WO2023276213A1 - 情報処理装置、情報処理方法及び情報処理プログラム - Google Patents
情報処理装置、情報処理方法及び情報処理プログラム Download PDFInfo
- Publication number
- WO2023276213A1 WO2023276213A1 PCT/JP2022/002805 JP2022002805W WO2023276213A1 WO 2023276213 A1 WO2023276213 A1 WO 2023276213A1 JP 2022002805 W JP2022002805 W JP 2022002805W WO 2023276213 A1 WO2023276213 A1 WO 2023276213A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- information processing
- model
- optimization
- information
- data
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Ceased
Links
Images















Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N20/00—Machine learning
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N5/00—Computing arrangements using knowledge-based models
- G06N5/01—Dynamic search techniques; Heuristics; Dynamic trees; Branch-and-bound
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N10/00—Quantum computing, i.e. information processing based on quantum-mechanical phenomena
- G06N10/60—Quantum algorithms, e.g. based on quantum optimisation, quantum Fourier or Hadamard transforms
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N20/00—Machine learning
- G06N20/10—Machine learning using kernel methods, e.g. support vector machines [SVM]
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/08—Learning methods
- G06N3/09—Supervised learning
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/08—Learning methods
- G06N3/0985—Hyperparameter optimisation; Meta-learning; Learning-to-learn
Definitions
- the present disclosure relates to an information processing device, an information processing method, and an information processing program.
- the present disclosure proposes an information processing device, an information processing method, and an information processing program capable of selecting an appropriate sample set from a data set.
- an information processing apparatus acquires a data supply method, a model to be learned, and specification information regarding the size and category of a sample set used for learning the model.
- an acquisition unit acquires a data supply method, a model to be learned, and specification information regarding the size and category of a sample set used for learning the model.
- an acquisition unit acquires a data supply method, a model to be learned, and specification information regarding the size and category of a sample set used for learning the model.
- an acquisition unit and a selection unit that selects a sample set to be used for learning the model from a data set based on the information entropy determined according to the model and the designation information.
- FIG. 4 is a flow chart showing a processing procedure by an information processing system; It is a figure which shows an example of the block configuration of an information processing system. It is a figure which shows an example of a user interface. It is a figure which shows a part of block configuration of an information processing system. It is a figure which shows a tunnel effect typically. It is a figure which shows an example of the main program of information processing.
- FIG. 10 is a flowchart showing the procedure of data selection optimization processing; FIG. It is a figure which shows an example of a processing program of data selection optimization. It is a figure which shows the structural example of the information processing apparatus of this indication.
- FIG. 4 is a diagram showing an example of a list of classes; It is a figure which shows an example of selection of the class which a user wants to study.
- FIG. 4 is a diagram showing an example of receiving data from a user; It is a figure which shows the 5th Example to which the information processing system is applied.
- FIG. 11 is a flow chart showing the procedure of processing in the fifth embodiment; FIG. It is a figure which shows the flow of an image determination process.
- 1 is a hardware configuration diagram showing an example of a computer that implements functions of an information processing apparatus; FIG.
- the former two namely semi-supervised learning and active learning, are countermeasures against the cost of labeling among data set collection (construction). Labeling is the process of adding information to data, and is usually done manually and therefore expensive.
- Labeling also includes processing that is difficult to achieve without advanced knowledge and work, such as measuring physical quantities based on scientific experiments and diagnosing pathological images.
- processing that is difficult to achieve without advanced knowledge and work, such as measuring physical quantities based on scientific experiments and diagnosing pathological images.
- the measurement of the bandgap of semiconductors, the optical properties of organic and inorganic molecules, the reaction rate, the measurement of the equilibrium divergence, etc. are also labeling from the viewpoint of learning prediction models for machine learning using these as data. can be regarded as
- active learning is a learning method in which one or more pieces of data are appropriately selected from a dataset, labeled, and used to update a prediction model (hereinafter simply referred to as "model"). Efficiently selecting the data to be labeled according to the model eliminates the need to label all the data, leading to a reduction in labeling costs.
- transfer learning is a technology that focuses on using information from another dataset rather than reducing the cost of labeling.
- transfer learning the user downloads a model embedded with information from another dataset from the system and updates (some of) the parameters of this model with the dataset at hand.
- the size (footprint) of the model distributed by the system generally tends to be large, but this is due to the size being able to handle various types of information.
- time and energy are consumed for information processing other than the prediction target. In other words, from the user's point of view, the information efficiency for the model is low.
- the information processing system 1 (see FIG. 1), which will be described in detail below, for example, when a model is presented by the user, provides the most efficient information for the user's model from the datasets that the information processing system 1 has access to. Offer a subset.
- the information processing system 1 selects the optimal (sample) subset for updating the model customized to the model owned by the user instead of commonly distributing the model that learned the information of the dataset, Offer a selected subset.
- An example of the information provided by the information processing system 1 is a subset sampled from a data set or data simulator. It should be noted that the information processing system 1 may provide various information such as a model learned by the subset as necessary, but the details of this point will be described later.
- the subset selected by the information processing system 1 is the data set that reduces the ambiguity of the model that the user has, in other words, the subset that is selected so that the efficiency of information extraction is maximized.
- Optimizing the selection of subsets by the information processing system 1 can be performed by a quantum annealing machine or a combinatorial optimization accelerator specializing in speeding up binary quadratic form combinatorial optimization in order to improve the accuracy of the optimization process. is realized using a combinatorial optimization machine (hereinafter also referred to as "optimization machine").
- the user can efficiently collect the data used for updating the model generated from the current information from existing datasets. Therefore, according to the information processing system 1, it is possible to obtain the effects of reducing the development period and development costs and increasing the number of trials.
- the user can obtain the subset that contributes the most to updating the model. Therefore, according to the information processing system 1, the model is optimized only for the information desired to be predicted, and the performance of the function is improved.
- the user can obtain a subset of unlabeled data that contributes most to updating the user's model. Therefore, according to the information processing system 1, it is possible to perform labeling or an analysis work corresponding to labeling in order from the data to be analyzed that is expected to have the most knowledge.
- optimization of subsets is realized using an optimization machine such as a quantum annealing machine. It is theoretically known that quantum annealing reaches a global optimal solution asymptotically, so it is possible to provide a more optimal subset than the greedy method approximation, which is a representative example of conventional combinatorial optimization implementation algorithms. can.
- an optimization machine such as a quantum annealing machine. It is theoretically known that quantum annealing reaches a global optimal solution asymptotically, so it is possible to provide a more optimal subset than the greedy method approximation, which is a representative example of conventional combinatorial optimization implementation algorithms. can.
- a system configuration example of the entire information processing system 1 will be described as a first embodiment, and then each process and application examples will be described.
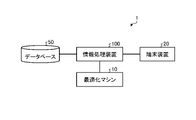
- FIG. 1 is a diagram showing a configuration example of an information processing system of the present disclosure.
- the information processing system 1 includes an optimization machine 10 , a terminal device 20 , a database 50 and an information processing device 100 .
- the information processing system 1 includes a database 50 that stores a large amount of data, an information processing device 100 that is a server that generates a subset from a data set, and a terminal device 20 that allows a user to issue a request to the information processing device 100 and receive the subset. , and an optimization machine 10 used by the information processing apparatus 100 to generate subsets.
- the information processing device 100, the optimization machine 10, the terminal device 20, and the database 50 are communicably connected by wire or wirelessly via a predetermined communication network (network NT).
- the information processing system 1 may include a plurality of information processing apparatuses 100 , a plurality of optimization machines 10 , a plurality of terminal devices 20 , and a plurality of databases 50 .
- the optimization machine 10 is a computer (optimization calculation dedicated machine) used to solve combinatorial optimization problems.
- optimization machine 10 is an optimization process accelerator for use in creating optimal subsets.
- the optimization machine 10 includes a quantum annealing machine, a combinatorial optimization machine (a dedicated machine for discrete optimization) such as an Ising machine, and the like. A specific example of the optimization machine 10 will be described later.
- the terminal device 20 is a computer used by the user.
- the terminal device 20 requests the subset from the information processing device 100 and receives the subset from the information processing device 100 .
- this subset may be used for learning the model, and may be used when actually learning the model at the terminal device 20 or at a later stage of the terminal device 20 .
- subsets are used as a set of references when aggregating model sizes. Note that the information processing system 1 may supply parameters that have been learned in a subset.
- the aspect of the subset request from the terminal device 20 may be the input (transmission) of the model itself. Also, instead of creating a model in advance by the user, the model may be determined according to guidance presented from the information processing system 1 side. Furthermore, the terminal device 20 may, for example, accept designation of the size of the subset (the number of data, etc.) as a request regarding the specification of the subset. Upon receiving the user's designation of the number of pieces of data in the subset, the terminal device 20 transmits designation information indicating the number of pieces of data in the subset designated by the user to the information processing device 100 . The terminal device 20 may transmit the data set collected by the user to the information processing device 100 .
- the terminal device 20 receives input from the user.
- the terminal device 20 accepts selection of the optimization machine 10 by the user.
- the terminal device 20 receives a user's operation on the displayed content as an input.
- the terminal device 20 may be any device as long as it can implement the processing described above.
- the terminal device 20 may be a device such as a smart phone, a tablet terminal, a notebook PC (Personal Computer), a desktop PC, a mobile phone, a PDA (Personal Digital Assistant), or the like.
- the database 50 is a database that stores large-scale data sets.
- the data set stored in the database 50 is a data set of a scale (large-scale data set) capable of learning a model that can be transferred to various uses.
- the information processing device 100 is a server device (computer) that selects subsets used for model learning and sample sets such as simulator outputs from the data sets stored in the database 50 .
- the information processing apparatus 100 selects a sample set based on a data supply method such as data supply from a dataset or simulation.
- the data supply method is data supply from a dataset.
- a sample set is a subset of a data set.
- Information processing apparatus 100 selects a sample set to be used for model learning from a data set based on information entropy determined according to the model to be learned and designation information regarding the size and category of the sample set to be used for model learning. select.
- the model we want to learn is a predictive model with learning parameters.
- the task of the model is the type of output of the model corresponding to the input of the model.
- the information entropy is information entropy calculated using the Kullback-Leibler information amount or the Fisher information amount, which will be described later in detail.
- the information processing device 100 receives information necessary for processing through communication with the optimization machine 10, the terminal device 20, and the database 50, and selects a subset to be used for model learning using the received information. .
- the information processing device 100 selects a subset from the database 50 and transmits the selected subset to the terminal device 20 in response to a request from the terminal device 20 .
- the information processing system 1 may add the data set from the terminal device 20 to a large-scale data set such as the data set stored in the database 50 when creating the optimal subset.
- FIG. 2 is a flow chart showing a processing procedure by the information processing system.
- the information processing device 100 first receives a data set request from the terminal device 20 (step S1).
- the information processing device 100 receives a data set provision request from the terminal device 20 .
- the request may have a specific format for the model itself, and is transmitted from the terminal device 20 to the information processing device 100 .
- the terminal device 20 may transmit, as a request, the class name of the category constituting the domain that the user wants to handle to the information processing device 100 .
- the data set itself collected by the user may be transmitted from the terminal device 20 to the information processing device 100 as a request.
- the information processing device 100 requests the optimization machine 10 for information on the optimal combination of data (step S2).
- the information processing apparatus 100 transmits necessary information to the optimization machine 10 in order to select optimal data for a user's request from large-scale data such as data sets stored in the database 50 .
- This information relates to restrictions on the size of data to be provided to the terminal device 20 and the amount of information a combination of data has, the details of which will be described later.
- the information processing device 100 provides data to the terminal device 20 according to the optimization (step S3).
- the information processing device 100 generates a subset of the datasets stored in the database 50 based on the results from the optimization machine 10 and provides the generated datasets to the terminal device 20 .
- step S4 the information processing apparatus 100 waits for the next request (step S4), and when the next request is received, returns to step S1 and repeats the process. Further, the information processing apparatus 100 terminates the process when a predetermined period of time has passed without the next request.
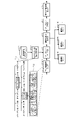
- FIG. 3 is a diagram showing an example of a block configuration of an information processing system.
- the information processing system 1 includes user interface units 21, 22, and 23, an information processing device 100 which is a main block and functions as a data set generation unit, and a data set storage connected to the main block. It consists of a certain database 50 and a plurality of optimization machines 10 that specialize in optimization processing.
- the information processing system 1 includes a plurality of optimization machines 10 such as an optimization machine 10a, an optimization machine 10b, and an optimization machine 10c. Note that the optimizing machine 10a, optimizing machine 10b, optimizing machine 10c, etc. will be referred to as "optimizing machine 10" when they are described without particular distinction.
- FIG. 3 shows three optimization machines 10, ie, the optimization machine 10a, the optimization machine 10b, and the optimization machine 10c, the information processing system 1 includes four or more optimization machines 10.
- the optimization machine 10 is a computer (computer) that uses the Ising model.
- the optimization machine 10 is a computer (combinatorial optimization machine) that solves combinatorial optimization problems using the Ising model.
- the optimization machine 10a is a quantum computer (quantum computer) that solves problems using quantum annealing.
- the optimization machine 10a can be realized by a quantum annealing method or a quantum annealer.
- the optimization machine 10b is a combinatorial optimization accelerator using CMOS (Complementary metal-oxide-semiconductor) or the like.
- the optimization machine 10c is a combinatorial optimization accelerator using a processor such as a GPU (Graphics Processing Unit) or an integrated circuit such as an FPGA (Field Programmable Gate Array).
- the optimization machine 10 is not limited to the hardware configuration of the optimization machine 10a, the optimization machine 10b, and the optimization machine 10c, and may have any hardware configuration.
- the information processing system 1 includes a user interface section 21 as a data input section, a user interface section 22 as a machine selection section, and a user interface section 23 as a data presentation section.
- the user interface unit 22 is an option, and may not be included in the information processing system 1 if the selection of the optimization machine 10 by the user is not accepted.
- the user interface units 21, 22, and 23 are realized by the terminal device 20. That is, the terminal device 20 has functions corresponding to the user interface units 21, 22, and 23, and accepts data input by the user, accepts the selection of the optimization machine 10 by the user, and presents provided information. Perform various processing.
- the user interface unit 21 is an interface for inputting data set information desired by the user, a model to be customized, and data sets actually collected by the user.
- the user interface unit 21 may be either a command line interface or a graphic interface.
- the simplest input is the model-only input.
- the user interface unit 21 inputs a neural network model learned by deep learning in a file generated according to a format.
- the user may be requested to provide the following four pieces of information.
- the user interface unit 21 receives inputs such as the following four pieces of information.
- the user interface unit 22 is an interface for selecting what kind of optimization method to use when realizing optimization when sampling data from a data set.
- optimization machines 10 There are already various machines (optimization machines 10) for optimization calculation specialized computers for realizing combinatorial optimization at high speed, and they can be used by users via cloud or the like.
