7と図8に示す例では、属性は、領域71にふくまれるいずれの属性であってもよく、例えば、分類部14を、商品82の属性としてサイズ71a~71iのいずれかの属性の中のタイプを予測するように構成することも可能である。
例えば、分類部14は、図8の画面80における商品82が、図7の画面70におけるカラー71bのいずれかのタイプに該当するかを予測する。図7と図8に示す例では、属性は、領域71にふくまれるいずれの属性であってもよく、例えば、分類部14を、商品82の属性としてサイズ71a~71iのいずれかの属性の中のタイプを予測するように構成することも可能である。
次に、図9を参照して、本実施形態による属性予測手法による効果について説明する。図9に、従来の属性予測手法と本実施形態による属性予測手法と性能比較を示す。比較結果を表す。ここではオブジェクトは商品とする。
グラフ9aは、単一のモダリティとして、画像データを用いて、オブジェクトの属性予測を行った結果を表す。グラフ9bは、単一のモダリティとして、テキストデータを用いてオブジェクトの属性予測を行った結果を表す。グラフ9cは、複数のモダリティとして、画像データとテキストデータを、アテンション重みなく連結して、属性予測を行った結果を表す。 グラフ9dは、本実施形態のように、複数のモダリティとして、画像データとテキストデータを、オブジェクトに従ったアテンション重みを用いて連結して、属性予測を行った結果を表す。
縦軸(R@P95)は、性能評価の指標として、正解データとの適合率(Precision)が95%であることの再現率(Recall)を示す。
グラフ9aは、単一のモダリティとして、画像データを用いて、オブジェクトの属性予測を行った結果を表す。グラフ9bは、単一のモダリティとして、テキストデータを用いてオブジェクトの属性予測を行った結果を表す。グラフ9cは、複数のモダリティとして、画像データとテキストデータを、アテンション重みなく連結して、属性予測を行った結果を表す。 グラフ9dは、本実施形態のように、複数のモダリティとして、画像データとテキストデータを、オブジェクトに従ったアテンション重みを用いて連結して、属性予測を行った結果を表す。
縦軸(R@P95)は、性能評価の指標として、正解データとの適合率(Precision)が95%であることの再現率(Recall)を示す。
図9のグラフから、まず、単一のモダリティを用いるより、複数のモダリティ(マルチモーダル)を用いる方が、商品(オブジェクト)の属性の予測性能が高いことがわかる。また、本実施形態のように、商品ごとに、画像データとテキストデータの間でアテンション重みを変えることにより、より精度高く商品(オブジェクト)の属性を識別できることがわかる。
以上説明したように、本実施形態によれば、分類装置は、オブジェクトに関連する複数のモダリティを入力として取得し、当該複数のモダリティに特徴値を生成してから、当該オブジェクトに従うアテンション重みで重みづけして連結し、連結した値から、当該オブジェクトの属性を識別する。このような処理により、単一のモダリティを用いる場合や、複数のモダリティを用いる場合であってもオブジェクトに従う重みづけを行わない場合と比較して、精度高くオブジェクトの属性を予測・識別することが可能となる。
これにより、オブジェクトの属性が定義されていない場合であっても、オブジェクトに関連する複数のモダリティから、当該属性を予測することができる。また、当該実施形態と、ECサイトにおける商品(オブジェクト)、画像データとテキストデータ(複数のモダリティ)に適用した場合に、ユーザによるショッピング体験の向上が期待でき、売り上げの向上につながりうる。また、ユーザ側/商品提供側にとって、商品アイテムのフィルタリングが容易になり、ユーザによる利便性の向上やマーケティング分析の向上に資する。
これにより、オブジェクトの属性が定義されていない場合であっても、オブジェクトに関連する複数のモダリティから、当該属性を予測することができる。また、当該実施形態と、ECサイトにおける商品(オブジェクト)、画像データとテキストデータ(複数のモダリティ)に適用した場合に、ユーザによるショッピング体験の向上が期待でき、売り上げの向上につながりうる。また、ユーザ側/商品提供側にとって、商品アイテムのフィルタリングが容易になり、ユーザによる利便性の向上やマーケティング分析の向上に資する。
なお、上記において特定の実施形態が説明されているが、当該実施形態は単なる例示であり、本発明の範囲を限定する意図はない。本明細書に記載された装置及び方法は上記した以外の形態において具現化することができる。また、本発明の範囲から離れることなく、上記した実施形態に対して適宜、省略、置換及び変更をなすこともできる。かかる省略、置換及び変更をなした形態は、請求の範囲に記載されたもの及びこれらの均等物の範疇に含まれ、本発明の技術的範囲に属する。
1:分類装置、10-i~n:モダリティ、11:取得部、12:特徴生成部、13:アテンション部、14:分類部、15:学習部、16:学習モデル記憶部、17:第1学習モデル、18:第2学習モデル、19:第3学習モデル
Claims (15)
- オブジェクトに関連する複数のモダリティと前記オブジェクトを識別する情報とを取得する取得手段と、
前記複数のモダリティそれぞれの特徴値を生成する特徴生成手段と、
前記複数のモダリティそれぞれの特徴値と前記オブジェクトを識別する情報に基づいて、前記複数のモダリティそれぞれに対応する重みを導出する導出手段と、
前記複数のモダリティそれぞれの特徴値を、前記対応する重みで重みづけして連結した連結値から、前記オブジェクトの属性を予測する予測手段と、
を有することを特徴とする情報処理装置。 - 前記導出手段は、前記複数の特徴値と前記オブジェクトを識別する情報から、前記複数のモダリティそれぞれの、前記属性の予測に対する重要度を示すアテンション重みを、前記複数の特徴値それぞれに対応する重みとして導出することを特徴とする請求項1に記載の情報処理装置。
- 前記複数のモダリティのアテンション重みは、合計で1であることを特徴とする請求項2に記載の情報処理装置。
- オブジェクトに関連する複数のモダリティと前記オブジェクトを識別する情報とを取得する取得手段と、
前記複数のモダリティを第1学習モデルに適用することにより、前記複数のモダリティに対する複数の特徴値を生成する特徴生成手段と、
