EP4489366A1 - Architecture matérielle de c ur personnalisé pour contrôle de congestion - Google Patents
Architecture matérielle de c ur personnalisé pour contrôle de congestion Download PDFInfo
- Publication number
- EP4489366A1 EP4489366A1 EP24186868.6A EP24186868A EP4489366A1 EP 4489366 A1 EP4489366 A1 EP 4489366A1 EP 24186868 A EP24186868 A EP 24186868A EP 4489366 A1 EP4489366 A1 EP 4489366A1
- Authority
- EP
- European Patent Office
- Prior art keywords
- rue
- core
- instruction
- event
- instructions
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
Images








Classifications
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04L—TRANSMISSION OF DIGITAL INFORMATION, e.g. TELEGRAPHIC COMMUNICATION
- H04L49/00—Packet switching elements
- H04L49/10—Packet switching elements characterised by the switching fabric construction
- H04L49/103—Packet switching elements characterised by the switching fabric construction using a shared central buffer; using a shared memory
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04L—TRANSMISSION OF DIGITAL INFORMATION, e.g. TELEGRAPHIC COMMUNICATION
- H04L47/00—Traffic control in data switching networks
- H04L47/10—Flow control; Congestion control
- H04L47/12—Avoiding congestion; Recovering from congestion
- H04L47/122—Avoiding congestion; Recovering from congestion by diverting traffic away from congested entities
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04L—TRANSMISSION OF DIGITAL INFORMATION, e.g. TELEGRAPHIC COMMUNICATION
- H04L47/00—Traffic control in data switching networks
- H04L47/10—Flow control; Congestion control
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04L—TRANSMISSION OF DIGITAL INFORMATION, e.g. TELEGRAPHIC COMMUNICATION
- H04L47/00—Traffic control in data switching networks
- H04L47/10—Flow control; Congestion control
- H04L47/12—Avoiding congestion; Recovering from congestion
- H04L47/125—Avoiding congestion; Recovering from congestion by balancing the load, e.g. traffic engineering
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04L—TRANSMISSION OF DIGITAL INFORMATION, e.g. TELEGRAPHIC COMMUNICATION
- H04L49/00—Packet switching elements
- H04L49/20—Support for services
- H04L49/205—Quality of Service based
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04L—TRANSMISSION OF DIGITAL INFORMATION, e.g. TELEGRAPHIC COMMUNICATION
- H04L49/00—Packet switching elements
- H04L49/65—Re-configuration of fast packet switches
Definitions
- the Internet protocol suite is a set of communication protocols used for servicing data transmissions between devices communicating information over the Internet or other computer networks.
- Transmission Control Protocol (“TCP") is a part of the Internet protocol suite that provides for connection-oriented, reliable, and ordered delivery of a stream of data packets between, for example, a web-browser application running on a client device and a web-server application running on a server device over a local or wide area network.
- TCP Transmission Control Protocol
- TCP Transmission Control Protocol
- incast is a many-to-one communication pattern commonly found in datacenters, which may result in incast congestion when multiple synchronized computing devices send data to the same receiver computing device in parallel.
- a long tail latency which is the amount of time for the last few packets among a series of packets to be transmitted, may prevent transmission of the next series of packets.
- the present disclosure provides a custom processor core that may be used for congestion control in transport protocols.
- Such transport protocols may employ a connection-oriented architecture that provides reliable packet delivery over a lossy and out-of-order network. Congestion control in such networks provides, on a per-connection basis, rate/retransmission parameters in reaction to network/endpoint congestion signals.
- the custom processor core may be programmable and may be used to implement state-of-the-art congestion control protocols or algorithms, such as Swift, data center TCP (DCTCP) or bottleneck bandwidth and round-trip time (BBR).
- DCTCP data center TCP
- BBR round-trip time
- the hardware architecture of the custom processor core allows for custom instructions, special register sets, and datapath enhancements for accelerating congestion control algorithms to achieve higher performance, without implementing new hardware each time a congestion control algorithm is updated.
- Congestion control in some transport protocols is implemented on a per-connection basis.
- the transport protocol hardware may provide a flexible interface to a programmable congestion control engine without prescribing any specific congestion control algorithm.
- any congestion control algorithm such as Swift, BBR, GCN, etc., can be employed.
- Hardware along the datapath of the transport protocol may be responsible for measuring various congestion signals and enforcing a rate computed by the congestion control algorithm for a connection.
- a connection between devices on a network allows for data to be communicated to and from connected devices.
- the devices may communicate over the connections using one or more protocols.
- reliable transport is a protocol that notifies the sources whether or not the delivery of data to an intended destination was successful.