- the user interface unit 22 may present content CT1 including information of each machine (optimization machine 10) as shown in FIG. 4 via a graphical user interface (GUI) or the like.
- GUI graphical user interface
- the user who confirmed the content CT1 selects the desired optimization machine 10 according to the purpose.
- FIG. 4 is a diagram showing an example of a user interface.
- Content CT1 in FIG. 4 shows a case where four optimization machines 10, machines A to D, are presented as selection candidates.
- the content CT1 includes information indicating evaluations of a plurality of items such as size, possibility of full connection, accuracy, speed, communication, and price for each of the four optimization machines 10, machines A to D.
- the presentation method shown in FIG. 4 is merely an example, and the presentation method to the user may take any form as long as the user can select the desired optimization machine 10 .
- the information processing device 100 in response to a request from the terminal device 20, the information processing device 100 generates content CT1 and transmits the generated content CT1 to the terminal device 20. After receiving the content CT1, the terminal device 20 displays the content CT1. A user who uses the terminal device 20 confirms the content CT1 displayed on the terminal device 20, compares the merits and demerits and the strengths and weaknesses of the four optimization machines 10, machines A to D, and then Select the optimization machine 10 to be used.
- the terminal device 20 that has received the selection of the optimization machine 10 by the user transmits information indicating the optimization machine 10 selected by the user to the information processing device 100 .
- the information processing apparatus 100 that has received the information indicating the optimization machine 10 selected by the user requests the optimization machine 10 selected by the user to perform processing.
- the user interface unit 23 is an interface that presents a subset of data sets to be provided according to the functions that the user wants to implement.
- the user interface section 23 may be either a command line interface or a graphic interface.
- the user interface unit 23 supplies a subset (data set).
- the user interface unit 23 may supply not only the subset but also parameters learned in the subset.
- the user interface unit 23 may supply parameters learned with the subset along with the subset.
- the user interface unit 23 may present the parameters learned from the original data set instead of the subset according to the user's designation.
- the user who receives the supply from the user interface unit 23 can also directly use the parameters of the obtained model.
- the information processing system 1 a data set necessary for learning is obtained. Since the data set required for learning is thus obtained, the information processing system 1 can design and relearn the functions to be implemented more efficiently and with higher performance.
- FIG. 5 is a diagram showing part of the block configuration of the information processing system.
- the core part of the information processing system 1 shown in FIG. A portion 135 is included.
- the configuration other than the database 50 is the configuration of the information processing apparatus 100, and corresponds to the configuration shown within the dotted line in FIG. 5 that are the same as those in FIG. 3 are denoted by the same reference numerals.
- the optimization coefficient extraction unit 132 is constructed by integrating the information gain calculation unit 132a and the QUBO coefficient calculation unit 132b shown in FIG. That is, the optimization coefficient extraction unit 132 performs both the information gain calculation unit 132a that calculates information gain and the QUBO coefficient calculation unit 132b that calculates QUBO (Quadratic Unconstrained Binary Optimization) coefficients. It is a component that has a function.
- the database 50 is a database in which a large amount of cross-cutting data (large-scale data) is stored.
- the database 50 stores arbitrary data sets such as Imagenet.
- the data reading unit 131a has a function of reading the database. For example, the data reading unit 131a acquires data from the database 50. FIG. The data reading unit 131a acquires the data of the class, if any class is specified in the request from the user.
- the user data input unit 131b is a module having a function of receiving requests from users.
- the request from the user has the following two input patterns.
- the first pattern is a pattern in which a prediction model that the user wants to learn is input.
- the second pattern is a pattern in which data already possessed by the user is entered.
- the optimization coefficient extraction unit 132 extracts the coefficient information of the objective function of optimization based on the formulation of combinatorial optimization described later from the data of the large-scale database and the data input by the user.
- the optimization machine communication unit 133 transmits the coefficient information of the objective function to the optimization machine 10 and receives the variables after optimization processing.
- the dataset selection unit 134 selects a subset (dataset) based on the optimization result.
- the output unit 135 outputs information based on the selection result. Details of each configuration of the information processing apparatus 100 will be described later.
- Quantum annealing is one of the methods for searching the energy ground state of the Ising model, and is considered to be a kind of quantum computation specifically used for the purpose of speeding up combinatorial optimization.
- the Ising model is a physical model originally proposed by physicist Ising in order to explain the phase transition phenomenon of a ferromagnetic material (magnet) with respect to temperature.
- the following equation (1) is the Hamiltonian (energy function) of the Ising model, which is a generalization of the original magnet model. This model is sometimes called the spin glass model to distinguish it from the original Ising model. .
- ⁇ i in Equation (1) is a physical quantity called spin, a variable that takes ⁇ 1 or 1, and the subscript represents a serial number.
- J ij is a constant called binding energy, which represents the magnitude of the interaction acting between two spins, and the subscript represents the serial number of the two spins.
- h k is a constant called a local magnetic field, and represents the magnitude of the local magnetic field acting on the spins, and the suffix is the spin number on which the local magnetic field acts.
- a combinatorial optimization problem is a problem of searching for an optimal solution expressed in the form of sets.
- Combinatorial optimization problems such as the traveling salesman problem, are known to have many problems that are difficult to calculate because exhaustive searches that cause combinatorial explosions are required to find exact optimal solutions.
- QUBO quadratic form unconstrained binary optimization
- b i in equation (2) is a binary variable that takes either a binary value of 0 or 1
- Q ij is the coefficient matrix of QUBO.
- QUBO can be transformed into a form equivalent to the energy function of the Ising model except for the constant term. Specifically, it can be confirmed by replacing b i with ⁇ i as in the following equation (3). Also, the coefficient matrices J ij and h k of the QUBO problem are expressed as the following equations (4) and (5).
- quantum annealing was devised with the idea of leaving the optimization to the realization of the physical ground state of the Ising model with these coefficients.
- Quantum annealing handles a model such as the following formula (6), which is an Ising model with a quantum fluctuation term added.
- the term of quantum fluctuation is first dominant to realize a superposition state of all combinations, and gradually the Hamiltonian of the Ising model is made dominant.
- the process is adiabatic, eventually the combination of spins reaches the ground state, ie the state that minimizes the energy. Therefore, if the coefficient matrices J ij and h k of the QUBO problem are set in the Hamiltonian of the Ising model in advance, the final spin combination of the Ising model corresponds to the binary variables.
- Quantum annealing is the process of embedding a combinatorial optimization problem in the Ising model and adiabatically transitioning from the state of quantum fluctuations to the ground state of the Ising model, thereby realizing the combinatorial optimization solution in the Ising spins. call.
- FIG. 6 is a diagram schematically showing the tunnel effect.
- optimization machines various types of hardware that simulate the Ising model, such as quantum computers and combinatorial optimization accelerators, are collectively referred to as optimization machines.
- the Kullback-Leibler information amount is an amount defined by the following formula (7) for two probability distributions.
- the Kullback-Leibler information content is the expected value of the uncertainty (entropy) of the two probability distributions, and can be considered as the amount of information that makes the predictions from the probability distributions more probable.
- Equation (8) The amount of information shown in Equation (8) can be Taylor-expanded as in Equation (9) below.
- J(w) is the Fisher information matrix (expected Fisher information matrix) represented by the following equation (10).
- the Fisher information matrix is a concept similar to the variation sensitivity of the amount of information to parameters. Also, the Fisher information matrix is known to have relationships such as the following equations (11) and (12).
- Equation (12) indicates that the Fisher information matrix is proportional to the inverse matrix of the parameter covariance matrix (precision matrix).
- the purpose of the information processing system 1 is to provide a subset S that best approximates the parameter w D learned with the data set D with the maximum likelihood parameter w S . From here on, it is assumed that the model handles a regression model as a discriminant model, and the case where the predicted distribution of data can be decomposed as in the following equation (13) is considered.
- Equation (17) When the model handles a regression model, for example, the aforementioned information gain shown in Equation (9) is changed as shown in Equation (17) below.
- M is the following formula (26), and V is the formula (27).
- H i (w) differs depending on whether the data is labeled data or unlabeled data. For example, if the data is labeled data, H i (w) is defined as in Equation (28) below.
- Equation (31) An example of a constraint is to resample as efficiently as possible.
- the number of re-samplings is added as a penalty term to the loss function as shown in Equation (31) below.
- factor ⁇ 1 is a parameter that adjusts the trade-off between resampling optimization and resampling efficiency. As the value of factor ⁇ 1 increases, resampling becomes more efficient, but the maximum likelihood parameters of the resampled subset deviate from the original maximum likelihood parameters.
- Equation (32) Another possible example is to set a default for the number of resamplings.
- the squared error between the number of resamplings and the predetermined number is added as a penalty term to the loss function, as in Equation (32) below.
- the coefficient ⁇ 2 is a parameter that adjusts the trade - off between optimization of resampling and restriction on the number of resamplings. Normally, priority is given to restriction on the number of resamplings, so this value is set to a large value.
- Equation (31) or Equation (32) has two variables w and b. Optimization for the variable b that determines the subset is essential. This is obtained by a special accelerator such as optimization machine 10 including quantum annealing.
- the information processing system 1 alternately repeats the following procedures. For w, a parameter w S estimated from the subset S is used, and for b, a parameter that minimizes L(w S ,b) is obtained. By repeating the above, the information processing system 1 can not only obtain the subset S, but also obtain the parameter w more easily than when learning with the entire data set.
- the second term C(b) is a penalty term for realizing the constraint, such as the following formulas (34) and (35).
- an optimization machine 10 such as an Ising machine such as a quantum annealing machine
- this objective function into the quadratic form of b, that is, the form of QUBO.
- the first term is not in quadratic form. Therefore, an auxiliary variable ⁇ represented by a square matrix with the dimension of the number of parameters is prepared, and an objective function such as the following equation (36) is considered.
- b and ⁇ are optimized simultaneously (alternately).
- w is optimized according to the use case, but it is not essential.
- the optimization of the auxiliary variable ⁇ can be done by finding ⁇ where the differential coefficient becomes 0 as shown in the following equation (38) with w and b fixed.
- the algorithm shown here is executed by the information processing system 1, and is an algorithm that performs, for example, the following processes (1-1) to (1-4).
- QPU Quantum Processing Unit
- the initial values in the above algorithm may be randomly determined. It should be noted that the method of obtaining the initial value is not limited to the above, and various methods of obtaining the initial value are conceivable.
- the optimization objective function can be transformed as shown in the following equation (43).
- Equation (43) holds when all the eigenvalues of J q (w,b) are 1.
- L UB (w,b) shown in Equation (44) below is the objective function.
- Equation (48) the objective function is as shown in Equation (48) below.
- Equation (50) Equation (50) below by adding the following penalty term. It is easy to see that when the penalty term goes to 0, it agrees with equation (48).
- the information processing system 1 fixes ⁇ and optimizes b by the optimization machine 10 such as quantum annealing, then fixes b and updates ⁇ by the information processing device 100 using a normal calculation algorithm, These optimizations are iterated alternately.
- the optimization machine 10 such as quantum annealing
- the algorithm shown here is executed by the information processing system 1, and is an algorithm that performs, for example, the following processes (2-1) to (2-4).
- the initial values in the above algorithm may be randomly determined. It should be noted that the method of obtaining the initial value is not limited to the above, and various methods of obtaining the initial value are conceivable.
- the objective function can be written as the following equation (59) using the binary variable set b.
- Equation (59) The objective function shown in Equation (59) can be transformed into the quadratic form of b by adding a penalty term as shown in Equation (60) below.
- ⁇ is not optimized by the optimization machine 10 such as quantum annealing, so it is optimized by the information processing device 100 using a normal calculation algorithm.
- the method of calculating the coefficients a ij is different, but the objective function using these coefficients is exactly the same as that of the regression model, so a detailed description of the algorithm will be omitted.
- s(x) is a K-dimensional vector of the following equation (64)
- u is a K-dimensional vector whose all components are 1
- e k is a K-dimensional vector whose only the k-th component is 1 and the others are 0 and
- equation (68) the objective function is given by equation (68) below.
- This problem can be transformed into a quadratic form by adding a penalty term such as the following equation (70).
- ⁇ is not optimized by the optimization machine 10 such as quantum annealing, it is optimized by the information processing device 100 using a normal calculation algorithm. Since the derivation is almost the same as the regression model and two-class classification method, detailed explanation is omitted.
- the processing flow of data selection optimization by the information processing apparatus 100 is the following processing (3-1) to (3-4).
- (3-1) Receive a file of a prediction model to be learned from the user.
- the main program is the program PG1 shown in FIG.
- FIG. 7 is a diagram showing an example of a main program for information processing.
- (4-1) Randomly generate a binary variable b.
- (4-2) Generate a subset S from the data set D based on the binary variable b.
- (4-3) Using the input module m and subset S, estimate the maximum likelihood parameter w S for the module m.
- (4-4) Fix the binary variable b and the module parameter w, and calculate the auxiliary variables (collectively X) for putting the problem in the QUBO format.
- the setting of the initial value of the binary variable b in (4-1) is not limited to random. For example, when the number of data is specified, the initial value of the binary variable b may be set so as to select the number of data that satisfies the specified number.
- FIG. 8 is a flowchart showing the procedure of data selection optimization processing.
- FIG. 8 is an example of the flow of data selection optimization processing by the information processing system 1 .
- the information processing apparatus 100 is the processing subject will be described as an example, but the processing subject is not limited to the information processing apparatus 100 and may be any device included in the information processing system 1 .
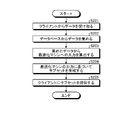
- the information processing apparatus 100 inputs user data and data sets (step S101).
- the information processing device 100 acquires user data from the terminal device 20 and acquires data sets from the database 50 .
- the information processing device 100 acquires a quadratic form matrix of the amount of information for the data combination (step S102). For example, the information processing apparatus 100 extracts a quadratic matrix of information amount from the objective function.
- the information processing device 100 transmits the coefficient matrix to the combinatorial optimization machine (step S103). For example, the information processing apparatus 100 transmits the coefficient matrix as an Ising parameter to the optimization machine 10 selected by the user.
- the information processing device 100 receives the optimized solution from the combinatorial optimization machine (step S104).
- the information processing apparatus 100 receives the solution calculated by the optimization machine 10 as the optimization solution from the optimization machine 10 that transmitted the Ising parameters.
- the information processing system 1 obtains combinations optimized by the optimization machine 10, which is a combination optimization machine.
- the information processing apparatus 100 determines whether or not a predetermined termination condition is satisfied (step S105).
- the termination condition may be that the number of times of processing reaches a threshold.
- the termination condition is that the number of iterations reaches a certain value or more.
- the termination condition is not limited to the number of iterations, and may be a convergence condition such as, for example, that the update width of the energy function due to the iterative step is below a certain value. Since this iterative algorithm does not necessarily reduce the energy in one step, the parameters and the like at that time may be stored each time the minimum energy is achieved. In this case, the information processing apparatus 100 may provide the user with the parameter stored as the minimum energy parameter when the end condition is satisfied.
