ES2705686T3 - Anticuerpos monoclonales contra c-Met - Google Patents
Anticuerpos monoclonales contra c-Met Download PDFInfo
- Publication number
- ES2705686T3 ES2705686T3 ES11711490T ES11711490T ES2705686T3 ES 2705686 T3 ES2705686 T3 ES 2705686T3 ES 11711490 T ES11711490 T ES 11711490T ES 11711490 T ES11711490 T ES 11711490T ES 2705686 T3 ES2705686 T3 ES 2705686T3
- Authority
- ES
- Spain
- Prior art keywords
- antibody
- region
- seq
- sequence
- met
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
- 210000004027 cell Anatomy 0.000 claims description 155
- 230000027455 binding Effects 0.000 claims description 127
- 206010028980 Neoplasm Diseases 0.000 claims description 59
- 239000000427 antigen Substances 0.000 claims description 59
- 108091007433 antigens Proteins 0.000 claims description 59
- 102000036639 antigens Human genes 0.000 claims description 59
- 238000000034 method Methods 0.000 claims description 53
- 238000011282 treatment Methods 0.000 claims description 49
- 235000001014 amino acid Nutrition 0.000 claims description 39
- 201000011510 cancer Diseases 0.000 claims description 37
- 239000013598 vector Substances 0.000 claims description 37
- 239000003814 drug Substances 0.000 claims description 31
- 239000012634 fragment Substances 0.000 claims description 30
- 150000001413 amino acids Chemical class 0.000 claims description 28
- 125000003275 alpha amino acid group Chemical group 0.000 claims description 25
- 238000006467 substitution reaction Methods 0.000 claims description 25
- 108060003951 Immunoglobulin Proteins 0.000 claims description 21
- 235000018417 cysteine Nutrition 0.000 claims description 21
- 102000018358 immunoglobulin Human genes 0.000 claims description 21
- XUJNEKJLAYXESH-UHFFFAOYSA-N cysteine Natural products SCC(N)C(O)=O XUJNEKJLAYXESH-UHFFFAOYSA-N 0.000 claims description 19
- 239000012636 effector Substances 0.000 claims description 19
- 239000013604 expression vector Substances 0.000 claims description 18
- 239000002773 nucleotide Substances 0.000 claims description 18
- 125000003729 nucleotide group Chemical group 0.000 claims description 18
- 230000035772 mutation Effects 0.000 claims description 17
- 239000008194 pharmaceutical composition Substances 0.000 claims description 17
- 230000035899 viability Effects 0.000 claims description 16
- 102000009203 Sema domains Human genes 0.000 claims description 13
- 108050000099 Sema domains Proteins 0.000 claims description 13
- 125000000539 amino acid group Chemical group 0.000 claims description 12
- KDXKERNSBIXSRK-UHFFFAOYSA-N Lysine Natural products NCCCCC(N)C(O)=O KDXKERNSBIXSRK-UHFFFAOYSA-N 0.000 claims description 11
- 125000000151 cysteine group Chemical group N[C@@H](CS)C(=O)* 0.000 claims description 10
- 238000004519 manufacturing process Methods 0.000 claims description 10
- 238000000746 purification Methods 0.000 claims description 10
- 238000001514 detection method Methods 0.000 claims description 9
- 230000002401 inhibitory effect Effects 0.000 claims description 9
- 230000015572 biosynthetic process Effects 0.000 claims description 8
- 230000002950 deficient Effects 0.000 claims description 8
- 230000008030 elimination Effects 0.000 claims description 8
- 238000003379 elimination reaction Methods 0.000 claims description 8
- KDXKERNSBIXSRK-YFKPBYRVSA-N L-lysine Chemical compound NCCCC[C@H](N)C(O)=O KDXKERNSBIXSRK-YFKPBYRVSA-N 0.000 claims description 7
- 239000004472 Lysine Substances 0.000 claims description 7
- MTCFGRXMJLQNBG-UHFFFAOYSA-N Serine Natural products OCC(N)C(O)=O MTCFGRXMJLQNBG-UHFFFAOYSA-N 0.000 claims description 7
- ROHFNLRQFUQHCH-YFKPBYRVSA-N L-leucine Chemical compound CC(C)C[C@H](N)C(O)=O ROHFNLRQFUQHCH-YFKPBYRVSA-N 0.000 claims description 6
- AYFVYJQAPQTCCC-UHFFFAOYSA-N Threonine Natural products CC(O)C(N)C(O)=O AYFVYJQAPQTCCC-UHFFFAOYSA-N 0.000 claims description 6
- 239000004473 Threonine Substances 0.000 claims description 6
- 230000033581 fucosylation Effects 0.000 claims description 6
- 230000001419 dependent effect Effects 0.000 claims description 5
- 229940079593 drug Drugs 0.000 claims description 5
- 230000004048 modification Effects 0.000 claims description 5
- 238000012986 modification Methods 0.000 claims description 5
- AYFVYJQAPQTCCC-GBXIJSLDSA-N L-threonine Chemical compound C[C@@H](O)[C@H](N)C(O)=O AYFVYJQAPQTCCC-GBXIJSLDSA-N 0.000 claims description 4
- 239000001963 growth medium Substances 0.000 claims description 4
- 238000005571 anion exchange chromatography Methods 0.000 claims description 3
- 231100000433 cytotoxic Toxicity 0.000 claims description 3
- 230000001472 cytotoxic effect Effects 0.000 claims description 3
- 239000003937 drug carrier Substances 0.000 claims description 3
