WO2024025638A1 - Methods for instance-based mesh coding - Google Patents
Methods for instance-based mesh coding Download PDFInfo
- Publication number
- WO2024025638A1 WO2024025638A1 PCT/US2023/023296 US2023023296W WO2024025638A1 WO 2024025638 A1 WO2024025638 A1 WO 2024025638A1 US 2023023296 W US2023023296 W US 2023023296W WO 2024025638 A1 WO2024025638 A1 WO 2024025638A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- prediction
- instances
- objects
- vertices
- mesh
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Ceased
Links
Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T9/00—Image coding
- G06T9/001—Model-based coding, e.g. wire frame
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/10—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding
- H04N19/102—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the element, parameter or selection affected or controlled by the adaptive coding
- H04N19/103—Selection of coding mode or of prediction mode
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/10—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding
- H04N19/102—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the element, parameter or selection affected or controlled by the adaptive coding
- H04N19/12—Selection from among a plurality of transforms or standards, e.g. selection between discrete cosine transform [DCT] and sub-band transform or selection between H.263 and H.264
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/10—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding
- H04N19/169—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the coding unit, i.e. the structural portion or semantic portion of the video signal being the object or the subject of the adaptive coding
- H04N19/17—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the coding unit, i.e. the structural portion or semantic portion of the video signal being the object or the subject of the adaptive coding the unit being an image region, e.g. an object
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/44—Decoders specially adapted therefor, e.g. video decoders which are asymmetric with respect to the encoder
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/50—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using predictive coding
- H04N19/597—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using predictive coding specially adapted for multi-view video sequence encoding
Definitions
- the present disclosure is directed a set of advanced video coding technologies including both lossless and lossy mesh coding technologies based on instances of meshes.
- VMesh is an ongoing MPEG standard to compress the static and dynamic mesh. VMesh separates the input mesh into a simplified base mesh and a residual mesh. The base mesh may be encoded at high quality while the remainder mesh may be encoded with subdivision surface fitting and displacement encoding to exploit local characteristic.
- a complex mesh often contains information about multiple instances to relate associate texture maps. This information is available at the encoding time.
- a mesh could be segmented into several parts based on their characteristics. For example, there are more polygons in the face region of a human mesh.
- determining the similarity may include comparing bounding boxes of the at least two of
- comparing the bounding boxes may include comparing ratios of dimensions of the bounding boxes.
- coding the volumetric data may include signaling different ones of codecs respective to ones of the at least two of the submeshes.
- coding the volumetric data may include signaling prediction of a first one of the at least two of the submeshes based on a prediction of a second one of the at least two of the submeshes.
- coding the volumetric data may include signaling only a single one prediction index for an entirety of the first one of the at least two of the submeshes.
- coding the volumetric data may include signaling only a plurality of prediction indices for the first one of the at least two of the submeshes.
- a first one of the plurality of prediction indices may be based on a first prediction index
- a second one of the plurality of prediction indices may be based on a second prediction index
- the first prediction index may be based on a first other prediction index which is of the second one of the at least two submeshes
- the second one of the plurality of prediction indices is based on a second other prediction index which is of a third one of the at least two submeshes.
- signaling prediction of the first one of the at least two of the submeshes may include signaling a first prediction index and a second prediction index
- the first prediction index may be a single index that is collectively set to each of a plurality of vertices of the first one of the at least two of the submeshes
- the second prediction index may be set to at least one other vertex of the first one of the at least two of the submeshes.
- At least one of the first prediction index and the second prediction index may be based on a prediction index set to at least one vertex of the second one of the at least two of the submeshes.
- FIG. 1 is a schematic illustrations of a diagram in accordance with embodiments.
- FIG. 2 is a simplified block diagram in accordance with embodiments.
- FIG. 3 is a simplified illustration in accordance with embodiments.
- FIG. 4 is a simplified illustration in accordance with embodiments.
- FIG. 5 is a simplified illustration in accordance with embodiments.
- FIG. 6 is a simplified illustration in accordance with embodiments.
- FIG. 7 is a simplified illustration in accordance with embodiments.
- FIG. 8 is a simplified illustration in accordance with embodiments.
- FIG. 9 is a simplified illustration in accordance with embodiments.
- FIG. 10 is a simplified illustration in accordance with embodiments.
- FIG. 11 is a simplified illustration in accordance with embodiments.
- Fig. 12 is a simplified illustration in accordance with embodiments.
- FIG. 13 is a simplified flow diagram in accordance with embodiments.
- FIG. 14 is a simplified flow diagram in accordance with embodiments.
- FIG. 15 is a simplified flow diagram in accordance with embodiments.
- FIG. 16 is a simplified illustration in accordance with embodiments.
- FIG. 17 is a simplified illustration in accordance with embodiments.
- FIG. 18 is a simplified illustration in accordance with embodiments.
- FIG. 19 is a simplified illustration in accordance with embodiments.
- Fig. 20 is a simplified flow diagram in accordance with embodiments.
- FIG. 21 is a simplified illustration in accordance with embodiments.
- Fig. 22 is a simplified flow diagram in accordance with embodiments.
- FIG. 23 is a simplified flow diagram in accordance with embodiments.
- Fig. 24 is a simplified diagram in accordance with embodiments.
- the embodiments may be implemented by processing circuitry (e.g., one or more processors or one or more integrated circuits).
- the one or more processors execute a program that is stored in a non-transitory computer-readable medium.
- Fig. 1 illustrates a simplified block diagram of a communication system 100 according to an embodiment of the present disclosure.
- the communication system 100 may include at least two terminals 102 and 103 interconnected via a network 105.
- a first terminal 103 may code video data at a local location for transmission to the other terminal 102 via the network 105.
- the second terminal 102 may receive the coded video data of the other terminal from the network 105, decode the coded data and display the recovered video data.
- Unidirectional data transmission may be common in media serving applications and the like.
- Fig. 1 illustrates a second pair of terminals 101 and 104 provided to support bidirectional transmission of coded video that may occur, for example, during videoconferencing.
- each terminal 101 and 104 may code video data captured at a local location for transmission to the other terminal via the network 105.
- Each terminal 101 and 104 also may receive the coded video data transmitted by the other terminal, may decode the coded data and may display the recovered video data at a local display device.
- the terminals 101, 102, 103 and 104 may be illustrated as servers, personal computers and smart phones but the principles of the present disclosure are not so limited. Embodiments of the present disclosure find application with laptop computers, tablet computers, media players and/or dedicated video conferencing equipment.
- the network 105 represents any number of networks that convey coded video data among the terminals 101, 102, 103 and 104, including for example wireline and/or wireless communication networks.
- the communication network 105 may exchange data in circuit-switched and/or packet-switched channels.
- Fig. 2 illustrates, as an example for an application for the disclosed subject matter, the placement of a video encoder and decoder in a streaming environment.
- the disclosed subject matter can be equally applicable to other video enabled applications, including, for example, video conferencing, digital TV, storing of compressed video on digital media including CD, DVD, memory stick and the like, and so on.
- a streaming system may include a capture subsystem 203, that can include a video source 201, for example a digital camera, creating, for example, an uncompressed video sample stream 213. That sample stream 213 may be emphasized as a high data volume when compared to encoded video bitstreams and can be processed by an encoder 202 coupled to the video source 201, which may be for example a camera as discussed above.
- the encoder 202 can include hardware, software, or a combination thereof to enable or implement aspects of the disclosed subject matter as described in more detail below.
- the encoded video bitstream 204 which may be emphasized as a lower data volume when compared to the sample stream, can be stored on a streaming server 205 for future use.
- One or more streaming clients 212 and 207 can access the streaming server 205 to retrieve copies 208 and 206 of the encoded video bitstream 204.
- a client 212 can include a video decoder 211 which decodes the incoming copy of the encoded video bitstream 208 and creates an outgoing video sample stream 210 that can be rendered on a display 209 or other rendering device (not depicted).
- the video bitstreams 204, 206 and 208 can be encoded according to certain video coding/compression standards. Examples of those standards are noted above and described further herein.
- Fig. 3 may be a functional block diagram of a video decoder 300 according to an embodiment of the present invention.
- a receiver 302 may receive one or more codec video sequences to be decoded by the decoder 300; in the same or another embodiment, one coded video sequence at a time, where the decoding of each coded video sequence is independent from other coded video sequences.
- the coded video sequence may be received from a channel 301, which may be a hardware/software link to a storage device which stores the encoded video data.
- the receiver 302 may receive the encoded video data with other data, for example, coded audio data and/or ancillary data streams, that may be forwarded to their respective using entities (not depicted).
- the receiver 302 may separate the coded video sequence from the other data.
- a buffer memory 303 may be coupled in between receiver 302 and entropy decoder / parser 304 (“parser” henceforth).
- parser henceforth
- the buffer 303 may not be needed, or can be small.
- the buffer 303 may be required, can be comparatively large and can advantageously of adaptive size.
- the video decoder 300 may include a parser 304 to reconstruct symbols 313 from the entropy coded video sequence. Categories of those symbols include information used to manage operation of the decoder 300, and potentially information to control a rendering device such as a display 312 that is not an integral part of the decoder but can be coupled to it.
- the control information for the rendering device(s) may be in the form of Supplementary Enhancement Information (SEI messages) or Video Usability Information (VUI) parameter set fragments (not depicted).
- SEI messages Supplementary Enhancement Information
- VUI Video Usability Information
- the parser 304 may parse / entropy-decode the coded video sequence received.
