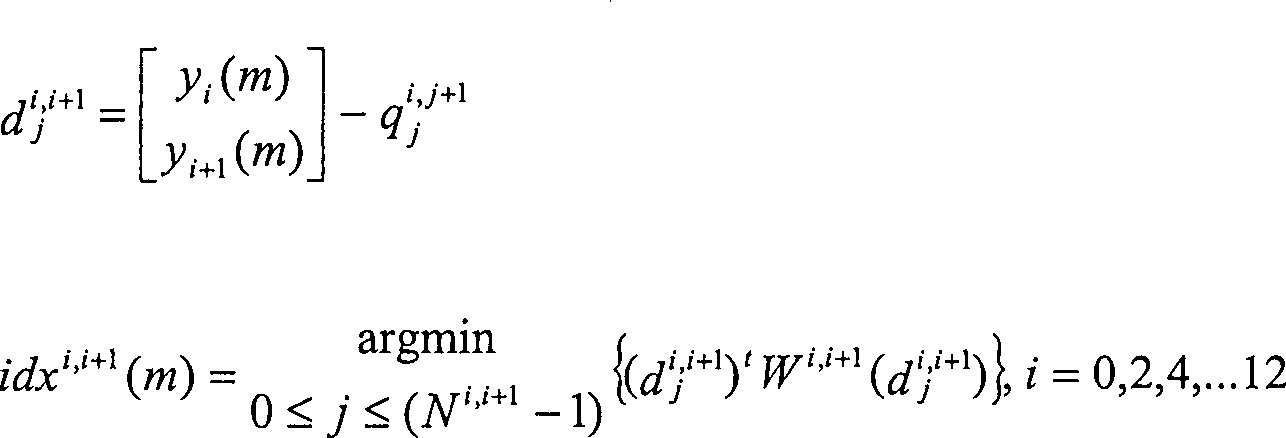-
Gebiet der
Erfindung
-
Die
vorliegende Erfindung betrifft ein Verfahren zum Verarbeiten empfangener
Daten in einem verteilten Spracherkennungsprozess. Die vorliegende
Erfindung betrifft auch eine Vorrichtung zum Verarbeiten empfangener
Daten in einem verteilten Spracherkennungsprozess. Die vorliegende
Erfindung ist geeignet, ohne darauf beschränkt zu sein, für das Verarbeiten
empfangener Daten, die sich auf Spracherkennungsparameter beziehen,
wenn sie über
eine Funkkommunikationsverbindung übertragen werden.
-
Hintergrund
der Erfindung
-
Die
Spracherkennung ist ein Prozess zum automatischen Erkennen von Klängen, Teilen
von Wörtern, Wörtern oder
Satzteilen von Sprache. Ein derartiger Prozess kann als Schnittstelle
zwischen Mensch und Maschine verwendet wer den, zusätzlich oder
anstelle der üblicherweise
verwendeten Mittel wie etwa Schalter, Tastaturen, der Maus usw.
Ein Spracherkennungsprozess kann auch verwendet werden, um automatisch
Informationen aus einer gesprochenen Kommunikation oder Nachricht
zu erlangen.
-
Es
wurden verschiedene Verfahren entwickelt und werden noch verbessert,
um eine automatische Spracherkennung zur Verfügung zu stellen. Einige Verfahren
basieren auf einem erweiterten Wissen mit entsprechenden heuristischen
Strategien, andere verwenden statistische Modelle.
-
In
typischen Spracherkennungsprozessen wird die zu verarbeitende Sprache
mehrere Male im Verlauf eines Abtastzeitschlitzes abgetastet, beispielsweise
50 oder 100 Mal pro Sekunde. Die abgetasteten Werte werden unter
der Verwendung von Algorithmen verarbeitet, um Spracherkennungsparameter
zur Verfügung zu
stellen. Beispielsweise besteht eine Art von Spracherkennungsparameter
aus einem Koeffizienten, der als Mel-Cepstral-Koeffizient bekannt
ist. Derartige Spracherkennungsparameter werden in der Form von
Vektoren angeordnet, auch als Felder bekannt, was als eine mit einem
bestimmten Ordnungsgrad angeordnete Parametergruppe oder -menge
aufgefasst werden kann. Der Abtastprozess wird für weitere Abtastzeitschlitze
wiederholt. Ein typisches Format besteht darin, dass für jeden
Abtastzeitschlitz ein Vektor erstellt wird.
-
Die
obige Parametrisierung und Platzierung in Vektoren stellt das dar,
was als Frontend-Verarbeitung eines Spracherkennungsprozesses bezeichnet
werden kann. Die oben beschriebenen in Vektoren angeordneten Spracherkennungsparameter
werden dann entsprechend der Spracherkennungstechniken analysiert, was
als Backend-Verarbeitung des Spracher kennungsprozesses bezeichnet
werden kann. In einem Spracherkennungsprozess, in dem der Frontend-Prozess
und der Backend-Prozess am gleichen Ort oder im gleichen Bauteil
durchgeführt
werden, ist die Wahrscheinlichkeit, Fehler in die Spracherkennungsparameter
beim Weiterleiten vom Frontend in das Backend einzuführen, minimal.
-
In
einem als verteilten Spracherkennungsprozess bekannten Prozess wird
der Frontend-Teil des Spracherkennungsprozesses vom Backend-Teil
entfernt durchgeführt.
An einem ersten Ort wird die Sprache abgetastet, parametrisiert
und die Spracherkennungsparameter in Vektoren angeordnet. Die Spracherkennungsparameter
werden quantisiert und dann an einen zweiten Ort, beispielsweise über eine
Kommunikationsverbindung eines eingerichteten Kommunikationssystems, übertragen.
