EP1130577A2 - Verfahren zur Rekonstruktion tieffrequenter Sprachanteile aus mittelhohen Frequenzanteilen - Google Patents
Verfahren zur Rekonstruktion tieffrequenter Sprachanteile aus mittelhohen Frequenzanteilen Download PDFInfo
- Publication number
- EP1130577A2 EP1130577A2 EP01102129A EP01102129A EP1130577A2 EP 1130577 A2 EP1130577 A2 EP 1130577A2 EP 01102129 A EP01102129 A EP 01102129A EP 01102129 A EP01102129 A EP 01102129A EP 1130577 A2 EP1130577 A2 EP 1130577A2
- Authority
- EP
- European Patent Office
- Prior art keywords
- frequency
- signal
- speech signal
- speech
- fundamental
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Granted
Links
Images





Classifications
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L21/00—Speech or voice signal processing techniques to produce another audible or non-audible signal, e.g. visual or tactile, in order to modify its quality or its intelligibility
- G10L21/02—Speech enhancement, e.g. noise reduction or echo cancellation
- G10L21/038—Speech enhancement, e.g. noise reduction or echo cancellation using band spreading techniques
Definitions
- the invention relates to a method and a device for reconstruction low-frequency speech components from medium-high frequency components.
- From US 4,091,237 A is a method for determining the basic voice frequency of a digital voice signal known in real time. Especially for signals with one restricted frequency range, such as phone signals, and with a high The speech signal is improved by reducing noise by filtering out noise become.
- the signal is split up and in by a plurality of bandpass filters corresponding histogram is formed from which the basic voice frequency is extracted. If the fundamental frequency is known, noise can be recognized by the fact that it is in have no harmonic relationship to the fundamental frequency.
- the previously described The method is used to determine the basic frequency characteristic of a voice determine.
- DE 37 33 983 describes a method for damping interference signals in a hearing aid known in which the signal is digitized and in individual Frequency ranges is divided. Frequency ranges with certain characteristics, such as rapid or very slow changes in the spectral distribution are damped and / or the cutoff frequencies are shifted. The signal cleaned in this way is in converted synthetic speech signals.
- the method described above and the associated devices is the The disadvantage is that the speech signal is not at all or only in an insufficient form is reconstructed in order to generate the most natural possible output speech signal.
- digital Voice amplification digital voice enhancement - DVE
- the procedure can also be used to Speech communication can be carried out inside the vehicle. However, it is Optimal sound quality is required to achieve acceptance among buyers.
- the invention is therefore based on the technical problem arising from the prior art Technique known as well as the associated device for the reconstruction low-frequency speech components from medium-high frequency components to further develop and design that for a reproduction of the disturbed Speech signal a reproduction that is as close to nature as possible is made possible.
- low-frequency signal components of the speech signal become synthetic generated, that is, reconstructed, and the remaining recorded speech signal added.
- the low-frequency speech components are reconstructed based on the unfiltered speech signals. This is exploited that the low-frequency speech parts accompanied by higher-frequency parts of the harmonics are so that the missing portions are estimated from the remaining signal to let.
- the frequencies of the harmonics of the fundamental frequency arranged below the limit frequency are determined and in addition to the fundamental frequency for a reconstruction of the low-frequency Frequency range used.
- the frequencies used for the reconstruction are marked with a respective spectral distribution and a predetermined amplitude to a synthetic Spectrum composed that the frequency range below the cutoff frequency in Voice signal corresponds. From this frequency segment and the speech signal above the reconstructed speech signal is then composed of the cutoff frequency.
- the low-frequency speech component therefore no longer has a noise signal since it is exclusively is composed of frequency components of the speech signal.
- the low-frequency speech component can also can be determined directly from the speech signal.
- one of several band filters existing comb filter based on the fundamental frequency and the frequencies of the harmonics arranged below the cutoff frequency, the Frequency positions of the individual bandpass filters, the cut-off frequencies and the Correspond to harmonics.
- the speech signal is then in the Filtered range below the cutoff frequency, allowing the signal components to pass become part of the actual speech signal. In this way too Reconstruction of a largely undisturbed speech signal in the low-frequency range of the speech signal possible.
- the decisive factor for the quality of the reconstruction of the low-frequency speech component is the Accuracy of the determined basic frequency of the speech signal. Since the Basic frequency continuously changed during speaking due to the sentence melody, a further improvement of the method is achieved in that at the beginning of a Speech contained speech section from the speech signal the fundamental frequency is determined and then this is adaptively tracked. Thus, in time The course of the speech signal determines the current fundamental frequency, so that the Reconstruction of the speech signal adapted as closely as possible to the course of the voice can be. An embodiment of such an adaptive tracking will continue explained in detail below.