- the coding of the coded video sequence can be in accordance with a video coding technology or standard, and can follow principles well known to a person skilled in the art, including variable length coding, Huffman coding, arithmetic coding with or without context sensitivity, and so forth.
- the parser 304 may extract from the coded video sequence, a set of subgroup parameters for at least one of the subgroups of pixels in the video decoder, based upon at least one parameters corresponding to the group. Subgroups can include Groups of Pictures (GOPs), pictures, tiles, slices, macroblocks, Coding Units (CUs), blocks, Transform Units (TUs), Prediction Units (PUs) and so forth.
- the entropy decoder / parser may also extract from the coded video sequence information such as transform coefficients, quantizer parameter values, motion vectors, and so forth.
- the parser 304 may perform entropy decoding / parsing operation on the video sequence received from the buffer 303, so to create symbols 313.
- the parser 304 may receive encoded data, and selectively decode particular symbols 313. Further, the parser 304 may determine whether the particular symbols 313 are to be provided to a Motion Compensation Prediction unit 306, a scaler / inverse transform unit 305, an Intra Prediction Unit 307, or a loop filter 311.
- Reconstruction of the symbols 313 can involve multiple different units depending on the type of the coded video picture or parts thereof (such as: inter and intra picture, inter and intra block), and other factors. Which units are involved, and how, can be controlled by the subgroup control information that was parsed from the coded video sequence by the parser 304. The flow of such subgroup control information between the parser 304 and the multiple units below is not depicted for clarity.
- decoder 300 can be conceptually subdivided into a number of functional units as described below. In a practical implementation operating under commercial constraints, many of these units interact closely with each other and can, at least partly, be integrated into each other. However, for the purpose of describing the disclosed subject matter, the conceptual subdivision into the functional units below is appropriate.
- a first unit is the scaler / inverse transform unit 305.
- the scaler / inverse transform unit is the scaler / inverse transform unit 305.
- 305 receives quantized transform coefficient as well as control information, including which transform to use, block size, quantization factor, quantization scaling matrices, etc. as symbol(s) 313 from the parser 304. It can output blocks comprising sample values, that can be input into aggregator 310.
- the output samples of the scaler / inverse transform 305 can pertain to an intra coded block; that is: a block that is not using predictive information from previously reconstructed pictures, but can use predictive information from previously reconstructed parts of the current picture.
- Such predictive information can be provided by an intra picture prediction unit 307.
- the intra picture prediction unit 307 generates a block of the same size and shape of the block under reconstruction, using surrounding already reconstructed information fetched from the current (partly reconstructed) picture 309.
- the aggregator 310 adds, on a per sample basis, the prediction information the intra prediction unit 307 has generated to the output sample information as provided by the scaler / inverse transform unit 305.
- the output samples of the scaler / inverse transform unit 305 can pertain to an inter coded, and potentially motion compensated block.
- a Motion Compensation Prediction unit 306 can access reference picture memory 308 to fetch samples used for prediction. After motion compensating the fetched samples in accordance with the symbols 313 pertaining to the block, these samples can be added by the aggregator 310 to the output of the scaler / inverse transform unit (in this case called the residual samples or residual signal) so to generate output sample information.
- the addresses within the reference picture memory form where the motion compensation unit fetches prediction samples can be controlled by motion vectors, available to the motion compensation unit in the form of symbols 313 that can have, for example X, Y, and reference picture components.
- Motion compensation also can include interpolation of sample values as fetched from the reference picture memory when subsample exact motion vectors are in use, motion vector prediction mechanisms, and so forth.
- the output samples of the aggregator 310 can be subject to various loop filtering techniques in the loop filter unit 311.
- Video compression technologies can include in-loop filter technologies that are controlled by parameters included in the coded video bitstream and made available to the loop filter unit 311 as symbols 313 from the parser 304, but can also be responsive to meta-information obtained during the decoding of previous (in decoding order) parts of the coded picture or coded video sequence, as well as responsive to previously reconstructed and loop-filtered sample values.
- the output of the loop filter unit 311 can be a sample stream that can be output to the render device 312 as well as stored in the reference picture memory 557 for use in future interpicture prediction.
- coded pictures once fully reconstructed, can be used as reference pictures for future prediction. Once a coded picture is fully reconstructed and the coded picture has been identified as a reference picture (by, for example, parser 304), the current reference picture 309 can become part of the reference picture buffer 308, and a fresh current picture memory can be reallocated before commencing the reconstruction of the following coded picture.
- the video decoder 300 may perform decoding operations according to a predetermined video compression technology that may be documented in a standard, such as ITU-T Rec. H.265.
- the coded video sequence may conform to a syntax specified by the video compression technology or standard being used, in the sense that it adheres to the syntax of the video compression technology or standard, as specified in the video compression technology document or standard and specifically in the profiles document therein.
- the complexity of the coded video sequence is within bounds as defined by the level of the video compression technology or standard. In some cases, levels restrict the maximum picture size, maximum frame rate, maximum reconstruction sample rate (measured in, for example megasamples per second), maximum reference picture size, and so on. Limits set by levels can, in some cases, be further restricted through Hypothetical Reference Decoder (HRD) specifications and metadata for HRD buffer management signaled in the coded video sequence.
- HRD Hypothetical Reference Decoder
- the receiver 302 may receive additional (redundant) data with the encoded video.
- the additional data may be included as part of the coded video sequence(s).
- the additional data may be used by the video decoder 300 to properly decode the data and/or to more accurately reconstruct the original video data.
- Additional data can be in the form of, for example, temporal, spatial, or signal-to-noise ratio (SNR) enhancement layers, redundant slices, redundant pictures, forward error correction codes, and so on.
- SNR signal-to-noise ratio
- Fig. 4 may be a functional block diagram of a video encoder 400 according to an embodiment of the present disclosure.
- the encoder 400 may receive video samples from a video source 401 (that is not part of the encoder) that may capture video image(s) to be coded by the encoder 400.
- the video source 401 may provide the source video sequence to be coded by the encoder (303) in the form of a digital video sample stream that can be of any suitable bit depth (for example: 8 bit, 10 bit, 12 bit, ...), any colorspace (for example, BT.601 Y CrCB, RGB, ...) and any suitable sampling structure (for example Y CrCb 4:2:0, Y CrCb 4:4:4).
- the video source 401 may be a storage device storing previously prepared video.
- the video source 401 may be a camera that captures local image information as a video sequence.
- Video data may be provided as a plurality of individual pictures that impart motion when viewed in sequence. The pictures themselves may be organized as a spatial array of pixels, wherein each pixel can comprise one or more samples depending on the sampling structure, color space, etc. in use. A person skilled in the art can readily understand the relationship between pixels and samples. The description below focuses on samples.
- the encoder 400 may code and compress the pictures of the source video sequence into a coded video sequence 410 in real time or under any other time constraints as required by the application. Enforcing appropriate coding speed is one function of Controller 402. Controller controls other functional units as described below and is functionally coupled to these units. The coupling is not depicted for clarity. Parameters set by controller can include rate control related parameters (picture skip, quantizer, lambda value of rate-distortion optimization techniques, .. .), picture size, group of pictures (GOP) layout, maximum motion vector search range, and so forth. A person skilled in the art can readily identify other functions of controller 402 as they may pertain to video encoder 400 optimized for a certain system design.
- a coding loop can consist of the encoding part of an encoder 400 (“source coder” henceforth) (responsible for creating symbols based on an input picture to be coded, and a reference picture(s)), and a (local) decoder 406 embedded in the encoder 400 that reconstructs the symbols to create the sample data that a (remote) decoder also would create (as any compression between symbols and coded video bitstream is lossless in the video compression technologies considered in the disclosed subject matter). That reconstructed sample stream is input to the reference picture memory 405.
- the reference picture buffer content is also bit exact between local encoder and remote encoder.
- the prediction part of an encoder “sees” as reference picture samples exactly the same sample values as a decoder would “see” when using prediction during decoding.
- This fundamental principle of reference picture synchronicity (and resulting drift, if synchronicity cannot be maintained, for example because of channel errors) is well known to a person skilled in the art.
- the operation of the “local” decoder 406 can be the same as of a “remote” decoder 300, which has already been described in detail above in conjunction with Fig. 3. Briefly referring also to Fig. 4, however, as symbols are available and en/decoding of symbols to a coded video sequence by entropy coder 408 and parser 304 can be lossless, the entropy decoding parts of decoder 300, including channel 301, receiver 302, buffer 303, and parser 304 may not be fully implemented in local decoder 406.
- the source coder 403 may perform motion compensated predictive coding, which codes an input frame predictively with reference to one or more previously-coded frames from the video sequence that were designated as “reference frames.” In this manner, the coding engine 407 codes differences between pixel blocks of an input frame and pixel blocks of reference frame(s) that may be selected as prediction reference(s) to the input frame.
- the local video decoder 406 may decode coded video data of frames that may be designated as reference frames, based on symbols created by the source coder 403. Operations of the coding engine 407 may advantageously be lossy processes.
- the coded video data may be decoded at a video decoder (not shown in Fig. 4)
- the reconstructed video sequence typically may be a replica of the source video sequence with some errors.
- the local video decoder 406 replicates decoding processes that may be performed by the video decoder on reference frames and may cause reconstructed reference frames to be stored in the reference picture memory 405, which may be for example a cache. In this manner, the encoder 400 may store copies of reconstructed reference frames locally that have common content as the reconstructed reference frames that will be obtained by a far-end video decoder (absent transmission errors).
