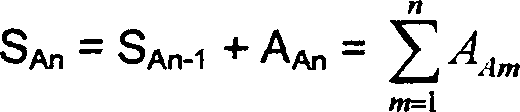-
Die vorliegende Erfindung betrifft
die Spracherkennung.
-
Spracherkennungssysteme analysieren
die Sprachäußerungen
einer Person, um das Gesagte zu identifizieren. In der Regel teilt
ein Prozessor ein die Sprachäußerung verkörperndes
Signal in eine Reihe von digitalen Rahmen ein, die jeweils ein kleines
Zeitinkrement der Sprachsequenz repräsentieren. Der Prozessor vergleicht
dann die digitalen Rahmen mit einer Gruppe von Modellsequenzen.
Jede Modellsequenz kann ein Wort aus einem Vokabular verkörpern. Eine
Modellsequenz kann auch für
einen Laut oder ein Phonem stehen, die einem Teil eines Wortes entsprechen.
Der Prozessor identifiziert das von einer Person Gesagte, indem
er die Modellsequenzen ermittelt, die am besten mit den digitalen
Rahmen übereinstimmen,
die die Sprachäußerung des
Sprechers verkörpern.
Spracherkennung ist der Gegenstand in dem US-Patent Nr. 4 805 218
mit dem Titel "Method
for Speech Analysis and Speech Recognition".
-
Für
jeden Vergleich mit einer Modellsequenz ist ein relativ großer Umfang
an Berechnungen erfordelich. Ein Spracherkennungssystem kann Zigtausend
Wörter
in seinem Vokabular umfassen, wobei jedes Wort eine entsprechende
Modellsequenz aufweist. Somit wäre
der für
einen Vergleich einer Sequenz von digitalen Rahmen mit Modellen
eines jeden Wortes des Vokabulars erforderliche Aufwand an Berechnungen
immens. Aus diesem Grund ist für
den Prozessor die Durchführung
einer Vorfilterprozedur, auch unter der Bezeichnung Schnellabgleichprozedur
bekannt, vorgesehen, um eine Teilliste der Wörter aus dem Vokabular auszuwählen. Zur
Ermittlung des von einer Person Gesagten vergleicht dann der Prozessor
den vorgefilterten Ergebniswörtern
entsprechende Modellsequenzen mit den digitalen Rahmen, die die
Sprachäußerung verkörpern. Ein
Verfahren der Vorfilterung wird in dem US-Patent Nr. 5 202 952 mit
dem Titel "Large-Vocabulary
Continuous Speech Prefiltering and Processing System" beschrieben.
-
Die Erfindung nach den Ansprüchen 1 bis
27 betrifft ein Verfahren und ein Gerät zur Vorfilterung mittels lexikalischer
Bäume zur
Identifizienrug von Wortgruppen für die Anwendung bei der Erkennung
von Sprachsequenzen. Zunächst
wird ein Wortvokabular mittels eines lexikalischen Baumes dargestellt.
Anschließend wird
eine erste Teilliste des Vokabulars, die einer zu einem ersten Zeitpunkt
beginnenden Sprachsequenz entsprechen kann, identifiziert, indem
Informationen über
die zu einem ersten Zeitpunkt beginnende Sprachsequenz in dem lexikalischen
Baum weitergegeben werden. Die Weitergabe kann die Durchführung eines
relativ groben Vergleichs der zum ersten Zeitpunkt beginnenden Sprachsequenz
mit Wörtern
in dem lexikalischen Baum umfassen. Es erfolgt zudem in gleicher
Weise die Identifizierung einer zweiten Teilliste des Vokabulars, die
einer zu einem zweiten Zeitpunkt beginnenden Sprachsequenz entsprechen
kann. Es werden in der Sprachsequenz enthaltene Wörter erkannt,
indem die zum ersten Zeitpunkt beginnende Sprachsequenz mit Wörtern aus
der ersten Teilliste des Vokabulars und eine zum zweiten Zeitpunkt
beginnende Sprachsequenz mit Wörtern
aus der zweiten Teilliste des Vokabulars verglichen werden. Der
Zustand des lexikalischen Baumes wird zwischen der Identifizierung
der ersten und der zweiten Teilliste nicht zurückgesetzt. Eine zum ersten Zeitpunkt
beginnende Sprachsequenz kann eine zum zweiten Zeitpunkt beginnende
Sprachsequenz überlagern.
-
Ausführungsformen der Erfindung
können
eines oder mehrere der folgenden Merkmale umfassen. Der Grobvergleich
kann die Weitergabe der Wahrscheinlichkeitswerte durch den lexikalischen
Baum beinhalten. Die Wahrscheinlichkeitswerte – scores – können als negative Logarithmen
geführt
werden, was die Verarbeitung der Wahrscheinlichkeitswerte vereinfacht.
-
Mit jedem Wahrscheinlichkeitswert
kann eine Anfangszeit assoziiert werden, die während der Weitergabe des Wahrscheinlichkeitswertes
durch den lexikalischen Baum zusammen mit dem Wahrscheinlichkeitswert
verschoben wird. Es kann ein Ergebniswort durch den Grobvergleich
generiert werden, wenn ein dem Wort entsprechender Wahrscheinlichkeitswert
aus einem dem Wort entsprechenden Knoten des lexikalischen Baumes
weitergegeben wird. Die Anfangszeit wird mit dem Wahrscheinlichkeitswert
weitergegeben und entspricht dem Zeitpunkt, zu dem das Wort gesprochen
wurde.
-
Die erste Teilliste des Vokabulars
kann eine erste Ergebniswortliste darstellen, und durch den Grobvergleich
gebildete Ergebniswörter
können
zur ersten Ergebniswortliste hinzugefügt werden. Wird ein erster Zeitpunkt
mit der ersten Ergebniswortliste assoziiert, so wird der ersten
Ergebniswortliste ein Wort hinzugefügt, wenn eine Anfangszeit,
die mit einem dem Wort entsprechenden Wahrscheinlichkeitswert assoziiert
wird, mit dem ersten Zeitpunkt übereinstimmt.
-
Es können Mehrfach-Ergebniswortlisten
geführt
werden, die jeweils mit einem bestimmten Zeitpunkt assoziiert werden.
Ein durch den Grobvergleich generiertes Ergebniswort kann zu Ergebniswortlisten
hinzugefügt
werden, die mit Zeitpunkten assoziiert werden, die der Anfangszeit
des Wortes bis zu einem bestimmten Zeitintervall entweder vorangehen
oder folgen. Das Zeitintervall kann mit der Wortlänge in Beziehung
gesetzt werden. Das Zeitintervall kann beispielsweise so gewählt werden,
dass das Ergebniswort Listen hinzugefügt wird, die sich über einen
Zeitraum erstrecken, der der Länge
des Wortes entspricht.
-
In den Listen können auch Wahrscheinlichkeitswerte
gespeichert werden, die während
des Grobvergleichs für
die Ergebniswörter
erzeugt wurden. Der Wahrscheinlichkeitswert eines Wortes kann modifiziert werden,
wenn das Wort einer Liste hinzugefügt wird, die einem Zeitpunkt
entspricht, der sich von der Anfangszeit des Wortes unterscheidet.
Zur Gewinnung eines modifizierten Wahrscheinlichkeitswertes kann
der Wahrscheinlichkeitswert auf der Basis der Differenz zwischen
dem ersten Zeitpunkt und einem Zeitpunkt modifiziert werden, mit
dem eine bestimmte Ergebniswortliste assoziiert wird.
-
Der lexikalische Baum kann jeweils
ein Phonem darstellende Knoten enthalten, so dass jedes Wort des
Vokabulars durch eine Folge von Knoten dargestellt wird, die zusammen
einer Folge von Phonemen entsprechen, die das Wort definieren. Wahrscheinlichkeitswerte
können
in dem lexikalischen Baum weitergegeben werden, indem die Wahrscheinlichkeitswerte
zwischen den Knoten des lexikalischen Baumes weitergegeben werden.
-
Mit jedem Knoten kann ein Sprachmodell-Wahrscheinlichkeitswert
assoziiert werden, der eine Wahrscheinlichkeit zum Ausdruck bringt,
mit der ein Wort einschließlich
dem durch den Knoten dargestellten Phonem in der Sprache auftritt.
Der mit einem Knoten assoziierte Sprachmodell-Wahrscheinlichkeitswert
und ein von dem Knoten aus weitergegebener Wahrscheinlichkeitswert
können
addiert werden. Der mit einem Knoten assoziierte Sprachmodell-Wahrscheinlichkeitswert
kann einem Anstieg eines besten Sprachmodell-Wahrscheinlichkeitswertes von einem
mit einem Ursprung des Knotens beginnenden Zweig des lexikalischen
Baumes bis zu einem mit dem Knoten beginnenden Zweig des lexikalischen
Baumes entsprechen.
-
Wahrscheinlichkeitswerte können während ihrer
Weitergabe in dem lexikalischen Baum normiert werden. So kann beispielsweise
eine aktualisierte Version des besten Wahrscheinlichkeitswertes
für ein
Zeitinkrement von den Wahrscheinlichkeitswerten für ein darauffolgendes
Zeitinkrement subtrahiert werden.
-
Aus der sich hieran anschließenden Beschreibung
einschließlich
der Zeichnungen werden weitere Merkmale und Vorteile verständlich sein.
