실시예들의 바람직한 실시예에 대해 구체적으로 설명하며, 그 예는 첨부된 도면에 나타난다. 첨부된 도면을 참조한 아래의 상세한 설명은 실시예들의 실시예에 따라 구현될 수 있는 실시예만을 나타내기보다는 실시예들의 바람직한 실시예를 설명하기 위한 것이다. 다음의 상세한 설명은 실시예들에 대한 철저한 이해를 제공하기 위해 세부 사항을 포함한다. 그러나 실시예들이 이러한 세부 사항 없이 실행될 수 있다는 것은 당업자에게 자명하다.
실시예들에서 사용되는 대부분의 용어는 해당 분야에서 널리 사용되는 일반적인 것들에서 선택되지만, 일부 용어는 출원인에 의해 임의로 선택되며 그 의미는 필요에 따라 다음 설명에서 자세히 서술한다. 따라서 실시예들은 용어의 단순한 명칭이나 의미가 아닌 용어의 의도된 의미에 근거하여 이해되어야 한다.
도 1은 실시예들에 따른 포인트 클라우드 콘텐트 제공 시스템의 예시를 나타낸다.
도 1에 도시된 포인트 클라우드 콘텐트 제공 시스템은 송신장치(transmission device)(10000) 및 수신장치(reception device)(10004)를 포함할 수 있다. 송신장치(10000) 및 수신장치(10004)는 포인트 클라우드 데이터를 송수신하기 위해 유무선 통신 가능하다.
실시예들에 따른 송신장치(10000)는 포인트 클라우드 비디오(또는 포인트 클라우드 콘텐트)를 확보하고 처리하여 송신할 수 있다. 실시예들에 따라, 송신장치(10000)는 고정국(fixed station), BTS(base transceiver system), 네트워크, AI(Ariticial Intelligence) 기기 및/또는 시스템, 로봇, AR/VR/XR 기기 및/또는 서버 등을 포함할 수 있다. 또한 실시예들에 따른 송신장치(10000)는 무선 접속 기술(예, 5G NR(New RAT), LTE(Long Term Evolution))을 이용하여, 기지국 및/또는 다른 무선 기기와 통신을 수행하는 기기, 로봇, 차량, AR/VR/XR 기기, 휴대기기, 가전, IoT(Internet of Thing)기기, AI 기기/서버 등을 포함할 수 있다.
실시예들에 따른 송신장치(10000)는 포인트 클라우드 비디오 획득부(Point Cloud Video Acquisition, 10001), 포인트 클라우드 비디오 인코더(Point Cloud Video Encoder, 10002) 및/또는 트랜스미터(Transmitter (or Communication module), 10003)를 포함한다
실시예들에 따른 포인트 클라우드 비디오 획득부(10001)는 캡쳐, 합성 또는 생성 등의 처리 과정을 통해 포인트 클라우드 비디오를 획득한다. 포인트 클라우드 비디오는 3차원 공간에 위치한 포인트들의 집합인 포인트 클라우드로 표현되는 포인트 클라우드 콘텐트로서, 포인트 클라우드 비디오 데이터, 포인트 클라우드 데이터 등으로 호칭될 수 있다. 실시예들에 따른 포인트 클라우드 비디오는 하나 또는 그 이상의 프레임들을 포함할 수 있다. 하나의 프레임은 정지 영상/픽쳐를 나타낸다. 따라서 포인트 클라우드 비디오는 포인트 클라우드 영상/프레임/픽처를 포함할 수 있으며, 포인트 클라우드 영상, 프레임 및 픽처 중 어느 하나로 호칭될 수 있다.
실시예들에 따른 포인트 클라우드 비디오 인코더(10002)는 확보된 포인트 클라우드 비디오 데이터를 인코딩한다. 포인트 클라우드 비디오 인코더(10002)는 포인트 클라우드 컴프레션(Point Cloud Compression) 코딩을 기반으로 포인트 클라우드 비디오 데이터를 인코딩할 수 있다. 실시예들에 따른 포인트 클라우드 컴프레션 코딩은 G-PCC(Geometry-based Point Cloud Compression) 코딩 및/또는 V-PCC(Video based Point Cloud Compression) 코딩 또는 차세대 코딩을 포함할 수 있다. 또한 실시예들에 따른 포인트 클라우드 컴프레션 코딩은 상술한 실시예에 국한되는 것은 아니다. 포인트 클라우드 비디오 인코더(10002)는 인코딩된 포인트 클라우드 비디오 데이터를 포함하는 비트스트림을 출력할 수 있다. 비트스트림은 인코딩된 포인트 클라우드 비디오 데이터뿐만 아니라, 포인트 클라우드 비디오 데이터의 인코딩과 관련된 시그널링 정보를 포함할 수 있다.
실시예들에 따른 트랜스미터(10003)는 인코딩된 포인트 클라우드 비디오 데이터를 포함하는 비트스트림을 송신한다. 실시예들에 따른 비트스트림은 파일 또는 세그먼트(예를 들면 스트리밍 세그먼트) 등으로 인캡슐레이션되어 방송망 및/또는 브로드밴드 망등의 다양한 네트워크를 통해 송신된다. 도면에 도시되지 않았으나, 송신장치(10000)는 인캡슐레이션 동작을 수행하는 인캡슐레이션부(또는 인캡슐레이션 모듈)을 포함할 수 있다. 또한 실시예들에 따라 인캡슐레이션부는 트랜스미터(10003)에 포함될 수 있다. 실시예들에 따라 파일 또는 세그먼트는 네트워크를 통해 수신장치(10004)로 송신되거나, 디지털 저장매체(예를 들면 USB, SD, CD, DVD, 블루레이, HDD, SSD 등)에 저장될 수 있다. 실시예들에 따른 트랜스미터(10003)는 수신장치(10004) (또는 리시버(Receiver, 10005))와 4G, 5G, 6G 등의 네트워크를 통해 유/무선 통신 가능하다. 또한 트랜스미터(10003)는 네트워크 시스템(예를 들면 4G, 5G, 6G 등의 통신 네트워크 시스템)에 따라 필요한 데이터 처리 동작을 수행할 수 있다. 또한 송신장치(10000)는 온 디맨드(On Demand) 방식에 따라 인캡슐레이션된 데이터를 송신할 수도 있다.
실시예들에 따른 수신장치(10004)는 리시버(Receiver, 10005), 포인트 클라우드 비디오 디코더(Point Cloud Decoder, 10006) 및/또는 렌더러(Renderer, 10007)를 포함한다. 실시예들에 따라 수신장치(10004)는 무선 접속 기술(예, 5G NR(New RAT), LTE(Long Term Evolution))을 이용하여, 기지국 및/또는 다른 무선 기기와 통신을 수행하는 기기, 로봇, 차량, AR/VR/XR 기기, 휴대기기, 가전, IoT(Internet of Thing)기기, AI 기기/서버 등을 포함할 수 있다.
실시예들에 따른 리시버(10005)는 포인트 클라우드 비디오 데이터를 포함하는 비트스트림 또는 비트스트림이 인캡슐레이션된 파일/세그먼트 등을 네트워크 또는 저장매체로부터 수신한다. 리시버(10005)는 네트워크 시스템(예를 들면 4G, 5G, 6G 등의 통신 네트워크 시스템)에 따라 필요한 데이터 처리 동작을 수행할 수 있다. 실시예들에 따른 리시버(10005)는 수신한 파일/세그먼트를 디캡슐레이션하여 비트스트림을 출력할수 있다. 또한 실시예들에 따라 리시버(10005)는 디캡슐레이션 동작을 수행하기 위한 디캡슐레이션부(또는 디캡슐레이션 모듈)을 포함할 수 있다. 또한 디캡슐레이션부는 리시버(10005)와 별개의 엘레멘트(또는 컴포넌트)로 구현될 수 있다.
포인트 클라우드 비디오 디코더(10006)는 포인트 클라우드 비디오 데이터를 포함하는 비트스트림을 디코딩한다. 포인트 클라우드 비디오 디코더(10006)는 포인트 클라우드 비디오 데이터가 인코딩된 방식에 따라 디코딩할 수 있다(예를 들면 포인트 클라우드 비디오 인코더(10002)의 동작의 역과정). 따라서 포인트 클라우드 비디오 디코더(10006)는 포인트 클라우드 컴프레션의 역과정인 포인트 클라우드 디컴프레션 코딩을 수행하여 포인트 클라우드 비디오 데이터를 디코딩할 수 있다. 포인트 클라우드 디컴프레션 코딩은 G-PCC 코딩을 포함한다.
렌더러(10007)는 디코딩된 포인트 클라우드 비디오 데이터를 렌더링한다. 렌더러(10007)는 포인트 클라우드 비디오 데이터 뿐만 아니라 오디오 데이터도 렌더링하여 포인트 클라우드 콘텐트를 출력할 수 있다. 실시예들에 따라 렌더러(10007)는 포인트 클라우드 콘텐트를 디스플레이하기 위한 디스플레이를 포함할 수 있다. 실시예들에 따라 디스플레이는 렌더러(10007)에 포함되지 않고 별도의 디바이스 또는 컴포넌트로 구현될 수 있다.
도면에 점선으로 표시된 화살표는 수신장치(10004)에서 획득한 피드백 정보(feedback information)의 송신 경로를 나타낸다. 피드백 정보는 포인트 클라우드 컨텐트를 소비하는 사용자와의 인터랙티비를 반영하기 위한 정보로서, 사용자의 정보(예를 들면 헤드 오리엔테이션 정보), 뷰포트(Viewport) 정보 등)을 포함한다. 특히 포인트 클라우드 콘텐트가 사용자와의 상호작용이 필요한 서비스(예를 들면 자율주행 서비스 등)를 위한 콘텐트인 경우, 피드백 정보는 콘텐트 송신측(예를 들면 송신장치(10000)) 및/또는 서비스 프로바이더에게 전달될 수 있다. 실시예들에 따라 피드백 정보는 송신장치(10000)뿐만 아니라 수신장치(10004)에서도 사용될 수 있으며, 제공되지 않을 수도 있다.
실시예들에 따른 헤드 오리엔테이션 정보는 사용자의 머리 위치, 방향, 각도, 움직임 등에 대한 정보이다. 실시예들에 따른 수신장치(10004)는 헤드 오리엔테이션 정보를 기반으로 뷰포트 정보를 계산할 수 있다. 뷰포트 정보는 사용자가 바라보고 있는 포인트 클라우드 비디오의 영역에 대한 정보이다. 시점(viewpoint)은 사용자가 포인트 클라우 비디오를 보고 있는 점으로 뷰포트 영역의 정중앙 지점을 의미할 수 있다. 즉, 뷰포트는 시점을 중심으로 한 영역으로서, 영역의 크기, 형태 등은 FOV(Field Of View) 에 의해 결정될 수 있다. 따라서 수신장치(10004)는 헤드 오리엔테이션 정보 외에 장치가 지원하는 수직(vertical) 혹은 수평(horizontal) FOV 등을 기반으로 뷰포트 정보를 추출할 수 있다. 또한 수신장치(10004)는 게이즈 분석 (Gaze Analysis) 등을 수행하여 사용자의 포인트 클라우드 소비 방식, 사용자가 응시하는 포인트 클라우 비디오 영역, 응시 시간 등을 확인한다. 실시예들에 따라 수신장치(10004)는 게이즈 분석 결과를 포함하는 피드백 정보를 송신장치(10000)로 송신할 수 있다. 실시예들에 따른 피드백 정보는 렌더링 및/또는 디스플레이 과정에서 획득될 수 있다. 실시예들에 따른 피드백 정보는 수신장치(10004)에 포함된 하나 또는 그 이상의 센서들에 의해 확보될 수 있다. 또한 실시예들에 따라 피드백 정보는 렌더러(10007) 또는 별도의 외부 엘레멘트(또는 디바이스, 컴포넌트 등)에 의해 확보될 수 있다. 도1의 점선은 렌더러(10007)에서 확보한 피드백 정보의 전달 과정을 나타낸다. 포인트 클라우드 콘텐트 제공 시스템은 피드백 정보를 기반으로 포인트 클라우드 데이터를 처리(인코딩/디코딩)할 수 있다. 따라서 포인트 클라우드 비디오 데이터 디코더(10006)는 피드백 정보를 기반으로 디코딩 동작을 수행할 수 있다. 또한 수신장치(10004)는 피드백 정보를 송신장치(10000)로 송신할 수 있다. 송신장치(10000)(또는 포인트 클라우드 비디오 데이터 인코더(10002))는 피드백 정보를 기반으로 인코딩 동작을 수행할 수 있다. 따라서 포인트 클라우드 콘텐트 제공 시스템은 모든 포인트 클라우드 데이터를 처리(인코딩/디코딩)하지 않고, 피드백 정보를 기반으로 필요한 데이터(예를 들면 사용자의 헤드 위치에 대응하는 포인트 클라우드 데이터)를 효율적으로 처리하고, 사용자에게 포인트 클라우드 콘텐트를 제공할 수 있다.
실시예들에 따라, 송신장치(10000)는 인코더, 송신 디바이스, 송신기, 송신기 등으로 호칭될 수 있으며, 수신장치(10004)는 디코더, 수신 디바이스, 수신기 등으로 호칭될 수 있다.
실시예들에 따른 도 1 의 포인트 클라우드 콘텐트 제공 시스템에서 처리되는 (획득/인코딩/송신/디코딩/렌더링의 일련의 과정으로 처리되는) 포인트 클라우드 데이터는 포인트 클라우드 콘텐트 데이터 또는 포인트 클라우드 비디오 데이터라고 호칭할 수 있다. 실시예들에 따라 포인트 클라우드 콘텐트 데이터는 포인트 클라우드 데이터와 관련된 메타데이터 내지 시그널링 정보를 포함하는 개념으로 사용될 수 있다.
도 1에 도시된 포인트 클라우드 콘텐트 제공 시스템의 엘리먼트들은 하드웨어, 소프트웨어, 프로세서 및/또는 그것들의 결합등으로 구현될 수 있다.
도 2는 실시예들에 따른 포인트 클라우드 콘텐트 제공 동작을 나타내는 블록도이다.
도 2의 블록도는 도 1에서 설명한 포인트 클라우드 콘텐트 제공 시스템의 동작을 나타낸다. 상술한 바와 같이 포인트 클라우드 콘텐트 제공 시스템은 포인트 클라우드 컴프레션 코딩(예를 들면 G-PCC)을 기반으로 포인트 클라우드 데이터를 처리할 수 있다.
실시예들에 따른 포인트 클라우드 콘텐트 제공 시스템(예를 들면 포인트 클라우드 송신장치(10000) 또는 포인트 클라우드 비디오 획득부(10001))은 포인트 클라우드 비디오를 획득할 수 있다(20000). 포인트 클라우드 비디오는 3차원 공간을 표현하는 좌표계에 속한 포인트 클라우드로 표현된다. 실시예들에 따른 포인트 클라우드 비디오는 Ply (Polygon File format or the Stanford Triangle format) 파일을 포함할 수 있다. 포인트 클라우드 비디오가 하나 또는 그 이상의 프레임들을 갖는 경우, 획득한 포인트 클라우드 비디오는 하나 또는 그 이상의 Ply 파일들을 포함할 수 있다. Ply 파일은 포인트의 지오메트리(Geometry) 및/또는 어트리뷰트(Attribute)와 같은 포인트 클라우드 데이터를 포함한다. 지오메트리는 포인트들의 포지션(위치)들을 포함한다. 각 포인트의 포지션은 3차원 좌표계(예를 들면 XYZ축들로 이루어진 좌표계 등)를 나타내는 파라미터들(예를 들면 X축, Y축, Z축 각각의 값)로 표현될 수 있다. 어트리뷰트는 포인트들의 어트리뷰트들(예를 들면, 각 포인트의 텍스쳐 정보, 색상(YCbCr 또는 RGB), 반사율(r), 투명도 등)을 포함한다. 하나의 포인트는 하나 또는 그 이상의 어트리뷰트들(또는 속성들)을 가진다. 예를 들어 하나의 포인트는 하나의 색상인 어트리뷰트를 가질 수도 있고, 색상 및 반사율인 두 개의 어트리뷰트들을 가질 수도 있다. 실시예들에 따라, 지오메트리는 포지션들, 지오메트리 정보, 지오메트리 데이터, 위치 정보, 위치 데이터 등으로 호칭 가능하며, 어트리뷰트는 어트리뷰트들, 어트리뷰트 정보, 어트리뷰트 데이터, 속성 정보, 속성 데이터 등으로 호칭할 수 있다. 또한 포인트 클라우드 콘텐트 제공 시스템(예를 들면 포인트 클라우드 송신장치(10000) 또는 포인트 클라우드 비디오 획득부(10001))은 포인트 클라우드 비디오의 획득 과정과 관련된 정보(예를 들면 깊이 정보, 색상 정보 등)으로부터 포인트 클라우드 데이터를 확보할 수 있다.
실시예들에 따른 포인트 클라우드 콘텐트 제공 시스템(예를 들면 송신장치(10000) 또는 포인트 클라우드 비디오 인코더(10002))은 포인트 클라우드 데이터를 인코딩할 수 있다(20001). 포인트 클라우드 콘텐트 제공 시스템은 포인트 클라우드 컴프레션 코딩을 기반으로 포인트 클라우드 데이터를 인코딩할 수 있다. 상술한 바와 같이 포인트 클라우드 데이터는 포인트의 지오메트리 정보 및 어트리뷰트 정보를 포함할 수 있다. 따라서 포인트 클라우드 콘텐트 제공 시스템은 지오메트리를 인코딩하는 지오메트리 인코딩을 수행하여 지오메트리 비트스트림을 출력할 수 있다. 포인트 클라우드 콘텐트 제공 시스템은 어트리뷰트를 인코딩하는 어트리뷰트 인코딩을 수행하여 어트리뷰트 비트스트림을 출력할 수 있다. 실시예들에 따라 포인트 클라우드 콘텐트 제공 시스템은 지오메트리 인코딩에 기초하여 어트리뷰트 인코딩을 수행할 수 있다. 실시예들에 따른 지오메트리 비트스트림 및 어트리뷰트 비트스트림은 멀티플렉싱되어 하나의 비트스트림으로 출력될 수 있다. 실시예들에 따른 비트스트림은 지오메트리 인코딩 및 어트리뷰트 인코딩과 관련된 시그널링 정보를 더 포함할 수 있다.
실시예들에 따른 포인트 클라우드 콘텐트 제공 시스템(예를 들면 송신장치(10000) 또는 트랜스미터(10003))은 인코딩된 포인트 클라우드 데이터를 송신할 수 있다(20002). 도1에서 설명한 바와 같이 인코딩된 포인트 클라우드 데이터는 지오메트리 비트스트림, 어트리뷰트 비트스트림으로 표현될 수 있다. 또한 인코딩된 포인트 클라우드 데이터는 포인트 클라우드 데이터의 인코딩과 관련된 시그널링 정보(예를 들면 지오메트리 인코딩 및 어트리뷰트 인코딩과 관련된 시그널링 정보)과 함께 비트스트림의 형태로 송신될 수 있다. 또한 포인트 클라우드 콘텐트 제공 시스템은 인코딩된 포인트 클라우드 데이터를 송신하는 비트스트림을 인캡슐레이션 하여 파일 또는 세그먼트의 형태로 송신할 수 있다.
실시예들에 따른 포인트 클라우드 콘텐트 제공 시스템(예를 들면 수신장치(10004) 또는 리시버(10005))은 인코딩된 포인트 클라우드 데이터를 포함하는 비트스트림을 수신할 수 있다. 또한 포인트 클라우드 콘텐트 제공 시스템(예를 들면 수신장치(10004) 또는 리시버(10005))은 비트스트림을 디멀티플렉싱할 수 있다.
포인트 클라우드 콘텐트 제공 시스템(예를 들면 수신장치(10004) 또는 포인트 클라우드 비디오 디코더(10005))은 비트스트림으로 송신되는 인코딩된 포인트 클라우드 데이터(예를 들면 지오메트리 비트스트림, 어트리뷰트 비트스트림)을 디코딩할 수 있다. 포인트 클라우드 콘텐트 제공 시스템(예를 들면 수신장치(10004) 또는 포인트 클라우드 비디오 디코더(10005))은 비트스트림에 포함된 포인트 클라우드 비디오 데이터의 인코딩과 관련된 시그널링 정보를 기반으로 포인트 클라우드 비디오 데이터를 디코딩할 수 있다. 포인트 클라우드 콘텐트 제공 시스템(예를 들면 수신장치(10004) 또는 포인트 클라우드 비디오 디코더(10005))은 지오메트리 비트스트림을 디코딩하여 포인트들의 포지션들(지오메트리)을 복원할 수 있다. 포인트 클라우드 콘텐트 제공 시스템은 복원한 지오메트리를 기반으로 어트리뷰트 비트스트림을 디코딩하여 포인트들의 어트리뷰트들을 복원할 수 있다. 포인트 클라우드 콘텐트 제공 시스템(예를 들면 수신장치(10004) 또는 포인트 클라우드 비디오 디코더(10005))은 복원된 지오메트리에 따른 포지션들 및 디코딩된 어트리뷰트를 기반으로 포인트 클라우드 비디오를 복원할 수 있다.
실시예들에 따른 포인트 클라우드 콘텐트 제공 시스템(예를 들면 수신장치(10004) 또는 렌더러(10007))은 디코딩된 포인트 클라우드 데이터를 렌더링할 수 있다(20004). 포인트 클라우드 콘텐트 제공 시스템(예를 들면 수신장치(10004) 또는 렌더러(10007))은 디코딩 과정을 통해 디코딩된 지오메트리 및 어트리뷰트들을 다양한 렌더링 방식에 따라 렌더링 방식에 따라 렌더링 할 수 있다. 포인트 클라우드 콘텐트의 포인트들은 일정 두께를 갖는 정점, 해당 정점 위치를 중앙으로 하는 특정 최소 크기를 갖는 정육면체, 또는 정점 위치를 중앙으로 하는 원 등으로 렌더링 될 수도 있다. 렌더링된 포인트 클라우드 콘텐트의 전부 또는 일부 영역은 디스플레이 (예를 들면 VR/AR 디스플레이, 일반 디스플레이 등)을 통해 사용자에게 제공된다.
실시예들에 따른 포인트 클라우드 콘텐트 제공 시스템(예를 들면 수신장치(10004))는 피드백 정보를 확보할 수 있다(20005). 포인트 클라우드 콘텐트 제공 시스템은 피드백 정보를 기반으로 포인트 클라우드 데이터를 인코딩 및/또는 디코딩할 수 있다. 실시예들에 따른 피드백 정보 및 포인트 클라우드 콘텐트 제공 시스템의 동작은 도 1에서 설명한 피드백 정보 및 동작과 동일하므로 구체적인 설명은 생략한다.
도 3은 실시예들에 따른 포인트 클라우드 비디오 캡쳐 과정의 예시를 나타낸다.
도 3은 도 1 내지 도 2에서 설명한 포인트 클라우드 콘텐트 제공 시스템의 포인트 클라우드 비디오 캡쳐 과정의 예시를 나타낸다.
포인트 클라우드 콘텐트는 다양한 3차원 공간(예를 들면 현실 환경을 나타내는 3차원 공간, 가상 환경을 나타내는3차원 공간 등)에 위치한 오브젝트(object) 및/또는 환경을 나타내는 포인트 클라우드 비디오(이미지들 및/또는 영상들)을 포함한다. 따라서 실시예들에 따른 포인트 클라우드 콘텐트 제공 시스템은 포인트 클라우드 콘텐트를 생성하기 위하여 하나 또는 그 이상의 카메라(camera)들(예를 들면, 깊이 정보를 확보할 수 있는 적외선 카메라, 깊이 정보에 대응되는 색상 정보를 추출 할 수 있는 RGB 카메라 등), 프로젝터(예를 들면 깊이 정보를 확보하기 위한 적외선 패턴 프로젝터 등), 라이다(LiDAR)등을 사용하여 포인트 클라우드 비디오를 캡쳐할 수 있다. 실시예들에 따른 포인트 클라우드 콘텐트 제공 시스템은 깊이 정보로부터 3차원 공간상의 포인트들로 구성된 지오메트리의 형태를 추출하고, 색상정보로부터 각 포인트의 어트리뷰트를 추출하여 포인트 클라우드 데이터를 확보할 수 있다. 실시예들에 따른 이미지 및/또는 영상은 인워드-페이싱(inward-facing) 방식 및 아웃워드-페이싱(outward-facing) 방식 중 적어도 어느 하나 이상을 기반으로 캡쳐될 수 있다.
도3의 왼쪽은 인워드-페이싱 방식을 나타낸다. 인워드-페이싱 방식은 중심 오브젝트를 둘러싸고 위치한 하나 또는 그 이상의 카메라들(또는 카메라 센서들)이 중심 오브젝트를 캡쳐하는 방식을 의미한다. 인워드-페이싱 방식은 핵심 객체에 대한 360도 이미지를 사용자에게 제공하는 포인트 클라우드 콘텐트(예를 들면 사용자에게 객체(예-캐릭터, 선수, 물건, 배우 등 핵심이 되는 객체)의 360도 이미지를 제공하는 VR/AR 콘텐트)를 생성하기 위해 사용될 수 있다.
도3의 오른쪽은 아웃워드-페이싱 방식을 나타낸다. 아웃워드-페이싱 방식은 중심 오브젝트를 둘러싸고 위치한 하나 또는 그 이상의 카메라들(또는 카메라 센서들)이 중심 오브젝트가 아닌 중심 오브젝트의 환경을 캡쳐하는 방식을 의미한다. 아웃워드-페이싱 방식은 사용자의 시점에서 나타나는 주변 환경을 제공하기 위한 포인트 클라우드 콘텐트(예를 들면자율 주행 차량의 사용자에게 제공될 수 있는 외부 환경을 나타내는 콘텐트)를 생성하기 위해 사용될 수 있다.
도면에 도시된 바와 같이, 포인트 클라우드 콘텐트는 하나 또는 그 이상의 카메라들의 캡쳐 동작을 기반으로 생성될 수 있다. 이 경우 각 카메라의 좌표계가 다를 수 있으므로 포인트 클라우드 콘텐트 제공 시스템은 캡쳐 동작 이전에 글로벌 공간 좌표계(global coordinate system)을 설정하기 위하여 하나 또는 그 이상의 카메라들의 캘리브레이션을 수행할 수 있다. 또한 포인트 클라우드 콘텐트 제공 시스템은 상술한 캡쳐 방식으로 캡쳐된 이미지 및/또는 영상과 임의의 이미지 및/또는 영상을 합성하여 포인트 클라우드 콘텐트를 생성할 수 있다. 또한 포인트 클라우드 콘텐트 제공 시스템은 가상 공간을 나타내는 포인트 클라우드 콘텐트를 생성하는 경우 도3에서 설명한 캡쳐 동작을 수행하지 않을 수 있다. 실시예들에 따른 포인트 클라우드 콘텐트 제공 시스템은 캡쳐한 이미지 및/또는 영상에 대해 후처리를 수행할 수 있다. 즉, 포인트 클라우드 콘텐트 제공 시스템은 원하지 않는 영역(예를 들면 배경)을 제거하거나, 캡쳐한 이미지들 및/또는 영상들이 연결된 공간을 인식하고, 구멍(spatial hole)이 있는 경우 이를 메우는 동작을 수행할 수 있다.
또한 포인트 클라우드 콘텐트 제공 시스템은 각 카메라로부터 확보한 포인트 클라우드 비디오의 포인트들에 대하여 좌표계 변환을 수행하여 하나의 포인트 클라우드 콘텐트를 생성할 수 있다. 포인트 클라우드 콘텐트 제공 시스템은 각 카메라의 위치 좌표를 기준으로 포인트들의 좌표계 변환을 수행할 수 있다. 이에 따라, 포인트 클라우드 콘텐트 제공 시스템은 하나의 넓은 범위를 나타내는 콘텐트를 생성할 수도 있고, 포인트들의 밀도가 높은 포인트 클라우드 콘텐트를 생성할 수 있다.
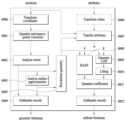
도 4는 실시예들에 따른 포인트 클라우드 인코더(Point Cloud Encoder)의 예시를 나타낸다.
도 4는 도 1의 포인트 클라우드 비디오 인코더(10002)의 예시를 나타낸다. 포인트 클라우드 인코더는 네트워크의 상황 혹은 애플리케이션 등에 따라 포인트 클라우드 콘텐트의 질(예를 들어 무손실-lossless, 손실-lossy, near-lossless)을 조절하기 위하여 포인트 클라우드 데이터(예를 들면 포인트들의 포지션들 및/또는 어트리뷰트들)을 재구성하고 인코딩 동작을 수행한다. 포인트 클라우드 콘텐트의 전체 사이즈가 큰 경우(예를 들어 30 fps의 경우 60 Gbps인 포인트 클라우드 콘텐트) 포인트 클라우드 콘텐트 제공 시스템은 해당 콘텐트를 리얼 타임 스트리밍하지 못할 수 있다. 따라서 포인트 클라우드 콘텐트 제공 시스템은 네트워크 환경등에 맞춰 제공하기 위하여 최대 타깃 비트율(bitrate)을 기반으로 포인트 클라우드 콘텐트를 재구성할 수 있다.
도 1 내지 도2 에서 설명한 바와 같이 포인트 클라우드 인코더는 지오메트리 인코딩 및 어트리뷰트 인코딩을 수행할 수 있다. 지오메트리 인코딩은 어트리뷰트 인코딩보다 먼저 수행된다.
실시예들에 따른 포인트 클라우드 인코더는 좌표계 변환부(Transformation Coordinates, 40000), 양자화부(Quantize and Remove Points (Voxelize), 40001), 옥트리 분석부(Analyze Octree, 40002), 서페이스 어프록시메이션 분석부(Analyze Surface Approximation, 40003), 아리스메틱 인코더(Arithmetic Encode, 40004), 지오메트리 리컨스트럭션부(Reconstruct Geometry, 40005), 컬러 변환부(Transform Colors, 40006), 어트리뷰트 변환부(Transfer Attributes, 40007), RAHT 변환부(40008), LOD생성부(Generated LOD, 40009), 리프팅 변환부(Lifting)(40010), 계수 양자화부(Quantize Coefficients, 40011) 및/또는 아리스메틱 인코더(Arithmetic Encode, 40012)를 포함한다.
좌표계 변환부(40000), 양자화부(40001), 옥트리 분석부(40002), 서페이스 어프록시메이션 분석부(40003), 아리스메틱 인코더(40004), 및 지오메트리 리컨스트럭션부(40005)는 지오메트리 인코딩을 수행할 수 있다. 실시예들에 따른 지오메트리 인코딩은 옥트리 지오메트리 코딩, 예측트리 지오메트리 코딩, 다이렉트 코딩(direct coding), 트라이숩 지오메트리 인코딩(trisoup geometry encoding) 및 엔트로피 인코딩을 포함할 수 있다. 다이렉트 코딩 및 트라이숩 지오메트리 인코딩은 선택적으로 또는 조합으로 적용된다. 또한 지오메트리 인코딩은 위의 예시에 국한되지 않는다.