- the amplitude of the at least one is below the Cutoff frequency generated frequency signal depending on the amplitudes of the frequency signals analyzed above the cutoff frequency are determined.
- Typical amplitude profiles of speech signals can preferably be used Find application not only in the frequency components, but also in the Amplitude distribution of the frequency components as precise an adaptation as possible to achieve natural speech signal.
- the cutoff frequency is dependent on the noise level, ie is determined in particular by the size of the interference signal. So it is low Interference signal levels, for example, only necessary to reduce the speech signal component below 200 Hz reconstruct, while it is necessary that the speech signal at high interference signal levels to be reconstructed in the frequency range below 500 Hz.
- the cutoff frequency can also be in Depending on the driving speed can be determined.
- One application of the method described above is in one to play recorded voice signals while the motor vehicle is moving, thereby providing a reproduce as natural a language impression as possible.
- Another application of the method according to the invention is to use a to reproduce a voice signal transmitted on a telephone connection.
- the basis lying problem is that the voice signals on telephone connections in the frequency range below 350 Hz contain no information. Therefore, for a lifelike reproduction of the speech signal from the low-frequency speech portion the frequency range above 350 Hz can be reconstructed. This can be done in carried out particularly advantageously by the method according to the invention become.
- Fig. 1 shows a frequency-amplitude diagram of the interior noise level in one moving motor vehicle for different speeds between 60 km / h and 160 km / h.
- this representation it is striking that especially at low frequencies below approx. 500 Hz the interior noise level compared to the others Frequencies of the interior noise signal increases sharply.
- the basic frequency and the first harmonics to the basic frequency in Frequency range below 1000 Hz and especially below 500 Hz is one Determination, i.e. a filtering out of the speech signal from the Interior noise signal considerably more difficult.
- Fig. 2 shows a speech signal which has been superimposed by a background signal in a time-frequency representation as a spectrogram.
- This spectrogram is e.g. obtained by a Fourier transform (FFT) from a microphone signal.
- FFT Fourier transform
- Fig. 2 indicate different gray values of the individual segments of the spectrogram different intensities.
- These latter narrow-band frequency components represent harmonics of the fundamental frequency of the corresponding speech signal, the - As described below - are evaluated according to the invention.
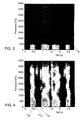
- Fig. 3 shows a spectrogram of the speech signal shown in Fig. 2 without the Background noise, so that even the low-frequency speech components as narrow-band Frequency components can be seen in the spectrogram below 500 Hz. This Parts of the language have to be reconstructed.
- FIG. 5 shows an example of a reconstructed speech signal in the area below the Cutoff frequency of approximately 400 Hz and Fig. 6 shows the composite reconstructed Speech signal from the reconstructed speech portion shown in FIG. 5 and the in Fig. 4 frequency portion shown above the cutoff frequency of the original Spectrum. How the reconstructed language components are obtained is described below described in detail with reference to FIGS. 7 to 9.
- FIG. 7 shows in a block diagram a device for the reconstruction of low-frequency speech components from medium-high frequency components.
- the speech signal is fed to a means 4 for determining frequency components ⁇ fa1 , ⁇ fa2 , ... of maxima in the speech signal above a predetermined cut-off frequency ⁇ 0 .
- the speech signal is first passed through a bandpass filter 6, so that only the frequency components between the cut-off frequency ⁇ 0 and a further frequency ⁇ 1 are cut out and passed on for further processing.
- ⁇ 0 is for example in the range from 200 to 500 Hz, in particular 350 Hz
- the frequency ⁇ 1 is in the range of 800 Hz, for example.
- the frequency section of the speech signal filtered out in this way is mixed in the mixing element 8, so that the sum and difference frequencies of the frequency components contained in the cut out section of the speech signal are formed.
- the difference frequencies are of interest, so that the signal emerging from the mixing element 8 is processed by means of a low-pass filter, so that only frequency components below an adjustable frequency ⁇ 2 are let through.
- the smallest difference frequency can thus be determined, which corresponds to the distance between two spectral components arranged adjacent to one another in the speech signal. Since these are two harmonics of the fundamental frequency, the difference frequency represents the fundamental frequency ⁇ g .
- This fundamental frequency is then fed to means 12 for the reconstruction of the speech signal.
- the voice signal is fed via a further input of the means 12 via a delay stage 14 and a low-pass filter 16.
- the means 12 have both the value of the fundamental frequency ⁇ g and a predetermined frequency section of the speech signal available for a reconstruction of the signal containing the speech.