- 125000003588 lysine group Chemical group [H]N([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])(N([H])[H])C(*)=O 0.000 claims description 3
- 125000000341 threoninyl group Chemical group [H]OC([H])(C([H])([H])[H])C([H])(N([H])[H])C(*)=O 0.000 claims description 3
- 239000004475 Arginine Substances 0.000 claims description 2
- 108091008875 B cell receptors Proteins 0.000 claims description 2
- 108010087819 Fc receptors Proteins 0.000 claims description 2
- 102000009109 Fc receptors Human genes 0.000 claims description 2
- FFEARJCKVFRZRR-BYPYZUCNSA-N L-methionine Chemical compound CSCC[C@H](N)C(O)=O FFEARJCKVFRZRR-BYPYZUCNSA-N 0.000 claims description 2
- ROHFNLRQFUQHCH-UHFFFAOYSA-N Leucine Natural products CC(C)CC(N)C(O)=O ROHFNLRQFUQHCH-UHFFFAOYSA-N 0.000 claims description 2
- 102100033320 Lysosomal Pro-X carboxypeptidase Human genes 0.000 claims description 2
- ODKSFYDXXFIFQN-UHFFFAOYSA-N arginine Natural products OC(=O)C(N)CCCNC(N)=N ODKSFYDXXFIFQN-UHFFFAOYSA-N 0.000 claims description 2
- 125000000637 arginyl group Chemical group N[C@@H](CCCNC(N)=N)C(=O)* 0.000 claims description 2
- 108010057284 lysosomal Pro-X carboxypeptidase Proteins 0.000 claims description 2
- 229930182817 methionine Natural products 0.000 claims description 2
- 102000003745 Hepatocyte Growth Factor Human genes 0.000 description 61
- 108090000100 Hepatocyte Growth Factor Proteins 0.000 description 61
- 108090000623 proteins and genes Proteins 0.000 description 44
- 241000699670 Mus sp. Species 0.000 description 37
- 230000014509 gene expression Effects 0.000 description 33
- 150000007523 nucleic acids Chemical class 0.000 description 33
- 239000003112 inhibitor Substances 0.000 description 32
- 102000005962 receptors Human genes 0.000 description 32
- 108020003175 receptors Proteins 0.000 description 32
- 229940024606 amino acid Drugs 0.000 description 26
- 108020004707 nucleic acids Proteins 0.000 description 26
- 102000039446 nucleic acids Human genes 0.000 description 26
- 102000004169 proteins and genes Human genes 0.000 description 26
- 241000699666 Mus <mouse, genus> Species 0.000 description 25
- 239000003795 chemical substances by application Substances 0.000 description 25
- 235000018102 proteins Nutrition 0.000 description 25
- 230000000694 effects Effects 0.000 description 24
- 208000037265 diseases, disorders, signs and symptoms Diseases 0.000 description 23
- 229940124597 therapeutic agent Drugs 0.000 description 22
- 239000000203 mixture Substances 0.000 description 21
- 239000000556 agonist Substances 0.000 description 19
- 238000002965 ELISA Methods 0.000 description 17
- 241001465754 Metazoa Species 0.000 description 17
- 238000002474 experimental method Methods 0.000 description 17
- 230000005764 inhibitory process Effects 0.000 description 17
- 101100112922 Candida albicans CDR3 gene Proteins 0.000 description 16
- 108010047041 Complementarity Determining Regions Proteins 0.000 description 16
- 229960002433 cysteine Drugs 0.000 description 16
- 230000010056 antibody-dependent cellular cytotoxicity Effects 0.000 description 15
- 239000000872 buffer Substances 0.000 description 14
- -1 carboplatin) Chemical class 0.000 description 14
- 150000001875 compounds Chemical class 0.000 description 14
- 208000035475 disorder Diseases 0.000 description 14
- 108090000765 processed proteins & peptides Proteins 0.000 description 14
- 230000001225 therapeutic effect Effects 0.000 description 14
- 210000004408 hybridoma Anatomy 0.000 description 13
- 210000002966 serum Anatomy 0.000 description 13
- 230000004614 tumor growth Effects 0.000 description 13
- 108700019146 Transgenes Proteins 0.000 description 12
- 238000003556 assay Methods 0.000 description 11
- 230000006870 function Effects 0.000 description 11
- 230000003053 immunization Effects 0.000 description 11
- 230000002829 reductive effect Effects 0.000 description 11
- 230000004913 activation Effects 0.000 description 10
- 230000009089 cytolysis Effects 0.000 description 10
- 239000003446 ligand Substances 0.000 description 10
- NFGXHKASABOEEW-UHFFFAOYSA-N 1-methylethyl 11-methoxy-3,7,11-trimethyl-2,4-dodecadienoate Chemical compound COC(C)(C)CCCC(C)CC=CC(C)=CC(=O)OC(C)C NFGXHKASABOEEW-UHFFFAOYSA-N 0.000 description 9
- MUBZPKHOEPUJKR-UHFFFAOYSA-N Oxalic acid Chemical compound OC(=O)C(O)=O MUBZPKHOEPUJKR-UHFFFAOYSA-N 0.000 description 9
- 239000005557 antagonist Substances 0.000 description 9
- 230000007423 decrease Effects 0.000 description 9
- 201000010099 disease Diseases 0.000 description 9
- 210000004602 germ cell Anatomy 0.000 description 9
- 238000011534 incubation Methods 0.000 description 9
- 102000004196 processed proteins & peptides Human genes 0.000 description 9
- 230000035755 proliferation Effects 0.000 description 9
- 238000012360 testing method Methods 0.000 description 9