도면에 도시된 바와 같이, 실시예들에 따른 좌표계 변환부(40000)는 포지션들을 수신하여 좌표계(coordinate)로 변환한다. 예를 들어, 포지션들은 3차원 공간 (예를 들면XYZ 좌표계로 표현되는 3차원 공간 등)의 위치 정보로 변환될 수 있다. 실시예들에 따른 3차원 공간의 위치 정보는 지오메트리 정보로 지칭될 수 있다.
실시예들에 따른 양자화부(40001)는 지오메트리를 양자화한다. 예를 들어, 양자화부(40001)는 전체 포인트들의 최소 위치 값(예를 들면 X축, Y축, Z축 에 대하여 각축상의 최소 값)을 기반으로 포인트들을 양자화 할 수 있다. 양자화부(40001)는 최소 위치 값과 각 포인트의 위치 값의 차이에 기 설정된 양자 스케일(quatization scale) 값을 곱한 뒤, 내림 또는 올림을 수행하여 가장 가까운 정수 값을 찾는 양자화 동작을 수행한다. 따라서 하나 또는 그 이상의 포인트들은 동일한 양자화된 포지션 (또는 포지션 값)을 가질 수 있다. 실시예들에 따른 양자화부(40001)는 양자화된 포인트들을 재구성하기 위해 양자화된 포지션들을 기반으로 복셀화(voxelization)를 수행한다. 2차원 이미지/비디오 정보를 포함하는 최소 단위는 픽셀(pixel)과 같이, 실시예들에 따른 포인트 클라우드 콘텐트(또는 3차원 포인트 클라우드 비디오)의 포인트들은 하나 또는 그 이상의 복셀(voxel)들에 포함될 수 있다. 복셀은 볼륨(Volume)과 픽셀(Pixel)의 조합어로서, 3차원 공간을 표현하는 축들(예를 들면 X축, Y축, Z축)을 기반으로 3차원 공간을 유닛(unit=1.0) 단위로 나누었을 때 발생하는 3차원 큐빅 공간을 의미한다. 양자화부(40001)는 3차원 공간의 포인트들의 그룹들을 복셀들로 매칭할 수 있다. 실시예들에 따라 하나의 복셀은 하나의 포인트만 포함할 수 있다. 실시예들에 따라 하나의 복셀은 하나 또는 그 이상의 포인트들을 포함할 수 있다. 또한 하나의 복셀을 하나의 포인트로 표현하기 위하여, 하나의 복셀에 포함된 하나 또는 그 이상의 포인트들의 포지션들을 기반으로 해당 복셀의 중앙점(center)의 포지션을 설정할 수 있다. 이 경우 하나의 복셀에 포함된 모든 포지션들의 어트리뷰트들은 통합되어(combined) 해당 복셀에 할당될(assigned)수 있다.
실시예들에 따른 옥트리 분석부(40002)는 복셀을 옥트리(octree) 구조로 나타내기 위한 옥트리 지오메트리 코딩(또는 옥트리 코딩)을 수행한다. 옥트리 구조는 팔진 트리 구조에 기반하여 복셀에 매칭된 포인트들을 표현한다.
실시예들에 따른 서페이스 어프록시메이션 분석부(40003)는 옥트리를 분석하고, 근사화할 수 있다. 실시예들에 따른 옥트리 분석 및 근사화는 효율적으로 옥트리 및 복셀화를 제공하기 위해서 다수의 포인트들을 포함하는 영역에 대해 복셀화하기 위해 분석하는 과정이다.
실시예들에 따른 아리스메틱 인코더(40004)는 옥트리 및/또는 근사화된 옥트리를 엔트로피 인코딩한다. 예를 들어, 인코딩 방식은 아리스메틱(Arithmetic) 인코딩 방법을 포함한다. 인코딩의 결과로 지오메트리 비트스트림이 생성된다.
컬러 변환부(40006), 어트리뷰트 변환부(40007), RAHT 변환부(40008), LOD생성부(40009), 리프팅 변환부(40010), 계수 양자화부(40011) 및/또는 아리스메틱 인코더(40012)는 어트리뷰트 인코딩을 수행한다. 상술한 바와 같이 하나의 포인트는 하나 또는 그 이상의 어트리뷰트들을 가질 수 있다. 실시예들에 따른 어트리뷰트 인코딩은 하나의 포인트가 갖는 어트리뷰트들에 대해 동일하게 적용된다. 다만, 하나의 어트리뷰트(예를 들면 색상)이 하나 또는 그 이상의 요소들을 포함하는 경우, 각 요소마다 독립적인 어트리뷰트 인코딩이 적용된다. 실시예들에 따른 어트리뷰트 인코딩은 컬러 변환 코딩, 어트리뷰트 변환 코딩, RAHT(Region Adaptive Hierarchial Transform) 코딩, 예측 변환(Interpolaration-based hierarchical nearest-neighbour prediction-Prediction Transform) 코딩 및 리프팅 변환 (interpolation-based hierarchical nearest-neighbour prediction with an update/lifting step (Lifting Transform)) 코딩을 포함할 수 있다. 포인트 클라우드 콘텐트에 따라 상술한 RAHT 코딩, 예측 변환 코딩 및 리프팅 변환 코딩은 선택적으로 사용되거나, 하나 또는 그 이상의 코딩들의 조합이 사용될 수 있다. 또한 실시예들에 따른 어트리뷰트 인코딩은 상술한 예시에 국한되는 것은 아니다.
실시예들에 따른 컬러 변환부(40006)는 어트리뷰트들에 포함된 컬러 값(또는 텍스쳐)을 변환하는 컬러 변환 코딩을 수행한다. 예를 들어, 컬러 변환부(40006)는 색상 정보의 포맷을 변환(예를 들어 RGB에서 YCbCr로 변환)할 수 있다. 실시예들에 따른 컬러 변환부(40006)의 동작은 어트리뷰트들에 포함된 컬러값에 따라 옵셔널(optional)하게 적용될 수 있다.
실시예들에 따른 지오메트리 리컨스트럭션부(40005)는 옥트리, 예측트리 및/또는 근사화된 옥트리를 재구성(디컴프레션)한다. 지오메트리 리컨스트럭션부(40005)는 포인트들의 분포를 분석한 결과에 기반하여 옥트리/복셀을 재구성한다. 재구성된 옥트리/복셀은 재구성된 지오메트리(또는 복원된 지오메트리)로 호칭될 수 있다.
실시예들에 따른 어트리뷰트 변환부(40007)는 지오메트리 인코딩이 수행되지 않은 포지션들 및/또는 재구성된 지오메트리를 기반으로 어트리뷰트들을 변환하는 어트리뷰트 변환을 수행한다. 상술한 바와 같이 어트리뷰트들은 지오메트리에 종속되므로, 어트리뷰트 변환부(40007)는 재구성된 지오메트리 정보를 기반으로 어트리뷰트들을 변환할 수 있다. 예를 들어, 어트리뷰트 변환부(40007)는 복셀에 포함된 포인트의 포지션값을 기반으로 그 포지션의 포인트가 가지는 어트리뷰트를 변환할 수 있다. 상술한 바와 같이 하나의 복셀에 포함된 하나 또는 그 이상의 포인트들의 포지션들을 기반으로 해당 복셀의 중앙점의 포지션이 설정된 경우, 어트리뷰트 변환부(40007)는 하나 또는 그 이상의 포인트들의 어트리뷰트들을 변환한다. 트라이숩 지오메트리 인코딩이 수행된 경우, 어트리뷰트 변환부(40007)는 트라이숩 지오메트리 인코딩을 기반으로 어트리뷰트들을 변환할 수 있다.
어트리뷰트 변환부(40007)는 각 복셀의 중앙점의 포지션(또는 포지션 값)으로부터 특정 위치/반경 내에 이웃하고 있는 포인트들의 어트리뷰트들 또는 어트리뷰트 값들(예를 들면 각 포인트의 색상, 또는 반사율 등)의 평균값을 계산하여 어트리뷰트 변환을 수행할 수 있다. 어트리뷰트 변환부(40007)는 평균값 계산시 중앙점으로부터 각 포인트까지의 거리에 따른 가중치를 적용할 수 있다. 따라서 각 복셀은 포지션과 계산된 어트리뷰트(또는 어트리뷰트 값)을 갖게 된다.
어트리뷰트 변환부(40007)는 K-D 트리 또는 몰톤 코드를 기반으로 각 복셀의 중앙점의 포지션으로부터 특정 위치/반경 내에 존재하는 이웃 포인트들을 탐색할 수 있다. K-D 트리는 이진 탐색 트리(binary search tree)로 빠르게 최단 이웃점 탐색(Nearest Neighbor Search-NNS)이 가능하도록 point들을 위치 기반으로 관리할 수 있는 자료 구조를 지원한다. 몰튼 코드는 모든 포인트들의 3차원 포지션을 나타내는 좌표값(예를 들면 (x, y, z))을 비트값으로 나타내고, 비트들을 믹싱하여 생성된다. 예를 들어 포인트의 포지션을 나타내는 좌표값이 (5, 9, 1)일 경우 좌표값의 비트 값은 (0101, 1001, 0001)이다. 비트 값을z, y, x 순서로 비트 인덱스에 맞춰 믹싱하면 010001000111이다. 이 값을 10진수로 나타내면 1095이 된다. 즉, 좌표값이 (5, 9, 1)인 포인트의 몰톤 코드 값은 1095이다. 어트리뷰트 변환부(40007)는 몰튼 코드 값을 기준으로 포인트들을 정렬하고depth-first traversal 과정을 통해 최단 이웃점 탐색(NNS)을 할 수 있다. 어트리뷰트 변환 동작 이후, 어트리뷰트 코딩을 위한 다른 변환 과정에서도 최단 이웃점 탐색(NNS)이 필요한 경우, K-D 트리 또는 몰톤 코드가 활용된다.
도면에 도시된 바와 같이 변환된 어트리뷰트들은 RAHT 변환부(40008) 및/또는 LOD 생성부(40009)로 입력된다.
실시예들에 따른 RAHT 변환부(40008)는 재구성된 지오메트리 정보에 기반하여 어트리뷰트 정보를 예측하는 RAHT코딩을 수행한다. 예를 들어, RAHT 변환부(40008)는 옥트리의 하위 레벨에 있는 노드와 연관된 어트리뷰트 정보에 기반하여 옥트리의 상위 레벨에 있는 노드의 어트리뷰트 정보를 예측할 수 있다.
실시예들에 따른 LOD생성부(40009)는 예측 변환 코딩을 수행하기 위하여LOD(Level of Detail)를 생성한다. 실시예들에 따른 LOD는 포인트 클라우드 콘텐트의 디테일을 나타내는 정도로서, LOD 값이 작을 수록 포인트 클라우드 콘텐트의 디테일이 떨어지고, LOD 값이 클 수록 포인트 클라우드 콘텐트의 디테일이 높음을 나타낸다. 포인트들을 LOD에 따라 분류될 수 있다.
실시예들에 따른 리프팅 변환부(40010)는 포인트 클라우드의 어트리뷰트들을 가중치에 기반하여 변환하는 리프팅 변환 코딩을 수행한다. 상술한 바와 같이 리프팅 변환 코딩은 선택적으로 적용될 수 있다.
실시예들에 따른 계수 양자화부(40011)은 어트리뷰트 코딩된 어트리뷰트들을 계수에 기반하여 양자화한다.
실시예들에 따른 아리스메틱 인코더(40012)는 양자화된 어트리뷰트들을 아리스메틱 코딩 에 기반하여 인코딩한다.
도 4의 포인트 클라우드 인코더의 엘레멘트들은 도면에 도시되지 않았으나 포인트 클라우드 제공 장치에 포함된 하나 또는 그 이상의 메모리들과 통신가능하도록 설정된 하나 또는 그 이상의 프로세서들 또는 집적 회로들(integrated circuits)을 포함하는 하드웨어, 소프트웨어, 펌웨어 또는 이들의 조합으로 구현될 수 있다. 하나 또는 그 이상의 프로세서들은 상술한 도 4의 포인트 클라우드 인코더의 엘레멘트들의 동작들 및/또는 기능들 중 적어도 어느 하나 이상을 수행할 수 있다. 또한 하나 또는 그 이상의 프로세서들은 도 4의 포인트 클라우드 인코더의 엘레멘트들의 동작들 및/또는 기능들을 수행하기 위한 소프트웨어 프로그램들 및/또는 인스트럭션들의 세트를 동작하거나 실행할 수 있다. 실시예들에 따른 하나 또는 그 이상의 메모리들은 하이 스피드 랜덤 억세스 메모리를 포함할 수도 있고, 비휘발성 메모리(예를 들면 하나 또는 그 이상의 마그네틱 디스크 저장 디바이스들, 플래쉬 메모리 디바이스들, 또는 다른 비휘발성 솔리드 스테이트 메모리 디바이스들(Solid-state memory devices)등)를 포함할 수 있다.
도 5 는 실시예들에 따른 복셀의 예시를 나타낸다.
도 5는 X축, Y축, Z축의 3가지 축으로 구성된 좌표계로 표현되는 3차원 공간상에 위치한 복셀을 나타낸다. 도 4에서 설명한 바와 같이 포인트 클라우드 인코더(예를 들면 양자화부(40001) 등)은 복셀화를 수행할 수 있다. 복셀은 3차원 공간을 표현하는 축들(예를 들면 X축, Y축, Z축)을 기반으로 3차원 공간을 유닛(unit=1.0) 단위로 나누었을 때 발생하는 3차원 큐빅 공간을 의미한다. 도 5는 두 개의 극점들(0,0,0) 및 (2d, 2d, 2d) 으로 정의되는 바운딩 박스(cubical axis-aligned bounding box)를 재귀적으로 분할(reculsive subdividing)하는 옥트리 구조를 통해 생성된 복셀의 예시를 나타낸다. 하나의 복셀은 적어도 하나 이상의 포인트를 포함한다. 복셀은 복셀군(voxel group)과의 포지션 관계로부터 공간 좌표를 추정 할 수 있다. 상술한 바와 같이 복셀은 2차원 이미지/영상의 픽셀과 마찬가지로 어트리뷰트(색상 또는 반사율 등)을 가진다. 복셀에 대한 구체적인 설명은 도 4에서 설명한 바와 동일하므로 생략한다.
도 6은 실시예들에 따른 옥트리 및 오큐판시 코드 (occupancy code)의 예시를 나타낸다.
도 1 내지 도 4에서 설명한 바와 같이 포인트 클라우드 콘텐트 제공 시스템(포인트 클라우드 비디오 인코더(10002)) 또는 포인트 클라우드 인코더(예를 들면 옥트리 분석부(40002))는 복셀의 영역 및/또는 포지션을 효율적으로 관리하기 위하여 옥트리 구조 기반의 옥트리 지오메트리 코딩(또는 옥트리 코딩)을 수행한다.
도 6의 상단은 옥트리 구조를 나타낸다. 실시예들에 따른 포인트 클라우드 콘텐트의 3차원 공간은 좌표계의 축들(예를 들면 X축, Y축, Z축)로 표현된다. 옥트리 구조는 두 개의 극점들(0,0,0) 및 (2d, 2d, 2d) 으로 정의되는 바운딩 박스(cubical axis-aligned bounding box)를 재귀적으로 분할(reculsive subdividing)하여 생성된다. 2d는 포인트 클라우드 콘텐트(또는 포인트 클라우드 비디오)의 전체 포인트들을 감싸는 가장 작은 바운딩 박스를 구성하는 값으로 설정될 수 있다. d는 옥트리의 깊이(depth)를 나타낸다. d값은 다음의 식에 따라 결정된다. 하기 식에서 (xint
n, yint
n, zint
n)는 양자화된 포인트들의 포지션들(또는 포지션 값들)을 나타낸다.
도 6의 상단의 중간에 도시된 바와 같이, 분할에 따라 전체 3차원 공간은 8개의 공간들로 분할될 수 있다. 분할된 각 공간은 6개의 면들을 갖는 큐브로 표현된다. 도 6 상단의 오른쪽에 도시된 바와 같이 8개의 공간들 각각은 다시 좌표계의 축들(예를 들면 X축, Y축, Z축)을 기반으로 분할된다. 따라서 각 공간은 다시 8개의 작은 공간들로 분할된다. 분할된 작은 공간 역시 6개의 면들을 갖는 큐브로 표현된다. 이와 같은 분할 방식은 옥트리의 리프 노드(leaf node)가 복셀이 될 때까지 적용된다.
도 6의 하단은 옥트리의 오큐판시 코드를 나타낸다. 옥트리의 오큐판시 코드는 하나의 공간이 분할되어 발생되는 8개의 분할된 공간들 각각이 적어도 하나의 포인트를 포함하는지 여부를 나타내기 위해 생성된다. 따라서 하나의 오큐판시 코드는 8개의 자식 노드(child node)들로 표현된다. 각 자식 노드는 분할된 공간의 오큐판시를 나타내며, 자식 노드는 1비트의 값을 갖는다. 따라서 오큐판시 코드는 8 비트 코드로 표현된다. 즉, 자식 노드에 대응하는 공간에 적어도 하나의 포인트가 포함되어 있으면 해당 노드는 1값을 갖는다. 자식 노드에 대응하는 공간에 포인트가 포함되어 있지 않으면 (empty), 해당 노드는 0값을 갖는다. 도 6에 도시된 오큐판시 코드는 00100001이므로 8개의 자식 노드 중 3번째 자식 노드 및 8번째 자식 노드에 대응하는 공간들은 각각 적어도 하나의 포인트를 포함함을 나타낸다. 도면에 도시된 바와 같이 3번째 자식 노드 및 8번째 자식 노드는 각각 8개의 자식 노드를 가지며, 각 자식 노드는 8비트의 오큐판시 코드로 표현된다. 도면은 3번째 자식 노드의 오큐판시 코드가 10000111이고, 8번째 자식 노드의 오큐판시 코드가 01001111임을 나타낸다. 실시예들에 따른 포인트 클라우드 인코더(예를 들면 아리스메틱 인코더(40004))는 오큐판시 코드를 엔트로피 인코딩할 수 있다. 또한 압축 효율을 높이기 위해 포인트 클라우드 인코더는 오큐판시 코드를 인트라/인터 코딩할 수 있다. 실시예들에 따른 수신장치(예를 들면 수신장치(10004) 또는 포인트 클라우드 비디오 디코더(10006))는 오큐판시 코드를 기반으로 옥트리를 재구성한다.
실시예들에 따른 포인트 클라우드 인코더(예를 들면 도 4의 포인트 클라우드 인코더, 또는 옥트리 분석부(40002))는 포인트들의 포지션들을 저장하기 위해 복셀화 및 옥트리 코딩을 수행할 수 있다. 하지만 3차원 공간 내 포인트들이 언제나 고르게 분포하는 것은 아니므로, 포인트들이 많이 존재하지 않는 특정 영역이 존재할 수 있다. 따라서 3차원 공간 전체에 대해 복셀화를 수행하는 것은 비효율 적이다. 예를 들어 특정 영역에 포인트가 거의 존재하지 않는다면, 해당 영역까지 복셀화를 수행할 필요가 없다.
따라서 실시예들에 따른 포인트 클라우드 인코더는 상술한 특정 영역(또는 옥트리의 리프 노드를 제외한 노드)에 대해서는 복셀화를 수행하지 않고, 특정 영역에 포함된 포인트들의 포지션을 직접 코딩하는 다이렉트 코딩(Direct coding)을 수행할 수 있다. 실시예들에 따른 다이렉트 코딩 포인트의 좌표들은 다이렉트 코딩 모드(Direct Coding Mode, DCM)으로 호칭된다. 또한 실시예들에 따른 포인트 클라우드 인코더는 표면 모델(surface model)을 기반으로 특정 영역(또는 노드)내의 포인트들의 포지션들을 복셀 기반으로 재구성하는 트라이숩 지오메트리 인코딩(Trisoup geometry encoding)을 수행할 수 있다. 트라이숩 지오메트리 인코딩은 오브젝트의 표현을 삼각형 메쉬(triangle mesh)의 시리즈로 표현하는 지오메트리 인코딩이다. 따라서 포인트 클라우드 디코더는 메쉬 표면으로부터 포인트 클라우드를 생성할 수 있다. 실시예들에 따른 다이렉트 코딩 및 트라이숩 지오메트리 인코딩은 선택적으로 수행될 수 있다. 또한 실시예들에 따른 다이렉트 코딩 및 트라이숩 지오메트리 인코딩은 옥트리 지오메트리 코딩(또는 옥트리 코딩)과 결합되어 수행될 수 있다.
다이렉트 코딩(Direct coding)을 수행하기 위해서는 다이렉트 코딩을 적용하기 위한 직접 모드(direct mode) 사용 옵션이 활성화 되어 있어야 하며, 다이렉트 코딩을 적용할 노드는 리프 노드가 아니고, 특정 노드 내에 한계치(threshold) 이하의 포인트들이 존재해야 한다. 또한 다이텍트 코딩의 대상이 되는 전체 포인트들의 개수는 기설정된 한계값을 넘어서는 안된다. 위의 조건이 만족되면, 실시예들에 따른 포인트 클라우드 인코더(또는 아리스메틱 인코더(40004))는 포인트들의 포지션들(또는 포지션 값들)을 엔트로피 코딩할 수 있다.
실시예들에 따른 포인트 클라우드 인코더(예를 들면 서페이스 어프록시메이션 분석부(40003))는 옥트리의 특정 레벨(레벨은 옥트리의 깊이 d보다는 작은 경우)을 정하고, 그 레벨부터는 표면 모델을 사용하여 노드 영역내의 포인트의 포지션을 복셀 기반으로 재구성하는 트라이숩 지오메트리 인코딩을 수행할 수 있다(트라이숩 모드). 실시예들에 따른 포인트 클라우드 인코더는 트라이숩 지오메트리 인코딩을 적용할 레벨을 지정할 수 있다. 예를 들어, 지정된 레벨이 옥트리의 깊이와 같으면 포인트 클라우드 인코더는 트라이숩 모드로 동작하지 않는다. 즉, 실시예들에 따른 포인트 클라우드 인코더는 지정된 레벨이 옥트리의 깊이값 보다 작은 경우에만 트라이숩 모드로 동작할 수 있다. 실시예들에 따른 지정된 레벨의 노드들의 3차원 정육면체 영역을 블록(block)이라 호칭한다. 하나의 블록은 하나 또는 그 이상의 복셀들을 포함할 수 있다. 블록 또는 복셀은 브릭(brick)에 대응될 수도 있다. 각 블록 내에서 지오메트리는 표면(surface)으로 표현된다. 실시예들에 따른 표면은 최대 한번 블록의 각 엣지(edge, 모서리)와 교차할 수 있다.
하나의 블록은 12개의 엣지들을 가지므로, 하나의 블록 내 적어도 12개의 교차점들이 존재한다. 각 교차점은 버텍스(vertex, 정점 또는 꼭지점)라 호칭된다. 엣지를 따라 존재하는 버텍스은 해당 엣지를 공유하는 모든 블록들 중 그 엣지에 인접한 적어도 하나의 오큐파이드 복셀(occupied voxel)이 있는 경우 감지된다. 실시예들에 따른 오큐파이드 복셀은 포인트를 포함하는 복셀을 의미한다. 엣지를 따라 검출된 버텍스의 포지션은 해당 엣지를 공유하는 모든 블록들 중 해당 엣지에 인접한 모든 복셀들의 엣지에 따른 평균 포지션(the average position along the edge of all voxels)이다.
버텍스가 검출되면 실시예들에 따른 포인트 클라우드 인코더는 엣지의 시작점(x, y, z), 엣지의 방향벡터(Δx, Δy, Δz), 버텍스 위치 값 (엣지 내의 상대적 위치 값)들을 엔트로피코딩할 수 있다. 트라이숩 지오메트리 인코딩이 적용된 경우, 실시예들에 따른 포인트 클라우드 인코더(예를 들면 지오메트리 리컨스트럭션부(40005))는 삼각형 재구성(triangle reconstruction), 업-샘플링(up-sampling), 복셀화 과정을 수행하여 복원된 지오메트리(재구성된 지오메트리)를 생성할 수 있다.
블록의 엣지에 위치한 버텍스들은 블록을 통과하는 표면(surface)를 결정한다. 실시예들에 따른 표면은 비평면 다각형이다. 삼각형 재구성 과정은 엣지의 시작점, 엣지의 방향 벡터와 버텍스의 위치값을 기반으로 삼각형으로 나타내는 표면을 재구성한다. 삼각형 재구성 과정은 다음과 같다. ①각 버텍스들의 중심(centroid)값을 계산하고, ②각 버텍스값에서 중심 값을 뺀 값들에 ③ 자승을 수행하고 그 값을 모두 더한 값을 구한다.
더해진 값의 최소값을 구하고, 최소값이 있는 축에 따라서 프로젝션 (Projection, 투영) 과정을 수행한다. 예를 들어 x 요소(element)가 최소인 경우, 각 버텍스를 블록의 중심을 기준으로 x축으로 프로젝션 시키고, (y, z) 평면으로 프로젝션 시킨다. (y, z)평면으로 프로젝션 시키면 나오는 값이 (ai, bi)라면 atan2(bi, ai)를 통해 θ값을 구하고, θ값을 기준으로 버텍스들(vertices)을 정렬한다. 하기의 표는 버텍스들의 개수에 따라 삼각형을 생성하기 위한 버텍스들의 조합을 나타낸다. 버텍스들은 1부터 n까지의 순서로 정렬된다. 하기 표는4개의 버텍스들에 대하여, 버텍스들의 조합에 따라 두 개의 삼각형들이 구성될 수 있음을 나타낸다. 첫번째 삼각형은 정렬된 버텍스들 중 1, 2, 3번째 버텍스들로 구성되고, 두번째 삼각형은 정렬된 버텍스들 중 3, 4, 1번째 버텍스들로 구성될 수 있다. .
Triangles formed from vertices ordered 1,…,n
n triangles
3 (1,2,3)
4 (1,2,3), (3,4,1)
5 (1,2,3), (3,4,5), (5,1,3)
6 (1,2,3), (3,4,5), (5,6,1), (1,3,5)
7 (1,2,3), (3,4,5), (5,6,7), (7,1,3), (3,5,7)
8 (1,2,3), (3,4,5), (5,6,7), (7,8,1), (1,3,5), (5,7,1)
9 (1,2,3), (3,4,5), (5,6,7), (7,8,9), (9,1,3), (3,5,7), (7,9,3)
10 (1,2,3), (3,4,5), (5,6,7), (7,8,9), (9,10,1), (1,3,5), (5,7,9), (9,1,5)
11 (1,2,3), (3,4,5), (5,6,7), (7,8,9), (9,10,11), (11,1,3), (3,5,7), (7,9,11), (11,3,7)
12 (1,2,3), (3,4,5), (5,6,7), (7,8,9), (9,10,11), (11,12,1), (1,3,5), (5,7,9), (9,11,1), (1,5,9)
업샘플링 과정은 삼각형의 엣지를 따라서 중간에 점들을 추가하여 복셀화 하기 위해서 수행된다. 업샘플링 요소 값(upsampling factor)과 블록의 너비를 기준으로 추가 점들을 생성한다. 추가점은 리파인드 버텍스(refined vertice)라고 호칭된다. 실시예들에 따른 포인트 클라우드 인코더는 리파인드 버텍스들을 복셀화할 수 있다. 또한 포인트 클라우드 인코더는 복셀화 된 포지션(또는 포지션 값)을 기반으로 어트리뷰트 인코딩을 수행할 수 있다.
도 7은 실시예들에 따른 이웃 노드 패턴의 예시를 나타낸다.
포인트 클라우드 비디오의 압축 효율을 증가시키기 위하여 실시예들에 따른 포인트 클라우드 인코더는 콘텍스트 어탭티브 아리스메틱 (context adaptive arithmetic) 코딩을 기반으로 엔트로피 코딩을 수행할 수 있다.
도 1 내지 도 6에서 설명한 바와 같이 포인트 클라우드 콘텐트 제공 시스템 또는 포인트 클라우드 인코더(예를 들면 포인트 클라우드 비디오 인코더(10002), 도 4의 포인트 클라우드 인코더 또는 아리스메틱 인코더(40004))는 오큐판시 코드를 곧바로 엔트로피 코딩할 수 있다. 또한 포인트 클라우드 콘텐트 제공 시스템 또는 포인트 클라우드 인코더는 현재 노드의 오큐판시 코드와 이웃 노드들의 오큐판시를 기반으로 엔트로피 인코딩(인트라 인코딩)을 수행하거나, 이전 프레임의 오큐판시 코드를 기반으로 엔트로피 인코딩(인터 인코딩)을 수행할 수 있다. 실시예들에 따른 프레임은 동일한 시간에 생성된 포인트 클라우드 비디오의 집합을 의미한다. 실시예들에 따른 인트라 인코딩/인터 인코딩의 압축 효율은 참조하는 이웃 노드들의 개수에 따라 달라질 수 있다. 비트가 커지면 복잡해지지만 한쪽으로 치우치게 만들어서 압축 효율이 높아질 수 있다. 예를 들어 3-bit context를 가지면, 2의 3승인 = 8가지 방법으로 코딩 해야 한다. 나누어 코딩을 하는 부분은 구현의 복잡도에 영향을 준다. 따라서 압축의 효율과 복잡도의 적정 수준을 맞출 필요가 있다.
도7은 이웃 노드들의 오큐판시를 기반으로 오큐판시 패턴을 구하는 과정을 나타낸다. 실시예들에 따른 포인트 클라우드 인코더는 옥트리의 각 노드의 이웃 노드들의 오큐판시(occupancy)를 판단하고 이웃 노드 패턴(neighbor pattern) 값을 구한다. 이웃 노드 패턴은 해당 노드의 오큐판시 패턴을 추론하기 위해 사용된다. 도7의 왼쪽은 노드에 대응하는 큐브(가운데 위치한 큐브) 및 해당 큐브와 적어도 하나의 면을 공유하는 6개의 큐브들(이웃 노드들)을 나타낸다. 도면에 도시된 노드들은 같은 뎁스(깊이)의 노드들이다. 도면에 도시된 숫자는 6개의 노드들 각각과 연관된 가중치들(1, 2, 4, 8, 16, 32, 등)을 나타낸다. 각 가중치는 이웃 노드들의 위치에 따라 순차적으로 부여된다.