前記複数のモダリティそれぞれの特徴値と前記オブジェクトを識別する情報とを第2学習モデルに適用することにより、前記複数の特徴値それぞれに対応する重みを導出する導出手段と、
前記複数のモダリティそれぞれの特徴値を、前記対応する重みで重みづけして連結した連結値を第3学習モデルに適用することにより、前記オブジェクトの属性を予測する予測手段と、
を有し、
前記第2学習モデルは前記オブジェクト毎に異なる重みを出力する学習モデルであることを特徴とする情報処理装置。 - 前記第2学習モデルは、前記複数の特徴値と前記オブジェクトを識別する情報を入力として、前記複数のモダリティそれぞれの、前記属性の予測に対する重要度を示すアテンション重みを、前記複数の特徴値それぞれに対応する重みとして出力する学習モデルであることを特徴とする請求項4に記載の情報処理装置。
- 前記複数のモダリティのアテンション重みは、合計で1であることを特徴とする請求項5に記載の情報処理装置。
- 前記第1学習モデルは、前記複数のモダリティを入力として、前記複数のモダリティを前記複数のモダリティ共通の潜在空間にマッピングすることにより当該複数のモダリティの特徴値を出力する学習モデルであることを特徴とする請求項4から6のいずれか1項に記載の情報処理装置。
- 前記第3学習モデルは、前記連結値を入力として、前記属性の予測結果を出力する学習モデルであることを特徴とする請求項4から7のいずれか1項に記載の情報処理装置。
- 前記取得手段は、前記複数のモダリティを符号化して、複数の符号化されたモダリティを取得し、
前記特徴生成手段は、前記複数の符号化されたモダリティそれぞれの特徴値を、前記複数のモダリティそれぞれの特徴値として生成することを特徴とする請求項1から8のいずれか1項に記載の情報処理装置。 - 前記オブジェクトは商品であり、前記複数のモダリティは、前記商品を表す画像のデータ、前記商品を説明するテキストのデータ、前記商品を説明する音声のデータ、のうちの2つ以上を含むことを特徴とする請求項1から9のいずれか1項に記載の情報処理装置。
- 前記オブジェクトの属性は、前記商品の色情報を含むことを特徴とする請求項1から10のいずれか1項に記載の情報処理装置。
- オブジェクトに関連する複数のモダリティと前記オブジェクトを識別する情報とを取得する取得工程と、
前記複数のモダリティそれぞれの特徴値を生成する特徴生成工程と、
前記複数のモダリティそれぞれの特徴値と前記オブジェクトを識別する情報に基づいて、前記複数のモダリティそれぞれに対応する重みを導出する導出工程と、
前記複数のモダリティそれぞれの特徴値を、前記対応する重みで重みづけして連結した連結値から、前記オブジェクトの属性を予測する予測工程と、
を有することを特徴とする情報処理方法。 - オブジェクトに関連する複数のモダリティと前記オブジェクトを識別する情報とを取得する取得工程と、
前記複数のモダリティを第1学習モデルに適用することにより、前記複数のモダリティに対する複数の特徴値を生成する特徴生成工程と、
前記複数のモダリティそれぞれの特徴値と前記オブジェクトを識別する情報を第2学習モデルに適用することにより、前記複数の特徴値それぞれに対応する重みを導出する導出工程と、
前記複数のモダリティそれぞれの特徴値を、前記対応する重みで重みづけして連結した連結値を第3学習モデルに適用することにより、前記オブジェクトの属性を予測する予測工程と、
を有し、
前記第2学習モデルは前記オブジェクト毎に異なる重みを出力する学習モデルであることを特徴とする情報処理方法。 - 情報処理をコンピュータに実行させるための情報処理プログラムであって、
該プログラムは、前記コンピュータに、
オブジェクトに関連する複数のモダリティと前記オブジェクトを識別する情報とを取得する取得処理と、
前記複数のモダリティそれぞれの特徴値を生成する特徴生成処理と、
前記複数のモダリティそれぞれの特徴値と前記オブジェクトを識別する情報に基づいて、前記複数のモダリティそれぞれに対応する重みを導出する導出処理と、
前記複数のモダリティそれぞれの特徴値を、前記対応する重みで重みづけして連結した連結値から、前記オブジェクトの属性を予測する予測処理と、
を含む処理を実行させるためのものである
ことを特徴とする情報処理プログラム。 - 情報処理をコンピュータに実行させるための情報処理プログラムであって、
該プログラムは、前記コンピュータに、
オブジェクトに関連する複数のモダリティと前記オブジェクトを識別する情報とを取得する取得処理と、
前記複数のモダリティを第1学習モデルに適用することにより、前記複数のモダリティに対する複数の特徴値を生成する特徴生成処理と、
前記複数のモダリティそれぞれの特徴値と前記オブジェクトを識別する情報を第2学習モデルに適用することにより、前記複数の特徴値それぞれに対応する重みを導出する導出処理と、
前記複数のモダリティそれぞれの特徴値を、前記対応する重みで重みづけして連結した連結値を第3学習モデルに適用することにより、前記オブジェクトの属性を予測する予測処理と、
を含む処理を実行させるためのものであり、
前記第2学習モデルは前記オブジェクト毎に異なる重みを出力する学習モデルであることを特徴とする情報処理プログラム。
Priority Applications (4)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US17/910,431 US20240202532A1 (en) | 2021-07-26 | 2021-07-26 | Information processing apparatus, information processing method, and storage medium |
| EP21928361.1A EP4152235A4 (en) | 2021-07-26 | 2021-07-26 | INFORMATION PROCESSING DEVICE, INFORMATION PROCESSING METHOD AND PROGRAM |
| PCT/JP2021/027527 WO2023007544A1 (ja) | 2021-07-26 | 2021-07-26 | 情報処理装置、情報処理方法、およびプログラム |