- the connections can be wired or wireless, e.g., through a hardware interconnect, cables physically connecting the devices (optionally through one or more intermediate devices), or through wireless transmission.
- a connection may be identified by a pair of connection IDs ("CIDs"), one in each direction of communication. CIDs may be allocated by a receiver device during the connection setup process and have no global significance outside of the parties involved.
- CIDs connection IDs
- a reliable transport protocol can be divided into four sub-blocks, transmission (TX), receive (RX), connection context (CTX) and the rate update engine (RUE).
- a connection context manager can trigger operations to be performed by the RUE, for example when certain events are identified by the manager. For example, a RUE operation may be triggered when the CTX manager identifies the receipt of ACK packets, the receipt of NACK packets, and packet retransmissions.
- the CTX manager is configured to generate requests for updating congestion control parameter values.
- the RUE computes new congestion control outputs, e.g., sliding window sizes, inter-packet gaps (IPG), and so on.
- a RUE response can include the congestion control outputs, for modifying how data is transmitted along the corresponding connection.
- the RUE can be updated in hardware to apply different types of congestion control algorithms for generating different congestion control outputs.
- the requests generated by the CTX manager as an example of RUE events.
- Responses generated by the RUE, e.g., the congestion control outputs, are examples of RUE responses.
- the responses are sent to the CTX manager, configured to adjust connections in accordance with the RUE responses,
- Connection contexts e.g., information about connections between a device implementing the example architecture and other devices may be stored in a cache that is separate from the example architecture, e.g., as part of transport protocol hardware. An entry in this connection cache is brought in or evicted whenever a new connection is formed or taken out, and the connection cache manager does not wait for a RUE event to get processed before evicting a connection. Therefore, it may happen that a RUE event for a connection is still under process while the connection is already evicted from the connection context cache.
- the connection cache stores the context of outstanding connections towards the RUE, which may be separate from connections managed by the hardware transport layer.
- aspects of the disclosure provide for a load balancer for load-balancing RUE events to be evenly distributed across the custom cores. Events from different connections have no ordering requirement, and therefore can be processed by any core independently. If there is already an outstanding request to a core for a certain connection, the subsequent request for the same connections is processed in order (to the previous request) and therefore should also go to the same core. In a state-full RUE operation, the CTX can leave multiple RUE events outstanding, versus a state-less RUE in which the core will not have more than one event outstanding for a particular connection. Event requests can be buffered until they are fetched and provided to the cores.
- aspects of the disclosure provide for a state manager implemented by the RUE.
- Stateful operation according to aspects of the disclosure allows for multipathing to be supported, another feature in which a single connection between end points is associated with multiple flows, e.g., data paths.
- Various implementations of multipathing require tracking connection state, which can be done in hardware through the RUE.
- the RUE can generate update congestion control parameters for each of the various flows or paths.
- the RUE can manage and update congestion control parameters for a connection with RUE event data characterizing the state of each flow or path operating within the connection.
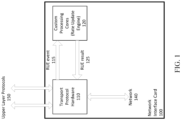
- Fig. 1 illustrates an example architecture in which a congestion control algorithm may be implemented.
- the architecture includes transport protocol hardware 110 in communication with a custom processor core implemented as part of a Rate Update Engine (RUE) 120, that is separate from the main transport protocol datapath.
- RUE Rate Update Engine
- the transport protocol hardware 110 may provide a flexible interface to the RUE 120, and generate RUE events 115 and receive results 125 from the RUE 120.
- Custom processor cores as described herein can be a processing unit, such as a CPU, a GPU, or an ASIC or FPGA, configured according to aspects of the disclosure.
- a network interface card (NIC) 100 can implement some or all of the upper layer protocols 150, the transport protocol hardware 110, and/or the RUE 120.
- the NIC 100 can be connected to a host device (not shown), which may be a node on the network 140 communicating with other nodes that may implement respective NICs, for example as described with reference to the NIC 100.
- Either the transport protocol hardware 110 and/or the RUE 120 implemented on the custom processing cores can receive and analyze incoming data packets to determine whether the rate of packet transmission along a connection should be updated. The determination can be based on, for example, predetermined thresholds of latency of data traffic volume being exceeded. Once it is determined that rate transmission parameters should be updated, the RUE 120 can determine the updated parameters in response to a generated RUE event.
- the specific process for congestion control can depend on the currently implemented algorithms on the custom processing cores.
- the transmitting node may attempt retransmission of the data packet at a later time.
- Peer connections may be formed over the network 140 between corresponding protocols of each layer.
- the ULP of each node may be configured to communicate with the RTP of the other nodes.
- the RUE 120 can be configured to perform any of a number of algorithms, such as Swift, BBR, GCN, etc., for performing congestion control.
