EP0454552A2 - ProcédÀ© et dispositif de codage bas débit de la parole - Google Patents
ProcédÀ© et dispositif de codage bas débit de la parole Download PDFInfo
- Publication number
- EP0454552A2 EP0454552A2 EP91401051A EP91401051A EP0454552A2 EP 0454552 A2 EP0454552 A2 EP 0454552A2 EP 91401051 A EP91401051 A EP 91401051A EP 91401051 A EP91401051 A EP 91401051A EP 0454552 A2 EP0454552 A2 EP 0454552A2
- Authority
- EP
- European Patent Office
- Prior art keywords
- coding
- frame
- frames
- pitch
- takes place
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Withdrawn
Links
- 238000000034 method Methods 0.000 title claims abstract description 34
- 239000011295 pitch Substances 0.000 claims description 31
- 239000013598 vector Substances 0.000 claims description 9
- 238000012545 processing Methods 0.000 claims description 5
- 239000011159 matrix material Substances 0.000 claims description 3
- 238000013139 quantization Methods 0.000 claims description 3
- 230000003044 adaptive effect Effects 0.000 claims description 2
- 230000009466 transformation Effects 0.000 claims 2
- 230000001755 vocal effect Effects 0.000 abstract description 5
- 238000004364 calculation method Methods 0.000 description 16
- 238000004458 analytical method Methods 0.000 description 6
- 230000015572 biosynthetic process Effects 0.000 description 6
- 230000006870 function Effects 0.000 description 6
- 238000003786 synthesis reaction Methods 0.000 description 6
- 238000010586 diagram Methods 0.000 description 4
- 238000001914 filtration Methods 0.000 description 4
- 238000005070 sampling Methods 0.000 description 4
- 230000005540 biological transmission Effects 0.000 description 3
- 230000005284 excitation Effects 0.000 description 3
- 230000008901 benefit Effects 0.000 description 2
- 238000013461 design Methods 0.000 description 2
- 230000000737 periodic effect Effects 0.000 description 2
- 238000007781 pre-processing Methods 0.000 description 2
- 230000008569 process Effects 0.000 description 2
- 238000001228 spectrum Methods 0.000 description 2
- 101000984710 Homo sapiens Lymphocyte-specific protein 1 Proteins 0.000 description 1
- 101001096074 Homo sapiens Regenerating islet-derived protein 4 Proteins 0.000 description 1
- 102100027105 Lymphocyte-specific protein 1 Human genes 0.000 description 1
- 102100037889 Regenerating islet-derived protein 4 Human genes 0.000 description 1
- 101150080038 Sur-8 gene Proteins 0.000 description 1
- 230000008859 change Effects 0.000 description 1
- 238000007405 data analysis Methods 0.000 description 1
- 230000001627 detrimental effect Effects 0.000 description 1
- 238000009432 framing Methods 0.000 description 1
- 238000004519 manufacturing process Methods 0.000 description 1
- 238000012216 screening Methods 0.000 description 1
- 238000007493 shaping process Methods 0.000 description 1
- 101150114085 soc-2 gene Proteins 0.000 description 1
- 230000003595 spectral effect Effects 0.000 description 1
- 238000005728 strengthening Methods 0.000 description 1
- 230000002194 synthesizing effect Effects 0.000 description 1
- 230000007704 transition Effects 0.000 description 1
- 238000009966 trimming Methods 0.000 description 1
- 210000001260 vocal cord Anatomy 0.000 description 1
Images





Classifications
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L19/00—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis
- G10L19/04—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis using predictive techniques
- G10L19/06—Determination or coding of the spectral characteristics, e.g. of the short-term prediction coefficients
- G10L19/07—Line spectrum pair [LSP] vocoders
Definitions
- the present invention relates to a method and a device for low bit rate coding of speech.
- the object of the invention is to overcome the aforementioned drawbacks.
- the subject of the invention is a low bit rate coding process for speech, characterized in that it consists, after having cut the speech signal into frames of constant length, to calculate the characteristics of N modeling filters of the vocal tract as well as the fundamental period (pitch), voicing and energy characteristics of the voice signal by determined intervals of N successive frames by calculating the energy of the speech signal a determined number P of times per frame to code all of these characteristics.
- Figure 1 a flowchart illustrating the speech coding method implemented by the invention.
- FIG. 2 a mode of coding the LSP coefficients of the analysis filter used in FIG. 1 to model the voice path.
- Figure 3 a table of LSP coefficients.
- Figure 5 is a pitch coding table.
- FIG. 6 is a flowchart illustrating the method for synthesizing the speech signal implemented by the invention.
- FIG. 7 a graph to illustrate a mode of interpolation of the synthesis filters implemented by the invention.
- Figure 8 an embodiment of a device for implementing the method according to the invention.
- the coding method according to the invention consists, after having cut the speech signal into frames of constant length of approximately 20 to 25 ms, as this usually takes place in vocoders, determining and coding the characteristics of the speech signal over N successive frames by determining the energy of the signal P times per frame.
- the synthesis of the speech signal on each frame then takes place by descrambling and decoding the values of the coded characteristics of the speech signal.
- step 3 After sampling the speech signal on each frame and quantizing the samples over a determined number of bits, these are pre-emphasized in step 3.
- the sampling operation makes the spectrum of the speech signal periodic
- the number of samples taken into account for the determination of the coefficients of the vocal tract modeling filter is limited in a known manner by making the product of the pre-emphasized samples of step 3 by a HAMMING window of duration equal to that of a frame, this window also having the advantage of strengthening the resonances.
- the coefficients k i of the vocal tract modeling filter are calculated in step 5 from autocorrelation coefficients R i defined by a relation of the form: where i is an integer varying from 0 to 10 for example, and S i represents a sample of pre-emphasized and windowed signal.
- the calculation of the coefficients K i can be carried out in step 5 by applying the known algorithm of M. LEROUX-GUEGUEN, a description of which can be found in the article of the journal IEEE Transactions or Acoustics Speech, and Signal Processing June 1977 titled "A fixed point computation of partial correlation coefficients"'. This calculation amounts to inverting a square matrix whose elements are the coefficients R i of the relation (1).