-
In den Zeichnungen zeigen:
-
1 einen
Blockschaltplan eines Systems für
kontinuierliche Spracherkennung,
-
2 ein
Blockdiagramm zu Prozeduren, die durch das Spracherkennungssystem
von 1 ausgeführt werden,
-
3 und 4 Programmablaufpläne der Prozeduren
von 2,
-
5 einen
Graphen eines lexikalischen Baums,
-
6 einen
Graphen eines Teils eines lexikalischen Baums von 5,
-
7, 8A und 8B Zustandsgraphen, die Knoten des lexikalischen
Baums von 5 darstellen,
-
9 und 10 Übersichten über die den Zuständen der
Zustandsgraphen der 7 und 8 entsprechenden Wahrscheinlichkeitswerte,
-
11 ein
Programmablaufplan einer Prozedur zur Verarbeitung von Knoten eines
lexikalischen Baums.
-
Entsprechend 1 gehört
zu einem Spracherkennungssystem 100 ein Eingabegerät wie ein
Mikrofon 105. Spricht eine Person in das Mikrofon 105,
so erzeugt dieses ein analoges elektrisches Signal 110,
das die geäußerte Sprachsequenz
repräsentiert.
Mit dem Mikrofon 105 ist eine Soundkarte 115 verbunden,
die das analoge elektrische Signal 110 empfängt. Bestandteil
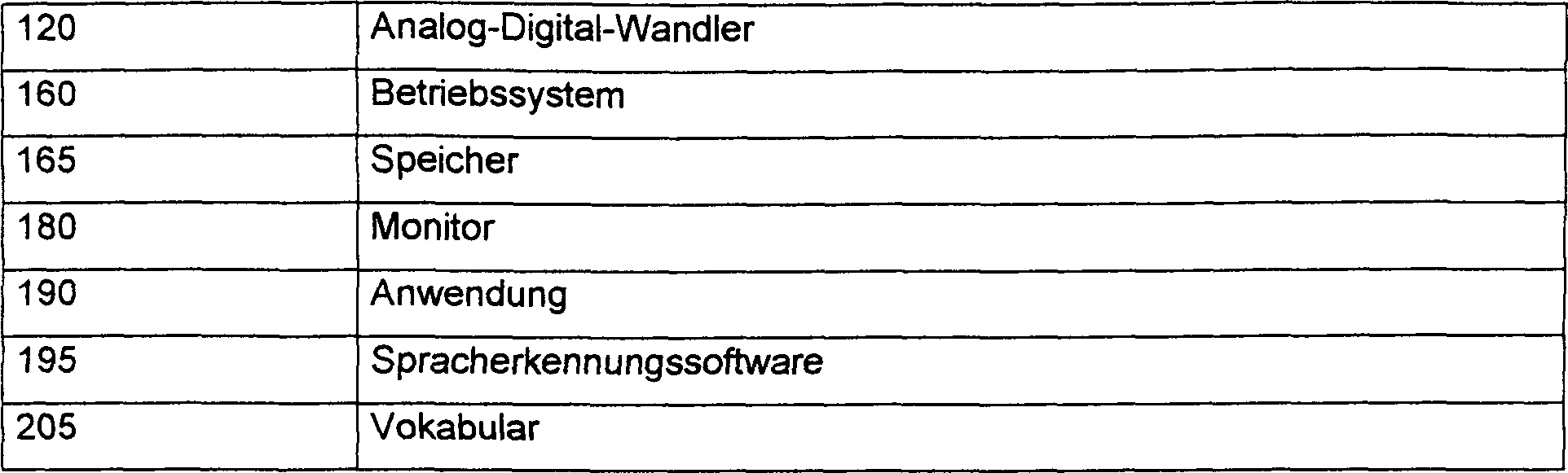
der Soundkarte ist ein Analog-Digital-(A/D)-Wandler 120. Der
A/D-Wandler 120 tastet periodisch das analoge elektrische
Signal 110 ab und erzeugt ein digitales Signal 125. Üblich ist
bei AID-Wandlern 120 beispielsweise eine Abtastfrequenz
von etwa 11 kHz, so dass das digitale Signal 125 in einem
Zeitabschnitt von 20 Millisekunden insgesamt 220 digitale Abtastwerte
enthält.
Jeder Zeitabschnitt von 20 Millisekunden entspricht einem Rahmen
des digitalen Signals 125.
-
Das digitale Signal 125 wird
dann einem Prozessor 130 zugeführt. Der Prozessor verarbeitet
die Abtastwerte entsprechend dem Rahmen des digitalen Signals 125 und
erzeugt eine Gruppe Parameter 135, die den Frequenzanteil
des Rahmens des digitalen Signals 125 (d. h. die Energie
des Rahmens in verschiedenen Frequenzbändern) repräsentiert (und den entsprechenden
Zeitraum von 20 Millisekunden des analogen Signals 110,
das die geäußerte Sprachsequenz
repräsentiert).
Bei den Parametern kann es sich um Frequenzparameter, Zepstralparameter
und von den Frequenzparametern und Zepstraiparametern abgeleitete
Signale handeln. Die Frequenzparameter repräsentieren den Inhalt der Sprachsequenz
in der jeweiligen Gruppe von Frequenzbändern und werden mit Hilfe
der schnellen Fourier-Transformation (FFT) erzeugt. Die Zepstralparameter
werden durch Ausführen
einer Kosinustransformation von Logarithmen der Frequenzparameter
erzeugt. Wie sich nachweisen ließ, heben Zepstralparameter
effektiver als Frequenzparameter die Informationen hervor, die für die Spracherkennung
wichtig sind. Unter Anwendung einer linearen IMELDA-Kombinationstransformation
oder ähnlicher
Methoden können
die Zepstralparameter vom Prozessor kombiniert werden.
-
Zur Betriebssystemsoftware 160,
mit der der Prozessor betrieben wird, gehört eine Speicherroutine 165.
Mit Hilfe der Speicherroutine 165 werden die Gruppen von
Parametern 135 in einem Puffer 170 gespeichert.
Nach Speicherung der Parameter für
eine ausreichende Anzahl von Rahmen im Puffer 170 stellt
die Speicherroutine 165 die Parametergruppen zu einem Sprachsequenzenpaket 175 zusammen.
-
Bestandteil der Betriebssystemsoftware 160 ist
auch die Überwachungssoftware 180.
Die Überwachungssoftware 180 ermittelt
einen Zählstand 185 der
Anzahl der zwar gespeicherten, aber noch nicht verarbeiteten Sprachsequenzenpakete 175.
Eine vom Prozessor 130 ausgeführte Anwendung 190 (beispielsweise ein
Textverarbeitungssystem) überprüft die Äußerungen
(Sprachsequenzen) regelmäßig anhand
des Zählstandes 185.
Beträgt
der Zählstand 185 Null,
so liegt keine Äußerung vor.
Entspricht der Zählstand
nicht Null, so ruft die Anwendung 190 die Spracherkennungssoftware 195 auf
und setzt an die Stelle des Sprachsequenzenpakets im Puffer 170 einen
Zeiger 200. Eine genauere Beschreibung, wie die Sprachäußerungen
empfangen und im Spracherkennungssystem gespeichert werden, sind
dem US-Patent Nr. 5 027 406 mit dem Titel "Method for Interactive Speech Recognition
and Training" zu
entnehmen, das durch Bezugnahme Bestandteil des vorliegenden Patents
wird.
-
Die Spracherkennungssoftware 195 ermittelt,
welche Wörter
gesprochen wurden, indem der Prozessor 130 veranlasst wird,
Rahmen aus dem Sprachsequenzenpaket 175 abzurufen und diese
Rahmen der Sprachsequenzen mit in einem Vokabular 205 gespeicherten
Modellsequenzen zu vergleichen. Die Spracherkennungssoftware veranlasst
dann den Prozessor, an die Anwendung 190 Textversionen
der gesprochenen Wörter
zu tiefem. Die Spracherkennungssoftware 195 steuert den
Prozessor bei der Ausführung
der kontinuierlichen Spracherkennung. Dies bedeutet, dass die sprechende
Person beim Sprechen in das Mikrofon 105 für die Spracherkennungssoftware
keine Pausen zwischen den Wörtern
einlegen muss, damit die Software in der Lage ist, die Wörter zu
erkennen. Eine genauere Beschreibung der kontinuierlichen Spracherkennung
ist dem US-Patent Nr. 5 202 952 mit dem Titel "Large-Vocabulary Continuous Speech Prefiltering
und Processing System" zu
entnehmen.
-
Entsprechend 2 führt
der Prozessor 130 zwei Prozeduren parallel nebeneinander
aus. Dabei nutzt der Prozessor eine Spracherkennungsprozedur 250,
um zu identifizieren, was eine Person gesagt hat, wozu ein Vergleich
zwischen den digitalen Rahmen, die die Sprachsequenz einer Person
verkörpern,
und den Modellsequenzen aus dem Vokabular 205 vorgenommen
wird. Der Prozessor wendet eine Vofilterprozedur 255 an,
um aus dem Vokabular 205 eine Liste von Ergebniswörtern zu
erstellen, die wahrscheinlich den Wörtern entsprechen, die, beginnend
mit einem bestimmten Zeitpunkt, von der Person gesprochen wurden.
Daraufhin wendet der Prozessor die Spracherkennungsprozedur 250 an,
um die Modellsequenzen für
diese Wörter
mit den digitalen Rahmen zu vergleichen, die die Sprachsequenzen
der Person repräsentieren.
