BRPI0808765B1 - Método e aparelho para processamento de um sinal de voz sintetizado em ocultação de perda de pacotes e decodificador de voz - Google Patents
Método e aparelho para processamento de um sinal de voz sintetizado em ocultação de perda de pacotes e decodificador de voz Download PDFInfo
- Publication number
- BRPI0808765B1 BRPI0808765B1 BRPI0808765-2A BRPI0808765A BRPI0808765B1 BR PI0808765 B1 BRPI0808765 B1 BR PI0808765B1 BR PI0808765 A BRPI0808765 A BR PI0808765A BR PI0808765 B1 BRPI0808765 B1 BR PI0808765B1
- Authority
- BR
- Brazil
- Prior art keywords
- voice signal
- signal
- tone
- subunit
- obtaining
- Prior art date
Links
- 238000000034 method Methods 0.000 title claims abstract description 53
- 230000008859 change Effects 0.000 claims abstract description 38
- 230000000737 periodic effect Effects 0.000 claims description 42
- 238000004458 analytical method Methods 0.000 claims description 15
- 230000002238 attenuated effect Effects 0.000 claims description 6
- 238000005562 fading Methods 0.000 claims description 6
- 230000002194 synthesizing effect Effects 0.000 claims description 4
- 230000008569 process Effects 0.000 abstract description 13
- 230000007704 transition Effects 0.000 abstract description 7
- 238000010586 diagram Methods 0.000 description 14
- 238000004891 communication Methods 0.000 description 3
- 238000004590 computer program Methods 0.000 description 3
- 230000007774 longterm Effects 0.000 description 3
- 238000005070 sampling Methods 0.000 description 3
- 108010014172 Factor V Proteins 0.000 description 2
- 230000003044 adaptive effect Effects 0.000 description 2
- 230000008901 benefit Effects 0.000 description 2
- 230000015572 biosynthetic process Effects 0.000 description 2
- 238000005516 engineering process Methods 0.000 description 2
- 238000003672 processing method Methods 0.000 description 2
- 230000003068 static effect Effects 0.000 description 2
- 238000003786 synthesis reaction Methods 0.000 description 2
- 230000005540 biological transmission Effects 0.000 description 1
- 238000004422 calculation algorithm Methods 0.000 description 1
- 238000004364 calculation method Methods 0.000 description 1
- 230000030279 gene silencing Effects 0.000 description 1
- 239000004615 ingredient Substances 0.000 description 1
Images







Classifications
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L19/00—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis
- G10L19/005—Correction of errors induced by the transmission channel, if related to the coding algorithm
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L19/00—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis
- G10L19/04—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis using predictive techniques
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L19/00—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis
- G10L19/02—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis using spectral analysis, e.g. transform vocoders or subband vocoders
- G10L19/0204—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis using spectral analysis, e.g. transform vocoders or subband vocoders using subband decomposition
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L19/00—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis
- G10L19/04—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis using predictive techniques
- G10L19/08—Determination or coding of the excitation function; Determination or coding of the long-term prediction parameters
- G10L19/097—Determination or coding of the excitation function; Determination or coding of the long-term prediction parameters using prototype waveform decomposition or prototype waveform interpolative [PWI] coders
Landscapes
- Engineering & Computer Science (AREA)
- Physics & Mathematics (AREA)
- Signal Processing (AREA)
- Health & Medical Sciences (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Human Computer Interaction (AREA)
- Acoustics & Sound (AREA)
- Multimedia (AREA)
- Computational Linguistics (AREA)
- Mobile Radio Communication Systems (AREA)
- Compression, Expansion, Code Conversion, And Decoders (AREA)
- Cable Transmission Systems, Equalization Of Radio And Reduction Of Echo (AREA)
- Data Exchanges In Wide-Area Networks (AREA)
- Fluid-Damping Devices (AREA)
- Telephone Function (AREA)
- Use Of Switch Circuits For Exchanges And Methods Of Control Of Multiplex Exchanges (AREA)
- Telephonic Communication Services (AREA)
- Input Circuits Of Receivers And Coupling Of Receivers And Audio Equipment (AREA)
- Networks Using Active Elements (AREA)
- Compounds Of Unknown Constitution (AREA)
- Communication Control (AREA)
- Radar Systems Or Details Thereof (AREA)
Abstract
método e aparelho para obter um fator de atenuação. a presente invenção refere-se a um método para obter um fator de atenuação. o método é adaptado para processar o sinal sintetizado em cancelamento de perda de pacotes, e inclui: obter uma tendência de mudança de um sinal; obter um fator de atenuação de acordo com a tendência de mudança do sinal. a presente invenção também descreve um aparelho para obter um fator de atenuação. um fator de atenuação autoadaptativo é dinamicamente ajustado utilizando a última tendência de mudança de um sinal de histórico utilizando a presente invenção. a suave transição dos dados de histórico para os últimos dados recebidos é realizada de modo que a velocidade de atenuação seja mantida a mais constante possível entre o sinal compensado e o sinal original para se adaptar à característica de vozes humanas variadas.
Description
[001] Este pedido reivindica a prioridade de Pedido Internacional N2_PCT/CN2008/070807, depositado em 25 de abril de 2008, que reivindica o benefício de prioridade do Pedido de Patente chinês N- 2007101696180, depositado em 5 de novembro de 2007. Os conteúdos dos pedidos identificados acima estão aqui incorporados a título de referência em sua totalidade.
[002] A presente invenção refere-se ao campo de processamento de sinal, e particularmente a um método e um aparelho para obter um fator de atenuação.
[003] Exige-se que uma transmissão de dados de voz seja em tempo real e confiável em um sistema de comunicação de voz em tempo real, por exemplo, um sistema VoIP (Voz sobre IP). Devido às características não-confiáveis de um sistema de rede, um pacote de dados pode ser perdido ou não atingir o destino a tempo em um procedimento de transmissão de uma extremidade de envio para uma extremidade de recepção. Esses dois tipos de situações são considerados como perda de pacote de rede pela extremidade de recepção. É inevitável que a perda de pacote de rede ocorra. Entretanto, a perda de pacote de rede é um dos fatores mais importantes que influenciam a qualidade de fala da voz. Portanto, um método de ocultação de perda de pacote resistente é necessário para recuperar o pacote de dados perdido no sistema de comunicação em tempo real de modo que uma boa qualidade de fala ainda seja obtida sob a situação da perda de pacote de rede.
[004] Na tecnologia de comunicação de voz em tempo real existente, na extremidade de envio, um codificador divide uma voz em banda larga em uma sub-banda alta e uma sub-banda baixa, e usa ADPCM (Modulação Adaptiva por Códigos de Pulsos Diferenciais) para codificar as duas sub-bandas respectivamente e enviá-las juntamente para a extremidade de recepção através da rede. Na extremidade de recepção, as duas sub-bandas são decodificadas respectivamente pelo decodificador ADPCM, e então o sinal final é sintetizado utilizando um filtro de síntese QMF (Filtro Espelhado em Quadratura).
[005] Diferentes métodos de Ocultação de Perda de Pacotes (PLC) são adotados para duas sub-bandas diferentes. Para um sinal de banda baixa, sob a situação sem perda de pacotes, um sinal de reconstrução não é alterado durante o FADING-CRUZADO. Sob a situação com perda de pacotes, para o primeiro quadro perdido, o sinal de histórico (o sinal de histórico é um sinal de voz antes do quadro perdido no presente documento de pedido) é analisado utilizando um indicador a curto prazo e um indicador a longo prazo, e informações de classificação de voz são extraídas. O sinal de quadro perdido é reconstruído utilizando uma LPC (codificação preditiva linear) baseada no método de repetição de tom, o indicador e as informações de classificação. O status de ADPCM também será atualizado de maneira síncrona até um bom quadro ser encontrado. Ademais, não só o sinal correspondente ao quadro perdido precisa ser gerado, como também uma seção de sinal adaptada para FADING-CRUZADO precisa ser gerada. Dessa maneira, uma vez que um quadro satisfatório é recebido, o FADING-CRUZADO é executado para processar o sinal de quadro satisfatório e a seção de sinal. Observa-se que esse tipo de FADING-CRUZADO ocorre apenas após a extremidade de recepção perder um quadro e receber o primeiro quadro satisfatório.