- F e represents the sampling frequency of the speech signal.
- the calculation of the fundamental period of the signal and the voicing takes place in a known manner by performing steps 9 and 10.
- the speech signal is classified into two categories of sounds, voiced sounds and unvoiced sounds.
- Voiced sounds that are produced from the vocal cords are compared to a series of impulses whose fundamental period is called "Pitch" in English.
- Unvoiced sounds produced by turbulence are assimilated to white noise.
- the method recognizes in step 10 for each frame a voiced sound, and a non-voiced sound otherwise. Recognition takes place after a preprocessing of the signal to reinforce useful information and limit that which is not.
- This preprocessing consists in carrying out a first low pass filtering of the signal, followed by bashing and a second filtering.
- the first filtering is carried out for example by means of a simple "Butterworth" filter of order 3 whose cutoff frequency at 3dB can be fixed at 600 Hertz .
- the trimming then places the signal samples whose level is below a certain predetermined threshold at zero amplitude, possibly variable depending on the amplitude of the voice signal. This raking makes it possible to accentuate the periodic aspect of the signal while reducing the details detrimental to subsequent processing.
- the second filtering makes it possible to smooth the results of the bashing by eliminating the high frequencies.
- a Butterworth filter identical to the first filter can be used.
- the energy calculation which takes place in step 8 is executed on four subframes. This calculation takes place by taking the logarithm to base 2 of the sum of the energies of each pre-emphasized samples of a subframe.
- the subframes in each frame are contiguous or overlap to have a length multiple of the "pitch".
- the coding of frame 3 is of scalar type. It is carried out in application of the algorithm known under the name "Adaptive Backward Sequential" as described for example in the article of the journal IEEE on selected areas in communications, Vol. 6 feb. 88 of MM. Sugamara N and FAYARDIN N (1988) entitled "Quantizer design in LSP speech analysis”.
- the coding algorithm is executed in descending order of the LSP coefficients, starting with the last of the ways shown in FIGS. 2 and 3.
- the coding of the last LSP coefficient ( 10) takes place linearly between two frequency values F10MIN and F10MAX and takes place on N V10 values coded linearly on NB10 bits.
- frames 1 and 2 are not coded directly, but it is the type of interpolation allowing them to be quantified as faithfully as possible which is coded.
- the coder determines among 3 interpolations represented by the graph of FIG. 4 which one seems to him to give the best approximation of the values of frames 1 and 2.
- the method then chooses from the 3 previous interpolations the one which minimizes the quantization error, estimated by means of a function D_INTER defined below by adopting the corresponding code value.
- D_INTER (i) W1. (LSPQ (case i, frame 1) -LSP (Frame 1)) 2 + W2. (LSPQ (case i, Frame 2) -LSP (Frame 2)) 2 where LSPQ (case i, Frame j) is the value of the odd LSP coefficient of the frame j quantified by means of type i interpolation.
- LSP (frame j) Actual value in frame j of the odd LSP coefficient to be quantified
- W1 value of the energy of frame 1
- This coding takes place on 8 bits.
- the pitch and voicing coding take place in step 14 on three consecutive frames.
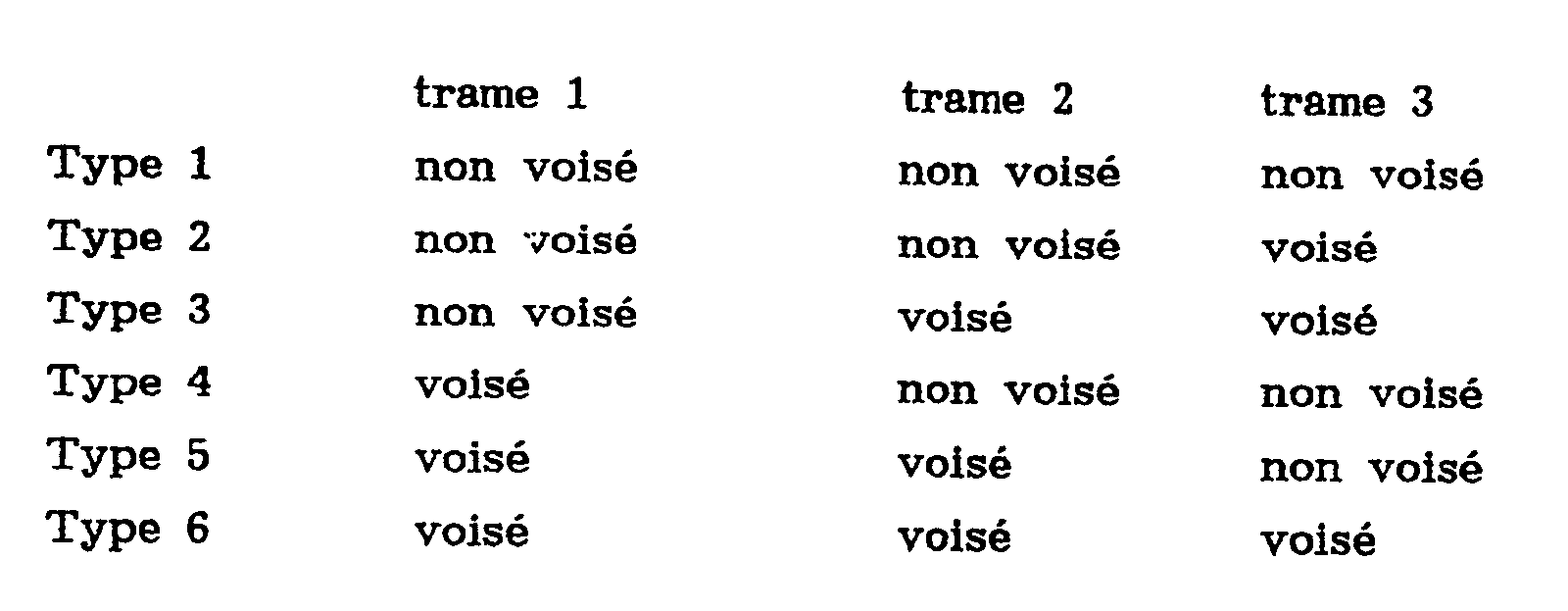
- the current voicing type is determined from six possible cases from the voices of frames 1, 2 and 3 and the voicing of frame 0 which precedes each group of frames 1, 2 and 3.