-
Das Vokabular 205 umfasst
Zigtausend Wörter.
Deshalb wäre
die Anzahl der Berechnungen, die ausgeführt werden müssten, um
eine Sequenz von digitalen Rahmen mit Modellen eines jeden Wortes
des Vokabulars zu vergleichen, außerordentlich groß. Der Prozessor 130 wendet
deshalb die Vofilterprozedur 255 an, um die Zahl der erforderlichen
Berechnungen zu reduzieren. Die Vofilterprozedur führt einen
Grobvergleich der Sequenz von digitalen Rahmen mit dem Vokabular
aus, um eine Teilliste des Vokabulars zu ermitteln, für die ein
gründlicherer
Vergleich unter Anwendung der Erkennungsprozedur 250 gerechtfertigt
ist.
-
Die Erkennungsprozedur 250 fordert
die Vorfilterprozedur 255 auf, eine Liste 260 mit
Wörtern
bereitzustellen, die beginnend mit einer Anfangszeit 265 geäußert worden
sein können.
Die Vorfilterprozedur 255 liefert daraufhin die angeforderte
Liste 260.
-
Die Spracherkennungsprozedur 250 ist
in 3 dargestellt. Der
Prozessor 130 wendet die Prozedur 250 an, um eine
Hypothese der Sequenz von Wörtern
zu erzeugen, die mit der größten Wahrscheinlichkeit
in einem Zeitraum gesprochen wurden, der mit einer Sprechpause beginnt
und mit einer solchen endet. Zu Beginn ruft der Prozessor einen
Rahmen digitaler Daten (Schritt 300) ab. Danach ermittelt
der Prozessor, ob der Rahmen einer Sprechpause tatsächlich oder
wahrscheinlich entspricht (Schritt 305). Der erste Rahmen
stimmt stets mit einer Sprechpause überein.
-
Wird ein Wort für den Rahmen in Erwägung gezogen,
so nimmt der Prozessor 130 einen genauen Abgleich vor,
um festzustehen, ob das Wort vom Benutzer wahrscheinlich geäußert wurde
(Schritt 310). Für
einen genauen Abgleich vergleicht der Prozessor den Rahmen mit einer
Modellsequenz für
das Wort. Bei dem Vergleich wird der Wahrscheinlichkeitswert für das Wort
vom Prozessor aktualisiert. Zur Vereinfachung der Verarbeitung werden
die Wahrscheinlichkeitswerte als negative Logarithmen geführt. Dementsprechend
steht ein niedrigerer Wahrscheinlichkeitswert für eine bessere Übereinstimmung
(eine hohe Wahrscheinlichkeit), während ein höherer Wahrscheinlichkeitswert
für eine
geringere Übereinstimmung
(eine niedrigere Wahrscheinlichkeit) steht, wobei die Wahrscheinlichkeit
der Übereinstimmung
mit größer werdendem
Wahrscheinlichkeitswert abnimmt.
-
Nach Durchführung eines genauen Abgleichs
bestimmt der Prozessor, ob das Wort wahrscheinlich vom Benutzer
gesprochen wurde (Schritt 315). Dazu vergleicht er den
aktuellen Wahrscheinlichkeitswert für das Wort (oder für einen
Teil des Wortes) mit einem Schwellenwert. Überschreitet der Wahrscheinlichkeitswert diesen
Schwellenwert, so stellt der Prozessor fest, dass das Wort sehr
wahrscheinlich keiner weiteren Untersuchung wert ist, und entfernt
die Hypothese, in der das Wort enthalten ist (Schritt 320).
-
Steht der Prozessor fest, dass das
Wort wahrscheinlich vom Benutzer gesprochen wurde, dann ermittelt
er weiterhin, ob das Wort endet (Schritt 325). Der Prozessor
stellt fest, dass ein Wort endet, wenn der Rahmen der letzten Komponente
des Modells für
das Wort entspricht.
-
Stellt der Prozessor fest, dass ein
Wort endet (Schritt 325) oder dass der Rahmen wahrscheinlich
einer Sprechpause entspricht (Schritt 305), dann fordert
er eine Liste der Worte an, die mit dem nächsten Rahmen beginnen können (Schritt 330).
Dazu sendet er an die Vorfilterprozedur 255 eine Anforderung
einer Liste von Wörtern,
die mit dem nächsten
Rahmen beginnen können.
Hatte der Prozessor bereits die Liste der Wörter angefordert, die mit dem
Rahmen beginnen, dann nutzt er die Liste wiederholt und fordert
die Liste nicht zusätzlich
noch einmal an.
-
Nach Erhalt der Wortliste bewertet
der Prozessor diese (Schritt 335). Wie ausführlich noch
beschrieben werden soll, enthält
die Wortliste, die von der Vorfilterprozedur 255 zurückgegeben
wurde, einen Wahrscheinlichkeitswert, der mit jedem Wort assoziiert
wird. Der Prozessor bewertet jedes Wort der Liste, indem er den
Listenwahrscheinlichkeitswert (SL) für das Wort
zur Erzeugung eines modifizierten Listenwahrscheinlichkeitswertes
(SL) wie folgt modifiziert: SML = SL + LC – LL,worin LC ein
Sprachmodellwahrscheinlichkeitswert ist, der die Häufigkeit
repräsentiert,
mit der das Paar Wärter, das
das Listenwort und das unmittelbar zuvor stehende Wort in der Hypothese
umfasst, die das Listenwort mit einschließt, in der Sprachsequenz gemeinsam
genutzt wurde, und LL ein Sprachmodellwahrscheinlichkeitswert
ist, der in dem Listenwahrscheinlichkeitswert enthalten ist und
der Häufgkeit
entspricht, mit der ohne Bezug auf den Kontext das Listenwort in
der Sprachsequenz verwendet wird. Der Prozessor addiert daraufhin den
modifizierten Listenwahrscheinlichkeitswert und den Wahrscheinlichkeitswert
für die
Hypothese, die das Listenwort enthält (d. h. den Wahrscheinlichkeitswert
für das
Wort oder die Folge von Wörtern,
von denen angenommen wird, dass sie in der untersuchten Sprachsequenz
dem Listenwort vorausgehen), und vergleicht das Ergebnis mit einem
Schwellenwert. Wenn das Ergebnis kleiner als der Schwellenwert ist,
dann hält
der Prozessor die das Listenwort einschließende Hypothese bereit (d.
h. der Prozessor berücksichtigt
weiterhin das Listenwort bei der Verarbeitung des nächsten Rahmens).
Im anderen Falle stellt der Prozessor fest, dass das Listenwort
keiner weiteren Berücksichtigung
wert ist und verwirft die dieses Listenwort einschließende Hypothese.
-
Nach Bewertung der Wortliste (Schritt 335),
der Feststellung, dass ein Wort nicht endet (Schritt 325), oder
der Verwertung einer Hypothese (Schritt 320) ermittelt
der Prozessor, ob das untersuchte Wort das letzte Wort ist, das
für den
Rahmen untersucht werden soll (Schritt 340). Ist das Wort
nicht das letzte Wort, geht der Prozessor zum folgenden Wort (Schritt 345) über und
nimmt einen genauen Abgleich für
dieses Wort vor (Schritt 310).
-
Handelt es sich bei dem Wort um das
letzte Wort des Rahmens, dann ermittelt der Prozessor, ob wertere
Sprachsequenzrahmen zu verarbeiten sind (Schritt 350).
Der Prozessor stellt fest, dass wertere Sprachsequenzrahmen zu verarbeiten
sind, wenn zwei Bedingungen erfüllt
sind. Erstens müssen
mehr Rahmen zur Verarbeitung bereitstehen. Zweitens darf der Knoten
mit dem besten Wahrscheinlichkeitswert für den gegebenen Rahmen oder
für einen
oder mehrere einer bestimmten Anzahl von unmittelbar vorausgehenden
Rahmen kein Sprechpausenknoten sein (d. h. es sind keine weiteren
Sprachsequenzrahmen zu verarbeiten, wenn der Sprechpausenknoten
der Knoten mit dem besten Wahrscheinlichkeitswert für den gegebenen
Rahmen oder für
eine festgelegte Anzahl von sequenziell vorausgehenden Rahmen ist).
Sind weitere Sprachsequenzrahmen zu verarbeiten, dann fordert der
Prozessor den nächsten
Rahmen an (Schritt 300) und wiederholt die Prozedur.
-
Stehen keine weiteren Sprachsequenzrahmen
zur Verarbeitung bereit, generiert der Prozessor die Ergebniswörter, die
der wahrscheinlichsten Hypothese entsprechen, die die Sprachsequenz
repräsentiert
(Schritt 355). Ausführliche
Darlegungen zu Spracherkennungsverfahren sind in dem US-Patent Nr.
4 805 218 mit dem Titel "Methods
for Speech Analysis and Speech Recognition" und in dem US-Patent Nr. 5 202 952
mit dem Titel "Large-Vocabulary
Continuous Speech Prefiltering and Processing System" enthalten.
-
Die Prozedur 255 der Vorfilterung
mittels lexikalischer Bäume
wird in 4 veranschaulicht.
Vor Beginn der Spracherkennungsprozedur 250 initialisiert
der Prozessor einen lexikalischen Baum. Der lexikalische Baum repräsentierit
das Vokabular 205, das auf den phonetischen Beziehungen
zwischen den im Vokabular enthaltenen Wörtern basiert. Jeder Knoten
des lexikalischen Baums repräsentiert
ein Phonem (d. h. einen Laut, der einem Teil eines Wortes oder von
Wörtern
entspricht).
