CN110969112B - Pedestrian identity alignment method under camera-crossing scene - Google Patents
Pedestrian identity alignment method under camera-crossing scene Download PDFInfo
- Publication number
- CN110969112B CN110969112B CN201911189515.XA CN201911189515A CN110969112B CN 110969112 B CN110969112 B CN 110969112B CN 201911189515 A CN201911189515 A CN 201911189515A CN 110969112 B CN110969112 B CN 110969112B
- Authority
- CN
- China
- Prior art keywords
- layer
- pedestrian
- convolution
- convolutional
- layers
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Expired - Fee Related
Links
Images





Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V20/00—Scenes; Scene-specific elements
- G06V20/30—Scenes; Scene-specific elements in albums, collections or shared content, e.g. social network photos or video
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F18/00—Pattern recognition
- G06F18/20—Analysing
- G06F18/25—Fusion techniques
- G06F18/253—Fusion techniques of extracted features
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- Data Mining & Analysis (AREA)
- General Physics & Mathematics (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Evolutionary Biology (AREA)
- Evolutionary Computation (AREA)
- Bioinformatics & Computational Biology (AREA)
- General Engineering & Computer Science (AREA)
- Artificial Intelligence (AREA)
- Life Sciences & Earth Sciences (AREA)
- Multimedia (AREA)
- Traffic Control Systems (AREA)
- Image Analysis (AREA)
Abstract
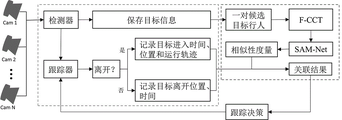
本发明提出一种跨摄像头场景下行人身份对齐方法,其在与解决跨摄像头下的行人关联问题,以对单摄像头下的目标行人进行持续正确的跟踪为基础,在目标离开摄像头视野区域后,进入盲区,跟踪断续,但当其再次出现在摄像头下时,能够重新识别出该行人并维持其身份标识不变延续跟踪。当检测器检测到新的行人时,将其加入待关联的候选池中,之后从候选池中选择一对行人使用F‑CCT模型完成图像预处理,处理后的图像将作为SAM‑Dets模型的输入数据并求得两个行人的外观适配度。候选池中的行人两两配对计算完外观适配度后,根据每对行人适配度并结合时空关系建立最小费用流图模型求解最优的行人关联解;最后根据关联结果对行人保持原有标识或者赋予新的身份标识。
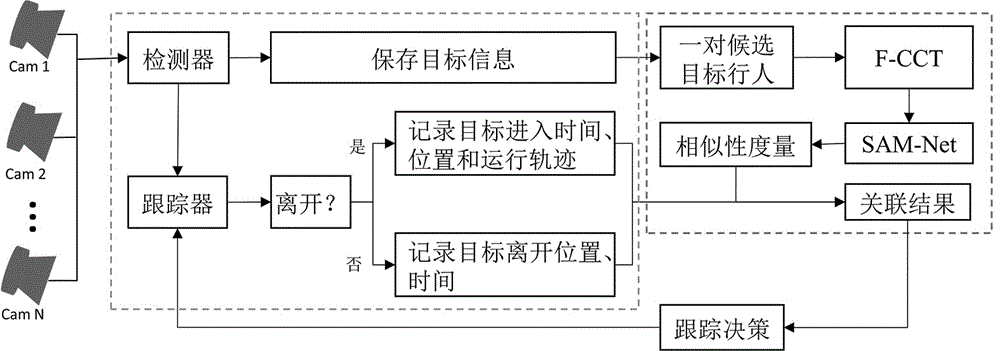
The invention proposes a pedestrian identity alignment method in a cross-camera scene, which solves the pedestrian association problem under the cross-camera, and is based on the continuous and correct tracking of the target pedestrian under a single camera. After the target leaves the camera field of view, Entering the blind spot, the tracking is intermittent, but when it reappears under the camera, it can re-identify the pedestrian and keep its identity unchanged and continue tracking. When the detector detects a new pedestrian, it is added to the candidate pool to be associated, and then a pair of pedestrians are selected from the candidate pool to complete the image preprocessing using the F‑CCT model, and the processed image will be used as the SAM‑Dets model. Enter the data and find the appearance fit of the two pedestrians. After the pedestrians in the candidate pool are paired to calculate the appearance fit, the minimum cost flow graph model is established according to the fit of each pair of pedestrians and combined with the space-time relationship to solve the optimal pedestrian correlation solution; finally, the pedestrians are kept original according to the correlation results. Identify or assign a new identity.
Description
技术领域technical field
本发明属于机器视觉、智能安防领域,尤其涉及一种跨摄像头场景下行人身份对齐方法。The invention belongs to the fields of machine vision and intelligent security, and in particular relates to a pedestrian identity alignment method in a cross-camera scene.
背景技术Background technique
随着经济社会的不断发展,人们对于安全的需求越来越大。因此,智能安防领域不断的被讨论和发展,使用范围也越来越大,类似于行人检测和跟踪等技术开始成为当前研究的热点问题。对于行人追踪问题,自然是跨摄像头下的研究才具有实际意义,且要求要对多个行人进行处理。尽管现在单摄像头场景下的行人跟踪技术已经相对成熟,但是多摄像头,尤其是非重叠视野区域情形下由于盲区的存在使得目标的时空信息变得不再可靠,从而给不同时刻不同空间下不同摄像头中同一目标的识别跟踪和检索造成了很大的困扰。所以,跨摄像头场景下的行人追踪技术这一研究正在被兴起。其中,最重要的部分便是在不同的摄像头下怎么让行人身份匹配。With the continuous development of economy and society, people's demand for safety is increasing. Therefore, the field of intelligent security is constantly being discussed and developed, and the scope of application is getting larger and larger, and technologies such as pedestrian detection and tracking have become a hot issue in current research. For the pedestrian tracking problem, it is naturally the research under the cross-camera that has practical significance, and requires the processing of multiple pedestrians. Although the pedestrian tracking technology in single-camera scenarios is relatively mature, the presence of blind spots in multi-cameras, especially in non-overlapping fields of view, makes the spatiotemporal information of the target unreliable. The identification, tracking and retrieval of the same target has caused great trouble. Therefore, research on pedestrian tracking technology in cross-camera scenarios is emerging. Among them, the most important part is how to match pedestrian identities under different cameras.
跨摄像头行人身份对齐主要是以行人为研究对象,关注非重叠视野区域的多摄像头多目标跟踪问题。这一问题,目前常见的解决机制是分为两个步骤:首先,使用检测和跟踪算法获得目标在单摄像头下得运行轨迹。其次,使用关联算法将摄像头间独立的行人运行轨迹进行关联整合,从而获得每个目标完整的运动轨迹。上述机制的局限在于只能处理离线的数据,本质上适用于检索场景,无法支持在线跟踪。究其原因在于,目标行人离开当前摄像头视域后,由于盲区的存在目标在进入下一摄像头视域时,时空信息均缺失,增加了将目标行人从上一个摄像头正确移交给下一个摄像头的难度。这种机制还产生了副效应:使得跨摄像头行人跟踪的结果严重依赖单摄像头下得行人跟踪效果。Cross-camera pedestrian identity alignment mainly focuses on pedestrians and focuses on multi-camera and multi-target tracking problems in non-overlapping visual fields. The current common solution mechanism for this problem is divided into two steps: First, use the detection and tracking algorithm to obtain the running trajectory of the target under a single camera. Secondly, use the association algorithm to associate and integrate the independent pedestrian running trajectories between cameras, so as to obtain the complete motion trajectory of each target. The limitation of the above mechanism is that it can only process offline data, which is essentially suitable for retrieval scenarios and cannot support online tracking. The reason is that after the target pedestrian leaves the field of view of the current camera, due to the existence of the blind spot, when the target enters the field of view of the next camera, the spatiotemporal information is missing, which increases the difficulty of correctly handing over the target pedestrian from the previous camera to the next camera. . This mechanism also has a side effect: the results of cross-camera pedestrian tracking rely heavily on the pedestrian tracking effect under a single camera.
