EP3635718B1 - Traitement de donnees sonores pour une separation de sources sonores dans un signal multicanal - Google Patents
Traitement de donnees sonores pour une separation de sources sonores dans un signal multicanal Download PDFInfo
- Publication number
- EP3635718B1 EP3635718B1 EP18737650.4A EP18737650A EP3635718B1 EP 3635718 B1 EP3635718 B1 EP 3635718B1 EP 18737650 A EP18737650 A EP 18737650A EP 3635718 B1 EP3635718 B1 EP 3635718B1
- Authority
- EP
- European Patent Office
- Prior art keywords
- components
- sources
- descriptors
- direct
- sound
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
Images





Classifications
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L21/00—Speech or voice signal processing techniques to produce another audible or non-audible signal, e.g. visual or tactile, in order to modify its quality or its intelligibility
- G10L21/02—Speech enhancement, e.g. noise reduction or echo cancellation
- G10L21/0272—Voice signal separating
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L21/00—Speech or voice signal processing techniques to produce another audible or non-audible signal, e.g. visual or tactile, in order to modify its quality or its intelligibility
- G10L21/02—Speech enhancement, e.g. noise reduction or echo cancellation
- G10L21/0272—Voice signal separating
- G10L21/0308—Voice signal separating characterised by the type of parameter measurement, e.g. correlation techniques, zero crossing techniques or predictive techniques
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L25/00—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00
- G10L25/78—Detection of presence or absence of voice signals
- G10L25/84—Detection of presence or absence of voice signals for discriminating voice from noise
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04R—LOUDSPEAKERS, MICROPHONES, GRAMOPHONE PICK-UPS OR LIKE ACOUSTIC ELECTROMECHANICAL TRANSDUCERS; ELECTRIC HEARING AIDS; PUBLIC ADDRESS SYSTEMS
- H04R5/00—Stereophonic arrangements
- H04R5/02—Spatial or constructional arrangements of loudspeakers
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L21/00—Speech or voice signal processing techniques to produce another audible or non-audible signal, e.g. visual or tactile, in order to modify its quality or its intelligibility
- G10L21/02—Speech enhancement, e.g. noise reduction or echo cancellation
- G10L21/0208—Noise filtering
- G10L2021/02082—Noise filtering the noise being echo, reverberation of the speech
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L21/00—Speech or voice signal processing techniques to produce another audible or non-audible signal, e.g. visual or tactile, in order to modify its quality or its intelligibility
- G10L21/02—Speech enhancement, e.g. noise reduction or echo cancellation
- G10L21/0208—Noise filtering
- G10L21/0216—Noise filtering characterised by the method used for estimating noise
- G10L2021/02161—Number of inputs available containing the signal or the noise to be suppressed
- G10L2021/02166—Microphone arrays; Beamforming
Definitions
- the present invention relates to the field of audio or acoustic signal processing and more particularly to the processing of real multi-channel sound content to separate the sound sources.
- a blind separation of the sources consists, from a number M of observations resulting from sensors distributed in this space E, in counting and extracting the number N of sources.
- each observation is obtained using a sensor which records the signal reaching a point in space where the sensor is located.
- the recorded signal then results from the mixing and propagation in the space E of the signals s i and is therefore affected by various disturbances specific to the environment crossed, such as noise, reverberation, interference, etc.
- x is the vector of the M recorded channels, s the vector of the N sources and A a so-called “mixing matrix” of dimension M ⁇ N containing the contributions from each source to each observation, and the abbreviation * symbolizes linear convolution.
- US 2005/060142 A1 describes a step of source separation of a multi-channel signal followed by an identification step. This document uses independent component analysis, ACl, based on a separation matrix, and can identify a dominant signal by two separate signals.
- US 2010/111290 A1 describes a step for separating sources of a signal that can be carried out using an analysis technique of independent components, AC1, as well as a step for estimating a type of sound after separation. The type of sound estimated is stationary or non-stationary. Obtaining a separation matrix seems implicit in view of the separation methods indicated.
- An example of beamforming to extract three sources positioned respectively at 0°, 90° and -120° azimuth is shown in figure 1 .
- Each of the directivities formed corresponds to the extraction of one of the sources of s.
- the total acoustic field can be modeled as the sum of the direct field of the sources of interest (represented in 1 on the picture 2 ), first reflections (secondary sources, represented in 2 on the picture 2 ) and a diffuse field (represented in 3 on the figure 2 ).
- the covariance matrix of the observations is then of full rank, whatever the actual number of sources active in the mixture: this means that the rank of Co can no longer be used to estimate the number of sources.
- a couple ( a i , t i ) corresponding to the active source i is estimated as follows:
- a representation in space of all the pairs ( a i , t i ) is performed in the form of a histogram, the “ clustering” is then performed on the histogram by maximum likelihood, depending on the position of the zone and the assumed position of the associated source, assuming a Gaussian distribution of the estimated positions of each zone around the actual position of the sources.
- the calculation of a bivariate descriptor includes the calculation of a consistency score between two components. This descriptor calculation makes it possible to know in a relevant way whether a pair of components corresponds to two direct components (2 sources) or whether at least one of the components comes from a reverberant effect.
- the calculation of a bivariate descriptor includes the determination of a delay between the two components of the couple. This determination of the delay and of the sign associated with this delay makes it possible to determine, for a pair of components, which component more probably corresponds to the direct signal and which component more probably corresponds to the reverberated signal.
- the delay between two components is determined by taking into account the delay maximizing an inter-correlation function between the two components of the couple. This method of obtaining the delay offers a reliable determination of a bivariate descriptor.
- the determination of the delay between two components of a couple is associated with a reliability indicator of the sign of the delay, a function of the coherence between the components of the couple.
- the determination of the delay between two components of a couple is associated with a reliability indicator of the sign of the delay, a function of the ratio of the maximum of an inter-correlation function for delays of opposite sign.
- the calculation of a univariate descriptor is a function of a matching between the mixing coefficients of a mixing matrix estimated from the source separation step and the characteristics of encoding of a plane wave type source. This descriptor calculation makes it possible, for a single component, to estimate the probability that the component is direct or reverberated.
- the classification of the components of the set of M components is carried out by taking into account all of the M components, and by calculating the most probable combination of the classifications of the M components.
- the calculation of the most probable combination is carried out by determining a maximum of the likelihood values expressed as the product of the conditional probabilities associated with the descriptors, for the possible combinations of classification of the M components.
- a step of pre-selection of the possible combinations is carried out on the basis of the univariate descriptors alone before the step of calculating the most probable combination.
- a step of pre-selection of the components is carried out on the basis of the univariate descriptors alone before the step of calculating the bivariate descriptors.
- the multichannel signal is an Ambisonic signal.
- the invention also applies to a computer program comprising code instructions for implementing the steps of the processing method as described previously, when these instructions are executed by a processor and to a storage medium, readable by a processor, on which is recorded a computer program comprising code instructions for the execution of the steps of the processing method as described.
- the device, program and storage medium have the same advantages as the method described previously, which they implement.
- FIG. 3 illustrates the main steps of a sound data processing method for a separation of N sound sources of a multi-channel sound signal picked up in a real environment in one embodiment of the invention.
- the method implements a step E310 of blind separation of sound sources (SAS). It is assumed here, in this embodiment, that the number of observations is equal to or greater than the number of active sources.
- the blind source separation step can be implemented, for example by using an independent component analysis (or “ICA”) algorithm, or even a component analysis algorithm main.
- ICA independent component analysis
- Ambisonia consists of a projection of the acoustic field on a basis of spherical harmonic functions, to obtain a spatialized representation of the sound stage.
- the Ambisonic formalism initially limited to the representation of spherical harmonic functions of order 1, was subsequently extended to higher orders.
- the Ambisonic formalism with a larger number of components is commonly referred to as “ Higher Order Ambisonics ” (or “HOA” hereafter).
- a content of order m contains a total of (m+1) 2 channels (4 channels at order 1, 9 channels at order 2, 16 channels at order 3, and so on).
- step E310 The blind separation of sources is therefore carried out in step E310 as explained previously.
- the components obtained at the output of the source separation step can be classified according to two classes of components: a first class of so-called direct components corresponding to the direct sound sources and a second class of so-called reverberated components corresponding to the reflections of the sources.
- step E320 a calculation of descriptors of the M components (s 1 , s 2 , ...s M ) resulting from the source separation step is implemented, descriptors which will make it possible to associate with each component extracts the class that corresponds to it: direct component or reverberant component.
- bi-varied descriptors which involve pairs of components (s j , s i ) and uni-varied descriptors calculated for a component s i .
- a set of first bivariate descriptors is calculated. These descriptors are representative of statistical relationships between the components of the pairs of the set of M components obtained.
- each direct component is mainly made up of the direct field of a source, comparable to a plane wave, to which is added a residual reverberation whose energy contribution is lower than that of the direct field.
- the sources being by nature statistically independent, there is therefore a weak correlation between the direct components extracted.
- each reverberant component is made up of early reflections, delayed and filtered versions of the direct field(s), and late reverberation.
- the reverberated components show a significant correlation with the direct components, and generally an identifiable group delay compared to the direct components.
- Coherence is ideally zero when s j and si are the direct fields of independent sources but it takes on a high value when s j and si are two contributions from the same source: the direct field and a first reflection or else two reflections.
- Such a coherence function therefore indicates a probability of having two direct components or two contributions from the same source (direct/reverberated or first reflection/subsequent reflections).
- the coherence value d ⁇ is less than 0.3 while in the second case d ⁇ reaches 0.7 in the presence of a single active source.
- the determination of a probability of belonging to the same class or to a different class for a pair of components can depend on the number of a priori active sources.
- this parameter may be taken into account in a particular embodiment.
- the probability densities of the figure 5 And 7 described below, and more generally all the probability densities of the descriptors, are learned statistically on databases including various acoustic conditions (reverberant/mass) and different sources (male/female voice, French languages/ English/).
- the components are classified in an informed manner: each source is associated with the closest extracted component spatially, the remaining being classified as reverberated components.
- To calculate the position of the component we use the first 4 coefficients of its mixing vector from the matrix A (i.e. order 1), the inverse of the separation matrix B.
- the coherence estimators deteriorate, whether they are the direct/reverberated or reverberated/reverberated pairs (in the presence of a single source, the direct/direct pair does not exist) .
- the probability densities strongly depend on the number of sources in the mixture, and the number of sensors available.
- This descriptor is therefore relevant for detecting whether a pair of extracted components corresponds to two direct components (2 true sources) or whether at least one of the two components comes from the room effect.
- step E320 another type of bivariate descriptor is calculated in step E320. Either this descriptor is calculated instead of the consistency type descriptor described above, or in addition to it.
- This descriptor will make it possible to determine, for a couple (direct/reverberated) which component is more likely the direct signal and which corresponds to the reverberated signal, based on the simple assumption that the first reflections are delayed and attenuated versions of the signal direct.
- This descriptor is based on another statistical relationship between the components, the delay between the two components of the couple.
- the relative value of the cross-correlation peak ⁇ jl,max to the other values of the cross-correlation function r jl ( ⁇ ) also provides information on the reliability of the group delay.
- FIG 6 illustrates the emergent nature of the autocorrelation peak between a direct component and a reverberated component.
- the cross-correlation maximum emerges clearly from the rest of the cross-correlation, reliably indicating that one of the components lags the other. It emerges in particular with respect to the values of the autocorrelation function for signs opposite to that of ⁇ jl,max (that of positive ⁇ on the figure 6 ) which are very small, whatever the value of ⁇ .
