BRPI0910793B1 - Metodo e discriminador para a classificaqao de diferentes segmentos de um sinal - Google Patents
Metodo e discriminador para a classificaqao de diferentes segmentos de um sinal Download PDFInfo
- Publication number
- BRPI0910793B1 BRPI0910793B1 BRPI0910793-2A BRPI0910793A BRPI0910793B1 BR PI0910793 B1 BRPI0910793 B1 BR PI0910793B1 BR PI0910793 A BRPI0910793 A BR PI0910793A BR PI0910793 B1 BRPI0910793 B1 BR PI0910793B1
- Authority
- BR
- Brazil
- Prior art keywords
- term
- short
- signal
- long
- segment
- Prior art date
Links
- 238000000034 method Methods 0.000 title claims abstract description 45
- 230000007774 longterm Effects 0.000 claims abstract description 84
- 230000005236 sound signal Effects 0.000 claims description 42
- 238000004458 analytical method Methods 0.000 claims description 29
- 238000012545 processing Methods 0.000 claims description 17
- 230000008569 process Effects 0.000 claims description 13
- 230000001419 dependent effect Effects 0.000 claims description 5
- 238000005070 sampling Methods 0.000 claims description 4
- 230000005284 excitation Effects 0.000 description 18
- 238000013459 approach Methods 0.000 description 17
- 230000003595 spectral effect Effects 0.000 description 16
- 238000013461 design Methods 0.000 description 10
- 238000004422 calculation algorithm Methods 0.000 description 9
- 239000000203 mixture Substances 0.000 description 7
- 238000007781 pre-processing Methods 0.000 description 7
- 230000003044 adaptive effect Effects 0.000 description 6
- 238000006243 chemical reaction Methods 0.000 description 6
- 238000012549 training Methods 0.000 description 6
- 230000000875 corresponding effect Effects 0.000 description 5
- 238000003066 decision tree Methods 0.000 description 5
- 230000003111 delayed effect Effects 0.000 description 5
- 238000010586 diagram Methods 0.000 description 5
- 238000013139 quantization Methods 0.000 description 5
- 230000009257 reactivity Effects 0.000 description 5
- 230000011218 segmentation Effects 0.000 description 5
- 230000008901 benefit Effects 0.000 description 4
- 238000004590 computer program Methods 0.000 description 4
- 230000001934 delay Effects 0.000 description 4
- 238000003786 synthesis reaction Methods 0.000 description 4
- 230000015572 biosynthetic process Effects 0.000 description 3
- 238000004364 calculation method Methods 0.000 description 3
- 230000008859 change Effects 0.000 description 3
- 230000006870 function Effects 0.000 description 3
- 238000012805 post-processing Methods 0.000 description 3
- 230000009467 reduction Effects 0.000 description 3
- 230000009466 transformation Effects 0.000 description 3
- 230000005540 biological transmission Effects 0.000 description 2
- 230000000694 effects Effects 0.000 description 2
- 239000000284 extract Substances 0.000 description 2
- 238000005259 measurement Methods 0.000 description 2
- 230000003446 memory effect Effects 0.000 description 2
- 238000010606 normalization Methods 0.000 description 2
- 230000010076 replication Effects 0.000 description 2
- 238000001228 spectrum Methods 0.000 description 2
- 230000006399 behavior Effects 0.000 description 1
- 230000009286 beneficial effect Effects 0.000 description 1
- 230000015556 catabolic process Effects 0.000 description 1
- 238000010276 construction Methods 0.000 description 1
- 230000008094 contradictory effect Effects 0.000 description 1
- 230000002596 correlated effect Effects 0.000 description 1
- 238000013144 data compression Methods 0.000 description 1
- 238000001514 detection method Methods 0.000 description 1
- 238000011156 evaluation Methods 0.000 description 1
- 238000000605 extraction Methods 0.000 description 1
- 238000001914 filtration Methods 0.000 description 1
- 230000000873 masking effect Effects 0.000 description 1
- 230000007246 mechanism Effects 0.000 description 1
- 238000012986 modification Methods 0.000 description 1
- 230000004048 modification Effects 0.000 description 1
- 230000008447 perception Effects 0.000 description 1
- 230000002829 reductive effect Effects 0.000 description 1
- 230000000717 retained effect Effects 0.000 description 1
- 230000003068 static effect Effects 0.000 description 1
- 238000012360 testing method Methods 0.000 description 1
- 238000000844 transformation Methods 0.000 description 1
- 230000001052 transient effect Effects 0.000 description 1
- 230000007704 transition Effects 0.000 description 1
- 238000012800 visualization Methods 0.000 description 1
Images






Classifications
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L19/00—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis
- G10L19/04—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis using predictive techniques
- G10L19/16—Vocoder architecture
- G10L19/18—Vocoders using multiple modes
- G10L19/20—Vocoders using multiple modes using sound class specific coding, hybrid encoders or object based coding
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L25/00—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00
- G10L25/78—Detection of presence or absence of voice signals
- G10L25/81—Detection of presence or absence of voice signals for discriminating voice from music
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L19/00—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L19/00—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis
- G10L19/04—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis using predictive techniques
- G10L19/16—Vocoder architecture
- G10L19/18—Vocoders using multiple modes
- G10L19/22—Mode decision, i.e. based on audio signal content versus external parameters
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L25/00—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L25/00—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00
- G10L25/78—Detection of presence or absence of voice signals
- G10L2025/783—Detection of presence or absence of voice signals based on threshold decision
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L25/00—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00
- G10L25/48—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00 specially adapted for particular use
- G10L25/51—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00 specially adapted for particular use for comparison or discrimination
Landscapes
- Engineering & Computer Science (AREA)
- Computational Linguistics (AREA)
- Signal Processing (AREA)
- Health & Medical Sciences (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Human Computer Interaction (AREA)
- Physics & Mathematics (AREA)
- Acoustics & Sound (AREA)
- Multimedia (AREA)
- Compression, Expansion, Code Conversion, And Decoders (AREA)
- Image Analysis (AREA)
Abstract
MÉTODO E DISCRIMINADOR PARA A CLASSIFICAÇÃO DE DIFERENTES SEGMENTOS DE UM SINAL. Para classificar os diferentes segmentos de um sinal de que abrange segmentos de pelo menos, um primeiro tipo e um segundo tipo, por exemplo segmentos de áudio e fala, o sinal é classificado como curto prazo (150) com base em pelo menos, um recurso de curto prazo extraído do sinal e um resultado de classificação de curto prazo (152) é entregue. O sinal também é classificado como longo prazo (154) com base em pelo menos, um recurso de curto prazo e em pelo menos, um recurso de longo prazo extraído do sinal e um resultado de classificação de longo prazo (156) é entregue. O resultado de classificação de curto prazo (152) e o resultado de classificação de longo prazo (156) são combinados (158) para fornecer um sinal de saída (160) indicado se um segmento do sinal é de primeiro tipo ou de segundo tipo.
Description
A invenção relata a abordagem para a classificação de diferentes segmentos de um sinal que abrange os segmentos de pelo menos, um primeiro tipo e um segundo tipo. A materialização da invenção refere-se ao campo da codificação de áudio e, particularmente, para a discriminação de fala/música sobre a codificação de um sinal de áudio.
Na arté, o dominio da codificação de esquemas de frequência, tal como o MP3 ou AAC, são conhecidos. Estes codificadores de dominio de frequência são baseados em uma conversão do dominio de tempo/dominio de frequência, um estágio de quantização subsequente, na qual o erro de quantização é controlado usando a informação de um módulo psicoacústicor e um estágio de codificação, no qual o co_e.ficiente., coeficientes espectral quantizado e as informações correspondentes são secundárias a codificação entrópica utilizando as tabelas de códigos
Por outro lado existem os codificadores que são muito bem adequados para o processamento da fala como o AMR-WB+ conforme descrito no 3GPP TS 26.290. Tal esquema de codificação de fala realiza uma analise Linear Preditiva. Tal filtragem LP é derivada de uma analise Linear Preditiva do sinal de entrada do dominio de tempo. Os coeficientes resultantes do filtro LP são então codificados e transmitidos como informação secundária. O processo é conhecido como Codificação Linear Preditiva (LPC). Na saida do filtro, o sinal residual preditivo ou o sinal de erro preditivo que também é conhecido como o sinal de excitação é codificado usando o estágio de análise-por-sintese do codificador ACELP ou, alternativamente, é codificado utilizando um codificador transformado, que usando uma transformada de Fourier com uma 5 sobreposição. A decisão entre a codificação ACELP e a codificação de Excitação da Transformada Codificada que também é chamada de codificação TCX é feita através de um algoritmo de malha fechada ou um algoritmo de malha aberta.
Os esquemas de codificação de áudio de dominio de frequência tal como os esquemas de codificação de alta eficiência- AAC, que combina um esquema de codificação AAC e uma técnica de replicação de largura de faixa espectral pode também ser combinado com um a joint stereo ou uma ferramenta de codificação de multicanal que também é conhecido como o nome de "MPEG surround".
Os esquemas...de. codificação de áudio de dominio são—vantajosos na medida ...em...que mostram, uma alta qualidade a baixas taxas de bits para os sinais de música. A qualidade dos sinais de voz em baixas taxas de bits, porém é problemática.
Por outro lado, os codificadores de fala como o AMR-WB+ também possuem um estágio de aprimoramento de alta frequência e uma funcionalidade estéreo. Os esquemas de codificação de fala mostram uma alta qualidade para sinais de fala- mesmo em baixas taxas de bits, mas mostram uma baixa qualidade para sinais de música em baixas taxas de bits.
Na visualização disponivel de um esquema de codificação acima mencionado, alguns dos quais são mais adequados para codificação de fala e outros sendo mais adequados para codificação de música, a segmentação automática e a classificação de um sinal de áudio a ser codificado é uma importante ferramenta em varias aplicações multimídia e podem ser utilizadas a fim de selecionar um processo apropriado para cada diferente classe que ocorre em um sinal de áudio. O desempenho geral da aplicação é fortemente dependente da confiabilidade da classificação do sinal de áudio. De fato, uma classificação errada gera seleções mal adaptadas e afinações dos seguintes processos.
A Fig. 6 mostra um design convencional de um codificador usado para codificar separadamente a codificação, dependente de fala e música na discriminação de um sinal de áudio. 0 design do codificador abrange um codificador de seção de fala 100 inclui um codificador de fala apropriado 102, por exemplo, um AMR-WB+ codificador de fala como descrito na "Extended Adaptive Multi-Rate - Wideband (AMR-WB+) codec", 3GPP TS 26.290 V6.3.0, 2005-06,——Especificação Técnica. Além disso, ■ -o—design do codificador abrange um codificador- de. seção de música 1.04- compreendendo de um codificador de música 106, por exemplo um codificador de música AAC como é, por exemplo, descrito na Generic Coding of Moving Pictures and Associated Audio: Advanced Audio Coding. International Standard 13818-7, ISO/IEC JTC1/SC29/WG11 Moving Pictures Expert Group, 1997.