- the predictor 404 may perform prediction searches for the coding engine 407. That is, for a new frame to be coded, the predictor 404 may search the reference picture memory 405 for sample data (as candidate reference pixel blocks) or certain metadata such as reference picture motion vectors, block shapes, and so on, that may serve as an appropriate prediction reference for the new pictures. The predictor 404 may operate on a sample block-by-pixel block basis to find appropriate prediction references. In some cases, as determined by search results obtained by the predictor 404, an input picture may have prediction references drawn from multiple reference pictures stored in the reference picture memory 405. [72] The controller 402 may manage coding operations of the source coder 403, which may be for example a video coder, including, for example, setting of parameters and subgroup parameters used for encoding the video data.
- Output of all aforementioned functional units may be subjected to entropy coding in the entropy coder 408.
- the entropy coder translates the symbols as generated by the various functional units into a coded video sequence, by loss-less compressing the symbols according to technologies known to a person skilled in the art as, for example Huffman coding, variable length coding, arithmetic coding, and so forth.
- the transmitter 409 may buffer the coded video sequence(s) as created by the entropy coder 408 to prepare it for transmission via a communication channel 411, which may be a hardware/software link to a storage device which would store the encoded video data.
- the transmitter 409 may merge coded video data from the source coder 403 with other data to be transmitted, for example, coded audio data and/or ancillary data streams (sources not shown).
- the controller 402 may manage operation of the encoder 400. During coding, the controller 402 may assign to each coded picture a certain coded picture type, which may affect the coding techniques that may be applied to the respective picture. For example, pictures often may be assigned as one of the following frame types:
- An Intra Picture may be one that may be coded and decoded without using any other frame in the sequence as a source of prediction. Some video codecs allow for different types of Intra pictures, including, for example Independent Decoder Refresh Pictures. A person skilled in the art is aware of those variants of I pictures and their respective applications and features.
- a Predictive picture may be one that may be coded and decoded using intra prediction or inter prediction using at most one motion vector and reference index to predict the sample values of each block.
- a Bi-directionally Predictive Picture may be one that may be coded and decoded using intra prediction or inter prediction using at most two motion vectors and reference indices to predict the sample values of each block.
- multiple-predictive pictures can use more than two reference pictures and associated metadata for the reconstruction of a single block.
- Source pictures commonly may be subdivided spatially into a plurality of sample blocks (for example, blocks of 4 x 4, 8 x 8, 4 x 8, or 16 x 16 samples each) and coded on a block-by- block basis.
- Blocks may be coded predictively with reference to other (already coded) blocks as determined by the coding assignment applied to the blocks’ respective pictures.
- blocks of 1 pictures may be coded non-predictively or they may be coded predictively with reference to already coded blocks of the same picture (spatial prediction or intra prediction).
- Pixel blocks of P pictures may be coded non-predictively, via spatial prediction or via temporal prediction with reference to one previously coded reference pictures.
- Blocks of B pictures may be coded non-predictively, via spatial prediction or via temporal prediction with reference to one or two previously coded reference pictures.
- the encoder 400 which may be for example a video coder, may perform coding operations according to a predetermined video coding technology or standard, such as ITU-T Rec. H.265. In its operation, the encoder 400 may perform various compression operations, including predictive coding operations that exploit temporal and spatial redundancies in the input video sequence.
- the coded video data therefore, may conform to a syntax specified by the video coding technology or standard being used.
- the transmitter 409 may transmit additional data with the encoded video.
- the source coder 403 may include such data as part of the coded video sequence. Additional data may comprise temporal/spatial/SNR enhancement layers, other forms of redundant data such as redundant pictures and slices, Supplementary Enhancement Information (SEI) messages, Visual Usability Information (VUI) parameter set fragments, and so on.
- SEI Supplementary Enhancement Information
- VUI Visual Usability Information
- Fig. 5 illustrates a simplified block-style workflow diagram 500 of exemplary view-port dependent processing an in Omnidirectional Media Application Format (OMAF) that may allow for 360-degree virtual reality (VR360) streaming described in OMAF.
- OMAF Omnidirectional Media Application Format
- video data A is acquired, such as data of multiple images and audio of same time instances in a case that the image data may represent scenes in VR360.
- the images Bi of the same time instance are processed by one or more of being stitched, mapped onto a projected picture with respect to one or more virtual reality (VR) angles or other angles/viewpoint(s) and region-wise packed. Additionally, metadata may be created indicating any of such processed information and other information so as to assist in delivering and rendering processes.
- VR virtual reality
- the projected pictures are encoded to data Ei and composed into a media file, and in viewport-independent streaming, and at video encoding block 1004, the video pictures are encoded as data E v as a single-layer bitstream, for example, and with respect to data B a the audio data may also be encoded into data E a at audio encoding block 1002.
- the data E a , E v , and Ei, the entire coded bitstream Fi and/or F may be stored at a (content delivery network (CDN)/cloud) server, and typically may be fully transmitted, such as at delivery block 1007 or otherwise, to an OMAF player 1020 and may be fully decoded by a decoder such that at least an area of a decoded picture corresponding to a current viewport is rendered to the user at display block 1016 with respect to the various metadata, fde playback, and orientation/viewport metadata, such as an angle at which a user may be looking through a VR image device with respect to viewport specifications of that device, from the head/eye tracking block 1008.
- CDN content delivery network
- a decoder such that at least an area of a decoded picture corresponding to a current viewport is rendered to the user at display block 1016 with respect to the various metadata, fde playback, and orientation/viewport metadata, such as an angle at which a user may be looking through a VR image device
- VR360 A distinct feature of VR360 is that only a viewport may be displayed at any particular time, and such feature may be utilized to improve the performance of omnidirectional video systems, through selective delivery depending on the user’s viewport (or any other criteria, such as recommended viewport timed metadata).
- viewportdependent delivery may be enabled by tile-based video coding according to exemplary embodiments.
- the OMAF player 1020 may similarly reverse one or more facets of such encoding with respect to the file/segment decapsulation of one or more of the data F’ and/or F ⁇ and metadata, decode the audio data E’i at audio decoding block 1010, the video data E’ v at video decoding block 1013, and the image data E’i at image decoding block 1014 to proceed with audio rendering of the data B’ a at audio rendering block 1011 and image rendering of the data D’ at image rendering block 1015 so as to output, in a VR360 format according to various metadata such as the orientation/viewport metadata, display data A’i at display block 1016 and audio data A’ s at the loudspeakers/headphones block 1012.
- the various metadata may influence ones of the data decoding and rendering processes depending on various tracks, languages, qualities, views, that may be selected by or for a user of the OMAF player 1020, and it is to be understood that the order of processing described herein is presented for exemplary embodiments and may be implemented in other orders according to other exemplary embodiments.
- FIG. 6 illustrates a simplified block-style content flow process diagram 600 for (coded) point cloud data with view-position and angle dependent processing of point cloud data (herein “V-PCC”) with respect to capturing/generating/(de)coding/rendering/displaying 6 degree-of- freedom media.
- V-PCC view-position and angle dependent processing of point cloud data
- the described features may be used separately or combined in any order and elements such as for encoding and decoding, among others illustrated, may be implemented by processing circuitry (e.g., one or more processors or one or more integrated circuits), and the one or more processors may execute a program that is stored in a non-transitory computer-readable medium according to exemplary embodiments.
- the diagram 600 illustrates exemplary embodiments for streaming of coded point cloud data according to V-PCC.
- a real-world visual scene or a computergenerated visual scene may be captured by a set of camera devices or synthesized by a computer as a volumetric data, and the volumetric data, which may have an arbitrary format, may be converted to a (quantized) point cloud data format, through image processing at the converting to point cloud block 1102.
- data from the volumetric data may be area data by area data converted into ones of points of the point cloud by pulling one or more of the values described below from the volumetric data and any associated data into a desired point cloud format according to exemplary embodiments.
- the volumetric data may be a 3D data set of 2D images, such as slices from which a 2D projection of the 3D data set may be projected for example.
- point cloud data formats include representations of data points in one or more various spaces and may be used to represent the volumetric data and may offer improvements with respect to sampling and data compression, such as with respect to temporal redundancies, and, for example, a point cloud data in an x, y, z, format representing, at each point of multiple points of the cloud data, color values (e.g., RGB, etc.), luminance, intensity, etc. and could be used with progressive decoding, polygon meshing, direct rendering, octree 3D representations of 2D quadtree data.
- the acquired point cloud data may be projected onto 2D images and encoded as image/video pictures with video-based point cloud coding (V-PCC).
- V-PCC video-based point cloud coding
- the projected point cloud data may be composed of attributes, geometry, occupancy map, and other metadata used for point cloud data reconstruction such as with painter’s algorithms, ray casting algorithms, (3D) binary space partition algorithms, among others for example.
- a scene generator may generate some metadata to be used for rendering and displaying 6 degrees-of-freedom (DoF) media, by a director’s intention or a user’s preference for example.
- DoF media may include the 360VR like 3D viewing of a scene from rotational changes on 3D axis X, Y, Z in addition to additional dimension allowing for movement front/back, up/down, and left/right with respect to a virtual experience within or at least according to point cloud coded data.
- the scene description metadata defines one or more scene composed of the coded point cloud data and other media data, including VR360, light field, audio, etc. and may be provided to one or more cloud servers and or file/segment encapsulation/decapsulation processing as indicated in Fig. 6 and related descriptions.