实现行人跨摄像头身份对齐的关键在于将不同视域内的同一目标行人正确关联。针对目前大部分跨摄像头行人跟踪算法中对于行人特征学习能力有限,并不能学习到较为鲁棒的行人特征。因此,最终影响到了后面的行人相似性度量的精度,最终造成了并不理想的数据关联结果。所以很难适应于跨摄像头行人跟踪的复杂环境。The key to achieving cross-camera identity alignment of pedestrians is to correctly associate the same target pedestrians in different fields of view. For most of the current cross-camera pedestrian tracking algorithms, the learning ability of pedestrian features is limited, and more robust pedestrian features cannot be learned. Therefore, the accuracy of the following pedestrian similarity measurement is finally affected, resulting in an unsatisfactory data association result. Therefore, it is difficult to adapt to the complex environment of cross-camera pedestrian tracking.
尽管现有的跨摄像头身份对齐相关的研究可以比较有效地解决一些对于离线数据的行人跟踪,但是并不能满足对于需要即时在线跟踪的要求,并且也不能在未知行人进出区域的时候进行有效的跟踪。Although the existing research related to cross-camera identity alignment can effectively solve some pedestrian tracking for offline data, it cannot meet the requirements for real-time online tracking, and it cannot effectively track unknown pedestrians entering and leaving the area. .
发明内容SUMMARY OF THE INVENTION
为了克服现有技术存在的空白和不足,本发明的方案在于解决跨摄像头下的行人关联问题,主要功能是给新进入目标分配新的身份表示或者与之前离开的目标关联成功,则将之前的目标赋予新的身份标识。其以对单摄像头下的目标行人进行持续正确的跟踪为基础,在目标离开摄像头视野区域后,进入盲区,跟踪断续,但当其再次出现在摄像头下时,能够重新识别出该行人并维持其身份标识不变延续跟踪。当检测器检测到新的行人时,将其加入待关联的候选池中,之后从候选池中选择一对行人使用F-CCT模型完成图像预处理,处理后的图像将作为SAM-Dets模型的输入数据并求得两个行人的外观适配度。候选池中的行人两两配对计算完外观适配度后,根据每对行人适配度并结合时空关系建立最小费用流图模型求解最优的行人关联解;最后根据关联结果对行人保持原有标识或者赋予新的身份标识,交由跟踪器延续跟踪。In order to overcome the gaps and deficiencies in the prior art, the solution of the present invention is to solve the pedestrian association problem under cross-cameras. The target is given a new identity. It is based on the continuous and correct tracking of the target pedestrian under a single camera. After the target leaves the camera's field of view, it enters the blind spot and the tracking is intermittent, but when it reappears under the camera, the pedestrian can be re-identified and maintained. Its identity does not change and continues tracking. When the detector detects a new pedestrian, it is added to the candidate pool to be associated, and then a pair of pedestrians are selected from the candidate pool to complete the image preprocessing using the F-CCT model, and the processed image will be used as the SAM-Dets model. Enter the data and find the appearance fit of the two pedestrians. After the pedestrians in the candidate pool are paired to calculate the appearance fit, the minimum cost flow graph model is established according to the fit of each pair of pedestrians and combined with the space-time relationship to solve the optimal pedestrian correlation solution; finally, the pedestrians are kept original according to the correlation results. Identify or assign a new identity to the tracker to continue tracking.
本发明具体采用以下技术方案:The present invention specifically adopts the following technical solutions:
一种跨摄像头场景下行人身份对齐方法,其特征在于,包括以下步骤:A method for aligning pedestrian identities across camera scenes, comprising the following steps:
步骤S1:多个摄像头各自将其通过检测器检测到的行人图像加入待关联的候选池中;步骤S2:对待关联的候选池中属于不同摄像头的两个行人图像计算外观适配度;Step S1: each of the plurality of cameras adds the pedestrian images detected by the detector to the candidate pool to be associated; Step S2: calculates the appearance fit of two pedestrian images belonging to different cameras in the candidate pool to be associated;
步骤S3:将待关联的候选池中的行人图像两两配对计算完外观适配度后,根据每对行人外观适配度,结合时空关系,建立最小费用流图模型,求解最优的行人关联解;Step S3: After the pedestrian images in the candidate pool to be associated are paired to calculate the appearance fit degree, according to the appearance fit degree of each pair of pedestrians, combined with the spatiotemporal relationship, a minimum cost flow graph model is established to solve the optimal pedestrian association untie;
步骤S4:根据步骤S3的关联结果,对行人进行保持原有标识或者赋予新的身份标识的操作。Step S4: According to the association result of step S3, the pedestrian is maintained with the original identification or given a new identification.
优选地,在步骤S1中,所述检测器为Faster R-CNN。Preferably, in step S1, the detector is Faster R-CNN.
优选地,步骤S2中,计算外观适配度具体包括以下步骤:Preferably, in step S2, calculating the degree of appearance fit specifically includes the following steps:
步骤A21:使用模糊C均值聚类F-CCT模型完成图像预处理,设行人图像A的整体性特征为X={x1,x2,...,xN},行人图像B的整体性特征为Y={y1,y2,...,yN};Step A21: Use the fuzzy C-means clustering F-CCT model to complete image preprocessing, and set the overall feature of pedestrian image A to be X={x 1 , x 2 ,...,x N }, and the overall feature of pedestrian image B The characteristic is Y={y 1 , y 2 ,...,y N };
步骤A22:将步骤S21处理后的图像作为融合细粒度表征的行人关联模型SAM-Dets的输入数据:以X为输入向量,Y为权值向量,通过所述融合细粒度表征的行人关联模型SAM-Dets编码行人A具有的局部细粒度特征f1;以Y为输入向量,X为权值向量,通过所述融合细粒度表征的行人关联模型SAM-Dets编码行人B具有的局部细粒度特征f2;Step A22: The image processed in step S21 is used as the input data of the pedestrian association model SAM-Dets fused with fine-grained representation: X is the input vector, Y is the weight vector, and the pedestrian association model SAM-Dets fused with fine-grained representation is used as the input vector. -Dets encode the local fine-grained feature f 1 of pedestrian A; take Y as the input vector and X as the weight vector, encode the local fine-grained feature f of pedestrian B by the pedestrian association model SAM-Dets fused with fine-grained representation 2 ;
步骤A23:将fs=(f1-f2)2作为两个核大小为1×1×4096的卷积层C的输入值,将softmax作为输出函数,输出一个二维向量(q1,q2),表示输入两个对象属于现实世界中同一个人的概率值,作为外观适配度。Step A23: Take f s =(f 1 -f 2 ) 2 as the input value of two convolutional layers C with kernel size of 1×1×4096, take softmax as the output function, and output a two-dimensional vector (q 1 , q 2 ), representing the probability value that the input two objects belong to the same person in the real world, as the appearance fit degree.
优选地,在步骤A22中,所述融合细粒度表征的行人关联模型SAM-Dets的结构包括:K个注意力分支和拼接层;每一所述注意力分支均包括以下六层,其中:Preferably, in step A22, the structure of the pedestrian association model SAM-Dets fused with fine-grained representation includes: K attention branches and splicing layers; each of the attention branches includes the following six layers, wherein:
第一层为卷积层A,用于提取输入的行人整体特征的高层特征;The first layer is the convolutional layer A, which is used to extract the high-level features of the overall pedestrian features of the input;
第二层为激活层,激活函数为softmax;The second layer is the activation layer, and the activation function is softmax;
第三层为维度扩大层;The third layer is the dimension expansion layer;
第四层为求和层,将行人整体特征与第三层获得的结果相加;The fourth layer is the summation layer, which adds the overall pedestrian characteristics to the results obtained in the third layer;
第五层为全局平均池化层,用于降低特征维度;The fifth layer is the global average pooling layer, which is used to reduce the feature dimension;
第六层为全连接层,用于完成输入向量与权值矩阵中的权值向量的内积计算;The sixth layer is the fully connected layer, which is used to complete the inner product calculation of the input vector and the weight vector in the weight matrix;
所述拼接层将K个注意力分支得到的结果按通道拼接,输出行人局部细粒度特征。The splicing layer splices the results obtained by the K attention branches by channel, and outputs the local fine-grained features of pedestrians.
优选地,所述卷积层A的卷积核尺寸为1×1,步长为1;所述维度扩大层将通道维度扩大为512维;所述全局平均池化层的尺寸为1×1,步长为1。Preferably, the size of the convolution kernel of the convolutional layer A is 1×1, and the stride is 1; the dimension expansion layer expands the channel dimension to 512 dimensions; the size of the global average pooling layer is 1×1 , with a step size of 1.
优选地,步骤S2中,计算外观适配度具体包括以下步骤:Preferably, in step S2, calculating the degree of appearance fit specifically includes the following steps:
步骤B21:使用模糊C均值聚类F-CCT模型完成图像预处理,设行人图像A的整体性特征为X={x1,x2,...,xN},行人图像B的整体性特征为Y={y1,y2,...,yN};Step B21: Use the fuzzy C-means clustering F-CCT model to complete image preprocessing, set the overall feature of pedestrian image A as X={x 1 ,x 2 ,...,x N }, the overall feature of pedestrian image B The characteristic is Y={y 1 , y 2 ,...,y N };
步骤B22:将行人图像A和行人图像B经过DR-ResNet基础网络提取行人抽象特征;Step B22: Extract the pedestrian abstract features from the pedestrian image A and the pedestrian image B through the DR-ResNet basic network;
步骤B23:使用卷积层B进一步提取目标行人高层特征,作为分类模型和融合细粒度表征的行人关联模型SAM-Dets的输入数据;所述分类模型分别输出行人图像A和行人图像B各自的身份识别表示号,所述融合细粒度表征的行人关联模型SAM-Dets输出行人A具有的局部细粒度特征f1,行人B具有的局部细粒度特征f2。Step B23: Use the convolutional layer B to further extract the high-level features of the target pedestrian as the input data of the classification model and the pedestrian association model SAM-Dets fused with fine-grained representation; the classification model outputs the respective identities of the pedestrian image A and the pedestrian image B respectively Identifying the representation number, the pedestrian association model SAM-Dets fused with fine-grained representation outputs the local fine-grained feature f 1 possessed by pedestrian A and the local fine-grained feature f 2 possessed by pedestrian B.
步骤B24:将fs=(f1-f2)2作为两个核大小为1×1×4096的卷积层C的输入值,将softmax作为输出函数,输出一个二维向量(q1,q2),表示输入两个对象属于现实世界中同一个人的概率值,作为外观适配度。Step B24: take f s =(f 1 -f 2 ) 2 as the input value of the two convolutional layers C with a kernel size of 1×1×4096, take softmax as the output function, and output a two-dimensional vector (q 1 , q 2 ), representing the probability value that the input two objects belong to the same person in the real world, as the appearance fit degree.
优选地,所述DR-ResNet基础网络包括两个权重共享的完全相同的深度卷积孪生神经基础网络模块R-ResNet;所述深度卷积孪生神经基础网络模块R-ResNet的结构包括四十九层卷积层、三个并行的卷积层、以及末端卷积层:Preferably, the DR-ResNet basic network includes two identical deep convolutional Siamese neural basic network modules R-ResNet with shared weights; the structure of the deep convolutional Siamese neural basic network module R-ResNet includes forty-nine layer convolutional layers, three parallel convolutional layers, and end convolutional layers:
其中,第一卷积层的卷积核大小为(7,7,64),max-pooling为(3,3),滑动步长为2;Among them, the convolution kernel size of the first convolution layer is (7, 7, 64), the max-pooling is (3, 3), and the sliding step size is 2;
第二卷积层到第四卷积层的卷积核大小分别为(1,1,64)、(3,3,64)、(1,1,256),激活函数都采用ReLu函数;该三层卷积层和激活函数组成一个卷积块,将该卷积块的输入值既作为第二卷积层的输入值,也作为卷积块的第三层激活函数的输入值;第五卷积层到第七卷积层,以及第八卷积层到第十卷积层都采用与第二卷积层到第四卷积层相同的结构;The convolution kernel sizes from the second convolutional layer to the fourth convolutional layer are (1,1,64), (3,3,64), (1,1,256) respectively, and the activation functions all use the ReLu function; the three layers The convolution layer and the activation function form a convolution block, and the input value of the convolution block is used both as the input value of the second convolution layer and the input value of the activation function of the third layer of the convolution block; the fifth convolution Layers to the seventh convolutional layer, and the eighth convolutional layer to the tenth convolutional layer all use the same structure as the second to the fourth convolutional layer;
第十一卷积层到第十三卷积层的卷积核大小分别为(1,1,128)、(3,3,128)、(1,1,512),激活函数都采用ReLu函数;该三层卷积层和激活函数组成一个卷积块,将该卷积块的输入值既作为第十一层卷积层的输入值,也作为卷积块的第三层激活函数的输入值;第十四卷积层到第十六卷积层、第十七卷积层到第十九卷积层以及第二十卷积层到第二十二卷积层都采了与第十一卷积层到第十三卷积层相同的结构;The convolution kernel sizes of the eleventh convolutional layer to the thirteenth convolutional layer are (1, 1, 128), (3, 3, 128), (1, 1, 512), and the activation functions all use the ReLu function ; The three-layer convolution layer and the activation function form a convolution block, and the input value of the convolution block is used as the input value of the eleventh convolution layer and the input of the activation function of the third layer of the convolution block. value; the fourteenth convolutional layer to the sixteenth convolutional layer, the seventeenth convolutional layer to the nineteenth convolutional layer, and the twentieth convolutional layer to the twenty-second convolutional layer all adopt the same value as the tenth convolutional layer. The same structure from a convolutional layer to the thirteenth convolutional layer;
第二十三卷积层到第二十五卷积层的卷积核大小分别为(1,1,256)、(3,3,256)、(1,1,1024),激活函数都采用ReLu函数;该三层卷积层和激活函数组成一个卷积块,将该卷积块的输入值既作为第二十三卷积层的输入值,也作为卷积块的第三层激活函数的输入值;第二十六卷积层到第二十八卷积层、第二十九卷积层到三十一卷积层、第三十二卷积层到第三十四卷积层、第三十五卷积层到三十七卷积层、第三十八卷积层到第四十卷积层均采用与第二十三卷积层到二十五卷积层相同的结构;The convolution kernel sizes of the twenty-third convolutional layer to the twenty-fifth convolutional layer are (1, 1, 256), (3, 3, 256), (1, 1, 1024), respectively, and the activation functions are all used ReLu function; the three-layer convolution layer and the activation function form a convolution block, and the input value of the convolution block is used as the input value of the twenty-third convolution layer and the activation function of the third layer of the convolution block. The input value of ; the twenty-sixth convolutional layer to the twenty-eighth convolutional layer, the twenty-ninth convolutional layer to the thirty-first convolutional layer, the thirty-second convolutional layer to the thirty-fourth convolutional layer , the thirty-fifth convolutional layer to the thirty-seventh convolutional layer, and the thirty-eighth convolutional layer to the fortieth convolutional layer all adopt the same structure as the twenty-third convolutional layer to the twenty-fifth convolutional layer ;
第四十一卷积层到第四十三卷积层的卷积核大小分别为(1,1,512)、(3,3,512)、(1,1,2048),激活函数都采用ReLu函数;该三层卷积层和激活函数组成一个卷积块,将该卷积块的输入值既作为第四十一卷积层的输入值,也作为卷积块的第三层激活函数的输入值;第四十四卷积层到第四十六卷积层、第四十七卷积层到四十九卷积层采用与第四十一卷积层到第四十二卷积层相同的结构;The convolution kernel sizes of the forty-first convolutional layer to the forty-third convolutional layer are (1, 1, 512), (3, 3, 512), (1, 1, 2048), respectively, and the activation functions are all used ReLu function; the three-layer convolution layer and the activation function form a convolution block, and the input value of the convolution block is used as both the input value of the 41st convolution layer and the activation function of the third layer of the convolution block. The input value of ; the forty-fourth convolutional layer to the forty-sixth convolutional layer, the forty-seventh convolutional layer to the forty-ninth convolutional layer are convolutional with the forty-first convolutional layer to the forty-second convolutional layer layers of the same structure;
在第四十九卷积层后为三个并行的卷积层,每个卷积层,使用2048个卷积核,第一并行卷积层到第三并行卷积层的尺寸大小分别为(3,3,1024)、(5,5,1024)和(7,7,1024),通过一个连接层将三个并行的卷积层的通道进行合并,其后的max-pooling为(4,4);After the forty-ninth convolutional layer, there are three parallel convolutional layers. Each convolutional layer uses 2048 convolution kernels. The sizes of the first parallel convolutional layer to the third parallel convolutional layer are ( 3, 3, 1024), (5, 5, 1024) and (7, 7, 1024), the channels of the three parallel convolutional layers are merged through a connection layer, and the subsequent max-pooling is (4, 4);
最后一层是使用1024个卷积核,且尺寸大小为(2,2,2048)的末端卷积层;The last layer is an end convolutional layer with 1024 convolution kernels and a size of (2, 2, 2048);
所述卷积层B使用2个卷积核,尺寸大小为(1,1,4096);The convolutional layer B uses 2 convolution kernels with a size of (1, 1, 4096);
所述所述融合细粒度表征的行人关联模型SAM-Dets的结构包括:K个注意力分支和拼接层;每一所述注意力分支均包括以下六层,其中:The structure of the pedestrian association model SAM-Dets fused with fine-grained representation includes: K attention branches and splicing layers; each of the attention branches includes the following six layers, wherein:
第一层为卷积层A,卷积核尺寸为1×1,步长为1;用于提取输入的行人整体特征的高层特征;The first layer is the convolution layer A, the size of the convolution kernel is 1×1, and the stride is 1; it is used to extract the high-level features of the input pedestrian overall features;
第二层为激活层,激活函数为softmax;The second layer is the activation layer, and the activation function is softmax;
第三层为维度扩大层,将通道维度扩大为512维;The third layer is the dimension expansion layer, which expands the channel dimension to 512 dimensions;
第四层为求和层,将行人整体特征与第三层获得的结果相加;The fourth layer is the summation layer, which adds the overall pedestrian characteristics to the results obtained in the third layer;
第五层为全局平均池化层,尺寸为1×1,步长为1,用于降低特征维度;The fifth layer is a global average pooling layer with a size of 1×1 and a step size of 1, which is used to reduce the feature dimension;
第六层为全连接层,用于完成输入向量与权值矩阵中的权值向量的内积计算;The sixth layer is the fully connected layer, which is used to complete the inner product calculation of the input vector and the weight vector in the weight matrix;
所述拼接层将K个注意力分支得到的结果按通道拼接,输出行人局部细粒度特征。The splicing layer splices the results obtained by the K attention branches by channel, and outputs the local fine-grained features of pedestrians.
优选地,在步骤S3中,根据每对行人外观适配度,结合时空关系,建立最小费用流图模型,求解最优的行人关联解的具体过程,包括以下步骤:Preferably, in step S3, according to the appearance fit of each pair of pedestrians, combined with the space-time relationship, a minimum cost flow graph model is established, and the specific process of solving the optimal pedestrian association solution includes the following steps:
步骤S31:设给定tp-1时刻下的完成即时对齐后的费用流图为


步骤S32:根据视野内行人集


步骤S33:删除所有对齐目标节点以及视野内行人集


优选地,在步骤S4中,对行人进行保持原有标识或者赋予新的身份标识的操作之后,交由跟踪器延续追踪;所述跟踪器采用采用KCF算法进行跟踪;所述KCF算法为每个行人分配一个跟踪器。Preferably, in step S4, after the operation of maintaining the original identification or giving a new identification identification to the pedestrian, the tracker is handed over to the tracker to continue tracking; the tracker adopts the KCF algorithm to track; the KCF algorithm is for each Pedestrians are assigned a tracker.
优选地,将摄像头的跟踪视野区域划分为核心区域和临界区域,在步骤S1中,通过所述检测器只检测临界区域的行人。Preferably, the tracking visual field area of the camera is divided into a core area and a critical area, and in step S1, only pedestrians in the critical area are detected by the detector.
相较于现有技术,本发明及其优选方案实现了跨摄像头行人的在线跟踪,其识别准确、效率高,且不受目标离开摄像头视野区域后,进入盲区,跟踪断续的影响。Compared with the prior art, the present invention and its preferred solution realize online tracking of pedestrians across cameras, with accurate identification and high efficiency, and are not affected by intermittent tracking after the target leaves the field of view of the camera and enters the blind spot.
其中,跟踪功能的实现由现有成熟FasterR-CNN实现行人检测,由KCF算法实现在线行人跟踪;而作为实现本发明及优选方案的核心在于根据时空信息和行人相似性值建立最小费用流图模型即时完成行人身份对齐任务,以及整合了F-CCT和SAM-Dets模型或SAM-Dets模型和DR-ResNet网络模型融合,解决了行人的外观适配度度量的问题。Among them, the realization of the tracking function is realized by the existing mature FasterR-CNN to realize the pedestrian detection, and the KCF algorithm is used to realize the online pedestrian tracking; and the core of the realization of the present invention and the preferred solution is to establish the minimum cost flow graph model according to the space-time information and the pedestrian similarity value. The task of pedestrian identity alignment is instantly completed, and the F-CCT and SAM-Dets models or the fusion of the SAM-Dets model and the DR-ResNet network model are integrated to solve the problem of pedestrian appearance fitness measurement.
附图说明Description of drawings
下面结合附图和具体实施方式对本发明进一步详细的说明:The present invention will be described in further detail below in conjunction with the accompanying drawings and specific embodiments:
图1是本发明实施例1整体流程示意图;1 is a schematic diagram of the overall flow of
图2是本发明实施例SAM-Dets模型结构示意图;2 is a schematic structural diagram of a SAM-Dets model according to an embodiment of the present invention;
图3是本发明实施例SAM-Dets模型网络结构示意图;3 is a schematic diagram of a network structure of a SAM-Dets model according to an embodiment of the present invention;
图4是本发明实施例2行人细粒度关联模型示意图;4 is a schematic diagram of a fine-grained association model for pedestrians in
图5是本发明实施例2在跨摄像头场景下行人身份对齐模型效果示意图1;5 is a schematic diagram 1 of the effect of a pedestrian identity alignment model in a cross-camera scene according to
图6是本发明实施例2在跨摄像头场景下行人身份对齐模型效果示意图2。FIG. 6 is a schematic diagram 2 of the effect of a pedestrian identity alignment model in a cross-camera scene according to
具体实施方式Detailed ways
为让本专利的特征和优点能更明显易懂,下文特举2个实施例,作详细说明如下:In order to make the features and advantages of this patent more obvious and easy to understand, two embodiments are given below, which are described in detail as follows:
如图1所示,在本发明的第一个实施例中,实现跨摄像头场景下行人身份对齐的整体方案包括以下步骤:As shown in FIG. 1, in the first embodiment of the present invention, the overall solution for realizing pedestrian identity alignment across camera scenes includes the following steps:
步骤S1:当行人进入到摄像头视野,多个摄像头各自将其通过检测器检测到的行人图像加入待关联的候选池中。Step S1: When the pedestrian enters the field of view of the camera, each of the plurality of cameras adds the pedestrian image detected by the detector to the candidate pool to be associated.
在本实施例中,检测器选用基于深度学习的目标检测代表性方法Faster R-CNN,其在选择候选框时使用RPN以检测网络共享全图的卷积特征,让分类和回归任务有相同的卷积特征。In this embodiment, the detector selects Faster R-CNN, a representative method of target detection based on deep learning, which uses RPN when selecting candidate frames to detect the convolutional features of the entire image shared by the network, so that the classification and regression tasks have the same Convolutional features.
步骤S2:对待关联的候选池中属于不同摄像头的两个行人图像计算外观适配度。Step S2: Calculate the appearance fit of two pedestrian images belonging to different cameras in the candidate pool to be associated.
在实施例中,计算外观适配度具体包括以下步骤:In an embodiment, calculating the appearance fit specifically includes the following steps:
步骤A21:使用模糊C均值聚类F-CCT模型完成图像预处理,设行人图像A的整体性特征为X={x1,x2,...,xN},行人图像B的整体性特征为Y={y1,y2,...,yN};使用模糊聚类算法对图像进行聚类域划分,通过源和目标图像的聚类域匹配,在聚类域间实现局部颜色亮度迁移,并引入隶属度因子提高颜色亮度迁移效果。Step A21: Use the fuzzy C-means clustering F-CCT model to complete image preprocessing, and set the overall feature of pedestrian image A to be X={x 1 , x 2 ,...,x N }, and the overall feature of pedestrian image B The feature is Y={y 1 , y 2 ,...,y N }; use fuzzy clustering algorithm to divide the clustering domain of the image, and achieve localization between the clustering domains by matching the clustering domains of the source and target images. Color brightness migration, and the introduction of membership factor to improve the effect of color brightness migration.
步骤A22:将步骤S21处理后的图像作为融合细粒度表征的行人关联模型SAM-Dets的输入数据:以X为输入向量,Y为权值向量,通过融合细粒度表征的行人关联模型SAM-Dets编码行人A具有的局部细粒度特征f1;以Y为输入向量,X为权值向量,通过融合细粒度表征的行人关联模型SAM-Dets编码行人B具有的局部细粒度特征f2。Step A22: The image processed in step S21 is used as the input data of the pedestrian association model SAM-Dets fused with fine-grained representation: X is the input vector, Y is the weight vector, and the pedestrian association model SAM-Dets is fused with fine-grained representation. Encode the local fine-grained feature f 1 of pedestrian A; take Y as the input vector and X as the weight vector, encode the local fine-grained feature f 2 of pedestrian B through the pedestrian association model SAM-Dets fused with fine-grained representation.
如图2所示,在本实施例中,融合细粒度表征的行人关联模型SAM-Dets,由多个注意力组成,模型中每个分支具有相同的功能模块,输入数据都为基础网络提取的行人全局特征。每一条注意力分支都一次经过局部检测器、全局池化和线性嵌入三个模块,最后将K条分支的结果按通道进行拼接获得注意力模型的完整输出结果。As shown in Figure 2, in this embodiment, the pedestrian association model SAM-Dets fused with fine-grained representation is composed of multiple attentions. Each branch in the model has the same functional module, and the input data is extracted by the basic network. Pedestrian global features. Each attention branch goes through the three modules of local detector, global pooling and linear embedding at a time, and finally the results of the K branches are spliced by channel to obtain the complete output of the attention model.
在局部检测器模块中,首先获取输入信息的高层特征,使用softmax函数对高层特征完成归一化得到符合概率分布取值区间的注意力权重,为下一步的求和操作需要先对高层特征的维度进行扩大处理,最后使用加权求和函数获得相应特征的注意力分配概率分布。全局池化模块和线性嵌入模块中,注意力分配概率分布筛选保留对应的行人特征,最后输出具有注意力分布的高层行人特征。In the local detector module, first obtain the high-level features of the input information, and use the softmax function to normalize the high-level features to obtain the attention weights that fit the value range of the probability distribution. The dimensions are enlarged, and finally, the weighted sum function is used to obtain the probability distribution of attention distribution of the corresponding features. In the global pooling module and the linear embedding module, the attention distribution probability distribution filters and retains the corresponding pedestrian features, and finally outputs the high-level pedestrian features with the attention distribution.
如图3所示,具体地,融合细粒度表征的行人关联模型SAM-Dets的网络结构包括:K个注意力分支和拼接层;每一注意力分支均包括以下六层,其中:As shown in Figure 3, specifically, the network structure of the pedestrian association model SAM-Dets fused with fine-grained representation includes: K attention branches and splicing layers; each attention branch includes the following six layers, where:
第一层为卷积层A,用于提取输入的行人整体特征的高层特征;The first layer is the convolutional layer A, which is used to extract the high-level features of the overall pedestrian features of the input;
第二层为激活层,激活函数为softmax;The second layer is the activation layer, and the activation function is softmax;
第三层为维度扩大层;The third layer is the dimension expansion layer;
第四层为求和层,将行人整体特征与第三层获得的结果相加;The fourth layer is the summation layer, which adds the overall pedestrian characteristics to the results obtained in the third layer;
第五层为全局平均池化层,用于降低特征维度;The fifth layer is the global average pooling layer, which is used to reduce the feature dimension;
第六层为全连接层,用于完成输入向量与权值矩阵中的权值向量的内积计算;The sixth layer is the fully connected layer, which is used to complete the inner product calculation of the input vector and the weight vector in the weight matrix;
拼接层将K个注意力分支得到的结果按通道拼接,输出行人局部细粒度特征。The splicing layer concatenates the results obtained by the K attention branches by channel, and outputs the local fine-grained features of pedestrians.
卷积层A的卷积核尺寸为1×1,步长为1;维度扩大层将通道维度扩大为512维;全局平均池化层的尺寸为1×1,步长为1。The size of the convolution kernel of convolutional layer A is 1×1 and the stride is 1; the dimension expansion layer expands the channel dimension to 512 dimensions; the size of the global average pooling layer is 1×1 and the stride is 1.
步骤A23:将要计算输入的一对行人的相似性值,转化成对f1和f2特征的相似性比较。引入一个无参数层Square层来对f1和f2特征求解平方差,作为f1和f2相似性比较层,并记该Square层为:fs=(f1-f2)2;将fs=(f1-f2)2作为两个核大小为1×1×4096的卷积层C的输入值,将softmax作为输出函数,输出一个二维向量(q1,q2),表示输入两个对象属于现实世界中同一个人的概率值,作为外观适配度。Step A23: Convert the similarity value of a pair of pedestrians input to be calculated into a similarity comparison of f 1 and f 2 features. A non-parameter layer Square layer is introduced to solve the square difference of f 1 and f 2 features, as the similarity comparison layer of f 1 and f 2 , and the Square layer is recorded as: f s =(f 1 -f 2 ) 2 ; f s =(f 1 -f 2 ) 2 is used as the input value of two convolutional layers C with kernel size of 1×1×4096, and softmax is used as the output function to output a two-dimensional vector (q 1 ,q 2 ), Represents the probability value that the input two objects belong to the same person in the real world, as the appearance fit.
进一步地,根据获得的一对行人间的相似性概率值作为图的权值,将新进入的行人和待关联的目标行人分别作为两个不同的顶点集合,建立带权值匹配图;通过求解最大权值匹配图问题的解,获得新进入的行人与等待关联的目标行人间的数据关联的解。Further, according to the obtained similarity probability value between a pair of pedestrians as the weight of the graph, the newly entered pedestrian and the target pedestrian to be associated are regarded as two different sets of vertices, respectively, to establish a matching graph with weights; by solving The solution of the maximum weight matching graph problem is obtained, and the solution of the data association between the newly entered pedestrian and the target pedestrian waiting to be associated is obtained.
步骤S3:将待关联的候选池中的行人图像两两配对计算完外观适配度后,根据每对行人外观适配度,结合时空关系,建立最小费用流图模型,求解最优的行人关联解。Step S3: After the pedestrian images in the candidate pool to be associated are paired to calculate the appearance fit degree, according to the appearance fit degree of each pair of pedestrians, combined with the spatiotemporal relationship, a minimum cost flow graph model is established to solve the optimal pedestrian association untie.
其具体包括以下步骤:It specifically includes the following steps:
步骤S31:设给定tp-1时刻下的完成即时对齐后的费用流图为


步骤S32:根据视野内行人集


步骤S33:删除所有对齐目标节点以及视野内行人集


步骤S4:根据步骤S3的关联结果,对行人进行保持原有标识或者赋予新的身份标识的操作,并交由跟踪器延续追踪;跟踪器采用采用KCF算法进行跟踪;KCF算法为每个行人分配一个跟踪器。该算法在目标区域形成循环矩阵,再利用循环矩阵在傅里叶空间可以对角化等一些性质,通过回归岭回归得到通用的预测公式。Step S4: According to the association result of Step S3, keep the original identification or assign a new identification to the pedestrian, and hand it over to the tracker to continue tracking; the tracker adopts the KCF algorithm to track; the KCF algorithm assigns each pedestrian a tracker. The algorithm forms a circulant matrix in the target area, and then uses some properties such as the circulant matrix can be diagonalized in Fourier space, and obtains a general prediction formula through regression ridge regression.
同时,本实施例中,将摄像头的跟踪视野区域划分为核心区域和临界区域,在步骤S1中,通过检测器只检测临界区域的行人。这是考虑到任何目标的进入和离开都必先经过临界区域,因此,只考察临界区域内的行人具有合理空间转移关系,以最大程度地保证后续行人对齐求解的普适性。Meanwhile, in this embodiment, the tracking field of view area of the camera is divided into a core area and a critical area, and in step S1, only pedestrians in the critical area are detected by the detector. This is to consider that the entry and exit of any target must first pass through the critical area. Therefore, only the pedestrians in the critical area have a reasonable spatial transfer relationship to ensure the universality of the subsequent pedestrian alignment solution to the greatest extent.
在本发明的第二个实施例中,如图4所示,其提供了步骤S2:对待关联的候选池中属于不同摄像头的两个行人图像计算外观适配度的另一种优选的可实现方案,其具体包括以下步骤:In the second embodiment of the present invention, as shown in FIG. 4 , it provides step S2: another preferred implementation of calculating the appearance adaptation degree of two pedestrian images belonging to different cameras in the candidate pool to be associated The scheme specifically includes the following steps:
步骤B21:使用模糊C均值聚类F-CCT模型完成图像预处理,设行人图像A的整体性特征为X={x1,x2,...,xN},行人图像B的整体性特征为Y={y1,y2,...,yN};Step B21: Use the fuzzy C-means clustering F-CCT model to complete image preprocessing, set the overall feature of pedestrian image A as X={x 1 ,x 2 ,...,x N }, the overall feature of pedestrian image B The characteristic is Y={y 1 , y 2 ,...,y N };
步骤B22:将行人图像A和行人图像B经过DR-ResNet基础网络提取行人抽象特征;Step B22: Extract the pedestrian abstract features from the pedestrian image A and the pedestrian image B through the DR-ResNet basic network;
步骤B23:使用卷积层B进一步提取目标行人高层特征,作为分类模型和融合细粒度表征的行人关联模型SAM-Dets的输入数据;分类模型分别输出行人图像A和行人图像B各自的身份识别表示号,融合细粒度表征的行人关联模型SAM-Dets输出行人A具有的局部细粒度特征f1,行人B具有的局部细粒度特征f2。Step B23: Use the convolutional layer B to further extract the high-level features of the target pedestrian as the input data of the classification model and the pedestrian association model SAM-Dets fused with fine-grained representation; the classification model outputs the respective identification representations of the pedestrian image A and the pedestrian image B respectively , the pedestrian association model SAM-Dets fused with fine-grained representation outputs the local fine-grained feature f 1 of pedestrian A and the local fine-grained feature f 2 of pedestrian B.
步骤B24:将fs=(f1-f2)2作为两个核大小为1×1×4096的卷积层C的输入值,将softmax作为输出函数,输出一个二维向量(q1,q2),表示输入两个对象属于现实世界中同一个人的概率值,作为外观适配度。Step B24: take f s =(f 1 -f 2 ) 2 as the input value of the two convolutional layers C with a kernel size of 1×1×4096, take softmax as the output function, and output a two-dimensional vector (q 1 , q 2 ), representing the probability value that the input two objects belong to the same person in the real world, as the appearance fit degree.
其中,DR-ResNet基础网络包括两个权重共享的完全相同的深度卷积孪生神经基础网络模块R-ResNet;深度卷积孪生神经基础网络模块R-ResNet的结构包括四十九层卷积层、三个并行的卷积层、以及末端卷积层:Among them, the DR-ResNet basic network includes two identical deep convolutional Siamese neural basic network modules R-ResNet with shared weights; the structure of the deep convolutional Siamese neural basic network module R-ResNet includes forty-nine convolutional layers, Three parallel convolutional layers, and end convolutional layers:
其中,第一卷积层的卷积核大小为(7,7,64),max-pooling为(3,3),滑动步长为2;Among them, the convolution kernel size of the first convolution layer is (7, 7, 64), the max-pooling is (3, 3), and the sliding step size is 2;
第二卷积层到第四卷积层的卷积核大小分别为(1,1,64)、(3,3,64)、(1,1,256),激活函数都采用ReLu函数;该三层卷积层和激活函数组成一个卷积块,将该卷积块的输入值既作为第二卷积层的输入值,也作为卷积块的第三层激活函数的输入值;第五卷积层到第七卷积层,以及第八卷积层到第十卷积层都采用与第二卷积层到第四卷积层相同的结构;The convolution kernel sizes from the second convolutional layer to the fourth convolutional layer are (1,1,64), (3,3,64), (1,1,256) respectively, and the activation functions all use the ReLu function; the three layers The convolution layer and the activation function form a convolution block, and the input value of the convolution block is used both as the input value of the second convolution layer and the input value of the activation function of the third layer of the convolution block; the fifth convolution Layers to the seventh convolutional layer, and the eighth convolutional layer to the tenth convolutional layer all use the same structure as the second to the fourth convolutional layer;
第十一卷积层到第十三卷积层的卷积核大小分别为(1,1,128)、(3,3,128)、(1,1,512),激活函数都采用ReLu函数;该三层卷积层和激活函数组成一个卷积块,将该卷积块的输入值既作为第十一层卷积层的输入值,也作为卷积块的第三层激活函数的输入值;第十四卷积层到第十六卷积层、第十七卷积层到第十九卷积层以及第二十卷积层到第二十二卷积层都采了与第十一卷积层到第十三卷积层相同的结构;The convolution kernel sizes of the eleventh convolutional layer to the thirteenth convolutional layer are (1, 1, 128), (3, 3, 128), (1, 1, 512), and the activation functions all use the ReLu function ; The three-layer convolution layer and the activation function form a convolution block, and the input value of the convolution block is used as the input value of the eleventh convolution layer and the input of the activation function of the third layer of the convolution block. value; the fourteenth convolutional layer to the sixteenth convolutional layer, the seventeenth convolutional layer to the nineteenth convolutional layer, and the twentieth convolutional layer to the twenty-second convolutional layer all adopt the same value as the tenth convolutional layer. The same structure from a convolutional layer to the thirteenth convolutional layer;
第二十三卷积层到第二十五卷积层的卷积核大小分别为(1,1,256)、(3,3,256)、(1,1,1024),激活函数都采用ReLu函数;该三层卷积层和激活函数组成一个卷积块,将该卷积块的输入值既作为第二十三卷积层的输入值,也作为卷积块的第三层激活函数的输入值;第二十六卷积层到第二十八卷积层、第二十九卷积层到三十一卷积层、第三十二卷积层到第三十四卷积层、第三十五卷积层到三十七卷积层、第三十八卷积层到第四十卷积层均采用与第二十三卷积层到二十五卷积层相同的结构;The convolution kernel sizes of the twenty-third convolutional layer to the twenty-fifth convolutional layer are (1, 1, 256), (3, 3, 256), (1, 1, 1024), respectively, and the activation functions are all used ReLu function; the three-layer convolution layer and the activation function form a convolution block, and the input value of the convolution block is used as the input value of the twenty-third convolution layer and the activation function of the third layer of the convolution block. The input value of ; the twenty-sixth convolutional layer to the twenty-eighth convolutional layer, the twenty-ninth convolutional layer to the thirty-first convolutional layer, the thirty-second convolutional layer to the thirty-fourth convolutional layer , the thirty-fifth convolutional layer to the thirty-seventh convolutional layer, and the thirty-eighth convolutional layer to the fortieth convolutional layer all adopt the same structure as the twenty-third convolutional layer to the twenty-fifth convolutional layer ;
第四十一卷积层到第四十三卷积层的卷积核大小分别为(1,1,512)、(3,3,512)、(1,1,2048),激活函数都采用ReLu函数;该三层卷积层和激活函数组成一个卷积块,将该卷积块的输入值既作为第四十一卷积层的输入值,也作为卷积块的第三层激活函数的输入值;第四十四卷积层到第四十六卷积层、第四十七卷积层到四十九卷积层采用与第四十一卷积层到第四十二卷积层相同的结构;The convolution kernel sizes of the forty-first convolutional layer to the forty-third convolutional layer are (1, 1, 512), (3, 3, 512), (1, 1, 2048), respectively, and the activation functions are all used ReLu function; the three-layer convolution layer and the activation function form a convolution block, and the input value of the convolution block is used as both the input value of the 41st convolution layer and the activation function of the third layer of the convolution block. The input value of ; the forty-fourth convolutional layer to the forty-sixth convolutional layer, the forty-seventh convolutional layer to the forty-ninth convolutional layer are convolutional with the forty-first convolutional layer to the forty-second convolutional layer layers of the same structure;
在第四十九卷积层后为三个并行的卷积层,每个卷积层,使用2048个卷积核,第一并行卷积层到第三并行卷积层的尺寸大小分别为(3,3,1024)、(5,5,1024)和(7,7,1024),通过一个连接层将三个并行的卷积层的通道进行合并,其后的max-pooling为(4,4);After the forty-ninth convolutional layer, there are three parallel convolutional layers. Each convolutional layer uses 2048 convolution kernels. The sizes of the first parallel convolutional layer to the third parallel convolutional layer are ( 3, 3, 1024), (5, 5, 1024) and (7, 7, 1024), the channels of the three parallel convolutional layers are merged through a connection layer, and the subsequent max-pooling is (4, 4);
最后一层是使用1024个卷积核,且尺寸大小为(2,2,2048)的末端卷积层;The last layer is an end convolutional layer with 1024 convolution kernels and a size of (2, 2, 2048);
卷积层B使用2个卷积核,尺寸大小为(1,1,4096)。Convolutional layer B uses 2 convolution kernels of size (1, 1, 4096).
如图5、图6所示,通过本实施例的方案,与现有的离线跨摄像头跟踪的方案均实现了跨摄像头跟踪的性能,区别在于,本实施例方案直接可以实现用于在线的跟踪。As shown in FIG. 5 and FIG. 6 , the solution of this embodiment and the existing offline cross-camera tracking solution both achieve the performance of cross-camera tracking. The difference is that the solution of this embodiment can directly realize online tracking. .
本专利不局限于上述最佳实施方式,任何人在本专利的启示下都可以得出其它各种形式的跨摄像头场景下行人身份对齐方法,凡依本发明申请专利范围所做的均等变化与修饰,皆应属本专利的涵盖范围。This patent is not limited to the above-mentioned best embodiment, anyone can come up with other various forms of pedestrian identity alignment methods in cross-camera scenes under the inspiration of this patent. Modifications should all fall within the scope of this patent.