As saídas dos codificadores 102 e 106 são conectadas a uma entrada de um multiplexador 108. As entradas dos codificadores 102 e 106 são seletivamente conectadas a uma linha de entrada 110 carregando um sinal de áudio de entrada. O sinal de áudio de entrada é aplicado seletivamente para o codificador de fala 102 ou o codificador de música 106 por meio de um comutador 112 mostrado esquematicamente na Fig. 6 e sendo controlado por um controle de comutação 114. Além disso, o design do codificador abrange um discriminador de fala/música 116 também recebe uma entrada no seu sinal de áudio de entrada e emite um sinal de controle para o controle de comutação 114. O controle de comutação 5 114 gera uma saida de um sinal indicador do modo em uma linha de 118 que é a entrada em uma segunda entrada do multiplexador 108, para que um sinal indicador de modo possa ser enviado junto com um sinal codificado. 0 sinal de indicador de modo pode ter somente um bit indicado que o bloco de dados associados com um bit do 10 indicador de modo ou é para a fala codificada ou música codificada de modo que, por exemplo, em um decodif icador nenhuma discriminação deve ser feita. Pelo contrário, com base no bit do indicador de modo apresentado junto com os dados codificados para o decodificador secundário de um sinal de comutação apropriado 15 possa ser—-gerada com base no indicador- de modo de encaminhamento - dos dados recebidos-—e—codificados em um decodificador apropriado de fala ou de música. A Fig. 6 e um design tradicional do codificador que é usado para codificar digitalmente os sinais de fala e música aplicada para a linha 110. Normalmente, os codificadores de fala funcionam melhor na fala e os codificadores de áudio funcionam melhor na música. Um esquema de codificação universal pode ser planejado usando um sistema multi-codificador que alterar de um codificador para outro de acordo com a natureza do sinal de entrada. O problema O problema não trivial aqui é planejar um classificador de sinal de entrada bem adequado que conduz o elemento de comutação. O classificador é o discriminador de fala/música 116 mostrado na Fig. 6. Frequentemente uma classificação confiável de um sinal de áudio introduz um alto atraso, considerando, por outro lado, o atraso é um fator importante nas aplicações em tempo real. No geral, é desejado que o atraso do algoritmo geral introduzido pelo discriminador de fala/música seja suficientemente baixo para ser capaz de usar os codificadores ligados na aplicação em tempo real. A Fig. 7 ilustra os atrasos experimentados design do codificador, como mostrado na Fig. 6. Supõe-se que o sinal aplicado na linha de entrada 110 deve ser codificada em uma base de estrutura de 1024 amostras em uma taxa de amostragem de 16 kHz de modo que o discriminador de fala/música deva emitir um "resultado em alguma estrutura, ou seja, a cada 64 milissegundos. A transmissão entre dois codificadores é efetuada, por exemplo, da .mesma forma como descrita na WO 2008/071353 A2-e o discriminador de fala/música- não de ve aumentar significantemente o atraso -do algoritmo do decodificador comutado que está no total de 1600 amostras sem considerar o atraso necessário para o discriminador de fala/música. É mais desejada fornecer a decisão de fala/música para a mesma estrutura a comutação de bloco AAC é decidido. A situação é descrita na Fig. 7 ilustrando ao longo comutação de bloco AAC tendo um comprimento de 2048 amostras, ou seja, bloco longo 120 abrange duas estruturas de 1024 amostras, um bloco curto AAC 122 de uma estrutura de 1024 amostras, e um AMR-WB+ superestrutura 124 de uma estrutura de 1024 amostras. Na Fig. 7, a decisão de comutação de bloco AAC e a decisão de fala/música são tomadas nas estruturas 126 e 128 respectivamente de 102 4 amostras, que cobre o mesmo periodo de tempo. As duas decisões são tomadas nesta posição em particular para fazer a codificação poder utilizar em um momento da janela de transição para ir adequadamente um modo para o outro. Em consequência, um atraso minimo de 512+64 amostras são introduzidas por duas decisões. Este atraso tem que ser adicionado ao atraso das 1024 amostras geradas por 50% de sobreposição forma a AAC MDCT que resulta um atraso minimo de 1600 amostras. Em um AAC convencional, somente a comutação de bloco é apresentado e o atraso é exatamente de 1600 amostras. Este atraso é necessário para comutar em um momento de um bloco longo para os blocos curtos quando os transitórios são detectados na estrutura 126. Esta comutação de comprimento de transformação é desejado para evitar o artefato de pré-eco. A estrutura decodificada 130 na Fig. 7 representa a primeira estrutura total que pode ser restituida no.decodificador secundário em qualquer- caso- (blocos longos rou- curtos) .. — — Em um codificador comutado utilizando o AAC como codificador de música, a decisão de comutação vindo de um estágio deve evitar adicionar também muito atrasos adicionais ao atraso original do AAC. O atraso adicional vem de uma estrutura lookahead 132 que é necessária para analise de sinal no estágio de decisão. Em uma taxa de amostragem de por exemplo 16kHz, o atraso AAC é de 100 ms quando o discriminador convencional de fala/música usa cerca de 500 ms de lookahead, que resultará em uma estrutura de codificação comutada com um atraso de 600 ms. O atraso total será seis vezes maior do que o atraso do AAC original. As abordagens convencionais como as descritasacima são desfavoráveis. Como uma classificação confiável de um sinal de áudio elevado, os atrasos indesejáveis são introduzidos de modo que a necessidade de uma nova abordagem exista para a discriminação de um sinal incluindo segmentos de diferentes tipos, onde um atraso adicional de algoritmo introduzido pelo discriminador seja suficientemente baixa de modo que os codificadores de comutação também possa ser usado para uma aplicação em tempo real. J. Wang, et. al. "Real-time speech/music classification with a hierarchical oblique decision tree", ICASSP 2008, Conferência Internacional IEEE sobre Acústica, Fala e Processamento de Sinal, 2008, de 31 de março de 2008 a 4 de abril de 2008 descreve uma abordagem para a classificação de fala/música utilizando recursos a curto e longo prazo derivados de um mesmo número de estruturas. Estes recursos a curto e longo prazo são usados- para classificar—-o- sinal, mas apenas as propriedades limitadas dos recursos de curto prazo são explorados-^—por exemplo, a reatividade da classificação não é explorada, embora tenha um papel importante para a maioria das aplicações de codificação de áudio.
A finalidade da invenção é fornecer uma melhor abordagem para a discriminação em um segmento de sinal de tipo diferente, mantendo qualquer atraso baixo introduzido pela discriminação.
Este finalidade é atingida pelo método da reivindicação 1 e pela discriminação da reivindicação 14. □ma materialização da invenção fornece um método para classificar diferentes segmentos de um sinal, o sinal abrangendo os segmentos de pelo menos, um primeiro tipo e um segundo tipo, o método abrange: classificação de curto prazo do sinal com base em pelo menos, um recurso de curto prazo extraido do sinal e 5 entregando um resultado de classificação de curto prazo; classificação de longo prazo do sinal com base em pelo menos, um recurso de curto e pelo menos, um recurso de longo prazo extraido do sinal e entregando um resultado da classificação de longo prazo; e combinando o resultado da classificação de curto prazo e o resultado da classificação de longo prazo para fornecer um sinal de saida indicando se um segmento do sinal é do primeiro tipo-ou do segundo tipo.
Outra materialização da invenção proporciona um_ discriminador,. abrangendo:um classificador -de curto prazo configurado para receber um sinal e fornecer um resultado de classificação de curto prazo do sinal com base em pelo menos, um recurso de curto prazo extraido do sinal, o sinal abrange segmentos de pelo menos, um 20 primeiro tipo e de um segundo tipo; um classificador de longo prazo configurado para receber um sinal e fornecer um resultado de classificação de longo prazo do sinal com base em pelo menos, um recurso de curto prazo do sinal e pelo menos, um recurso de longo prazo extraido do 25 sinal;um circuito de decisão configurado para combinar o resultado de classificação de curto prazo e o resultado declassificação de longo prazo para fornecer um sinal de saida indicando se um segmento do sinal é do primeiro tipo ou do Segundo tipo. A materialização de invenção fornece um sinal de saida com base na comparação do resultado da analise de curto prazo para o resultado da analise de longo prazo.
A materialização de invenção relaciona uma abordagem para classificar os diferentes segmentos não- sobreposição de curto espaço de tempo de um sinal de áudio, quer como fala ou como não-fala ou outras classes. A abordagem é baseada na extração de recursos e a analise de suas estatísticas de duas diferentes de análises de comprimentos de janela. A primeira janela é longa e principalmente para o passado. A ■primeira janela é usada para obter um indicio de decisão confiável mas atrasada para a classificação de um sinal. A segunda janela é curtate considera principalmente- o processo de -segmento no memento presente ou no segmento atual. A segunda janela é usada-para—obter um indicio de decisão instantânea. As duas dicas de decisão são combinadas de modo mais eficiente, preferencialmente por meio de uma decisão de histerese que obtém a informação da memória a partir do indicio de decisão atrasada e a informação instantânea a partir da instantânea.
As materializações de uma invenção usam recursos de curto prazo ambos no classificador de curto prazo e no classificador de longo prazo de modo que os dois classificadores explorem estatísticas diferentes do mesmo recurso. O classificador de curto tempo extrai somente a informação instantânea uma vez que ele tem acesso apenas a um conjunto de recursos. Por exemplo, ele pode explorar o meio dos recursos. Por outro lado, o classificador de longo prazo tem acesso a vários conjuntos de recursos uma vez que ele considera varias estruturas. Como consequência, o classificador de longo prazo pode explorar mais características do sinal ao explorar estatísticas de mais estruturas que o classificador de curto prazo. Por exemplo, o classificador de longo prazo pode explorar a variação do recurso ou a evolução dos recursos todo tempo. Assim, o classificador de longo prazo pode explorar mais informações que o classificador de curto prazo, mas introduz atraso ou latência. Entretanto, os recursos de longo prazo, apesar de introduzir o atraso ou a latência, fará o resultado de classificação de longo prazo mais robusto e confiável. Em algumas materializações os classificadores de curto prazo e de longo prazo podem considerar os mesmos recursos de curto prazo, que podem ser calculados uma vez e utilizados para _ ambos os classificadores.— Assim, em—tal “materialização o classificador de longo- praze—pode -receber recursos de curto prazo diretamente a partir do classificador de curto prazo. A nova abordagem permite, assim, obter uma classificação que é robusta, introduzindo um atraso baixo. Outras abordagens convencionais, a materialização da invenção limita o atraso introduzido pela decisão de fala/música que mantinha uma decisão confiável. Em uma materialização da invenção, o lookahead é limitado a 128 amostras, o que resulta em um atraso de somente 108 ms.
A materialização da invenção será descrita abaixo com a referência acompanhada de desenhos, no qual: Fig. 1 é um diagrama de bloco de um discriminador de fala/música de acordo com uma materialização da invenção; Fig. 2 ilustra a janela de analise usada pelo classificador de longo e curto prazo do discriminador da Fig. 1; Fig. 3 ilustra a decisão de histerese utilizada no discriminador da Fig. 1; Fig. 4 é um diagrama de bloco de um esquema exemplar de codificação abrangendo um discriminador de acordo com uma materialização da invenção; Fig. 5 é um diagrama de bloco de um esquema de decodificação correspondente ao esquema de codificação da Fig. 4; Fig. 6 mostra um design convencional de codificador usado para codificar separadamente o dependente de fala e música em uma discriminação de um sinal de áudio; e Fig. 7 ilustra os -atrasos experimentado’ no design do codificador mos t r ado-na Fig. 6.- ■ —
Fig. 1 é um diagrama de bloco de um discriminador de fala/música 116 de acordo com uma materialização da invenção. O discriminador de fala/música 116 abrange um classificador de curto prazo 150 recebe na entrada um sinal de entrada, por exemplo, um sinal de áudio abrangendo os segmentos de fala e música. O classificador de curto prazo 150 emite na linha de saida 152 um resultado de classificação de curto prazo, o indicio de decisão instantânea. O discriminador 116 abrange ainda um classificador de longo prazo 154 que também recebe um sinal de entrada e saida em uma linha de saida 156 o resultado de classificação de longo prazo e o indicio de decisão atrasada. Além disso, um circuito de decisão de histerese 158 é fornecido que combina os sinais a partir do classificador de curto prazo 150 e do classificador de longo prazo 154 será descrito de modo mais detalhada abaixo para gerar um sinal decisão de fala/música que é a saida na linha 160 e 5 pode ser usada para controlar o processo posterior de um segmento de uma sinal de saída do modo como está descrito acima com relação a Fig. 6, ou seja o sinal de decisão de fala/música 160 pode ser usado para rotear o segmento do sinal de entra que tem sido classificado para um codificador de fala ou para um codificador de 10 áudio. Assim, de acordo com uma materialização da invenção dois diferentes classificadores 150 e 154 são usados em paralelo nó sTihal de entrada aplicado para os respectivos classificadores por meio de uma linha 110. Os dois classificadores 15 são chamados de_ classificador de. longo prazo* 154- e classificador' de curto prazo 150,_ onde o... em que -os dois classificadores diferentes, analisando as estatísticas das características em que a operação sobre as janelas de análise. Os dois classificadores entregam os sinais de saída 152 and 156, nomeados de indício de 20 decisão instantâneo (IDC) e o indício de decisão atrasada (DDC). O classificador de curto prazo 150 gera o IDC com base nos recursos de curto prazo que têm o objetivo de capturar informações instantâneas sobre a natureza do sinal de entrada. Eles estão relacionados com atributos de curto prazo do sinal que podem alterar rapidamente a qualquer momento. Em consequência os recursos de curto prazo deverão ser reativados e não introduzir um atraso longo de todo o processo de discriminação. Por exemplo, desde que a fala é considerado quase estacionária com duração de 5-20ms, os recursos de curto prazo podem ser calculado em cad estrutura de 16 ms em um sinal de amostra de 16 kHz. O classificador de longo prazo 154 gera o DDC com base nos recursos resultantes a partir de longas observações do sinal (recursos de longo prazo) e, portanto, permite alcançar a classificação mais confiável. A Fig. 2 ilustra a janela de analise usada pelo classificador de longo prazo 154 e pelo classificador de curto prazo 150 mostrado na Fig. 1. Assumindo uma estrutura de 1024 amostras em uma taxa de amostragem de 16 kHz o comprimento da janela do classificador de longo prazo 162 é de 4*1024+128 amostras, ou seja, a janela do classificador de longo prazo 162tfãnspõe“ quatro estruturas do sinal de áudio e as 128 amostras adicionais são necessárias pelo classificador de longo prazo 154 para fazer esta, analise._ Este atraso- adicionai, que 'é também referido como um "lookahead", é indicado— na Fig—2 no sinal de referencia 164. A Fig. 2 também mostra a janela do classificador de curto prazo 166 que é 1024+128 amostras, ou seja transpõe uma estrutura do sinal de áudio e o atraso adicional necessário par analisar o segmento atual. O segmento atual é indicado em 128 como o segmento para o qual a decisão de fala/música precisa ser feita. A janela do classificador de longo prazo indicada na Fig. 2 é suficientemente longa para obter os 4-Hz da modulação de energia da característica da fala. Os 4-Hz da modulação de energia são uma característica relevante e distinta da fala que é tradicionalmente explorada em um robusto discriminador de fala/músicas usadas como por exemplo por Scheirer E. e Slaney M., "Construction and Evaluation of a Robust Multifeature Speech/Music Discriminator", ICASSP'97, Munich, 1997. Os 4-Hz da modulação de energia são um recurso que pode ser somente extraído pela observação de um sinal em um longo segmento de tempo. O atraso adicional que é introduzido pelo discriminador de fala/música é igual ao lookahead 164 de 128 amostras que é necessário para cada um dos classificadores 150 e 154 fazem a respectiva análise, como uma analise perceptiva linear preditiva como é descrito por H. Hermansky, "Perceptive linear prediction (pip) analysis of speech,"Journal of the Acoustical Society of America, vol. 87, no. 4, pp. 1738-1752, 1990 e H. Hermansky, et al., "Perceptually based linear predictive analysis of speech," ICASSP 5.509-512, 1985. Assim, quando usamos o discriminador da materialização acima em “um design dê codificador como mostrado na Fig. 6, o atraso total dos codificadores de comutação 102 e 106 serão 1600+128 amostras que é 108 milissegundos que- é suf-icí entemente—baixo-para aplicações em tempo real.
