Binaural speech enhancement method based on deep learning
Technical Field
The invention relates to the technical field of speech enhancement, in particular to a binaural speech enhancement method based on deep learning.
Background
At present, the speech enhancement technology mainly removes background noise and directional noise interference in speech signals, improves speech quality and intelligibility, and thus obtains better performance in speech recognition and human ear understanding. In the enhancement technology taking single-channel voice as output, background noise can be suppressed by utilizing different characteristics of voice and noise in a time-frequency domain of single-channel input, and directional noise can be better removed by utilizing spatial information of target voice and interference signals in multi-channel input. In binaural hearing, human ears can improve the comprehension of voice by using the spatial information difference between a target and an interference signal in dual-channel voice, and can perform positioning by using the spatial information of a target sound source. In most traditional speech enhancement with dual channels as output, only interference removal is considered, no special processing is performed on the spatial information of target speech, and the suppression effect on non-stationary noise is poor.
Disclosure of Invention
The invention aims to solve the defects in the prior art.
In order to achieve the aim, the invention discloses a binaural speech enhancement method based on deep learning, which comprises the following steps:
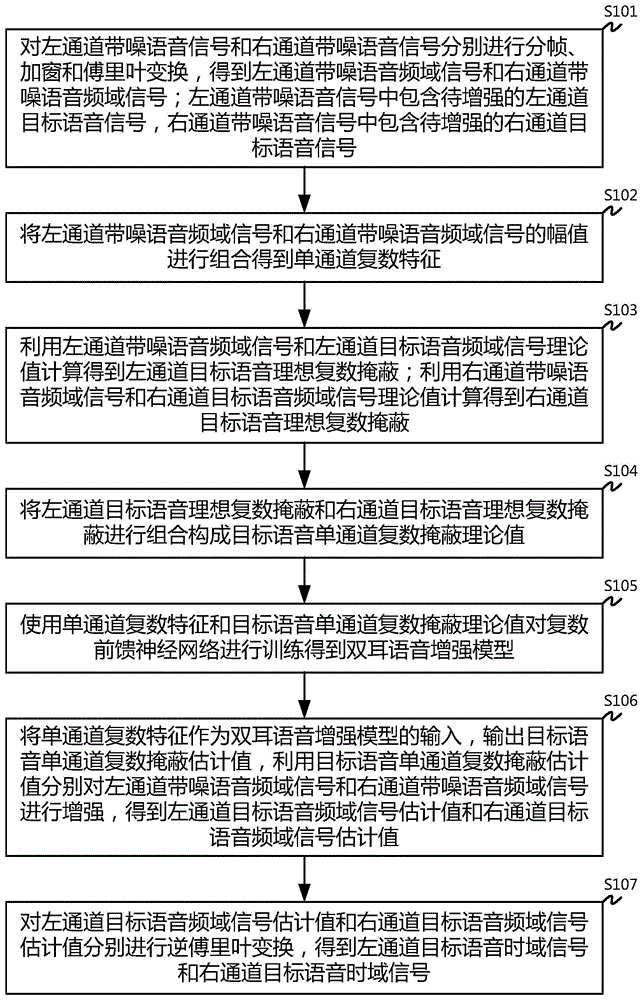
respectively performing framing, windowing and Fourier transformation on the noisy speech signal of the left channel and the noisy speech signal of the right channel to obtain a noisy speech frequency domain signal of the left channel and a noisy speech frequency domain signal of the right channel; the left channel noisy speech signal comprises a left channel target speech signal to be enhanced, and the right channel noisy speech signal comprises a right channel target speech signal to be enhanced;
combining the amplitudes of the left channel voice frequency domain signal with noise and the right channel voice frequency domain signal with noise to obtain single-channel complex characteristics;
calculating by using the left channel noisy speech frequency domain signal and the left channel target speech frequency domain signal theoretical value to obtain a left channel target speech ideal complex mask; calculating by using the theoretical values of the right channel noisy speech frequency domain signal and the right channel target speech frequency domain signal to obtain an ideal complex masking of the right channel target speech;
combining the left channel target voice ideal complex masking and the right channel target voice ideal complex masking to form a target voice single-channel complex masking theoretical value;
training a complex feedforward neural network by using a single-channel complex feature and a target voice single-channel complex masking theoretical value to obtain a binaural voice enhancement model;
the single-channel complex feature is used as the input of a binaural voice enhancement model, a target voice single-channel complex masking estimated value is output, and a left-channel noisy voice frequency domain signal and a right-channel noisy voice frequency domain signal are respectively enhanced by the target voice single-channel complex masking estimated value to obtain a left-channel target voice frequency domain signal estimated value and a right-channel target voice frequency domain signal estimated value;
and respectively carrying out inverse Fourier transform on the estimated value of the left channel target voice frequency domain signal and the estimated value of the right channel target voice frequency domain signal to obtain a left channel target voice time domain signal and a right channel target voice time domain signal.
