EP4531038A1 - Génération d'un signal audio multicanal et signal de données audio représentant un signal audio multicanal - Google Patents
Génération d'un signal audio multicanal et signal de données audio représentant un signal audio multicanal Download PDFInfo
- Publication number
- EP4531038A1 EP4531038A1 EP23199816.2A EP23199816A EP4531038A1 EP 4531038 A1 EP4531038 A1 EP 4531038A1 EP 23199816 A EP23199816 A EP 23199816A EP 4531038 A1 EP4531038 A1 EP 4531038A1
- Authority
- EP
- European Patent Office
- Prior art keywords
- audio signal
- signal
- transient
- downmix
- neural network
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Withdrawn
Links
Images















Classifications
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L19/00—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis
- G10L19/008—Multichannel audio signal coding or decoding using interchannel correlation to reduce redundancy, e.g. joint-stereo, intensity-coding or matrixing
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L19/00—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis
- G10L19/02—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis using spectral analysis, e.g. transform vocoders or subband vocoders
- G10L19/022—Blocking, i.e. grouping of samples in time; Choice of analysis windows; Overlap factoring
- G10L19/025—Detection of transients or attacks for time/frequency resolution switching
Definitions
- the invention relates to generation of a multichannel audio signals and/or an audio data signal representing a multichannel audio signal, and in particular, but not exclusively, to encoding and/or decoding of stereo signals.
- VR Virtual Reality
- AR Augmented Reality
- equipment is being developed for both rendering the experience as well as for capturing or recording suitable data for such applications.
- relatively low cost equipment is being developed for allowing gaming consoles to provide a full VR experience. It is expected that this trend will continue and indeed will increase in speed with the market for VR and AR reaching a substantial size within a short time scale.
- a prominent field explores the reproduction and synthesis of realistic and natural spatial audio. The ideal aim is to produce natural audio sources such that the user cannot recognize the difference between a synthetic or an original one.
- a lot of research and development effort has focused on providing efficient and high quality audio encoding and audio decoding for spatial audio.
- a frequently used spatial audio representation is multichannel audio representations, including stereo representation, and efficient encoding of such multichannel audio based on downmixing multichannel audio signals to downmix channels with fewer channels have been developed.
- One of the main advances in low bit-rate audio coding has been the use of parametric multichannel coding where a downmix signal is generated together with parametric data that can be used to upmix the downmix signal to recreate the multichannel audio signal.
- a multichannel input signal is downmixed to a lower number of channels (e.g. two to one) and multichannel image (stereo) parameters are extracted.
- the downmix signal is encoded using a more traditional audio coder (e.g. a mono audio encoder).
- the bitstream of the downmix is multiplexed with the encoded multichannel image parameter bitstream. This bitstream is then transmitted to the decoder, where the process is inverted.
- the downmix audio signal is decoded, after which the multichannel audio signal is reconstructed guided by the encoded multichannel image/ upmix parameters.
- the decoding is based on the use of the so-called de-correlation process.
- the de-correlation process generates a decorrelated helper signal from the monaural signal.
- both the monaural signal and the decorrelated helper signal are used to generate the upmixed stereo signal based on the upmix parameters.
- the two signals may be multiplied by a time- and frequency-dependent 2x2 matrix having coefficients determined from the upmix parameters to provide the output stereo signal.
- a further issue is that it is often particularly desirable to reduce the complexity and computational load, especially at the decoder side.
- an improved approach would be advantageous.
- an approach allowing increased flexibility, improved adaptability, an improved performance, increased audio quality, improved audio quality to data rate trade-off, reduced complexity and/or resource usage, improved encoder side input on decoder side operation/processing, reduced computational load, facilitated implementation and/or an improved spatial audio experience would be advantageous.
- the Invention seeks to preferably mitigate, alleviate or eliminate one or more of the above mentioned disadvantages singly or in any combination.
- an audio apparatus for generating an output multichannel audio signal
- the audio apparatus comprising: a receiver arranged to receive an audio data signal, the audio data signal comprising (data describing): a downmix audio signal being a downmix of a first multichannel audio signal; sets of upmix parameters for time frequency segments of the downmix audio signal, each set of upmix parameters comprising at least: a level difference parameter indicative of a level difference between channels of the first multichannel audio signal (in a time frequency segment); a correlation parameter indicative of a coherence between channels of the first multichannel audio signal; and a phase difference parameter indicative of a phase difference between channels of the first multichannel audio signal; and neural network control data including: at least one transient parameter indicative of a transient property for the first multichannel audio signal, the transient parameter having a different time frequency resolution than the sets of upmix parameters; an audio signal generator arranged to generate the output multichannel audio signal by upmixing the downmix audio signal in dependence on the set of upmix parameters and the neural network control
- the approach may provide an improved audio experience in many embodiments. For many signals and scenarios, the approach may provide improved generation/ reconstruction of a multichannel audio signal with an improved perceived audio quality.
- the approach may not only provide substantially improved representation of the transients of the original first multichannel audio signal in the generated output multichannel audio signal but may also provide improved upmixing with parameters more closely representing relationships between channels of the multichannel audio signals as the impact of transient behavior may be compensated.
- the approach may provide a particularly advantageous arrangement which in many embodiments and scenarios may allow a facilitated and/or improved possibility of utilizing artificial neural networks in audio processing, including typically multichannel audio decoding/reproduction.
- the approach may allow an advantageous employment of an artificial neural network in generating a multichannel audio signal from a downmix audio signal.
- the approach may in many embodiments allow an improved multichannel audio signal to be generated by allowing the encoder to adapt/ modify the processing of the apparatus generating the multichannel audio signal based on transient properties.
- the approach may enable or facilitate guidance by an encoder by providing a particular approach that is compatible with and exploits advantages that can be achieved by employing an artificial neural network as part of the audio processing.
- the approach may provide an efficient implementation and may in many embodiments allow a reduced complexity and/or resource usage.
- the approach may in many scenarios allow a reduced data rate for data representing a multichannel audio signal using a downmix signal. Indeed, in many embodiments, substantially improved audio quality may be achieved with very little increase in the overall data rate.
- the approach may in many embodiments allow reduced complexity and/or resource usage at the decoder/ generating/ reconstruction side.
- the samples of the downmix audio signal may be time domain samples or may be frequency domain samples (specifically subband samples).
- the samples may span a particular time and frequency range.
- the artificial neural network is a trained artificial neural network.
- the artificial neural network may be a trained artificial neural network trained by training data including training downmix audio signals and training upmix parameters and neural network control data generated from training multichannel audio signals; the training employing a cost function comparing the training multichannel audio signals to output multi-channel signals generated by the audio signal generator, using the training upmix parameter and neural network control data, from the training downmix signals.
- the artificial neural network may be a trained artificial neural network(s) trained by training data including training data representing a range of relevant audio sources including recording of videos, movies, telecommunications, etc.
- the generator may be arranged to generate the multichannel audio signal by applying a matrix multiplication to the downmix signal and an auxiliary audio signal with the coefficients of the matrix being determined as a function of parameters of the upmix parameters.
- the matrix may be time- and frequency-dependent.
- the audio apparatus may specifically be an audio decoder apparatus.
- the transient parameter data values may be referred to as metadata, conditioning features, latent representations, conditioning variables, and/or composites.
- Each time frequency segment may consist in/correspond to a time interval and a frequency interval.
- Each time frequency segment may be a time frequency tile.
- the time frequency segments may be disjoint, and may be disjoint in both the frequency domain and/or time domain.
- the time frequency segments or tiles may be different time intervals and frequency intervals. Each time frequency segment/tile may represent a frequency interval in a time interval.
- the first multichannel audio signal may be divided into time segments/intervals and a frequency representation of the signal in the time segment/interval may be provided by signal values representing different frequency segments of the signal in the time segment/interval.
- the transient parameter having a different time frequency resolution than the sets of upmix parameters may be a different time resolution and/or a different frequency resolution.
- the transient parameter and the upmix parameters may have the same time resolution but have different frequency resolution.
- the transient parameter may typically have a coarser frequency resolution than the upmix parameters.
- the transient parameter may provide only a single parameter value.