A referência é agora feita para a Fig. 3 descrevendo a combinação do sinal de saida 152 e 156 dos classificadores 150 e 154 do discriminador 116 para obter um sinal de decisão de fala/música 160. O indício de decisão atrasada DDC e o indício de decisão instantânea IDC, de acordo com uma materialização da invenção, é combinado ao usar uma decisão de histerese. Os processos de histerese são amplamente utilizados para divulgar decisões processo a fim de estabilizá-los. A Fig. 3 ilustra uma decisão de dois estados de histerese como uma função do DDC e do IDC para determinar se o sinal decisão de fala/música indicar um segmento atualmente processado do sinal de entrada como sendo um segmento de fala ou de um segmento de música. Os ciclos de características da histerese é visualizado na Fig. 3 e o IDC e o DDC são normalizados pelos classificadores 150 e 154 de tal forma que os valores estão entre -1 e 1, onde -1 significa que a probabilidade é totalmente semelhante à música, e 1 significa que a probabilidade é totalmente semelhante à fala.
A decisão é baseada nos valores de uma função F(IDC,DDC), esses exemplos que serão descritos abaixo. Na Fig. 3, F1(DDC, IDC) indica um limite que F(IDC,DDC) deve atravessar para ir do estado de música para o estado de fala. A F2(DDC,IDC) indica um limite que F(IDC, DDC) deve atravessar para ir do estado de fala para o estado de música. A decisão final D(n) para um segmento atual ou estrutura atual tendo o índice n, pode então ser cãlculãda com bas'd no seguinte pseudocódigo: %Hysteresis Decision Pseudo Code 1 f (D (n-1) ==music) If (F (IDC, DDC) <F1 (DDC,.IDC) ). • D(n)==music Else D (n)==speech Else If(F(IDC, DDC)>F2(DDC,IDC) ) D(n)==speech Else D(n)==music %End Hysteresis Decision Pseudo Code De acordo com uma materialização da invenção a função F(IDC,DDC) e o limite acima mencionado, são definidas a seguir: F(IDC,DDC)=IDC Fl(IDC,DDC)=0.4-0.4* DDC F2(IDC,DDC)=-0.4-0.4*DDC Alternativamente, as seguintes definições podem ser usadas: F(IDC,DDC)=(2*IDC+DDC)/3 Fl(IDC,DDC)=-0.75*DDC F2(IDC,DDC)=-0.75*DDC Quando usamos a ultima definição do ciclo de histerese e a decisão é feita somente com base no limite de uma única adaptativa.
A invenção não é limitada pela decisão de ‘histerese ” descrita” ~acima. Nas materializações seguintes adicionais, será descrito que, combinamos os resultados da análise para a obtenção do sinal de. saida.. - — Um limite simples pode _ ser usado no lugar da decisão de histerese fazendo de uma forma que o limite explore as características da DDC e IDC. O DDC é considerado como o indicio discriminante mais confiável, uma vez que se a trata da observação mais demorada do sinal. Entretanto, o DDC é calculado parcialmente com base em uma observação anterior do sinal. Um classificador convencional que somente compara o valor DDC para o limite 0, e pela classificação do segmento como semelhante à fala quando DDOO ou ao contrario, como semelhante à música, temos uma decisão de atraso. Em uma materialização da invenção, podemos adaptar o limite explorando o IDC e tomar a decisão mais reativa. Para este propósito, o limite pode ser adaptado com base no seguinte pseudocódigo: % Pseudo code of adaptive thresholding If (DDO-0.5*IDC) D (n)==speech Else D(n)==music %End of adaptive thresholding Em outra materialização, o DDC pode ser usado para tornar o IDC mais confiável. O IDC é conhecido por ser reativo mas não tão confiável quanto o DDC. Além disso, observando a evolução do DDC entre o segmento anterior e o atual pode dar mais uma indicação de como a estrutura 166 na Fig. 2 influencia o DDC calculado no segmento 162. A nota DDC(n)' é usada para o valor attral dõ- DDC-e DDC(n-l) para o valor. Utilizando ambos os valores, DDC(n) e DDC(n-l), o IDC pode ser mais confiável usando uma árvore de jiecisão como é_descritora seguirt — — — ~ % Pseudo code of decision tree — - - — If(IDC>0 && DDC(n)>0) D(n)=speech Else if (IDCCO && DDC(n)<0) D(n)=music Else if (IDOO && DDC (n)-DDC (n-1) >0 ) D(n)=speech Else if (IDC<0 && DDC(n)-DDC(n-1)<0) D(n)=music Else if (DDOO) D(n)=speech Else D(n)=music %End of decision tree Na árvore de decisão acima, a decisão é tomada diretamente se ambas as dicas mostrarem o mesmo valor. Se as duas dicas dão indicações contraditórias, observamos para a evolução da DDC. Se a diferença de DDC(n)-DDC(n-1) é positiva, podemos supor que o segmento atual é semelhante à fala. De outra maneira, podemos supor que o segmento atual é semelhante à música. Se esta nova indicação vai na mesma direção do IDC, a decisão final é tomada. Se ambas as tentativas falham ao dar uma decisão clara, a decisão é tomada por considerar somente o atraso no indicio DDC desde que a confiabilidade do IDC não possa ser validada.
No seguinte, os respectivos classificadores 150 e 154~*3e acordo com uma materialização da invenção serão descritos detalhadamente. _ .Começando pelo primeiro lugar o-classificador de ~ longo prazo 154 é o mesmo que - se aplica para cada subestrutura de 256 amostras em um conjunto de recursos. O primeiro recurso é o Coeficiente Cepstral de Perceptiva Linear Preditiva (PLPCC) como descrito por H. Hermansky, "Perceptive linear prediction (plp) analysis of speech,"Journal of the Acoustical Society of America, vol. 87, no. 4, pp. 1738-1752, 1990 e H. Hermansky, et al., "Perceptually based linear predictive analysis of speech," ICASSP 5.509-512, 1985. Os PLPCCs são eficientes para classificação de fala ao utilizar a avaliação da percepção auditiva humana. Este recurso pode ser usado para discriminar a fala e a música e, realmente permite as características dos formantes da fala, bem como a modulação silábica da fala de 4 Hz, observando a variação do recurso ao longo do tempo.
Entretanto, para ser mais robusto, os PLPCCs são combinados com outro recurso que é capaz de capturar tom das informações, que é outra caracteristica importante da fala e pode ser critica na codificação. Realmente, a codificação da fala baseia-se na suposição que um sinal de saida é um sinal pseudo mono-periódico. Os esquemas de codificação da fala são eficientes para tal sinal. Por outro lado, as características do tom da fala prejudica muitos a eficiência da codificação dos codificadores de música. A flutuação do atraso de tom suave determina o vibrato natural da fala faz com que a representação de frequência nos codificadores de música sejam incapazes de compactar a energia grande que é necessária para a obtenção de uma alta eficiência de codificação.
Os seguintes recursos das características do tom podem ser. determinadas como: Taxa de Energia dos Pulsos Glótico: - Este recurso calcula a taxa de energia entre os pulsos glóticos e o sinal residual de LPC. Os pulsos glóticos são extraídos do sinal residual de LPC utilizando um algoritmo pick- peaking. Geralmente, o residual de LPC de um segmento sonoro mostra uma grande estrutura semelhante a pulso vindo da vibração glótica. O recurso é alto durante os segmentos sonoros. Ganho Perceptivo de Longo Prazo: É o ganho geralmente calculado nos codificadores de fala (ver exemplos "Extended Adaptive Multi-Rate - Wideband (AMR-WB+) codec", 3GPP TS 26.290 V6.3.0, 2005-06, Especificação Técnica) durante o perceptivo de longo prazo. Este recurso mede a periodicidade do sinal e é baseado no atraso estimativo do tom. Flutuação do atraso de tom: Este recurso determina a diferença do atraso estimativo do tom presente quando comparado a ultima sub- estrutura. Para o vozeamento da fala este recurso deve ser baixo mas não zero e evolui suavemente.
Uma vez que o classificador de longo prazo tem extraido o conjunto requerido de recursos, um classificador estático é usado para extrair estes recursos. O classificador é primeiro treinado extraindo os recursos em um conjunto de treinamento de fala e conjunto de treinamento de música. Os recursos extraidos são normalizados para um valor médio de 0 e uma variação de 1 em ambos os conjuntos de treinamento. Para cada conjunto de treinamento, os recursos extraidos e normalizados são reunidos dentro de uma janela do classificador de longo prazo e .modelados pelo,_ Gaussians Mixture Model—- (GMM) usando cinco gaussianos.. Ao fim da sequência de treinamento um conjunto de parâmetros de normalização e dois conjuntos de parâmetros GMM são obtidos e salvos.
Para cada estrutura para classificar, os recursos são extraidos primeiros e normalizados com os parâmetros de normalização. A semelhança máxima para a fala (lld_speech) e a t semelhança máxima para a música (lld_music) são calculadas para os recursos extraidos e normalizados usando o GMM de classe de fala e o GMM de classe de música, respectivamente. O indicio de decisão atrasada DDC é então calculada pela seguinte: DDC=(lld_speech- lld_music)/(abs(lld_music)+abs(lld_speech)) O DDC está vinculado entre -1 e 1, e é positive quando a semelhança máxima para a fala seja maior que a semelhança máxima para a música, lld_speech>lld_music. O classificador de curto prazo utiliza como recurso de curto prazo o PLPCCs. Exceto no classificador de longo prazo, este recurso é somente analisado na janela 128. As estatísticas neste recurso são extraídas neste curto período por um Gaussians Mixture Model (GMM) usando cinco gaussianos. Os dois modelos são treinados, um para música, e outro para fala. Vale a pena notificar, que os dois modelos são diferentes daqueles obtidos pelo classificador de longo prazo. Para cada estrutura para classificar, os PLPCCs são extraídos primeiro e a semelhança máxima para a fala (lld_speech) e a semelhança máxima para a música (lT3_music) são calculados usando o GMM de classe de fala e a GMM de classe de música, respectivamente. O indício de decisão instantânea IDC^e então calculada a—seguir: — — — — . IDC=(lld_speech- —- -- - - ' lld_music)/(abs(lld_music)+abs(lld_speech)) O IDC é variável entre -1 e 1.