-
Entsprechend den 5 und 6 weist
der lexikalische Baum 500 einen Wurzelknoten 505 auf,
der neue in den lexikalischen Baum übertragene Wörter verkörpert. Der
lexikalische Baum erstreckt sich von dem Wurzelknoten 505 zu
einer Gruppe 510 von Knoten, die den Phonemen entsprechen,
mit denen die Wörter
beginnen. Von dem Wurzelknoten 505 kann auch ein Sprechpausenknoten 512 erreicht
werden, der die Sprechpause verkörpert.
-
Jeder Knoten in der Gruppe 510 repräsentiert
ein Phonem, das am Beginn eines oder mehrerer Wörter steht. In dem Bereich 600 des
in 6 dargestellten lexikalischen
Baums 500 beispielsweise entspricht ein Knoten 610 allen
Wörtern
des Vokabulars, die mit dem Phonem "H" beginnen.
Die Knoten der Gruppe 510 umfassen zusammen Darstellungen
des Anfangsphonems eines jeden Wortes des Vokabulars.
-
Der lexikalische Baum verzweigt sich
immer werter bis zu den äußersten
Koten 515, die die aktuellen Wörter des Vokabulars verkörpern. Der äußerste Knoten 615 von 6 entspricht z. B. dem Wort "healing", wie durch das Quadrat
dargestellt ist. Auch ein Knoten des Baums in der mittleren Ebene
kann ein Wort des Vokabulars verkörpern. Der Knoten 520 könnte beispielsweise
ein bestimmtes Wort des Vokabulars und außerdem die ersten zwei Phoneme
anderer Wörter
des Vokabulars repräsentieren.
In gleicher Weise ist der äußerste Knoten 620 von 6 eine Entsprechung der
Wörter "heal" sowie "heel", gleichzeitig aber
auch der ersten drei Phoneme der Wörter "heals", "heels" und "healing". Der Knoten 620 zeigt
zudem, dass ein äußerster Knoten
mehreren, nicht nur einem Ergebniswort entsprechen kann, da sich
mehrere Wörter
in der phonetischen Schreibweise gleichen können. Wie 6 zu entnehmen ist, können äußerste Knoten in unterschiedlichen
Ebenen innerhalb des lexikalischen Baums auftreten.
-
Wenden wir uns wieder 4 zu. Der Prozessor 130 beginnt
mit der Vorfilterprozedur 255, indem er den nächstfolgenden
Rahmen von Daten aus dem Sprachsequenzenpaket 175 abruft
(Schritt 400). Unmittelbar nach der Initialisierung ist
der nächstfolgende
Datenrahmen der erste Datenrahmen im Sprachsequenzenpaket 175.
Danach ist der nächste
Datenrahmen derjenige, der dem letzten Datenrahmen folgt, der von
der Vorfilterprozedur verarbeitet wurde. Es sei darauf hingewiesen,
dass die Vorfilterprozedur 255 zwischen Listenanforderungen
den lexikalischen Baum nicht reinitialisiert. Deshalb entspricht
der Zustand des lexikalischen Baums, bei dem eine Wortliste angefordert
wird, dem Zustand des lexikalischen Baums, nachdem eine vorausgehende
Wortliste zurückgegeben
wurde.
-
Nach Abruf eines Datenrahmens ermittelt
der Prozessor 130 im Baum einen aktiven Knoten, der nach sich
keine unverarbeiteten aktiven Nachfolger aufweist (Schritt 405).
Die Nachfolger eines Knotens können auch
als Unterknoten des Knotens bezeichnet werden.
-
Wird der lexikalische Baum initialisiert,
so ist der Sprechpausenknoten 512 der einzige aktive Knoten.
-
Durch Starten mit einem Knoten ohne
unverarbeitete aktive Unterknoten wird Speicherplatz eingespart,
der zur Verarbeitung der Knoten benötigt wird. Wie oben dargelegt,
werden Änderungen
im lexikalischen Baum über
den Baum nach unten weitergegeben (d. h. vom Wurzelknoten zu den äußersten
Knoten). Da Änderungen
für weiter
unten im Baum befindliche Knoten die Verarbeitung der sich höher im Baum
befindlichen Knoten nicht beeinflussen, kann der Prozessor die Knoten
ohne Herstellen einer zweiten Kopie des lexikalischen Baums im Speicher
verarbeiten, indem er mit einem Knoten beginnt, der keine unverarbeiteten
aktiven Unterknoten aufweist.
-
Daraufhin verarbeitet der Prozessor 130 den
aktuellen Knoten (Schritt 410). Während der Verarbeitung des
Knotens stellt der Prozessor fest, ob der Knoten zusätzliche
aktive Knoten hervorbringt oder als inaktiver Knoten zu betrachten
ist. Handelt es sich dabei um einen äußersten Knoten, stellt der
Prozessor zudem fest, ob das dem Knoten entsprechende Ergebniswort
einer Wortliste für
einen Zeitpunkt, der mit dem Knoten assoziiert wurde, hinzugefügt werden
soll.
-
Nach der Verarbeitung des Knotens
(Schritt 410) stellt der Prozessor 130 fest, ob
der Knoten im Baum am weitesten oben angeordnet ist (d. h. der Wurzelknoten
ist) (Schritt 415). Ist der Knoten nicht am weitesten oben
angeordnet, schreitet der Prozessor zum nächsten keine unverarbeiteten
aktiven Unterknoten umfassenden Knoten (Schritt 420) voran
und verarbeitet diesen Knoten (Schritt 410). Es sei darauf
hingewiesen, dass der Prozessor bei der Suche nach dem nächsten zu
verarbeitenden Knoten inaktive Knoten mit aktiven Unterknoten oder
aktiven Geschwisterknoten berücksichtigt.
-
Handelt es sich bei dem verarbeiteten
Knoten um den höchsten
aktiven Knoten (Schritt 415), so verarbeitet der Prozessor 130 den
Sprechpausenknoten 512 (Schritt 425). Generell
wird der Sprechpausenknoten verarbeitet, indem der Rahmen mit einem
Sprechpausenmodell verglichen und der sich ergebende Wahrscheinlichkeitswert
und der minimale aktuelle Wahrscheinlichkeitswert für den Sprechpausenknoten
sowie der Wahrscheinlichkeitswert für den Wurzelknoten 505 addiert
werden. Die Knotenverarbeitung wird nachfolgend ausführlicher
behandelt.
-
Als Nächstes stellt der Prozessor
den lexikalischen Baum wieder auf die Anfangswerte zurück (Schritt 430).
Wie nachfolgend ausgeführt
werden soll, stellt der Prozessor den Baum immer dann wieder auf
die Anfangswerte zurück,
wenn der Sprechpausenknoten 512 aktiv ist oder ein Ergebniswort
von einem äußersten Knoten
des lexikalischen Baums generiert wurde, unabhängig davon, ob das Ergebniswort
der Wortliste hinzugefügt
wurde. Der Prozessor stellt den Baum auf die Anfangswerte zurück, indem
er den Wahrscheinlichkeitswert für
den Wurzelknoten 505 durch den kleinsten Wahrscheinlichkeitswert
für den
Sprechpausenknoten 512 und die kleinsten Wahrscheinlichkeitswerte
für beliebige
durch äußerste Knoten
des lexikalischen Baums für
den aktuellen Rahmen generierte Ergebniswörter ersetzt. Ist der Sprechpausenknoten
inaktiv und hat kein äußerster
Knoten ein Ergebniswort generiert, dann ersetzt der Prozessor den
Wahrscheinlichkeitswert für
den Wurzelknoten 505 durch einen schlechten Wahrscheinlichkeitswert
(d. h. einen Wahrscheinlichkeitswert, der großer ist als ein Eliminierschwellenwert).
-
Daraufhin steift der Prozessor 130 fest,
ob der Wortliste für
den angeforderten Zeitpunkt noch mehr Ergebniswörter hinzugefügt werden
können
(Schritt 435). Sind im lexikalischen Baum keine aktiven
Knoten vorhanden, die der Sprachsequenz entsprechen, die zu der,
vor oder kurz nach der Anfangszeit begann, für die die Liste angefordert
wurde, und entspricht der letzte zu verarbeitende Rahmen einem Zeitpunkt,
der kurz nach der Anfangszeit liegt, für die die Liste angefordert
wurde, so können
der Wortliste keine werteren Ergebniswörter hinzugefügt werden.
Wie nachfolgend ausgeführt
werden soll, wird ein vom lexikalischen Baum generiertes Ergebniswort
der Wortliste hinzugefügt,
die der Anfangszeit des Wortes entspricht, sowie Wortlisten, die
den Zeitpunkten entsprechen, die vor oder nach der Anfangszeit des
Wortes liegen. Aus diesem Grund wartet der Prozessor, bis entsprechend
der Sprachsequenz, die kurz nach der Anfangszeit für die Wortliste
begann, keine aktiven Knoten mehr in dem Baum vorhanden sind. Wenn
mehr Ergebniswörter
hinzugefügt
werden können,
ruft der Prozessor den nächsten
Datenrahmen vom Sprachsequenzenpaket 175 ab (Schritt 400) und
wiederholt die oben beschriebenen Schritte.
