EP0594480A1 - Procédé de détection de la parole - Google Patents
Procédé de détection de la parole Download PDFInfo
- Publication number
- EP0594480A1 EP0594480A1 EP93402522A EP93402522A EP0594480A1 EP 0594480 A1 EP0594480 A1 EP 0594480A1 EP 93402522 A EP93402522 A EP 93402522A EP 93402522 A EP93402522 A EP 93402522A EP 0594480 A1 EP0594480 A1 EP 0594480A1
- Authority
- EP
- European Patent Office
- Prior art keywords
- frames
- noise
- frame
- speech
- fricative
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Granted
Links
- 238000001514 detection method Methods 0.000 title claims description 73
- 238000000034 method Methods 0.000 claims abstract description 85
- 238000001228 spectrum Methods 0.000 claims abstract description 18
- 238000004422 calculation algorithm Methods 0.000 claims description 43
- 238000012545 processing Methods 0.000 claims description 38
- 230000001755 vocal effect Effects 0.000 claims description 31
- 238000004364 calculation method Methods 0.000 claims description 23
- 230000003595 spectral effect Effects 0.000 claims description 17
- 238000001914 filtration Methods 0.000 claims description 15
- 239000013598 vector Substances 0.000 claims description 5
- 238000004061 bleaching Methods 0.000 claims description 4
- 230000003111 delayed effect Effects 0.000 claims description 3
- 239000000284 extract Substances 0.000 claims description 2
- 230000002087 whitening effect Effects 0.000 abstract description 5
- 230000008569 process Effects 0.000 description 29
- 230000006870 function Effects 0.000 description 17
- 238000005314 correlation function Methods 0.000 description 10
- 238000013459 approach Methods 0.000 description 9
- 230000029058 respiratory gaseous exchange Effects 0.000 description 7
- 238000004458 analytical method Methods 0.000 description 6
- 230000001629 suppression Effects 0.000 description 6
- 241000135309 Processus Species 0.000 description 5
- 238000012790 confirmation Methods 0.000 description 5
- 238000005070 sampling Methods 0.000 description 5
- 230000003044 adaptive effect Effects 0.000 description 4
- 230000008859 change Effects 0.000 description 4
- 238000011282 treatment Methods 0.000 description 4
- 230000001627 detrimental effect Effects 0.000 description 3
- 230000002123 temporal effect Effects 0.000 description 3
- 238000012360 testing method Methods 0.000 description 3
- 230000005534 acoustic noise Effects 0.000 description 2
- 239000000654 additive Substances 0.000 description 2
- 230000000996 additive effect Effects 0.000 description 2
- 210000004027 cell Anatomy 0.000 description 2
- 238000013461 design Methods 0.000 description 2
- 230000000694 effects Effects 0.000 description 2
- 238000009499 grossing Methods 0.000 description 2
- 239000011159 matrix material Substances 0.000 description 2
- 238000005259 measurement Methods 0.000 description 2
- 230000009467 reduction Effects 0.000 description 2
- 238000012552 review Methods 0.000 description 2
- KRQUFUKTQHISJB-YYADALCUSA-N 2-[(E)-N-[2-(4-chlorophenoxy)propoxy]-C-propylcarbonimidoyl]-3-hydroxy-5-(thian-3-yl)cyclohex-2-en-1-one Chemical compound CCC\C(=N/OCC(C)OC1=CC=C(Cl)C=C1)C1=C(O)CC(CC1=O)C1CCCSC1 KRQUFUKTQHISJB-YYADALCUSA-N 0.000 description 1
- 238000006677 Appel reaction Methods 0.000 description 1
- 241000272194 Ciconiiformes Species 0.000 description 1
- 241001475178 Dira Species 0.000 description 1
- 241001644893 Entandrophragma utile Species 0.000 description 1
- 238000007476 Maximum Likelihood Methods 0.000 description 1
- 241001080024 Telles Species 0.000 description 1
- 240000008042 Zea mays Species 0.000 description 1
- 230000002411 adverse Effects 0.000 description 1
- 238000005311 autocorrelation function Methods 0.000 description 1
- 230000001427 coherent effect Effects 0.000 description 1
- 239000000470 constituent Substances 0.000 description 1
- 238000010276 construction Methods 0.000 description 1
- 230000007423 decrease Effects 0.000 description 1
- 238000011161 development Methods 0.000 description 1
- 238000010586 diagram Methods 0.000 description 1
- 238000005315 distribution function Methods 0.000 description 1
- 229940082150 encore Drugs 0.000 description 1
- 230000006872 improvement Effects 0.000 description 1
- 238000013139 quantization Methods 0.000 description 1
- 238000010183 spectrum analysis Methods 0.000 description 1
- LXMSZDCAJNLERA-ZHYRCANASA-N spironolactone Chemical compound C([C@@H]1[C@]2(C)CC[C@@H]3[C@@]4(C)CCC(=O)C=C4C[C@H]([C@@H]13)SC(=O)C)C[C@@]21CCC(=O)O1 LXMSZDCAJNLERA-ZHYRCANASA-N 0.000 description 1
- 238000012546 transfer Methods 0.000 description 1
Classifications
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L25/00—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00
- G10L25/78—Detection of presence or absence of voice signals
- G10L25/87—Detection of discrete points within a voice signal
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L25/00—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00
- G10L25/93—Discriminating between voiced and unvoiced parts of speech signals
- G10L2025/932—Decision in previous or following frames
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L25/00—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00
- G10L25/93—Discriminating between voiced and unvoiced parts of speech signals
- G10L2025/937—Signal energy in various frequency bands
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L21/00—Speech or voice signal processing techniques to produce another audible or non-audible signal, e.g. visual or tactile, in order to modify its quality or its intelligibility
- G10L21/02—Speech enhancement, e.g. noise reduction or echo cancellation
- G10L21/0208—Noise filtering
- G10L21/0216—Noise filtering characterised by the method used for estimating noise
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L25/00—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00
- G10L25/27—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00 characterised by the analysis technique
Definitions
- the present invention relates to a speech detection method.
- the subject of the present invention is a method for detecting and denoising speech which makes it possible to detect as safely as possible the beginnings and end times of speech signals whatever the types of speech sounds, and which makes it possible to denois the most Signals thus detected can be effectively detected, even when the statistical characteristics of the noise affecting these signals vary widely.
- the method of the invention consists in carrying out in a low-noise environment a detection of voiced frames, and in detecting a vocal nucleus to which a confidence interval is attached.
- Spectral whitening and denoising do not apply sequentially, but in parallel, whitening allowing the detection of unvoiced sounds, denoising an improvement in the quality of the voice signal to be recognized.
- the "elementary" level of voicing detection is an algorithm for calculating and thresholding the correlation function. The result is assessed by the higher level.
- frame the elementary time unit of processing.
- the duration of a frame is conventionally 12.8 ms, but can, of course, have different values (achievements in mathematical language).
- the treatments use discrete Fourier transforms of the processed signals. These Fourier transforms are applied to all of the samples obtained on two consecutive frames, which corresponds to performing a Fourier transform over 25.8 ms.
- the preferred embodiment of the invention is described below with reference to the analysis of signals from very noisy avionic environments, which makes it possible to have starting information which is the micro alternation that use the pilots. This information indicates a time zone close to the signal to be processed.
- N3 around 30.
- This detection is done by fricative detection and is described below.
- Each acquired frame is no longer bleached but only denoised, then configured for recognition.
- a voicing test is carried out on each frame.
- the acoustic vector is effectively sent to the recognition algorithm.
- N4 about 30 frames
- the frames between the end of voicing and this end of speech are denoised, then parameterized and sent to the pure voice recognition system for processing.
- this process is local to the spoken speech (that is to say, it treats each sentence or each set of words without "gap" between words), and therefore makes it possible to be very adaptive to any change in noise statistics, especially since we use adaptive algorithms for auto-regressive noise modeling, and relatively sophisticated theoretical models for the detection of noise frames and the detection of fricatives.
- the process is launched as soon as a voicing is detected.
- Expertise consists in combining the different results obtained using these tools, so as to highlight coherent sets, forming the vocal nucleus for example, or blocks of fricative sounds (plosives), not seen.
- voicing detection process For the voicing detection expertise, use is made of a known voicing detection process, which, for a given frame, decides whether this frame is voiced or not, by returning the value of the "pitch" associated with this frame.
- the "pitch” is the frequency of repetition of the voicing pattern. This pitch value is zero, if there is no voicing, and not zero otherwise.
- This elementary voicing detection is done without using results relating to the preceding frames, and without predicting results relating to future frames.
- a vowel nucleus can consist of several voiced segments, separated by unvoiced holes, an expertise is necessary, in order to validate or not a voicing.
- this hole may be part of the vowel nucleus and we cannot yet make a final decision.
- the hole size is reset, for processing of the next unvoiced frames.
- This procedure is used for each frame, and after calculating the pitch associated with this frame.
- This elementary voicing detection is done without using results relating to the preceding frames, and without predicting results relating to future frames.
- fricative blocks should not be too large. Also, an expertise intervening after the detection of these sounds is necessary.
- fricative will refer just as well to unvoiced fricatives as to unvoiced plosives.
- This expertise is used to detect the fricative blocks preceding or following the vowel nucleus.
- the benchmark chosen in this expertise is therefore the vocal core.
- the AMDF function is a distance between the signal and its delayed form. However, this distance is a distance which does not admit an associated scalar product, and which therefore does not allow the concept of orthogonal projection to be introduced. However, in a noisy environment, the orthogonal projection of the noise can be zero, if the axis of projection is well chosen. AMDF is therefore not an adequate solution in noisy environments.
- Noise whiteness in practice is not a valid assumption. However, the result remains good approximation as soon as the noise correlation function decreases rapidly, and for k sufficiently large, as in the case of pink noise (white noise filtered by a bandpass), where the correlation function is a cardinal sine, therefore practically zero as soon as k is sufficiently large.
- x (n) be the processed signal where n e ⁇ 0, ..., N-1 ⁇ .
- the observation window must always be the same regardless of k. So that if n-k is less than 0, it is necessary to have stored in memory the past values of the signal x (n), so as to calculate the function r (k) on as many points, whatever k. The value of the constant K no longer matters.
- This function r (k) being calculated, it is then a question of thresholding it.
- the threshold is chosen experimentally, according to the dynamics of the signals processed.
- the detection algorithm aims to detect the start and end of speech from a whitened version of the signal, while the denoising algorithm requires knowledge of the average noise spectrum.
- To build the noise models which will make it possible to whiten the speech signal for the detection of unvoiced sounds as described below, and to denoise the speech signal, it is obvious that it is necessary to detect the noise frames , and confirm them as such.
- Pr ⁇ X ⁇ x ⁇ P (x, m
- ⁇ , ⁇ ) ⁇ P (x, y
- ⁇ 1 , ⁇ 2 ) ⁇ P (x, m
- a ⁇ .
- f ⁇ (x, y) f (x, y
- ⁇ , ⁇ ), h ⁇ (x, y) h (x, y
- ⁇ , ⁇ ) and P ⁇ (x, y) P (x, y
- H (f) U [- (f0-B / 2, -f0 + B / 2] (f) + U [f0-B / 2, f0 + B / 2] (f), where U denotes the characteristic function of the interval in index and f o the central frequency of the filter.
- m m 1 / m 2
- ⁇ 1 m 1 / ⁇ 1
- ⁇ 2 m 2 / ⁇ 2 .
- ⁇ 1 and a 2 are large enough that the random variables of Ci and C 2 can be considered as positive random variables.
- H 1 ⁇ U ⁇ V is true
- H 2 ⁇ U ⁇ V is false.
- 1 [1 / s, s].
- This decision rule admits a correct decision probability, the expression of which will in fact depend on the value of the probabilities Pr ⁇ H 1 ⁇ and Pr ⁇ H 2 ⁇ . However, these probabilities are generally not known in practice.
- C 2 is the class of energies corresponding to noise alone.
- the object of this processing aims to highlight, not all the noise frames, but only a few having a high probability of being made up only of noise. We therefore have every interest in making the algorithm very selective.
- this selectivity is also obtained by the choice of r: chosen too large, there is a risk of considering energies as representative of the noise, whereas these are breathing energies, for example, having a signal to noise ratio less than r. Conversely, choosing an r that is too small can limit the accessible P FA , which would then be too high to be acceptable.
- the frame having the minimum energy among the Ni frames is therefore assumed to consist only of noise. We then look for all the frames compatible with this frame in the sense recalled above, using the aforementioned models.
- the noise detection algorithm will search, among a set of frames T 1 , ..., T n , for those which can be considered as noise.
- Noise Noise U ⁇ E (T i ) ⁇ End for Autoregressive Model of noise.
- the noise confirmation algorithm provides a certain number of frames which can be considered as noise with a very high probability, we seek to construct, from the data of the temporal samples, an autoregressive model of the noise.
- x (n) designates the noise samples
- x (n) ⁇ 1 ⁇ i p P a i x (ni) + b (n)
- p is the order of the model
- a i the coefficients of the model to be determined