Assim, o classificador de curto prazo 150 gera o resultado de classificação de curto prazo do sinal com base no recurso "Coeficiente Cepstral de Perceptiva Linear Preditiva (PLPCC)", e o classificador de longo prazo 154 gera o resultado de classificação de longo prazo do sinal com base no mesmo recurso "Coeficiente Cepstral de Perceptiva Linear Preditiva (PLPCC)" e o(s) recurso(s) adicional(s) acima mencionado (s), por exemplo, o(s) recurso (s) da característica (s) do tom. Além do mais, o classificador de longo prazo pode explorar diferentes características do recurso compartilhado, por exemplo, o PLPCCs, tem como acesso uma janela de observação mais longa. Assim, a combinação dos resultados de curto e longo prazo, os recursos de curto prazo são considerados suficientemente para a classificação, por exemplo, suas propriedades são suficientemente exploradas. Abaixo uma materialização para os respectivos classificadores 150 e 154 serão descritos de um modo mais detalhado. Os recursos de curto prazo analisados pelo classificador de curto prazo de acordo com esta materialização corresponde principalmente ao Coeficiente Cepstral de Perceptiva Linear Preditiva (PLPCCs) mencionado acima. Os PLPCCs são amplamente usados na fala e no reconhecimento da fala assim como OS”*MFCCs (ver acima) . Os PLPCCs são retidos uma vez que eles compartilham uma grande parte da funcionalidade da Linear Preditiva (LP) .que é usado no mais moderno codificador de fa±a e assim implementado. em_.um. codificador de áudio—ligado-.— O PLPCCs pode extrair a estrutura de formantes da fala como o LP faz, mas levando em conta as considerações perceptivas, o PLPCCs tem mais falantes independentes e portanto, mais relevantes relativos a informação linguística. Uma ordem de 16 é usada na amostra do sinal de entrada de 16 kHz.
Além dos PLPCCs, uma força de vozeamento é calculada como um recurso de curto prazo. A força de vozeamento não é considerado para realmente ser discriminada por si, mas é benéfico na associação com a PLPCCs na dimensão de recursos. A força de vozeamento permite atrair a dimensão de recurso pelo menos, dois grupos correspondentes, respectivamente, para pronuncias de fala de vozeamento e não vozeadas. É baseado em um calculo de mérito usando diferentes Parâmetros, isto é um Contador de cruzamento por zero, inclinação espectral (tilt), a estabilidade do tom (ps) , e a correlação normalizada di tom (nc) .
Todos os quatro parâmetros são normalizados entre 0 e 1 de maneira que o 0 corresponda ao sinal não sonoro e 1 corresponda a um sinal tipicamente sonoro. Nesta materialização a força de vozeamento é inspirado nos critérios de classificação de fala utilizados no VMR-WB codificador de fala descrito por Milan Jelinek e Redwan Salami, "Wideband speech coding advances in vmr-wb standard," IEEE Trans, on Audio, Speech and Language Processing, vol. 15, no. 4, pp. 1167-1179, maio de 2007. É baseado em um evolução do rastreador de tom baseado na auto-correlação. Para o indice de estrutura k a força dè vozeamento u(k) tern a forma abaixo: A capacidade de discriminação de recursos de curto prazo é avaliada pela Gaussian Mixture Models (GMMS) como um classificador. Dois GMMs, um para a classe de fala e outro para a classe de música, são aplicados. Um número de mesclas são feitas apresentando variações a fim de avaliar o efeito no desempenho. A tabela Imostra a taxa de precisão pás os diferentes números de mesclas. Uma decisão é calculada para cada segmento de quatro estruturas sucessivas. O atraso total é então igual a 64ms que é adequado para um codificador comutado de áudio. Pode ser observado que o desempenho aumenta com o número de mesclas. O intervalo entre 1-GMMs e 5-GMMs é particularmente importante e pode ser explicado pelo fato de que a representação dos formantes da fala é muito complexa para ser suficientemente definida somente por um gaussiano.
A capacidade de discriminação de recursos de curto prazo é avaliada pela Gaussian Mixture Models (GMMS) como um classificador. Dois GMMs, um para a classe de fala e outro para a classe de música, são aplicados. Um número de mesclas são feitas apresentando variações a fim de avaliar o efeito no desempenho. A tabela Imostra a taxa de precisão pás os diferentes números de mesclas. Uma decisão é calculada para cada segmento de quatro estruturas sucessivas. O atraso total é então igual a 64ms que é adequado para um codificador comutado de áudio. Pode ser observado que o desempenho aumenta com o número de mesclas. O intervalo entre 1-GMMs e 5-GMMs é particularmente importante e pode ser explicado pelo fato de que a representação dos formantes da fala é muito complexa para ser suficientemente definida somente por um gaussiano. Tabela 1: % de precisão da classificação de recursos de curto prazo Retorne para o classificador de longo prazo 154, é observado que vários trabalhos, por exemplo, M. J. Carey, et. al. "A comparison of features for speech and music discrimination," Proc. IEEE Int. Conf. Acoustics, Speech and Signal Processing, ICASSP, vol. 12, pp. 149 a 152, março de 1999, considera que as variações dos recursos de estatística são mais exigentes do que os próprios recursos. Como uma regra geral, a música pode ser considerada mais fixo e geralmente exibir uma _ va_riação_baixa .„ De modo contrario,- a fala pode ser- facilmente * distinguida pela sua excelente energia de modulação -de 4-Hz—como-o sinal que altera periodicamente entre um segmento sonoro e não sonoro. Além disso a sucessão de diferentes fonemas faz o recurso da fala ser menos constante. Nesta materialização, os dois recursos de longo prazo são considerados, um baseado em um cálculo da variância e o outro baseado um conhecimento priori da entonação da fala. Os recursos de longo prazo são adaptados para o atraso baixo SMD (discriminação de fala/música). A variação de movimento dos PLPCCs consiste da variação do calculo para cada conjunto de PLPCCs sobre uma janela de analise de sobreposição cobrindo varias estruturas a fim de enfatizar a ultima estrutura. Para limitar a latência introduzida, 25 a janela de analise é assimétrica e considera somente a estrutura atual e o histórico anterior. Em um primeiro etapa, a média em movimento mam(k) dos PLPCCs é calculada sobre a ultima estrutura N como descrita a seguir:
Tabela 1: % de precisão da classificação de recursos de curto prazo Retorne para o classificador de longo prazo 154, é observado que vários trabalhos, por exemplo, M. J. Carey, et. al. "A comparison of features for speech and music discrimination," Proc. IEEE Int. Conf. Acoustics, Speech and Signal Processing, ICASSP, vol. 12, pp. 149 a 152, março de 1999, considera que as variações dos recursos de estatística são mais exigentes do que os próprios recursos. Como uma regra geral, a música pode ser considerada mais fixo e geralmente exibir uma _ va_riação_baixa .„ De modo contrario,- a fala pode ser- facilmente * distinguida pela sua excelente energia de modulação -de 4-Hz—como-o sinal que altera periodicamente entre um segmento sonoro e não sonoro. Além disso a sucessão de diferentes fonemas faz o recurso da fala ser menos constante. Nesta materialização, os dois recursos de longo prazo são considerados, um baseado em um cálculo da variância e o outro baseado um conhecimento priori da entonação da fala. Os recursos de longo prazo são adaptados para o atraso baixo SMD (discriminação de fala/música). A variação de movimento dos PLPCCs consiste da variação do calculo para cada conjunto de PLPCCs sobre uma janela de analise de sobreposição cobrindo varias estruturas a fim de enfatizar a ultima estrutura. Para limitar a latência introduzida, 25 a janela de analise é assimétrica e considera somente a estrutura atual e o histórico anterior. Em um primeiro etapa, a média em movimento mam(k) dos PLPCCs é calculada sobre a ultima estrutura N como descrita a seguir: onde o PLPm(k) o coeficiente cepstral mth sobre um total dos coeficientes M vindo da estrutura kth. A variação de movimento mvm(k) é então definida como:
onde o PLPm(k) o coeficiente cepstral mth sobre um total dos coeficientes M vindo da estrutura kth. A variação de movimento mvm(k) é então definida como: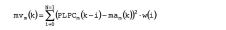 onde w é a uma janela de comprimento N que 10 esta nesta materialização uma inclinação de rampa definida da _ _sequinte_forma:w(i) = (N-i) /N-(N + 1) /2 A variação de movimento é _ finalmente calculada sobreadimensãocepstral:
onde w é a uma janela de comprimento N que 10 esta nesta materialização uma inclinação de rampa definida da _ _sequinte_forma:w(i) = (N-i) /N-(N + 1) /2 A variação de movimento é _ finalmente calculada sobreadimensãocepstral: O tom da fala possui propriedade excelente e parte deles pode somente ser observados na janela longa de analise. Realmente o tom de voz é suavemente instável durante os segmentos sonoros, mas raramente é constante. De modo contrario, a 20 música exibe muito frequentemente o tom constante durante toda a duração de uma nota e altera repentinamente durantes os transientes. Os recursos de longo prazo abrangem esta característica observando a entonação em um segmento de longo período. Um parâmetro de entonação pc(k) é definido como:
O tom da fala possui propriedade excelente e parte deles pode somente ser observados na janela longa de analise. Realmente o tom de voz é suavemente instável durante os segmentos sonoros, mas raramente é constante. De modo contrario, a 20 música exibe muito frequentemente o tom constante durante toda a duração de uma nota e altera repentinamente durantes os transientes. Os recursos de longo prazo abrangem esta característica observando a entonação em um segmento de longo período. Um parâmetro de entonação pc(k) é definido como: onde p(k) é o atraso de tom calculado no indice da estrutura k na amostra de sinal residual LP em 16Hz. A partir do parâmetro de entonação, um mérito da fala, sm(k), é calculado de modo que é esperado que a fala mostre um atraso de tom suavemente instável durante os segmentos sonoros e uma forte inclinação espectral diante de altas frequências durantes os segmentos não sonoros:
onde p(k) é o atraso de tom calculado no indice da estrutura k na amostra de sinal residual LP em 16Hz. A partir do parâmetro de entonação, um mérito da fala, sm(k), é calculado de modo que é esperado que a fala mostre um atraso de tom suavemente instável durante os segmentos sonoros e uma forte inclinação espectral diante de altas frequências durantes os segmentos não sonoros: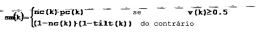 onde nc(k), inclinação(k) , e v(k) são definidos como acima (ver o classificador de curto prazo) . O mérito da fala é medido então pela janela w definida acima e integrada sobre as últimas estruturas N:
onde nc(k), inclinação(k) , e v(k) são definidos como acima (ver o classificador de curto prazo) . O mérito da fala é medido então pela janela w definida acima e integrada sobre as últimas estruturas N: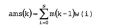 A entonação é também uma indicação importante de que o sinal é adequado para um codificador de fala ou áudio.
A entonação é também uma indicação importante de que o sinal é adequado para um codificador de fala ou áudio.
Realmente os codificadores de fala trabalham principalmente no dominio de tempo e fazem a suposição de que o sinal é harmônico e quasi-estacionários nos segmentos de tempo de cerca de 5ms. Desta forma eles podem modelar eficientemente a flutuação do tom natural da fala. De modo contrario, a mesma flutuação prejudica a eficiência geral dos codificadores de áudio que exploram as transformações lineares na janela longa de analise. A energia principal do sinal é então espalhada sobre vários coeficientes de transformada.