도 7의 오른쪽은 이웃 노드 패턴 값을 나타낸다. 이웃 노드 패턴 값은 오큐파이드 이웃 노드(포인트를 갖는 이웃 노드)의 가중치가 곱해진 값들의 합이다. 따라서 이웃 노드 패턴 값은 0에서 63까지의 값을 갖는다. 이웃 노드 패턴 값이 0 인 경우, 해당 노드의 이웃 노드 중 포인트를 갖는 노드(오큐파이드 노드)가 없음을 나타낸다. 이웃 노드 패턴 값이 63인 경우, 이웃 노드들이 전부 오큐파이드 노드들임을 나타낸다. 도면에 도시된 바와 같이 가중치1, 2, 4, 8가 부여된 이웃 노드들은 오큐파이드 노드들이므로, 이웃 노드 패턴 값은 1, 2, 4, 8을 더한 값인 15이다. 포인트 클라우드 인코더는 이웃 노드 패턴 값에 따라 코딩을 수행할 수 있다(예를 들어 이웃 노드 패턴 값이 63인 경우, 64가지의 코딩을 수행). 실시예들에 따라 포인트 클라우드 인코더는 이웃 노드 패턴 값을 변경 (예를 들면 64를 10 또는 6으로 변경하는 테이블을 기반으로) 하여 코딩의 복잡도를 줄일 수 있다.
도 8은 실시예들에 따른 LOD 별 포인트 구성의 예시를 나타낸다.
도 1 내지 도 7에서 설명한 바와 같이, 어트리뷰트 인코딩이 수행되기 전 인코딩된 지오메트리는 재구성(디컴프레션) 된다. 다이렉트 코딩이 적용된 경우, 지오메트리 재구성 동작은 다이렉트 코딩된 포인트들의 배치를 변경하는 것을 포함할 수 있다(예를 들면 다이렉트 코딩된 포인트들을 포인트 클라우드 데이터의 앞쪽에 배치). 트라이숩 지오메트리 인코딩이 적용된 경우, 지오메트리 재구성 과정은 삼각형 재구성, 업샘플링, 복셀화 과정을 어트리뷰트는 지오메트리에 종속되므로, 어트리뷰트 인코딩은 재구성된 지오메트리를 기반으로 수행된다.
포인트 클라우드 인코더(예를 들면 LOD 생성부(40009))는 포인트들을 LOD별로 분류(reorganization)할 수 있다. 도면은 LOD에 대응하는 포인트 클라우드 콘텐트를 나타낸다. 도면의 왼쪽은 오리지널 포인트 클라우드 콘텐트를 나타낸다. 도면의 왼쪽에서 두번째 그림은 가장 낮은 LOD의 포인트들의 분포를 나타내며, 도면의 가장 오른쪽 그림은 가장 높은 LOD의 포인트들의 분포를 나타낸다. 즉, 가장 낮은 LOD의 포인트들은 드문드문(sparse) 분포하며, 가장 높은 LOD의 포인트들은 촘촘히 분포한다. 즉, 도면 하단에 표시된 화살표 방향에 따라 LOD가 증가할수록 포인트들 간의 간격(또는 거리)는 더 짧아진다.
도 9는 실시예들에 따른 LOD 별 포인트 구성의 예시를 나타낸다.
도 1 내지 도 8에서 설명한 바와 같이 포인트 클라우드 콘텐트 제공 시스템, 또는 포인트 클라우드 인코더(예를 들면 포인트 클라우드 비디오 인코더(10002), 도 4의 포인트 클라우드 인코더, 또는 LOD 생성부(40009))는 LOD를 생성할 수 있다. LOD는 포인트들을 설정된 LOD 거리 값(또는 유클리이디언 디스턴스(Euclidean Distance)의 세트)에 따라 리파인먼트 레벨들(refinement levels)의 세트로 재정열(reorganize)하여 생성된다. LOD 생성 과정은 포인트 클라우드 인코더뿐만 아니라 포인트 클라우드 디코더에서도 수행된다.
도 9의 상단은 3차원 공간에 분포된 포인트 클라우드 콘텐트의 포인트들의 예시(P0내지 P9)를 나타낸다. 도 9의 오리지널 오더(Original order)는 LOD 생성전 포인트들 P0내지 P9의 순서를 나타낸다. 도 9의 LOD 기반 오더 (LOD based order)는 LOD 생성에 따른 포인트들의 순서를 나타낸다. 포인트들은 LOD별 재정열된다. 또한 높은 LOD는 낮은 LOD에 속한 포인트들을 포함한다. 도 9에 도시된 바와 같이 LOD0는 P0, P5, P4 및 P2를 포함한다. LOD1은 LOD0의 포인트들과 P1, P6 및 P3를 포함한다. LOD2는 LOD0의 포인트들, LOD1의 포인트들 및 P9, P8 및 P7을 포함한다.
도 4에서 설명한 바와 같이 실시예들에 따른 포인트 클라우드 인코더는 예측 변환 코딩, 리프팅 변환 코딩 및 RAHT 변환 코딩을 선택적으로 또는 조합하여 수행할 수 있다.
실시예들에 따른 포인트 클라우드 인코더는 포인트들에 대한 예측기(predictor)를 생성하여 각 포인트의 예측 어트리뷰트(또는 예측 어트리뷰트값)을 설정하기 위한 예측 변환 코딩을 수행할 수 있다. 즉, N개의 포인트들에 대하여 N개의 예측기들이 생성될 수 있다. 실시예들에 따른 예측기는 각 포인트의 LOD 값과 LOD별 설정된 거리 내에 존재하는 이웃 포인트들에 대한 인덱싱 정보 및 이웃 포인트들까지의 거리 값을 기반으로 가중치(=1/거리) 값을 계산하할 수 있다.
실시예들에 따른 예측 어트리뷰트(또는 어트리뷰트값)은 각 포인트의 예측기에 설정된 이웃 포인트들의 어트리뷰트들(또는 어트리뷰트 값들, 예를 들면 색상, 반사율 등)에 각 이웃 포인트까지의 거리를 기반으로 계산된 가중치(또는 가중치값)을 곱한 값의 평균값으로 설정된다. 실시예들에 따른 포인트 클라우드 인코더(예를 들면 계수 양자화부(40011)는 각 포인트의 어트리뷰트(어트리뷰트 값)에서 예측 어트리뷰트(어트리뷰트값)을 뺀 잔여값들(residuals, 잔여 어트리뷰트, 잔여 어트리뷰트값, 어트리뷰트 예측 잔여값, 속성 잔차값 등으로 호칭할 수 있다)을 양자화(quatization) 및 역양자화(inverse quantization)할 수 있다. 양자화 과정은 다음의 표에 나타난 바와 같다.다D
Attribute prediction residuals quantization pseudo code
| int PCCQuantization(int value, int quantStep) { |
| if( value >=0) { |
| return floor(value / quantStep + 1.0 / 3.0); |
| } else { |
| return -floor(-value / quantStep + 1.0 / 3.0); |
| } |
| } |
Attribute prediction residuals inverse quantization pseudo code
| int PCCInverseQuantization(int value, int quantStep) { |
| if( quantStep ==0) { |
| return value; |
| } else { |
| return value * quantStep; |
| } |
| } |
실시예들에 따른 포인트 클라우드 인코더(예를 들면 아리스메틱 인코더(40012))는 각 포인트의 예측기에 이웃한 포인트들이 있는 경우, 상술한 바와 같이 양자화 및 역양자화된 잔여값을 엔트로피 코딩 할 수 있다. 실시예들에 따른 포인트 클라우드 인코더(예를 들면 아리스메틱 인코더(40012))는 각 포인트의 예측기에 이웃한 포인트들이 없으면 상술한 과정을 수행하지 않고 해당 포인트의 어트리뷰트들을 엔트로피 코딩할 수 있다.
실시예들에 따른 포인트 클라우드 인코더 (예를 들면 리프팅 변환부(40010))는 각 포인트의 예측기를 생성하고, 예측기에 계산된 LOD를 설정 및 이웃 포인트들을 등록하고, 이웃 포인트들까지의 거리에 따른 가중치를 설정하여 리프팅 변환 코딩을 수행할 수 있다. 실시예들에 따른 리프팅 변환 코딩은 상술한 예측 변환 코딩과 유사하나, 어트리뷰트값에 가중치를 누적 적용한다는 점에서 차이가 있다. 실시예들에 따른 어트리뷰트값에 가중치를 누적 적용하는 과정은 다음과 같다.
1) 각 포인트의 가중치 값을 저장하는 배열 QW(QuantizationWieght)를 생성한다. QW의 모든 요소들의 초기값은 1.0이다. 예측기에 등록된 이웃 노드의 예측기 인덱스의 QW 값에 현재 포인트의 예측기의 가중치를 곱한 값을 더한다.
2) 리프트 예측 과정: 예측된 어트리뷰트 값을 계산하기 위하여 포인트의 어트리뷰트 값에 가중치를 곱한 값을 기존 어트리뷰트값에서 뺀다.
3) 업데이트웨이트(updateweight) 및 업데이트(update)라는 임시 배열들을 생성하고 임시 배열들을 0으로 초기화한다.
4) 모든 예측기에 대해서 계산된 가중치에 예측기 인덱스에 해당하는 QW에 저장된 가중치를 추가로 곱해서 산출된 가중치를 업데이트웨이트 배열에 이웃 노드의 인덱스로 누적으로 합산한다. 업데이트 배열에는 이웃 노드의 인덱스의 어트리뷰트 값에 산출된 가중치를 곱한 값을 누적 합산한다.
5) 리프트 업데이트 과정: 모든 예측기에 대해서 업데이트 배열의 어트리뷰트 값을 예측기 인덱스의 업데이트웨이트 배열의 가중치 값으로 나누고, 나눈 값에 다시 기존 어트리뷰트 값을 더한다.
6) 모든 예측기에 대해서, 리프트 업데이트 과정을 통해 업데이트된 어트리뷰트 값에 리프트 예측 과정을 통해 업데이트 된(QW에 저장된) 가중치를 추가로 곱하여 예측 어트리뷰트 값을 산출한다. 실시예들에 따른 포인트 클라우드 인코더(예를 들면 계수 양자화부(40011))는 예측 어트리뷰트 값을 양자화한다. 또한 포인트 클라우드 인코더(예를 들면 아리스메틱 인코더(40012))는 양자화된 어트리뷰트 값을 엔트로피 코딩한다.
실시예들에 따른 포인트 클라우드 인코더(예를 들면 RAHT 변환부(40008))는 옥트리의 하위 레벨에 있는 노드와 연관된 어트리뷰트를 사용하여 상위 레벨의 노드들의 어트리뷰트를 에측하는 RAHT 변환 코딩을 수행할 수 있다. RAHT 변환 코딩은 옥트리 백워드 스캔을 통한 어트리뷰트 인트라 코딩의 예시이다. 실시예들에 따른 포인트 클라우드 인코더는 복셀에서 전체 영역으로 스캔하고, 각 스텝에서 복셀을 더 큰 블록으로 합치면서 루트 노드까지의 병합 과정을 반복수행한다. 실시예들에 따른 병합 과정은 오큐파이드 노드에 대해서만 수행된다. 엠티 노드(empty node)에 대해서는 병합 과정이 수행되지 않으며, 엠티 노드의 바로 상위 노드에 대해 병합 과정이 수행된다.
하기의 식은 RAHT 변환 행렬을 나타낸다.
는 레벨 l에서의 복셀들의 평균 어트리뷰트 값을 나타낸다.
는
와
로부터 계산될 수 있다.
와
의 가중치는
과
이다.
는 로-패스(low-pass) 값으로, 다음 상위 레벨에서의 병합 과정에서 사용된다.
은 하이패스 계수(high-pass coefficients)이며, 각 스텝에서의 하이패스 계수들은 양자화되어 엔트로피 코딩 된다(예를 들면 아리스메틱 인코더(400012)의 인코딩). 가중치는
로 계산된다. 루트 노드는 마지막
과
을 통해서 다음과 같이 생성된다.,
gDC값 또한 하이패스 계수와 같이 양자화되어 엔트로피 코딩된다.
도 10은 실시예들에 따른 포인트 클라우드 디코더(Point Cloud Decoder)의 예시를 나타낸다.
도 10에 도시된 포인트 클라우드 디코더는 도 1에서 설명한 포인트 클라우드 비디오 디코더(10006) 예시로서, 도 1에서 설명한 포인트 클라우드 비디오 디코더(10006)의 동작 등과 동일 또는 유사한 동작을 수행할 수 있다. 도면이 도시된 바와 같이 포인트 클라우드 디코더는 하나 또는 그 이상의 비트스트림(bitstream)들에 포함된 지오메트리 비트스트림(geometry bitstream) 및 어트리뷰트 비트스트림(attribute bitstream)을 수신할 수 있다. 포인트 클라우드 디코더는 지오메트리 디코더(geometry decoder)및 어트리뷰트 디코더(attribute decoder)를 포함한다. 지오메트리 디코더는 지오메트리 비트스트림에 대해 지오메트리 디코딩을 수행하여 디코딩된 지오메트리(decoded geometry)를 출력한다. 어트리뷰트 디코더는 디코딩된 지오메트리 및 어트리뷰트 비트스트림을 기반으로 어트리뷰트 디코딩을 수행하여 디코딩된 어트리뷰트들(decoded attributes)을 출력한다. 디코딩된 지오메트리 및 디코딩된 어트리뷰트들은 포인트 클라우드 콘텐트를 복원(decoded point cloud)하는데 사용된다.
도 11은 실시예들에 따른 포인트 클라우드 디코더(Point Cloud Decoder)의 예시를 나타낸다.
도 11에 도시된 포인트 클라우드 디코더는 도 10에서 설명한 포인트 클라우드 디코더의 예시로서, 도 1 내지 도 9에서 설명한 포인트 클라우드 인코더의 인코딩 동작의 역과정인 디코딩 동작을 수행할 수 있다.
도 1 및 도 10에서 설명한 바와 같이 포인트 클라우드 디코더는 지오메트리 디코딩 및 어트리뷰트 디코딩을 수행할 수 있다. 지오메트리 디코딩은 어트리뷰트 디코딩보다 먼저 수행된다.
실시예들에 따른 포인트 클라우드 디코더는 아리스메틱 디코더(arithmetic decode, 11000), 옥트리 합성부(synthesize octree, 11001), 서페이스 오프록시메이션 합성부(synthesize surface approximation, 11002), 지오메트리 리컨스트럭션부(reconstruct geometry, 11003), 좌표계 역변환부(inverse transform coordinates, 11004), 아리스메틱 디코더(arithmetic decode, 11005), 역양자화부(inverse quantize, 11006), RAHT변환부(11007), LOD생성부(generate LOD, 11008), 인버스 리프팅부(Inverse lifting, 11009), 및/또는 컬러 역변환부(inverse transform colors, 11010)를 포함한다.
아리스메틱 디코더(11000), 옥트리 합성부(11001), 서페이스 오프록시메이션 합성부(11002), 지오메트리 리컨스럭션부(11003), 좌표계 역변환부(11004)는 지오메트리 디코딩을 수행할 수 있다. 실시예들에 따른 지오메트리 디코딩은 다이렉트 디코딩(direct decoding) 및 트라이숩 지오메트리 디코딩(trisoup geometry decoding)을 포함할 수 있다. 다이렉트 디코딩 및 트라이숩 지오메트리 디코딩은 선택적으로 적용된다. 또한 지오메트리 디코딩은 위의 예시에 국한되지 않으며, 도 1 내지 도 9에서 설명한 지오메트리 인코딩의 역과정으로 수행된다.
실시예들에 따른 아리스메틱 디코더(11000)는 수신한 지오메트리 비트스트림을 아리스메틱 코딩을 기반으로 디코딩한다. 아리스메틱 디코더(11000)의 동작은 아리스메틱 인코더(40004)의 역과정에 대응한다.
실시예들에 따른 옥트리 합성부(11001)는 디코딩된 지오메트리 비트스트림으로부터 (또는 디코딩 결과 확보된 지오메트리에 관한 정보)로부터 오큐판시 코드를 획득하여 옥트리를 생성할 수 있다. 오큐판시 코드에 대한 구체적인 설명은 도 1 내지 도 9에서 설명한 바와 같다.
실시예들에 따른 서페이스 오프록시메이션 합성부(11002)는 트라이숩 지오메트리 인코딩이 적용된 경우, 디코딩된 지오메트리 및/또는 생성된 옥트리에 기반하여 서페이스를 합성할 수 있다.
실시예들에 따른 지오메트리 리컨스트럭션부(11003)는 서페이스 및 또는 디코딩된 지오메트리에 기반하여 지오메트리를 재생성할 수 있다. 도 1 내지 도 9에서 설명한 바와 같이, 다이렉트 코딩 및 트라이숩 지오메트리 인코딩은 선택적으로 적용된다. 따라서 지오메트리 리컨스트럭션부(11003)는 다이렉트 코딩이 적용된 포인트들의 포지션 정보들을 직접 가져와서 추가한다. 또한, 트라이숩 지오메트리 인코딩이 적용된 경우, 지오메트리 리컨스트럭션부(11003)는 지오메트리 리컨스트럭션부(40005)의 재구성 동작, 예를 들면 삼각형 재구성, 업-샘플링, 복셀화 동작을 수행하여 지오메트리를 복원할 수 있다. 구체적인 내용은 도 6에서 설명한 바와 동일하므로 생략한다. 복원된 지오메트리는 어트리뷰트들을 포함하지 않는 포인트 클라우드 픽쳐 또는 프레임을 포함할 수 있다.
실시예들에 따른 좌표계 역변환부(11004)는 복원된 지오메트리를 기반으로 좌표계를 변환하여 포인트들의 포지션들을 획득할 수 있다.
아리스메틱 디코더(11005), 역양자화부(11006), RAHT 변환부(11007), LOD생성부(11008), 인버스 리프팅부(11009), 및/또는 컬러 역변환부(11010)는 도 10에서 설명한 어트리뷰트 디코딩을 수행할 수 있다. 실시예들에 따른 어트리뷰트 디코딩은 RAHT(Region Adaptive Hierarchial Transform) 디코딩, 예측 변환(Interpolaration-based hierarchical nearest-neighbour prediction-Prediction Transform) 디코딩 및 리프팅 변환 (interpolation-based hierarchical nearest-neighbour prediction with an update/lifting step (Lifting Transform)) 디코딩을 포함할 수 있다. 상술한 3가지의 디코딩들은 선택적으로 사용되거나, 하나 또는 그 이상의 디코딩들의 조합이 사용될 수 있다. 또한 실시예들에 따른 어트리뷰트 디코딩은 상술한 예시에 국한되는 것은 아니다.
실시예들에 따른 아리스메틱 디코더(11005)는 어트리뷰트 비트스트림을 아리스메틱 코딩으로 디코딩한다.
실시예들에 따른 역양자화부(11006)는 디코딩된 어트리뷰트 비트스트림 또는 디코딩 결과 확보한 어트리뷰트에 대한 정보를 역양자화(inverse quantization)하고 역양자화된 어트리뷰트들(또는 어트리뷰트 값들)을 출력한다. 역양자화는 포인트 클라우드 인코더의 어트리뷰트 인코딩에 기반하여 선택적으로 적용될 수 있다.
실시예들에 따라 RAHT 변환부(11007), LOD생성부(11008) 및/또는 인버스 리프팅부(11009)는 재구성된 지오메트리 및 역양자화된 어트리뷰트들을 처리할 수 있다. 상술한 바와 같이 RAHT 변환부(11007), LOD생성부(11008) 및/또는 인버스 리프팅부(11009)는 포인트 클라우드 인코더의 인코딩에 따라 그에 대응하는 디코딩 동작을 선택적으로 수행할 수 있다.
실시예들에 따른 컬러 역변환부(11010)는 디코딩된 어트리뷰트들에 포함된 컬러 값(또는 텍스쳐)을 역변환하기 위한 역변환 코딩을 수행한다. 컬러 역변환부(11010)의 동작은 포인트 클라우드 인코더의 컬러 변환부(40006)의 동작에 기반하여 선택적으로 수행될 수 있다.
도 11의 포인트 클라우드 디코더의 엘레멘트들은 도면에 도시되지 않았으나 포인트 클라우드 제공 장치에 포함된 하나 또는 그 이상의 메모리들과 통신가능하도록 설정된 하나 또는 그 이상의 프로세서들 또는 집적 회로들(integrated circuits)을 포함하는 하드웨어, 소프트웨어, 펌웨어 또는 이들의 조합으로 구현될 수 있다. 하나 또는 그 이상의 프로세서들은 상술한 도 11의 포인트 클라우드 디코더의 엘레멘트들의 동작들 및/또는 기능들 중 적어도 어느 하나 이상을 수행할 수 있다. 또한 하나 또는 그 이상의 프로세서들은 도11의 포인트 클라우드 디코더의 엘레멘트들의 동작들 및/또는 기능들을 수행하기 위한 소프트웨어 프로그램들 및/또는 인스트럭션들의 세트를 동작하거나 실행할 수 있다.
도 12는 실시예들에 따른 송신장치의 예시이다.
도 12에 도시된 송신장치는 도 1의 송신장치(10000) (또는 도 4의 포인트 클라우드 인코더)의 예시이다. 도 12에 도시된 송신장치는 도 1 내지 도 9에서 설명한 포인트 클라우드 인코더의 동작들 및 인코딩 방법들과 동일 또는 유사한 동작들 및 방법들 중 적어도 어느 하나 이상을 수행할 수 있다. 실시예들에 따른 송신장치는 데이터 입력부(12000), 양자화 처리부(12001), 복셀화 처리부(12002), 옥트리 오큐판시 코드 (Occupancy code) 생성부(12003), 표면 모델 처리부(12004), 인트라/인터 코딩 처리부(12005), 아리스메틱 (Arithmetic) 코더(12006), 메타데이터 처리부(12007), 색상 변환 처리부(12008), 어트리뷰트 변환 처리부(또는 속성 변환 처리부)(12009), 예측/리프팅/RAHT 변환 처리부(12010), 아리스메틱 (Arithmetic) 코더(12011) 및/또는 송신 처리부(12012)를 포함할 수 있다.
실시예들에 따른 데이터 입력부(12000)는 포인트 클라우드 데이터를 수신 또는 획득한다. 데이터 입력부(12000)는 포인트 클라우드 비디오 획득부(10001)의 동작 및/또는 획득 방법(또는 도2에서 설명한 획득과정(20000))과 동일 또는 유사한 동작 및/또는 획득 방법을 수행할 수 있다.
데이터 입력부(12000), 양자화 처리부(12001), 복셀화 처리부(12002), 옥트리 오큐판시 코드 (Occupancy code) 생성부(12003), 표면 모델 처리부(12004), 인트라/인터 코딩 처리부(12005), Arithmetic 코더(12006)는 지오메트리 인코딩을 수행한다. 실시예들에 따른 지오메트리 인코딩은 도 1 내지 도 9에서 설명한 지오메트리 인코딩과 동일 또는 유사하므로 구체적인 설명은 생략한다.
실시예들에 따른 양자화 처리부(12001)는 지오메트리(예를 들면 포인트들의 위치값, 또는 포지션값)을 양자화한다. 양자화 처리부(12001)의 동작 및/또는 양자화는 도 4에서 설명한 양자화부(40001)의 동작 및/또는 양자화와 동일 또는 유사하다. 구체적인 설명은 도 1 내지 도 9에서 설명한 바와 동일하다.
실시예들에 따른 복셀화 처리부(12002)는 양자화된 포인트들의 포지션 값을 복셀화한다. 복셀화 처리부(12002)는 도 4에서 설명한 양자화부(40001)의 동작 및/또는 복셀화 과정과 동일 또는 유사한 동작 및/또는 과정을 수행할 수 있다. 구체적인 설명은 도 1 내지 도 9에서 설명한 바와 동일하다.
실시예들에 따른 옥트리 오큐판시 코드 생성부(12003)는 복셀화된 포인트들의 포지션들을 옥트리 구조를 기반으로 옥트리 코딩을 수행한다. 옥트리 오큐판시 코드 생성부(12003)는 오큐판시 코드를 생성할 수 있다. 옥트리 오큐판시 코드 생성부(12003)는 도 4 및 도 6에서 설명한 포인트 클라우드 인코더 (또는 옥트리 분석부(40002))의 동작 및/또는 방법과 동일 또는 유사한 동작 및/또는 방법을 수행할 수 있다. 구체적인 설명은 도 1 내지 도 9에서 설명한 바와 동일하다.
실시예들에 따른 표면 모델 처리부(12004)는 표면 모델(surface model)을 기반으로 특정 영역(또는 노드)내의 포인트들의 포지션들을 복셀 기반으로 재구성하는 트라이숩 지오메트리 인코딩을 수행할 수 있다. 포면 모델 처리부(12004)는 도 4 에서 설명한 포인트 클라우드 인코더(예를 들면 서페이스 어프록시메이션 분석부(40003))의 동작 및/또는 방법과 동일 또는 유사한 동작 및/또는 방법을 수행할 수 있다. 구체적인 설명은 도 1 내지 도 9에서 설명한 바와 동일하다.
실시예들에 따른 인트라/인터 코딩 처리부(12005)는 포인트 클라우드 데이터를 인트라/인터 코딩할 수 있다. 인트라/인터 코딩 처리부(12005)는 도 7에서 설명한 인트라/인터 코딩과 동일 또는 유사한 코딩을 수행할 수 있다. 구체적인 설명은 도 7에서 설명한 바와 동일하다. 실시예들에 따라 인트라/인터 코딩 처리부(12005)는 아리스메틱 코더(12006)에 포함될 수 있다.
실시예들에 따른 아리스메틱 코더(12006)는 포인트 클라우드 데이터의 옥트리 및/또는 근사화된 옥트리를 엔트로피 인코딩한다. 예를 들어, 인코딩 방식은 아리스메틱(Arithmetic) 인코딩 방법을 포함한다. . 아리스메틱 코더(12006)는 아리스메틱 인코더(40004)의 동작 및/또는 방법과 동일 또는 유사한 동작 및/또는 방법을 수행한다.
실시예들에 따른 메타데이터 처리부(12007)는 포인트 클라우드 데이터에 관한 메타데이터, 예를 들어 설정 값 등을 처리하여 지오메트리 인코딩 및/또는 어트리뷰트 인코딩 등 필요한 처리 과정에 제공한다. 또한 실시예들에 따른 메타데이터 처리부(12007)는 지오메트리 인코딩 및/또는 어트리뷰트 인코딩과 관련된 시그널링 정보를 생성 및/또는 처리할 수 있다. 실시예들에 따른 시그널링 정보는 지오메트리 인코딩 및/또는 어트리뷰트 인코딩과 별도로 인코딩처리될 수 있다. 또한 실시예들에 따른 시그널링 정보는 인터리빙 될 수도 있다.
색상 변환 처리부(12008), 어트리뷰트 변환 처리부(12009), 예측/리프팅/RAHT 변환 처리부(12010), 아리스메틱 (Arithmetic) 코더(12011)는 어트리뷰트 인코딩을 수행한다. 실시예들에 따른 어트리뷰트 인코딩은 도 1 내지 도 9에서 설명한 어트리뷰트 인코딩과 동일 또는 유사하므로 구체적인 설명은 생략한다.
실시예들에 따른 색상 변환 처리부(12008)는 어트리뷰트들에 포함된 색상값을 변환하는 색상 변환 코딩을 수행한다. 색상 변환 처리부(12008)는 재구성된 지오메트리를 기반으로 색상 변환 코딩을 수행할 수 있다. 재구성된 지오메트리에 대한 설명은 도 1 내지 도 9에서 설명한 바와 동일하다. 또한 도 4에서 설명한 컬러 변환부(40006)의 동작 및/또는 방법과 동일 또는 유사한 동작 및/또는 방법을 수행한다. 구체적인 설명은 생략한다.
실시예들에 따른 어트리뷰트 변환 처리부(12009)는 지오메트리 인코딩이 수행되지 않은 포지션들 및/또는 재구성된 지오메트리를 기반으로 어트리뷰트들을 변환하는 어트리뷰트 변환을 수행한다. 어트리뷰트 변환 처리부(12009)는 도 4에 설명한 어트리뷰트 변환부(40007)의 동작 및/또는 방법과 동일 또는 유사한 동작 및/또는 방법을 수행한다. 구체적인 설명은 생략한다. 실시예들에 따른 예측/리프팅/RAHT 변환 처리부(12010)는 변환된 어트리뷰트들을 RAHT 코딩, 예측 변환 코딩 및 리프팅 변환 코딩 중 어느 하나 또는 조합하여 코딩할 수 있다. 예측/리프팅/RAHT 변환 처리부(12010)는 도 4에서 설명한 RAHT 변환부(40008), LOD 생성부(40009) 및 리프팅 변환부(40010)의 동작들과 동일 또는 유사한 동작들 중 적어도 하나 이상을 수행한다. 또한 예측 변환 코딩, 리프팅 변환 코딩 및 RAHT 변환 코딩에 대한 설명은 도 1 내지 도 9에서 설명한 바와 동일하므로 구체적인 설명은 생략한다.
실시예들에 따른 아리스메틱 코더(12011)는 코딩된 어트리뷰트들을 아리스메틱 코딩에 기반하여 인코딩할 수 있다. 아리스메틱 코더(12011)는 아리스메틱 인코더(400012)의 동작 및/또는 방법과 동일 또는 유사한 동작 및/또는 방법을 수행한다.
실시예들에 따른 송신 처리부(12012)는 인코딩된 지오메트리 및/또는 인코딩된 어트리뷰트, 메타 데이터 정보를 포함하는 각 비트스트림을 송신하거나, 인코딩된 지오메트리 및/또는 인코딩된 어트리뷰트, 메타 데이터 정보를 하나의 비트스트림으로 구성하여 송신할 수 있다. 실시예들에 따른 인코딩된 지오메트리 및/또는 인코딩된 어트리뷰트, 메타 데이터 정보가 하나의 비트스트림으로 구성되는 경우, 비트스트림은 하나 또는 그 이상의 서브 비트스트림들을 포함할 수 있다. 실시예들에 따른 비트스트림은 시퀀스 레벨의 시그널링을 위한 SPS (Sequence Parameter Set), 지오메트리 정보 코딩의 시그널링을 위한 GPS(Geometry Parameter Set), 어트리뷰트 정보 코딩의 시그널링을 위한 APS(Attribute Parameter Set), 타일 레벨의 시그널링을 위한 TPS (Tile Parameter Set)를 포함하는 시그널링 정보 및 슬라이스 데이터를 포함할 수 있다. 슬라이스 데이터는 하나 또는 그 이상의 슬라이스들에 대한 정보를 포함할 수 있다. 실시예들에 따른 하나의 슬라이스는 하나의 지오메트리 비트스트림(Geom00) 및 하나 또는 그 이상의 어트리뷰트 비트스트림들(Attr00, Attr10)을 포함할 수 있다.
슬라이스(slice)란, 코딩된 포인트 클라우드 프레임의 전체 또는 일부를 나타내는 신택스 엘리먼트의 시리즈를 말한다.