-
Können
der Wortliste keine Ergebniswörter
hinzugefügt
werden (Schritt 435), so gibt der Prozessor die Wortliste
zur Prozedur 250 zurück
(Schritt 440). Enthält
die Wortliste mehr als eine festgelegte Anzahl von Ergebniswörtern, so
entfernt der Prozessor 130 vor der Rückgabe der liste Ergebniswörter aus
der Liste. Der Prozessor entfernt die Ergebniswörter, die mit geringster Wahrscheinlichkeit
der Sprachsequenz des Benutzers entsprechen, und entfernt ausreichend
viele Ergebniswörter,
so dass die Anzahl der in der Liste enthaltenen Ergebniswörter auf
die festgelegte Anzahl von Ergebniswörtern reduziert wird. Der Prozessor
entfernt auch alle Wortlisten für
Zeitpunkte vor der jeweils angeforderten Anfangszeit.
-
Jeder Knoten des lexikalischen Baums 500 (5) verkörpert eine Folge von Zuständen für ein bestimmtes
Phonem. 7 zeigt z. B.
einen Knoten 700, der einen ersten Zustand 705,
einen zweiten Zustand 710 und einen dritten Zustand 715 umfasst.
Ein Vergleich mit einem digitalen Rahmen kann dazu führen, dass der
sich in einem bestimmten Zustand befindende Wahrscheinlichkeitswert
in diesem Zustand bleibt (über
den Pfad 720). Ein Wahrscheinlichkeitswert bleibt in dem
Zustand, wenn er, nachdem er auf der Grundlage eines Vergleichs
mit einem Modell für
einen Zustand abgeglichen wurde, besser ist als ein Wahrscheinlichkeitswert, der
von einem vorausgehenden Zustand oder Knoten übertragen wurde, oder wenn
kein Wahrscheinlichkeitswert von einem vorausgehenden Zustand oder
Knoten übertragen
wurde. Der Vergleich kann auch bewirken, dass der Wahrscheinlichkeitswert
zu einem nachfolgenden Zustand über
den Pfad 725 übertragen
wird. Ein Wahrscheinlichkeitswert wird auf einen nachfolgenden Zustand übertragen,
wenn er, nachdem er auf der Grundlage eines Vergleichs mit einem
Modell für
den nachfolgenden Zustand abgeglichen wurde, besser als der Wahrscheinlichkeitswert
des nachfolgenden Zustands ist oder wenn kein Wahrscheinlichkeitswert
mit dem nachfolgenden Zustand assoziiert wird. Der Wahrscheinlichkeitswert
für den
dritten Zustand 715 kann an einen oder mehrere nachfolgende
Knoten über
einen Pfad 730 übertragen
werden.
-
Entsprechend 8A wird der Knoten 512, der
der Sprechpause entspricht, durch einen einzigen Zustand 800 repräsentiert.
Jeder Vergleich mit einem digitalen Rahmen kann dazu führen, dass
ein Wahrscheinlichkeitswert in dem Knoten in dem Zustand 800 bleibt
(über den
Pfad 805) und kann außerdem
dazu führen, dass
der Wahrscheinlichkeitswert über
den Pfad 810 an den Wurzelknoten 505 übertragen
wird.
-
Entsprechend 8B wird der Wurzelknoten 505 durch
einen einzigen Zustand 850 repräsentiert. Ein Vergleich mit
einem Rahmen führt
dazu, dass der Wahrscheinlichkeitswert in dem Knoten über den
Pfad 855 an einen oder mehrere nachfolgende Knoten übertragen
wird (einschließlich
des Sprechpausenknotens 512).
-
Jeder Zustand eines Knotens lässt sich
durch vier Werte wiedergeben: einen Wahrscheinlichkeitswert, eine
Anfangszeit, einen Penaltypunktwert – penalty – für Verlassen und einen Penaltypunktwert
für Bleiben. Der
Wahrscheinlichkeitswert steht für
die Wahrscheinlichkeit, dass eine Folge von digitalen Rahmen den
lexikalischen Baum in den Zustand versetzt hat (d. h. die Wahrscheinlichkeit,
dass die Folge der Rahmen dem Ergebniswort oder einem Teil eines
Ergebniswortes entspricht, mit denen der Zustand übereinstimmt).
Wie erwähnt,
werden die Wahrscheinlichkeitswerte als negative logarithmische
Werte geführt.
-
Die Anfangszeit identifiziert den
in der Hypothese angenommenen Zeitpunkt, zu dem die Person das Wort
oder die Wörter,
die durch den Zustand repräsentiert
werden, zu sprechen begann. Die Anfangszeit identifiziert insbesondere
den Zeitpunkt, zu dem der mit dem Zustand assoziierte Wahrscheinlichkeitswert
in den lexikalischen Baum eintrat (d. h. den Zeitpunkt, zu dem der
Wahrscheinlichkeitswert von dem Zustand 800 entlang dem
Pfad 810 weitergegeben wurde).
-
Bei den Penaltypunktwerten für Verlassen
und Bleiben handelt es sich um feste Werte, die mit dem Zustand
assoziiert werden. Der Penaltypunktwert für Bleiben und jeder in dem
Zustand bleibende Wahrscheinlichkeitswert werden addiert. Der Penaltypunktwert
für Bleiben
ist der länge
des durch den Zustand wiedergegebenen Lauts und der Länge des
Phonems, das durch den Knoten repräsentiert wird, dem der Zustand
zugeordnet wird, umgekehrt proportional. Der Penaftypunktwert für Bleiben
könnte
beispielsweise -log (1 – 1/davg) proportional sein, wobei davg die
durchschnittliche Dauer des durch den Zustand verkörperten
Lauts, angegeben in Rahmen, ist. So ist der Penaltypunktwert für Bleiben
ein relativ großer
Wert, wenn der dem Zustand entsprechende Laut nur über einen
kurzen Zeitraum hinweg andauert, und ein relativ kleiner Wert, wenn
der dem Zustand entsprechende Laut über einen langen Zeitraum andauert.
-
Der Penaltypunktwert für Verlassen
und jeder den Zustand verlassende Wahrscheinlichkeitswert werden
addiert, der Penaltypunktwert schließt eine Komponente der Dauer
und eine Sprachmodellkomponente ein. Die Komponente der Dauer ist
der Länge
des durch den Zustand repräsentierten
Lauts und der Länge
des Phonems, das durch den Knoten repräsentiert wird, dem der Zustand
zugeordnet wird, direkt proportional. Die Komponente der Dauer des
Penaltypunktwertes für
Verlassen könnte
beispielsweise -log (1/davg) proportional sein.
So hat die Komponente der Dauer des Penaltypunktwertes für Verlassen
einen relativ großen
Wert, wenn der dem Zustand entsprechende Laut über einen langen Zeitraum andauert,
und einen relativ kleinen Wert, wenn der dem Zustand entsprechende
Laut über
einen kurzen Zeitraum hinweg andauert.
-
Die Sprachmodellkomponenten der für Verlassen
geltenden Penaltypunktwerte für
alle Zustände
in einem bestimmten Knoten repräsentieren
zusammen einen Sprachmodellwahrscheinlichkeitswert für das mit diesem
Knoten assoziierte Phonem. Der Sprachmodellwahrscheinlichkeitswert
steht für
die Wahrscheinlichkeit, dass ein Wort einschließlich des Phonems in einer
Sprachsequenz auftritt. Der Sprachmodellwahrscheinlichkeitswert,
der in den einem Knoten zugeordneten Penaftypunktwerten für Verlassen
enthalten ist, entspricht dem Anstieg des besten Sprachmodellwahrscheinlichkeitswertes
für den
Zweig des lexikalischen Baums, der mit dem Knoten beginnt, im Vergleich
zu dem Zweig des lexikalischen Baums, der mit dem Ursprung des Knotens
beginnt.
-
Bei den folgenden Ausführungen
wird davon ausgegangen, dass mit dem Zustand 800 oder dem
Zustand 850 keine Penattypunktwerte für Verfassen oder Bleiben assoziiert
werden. Dasselbe Ergebnis könnte erzielt
werden, indem die Penaltypunktwerte für Verlassen und Bleiben für die Zustände 800 und 850 gleich Null
gesetzt werden. Bei den folgenden Ausführungen wird des Weiteren angenommen,
dass der erste Rahmen der erste Rahmen ist, der einer Sprachsequenz
entspricht, und nicht einer Sprechpause.
-
9 zeigt
ein vereinfachtes Beispiel dafür,
wie die Wahrscheinlichkeitswerte durch den lexikalischen Baum weitergegeben
werden. Bevor der erste Rahmen abgerufen wird (Zeile 900), hat der
Zustand 800 (der der Sprechpause entspricht) einen Wahrscheinlichkeitswert
von 0, und keine anderen Knoten sind aktiv. Der Wahrscheinlichkeitswert
gleich 0 bedeutet, dass eine einhundertprozentige Wahrscheinlichkeit
vorliegt, dass das System mit einer Sprechpause beginnt.
-
Nachdem der erste Rahmen angefordert
wurde (Reihe 905), wird der Wahrscheinlichkeitswert für den Zustand 800 (SA1) dem akustischen Wahrscheinlichkeitswert
(AA1) gleich gesetzt, der sich aus einem
akustischen Abgleich des ersten Rahmens mit dem akustischen Modell
ergibt, das dem Zustand 800 entspricht (d. h. dem akustischen
Modell für
eine Sprechpause). Also wird der Wahrscheinlichkeitswert für den Zustand 800 (SA1) der Wahrscheinlichkeit gleich gesetzt,
dass der erste Rahmen der Sprechpause entspricht.
