EP3720149A1 - Appareil, procédé, programme informatique ou système de rendu de données audio - Google Patents
Appareil, procédé, programme informatique ou système de rendu de données audio Download PDFInfo
- Publication number
- EP3720149A1 EP3720149A1 EP19166572.8A EP19166572A EP3720149A1 EP 3720149 A1 EP3720149 A1 EP 3720149A1 EP 19166572 A EP19166572 A EP 19166572A EP 3720149 A1 EP3720149 A1 EP 3720149A1
- Authority
- EP
- European Patent Office
- Prior art keywords
- virtual
- virtual sound
- user
- rendering
- audio
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Granted
Links
Images






Classifications
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04S—STEREOPHONIC SYSTEMS
- H04S5/00—Pseudo-stereo systems, e.g. in which additional channel signals are derived from monophonic signals by means of phase shifting, time delay or reverberation
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04S—STEREOPHONIC SYSTEMS
- H04S2400/00—Details of stereophonic systems covered by H04S but not provided for in its groups
- H04S2400/11—Positioning of individual sound objects, e.g. moving airplane, within a sound field
Definitions
- Examples of the present disclosure relate to apparatuses, methods, computer programs and systems for rendering audio data. Some examples, though without prejudice to the foregoing, relate to spatial rendering of speech and a real-time language translation of the same.
- the rendering of audio in a virtual sound space in conventional mediated reality systems (such as, not least for example, rendering of speech in a first language and the rendering of a translation of the same in another language in an immersive aural environment of a virtual reality system) is not always optimal.
- a speech-to-speech audio translation service In a conventional mono voice call between a first user (who speaks a first language) and a second user (who speaks a second language), where a speech-to-speech audio translation service is provided, the first user talks to the second used in the first language.
- the first user's speech is transmitted to the second user who is able to hear the same.
- the first user's speech is also additionally routed to a data centre that carries out an automated language translation of the first user's speech to a second language. This translation of the speech is transmitted to the second user and also the first user both of whom are able to hear the same. This may then be followed by a response by the second user, with a translation of the same provided to both users.
- Such an experience differs from a traditional voice call in the sense that one user should not start to talk immediately following the other user's initial speech, but should await until after the translation of the same.
- a traditional mono voice call it is not possible to mix the original speech and the translated speech as this would make the speeches impossible to understand (known as the "interfering talker" problem for a mono signal/channel).
- an apparatus comprising means configured to cause:
- chipset comprising processing circuitry configured to perform the above method.
- modules, device and/or system comprising means for performing the above method.
- an apparatus comprising:
- non-transitory computer readable medium encoded with instructions that, when performed by at least one processor, causes at least the following to be performed:
- the first and second virtual sound objects may be simultaneously rendered in the virtual sound scene, and the spatial rendering of the first and second virtual sound objects may be controlled such that, at least whilst the first and second virtual sound objects are simultaneously spatially rendered, the first and second virtual positions differ.
- the spatial rendering of the first and second virtual sound objects is controlled such that a first virtual direction of the spatially rendered first virtual sound object differs from the second virtual direction of the spatially rendered second virtual sound object.
- the second audio content is a translation (for example a real time language translation) of the first audio content.
- FIG. 500 The Figures schematically illustrate an apparatus 500 comprising means 501 for causing:
- various, but not necessarily all, examples of the disclosure may provide the technical advantage of improved rendering of the first and second audio data that enables a user to distinguish and differentiate the first and second virtual sounds objects which thereby enhances the user's listening experience and better enables the user to perceive and focus on one of the first or second virtual sound objects and hence perceive the first or second audio content represented thereby.
- the control of the spatial rendering in examples of the disclosure takes advantage of the so-called "cocktail party effect" wherein, due to differing spatial placement of audio sources, a user is capable of concentrating on one of many audio sources regardless of their temporal overlap.
- this enables the overlapping/simultaneous/parallel rendering of the first and second audio data and may thus avoids/mitigate the issues of the simultaneous playback of more than one voice/speech in a conventional monoaudio/single channel communication/ mono voice call.
- Figs. 1A, 2A and 3A illustrate an example of first person perspective mediated reality.
- mediated reality means the rendering of mediated reality for the purposes of achieving mediated reality for a remote user, for example augmented reality or virtual reality. It may or may not be user interactive.
- the mediated reality may support one or more of: 3DoF, 3DoF+ or 6DoF.
- FIGs. 1A, 2A and 3A illustrate, at a first time, each of: a real space 50, a virtual sound space 20 and a virtual visual space 60 respectively.
- a 'virtual space' may be defined as the virtual sound space 20 and/or the virtual visual space 60.
- the virtual space may comprise just the virtual sound space 20.
- a user 51 in the real space 50 has a position defined by a (real world) location 52 and a (real world) orientation 53 (i.e. the user's real world point-of-view).
- the location 52 is a three-dimensional location and the orientation 53 is a three-dimensional orientation.
- an orientation 53 of the user 51 controls/determines a virtual orientation 73 of a virtual user 71 within a virtual space, e.g. the virtual visual space 60 and/or the virtual sound space 20.
- the virtual user 71 represents the user 51 within the virtual space.
- There is a correspondence between the orientation 53 and the virtual orientation 73 such that a change in the (real world) orientation 53 produces the same change in the virtual orientation 73.
- a change in the location 52 of the user 51 does not change the virtual location 72 or virtual orientation 73 of the virtual user 71.
- the virtual orientation 73 of the virtual user 71, in combination with a virtual field of view 74 defines a virtual visual scene 75 of the virtual user 71 within the virtual visual space 60.
- the virtual visual scene 75 represents a virtual observable region within the virtual visual space 60 that the virtual user 71 can see.
- Such a 'virtual visual scene 75 for the virtual user 71' may correspond to a virtual visual 'sub-scene'.
- the virtual visual scene 75 may determine what visual content (and virtual visual spatial position of the same with respect to the virtual user's position) is rendered to the virtual user.
- a virtual sound scene 76 of the virtual user may affect what audio content (and virtual aural spatial position of the same with respect to the virtual user's position) is rendered to the virtual user.
- the virtual orientation 73 of the virtual user 71 in combination with a virtual field of hearing (i.e. an audio equivalent/analogy to a visual field of view) may define a virtual sound scene (or audio scene) 76 of the virtual user 71 within the virtual sound space (or virtual audio space) 20.
- the virtual sound scene 76 represents a virtual audible region within the virtual sound space 20 that the virtual user 71 can hear.
- Such a 'virtual sound scene 76 for the virtual user 71' may correspond to a virtual audio 'sub-scene'.
- the virtual sound scene 76 may determine what audio content (and virtual spatial position/orientation of the same) is rendered to the virtual user.
- a virtual visual scene 75 is that part of the virtual visual space 60 that is rendered/visually displayed to a user.
- a virtual sound scene 76 is that part of the virtual sound space 20 that is rendered/audibly output to a user.
- the virtual sound space 20 and the virtual visual space 60 correspond in that a position within the virtual sound space 20 has an equivalent position within the virtual visual space 60.
- a change in the location 52 of the user 51 does not change the virtual location 72 or virtual orientation 73 of the virtual user 71.
- the situation is as described for 3DoF and in addition it is possible to change the rendered virtual sound scene 76 and the displayed virtual visual scene 75 by movement of a location 52 of the user 51.
- a location 52 of the user 51 For example, there may be a mapping between the location 52 of the user 51 and the virtual location 72 of the virtual user 71.
- a change in the location 52 of the user 51 produces a corresponding change in the virtual location 72 of the virtual user 71.
- a change in the virtual location 72 of the virtual user 71 changes the rendered virtual sound scene 76 and also changes the rendered virtual visual scene 75.
- FIGs. 1B, 2B and 3B illustrate the consequences of a change in position, i.e. a change in location 52 and orientation 53, of the user 51 on respectively the rendered virtual sound scene 76 ( Fig. 2B ) and the rendered virtual visual scene 75 ( Fig. 3B ).
- Immersive or spatial audio may consist, e.g., of a channel-based bed and audio objects, metadata-assisted spatial audio (MASA) and audio objects, first-order or higher-order ambisonics (FOA/HOA) and audio objects, any combination of these such as audio objects only, or any equivalent spatial audio representation.
- MASA metadata-assisted spatial audio
- FOA/HOA first-order or higher-order ambisonics
- audio objects any combination of these such as audio objects only, or any equivalent spatial audio representation.