- This ratio which is called emergence, is an ad hoc criterion whose relevance is verified in practice: it takes values close to 1 for independent signals, i.e. 2 direct components, and higher values for correlated signals such as a direct component and a reverberant component. In the aforementioned case of the curve (1) of the figure 6 , the emergence value is 4.
- descriptor d ⁇ which determines, for each assumed direct/reverberated pair, the probability for each component of the pair of being the direct component or the reverberated component.
- This descriptor is a function of the sign of ⁇ max, of the average coherence between the components and of the emergence of the maximum of intercorrelation.
- this descriptor is sensitive to noise, and in particular to the presence of several simultaneous sources, as illustrated on curve (2) of the figure 6 : in the presence of 2 sources, even if the maximum correlation always emerges, its relative value - 2.6 - is lower due to the presence of an interfering source which reduces the correlation between the extracted components.
- the reliability of the sign of the delay will be measured as a function of the value of the emergence, which will be weighted by the a priori number of sources to be detected.
- step E330 a probability of belonging to a first class of direct components or a second class of reverberated components is calculated for a pair of components.
- s j identified as being ahead of si we estimate the probability that s j is direct and si reverberated by a two-dimensional law.
- the sign of lag is a reliable indicator when both coherence and emergence have medium or high values. A weak emergence or a weak coherence will make the direct/reverberant or reverberant/direct pairs equally probable.
- a set of second so-called univariate descriptors representative of encoding characteristics of the components of the set of M components obtained is also calculated.
- the encoding of a source coming from a given direction is carried out with mixing coefficients depending, among other things, on the directivity of the sensors.
- the source can be considered as a point and where the wavelengths are large compared to the size of the antenna, the source can be considered as a plane wave. This assumption is generally verified in the case of an ambisonic microphone which is small, provided that the source is far enough from the microphone (in practice, one meter is enough).
- the j th column of the estimated mixing matrix A obtained by inverting the separation matrix B, will contain the mixing coefficients associated with it. If this component is direct, that is to say it corresponds to a single source, the mixing coefficients of the column Aj will tend towards the characteristics of the microphone encoding for a plane wave. In the case of a reverberated component, sum of several reflections and of a diffuse field, the estimated mixing coefficients will be more random and will not correspond to the encoding of a single source with a precise direction of arrival.
- plane wave criterion 3 To 1 I 2 To 2 I 2 + To 3 I 2 + To 4 I 2
- the criterion c op is by definition equal to 1 in the case of a plane wave. In the presence of a correctly identified direct field, the plane wave criterion will remain very close to the value 1. Conversely, in the case of a reverberated component, the multitude of contributions (early reflections and late reverberation) with levels equivalent energy will generally move the plane wave criterion away from its ideal value.
- the probability laws (probability density) associated with this descriptor depending on the number of simultaneously active sources (1 or 2) and the ambisonic order of the analyzed content (orders 1 to 2).
- the value of the plane wave criterion is concentrated around the value 1 for the direct components.
- the distribution is more uniform, with however a slightly asymmetrical shape, because of the descriptor itself which is asymmetrical, with a 1/x shape.
- the distance between the distributions of the two classes allows a fairly reliable discrimination between the plane wave type components and the more diffuse ones.
- the descriptors calculated in step E320 and presented here are based both on the statistics of the extracted components (mean coherence and group delay) and on the estimated mixing matrix (plane wave criterion). These make it possible to determine conditional probabilities of belonging of a component to one of the two classes C d or C r .
- step E340 determines a classification of the components of the set of M components, according to the two classes.
- C j the corresponding class.
- the problem finally comes down to choosing among a total of 2 M potential configurations assumed to be equiprobable.
- the approach chosen can be exhaustive and then consists in estimating the likelihood of all the possible configurations, from the descriptors determined in step E320 and the distributions associated with them and which are calculated in step E330.
- a pre-selection of the configurations can be carried out to reduce the number of configurations to be tested, and therefore the complexity of the implementation of the solution.
- This pre-selection can be done for example according to the plane wave criterion alone by classifying certain components in the category C r , when the value of their c op criterion deviates too much from the theoretical value of a plane wave 1: in the case of ambisonic signals, one can see on the distributions of the figure 7 that we can, whatever the configuration (order or number of sources) and a priori without loss of robustness, classify in the category C r the components whose c op verifies one of the following inequalities: ⁇ vs op ⁇ 0.7 vs op > 1.5
- This pre-selection makes it possible to reduce the number of configurations to be tested by pre-classifying certain components, by excluding the configurations which impose class C d on these pre-classified components.
- Another possibility to further reduce the complexity is to exclude the pre-classified components from the calculation of the bivariate descriptors and the calculation of the likelihood, which reduces the number of bivariate criteria to be calculated and therefore even more the complexity. treatment.
- the likelihood is expressed as the product of the conditional probabilities associated with each of the K descriptors, assuming they are independent: where d is the vector of descriptors and C a vector representing a configuration (ie the combination of the supposed classes of the M components), as defined above.
- This equation is the one ultimately used to determine the most likely configuration in the Bayesian classifier described here for this embodiment.
- Bayesian classifier presented here is only an example of an implementation, it could be replaced, among other things, by a support vector machine or a neural network.
- the configuration presenting the maximum likelihood is retained, indicating the direct or reverberated class associated with each of the M components C (C 1 , ..., C i , ..., C M ).
- the processing described here is performed in the time domain, but can also be, in a variant embodiment, applied in a transformed domain.
- the useful bandwidth can be reduced depending on the potential imperfections of the capture system, at high frequencies (presence of spatial folding) or at low frequencies (impossibility of finding the theoretical directivities of the microphone encoding).
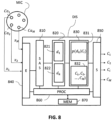
- FIG 8 here represents an embodiment of a processing device (DIS) according to one embodiment of the invention.
- Sensors Ca 1 to Ca M represented here in the form of a spherical microphone MIC make it possible to acquire, in a real medium, therefore reverberant, M mixing signals x ( x 1 , ..., x i , ... , x M ), from a multichannel signal.
- microphones or sensors can be provided. These sensors can be integrated into the DIS device or outside the device, the resulting signals then being transmitted to the processing device which receives them via its input interface 840. In a variant, these signals can simply be obtained beforehand and imported in memory of the DIS device.
- This memory can comprise a computer program comprising the code instructions for the implementation of the stages of the treatment method as described for example with reference to the picture 3 and in particular the steps of applying source separation processing to the captured multi-channel signal and obtaining a set of M sound components, with M ⁇ N, of calculating a set of first so-called bi-varied descriptors, representative of statistical relations between the components of the pairs of the set of M components obtained and of a set of second descriptors called univariate representative of encoding characteristics of the components of the set of M components obtained and classification of the components of the set of M components, according to two classes of components, a first class of N so-called direct components corresponding to the N direct sound sources and a second class of MN so-called reverberated components, by calculating the probability of belonging to one of the two classes, a function of the sets of first and second descriptors.
- the device comprises a source separation processing module 810 applied to the picked up multi-channel signal to obtain a set of M sound components s (s 1 , ..., s i , .. s M ), with M ⁇ N.
- the M components are supplied as input to a computer 820 capable of calculating a set of first so-called bi-varied descriptors, representative of statistical relationships between the components of the pairs of the set of M components obtained and a set of second so-called univariate descriptors -varied representative of encoding characteristics of the components of the set of M components obtained.
- a classification module 830 or classifier capable of classifying components of the set of M components, according to two classes of components, a first class of N so-called direct components corresponding to the N direct sound sources and a second class of M-N so-called reverberated components.
- the classification module includes a module 831 for calculating the probability of belonging to one of the two classes of the components of the set M, a function of the sets of first and second descriptors.
- the classifier uses descriptors related to the correlation between the components to determine which are direct signals (ie true sources) and which are reverberation residues. It also uses descriptors related to the mixing coefficients estimated by SAS, to assess the conformity between the theoretical encoding of a single source and the estimated encoding of each component. Some of the descriptors are therefore a function of a couple of components (for the correlation), and others are functions of a single component (for the conformity of the estimated microphone encoding).
- a likelihood calculation module 832 makes it possible to determine, in one embodiment, the most probable combination of the classifications of the M components by calculating likelihood values as a function of the probabilities calculated in module 831 and for the possible combinations.
- the device comprises an output interface 850 to deliver the component classification information, for example to another processing device which can use this information to enhance the sound of the discriminated sources, to denoise them or to perform a mixing from several discriminating sources.
- Another possible processing can also be to analyze or locate the sources to optimize the processing of a voice command.
- the device DIS can be integrated into a microphone antenna to effect, for example, recordings of sound scenes or for voice command sound recording.
- the device can also be integrated into a communication terminal capable of. process signals picked up by a plurality of sensors integrated or remote from the terminal.
Landscapes
- Engineering & Computer Science (AREA)
- Physics & Mathematics (AREA)
- Acoustics & Sound (AREA)
- Signal Processing (AREA)
- Health & Medical Sciences (AREA)
- Computational Linguistics (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Human Computer Interaction (AREA)
- Multimedia (AREA)
- Quality & Reliability (AREA)
- Circuit For Audible Band Transducer (AREA)
- Measurement Of Velocity Or Position Using Acoustic Or Ultrasonic Waves (AREA)
- Measurement Of Mechanical Vibrations Or Ultrasonic Waves (AREA)
Description
- La présente invention se rapporte au domaine du traitement de signal audio ou acoustique et plus particulièrement au traitement de contenus sonores multicanal réels pour séparer les sources sonores.
- La séparation de sources dans un signal sonore multicanal permet de multiples applications. Elle peut par exemple être utilisée :
- ∘ Pour le divertissement (karaoké : suppression de la voix),
- ∘ Pour la musique (mixage des sources séparées dans un contenu multicanal),
- ∘ Pour les télécommunications (rehaussement de la voix, débruitage),
- ∘ Pour la domotique (commande vocale),
- ∘ Pour le codage audio multicanal,
- ∘ Pour la localisation de sources et cartographie en imagerie.
- Dans un espace E dans lequel un nombre N de sources émettent un signal si, une séparation aveugle des sources consiste, à partir d'un nombre M d'observations issues de capteurs répartis dans cet espace E, à dénombrer et extraire le nombre N de sources. En pratique, chaque observation est obtenue à l'aide d'un capteur qui enregistre le signal parvenu jusqu'en un point de l'espace où se situe le capteur. Le signal enregistré résulte alors du mélange et de la propagation dans l'espace E des signaux si et se trouve donc affecté de différentes perturbations propres au milieu traversé comme par exemple le bruit, la réverbération, les interférences, etc...
- La captation multicanal d'un nombre N de sources sonores si se propageant en champ libre et considérées comme ponctuelles se formalise comme une opération matricielle :
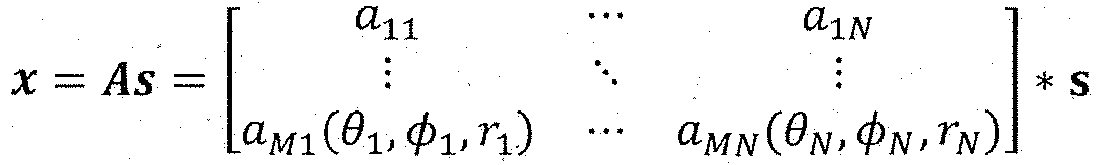
- Où x est le vecteur des M canaux enregistrés, s le vecteur des N sources et A une matrice dite « matrice de mélange » de dimension M×N contenant les contributions de chaque source à chaque observation, et le sigle * symbolise la convolution linéaire. Selon le milieu de propagation et le format de l'antenne, la matrice A peut prendre différentes formes. Dans le cas d'une antenne coïncidente (tous les microphones de l'antenne sont concentrés en un même point de l'espace) en milieu anéchoïque, A est une simple matrice de gains. Dans le cas d'une antenne non coïncidente, en milieu anéchoïque ou réverbérant, la matrice A devient une matrice de filtre. Dans ce cas, on exprime généralement la relation dans le domaine fréquentiel x ( f ) = As ( f ), où A s'exprime comme une matrice de coefficients complexes.
- Dans le cas où la captation du signal sonore se fait dans un environnement anéchoïque, et si l'on se place dans l'hypothèse où le nombre de sources N est inférieur au nombre d'observations M, l'analyse (i.e. l'identification du nombre de sources et de leurs positions) et la décomposition de la scène en objets, i.e. les sources, peuvent être facilement réalisées de manière conjointe par un algorithme d'analyse en composantes indépendantes (ou « ACI » ci-après). Ces algorithmes permettent d'identifier la matrice B de séparation de dimensions NxM, pseudo-inverse de A, qui permet de déduire les sources à partir des observations grâce à l'équation suivante :