- the transient parameter may provide only a single value for the entire frequency band.
- the frequency spectrum is not divided and the time frequency segments/tiles may be time segments/ intervals (for the neural network control data).
- the audio signal generator is arranged to generate the output multichannel audio signal by applying upmix coefficients to the downmix audio signal and a decorrelated signal generated from the downmix audio signal, and the artificial neural network is arranged to generate the upmix coefficients.
- the audio signal generator may specifically be arranged to generate the output multichannel audio signal by applying a matrix multiplication to (samples of) the downmix audio signal and the decorrelated signal with the matrix coefficients being determined by the artificial neural network.
- the audio signal generator is arranged to generate a decorrelated signal from the downmix audio signal and to generate at least one channel of the output multichannel audio signal by upmixing the downmix audio signal and the decorrelated signal, and the artificial neural network is arranged to control the generation of the decorrelated signal.
- the artificial neural network may in many embodiments be arranged to generate signal samples of the decorrelated signal. In some embodiments, the artificial neural network may be arranged to generate parameter values for a decorrelator to which the downmix audio signal is applied to generate the decorrelated signal.
- the artificial neural network comprises inputs for a segment of samples of the downmix audio signal and outputs providing samples of a segment of the output multichannel audio signal.
- This may provide an advantageous approach for many scenarios and may provide an implementation highly suitable for employing artificial neural networks, including e.g. providing an advantageous trade-off between complexity, computational resources and/or the perceived audio quality of the generated multichannel audio signal.
- the neural network control data comprises an interchannel level difference for each of a plurality of transients.
- the feature may allow improved audio quality to data rate trade-off.
- the neural network control data comprises a timing parameter indicative of a timing of at least one transient.
- the feature may allow improved audio quality to data rate trade-off.
- the neural network control data comprises no inter-channel correlation or inter-channel phase difference data for at least some transients of the first multichannel audio signal.
- the feature may allow improved audio quality to data rate trade-off.
- the neural network control data has a lower frequency resolution than the upmix parameters.
- the at least one transient parameter may not be frequency dependent.
- a transient parameter value may apply to the entire frequency range of the downmix audio signal/multichannel audio signal.
- a transient parameter value may be common to a plurality, and possibly all, subbands.
- the neural network control data comprises data indicative of a probability distribution property for transients of the first multichannel audio signal.
- audio apparatus for generating an audio data signal
- the audio apparatus comprising: a receiver receiving a first multichannel audio signal; a downmixer arranged to downmix the first multichannel audio signal to a downmix audio signal and determining sets of upmix parameters for time frequency segments of the downmix audio signal, each set of upmix parameters comprising at least: a level difference parameter indicative of a level difference between channels of the multichannel audio signal; a correlation parameter indicative of a coherence between channels of the multichannel audio signal; and a phase difference parameter indicative of a phase difference between channels of the multichannel audio signal; a transient detector arranged to determine at least one transient parameter indicative of a transient property of the first multichannel audio signal, the at least one transient parameter having a different time frequency resolution than the sets of upmix parameters; and a generator arranged to generate the audio data signal to comprise the downmix audio signal, the sets of upmix parameters, and neural network control data comprising the at least one transient parameter.
- the transient detector is arranged to detect a transient in response to a detection that a first level difference measure indicative of a level difference between channels of the first multichannel audio signal differs from a second level difference measure indicative of a level difference between the channels by more than a threshold, the first level difference measure being determined for a shorter time interval than the second level difference, and to determine the at least one transient parameter to be indicative of the first level difference measure.
- method of generating an output multichannel audio signal comprising: receiving an audio data signal, the audio data signal comprising: a downmix audio signal being a downmix of a first multichannel audio signal; sets of upmix parameters for time frequency segments of the downmix audio signal, each set of upmix parameters comprising at least: a level difference parameter indicative of a level difference between channels of the first multichannel audio signal; a correlation parameter indicative of a coherence between channels of the first multichannel audio signal; and a phase difference parameter indicative of a phase difference between channels of the first multichannel audio signal; and neural network control data including: at least one transient parameter indicative of a transient property for the first multichannel audio signal, the at least one transient parameter having a different time frequency resolution than the sets of upmix parameters; generating the output multichannel audio signal by upmixing the downmix audio signal in dependence on the set of upmix parameters and the neural network control data, the output multichannel audio signal being generated in dependence on an output from an artificial neural network having input nodes receiving the
- a method of operation of generating an audio data signal comprises: receiving a first multichannel audio signal; downmixing the first multichannel audio signal to a downmix audio signal and determining sets of upmix parameters for time frequency segments of the downmix audio signal, each set of upmix parameters comprising at least: a level difference parameter indicative of a level difference between channels of the multichannel audio signal; a correlation parameter indicative of a coherence between channels of the multichannel audio signal; and a phase difference parameter indicative of a phase difference between channels of the multichannel audio signal; determining at least one transient parameter indicative of a transient property of the first multichannel audio signal, the at least one transient parameter having a different time frequency resolution than the sets of upmix parameters; and generating the audio data signal to comprise the downmix audio signal, the sets of upmix parameters and neural network control data comprising the at least one transient parameter.
- FIG. 1 illustrates some elements of an audio apparatus for generating an output multichannel audio signal in accordance with some embodiments of the invention.
- FIG. 2 illustrates an example of an audio apparatus arranged to generate an audio data signal representing a multichannel audio signal henceforth referred to as the first multichannel audio signal.
- the audio data signal generated by the audio apparatus of FIG. 2 may specifically be fed to the audio apparatus of FIG. 1 which may be arranged to generate the output multichannel audio signal as a replica of the first multichannel audio signal.
- the audio apparatus of FIG. 1 will also be referred to as a decoder audio apparatus (or just as a decoder) and the audio apparatus of FIG. 2 will also be referred to as an encoder audio apparatus (or just as an encoder).
- the decoder audio apparatus comprises a receiver 101 which is arranged to receive a data signal/ bitstream comprising a downmix audio signal which is a downmix of a multichannel audio signal.
- the data signal/ bitstream may specifically be one generated by the encoder audio apparatus to represent the first multichannel audio signal.
- the multichannel audio signal is a stereo signal and the downmix signal is a mono signal, but it will be appreciated that the described approach and principles are equally applicable to the multichannel audio signal having more than two channels and to the downmix signal having more than a single channel (albeit fewer channels than the multichannel audio signal).
- the received data signal includes upmix parametric data which comprises sets of upmix parameters for upmixing the downmix audio signal.
- the upmix parameters may specifically be parameters that indicate relationships between the signals of different audio channels of the multichannel audio signal (specifically the stereo signal) and/or between the downmix signal and audio channels of the multichannel audio signal.
- the upmix parameters may be indicative of time differences, phase differences, level/intensity differences and/or a measure of similarity, such as correlation.
- a set of upmix parameters comprises at least the following:
- a set of parameters may specifically include an IID, ICC, and IPD parameter determined in accordance with ISO/IEC 23003-3:2020 Information technology - MPEG audio technologies - Part 3: Unified speech and audio coding.
- the upmix parameters are provided on a per time and per frequency basis (time frequency tiles). For example, new parameters may periodically be provided for each of a set of subbands.
- the encoder audio apparatus accordingly is arranged to receive a first multichannel audio signal and to generate an audio data signal that represents the first multichannel audio signal with the representation including a downmix audio signal and the sets of upmix parameters.
- the encoder audio apparatus may be a Parametric Stereo (PS) encoder that receives a stereo signal and encodes it as a mono audio signal with associated upmix parametric data.
- PS Parametric Stereo
- the downmix audio signal is encoded and the receiver 101 is arranged to decode the downmix audio signal to provide the downmix audio signal, i.e. the mono signal in the specific example as well as the sets of upmix parameters and any other required data.
- the receiver 101 is coupled to an audio signal generator 103 which generates the multichannel audio signal from the downmix signal and based on the upmix parameters.
- the audio signal generator 103 comprises an artificial neural network 105 that is coupled to a multichannel audio signal generator 107 which provides the output multichannel audio signal.
- the artificial neural network 105 may generate output samples/values based on the upmix parameters being provided as input values to the artificial neural network. In many embodiments, the downmix audio samples may also be provided to the artificial neural network 105.