- a coding table represented in FIG. 5 makes it possible to associate with any pitch value a number from the table whose value subsequently designated by "N array" is the closest to the pitch.
- the code 0 is assigned to type 1.
- a code equal to the value "N. table” of the pitch of frame 3 is assigned to type 2.
- a code equal to 64 to which is added the value "N. table” of the pitch of frame 3 is assigned to type 3.
- a code equal to 128 to which is added the value "N. table” of the pitch of frame 1 is assigned to type 4.
- a code equal to 192 to which is added the value "N. table of the pitch of frame 1 is assigned to type 5. Coding of type 6 takes place in a very particular way by projecting the vector composed of the three values of the pitches of the three frames on the 3 vectors (Vect 1, Vect 2, Vect 3) eigen to code the three projections obtained.
- Vect 1, Vect 2, Vect 3 are an approximation of the first 3 eigen vectors of the intercorrelation matrix.
- N.tableau which is the closest to the average (P1 + P2 + P3) / 3 of the pitches of frames 1, 2 and 3.
- the corresponding code is then coded on the 63 values of the coding table.
- the projection on the second eigenvector (Vect 2) is equal to the scalar product of the pitches of frames 1, 2 and 3 by the second eigenvector (Vect 2) and the projection on the third eigenvector (Vect 3) is equal to the product scalar pitch of frames 1, 2 and 3 by the third eigenvector (Vect 3).
- the corresponding codes can be obtained respectively on only 4 and 3 values from the coding table.
- the coding of the energy which is carried out on stage 15 takes place in a known manner and described in patent application FR 2 631 146 on three consecutive frames. Four energy values corresponding to the 4 sub-fields of each of the three fields are coded. However, in order to eliminate the redundant information in these 12 values, a Main Component Analysis of the type described has the title "Data analysis elements" in the book by MM. DIDAY, LEMAIRE, POUGET and TESTU published by Dunod, is performed. Coding takes place in two stages. A first step is to make a basic change. The energy vector of dimension 12, composed of the 12 energy values of the 3 frames is projected on the first 3 main axes determined during the analysis by principal components (more than 97% of the information is contained in these 3 projections) .
- the second step consists in quantifying these 3 projections, the first projection is quantized on 4 bits, the second on 3 bits and the third on 2 bits.
- the synthesis takes place according to steps 17 to 28 of the flow diagram of FIG. 6, on the one hand, steps 17 to 21 for descrambling and decoding the values of the coefficients LSP of the filter (step 18), of the pitch (step 19), of the voicing and of the energy (step 20) for three consecutive frames and on the other hand, according to steps 22 to 28 which carry out the synthesis of the speech signal successively for each of the three frames on the basis of the information obtained during the execution of steps 17 to 21.
- Descreening and decoding follow procedures reverse to the screening and decoding procedures defined during the analysis illustrated by the flowchart of FIG. 1.
- the shaping of the synthesis filter consists in performing in step 23 an interpolation calculation of the LSP coefficients on four subframes and a calculation to transform the LSP coefficients into coefficients A i . This last calculation is followed in step 24 by a gain calculation of the synthesis filter for the 4 subframes to which is added a calculation of the energy of the excitation signal of the filter. In order to avoid sudden transitions between dissimilar filters, these are done in step 23 in four steps every quarter of a frame.
- LSP (SS Tr i , TrN) (LSP (TrN-1) * (4-i) + LSP (TrN) * i) / 4
- LSP (SS Tri, Tr N) designates the value of the interpolated filter in subframe i of frame N.
- the 12 decoded energies correspond to the energy of the speech signal after pre-emphasis, it is necessary to obtain the energy of the excitation signal divide the energy by the gain of the filter.
- the gain of the filter of each subframe is calculated using the coefficients K i according to the relation
- the last step consists in determining the value of the standard deviation of the energy of each subframe (value used during the calculation of the excitation).
- the entire coding and decoding method according to the invention can be executed by means of a microprogrammed structure formed as shown by way of example in FIG. 8 by a signal processing microprocessor 29 such as that sold by the company Texas Instrument under the designation TMS 320C25.
- a signal processing microprocessor 29 such as that sold by the company Texas Instrument under the designation TMS 320C25.
- the speech signal is first sampled by an analog to digital converter 30 before being applied to a data bus 31 of the microprocessor 29.
- An analog filter 32 coupled to an automatic gain control device 33 filters the signal speech before sampling.
- the programs and the data implemented for the execution of the method according to the invention are recorded in a read-only memory 34 and in a random access memory 35 connected to the microprocessor 29.
- An interface circuit 36 connects the microprocessor 29 via from a data line 37 to transmission devices external to the vocoder, not shown.
Landscapes
- Engineering & Computer Science (AREA)
- Physics & Mathematics (AREA)
- Spectroscopy & Molecular Physics (AREA)
- Computational Linguistics (AREA)
- Signal Processing (AREA)
- Health & Medical Sciences (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Human Computer Interaction (AREA)
- Acoustics & Sound (AREA)
- Multimedia (AREA)
- Compression, Expansion, Code Conversion, And Decoders (AREA)
Abstract
Description
- La présente invention concerne un procédé et un dispositif de codage bas débit de la parole.
- Elle s'applique notamment à la réalisation de vocodeurs pour les liaisons radio HF, ou de ceux utilisés pour la messagerie vocale.