- FIG 4 schematically illustrates a flow chart of a method 400 according to an example of the present disclosure.
- the component blocks of FIG. 4 are functional and the functions described may or may not be performed by a single physical entity (such as an apparatus is described with reference to FIG. 5 ).
- first audio data representative of first audio content is received.
- the first audio data is rendered as a first virtual sound object in a virtual sound scene such that it is spatially rendered with a first virtual position within the virtual sound scene.
- the second audio data is rendered as a second virtual sound object in the virtual sound scene such that it is spatially rendered with a second virtual position within the virtual sound scene.
- the spatial rendering of the first and second virtual sound objects are controlled such that the first and second virtual positions differ.
- the received audio data may be spatial audio or audio with associated metadata representative of virtual position at which the audio content is to be rendered.
- the received audio may not comprise or be preassociated with a virtual position at which the audio content is to be rendered (particularly for the second content which may be newly generated audio content comprising a machine translation of the first audio content).
- the initial virtual position may be determined from the audio data itself.
- the audio data comprises, or is associated with metadata representative of a virtual position at which the virtual audio content is to be rendered
- the initial virtual position may be determined from the metadata.
- the initial virtual position may be predetermined or determined from a user setting/user preference, e.g. the renderer may be configured such that the first virtual audio content is virtually positioned at an orientation/direction of x 0 .
- the initial capture of the audio need not be spatial.
- the initial spatial placement can be based on the capture, a setting by a transmitting user, a spatialization by a service/system such as a conferencing system, or a setting by a receiving user. For example, there could be a "preferred position" for the receiving user, in which case the first virtual position of the first virtual sound object may be positioned there.
- the second audio content comprises a modified version of the first audio content.
- the first audio content comprises speech (e.g. from a user in a voice call with another user) in a first language and the second audio content comprises a translation of the speech into a second language.
- the second audio content is a real time language translation of the first audio content.
- first and second virtual sound objects may occur sequentially or overlapping in time such that they are rendered simultaneously (albeit possibly with a delay/lag, e.g., due to the lookahead required by the language translation).
- the first and second virtual sound objects are simultaneously rendered in the virtual sound scene, and the spatial rendering of the first and second virtual sound objects is controlled such that, at least whilst the first and second virtual sound objects are simultaneously spatially rendered, the first and second virtual positions differ.
- each of the first and second virtual sound objects has a finite duration and, following completion of the spatial rendering of the first virtual sound object, the spatial rendering of the second virtual sound object may move, e.g., so as to correspond to the virtual position of where the first virtual sound object was spatially rendered or to the virtual position corresponding to the "preferred position" for the receiving user.
- FIG. 5 schematically illustrates an apparatus 500 which is configured to receive the first and second audio data 701,702 representative of first and second audio content 101,102 respectively.
- the apparatus is configured to render the first audio data 701 as a first virtual sound object 601 (which is itself also representative of the first audio content 101) such that it is spatially rendered in a virtual sound scene with a first virtual position (as is schematically illustrated in FIG. 6 ).
- the apparatus is also configured to render the second audio data 702 as a second virtual sound object 602 (which is itself also representative of the second audio content 102) such that it is spatially rendered in the virtual sound scene with a second virtual position different to the first virtual position (as is schematically illustrated in FIG. 6 ).
- FIG. 6 schematically illustrates a virtual sound scene 600.
- the virtual sound scene 600 is a representation of a virtual sound space as listened to from the point-of-view of a second user 802.
- the user's point of view corresponds to the user's position 802p - which comprises the user's location 8021 and/or the user's orientation/direction 802o.
- the first virtual sound object 601 is spatially rendered so as to have a perceived first virtual position 601p (which comprises the first virtual sound object's location 6011 and/or virtual orientation/direction 601o).
- the second virtual sound object 602 is spatially rendered so as to have a perceived second virtual position 602p (which comprises the second virtual sound object's location 6021 and/or virtual orientation/direction 602o).
- the second virtual position 602p is controlled such that it has a different virtual position to the first virtual position 601 p.
- FIG.6 schematically illustrates the virtual sound scene from a plan/elevation viewpoint, i.e. such that the illustrated separation angle ⁇ between the first and second virtual positions relates to an azimuthal angle relative to the second user/listener 802.
- the spatial rendering of the first and second virtual sound objects 601, 602 is controlled such that the first virtual orientation 601o of the spatially rendered first virtual sound object 601 differs from the second virtual orientation 602o of the spatially rendered second virtual sound object 602.
- the spatial rendering of the first and second virtual sound objects 601,602 is controlled such that the first virtual orientation/direction 601o differs from the second virtual orientation/direction 602o by an azimuthal angle of greater than: 15°, 30°, 45°, 60°, 75°, 90°, 105°, 120°, 135°, 150°, or 165°.
- the first and second virtual positions 601p,602p are controlled so as to be spatially "maximally" separated.
- Such a maximal separation may correspond to a maximal directional separation of the first and second virtual positions or alternatively a maximal directional separation whilst ensuring that both the first and second virtual sound objects 601,602 remain within the same hemisphere of the user's point of view (e.g. the hemisphere in front of the user).
- the spatial rendering of the first virtual sound object 601 is controlled such that, during a first time period between a start of the spatial rendering of the first virtual sound object 601 and a start of the rendering of the second virtual sound object 602, the first virtual position 601p is moved.
- the first virtual sound object 601 may be rendered in an initial virtual position 601p upon commencement of its rendering and the virtual position 601p may then move so as to "make room" for the commencement of the rendering of the second virtual sound object 602.
- the first virtual sound object 601 may be rendered at a virtual position 601p directly in front of the user's point of view, the virtual position 601 p may then move to one side such that the second virtual sound object 602 may be rendered directly in front of the user's point of view (thereby maintaining a difference in first and second virtual positions 601p,602p).
- the virtual position 601p of the first virtual sound object 601 may be moved so that its virtual position mirrors that of the virtual position 602p of the second virtual sound object 602 relative to the user 802, i.e. such that the first and second virtual sound positions 601p,602p "mirror" each other relative to the user 802.
- the virtual position 601p at which the first virtual sound object 601 is spatially rendered may then be controlled so as to move during the determined first time period and prior to starting the spatial rendering of the second virtual sound object 602.
- the control of the spatial rendering of the first virtual sound object 601 may be based on an upcoming commencement of the rendering of the second virtual sound object 602.
- the spatial rendering of the first virtual sound object 601, not least its first virtual position 601p is connected to and may be adapted based on the state of spatial rendering of the second virtual sound object 602 (i.e. if it has yet started) or adapted automatically based on signal activity.
- the first audio content 101 of the first virtual sound object 601 comprises speech/voice/talking in a first language
- the second audio content 102 of the second virtual sound object 602 relates to a real time language translation of the speech into a second language, such that the second audio content 102 comprises speech/voice/talking in the second language.
- the receipt and rendering of the translation would be behind that of the original speech (e.g. not least due to the processing of the original speech to generate the translated speech).
- the transmission and/or rendering of the original speech can be delayed until the translation is ready.
- the original speech can initially be rendered in one virtual position (for example an optimal position such as substantially directly in front of the user) and it can then begin to "make room” for the translation upon the start of the rendering of the translation (so that it instead can be rendered in the optimal position).
- one virtual position for example an optimal position such as substantially directly in front of the user
- this may enable the second user 802 to distinguish and differentiate the first and second virtual sounds objects 601,602 which thereby enhances the user's listening experience and better enables the user to perceive and focus on one of the first or second virtual sound objects 601, 602 and hence perceive the first or second audio content 101,102 represented thereby.
- the spatial rendering of the second virtual sound object 602 is controlled such that, during a second time period between an end of the spatial rendering of the first virtual sound object 601, the second virtual position 602p is moved.
- the first virtual sound object 601 may be rendered at a virtual position 601 p directly in front of the user's point of view.
- the second virtual sound object 602 may be rendered at a differing virtual position 602p, e.g. to the side of the user's point of view.
- the virtual position 602p of the second virtual sound object 602 may be moved to the (former) virtual position of (the now ceased rendered) first virtual sound object 601, i.e. directly in front of the user's point of view.
- Such movement may be smooth/gradual, i.e., such that the second virtual sound object 602 does not seem to jut disappear at one position and appear at another position.