- step S105 If the predetermined termination condition is not satisfied (step S105: No), the information processing apparatus 100 returns to step S102 and repeats the process. In this way, the information processing apparatus 100 performs feedback processing because of the alternating optimization.
- step S105 When the predetermined termination condition is satisfied (step S105: Yes), the information processing apparatus 100 selects data to be provided (step S106). For example, the information processing apparatus 100 selects a subset from the data set when a predetermined termination condition is satisfied. The information processing apparatus 100 then outputs the selected data set (step S107). For example, the information processing apparatus 100 provides the user with the selected subset as a data set.
- FIG. 9 is a diagram showing an example of a data selection optimization processing program.
- the function "resample_optimal_subset(model, dataset)" shown in the program PG2 is a function for resampling the subset shown on the fifth line in FIG. 7, and corresponds to the function that outputs the subset.
- a program PG2 shown in FIG. 9 expresses the processing shown in FIG. 8 as a program example. Since the program PG2 shown in FIG. 9 is the same as the processing shown in FIG. 8, detailed description thereof will be omitted.
- the information processing apparatus 100 stores programs (functions) as shown in FIGS. 7 and 9 and programs (functions) called by each program in the function information storage unit 122 (see FIG. 10), Execute the process using
- the information processing device 100 extracts the coefficient matrix as the Ising parameters to be transmitted to the optimization machine 10 from the objective function regarding the amount of information determined according to the task of the model.
- the information processing device 100 extracts the coefficient matrix using the above-described program or the like.
- the coefficient matrix is an array composed of coefficients related to first-order or higher-order terms of variables to be optimized extracted from the objective function.
- the information processing apparatus 100 uses the extracted coefficient matrix to set the coupling constant between spins and the local magnetic field of the optimization machine 10 .
- the information processing device 100 transmits the extracted coefficient matrix to the optimization machine 10 .
- the optimization machine 10 performs annealing processing, calculates a combination of basis spins of the Ising model, and transmits the combination to the information processing apparatus 100 .
- the information processing apparatus 100 receives the combination of basis spins of the Ising model calculated by the optimization machine 10 as a calculation result, and selects a subset from the data set based on the received calculation result.
- FIG. 10 is a diagram illustrating a configuration example of an information processing apparatus according to the present disclosure.
- the information processing device 100 has a communication section 110, a storage section 120, and a control section .
- the information processing apparatus 100 includes an input unit (for example, a keyboard, a mouse, etc.) that receives various operations from an administrator of the information processing apparatus 100, and a display unit (for example, a liquid crystal display, etc.) for displaying various information. may have.
- the communication unit 110 is implemented by, for example, a NIC (Network Interface Card) or the like.
- the communication unit 110 is wired or wirelessly connected to a predetermined network (not shown), and transmits and receives information to and from the optimization machine 10, the terminal device 20, the database 50, and the like. Also, the communication unit 110 may transmit and receive information to and from a user terminal (not shown) used by the user.
- the storage unit 120 is implemented by, for example, a semiconductor memory device such as RAM (Random Access Memory) or flash memory, or a storage device such as a hard disk or optical disk.
- the storage unit 120 according to the first embodiment has a data storage unit 121 and a function information storage unit 122, as shown in FIG.
- the data storage unit 121 stores various data such as data received from the terminal device 20 and the database 50.
- the function information storage unit 122 stores function information such as various programs.
- the function information storage unit 122 stores information of various functions (programs) used for information processing according to the present disclosure.
- the function information storage unit 122 stores function programs such as programs PG1 and PG2.
- the function information storage unit 122 may store information of functions used for processing among the above-described formulas.
- the storage unit 120 may store various types of information, not limited to the above, depending on the purpose.
- control unit 130 uses a CPU, MPU (Micro Processing Unit), or the like to operate a program (for example, an information processing program according to the present disclosure, etc.) stored inside the information processing apparatus 100 in a RAM (Random Access Memory) or the like. It is realized by being executed as a region. Also, the control unit 130 is implemented by an integrated circuit such as an ASIC (Application Specific Integrated Circuit) or FPGA, for example.
- ASIC Application Specific Integrated Circuit
- FPGA Field-programmable gate array
- control unit 130 has an acquisition unit 131, an optimization coefficient extraction unit 132, an optimization machine communication unit 133, a data set selection unit 134, and an output unit 135. Implements or performs the described information processing functions and operations. Note that the internal configuration of the control unit 130 is not limited to the configuration shown in FIG. 10, and may be another configuration as long as it performs information processing to be described later.
- the acquisition unit 131 has the functions of a data reading unit 131a and a user data input unit 131b. Acquisition unit 131 acquires various types of information. Acquisition unit 131 acquires information stored in storage unit 120 . Acquisition unit 131 acquires a data set.
- the acquisition unit 131 acquires tasks corresponding to models to be learned. For example, the acquisition unit 131 acquires information indicating a model that the user wants to learn from the terminal device 20 used by the user. The acquisition unit 131 acquires information indicating the task of the model that the user wants to learn from the terminal device 20 used by the user. For example, the acquisition unit 131 acquires tasks corresponding to models to be learned from the storage unit 120 . The acquisition unit 131 acquires information on a model that the user wants to learn. For example, the acquisition unit 131 acquires information indicating a task corresponding to a model that the user wants to learn from the storage unit 120 in which tasks are stored in association with each model.
- the acquisition unit 131 acquires specification information regarding the size and category of the sample set used for model learning. For example, the acquisition unit 131 acquires designation information regarding the number of data used for model learning. For example, the acquisition unit 131 acquires designation information that designates the number of pieces of data to be used for model learning from the terminal device 20 used by the user. For example, the acquisition unit 131 acquires designation information that designates the number of pieces of data to be selected as a subset from the terminal device 20 used by the user.
- the acquisition unit 131 acquires designation information that designates selection of as few data as possible. For example, when the user does not specify the number of data, the acquisition unit 131 acquires specification information specifying a predetermined number (for example, an initial set number). For example, when the user does not specify the number of data, the acquisition unit 131 acquires specification information specifying a predetermined number (for example, an initial set number) stored in the storage unit 120 .
- a predetermined number for example, an initial set number
- the acquisition unit 131 acquires specification information specifying a predetermined number (for example, an initial set number) stored in the storage unit 120 .
- the acquisition unit 131 receives various information via the communication unit 110 .
- Acquisition unit 131 receives various types of information from an external information processing device.
- the acquisition unit 131 receives data from the terminal device 20 and the database 50 .
- the optimization coefficient extraction unit 132 is an extraction unit that performs information extraction processing.
- the optimization coefficient extractor 132 extracts a coefficient matrix corresponding to the input of the optimization machine 10 from the objective function.
- the optimization coefficient extractor 132 extracts a coefficient matrix.
- the optimization coefficient extraction unit 132 extracts a coefficient matrix corresponding to the Ising coefficients from the objective function.
- the optimization coefficient extracting unit 132 extracts a coefficient matrix from the objective function indicating the information gain according to the task.
- the optimization coefficient extraction unit 132 extracts a coefficient matrix from the objective function regarding the Kullback-Leibler information amount.
- the optimization coefficient extraction unit 132 extracts a coefficient matrix from the objective function expressed as the energy function of the Ising model.
- the optimization coefficient extraction unit 132 extracts a coefficient matrix from the objective function expressed in QUBO format. For example, if the model that the user wants to learn is a regression model and the number of data is not specified, the optimization coefficient extraction unit 132 extracts a coefficient matrix from the objective function as shown in Equation (50). In addition, when the model that the user wants to learn is a regression model and the number of data is specified, the optimization coefficient extraction unit 132 extracts a coefficient matrix from the objective function as shown in Equation (51).
- the optimization coefficient extraction unit 132 extracts a coefficient matrix from the objective function as shown in Equation (60). Also, when the model that the user wants to learn is a two-class classification model and the number of data is specified, the optimization coefficient extraction unit 132 extracts a coefficient matrix from the objective function as shown in Equation (61). For example, if the model that the user wants to learn is a multi-class classification model and the number of data is not specified, the optimization coefficient extraction unit 132 extracts a coefficient matrix from the objective function as shown in Equation (70).
- the optimization coefficient extraction unit 132 extracts a coefficient matrix from the objective function as shown in Equation (71).
- the optimization coefficient extraction unit 132 may extract parameters corresponding to the model that the user wants to learn.
- the optimization coefficient extraction unit 132 extracts the parameter w to be set in the objective function from the model that the user wants to learn.
- the optimization coefficient extraction unit 132 acquires parameters corresponding to the model to be learned from the storage unit 120 .
- the optimization coefficient extraction unit 132 acquires information indicating parameters corresponding to the model that the user wants to learn from the storage unit 120 in which parameters are stored in association with each model.
- the optimization coefficient extraction unit 132 optimizes parameters based on the calculation results received by the optimization machine communication unit 133 from the optimization machine 10 .
- the optimization coefficient extraction unit 132 optimizes parameters other than the parameters optimized by the optimization machine 10 .
- the optimization coefficient extraction unit 132 fixes the binary variable b i based on the calculation result of the optimization machine 10 and updates ⁇ with a normal calculation algorithm.
- the optimization coefficient extraction unit 132 calculates the optimum value of ⁇ using equations (52) and (53).
- the optimization coefficient extraction unit 132 calculates the optimum value of ⁇ using Equation (62) or the like.
- the optimization coefficient extraction unit 132 similarly calculates the optimum value of ⁇ when the model that the user wants to learn is a multi-class classification model.
- the optimization machine communication unit 133 communicates with the optimization machine 10 via the communication unit 110 and transmits and receives information to and from the optimization machine 10 .
- the optimization machine communication unit 133 instructs the optimization machine 10 to perform calculations.
- the optimization machine communication unit 133 transmits parameters of the Ising model to the optimization machine 10 .
- the optimization machine communication unit 133 instructs the optimization machine 10 to perform calculation by transmitting the parameters of the Ising model to the optimization machine 10 .
- the optimization machine communication unit 133 transmits the coefficient matrix extracted by the optimization coefficient extraction unit 132 to the optimization machine 10 that performs combinatorial optimization calculations.
- the optimization machine communication unit 133 receives various information from the optimization machine 10.
- the optimization machine communication unit 133 receives the calculation result of the optimization machine 10 from the optimization machine 10 .
- the optimization machine communication unit 133 transmits the coefficient matrix corresponding to the objective function to the optimization machine 10 that performs combinatorial optimization calculations.
- the optimization machine communication unit 133 receives the calculation result of the combinatorial optimization calculation from the optimization machine 10 .
- the optimization machine communication unit 133 receives from the optimization machine 10 calculation results indicating variables after the combinational optimization calculation.
- the optimizing machine communication unit 133 receives from the optimizing machine 10 calculation results for binary variables each corresponding to data.
- the optimization machine communication unit 133 transmits the coefficient matrix to the optimization machine 10, which is a quantum computer or a combinatorial optimization accelerator.
- the optimization machine communication unit 133 transmits the coefficient matrix to the optimization machine 10 selected by the user from among the plurality of optimization machines 10 .
- the data set selection unit 134 is a selection unit that selects a sample set such as a data set.
- the dataset selection unit 134 selects a subset to be used for model learning from the dataset based on the objective function regarding the amount of information determined according to the task and the number determined using the specified information.
- a dataset selector 134 selects a sample set to optimize an objective function indicative of the information entropy provided to the model.
- Data set selection unit 134 selects a subset based on an objective function that indicates the information gain according to the task.
- the dataset selection unit 134 selects a subset based on an objective function related to the Kullback-Leibler information amount.
- the dataset selection unit 134 selects a subset based on an objective function expressed as an energy function of the Ising model.
- the dataset selection unit 134 selects a subset based on the objective function expressed in QUBO format.
- the dataset selection unit 134 selects subsets based on the calculation results of the optimization machine 10 obtained from the optimization machine 10 .
- the data set selection unit 134 selects data whose binary variable b i corresponding to the data is 1 as data to be added to the subset. Also, based on the calculation result of the optimization machine 10, the data set selection unit 134 does not add data whose binary variable b i corresponding to the data is 0 to the subset. In this way, the data set selection unit 134 generates a subset consisting of data whose binary variable bi is 1 according to the value of the binary variable bi based on the calculation result of the optimization machine 10 .
- the output unit 135 performs information output processing.
- the output unit 135 outputs information about the samples selected by the dataset selection unit 134 .
- the output unit 135 outputs information about the subset.
- the output unit 135 transmits various information via the communication unit 110 .
- the output unit 135 transmits the sample set.
- the output unit 135 transmits the subset as a sample set to the terminal device 20 used by the user.
- the output unit 135 may transmit a learned model learned using a sample set such as a subset to the terminal device 20 used by the user.
- the information processing apparatus 100 may have a learning unit that learns the model. The learning unit of the information processing device 100 learns the trained model using the subset.
- the information processing device 100 may also acquire a trained model trained using a subset from an external device (referred to as a "learning device") that executes learning processing for learning the model.
- the information processing apparatus 100 may transmit the subset to the learning device and receive from the learning device the trained model that the learning device has learned through the learning process. The information processing device 100 then transmits the trained model received from the learning device to the terminal device 20 .
- the information processing apparatus 100 may have a content generation unit that generates various types of content such as the content CT1.
- the content generator generates content to be provided to the terminal device 20 .
- the content generation unit generates content using various technologies such as Java (registered trademark) as appropriate.
- the content generation unit may generate the content CT1 or the like based on the format of CSS, JavaScript (registered trademark), or HTML.
- the content generation unit may generate the content CT1 or the like in various formats such as JPEG (Joint Photographic Experts Group), GIF (Graphics Interchange Format), and PNG (Portable Network Graphics).
- FIG. 11 is a diagram illustrating a configuration example of an optimization machine.
- the configuration of an optimization machine 10a which is a quantum computer, will be described.
- the optimization machine 10a has a communication section 11, a storage section 12, a quantum device section 13, and a control section .
- the optimization machine 10a has an input unit (for example, a keyboard, a mouse, etc.) that receives various operations from the administrator of the optimization machine 10a, and a display unit (for example, a liquid crystal display, etc.) for displaying various information. may have.
- the communication unit 11 is implemented by, for example, a NIC, a communication circuit, or the like.
- the communication unit 11 is connected to a predetermined network (such as the Internet) by wire or wirelessly, and transmits and receives information to and from other devices such as the information processing device 100 via the network.
- a predetermined network such as the Internet
- the storage unit 12 is implemented by, for example, a semiconductor memory device such as a RAM or flash memory, or a storage device such as a hard disk or optical disc.
- the storage unit 12 stores various types of information used for displaying information.
- the quantum device unit 13 executes various quantum calculations.
- the quantum device section 13 is realized by a quantum processing unit (QPU: Quantum Processing Unit).
- QPU Quantum Processing Unit
- the quantum device unit 13 realizes the ground state of the Ising model, for example, based on the parameters of the Ising model received from another device such as the information processing device 100 .