- Dans ces domaines, le volume d'informations à transmettre se heurte de plus en plus aux limites technologiques des équipements susceptibles de véhiculer la parole. Ainsi pour des transmissions dont le débit est inférieur à 2400 bits par seconde, les techniques de codage connues (MIC, DELTA, RELP etc... ) ne sont plus adaptées, le signal de parole ne pouvant plus être transmis par sa forme d'onde. Pour assurer ces transmissions il devient nécessaire d'utiliser les techniques de codage beaucoup plus sophistiquées des vocodeurs. Ainsi, la plupart des vocodeurs très bas débit utilisent une technique de codage vectoriel de leur filtre numérique pour modéliser le conduit vocal. Cette modélisation a lieu par recherche d'une référence dans un dictionnaire. Cependant cette technique qui est à la fois très compliquée et coûteuse à mettre en oeuvre ne permet pas d'obtenir une quantification fine du signal de parole. Les difficultés viennent en outre du fait que l'énergie du signal est souvent mal représentée et donc mal codée, de la sorte les brusques variations d'amplitude du signal vocal ne peuvent plus être restituées correctement.
- Le but de l'invention est de pallier les inconvénients précités.
- A cet effet, l'invention a pour objet un procédé de codage à bas débit de la parole, caractérisé en ce qu'il consiste après avoir découpé le signal de parole en trames de longueur constante, à calculer les caractéristiques de N filtres de modélisation du conduit vocal ainsi que les caractéristiques de période fondamentale (pitch), de voisement et d'énergie du signal vocal par intervalles déterminés de N trames successives en calculant l'énergie du signal de parole un nombre P déterminé de fois par trame pour coder l'ensemble de ces caractéristiques. D'autres caractéristiques et avantages de l'invention apparaîtront à l'aide de la description faite en regard des dessins annexés qui représentent :
- La figure 1 un organigramme illustrant le procédé de codage de la parole mis en oeuvre par l'invention.
- La figure 2 un mode de codage des coefficients LSP du filtre d'analyse mis en oeuvre à la figure 1 pour modéliser le conduit vocal.
- La figure 3 un tableau de coefficients LSP.
- La figure 4 des chemins de codage de trames par interpolation.
- La figure 5 une table de codage de "pitch".
- La figure 6 un organigramme illustrant le procédé de synthèse du signal de parole mis en oeuvre par l'invention.
- La figure 7 un graphe pour illustrer un mode d'interpolation des filtres de synthèse mis en oeuvre par l'invention.
- La figure 8 un mode de réalisation d'un dispositif pour la mise en oeuvre du procédé selon l'invention.
- Le procédé de codage selon l'invention consiste après avoir découpé le signal de parole en trames de longueur constante d'environ 20 à 25 ms, comme ceci a lieu habituellement dans les vocodeurs, à déterminer et coder les caractéristiques du signal de parole sur N trames successives en déterminant l'énergie du signal P fois par trame.
- La synthèse du signal de parole sur chaque trame a lieu ensuite en procédant au détramage et au décodage des valeurs des caractéristiques codées du signal de parole.
- Les étapes représentatives d'un procédé de codage selon l'invention appliquées à un cas où N = 3 trames successives sont analysées sont représentées sur l'organigramme de la figure 1. Sur cet organigramme le procédé commence aux étapes 1 à 6, par le calcul sur la première trame analysée des coefficients "LSP" où "LSP" est l'abréviation anglaise de "Line Spectrum Pair", d'un filtre d'analyse modélisant le conduit vocal : ce calcul peut être effectué par exemple en suivant la méthode connue décrite dans l'article de MM. Peter KABAL et Ravi PRAKASA RAMACHANDRAN ayant pour titre "The computation of line spectral Frequencies using Chebyshev polynomials" publié dans IEE Transactions on Acoustics, Speech and Signal Processing ASSP-34 Dec. 86.
- Après échantillonnage du signal de parole sur chaque trame et quantification des échantillons sur un nombre déterminé de bits ceux-ci sont préaccentués à l'étape 3. Comme l'opération d'échantillonnage rend périodique le spectre du signal de parole, le nombre d'échantillons pris en compte pour la détermination des coefficients du filtre de modélisation du conduit vocal est limité de façon connue en faisant le produit des échantillons préaccentués de l'étape 3 par une fenêtre de HAMMING de durée égale à celle d'une trame, cette fenêtre présentant aussi l'avantage de renforcer les résonances.
- Les coefficients ki du filtre de modélisation du conduit vocal sont calculés à l'étape 5 à partir de coefficients d'autocorrélation Ri définis par une relation de la forme :
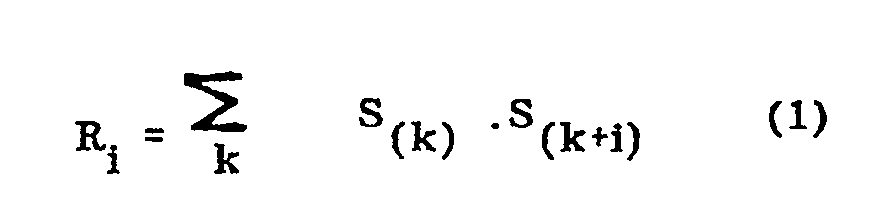
où i est un nombre entier variant de 0 à 10 par exemple, et Si représente un échantillon de signal préaccentué et fenêtré. - Le calcul des coefficients Ki peut être effectué à l'étape 5 en appliquant l'algorithme connu de M. LEROUX-GUEGUEN dont une description peut être trouvée dans l'article de la revue IEEE Transactions ou Acoustics Speech, and Signal Processing June 1977 ayant pour titre "A fixed point computation of partial correlation coefficients"'. Ce calcul revient à inverser une matrice carrée dont les éléments sont les coefficients Ride la relation (1).
- Le passage des coefficients de réflexions à des coefficients de prédiction Ai a lieu à l'étape 8. Ce passage utilise aussi un algorithme connu sous le nom d'algorithme de M. Levison dont une description peut être trouvée dans l'article intitulé :
"The Wiener RM5 error croterion in filter design and prediction J Math Phys, 25 pp 614-617 (1947)" - Enfin les coefficients LSP du filtre sont calculés à partir de deux polynômes P et Q décrits comme suit dans le plan des transformées en Z, où Z est la variable complexe de ces polynômes,



- Si ejαi et ej βi désignent les racines des polynômes P et Q les coefficients LSP sont par définition les fréquences fi et gi des arguments de ces racines
soit :

- Dans ce calcul Fe représente la fréquence d'échantillonnage du signal de parole.
