EP1194923B1 - Procedes et dispositifs d'analyse et de synthese audio - Google Patents
Procedes et dispositifs d'analyse et de synthese audio Download PDFInfo
- Publication number
- EP1194923B1 EP1194923B1 EP00953223A EP00953223A EP1194923B1 EP 1194923 B1 EP1194923 B1 EP 1194923B1 EP 00953223 A EP00953223 A EP 00953223A EP 00953223 A EP00953223 A EP 00953223A EP 1194923 B1 EP1194923 B1 EP 1194923B1
- Authority
- EP
- European Patent Office
- Prior art keywords
- frames
- samples
- module
- synthesis
- audio signal
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Expired - Lifetime
Links
- 230000015572 biosynthetic process Effects 0.000 title claims abstract description 61
- 238000003786 synthesis reaction Methods 0.000 title claims abstract description 58
- 238000004458 analytical method Methods 0.000 title claims abstract description 46
- 238000000034 method Methods 0.000 title claims abstract description 42
- 238000001228 spectrum Methods 0.000 claims abstract description 58
- 230000005236 sound signal Effects 0.000 claims abstract description 48
- 238000012545 processing Methods 0.000 claims abstract description 16
- 230000001131 transforming effect Effects 0.000 claims abstract description 7
- 230000003595 spectral effect Effects 0.000 claims description 60
- 238000000605 extraction Methods 0.000 claims description 12
- 230000005540 biological transmission Effects 0.000 claims description 7
- 230000002194 synthesizing effect Effects 0.000 claims description 7
- 238000002407 reforming Methods 0.000 abstract 1
- 239000013598 vector Substances 0.000 description 62
- 238000013139 quantization Methods 0.000 description 37
- 230000006870 function Effects 0.000 description 18
- 238000010586 diagram Methods 0.000 description 11
- 230000006835 compression Effects 0.000 description 9
- 238000007906 compression Methods 0.000 description 9
- 230000006837 decompression Effects 0.000 description 9
- 230000009466 transformation Effects 0.000 description 8
- 238000004364 calculation method Methods 0.000 description 7
- 230000006978 adaptation Effects 0.000 description 6
- 238000009499 grossing Methods 0.000 description 6
- 238000010606 normalization Methods 0.000 description 6
- 239000002131 composite material Substances 0.000 description 5
- 238000012886 linear function Methods 0.000 description 5
- 230000008569 process Effects 0.000 description 5
- 238000005070 sampling Methods 0.000 description 5
- 238000001308 synthesis method Methods 0.000 description 5
- 230000002123 temporal effect Effects 0.000 description 5
- 102100032077 Neuronal calcium sensor 1 Human genes 0.000 description 4
- 101710133725 Neuronal calcium sensor 1 Proteins 0.000 description 4
- 230000000873 masking effect Effects 0.000 description 4
- 238000002156 mixing Methods 0.000 description 4
- 238000012360 testing method Methods 0.000 description 4
- 101100129500 Caenorhabditis elegans max-2 gene Proteins 0.000 description 3
- 101100083446 Danio rerio plekhh1 gene Proteins 0.000 description 3
- 239000000284 extract Substances 0.000 description 3
- 238000012986 modification Methods 0.000 description 3
- 230000004048 modification Effects 0.000 description 3
- 238000011002 quantification Methods 0.000 description 3
- 101100459912 Caenorhabditis elegans ncs-1 gene Proteins 0.000 description 2
- 101000822695 Clostridium perfringens (strain 13 / Type A) Small, acid-soluble spore protein C1 Proteins 0.000 description 2
- 101000655262 Clostridium perfringens (strain 13 / Type A) Small, acid-soluble spore protein C2 Proteins 0.000 description 2
- 101000655256 Paraclostridium bifermentans Small, acid-soluble spore protein alpha Proteins 0.000 description 2
- 101000655264 Paraclostridium bifermentans Small, acid-soluble spore protein beta Proteins 0.000 description 2
- 230000008901 benefit Effects 0.000 description 2
- 238000001514 detection method Methods 0.000 description 2
- 239000006185 dispersion Substances 0.000 description 2
- 238000001914 filtration Methods 0.000 description 2
- 238000012546 transfer Methods 0.000 description 2
- PXFBZOLANLWPMH-UHFFFAOYSA-N 16-Epiaffinine Natural products C1C(C2=CC=CC=C2N2)=C2C(=O)CC2C(=CC)CN(C)C1C2CO PXFBZOLANLWPMH-UHFFFAOYSA-N 0.000 description 1
- 101100459896 Caenorhabditis elegans ncl-1 gene Proteins 0.000 description 1
- 238000013459 approach Methods 0.000 description 1
- 238000005311 autocorrelation function Methods 0.000 description 1
- 238000004061 bleaching Methods 0.000 description 1
- 230000008859 change Effects 0.000 description 1
- 238000006243 chemical reaction Methods 0.000 description 1
- 238000004891 communication Methods 0.000 description 1
- 238000007796 conventional method Methods 0.000 description 1
- 238000012937 correction Methods 0.000 description 1
- 230000003111 delayed effect Effects 0.000 description 1
- 230000001419 dependent effect Effects 0.000 description 1
- 230000000694 effects Effects 0.000 description 1
- 210000004704 glottis Anatomy 0.000 description 1
- 238000003780 insertion Methods 0.000 description 1
- 230000037431 insertion Effects 0.000 description 1
- 238000005457 optimization Methods 0.000 description 1
- 230000008520 organization Effects 0.000 description 1
- 230000000717 retained effect Effects 0.000 description 1
- 230000011218 segmentation Effects 0.000 description 1
- 238000010183 spectrum analysis Methods 0.000 description 1
- 238000011282 treatment Methods 0.000 description 1
Images