- L'étape préalable d'estimation de la dimension du problème, i.e. l'estimation de la taille de la matrice de séparation, soit du nombre de sources N, est classiquement fait en calculant le rang de la matrice de covariance Co = E{ xxT } des observations, qui est, dans ce cas anéchoïque, égal au nombre de sources :

- Quant à la localisation des sources, elle peut être déduite de la matrice d'encodage A = B -1 et de la connaissance des propriétés spatiales de l'antenne utilisée, notamment la distance entre les capteurs et leurs directivités.
- Parmi les algorithmes les plus connus d'ACI, on peut citer JADE de J.F Cardoso et A. Souloumiac. ("Blind beamforming for non-gaussian signals" dans "IEE Proceedings F - Radar and Signal Processing", volume 140, issue 6, Dec. 1993) ou Infomax d'Amari et. al. ("A new learning algorithm for blind signal séparation, Advances" dans "neural information processing systems", 1996)
- Le document
US 2005/060142 A1 décrit une étape de séparation de source d'un signal multi-canal suivie d'une étape d'identification. Ce document utilise une analyse de composantes indépendantes, ACl, basée sur une matrice de séparation, et peut identifier un signal dominant par deux signaux séparés.Le documentUS 2010/111290 A1 décrit une étape de séparation de sources d'un signal pouvant être réalisée à l'aide d'une technique d'analyse de composantes indépendantes, ACl, ainsi qu'une étape d'estimation d'un type de son après séparation. Le type de son estimé est stationnaire ou non-stationnaire. L'obtention d'une matrice de séparation semble implicite au vu des procédés de séparation indiqués.En outre, le document BAQUÉ MATHIEU ET AL: "Séparation of Direct Sounds from Early Reflections Using the Entropy Rate Bound Minimization Algorithm", 60ème Conférence Internationale de l'AES: DREAMS (DEREVERBERATION AND REVERBERATION OF AUDIO, MUSIC, AND SPEECH); AES, 60 EAST 42ND STREET, ROOM 2520, NEW YORK 10165-2520, USA, 27 janvier 2016 (2016-01-27), décrit une étude expérimentale utilisant une mesure de débit entropique pour séparer les sons directs de leurs réflexions. - En pratique, dans certaines conditions, l'étape de séparation s = Bx revient à faire de la formation de voies sous contrainte (ou « beamforming » ci-après) : la combinaison de différents canaux donnée par la matrice B consiste à appliquer un filtre spatial dont la directivité revient à imposer un gain unité dans la direction de la source que l'on veut extraire, et un gain nul dans la direction des sources interférentes. Un exemple de beamforming pour extraire trois sources positionnées à respectivement 0°, 90° et -120° d'azimuth est illustré à la
figure 1 . Chacune des directivités formées correspond à l'extraction d'une des sources de s. - En présence d'un mélange de sources capté dans des conditions réelles, l'effet de salle va générer un champ sonore dit réverbéré, noté xr , qui va s'ajouter aux champs directs des sources :

- Le champ acoustique total peut être modélisé comme la somme du champ direct des sources d'intérêt (représenté en 1 sur la
figure 2 ), des premières réflexions (sources secondaires, représentées en 2 sur lafigure 2 ) et d'un champ diffus (représenté en 3 sur lafigure 2 ). La matrice de covariance des observations est alors de rang plein, quel que soit le nombre réel de sources actives dans le mélange : cela signifie que l'on ne peut plus utiliser le rang de Co pour estimer le nombre de sources. - Ainsi, lorsqu'on utilise un algorithme de SAS pour séparer des sources en milieu réverbérant, la matrice de séparation B de taille MxM est obtenue, générant en sortie M sources s̃j , 1 ≤ j ≤ M, au lieu des N désirées, les M-N dernières composantes contenant essentiellement du champ réverbéré, par l'opération matricielle :

- Ces composantes supplémentaires posent plusieurs problèmes :
- pour l'analyse de scène : on ne sait pas a priori quelles sont les composantes relatives aux sources et les composantes induites par l'effet de salle.
- pour la séparation des sources par formation de voies : chaque composante supplémentaire induit des contraintes sur les directivités formées et dégrade généralement le facteur de directivité avec pour conséquence un rehaussement du niveau de réverbération dans les signaux extraits.
- Les méthodes existantes de comptage de sources pour des contenus multicanal sont souvent basées sur une hypothèse de parcimonie dans le domaine temps-fréquence, c'est-à-dire sur le fait que pour chaque zone temps-fréquence, une seule source ou un nombre limité de sources va avoir une contribution énergétique non-négligeable. Pour la plupart d'entre-elles, une étape de localisation de la source la plus énergétique est effectuée pour chaque zone (ou « bin » en anglais), puis les zones sont agrégées (étape dite de « clustering » en anglais) pour reconstruire la contribution totale de chaque source.
- L'approche DUET (Pour « Degenerate Unmixing Estimation Technique ») décrite par exemple dans le document « Blind séparation of disjoint orthogonal signals: Demixing n sources from 2 mixtures.» des auteurs A. Jourjine, S. Rickard, et O. Yilmaz, publié en 2000 dans ICASSP'00, permet de localiser et extraire N sources en conditions anéchoïques à partir de seulement deux observations non coïncidentes, en faisant l'hypothèse que les sources ont des supports fréquentiels disjoints, soit

- Après une décomposition des observations en sous-bandes fréquentielles, typiquement réalisée via une transformée de Fourier à court-terme, une amplitude ai et un retard ti sont estimés pour chaque sous-bande en se basant sur l'équation de mélange théorique :

- Dans chaque bande de fréquence f, un couple (ai, ti) correspondant à la source i active est estimée de la façon suivante :