- fde/segment encapsulation block 1106 processes such that the coded point cloud data are composed into a media fde for fde playback or a sequence of an initialization segment and media segments for streaming according to a particular media container fde format such as one or more video container formats and such as may be used with respect to DASH described below, among others as such descriptions represent exemplary embodiments.
- the fde container also may include the scene description metadata, such as from the scene generator block 1109, into the fde or the segments.
- the fde is encapsulated depending on the scene description metadata to include at least one view position and at least one or more angle views at that/those view position(s) each at one or more times among the 6DoF media such that such fde may be transmitted on request depending on user or creator input.
- a segment of such fde may include one or more portions of such fde such as a portion of that 6DoF media indicating a single viewpoint and angle thereat at one or more times; however, these are merely exemplary embodiments and may be changed depending on various conditions such as network, user, creator capabilities and inputs.
- the point cloud data is partitioned into multiple 2D/3D regions, which are independently coded such as at one or more of video encoding block 1104 and image encoding block 1105. Then, each independently coded partition of point cloud data may encapsulated at fde/segment encapsulation block 1106 as a track in a fde and/or segement.
- each point cloud track and/or a metadata track may include some useful metadata for view-position/angle dependent processing.
- the metadata such as included in a fde and/or segment encapsulated with respect to the fde/segment encapsulation block, useful for the view- position/angle dependent processing includes one or more of the following: layout information of 2D/3D partitions with indices, (dynamic) mapping information associating a 3D volume partition with one or more 2D partitions (e g.
- any of atile/tile group/slice/sub-picture 3D positions of each 3D partition on a 6D0F coordinate system, representative view position/angle lists, selected view position/angle lists corresponding to a 3D volume partition, indices of 2D/3D partitions corresponding to a selected view position/angle, quality (rank)information of each 2D/3D partition, and rendering information of each 2D/3D partition for example depending on each view position/angle.
- Calling on such metadata when requested may allow for more efficient processing with respect to specific portions of the 6D0F media desired with respect to such metadata such that the V-PCC player may deliver higher quality images of focused on portions of the 6D0F media than other portions rather than delivering unused portions of that media.
- the file or one or more segments of the file may be delivered using a delivery mechanism (e.g, by Dynamic Adaptive Streaming over HTTP (DASH)) directly to any of the V-PCC player 1125 and a cloud server, such as at the cloud server block 1107 at which the cloud server can extract one or more tracks and/or one or more specific 2D/3D partitions from a file and may merge multiple coded point cloud data into one data.
- a delivery mechanism e.g, by Dynamic Adaptive Streaming over HTTP (DASH)
- DASH Dynamic Adaptive Streaming over HTTP
- the view-position/angle metadata may be delivered, from the file/segment encapsulation block 1106 or otherwise processed from the file or segments already at the cloud server, at cloud server block 1107 such that the cloud sever may extract appropriate partition(s) from the store file(s) and merge them (if necessary) depending on the metadata from the client system having the V-PCC player 1125 for example, and the extracted data can be delivered to the client, as a file or segments.
- a file decapsulator processes the file or the received segments and extracts the coded bitstreams and parses the metadata, and at video decoding and image decoding blocks, the coded point cloud data are then decoded into decoded and reconstructed, at point cloud reconstruction block 1112, to point cloud data, and the reconstructed point cloud data can be displayed at display block 1114 and/or may first be composed depending on one or more various scene descriptions at scene composition block 1113 with respect to scene description data according to the scene generator block 1109.
- V-PCC flow represents advantages with respect to a V-PCC standard including one or more of the described partitioning capabilities for multiple 2D/3D areas, a capability of a compressed domain assembly of coded 2D/3D partitions into a single conformant coded video bitstream, and a bitstream extraction capability of coded 2D/3D of a coded picture into conformant coded bitstreams, where such V-PCC system support is further improved by including container formation for a VVC bitstream to support a mechanism to contain metadata carrying one or more of the above-described metadata.
- the term “mesh” indicates a composition of one or more polygons that describe the surface of a volumetric object.
- Each polygon is defined by its vertices in 3D space and the information of how the vertices are connected, referred to as connectivity information.
- vertex attributes such as colors, normals, etc.
- Attributes could also be associated with the surface of the mesh by exploiting mapping information that parameterizes the mesh with 2D attribute maps.
- mapping may be described by a set of parametric coordinates, referred to as UV coordinates or texture coordinates, associated with the mesh vertices.
- 2D attribute maps are used to store high resolution attribute information such as texture, normals, displacements etc. Such information could be used for various purposes such as texture mapping and shading according to exemplary embodiments.
- a dynamic mesh sequence may require a large amount of data since it may consist of a significant amount of information changing over time. Therefore, efficient compression technologies are required to store and transmit such contents.
- Mesh compression standards IC, MESHGRID, FAMC were previously developed by MPEG to address dynamic meshes with constant connectivity and time varying geometry and vertex attributes. However, these standards do not take into account time varying attribute maps and connectivity information. DCC (Digital Content Creation) tools usually generate such dynamic meshes. In counterpart, it is challenging for volumetric acquisition techniques to generate a constant connectivity dynamic mesh, especially under real time constraints. This type of contents is not supported by the existing standards.
- a “mesh”, or an “input mesh” or the like, is data of multiple, at least two, vertices.
- Fig. 7 represents an example framework 700 of one dynamic mesh compression such as for a 2D atlas sampling based method.
- Each frame of the input meshes 1201 can be preprocessed by a series of operations, e.g., tracking, remeshing, parameterization, voxelization.
- these operations can be encoder-only, meaning they might not be part of the decoding process and such possibility may be signaled in metadata by a flag such as indicating 0 for encoder only and 1 for other.
- 2D UV atlases 1202 where each vertex of the mesh has one or more associated UV coordinates on the 2D atlas.
- the meshes can be converted to multiple maps, including the geometry maps and attribute maps, by sampling on the 2D atlas. Then these 2D maps can be coded by video/image codecs, such as HEVC, VVC, AVI, AVS3, etc.
- video/image codecs such as HEVC, VVC, AVI, AVS3, etc.
- the meshes can be reconstructed from the decoded 2D maps. Any postprocessing and filtering can also be applied on the reconstructed meshes 1204.
- other metadata might be signaled to the decoder side for the purpose of 3D mesh reconstruction.
- the chart boundary information, including the uv and xyz coordinates, of the boundary vertices can be predicted, quantized and entropy coded in the bitstream.
- the quantization step size can be configured in the encoder side to tradeoff between the quality and the bitrates.
- a 3D mesh can be partitioned into several segments (or patches/charts). Each segment is composed of a set of connected vertices associated with their geometry, attribute, and connectivity information.
- the UV parameterization process 1302 of mapping from 3D mesh segments onto 2D charts maps one or more mesh segments 1301 onto a 2D chart 1303 in the 2D UV atlas 1304.
- Each vertex (v n ) in the mesh segment will be assigned with a 2D UV coordinates in the 2D UV atlas.
- the vertices (v n ) in a 2D chart form a connected component as their 3D counterpart.
- the geometry, attribute, and connectivity information of each vertex can be inherited from their 3D counterpart as well.
- information may be indicated that vertex V4 connects directly to vertices vo, vs, vi, and V3, and similarly information of each of the other vertices may also be likewise indicated.
- 2D texture mesh would, according to exemplary embodiments, further indicate information, such as color information, in a patch-by-patch basis such as by patches of each triangle, e.g., V2, vs, V3.
- a vertex in 3D could corresponds to multiple vertices in 2D UV atlas.
- the same 3D mesh segment is mapped to multiple 2D charts, instead of a single chart as in Fig. 8, in the 2D UV atlas.
- 3D vertices vi and V4 each have two 2D correspondences vi,vr, and V4, V4’, respectively.
- a general 2D UV atlas of a 3D mesh may consist of multiple charts as shown in Figure 14, where each chart may contain multiple (usually more than or equal to 3) vertices associated with their 3D geometry, attribute, and connectivity information.
- Fig. 10 shows an example 1000 illustrating a derived triangulation in a chart with boundary vertices Bo, B1, B2, B3, B4, B5, B6, B7.
- any triangulation method can be applied to create connectivity among the vertices (including boundary vertices and sampled vertices). For example, for each vertex, find the closest two vertices. Or for all vertices, continuously generate triangles until a minimum number of triangles is achieved after a set number of tries.
- the connectivity information can be also reconstructed by explicit signaling. If a polygon cannot be recovered by implicit rules, the encoder can signal the connectivity information in the bitstream according to exemplary embodiments.
- the example 1000 may represent one such patch, such a patch formed of vertices vs, V2, vs shown in any of Figs. 14 and 15.
- Boundary vertices B0, B1, B2, B3, B4, B5, B6, B7 are defined in the 2D UV space.
- the filled vertices are boundary vertices because they are on the boundary edges of a connected component (a patch/chart).
- a boundary edge can be determined by checking if the edge is only appeared in one triangle.
- geometry information e.g., the 3D XYZ coordinates even though currently in the 2D UV parametric form, and the 2D UV coordinates.
- UV2XYZ may be a ID-array of indices that correspond each 2D UV vertex to a 3D XYZ vertex.
- a subset of the mesh vertices may be coded first, together with the connectivity information among them.
- the connection among these vertices may not exist as they are subsampled from the original mesh.
- There are different ways to signal the connectivity information among the vertices and such subset is therefore referred to as the base mesh or as base vertices.