- the congestion control algorithm may be implemented in software, firmware, or hardware.
- the congestion control algorithm may be implemented in any combination of host software, in firmware of the NIC 100, or in a hardware rate update engine, such as the RUE 120.
- custom processing core By using a custom processing core, it can be updated with programming as new congestion control algorithms evolve. Moreover, the custom processing core provides lower latency and higher performance. Customizing the processing core using custom hardware acceleration instructions, special register sets, and data path event-result handling operations allows for the processor to have a smaller physical size compared to generic processors.
- the proposed architecture is to offload the RUE event processing and RUE result generation for congestion control algorithms, resulting in significantly better power-performance-area (PPA) compared to generic processors.
- PPA power-performance-area
- the custom processing cores described herein are configured to load-balance RUE events based on inbound connections. By load-balancing the RUE events, overall efficiency is improved by balancing utilization of all available cores.
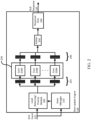
- the custom cores 230 can execute a congestion control algorithm. Input to the cores 230A-N can be stored in memory structure 240, load-balanced according to module 205. Results from the custom cores 230 may be stored in a memory structure 240 and loaded by an arbiter 250, such as a round robin arbiter, into a Response first-in-first-out (FIFO) register 260. In this regard, the transport protocol hardware 110 can consume and enforce updated parameters provided by the congestion algorithm.
- an arbiter 250 such as a round robin arbiter
- Multiple custom cores 230 can be operated in parallel to scale RUE event processing.
- events are distributed up to all of the cores.
- Load balancing mechanisms implemented by the module 205 can cause events to be distributed based on whether certain events come from the same connection.
- the module 205 enforces the ordering of events per core, by load-balancing events based on related connections between enqueued events.
- the module 205 also tracks the connections which have events outstanding or queued with each core.
- events from different connections have no ordering requirement, and therefore can be processed by any core independently.
- the module 205 can schedule event A to one core for processing, and event B to a second core for processing.
- the module 205 checks to see if other events from the same connection as the new event have been scheduled, and if so, schedules the new event to the same core.
- subsequent requests from the connection are processed in order to the previous request and should go to the same core. For example, two events A and B are produced on the same connection. Event A is received by the module 205 and scheduled for processing on core A. Afterwards, Event B is received by the module 205. As event B is subsequent to event A on the same connection, the module 205 also schedules event B to core A.
- the module 205 balances events across all cores, so as to not over- or under-utilize any particular core at any time. For example, when multiple possible cores are available for scheduling based on the load balancing mechanisms described herein, the module 205 can select the core with the lowest current utilization. If there is a tie between the events, the module 205 can randomly select a core or select a core according to a round-robin or other format.
- Module 205 is configured to buffer incoming RUE events before sending to cores A through N.
- the module 205 can send the events to their respective destination cores in bursts of one or more events.
- the module 205 can be configured for maintaining the ordering of events per core, while the same or another module, such as state manager 210, is configured to assign events to various cores, for example in accordance with the rules described above.
- state manager 210 is configured to assign events to the custom cores, the state manager can store information related to received events. This tracking information can be stored in a CAM, hash table, or other data structure implemented as part of the state manager 210 (not shown).
- Fig. 3B illustrates an example "clamp" instruction.
- the clamp instruction may be used to restrict a number between two other numbers. If a given number is within a specified range, that given number will retain its value. However, if the given number is below a minimum value for the specified range, the value of the given number will be adjusted to the minimum for the specified range. Similarly, if the given number is greater than a maximum of the specified range, the value of the given number will be adjusted to the maximum for the given range.
- a clamp instruction can be used as part of generating a congestion window.
- Fig. 3C illustrates an example of a GetPacketTiming function. This function obtains timing information related to a packet. Examples of such timing information include round trip time (RTT).
- RTT round trip time
- VLIW very large instruction words
- a custom architecture such as described in connection with Fig. 4 , may identify optimal instructions for each of a plurality of parallel execution pipelines. The total number of execution pipelines provides for tradeoff between performance and physical space consumed.
- Fig. 4 illustrates an example architecture for parallel execution of independent instructions.
- the architecture includes a core having three independent execution functional units 430, 440, 450, but it should be understood that the number of execution functional units may be modified.
- Each of the execution functional units 430, 440, 450 can be a processing unit dedicated to performing different types of congestion control instructions.
- Each processing execution functional unit may include one or more computational units.
- each execution functional unit 430, 440, 450 may include a respective arithmetic logic unit (ALU) 432, 442, 452.
- ALU arithmetic logic unit
- each execution functional unit 430, 440, 450 may include one or more additional computational units dedicated to processing specific types of instructions.