Classifications
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L19/00—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis
- G10L19/02—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis using spectral analysis, e.g. transform vocoders or subband vocoders
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L19/00—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis
- G10L19/04—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis using predictive techniques
- G10L19/08—Determination or coding of the excitation function; Determination or coding of the long-term prediction parameters
- G10L19/10—Determination or coding of the excitation function; Determination or coding of the long-term prediction parameters the excitation function being a multipulse excitation
Definitions
- the present invention relates to the analysis and synthesis of audio signals from representations of these signals in the spectral domain.
- the signal spectrum is obtained by transforming successive frames to the frequency domain.
- the transformation used is most often Fast Fourier Transform (FFT); but other known transforms are usable.
- FFT Fast Fourier Transform
- the number N of samples per frame is typically of the order of 100 to 500, which represents frames of a few tens of milliseconds.
- the TFR is performed on 2N points, N samples being zero added to the N samples of the frame.
- the spectrum obtained by Fourier transform of the signal frame is the convolution of the real spectrum of the signal by the Fourier transform of the signal analysis window.
- This analysis window which weights the samples of each frame, is necessary to take into account the finite duration of the frame. If the signal frame is directly subjected to the TFR, that is to say if a rectangular analysis window is used, the spectrum obtained is disturbed by the secondary peaks of the TFR of the analysis window.
- windows having better spectral properties that is to say, weighting functions whose support is limited to N samples and whose Fourier transform has its energy concentrated in a narrow peak with a strong attenuation of the secondary peaks. The most common of these windows are the Hamming, Hanning and Kaiser windows.
- US-A-5,878,388 relates to a method of analyzing and synthesizing the voice.
- US-A-5,911,130 relates to compression and decompression of audio signal.
- WOLA Weighted OLA
- An object of the invention is to provide a diagram for analyzing and synthesizing audio signals that makes it possible to limit the rate of the analysis frames, while using analysis windows having good spectral properties.
- the invention proposes a method for analyzing an audio signal processed by successive frames of N samples, in which the samples of each frame are weighted by an analysis window of Hamming, Hanning, Kaiser or similar type, and a calculation is made.
- spectrum of the audio signal by transforming each frame of weighted samples in the frequency domain, and processing the spectrum of the audio signal to output synthesis parameters of a signal derived from the analyzed audio signal.
- the successive frames comprise an alternation of frames for which complete sets of synthesis parameters are provided, which have mutual overlays of less than N / 2 samples, ie less than 50%, and frames for which delivers incomplete sets of synthesis parameters.
- Frames for which complete sets of synthesis parameters are not delivered may not be spectrally analyzed. Alternatively, an analysis can nevertheless be performed for these frames, so delivering incomplete sets of synthesis parameters including data representing an interpolation error of at least one of the synthesis parameters and / or data representing an interpolation filter of at least one of the synthesis parameters.
- the processing of the spectrum of the audio signal comprises an extraction of coding parameters for the transmission and / or storage of the coded audio signal.
- the processing of the spectrum of the audio signal comprises a denoising by spectral subtraction. Other areas of application can still be considered among the audio treatments.
- a second aspect of the invention relates to a method of synthesis an audio signal, in which a set of successive overlapping fields of N samples of the audio signal weighted by an analysis window is evaluated, by transforming in the time domain spectral estimates respectively corresponding to said frames, and the evaluated frames are combined to form the synthesized signal.
- the spectral estimates are obtained by processing synthesis parameters respectively associated with the frames of said subset while, for the frames not belonging to the subset, the spectral estimates are obtained with a interpolation of at least a part of the synthesis parameters.
- the successive frames of said subset have mutual time offsets of M samples, the number M being greater than N / 2, whereas the successive frames of said set have mutual time offsets of M / p samples, p being an integer plus 1. That each evaluated frame is modified by applying to it a processing corresponding to a division by said analysis window and to a multiplication by a synthesis window, and the synthesized signal is formed as an overlapping sum of the modified frames.
- the invention also proposes audio processing devices comprising means for implementing the methods of analysis and synthesis above.
- the encoder and decoder described below are digital circuits which can, as is customary in the field of audio signal processing, be implemented by programming a digital signal processor (DSP) or an integrated circuit. specific application (ASIC).
- DSP digital signal processor
- ASIC application specific application
- the audio coder shown in FIG. 1 processes an input audio signal x which, in the nonlimiting example considered hereinafter, is a speech signal.
- the signal x is available in digital form, for example at a sampling frequency F e of 8 kHz. It is for example delivered by an analog-digital converter processing the amplified output signal of a microphone.
- the input signal x can also be formed from another version, analog or digital, coded or not, of the speech signal.
- the encoder comprises a module 1 which forms successive audio signal frames for the various processes performed, and an output multiplexer 6 which delivers an output stream ⁇ containing for each frame quantization parameter sets from which a decoder will be able to to synthesize a decoded version of the audio signal.
- Each frame 2 is composed of a number N of consecutive samples of the audio signal x.
- N 256
- the module 1 multiplies the samples of each frame 2 by a windowing function f A , preferably chosen for its good spectral properties.
- a windowing function f A preferably chosen for its good spectral properties.
- f AT ( i ) 1 two ( 1 + cos ( two ⁇ i - ( NOT - 1 ) / two NOT ) ) or a window of Kaiser, of expression: f AT ( i ) I 0 ( ⁇ 1 - ( i - ( NOT - 1 ) / two NOT ) two ) I 0 ( ⁇ ) where ⁇ is a coefficient for example equal to 6, and I 0 (.) denotes the Bessel function of index 0.
- the encoder of FIG. 1 carries out an analysis of the audio signal in the spectral domain. It comprises a module 3 which calculates the Fast Fourier Transform (TFR) of each signal frame.
- TFR Fast Fourier Transform
- the TFR 3 module obtains the spectrum of the signal for each frame whose module and phase are respectively denoted
- a fundamental frequency detector 4 estimates for each signal frame a value of the fundamental frequency F 0 .
- the detector 4 can apply any known method of analyzing the speech signal of the frame to estimate the fundamental frequency F 0 , for example a method based on the autocorrelation function or the AMDF function, possibly preceded by a linear prediction bleaching module.
- the estimation can also be carried out in the spectral domain or in the cepstral domain.
- Another possibility is to evaluate the time intervals between the consecutive breaks of the speech signal attributable to closures of the speaker's glottis occurring during the duration of the frame.
- Well known methods that can be used to detect such micro-breaks are described in the following articles: M.
- the estimated fundamental frequency F 0 is quantized, for example scalar, by a module 5, which supplies the output multiplexer 6 with an iF index for quantizing the fundamental frequency for each frame of the signal.
- the encoder uses cepstral parametric modelings to represent an upper envelope and a lower envelope of the audio signal spectrum.
- the first step of the cepstral transformation consists in applying to the signal spectrum module a spectral compression function, which can be a logarithmic or root function.
- ) in the case of a logarithmic compression or LX ( i )
- the compressed spectrum LX of the audio signal is processed by a module 9 which extracts spectral amplitudes associated with the harmonics of the signal corresponding to the multiples of the estimated fundamental frequency F0. These Amplitudes are then interpolated by a module 10 to obtain a compressed upper envelope denoted LX_sup.
- the spectral compression could similarly be performed after the determination of the amplitudes associated with the harmonics. It could also be done after the interpolation, which would only change the shape of the interpolation functions.
- the module 9 for extracting the maxima takes into account the possible variation of the fundamental frequency on the analysis frame, errors that can be made by the detector 4, as well as inaccuracies related to the discrete nature of the frequency sampling. For this, the search for the amplitudes of the spectral peaks does not consist simply in taking the values LX (i) corresponding to the indices i such that iF e / 2N is the frequency closest to a harmonic frequency kF 0 (k ⁇ 1 ).
- the spectral amplitude selected for a harmonic of order k is a local maximum of the modulus of the spectrum in the vicinity of the frequency kF 0 (this amplitude is obtained directly in compressed form when the spectral compression 8 is performed before the extraction of the maxima 9 ).
- FIGS. 4 and 5 show an example of the shape of the compressed spectrum LX, where it can be seen that the maximum amplitudes of the harmonic peaks do not necessarily coincide with the amplitudes corresponding to the integer multiples of the estimated fundamental frequency F 0 .
- the flanks of the peaks being rather steep, a small positioning error of the fundamental frequency F 0 , amplified by the harmonic index k, can strongly distort the estimated upper envelope of the spectrum and cause a poor modeling of the formational structure of the signal.
- the interpolation is performed between points whose abscissa is the frequency corresponding to the maximum of the amplitude of a spectral peak, and whose ordinate is this maximum, before or after compression.
- the interpolation performed to calculate the upper envelope LX_sup is a simple linear interpolation.
- Another form of interpolation could be used (for example polynomial or spline).
- the interpolation is performed between points whose abscissa is a frequency kF 0 that is a multiple of the fundamental frequency (in fact the closest frequency in the discrete spectrum) and whose ordinate is the maximum amplitude, before or after compression, of the spectrum in the vicinity of this multiple frequency.
- the width of this search interval depends on the sampling frequency F e , the size 2N of the TFR and the range of possible variation of the fundamental frequency. This width is typically of the order of ten frequencies with the examples of values previously considered. It can be made adjustable according to the value F 0 of the fundamental frequency and the number k of the harmonic.
- a non-linear distortion of the frequency scale is operated on the upper envelope compressed by a module 12 before the module 13 performs the inverse fast Fourier transform (TFRI) providing the Cepstral coefficients cx_sup.
- TFRI inverse fast Fourier transform
- Nonlinear distortion can more effectively minimize the modeling error. It is for example carried out according to a frequency scale of Mel or Bark type. This distortion may possibly depend on the estimated fundamental frequency F 0 .
- the TFRI module 13 needs to compute only a cepstral vector of NCS cepstral coefficients of orders 0 to NCS-1.
- NCS can be equal to 16.
- a post-filtering in the cepstral domain is applied by a module 15 to the compressed upper envelope LX_sup.
- a (z) is the transfer function of a linear prediction filter of the audio signal
- ⁇ 1 and ⁇ 2 are coefficients between 0 and 1
- ⁇ is an optionally zero preemphasis coefficient.
- a normalization module 16 further modifies the cepstral coefficients by imposing the exact modeling constraint of a point of the initial spectrum, which is preferably the most energetic point among the spectral maxima extracted by the module 9 In practice, this normalization only modifies the value of the coefficient p (0).
- the normalization module 16 operates in the following way: it recalculates a value of the spectrum synthesized at the frequency of the maximum indicated by the module 9, by Fourier transform of the truncated and post-lifted cepstral coefficients, taking into account the non-distortion linear of the frequency axis; it determines a gain of normalization g N by the logarithmic difference between the value of the maximum provided by the module 9 and this recalculated value; and he adds the gain g N to the post-lifted cepstral coefficient c p (0). This standardization can be seen as part of post-layering.
- the post-scaled and normalized cepstral coefficients are quantized by a module 18 which transmits corresponding quantization indices icxs to the output multiplexer 6 of the encoder.
- the module 18 can operate by vector quantization from cepstral vectors formed of post-lifted and normalized coefficients, denoted here cx [n] for the n-rank signal frame.
- cx [n] 16 cepstral coefficients cx [n, 0], cx [n, 1], ..., cx [n, NCS-1] is distributed in four sub-groups. cepstral vectors each containing four consecutive order coefficients.
- the cepstral vector cx [n] can be processed by the means represented in FIG. 6, forming part of the quantization module 18.
- cx p [ not , i ] ( 1 - ⁇ ( i ) ) . rcx [ not , i ] + ⁇ ( i ) . rcx [ not - 1 , i ]
- rcx [n] denotes a residual prediction vector for the frame of rank n whose components are respectively denoted rcx [n, 0], rcx [n, 1], ..., rcx [n, NCS-1]
- ⁇ (i) denotes a prediction coefficient chosen to be representative of a supposed inter-frame correlation.
- the numerator of the relation (10) is obtained by a subtractor 20, whose components of the output vector are divided by the quantities 2- ⁇ (i) in 21.
- the residual vector rcx [n] is subdivided into four subvectors, corresponding to the subdivision into four cepstral subvectors.
- the unit 22 proceeds to the vector quantization of each sub-vector of the residual vector rcx [n].
- This quantization can consist, for each sub-vector srcx [n], of selecting in the dictionary the quantized sub-vector srcx_q [n] which minimizes the quadratic error ⁇ srcx [n] -srcx_q [n] ⁇ 2 .
- the set icxs of the quantization index icx, corresponding to the addresses in the dictionaries or dictionaries of the quantized residual sub-vectors srcx_q [n] is supplied to the output multiplexer 6.
- the unit 22 also delivers the values of the quantized residual sub-vectors, which form the vector rcx_q [n]. This latter is delayed by one frame at 23, and its components are multiplied by the coefficients ⁇ (i) at 24 to supply the vector at the negative input of the subtractor 20. This latter vector is, on the other hand, supplied to a adder 25, whose other input receives a vector formed by the components of the quantized residue rcx_q [n] respectively multiplied by the quantities 1- ⁇ (i) at 26. The adder 25 thus delivers the quantized cepstral vector cx_q [n] that will recover the decoder.
- the prediction coefficient ⁇ (i) can be optimized separately for each of the cepstral coefficients.
- the quantization dictionaries can also be optimized separately for each of the four cepstral subvectors.
- a second quantization mode can be provided as well as a process for selecting the one of the two modes that minimizes a least squares criterion with the cepstral coefficients to be quantized, and transmits with the quantization indices of the frame a bit indicating which of the two modes has been selected.
- the adaptation module 29 controls the post-lifter 15 so as to minimize a module difference between the spectrum of the audio signal and the corresponding module values calculated at 28.
- This module difference can be expressed by a sum of absolute values of amplitude differences, compressed or not, corresponding to one or more of the harmonic frequencies. This sum can be weighted according to the spectral amplitudes associated with these frequencies.
- the module difference taken into account in the adaptation of the post-lifts would take into account all the harmonics of the spectrum.
- the module 28 can resynthesize the spectral amplitudes only for one or more multiple frequencies of the fundamental frequency F 0 , selected on the basis of the importance of the absolute value of the spectrum module.
- the adaptation module 29 may for example consider the three most intense spectral peaks in the calculation of the module gap to be minimized.
- the adaptation module 29 estimates a spectral masking curve of the audio signal by means of a psychoacoustic model, and the frequencies taken into account in the calculation of the module deviation to be minimized are selected on the basis of the importance of the modulus of the spectrum relative to the masking curve (for example, the three frequencies for which the spectrum modulus is greater than the masking curve) can be taken.
- Various conventional methods can be used to calculate the masking curve from the audio signal.
- the module 29 can use a filter identification model.
- a simpler method consists in predefining a set of post-scaling parameter sets, that is to say a set of pairs ⁇ 1 , ⁇ 2 in the case of post-scaling according to the relations (8), performing the operations of the modules 15, 16, 18 and 28 for each of these sets of parameters, and retaining that of the sets of parameters which leads to the minimum module gap between the signal spectrum and the recalculated values.
- the quantization indices provided by the module 18 are then those that relate to the best set of parameters.
- the encoder determines coefficients cx_inf representing a compressed lower envelope LX_inf.
- a module 30 extracts from the compressed spectrum LX spectral amplitudes associated with frequencies located in areas of the intermediate spectrum with respect to the multiple frequencies of the estimated fundamental frequency F 0 .
- each amplitude associated with a frequency located in an intermediate zone between two successive harmonics kF 0 and (k + 1) .F 0 simply corresponds to the frequency modulus for the frequency (k + 1/2) .F 0 located in the middle of the interval separating the two harmonics.
- this amplitude could be an average of the spectrum modulus over a small range surrounding this frequency (k + 1/2) .F 0 .
- a module 31 interpolates, for example linear, the spectral amplitudes associated with the frequencies located in the intermediate zones to obtain the compressed lower envelope LX_inf.
- the cepstral transformation applied to this compressed lower envelope LX_inf is performed according to a frequency scale resulting from a nonlinear distortion applied by a module 32.
- the TFRI module 33 calculates a cepstral vector of NCI cepstral coefficients cx_inf of orders 0 to NCl-1 representing the lower envelope.
- the non-linear transformation of the frequency scale for the cepstral transformation of the lower envelope can be performed to a finer scale at high frequencies than at low frequencies, which advantageously makes it possible to model the unvoiced components of the signal at high frequencies.
- the cepstral coefficients cx_inf representing the compressed lower envelope are quantized by a module 34, which can operate in the same way as the module 18 for quantizing the cepstral coefficients representing the compressed upper envelope.
- the vector thus formed is subjected to vector quantization prediction residue, performed by means identical to those shown in Figure 6 but without subdivision into sub-vectors.
- the encoder shown in FIG. 1 does not include any particular device for coding the phases of the harmonic spectrum of the audio signal.
- it includes means 36-40 for encoding temporal information related to the phase of the non-harmonic component represented by the lower envelope.
- a spectral decompression module 36 and a TFRI module 37 form a temporal estimation of the frame of the non-harmonic component.
- the module 36 applies a reciprocal decompression function of the compression function applied by the module 8 (that is to say an exponential or a power function 1 / ⁇ ) to the compressed lower envelope LX_inf produced by the module of interpolation 31. This provides the modulus of the estimated frame of the non-harmonic component, whose phase is taken equal to that ⁇ X of the spectrum of the signal X on the frame.
- the inverse Fourier transform performed by the module 37 provides the estimated frame of the non-harmonic component.
- the module 38 subdivides this estimated frame of the non-harmonic component into several time segments.
- the module 38 calculates the energy equal to the sum of the squares of the samples, and forms a vector E1 formed of eight positive real components equal to the eight calculated energies.
- the largest of these eight energies, denoted EM, is also determined to be provided, with the vector E1, to a normalization module 39.
- This module divides each component of the vector E1 by EM, so that the standardized vector Emix is composed of eight components between 0 and 1. It is this normalized vector Emix, or weighting vector, which is subjected to quantization by the module 40.
- the latter can operate a vector quantization with a determined dictionary at a time. prior learning.
- the quantization index iEm is provided by the module 40 to the output multiplexer 6 of the encoder.
- FIG. 7 shows an alternative embodiment of the means employed by the coder of FIG. 1 for determining the energy-weighting Emix vector of the frame of the non-harmonic component.
- the spectral decompression modules 36, 37 and TFRI operate as those having the same references in FIG. 1.
- a selection module 42 is added to determine the value of the spectrum module subjected to the inverse Fourier transform 37. Based on the estimated fundamental frequency F 0 , the module 42 identifies harmonic regions and non-harmonic regions of the audio signal spectrum. For example, a frequency will be considered as belonging to a harmonic region if it is in a frequency interval centered on a harmonic kF 0 and of width corresponding to a synthesized spectral line width, and to a non-harmonic region otherwise.
- the complex signal subjected to the TFRI 37 is equal to the value of the spectrum, that is to say that its modulus and its phase correspond to the values
- this complex signal has the same phase ⁇ X as the spectrum and a modulus given by the lower envelope after spectral decompression 36. This procedure according to FIG. provides a more accurate modeling of non-harmonic regions.
- the decoder shown in FIG. 8 comprises a demultiplexer input 45 which extracts from the bit stream ⁇ , coming from an encoder according to FIG. 1, the indices iF, icxs, icxi, iEm of quantization of the fundamental frequency F 0 , cepstral coefficients representing the compressed upper envelope, coefficients representing the compressed lower envelope, and the Emix weighting vector, and distributes them respectively to modules 46, 47, 48 and 49.
- These modules 46-49 comprise quantization dictionaries similar to those of the modules 5, 18, 34 and 40 of Figure 1, in order to restore the values of the quantized parameters.
- the modules 47 and 48 have dictionaries for forming the quantized prediction residues rcx_q [n], and they deduce therefrom the quantified cepstral vectors cx_q [n] with elements identical to the elements 23-26 of FIG. 6. These quantified cepstral vectors cx_q [n] provide the cepstral coefficients cx_sup_q and cx_inf_q processed by the decoder.
- a module 51 calculates the fast Fourier transform of the cepstral coefficients cx_sup for each signal frame.
- the frequency scale of the resulting compressed spectrum is modified non-linearly by a module 52 applying the reciprocal non-linear transformation of that of the module 12 of FIG. 1, and which provides the LX_sup estimate of the compressed upper envelope.
- a spectral decompression of LX_sup operated by a module 53, provides the upper envelope X_sup comprising the estimated values of the multi-frequency spectrum module of the fundamental frequency F 0 .
- the module 54 synthesizes the spectral estimation X v of the harmonic component of the audio signal, by a sum of spectral lines centered on the multiple frequencies of the fundamental frequency F 0 and whose amplitudes (in module) are those given by the envelope superior X_sup.
- the decoder of FIG. 8 is able to extract information on this phase from cepstral coefficients cx_sup_q representing the compressed upper envelope. This phase information is used to assign a phase ⁇ (k) to each of the spectral lines determined by the module 54 in the estimation of the harmonic component of the signal.
- the speech signal can be considered to be at minimum phase.
- minimal phase information can easily be deduced from cepstral modeling. This Minimum phase information is therefore calculated for each harmonic frequency.
- the minimum phase hypothesis means that the energy of the synthesized signal is located at the beginning of each period of the fundamental frequency F 0 .
- the module 56 deduces from the post-lifted cepstral coefficients and smoothed the minimum phase assigned to each spectral line representing a harmonic peak of the spectrum.
- the operations carried out by the minimum phase smoothing and extraction modules 56, 57 are illustrated by the flowchart of FIG. 9.
- the module 56 examines the variations of the cepstral coefficients to apply a smaller smoothing in the presence of sudden variations. only in the presence of slow variations. For this, he performs the smoothing of the cepstral coefficients by means of a forgetting factor ⁇ C chosen as a function of a comparison between a th th threshold and a distance between two successive sets of post-lifted cepstral coefficients.
- the threshold of th is itself adapted according to the variations of the cepstral coefficients.
- the first step 60 consists in calculating the distance d between the two successive vectors relative to the n-1 and n frames. These vectors, noted here cxp [n-1] and cxp [n], correspond for each frame to the set of NCS post-lifted cepstral coefficients representing the compressed upper envelope.
- the distance used may in particular be the Euclidean distance between the two vectors or a quadratic distance.
- Two smoothings are first performed, respectively by means of forgetting factors ⁇ min and ⁇ max , to determine a minimum distance d min and a maximum distance d max .
- the forgetting factors ⁇ min and ⁇ max are themselves selected from two distinct values, respectively ⁇ min1 , ⁇ min2 and ⁇ max1 , ⁇ max2 between 0 and 1, the indices ⁇ min1 , ⁇ max1 being each substantially closer to 0 than indices ⁇ min2 , ⁇ max2 If d> d min (test 61), the forgetting factor ⁇ min is equal to ⁇ min1 (step 62); otherwise it is taken equal to ⁇ min2 (step 63). In step 64, the minimum distance d min is taken equal to ⁇ min .d min + (1- ⁇ min ) .d.
- step 66 the forgetting factor ⁇ max is equal to ⁇ max1 (step 66); otherwise it is taken equal to ⁇ max2 (step 67).
- step 68 the minimum distance d max is taken equal to ⁇ max .d max + (1- ⁇ max ) .d.
- the ⁇ c ⁇ c is assumed to be relatively close to 0 (step 72). It is considered in this case that the corresponding signal is of the non-stationary type, so that it is not necessary to keep a large memory of the previous cepstral coefficients. If d ⁇ d th , we adopt at step 73 for the forgetting factor ⁇ c a value ⁇ c2 less close to 0 in order to further smooth the cepstral coefficients.
- the module 57 then calculates the minimum phases ⁇ (k) associated with the harmonics kF 0 .
- ⁇ m 1 NCS - 1 cxl [ not , m ] .
- sin ( two ⁇ mk F 0 / F e ) where cx1 [n, m] denotes the smoothed cepstral coefficient of order m for the frame n.
- step 75 the harmonic index k is initialized to 1.
- the phase ⁇ (k) and the cepstral index m are initialized respectively at 0 and 1 in step 76
- the module 57 adds to the phase ⁇ (k) the quantity -2.cxl [n, m] .sin (2 ⁇ mk.F 0 / F e ).
- the cepstral index m is incremented in step 78 and compared to NCS in step 79. Steps 77 and 78 are repeated as long as NCS.
- m NCS
- the calculation of the minimum phase is completed for the harmonic k, and the index k is incremented in step 80.
- the calculation of minimum phases 76-79 is renewed for the next harmonic as long as kF 0 ⁇ F e / 2 (test 81).
- the module 54 takes into account a constant phase over the width of each spectral line, equal to the minimum phase ⁇ (k) supplied for the corresponding harmonic k by the module 57.
- the estimate X v of the harmonic component is synthesized by summation of spectral lines positioned at the harmonic frequencies of the fundamental frequency F 0. During this synthesis, it is possible to position the spectral lines on the frequency axis with a resolution greater than the resolution. of the Fourier transform. For this, a reference spectral line is precalculated once and for all according to the higher resolution. This calculation can consist of a Fourier transform of the analysis window f A with a transform size of 16384 points, providing a resolution of 0.5 Hz per point.
- each harmonic line is then performed by the module 54 by positioning the high resolution reference line on the frequency axis, and by sub-sampling this reference spectral line to reduce to the 16.625 Hz resolution of the Fourier transform on 512 points. This makes it possible to accurately position the spectral line.
- the TFR module 85 of the decoder of FIG. 8 receives NCI coefficients quasified cx_inf_q of orders 0 to NCI-1, and it advantageously completes them by the NCS-NCI coefficients cepstral cx_sup_q d NCI order to NCS -1 representing the upper envelope. In fact, it can be estimated as a first approximation that the rapid variations of the compressed lower envelope are well reproduced by those of the compressed upper envelope. In another embodiment, the TFR 85 module could only consider the NCI cepstral parameters cx_inf_q.
- the module 86 converts the frequency scale reciprocally from the conversion operated by the module 32 of the encoder, in order to restore the estimate LX_inf of the compressed lower envelope, submitted to the spectral decompression module 87.
- the decoder has a lower envelope X_inf comprising the values of the spectrum module in the valleys located between the harmonic peaks.
- This envelope X_inf will modulate the spectrum of a noise frame whose phase is processed according to the quantified weighting vector Emix extracted by the module 49.
- a generator 88 delivers a normalized noise frame whose segments of 4 ms are weighted in a module 89 according to the standardized components of the Emix vector provided by the module 49 for the current frame.
- This noise is a high-pass filtered white noise to account for the low level that normally has the unvoiced component at low frequencies.
- the Fourier transform of the resulting frame is calculated by the TFR module 91.
- the spectral estimate X uv of the non-harmonic component is determined by the spectral synthesis module 92 which performs frequency-frequency weighting. This weighting consists in multiplying each complex spectral value provided by the TFR module 91 by the value of the lower envelope X_inf obtained for the same frequency by the spectral decompression module 87.
- the spectral estimates X v , X uv of the harmonic (voiced in the case of a speech signal) and non-harmonic (or non-voiced) components are combined by a mixing module 95 controlled by a module 96 for analyzing the degree of harmonicity (or voicing) of the signal.
- the analysis module 96 comprises a unit 97 for estimating a degree of voicing W depending on the frequency, from which four gains depending on the frequency are calculated.
- the frequency namely two gains g v , g uv controlling the relative importance of the harmonic and non-harmonic components in the synthesized signal, and two gains g v_ ⁇ , g uv_ ⁇ used to noise the phase of the harmonic component.
- the degree of voicing W (i) is a continuously variable value between 0 and 1 determined for each frequency index i (0 ⁇ i ⁇ N) as a function of the upper envelope X_sup (i) and the lower envelope X_inf (i) obtained for this frequency i by the decompression modules 53, 87.
- the threshold Vth (F 0 ) corresponds to the average dynamic calculated on a synthetic spectrum purely voiced at the fundamental frequency. It is advantageously chosen depending on the fundamental frequency F 0 .
- the degree of voicing W (i) for a frequency other than the harmonic frequencies is obtained simply as being equal to that estimated for the nearest harmonic.
- the gain g v (i), which depends on the frequency, is obtained by applying a non-linear function to the degree of voicing W (i) (block 98).
- phase ⁇ v ' of the mixed harmonic component is the result of a linear combination of the phases ( ⁇ v , ⁇ uv of the harmonic and non-harmonic components X v , X uv synthesized by the modules 54, 92.
- the gains g v_ ⁇ , g uv_ ⁇ respectively applied to these phases are calculated from the degree of voicing W and weighted also according to the frequency index i, since the sound of the phase is only really useful for beyond a certain frequency.
- a first gain g v1_ ⁇ is calculated by applying a non-linear function to the degree of voicing W (i), as shown schematically by block 100 in FIG. 10.
- a multiplier 101 multiplies for each index frequency i the gain g v1_ ⁇ by another gain g v2_ ⁇ dependent only on the frequency index i, to form the gain g v_ ⁇ (i).
- the gain g v2_ ⁇ (i) depends non-linearly on the frequency index i, for example as indicated in FIG.
- . exp [ j ⁇ v ' ( i ) ] + boy Wut uv ( i ) . X uv ( i ) with ⁇ v ' ( i ) boy Wut v_ ⁇ ( i ) . ⁇ v ( i ) + boy Wut uv_ ⁇ ( i ) .
- ⁇ v (i) denotes the argument of the complex number X v (i) supplied by the module 54 for the index frequency i (block 104 of FIG. 1.0), and ⁇ uv (i) designates the complex number argument X uv (i) provided by the module 92 (block 105 of FIG. 10).
- This combination is achieved by the multipliers 106-110 and the adders 111-112 shown in FIG.
- the frames successively obtained in this way are finally processed by the time synthesis module 116 which forms the decoded audio signal x.
- the time synthesis module 116 performs an overlap sum of frames modified with respect to those successively evaluated at the output of the module 115.
- the modification can be seen in two steps illustrated respectively by FIGS. 14 and 15.
- the first step (FIG. 14) consists in multiplying each frame 2 'delivered by the TFRI module 115 by a window 1 / f A inverse to the analysis window f A used by the module 1 of the encoder. The samples of the resulting 2 "frame are therefore weighted uniformly.
- each sample of the decoded audio signal x thus obtained is assigned a uniform overall weight equal to A. This overall weight comes from the contribution of a single frame if the sample has in this frame a rank i such that L ⁇ i ⁇ N - L, and comprises the summed contributions of two successive frames if 0 ⁇ i ⁇ L where NL ⁇ i ⁇ N.
- FIG. 16 shows the appearance of the composite window f C in the case where the analysis window f A is a Hamming window and the synthesis window f S has the form given by the relations (19) to (21) .
- f S ( i ) AT . i / L for 0 ⁇ i ⁇ The
- the coder of FIG. 1 can increase the rate of frame formation and analysis, in order to transmit more quantization parameters to the decoder.
- a frame of N 256 samples (32 ms) is formed every 20 ms.
- the notations cx_q [n-1] and cx_q [n] designate determined quasified cepstral vectors, for two successive frames of entire rank, by the quantization module 18 and / or by the module of Quantization 34. These vectors comprise for example four consecutive cepstral coefficients each. They could also include more cepstral coefficients.
- a module 120 interpolates these two cepstral vectors cx_q [n-1] and cx_q [n], in order to estimate an intermediate value cx_i [n-1/2].
- the interpolation performed by the module 120 can be a simple arithmetic mean of the vectors cx_q [n-1] and cx_q [n].
- the module 120 could apply a more sophisticated interpolation formula, for example polynomial, also based on the cepstral vectors obtained for frames prior to the n-1 frame.
- the interpolation takes into account the relative position of each interpolated frame.
- the coder also calculates the cepstral coefficients cx [n-1/2] relative to the half-integer rank frame.
- these cepstral coefficients are those provided by the TFRI module 13 after post-scaling (for example with the same post-scaling coefficients as for the previous frame n-1) and normalization 16.
- the cepstral coefficients cx [n-1/2] are those delivered by the TFRI module 33.
- a subtractor 121 forms the difference ecx [n-1/2] between the cepstral coefficients cx [n-1/2] calculated for the half-integer field and the coefficients cx_i [n-1/2] estimated by interpolation.
- This difference is provided to a quantization module 122 which addresses quantization indices icx [n-1/2] to the output multiplexer 6 of the encoder.
- the module 122 operates for example by vector quantization ecx interpolation errors [n-1/2] successively determined for frames of half-integer rank.
- This quantization of the interpolation error can be carried out by the coder for each of the NCS + NCI coefficients used by the decoder, or only for some of them, typically those of orders the little ones.
- Fig. 19 Corresponding means of the decoder are illustrated in Fig. 19.
- the decoder operates essentially as described with reference to Fig. 8 to determine the full rank signal frames.
- An interpolation module 124 identical to the encoder module 120 estimates the intermediate coefficients cx_i [n-1/2] from the quantized coefficients cx_q [n-1] and cx_q [n] provided by the module 47 and / or the module 48 from the indexes icxs, icxi extracted from the stream ⁇ .
- a parameter extraction module 125 receives the quantization index icx [n-1/2] from the input demultiplexer 45 of the decoder, and deduces therefrom the quantized interpolation error ecx_q [n-1/2] from the same quantization dictionary as used by the encoder module 122.
- An adder 126 sums the cepstral vectors cx_i [n-1/2] and ecx_q [n-1/2] in order to provide the cepstral coefficients cx [n-1/2] which will be used by the decoder (modules 51- 57, 95, 96, 115 and / or modules 85-87, 92, 95, 96, 115) to form the interpolated frame of rank n-1/2.
- the decoder can also interpolate the other parameters F 0 , Emix used to synthesize the signal frames.
- the fundamental frequency F 0 can be interpolated linearly, either in the time domain or (preferably) directly in the frequency domain.
- the Emix energy weighting vector it is necessary to perform the interpolation after denormalization and taking into account, of course, time offs between frames.
- the coder uses the cepstral vectors cx_q [n], cx_q [n-1], ..., cx_q [nr] and cx_q [n-1/2] calculated for the last past frames. (r ⁇ 1) to identify an optimal interpolator filter which, when subjected to quantized cepstral vectors cx_q [nr], ..., cx_q [n] relative to the frames of full rank, delivers an interpolated cepstral vector cx_i [n-1/2] which has a minimal distance with the vector cx [n-1/2] calculated for the last frame of half-whole rank.
- this interpolator filter 128 is present in the encoder, and a subtractor 129 subtracts its output cx_i [n-1/2] from the calculated cepstral vector cx [n-1/2].
- a minimization module 130 determines the parameter set ⁇ P ⁇ of the interpolator filter 128, for which the ecx interpolation error [n-1/2] delivered by the subtracter. 129 presents a minimum standard.
- This set of parameters ⁇ P ⁇ is addressed to a quantization module 131 which provides a quantization index corresponding to the output multiplexer 6 of the encoder.
- the decoder From the quantization iP indexes of the parameters ⁇ P ⁇ obtained in the bit stream ⁇ , the decoder reconstructs the interpolator filter 128 (to the quantization errors near), and processes the spectral vectors cx_q [nr], ..., cx_q [ n] in order to estimate the cps [n-1/2] cepstral coefficients used to synthesize half-integer ranks.
- the decoder can use a simple interpolation method (without transmission of parameters by the coder for half-integer frames), an interpolation method taking into account an interpolation error. quantized (according to Figs. 17 and 18), or an interpolation method with an optimal interpolator filter (according to Fig. 19) for evaluating the half-integer rank frames in addition to the full-rank frames evaluated directly as explained with reference to Figs. FIGS. 8 to 13.
- the temporal synthesis module 116 can then combine all of these evaluated frames to form the synthesized signal x in the manner explained below. with reference to Figures 14, 21 and 22.
- the module 116 performs an overlap sum of frames modified with respect to those successively evaluated at the output of the module 115, and this modification can be seen in two steps, the first of which is identical to that previously described with reference to FIG. 14 (divide the samples of the frame 2 'by the analysis window f A ).
- the synthesis window f S ' ( i ) grows gradually for i ranging from N / 2 - M / p to N / 2. It is for example a sinusoid raised on the interval N / 2 - M / p ⁇ i ⁇ N / 2 + M / p.
- the synthesis window f S ' may be, on this interval, a Hamming window (as shown in Figure 21) or a Hanning window.
- FIG. 21 shows the successive frames 2 "repositioned in time by the module 116.
- the hatches indicate the portions removed from the frames (synthesis window at 0. It can be seen that by performing the overlap sum of the samples of the successive frames, the property (25) ensures homogeneous weighting of the samples of the synthesized signal.
- the procedure for weighting the frames obtained by inverse Fourier transform of the Y spectra can be carried out in a single step, with a composite window.
- f VS ' ( i ) f S ( i ) / f AT ( i ) .
- Figure 22 shows the shape of the composite window f VS ' in case the windows f A and f S ' are Hamming type.
- Interpolated frames may be subject to reduced transmission of coding parameters, as previously described, but this is not required.
- This embodiment makes it possible to maintain a relatively large interval M between two analysis frames, and thus to limit the required transmission rate, while limiting the discontinuities that may appear due to the size of this interval relative to the scales.
- typical times of the variations of the parameters of the audio signal notably the cepstral coefficients and the fundamental frequency.
Landscapes
- Engineering & Computer Science (AREA)
- Physics & Mathematics (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Computational Linguistics (AREA)
- Signal Processing (AREA)
- Health & Medical Sciences (AREA)
- Spectroscopy & Molecular Physics (AREA)
- Human Computer Interaction (AREA)
- Acoustics & Sound (AREA)
- Multimedia (AREA)
- Compression, Expansion, Code Conversion, And Decoders (AREA)
- Analysing Materials By The Use Of Radiation (AREA)
- Solid-Sorbent Or Filter-Aiding Compositions (AREA)
- Investigating Or Analysing Materials By The Use Of Chemical Reactions (AREA)
- Diaphragms For Electromechanical Transducers (AREA)
Description
- La présente invention concerne l'analyse et la synthèse des signaux audio, à partir de représentations de ces signaux dans le domaine spectral.
- Elle s'applique en particulier, mais non exclusivement, au codage de la parole, en bande étroite ou en bande élargie, dans diverses gammes de débit de codage. Parmi les autres domaines d'application, on peut citer le débruitage par soustraction spectrale (voir EP-A-0 534 837 ou WO99/14739)
- Dans les procédés d'analyse en question, le spectre du signal est obtenu en transformant des trames successives vers le domaine fréquentiel. La transformation employée est le plus souvent la transformée de Fourier rapide (TFR) ; mais d'autres transformées connues sont utilisables. Dans le cas fréquent d'un échantillonnage du signal à 8 kHz, le nombre N d'échantillons par trames est typiquement de l'ordre de 100 à 500, ce qui représente des trames de quelques dizaines de millisecondes. Pour bénéficier de la résolution maximale en fréquence, la TFR est effectuée sur 2N points, N échantillons à zéro étant ajoutés aux N échantillons de la trame.
- Le spectre obtenu par transformée de Fourier de la trame de signal est la convolution du spectre réel du signal par la transformée de Fourier de la fenêtre d'analyse du signal. Cette fenêtre d'analyse, qui pondère les échantillons de chaque trame, est nécessaire à la prise en compte de la durée finie de la trame. Si la trame de signal est directement soumise à la TFR, c'est-à-dire si on utilise une fenêtre d'analyse rectangulaire, le spectre obtenu est perturbé par les pics secondaires de la TFR de la fenêtre d'analyse. Pour limiter cet inconvénient, qui est particulièrement sensible lorsque des paramètres représentant le signal ou le bruit doivent être extraits des spectres, on a recours à des fenêtres ayant de meilleures propriétés spectrales, c'est-à-dire des fonctions de pondération dont le support est limité à N échantillons et dont la transformée de Fourier a son énergie concentrée dans un pic étroit avec une forte atténuation des pics secondaires. Les plus courantes de ces fenêtres sont les fenêtres de Hamming, de Hanning et de Kaiser.
- Dans la méthode d'analyse et de synthèse dite OLA (« Overlap-And-Add »), les trames successives présentent des recouvrements mutuels de 50 % (N/2 échantillons). Comme les fenêtres d'analyse couramment utilisées vérifient la propriété fA(i+N/2) + fA(i) = 1, la synthèse peut être effectuée simplement en effectuant la somme à recouvrement des trames de N échantillons successivement calculées par transformée de Fourier inverse des spectres.
- US-A-5,878,388 se rapporte à un procédé d'analyse et de synthèse de la voix. L'article d'AHMADI S. et Al : "New techniques for sinusoidal coding of speech at 2400 bps", CONFERENCE RECORD OF THIRTIETH ASILOMAR CONFERENCE ON SIGNALS, SYSTEMS AND COMPUTERS, Pacific Grove, CA, USA, IEEE Comput. Soc. Press, USA, se rapporte à un procédé d'analyse et de synthèse de la voix. L'article de R.E. Crochière, « A weighted overlap-add method for short-time Fourier analysis synthesis », IEEE Trans. on ASSP, Vol ASSP 28, février 1980, pages 99-102, se rapporte à un procédé d'analyse et de synthèse par transformation de Fourier à court-terme. US-A-5,911,130 se rapporte de la compression et décompression de signal audio.
- Dans le but d'affiner la représentation spectrale, certaines méthodes dites WOLA (« Weighted OLA ») utilisent à l'analyse des trames dont les recouvrements mutuels sont de plus de 50 %. A la synthèse, il est nécessaire de repondérer les échantillons des trames avant de les sommer. Ces méthodes augmentent la complexité de l'analyse et de la synthèse. Dans des applications de codage, elles augmentent également le débit de transmission requis.
- Un but de l'invention est de proposer un schéma d'analyse et synthèse de signaux audio qui permette de limiter la cadence des trames d'analyse, tout en utilisant des fenêtres d'analyse ayant de bonnes propriétés spectrales.
- L'invention propose un procédé d'analyse d'un signal audio traité par trames successives de N échantillons, dans lequel on pondère les échantillons de chaque trame par une fenêtre d'analyse de type Hamming, Hanning, Kaiser ou analogue, on calcule un spectre du signal audio en transformant chaque trame d'échantillons pondérés dans le domaine fréquentiel, et on traite le spectre du signal audio pour délivrer des paramètres de synthèse d'un signal dérivé du signal audio analysé. Suivant l'invention, les trames successives comportent une alternance de trames pour lesquelles on délivre des jeux complets de paramètres de synthèse, qui présentent des recouvrements mutuels de moins de N/2 échantillons, soit moins de 50 %, et de trames pour lesquelles on délivre des jeux incomplets de paramètres de synthèse.
- Les trames pour lesquelles ne sont pas délivrés des jeux complets de paramètres de synthèse peuvent ne faire l'objet d'aucune analyse spectrale. En variante, une analyse peut néanmoins être effectuée pour ces trames, afin de délivrer des jeux incomplets de paramètres de synthèse incluant des données représentant une erreur d'interpolation d'au moins un des paramètres de synthèse et/ou des données représentant un filtre d'interpolation d'au moins un des paramètres de synthèse.
- Dans un premier domaine d'application du procédé, le traitement du spectre du signal audio comporte une extraction de paramètres de codage en vue de la transmission et/ou du stockage du signal audio codé. Dans un second domaine d'application du procédé, le traitement du spectre du signal audio comporte un débruitage par soustraction spectrale. D'autres domaines d'application peuvent encore être envisagés parmi les traitements audio.
- Un second aspect de l'invention se rapporte à un procédé de synthèse d'un signal audio, dans lequel on évalue un ensemble de trames recouvrantes successives de N échantillons du signal audio pondérés par une fenêtre d'analyse, en transformant dans le domaine temporel des estimations spectrales correspondant respectivement auxdites trames, et on combine les trames évaluées pour former le signal synthétisé. Pour un sous-ensemble des trames évaluées, les estimations spectrales sont obtenues en traitant des paramètres de synthèse respectivement associés aux trames dudit sous-ensemble tandis que, pour les trames ne faisant pas partie du sous-ensemble, les estimations spectrales sont obtenues avec une interpolation d'une partie au moins des paramètres de synthèse. Les trames successives dudit sous-ensemble présentent des décalages temporels mutuels de M échantillons, le nombre M étant plus grand que N/2, tandis que les trames successives dudit ensemble présentent des décalages temporels mutuels de M/p échantillons, p étant un entier plus grand que 1. On modifie chaque trame évaluée en lui appliquant un traitement correspondant à une division par ladite fenêtre d'analyse et à une multiplication par une fenêtre de synthèse, et on forme le signal synthétisé comme une somme à recouvrement des trames modifiées. Les échantillons d'une trame ayant des rangs i numérotés de 0 à N-1, la fenêtre de synthèse