- Les fréquences fi et gi sont conservées dans une mémoire, non représentée et les calculs précédents sont recommencés sur les échantillons des deux trames qui suivent. Lorsque les paramètres de trois trames consécutives sont calculés et que trois jeux de coefficients ont été stockés le procédé passe à leur codage à l'étape 13.
- Le calcul de la période fondamentale du signal et du voisement a lieu de façon connue par exécution des étapes 9 et 10. Au cours de ces étapes le signal de parole est classé en deux catégories de sons, les sons voisés et les sons non voisés. Les sons voisés qui sont produits à partir des cordes vocales sont assimilés à une suite d'impulsions dont la période du fondamental porte le nom de "Pitch" en anglais. Les sons non voisés qui sont produits par des turbulences sont assimilés à du bruit blanc. Ainsi lorsque le signal de parole présente des périodicités marqués le procédé reconnaît à l'étape 10 pour chaque trame un son voisé, et un son non voisé dans le cas contraire. La reconnaissance a lieu après un prétraitement du signal pour renforcer les informations utiles et limiter celles quine le sont pas. Ce prétraitement consiste à effectuer un premier filtrage passe bas du signal, suivi d'un ébasage et d'un deuxième filtrage. Comme la fréquence fondamentale du signal de parole varie entre 50 et 400 Hertz le premier filtrage est effectué par exemple au moyen, d'un simple filtre de "Butterworth" d'ordre 3 dont la fréquence de coupure à 3dB peut être fixée à 600 Hertz. L'ébasage place ensuite à une amplitude nulle les échantillons du signal dont le niveau est inférieur à un certain seuil prédéterminé variable éventuellement suivant l'amplitude du signal vocal. Cet ébasage permet d'accentuer l'aspect périodique du signal tout en diminuant les détails nuisibles aux traitements ultérieurs.
- Enfin, le deuxième filtrage permet de lisser les résultats de l'ébasage en éliminant les hautes fréquences. A cette fin, un filtre de Butterworth identique au pemier filtre peut être utilisé.
- Les calculs du pitch et du voisement ont lieu de façon connue par utilisation de la fonction AMDF (Average Magnitude Difference Function). Ils se déroulent suivant cinq étapes qui consistent :
- 1. A calculer une décision préliminaire de voisement à partir des valeurs de l'énergie, du filtre de modélisation et du nombre de passages par l'amplitude nulle du signal.
- 2. A calculer un seuil de voisement à partir de la décision du voisement préliminaire, de l'énergie basse fréquence et de constantes internes.
- 3. A calculer pour chaque valeur de R une fonction AMDF(k) =SOMME| (S(n) - S(n-k)| (8) où s(n) représente le signal prétraité, et à calculer les valeurs maximales de cette fonction.
- 4. A comparer et étudier les valeurs maximales obtenues pour en déduire le voisement et le pitch de la trame.
- 5. Et à corriger le voisement et le pitch de la trame précédente en fonction des résultats de la trame courante pour conserver une certaine stationnarité au voisement.
- Le calcul d'énergie qui a lieu à l'étape 8 est exécuté sur quatre sous trames. Ce calcul a lieu en prenant le logarithme à base 2 de la somme des énergies de chaque échantillons préaccentué d'une sous trame.
- Les sous trames dans chaque trame sont jointives ou se chevauchent pour avoir une longueur multiple du "pitch".
- Une fois que les caractéristiques, de modélisation du filtre, d'énergie, de voisement et de pitch sont obtenues pour trois trames successives le procédé passe à leur codage selon les étapes 13 à 16. Le codage du filtre des trois trames désignées ci-après par trame 1, trame 2 et trame 3 s'effectue en deux temps en commençant par la trame 3.
- Le codage de la trame 3 est de type scalaire. Il s'effectue en application de l'algorithme connue sous l'appellation "Backward Sequential adaptative" tel que décrit par exemple dans l'article de la revue IEEE on selected areas in communications, Vol. 6 feb. 88 de MM. Sugamara N et FAYARDIN N (1988) ayant pour titre "Quantizer design in LSP speech analysis".
- L'algorithme de codage est exécuté dans l'ordre décroissant des coefficients LSP en commençant par le dernier des manières représentées aux figures 2 et 3. Pour un filtre de modélisation du conduit vocal à 10 coefficients LSP par exemple le codage du dernier coefficient LSP(10) a lieu de façon linéaire entre deux valeurs de fréquences F₁₀MIN et F₁₀MAX et a lieu sur NV10 valeurs codées linéairement sur NB₁₀ bits.
- Les codages des LSP(i) autres coefficients pour i = 9, 8...1 a lieu par comparaison du coefficient LSPQ(i+1) à une valeur de fréquence maximum FiMAX
- Si LSPQ(i + 1)>FiMAX alors le codage du coefficient est effectué linéairement entre deux valeurs FiMIN et FiMAX sur NVi valeurs et donc sur NBi bits.
- Si LSP(i+1)<FiMAX alors le codage du coefficient est effectué linéairement entre FiMIN et LSPQ(i+1) sur NVi valeurs et donc sur NBibits.
- Au cours du codage des trames 1 et 2 une bonne approximation des valeurs de coefficients LSP correspondant aux trames 1 et 2 est obtenue à partir de l'interpolation entre les trames 0 (trame 0 = trame 3 du groupe de 3 trames précédentes) et 3. Dans ce processus les trames 1 et 2 ne sont pas codées directement mais c'est le type d'interpolation permettant de les quantifier le plus fidèlement possible qui est codé.
- Pour chacune des valeurs de coefficients LSP d'ordre impairs des trames 1 ou 2, le codeur détermine parmi 3 interpolations représentées par le graphe de la figure 4 celle qui lui semble donner la meilleure approximation des valeurs des trames 1 et 2.