실시예들에 따른 TPS는 하나 또는 그 이상의 타일들에 대하여 각 타일에 관한 정보(예를 들면 bounding box의 좌표값 정보 및 높이/크기 정보 등)을 포함할 수 있다. 지오메트리 비트스트림은 헤더와 페이로드를 포함할 수 있다. 실시예들에 따른 지오메트리 비트스트림의 헤더는 GPS에 포함된 파라미터 세트의 식별 정보(geom_ parameter_set_id), 타일 식별자(geom_tile_id), 슬라이스 식별자(geom_slice_id) 및 페이로드에 포함된 데이터에 관한 정보 등을 포함할 수 있다. 상술한 바와 같이 실시예들에 따른 메타데이터 처리부(12007)는 시그널링 정보를 생성 및/또는 처리하여 송신 처리부(12012)로 송신할 수 있다. 실시예들에 따라, 지오메트리 인코딩을 수행하는 엘레멘트들 및 어트리뷰트 인코딩을 수행하는 엘레멘트들은 점선 처리된 바와 같이 상호 데이터/정보를 공유할 수 있다. 실시예들에 따른 송신 처리부(12012)는 트랜스미터(10003)의 동작 및/또는 송신 방법과 동일 또는 유사한 동작 및/또는 송신 방법을 수행할 수 있다. 구체적인 설명은 도 1 내지 도 2에서 설명한 바와 동일하므로 생략한다.
도 13은 실시예들에 따른 수신장치의 예시이다.
도 13에 도시된 수신장치는 도 1의 수신장치(10004) (또는 도 10 및 도 11의 포인트 클라우드 디코더)의 예시이다. 도 13에 도시된 수신장치는 도 1 내지 도 11에서 설명한 포인트 클라우드 디코더의 동작들 및 디코딩 방법들과 동일 또는 유사한 동작들 및 방법들 중 적어도 어느 하나 이상을 수행할 수 있다.
실시예들에 따른 수신장치는 수신부(13000), 수신 처리부(13001), 아리스메틱 (arithmetic) 디코더(13002), 오큐판시 코드 (Occupancy code) 기반 옥트리 재구성 처리부(13003), 표면 모델 처리부(삼각형 재구성, 업-샘플링, 복셀화)(13004), 인버스(inverse) 양자화 처리부(13005), 메타데이터 파서(13006), 아리스메틱 (arithmetic) 디코더(13007), 인버스(inverse)양자화 처리부(13008), 예측/리프팅/RAHT 역변환 처리부(13009), 색상 역변환 처리부(13010) 및/또는 렌더러(13011)를 포함할 수 있다. 실시예들에 따른 디코딩의 각 구성요소는 실시예들에 따른 인코딩의 구성요소의 역과정을 수행할 수 있다.
실시예들에 따른 수신부(13000)는 포인트 클라우드 데이터를 수신한다. 수신부(13000)는 도 1의 리시버(10005)의 동작 및/또는 수신 방법과 동일 또는 유사한 동작 및/또는 수신 방법을 수행할 수 있다. 구체적인 설명은 생략한다.
실시예들에 따른 수신 처리부(13001)는 수신한 데이터로부터 지오메트리 비트스트림 및/또는 어트리뷰트 비트스트림을 획득할 수 있다. 수신 처리부(13001)는 수신부(13000)에 포함될 수 있다.
아리스메틱 디코더(13002), 오큐판시 코드 기반 옥트리 재구성 처리부(13003), 표면 모델 처리부(13004) 및 인버스 양자화 처리부(13005)는 지오메트리 디코딩을 수행할 수 있다. 실시예들에 따른 지오메트리 디코딩은 도 1 내지 도 10에서 설명한 지오메트리 디코딩과 동일 또는 유사하므로 구체적인 설명은 생략한다.
실시예들에 따른 아리스메틱 디코더(13002)는 지오메트리 비트스트림을 아리스메틱 코딩을 기반으로 디코딩할 수 있다. 아리스메틱 디코더(13002)는 아리스메틱 디코더(11000)의 동작 및/또는 코딩과 동일 또는 유사한 동작 및/또는 코딩을 수행한다.
실시예들에 따른 오큐판시 코드 기반 옥트리 재구성 처리부(13003)는 디코딩된 지오메트리 비트스트림으로부터 (또는 디코딩 결과 확보된 지오메트리에 관한 정보)로부터 오큐판시 코드를 획득하여 옥트리를 재구성할 수 있다. 오큐판시 코드 기반 옥트리 재구성 처리부(13003)는 옥트리 합성부(11001)의 동작 및/또는 옥트리 생성 방법과 동일 또는 유사한 동작 및/또는 방법을 수행한다. 실시예들에 따른 표면 모델 처리부(13004)는 트라이숩 지오메트리 인코딩이 적용된 경우, 표면 모델 방식에 기반하여 트라이숩 지오메트리 디코딩 및 이와 관련된 지오메트리 리컨스트럭션(예를 들면 삼각형 재구성, 업-샘플링, 복셀화)을 수행할 수 있다. 표면 모델 처리부(13004)는 서페이스 오프록시메이션 합성부(11002) 및/또는 지오메트리 리컨스트럭션부(11003)의 동작과 동일 또는 유사한 동작을 수행한다.
실시예들에 따른 인버스 양자화 처리부(13005)는 디코딩된 지오메트리를 인버스 양자화할 수 있다.
실시예들에 따른 메타데이터 파서(13006)는 수신한 포인트 클라우드 데이터에 포함된 메타데이터, 예를 들어 설정 값 등을 파싱할 수 있다. 메타데이터 파서(13006)는 메타데이터를 지오메트리 디코딩 및/또는 어트리뷰트 디코딩에 전달할 수 있다. 메타데이터에 대한 구체적인 설명은 도 12에서 설명한 바와 동일하므로 생략한다.
아리스메틱 디코더(13007), 인버스 양자화 처리부(13008), 예측/리프팅/RAHT 역변환 처리부(13009) 및 색상 역변환 처리부(13010)는 어트리뷰트 디코딩을 수행한다. 어트리뷰트 디코딩는 도 1 내지 도 10에서 설명한 어트리뷰트 디코딩과 동일 또는 유사하므로 구체적인 설명은 생략한다.
실시예들에 따른 아리스메틱 디코더(13007)는 어트리뷰트 비트스트림을 아리스메틱 코딩으로 디코딩할 수 있다. 아리스메틱 디코더(13007)는 재구성된 지오메트리를 기반으로 어트리뷰트 비트스트림의 디코딩을 수행할 수 있다. 아리스메틱 디코더(13007)는 아리스메틱 디코더(11005)의 동작 및/또는 코딩과 동일 또는 유사한 동작 및/또는 코딩을 수행한다.
실시예들에 따른 인버스 양자화 처리부(13008)는 디코딩된 어트리뷰트 비트스트림을 인버스 양자화할 수 있다. 인버스 양자화 처리부(13008)는 역양자화부(11006)의 동작 및/또는 역양자화 방법과 동일 또는 유사한 동작 및/또는 방법을 수행한다.
실시예들에 따른 예측/리프팅/RAHT 역변환 처리부(13009)는 재구성된 지오메트리 및 역양자화된 어트리뷰트들을 처리할 수 있다. 예측/리프팅/RAHT 역변환 처리부(13009)는 RAHT 변환부(11007), LOD생성부(11008) 및/또는 인버스 리프팅부(11009)의 동작들 및/또는 디코딩들과 동일 또는 유사한 동작들 및/또는 디코딩들 중 적어도 어느 하나 이상을 수행한다. 실시예들에 따른 색상 역변환 처리부(13010)는 디코딩된 어트리뷰트들에 포함된 컬러 값(또는 텍스쳐)을 역변환하기 위한 역변환 코딩을 수행한다. 색상 역변환 처리부(13010)는 컬러 역변환부(11010)의 동작 및/또는 역변환 코딩과 동일 또는 유사한 동작 및/또는 역변환 코딩을 수행한다. 실시예들에 따른 렌더러(13011)는 포인트 클라우드 데이터를 렌더링할 수 있다.
도 14는 실시예들에 따른 포인트 클라우드 데이터 송수신 방법/장치와 연동 가능한 구조의 예시를 나타낸다.
도 14의 구조는 서버(1460), 로봇(1410), 자율 주행 차량(1420), XR 장치(1430), 스마트폰(1440), 가전(1450) 및/또는 HMD(1470) 중에서 적어도 하나 이상이 클라우드 네트워크(1410)와 연결된 구성을 나타낸다. 로봇(1410), 자율 주행 차량(1420), XR 장치(1430), 스마트폰(1440) 또는 가전(1450) 등은 장치라 호칭된다. 또한, XR 장치(1430)는 실시예들에 따른 포인트 클라우드 데이터 (PCC) 장치에 대응되거나 PCC장치와 연동될 수 있다.
클라우드 네트워크(1400)는 클라우드 컴퓨팅 인프라의 일부를 구성하거나 클라우드 컴퓨팅 인프라 안에 존재하는 네트워크를 의미할 수 있다. 여기서, 클라우드 네트워크(1400)는 3G 네트워크, 4G 또는 LTE(Long Term Evolution) 네트워크 또는 5G 네트워크 등을 이용하여 구성될 수 있다.
서버(1460)는 로봇(1410), 자율 주행 차량(1420), XR 장치(1430), 스마트폰(1440), 가전(1450) 및/또는 HMD(1470) 중에서 적어도 하나 이상과 클라우드 네트워크(1400)을 통하여 연결되고, 연결된 장치들(1410 내지 1470)의 프로세싱을 적어도 일부를 도울 수 있다.
HMD (Head-Mount Display)(1470)는 실시예들에 따른 XR 디바이스 및/또는 PCC 디바이스가 구현될 수 있는 타입 중 하나를 나타낸다. 실시예들에 따른HMD 타입의 디바이스는, 커뮤니케이션 유닛, 컨트롤 유닛, 메모리 유닛, I/O 유닛, 센서 유닛, 그리고 파워 공급 유닛 등을 포함한다.
이하에서는, 상술한 기술이 적용되는 장치(1410 내지 1450)의 다양한 실시 예들을 설명한다. 여기서, 도 14에 도시된 장치(1410 내지 1450)는 상술한 실시예들에 따른 포인트 클라우드 데이터 송수신장치와 연동/결합될 수 있다.
<PCC+XR>
XR/PCC 장치(1430)는 PCC 및/또는 XR(AR+VR) 기술이 적용되어, HMD(Head-Mount Display), 차량에 구비된 HUD(Head-Up Display), 텔레비전, 휴대폰, 스마트 폰, 컴퓨터, 웨어러블 디바이스, 가전 기기, 디지털 사이니지, 차량, 고정형 로봇이나 이동형 로봇 등으로 구현될 수도 있다.
XR/PCC 장치(1430)는 다양한 센서들을 통해 또는 외부 장치로부터 획득한 3차원 포인트 클라우드 데이터 또는 이미지 데이터를 분석하여 3차원 포인트들에 대한 위치 데이터 및 어트리뷰트 데이터를 생성함으로써 주변 공간 또는 현실 객체에 대한 정보를 획득하고, 출력할 XR 객체를 렌더링하여 출력할 수 있다. 예컨대, XR/PCC 장치(1430)는 인식된 물체에 대한 추가 정보를 포함하는 XR 객체를 해당 인식된 물체에 대응시켜 출력할 수 있다.
<PCC+XR+모바일폰>
XR/PCC 장치(1430)는 PCC기술이 적용되어 모바일폰(1440) 등으로 구현될 수 있다.
모바일폰(1440)은 PCC 기술에 기반하여 포인트 클라우드 콘텐츠를 디코딩하고, 디스플레이할 수 있다.
<PCC+자율주행+XR>
자율 주행 차량(1420)은 PCC 기술 및 XR 기술이 적용되어, 이동형 로봇, 차량, 무인 비행체 등으로 구현될 수 있다.
XR/PCC 기술이 적용된 자율 주행 차량(1420)은 XR 영상을 제공하는 수단을 구비한 자율 주행 차량이나, XR 영상 내에서의 제어/상호작용의 대상이 되는 자율 주행 차량 등을 의미할 수 있다. 특히, XR 영상 내에서의 제어/상호작용의 대상이 되는 자율 주행 차량(1420)은 XR 장치(1430)와 구분되며 서로 연동될 수 있다.
XR/PCC영상을 제공하는 수단을 구비한 자율 주행 차량(1420)은 카메라를 포함하는 센서들로부터 센서 정보를 획득하고, 획득한 센서 정보에 기초하여 생성된 XR/PCC 영상을 출력할 수 있다. 예컨대, 자율 주행 차량(1420)은 HUD를 구비하여 XR/PCC 영상을 출력함으로써, 탑승자에게 현실 객체 또는 화면 속의 객체에 대응되는 XR/PCC 객체를 제공할 수 있다.
이때, XR/PCC 객체가 HUD에 출력되는 경우에는 XR/PCC 객체의 적어도 일부가 탑승자의 시선이 향하는 실제 객체에 오버랩되도록 출력될 수 있다. 반면, XR/PCC 객체가 자율 주행 차량의 내부에 구비되는 디스플레이에 출력되는 경우에는 XR/PCC 객체의 적어도 일부가 화면 속의 객체에 오버랩되도록 출력될 수 있다. 예컨대, 자율 주행 차량(1220)은 차로, 타 차량, 신호등, 교통 표지판, 이륜차, 보행자, 건물 등과 같은 객체와 대응되는 XR/PCC 객체들을 출력할 수 있다.
실시예들에 의한 VR (Virtual Reality) 기술, AR (Augmented Reality) 기술, MR (Mixed Reality) 기술 및/또는 PCC(Point Cloud Compression)기술은, 다양한 디바이스에 적용 가능하다.
즉, VR 기술은, 현실 세계의 객체나 배경 등을 CG 영상으로만 제공하는 디스플레이 기술이다. 반면, AR 기술은, 실제 사물 영상 위에 가상으로 만들어진 CG 영상을 함께 보여 주는 기술을 의미한다. 나아가, MR 기술은, 현실세계에 가상 객체들을 섞고 결합시켜서 보여준다는 점에서 전술한 AR 기술과 유사하다. 그러나, AR 기술에서는 현실 객체와 CG 영상으로 만들어진 가상 객체의 구별이 뚜렷하고, 현실 객체를 보완하는 형태로 가상 객체를 사용하는 반면, MR 기술에서는 가상 객체가 현실 객체와 동등한 성격으로 간주된다는 점에서 AR 기술과는 구별이 된다. 보다 구체적으로 예를 들면, 전술한 MR 기술이 적용된 것이 홀로그램 서비스 이다.
다만, 최근에는 VR, AR, MR 기술을 명확히 구별하기 보다는 XR (extended Reality) 기술로 부르기도 한다. 따라서, 본 발명의 실시예들은 VR, AR, MR, XR 기술 모두에 적용 가능하다. 이러한 기술은 PCC, V-PCC, G-PCC 기술 기반 인코딩/디코딩이 적용될 수 있다.
실시예들에 따른 PCC방법/장치는 자율 주행 서비스를 제공하는 차량에 적용될 수 있다.
자율 주행 서비스를 제공하는 차량은 PCC 디바이스와 유/무선 통신이 가능하도록 연결된다.
실시예들에 따른 포인트 클라우드 데이터 (PCC) 송수신장치는 차량과 유/무선 통신이 가능하도록 연결된 경우, 자율 주행 서비스와 함께 제공할 수 있는 AR/VR/PCC 서비스 관련 콘텐트 데이터를 수신/처리하여 차량에 송신할 수 있다. 또한 포인트 클라우드 데이터 송수신장치 차량에 탑재된 경우, 포인트 클라우드 송수신장치는 사용자 인터페이스 장치를 통해 입력된 사용자 입력 신호에 따라 AR/VR/PCC 서비스 관련 콘텐트 데이터를 수신/처리하여 사용자에게 제공할 수 있다. 실시예들에 따른 차량 또는 사용자 인터페이스 장치는 사용자 입력 신호를 수신할 수 있다. 실시예들에 따른 사용자 입력 신호는 자율 주행 서비스를 지시하는 신호를 포함할 수 있다.
도 1 내지 도 14에서 설명한 것과 같이 포인트 클라우드 데이터는 포인트들의 집합으로 구성되며, 각 포인트는 지오메트리 데이터(지오메트리 정보)와 어트리뷰트 데이터(어트리뷰트 정보)를 가질 수 있다. 지오메트리 데이터는 각 포인트의 3차원 위치 정보(예를 들어, x, y, z축의 좌표값)이다. 즉, 각 포인트의 위치는 3차원 공간을 나타내는 좌표계상의 파라미터들(예를 들면 공간을 나타내는 3개의 축인 X축, Y축 및 Z축의 파라미터들 (x, y, z))로 표현된다. 그리고, 어트리뷰트 정보는 포인트의 색상(RGB, YUV 등), 반사도(reflectance), 법선(normal vectors), 투명도(transparency) 등을 의미할 수 있다. 어트리뷰트 정보는 스칼라 또는 벡터 형태로 표현될 수 있다.
실시예들에 따르면, 포인트 클라우드 데이터의 종류 및 취득 방법에 따라 정적 포인트 클라우드 데이터의 카테고리 1, 동적 포인트 클라우드 데이터의 카테고리 2, 동적으로 움직이면서 취득한 카테고리 3으로 포인트 클라우드 데이터를 분류할 수 있다. 카테고리 1의 경우, 오브젝트나 공간에 대해 포인트들의 밀도가 높은 단일 프레임의 포인트 클라우드로 구성된다. 카테고리 3 데이터는 이동하면서 취득된 다수개의 프레임들을 갖는 프레임-기반 데이터 및 대규모 공간에 대해 라이다 센서를 통해 취득된 포인트 클라우드와 2D 영상으로 취득된 색상 영상이 정합된 단일 프레임의 융합된(fused) 데이터로 구분될 수 있다.
실시예들에 따르면, 다수개의 프레임들을 갖는 프레임-기반 포인트 클라우드 데이터와 같이 시간에 따른 멀티플 프레임들(multiple frames)을 갖는 3차원 포인트 클라우드 데이터를 효율적으로 압축하기 위하여 인터 예측(inter prediction) 코딩/디코딩이 사용될 수 있다. 인터 예측 코딩/디코딩은 지오메트리 정보 및/또는 어트리뷰트 정보에 적용될 수 있다. 인터 예측은 화면간 예측 또는 프레임간 예측이라고 지칭될 수 있고, 인트라 예측은 화면 내 예측이라고 지칭될 수 있다.
실시예들에 따르면, 포인트 클라우드 데이터 송수신 장치/방법은 멀티플 프레임 간 다방향 예측이 가능하다. 포인트 클라우드 데이터 송수신 장치/방법은 프레임들의 코딩 순서와 디스플레이 순서를 분리하여, 정해진 코딩 순서에 따라 포인트 클라우드 데이터를 예측할 수 있다. 실시예들에 따른 포인트 클라우드 데이터 송수신 장치/방법은 멀티플 프레임 간 참조를 통해 예측 트리 구조에서 인터 예측를 수행할 수 있다.
또한, 실시예들에 따르면, 포인트 클라우드 데이터 송수신 장치/방법은 누적된 참조 프레임을 생성하여 인터 예측을 수행할 수 있다. 누적된 참조 프레임은 복수의 참조 프레임들이 누적된 것일 수 있다.
실시예들에 따른 포인트 클라우드 데이터 송수신 장치/방법은 한 개 이상의 프레임들을 가지는 포인트 클라우드 데이터의 압축 효율을 높이기 위한 방법으로써 멀티플 프레임 간 예측 기술을 적용하기 위해 예측 유닛(prediction unit)을 정의할 수 있다. 실시예들에 따른 예측 유닛(prediction unit)은 유닛, 제 1 유닛, 영역, 제 1 영역, 박스, 구역, 단위 등 다양한 용어로 지칭될 수 있다.
실시예들에 따른 포인트 클라우드 데이터 송수신 장치/방법은 포인트 클라우드 (point cloud)로 구성된 데이터를 압축/복원할 수 있다. 구체적으로, 한 개 이상의 프레임들을 가지는 포인트 클라우드의 효과적인 압축을 위해 라이다(LiDAR) 센서로 캡처된 포인트 클라우드의 캡처 특성 및 예측 유닛에 포함된 데이터 분포를 고려하여 모션 에스티메이션 및 데이터 예측을 수행할 수 있다.
도 15는 실시예들에 따른 프레임 간 인터 예측의 예시를 나타낸다.
도 15를 참조하면, 포인트 클라우드 데이터는 복수의 프레임들을 포함한다. 복수의 프레임들은 GOF(Group Of Frames)로 지칭될 수 있다. 이때, 실시예들에 따른 송수신 장치/방법에서 부호화 또는 복호화를 수행하는 프레임을 현재 프레임(Current frame)이라고 하고, 현재 프레임의 부호화 또는 복호화를 수행하기 위해 참조하는 프레임을 참조 프레임(Reference frame)이라고 지칭할 수 있다.
실시예들에 따른 송수신 장치/방법은 포인트 클라우드 데이터를 예측하기 위한 예측 트리 구조 생성 시 화면 간 예측(인터 예측)을 수행할 수 있다. 예측 트리 구조에서 인터 예측 시 현재 프레임(current frame) 직전에 코딩된 프레임을 참조 프레임(reference frame)으로 정하고, 현재 프레임에서 현재 포인트(current point) 이전에 복호화 된 포인트(1505)와 애지무스(azimuth)가 가장 유사하고, 레이저아이디(laserID)가 동일한 포인트(1504)를 참조 프레임에서 찾는다. 그리고, 그 포인트(1504)로부터 애지무스(azimuth)가 큰 것 중에 가장 가까운 포인트(1502) 또는 그 다음으로 가까운 포인트(1503)를 현재 포인트(1501)의 예측값, 즉, 예측기(predictor)로 정할 수 있다. 이때, 가장 가까운 포인트를 예측기로 정하는 경우 및 두 번째로 가까운 포인트를 예측기로 정하는 경우를 플래그(flag)로 분리하여 시그널링(signaling)함으로써, 인터 예측 시 어떤 포인트 정보를 현재 포인트(current point)의 위치(position)으로 삼을지 판단한 후, 해당 예측기의 정보가 수신기로 전달될 수 있다.
실시예들에 따른 예측값 또는 예측기(predictor)는 현재 포인트를 예측하기 위한 후보 포인트로 지칭할 수 있다.
실시예들에 따른 송수신 장치/방법은 도 1의 송수신 장치, 도 2의 송수신, 도 4의 포인트 클라우드 인코더, 도 10, 도 11의 포인트 클라우드 디코더, 도 12의 송신장치, 도 13의 수신장치, 도 14의 디바이스들, 도 44의 송신 장치/방법, 도 45의 수신 장치/방법, 도46의 송신 장치/방법, 도47의 수신 장치/방법, 도 48의 송신 방법 또는 도 49의 수신 방법과 대응하거나, 조합될 수 있으며, 실시예들에 따른 송수신 장치/방법은 도 15에서 설명하는 프레임 간 인터 예측을 수행할 수 있다.
도 16은 실시예들에 따른 그룹오브프레임(Group of Frame, GoF)를 나타낸다.
실시예들에 따른 GoF(Group of Frames)(1600)는 프레임들의 그룹을 나타내는 것으로서, GoP(Group of Pictures)라고 지칭될 수도 있다. GoF(1600)를 구성하는 프레임들은 인트라 프레임(intra frame, I frame)(1610), 예측 프레임(predicted frame, P frame)(1620) 및/또는 양방향 예측 프레임(bidirectional frame, B frame)(미도시)을 포함한다. 인트라 프레임(I프레임)(1610)은 다른 프레임을 참조하지 않은 프레임을 나타낼 수 있다. I프레임(1610)은 GoF(1600) 내에서 첫번째 프레임이므로 이전 프레임이 없고 다른 프레임을 참조하지 않는다. 예측 프레임(P프레임)(1620)은 이전의 I프레임(1610) 또는 다른 P프레임(1620)을 참조하여 예측된 프레임을 나타낸다. 양방향 예측 프레임(B프레임)은 양 방향으로 I프레임(1610) 또는 P프레임(1620)을 참조하여 예측된 프레임을 나타낼 수 있다.
도16을 참조하면, 예측 방향(Prediction direction)(1630)이 도시된다. 실시예들에 따른 송수신 장치/방법은 바로 이전에 복호화 또는 부호화 된 프레임의 정보로 현재 프레임을 예측할 수 있다. 다만, 바로 이전의 프레임 정보만으로 예측 시, 프레임 간 중복되는 정보가 많음에도 오로지 단 방향으로만 예측이 가능하므로, 다 방향 예측이 허용되지 못하고 하나 이상의 참조 프레임의 정보를 사용하지 못하여 전송 효율이 저하될 수 있다.
실시예들에 따른 송수신 장치/방법은 포인트 클라우드 데이터 예측 시 프레임 간 다방향 예측을 수행할 수 있다. 실시예들에 따른 송수신 장치는 코딩 순서와 디스플레이 순서를 분리하여 현재 프레임의 직전에 코딩된 프레임만 참조하는 것이 아니라 디스플레이 순서에 상관없이 하나 이상의 참조 프레임을 활용하여 현재 프레임의 포인트 클라우드 데이터를 예측할 수 있다.
실시예들에 따른 송수신 장치/방법은 예측 지오메트리(predictive geometry) 인터 예측(화면 간 예측) 시 복수의 프레임들(또는, 멀티플 프레임)을 참조하여 포인트 클라우드 데이터를 예측할 수 있다.
또한, 실시예들에 따른 송수신 장치/방법은 예측 지오메트리(predictive geometry) 인터 예측(화면 간 예측) 시 코딩 순서와 디스플레이 순서를 분리하여 코딩 순서에 따라 부호화 또는 복호화 할 수 있다.
또한, 실시예들에 따른 송수신 장치/방법은 예측 지오메트리(predictive geometry) 인터 예측(화면 간 예측) 시 양방향 프레임과 단방향 프레임을 구분하여 사용될 수 있다.
또한, 실시예들에 따른 송수신 장치/방법은 다방향 프레임에서 예측 지오메트리(predictive geometry) 예측 시 각 노드(node)에 대하여 양방향, 단방향, 전방향 및 후방향(또는, 역방향) 예측 중 유리한 예측방향을 선택할 수 있다.
또한, 실시예들에 따른 송수신 장치/방법은 예측 지오메트리(Predictive geometry) 예측 시 각 노드에 대하여 화면 간(인터)/화면 내(인트라) 예측 여부를 판단하여 시그널링 할 수 있다.
또한, 실시예들에 따른 송수신 장치/방법에서 코딩 순서로 복호화 된 프레임들은 디스플레이 순서로 재정렬될 수 있다. 한 개 이상의 참조 프레임을 사용하여 예측 시, 참조할 프레임 정보는 해당 노드가 포함된 프레임의 예측이 종료될 때까지 저장될 수 있다.
실시예들에 따른 송수신 장치/방법은 화면 간 예측(인터 예측)을 위해 선택된 주변의 참조 프레임들을 하나의 누적된 포인트 클라우드 데이터로 생성할 수 있다.
또한, 실시예들에 따른 송수신 장치/방법은 화면 간 예측(인터 예측)에서 현재 프레임의 현재 포인트(또는, 노드)를 예측하기 위해 누적된 참조 프레임 데이터 중 가장 적합한 데이터를 선택하고, 현재 포인트의 값을 대신할 수 있다.
또한, 실시예들에 따른 송수신 장치/방법은 누적된 참조 프레임 데이터 중 가장 관련성이 높은 한 개 이상의 데이터를 선택하여, 하나의 노드 정보로 생성하고 현재 프레임의 현재 노드의 예측값으로 사용할 수 있다.
또한, 실시예들에 따른 송수신 장치/방법은 누적된 참조 프레임 데이터 중 가장 관련성이 높은 한 개 이상의 데이터를 선택하고, 그룹핑하여 예측 방향을 선택할 수 있다.
실시예들에 따른 송수신 장치/방법에서 복수의 참조 프레임들을 이용하는 경우, 참조 프레임의 디스플레이 순서, 프레임 식별자 또는 프레임 인덱스에 대하여 현재 프레임의 위치, 프레임 식별자 또는 프레임 인덱스 대비 작은 값을 사용할 지, 큰 값을 사용할 지에 따라 적용 방법이 다를 수 있다.
참조 프레임의 디스플레이 순서, 프레임 식별자 또는 프레임 인덱스가 현재 프레임보다 작은 값을 사용하는 경우, 실시예들에 따른 송수신 장치/방법은 하나 이상의 해당 참조 프레임을 버퍼에 저장할 수 있다.
참조 프레임의 디스플레이 순서, 프레임 식별자 또는 프레임 인덱스가 현재 프레임보다 큰 값을 사용하는 경우, 디스플레이 순서와 별도로 코딩 순서가 정의될 수 있다. 실시예들에 따른 프레임들의 코딩 순서는 GOF(Group Of Frame) 마다 달라질 수 있고, 항상 일정한 순서로 고정될 수 있다.
현재 프레임이 하나 이상의 참조 프레임을 활용하여 예측되는 경우, 모든 참조 프레임의 위치가 현재 프레임보다 디스플레이 순서 상 앞(forward)인지, 참조 프레임의 위치가 현재프레임을 기준으로 디스플레이 순서 상 앞과 뒤(bi-directional)로 나뉘어 있는지, 또는 모든 참조 프레임이 현재 프레임 보다 뒤에(backward) 위치하는지 여부가 실시예들에 따른 송수신 장치에 전달될 수 있다. 또한, 단일 참조 프레임만 사용 했는지 복수 개의 참조 프레임을 사용했는지 여부가 전달될 수 있다.
실시예들에 따른 송수신 장치/방법은 도 1의 송수신 장치, 도 2의 송수신, 도 4의 포인트 클라우드 인코더, 도 10, 도 11의 포인트 클라우드 디코더, 도 12의 송신장치, 도 13의 수신장치, 도 14의 디바이스들, 도 44의 송신 장치/방법, 도 45의 수신 장치/방법, 도46의 송신 장치/방법, 도47의 수신 장치/방법, 도 48의 송신 방법 또는 도 49의 수신 방법과 대응하거나, 조합될 수 있으며, 실시예들에 따른 송수신 장치/방법은 도 16 및 이와 관련하여 설명하는 프레임 간 인터 예측을 수행할 수 있다.
도 17은 실시예들에 따른 프레임 간 포워드(전방향) 예측 참조 방법을 나타낸다. 도 17은 실시예들에 따른 복수의 프레임들의 종류 및 프레임들 간 참조 방향, 프레임들의 디스플레이 순서 및 코딩 순서를 나타낸다.
도17을 참조하면, m프레임(m-frame)(1730)은 복수의 프레임들을 참조하는 프레임을 나타낼 수 있다. 예를들어, 디스플레이 순서가 3번인 m프레임(m-frame)(1730)은 디스플레이 순서가 1번인 I프레임(1710)과 디스플레이 순서가 2번인 P프레임(1720)을 참조할 수 있다.
포워드 예측(Forward prediction): 멀티 프레임(Multi-frame)을 참조하는 경우, 먼저 코딩된 프레임들 중 참조 프레임을 선택하는 경우 도17과 같이 디스플레이 순서(display order)와 코딩 순서(coding order)는 동일할 수 있고, 관련성이 높은 참조 프레임이 현재 프레임과 디스플레이 순서가 바로 이웃하지 않을 수 있다. 포워드 예측은 전방향 예측으로서, 현재 프레임보다 디스플레이 순서가 앞서는 프레임들 중 적어도 어느 하나 이상의 프레임들을 참조하는 예측 방법을 나타낼 수 있다.