- the multichannel audio signal generator 107 is arranged to generate the output multichannel audio signal from the output of the artificial neural network 105 and in many cases also from the downmix audio signal. It will be appreciated that the specific function of the multichannel audio signal generator 107 and the artificial neural network 105 (and the training thereof) will be different in different embodiments and a number of approaches will be described later.
- the encoder audio apparatus comprises a receiver 201 which receives the first multichannel audio signal from an internal or external source.
- the receiver 201 is coupled to a downmixer 203 that is arranged to downmix the first multichannel audio signal to generate a downmix audio signal which is a signal that has fewer channels than the first multichannel audio signal.
- the downmixer 203 proceeds to generate sets of upmix parameters where each set of upmix parameters as described previously with respect to the audio data signal comprises at least a level difference parameter indicative of a level difference between channels of the multichannel audio signal; a correlation parameter indicative of a coherence between channels of the multichannel audio signal; and a phase difference parameter indicative of a phase difference between channels of the multichannel audio signal.
- the first multichannel audio signal may specifically be a stereo signal and the upmix parameters may be generated from the samples of a left and right channel signal of the input stereo signal.
- the downmix audio signal is a mono downmix audio signal.
- the encoder audio apparatus further comprises a data signal generator 205 which generates the audio data signal to include data representing the downmix audio signal and the upmix parameters.
- the encoder audio apparatus and the decoder audio apparatus are arranged to perform subband processing.
- the upmix parameters may be generated for different (frequency) subbands of the first multichannel audio signal and the downmix audio signal.
- the receiver 201 or the downmixer 203 may comprise a filter bank which is arranged to generate a frequency subband representation of the downmix audio signal.
- the receiver 201 or the downmixer 203 may comprise a filter bank that is applied to all the channels of the first multichannel audio signal such that each channel signal is divided into subbands.
- the downmixing may then be performed on a per subband basis with upmix parameters being determined for each subband and a subband downmix signal being generated.
- the subband downmix audio signal may then in some cases be included directly in the audio data signal as a subband downmix audio signal or may be transformed to the time domain to provide a time domain signal.
- the filter bank may be Quadrature Mirror Filter (QMF) bank or may e.g. be implemented by a Fast Fourier Transform (FFT), but it will be appreciated that many other filter banks and approaches for dividing an audio signal into a plurality of subband signals are known and may be used.
- the filterbank may specifically be a complex-valued pseudo QMF bank, resulting in e.g. 32 or 64 complex-valued sub-band signals.
- the processing is furthermore typically performed in time segments.
- the first multichannel audio signal is divided into time intervals/segments with a conversion to the frequency/subband domain by applying e.g. an FFT or QMF filtering to the samples of each signal.
- each channel of the multichannel audio signal may be divided into time segments of e.g. 2048, 1024, or 512 samples.
- These signals may then be processed to generate samples for e.g. 64, 32 or 16 subbands.
- a set of samples may be determined for each subband of the downmix audio signal.
- a set of upmix parameters may be generated for each time segment/ interval and frequency interval/subband.
- time domain samples is not directly coupled to the number of subbands.
- every N input samples will lead to N sub-band samples (one for every sub-band).
- An oversampled filterbank will produce more output samples. E.g. for every N input samples, it would generate k*N output samples, i.e., k consecutive samples for every band.
- sets of upmix parameters may be generated with each set being provided for a given time interval and a given frequency interval, also referred to as a given time frequency tile or segment.
- Each set of upmix parameters may as previously described specifically include an IID, ICC, and IPD value and thus these parameters are provided with a given time resolution and a given frequency resolution.
- the time intervals may vary but typically have a fixed duration in many embodiments.
- the subband size/ frequency resolution may also be fixed/constant for all subbands but in many embodiments the subbands may have different resolutions/ sizes.
- the filterbank may be arranged to generate subband signals for subbands having equal bandwidth, and in many other embodiments, the filterbank may be arranged to generate subband signals with subbands having different bandwidths. For example, a higher frequency subbands may have a higher bandwidth than a lower frequency subband. Also, subbands may be grouped together to form a higher bandwidth sub-band.
- the subbands may have a bandwidth in the range from 10Hz to 10000Hz.
- the audio signal generator 103 as mentioned comprises an artificial neural network 105 that is part of the generation of the output multichannel audio signal from the downmix audio signal and the sets of upmix parameters.
- the artificial neural network 105 may for example in various embodiments be arranged to e.g. generate parameter values/ weights for an upmixing of the downmix audio signal, to generate a decorrelation auxiliary audio signal corresponding to the downmix audio signal, to directly generate upmixed channel signals for an output multichannel audio signal etc.
- An artificial neural network as used in the described functions may be a network of nodes arranged in layers and with each node holding a node value.
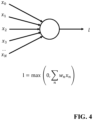
- FIG. 3 illustrates an example of a section of an artificial neural network.
- the node value for a given node may be calculated to include contributions from some or often all nodes of a previous layer of the artificial neural network. Specifically, the node value for a node may be calculated as a weighted summation of the node values of all the nodes output of the previous layer. Typically, a bias may be added and the result may be subjected to an activation function.
- the activation function provides an essential part of each neuron by typically providing a non-linearity. Such non-linearities and activation functions provides a significant effect in the learning and adaptation process of the neural network. Thus, the node value is generated as a function of the node values of the previous layer.
- the artificial neural network may specifically comprise an input layer 301 comprising a plurality of nodes receiving the input data values for the artificial neural network.
- the node values for nodes of the input layer may typically directly be the input data values to the artificial neural network and thus may not be calculated from other node values.
- the artificial neural network may further comprise none, one, or more hidden layers 303, 305 or processing layers.
- the node values are typically generated as a function of the node values of the nodes of the previous layer, and specifically a weighted combination and added bias followed by an activation function (such as a sigmoid, ReLu, or tanh function may be applied).
- the node output or value may be calculated using a plurality of functions.
- Such operations may be performed by each node of the artificial neural network (except for typically the input nodes).
- the artificial neural network further comprises an output layer 307 which provides the output from the artificial neural network, i.e. the output data of the artificial neural network is the node values of the output layer.
- the output node values are generated by a function of the node values of the previous layer.
- the node values of the output layer are accessible and provide the result of the operation of the artificial neural network.
- a number of different networks structures and toolboxes for artificial neural network have been developed and in many embodiments the artificial neural network may be based on adapting and customizing such a network.
- An example of a network architecture that may be suitable for the applications mentioned above is WaveNet by van den Oord et al which is described in Oord, Aaron van den, Sander Dieleman, Heiga Zen, Karen Simonyan, Oriol Vinyals, Alex Graves, Nal Kalchbrenner, Andrew Senior, and Koray Kavukcuoglu. "Wavenet: A generative model for raw audio.” arXiv preprint arXiv: 1609.03499 (2016 ).
- WaveNet is an architecture used for the synthesis of time domain signals using dilated causal convolution, and has been successfully applied to audio signals.
- the filter product of the equation may typically provide a filtering effect with the gating product providing a weighting of the result which may in many cases effectively allow the contribution of the node to be reduced to substantially zero (i.e. it may allow or "cutoff' the node providing a contribution to other nodes thereby providing a "gate" function).
- the gate function may result in the output of that node being negligible, whereas in other cases it would contribute substantially to the output. Such a function may substantially assist in allowing the neural network to effectively learn and be trained.
- An artificial neural network may in some cases further be arranged to include additional contributions that allow the artificial neural network to be dynamically adapted or customized for a specific desired property or characteristics of the generated output.
- a set of values may be provided to adapt the artificial neural network. These values may be included by providing a contribution to some nodes of the artificial neural network. These nodes may be specifically input nodes but may typically be nodes of a hidden or processing layer.
- Such adaptation values may for example be weighted and added as a contribution to the weighted summation/ correlation value for a given node. For example, for WaveNet such adaptation values may be included in the activation function.
- y is a vector representing the adaptation values and V represents suitable weights for these values.
- neural network approach that may be suitable for many embodiments and implementations.
- many other types and structures of neural network may be used.