- Une représentation dans l'espace de l'ensemble des couples (ai, ti) est effectuée sous forme d'histogramme, le « clustering » est alors effectuée sur l'histogramme par maximum de vraisemblance, fonction de la position de la zone et de la position supposée de la source associée, en supposant une distribution gaussienne des positions estimées de chaque zone autour de la position réelle des sources.
- En pratique, l'hypothèse de parcimonie des sources dans le domaine temps-fréquence est souvent mise en défaut, ce qui constitue une limitation importante de ces approches pour le dénombrement de sources, car les directions d'arrivée pointées pour chaque zone résultent alors d'une combinaison des contributions de plusieurs sources et le « clustering » ne s'effectue plus correctement. De plus, pour l'analyse de contenus captés en conditions réelles, la présence de réverbération peut d'une part dégrader la localisation des sources et d'autre part engendrer une sur-estimation du nombre de sources réelles lorsque des premières réflexions atteignent un niveau énergétique suffisant pour être perçues comme des sources secondaires.
- La présente invention vient améliorer la situation.
Elle propose à cet effet, un procédé de traitement de données sonores pour une séparation de N sources sonores d'un signal sonore multicanal capté en milieu réel. Le procédé est tel qu'il comporte les étapes suivantes : - application d'un traitement de séparation de sources au signal multicanal capté et obtention d'une matrice de séparation et d'un ensemble de M composantes sonores, avec M≥N ;
- calcul d'un ensemble de premiers descripteurs dit bi-variés, représentatifs d'une mesure de corrélation entre les composantes des couples de l'ensemble des M composantes obtenu ;
- calcul d'un ensemble de seconds descripteurs dit uni-variés représentatifs de caractéristiques d'encodage des composantes de l'ensemble des M composantes obtenu, le calcul étant fonction d'une mise en correspondance entre les caractéristiques d'encodage estimées et issues d'une matrice inverse de la matrice de séparation et des caractéristiques d'encodage théoriques d'une source de type onde plane ;
- classification des composantes de l'ensemble des M composantes, selon deux classes de composantes, une première classe de N composantes dites directes correspondant aux N sources sonores directes et une deuxième classe de M-N composantes dites réverbérées, par un calcul de probabilité d'appartenance à une des deux classes, fonction des ensembles de premiers et seconds descripteurs.
- Les différents modes particuliers de réalisation mentionnés ci-après peuvent être ajoutés indépendamment ou en combinaison les uns avec les autres, aux étapes du procédé de traitement défini ci-dessus.
- Dans un mode de réalisation particulier, le calcul d'un descripteur bi-varié comporte le calcul d'un score de cohérence entre deux composantes. Ce calcul de descripteur permet de façon pertinente de savoir si un couple de composantes correspond à deux composantes directes (2 sources) ou si au moins une des composantes provient d'un effet réverbérant.
- Selon un mode de réalisation, le calcul d'un descripteur bi-varié comporte la détermination d'un retard entre les deux composantes du couple.
Cette détermination du retard et du signe associé à ce retard permet de déterminer, pour un couple de composantes, quelle composante correspond plus probablement au signal direct et quelle composante correspond plus probablement au signal réverbéré. - Selon une implémentation possible de ce calcul de descripteur, le retard entre deux composantes est déterminé par la prise en compte du retard maximisant une fonction d'inter-corrélation entre les deux composantes du couple.
Cette méthode d'obtention du retard offre une détermination d'un descripteur bi-varié fiable. - Dans un mode de réalisation particulier, la détermination du retard entre deux composantes d'un couple est associée à un indicateur de fiabilité du signe du retard, fonction de la cohérence entre les composantes du couple.
- Dans une variante de réalisation, la détermination du retard entre deux composantes d'un couple est associée à un indicateur de fiabilité du signe du retard, fonction du rapport du maximum d'une fonction d'inter-corrélation pour des retards de signe opposé.
Ces indicateurs de fiabilité permettent de rendre plus fiable la probabilité, pour un couple de composantes appartenant à une classe différente, que chaque composante du couple soit la composante directe ou la composante réverbérée. - Selon un mode de réalisation, le calcul d'un descripteur uni-varié est fonction d'une mise en correspondance entre des coefficients de mélange d'une matrice de mélange estimée à partir de l'étape de séparation de sources et des caractéristiques d'encodage d'une source de type onde plane.
Ce calcul de descripteur permet pour une composante seule, d'estimer la probabilité que la composante soit directe ou réverbérée. - Dans un mode de réalisation, la classification des composantes de l'ensemble des M composantes s'effectue par la prise en compte de l'ensemble des M composantes, et par le calcul de la combinaison la plus probable des classifications des M composantes.
- Dans une implémentation possible de cette approche globale, le calcul de la combinaison la plus probable s'effectue par la détermination d'un maximum des valeurs de vraisemblance exprimées comme le produit des probabilités conditionnelles associées aux descripteurs, pour les combinaisons possibles de classification des M composantes.
- Dans un mode de réalisation particulier, une étape de pré-selection des combinaisons possibles est effectuée en se basant sur les seuls descripteurs uni-variés avant l'étape de calcul de la combinaison la plus probable.
- Cela diminue ainsi les calculs de vraisemblance à effectuer sur les combinaisons possibles puisque ce nombre de combinaisons est restreint par cette étape de pré-sélection.
- Dans une variante de réalisation, une étape de pré-selection des composantes est effectuée en se basant sur les seuls descripteurs uni-variés avant l'étape de calcul des descripteurs bi-variés.
- Ainsi, le nombre de descripteurs bi-variés à calculer est restreint, ce qui diminue la complexité du procédé.
- Dans un exemple de réalisation, le signal multicanal est un signal ambisonique.
- Cette méthode de traitement ainsi décrite s'applique parfaitement à ce type de signaux.
- L'invention se rapporte également à un dispositif de traitement de données sonores mis en oeuvre pour effectuer un traitement de séparation de N sources sonores d'un signal sonore multicanal capté par une pluralité de capteurs en milieu réel. Le dispositif est tel qu'il comporte :
- une interface d'entrée pour recevoir les signaux captés par une pluralité de capteurs, du signal sonore multicanal;
- un circuit de traitement comportant un processeur et apte à mettre en oeuvre:
- o un module de traitement de séparation de sources appliqué au signal multicanal capté pour obtenir une matrice de séparation et un ensemble de M composantes sonores, avec M≥N ;
- o un calculateur apte à calculer un ensemble de premiers descripteurs dit bi-variés, représentatifs d'une mesure de corrélation entre les composantes des couples de l'ensemble des M composantes obtenu et un ensemble de seconds descripteurs dit uni-variés représentatifs de caractéristiques d'encodage des composantes de l'ensemble des M composantes obtenu, le calcul étant fonction d'une mise en correspondance entre les caractéristiques d'encodage estimées et issues d'une matrice inverse de la matrice de séparation et des caractéristiques d'encodage théoriques d'une source de type onde plane ;
- o un module de classification des composantes de l'ensemble des M composantes, selon deux classes de composantes, une première classe de N composantes dites directes correspondant aux N sources sonores directes et une deuxième classe de M-N composantes dites réverbérées, par un calcul de probabilité d'appartenance à une des deux classes, fonction des ensembles de premiers et seconds descripteurs ;
- une interface de sortie pour délivrer l'information de classification des composantes.
- L'invention s'applique également à un programme informatique comportant des instructions de code pour la mise en oeuvre des étapes du procédé de traitement tel que décrit précédemment, lorsque ces instructions sont exécutées par un processeur et à un support de stockage, lisible par un processeur, sur lequel est enregistré un programme informatique comprenant des instructions de code pour l'exécution des étapes du procédé de traitement tel que décrit.
Le dispositif, programme et support de stockage présentent les mêmes avantages que le procédé décrit précédemment, qu'ils mettent en oeuvre. - D'autres caractéristiques et avantages de l'invention apparaîtront plus clairement à la lecture de la description suivante, donnée uniquement à titre d'exemple non limitatif, et faite en référence aux dessins annexés, sur lesquels :
- la
figure 1 illustre une formation de voie pour extraire trois sources selon une méthode de séparation de sources de l'état de l'art tel que décrit précédemment ; - la
figure 2 illustre une réponse impulsionnelle avec effet de salle tel que décrit précédemment ; - la
figure 3 illustre sous forme d'organigramme, les étapes principales d'un procédé de traitement selon un mode de réalisation de l'invention ; - la
figure 4 illustre en fonction de la fréquence, des fonctions de cohérence représentant des descripteurs bi-variés entre deux composantes selon un mode de réalisation de l'invention, et selon différents couples de composantes ; - la
figure 5 illustre les densités de probabilités des cohérences moyennes représentants des descripteurs bi-variés selon un mode de réalisation de l'invention et pour différents couples de composantes et différents nombres de sources ; - la
figure 6 illustre des fonctions d'inter-corrélâtion entre deux composantes de classe différentes selon un mode de réalisation de l'invention et selon le nombre de sources ; - la
figure 7 illustre les densités de probabilité d'un critère d'onde plane en fonction de la classe de la composante, de l'ordre ambisonique et du nombre de sources, pour un mode de réalisation particulier de l'invention ; - la
figure 8 illustre une représentation matérielle d'un dispositif de traitement selon un mode de réalisation de l'invention, mettant en oeuvre un procédé de traitement selon un mode de réalisation de l'invention ; et - La
figure 9 illustre un exemple de calcul de loi de probabilité pour un critère, de cohérence entre une composante directe et une composante réverbérée selon un mode de réalisation de l'invention. - La
figure 3 illustre les principales étapes d'un procédé de traitement de données sonores pour une séparation de N sources sonores d'un signal sonore multicanal capté en milieu réel dans un mode de réalisation de l'invention. - Ainsi, à partir d'un signal multicanal capté par une pluralité de capteurs placés dans un milieu réel, c'est-à-dire réverbérant, et délivrant un nombre M d'observations issues de ces capteurs (x (x 1, ..., xM )), le procédé met en oeuvre une étape E310 de séparation aveugle de sources sonores (SAS). On suppose ici, dans ce mode de réalisation que le nombre d'observations est égal ou supérieur au nombre de sources actives.
- L'utilisation d'un algorithme de séparation aveugle de sources appliqué aux M observations, permet dans le cas d'un milieu réverbérant, d'extraire par formation de voies M composantes sonores associées à une matrice de mélange estimée AMxM, soit :
s = Bx avec x le vecteur des M observations, B la matrice de séparation estimée par la séparation en aveugle de sources, de dimensions MxM et s le vecteur des M composantes sonores extraites. Parmi celles-ci se trouvent théoriquement N sources sonores et M-N composantes résiduelles correspondant à de la réverbération. - Pour obtenir la matrice B de séparation, l'étape de séparation aveugle de sources peut être mise en oeuvre, par exemple en utilisant un algorithme d'analyse en composantes indépendantes (ou « ACI »), ou encore un algorithme d'analyse en composantes principales.
- Dans un exemple de réalisation, on s'intéresse aux signaux multicanal de type ambisonique.
- L'ambisonie consiste en une projection du champ acoustique sur une base de fonctions harmoniques sphériques, pour obtenir une représentation spatialisée de la scène sonore. La fonction

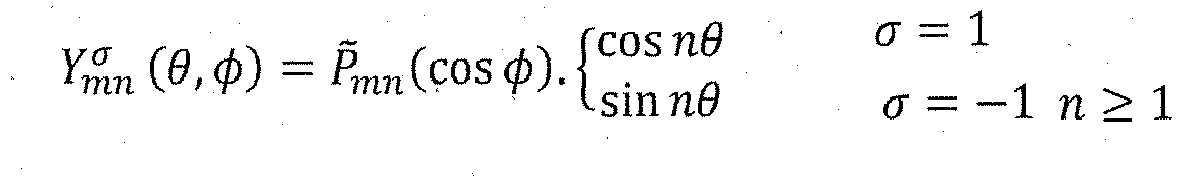

et
- En pratique, un encodage ambisonique réel se fait à partir d'un réseau de capteurs, généralement répartis sur une sphère. Les signaux capturés sont combinés pour synthétiser un contenu ambisonique dont les canaux respectent au mieux les directivités des harmoniques sphériques. On décrit ci-après les principes de base de l'encodage ambisonique.
- Le formalisme ambisonique, initialement limité à la représentation de fonctions harmoniques sphériques d'ordre 1, a par la suite été étendu aux ordres supérieurs. Le formalisme ambisonique avec un nombre de composantes plus important est communément nommé « Higher Order Ambisonics » (ou « HOA » ci-après).
- A chaque ordre m correspondent 2m+1 fonctions harmoniques sphériques. Ainsi, un contenu d'ordre m contient un total de (m+1)2 canaux (4 canaux à l'ordre 1, 9 canaux à l'ordre 2, 16 canaux à l'ordre 3, et ainsi de suite).
- On entend ci-après par « composantes ambisoniques » le signal ambisonique dans chaque canal ambisonique, en référence aux « composantes vectorielles » dans une base vectorielle qui serait formée par chaque fonction harmonique sphérique. Ainsi par exemple, on peut compter :
- une composante ambisonique pour l'ordre m=0,
- trois composantes ambisoniques pour l'ordre m=1,
- cinq composantes ambisoniques pour l'ordre m=2,
- sept composantes ambisoniques pour l'ordre m=3, etc.
- Les signaux ambisoniques captés pour ces différentes composantes sont alors répartis sur un nombre M de canaux qui se déduit de l'ordre maximum m qu'il est prévu de capter dans la scène sonore. Par exemple, si une scène sonore est captée avec un microphone ambisonique à 20 capsules piézoélectriques, alors l'ordre ambisonique maximum capté est m=3, afin qu'il n'y ait pas plus de 20 canaux M=(m+1)2, le nombre de composantes ambisoniques considérées est 7+5+3+1 = 16 et le nombre M de canaux est M=16, donné par ailleurs par la relation M=(m+1)2, avec m=3.
- Ainsi dans l'exemple d'implémentation où le signal multicanal est un signal ambisonique, l'étape E310 reçoit les signaux x ( x 1, ..., x 1 , ..., xM ), captés par un microphone réel, en milieu réverbérant et qui reçoit des trames de contenus sonores ambisoniques sur M= (m+1)2 canaux et contenant N sources.
- La séparation en aveugle de sources est donc effectuée à l'étape E310 comme expliqué précédemment.
- Cette étape permet à la fois d'extraire M composantes et la matrice de mélange estimée. Les composantes obtenues en sortie de l'étape de séparation de sources peuvent être classées selon deux classes de composantes : une première classe de composantes dites directes correspondant aux sources sonores directes et une deuxième classe de composantes dites réverbérées correspondants aux réflexions des sources.
- A l'étape E320, un calcul de descripteurs des M composantes (s1, s2, ...sM) issues de l'étape de séparation des sources est mis en oeuvre, descripteurs qui vont permettre d'associer à chaque composante extraite la classe qui lui correspond : composante directe ou composante réverbérée.
- Deux types de descripteurs sont calculés ici : des descripteurs bi-variés qui font intervenir des couples de composantes (sj, si) et des descripteurs uni-variés calculés pour une composante si.
- Ainsi, un ensemble de premiers descripteurs bi-variés est calculé. Ces descripteurs sont représentatifs de relations statistiques entre les composantes des couples de l'ensemble des M composantes obtenu.
- Trois cas de figures peuvent être modélisés en fonction des classes respectives des composantes :
- Les deux composantes sont des champs directs,
- L'une des deux composantes est directe et l'autre est réverbérée,
- Les deux composantes sont réverbérées.
- En effet, chaque composante directe est principalement constituée du champ direct d'une source, assimilable à une onde plane, auquel s'ajoute une réverbération résiduelle dont la contribution énergétique est inférieure à celle du champ direct. Les sources étant par nature statistiquement indépendantes, il y a donc une faible corrélation entre les composantes directes extraites.
- A l'inverse, chaque composante réverbérée est constituée de premières réflexions, versions retardées et filtrées du ou des champs directs, et d'une réverbération tardive. Ainsi, les composantes réverbérées présentent une corrélation significative avec les composantes directes, et généralement un retard de groupe identifiable par rapport aux composantes directes.
- La fonction de cohérence