Tanto os recursos de curto prazo quanto os recursos de longo prazo são avaliados usando um classificador 5 estatístico obtendo assim o resultado de classificação de longo prazo (DDC). Os dois recursos são calculados usando as estruturas N = 25 estruturas, por exemplo, considerando o 400 ms do histórico anterior de um sinal. Uma Analise de Discriminantes Lineares (LDA) é primeiramente aplicado usando 3-GMMs no espaço reduzido unidimensional. A tabela 2 mostra o desempenho medido no treinamento e o conjunto de teste quando os segmentos classificados para as quatro estruturas sucessivas. Tabela 2: de precisão da classificação de recursos de longo prazo Os sistemas de classificadores combinados de acordo com a materialização da invenção combina apropriadamente os recursos de curto e longo prazo de modo que eles trazem sua contribuição especifica para a decisão final. Para este propósito um estágio decisão final de histerese como descrito acima pode ser usado, onde o efeito de memória é direcionado pelo DDC ou o indicio discriminante de longo prazo (LTDC) enquanto a saida imediata vem do IDC ou do indício discriminante de curto prazo (STDC). As duas dicas são saídas dos classificadores de longo e curto prazo como ilustrado na Fig. 1. A decisão é tomada com base no IDC mas é estabilizada pelo DDC que controla dinamicamente os limites que determinam uma mudança de estado.
Tabela 2: de precisão da classificação de recursos de longo prazo Os sistemas de classificadores combinados de acordo com a materialização da invenção combina apropriadamente os recursos de curto e longo prazo de modo que eles trazem sua contribuição especifica para a decisão final. Para este propósito um estágio decisão final de histerese como descrito acima pode ser usado, onde o efeito de memória é direcionado pelo DDC ou o indicio discriminante de longo prazo (LTDC) enquanto a saida imediata vem do IDC ou do indício discriminante de curto prazo (STDC). As duas dicas são saídas dos classificadores de longo e curto prazo como ilustrado na Fig. 1. A decisão é tomada com base no IDC mas é estabilizada pelo DDC que controla dinamicamente os limites que determinam uma mudança de estado.
O Classificador de longo prazo 154 usa ambos os recursos de longo e curto prazo anteriormente definidos com um LDA 5 seguido por 3-GMMs. O DDC é igual a proporção logarítmica de classificador de longo prazo semelhante a classe de fala e a classe de musica calculada obre a ultima estrutura 4 X K. O numero das estruturas levadas em conta pode variar com o parâmetro K a fim de adicional mais ou menos efeito de memória na decisão final. De modo contrario, o classificador de curto prazo utiliza somente recursos de curto prazo com os 5-GMMs que mostram um bom compromisso entre o desempenho e complexidade. O IDC é igual a = * proporção logarítmica do classificador de curto prazo semelhante a classe de fala e a classe de musica calculada somente sobre as 15^ ultimas 4 estruturas. „ _ _ — — — A fim de avaliar a abordagem bnvent-i-va-,- especialmente par um codificador comutado de áudio, três diferentes tipos de desempenho foram avaliados. Uma primeira medição de desempenho e a fala convencional contra o desempenho da musica (SvM). É avaliado em mais de um grande conjunto de musicas e itens de fala. Uma segunda medição de desempenho é feita com um grande e único item que possui segmentos de fala e musica alternando a cada 3 segundos. A precisão de discriminação é então chamada de desempenho fala antes/depois da musica (SabM) e reflete principalmente a reatividade do sistema Finalmente, a estabilidade da decisão é avaliada pelo desempenho da classificação em um grande conjunto de musicas e itens de fala. A mescla entre fala e musica é feito em niveis diferentes a partir de um item para outro. O desempenho da fala sobre a musica (SoM) é então obtido pelo calculo da proporção da comutação de classe de numero que ocorrem sobre o numero total de estruturas.
O classificador de longo e curto prazo são usados como referencias para avaliação da abordagem do classificador simples convencional. O classificador de curto prazo mostra uma boa reatividade quando tem baixa estabilidade e a capacidade de discriminação em geral. Por outro lado, o classificador de longo prazo, especialmente por meio do aumento do número de estruturas 4 X K, pode alcançar uma melhor estabilidade e comportamento discriminatório por comprometer a reatividade da decisão. Quando comparado com a abordagem convencional que acabamos de mencionar, o-desempenho" do” sistema classificador combinado de acordo com a invenção tem várias vantagens. Uma vantagem é que ele mantém uma boa fala pura contra jim —desempenho- de -discriminação de- música enquanto preserva a .reatividade _dç>- .sistema—. Uma outra—vantagem -é-a— boa troca entre reatividade e estabilidade.
No seguinte, a referencia é feita para as Figs. 4 e 5 ilustrando os esquemas de codificação e decodificação exemplar que incluem um a discriminador ou estágio de decisão operando de acordo com uma materialização da invenção. De acordo com os esquemas de codificação exemplar na Fig. 4 um sinal mono, um sinal estéreo ou um sinal multicanal sinal é a entrada em um estágio de pré-processamento comum 200.
O estágio de pré-processamento comum 200 pode ter uma funcionalidade joint stereo, uma funcionalidade surround, e/ou uma funcionalidade de extensão de largura de banda. Na saida de estágio 200 existe um canal mono, um canal estéreo ou canais múltiplos que é a saída de entrada em um ou mais comutadores 202. O comutador 202 pode ser fornecido para cada saida de estágio 200, quanto o estágio 200 possui duas ou mais saidas, por exemplo, quando as saidas do estágio 200 possuem um sinal estéreo ou um sinal de multicanal. De modo exemplar, o primeiro canal de um sinal estéreo pode ser um canal de fala e o segundo canal de um sinal estéreo pode ser um canal de musica. Neste caso, a decisão em um estágio de decisão 204 pode ser diferente entre os dois canais ao mesmo tempo.
O comutador 202 é controlado pelo estágio de decisão 204. 0 estágio de decisão é composto com um discriminador de acordo com uma materialização da invenção e recebe, como um - — sinal- de- entrada,” um* sinal” dentro do estágio 200 ou um sinal de saida pelo estágio 200. De forma alternativa, o estágio de decisão 204 pode também receber uma informação^ secundaria .que. é .incluída no sinal mono, no sinal estéreo ou no sinal multicanal ou é pelo menos, associada com tal sinal, onde a informação é existente, que esta, por exemplo, gerada quando inicialmente é produzido o sinal mono, o sinal estéreo ou o sinal multicanal. Em uma materialização, o estágio de decisão não controla o estágio de pré-processamento 200, e a seta entre o estágio 204 e 200 não existe. Em outra materialização, o processo no estágio 200 é controlado até um certo grau pelo estágio de decisão 204 a fim de definir um ou mais parâmetros no estágio 200 com base na decisão. Isto, porém não influencia o algoritmo geral de 200 estágio de modo que as principais funcionalidades do estágio 200 está ativa, independentemente da decisão no estágio 204.
O estágio de decisão 204 aciona o comutador 202 a fim de alimentar a saida do estágio de pré-processamento comum ou em uma porção de codificação de frequência 206 ilustrada na seção superior da Fig. 4 ou um dominio LPC- codificando a porção 208 ilustrada na seção inferior da Fig. 4.
Em uma materialização, o comutador 202 altera em duas seções codificadas 206, 208. Em outra materialização, pode existir seções codificadas adicionais com uma terceira seções codificadas, ou uma quarta seções codificadas ou até mesmo muitas seções codificadas. Em uma materialização com três seções codificadas, a terceira seções codificadas pode ser idêntica a segunda seções codificadas, mas inclui uma codificação de -excitação~diferentes pafã“ a” codificação de excitação 210 na segunda seção 208 . Tal como a materialização, a segunda seção abrange O LPC estágio 2_12 e o .codebook’ é baseado no codi-ficador de excitação 210 tal como. no.. ACELP, e a terceira seção abrange um — estágio LPC e um codificador de excitação operando a representação do sinal de saída do estágio.
A frequência de domínio da secção de codificação abrange um bloco de conversão espectral 214 que é operativo para converter o sinal de saída do estágio de pré-processamento comum dentro do domínio do espectro. 0 bloco de conversão espectral pode incluir um algoritmo MDCT, um QMF e um algoritmo FFT, a analise de Wavelet ou um banco de filtro, tal como os bancos de filtro criticamente amostrados possui um certo numero de canais de banco de filtro, onde o sinal de sub-banda neste banco de filtro pode ser o sinal real valorizado ou o sinal complexo valorizados. A saída do bloco de conversão espectral 214 é codificada usando um codificador de áudio espectral 216, que pode incluir blocos de processamento tal como é conhecido a partir do esquema de codificação AAC.
A seção codificada baixa 208 é composta de um analisador de modelo de origem como LPC 212, que gera dois tipos de sinais. Um sinal é um sinal de informação LPC, que é usado para controlar a característica do filtro de síntese filtro sintetizador LPC. Esta informação LPC é transmitida por um decodificador. O outro sinal de entrada o do estágio 212 LPC é um sinal de excitação ou um sinal de domínio LPC, que é de entrada em um codificador de excitação 210. O codificador de excitação 210 pode vir de qualquer codificador modelo fonte-filtro como um — codificador - CELP,“ 'um “ cõdificador* ÂCELP ou qualquer outro codificador, que processa um sinal de domínio LPC.
Outra implementação do codificador de excitação- pode ser uma codificação de transformada do. sinal _de .excitação-. Em tal materialização, o sinal de excitação não é codificado usando um mecanismo de codebook ACELP, mas o sinal de excitação é convertido em uma representação espectral e os valores representação espectral tais como sinais de sub-bandas em caso de banco de filtro ou coeficientes de frequência no caso de uma transformação como uma FFT são codificados para obter uma compressão de dados. Uma implementação deste tipo de codificador de excitação é o modo de codificação conhecido como AMR-WB+.
A decisão no estágio de decisão 204 pode ser um sinal adaptativo de modo que o estágio de decisão 204 desenvolve uma discriminação da musica/fala e controla o comutador 202 de tal modo que os sinais de música estão inseridos na seção superior 206, e os sinais de fala são inseridos na seção inferior 208. Em uma materialização, o estágio de 204 abastece suas informações de decisão em um fluxo de bits de saida, de modo que um decodificador pode usar essa informação de decisão, a fim de executar as 5 operações de decodificação correta. Tais um decodificador é ilustrado na Fig. 5. Após a transmissão, o sinal de saida do codificador de áudio espectral 216 é a entrada em um decodificador espectral de áudio 218. A saida do decodificador de áudio espectral 218 é a entrada em um 10 conversor de dominio do tempo 220. A saida do codificador de excitação 210 da Fig. 4 é de entrada em um decodificador de excitação 222, que gera um sinal de dominio LPC. O sinal de - -dominio LPC é a^entrada“em um eTstágio de sintese LPC 224, que recebe, como uma entrada, as informações LPC geradas pela analise 15 de estágio 212 correspondente .^ A s_aida. do_.conversor de dominio- do - tempo 220 e/ou a saida do estágio, de síntese LPC.. 2.2A~ é_ a entrada em um comutador 226. O comutador 226 é controlado por meio de um sinal de controle do comutador, que foi, por exemplo, gerado pelo estágio de decisão 204, ou que tenham sido fornecidos 20 externamente, como por um criador do sinal mono original, sinal estéreo ou sinal multicanal. A saida do comutador 226 é um sinal mono completo que é subsequentemente a entrada em um estágio de pós- processamento de 228, o que pode realizar um processamento joint 25 stereo ou uma extensão da largura de banda, etc. De modo alternativo a saida do comutador também pode ser um sinal estéreo ou um sinal multicanal. É um sinal estéreo, quando o pré- processamento inclui um canal de redução para dois canais. Pode até ser um sinal de multicanal, quando uma redução de canal para três canais ou nenhuma redução de canal em todos, mas somente uma replicação de faixa espectral é realizada.
Dependendo das funcionalidades específicas do estágio de pós-processamento comum, um sinal mono, um sinal estéreo ou um sinal de multicanal é emitido, que tem, quando o estágio de pós-processamento 228 executa uma operação de extensão de banda larga, uma largura de banda maior do que o sinal de entrada no bloco 228.
Em uma materialização, o comutador 226 alterna entre as duas seções de decodif icação 218, 220 e 222, 224. Em outra materialização, pode haver outras seções de decodificação adicionais, como“uma~tèfCeirã seção He decodificação, ou mesmo uma quarta seção de decodificação ou até mesmo mais seções de decodificação. Em uma _ materialização_ com „três seções -de decodif icação, a terceira seção de decodif icaçã.o_ pode ser— semelhante a segunda seção de decodificação, mas inclui um decodificador de excitação diferente do decodificador excitação 222 segunda seção 222, 224. Em tal materialização, segunda seção composta de um estágio LPC 224 e um codebook com base no decodificador de excitação como em um ACELP, e a terceira seção composta de um estádio LPC e um decodificador de excitação operando uma representação espectral do sinal de saída do estágio 224 LPC fase.