- the delay stage 14 is used to compensate for the time span ⁇ t that is required for determining the fundamental frequency ⁇ g and the low-pass filter 16 is used to sensibly reduce the amount of data that is fed to the means 12 for the reconstruction of the speech signal.
- the means 12 for the reconstruction of the speech signal below the cut-off frequency ⁇ 0 has two alternative methods in terms of circuitry.
- the fundamental frequency ⁇ g is used to generate a signal in the reconstructed speech signal that corresponds to the fundamental tone of the speech.
- the aim is to generate all the harmonics in the frequency section of the speech signal to be reconstructed, ie to simulate them.
- the voice signal is delayed by a time difference .DELTA.t via a further delay stage 18 in order to allow adaptation to the time period necessary for the reconstruction of the low-frequency voice component.
- a high-pass filter 20 in which the speech signal is filtered out above the cut-off frequency ⁇ 0
- both this high-pass filtered signal and the reconstructed speech signal for frequencies ⁇ ⁇ 0 converge in the sum element 22, from which the reconstructed spectrogram shown in FIG. 6 is generated becomes.
- This spectrogram therefore consists on the one hand of the frequency component reconstructed below the cutoff frequency ⁇ 0 and of the original frequency spectrum above the cutoff frequency ⁇ 0 .
- the spectrogram generated in this way leads to an almost natural-sounding speech reproduction.
- the fundamental frequency ⁇ g generally does not remain constant in a speech signal due to the speech melody. It is therefore necessary to constantly redetermine the fundamental frequency ⁇ g . On the one hand, this can be done by continuously running through the previously described method, which was previously described with the aid of elements 4, 6, 8 and 10. On the other hand, however, more precise adaptive tracking of the fundamental frequency ⁇ g can be carried out. This is possible with a device which is shown in FIG. 8.
- the fundamental frequency ⁇ g, 0 initially determined at the beginning of a speech signal is multiplied to N times the value with the aid of a multiplication element 24.
- the (N-1) th harmonic to the fundamental frequency is thus calculated.
- the frequency of these harmonics is referred to below as the control harmonic and the associated frequency is denoted by ⁇ r .
- the frequency ⁇ r is introduced into a control loop via a multi-port switch.
- the output of the multiplication element 24 is transferred from the multi-port switch 26 to the mixing element 28.
- the multi-port switch 26 is switched so that ⁇ r , is passed on to the mixing element 28.
- ⁇ r is exactly the frequency of the (N-1) th harmonic.
- the mixing element 28 forms the difference between ⁇ r and ⁇ m .
- a sine wave generator generates a sinusoidal signal with the frequency that is specified by its input signal ⁇ d . This is fed to a mixing element 32 which mixes the speech signal and this sinusoidal signal. After mixing has taken place, the mixed signal is output from the mixing element 32, which is fed to a control element 34 for determining the frequency-dependent power distribution in the mixed signal in relation to the fixed frequency ⁇ m .
- the frequency ⁇ r of the control harmonic does not correspond to the current frequency of the corresponding harmonic in the speech signal, the power distribution will not reach its maximum at the frequency ⁇ m , but at a position shifted by a difference value ⁇ .
- a correction value for ⁇ can thus be determined, which is added to the current value of the frequency ⁇ r of the control harmonic. This results in the new value of the frequency ⁇ r, new , which is fed to the control loop again via the multiport switch 26. Subsequently, mixing takes place again in the mixing element 28 with a subsequent control sequence, as described above.
- the value ⁇ r is branched off from the control loop and output via a multiplication element 38, in which the current frequency ⁇ r is acted on by the factor 1 / N in order to generate the value of the fundamental frequency ⁇ g, adapt .
- the value of the fundamental frequency ⁇ g is thus continuously adaptively tracked, as a result of which the reconstruction of the low-frequency speech component from the medium-high frequency components is improved and brought closer to a natural speech signal.