- many different approaches for generating a neural network have been, and are being, developed including neural networks using complex structures and processes that differ from the ones described above.
- the approach is not limited to any specific neural network approach and any suitable approach may be used without detracting from the invention.
- the encoder audio apparatus is arranged to generate control data for the artificial neural network 105 which is included in the audio data signal and transmitted to the decoder audio apparatus where it is provided as an input to the artificial neural network.
- This neural network control data is thus data that is processed by the artificial neural network 105 and with the output of the artificial neural network 105 being dependent on the neural network control data.
- the encoder audio apparatus is arranged to determine the neural network control data to include at least one transient parameter that is dependent on/ represents a transient property for the first multichannel audio signal.
- the specific transient parameter(s) and property(ies) that are transmitted and input to the artificial neural network 105 may be different in different embodiments.
- the transient data may include an indication of one or more of a presence, number, time, duration, amplitude, interchannel level difference, interchannel phase difference, interchannel coherence for one or more transients that are present in the first multichannel audio signal (and often in the downmix audio signal).
- the transient data/parameter is provided with a different time frequency resolution than the sets of upmix parameters, and indeed in many cases may be provided with a finer timing resolution or coarser frequency resolution than the sets of upmix parameters, and indeed in many cases with both a finer time resolution and a coarser frequency resolution.
- a timing of a transient may be indicated with a timing granularity that is finer than the (processing) time segments/intervals and e.g. a non-frequency dependent interchannel level difference may be provided.
- the sets of upmix parameters may be provided for time frequency tiles corresponding to the subbands and time segments of the processing as previously described (e.g. with a fixed number of samples per time segment and subband).
- the transient parameter values may in some cases be provided with a finer time resolution.
- the timing or duration of a transient may be provided with a higher time resolution than the sampling times of the subband samples.
- the transient property may be provided with a coarser frequency resolution than for the sets of upmix parameters.
- a set of upmix parameters may be provided for each subband whereas a single common transient parameter value is provided for a plurality, and possibly all, subbands.
- a set of one or more parameters may be provided for each of a set of detected transients.
- the parameters may specifically include an indication of a channel level difference between channels of the first multichannel audio signal.
- FIG. 6 A specific example of a time segment/ frame FRM in which three transients are detected is shown in FIG. 6 .
- three transients are detected at positions p 0 , p 1 , and pz.
- These positions/ time instants may be encoded and included in the audio data signal and accordingly transmitted to the decoder audio apparatus.
- an amplitude level difference is determined for the transient and is included in the audio data signal.
- an IID Interchannel Intensity Difference
- a positive IID can correspond to a left panning
- a negative IID can correspond to a right panning of the transient signal.
- the individual amplitudes a 0 , a 1 and a 2 can additionally or alternatively be transmitted.
- the transient data may be used to encode a representation of the detected transients.
- the duration of a transient may be determined, encoded, and communicated to the decoder audio apparatus in the audio data signal.
- the parameter values may be quantized into relatively few levels, and thus a relatively low number of bits may be used for each value.
- word lengths may be no more than 1, 2, 3, or 4 bits.
- amplitude values may be quantized into a few levels (e.g. 5 or 7 discrete levels) using only a few bits.
- the encoding of the parameter values in the audio data signal may for example use absolute or differential encoding.
- the three IID values corresponding to positions p 0 , p 1 and p 2 may be coded differentially to the (average over the frequency bands) IID transmitted (per band) for the whole frame.
- the encoder audio apparatus may accordingly generate transient data indicative of transients in the first multichannel audio signal and provide it to the decoder audio apparatus where it is input to the artificial neural network 105.
- the encoder audio apparatus may provide this with different time frequency resolution than the upmix parameters thereby allowing the transient data to be optimized independently.
- a coarser frequency resolution can be employed, and in many scenarios the transient data may not include any frequency dependency but rather the same parameter value may be provided for all subbands of the downmix audio signal.
- coarse quantization of the parameter values into few discrete levels may also be achieved. Accordingly, a very low data overhead may in many embodiments be achieved.
- it has been found that the provision of this transient data/information to the artificial neural network 105 of an upmixer can result in a substantially improved perceived audio quality, and in particular may very significantly improve the perceived audio realism for some scenarios and environments.
- FIG. 7 illustrates an example of elements of a transient detector 207 that may be used in the encoder audio apparatus.
- the transient detector 207 may be arranged to detect transients in a stereo signal.
- the transient detection may be performed independently for the different channels, and in the example specifically the left and right channels, with the detections being combined thereafter. In other embodiments, it may be based on information from both channels directly, such as e.g. by considering the downmix audio signal. Such an approach may be beneficial as it can make use of the interchannel level (e.g. IID) parameters. The following examples will mainly consider such approaches.
- IID interchannel level
- the transient detector 207 may detect a transient in response to a detection that a first level difference measure indicative of a level difference between channels of the first multichannel audio signal (specifically a first IID measure) differs from a second level difference measure indicative of a level difference between the channels (specifically a second IID measure for the same channels) by more than a threshold where the first level difference measure is determined for a shorter time interval than the second level difference.
- the shorter time interval may not exceed 10%, 20%, 30%, or 50% of the time interval for the second level difference.
- the transient detector 207 includes an analysis filterbank 701 which typically decomposes the left and right stereo channels into a time-frequency (TF) representation where the distribution of center-frequencies e.g. follows the logarithmically-spaced critical bands of the human auditory system (inner ear).
- the spectral decomposition may be performed using a hybrid quadrature mirror filterbank (QMF) that produces fine resolution at low frequencies, with the resolution decreasing (bandwidth increasing) as the frequency increases.
- QMF quadrature mirror filterbank
- the QMF decomposition may produce complex-valued outputs and the transient detector 207 comprises an envelope circuit 703 which determines the real envelope of both left and right channels.
- the square-root operation may be omitted to reduce complexity.
- This envelope is a type of (absolute) spectrogram with there being no summation over the different bands to generate a time-domain envelope.
- the transient detector 207 comprises a detection circuit 705 which is coupled to the envelope circuit 703 and which in the example processes the current and previous frames of time frequency samples.
- the IID over the windowed frames is determined (e.g. using an approach similar to a legacy PS coder which incorporates the symmetric Hanning window). This IID value serves as a baseline to predict the perceptual effect of detected transients later in the processing and will be denoted by ⁇ .
- IID w 10 log 10 l w 2 / r w 2
- IID w Values of IID w that deviate from ⁇ can be considered as transient candidates and these may have their IID values encoded separately from the baseline IID ⁇ . It should be noted that IID values may be computed at each QMF time instant per frequency band or aggregated across frequencies either globally or according to a customized binning scheme that may or may not omit certain frequencies that are not relevant to detecting certain transients.
- a perceptually-motivated step may evaluate the perceptual effect of the (PS) coder on the detected transients. It may compare the set of IID w , to ⁇ and filter out those transients that are not affected by the baseline (legacy) IID reconstruction in the decoder. This helps to reduce the number of parameters that has to be sent in the bitstream, thus keeping the resulting bit-rate under control.
- the perceptual filtering step has two objectives:
- the first objective is perceptually motivated and is based on the deviation of the transient's IID parameter from the overall estimated frame parameter. If this deviation exceeds a certain threshold, then the transient is included as part of the stereo transient parameters.
- the second objective can further reduce the bit rate, but bundling transients based on their stereo properties and assigning them to a virtual source (object) in the stereo image. This way only timing information and not both timing and IID features have to be transmitted for the same source if the IID value for the given source is stable over time.
- FIG. 8 illustrates the same stereo transient representation as in FIG. 5 and 6 but with an average IID of the frame also being shown ( ⁇ ) along with an IID range around the average IID given by ⁇ ⁇ .
- the transients that fall outside of the indicated range may be represented by parameters that are included in the audio data signal.
- ⁇ can be tuned based on perceptual (listening) tests or models which may e.g. determined the Just Noticeable Difference (JND) between the transient and average frame IID.
- JND Just Noticeable Difference
- the JND is also a function of the IID level - typically, the larger the IID, the larger the JND, the region between ⁇ ⁇ ⁇ can be replaced with a region of exclusion around the IID w level itself as shown in FIG. 9 . If the average IID of the frame falls within this range, then the transient can be ignored and will not be encoded (as in the example is the case for transient p 1 ).