- the execution functional units 430, 440, 450 independently execute instructions in parallel.
- the first execution functional unit 430 executes Instruction 1
- second execution functional unit 440 executes Instruction 2
- third execution functional unit 450 executes Instruction 3.
- Instructions may be funneled to a particular execution functional unit depending on the type of instruction. For example, all Clamp and Log2Floor instructions may be sent to the first execution functional unit 430 for processing because of its inclusion of the Clamp/Log2Floor processing unit 432. Divide or multiple instructions may be sent to either the first execution functional unit 430 or the second execution functional unit 440.
- GetPacketTiming and GetSmoothed instructions may all be sent to the third execution functional unit 450 because of its inclusion of the GetPacketTiming/GetSmoothed processing unit 454.
- Allocation of instructions to the appropriate execution functional unit may be performed by any of a variety of mechanisms or components.
- a compiler or assembler may convert high level software code (e.g., in C, C++, etc.) to a low-level stream of instructions to the processor.
- the compiler or assembler may have an awareness of the capabilities of each execution functional unit and may set up the instructions in such a way that the instructions would only be enabled for the correct execution functional pipeline.
- the architecture may further include a multiported register file 470.
- the register file may be made to cater to specific needs of congestion control algorithms.
- the multiported register file 470 may include a number of registers, with each specific to some aspect of the congestion control algorithm.
- An Instruction Memory may be a static random access memory (SRAM) memory which can fit all the instructions required for the congestion control algorithms on chip without having to fetch the instructions through cache / dynamic random access memory (DRAM) memory hierarchies.
- the instruction memory may be shared between a pair of custom cores, reducing the area footprint of the instruction memory.
- Fig. 5 illustrates an example architecture including a shared instruction memory 580.
- the shared instruction memory 580 may include two or more read ports, wherein each custom core 530, 540 sharing the shared instruction memory accesses the shared instruction memory 580 through a separate port.
- Each custom core 530, 540 may have its own data memory 535, 545, respectively.
- the shared instruction memory 580 provides instructions to two separate custom cores 530, 540.
- both the cores 530, 540 may be fetching the same instruction.
- the same read address may be requested by both cores 530, 540. If this happens every cycle, all the memories are enabled every cycle due to the XOR structure of the shared instruction memory.
- Collision avoidance module 590 e.g., a module configured to implement a collision avoidance algorithm, may mitigate such address collisions. For example, to reduce the power consumed, the collision avoidance module 590 snoops read addresses from both cores 530, 540.
- the stall may be a pause, such as for one or more cycles. This skews the instruction fetch between the two cores 530, 540 and avoids the address collision, resulting in lower power consumption.
- Fig. 6 illustrates an example of the shared instruction memory.
- the memory may be partitioned into several physical banks 5000, 5001 and an additional XOR bank 5002.
- a 2K deep logical memory may be partitioned into two 1K deep physical memories.
- X[i] A[i] ⁇ B[i].
- Each write operation requires 2 cycles, 1 cycle to read all the memories and 1 cycle to write to the bank and the XOR bank.
- Fig. 7 illustrates an example of reading data from the different banks of Fig. 6 .
- the data can be fetched from each of the physical memory banks 5000, 5001.
- the first requestor 1 accesses the primary physical bank, based on logical to physical memory mapping, e.g., rd_addr[1].
- A[i] B[i] ⁇ X[i]
- X[i] is the read address from the first requestor, e.g., rd_addr[1].
- the algorithmic memory may support two read operations every cycle. Each write operation may take two clock cycles: 1 cycle to read all the banks and 1 cycle to update the data in the primary bank and XOR bank.
- Bank collision may be avoided in a variety of ways.
- One example includes address collision detection.
- address collision detection logic detects if both custom cores are using the same address resulting in bank collisions. In such instances, the address collision detection logic asserts a single cycle stall to the core to break the unintended synchronization between the two cores.
- Another example for bank collision avoidance is bank rotation.
- each of the most significant bits of the addresses presented to the memory are hashed using a simple hash function to generate a unique value per row. The physical bank to access is determined by the logical bank address plus the hash value, which randomizes the bank accesses resulting in lower bank collision.
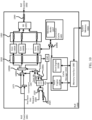
- Fig. 8 shows processor 830 with CPU core 830A and registers 830B.
- RUE events such as RUE event 831A
- RUE event memory 820 from which they can be retrieved by the custom core 830 for processing.
- the custom core 830 writes RUE response 831B to RUE response memory 840.
- the RUE event 831A and RUE response 831B may have sub fields, such as Cwnd, RTO, Delay, etc.