또한, I프레임(I-frame)이 인터 예측(inter prediction)만 가능한 프레임이고, P프레임(P-frame)은 포워드(forward) 방향으로 단일 참조 프레임만 사용하는 경우, M프레임(m-frame)은 참조 방향에 상관없이 한 개 이상의 참조 프레임의 정보를 활용하는 성격을 가질 수 있다.
도 17을 참조하면, 복수의 프레임들의 디스플레이 순서와 코딩 순서는 동일하다. 그리고, I프레임(1710)을 제외한 나머지 프레임들(P프레임 또는 M프레임)은 디스플레이 순서 또는 코딩 순서가 자신보다 앞서는 프레임들을 참조할 수 있다. 예를 들어, 디스플레이 순서가 8번인 프레임은 디스플레이 순서가 7번인 프레임과 디스플레이 순서가 4번인 프레임을 참조할 수 있다. 즉, 디스플레이 순서가 8번인 프레임의 현재 포인트를 예측하기 위해 디스플레이 순서가 7번, 6번인 프레임의 포인트를 참조할 수 있다.
도 18은 실시예들에 따른 프레임 간 백워드(역방향 또는 후방향) 예측 참조 방법을 나타낸다. 즉, 후방향에 위치한 참조 프레임을 활용하여 예측하는 실시예를 나타낸다.
도 18을 참조하면, 참조 방향(reference direction)을 통해 참조하는 프레임의 위치가 확인된다. 실시예들에 따른 송수신 장치/방법은 GOF중 I프레임(I-frame)(1810)을 코딩하고, I프레임(1810)을 참조하여 앞(forward)방향으로 단일 프레임만 참조하는 P프레임(P-frame)(1830)을 예측한 후, I 프레임과 P 프레임 사이에 있는 m프레임(m-frame)(1820)은 P프레임(P-frame)(1830)과 먼저 코딩된 m프레임(m-frame)의 정보를 활용하여 예측할 수 있다. 이때, 디스플레이 순서(display order)와 코딩순서(coding order)는 서로 다를 수 있으며, 참조 방향(reference direction)은 m프레임(m-frame)과 P프레임(P-frame)의 지정된 위치에 따라 다를 수 있다.
도 18을 참조하면, 실시예들에 따른 송수신 장치/방법은 디스플레이 순서가 더 뒤에 위치하는 프레임을 참조하여 현재 프레임을 예측할 수 있다. 예를 들어, 디스플레이 순서가 2번인 프레임은 디스플레이 순서가 4번인 프레임을 참조하여 현재 포인트를 예측할 수 있다. 즉, 디스플레이 순서가 2번인 프레인의 현재 포인트를 예측하기 위해 디스플레이 순서가 4번인 프레임의 포인트를 참조할 수 있다.
도 19는 실시예들에 따른 프레임 간 Bi-direction(양방향) 예측 참조 방법을 나타낸다. 도 19를 참조하면, m프레임(1920)은 디스플레이 순서 상 전방향(forward) 및 후방향(backward)에 위치한 프레임들을 참조한다.
m프레임(m-frame)(1920)이 양방향(bi-direction) 참조를 허용하는 경우, 실시예들에 따른 송수신 장치는 I프레임(1910) 및 P프레임(P-frame)(1930)을 먼저 코딩하고, I프레임(1910)과 P프레임(P-frame)(1930) 사이에 있는 m프레임(m-frame)(1920)을 양방향 정보를 활용하여 예측할 수 있다. 이때, 먼저 코딩된 m프레임(m-frame)이 있다면, 해당 프레임도 참조 프레임으로 추가되어 사용될 수 있다.
도 19을 참조하면, 실시예들에 따른 송수신 장치/방법은 디스플레이 순서 상 전후방향에 위치하는 프레임을 참조하여 현재 프레임을 예측할 수 있다. 예를 들어, 디스플레이 순서가 2번인 프레임은 디스플레이 순서가 각각 1번 및 4번인 프레임들을 참조하여 현재 포인트를 예측할 수 있다. 즉, 디스플레이 순서가 2번인 프레인의 현재 포인트를 예측하기 위해 디스플레이 순서가 1번인 프레임의 포인트와 디스플레이 순서가 4번인 프레임의 포인트를 참조할 수 있다.
실시예들에 따른 송수신 장치/방법은 도 1의 송수신 장치, 도 2의 송수신, 도 4의 포인트 클라우드 인코더, 도 10, 도 11의 포인트 클라우드 디코더, 도 12의 송신장치, 도 13의 수신장치, 도 14의 디바이스들, 도 44의 송신 장치/방법, 도 45의 수신 장치/방법, 도46의 송신 장치/방법, 도47의 수신 장치/방법, 도 48의 송신 방법 또는 도 49의 수신 방법과 대응하거나, 조합될 수 있으며, 실시예들에 따른 송수신 장치/방법은 도 17 내지 도 19에서 설명하는 프레임 간 인터 예측을 수행할 수 있다.
전술한 세 가지 참조 방향에 따라, 참조 프레임이 한 개 이상의 프레임들에서 참조되는 경우, 참조 프레임의 정보는 별도의 버퍼(buffer)에 사용이 완료될 때까지 저장될 수 있다. 그리고, 참조 프레임의 정보는 사용이 완료된 후 버퍼(buffer)에서 삭제될 수 있다.
복수의 프레임들(multi-frame)을 참조하는 방법은 실시예들에 따른 지오메트리(geometry) 예측, 어트리뷰트(attribute) 예측 등에 적용될 수 있으며, 지오메트리(geometry)와 어트리뷰트(attribute) 각각의 화면 간 예측(인터 예측) 시 참조 프레임(frame) 정보는 서로 분리되어 사용되거나, 동일한 참조 프레임이 사용될 수 있다.
실시예들에 따른 멀티 프레임(multi-frame) 간 참조는 전방향(forward), 역방향(backward) 및 양방향(bi-directional) 방법(method)으로 분리되어 기술되었으나, 동일한 시퀀스(sequence)에서 여러가지 방법들이 복합적으로 적용될 수 있다.
이하, 실시예들에 따른 복수의 참조 프레임들을 활용한 노드 예측 방법을 설명한다. 실시예들에 따른 노드는 포인트로 지칭될 수 있다.
실시예들에 따른 포인트 클라우드 데이터의 인터 예측 시 복수의 참조 프레임들을 사용하여 다음의 예측 방법들을 적용할 수 있다. 실시예들에 따른 예측 방법은 예측 지오메트리(predictive geometry)의 화면 간 예측에 적용될 수 있다.
도 20은 실시예들에 따른 전방향(Forward) 인터 예측 방법을 나타낸다.
전방향 예측(Forward prediction)
도20을 참조하면, 현재 프레임(Current frame)과 디스플레이 순서(display order) 상 가장 가까운 참조 프레임(reference frame)을 제1 참조 프레임(reference frame 1), 그 다음으로 가까운 참조 프레임(reference frame)을 제2 참조 프레임(reference frame2)이라고 한다.
실시예들에 따른 송수신 장치/방법은 현재 프레임에서 예측할 포인트(또는, 노드)(2014)를 예측하기 위해 이전에 복호화(decoding)된 포인트인 Prev.Decoded point(Prev.Point)(2002)를 기준으로 레이저ID(laser ID)가 동일하고, 유사 애지무스(azimuth)값을 가지는 포인트를 제1 참조 프레임에서 찾고, 제1 참조 프레임(reference frame1)에서 래디우스(radius) 값이 Prev.Point(2002)보다 큰 것 중 가장 가까운 것을 제1 예측기(predictor)(P1, 2006)로 정하고, 그 다음 가까운 포인트를 제2 예측기(predictor)(P1', 2008)로 정한다. 그 다음 제2 참조 프레임(reference frame 2)에서 P1(2006)과 레이저ID(laserID)가 동일하고, 유사한 애지무스(azimuth) 값을 가지며, 가장 유사한 래디우스(radius) 값을 가지는 포인트를 제3 예측기(predictor)(P2, 2010)로 정하고, 동일 laserID, 유사 애지무스(azimuth) 값을 가지고, P2(2010)보다 래디우스(radius) 값이 큰 것 중 가장 가까운 포인트를 제4 예측기(predictor)(P2', 2012)로 정한다.
실시예들에 따른 송수신 장치/방법은 4개의 예측기(predictor)들을 독립적으로 비교했을 때 현재 포인트(current point, 2014)와 가장 유사한 예측기(predictor)를 예측값으로 설정하거나, P1(2006)과 P2(2010)의 조합, P1(2006)과 P2'(2012), P1'(2008)과 P2(2010), P1'(2008)와 P2'(2012)의 조합 중 가장 현재 포인트(2014)와 유사한 베스트 케이스(best case)를 찾아 현재 포인트(2014)의 예측값으로 사용할 수 있다. 또는, 실시예들에 따른 송수신 장치/방법은 각 참조 프레임(reference frame)에서 찾은 예측기(predictor)를 대표하는 값(예를들면, 평균)을 산출한 후, 대표값의 각각을 현재 포인트(current point or current node)와 비교하거나, 대표값들의 조합으로 예측값을 계산할 수 있다. 두 개 이상의 예측기(predictor) 정보를 조합하여 현재 포인트 정보를 예측할 때, 산술평균, 기하평균, 디스플레이 순서(display order) 차이에 따른 가중치 등을 적용하여 예측값을 계산할 수 있다.
실시예들에 따른 송수신 장치/방법은 현재 프레임의 현재 포인트(2014)를 예측하기 위해, 현재 프레임에서 이전에 복호화된 제1 포인트(2002)를 기반으로 레이저ID가 동일하고, 유사한 애지무스 값을 갖는 제2 포인트(2004)를 제1 참조 프레임에서 찾을 수 있다. 그리고, 제1 참조 프레임에서 래디우스 값이 제1 포인트(2002)보다 큰 포인트들 중 가장 가까운 제3 포인트(2006)를 제1 예측기(predictor, P1, 2006) 또는 제1 후보포인트(P1, 2006)으로 정하고, 그 다음으로 가까운 제4 포인트(2008)을 제2 예측기(P1', 2008)로 정할 수 있다. 그리고, 제2 참조 프레임에서 제1 예측기(2006)와 레이저ID가 동일하고 유사한 애지무스 값을 가지며, 가장 가까운 래디우스 값을 가지는 제5 포인트(2010)를 제3 예측기(P2, 2010)으로 정하고, 동일 레이저ID 및 유사 애지무스 값을 가지고, 제5 포인트(2010) 보다 래디우스 값이 큰 포인트들 중 가장 가까운 포인트(2012)를 제4 예측기(P2', 2012)로 정할 수 있다.
실시예들에 따른 송수신 장치/방법은 4 개의 예측기 또는 후보 포인트를 독립적으로 현재 포인트와 비교하여 가장 가까운 예측기를 예측값으로 정하거나, 네 개 중 어느 두 가지 이상의 예측기들의 조합으로 현재 포인트(2014)의 예측 값을 정할 수 있다. 예를 들어, 각 참조 프레임에서 찾은 예측기들의 평균을 산출하여 현재 포인트(2014)와 비교하거나 평균 값들의 조합으로 현재 포인트(2014)를 예측할 수 있다.
도 21은 실시예들에 따른 전방향(Forward) 인터 예측 방법을 나타낸다.
도21을 참조하면, 현재 프레임(Current frame)과 디스플레이 순서(display order) 상 가장 가까운 참조 프레임(reference frame)을 제1 참조 프레임(reference frame 1), 그 다음 가까운 참조 프레임(reference frame)을 제2 참조 프레임(reference frame2)이라고 한다.
실시예들에 따른 송수신 장치/방법은 현재 프레임에서 예측할 포인트(또는, 노드)(2112)를 예측하기 위해 현재 포인트에서 예측할 포인트 이전에 복호화 된 포인트인 prev. Decoded point(Prev.Point)(2102)를 기준으로 제1 참조 프레임(reference frame 1)에서 laserID가 동일하고 유사 애지무스(azimuth) 값을 가지는 포인트(2104)를 찾고, 래디우스(radius) 값이 Prev.Point(2102)보다 큰 것 중에 가장 가까운 것을 제1 예측기(predictor)(P1, 2106)로 정하고, 그 다음 제2 참조 프레임(reference frame 2)에서 P1(2106)과 laserID가 동일하고, 유사 애지무스(azimuth) 값을 가지며 가장 유사한 래디우스(radius) 값을 가지는 포인트(2108)로부터 동일 laserID를 가지고, 유사한 애지무스(azimuth) 값을 가지며, 래디우스(radius) 값이 큰 포인트들 중 가장 가까운 포인트를 제2 예측기(predictor)(P2)(2110)으로 정한다.
실시예들에 따른 송수신 장치/방법은 P1(2106)과 P2(2110) 각각을 현재 프레임의 현재 포인트(2112)와 비교하여 가장 가까운 값을 선택하기 위해 각 포인트마다 비교하거나 P1(2106)과 P2(2110)의 조합까지 포함하여 총 세 가지 조건 중 가장 최선의 케이스(best case)를 찾아 현재 포인트의 예측값으로 사용할 수 있다. 두 개 이상의 예측기(predictor) 정보를 조합하여 현재 포인트 정보를 예측할 때는 산술평균, 기하평균, 디스플레이 순서(display order) 차이에 따른 가중치 등을 적용하여 예측값을 계산할 수 있다.
실시예들에 따른 송수신 장치/방법은 현재 프레임의 현재 포인트(2112)를 예측하기 위해, 현재 프레임에서 이전에 복호화된 제1 포인트(2102)를 기반으로 레이저ID가 동일하고, 유사한 애지무스 값을 갖는 제2 포인트(2104)를 제1 참조 프레임에서 찾을 수 있다. 그리고, 제1 참조 프레임에서 래디우스 값이 제1 포인트(2102)보다 큰 포인트들 중 가장 가까운 제3 포인트(2106)를 제1 예측기(predictor, P1, 2106) 또는 제1 후보포인트(P1, 2106)으로 정할 수 있다. 그리고, 제2 참조 프레임에서 제1 예측기(2106)와 레이저ID가 동일하고 유사한 애지무스 값을 가지며, 가장 가까운 래디우스 값을 가지는 제4 포인트(2108)를 찾고, 제4 포인트(2108)와 동일 레이저ID를 가지고 유사 애지무스 값을 가지며, 래디우스 값이 큰 포인트들 중 가장 가까운 포인트(2110)를 제2 예측기(P2, 2110)로 정할 수 있다.
실시예들에 따른 송수신 장치/방법은 제1 예측기(2106) 및 제2 예측기(2110)를 각각 독립적으로 현재 포인트(2112)와 비교하여 가장 가까운 예측기를 예측값으로 정하거나, 예측기들의 조합까지 포함하여 총 세 가지 방법으로 현재 포인트(2112)의 예측 값을 정할 수 있다.
도 22는 실시예들에 따른 전방향(Forward) 인터 예측 방법을 나타낸다.
도22를 참조하면, 현재 프레임(Current frame)과 디스플레이 순서(display order) 상 가장 가까운 참조 프레임(reference frame)을 제1 참조 프레임(reference frame 1), 그 다음 가까운 참조 프레임(reference frame)을 제2 참조 프레임(reference frame2)이라고 한다.
실시예들에 따른 송수신 장치/방법은 현재 프레임에서 예측할 포인트(또는, 노드)(2214)를 예측하기 위해 현재 포인트에서 예측할 포인트 이전에 복호화 된 포인트인 prev. Decoded point(Prev.Point)(2202)를 기준으로 제1 참조 프레임에서 laserID가 동일하고 유사 애지무스(azimuth)값을 가지는 포인트(2204)를 찾고 래디우스(radius)가 Prev.Point(2202)보다 큰 포인트들 중 가장 가까운 것을 제1 예측기(predictor)(P1, 2206)으로 정하고, 그 다음 가까운 포인트를 제2 예측기(predictor)(P1', 2208)로 삼는다. 그리고, 제2 참조 프레임(reference frame 2)에서 P1'(2208)과 laserID가 동일하고, 유사한 애지무스(azimuth) 값을 가지며 가장 유사한 래디우스(radius)를 가지는 포인트를 제3 예측기(predictor)(P2, 2210)로 정하고, 동일 laserID, 유사한 애지무스(azimuth)를 가지고, P2(2210)보다 래디우스(radius)가 큰 포인트들 중 가장 가까운 포인트를 제4 예측기(predictor)(P2', 2212)로 정한다.
실시예들에 따른 송수신 장치는 P2(2210)와 P1'(2208)를 현재 포인트와 비교하여 가장 가까운 값을 가지는 예측기(predictor)를 예측값으로 결정하여 시그널링(signaling)하거나, P1'(2208)과 P2(2210)의 조합을 통해 예측값을 계산할 수 있다. 또한, 필요에 따라 P2'(2212)와 P1(2206) 중 하나 혹은 전부를 후보(candidate) 포인트로 정할 수 있다. 또한, 두 개 이상의 예측기(predictor) 정보를 조합하여 현재 포인트 정보를 예측할 때는 산술평균, 기하평균, 디스플레이 순서(display order) 차이에 따른 가중치 등을 적용하여 예측값을 계산할 수 있다.
실시예들에 따른 송수신 장치/방법은 현재 프레임의 현재 포인트(2214)를 예측하기 위해, 현재 프레임에서 이전에 복호화된 제1 포인트(2202)를 기반으로 레이저ID가 동일하고, 유사한 애지무스 값을 갖는 제2 포인트(2204)를 제1 참조 프레임에서 찾을 수 있다. 그리고, 제1 참조 프레임에서 래디우스 값이 제1 포인트(2202)보다 큰 포인트들 중 가장 가까운 제3 포인트(2206)를 제1 예측기(predictor, P1, 2206) 또는 제1 후보포인트(P1, 2206)으로 정하고, 그 다음으로 가까운 제4 포인트(2208)를 제2 예측기(P1', 2208)로 정할 수 있다. 그리고, 제2 참조 프레임에서 제2 예측기(2208)와 레이저ID가 동일하고 유사한 애지무스 값을 가지며, 가장 가까운 래디우스 값을 가지는 제5 포인트(2210)를 찾아 제3 예측기(P2, 2210)으로 정하고, 동일 레이저ID를 가지고 유사 애지무스 값을 가지며, 제5 포인트(2210)보다 래디우스 값이 큰 포인트들 중 가장 가까운 포인트(2212)를 제4 예측기(P2', 2212)로 정할 수 있다.
실시예들에 따른 송수신 장치/방법은 4 개의 예측기 또는 후보 포인트를 독립적으로 현재 포인트와 비교하여 가장 가까운 예측기를 예측값으로 정하거나, 네 개 중 어느 두 가지 이상의 예측기들의 조합으로 현재 포인트(2214)의 예측 값을 정할 수 있다. 예를 들어, 각 참조 프레임에서 찾은 예측기들의 평균을 산출하여 현재 포인트(2214)와 비교하거나 평균 값들의 조합으로 현재 포인트(2214)를 예측할 수 있다.
도 23은 실시예들에 따른 양방향(Bi-directional) 인터 예측 방법을 나타낸다.
도 23을 참조하면, 디스플레이 순서(display order) 상 현재 프레임(current frame)보다 앞서는 참조 프레임(reference frame)을 제1 참조 프레임(reference frame 1)이라고 하고, 현재 프레임(current frame)보다 순서(order) 값이 더 큰 참조 프레임(reference frame)을 제2 참조 프레임(reference frame2)이라고 지칭할 수 있다. 제2 참조 프레임은 디스플레이 순서 상 현재 프레임보다 뒤에 위치한다.
실시예들에 따른 송수신 장치는 현재 프레임에서 예측할 포인트(또는, 노드)(2312)를 예측하기 위해 현재 프레임에서 예측할 포인트 이전에 복호화(decoding) 된 포인트인 prev. Decoded point(Prev.Point)(2302)를 기준으로 제1 참조 프레임(reference frame1)에서 laserID가 동일하고, 유사 애지무스(azimuth)값을 가지는 포인트(2304)를 찾고 래디우스(radius) 값이 Prev.Point(2302)보다 큰 포인트들 중 가장 가까운 포인트를 제1 예측기(predictor)(P1, 2306)로 정하고, 그 다음 가까운 포인트를 제2 예측기(P1', 2308)로 정한다. 그리고, 제2 참조 프레임(reference frame 2)에서 P1'(2308)과 laserID가 동일하고, 유사한 애지무스(azimuth)를 가지며 가장 유사한 래디우스(radius)를 가지는 포인트를 제3 예측기(predictor)(P2, 2310)로 정하고 P1'(2308)과 P2(2310) 2개의 예측기(predictor)를 독립적으로 비교했을 때 현재 포인트와 가장 유사한 예측기(predictor)를 예측값으로 설정하거나, P1'(2308) 와 P2(2310)의 조합 까지 고려하여 가장 최선의 케이스를 찾아 현재 포인트의 예측값으로 사용할 수 있다 또한, 두 개 이상의 예측기(predictor) 정보를 조합하여 현재 포인트 정보를 예측할 때는 산술평균, 기하평균, 디스플레이 순서(display order) 차이에 따른 가중치 등을 적용하여 예측값을 계산할 수 있다.
실시예들에 따른 송수신 장치/방법은 현재 프레임의 현재 포인트(2312)를 예측하기 위해, 현재 프레임에서 이전에 복호화된 제1 포인트(2302)를 기반으로 레이저ID가 동일하고, 유사한 애지무스 값을 갖는 제2 포인트(2304)를 제1 참조 프레임에서 찾을 수 있다. 그리고, 제1 참조 프레임에서 래디우스 값이 제1 포인트(2302)보다 큰 포인트들 중 가장 가까운 제3 포인트(2306)를 제1 예측기(predictor, P1, 2306) 또는 제1 후보포인트(P1, 2306)으로 정하고, 그 다음으로 가까운 제4 포인트(2308)를 제2 예측기(P1', 2308)로 정할 수 있다. 그리고, 제2 참조 프레임에서 제2 예측기(2308)와 레이저ID가 동일하고 유사한 애지무스 값을 가지며, 가장 가까운 래디우스 값을 가지는 제5 포인트(2310)를 찾아 제3 예측기(P2, 2310)으로 정할 수 있다.
실시예들에 따른 송수신 장치/방법은 4 개의 예측기 또는 후보 포인트를 독립적으로 현재 포인트와 비교하여 가장 가까운 예측기를 예측값으로 정하거나, 네 개 중 어느 두 가지 이상의 예측기들의 조합으로 현재 포인트(2214)의 예측 값을 정할 수 있다. 예를 들어, 각 참조 프레임에서 찾은 예측기들의 평균을 산출하여 현재 포인트(2214)와 비교하거나 평균 값들의 조합으로 현재 포인트(2214)를 예측할 수 있다.
도 24는 실시예들에 따른 양방향(Bi-directional) 인터 예측 방법을 나타낸다.
도 24를 참조하면, 디스플레이 순서(display order) 상 현재 프레임(current frame)보다 앞서는 참조 프레임(reference frame)을 제1 참조 프레임(reference frame 1)이라고 하고, 현재 프레임(current frame)보다 순서(order) 값이 더 큰 참조 프레임(reference frame)을 제2 참조 프레임(reference frame2)이라고 지칭할 수 있다. 제2 참조 프레임은 디스플레이 순서 상 현재 프레임보다 뒤에 위치한다.
실시예들에 따른 송수신 장치는 현재 프레임에서 예측할 포인트(또는, 노드)(2416)를 예측하기 위해 현재 프레임에서 예측할 포인트 이전에 복호화(decoding) 된 포인트인 prev. Decoded point(Prev.Point)(2402)를 기준으로 제1 참조 프레임(reference frame1)에서 laserID가 동일하고, 유사 애지무스(azimuth)값을 가지는 포인트(2404)를 찾고 래디우스(radius) 값이 Prev.Point(2402)보다 큰 포인트들 중 가장 가까운 포인트를 제1 예측기(predictor)(P1, 2408)로 정하고, 그 다음 가까운 포인트를 제2 예측기(predictor)(P1', 2410)로 정한다. 그리고, 제2 참조 프레임(reference frame 2)에서 prev. Decoded point(Prev.Point)(2402)를 기준으로 laserID가 동일하고, 유사 애지무스(azimuth)값을 가지며, 가장 유사한 래디우스(radius)를 가지는 포인트(2406)를 찾고, 그 포인트(2406)보다 래디우스(radius)가 큰 포인트들 중 가장 차이가 적은 포인트를 P2(2412)로 정한다. P2'(2414)는 래디우스(radius)가 P2(2412)보다 큰 포인트들 중 가장 가까운 포인트로 정해진다.
실시예들에 따른 송수신 장치는 현재 프레임의 현재 포인트(또는, 노드)(2416)를 예측할 때, 4 개의 예측기(P1, P1', P2, P2')를 개별적으로 비교하거나 두 개의 예측기끼리 정보를 조합한 결과 중 최선의 후보(best candidate)를 선택할 수 있다. 두 개 이상의 예측기(predictor) 정보를 조합하여 현재 포인트 정보를 예측할 때는 산술평균, 기하평균, 디스플레이 순서(display order) 차이에 따른 가중치 등을 적용하여 예측값을 계산할 수 있다.
실시예들에 따른 송수신 장치/방법은 현재 프레임의 현재 포인트(2416)를 예측하기 위해, 현재 프레임에서 이전에 복호화된 제1 포인트(2402)를 기반으로 레이저ID가 동일하고, 유사한 애지무스 값을 갖는 제2 포인트(2404)를 제1 참조 프레임에서 찾을 수 있다. 그리고, 제1 참조 프레임에서 래디우스 값이 제1 포인트(2402)보다 큰 포인트들 중 가장 가까운 제3 포인트(2408)를 제1 예측기(predictor, P1, 2408) 또는 제1 후보포인트(P1, 2408)으로 정하고, 그 다음으로 가까운 제4 포인트(2410)를 제2 예측기(P1', 2410)로 정할 수 있다. 그리고, 제2 참조 프레임에서 제1 포인트(2402)를 기준으로 레이저ID가 동일하고 유사 애지무스 값을 가지며, 가장 유사한 래디우스를 가지는 제5 포인트(2406)을 찾고, 제5 포인트(2406)보다 래디우스가 큰 포인트들 중 가장 차이가 적은 포인트를 제3 예측기(P2, 2412)로 정하며, 그 다음으로 차이가 적은 포인트를 제4 예측기(P2', 2414)로 정할 수 있다.
실시예들에 따른 송수신 장치/방법은 4 개의 예측기 또는 후보 포인트를 독립적으로 현재 포인트와 비교하여 가장 가까운 예측기를 예측값으로 정하거나, 네 개 중 어느 두 가지 이상의 예측기들의 조합으로 현재 포인트(2416)의 예측 값을 정할 수 있다. 예를 들어, 각 참조 프레임에서 찾은 예측기들의 평균을 산출하여 현재 포인트(2416)와 비교하거나 평균 값들의 조합으로 현재 포인트(2416)를 예측할 수 있다.
도 25는 실시예들에 따른 양방향(Bi-directional) 인터 예측 방법을 나타낸다.
도 25를 참조하면, 디스플레이 순서(display order) 상 현재 프레임(current frame)보다 앞서는 참조 프레임(reference frame)을 제1 참조 프레임(reference frame 1)이라고 하고, 현재 프레임(current frame)보다 순서(order) 값이 큰 참조 프레임(reference frame)을 제2 참조 프레임(reference frame2)이라고 지칭할 수 있다. 제2 참조 프레임은 디스플레이 순서 상 현재 프레임보다 뒤에 위치한다.
실시예들에 따른 송수신 장치는 현재 프레임에서 예측할 포인트(또는, 노드)(2514)를 예측하기 위해 현재 프레임에서 예측할 포인트 이전에 복호화(decoding) 된 포인트인 prev. Decoded point(Prev.Point)(2502)를 기준으로 제1 참조 프레임(reference frame1)에서 laserID가 동일하고, 유사 애지무스(azimuth)값을 가지는 포인트(2504)를 찾고 래디우스(radius) 값이 Prev.Point(2502)보다 큰 포인트들 중 가장 가까운 포인트를 제1 예측기(predictor)(P1, 2506)로 정하고, 그 다음 가까운 포인트를 제2 예측기(predictor)(P1', 2508)로 정할 수 있다. 그리고, 제2 참조 프레임(reference frame 2)에서 prev. Decoded point(Prev.Point)(2502)와 P1(2506)과 laserID가 동일하고, 유사 애지무스(azimuth)값을 가지며, 래디우스(radius) 값이 P1(2506)과 Prev.Point(2502)보다 더 큰 순서대로 포인트를 선택하여 각각 P2(2510), P2'(2512)로 지정할 수 있다.
실시예들에 따른 송수신 장치는 현재 프레임의 현재 포인트(또는, 노드)(2514)를 예측할 때, 4 개의 예측기(P1, P1', P2, P2')를 개별적으로 비교하거나 두 개의 예측기끼리 정보를 조합한 결과 중 최선의 후보(best candidate)를 선택할 수 있다. 두 개 이상의 예측기(predictor) 정보를 조합하여 현재 포인트 정보를 예측할 때는 산술평균, 기하평균, 디스플레이 순서(display order) 차이에 따른 가중치 등을 적용하여 예측값을 계산할 수 있다.
실시예들에 따른 송수신 장치/방법은 현재 프레임의 현재 포인트(2514)를 예측하기 위해, 현재 프레임에서 이전에 복호화된 제1 포인트(2502)를 기반으로 레이저ID가 동일하고, 유사한 애지무스 값을 갖는 제2 포인트(2504)를 제1 참조 프레임에서 찾을 수 있다. 그리고, 제1 참조 프레임에서 래디우스 값이 제1 포인트(2502)보다 큰 포인트들 중 가장 가까운 제3 포인트(2506)를 제1 예측기(predictor, P1, 2506) 또는 제1 후보포인트(P1, 2506)으로 정하고, 그 다음으로 가까운 제4 포인트(2508)를 제2 예측기(P1', 2508)로 정할 수 있다. 그리고, 제2 참조 프레임에서 제1 포인트(2502)를 기준으로 레이저ID가 동일하고 유사 애지무스 값을 가지며, 래디우스 값이 제3 포인트(2506) 및 제1 포인트(2502)보다 더 큰 순서대로 포인트를 선택하여 제3 예측기(P2, 2510)과 제4 예측기(P2', 2512)를 정할 수 있다.
도 26은 실시예들에 따른 역방향(Backward) 인터 예측 방법을 나타낸다.
도 26을 참조하면, 디스플레이 순서(display order) 상 현재 프레임(current frame)보다 이후인 프레임들 중 현재 프레임과 가까운 참조 프레임(reference frame)을 제1 참조 프레임(reference frame 1)이라고 하고, 현재 프레임(current frame)과 제1 참조 프레임보다 순서(order) 값이 큰 참조 프레임(reference frame)을 제2 참조 프레임(reference frame2)이라고 지칭할 수 있다. 제2 참조 프레임 디스플레이 순서 상 제1 참조 프레임보다 뒤에 위치한다.