- the perceptual filtering step may further include a model of masking. Similar to the region of exclusion, the masking model may indicate that a given transient cannot be sufficiently perceived by the user based on the background noise, for example.
- short term properties are accordingly compared to longer term properties and a transient is detected in terms of these differing sufficiently.
- the magnitude of the time-frequency representation of a signal (e.g. a channel signal of the first multichannel audio signal or of the downmix audio signal) is determined, and the resulting frequency envelopes are summed across frequencies.
- Two smoothed versions of this envelope may then be created with one tracking the envelope more slowly than the other.
- a slowly varying residual envelope value is determined, and the other value is determined with a time-constant that tracks the envelope much faster.
- a first order exponential smoothing or e.g. a smoothing moving average filter can be applied to create the smoothed envelope.
- the instantaneous envelope can also be used.
- m s ⁇ n ⁇ s m ⁇ n + 1 ⁇ ⁇ s m s ⁇ n ⁇ 1
- m f ⁇ n ⁇ f m ⁇ n + 1 ⁇ ⁇ f m f ⁇ n ⁇ 1
- m s ( n ) and m f ( n ) are the slow and fast envelopes respective with ⁇ s , ⁇ f ⁇ (0,1] and ⁇ f » ⁇ s .
- Such an approach is e.g. described in Adami, A., Herzog, A., Disch, S. and Herre, J., 2017, October. "Transient-to-noise ratio restoration of coded applause-like signals", 2017 IEEE Workshop on Applications of Signal Processing to Audio and Acoustics (WASPAA) (pp. 349-353). IEEE.
- the measure may be used to detect the transients and the timing of these. Specifically, if g(n) exceeds a threshold, it may be considered that a transient has been detected. In some cases, the measure g(n) may then be compared to a second threshold (which may specifically be the same as the first threshold) and if it falls below this second threshold than the end of the transient may be considered to have been detected. Thus, the approach may detect both the beginning and the end of a transient, and accordingly may also detect the duration.
- the intervals between onset and offset of the transients in the first multichannel audio signal and/or the downmix audio signal can further be used to filter out non-transient components that have longer durations and thus the transient detection may only detect relatively short transients rather than longer duration step changes.
- the encoder audio apparatus may in some cases separate the downmix audio signal into a set of transients and a residual signal having these transients removed. For example, a part of the downmix audio signal between the detection of the onset of a transition and the detection of the end of a transition may be extracted and represented as a separate transient with the resulting downmix audio signal representing a residual signal.
- a softer separation into transients and a residual signal may be performed by using a weighted rather than binary selection.
- FIG. 10 illustrates an example of a stereo input signal m ( n ) (with the two channels being represented overlaid by each other and with different shades of grey) being separated into a stereo transient signal t ( n ) and a stereo residual signal r(n).
- Another approach to separate transients is to track the residual signal r ( n ) using a minimum tracking of the envelopes (based on the minimum statistics approach for stationary noise tracking e.g. described in Martin, Rainer. "Noise power spectral density estimation based on optimal smoothing and minimum statistics.” IEEE Transactions on speech and audio processing 9.5 (2001): 504-512 .) per frequency band.
- source separation techniques employing neural networks may be employed.
- An example of such technology can be found in Daniel Stoller, Sebastian Ewert, Simon Dixon, "Wave-U-Net: A Multi-Scale Neural Network for End-to-End Audio Source Separation", http://arxiv.org/abs/1806.03185, 2018 .
- Transient detection may be performed using a neural network model that has been trained to detect the location of transients using various neural network embodiments such as fully-connected, convolutional, or recurrent layers.
- a block diagram of a neural network and its training is illustrated in FIG. 11 .
- the input corresponds to either the current frame or a combination of the current (F) and previous (F-1) frame, where time blocks of the previous frame can serve as additional padding in case a transient occurs at the beginning of the current block F.
- the samples can correspond to all time frequency samples or a range of frequency samples relevant for transient detection. (for example, for clapping, most of the energy lies between 1 and 3 kHz).
- the training data can consist of 2 ⁇ f ⁇ n input blocks, and the labels corresponding to a 1 ⁇ n vector of 1s or 0s indicating the transient position of the training data.
- a transient presence flag can be added that indicates whether the frame includes at least a single transient, to the training labels, producing a 1 ⁇ (n+1) vector label.
- the audio signal generator 103 may generate the output multichannel audio signal using an artificial neural network as part of the processing and with the artificial neural network having an input comprising both the sets of upmix parameters and the transition parameters.
- the artificial neural network may be generated by the artificial neural network in different embodiments.
- the artificial neural network 105 comprises inputs for a segment of samples of the downmix audio signal.
- the samples may be time domain samples of the downmix audio signal.
- the samples may e.g. be time frequency samples, such as specifically subband samples of a frame/ segment.
- the artificial neural network 105 may be arranged to directly generate the output multichannel audio signal.
- the artificial neural network 105 may have output nodes that directly provide samples of the output multichannel audio signal.
- the samples may in some embodiments directly be time domain samples of the channel signals of the output multichannel audio signal.
- the artificial neural network 105 may generate subband samples of the output multichannel audio signals.
- the generated output multichannel audio signal samples may be fed to the multichannel audio signal generator 107 which in the former example e.g. may simply forward the samples or e.g. may perform post processing of the generated samples of the output multichannel audio signal.
- the multichannel audio signal generator 107 may perform a processing that e.g. includes a frequency to time domain transformation to convert subband samples into time domain samples.
- the decoder audio apparatus may be arranged to generate a decorrelated version of the downmix audio signal by inputting the downmix audio signal to a suitable decorrelator.
- samples of both the downmix audio signal and the decorrelated signal may e.g. be provided to the artificial neural network 105 for the generation of the samples of the output multichannel audio signal.
- the training of the artificial neural network 105 may for example be performed by generating a large number of training input multichannel audio signals that are processed by an encoder audio apparatus in accordance with e.g. prescribed specifications or standards.
- the data may then be provided to the decoder audio apparatus which may from these generate an output multichannel audio signal.
- a cost function for the training may then be determined by a comparison of the generated output multichannel audio signal and the original training input multichannel audio signal.
- the decoder audio apparatus may be arranged to generate the output multichannel audio signal in response to an upmixing of the downmix audio signal and a decorrelated signal which is a decorrelated version of the downmix audio signal.
- the decorrelated signal may have the same overall properties as the downmix audio signal in terms of frequency envelope, average energy etc., but being decorrelated with the downmix audio signal.
- This upmix procedure is typically operated in a time- and frequency dependent way with the upmix parameters being time and frequency dependent.
- a set of upmix coefficients h xy are typically determined for each time segment/frame and each subband.
- the upmix coefficients are determined from the received sets of upmix parameters. The exact dependency of the upmix coefficients on the sets of upmix parameters will be dependent on the specific embodiment.
- the artificial neural network 105 may be arranged to generate the decorrelated signal, and thus based on an input including samples of the downmix audio signal, the sets of upmix parameters, and the transient parameter(s) the artificial neural network 105 proceeds to generate samples of the decorrelated signal. These samples (and thus the decorrelated signal generated by the artificial neural network 105) may then be fed to the audio signal generator 103 where the matrix multiplication upmix is performed.
- the audio signal generator 103 is arranged to generate the output multichannel audio signal from the downmix audio signal as well as from a decorrelated audio signal in dependence on the parametric upmix data.
- the generator may specifically for the stereo case generate the output multichannel audio signal by applying a time- and frequency-dependent 2x2 matrix multiplication to the samples of the downmix audio signal and the decorrelated signal.
- the coefficients of the 2x2 matrix are determined from the upmix parameters of the upmix parametric data, typically on a time and frequency band basis.
- the audio signal generator 103 may apply matrix multiplications with matrices of suitable dimensions.
- the upmixing includes generating a decorrelated signal of the mono audio signal determined by applying the downmix audio signal to a decorrelator function. It has been found that by generating a decorrelated signal and mixing this with the mono audio signal, an improved quality of the upmix signal is perceived and therefore decoders have been developed to exploit this.