| JP2022508495A JP7087220B1 (ja) | 2021-07-26 | 2021-07-26 | 情報処理装置、情報処理方法、およびプログラム |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| PCT/JP2021/027527 WO2023007544A1 (ja) | 2021-07-26 | 2021-07-26 | 情報処理装置、情報処理方法、およびプログラム |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2023007544A1 true WO2023007544A1 (ja) | 2023-02-02 |
Family
ID=82067870
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2021/027527 Ceased WO2023007544A1 (ja) | 2021-07-26 | 2021-07-26 | 情報処理装置、情報処理方法、およびプログラム |
Country Status (4)
| Country | Link |
|---|---|
| US (1) | US20240202532A1 (ja) |
| EP (1) | EP4152235A4 (ja) |
| JP (1) | JP7087220B1 (ja) |
| WO (1) | WO2023007544A1 (ja) |
Families Citing this family (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20240331268A1 (en) * | 2023-03-29 | 2024-10-03 | Toyota Research Institute, Inc. | Systems and methods for generating an image using interpolation of features |
| JP2024154148A (ja) * | 2023-04-18 | 2024-10-30 | キヤノン株式会社 | 情報処理装置、情報処理方法及びコンピュータプログラム |
Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2019049945A (ja) * | 2017-09-12 | 2019-03-28 | ヤフー株式会社 | 抽出装置、抽出方法、抽出プログラム、及びモデル |
| JP2020140362A (ja) * | 2019-02-27 | 2020-09-03 | Kddi株式会社 | 推定装置、推定方法及び推定プログラム |
Family Cites Families (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP6884116B2 (ja) * | 2018-03-19 | 2021-06-09 | ヤフー株式会社 | 情報処理装置、情報処理方法、およびプログラム |
| WO2019222759A1 (en) * | 2018-05-18 | 2019-11-21 | Synaptics Incorporated | Recurrent multimodal attention system based on expert gated networks |
| US10949907B1 (en) * | 2020-06-23 | 2021-03-16 | Price Technologies Inc. | Systems and methods for deep learning model based product matching using multi modal data |
-
2021
- 2021-07-26 US US17/910,431 patent/US20240202532A1/en active Pending
- 2021-07-26 JP JP2022508495A patent/JP7087220B1/ja active Active
- 2021-07-26 WO PCT/JP2021/027527 patent/WO2023007544A1/ja not_active Ceased
- 2021-07-26 EP EP21928361.1A patent/EP4152235A4/en not_active Withdrawn
Patent Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2019049945A (ja) * | 2017-09-12 | 2019-03-28 | ヤフー株式会社 | 抽出装置、抽出方法、抽出プログラム、及びモデル |
| JP2020140362A (ja) * | 2019-02-27 | 2020-09-03 | Kddi株式会社 | 推定装置、推定方法及び推定プログラム |
Non-Patent Citations (3)
| Title |
|---|
| See also references of EP4152235A4 |
| TAMURA, SATOSHI; ISHIKAWA, MASATO; HASHIBA, TAKASHI; TAKEUCHI, SHINICHI; HAYAMIZU, SATORU: "Multimodal speech recognition using multimodal voice activity detection", IEICE TECHNICAL REPORT, vol. 109, no. 376, 15 February 2010 (2010-02-15), pages 345 - 350, XP009542815 * |
| TIANGANG ZHU: "Multimodal Joint Attribute Prediction and Value Extraction for E-commerce Product", PROCEEDINGS OF THE 2020 CONFERENCE ON EMPIRICAL METHODS IN NATURAL LANGUAGE PROCESSING (EMNLP, November 2020 (2020-11-01), pages 2129 - 2139 |