La cohérence est idéalement nulle lorsque sj et si sont les champs directs de sources indépendantes mais elle prend une valeur élevée lorsque sj et si sont deux contributions d'une même source : le champ direct et une première réflexion ou bien deux réflexions. - Une telle fonction de cohérence indique donc une probabilité d'avoir deux composantes directes ou deux contributions d'une même source (directe/réverbérée ou première réflexion/réflexions ultérieures).
- En pratique, les interspectres et autospectres pourront être calculés en segmentant les composantes extraites en K trames (adjacentes ou avec recouvrement), en appliquant une transformée à Fourier à court-terme à chaque trame k de ces K trames pour produire les spectres instantanés Sj (k,f), et en moyennant les observations sur les K trames :

- Le descripteur utilisé pour un signal large bande est la moyenne sur l'ensemble des fréquences de la fonction de cohérence entre deux composantes, soit :

Lafigure 4 donne un aperçu des valeurs de cohérence en fonction de la fréquence pour les cas suivants : - Cas N°1 où les valeurs de cohérence sont obtenues pour deux composantes directes issues de 2 sources distinctes.
- Cas N°2 où les valeurs de cohérence sont obtenues pour un couple de composantes directes et réverbérée pour une seule source active.
- Cas N°3 où les valeurs de cohérence sont obtenues pour un couple de composantes directe et réverbérée mais lorsque deux sources sont actives simultanément.
- On remarque que dans le premier cas, la valeur de cohérence dγ est inférieur à 0.3 alors que dans le second cas dγ atteint 0.7 en présence d'une seule source active. Ces valeurs reflètent bien à la fois l'indépendance des signaux directs et la relation liant un signal direct et le même signal réverbéré, en l'absence d'interférences. Cependant, en incorporant une seconde source active dans le mélange initial (Cas N°3), la cohérence moyenne du cas direct/réverbéré descend à 0.55 et se retrouve fortement dépendante du contenu spectral et du niveau énergétique des différentes sources. Ici, la concurrence des différentes sources fait chuter la cohérence en basses fréquences, tandis que les valeurs sont plus élevées au-dessus de 5500 Hz en raison d'une plus faible contribution de la source interférente.
- On remarque donc que la détermination d'une probabilité d'appartenance à une même classe ou à une classe différente pour un couple de composante, peut dépendre du nombre de sources a priori actives. Pour l'étape de classification E340 décrite ultérieurement, ce paramètre pourra être pris en compte dans un mode particulier de réalisation.
- A l'étape E330 de la
figure 3 , un calcul de probabilité est déduit du descripteur ainsi décrit. - En pratique, les densités de probabilités des
figures 5 et7 décrites ci-après, et plus généralement toutes les densités de probabilité des descripteurs, sont apprises de manière statistique sur des bases de données comprenant des conditions acoustiques variées (réverbérantes/mâtes) et différentes sources (voix d'homme/femme, langues française/anglaise/...). Les composantes sont classées de manière informée : à chaque source est associée la composante extraite la plus proche spatialement, les restantes étant classées comme composantes réverbérées. Pour calculer la position de la composante, on utilise les 4 premiers coefficients de son vecteur de mélange issu de la matrice A (soit l'ordre 1), inverse de la matrice de séparation B. En faisant l'hypothèse que ce vecteur suit la règle d'encodage d'une onde plane soit :

Une fois les signaux classés, les différents descripteurs sont calculés. Du nuage de points - issus de la base de données - pour une classe donnée est extrait un histogramme de valeurs du descripteur à partir duquel une densité de probabilité est choisie parmi une collection de densités de probabilité, sur la base d'une distance, généralement la divergence de Kullback-Leibler. Lafigure 9 montre un exemple de calcul de loi pour le critère de cohérence entre une composante directe et une composante réverbérée : la loi log-normale a été sélectionnée parmi une dizaine de lois car elle minimise la divergence de Kullback-Leibler.
Pour l'exemple d'un signal ambisonique, lafigure 5 représente les distributions (densité de probabilité ou pdf pour « Probability density function » en anglais) associées à la valeur de la cohérence moyenne entre deux composantes. - Les lois de probabilité représentées ici sont présentées pour une captation microphonique ambisonique à 4 canaux (ambisonie ordre 1) ou 9 canaux (ambisonie d'ordre 2), dans le cas d'une ou deux sources actives simultanément. On observe tout d'abord que la cohérence moyenne dγ prend des valeurs nettement plus faibles pour des couples de composantes directes par rapport aux cas où au moins une des composantes est réverbérée, et cette observation est d'autant plus marquée que l'ordre ambisonique est élevé. Cela est dû à une meilleure sélectivité de la formation de voies lorsque le nombre de canaux est plus important, et donc à une meilleure séparation des composantes extraites.
- On constate également qu'en présence de deux sources actives, les estimateurs de cohérence se dégradent, que ce soient les couples direct/réverbéré ou réverbéré/réverbéré (en présence d'une seule source, le couple direct/direct n'existe pas).
En définitive, il apparaît que les densités de probabilité dépendent fortement du nombre de sources dans le mélange, et du nombre de capteurs à disposition. - Ce descripteur est donc pertinent pour détecter si un couple de composantes extraites correspond à deux composantes directes (2 vraies sources) ou si au moins l'une des deux composantes provient de l'effet de salle.
- Dans un mode de réalisation de l'invention, un autre type de descripteur bi-varié est calculé à l'étape E320. Soit ce descripteur est calculé à la place du descripteur de type cohérence décrit précédemment, soit en complément de celui-ci.
- Ce descripteur va permettre de déterminer, pour un couple (direct/réverbéré) quelle composante est plus probablement le signal direct et laquelle correspond au signal réverbéré, en se basant sur l'hypothèse simple que les premières réflexions sont des versions retardées et atténuées du signal direct.
- Ce descripteur est basé sur une autre relation statistique entre les composantes, le retard entre les deux composantes du couple. On définit le retard τjl,max comme le retard qui maximise la fonction d'intercorrélation r jl (τ) = Et { sj (t)sl (t - τ)} entre les composantes d'un couple de composantes sj et sl :

- Lorsque sj est un signal direct et sl une réflexion associée, le tracé de la fonction d'intercorrélation fera généralement apparaître un τjl,max négatif. Ainsi, si l'on sait que l'on est en présence d'un couple de composantes direct/réverbéré, on peut ainsi théoriquement attribuer la classe à chacune des composantes grâce au signe de τjl,max.
- En pratique, l'estimation du signe de τjl,max est souvent très bruitée, voire même parfois inversée :
- Lorsque la scène est constituée d'une seule source, il n'y a pas forcément de délai de groupe qui émerge distinctement si le champ réverbérée est composé de multiples réflexions et de réverbération tardive. De plus les composantes directes extraites par SAS contiennent toujours un résidu d'effet de salle plus ou moins important, qui va bruiter la mesure du délai.
- Lorsque plusieurs sources sont présentes, les interférences viennent perturber la mesure, à plus forte raison si les trames d'analyse sont courtes et que tous les champs directs n'ont pas été parfaitement séparés.
- Pour ces raisons, on peut choisir de fiabiliser le signe de τ jl,max utilisé comme descripteur, grâce à un indicateur de robustesse ou de fiabilité.
- La cohérence moyenne entre les composantes permet d'évaluer la pertinence du couple direct/réverbéré comme vu précédemment. Si celle-ci est forte, on peut espérer que le délai de groupe sera un descripteur fiable.
- D'autre part, la valeur relative du pic d'intercorrélation τjl,max aux autres valeurs de la fonction d'intercorrélation r jl (τ) renseigne également sur la fiabilité du délai de groupe. La
figure 6 illustre le caractère émergent du pic d'autocorrélation entre une composante directe et une composante réverbérée. Sur la partie haute (1) de lafigure 6 où une seule source est présente, le maximum d'intercorrélation émerge clairement du reste de l'intercorrélation, indiquant de manière fiable que l'une des composantes est en retard par rapport à l'autre. Il émerge notamment par rapport aux valeurs de la fonction d'autocorrélation pour des signes opposés à celui de τ jl,max (celle des τ positifs sur lafigure 6 ) qui sont très faibles, quelle que soit la valeur de τ. - Dans une réalisation particulière, on définit un second indicateur de fiabilité du signe du retard appelé émergence, en calculant le rapport entre la valeur absolue de l'intercorrélation à τmax et celle du maximum de corrélation pour des τ de signe opposé à celui de τjl,max :



- Ce ratio, que l'on nomme émergence, est un critère ad hoc dont la pertinence se vérifie en pratique : il prend des valeurs proches de 1 pour des signaux indépendants, i.e. 2 composantes directes, et des valeurs plus élevées pour des signaux corrélées comme une composante directe et une composante réverbérée. Dans le cas précité de la courbe (1) de la
figure 6 , la valeur d'émergence est de 4. - On a donc un descripteur d τ qui détermine, pour chaque couple supposé direct/réverbéré, la probabilité pour chaque composante du couple d'être la composante directe ou la composante réverbérée. Ce descripteur est fonction du signe de τmax, de la cohérence moyenne entre les composantes et de l'émergence du maximum d'intercorrélation.
- Il faut noter que ce descripteur est sensible au bruit, et notamment à la présence de plusieurs sources simultanées, comme illustré sur la courbe (2) de la
figure 6 : en présence de 2 sources, même si le maximum de corrélation émerge toujours, sa valeur relative - 2.6 - est moindre du fait de la présence d'une source interférente qui réduit la corrélation entre les composantes extraites. Dans une réalisation particulière, on mesurera la fiabilité du signe du retard en fonction de la valeur de l'émergence, que l'on pondérera par le nombre a priori de sources à détecter. - Avec ce descripteur, on calcule à l'étape E330 une probabilité d'appartenance à une première classe de composantes directes ou une seconde classe de composants réverbérées pour un couple de composantes. Pour sj identifiée comme étant en avance sur si, on estime la probabilité que sj soit directe et si réverbérée par une loi à deux dimensions.
- Logiquement, on estime alors la probabilité que sj soit réverbérée et sl directe alors même que sj est en avance de phase comme le complément à 1 du cas direct/réverbéré :

- Ce descripteur n'est utilisable que pour les couples direct/réverbéré. Les couples direct/direct et réverbéré/réverbéré ne sont pas concernés par ce descripteur, on les considère donc comme équiprobables :

- Le signe du retard est un indicateur fiable lorsqu'à la fois la cohérence et l'émergence ont des valeurs moyennes ou élevées. Une émergence faible ou une cohérence faible vont rendre les couples direct/réverbéré ou réverbéré/direct équiprobables.
- A l'étape E320, est également calculé un ensemble de seconds descripteurs dit uni-variés représentatifs de caractéristiques d'encodage des composantes de l'ensemble des M composantes obtenu.
- Connaissant le système de captation utilisé, l'encodage d'une source provenant d'une direction donnée s'effectue avec des coefficients de mélange dépendant, entre autres, de la directivité des capteurs. Dans le cas où la source peut être considérée comme ponctuelle et où les longueurs d'onde sont grandes par rapport à la taille de l'antenne, on peut considérer la source comme une onde plane. Cette hypothèse se vérifie généralement dans le cas d'un microphone ambisonique qui est de petite taille, pour peu que la source soit suffisamment éloignée du microphone (en pratique, un mètre suffit).
- Pour une composante sj extraite par SAS, la jème colonne de la matrice de mélange estimée A, obtenue par inversion de la matrice de séparation B, va contenir les coefficients de mélange associés à celle-ci. Si cette composante est directe, c'est-à-dire qu'elle correspond à une seule source, les coefficients de mélange de la colonne Aj vont tendre vers les caractéristiques de l'encodage microphoniques pour une onde plane. Dans le cas d'une composante réverbérée, somme de plusieurs réflexions et d'un champ diffus, les coefficients de mélange estimés seront plus aléatoires et ne correspondront pas à l'encodage d'une seule source avec une direction d'arrivée précise.
- On peut donc se servir de la conformité entre les coefficients de mélange estimés et les coefficients de mélange théoriques pour une source seule pour estimer une probabilité que la composante soit directe ou réverbérée.
- Dans le cas d'une captation microphonique ambisonique d'ordre 1, l'encodage d'une onde plane sj d'incidence (θj, φj) au format ambisonique dit N3D s'effectue suivant la formule :