- 238000002877 time resolved fluorescence resonance energy transfer Methods 0.000 description 9
- 210000004881 tumor cell Anatomy 0.000 description 9
- 108020004705 Codon Proteins 0.000 description 8
- FAPWRFPIFSIZLT-UHFFFAOYSA-M Sodium chloride Chemical compound [Na+].[Cl-] FAPWRFPIFSIZLT-UHFFFAOYSA-M 0.000 description 8
- OHDRQQURAXLVGJ-HLVWOLMTSA-N azane;(2e)-3-ethyl-2-[(e)-(3-ethyl-6-sulfo-1,3-benzothiazol-2-ylidene)hydrazinylidene]-1,3-benzothiazole-6-sulfonic acid Chemical compound [NH4+].[NH4+].S/1C2=CC(S([O-])(=O)=O)=CC=C2N(CC)C\1=N/N=C1/SC2=CC(S([O-])(=O)=O)=CC=C2N1CC OHDRQQURAXLVGJ-HLVWOLMTSA-N 0.000 description 8
- 238000006243 chemical reaction Methods 0.000 description 8
- 238000010790 dilution Methods 0.000 description 8
- 239000012895 dilution Substances 0.000 description 8
- 238000002649 immunization Methods 0.000 description 8
- 238000000338 in vitro Methods 0.000 description 8
- 239000012528 membrane Substances 0.000 description 8
- 230000026731 phosphorylation Effects 0.000 description 8
- 238000006366 phosphorylation reaction Methods 0.000 description 8
- 239000013612 plasmid Substances 0.000 description 8
- 239000013641 positive control Substances 0.000 description 8
- 238000007920 subcutaneous administration Methods 0.000 description 8
- 238000011830 transgenic mouse model Methods 0.000 description 8
- 108091035707 Consensus sequence Proteins 0.000 description 7
- 102000004127 Cytokines Human genes 0.000 description 7
- 108090000695 Cytokines Proteins 0.000 description 7
- 108010021625 Immunoglobulin Fragments Proteins 0.000 description 7
- 102000008394 Immunoglobulin Fragments Human genes 0.000 description 7
- 241000699660 Mus musculus Species 0.000 description 7
- 238000011579 SCID mouse model Methods 0.000 description 7
- 238000005516 engineering process Methods 0.000 description 7
- 238000002360 preparation method Methods 0.000 description 7
- 230000009467 reduction Effects 0.000 description 7
- 230000004044 response Effects 0.000 description 7
- 230000009261 transgenic effect Effects 0.000 description 7
- 238000005406 washing Methods 0.000 description 7
- FDKXTQMXEQVLRF-ZHACJKMWSA-N (E)-dacarbazine Chemical compound CN(C)\N=N\c1[nH]cnc1C(N)=O FDKXTQMXEQVLRF-ZHACJKMWSA-N 0.000 description 6
- 108091032973 (ribonucleotides)n+m Proteins 0.000 description 6
- 239000012114 Alexa Fluor 647 Substances 0.000 description 6
- 241000283707 Capra Species 0.000 description 6
- 206010073140 Clear cell sarcoma of soft tissue Diseases 0.000 description 6
- 108020004414 DNA Proteins 0.000 description 6
- PEDCQBHIVMGVHV-UHFFFAOYSA-N Glycerine Chemical compound OCC(O)CO PEDCQBHIVMGVHV-UHFFFAOYSA-N 0.000 description 6
- 241000282560 Macaca mulatta Species 0.000 description 6
- NWIBSHFKIJFRCO-WUDYKRTCSA-N Mytomycin Chemical compound C1N2C(C(C(C)=C(N)C3=O)=O)=C3[C@@H](COC(N)=O)[C@@]2(OC)[C@@H]2[C@H]1N2 NWIBSHFKIJFRCO-WUDYKRTCSA-N 0.000 description 6
- 229920001213 Polysorbate 20 Polymers 0.000 description 6
- 230000033115 angiogenesis Effects 0.000 description 6
- 230000006907 apoptotic process Effects 0.000 description 6
- 230000000903 blocking effect Effects 0.000 description 6
- 201000000292 clear cell sarcoma Diseases 0.000 description 6
- 238000010367 cloning Methods 0.000 description 6
- 238000000576 coating method Methods 0.000 description 6
- 239000002299 complementary DNA Substances 0.000 description 6
- 230000021615 conjugation Effects 0.000 description 6
- 238000012217 deletion Methods 0.000 description 6
- 230000037430 deletion Effects 0.000 description 6
- 230000012010 growth Effects 0.000 description 6
- 239000000463 material Substances 0.000 description 6
- 239000002609 medium Substances 0.000 description 6
- 239000013642 negative control Substances 0.000 description 6
- 239000000256 polyoxyethylene sorbitan monolaurate Substances 0.000 description 6
- 235000010486 polyoxyethylene sorbitan monolaurate Nutrition 0.000 description 6
- 238000002415 sodium dodecyl sulfate polyacrylamide gel electrophoresis Methods 0.000 description 6
- 239000000243 solution Substances 0.000 description 6
- 241000894007 species Species 0.000 description 6
- 238000012413 Fluorescence activated cell sorting analysis Methods 0.000 description 5
- 108010054477 Immunoglobulin Fab Fragments Proteins 0.000 description 5
- 102000001706 Immunoglobulin Fab Fragments Human genes 0.000 description 5
- 238000004458 analytical method Methods 0.000 description 5
- 239000011324 bead Substances 0.000 description 5
- 230000005754 cellular signaling Effects 0.000 description 5
- 230000008859 change Effects 0.000 description 5
- 239000003153 chemical reaction reagent Substances 0.000 description 5
- 239000011248 coating agent Substances 0.000 description 5
- 230000003111 delayed effect Effects 0.000 description 5