- L'invention propose également des dispositifs de traitement audio comprenant des moyens pour la mise en oeuvre des procédés d'analyse et de synthèse ci-dessus.
- D'autres particularités et avantages de la présente invention apparaîtront dans la description ci-après d'exemples de réalisation non limitatifs, en référence aux dessins annexés, dans lesquels :
- la figure 1 est un schéma synoptique d'un codeur audio selon l'invention ;
- les figures 2 et 3 sont des diagrammes illustrant la formation des trames de signal audio dans le codeur de la figure 1 ;
- les figures 4 et 5 sont des graphiques montrant un exemple de spectre du signal audio et illustrant l'extraction des enveloppes supérieure et inférieure de ce spectre ;
- la figure 6 est un schéma synoptique d'un exemple de moyens de quantification utilisables dans le codeur de la figure 1 ;
- la figure 7 est un schéma synoptique de moyens utilisables pour extraire des paramètres se rapportant à la phase de la composante non-harmonique dans une variante du codeur de la figure 1 ;
- la figure 8 est un schéma synoptique d'un décodeur audio correspondant au codeur de la figure 1 ;
- la figure 9 est un organigramme d'un exemple de procédure de lissage de coefficients spectraux et d'extraction de phases minimales mise en oeuvre dans le décodeur de la figure 8 ;
- la figure 10 est un schéma synoptique de modules d'analyse et de mixage spectral de composantes harmonique et non-harmonique du signal audio ;
- les figures 11 à 13 sont des graphiques montrant des exemples de fonctions non-linéaires utilisables dans le module d'analyse de la figure 10;
- les figures 14 et 15 sont des diagrammes illustrant une façon de procéder à la synthèse temporelle des trames de signal dans le décodeur de la figure 8 ;
- les figures 16 et 17 sont des graphiques montrant des fonctions de fenêtrage utilisables dans la synthèse des trames suivant les figures 14 et 15;
- les figures 18 et 19 sont des schémas synoptiques de moyens d'interpolation utilisables dans une variante de réalisation du codeur et du décodeur ;
- la figure 20 est un schéma synoptique de moyens d'interpolation utilisables dans une autre variante de réalisation du codeur ; et
- les figures 21 et 22 sont des diagrammes illustrant une autre façon de procéder à la synthèse temporelle des trames de signal dans le décodeur de la figure 8, à l'aide d'une interpolation de paramètres.
- Le codeur et le décodeur décrits ci-après sont des circuits numériques qui peuvent, comme il est usuel dans le domaine du traitement des signaux audio, être réalisés par programmation d'un processeur de signal numérique (DSP) ou d'un circuit intégré d'application spécifique (ASIC).
- Le codeur audio représenté sur la figure 1 traite un signal audio d'entrée x qui, dans l'exemple non-limitatif considéré ci-après, est un signal de parole. Le signal x est disponible sous forme numérique, par exemple à une fréquence d'échantillonnage Fe de 8 kHz. Il est par exemple délivré par un convertisseur analogique-numérique traitant le signal de sortie amplifié d'un microphone. Le signal d'entrée x peut également être formé à partir d'une autre version, analogique ou numérique, codée ou non, du signal de parole.
- Le codeur comprend un module 1 qui forme des trames successives de signal audio pour les différents traitements effectués, et un multiplexeur de sortie 6 qui délivre un flux de sortie Φ contenant pour chaque trame des jeux de paramètres de quantification à partir desquels un décodeur sera capable de synthétiser une version décodée du signal audio.
- La structure des trames est illustrée par les figures 2 et 3. Chaque trame 2 est composée d'un nombre N d'échantillons consécutifs du signal audio x. Les trames successives présentent des décalages temporels mutuels correspondant à M échantillons, de sorte que leur recouvrement est de L = N-M échantillons du signal. Dans l'exemple considéré, où N = 256, M = 160 et L = 96, la durée des trames 2 est de N/Fe = 32 ms, et une trame est formée toutes les M/Fe = 20 ms.
- De façon classique, le module 1 multiplie les échantillons de chaque trame 2 par une fonction de fenêtrage fA, de préférence choisie pour ses - bonnes propriétés spectrales. Les échantillons x(i) de la trame étant numérotés de i = 0 à i = N-1, la fenêtre d'analyse fA(i) peut ainsi être une fenêtre de Hamming, d'expression :