[006] Durante o processo de realizar a presente invenção, o inventor percebeu pelo menos os seguintes problemas na técnica anterior: a energia do sinal sintetizado é controlada utilizando um fator de atenuação autoadaptativo estático na técnica anterior. Embora o fator de atenuação definido mude gradualmente, sua velocidade de atenuação, ou seja, o valor do fator de atenuação, é o mesmo com relação à mesma classificação de voz. Entretanto, as vozes humanas são variadas. Se o fator de atenuação não combinar com a característica de vozes humanas, ocorrerá um ruído desconfortável no sinal de reconstrução, particularmente no fim das vogais fixas. O fator de atenuação autoadaptativo estático pode não ser adaptado para a característica de vozes humanas diferentes.
[007] A situação mostrada na figura 1 é tirada como um exemplo, onde To é o período de tom do sinal histórico. O sinal superior corresponde a um sinal original, ou seja, um diagrama esquemático em forma de onda sob a situação sem perda de pacotes. O sinal inferior com linha tracejada é um sinal sintetizado de acordo com a técnica anterior. Como pode ser observado a partir da figura, o sinal sintetizado não mantém a mesma velocidade de atenuação com o sinal original. Se houver muitas vezes a mesma repetição de tom, o sinal sintetizado irá produzir ruído musical óbvio de modo que a diferença entre a situação do sinal sintetizado e a situação desejada seja grande.
[008] Uma modalidade da presente invenção proporciona um método e um aparelho para obter um fator de atenuação adaptado de modo a obter um fator de atenuação autoadaptativo e dinamicamente ajustável usado no processamento de sinal sintético.
[009] Uma modalidade da presente invenção proporciona um método para obter o fator de atenuação adaptado para processar o sinal sintetizado em ocultação de perda de pacotes, incluindo:
[0010] obter uma tendência de mudança de um sinal; e
[0011] obter um fator de atenuação de acordo com a tendência de mudança do sinal.
[0012] Uma modalidade da presente invenção também proporciona um aparelho para obter um fator de atenuação para processar um sinal sintetizado em ocultação de perda de pacotes. O aparelho para obter um fator de atenuação é configurado para:
[0013] obter uma tendência de mudança de um sinal; e
[0014] obter um fator de atenuação de acordo com a tendência de mudança obtida.
[0015] Uma modalidade da presente invenção também proporciona um método e um aparelho para obter um fator de atenuação adaptado para realizar a transição suave dos dados de histórico para os últimos dados recebidos.
[0016] Para realizar o objetivo acima, uma modalidade da invenção proporciona um método para processamento de sinal, adaptado para processar um sinal sintetizado em ocultação de perda de pacotes, incluindo:
[0017] obter uma tendência de mudança de um sinal;
[0018] obter um fator de atenuação de acordo com a tendência de mudança do sinal; e
[0019] obter um quadro perdido reconstruído após a atenuação de acordo com o fator de atenuação.
[0020] Uma modalidade da presente invenção também proporciona um aparelho para processamento de sinal para processar um sinal sintetizado em ocultação de perda de pacotes, incluindo:
[0021] o aparelho para obter um fator de atenuação para processar um sinal sintetizado em ocultação de perda de pacotes; e
[0022] uma unidade de reconstrução de quadro perdido adaptada para obter um quadro perdido reconstruído após a atenuação de acordo com o fator de atenuação.
[0023] Uma modalidade da presente invenção também proporciona um decodificador de voz adaptado para decodificar o sinal de voz, inclusive uma unidade de decodificação de banda baixa, uma unidade de decodificação de banda alta e uma unidade de filtro espelhado em quadratura.
[0024] A unidade de decodificação de banda baixa é adaptada para decodificar um sinal de decodificação de banda baixa recebido, e compensar um sinal de baixa perdido.
[0025] A unidade de decodificação de banda alta é adaptada para decodificar um sinal de decodificação de banda alta, e compensar um sinal de banda alta perdido.
[0026] A unidade de filtro espelhado em quadratura é adaptada para obter um sinal de saída final sintetizando o sinal de decodificação de banda baixa e o sinal de decodificação de banda alta.
[0027] A unidade de sinal de decodificação de banda baixa inclui uma subunidade de sinal de decodificação de banda baixa, uma LPC baseada na subunidade de repetição de tom e uma subunidade de "fading" cruzado.
[0028] A subunidade de decodificação de banda baixa é adaptada para decodificar um sinal de fluxo de banda baixa recebido.
[0029] A LPC baseada na subunidade de repetição de tom é adaptada para gerar um sinal sintetizado correspondente ao quadro perdido.
[0030] A subunidade de "fading" cruzado é adaptada para realizar o fading cruzado do sinal processado pela subunidade de decodificação de banda baixa e sinal sintetizado correspondente ao quadro perdido gerado pela LPC baseada na subunidade de repetição de tom.
[0031] A LPC baseada na subunidade de repetição de tom inclui um módulo de análise e um módulo de processamento de sinal.
[0032] O módulo de análise é adaptado para analisar um sinal de histórico e gerar um sinal de quadro perdido reconstruído.
[0033] Uma modalidade da presente invenção proporciona ainda um produto de programa de computador, incluindo códigos de programa de computador que permitem que um computador execute qualquer etapa no método para obter o fator de atenuação adaptado para processar o sinal sintetizado em ocultação de perda de pacotes ou qualquer etapa no método de processamento de sinal para processar um sinal sintetizado em ocultação de perda de pacotes quando os códigos de programa de computador forem executados pelo computador.
[0034] Comparadas com a técnica anterior, as modalidades da presente invenção possuem as seguintes vantagens:
[0035] um fator de atenuação autoadaptativo é ajustado de maneira dinâmica utilizando a tendência de mudança de um sinal histórico. A transição suave dos dados históricos para os últimos dados recebidos é realizada de modo que a velocidade de atenuação entre o sinal compensado e o sinal original seja mantida a mais constante possível para adaptar a característica de vozes humanas diferentes.
[0036] A figura 1 é um diagrama esquemático que ilustra o sinal original e o sinal sintetizado de acordo com a técnica anterior;
[0037] a figura 2 é um fluxograma que ilustra um método para obter um fator de atenuação de acordo com a Modalidade 1 da presente invenção;
[0038] a figura 3 é um diagrama esquemático que ilustra os princípios do codificador;
[0039] a figura 4 é um diagrama esquemático que ilustra o módulo de uma LPC baseada na subunidade de repetição de tom da unidade de decodificação de banda baixa;
[0040] a figura 5 é um diagrama esquemático que ilustra um sinal de saída após adotar o método de atenuação dinâmica de acordo com a Modalidade 1 da presente invenção;
[0041] as figuras 6A e 6B são diagramas esquemáticos que ilustram a estrutura do aparelho para obter um fator de atenuação de acordo com a Modalidade 2 da presente invenção;
[0042] a figura 7 é um diagrama esquemático que ilustra o cenário de aplicação do aparelho para obter um fator de atenuação de acordo com a Modalidade 2 da presente invenção;
[0043] as figuras 8A e 8B são diagramas esquemáticos que ilustram a estrutura do aparelho para processamento de sinal de acordo com a Modalidade 3 da presente invenção;
[0044] a figura 9 é um diagrama esquemático que ilustra o módulo do decodificador de voz de acordo com a Modalidade 4 da presente invenção;
[0045] a figura 10 é um diagrama esquemático que ilustra o módulo da unidade de decodificação de banda baixa no decodificador de voz de acordo com a Modalidade 4 da presente invenção;
[0046] a figura 11 é um diagrama esquemático que ilustra o módulo da LPC baseada na subunidade de repetição de tom de acordo com a Modalidade 4 da presente invenção.
[0047] A presente invenção será descrita em mais detalhes com referência aos desenhos e modalidades.
[0048] Proporciona-se um método para obter um fator de atenuação na Modalidade 1 da presente invenção, adaptado para processar o sinal sintetizado em ocultação de perda de pacotes, como mostrado na Figura 2, incluindo as seguintes etapas.
[0049] Etapa s101, obtém-se uma tendência de mudança de um sinal;
[0050] Especificamente, a tendência de mudança pode ser expressa nos seguintes parâmetros: (1) a razão da energia do último sinal periódico de tom para a energia do sinal periódico de tom anterior no sinal; (2) a razão da diferença entre o valor de amplitude máximo e o valor de amplitude mínimo do último sinal periódico de tom para a diferença entre o valor de amplitude máximo e o valor de amplitude mínimo do sinal periódico de tom anterior no sinal.
[0051] Etapa s102, obtém-se um fator de atenuação de acordo com a tendência de mudança.
[0052] O método de processamento específico da Modalidade 1 da presente invenção será descrito juntamente com o cenário de aplicação específico.