- the decorrelated signal is typically generated by a decorrelator in the form of an all-phase filter that is applied to the mono audio signal.
- an all pass filter tends to result in a multichannel audio signal being generated that is perceived to be of improved quality, it is still not ideal, and some audio quality degradation may often be perceived.
- the decorrelated signal is not generated by a straightforward filtering of the downmix/ mono audio signal, but rather a decorrelated audio signal is generated by the artificial neural network 105 with the decorrelated signal being used by the multichannel audio signal generator 107 to generate the multichannel audio signal based on the upmix parameters.
- the artificial neural network 105 may thus directly be trained to generate the decorrelated signal. It has been found that this may in many embodiments provide a substantially improved performance with a more realistic sounding output multichannel audio signal typically be perceived.
- the artificial neural network 105 may not directly generate the decorrelated signal but may for example generate one or more parameters for a decorrelator which is applied to the downmix audio signal to generate the decorrelated signal.
- the artificial neural network 105 may as an output generate parameters, such as filter coefficients, for an all pass filter that is applied to the downmix audio signal to generate the decorrelated signal.
- the training of the artificial neural network 105 may for example be performed by generating a large number of training input multichannel audio signals that are processed by an encoder audio apparatus in accordance with e.g. prescribed specifications or standards. The generated data may then be provided to the decoder audio apparatus which may from these generate an output multichannel audio signal. A cost function for the training may then be determined by a comparison of the generated output multichannel audio signal and the original training input multichannel audio signal. Thus, the training of the artificial neural network 105 may be based on an end to end cost function that includes the upmixing etc. Such a trained artificial neural network has been found to result in improved audio quality in many scenarios and for many signals.
- the artificial neural network 105 may be arranged to directly generate the upmix coefficients for upmixing the downmix audio signal and one or more auxiliary signals, such as specifically for upmixing the downmix audio signal and a decorrelated signal.
- the artificial neural network 105 may thus directly generate the coefficients of the upmix matrix: h 11 h 12 h 21 h 22
- the upmix procedure may include a pre-trained network determining upmix parameters that are applied to the downmix audio signal and at least one decorrelated signal to generate the upmixed output multichannel audio signal.
- the artificial neural network 105 may be trained to directly generate the coefficients h xx , for a given set of legacy PS parameters (represented by the sets of upmix parameters) and a given set of stereo transient sequences (represented by the transient parameters), while minimizing the (perceptual) loss of the synthesized stereo output signal compared to the original stereo signal.
- An example architecture could be a fully connected network, receiving the PS parameters for the current frame, the PS parameters of the previous frame, the current sample index n and the value of the stereo transient sequence at that position.
- An example of the input parameters temporal relations are illustrated in FIG. 12 .
- FIG. 13 illustrates elements of a simplified diagram of a fully connected network which has input nodes for the PS parameters, the stereo transient sequence s[n] and the relative sample position n inside the frame. For simplicity only a few connections and only the real-valued part of the upmix entry h are shown.
- the legacy upmix equations may be employed first to pre-calculate the upmix entries at frame F-1 and frame F.
- coefficients calculated by predetermined formulas/equations may then be input to the artificial neural network 105 and modified coefficients may be calculated. This may result in a lower complexity network as no network capacity needs to be applied in modelling the original upmix equations.
- An alternative network architecture may employ so-called gated activation units, as e.g. also employed in WaveNet.
- the neural network control data comprises data indicative of a probability distribution property for transients of the first multichannel audio signal.
- the transient data may (alternatively or additionally) provide an indication of a probability distribution for the transients.
- the transient data may include stochastic components where e.g. some parameters like amplitude and or duration may be synthesized using a stochastic (noise-like) process.
- the upmixing to generate the output multichannel audio signal employs an artificial neural network which in addition to the normal signals and parameters that are used to perform upmixing (e.g. the downmix audio signal and upmix parameters relating properties between different channels of the original multichannel audio signal) is provided with control data that is determined in dependence on transient properties of the original multichannel signal/ downmix audio signal.
- an artificial neural network which in addition to the normal signals and parameters that are used to perform upmixing (e.g. the downmix audio signal and upmix parameters relating properties between different channels of the original multichannel audio signal) is provided with control data that is determined in dependence on transient properties of the original multichannel signal/ downmix audio signal.
- the inclusion of the transient data and information allows for information that may otherwise be lost (due to not being sufficiently represented by the upmix parameters) to be taken into account by the artificial neural network thus allowing a better training and output of the artificial neural network.
- the representation of the transient information using a different time frequency resolution of the transient information than used for the upmix parameters has been found to allow a substantially improved upmixing and audio quality while only introducing a small overhead.
- a very coarse frequency resolution including having no frequency dependency of the transient parameter values, may still allow very accurate and substantially improved upmixing that includes transient components.
- a different time resolution including in particular allowing a finer time resolution than the segments/time intervals used for upmix parameters allow improved audio quality, and in particular allows much better representation of some audio components and sounds.
- an audio signal representing an applause from a group of people may be considered.
- Such applause signals tend to consist of a seemingly random (spatial) superposition of individual claps, i.e. short bursts of energy in time.
- estimating a set of stereo parameters and interpolating these between frames does not lead to an accurate reconstruction of the stereo signal at the decoder.
- fine-grained estimates of transient-specific parameters may also increase the overall bit-rate.
- the signal of FIG. 14 may be considered.
- the figure illustrates an example of the time-frequency decomposition of an applause stereo signal sampled at 44.1 kHz (spectrogram).
- the signal consists of background and foreground applause, where the background applause is dominant below 3 kHz.
- the foreground claps are clearly panned to the left as they do not appear as prominently in the right channel.
- the time-frequency energy for the background clapping is quite random and noise-like.
- FIG. 15 The output of a conventional parametric stereo decoder for the same segment is shown in FIG. 15 .
- this approach results in a smeared-out background applause and foreground clapping.
- the conventional approach of stereo parameter interpolation does not work very well here.
- the smearing effect results in a musical tones-like effect, with clear generation of harmonic components.
- the foreground claps are also slightly smeared out in time and lose their panning characteristics (IID): some foreground claps now also appear more prominently in the right channel. The latter effects are a result of the stereo parameter estimator's frame-by-frame update rate.
- the stereo parameters are estimated by first windowing the two frames such that the energy near the beginning of the previous frame and end of the current frame is attenuated.
- the distribution of phase, intensity and coherence from the background applause between left and right channels will largely determine the estimated stereo parameters, even though for the foreground clap, the parameters should be different since at least for the IID, it is clear that the signal is panned to the left.
- transient data with a higher time resolution allows for additional information that can be included in the artificial neural network 105 by a training process thereby allowing an improved output audio signal to be generated.
- the approach may in particular allow such transient information to be adapted to the specific importance of information of the transients. Indeed, for the transients, it has been found that the artificial neural network is much less sensitive to frequency dependencies than to timing accuracy and the described approach, the transient data may be adapted/generated accordingly and is not limited to follow the same resolutions as for the upmix data.
- interchannel level differences may be significant and e.g. allow an accurate representation of the spatial position (e.g. in a stereo image) of the transients.
- the only interchannel information provided for the transient may be an interchannel level difference indication.
- the transient data may not include any interchannel phase difference or interchannel coherence. Indeed, such information provides substantially less relevant information to the artificial neural network and typically has significantly less impact on the resulting audio quality of the generated output multichannel signal.
- the artificial neural network 105 is specifically trained to provide suitable output data by employing a training process e.g. as part of the manufacturing or design phase.
- the result of the training process such as coefficients etc. for the different nodes, may be performed once with the results than being used for all manufactured apparatuses.
- Artificial neural networks are adapted to specific purposes by a training process which are used to adapt/ tune/ modify the weights and other parameters (e.g. bias) of the artificial neural network. It will be appreciated that many different training processes and algorithms are known for training artificial neural networks. Typically, training is based on large training sets where a large number of examples of input data are provided to the network. Further, the output of the artificial neural network is typically (directly or indirectly) compared to an expected or ideal result. A cost function may be generated to reflect the desired outcome of the training process. In a typical scenario known as supervised learning, the cost function often represents the distance between the prediction and the ground truth for a particular input data. Based on the cost function, the weights may be changed and by reiterating the process for the modified weights, the artificial neural network may be adapted towards a state for which the cost function is minimized.