- an example of such edge-based vertex prediction is shown or more specifically of vertex geometry prediction using intra prediction by extrapolation by extending a triangle to a parallelogram, as shown on the left, and interpolation by weighted averaging of two existing vertices as shown in the right.
- interpolation among these base vertices can be done along the connected edges.
- the middle point of each edge can be generated as predictors.
- the geometry locations of these interpolated points are therefore (weighted) average of the two neighboring decoded vertices (the dashed points 1802 in Fig. 11 left).
- Having more than 1 middle point between two already decoded vertices can also be done in a similar way.
- the actual vertices to be coded can therefore be reconstructed by adding the displacement vectors to the predictors (Fig. 7 middle). After decoding these additional vertices, the connection among the newly decoded vertices and the existing base vertices are still maintained. In addition, connection among the newly decoded vertices can be further established. Together with the base vertices, more intermediate vertices predictors can be generated along the new edges (Fig. 7 right) by connecting these newly decoded vertices 1803 and base vertices together. Therefore, more actual vertices to be decoded are present with associated displacement vectors.
- mesh vertices of a mesh frame 1902 can also be predicted from decoded vertices of a previously coded mesh frame 1901.
- This prediction mechanism is referred to as inter prediction.
- Examples of mesh geometry inter prediction are illustrated in the example 1200 of Fig. 12 showing vertex geometry prediction using inter prediction (previous mesh frame’s vertices become predictors of current frame’s vertices).
- the displacement vector or prediction error from the to-be-coded vertex to the vertex predictor, is to be further coded.
- a number of methods are implemented for dynamic mesh compression and are part of the above-mentioned edge-based vertex prediction framework, where a base mesh is coded first and then more additional vertices are predicted based on the connectivity information from the edges of the base mesh. Note that they can be applied individually or by any form of combinations.
- vertices inside a mesh may be obtained and can be divided at S202 into different groups for prediction purposes, for example see Fig. 10.
- the division is done using the patch/chart partitioning at S204 as previously discussed.
- the division is done under each patch/chart S205.
- the decision S203 whether to proceed to S204 or S205 may be signaled by a flag or the like.
- S205 several vertices of the same patch/chart form a prediction group and will share the same prediction mode, while several other vertices of the same patch/chart can use another prediction mode.
- Such grouping at S206 can be assigned at different levels by determining respective number of vertices involved per group. For example, every 64, 32 or 16 vertices following a scan order inside a patch/chart will be assigned the same prediction mode according to exemplary embodiments and other vertices may be differently assigned.
- a prediction mode can be intra prediction mode or inter prediction mode. This can be signaled or assigned.
- a mesh frame or mesh slice is determined to be in intra type at S207, such as by checking whether a flag of that mesh frame or mesh slice indicates an intra type, then all groups of vertices inside that mesh frame or mesh slice shall use intra prediction mode; otherwise, at S208 either intra prediction or inter prediction mode may be chosen per group for all vertices therein.
- a group of mesh vertices using intra prediction mode its vertices can only be predicted by using previously coded vertices inside the same sub-partition of the current mesh.
- the sub-partition can be the current mesh itself according to exemplary embodiments
- its vertices can only be predicted by using previously coded vertices from another mesh frame according to exemplary embodiments.
- Each of the above-noted information may be determined and signaled by a flag or the like. Said prediction features may occur at S210 and results of said prediction and signaling may occur at S211
- the residue will be a 3D displacement vector, indicating the shift from the current vertex to its predictor.
- the residues of a group of vertices need to be further compressed.
- transformation at S211, along with the signaling thereof, can be applied to the residues of a vertex group, before entropy coding.
- the following methods may be implemented to handle the coding of a group of displacement vectors. For example, in one method, to properly signal the case where a group of displacement vectors, some displacement vectors, or its components have only zero values.
- a flag is signaled for each displacement vectors whether this vector has any non-zero component, and if no, the coding of all components for this displacement vector can be skipped. Further, in another embodiment, a flag is signaled for each group of displacement vectors whether this group has any non-zero vectors, and if no, the coding of all displacement vectors of this group can be skipped. Further, in another embodiment, a flag is signaled for each component of a group of displacement vectors whether this component of the group has any non-zero vectors, and if no, the coding of this component of all displacement vectors s of this group can be skipped.
- a flag may be signaled for each group of displacement vectors whether this group needs to go through transformation, and if no, the transform coding of all displacement vectors of this group can be skipped.
- a flag is signaled for each component of a group of displacement vectors whether this component of the group needs to go through transformation, and if no, the transform coding of this component of all displacement vectors of this group can be skipped.
- Fig. 14 shows the example flowchart 1400 where, at S221 a mesh frame can be obtained coded as an entire data unit, meaning all vertices or attributes of the mesh frame may have correlation among them. Alternatively, depending on a determination at S222, a mesh frame can be divided at S223 into smaller independent sub-partitions, similar in concept to slices or tiles in 2D videos or images. A coded mesh frame or a coded mesh sub-partition can be assigned with a prediction type at S224. Possible prediction types include intra coded type and inter coded type. For intra coded type, only predictions from the reconstructed parts of the same frame or slice are allowed at S225.
- inter prediction type will allow at S225 predictions from a previously coded mesh frame, in addition to intra mesh frame predictions.
- inter prediction type may be classified with more sub-types such as P type or B type.
- P type only one predictor can be used for prediction purposes
- B type two predictors, from two previously coded mesh frames, may be used to generate the predictor. Weighted average of the two predictors can be one example.
- the mesh frame is coded as a whole, the frame can be regarded as an intra or inter coded mesh frame.
- P or B type may be further identified via signaling.
- each of the sub-partitions occurs at S224.
- Each of the above-noted information may be determined and signaled by a flag or the like, and like with S210 and S211 of Fig. 13, said prediction features may occur at S226 and results of said prediction and signaling may occur at S227.
- exemplary embodiments may generate the displacement vectors of a third layer 2303 of a mesh, based on one or more the reconstructed vertices of its previous layer(s) such as a second layer 2302 and a first layer 2301. Assuming the index of the second layer 2302 is T, the predictors for vertices in third layer 2303 T+l are generated based on the reconstructed vertices of at least the current layer or second layer 2302.
- An example of such layer based prediction structure is shown example 1600 in Fig. 16 which illustrates reconstruction based vertex prediction: progressive vertex prediction using edge-based interpolation, where predictors are generated based on previously decoded vertices, not predictor vertices.
- the first layer 2301 may be a mesh bounded by a first polygon 2340 having, as vertices thereof, decoded vertices, at boundaries thereof, and interpolated vertices, along ones of lines between ones of those decoded vertices.
- a first polygon 2340 having, as vertices thereof, decoded vertices, at boundaries thereof, and interpolated vertices, along ones of lines between ones of those decoded vertices.
- an additional polygon 2341 may be formed by displacement vectors from ones of the interpolated vertices of the first layer to additional vertices of the second layer 2302, and as such, a total number of vertices of the second layer 2302 may be greater than that of the first layer 2301.
- the additional vertices of the second layer 2302, along with the decoded vertices from the first layer 2301, may then serve in the coding in a similar manner as did the decoded vertices served in proceeding from the first layer 2301 to the second layer 2303; that is, multiple additional polygons may be formed.
- the example 1900 in Fig. 19 illustrating such progressive coding where, unlike in Fig. 16, the example 1900 illustrates that, in proceeding from the first layer 2601 to the second layer 2603 and then to the third layer 2603, each of the additionally formed polygons may be entirely within a polygon formed by bounds of the first layer 2601.
- Vj and Vk are reconstructed vertices of previous layers
- each of P, R and D represents a 3D vector under the context of 3D mesh representation.
- D is the decoded displacement vector, and quantization may or may not apply to this vector.
- the vertex prediction using reconstructed vertices may only apply to certain layers. For example, layer 0 and layer 1. For other layers, the vertex prediction can still use neighboring predictor vertices without adding displacement vectors to them for reconstruction. So that these other layers can be processed at the same time without waiting one previous layer to reconstruct. According to exemplary embodiments, for each layer, whether to choose reconstruction based vertex prediction or predictor based vertex prediction, can be signaled, or the layer (and its subsequent layers) that does not use reconstruction based vertex prediction, can be signaled.
- a dynamic mesh sequence may nonetheless require a large amount of data since it may consist of a significant amount of information changing over time, and as such, efficient compression technologies are required to store and transmit such contents.
- an important advantage may be achieved by inferring the connectivity information from the sampled vertices plus boundary vertices on decoder side. This is a major part in decoding process, and a focus of further examples described below.
- the connectivity information of the base mesh can be inferred (derived) from the decoded boundary vertices and the sampled vertices for each chart on both encoder and decoder sides.
- any triangulation method can be applied to create connectivity among vertices (including boundary vertices and sampled vertices).
- vertices including boundary vertices and sampled vertices.
- similar methods of creating connectivity still apply although, according to exemplary embodiments, it may be signaled to use different triangulation methods for boundary vertices and sampled vertices.
- a number of occupied points is larger than or equal to 3 (examples of occupied or unoccupied points are highlighted in Fig. 18 which shows an occupancy map example 1800 which each circle representing an integer pixel), and the connectivity of triangles among the 4 points can be inferred by certain rules. For example, as illustrated in the example 1700 of Fig.
- the reconstructed mesh is a triangle mesh as in Fig. 17 and as in at least as a regular triangle mesh in the internal portions of Fig. 18, which may not be determined to not be signaled according to such regularity but instead may be coded and decoded by inference rather than by individual signaling, and as irregular triangles at the perimeter which are to be signaled individually.