- the custom core 830 may have dedicated custom state registers, e.g., registers 830B for these sub fields. RUE event sub fields are fetched and stored in these dedicated special registers.
- the RUE response sub fields are stored in their dedicated special registers.
- the RUE response memory 840 may be loaded with the computed values from the special registers for the RUE response fields after all processing is done and when the RUE response is ready to be sent to transport protocol hardware.
- Fig. 9 is a flow diagram illustrating an example method 900 according to aspects of the disclosure.
- an instruction for congestion control is received at a computing device having a plurality of customized cores.
- the instruction is input to a given one of the plurality of customized cores.
- the given one of the customized cores processes the instruction independently of processing by other cores in the plurality of customized cores.
- the given one of the customized cores provides the processed instruction to a multiported register file.
- FIG. 10 is a block diagram of an example rate update engine 1000 implementing state cache management, according to aspects of the disclosure.
- rate update engine 1000 may be implemented according to the description with reference to FIG. 2 and RUE 120, with elements shown in Fig. 10 implemented as part of state manager 210.
- the RUE engine 1000 works on congestion control state ("CC-state") presented in RUE events, such as RUE event 1001.
- the RUE outputs RUE responses, such as RUE response 1002.
- the RUE 1000 maintains a connection cache 1005 of connection states, which can be further backed up by system memory 1065 accessible to the RUE 1000.
- CC-state can include any information needed for performing a congestion control algorithm for generating updated congestion control parameters for a connection.
- CC-state information can include connection latency, number packet drops, congestion window size, etc.
- CC-state information can specify information related to the congestion of a connection, for each flow or path on the connection.
- Some congestion control algorithms factor in the state of different flows or paths of a connection before generating updated congestion control parameters. By maintaining the state of each flow, these algorithms can be executed more effectively, at least because each flow can be taken into account for generating updated congestion control parameters to reduce congestion on a connection.
- connection cache 1005 can be implemented alongside content-addressable memory (CAM) 1115, with system memory backing up the CC-state data in SRAM, as examples.
- Manager 1010 is configured with fetch engine 1010A and eviction engine 1010B for fetching and evicting connections, respectively, to and from the connection cache 1005.
- the connection cache 1005 can be divided into multiple SRAM banks 1007, with each of the cores A through N interfacing with one or more of the banks 1007.
- the fetch engine 1010A is configured to write to the connection cache 1005 when fetched data from system memory (not shown) arrives.
- the eviction engine 1010B reads the connection cache 1005 and writes to system memory.
- the eviction engine 1010B evicts CC-states from the connection cache 1005, based on, for example, whether the cache occupancy exceeds a predetermined threshold, the corresponding connection to the CC-state has no outstanding RUE responses, and/or if the connection is not active.
- the RUE event 1001 can include an identifier for comparing to identify a corresponding CC-state, either in system memory or the connection cache 1005.
- connection cache 1005 While a CC-state is present in the connection cache 1005, the CC-state is managed, e.g., updated, written to, read from, the cores A through N.
- the connection cache 1005 can be accessed through LOAD or STORE instructions, defined according to an instruction set architecture for the custom cores, according to aspects of the disclosure.
- the contents of the connection cache 1005 are accessible through PUSH and POP instructions, for example to PUSH an address to the cache 1005 and then POP the cache 1005 to read the contents.
- a PUSH instruction can write data to the cache 1005 at a specified address.
- a connection ID from RUE event 1001 is looked up in the CAM 1115 to determine if the connection is present in the connection cache 1005.
- Events which HIT in the CAM 1115 are sent to core queues 1030.
- the core queues 1030 can include one or more respective queues of RUE events for processing on a corresponding cores A through N.
- Core queues 1030 can be accessed by the cores 1000A through 1000N, for example through defined PUSH and POP instructions, such as the instructions described above with reference to the connection cache 1005.
- the CAM 1115 can track information about the position of various RUE events received by the RUE 1000. For example, the CAM 1115 can track RUE events in the missing queue 1025, per connection. Other information the CAM 1115 can track which events are outstanding, e.g., haven't been processed, which fetch requests are pending, whether a connection is active, and the core ID of cores assigned to each request.
- Missing queue 1025 can be implemented as one or more queues, for example as linked list queues.
- the depth of the queue 1025 can cover the system memory read latency with the number of queues equal to the depth of the missing queue 1025.
- the fetch engine 1025A fetches the CC-state for the enqueued event from system memory and writes the CC-state to the connection cache 1005.
- the missing queue 1025 can dequeue a RUE event after the corresponding CC-state is fetched, and forwarded to the core queues 1030.