[0053] Um método para obter um fator de atenuação que é adaptado para processar o sinal sintetizado em ocultação de perda de pacotes é proporcionado na Modalidade 1 da presente invenção.
[0054] Como mostrado na figura 3, diferentes métodos de PLC são adotados para duas sub-bandas diferentes. O método de PLC para a parte de banda baixa é mostrado como a parte 1 em um quadro tracejado na figura 3. Enquanto um quadro tracejado 2 na figura 3 é correspondente ao algoritmo de PLC da banda alta. Para um sinal de banda alta, zh^ é um sinal de banda alta finalmente produzido. Após obter o sinal de banda baixa zl(n>> e o sinal de banda alta zh(n), o QMF é executado para o sinal de banda baixa e o sinal de banda alta e um sinal de banda larga finalmente produzido yW é sintetizado.
[0055] Apenas o sinal de banda baixa é descrito em detalhes a seguir.
[0056] Sob a situação sem perda de quadro, o sinal , é obtido após a decodificação do quadro atual recebido pelo decodificador ADPCM de banda baixa, e a saída
, é obtido após a decodificação do quadro atual recebido pelo decodificador ADPCM de banda baixa, e a saída  correspondente ao quadro atual. Nessa situação, o sinal de reconstrução não é alterado durante o FADING-CRUZADO, que é
correspondente ao quadro atual. Nessa situação, o sinal de reconstrução não é alterado durante o FADING-CRUZADO, que é  , onde L é o comprimento do quadro;
, onde L é o comprimento do quadro;
[0057] Sob a situação com perda de quadros, com relação ao primeiro quadro perdido, o sinal de histórico zl(n), n<o é analisado utilizando um indicador a curto prazo e um indicador a longo prazo, e informações de classificação de voz são extraídas. Adotando-se os indicadores acima e as informações de classificação, o sinal yl( n) é gerado utilizando um método de LPC baseada na repetição de tom. E o sinal de quadro perdido zl(n) é reconstruído como zl(n)=yl(n) n==0,... Ademais, o status de ADPCM também será atualizado de maneira síncrona até um quadro satisfatório ser obtido. Observa-se que não só o sinal correspondente ao quadro perdido precisa ser gerado, como também um sinal de 10ms , yl(n) n=L,... -1 adaptado para FADING-CRUZADO precisa ser gerado, o M é o número de pontos de amostragem de sinal que são incluídos no processo quando calcula-se a energia. Dessa maneira, uma vez que um quadro satisfatório é recebido, o FADING-CRUZADO é executado para xl( n)n=L,...-1,e yl(n), n=L... -1 observa-se que esse tipo de FADING-CRUZADO ocorre apenas após uma perda de quadro e quando a extremidade de recepção recebe os primeiros dados de quadro satisfatórios.
[0058] Uma LPC baseada no método de repetição de tom na figura 3 é conforme mostrado na figura 4.
[0059] Quando o quadro de dados for um quadro satisfatório, é armazenado em um buffer para uso no futuro.
[0060] Quando o primeiro quadro perdido for encontrado, o sinal final yl(n) precisa ser sintetizado em duas etapas. Na primeira, o sinal de histórico zl(n), n 297,...,1é analisado. Então, o sinal yl(n) n 0,..,L1 w = o,-”Ã-i é sintetizado de acordo com o resultado da análise, onde Léo comprimento de quadro do quadro de dados, ou seja, o número de pontos de amostragem correspondente a um quadro de sinal, Q é o comprimento do sinal que é necessário para analisar o sinal de histórico.
[0061] O módulo de LPC baseado na repetição de tom inclui especificamente as seguintes partes.
[0062] O filtro de análise a curto prazo A(z)e o filtro de síntese 1/ A(z) sã0 fjitros de Predição Linear (LP) baseados na ordem P . O filtro de análise de LP é definido como:
[0063] Através da análise de LP do sinal de histórico zl(n) n -Q,..,com o filtro A(z) um sinal residual e(n),n -Q,.., correspondente ao sinal de histórico zl(n) n -Q,..,é obtido: p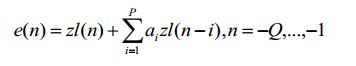
[0064] O sinal perdido é compensado por um método de repetição T de tom. Portanto, primeiramente, um período de tom 0 correspondente ao sinal de histórico zl(n),nQ,..precisa ser estimado. As etapas são as seguintes: O zl(n) é pré-processado para remover um ingrediente de baixa frequência inútil em uma análise de LTP (predição a longo prazo), e o período de tom T0 do zl(n) pode ser obtido pela análise de LTP. A classificação de voz é obtida apesar de combinar um módulo de classificação de sinal após obter o período de tom T°.
[0065] As classificações de voz são conforme mostrado na tabela 1 a seguir:
[0066] Um módulo de repetição de tom é adaptado para estimar um sinal residual de LP e(n),n 0••• de um quadro perdido. Antes de a repetição de tom ser executada, se a classificação da voz não for VOICED, a seguinte fórmula é adotada para limitar a amplitude de uma amostra:
[0067] onde,
[0068] Se a classificação da voz for VOICED, o residual correspondente ao sinal perdido for obtida adotando uma etapa de repetição do sinal residual correspondente ao sinal do último período de tom no sinal de um quadro satisfatório recentemente recebido, que é:
residual correspondente ao sinal perdido for obtida adotando uma etapa de repetição do sinal residual correspondente ao sinal do último período de tom no sinal de um quadro satisfatório recentemente recebido, que é:
[0069] Com relação a outras classificações de vozes, para evitar que a periodicidade do sinal gerado seja muito intensa (com relação ao sinal sem voz, se a periodicidade for muito intensa, pode-se ouvir algum ruído desconfortável como um ruído sonoro), o sinal residual e(n),n 0•••,L-1correspondente ao sinal perdido é gerado utilizando a seguinte fórmula:
[0070] Além de gerar o sinal residual correspondente ao quadro perdido, os sinais residuais , amostras adicionais /V continuam a ser gerados para gerar um sinal adaptado para FADING-CRUZADO, de modo a garantir a combinação suave entre o quadro perdido e o primeiro quadro satisfatório após o quadro perdido.
amostras adicionais /V continuam a ser gerados para gerar um sinal adaptado para FADING-CRUZADO, de modo a garantir a combinação suave entre o quadro perdido e o primeiro quadro satisfatório após o quadro perdido.
[0071] Após gerar o sinal residual correspondente ao quadro perdido e o FADING-CRUZADO, um sinal de quadro perdido de reconstrução obtido utilizando a seguinte fórmula: 8
obtido utilizando a seguinte fórmula: 8
[0072] onde o sinal residual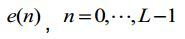 é 0 Sjna| residual obtido das etapas de repetição de tom acima.
é 0 Sjna| residual obtido das etapas de repetição de tom acima.
[0073] Também, com amostras adaptadas para FADING-CRUZADO são gerados utilizando a fórmula acima.
com amostras adaptadas para FADING-CRUZADO são gerados utilizando a fórmula acima.
[0074] Para realizar uma suave transição de energia, antes de executar o QMF com o sinal de banda alta, o sinal de banda baixa também precisa realizar o FADING-CRUZADO, as regras são mostradas como a tabela a seguir:
[0075] Na tabela acima, zl(n) é um sinal finalmente produzido correspondente ao quadro xl(n)atual; é o sinal do quadro satisfatório correspondente ao quadro atual; yl(n) é um sinal sintetizado correspondente ao mesmo tempo do quadro atual, onde Léo comprimento de quadro, N é o número de amostras que executam FADING-CRUZADO.
[0076] Com relação a diferentes classificações de voz, a energia de sinal em é controlada antes de executar FADING-CRUZADO de acordo com o coeficiente correspondente a cada amostra. O valor das alterações de coeficiente de acordo com classificações de voz diferentes e a situação de perda de pacotes.
é controlada antes de executar FADING-CRUZADO de acordo com o coeficiente correspondente a cada amostra. O valor das alterações de coeficiente de acordo com classificações de voz diferentes e a situação de perda de pacotes.
[0077] Em detalhes, no caso onde os últimos dois sinais periódicos de tom no sinal de histórico recebido é o sinal original como mostrado na figura 5, o fator de atenuação dinâmico autoadaptativo é dinamicamente ajustado de acordo com a tendência de mudança dos últimos dois períodos de tom no sinal de histórico. O método de ajuste detalhado inclui as seguintes etapas:
[0078] Etapa s201, a tendência de mudança do sinal é obtida.