- Où

- Il existe en effet plusieurs formats ambisoniques, qui se différencient notamment par la normalisation des différentes composantes regroupées en ordre. On considère ici le format connu N3D. Les différents formats sont par exemple décrits au lien suivant :
https://en.wikipedia.org/wiki/Ambisonic data exchange formats. - On peut ainsi déduire des coefficients d'encodage d'une source un critère, nommé critère onde plane, qui illustre la conformité entre les coefficients de mélange estimés et l'équation théorique d'une onde plane encodée seule :

- Le critère cop est par définition égal à 1 dans le cas d'une onde plane. En présence d'un champ direct correctement identifié, le critère onde plane restera très proche de la valeur 1. A l'inverse, dans le cas d'une composante réverbérée, la multitude des contributions (premières réflexions et réverbération tardive) avec des niveaux énergétiques équivalents vont généralement éloigner le critère onde plane de sa valeur idéale.
- Pour ce descripteur comme pour les autres, la distribution associée et calculé en E330, connaît une certaine variabilité, en fonction notamment du niveau de bruit présent dans les composantes extraites. Ce bruit est constitué principalement de la réverbération résiduelle et des contributions des sources interférentes qui n'auront pas été parfaitement annulées. On peut donc choisir, pour affiner l'analyse, d'estimer la distribution des descripteurs en fonction :
- Du nombre de canaux utilisés (donc ici de l'ordre ambisonique), qui influe sur la sélectivité du « beamforming » et donc sur le niveau de bruit résiduel,
- du nombre de sources contenues dans le mélange (comme pour les descripteurs précédents), dont l'augmentation entraine mécaniquement une hausse du niveau de bruit et une plus grande variance dans l'estimation de la matrice de séparation B, donc de A.
- On peut observer sur la
figure 7 les lois de probabilités (densité de probabilité) associées à ce descripteur, en fonction du nombre de sources actives simultanément (1 ou 2) et de l'ordre ambisonique du contenu analysé (ordres 1 à 2). Conformément à l'hypothèse initiale, la valeur du critère onde plane est concentrée autour de la valeur 1 pour les composantes directes. Pour les composantes réverbérées, la distribution est plus uniforme, avec cependant une forme légèrement asymétrique, à cause du descripteur lui-même qui est asymétrique, avec une forme en 1/x. - La distance entre les distributions des deux classes permet une discrimination assez fiable entre les composantes de type ondes planes et celles plus diffuses.
- Ainsi, les descripteurs calculés à l'étape E320 et exposés ici sont basés à la fois sur les statistiques des composantes extraites (cohérence moyenne et retard de groupe) et sur la matrice de mélange estimée (critère onde plane). Ceux-ci permettent de déterminer des probabilités conditionnelles d'appartenance d'une composante à une des deux classes Cd ou Cr.
- A partir du calcul de ces probabilités, il est alors possible, à l'étape E340 de déterminer une classification des composantes de l'ensemble des M composantes, selon les deux classes.
- Pour une composante sj, on note Cj la classe correspondante. S'agissant de classer l'ensemble des M composantes extraites, on nomme "configuration" le vecteur des classes C de dimension 1xM tel que :
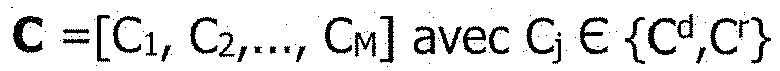
- Sachant qu'il existe deux classes possibles pour chaque composante, le problème revient finalement à choisir parmi un total de 2M configurations potentielles supposées équiprobables. Pour ce faire, la règle du maximum a posteriori est appliquée : connaissant L(C i) la vraisemblance de la i eme configuration, la configuration retenue sera celle possédant la vraisemblance maximale, c'est-à-dire :
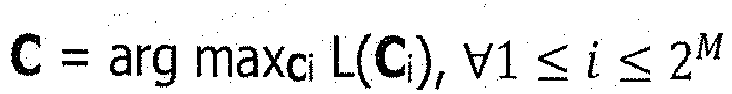
- L'approche choisie peut être exhaustive et consiste alors à estimer la vraisemblance de toutes les configurations possibles, à partir des descripteurs déterminés à l'étape E320 et des distributions qui leur sont associées et qui sont calculés à l'étape E330.
- Selon une autre approche, une pré-sélection des configurations peut être effectuée pour réduire le nombre de configuration à tester, et donc la complexité de la mise en oeuvre de la solution. Cette pré-sélection peut se faire par exemple selon le critère onde plane seul en classant certaines composantes dans la catégorie Cr , dès lors que la valeur de leur critère cop s'éloigne trop de la valeur théorique d'une onde plane 1 : dans le cas de signaux ambisoniques, on peut voir sur les distributions de la
figure 7 que l'on peut, quelle que soit la configuration (ordre ou nombre de sources) et a priori sans perte de robustesse, classer dans la catégorie Cr les composantes dont le cop vérifie l'une des inégalités suivantes :
- Cette pré-sélection permet de réduire le nombre de configurations à tester en pré-classant certaines composantes, en excluant les configurations qui impose la classe Cd à ces composantes pré-classées.
- Une autre possibilité pour réduire plus encore la complexité est d'exclure les composantes pré-classées du calcul des descripteurs bi-variés et du calcul de la vraisemblance, ce qui réduit le nombre de critères bi-variés à calculer et donc encore plus la complexité de traitement.
- Pour estimer la vraisemblance de chaque configuration à l'aide des descripteurs calculés, une approche naïve bayésienne peut être utilisée. Dans ce type d'approche, on se donne un ensemble de descripteurs dk pour chaque composante sj Pour chaque descripteur, on formule la probabilité pour la composante sj d'appartenir à la classe Cα (α=d ou r) grâce à la loi de Bayes :

- Les deux classes Cr et Cd étant supposées équiprobables, il en découle :


- On obtient alors :


- Pour un descripteur bi-varié (comme par exemple la cohérence) faisant intervenir deux composantes sj et si et leurs classes respectives supposées, on étend l'expression précédente:

- La vraisemblance s'exprime comme le produit des probabilités conditionnelles associées à chacun des K descripteurs, si l'on suppose que ceux-ci sont indépendants :
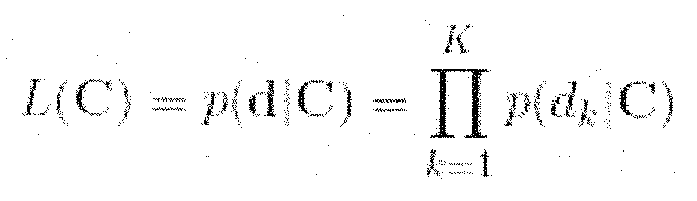
- Plus précisément, un nombre K1 de descripteurs uni-variés est mis à profit pour chacune des composantes, tandis qu'un nombre K2 de descripteurs bi-variés est utilisé pour chaque paire de composantes. Les lois de probabilités des descripteurs étant établies en fonction du nombre de sources supposé et du nombre de canaux (l'indice m représente l'ordre ambisonique, dans le cas d'une captation de ce type), on formule alors l'expression finale de la vraisemblance :

- dk (j) est la valeur du descripteur d'indice k pour la composante sj ;
- dk (j, l) est la valeur du descripteur bi-varié d'indice k pour les composantes sj et sl ;
- Cj et Cl sont les classes supposées des composantes j et / ;
- N est le nombre de sources actives associé à la configuration évaluée :

- Pour des raisons calculatoires, on préfère à la vraisemblance sa version logarithmique (log-vraisemblance) :