- Arbitrator circuit 1020 can select between dequeuing a RUE event from the missing queue 1025 and selecting the RUE event 1001 or pre-fetch request 1009 for passing to the CAM 1115. For example, if the missing queue 1025 is not empty, the arbitrator circuit 1020 is configured to dequeue an event from the queue 1025, otherwise receives and forwards RUE events 1001 or pre-fetch request 1009.
- the cache manager 1010 fetches the CC-state data for the missed event from the connection cache 1005.
- a pre-fetch hint request 1009 can come before the RUE event, which the cache manager receives for fetching the corresponding CC-state before the RUE event arrives.
- a pre-fetch hint request can be generated as part of a connection becoming active, e.g., to indicate that a request to fetch a corresponding CC-state is likely to occur.
- a pre-fetch hint can also be issued whenever a connection is evicted from the hardware transport layer of another system configured for issuing RUE events.
- the fetch engine 1010A is configured to fetch CC-states from system memory in the event of a MISS in the CAM 1115, and/or in response to a pre-fetch request 1009.
- the cache manager 1010 allocates a cache index from a free list and installs the cache index in the CAM 1115 where the fetched CC-state is cached.
- the cache index is also forwarded to the cores 1000A through 1000N.
- RUE responses from the cores 1000A-1000N include the cache index, which is used to update the connection cache 1005.
- a single state manager is used for all the cores 1000A-1000N, coherency issues are eliminated as there is just one component managing reads and writes to the connection cache 1005.
- pre-fetch request 1009 can be a pre-eviction request. for evicting CC-state data for a connection.
- the hardware can be configured to send pre-fetch or pre-eviction requests in response to generating or deleting connections, respectively.
- the RUE can operate more efficiently, for example because there are fewer cache misses when searching for CC-state data.
- the cache requirement for the RUE can also be reduced, for example because pre-eviction requests can cause CC-state data to not be stored for connections that have already been deleted (and therefore will not generate new RUE events).
- Core queues 1030 output a next core identifier 1045, which is used by the RUE 1000 for determining the next core to assign a RUE event to, by ID.
- the next core identifier 1045 can be the core with the lowest given occupancy at the time the identifier 1045 is emitted.
- Output queues 1050 receive RUE responses generated by the cores 1000A-N, which is passed to a round-robin module 1055.
- the round-robin module 1055 is configured to output RUE responses in a round-robin fashion, taken from each core in turn. In other examples, other approaches are used to determine the order at which RUE responses are enqueued in response queue 1060. For example, the output from the round-robin module 1055 may be random or weighted.
- the RUE 1000 can include a number of connection circuits 1099, which can be, for example, multiplexers.
- the connection circuits 1099A, 1099B, 1099C, and 1099D. are configured to route or multiplex incoming signals to their respective destination, allowing for multiple source elements to communicate with the same destination element, and vice versa.
- elements 1115, 1030, 1040, 1045, 1099A, 1099B, 1099C, and 1099D can form at least part of module 205.
- Connection circuit 1099A can receive the next core identifier 1045 and a code identifier 1040 from CAM 1115. If the CAM 1115 identifies a core, the 1099A selects and forwards the identifier 1040, otherwise, the circuit 1099A forwards the core identifier 1045 with the current least occupancy.
- the CAM 1115 may forward a core identifier, for example, that identifies the core which has already been assigned processing an earlier RUE event for the same connection as the currently received RUE event.
- Connection circuit 1099B can receive the output of 1099A and control signal 1085.
- Control signal 1085 can be generated and received through software to optionally override some load-balancing operations performed as described herein. For example, if a control signal 1085 is received by connection circuit 1099B or 1099C, the connection circuits forwards the value of the control signal, overwriting whatever the output from those circuits would have been. For example, if control signal 1085 is received by the connection circuit 1099B with a core identifier to overwrite the output of connection circuit 1099A, then connection circuit 1099B outputs the core identifier value in the control signal 1085.
- connection circuit 1099C can forward the RUE event 1001 to connection circuit 1099D, in response to receiving control signal 1085. Without the control signal 1085, RUE event 1001 is forwarded to connection circuit 1099C after waiting for a number of cycles in delay circuit 1075. The RUE event 1001 is delayed to wait for the CAM 115 to return a core identifier, to forward along with the RUE event 1001 to the connection circuit 1099D. If the core identifier is overwritten, for example by control signal 1085, delaying the RUE event 1001 is not needed, and the delay circuit 1075 can be bypassed.
- the system and methods described herein are advantageous in that they provide an optimization between processing speed and power, and physical space consumed by processing components. By dedicating computing cores to specific congestion control instructions, congestion control algorithms can be computed at faster speeds.