- this may enhance the user's listening experience and better enable the user to perceive and focus on the second virtual sound object 602 and hence perceive the second audio content 102 represented thereby.
- the virtual position 602p at which the second virtual sound object 602 is spatially rendered may then be controlled so as to move during the determined second time period where either the speed of the movement or at least one position during the movement may indicate the time left for presentation of the second virtual sound object 602. For example, there could be user-set position/direction for the second virtual sound object 602 when there is a predetermine amount of time, e.g. 5 seconds. left in the presentation of the second virtual sound object 602.
- the control of the spatial rendering of the second virtual sound object 602 may be based on the completion of the rendering of the first virtual sound object 601.
- the spatial rendering of the second virtual sound object 602, not least its second virtual position 602p is connected to and may be adapted based on the state of spatial rendering of the first virtual sound object 601 (i.e. if it is still active/ongoing or has completed) or adapted automatically based on signal activity.
- the apparatus 500 is configured to receive a user input to control the spatial rendering of one of the first or second virtual sound objects 601, 602. Responsive to receipt of the user input, the spatial rendering of the one of the first or second virtual sound objects 601,602 is changed. Furthermore, responsive to the user-controlled change of the spatial rendering of the one of the first or second virtual sound objects 601,602, the spatial rendering of the other of the second or first virtual sound object 602,601 is changed. In other words, the control of the spatial rendering of the first virtual sound object 601 may be based on the user-controlled changes to the spatial rendering of the second virtual sound object 602, and vice versa.
- the spatial rendering of the first and second virtual sound objects 601,602, not least their respective first and second virtual positions 601 p,602p are connected and may be adapted based on user input. For example, responsive to a user input to reduce the volume for one of the virtual sound objects 601,602, this may cause the automatic movement of a virtual position 601p,602p of one or both of the virtual sound objects 601,602 (e.g. move the virtual position of the virtual sound object with the reduced volume away from a central position of user's field of hearing, and move the virtual position of other virtual sound object towards the central position of user's field of hearing).
- this may cause the automatic decreasing of the volume for the other virtual sound object. This may be, e.g., because it is signalled that a pair of sound objects is connected and considered alternatives with concurrent playback.
- one virtual sound object is in a first language and the second virtual sound object is a translation in a second language corresponding to the first language voice signal.
- the change in spatial rendering may comprise: one or more of:
- the apparatus 500 is configured to receive a user input to control a change in the spatial rendering of one of the first or second virtual sound objects 601,602. Following which, the apparatus 500 generates a signal indicative of the user's user-controlled change of the spatial rendering of the first or second virtual sound objects 601,602. The apparatus 500 may then transmit the signal to a further apparatus (e.g. further apparatus 803 of FIG. 8 ).
- a further apparatus e.g. further apparatus 803 of FIG. 8 .
- the further apparatus may comprise means configured to cause:
- the user's user-controlled change of the spatial rendering of the first or second virtual sound object 601, 602 may trigger a corresponding change in the spatial rendering, at the further apparatus, of the third and/or fourth virtual sound objects.
- the further apparatus 803 may additionally comprise means configured to cause: transmitting, to the apparatus 500, one or more of the first and second audio data 701,702 representative of the first and second audio content 101,102; receiving the signal from the apparatus 500; and controlling the transmission of one or more of the first and second audio data 701,702 based on the received signal.
- the further apparatus 803 may be the source of the first and second audio content 101,102 for the first and second audio data 701,702.
- the further apparatus may capture first audio content 101 and may generate second audio content 102 therefrom (or may transmit the first audio content 101 to a separate remote apparatus, e.g. server, which generates second audio content 102 therefrom).
- the transmission of the first and/or second audio data 701,702 may be controlled.
- the user could be signalled to the further apparatus which then ceases the transmission of the first or second audio data 701,702, thereby conserving bandwidth.
- the user's termination of the rendering of the first or second virtual sound objects 601,602 could trigger a notification/prompt/alert thereby notifying a user of the further apparatus 803 of dismissal of one of the first or second virtual sound objects 601,602 by the second user 802 of the apparatus 500.
- a notification to the user of the further apparatus 803 of whether the second user 802 of the apparatus 500 has modified the rendering of the first virtual sound object 601 so as to de-emphasise the same (e.g.
- a system comprising the apparatus 500 and the further apparatus 803 as described above.
- the further apparatus 803 may comprise means configured to cause: determining a second time period between an end of the spatial rendering of the first virtual sound object 601 and an end of the rendering of the second virtual sound object 602; and rendering an end portion of the second virtual sound object 602, during the determined second time period after the end of the rendering of the first virtual sound object 601.
- the first audio content 101 may be generated by a first user, for example it may be the first user's voice/speech in a first language which is captured as first audio data 701 by an audio capture device of the first user.
- the captured first audio data 701 of the first user talking in the first language may be sent/transmitted to and received by the apparatus 500.
- the second audio data 702 is representative of a translation of the first user's speech.
- the first audio content 101 undergoes an automatic language translation to generate second audio content 102 being an aural translation of first audio content, and wherein the second audio data is representative of the second audio content 102.
- Automatic language translation can be achieved using various means.
- an application or a service e.g. in the cloud
- the input and output languages may be given/pre-selected, or the input language may be recognized as part of the overall recognition task.
- Automatic language translation can utilize, e.g., speech-to-text (STT) and text-to-speech (TTS) techniques.
- At least one task in the chain may be performed by means of artificial intelligence (Al) such as deep neural networks (DNN).
- the automatic language service may be provided by a client device, e.g. a user's mobile communications device/smart phone, or a server.
- the captured first audio data 701 representative of first audio content 101 may be processed and translated to the second language locally, i.e. on the first user's device, or alternatively, the first audio content may be sent to a remote device, such as a server, to undergo speech-to-speech translation to generate the second audio data 702 representative of second audio content 102 (i.e. translated speech in the second language) derived from the first audio content 101 (i.e. the original speech in the first language).
- the second audio data 702 of the translation of the first user talking may be sent/transmitted to and received by the apparatus 500.
- the transmission and receipt of the first or second audio data 701,702 may be via any suitable wired or wireless connection or wired or wireless communication network.
- the transmission and receipt of the first or second audio data 701, 702 may utilise any suitable codec, such as speech and audio codecs.
- immersive audio codecs may be used which support a multitude of operating points ranging from a low bit rate operation to transparency as well as a range of service capabilities, e.g., from mono to stereo to fully immersive audio encoding/decoding/rendering.
- An example of such a codec is the 3GPP IVAS (Immersive Voice and Audio Services) codec which is an extension of the 3GPP EVS codec and is intended for new immersive voice and audio services over 4G/5G.
- Such immersive services include, e.g., immersive voice and audio for virtual reality (VR).
- the multi-purpose audio codec is expected to handle the encoding, decoding and rendering of speech, music and generic audio. It is expected to support channel-based audio and scene-based audio inputs including spatial information about the sound field and sound sources. It is also expected to operate with low latency to enable conversational services as well as support high error robustness under various transmission conditions.
- the first and second audio data input signals may be provided to an IVAS encoder in one of its supported formats (and in some allowed combinations of the formats).
- the IVAS decoder may likewise output the audio content in supported formats. In a pass-through mode the audio data could be provided in its original format after transmission (encoding/decoding).
- examples of the present disclosure can take the form of a method, an apparatus or a computer program. Accordingly, various, but not necessarily all, examples can be implemented in hardware, software or a combination of hardware and software.
- the above described functionality and method operations may be performed by an apparatus (for example such as the apparatus 500 illustrated in FIGs. 5 and 7 ) which include one or more components for effecting the above described functionality. It is contemplated that the functions of these components can be combined in one or more components or performed by other components of equivalent functionality.
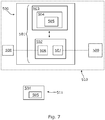
- FIG. 7 schematically illustrates a block diagram of an apparatus 500.
- the apparatus 500 comprises a controller 501.
- Implementation of the controller 501 can be as controller circuitry.
- Implementation of the controller 501 can be in hardware alone (for example processing circuitry comprising one or more processors and memory circuitry comprising one or more memory elements), have certain aspects in software including firmware alone or can be a combination of hardware and software (including firmware).
- the controller 501 can be implemented using instructions that enable hardware functionality, for example, by using executable computer program instructions in a general-purpose or special-purpose processor that can be stored on a computer readable storage medium (disk, memory etc.) or carried by a signal carrier to be performed by such a processor.