Preferably, the steps of framing, windowing and fourier transforming the left and right channel noisy speech signals are performed, in particular,
respectively carrying out framing and windowing on the noisy speech signal of the left channel and the noisy speech signal of the right channel, taking 1024 sampling points as a frame signal, and if the length is insufficient, firstly filling zero to 1024 points; then windowing each frame of signal, wherein a Hamming window is adopted as a windowing function; and finally, carrying out Fourier transform on each frame of signal.
Preferably, the single-channel complex feature XC=|XL|+j|XRWhere j is the complex imaginary unit, | XLI is the amplitude of the left channel voice frequency domain signal with noise, | XRAnd | is the amplitude of the noise-containing speech frequency domain signal of the right channel.
Preferably, the left channel target speech ideal complex masking is:
wherein j is complex imaginary unit, XLIs a complex number, is a left channel noisy speech frequency domain signal, SLThe signal is a complex number, the theoretical value of the left channel target voice frequency domain signal is shown, and r and i represent the real part and the imaginary part of the complex number;
preferably, the ideal complex masking of the right channel target speech is:
wherein j is complex imaginary unit, XRIs a complex number, is a right channel noisy speech frequency domain signal, SRThe expression r and i is the complex number, the theoretical value of the target speech frequency domain signal of the right channel, and the real part and the imaginary part of the complex number are taken.
Preferably, the target voice single-channel complex masking theoretical value MC=ML+jMRWhere j is the complex imaginary unit, MLFor ideal complex masking of the left channel target speech, MRIdeal complex masking for the right channel target speech.
Preferably, the step of training the complex feedforward neural network to obtain the binaural speech enhancement model by using the single-channel complex feature and the target speech single-channel complex masking theoretical value, specifically,
the complex feedforward neural network is a fully-connected neural network with 4 layers, and each layer in the network has 1024 hidden-layer complex nodes. The activation function of each neuron uses a linear modification unit and acts on the real part and imaginary part of the complex number node, respectively, with the expression f (x) max (0, x).
And performing front-and-back frame expansion on the single-channel complex feature to obtain a single-channel complex expansion feature, outputting a target voice single-channel complex masking estimation value as the input of a complex feedforward neural network, taking a target voice single-channel complex masking theoretical value as a training target of the complex feedforward neural network, and continuously reducing the mean square error between the target voice single-channel complex masking estimation value and the target voice single-channel complex masking theoretical value through iteration.
Preferably, the single-channel complex masking estimate MC′=ML′+jMR', where j is the complex imaginary unit, ML' is an estimate of the ideal complex masking of the left channel target speech, MR' is an estimate of the ideal complex masking of the right channel target speech.
Preferably, the left channel target voice frequency domain signal estimated value X'L=M′L*XLWherein M isL' is an estimate of the ideal complex masking of the left channel target speech, XLA voice frequency domain signal with noise of a left channel is obtained;
preferably, the right channel target speech frequency domain signal estimated value X'R=M′R*XRWherein M isR' estimation value, X, of ideal complex masking of target speech of right channelRAnd the right channel is a voice frequency domain signal with noise.
The invention has the advantages that: the method has the advantages that the ideal complex masking of the left channel and the right channel is utilized to construct single-channel complex masking, and the single-channel complex masking is estimated through a complex feedforward neural network, so that the purpose of jointly processing the left channel and the right channel is achieved, and the spatial information of a target sound source is kept while noise interference is suppressed. By containing enough noise types and orientations in the training data, the generalization capability of the deep neural network can be fully utilized, the robustness of the model is improved, and the purpose of binaural speech enhancement is achieved.
Drawings
In order to more clearly illustrate the technical solutions of the embodiments of the present invention, the drawings used in the description of the embodiments will be briefly introduced below, and it is obvious that the drawings in the following description are only some embodiments of the present invention, and it is obvious for those skilled in the art that other drawings can be obtained according to the drawings without creative efforts.
Fig. 1 is a flowchart of a binaural speech enhancement method based on deep learning.
Detailed Description
In order to make the objects, technical solutions and advantages of the embodiments of the present invention clearer, the technical solutions in the embodiments of the present invention will be clearly and completely described below with reference to the drawings in the embodiments of the present invention, and it is obvious that the described embodiments are some, but not all, embodiments of the present invention. All other embodiments, which can be derived by a person skilled in the art from the embodiments given herein without making any creative effort, shall fall within the protection scope of the present invention.
Fig. 1 is a flowchart of a binaural speech enhancement method based on deep learning. As shown in fig. 1, includes:
step S101: and respectively performing framing, windowing and Fourier transformation on the voice signal with noise of the left channel and the voice signal with noise of the right channel to obtain a voice frequency domain signal with noise of the left channel and a voice frequency domain signal with noise of the right channel.
The left-channel noisy speech signal comprises a left-channel target speech signal to be enhanced, and the right-channel noisy speech signal comprises a right-channel target speech signal to be enhanced.