- aspects of this disclosure can be implemented in digital electronic circuitry, in tangibly-embodied computer software or firmware, and/or in computer hardware, such as the structure disclosed herein, their structural equivalents, or combinations thereof.
- aspects of this disclosure can further be implemented as one or more computer programs, such as one or more engines or modules of computer program instructions encoded on one or more tangible non-transitory computer storage media for execution by, or to control the operation of, one or more data processing apparatus.
- the NIC 100 and other devices of the network 140 can be capable of direct and indirect communication over the network. Devices of the network 140 can set up listening sockets that may accept an initiating connection for sending and receiving information.
- the network 140 itself can include various configurations and protocols including the Internet, World Wide Web, intranets, virtual private networks, wide area networks, local networks, and private networks using communication protocols proprietary to one or more companies.
- the network 140 can support a variety of short- and long-range connections.
- the short- and long-range connections may be made over different bandwidths, such as 2.402 GHz to 2.480 GHz (commonly associated with the Bluetooth ® standard), 2.4 GHz and 5 GHz (commonly associated with the Wi-Fi ® communication protocol); or with a variety of communication standards, such as the LTE ® standard for wireless broadband communication.
- the network 140 in addition or alternatively, can also support wired connections between the devices, including over various types of Ethernet connection.
- a computer storage medium can be a machine-readable storage device, a machine-readable storage substrate, a random or serial access memory device, or combinations thereof.
- the computer program instructions can be encoded on an artificially generated propagated signal, such as a machine-generated electrical, optical, or electromagnetic signal, that is generated to encode information for transmission to suitable receiver apparatus for execution by a data processing apparatus.
- a computer program may, but need not, correspond to a file in a file system.
- a computer program can be stored in a portion of a file that holds other programs or data, e.g., one or more scripts, in a single file, or in multiple coordinated files, e.g., files that store one or more engines, modules, sub-programs, or portions of code.
- Host devices for receiving and transmitting data through a NIC can refer to data processing hardware and encompasses various apparatus, devices, and machines for processing data, including programmable processors, a computer, or combinations thereof.
- the data processing apparatus can include special purpose logic circuitry, such as a field programmable gate array (FPGA) or an application specific integrated circuit (ASIC), such as a Tensor Processing Unit (TPU).
- FPGA field programmable gate array
- ASIC application specific integrated circuit
- TPU Tensor Processing Unit
- the data processing apparatus can include code that creates an execution environment for computer programs, such as code that constitutes processor firmware, a protocol stack, a database management system, an operating system, or combinations thereof.
- computer program refers to a program, software, a software application, an app, a module, a software module, a script, or code.
- the computer program can be written in any form of programming language, including compiled, interpreted, declarative, or procedural languages, or combinations thereof.
- the computer program can be deployed in any form, including as a standalone program or as a module, component, subroutine, or other unit suitable for use in a computing environment.
- the computer program can correspond to a file in a file system and can be stored in a portion of a file that holds other programs or data, such as one or more scripts stored in a markup language document, in a single file dedicated to the program in question, or in multiple coordinated files, such as files that store one or more modules, sub programs, or portions of code.
- the computer program can be executed on one computer or on multiple computers that are located at one site or distributed across multiple sites and interconnected by a data communication network.
- engine can refer to a software-based or hardware-based system, subsystem, or process that is configured to perform one or more specific functions.
- the engine can be implemented as one or more software modules or components or can be installed on one or more computers in one or more locations.
- a particular engine can have one or more processors or computing devices dedicated thereto, or multiple engines can be installed and running on the same processor or computing device.
- an engine can be implemented as a specially configured circuit, while in other examples, an engine can be implemented in a combination of software and hardware.
- the processes and logic flows described herein can be performed by one or more computers executing one or more computer programs to perform functions by operating on input data and generating output data.
- the processes and logic flows can also be performed by special purpose logic circuitry, or by a combination of special purpose logic circuitry and one or more computers. While operations are depicted in the drawings and recited in the claims in a particular order, this should not be understood as requiring that such operations be performed in the particular order shown or in sequential order, or that all illustrated operations be performed, to achieve desirable results. In certain circumstances, multitasking and parallel processing may be advantageous.
- the separation of various system modules and components in the examples described above should not be understood as requiring such separation in all examples, and it should be understood that the described program components and systems can be integrated together in one or more software or hardware-based devices or computer-readable media.
- Implementations of the present technology can each include, but are not limited to, the following.