- b (n) the modeling noise, assumed to be white and Gaussian if we follow a maximum likelihood approach.
- the rejector filter H (z) whitens the signal, so that the signal at the output of this filter is a speech signal (filtered therefore distorted), added to a generally white and Gaussian noise.
- the signal obtained is in fact unsuitable for recognition, because the rejector filter distorts the original speech signal.
- X 1 (n) ..., X M (n) be the M + 1 FFT of the M noise frames confirmed as such, these FFT being obtained by weighting the initial time signal by an adequate apodization window.
- C uu is the average spectrum of the total signal u (n) available only on a single frame.
- this frame must be configured so that it can intervene in the recognition process. There is therefore no question of carrying out any average of the signal u (n) all the more since the speech signal is a particularly non-stationary signal.
- ⁇ c UU be the FFT- 1 of ⁇ C UU .
- ⁇ c UU (k) f (k) v (k) where v (k) is the FFT- 1 of V (k).
- the method of the invention applies the algorithm of the previous smoothed correlogram to the average noise spectrum M xx (n).
- An FFT- 1 can possibly make it possible to recover the denoised time signal.
- the denoised spectrum ⁇ S (n) obtained is the spectrum used for parameterization with a view to recognizing the frame.
- the decision rule is expressed in the following form:
- ⁇ 1 , ⁇ 2 ) is then: or
- the optimal threshold is that for which P c (s, m
- the sounds / F /, / S /, / CH / are located spectrally in a frequency band which extends from approximately 4 KHz to more than 5KHz.
- the sounds / P /, / T /, / Q / as short phenomena in time, are spread over a wider band.
- the spectrum of these fricative sounds is relatively flat, so that the fricative signal in this band can be modeled by a narrow band signal. This can be realistic in certain practical cases without resorting to the bleaching described above. In most cases, however, it is a good idea to work on a whitened signal to ensure a suitable narrowband noise model.
- s (n) be the speech signal in the band studied and x (n) the noise in this same band.
- the signals s (n) and x (n) are assumed to be independent.
- the class C 2 corresponds to the energy V of the noise alone observed on M points.
- u (n) is a signal itself Gaussian, so that: Similarly:
- V ⁇ 0 ⁇ n ⁇ M-1 y (n) 2 ⁇ N (M ⁇ x 2 , 2 ⁇ x 2 ⁇ 0 ⁇ i ⁇ M-1.0 ⁇ j ⁇ M-1 g f0, B (ij) 2 ) , where y (n) denotes, we recall, another value noise x (n) over a time slice different from that where u (n) is observed.
- y (n) denotes, we recall, another value noise x (n) over a time slice different from that where u (n) is observed.
- the model of the fricative signal is not the same as previously.
- the voiced sound is independent of the noise x (n) which is here Gaussian narrow band.
- the noise must be Gaussian white. If the original noise is not white, we can approach this model by actually sub-sampling the observed signal, that is to say by considering only one sample out of 2, 3, or even more, depending on the noise autocorrelation function, and assuming that the speech signal thus subsampled still has detectable energy. But it is also possible, and this is preferable, to use this algorithm on a signal whitened by a rejector filter, since then the residual noise is approximately white and Gaussian.
- E (T i ) is compatible with E o (Decision on the value of E (T i ) / E 0 ).
- E (T i ) is compatible with E o (Decision on the value of E (T i ) / E 0 ).
- the signal-to-noise ratio r can be estimated or fixed in a heuristic manner, provided that some preliminary experimental measurements, characteristic of the field of application, are carried out, so as to fix an order of magnitude of the signal-to-noise ratio presented by the fricatives in the chosen band.
- the probability p of the presence of unvoiced speech is also a heuristic datum which modulates the selectivity of the algorithm, in the same way as the signal-to-noise ratio.
- This data can be estimated according to the vocabulary used and the number of frames on which the search for unvoiced sounds is made.
Landscapes
- Engineering & Computer Science (AREA)
- Computational Linguistics (AREA)
- Signal Processing (AREA)
- Health & Medical Sciences (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Human Computer Interaction (AREA)
- Physics & Mathematics (AREA)
- Acoustics & Sound (AREA)
- Multimedia (AREA)
- Mobile Radio Communication Systems (AREA)
- Compression, Expansion, Code Conversion, And Decoders (AREA)
- Electrically Operated Instructional Devices (AREA)
- Complex Calculations (AREA)
Abstract
Description
- La présente invention se rapporte à un procédé de détection de la parole.
- Lorsqu'on cherche à déterminer le début et la fin effectifs de la parole, diverses solutions sont envisageable :
- (1) On peut travailler sur l'amplitude instantanée par référence à un seuil déterminé expérimentalement et confirmer la détection de parole par une détection de voisement (voir article "La discrimination parole- bruit et ses applications" de V. PETIT/F. DUMONT, paru dans la Revue Technique THOMSON-CSF - Vol. 12 - N°4, déc. 1980).
- (2) On peut aussi travailler sur l'énergie du signal total sur une tranche temporelle de durée T, en seuillant, toujours expérimentalement, cette énergie à l'aide d'histogrammes locaux, par exemple, et confirmer ensuite à l'aide d'une détection de voisement, ou du calcul de l'énergie minimale d'une voyelle. L'utilisation de l'énergie minimale d'une voyelle est une technique décrite dans le rapport "AMADEUS Version 1.0" de J.L. GAUVAIN du laboratoire LIMSI du CNRS.
- (3) Les systèmes précédents permettent la détection de voisement, mais non pas du début et de la fin effectifs de la parole, c'est-à-dire la détection des sons fricatifs non voisés (/F/, /S/, /CH/) et des sons plosifs non voisés (P/, /T/, /Q/). Il faut donc les compléter par un algorithme de détection de ces fricatives. Une première technique peut consister en l'utilisation d'histogrammes locaux, comme le préconise l'article "Problème de détection des frontières de mots en présence de bruit additifs" de P. WACRENIER, paru dans le mémoire de D.E.A. de l'université de PARIS-SUD, Centre d'Orsay.
- D'autres techniques voisines des précédentes et relativement proches de celle exposée ici, ont été présentées dans l'article "A Study of Endpoint Detection Algorithms in Adverse Conditions: Incidence on a DTW and HMM Recognizer" de J.C. JUNQUA/B. REAVES/B. MAK, lors du Congrès EUROSPEECH 1991.
- Dans toutes ces approches, une grande part est faite à l'heuristique, et peu d'outils théoriques puissants sont utilisés.
- Les travaux sur le débruitage de la parole similaires à ceux présentés ici sont beaucoup plus nombreux, et l'on citera en particulier le livre "Speech Enhancement" de J.S. LIM aux Editions Prentice-Hall Signal Processing Series "Suppression of Acoustic Noise in Speech Using Spectral Substraction" de S.F. BOLL, paru dans la revue IEEE Transactions on Acoustics, speech, and signal processing, vol. ASSP-27, N°2, Avril 1989, et "Noise Reduction For Speech Enhancement In Cars : Non-Linear Spectral Subtraction/Kalman Filtering" de P. LOCKWOOD, C. BAILLARGEAT, J.M. GILLOT, J. BOUDY, G. FAUCON paru dans la revue EUROSPEECH 91. On ne citera que des techniques de débruitage dans le domaine spectral, et il sera question par la suite de débruitage "spectral" par abus de langage.
- Dans tous ces travaux, la relation étroite entre détection et débruitage n'est jamais réellement mise en évidence, sauf dans l'article "Suppression of Acoustic Noise in Speech Using Spectral Subtraction", qui propose une solution empirique à ce problème.
- Or, il est évident qu'un débruitage de la parole, lorsqu'on ne dispose pas de deux canaux d'enregistrements, nécessite l'utilisation de trames de bruit "pur", non polluées par la parole, ce qui nécessite de définir un outil de détection capable de distinguer entre bruit et bruit + parole.
- La présente invention a pour objet un procédé de détection et de débruitage de la parole qui permette de détecter le plus sûrement possible les débuts et fins effectifs de signaux de parole quels que soient les types de sons de parole, et qui permette de débruiter le plus efficacement possible les signaux ainsi détectés, même lorsque les caractéristiques statistiques du bruit affectant ces signaux varient fortement.
- Le procédé de l'invention consiste à effectuer en milieu peu bruité une détection de trames voisées, et à détecter un noyau vocalique auquel on attache un intervalle de confiance.
- En milieu bruité, après avoir effectué la détection d'au moins une trame voisée, on recherche des trames de bruit précédant cette trame voisée, on construit un modèle autorégressif de bruit et un spectre moyen de bruit, on blanchit par filtre réjecteur et on débruite par débruiteur spectral les trames précédant le voisement, on recherche le début effectif de la parole dans ces trames blanchies, on extrait des trames débruitées comprises entre le début effectif de la parole et la première trame voisée les vecteurs acoustiques utilisés par le système de reconnaissance vocale, tant que des trames voisées sont détectées, celles-ci sont débruitées puis paramétrisées en vue de leur reconnaissance (c'est-à-dire que l'on extrait les vecteurs acoustiques adaptés à la reconnaissance de ces trames), lorsqu'on ne détecte plus de trames voisées, on recherche la fin effective de la parole, on débruite puis on paramétrise les trames comprises entre la dernière trame voisée et la fin effective de la parole.
- Dans toute la suite, lorsqu'il sera question de paramétrisation des trames, il faudra entendre que l'on extrait de la trame le vecteur acoustique (ou de manière équivalente, les paramètres acoustiques) utilisés par l'algorithme de reconnaissance.
- Un exemple de tels paramètres acoustiques sont les coefficients cepstraux bien connus des spécialistes du traitement de la parole.
- Dans toute la suite, on entendra par blanchiment, l'application du filtrage réjecteur calculé à partir du modèle autorégressif du bruit, et par débruitage, l'application du débruiteur spectral.
- Blanchiment et débruitage spectral ne s'appliquent pas de manière séquentielle, mais en parallèle, le blanchiment permettant la détection de sons non voisés, le débruitage une amélioration de la qualité du signal vocal à reconnaître.
- Ainsi, le procédé de l'invention est caractérisé par l'utilisation d'outils théoriques permettant une approche rigoureuse des problèmes de détection (voisement et fricatives), par sa grande adaptativité, car ce procédé est avant tout un procédé local au mot. Les caractéristiques statistiques du bruit peuvent évoluer dans le temps, le procédé restera capable de s'y adapter, par construction. Il est également caractérisé par l'élaboration d'expertises de détection à partir des résultats d'algorithmes de traitement du signal (on minimise ainsi le nombre de fausses alarmes, dues à la détection, en prenant en compte la nature particulière du signal de parole), par des processus de débruitage couplés à la détection de parole, par une approche en "temps réel", et ce, à tous les niveaux de l'analyse, par sa synergie avec d'autres techniques de traitement du signal vocal, par l'utilisation de deux débruiteurs différents :
- * Filtrage de réjection, principalement utilisé pour la détection de fricatives, en vertu de ses propriétés de blanchiment.
- * Filtrage de Wiener en particulier, utilisé pour débruiter le signal de parole en vue de sa reconnaissance. On peut aussi utiliser une soustraction spectrale.
- Il faut donc distinguer dans le procédé de l'invention, trois niveaux de traitement :
- - Le niveau "élémentaire" qui met en oeuvre des algorithmes de traitement du signal qui sont en fait les éléments de base de tous les traitements de niveau supérieur.
- Ainsi, le niveau "élémentaire" de détection de voisement est un algorithme de calcul et de seuillage de la fonction de corrélation. Le résultat est expertisé par le niveau supérieur.
- Ces traitements s'implantent sur processeurs de traitement du signal, par exemple du type DSP 96000.
- - Le niveau intermédiaire d'expertise élabore des détections de voisements et de début de parole "intelligentes", compte tenu de la détection "brute" fournie par le niveau élémentaire. L'expertise peut faire appel à un langage informatique approprié, type Prolog.
- - Le niveau "supérieur" ou utilisateur gère en temps réel les différents algorithmes de détection, de débruitage et d'analyse du signal vocal. Le langage C, par exemple, est approprié à l'implémentation de cette gestion.
- L'invention est décrite en détail ci-dessous selon le plan suivant. On décrit d'abord l'algorithme qui permet d'enchaîner de façon appropriée les différentes techniques de traitement du signal et d'expertises nécessaires.
- On supposera à ce niveau de traitement le plus élevé dans la hiérarchie de conception, que l'on dispose de méthodes fiables de détection et de débruitage, comportant tous les algorithmes de traitement de signal, toutes les expertises, nécessaires et suffisants. Cette description est donc très générale. Elle est même indépendante des algorithmes d'expertises et de traitement du signal décrits ci-après. Elle peut donc s'appliquer à d'autres techniques que celles décrites ici.
- On décrit ensuite les expertises de détection de voisement, de début et fin de parole, à l'aide d'algorithmes de niveau élémentaire dont certains exemples sont cités.
- On décrit enfin les méthodes utilisées pour la détection et le débruitage de la parole.
- Ce sont les résultats de ces techniques (Parole voisée, non voisée, ...) qui sont utilisés par les niveaux supérieurs de traitement
- Conventions et vocabulaire employé.
- On appellera trame, l'unité temporelle élémentaire de traitement. La durée d'une trame est classiquement de 12.8 ms, mais peut, bien entendu, avoir des valeurs (réalisations en langage mathématique) différentes. Les traitements font appel à des transformées de Fourier discrètes des signaux traités. Ces transformées de Fourier sont appliquées à l'ensemble des échantillons obtenus sur deux trames consécutives, ce qui correspond à effectuer une transformée de Fourier sur 25.8 ms.
- Lorsque deux transformées de Fourier sont consécutives dans le temps, ces transformées sont calculées, non pas sur quatre trames consécutives, mais sur trois trames consécutives avec un recouvrement d'une trame. Ceci est illustré par le schéma suivant :