Landscapes
- Engineering & Computer Science (AREA)
- Acoustics & Sound (AREA)
- Computational Linguistics (AREA)
- Signal Processing (AREA)
- Health & Medical Sciences (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Human Computer Interaction (AREA)
- Quality & Reliability (AREA)
- Multimedia (AREA)
- Physics & Mathematics (AREA)
- Fittings On The Vehicle Exterior For Carrying Loads, And Devices For Holding Or Mounting Articles (AREA)
- Mobile Radio Communication Systems (AREA)
- Telephone Function (AREA)
- Transmission Systems Not Characterized By The Medium Used For Transmission (AREA)
- Compression, Expansion, Code Conversion, And Decoders (AREA)
- Measurement Of Mechanical Vibrations Or Ultrasonic Waves (AREA)
Abstract
Description
- Fig. 1
- eine spektrale Innengeräuschverteilung in einem fahrenden Kraftfahrzeug für unterschiedliche Fahrgeschwindigkeiten,
- Fig. 2
- ein Spektrogramm eines im tieffrequenten Bereich von einem Störsignal überlagerten Sprachsignals,
- Fig. 3
- ein Spektrogramm des in Fig. 2 dargestellten Sprachsignals ohne Störsignal,
- Fig. 4
- ein Spektrogramm des in Fig. 3 dargestellten Sprachsignals ohne Frenquenzanteile unterhalb der Grenzfrequenz von ca. 400 Hz,
- Fig. 5
- ein Spektrogramm der im Spektralbereich unterhalb der Grenzfrequenz von ca. 400 Hz rekonstruierten Sprachanteile,
- Fig. 6
- das vollständige rekonstruierte Sprachsignal entsprechend dem in Fig. 3 dargestellten Sprachsignal ohne Störsignalanteil,
- Fig. 7
- ein Blockschaltbild eines Ausführungsbeispiels einer erfindungsgemäßen Vorrichtung zur Rekonstruktion tieffrequenter Sprachanteile aus mittelhohen Frequenzanteilen,
- Fig. 8
- eine Einrichtung zur adaptiven Nachführung der Grundfrequenz und
- Fig. 9
- die spektrale Verteilung der Kennlinien der Bandfilter des Regelelementes zum Feststellen der frequenzabhängigen Leistungsverteilung im Mischspektrum in Bezug auf die feststehende Mischungsfrequenz von 2000 Hz.
Claims (16)
- Verfahren zur Rekonstruktion tieffrequenter Sprachanteile aus mittelhohen Frequenzanteilen,bei dem oberhalb einer Grenzfrequenz (ω0) mindestens zwei benachbart angeordnete Frequenzanteile (ωfa1, ωfa2, ...) mit erhöhter Amplitude im Sprachsignal bestimmt werden undbei dem die Grundfrequenz (ωg) des Sprachsignals als Frequenzdifferenz zwischen den mindestens zwei benachbarten Frequenzanteilen (ωfa1, ωfa2, ...) bestimmt wird undbei dem mit Hilfe der ermittelten Grundfrequenz (ωg) und des Sprachsignals der tieffrequente Frequenzbereich unterhalb der Grenzfrequenz (ωg) rekonstruiert wird.
- Verfahren nach Anspruch 1, bei dem aus der Grundfrequenz (ωg) die Frequenzen (ωh1, ωh2, ...) der unterhalb der Grenzfrequenz (ω0) angeordneten Harmonischen der Grundfrequenz (ωg) bestimmt und neben der Grundfrequenz (ωg) für das Rekonstruieren des tieffrequenten Frequenzbereiches verwendet werden.
- Verfahren nach Anspruch 1, bei dem mit Hilfe eines mehrere Bandfilter aufweisenden Kammfilters auf der Basis der Grundfrequenz (ωg) und der Frequenzen der unterhalb der Grenzfrequenz (ω0) angeordneten Harmonischen die Frequenzpositionen der Bandfilter eingerichtet werden, mit deren Hilfe das Sprachsignals im Bereich unterhalb der Grenzfrequenz (ω0) gefiltert wird.
- Verfahren nach einem der Ansprüche 1 bis 3, bei dem zu Beginn eines Sprache enthaltenen Sprachabschnittes aus dem Sprachsignal die Grundfrequenz (ωg) bestimmt wird und anschließend die Grundfrequenz (ωg) adaptiv nachgeführt wird.
- Verfahren nach Anspruch 4,bei dem für eine adaptive Nachführung der Grundfrequenz (ωg) aus dem aktuellen Wert der Grundfrequenz (ωg) die Frequenz (ωr) einer Regelharmonischen als N-te Harmonische berechnet wird,bei dem die Differenz zwischen der Frequenz (ωr) der Regelharmonischen und einer feststehenden Mischungsfrequenz (ωm) gebildet wird,bei dem ein sinusförmiges Signal (sin(ωd)) mit der sich aus der Differenzbildung ergebenden Differenz- oder Summenfrequenz (ωd) erzeugt wird,bei dem das sinusförmige Signal (sin(ωd)) mit dem Sprachsignal gemischt und ein Mischsignal erzeugt wird,bei dem im Mischsignal die frequenzabhängige Leistungsverteilung in Bezug auf die feststehende Mischungsfrequenz (ωm) festgestellt wird,bei dem aus der Leistungsverteilung ein Korrekturwert (Δω) für die Frequenz (ωr) der Regelharmonischen berechnet wird,bei dem die Frequenz (ωr) der Regelharmonischen um den Korrekturwert (Δω) verändert und einer erneuten Mischung mit der feststehenden Mischungsfrequenz (ωm) zugeleitet wird undbei dem die Grundfrequenz (ωg) ausgegeben wird, die dem entsprechenden Bruchteil 1/N der Frequenz (ωr) entspricht.