- a general-purpose or special-purpose processor that can be stored on a computer readable storage medium (disk, memory etc.) or carried by a signal carrier to be performed by such a processor.
- the apparatus 500 comprises a controller 501 which is provided by a processor 502 and memory 503.
- a single processor 502 and a single memory are illustrated in other implementations there can be multiple processors and/or there can be multiple memories some or all of which can be integrated/removable and/or can provide permanent/semi-permanent/ dynamic/cached storage.
- the memory 503 stores a computer program 504 comprising computer program code/ instructions 505 that control the operation of the apparatus 500 when loaded into the processor 502.
- the computer program code 505 provides the logic and routines that enable the apparatus 500 to perform the methods presently described.
- the processor 502 is configured to read from and write to the memory 503.
- the processor 502 can also comprise an input interface 506 via which data and/or commands are input to the processor 502, and an output interface 507 via which data and/or commands are output by the processor 502.
- the apparatus 500 therefore comprises:
- the computer program 504 can arrive at the apparatus 500 via any suitable delivery mechanism 511.
- the delivery mechanism 511 can be, for example, a non-transitory computer-readable storage medium, a computer program product, a memory device, a record medium such as a compact disc read-only memory, or digital versatile disc, or an article of manufacture that tangibly embodies the computer program 504.
- the delivery mechanism can be a signal configured to reliably transfer the computer program 504.
- the apparatus 500 can receive, propagate or transmit the computer program 504 as a computer data signal.
- the apparatus 500 may comprise a transmitting device and a receiving device for communicating with remote devices via a communications channel (not shown).
- any such computer program code 505 can be loaded onto a computer or other programmable apparatus (i.e., hardware) to produce a machine, such that the code/instructions when performed on the programmable apparatus create means for implementing the functions specified in the blocks.
- the computer program code 505 can also be stored in a computer-readable medium that can direct a programmable apparatus to function in a particular manner, such that the instructions stored in the computer-readable memory produce an article of manufacture including instruction means which implement the function specified in the blocks.
- the computer program code 505 can also be loaded onto a programmable apparatus to cause a series of operational actions to be performed on the programmable apparatus to produce a computer-implemented process such that the instructions which are performed on the programmable apparatus provide actions for implementing the functions specified in the blocks.
- references to 'computer-readable storage medium', 'computer program product', 'tangibly embodied computer program' etc. or a 'controller', 'computer', 'processor' etc. should be understood to encompass not only computers having different architectures such as single /multi-processor architectures and sequential (Von Neumann)/parallel architectures but also specialized circuits such as field-programmable gate arrays (FPGA), application specific circuits (ASIC), signal processing devices and other devices.
- References to computer program, instructions, code etc. should be understood to encompass software for a programmable processor or firmware such as, for example, the programmable content of a hardware device whether instructions for a processor, or configuration settings for a fixed-function device, gate array or programmable logic device etc.
- circuitry refers to all of the following:
- circuitry would also cover an implementation of merely a processor (or multiple processors) or portion of a processor and its (or their) accompanying software and/or firmware.
- circuitry would also cover, for example and if applicable to the particular claim element, a baseband integrated circuit or applications processor integrated circuit for a mobile phone or a similar integrated circuit in a server, a cellular network device, or other network device.
- the apparatus 500 described can alternatively or in addition comprise an apparatus which in some other embodiments comprises a distributed system of apparatuses, for example, a client/server apparatus system.
- a distributed system of apparatuses for example, a client/server apparatus system.
- each apparatus forming a component and/or part of the system provides (or implements) one or more features which collectively implement an example of the present disclosure.
- the apparatus 500 is re-configured by an entity other than its initial manufacturer to implement an example of the present disclosure by being provided with additional software, for example by a user downloading such software, which when executed causes the apparatus 500 to implement an example of the present disclosure (such implementation being either entirely by the apparatus 500 or as part of a system of apparatuses as mentioned hereinabove).
- the apparatus 500 may be comprised in a device 510 and additionally comprise further components/modules 508, 509 for providing additional functionality, e.g. such as not least: data interfaces for wired/wireless data connectively, user input (e.g. buttons, microphone, touch screen altogether output devices (e.g. speakers for spatial audio rendering, display, haptic means), and sensors (not least for detecting: movement, position and orientation).
- additional functionality e.g. such as not least: data interfaces for wired/wireless data connectively, user input (e.g. buttons, microphone, touch screen ...) output devices (e.g. speakers for spatial audio rendering, display, haptic means), and sensors (not least for detecting: movement, position and orientation).
- the apparatus 500 can be not least for example one or more of: a client device, a server device, a user equipment device, a wireless communications device, a portable device, a handheld device, a wearable device, a head mountable device etc.
- the apparatus 500 can be embodied by a computing device, not least such as those mentioned above.
- the apparatus 500 can be embodied as a chip, chip set or module, i.e. for use in any of the foregoing.
- the apparatus 500 is embodied on a hand held portable electronic device, such as a mobile telephone, wearable computing device or personal digital assistant, that can additionally provide one or more audio/text/video communication functions (e.g. tele-communication, video-communication, and/or text transmission (Short Message Service (SMS)/ Multimedia Message Service (MMS)/emailing) functions), interactive/non-interactive viewing functions (e.g. web-browsing, navigation, TV/program viewing functions), music recording/playing functions (e.g. Moving Picture Experts Group-1 Audio Layer 3 (MP3) or other format and/or (frequency modulation/amplitude modulation) radio broadcast recording/playing), downloading/sending of data functions, image capture function (e.g. using a (e.g. in-built) digital camera), and gaming functions.
- audio/text/video communication functions e.g. tele-communication, video-communication, and/or text transmission (Short Message Service (S)/ Multimedia Message Service (MMS)/emailing)
- the apparatus 500 can be provided in an electronic device, for example, mobile terminal, according to an exemplary embodiment of the present disclosure. It should be understood, however, that a mobile terminal is merely illustrative of an electronic device that would benefit from examples of implementations of the present disclosure and, therefore, should not be taken to limit the scope of the present disclosure to the same. While in certain implementation examples, the apparatus 500 can be provided in a mobile terminal, other types of electronic devices, such as, but not limited to, hand portable electronic devices, wearable computing devices, portable digital assistants (PDAs), pagers, mobile computers, desktop computers, televisions, gaming devices, laptop computers, cameras, video recorders, GPS devices and other types of electronic systems, can readily employ examples of the present disclosure. Furthermore, devices can readily employ examples of the present disclosure regardless of their intent to provide mobility.
- PDAs portable digital assistants
- the apparatus 500 can be provided in a module.
- module' refers to a unit or apparatus 500 that excludes certain parts/components that would be added by an end manufacturer or a user.
- the above described examples may find application as enabling components of: telecommunication systems; electronic systems including consumer electronic products; distributed computing systems; media systems for generating or rendering media content including audio, visual and audio visual content and mixed, mediated, virtual and/or augmented reality; personal systems including personal health systems or personal fitness systems; navigation systems; automotive systems; user interfaces also known as human machine interfaces; networks including cellular, non-cellular, and optical networks; ad-hoc networks; the internet; the internet of things; virtualized networks; and related software and services.
- each of the components described above can be one or more of any device, means or circuitry embodied in hardware, software or a combination of hardware and software that is configured to perform the corresponding functions of the respective components as described above.
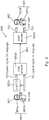
- FIG. 8 schematically illustrates a high-level illustration of a system 800 and use case (namely automatic speech translation) according to an example of the present disclosure.
- the further apparatus 803 comprises: an aural rendering module/headphones 803a for spatially rendering virtual sound objects, a mobile computing module/mobile device 803b comprising, not least a processor, a memory, a user interface and a display for enabling user control, audio pickup, and connectivity.
- the further apparatus 803 also comprises means 803c for performing Real Time Language Translation (RTLT) of the first user's speech translating it into a language understood by the second user 802.
- RTLT Real Time Language Translation
- Audio signals for two language tracks are received by an IVAS encoder 803d of the apparatus 803.
- the resulting bit stream 804 output from the IVAS encoder is transmitted over a network to an IVAS decoder/renderer 500d of the apparatus 500 of the second user 802.
- the IVAS decoder/renderer 500d decodes the two language tracks to (re-)create the first and second audio data 701, 702, which are aurally output via spatial rendering such that the second user 802 hears both the original speech/first audio content 101 and its translation/second audio content 102 as spatially separated first and second virtual sound objects 601, 602 as described further below with respect to FIGs. 9A and 9B .