- Les trois cas d'interpolations possibles cas 0, cas1 et cas 2 donnent pour les trames 1 et 2 des coefficients LSPQ définis en liaison avec la figure 4 comme suit. (LSPQ (trame i) = Valeur Quantifiée du LSP de la trame i



- Le procédé choisit ensuite parmi les 3 interpolations précédentes celle qui minimise l'erreur de quantification, estimée au moyen d'une fonction D_INTER définie ci-dessous en adoptant la valeur de code correspondante.
- La fonction D_INTER est définie comme suit.

- LSP(trame j) = Valeur réelle dans la trame j du coefficient LSP impair à quantifier
- W1 = valeur de l'énergie de la trame 1
- W2 = valeur de l'énergie de la trame 2
- On obtient ainsi 5 codes de 3 cas chacun, soit 3⁵=243 cas possibles. Le code obtenu est égal à
Code LSP1 + 3.Code LSP3 + 9.Code LSP5 + 27.Code LSP7 + 81.Code LSP9 - Ce codage tient sur 8 bits.
- Le codage du pitch et du voisement ont lieu à l'étape 14 sur trois trames consécutives.
- Le type de voisement courant est déterminé parmi six cas possibles à partir des voisements des trames 1, 2 et 3 et du voisement de la trame 0 qui précède chaque groupe de trames 1, 2 et 3.
- Les types de cas possibles considérés sont les suivants.
- Une table de codage représenté à la figure 5 permet d'associer à toute valeur du pitch un nombre de la table dont la valeur désignée par la suite par "N tableau" est la plus proche du pitch.
- Le codage des six types de cas possibles précédents a lieu alors de la manière suivante:
- Le code 0 est attribué au type 1. Un code égal à la valeur "N.tableau" du pitch de la trame 3 est attribué au type 2. Un code égal à 64 auquel est ajouté la valeur "N.tableau" du pitch de la trame 3 est attribué au type 3. Un code égal à 128 auquel est ajouté la valeur "N. tableau " du pitch de la trame 1 est attribué au type 4. Un code égal à 192 auquel est ajouté la valeur "N.tableau du pitch de la trame 1 est attribué au type 5. Le codage du type 6 a lieu de façon toute particulière en projetant le vecteur composé des trois valeurs des pitchs des trois trames sur les 3 vecteurs (Vect 1, Vect 2, Vect 3) propres pour coder les trois projections obtenues. Ces trois vecteurs Vect 1, Vect 2, Vect 3 sont une approximation des 3 premiers vecteurs propres de la matrice d'intercorrélation. Comme la projection sur le premier vecteur propre donne la moyenne des pitchs il est plus simple de prendre directement comme code pour la première projection la valeur "N.tableau" qui est la plus proche de la moyenne (P₁ + P₂ + P₃)/3 des pitchs des trames 1, 2 et 3. Le code correspondant est alors codé sur les 63 valeurs de la table de codage.
- La projection sur le deuxième vecteur propre (Vect 2) est égale au produit scalaire des pitchs des trames 1, 2 et 3 par le deuxième vecteur propre (Vect 2) et la projection sur le troisième vecteur propre (Vect 3) est égale au produit scalaire des pitchs des trames 1, 2 et 3 par le troisième vecteur propre (Vect 3).
- Les codes correspondants peuvent être obtenus respectivement sur seulement 4 et 3 valeurs de la table de codage.
- Le codage de l'énergie qui est effectué à l'étage 15 a lieu de façon connue et décrite dans la demande de brevet FR 2 631 146 sur trois trames consécutives. Quatre valeur de l'énergie correspondant aux 4 sous trames de chacune des trois trames sont codées. Cependant pour éliminer l'information redondante dans ces 12 valeurs une Analyse par Composantes Principales du type de celle décrite ayant pour titre "Eléments d'analyse des données" dans le livre de MM. DIDAY, LEMAIRE, POUGET et TESTU publié par Dunod, est effectuée. Le codage a lieu selon deux étapes. Une première étape consiste à effectuer un changement de base. Le vecteur énergie de dimension 12, composé des 12 valeurs d'énergie des 3 trames est projeté sur les 3 premiers axes principaux déterminés lors de l'analyse par composantes principales (plus de 97% de l'information est contenue dans ces 3 projections ).
- La deuxième étape consiste à quantifier ces 3 projections, la première projection est quantifiée sur 4 bits, la deuxième sur 3 bits et la troisième sur 2 bits.
- Le codage de l'énergie ainsi obtenu est alors défini sur 4 + 3 +2 = 9 bits.
- Le tramage qui est effectué à l'étape 16 consiste à effectuer un regroupement de tous les codes pour former un mot continu de 54 bits décomposés comme suite :
- 1) Code énergie 3 trames sur 9 bits.
- 2) Code pitch 3 trames sur 10 bits.
- 3) Code filtre trame 3 sur 27 bits.
- 4) Code filtres trames 1 et 2 sur 8 bits.
soit au total 9 + 10+27 + 8 = 54 bits. - A titre d'exemple pour le cas d'une durée de trame de 22.5 ms, le procédé permet d'obtenir dans ces conditions un débit binaire par seconde de 54/(3*0.0225) = 800 bits par seconde.
- La synthèse c'est-à-dire le décodage du signal de parole se déroule selon les étapes 17 à 28 de l'organigramme de la figure 6 suivant d'une part, les étapes 17 à 21 pour détramer et décoder les valeurs des coefficients LSP du filtre (étape 18), du pitch (étape 19), du voisement et de l'énergie (étape 20) pour trois trames consécutives et d'autre part, suivant les étapes 22 à 28 qui réalisent la synthèse du signal de parole successivement pour chacune des trois trames à partir des informations obtenues lors de l'exécution des étapes 17 à 21. Le détramage et le décodage suivent des procédures inverses aux procédures de tramage et de décodage définie lors de l'analyse illustrée par l'organigramme de la figure 1. La mise en forme du filtre de synthèse consiste à effectuer à l'étape 23 un calcul d'interpolation des coefficients LSP sur quatre sous trames et un calcul pour transformer les coefficients LSP en coefficients Ai. Ce dernier calcul est suivi à l'étape 24 par un calcul de gain du filtre de synthèse pour les 4 sous trames auquel est ajouté un calcul de l'énergie du signal d'excitation du filtre. Afin d'éviter des transitions brutales entre filtres dissemblables celles-ci se font à l'étape 23 en quatre étapes tous les quarts de trame. Les quatre filtres interpolés doivent alors vérifier une relation de la forme :
LSP(SS Tri, TrN)=(LSP(TrN-1)*(4-i)+LSP(TrN)*i)/4
où LSP(SS Tri, Tr N) désigne la valeur du filtre interpôlé dans la sous trame i de la trame N. - L'interpolation a lieu suivant le schéma de la figure 7.