[0079] A tendência de mudança de sinal pode ser expressa pela razão da energia do último sinal de período de tom para a energia do sinal de período de tom anterior no sinal, ou seja, a energia Ei e E2 dos últimos dois sinais de períodos de tom no sinal de histórico, e a razão das duas energias é calculada.
[0080] E1é a energia do último sinal de período de tom, E 2 é a energia do sinal de período de tom anterior, e T0 e 0 periodo de tom correspondente ao sinal de histórico.
[0081] Opcionalmente, a tendência de mudança de sinal pode ser expressa pela razão das diferenças de "pico-vale" dos últimos dois períodos de tom no sinal de histórico.
[0082] onde, é a diferença entre o valor de amplitude máximo o valor de amplitude mínimo do último sinal periódico de tom, é a diferença entre o valor de amplitude máximo e o valor de amplitude mínimo do sinal periódico de tom anterior, e a razão é calculada como:
[0083] Etapa s202, o sinal sintetizado é dinamicamente atenuado de acordo com a tendência de mudança obtida do sinal.
[0084] A fórmula de cálculo é mostrada da seguinte maneira:
[0085] onde, é o sinal de quadro perdido de reconstrução, Néo comprimento do sinal sintetizado, e C é o coeficiente de atenuação autoadaptativo cujo valor é:
é o sinal de quadro perdido de reconstrução, Néo comprimento do sinal sintetizado, e C é o coeficiente de atenuação autoadaptativo cujo valor é:
[0086] Sob a situação do fator de atenuação é necessário ajustar
é necessário ajustar  para évitar mostrar uma situação onde o fator de atenuação correspondente às amostras é negativo.
para évitar mostrar uma situação onde o fator de atenuação correspondente às amostras é negativo.
[0087] Em particular, para evitar a situação onde o valor de amplitude correspondente a uma amostra é excedido sob a situação de R>1, o sinal sintetizado é dinamicamente atenuado utilizando a fórmula da etapa s202 na presente modalidade que leva em consideração apenas a situação de R <1.
[0088] Em particular, para evitar a situação onde a velocidade de atenuação do sinal com menos energia é muito rápida, apenas sob a situação onde excede um certo valor limite, o sinal sintetizado é dinamicamente atenuado utilizando a fórmula da etapa s202 na presente modalidade.
[0089] Em particular, para evitar que a velocidade de atenuação do sinal sintetizado seja muito rápida, especialmente sob a situação de perda de quadro contínua, um valor-limite superior é ajustado para o coeficiente de atenuação c. Quando C*(n+1) eXcede um valor-limite, o coeficiente de atenuação é ajustado como o valor limite superior.
[0090] Em particular, sob a situação de um ambiente de rede ruim e perda contínua de quadro, uma certa condição pode ser estabelecida para evitar uma velocidade de atenuação muito rápida. Por exemplo, pode-se levar em consideração que, quando o número de quadros perdidos exceder um número fixado, por exemplo, dois quadros; ou quando o sinal correspondente ao quadro perdido exceder um comprimento fixado, por exemplo, 20ms; ou em pelo menos uma das condições acima do coeficiente de atenuação atual atingir um valor limiar fixado, o coeficiente de atenuação c precisa ser ajustado para evitar a velocidade de atenuação muito rápida que pode resultar na situação onde o sinal de saída é silenciado.
atingir um valor limiar fixado, o coeficiente de atenuação c precisa ser ajustado para evitar a velocidade de atenuação muito rápida que pode resultar na situação onde o sinal de saída é silenciado.
[0091] Por exemplo, sob a amostragem de situação a uma frequência de 8k e o comprimento de quadro de 40 amostras, o número de quadros perdidos pode ser ajustado como 4, e após o fator de atenuação torna-se menor que 0,9, o coeficiente de atenuação c é ajustado para ser um valor menor. A regra de ajustar o menor valor é a seguinte.
torna-se menor que 0,9, o coeficiente de atenuação c é ajustado para ser um valor menor. A regra de ajustar o menor valor é a seguinte.
[0092] Hipoteticamente, é previsto que o coeficiente de atenuação atual é C e o valor de fator de atenuação é V, e o fator de atenuação V pode ser atenuado para 0 após as amostras vlc. Enquanto uma situação mais desejada é aquela onde o fator de atenuação V deve ser atenuado para 0 após as amostras . Então, o coeficiente de atenuação c é ajustado para:
. Então, o coeficiente de atenuação c é ajustado para:
[0093] Como mostrado na figura 5, o sinal superior é o sinal original; o sinal intermediário é o sinal sintetizado. Como observado na figura, embora o sinal possua algum grau de atenuação, o sinal ainda permanece sonante intensivo. Se a duração for muito longa, o sinal pode ser mostrado como um ruído musical, especialmente no fim do som. O sinal inferior é o sinal após a utilização da atenuação dinâmica na modalidade da presente invenção, que pode ser muito similar ao sinal original.
[0094] De acordo com o método proporcionado pela modalidade mencionada acima, o fator de atenuação autoadaptativo é dinamicamente ajustado utilizando a tendência de mudança do sinal de histórico, de modo que a transição suave dos dados de histórico para os últimos dados recebidos possa ser realizada. A velocidade de atenuação é mantida a mais constante possível entre o sinal compensado e o sinal original para adaptar a característica de vozes humanas variadas.
[0095] Um aparelho para obter um fator de atenuação é proporcionado na Modalidade 2 da presente invenção, adaptado para processar o sinal sintetizado em ocultação de perda de pacotes, incluindo:
[0096] uma unidade de obtenção de tendência de mudança 10, adaptada para obter uma tendência de mudança de um sinal;
[0097] uma unidade de obtenção de fator de atenuação 20, adaptada para obter um fator de atenuação de acordo com a tendência de mudança obtidas pela unidade de obtenção de tendência de mudança 10.
[0098] A unidade de obtenção de fator de atenuação 20 inclui adicionalmente: uma unidade de obtenção de coeficiente de atenuação 21, adaptada para gerar o coeficiente de atenuação de acordo com a tendência de mudança obtida pela unidade de obtenção de tendência de mudança 10; uma subunidade de obtenção de fator de atenuação 22, adaptada para obter um fator de atenuação de acordo com o coeficiente de atenuação gerado pela subunidade de obtenção de fator de atenuação 21. A unidade de obtenção de fator de atenuação 20 inclui ainda: uma subunidade de ajuste de coeficiente de atenuação 23, adaptada para ajustar o valor do coeficiente de atenuação obtido pela subunidade de obtenção de coeficiente de atenuação 21 a um determinado valor mediante determinadas condições que incluem pelo menos uma das seguintes características: se o valor do coeficiente de atenuação exceder um valor-limite superior; se houver a situação de perda contínua de quadro; e se a velocidade de atenuação for muito rápida.
[0099] O método para obter um fator de atenuação na modalidade acima é o mesmo método para obter um fator de atenuação nas modalidades do método.
[00100] Em detalhes, a tendência de mudança obtida pela unidade de obtenção de tendência de mudança 10 pode ser expressa nos seguintes parâmetros: (1) a razão da energia do último sinal periódico de tom para a energia do sinal periódico de tom anterior no sinal; (2) a razão da diferença entre o valor de amplitude máximo e o valor de amplitude mínimo do último sinal periódico de tom para a diferença entre o valor de amplitude máximo e o valor de amplitude mínimo do sinal periódico de tom anterior no sinal.
[00101] Quando a tendência de mudança for expressa na razão de energia em (1), a estrutura do aparelho para obter um fator de atenuação é conforme mostrado na figura 6A. A unidade de obtenção de tendência de mudança 10 inclui ainda:
[00102] uma subunidade de obtenção de energia 11 adaptada para obter a energia do último sinal periódico de tom e a energia do sinal periódico de tom anterior;
[00103] uma subunidade de obtenção de razão de energia 12 adaptada para obter a razão da energia do último sinal periódico de tom para a energia do sinal periódico de tom anterior obtido pela subunidade de obtenção de energia 11 e usa a razão para mostrar a tendência de mudança do sinal.
[00104] Quando a tendência de mudança for expressa na razão de diferença de amplitude em (2), a estrutura do aparelho para obter um fator de atenuação é conforme mostrada na figura 6B. A unidade de obtenção de tendência de mudança 10 inclui ainda:
[00105] uma subunidade de obtenção de diferença de amplitude 13, adaptada para obter a diferença entre o valor de amplitude máximo e o valor de amplitude mínimo do último sinal periódico de tom, e a diferença entre o valor de amplitude máximo e o valor de amplitude mínimo do sinal periódico de tom anterior;
[00106] uma subunidade de obtenção de razão de diferença de amplitude 14, adaptada para obter a razão da diferença entre o valor de amplitude máximo e o valor de amplitude mínimo do último sinal periódico de tom para a diferença entre o valor de amplitude máximo e o valor de amplitude mínimo do sinal periódico de tom anterior, e usar a razão para mostrar a tendência de mudança do sinal.