ou une fenêtre de Hanning d'expression :
ou encore une fenêtre de Kaiser, d'expression :
où α est un coefficient par exemple égal à 6, et I0(.) désigne la fonction de Bessel d'indice 0. - Le codeur de la figure 1 procède à une analyse du signal audio dans le domaine spectral. Il comporte un module 3 qui calcule la transformée de Fourier rapide (TFR) de chaque trame de signal. La trame de signal est mise en forme avant d'être soumise au module de TFR 3 : le module 1 lui adjoint N = 256 échantillons à zéro afin d'obtenir la résolution maximale de la transformée de Fourier, et il effectue d'autre part une permutation circulaire des 2N = 512 échantillons afin de compenser les effets de phase résultant de la fenêtre d'analyse. Cette modification de la trame est illustrée par la figure 3. La trame dont on calcule la transformée de Fourier rapide sur 2N = 512 points commence par les N/2 = 128 derniers échantillons pondérés de la trame, suivis par les N = 256 échantillons à zéro, et se termine par les N/2 = 128 premiers échantillons pondérés de la trame.
- Le module de TFR 3 obtient le spectre du signal pour chaque trame, dont le module et la phase sont respectivement notés |X| et ϕX, ou |X(i)| et ϕX(i) pour les index de fréquence i = 0 à i = 2N-1 (grâce à la symétrie de la transformée de Fourier et des trames, on peut se limiter aux valeurs pour 0≤i<N).
- Un détecteur de fréquence fondamentale 4 estime pour chaque trame de signal une valeur de la fréquence fondamentale F0. Le détecteur 4 peut appliquer toute méthode connue d'analyse du signal de parole de la trame pour estimer la fréquence fondamentale F0, par exemple une méthode basée sur la fonction d'autocorrélation ou la fonction AMDF, éventuellement précédée d'un module de blanchiment par prédiction linéaire. L'estimation peut également être effectuée dans le domaine spectral ou dans le domaine cepstral. Une autre possibilité est d'évaluer les intervalles de temps entre les ruptures consécutives du signal de parole attribuables à des fermetures de la glotte du locuteur intervenant pendant la durée de la trame. Des méthodes bien connues utilisables pour détecter de telles micro-ruptures sont décrites dans les articles suivants : M. Basseville et al., « Sequential detection of abrupt changes in spectral characteristics of digital signals » (IEEE Trans. on Information Theory, 1983, Vol. IT-29, n° 5, pages 708-723) ; R. Andre-Obrecht, « A new statistical approach for the automatic segmentation of continuous speech signals » (IEEE Trans. on Acous., Speech and Sig. Proc., Vol. 36, N°1, janvier 1988) ; et C. MURGIA et al., « An algorithm for the estimation of glottal closure instants using the sequential detection of abrupt changes in speech signals » (Signal Processing VII, 1994, pages 1685-1688).
- La fréquence fondamentale estimée F0 fait l'objet d'une quantification, par exemple scalaire, par un module 5, qui fournit au multiplexeur de sortie 6 un index iF de quantification de la fréquence fondamentale pour chaque trame du signal.
- Le codeur utilise des modélisations paramétriques cepstrales pour représenter une enveloppe supérieure et une enveloppe inférieure du spectre du signal audio. La première étape de la transformation cepstrale consiste à appliquer au module du spectre du signal une fonction de compression spectrale, qui peut être une fonction logarithmique ou en racine. Le module 8 du codeur opère ainsi, pour chaque valeur X(i) du spectre du signal (0 ≤ i < N), la transformation suivante:

dans le cas d'une compression logarithmique ou
dans le cas d'une compression en racine, γ étant un exposant compris entre 0 et 1. - Le spectre comprimé LX du signal audio est traité par un module 9 qui extrait des amplitudes spectrales associées aux harmoniques du signal correspondant aux multiples de la fréquence fondamentale estimée F0. Ces amplitudes sont ensuite interpolées par un module 10 afin d'obtenir une enveloppe supérieure comprimée notée LX_sup.
- Il est à noter que la compression spectrale pourrait de façon équivalente être effectuée après la détermination des amplitudes associées aux harmoniques. Elle pourrait également être effectuée après l'interpolation, ce qui ne ferait que modifier la forme des fonctions d'interpolation.
- Le module 9 d'extraction des maxima tient compte de l'éventuelle variation de la fréquence fondamentale sur la trame d'analyse, des erreurs que peut commettre le détecteur 4, ainsi que des imprécisions liées au caractère discret de l'échantillonnage en fréquence. Pour cela, la recherche des amplitudes des pics spectraux ne consiste pas simplement à prendre les valeurs LX(i) correspondant aux index i tels que i.Fe/2N soit la fréquence la plus proche d'une harmonique de fréquence k.F0 (k ≥ 1). L'amplitude spectrale retenue pour une harmonique d'ordre k est un maximum local du module du spectre au voisinage de la fréquence k.F0 (cette amplitude est obtenue directement sous forme comprimée lorsque la compression spectrale 8 est effectuée avant l'extraction des maxima 9).
- Les figures 4 et 5 montrent un exemple de forme du spectre comprimé LX, où on voit que les amplitudes maximales des pics harmoniques ne coïncident pas nécessairement avec les amplitudes correspondant aux multiples entiers de la fréquence fondamentale estimée F0. Les flancs des pics étant assez raides, une petite erreur de positionnement de la fréquence fondamentale F0, amplifiée par l'indice d'harmonique k, peut distordre fortement l'enveloppe supérieure estimée du spectre et provoquer une mauvaise modélisation de la structure formantique du signal. Par exemple, prendre directement l'amplitude spectrale pour la fréquence 3.F0 dans le cas des figures 4 et 5 produirait une erreur importante dans l'extraction de l'enveloppe supérieure au voisinage de l'harmonique d'ordre k = 3, alors qu'il s'agit d'une zone énergétiquement importante dans l'exemple dessiné. En effectuant l'interpolation à partir du véritable maximum, on évite ce genre d'erreur d'estimation de l'enveloppe supérieure.
- Dans l'exemple représenté sur la figure 4, l'interpolation est effectuée entre des points dont l'abscisse est la fréquence correspondant au maximum de l'amplitude d'un pic spectral, et dont l'ordonnée est ce maximum, avant ou après compression.
- L'interpolation effectuée pour calculer l'enveloppe supérieure LX_sup est une simple interpolation linéaire. Bien entendu une autre forme d'interpolation pourrait être utilisée (par exemple polynomiale ou spline).
- Dans la variante préférée représentée sur la figure 5, l'interpolation est effectuée entre des points dont l'abscisse est une fréquence k.F0 multiple de la fréquence fondamentale (en fait la fréquence la plus proche dans le spectre discret) et dont l'ordonnée est l'amplitude maximale, avant ou après compression, du spectre au voisinage de cette fréquence multiple.
- En comparant les figures 4 et 5, on peut voir que le mode d'extraction selon la figure 5, qui repositionne les pics sur les fréquences harmoniques, conduit à une meilleure précision sur l'amplitude des pics que le décodeur attribuera aux fréquences multiples de la fréquence fondamentale. Il peut se produire un léger déplacement en fréquence de la position de ces pics, ce qui n'est pas perceptuellement très important et n'est d'ailleurs pas évité non plus dans le cas de la figure 4. Dans le cas de la figure 4, les points d'ancrage pour l'interpolation sont confondus avec les sommets des pics harmoniques. Dans le cas de la figure 5, on impose que ces points d'ancrage se trouvent précisément aux fréquences multiples de la fréquence fondamentale, leurs amplitudes correspondant à celles des pics.
- L'intervalle de recherche du maximum d'amplitude associé à une harmonique de rang k est centré sur l'index i de la fréquence de la TFR la plus proche de k.F0, c'est-à-dire