- the quantum device unit 13 realizes the optimum spin arrangement in which the Ising model is in the ground energy state. That is, the quantum device unit 13 realizes a state in which the optimization problem is optimized.
- the quantum device unit 13 is composed of, for example, a plurality of quantum bits.
- the quantum device section 13 is previously cooled to near absolute zero.
- the quantum device unit 13 internally evolves the ratio between the Ising model and the horizontal magnetic field model (quantum fluctuation model) over time.
- an optimum spin arrangement corresponding to the parameters of the Ising model is realized on the quantum device section 13 .
- the optimum spin arrangement of the Ising model is physically realized on the quantum device section 13 .
- the quantum device unit 13 can optimize the discrete optimization problem.
- the quantum device unit 13 can optimize a binary quadratic objective function optimization problem.
- the control unit 14 is realized, for example, by executing a program stored inside the optimization machine 10a using a RAM or the like as a work area by a CPU, MPU, or the like. Also, the control unit 14 is a controller, and may be implemented by an integrated circuit such as an ASIC or FPGA, for example.
- control unit 14 has an acquisition unit 141, a calculation unit 142, and a transmission unit 143, and implements or executes the information processing functions and actions described below.
- the internal configuration of the control unit 14 is not limited to the configuration shown in FIG. 11, and may be another configuration as long as it performs information processing described later.
- the acquisition unit 141 receives various information. Acquisition unit 141 receives various types of information from an external information processing device. Acquisition unit 141 receives various types of information from other information processing apparatuses such as information processing apparatus 100 .
- the acquisition unit 141 performs calculation using the quantum device unit 13 and receives an instruction for measurement from another information processing apparatus such as the information processing apparatus 100 .
- the acquisition unit 141 receives parameters of the Ising model as an instruction for calculation (measurement) by the quantum device unit 13 .
- the acquisition unit 141 acquires various types of information. Acquisition unit 141 acquires information from storage unit 12 . The acquisition unit 141 acquires various types of information from an external information processing device such as the information processing device 100 . Acquisition unit 141 acquires input information accepted by the input unit. For example, the acquisition unit 141 acquires information about parameters of the Ising model from an external information processing device. The acquisition unit 141 acquires the measurement result (calculation result) of the quantum device unit 13 by the calculation unit 142 .
- the calculation unit 142 executes various calculations.
- the calculation unit 142 executes calculation using the quantum device unit 13 .
- the calculation unit 142 measures the quantum device unit 13 .
- the calculation unit 142 measures the quantum device unit 13 in which the optimum spin arrangement of the Ising model is realized.
- the calculation unit 142 performs calculation using the Ising parameters received by the acquisition unit 141 from the information processing device 100 .
- the transmission unit 143 transmits various types of information to an external information processing device. For example, the transmission unit 143 transmits various information to other information processing devices such as the information processing device 100 . The transmission unit 143 transmits information stored in the storage unit 12 .
- the transmission unit 143 transmits various types of information based on information from other information processing devices such as the information processing device 100 .
- the transmission unit 143 transmits various information based on the information stored in the storage unit 12 .
- the transmission unit 143 transmits the measurement result of the quantum device unit 13 by the calculation unit 142 to the device that instructed the calculation.
- the transmission unit 143 transmits the measurement result of the quantum device unit 13 by the calculation unit 142 to the parameter transmission source.
- the transmission unit 143 transmits the measurement result of the quantum device unit 13 by the calculation unit 142 to the calculation request source.
- the transmission unit 143 transmits the measurement result of the quantum device unit 13 by the calculation unit 142 to another information processing apparatus such as the information processing apparatus 100 .
- the transmission unit 143 transmits to the information processing device 100 the Ising spin value calculated (measured) using the parameters received from the information processing device 100 .
- the information processing device 100 provides various information to the terminal device 20 in response to a request from the terminal device 20 .
- FIG. 12 is a diagram showing an example of a list of classes.
- Content CT2 shown in FIG. 12 shows a list of sample images for each of a plurality of classes such as "mouse”, “cow”, "tiger”, and "tatsu”.
- the information processing device 100 may accept selection of a class that the user wants to study from the terminal device 20 .
- the information processing apparatus 100 may provide content CT3 as shown in FIG. 13 to the terminal device 20 and accept the user's class selection via the content CT3.
- FIG. 13 is a diagram showing an example of selection of a class that the user wants to study.
- the content CT3 shown in FIG. 13 is content for receiving the user's selection of class CL1 corresponding to "mouse", class CL2 corresponding to "cow", and the like.
- the information processing device 100 receives from the terminal device 20 information indicating which class the user has selected. For example, a user may set the request type to "all known" if all classes are known.
- the information processing apparatus 100 may request the terminal apparatus 20 for (negative) data suitable for classes and tasks that are not handled.
- the information processing apparatus 100 receives class and task data that the terminal device 20 wants to handle from the terminal device 20 .
- the information processing apparatus 100 may provide content CT4 as shown in FIG. 14 to the terminal device 20 and receive data from the user via the content CT4.
- FIG. 14 is a diagram showing an example of receiving data from a user.
- the content CT4 shown in FIG. 14 shows an example of receiving data of the class "day lily".
- the information processing apparatus 100 may check whether there is a class similar to the class or data set, and if there is a similar one, notify the user. For example, if there is a similar class, the information processing device 100 may send a message to the terminal device 20 used by the user, saying, "Isn't this class correct?" The terminal device 20 outputs the received message. After confirming that the class is new, the information processing apparatus 100 may proceed to actual optimum learning data selection processing.
- the information processing system 1 described above may be used for various purposes such as classification of specific domains. In this regard, some examples are given below. In addition, the target to which the information processing system 1 is applied is not limited to the examples shown below.
- the former is for the machine learning industry, such as imagenet classification
- the latter is for businesses and individual users.
- Examples of businesses include Web services such as picture books.
- Examples for individual users include general users who want to create original recognition modules by collecting pictures and voices of wild birds.
- the purpose of the fifth embodiment is to generate a macaque image classifier (hereinafter simply referred to as a "classifier") that classifies macaque images in the animal classification map.
- a macaque image classifier hereinafter simply referred to as a "classifier”
- Prerequisites for the fifth embodiment are as follows. ⁇ Only Cercopithecidae should be input. ⁇ A sufficient number of images have been collected for all classes of macaques. ⁇ There is no data for Cercopithecidae other than macaques. I want only a dataset ⁇ The server side has a large amount of data of all classes of the animal kingdom classification map ⁇ The server side has a general-purpose image feature extractor
- FIG. 15 is a diagram showing a fifth embodiment to which the information processing system is applied. It should be noted that descriptions of the same points as those described above will be omitted as appropriate. First, each component shown in FIG. 15 will be described.
- the animal lineage data set 50-1 is an animal image data set.
- Animal strain data set 50-1 corresponds to database 50 described above.
- the animal strain data set 50-1 is a huge data set with 100 images for each of all animal kingdom classes.
- the Cercopithecidae reading unit 131a-1 has a function of acquiring Cercopithecidae data.
- the Cercopithecidae reader 131a-1 corresponds to the data reader 131a described above.
- the Cercopithecidae reading unit 131a-1 is a module that reads all data of all classes of Cercopithecidae.
- the Cercopithecidae reading unit 131a-1 acquires Cercopithecidae data from the animal strain data set 50-1.
- the Cercopithecidae reading unit 131a-1 as shown in the first target group TG1 in FIG. Get the image data of
- the macaque image input unit 131b-1 has a function of acquiring macaque data.
- the macaque image input unit 131b-1 corresponds to the above-described user data input unit 131b.
- the macaque genus image input unit 131b-1 acquires 100 data sets for each of all macaque genus classes prepared by the client (also referred to as “user”) side.
- the macaque genus image input unit 131b-1 acquires image data of each of a plurality of classes belonging to the macaque genus, as shown in the second target group TG2 in FIG.
- the data set merging unit 231 has a function of merging Cercopithecidae images (other than macaques) and input macaque images.
- the data set merging unit 231 merges the first image group acquired by the Cercopithecidae reading unit 131a-1 and the second image group acquired by the macaque image input unit 131b-1 to obtain a third image group. to generate
- the combinatorial optimization execution unit 232 has a function of executing combinatorial optimization processing based on merge data.
- the optimal combination execution unit 232 corresponds to the optimization coefficient extraction unit 132 and the optimization machine communication unit 133 .
- the combinatorial optimum execution unit 232 extracts a coefficient matrix, transmits the extracted coefficient matrix to the optimization machine 10, and receives calculation results from the optimization machine 10. FIG.
- the dataset selection unit 134 in FIG. 15 corresponds to the dataset selection unit 134 described above.
- the data set selection unit 134 has a function of selecting optimum data based on the result of combinatorial optimization processing by the combinatorial optimum execution unit 232 .
- the data set selection unit 134 selects subsets from the merged data based on the result of combinatorial optimization processing by the combinatorial optimization execution unit 232 .
- the non-macaque image output unit 135-1 has a function of outputting a non-macaque data set selected from the Cercopithecidae set.
- the non-macaque image output unit 135-1 corresponds to the output unit 135 described above.
- the non-macaque image output unit 135-1 outputs data of the selected subset other than macaques.
- the non-macaque image output unit 135-1 outputs image data included in the first image group in the selected subset as image data other than macaques.
- the optimization machine 10 corresponds to the optimization machine 10 described above.
- the optimization machine 10 inputs the coefficient matrix (QUBO matrix) created by the combination optimization execution unit 232 and outputs the combination result.
- QUBO matrix coefficient matrix
- FIG. 16 is a flow chart showing the procedure of processing in the fifth embodiment.
- FIG. 16 is an example of the flow of processing in the fifth embodiment by the information processing system 1.
- FIG. 1 a case where the information processing apparatus 100 is the processing subject will be described as an example, but the processing subject is not limited to the information processing apparatus 100 and may be any device included in the information processing system 1 .
- the information processing apparatus 100 receives data from the client (step S201).
- the information processing device 100 acquires data from the terminal device 20 used by the user.
- the information processing apparatus 100 receives various information from clients.
- the information processing apparatus 100 acquires information indicating a domain for which data is desired, such as Cercopithecidae.
- the information processing apparatus 100 acquires information indicating a class that already exists on the client side, such as a class within the macaque genus.
- the information processing apparatus 100 acquires a data set that already exists on the client side.
- the information processing device 100 collects data from the database (step S202). For example, the information processing apparatus 100 acquires necessary data from the database 50 such as the animal strain data set 50-1. For example, the information processing apparatus 100 collects necessary data from a database 50 having animal image sets and the like. Also, for example, the information processing apparatus 100 acquires a data set excluding positive classes, such as classes within the genus Macaque, of the domain (Cercopithecidae) specified by the client.
- the information processing device 100 calculates inputs to the optimization machine from the collected data (step S203). For example, the information processing apparatus 100 calculates a coefficient matrix as an input to the optimization machine 10 from the collected data.
- the information processing device 100 generates subsets based on the output of the optimization machine (step S204). For example, the information processing apparatus 100 transmits a coefficient matrix to the optimization machine 10 and receives calculation results calculated by the optimization machine 10 from the optimization machine 10 . For example, the information processing device 100 selects a subset from the collected data based on the calculation results of the optimization machine 10 . Thus, the information processing apparatus 100 selects the optimum subset from the dataset.
- the optimal subset is qualitatively a combination of data that are similar, for example, to the input data and dissimilar to each other.
- the information processing device 100 selects a subset according to the following procedure.
- the information processing apparatus 100 generates a feature quantity set from a data set using an existing feature extractor.
- the information processing apparatus 100 then generates input data to the optimization machine 10 from the feature set.
- the input data is, for example, a coefficient matrix in binary quadratic form formulation of information amount gain.
- the information processing apparatus 100 acquires information indicating a data combination that maximizes the information amount gain from the optimization machine 10 .
- the information processing apparatus 100 selects a subset based on the acquired information indicating the combination.
- the information processing device 100 provides the subset to the client (step S205). For example, the information processing apparatus 100 presents the subset to the client side. For example, the information processing device 100 transmits the subset to the terminal device 20 used by the user.
- the client collects the data of the class that it wants to classify. For example, the client collects image data for several types of macaques.
- the client sends class data to the information processing apparatus 100 and requests provision of extra-class data.
- the client specifies a domain (Cercopithecidae) from a browser or the like presented by the information processing apparatus 100 .
- the client specifies a collected class (such as species within the Macaque genus) instead of the class it wishes to be served.
- the client receives out-of-class data.
- the terminal device 20 used by the user receives data from the information processing device 100 .
- the client also utilizes out-of-class data to obtain in-class and out-of-class discriminators.
- the client trains the classifier with the collected class data and the provided out-of-class data.
- the terminal device 20 used by the user learns a discriminator (model) using the data it owns and the data received from the information processing device 100 .
- the client makes it possible to use the learned discriminator in combination with the class classifier learned from the collected class data.
- the terminal device 20 used by the user performs a first process, which is a process for determining whether an image is an image of the genus Macaque, using a discriminator. uses a classifier to perform a second process of classifying the type of macaques contained in the image.
- FIG. 17 is a diagram showing the flow of image determination processing.
- the terminal device 20 is the subject of processing
- the subject of processing is not limited to the terminal device 20 and may be any device included in the information processing system 1 .
- the terminal device 20 performs processing to determine whether the image IM1 to be processed is an image of the genus Macaque (step S301). For example, the terminal device 20 inputs the image IM1 to a discriminator, and determines whether the image IM1 is an image of the genus Macaques based on the output result of the discriminator.
- the terminal device 20 ends the process without performing the second process. For example, when it is determined in the first process that the image IM1 is not an image of the genus Macaques, the terminal device 20 outputs a result RS1 indicating that the image is not of the genus Macaques, and ends the process.
- the terminal device 20 performs a process of classifying the object included in the image IM1 as belonging to the genus Macaques (step S302). For example, the terminal device 20 inputs the image IM1 to a classifier, and classifies the object included in the image IM1 as belonging to the genus Macaques based on the output result of the classifier. In FIG. 17, the terminal device 20 outputs a result RS2 indicating that the object included in the image IM1 is a Japanese macaque belonging to the genus Macaques, and ends the process.
- the bandgap of a semiconductor is an important physical quantity that determines the properties of various functions of semiconductors.
- the measurement requires time and effort by experts in the field, so it is desirable to select samples to be measured as efficiently as possible.
- the magnetic susceptibility of a magnetic material, the dielectric constant of a dielectric, etc. are also important physical quantities that determine the characteristics of their respective functions, but their measurement requires a special measuring instrument. This applies not only to inorganic compounds but also to functional materials such as organic compounds.
- biomolecules particularly genetic testing
- biomolecules usually include proteins, RNA (Ribonucleic Acid), DNA (Deoxyribonucleic Acid), and the like. All biomolecules are macromolecules composed of one-dimensional arrays of basic molecular structures, and various macroscopic functions of living organisms based on each biomolecule are arranged in a determined region of the one-dimensional arrays. It is known to be determined by patterns.