- a quad mesh of such regular internal triangles shown in Fig. 18 may be inferred as such quad mesh of the example (1) of Fig. 17 thereby reducing even the amount of complexity from inferring the internal regular triangles as instead inferring a reduced number of internal regular quad meshes.
- a quad mesh may be reconstructed when the 4 neighboring points are determined to be all occupied such as in the example (1) of Fig. 17.
- reconstructed mesh in the example 1800 can be a hybrid type, that is, some regions in the mesh frame generate triangle meshes while other regions generate quad meshes, and some of said triangle meshes may be regular as compared to other triangle meshes therein and some may be irregular, such as ones of the boundary though not necessary all of such meshes on the boundary.
- such connectivity types can be signaled in high- level syntax, such as sequence header, slice header.
- connectivity information can be also reconstructed by explicitly signaling, such as for the irregularly shaped triangle meshes. That is, if it is determined that a polygon cannot be recovered by implicit rules, the encoder can signal the connectivity information in the bitstream. And according to exemplary embodiments, the overhead of such explicit signaling may be reduced depending on the boundaries of polygons. For example, as shown with the example 1800 in Fig. 18, the connectivity information of triangles would be signaled to be reconstructed by both implicit rules, such as according to the regular examples 2400 in Fig. 17 which may be inferred, and explicit signaling for ones of the irregular shaped polygons shown at least on the mesh boundaries in Fig. 18.
- the connectivity information may be signaled by prediction, such that only the difference from the inferred connectivity (as prediction) from one mesh to another may be signaled in bitstream.
- the orientation of inferred triangles can be either signaled for all charts in high-level syntax, such as sequence header, slice header, etc., or fixed (assumed) by encoder and decoder according to exemplary embodiments.
- the orientation of inferred triangles can be also signaled differently for each chart.
- any reconstructed mesh may have different connectivity from the original mesh.
- the original mesh may be a triangle mesh
- the reconstructed mesh may be a polygonal mesh (e.g., quad mesh).
- the connectivity information of any base vertices may not be signaled and instead the edges among base vertices may be derived using the same algorithm at both encoder and decoder side.
- the coding may take advantage of such information by therefore determining that such vertices are occupied as a base and thereby later inferring such that the connectivity information of any base vertices may not be signaled and instead the edges among base vertices may be derived using the same algorithm at both encoder and decoder side.
- interpolation of predicted vertices for the additional mesh vertices may be based on the derived edges of the base mesh.
- a flag may be used to signal whether the connectivity information of the base vertices is to be signaled or derived, and such flag can be signaled at different level of the bitstream, such as at sequences level, frame level, etc.
- the edges among the base vertices are first derived using the same algorithm at both encoder and decoder side. Then compared with the original connectivity of the base mesh vertices, the difference between the derived edges and the actual edges will be signaled. Therefore, after decoding the difference, the original connectivity of the base vertices can be restored.
- a derived edge if determined to be wrong when compared to the original edge, such information may signaled in the bitstream (by indicating the pair of vertices that form this edge); and for an original edge, if not derived, may be signaled in the bitstream (by indicating the pair of vertices that form this edge).
- connectivity on boundary edges and vertex interpolation involving boundary edges may be done separately from the internal vertices and edges.
- the technical problems noted above may be advantageously improved upon by one or more of these technical solutions.
- a dynamic mesh sequence may require a large amount of data since it may consist of a significant amount of information changing over time, and therefore, the exemplary embodiments described herein represent at least efficient compression technologies to store and transmit such contents.
- an instance may be a mesh of an object or a part of an object.
- the illustration example 2100 of Fig. 21 illustrates a mesh example 2801 in which various instances
- each of the instances 2801, 2802, 2803, and 2804 are illustrated in respective ones of bounding boxes which will be described further below, but, as a note, it may be considered that the instance 2801 may be illustrated as a bounded by a “mesh-based bounding box” whereas each of instances 2802, 2803, and 2804 may be considered illustrated as bounding by respective ones of an “instance-based bounding box.”
- the proposed methods may be used separately or combined in any order.
- the proposed methods may be used for arbitrary polygon mesh, but even though only a triangle mesh may have been used for demonstration of various embodiments.
- an input mesh may contain one or multiple instances, that a submesh is a part of input mesh with an instance or multiple instance, and that multiple instances can be grouped to form a submesh.
- FIG. 20 illustrates an example 2000 in which it is proposed to separately quantize different objects or parts at a given input bitdepth (where that bitdepth may be referred to as “QP”).
- QP input bitdepth
- a submesh can be an object, an instance of an object or a segmented region, and will be quantized at S2702 independently according to exemplary embodiments.
- a mesh M with m points in (x, y, z) coordinate may be quantized at S2702 by a QP bitdepth.
- the quantization step size for all three dimensions (x, y, z) may be decided based on a largest length of the bounding box in all dimension - d bbox > 0.
- same quantization step size may applied at S2704 for all objects, identified at S2703, in the mesh as and a scalar quantization thereof may applied for the y -th point at i-th coordinate as where is an offset parameter for quantization. is the minimum coordinate of the mesh in M at i-th dimension.
- Notation [ J stands for the floor rounding operator.
- the dequantized coordinate may be calculated with uniform dequantization as follow with the mean square error of quantization as
- the quantization step size of every instance, each of instances 2802 (representing a mesh of a cup), 2803 (representing a mesh of a spoon), and 2804 (representing a mesh of a plate), may always smaller than or equal to the mesh-based quantization step size that satisfies [150] Therefore, the quantization error for each instance becomes smaller, thus reducing the overall quantization error.
- the bitdepth may be assigned adaptively for each instance/region, referred to as a “submesh” in S2902, and may be decided based on the face density of that particular instance.
- Each submesh may be obtained from the volumetric data of the mesh which may itself have signaled each instance within the mesh individually, and each submesh being derived from that mesh on per instance basis at S2902.
- each of the instances 2802, 2803, and 2804 may be assigned its own respective bitdepth, at S2904, depending on its own particular face density or numbers of vertices, forming one or more of the above-described polygons, therein.
- a total number of faces is n
- corresponding faces for submesh A-th is n k that satisfies where K is the total number of submeshes.
- the submesh face density is defined a
- the adaptive quantization for instance k can be defined in a limited range [QP min , QP max ] as - Eq. (7)
- a mesh is represented as a base-mesh B and its corresponding displacement D and quantized at S2702 at different bitdepth.
- the bithdepth base mesh QP k can be calculated from Eq. (3), and the bitdepth of its displacement could be derived as wit s the adaptive scaling factor and offset for the ;th object.
- adaptive bitdepth parameters based on minimizing distortion may be used.
- the mean squared error (MSE) of a quantization method is P may be as in Eq. (4).
- the MSE of each submesh is derived as where co k>0 is a weighting factor.
- co_k l Vk.
- a linear search is performed for each submesh to find the best bithdepth for base mesh that satisfies
- there may be signaling of quantization for each object such as by signaling at S2907 signal bithdepth through bitstream.
- the set of base quantization bitdepth in the increasing order may be with corresponding displacement quantization bitdepth
- This information may be signaled as mesh instance parameter syntax.
- b 0 bits may be used to signal a bounding box offset
- All instances may share the same bounding box offset.
- Number K — 1 is limited to b ⁇ bit
- the maximum base quantization bithdepth is b 2 bit
- the maximum difference in bitdepth between base and displacement is b 3 bit.
- b 3 4.
- An example syntax table is shown below, where the instances are arranged in the order of ascending quantization values. In this way, the signaled quantization difference for each instance may be always non-negative. In a more general case, the instances may not be arranged by quantization values, for each instance, and in addition to the absolute difference, the sign may also be signaled.
- u(n) is unsigned integer using n bits
- i(n) is integer using n bits
- mips_quant() is a series of signaling data
- mips_min_bbox[k] is the minimum of the bounding box at i-th dimension
- mips num instances minusl is the number of instances - 1 in the mesh
- mips base bitdepth minusl is the bitdepth of the first instance in the order
- mips_base_quant[k] is the difference in quantization of the (fc + l)-th and fc-th submesh. As the quantization set is sorted in the increasing order, this number is always non-negative
- mips_dist_quant[k] is the fc-th quantization data for base mesh bithdepth.
- multiple instances may be grouped to K groups with a same bitdepth to reduce the signaling overhead.
- Instances may be clustered based on the maximum distance of the bounding box with a simple clustering method like K-mean clustering.
- Fig. 23 illustrates an example 2300 flowchart in which an instance-based matching prediction (IMP) method is used to find a redundant mesh and encode corresponding displacement, which may advantageously normalize instances to maximize their similarity, and may be used with any of the embodiments described above.
- IMP instance-based matching prediction
- an input mesh may be obtained and partitioned into to multiple submeshes as described above.
- a submesh could be an instance of an individual object or a part of an object according to exemplary embodiments.
- instances may be aligned and normalised so that only transitional asset may be reused.
- Scale and orientation information may be signaled through channel for IMP mode, and given input mesh .M with m instances, an instance i-th may have a corresponding bounding box of d y . And as such, similar instances with a same ratio of the bounding box may be grouped to one asset group.
- pairwise dlPSNR peak signal to noise ratio
- T may be applied to verify the similarity and remove outlier instances.
- IMP may be used to encode instances in an asset group S with large than one in size .
- the first instance is encoded, and its decoded version is used as a base mesh for the remainder instance in the group. For example:
- coding at S2805 may be signaled to code the submeshes independently into sub-bitstreams.