실시예들에 따른 송수신 장치는 현재 프레임에서 예측할 포인트(또는, 노드)(2614)를 예측하기 위해 현재 프레임에서 예측할 포인트 이전에 복호화(decoding) 된 포인트인 prev. Decoded point(Prev.Point)(2602)를 기준으로 제1 참조 프레임(reference frame1)에서 laserID가 동일하고, 유사 애지무스(azimuth)값을 가지는 포인트(2604)를 찾고 래디우스(radius) 값이 Prev.Point(2602)보다 큰 포인트들 중 가장 가까운 포인트를 제1 예측기(predictor)(P1, 2606)로 정하고, 그 다음 가까운 포인트를 제2 예측기(predictor)(P1', 2608)로 정할 수 있다. 그리고, 제2 참조 프레임(reference frame 2)에서 P1(2606), P1'(2608) 각각에 대해 laserID와 유사 애지무스(azimuth)값을 가지며, 래디우스(radius) 값이 P1(2606), P1'(2608)과 가장 유사한 포인트를 찾아 각각 P2(2610), P2'(2612)로 정할 수 있다.
실시예들에 따른 송수신 장치는 현재 프레임의 현재 포인트(또는, 노드)(2614)를 예측할 때, 4 개의 예측기(P1, P1', P2, P2')를 개별적으로 비교하거나 두 개의 예측기끼리 정보를 조합한 결과 중 최고의 후보(best candidate)를 선택할 수 있다. 두 개 이상의 예측기(predictor) 정보를 조합하여 현재 포인트 정보를 예측할 때는 산술평균, 기하평균, 디스플레이 순서(display order) 차이에 따른 가중치 등을 적용하여 예측값을 계산할 수 있다.
실시예들에 따른 송수신 장치/방법은 현재 프레임의 현재 포인트(2614)를 예측하기 위해, 현재 프레임에서 이전에 복호화된 제1 포인트(2602)를 기반으로 레이저ID가 동일하고, 유사한 애지무스 값을 갖는 제2 포인트(2604)를 제1 참조 프레임에서 찾을 수 있다. 그리고, 제1 참조 프레임에서 래디우스 값이 제1 포인트(2602)보다 큰 포인트들 중 가장 가까운 제3 포인트(2606)를 제1 예측기(predictor, P1, 2606) 또는 제1 후보포인트(P1, 2606)으로 정하고, 그 다음으로 가까운 제4 포인트(2608)를 제2 예측기(P1', 2608)로 정할 수 있다. 그리고, 제2 참조 프레임에서 제3 포인트(2606) 및 제4 포인트(2608)에 대하여 각각 레이저ID가 동일하고 유사 애지무스 값을 가지며, 래디우스 값이 제3 포인트(2606) 및 제4 포인트(2608) 각각과 가장 가까운 포인트를 찾아 제3 예측기(P2, 2610)과 제4 예측기(P2', 2612)를 정할 수 있다.
도 27은 실시예들에 따른 역방향(Backward) 인터 예측 방법을 나타낸다.
도 27을 참조하면, 디스플레이 순서(display order) 상 현재 프레임(current frame)보다 이후인 프레임들 중 현재 프레임과 가까운 참조 프레임(reference frame)을 제1 참조 프레임(reference frame 1)이라고 하고, 현재 프레임(current frame)과 제1 참조 프레임보다 순서(order) 값이 큰 참조 프레임(reference frame)을 제2 참조 프레임(reference frame2)이라고 지칭할 수 있다. 제2 참조 프레임 디스플레이 순서 상 제1 참조 프레임보다 뒤에 위치한다.
실시예들에 따른 송수신 장치는 현재 프레임에서 예측할 포인트(또는, 노드)(2714)를 예측하기 위해 현재 프레임에서 예측할 포인트 이전에 복호화(decoding) 된 포인트인 prev. Decoded point(Prev.Point)(2702)를 기준으로 제1 참조 프레임(reference frame1)에서 laserID가 동일하고, 유사 애지무스(azimuth)값을 가지는 포인트(2704)를 찾고 래디우스(radius) 값이 Prev.Point(2702)보다 큰 포인트들 중 가장 가까운 포인트를 제1 예측기(predictor)(P1, 2706)로 정하고, 그 다음 가까운 포인트를 제2 예측기(predictor)(P1', 2708)로 정할 수 있다. 그리고, 제2 참조 프레임(reference frame 2)에서 P1'(2708)에 대해 laserID와 유사 애지무스(azimuth)값을 가지며, 래디우스(radius) 값이 가장 유사한 포인트를 P2(2712)로 정하고, P2(2712)보다 래디우스(radius) 값이 작고, Prev.Point(2702)보다 큰 포인트를 P2'(2710)으로 정할 수 있다.
실시예들에 따른 송수신 장치는 현재 프레임의 현재 포인트(또는, 노드)(2714)를 예측할 때, 4 개의 예측기(P1, P1', P2, P2')를 개별적으로 비교하거나 두 개의 예측기끼리 정보를 조합한 결과 중 최고의 후보(best candidate)를 선택할 수 있다. 두 개 이상의 예측기(predictor) 정보를 조합하여 현재 포인트 정보를 예측할 때는 산술평균, 기하평균, 디스플레이 순서(display order) 차이에 따른 가중치 등을 적용하여 예측값을 계산할 수 있다.
실시예들에 따른 송수신 장치/방법은 현재 프레임의 현재 포인트(2714)를 예측하기 위해, 현재 프레임에서 이전에 복호화된 제1 포인트(2702)를 기반으로 레이저ID가 동일하고, 유사한 애지무스 값을 갖는 제2 포인트(2704)를 제1 참조 프레임에서 찾을 수 있다. 그리고, 제1 참조 프레임에서 래디우스 값이 제1 포인트(2702)보다 큰 포인트들 중 가장 가까운 제3 포인트(2706)를 제1 예측기(predictor, P1, 2706) 또는 제1 후보포인트(P1, 2706)으로 정하고, 그 다음으로 가까운 제4 포인트(2708)를 제2 예측기(P1', 2708)로 정할 수 있다. 그리고, 제2 참조 프레임에서 제4 포인트(2708)에 대하여 레이저ID가 동일하고 유사 애지무스 값을 가지며, 래디우스 값이 가장 유사한 제5 포인트(2712)를 제3 예측기(P2, 2712)로 정하고, 래디우스 값이 제5 포인트(2712)보다 작고 제1 포인트(2702)보다 큰 포인트를 제4 예측기(P2', 2710)으로 정할 수 있다.
도 28은 실시예들에 따른 역방향(Backward) 인터 예측 방법을 나타낸다.
도 28을 참조하면, 디스플레이 순서(display order) 상 현재 프레임(current frame)보다 이후인 프레임들 중 현재 프레임과 가까운 참조 프레임(reference frame)을 제1 참조 프레임(reference frame 1)이라고 하고, 현재 프레임(current frame)과 제1 참조 프레임보다 순서(order) 값이 큰 참조 프레임(reference frame)을 제2 참조 프레임(reference frame2)이라고 지칭할 수 있다. 제2 참조 프레임 디스플레이 순서 상 제1 참조 프레임보다 뒤에 위치한다.
실시예들에 따른 송수신 장치는 현재 프레임에서 예측할 포인트(또는, 노드)(2812)를 예측하기 위해 현재 프레임에서 예측할 포인트 이전에 복호화(decoding) 된 포인트인 prev. Decoded point(Prev.Point)(2802)를 기준으로 제1 참조 프레임(reference frame1)에서 laserID가 동일하고, 유사 애지무스(azimuth)값을 가지는 포인트(2804)를 찾고 래디우스(radius) 값이 Prev.Point(2802)보다 큰 포인트들 중 가장 가까운 포인트를 제1 예측기(predictor)(P1, 2806)로 정하고, 그 다음 가까운 포인트를 제2 예측기(predictor)(P1', 2808)로 정할 수 있다. 그리고, 제2 참조 프레임(reference frame 2)에서 P1'(2808) 대해 laserID와 유사 애지무스(azimuth)값을 가지며, 래디우스(radius) 값이 P1'(2808)과 가장 유사한 포인트를 P2(2810)로 정할 수 있다.
실시예들에 따른 송수신 장치는 현재 프레임의 현재 포인트(또는, 노드)(2812)를 예측할 때, 3 개의 예측기(P1, P1', P2)를 개별적으로 비교하거나 두 개의 예측기끼리 정보를 조합한 결과 중 최고의 후보(best candidate)를 선택할 수 있다. 두 개 이상의 예측기(predictor) 정보를 조합하여 현재 포인트 정보를 예측할 때는 산술평균, 기하평균, 디스플레이 순서(display order) 차이에 따른 가중치 등을 적용하여 예측값을 계산할 수 있다.
실시예들에 따른 송수신 장치/방법은 현재 프레임의 현재 포인트(2812)를 예측하기 위해, 현재 프레임에서 이전에 복호화된 제1 포인트(2802)를 기반으로 레이저ID가 동일하고, 유사한 애지무스 값을 갖는 제2 포인트(2804)를 제1 참조 프레임에서 찾을 수 있다. 그리고, 제1 참조 프레임에서 래디우스 값이 제1 포인트(2802)보다 큰 포인트들 중 가장 가까운 제3 포인트(2806)를 제1 예측기(predictor, P1, 2806) 또는 제1 후보포인트(P1, 2806)으로 정하고, 그 다음으로 가까운 제4 포인트(2808)를 제2 예측기(P1', 2808)로 정할 수 있다. 그리고, 제2 참조 프레임에서 제4 포인트(2808)에 대하여 동일한 레이저ID와 유사한 애지무스 값을 가지고 래디우스 값이 제4 포인트(2808)와 가장 유사한 제5 포인트(2810)를 찾아 제3 예측기(P2, 2810)로 정할 수 있다.
실시예들에 따르면, 동일한 laserID 및 유사한 애지무스(azimuth) 값을 가질 때 래디우스(radius) 값의 차이만으로 포인트들을 비교하지만 비교 대상은 애지무스(azimuth) 값 또는laserID로 대체될 수 있다. 또한, laserID, azimuth 및 radius 중 하나 이상의 요소를 비교할 수도 있다. 참조 방향 세 가지는 프레임 단위로 다를 수 있고, 포인트(또는, 노드) 단위로 다를 수 있으며, 포인트 단위로 다른 경우 하나라도 멀티플 프레임(multiple-frame)을 참조하는 포인트(또는, 노드)가 있을 때 포인트가 속한 프레임 또는 예측 트리(predictive tree)의 예측이 완료 될 때까지 참조 프레임 정보가 유지되거나, 멀티플 프레임(multiple-frame)을 참조한 포인트(또는, 노드)의 예측 완료 시점에 참조 프레임(reference frame) 정보가 삭제될 수 있다.
실시예들에 따르면, 송수신 장치는 laserID, azimuth 값 및 radius 값 중 적어도 어느 하나를 기반으로 프레임 간 포인트들을 비교할 수 있다. 예를들어, 현재 포인트 이전에 디코딩된 포인트(Prev. Decoded Point)의 laserID, aimuth 값 및 radius 값 중 적어도 어느 하나를 기반으로 참조 프레임에 속한 포인트들을 비교하여 참조 포인트 또는 예측기(predictor)를 정할 수 있다. 실시예들에 따른 송수신 장치는 복수의 예측기들을 정할 수 있고, 복수의 예측기들을 조합하여 현재 포인트를 예측할 수 있다.
실시예들에 따른 송수신 장치는 찾은 포인트들(또는, 예측기들) 중 베스트 케이스(best case)를 선택하기 위하여 찾은 정보가 특정 기준보다 큰 경우 일부 포인트는 탐색 대상에서 제외 할 수 있다. 예를들어, 실시예들에 따른 P1, P1', P2, P2'에서 일부 또는 전체가 현재 포인트(current point)와의 차이가 임계치(threshold)보다 큰 경우 베스트 케이스(best case) 탐색 대상에서 해당 포인트가 제외될 수 있다. 현재 포인트(Current point)와 차이는 애지무스(azimuth) 값 또는 래디우스(radius) 차이가 될 수도 있고, 유클리디안(euclidean) 거리 및 그밖에 거리를 비교할 수 있는 다른 척도가 적용될 수 있으며, 어트리뷰트 정보의 차이가 될 수 있다.
실시예들에 따른 송수신 장치/방법은 도 1의 송수신 장치, 도 2의 송수신, 도 4의 포인트 클라우드 인코더, 도 10, 도 11의 포인트 클라우드 디코더, 도 12의 송신장치, 도 13의 수신장치, 도 14의 디바이스들, 도 44의 송신 장치/방법, 도 45의 수신 장치/방법, 도46의 송신 장치/방법, 도47의 수신 장치/방법, 도 48의 송신 방법 또는 도 49의 수신 방법과 대응하거나, 조합될 수 있으며, 실시예들에 따른 송수신 장치/방법은 도 20 내지 도 28에서 설명하는 전방향, 양방향 또는 역방향의 프레임 간 인터 예측을 수행할 수 있다.
즉, 실시예들에 따른 송수신 장치/방법은 디스플레이 순서 상 현재 프레임의 앞 또는 뒤에 위치한 복수의 프레임들에 속한 포인트들를 참조하여 현재 프레임의 현재 포인트를 예측할 수 있다.
또한, 실시예들에 따른 송수신 장치/방법은 레이저ID, 애지무스, 래디우스 뿐만 아니라 좌표계의 특성에 따라 X, Y, Z 값을 비교함으로써 참조 프레임에서 참조할 예측기 또는 후보 포인트들을 선택할 수 있다.
실시예들에 따른 송수신 장치/방법은 참조 프레임에서 특정한 임계치를 기준으로 현재 포인트와의 거리 차이에 따라 예측기 또는 후보 포인트를 선택할 수 있다. 예를 들어, 어떤 포인트가 현재 포인트와의 특성 차이가 임계치 이상인 경우, 해당 포인트는 예측기 또는 후보 포인트로 선택되지 않을 수 있다.
실시예들에 따라 복수의 프레임들을 참조하여 포인트 클라우드 데이터 예측 시, 현재 프레임에서 속한 현재 포인트의 정보를 보다 정확하게 예측할 수 있다. 따라서, 예측된 정보와 실제 정보의 차이가 줄어들어 잔차(residual)이 감소하고, 송수신되는 데이터의 양이 절감되어 송수신 효율이 높으며, 복호화 또는 부호화 레이턴시를 낮출 수 있다.
도 29는 실시예들에 따른 GOF(Group of Frames)를 나타낸다.
실시예들에 따른 송수신 장치/방법은 누적 참조 프레임을 사용하여 화면 간 예측(인터 예측)을 수행할 수 있다. 현재 프레임의 현재 노드를 예측 시 화면 간 예측의 정확도를 향상하기 위해서 한 개 이상의 참조 프레임이 선택될 수 있다.
도 29를 참조하면, GoF(Group of Frame)에 속하는 8개의 프레임들 중 현재 프레임(2920)을 예측하기 위해 7개의 참조 후보들(reference candidates)(2910) 중에서 두 개의 프레임을 참조 프레임(reference frame)(2930)으로 선택하는 시나리오를 나타낸다. 참조 프레임으로 사용하기 위해 해당 참조 프레임은 현재 프레임보다 우선 복호화(decoded)되어야 하며, 복호화(decoding) 순서는 시그널링 될 수 있다. 또한, 참조 프레임(reference frame)의 디스플레이 순서(display order) 또는 GOF 중 몇 번째 프레임인지에 대한 정보가 시그널링 될 수 있다.
도 30은 실시예들에 따른 누적 참조 프레임을 나타낸다.
도 29에서 선택된 참조 프레임(2930)들은 도 30과 같이 누적된 포인트 클라우드 데이터 형태로 생성된 후 현재 프레임과 비교하기 위해 정렬된(sorting) 누적 참조 프레임으로 생성될 수 있다.
실시예들에 따른 송수신 장치/방법은 선택된 참조 프레임들을 누적한 누적 참조 프레임(cumulative reference frame)(3010)을 생성하고, 누적 참조 프레임의 포인트들을 정렬하여 정렬된 누적 참조 프레임(3020)을 생성할 수 있다. 실시예들에 따른 송수신 장치/방법은 현재 프레임의 현재 포인트와 누적 참조 프레임(3020) 내의 포인트를 비교하여 현재 포인트를 예측하기 위한 후보 포인트들을 선택할 수 있다.
도 31은 실시예들에 따른 누적 참조 프레임을 활용한 현재 포인트 예측 방법을 나타낸다.
실시예들에 따른 송수신 장치/방법은 선택된 참조 프레임들을 하나의 포인트 클라우드로 취합한 후 현재 프레임의 정렬(sorting) 방법과 동일하게 포인트들을 정렬한다. 정렬 후 도 31과 같이 현재 프레임의 현재 포인트(또는, 노드)(3114) 직전의 복호화된 포인트(decoded point)(3102)의 laser ID, 애지무스(azimuth) 값과 래디우스(radius) 값이 가장 유사한 포인트(3104)를 누적 참조 프레임의 포인트 클라우드에서 찾는다. 이때, 복호화된 포인트(decoded point)(3102)와 유사한 포인트는 하나 이상이 될 수 있으나 중복 포인트(duplicate point)로 간주하고 복호화된 포인트(decoded point)(3102)를 기준으로 1) 애지무스(azimuth) 값이 더 크고 가장 가까운 위치의 포인트(3106)를 후보로 선택할 수 있다. 2) 1번 포인트(3106)를 기점으로 동일 laserID, 유사한 애지무스(azimuth) 값을 가지면서 래디우스(radius) 값이 더 큰 포인트(3108)를 후보로 선택할 수 있다. 3) 복호화된 포인트(decoded point)(3102)를 기준으로 애지무스(azimuth)가 더 작고 가장 가까운 위치의 포인트(3110)를 후보로 선택할 수 있다. 4) 3번 포인트(3110)를 기점으로 동일 laserID, 유사한 애지무스(azimuth) 값을 가지면서 래디우스(radius) 값이 더 큰 포인트(3112)를 후보로 선택할 수 있다. 따라서, 실시예들에 따른 송수신 장치/방법은 현재 프레임의 현재 포인트를 예측하기 위해 총 4개의 후보 포인트들을 찾을 수 있다.
실시예들에 따른 송수신 장치/방법은 현재 프레임의 현재 포인트(3114)를 예측하기 위해, 현재 프레임에서 이전에 복호화된 제1 포인트(3102)를 기반으로 레이저ID가 동일하고, 유사한 애지무스 값과 래디우스 값을 가진 제2 포인트(3104)를 누적 참조 프레임에서 찾을 수 있다. 그리고, 누적 참조 프레임에서 제1 포인트(3102)보다 애지무스 값이 더 크면서 가장 가까운 위치의 제3 포인트(3106)를 후보 포인트로 선택할 수 있다. 또한, 제3 포인트(3106)와 동일한 레이저아이디, 유사한 애지무스 값을 가지면서 래디우스 값이 더 큰 제4 포인트(3108)를 후보 포인트로 선택할 수 있다. 또한, 제1 포인트(3102)를 기준으로 애지무스가 값이 더 작고 가장 가까운 위치의 제5 포인트(3110)를 후보 포인트로 선택할 수 있다. 또한, 제5 포인트(3110)을 기준으로 동일한 레이저ID와 유사한 애지무스 값을 가지면서 래디우스 값이 더 큰 제6 포인트(3112)를 후보 포인트로 선택할 수 있다.
실시예들에 따른 예측값 선정 방법.
방법 1. 선택된 4개의 포인트들을 이용해서 현재 포인트(current point)(3114)의 위치가 누적 참조 프레임(cumulative reference frame)에서 애지무스(azimuth)를 기준으로 1번(3106), 2번 포인트(3108)와 가까운지, 3번(3110), 4번 포인트(3112)와 가까운지를 찾는다. 이후, 래디우스(radius)를 기준으로 1번(3106), 3번 포인트(3110) 또는 2번(3108), 4번 포인트(3112)와 가까운지 비교하여 포인트 그룹을 찾는다.
1번(3106), 2번 포인트(3108)는 현재 포인트(3114)와 동일한(또는, 유사한) 애지무스(azimuth) 값을 가지므로 대표하는 애지무스 값 하나를 선정할 수 있고, 마찬가지로 3번(3110), 4번 포인트(3112)도 대표하는 애지무스 값 하나를 선정할 수 있으므로, 대표 애지무스(azimuth) 값과 현재 포인트(current point)(3114)의 애지무스(azimuth) 값을 비교하여 가장 유사한 포인트 그룹(point group)을 선정할 수 있다.(decoded point를 기준 larger azimuth group 또는 smaller azimuth group) 선정된 애지무스 그룹(azimuth group) 내에서 두 개의 포인트들 중 가장 가까운 포인트를 현재 노드(3114)의 예측값으로 사용할 지, 아니면 두 개의 포인트들의 평균 값을 사용할지에 따라 아래와 같이 3개의 모드가 시그널링 될 수 있다.
실시예들에 따른 송수신 장치/방법은 후보 포인트들을 애지무스 값을 기반으로 그룹핑하고, 대표 애지무스 값을 기준으로 현재 포인트와 비교하여 유사한 포인트 그룹을 선택할 수 있다. 그리고, 선택된 포인트 그룹에 속한 포인트들 중 가장 가까운 포인트의 현재 포인트의 예측값으로 사용하거나, 포인트들의 평균을 현재 포인트의 예측값으로 사용할 수 있다.
mode description
0 Similar radius to decoded point
1 Larger radius than decoded point
2 Averaged radius
방법 2. 선택된 4개의 포인트들의 조합을 이용하여 현재 포인트(current point)(3114)의 위치를 후(backward) 방향 (포인트3번 및 포인트 4번의 조합)으로 예측하는게 유리한지, 전(forward) 방향(포인트 1번 및 2번의 조합)으로 예측하는게 유리한지, 양방향(bi-directional)(포인트 1번 및 3번의 조합) 방향으로 예측하는게 유리한지, 먼 거리 양방향(farther bi directional)(포인트 2번 및 4번의 조합)방향으로 예측하는게 유리한지 판단하여 시그널링 할 수 있다.
mode description
0 Forward direction
1 Backward direction
2 Bi-direction
3 Farther bi-direction
실시예들에 따른 송수신 장치/방법은 도 1의 송수신 장치, 도 2의 송수신, 도 4의 포인트 클라우드 인코더, 도 10, 도 11의 포인트 클라우드 디코더, 도 12의 송신장치, 도 13의 수신장치, 도 14의 디바이스들, 도 44의 송신 장치/방법, 도 45의 수신 장치/방법, 도46의 송신 장치/방법, 도47의 수신 장치/방법, 도 48의 송신 방법 또는 도 49의 수신 방법과 대응하거나, 조합될 수 있으며, 실시예들에 따른 송수신 장치/방법은 도 29 내지 도 31에서 설명하는 누적 참조 프레임을 활용한 인터 예측 및 예측 방법에 관한 시그널링을 수행할 수 있다.
실시예들에 따라 복수의 프레임들을 누적한 누적 프레임을 참조하여 포인트 클라우드 데이터 예측 시, 현재 프레임에서 속한 현재 포인트의 정보를 보다 정확하게 예측할 수 있다. 따라서, 예측된 정보와 실제 정보의 차이가 줄어들어 잔차(residual)이 감소하고, 송수신되는 데이터의 양이 절감되어 송수신 효율이 높으며, 복호화 또는 부호화 레이턴시를 낮출 수 있다.
도 32는 실시예들에 따른 부호화된 비트스트림의 예시이다.
실시예들에 따른 비트스트림은 도 1의 송신장치(10000), 도 2의 송신 방법, 도 4의 인코더, 도 12의 송신 장치, 도 14의 디바이스들, 도 16의 송신 방법/장치, 도 30, 도32의 송신 방법/장치를 기반으로 송신될 수 있다. 또한, 실시예들에 따른 비트스트림은 도 1의 수신장치(20000), 도 2의 수신 방법, 도 11의 디코더, 도 13의 수신 장치, 도 14의 디바이스들 및/또는 도 31, 도 33의 수신 방법/장치에 기반하여 수신될 수 있다.
실시예들을 추가/수행 하기 위해서 관련 정보를 시그널링 할 수 있다. 이하, 실시예들에 따른 파라미터(메타데이터, 시그널링 정보 등 다양하게 호칭 가능함)는 후술하는 실시예들에 따른 송신기의 프로세스 상 생성될 수 있고, 실시예들에 따른 수신기에 전달되어 재구성 과정에 이용될 수 있다. 예를 들어, 실시예들에 따른 파라미터는 후술하는 실시예들에 따른 송신 장치의 메타데이터 처리부(또는 메타데이터 제너레이터)에서 생성되고, 실시예들에 따른 수신 장치의 메타데이터 파서에서 획득될 수 있다.
실시예들에 따른 송수신 장치는 멀티플 프레임(multiple frame) 또는 누적 참조 프레임(cumulative reference frame)을 활용하여 예측 지오메트리 노드(predictive geometry node) 예측을 위한 정보를 정의할 수 있다. 실시예들에 따른 시퀀스 파라미터 세트(sequence parameter set)는 멀티플 프레임(multiple frame) 또는 누적 참조 프레임(cumulative reference frame)을 활용한 예측 지오메트리 노드(predictive geometry node) 예측 여부를 나타내고, 이를 위해 필요한 정보를 실시 방법에 따라 시퀀스 파라미터 세트(sequence parameter set)에 관련 정보의 전부 또는 일부를 전달하고, 지오메트리 파라미터 세트(geometry parameter set), 슬라이스 헤더(slice header), SEI메시지(SEI message), 데이터 유닛 헤더(Data unit header) 등에서 각각의 정보를 전달할 수 있다.
또한, 실시예들에 따른 송수신 장치는 멀티플 프레임 예측 관련 정보들 또는 누적 프레임 예측 관련 정보들을 어플리케이션, 시스템에 따라 상응되는 위치 혹은 별도의 위치에 정의하여 적용 범위, 적용 방법 등을 다르게 사용할 수 있다. 상위에 유사 기능을 포함하고 있는 정보가 시그널링 될 경우 하위 개념의 파라미터 세트(parameter set)에서는 시그널링이 생략되어도 적용 가능할 수 있다. 또한, 아래 정의된 신택스 요소(syntax element)가 현재 포인트 클라우드 데이터 스트림(point cloud data stream) 뿐 아니라 복수의 포인트 클라우드 데이터 스트림(point cloud data stream)에 적용될 수 있는 경우 상위 개념의 파라미터 세트(parameter set) 등을 통해 전달될 수 있다.
실시예들에 따른 비트스트림은 포인트 클라우드 데이터를 예측하기 위해 멀티플 프레임 참조하거나 누적 프레임을 참조하는 예측 방법에 관한 정보를 포함할 수 있다.
실시예들에 따른 송수신 장치는 복수의 프레임들을 사용한 예측을 수행하기 위해 관련 정보를 시그널링 할 수 있다. 이하, 실시예들에 따른 파라미터(메타데이터, 시그널링 정보 등 다양하게 호칭 가능함)는 후술하는 실시예들에 따른 송신 장치의 프로세스 상 생성될 수 있고, 실시예들에 따른 수신 장치에 전달되어 포인트 클라우드 데이터 재구성 과정에 사용될 수 있다. 예를 들어, 실시예들에 따른 파라미터는 도 12의 메타데이터 처리부(또는 메타데이터 제너레이터)(12007)에서 생성되고, 도 13의 메타데이터 파서(13006)에서 획득될 수 있다.
도 32는 부호화된 포인트 클라우드 구성을 나타낸다.
도 32에 도시된 약어는 다음을 나타낸다.
SPS: 시퀀스 파라미터 세트(Sequence Parameter Set)
GPS: 지오메트리 파라미터 세트(Geometry Parameter Set)
APS: 어트리뷰트 파라미터 세트(Attribute Parameter Set)
TPS: 타일 파라미터 세트(Tile Parameter Set)
Geom: 지오메트리 비트스트림(Geometry bitstream) = geometry slice header+ geometry slice data
Attr: 어트리뷰트 비트스트림(Attribute bitstream) = attribute slice header + attribute slice data
실시예들에 따른 슬라이스(slice)는 데이터유닛(data unit)으로 지칭될 수 있다. 슬라이스 헤더(slice header)는 데이터유닛헤더(data unit header)로 지칭될 수 있다. 그밖에 슬라이스(slice)는 브릭(brick), 박스(box), 영역(region) 등 유사한 의미를 가진 다른 용어로 지칭될 수 있다.
실시예들에 따른 비트스트림은 포인트 클라우드를 영역별로 나누어 처리할 수 있도록 타일, 또는 슬라이스를 제공할 수 있다. 영역별로 나눌때 각각의 영역은 서로 다른 중요도를 가질 수 있다. 실시예들에 따른 송수신 장치는 그 중요도에 따라서 다른 필터, 다른 필터 유닛을 적용할 수 있게 제공함으로써 복잡도(complexity)는 높으나 결과 품질(quality)가 좋은 필터링 방법을 중요한 영역에 사용할 수 있는 방안을 제공할 수 있다. 또한, 수신기의 처리능력(capacity)에 따라서 포인트 클라우드 전체에 복잡한 필터링 방법을 사용하는 대신 영역별로 (타일로 나누어지거나 슬라이스로 나누어진 영역) 서로 다른 필터링을 적용할 수 있게 함으로서 사용자에게 중요한 영역에 더 좋은 화질과 시스템 상으로 적절한 레이턴시(latency)을 보장할 수 있다. 포인트 클라우드는 타일(Tile)로 나누어지는 경우, 각 타일별로 다른 필터, 다른 필터 유닛을 적용할 수 있다. 포인트 클라우드는 슬라이스(Slice)로 나누어지는 경우, 각 슬라이스별로 다른 필터, 다른 필터 유닛을 적용할 수 있다.
도 33은 실시예들에 따른 시퀀스 파라미터 세트(seq_parameter_set)의 신택스(syntax) 예시이다.
실시예들에 따른 비트스트림은 멀티플 참조 프레임을 활용한 포인트(또는, 노드) 예측 정보를 시퀀스 파라미터 세트(SPS)에 포함할 수 있다. 즉, SPS를 통하여 멀티플 참조 프레임 예측 정보가 시그널링 될 수 있다.
SPS_인터인에이블(sps_interEnable): 해당 시퀀스(sequence)가 인터 예측(inter prediction)을 허용하는지 여부를 나타내는 플래그이다. True이면 해당 시퀀스 중 일부 프레임은 인터 예측(또는, 화면 간 예측)을 허용함을 나타내고, false이면 시퀀스에 포함된 모든 프레임(frame)은 인트라 예측(intra prediction)(또는, 화면 내 예측)만 가능함을 나타낼 수 있다.
넘그룹오브프레임(numGroupOfFrame) : SPS_인터인에이블(sps_interEnable)이 true인 경우, 인터 예측 프레임(intra prediction frame)에 해당하는 랜덤 접근 포인트(random access point)의 주기를 나타낸다. 예를 들어, 넘그룹오브프레임 (numGroupOfFrame)이 8이면 가장 첫 번째 프레임은 인트라 예측(intra prediction)을 통해 예측하고, 이후 7개의 프레임들은 인터 예측(inter prediction)을 통해 예측함을 나타낸다. 그리고, 8번째 이후 프레임(frame)은 다시 인트레 예측(intra prediction)을 할 수 있다. 해당 값은 시퀀스(sequence)마다 다를 수 있다.