-
Der Abruf des ersten Rahmens führt auch
dazu, dass der Zustand 705 aktiv wird. Nimmt man an, dass der
Knoten 700 einem Phonem entspricht, das der Beginn eines Wortes
ist, so wird der Wahrscheinlichkeitswert für den Zustand 705 (SB1) dem akustischen Wahrscheinlichkeitswert
(AB1) gleich gesetzt, der sich aus einem
akustischen Abgleich des ersten Rahmens mit dem akustischen Modell
ergibt, das dem Zustand 705 entspricht. So wird der Wahrscheinlichkeitswert
für den
Zustand 705 (SB1) der Wahrscheinlichkeit
gleich gesetzt, dass der erste Rahmen dem Zustand 705 entspricht.
Die Anfangszeit für
den Zustand 705 (SB1) wird dem
Zeitpunkt gleich gesetzt, der mit dem ersten Rahmen assoziiert wird.
Dieser Wert für
die Anfangszeit zeigt an, dass der Wahrscheinlichkeitswert im Zustand 705 ein
Wort repräsentiert,
das zu dem Zeitpunkt begann, der dem ersten Rahmen entspricht. Die
Anfangszeit bewegt sich gemeinsam mit dem Wahrscheinlichkeitswert,
während
dieser durch den lexikalischen Baum weitergegeben wird.
-
Nachdem der zweite Rahmen abgerufen
wurde (Reihe 910), wird der Wahrscheinlichkeitswert für den Zustand 800 (SA2) der Summe aus dem vorhergehenden Wahrscheinlichkeitswert
für den
Zustand (SA1) und dem akustischen Wahrscheinlichkeitswert
(AA2) gleich gesetzt, der sich aus einem
akustischen Abgleich des zweiten Rahmens mit dem akustischen Modell
für eine
Sprechpause ergibt: SA2 =
SA1 + AA2 = AA1 + AA2.
-
Wie oben erwähnt, ist jeder der Wahrscheinlichkeitswerte
gleich einer negativen logarithmischen Wahrscheinlichkeit. Demzufolge
entspricht das Addieren von Wahrscheinlichkeitswerten dem Multiplizieren der
Wahrscheinlichkeiten. So ist der Wahrscheinlichkeitswert für den Zustand 800 (SA2) gleich der Wahrscheinlichkeit, dass sowohl
der erste als auch der zweite Rahmen einer Sprechpause entsprechen.
Dieser Prozess wird für
die nachfolgenden Rahmen wiederholt (z. B. Zeilen 915 und 920),
so dass der Wahrscheinlichkeitswert für den Zustand 800 bei
einem Rahmen "n" (SAn)
gleich zu setzen ist mit:
-
-
Bei diesem Ausdruck wird davon ausgegangen,
dass der Sprechpausenknoten 512 vom Wurzelknoten 505 nicht
auf den Anfangswert zurückgestellt
wurde. Erfolgt bei einem Rahmen n das Zurückstellen auf den Anfangswert,
so wird der Wert SAn–1, durch den Wahrscheinlichkeitswert
des Wurzelknotens 505 für
den Rahmen n – 1
ersetzt.
-
Nachdem der zweite Rahmen abgerufen
wurde, wird der Wahrscheinlichkeitswert für den Zustand 705 (SB2) gleich gesetzt mit: SB2 = min (SB1 + stayB, SA1) + AB2,worin AB2 der
akustische Wahrscheinlichkeitswert ist, der sich aus einem akustischen
Abgleich des zweiten Rahmens mit dem akustischen Modell ergibt,
das dem Zustand 705 entspricht, und stayB der
für Bleiben
geltende Penaltypunktwert für
den Zustand 705 ist. Der Wahrscheinlichkeitswert für den Zustand 705 (SB2) entspricht einer der wahrscheinlicheren
der zwei Alternativen: (1) der erste Rahmen war eine Sprechpause,
der zweite Rahmen der Laut, der durch den Zustand 705 repräsentiert
wurde, oder (2) sowohl der erste als auch der zweite Rahmen waren
der Laut, der durch den Zustand 705 repräsentiert
wurde. Die erste Alternative ist einem Übergang von Zustand 800 zu
Zustand 705 entlang dem Pfad 810 gleich zu setzen.
Die zweite Alternative ist einem Übergang vom Zustand 705 zurück in den
Zustand 705 entlang dem Pfad 720 gleich zu setzen. Ist
die erste Alternative die wahrscheinlichere, so wird die Anfangszeit,
die dem ersten Rahmen entspricht, der vor dem Zustand 705 gespeichert
wurde, durch einen Wert ersetzt, der dem zweiten Rahmen entspricht.
Dieser Wert zeigt an, dass der Wahrscheinlichkeitswert bei Zustand 705 ein
Wort repräsentiert,
das mit dem zweiten Rahmen begann.
-
Nach Abruf des zweiten Rahmens wird
der Zustand 710 aktiv. Der Wahrscheinlichkeitswert für den Zustand 710 (SC2) wird gleich gesetzt mit: SC2 = SB1 + leaveB + AC2 worin
AC2 der akustische Wahrscheinlichkeitswert
ist, der aus einem akustischen Abgleich des zweiten Rahmens mit
dem akustischen Modell gewonnen wurde, das dem Zustand 710 entspricht,
und leaveB der für Verlassen geltende Penaltypunktwert
für den
Zustand 705 ist. In gleicher Weise sind leaveC und
leaveD für
das Verlassen geltende Penaltypunktwerte für die Zustände 710 bzw. 715.
Die Summe der Sprachmodellkomponenten von leaveB,
leaveC und leaveD repräsentiert
den Sprachmodellwahrscheinlichkeitswert für das durch den Knoten 700 verkörperte Phonem.
-
Die Methodik zur Bestimmung der Zustandswahrscheinlichkeitswerte
für die
Zustände,
die sich vom Sprechpausenzustand unterscheiden, lässt sich
allgemein wie folgt ausdrücken:
Si,j = min(Si,j–1 +
stayi, Si–1,j–1 +
leavej–1)
+ Ai,j bei i größer als Null (wo i gleich Null
der Sprechpause entspricht) und mit der Grenzbedingung, dass der
Wahrscheinlichkeitswert für
einen inaktiven Zustand gleich unendlich oder einem entsprechend
großen
Wert ist. Die Anfangszeit für
den Zustand kann wie folgt ausgedrückt werden:
ti,j = ti,j–1 für Si,j–1 +
stayi = Si–1,j–1 +
leavej–1 oder
ti,j = ti–1,j–1 für Si,j–1 +
stayi > Si–1,j–1 +
leavei–1,bei
i und j größer als
Null und mit der Grenzbedingung, dass der Zeitwert für einen
gerade aktiv gewordenen Zustand den Rahmen repräsentiert, bei dem der Zustand
aktiv wurde. Wie vorstehend erwähnt,
lassen sich die Zustandswahrscheinlichkeitswerte für den Sprechpausenzustand
wie folgt bestimmen:
mit der Grenzbedingung, dass
S
0,0 gleich Null ist. Eine noch allgemeinere
Form, in der die Wahrscheinlichkeitswerte als Funktionen der verschiedenen
Parameter ausgedrückt
sind, ist in
10 veranschaulicht.
-
Wenden wir uns nun 11 zu. Ein Knoten kann entsprechend einer
Prozedur 435 verarbeitet werden. Zunächst aktualisiert der Prozessor 130 die
Wahrscheinlichkeitswerte und Zeitwerte für jeden Zustand des Knotens
(Schritt 1100). Dies geschieht, indem der Prozessor akustische
Wahrscheinlichkeitswerte erzeugt und die oben erörterten Gleichungen anwendet.
-
War der letzte Zustand des Knotens
vor der Aktualisierung der Wahrscheinlichkeitswerte für den Knoten
aktiv, so nutzt der Prozessor den Wahrscheinlichkeitswert für den letzten
Zustand, um Wahrscheinlichkeitswerte für eventuell vorhandene inaktive
Unterknoten des Knotens zu erzeugen. Wird ein Ausdünnungsschwellenwert
vom erzeugten Wahrscheinlichkeitswert für einen Unterknoten nicht überschritten,
so aktiviert der Prozessor diesen Unterknoten und liefert für den Unterknoten
den erzeugten Wahrscheinlichkeitswert.
-
Anschließend stellt der Prozessor fest,
ob der Wahrscheinlichkeitswert eines beliebigen Zustands des Knotens
den Ausdünnungsschwellenwert überschreitet
(Schritt 1105). Überschreitet
ein Wahrscheinlichkeitswert den Ausdünnungsschwellenwert, so wird
die Wahrscheinlichkeit, dass das durch den Wahrscheinlichkeitswert
repräsentierte
Wort gesprochen wurde, als zu gering erachtet, als dass es einer
weiteren Untersuchung wert wäre.
Der Prozessor dünnt
also den lexikalischen Baum durch Deaktivieren eines beliebigen
Zustands aus, der einen Wahrscheinlichkeitswert hat, der den Ausdünnungsschwellenwert überschreitet
(Schritt 1110). Ist jeder Zustand des Knotens deakvitiert,
so deaktiviert der Prozessor auch den Knoten. Der Prozessor kann
einen Knoten oder Zustand deaktivieren, indem er einen Datensatz
löscht,
der mit dem Knoten oder Zustand assoziiert ist, oder indem er in
dem Datensatz anzeigt, dass der Knoten oder Zustand inaktiv ist.