- the features may be alone or in combination with one or more other features described herein. In some examples, the following features are included in combination:
Landscapes
- Engineering & Computer Science (AREA)
- Computer Networks & Wireless Communication (AREA)
- Signal Processing (AREA)
- Quality & Reliability (AREA)
- Data Exchanges In Wide-Area Networks (AREA)
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US202363525462P | 2023-07-07 | 2023-07-07 | |
| US18/763,556 US20250016100A1 (en) | 2023-07-07 | 2024-07-03 | Hardware Architecture of Custom Core for Congestion Control |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| EP4489366A1 true EP4489366A1 (fr) | 2025-01-08 |
Family
ID=91853215
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| EP24186868.6A Pending EP4489366A1 (fr) | 2023-07-07 | 2024-07-05 | Architecture matérielle de c ur personnalisé pour contrôle de congestion |
Country Status (2)
| Country | Link |
|---|---|
| US (1) | US20250016100A1 (fr) |
| EP (1) | EP4489366A1 (fr) |
Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| EP3930272A1 (fr) * | 2020-06-22 | 2021-12-29 | Google LLC | Moteur de mise à jour de débit pour un protocole de transport fiable |
| US20230139762A1 (en) * | 2022-05-17 | 2023-05-04 | Intel Corporation | Programmable architecture for stateful data plane event processing |
-
2024
- 2024-07-03 US US18/763,556 patent/US20250016100A1/en active Pending
- 2024-07-05 EP EP24186868.6A patent/EP4489366A1/fr active Pending
Patent Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| EP3930272A1 (fr) * | 2020-06-22 | 2021-12-29 | Google LLC | Moteur de mise à jour de débit pour un protocole de transport fiable |
| US20230139762A1 (en) * | 2022-05-17 | 2023-05-04 | Intel Corporation | Programmable architecture for stateful data plane event processing |
Also Published As
| Publication number | Publication date |
|---|---|
| US20250016100A1 (en) | 2025-01-09 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US20230139762A1 (en) | Programmable architecture for stateful data plane event processing | |
| US20220309025A1 (en) | Multi-path rdma transmission | |
| EP3823229B1 (fr) | Contrôle de congestion programmable | |
| US12531806B2 (en) | Network interface device with flow control capability | |
| US7773630B2 (en) | High performance memory based communications interface | |
| US7908372B2 (en) | Token based flow control for data communication | |
| CN113728315A (zh) | 促进网络接口控制器(nic)中的有效消息匹配的系统和方法 | |
| US20220124035A1 (en) | Switch-originated congestion messages | |
| CN104821887B (zh) | 通过具有不同延迟的存储器进行分组处理的设备和方法 | |
| US12413516B2 (en) | Network interface device-based computations | |
| US20230224261A1 (en) | Network interface device | |
| CN103229145A (zh) | 用于电信网络应用的无锁缓冲器管理方案 | |
| Arslan et al. | Nanotransport: A low-latency, programmable transport layer for nics | |
| US11785087B1 (en) | Remote direct memory access operations with integrated data arrival indication | |
| CN112953967A (zh) | 网络协议卸载装置和数据传输系统 | |
| US12373367B2 (en) | Remote direct memory access operations with integrated data arrival indication | |
| Singhvi et al. | Falcon: A reliable, low latency hardware transport | |
| US7924848B2 (en) | Receive flow in a network acceleration architecture | |
| US20060262799A1 (en) | Transmit flow for network acceleration architecture | |
| EP4489366A1 (fr) | Architecture matérielle de c ur personnalisé pour contrôle de congestion | |
| HK40123039A (en) | Hardware architecture of custom core for congestion control | |
| WO2021208097A1 (fr) | Procédés et appareils de gestion de ressources d'une connexion réseau pour traiter des tâches à travers le réseau | |
| CN119452348B (zh) | 分组高速缓存逐出引擎的硬件架构 | |
| Zhang et al. | TRNIC: A high-performance RDMA NIC with triple-table bitmap for efficient out-of-order packet reordering in multipath transmission |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PUAI | Public reference made under article 153(3) epc to a published international application that has entered the european phase |
Free format text: ORIGINAL CODE: 0009012 |
|
| STAA | Information on the status of an ep patent application or granted ep patent |
Free format text: STATUS: THE APPLICATION HAS BEEN PUBLISHED |
|
| AK | Designated contracting states |
Kind code of ref document: A1 Designated state(s): AL AT BE BG CH CY CZ DE DK EE ES FI FR GB GR HR HU IE IS IT LI LT LU LV MC ME MK MT NL NO PL PT RO RS SE SI SK SM TR |
|
| STAA | Information on the status of an ep patent application or granted ep patent |
Free format text: STATUS: REQUEST FOR EXAMINATION WAS MADE |
|
| 17P | Request for examination filed |
Effective date: 20250708 |
|
| REG | Reference to a national code |
Ref country code: HK Ref legal event code: DE Ref document number: 40123039 Country of ref document: HK |