[00107] Um diagrama esquemático que ilustra o cenário de aplicação do aparelho para obter um fator de atenuação de acordo com a Modalidade 2 da presente invenção é conforme mostrado na figura 7. O fator de atenuação autoadaptativo é dinamicamente ajustado utilizando a tendência de mudança do sinal de histórico.
[00108] Utilizando-se o aparelho proporcionado pela modalidade mencionada acima, o fator de atenuação autoadaptativo é dinamicamente ajustado utilizando a tendência de mudança do sinal de histórico de modo que a suave transição dos dados de histórico para os últimos dados recebidos seja realizada. A velocidade de atenuação é mantida a mais constante possível entre o sinal compensado e o sinal original para adaptar a característica de vozes humanas variadas.
[00109] Proporciona-se um aparelho para processamento de sinal na Modalidade 3 da presente invenção, adaptado para processar o sinal sintetizado em ocultação de perda de pacotes, conforme mostrado na figura 8A e figura 8B. Baseado na Modalidade 2, adiciona-se uma unidade de reconstrução de quadro perdido 30 relacionada a uma unidade de obtenção de fator de atenuação. A unidade de reconstrução de quadro perdido 30 obtém um quadro reconstruído perdido após atenuação de acordo com o fator de atenuação obtido pela unidade de obtenção de fator de atenuação 20.
[00110] Utilizando-se o aparelho proporcionado pela modalidade mencionada acima, o fator de atenuação autoadaptativo é dinamicamente ajustado utilizando a tendência de mudança do sinal de histórico, e um quadro perdido reconstruído após a atenuação ser obtida de acordo com o fator de atenuação, de modo que seja realizada uma transição suave dos dados de histórico para os últimos dados recebidos. A velocidade de atenuação é mantida a mais constante possível entre o sinal compensado e o sinal original para se adaptar à característica de vozes humanas variadas.
[00111] Proporciona-se um decodificador de voz pela Modalidade 4 da presente invenção, como mostrado na figura 9. O decodificador de voz inclui: uma unidade de decodificação de banda alta 40 é adaptada para decodificar um sinal de decodificação de banda alta recebido e compensar um sinal de banda alta perdido; uma unidade de decodificação de banda baixa 50 é adaptada para decodificar um sinal de decodificação de banda baixa recebido e compensar um sinal de banda baixa perdido; e uma unidade de filtro espelhado em quadratura 60 é adaptada para obter um sinal de saída final sintetizando o sinal de decodificação de banda baixa e o sinal de decodificação de banda alta. A unidade de decodificação de banda alta 40 decodifica o sinal de fluxo de banda alta recebido pela extremidade de recepção, e sintetiza o sinal de banda alta perdido. A unidade de decodificação de banda baixa 50 decodifica o sinal de fluxo de banda baixa recebido pela extremidade de recepção e sintetiza o sinal de banda baixa perdido. A unidade de filtro espelhado em quadratura 60 obtém o sinal de decodificação final sintetizando o sinal de decodificação de banda baixa enviado pela unidade de decodificação de banda baixa 50 e o sinal de decodificação de banda alta enviado pela unidade de decodificação de banda alta 40.
[00112] Para a unidade de decodificação de banda baixa 50, como mostrado na figura 10, incluem-se as seguintes unidades. Uma LPC baseada na subunidade de repetição de tom 51 que é adaptada para gerar um sinal sintetizado correspondente ao quadro perdido, uma subunidade de decodificação de banda baixa 52 que é adaptada para decodificar um sinal de fluxo de banda baixa recebido, e uma subunidade de fading cruzado 53 que é adaptada para realizar o fading cruzado do sinal decodificado pela subunidade de decodificação de banda baixa e o sinal sintetizado correspondente ao quadro perdido gerado pela LPC baseada na subunidade de repetição de tom.
[00113] A subunidade de decodificação de banda baixa 52 decodifica o sinal de fluxo de banda baixa recebido. A LPC baseada na subunidade de repetição de tom 51 gera o sinal sintetizado executando uma LPC no sinal de banda baixa perdido. E, por fim, a subunidade de fading cruzado 53 realiza o fading cruzado do sinal processado pela subunidade de decodificação de banda baixa 52 e o sinal sintetizado para obter um sinal de decodificação final após a compensação de quadro perdido.
[00114] A LPC baseada na subunidade de repetição de tom 51, como mostrado na figura 10, inclui ainda um módulo de análise 511 e um módulo de processamento de sinal 512. O módulo de análise 511 analisa um sinal de histórico, e gera um sinal de quadro perdido reconstruído; o módulo de processamento de sinal 512 obtém uma tendência de mudança de um sinal, e obtém um fator de atenuação de acordo com a tendência de mudança do sinal, e atenua o sinal de quadro perdido reconstruído, e obtém um quadro perdido reconstruído após a atenuação.
[00115] O módulo de processamento de sinal 512 inclui ainda uma unidade de obtenção de fator de atenuação 5121 e uma unidade de reconstrução de quadro perdido 5122. A unidade de obtenção de fator de atenuação 5121 obtém uma tendência de mudança de um sinal, e obtém um fator de atenuação de acordo com a tendência de mudança; a unidade de reconstrução de quadro perdido 5122 atenua o sinal de quadro perdido reconstruído de acordo com o fator de atenuação, e obtém um quadro perdido reconstruído após a atenuação. O módulo de processamento de sinal 512 inclui duas estruturas correspondentes aos diagramas esquemáticos que ilustram a estrutura do aparelho para processamento de sinal na figura 8A e 8B, respectivamente.
[00116] A unidade de obtenção de fator de atenuação 5121 inclui duas estruturas correspondentes aos diagramas esquemáticos que ilustram a estrutura do aparelho para obter um fator de atenuação na figura 6A e 6B, respectivamente. As funções específicas e meios de implementação dos módulos acima e unidades podem se referir ao conteúdo revelado nas modalidades do método. Detalhes desnecessários não serão repetidos aqui.
[00117] Através da descrição das modalidades mencionadas acima, os versados na técnica podem entender claramente que a presente invenção pode ser realizada dependendo do software mais a plataforma de hardware geral e necessária, e certamente também pode ser realizada por hardware. Entretanto, na maioria das situações, o formador é uma modalidade preferível. Baseado em tal entendimento, a essência ou a parte que contribui para a técnica anterior no esquema técnico da presente invenção pode ser expressa sob a forma de produto de software que é armazenado em um meio de armazenamento, e o produto de software inclui algumas instruções para instruir um dispositivo para executar as modalidades da presente invenção.
[00118] Apesar de a ilustração e descrição da presente descrição serem determinadas com referência às modalidades dessa, deve ser avaliado por versados na técnica que várias alterações em formas e detalhes podem ser feitas sem que se abandone o escopo da descrição.
Claims (15)
1. Método para processamento de um sinal de voz sintetizado em ocultação de perda de pacotes, compreendendo: obter uma tendência de mudança do sinal de voz; caracterizado pelo fato de que obter uma tendência de mudança do sinal de voz compreende: obter uma razão de energia de um último sinal de voz periódico de tom para energia de um sinal de voz periódico de tom anterior no sinal de voz, ou obter uma razão de uma diferença entre um valor de amplitude máximo e um valor de amplitude mínimo do último sinal de voz periódico de tom para uma diferença entre um valor de amplitude máximo e um valor de amplitude mínimo do sinal de voz periódico de tom anterior no sinal de voz; obter um fator de atenuação de acordo com a tendência de mudança do sinal de voz; e obter um quadro perdido reconstruído após atenuar de acordo com o fator de atenuação.
2. Método, de acordo com a reivindicação 1, caracterizado pelo fato de que obter um fator de atenuação de acordo com a tendência de mudança do sinal de voz compreende: obter o fator de atenuação de acordo com a tendência de mudança do sinal de voz quando a razão for menor que 1.
3. Método, de acordo com a reivindicação 1, caracterizado pelo fato de que obter um fator de atenuação de acordo com a tendência de mudança do sinal de voz compreende: obter o fator de atenuação de acordo com a tendência de mudança do sinal de voz quando a energia do último sinal de voz periódico de tom for maior que um valor limite predefinido.