- the neural network may have two different flows of information from input to output (forward pass) and from output to input (backward pass).
- forward pass the data is processed by the neural network as described above while in the backward pass the weights are updated to minimize the cost function.
- backward propagation follows the gradient direction of the cost function landscape.
- Other approaches known for training artificial neural networks include for example Levenberg-Marquardt algorithm, the conjugate gradient method, and the Newton method etc.
- the training processor may use a Parametric Stereo scheme (e.g. in accordance with a suitable standardized approach).
- a frequency- and time-dependent matrix operation e.g. a rotation operation
- a frequency- and time-dependent matrix operation e.g. a rotation operation
- a 2x2 matrix multiplication/ complex value multiplication is applied to the input stereo signals to e.g. substantially align one of the rotated channel signals to have a maximum signal value.
- This channel may be used as the mono-signal and the rotation is typically performed on a frame basis.
- the rotation value may be stored as part of the upmix parametric data (or a parameter allowing this to be determined may be included in the upmix parametric data).
- the opposite rotation may be performed to reconstruct the stereo signal.
- the rotation of the stereo signal results in another stereo signal of which one channel is accordingly aligned with the maximum intensity.
- the other channel is typically discarded in a Parametric Stereo encoder in order to reduce the data rate.
- a decorrelated signal is typically generated at the decoder and used for the upmixing process.
- this second signal may be used as a residual signal for the downmixing as it may represent the information discarded in the encoder, and thus it represents the ideal signal to be reconstructed in the decoder as part of an upmixing process.
- a training processor may from training multichannel audio signals generate training downmix signals and sets of upmix parameters and transient parameters (and possibly a training residual signal).
- This training data may be fed to an decoder audio apparatus comprising the artificial neural network 105 to generate an output multichannel audio signal.
- a cost function is applied to determine a cost value for each training downmix audio signal and/or for the combined set of training downmix audio signals (e.g. an average cost value for the training sets is determined).
- the cost function may include various components.
- the cost function will include at least one component that reflects how close a generated signal is to a reference signal, i.e. a so-called reconstruction error. In some embodiments the cost function will include at least one component that reflects how close a generated signal is to a reference signal from a perceptual point of view.
- the generated multichannel audio signal may be compared to the original multichannel audio signal input to the encoder audio apparatus and a difference measure may be determined and used as a cost function. This process may be generated for all training sets to generate an overall cost function.
- a correlation may be performed with the cost value having a monotonically decreasing value for the increasing correlation value.
- the two signals may be subtracted from each other and a power measure for the difference signal may be used as a cost value. It will be appreciated that many other approaches are available and may be used.
- the cost function generates a cost value that reflects how closely the generated multichannel audio signal match the corresponding original training multichannel audio signals.
- the training processor may adapt the weights of the artificial neural network 105. For example, a back-propagation approach may be used. In particular, the training processor may adjust the weights of the artificial neural network 105 based on the cost value. For example, given the derivative (representing the slope) of the weights with respect to the cost function the weights values are modified to go in the direction of the slope. For a simple/minima account one can refer to the training of the perceptron (single neuron) in case of backward pass of a single data input.
- the process may be iterated until the artificial neural network is considered to be trained. For example, training may be performed for a predetermined number of iterations. As another example, training may be continued until the weights change be less than a predetermined amount. Also very common, a validation stop is implemented where the network is tested again a validation metric and stopped when reaching the expected outcome.
- the audio apparatus(s) may specifically be implemented in one or more suitably programmed processors.
- the artificial neural networks may be implemented in one more such suitably programmed processors.
- the different functional blocks, and in particular the artificial neural networks, may be implemented in separate processors and/or may e.g. be implemented in the same processor.
- An example of a suitable processor is provided in the following.
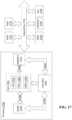
- FIG. 17 is a block diagram illustrating an example processor 1700 according to embodiments of the disclosure.
- Processor 1700 may be used to implement one or more processors implementing an apparatus as previously described or elements thereof (including in particular one more artificial neural network).
- Processor 1700 may be any suitable processor type including, but not limited to, a microprocessor, a microcontroller, a Digital Signal Processor (DSP), a Field ProGrammable Array (FPGA) where the FPGA has been programmed to form a processor, a Graphical Processing Unit (GPU), an Application Specific Integrated Circuit (ASIC) where the ASIC has been designed to form a processor, or a combination thereof.
- DSP Digital Signal Processor
- FPGA Field ProGrammable Array
- GPU Graphical Processing Unit
- ASIC Application Specific Integrated Circuit
- the processor 1700 may include one or more cores 1702.
- the core 1702 may include one or more Arithmetic Logic Units (ALU) 1704.
- ALU Arithmetic Logic Units
- the core 1702 may include a Floating Point Logic Unit (FPLU) 1706 and/or a Digital Signal Processing Unit (DSPU) 1708 in addition to or instead of the ALU 1704.
- FPLU Floating Point Logic Unit
- DSPU Digital Signal Processing Unit
- the processor 1700 may include one or more registers 1712 communicatively coupled to the core 1702.
- the registers 1712 may be implemented using dedicated logic gate circuits (e.g., flip-flops) and/or any memory technology. In some embodiments the registers 1712 may be implemented using static memory.
- the register may provide data, instructions and addresses to the core 1702.
- processor 1700 may include one or more levels of cache memory 1710 communicatively coupled to the core 1702.
- the cache memory 1710 may provide computer-readable instructions to the core 1702 for execution.
- the cache memory 1710 may provide data for processing by the core 1702.
- the computer-readable instructions may have been provided to the cache memory 1710 by a local memory, for example, local memory attached to the external bus 1716.
- the cache memory 1710 may be implemented with any suitable cache memory type, for example, Metal-Oxide Semiconductor (MOS) memory such as Static Random Access Memory (SRAM), Dynamic Random Access Memory (DRAM), and/or any other suitable memory technology.
- MOS Metal-Oxide Semiconductor
- the processor 1700 may include a controller 1714, which may control input to the processor 1700 from other processors and/or components included in a system and/or outputs from the processor 1700 to other processors and/or components included in the system. Controller 1714 may control the data paths in the ALU 1704, FPLU 1706 and/or DSPU 1708. Controller 1714 may be implemented as one or more state machines, data paths and/or dedicated control logic. The gates of controller 1714 may be implemented as standalone gates, FPGA, ASIC or any other suitable technology.
- the registers 1712 and the cache 1710 may communicate with controller 1714 and core 1702 via internal connections 1720A, 1720B, 1720C and 1720D.
- Internal connections may be implemented as a bus, multiplexer, crossbar switch, and/or any other suitable connection technology.
- Inputs and outputs for the processor 1700 may be provided via a bus 1716, which may include one or more conductive lines.
- the bus 1716 may be communicatively coupled to one or more components of processor 1700, for example the controller 1714, cache 1710, and/or register 1712.
- the bus 1716 may be coupled to one or more components of the system.
- the bus 1716 may be coupled to one or more external memories.
- the external memories may include Read Only Memory (ROM) 1732.
- ROM 1732 may be a masked ROM, Electronically Programmable Read Only Memory (EPROM) or any other suitable technology.
- the external memory may include Random Access Memory (RAM) 1733.
- RAM 1733 may be a static RAM, battery backed up static RAM, Dynamic RAM (DRAM) or any other suitable technology.
- the external memory may include Electrically Erasable Programmable Read Only Memory (EEPROM) 1735.
- the external memory may include Flash memory 1734.
- the External memory may include a magnetic storage device such as disc 1736. In some embodiments, the external memories may be included in a system.
- the invention can be implemented in any suitable form including hardware, software, firmware, or any combination of these.
- the invention may optionally be implemented at least partly as computer software running on one or more data processors and/or digital signal processors.
- the elements and components of an embodiment of the invention may be physically, functionally and logically implemented in any suitable way. Indeed the functionality may be implemented in a single unit, in a plurality of units or as part of other functional units. As such, the invention may be implemented in a single unit or may be physically and functionally distributed between different units, circuits and processors.