- Verfahren nach Anspruch 5, bei dem für eine Bestimmung die Leistungsverteilung das Mischsignal einer Mehrzahl von Bandfiltern (BFn) zugeleitet wird, die nebeneinanderliegende Frequenzbereiche zentriert um die feste Mischungsfrequenz herum abdecken,
- Verfahren nach einem der Ansprüche 1 bis 6, bei dem die Amplitude des mindestens einen unterhalb der Grenzfrequenz erzeugten Frequenzsignals in Abhängigkeit von den Amplituden der oberhalb der Grenzfrequenz analysierten Frequenzsignale bestimmt wird.
- Verfahren nach einem der Ansprüche 1 bis 7, bei dem die Grenzfrequenz in Abhängigkeit vom Geräuschpegel bestimmt wird.
- Verfahren nach einem der Ansprüche 1 bis 8, bei dem das Sprachsignal vor einer Umwandlung in ein Spektrogramm einer Störsignalbefreiung unterzogen wird.
- Anwendung eines Verfahrens nach einem der Ansprüche 1 bis 9 für die Wiedergabe eines in einem fahrenden Kraftfahrzeug aufgenommenen Sprachsignals.
- Anwendung eines Verfahrens nach einem der Ansprüche 1 bis 9 für die Wiedergabe eines Sprachsignals, das mittels einer Telefonverbindung übertragen wird.
- Vorrichtung zur Rekonstruktion tieffrequenter Sprachanteile aus mittelhohen Frequenzanteilen, insbesondere zur Durchführung eines Verfahren nach einem der Ansprüche 1 bis 11,mit Mitteln (4) zur Bestimmung von Frequenzanteile (ωfa1, ωfa2, ...) von Maxima im Sprachsignal oberhalb einer vorgegebenen Grenzfrequenz (ω0),mit Mitteln (8) zum Mischen der Frequenzanteile (ωfa1, ωfa2, ...) zur Bestimmung der Grundfrequenz (ωg) des Sprachsignals als Differenzfrequenz zwischen jeweils zwei benachbarten Frequenzanteilen (ωfa1, ωfa2, ...) undmit Mitteln (12) zur Rekonstruktion des Sprachsignals unterhalb der Grenzfrequenz (ω0) aus der ermittelten Grundfrequenz (ωg) und dem Sprachsignal.
- Vorrichtung nach Anspruch 12, dadurch gekennzeichnet, daß die Mittel (12) zur Rekonstruktion des Sprachsignals unterhalb der Grenzfrequenz (ω0) das Spektrogramm aus der Grundfrequenz (ωg) und den Frequenzen (ωh1, ωh2, ...) der unterhalb der Grenzfrequenz (ω0) angeordneten Harmonischen der Grundfrequenz (ωg) mit einer vorgegebenen Spektralverteilung und einer vorgegebenen Amplitudenverteilung bestimmt.
- Vorrichtung nach Anspruch 12, dadurch gekennzeichnet, daß die Mittel (12) einen Kammfilter mit einer Mehrzahl von Bandfiltern aufweisen, wobei die Frequenzen der Bandfilter auf der Basis der Grundfrequenz (ωg) und ggf. ein oder mehrerer unterhalb der Grenzfrequenz (ω0) angeordneter Harmonischer der Grundfrequenz (ωg) einstellbar sind.
- Vorrichtung nach einem der Ansprüche 12 bis 14, dadurch gekennzeichnet, daß für ein adaptives Nachführen der Grundfrequenz (ωg) vorgesehen sind,ein Multiplikatorelement (24) zum Erzeugen der N-ten Harmonischen der Grundfrequenz als Frequenz (ωr) einer Regelharmonischen,ein Mischelement (28) zum Mischen der Frequenz (ωr) der Regelharmonischen mit einer feststehenden Mischungsfrequenz (ωm),einem Sinusgenerator (30) zum Mischen der sich aus der Mischung ergebenden Differenz- oder Summenfrequenz (ωd),einem Mischelement (32) zum Mischen des sinusförmigen Signals (sin(ωd)) mit dem Sprachsignal und zum Erzeugen eines Mischsignals erzeugt wird,einem Regelelement (34) zum Feststellen der frequenzabhängigen Leistungsverteilung im Mischsignal in Bezug auf die feststehende Mischungsfrequenz (ωm) und zum Berechnen eines ein Korrekturwert (Δω) für die Frequenz (ωr) der Regelharmonischen aus der Leistungsverteilung,einem Mischelement (36) zum Verändern der Frequenz (ωr) der Regelharmonischen um den Korrekturwert (Δω) undmit einem Multiplikatorelement (38) zum Berechnen des Bruchteils 1/N der Frequenz (ωr) als Grundfrequenz (ωg).