Oft kann der erste Ort ein Fernendgerät und der zweite Ort eine zentrale
Verarbeitungsstation sein. Die empfangenen Spracherkennungsparameter
werden dann entsprechend der Spracherkennungstechniken am zweiten
Ort analysiert. Die quantisierten Spracherkennungsparameter und
ihre Anordnung in Vektoren stellen Daten dar, die von der ersten
Station gesendet und von der zweiten Station empfangen werden. Um
die Übertragung
dieser Daten zu erleichtern, werden die Daten typischerweise in
einer Framestruktur angeordnet, die eine Mehrzahl von Datenframes
umfasst, wobei jedem ein entsprechender Headerframe vorausgeht,
der entsprechende gemeinsame Headerinformationen umfasst. Der Headerframe
kann auch dergestalt sein, dass ein Headerframe zusätzlich Headerinformationen
umfasst, die nur spezifisch für
diesen Headerframe oder für
den bestimmten, diesem Headerframe entsprechenden, Datenframe, ist.
-
Viele
Arten von Kommunikationsverbindungen in vielen Arten von Kommunikationssystemen
können zur
Verwendung in einem verteilten Spracherkennungsprozess in Betracht
gezogen werden. Ein Beispiel ist ein konventionelles drahtgebundenes
Kommunikationssystem, beispielsweise ein öffentliches Telefonnetz. Ein anderes
Beispiel ist ein Funkkommunikationssystem, wie beispielsweise TETRA.
Ein anderes Beispiel ist ein zellulares Funkkommunikationssystem.
Ein Beispiel eines geeigneten zellularen Kommunikationssystems ist ein
globales System für
mobile Kommunikationssysteme (GSM), ein anderes Beispiel sind Systeme
wie etwa das universale Mobiltelekommunikationssystem (UMTS), das
sich momentan in der Standardisierung befindet.
-
Um
jegliche Verwirrung zu vermeiden, wird betont, dass die oben beschriebenen
Datenframes nicht mit den Übertragungsframes
verwechselt werden sollen, die danach in der Übertragung der Daten über die Kommunikationsverbindung
des Kommunikationssystems verwendet werden, in dem die Daten von
einem ersten Ort an einen zweiten Ort übertragen werden, beispielsweise
die Zeitmultiplex-Zeitframes ("TDMA
= time division multiple access")
eines zellularen GSM-Funkkommunikationssystems.
-
Die
Verwendung einer beliebigen Kommunikationsverbindung in einem beliebigen
Kommunikationssystem bringt die Möglichkeit mit sich, dass Fehler
in die Daten und auch in die Headerinformationen eingeführt werden,
die vom ersten Ort an den zweiten Ort über die Kommunikationsverbindung übertragen
werden.
-
Aufgrund
der spezialisierten Spracherkennungstechniken, denen die Sprachparameter
unterworfen werden, ist es wünschenswert,
Mittel zum Verarbeiten der empfangenen Daten zur Verfügung zu
stellen, die einen Grad an Widerstandsfähigkeit gegenüber Fehlern,
die in die Headerinformationen eingeführt wurden, in einer Weise
anbieten, die insbesondere zu den Charakteristiken des verteilten
Spracherkennungsprozesses passt.
-
Des
weiteren ist es bekannt, in Kommunikationssystemen Fehlerdetektionstechniken
zur Verfügung zu
stellen, so dass das Vorhandensein eines Fehlers in einem gegebenen
Abschnitt von übermittelter
Information detektierbar ist. Eine wohlbekannte Technik ist das
zyklische Redundanzcodieren ("cyclic
redundancy coding").
Es ist ebenso bekannt, automatische Fehlerkorrekturtechniken in
Kommunikationssystemen zur Verfügung
zu stellen, so dass ein Fehler in einem gegebenen Abschnitt von übertragener
Information korrigiert wird. Eine wohlbekannte Technik ist die Golay-Fehlerkorrektur.
Es ist ebenso bekannt, Fehlerdetektion und Fehlerkorrektur in Kombination
einzusetzen.
-
Wenn
eine automatische Fehlerkorrektur angewendet wird, besteht das Risiko,
dass die korrigierte Form des gesamten Informationsabschnittes,
der korrigiert wird, weitere Diskrepanzen abweichend vom ursprünglichen
Fehlerbestandteil enthält,
da derartige verfahren dazu neigen, eine Näherung an eine beste, als insgesamt
richtig angesehene Lösung
zu beteiligen. Dies ist bei Vorwärtsfehlerkorrekturtechniken
der Fall, die das Codieren unter der Verwendung eines Codierschemas
auf Blockbasis einsetzen. Ein derartiges Beispiel ist Golay-Codieren,
das es beispielsweise ermöglicht,
12 Informationsbits in 24 Bits zu senden, während bis zu 3 Fehler korrigiert
werden dürfen.
Die Korrekturtechnik bedingt die Korrektur eines ganzen Informationsabschnitts
beispielsweise eines gesamten Headerframes in einer Verbundweise.
Wenn jedoch mehr als 3 Fehler in den 24 Bits vorkommen, dann korrigiert
die Korrekturtechnik den gesamten Header in eine falsch korrigierte Version.
Es ist wünschenswert,
Mittel zum Verarbeiten empfangener Daten zur Verfügung zu
stellen, die die Probleme erleichtern, die mit der Verbundkorrektur
eines gesamten Headerframes in eine falsch korrigierte Version in
einem verteilten Spracherkennungsprozess verbunden sind.
-
Des
weiteren sind Techniken zur automatischen Fehlerkorrektur, die evtl.
keine Sekundärprobleme beim
Anwenden auf andere Informationsformen verursachen, nicht notwendigerweise
ohne Probleme, wenn sie auf Fehler in den oben beschriebenen Headerframes
in einem verteilten Spracherkennungsprozess angewendet werden, teilweise
aufgrund der Art und Weise, wie die Daten in den entsprechenden
Datenframes unter der Verwendung der entsprechenden Headerframeinformation
verarbeitet werden. Deshalb ist es wünschenswert, Mittel zum Verarbeiten
empfangener Daten in einem verteilten Spracherkennungsprozess zur Verfügung zu
stellen, die Sekundärprobleme
erleichtern.