- On décrit d'abord ici le fonctionnement de l'algorithme au niveau de conception le plus proche de l'utilisateur.
- Le mode de mise en oeuvre préféré de l'invention est décrit ci-dessous en référence à l'analyse des signaux issus d'environnements avioniques très bruités, ce qui permet de disposer d'une information de départ qui est l'alternat micro qu'utilisent les pilotes. Cette information indique une zone temporelle proche du signal à traiter.
- Cependant, cet alternat peut être plus ou moins rapproché du début effectif de la parole, et on ne peut donc y accorder qu'un faible crédit pour toute détection précise. Il va donc falloir préciser le début effectif de parole à partir de cette première information.
- Dans un premier temps, on recherche la première trame voisée située aux alentours de cet alternat. Cette première trame voisée, est recherchée tout d'abord parmi les N1 trames qui précèdent l'alternat (N1 = environ 30 trames). Si cette trame voisée n'est pas trouvée parmi ces N1 trames, alors on recherche le voisement sur les trames qui suivent l'alternat, au fur et à mesure qu'elles se présentent.
- Dès que la première trame voisée est trouvée par ce procédé, on va initialiser les débruiteurs. Pour cela, il faut mettre en évidence des trames constituées uniquement de bruit. Ces trames de bruit sont recherchées parmi les N2 trames qui précèdent la première trame voisée (N2 = environ 40 trames). En effet, chacune de ces N2 trames est soit :
- * constituée de bruit seul
- * constituée de bruit + respiration
- * constituée de bruit + fricative ou occlusive non voisée.
- L'hypothèse faite est que l'énergie du bruit est en moyenne inférieure à celle du bruit + respiration, elle-même inférieure à celle du bruit + fricative.
- Donc, si on considère parmi les N2 trames, celle qui présente l'énergie la plus faible, il est fort probable que cette trame n'est constituée que de bruit.
- A partir de la connaissance de cette trame, on recherche toutes celles qui sont compatibles avec elle, et compatibles 2 à 2, au sens donné plus loin, au paragraphe "Compatibilités entre énergies".
- . Lorsque les trames de bruit ont été détectées, on construit les deux modèles de bruit qui vont servir par la suite :
- * Modèle autorégressif du bruit permettant de construire le filtrage réjecteur qui blanchit le bruit.
- * Spectre moyen de bruit pour débruitage spectral.
- Ces modèles sont décrits ci-dessous.
- Les modèles de bruit étant construits, on blanchit (par filtre réjecteur et on débruite (par débruiteur spectral) les N3 trames qui précèdent le voisement et parmi lesquelles on va chercher le début effectif de parole (N3 = environ 30). Il va de soi que N3 est inférieur à N2. Cette détection se fait par détection de fricative et est décrite ci-dessous.
- Lorsque le début de parole est connu, on débruite toutes les trames comprises entre le début de parole et la première trame voisée, puis on paramétrise ces trames en vue de leur reconnaissance. Au fur et à mesure que ces trames sont débruitées et paramétrisées, elles sont envoyées au système de reconnaissance.
- Puisque le début effectif de parole est connu, on peut continuer à traiter les trames qui suivent la première trame voisée.
- Chaque trame acquise n'est plus blanchie mais seulement débruitée, puis paramétrisée pour sa reconnaissance. On effectue sur chaque trame un test de voisement.
- Si cette trame est voisée, le vecteur acoustique est effectivement envoyé à l'algorithme de reconnaissance.
- Si elle n'est pas voisée, on cherche si elle est en fait la dernière trame du noyau vocalique en cours.
- Si ce n'est pas la dernière trame du noyau vocalique, on acquiert une nouvelle trame et on réitère le procédé, jusqu'au moment où l'on trouve la dernière trame voisée.
- Lorsque la dernière trame voisée est détectée, on blanchit les N4 trames qui suivent cette dernière trame voisée (N4 = environ 30 trames), puis on recherche la fin effective de la parole parmi ces N4 trames blanchies. Le procédé associé à cette détection est décrit ci-dessous.
- Lorsque la fin effective de parole est détectée, les trames comprises entre la fin de voisement et cette fin de parole, sont débruitées, puis paramétrisées et envoyées au système de reconnaissance vocale pure en vue de leur traitement.
- Lorsque la dernière trame de parole a été débruitée, paramétrisée et envoyée au système de reconnaissance, on réinitialise tous les paramètres de traitement, en vue du traitement de l'élocution suivante.
- Comme on peut le voir, ce procédé est local à l'élocution traitée (c'est-à-dire qu'il traite chaque phrase ou chaque ensemble de mots sans "trou" entre mots), et permet donc d'être très adaptatif à tous changements de statistiques du bruit, d'autant plus que l'on utilise des algorithmes adaptatifs pour la modélisation auto-régressive du bruit, et des modèles théoriques relativement sophistiqués pour la détection des trames de bruit et la détection des fricatives.
- En l'absence d'alternat, le procédé est lancé dès qu'un voisement est détecté.
- Une simplification notable du procédé décrit ci-dessus est possible lorsque les signaux traités sont peu bruités. L'utilisation des algorithmes de débruitage et de blanchiment peut alors se révéler inutile, voire néfaste, lorsque le niveau de bruit est négligeable (ambiance laboratoire). Ce phénomène est connu, notamment dans le cas du débruitage, où débruiter un signal très peu bruité peut induire une déformation de la parole préjudiciable à une bonne reconnaissance.
- Les simplifications résident :
- - dans la suppression du débruitage spectral pour reconnaissance en vue d'éviter toute déformation de la parole, ne compensant pas le gain en rapport signal sur bruit que l'on pourrait obtenir par débruitage, et préjudiciable alors à une bonne reconnaissance.
- - dans l'éventuelle suppression du filtre de blanchiment (et donc du calcul du modèle autorégressif du bruit, ce qui implique aussi la suppression du module de confirmation de bruit). Cette suppression n'est pas forcément nécessaire en milieu peu bruité. Des essais préalables sont préférables pour en décider.
- On va maintenant exposer en détail les procédures d'expertise de détection de voisement et détection de fricative
- Ces procédures d'expertises font appel à des outils bien connus de traitement du signal et de détection, qui sont autant d'automates de base, dont l'aptitude est de décider de manière brute si la trame traitée est voisée ou non, est une trame de fricative non voisée ou de plosive non voisée...
- L'expertise consiste à combiner les différents résultats obtenus à l'aide desdits outils, de manière à mettre en évidence des ensembles cohérents, formant le noyau vocalique par exemple, ou des blocs de sons fricatifs (plosifs), non voisés.
- Par nature, le langage d'implémentation de telles procédures est de préférence le PROLOG.
- A la différence du processus décrit ci-dessus, cette expertise est la même que le milieu soit bruité ou non.
- Pour l'expertise de détection de voisement, on fait appel à un processus connu de détection de voisement, qui, pour une trame donnée, décide si cette trame est voisée ou non, en renvoyant la valeur du "pitch" associé à cette trame. Le "pitch" est la fréquence de répétition du motif de voisement. Cette valeur de pitch est nulle, s'il n'y a pas de voisement, et non nulle sinon.
- Cette détection élémentaire de voisement se fait sans utiliser des résultats portant sur les trames précédentes, et sans présager du résultat portant sur les trames futures.
- Comme un noyau vocalique peut être constitué de plusieurs segments voisés, séparés de trous non voisés, une expertise est nécessaire, afin de valider ou non un voisement.
- On va maintenant exposer les règles générales de l'expertise.
- Règle 1 : Entre deux trames voisées consécutives ou séparées d'un nombre relativement faible de trames (de l'ordre de trois ou quatre trames), les valeurs de pitch obtenues ne peuvent différer de plus d'un certain delta (environ ± 20 Hz en fonction du locuteur). Par contre, lorsque l'écart entre deux trames voisées excède un certain nombre de trames, la valeur de pitch peut évoluer très vite.
- Règle 2 : Un noyau vocalique est constitué de trames voisées entrecoupées de trous. Ces trous doivent vérifier la condition suivante: la taille d'un trou ne doit pas excéder une taille maximale, qui peut être fonction du locuteur et surtout du vocabulaire (environ 40 trames). La taille du noyau est la somme du nombre de trames voisées et de la taille des trous de ce noyau.
- Règle 3 : le début effectif du noyau vocalique est donné dès que la taille du noyau est suffisamment grande (environ 4 trames).
- Règle 4: la fin du noyau vocalique est déterminée par la dernière trame voisée suivie d'un trou excédant la taille maximale permise pour un trou dans le noyau vocalique.
- On utilise les règles précédentes de la manière exposée ci-dessous, et lorsqu'une valeur de pitch a été calculée.
- Première partie de l'expertise :
- On valide ou non la valeur du pitch calculée, en fonction de la valeur du pitch de la trame précédente et de la dernière valeur non nulle du pitch, et ce en fonction du nombre de trames séparant la trame actuellement traitée et celle du dernier pitch non nul. Ceci correspond à l'application de la règle 1.
- Deuxième partie de l'expertise :
- Cette deuxième partie de l'expertise se décompose suivant différents cas.
- Cas 1 : Première trame voisée :
- - On incrémente la taille possible du noyau, qui vaut donc 1
- - Le début possible du noyau vocalique est donc la trame actuelle
- - La fin possible du noyau vocalique est donc la trame actuelle
- Cas 2 : La trame actuelle est voisée ainsi que la précédente.
- On traite donc un segment voisé.
- - On incrémente le nombre possible de trames voisées du noyau
- - On incrémente la taille possible du noyau
- - La fin possible du noyau peut être la trame actuelle qui est aussi la fin possible du segment. Si la taille du noyau est suffisamment grande (environ quatre trames, comme précisé ci-dessus). Et Si le début effectif du noyau vocalique n'est pas connu. Alors :
- - le début du noyau est la première trame détectée comme voisée.
- Ceci correspond à la mise en oeuvre de la règle 3.
- Cas 3 : la trame actuelle n'est pas voisée, alors que la trame précédente l'est.
- On est en train de traiter la première trame d'un trou.
- - On incrémente la taille du trou, qui passe à 1
- Cas 4 : La trame actuelle n'est pas voisée et la trame précédente non plus.
- On est en train de traiter un trou.
-
- - On incrémente la taille du trou.
- Si la taille du trou excède la taille maximale autorisée pour un trou du noyau vocalique,
- Si le début effectif de voisement est connu,
- la fin du noyau vocalique est la dernière trame voisée déterminée avant ce trou. On arrête l'expertise et on réinitialise toutes les données pour le traitement de la prochaine élocution. (cf règle 4)
- Si le début effectif de parole n'est toujours pas connu,
- On continue l'expertise sur les trames suivantes après réinitialisation de tous les paramètres utilisés, car ceux qui ont été actualisés précédemment ne sont pas valides.
- Sinon, ce trou fait peut-être partie du noyau vocalique et on ne peut pas encore prendre de décision définitive.
- Cas 5 : La trame actuelle est voisée et la précédente ne l'est pas.
- On vient de terminer un trou, et on commence un nouveau segment voisé.
- - On incrémente le nombre de trames voisées du noyau.
- - On incrémente la taille du noyau.
- - On ajoute à la taille actuelle du noyau la taille de ce trou.
- - On réinitialise la taille du trou, pour traitement des prochaines trames non voisées.
- Si le début effectif du voisement n'est pas encore connu, Et Si la taille du noyau est désormais suffisante(Règle 3), Alors :
- - le début du voisement est le début du segment voisé précédant le trou que l'on vient de terminer. Sinon, ce trou ne peut pas faire partie du noyau vocalique :
- Si le début effectif du voisement est connu,
-
- - la fin du noyau vocalique est la dernière trame voisée déterminée avant ce trou. On arrête l'expertise et on réinitialise toutes les données pour le traitement de la prochaine élocution. (cf règle 4).
- Si le début effectif de voisement n'est toujours pas connu,
-
- - On continue l'expertise sur les trames suivantes après réinitialisation de tous les paramètres utilisés, car ceux qui ont été actualisés précédemment ne sont pas valides.
- Cette procédure est utilisée à chaque trame, et après calcul du pitch associé à cette trame.
- Expertise de détection de la parole non voisée.
- On utilise ici un processus connu en soi de détection de parole non voisée.
- Cette détection élémentaire de voisement se fait sans utiliser des résultats portant sur les trames précédentes, et sans présager du résultat portant sur les trames futures.
- Des signaux de parole non voisés placés en début ou en fin d'élocution, peuvent être constitués :
- - d'un seul segment fricatif comme dans "chaff'
- - d'un segment fricatif suivi d'un segment occlusif comme dans "stop"
- - d'un seul segment occlusif comme dans "parole"
- Il y a donc possibilité de trous dans l'ensemble de trames non voisées.
- De plus, de tels blocs fricatifs ne doivent pas être trop grands. Aussi, une expertise intervenant après la détection de ces sons est-elle nécessaire.
- Dans la suite, par abus de langage, le terme fricatif se rapportera tout aussi bien à des fricatives non voisées qu'à des plosives non voisées.
- Règles générales de l'expertise.
- L'expertise exposée ici est similaire à celle décrite ci-dessus dans le cas du voisement. Les différences tiennent essentiellement dans la prise en compte des paramètres nouveaux que sont la distance entre le noyau vocalique et le bloc fricatif, et la taille du bloc fricatif.
- Règle 1 : la distance entre le noyau vocalique et la première trame fricative détectée ne doit pas être trop grande (environ 15 trames maximum) .
- Règle 2 : la taille d'un bloc fricatif ne doit pas être trop grande. Ceci signifie de manière équivalente, que la distance entre le noyau vocalique et la dernière trame détectée comme fricative ne doit pas être trop grande (environ 10 trames maximum).
- Règle 3 la taille d'un trou dans un bloc fricatif ne doit pas excéder une taille maximale (environ 15 trames maximum). La taille totale du noyau est la somme du nombre de trames voisées et de la taille des trous dans ce noyau.
- Règle 4: le début effectif du bloc fricatif est déterminé dès que la taille d'un segment est devenue suffisante, et que la distance entre le noyau vocalique et la première trame de ce segment fricatif traité n'est pas trop grande, conformément à la règle 1. Le début effectif du bloc fricatif correspond à la première trame de ce segment.