Em outra materialização, o estágio de pré- processamento comum composto de um bloco surround/estéreo, que gera, como saída, os parâmetros joint stereo e um sinal de saída mono, que é gerado pelo downmixing do sinal de entrada, que é um sinal que possui dois ou mais canais. Normalmente, o sinal de saída do bloco pode também pode ser um sinal de que possui mais canais, mas devido à operação downmixing, o número de canais para a saída do bloco será menor do que o número de canais de entrada no bloco. Nesta materialização, a seção de codificação de frequência composta de um estágio de conversão de espectro e um estágio de quantização/codificação subsequentemente conectadas. O estágio de quantização/codificação pode incluir qualquer das funcionalidades como é conhecido desde os modernos codificadores no domínio da frequência, como o codificador AAC. Além disso, a operação do estágio de quantização/codificação pode ser controlada por meio de um módulo de psicoacústica, que gera informações psicoacústicas, como um mascaramento psicoacústico do limite sobre a frequência, onde essa informação é a entrada no estágio. De —preferência, a conversão espectral—é-feita usando—uma . operação de— —MDCT queT prefe-rencialmente,. é a operação MDCT time-warped,_ onde a força ou, em geral, a força de deformação pode ser controlada entre zero e uma alta força de deformação. Em uma força deformação zero, a operação de MDCT é uma operação de MDCT direta conhecido na arte. O codificador de domínio LPC pode incluir um núcleo ACELP cálculo de um ganho de tom, com defasagem de tome/ou as informações do codebook como um índice de codebook e um ganho de código. Embora algumas das figuras ilustrem os blocos de diagramas de um aparelho, é de observado que estas figuras, ao mesmo tempo, ilustrando um método, no qual as funcionalidades do bloco correspondente para os estágios do método. A materialização da invenção foi descrita acima com base em um sinal de saída de áudio composto de diferentes segmentos ou estruturas, os diferentes segmentos ou estruturas sendo associados com a informação da fala ou da musica. A invenção não se limita a tais materializações, ao contrário, a abordagem para a classificação de diferentes segmentos de um sinal composto de pelo menos, segmentos de tipo um primeiro e um segundo tipo, também pode ser aplicado a sinais de áudio composto por três ou mais tipos de segmentos diferentes, cada qual se deseja ser codificado por diferentes esquemas de codificação. Os exemplos de tipos de segmento, são: Segmentos estacionários/não-estacionários podem ser úteis para o uso de diferente bancos de filtro, janelas ou adaptação de codificação. Por exemplo, uma transitória deve ser codificada com um banco de filtro de resolução de tempo adequada, enquanto uma senóide pura deve ser codificado com um banco de filtro de resolução de frequência adequado Sonoro/não sonoro: os segmentos sonoros são bem tratados pelo codificador CELP, mas para segmentos não sonoros muitos bits são desperdiçados A codificação paramétrica será mais eficiente. Silencioso/ativado: o segmento silencioso pode ser codificado com menos bits que o segmento ativado.
Harmônico/não-harmônico: Será útil para a utilização da codificação segmentos harmônicos usando uma linear preditiva no dominio da frequência. Além disso, a invenção não se limita ao campo das técnicas de áudio, em vez disso, a abordagem descrita acima para a classificação de um sinal pode ser aplicada a outros tipos de sinais, como os sinais de video ou dados, onde esses respectivos sinais incluem segmentos de tipos diferentes, que exigem um processamento diferente como, por exemplo:
A presente invenção pode ser adaptada para todas as aplicações em tempo real que precisam de uma segmentação de um sinal de tempo. Por exemplo, a detecção do rosto a partir de uma câmera de video de vigilância pode ser baseado em um classificador que determina para cada pixel de um quadro (aqui um quadro corresponde a uma foto tirada em um tempo n) se ele pertence ao rosto de uma pessoa ou não. A classificação (ou seja, a segmentação do rosto) deve ser feita para cada quadros simples do fluxo de video. No entanto, usando a presente invenção, a segmentação "Ho quadro- atual pode levar em conta os sucessivos quadros anteriores para obter uma precisão melhor segmentação tendo a vantagem de.„que as ..imagens .sucessivas estão—fortemente correlacionados. Os dois clas_s.ificado.res podem ser então - - aplicadas. Um considerando apenas o quadro atual e outro considerando um conjunto de quadros, incluindo o quadro atual e anterior. O último classificador pode integrar o conjunto de quadros e determinar a região de probabilidade para a posição do rosto. A decisão do classificador feito apenas sobre o quadro atual, será então comparada com as regiões de probabilidade. A decisão pode ser validada ou modificada. A materialização da invenção usa o comutador pra alterar entre as seções de modo que somente uma seção receba um sinal a ser processado e a outra seção não receba o sinal. Em uma materialização alternativa, entretanto, o comutador pode também ser organizado depois do estágio de processamento ou seções, por exemplo, o codificador de áudio e de fala, de modo que ambas as seções processam o mesmo sinal em paralelo. A entrada de sinal por uma dessas seções é escolhida para ser a saida, por exemplo, a ser escrito em um fluxo continuo de saida.
Enquanto a materialização da invenção foi descrita com base nos sinais digitais, os segmentos dos quais foram determinados por um número predefinido de amostras obtidos na mesma taxa de amostragem especifica, a invenção não é limitada para tais sinais, especialmente, também é aplicada a sinais analógicos nos quais o segmento deveria então ser determinado por um alcance especifico de frequência ou periodo de tempo do sinal analógico. Além disso, a materialização da invenção foi descrita em combinação com codificadores incluindo o discriminador. É observado que, basicamente, a abordagem de acordo com uma materialização . da invenção para, classificação ...de sinais pode também ser aplicada a _ deç.od.ifica_dox_e_s__r_e_G.e.b_end.Q__um sinal codificado para que diferentes esquemas codificados possam ser classificados, permitindo assim que o sinal codificado para ser fornecido a um decodificador apropriado.
Dependendo dos requisitos de implementação de alguns dos métodos criativos, os métodos inventivos possam ser implementados em hardware ou software. A aplicação pode ser realizada utilizando um meio de armazenamento digital, em particular, um disco, um DVD ou um CD com controlo eletrônico de leitura de sinais nele armazenados, que co-operam com sistemas de computador programáveis de tal forma que os métodos inventivos são executadas. Normalmente, a presente invenção é, portanto, um produto de programa de computador com um código de programa armazenado em um portador de leitura de máquina, o código do programa que está sendo operado para a realização dos métodos criativos quando o produto de programa de computador é executado em um computador. Em outras palavras, os métodos criativos são, portanto, um programa de computador com um código de programa para realizar pelo menos um dos métodos criativos quando o programa de computador é executado em um computador.
A materialização descrita acima são meramente ilustrativas para os princípios da atual invenção. É entendido que as modificações e variações da disposição e os detalhes descritos neste documento será aparente para os outros qualificados na arte.
É a intenção, portanto, ser limitada somente pelo escopo das reivindicações da iminente patente e não com os detalhes específicos, apresentados por meio da descrição e explicação das .encarnações neste dommentn — - Na .materialização acima, o sinal é descrito como composto de uma pluralidade estruturas, onde uma estrutura atual é avaliada por uma decisão de comutação. É observado que o segmento atual do sinal que é avaliado por uma decisão de comutação pode ser uma estrutura, entretanto, a invenção não é limitada a tais materializações. Além disso, um segmento do sinal pode ser composto de uma pluralidade, por exemplo, duas ou mais estruturas.
Além disso, na descrição acima a materialização do classificador de curto prazo e do classificador de longo prazo usando o mesmo recurso(s) de curto prazo. Esta abordagem pode ser usada para diferentes motivos, como a necessidade de calcular os recursos de curto prazo somente uma vez, para explorar o mesmo por dois classificadores de formas diferentes ó que irá reduzir a complexidade do sistema, como por exemplo, o recurso de curto prazo pode ser calculado por um dos classificadores curto prazo ou de longo prazo e fornecidos por outro classificador. Também, a comparação entre os resultados do classificador de curto prazo e 5 do longo prazo pode ser mais relevante do que a contribuição para da estrutura atual no resultado de classificação de longo prazo é mais facilmente deduzida pela comparação com o resultado de classificação de curto prazo uma vez que os classificadores compartilham recursos comuns. A invenção é, entretanto, não é restrita a tal abordagem e o classificador de longo prazo não é restrito para usar o recurso (s) de curto prazo como classificador de curto prazo, por exemplo, tanto o classificador de curto prazo e classificador de longo prazo pode calcular seu respectivo recurso (s) de curto prazo que é diferente para.cada=um... .. -- - __Enqu-anto_ uma. materialização - descrita acima mencionou o uso de PLPCCs como recurso de curto prazo, é observado que outros recursos podem ser considerados, por exemplo, a variabilidade do PLPCCs.
Claims (16)
1. "MÉTODO E DISCRIMINADOR PARA A CLASSIFICAÇÃO DE DIFERENTES SEGMENTOS DE UM SINAL DE AÚDIO", caracterizado pelo sinal de áudio compreender segmento de fala e segmento de música e o método compreender: Classificação de curto prazo por um classificador de curto prazo (150), o sinal de áudio usando pelo menos um recurso de curto prazo e pelo menos um recurso de longo prazo extraidos do sinal de áudio e entregam um resultado de classificação de longo prazo (156), e aplicação de resultado de classificação de curto prazo e do resultado de classificação de longo prazo a um circuito de decisão (158) acoplado a uma saida do classificador de curto prazo (150) e a uma saida do classificador de longo prazo (154), o circuito de decisão (158) combinando o resultado de classificação de curto prazo (152) e a classificação de longo prazo (156) para fornecer um sinal de saida (160), que indica se o segmento atual do sinal de áudio é um segmento de fala ou de um segmento de música.
2. Método, de acordo com a reivindicação 1, caracterizado pela etapa de combinação compreender em fornecer o sinal de saida como base em uma comparação do resultado da classificação de curto prazo (152) para o resultado da classificação de longo prazo (156).
3. Método, de acordo com a reivindicação 1 ou 2, caracterizado por compreender: pelo menos, um recurso de curto prazo é obtido através da análise de um segmento atual do sinal de áudio que deve ser classificado; e pelo menos, um recurso de longo prazo é obtido através da análise de um segmento atual do sinal de áudio e um ou mais segmentos anteriores do sinal de áudio.
4. Método, de acordo com uma das reivindicações 1 a 3, caracterizado por compreender: pelo menos, um recurso de curto prazo é obtido através da janela de análise (168) de um primeiro comprimento e um método de primeira análise; e pelo menos, um recurso de longo prazo é obtido através da janela de análise (162) de um segundo comprimento e um método de segunda análise, o primeiro comprimento sendo mais curto que o segundo comprimento, e os métodos da primeira e segunda análise sendo diferentes.
5. Método da reivindicação 4, caracterizado pelo primeiro comprimento transpor um segmento atual do sinal de áudio, o segundo comprimento transpõe o segmento atual do sinal de áudio e um ou mais segmentos anteriores do sinal de áudio, e os primeiro e segundo comprimentos abrange um periodo adicional (164), cobrindo um periodo de análise.
6. Método, de acordo com uma das reivindicações 1 a 5, caracterizado por combinar o resultado da classificação de curto prazo (152) e o resultado da classificação de longo prazo (156), compreendendo uma decisão de histerese com base no resultado combinado, onde o resultado combinado inclui o resultado da classificação de curto prazo (152) e o resultado de classificação de longo prazo (156), cada ponderado por um fator de ponderação predeterminado.
7. Método, de acordo com uma das reivindicações 1 a 6, caracterizado pelo sinal de áudio ser um sinal digital e um segmento do sinal de áudio compreende como número predeterminado das amostras obtidas em uma taxa de amostragem especifica.
8. Método, de acordo com uma das reivindicações 1 a 7, caracterizado por: pelo menos, um recurso de curto prazo abrange os parâmetros PLPCCs; e pelo menos, um recurso de longo prazo abrange a informação da característica do tom.
9. Método, de acordo com uma das reivindicações 1 a 8, caracterizado pelo recurso de curto prazo ser utilizado pela classificação de curto prazo e o recurso de curto prazo ser utilizado pela classificação de longo prazo são as mesmas ou diferentes.