- Proteins are also known as the basic biomolecules that make up the body and structure of living organisms. There are a huge number of types of proteins in the world, but all of them consist of 20 (21) types of amino acids arranged in a one-dimensional array with a length of several thousand to hundreds of millions. A large number of proteins are known that have unique functions depending on the pattern of the regions of .
- proteins include, for example, activating enzymes (enzymes), forming biostructures (e.g. collagen and keratin), transporting lipids and cholesterol (e.g. albumin, apolipoprotein), nutrition and ions. stores (e.g. ovalbumin, ferritin, hemosiderin), constitutes muscles and participates in movement (e.g. actin, myosin), participates in immune functions called antibodies (e.g. globulin), and converts proteins based on DNA information It participates in the expression function of synthesis, regulates the action of other proteins (for example, calmodulin), and the like.
- activating enzymes e.g. collagen and keratin
- transporting lipids and cholesterol e.g. albumin, apolipoprotein
- nutrition and ions ions. stores (e.g. ovalbumin, ferritin, hemosiderin)
- constitutes muscles and participates in movement e.g. actin, myosin
- RNA and DNA are known as biomolecules that are the substance of genes. be. Similar to proteins, RNA and DNA also have sequences of basic units, each of which consists of deoxyribose (pentose), nucleic acid, and four types of bases (adenine (A), guanine (G), cytosine (C ) or thymine (T)) is a polymer in which deoxynucleotides are arranged in a one-dimensional array.
- RNA and DNA, like proteins have unique functions according to their sequence (code) patterns.
- the basic functions of DNA and RNA are self-replication (transcription) and protein synthesis, but more detailed functions (blocks) of transcription and synthesis include, for example, the translation function for protein synthesis in messenger RNA, Functions of transcription activity by promoter DNA and the like can be mentioned.
- a coding region is a region whose correspondence with the protein to be produced or information on the traits of the organism as a result thereof has been clarified.
- the non-coding region is a region that has not been clearly related to the protein to be produced or the trait of the organism that expresses it, and has been thought to be a region unrelated to genetic information at first glance.
- non-coding regions have a low correlation with genetic information and have not been investigated much.
- DNA and the like the idea of actively analyzing information from regions other than the coding region and utilizing it for analysis of its functions is progressing.
- certain intractable neurological diseases are caused by the accumulation of abnormal proteins ( ⁇ -ciscrein, Lewy bodies, etc.) in brain cells.
- abnormal proteins ⁇ -ciscrein, Lewy bodies, etc.
- the region that is considered to be related to this abnormal protein is known from examples of familial (hereditary) cases, etc., but in the case of a sporadic type that is not familial (hereditary), which region is It is not clear whether they are involved.
- the information processing system 1 efficiently searches these proteins, RNA, and DNA for new sequence patterns unique to their respective functions, and is used to discover new functions from the searched patterns. be able to.
- the information processing system 1 utilizes predictive models to acquire new information from the data set.
- the prediction model here means that, when a sequence pattern of biomolecules is input, a prediction value or probability distribution score that the sequence pattern has that function is output.
- a prediction model discrimination model
- a data set of correspondence relationships such as sequence patterns and predicted values of functions is required. This data set is constructed by measuring information about the function to be predicted for each of a large number of sequence patterns. Alternatively, it may be obtained by reverse lookup based on function information from a known database.
- procedure #2 Learning statistical prediction model by machine learning
- procedure #2 will be described.
- the information processing system 1 designs a prediction model with parameters and obtains the parameters by machine learning technology.
- a typical prediction model is a neural network, and parameters can be obtained by deep learning.
- the design of the prediction model differs depending on the function to be predicted, but the design policy can be roughly summarized as follows.
- ⁇ The input layer is configured to allow input of array pattern information.
- the middle tier is configured based on the developer's settings.
- ⁇ The output layer is configured according to the function to be predicted.
- the design guideline (a) is the following policy.
- the final layer is a linear layer. If the evaluation value is a continuous value, a prediction model based on a regression model is adopted. In the case of a neural network prediction model, a linear layer is used as the final layer (output layer). By using a linear layer as the output layer, it is possible to use the regression model as described in the third embodiment. If it is desired to predict not only the predicted values of continuous values themselves, but also their standard deviations and variances, a variational autocoder may be used to produce average predicted values and variance predicted values. A regression model is trained to minimize the squared error. Variational autoencoders learn to maximize the lower bound of the log-likelihood considering the variance (often not including the covariance).
- the design guideline (b) is the following policy.
- Two-class classification uses a linear layer with a logistic regression function in the final layer, as described in the third example.
- a logistic regression function is a function that outputs a value between 0 and 1 for any given input. We learn this structure to minimize its entropy, or logistic entropy, as approximating a probability between 0 and 1.
- the design guideline (c) is the following policy.
- Multi-class classification uses a linear layer with a softmax function as the final layer, as described in the third embodiment.
- a softmax function is a function where for any input, the output is the score of any of the possible classes, but these scores are normalized so that all scores add up to 1. This structure can be learned to be viewed as a multi-class probability value in multi-class classification. Training is done to minimize the softmax entropy.
- the above is the design method for the output layer of a commonly used neural network prediction model.
- procedure #3 Selection of optimal sample by information processing system 1
- the prediction model has been constructed by the above procedure, the following is the main scope of application of the information processing system 1 in the sixth embodiment.
- the sample information can be provided.
- a guideline for increasing the amount of information is adopted as a guideline for selecting an appropriate sample from a huge area.
- the greedy method is generally used as a general-purpose approximation method.
- the greedy method is a method of efficiently searching a huge search area and is less likely to cause an explosion in computation time. Therefore, if appropriate samples are selected by this method, appropriate samples can be efficiently selected.
- the greedy method is versatile and fast, we would like to adopt it if there is a better approximation.
- quantum annealing which is guaranteed to reach the optimal solution under ideal conditions (conditions where adiabatic approximation is satisfied), narrows the huge search area.
- the method and formulation are as described in the first to fourth embodiments.
- quantum annealing there is also a simulation of thermal annealing (simulated annealing) as an example in which it is guaranteed that the optimal solution is reached.
- procedure #4 Analysis of Selected Samples
- procedure #4 will be described. Finally, analyzes are performed on selected samples. The original purpose is to determine whether a sample has a function or not, to classify the function into categories, or to quantify the degree of function.
- the prediction model that is, the knowledge that has already been analyzed, is moderately ambiguous, so it is possible to construct an efficient data set by evaluating from samples that provide a large amount of information.
- new sequence patterns especially from non-coding regions
- new functions common to these sequence patterns not only the prediction model but also the researchers themselves can use their own knowledge. can be expanded effectively.
- the processes according to the above-described embodiments and modifications may be implemented in various different forms (modifications) other than the above-described embodiments and modifications.
- the data set that is the population from which subsets are selected may be read as "first data set”
- the subset selected from the first data set may be read as "second data set”.
- the information processing device 100 and the optimization machine 10 are separate entities, but the information processing device 100 and the optimization machine 10 may be integrated.
- the optimization machine 10 may be placed on the edge side.
- the information processing apparatus 100 and the optimization machine 10 may be integrated.
- each component of each device illustrated is functionally conceptual and does not necessarily need to be physically configured as illustrated.
- the specific form of distribution/integration of each device is not limited to the illustrated one, and all or part of them can be functionally or physically distributed/integrated in arbitrary units according to various loads and usage conditions. Can be integrated and configured.
- the information processing apparatus includes an acquisition unit (for example, corresponding to the acquisition unit 131 in the embodiment), a selection unit (for example, data corresponding to the set selection unit 134).
- the acquisition unit acquires the data supply method, the model to be learned, and specification information regarding the size and category of the sample set used for learning the model.
- the selection unit selects a sample set to be used for learning the model from the data set based on the information entropy determined according to the model and the specified information.
- the information processing device selects a sample set from the data set based on the objective function determined according to the model to be learned and the specified information. This allows the information processing device to select an appropriate sample set from the data set.
- the data supply method is data supply from the dataset, and the sample set is a subset of the dataset.
- the information processing device can select an appropriate sample set from the dataset by receiving data supply from the dataset and selecting a subset of the dataset as the sample set.
- the model you want to learn is a predictive model with learning parameters, and the task of the model is the type of output corresponding to the input.
- the information processing apparatus can select an appropriate sample set from the data set by selecting the prediction model with the learning parameter as the model to be learned.
- the information entropy brought to the model is the information entropy calculated using the Kullback-Leibler information amount (sometimes referred to as the "Kullback-Leibler information amount") or the Fisher information amount.
- the information processing apparatus selects a sample set from the dataset based on the information entropy calculated using the Kullback-Leibler information amount or the Fisher information amount. A sample set can be selected.
- the selection unit also selects the sample set so as to optimize the objective function that indicates the information entropy brought to the model.
- the information processing device can select an appropriate sample set from the data set by selecting the sample set so as to optimize the objective function indicating information entropy.
- the selection unit selects a sample set based on an objective function expressed in QUBO (Quadratic Unconstrained Binary Optimization) format.
- QUBO Quadrattic Unconstrained Binary Optimization
- the information processing device also includes an optimization machine communication unit (for example, corresponding to the optimization machine communication unit 133 in the embodiment).
- the optimization machine communication unit transmits the coefficient matrix corresponding to the objective function to the optimization machine (for example, corresponding to the optimization machine 10 in the embodiment) that performs the combinatorial optimization calculation, and the optimization machine performs the combinatorial optimization calculation.
- the selection unit selects a sample set based on the calculation result. In this way, the information processing device can select an appropriate sample set from the data set by selecting the sample set from the data set based on the objective function indicating the gain using the calculation result of the optimization machine. can.
- the optimization machine communication unit receives calculation results indicating variables after combination optimization calculation from the optimization machine.
- the information processing device can select an appropriate sample set from the data set by selecting the sample set from the data set using the variables after the combinatorial optimization calculation received from the optimization machine. .
- the optimizing machine communication unit receives from the optimizing machine the calculation results regarding the binary variables each corresponding to the data.
- the information processing device can select an appropriate sample set from the data set by selecting the sample set from the data set using the optimized binary variables received from the optimization machine.
- the optimization machine communication unit transmits the coefficient matrix to the quantum computer or the combinatorial optimization accelerator.
- the information processing device can select an appropriate sample set from the data set by selecting the sample set from the data set using the calculation results from the quantum computer or the combinatorial optimization accelerator.
- the optimization machine communication unit transmits the coefficient matrix to the optimization machine selected by the user from among the plurality of optimization machines.
- the information processing device can select a sample set according to the user's selection by transmitting the coefficient matrix to the optimization machine selected by the user from among a plurality of optimization machines.
- a suitable sample set can be selected from the dataset.
- the information processing device also includes an extraction unit (for example, corresponding to the optimization coefficient extraction unit 132 in the embodiment).
- the extraction unit extracts the coefficient matrix.
- the optimization machine communication unit transmits the coefficient matrix extracted by the extraction unit to the optimization machine. In this way, the information processing device can receive appropriate calculation results from the optimization machine by transmitting the extracted coefficient matrix to the optimization machine, and can select an appropriate sample set from the data set. can.
- the extraction unit extracts a coefficient matrix corresponding to the Ising coefficient from the objective function.
- the information processing apparatus can receive appropriate calculation results from the optimization machine by transmitting the coefficient matrix corresponding to the Ising coefficients extracted from the objective function to the optimization machine, and can receive appropriate calculation results from the data set. sample set can be selected.
- the acquisition unit acquires a model that is a prediction model that the user wants to learn.
- the information processing device can select an appropriate sample set from the data set for the prediction model that the user wants to learn.
- the information processing device also includes an output unit (for example, corresponding to the output unit 135 in the embodiment).
- the output unit outputs information about the sample set selected by the selection unit. In this way, the information processing device can provide appropriate information according to the selected sample set by outputting information about the selected sample set.
- the output unit transmits the sample set to the terminal device used by the user (for example, corresponding to the terminal device 20 in the embodiment).
- the information processing device can provide the selected sample set to the user by transmitting the sample set to the terminal device used by the user.
- the output unit transmits the trained model trained using the sample set to the terminal device used by the user.
- the information processing device can provide the user with an appropriately trained model by transmitting the trained model trained using the sample set to the terminal device used by the user.
- FIG. 18 is a hardware configuration diagram showing an example of a computer that implements the functions of the information processing apparatus.
- the information processing apparatus 100 will be described below as an example.
- the computer 1000 has a CPU 1100 , a RAM 1200 , a ROM (Read Only Memory) 1300 , a HDD (Hard Disk Drive) 1400 , a communication interface 1500 and an input/output interface 1600 .
- Each part of computer 1000 is connected by bus 1050 .
- the CPU 1100 operates based on programs stored in the ROM 1300 or HDD 1400 and controls each section. For example, the CPU 1100 loads programs stored in the ROM 1300 or HDD 1400 into the RAM 1200 and executes processes corresponding to various programs.
- the ROM 1300 stores a boot program such as BIOS (Basic Input Output System) executed by the CPU 1100 when the computer 1000 is started, and programs dependent on the hardware of the computer 1000.
- BIOS Basic Input Output System
- the HDD 1400 is a computer-readable recording medium that non-temporarily records programs executed by the CPU 1100 and data used by such programs.
- the HDD 1400 is a recording medium that records an information processing program such as an information processing program according to the present disclosure, which is an example of the program data 1450 .
- a communication interface 1500 is an interface for connecting the computer 1000 to an external network 1550 (for example, the Internet).
- CPU 1100 receives data from another device via communication interface 1500, and transmits data generated by CPU 1100 to another device.
- the input/output interface 1600 is an interface for connecting the input/output device 1650 and the computer 1000 .
- the CPU 1100 receives data from input devices such as a keyboard and mouse via the input/output interface 1600 .
- the CPU 1100 also transmits data to an output device such as a display, speaker, or printer via the input/output interface 1600 .
- the input/output interface 1600 may function as a media interface for reading a program or the like recorded on a predetermined recording medium.
- Media include, for example, optical recording media such as DVD (Digital Versatile Disc) and PD (Phase change rewritable disk), magneto-optical recording media such as MO (Magneto-Optical disk), tape media, magnetic recording media, semiconductor memories, etc. is.
- the CPU 1100 of the computer 1000 implements the functions of the control unit 130 and the like by executing an information processing program such as an information processing program loaded on the RAM 1200 .
- the HDD 1400 also stores an information processing program such as an information processing program according to the present disclosure, and data in the storage unit 120 .
- CPU 1100 reads and executes program data 1450 from HDD 1400 , as another example, these programs may be obtained from another device via external network 1550 .
- the present technology can also take the following configuration.
- an acquisition unit that acquires a data supply method, a model to be learned, and specification information regarding the size and category of a sample set used for learning the model; a selection unit that selects a sample set to be used for learning the model from a data set based on the information entropy determined according to the model and the specified information; Information processing device.