- Each submesh can be coded by mesh codecs with different coding parameters. Note that each submesh can be also coded by different mesh codecs, in which case the codec index indicating which mesh codec is used needs to be signaled such as in the header of the sub-bitstream.
- Sub-bitstreams of submeshes can be encoded and decoded in parallel without data dependency issue according to exemplary embodiments.
- an additional flag may be considered so as to indicate a mode of coding the submeshes dependently as well.
- a submesh can be coded by prediction from other submeshes which are already coded.
- Prediction indices can be coded to indicate which sub-mesh to be used as prediction.
- the prediction indices can be signaled at different levels.
- only one prediction index may be coded for the entire submesh, so that all the vertices in current submesh will be predicted from the same submesh as indicated by the index according to exemplary embodiments.
- the prediction indices may be signaled for each vertex of current submesh, so that each vertex can predict from different submeshes.
- the prediction indices can be coded by predictive coding as well, where the prediction index of a vertex can be predicted from neighboring coded vertices.
- the prediction index residual can be then coded by arithmetic coding according to exemplary embodiments.
- the prediction indices may be signaled at an intermediate level between vertexlevel and submesh-level, e.g., at the group-of-vertices level, where a group of vertices share the same prediction index.
- the prediction index of different groups can be also coded by predictive coding according to exemplary embodiments.
- each vertex can be either predicted from the vertices in corresponding submesh, such as described above with any of Figs. 13, 14, and 15.
- a rigid motion may be estimated from the prediction submesh to current submesh, and the parameters of the rigid motion (e.g., rotation and translation parameters) can be coded.
- the residual of the current vertex’s attribute can be obtained by subtracting the corresponding vertex’s attribute in the transformed prediction submesh.
- the attribute of the vertex can include but not limited to the following: geometry, color, normal, uv coordinates, connectivity etc.
- the residual information can then be coded by arithmetic coding according to exemplary embodiments.
- Such coding may be applied to code material and texture information for each submesh.
- This information can include but is not necessarily limited to the following: ambient color, diffuse color, specular color, focus of specular highlights, factor for dissolve, illumination model, texture image id etc.
- one submesh only allows one set of material and texture information, and in such case, this information can be simply coded at the header of the sub-bitstream.
- one submesh can have more than one sets of material and texture information, and in this case, those sets can be coded at the header of the sub-bitstream. Note that these parameters in different sets can be coded independently or dependently. If the dependent coding is applied, predictions can be applied, and the prediction residual of material parameters can be coded instead. Then, for each vertex in the submesh, a material id can be coded to indicate which set of material information is used for this vertex.
- the material id can be coded by predicting from neighboring coded vertices to reduce the redundancies, according to exemplary embodiments.
- each instance may be considered as a 3D asset since, in 3D design according to exemplary embodiments herein, the asset may be frequently used to reduces cost in designing models, especially for composite of complex scenes.
- a 3D model may be reused with or without modified textures at difference in scale, orientation, etc.
- the meshes may be normalized to a position, a size, and orientations based on a PCA (principal component analysis) or bilateral symmetry plane and thereby more efficiently retrieved.
- PCA principal component analysis
- FIG. 24 shows a computer system 2400 suitable for implementing certain embodiments of the disclosed subject matter.
- the computer software can be coded using any suitable machine code or computer language, that may be subject to assembly, compilation, linking, or like mechanisms to create code comprising instructions that can be executed directly, or through interpretation, micro-code execution, and the like, by computer central processing units (CPUs), Graphics Processing Units (GPUs), and the like.
- CPUs central processing units
- GPUs Graphics Processing Units
- the instructions can be executed on various types of computers or components thereof, including, for example, personal computers, tablet computers, servers, smartphones, gaming devices, internet of things devices, and the like.
- the components shown in FIG. 24 for computer system 2400 are exemplary in nature and are not intended to suggest any limitation as to the scope of use or functionality of the computer software implementing embodiments of the present disclosure. Neither should the configuration of components be interpreted as having any dependency or requirement relating to any one or combination of components illustrated in the exemplary embodiment of a computer system 2400.
- Computer system 2400 may include certain human interface input devices.
- a human interface input device may be responsive to input by one or more human users through, for example, tactile input (such as: keystrokes, swipes, data glove movements), audio input (such as: voice, clapping), visual input (such as: gestures), olfactory input (not depicted).
- the human interface devices can also be used to capture certain media not necessarily directly related to conscious input by a human, such as audio (such as: speech, music, ambient sound), images (such as: scanned images, photographic images obtain from a still image camera), video (such as two-dimensional video, three-dimensional video including stereoscopic video).
- Input human interface devices may include one or more of (only one of each depicted): keyboard 2401, mouse 2402, trackpad 2403, touch screen 2410, joystick 2405, microphone 2406, scanner 2408, camera 2407.
- Computer system 2400 may also include certain human interface output devices.
- Such human interface output devices may be stimulating the senses of one or more human users through, for example, tactile output, sound, light, and smell/taste.
- Such human interface output devices may include tactile output devices (for example tactile feedback by the touch-screen 2410, or joystick 2405, but there can also be tactile feedback devices that do not serve as input devices), audio output devices (such as: speakers 2409, headphones (not depicted)), visual output devices (such as screens 2410 to include CRT screens, LCD screens, plasma screens, OLED screens, each with or without touch-screen input capability, each with or without tactile feedback capability — some of which may be capable to output two dimensional visual output or more than three dimensional output through means such as stereographic output; virtual-reality glasses (not depicted), holographic displays and smoke tanks (not depicted)), and printers (not depicted).
- Computer system 2400 can also include human accessible storage devices and their associated media such as optical media including CD/DVD ROM/RW 2420 with CD/DVD 2411 or the like media, thumb-drive 2422, removable hard drive or solid state drive 2423, legacy magnetic media such as tape and floppy disc (not depicted), specialized ROM/ASIC/PLD based devices such as security dongles (not depicted), and the like.
- optical media including CD/DVD ROM/RW 2420 with CD/DVD 2411 or the like media, thumb-drive 2422, removable hard drive or solid state drive 2423, legacy magnetic media such as tape and floppy disc (not depicted), specialized ROM/ASIC/PLD based devices such as security dongles (not depicted), and the like.
- Computer system 2400 can also include interface 2499 to one or more communication networks 2498.
- Networks 2498 can for example be wireless, wireline, optical.
- Networks 2498 can further be local, wide-area, metropolitan, vehicular and industrial, real-time, delay-tolerant, and so on.
- Examples of networks 2498 include local area networks such as Ethernet, wireless LANs, cellular networks to include GSM, 3G, 4G, 5G, LTE and the like, TV wireline or wireless wide area digital networks to include cable TV, satellite TV, and terrestrial broadcast TV, vehicular and industrial to include CANBus, and so forth.
- Certain networks 2498 commonly require external network interface adapters that attached to certain general-purpose data ports or peripheral buses (2450 and 2451) (such as, for example USB ports of the computer system 2400; others are commonly integrated into the core of the computer system 2400 by attachment to a system bus as described below (for example Ethernet interface into a PC computer system or cellular network interface into a smartphone computer system).
- computer system 2400 can communicate with other entities.
- Such communication can be uni -directional, receive only (for example, broadcast TV), uni-directional send-only (for example CANbusto certain CANbus devices), or bi-directional, for example to other computer systems using local or wide area digital networks.
- Certain protocols and protocol stacks can be used on each of those networks and network interfaces as described above.
- Aforementioned human interface devices, human-accessible storage devices, and network interfaces can be attached to a core 2440 of the computer system 2400.
- the core 2440 can include one or more Central Processing Units (CPU) 2441, Graphics Processing Units (GPU) 2442, a graphics adapter 2417, specialized programmable processing units in the form of Field Programmable Gate Areas (FPGA) 2443, hardware accelerators for certain tasks 2444, and so forth.
- CPU Central Processing Unit
- GPU Graphics Processing Unit
- FPGA Field Programmable Gate Areas
- ROM Read-only memory
- RAM Random-access memory
- internal mass storage such as internal non-user accessible hard drives, SSDs, and the like 2447
- the system bus 2448 can be accessible in the form of one or more physical plugs to enable extensions by additional CPUs, GPU, and the like.
- the peripheral devices can be attached either directly to the core’s system bus 2448, or through a peripheral bus 2449. Architectures for a peripheral bus include PCI, USB, and the like.
- CPUs 2441, GPUs 2442, FPGAs 2443, and accelerators 2444 can execute certain instructions that, in combination, can make up the aforementioned computer code. That computer code can be stored in ROM 2445 or RAM 2446. Transitional data can be also be stored in RAM 2446, whereas permanent data can be stored for example, in the internal mass storage 2447. Fast storage and retrieval to any of the memory devices can be enabled through the use of cache memory, that can be closely associated with one or more CPU 2441, GPU 2442, mass storage 2447, ROM 2445, RAM 2446, and the like.
- the computer readable media can have computer code thereon for performing various computer-implemented operations.
- the media and computer code can be those specially designed and constructed for the purposes of the present disclosure, or they can be of the kind well known and available to those having skill in the computer software arts.
- the computer system having architecture 2400, and specifically the core 2440 can provide functionality as a result of processor(s) (including CPUs, GPUs, FPGA, accelerators, and the like) executing software embodied in one or more tangible, computer-readable media.