- Vorrichtung nach Anspruch 15, dadurch gekennzeichnet, daß das Regelelement (34) eine Mehrzahl von Bandfiltern aufweist, die zentrisch zur Mischungsfrequenz (ωm) nebeneinanderliegende Frequenzbereiche abdecken.
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| DE10010037 | 2000-03-02 | ||
| DE10010037A DE10010037B4 (de) | 2000-03-02 | 2000-03-02 | Verfahren zur Rekonstruktion tieffrequenter Sprachanteile aus mittelhohen Frequenzanteilen |
Publications (3)
| Publication Number | Publication Date |
|---|---|
| EP1130577A2 true EP1130577A2 (de) | 2001-09-05 |
| EP1130577A3 EP1130577A3 (de) | 2002-09-18 |
| EP1130577B1 EP1130577B1 (de) | 2007-06-06 |
Family
ID=7633152
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| EP01102129A Expired - Lifetime EP1130577B1 (de) | 2000-03-02 | 2001-02-01 | Verfahren zur Rekonstruktion tieffrequenter Sprachanteile aus mittelhohen Frequenzanteilen |
Country Status (3)
| Country | Link |
|---|---|
| EP (1) | EP1130577B1 (de) |
| AT (1) | ATE364221T1 (de) |
| DE (2) | DE10010037B4 (de) |
Cited By (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| EP1814107A1 (de) * | 2006-01-31 | 2007-08-01 | Harman Becker Automotive Systems GmbH | Verfahren und entsprechendes System zur Erweiterung der spektralen Bandbreite eines Sprachsignals |
| CN111863006A (zh) * | 2019-04-30 | 2020-10-30 | 华为技术有限公司 | 一种音频信号处理方法、音频信号处理装置和耳机 |
| CN112151065A (zh) * | 2019-06-28 | 2020-12-29 | 力同科技股份有限公司 | 单音信号频率检测方法、装置、设备及计算机存储介质 |
| CN113362840A (zh) * | 2021-06-02 | 2021-09-07 | 浙江大学 | 基于内建传感器欠采样数据的通用语音信息恢复装置及方法 |
Families Citing this family (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| DE102024101130B3 (de) | 2024-01-16 | 2025-03-20 | Cariad Se | Verfahren zum Abspielen von digitalen Audiodaten in einem Kraftfahrzeug sowie Kraftfahrzeug |
Family Cites Families (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US4091237A (en) * | 1975-10-06 | 1978-05-23 | Lockheed Missiles & Space Company, Inc. | Bi-Phase harmonic histogram pitch extractor |
| US4490843A (en) * | 1982-06-14 | 1984-12-25 | Bose Corporation | Dynamic equalizing |
| US4700390A (en) * | 1983-03-17 | 1987-10-13 | Kenji Machida | Signal synthesizer |
| EP0240286B1 (de) * | 1986-04-01 | 1992-12-09 | Matsushita Electric Industrial Co., Ltd. | Erzeuger von niederfrequenten Tönen |
| JP2779886B2 (ja) * | 1992-10-05 | 1998-07-23 | 日本電信電話株式会社 | 広帯域音声信号復元方法 |
-
2000
- 2000-03-02 DE DE10010037A patent/DE10010037B4/de not_active Expired - Fee Related
-
2001
- 2001-02-01 DE DE50112581T patent/DE50112581D1/de not_active Expired - Lifetime
- 2001-02-01 EP EP01102129A patent/EP1130577B1/de not_active Expired - Lifetime
- 2001-02-01 AT AT01102129T patent/ATE364221T1/de not_active IP Right Cessation
Cited By (8)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| EP1814107A1 (de) * | 2006-01-31 | 2007-08-01 | Harman Becker Automotive Systems GmbH | Verfahren und entsprechendes System zur Erweiterung der spektralen Bandbreite eines Sprachsignals |
| US7756714B2 (en) | 2006-01-31 | 2010-07-13 | Nuance Communications, Inc. | System and method for extending spectral bandwidth of an audio signal |
| CN111863006A (zh) * | 2019-04-30 | 2020-10-30 | 华为技术有限公司 | 一种音频信号处理方法、音频信号处理装置和耳机 |
| CN111863006B (zh) * | 2019-04-30 | 2024-07-16 | 华为技术有限公司 | 一种音频信号处理方法、音频信号处理装置和耳机 |
| CN112151065A (zh) * | 2019-06-28 | 2020-12-29 | 力同科技股份有限公司 | 单音信号频率检测方法、装置、设备及计算机存储介质 |
| CN112151065B (zh) * | 2019-06-28 | 2024-03-15 | 力同科技股份有限公司 | 单音信号频率检测方法、装置、设备及计算机存储介质 |
| CN113362840A (zh) * | 2021-06-02 | 2021-09-07 | 浙江大学 | 基于内建传感器欠采样数据的通用语音信息恢复装置及方法 |
| CN113362840B (zh) * | 2021-06-02 | 2022-03-29 | 浙江大学 | 基于内建传感器欠采样数据的通用语音信息恢复装置及方法 |
Also Published As
| Publication number | Publication date |
|---|---|
| ATE364221T1 (de) | 2007-06-15 |
| DE10010037B4 (de) | 2009-11-26 |
| EP1130577A3 (de) | 2002-09-18 |
| EP1130577B1 (de) | 2007-06-06 |
| DE50112581D1 (de) | 2007-07-19 |