- 230000002068 genetic effect Effects 0.000 description 5
- 230000036541 health Effects 0.000 description 5
- 238000001802 infusion Methods 0.000 description 5
- 238000003780 insertion Methods 0.000 description 5
- 230000037431 insertion Effects 0.000 description 5
- 102000006495 integrins Human genes 0.000 description 5
- 108010044426 integrins Proteins 0.000 description 5
- 230000003834 intracellular effect Effects 0.000 description 5
- 238000012423 maintenance Methods 0.000 description 5
- 229920001184 polypeptide Polymers 0.000 description 5
- 239000000047 product Substances 0.000 description 5
- 239000011780 sodium chloride Substances 0.000 description 5
- 239000006228 supernatant Substances 0.000 description 5
- 210000001519 tissue Anatomy 0.000 description 5
- 229910052720 vanadium Inorganic materials 0.000 description 5
- XLYOFNOQVPJJNP-UHFFFAOYSA-N water Substances O XLYOFNOQVPJJNP-UHFFFAOYSA-N 0.000 description 5
- 230000003442 weekly effect Effects 0.000 description 5
- 108010022366 Carcinoembryonic Antigen Proteins 0.000 description 4
- 102100025475 Carcinoembryonic antigen-related cell adhesion molecule 5 Human genes 0.000 description 4
- AOJJSUZBOXZQNB-TZSSRYMLSA-N Doxorubicin Chemical compound O([C@H]1C[C@@](O)(CC=2C(O)=C3C(=O)C=4C=CC=C(C=4C(=O)C3=C(O)C=21)OC)C(=O)CO)[C@H]1C[C@H](N)[C@H](O)[C@H](C)O1 AOJJSUZBOXZQNB-TZSSRYMLSA-N 0.000 description 4
- GHASVSINZRGABV-UHFFFAOYSA-N Fluorouracil Chemical compound FC1=CNC(=O)NC1=O GHASVSINZRGABV-UHFFFAOYSA-N 0.000 description 4
- 108700012941 GNRH1 Proteins 0.000 description 4
- 241000287828 Gallus gallus Species 0.000 description 4
- 239000000579 Gonadotropin-Releasing Hormone Substances 0.000 description 4
- 208000008839 Kidney Neoplasms Diseases 0.000 description 4
- GQYIWUVLTXOXAJ-UHFFFAOYSA-N Lomustine Chemical compound ClCCN(N=O)C(=O)NC1CCCCC1 GQYIWUVLTXOXAJ-UHFFFAOYSA-N 0.000 description 4
- 108091028043 Nucleic acid sequence Proteins 0.000 description 4
- 239000002202 Polyethylene glycol Substances 0.000 description 4
- 239000012980 RPMI-1640 medium Substances 0.000 description 4
- 240000004808 Saccharomyces cerevisiae Species 0.000 description 4
- 108010019530 Vascular Endothelial Growth Factors Proteins 0.000 description 4
- 102000005789 Vascular Endothelial Growth Factors Human genes 0.000 description 4
- RJURFGZVJUQBHK-UHFFFAOYSA-N actinomycin D Natural products CC1OC(=O)C(C(C)C)N(C)C(=O)CN(C)C(=O)C2CCCN2C(=O)C(C(C)C)NC(=O)C1NC(=O)C1=C(N)C(=O)C(C)=C2OC(C(C)=CC=C3C(=O)NC4C(=O)NC(C(N5CCCC5C(=O)N(C)CC(=O)N(C)C(C(C)C)C(=O)OC4C)=O)C(C)C)=C3N=C21 RJURFGZVJUQBHK-UHFFFAOYSA-N 0.000 description 4
- 239000004480 active ingredient Substances 0.000 description 4
- 230000004075 alteration Effects 0.000 description 4
- 230000002491 angiogenic effect Effects 0.000 description 4
- 230000001093 anti-cancer Effects 0.000 description 4
- 230000009830 antibody antigen interaction Effects 0.000 description 4
- 239000003963 antioxidant agent Substances 0.000 description 4
- 235000006708 antioxidants Nutrition 0.000 description 4
- 210000004978 chinese hamster ovary cell Anatomy 0.000 description 4
- 230000024203 complement activation Effects 0.000 description 4
- 238000010276 construction Methods 0.000 description 4
- 231100000599 cytotoxic agent Toxicity 0.000 description 4
- 238000006471 dimerization reaction Methods 0.000 description 4
- 239000006185 dispersion Substances 0.000 description 4
- 238000010494 dissociation reaction Methods 0.000 description 4
- 230000005593 dissociations Effects 0.000 description 4
- 102000052116 epidermal growth factor receptor activity proteins Human genes 0.000 description 4
- 108700015053 epidermal growth factor receptor activity proteins Proteins 0.000 description 4
- 210000002919 epithelial cell Anatomy 0.000 description 4
- 239000003102 growth factor Substances 0.000 description 4
- 230000003054 hormonal effect Effects 0.000 description 4
- 230000001900 immune effect Effects 0.000 description 4
- 229940072221 immunoglobulins Drugs 0.000 description 4
- 238000001727 in vivo Methods 0.000 description 4
- 230000003993 interaction Effects 0.000 description 4
- 210000004962 mammalian cell Anatomy 0.000 description 4
- 239000003550 marker Substances 0.000 description 4
- 230000007246 mechanism Effects 0.000 description 4
- 201000001441 melanoma Diseases 0.000 description 4
- GLVAUDGFNGKCSF-UHFFFAOYSA-N mercaptopurine Chemical compound S=C1NC=NC2=C1NC=N2 GLVAUDGFNGKCSF-UHFFFAOYSA-N 0.000 description 4
- 229960004857 mitomycin Drugs 0.000 description 4
- YOHYSYJDKVYCJI-UHFFFAOYSA-N n-[3-[[6-[3-(trifluoromethyl)anilino]pyrimidin-4-yl]amino]phenyl]cyclopropanecarboxamide Chemical compound FC(F)(F)C1=CC=CC(NC=2N=CN=C(NC=3C=C(NC(=O)C4CC4)C=CC=3)C=2)=C1 YOHYSYJDKVYCJI-UHFFFAOYSA-N 0.000 description 4