Also Published As
| Publication number | Publication date |
|---|---|
| JP7087220B1 (ja) | 2022-06-20 |
| US20240202532A1 (en) | 2024-06-20 |
| EP4152235A4 (en) | 2023-04-26 |
| EP4152235A1 (en) | 2023-03-22 |
| JPWO2023007544A1 (ja) | 2023-02-02 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US10360623B2 (en) | Visually generated consumer product presentation | |
| US11037071B1 (en) | Cross-category item associations using machine learning | |
| CN107622427A (zh) | 深度学习的方法、装置及系统 | |
| CN110851694B (zh) | 基于用户记忆网络和树形结构的深度模型的个性化推荐系统 | |
| US20180068009A1 (en) | Point-in-time dependent identification for offering interactive services in a user web journey | |
| CN108109049A (zh) | 服饰搭配预测方法、装置、计算机设备及存储介质 | |
| CN103886486A (zh) | 一种基于支持向量机svm的电子商务推荐方法 | |
| Patil et al. | Studying the contribution of machine learning and artificial intelligence in the interface design of e-commerce site | |
| JP7087220B1 (ja) | 情報処理装置、情報処理方法、およびプログラム | |
| Chornous et al. | A hybrid user-item-based collaborative filtering model for e-commerce recommendations | |
| Hameed et al. | Clothing image classification using VGG-19 deep learning model for e-commerce web application | |
| Buradagunta et al. | Attention-driven fusion of pre-trained model features for superior recommender systems | |
| Rinanda | Implementation of PNN, ANN And K-NN Algorithms on Indonesian Marketplace Reviews on Google Play Store | |
| JP2023149688A (ja) | 情報処理装置、情報処理方法、およびプログラム | |
| JP2023149687A (ja) | 情報処理装置、情報処理方法、モデル構築方法、およびプログラム | |
| JP2020135392A (ja) | 情報処理装置、情報処理方法及び情報処理プログラム | |
| JP2019106099A (ja) | 提供プログラム、提供装置、および提供方法 | |
| CN112488355A (zh) | 基于图神经网络预测用户评级的方法和装置 | |
| KR20210152178A (ko) | 화장대 큐레이션서비스장치 및 그 장치의 구동방법, 그리고 컴퓨터 판독가능 기록매체 | |
| JP7445782B2 (ja) | 情報処理装置、情報処理方法、およびプログラム | |
| CN116431823A (zh) | 基于知识图谱的时尚分析方法、装置、设备及存储介质 | |
| EP4195135A1 (en) | Information processing device, information processing method, information processing system, and program | |
| Alodat | Deep Transfer Learning and Intelligent Item Packing in Retail Management | |
| Harris et al. | Deep Learning for Online Fashion: A Novel Solution for the Retail E-Commerce Industry | |
| Prakash et al. | Enhancing Clothing Size Prediction in E-Commerce: A Machine Learning Approach for Improved Customer Experience |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| ENP | Entry into the national phase |
Ref document number: 2022508495 Country of ref document: JP Kind code of ref document: A |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 17910431 Country of ref document: US |
|
| ENP | Entry into the national phase |
Ref document number: 2021928361 Country of ref document: EP Effective date: 20220908 |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |