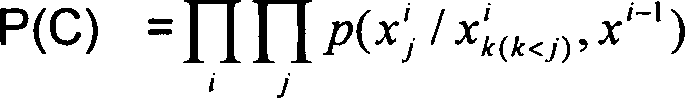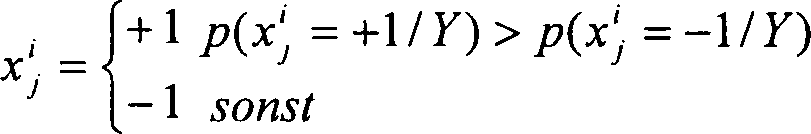-
Das Gebiet der Erfindung ist das
der Übertragung
oder Ausstrahlung von Digitaldaten-Signalen. Genauer genommen betrifft
die Erfindung das Dekodieren gesendeter Digitaldaten und insbesondere
das Quellendekodieren. Noch genauer ist die Erfindung für das Dekodieren
mit Hilfe einer Quellenkodierung codierter Daten verwendbar, die
von entropischen Codes vom Code-Typ variabler Länge Gebrauch macht (VLC, auf englisch:
"variable length code").
-
Die heute häufig verwendeten digitalen
Kommunikationssysteme basieren auf Kodierungssystemen, die einerseits
eine Quellenkodierung und andererseits eine Kanalkodierung verwenden.
Diese beiden Kodierungen sind üblicherweise
separat optimiert. Der Quellencodierer hat das Ziel, die Redundanz
des zu sendenden Quellensignals größtmöglich zu verringern. Danach
bringt der Kanalcodierer auf kontrollierte Weise Redundanz ein,
um diese Information vor Störungen
zu schützen,
die jeder Übertragung
innewohnen.
-
Derzeit werden die besten Ergebnisse
mit einer Quellenkodierung (Audio-, Bild- und/oder Videoquelle) mit
diskreten Cosinus-Transformations- (DCT, auf englisch: "discrete
cosine transform") oder insbesondere Wavelett-Kodierern erzielt,
die mit VLC-Codes verbunden sind. Die Kanalkodierung verwendet vorzugsweise das
Konzept der Turbo-Codes [1] (die Literaturstellen sind im Anhang
C zusammengestellt, um das Lesen der vorliegenden Beschreibung zu
erleichtern) und allgemeiner iterativer Decodierer mit weichen Entscheidungen. Diese
Techniken haben einen entscheidenden Schritt in Richtung auf die
von Shannon [2] definierte theoretische Grenze ermöglicht.
-
Jedoch ist die optimale Trennung
der Quellenkodierung und der Kanalkodierung außer für Codes, deren Länge gegen
Unendlich geht, nicht garantiert. Daher sind Untersuchungen gleichfalls
darauf gerichtet, mit Kanalcodes endlicher Länge gemeinsame Quellen-Kanal-Kodierungs-und/Dekodierungssysteme
zu schaffen.
-
Die Erfindung betrifft somit das
Dekodieren entropischer Codes und insbesondere, aber nicht ausschließlich, die
gemeinsame Quellen-Kanal-Dekodierung
eines Systems, das einen entropischen Code verwendet.
-
Das gemeinsame Dekodieren weist eine
Reihe von Anwendungsgebieten auf, beispielsweise die Übertragung
von Videobildern, insbesondere gemäß der Norm MPEG4 (Moving Picture
Expert Group).
-
Die Codes mit variabler Länge sind
gut bekannt. Beispielhaft wird im Anhang A kurz der Huffman-Code dargestellt.
Die im nachfolgenden beschriebene bestimmte Ausführungsform der Erfindung eignet
sich insbesondere, aber nicht ausschließlich für diesen Typ entropischen Codes.
-
Die Codes mit variabler Länge stellen
einen erheblichen Einsatz für
das Beschränken
des durch das gesendete Signal belegten Bandes dar, jedoch führt ihre
Verwendung dazu, daß die Übertragung
weniger robust gegenüber
Fehlern wird. Zudem ist es schwierig, die a priori Wahrscheinlichkeiten
der zu dekodierenden Quelle zu verwenden, weil man weder den Anfang
noch das Ende jedes Wortes kennt, da ja deren Länge per definitionem variabel
ist.
-
Verschiedene Techniken sind vorgeschlagen
worden, um eine gemeinsame Quellen-Kanal-Dekodierung, die mit der
Verwendung dieser Codes mit variabler Länge verbunden ist, durchzuführen. Insbesondere:
- – K.
Sayood und N. Demir haben in [4] eine Dekodierung auf der Ebene
der Wörter
der VLC-Codes vorgeschlagen. Man findet zwei Hauptnachteile dieser
Art der Dekodierung, nämlich
eine Komplexität
des Gitters, die mit der Anzahl der verschiedenen VCL-Wörter schnell
zunimmt, und eine Dekodierung, die auf der Ebene der Symbole (oder
Wörter)
bleibt.
- – Ahshun
H Murad und Thomas E. Fuja [5] schlagen ein Supergitterverfahren
vor, bei dem das Decodiergitter dasjenige ist, das durch das Produkt
des Kanaldecodiergitters, des Quellendecodiergitters und des die
Quelle darstellenden Gitters erhalten wird. Diese Lösung ist
durch die Komplexität
der Dekodierung offensichtlich beschränkt.
- – K.
P. Subbalaskshmi und J. Vaisey [6] geben eine Gitterstruktur an,
die es möglich
macht, den Anfang und das Ende jedes Wortes zu kennen und damit
diese Information a priori auf die gesendeten VLC-Wörter anzuwenden.
Dieser Decodierer arbeitet auf Wortebene und verschiebt nicht zugehörende Informationen nicht
auf die decodierten Bits.
- – Jiangtao
Wen und John D. Villasenor [7] verwenden einen Dekodierungsblock,
der auf Wortebene arbeitet und eine Zuverlässigkeit verringert, was die
decodierte Folge betrifft. Dieser Decodierer verwendet die Anzahl
der VLC-Wörter
in der empfangenen Folge als a priori Information.
-
Der Erfindung liegt insbesondere
die Aufgabe zugrunde, die verschiedenen Nachteile dieser bekannten
Techniken zu überwinden.
-
Genauer genommen liegt eine Aufgabe
der Erfindung darin, eine Technik zum Dekodieren mit Hilfe eines
entropischen Codes codierter Daten zu schaffen, die eine Verringerung
der Symbolfehlerrate ermöglicht, insbesondere
im Verhältnis
zu den getrennten Decodierschemata (Tandem).
-
Im Hinblick auf die Ausführung liegt
eine Aufgabe der Erfindung darin, eine derartige Decodiertechnik zu
schaffen, die im Vergleich zu den bekannten Techniken eine stark
verringerte Komplexität
aufweist.
-
Insbesondere liegt eine Aufgabe der
Erfindung darin, eine Decodiertechnik zu schaffen, die eine vernünftige Betriebskomplexität aufweist,
d. h. in der Praxis bei vernünftigen
Kosten ausführbar
ist, und bei der insbesondere die Anzahl verschiedener Wörter, die
vom entropischen Code berücksichtigt
werden, hoch ist.
-
Der Erfindung liegt ebenfalls die
Aufgabe zugrunde, eine Technik schaffen, die vertrauliche Informationen
auf Bitebene liefert, die durch die Kanaldekodierung verwertbar
sind.
-
Mit anderen Worten liegt eine bestimmte
Aufgabe der Erfindung darin, gemeinsame Quellen-Kanal-Decodierverfahren
zu schaffen, die an entropische Codes, insbesondere die VLC- und
RVLC-Codes, angepaßt
sind.
-
Eine nochmals weitere Aufgabe der
Erfindung liegt darin, eine Decodiertechnik zu schaffen, die eine Verbesserung
der mit den bekannten Kanal-Codes
und insbesondere mit Turbo-Codes verwendeten Codierern erhaltene
Leistungsfähigkeit
gestattet.
-
Diese sowie andere Aufgaben, die
durch das Nachfolgende klarer werden, werden mit Hilfe eines Verfahrens
zum Dekodieren von empfangenen Digitaldaten, die gesendeten Digitaldaten
entsprechen, welche mittels eines entropischen Codes codiert worden
sind, der jedem Wort eines Alphabets eine unterschiedliche Bitfolge
zuordnet, deren Länge
eine Funktion der Auftrittswahrscheinlichkeit dieses Wortes ist,
erreicht.
-
Erfindungsgemäß wird dieses Verfahren mit
einem Decodiergitter ausgeführt,
bei dem jeder Übergang einem
Binärwert
von 0 oder 1 eines der Bits einer Bitfolge entspricht, die einem
der genannten Wörter
entspricht.
-
Mit anderen Worten beruht die Erfindung
auf einem neuen Ansatz zum Dekodieren von Codes mit variabler Länge, bei
dem man die Übergänge auf
Bitebene und nicht klassisch auf Wort- oder Symbolebene berücksichtigt.
-
Dieser Ansatz ist neu und nicht naheliegend,
weil der Fachmann davon überzeugt
ist, daß dadurch, daß die Symbole
variable Längen
aufweisen, ein Arbeiten auf Symbolniveau erforderlich ist, um ihren
Anfang und ihr Ende zu kennen. Die Erfinder zeigen, daß dies nicht
erforderlich ist.
-
Zudem gestattet die Verarbeitung
auf Bitebene, eine durch einen Decodierkanal auswertbare Information
zu erhalten und so eine gemeinsame Dekodierung durchzuführen, wie
es im Nachfolgenden deutlicher wird.
-
Der entropische Code kann in der
Form eines binären
Baums dargestellt werden, der einen Wurzelknoten, eine Vielzahl
von Zwischenknoten und eine Vielzahl von Blattknoten umfaßt, wobei
eine Bitfolge einem der erwähnten
Wörter
entspricht, die unter Berücksichtigung
der aufeinanderfolgenden Übergänge des Baums gebildet
werden, vom Wurzelknoten bis zu dem dem besagten Wort zugeordneten
Blattknoten. In diesem Fall umfassen vorteilhafterweise die Zustände jeder
Stufe des Gitters einen einzigen, extremal genannten Zustand, der
dem Wurzelknoten und der Menge der Blattknoten entspricht, sowie
einen unterschiedlichen, Zwischenzustand genannten Zustand für jeden
der Zwischenknoten.
-
So erhält man ein einfaches Gitter
mit einer verringerten Anzahl von Zuständen.
-
Vorzugsweise ordnet man jedem Übergang
des Gitters eine Wahrscheinlichkeitsinformation zu. Die Wahrscheinlichkeitsinformation
ist vorteilhafterweise eine Metrik, die einerseits eine für den Sendekanal
repräsentative
Information und andererseits eine a priori Information über den
entropischen Code berücksichtigt.
-
Beispielsweise gehört die a
priori Information der Gruppe an, die folgendes umfaßt:
- – den
eingesetzten entropischen Code und/oder
- – die
a priori Wahrscheinlichkeiten jedes Wortes des Codes und/oder
- – die
Zahl der gesendeten Wörter
und/oder
- – Grenzwerte
für die
Koeffizienten.
-
So ist für jeden der erwähnten Übergänge die
folgende Wahrscheinlichkeit berechenbar: Γi[(xk, xpk ), dk, dk–1]
= Pr(xk/ak = i)Pr(ypk /ak = i, dk, dk–1)Pr{ak = i, dk/dk–1} deren
Informationen und Parameter nachfolgend beschrieben sind.
-
Der entropische Code kann insbesondere
der Gruppe angehören,
die folgendes umfaßt:
- – die
Huffman-Codes,
- – die
reversiblen Codes variabler Länge
(RVLC).
-
Im Fall eines RVLC-Codes wird die
a priori Information vorzugsweise für eine Vorlaufphase des erwähnten Gitters
und eine Rücklaufphase
des erwähnten
Gitters verwendet.
-
Die Erfindung betrifft ebenfalls
ein gemeinsames Quellen-Kanal-Decodierverfahren
eines empfangenen digitalen Signals, das auf diesem Ansatz beruht,
wobei die Quellenkodierung einen entropischen Code verwendet, der
jedem Wort eines Alphabets eine unterschiedliche Bitfolge zugeordnet,
deren Länge
eine Funktion der Auftrittswahrscheinlichkeit des Wortes ist.
-
Erfindungsgemäß führt das gemeinsame Decodierverfahren
eine Quellendekodierung aus, die mindestens ein Decodiergitter verwendet,
von dem jeder Übergang
einem Binärwert
von 0 oder 1 eines der Bits einer Bitfolge entspricht, die einem
der erwähnten
Wörter
entspricht, wobei die Quellendekodierung eine der Kanaldekodierung
nicht zugehörende
oder extrinsische Information liefert.
-
Die Kanaldekodierung kann vorteilhafterweise
eine Dekodierung des Typs Turbo-Code verwenden, der auf einer Anwendung
des parallelen oder seriellen Typs beruhen kann.
-
Vorteilhafterweise beruht das erfindungsgemäße gemeinsame
Decodierverfahren auf einer iterativen Anwendung.
-
In diesem Fall kann jede der Iterationen
sequentiell einen Schritt der Kanaldekodierung und einen Schritt
der Quellendekodierung umfassen, wobei der Schritt der Kanaldekodierung
eine Kanalinformation liefert, die bei dem Schritt der Quellendekodierung
berücksichtigt
wird, wobei letztere eine a priori Information liefert, die bei
dem Schritt der Kanaldekodierung berücksichtigt wird.
-
Insbesondere kann das Verfahren umfassen:
- – einen
ersten Schritt der Kanaldekodierung,
- – einen
ersten Schritt der Quellendekodierung, die vom ersten Schritt der
Kanaldekodierung gespeist wird,
- – einen
zweiten Schritt der Kanaldekodierung, der vom ersten Schritt der
Kanaldekodierung und vom ersten Schritt der Quellendekodierung gespeist
wird, über
eine Verschachtelungsvorrichtung, die identisch ist mit der beim
Kodieren verwendeten Verschachtelungsvorrichtung, und welche den
ersten Schritt der Kanaldekodierung über eine zur erwähnten Verschachtelungsvorrichtung
symmetrische Entschachtelungsvorrichtung speist,
- – einen
zweiten Schritt der Quellendekodierung, der vom zweiten Schritt
der Kanaldekodierung über
die erwähnte
Entschachtelungsvorrichtung gespeist wird und den erwähnten ersten
Schritt der Kanaldekodierung speist.
-
Gemäß einem weiteren Aspekt der
Erfindung betrifft diese auch ein gemeinsames Quellen-Kanal-Decodiervertahren
für ein
empfangenes digitales Signal, wobei die Quellenkodierung einen entropischen
Code verwendet, der jedem Wort eines Alphabets eine unterschiedliche
Bitfolge zuordnet, deren Länge
eine Funktion der Auftrittswahrscheinlichkeit dieses Worts ist,
wobei das Verfahren ein Kanaldecodiergitter einsetzt, das dem Kanalcodiergitter ähnlich ist,
bei dem jedem Zustand jeder Ebene eine Information zugeordnet wird,
die für
eine durch diesen Zustand laufende Folge von decodierten Bits aus
der Vergangenheit, im Verhältnis
zur Richtung des Weges durch das Gitter, repräsentativ ist, wobei die Position
des betrachteten Bits im Baum den entropischen Code und/oder eine
Information zum Verifizieren der Zahl der decodierten Wörter und/oder
den von den decodierten Bits angenommenen Wert darstellt.
-
In diesem Fall umfaßt das gemeinsame
Decodierverfahren vorteilhafterweise für jeden der genannten Zustände die
folgenden Schritte:
- – Hinzufügen der Kanalmetrik und der
Quellenmetrik zu den beiden in diesem Zustand ankommenden Zweigen,
- – Vergleichen
der zwei neuen erhaltenen Metriken und Wahl der schwächsten,
- – wenn
die die Position angebende Information das Ende eines Wortes angibt,
Annehmen, daß der
Knoten ein Blatt eines Baumes ist, sonst Fortschreiten zum nachfolgenden
Knoten im Baum.
-
Vorzugsweise verwendet das Verfahren
ein iteratives Verfahren, das beispielsweise die nachfolgenden Schritte
enthalten kann:
- – erste Kanaldekodierung, die
ein Kanaldekodierungsgitter verwendet, bei dem jeder Zustand über eine
Information verfügt,
welche die Position des betrachteten Bits in dem das erwähnte entropische
Code darstellenden Baum bezeichnet,
- – zweite
Kanaldekodierung, gespeist von der ersten Kanaldekodierung über eine
Verschachtelungsvorrichtung, die identisch ist zu der beim Kodieren
eingesetzten, und welche die erste Kanaldekodierung über eine Entschachtelungsvorrichtung
speist, die zur erwähnten
Verschachtelungsvorrichtung symmetrisch ist.
- – Quellendekodierung,
gespeist von der erwähnten
zweiten Kanaldekodierung über
die besagte Entschachtelungsvorrichtung.
-
Auch in diesem Fall verwendet man
vorteilhafterweise eine Dekodierung vom Typ Turbo-Code (parallel
oder seriell).
-
Vorteilhafterweise verwendet jede
Iteration der erwähnten
Dekodierung des Typs Turbo-Code eine Blockmatrix, welche Zeilen
und Spalten aufweist und auf welche eine Zeilendekodierung (bzw.
Spaltendekodierung) angewandt wird, gefolgt von einer Spaltendekodierung
(bzw. Zeilendekodierung), und man verwendet diese a priori Information
für die
Zeilendekodierung (bzw. Spaltendekodierung).
-
In diesem Fall entspricht vorzugsweise
jede Zeile (bzw. Spalte) einem Codewort, das aus k Informationsbits
und n – k
Füllbits
gebildet ist, und die a priori Information wird auf die k Informationsbits
angewendet.
-
Insbesondere wenn der verwendete
Code ein RVLC-Code ist, ist es von Vorteil, das Kanaldekodierungsgitter
und das Quellendekodierungsgitter miteinander zu verketten, wobei
die Kanaldekodierung durch eine a priori Information bezüglich der
Quelle gesteuert wird.
-
Man kann ferner einen "List-Viterbi"
genannten Algorithmus der parallelen oder seriellen Art verwenden,
der einem Schritt zum Ersetzen einer von der Quelle nicht zugelassenen
Folge durch die am wahrscheinlichsten zugelassene Folge auf dem
Weg durch das Kanaldekodierungsgitter zugeordnet ist, oder einen "SUBMAP"
genannten Algorithmus sowohl beim Hinlauf als auch beim Rücklauf durch
das Kanaldekodierungsgitter verwenden.
-
Vorzugsweise führt das Decodierverfahren ebenfalls
einen Schritt zum Erfassen des Endes der zu dekodierenden Codewortfolge
aus.
-
Dieser Erfassungsschritt kann insbesondere
auf der Anwendung wenigstens einer der Techniken aus der Gruppe
basieren, die folgendes umfaßt:
- – Einfügen einer
Information bezüglich
des Endes der Folge beim Senden,
- – Einfügen von
Füllbits,
damit das Kanaldecodiergitter, das der gesendeten Folge zugeordnet
ist, in einem bekannten Zustand endet,
- – Verwenden
der "Tail-biting" genannten Technik,
- – Verwenden
eines kreisförmigen
Gitters.
-
Vorteilhafterweise umfaßt das Verfahren
in den nachfolgend angesprochenen verschiedenen Ausführungsformen
auch einen Schritt zum Suchen der mit der höchsten Wahrscheinlichkeit zugelassenen
Folge mit Hilfe eines reduzierten Symbolgitters, das einen einzigen
Ausgangszustand (d0) aufweist, von dem genau so viele Worte ausgehen
und bei dem genau so viele Worte ankommen, wie Codewörter existieren.
-
Es ist klar, daß die Erfindung ebenfalls alle
Vorrichtungen zum Dekodieren von Digitaldaten betrifft, die eines
der vorstehend beschriebenen Decodierverfahren ausführen, sowie
die Systeme zum Senden eines digitalen Signals, die beim Senden
eine entropische Quellenkodierung und eine Kanalkodierung und beim
Empfangen eine Dekodierung verwenden, wie sie vorstehend beschrieben
ist.
-
Andere Merkmale und Vorteile der
Erfindung werden beim Lesen der nachfolgenden Beschreibung von bevorzugten
Ausführungsformen
der Erfindung klar, die lediglich beispielhaft und nicht einschränkend dargestellt
werden, sowie der nachfolgenden Zeichnungen, bei denen:
-
1 ein
Beispiel eines Huffman-Codes in Form eines Binärbaumes zeigt,
-
2 ein
reduziert genanntes Symbolgitter veranschaulicht, das dem Baum aus 1 entspricht,
-
3 ein
reduziert genanntes erfindungsgemäßes Binärgitter zeigt, das den Baum
aus 1 entspricht,
-
4 ein
Schema ist, das eine gemeinsame Dekodierungsstruktur vom Typ Turbo-Code
veranschaulicht, die ein Modul "SISO_huff" gemäß der Erfindung verwendet,
-
5 den
Ablauf des gemeinsamen Quellen-Kanal-Decodieralgorithmus gemäß einer
zweiten Ausführungsform
veranschauchlicht,
-
6 ein
iteratives gemeinsames Decodierschema zeigt, das den in 5 veranschauchlichten Algorithmus
ausführt,
-
7 eine
Kombination der Verfahren der 4 und 6 darstellt,
-
8 die
Konstruktion einer Huffman-Kodierung, kommentiert im Anhang A, veranschaulicht,
-
9 die
Matrix der Turbo-Dekodierung in Blöcken des Huffman-Codes darstellt,
-
10 eine
gemeinsame Dekodierung von RVLC-Codes veranschaulicht, 11 und 12 zwei Ausführungsformen einer gemeinsamen
Dekodierung von RVLC-Codes mit Turbo-Codes unter Verwendung eines reduzierten
Gitters darstellen.
-
Bevorzugte Ausführungsformen
-
1. Einführung
-
Der Erfindung liegt daher insbesondere
die Aufgabe zugrunde, eine Decodiertechnik zu schaffen, die die
Symbolfehlerrate verringert, indem die a priori Informationen auf
die Quelle, Wahrscheinlichkeiten auf VLC-Codewörter oder Übergangswahrscheinlichkeiten
zwischen den Wörtern
angewendet werden. Man hat festgestellt, daß diese Verringerung höher ist,
wenn die Decodierer die a priori Informationen auf die Quelle auf Bitebene
anwenden, weil das Wiedergewinnen von Kanaldekodierungsinformationen
nur auf Bitebene stattfinden kann.
-
Bis jetzt arbeitet der größte Teil
der vorgeschlagenen Verfahren zum Dekodieren von VLC-Codes auf Wortebene
(oder Symbolebene, wobei diese beiden Ausdrücke im nachfolgenden unterschiedslos
verwendet werden), und kann daher keine Informationen liefern, die
nicht der Bitebene zugehörig
sind. Zudem werden diese Verfahren zum größten Teil sehr komplex und
sind daher in der Praxis nicht realisierbar, weil die Anzahl der
verschiedenen zu übertragenden
Wörter
sich vergrößert. Der
einzige Versuch auf Bitebene ist in [5] dargestellt. Es ist klar,
daß diese
Lösung
eine sehr hohe und schnell redhibitorische Betriebskomplexität aufweist.
-
Demgegenüber erlaubt die Technik der
Erfindung die Bestimmung nicht nur der optimalen Wortfolge, sondern
ebenfalls der jedem Bit jedes Worts zugeordneten Zuverlässigkeit.
Hierfür
wendet die Erfindung eine a priori Information auf die Quelle an,
d. h. die a priori Wahrscheinlichkeit der VLC-Codewörter, oder diejenige des Markov-Übergangs
zwischen den Codewörtern.
-
Diese Technik kann vorteilhafterweise
in einem iterativen Schema vom Typ Turbo-Code verwendet werden und
verbessert die Leistungsfähigkeit
der Übertragung.
-
2. Notation
-
Nachfolgend wird die folgende Notation
verwendet:
- – Eine weiche Entscheidung
entspricht einer reellen nicht-binären Entscheidung. Eine Schwelle
darauf liefert eine harte Entscheidung. Eine weiche Entscheidung
wird auch eine "Soft"-Entscheidung genannt.
- – Das
Verhältnis
Eb/No entspricht
dem Verhältnis
zwischen der vom verwendeten Bit empfangenen Energie, dividiert
durch die spektrale monolaterale Dichte des Rauschens.
- – Das
DC-Band (direct component) eines Bildes ist die kontinuierliche
Komponente des Bildes nach der Wavelett- oder DCT-Transformation.
- – Eine
empfangene Bitfolge wird mit X oder Y bezeichnet. Diese Folge setzt
sich aus mit xi bezeichneten Wörtern zusammen,
wobei diese Wörter
aus mit x i / j bezeichneten Bits zusammengesetzt sind.
- – Man
verwendet die Notation p(a) = Pr{xi =
a}.
- – Ein
RVLC-Code (auf englisch: "reversible VLC") [8] ist ein Code mit
variabler Länge,
dessen Wörter
sich in beide Richtungen dekodieren.
- – Ein
SISO-Algorithmus ("Soft-in/Soft-Out") hat als Eingabe "Soft"-Werte
und liefert "Soft"-Ausgaben.
-
3. "Soft"-Quellendekodierung
von Codes mit variabler Länge
-
In Anhang B ist gezeigt, wie es möglich ist,
die von einem Huffman-Codierer
(siehe Anhang A) gesendete Information der Abfolge der Wörter mit
variabler Länge
wiederzugewinnen, indem ein Modell der Quelle erzeugt wird, entweder
durch ein zufallsbasiertes Verfahren, das unabhängige Symbole erzeugt, oder
durch ein Markovsches zufallsbasiertes Verfahren.
-
Die 1 zeigt
ein Beispiel eines Huffman-Codes in Form eines binären Baumes.
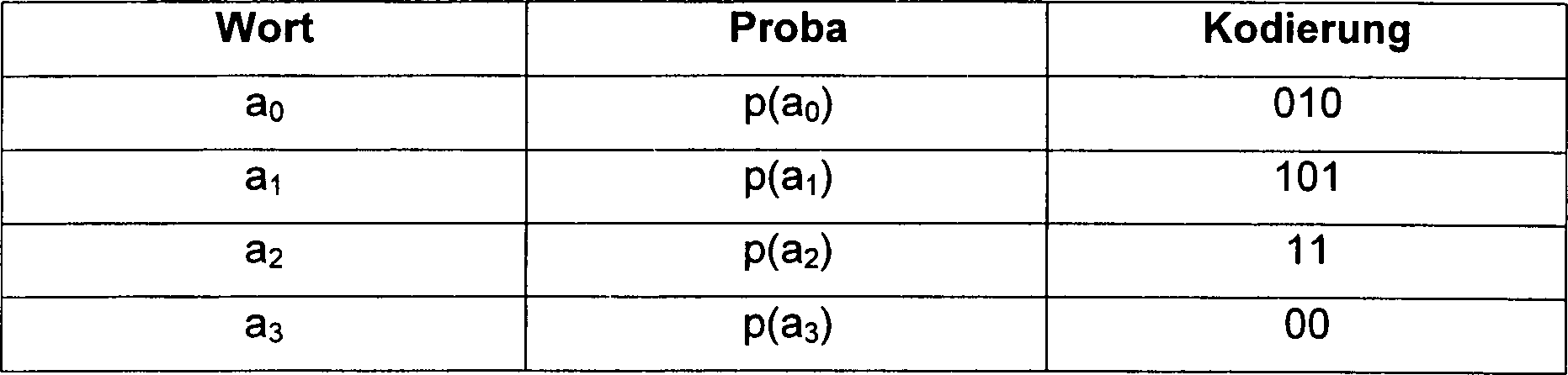
Der besteht aus fünf Worten
a, b, c, d, e mit den Wahrscheinlichkeiten p(a), p(b), p(c), p(d)
und p(e) und mit der Länge
3, 3, 2, 2 bzw. 2.
-
Die entsprechende Codiertabelle ist
nachstehend wiedergegeben.
-
-
Wenn man sich gemäß dem Ansatz der Erfindung
auf die Bitebene begibt, stellt man fest, daß vier Zustände erforderlich sind, um den
Baum aus 1 in Form eines
Gitters zu beschreiben. Diese Zustände sind dO für den Anfang
und das Ende der Symbole, d1, d2 und d3 für die Zwischenpositionen. Es
wird angemerkt, daß demgegenüber auf
der Symbolebene ein einziger Zustand d0 ausreichen kann, wie es
in 2 veranschaulicht
ist. Das so definierte reduzierte Symbolgitter ist also ein Gitter
mit einem einzigen Zustand d0 mit genau so vielen ausgehenden und
ankommenden Ästen
wie existierenden VLC-Worten. In dem Beispiel der 1 weist das Gitter in jeder Stufe (t – 2, t – 1, t)
fünf Äste auf,
die den Worten a, b, c, d und e entsprechen.
-
Das reduzierte Symbolgitter wendet
die a priori Wahrscheinlichkeiten auf die Wörter der Quelle an, wobei es
auf der Wortebene arbeitet. Dieses Gitter kann während des die Markov-Wahrscheinlichkeiten
verwendenden Dekodierens auch als beigefügtes Gitter verwendet werden.
Wie nachfolgend zu sehen ist, kann dieses reduzierte Gitter vorteilhafterweise
als Komplement der Dekodierung der Erfindung verwendet werden.
-
4. Erfindungsgemäße Dekodierung
auf der Bitebene
-
Es wurde festgestellt, daß gemäß den bekannten
Techniken die Decodierverfahren einer VLC-Quelle die a priori Wahrscheinlichkeiten
von VLC-Wörtern auf
der Wortebene verwenden, was es verhindert, die Zuverlässigkeit
auf jedes Bit der decodierten Folge zu verschieben. Im nachfolgenden
wird deutlich, wie die a priori Wahrscheinlichkeiten auf den Wörtern in
ein Produkt aus einer a priori Wahrscheinlichkeit auf den Bits zerlegbar
sind, und anschließend
werden die Decodierverfahren beschrieben, die sich für diesen
Ansatz anbieten.
-
4.1 Verwendung der a priori
Wahrscheinlichkeiten der VLC-Codewörter auf der Bitebene
-
Dieser Abschnitt erklärt die Zerlegung
der Wahrscheinlichkeiten der Wörter
in ein Produkt aus binären Wahrscheinlichkeiten.
-
Wir nehmen das Beispiel des Wortes
a: Aus dem Baum der 1 ergibt
sich: p(a) = Pr{xi = a} = Pr{xi0 = 1, xi1 = 1, xi2 = 1} (8)
-
Diese Wahrscheinlichkeit kann gemäß der folgenden
Gleichung zerlegt werden: p(a) = Pr{xi0 = 1}Pr{xi1 = 1/xi0 = 1}Pr{xi2 = 1/xi0 = 1,
xi1 = 1} (9)
-
Die Wahrscheinlichkeit p(a) ist somit
das Produkt aus drei Wahrscheinlichkeiten, die jedem der Bits des
Worts a zugeordnet sind.
-
Mit einem Gitter, das die Position
des Bits in dem Wort, das decodiert wird, anzeigt, gestatten diese binären Wahrscheinlichkeiten
die Durchführung
einer binären
"Soft"-Dekodierung. Pr(xi1 = 1/xi0 = 1)
-
Wenn man beispielsweise weiß, daß man in
der zweiten Position des Worts a ist, ist die auf dem Ast zu verwendende
Wahrscheinlichkeit: Pr{xik = +1/(xij = +1, j < k}
-
Wir berechnen für das Wort a und für k = 0,1,2
die Wahrscheinlichkeiten für
das Wort a: Pr{xi0 = 1} = Pr{spitzei,0 = S1} = p(a) + p(b) + p(c) (10)
-
Der Ast der
1 gibt sofort die Lösung an. Aus den verschiedenen
Spitzen des Baumes lassen sich die folgenden Gleichungen ableiten:
-
Diese Berechnung kann einfach auf
den Fall eines reellen Huffman-Codes verallgemeinert werden. Wenn
C = (w
i) die Gesamtheit der Huffman-Codeworte
ist,
Sk = {n∊N∣∀p < k, wnp = xip } die
Gesamtheit der Indizes der Wörter
ist, deren erste k Bits gleich den ersten k Bits des Wortes x
i sind und
Ssk = {n ∊ S∣w0k =
s} die Indizes von S
k der Worte sind,
deren k
tes Bit gleich s(s ∊ {0,
1}) ist, erhält
man:
-
Dieses Prinzip der Berechnung ist
hier in dem Fall einer Quelle unabhängiger Wörter veranschaulicht. Für eine Markov-Quelle
ist das Prinzip dasselbe, außer
daß die
berechnete Wahrscheinlichkeitsverteilung vom zuvor gefundenen Wort
abhängt.
Daher ist die Berechnung für
alle möglichen
vorhergehenden Wörter
durchzuführen.
-
Wenn diese Zerlegung einmal für alle VLC-Codewörter durchgeführt ist,
muß man
das reduzierte Binärgitter
finden, das die Verwendung der binären Wahrscheinlichkeiten erlaubt.
Die Zerlegung von p(a), p(b), ... in ein Produkt aus binären Wahrscheinlichkeiten
bewirkt eine bestimmte Beziehung zwischen den binären Wahrscheinlichkeiten
und den Wahrscheinlichkeiten der Wörter. Diese Beziehungen sind
nur dann erfüllt, wenn
es eine bijektive Abbildung zwischen den Ästen des Baums und jenen des
Gitters gibt. Man braucht daher ein Gitter geringstmöglicher
Komplexität,
das die Position der Bits in jedem Wort angibt und parallele identische
Zeige vermeidet (gleicher Ausgangszustand, gleicher Endzustand und
gleiche Markierung).
-
Zunächst wird der Algorithmus zum
Konstruieren des reduzierten binären
Gitters beschrieben. Dann werden der Algorithmus zum Dekodieren
auf diesem Gitter und insbesondere die Verwendung der binären a priori
Wahrscheinlichkeiten angegeben.
-
4.2.1
Algorithmus zum Konstruieren des reduzierten binären Gitters Initialisierung
des Gitters
-
-
Im Fall unseres Beispiels erhält man so
das Gitter der 3.
-
Dieses Gitter gibt die Position des
Bits in dem Wort an. Wenn man in dem Zustand i ist, weiß man, ausgehend
von dem Baum, daß man
in der Position j des verarbeiteten Wortes ist, weil eine bijektive
Korrespondenz zwischen den Zuständen
i des Gitters und den Positionen j des Baumes existiert.
-
4.2.2 Algorithmus zum
Dekodieren ausgehend von dem reduzierten binären Gitter
-
Der auf diesem Gitter für die nachfolgend
angegebenen Simulationen verwendete Decodieralgorithmus ist ein
Algorithmus vom Typ BCJR (Bahl Cocke Jelinek Raviv) [13], modifiziert
durch Benedetto in [14] zum Verarbeiten paralleler Äste.
-
Die auf jedem Ast berechnete Metrik
berücksichtigt
das Wissen, das man auf dem Kanal hat, und zuvor berechneten binären a prori
Wahrscheinlichkeiten. Genauer genommen ist die Berechnungsformel
auf einem Ast [15]: Γi[(xk, xpk ), dk, dk–1]
= Pr(xk/ak = i)Pr(ypk /ak = i, dk, dk–1)Pr{ak = i, dk/dk–1} (14)
-
Zu dem diskreten Zeitpunkt k ist
das Paar (xk, x p / k) das Wahrscheinlichkeitspaar
der empfangenen Bits, dk–1 und dk sind
der Ausgangszustand bzw. der Endzustand des Astes, ak ist
das dem Ast zuordnete Informationsbit.
-
Die beiden ersten Terme rechts in
der Gleichung (14) nehmen Bezug auf das Wissen, das man auf dem
Kanal hat. Der dritte, Pr{ak = i, dkdk–1} entspricht der binären a priori
Wahrscheinlichkeit.
-
Allgemeiner gesagt, kann diese a
priori Information auf der Quelle unterschiedlichen Typs sein.
-
- – Entweder
sie entspricht der Kenntnis der Tabelle des Huffman-Codes, reversibel
(RVLC) oder nicht. In diesem Fall besteht die a priori Information
aus den Wahrscheinlichkeiten, die in dem Ensemble {0, 1, 0.5} erscheinen.
- – Oder
sie entspricht der Kenntnis der Tabelle des Huffman-Codes, reversibel
oder nicht, und Wahrscheinlichkeiten der zugeordneten Wörter. In
diesem Fall besteht sie aus Wahrscheinlichkeiten, die in dem Segment
[0,1] erscheinen,
- – Oder
sie entspricht der Kenntnis der Anzahl gesendeter Wörter, der
Anzahl der Bits oder der Grenzwerte, die die Koeffizienten annehmen
können.
Dieses Gitter ist verwendbar in einer binären Soft-Dekodierung vom Typ
-
BCJR oder vom Typ SOVA (auf englisch:
"Soft Output Viterbi Algorithm"). Während der Verwendung von a
priori Markov-Wahrscheinlichkeiten erfordert die Soft-Dekodierung,
wenn man den BCJR-Algorithmus verwendet, eine parallele Verarbeitung,
die für
jeden Zustand das wahrscheinlichste vorhergehende Wort anzeigt.
Diese Verarbeitung wird selbst durch das reduzierte Symbolgitter
realisiert. Diese Erhöhung
der Komplexität
impliziert eine Präferenz
für den
SOVA- oder den SUBMAP-Algorithmus
[11].
-
4.3 Verallgemeinerungen
-
Die vorgestellte Methode kann problemlos
auf den Fall verallgemeinert werden, in dem die Huffman-Tabelle
mehr Bits enthält.
Jedoch erhöht
sich die Komplexität
des reduzierten binären
Gitters mit der Anzahl der Wörter
der Huffman-Tabelle.
-
Die Anwendung der erfindungsgemäßen Methode
auf RVLC-Codes [8] kann ebenfalls in Betracht gezogen werden.
Das Blockgitter "SISO_huff" kann beim Dekodieren in die andere Richtung
verwendet werden, jedoch impliziert dies eine Erhöhung der
Komplexität.
Eine Alternative besteht darin, die a priori Wahrscheinlichkeiten
in einer Richtung für
die "Forward"-Phase und in der anderen Richtung für die "Backward"-Phase
zu verwenden.
-
Andererseits ist es interessant,
unter den äquivalenten
Huffman-Codes [17] denjenigen zu suchen, der für die "Soft"-Dekodierung des
Blocks "SISO huff" am besten angepaßt ist.
-
5. Gemeinsame Quellen-Kanal-Dekodierung
-
5.1 Prinzipschema der
Verwendung des Blocks "SISO_huff".
-
Die reduzierten oder "SISO_huff"
binären
Gitter ermöglichen
eine Dekodierung vom Typ SISO und können sich daher in ein iteratives
Dekodierungsschema, wie das der 4,
einfügen.
-
Jeder Dekodierungsblock 41 bis 44 der 4 gewinnt die extrinsische
Information der zu dekodierenden Bits und leitet diese Information
an den nachfolgenden Block weiter. Die Informationen, die zwischen
den verschiedenen Blöcken
zirkulieren, sind wie in der Literaturquelle [15] extrinische Wahrscheinlichkeiten.
-
Zwei Kanal-Decodierer DEC1 und DEC2, 41 und 43,
gewinnen zwei aufeinanderfolgende verschiedene extrinische Informationen,
die durch den Block "SISO_huff" 42 oder 44 oder
durch den anderen Kanaldecoder 41 oder 43 verwendet
werden. Die extrinische Information 451 , 452 , die vom folgenden Kanaldecodierer verwendet
wird, ist diejenige, die üblicherweise
in den Turbo-Codes
verwendet wird. Die vom Block "SISO_huff" 42, 44 verwendete
Information, dick dargestellt, 461 , 462 entspricht dieser ersten Information,
aus der man die Information vom vorhergehenden Block "SISO_huff" 44, 42 entfernt
hat, was mit dem Ziel erfolgt, die Regel zu beachten, gemäß welcher
kein Block der iterativen Dekodierung eine Information verwenden
darf, die er bereits erzeugt hat.
-
Die globale Struktur des iterativen
Decodierers ist nicht im Detail diskutiert. Sie ist als solche tatsächlich bekannt
[1]. Die Module E471 und 472 sind Verschachtelungsvorrichtungen
(identisch zu den beim Kodieren verwendeten) und das Modul E*48 ist
eine Entschachtelungsvorrichtung, die symmetrisch zur Verschachtelungsvorrichtung
ist.
-
Die berücksichtigten Informationen
sind die folgenden:
- – Xk:
Wahrscheinlichkeitsinformation, empfangenen auf den gesendeten Informationsbits,
- – Yik: Wahrscheinlichkeitsinformation auf den
paritätischen,
vom Codierer 1 ausgegebenen Bits,
- – Y2k: Wahrscheinlichkeitsinformation auf den
paritätischen,
vom Codierer 2 ausgegebenen Bits
Proba: a priori Wahrscheinlichkeit
- – Ausgang_hart:
Decodiertes Informationsbit
-
Dieses Schema ist ein Beispiel einer
gemeinsamen iterativen Dekodierung, wo die a priori Information und
die Kanalinformation der Reihe nach auf ihren zugeordneten Gittern
verwendet werden. Es ist ferner vorstellbar, diese beiden Informationen
auf dem Kanaldecodierergitter gemeinschaftlich zu nutzen, wie es
das zweite vorgeschlagene Verfahren zeigt.
-
5.2 Zweiter gemeinsamer
Quellen-Kanal-Decodierrhythmus
-
Die in 4 vorgeschlagene
gemeinsame Dekodierung realisiert iterativ und sequentiell die beiden Dekodierungsfunktionen.
Nachfolgend wird eine Technik vorgestellt, bei der ein einziger
Decodierblock gleichzeitig die beiden Operationen durchführt. Diese
Technik ist auch auf das Dekodieren einer Markovschen Quelle anwendbar.
-
Das entwickelte Konzept ist auf die
ganze Übertragungskette
anwendbar, die aus einem Kanaldecodiergitter (in Konvolution oder
Block) und einer als ein Baum darstellbaren Quelle zusammengesetzt
ist.
-
5.2.1 Algorithmus zum
Konstruieren des Gitters
-
Das verwendete Gitter ist das des
Kanalcodierers, und eine neue Konstruktion ist nicht erforderlich.
-
5.2.2 Decodieralgorithmus
-
Der Decodieralgorithmus ist vom Viterbi-Typ.
Er decodiert die wahrscheinlichste Wortfolge. Die Berechnung der
Metrik benötigt
die Eingabe nicht nur der Kanalinformation (normaler Fall), sondern
auch der binären
a priori Wahrscheinlichkeiten.
-
Allgemeiner ordnet man jedem Zustand
jeder Stufe eine Information zu, die von der Folge (die diesen Zustand
passiert) von decodierten Bits aus der Vergangenheit im Verhältnis zur
Richtung des Weges durch das Gitter abhängt. Diese Information kann
insbesondere die Position des betrachteten Bits in dem den entropischen
Code repräsentierenden
Baum bestimmen. Sie kann ferner beispielsweise eine Verifikation
der Anzahl der decodierten Wörter
oder die Belegung durch die decodierten Koeffizienten sein.
-
Diese Methode ähnelt der von Hagenauer [15]
vorgestellten, wird hier jedoch auf Codes mit variabler Länge angewendet.
-
Hierfür muß der Algorithmus wissen, welchem
Ast des Huffman-Baums der momentan auf dem Kanaldecodierer verarbeitete
Ast entspricht. Diese Information genügt ihm, um die adäquate binäre a priori
Wahrscheinlichkeit auszugeben (berechnet wie im Abschnitt 4.1 und
vorzugsweise in einer Tabelle gespeichert).
-
Diese Information ist einfach zugänglich,
indem man die Position des Bits im Baum für jede Stufe und jeden Zustand
des Kanaldecodiergitters auf dem laufenden hält.
-
Für
jede Stufe des Kanaldecodierers
für jeden Zustand,
-
Es wird Bezug genommen auf das Beispiel
des Baums in 1. Der
Algorithmus läuft
ab, wie es in 5 dargestellt
ist. In der betrachteten Stufe gibt es zwei Folgen, die gleichzeitig
im zweiten Zustand des Gitters ankommen. Jede entspricht einer Verkettung
von verschiedenen VLC-Wörtern.
Die erste auf dem durchgezogene Strich entspricht der Aussendung
von e, d, ... und die zweite auf dem punktierten Strich vom b, e, ....
Die a priori Wahrscheinlichkeit des Astes für jede von ihnen, P[S2][0]
et P[S0][1] hängt
vom Knoten Si ab, der auf der Folge vermerkt ist, sowie vom Bit
0 oder 1, das den Zweig markiert. Wenn die Berechnung der Wahrscheinlichkeit
des Zweigs einmal durch die Beziehung (6) durchgeführt ist,
kann man herkömmliches ACS
machen.
-
Diese Lösung ist sehr interessant,
weil sie im Gegensatz zur Blocklösung
"SISO_huff" nicht durch den Umfang der Huffman-Tabelle in der Komplexität beschränkt ist
und die aktuelle Komplexität
der Kanaldecodierer nur sehr wenig erhöht.
-
6. Anwendung des zweiten
Algorithmus auf ein iteratives Schema einer gemeinsamen Dekodierung
-
6.1 Verwendung
dieser Methode in einem iterativen Schema
-
Ein Schema zur Verwendung in einer
iterativen Dekodierung ist in 6 dargestellt.
-
Der erste Decodierer 61 verwendet
die Kanalinformation und die a priori Information auf demselben Gitter.
Demgegenüber
kann der zweite Decodierer 62 die a priori Information
nicht verwenden, weil die Verschachtelungseinrichtung 63,
bezeichnet mit E, die Beziehungen zwischen den VLC-Codewörtern zerstört. Letzterer
verwendet somit die Wahrscheinlichkeiten p(0) und p(1), die in den
meisten Fällen
verschieden sind.
-
6.2 Kumulierung beider
Ansätze
einer gemeinsamen Dekodierung.
-
Es ist möglich, die beiden vorstehend
vorgeschlagenen Verfahren in einem iterativen Schema zu verwenden,
so wie es beispielhaft in 7 angegeben
ist. In dieser Figur sind die Benennungen identisch zu den bisher
verwendeten.
-
Das Ausarbeiten einer die Beziehungen
zwischen den Wörtern
erhaltenden Verschachtelungseinrichtung erlaubt es, einen Kompromiß zu finden
zwischen einer optimalen binären
Verschachtelung und Erhaltung der a priori Struktur auf den Wörtern.
-
7. Fall der
Turbo-Codes im Block
-
Jede Iteration von Turbo-Codes im
Block umfaßt
eine "Soft"-Dekodierung (mit gewichteten Entscheidungen) von Zeilen,
gefolgt von einer "Soft"-Dekodierung
von Spalten (oder umgekehrt). Die nachfolgend beschriebene Methode
ist auf die gleiche Weise verwendbar, unabhängig davon, ob die a priori
Information auf eine Zeilendekodierung oder auf eine Spaltendekodierung
angewendet wird. Es muß ebenfalls
angemerkt werden, daß die
a priori Information für
die konvolutiven Turbo-Codes nur in einer Richtung (Zeile oder Spalte) verwendet
werden kann, weil die Verschachtelungseinrichtung die Ordnung der
Bits für
die andere Richtung zerstört.
-
Jede Zeile (oder Spalte) der Blockmatrix
entspricht einem Codewort. Für
einen Code mit dem Wirkungsgrad k/n enthält ein Codewort k Informationsbits
und n – k
redundante Bits.
-
Wenn man die Gesamtheit der k ersten
Bits mit K und diejenige der n – k
gleichen Bits mit M bezeichnet, erhält man die Gleichung der a
priori Wahrscheinlichkeit des Codewortes C zu
P(C)
= P(K, M) = P(K) × P(M/K)
= P(K)
-
Die a priori Information wird also
auf die k ersten Bits jedes Codeworts angewendet.
-
Daraus wird abgeleitet, daß die Wahrscheinlichkeit
eines Wortes gegeben ist durch
- – wenn die
durch die Quelle gesendeten Wörter
unabhängig
sind:
- – wenn
die gesendeten Wörter
einem Markov-Prozeß der
Ordnung 1 folgen, wie beispielsweise in dem Fall eines
Unterband-Bildcodierers, was die kontinuierliche Komponente betrifft:
-
Am Ende jeder Gruppe von k Bits muß der Knoten
des Baums des Huffman-Codes, bei dem man angekommen ist, im Speicher
aufbewahrt werden, um ihn für
das Dekodieren der folgenden Gruppe von k Bits zu verwenden, wie
es in 9 veranschaulicht
ist. Um sich des Knotens sicher zu sein, von dem man bei jedem Anfang
eines Codewortes ausgeht, kann man diese Information mit versenden,
was jedoch die Komprimierung stark verringert.
-
Es muß angemerkt werden, daß das allgemeine
Schema zum Dekodieren von Turbo-Codes unabhängig davon, ob man die Turbo-Codes
im Block oder konvolutiv verwendet, das gleiche ist. Der Unterschied
verbleibt in der Verschachtelungseinrichtung und in jedem der beiden
Decodieren DEC1 und DEC2.
-
B. Fall der RVLC-Codes
-
Nachfolgend wird eine Variante der
Erfindung beschrieben, die ein Decodierverfahren für RVLC-Codes
verwendet, das eine a priori Information auf die Quelle anwendet.
-
Eine Besonderheit dieses Verfahrens
ist die Anwendung von a priori Informationen auf die Quelle sowohl
bei der Hinlauf- als auch bei der Rücklaufphase durch das Gitter
dank der Eigenschaft, daß eine
Dekodierung in den beiden Richtungen von RVLC-Codes erfolgt.
-
8.1 Stand der Technik
der RVLC-Dekodierung
-
Die RVLC-Codes [8] sind vorgeschlagen
worden, um die Robustheit von Codes mit variabler Länge zu erhöhen.
-
Die RVLC-Codes sind eine Erweiterung
der Huffman-Codes. Sie verifizieren die Bedingung, die durch den
Präfix
in den beiden Richtungen gegeben ist. Folglich, wenn man eine RVLC-Wortfolge
in der einen oder in der anderen Richtung nimmt, ist es für diese
binäre
Folge nicht immer so, daß sie
gleichzeitig für
ein Code-Element repräsentativ
ist und den Anfang des Codes eines anderen Elements bildet. Diese
Doppeleigenschaft geht auf der Komprimierungsebene verloren und
verursacht Einschränkungen
bei der Herstellung eines Huffman-Codes. Es wird angemerkt, daß die RVLC-Codes
symmetrisch oder asymmetrisch sein können.
-
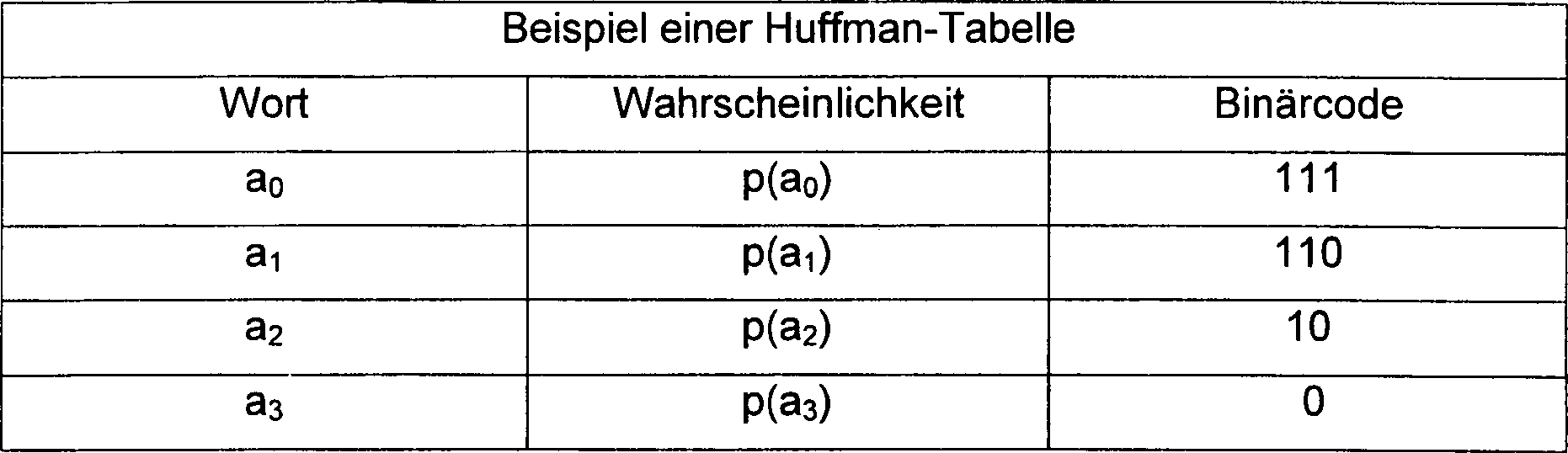
Das nachstehende Beispiel zeigt den
Fall eines symmetrischen RVLC-Codes
mit vier Wörtern.
-
-
Außerdem sind einige Methoden
zum Dekodieren dieser Codes bereits beschrieben worden:
- – R.
Bauer und J. Hagenauer [20] schlagen eine weiche iterative Dekodierung
vor, die den Kanaldecodierer und den Quellendecodierer verbindet,
der ein auf der Bitebene verwendetes Gitter ist, das den RVLC-Code repräsentiert,
- – J.
Wien und J. Villasenor [21] geben ein einfaches Mittel an, um die
Eigenschaften der Reversibilität
von RVLC-Codes zu verwenden, indem die harten Bitwerte verarbeitet
werden.
-
8.2 Stand der Technik
der Dekodierung von VLC mit dem List-Viterbi-Algorithmus
-
Die Verwendung des List-Vitberi-Algorithmus
erlaubt es, die Folgen in der Reihenfolge der Auftrittswahrscheinlichkeit
zu klassifizieren und im Speicher aufzubewahren. Diese Speicherung
gestattet die Verwendung bestimmter Folgen, wenn die wahrscheinlichste
Folge eine a priori Bedingung nicht erfüllt.
-
Dieser Algorithmus ist von Murad
und Fuja für
die Dekodierung von VLC-Codes
verwendet worden, wenn der Decodieren beim Empfang die Anzahl der
gesendeten Wörter
kennt [22], [23].
-
8.3 Hard- und Soft-Quellendekodierung
von RVLC-Codes
-
8.3.1 Hard-Dekodierung
von RVLC-Codes
-
Während
einer verrauschten VLC- oder RVLC-Wortfolge können verschiedene Fehler erkannt
werden, um die Dekodierung des entsprechenden Strangs zu stoppen.
Diese Fehler sind von verschiedener Art [24]:
- -
Der Wert übersteigt
die bestehenden Grenzen,
- - RVLC-Wort außerhalb
der bestehenden Tabelle,
- - Anzahl der erfaßten
Wörter übersteigt
die vorgesehene Anzahl.
-
Die ersten beiden Fehlerarten entsprechen
der Dekodierung eines Worts, das in der Huffman-Tabelle nicht vorhanden
ist.
-
Die Fehlererkennung gestattet ein
Anhalten der Dekodierung und eine grobe Lokalisierung des Fehlers.
Mit VLC-Codes wird der Rest des Strangs als verloren betrachtet.
Mit RVLC-Codes kann man die Dekodierung in Rückwärtsrichtung, beginnend am Ende
(unter Berücksichtigung,
ob man weiß,
wo die Folge endet) bis zum Erkennen eines Fehlers beginnen. Die
Verwendung von RVLC ermöglicht
es somit, einen Teil der Informationen wiederzuerlangen. Eine mögliche Decodierstrategie
ist in [22] zusammengefaßt.
Letztere unterscheidet die Fälle,
in denen die Dekodierungen beim Hinlauf und beim Rücklauf einen
Fehler erkennen oder nicht.
-
Eine Lösung zum Beheben der beiden
ersten Fehlerarten besteht darin, eine Hard-Dekodierung durchzuführen, indem
unter den zugelassenen Folgen diejenige gesucht wird, die mit der
empfangenen Folge am stärksten
korreliert ist. Diese Suche findet mit Hilfe des bereits kommentierten
reduzierten Symbolgitters statt.
-
8.3.2 Gemeinsame Soft-Quellen-Kanal-Dekodierung
von RVLC-Codes
-
Bis heute sind für die gemeinsame Quellen-Kanal-Dekodierung
von VLC- und RVLC-Codes
mehrere Methoden vorgeschlagen worden.
-
Die optimale, jedoch sehr komplexe
Methode ist diejenige der Multiplikation der Kanal- und Quellengitter
[5].
-
Eine suboptimale Methode besteht
darin, Kanal- und Quellengitter wie oben diskutiert in Reihe zu schalten,
gegebenenfalls getrennt durch eine Verschachtelungsvorrichtung,
wenn der Algorithmus iterativ ist [20]. Diese Methode wird mit der
Anzahl der Wörter
in der VLC- oder RVLC-Tabelle schnell komplex.
-
Eine weitere Methode, die viel weniger
komplex ist, sieht die Verkettung der beiden Gitter vor. Die Kanaldekodierung
wird so durch die Anwendung der a priori Information auf die Quelle
gesteuert, wie es oben vorgeschlagen worden ist.
-
Diese drei Methoden können mit
den Turbo-Codes gemeinsam verwendet werden, allerdings sind lediglich
die letzten beiden auf der Kompromißebene Verstärkung/Berechnungskomplexität in Betracht
zu ziehen.
-
Ein erstes neues Verfahren gemäß der Erfindung
stützt
sich auf die zweite genannte Methode zum Dekodieren der VLC und
erstreckt diese auf RVLC-Codes unter Verwendung eines List-Viterbi-Algorithmus
vom parallelen oder seriellen Typ [25]. Die Notwendigkeit des List-Viterbi-Algorithmus
für die
Dekodierung von RVLC-Codes erklärt
sich aus dem Umstand, daß die
Folgen im Gegensatz zum Fall der Dekodierung von VLC-Codes beim
Empfang nicht alle zugelassen sind. Eine Speicherung der wahrscheinlichsten
zugelassenen Folgen ermöglicht
deren Wiederverwendung zum Ersetzen einer nicht zugelassenen Folge
während
der Decodierphase entlang des Kanaldekodierungsgitters.
-
Dieses neue Verfahren erstreckt sich
außerdem
auf den Fall der VLC- oder RVLC-Dekodierung, angewendet auf reelle
Daten, bei denen man beispielsweise eine ergänzende a priori Information über die
Anzahl der Wörter
in der Folge, über
das Intervall der Werte, die die Koeffizienten annehmen können, hat.
-
Ein zweites neues Decodierverfahren
für RVLC-Codes
besteht darin, das Äquivalent
des List-Viterbi-Algorithmus für
den SUBMAP-Algorithmus [26] zu verwenden, und zwar in den beiden
Dekodierungsrichtungen, wie es in 10 veranschaulicht
ist. Der Vorteil der Verarbeitung mit dem SUBMAP-Algorithmus folgt aus
deren Arbeitsweise.
-
Dieser Algorithmus teilt sich in
drei Phasen:
- – "Forward"-Phase 110 oder
Hinlaufphase, wobei die Folge in einer Richtung decodiert wird,
- – "Backward"-Phase
111 oder Rücklaufphase,
wobei die Folge in der anderen Richtung decodiert wird,
- – A-posteriori-Wahrscheinlichkeitsphase
(A Posteriori Probability, APP) 112, wobei die Ergebnisse
der beiden vorhergehenden Phasen verwendet werden, um dem APP decodierte
Bits zurückzugeben.
-
Die RVLC-Dekodierung findet infolge
ihrer Decodiereigenschaft in den beiden Richtungen auch in den beiden
Richtungen statt. Die Analogie zwischen der Kanaldekodierung und
der Quellendekodierung zeigt, daß eine Kombination der beiden
sich als vorteilhaft herausstellen kann. Somit kann jede Decodierrichtung
während
der Dekodierung der empfangenen Folge auf dem Kanaldekodierungsgitter
ihre a priori Information 113 verwenden. Um die a priori
Information in der Richtung "Backward" am besten zu nutzen, ist
es interessant zu wissen, welcher der Endzustand des Gitters ist.
Diese Information wird entweder durch ihre Übertragung, oder durch Verwenden
von Füllbits,
oder durch Verwenden der "Tail biting"-Technik oder durch ein kreisförmiges Gitter
erhalten [27].
-
Die verwendete a priori Information
kann wie bereits erwähnt
von zwei Arten sein.
-
Wenn die Soft-Kanal-Dekodierung einmal
unter Verwendung der a priori Information durchgeführt ist, ist
die erhaltene Soft-Folge nicht notwendigerweise eine zugelassene
Folge, weil die APP-Phase dies nicht garantiert, auch wenn die Forward-
und Backward-Phasen diese Bedingung garantieren. Es ist daher von
Vorteil, dieser durch die Quelle gesteuerten Kanaldekodierung ein
reduziertes Symbolgitter 114 folgen zu lassen, das die
wahrscheinlichste zugelassene Folge liefert.
-
8.4. Soft-Kanal-Dekodierung
unter Verwendung der Turbo-Codes
-
Die zuvor genannten Decodiermethoden
lassen sich vorteilhafterweise in einem Schema vom Typ Turbo-Code
verwenden. Der Kanalcodierer wird dann durch die Turbo-Codes ersetzt,
was die Beobachtung der Verstärkung
ermöglicht,
die bei geringem Rauschabstand im gesamten Bereich der Rauschabstände erhalten wird.
-
Die erste Methode besteht in der
Verwendung des Quellengitters 120 in Reihe mit den beiden
Decodierern, wie es in der 11 gezeigt.
-
Die zweite Methode greift das zweite,
oben beschriebene Prinzip auf: Das Kanalgitter verwendet die a priori
Information direkt, wie in 12 dargestellt.
Genau so wie im vorhergehenden Abschnitt ist es für die beste
Verwertung der a priori Information in der Backward-Richtung von
Interesse zu wissen, welches der Endzustand des Gitters ist. Diese
Information wird entweder durch ihre Übertragung oder durch Verwenden
von Füllbits
oder durch Verwenden einer zirkulären Kodierungstechnik erhalten,
die gleichwertig ist für
die Recursive Systematic Codes (RSC) des "Tail-biting" für die Non
Systematic Codes (NSC) [28].
-
9 Leistungen
-
Es wurde eine Möglichkeit der Durchführung einer
Dekodierung mit weicher Entscheidung und Huffman-Codes gezeigt.
Im Vergleich mit den bereits veröffentlichten
Arbeiten erlaubt die Methode der Erfindung die Verarbeitung auf der
Bitebene. Es ist somit möglich,
in einem Kanaldekodierungsschema vom Typ Turbo-Code einen Quellendekodierungsblock
an den gewichteten Ein- und Ausgängen
einzuführen,
genannt "SISO_huff". Eine andere Möglichkeit besteht darin, die
a priori Information direkt auf der Ebene des Kanaldecodierers auf
die Quelle anzuwenden. Diese zweite Methode ist deutlich weniger
komplex und liefert Ergebnisse, die mit den "SISO_huff" erhaltenen
gleichwertig sind.
-
Die durch diesen Schematyp erbrachten
Leistungen hängen
einerseits von dem Modell ab, das für die Quelle mit der a priori
Kenntnis von Wahrscheinlichkeiten von Huffman-Symbolen oder ihrer Übergangswahrscheinlichkeiten
verwendet wird, und andererseits von dem Verhältnis Eb/N0 auf dem Kanal ab.
-
In den von uns durchgeführten Vergleichen
bewerten wir unsere Verstärkung
im Vergleich zum entsprechenden Tandem-Schema. Im Bereich der binären Fehlerrate
um 10–2 bis
10–3 ermöglichen
die beiden neuen Techniken Verstärkungen
zwischen 0,5 und 1 dB von ihrer ersten Iteration an, und zwar mit
NSC-Codierern (auf englisch: "Non Systematic Coder").
-
Außerdem verbessert ihre Verwendung
in einem iterativen Schema vom Typ Turbo-Code die Leistung von 0,5
bis 1,5 dB, wobei die Verstärkung
eine Funktion des Verhältnisses
S/B und der Restredundanz ist. Zudem gestattet die gemeinsame Nutzung
der zwei Methoden die Hoffnung auf eine nochmals erheblich verbesserte
kumulierte Verstärkung.
-
In den genannten Verstärkungsspannen
sind die höchsten
Werte bei niedrigem Rauschabstand erhalten worden, wodurch es möglich ist,
den Betriebsbereich der Übertragung
erheblich zu vergrößern. Es
ist ebenfalls anzumerken, daß dies
in einem vom Schema vom Typ Turbo-Code eine gleiche Verschiebung,
und zwar zwischen 0,5 und 1,5 dB, eines Einsatzpunktes des Turbo-Code-Effekts
ermöglicht.
-
Das erste Verfahren erfordert den
Ablauf eines Decodieralgorithmus auf dem Gitter „SISO_huff", während das
zweite lediglich erfordert, daß während der
Dekodierung auf dem Kanaldecodiergitter eine Tabelle auf dem neuesten Stand
gehalten wird. Zudem weist das zweite im Gegensatz zum ersten Verfahren
eine Berechnungskomplexität
auf, die mit der Anzahl der Wörter
in der VLC-Tabelle
nicht steigt.
-
Die Verwendung von Codes mit variabler
Länge vom
Huffman-Typ ist sehr weit gestreut, wobei diese Decodiertechniken
in vielen Kontexten auftreten können.
Die Anwendungen sind vielfältig.
Beispielsweise findet man Huffman-Tabellen in der MPEG4-Norm für die Kodierung
von Koeffizienten des DC- und des AC-Bandes für die intracodierten Bilder,
aber auch für
die Kodierung von Bewegungsvektoren.
-
Die Erfindung kann ebenfalls in einer
vollständigen Übertragungskette
verwendet werden, unter Berücksichtigung
eines normgerechten oder normnahen Bildcodiersystems und eines Kanalmodells,
das für
den mobilen Radiokanalbetrieb wie BRAN („Broadcast Radio Network")
repräsentativ
ist.
-
ANHANG A
-
Huffman-Kodierung
-
Der Huffman-Code ([18]) ist eine
entropische Kodierung, die eine Quelle komprimiert, indem die Daten mit
geringer Wahrscheinlichkeit in eine binäre Länge kodiert werden, die größer als
der Mittelwert ist, und diejenigen mit einer hohen Wahrscheinlichkeit
in eine kurze binäre
Länge codiert
werden. Der Huffman-Code wird häufig
benutzt, weil es keine anderen ganzzahligen Codes gibt (bei denen
die Symbole auf eine ganze Zahl von Bits codiert werden), die eine
geringere durchschnittliche Anzahl von Bits pro Symbol liefern.
Eine seiner wesentlichen Charakteristiken besteht darin, daß eine binäre Folge
nicht immer einem codierten Element entsprechen muß und gleichzeitig
den Anfang des Codes eines anderen Elements bildet. Diese Eigenschaft
der Huffman-Kodierung gestattet eine Darstellung mit Hilfe einer
binären
Baumstruktur, wo die Gesamtheit der Wörter durch die Gesamtheit der
Wege vom Baumknoten zu den Baumblättern dargestellt wird.
-
Es gibt viele Arten, die Konstruktion
des Huffman-Codes darzustellen. Die am einfachsten erscheinende
basiert auf einer Baumstruktur.
-
Es seien N Wörter ai mit
entsprechenden Wahrscheinlichkeiten p(ai)
gegeben. Der Baum wird ausgehend von seinen N Endspitzen konstruiert.
-
Jede Endspitze i wird durch die Wahrscheinlichkeit
p(ai) beeinflußt und gestattet die binäre Zerlegung des
Wortes ai.
-
Der Baumkonstruktionsalgorithmus
besteht darin, in jedem Schritt die beiden kleinsten Wahrscheinlichkeiten
des vorhergehenden Schritts zu addieren, um sie in einer Spitze
zusammenzuführen,
die von der summierten Wahrscheinlichkeit abhängt.
-
Im letzten Schritt erhält man eine
Wahrscheinlichkeitssumme 1, das ist der Baumknoten.