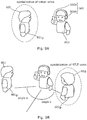
- FIG. 9A schematically illustrates a spatialization, i.e. the virtual positioning in a virtual sound scene of a second user 802, of the spatial rendering of a first virtual sound object 601 (namely the spatial rendering of the caller's voice/original voice track/first track/first audio content) which, for the purposes of illustration, is visually represented in FIG. 9A as an avatar representation of the caller/other user.
- FIG.9A shows the second user 802 using an apparatus 500 to have an IVAS voice call with the other user/caller (not shown).
- the apparatus 500 comprises a mobile device 500a (not least for: data connection/connectivity to an apparatus of the other user, user input/control and audio pickup) and headphones 500b (for the spatial audio rendering/presentation to the second user 802).
- the caller's voice/first audio content is provided as a directional sound source, i.e. a rendered first virtual sound object 601 having a first virtual position 601p, namely, in this example an azimuthal angle a as shown in FIG. 9B .
- FIG. 9B schematically illustrates the additionally spatialization/virtual positioning of the spatial rendering of a second virtual sound object 602 (namely a spatial rendering of a real time language translation "RTLT" of the caller's voice/RTLT voice track/second track/second audio content) which, for the purposes of illustration, is visually represented in FIG.9B as a further avatar representation of the caller/other user.
- second virtual sound object 602 is spatially rendered with a virtual position 602p that spatially mirrors the virtual position 601p of the first virtual sound object 601.
- angle a for the spatial rendering of the first virtual sound object 601 and an angle b for spatial rendering of the second virtual sound object 602 relative to a line running perpendicular to the line running between user's ears in a default orientation/direction/horizontal plane/horizon.
- the angles a and b may be the same.
- angle b may depend on angle a and some additional parameter, such as an additional parameter that may be sent by the caller, set by the receiving device, or depend on some parameter related to the RTLT transmission, e.g. not least relating to the transmission of the second audio data and/or start, duration and end times of the second audio content represented by the second audio data.
- the angle a may initially be small (e.g. 0°) i.e. such that the first virtual sound object 601 is rendered substantially directly in front of the second user 802.
- the spatial rendering of the first virtual sound object 601 for the original voice track may move so as to "make room" for the spatial rendering of the second virtual sound object 602 for the RTLT voice track, i.e.
- the virtual position 601p of the first virtual sound object 601 may move (e.g. angle a is increased) so as to accommodate the spatial rendering of the second virtual sound object 602 and its opposing angle b of its virtual position 602p.
- This may enable an increased spatial separation of the spatialization of the rendering first and second virtual sound objects 601,602.
- This may help the second user 802 to better separate and distinguish between the first and second virtual sound objects 601,602 (i.e. the original voice and translation of the same) such that the two voices/languages can be presented, at least in part simultaneously (as discussed further below with respect to FIG. 10A ).
- the angles a and b can depend on various attributes and signalling.
- voice activity and RTLT track duration information can be used to indicate to the second user 802, without a display or additional audio prompts, the length of the current RTLT track (i.e. second audio content) that still remains.
- the virtual position 602p of the second virtual sound object 602 may begin to move towards the centre front of the user's virtual sound scene. Accordingly, when such a movement occurs, the second user 802 is notified that the certain time threshold has been crossed.
- FIG. 10A schematically illustrates a time line of an example of the rendering of spatial RTLT according to the present disclosure.
- the RTLT is provided by a local service on a device of the first user 801.
- the first user 801 talks to the second user 802 via a voice communication channel.
- the first user's speech/talking corresponds to first audio content 101, which is transmitted, via first audio data, to a device of the second user 802.
- the first audio data, representative of the first audio content 101/first user's speech is spatially rendered to the second user 802 as a first virtual sound object 601.
- the first user's speech is translated, via RTLT, to translated speech which corresponds to second audio content 102 that is transmitted, via second audio data, to the second user 802.
- the second audio data representative of the second audio content 102/first user's translated speech, is spatially rendered to the second user 802 as a second virtual sound object 602.
- time offset 1001a between the start of the first audio content 101 and a start of the second audio content 102, wherein the time offset 1001a is less that the duration of the first audio content 101.
- time offset 1002a between the start of the rendering of the first virtual sound object 601 and a start of the rendering of the second virtual sound object 602, wherein the time offset 1002a is less that the duration of the first virtual sound object 601, such that the rendering of the second virtual sound object 602 begins before the end of the rendering of the first virtual sound object 601.
- the system may translate word-by-word or sentence-by-sentence instead of one active passage at a time.
- the time offsets between the original voice segment and the translated segments need not be fixed.
- the length of a segment of original speech that triggers the activation of translation of the same may vary.
- the provision of the separate voice tracks (original voice/speech and translation of the same, i.e. the first and second audio data representative of the first and second audio content) via an encoding/decoding (such as via IVAS encoders) and their spatial rendering enables such simultaneous playback/rendering to be feasible and intelligible by the second user 802 (taking advantage of the "cocktail party effect").
- the time offset 1001a (secondary track offset) and the time offset 1001b (secondary track end offset) or any equivalent signalling concerning the same provides information about how long the duration of the active RTLT track/second audio content 102 is and how its presentation time relates to the presentation time of the current active audio passage/first audio content 101. This information can be provided at least to the receiving device and the second user 802 (as well as to the encoder-side device and a first user 801).
- An active signal tail reproduction 602t is an example of a locally generated/rendered downstream audio indication for the first user 801.
- the tail of the translation 602 can, e.g., based on the time offset and duration signalling, be spatially rendered to the talker/first user 801. This way the first user 801 receives an indication on how long the second user 802 is still listening to incoming audio/second virtual sound object 602.
- This can be used to control the tail reproduction on the transmitting side, by ending reproduction the tail reproduction 602t of the upon recipient request.
- the first user 801 not only is the first user 801 made aware of the time delay between the systems (e.g. not least a time delay in the generation of the first audio content 101 and the rendering of the translation of the same/second virtual sound object 602), but the first user 801 also receives an indication of the dismissing of the secondary audio/ second virtual sound object 602 by the second user 802.
- FIG. 10B schematically illustrates a time line of a further example of the rendering of spatial RTLT according to the present disclosure, somewhat similar to that of FIG. 10A , except that there is no overlapping/simultaneous rendering of the original speech and translation.
- the speech/talking/first audio content 101 of the first user 801 is transmitted, via first audio data, to a device of the second user 802.
- the first audio data representative of the first audio content 101/first user's speech, is spatially rendered to the second user 802 as a first virtual sound object 601.
- the first user's speech is translated, via a RTLT service local to the first user's device, to translated speech which corresponds to second audio content 102 that is transmitted, via second audio data, to the second user 802.
- the transmission of the second audio data occurs sequentially to the transmission of the first audio data, taking into account the duration of the first audio content 101 as well as accommodating for any lag/delay e.g. during transmission.
- the second audio data is spatially rendered to the second user 802 as a second virtual sound object 602.
- the second audio content 102 may also be spatially rendered locally to the first user 801 as a third virtual sound object 603, wherein the timing of the spatial rendering of the third virtual sound object 603 on first user's device is in synchronisation with the timing of the rendering of the second virtual sound object 602 on second user's device.
- the above process may be repeat from the perspective of the second user 802, i.e. wherein the speech/first audio content 101 (2) of the second user 802 is spatially rendered to the first user 801 as first virtual sound object 601 (2), and the translated speech/second audio content 102(2) of the second user 802 is rendered to the first user 801 as second virtual sound object 602(2).
- the translated speech/second audio content 102(2) may also be rendered to the second user 802 as virtual sound object 604(2).
- FIGs.11A-C schematically illustrate an example of user control of the spatial rendering of one of the first and second virtual sound objects 601, 602, which may represent a first voice track and a secondary related voice track (e.g. a RTLT track of the first voice track).
- the second user 802 receives two voice tracks: an original voice track and an RTLT targeting the user's own language which are spatially rendered as first and second virtual sound objects 601,602.
- the second user 802 is not able to understand much/any of the original voice track/first virtual sound object 601, and wishes to make it less disturbing/distracting.
- the user provides a user input to reduce the volume of (or completely mute) the rendering of the original voice track/first virtual sound object 601 so as to enable the user to better concentrate on the translated voice track/second virtual sound object 602.