| DE10010037A1 (de) | 2001-09-06 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| DE2719973C2 (de) | ||
| DE2818204C2 (de) | Signalverarbeitungsanlage zur Ableitung eines störverringerten Ausgangssignals | |
| DE60027438T2 (de) | Verbesserung eines verrauschten akustischen signals | |
| DE60212696T2 (de) | Bandbreitenvergrösserung für audiosignale | |
| DE60009206T2 (de) | Rauschunterdrückung mittels spektraler Subtraktion | |
| DE19747885B4 (de) | Verfahren zur Reduktion von Störungen akustischer Signale mittels der adaptiven Filter-Methode der spektralen Subtraktion | |
| EP1386307B1 (de) | Verfahren und vorrichtung zur bestimmung eines qualitätsmasses eines audiosignals | |
| EP1143416A2 (de) | Geräuschunterdrückung im Zeitbereich | |
| DE2526034A1 (de) | Hoerhilfeverfahren und vorrichtung zur durchfuehrung des verfahrens | |
| EP1091349A2 (de) | Verfahren und Vorrichtung zur Geräuschunterdrückung bei der Sprachübertragung | |
| WO2001020965A2 (de) | Verfahren zur bestimmung einer momentanen akustischen umgebungssituation, anwendung des verfharens und ein hörgerät | |
| EP1280138A1 (de) | Verfahren zur Analyse von Audiosignalen | |
| DE69616724T2 (de) | Verfahren und System für die Spracherkennung | |
| WO2002093557A1 (de) | Vorrichtung und verfahren zum analysieren eines audiosignals hinsichtlich von rhythmusinformationen | |
| EP1247425A2 (de) | Verfahren zum betrieb eines hörgerätes und ein hörgerät | |
| EP0772764B1 (de) | Verfahren und vorrichtung zum bestimmen der tonalität eines audiosignals | |
| EP0658874B1 (de) | Verfahren und Schaltungsanordnung zur Vergrösserung der Bandbreite von schmalbandigen Sprachsignalen | |
| WO2001047335A2 (de) | Verfahren zur elimination von störsignalanteilen in einem eingangssignal eines auditorischen systems, anwendung des verfahrens und ein hörgerät | |
| EP1130577B1 (de) | Verfahren zur Rekonstruktion tieffrequenter Sprachanteile aus mittelhohen Frequenzanteilen | |
| DE19832472A1 (de) | Vorrichtung und Verfahren zur Beeinflussung eines Audiosignals in Abhängigkeit von Umgebungsgeräuschen | |
| DE10025655B4 (de) | Verfahren zum Entfernen einer unerwünschten Komponente aus einem Signal und System zum Unterscheiden zwischen unerwünschten und erwünschten Signalkomponenten | |
| EP1453355A1 (de) | Signalverarbeitung in einem Hörgerät | |
| DE3133107A1 (de) | Persoenlicher schallschutz | |
| DE10150519B4 (de) | Verfahren und Anordnung zur Sprachverarbeitung | |
| DE69015753T2 (de) | Tonsyntheseanordnung. |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PUAI | Public reference made under article 153(3) epc to a published international application that has entered the european phase |
Free format text: ORIGINAL CODE: 0009012 |
|
| AK | Designated contracting states |
Kind code of ref document: A2 Designated state(s): AT BE CH CY DE DK ES FI FR GB GR IE IT LI LU MC NL PT SE TR |
|
| AX | Request for extension of the european patent |
Free format text: AL;LT;LV;MK;RO;SI |
|
| PUAL | Search report despatched |
Free format text: ORIGINAL CODE: 0009013 |
|
| AK | Designated contracting states |
Kind code of ref document: A3 Designated state(s): AT BE CH CY DE DK ES FI FR GB GR IE IT LI LU MC NL PT SE TR |
|
| AX | Request for extension of the european patent |
Free format text: AL;LT;LV;MK;RO;SI |
|
| 17P | Request for examination filed |
Effective date: 20030318 |
|
| AKX | Designation fees paid |
Designated state(s): AT BE CH CY DE DK ES FI FR GB GR IE IT LI LU MC NL PT SE TR |
|
| GRAP | Despatch of communication of intention to grant a patent |
Free format text: ORIGINAL CODE: EPIDOSNIGR1 |
|
| GRAS | Grant fee paid |
Free format text: ORIGINAL CODE: EPIDOSNIGR3 |
|
| GRAA | (expected) grant |
Free format text: ORIGINAL CODE: 0009210 |
|
| AK | Designated contracting states |
Kind code of ref document: B1 Designated state(s): AT BE CH CY DE DK ES FI FR GB GR IE IT LI LU MC NL PT SE TR |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: FI Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20070606 |