- Afin d'améliorer la résolution dans les basses fréquences et donc de représenter plus fidèlement les amplitudes des harmoniques dans cette zone, une distorsion non-linéaire de l'échelle des fréquences est opérée sur l'enveloppe supérieure comprimée par un module 12 avant que le module 13 effectue la transformée de Fourier rapide inverse (TFRI) fournissant les coefficients cepstraux cx_sup.
- La distorsion non-linéaire permet de minimiser plus efficacement l'erreur de modélisation. Elle est par exemple effectuée selon une échelle de fréquences de type Mel ou Bark. Cette distorsion peut éventuellement dépendre de la fréquence fondamentale estimée F0. La figure 1 illustre le cas de l'échelle Mel. La relation entre les fréquences F du spectre linéaire, exprimées en hertz, et les fréquences F' de l'échelle Mel est la suivante :

- Afin de limiter le débit de transmission, une troncature des coefficients cepstraux cx_sup est effectuée. Le module de TFRI 13 a besoin de calculer seulement un vecteur cepstral de NCS coefficients cepstraux d'ordres 0 à NCS-1. A titre d'exemple, NCS peut être égal à 16.
- Un post-filtrage dans le domaine cepstral, appelé post-liftrage, est appliqué par un module 15 à l'enveloppe supérieure comprimée LX_sup. Ce post-liftrage correspond à une manipulation des coefficients cepstraux cx_sup délivrés par le module de TRFI 13, qui correspond approximativement à un post-filtrage de la partie harmonique du signal par une fonction de transfert ayant la forme classique :

où A(z) est la fonction de transfert d'un filtre de prédiction linéaire du signal audio, γ1 et γ2 sont des coefficients compris entre 0 et 1, et µ est un coefficient de préaccentuation éventuellement nul. La relation entre le coefficient post-liftré d'ordre i, noté cp(i), et le coefficient cepstral correspondant c(i) =-cx_sup(i) délivré par le module 13 est alors :
- Le coefficient de préaccentuation optionnel µ peut être contrôlé en posant comme contrainte de préserver la valeur du coefficient cepstral cx_sup(1) relatif à la pente. En effet, la valeur c(1) = cx_sup(1) d'un bruit blanc filtré par le filtre de préaccentuation correspond au coefficient de préaccentuation. On peut ainsi choisir ce dernier de la façon suivante :

- Après le post-liftre 15, un module de normalisation 16 modifie encore les coefficients cepstraux en imposant la contrainte de modélisation exacte d'un point du spectre initial, qui est de préférence le point le plus énergétique parmi les maxima spectraux extraits par le module 9. En pratique, cette normalisation modifie seulement la valeur du coefficient cp(0).
- Le module de normalisation 16 fonctionne de la façon suivante : il recalcule une valeur du spectre synthétisé à la fréquence du maximum indiqué par le module 9, par transformée de Fourier des coefficients cepstraux tronqués et post-liftrés, en tenant compte de la distorsion non-linéaire de l'axe des fréquences ; il détermine un gain de normalisation gN par la différence logarithmique entre la valeur du maximum fournie par le module 9 et cette valeur recalculée ; et il ajoute le gain gN au coefficient cepstral post-liftré cp(0). Cette normalisation peut être vue comme faisant partie du post-liftrage.
- Les coefficients cepstraux post-liftrés et normalisés font l'objet d'une quantification par un module 18 qui transmet des index de quantification correspondants icxs au multiplexeur de sortie 6 du codeur.
- Le module 18 peut fonctionner par quantification vectorielle à partir de vecteurs cepstraux formés de coefficients post-liftrés et normalisés, notés ici cx[n] pour la trame de signal de rang n. A titre d'exemple, le vecteur cepstral cx[n] de NCS = 16 coefficients cepstraux cx[n,0], cx[n,1], ..., cx[n,NCS-1] est distribué en quatre sous-vecteurs cepstraux contenant chacun quatre coefficients d'ordres consécutifs. Le vecteur cepstral cx[n] peut être traité par les moyens représentés sur la figure 6, faisant partie du module de quantification 18. Ces moyens mettent en oeuvre, pour chaque composante cx[n,i], un prédicteur de la forme :

où rcx[n] désigne un vecteur résiduel de prédiction pour la trame de rang n dont les composantes sont respectivement notées rcx[n,0], rcx[n,1], ..., rcx[n,NCS-1], et α(i) désigne un coefficient de prédiction choisi pour être représentatif d'une corrélation inter-trame supposée. Après quantification des résidus, ce vecteur résiduel est défini par :
où rcx_q[n-1] désigne le vecteur résiduel quantifié pour la trame de rang n-1, dont les composantes sont respectivement notées rcx_q[n,0], rcx_q[n,1], ..., rcx_q[n,NCS-1]. - Le numérateur de la relation (10) est obtenu par un soustracteur 20, dont les composantes du vecteur de sortie sont divisées par les quantités 2-α(i) en 21. Aux fins de la quantification, le vecteur résiduel rcx[n] est subdivisé en quatre sous-vecteurs, correspondant à la subdivision en quatre sous-vecteurs cepstraux. Sur la base d'un dictionnaire obtenu par apprentissage préalable, l'unité 22 procède à la quantification vectorielle de chaque sous-vecteur du vecteur résiduel rcx[n]. Cette quantification peut consister, pour chaque sous-vecteur srcx[n], à sélectionner dans le dictionnaire le sous-vecteur quantifié srcx_q[n] qui minimise l'erreur quadratique ∥srcx[n]-srcx_q[n]∥2. L'ensemble icxs des index de quantification icx, correspondant aux adresses dans le ou les dictionnaires des sous-vecteurs résiduels quantifiés srcx_q[n], est fourni au multiplexeur de sortie 6.
- L'unité 22 délivre également les valeurs des sous-vecteurs résiduels quantifiés, qui forment le vecteur rcx_q[n]. Celui-ci est retardé d'une trame en 23, et ses composantes sont multipliées par les coefficients α(i) en 24 pour fournir le vecteur à l'entrée négative du soustracteur 20. Ce dernier vecteur est d'autre part fourni à un additionneur 25, dont l'autre entrée reçoit un vecteur formé par les composantes du résidu quantifié rcx_q[n] respectivement multipliées par les quantités 1-α(i) en 26. L'additionneur 25 délivre ainsi le vecteur cepstral quantifié cx_q[n] que récupérera le décodeur.
- Le coefficient de prédiction α(i) peut être optimisé séparément pour chacun des coefficients cepstraux. Les dictionnaires de quantification peuvent aussi être optimisés séparément pour chacun des quatre sous-vecteurs cepstraux. D'autre part, il est possible, de façon connue en soi, de normaliser les vecteurs cepstraux avant d'appliquer le schéma de prédiction/quantification, à partir de la variance des cepstres.
- Il est à noter que le schéma ci-dessus de quantification des coefficients cepstraux peut n'être appliqué que pour certaines seulement des trames. Par exemple, on peut prévoir un second mode de quantification ainsi qu'un processus de sélection de celui des deux modes qui minimise-un critère de moindres carrés avec les coefficients cepstraux à quantifier, et transmettre avec les index de quantification de la trame un bit indiquant lequel des deux modes a été sélectionné.
- Les coefficients cepstraux quantifiés cx_sup_q = cx_q[n] fournis par l'additionneur 25 sont adressés à un module 28 qui recalcule les amplitudes spectrales associées à une ou plusieurs des harmoniques de la fréquence fondamentale F0 (figure 1). Ces amplitudes spectrales sont par exemple calculées sous forme comprimée, en appliquant la transformée de Fourier aux coefficients cepstraux quantifiés en tenant compte de la distorsion non-linéaire de l'échelle des fréquences utilisée dans la transformation cepstrale. Les amplitudes ainsi recalculées sont fournies à un module d'adaptation 29 qui les compare à des amplitudes de maxima déterminées par le module d'extraction 9.
- Le module d'adaptation 29 contrôle le post-liftre 15 de façon à minimiser un écart de module entre le spectre du signal audio et les valeurs de module correspondantes calculées en 28. Cet écart de module peut être exprimé par une somme de valeurs absolues de différences d'amplitudes, comprimées ou non, correspondant à une ou plusieurs des fréquences harmoniques. Cette somme peut être pondérée en fonction des amplitudes spectrales associées à ces fréquences.
- De façon optimale, l'écart de module pris en compte dans l'adaptation du post-liftrage tiendrait compte de toutes les harmoniques du spectre. Cependant, afin de réduire la complexité de l'optimisation, le module 28 peut ne resynthétiser les amplitudes spectrales que pour une ou plusieurs fréquences multiples de la fréquence fondamentale F0, sélectionnées sur la base de l'importance du module du spectre en valeur absolue. Le module d'adaptation 29 peut par exemple considérer les trois pics spectraux les plus intenses dans le calcul de l'écart de module à minimiser.
- Dans une autre réalisation, le module d'adaptation 29 estime une courbe de masquage spectral du signal audio au moyen d'un modèle psychoacoustique, et les fréquences prises en compte dans le calcul de l'écart de module à minimiser sont sélectionnées sur la base de l'importance du module du spectre relativement à la courbe de masquage (on peut par exemple prendre les trois fréquences pour lesquelles le module du spectre dépasse le plus de la courbe de masquage). Différentes méthodes classiques sont utilisables pour calculer la courbe de masquage à partir du signal audio. On peut par exemple utiliser celle développée par J.D. Johnston (« Transform Coding of Audio Signals Using Perceptual Noise Criteria », IEEE Journal on Selected Area in Communications, Vol. 6, No. 2, février 1988).
- Pour réaliser l'adaptation du post-liftrage, le module 29 peut utiliser un modèle d'identification de filtre. Une méthode plus simple consiste à prédéfinir un ensemble de jeux de paramètres de post-liftrage, c'est-à-dire un ensemble de couples γ1, γ2 dans le cas d'un post-liftrage selon les relations (8), à effectuer les opérations incombant aux modules 15, 16, 18 et 28 pour chacun de ces jeux de paramètres, et à retenir celui des jeux de paramètres qui conduit à l'écart de module minimal entre le spectre du signal et les valeurs recalculées. Les index de quantification fournis par le module 18 sont alors ceux qui se rapportent au meilleur jeu de paramètres.
- Par un processus analogue à celui de l'extraction des coefficients cx_sup représentant l'enveloppe supérieure comprimée LX_sup du spectre du signal, le codeur détermine des coefficients cx_inf représentant une enveloppe inférieure comprimée LX_inf. Un module 30 extrait du spectre comprimé LX des amplitudes spectrales associées à des fréquences situées dans des zones du spectre intermédiaires par rapport aux fréquences multiples de la fréquence fondamentale estimée F0.
- Dans l'exemple illustré par les figures 4 et 5, chaque amplitude associée à une fréquence située dans une zone intermédiaire entre deux harmoniques successives k.F0 et (k+1).F0 correspond simplement au module du spectre pour la fréquence (k+1/2).F0 située au milieu de l'intervalle séparant les deux harmoniques. Dans une autre réalisation, cette amplitude pourrait être une moyenne du module du spectre sur une petite plage entourant cette fréquence (k+1/2).F0.
- Un module 31 procède à une interpolation, par exemple linéaire, des amplitudes spectrales associées aux fréquences situées dans les zones intermédiaires pour obtenir l'enveloppe inférieure comprimée LX_inf.
- La transformation cepstrale appliquée à cette enveloppe inférieure comprimée LX_inf est effectuée suivant une échelle de fréquences résultant d'une distorsion non-linéaire appliquée par un module 32. Le module de TFRI 33 calcule un vecteur cepstral de NCI coefficients cepstraux cx_inf d'ordres 0 à NCl-1 représentant l'enveloppe inférieure. NCI est un nombre qui peut être sensiblement plus petit que NCS, par exemple NCI = 4.
- La transformation non-linéaire de l'échelle des fréquences pour la transformation cepstrale de l'enveloppe inférieure peut être réalisée vers une échelle plus fine aux hautes fréquences qu'aux basses fréquences, ce qui permet avantageusement de bien modéliser les composantes non-voisées du signal aux hautes fréquences. Toutefois, pour assurer une homogénéité de représentation entre l'enveloppe supérieure et l'enveloppe inférieure, on pourra préférer adopter dans le module 32 la même échelle que dans le module 12 (Mel dans l'exemple considéré).
- Les coefficients cepstraux cx_inf représentant l'enveloppe inférieure comprimée sont quantifiés par un module 34, qui peut fonctionner de la même manière que le module 18 de quantification des coefficients cepstraux représentant l'enveloppe supérieure comprimée. Dans le cas considéré, où on se limite à NCI = 4 coefficients cepstraux pour l'enveloppe inférieure, le vecteur ainsi formé est soumis à une quantification vectorielle de résidu de prédiction, effectuée par des moyens identiques à ceux représentés sur la figure 6 mais sans subdivision en sous-vecteurs. L'index de quantification icx = icxi déterminé par le quantificateur vectoriel 22 pour chaque trame relativement aux coefficients cx_inf est fourni au multiplexeur de sortie 6 du codeur.
- Le codeur représenté sur la figure 1 ne comporte aucun dispositif particulier pour coder les phases du spectre aux harmoniques du signal audio.
- En revanche, il comporte des moyens 36-40 pour coder une information temporelle liée à la phase de la composante non-harmonique représentée par l'enveloppe inférieure.
- Un module 36 de décompression spectrale et un module 37 de TFRI forment une estimation temporelle de la trame de la composante non-harmonique. Le module 36 applique une fonction de décompression réciproque de la fonction de compression appliquée par le module 8 (c'est-à-dire une exponentielle ou une fonction puissance 1/γ) à l'enveloppe inférieure comprimée LX_inf produite par le module d'interpolation 31. Ceci fournit le module de la trame estimée de la composante non-harmonique, dont la phase est prise égale à celle ϕX du spectre du signal X sur la trame. La transformée de Fourier inverse effectuée par le module 37 fournit la trame estimée de la composante non-harmonique.
- Le module 38 subdivise cette trame estimée de la composante non-harmonique en plusieurs segments temporels. La trame délivrée par le module 37 se composant de 2N = 512 échantillons pondérés comme illustré par la figure 3, le module 38 considère seulement les N/2 = 128 premiers échantillons et les N/2 = 128 derniers échantillons, et les subdivise par exemple en huit segments de 32 échantillons consécutifs représentant chacun 4 ms de signal.
- Pour chaque segment, le module 38 calcule l'énergie égale à la somme des carrés des échantillons, et forme un vecteur E1 formé de huit composantes réelles positives égales aux huit énergies calculées. La plus grande de ces huit énergies, notée EM, est également déterminée pour être fournie, avec le vecteur E1, à un module de normalisation 39. Celui-ci divise chaque composante du vecteur E1 par EM, de sorte que le vecteur normalisé Emix est formé de huit composantes comprises entre 0 et 1. C'est ce vecteur normalisé Emix, ou vecteur de pondération, qui est soumis à la quantification par le module 40. Celui-ci peut opérer une quantification vectorielle avec un dictionnaire déterminé lors d'un apprentissage préalable. L'index de quantification iEm est fourni par le module 40 au multiplexeur de sortie 6 du codeur.
- La figure 7 montre une variante de réalisation des moyens employés par le codeur de la figure 1 pour déterminer le vecteur Emix de pondération énergétique de la trame de la composante non-harmonique. Les modules 36, 37 de décompression spectrale et de TFRI fonctionnent comme ceux qui portent les mêmes références sur la figure 1. Un module de sélection 42 est ajouté pour déterminer la valeur du module du spectre soumis à la transformée de Fourier inverse 37. Sur la base de la fréquence fondamentale estimée F0, le module 42 identifie des régions harmoniques et des régions non-harmoniques du spectre du signal audio. Par exemple, une fréquence sera considérée comme appartenant à une région harmonique si elle se trouve dans un intervalle de fréquences centré sur une harmonique k.F0 et de largeur correspondant à une largeur de raie spectrale synthétisée, et à une région non-harmonique sinon. Dans les régions non-harmoniques, le signal complexe soumis à la TFRI 37 est égal à la valeur du spectre, c'est-à-dire que son module et sa phase correspondent aux valeurs |X| et ϕX fournies par le module de TFR 3. Dans les régions harmoniques, ce signal complexe a la même phase ϕX que le spectre et un module donné par l'enveloppe inférieure après décompression spectrale 36. Cette façon de procéder selon la figure 7 procure une modélisation plus précise des régions non-harmoniques.
- Le décodeur représenté sur la figure 8 comprend un démultiplexeur d'entrée 45 qui extrait du flux binaire Φ, issu d'un codeur selon la figure 1, les index iF, icxs, icxi, iEm de quantification de la fréquence fondamentale F0, des coefficients cepstraux représentant l'enveloppe supérieure comprimée, des coefficients représentants l'enveloppe inférieure comprimée, et du vecteur de pondération Emix, et les distribue respectivement à des modules 46, 47, 48 et 49. Ces modules 46-49 comportent des dictionnaires de quantification semblables à ceux des modules 5, 18, 34 et 40 de la figure 1, afin de restituer les valeurs des paramètres quantifiés. Les modules 47 et 48 ont des dictionnaires pour former les résidus de prédiction quantifiés rcx_q[n], et ils en déduisent les vecteurs cepstraux quantifiés cx_q[n] avec des éléments identiques aux éléments 23-26 de la figure 6. Ces vecteurs cepstraux quantifiés cx_q[n] fournissent les coefficients cepstraux cx_sup_q et cx_inf_q traités par le décodeur.
- Un module 51 calcule la transformée de Fourier rapide des coefficients cepstraux cx_sup pour chaque trame de signal. L'échelle des fréquences du spectre comprimé qui en résulte est modifiée non-linéairement par un module 52 appliquant la transformation non-linéaire réciproque de celle du module 12 de la figure 1, et qui fournit l'estimation LX_sup de l'enveloppe supérieure comprimée. Une décompression spectrale de LX_sup, opérée par un module 53, fournit l'enveloppe supérieure X_sup comportant les valeurs estimées du module du spectre aux fréquences multiples de la fréquence fondamentale F0. Le module 54 synthétise l'estimation spectrale Xv de la composante harmonique du signal audio, par une somme de raies spectrales centrées sur les fréquences multiples de la fréquence fondamentale F0 et dont les amplitudes (en module) sont celles données par l'enveloppe supérieure X_sup.
- Bien que le flux numérique d'entrée Φ ne comporte pas d'informations spécifiques sur la phase du spectre du signal aux harmoniques de la fréquence fondamentale, le décodeur de la figure 8 est capable d'extraire de l'information sur cette phase à partir des coefficients cepstraux cx_sup_q représentant l'enveloppe supérieure comprimée. Cette information de phase est utilisée pour affecter une phase ϕ(k) à chacune des raies spectrales déterminées par le module 54 dans l'estimation de la composante harmonique du signal.
- En première approximation, le signal de parole peut être considéré comme étant à phase minimale. D'autre part, il est connu que l'information de phase minimale peut se déduire facilement d'une modélisation cepstrale. Cette information de phase minimale est donc calculée pour chaque fréquence harmonique. L'hypothèse de phase minimale signifie que l'énergie du signal synthétisé est localisée au début de chaque période de la fréquence fondamentale F0.
- Pour être plus proche d'un signal de parole réel, on introduit un peu de dispersion au moyen d'un post-liftrage spécifique des cepstres lors de la synthèse de la phase. Avec ce post-liftrage, effectué par le module 55 de la figure 8, il est possible d'accentuer les résonances formantiques de l'enveloppe et donc de contrôler la dispersion des phases. Ce post-liftrage est par exemple de la forme (8).
- Pour limiter les ruptures de phase, il est préférable de lisser les coefficients cepstraux post-liftrés, ce qui est effectué par le module 56. Le module 57 déduit des coefficients cepstraux post-liftrés et lissés la phase minimale affectée à chaque raie spectrale représentant un pic harmonique du spectre.
- Les opérations effectuées par les modules 56, 57 de lissage et d'extraction de la phase minimale sont illustrées par l'organigramme de la figure 9. Le module 56 examine les variations des coefficients cepstraux pour appliquer un lissage moins important en présence de variations brusques qu'en présence de variations lentes. Pour cela, il effectue le lissage des coefficients cepstraux au moyen d'un facteur d'oubli λC choisi en fonction d'une comparaison entre un seuil dth et une distance d'entre deux jeux successifs de coefficients cepstraux post-liftrés. Le seuil dth est lui-même adapté en fonction des variations des coefficients cepstraux.
- La première étape 60 consiste à calculer la distance d entre les deux vecteurs successifs relatifs aux trames n-1 et n. Ces vecteurs, notés ici cxp[n-1] et cxp[n], correspondent pour chaque trame à l'ensemble des NCS coefficients cepstraux post-liftrés représentant l'enveloppe supérieure comprimée. La distance utilisée peut notamment être la distance euclidienne entre les deux vecteurs ou encore une distance quadratique.
- Deux lissages sont d'abord effectués, respectivement au moyen de facteurs d'oubli λmin et λmax, pour déterminer une distance minimale dmin et une distance maximale dmax. Le seuil dth est ensuite déterminé à l'étape 70 comme étant situé entre les distances minimale et maximale dmin, dmax: dth = β.dmax + (1-β).dmin, le coefficient β étant par exemple égal à 0,5.
- Dans l'exemple représenté, les facteurs d'oubli λmin et λmax sont eux-mêmes sélectionnés parmi deux valeurs distinctes, respectivement λmin1, λmin2 et λmax1, λmax2 comprises entre 0 et 1, les indices λmin1, λmax1 étant chacun sensiblement plus près de 0 que les indices λmin2, λmax2 Si d > dmin (test 61), le facteur d'oubli λmin est égal à λmin1 (étape 62) ; sinon il est pris égal à λmin2 (étape 63). A l'étape 64, la distance minimale dmin est prise égale à λmin.dmin + (1-λmin).d. Si d > dmax (test 65), le facteur d'oubli λmax est égal à λmax1 (étape 66) ; sinon il est pris égal à λmax2 (étape 67). A l'étape 68, la distance minimale dmax est prise égale à λmax.dmax + (1-λmax).d.
- Si la distance d entre les deux vecteurs cepstraux consécutifs est plus grande que le seuil dth (test 71), on adopte pour le facteur d'oubli λc une valeur λc1 relativement proche de 0 (étape 72). On considère dans ce cas que le signal correspondant est de type non stationnaire, de sorte qu'il n'y a pas lieu de conserver une grande mémoire des coefficients cepstraux antérieurs. Si d ≤ dth, on adopte à l'étape 73 pour le facteur d'oubli λc une valeur λc2 moins proche de 0 afin de lisser davantage les coefficients cepstraux. Le lissage est effectué à l'étape 74, où le vecteur cxl[n] de coefficients lissés pour la trame courante n est déterminé par :