10. Método para processar um sinal de áudio compreendendo os segmentos de pelo menos de um primeiro e um segundo tipo, o método sendo caracterizado por compreender: classificação (116) de um segmento atual do sinal de áudio de acordo com o método de uma das reivindicações 1 a 9; dependente do sinal de saida (160) fornecido pela etapa de classificação (116), processamento (102, 206, 106, 208) o segmento atual de acordo com um primeiro ou um segundo processo, e saida do segmento de processado.
11. Método, de acordo com a reivindicação 10, caracterizado pelo segmento ser processado por um codificador de voz (102) quando o sinal de saida (160) indicar que o segmento é um segmento de fala; e o segmento é processado por um codificador de música (106) quando o sinal de saida (160) indicar que o segmento é um segmento de música.
12. Método, de acordo com a reivindicação 11, caracterizado por compreender ainda: combinação (108) do codificador de segmento e informação para o sinal de saida (160) indicando o tipo de segmento.
13. Discriminador, caracterizado por compreender: um classificador de curto prazo (150) configurado para receber um sinal de áudio e fornecer o resultado da classificação de curto prazo (152) do sinal de áudio usando apenas um recurso de curto prazo extraido do sinal de áudio, o sinal de áudio compreendendo segmentos de fala e de música; um classificador de longo prazo (154) configurado para receber um sinal de áudio e fornecer o resultado da classificação de longo prazo (156) do sinal de áudio usando pelo menos um recurso de curto prazo e pelo menos um recurso de longo prazo extraidos do sinal de áudio; e um circuito de decisão (158), acoplado a uma saida do classificador de curto prazo (150) e a uma saida do classificador de longo prazo (154), para receber o resultado de classificação de curto prazo (152) e o resultado de classificação de longo prazo (156), o circuito de decisão (158) sendo configurado para combinar o resultado de classificação de curto prazo (152) e o resultado de classificação de longo prazo (156) para fornecer um sinal de saida (160), que indica se o segmento atual do sinal de áudio é um segmento de fala ou de um segmento de música.
14. Discriminador, de acordo com a reivindicação 13, caracterizado pelo circuito de decisão (158) configurado para fornecer o sinal de saida com base em uma comparação do resultado da classificação de curto prazo (152) para o resultado da classificação de longo prazo (156).
15. Aparelho de processamento de sinal de áudio, caracterizado por compreender: uma entrada (110) configurada para receber um sinal de áudio para ser processado, onde o sinal de áudio é composto de segmentos de fala e musica; um primeiro estágio de processamento (102; 206), configurado para processar os segmentos de fala; um segundo estágio de processamento (104; 208) configurado para processar os segmentos de musica; um discriminador (116; 204) da reivindicação 14 ou 15 acoplado a entrada; e um dispositivo de comutação (112; 202) acoplado entre a entrada (110) e o primeiro e segundo estágios de processamento (102, 104; 206, 208) e configurado para aplicar o sinal de áudio da entrada (110) para um dos primeiro e segundo estágios de processamento (102, 104; 206, 208) dependente no sinal de saida (160) para o discriminador (116).
16. Codificador de áudio, caracterizado por compreender um aparelho de processamento de sinal de áudio, de acordo com a reivindicação 15.
Applications Claiming Priority (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US7987508P | 2008-07-11 | 2008-07-11 | |
| US61/079,875 | 2008-07-11 | ||
| PCT/EP2009/004339 WO2010003521A1 (en) | 2008-07-11 | 2009-06-16 | Method and discriminator for classifying different segments of a signal |
Publications (3)
| Publication Number | Publication Date |
|---|---|
| BRPI0910793A2 BRPI0910793A2 (pt) | 2016-08-02 |
| BRPI0910793B1 true BRPI0910793B1 (pt) | 2020-11-24 |
| BRPI0910793B8 BRPI0910793B8 (pt) | 2021-08-24 |
Family
ID=40851974
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| BRPI0910793A BRPI0910793B8 (pt) | 2008-07-11 | 2009-06-16 | Método e discriminador para a classificação de diferentes segmentos de um sinal |
Country Status (19)
| Country | Link |
|---|---|
| US (1) | US8571858B2 (pt) |
| EP (1) | EP2301011B1 (pt) |
| JP (1) | JP5325292B2 (pt) |
| KR (2) | KR101380297B1 (pt) |
| CN (1) | CN102089803B (pt) |
| AR (1) | AR072863A1 (pt) |
| AU (1) | AU2009267507B2 (pt) |
| BR (1) | BRPI0910793B8 (pt) |
| CA (1) | CA2730196C (pt) |
| CO (1) | CO6341505A2 (pt) |
| ES (1) | ES2684297T3 (pt) |
| MX (1) | MX2011000364A (pt) |
| MY (1) | MY153562A (pt) |
| PL (1) | PL2301011T3 (pt) |
| PT (1) | PT2301011T (pt) |
| RU (1) | RU2507609C2 (pt) |
| TW (1) | TWI441166B (pt) |
| WO (1) | WO2010003521A1 (pt) |
| ZA (1) | ZA201100088B (pt) |
Families Citing this family (48)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| PL3002750T3 (pl) * | 2008-07-11 | 2018-06-29 | Fraunhofer-Gesellschaft zur Förderung der angewandten Forschung e.V. | Koder i dekoder audio do kodowania i dekodowania próbek audio |
| CN101847412B (zh) * | 2009-03-27 | 2012-02-15 | 华为技术有限公司 | 音频信号的分类方法及装置 |
| KR101666521B1 (ko) * | 2010-01-08 | 2016-10-14 | 삼성전자 주식회사 | 입력 신호의 피치 주기 검출 방법 및 그 장치 |
| BR112013008463B8 (pt) * | 2010-10-06 | 2022-04-05 | Fraunhofer Ges Zur Foerderung Der Angewandten Forschubg E V | Aparelho e método para processar um sinal de áudio e para prover uma granularidade temporal maior para um codec de fala e áudio unificado combinado (usac) |
| US8521541B2 (en) * | 2010-11-02 | 2013-08-27 | Google Inc. | Adaptive audio transcoding |
| CN103000172A (zh) * | 2011-09-09 | 2013-03-27 | 中兴通讯股份有限公司 | 信号分类方法和装置 |
| US20130090926A1 (en) * | 2011-09-16 | 2013-04-11 | Qualcomm Incorporated | Mobile device context information using speech detection |
| EP2772914A4 (en) * | 2011-10-28 | 2015-07-15 | Panasonic Corp | DECODER FOR HYBRID SOUND SIGNALS, COORDINATORS FOR HYBRID SOUND SIGNALS, DECODING PROCEDURE FOR SOUND SIGNALS AND CODING SIGNALING PROCESSES |
| CN105163398B (zh) | 2011-11-22 | 2019-01-18 | 华为技术有限公司 | 连接建立方法和用户设备 |
| US9111531B2 (en) * | 2012-01-13 | 2015-08-18 | Qualcomm Incorporated | Multiple coding mode signal classification |
| JP5724044B2 (ja) * | 2012-02-17 | 2015-05-27 | 華為技術有限公司Huawei Technologies Co.,Ltd. | 多重チャネル・オーディオ信号の符号化のためのパラメトリック型符号化装置 |
| US20130317821A1 (en) * | 2012-05-24 | 2013-11-28 | Qualcomm Incorporated | Sparse signal detection with mismatched models |
| CN107195313B (zh) | 2012-08-31 | 2021-02-09 | 瑞典爱立信有限公司 | 用于语音活动性检测的方法和设备 |
| US9589570B2 (en) * | 2012-09-18 | 2017-03-07 | Huawei Technologies Co., Ltd. | Audio classification based on perceptual quality for low or medium bit rates |
| TWI612518B (zh) * | 2012-11-13 | 2018-01-21 | Samsung Electronics Co., Ltd. | 編碼模式決定方法、音訊編碼方法以及音訊解碼方法 |
| US9100255B2 (en) * | 2013-02-19 | 2015-08-04 | Futurewei Technologies, Inc. | Frame structure for filter bank multi-carrier (FBMC) waveforms |
| PL2959481T3 (pl) | 2013-02-20 | 2017-10-31 | Fraunhofer Ges Forschung | Urządzenie i sposób generowania zakodowanego sygnału audio lub dekodowania zakodowanego sygnału audio przy użyciu części wielozakładkowej |
| CN104347067B (zh) | 2013-08-06 | 2017-04-12 | 华为技术有限公司 | 一种音频信号分类方法和装置 |
| US9666202B2 (en) | 2013-09-10 | 2017-05-30 | Huawei Technologies Co., Ltd. | Adaptive bandwidth extension and apparatus for the same |
| KR101498113B1 (ko) * | 2013-10-23 | 2015-03-04 | 광주과학기술원 | 사운드 신호의 대역폭 확장 장치 및 방법 |
| US10090004B2 (en) * | 2014-02-24 | 2018-10-02 | Samsung Electronics Co., Ltd. | Signal classifying method and device, and audio encoding method and device using same |
| CN105096958B (zh) | 2014-04-29 | 2017-04-12 | 华为技术有限公司 | 音频编码方法及相关装置 |
| RU2765985C2 (ru) | 2014-05-15 | 2022-02-07 | Телефонактиеболагет Лм Эрикссон (Пабл) | Классификация и кодирование аудиосигналов |
| CN107424622B (zh) * | 2014-06-24 | 2020-12-25 | 华为技术有限公司 | 音频编码方法和装置 |
| US9886963B2 (en) * | 2015-04-05 | 2018-02-06 | Qualcomm Incorporated | Encoder selection |
| JP6567691B2 (ja) * | 2015-05-20 | 2019-08-28 | テレフオンアクチーボラゲット エルエム エリクソン(パブル) | マルチチャネルオーディオ信号のコード化 |
| US10706873B2 (en) * | 2015-09-18 | 2020-07-07 | Sri International | Real-time speaker state analytics platform |
| WO2017196422A1 (en) * | 2016-05-12 | 2017-11-16 | Nuance Communications, Inc. | Voice activity detection feature based on modulation-phase differences |
| US10699538B2 (en) * | 2016-07-27 | 2020-06-30 | Neosensory, Inc. | Method and system for determining and providing sensory experiences |
| WO2018048907A1 (en) | 2016-09-06 | 2018-03-15 | Neosensory, Inc. C/O Tmc+260 | Method and system for providing adjunct sensory information to a user |
| CN107895580B (zh) * | 2016-09-30 | 2021-06-01 | 华为技术有限公司 | 一种音频信号的重建方法和装置 |
| US10744058B2 (en) | 2017-04-20 | 2020-08-18 | Neosensory, Inc. | Method and system for providing information to a user |
| US10325588B2 (en) | 2017-09-28 | 2019-06-18 | International Business Machines Corporation | Acoustic feature extractor selected according to status flag of frame of acoustic signal |
| KR20210102899A (ko) | 2018-12-13 | 2021-08-20 | 돌비 레버러토리즈 라이쎈싱 코오포레이션 | 이중 종단 미디어 인텔리전스 |
| RU2761940C1 (ru) * | 2018-12-18 | 2021-12-14 | Общество С Ограниченной Ответственностью "Яндекс" | Способы и электронные устройства для идентификации пользовательского высказывания по цифровому аудиосигналу |
| US12118987B2 (en) | 2019-04-18 | 2024-10-15 | Dolby Laboratories Licensing Corporation | Dialog detector |
| CN110288983B (zh) * | 2019-06-26 | 2021-10-01 | 上海电机学院 | 一种基于机器学习的语音处理方法 |
| WO2021062276A1 (en) | 2019-09-25 | 2021-04-01 | Neosensory, Inc. | System and method for haptic stimulation |
| US11467668B2 (en) | 2019-10-21 | 2022-10-11 | Neosensory, Inc. | System and method for representing virtual object information with haptic stimulation |
| US11079854B2 (en) | 2020-01-07 | 2021-08-03 | Neosensory, Inc. | Method and system for haptic stimulation |
| WO2021207825A1 (en) * | 2020-04-16 | 2021-10-21 | Voiceage Corporation | Method and device for speech/music classification and core encoder selection in a sound codec |