- Comme les 12 énergies décodées correspondent à l'énergie du signal de parole après préaccentuation, il faut pour obtenir l'énergie du signal d'excitation diviser l'énergie par le gain du filtre.
- Le gain du filtre de chaque sous trame est calculé en utilisant les coefficients Ki suivant la relation
- Gain du filtre

- Enfin la dernière étape consiste à déterminer la valeur de l'écart type de l'énergie de chaque sous trame (valeur utilisée lors du calcul de l'excitation).
- L'ensemble du procédé de codage et de décodage selon l'invention sont exécutables au moyen d'une structure microprogrammée formée de la façon représentée à titre d'exemple sur la figure 8 par un microprocesseur de traitement du signal 29 tel que celui commercialisé par la société Texas Instrument sous la désignation TMS 320C25. Suivant cette structure le signal de parole est d'abord échantillonné par un convertisseur analogique numérique 30 avant d'être appliqué sur un bus de donnée 31 du microprocesseur 29. Un filtre analogique 32 couplé à un dispositif de contrôle automatique de gain 33 filtre le signal de parole avant son échantillonnage. Les programmes et les données mis en oeuvre pour l'exécution du procédé selon l'invention sont inscrits dans une mémoire morte 34 et dans une mémoire vive 35 reliées au microprocesseur 29. Un circuit d'interface 36 relie le microprocesseur 29 par l'intermédiaire d'une ligne de donnée 37 à des dispositifs de transmission extérieurs au vocodeur non représentés.
- Un dispositif de réception de la parole formé d'un haut parleur 38, d'un amplificateur de puissance 39, un filtre analogique 40, est relié au microprocesseur par l'intermédiaire d'un convertisseur numérique analogique 41.
Claims (9)
- Procédé de codage à bas débit de la parole, caractérisé en ce qu'il consiste après avoir découpé le signal de parole en trames de longueur constante, à calculer (4...10) les caractéristiques de N filtres de modélisation du conduit vocal ainsi que les caractéristiques de période fondamentale (pitch), de voisement et d'énergie du signal vocal par intervalles déterminés de N trames successives en calculant l'énergie du signal de parole en nombre P déterminé de fois par trame pour coder l'ensemble de ces caractéristiques.
- Procédé selon la revendication 1, caractérisé en ce que les caractéristiques des filtres de modélisation du conduit vocal sont formés de coefficients LSP.
- Procédé selon l'une quelconque des revendications 1 et 2, caractérisé en ce que le nombre N est égal à trois.
- Procédé selon la revendication 3, caractérisé en ce que le codage des coefficients LSP a lieu scalairement sur une première trame et par interpolation sur les deux autres.
- Procédé selon la revendication 4, caractérisé en ce que le codage scalaire des coefficients de la troisième trame a lieu par application de l'algorithme "Backward Sequential Adaptative".
- Procédé selon l'une quelconque des revendications 4 et 5, caractérisé en ce que le codage par interpolation sur les deux autres trames a lieu par recherche parmi trois interpolations possibles celle qui présente l'erreur de quantification minimum.
- Procédé selon l'une quelconque des revendications 1 à 6, caractérisé en ce que le codage de la période fondamentale (pitch) et du voisement ont lieu sur trois trames consécutives et a lieu par adressage direct d'une table de codage par la valeur du (pitch) lorsqu'il existe au moins un son non voisé dans une trame et par codage d'une valeur de pitch obtenue par transformation vectorielle des valeurs de "pitch" existant sur les trois trames lorsque le son est voisé sur les trois trames, dans cette transformation le vecteur composé des trois valeurs des pitchs des trois trames est projeté sur les trois premiers vecteurs propres d'une matrice d'intercorrélation et les trois valeurs des trois projections sont codés.
- Procédé selon l'une quelconque des revendications 1 à 7, caractérisé en ce que le codage de l'énergie est effectué sur 4 sous trames dans chaque trame.
- Dispositif pour la mise en oeuvre du procédé selon l'une quelconque des revendications 1 à 8, caractérisé en ce qu'il comprend une structure microprogrammée composé d'une mémoire morte 34 et d'une mémoire vive 35 reliées a un microprocesseur de traitement du signal 29, le microprocesseur 29 étant relié d'une part, à un convertisseur analogique numérique 31 pour convertir le signal de parole en échantillons numériques et d'autre part à un convertisseur numérique analogique pour convertir les échantillons de parole formés par le microprocesseur en signaux analogiques pour exciter un dispositif 38 de restitution du son ainsi qu'à ligne de donnée extérieure 37 pour un circuit d'interface 36.