-
Im
Stand der Technik ist ein Verfahren zum Verarbeiten empfangener
Daten in einem verteilten Spracherkennungsprozess in der internationalen
Patentanmeldung WO 95 177 46 A offenbart, aber ein Betrieb wie in
der jetzt zu beschreibenden Erfindung ist nicht im Stand der Technik
offenbart oder nahegelegt.
-
Zusammenfassung der Erfindung
-
Vorliegende
Erfindung betrifft einige oder alle der obigen Aspekte.
-
Gemäß einem
ersten Aspekt der vorliegenden Erfindung wird ein Verfahren zum
Verarbeiten empfangener Daten in einem verteilten Spracherkennungsprozess
zur Verfügung
gestellt, wie in Anspruch 1 beansprucht.
-
Entsprechend
einem anderen Aspekt der Erfindung wird eine Vorrichtung zum Verarbeiten
empfangener Daten in einem verteilten Spracherkennungsprozess zur
Verfügung
gestellt, wie in Anspruch 7 beansprucht.
-
Weitere
Aspekte der Erfindung sind in den abhängigen Ansprüchen beansprucht.
-
Die
vorliegende Erfindung ist darauf gerichtet, Mittel zum Verarbeiten
empfangener Daten zur Verfügung
zu stellen, die insbesondere geeignet sind für die Beschaffenheit des verteilten
Spracherkennungsprozesses, die Form, in der Daten darin empfangen
werden, wenn sie von einem ersten Ort an einen zweiten Ort übertragen
werden und die Art und Weise, in der derartige Daten nach dem Empfang
an einem zweiten Ort in einem verteilten Spracherkennungsprozess
verarbeitet werden.
-
Insbesondere
wird in dem Verfahren der vorliegenden Erfindung die Möglichkeit,
Latenzzeiten in einem Spracherkennungsprozess zu ermöglichen,
ausgenutzt. Speziell wird der Faktor ausgenutzt, dass in einem verteilten
Spracherkennungsprozess eine Latenzzeit in Richtung des Beginns
einer Nachricht oft insbesondere akzeptierbar ist, wenn sie mit
einer niedrigen Latenzzeit am Ende einer Nachricht kombiniert wird.
-
Zusätzliche
spezielle Vorteile werden aus der folgenden Beschreibung und den
Figuren ersichtlich.
-
Kurze Beschreibung
der Zeichnungen
-
1 ist
eine schematische Darstellung eines in Vektoren angeordneten Spracherkennungsparameters,
der Abtastzeitframes einer Ausführungsform
der vorliegenden Erfindung entspricht.
-
2 ist
eine schematische Darstellung eines Headerframes und in einem Datenframe
angeordneten Bit-Stromframes
einer Ausführungsform
der vorliegenden Erfindung.
-
3 ist
eine schematische Darstellung von Datenframes und Headerframes einer
Ausführungsform der
vorliegenden Erfindung.
-
4 ist
ein Prozessablaufdiagramm einer Ausführungsform der vorliegenden
Erfindung.
-
Beschreibung einer bevorzugten
Ausführungsform
der Erfindung
-
In
den unten beschriebenen beispielhaften Ausführungsformen werden die Spracherkennungsparameter
in Vektoren arrangiert, die Abtastzeitframes, wie schematisch in 1 dargestellt,
entsprechen.
-
Ein
Abschnitt eines zu verarbeitenden Sprachsignals 101 ist
in 1 abgebildet. Das Sprachsignal 100 ist
in stark vereinfachter Form dargestellt, da es in der Praxis aus
einer wesentlich komplizierteren Sequenz von Abtastwerten besteht.
Die Abtastzeitframes, von denen in 1 ein erster
Abtastzeitframe 121, ein zweiter Abtastzeitframe 122,
ein dritter Abtastzeitframe 123 und ein vierter Abtastzeitframe 124 gezeigt
sind, sind über
das Sprachsignal gelegt, wie in 1 abgebildet.
In der unten beschriebenen Ausführungsform
gibt es 100 Abtastzeitframes pro Sekunde. Das Sprachsignal wird
wiederholt im Verlauf jedes Abtastzeitframes abgetastet.
-
In
den unten beschriebenen Ausführungsformen
ist der Spracherkennungsprozess einer, in dem insgesamt vierzehn
Spracherkennungsparameter eingesetzt werden. Die ersten zwölf davon
sind die ersten zwölf statischen
Mel-Cepstral-Koeffizienten,
d. h. c(m) = [c1(m),
C2(m), ..., c12(m)]T,wobei m die Abtastzeitframenummer
bezeichnet. Der dreizehnte eingesetzte Spracherkennungsparameter
ist der – nullte
Cepstralkoeffizient, d. h. c0 (m). Der vierzehnte
eingesetzte Spracherkennungsparameter ist ein logarithmischer Energieterm,
d. h. log [E(m)]. Die Details dieser Koeffizienten und ihre Verwendung
in Spracherkennungsprozessen ist im Stand der Technik wohlbekannt
und bedarf hier keiner weiteren Beschreibung. Des weiteren sei es
vermerkt, dass die Erfindung in anderen Kombinationen von Cepstralkoeffizienten,
die Spracherkennungsparameter bilden, durchgeführt werden kann, gleichermaßen mit
einer anderen Auswahl oder anderen Schemata von Spracherkennungsparametern
als die Cepstralkoeffizienten.