4. Método, de acordo com a reivindicação 1, caracterizado pelo fato de que a razão da energia do último sinal de voz periódico de tom para a energia do sinal de voz periódico de tom anterior no sinal de voz é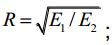 ; em que E1 é a energia do último sinal de voz periódico de tom, E2- é a energia do sinal de voz periódico de tom anterior.
; em que E1 é a energia do último sinal de voz periódico de tom, E2- é a energia do sinal de voz periódico de tom anterior.
5. Método, de acordo com a reivindicação 1, caracterizado pelo fato de que a razão da diferença entre o valor de amplitude máximo e o valor de amplitude mínimo do último sinal de voz periódico de tom para a diferença entre o valor de amplitude máximo e o valor de amplitude mínimo do sinal de voz periódico de tom anterior no sinal de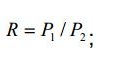 em que,E1 éa diferença entre o valor de amplitude máximo e o valor de amplitude mínimo do último sinal de voz periódico de tom, / ’ é a diferença entre o valor de amplitude máximo e o valor de amplitude mínimo do sinal de voz periódico de tom anterior.
em que,E1 éa diferença entre o valor de amplitude máximo e o valor de amplitude mínimo do último sinal de voz periódico de tom, / ’ é a diferença entre o valor de amplitude máximo e o valor de amplitude mínimo do sinal de voz periódico de tom anterior.
6. Método, de acordo com a reivindicação 4 ou 5, caracterizado pelo fato de que o fator de atenuação obtido de acordo com a tendência de mudança do sinal de voz é em que, E é o coeficiente de atenuação;
em que, E é o coeficiente de atenuação;  , N é o T comprimento do sinal de voz sintetizado; 0 e o comprimento de um período de tom.
, N é o T comprimento do sinal de voz sintetizado; 0 e o comprimento de um período de tom.
7. Método, de acordo com a reivindicação 6, caracterizado pelo fato de que o fator de atenuação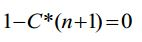 é definido quando o fator de atenuação for
é definido quando o fator de atenuação for 
8. Método, de acordo com a reivindicação 6, caracterizado pelo fato de que o valor limite superior é predefinido para o coeficiente de atenuação C, e o coeficiente de atenuação C é definido para ser o limite superior quando obtido de acordo com
obtido de acordo com  exceder um valor limite.
exceder um valor limite.
9. Método, de acordo com a reivindicação 6, caracterizado pelo fato de que o coeficiente de atenuação C é reduzido quando a velocidade de atenuação for rápida demais.
10. Método, de acordo com a reivindicação 9, caracterizado pelo fato de que o coeficiente de atenuação C sendo reduzido está: predefinindo o sinal de voz para ser atenuado para 0 após M amostras; e definindo o coeficiente de atenuação ajustado c=v em que V é um fator de atenuação atual.
11. Método, de acordo com a reivindicação 1, caracterizado pelo fato de que o quadro perdido reconstruído após atenuar obtido de acordo com a tendência de mudança do sinal de voz é: em que;
em que; 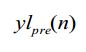 é um sinal de voz de quadro perdido reconstruído, N é o comprimento do sinal de voz sintetizado, C é o coeficiente de atenuação
é um sinal de voz de quadro perdido reconstruído, N é o comprimento do sinal de voz sintetizado, C é o coeficiente de atenuação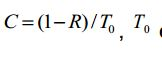 , é o comprimento do período de tom.
, é o comprimento do período de tom.
12. Aparelho para processar um sinal de voz sintetizado em ocultação de perda de pacotes, em que o aparelho compreende: uma unidade de obtenção de tendência de mudança adaptada para obter uma tendência de mudança do sinal de voz; e uma unidade de obtenção de fator de atenuação adaptada para obter um fator de atenuação de acordo com a tendência de mudança obtida pela unidade de obtenção de tendência de mudança; uma unidade de reconstrução de quadro perdido adaptada para obter um quadro perdido após atenuar de acordo com o fator de atenuação; caracterizado pelo fato de que a unidade de obtenção de tendência de mudança compreende: uma subunidade de obtenção de energia adaptada para obter energia de um último sinal de voz periódico de tom e energia de um sinal de voz periódico de tom anterior no sinal de voz; e uma subunidade de obtenção de razão de energia adaptada para obter uma razão da energia do último sinal de voz periódico de tom para a energia do sinal de voz periódico de tom anterior no sinal de voz obtido pela subunidade de obtenção de energia, em que a razão é usada para expressar a tendência de mudança do sinal de voz; ou uma subunidade de obtenção de diferença de amplitude adaptada para obter a diferença entre um valor de amplitude máximo e um valor de amplitude mínimo de um último sinal de voz periódico de tom, e a diferença entre um valor de amplitude máximo e um valor de amplitude mínimo de um sinal de voz periódico de tom anterior no sinal de voz; e uma subunidade de obtenção de razão de diferença de amplitude adaptada para obter uma razão da diferença do último sinal de voz periódico de tom para a diferença do sinal de voz periódico de tom anterior no sinal de voz, em que a diferença do último sinal de voz periódico de tom e a diferença do sinal de voz periódico de tom anterior são obtidas pela subunidade de obtenção de diferença de amplitude, e a razão é usada para expressar a tendência de mudança do sinal de voz.
13. Aparelho, de acordo com a reivindicação 12, caracterizado pelo fato de que a unidade de obtenção de fator de atenuação compreende: uma subunidade de obtenção de coeficiente de atenuação adaptada para gerar um coeficiente de atenuação de acordo com a tendência de mudança obtida pela unidade de obtenção de tendência de mudança; e uma subunidade de obtenção de fator de atenuação adaptada para obter o fator de atenuação de acordo com o coeficiente de atenuação gerado pela subunidade de obtenção de fator de atenuação.
14. Aparelho, de acordo com a reivindicação 13, caracterizado pelo fato de que a unidade de obtenção de fator de atenuação ainda compreende: uma subunidade de ajuste de coeficiente de atenuação adaptada para ajustar o valor do coeficiente de atenuação obtido pela subunidade de obtenção de coeficiente de atenuação para ser um determinado valor quando uma determinada condição for satisfeita; em que a determinada condição compreende pelo menos uma das seguintes condições: se o valor do coeficiente de atenuação exceder um valor limite superior; se existir uma situação de perda contínua de quadro; e se uma velocidade de atenuação for rápida demais.
15. Decodificador de voz, compreendendo: uma unidade de decodificação de banda baixa, uma unidade de decodificação de banda alta e uma unidade de filtro espelhado em quadratura, em que: a unidade de decodificação de banda baixa é adaptada para decodificar um sinal de voz de decodificação de banda baixa recebido, e compensar um sinal de voz de banda baixa perdido; a unidade de decodificação de banda alta é adaptada para decodificar um sinal de voz de decodificação de banda alta recebido, e compensar um sinal de voz de banda alta perdido; a unidade de filtro espelhado em quadratura é adaptada para obter um sinal de voz de saída final ao sintetizar o sinal de voz de decodificação de banda baixa e o sinal de voz de decodificação de banda alta; a unidade de decodificação de banda baixa compreende uma subunidade de decodificação de banda baixa, uma codificação de predição linear baseada em uma subunidade de repetição de tom e uma subunidade de fading cruzado; em que a subunidade de decodificação de banda baixa é adaptada para decodificar um sinal de voz de fluxo de banda baixa recebido; a codificação de predição linear (LPC) baseada na subunidade de repetição de tom é adaptada para gerar um sinal de voz sintetizado correspondendo a um quadro perdido; a subunidade de fading cruzado é adaptada para realizar o fading cruzado do sinal de voz processado pela subunidade de decodificação de banda baixa e o sinal de voz sintetizado correspondendo ao quadro perdido gerado pela LPC baseada na subunidade de repetição de tom; caracterizado pelo fato de que a LPC baseada na subunidade de repetição de tom compreende um módulo de análise e um aparelho como definido em qualquer uma das reivindicações 12 a 14, em que o módulo de análise é adaptado para analisar um histórico de sinal de voz, e gerar um sinal de voz reconstruído do quadro perdido.