In ähnlicher
Weise kann der Prozessor einen Knoten oder Zustand aktivieren, indem
er einen Datensatz erzeugt und den Datensatz mit dem Knoten oder
Zustand assoziiert oder in einem vorhandenen Datensatz anzeigt,
dass der Knoten oder Zustand aktiv ist.
-
Der Prozessor kann einen dynamischen
Ausdünnungsschwellenwert
(Tdynamic) anwenden, der zu jeder Zeit Änderungen
des durchschnittlichen oder besten Wahrscheinlichkeitswertes im
lexikalischen Baum berücksichtigt.
Der dynamische Ausdünnungsschwellenwert
kann als die Summe aus einem festen Ausdünnungsschwellenwert und einem
Normierungsfaktor (norm) verstanden werden. In diesem Falle deaktiviert
der Prozessor jeden Zustand j, bei dem gilt: Sj > Tdynamic = Tfixed +
norm.
-
Der Normierungsfaktor (norm) könnte beispielsweise
dem niedrigsten Wahrscheinlichkeitswert im lexikalischen Baum vom
vorausgehenden Rahmen entsprechen. Der Normierungsfaktor könnte aber
auch durch genaues Berechnen des niedrigsten Wahrscheinlichkeitswertes
im lexikalischen Baum für
den aktuellen Rahmen in einem ersten Durchgang durch den lexikalischen
Baum und durch anschließendes
Vergleichen aller Wahrscheinlichkeitswerte mit einem Schwellenwert
ermittelt werden, der auf dem Wahrscheinlichkeitswert während eines
zweiten Durchgangs durch den lexikalischen Baum basiert. Das zweite
Verfahren ist offensichtlich genauer, da es den Vergleich mit dem
aktuellen Rahmen einschließt.
Das zweite Verfahren erfordert jedoch zusätzliche Verarbeitungsschritte,
die sich daraus ergeben, dass zwei Durchgänge durch den lexikalischen
Baum nötig
sind.
-
Bei einer Ausführungsform des Verfahrens wird
eine Schätzung
des Vergleichs mit dem aktuellen Rahmen angewendet, um den größten Nutzen
aus dem zweiten Verfahren zu ziehen, wobei nur ein einziger Durchgang
durch den lexikalischen Baum erforderlich wird. Bei der Ausführungsform
werden die Zustandswahrscheinlichkeitswerte für den Sprechpausenzustand wie
folgt bestimmt: S0,j =
S0,j–1 +
A0,j – normj,wobei die Grenzbedingung gilt, dass
S0,0 gleich Null ist. Die Wahrscheinlichkeitswerte
für andere
Zustände
werden wie folgt bestimmt: Si,j =
min (Si,j–1 +
stayj, Si–1,j–1 +
leavei–1)
+ Ai,j – normj,bei i größer als Null (wo i = Null der
Sprechpause entspricht) und mit der Grenzbedingung, dass der Wahrscheinlichkeitswert
für einen
inaktiven Zustand einem großen
Wert entspricht. Der Wert für
normj entspricht dem aktualisierten Wahrscheinlichkeitswert
(ohne Normierung) für
den Zustand (Sx), der den niedrigsten Wahrscheinlichkeitswert
im vorhergehenden Rahmen (j – 1)
hatte: Sx,j = Sx,j–1 +
Ax,j.
-
Die Verwendung dieses Normierungsfaktors
bedeutet, dass sich, wenn der Zustand, der im vorausgehenden Rahmen
den niedrigsten Wahrscheinlichkeitswert aufweist, als der Zustand
erhalten bleibt, der im aktuellen Rahmen den niedrigsten Wahrscheinlichkeitswert
aufweist, für
den Zustand ein Wahrscheinlichkeitswert ergibt, der gleich dem Penaltypunktwert
für Bleiben
ist, der mit dem Zustand (stayx) assoziiert
wird.
-
Bei einer anderen Ausführungsform
der Prozedur 425 nimmt der Prozessor 130 eine
Ausdünnung
als einen Unterschritt des Schritts Aktualisierung der Wahrscheinlichkeitswerte
für die
Zustände
(Schritt 1100) vor. Der Prozessor überwacht während des Aktualisierungsprozesses
die Wahrscheinlichkeitswerte und deaktiviert sofort einen Zustand,
wenn der Wahrscheinlichkeitswert des Zustands den Ausdünnungsschwellenwert überschreitet.
Auf der Grundlage dieses Verfahrens können Verarbeitungsschritte
des Prozessors reduziert werden, die mit dem akustischen Abgleich
assoziiert werden.
-
Ein Zustand kann durch zwei Arten
akustischer Modelle verkörpert
werden: ein einfach generisches Modell, das die Auswirkungen eines
vorausgehenden Lauts auf den durch den Zustand repräsentierten
Laut berücksichtigt,
und ein doppelt generisches Modell, das den Laut unabhängig von
dem vorausgehenden Laut betrachtet. Der Prozessor vergleicht einen
Rahmen mit einem bestimmten akustischen Modell nur einmal und verwendet
den sich aus dem Vergleich ergebenden Wahrscheinlichkeitswert wiederholt,
wenn zusätzliche
Zustände
durch dasselbe akustische Modell verkörpert werden. Da es beachtlich
weniger doppelt generische Modelle als einfach generische gibt,
ist es weitaus wahrscheinlicher, dass ein Vergleich eines Rahmens
mit einem doppelt generischen Modell wiederholt genutzt werden kann
als ein Vergleich mit einem einfach generischen Modell. Dementsprechend
machen doppelt generische Modelle einen geringeren Verarbeitungsumfang
als einfach generische erforderlich.
-
Aus diesem Grunde führt der
Prozessor 130 zunächst
den akustischen Abgleich mit Hilfe eines doppelt generischen Modells
durch. Überschreitet
der resultierende Wahrscheinlichkeitswert einen Qualitätsschwellenwert,
so speichert der Prozessor den Wahrscheinlichkeitswert. Überschreitet
der resultierende Wahrscheinlichkeitswert den Qualitätsschwellenwert
nicht, so führt
der Prozessor den akustischen Abgleich unter Nutzung des einfach
generischen Modells aus und aktualisiert den Wahrscheinlichkeitswert
unter Verwendung der Ergebnisse des akustischen Abgleichs. Danach
vergleicht der Prozessor den Wahrscheinlichkeitswert mit dem Ausdünnungsschwellenwert
und deaktiviert den Zustand, wenn der Wahrscheinlichkeitswert den
Ausdünnungsschwellenwert überschreitet.
-
Für
den Prozessor verringert sich des Weiteren der Verarbeitungsumfang
im Zusammenhang mit dem akustischen Abgleich, indem für den vorausgehenden
Rahmen erzeugte akustische Wahrscheinlichkeitswerte genutzt werden,
wenn der aktuelle Rahmen vom vorausgehenden Rahmen durch weniger
als einen bestimmten Betrag getrennt ist. Der Prozessor ermittelt
den Abstand zwischen dem aktuellen Rahmen und dem vorausgehenden
Rahmen, indem er die Euklidische Entfernung zwischen den zwei Rahmen
als die Summe der Quadrate der Differenzen zwischen den entsprechenden
Parametern der zwei Rahmen berechnet.
-
Anschließend stellt der Prozessor 130 fest,
ob ein Ergebniswort einer Wortliste hinzuzufügen ist (Schritt 1115).
Ein Ergebniswort wird einer Wortliste hinzugefügt, wenn der zu verarbeitende
Knoten dem letzten Phonem eines Wortes entspricht, ein Wahrscheinlichkeitswert
aus dem letzten Zustand des Knotens weitergegeben wurde und der
Wahrscheinlichkeitswert kleiner als ein Listenschwellenwert ist.
Vor dem Vergleich des Wahrscheinlichkeitswertes mit dem Listenschwellenwert
addiert der Prozessor einen Sprachmodellwahrscheinlichkeitswert
und den Wahrscheinlichkeitswert. Der Sprachmodellwahrscheinlichkeitswert
entspricht der Differenz zwischen dem Sprachmodellwahrscheinlichkeitswert
für das
Wort und dem inkrementalen Sprachmodellwahrscheinlichkeitswert,
der bereits in dem Wahrscheinlichkeitswert enthalten ist. Im Allgemeinen
ist der Listenschwellenwert kleiner als der Ausdünnungsschwellenwert. Entspricht
der zu verarbeitende Knoten dem letzten Phonem mehrerer Wörter mit
gleicher phonetischer Schreibweise, dann werden alle die Ergebniswörter, denen
der Knoten entspricht, der Wortliste hinzugefügt.
-
Sind die genannten Bedingungen erfüllt, so
fügt der
Prozessor der Wortliste das Ergebniswort bzw. die Ergebniswörter hinzu
(Schritt 1120). Ein Ergebniswort in der Wortliste wird
zusammen mit dem aus dem letzten Zustand weitergegebenen Wahrscheinlichkeitswert
gespeichert. Befindet sich das Ergebniswort bereits in der Liste,
so speichert der Prozessor zusammen mit der Liste den besseren Wert,
entweder den bereits mit der Liste gespeicherten Wahrscheinlichkeitswert
oder den aus dem letzten Zustand weitergegebenen Wahrscheinlichkeitswert.