- the data supply method is data supply from the dataset, and the sample set is a subset of the dataset.
- the model to be learned is a prediction model with learning parameters, and the task of the model is the type of output corresponding to the input.
- the information processing device according to (1) or (2).
- the information entropy provided to the model is the information entropy calculated using the Kullback-Leibler information quantity or the Fisher information quantity.
- the information processing device according to any one of (1) to (3).
- the selection unit The information processing apparatus according to any one of (1) to (4), wherein the sample set is selected so as to optimize an objective function indicative of information entropy provided to the model.
- the selection unit The information processing apparatus according to (5), wherein the sample set is selected based on the objective function expressed in QUBO (Quadratic Unconstrained Binary Optimization) format.
- an optimization machine communication unit that transmits a coefficient matrix corresponding to the objective function to an optimization machine that performs combinatorial optimization calculations and receives calculation results of the combinatorial optimization calculations from the optimization machine; with The selection unit The information processing apparatus according to (5) or (6), wherein the sample set is selected based on the calculation result.
- the optimization machine communication unit The information processing device according to (7), wherein the calculation result indicating the variable after the combinatorial optimization calculation is received from the optimization machine.
- the optimization machine communication unit The information processing apparatus according to (8), wherein the calculation results for binary variables each corresponding to data are received from the optimization machine.
- the optimization machine communication unit The information processing device according to any one of (7) to (9), which transmits the coefficient matrix to a quantum computer or a combinatorial optimization accelerator.
- the optimization machine communication unit The information processing apparatus according to any one of (7) to (10), wherein the coefficient matrix is transmitted to the optimization machine selected by the user from among a plurality of optimization machines.
- an extraction unit that extracts the coefficient matrix; with The optimization machine communication unit The information processing apparatus according to any one of (7) to (11), wherein the coefficient matrix extracted by the extraction unit is transmitted to the optimization machine.
- the extractor is The information processing device according to (12), wherein the coefficient matrix corresponding to the Ising coefficient is extracted from the objective function.
- the acquisition unit The information processing apparatus according to any one of (1) to (13), wherein the model, which is a prediction model that a user wants to learn, is acquired.
- an output unit that outputs information about the sample set selected by the selection unit; The information processing apparatus according to any one of (1) to (14).
- the output unit The information processing device according to (15), wherein the sample set is transmitted to a terminal device used by a user.
- the output unit The information processing device according to (15) or (16), wherein a trained model learned using the sample set is transmitted to a terminal device used by a user.
- information processing system 100 information processing device 110 communication unit 120 storage unit 121 data storage unit 122 function information storage unit 130 control unit 131 acquisition unit 132 optimization coefficient extraction unit 133 optimization machine communication unit 134 data set selection unit 135 output unit 10 Optimization Machine 11 Communication Unit 12 Storage Unit 13 Quantum Device Unit 14 Control Unit 141 Acquisition Unit 142 Calculation Unit 143 Transmission Unit 20 Terminal Device 50 Database
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Software Systems (AREA)
- Physics & Mathematics (AREA)
- General Physics & Mathematics (AREA)
- Data Mining & Analysis (AREA)
- Artificial Intelligence (AREA)
- Evolutionary Computation (AREA)
- Mathematical Physics (AREA)
- General Engineering & Computer Science (AREA)
- Computing Systems (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Medical Informatics (AREA)
- Pure & Applied Mathematics (AREA)
- Mathematical Optimization (AREA)
- Mathematical Analysis (AREA)
- Computational Mathematics (AREA)
- Condensed Matter Physics & Semiconductors (AREA)
- Computational Linguistics (AREA)
- Management, Administration, Business Operations System, And Electronic Commerce (AREA)
Abstract
Description
1.概要
1-1.背景(課題等)
1-2.本開示の概要(処理・効果等)
2.第1の実施例
2-1.情報処理システムの装置構成
2-2.情報処理システムの全体処理フロー
2-3.情報処理システムのブロック全体像
2-3-1.最適化マシン
2-3-2.ユーザインターフェース
2-3-2-1.ユーザインターフェース部(データ入力部)
2-3-2-2.ユーザインターフェース部(マシン選択部)
2-3-2-3.ユーザインターフェース部(データ出力部)
2-3-3.情報処理装置(メインブロック)
3.第2の実施例
3-1.量子アニーリングと組合せ最適化問題
3-2.データセットからのサンプル抽出最適化
3-3.リサンプリング最適化の量子アニーリング等への実装
4.第3の実施例
4-1.回帰モデル
4-2.二クラス分類モデル
4-3.多クラス分類モデル
5.第4の実施例
5-1.情報処理のメインプログラム例
5-2.データ選択最適化の処理フロー例
5-3.データ選択最適化の処理プログラム例
6.情報処理装置の構成
7.最適化マシンの構成
8.ユーザへの提示例
8-1.クラスのリスト
8-2.クラスの選択
8-3.データの受付け
9.適用例
9-1.第5の実施例(画像分類)
9-2.第6の実施例(生体分子)
10.その他の構成例等
10-1.その他の構成例
10-2.プログラムやパラメータ等の処理に用いる情報の生成方法
10-3.その他
11.本開示に係る効果
12.ハードウェア構成
本開示の詳細を説明する前に、本開示に係る技術的な背景の概要及び本開示の概要について説明する。なお、以下の技術的な説明の中で従来技術に関する詳細な説明は適宜省略する。
まず、本開示に関連する課題について以下詳述する。深層学習等の機械学習においては、モデルの学習に用いるデータセットの収集は容易ではなく、データセットを収集するコストの軽減は課題の一つである。データセットを収集するコストの削減を、学習方法で解決しようとする試みはいくつか知られており、例えば以下の三つの学習方法が挙げられる。
・半教師学習: ラベリングされてないデータをそのまま活用する学習方法
・能動学習: ラベリングされてないデータをラベリングしながら学習する方法
・転移学習: 別のデータセットで学習済みのモデルを活用する学習方法
そこで、以下で詳細を説明する情報処理システム1(図1参照)は、例えばユーザからモデルが提示された場合、情報処理システム1がアクセスできるデータセットから、ユーザのモデルにとって最も効率よく情報をもたらすサブセットを提供する。
[2-1.情報処理システムの装置構成]
まず、図1に示す情報処理システム1の構成について説明する。図1は、本開示の情報処理システムの構成例を示す図である。図1に示すように、情報処理システム1は、最適化マシン10と、端末装置20と、データベース50と、情報処理装置100とが含まれる。例えば、情報処理システム1は、大量データを格納したデータベース50、データセットからサブセットを生成するサーバである情報処理装置100、ユーザが情報処理装置100にリクエストを出し、サブセットを受け取るための端末装置20、及び、情報処理装置100がサブセットを生成するために利用する最適化マシン10で構成される。
次に、図2を用いて情報処理システムの全体処理フローを説明する。図2は、情報処理システムによる処理手順を示すフローチャートである。
次に、図3を用いて情報処理システムのブロック全体像を説明する。図3は、情報処理システムのブロック構成の一例を示す図である。
情報処理システム1には、最適化マシン10a、最適化マシン10b、最適化マシン10c等の複数の最適化マシン10が含まれる。なお、最適化マシン10a、最適化マシン10b、最適化マシン10c等について、特に区別せずに説明する場合は、「最適化マシン10」と記載する。なお、図3では、最適化マシン10a、最適化マシン10b、最適化マシン10cの3台の最適化マシン10を示すが、情報処理システム1には、4台以上の最適化マシン10が含まれてもよい。最適化マシン10は、イジングモデルを用いるコンピュータ(計算機)である。最適化マシン10は、イジングモデルを用いて、組合せ最適化問題を解くコンピュータ(組合せ最適化マシン)である。
情報処理システム1には、データ入力部であるユーザインターフェース部21、マシン選択部であるユーザインターフェース部22、及びデータ提示部であるユーザインターフェース部23が含まれる。なお、ユーザインターフェース部22はオプションであり、ユーザによる最適化マシン10の選択を受け付けない場合は、情報処理システム1に含まれてなくてもよい。
まず、データ入力部であるユーザインターフェース部21に対応する機能について説明する。ユーザインターフェース部21は、ユーザが欲しいデータセットの情報や、カスタマイズしてほしい対象となるモデル、実際にユーザが集めたデータセットを入力するためのインターフェースである。ユーザインターフェース部21は、コマンドラインインターフェースでも、グラフィックインターフェースでもよい。
・データはラベリング済みを使うか自分でラベリングするか
・データのドメインはなにか(画像、音声、言語、項目データ・・・)
・ドメインやクラス名はシステムが保持している既存のクラスか未知のクラスか
例えば、情報処理システム1においては、上記の4つの情報等のアンケートの答えに従って内部で処理が分岐していくものとする。
次に、マシン選択部であるユーザインターフェース部22に対応する機能について説明する。ユーザインターフェース部22は、データセットからデータのサンプリングする際の最適化を実現するときに、最適化方法としてどのような方法を使うかを選択するためのインターフェースである。組合せ最適化を高速に実現するための最適化計算特化型計算機にはすでに様々なマシン(最適化マシン10)があり、クラウド等を介してユーザが利用することもできる。
次に、データ出力部であるユーザインターフェース部23に対応する機能について説明する。ユーザインターフェース部23は、ユーザが実現したい機能に合わせて提供するデータセットのサブセットを提示するインターフェースである。ユーザインターフェース部23は、コマンドラインインターフェースでも、グラフィックインターフェースでもよい。
次に、メインブロックである情報処理装置100等の情報処理システム1のコア部分について、図3及び図5を用いて説明する。図5は、情報処理システムのブロック構成の一部を示す図である。図5に示す情報処理システム1のコア部分には、データベース50、データ読み取り部131a、ユーザデータ入力部131b、最適化係数抽出部132、最適化マシン通信部133、データセット選択部134、及び出力部135が含まれる。
ここから、第2の実施例として、本開示の中心部分である量子アニーリングを使ったデータ抽出最適化の実現方法を説明する。以下では、本体のデータの組合せの最適化の説明に先立って、量子アニーリングと組合せ最適化について説明する。その後、データセットからのサンプル抽出の組合せ最適化の定式化を示す。最後に、サンプル抽出の組合せ最適化の組合せ最適化マシン上への実装方法を説明する。
量子アニーリングは、イジングモデルのエネルギー基底状態を探索する方法の一つであり、組合せ最適化の高速化という用途に特化して用いられる量子計算の一種と考えられている。イジングモデルは、もともと強磁性体(磁石)の温度に対する相転移現象を説明するために、物理学者イジングにより提案された物理モデルである。以下の式(1)は、もとの磁石のモデルを一般化したイジングモデルのハミルトニアン(エネルギー関数)であり、このモデルをもとのイジングによるモデルと区別して、スピングラスモデルと呼ぶこともある。





ここから、データセットからのサンプル抽出最適化について説明するが、サンプル抽出最適化の説明に先立って最適化の基準となる情報量について説明する。ここでは、カルバックライブラー情報量とフィッシャー情報行列について簡単に説明する。