- Such a user-controlled reduction in the volume of the original voice track/first virtual sound object 601 automatically controls the rendering of the RTLT track/second virtual sound object 602 so as to make the RTLT track/second virtual sound object 602 more pronounced/emphasised and easier to listen to in some additional way.
- the rendering of the RTLT track/second virtual sound object 602 is automatically repositioned to the front centre of the second user 802, as shown in FIG. 9C .
- An alternative modification to the spatial rendering would be to increase the spatial separation of the first and second virtual sound objects 601,602 (e.g. where the volume of one is reduced - but not muted), for example not least by increasing angles a and b as (discussed with respect to FIG 9B ).
- FIGs. 12A and 12B schematically illustrate an example of user control of the spatial rendering of one of the first and second virtual sound objects 601, 602, wherein upon a first user 801 controlling the movement of one of the first and second virtual sound objects 601, 602, the other of the first and second virtual sound objects 601, 602 is automatically moved. For example, upon a user command to change the virtual position of the second virtual sound object, this triggers the virtual position of the second virtual sound object to be automatically re-positioned, thereby maintaining a spatial separation between the first and second virtual sound objects 601,602.
- FIGs. 13A -13C schematically illustrate a user control use case (referred to as "secondary track dismissal") that particularly relates to RTLT systems (and any other system where the length of an active audio passage is transmitted or otherwise known upon its the rendering).
- second track dismissal a user control use case
- FIG.10A there can be a tail of RTLT voice track/second virtual sound object 602 that is presented also to the first user 801 whose voice is being translated, namely the virtual sound object portion/tail reproduction 602t.
- the first user 801 knows there is active content being consumed by the receiving/second user 802.
- the talker (user 1) 801 is still talking, but in FIG. 13B the first user 801 has stopped talking with the tail 602t playback continuing.
- the second user 802 is not talking.
- the two users 801, 802 may, e.g., at least partly understand each other.
- the second user 802 to some degree understands the first language of first user's 801 speech, but he requires help via the RTLT/second virtual sound object 602.
- the message in this case the original voice in language 1 may have been enough
- it may be indicated to the second user 802 that the translation is still significantly behind (e.g. 10 secs for a long utterance).
- the second user 802 at this point dismisses the secondary audio track/second virtual sound object 602 via their UI.
- the corresponding tail reproduction 602t ends also for the first user 801.
- there is thus no more playback although the RTLT track from user 1 may still have content, i.e. remaining tail which is not being rendered to either user. Both users know that it is now fine to continue talking.
- a further user command/user selection that may be signalled from the receiving device to the transmitting device relates to a selection of the language track. For example, in some cases it may be that it is not known which translation is desired by the recipient/second user 802.
- a transmitting device (or service) may thus send more than one translation as separate virtual sound objects, i.e. there may be a plurality of second virtual sound objects each spatially rendered with differing virtual positions.
- the second user 802 may then indicate which one of the plurality of second virtual sound objects/ plurality of translations he wished to receive.
- the user selection is provided to the transmitting device, which can discontinue sending the remaining, non-selected, plurality of second virtual sound objects, as these are unnecessary, thereby conserving bandwidth.
- additional indications can be signalled and conveyed to the user(s) 801, 802 based on the usage of the secondary track/second virtual sound object at the other end.
- Possible indications include signalling how the second user 802 utilizes the original voice track/first virtual sound object 601 relative to the secondary track/second virtual sound object 602 and vice versa.
- the first user 801 does not know how well the second user 802 understands the original language and how well the second user 802 understands the translation. These pieces of information can be valuable for the first user 801.
- it can be signalled to the first user 801, e.g., what type of changes the second user 802 makes in their virtual sound scene.
- first user 801 can be tracked the relative volumes at playback, the spatial modification by the receiving second user 802, the usage of replay functionality (discussed below) and so on.
- This can be indicated to first user 801, e.g., by modifying the RTLT tail position 604t and/or volume.
- a user adjusting the spatial placement of a virtual sound object towards back is indicative that it is not considered so important.
- moving a virtual sound object towards front is indicative that it is considered important. This can allow for the first user 801 to get feedback spatially on how important the second user 802 feels the translation is.
- a further use case relates to a conference call system or any other suitable service based on at least one audio input, where a virtual sound scene is delivered to a receiving user that is created, e.g. by a conference call service.
- the virtual sound scene may include, e.g., at least two independent talkers (for example users calling from their respective homes) or at least two talkers from the same capture space (for example a shared meeting room), where each talker may be represented by at least one virtual sound object for their native language speech and a further virtual sound object for their RTLT speech.
- the virtual sound scene may be presented such that in a first direction the user hears a first talker's speech in a first language, in a second direction the user hears a second talker's speech in second language, in a third direction the user hears the first talker's speech in a third language, and in a fourth direction the user hears the second talker's speech in a fourth language.
- the virtual sound scene of the receiving user may be presented such that the user hears the first talker's speech in first language in the first direction or the first talker's speech in the third language in the third direction; and the second talker's speech in the second language in the second direction or the second talker's speech in the fourth language in the fourth direction.
- the first and the third direction may be the same direction
- the second and the fourth direction may be the same direction.
- An additional use case relates to spatial replay of the translation.
- a first user talks in a first language, which is translated into second language. Both language tracks are transmitted to second user and presented spatially as virtual sound objects.
- the first user may, e.g., have a problem to which they need help from second user.
- the first user describes the issue and second user answers.
- the first user has trouble understanding the answer, and wishes to replay a part of it.
- the first user thus rewinds the translation track.
- This change in playback duration can be transmitted to the second user, who thus knows there is still active playback at the other end (even though second user is not talking anymore).
- the replay can be rendered in a different spatial position as the real-time translation playback.
- the replay may hence be a new spatially rendered virtual sound object.
- user may locally create new instances of the utterance and, e.g., save at least one of them for later consumption.
- a second example related to the spatial replay of the translation is a language training service.
- a student calls to a tutor.
- the student practices pronunciation of an utterance.
- the tutor may rate the utterance and transmit back a correct pronunciation and the student's pronunciation.
- Student can spatially replay and compare the pronunciations, i.e. the virtual sound objects.
- the replay in particular can allow the tutor to instruct several students in parallel, where each student is able to use the "downtime" when the tutor is instructing (actively sending voice/speech to) another student in a constructive way by comparing pronunciations.
- the relative spatial positioning can indicate the closeness of the pronunciation to the correct one. For example, this may be based on the rating of the expert tutor or an automatic analysis system.
- the: volume, spatial position, and usage of certain related audio tracks/virtual sound objects may be controlled. At least for some audio tracks/virtual sound objects, such as the RTLT audio tracks that are not from any live/real talker, there may also be temporal modifications, such as the replay functionality discussed above.
- a further use case relates to a voice memo of the utterances/key words that may be collected during the translated call to aid in understanding the translation.
- This can relate to additional usage of an augmented reality (AR) device.
- AR augmented reality
- this can relate to embodiments where there is text being transmitted.
- a user has a problem with a rental car. The user places a call using RTLT with a rental company service person. The user discusses his problem with the service person, and the translated messages are saved. Subsequently, an error message is displayed on the car that the user does not understand.
- AR device mobile device, AR glasses, etc.
- the corresponding key words (vs. the error message) from the original language are mapped with the translated and saved comments. Such translated and saved comments may be replayed to the user.
- the spatial rendering and functionality of the various examples described above can also be utilized for other use cases.
- One such vast area of use cases is different entertainment audio effects and modifications. People in general like to utilize various modifications and funny effects in their communications, which is currently seen in various social media applications and services. When it comes to conversational voice services, a problem with standardized legacy voice systems however is that any funny modifications (if they were applied for the codec ingest) would override the original voice. This is generally not desirable. For example, a child having a voice call with their parent might wish to use a funny filter by default, while their parent receiving the call could like to have the option to hear the original voice regardless of the modification. Examples of the disclosure would allow to solve this mismatch in a straightforward manner by providing at least two virtual sound objects with spatial rendering.
- a user may apply a filter to their voice and make it cartoony.
- Both the original voice track and the modified version of the same, i.e. a cartoony voice track may be delivered and spatially rendered to the recipient.
- the spatial audio controls discussed above may also apply.
- Such entertainment use case examples enabled by examples of the present disclose include:
- Yet another use case is an advertisement object.