- 229940127084 other anti-cancer agent Drugs 0.000 description 4
- 229920001223 polyethylene glycol Polymers 0.000 description 4
- 230000005180 public health Effects 0.000 description 4
- 238000001959 radiotherapy Methods 0.000 description 4
- 230000001105 regulatory effect Effects 0.000 description 4
- 239000000523 sample Substances 0.000 description 4
- 239000002904 solvent Substances 0.000 description 4
- 235000000346 sugar Nutrition 0.000 description 4
- 230000004083 survival effect Effects 0.000 description 4
- 238000002560 therapeutic procedure Methods 0.000 description 4
- WYWHKKSPHMUBEB-UHFFFAOYSA-N tioguanine Chemical compound N1C(N)=NC(=S)C2=C1N=CN2 WYWHKKSPHMUBEB-UHFFFAOYSA-N 0.000 description 4
- 239000003053 toxin Substances 0.000 description 4
- 231100000765 toxin Toxicity 0.000 description 4
- 108700012359 toxins Proteins 0.000 description 4
- 238000013414 tumor xenograft model Methods 0.000 description 4
- 229940121358 tyrosine kinase inhibitor Drugs 0.000 description 4
- STQGQHZAVUOBTE-UHFFFAOYSA-N 7-Cyan-hept-2t-en-4,6-diinsaeure Natural products C1=2C(O)=C3C(=O)C=4C(OC)=CC=CC=4C(=O)C3=C(O)C=2CC(O)(C(C)=O)CC1OC1CC(N)C(O)C(C)O1 STQGQHZAVUOBTE-UHFFFAOYSA-N 0.000 description 3
- WEVYAHXRMPXWCK-UHFFFAOYSA-N Acetonitrile Chemical compound CC#N WEVYAHXRMPXWCK-UHFFFAOYSA-N 0.000 description 3
- 102000019034 Chemokines Human genes 0.000 description 3
- 108010012236 Chemokines Proteins 0.000 description 3
- VYZAMTAEIAYCRO-BJUDXGSMSA-N Chromium-51 Chemical compound [51Cr] VYZAMTAEIAYCRO-BJUDXGSMSA-N 0.000 description 3
- 206010009944 Colon cancer Diseases 0.000 description 3
- 208000001333 Colorectal Neoplasms Diseases 0.000 description 3
- SHZGCJCMOBCMKK-UHFFFAOYSA-N D-mannomethylose Natural products CC1OC(O)C(O)C(O)C1O SHZGCJCMOBCMKK-UHFFFAOYSA-N 0.000 description 3
- 108010092160 Dactinomycin Proteins 0.000 description 3
- 102100031940 Epithelial cell adhesion molecule Human genes 0.000 description 3
- LFQSCWFLJHTTHZ-UHFFFAOYSA-N Ethanol Chemical compound CCO LFQSCWFLJHTTHZ-UHFFFAOYSA-N 0.000 description 3
- 241000282326 Felis catus Species 0.000 description 3
- PNNNRSAQSRJVSB-SLPGGIOYSA-N Fucose Natural products C[C@H](O)[C@@H](O)[C@H](O)[C@H](O)C=O PNNNRSAQSRJVSB-SLPGGIOYSA-N 0.000 description 3
- 108700005091 Immunoglobulin Genes Proteins 0.000 description 3
- 108010065805 Interleukin-12 Proteins 0.000 description 3
- 102000013462 Interleukin-12 Human genes 0.000 description 3
- SHZGCJCMOBCMKK-DHVFOXMCSA-N L-fucopyranose Chemical compound C[C@@H]1OC(O)[C@@H](O)[C@H](O)[C@@H]1O SHZGCJCMOBCMKK-DHVFOXMCSA-N 0.000 description 3
- 239000005517 L01XE01 - Imatinib Substances 0.000 description 3
- 239000002136 L01XE07 - Lapatinib Substances 0.000 description 3
- 206010027476 Metastases Diseases 0.000 description 3
- 108010008707 Mucin-1 Proteins 0.000 description 3
- 102000007298 Mucin-1 Human genes 0.000 description 3
- 206010061902 Pancreatic neoplasm Diseases 0.000 description 3
- 108091000080 Phosphotransferase Proteins 0.000 description 3
- DNIAPMSPPWPWGF-UHFFFAOYSA-N Propylene glycol Chemical compound CC(O)CO DNIAPMSPPWPWGF-UHFFFAOYSA-N 0.000 description 3
- 206010060862 Prostate cancer Diseases 0.000 description 3
- 108010072866 Prostate-Specific Antigen Proteins 0.000 description 3
- 102100038358 Prostate-specific antigen Human genes 0.000 description 3
- 208000000236 Prostatic Neoplasms Diseases 0.000 description 3
- 102000004022 Protein-Tyrosine Kinases Human genes 0.000 description 3
- 108090000412 Protein-Tyrosine Kinases Proteins 0.000 description 3
- 102000008022 Proto-Oncogene Proteins c-met Human genes 0.000 description 3
- 108010089836 Proto-Oncogene Proteins c-met Proteins 0.000 description 3
- 206010038389 Renal cancer Diseases 0.000 description 3
- PLXBWHJQWKZRKG-UHFFFAOYSA-N Resazurin Chemical compound C1=CC(=O)C=C2OC3=CC(O)=CC=C3[N+]([O-])=C21 PLXBWHJQWKZRKG-UHFFFAOYSA-N 0.000 description 3
- 102000006382 Ribonucleases Human genes 0.000 description 3
- 108010083644 Ribonucleases Proteins 0.000 description 3
- 102100024598 Tumor necrosis factor ligand superfamily member 10 Human genes 0.000 description 3
- 101710097160 Tumor necrosis factor ligand superfamily member 10 Proteins 0.000 description 3
- JXLYSJRDGCGARV-WWYNWVTFSA-N Vinblastine Natural products O=C(O[C@H]1[C@](O)(C(=O)OC)[C@@H]2N(C)c3c(cc(c(OC)c3)[C@]3(C(=O)OC)c4[nH]c5c(c4CCN4C[C@](O)(CC)C[C@H](C3)C4)cccc5)[C@@]32[C@H]2[C@@]1(CC)C=CCN2CC3)C JXLYSJRDGCGARV-WWYNWVTFSA-N 0.000 description 3
- 239000002671 adjuvant Substances 0.000 description 3
- 238000001042 affinity chromatography Methods 0.000 description 3
- 229950010817 alvocidib Drugs 0.000 description 3
- BIIVYFLTOXDAOV-YVEFUNNKSA-N alvocidib Chemical compound O[C@@H]1CN(C)CC[C@@H]1C1=C(O)C=C(O)C2=C1OC(C=1C(=CC=CC=1)Cl)=CC2=O BIIVYFLTOXDAOV-YVEFUNNKSA-N 0.000 description 3