- Le module 57 calcule ensuite les phases minimales ϕ(k) associées aux harmoniques k.F0. De façon connue, la phase minimale pour une harmonique d'ordre k est donnée par :
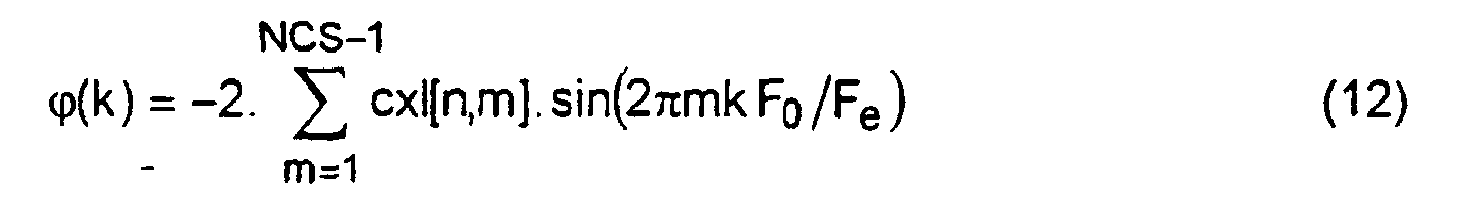
où cxl[n,m] désigne le coefficient cepstral lissé d'ordre m pour la trame n. - A l'étape 75, l'index d'harmonique k est initialisé à 1. Pour initialiser le calcul de la phase minimale affectée à l'harmonique k, la phase ϕ(k) et l'index cepstral m sont initialisés respectivement à 0 et 1 à l'étape 76 A l'étape 77, le module 57 ajoute à la phase ϕ(k) la quantité -2.cxl[n,m].sin(2πmk.F0/Fe). L'index cepstral m est incrémenté à l'étape 78 et comparé à NCS à l'étape 79. Les étapes 77 et 78 sont répétées tant que m < NCS. Quand m = NCS, le calcul de la phase minimale est terminé pour l'harmonique k, et l'index k est incrémenté à l'étape 80. Le calcul de phases minimales 76-79 est renouvelé pour l'harmonique suivante tant que k.F0 < Fe/2 (test 81).
- Dans l'exemple de réalisation selon la figure 8, le module 54 tient compte d'une phase constante sur la largeur de chaque raie spectrale, égale à la phase minimale ϕ(k) fournie pour l'harmonique correspondante k par le module 57.
- L'estimation Xv de la composante harmonique est synthétisée par sommation de raies spectrales positionnées aux fréquences harmoniques de la fréquence fondamentale F0 Lors de cette synthèse, on peut positionner les raies spectrales sur l'axe des fréquences avec une résolution supérieure à la résolution de la transformée de Fourier. Pour cela, on précalcule une fois pour toutes une raie spectrale de référence selon la résolution supérieure. Ce calcul peut consister en une transformée de Fourier de la fenêtre d'analyse fA avec une taille de transformée de 16384 points, procurant une résolution de 0,5 Hz par point. La synthèse de chaque raie harmonique est alors effectuée par le module 54 en positionnant sur l'axe des fréquences la raie de référence à haute résolution, et en sous-échantillonnant cette raie spectrale de référence pour se ramener à la résolution de 16,625 Hz de la transformée de Fourier sur 512 points. Ceci permet de positionner avec précision la raie spectrale.
- Pour la détermination de l'enveloppe inférieure, le module de TFR 85 du décodeur de la figure 8 reçoit les NCI coefficients cepstraux quantifiés cx_inf_q d'ordres 0 à NCI - 1, et il les complète avantageusement par les NCS - NCI coefficients cepstraux cx_sup_q d'ordre NCI à NCS -1 représentant l'enveloppe supérieure. En effet, on peut estimer en première approximation que les variations rapides de l'enveloppe inférieure comprimée sont bien reproduites par celles de l'enveloppe supérieure comprimée. Dans une autre réalisation, le module de TFR 85 pourrait ne considérer que les NCI paramètres cepstraux cx_inf_q.
- Le module 86 convertit l'échelle de fréquences de manière réciproque de la conversion opérée par le module 32 du codeur, afin de restituer l'estimation LX_inf de l'enveloppe inférieure comprimée, soumise au module de décompression spectrale 87. En sortie du module 87, le décodeur dispose d'une enveloppe inférieure X_inf comportant les valeurs du module du spectre dans les vallées situées entre les pics harmoniques.
- Cette enveloppe X_inf va moduler le spectre d'une trame de bruit dont la phase est traitée en fonction du vecteur de pondération quantifié Emix extrait par le module 49. Un générateur 88 délivre une trame de bruit normalisé dont les segments de 4 ms sont pondérés dans un module 89 conformément aux composantes normalisées du vecteur Emix fourni par le module 49 pour la trame courante. Ce bruit est un bruit blanc filtré passe-haut pour tenir compte du faible niveau qu'a en principe la composante non-voisée aux basses fréquences. A partir du bruit pondéré en énergie, le module 90 forme des trames de 2N = 512 échantillons en appliquant la fenêtre d'analyse fA, l'insertion de 256 échantillons à zéro et la permutation circulaire pour la compensation de phase conformément à ce qui a été expliqué en référence à la figure 3. La transformée de Fourier de la trame résultante est calculée par le module TFR 91.
- L'estimation spectrale Xuv de la composante non-harmonique est déterminée par le module de synthèse spectrale 92 qui effectue une pondération fréquence par fréquence. Cette pondération consiste à multiplier chaque valeur spectrale complexe fournie par le module de TFR 91 par la valeur de l'enveloppe inférieure X_inf obtenue pour la même fréquence par le module de décompression spectrale 87.
- Les estimations spectrales Xv, Xuv des composantes harmonique (voisée dans le cas d'un signal de parole) et non-harmonique (ou non-voisée) sont combinées par un module de mixage 95 contrôlé par un module 96 d'analyse du degré d'harmonicité (ou de voisement) du signal.
- L'organisation de ces modules 95, 96 est illustrée par la figure 10. Le module d'analyse 96 comporte une unité 97 d'estimation d'un degré de voisement W dépendant de la fréquence, à partir duquel sont calculés quatre gains dépendant de la fréquence, à savoir deux gains gv, guv contrôlant l'importance relative des composantes harmonique et non-harmonique dans le signal synthétisé, et deux gains gv_ϕ, guv_ϕ utilisés pour bruiter la phase de la composante harmonique.
- Le degré de voisement W(i) est une valeur à variation continue comprise entre 0 et 1 déterminée pour chaque index de fréquence i (0 ≤ i < N) en fonction de l'enveloppe supérieure X_sup(i) et de l'enveloppe inférieure X_inf(i) obtenues pour cette fréquence i par les modules de décompression 53, 87. Le degré de voisement W(i) est estimé par l'unité 97 pour chaque index de fréquence i correspondant à une harmonique de la fréquence fondamentale F0, à savoir

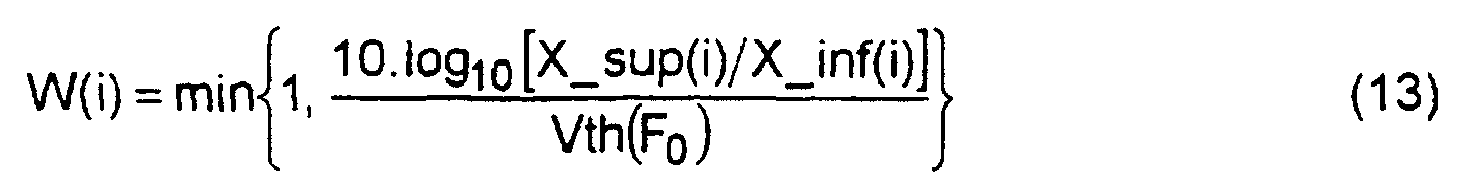
Le seuil Vth(F0) correspond à la dynamique moyenne calculée sur un spectre synthétique purement voisé à la fréquence fondamentale. Il est avantageusement choisi dépendant de la fréquence fondamentale F0. - Le degré de voisement W(i) pour une fréquence autre que les fréquences harmoniques est obtenu simplement comme étant égal à celui estimé pour l'harmonique la plus proche.
- Le gain gv(i), qui dépend de la fréquence, est obtenu en appliquant une fonction non-linéaire au degré de voisement W(i) (bloc 98). Cette fonction non-linéaire a par exemple la forme représentée sur la figure 11 :
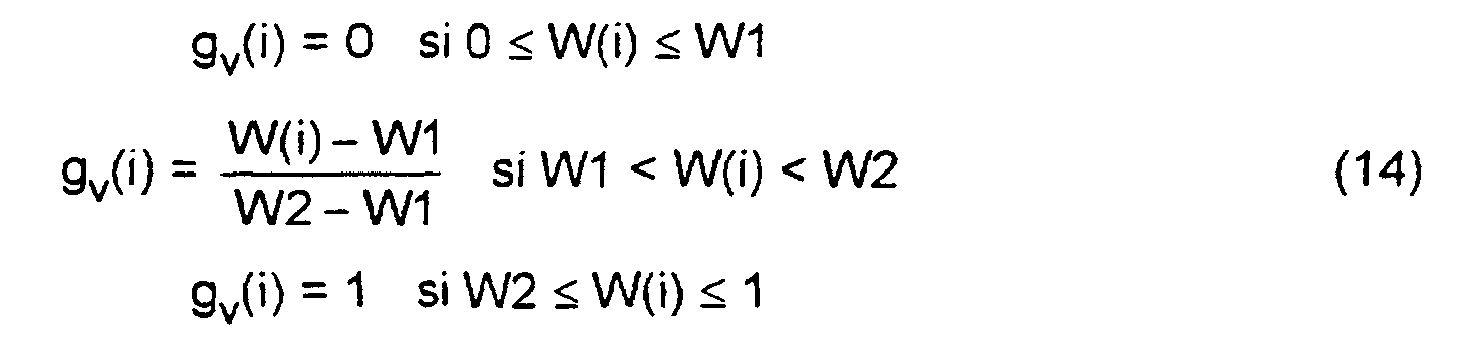
les seuils W1, W2 étant tels que 0 < W1 < W2 < 1. Le gain guv peut être calculé de manière semblable au gain gv (la somme des deux gains gv, guv étant constante, par exemple égale à 1), ou déduit simplement de celui-ci par la relation guv(i) = 1 - gv(i), comme schématisé par le soustracteur 99 sur la figure 10. - Il est intéressant de pouvoir bruiter la phase de la composante harmonique du signal à une fréquence donnée si l'analyse du degré de voisement montre que le signal est plutôt de type non-harmonique à cette fréquence. Pour cela, la phase