Die in einer Wortliste enthaltenen Wahrscheinlichkeitswerte für Ergebniswörter werden
zusammen mit der Wortliste zurückgegeben.
Diese Wahrscheinlichkeitswerte werden von der Prozedur 250 für den detaillierten
Abgleich genutzt.
-
Der Prozessor 130 fügt zudem
das Ergebniswort zu Wortlisten für
Zeitpunkte hinzu, die vor der Anfangszeit liegen oder ihr folgen.
Dies geschieht, um mögliche
Abweichungen der Anfangszeit des Wortes zu berücksichtigen, die durch die
Auswahl des besseren Wahrscheinlichkeitswertes, des Wahrscheinlichkeitswertes,
der in einem Zustand bleibt, oder des von einem vorausgehenden Zustand
weitergegebenen Wahrscheinlichkeitswertes bedingt sind. Mittels
Weitergabe des Ergebniswortes durch eine größere Anzahl von Listen gewährleistet
der Prozessor, dass diese Abweichungen nicht die Genauigkeit des
Spracherkennungssystems beeinträchtigen.
-
Der Prozessor verteilt auf der Basis
der Länge
des Wortes das Ergebniswort an eine größere Anzahl von Listen. Genauer
gesagt, fügt
der Prozessor das Ergebniswort Listen für Zeitpunkte, die um eine halbe
Länge des
Wortes von der Anfangszeit versetzt sind, solange hinzu, wie die
halbe Länge
des Wortes nicht den Maximalwert (beispielsweise zehn Rahmen) überschreitet.
Ist z. B. ein Wort zwanzig Rahmen lang, so fügt der Prozessor das Ergebniswort
Wortlisten hinzu, die den zehn Rahmen entsprechen, die vor dem Rahmen
liegen, der durch die Anfangszeit repräsentiert wird ("der Anfangsrahmen"), und die den zehn
Rahmen entsprechen, die dem Anfangsrahmen folgen. Der Prozessor
gewichtet den Wahrscheinlichkeitswert des Ergebniswortes anhand
des Abstands zwischen dem Rahmen für eine bestimmte Liste und
dem Anfangsrahmen. So könnte der
Prozessor beispielsweise einen Penaltypunktwert von 25 und den Wahrscheinlichkeitswert
für jeden
vom Anfangsrahmen getrennten Rahmen addieren. Der Prozessor fügt z. B.
keiner Liste das Ergebniswort hinzu, bei dem durch die Gewichtung
der Wahrscheinlichkeitswert den Schwellenwert überschreitet. Bei diesem Beispiel
können
der Wortliste für
den angeforderten Zeitpunkt mehr Ergebniswörter hinzugefügt werden
(Schritt 440), so lange aktive Knoten im lexikalischen
Baum entsprechend der Sprachsequenz vorhanden sind, die zehn Rahmen
nach der Anfangszeit, für
die die Liste angefordert wurde, oder davor begann, und solange
der letzte zu verarbeitende Rahmen dem Zeitpunkt mindestens zehn
Rahmen nach der Anfangszeit entspricht.
-
Nach Hinzufügen eines Ergebniswortes zur
Wortliste (Schritt 1120) speichert der Prozessor den Wahrscheinlichkeitswert,
der mit dem Ergebniswort als ein Anfangswahrscheinlichkeitswert
zum Rückstellen
auf die Anfangswerte im Baum assoziiert wird (Schritt 1125).
Die durch den lexikalischen Baum erfolgende Generierung eines Ergebniswortes
bedeutet, dass der aktuelle Rahmen dem letzten Rahmen des Ergebniswortes
entsprechen kann (wobei die Wahrscheinlichkeit einer solchen Übereinstimmung
durch den Wahrscheinlichkeitswert wiedergegeben werden kann, der
mit dem Wort assoziiert wird). Dies bedeutet, dass der nächste Rahmen dem
Beginn eines Wortes oder einer Sprechpause entsprechen kann. Der
Prozessor 130 stellt den Baum wieder auf die Anfangswerte
zurück
(Schritt 430 von 4),
um diese Möglichkeit
zu berücksichtigen.
-
Für
einen bestimmten Rahmen kann eine größere Anzahl von Knoten Ergebniswörter generieren.
Der Baum braucht jedoch nur einmal auf die Anfangswerte zurückgestellt
werden. Unter diesem Aspekt speichert der Prozessor nur den mit
einem Wort (SW) assoziierten Wahrscheinlichkeitswert
als den Rückstellwahrscheinlichkeitswert
(SRS), wenn das Wort das erste Ergebniswort
ist, das vom Baum für
den aktuellen Rahmen generiert werden soll oder wenn der Wahrscheinlichkeitswert
des Wortes kleiner als der Wahrscheinlichkeitswert aller anderen
Ergebniswörter
ist, die durch zuvor verarbeitete Knoten für den aktuellen Rahmen (SRS')
generiert wurden: SRS =
min(SW, SRS').
-
Durch Speichern nur des niedrigsten
Wahrscheinlichkeitswertes (d. h. des Wahrscheinlichkeitswertes, der
die größte Wahrscheinlichkeit
verkörpert,
dass der aktuelle Rahmen der letzte Rahmen eines Wortes war) gewährleistet
der Prozessor, dass der Baum wieder auf den Anfangswert zurückgesetzt
wird, wobei die größte Wahrscheinlichkeit
dafür genutzt
wird, dass der nächste
Rahmen der erste Rahmen eines neuen Wortes ist.
-
Zum Rückstellen des Baums (Schritt 430 von 4) aktiviert der Prozessor
den Wurzelknoten 505 und assoziiert das Minimum des Rückstellwahrscheinlichkeitswertes
(SRS) und den Wahrscheinlichkeitswert für den Sprechpausenknoten 512 mit
dem Wurzelknoten. Bei der Verarbeitung des nächsten Rahmens kann der aktive
Wurzelknoten 505 dazu genutzt werden, die Knoten in der
Gruppe 510 oder den Sprechpausenknoten 512 zu
aktivieren.
-
Das Verarbeiten des Knotens ist beendet,
wenn der Prozessor einen Wahrscheinlichkeitswer zum Rückstellen
des Baums auf die Anfangswerte (Schritt 1125) gespeichert
hat oder wenn kein Ergebniswort der Wortliste hinzuzufügen ist
(Schritt 1115).
-
Für
den Prozessor können
andere Verfahren zur Verringerung des mit der Prozedur 255 im
Zusammenhang stehenden Verarbeitungsumfangs angewendet werden. Wenn
der lexikalische Baum z. B. sequenzielle Knoten enthält, die
keine Zweige aufweisen (z. B. ein erster Knoten, der der einzige
Unterknoten eines zweiten Knotens ist, der seinerseits der einzige
Unterknoten eines dritten Knotens ist), ersetzt z. B. der Prozessor
diese Knoten durch einen einzigen Knoten.
-
Bei einer weiteren Verfahrensabwandlung
könnte
der Prozessor 130, wenn von ihm ein Zweig eines lexikalischen
Baums festgestellt wird, ein phonemvorausschauendes Verfahren anwenden.
Wenn ein Knoten einen Wahrscheinlichkeitswert an mehrere Unterknoten
weitergibt, führt
der Prozessor für
jeden Unterknoten einen relativ groben akustischen Abgleich durch.
Der Prozessor bildet insbesondere Durchschnittswerte für die nächsten vier
Rahmen, um einen geglätteten
Rahmen zu erzeugen, und vergleicht den geglätteten Rahmen mit einem akustischen
geglätteten
Modell für
das Phonem, das jedem Unterknoten entspricht, um einen ursprünglichen
akustischen Wahrscheinlichkeitswert für jeden Unterknoten zu erzeugen.
Das akustische geglättete
Modell ist kontextunabhängig
und repräsentiert
den ersten geglätteten
Rahmen des Phonems. Der Prozessor addiert für jeden Unterknoten den ursprünglichen
akustischen Wahrscheinlichkeitswert und einen Teil des inkrementalen
Sprachmodellwahrscheinlichkeitswertes für den Knoten und den Wahrscheinlichkeitswert für den Knoten.
Der Prozessor eliminiert alle Unterknoten, für die der ursprüngliche
Wahrscheinlichkeitswert einen zweiten Ausdünnungsschwellenwert überschreitet.
Danach führt
der Prozessor einen verfeinerten akustischen Abgleich für den/die
verbleibenden Unterknoten durch.
-
Der Verarbeitungsumfang wird für den Prozessor 130 des
Weiteren reduziert, indem mit jedem Knoten ein Zählwert aktiver Unterknoten
assoziiert wird. Wenn der Prozessor anschließend einen Knoten ausdünnt, verringert
er auch schrittweise den Zählwert
für jeden
Ursprung des Knotens. In gleicher Weise erhöht der Prozessor, wenn er den
Knoten aktiviert, den Zählwert
schrittweise für
jeden Ursprung eines Knotens. Diese Zählwerte vereinfachen die Identifikation
des ersten und letzten aktiven Knotens. Der Prozessor speichert
zudem schrittweise Geschwisterknoten (d. h. Knoten, die unmittelbar
Unterknoten desjenigen Knotens sind) im Speicher, wobei jeder Knoten
einen Zeiger auf den ersten Unterknoten des jeweiligen Knotens enthält.
-
-
-
-
-
-
Fig.
7, 8A, 8B
Fig. 9 und 10
-