- 239000003242 anti bacterial agent Substances 0.000 description 3
- 230000002280 anti-androgenic effect Effects 0.000 description 3
- 230000001772 anti-angiogenic effect Effects 0.000 description 3
- 230000000692 anti-sense effect Effects 0.000 description 3
- 230000000890 antigenic effect Effects 0.000 description 3
- 230000003305 autocrine Effects 0.000 description 3
- 210000003719 b-lymphocyte Anatomy 0.000 description 3
- 229960000397 bevacizumab Drugs 0.000 description 3
- 229960000074 biopharmaceutical Drugs 0.000 description 3
- 239000006143 cell culture medium Substances 0.000 description 3
- 230000010261 cell growth Effects 0.000 description 3
- 230000001413 cellular effect Effects 0.000 description 3
- 229960005395 cetuximab Drugs 0.000 description 3
- 239000002738 chelating agent Substances 0.000 description 3
- KRKNYBCHXYNGOX-UHFFFAOYSA-N citric acid Chemical compound OC(=O)CC(O)(C(O)=O)CC(O)=O KRKNYBCHXYNGOX-UHFFFAOYSA-N 0.000 description 3
- 230000004540 complement-dependent cytotoxicity Effects 0.000 description 3
- 239000012228 culture supernatant Substances 0.000 description 3
- 239000002619 cytotoxin Substances 0.000 description 3
- STQGQHZAVUOBTE-VGBVRHCVSA-N daunorubicin Chemical compound O([C@H]1C[C@@](O)(CC=2C(O)=C3C(=O)C=4C=CC=C(C=4C(=O)C3=C(O)C=21)OC)C(C)=O)[C@H]1C[C@H](N)[C@H](O)[C@H](C)O1 STQGQHZAVUOBTE-VGBVRHCVSA-N 0.000 description 3
- 229940121647 egfr inhibitor Drugs 0.000 description 3
- 230000005284 excitation Effects 0.000 description 3
- 238000001943 fluorescence-activated cell sorting Methods 0.000 description 3
- 229960002949 fluorouracil Drugs 0.000 description 3
- 229960005277 gemcitabine Drugs 0.000 description 3
- SDUQYLNIPVEERB-QPPQHZFASA-N gemcitabine Chemical compound O=C1N=C(N)C=CN1[C@H]1C(F)(F)[C@H](O)[C@@H](CO)O1 SDUQYLNIPVEERB-QPPQHZFASA-N 0.000 description 3
- 208000005017 glioblastoma Diseases 0.000 description 3
- 239000000833 heterodimer Substances 0.000 description 3
- KTUFNOKKBVMGRW-UHFFFAOYSA-N imatinib Chemical compound C1CN(C)CCN1CC1=CC=C(C(=O)NC=2C=C(NC=3N=C(C=CN=3)C=3C=NC=CC=3)C(C)=CC=2)C=C1 KTUFNOKKBVMGRW-UHFFFAOYSA-N 0.000 description 3
- RAXXELZNTBOGNW-UHFFFAOYSA-N imidazole Natural products C1=CNC=N1 RAXXELZNTBOGNW-UHFFFAOYSA-N 0.000 description 3
- 229940127121 immunoconjugate Drugs 0.000 description 3
- 230000001939 inductive effect Effects 0.000 description 3
- 239000004615 ingredient Substances 0.000 description 3
- 229940117681 interleukin-12 Drugs 0.000 description 3
- 201000010982 kidney cancer Diseases 0.000 description 3
- 229960004891 lapatinib Drugs 0.000 description 3
- BCFGMOOMADDAQU-UHFFFAOYSA-N lapatinib Chemical compound O1C(CNCCS(=O)(=O)C)=CC=C1C1=CC=C(N=CN=C2NC=3C=C(Cl)C(OCC=4C=C(F)C=CC=4)=CC=3)C2=C1 BCFGMOOMADDAQU-UHFFFAOYSA-N 0.000 description 3
- 238000012417 linear regression Methods 0.000 description 3
- 238000011068 loading method Methods 0.000 description 3
- 239000006166 lysate Substances 0.000 description 3
- 238000004949 mass spectrometry Methods 0.000 description 3
- CFCUWKMKBJTWLW-BKHRDMLASA-N mithramycin Chemical compound O([C@@H]1C[C@@H](O[C@H](C)[C@H]1O)OC=1C=C2C=C3C[C@H]([C@@H](C(=O)C3=C(O)C2=C(O)C=1C)O[C@@H]1O[C@H](C)[C@@H](O)[C@H](O[C@@H]2O[C@H](C)[C@H](O)[C@H](O[C@@H]3O[C@H](C)[C@@H](O)[C@@](C)(O)C3)C2)C1)[C@H](OC)C(=O)[C@@H](O)[C@@H](C)O)[C@H]1C[C@@H](O)[C@H](O)[C@@H](C)O1 CFCUWKMKBJTWLW-BKHRDMLASA-N 0.000 description 3
- KKZJGLLVHKMTCM-UHFFFAOYSA-N mitoxantrone Chemical compound O=C1C2=C(O)C=CC(O)=C2C(=O)C2=C1C(NCCNCCO)=CC=C2NCCNCCO KKZJGLLVHKMTCM-UHFFFAOYSA-N 0.000 description 3
- 229960001156 mitoxantrone Drugs 0.000 description 3
- 208000002154 non-small cell lung carcinoma Diseases 0.000 description 3
- 235000006408 oxalic acid Nutrition 0.000 description 3
- 201000002528 pancreatic cancer Diseases 0.000 description 3
- 229960001972 panitumumab Drugs 0.000 description 3
- 230000036961 partial effect Effects 0.000 description 3
- 210000003819 peripheral blood mononuclear cell Anatomy 0.000 description 3
- 238000002823 phage display Methods 0.000 description 3
- 102000020233 phosphotransferase Human genes 0.000 description 3
- 229960003171 plicamycin Drugs 0.000 description 3
- 229920000642 polymer Polymers 0.000 description 3
- 239000000843 powder Substances 0.000 description 3
- 239000003755 preservative agent Substances 0.000 description 3
- 230000002265 prevention Effects 0.000 description 3
- 230000008569 process Effects 0.000 description 3
- 238000000159 protein binding assay Methods 0.000 description 3
- 230000005855 radiation Effects 0.000 description 3
- 239000011347 resin Substances 0.000 description 3
- 229920005989 resin Polymers 0.000 description 3
- 230000000717 retained effect Effects 0.000 description 3