- a local service on the device can analyse a user's speech and fetch a suitable audio advertisement. This is added to the stream as a separate spatially rendered virtual sound object.
- the receiving user may receive some perks (e.g., free call or other service) based on how they treat the advertisement virtual sound object rendering. For example, should the recipient mute or dismiss the advertisement, they receive nothing; should they let it play, they receive points/credit.
- an alert there is a local alert service on the device (or a connected device). For example, a user may be walking while on a voice call, slip and fall. A locally generated alert is sent as separate virtual sound object to the recipient of the call to inform them of a potential medical emergency.
- a remote/network operated alert service on the device. For example, a user is on a call and the authorities are aware of a bear moving about in the area of the cell. The network adds a virtual spatial object to the user's downstream audio package giving a warning to the user.
- negotiation takes place to establish the audio call between the at least two parties.
- negotiation can explicitly include, e.g., RTLT features (or any other suitable features), or it can implicitly allow for such features.
- RTLT features or any other suitable features
- supporting several virtual sound object streams (at least two for the RTLT) and suitable dependency signalling for the streams it is possible to pass an RTLT signal through the IVAS codec.
- Advanced user manipulations, such as dismissing a secondary audio track playback such that this information is available for the encoder-side device will require additional signalling such as suitable codec mode request (CMR).
- CMR codec mode request
- Such request could be called, e.g., Alternative audio Track Request (ATR).
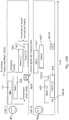
- FIG. 15 schematically illustrates two further high-level illustrations of systems (with differing system architecture/signal routing) to that of FIG. 7 .
- a speech signal in a first language from a first user 801 is encoded using an IVAS encoder 803d of an apparatus 803 of the first user 801.
- a node/server 1501 in the network processes and decodes the incoming IVAS bitstream, translates the speech signal into a second language (i.e. understood by a second user 802), and encodes at least the translated signal and repacketizes the audio for transmission.
- one or two streams are thus sent from the network node to an IVAS decoder 500d of an apparatus 500 of a receiving second user 802.
- the IVAS decoder/renderer 500d,500 outputs the two language tracks 701, 702 as first and second virtual sound objects for spatial rendering/audio presentation such that the second user 802 can hear the original audio and the translation.
- a speech signal in a first language from a first user 801 is encoded using an IVAS encoder 803d of an apparatus 803 of the first user 801. It is transmitted to a second user 802 for decoding and spatial rendering.
- RTLT service 1502 that decodes, translates, and encodes the speech signal then transmits the translated signal to a second user 802 for decoding and spatial rendering.
- the system architecture of FIG.7 has some benefits over those of FIG.15 , namely relating to 1) reduced delay between the original speech (1st language) and the translation (2nd language), and 2) user control.
- the delay reduction happens for two reasons.
- the local RTLT can in some implementations bypass at least some audio processing (that will introduce delay) that the regular IVAS input will be subject to. This can relate to, for example, equalization of the microphone signal(s) and so on.
- Such processing may be bypassed for the RTLT ingest because the output from the RTLT is a synthetic speech which can be automatically controlled.
- the RTLT ingest need not sound optimal to a human listener, only its output should appear natural.
- there is no additional decoding/encoding delay in the path which would introduce delay for the signal.
- maximal control over the features is allowed with encoder-side operation and in-band signalling. This advantage relates also to other use cases than RTLT.
- FIG. 15 There are use cases where a network service, e.g. as per FIG. 15 , is needed or preferred to that of FIG. 8 .
- a network service e.g. as per FIG. 15
- each block (of the flowchart illustrations and block diagrams), and combinations of blocks, can be implemented by computer program instructions of a computer program.
- These program instructions can be provided to one or more processor(s), processing circuitry or controller(s) such that the instructions which execute on the same create means for causing implementing the functions specified in the block or blocks, i.e. such that the method can be computer implemented.
- the computer program instructions can be executed by the processor(s) to cause a series of operational steps/actions to be performed by the processor(s) to produce a computer implemented process such that the instructions which execute on the processor(s) provide steps for implementing the functions specified in the block or blocks.
- the blocks support: combinations of means for performing the specified functions; combinations of actions for performing the specified functions; and computer program instructions/algorithm for performing the specified functions. It will also be understood that each block, and combinations of blocks, can be implemented by special purpose hardware-based systems which perform the specified functions or actions, or combinations of special purpose hardware and computer program instructions.
- modules, means or circuitry that provide the functionality for performing/applying the actions of the method.
- the modules, means or circuitry can be implemented as hardware, or can be implemented as software or firmware to be performed by a computer processor.
- firmware or software examples of the present disclosure can be provided as a computer program product including a computer readable storage structure embodying computer program instructions (i.e. the software or firmware) thereon for performing by the computer processor.
- features have been described with reference to certain examples, those features can also be present in other examples whether described or not. Accordingly, features described in relation to one example/aspect of the disclosure can include any or all of the features described in relation to another example/aspect of the disclosure, and vice versa, to the extent that they are not mutually inconsistent.
- any number or combination of intervening components can exist (including no intervening components), i.e. so as to provide direct or indirect communication. Any such intervening components can include hardware and/or software components.
- the "determining" can include, not least: calculating, computing, processing, deriving, investigating, looking up (e.g., looking up in a table, a database or another data structure), ascertaining and the like. Also, “determining” can include receiving (e.g., receiving information), accessing (e.g., accessing data in a memory) and the like. Also, “determining” can include resolving, selecting, choosing, establishing, and the like.
- references to "a/an/the” [feature, element, component, means ...] are to be interpreted as "at least one" [feature, element, component, means ...] unless explicitly stated otherwise. That is any reference to X comprising a/the Y indicates that X can comprise only one Y or can comprise more than one Y unless the context clearly indicates the contrary. If it is intended to use 'a' or 'the' with an exclusive meaning then it will be made clear in the context. In some circumstances the use of 'at least one' or 'one or more' can be used to emphasis an inclusive meaning but the absence of these terms should not be taken to infer and exclusive meaning.
- the presence of a feature (or combination of features) in a claim is a reference to that feature) or combination of features) itself and also to features that achieve substantially the same technical effect (equivalent features).
- the equivalent features include, for example, features that are variants and achieve substantially the same result in substantially the same way.
- the equivalent features include, for example, features that perform substantially the same function, in substantially the same way to achieve substantially the same result.