- processor(s) including CPUs, GPUs, FPGA, accelerators, and the like
- Such computer-readable media can be media associated with user-accessible mass storage as introduced above, as well as certain storage of the core 2440 that are of non-transitory nature, such as core-internal mass storage 2447 or ROM 2445.
- the software implementing various embodiments of the present disclosure can be stored in such devices and executed by core 2440.
- a computer-readable medium can include one or more memory devices or chips, according to particular needs.
- the software can cause the core 2440 and specifically the processors therein (including CPU, GPU, FPGA, and the like) to execute particular processes or particular parts of particular processes described herein, including defining data structures stored in RAM 2446 and modifying such data structures according to the processes defined by the software.
- the computer system can provide functionality as a result of logic hardwired or otherwise embodied in a circuit (for example: accelerator 2444), which can operate in place of or together with software to execute particular processes or particular parts of particular processes described herein.
- Reference to software can encompass logic, and vice versa, where appropriate.
- Reference to a computer- readable media can encompass a circuit (such as an integrated circuit (IC)) storing software for execution, a circuit embodying logic for execution, or both, where appropriate.
- the present disclosure encompasses any suitable combination of hardware and software.
Landscapes
- Engineering & Computer Science (AREA)
- Multimedia (AREA)
- Signal Processing (AREA)
- Physics & Mathematics (AREA)
- General Physics & Mathematics (AREA)
- Theoretical Computer Science (AREA)
- Discrete Mathematics (AREA)
- Compression Or Coding Systems Of Tv Signals (AREA)
Abstract
Description



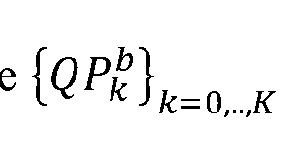



Claims
Priority Applications (4)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| KR1020247017952A KR20240101612A (en) | 2022-07-26 | 2023-05-24 | Methods for instance-based mesh coding |
| EP23847126.2A EP4562610A4 (en) | 2022-07-26 | 2023-05-24 | METHOD FOR INSTANCE-BASED MESH CODING |
| CN202380014234.9A CN118251701A (en) | 2022-07-26 | 2023-05-24 | Example-based grid coding method |
| JP2024547909A JP7842883B2 (en) | 2022-07-26 | 2023-05-24 | Methods, apparatus, and computer programs for instance-based mesh coding |
Applications Claiming Priority (4)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US202263392409P | 2022-07-26 | 2022-07-26 | |
| US63/392,409 | 2022-07-26 | ||
| US18/312,338 US12439082B2 (en) | 2022-07-26 | 2023-05-04 | Methods for instance-based mesh coding |
| US18/312,338 | 2023-05-04 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2024025638A1 true WO2024025638A1 (en) | 2024-02-01 |
Family
ID=89664055
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/US2023/023296 Ceased WO2024025638A1 (en) | 2022-07-26 | 2023-05-24 | Methods for instance-based mesh coding |
Country Status (6)
| Country | Link |
|---|---|
| US (1) | US12439082B2 (en) |
| EP (1) | EP4562610A4 (en) |
| JP (1) | JP7842883B2 (en) |
| KR (1) | KR20240101612A (en) |
| CN (1) | CN118251701A (en) |
| WO (1) | WO2024025638A1 (en) |
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2025211289A1 (en) * | 2024-04-05 | 2025-10-09 | パナソニック インテレクチュアル プロパティ コーポレーション オブ アメリカ | Encoding method, decoding method, encoding device, and decoding device |
| WO2025243923A1 (en) * | 2024-05-20 | 2025-11-27 | パナソニック インテレクチュアル プロパティ コーポレーション オブ アメリカ | Encoding method, decoding method, encoding device, and decoding device |
Families Citing this family (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20250337952A1 (en) * | 2022-04-27 | 2025-10-30 | Interdigital Ce Patent Holdings, Sas | Providing segmentation information for immersive video |
Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20060290695A1 (en) * | 2001-01-05 | 2006-12-28 | Salomie Ioan A | System and method to obtain surface structures of multi-dimensional objects, and to represent those surface structures for animation, transmission and display |
| US10121279B1 (en) * | 2014-07-14 | 2018-11-06 | Ansys, Inc. | Systems and methods for generating a mesh |
| US20200410752A1 (en) * | 2019-06-25 | 2020-12-31 | HypeVR | Optimized volumetric video playback |
Family Cites Families (8)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN101622874A (en) | 2007-01-23 | 2010-01-06 | 欧几里得发现有限责任公司 | Object archival systems and methods |
| WO2012040883A1 (en) | 2010-09-30 | 2012-04-05 | Technicolor (China) Technology Co., Ltd. | Method and apparatus for encoding geometry patterns, and method and apparatus for decoding geometry patterns |
| KR20140116114A (en) | 2012-01-21 | 2014-10-01 | 톰슨 라이센싱 | Method and apparatus for compressing texture information of three-dimensional (3d) models |
| US11823421B2 (en) * | 2019-03-14 | 2023-11-21 | Nokia Technologies Oy | Signalling of metadata for volumetric video |
| US11450030B2 (en) * | 2019-09-24 | 2022-09-20 | Apple Inc. | Three-dimensional mesh compression using a video encoder |
| WO2021136878A1 (en) * | 2020-01-02 | 2021-07-08 | Nokia Technologies Oy | A method, an apparatus and a computer program product for volumetric video encoding and decoding |
| US11836953B2 (en) * | 2020-10-06 | 2023-12-05 | Sony Group Corporation | Video based mesh compression |
| WO2023281929A1 (en) * | 2021-07-08 | 2023-01-12 | ソニーグループ株式会社 | Information processing device and method |
-
2023
- 2023-05-04 US US18/312,338 patent/US12439082B2/en active Active
- 2023-05-24 WO PCT/US2023/023296 patent/WO2024025638A1/en not_active Ceased
- 2023-05-24 KR KR1020247017952A patent/KR20240101612A/en active Pending
- 2023-05-24 CN CN202380014234.9A patent/CN118251701A/en active Pending
- 2023-05-24 EP EP23847126.2A patent/EP4562610A4/en active Pending
- 2023-05-24 JP JP2024547909A patent/JP7842883B2/en active Active
Patent Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20060290695A1 (en) * | 2001-01-05 | 2006-12-28 | Salomie Ioan A | System and method to obtain surface structures of multi-dimensional objects, and to represent those surface structures for animation, transmission and display |
| US10121279B1 (en) * | 2014-07-14 | 2018-11-06 | Ansys, Inc. | Systems and methods for generating a mesh |
| US20200410752A1 (en) * | 2019-06-25 | 2020-12-31 | HypeVR | Optimized volumetric video playback |
Non-Patent Citations (1)
| Title |
|---|
| See also references of EP4562610A4 * |
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2025211289A1 (en) * | 2024-04-05 | 2025-10-09 | パナソニック インテレクチュアル プロパティ コーポレーション オブ アメリカ | Encoding method, decoding method, encoding device, and decoding device |
| WO2025243923A1 (en) * | 2024-05-20 | 2025-11-27 | パナソニック インテレクチュアル プロパティ コーポレーション オブ アメリカ | Encoding method, decoding method, encoding device, and decoding device |
Also Published As
| Publication number | Publication date |
|---|---|
| US12439082B2 (en) | 2025-10-07 |
| EP4562610A1 (en) | 2025-06-04 |
| US20240040148A1 (en) | 2024-02-01 |
| EP4562610A4 (en) | 2025-10-29 |
| JP2025508398A (en) | 2025-03-26 |
| JP7842883B2 (en) | 2026-04-08 |
| CN118251701A (en) | 2024-06-25 |
| KR20240101612A (en) | 2024-07-02 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US12192521B2 (en) | Displacement coding for mesh compression | |
| WO2023229762A1 (en) | Dynamic mesh compression using inter and intra prediction | |
| US12439082B2 (en) | Methods for instance-based mesh coding | |
| US12284349B2 (en) | Adaptive quantization for instance-based mesh coding | |
| US12542926B2 (en) | Motion field coding in dynamic mesh compression | |
| US20240137564A1 (en) | Fast computation of local coordinate system for displacement vectors in mesh coding | |
| US12406403B2 (en) | Vertex prediction based on mesh triangulation derivation | |
| US12602837B2 (en) | On sub-division of mesh sequences | |
| US20240348826A1 (en) | Adaptive wavelet transform | |
| US20240242389A1 (en) | Displacement vector coding for 3d mesh | |
| US12401823B2 (en) | Vertex prediction based on decoded neighbors | |
| EP4649668A2 (en) | Integrating duplicated vertices and vertices grouping in mesh motion vector coding | |
| WO2024147806A1 (en) | Bitstream syntax for mesh displacement coding | |
| US20240394924A1 (en) | Position coding in mesh compression | |
| US20240346702A1 (en) | Vertex position coding in lossless mesh compression | |
| WO2024151293A1 (en) | Bitstream syntax for mesh motion field coding | |
| WO2024178068A1 (en) | Adaptive integrating duplicated vertices in mesh motion vector coding | |
| WO2024147805A1 (en) | Vertices grouping in mesh motion vector coding |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 23847126 Country of ref document: EP Kind code of ref document: A1 |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 202380014234.9 Country of ref document: CN |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 2024547909 Country of ref document: JP |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 2023847126 Country of ref document: EP |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| ENP | Entry into the national phase |
Ref document number: 2023847126 Country of ref document: EP Effective date: 20250226 |
|
| WWP | Wipo information: published in national office |
Ref document number: 2023847126 Country of ref document: EP |