- 230000002441 reversible effect Effects 0.000 description 3
- BTIHMVBBUGXLCJ-OAHLLOKOSA-N seliciclib Chemical compound C=12N=CN(C(C)C)C2=NC(N[C@@H](CO)CC)=NC=1NCC1=CC=CC=C1 BTIHMVBBUGXLCJ-OAHLLOKOSA-N 0.000 description 3
- 230000019491 signal transduction Effects 0.000 description 3
- 230000011664 signaling Effects 0.000 description 3
- 150000008163 sugars Chemical class 0.000 description 3
- 239000003826 tablet Substances 0.000 description 3
- 231100000331 toxic Toxicity 0.000 description 3
- 230000002588 toxic effect Effects 0.000 description 3
- 238000012546 transfer Methods 0.000 description 3
- 230000010474 transient expression Effects 0.000 description 3
- 230000005740 tumor formation Effects 0.000 description 3
- 208000029729 tumor suppressor gene on chromosome 11 Diseases 0.000 description 3
- 239000005483 tyrosine kinase inhibitor Substances 0.000 description 3
- 239000003981 vehicle Substances 0.000 description 3
- 231100000747 viability assay Toxicity 0.000 description 3
- 238000003026 viability measurement method Methods 0.000 description 3
- 229960003048 vinblastine Drugs 0.000 description 3
- JXLYSJRDGCGARV-XQKSVPLYSA-N vincaleukoblastine Chemical compound C([C@@H](C[C@]1(C(=O)OC)C=2C(=CC3=C([C@]45[C@H]([C@@]([C@H](OC(C)=O)[C@]6(CC)C=CCN([C@H]56)CC4)(O)C(=O)OC)N3C)C=2)OC)C[C@@](C2)(O)CC)N2CCC2=C1NC1=CC=CC=C21 JXLYSJRDGCGARV-XQKSVPLYSA-N 0.000 description 3
- 238000001262 western blot Methods 0.000 description 3
- DEQANNDTNATYII-OULOTJBUSA-N (4r,7s,10s,13r,16s,19r)-10-(4-aminobutyl)-19-[[(2r)-2-amino-3-phenylpropanoyl]amino]-16-benzyl-n-[(2r,3r)-1,3-dihydroxybutan-2-yl]-7-[(1r)-1-hydroxyethyl]-13-(1h-indol-3-ylmethyl)-6,9,12,15,18-pentaoxo-1,2-dithia-5,8,11,14,17-pentazacycloicosane-4-carboxa Chemical compound C([C@@H](N)C(=O)N[C@H]1CSSC[C@H](NC(=O)[C@H]([C@@H](C)O)NC(=O)[C@H](CCCCN)NC(=O)[C@@H](CC=2C3=CC=CC=C3NC=2)NC(=O)[C@H](CC=2C=CC=CC=2)NC1=O)C(=O)N[C@H](CO)[C@H](O)C)C1=CC=CC=C1 DEQANNDTNATYII-OULOTJBUSA-N 0.000 description 2
- IAKHMKGGTNLKSZ-INIZCTEOSA-N (S)-colchicine Chemical compound C1([C@@H](NC(C)=O)CC2)=CC(=O)C(OC)=CC=C1C1=C2C=C(OC)C(OC)=C1OC IAKHMKGGTNLKSZ-INIZCTEOSA-N 0.000 description 2
- VBICKXHEKHSIBG-UHFFFAOYSA-N 1-monostearoylglycerol Chemical compound CCCCCCCCCCCCCCCCCC(=O)OCC(O)CO VBICKXHEKHSIBG-UHFFFAOYSA-N 0.000 description 2
- VSNHCAURESNICA-NJFSPNSNSA-N 1-oxidanylurea Chemical compound N[14C](=O)NO VSNHCAURESNICA-NJFSPNSNSA-N 0.000 description 2
- IIZPXYDJLKNOIY-JXPKJXOSSA-N 1-palmitoyl-2-arachidonoyl-sn-glycero-3-phosphocholine Chemical compound CCCCCCCCCCCCCCCC(=O)OC[C@H](COP([O-])(=O)OCC[N+](C)(C)C)OC(=O)CCC\C=C/C\C=C/C\C=C/C\C=C/CCCCC IIZPXYDJLKNOIY-JXPKJXOSSA-N 0.000 description 2
- UEJJHQNACJXSKW-UHFFFAOYSA-N 2-(2,6-dioxopiperidin-3-yl)-1H-isoindole-1,3(2H)-dione Chemical compound O=C1C2=CC=CC=C2C(=O)N1C1CCC(=O)NC1=O UEJJHQNACJXSKW-UHFFFAOYSA-N 0.000 description 2
- QKNYBSVHEMOAJP-UHFFFAOYSA-N 2-amino-2-(hydroxymethyl)propane-1,3-diol;hydron;chloride Chemical compound Cl.OCC(N)(CO)CO QKNYBSVHEMOAJP-UHFFFAOYSA-N 0.000 description 2
- IZHVBANLECCAGF-UHFFFAOYSA-N 2-hydroxy-3-(octadecanoyloxy)propyl octadecanoate Chemical compound CCCCCCCCCCCCCCCCCC(=O)OCC(O)COC(=O)CCCCCCCCCCCCCCCCC IZHVBANLECCAGF-UHFFFAOYSA-N 0.000 description 2
- ZTOJFFHGPLIVKC-UHFFFAOYSA-N 3-ethyl-2-[(3-ethyl-6-sulfo-1,3-benzothiazol-2-ylidene)hydrazinylidene]-1,3-benzothiazole-6-sulfonic acid Chemical compound S1C2=CC(S(O)(=O)=O)=CC=C2N(CC)C1=NN=C1SC2=CC(S(O)(=O)=O)=CC=C2N1CC ZTOJFFHGPLIVKC-UHFFFAOYSA-N 0.000 description 2
- PBCZSGKMGDDXIJ-HQCWYSJUSA-N 7-hydroxystaurosporine Chemical compound N([C@H](O)C1=C2C3=CC=CC=C3N3C2=C24)C(=O)C1=C2C1=CC=CC=C1N4[C@H]1C[C@@H](NC)[C@@H](OC)[C@]3(C)O1 PBCZSGKMGDDXIJ-HQCWYSJUSA-N 0.000 description 2
- 206010069754 Acquired gene mutation Diseases 0.000 description 2
- 102100022900 Actin, cytoplasmic 1 Human genes 0.000 description 2
- 108010085238 Actins Proteins 0.000 description 2
- 208000031261 Acute myeloid leukaemia Diseases 0.000 description 2
- 208000009746 Adult T-Cell Leukemia-Lymphoma Diseases 0.000 description 2
- 208000016683 Adult T-cell leukemia/lymphoma Diseases 0.000 description 2
- 102100021266 Alpha-(1,6)-fucosyltransferase Human genes 0.000 description 2
- 102400000068 Angiostatin Human genes 0.000 description 2
- 108010079709 Angiostatins Proteins 0.000 description 2
- CIWBSHSKHKDKBQ-JLAZNSOCSA-N Ascorbic acid Chemical compound OC[C@H](O)[C@H]1OC(=O)C(O)=C1O CIWBSHSKHKDKBQ-JLAZNSOCSA-N 0.000 description 2
- 102000015790 Asparaginase Human genes 0.000 description 2
- 108010024976 Asparaginase Proteins 0.000 description 2
- 206010003571 Astrocytoma Diseases 0.000 description 2
- 208000032791 BCR-ABL1 positive chronic myelogenous leukemia Diseases 0.000 description 2
- 206010005003 Bladder cancer Diseases 0.000 description 2