- Règle 5 : la fin du bloc fricatif est déterminée par la dernière trame du bloc fricatif suivie d'un trou excédant la taille maximale autorisée pour un trou dans le noyau vocalique, et lorsque la taille du bloc fricatif ainsi déterminé n'est pas trop grande conformément à la règle 2.
- Cette expertise est utilisée pour détecter les blocs fricatifs précédant le noyau vocalique ou le suivant. Le repère choisi dans cette expertise est donc le noyau vocalique.
- Dans le cas de la détection d'un bloc fricatif précédant le noyau vocalique, le traitement se fait en partant de la première trame de voisement, donc en "remontant" dans le temps. Aussi, lorsque l'on dit qu'une trame i suit une trame j (précédemment traitée), il faut entendre par là : vis-à-vis de cette première trame du noyau vocalique. Dans la réalité, la trame j est chronologiquement postérieure à la trame i. Ce que l'on dénomme début du bloc fricatif dans l'expertise décrite ci-après, est en fait, chronologiquement, la fin de ce bloc, et ce que l'on appelle fin du bloc fricatif, est en fait le début chronologique de ce bloc. La distance entre noyau vocalique et trame détectée comme fricative est la distance entre la première trame du bloc voisé et cette trame de fricative.
- Dans le cas de la détection d'un bloc fricatif situé après le noyau vocalique, le traitement se fait après la dernière trame voisée, et suit donc l'ordre chronologique naturel, et les termes de l'expertise sont parfaitement adéquats.
- Cas 1 : Tant qu'il n'y a pas de détection de fricative, on est dans un trou qui suit le noyau vocalique et précède le bloc fricatif.
- - On incrémente la distance entre le segment voisé et le bloc fricatif. Cette distance ainsi calculée est un minorant de la distance entre le bloc fricatif et le noyau vocalique. Cette distance sera figée dès que la première trame de fricative sera détectée.
- Cas 2 : Première détection de fricative, On commence à traiter un segment fricatif.
- - On initialise la taille du bloc fricatif à 1.
- - On fige la distance entre le bloc voisé et le bloc fricatif.
- Si la distance entre le noyau vocalique et le bloc fricatif n'est pas trop grande (conformément à la règle 2).
- Alors :
- - Le début possible du bloc fricatif peut être la trame actuelle.
- - La fin possible du bloc fricatif peut être la trame actuelle. Si la taille du bloc fricatif est suffisamment grande Et Si le début effectif du bloc fricatif n'est pas encore connu, alors :
- - le début du noyau peut être confirmé.
- On notera que ce Si (dans "Si la taille du bloc fricatif est suffisamment grande") est inutile si la taille minimale pour un bloc fricatif est supérieure à une trame, mais lorsqu'on cherche à détecter des occlusives en milieu bruité, celles-ci peuvent n'apparaître que sur la durée d'une seule trame. Il faut donc prendre alors la taille minimale d'un bloc fricatif égale à 1, et conserver cette condition.
- Si la distance entre le noyau vocalique et le bloc fricatif est trop grande (cf règle 2).
- Il n' y pas de bloc fricatif acceptable.
- - On réinitialise pour le traitement de la prochaine élocution.
- - On sort du traitement.
- Comme le test sur la distance entre noyau vocalique et bloc fricatif est réalisé dès la première détection de fricative, il ne sera pas renouvelé dans les cas suivants, d'autant plus que si cette distance est ici trop grande, la procédure est arrêtée pour cette élocution.
- Cas 3 : La trame actuelle et la précédente sont toutes les deux des trames de fricatives.
- On est en train de traiter une trame qui se situe en plein dans un segment fricatif acceptable (situé à une distance correcte du noyau vocalique conformément à la règle 1).
- - La fin possible du bloc fricatif est la trame actuelle.
- - On incrémente la taille du bloc fricatif.
- Si la taille du bloc fricatif est suffisamment grande (cf règle 4).
- Et Si la taille de ce bloc n'est pas trop grande (cf règle 2).
- Et Si le début effectif du bloc fricatif n'est pas encore connu, alors :
- - le début du noyau peut être confirmé comme étant le début de ce segment fricatif. Cas 4: La trame actuelle n'est pas une fricative contrairement à la trame précédente. On est en train de traiter la première trame d'un trou situé à l'intérieur du bloc fricatif.
- - On incrémente la taille totale du trou (qui devient égale à 1). Cas 5 : Ni la trame actuelle ni la précédente ne sont des trames de fricatives. On est en train de traiter une trame située en plein dans un trou du bloc fricatif.
- - On incrémente la taille totale du trou.
- Si la taille actuelle du bloc fricatif augmentée de la taille du trou est supérieure à la taille maximale autorisée pour un bloc fricatif (règle 2).
- Ou Si la taille du trou est trop grande.
- Si le début du bloc fricatif est connu,
- alors :
- - La fin du bloc fricatif est la dernière trame détectée comme fricative.
- - On réinitialise toutes les données de manière à traiter la prochaine élocution.
- Sinon :
- - on réinitialise toutes les données, même celles qui ont été précédemment actualisées, car elles ne sont plus valides. On traite alors la prochaine trame.
- Sinon, ce trou fait peut-être partie du bloc fricatif et on ne peut pas encore prendre de décision définitive. Cas 6 : La trame actuelle est une trame de fricative contrairement à la trame précédente. On traite la première trame d'un segment fricatif situé après un trou.
- - On incrémente la taille du bloc fricatif.
- Si la taille actuelle du bloc fricatif augmentée de la taille du trou précédemment détecté est supérieure à la taille maximale autorisée pour un bloc fricatif, Ou Si la taille du trou est trop grande,
- alors : Si le début du bloc fricatif est connu, alors :
- - La fin du bloc fricatif est alors la dernière trame détectée comme fricative.
- - On réinitialise toutes les données de manière à traiter la prochaine élocution. Sinon,
- - On réinitialise toutes les données, même celles qui ont été précédemment actualisées, car elles ne sont pas valides. On traite alors la prochaine trame.
- Sinon, (le trou fait partie du segment fricatif).
- - La taille du bloc fricatif est augmentée de la taille du trou
- - La taille du trou est réinitialisée à O Si la taille du bloc fricatif est suffisamment grande Et Si cette taille n'est pas trop grande Et Si le début effectif du bloc fricatif n'est pas connu
- Alors :
- - Le début du noyau peut être confirmé.
- Simplification dans le cas d'un milieu peu bruité.
- Dans le cas où l'utilisateur estime que le milieu est insuffisamment bruité pour nécessiter les traitements sophistiqués précédents, il est possible, non seulement de simplifier l'expertise présentée ci-dessus, mais même de l'éliminer. Dans ce cas, la détection de parole se réduira à une simple détection du noyau vocalique auquel on attache un intervalle de confiance exprimé en nombre de trames, ce qui se révèle suffisant pour améliorer les performances d'un algorithme de reconnaissance vocale. Il est ainsi possible de débuter la reconnaissance une dizaine, voire une quinzaine de trames avant le début du noyau vocalique, et de l'achever, une dizaine, voire une quinzaine de trames après le noyau vocalique.
- Algorithmes de Traitement du Signal.
- Les procédures et méthodes de calcul décrits ci-après sont les constituants utilisés par les algorithmes d'expertises et de gestion. De telles fonctions sont avantageusement implantées sur un processeur de signaux et le langage utilisé est de préférence l'Assembleur.
- Pour la détection de voisement en milieu peu bruité, une solution intéressante est le seuillage de l'A.M.D.F. (Average Magnitude Difference Function) dont la description peut être trouvée par exemple dans l'ouvrage "Traitement de la parole" de R. BOITE/M. KUNT paru aux éditions Presses Polytechniques Romandes.
- L'AMDF est la fonction D(k) = En 1 x(n+k) - x(n) 1. Cette fonction est bornée par la fonction de corrélation, selon :
- D(k) ≦ 2(Γx(0) - Γx(k))½. Cette fonction présente donc des "pics" vers le bas, et doit donc être seuillée comme la fonction de corrélation.
- D'autres méthodes basées sur le calcul du spectre du signal sont envisageables, pour des résultats tout aussi acceptables (article "traitement de la parole" précité). Toutefois, il est intéressant d'utiliser la fonction AMDF, pour de simples questions de coûts de calcul.
- En milieu bruité, la fonction AMDF est une distance entre le signal et sa forme retardée. Cependant, cette distance est une distance qui n'admet pas de produit scalaire associé, et qui ne permet donc pas d'introduire la notion de projection orthogonale. Or, dans un milieu bruité, la projection orthogonale du bruit peut être nulle, si l'axe de projection est bien choisi. L'AMDF n'est donc pas une solution adéquate en milieu bruité.
- Le procédé de l'invention est alors basé sur la corrélation, car la corrélation est un produit scalaire et effectue une projection orthogonale du signal sur sa forme retardée. Cette méthode est, par là-même, plus robuste au bruit que d'autres techniques, telles l'AMDF. En effet, supposons que le signal observé soit x(n) = s(n) + b(n) où b(n) est un bruit blanc indépendant du signal utile s(n). La fonction de corrélation est par définition :
- rx(k) = E[x(n)x(n-k)], donc rx(k) = E[s(n)s(n-k)] + E[b(n)b(n-k)] = rs(k) + rb(k) Comme le bruit est blanc : rx(O) = rs(O) + rb(O) et rx(k) = rs(k) pour k ≠0 .
- La blancheur du bruit en pratique n'est pas une hypothèse valide. Cependant, le résultat reste une bonne approximation dès que la fonction de corrélation du bruit décroît rapidement, et pour k suffisamment grand, comme dans le cas d'un bruit rose (bruit blanc filtré par un passe-bande), où la fonction de corrélation est un sinus cardinal, donc pratiquement nulle dès que k est suffisamment grand.
- On va décrire maintenant une procédure de calcul de pitch et de détection de pitch applicable aux milieux bruités comme aux milieux peu bruités.
- Soit x(n) le signal traité où n e { 0, ..., N-1 }.
- Dans le cas de l'AMDF, r(k) = D(k) = En |x(n+k) - x(n).
- Dans le cas de la corrélation, l'espérance mathématique permettant d'accéder à la fonction de corrélation ne peut qu'être estimée, de sorte que la fonction r(k) est : r(k) = K Σ0≦n≦N-1 x(n)x(n-k) où K est une constante de calibration.
- Dans les deux cas, on obtient théoriquement la valeur du pitch en procédant comme suit : r(k) est maximale en k = 0. Si le second maximum de r(k) est obtenu en k = ko, alors la valeur du voisement est Fo = Fe/k0 où Fe est la fréquence d'échantillonnage.
- Cependant, cette description théorique doit être révisée en pratique.
- En effet, si le signal n'est connu que sur les échantillons 0 à N-1, alors x(n-k) est pris nul tant que n n'est pas supérieur à k. Il n'y aura donc pas le même nombre de points de calcul d'une valeur k à l'autre. Par exemple, si la fourchette du pitch est prise égale à [100 Hz, 333 Hz], et ce, pour une fréquence d'échantillonnage de 10 KHz, l'indice k1 correspondant à 100 Hz vaut:
- k1 = Fe/F0 = 10000/100 = 100 et celui correspondant à 333 Hz vaut k2 = Fe/F0 = 10000/333 = 30.
- Le calcul du pitch pour cette fourchette se fera donc de k = 30 à k = 100.
- Si on dispose par exemple de 256 échantillons (2 trames de 12,8 ms échantillonnées à 10 KHz), le calcul de r(30) se fait de n = 30 à n = 128, soit sur 99 points et celui de r(100) de n = 100 à 128, soit sur 29 points.
- Les calculs ne sont donc pas homogènes entre eux et n'ont pas la même validité.
- Pour que le calcul soit correct, il faut que la fenêtre d'observation soit toujours la même quel que soit k. De sorte que si n-k est inférieure à 0, il faut avoir conservé en mémoire les valeurs passées du signal x(n), de manière à calculer la fonction r(k)sur autant de points, quel que soit k. La valeur de la constante K n'importe plus.
- Ceci n'est préjudiciable au calcul du pitch que sur la première trame réellement voisée, puisque, dans ce cas, les échantillons utilisés pour le calcul sont issus d'une trame non voisée, et ne sont donc pas représentatifs du signal à traiter. Cependant, dès la troisième trame voisée consécutive, lorsqu'on travaille, par exemple, par trames de 128 points échantillonnés à 10 KHz, le calcul du pitch sera valide. Ceci suppose, de manière générale, qu'un voisement dure au minimum 3x12,8 ms, ce qui est une hypothèse réaliste. Cette hypothèse devra être prise en compte lors de l'expertise, et la durée minimale pour valider un segment voisé sera de 3x12,8 ms dans cette même expertise.
- Cette fonction r(k) étant calculée, il s'agit ensuite de la seuiller. Le seuil est choisi expérimentalement, selon la dynamique des signaux traités. Ainsi, dans un exemple d'application, où la quantification se fait sur 16 bits, où la dynamique des échantillons n'excède pas ± 10000, et où les calculs se font pour N = 128 (Fréquence d'échantillonnage de 10 KHz), on a choisi Seuil = 750000. Mais rappelons que ces valeurs ne sont données qu'à titre d'exemple pour des applications particulières, et doivent être modifiées pour d'autres applications. En tout cas, cela ne change rien à la méthodologie décrite ci-dessus.
- On va maintenant exposer le procédé de détection des trames de bruit.
- En-dehors du noyau vocalique, les trames de signal que l'on peut rencontrer, sont de trois types :
- 1) bruit seul
- 2) bruit + fricative non voisée
- 3) bruit + respiration.
- L'algorithme de détection vise à détecter le début et la fin de parole à partir d'une version blanchie du signal, tandis que l'algorithme de débruitage nécessite la connaissance du spectre moyen de bruit. Pour construire les modèles de bruit qui vont permettre de blanchir le signal de parole en vue de la détection des sons non voisés comme décrit ci-dessous, et pour débruiter le signal de parole, il est évident qu'il faut détecter les trames de bruit, et les confirmer en tant que telles. Cette recherche des trames de bruit se fait parmi un nombre de trames Ni défini par l'utilisateur une fois pour toutes pour son application (par exemple pour Ni = 40), ces Ni trames étant situées avant le noyau vocalique.
- Rappelons que cet algorithme permet la mise en oeuvre de modèles de bruit, et n'est donc pas utilisé lorsque l'utilisateur juge le niveau de bruit insuffisant.
- On va d'abord définir les variables aléatoires gaussiennes "positives":
- Une variable aléatoire X sera dite positive lorsque Pr{ X < 0 } «1 .
- Soit Xo la variable centrée normalisée associée à X. On a :
- Pr { X < 0 } = Pr { Xo <-m/σ} où m = E[X] et σ2 = E[(X-m)2].
- Dès que m/σ est suffisamment grand, X peut être considérée comme positive.
- Lorsque X est gaussienne, on désigne par F(x) la fonction de répartition de la loi normale, et on a : Pr {X < 0 } = F(-m/σ) pour X ∈ N(m,σ2)
- Une propriété essentielle immédiate est que la somme X de N variables gaussiennes positives indépendantes Xi ∈ N (mi ; σi 2) reste une variable gaussienne positive :