In a specific embodiment, framing and windowing are respectively carried out on a noisy speech signal of a left channel and a noisy speech signal of a right channel, 1024 sampling points are taken as a frame signal, and if the length is insufficient, zero padding is carried out to 1024 points; then windowing each frame of signal, wherein a Hamming window is adopted as a windowing function; and finally, carrying out Fourier transform on each frame of signal to obtain a left channel voice frequency domain signal with noise and a right channel voice frequency domain signal with noise.
Step S102: and combining the amplitudes of the left channel voice frequency domain signal with noise and the right channel voice frequency domain signal with noise to obtain single-channel complex characteristics.
In particular, a single-channel complex feature XC=|XL|+j|XRWhere j is the complex imaginary unit, | XLI is the amplitude of the left channel voice frequency domain signal with noise, | XRAnd | is the amplitude of the noise-containing speech frequency domain signal of the right channel.
Step S103: calculating by using the left channel noisy speech frequency domain signal and the left channel target speech frequency domain signal theoretical value to obtain a left channel target speech ideal complex mask; and calculating to obtain the ideal complex masking of the right channel target voice by using the theoretical value of the right channel noisy voice frequency domain signal and the right channel target voice frequency domain signal.
Specifically, the ideal complex masking of the left channel target speech is:
wherein j is complex imaginary unit, XLIs a complex number, is a left channel noisy speech frequency domain signal, SLThe expression r and i is the real part and the imaginary part of the complex number, and is the theoretical value of the target speech frequency domain signal of the left channel.
The ideal complex masking of the right channel target speech is:
wherein j is complex imaginary unit, XRIs a complex number, is a right channel noisy speech frequency domain signal, SRIs complex, is the frequency domain signal of the right channel target voiceIn terms of values, r and i denote the real and imaginary parts of the complex number.
Step S104: and combining the left channel target voice ideal complex masking and the right channel target voice ideal complex masking to form a target voice single-channel complex masking theoretical value.
Specifically, the target voice single-channel complex masking theoretical value MC=ML+jMRWhere j is the complex imaginary unit, MLFor ideal complex masking of the left channel target speech, MRIdeal complex masking for the right channel target speech.
Step S105: and training the complex feedforward neural network by using the single-channel complex feature and the target voice single-channel complex masking theoretical value to obtain a binaural voice enhancement model.
In one embodiment, the complex feedforward neural network is a 4-layer fully-connected neural network, and each layer in the network has 1024 hidden-layer complex nodes. The activation function of each neuron uses a linear modification unit and acts on the real part and imaginary part of the complex number node, respectively, with the expression f (x) max (0, x).
And performing front-and-back frame expansion on the single-channel complex feature to obtain a single-channel complex expansion feature, outputting a target voice single-channel complex masking estimation value as the input of a complex feedforward neural network, taking a target voice single-channel complex masking theoretical value as a training target of the complex feedforward neural network, and continuously reducing the mean square error between the target voice single-channel complex masking estimation value and the target voice single-channel complex masking theoretical value through iteration.
Step S106: and taking the single-channel complex feature as the input of a binaural voice enhancement model, outputting a target voice single-channel complex masking estimated value, and enhancing the left-channel noisy voice frequency domain signal and the right-channel noisy voice frequency domain signal respectively by using the target voice single-channel complex masking estimated value to obtain a left-channel target voice frequency domain signal estimated value and a right-channel target voice frequency domain signal estimated value.
Specifically, a single-channel complex masking estimate MC′=ML′+jMR', wherein j isComplex imaginary unit, ML' is an estimate of the ideal complex masking of the left channel target speech, MR' is an estimate of the ideal complex masking of the right channel target speech.
Left channel target voice frequency domain signal estimated value X'L=M′L*XLWherein M isL' is an estimate of the ideal complex masking of the left channel target speech, XLAnd the left channel is a voice frequency domain signal with noise.
Right channel target voice frequency domain signal estimated value X'R=M′R*XRWherein M isR' estimation value, X, of ideal complex masking of target speech of right channelRAnd the right channel is a voice frequency domain signal with noise.
Step S107: and respectively carrying out inverse Fourier transform on the estimated value of the left channel target voice frequency domain signal and the estimated value of the right channel target voice frequency domain signal to obtain a left channel target voice time domain signal and a right channel target voice time domain signal.
The invention provides a binaural speech enhancement method based on deep learning, which constructs single-channel complex masking by utilizing ideal complex masking of a left channel and a right channel, estimates the single-channel complex masking through a complex feedforward neural network, achieves the purpose of jointly processing the left channel and the right channel, and further keeps the spatial information of a target sound source while inhibiting noise interference. By containing enough noise types and orientations in the training data, the generalization capability of the deep neural network can be fully utilized, the robustness of the model is improved, and the purpose of binaural speech enhancement is achieved.
The above embodiments are provided to further explain the objects, technical solutions and advantages of the present invention in detail, it should be understood that the above embodiments are merely exemplary embodiments of the present invention and are not intended to limit the scope of the present invention, and any modifications, equivalents, improvements and the like made within the spirit and principle of the present invention should be included in the scope of the present invention.