- Un premier gain gv1_ϕ est calculé en appliquant une fonction non-linéaire au degré de voisement W(i), comme schématisé par le bloc 100 sur la figure 10. Cette fonction non-linéaire peut avoir la forme représentée sur la figure 12 :

les seuils W3 et W4 étant tels que 0 < W3 < W4 < 1, et le gain minimal G1 étant compris entre 0 et 1. - Un multiplieur 101 multiplie pour chaque fréquence d'index i le gain gv1_ϕ par un autre gain gv2_ϕ dépendant seulement de l'index de fréquence i, pour former le gain gv_ϕ(i). Le gain gv2_ϕ(i) dépend non-linéairement de l'index de fréquence i, par exemple comme indiqué sur la figure 13 :

les index i1 et i2 étant tels que 0 < i1 < i2 ≤ N, et le gain minimal G2 étant compris entre 0 et 1. Le gain guv_ϕ(i) peut être calculé simplement comme étant égal à 1 - gv_ϕ(i) = 1 - gv1_ϕ(i)·gv2_ϕ(i) (soustracteur 102 de la figure 10). - Le spectre complexe Y du signal synthétisé est produit par le module de mixage 95, qui réalise la relation de mixage suivante, pour 0 ≤ i < N :

avec
où ϕv(i) désigne l'argument du nombre complexe Xv(i) fourni par le module 54 pour la fréquence d'index i (bloc 104 de la figure 1.0), et ϕuv(i) désigne l'argument du nombre complexe Xuv(i) fourni par le module 92 (bloc 105 de la figure 10). Cette combinaison est réalisée par les multiplieurs 106-110 et les additionneurs 111-112 représentés sur la figure 10. - Le spectre mixé Y(i) pour 0 ≤ i < 2N (avec Y(2N-1-i) =Y(i)) est ensuite transformé dans le domaine temporel par le module de TFRI 115 (figure 8). On ne retient que les N/2 = 128 premiers et les N/2 = 128 derniers échantillons de la trame de 2N = 512 échantillons produite par le module 115, et on applique la permutation circulaire inverse de celle illustrée par la figure 3 pour obtenir la trame synthétisée de N = 256 échantillons pondérés par la fenêtre d'analyse fA.
- Les trames successivement obtenues de cette manière sont finalement traitées par le module de synthèse temporelle 116 qui forme le signal audio décodé x̂.
- Le module de synthèse temporelle 116 effectue une somme à recouvrement de trames modifiées par rapport à celles successivement évaluées en sortie du module 115. La modification peut être vue en deux étapes illustrées respectivement par les figures 14 et 15.
- La première étape (figure 14) consiste à multiplier chaque trame 2' délivrée par le module de TFRI 115 par une fenêtre 1/fA inverse de la fenêtre d'analyse fA employée par le module 1 du codeur. Les échantillons de la trame 2" qui en résultent sont donc pondérés uniformément.
- La seconde étape (figure 15) consiste à multiplier les échantillons de cette trame 2" par une fenêtre de synthèse fS vérifiant les propriétés suivantes :


où A désigne une constante positive arbitraire, par exemple A = 1. La fenêtre de synthèse fS(i) croît progressivement de 0 à A pour i allant de 0 à L. C'est par exemple une demi-sinusoïde surélevée :
- Après avoir repondéré chaque trame 2" par la fenêtre de synthèse fS, le module 116 positionne les trames successives avec leurs décalages temporels de M = 160 échantillons et leurs recouvrements temporels de L = 96 échantillons, puis il effectue la somme des trames ainsi positionnées dans le temps. Du fait des propriétés (19) et (20) de la fenêtre de synthèse fS, chaque échantillon du signal audio décodé x̂ ainsi obtenu est affecté d'un poids global uniforme égal à A. Ce poids global provient de la contribution d'une trame unique si l'échantillon a dans cette trame un rang i tel que L ≤ i < N - L, et comporte les contributions sommées de deux trames successives si 0 ≤ i < L où N-L ≤ i < N.
- On peut ainsi effectuer la synthèse temporelle de façon simple même si, comme dans le cas considéré, le recouvrement L entre deux trames successives est plus petit que la moitié de la taille N de ces trames.
- Les deux étapes exposées ci-dessus pour la modification des trames de signal peuvent être fusionnées en une seule étape. Il suffit de précalculer une fenêtre composée fC(i) = fS(i)/fA(i), et de multiplier simplement les trames 2' de N = 256 échantillons délivrées par le module 115 par la fenêtre composée fC avant d'effectuer la sommation à recouvrement.
- La figure 16 montre l'allure de la fenêtre composée fC dans le cas où la fenêtre d'analyse fA est une fenêtre de Hamming et la fenêtre de synthèse fS a la forme donnée par les relations (19) à (21).
- D'autres formes de la fenêtre de synthèse fS vérifiant les relations (19) et (20) peuvent être employées. Dans la variante de la figure 17, c'est une fonction affine par morceaux définie par :

- Afin d'améliorer la qualité de codage du-signal audio, le codeur de la figure 1 peut augmenter la cadence de formation et d'analyse des trames, afin de transmettre davantage de paramètres de quantification au décodeur. Dans la structure de trame représentée sur la figure 2, une trame de N = 256 échantillons (32 ms) est formée toutes les 20 ms. Ces trames de 256 échantillons pourraient être formées à une cadence supérieure, par exemple de 10 ms, deux trames successives ayant alors un décalage de M/2 = 80 échantillons et un recouvrement de 176 échantillons.
- Dans ces conditions, on peut transmettre les jeux complets de paramètres de quantification iF, icxs, icxi, iEm pour seulement un sous-ensemble des trames, et transmettre pour les autres trames des paramètres permettant d'effectuer une interpolation adéquate au niveau du décodeur. Dans l'exemple envisagé ci-dessus, le sous-ensemble pour lequel des jeux de paramètres complets sont transmis peut être constitué par les trames de rang entier n, dont la périodicité est de M/Fe = 20 ms, et les trames pour lesquelles une interpolation est effectuée peuvent être celles de rang demi-entier n + 1/2 qui sont décalées de 10 ms par rapport aux trames du sous-ensemble.
- Dans la réalisation illustrée par la figure 18, les notations cx_q [n-1] et cx_q[n] désignent des vecteurs cepstraux quantifiés déterminés, pour deux trames successives de rang entier, par le module de quantification 18 et/ou par le module de quantification 34. Ces vecteurs comprennent par exemple quatre coefficients cepstraux consécutifs chacun. Ils pourraient également comprendre davantage de coefficients cepstraux.
- Un module 120 effectue une interpolation de ces deux vecteurs cepstraux cx_q[n-1] et cx_q[n], afin d'estimer une valeur intermédiaire cx_i[n-1/2]. L'interpolation effectuée par le module 120 peut être une simple moyenne arithmétique des vecteurs cx_q[n-1] et cx_q[n]. En variante, le module 120 pourrait appliquer une formule d'interpolation plus sophistiquée, par exemple polynomiale, en se fondant également sur les vecteurs cepstraux obtenus pour des trames antérieures à la trame n-1. D'autre part, si plus d'une trame interpolée est intercalée entre deux trames consécutives de rang entier, l'interpolation tient compte de la position relative de chaque trame interpolée.
- A l'aide des moyens précédemment décrits, le codeur calcule également les coefficients cepstraux cx[n-1/2] relatifs à la trame de rang demi-entier. Dans le cas de l'enveloppe supérieure, ces coefficients cepstraux sont ceux fournis par le module de TFRI 13 après post-liftrage 15 (par exemple avec les mêmes coefficients de post-liftrage que pour la trame précédente n-1) et normalisation 16. Dans le cas de l'enveloppe inférieure, les coefficients cepstraux cx[n-1/2] sont ceux délivrés par le module de TFRI 33.
- Un soustracteur 121 forme la différence ecx[n-1/2] entre les coefficients cepstraux cx[n-1/2] calculés pour la trame de rang demi-entier et les coefficients cx_i[n-1/2] estimés par interpolation. Cette différence est fournie à un module de quantification 122 qui adresse des index de quantification icx[n-1/2] au multiplexeur de sortie 6 du codeur. Le module 122 fonctionne par exemple par quantification vectorielle des erreurs d'interpolation ecx[n-1/2] successivement déterminées pour les trames de rang demi-entier.
- Cette quantification de l'erreur d'interpolation peut être effectuée par le codeur pour chacun des NCS + NCI coefficients cepstraux utilisés par le décodeur, ou seulement pour certains d'entre eux, typiquement ceux d'ordres les plus petits.
- Les moyens correspondants du décodeur sont illustrés par la figure 19. Le décodeur fonctionne essentiellement comme celui décrit en référence à la figure 8 pour déterminer les trames de signal de rang entier. Un module d'interpolation 124 identique au module 120 du codeur estime les coefficients intermédiaires cx_i[n-1/2] à partir des coefficients quantifiés cx_q[n-1] et cx_q[n] fournis par le module 47 et/ou le module 48 à partir des index icxs, icxi extraits du flux Φ. Un module d'extraction de paramètres 125 reçoit l'index de quantification icx[n-1/2] depuis le démultiplexeur d'entrée 45 du décodeur, et en déduit l'erreur d'interpolation quantifiée ecx_q[n-1/2] à partir du même dictionnaire de quantification que celui utilisé par le module 122 du codeur. Un additionneur 126 fait la somme des vecteurs cepstraux cx_i[n-1/2] et ecx_q[n-1/2] afin de fournir les coefficients cepstraux cx[n-1/2] qui seront utilisés par le décodeur (modules 51-57, 95, 96, 115 et/ou modules 85-87, 92, 95, 96, 115) pour former la trame interpolée de rang n-1/2.
- Si certains seulement des coefficients cepstraux ont fait l'objet d'une quantification d'erreur d'interpolation, les autres sont déterminés par le décodeur par une interpolation simple, sans correction.
- Le décodeur peut également interpoler les autres paramètres F0, Emix utilisés pour synthétiser les trames de signal. La fréquence fondamentale F0 peut être interpolée linéairement, soit dans le domaine temporel, soit (de préférence) directement dans le domaine fréquentiel. Pour l'interpolation éventuelle du vecteur de pondération énergétique Emix, il convient d'effectuer l'interpolation après dénormalisation et en tenant compte bien entendu des décalages temporels entre trames.
- Il est à noter qu'il est particulièrement avantageux, pour interpoler la représentation des enveloppes spectrales, d'effectuer cette interpolation dans le domaine cepstral. Contrairement à une interpolation effectuée sur d'autres paramètres, tels que les coefficients LSP (« Line Spectrum Pairs »), l'interpolation linéaire des coefficients cepstraux correspond à l'interpolation linéaire des amplitudes spectrales comprimées.
- Dans la variante représentée sur la figure 20, le codeur utilise les vecteurs cepstraux cx_q[n], cx_q[n-1], ... , cx_q[n-r] et cx_q[n-1/2] calculés pour les dernières trames passées (r ≥ 1) pour identifier un filtre interpolateur optimal qui, lorsqu'on lui soumet les vecteurs cepstraux quantifiés cx_q[n-r], ..., cx_q[n] relatifs aux trames de rang entier, délivre un vecteur cepstral interpolé cx_i[n-1/2] qui présente une distance minimale avec le vecteur cx[n-1/2] calculé pour la dernière trame de rang demi-entier.
- Dans l'exemple représenté sur la figure 20, ce filtre interpolateur 128 est présent dans le codeur, et un soustracteur 129 retranche sa sortie cx_i[n-1/2] du vecteur cepstral calculé cx[n-1/2]. Un module de minimisation 130 détermine le jeu de paramètres {P} du filtre interpolateur 128, pour lequel l'erreur d'interpolation ecx[n-1/2] délivrée par le soustracteur. 129 présente une norme minimale. Ce jeu de paramètres {P} est adressé à un module de quantification 131 qui fournit un index de quantification correspondant iP au multiplexeur de sortie 6 du codeur.
- En fonction du débit alloué dans le flux Φ aux index de quantification des paramètres {P} définissant le filtre interpolateur optimal 128, on pourra adopter une quantification plus ou moins fine de ces paramètres, ou une forme plus ou moins élaborée du filtre interpolateur, ou encore prévoir plusieurs filtres interpolateurs quantifiés de manière distincte pour différents vecteurs de coefficients cepstraux.
- Dans une réalisation simple, le filtre interpolateur 128 est linéaire, avec r=1 :

et le jeu de paramètres {P} se limite au coefficient ρ compris entre 0 et 1. - A partir des index iP de quantification des paramètres {P} obtenus dans le flux binaire ϕ, le décodeur reconstruit le filtre interpolateur 128 (aux erreurs de quantification près), et traite les vecteurs spectraux cx_q[n-r], ... , cx_q[n] afin d'estimer les coefficients cepstraux cx[n-1/2] utilisés pour synthétiser les trames de rang demi-entier.
- De façon générale, le décodeur peut utiliser une méthode d'interpolation simple (sans transmission de paramètres de la part du codeur pour les trames de rang demi-entier), une méthode d'interpolation avec prise en compte d'une erreur d'interpolation quantifiée (selon les figures 17 et 18), ou une méthode d'interpolation avec un filtre interpolateur optimal (selon la figure 19) pour évaluer les trames de rang demi-entier en plus des trames de rang entier évaluées directement comme expliqué en référence aux figures 8 à 13. Le module 116 de synthèse temporelle peut alors combiner l'ensemble de ces trames évaluées pour former le signal synthétisé x̂ de la manière expliquée ci-après en référence aux figures 14, 21 et 22.
- Comme dans la méthode de synthèse temporelle précédemment décrite, le module 116 effectue une somme à recouvrement de trames modifiées par rapport à celles successivement évaluées en sortie du module 115, et cette modification peut être vue en deux étapes dont la première est identique à celle précédemment décrite en référence à la figure 14 (diviser les échantillons de la trame 2' par la fenêtre d'analyse fA).
- La seconde étape (figure 21) consiste à multiplier les échantillons de la trame renormalisée 2" par une fenêtre de synthèse



où A désigne une constante positive arbitraire, par exemple A = 1, et p est l'entier tel que le décalage temporel entre les trames successives (calculées directement et interpolées) soit de M/p échantillons, soit p = 2 dans l'exemple décrit. La fenêtre de synthèse