-
Die
vierzehn Parameter werden für
jeden Abtastzeitframe in einen entsprechenden Vektor angeordnet oder
formatiert, der auch als Feld bekannt ist, wie in
1 dargestellt.
Der Vektor
131 entspricht dem Abtastzeitframe
121,
der Vektor
132 entspricht dem Abtastzeitframe
122,
der Vektor
133 entspricht dem Abtastzeitframe
123 und
der Vektor
134 entspricht dem Abtastzeitframe
124.
Ein derartiger Vektor kann allgemein dargestellt werden durch
-
Die
Spracherkennungsparameter werden vor der Übertragung von einem ersten
Ort an einen zweiten Ort verarbeitet. In der unten beschriebenen
Ausführungsform
wird dies wie folgt durchgeführt.
Die Parameter des Vektors 131 werden quantisiert. Dies
ist durch das direkte Quanitisieren des Vektors mit einem geteilten Vektorquantisierer
("split vector quantizer") realisiert. Die
Koeffizienten werden in Paare gruppiert und jedes Paar wird unter
Verwendung eines für
dieses entsprechende Paar vorbestimmten Vektorquantisierungscodebuchs
(VQ) quantisiert. Die sich ergebende Menge von Indexwerten wird
dann verwendet, um den Sprachframe darzustellen. Die Koeffizientenpaarungen
von Frontend-Parametern stellen sich wie in Tabelle 1 abgebildet dar,
zusammen mit der für
jedes Paar verwendeten Codebuchgröße.
-
Tabelle
1 Eigenschaftspaarungen
der geteilten Vektorquantisierung
-
Man
findet den nähesten
VQ-Schwerpunkt unter Verwendung eines gewichteten euklidischen Abstandes,
um den Index zu bestimmen,
wobei
q i,i+1 / j den j-ten Codevektor im Codebuch Q
i,i+1 bezeichnet,
N
i,i+1 die Größe des Codebuchs ist, W
i,i+1 die (möglicherweise Gleichheit) gewichtete
Matrix, die für
das Codebuch Q
i,i+1 anzuwendende Matrix
ist und idx
i,i+1 (m) den Codebuchindex bezeichnet,
der zur Darstellung des Vektors [y
i(m),
y
i+1(m)]
T gewählt wurde.
-
Die
erstellten Indizes werden dann in der Form von 44 Bits dargestellt.
Diese 44 Bits werden in den ersten 44 Schlitzen eines Bitstromframes 150 platziert,
wie es vom Referenzzeichen 141 der 1 dargestellt wird.
Die entsprechenden für
den folgenden Vektor, nämlich
den Vektor 132, erstellten 44 Bits werden in den nächsten 44
Schlitzen des Bitstromframes 150 platziert, wie vom Referenzzeichen 142 der 1 dargestellt. Die
verbleibenden Bits des Bitstromframes 150 bestehen aus
4 Bits zyklischem Redundanzcode, wie vom Referenzzeichen 146 der 1 dargestellt,
wobei der Wert der Bits bestimmt wird, so dass eine Fehlerdetektion in
bekannter Art und Weise für
die Gesamtheit der vorausgehenden 88 Bits des Bitstromframes 150 zur
Verfügung
gestellt wird. In ähnlicher
Weise werden die vom Vektor 133 zur Verfügung gestellten
44 Bits in den ersten 44 Schlitzen eines zweiten Bitstromframes 155,
wie vom Referenzzeichen 143 der 1 dargestellt, platziert.
Ebenso werden die für
den folgenden Vektor, nämlich
den Vektor 134, erstellten entsprechenden 44 Bits in den
nächsten
44 Schlitzen des Bitstromframes 155, wie vom Referenzzeichen 144 der 1 dargestellt,
platziert. Die verbleibenden Bits des Bitstromframes 155 bestehen
aus 4 Bits zyklischem Redundanzcode, wie vom Referenzzeichen 148 der 1 dargestellt.
Diese Anordnung wird die folgenden Vektoren wiederholt. Das oben
beschriebene Format des Bitstromframes, in dem Bitdaten zweier Vektoren
in einem einzigen kombinierten Bitstromframe angeordnet werden,
ist lediglich beispielhaft. Beispielsweise könnten die Daten eines jeden
Vektors stattdessen in einem einzigen Bitstromframe ange ordnet werden,
der seine eigenen Fehlerdetektionsbits enthält. In ähnlicher Weise ist die Anzahl
von Schlitzen pro Bitstromframe lediglich beispielhaft.
-
Die
enthaltenen und angeordneten Daten in den oben beschriebenen Bitstromframes
wird weiterhin wie in 2 abgebildet angeordnet. Die
Bitstromframes sind in Datenframes angeordnet, wobei jeder Datenframe
einen oder mehreren Bitstromframes enthält. In der vorliegenden Ausführungsform
enthält
jeder Datenframe 12 Bitstromframes. Im vorliegenden Beispiel ist
deshalb der Datenframe 230 in 2 abgebildet
und besteht aus den Bitstromframes 150 und 155 plus
10 weiteren Bitstromframes, mit 211-220 bezeichnet.
Dem Datenframe 230 geht sein eigener entsprechender Headerframe 240 voraus,
wie in 2 abgebildet. Die entsprechenden Datenframes,
dem jeder sein entsprechender Headerframe vorausgeht, sind fortlaufend
wie in 3 abgebildet angeordnet, wobei der Headerframe 240 seinem
entsprechenden Datenframe 230 vorausgeht, der Headerframe 310 seinem
entsprechenden Datenframe 320 vorausgeht und der Headerframe
330 seinem entsprechenden Datenframe 340 vorausgeht. In
der Praxis folgen viele derartige Headerframes mit entsprechenden
Datenframes. In der vorliegenden Ausführungsform besteht jeder Headerframe
aus 24 Schlitzen. Das oben beschriebene Format der Datenframes und
Headerframes ist lediglich beispielhaft. Ähnlich sind die Anzahl von
Bitstromframes pro Datenframe und die Anzahl von Schlitzen in einem
Headerframe lediglich beispielhaft.