| US11497675B2 (en) | 2020-10-23 | 2022-11-15 | Neosensory, Inc. | Method and system for multimodal stimulation |
| EP4275204B1 (en) * | 2021-01-08 | 2025-05-28 | VoiceAge Corporation | Method and device for unified time-domain / frequency domain coding of a sound signal |
| US11862147B2 (en) | 2021-08-13 | 2024-01-02 | Neosensory, Inc. | Method and system for enhancing the intelligibility of information for a user |
| US12272341B2 (en) * | 2021-11-08 | 2025-04-08 | Lemon Inc. | Controllable music generation |
| US11995240B2 (en) | 2021-11-16 | 2024-05-28 | Neosensory, Inc. | Method and system for conveying digital texture information to a user |
| US12300259B2 (en) | 2022-03-10 | 2025-05-13 | Roku, Inc. | Automatic classification of audio content as either primarily speech or primarily non-speech, to facilitate dynamic application of dialogue enhancement |
| CN116070174A (zh) * | 2023-03-23 | 2023-05-05 | 长沙融创智胜电子科技有限公司 | 一种多类别目标识别方法及系统 |
Family Cites Families (23)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| IT1232084B (it) * | 1989-05-03 | 1992-01-23 | Cselt Centro Studi Lab Telecom | Sistema di codifica per segnali audio a banda allargata |
| JPH0490600A (ja) * | 1990-08-03 | 1992-03-24 | Sony Corp | 音声認識装置 |
| JPH04342298A (ja) * | 1991-05-20 | 1992-11-27 | Nippon Telegr & Teleph Corp <Ntt> | 瞬時ピッチ分析方法及び有声・無声判定方法 |
| RU2049456C1 (ru) * | 1993-06-22 | 1995-12-10 | Вячеслав Алексеевич Сапрыкин | Способ передачи речевых сигналов |
| US6134518A (en) | 1997-03-04 | 2000-10-17 | International Business Machines Corporation | Digital audio signal coding using a CELP coder and a transform coder |
| JP3700890B2 (ja) * | 1997-07-09 | 2005-09-28 | ソニー株式会社 | 信号識別装置及び信号識別方法 |
| RU2132593C1 (ru) * | 1998-05-13 | 1999-06-27 | Академия управления МВД России | Многоканальное устройство для передачи речевых сигналов |
| SE0004187D0 (sv) | 2000-11-15 | 2000-11-15 | Coding Technologies Sweden Ab | Enhancing the performance of coding systems that use high frequency reconstruction methods |
| US6785645B2 (en) * | 2001-11-29 | 2004-08-31 | Microsoft Corporation | Real-time speech and music classifier |
| DE60202881T2 (de) | 2001-11-29 | 2006-01-19 | Coding Technologies Ab | Wiederherstellung von hochfrequenzkomponenten |
| AUPS270902A0 (en) * | 2002-05-31 | 2002-06-20 | Canon Kabushiki Kaisha | Robust detection and classification of objects in audio using limited training data |
| JP4348970B2 (ja) * | 2003-03-06 | 2009-10-21 | ソニー株式会社 | 情報検出装置及び方法、並びにプログラム |
| JP2004354589A (ja) * | 2003-05-28 | 2004-12-16 | Nippon Telegr & Teleph Corp <Ntt> | 音響信号判別方法、音響信号判別装置、音響信号判別プログラム |
| EP1758274A4 (en) * | 2004-06-01 | 2012-03-14 | Nec Corp | INFORMATION SUPPLY SYSTEM, PROCESS AND PROGRAM |
| US7130795B2 (en) * | 2004-07-16 | 2006-10-31 | Mindspeed Technologies, Inc. | Music detection with low-complexity pitch correlation algorithm |
| JP4587916B2 (ja) * | 2005-09-08 | 2010-11-24 | シャープ株式会社 | 音声信号判別装置、音質調整装置、コンテンツ表示装置、プログラム、及び記録媒体 |
| CN101512639B (zh) | 2006-09-13 | 2012-03-14 | 艾利森电话股份有限公司 | 用于语音/音频发送器和接收器的方法和设备 |
| CN1920947B (zh) * | 2006-09-15 | 2011-05-11 | 清华大学 | 用于低比特率音频编码的语音/音乐检测器 |
| RU2426179C2 (ru) * | 2006-10-10 | 2011-08-10 | Квэлкомм Инкорпорейтед | Способ и устройство для кодирования и декодирования аудиосигналов |
| BRPI0718738B1 (pt) * | 2006-12-12 | 2023-05-16 | Fraunhofer-Gesellschaft Zur Forderung Der Angewandten Forschung E.V. | Codificador, decodificador e métodos para codificação e decodificação de segmentos de dados representando uma corrente de dados de domínio de tempo |
| KR100964402B1 (ko) * | 2006-12-14 | 2010-06-17 | 삼성전자주식회사 | 오디오 신호의 부호화 모드 결정 방법 및 장치와 이를 이용한 오디오 신호의 부호화/복호화 방법 및 장치 |
| KR100883656B1 (ko) * | 2006-12-28 | 2009-02-18 | 삼성전자주식회사 | 오디오 신호의 분류 방법 및 장치와 이를 이용한 오디오신호의 부호화/복호화 방법 및 장치 |
| US8428949B2 (en) * | 2008-06-30 | 2013-04-23 | Waves Audio Ltd. | Apparatus and method for classification and segmentation of audio content, based on the audio signal |
-
2009
- 2009-06-16 CN CN2009801271953A patent/CN102089803B/zh active Active
- 2009-06-16 PL PL09776747T patent/PL2301011T3/pl unknown
- 2009-06-16 AU AU2009267507A patent/AU2009267507B2/en active Active
- 2009-06-16 KR KR1020137004921A patent/KR101380297B1/ko active Active
- 2009-06-16 JP JP2011516981A patent/JP5325292B2/ja active Active
- 2009-06-16 EP EP09776747.9A patent/EP2301011B1/en active Active
- 2009-06-16 CA CA2730196A patent/CA2730196C/en active Active
- 2009-06-16 ES ES09776747.9T patent/ES2684297T3/es active Active
- 2009-06-16 RU RU2011104001/08A patent/RU2507609C2/ru active
- 2009-06-16 PT PT09776747T patent/PT2301011T/pt unknown
- 2009-06-16 WO PCT/EP2009/004339 patent/WO2010003521A1/en not_active Ceased
- 2009-06-16 MX MX2011000364A patent/MX2011000364A/es active IP Right Grant
- 2009-06-16 MY MYPI2011000077A patent/MY153562A/en unknown
- 2009-06-16 KR KR1020117000628A patent/KR101281661B1/ko active Active
- 2009-06-16 BR BRPI0910793A patent/BRPI0910793B8/pt active IP Right Grant
- 2009-06-29 TW TW098121852A patent/TWI441166B/zh active
- 2009-07-07 AR ARP090102544A patent/AR072863A1/es active IP Right Grant
-
2011
- 2011-01-04 ZA ZA2011/00088A patent/ZA201100088B/en unknown
- 2011-01-07 CO CO11001544A patent/CO6341505A2/es active IP Right Grant
- 2011-01-11 US US13/004,534 patent/US8571858B2/en active Active
Also Published As
| Publication number | Publication date |
|---|---|
| KR101380297B1 (ko) | 2014-04-02 |
| KR101281661B1 (ko) | 2013-07-03 |
| CA2730196A1 (en) | 2010-01-14 |
| US8571858B2 (en) | 2013-10-29 |
| ES2684297T3 (es) | 2018-10-02 |
| EP2301011B1 (en) | 2018-07-25 |
| BRPI0910793A2 (pt) | 2016-08-02 |
| RU2507609C2 (ru) | 2014-02-20 |
| RU2011104001A (ru) | 2012-08-20 |
| AU2009267507A1 (en) | 2010-01-14 |
| US20110202337A1 (en) | 2011-08-18 |
| TWI441166B (zh) | 2014-06-11 |
| MX2011000364A (es) | 2011-02-25 |
| JP5325292B2 (ja) | 2013-10-23 |
| PL2301011T3 (pl) | 2019-03-29 |
| CN102089803A (zh) | 2011-06-08 |
| ZA201100088B (en) | 2011-08-31 |
| BRPI0910793B8 (pt) | 2021-08-24 |
| KR20110039254A (ko) | 2011-04-15 |
| AU2009267507B2 (en) | 2012-08-02 |
| EP2301011A1 (en) | 2011-03-30 |
| MY153562A (en) | 2015-02-27 |
| CO6341505A2 (es) | 2011-11-21 |
| PT2301011T (pt) | 2018-10-26 |
| TW201009813A (en) | 2010-03-01 |
| JP2011527445A (ja) | 2011-10-27 |
| HK1158804A1 (en) | 2012-07-20 |
| AR072863A1 (es) | 2010-09-29 |
| CA2730196C (en) | 2014-10-21 |
| KR20130036358A (ko) | 2013-04-11 |
| CN102089803B (zh) | 2013-02-27 |
| WO2010003521A1 (en) | 2010-01-14 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| BRPI0910793B1 (pt) | Metodo e discriminador para a classificaqao de diferentes segmentos de um sinal | |
| CN101971251B (zh) | 像言语的信号和不像言语的信号的多模式编解码方法及装置 | |
| BR112015005980B1 (pt) | Método para codificar sinais e codificador de áudio | |
| Fuchs | The effects of mp3 compression on acoustic measurements of fundamental frequency and pitch range | |
| Chelali et al. | Text dependant speaker recognition using MFCC, LPC and DWT | |
| Shahnawazuddin et al. | Developing speaker independent ASR system using limited data through prosody modification based on fuzzy classification of spectral bins | |
| Vuppala et al. | Improved consonant–vowel recognition for low bit‐rate coded speech | |
| Pulakka | Development and evaluation of artificial bandwidth extension methods for narrowband telephone speech | |
| Sankar et al. | Mel scale-based linear prediction approach to reduce the prediction filter order in CELP paradigm | |
| Sankar et al. | An investigation on the degradation of different features extracted from the compressed American English speech using narrowband and wideband codecs | |
| Gump | Unsupervised methods for evaluating speech representations | |
| US20110119067A1 (en) | Apparatus for signal state decision of audio signal | |
| Misra et al. | Analysis and extraction of LP-residual for its application in speaker verification system under uncontrolled noisy environment | |
| Kocharov et al. | Articulatory motivated acoustic features for speech recognition. | |
| Das et al. | Modeling the temporal envelope of sub-band signals for improving the performance of children’s speech recognition system in zero-resource scenario | |
| Guo | Transform Domain Long Term Prediction for Audio Coding | |
| Kolossa | Performance analysis of wavelet-based voice activity detection | |
| Hansen | Robust Speech Processing & Recognition: Speaker ID, Language ID, Speech Recognition/Keyword Spotting, Diarization/Co-Channel/Environmental Characterization, Speaker State Assessment | |
| Shao et al. | MAP prediction of pitch from MFCC vectors for speech reconstruction. | |
| Rahaman et al. | Special feature extraction techniques for Bangla speech | |
| Ismail et al. | A novel particle based approach for robust speech spectrum Vector Quantization | |
| Priyadarshani | Speaker dependent speech recognition on a selected set of sinhala words | |
| HK1158804B (en) | Method and discriminator for classifying different segments of a signal | |
| Daoudi | State of the art in speech and audio processing | |
| Ismail et al. | A novel energy distribution comparison approach for robust speech spectrum vector quantization. |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| B06F | Objections, documents and/or translations needed after an examination request according [chapter 6.6 patent gazette] | ||
| B06T | Formal requirements before examination [chapter 6.20 patent gazette] | ||
| B15K | Others concerning applications: alteration of classification |
Free format text: AS CLASSIFICACOES ANTERIORES ERAM: F27D 1/18 , F27D 11/10 , H05B 7/10 , F16C 32/06 Ipc: G10L 19/20 (2013.01), G10L 19/22 (2013.01), G10L 2 |
|
| B06A | Patent application procedure suspended [chapter 6.1 patent gazette] | ||
| B09A | Decision: intention to grant [chapter 9.1 patent gazette] | ||
| B16A | Patent or certificate of addition of invention granted [chapter 16.1 patent gazette] |
Free format text: PRAZO DE VALIDADE: 10 (DEZ) ANOS CONTADOS A PARTIR DE 24/11/2020, OBSERVADAS AS CONDICOES LEGAIS. |
|
| B16C | Correction of notification of the grant [chapter 16.3 patent gazette] |
Free format text: REF. RPI 2603 DE 24/11/2020 QUANTO AO ENDERECO. |