- La figure 21 montre les trames successives 2" repositionnées dans le temps par le module 116. Les hachures indiquent les portions éliminées des trames (fenêtre de synthèse à 0). On voit qu'en effectuant la somme à recouvrement des échantillons des trames successives, la propriété (25) assure une pondération homogène des échantillons du signal synthétisé.
- Comme dans la méthode de synthèse illustrée par les figures 14 et 15, la procédure de pondération des trames obtenues par transformée de Fourier inverse des spectres Y peut être effectuée en une seule étape, avec une fenêtre composée



- Comme la méthode de synthèse temporelle illustrée par les figures 14 à 17, celle illustrée par les figures 14, 21 et 22 permet de prendre en compte un recouvrement L entre deux trames d'analyse (pour lesquelles l'analyse est effectuée de façon complète) plus petit que la moitié que la taille N de ces trames. De façon générale, cette dernière méthode est applicable lorsque les trames d'analyse successives présentent des décalages temporels mutuels M de plus de N/2 échantillons (même éventuellement de plus de N échantillons si un très bas débit est requis), l'interpolation conduisant à un ensemble de trames dont les décalages temporels mutuels sont de moins de N/2 échantillons.
- Les trames interpolées peuvent faire l'objet d'une transmission réduite de paramètres de codage, comme décrit précédemment, mais cela n'est pas obligatoire. Ce mode de réalisation permet de conserver un intervalle M relativement grand entre deux trames d'analyse, et donc de limiter le débit de transmission requis, tout en limitant les discontinuités susceptibles d'apparaître en raison de la taille de cet intervalle par rapport aux échelles de temps typiques des variations des paramètres du signal audio, notamment les coefficients cepstraux et la fréquence fondamentale.
Claims (13)
- Procédé d'analyse d'un signal audio (x) traité par trames successives de N échantillons, dans lequel on pondère les échantillons de chaque trame par une fenêtre d'analyse (fA) de type Hamming, Hanning, Kaiser ou analogue, on calcule un spectre du signal audio en transformant chaque trame d'échantillons pondérés dans le domaine fréquentiel, et on traite le spectre du signal audio pour délivrer des paramètres (cx_sup, cx_inf, Emix) de synthèse d'un signal dérivé du signal audio analysé, caractérisé en ce que les trames successives comportent une alternance de trames pour lesquelles on délivre des jeux complets de paramètres de synthèse et de trames pour lesquelles on délivre des jeux incomplets de paramètres de synthèse, et en ce que les trames successives pour lesquelles on délivre des jeux complets de paramètres de synthèse présentent des recouvrements mutuels de moins de N/2 échantillons.
- Procédé selon la revendication 1, dans lequel les jeux incomplets de paramètres de synthèse incluent des données (icx[n-1/2]) représentant une erreur (ecx[n-1/2]) d'interpolation d'au moins un des paramètres de synthèse.
- Procédé selon la revendication 1, dans lequel les jeux incomplets de paramètres de synthèse incluent des données (iP) représentant un filtre (128) d'interpolation d'au moins un des paramètres de synthèse.
- Procédé selon l'une quelconque des revendications 1 à 3, dans lequel le traitement du spectre du signal audio (x) comporte une extraction de paramètres de codage (cx_sup, cx_inf, Emix) en vue de la transmission et/ou du stockage du signal audio codé.
- Procédé selon l'une quelconque des revendications 1 à 3, dans lequel le traitement du spectre du signal audio (x) comporte un débruitage par soustraction spectrale.
- Dispositif de traitement audio, comprenant des moyens d'analyse qui réalisent un procédé selon l'une quelconque des revendications 1 à 5.
- Procédé de synthèse d'un signal audio, dans lequel on évalue un ensemble de trames recouvrantes successives de N échantillons du signal audio pondérés par une fenêtre d'analyse (fA), en transformant dans le domaine temporel des estimations spectrales (Y) correspondant respectivement auxdites trames, et on combine les trames évaluées pour former le signal synthétisé (x̂), caractérisé en ce que, pour un sous-ensemble des trames évaluées, les estimations spectrales sont obtenues en traitant des paramètres de synthèse (cx_sup_q, cx_inf_q, Emix) respectivement associés aux trames dudit sous-ensemble tandis que, pour les trames ne faisant pas partie du sous-ensemble, les estimations spectrales sont obtenues avec une interpolation d'une partie au moins des paramètres de synthèse, en ce que les trames successives dudit sous-ensemble présentent des décalages temporels mutuels de M échantillons, le nombre M étant plus grand que N/2, tandis que les trames successives dudit ensemble présentent des décalages temporels mutuels de M/p échantillons, p étant un entier plus grand que 1, en ce qu'on modifie chaque trame évaluée en lui appliquant un traitement correspondant à une division par ladite fenêtre d'analyse (fA) et à une multiplication par une fenêtre de synthèse



- Procédé selon la revendication 7, dans lequel la fenêtre de synthèse

- Procédé selon la revendication 8, dans lequel la fenêtre de synthèse

- Procédé selon l'une quelconque des revendications 7 à 9, dans lequel des données (icx_q[n-1/2]) représentant une erreur d'interpolation (ecx_q[n-1/2]) sont associées aux trames ne faisant pas partie dudit sous-ensemble, et sont utilisées pour corriger au moins un des paramètres de synthèse interpolés (cx_i[n-1/2]).
- Procédé selon l'une quelconque des revendications 7 à 9, dans lequel des données (iP) représentant un filtre interpolateur (128) sont associées aux trames ne faisant pas partie dudit sous-ensemble, et sont utilisées pour interpoler au moins un des paramètres de synthèse.
- Procédé selon l'une quelconque des revendications 7 à 11, dans lequel les paramètres de synthèse comprennent des coefficients cepstraux (cx[n]) soumis à l'interpolation.
- Dispositif de traitement audio, comprenant des moyens de synthèse qui réalisent un procédé selon l'une quelconque des revendications 7 à 12.
Applications Claiming Priority (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| FR9908638 | 1999-07-05 | ||
| FR9908638A FR2796194B1 (fr) | 1999-07-05 | 1999-07-05 | Procedes et dispositifs d'analyse et de synthese audio |
| PCT/FR2000/001904 WO2001003116A1 (fr) | 1999-07-05 | 2000-07-04 | Procedes et dispositifs d'analyse et de synthese audio |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| EP1194923A1 EP1194923A1 (fr) | 2002-04-10 |
| EP1194923B1 true EP1194923B1 (fr) | 2006-01-18 |
Family
ID=9547707
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| EP00953223A Expired - Lifetime EP1194923B1 (fr) | 1999-07-05 | 2000-07-04 | Procedes et dispositifs d'analyse et de synthese audio |
Country Status (6)
| Country | Link |
|---|---|
| EP (1) | EP1194923B1 (fr) |
| AT (1) | ATE316284T1 (fr) |
| AU (1) | AU6575100A (fr) |
| DE (1) | DE60025615D1 (fr) |
| FR (1) | FR2796194B1 (fr) |
| WO (1) | WO2001003116A1 (fr) |
Family Cites Families (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US5226084A (en) * | 1990-12-05 | 1993-07-06 | Digital Voice Systems, Inc. | Methods for speech quantization and error correction |
| US5765127A (en) * | 1992-03-18 | 1998-06-09 | Sony Corp | High efficiency encoding method |
| JP3152109B2 (ja) * | 1995-05-30 | 2001-04-03 | 日本ビクター株式会社 | オーディオ信号の圧縮伸張方法 |
-
1999
- 1999-07-05 FR FR9908638A patent/FR2796194B1/fr not_active Expired - Fee Related
-
2000
- 2000-07-04 WO PCT/FR2000/001904 patent/WO2001003116A1/fr not_active Ceased
- 2000-07-04 DE DE60025615T patent/DE60025615D1/de not_active Expired - Lifetime
- 2000-07-04 AT AT00953223T patent/ATE316284T1/de not_active IP Right Cessation
- 2000-07-04 EP EP00953223A patent/EP1194923B1/fr not_active Expired - Lifetime
- 2000-07-04 AU AU65751/00A patent/AU6575100A/en not_active Abandoned
Also Published As
| Publication number | Publication date |
|---|---|
| WO2001003116A1 (fr) | 2001-01-11 |
| FR2796194B1 (fr) | 2002-05-03 |
| FR2796194A1 (fr) | 2001-01-12 |
| ATE316284T1 (de) | 2006-02-15 |
| DE60025615D1 (de) | 2006-04-06 |
| EP1194923A1 (fr) | 2002-04-10 |
| AU6575100A (en) | 2001-01-22 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| EP0782128B1 (fr) | Procédé d'analyse par prédiction linéaire d'un signal audiofréquence, et procédés de codage et de décodage d'un signal audiofréquence en comportant application | |
| EP3244407B1 (fr) | Appareil et procédé pour modifier une représentation paramétrée | |
| EP1994531B1 (fr) | Codage ou decodage perfectionnes d'un signal audionumerique, en technique celp | |
| EP1692689B1 (fr) | Procede de codage multiple optimise | |
| WO2004070705A1 (fr) | Procede pour le traitement numerique differencie de la voix et de la musique, le filtrage de bruit, la creation d’effets speciaux et dispositif pour la mise en oeuvre dudit procede | |
| WO2005106852A1 (fr) | Procede et systeme ameliores de conversion d'un signal vocal | |
| EP0801790A1 (fr) | Procede de codage de parole a analyse par synthese | |
| EP0721180A1 (fr) | Procédé de codage de parole à analyse par synthèse | |
| EP1606792A1 (fr) | Procede d analyse d informations de frequence fondament ale et procede et systeme de conversion de voix mettant en oeuvre un tel procede d analyse | |
| EP4487323B1 (fr) | Codage et décodage optimisé d'un signal audio utilisant un auto-encodeur à base de réseau de neurones | |
| Cho et al. | A spectrally mixed excitation (SMX) vocoder with robust parameter determination | |
| EP1192619B1 (fr) | Codage et decodage audio par interpolation | |
| EP1194923B1 (fr) | Procedes et dispositifs d'analyse et de synthese audio | |
| EP1192621B1 (fr) | Codage audio avec composants harmoniques | |
| EP1192618B1 (fr) | Codage audio avec liftrage adaptif | |
| EP1190414A1 (fr) | Codage et decodage audio avec composantes harmoniques et phase minimale | |
| EP1192620A1 (fr) | Codage et decodage audio incluant des composantes non harmoniques du signal | |
| EP1605440B1 (fr) | Procédé de séparation de signaux sources à partir d'un signal issu du mélange | |
| WO2013135997A1 (fr) | Modification des caractéristiques spectrales d'un filtre de prédiction linéaire d'un signal audionumérique représenté par ses coefficients lsf ou isf | |
| FR2739482A1 (fr) | Procede et dispositif pour l'evaluation du voisement du signal de parole par sous bandes dans des vocodeurs | |
| FR2737360A1 (fr) | Procedes de codage et de decodage de signaux audiofrequence, codeur et decodeur pour la mise en oeuvre de tels procedes | |
| FR2773653A1 (fr) | Dispositifs de codage/decodage de donnees, et supports d'enregistrement memorisant un programme de codage/decodage de donnees au moyen d'un filtre de ponderation frequentielle | |
| FR2980620A1 (fr) | Traitement d'amelioration de la qualite des signaux audiofrequences decodes | |
| WO2002029786A1 (fr) | Procede et dispositif de codage segmental d'un signal audio | |
| WO2008081141A2 (fr) | Codage d'unites acoustiques par interpolation |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PUAI | Public reference made under article 153(3) epc to a published international application that has entered the european phase |
Free format text: ORIGINAL CODE: 0009012 |
|
| 17P | Request for examination filed |
Effective date: 20020103 |
|
| AK | Designated contracting states |
Kind code of ref document: A1 Designated state(s): AT BE CH CY DE DK ES FI FR GB GR IE IT LI LU MC NL |
|
| AX | Request for extension of the european patent |
Free format text: AL;LT;LV;MK;RO;SI |
|
| RAP1 | Party data changed (applicant data changed or rights of an application transferred) |
Owner name: NORTEL NETWORKS FRANCE |
|
| 17Q | First examination report despatched |
Effective date: 20040226 |
|
| GRAP | Despatch of communication of intention to grant a patent |
Free format text: ORIGINAL CODE: EPIDOSNIGR1 |
|
| GRAS | Grant fee paid |
Free format text: ORIGINAL CODE: EPIDOSNIGR3 |
|
| GRAA | (expected) grant |
Free format text: ORIGINAL CODE: 0009210 |
|
| AK | Designated contracting states |
Kind code of ref document: B1 Designated state(s): AT BE CH CY DE DK ES FI FR GB GR IE IT LI LU MC NL |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: IT Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT;WARNING: LAPSES OF ITALIAN PATENTS WITH EFFECTIVE DATE BEFORE 2007 MAY HAVE OCCURRED AT ANY TIME BEFORE 2007. THE CORRECT EFFECTIVE DATE MAY BE DIFFERENT FROM THE ONE RECORDED. Effective date: 20060118 Ref country code: NL Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20060118 Ref country code: IE Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20060118 Ref country code: GB Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20060118 Ref country code: FI Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20060118 Ref country code: AT Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20060118 |
|
| REG | Reference to a national code |
Ref country code: GB Ref legal event code: FG4D Free format text: NOT ENGLISH |
|
| REG | Reference to a national code |
Ref country code: CH Ref legal event code: EP |
|
| REG | Reference to a national code |
Ref country code: IE Ref legal event code: FG4D Free format text: LANGUAGE OF EP DOCUMENT: FRENCH |
|
| REF | Corresponds to: |
Ref document number: 60025615 Country of ref document: DE Date of ref document: 20060406 Kind code of ref document: P |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: DK Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20060418 |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: DE Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20060419 |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: ES Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20060429 |
|
| NLV1 | Nl: lapsed or annulled due to failure to fulfill the requirements of art. 29p and 29m of the patents act | ||
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: LI Free format text: LAPSE BECAUSE OF NON-PAYMENT OF DUE FEES Effective date: 20060731 Ref country code: CH Free format text: LAPSE BECAUSE OF NON-PAYMENT OF DUE FEES Effective date: 20060731 Ref country code: MC Free format text: LAPSE BECAUSE OF NON-PAYMENT OF DUE FEES Effective date: 20060731 Ref country code: BE Free format text: LAPSE BECAUSE OF NON-PAYMENT OF DUE FEES Effective date: 20060731 |
|
| GBV | Gb: ep patent (uk) treated as always having been void in accordance with gb section 77(7)/1977 [no translation filed] |
Effective date: 20060118 |
|
| REG | Reference to a national code |
Ref country code: IE Ref legal event code: FD4D |
|
| PLBE | No opposition filed within time limit |
Free format text: ORIGINAL CODE: 0009261 |
|
| STAA | Information on the status of an ep patent application or granted ep patent |
Free format text: STATUS: NO OPPOSITION FILED WITHIN TIME LIMIT |
|
| 26N | No opposition filed |
Effective date: 20061019 |
|
| REG | Reference to a national code |
Ref country code: CH Ref legal event code: PL |
|
| REG | Reference to a national code |
Ref country code: FR Ref legal event code: ST Effective date: 20070330 |
|
| BERE | Be: lapsed |
Owner name: NORTEL NETWORKS FRANCE Effective date: 20060731 |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: GR Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20060419 Ref country code: FR Free format text: LAPSE BECAUSE OF NON-PAYMENT OF DUE FEES Effective date: 20060731 |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: LU Free format text: LAPSE BECAUSE OF NON-PAYMENT OF DUE FEES Effective date: 20060704 |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: CY Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20060118 |