-
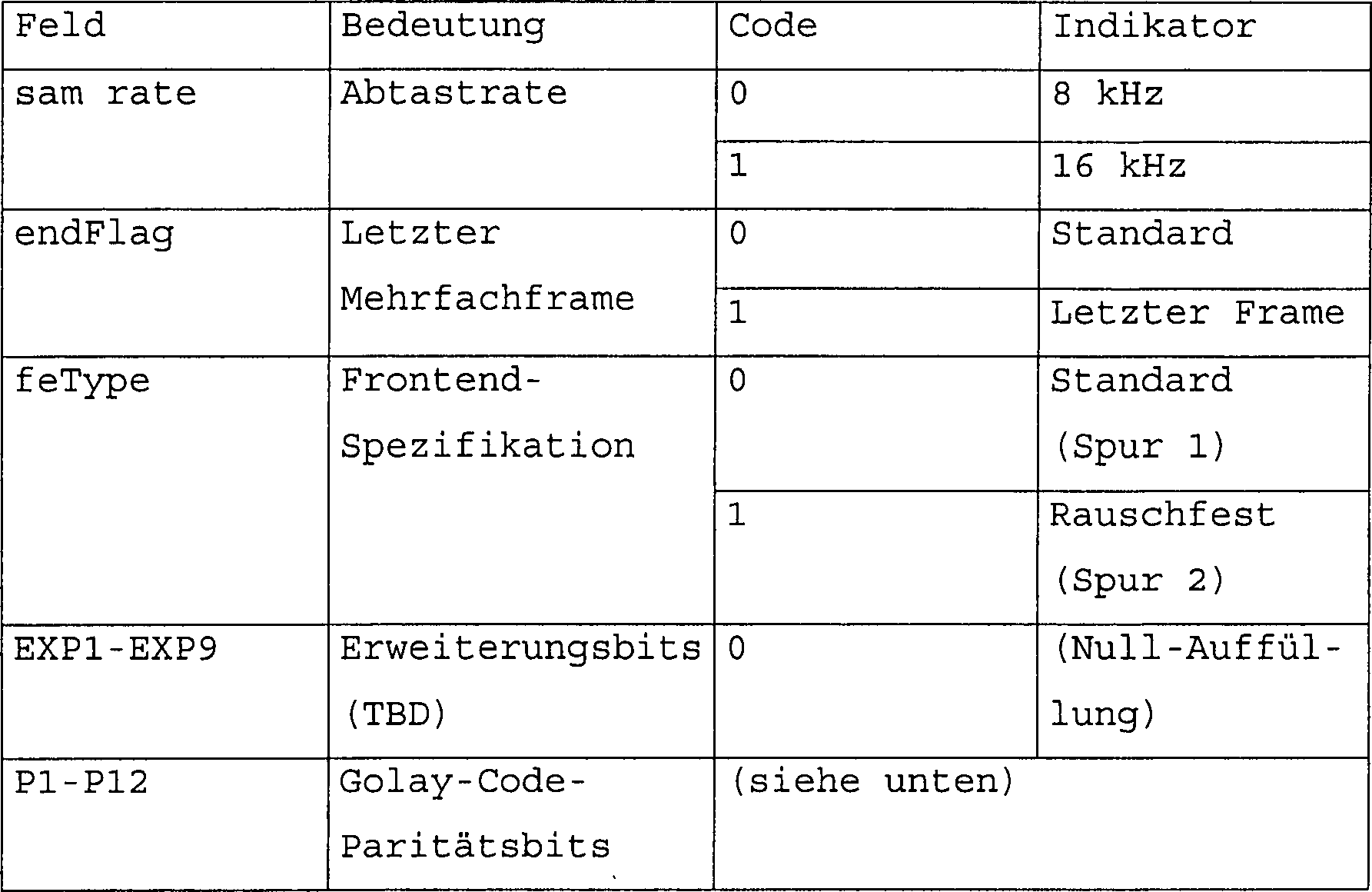
Jeder
Headerframe umfasst gemeinsame Headerinformationen. Dies sind Informationen,
die in jedem Header gleich sind. Diese Informationen werden verwendet,
wenn die Daten, wie oben beschrieben, verarbeitet werden, wobei
das Bei spiel gegeben wurde, dass die verwendete Information diejenige
war, welche Abtastrate anwendbar ist. Im vorliegenden Beispiel sind
die möglichen
Abtastratenwerte 8 kHz und 16 kHz. Eine andere Möglichkeit sind Informationen,
ob ein Standard- oder ein rauschfestes Protokoll oder Spur anwendbar ist.
-
Jeder
Headerframe kann optional weiterhin framespezifische Informationen
umfassen, dies sind Informationen, die sich zu einem gewissen Grad
für unterschiedliche
Köpfe unterscheidet.
Ein Beispiel für
framesspezifische Informationen enthält einen Nachrichtenende-Indikator,
dies ist ein Signal, das anzeigt, dass die Nachricht endet, entsprechend
einem ersten Nachrichtenende-Erkennungsverfahren. In den vorliegenden
Beispielen besteht das erste Nachrichtenende-Erkennungsverfahren aus dem Suchen nach
aus lauter Nullen bestehenden Bitstromframes innerhalb des letzten
Datenframes, was von dem Nachrichtenende-Indikator innerhalb des
Headers angezeigt wird, die vom Sender eingefügt werden, um den Datenframe
bis zur richtigen Länge
aufzufüllen.