- Cette équation est celle utilisée en définitive pour déterminer la configuration la plus vraisemblable dans le classificateur bayésien décrit ici pour ce mode de réalisation.
- Le classificateur bayésien présenté ici n'est qu'un exemple d'implémentation, il pourrait être remplacé, entre autres, par une machine à vecteurs de support ou un réseau de neurones.
- Au final, la configuration présentant le maximum de vraisemblance est retenue, indiquant la classe directe ou réverbérée associée à chacune des M composantes C(C1, ..., Ci, ..., CM).
- De cette combinaison, il est donc déduit les N composantes correspondant aux N sources directes actives.
- Le traitement décrit ici est effectué dans le domaine temporel, mais peut aussi être, dans une variante de réalisation, appliqué dans un domaine transformé.
- Le procédé tel que décrit en référence à la
figure 3 étant alors mis en oeuvre par sous-bandes de fréquence après passage dans le domaine transformé des signaux captés. - Par ailleurs, la bande passante utile peut être réduite en fonction des imperfections potentielles du système de captation, en hautes fréquences (présence de repliement spatial) ou en basses fréquences (impossibilité de retrouver les directivités théoriques de l'encodage microphonique).
- La
figure 8 représente ici une forme de réalisation d'un dispositif (DIS) de traitement selon un mode de réalisation de l'invention. - Des capteurs Ca1 à CaM représentés ici sous la forme d'un microphone sphérique MIC permettent d'acquérir, dans un milieu réel, donc réverbérant, M signaux de mélange x ( x 1, ..., xi , ..., xM ), à partir d'un signal multicanal.
- Bien entendu, d'autres formes de microphones ou de capteurs peuvent être prévues. Ces capteurs peuvent être intégrés au dispositif DIS ou bien en dehors du dispositif, les signaux en résultant étant alors transmis au dispositif de traitement qui les reçoit via son interface d'entrée 840. Dans une variante, ces signaux peuvent simplement être obtenus préalablement et importés en mémoire du dispositif DIS.
- Ces M signaux sont alors traités par un circuit de traitement et des moyens informatiques tels qu'un processeur PROC en 860 et une mémoire de travail MEM en 870. Cette mémoire peut comporter un programme informatique comportant les instructions de code pour la mise en oeuvre des étapes du procédé de traitement tel que décrit par exemple en référence à la
figure 3 et notamment les étapes d'application d'un traitement de séparation de sources au signal multicanal capté et obtention d'un ensemble de M composantes sonores, avec M≥N, de calcul d'un ensemble de premiers descripteurs dit bi-variés, représentatifs de relations statistiques entre les composantes des couples de l'ensemble des M composantes obtenu et d'un ensemble de seconds descripteurs dit uni-variés représentatifs de caractéristiques d'encodage des composantes de l'ensemble des M composantes obtenu et de classification des composantes de l'ensemble des M composantes, selon deux classes de composantes, une première classe de N composantes dites directes correspondant aux N sources sonores directes et une deuxième classe de M-N composantes dites réverbérées, par un calcul de probabilité d'appartenance à une des deux classes, fonction des ensembles de premiers et seconds descripteurs. - Ainsi, le dispositif comporte un module 810 de traitement de séparation de sources appliqué au signal multicanal capté pour obtenir un ensemble de M composantes sonores s (s1 , ..., si, .. sM), avec M≥N. Les M composantes sont fournies en entrée d'un calculateur 820 apte à calculer un ensemble de premiers descripteurs dit bi-variés, représentatifs de relations statistiques entre les composantes des couples de l'ensemble des M composantes obtenu et un ensemble de seconds descripteurs dit uni-variés représentatifs de caractéristiques d'encodage des composantes de l'ensemble des M composantes obtenu.
- Ces descripteurs sont utilisés par un module de classification 830 ou classificateur, apte à classer des composantes de l'ensemble des M composantes, selon deux classes de composantes, une première classe de N composantes dites directes correspondant aux N sources sonores directes et une deuxième classe de M-N composantes dites réverbérées.
- Pour cela, le module de classification comporte un module 831 de calcul de probabilité d'appartenance à une des deux classes des composantes de l'ensemble M, fonction des ensembles de premiers et seconds descripteurs.
- Le classificateur utilise des descripteurs liés à la corrélation entre .les composantes pour déterminer lesquelles sont des signaux directs (c'est à dire des vraies sources) et lesquelles sont des résidus de réverbération. Il utilise également des descripteurs liés aux coefficients de mélange estimés par SAS, pour évaluer la conformité entre l'encodage théorique d'une source seule et l'encodage estimé de chaque composante. Certains des descripteurs sont donc fonction d'un couple de composantes (pour la corrélation), et d'autres sont fonctions d'une composante seule (pour la conformité de l'encodage microphonique estimé).
- Un module 832 de calcul de vraisemblance permet de déterminer, dans un mode de réalisation, la combinaison le plus probable des classifications des M composantes par un calcul de valeurs de vraisemblance fonction des probabilités calculées au module 831 et pour les combinaisons possibles.
- Enfin, le dispositif comporte une interface de sortie 850 pour délivrer l'information de classification des composantes, par exemple à un autre dispositif de traitement qui peut utiliser cette information pour rehausser le son des sources discriminés, pour les débruiter ou bien pour effectuer un mixage de plusieurs sources discriminées. Un autre traitement possible peut également être d'analyser ou de localiser les sources pour optimiser le traitement d'une commande vocale.
- Bien d'autres applications utilisant l'information de classification ainsi déterminée, sont alors possibles.
- Le dispositif DIS peut être intégré dans une antenne microphonique pour effectuer par exemple des captations de scènes sonores ou pour une prise de son de commande vocale. Le dispositif peut également être intégré dans un terminal de communication apte à. traiter des signaux captés par une pluralité de capteurs intégrés ou déportés du terminal.
Claims (14)
- Procédé de traitement de données sonores pour une séparation de N sources sonores d'un signal sonore multicanal capté en milieu réel, le procédé comportant les étapes suivantes :- application (E310) d'un traitement de séparation de sources au signal multicanal capté et obtention d'une matrice de séparation et d'un ensemble de M composantes sonores, avec M≥N ;- calcul (E320) d'un ensemble de premiers descripteurs dit bi-variés, représentatifs d'une mesure de corrélation entre les composantes des couples de l'ensemble des M composantes obtenu ;- calcul (E320) d'un ensemble de seconds descripteurs dit uni-variés représentatifs de caractéristiques d'encodage des composantes de l'ensemble des M composantes obtenu, le calcul étant fonction d'une mise en correspondance entre les caractéristiques d'encodage estimées et issues d'une matrice inverse de la matrice de séparation et des caractéristiques d'encodage théoriques d'une source de type onde plane ;- classification (E340) des composantes de l'ensemble des M composantes, selon deux classes de composantes, une première classe de N composantes dites directes correspondant aux N sources sonores directes et une deuxième classe de M-N composantes dites réverbérées, par un calcul (E330) de probabilité d'appartenance à une des deux classes, fonction des ensembles de premiers et seconds descripteurs.
- Procédé selon la revendication 1, dans lequel le calcul d'un descripteur bi-varié comporte le calcul d'un score de cohérence entre deux composantes.
- Procédé selon l'une des revendications 1 à 2, dans lequel le calcul d'un descripteur bi-varié comporte la détermination d'un retard entre les deux composantes du couple.
- Procédé selon la revendication 3, dans lequel le retard entre deux composantes est déterminé par la prise en compte du retard maximisant une fonction d'inter-corrélation entre les deux composants du couple.
- Procédé selon l'une des revendications 3 ou 4, dans lequel la détermination du retard entre deux composantes d'un couple est associée à un indicateur de fiabilité du signe du retard, fonction de la cohérence entre les composantes du couple.
- Procédé selon l'une des revendications 3 ou 5, dans lequel la détermination du retard entre deux composantes d'un couple est associée à un indicateur de fiabilité du signe du retard, fonction du rapport du maximum d'une fonction d'inter-corrélation pour des retards de signe opposé.
- Procédé selon l'une des revendications 1 à 6, dans lequel la classification des composantes de l'ensemble des M composantes s'effectue par la prise en compte de l'ensemble des M composantes, et par le calcul de la combinaison la plus probable des classifications des M composantes.
- Procédé selon la revendication 7, dans lequel le calcul de la combinaison la plus probable s'effectue par la détermination d'un maximum des valeurs de vraisemblance exprimées comme le produit des probabilités conditionnelles associées aux descripteurs, pour les combinaisons possibles de classification des M composantes.
- Procédé selon la revendication 7, dans lequel une étape de pré-selection des combinaisons possibles est effectuée en se basant sur les seuls descripteurs uni-variés avant l'étape de calcul de la combinaison la plus probable.
- Procédé selon l'une des revendications précédentes, dans lequel une étape de pré-selection des composantes est effectuée en se basant sur les seuls descripteurs uni-variés avant l'étape de calcul des descripteurs bi-variés.
- Procédé selon l'une des revendications précédentes, dans lequel le signal multicanal est un signal ambisonique.
- Dispositif de traitement de données sonores mis en oeuvre pour effectuer un traitement de séparation de N sources sonores d'un signal sonore multicanal capté par une pluralité de capteurs en milieu réel, le dispositif comportant:- une interface d'entrée pour recevoir les signaux captés par une pluralité de capteurs, du signal sonore multicanal;- un circuit de traitement comportant un processeur et apte à controler:∘ un module de traitement de séparation de sources appliqué au signal multicanal capté pour obtenir une matrice de séparation et un ensemble de M composantes sonores, avec M≥N ;o un calculateur apte à calculer un ensemble de premiers descripteurs dit bi-variés, représentatifs d'une mesure de corrélation entre les composantes des couples de l'ensemble des M composantes obtenu et un ensemble de seconds descripteurs dit uni-variés représentatifs de caractéristiques d'encodage microphonique des composantes de l'ensemble des M composantes obtenu, le calcul étant fonction d'une mise en correspondance entre les caractéristiques d'encodage estimées et issues d'une matrice inverse de la matrice de séparation et des caractéristiques d'encodage théoriques d'une source de type onde plane ;∘ un module de classification des composantes de l'ensemble des M composantes, selon deux classes de composantes, une première classe de N composantes dites directes correspondant aux N sources sonores directes et une deuxième classe de M-N composantes dites réverbérées, par un calcul de probabilité d'appartenance à une des deux classes, fonction des ensembles de premiers et seconds descripteurs ;- une interface de sortie pour délivrer l'information de classification des composantes.
- Programme informatique comportant des instructions de code pour la mise en oeuvre des étapes du procédé de traitement selon l'une des revendications 1 à 11, lorsque ces instructions sont exécutées par un processeur.
- Support de stockage, lisible par un processeur, sur lequel est enregistré un programme informatique comprenant des instructions de code pour l'exécution des étapes du procédé de traitement selon l'un des revendications 1 à 11.
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| FR1755183A FR3067511A1 (fr) | 2017-06-09 | 2017-06-09 | Traitement de donnees sonores pour une separation de sources sonores dans un signal multicanal |
| PCT/FR2018/000139 WO2018224739A1 (fr) | 2017-06-09 | 2018-05-24 | Traitement de donnees sonores pour une separation de sources sonores dans un signal multicanal |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| EP3635718A1 EP3635718A1 (fr) | 2020-04-15 |
| EP3635718B1 true EP3635718B1 (fr) | 2023-06-28 |
Family
ID=59746081
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| EP18737650.4A Active EP3635718B1 (fr) | 2017-06-09 | 2018-05-24 | Traitement de donnees sonores pour une separation de sources sonores dans un signal multicanal |
Country Status (5)
| Country | Link |
|---|---|
| US (1) | US11081126B2 (fr) |
| EP (1) | EP3635718B1 (fr) |
| CN (1) | CN110709929B (fr) |
| FR (1) | FR3067511A1 (fr) |
| WO (1) | WO2018224739A1 (fr) |
Families Citing this family (11)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN110473566A (zh) * | 2019-07-25 | 2019-11-19 | 深圳壹账通智能科技有限公司 | 音频分离方法、装置、电子设备及计算机可读存储介质 |
| WO2021164001A1 (fr) * | 2020-02-21 | 2021-08-26 | Harman International Industries, Incorporated | Procédé et système permettant d'améliorer la séparation de la voix par élimination du chevauchement |
| JP7351401B2 (ja) * | 2020-02-26 | 2023-09-27 | 日本電信電話株式会社 | 信号処理装置、信号処理方法、およびプログラム |
| CN113450823B (zh) * | 2020-03-24 | 2022-10-28 | 海信视像科技股份有限公司 | 基于音频的场景识别方法、装置、设备及存储介质 |
| WO2022079854A1 (fr) * | 2020-10-15 | 2022-04-21 | 日本電信電話株式会社 | Dispositif, procédé et programme d'amélioration de signal acoustique |
| FR3116348A1 (fr) * | 2020-11-19 | 2022-05-20 | Orange | Localisation perfectionnée d’une source acoustique |
| CN112599144B (zh) * | 2020-12-03 | 2023-06-06 | Oppo(重庆)智能科技有限公司 | 音频数据处理方法、音频数据处理装置、介质与电子设备 |
| JP7552742B2 (ja) * | 2021-02-15 | 2024-09-18 | 日本電信電話株式会社 | 音源分離装置、音源分離方法、およびプログラム |
| KR20230153409A (ko) * | 2021-03-11 | 2023-11-06 | 돌비 레버러토리즈 라이쎈싱 코오포레이션 | 미디어 유형에 기반한 잔향 제거 |
| US20230057082A1 (en) * | 2021-08-19 | 2023-02-23 | Sony Group Corporation | Electronic device, method and computer program |
| CN116229997B (zh) * | 2022-12-27 | 2026-03-10 | 中国电信股份有限公司 | 多通道音频数据增强处理方法、装置、设备及介质 |