멀티프레임인에이블플래그(multiFrameEnableFlag): 인터 예측(inter prediction)을 허용할 때 해당 시퀀스(sequence)가 인터 예측 시 복수 개의 참조 프레임을 통해 예측함을 허용하는지 여부를 나타낸다. True일 때, 인터 예측에 해당하는 프레임의 일부는 복수의 참조 프레임을 이용하여 예측함을 나타내며, false의 경우 단일 프레임(single frame)만을 이용하여 예측함을 나타낼 수 있다.
코딩오더[넘그룹오브프레임](CodingOrder[numGroupOfFrame]): 멀티프레임인에이블플래그(multiFrameEnableFlag)가 true인 경우, 디스플레이할 때 프레임과 참조할 프레임의 순서가 다를 수 있으므로 GOF(Group of Frame) 단위로 인터 예측(inter prediction) 시 코딩(coding) 순서를 시그널링 할 수 있다. 코딩오더(CodingOrder)는 SPS에서 선언되어 모든 시퀀스(sequence)에 적용될 수 있으며, 생략될 경우 프레임 단위로 시그널링 될 수도 있다.
도 34는 실시예들에 따른 지오메트리 파라미터 세트(geometry_parameter_set)의 신택스(syntax) 예시이다.
실시예들에 따른 비트스트림은 멀티플 참조 프레임을 활용한 포인트(또는, 노드) 예측 정보를 지오메트리 파라미터 세트(GPS)에 포함할 수 있다. 즉, GPS를 통하여 멀티플 참조 프레임 예측 정보가 시그널링 될 수 있다.
Gps_인터인에이블(gps_interEnable): 해당 프레임이 인터 예측을 허용하는지 여부를 나타내는 플래그이다. True이면 해당 시퀀스 중 일부 프레임은 인터 예측을 허용함을 나타내고, false인 경우 시퀀스(sequence)에 포함된 모든 프레임(frame)은 인트라 예측만 가능함을 나타낼 수 있다.
Gps_멀티프레임인에이블플래그(gps_multiFrameEnableFlag): 해당 프레임이 인터 예측 프레임(inter prediction frame)에 해당할 때 (gps_interEnable이 true일 때) 한 개 이상의 참조 프레임으로 예측이 되었는지 여부를 나타낸다.
Gps_넥스트디스플레이인덱스(gps_nextDisplayIndex): 해당 프레임 다음에 코딩 해야 하는 프레임의 디스플레이 인덱스 또는 프레임 인덱스를 나타낸다. 이는 SPS에 있는 코딩오더와 매칭하여 상속 받아 프레임 인덱스와 코딩 오더와의 차이, 즉, 잔차(residual)로 계산되거나, 코딩오더(CodingOrder)가 sps상에서 생략되었을 때 대체할 수 있는 정보로 쓰일 수 있다. Gps_넥스트디스플레이인덱스(gps_nextDisplayIndex)는 현재 프레임의 인덱스 또는 디스플레이 인덱스 기준 프레임의 위치의 차이로 시그널링 될 수도 있고, GoF 단위로 현재 프레임과의 위치 차이가 될 수 있고, GoF 단위에서 할당되는 인덱스가 될 수도 있다.
Gps_넘레프프레임(gps_numRefFrame): 현재 프레임(frame)을 예측할 떄 참조하는 프레임의 수를 나타낼 수 있다.
Gps_레프인덱스[넘레프프레임](gps_refIndex[numRefFrame]): 현재 프레임을 예측 할 떄 참조할 프레임의 인덱스를 나타낼 수 있다. 인덱스는 현재 프레임 기준 디스플레이 인덱스의 차이이거나 GoF 단위에서의 위치 차이를 나타낼 수도 있고, 전체 프레임들 중 몇 번 째 프레임을 참조했는지를 나타내어 시그널링 할 수 있다.
도 35는 실시예들에 따른 어트리뷰트 파라미터 세트(attribute_parameter_set)의 신택스(syntax) 예시이다.
실시예들에 따른 비트스트림은 멀티플 참조 프레임을 활용한 포인트(또는, 노드) 예측 정보를 어트리뷰트 파라미터 세트(APS)에 포함할 수 있다. 즉, APS를 통하여 멀티플 참조 프레임 예측 정보가 시그널링 될 수 있다.
Aps_인터인에이블(aps_interEnable): 해당 프레임이 인터 예측을 허용하는지 여부를 나타내는 플래그(flag)이다. True이면, 해당 시퀀스 중 일부 프레임은 인터 예측을 허용함을 나타내고, false이면 시퀀스에 포함된 모든 프레임은 인트라 예측 만 가능함을 나타낼 수 있다. Aps_인터인에이블(aps_interEnable)은 gps_인터인에이블(gps_interEnable)의 정보를 상속받아 전달 될 수 있고, 별도로 관리 될 수 있다.
Aps_멀티프레임인에이블플래그(aps_multiFrameEnableFlag): 해당 프레임이 인터 예측 프레임(inter prediction frame)에 해당할 때(aps_interEnable이 true일 때), 한 개 이상의 참조 프레임으로 예측이 되었는지 여부를 나타낸다. Aps_멀티프레임인에이블플래그(aps_multiFrameEnableFlag)는 GPS에서 상속받아 쓸 수 있고, 별도의 정보로 관리되어 시그널링 될 수 있다.
Aps_넥스트디스플레이인덱스(aps_nextDisplayIndex): 해당 프레임 다음에 코딩해야 하는 프레임의 디스플레이 인덱스 또는 프레임 인덱스를 나타낸다. 이는 SPS에 있는 코딩오더와 매칭하여 상속 받아 프레임 인덱스와 코딩 오더와의 차이, 즉, 잔차(residual)로 계산되거나, 코딩오더(CodingOrder)가 sps상에서 생략되었을 때 대체할 수 있는 정보로 쓰일 수 있다. Aps_넥스트디스플레이인덱스(aps_nextDisplayIndex)는 현재 프레임의 인덱스 또는 디스플레이 인덱스 기준 프레임의 위치의 차이로 시그널링 될 수도 있고, GoF 단위로 현재 프레임과의 위치 차이가 될 수 있고, GoF 단위에서 할당되는 인덱스가 될 수도 있다. 또는, gps_nextDisplayIndex에서 사용하는 정보를 상속받아 사용할 수 있다.
Aps_넘레프프레임(aps_numRefFrame): 현재 프레임(frame)의 속성정보를 예측할 때 참조하는 프레임(frame)의 수를 나타낼 수 있다. 해당 정보는 GPS의 gps_numRefFrame과 동일 할 수 있고, 분리되어 관리될 수 있다.
Aps_레프인덱스[넘레프프레임](aps_refIndex[numRefFrame]) 현재 프레임의 속성정보를 예측할 때 참조할 프레임(frame)의 인덱스를 나타낼 수 있다. 인덱스는 현재 프레임 기준 디스플레이 인덱스의 차이 이거나 GoF 단위에서의 위치 차이를 나타낼 수 있고, 전체 프레임들 중 몇 번 째 프레임을 참조했는지를 나타낼 수 있다. 해당 정보는 GPS의 gps_refIndex[numRefFrame]과 동일할 수 있고, 분리되어 관리될 수도 있다.
예측 지오메트리(Predictive geometry)에서 각 포인트(또는, 노드)들은 실시예를 적용하기 위해 다음과 같은 정보를 시그널링 할 수 있다.
실시예들에 따른 송수신 장치/방법은 각 노드마다 현재 포인트(current point)를 예측하기 위한 모드(mode)로서, none 모드, singlePoint 모드, multiPoint 모드, MultiPointAverage모드를 적용할 수 있다. None모드는 기존의 인트라 예측(intra prediction)에서 쓰였던 4개의 모드(mode)를 그대로 사용함을 나타낸다. SinglePoint모드는 참조 프레임에서 찾은 포인트 후보들을 별도로 처리하지 않고 포인트들 중 어느 하나로 예측값을 정하는 모드이다. multiPoint모드는 참조 프레임에서 찾은 포인트들의 조합, 즉 포인트들의 평균, 가중평균 또는 기하평균 등을 사용하여 예측값을 정하는 모드이다. MultiPointAverage모드는 포인트의 전체 조합 혹은 포인트 중 일부의 조합 으로 예측하는 모드를 나타낼 수 있다.
실시예들에 따른 송수신 장치/방법은 각 모드를 적용하기 전 참조 프레임 들에서 찾은 포인트 중에 현재 포인트와의 거리가 미리 정해진 임계치(threshold)보다 큰 경우 현재 포인트를 예측할 포인트 후보에서 제외시킬 수 있다. 임계치를 넘은 포인트들을 제외한 후에 남은 포인트 후보의 수가 한 개 이하인 경우 아래의 인터 예측 구조에서 none 또는 singlePoint모드에 대해서만 고려하여 예측 방법을 결정할 수 있다. 또한, 남은 포인트 후보의 수가 두 개 이하 인 경우 아래의 인터 예측 구조에서 MultiPointAverage모드와 none 모드를 제외하고 singlePoint 모드, multiPoint 모드에 대해서만 계산할 수 있다. 또한, 포인트 대상이 모두 포함된 경우에 대해서는 none모드를 제외하고 multiPoint 모드, MultiPointAverage 모드 중 best case를 찾아 시그널링 할 수 있다.
각 예측 모드는 하위 4개의 모드를 포함하고 있으며, 하나의 노드(또는, 포인트)당 최대 12개의 모드를 계산하고, 최소 8개의 하위 모드에 대해 예측된 값과 현재 포인트간의 잔차(residual)을 찾아 잔차가 가장 작은 모드를 시그널링하면, 복호화기(decoder)에서 해당 정보를 받아 재구성하는데 쓸 수 있다.
도 36 내지 도38은 실시예들에 따른 현재 포인트 예측 방법의 예시이다.
도36 내지 도38을 참조하면, 실시예들에 따른 송수신 장치/방법에서 예측 지오메트리(predictive geometry)를 사용할 때, single point 모드를 이용한 현재 노드 예측 시 사용되는 내부 프로세스를 나타낸다. 현재 포인트를 예측하기 위해 멀티 프레임을 사용하고 예측 시 사용할 후보 포인트가 4개 일 때 각 케이스들은 각 후보 포인트들을 의미한다. 해당 포인트들이 현재 노드를 대신하는 경우 잔차가 가장 작은 포인트를 predMode, 이 때의 포인트 정보를 pred, 해당 모드를 적용했을 때의 잔차를 minResidual로 return하여 송신기에서 엔트로피 부호화(entropy encoding) 및 수신기에서 복호화(decoding) 하여 예측 시 사용할 수 있다.
실시예들에 따른 송수신 장치/방법은 현재 포인트를 예측하기 위해 참조 프레임에서 선택된 후보 포인트들을 각각 독립적으로 현재 포인트와 비교하고, 현재 포인트와 차이가 가장 적은 후보 포인트로 현재 포인트를 예측할 수 있다.
도 39는 실시예들에 따른 현재 포인트 예측 방법의 예시이다.
도 39를 참조하면, 실시예들에 따른 송수신 장치/방법에서 예측 지오메트리(predictive geometry)를 사용할 때, multi point 모드를 이용한 현재 노드 예측 시 사용되는 내부 프로세스를 나타낸다. 현재 포인트를 예측하기 위해 멀티 프레임(multi frame)을 사용하고 예측 시 사용할 후보 포인트가 4개 일 때 각 케이스들은 각 후보 포인트들의 조합 혹은 평균을 의미한다. 해당 모드를 적용했을 때의 값이 현재 노드를 대신하는 경우 잔차가 가장 작은 포인트를 predMode, 이 때의 포인트 정보를 pred, 해당 모드를 적용했을 때의 잔차를 minResidual로 return하여 송신기에서 엔트로피 부호화(entropy encoding) 및 수신기에서 복호화(decoding) 하여 예측 시 사용할 수 있다.
실시예들에 따른 송수신 장치/방법은 현재 포인트를 예측하기 위해 참조 프레임에서 선택된 후보 포인트들의 조합을 기반으로 산출된 값을 현재 포인트와 비교할 수 있고, 가장 차이가 적은 값으로 현재 포인트를 예측할 수 있다. 후보 포인트들에 대한 정보 및 후보 포인트들을 조합하기 위한 모드 정보, 잔차 정보 등은 시그널링되어 현재 포인트 예측에 사용될 수 있다.
도 40은 실시예들에 따른 현재 포인트 예측 방법의 예시이다.
도 40을 참조하면, 실시예들에 따른 송수신 장치/방법에서 예측 지오메트리(predictive geometry)를 사용할 때, multi point들의 평균값이 현재 노드 예측 시 사용되는 내부 프로세스를 나타낸다. 현재 포인트를 예측하기 위해 멀티 프레임(multi frame)을 사용하고 예측 시 사용할 후보 포인트가 4개 일 때 각 케이스들은 각 후보 포인트들의 조합 혹은 평균을 의미할 수 있다. 케이스 2 및 4는, 4개의 포인트 중 가장 먼 포인트를 제외한 나머지 포인트에 대해 평균 또는 기하평균을 계산한 값이다. 각 케이스에서 예측한 값들 중 어느 하나로 현재 노드를 대신하는 경우, 잔차가 가장 작은 포인트를 predMode, 이 때의 포인트 정보를 pred, 해당 모드를 적용했을 때의 잔차를 minResidual로 return하여 송신기에서 엔트로피 부호화(entropy encoding) 및 수신기에서 복호화(decoding) 하여 예측 시 사용할 수 있다.
실시예들에 따른 송수신 장치/방법은 현재 포인트를 예측하기 위해 참조 프레임에서 선택된 후보 포인트들의 조합을 기반으로 산출된 값을 현재 포인트와 비교할 수 있고, 가장 차이가 적은 값으로 현재 포인트를 예측할 수 있다. 후보 포인트들에 대한 정보 및 후보 포인트들을 조합하기 위한 모드 정보, 잔차 정보 등은 시그널링되어 현재 포인트 예측에 사용될 수 있다.
실시예들에 따른 송수신 장치/방법은 도 1의 송수신 장치, 도 2의 송수신, 도 4의 포인트 클라우드 인코더, 도 10, 도 11의 포인트 클라우드 디코더, 도 12의 송신장치, 도 13의 수신장치, 도 14의 디바이스들, 도 44의 송신 장치/방법, 도 45의 수신 장치/방법, 도46의 송신 장치/방법, 도47의 수신 장치/방법, 도 48의 송신 방법 또는 도 49의 수신 방법과 대응하거나, 조합될 수 있으며, 실시예들에 따른 송수신 장치/방법은 도 33 내지 도 39에서 설명하는 참조 프레임을 활용한 인터 예측 및 예측 방법에 관한 시그널링을 수행할 수 있다.
도 41은 실시예들에 따른 시퀀스 파라미터 세트(seq_parameter_set)의 신택스(syntax) 예시이다.
누적 참조 프레임을 활용한 노드(또는, 포인트) 예측 정보는 SPS에 추가 되어 시그널링 될 수 있다.
SPS_인터인에이블(sps_interEnable): 해당 시퀀스(sequence)가 인터 예측(inter prediction)을 허용하는지 여부를 나타내는 플래그(flag)이다. True이면 해당 sequence 중 일부 프레임은 인터 예측을 허용함을 나타내고, false이면 sequence에 포함된 모든 프레임은 인트라 예측만 가능함을 나타낼 수 있다.
넘그룹오브프레임(numGroupOfFrame): sps_interEnable이 true이면 인트라 예측 프레임에 해당하는 랜덤 어세스 포인트(random access point)의 주기를 나타낼 수 있다. 예를 들어, numGroupOfFrame이 8이면 가장 첫 번째 프레임은 인트라 예측(intra prediction)으로 예측하고, 이후 7개의 프레임에 대해서는 인터 예측을 통해 예측한다. 그리고, 그 다음 프레임은 다시 인트라 예측을 함을 나타낼 수 있다. 해당 값은 sequence마다 다를 수 있다.
누적프레임인에이블플래그(cumulFrameEnableFlag): 인터 예측을 허용할 때 해당 sequence가 인터 예측 시 참조 프레임을 누적하여 사용할지 여부를 나타낼 수 있다.
도 42는 실시예들에 따른 지오메트리 파라미터 세트(geometry_parameter_set)의 신택스(syntax) 예시이다.
누적 참조 프레임을 활용한 노드(또는, 포인트) 예측 정보는 GPS에 추가 되어 시그널링 될 수 있다.
GPS_인터인에이블(gps_interEnable): 해당 프레임이 인터 예측을 허용하는지 여부를 나타내는 플래그이다. True이면 해당 sequence 중 일부 프레임은 인터 예측을 허용함을 나타내고, false이면 sequence에 포함된 모든 프레임은 인트라 예측만 가능함을 나타낼 수 있다.
GPS_누적프레임인에이블플래그(gps_cumulFrameEnableFlag): 해당 프레임이 인터 예측 프레임에 해당할 때 (gps_interEnable이 true일 때) 누적 참조 프레임을 이용하여 예측이 되었는지 여부를 나타낸다.
GPS_넘레프프레임(gps_numRefFrame) 현재 프레임을 예측할 때 누적 참조 프레임에 포함된 프레임의 수를 나타낼 수 있다.
레프인덱스[넘레프프레임](RefIndex[numRefFrame]): 현재 프레임을 예측 할 때 누적 참조 프레임을 만들기 위해 필요한 프레임의 인덱스를 나타낼 수 있다. 인덱스는 현재 프레임 기준 디스플레이 인덱스의 차이이거나 GoF 단위에서의 위치 차이를 나타낼 수 있고, 전체 프레임 중 몇 번 째 프레임을 참조했는지를 나타낼 수 있다.
예측방향(predictionDirection): 누적 참조 프레임을 만든 후 현재 프레임의 각 노드를 예측하기 위해 선정된 후보 포인트들 중 아래의 모드 정보를 활용해 어떤 방향의 정보를 선택할 것인지를 나타낼 수 있다.
mode description
0 Forward direction
1 Backward direction
2 Bi-direction
3 Farther bi-direction
도 43은 실시예들에 따른 어트리뷰트 파라미터 세트(attribute_parameter_set)의 신택스(syntax) 예시이다.
누적 참조 프레임을 활용한 노드(또는, 포인트) 예측 정보는 APS에 추가 되어 시그널링 될 수 있다.
APS_인터인에이블(aps_interEnable): 해당 프레임이 인터 예측을 허용하는지 여부를 나타내는 플래그이다. True이면 해당 sequence 중 일부 프레임은 인터 예측을 허용함을 나타내고, false이면 sequence에 포함된 모든 프레임은 인트라 예측만 가능함을 나타낼 수 있다. aps_interEnable은 gps_interEnable의 정보를 상속받아 전달 될 수도 있고, 별도로 관리 될 수도 있다.
APS_누적프레임인에이블플래그(aps_cumulFrameEnableFlag): 해당 프레임이 인터 예측 프레임에 해당할 때 (aps_interEnable이 true일 때) 포인트 클라우드 속성정보 예측 시 누적 참조 프레임을 이용하여 예측이 되었는지 여부를 나타낸다.
APS_넘레프프레임(aps_numRefFrame) 현재 프레임을 예측할 때 누적 참조 프레임에 포함된 프레임의 수를 나타낼 수 있다.
레프인덱스[넘레프프레임](RefIndex[numRefFrame]): 현재 프레임을 예측 할 때 누적 참조 프레임을 만들기 위해 필요한 프레임의 인덱스를 나타낼 수 있다. 인덱스는 현재 프레임 기준 디스플레이 인덱스의 차이이거나 GoF 단위에서의 위치 차이를 나타낼 수 있고, 전체 프레임 중 몇 번 째 프레임을 참조했는지를 나타낼 수 있다. 해당 정보는 GPS에서 상속받아 사용할 수도 있고, 별도의 index로 관리 될 수도 있다.
예측방향(predictionDirection): 누적 참조 프레임을 만든 후 현재 프레임의 각 노드를 예측하기 위해 선정된 후보 포인트들 중 아래의 모드 정보를 활용해 어떤 방향의 정보를 선택할 것인지를 나타낼 수 있다. 해당 정보는 GPS에서 상속받아 사용할 수도 있고, 별도의 index로 관리 될 수도 있다.
도 44는 실시예들에 따른 포인트 클라우드 데이터의 송신 장치/방법을 나타내는 플로우 차트이다.
실시예들에 따른 송수신 장치/방법은 도 1의 송수신 장치, 도 2의 송수신, 도 4의 포인트 클라우드 인코더, 도 10, 도 11의 포인트 클라우드 디코더, 도 12의 송신장치, 도 13의 수신장치, 도 14의 디바이스들, 도 44의 송신 장치/방법, 도 45의 수신 장치/방법, 도46의 송신 장치/방법, 도47의 수신 장치/방법, 도 48의 송신 방법 또는 도 49의 수신 방법과 대응하거나, 조합될 수 있으며, 실시예들에 따른 송수신 장치/방법은 복수의 참조 프레임을 활용한 인터 예측 및 예측 방법에 관한 시그널링을 수행할 수 있다.
도 44는 포인트 클라우드 데이터의 처리 과정을 나타내는 플로우 차트이자, 처리 과정의 각 단계를 수행하는 구성 요소들을 나타내는 관점에서 포인트 클라우드 데이터 송수신 장치/방법으로 이해될 수 있다.
실시예들에 따른 송신 장치/방법은 포인트 클라우드 데이터가 입력되면 예측 지오메트리(predictive geometry)를 이용한 압축을 용이하게 하기 위해 데이터를 클러스터링(clustering) 및 정렬(sorting)할 수 있다.(4410)
처리 후 포인트 클라우드 데이터에 대한 인트라 예측(intra prediction) 여부를 확인(4421)하여 인트라 예측 프레임(intra prediction frame)인 경우 지오메트리 인트라 예측(geometry intra prediction)이 수행(4426)될 수 있다. 인트라 예측이 아닌 경우 인터 예측(inter prediction)을 위해 참조 프레임을 하나만 참조하는지 복수의 참조 프레임을 참조하는지 여부를 판단(4422)한다. 하나의 참조 프레임을 예측에 사용한 경우, 단일 참조 프레임 내에서 내부 기준에 따라 현재 포인트 이전에 처리된 포인트 기준으로 가장 가까운 포인트를 찾을 수 있다(4423). 복수 참조 프레임을 사용하여 예측을 할 경우, 각 참조 프레임에서 현재 포인트 이전에 처리된 포인트를 기준으로 내부 프로세스에 따라 현재 포인트와 가장 가까운 포인트를 찾는다(4424). 예측에 사용할 포인트 후보(point candidates)로 인터 예측(inter prediction)을 수행(4425)할 수 있고, 인트라 예측(intra prediction) 및 인터 예측(inter prediction)이 종료된 포인트들은 코딩순서에 따라 다음 프레임의 예측에 사용하기 위해 참조 프레임 버퍼(reference frame buffer)에 입력될 수 있다. 모든 노드에 대해 예측 모드가 결정된 후에는 예측 모드가 적용되었을 때 발생할 수 있는 잔차(residual), 참조 프레임 정보 등을 엔트로피 부호화(entropy coding)하고, 출력 비트스트림(bitstream)으로 생성할 수 있다.
도 44에서 도시되는 구성요소 블록들은 포인트 클라우드 데이터를 처리하기 위한 과정들을 수행하는 프로세서 및 프로세서를 작동하는 명령어로 구성될 수 있으며, 유닛, 프로세서, 모듈 등으로 지칭될 수 있다. 도 44는 포인트 클라우드 데이터를 처리하기 위한 프로세서 또는 모듈 등 구성들의 조합으로 이루어진 처리 장치를 나타내거나 각각의 구성요소가 수행하는 데이터 처리 과정을 도시하는 데이터 처리 방법을 나타낼 수 있다.
도 44를 참조하면, 실시예들에 따른 포인트 클라우드 데이터 송수신 장치/방법은 포인트 클라우드 데이터를 클러스터링 또는 정렬하고(4410), 인트라 예측 여부를 확인(4421)하여 인트라 예측이 아닌 경우 복수의 프레임들을 참조하는지 여부를 확인(4422)할 수 있다. 복수의 프레임들을 참조하는 경우, 복수의 프레임들을 기반으로 현재 포인트와 가장 가까운 후보 포인트들을 탐색하고(4424), 후보 포인트들을 사용하여 예측 모드에 따라 현재 포인트를 예측할 수 있다(4425).
도 45는 실시예들에 따른 포인트 클라우드 데이터의 수신 장치/방법을 나타내는 플로우 차트이다.
실시예들에 따른 송수신 장치/방법은 도 1의 송수신 장치, 도 2의 송수신, 도 4의 포인트 클라우드 인코더, 도 10, 도 11의 포인트 클라우드 디코더, 도 12의 송신장치, 도 13의 수신장치, 도 14의 디바이스들, 도 44의 송신 장치/방법, 도 45의 수신 장치/방법, 도46의 송신 장치/방법, 도47의 수신 장치/방법, 도 48의 송신 방법 또는 도 49의 수신 방법과 대응하거나, 조합될 수 있으며, 실시예들에 따른 송수신 장치/방법은 실시예들에 따른 송수신 장치/방법은 복수의 참조 프레임을 활용한 인터 예측 및 예측 방법에 관한 시그널링을 수행할 수 있다.
도 45는 포인트 클라우드 데이터의 처리 과정을 나타내는 플로우 차트이자, 처리 과정의 각 단계를 수행하는 구성 요소들을 나타내는 관점에서 포인트 클라우드 데이터 송수신 장치/방법으로 이해될 수 있다.
실시예들에 따른 수신 장치/방법은 수신된 비트스트림에 대해 엔트로피 디코딩(entropy decoding)을 하고(4510), 해당 프레임이 인트라 예측을 위한 프레임이라면 기존의 인트라 예측을 위한 방식을 적용(4526) 후 포인트 클라우드 데이터의 지오메트리 정보를 업데이트 할 수 있다. 인트라 예측이 아닌 경우, 단일 참조 프레임으로 예측이 되었는지 여부를 확인(4522)하고 단일 프레임을 참조한 경우 예측 모드 및 참조 프레임 정보에 따라 참조 프레임으로부터 미리 지정된 기준으로 가장 가까운 포인트를 찾고(4523), 실시예들에 따른 송신 장치로 부터 수신한 예측 모드에 따라 현재 노드를 예측하고, 잔차를 더하여 현재 노드에 입력하며, 예측 지오메트리(predictive geometry)의 트리(tree)의 리프 노드(leaf node)까지 모두 재구성이 끝날 때까지 반복한다. 복수 프레임을 참조한 경우, 예측 모드 및 참조 프레임들을 참조 프레임 버퍼(reference frame buffer)에서 불러와 참조 프레임들에서 미리 지정된 기준에 따라 가장 가까운 포인트를 찾고(4524), 실시예들에 따른 송신 장치로부터 수신한 예측 모드에 따라 예측하고 잔차를 더하여 현재 노드에 입력할 수 있다. 이때, 예측 모드에 따라 모든 노드에 대해 예측이 끝난 후에 재구성(reconstruction)을 하면, 재구성된 포인트(reconstructed point)는 속성 정보 예측에 사용되기 위해 속성 정보 예측 모듈로 보내질 수 있다.
도 45에서 도시되는 구성요소 블록들은 포인트 클라우드 데이터를 처리하기 위한 과정들을 수행하는 프로세서 및 프로세서를 작동하는 명령어로 구성될 수 있으며, 유닛, 프로세서, 모듈 등으로 지칭될 수 있다. 도 45는 포인트 클라우드 데이터를 처리하기 위한 프로세서 또는 모듈 등 구성들의 조합으로 이루어진 처리 장치를 나타내거나 각각의 구성요소가 수행하는 데이터 처리 과정을 도시하는 데이터 처리 방법을 나타낼 수 있다.
도 45를 참조하면, 실시예들에 따른 포인트 클라우드 데이터 송수신 장치/방법은 포인트 클라우드 데이터를 디코딩하고(4510), 인트라 예측 여부를 확인(4521)하여 인트라 예측이 아닌 경우 복수의 프레임들을 참조하는지 여부를 확인(4522)할 수 있다. 복수의 프레임들을 참조하는 경우, 복수의 프레임들을 기반으로 현재 포인트와 가장 가까운 후보 포인트들을 탐색하고(4524), 후보 포인트들을 사용하여 예측 모드에 따라 현재 포인트를 예측할 수 있다(4525).
도 46은 실시예들에 따른 포인트 클라우드 데이터의 송신 장치/방법을 나타내는 플로우 차트이다.
실시예들에 따른 송수신 장치/방법은 도 1의 송수신 장치, 도 2의 송수신, 도 4의 포인트 클라우드 인코더, 도 10, 도 11의 포인트 클라우드 디코더, 도 12의 송신장치, 도 13의 수신장치, 도 14의 디바이스들, 도 44의 송신 장치/방법, 도 45의 수신 장치/방법, 도46의 송신 장치/방법, 도47의 수신 장치/방법, 도 48의 송신 방법 또는 도 49의 수신 방법과 대응하거나, 조합될 수 있으며, 실시예들에 따른 송수신 장치/방법은 복수의 참조 프레임 또는 누적 참조 프레임을 활용한 인터 예측 및 예측 방법에 관한 시그널링을 수행할 수 있다.
도 46은 포인트 클라우드 데이터의 처리 과정을 나타내는 플로우 차트이자, 처리 과정의 각 단계를 수행하는 구성 요소들을 나타내는 관점에서 포인트 클라우드 데이터 송수신 장치/방법으로 이해될 수 있다.
실시예들에 따른 송수신 장치/방법은 포인트 클라우드 데이터가 입력되면 예측 지오메트리(predictive geometry)를 이용한 압축에 용이하게 하기 위해 데이터를 클러스터링(clustering) 및 정렬(sorting)을 한다.(4610) 처리후의 포인트 클라우드 데이터는 인트라 예측(intra prediction)인지 여부를 확인(4621)하여 인트라 예측 프레임(intra prediction frame)인 경우 지오메트리 인트라 예측(geometry intra prediction)(4626)을 하고, 아닌 경우 인터 예측(inter prediction)을 위해 참조 프레임(reference frame)을 누적하여 예측할지 여부를 확인(4622)한다 하나의 참조 프레임만 예측에 쓴 경우에는 단일 참조 프레임 내에서 내부 기준에 따라 현재 포인트 이전에 처리된 포인트 기준으로 가장 가까운 포인트들을 찾고(4623) 누적 참조 프레임을 이용한 예측을 할 경우 참조할 프레임의 정보를 지정하고, 지정된 참조 프레임을 하나의 포인트 클라우드로 누적한 후 정렬한다(4623). 누적 참조 프레임에서 현재 포인트 이전에 처리된 포인트를 기준으로 내부 프로세스에 따라 현재 포인트와 가장 가까운 포인트를 찾는다. 가장 가까운 포인트를 기준으로 애지무스(azimuth) 방향으로 양 옆으로 가장 가까운 포인트 두 개를 찾고, 찾은 두 개의 포인트를 기준으로 래디우스가 더 큰 포인트 중 가장 가까운 포인트를 찾아 현재 노드를 예측하기 위한 후보 포인트들을 찾는다. 후보 포인트들 중에서 현재 노드를 예측하기에 가장 적합한 포인트 그룹 또는 예측 방향을 선택하고, 인터 예측을 한다(4625). 인트라 예측 및 인터 예측이 끝난 포인트들은 코딩 순서에 따라 다음 프레임의 예측에 사용하기 위해 참조 프레임 버퍼(reference frame buffer)에 입력된다. 모든 노드에 대해 예측 모드가 결정된 후에는 예측 모드가 적용되었을 때 발생할 수 있는 잔차(residual), 참조 프레임 정보 등을 엔트로피 코딩(entropy coding)하고, 출력 비트스트림을 생성할 수 있다.