Claims (1)









Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN201911189515.XA CN110969112B (en) | 2019-11-28 | 2019-11-28 | Pedestrian identity alignment method under camera-crossing scene |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN201911189515.XA CN110969112B (en) | 2019-11-28 | 2019-11-28 | Pedestrian identity alignment method under camera-crossing scene |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN110969112A CN110969112A (en) | 2020-04-07 |
| CN110969112B true CN110969112B (en) | 2022-08-16 |
Family
ID=70031971
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN201911189515.XA Expired - Fee Related CN110969112B (en) | 2019-11-28 | 2019-11-28 | Pedestrian identity alignment method under camera-crossing scene |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN110969112B (en) |
Families Citing this family (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN110969571A (en) * | 2019-11-29 | 2020-04-07 | 福州大学 | Method and system for specified self-adaptive illumination migration in camera-crossing scene |
| TWI718981B (en) * | 2020-08-10 | 2021-02-11 | 威聯通科技股份有限公司 | Cross-sensor object attribute analysis method and system |
| CN112287868B (en) * | 2020-11-10 | 2021-07-13 | 上海依图网络科技有限公司 | A method and device for human action recognition |
| CN112950954B (en) * | 2021-02-24 | 2022-05-20 | 电子科技大学 | An intelligent parking license plate recognition method based on high-level camera |
| CN113947782B (en) * | 2021-10-14 | 2024-06-07 | 哈尔滨工程大学 | Pedestrian target alignment method based on attention mechanism |
| CN114565636A (en) * | 2022-02-28 | 2022-05-31 | 重庆长安汽车股份有限公司 | Target association method based on multiple cameras |
| CN121213619B (en) * | 2025-11-25 | 2026-03-17 | 北京利斯达新技术有限公司 | A method and device for multi-target cooperative tracking across cameras |
Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN106056581A (en) * | 2016-05-23 | 2016-10-26 | 北京航空航天大学 | Method of extracting infrared pedestrian object by utilizing improved fuzzy clustering algorithm |
| CN108198200A (en) * | 2018-01-26 | 2018-06-22 | 福州大学 | The online tracking of pedestrian is specified under across camera scene |
| CN108257158A (en) * | 2018-03-27 | 2018-07-06 | 福州大学 | A kind of target prediction and tracking based on Recognition with Recurrent Neural Network |
| CN110428448A (en) * | 2019-07-31 | 2019-11-08 | 腾讯科技(深圳)有限公司 | Target detection tracking method, device, equipment and storage medium |
Family Cites Families (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US8842881B2 (en) * | 2012-04-26 | 2014-09-23 | General Electric Company | Real-time video tracking system |
| PL3209033T3 (en) * | 2016-02-19 | 2020-08-10 | Nokia Technologies Oy | Controlling audio rendering |
-
2019
- 2019-11-28 CN CN201911189515.XA patent/CN110969112B/en not_active Expired - Fee Related
Patent Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN106056581A (en) * | 2016-05-23 | 2016-10-26 | 北京航空航天大学 | Method of extracting infrared pedestrian object by utilizing improved fuzzy clustering algorithm |
| CN108198200A (en) * | 2018-01-26 | 2018-06-22 | 福州大学 | The online tracking of pedestrian is specified under across camera scene |
| CN108257158A (en) * | 2018-03-27 | 2018-07-06 | 福州大学 | A kind of target prediction and tracking based on Recognition with Recurrent Neural Network |
| CN110428448A (en) * | 2019-07-31 | 2019-11-08 | 腾讯科技(深圳)有限公司 | Target detection tracking method, device, equipment and storage medium |
Non-Patent Citations (5)
| Title |
|---|
| An Equalized Global Graph Model-Based Approach for Multicamera Object Tracking;W.Chen 等;《in IEEE Transactions on Circuits and Systems for Video Technology》;20160711;全文 * |
| 余春艳 等.鉴别性特征学习模型实现跨摄像头下行人即时对齐.《计算机辅助设计与图形学学报》.2019,第31卷(第4期),第602-611页. * |
| 基于深度学习和时空约束的跨摄像头行人跟踪;夏天 等;《计算机与数字工程》;20171130;第45卷(第11期);全文 * |
| 联合多级深度特征表示和有序加权距离融合的视频行人再识别方法;孙锐 等;《光学学报》;20190930;第39卷(第9期);全文 * |
| 鉴别性特征学习模型实现跨摄像头下行人即时对齐;余春艳 等;《计算机辅助设计与图形学学报》;20190415;第31卷(第4期);正文第1-4节 * |
Also Published As
| Publication number | Publication date |
|---|---|
| CN110969112A (en) | 2020-04-07 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN110969112B (en) | Pedestrian identity alignment method under camera-crossing scene | |
| CN108198200B (en) | Method for tracking specified pedestrian on line under cross-camera scene | |
| CN109858390B (en) | Human skeleton behavior recognition method based on end-to-end spatiotemporal graph learning neural network | |
| CN111259837B (en) | A method and system for pedestrian re-identification based on part attention | |
| CN110717411A (en) | A Pedestrian Re-identification Method Based on Deep Feature Fusion | |
| CN111860291A (en) | Multimodal pedestrian identification method and system based on pedestrian appearance and gait information | |
| CN110147743A (en) | A real-time online pedestrian analysis and counting system and method in complex scenes | |
| CN114613013A (en) | End-to-end human behavior recognition method and model based on skeleton nodes | |
| CN111680560A (en) | A pedestrian re-identification method based on spatiotemporal features | |
| CN111639564B (en) | Video pedestrian re-identification method based on multi-attention heterogeneous network | |
| CN116935486B (en) | Sign language identification method and system based on skeleton node and image mode fusion | |
| CN109086659B (en) | Human behavior recognition method and device based on multi-channel feature fusion | |
| CN114419671A (en) | Hypergraph neural network-based occluded pedestrian re-identification method | |
| CN106846378B (en) | A Cross-Camera Target Matching and Tracking Method Combined with Spatiotemporal Topology Estimation | |
| CN112651262A (en) | Cross-modal pedestrian re-identification method based on self-adaptive pedestrian alignment | |
| CN118135659B (en) | Cross-view gait recognition method based on multi-scale skeleton space-time feature extraction | |
| CN110705344B (en) | Crowd counting model based on deep learning and implementation method thereof | |
| CN101616309A (en) | Non-overlapping visual field multiple-camera human body target tracking method | |
| CN105095870A (en) | Pedestrian re-recognition method based on transfer learning | |
| CN109214263A (en) | A kind of face identification method based on feature multiplexing | |
| Hsu et al. | GAITTAKE: Gait recognition by temporal attention and keypoint-guided embedding | |
| Miao et al. | ClothingNet: Cross-domain clothing retrieval with feature fusion and quadruplet loss | |
| CN104850857B (en) | Across the video camera pedestrian target matching process of view-based access control model spatial saliency constraint | |
| CN112507835B (en) | Method and system for analyzing multi-target object behaviors based on deep learning technology | |
| CN110032952A (en) | A kind of road boundary point detecting method based on deep learning |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant | ||
| CF01 | Termination of patent right due to non-payment of annual fee |
Granted publication date: 20220816 |
|
| CF01 | Termination of patent right due to non-payment of annual fee |