Family Cites Families (19)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US6879952B2 (en) * | 2000-04-26 | 2005-04-12 | Microsoft Corporation | Sound source separation using convolutional mixing and a priori sound source knowledge |
| US20040086130A1 (en) * | 2002-05-03 | 2004-05-06 | Eid Bradley F. | Multi-channel sound processing systems |
| US7809145B2 (en) * | 2006-05-04 | 2010-10-05 | Sony Computer Entertainment Inc. | Ultra small microphone array |
| US7099821B2 (en) * | 2003-09-12 | 2006-08-29 | Softmax, Inc. | Separation of target acoustic signals in a multi-transducer arrangement |
| KR100647286B1 (ko) * | 2004-08-14 | 2006-11-23 | 삼성전자주식회사 | 교차채널 간섭을 제거하기 위한 후처리장치 및 방법과이를 이용한 다채널 음원 분리장치 및 방법 |
| WO2007029412A1 (fr) * | 2005-09-01 | 2007-03-15 | Matsushita Electric Industrial Co., Ltd. | Dispositif de traitement de signal acoustique multicanal |
| WO2007103037A2 (fr) * | 2006-03-01 | 2007-09-13 | Softmax, Inc. | Système et procédé permettant de produire un signal séparé |
| FR2899424A1 (fr) * | 2006-03-28 | 2007-10-05 | France Telecom | Procede de synthese binaurale prenant en compte un effet de salle |
| FR2903562A1 (fr) * | 2006-07-07 | 2008-01-11 | France Telecom | Spatialisation binaurale de donnees sonores encodees en compression. |
| CN101622669B (zh) * | 2007-02-26 | 2013-03-13 | 高通股份有限公司 | 用于信号分离的系统、方法及设备 |
| WO2008120933A1 (fr) * | 2007-03-30 | 2008-10-09 | Electronics And Telecommunications Research Institute | Dispositif et procédé de codage et décodage de signal audio multi-objet multicanal |
| US8131542B2 (en) * | 2007-06-08 | 2012-03-06 | Honda Motor Co., Ltd. | Sound source separation system which converges a separation matrix using a dynamic update amount based on a cost function |
| GB0720473D0 (en) * | 2007-10-19 | 2007-11-28 | Univ Surrey | Accoustic source separation |
| JP5195652B2 (ja) * | 2008-06-11 | 2013-05-08 | ソニー株式会社 | 信号処理装置、および信号処理方法、並びにプログラム |
| JP4816711B2 (ja) * | 2008-11-04 | 2011-11-16 | ソニー株式会社 | 通話音声処理装置および通話音声処理方法 |
| US20110058676A1 (en) * | 2009-09-07 | 2011-03-10 | Qualcomm Incorporated | Systems, methods, apparatus, and computer-readable media for dereverberation of multichannel signal |
| KR101567461B1 (ko) * | 2009-11-16 | 2015-11-09 | 삼성전자주식회사 | 다채널 사운드 신호 생성 장치 |
| US9165565B2 (en) * | 2011-09-09 | 2015-10-20 | Adobe Systems Incorporated | Sound mixture recognition |
| US9654894B2 (en) * | 2013-10-31 | 2017-05-16 | Conexant Systems, Inc. | Selective audio source enhancement |
-
2017
- 2017-06-09 FR FR1755183A patent/FR3067511A1/fr not_active Ceased
-
2018
- 2018-05-24 US US16/620,314 patent/US11081126B2/en active Active
- 2018-05-24 CN CN201880037758.9A patent/CN110709929B/zh active Active
- 2018-05-24 EP EP18737650.4A patent/EP3635718B1/fr active Active
- 2018-05-24 WO PCT/FR2018/000139 patent/WO2018224739A1/fr not_active Ceased
Also Published As
| Publication number | Publication date |
|---|---|
| US20200152222A1 (en) | 2020-05-14 |
| WO2018224739A1 (fr) | 2018-12-13 |
| FR3067511A1 (fr) | 2018-12-14 |
| EP3635718A1 (fr) | 2020-04-15 |
| CN110709929A (zh) | 2020-01-17 |
| CN110709929B (zh) | 2023-08-15 |
| US11081126B2 (en) | 2021-08-03 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| EP3635718B1 (fr) | Traitement de donnees sonores pour une separation de sources sonores dans un signal multicanal | |
| EP3807669B1 (fr) | Localisation de sources sonores dans un environnement acoustique donné | |
| JP4406428B2 (ja) | 信号分離装置、信号分離方法、信号分離プログラム及び記録媒体 | |
| EP2898707B1 (fr) | Calibration optimisee d'un systeme de restitution sonore multi haut-parleurs | |
| EP4046390B1 (fr) | Localisation perfectionnee d'une source acoustique | |
| Wang et al. | Over-determined source separation and localization using distributed microphones | |
| US10078785B2 (en) | Video-based sound source separation | |
| May et al. | Requirements for the evaluation of computational speech segregation systems | |
| EP4248231A1 (fr) | Localisation perfectionnée d'une source acoustique | |
| WO2016162515A1 (fr) | Procédé de séparation de sources pour signaux parcimonieux | |
| WO2011076696A1 (fr) | Procede pour estimer le nombre de sources incidentes a un reseau de capteurs par estimation de la statistique du bruit | |
| EP3559947B1 (fr) | Traitement en sous-bandes d'un contenu ambisonique réel pour un décodage perfectionné | |
| EP3025342B1 (fr) | Procédé de suppression de la réverbération tardive d'un signal sonore | |
| Zohny et al. | Modelling interaural level and phase cues with Student's t-distribution for robust clustering in MESSL | |
| EP4315328B1 (fr) | Estimation d'un masque optimise pour le traitement de donnees sonores acquises | |
| Cobos et al. | Two-microphone separation of speech mixtures based on interclass variance maximization | |
| Hammond et al. | Robust full-sphere binaural sound source localization | |
| EP1359685A1 (fr) | Séparation des sources pour des signaux cyclostationnaires | |
| Li et al. | Separation of Multiple Speech Sources in Reverberant Environments Based on Sparse Component Enhancement | |
| Bentsen et al. | The impact of exploiting spectro-temporal context in computational speech segregation | |
| Hammond | Methods for Robust Binaural Sound Source Localisation | |
| US11835625B2 (en) | Acoustic-environment mismatch and proximity detection with a novel set of acoustic relative features and adaptive filtering | |
| RU2788939C1 (ru) | Способ и устройство для определения глубокого фильтра | |
| Hadadi et al. | Blind Localization of Early Room Reflections with Arbitrary Microphone Array | |
| Cheng et al. | Using spatial audio cues from speech excitation for meeting speech segmentation |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| STAA | Information on the status of an ep patent application or granted ep patent |
Free format text: STATUS: UNKNOWN |
|
| STAA | Information on the status of an ep patent application or granted ep patent |
Free format text: STATUS: THE INTERNATIONAL PUBLICATION HAS BEEN MADE |
|
| PUAI | Public reference made under article 153(3) epc to a published international application that has entered the european phase |
Free format text: ORIGINAL CODE: 0009012 |
|
| STAA | Information on the status of an ep patent application or granted ep patent |
Free format text: STATUS: REQUEST FOR EXAMINATION WAS MADE |
|
| 17P | Request for examination filed |
Effective date: 20191210 |
|
| AK | Designated contracting states |
Kind code of ref document: A1 Designated state(s): AL AT BE BG CH CY CZ DE DK EE ES FI FR GB GR HR HU IE IS IT LI LT LU LV MC MK MT NL NO PL PT RO RS SE SI SK SM TR |
|
| AX | Request for extension of the european patent |
Extension state: BA ME |
|
| RAP1 | Party data changed (applicant data changed or rights of an application transferred) |
Owner name: ORANGE |
|
| DAV | Request for validation of the european patent (deleted) | ||
| DAX | Request for extension of the european patent (deleted) | ||
| RAP3 | Party data changed (applicant data changed or rights of an application transferred) |
Owner name: ORANGE |
|
| STAA | Information on the status of an ep patent application or granted ep patent |
Free format text: STATUS: EXAMINATION IS IN PROGRESS |
|
| 17Q | First examination report despatched |
Effective date: 20211006 |
|
| GRAP | Despatch of communication of intention to grant a patent |
Free format text: ORIGINAL CODE: EPIDOSNIGR1 |
|
| STAA | Information on the status of an ep patent application or granted ep patent |
Free format text: STATUS: GRANT OF PATENT IS INTENDED |
|
| INTG | Intention to grant announced |
Effective date: 20230310 |
|
| RIN1 | Information on inventor provided before grant (corrected) |
Inventor name: GUERIN, ALEXANDRE Inventor name: BAQUE, MATHIEU |
|
| GRAS | Grant fee paid |
Free format text: ORIGINAL CODE: EPIDOSNIGR3 |
|
| GRAA | (expected) grant |
Free format text: ORIGINAL CODE: 0009210 |
|
| STAA | Information on the status of an ep patent application or granted ep patent |
Free format text: STATUS: THE PATENT HAS BEEN GRANTED |
|
| AK | Designated contracting states |
Kind code of ref document: B1 Designated state(s): AL AT BE BG CH CY CZ DE DK EE ES FI FR GB GR HR HU IE IS IT LI LT LU LV MC MK MT NL NO PL PT RO RS SE SI SK SM TR |
|
| REG | Reference to a national code |
Ref country code: CH Ref legal event code: EP |
|
| REG | Reference to a national code |
Ref country code: AT Ref legal event code: REF Ref document number: 1583444 Country of ref document: AT Kind code of ref document: T Effective date: 20230715 |
|
| REG | Reference to a national code |
Ref country code: IE Ref legal event code: FG4D Free format text: LANGUAGE OF EP DOCUMENT: FRENCH |
|
| REG | Reference to a national code |
Ref country code: DE Ref legal event code: R096 Ref document number: 602018052425 Country of ref document: DE |
|
| REG | Reference to a national code |
Ref country code: LT Ref legal event code: MG9D |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: SE Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20230628 Ref country code: NO Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20230928 |
|
| REG | Reference to a national code |
Ref country code: NL Ref legal event code: MP Effective date: 20230628 |
|
| REG | Reference to a national code |
Ref country code: AT Ref legal event code: MK05 Ref document number: 1583444 Country of ref document: AT Kind code of ref document: T Effective date: 20230628 |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: RS Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20230628 Ref country code: NL Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20230628 Ref country code: LV Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20230628 Ref country code: LT Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20230628 Ref country code: HR Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20230628 Ref country code: GR Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20230929 |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: FI Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20230628 |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: SK Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20230628 |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: ES Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20230628 |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: IS Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20231028 |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: SM Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20230628 Ref country code: SK Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20230628 Ref country code: RO Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20230628 Ref country code: PT Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20231030 Ref country code: IS Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20231028 Ref country code: ES Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20230628 Ref country code: EE Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20230628 Ref country code: CZ Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20230628 Ref country code: AT Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20230628 |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: PL Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20230628 |
|
| REG | Reference to a national code |
Ref country code: DE Ref legal event code: R097 Ref document number: 602018052425 Country of ref document: DE |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: DK Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20230628 |
|
| PLBE | No opposition filed within time limit |
Free format text: ORIGINAL CODE: 0009261 |
|
| STAA | Information on the status of an ep patent application or granted ep patent |
Free format text: STATUS: NO OPPOSITION FILED WITHIN TIME LIMIT |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: IT Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20230628 |
|
| 26N | No opposition filed |
Effective date: 20240402 |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: SI Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20230628 |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: BG Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20230628 |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: BG Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20230628 |
|
| REG | Reference to a national code |
Ref country code: CH Ref legal event code: PL |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: MC Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20230628 |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: LU Free format text: LAPSE BECAUSE OF NON-PAYMENT OF DUE FEES Effective date: 20240524 |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: MC Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20230628 Ref country code: LU Free format text: LAPSE BECAUSE OF NON-PAYMENT OF DUE FEES Effective date: 20240524 Ref country code: CH Free format text: LAPSE BECAUSE OF NON-PAYMENT OF DUE FEES Effective date: 20240531 |
|
| REG | Reference to a national code |
Ref country code: BE Ref legal event code: MM Effective date: 20240531 |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: IE Free format text: LAPSE BECAUSE OF NON-PAYMENT OF DUE FEES Effective date: 20240524 |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: BE Free format text: LAPSE BECAUSE OF NON-PAYMENT OF DUE FEES Effective date: 20240531 |
|
| PGFP | Annual fee paid to national office [announced via postgrant information from national office to epo] |
Ref country code: DE Payment date: 20250423 Year of fee payment: 8 |
|
| PGFP | Annual fee paid to national office [announced via postgrant information from national office to epo] |
Ref country code: FR Payment date: 20250423 Year of fee payment: 8 |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: CY Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT; INVALID AB INITIO Effective date: 20180524 |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: HU Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT; INVALID AB INITIO Effective date: 20180524 |
|
| PGFP | Annual fee paid to national office [announced via postgrant information from national office to epo] |
Ref country code: GB Payment date: 20260317 Year of fee payment: 9 |