Landscapes
- Physics & Mathematics (AREA)
- Engineering & Computer Science (AREA)
- Acoustics & Sound (AREA)
- Signal Processing (AREA)
- Stereophonic System (AREA)
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| EP19166572.8A EP3720149B1 (fr) | 2019-04-01 | 2019-04-01 | Appareil, procédé, programme informatique ou système de rendu de données audio |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| EP19166572.8A EP3720149B1 (fr) | 2019-04-01 | 2019-04-01 | Appareil, procédé, programme informatique ou système de rendu de données audio |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| EP3720149A1 true EP3720149A1 (fr) | 2020-10-07 |
| EP3720149B1 EP3720149B1 (fr) | 2025-11-19 |
Family
ID=66049081
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| EP19166572.8A Active EP3720149B1 (fr) | 2019-04-01 | 2019-04-01 | Appareil, procédé, programme informatique ou système de rendu de données audio |
Country Status (1)
| Country | Link |
|---|---|
| EP (1) | EP3720149B1 (fr) |
Cited By (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20220377489A1 (en) * | 2020-01-14 | 2022-11-24 | Fraunhofer-Gesellschaft zur Förderung der angewandten Forschung e.V. | Apparatus and Method for Reproducing a Spatially Extended Sound Source or Apparatus and Method for Generating a Description for a Spatially Extended Sound Source Using Anchoring Information |
| EP3948862A4 (fr) * | 2019-04-02 | 2022-12-28 | Nokia Technologies Oy | Extension de codec audio |
| CN116490922A (zh) * | 2021-09-27 | 2023-07-25 | 腾讯美国有限责任公司 | 声学场景和视觉场景的一致性 |
| CN120602885A (zh) * | 2025-08-07 | 2025-09-05 | 歌尔股份有限公司 | 音频设备及其控制方法、存储介质 |
Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20070016401A1 (en) * | 2004-08-12 | 2007-01-18 | Farzad Ehsani | Speech-to-speech translation system with user-modifiable paraphrasing grammars |
| WO2014130221A1 (fr) * | 2013-02-22 | 2014-08-28 | Dolby Laboratories Licensing Corporation | Appareil et procédé de rendu spatial audio |
| EP3293987A1 (fr) * | 2016-09-13 | 2018-03-14 | Nokia Technologies Oy | Traitement audio |
-
2019
- 2019-04-01 EP EP19166572.8A patent/EP3720149B1/fr active Active
Patent Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20070016401A1 (en) * | 2004-08-12 | 2007-01-18 | Farzad Ehsani | Speech-to-speech translation system with user-modifiable paraphrasing grammars |
| WO2014130221A1 (fr) * | 2013-02-22 | 2014-08-28 | Dolby Laboratories Licensing Corporation | Appareil et procédé de rendu spatial audio |
| EP3293987A1 (fr) * | 2016-09-13 | 2018-03-14 | Nokia Technologies Oy | Traitement audio |
Cited By (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| EP3948862A4 (fr) * | 2019-04-02 | 2022-12-28 | Nokia Technologies Oy | Extension de codec audio |
| US12067992B2 (en) | 2019-04-02 | 2024-08-20 | Nokia Technologies Oy | Audio codec extension |
| US20220377489A1 (en) * | 2020-01-14 | 2022-11-24 | Fraunhofer-Gesellschaft zur Förderung der angewandten Forschung e.V. | Apparatus and Method for Reproducing a Spatially Extended Sound Source or Apparatus and Method for Generating a Description for a Spatially Extended Sound Source Using Anchoring Information |
| US12238504B2 (en) * | 2020-01-14 | 2025-02-25 | Fraunhofer-Gesellschaft zur Förderung der angewandten Forschung e.V. | Apparatus and method for reproducing a spatially extended sound source or apparatus and method for generating a description for a spatially extended sound source using anchoring information |
| CN116490922A (zh) * | 2021-09-27 | 2023-07-25 | 腾讯美国有限责任公司 | 声学场景和视觉场景的一致性 |
| CN120602885A (zh) * | 2025-08-07 | 2025-09-05 | 歌尔股份有限公司 | 音频设备及其控制方法、存储介质 |
Also Published As
| Publication number | Publication date |
|---|---|
| EP3720149B1 (fr) | 2025-11-19 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US12302088B2 (en) | Binaural sound in visual entertainment media | |
| EP3720149B1 (fr) | Appareil, procédé, programme informatique ou système de rendu de données audio | |
| UA130517C2 (uk) | Пристрій обробки звуку у звукових послугах з ефектом присутності | |
| EP3588926B1 (fr) | Appareils et procédés associés de présentation spatiale de contenu audio | |
| EP3422744B1 (fr) | Appareil et procédés associés | |
| CN117041607A (zh) | 用于音频渲染的方法和装置 | |
| US20220171593A1 (en) | An apparatus, method, computer program or system for indicating audibility of audio content rendered in a virtual space | |
| CN107301028A (zh) | 一种基于多人远程通话的音频数据处理方法及装置 | |
| US20230370801A1 (en) | Information processing device, information processing terminal, information processing method, and program | |
| CN112689825B (zh) | 实现远程用户访问介导现实内容的装置、方法、计算机程序 | |
| US11930350B2 (en) | Rendering audio | |
| US12328566B2 (en) | Information processing device, information processing terminal, information processing method, and program | |
| EP3691298A1 (fr) | Appareil méthode et programme d'ordinateur permettant la communication audio en temps réel entre utilisateurs en audio immerssion | |
| CN115550831B (zh) | 通话音频的处理方法、装置、设备、介质及程序产品 | |
| GB2639006A (en) | A multi-participant, spatial audio service | |
| WO2026005772A1 (fr) | Communication de champ sonore immersif à l'aide d'un réseau de haut-parleurs | |
| EP3734966A1 (fr) | Appareil et procédés associés de présentation d'audio |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PUAI | Public reference made under article 153(3) epc to a published international application that has entered the european phase |
Free format text: ORIGINAL CODE: 0009012 |
|
| STAA | Information on the status of an ep patent application or granted ep patent |
Free format text: STATUS: THE APPLICATION HAS BEEN PUBLISHED |
|
| AK | Designated contracting states |
Kind code of ref document: A1 Designated state(s): AL AT BE BG CH CY CZ DE DK EE ES FI FR GB GR HR HU IE IS IT LI LT LU LV MC MK MT NL NO PL PT RO RS SE SI SK SM TR |
|
| AX | Request for extension of the european patent |
Extension state: BA ME |
|
| STAA | Information on the status of an ep patent application or granted ep patent |
Free format text: STATUS: REQUEST FOR EXAMINATION WAS MADE |
|
| 17P | Request for examination filed |
Effective date: 20210406 |
|
| RBV | Designated contracting states (corrected) |
Designated state(s): AL AT BE BG CH CY CZ DE DK EE ES FI FR GB GR HR HU IE IS IT LI LT LU LV MC MK MT NL NO PL PT RO RS SE SI SK SM TR |
|
| STAA | Information on the status of an ep patent application or granted ep patent |
Free format text: STATUS: EXAMINATION IS IN PROGRESS |
|
| 17Q | First examination report despatched |
Effective date: 20221122 |
|
| GRAP | Despatch of communication of intention to grant a patent |
Free format text: ORIGINAL CODE: EPIDOSNIGR1 |
|
| STAA | Information on the status of an ep patent application or granted ep patent |
Free format text: STATUS: GRANT OF PATENT IS INTENDED |
|
| INTG | Intention to grant announced |
Effective date: 20250122 |
|
| GRAJ | Information related to disapproval of communication of intention to grant by the applicant or resumption of examination proceedings by the epo deleted |
Free format text: ORIGINAL CODE: EPIDOSDIGR1 |
|
| STAA | Information on the status of an ep patent application or granted ep patent |
Free format text: STATUS: EXAMINATION IS IN PROGRESS |
|
| GRAP | Despatch of communication of intention to grant a patent |
Free format text: ORIGINAL CODE: EPIDOSNIGR1 |
|
| STAA | Information on the status of an ep patent application or granted ep patent |
Free format text: STATUS: GRANT OF PATENT IS INTENDED |
|
| INTC | Intention to grant announced (deleted) | ||
| INTG | Intention to grant announced |
Effective date: 20250617 |
|
| GRAS | Grant fee paid |
Free format text: ORIGINAL CODE: EPIDOSNIGR3 |
|
| GRAA | (expected) grant |
Free format text: ORIGINAL CODE: 0009210 |
|
| STAA | Information on the status of an ep patent application or granted ep patent |
Free format text: STATUS: THE PATENT HAS BEEN GRANTED |
|
| AK | Designated contracting states |
Kind code of ref document: B1 Designated state(s): AL AT BE BG CH CY CZ DE DK EE ES FI FR GB GR HR HU IE IS IT LI LT LU LV MC MK MT NL NO PL PT RO RS SE SI SK SM TR |
|
| REG | Reference to a national code |
Ref country code: CH Ref legal event code: F10 Free format text: ST27 STATUS EVENT CODE: U-0-0-F10-F00 (AS PROVIDED BY THE NATIONAL OFFICE) Effective date: 20251119 Ref country code: GB Ref legal event code: FG4D |
|
| REG | Reference to a national code |
Ref country code: DE Ref legal event code: R096 Ref document number: 602019078191 Country of ref document: DE |
|
| REG | Reference to a national code |
Ref country code: IE Ref legal event code: FG4D |
|
| REG | Reference to a national code |
Ref country code: NL Ref legal event code: MP Effective date: 20251119 |
|
| PGFP | Annual fee paid to national office [announced via postgrant information from national office to epo] |
Ref country code: GB Payment date: 20260312 Year of fee payment: 8 |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: ES Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20251119 |
|
| REG | Reference to a national code |
Ref country code: LT Ref legal event code: MG9D |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: NO Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20260219 |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: FI Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20251119 Ref country code: AT Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20251119 Ref country code: HR Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20251119 |
|
| REG | Reference to a national code |
Ref country code: AT Ref legal event code: MK05 Ref document number: 1859930 Country of ref document: AT Kind code of ref document: T Effective date: 20251119 |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: NL Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20251119 |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: RS Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20260219 |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: IS Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20260319 |
|
| PGFP | Annual fee paid to national office [announced via postgrant information from national office to epo] |
Ref country code: FR Payment date: 20260309 Year of fee payment: 8 |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: PT Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20260319 |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: PL Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20251119 |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: LV Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20251119 |