Résultat fondamental : - Si X = X1/X2 où X1 et X2 sont toutes deux des variables aléatoires gaussiennes, indépendantes, telles que X1 ∈ N(m1 ; σ1 2) et X2 ∈ N( m2 ; σ2 2), on pose m = m1/m2, α1 = m1/σ1, a2 = m2/σ2.
- Lorsque α1 et α2 sont suffisamment grands pour pouvoir supposer X1 et X2 positives, la densité de probabilité fx(x) de X = X1/X2 peut alors être approchée par :

- U(x) = 1 si x ≦ 0 et U(x)=0 si x < 0
- Dans toute la suite, on posera :

de sorte que : fx(x) = f(x,m |α1,α2).U(x) Soit
- Pr {X < x} = P(x,m |α1,α2) f(x,y |α,β) = ∂P(x,y |α,β)/∂x et f(x,y |α1,α2) = ∂P(x,m |α1,α2)/∂x Cas particulier : a = β. On posera: fα(x,y) = f(x,y |α,β ), hα(x,y) = h(x,y |α,β) et Pα(x,y) = P(x,y |α,β)
- On va décrire ci-dessous quelques modèles de base de variables gaussiennes "positives" utilisables dans la suite.
- (1) Signal à énergie déterministe : Soient les échantillons x(0),...x(N-1) d'un signal quelconque, dont l'énergie est déterministe et constante, ou approximée par une énergie déterministe ou constante. On a donc U = Σ0≦n≦N-1x(n)2∈N(Nµ, 0) où µ = (1/N)Σ0≦n≦N-1x(n)2
- Prenons comme exemple le signal x(n) =Acos(n+θ) où θ est équiréparti entre [0,2π]. Pour N suffisamment grand, on a :
- (1/N) E0≦n≦N-1x(n)2# E[x(n)2] =A2/2. Pour N assez grand, U peut être assimilé à NA2/2 et donc à une énergie constante.
- (2) Processus Blanc Gaussien : Soit un processus blanc et gaussien x(n) tel que σx 2 = E[x(n)2] . Pour N suffisamment grand, U = Σ0≦n≦N-1x(n)2 ∈ N(Nσx 2 ; 2Nσx 4). Le paramètre a est a = (N/2)1/2
- (3) Processus Gaussien Bande Etroite : Le bruit x(n) est issu de l'échantillonnage du processus x(t), lui-même issu du filtrage d'un bruit blanc gaussien b(t) par un filtre passe bande h(t) : x(t) = (h*b)(t), en supposant que la fonction de transfert du filtre h(t) est :
- H(f) = U[-(f0-B/2,-f0+B/2](f) + U[f0-B/2,f0+B/2](f), où U désigne la fonction caractéristique de l'intervalle en indice et fo la fréquence centrale du filtre.
- On a donc U ∈ N( Nσx 2,2σx 4Σ0≦i≦N-1,0≦j≦N-1gf0,B,Te(i-j)2) avec gf0,B,Te(k) = cos(2πtkf0Te)sinc(πkBTe) Le paramètre a et a = N/[2Σ0≦i≦N-1,0≦j≦N-1gf0,B,Te(i-j)2]½ - Sous-échantillonnage d'un processus gaussien : Ce modèle est plus pratique que théorique. Si la fonction de corrélation est inconnue, on sait cependant que : lim k→+∞ Γx(k) = 0. Donc, pour k assez grand tel que k > ko, la fonction de corrélation tend vers 0. Aussi, au lieu de traiter la suite d'échantillons x(0)...x(N-1 ), peut-on traiter la sous-suite x(0), x(ko),x(2ko),..., et l'énergie associée à cette suite reste une variable aléatoire positive gaussienne, à condition qu'il reste dans cette sous-suite suffisamment de points pour pouvoir appliquer les approximations dues au théorème central-limite. Compatibilité entre énergies.
- Soient Ci = N(m1,σ2) et C2 = N(m2,σ2 2) On pose : m = m1/m2, α1 = m1/σ1 et α2 = m2/σ2. α1 et a2 sont suffisamment grands pour que les variables aléatoires de Ci et C2 puissent être considérées comme des variables aléatoires positives.
- Soit (U,V) où (U,V) appartient à (C1UC2)X(C1UC2).
- Comme précédemment, U et V sont supposées indépendantes.
- On pose U ≡ V ⇔ (U,V) ∈ (C1XC1)U(C2UC2).
- Soit (u,v) une valeur du couple (U,V). Si x = u/v, x est une valeur de la variable aléatoire X = U/V.
- Soit s >1. 1/s < x <s ⇔ On décide que U ≡ V est vrai, ce qui sera la décision D = D1 x < 1/s ou x > s ⇔ On décide que U ≡ V est faux, ce qui sera la décision D = D2 Cette règle de décision est donc associée à 2 hypothèses :
- H1⇔U≡V est vrai, H2⇔U≡V est faux. On posera 1 = [1/s,s].
- La règle de détection s'exprime encore selon : x ∈ I⇔D=D1, x ∈ R-I ⇔ D=D2 On dira que u et v sont compatibles lorsque la décision D = D1 sera prise.
- Cette règle de décision admet une probabilité de décision correcte, dont l'expression dépendra en fait de la valeur des probabilités Pr{H1} et Pr{H2}. Or, ces probabilités ne sont en général pas connues en pratique.
- On préfère alors une approche du type Neyman-Pearson, puisque la règle de décision se réduit à deux hypothèses, en cherchant à assurer une certaine valeur fixée a priori pour la probabilité de fausse alarme qui est :

- Le choix des modèles des signaux et des bruits détermine α1 et a2. Nous allons voir qu'alors m apparaît comme homogène à un rapport signal sur bruit qui sera fixé de manière heuristique. Le seuil est alors fixé de manière à assurer une certaine valeur de Pfa . Cas particulier : α1 = α2 = α. Il vient alors : Pfa = Pα(s,m) - Pα(1/s,m) Compatibilité d'un ensemble de valeurs :
- Soit { u1,..., un} un ensemble de valeurs de variables aléatoires gaussiennes positives. On dira que ces valeurs sont compatibles entre elles, si et seulement si les ui sont compatibles 2 à 2.
- Modèles du signal et du bruit utilisés par le procédé de l'invention.
- Afin d'appliquer les procédures correspondant aux rappels théoriques précédents, il faut fixer un modèle du bruit et du signal. Nous utiliserons l'exemple suivant. Ce modèle est régi par les hypothèses suivantes : Hypothèse 1 : Nous supposons ne pas connaître le signal utile dans sa forme, mais nous ferons l'hypothèse suivante : V la valeur s(0),...,s(N-1) de s(n), l'énergie S = (1/N) Σ0≦n≦N-1 s(n)2 est bornée par µs 2, et ce, dès que N est suffisamment grand, de sorte que :


- Si on considère N échantillons x(n) de ce bruit, et qu'on pose : gfO,B,Te(k) = cos(2πkf0Te)sinc(πkBTe), on a:

-

- Ce coefficient de corrélation n'est que l'expression dans le domaine temporel du coefficient de corrélation spatial défini par :
- E[s(n)x(n)]/(E[s(n)2]E[x(n)2])1/2 lorsque les processus sont ergodiques.
- Soit u(n) = s(n) + x(n) le signal total, et U = Σ0≦n≦N-1-u(n)2.
- On peut alors approximer U par : U = Σ0≦n≦N-1s(n)2 + Σ0≦n≦N-1x(n)2
- Comme on a : Σ0≦n≦N-1s(n)2 ≧ µs 2,
- on aura : U ≧ Nµs 2 + Σ0≦n≦N-1x(n)2.
- Hypothèse 4 : Comme nous supposons que le signal présente une énergie moyenne bornée, nous supposerons qu'un algorithme capable de détecter une énergie µs 2, sera capable de détecter tout signal d'énergie supérieure. Compte tenu des hypothèses précédentes, on définit la classe Ci comme étant la classe des énergies lorsque le signal utile est présent. Selon l'hypothèse 3, U ≧ Nµs 2 + Σ0≦n≦N-1x(n)2, et selon l'hypothèse 4, si on détecte l'énergie Nµs 2 + Σ0≦n≦N-1x(n)2, on saura détecter aussi l'énergie totale U.
- D'après l'hypothèse 2,
-









- Compte tenu des modèles précédents, et le calcul du seuil ayant été fait, on applique alors l'algorithme suivant de détection et de confirmation de bruit, basé essentiellement sur la notion de compatibilité, telle que décrite ci-dessus.
- La recherche et la confirmation des trames de bruit se fait parmi un nombre de trames Ni défini par l'utilisateur une fois pour toute pour son application (par exemple Ni = 40), ces trames étant situées avant le noyau vocalique. On fait l'hypothèse suivante: l'énergie des trames de bruit seul est en moyenne inférieure à celle des trames de bruit+respiration et de bruit signal. La trame présentant l'énergie minimale parmi les Ni trames, est donc supposée n'être constituée que de bruit. On cherche alors toutes les trames compatibles avec cette trame au sens rappelé ci-dessus, en utilisant les modèles précités.
- L'algorithme de détection de bruit va chercher, parmi un ensemble de trames T1,...,Tn, celles qui peuvent être considérées comme du bruit.
- Soient E(T1),...,E(Tn), les énergies de ces trames, calculées sous la forme : E(Ti)= Σ0≦n≦N-1 u(n)2 où u(n) sont les N échantillons constituant la trame T.
- On fait l'hypothèse suivante : la trame présentant l'énergie la plus faible est une trame de bruit. Soit To cette trame.
- L'algorithme se déroule comme suit :
- L'ensemble des trames de bruit est initialisé: Bruit={To}
- Pour i décrivant { E(T1),...,E(Tn)} - {E(Ti0)} Faire Si E(T) est compatible avec chaque élément de Bruit:
- Bruit = Bruit U {E(Ti)} Fin pour Modèle Autorégressif du bruit.
- Puisque l'algorithme de confirmation de bruit fournit un certain nombre de trames qui peuvent être considérées comme du bruit avec une très forte probabilité, on cherche à construire, à partir de la donnée des échantillons temporels, un modèle autorégressif du bruit.
- Si x(n) désigne les échantillons de bruit, on modélise x(n) sous la forme: x(n) = Σ1≦ip P ai x(n-i) + b(n) , où p est l'ordre du modèle, les ai, les coefficients du modèle à déterminer et b(n) le bruit de modélisation, supposé blanc et gaussien si on suit une approche par maximum de vraisemblance.
- Ce type de modélisation est largement décrit dans la littérature notamment dans "Spectrum Analysis A Modern Perspective", de S.M. KAY et S.L. MARPLE Jr, paru dans Proceedings of the IEEE, Vol. 69, N° 11, novembre 1981..
- Quant aux algorithmes de calcul du modèle, de nombreuses méthodes sont disponibles (Burg, Levinson-Durbin, Kalman, Fast Kalman...).
- On utilise de préférence les méthodes du type Kalman et Fast Kalman, voir articles "Le Filtrage Adaptatif Transverse" de O.MACCHI/ M.BELLANGER paru dans la revue Traitement du Signal, Vol. 5, N° 3, 1988 et "Analyse des signaux et filtrage numérique adaptatif" de M.BELLANGER paru dans la Collection CNET-ENST, MASSON, qui présentent de très bonnes performances temps réel. Mais ce choix n'est pas le seul possible. L'ordre du filtre est par exemple choisi égal à 12, sans que cette valeur soit limitative.
- Filtrage réjecteur
- Soit u(n) = s(n) + x(n) le signal total, composé du signal de parole s(n) et du bruit x(n) .
- Soit le filtre H(z) = 1 - Σ1≦i≦p aiz-i.
- Appliqué au signal U(z),on obtient H(z)U(z) = H(z)S(z) + H(z)X(z).
- Or : H(z)X(z) = B(z) = > H(z)U(z) = H(z)S(z) + B(z)
- Le filtre réjecteur H(z) blanchit le signal, de sorte que le signal en sortie de ce filtre est un signal de parole (filtré donc déformé), additionné d'un bruit généralement blanc et gaussien.
- Le signal obtenu est en fait impropre à la reconnaissance, car le filtre réjecteur déforme le signal de parole originel.
- Cependant, le signal obtenu étant perturbé par un bruit pratiquement blanc et gaussien, il s'ensuit que ce signal est très intéressant pour effectuer une détection du signal s(n) selon la théorie exposée ci-dessous, selon laquelle on garde le signal large bande obtenu, ou on le filtre préalablement dans la bande des fricatives, comme décrit ci-dessous (cf "détection de fricatives").
- C'est pour cette raison que l'on utilise ce filtrage réjecteur après modélisation auto-régressive du bruit. Spectre moyen de bruit.
- Comme l'on dispose d'un certain nombre de trames confirmées comme étant des trames de bruit, on peut alors calculer un spectre moyen de ce bruit, de manière à implanter un filtrage spectral, du type soustraction spectrale ou filtrage de WIENER.
- On choisit par exemple le filtrage de WIENER. Aussi, a-t-on besoin de calculer Cxx(f) = E[|X(f)|2] qui représente le spectre moyen de bruit. Comme les calculs sont numériques, on n'a accès qu'à des FFT de signaux numériques pondérés par une fenêtre de pondération. De plus, la moyenne spatiale ne peut qu'être approximée.
- Soient X1(n)...,XM(n) les M+1 FFT des M trames de bruit confirmées comme telles, ces FFT étant obtenues par pondération du signal temporel initial par une fenêtre d'apodisation adéquate.
- Cxx(f) = E[|X(f)2] est approximé par :

- Les performances de cet estimateur sont données par exemple dans le livre "Digital signal processing" de L.RABINER/C.M.RADER paru chez IEEE Press.
- Pour ce qui est du filtre de Wiener, on rappelle ci-dessous quelques résultats classiques, explicités notamment dans l'ouvrage "Speech Enhancement" de J.S. LIM paru aux Editions Prentice-Hall Signal Processing Series.
- Soit u(t) = s(t) + x(t) le signal total observé, où s(t) désigne le signal utile (de parole) et x(t) le bruit. Dans le domaine fréquentiel, on obtient : U(f) = S(f) + X(f), avec des notations évidentes.
- On cherche alors le filtre H(f), de sorte que le signal ^S(f) = H(f)U(f) soit le plus proche de S(f) au sens de la norme L2. On cherche donc H(f) minimisant : E[|S(f)-^S(f)|2].
- On démontre alors que: H(f) = 1 - (CXX(f)/CUU(f)) où Cxx(f) = E[|X(f)2] et Cuu(f) = E[|U(f)2|].
- Ce type de filtre, parce que son expression est directement fréquentielle, est particulièrement intéressant à appliquer dès que la paramétrisation est basée sur le calcul du spectre. Implémentation par corrélogramme lissé.
- En pratique, Cxx et Cuu ne sont pas accessibles. On ne peut que les estimer. Une procédure d'estimation de Cxx(f) a été décrite ci-dessus.
- Cuu est le spectre moyen du signal total u(n) dont l'on ne dispose que sur une seule et unique trame. De plus, cette trame doit être paramétrisée de manière à pouvoir intervenir dans le processus de reconnaissance. Il n'est donc pas question d'effectuer une moyenne quelconque du signal u(n) d'autant plus que le signal de parole est un signal particulièrement non-stationnaire.
- Il faut donc construire, à partir de la donnée de u(n), une estimation de Cuu(n). On utilise alors le corrélogramme lissé.
- On estime alors Cuu(n) par : ^CUU(k) = Σ0 ≦ n ≦ N - 1 F(k-n) |X(n)|2
- où F est une fenêtre de lissage construite comme suit, et N le nombre de points permettant le calcul des FFT : N = 256 points par exemple..
- On choisit une fenêtre de lissage dans le domaine temporel :
- f(n) = ao + a1cos(2πn/N) + a2cos(4πn/N). Ces fenêtres sont largement décrites dans l'article précité: "On the Use of Windows for Hamming Analysis with the Discrete Fourier Transform de F.J.HARRIS paru dans Proceedings of the IEEE, Vol.66, N° 1, January 1978.
- La fonction F(k) est alors simplement la Transformée de Fourier Discrète de f(n).
- ^CUU(k) = Σ 0≦n≦N-1 F(k-n) |X(n)|2 apparaît comme une convolution discrète entre F(k) et V(k) = |X(k)2|, de sorte que ^CUU = F*V
- Soit ^cUU la FFT-1 de ^CUU. ^cUU(k) = f(k)v(k) où v(k) est la FFT-1 de V(k).
- On calcule donc ^CUU(k) selon l'algorithme dit de corrélogramme lissé suivant :
- (1) Calcul de v(k) par FFT inverse de V(n) = |X(n) 2
- (2) Calcul du produit f.v
- (3) FFT directe du produit f.v qui aboutit à ^CUU
- Plutôt que d'appliquer le même estimateur pour le bruit et le signal total, le procédé de l'invention applique l'algorithme du corrélogramme lissé précédent au spectre moyen de bruit Mxx(n).
- ^CXX(k) est donc obtenu par :
-

- Le signal débruité a pour spectre : ^S(n) = AH(n)U(n)
- Une FFT-1 peut permettre, éventuellement, de récupérer le signal temporel débruité.
- Le spectre débruité ^S(n) obtenu est le spectre utilisé pour la paramétrisation en vue de la reconnaissance de la trame.
- Pour effectuer la détection des signaux non voisés, on utilise également les procédures décrites ci-dessus, puisque l'on dispose d'énergies représentatives du bruit (voir ci-dessus l'algorithme de détection du bruit). Détection d'activité. Soient Ci = N(m1,σ1 2) et C2 = N(m2,σ2 2).
- Puisqu'on dispose d'un algorithme capable de mettre en évidence des valeurs de variables aléatoires appartenant à la même classe, de la classe C2 (par exemple), et ce, avec une très faible probabilité d'erreur, il devient alors beaucoup plus facile de décider, par observation du couple U/V, si U appartient à la classe Ci ou à la classe C2. Il y a donc deux hypothèses distinctes possibles,
-



- On pose : m = m1/m2, α1 = m1/σ1 et a2 = m2/a2.
- Soit un couple (U,V) de variables aléatoires, où on suppose que V ∈ C2 et U ∈ C1UC2. U et V sont supposées indépendantes. En observant la variable X = U/V, on cherche à prendre une décision entre les deux suivantes possibles: "C1XC2", C2XC2".
- On a donc deux hypothèses:

- Soit p=Pr{U∈C1}.
- La règle de décision s'exprime sous la forme suivante :

- La probabilité de décision correcte Pc(s,m |α1,α2) est alors :


- ∂Pc(s,m |α1,α2)/∂s = 0 ⇔ pf(s,m |α1,α2) - (1-p)f(s,1 α2,α2) = 0
- Approche type Neyman-Pearson
- Dans l'approche précédente, on supposait connaître la probabilité p. Lorsque cette probabilité est inconnue, on peut utiliser une approche type Neyman-Pearson.
- On définit les probabilités de non détection et de fausse alarme :

- Ona:

- On se fixe alors Pfa ou Pnd, pour déterminer la valeur du seuil.
- Afin d'appliquer la détection d'activité telle que décrite ci-dessus au cas de la parole, il est nécessaire d'établir un modèle énergétique des signaux non voisés compatible avec les hypothèses qui président au bon fonctionnement des procédés décrits ci-dessus. On cherche donc un modèle des énergies des fricatives non voisées /F/, /S/, /CH) et des plosives non voisées /P/, /T/, /Q/, qui permettent d'obtenir des énergies dont la loi statistique est approximativement une gaussienne.
- Modèle 1.
- Les sons /F/,/S/,/CH/ se situent spectralement dans une bande de fréquence qui s'étale d'environ 4 KHz à plus de 5KHz. Les sons /P/, /T/, /Q/ en tant que phénomènes courts dans le temps, s'étalent sur une bande plus large. Dans la bande choisie, on suppose que le spectre de ces sons fricatifs est relativement plat, de sorte que le signal fricatif dans cette bande peut se modéliser par un signal bande étroite. Ceci peut être réaliste dans certains cas pratiques sans avoir recours au blanchiment décrit ci-dessus. Cependant, dans la plupart des cas, il est judicieux de travailler sur un signal blanchi de manière à assurer un modèle de bruit à bande étroite convenable.
- En acceptant un tel modèle de bruit à bande étroite, on a donc à traiter le rapport de deux énergies qui peut être traité par les procédés décrits ci-dessus.
- Soient s(n) le signal de parole dans la bande étudiée et x(n) le bruit dans cette même bande. Les signaux s(n) et x(n) sont supposés indépendants.
- La classe Ci correspond à l'énergie du signal total u(n) = s(n) + x(n) observé sur N points, la classe C2 correspond à l'énergie V du bruit seul observé sur M points.
- Les signaux étant gaussiens et indépendants, u(n) est un signal lui-même gaussien, de sorte que :

- V = Σ0≦n≦M-1y(n)2 ∈ N(Mσx 2, 2σx 2Σ0≦i≦M-1,0≦j≦M-1gf0,B(ij)2), où y(n) désigne, on le rappelle, une autre valeur du bruit x(n) sur une tranche temporelle différente de celle où on observe u(n). On peut donc appliquer les résultats théoriques ci-dessus avec :
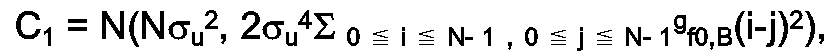




- On remarquera que m = (N/M)(1+r) où r = σx 2/σx 2 désigne finalement le rapport signal sur bruit.
- Pour achever complètement la résolution de ce problème, il faut pouvoir connaître le rapport signal sur bruit r ainsi que la probabilité de présence p du signal utile. Ce qui paraît être ici une limitation est commun aux deux autres modèles traités ci-dessous.
- Modèle 2.
- Comme dans le cas du modèle 1, on cherche à détecter uniquement les fricatives non voisées, donc à détecter un signal dans une bande particulière.
- Ici, le modèle du signal fricatif n'est pas le même que précédemment. On suppose que les fricatives présentent l'énergie minimale µs 2 = E 0≦n≦N-1s(n)2 connue, grâce par exemple à un apprentissage, ou estimée.
- Le son voisé est indépendant du bruit x(n) qui est ici gaussien bande étroite.
- Si y(n), pour n compris entre 0 et M-1, désigne une autre valeur du bruit x(n) sur une tranche temporelle distincte de celle où est observé le signal total u(n) = s(n) + x(n), on aura :
- V = Σ0≦n≦N-1 y(n)2 ∈ N( Mσx 2,2Tr(Cx,M 2)) où Cx,M désigne la matrice de corrélation du M-uplet : t (y(0),...,y(M-1))
- En ce qui concerne l'énergie U = E o ≦n≦N-1 u(n)2 du signal total, celle-ci peut s'exprimer selon :
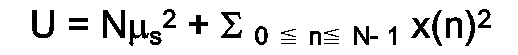
- Ce résultat s'obtient en supposant que l'indépendance entre s(n) et x(n) s'exprime par la décorrélation au sens temporel du terme, c'est-à -dire que l'on peut écrire :

- Comme V'=Σ0≦n≦N-1 x(n)2 ∈ N( Nσx 2, 2Tr(Cx,N2)) où Cx,N désigne la matrice de corrélation du N-uplet : t (x(0),...,x(N-1)), on a alors:

- On peut donc appliquer les résultats théoriques ci-dessus avec :

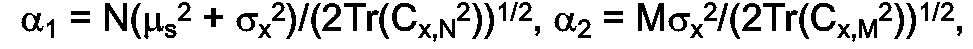
- On remarquera que m = (N/M)(1+r) où r = µs 2/σx 2 désigne finalement le rapport signal sur bruit. La même remarque que celle du Modèle 1, concernant le rapport signal sur bruit r et la probabilité p de présence du signal utile, est valable ici.
- Dans ce modèle, on cherche à effectuer une détection de tous les signaux non voisés, avec une hypothèse bruit blanc gaussien.
- Le modèle signal bande étroite utilisé précédemment, n'est donc plus valable. On ne peut donc que supposer avoir affaire à un signal large bande dont on connaît l'énergie minimale µS 2.
- Il vient donc :