Applications Claiming Priority (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN2007101696180A CN101207665B (zh) | 2007-11-05 | 2007-11-05 | 一种衰减因子的获取方法 |
| CN200710169618.0 | 2007-11-05 | ||
| PCT/CN2008/070807 WO2009059497A1 (en) | 2007-11-05 | 2008-04-25 | Method and apparatus for getting attenuation factor |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| BRPI0808765A2 BRPI0808765A2 (pt) | 2014-09-16 |
| BRPI0808765B1 true BRPI0808765B1 (pt) | 2020-09-15 |
Family
ID=39567522
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| BRPI0808765-2A BRPI0808765B1 (pt) | 2007-11-05 | 2008-04-25 | Método e aparelho para processamento de um sinal de voz sintetizado em ocultação de perda de pacotes e decodificador de voz |
Country Status (12)
| Country | Link |
|---|---|
| US (2) | US8320265B2 (pt) |
| EP (2) | EP2161719B1 (pt) |
| JP (2) | JP4824734B2 (pt) |
| KR (1) | KR101168648B1 (pt) |
| CN (4) | CN101207665B (pt) |
| AT (2) | ATE458241T1 (pt) |
| BR (1) | BRPI0808765B1 (pt) |
| DE (3) | DE602008000668D1 (pt) |
| DK (1) | DK2056292T3 (pt) |
| ES (1) | ES2340975T3 (pt) |
| PL (1) | PL2056292T3 (pt) |
| WO (1) | WO2009059497A1 (pt) |
Families Citing this family (23)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN101325631B (zh) * | 2007-06-14 | 2010-10-20 | 华为技术有限公司 | 一种估计基音周期的方法和装置 |
| CN100550712C (zh) * | 2007-11-05 | 2009-10-14 | 华为技术有限公司 | 一种信号处理方法和处理装置 |
| CN101483042B (zh) * | 2008-03-20 | 2011-03-30 | 华为技术有限公司 | 一种噪声生成方法以及噪声生成装置 |
| KR100998396B1 (ko) * | 2008-03-20 | 2010-12-03 | 광주과학기술원 | 프레임 손실 은닉 방법, 프레임 손실 은닉 장치 및 음성송수신 장치 |
| JP5150386B2 (ja) * | 2008-06-26 | 2013-02-20 | 日本電信電話株式会社 | 電磁ノイズ診断装置、電磁ノイズ診断システム及び電磁ノイズ診断方法 |
| JP5694745B2 (ja) * | 2010-11-26 | 2015-04-01 | 株式会社Nttドコモ | 隠蔽信号生成装置、隠蔽信号生成方法および隠蔽信号生成プログラム |
| EP2487350A1 (de) * | 2011-02-11 | 2012-08-15 | Siemens Aktiengesellschaft | Verfahren zur Regelung einer Gasturbine |
| CN107068156B (zh) | 2011-10-21 | 2021-03-30 | 三星电子株式会社 | 帧错误隐藏方法和设备以及音频解码方法和设备 |
| EP2772910B1 (en) * | 2011-10-24 | 2019-06-19 | ZTE Corporation | Frame loss compensation method and apparatus for voice frame signal |
| KR102259112B1 (ko) | 2012-11-15 | 2021-05-31 | 가부시키가이샤 엔.티.티.도코모 | 음성 부호화 장치, 음성 부호화 방법, 음성 부호화 프로그램, 음성 복호 장치, 음성 복호 방법 및 음성 복호 프로그램 |
| MY198868A (en) * | 2013-02-05 | 2023-10-02 | Ericsson Telefon Ab L M | Method and appartus for controlling audio frame loss concealment |
| CN104299614B (zh) | 2013-07-16 | 2017-12-29 | 华为技术有限公司 | 解码方法和解码装置 |
| CN108364657B (zh) | 2013-07-16 | 2020-10-30 | 超清编解码有限公司 | 处理丢失帧的方法和解码器 |
| CN103714820B (zh) * | 2013-12-27 | 2017-01-11 | 广州华多网络科技有限公司 | 参数域的丢包隐藏方法及装置 |
| US10035557B2 (en) * | 2014-06-10 | 2018-07-31 | Fu-Long Chang | Self-balancing vehicle frame |
| CN106683681B (zh) | 2014-06-25 | 2020-09-25 | 华为技术有限公司 | 处理丢失帧的方法和装置 |
| US9978400B2 (en) * | 2015-06-11 | 2018-05-22 | Zte Corporation | Method and apparatus for frame loss concealment in transform domain |
| US10362269B2 (en) * | 2017-01-11 | 2019-07-23 | Ringcentral, Inc. | Systems and methods for determining one or more active speakers during an audio or video conference session |
| CN113496706B (zh) * | 2020-03-19 | 2023-05-23 | 抖音视界有限公司 | 音频处理方法、装置、电子设备及存储介质 |
| CN111554308B (zh) * | 2020-05-15 | 2024-10-15 | 腾讯科技(深圳)有限公司 | 一种语音处理方法、装置、设备及存储介质 |
| CN116166932A (zh) * | 2023-01-30 | 2023-05-26 | 左嵩 | 生理信号的噪声抑制方法及系统 |
| CN116312571A (zh) * | 2023-02-01 | 2023-06-23 | 深圳大学 | 丢包补偿模型训练方法、丢包补偿方法及装置 |
| CN120602432A (zh) * | 2024-06-19 | 2025-09-05 | 中兴通讯股份有限公司 | 调整网络队列参数的方法和设备、计算机可读介质、计算机程序产品 |
Family Cites Families (41)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2654643B2 (ja) | 1987-03-11 | 1997-09-17 | 東洋通信機株式会社 | 音声分析方法 |
| JPH06130999A (ja) | 1992-10-22 | 1994-05-13 | Oki Electric Ind Co Ltd | コード励振線形予測復号化装置 |
| US5787430A (en) | 1994-06-30 | 1998-07-28 | International Business Machines Corporation | Variable length data sequence backtracking a trie structure |
| US5699485A (en) * | 1995-06-07 | 1997-12-16 | Lucent Technologies Inc. | Pitch delay modification during frame erasures |
| JP3095340B2 (ja) | 1995-10-04 | 2000-10-03 | 松下電器産業株式会社 | 音声復号化装置 |
| TW326070B (en) | 1996-12-19 | 1998-02-01 | Holtek Microelectronics Inc | The estimation method of the impulse gain for coding vocoder |
| US6011795A (en) | 1997-03-20 | 2000-01-04 | Washington University | Method and apparatus for fast hierarchical address lookup using controlled expansion of prefixes |
| JP3567750B2 (ja) | 1998-08-10 | 2004-09-22 | 株式会社日立製作所 | 圧縮音声再生方法及び圧縮音声再生装置 |
| US7423983B1 (en) | 1999-09-20 | 2008-09-09 | Broadcom Corporation | Voice and data exchange over a packet based network |
| JP2001228896A (ja) | 2000-02-14 | 2001-08-24 | Iwatsu Electric Co Ltd | 欠落音声パケットの代替置換方式 |
| US20070192863A1 (en) | 2005-07-01 | 2007-08-16 | Harsh Kapoor | Systems and methods for processing data flows |
| EP1199709A1 (en) | 2000-10-20 | 2002-04-24 | Telefonaktiebolaget Lm Ericsson | Error Concealment in relation to decoding of encoded acoustic signals |
| JPWO2002071389A1 (ja) | 2001-03-06 | 2004-07-02 | 株式会社エヌ・ティ・ティ・ドコモ | オーディオデータ補間装置および方法、オーディオデータ関連情報作成装置および方法、オーディオデータ補間情報送信装置および方法、ならびにそれらのプログラムおよび記録媒体 |
| US6816856B2 (en) | 2001-06-04 | 2004-11-09 | Hewlett-Packard Development Company, L.P. | System for and method of data compression in a valueless digital tree representing a bitset |
| US6785687B2 (en) | 2001-06-04 | 2004-08-31 | Hewlett-Packard Development Company, L.P. | System for and method of efficient, expandable storage and retrieval of small datasets |
| US7711563B2 (en) | 2001-08-17 | 2010-05-04 | Broadcom Corporation | Method and system for frame erasure concealment for predictive speech coding based on extrapolation of speech waveform |
| US7143032B2 (en) * | 2001-08-17 | 2006-11-28 | Broadcom Corporation | Method and system for an overlap-add technique for predictive decoding based on extrapolation of speech and ringinig waveform |
| EP1292036B1 (en) | 2001-08-23 | 2012-08-01 | Nippon Telegraph And Telephone Corporation | Digital signal decoding methods and apparatuses |
| CA2388439A1 (en) * | 2002-05-31 | 2003-11-30 | Voiceage Corporation | A method and device for efficient frame erasure concealment in linear predictive based speech codecs |
| US20040064308A1 (en) | 2002-09-30 | 2004-04-01 | Intel Corporation | Method and apparatus for speech packet loss recovery |
| KR20030024721A (ko) | 2003-01-28 | 2003-03-26 | 배명진 | 보이스-펜에서 녹음소리를 정답게 들려주는소프트사운드기능 |