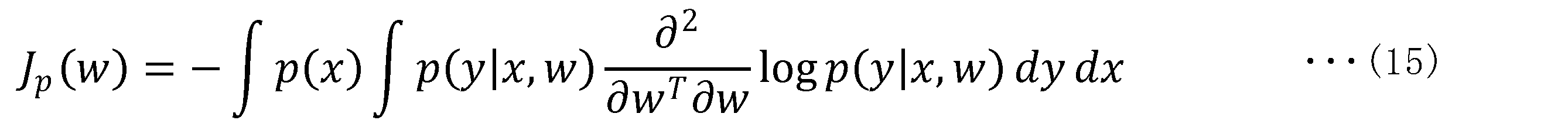



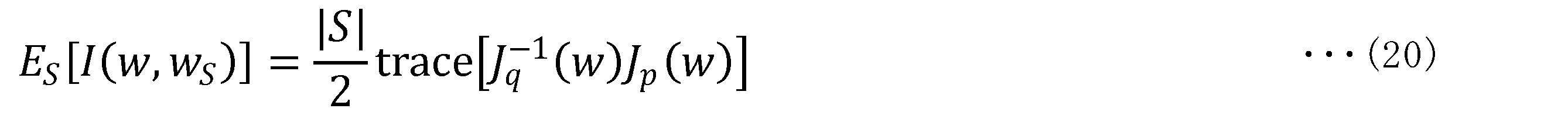





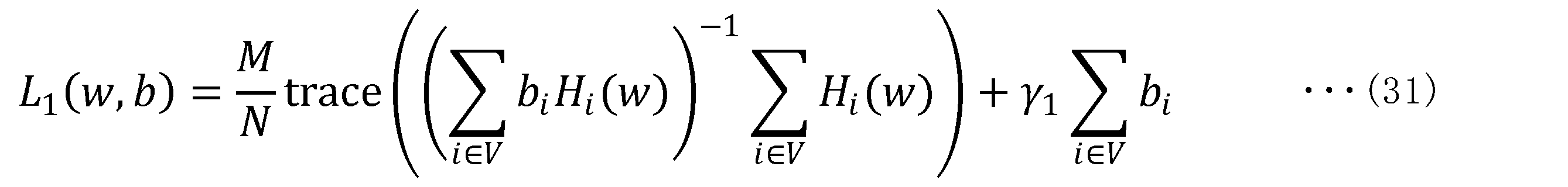

次に、リサンプリング最適化の量子アニーリング等への実装について説明する。情報処理システム1においては、最適なサブセットのリサンプリングのために最小化したい目的関数は次の式(33)のように与えられる。



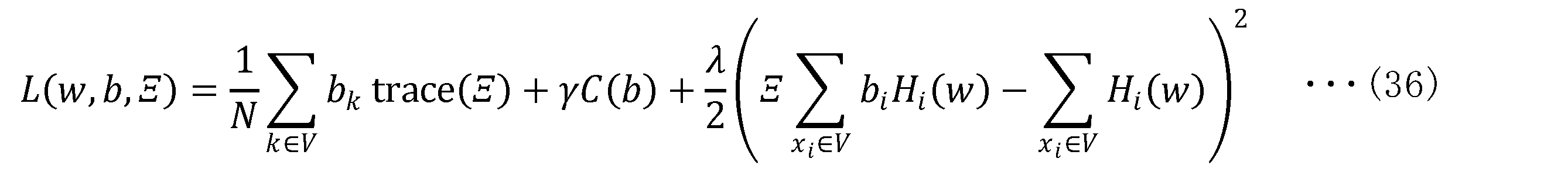


(1-2):量子アニーリングマシン(QPU:Quantum Processing Unit)等を用いて、wとΞを固定して、bをb*で更新する。
(1-3):通常の演算装置(CPUやGPU)を用いて、
(ア)bからサブセットSを求め、
(イ)サブセットSから最尤パラメータwSを求め、w=wSとする(省略可)。
(ウ)bとw=wSを固定して、ΞをΞ*で更新する。
(1-4):(1-2)及び(1-3)を、所定の終了条件を満たすまで繰り返す。
ここから、第3の実施例として、第2の実施例に対してさらなる近似及びモデルの限定を行い、よりシンプルに実装する例を説明する。

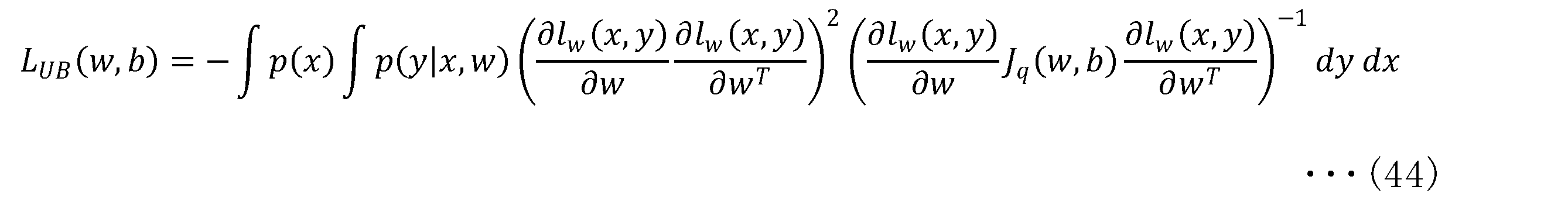
まず、回帰モデルの場合について説明する。回帰モデルでは、モデルとして、分散を1に規格化した次の式(45)に示すような正規分布モデルを考える。









(2-1):パラメータwと変数ξを一つ決める。
(2-2):量子アニーリングマシン(QPU)等を用いて、wとξを固定して、bをb*で更新する。
(2-3):通常の演算装置(CPUやGPU)を用いて、
(ア)bからサブセットSを求め、
(イ)サブセットSから最尤パラメータwSを求め、w=wSとする(ユースケースにより省略可)。
(ウ)bとw=wSを固定して最適パラメータξ^*を求め、ξをξ*で更新する。
(2-4):(2-2)、(2-3)を、所定の終了条件を満たすまで繰り返す。
次に、二クラス分類モデルの場合について説明する。例えば、以下の式(54)を用いて、モデルとして、二クラス分類に用いられるロジスティック回帰を考える。


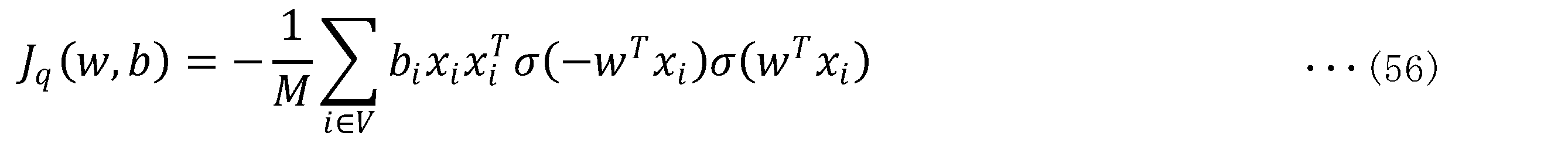






次に、多クラス分類モデの場合について説明する。例えば、以下の式(63)を用いて、モデルとして、Kクラス分類に用いられるソフトマックス関数を考える。







ここから、第4の実施例として、第2の実施例及び第3の実施例の計算過程を踏まえて、データ選択最適化の処理フローとそのプログラム例を説明する。
(3-1):ユーザから学習したい予測モデルのファイルを受け取る。
(3-2):システムがもつ大規模データセットをサーバ上で扱える状態にする。
(3-3):もしユーザからのデータがあればそれもマージして使えるようにする。
(3-4):マージされたデータセットから最適なサブセットをリサンプリングする。
上記処理(3-1)~(3-4)は、プログラムではメインプログラムに相当する。メインプログラムでは、まず、ユーザが学習したい機能を実現する関数モジュールを展開する。続いて、システムが保持するデータセットをユーザが指定する条件の下でメモリ上に展開する。また、ユーザからのデータセットがあれば、システムのデータセットとマージする。最後に、モデルとデータセットからデータセットの最適リサンプリングを行い、サブセットを生成する。
(4-1):ランダムにバイナリ変数bを生成する。
(4-2):バイナリ変数bを元にして、データセットDからサブセットSを生成する。
(4-3):入力されたモジュールmとサブセットSを用いて、モジュールmに関する最尤パラメータwSの推定を行う。
(4-4):バイナリ変数bとモジュールのパラメータwを固定して、問題をQUBO形式にするための補助変数(まとめてXと記載する)を計算する。
(4-5):パラメータwと補助変数Xを用いて、QUBOの(二次の)係数行列qを算出する。
(4-6):QUBOの係数行列qを量子アニーリングマシン等の最適化マシン10に送信し、最適化されたバイナリ変数bを受け取る。
(4-7):(4-2)から(4-6)を所定の終了条件まで繰り返した後、サブセットSを出力する。
なお、(4-1)におけるバイナリ変数bの初期値の設定についてはランダムに限られない。例えば、バイナリ変数bの初期値は、データ数の指定がある場合、その指定された数を満たした数のデータを選択するように設定されてもよい。
次に、図8を用いて、データ選択最適化の処理フローについて説明する。図8は、データ選択最適化の処理の手順を示すフローチャートである。図8は、情報処理システム1によるデータ選択最適化の処理のフローの例である。以下では、情報処理装置100を処理主体とする場合を一例として示すが、処理主体は、情報処理装置100に限らず、情報処理システム1に含まれるいずれの装置であってもよい。
ここで、図9を用いて上述した処理に対応するプログラムの一例を説明する。図9は、データ選択最適化の処理プログラムの一例を示す図である。プログラムPG2に示す関数「resample_optimal_subset(model, dataset)」は、図7中の5行目に示すサブセットのリサンプリングの関数であり、subsetを出力する関数に対応する。例えば、図9に示すプログラムPG2は、図8に示した処理をプログラム例として表したものである。図9に示すプログラムPG2は、図8に示した処理と同様であるため、詳細な説明は省略する。
次に、情報処理装置100の構成について説明する。図10は、本開示の情報処理装置の構成例を示す図である。
次に、計算を実行する最適化マシン10の構成について説明する。図11は、最適化マシンの構成例を示す図である。図11の例では、最適化マシン10の一例として、量子コンピュータである最適化マシン10aの構成を説明する。
ここで、情報処理システム1において各種情報のユーザへの提示例について、以下説明する。例えば、情報処理装置100は、端末装置20からリクエストに応じて、様々な情報を端末装置20へ提供する。
例えば、情報処理装置100が扱っているクラス、タスクのデータセットを端末装置20が要求した場合、情報処理装置100は、扱っているクラスのリストを開示してもよい。情報処理装置100は、図12に示すようなコンテンツCT2を端末装置20に提供してもよい。図12は、クラスのリストの一例を示す図である。図12に示すコンテンツCT2は、「ねずみ」、「うし」、「とら」、「たつ」等の複数のクラスの各々のサンプル画像のリストを示す。
例えば、情報処理装置100は、端末装置20からユーザが学習したいクラスの選択を受け付けてもよい。情報処理装置100は、図13に示すようなコンテンツCT3を端末装置20に提供し、コンテンツCT3を介してユーザのクラスの選択を受け付けてもよい。図13は、ユーザが学習したいクラスの選択の一例を示す図である。図13に示すコンテンツCT3は、「ねずみ」に対応するクラスCL1、「うし」に対応するクラスCL2等に対するユーザの選択を受け付けるためのコンテンツである。情報処理装置100は、ユーザが選択したクラスのどれかであるかを示す情報を端末装置20から受信する。例えば、ユーザは、すべて既知のクラスならば、リクエストタイプを「すべて既知」としてもよい。
なお、情報処理装置100は、扱っていないクラス、タスクに適した(ネガティブ)データを端末装置20に要求してもよい。情報処理装置100は、端末装置20が扱いたいクラス、タスクのデータを端末装置20から受け付ける。情報処理装置100は、図14に示すようなコンテンツCT4を端末装置20に提供し、コンテンツCT4を介してユーザからデータを受け付けてもよい。図14は、ユーザからのデータの受付けの一例を示す図である。図14に示すコンテンツCT4は、クラス「ニッコウキスゲ」のデータを受け付ける場合の一例を示す。
上述した情報処理システム1は、例えば特定ドメインの種別分類等の種々の用途に利用されてもよい。この点について、以下いくつか例示を示す。なお、情報処理システム1を適用する対象は、以下に示す例に限られない。
ここから、情報処理システム1の適用例を示す第5の実施例として、動物の属に関する属内外の二クラス判別に情報処理システム1が適用された場合について説明する。なお、第5の実施例では、動物の属に関する属内外の二クラス判別の例であるが、前述のように、他クラス分類を用いた動物の種類のクラス分類であってもよい。さらに、動物ではなく、高山植物の画像分類であってもよい。データは必ずしも画像である必要はなく、音声によるものであってもよい。例えば、セミの鳴き声分類や野鳥の鳴き声による分類であってもよい。他に回帰問題の例としては、不動産の価格分類であってもよい。
・入力されるのは、オナガザル科だけとする
・マカク属はどのクラスも、十分な数の画像を収集済み
・マカク属以外のオナガザル科のデータは全くない
・クライアント側で学習できるので、サーバからはデータセットだけ欲しい
・サーバ側には、動物界分類図の全クラスのデータが多数格納済み
・サーバ側には、汎用の画像特徴抽出器がある
例えば、機械学習のラベリングを様々な科学実験の計測評価と捉えると、多数ある調査対象のどのサンプルから評価すべきかの指針がわかる能動学習による効率アップの意義は大きい。
まず、手順#1について説明する。情報処理システム1では、新たな情報をデータセットから獲得するため、予測モデルを活用している。ここでいう予測モデルとは、生体分子の配列パターンを入力すると、その配列パターンがその機能を持っている予測値、あるいは、確率分布のスコアを出力する。例えば、前述の神経難病の例であれば、異常タンパク質の合成に関与する配列パターンに該当するかの予測モデル(判別モデル)ある。このような予測モデルを構築するためには、まず、配列パターンと機能の予測値等の対応関係のデータセットが必要である。このデータセットは、多数の配列パターンについて、それぞれ、予測したい機能に関する情報を計測することで構築する。あるいは、既知のデータベースから機能の情報を元に逆引きして求めてもよい。
次に手順#2について説明する。手順#1に続いて、情報処理システム1では、パラメータつきの予測モデルを設計して、そのパラメータを機械学習技術で求める。代表的な予測モデルは、ニューラルネットであり、深層学習でパラメータを求めることができる。
・入力層は、配列パターンの情報を入力できる構成をしている。
・中間層は、開発者の設定に基づき構成される。
・出力層は、予測したい機能に合わせて構成する。
次に手順#3について説明する。上述の手順により、予測モデルが構築できたので、以降が第6の実施例における情報処理システム1の主な適用範囲である。第6の実施例によれば、予測モデルにとって、最も曖昧なデータ空間上の領域、すなわち、検証すると得られる情報量が最も大きい領域を、示すことができる。あるいは、そのサンプル情報を提供することができる。また、第6の実施例によれば、複数のサンプルを同時に提供することができ、そのサンプルは、情報量が多くなるように、互いに類似していないサンプル同士が選ばれる。
次に手順#4について説明する。最後に、選択されたサンプルに関する解析を行う。もともとの目的は、サンプルの機能の有無の判別、あるいは、機能のカテゴリへの分類、あるいは、機能の程度の定量化である。
上述した実施形態や変形例に係る処理は、上記実施形態や変形例以外にも種々の異なる形態(変形例)にて実施されてよい。なお、上述した例において、サブセットを選択する母集団となるデータセットを「第1データセット」と読み替え、第1データセットから選択されるサブセットを「第2データセット」と読み替えてもよい。
なお、上記の例では、情報処理装置100と、最適化マシン10とが別体である場合を示したが、情報処理装置100と最適化マシン10とは一体であってもよい。例えば、最適化マシン10が超伝導を使わずデジタル回路で実現された場合、最適化マシン10はエッジ側に配置されてもよい。例えば、イジングモデルを用いた計算がエッジ側で行われる場合、情報処理装置100と最適化マシン10とが一体であってもよい。
上述した情報処理やパラメータ等を生成する方法が提供されてもよい。また、上述した最適化マシン10が計算を実行する際に用いるプログラムを生成する方法が提供されてもよい。
また、上記各実施形態において説明した各処理のうち、自動的に行われるものとして説明した処理の全部または一部を手動的に行うこともでき、あるいは、手動的に行われるものとして説明した処理の全部または一部を公知の方法で自動的に行うこともできる。この他、上記文書中や図面中で示した処理手順、具体的名称、各種のデータやパラメータを含む情報については、特記する場合を除いて任意に変更することができる。例えば、各図に示した各種情報は、図示した情報に限られない。
上記のように、本開示に係る情報処理装置(例えば実施形態では情報処理装置100に対応)は、取得部(例えば実施形態では取得部131に対応)と、選択部(例えば、実施形態ではデータセット選択部134に対応)とを備える。取得部は、データ供給方法と、学習したいモデルと、モデルの学習に用いるサンプルセットのサイズとカテゴリに関する指定情報とを取得する。選択部は、モデルに応じて決定される情報エントロピーと、指定情報とに基づいて、データセットから、モデルの学習に用いるサンプルセットを選択する。
上述してきた各実施形態や変形例に係る情報処理装置100等の情報機器は、例えば図18に示すような構成のコンピュータ1000によって実現される。図18は、情報処理装置の機能を実現するコンピュータの一例を示すハードウェア構成図である。以下、情報処理装置100を例に挙げて説明する。コンピュータ1000は、CPU1100、RAM1200、ROM(Read Only Memory)1300、HDD(Hard Disk Drive)1400、通信インターフェイス1500、及び入出力インターフェイス1600を有する。コンピュータ1000の各部は、バス1050によって接続される。
(1)
データ供給方法と、学習したいモデルと、前記モデルの学習に用いるサンプルセットのサイズとカテゴリに関する指定情報とを取得する取得部と、
前記モデルに応じて決定される情報エントロピーと、前記指定情報とに基づいて、データセットから、前記モデルの学習に用いるサンプルセットを選択する選択部と、
を備える情報処理装置。
(2)
前記データ供給方法は、前記データセットからのデータ供給であって、前記サンプルセットは前記データセットのサブセットである
(1)に記載の情報処理装置。
(3)
前記学習したいモデルは、学習パラメータ付きの予測モデルであって、前記モデルのタスクとは、入力に対応する出力の種別である、
(1)または(2)に記載の情報処理装置。
(4)
前記モデルにもたらされる情報エントロピーは、カルバック・ライブラー情報量、または、フィッシャー情報量を用いて算出される情報エントロピーである、
(1)~(3)のいずれか1つに記載の情報処理装置。
(5)
前記選択部は、
前記モデルにもたらされる情報エントロピーを示す目的関数を最適化するように、前記サンプルセットを選択する
(1)~(4)のいずれか1つに記載の情報処理装置。
(6)
前記選択部は、
QUBO(Quadratic Unconstrained Binary Optimization)形式で表現される前記目的関数に基づいて、前記サンプルセットを選択する
(5)に記載の情報処理装置。
(7)
組合せ最適化計算を行う最適化マシンに前記目的関数に対応する係数行列を送信し、前記最適化マシンから前記組合せ最適化計算の計算結果を受信する最適化マシン通信部、
を備え、
前記選択部は、
前記計算結果に基づいて、前記サンプルセットを選択する
(5)または(6)に記載の情報処理装置。
(8)
前記最適化マシン通信部は、
前記組合せ最適化計算後の変数を示す前記計算結果を前記最適化マシンから受信する
(7)に記載の情報処理装置。
(9)
前記最適化マシン通信部は、
各々がデータに対応するバイナリ変数に関する前記計算結果を前記最適化マシンから受信する
(8)に記載の情報処理装置。
(10)
前記最適化マシン通信部は、
量子コンピュータ、または組合せ最適化アクセラレータに前記係数行列を送信する
(7)~(9)のいずれか1つに記載の情報処理装置。
(11)
前記最適化マシン通信部は、
複数の最適化マシンのうち、ユーザにより選択された前記最適化マシンに前記係数行列を送信する
(7)~(10)のいずれか1つに記載の情報処理装置。
(12)
前記係数行列を抽出する抽出部、
を備え、
前記最適化マシン通信部は、
前記抽出部により抽出された前記係数行列を前記最適化マシンに送信する
(7)~(11)のいずれか1つに記載の情報処理装置。
(13)
前記抽出部は、
前記目的関数からイジング係数に対応する前記係数行列を抽出する
(12)に記載の情報処理装置。
(14)
前記取得部は、
ユーザが学習したい予測モデルである前記モデルを取得する
(1)~(13)のいずれか1つに記載の情報処理装置。
(15)
前記選択部により選択された前記サンプルセットに関する情報を出力する出力部、
を備える
(1)~(14)のいずれか1つに記載の情報処理装置。
(16)
前記出力部は、
前記サンプルセットをユーザが利用する端末装置へ送信する
(15)に記載の情報処理装置。
(17)
前記出力部は、
前記サンプルセットを用いて学習された学習済みモデルをユーザが利用する端末装置へ送信する
(15)または(16)に記載の情報処理装置。
(18)
データ供給方法と、学習したいモデルと、前記モデルの学習に用いるサンプルセットのサイズとカテゴリに関する指定情報とを取得し、
前記モデルに応じて決定される情報エントロピーと、前記指定情報とに基づいて、データセットから、前記モデルの学習に用いるサンプルセットを選択する
処理を実行する情報処理方法。
(19)
データ供給方法と、学習したいモデルと、前記モデルの学習に用いるサンプルセットのサイズとカテゴリに関する指定情報とを取得し、
前記モデルに応じて決定される情報エントロピーと、前記指定情報とに基づいて、データセットから、前記モデルの学習に用いるサンプルセットを選択する
処理を実行させる情報処理プログラム。
100 情報処理装置
110 通信部
120 記憶部
121 データ記憶部
122 関数情報記憶部
130 制御部
131 取得部
132 最適化係数抽出部
133 最適化マシン通信部
134 データセット選択部
135 出力部
10 最適化マシン
11 通信部
12 記憶部
13 量子デバイス部
14 制御部
141 取得部
142 計算部
143 送信部
20 端末装置
50 データベース
Claims (19)
- データ供給方法と、学習したいモデルと、前記モデルの学習に用いるサンプルセットのサイズとカテゴリに関する指定情報とを取得する取得部と、