Der Nachrichtenende-Indikator besteht aus einer einzigen Bitmenge
innerhalb des framespezifischen Datenabschnitts des Headers. Ein
anderes Beispiel framespezifischer Information ist eines, das eigentlich
einen Parallelkanal zur Sprache darstellt, beispielsweise ein Signal
eines Tastendrucks.
-
Ein
optionaler Aspekt der vorliegenden Erfindung, in dem die Headerinformation
unter Verwendung eines Codierschemas auf Blockbasis mit einer Vorwärtsfehlerkorrektur
codiert ist, wird in den unten beschriebenen beispielhaften Ausführungsformen
eingesetzt. Die spezielle Art einer derartigen in den vorliegenden
Beispielen eingesetzten Fehlersicherung ist die Golay-Fehlersicherung,
deren allgemeine Eigenschaften und Verwendungsmöglichkeiten im Stand der Technik
wohlbekannt sind. Im vorliegenden Fall sind die speziellen Werte
usw. wie folgt eingesetzt. Die Information für den Headerframe wird in einem
[24, 12, 28] erweiterten systematischen Golay-Codewort dargestellt.
Dieser Code unterstützt
12 Bits an Daten und hat eine Fehlerkorrekturmöglichkeit für bis zu 3 Bitfehler. Dieser
Prozess stellt eine Kapazität
bis insgesamt 24 Bits zur Verfügung, bestehend
aus 12 für
die Headerinformation verfügbarer
Bits plus 12 Paritätsbits
aus der Fehlersicherung. Wenn die zu verwendende Headerinformation
derart ist, dass sie weniger als ihre insgesamt verfügbaren 12 Bits
im Schema benötigt,
dann können
derartige Bits dauerhaft auf Null gesetzt werden und effektiv als
verfügbar
zur Benutzung bei zukünftigen Änderungen
bestimmt werden, d. h. sogenannte Erweiterungsbits. Das Anordnen
der 24 Bits in Felder wird in dem Fachmann bekannter Art und Weise
durchgeführt.
Im vorliegenden Beispiel ist die Anordnung wie in unten stehender
Tabelle 2 abgebildet und die Definition dieser Felder ist in unten
stehender Tabelle 3 abgebildet.
-
-
-
Das
verwendete Golay-Erzeugungspolynom ist g1(X) = 1 + x2 + x4 + x5 + x6 + x10 + x11
-
Der
Standard- [23, 12] Golay-Code ist mit der Hinzufügung eines geraden Gesamtparitätskontrollbits auf
24 Bits erweitert. Die Paritätsbits
des Codeworts werden unter der Verwendung der Berechnung
erstellt,
wobei T die Matrixtransponierung bezeichnet.
-
Um
jegliche Verwirrung zu vermeiden, wird betont, dass die oben beschriebenen
Headerframes, Bitstromframes und Datenframes nicht mit den Übertragungsframes
verwechselt werden sollten, die dann bei der Übertragung der Bitstromdaten über die
Kommunikationsverbindung des Kommunikationssystems verwendet werden,
in dem die Daten von einem ersten Ort an einen zweiten Ort übertragen
werden, beispielsweise die Zeitmultiplex-Zeitframes ("TDMA = time division
multiple access")
eines zellularen GSM-Funkkommunikationssystems, welches das in den
hierin beschriebenen Ausführungsformen
verwendete Kommunikationssystem ist. Im vorliegenden Beispiel besteht
der erste Ort aus einer Fernbenutzerstation und der zweite, d. h.
Empfangsort, besteht aus einer zentralen Verarbeitungsstation, die
beispielsweise bei einer Basisstation des zellularen Kommunikationssystems
lokalisiert sein kann. Folglich werden in den hier beschriebenen
Ausführungsformen
die Spracherkennungsparameter vom ersten Ort an den zweiten Ort über eine
Funkkommunikationsverbin dung übertragen.
Es ist jedoch erwünscht,
dass die Eigenschaften des ersten Ortes und des zweiten Ortes von
der Art des in Erwägung
ziehenden Kommunikationssystems und der Anordnung des Prozesses
zur verteilten Spracherkennung darin abhängen.
-
Die
Headerframes und Datenframes werden aus ihrem Übertragungsformat am zweiten
Ort wiederhergestellt, nachdem sie dorthin übertragen wurden. Danach werden
die in den Headerframes und Datenframes enthaltenen Daten unter
Verwendung der entsprechenden Headerframeinformationen verarbeitet.
Eine Art, die entsprechenden Headerframeinformationen zu verwenden,
besteht darin, dass die darin enthaltenen Informationen, welche
Abtastrate eingesetzt wurde, verwendet werden. Das Verarbeiten der
Daten enthält
das Erlangen der Spracherkennungsparameter aus den Bitstromframes
sowie das Ausführen
der Spracherkennung selbst. Alternativ kann das Verarbeiten das
Durchführen
von Prozeduren enthalten, die von geeigneten Arten der framespezifischen
Headerinformationen abgeleitet wurden. In einem oben beschriebenen
Beispiel stellt die framespezifische Headerinformation eigentlich
einen der Sprache parallelen Kanal dar, beispielsweise ein Signal
für einen
Tastendruck, und folglich kann die Verarbeitung das geeignete Antworten
in wohlbekannter Art und Weise auf ein derartiges Signal enthalten.
-
Das
Erlangen der Spracherkennungsparameter aus den Bitstromframes, wie
im obigen Absatz erwähnt,
wird wie folgt durchgeführt.
Die Spracherkennungsparameter werden aus den Bitstromframes durch Ausführen einer
umgekehrten Version der oben beschriebenen Vektorquantisierungsprozedur
erlangt. Speziell werden aus dem Bitstrom Indizes extra hiert, und
unter Verwendung dieser Indizes werden Vektoren in der Form
wiederhergestellt. Ebenso
muss, da in den unten stehenden beispielhaften Ausführungsformen
die Headerinformation mit einer Vorwärtsfehlerkorrektur unter Verwendung
eines Codierschemas auf Blockbasis codiert ist, eine derartige Fehlerkorrektur
decodiert werden, nachdem die Daten am zweiten Ort empfangen wurden.