| EP1589330B1 (en) * | 2003-01-30 | 2009-04-22 | Fujitsu Limited | Audio packet vanishment concealing device, audio packet vanishment concealing method, reception terminal, and audio communication system |
| US7415472B2 (en) | 2003-05-13 | 2008-08-19 | Cisco Technology, Inc. | Comparison tree data structures of particular use in performing lookup operations |
| US7415463B2 (en) | 2003-05-13 | 2008-08-19 | Cisco Technology, Inc. | Programming tree data structures and handling collisions while performing lookup operations |
| JP2005024756A (ja) | 2003-06-30 | 2005-01-27 | Toshiba Corp | 復号処理回路および移動端末装置 |
| US7302385B2 (en) | 2003-07-07 | 2007-11-27 | Electronics And Telecommunications Research Institute | Speech restoration system and method for concealing packet losses |
| US20050049853A1 (en) | 2003-09-01 | 2005-03-03 | Mi-Suk Lee | Frame loss concealment method and device for VoIP system |
| JP4365653B2 (ja) | 2003-09-17 | 2009-11-18 | パナソニック株式会社 | 音声信号送信装置、音声信号伝送システム及び音声信号送信方法 |
| KR100587953B1 (ko) * | 2003-12-26 | 2006-06-08 | 한국전자통신연구원 | 대역-분할 광대역 음성 코덱에서의 고대역 오류 은닉 장치 및 그를 이용한 비트스트림 복호화 시스템 |
| JP4733939B2 (ja) | 2004-01-08 | 2011-07-27 | パナソニック株式会社 | 信号復号化装置及び信号復号化方法 |
| CN1930607B (zh) | 2004-03-05 | 2010-11-10 | 松下电器产业株式会社 | 差错隐藏装置以及差错隐藏方法 |
| US7034675B2 (en) * | 2004-04-16 | 2006-04-25 | Robert Bosch Gmbh | Intrusion detection system including over-under passive infrared optics and a microwave transceiver |
| JP4345588B2 (ja) * | 2004-06-24 | 2009-10-14 | 住友金属鉱山株式会社 | 希土類−遷移金属−窒素系磁石粉末とその製造方法、および得られるボンド磁石 |
| US8725501B2 (en) | 2004-07-20 | 2014-05-13 | Panasonic Corporation | Audio decoding device and compensation frame generation method |
| KR20060011417A (ko) | 2004-07-30 | 2006-02-03 | 삼성전자주식회사 | 음성 출력과 영상 출력을 제어하는 장치와 제어 방법 |
| EP1846921B1 (en) | 2005-01-31 | 2017-10-04 | Skype | Method for concatenating frames in communication system |
| WO2006098274A1 (ja) | 2005-03-14 | 2006-09-21 | Matsushita Electric Industrial Co., Ltd. | スケーラブル復号化装置およびスケーラブル復号化方法 |
| US20070174047A1 (en) | 2005-10-18 | 2007-07-26 | Anderson Kyle D | Method and apparatus for resynchronizing packetized audio streams |
| KR100745683B1 (ko) * | 2005-11-28 | 2007-08-02 | 한국전자통신연구원 | 음성의 특징을 이용한 패킷 손실 은닉 방법 |
| CN1983909B (zh) | 2006-06-08 | 2010-07-28 | 华为技术有限公司 | 一种丢帧隐藏装置和方法 |
| CN101000768B (zh) * | 2006-06-21 | 2010-12-08 | 北京工业大学 | 嵌入式语音编解码的方法及编解码器 |
-
2007
- 2007-11-05 CN CN2007101696180A patent/CN101207665B/zh active Active
-
2008
- 2008-04-25 CN CN2008800010241A patent/CN101578657B/zh active Active
- 2008-04-25 CN CN2012101846225A patent/CN102682777B/zh active Active
- 2008-04-25 CN CN201110092815.3A patent/CN102169692B/zh active Active
- 2008-04-25 WO PCT/CN2008/070807 patent/WO2009059497A1/zh not_active Ceased
- 2008-04-25 BR BRPI0808765-2A patent/BRPI0808765B1/pt active IP Right Grant
- 2008-11-04 KR KR1020080108895A patent/KR101168648B1/ko active Active
- 2008-11-04 US US12/264,593 patent/US8320265B2/en active Active
- 2008-11-05 DE DE602008000668T patent/DE602008000668D1/de active Active
- 2008-11-05 AT AT08168328T patent/ATE458241T1/de not_active IP Right Cessation
- 2008-11-05 DK DK08168328.6T patent/DK2056292T3/da active
- 2008-11-05 DE DE202008017752U patent/DE202008017752U1/de not_active Expired - Lifetime
- 2008-11-05 ES ES08168328T patent/ES2340975T3/es active Active
- 2008-11-05 PL PL08168328T patent/PL2056292T3/pl unknown
- 2008-11-05 AT AT09178182T patent/ATE484052T1/de not_active IP Right Cessation
- 2008-11-05 JP JP2008284260A patent/JP4824734B2/ja active Active
- 2008-11-05 EP EP09178182A patent/EP2161719B1/en active Active
- 2008-11-05 DE DE602008002938T patent/DE602008002938D1/de active Active
- 2008-11-05 EP EP08168328A patent/EP2056292B1/en active Active
-
2009
- 2009-09-09 US US12/556,048 patent/US7957961B2/en active Active
-
2010
- 2010-03-17 JP JP2010060127A patent/JP5255585B2/ja active Active
Also Published As
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| BRPI0808765B1 (pt) | Método e aparelho para processamento de um sinal de voz sintetizado em ocultação de perda de pacotes e decodificador de voz | |
| RU2667029C2 (ru) | Аудиодекодер и способ обеспечения декодированной аудиоинформации с использованием маскирования ошибки, модифицирующего сигнал возбуждения во временной области | |
| RU2678473C2 (ru) | Аудиодекодер и способ обеспечения декодированной аудиоинформации с использованием маскирования ошибки на основании сигнала возбуждения во временной области | |
| JP4658596B2 (ja) | 線形予測に基づく音声コーデックにおける効率的なフレーム消失の隠蔽のための方法、及び装置 | |
| KR101406742B1 (ko) | 피치 주기 보정을 이용한 디지털 오디오 신호의 손실 블록의 합성 방법 | |
| RU2675777C2 (ru) | Устройство и способ улучшенного плавного изменения сигнала в различных областях во время маскирования ошибок | |
| JP5849106B2 (ja) | 低遅延の統合されたスピーチ及びオーディオ符号化におけるエラー隠しのための装置及び方法 | |
| JP5624192B2 (ja) | オーディオコーディングシステム、オーディオデコーダ、オーディオコーディング方法及びオーディオデコーディング方法 | |
| ES2644967T3 (es) | Extensión adaptativa del ancho de banda y aparato para la misma | |
| US8630864B2 (en) | Method for switching rate and bandwidth scalable audio decoding rate | |
| US20110007827A1 (en) | Concealment of transmission error in a digital audio signal in a hierarchical decoding structure | |
| CN113454714B (zh) | 根据mdct系数的频谱形状估计 | |
| JP5289319B2 (ja) | 隠蔽フレーム(パケット)を生成するための方法、プログラムおよび装置 | |
| US20090018823A1 (en) | Speech coding | |
| KR20090076797A (ko) | 고역 시그널에 대한 프레임 삭제 은폐 수행 방법 및 장치 | |
| HK1155844B (zh) | 信号处理方法和装置 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| B15K | Others concerning applications: alteration of classification |
Free format text: PROCEDIMENTO AUTOMATICO DE RECLASSIFICACAO. AS CLASSIFICACOES IPC ANTERIORES ERAM: G10L 19/04; H04L 1/00; H04L 12/56. Ipc: G10L 19/005 (2013.01), G10L 19/02 (2013.01), G10L Ipc: G10L 19/005 (2013.01), G10L 19/02 (2013.01), G10L |
|
| B06F | Objections, documents and/or translations needed after an examination request according [chapter 6.6 patent gazette] | ||
| B06U | Preliminary requirement: requests with searches performed by other patent offices: procedure suspended [chapter 6.21 patent gazette] | ||
| B06A | Patent application procedure suspended [chapter 6.1 patent gazette] | ||
| B09A | Decision: intention to grant [chapter 9.1 patent gazette] | ||
| B16A | Patent or certificate of addition of invention granted [chapter 16.1 patent gazette] |
Free format text: PRAZO DE VALIDADE: 10 (DEZ) ANOS CONTADOS A PARTIR DE 15/09/2020, OBSERVADAS AS CONDICOES LEGAIS. |