|
| REG | Reference to a national code |
Ref country code: GB Ref legal event code: FG4D Free format text: NOT ENGLISH |
|
| REG | Reference to a national code |
Ref country code: CH Ref legal event code: EP |
|
| REG | Reference to a national code |
Ref country code: IE Ref legal event code: FG4D Free format text: LANGUAGE OF EP DOCUMENT: GERMAN |
|
| REF | Corresponds to: |
Ref document number: 50112581 Country of ref document: DE Date of ref document: 20070719 Kind code of ref document: P |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: SE Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20070906 |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: ES Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20070917 |
|
| NLV1 | Nl: lapsed or annulled due to failure to fulfill the requirements of art. 29p and 29m of the patents act | ||
| GBV | Gb: ep patent (uk) treated as always having been void in accordance with gb section 77(7)/1977 [no translation filed] |
Effective date: 20070606 |
|
| REG | Reference to a national code |
Ref country code: IE Ref legal event code: FD4D |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: NL Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20070606 Ref country code: PT Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20071106 Ref country code: IE Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20070606 |
|
| EN | Fr: translation not filed | ||
| PLBE | No opposition filed within time limit |
Free format text: ORIGINAL CODE: 0009261 |
|
| STAA | Information on the status of an ep patent application or granted ep patent |
Free format text: STATUS: NO OPPOSITION FILED WITHIN TIME LIMIT |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: DK Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20070606 Ref country code: GR Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20070907 Ref country code: GB Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20070606 Ref country code: IT Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20070606 |
|
| 26N | No opposition filed |
Effective date: 20080307 |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: FR Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20080201 |
|
| BERE | Be: lapsed |
Owner name: VOLKSWAGEN A.G. Effective date: 20080228 |
|
| REG | Reference to a national code |
Ref country code: CH Ref legal event code: PL |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: CH Free format text: LAPSE BECAUSE OF NON-PAYMENT OF DUE FEES Effective date: 20080229 Ref country code: MC Free format text: LAPSE BECAUSE OF NON-PAYMENT OF DUE FEES Effective date: 20080228 Ref country code: LI Free format text: LAPSE BECAUSE OF NON-PAYMENT OF DUE FEES Effective date: 20080229 |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: BE Free format text: LAPSE BECAUSE OF NON-PAYMENT OF DUE FEES Effective date: 20080228 |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: AT Free format text: LAPSE BECAUSE OF NON-PAYMENT OF DUE FEES Effective date: 20080201 |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: CY Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20070606 |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: LU Free format text: LAPSE BECAUSE OF NON-PAYMENT OF DUE FEES Effective date: 20080201 |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: TR Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20070606 |
|
| PGFP | Annual fee paid to national office [announced via postgrant information from national office to epo] |
Ref country code: DE Payment date: 20160229 Year of fee payment: 16 |
|
| REG | Reference to a national code |
Ref country code: DE Ref legal event code: R119 Ref document number: 50112581 Country of ref document: DE |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: DE Free format text: LAPSE BECAUSE OF NON-PAYMENT OF DUE FEES Effective date: 20170901 |