Im vorliegenden Golay-Fehlersicherungsfall
kann ein derartiges Codieren auf eine von mehreren verschiedenen, dem
Fachmann wohlbekannten Weisen durchgeführt werden.
-
Folglich
ist oben ein verteilter Spracherkennungsprozess beschrieben, in
dem Daten in einer Framestruktur angeordnet werden, die eine Mehrzahl
von Datenframes umfasst, denen entsprechende Headerframes vorangehen,
die Headerinformationen umfassen, die allgemeine Headerinformationen
enthalten, wobei besagte Daten an einem zweiten Ort empfangen werden,
nachdem sie von einem ersten Ort übertragen wurden, und besagte
Daten werden unter der Verwendung entsprechender Headerframeinformationen
verarbeitet, und in denen die Headerinformation unter Verwendung
eines Codierschemas auf Blockbasis mit einer Vorwärtsfehlerkorrektur
codiert ist.
-
Das
Verfahren zum Verarbeiten empfangener Daten in einem derartigen
Spracherkennungsprozess gemäß einer
ersten Ausführungsform
ist im Prozessflussdiagramm 400 der 4 abgebildet.
Bezugnehmend auf 4 zeigt der Funktionskasten 410 den
Schritt des Vergleichens einer empfangenen Form besagter gemeinsamer
Headerinformationen von jedem einer Mehrzahl von Headerframes. In
der vorliegenden Ausführungsform
besteht dies aus dem Vergleichen der empfangenen Form gemeinsamer
Headerinformationen vom Headerframe 240, Headerframe 310,
Headerframe 330 und den folgenden Headerframes. Die zu
vergleichenden gemeinsamen Headerframeinformationen sind in der
vorliegenden Ausführungsform
der angezeigte Wert der Abtastrate und ob die Spur eine Standard- oder eine rauschfeste
Spur ist.
-
Der
nächste
Schritt besteht im Klassifizieren, wenn eine vorherbestimmte Anzahl
besagter Headerframes gefunden wurde, die die gleiche empfangene
Form der besagten gemeinsamen Headerinformation besitzt, der gleichen
empfangenen Form als eine Referenz, wie im Funktionskasten 420 der 4 abgebildet.
In der vorliegenden Ausführungsform
ist die vorherbestimmte Anzahl 30, aber diese Zahl wird man im Allgemeinen
gemäß den Anforderungen
des speziellen in der Erwägung
stehenden Systems wählen.
Durch das Ausführen
dieses Verfahrensschritts wird über
die Werte in den gemeinsamen Headerinformationen, die verwendet
werden sollen, Sicherheit erlangt. Die Verzögerung, die durch das Ausführen dieser
Prozedur eingeführt wird,
insbesondere wenn die vorherbestimmte Anzahl auf ein wesentlich
höheres
Niveau eingestellt ist, wird in der vorliegenden Erfindung angepasst,
da sie von den Eigenschaften eines Systems zur verteilten Spracherkennung
Gebrauch macht, in dem Latenzzeiten am Beginn einer Nachricht relativ
gut akzeptierbar sind.
-
Der
nächste
Schritt besteht darin, einen oder mehrere empfangene Datenframes
zu verarbeiten, die entsprechenden Headerframes entsprechen, deren
empfangene Form der gemeinsamen Headerinformation sich von besagter
Referenz unterscheidet, indem die Referenzform anstatt der empfangenen
unterschiedlichen Form verwendet wird, wie im Funktionskasten 430 der 4 abgebildet.
Folglich werden falsch empfangene oder nicht vertrauenswürdige Versionen
der gemeinsamen Headerinformation ausgeschlossen und stattdessen
die relevanten Datenframes bevorzugt gemäß den richtigen gemeinsamen
Headerinformationen verarbeitet.
-
Eine
Version der vorliegenden Ausführungsform
enthält
die Option, mit der Headerinformationen weiterhin framespezifische
Headerinformationen umfassen, insbesondere die framespezifischen
Headerinformationen, die eigentlich einen Kanal parallel zur Sprache
darstellen, nämlich
ein Signal eines Tastendrucks. Ein normales Verarbeiten enthält das geeignete
Antworten auf dieses Signal in einer wohlbekannten Art und Weise.
In dieser Version der vorliegenden Ausführungsform jedoch sind die
framespezifischen Headerinformationen eines oder mehrerer Headerframes,
deren empfangene Form der gemeinsame Headerinformationen sich von
der besagten Referenz unterscheidet, vom Gebrauch ausgeschlossen,
d. h. die Antwort auf das Tastendrucksignal ist blockiert. Indem
dies durchgeführt
wird, wird eine nicht vertrauenswürdige Instruktion vermieden,
was auf dem Aspekt basiert, dass wenn die gemeinsame Headerinformation
dieses Headerframes falsch ist, dann damit eine erhöhte Wahrscheinlichkeit
einhergeht, dass die framespezifische Information innerhalb des
gleichen Headerframes ebenso falsch ist.
-
Eine
andere Version der vorliegenden Ausführungsform enthält weiterhin
die Option, dass die Headerinformation weiterhin framespezifische
Headerinformationen umfasst, insbesondere enthält es ein Feld, das dazu benutzt
wird, einen Nachrichtenende-Indikator eines ersten Nachrichtenende-Erkennungsverfahrens
anzuzeigen, wenn es angebracht ist. Das erste Nachrichtenende-Erkennungsverfahren
ist, wie es vorhergehend weiter oben beschrieben wurde. Unter Bezugnahme
auf das weiter oben beschriebene beispielhafte Headerfeldlayout
und unter Bezugnahme auf Tabellen 2 und 3 sei es vermerkt, dass
das Nachrichtenende-Indikatorfeld einen oder mehrere der zukünftigen
Erweiterungsplätze,
die in diesen Tabellen verfügbar
sind, verwendet. Eine normale Verarbeitung enthält das Antworten auf diesen
Nachrichtenende-Indikator, indem eine Nachrichtenende-Prozedur ausgeführt wird.