도 46에서 도시되는 구성요소 블록들은 포인트 클라우드 데이터를 처리하기 위한 과정들을 수행하는 프로세서 및 프로세서를 작동하는 명령어로 구성될 수 있으며, 유닛, 프로세서, 모듈 등으로 지칭될 수 있다. 도 46는 포인트 클라우드 데이터를 처리하기 위한 프로세서 또는 모듈 등 구성들의 조합으로 이루어진 처리 장치를 나타내거나 각각의 구성요소가 수행하는 데이터 처리 과정을 도시하는 데이터 처리 방법을 나타낼 수 있다.
도 46를 참조하면, 실시예들에 따른 포인트 클라우드 데이터 송수신 장치/방법은 포인트 클라우드 데이터를 클러스터링 또는 정렬하고(4610), 인트라 예측 여부를 확인(4621)하여 인트라 예측이 아닌 경우 누적 참조 프레임을 사용하는지 여부를 확인(4622)할 수 있다. 누적 참조 프레임을 참조하는 경우, 복수의 프레임들을 기반으로 누적 참조 프레임을 생성하고 포인트들을 정렬한다(4624). 그리고, 누적 참조 프레임에서 현재 포인트와 가장 가까운 후보 포인트들을 탐색하고, 후보 포인트(또는, 예측기)들을 사용하여 예측 모드에 따라 현재 포인트를 예측할 수 있다(4625).
실시예들에 따라 복수의 프레임들을 참조하여 포인트 클라우드 데이터 예측 시, 현재 프레임에서 속한 현재 포인트의 정보를 보다 정확하게 예측할 수 있다. 따라서, 예측된 정보와 실제 정보의 차이가 줄어들어 잔차(residual)이 감소하고, 송수신되는 데이터의 양이 절감되어 송수신 효율이 높으며, 복호화 또는 부호화 레이턴시를 낮출 수 있다.
도 47은 실시예들에 따른 포인트 클라우드 데이터의 수신 장치/방법을 나타내는 플로우 차트이다.
실시예들에 따른 송수신 장치/방법은 도 1의 송수신 장치, 도 2의 송수신, 도 4의 포인트 클라우드 인코더, 도 10, 도 11의 포인트 클라우드 디코더, 도 12의 송신장치, 도 13의 수신장치, 도 14의 디바이스들, 도 44의 송신 장치/방법, 도 45의 수신 장치/방법, 도46의 송신 장치/방법, 도47의 수신 장치/방법, 도 48의 송신 방법 또는 도 49의 수신 방법과 대응하거나, 조합될 수 있으며, 실시예들에 따른 송수신 장치/방법은 복수의 참조 프레임 또는 누적 참조 프레임을 활용한 인터 예측 및 예측 방법에 관한 시그널링을 수행할 수 있다.
도 47은 포인트 클라우드 데이터의 처리 과정을 나타내는 플로우 차트이자, 처리 과정의 각 단계를 수행하는 구성 요소들을 나타내는 관점에서 포인트 클라우드 데이터 송수신 장치/방법으로 이해될 수 있다.
실시예들에 따른 송수신 장치/방법은 수신된 비트스트림(bitstream)에 대해 엔트로피 디코딩(entropy decoding)(4710)을 하고, 해당 프레임이 인트라 예측을 위한 프레임이라면 기존의 인트라 예측을 위한 방식을 적용 후 포인트 클라우드의 지오메트리 정보를 업데이트하고, 아니면 단일 참조 프레임으로 예측이 되었는지 여부를 확인(4722)하여 단일 프레임을 참조한 경우 예측 모드 및 참조 프레임 정보에 따라 참조 프레임으로 부터 미리 지정된 기준으로 가장 가까운 포인트를 찾고(4723), 송신 장치로 부터 받은 예측 모드에 따라 현재 노드를 예측하고, 잔차(residual)를 더하여 현재 노드에 입력하고, 예측 지오메트리(predictive geometry)의 트리의 리프노드(leaf node)까지 모두 재구성이 끝날 때까지 반복한다. 누적 참조 프레임을 이용한 예측의 경우(4722), 예측 모드 및 참조 프레임들을 참조 프레임 버퍼(reference frame buffer)에서 불러와 참조 프레임들로부터 누적된 참조 프레임을 생성하고, 미리 지정된 예측 기준에 따라 포인트 후보를 찾고, 예측값을 계산하거나 그대로 승계한다. 송신기로 부터 받은 잔차를 더하여 현재 노드에 입력한다. 이 때 예측 모드에 따라 모든 노드에 대해 예측이 끝난 후에 재구성(reconstruction)을 하고 나면 재구성된 포인트(reconstructed point)는 속성 정보 예측에 사용되기 위해 속성 정보 예측 모듈로 보내질 수 있다.
도 47에서 도시되는 구성요소 블록들은 포인트 클라우드 데이터를 처리하기 위한 과정들을 수행하는 프로세서 및 프로세서를 작동하는 명령어로 구성될 수 있으며, 유닛, 프로세서, 모듈 등으로 지칭될 수 있다. 도 47는 포인트 클라우드 데이터를 처리하기 위한 프로세서 또는 모듈 등 구성들의 조합으로 이루어진 처리 장치를 나타내거나 각각의 구성요소가 수행하는 데이터 처리 과정을 도시하는 데이터 처리 방법을 나타낼 수 있다.
도 47를 참조하면, 실시예들에 따른 포인트 클라우드 데이터 송수신 장치/방법은 포인트 클라우드 데이터를 디코딩하고(4710), 인트라 예측 여부를 확인(4571)하여 인트라 예측이 아닌 경우 누적 참조 프레임을 사용하는지 여부를 확인(4722)할 수 있다. 누적 참조 프레임을 사용하는 경우, 복수의 프레임들을 기반으로 누적 참조 프레임을 생성하고, 누적 참조 프레임에서 현재 포인트와 가장 가까운 후보 포인트들을 탐색한다(4724). 그리고, 탐색된 후보 포인트들을 기반으로 예측 모드에 따라 현재 포인트를 예측할 수 있다(4725).
도 48은 실시예들에 따른 포인트 클라우드 데이터 송신 방법을 나타내는 플로우 차트이다.
실시예들에 따른 송수신 장치/방법은 도 1의 송수신 장치, 도 2의 송수신, 도 4의 포인트 클라우드 인코더, 도 10, 도 11의 포인트 클라우드 디코더, 도 12의 송신장치, 도 13의 수신장치, 도 14의 디바이스들, 도 44의 송신 장치/방법, 도 45의 수신 장치/방법, 도46의 송신 장치/방법, 도47의 수신 장치/방법, 도 48의 송신 방법 또는 도 49의 수신 방법과 대응하거나, 조합될 수 있으며, 실시예들에 따른 송수신 장치/방법은 복수의 참조 프레임 또는 누적 참조 프레임을 활용한 인터 예측 및 예측 방법에 관한 시그널링을 수행할 수 있다.
실시예들에 따른 송신 방법은 포인트 클라우드 데이터를 인코딩하는 단계(S4800) 및 포인트 클라우드 데이터를 포함하는 비트스트림을 전송하는 단계(S4810)을 포함한다.
도 15에서 설명한 것과 같이 포인트 클라우드 데이터는 복수의 프레임들을 포함할 수 있다.
포인트 클라우드 데이터를 인코딩하는 단계(S4800)는 제1 프레임에 속하는 제1 포인트를 예측하는 단계를 포함할 수 있다. 제1 프레임은 현재 프레임(current frame)을 나타내고 제1 포인트는 현재 포인트(current point)를 나타낼 수 있다. 즉, 실시예들에 따른 송신 방법에서 포인트 클라우드 데이터를 인코딩하는 단계(S4800)는 현재 프레임에 속하는 현재 포인트를 예측하는 단계를 포함한다. 이때, 예측하는 단계는 복수의 프레임들 중 적어도 하나 이상의 프레임들에 속하는 포인트들을 기반으로 현재 포인트를 예측할 수 있다.
현재 프레임에 속하는 현재 포인트를 예측하는 방법에 대하여 도 20 내지 도 28에서 설명하며, 도 30 및 도31에서 설명한다.
현재 포인트를 예측하기 위하여 참조하는 적어도 하나 이상의 프레임들은 그 순서가 현재 프레임 이전이거나, 이후일 수 있다. 또한, 적어도 하나 이상의 프레임들 중 어느 하나의 프레임은 현재 프레임의 이전이고, 다른 하나의 프레임의 현재 프레임의 이후일 수 있다. 현재 프레임에서 참조하는 적어도 하나 이상의 프레임들은 그 순서에 따라 전방향(forward) 예측, 후방향(backward) 예측 또는 양방향(bi-directional) 예측이 수행될 수 있다. 이때, 순서는 디스플레이 순서 또는 코딩 순서일 수 있다.
도 20 내지 도 28은 전방향(forward) 예측, 후방향(backward) 예측 또는 양방향(bi-directional) 예측 방법에 대하여 설명한다.
도 20 내지 도 28을 참조하면, 예측하는 단계는 현재 프레임 내의 현재 포인트 이전에 처리된 제2 포인트를 기반으로 적어도 하나 이상의 프레임들 중 어느 하나에 속하는 제3 포인트를 탐색한다. 이떄, 제2 포인트는 현재 포인트 이전에 복호화된 포인트를 나타낼 수 있고, 제3 포인트는 제2 포인트와 유사한 포인트를 나타낼 수 있다. 제3 포인트는 레이저ID, 애지무스 또는 래디우스 값을 기반으로 제2 포인트와 유사 여부가 판단될 수 있다. 즉, 제3 포인트는 레이저ID가 제2 포인트와 동일하고, 애지무스 또는 래디우스 값이 가장 가까운 포인트일 수 있다.
또한, 예측하는 단계는, 제2 포인트 또는 제3 포인트를 기반으로 현재 포인트를 예측하기 위한 복수의 후보 포인트들을 선택할 수 있다. 후보 포인트는 예측기 또는 포인트 후보 등으로 지칭될 수 있고, 현재 포인트의 예측값을 산출하기 위해 사용되는 포인트를 나타낼 수 있다. 후보 포인트들은 레이저ID, 애지무스 또는 래디우스 값을 기반으로 선택될 수 있다. 그리고, 현재 포인트는 후보 포인트들 중 어느 하나의 값으로 예측되거나, 복수의 후보 포인트들을 조합한 값으로 예측될 수 있다. 후보 포인트들은 평균 또는 가중치 적용 등 다양한 방법으로 조합될 수 있다. 즉, 현재 포인트는 적어도 두 개 이상의 후보 포인트들에 기초하여 예측될 수 있다.
예를들어, 적어도 하나 이상의 프레임들은 제2 프레임 및 제3 프레임을 포함할 수 있다. 예측하는 단계는, 제2 프레임에서 제2 포인트 또는 제3 포인트를 기반으로 탐색한 제4 포인트를 제1 후보 포인트로 정하고, 제3 프레임에서 제4 포인트를 기반으로 탐색한 제5 포인트를 제2 후보 포인트로 정할 수 있다. 그리고, 제1 후보 포인트 및 제2 후보 포인트를 기반으로 현재 포인트를 예측한다. 이떄, 제1 포인트(현재 포인트) 내지 제5 포인트는 식별정보(레이저ID), 애지무스 및 래디우스 정보 중 적어도 어느 하나의 정보를 포함한다.
포인트 클라우드 데이터 처리 시, 비트스트림은 복수의 프레임들을 기반으로 예측이 수행되는지 여부를 나타내는 정보를 포함하고, 현재 포인트를 예측하기 위해 참조하는 적어도 하나 이상의 프레임들을 식별하기 위한 정보를 포함할 수 있다. 따라서, 실시예들에 따른 수신 장치/방법은 멀티 프레임 기반 예측 수행 여부 정보 및 참조하는 프레임들의 식별 정보를 통해 현재 포인트를 복원할 수 있다.
실시예들에 따른 비트스트림에 포함된 시그널링 정보는 도 32 내지 도35 및 도 41 내지 도43에서 설명한다.
실시예들에 따른 송신 방법은 도44 및 도46에 도시된 송신 장치/방법의 구성들에 의하여 수행될 수 있다. 도 44의 예측부(4420) 또는 도 46의 예측부(4620)는 실시예들에 따른 멀티 프레임 기반의 예측을 수행할 수 있다. 구성의 명칭은 예측 유닛, 예측 모듈, 예측 프로세서 등 다양하게 지칭될 수 있으며, 실시예들에 따른 송신 장치/방법을 나타내는 다른 도면들과 연결 또는 조합될 수 있다.
실시예들에 따른 송신 장치는 복수의 프레임들을 포함하는 포인트 클라우드 데이터를 인코딩하는 인코더 및 포인트 클라우드 데이터를 포함하는 비트스트림을 전송하는 트랜스미터를 포함할 수 있다. 실시예들에 따른 송신 장치는 전술한 송신 방법의 처리 과정을 수행하는 유닛, 모듈 또는 프로세서 등을 구성 요소로 하는 장치로 나타내질 수 있다.
도 49는 실시예들에 따른 포인트 클라우드 데이터 수신 방법을 나타내는 플로우 차트이다.
실시예들에 따른 송수신 장치/방법은 도 1의 송수신 장치, 도 2의 송수신, 도 4의 포인트 클라우드 인코더, 도 10, 도 11의 포인트 클라우드 디코더, 도 12의 송신장치, 도 13의 수신장치, 도 14의 디바이스들, 도 44의 송신 장치/방법, 도 45의 수신 장치/방법, 도46의 송신 장치/방법, 도47의 수신 장치/방법, 도 48의 송신 방법 또는 도 49의 수신 방법과 대응하거나, 조합될 수 있으며, 실시예들에 따른 송수신 장치/방법은 복수의 참조 프레임 또는 누적 참조 프레임을 활용한 인터 예측 및 예측 방법에 관한 시그널링을 수행할 수 있다.
실시예들에 따른 수신 방법은 포인트 클라우드 데이터를 포함하는 비트스트림을 수신하는 단계(S4900) 및 포인트 클라우드 데이터를 디코드하는 단계(S4910)를 포함한다.
도 15에서 설명한 것과 같이 포인트 클라우드 데이터는 복수의 프레임들을 포함할 수 있다.
포인트 클라우드 데이터를 디코딩하는 단계(S4910)는 제1 프레임에 속하는 제1 포인트를 예측하는 단계를 포함할 수 있다. 제1 프레임은 현재 프레임(current frame)을 나타내고 제1 포인트는 현재 포인트(current point)를 나타낼 수 있다. 즉, 실시예들에 따른 수신 방법에서 포인트 클라우드 데이터를 디코딩하는 단계(S4910)는 현재 프레임에 속하는 현재 포인트를 예측하는 단계를 포함한다. 이때, 예측하는 단계는 복수의 프레임들 중 적어도 하나 이상의 프레임들에 속하는 포인트들을 기반으로 현재 포인트를 예측할 수 있다.
현재 프레임에 속하는 현재 포인트를 예측하는 방법에 대하여 도 20 내지 도 28에서 설명하며, 도 30 및 도31에서 설명한다.
현재 포인트를 예측하기 위하여 참조하는 적어도 하나 이상의 프레임들은 그 순서가 현재 프레임 이전이거나, 이후일 수 있다. 또한, 적어도 하나 이상의 프레임들 중 어느 하나의 프레임은 현재 프레임의 이전이고, 다른 하나의 프레임의 현재 프레임의 이후일 수 있다. 현재 프레임에서 참조하는 적어도 하나 이상의 프레임들은 그 순서에 따라 전방향(forward) 예측, 후방향(backward) 예측 또는 양방향(bi-directional) 예측이 수행될 수 있다. 이때, 순서는 디스플레이 순서 또는 코딩 순서일 수 있다.
도 20 내지 도 28은 전방향(forward) 예측, 후방향(backward) 예측 또는 양방향(bi-directional) 예측 방법에 대하여 설명한다.
도 20 내지 도 28을 참조하면, 예측하는 단계는 현재 프레임 내의 현재 포인트 이전에 처리된 제2 포인트를 기반으로 적어도 하나 이상의 프레임들 중 어느 하나에 속하는 제3 포인트를 탐색한다. 이떄, 제2 포인트는 현재 포인트 이전에 복호화된 포인트를 나타낼 수 있고, 제3 포인트는 제2 포인트와 유사한 포인트를 나타낼 수 있다. 제3 포인트는 레이저ID, 애지무스 또는 래디우스 값을 기반으로 제2 포인트와 유사 여부가 판단될 수 있다. 즉, 제3 포인트는 레이저ID가 제2 포인트와 동일하고, 애지무스 또는 래디우스 값이 가장 가까운 포인트일 수 있다.
또한, 예측하는 단계는, 제2 포인트 또는 제3 포인트를 기반으로 현재 포인트를 예측하기 위한 복수의 후보 포인트들을 선택할 수 있다. 후보 포인트는 예측기 또는 포인트 후보 등으로 지칭될 수 있고, 현재 포인트의 예측값을 산출하기 위해 사용되는 포인트를 나타낼 수 있다. 후보 포인트들은 레이저ID, 애지무스 또는 래디우스 값을 기반으로 선택될 수 있다. 그리고, 현재 포인트는 후보 포인트들 중 어느 하나의 값으로 예측되거나, 복수의 후보 포인트들을 조합한 값으로 예측될 수 있다. 후보 포인트들은 평균 또는 가중치 적용 등 다양한 방법으로 조합될 수 있다. 즉, 현재 포인트는 적어도 두 개 이상의 후보 포인트들에 기초하여 예측될 수 있다.
예를들어, 적어도 하나 이상의 프레임들은 제2 프레임 및 제3 프레임을 포함할 수 있다. 예측하는 단계는, 제2 프레임에서 제2 포인트 또는 제3 포인트를 기반으로 탐색한 제4 포인트를 제1 후보 포인트로 정하고, 제3 프레임에서 제4 포인트를 기반으로 탐색한 제5 포인트를 제2 후보 포인트로 정할 수 있다. 그리고, 제1 후보 포인트 및 제2 후보 포인트를 기반으로 현재 포인트를 예측한다. 이떄, 제1 포인트(현재 포인트) 내지 제5 포인트는 식별정보(레이저ID), 애지무스 및 래디우스 정보 중 적어도 어느 하나의 정보를 포함한다.
포인트 클라우드 데이터 처리 시, 비트스트림은 복수의 프레임들을 기반으로 예측이 수행되는지 여부를 나타내는 정보를 포함하고, 현재 포인트를 예측하기 위해 참조하는 적어도 하나 이상의 프레임들을 식별하기 위한 정보를 포함할 수 있다. 따라서, 실시예들에 따른 수신 장치/방법은 멀티 프레임 기반 예측 수행 여부 정보 및 참조하는 프레임들의 식별 정보를 통해 현재 포인트를 복원할 수 있다.
실시예들에 따른 비트스트림에 포함된 시그널링 정보는 도 32 내지 도35 및 도 41 내지 도43에서 설명한다.
실시예들에 따른 수신 방법은 도45 및 도47에 도시된 수신 장치/방법의 구성들에 의하여 수행될 수 있다. 도 45의 예측부(4520) 또는 도 47의 예측부(4620)는 실시예들에 따른 멀티 프레임 기반의 예측을 수행할 수 있다. 구성의 명칭은 예측 유닛, 예측 모듈, 예측 프로세서 등 다양하게 지칭될 수 있으며, 실시예들에 따른 수신 장치/방법을 나타내는 다른 도면들과 연결 또는 조합될 수 있다.
실시예들에 따른 수신 장치는 복수의 프레임들을 포함하는 포인트 클라우드 데이터를 수신하는 수신부 및 포인트 클라우드 데이터를 포함하는 비트스트림을 디코딩하는 디코더를 포함할 수 있다. 실시예들에 따른 수신 장치는 전술한 수신 방법의 처리 과정을 수행하는 유닛, 모듈 또는 프로세서 등을 구성 요소로 하는 장치로 나타내질 수 있다.
실시예들에 따른 송수신 장치/방법은 포인트 클라우드 컨텐츠의 예측 지오메트리(predictive geometry) 방식에서 화면 간 움직임 예측을 위해 복수 개의 참조 프레임을 고려하는 방법에 대해 제안한다. 다수의 프레임을 사용함으로써 예측의 정확도가 향상되고, 미리 예측된 프레임을 통해 노드를 예측함으로써 트리 생성(tree generation) 과정에서 발생하는 부호화 시간(encoding time)이 감소될 수 있다.
본 발명은 포인트 클라우드 컨텐츠의 예측 지오메트리(predictive geometry) 방식에서 화면 간 움직임 예측을 위해 누적 참조 프레임을 고려하는 방법에 대해 제안하였다. 다수의 프레임을 사용함으로써 예측의 정확도 향상이 가능하고, 미리 예측된 프레임을 통해 노드를 예측함으로써 트리 생성(tree generation)과정에서 발생하는 인코딩 시간(encoding time)이 감소할 수 있다.
상술한 실시예들에 따른 송수신 장치의 프로세스는 이하의 포인트 클라우드 컴프레션 처리와 결합되어 설명될 수 있다. 또한 본 문서에서 설명하는 실시예들에 따른 동작은 실시예들에 따라서 메모리 및/또는 프로세서를 포함하는 송수신 장치에 의해 수행될 수 있다. 메모리는 실시예들에 따른 동작을 처리/제어하기 위한 프로그램들을 저장할 수 있고, 프로세서는 본 문서에서 설명한 다양한 동작을 제어할 수 있다. 프로세서는 컨트롤러 등으로 지칭가능하다. 실시예들에 동작들은 펌웨어, 소프트웨어, 및/또는 그것들의 조합에 의해 수행될 수 있고, 펌웨어, 소프트웨어, 및/또는 그것들의 조합은 프로세서에 저장되거나 메모리에 저장될 수 있다.
본 문서에서 설명하는 실시예들에 따른 동작은 실시예들에 따라서 메모리 및/또는 프로세서를 포함하는 송수신 장치에 의해 수행될 수 있다. 메모리는 실시예들에 따른 동작을 처리/제어하기 위한 프로그램들을 저장할 수 있고, 프로세서는 본 문서에서 설명한 다양한 동작을 제어할 수 있다. 프로세서는 컨트롤러 등으로 지칭가능하다. 실시예들에 동작들은 펌웨어, 소프트웨어, 및/또는 그것들의 조합에 의해 수행될 수 있고, 펌웨어, 소프트웨어, 및/또는 그것들의 조합은 프로세서에 저장되거나 메모리에 저장될 수 있다.
실시예들은 방법 및/또는 장치 관점에서 설명되었으며, 방법의 설명 및 장치의 설명은 상호 보완하여 적용될 수 있다.
설명의 편의를 위하여 도면을 나누었으나, 각 도면에 서술되어 있는 실시예들을 병합하여 새로운 실시예를 구현하도록 설계할 수 있다. 그리고, 통상의 기술자의 필요에 따라, 이전에 설명된 실시예들을 실행하기 위한 프로그램이 기록되어 있는 컴퓨터에서 판독 가능한 기록 매체를 설계하는 것도 실시예들의 권리범위에 속한다. 실시예들에 따른 장치 및 방법은 상술한 바와 같이 설명된 실시예들의 구성과 방법이 한정되게 적용될 수 있는 것이 아니라, 실시예들은 다양한 변형이 이루어질 수 있도록 각 실시 예들의 전부 또는 일부가 선택적으로 조합되어 구성될 수도 있다. 실시예들의 바람직한 실시예에 대하여 도시하고 설명하였지만, 실시예들은 상술한 특정 실시예에 한정되지 아니하며, 청구범위에서 청구하는 실시예들의 요지를 벗어남이 없이 당해 발명이 속하는 기술분야에서 통상의 지식을 가진 자에 의해 다양한 변형실시가 가능한 것은 물론이고, 이러한 변형실시들은 실시예들의 기술적 사상이나 전망으로부터 개별적으로 이해돼서는 안 될 것이다.
실시예들의 장치의 다양한 구성요소들은 하드웨어, 소프트웨어, 펌웨어 또는 그것들의 조합에 의해 수행될 수 있다. 실시예들의 다양한 구성요소들은 하나의 칩, 예를 들면 하나의 하드웨어 서킷으로 구현될 수 있다 실시예들에 따라, 실시예들에 따른 구성요소들은 각각 별도의 칩들로 구현될 수 있다. 실시예들에 따라, 실시예들에 따른 장치의 구성요소들 중 적어도 하나 이상은 하나 또는 그 이상의 프로그램들을 실행 할 수 있는 하나 또는 그 이상의 프로세서들로 구성될 수 있으며, 하나 또는 그 이상의 프로그램들은 실시예들에 따른 동작/방법들 중 어느 하나 또는 그 이상의 동작/방법들을 수행시키거나, 수행시키기 위한 인스트럭션들을 포함할 수 있다.
실시예들에 따른 장치의 방법/동작들을 수행하기 위한 실행 가능한 인스트럭션들은 하나 또는 그 이상의 프로세서들에 의해 실행되기 위해 구성된 일시적이지 않은 CRM 또는 다른 컴퓨터 프로그램 제품들에 저장될 수 있거나, 하나 또는 그 이상의 프로세서들에 의해 실행되기 위해 구성된 일시적인 CRM 또는 다른 컴퓨터 프로그램 제품들에 저장될 수 있다.
또한, 실시예들에 따른 메모리는 휘발성 메모리(예를 들면 RAM 등)뿐 만 아니라 비휘발성 메모리, 플래쉬 메모리, PROM등을 전부 포함하는 개념으로 사용될 수 있다. 또한, 인터넷을 통한 전송 등과 같은 캐리어 웨이브의 형태로 구현되는 것도 포함될 수 있다. 또한, 프로세서가 읽을 수 있는 기록매체는 네트워크로 연결된 컴퓨터 시스템에 분산되어, 분산방식으로 프로세서가 읽을 수 있는 코드가 저장되고 실행될 수 있다.
본 명세서에서 “/”와 “,”는 “및/또는”으로 해석된다. 예를 들어, “A/B”는 “A 및/또는 B”로 해석되고, “A, B”는 “A 및/또는 B”로 해석된다. 추가적으로, “A/B/C”는 “A, B 및/또는 C 중 적어도 하나”를 의미한다. 또한, “A, B, C”도 “A, B 및/또는 C 중 적어도 하나”를 의미한다. 추가적으로, 본 명세서에서 “또는”은 “및/또는”으로 해석된다. 예를 들어, “A 또는 B”은, 1) “A” 만을 의미하고, 2) “B” 만을 의미하거나, 3) “A 및 B”를 의미할 수 있다. 달리 표현하면, 본 문서의 “또는”은 “추가적으로 또는 대체적으로(additionally or alternatively)”를 의미할 수 있다.
제1, 제2 등과 같은 용어는 실시예들의 다양한 구성요소들을 설명하기 위해 사용될 수 있다. 하지만 실시예들에 따른 다양한 구성요소들은 위 용어들에 의해 해석이 제한되지 않는다. 이러한 용어는 하나의 구성요소를 다른 구성요소와 구별하기 위해 사용되는 것에 불과하다. 예를 들어, 제1 사용자 인풋 시그널은 제2사용자 인풋 시그널로 지칭될 수 있다. 이와 유사하게, 제2사용자 인풋 시그널은 제1사용자 인풋시그널로 지칭될 수 있다. 이러한 용어의 사용은 다양한 실시예들의 범위 내에서 벗어나지 않는 것으로 해석되어야만 한다. 제1사용자 인풋 시그널 및 제2사용자 인풋 시그널은 모두 사용자 인풋 시그널들이지만, 문맥 상 명확하게 나타내지 않는 한 동일한 사용자 인풋 시그널들을 의미하지 않는다.
실시예들을 설명하기 위해 사용된 용어는 특정 실시예들을 설명하기 위한 목적으로 사용되고, 실시예들을 제한하기 위해서 의도되지 않는다. 실시예들의 설명 및 청구항에서 사용된 바와 같이, 문맥 상 명확하게 지칭하지 않는 한 단수는 복수를 포함하는 것으로 의도된다. 및/또는 표현은 용어 간의 모든 가능한 결합을 포함하는 의미로 사용된다. 포함한다 표현은 특징들, 수들, 단계들, 엘리먼트들, 및/또는 컴포넌트들이 존재하는 것을 설명하고, 추가적인 특징들, 수들, 단계들, 엘리먼트들, 및/또는 컴포넌트들을 포함하지 않는 것을 의미하지 않는다. 실시예들을 설명하기 위해 사용되는, ~인 경우, ~때 등의 조건 표현은 선택적인 경우로만 제한 해석되지 않는다. 특정 조건을 만족하는 때, 특정 조건에 대응하여 관련 동작을 수행하거나, 관련 정의가 해석되도록 의도되었다.
또한, 본 문서에서 설명하는 실시예들에 따른 동작은 실시예들에 따라서 메모리 및/또는 프로세서를 포함하는 송수신장치에 의해 수행될 수 있다. 메모리는 실시예들에 따른 동작을 처리/제어하기 위한 프로그램들을 저장할 수 있고, 프로세서는 본 문서에서 설명한 다양한 동작을 제어할 수 있다. 프로세서는 컨트롤러 등으로 지칭가능하다. 실시예들에 동작들은 펌웨어, 소프트웨어, 및/또는 그것들의 조합에 의해 수행될 수 있고, 펌웨어, 소프트웨어, 및/또는 그것들의 조합은 프로세서에 저장되거나 메모리에 저장될 수 있다.
한편, 상술한 실시예들에 따른 동작은 실시예들 따른 송신장치 및/또는 수신장치에 의해서 수행될 수 있다. 송수신장치는 미디어 데이터를 송수신하는 송수신부, 실시예들에 따른 프로세스에 대한 인스트럭션(프로그램 코드, 알고리즘, flowchart 및/또는 데이터)을 저장하는 메모리, 송/수신장치의 동작들을 제어하는 프로세서를 포함할 수 있다.
프로세서는 컨트롤러 등으로 지칭될 수 있고, 예를 들어, 하드웨어, 소프트웨어, 및/또는 그것들의 조합에 대응할 수 있다. 상술한 실시예들에 따른 동작은 프로세서에 의해 수행될 수 있다. 또한, 프로세서는 상술한 실시예들의 동작을 위한 인코더/디코더 등으로 구현될 수 있다.