前記モデルに応じて決定される情報エントロピーと、前記指定情報とに基づいて、データセットから、前記モデルの学習に用いるサンプルセットを選択する選択部と、
を備える情報処理装置。 - 前記データ供給方法は、前記データセットからのデータ供給であって、前記サンプルセットは前記データセットのサブセットである
請求項1に記載の情報処理装置。 - 前記学習したいモデルは、学習パラメータ付きの予測モデルであって、前記モデルのタスクとは、入力に対応する出力の種別である、
請求項1に記載の情報処理装置。 - 前記モデルにもたらされる情報エントロピーは、カルバック・ライブラー情報量、または、フィッシャー情報量を用いて算出される情報エントロピーである、
請求項1に記載の情報処理装置。 - 前記選択部は、
前記モデルにもたらされる情報エントロピーを示す目的関数を最適化するように、前記サンプルセットを選択する
請求項1に記載の情報処理装置。 - 前記選択部は、
QUBO(Quadratic Unconstrained Binary Optimization)形式で表現される前記目的関数に基づいて、前記サンプルセットを選択する
請求項5に記載の情報処理装置。 - 組合せ最適化計算を行う最適化マシンに前記目的関数に対応する係数行列を送信し、前記最適化マシンから前記組合せ最適化計算の計算結果を受信する最適化マシン通信部、
を備え、
前記選択部は、
前記計算結果に基づいて、前記サンプルセットを選択する
請求項5に記載の情報処理装置。 - 前記最適化マシン通信部は、
前記組合せ最適化計算後の変数を示す前記計算結果を前記最適化マシンから受信する
請求項7に記載の情報処理装置。 - 前記最適化マシン通信部は、
各々がデータに対応するバイナリ変数に関する前記計算結果を前記最適化マシンから受信する
請求項8に記載の情報処理装置。 - 前記最適化マシン通信部は、
量子コンピュータ、または組合せ最適化アクセラレータに前記係数行列を送信する
請求項7に記載の情報処理装置。 - 前記最適化マシン通信部は、
複数の最適化マシンのうち、ユーザにより選択された前記最適化マシンに前記係数行列を送信する
請求項7に記載の情報処理装置。 - 前記係数行列を抽出する抽出部、
を備え、
前記最適化マシン通信部は、
前記抽出部により抽出された前記係数行列を前記最適化マシンに送信する
請求項7に記載の情報処理装置。 - 前記抽出部は、
前記目的関数から前記最適化マシンの入力に対応する前記係数行列を抽出する
請求項12に記載の情報処理装置。 - 前記取得部は、
ユーザが学習したい予測モデルである前記モデルを取得する
請求項1に記載の情報処理装置。 - 前記選択部により選択された前記サンプルセットに関する情報を出力する出力部、
を備える
請求項1に記載の情報処理装置。 - 前記出力部は、
前記サンプルセットをユーザが利用する端末装置へ送信する
請求項15に記載の情報処理装置。 - 前記出力部は、
前記サンプルセットを用いて学習された学習済みモデルをユーザが利用する端末装置へ送信する
請求項15に記載の情報処理装置。 - データ供給方法と、学習したいモデルと、前記モデルの学習に用いるサンプルセットのサイズとカテゴリに関する指定情報とを取得し、
前記モデルに応じて決定される情報エントロピーと、前記指定情報とに基づいて、データセットから、前記モデルの学習に用いるサンプルセットを選択する
処理を実行する情報処理方法。 - データ供給方法と、学習したいモデルと、前記モデルの学習に用いるサンプルセットのサイズとカテゴリに関する指定情報とを取得し、
前記モデルに応じて決定される情報エントロピーと、前記指定情報とに基づいて、データセットから、前記モデルの学習に用いるサンプルセットを選択する
処理を実行させる情報処理プログラム。
Priority Applications (4)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| EP22832381.2A EP4365781A4 (en) | 2021-06-30 | 2022-01-26 | INFORMATION PROCESSING DEVICE, METHOD AND PROGRAM |
| US18/571,740 US20240127122A1 (en) | 2021-06-30 | 2022-01-26 | Information processing device, information processing method, and information processing program |
| JP2023531355A JPWO2023276213A1 (ja) | 2021-06-30 | 2022-01-26 | |
| CN202280044786.XA CN117546186A (zh) | 2021-06-30 | 2022-01-26 | 信息处理设备、信息处理方法和信息处理程序 |
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2021109634 | 2021-06-30 | ||
| JP2021-109634 | 2021-06-30 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2023276213A1 true WO2023276213A1 (ja) | 2023-01-05 |
Family
ID=84691050
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2022/002805 Ceased WO2023276213A1 (ja) | 2021-06-30 | 2022-01-26 | 情報処理装置、情報処理方法及び情報処理プログラム |
Country Status (5)
| Country | Link |
|---|---|
| US (1) | US20240127122A1 (ja) |
| EP (1) | EP4365781A4 (ja) |
| JP (1) | JPWO2023276213A1 (ja) |
| CN (1) | CN117546186A (ja) |
| WO (1) | WO2023276213A1 (ja) |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| EP4592905A1 (en) | 2024-01-26 | 2025-07-30 | Fujitsu Limited | Arithmetic program, arithmetic method, and information processing device |
Families Citing this family (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20240126834A1 (en) * | 2022-10-03 | 2024-04-18 | Sap Se | Iterative Quantum Annealing |
-
2022
- 2022-01-26 WO PCT/JP2022/002805 patent/WO2023276213A1/ja not_active Ceased
- 2022-01-26 US US18/571,740 patent/US20240127122A1/en active Pending
- 2022-01-26 EP EP22832381.2A patent/EP4365781A4/en not_active Withdrawn
- 2022-01-26 CN CN202280044786.XA patent/CN117546186A/zh not_active Withdrawn
- 2022-01-26 JP JP2023531355A patent/JPWO2023276213A1/ja not_active Abandoned
Non-Patent Citations (5)
| Title |
|---|
| ANONYMOUS: "Cross entropy -", WIKIPEDIA, 29 December 2018 (2018-12-29), XP093018543, Retrieved from the Internet <URL:https://en.wikipedia.org/w/index.php?title=Cross_entropy&oldid=875854246> [retrieved on 20230127] * |
| KAIMING HEXIANGYU ZHANGSHAOQING RENJIAN SUN, DEEP RESIDUAL LEARNING FOR IMAGE RECOGNITION, 23 June 2021 (2021-06-23), Retrieved from the Internet <URL:https://arxiv.org/abs/1512.03385> |
| KRISHNATEJA KILLAMSETTY; DURGA SIVASUBRAMANIAN; GANESH RAMAKRISHNAN; RISHABH IYER: "GLISTER: Generalization based Data Subset Selection for Efficient and Robust Learning", ARXIV.ORG, CORNELL UNIVERSITY LIBRARY, 201 OLIN LIBRARY CORNELL UNIVERSITY ITHACA, NY 14853, 1 January 1900 (1900-01-01), 201 Olin Library Cornell University Ithaca, NY 14853 , XP081842756 * |
| RAHMAN MUHAMMED TAHSIN; JAVAD-KALBASI MOHAMMAD; VALAEE SHAHROKH: "Near-Optimal Resampling in Particle Filters Using the Ising Energy Model", ICASSP 2021 - 2021 IEEE INTERNATIONAL CONFERENCE ON ACOUSTICS, SPEECH AND SIGNAL PROCESSING (ICASSP), IEEE, 6 June 2021 (2021-06-06), pages 5464 - 5468, XP033954704, DOI: 10.1109/ICASSP39728.2021.9413633 * |
| See also references of EP4365781A4 |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| EP4592905A1 (en) | 2024-01-26 | 2025-07-30 | Fujitsu Limited | Arithmetic program, arithmetic method, and information processing device |
Also Published As
| Publication number | Publication date |
|---|---|
| EP4365781A4 (en) | 2024-10-30 |
| JPWO2023276213A1 (ja) | 2023-01-05 |
| US20240127122A1 (en) | 2024-04-18 |
| CN117546186A (zh) | 2024-02-09 |
| EP4365781A1 (en) | 2024-05-08 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| Nadimi-Shahraki et al. | A systematic review of the whale optimization algorithm: theoretical foundation, improvements, and hybridizations | |
| Xu et al. | Collaborative APIs recommendation for artificial intelligence of things with information fusion | |
| Arowolo et al. | A survey of dimension reduction and classification methods for RNA-Seq data on malaria vector | |
| CN115472221B (zh) | 一种基于深度学习的蛋白质适应度预测方法 | |
| US20220229862A1 (en) | A system and method for processing biology-related data, a system and method for controlling a microscope and a microscope | |
| Saltzberg et al. | Modeling biological complexes using integrative modeling platform | |
| Huang et al. | Sequential optimal experimental design of perturbation screens guided by multi-modal priors | |
| CN114579892A (zh) | 一种基于跨城市兴趣点匹配的用户异地访问位置预测方法 | |
| Li et al. | Auto-gas: Automated proxy discovery for training-free generative architecture search | |
| JP2008225907A (ja) | 言語解析モデル学習装置、言語解析モデル学習方法、言語解析モデル学習プログラムならびにその記録媒体 | |
| WO2023276213A1 (ja) | 情報処理装置、情報処理方法及び情報処理プログラム | |
| Zhang et al. | FMCA-DTI: a fragment-oriented method based on a multihead cross attention mechanism to improve drug–target interaction prediction | |
| US20250139386A1 (en) | Artificial intelligence systems and methods for enabling natural language transcriptomics analysis | |
| KR20230006439A (ko) | 인공지능 모델의 학습을 위한 정형화된 연구 기록 데이터 자동생성 방법, 장치 및 컴퓨터프로그램 | |
| CN112966743A (zh) | 基于多维度注意力的图片分类方法、系统、设备及介质 | |
| Zhou et al. | scDLC: a deep learning framework to classify large sample single-cell RNA-seq data | |
| Islam et al. | DTI-SNNFRA: Drug-target interaction prediction by shared nearest neighbors and fuzzy-rough approximation | |
| Khan et al. | Ant colony optimization based hierarchical multi-label classification algorithm | |
| Hu et al. | Accelerating multi-objective neural architecture search by random-weight evaluation | |
| JP7425210B2 (ja) | 情報処理システムおよび最適解探索処理方法 | |
| George et al. | Significance of global vectors representation in protein sequences analysis | |
| Gregory et al. | MarkerMap: nonlinear marker selection for single-cell studies | |
| Mu et al. | iPseU-Layer: identifying RNA pseudouridine sites using layered ensemble model | |
| CN114579757B (zh) | 一种基于知识图谱辅助的文本处理方法和装置 | |
| CN114329102B (zh) | 数据处理方法、装置、设备及存储介质 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 22832381 Country of ref document: EP Kind code of ref document: A1 |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 2023531355 Country of ref document: JP |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 18571740 Country of ref document: US |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 202280044786.X Country of ref document: CN |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 2022832381 Country of ref document: EP |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| ENP | Entry into the national phase |
Ref document number: 2022832381 Country of ref document: EP Effective date: 20240130 |
|
| WWW | Wipo information: withdrawn in national office |
Ref document number: 2022832381 Country of ref document: EP |