In dieser Version der vorliegenden Ausführungsform jedoch wird die
framespezifische Headerinformation eines oder mehrerer Headerframes,
deren empfangene Form der gemeinsamen Headerinformation sich von
der besagten Referenz unterscheidet, und zwar der Nachrichtenende-Indikator
des ersten Nachrichtenende-Erkennungsverfahrens, in einer anderen
Weise verwendet als die framespezifischen Headerinformationen derjenigen
Headerframes, deren empfangene Form der gemeinsamen Headerinformation
die gleiche ist wie die besagte Referenz. Insbesondere wird als
Antwort darauf, welchen Nennwert der Nachrichtenende-Indikator aufweist,
anstatt tatsächlich
die Nachrichtenende-Prozedur auszuführen, stattdessen eine zweite
Nachrichtenende-Prozedur angesteuert. Somit wird zum einen eine
möglicherweise
falsche Ausführung
der Nachrichtenende-Prozedur aufgrund des Vermeidens der Notwendigkeit
vermieden, dem Indikator zu antworten, wenn der Indikator sich evtl.
bereits in einem Fehlerzustand befindet, nachdem er in einen Headerframe
enthalten ist, der bereits falsche gemeinsame Informationen besitzt,
zum anderen wurde eine alternative Nachrichtenende-Prozedur im Sinne
einer Sicherung aktiviert, um sicherzustellen, dass das Nachrichtenende
tatsächlich
detektiert wird, wenn die Nachrichtenende-Anzeige tatsächlich richtig
war, obwohl sie in einem teilweise falschen Headerframe enthalten
war. Man sollte sich bewusst sein, dass die oben beschriebene Nachrichtenende-Thematik
lediglich ein Beispiel der framespezifischen Informationstypen repräsentiert,
die gemäß der Erfindung
und gemäß den Diskrepanzen
in den gemeinsamen Headerinformationen unterschiedlich behandelt
werden können.
Allerdings ist dieser Aspekt der Erfindung im Gegensatz dazu auf beliebige
framespezifische Informationsarten anwendbar, die von einer vorsichtigen
Behandlung profitieren, wenn es Verdachtsmomente gibt, dass die
Information eine höhere
Wahrscheinlichkeit eines Fehlers in Headerframes aufweist, die bereits
das Vorhandensein eines Fehlers in den gemeinsamen Informationen,
die Teil desselben sind, gezeigt haben.
-
Alle
oben beschriebenen Ausführungsformen
können
die optionale Eigenschaft aufweisen, dass die besagte Headerinformation
mit einer Vorwärtsfehlerkorrektur
codiert ist. unter Verwendung eines Codierschemas auf Blockbasis.
Die Details, wie ein derartiges Schema ausgeführt wird, sind bereits oben
dargelegt worden. Ist diese Eigenschaft enthalten, werden die Vorteile
der vorliegenden Erfindung insbesondere aufgrund der Verbundeigenschaften
derartiger Fehlerkorrekturarten verstärkt. Nachdem der gesamte Headerframe
in einer Verbundweise korrigiert wird, wenn sich die gemeinsame
Headerinformation von dem unterscheidet, was empfangen werden sollte,
wird höchstwahrscheinlich
der Rest der Headerinformation im Wesentlichen ebenfalls fehlerhaft sein.
Im vorliegenden Beispiel tritt dies insbesondere wahrscheinlich
dann ein, wenn mehr als drei Bits in einem Headerframe fehlerhaft
sind.
-
In
den bisherigen Ausführungsformen
werden die Datenframes, die empfangen wurden, bevor die Referenz
bestimmt ist, einfach von der späteren
Verarbeitungsphase ausgeschlossen. Im Sinne eines Ausgleichs bietet
dies die Vorteile eines reduzierten Verarbeitens. In alternativen
Ausführungsformen
jedoch werden die Datenframes, die vor der Bestimmung der besagten
Referenz empfangen wurden, gepuffert, bevor sie nach der Bestimmung
der besagten Referenz verarbeitet werden. Im Sinne eines Ausgleichs
bieten diese alternativen Ausführungsformen
eine bessere Qualität
in dem Sinne, dass die Daten nicht verloren gehen, obwohl zusätzliches
Verarbeiten einschließlich
zusätzlicher
Pufferung benötigt
wird. Diese alternative Ausführungsformen
stellen darüber
hinaus einen zusätzlich
vorteilhaften Gebrauch der Latenzzeitcharakteristiken eines verteilten
Spracherkennungsprozesses zur Verfügung, insbesondere den Aspekt,
dass die Latenzzeit am Beginn der Nachricht relativ gut toleriert
wird.
-
Im
Fall der oben beschriebenen Ausführungsform
werden die beschriebenen Datenverarbeitungsschritte von einem programmierbaren
Digitalsignalverarbeitungsbauelement, wie etwa einem aus der DSP 56xxx-Bauelementefamilie
(Warenzeichen) von Motorola durchgeführt. Alternativ kann eine anwendungsspezifische
integrierte Schaltung ("ASIC
= application specific integrated circuit") verwendet werden. Es gibt weitere
Möglichkeiten.
Beispielsweise kann eine Schnittstelleneinheit verwendet werden,
die zwischen einem Funkempfänger
und einem Computersystem vermittelt, das einen Teil eines Backend-Spracherkennungsprozessors
bildet.