- Pour utiliser ce modèle, le bruit doit être blanc gaussien. Si le bruit d'origine n'est pas blanc, on peut s'approcher de ce modèle en sous-échantillonnant en fait le signal observé, c'est-à-dire en ne considérant qu'un échantillon sur 2, 3, voire plus, suivant la fonction d'autocorrélation du bruit, et en supposant que le signal de parole ainsi sous-échantillonné présente encore une énergie décelable. Mais on peut aussi, et cela est préférable, utiliser cet algorithme sur un signal blanchi par filtre réjecteur, puisqu'alors le bruit résiduel est approximativement blanc et gaussien.
- Les remarques précédentes concernant la valeur a priori du rapport signal à bruit et de la probabilité de présence du signal utile, restent encore et toujours valables.
- Algorithmes de détection des sons non voisés.
- En utilisant les modèles précédents, on expose ci-dessous deux algorithmes de détection des sons non voisés.
- Algorithme 1 :
- Disposant d'énergies représentatives de bruit, on peut moyenner ces énergies de sorte que l'on obtient une énergie de "référence" de bruit. Soir Eo cette énergie. Pour N3 trames T1, ..., Tn qui précèdent la première trame voisée, on procède comme suit :
- Soient E(T1), ..., E(Tn), les énergies de ces trames, calculées sous la forme E(Ti) = Σ0≦n≦N-1u(n)2 où u(n) sont les N échantillons constituant la trame T.
- Pour E(Ti) décrivant {E(T1), ..., E(Tn)}
- Faire
- Si E(Ti) est compatible avec Eo (Décision sur la valeur de E(Ti)/E0).
- Détection sur la trame T.
- Fin pour.
- Algorithme 2 :
- Cet algorithme est une variante du précédent. On utilise pour Eo, soit l'énergie moyenne des trames détectées comme du bruit, soit la valeur de l'énergie la plus faible de toutes les trames détectées comme du bruit.
- Puis on procède comme suit :
- Pour E(Ti) décrivant {E(T1), ..., E(Tn)}.
- Faire
- Si E(Ti) est compatible avec Eo (Décision sur la valeur de E(Ti)/E0).
- Détection sur la trame T.
- Sinon Eo = E(T).
- Fin pour
- Le rapport signal à bruit r peut être estimé ou fixé de manière heuristique, à condition d'effectuer quelques mesures expérimentales préalables, caractéristiques du domaine d'application, de manière à fixer un ordre de grandeur du rapport signal sur bruit que présentent les fricatives dans la bande choisie.
- La probabilité p de présence de la parole non voisée est, elle-aussi, une donnée heuristique, qui module la sélectivité de l'algorithme, au même titre d'ailleurs que le rapport signal à bruit. Cette donnée peut être estimée suivant le vocabulaire utilisé et le nombre de trames sur lequel se fait la recherche de sons non voisés.
- Simplification dans le cas d'un milieu faiblement bruité.
- Dans le cas d'un milieu faiblement bruité, pour lequel aucun modèle de bruit n'a été déterminé, en vertu des simplifications proposées ci-dessus, la théorie rappelée précédemment justifie l'utilisation d'un seuil, qui n'est pas lié de manière bijective au rapport signal à bruit, mais qui sera fixé de manière totalement empirique.
- Une alternative intéressante pour des milieux où le bruit est négligeable, est de se contenter de la détection de voisement, d'éliminer la détection des sons non voisés, et de fixer le début de parole à quelques trames avant le noyau vocalique (environ 15 trames) et la fin de parole à quelques trames après la fin du noyau vocalique (environ 15 trames).
Si le trou que l'on vient de finir peut faire partie du noyau vocalique, (c'est-à-dire si sa taille est inférieure à la taille maximale autorisée pour un trou du noyau selon la règle 2).
Claims (12)
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| FR9212582 | 1992-10-21 | ||
| FR9212582A FR2697101B1 (fr) | 1992-10-21 | 1992-10-21 | Procédé de détection de la parole. |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| EP0594480A1 true EP0594480A1 (fr) | 1994-04-27 |
| EP0594480B1 EP0594480B1 (fr) | 1999-08-18 |
Family
ID=9434731
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| EP93402522A Expired - Lifetime EP0594480B1 (fr) | 1992-10-21 | 1993-10-13 | Procédé de détection de la parole |
Country Status (5)
| Country | Link |
|---|---|
| US (1) | US5572623A (fr) |
| EP (1) | EP0594480B1 (fr) |
| JP (1) | JPH06222789A (fr) |
| DE (1) | DE69326044T2 (fr) |
| FR (1) | FR2697101B1 (fr) |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| EP0718820A3 (fr) * | 1994-12-19 | 1998-06-03 | Matsushita Electric Industrial Co., Ltd. | Dispositif de codage de parole, d'analyse prédictive linéaire et de réduction du bruit |
Families Citing this family (35)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP3522012B2 (ja) * | 1995-08-23 | 2004-04-26 | 沖電気工業株式会社 | コード励振線形予測符号化装置 |
| FR2744277B1 (fr) * | 1996-01-26 | 1998-03-06 | Sextant Avionique | Procede de reconnaissance vocale en ambiance bruitee, et dispositif de mise en oeuvre |
| FR2765715B1 (fr) | 1997-07-04 | 1999-09-17 | Sextant Avionique | Procede de recherche d'un modele de bruit dans des signaux sonores bruites |
| US6711536B2 (en) * | 1998-10-20 | 2004-03-23 | Canon Kabushiki Kaisha | Speech processing apparatus and method |
| JP2002073072A (ja) * | 2000-08-31 | 2002-03-12 | Sony Corp | モデル適応装置およびモデル適応方法、記録媒体、並びにパターン認識装置 |
| US7117145B1 (en) * | 2000-10-19 | 2006-10-03 | Lear Corporation | Adaptive filter for speech enhancement in a noisy environment |
| US7941313B2 (en) * | 2001-05-17 | 2011-05-10 | Qualcomm Incorporated | System and method for transmitting speech activity information ahead of speech features in a distributed voice recognition system |
| US7203643B2 (en) * | 2001-06-14 | 2007-04-10 | Qualcomm Incorporated | Method and apparatus for transmitting speech activity in distributed voice recognition systems |
| KR100463657B1 (ko) * | 2002-11-30 | 2004-12-29 | 삼성전자주식회사 | 음성구간 검출 장치 및 방법 |
| JP4635486B2 (ja) * | 2004-06-29 | 2011-02-23 | ソニー株式会社 | 概念獲得装置及びその方法、並びにロボット装置及びその行動制御方法 |
| KR100640865B1 (ko) | 2004-09-07 | 2006-11-02 | 엘지전자 주식회사 | 음성 품질 향상 방법 및 장치 |
| US8170875B2 (en) | 2005-06-15 | 2012-05-01 | Qnx Software Systems Limited | Speech end-pointer |
| US8311819B2 (en) * | 2005-06-15 | 2012-11-13 | Qnx Software Systems Limited | System for detecting speech with background voice estimates and noise estimates |
| JP4722653B2 (ja) * | 2005-09-29 | 2011-07-13 | 株式会社コナミデジタルエンタテインメント | 音声情報処理装置、音声情報処理方法、ならびに、プログラム |
| WO2007057879A1 (fr) * | 2005-11-17 | 2007-05-24 | Shaul Simhi | Detection d'activite vocale personnalisee |
| US8417185B2 (en) * | 2005-12-16 | 2013-04-09 | Vocollect, Inc. | Wireless headset and method for robust voice data communication |
| FI20051294A0 (fi) * | 2005-12-19 | 2005-12-19 | Noveltech Solutions Oy | Signaalinkäsittely |
| US7773767B2 (en) | 2006-02-06 | 2010-08-10 | Vocollect, Inc. | Headset terminal with rear stability strap |
| US7885419B2 (en) | 2006-02-06 | 2011-02-08 | Vocollect, Inc. | Headset terminal with speech functionality |
| US8775168B2 (en) * | 2006-08-10 | 2014-07-08 | Stmicroelectronics Asia Pacific Pte, Ltd. | Yule walker based low-complexity voice activity detector in noise suppression systems |
| KR100930584B1 (ko) * | 2007-09-19 | 2009-12-09 | 한국전자통신연구원 | 인간 음성의 유성음 특징을 이용한 음성 판별 방법 및 장치 |
| CN101911183A (zh) * | 2008-01-11 | 2010-12-08 | 日本电气株式会社 | 信号分析控制、信号分析、信号控制系统、装置以及程序 |
| JP5668923B2 (ja) * | 2008-03-14 | 2015-02-12 | 日本電気株式会社 | 信号分析制御システム及びその方法と、信号制御装置及びその方法と、プログラム |
| US8509092B2 (en) * | 2008-04-21 | 2013-08-13 | Nec Corporation | System, apparatus, method, and program for signal analysis control and signal control |
| USD605629S1 (en) | 2008-09-29 | 2009-12-08 | Vocollect, Inc. | Headset |
| US8160287B2 (en) | 2009-05-22 | 2012-04-17 | Vocollect, Inc. | Headset with adjustable headband |
| US8438659B2 (en) | 2009-11-05 | 2013-05-07 | Vocollect, Inc. | Portable computing device and headset interface |
| US9280982B1 (en) * | 2011-03-29 | 2016-03-08 | Google Technology Holdings LLC | Nonstationary noise estimator (NNSE) |
| US8838445B1 (en) * | 2011-10-10 | 2014-09-16 | The Boeing Company | Method of removing contamination in acoustic noise measurements |
| US9099098B2 (en) * | 2012-01-20 | 2015-08-04 | Qualcomm Incorporated | Voice activity detection in presence of background noise |
| CN103325388B (zh) * | 2013-05-24 | 2016-05-25 | 广州海格通信集团股份有限公司 | 基于最小能量小波框架的静音检测方法 |
| JP6989003B2 (ja) * | 2018-05-10 | 2022-01-05 | 日本電信電話株式会社 | ピッチ強調装置、その方法、プログラム、および記録媒体 |
| DE102019102414B4 (de) * | 2019-01-31 | 2022-01-20 | Harmann Becker Automotive Systems Gmbh | Verfahren und System zur Detektion von Reibelauten in Sprachsignalen |
| KR102429256B1 (ko) * | 2021-12-31 | 2022-08-04 | 주식회사 에이슬립 | 음향 정보를 통해 사용자의 수면 상태를 분석하기 위한 방법, 컴퓨팅 장치 및 컴퓨터 프로그램 |
| CN116343763B (zh) * | 2023-03-14 | 2025-11-11 | 东南大学 | 一种基于混合特征的音频预警精准辨识方法 |
Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| EP0335521A1 (fr) * | 1988-03-11 | 1989-10-04 | BRITISH TELECOMMUNICATIONS public limited company | Détection de la présence d'un signal de parole |
| US4959865A (en) * | 1987-12-21 | 1990-09-25 | The Dsp Group, Inc. | A method for indicating the presence of speech in an audio signal |
| EP0459363A1 (fr) * | 1990-05-28 | 1991-12-04 | Matsushita Electric Industrial Co., Ltd. | Système de codage du signal de parole |
Family Cites Families (8)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US4972490A (en) * | 1981-04-03 | 1990-11-20 | At&T Bell Laboratories | Distance measurement control of a multiple detector system |
| US4627091A (en) * | 1983-04-01 | 1986-12-02 | Rca Corporation | Low-energy-content voice detection apparatus |
| US4912764A (en) * | 1985-08-28 | 1990-03-27 | American Telephone And Telegraph Company, At&T Bell Laboratories | Digital speech coder with different excitation types |
| US4852181A (en) * | 1985-09-26 | 1989-07-25 | Oki Electric Industry Co., Ltd. | Speech recognition for recognizing the catagory of an input speech pattern |
| US4777649A (en) * | 1985-10-22 | 1988-10-11 | Speech Systems, Inc. | Acoustic feedback control of microphone positioning and speaking volume |
| JP2884163B2 (ja) * | 1987-02-20 | 1999-04-19 | 富士通株式会社 | 符号化伝送装置 |
| US5276765A (en) * | 1988-03-11 | 1994-01-04 | British Telecommunications Public Limited Company | Voice activity detection |
| US5097510A (en) * | 1989-11-07 | 1992-03-17 | Gs Systems, Inc. | Artificial intelligence pattern-recognition-based noise reduction system for speech processing |
-
1992
- 1992-10-21 FR FR9212582A patent/FR2697101B1/fr not_active Expired - Lifetime
-
1993
- 1993-10-13 DE DE69326044T patent/DE69326044T2/de not_active Expired - Fee Related
- 1993-10-13 EP EP93402522A patent/EP0594480B1/fr not_active Expired - Lifetime
- 1993-10-21 US US08/139,740 patent/US5572623A/en not_active Expired - Lifetime
- 1993-10-21 JP JP5285608A patent/JPH06222789A/ja active Pending
Patent Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US4959865A (en) * | 1987-12-21 | 1990-09-25 | The Dsp Group, Inc. | A method for indicating the presence of speech in an audio signal |
| EP0335521A1 (fr) * | 1988-03-11 | 1989-10-04 | BRITISH TELECOMMUNICATIONS public limited company | Détection de la présence d'un signal de parole |
| EP0459363A1 (fr) * | 1990-05-28 | 1991-12-04 | Matsushita Electric Industrial Co., Ltd. | Système de codage du signal de parole |
Non-Patent Citations (3)
| Title |
|---|
| E.S. DERMATAS ET AL.: "Fast endpoint detection algorithm for isolated word recognition in office environment", ICASSP 91, vol. 1, 14 May 1991 (1991-05-14), TORONTO, pages 733 - 736, XP000245333, DOI: doi:10.1109/ICASSP.1991.150444 * |
| M. CHUNG ET AL.: "Word boundary detection and speech recognition of noisy speech by means of iterative noise cancellation techniques", ICASSP 85, vol. 4, 26 March 1985 (1985-03-26), TAMPA FLORIDA, pages 1838, XP002034470 * |
| S.F. BOLL: "Suppression of acoustic noise in speech using spectral subtraction", IEEE TRANS. ON ASSP, vol. 27, no. 2, April 1979 (1979-04-01), pages 113 - 120, XP000572856, DOI: doi:10.1109/TASSP.1979.1163209 * |
Cited By (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| EP0718820A3 (fr) * | 1994-12-19 | 1998-06-03 | Matsushita Electric Industrial Co., Ltd. | Dispositif de codage de parole, d'analyse prédictive linéaire et de réduction du bruit |
| US6067518A (en) * | 1994-12-19 | 2000-05-23 | Matsushita Electric Industrial Co., Ltd. | Linear prediction speech coding apparatus |
| US6167373A (en) * | 1994-12-19 | 2000-12-26 | Matsushita Electric Industrial Co., Ltd. | Linear prediction coefficient analyzing apparatus for the auto-correlation function of a digital speech signal |
| US6205421B1 (en) | 1994-12-19 | 2001-03-20 | Matsushita Electric Industrial Co., Ltd. | Speech coding apparatus, linear prediction coefficient analyzing apparatus and noise reducing apparatus |
| EP1391878A3 (fr) * | 1994-12-19 | 2011-02-09 | Panasonic Corporation | Dispositif de codage de parole, d'analyse prédictive linéaire et de réduction du bruit |
Also Published As
| Publication number | Publication date |
|---|---|
| JPH06222789A (ja) | 1994-08-12 |
| DE69326044D1 (de) | 1999-09-23 |
| US5572623A (en) | 1996-11-05 |
| EP0594480B1 (fr) | 1999-08-18 |
| DE69326044T2 (de) | 2000-07-06 |
| FR2697101B1 (fr) | 1994-11-25 |
| FR2697101A1 (fr) | 1994-04-22 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| EP0594480B1 (fr) | Procédé de détection de la parole | |
| EP2415047B1 (fr) | Classification du bruit de fond contenu dans un signal sonore | |
| EP1154405B1 (fr) | Procédé et dispositif de reconnaissance vocale dans des environnements a niveau de bruit fluctuant | |
| EP0993671B1 (fr) | Procede de recherche d'un modele de bruit dans des signaux sonores bruites | |
| EP2419900B1 (fr) | Procede et dispositif d'evaluation objective de la qualite vocale d'un signal de parole prenant en compte la classification du bruit de fond contenu dans le signal | |
| Shao et al. | A computational auditory scene analysis system for speech segregation and robust speech recognition | |
| EP2002428B1 (fr) | Procede de discrimination et d'attenuation fiabilisees des echos d'un signal numerique dans un decodeur et dispositif correspondant | |
| FR2522179A1 (fr) | Procede et appareil de reconnaissance de paroles permettant de reconnaitre des phonemes particuliers du signal vocal quelle que soit la personne qui parle | |
| EP0620546B1 (fr) | Procédé de détection énergétique de signaux noyés dans du bruit | |
| EP0867856A1 (fr) | "Méthode et dispositif de detection d'activité vocale" | |
| FR2771542A1 (fr) | Procede de filtrage frequentiel applique au debruitage de signaux sonores mettant en oeuvre un filtre de wiener | |
| CA2404441C (fr) | Parametres robustes pour la reconnaissance de parole bruitee | |
| EP3627510B1 (fr) | Filtrage d'un signal sonore acquis par un systeme de reconnaissance vocale | |
| CA2304012A1 (fr) | Procede de detection d'activite vocale | |
| Gul et al. | Single-channel speech enhancement using colored spectrograms | |
| Aliouat et al. | A new deep learning forward BSS (D-FBSS) algorithm for acoustic noise reduction and speech enhancement | |
| EP0621582B1 (fr) | Procédé de reconnaissance de parole à apprentissage | |
| CN117542378A (zh) | 语音情绪识别方法、装置、电子设备及存储介质 | |
| Gul et al. | Single channel speech enhancement by colored spectrograms | |
| Ekpenyong et al. | Speech quality enhancement in digital forensic voice analysis | |
| EP0821345B1 (fr) | Procédé d'extraction de la fréquence fondamentale d'un signal de parole | |
| JP2968976B2 (ja) | 音声認識装置 | |
| EP1605440B1 (fr) | Procédé de séparation de signaux sources à partir d'un signal issu du mélange | |
| Figueiredo et al. | A comparative study on filtering and classification of bird songs | |
| França et al. | Noise Reduction in Speech Signals Using Discrete-time Kalman Filters Combined with Wavelet Transforms |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PUAI | Public reference made under article 153(3) epc to a published international application that has entered the european phase |
Free format text: ORIGINAL CODE: 0009012 |
|
| AK | Designated contracting states |
Kind code of ref document: A1 Designated state(s): DE GB |
|
| 17P | Request for examination filed |
Effective date: 19940527 |
|
| GRAG | Despatch of communication of intention to grant |
Free format text: ORIGINAL CODE: EPIDOS AGRA |
|
| 17Q | First examination report despatched |
Effective date: 19980922 |
|
| GRAG | Despatch of communication of intention to grant |
Free format text: ORIGINAL CODE: EPIDOS AGRA |
|
| GRAH | Despatch of communication of intention to grant a patent |
Free format text: ORIGINAL CODE: EPIDOS IGRA |
|
| GRAH | Despatch of communication of intention to grant a patent |
Free format text: ORIGINAL CODE: EPIDOS IGRA |
|
| GRAH | Despatch of communication of intention to grant a patent |
Free format text: ORIGINAL CODE: EPIDOS IGRA |
|
| GRAA | (expected) grant |
Free format text: ORIGINAL CODE: 0009210 |
|
| AK | Designated contracting states |
Kind code of ref document: B1 Designated state(s): DE GB |
|
| REF | Corresponds to: |
Ref document number: 69326044 Country of ref document: DE Date of ref document: 19990923 |
|
| RAP2 | Party data changed (patent owner data changed or rights of a patent transferred) |
Owner name: THOMSON-CSF SEXTANT |
|
| GBT | Gb: translation of ep patent filed (gb section 77(6)(a)/1977) |
Effective date: 19991020 |
|
| PLBE | No opposition filed within time limit |
Free format text: ORIGINAL CODE: 0009261 |
|
| STAA | Information on the status of an ep patent application or granted ep patent |
Free format text: STATUS: NO OPPOSITION FILED WITHIN TIME LIMIT |
|
| 26N | No opposition filed | ||
| REG | Reference to a national code |
Ref country code: GB Ref legal event code: IF02 |
|
| PGFP | Annual fee paid to national office [announced via postgrant information from national office to epo] |
Ref country code: DE Payment date: 20081014 Year of fee payment: 16 |
|
| PGFP | Annual fee paid to national office [announced via postgrant information from national office to epo] |
Ref country code: GB Payment date: 20081008 Year of fee payment: 16 |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: DE Free format text: LAPSE BECAUSE OF NON-PAYMENT OF DUE FEES Effective date: 20100501 |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: GB Free format text: LAPSE BECAUSE OF NON-PAYMENT OF DUE FEES Effective date: 20091013 |