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| FR9005400 | 1990-04-27 | ||
| FR9005400A FR2661541A1 (fr) | 1990-04-27 | 1990-04-27 | Procede et dispositif de codage bas debit de la parole. |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| EP0454552A2 true EP0454552A2 (fr) | 1991-10-30 |
| EP0454552A3 EP0454552A3 (en) | 1992-01-02 |
Family
ID=9396170
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| EP19910401051 Withdrawn EP0454552A3 (en) | 1990-04-27 | 1991-04-19 | Method and apparatus for low bitrate speech coding |
Country Status (5)
| Country | Link |
|---|---|
| EP (1) | EP0454552A3 (fr) |
| JP (1) | JPH05507796A (fr) |
| CA (1) | CA2079884A1 (fr) |
| FR (1) | FR2661541A1 (fr) |
| WO (1) | WO1991017541A1 (fr) |
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| FR2684225A1 (fr) * | 1991-11-22 | 1993-05-28 | Thomson Csf | Procede de quantification de l'energie du signal de parole dans un vocodeur a tres faible debit. |
| EP0573398A3 (fr) * | 1992-06-01 | 1994-02-16 | Hughes Aircraft Co |
Family Cites Families (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CA1203906A (fr) * | 1982-10-21 | 1986-04-29 | Tetsu Taguchi | Vocodeur a trame de longueur variable |
| US4852179A (en) * | 1987-10-05 | 1989-07-25 | Motorola, Inc. | Variable frame rate, fixed bit rate vocoding method |
| FR2654542B1 (fr) * | 1989-11-14 | 1992-01-17 | Thomson Csf | Procede et dispositif de codage de filtres predicteurs de vocodeurs tres bas debit. |
-
1990
- 1990-04-27 FR FR9005400A patent/FR2661541A1/fr not_active Withdrawn
-
1991
- 1991-04-19 WO PCT/FR1991/000329 patent/WO1991017541A1/fr not_active Ceased
- 1991-04-19 EP EP19910401051 patent/EP0454552A3/fr not_active Withdrawn
- 1991-04-19 JP JP91508756A patent/JPH05507796A/ja active Pending
- 1991-04-19 CA CA 2079884 patent/CA2079884A1/fr not_active Abandoned
Cited By (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| FR2684225A1 (fr) * | 1991-11-22 | 1993-05-28 | Thomson Csf | Procede de quantification de l'energie du signal de parole dans un vocodeur a tres faible debit. |
| EP0543700A3 (en) * | 1991-11-22 | 1993-09-29 | Thomson-Csf | Method for quantification of speed signal energy in a low bit rate vocoder |
| EP0573398A3 (fr) * | 1992-06-01 | 1994-02-16 | Hughes Aircraft Co | |
| US5495555A (en) * | 1992-06-01 | 1996-02-27 | Hughes Aircraft Company | High quality low bit rate celp-based speech codec |
Also Published As
| Publication number | Publication date |
|---|---|
| CA2079884A1 (fr) | 1991-10-28 |
| JPH05507796A (ja) | 1993-11-04 |
| FR2661541A1 (fr) | 1991-10-31 |
| EP0454552A3 (en) | 1992-01-02 |
| WO1991017541A1 (fr) | 1991-11-14 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| RU2257556C2 (ru) | Квантование коэффициентов усиления для речевого кодера линейного прогнозирования с кодовым возбуждением | |
| JP3241959B2 (ja) | 音声信号の符号化方法 | |
| EP0782128B1 (fr) | Procédé d'analyse par prédiction linéaire d'un signal audiofréquence, et procédés de codage et de décodage d'un signal audiofréquence en comportant application | |
| EP1320087B1 (fr) | Synthèse d'un signal d'excitation utilisé dans un générateur de bruit de confort | |
| US5067158A (en) | Linear predictive residual representation via non-iterative spectral reconstruction | |
| JP4222951B2 (ja) | 紛失フレームを取扱うための音声通信システムおよび方法 | |
| EP0700032B1 (fr) | Procédés et dispositif avec attribution de bits pour la quantisation et la déquantisation de signaux de parole transformés | |
| EP0865028A1 (fr) | Décodeur de parole à interpolation de formes d'ondes utilisant des fonctons pline | |
| US5991725A (en) | System and method for enhanced speech quality in voice storage and retrieval systems | |
| EP0865029B1 (fr) | Interpolation de formes d'onde par décomposition en bruit et en signaux périodiques | |
| EP2080194B1 (fr) | Attenuation du survoisement, notamment pour la generation d'une excitation aupres d'un decodeur, en absence d'information | |
| EP0428445B1 (fr) | Procédé et dispositif de codage de filtres prédicteurs de vocodeurs très bas débit | |
| EP1125283A1 (fr) | Procede de quantification des parametres d'un codeur de parole | |
| EP0715297B1 (fr) | Reconstruction d'une séquence de paramètres de codage de parole par classification et établissement d'un inventaire de profils de paramètres | |
| SE470577B (sv) | Förfarande och anordning för kodning och/eller avkodning av bakgrundsljud | |
| US6535847B1 (en) | Audio signal processing | |
| US5812966A (en) | Pitch searching time reducing method for code excited linear prediction vocoder using line spectral pair | |
| EP0454552A2 (fr) | ProcédÀ© et dispositif de codage bas débit de la parole | |
| JPH09508479A (ja) | バースト励起線形予測 | |
| US7603271B2 (en) | Speech coding apparatus with perceptual weighting and method therefor | |
| JP2000132193A (ja) | 信号符号化装置及び方法、並びに信号復号装置及び方法 | |
| JP3437421B2 (ja) | 楽音符号化装置及び楽音符号化方法並びに楽音符号化プログラムを記録した記録媒体 | |
| JP3163206B2 (ja) | 音響信号符号化装置 | |
| EP1192619B1 (fr) | Codage et decodage audio par interpolation | |
| EP0987680A1 (fr) | Traitement de signal audio |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PUAI | Public reference made under article 153(3) epc to a published international application that has entered the european phase |
Free format text: ORIGINAL CODE: 0009012 |
|
| AK | Designated contracting states |
Kind code of ref document: A2 Designated state(s): DE ES GB IT |
|
| PUAL | Search report despatched |
Free format text: ORIGINAL CODE: 0009013 |
|
| AK | Designated contracting states |
Kind code of ref document: A3 Designated state(s): DE ES GB IT |
|
| 17P | Request for examination filed |
Effective date: 19920624 |
|
| RAP1 | Party data changed (applicant data changed or rights of an application transferred) |
Owner name: THOMSON-CSF |
|
| 17Q | First examination report despatched |
Effective date: 19940803 |
|
| STAA | Information on the status of an ep patent application or granted ep patent |
Free format text: STATUS: THE APPLICATION IS DEEMED TO BE WITHDRAWN |
|
| 18D | Application deemed to be withdrawn |
Effective date: 19941214 |