-
Es verbleibt ein Markieren der Äste des
erhaltenen Baums, indem man die nach rechts abzweigenden Äste jeder
Spitze mit 1 und die nach links abzweigenden Äste mit 0 indiziert. Die binäre Zerlegung
des Wortes ai wird dann dadurch erhalten,
daß man
den Baum ausgehend von der Spitze mit der Wahrscheinlichkeit 1 zur Spitze
i absteigt.
-
Das diskutierte Beispiel nimmt, wie
es in der 6 gezeigt
ist, den Fall von vier Wörtern
an.
-
-
ANHANG B
-
Quellendekodierung von unabhängigen oder
Markovschen Symbolen Für
die Dekodierung einer kodierten Folge werden zwei optimale Strukturen
verwendet. Jede basiert auf einem anderen Kriterium, dem Kriterium
der wahrscheinlichsten Folge oder dem Kriterium des wahrscheinlichsten
Symbols, derzeit MAP (Maximum a posteriori) genannt.
-
1. Viterbi-Algorithmus
-
Die Suche der wahrscheinlichsten
Folge findet mit dem Viterbi-Algorithmus [
9], der die wahrscheinlichste
gesendete Folge X in Kenntnis der empfangenen Folge Y sucht:
-
Da die logarithmische Funktion streng
sichelförmig
ist, ist es gleichwertig, log P(X/Y) zu maximieren
-
Durch Anwendung des Gesetzes von
Bayes:
P(X/Y)P(Y)
= P(Y/X)P(X) (3) wird
das Kriterium zu:
-
Die a posteriori Information auf
X ist somit in zwei Terme zerlegt. Der erste log P(Y/X) betrifft
die vom Kanal gelieferte Information, während der zweite log P(X) die
a priori Information auf der gesendeten Folge betrifft.
-
Wenn die Rauschproben des Kanals
unabhängig
sind, kann das Rauschgesetz P(Y/X) als das Produkt der Gesetze der
Wahrscheinlichkeiten des Rauschens, das jedes der Wörter x
i und y
i stört, und
der übertragenen
Bits x
i und y
i formuliert
werden:
-
Was die a priori Wahrscheinlichkeit
P(X) betrifft, sind die beiden in Betracht gezogenen Hypothesen:
- – die
von der Quelle gesendeten Wörter
sind unabhängig:
- – die
gesendeten Wörter
folgen einem Markovschen Prozeß der
Ordnung 1, wie beispielsweise in dem Fall eines Unterband-Bildcodierers,
was die kontinuierliche Komponente betrifft. Man erhält also:
-
Üblicherweise
enthält
die dem Viterbi-Algorithmus folgende Dekodierung eine ACS (Add Compare
Select) Phase: In jeder Stufe und in jedem Zustand addiert man die
Metrik des Astes, der jeder der beiden gleichzeitigen Folgen zugeordnet
ist, vergleicht die beiden erhaltenen Metriken und wählt die
Folge der schwächsten Sequenz
aus.
-
2 MAP-Algorithmus
-
Die Dekodierung gemäß MAP erfolgt
gemäß der nachstehenden
Regel:
-
Die Berechnung der Wahrscheinlichkeit
p(x i / j = +1/Y) ist komplex. Diese Komplexität kann unter dem Preis eines
Leistungsverlustes verringert werden. Der weniger komplexe Algorithmus
heißt
SUBMAP-Algorithmus [11].
-
3 Gewichtung der Entscheidungen
des Decodierers
-
Diese Gewichtung ist eine Zuverlässigkeitsinformation
der durch den Decodierer durchgeführten Schätzung. Diese „soff",
manchmal extrinsisch genannte Information kann von einem externen
Decodierer, einem Quellendecodierer oder jeder anderen Vorrichtung
verwendet werden, die in den Empfang der Information eingreift [12].
-
Mehrere Algorithmen liefern gewichtete
Entscheidungen auf den decodierten Werten:
- – der SOVA-Algorithmus
(Soff Output Viterbi Algorithm) [13] basiert auf einer leichten
Modifikation des Viterbi Algorithmus;
- – der
BCJR-Algorithmus (Bahl Cocke Jelinek Raviv) [14] baut auf dem MAP-Kriterium auf.
-
Eine VLC-codierte Quelle oder ein
Ausgang eines Kanalcodierers können
durch ein Gitter repräsentiert
werden, aus dem die extrinsische Information extrahierbar ist. Ein
Teil der Erfindung schlägt
vor, ein Gitter ausgehend vom VLC-Code der Quelle zu konstruieren.
-
ANHANG C
-
Literaturstellen
-
- [1] C. Berrou, A Glavieux, und P. Thitimajshima, „Near Shannon
limit errorcorrecting coding and decoding: Turbo-Codes". Proceeings
of ICC, Seiten 1064– 1070,
Mai 1993.
- [2] C. E. Shaanon, „A
Mathematical Theory of Communication", Band 27, Bell System Techn.
J., 1948.
- [3] S. B. Zahir Azami, „Codage
conjoint Source/Canal, protection hiérarchi que". PhD thesis,
ENST Paris, Mai 1999.
- [4] N. Dernir und K. Sayood, „Joint source/channel coding
for variable length codes". In Data Compression Conference (DCC),
Seiten 139–148,
Snowbird, Utah, USA, März
1998.
- [5] A. N. Murad und T. E. Fuja, „Joint source-channel decoding
of variable length encoded sources". In Information Theory Workshop
(ITW), Seiten 94–95,
Killarney, Irland, Juni 1998.
- [6] K. P. Subbalakshmi and J. Valsey, „Joint source-channel decoding
of entropy coded Markow sources over binary symmetric channels".
In Proceedings of ICC, Seite Session 12, Vancouver, Kanada, Juni
1999.
- [7] J. Wien und J. D. Villasenor, „Utilizing soft Information
on decoding of variable length codes" In Data Compression Conference
(DCC), Snowbird, Utah, März
1999.
- [8] Y. Takishima, M. Wada und N. Muakami, „Reversible variable length
codes". IEEE Transactions on Communications, 43: 158–162, 1995.
- [9] A. Viterbi, „Error
bounds for convolutional codes and an asymptotically optimal decoding
algorithm", IEEE Transactions on Information Theory, 13: 260– 269, 1967.
- [10] W. Koch und A. Baier, „Optimum and sub-optimum detection
of coded data disturbed by time-varying intersymbol interference",
Proceedings GLOBECOM, Seiten 1679–1684, Dezember 1990.
- [11] P. Robertson, E. Villebrun und H. Hoeher, „A comparison
of optimal and sub-optimal map decoding algrothims operating in
the log-domain", in Proceedings of ICC, Seiten 1009–1013, Seattle,
Washington, Juni 1995.
- [12] J. Hagenauer, „Soft-in/Soft-out:
the benefit of using soff values in all stages of digital receiver",
Institut for communications technology, 1990.
- [13] J. Hagenauer und P. Hoeher, „A Viterbi algorighm with
soft-decision outputs and its applications", Proceedings GLOBECOM,
Seiten 1680–1686,
November 1989.
- [14] L. R. Bahl, J. Cocke, F. Jelinek, und J. Raviv, „Optimal
decoding of linear codes for minimizing symbol error rate". IEEE
Transactions on Information Theory, Seiten 284–287, März 1974.
- [15] S. Benedetto und G. Montorsi, „Generalized concatenated
codes with interleavers". In International Symposium on Turbocodes,
Seiten 32–39,
Brest, September 1997.
- [16] J. Haagenauer, „Source-controlled
channel decoding", IEEE Transactions on Communications, 43: 2449–2457, September
1995.
- [17] A. E. Escott und S. Perkins, „Binary Huffman equivalent
codes with a short synchronizing codeword", IEEE Transactions on
Information Theory, 44: 346–351,
Januar 1998.
- [18] D. A. Huffman, „Method
for the reconstruction of minimum redundancy codes", Key Papers
in The development of Information Theory, Seiten 47–50, 1952.
- [19] K. Sayood und J. C. Borkenhagen, „Utilization of correlation
in low rate dpcm systems for channel error protection". In Proceedings
of ICC, Seiten 1868– 1892,
Juni 1986.
-
Literaturstellen
-
- [20] R. Bauer und J. Hagenauer, „Iterative source/chapel decoding
using reversible variable length codes". In Data Compression Conference
(DCC), Snowbird, Utah, März
2000.
- [21] J. Wien und J. D. Vaillasenor, „A class of reversible variable
length codes for robust image and video coding". In ICIP, Band 2,
Seiten 65–68,
Santa Barbara, CA, Oktober 1997.
- [22] A. H. Murad und T. E. Fuja, „Robust transmission of variable-length
encoded sources". In IEEE Wireless Communications and Networking
Conerence, New Orleans, L. A., September 1999.
- [23] A. H. Murad und T. E. Fuja, „Variable length source codes,
channel codes, and list-decoding". In Information Theory Workshop
(ITW), Kruger National Park, South Afrika, Juni 1999.
- [24] Video Group, „Error-resilient
video coding in the ISP MPEG4 standard", R. Talluri 1997.
- [25] N. Sehadri und C. E. Sundberg, „List Viterbi decoding algorithms
with applications". IEEE transactions on communications, 42: 313–329, Februar
1994. [26] P. Robertson, E. Villebrun und P. Hoeher, „A comparisonof optimal
and suboptimal map decoding algorithms operating in the log-domain".
In Proceedings of ICC, Seiten 1009–1013, Seattle, Washington,
Juni 1995.
- [27] J. C. Carlach, D. Castelein und P. Combelles, „Soft-decoding
of convolutional block codes for an intreactive televisionreturn
channel". In International Conference on Universal Communications
Records, Seiten 249–253, San
Diego, CA, Oktober 1997.
- [28] C. Berrou, C. Douillard und M. Jezequel, „Multiple
parallel concatenation of circular recursive systematic concolutional
(CRSC) codes". In Annales des télécommunications, Seiten 166–172, März 1997.