Landscapes
- Engineering & Computer Science (AREA)
- Physics & Mathematics (AREA)
- Mathematical Physics (AREA)
- Computational Linguistics (AREA)
- Signal Processing (AREA)
- Health & Medical Sciences (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Human Computer Interaction (AREA)
- Acoustics & Sound (AREA)
- Multimedia (AREA)
- Stereophonic System (AREA)
Priority Applications (4)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| EP23199816.2A EP4531038A1 (fr) | 2023-09-26 | 2023-09-26 | Génération d'un signal audio multicanal et signal de données audio représentant un signal audio multicanal |
| CN202480061801.0A CN121925702A (zh) | 2023-09-26 | 2024-09-12 | 多通道音频信号和表示多通道音频信号的音频数据信号的生成 |
| PCT/EP2024/075444 WO2025067884A1 (fr) | 2023-09-26 | 2024-09-12 | Génération d'un signal audio multicanal et signal de données audio représentant un signal audio multicanal |
| TW113136086A TW202516496A (zh) | 2023-09-26 | 2024-09-24 | 多聲道音訊信號及表示多聲道音訊信號之音訊資料信號的產生 |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| EP23199816.2A EP4531038A1 (fr) | 2023-09-26 | 2023-09-26 | Génération d'un signal audio multicanal et signal de données audio représentant un signal audio multicanal |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| EP4531038A1 true EP4531038A1 (fr) | 2025-04-02 |
Family
ID=88204059
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| EP23199816.2A Withdrawn EP4531038A1 (fr) | 2023-09-26 | 2023-09-26 | Génération d'un signal audio multicanal et signal de données audio représentant un signal audio multicanal |
Country Status (4)
| Country | Link |
|---|---|
| EP (1) | EP4531038A1 (fr) |
| CN (1) | CN121925702A (fr) |
| TW (1) | TW202516496A (fr) |
| WO (1) | WO2025067884A1 (fr) |
Citations (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20090319282A1 (en) * | 2004-10-20 | 2009-12-24 | Agere Systems Inc. | Diffuse sound shaping for bcc schemes and the like |
-
2023
- 2023-09-26 EP EP23199816.2A patent/EP4531038A1/fr not_active Withdrawn
-
2024
- 2024-09-12 WO PCT/EP2024/075444 patent/WO2025067884A1/fr active Pending
- 2024-09-12 CN CN202480061801.0A patent/CN121925702A/zh active Pending
- 2024-09-24 TW TW113136086A patent/TW202516496A/zh unknown
Patent Citations (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20090319282A1 (en) * | 2004-10-20 | 2009-12-24 | Agere Systems Inc. | Diffuse sound shaping for bcc schemes and the like |
Non-Patent Citations (9)
| Title |
|---|
| ADAMI, A.HERZOG, A.DISCH, S.HERRE, J.: "Transient-to-noise ratio restoration of coded applause-like signals", IEEE WORKSHOP ON APPLICATIONS OF SIGNAL PROCESSING TO AUDIO AND ACOUSTICS (WASPAA, October 2017 (2017-10-01), pages 349 - 353, XP033264960, DOI: 10.1109/WASPAA.2017.8170053 |
| E. SCHUIJERSJ. BREEBAARTH. PUMHAGENJ. ENGDEGARD: "Low Complexity Parametric Stereo Coding", 116TH AES, BERLIN, GERMANY, 2004 |
| E. SCHUIJERSW. OOMENB. DEN BRINKERJ. BREEBAART: "Advances in Parametric Coding for High-Quality Audio", 114TH AES CONVENTION, AMSTERDAM, THE NETHERLANDS, 2003 |
| JOAN SERR\`A ET AL: "Mono-to-stereo through parametric stereo generation", ARXIV.ORG, CORNELL UNIVERSITY LIBRARY, 201 OLIN LIBRARY CORNELL UNIVERSITY ITHACA, NY 14853, 26 June 2023 (2023-06-26), XP091547784 * |
| KUNTZ ACHIM ET AL: "The Transient Steering Decorrelator Tool in the Upcoming MPEG Unified Speech and Audio Coding Standard", AES CONVENTION 131; OCTOBER 2011, AES, 60 EAST 42ND STREET, ROOM 2520 NEW YORK 10165-2520, USA, 19 October 2011 (2011-10-19), XP040567607 * |
| MARTINRAINER: "Noise power spectral density estimation based on optimal smoothing and minimum statistics", IEEE TRANSACTIONS ON SPEECH AND AUDIO PROCESSING, vol. 9.5, 2001, pages 504 - 512 |
| PARK SU YEON ET AL: "Subband-based upmixing of stereo to 5.1-channel audio signals using deep neural networks", 2016 INTERNATIONAL CONFERENCE ON INFORMATION AND COMMUNICATION TECHNOLOGY CONVERGENCE (ICTC), IEEE, 19 October 2016 (2016-10-19), pages 377 - 380, XP033015750, DOI: 10.1109/ICTC.2016.7763500 * |
| VAN DEN OORDAARON VAN DENSANDER DIELEMANHEIGA ZENKAREN SIMONYANORIOL VINYALSALEX GRAVESNAL KALCHBRENNERANDREW SENIORKORAY KAVUKCUO: "Wavenet: A generative model for raw audio", ARXIV PREPRINT ARXIV: 1609.03499, 2016 |
| XAVIER GLOROTANTOINE BORDESYOSHUA BENGIO: "Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics", PMLR, vol. 15, 2011, pages 315 - 323 |
Also Published As
| Publication number | Publication date |
|---|---|
| CN121925702A (zh) | 2026-04-24 |
| TW202516496A (zh) | 2025-04-16 |
| WO2025067884A1 (fr) | 2025-04-03 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| EP3544005A1 (fr) | Encodeur audio, décodeur audio, procédé de codage audio et procédé de décodage audio de quantification juxtaposée pour codage vocal et audio dans le domaine fréquentiel | |
| Bahrman et al. | A hybrid model for weakly-supervised speech dereverberation | |
| Fan et al. | A regression approach to binaural speech segregation via deep neural network | |
| EP4588042B1 (fr) | Génération de signal audio multicanal | |
| EP4531038A1 (fr) | Génération d'un signal audio multicanal et signal de données audio représentant un signal audio multicanal | |
| US20260088034A1 (en) | Generation of multichannel audio signal and data signal representing a multichannel audio signal | |
| EP4339943A1 (fr) | Génération de signal audio multicanal | |
| Nikunen et al. | Multichannel audio upmixing based on non-negative tensor factorization representation | |
| EP4531039A1 (fr) | Génération d'un signal audio multicanal et signal de données audio représentant un signal audio multicanal | |
| AU2024351984A1 (en) | Generation of multichannel audio signal and audio data signal representing a multichannel audio signal | |
| EP4576071A1 (fr) | Génération de signal audio multicanal | |
| EP4687140A1 (fr) | Appareil de codage audio multicanal et son procédé de fonctionnement | |
| EP4672231A1 (fr) | Génération de signal audio multicanal | |
| Wang et al. | Speech enhancement methods based on binaural cue coding | |
| WO2025132058A1 (fr) | Génération de signal audio multicanal | |
| EP4672229A1 (fr) | Génération et traitement d'un signal de données audio codé | |
| Kulmer et al. | Phase Estimation Fundamentals |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PUAI | Public reference made under article 153(3) epc to a published international application that has entered the european phase |
Free format text: ORIGINAL CODE: 0009012 |
|
| STAA | Information on the status of an ep patent application or granted ep patent |
Free format text: STATUS: THE APPLICATION HAS BEEN PUBLISHED |
|
| AK | Designated contracting states |
Kind code of ref document: A1 Designated state(s): AL AT BE BG CH CY CZ DE DK EE ES FI FR GB GR HR HU IE IS IT LI LT LU LV MC ME MK MT NL NO PL PT RO RS SE SI SK SM TR |
|
| STAA | Information on the status of an ep patent application or granted ep patent |
Free format text: STATUS: THE APPLICATION IS DEEMED TO BE WITHDRAWN |
|
| 18D | Application deemed to be withdrawn |
Effective date: 20251003 |