- 206010006187 Breast cancer Diseases 0.000 description 2
- 208000026310 Breast neoplasm Diseases 0.000 description 2
- COVZYZSDYWQREU-UHFFFAOYSA-N Busulfan Chemical compound CS(=O)(=O)OCCCCOS(C)(=O)=O COVZYZSDYWQREU-UHFFFAOYSA-N 0.000 description 2
- 241000208199 Buxus sempervirens Species 0.000 description 2
- DLGOEMSEDOSKAD-UHFFFAOYSA-N Carmustine Chemical compound ClCCNC(=O)N(N=O)CCCl DLGOEMSEDOSKAD-UHFFFAOYSA-N 0.000 description 2
- 108090000994 Catalytic RNA Proteins 0.000 description 2
- 102000053642 Catalytic RNA Human genes 0.000 description 2
- 206010008342 Cervix carcinoma Diseases 0.000 description 2
- 208000010833 Chronic myeloid leukaemia Diseases 0.000 description 2
- PTOAARAWEBMLNO-KVQBGUIXSA-N Cladribine Chemical compound C1=NC=2C(N)=NC(Cl)=NC=2N1[C@H]1C[C@H](O)[C@@H](CO)O1 PTOAARAWEBMLNO-KVQBGUIXSA-N 0.000 description 2
- 108091026890 Coding region Proteins 0.000 description 2
- CMSMOCZEIVJLDB-UHFFFAOYSA-N Cyclophosphamide Chemical compound ClCCN(CCCl)P1(=O)NCCCO1 CMSMOCZEIVJLDB-UHFFFAOYSA-N 0.000 description 2
- UHDGCWIWMRVCDJ-CCXZUQQUSA-N Cytarabine Chemical compound O=C1N=C(N)C=CN1[C@H]1[C@@H](O)[C@H](O)[C@@H](CO)O1 UHDGCWIWMRVCDJ-CCXZUQQUSA-N 0.000 description 2
- 101710112752 Cytotoxin Proteins 0.000 description 2
- FBPFZTCFMRRESA-FSIIMWSLSA-N D-Glucitol Natural products OC[C@H](O)[C@H](O)[C@@H](O)[C@H](O)CO FBPFZTCFMRRESA-FSIIMWSLSA-N 0.000 description 2
- FBPFZTCFMRRESA-JGWLITMVSA-N D-glucitol Chemical compound OC[C@H](O)[C@@H](O)[C@H](O)[C@H](O)CO FBPFZTCFMRRESA-JGWLITMVSA-N 0.000 description 2
- 108010053187 Diphtheria Toxin Proteins 0.000 description 2
- 102000016607 Diphtheria Toxin Human genes 0.000 description 2
- 239000006144 Dulbecco’s modified Eagle's medium Substances 0.000 description 2
- KCXVZYZYPLLWCC-UHFFFAOYSA-N EDTA Chemical compound OC(=O)CN(CC(O)=O)CCN(CC(O)=O)CC(O)=O KCXVZYZYPLLWCC-UHFFFAOYSA-N 0.000 description 2
- 101150029707 ERBB2 gene Proteins 0.000 description 2
- 241000196324 Embryophyta Species 0.000 description 2
- 206010014733 Endometrial cancer Diseases 0.000 description 2
- 206010014759 Endometrial neoplasm Diseases 0.000 description 2
- 108010066687 Epithelial Cell Adhesion Molecule Proteins 0.000 description 2
- 208000000461 Esophageal Neoplasms Diseases 0.000 description 2
- 201000008808 Fibrosarcoma Diseases 0.000 description 2
- 208000022072 Gallbladder Neoplasms Diseases 0.000 description 2
- 102000003886 Glycoproteins Human genes 0.000 description 2
- 108090000288 Glycoproteins Proteins 0.000 description 2
- HTTJABKRGRZYRN-UHFFFAOYSA-N Heparin Chemical class OC1C(NC(=O)C)C(O)OC(COS(O)(=O)=O)C1OC1C(OS(O)(=O)=O)C(O)C(OC2C(C(OS(O)(=O)=O)C(OC3C(C(O)C(O)C(O3)C(O)=O)OS(O)(=O)=O)C(CO)O2)NS(O)(=O)=O)C(C(O)=O)O1 HTTJABKRGRZYRN-UHFFFAOYSA-N 0.000 description 2
- 101000819490 Homo sapiens Alpha-(1,6)-fucosyltransferase Proteins 0.000 description 2
- 101000959820 Homo sapiens Interferon alpha-1/13 Proteins 0.000 description 2
- 101001057156 Homo sapiens Melanoma-associated antigen C2 Proteins 0.000 description 2
- 101001012157 Homo sapiens Receptor tyrosine-protein kinase erbB-2 Proteins 0.000 description 2
- DGAQECJNVWCQMB-PUAWFVPOSA-M Ilexoside XXIX Chemical compound C[C@@H]1CC[C@@]2(CC[C@@]3(C(=CC[C@H]4[C@]3(CC[C@@H]5[C@@]4(CC[C@@H](C5(C)C)OS(=O)(=O)[O-])C)C)[C@@H]2[C@]1(C)O)C)C(=O)O[C@H]6[C@@H]([C@H]([C@@H]([C@H](O6)CO)O)O)O.[Na+] DGAQECJNVWCQMB-PUAWFVPOSA-M 0.000 description 2
- 108010067060 Immunoglobulin Variable Region Proteins 0.000 description 2
- 102000017727 Immunoglobulin Variable Region Human genes 0.000 description 2
- 102100040019 Interferon alpha-1/13 Human genes 0.000 description 2
- 208000007766 Kaposi sarcoma Diseases 0.000 description 2
- 125000000998 L-alanino group Chemical group [H]N([*])[C@](C([H])([H])[H])([H])C(=O)O[H] 0.000 description 2
- 125000000393 L-methionino group Chemical group [H]OC(=O)[C@@]([H])(N([H])[*])C([H])([H])C(SC([H])([H])[H])([H])[H] 0.000 description 2
- FBOZXECLQNJBKD-ZDUSSCGKSA-N L-methotrexate Chemical compound C=1N=C2N=C(N)N=C(N)C2=NC=1CN(C)C1=CC=C(C(=O)N[C@@H](CCC(O)=O)C(O)=O)C=C1 FBOZXECLQNJBKD-ZDUSSCGKSA-N 0.000 description 2
- 239000005551 L01XE03 - Erlotinib Substances 0.000 description 2
- 208000018142 Leiomyosarcoma Diseases 0.000 description 2
- 206010058467 Lung neoplasm malignant Diseases 0.000 description 2
- 206010025323 Lymphomas Diseases 0.000 description 2
- 108010010995 MART-1 Antigen Proteins 0.000 description 2
- 208000006644 Malignant Fibrous Histiocytoma Diseases 0.000 description 2
- 102100028389 Melanoma antigen recognized by T-cells 1 Human genes 0.000 description 2
- 102100027252 Melanoma-associated antigen C2 Human genes 0.000 description 2
- 206010027406 Mesothelioma Diseases 0.000 description 2
- VFKZTMPDYBFSTM-KVTDHHQDSA-N Mitobronitol Chemical compound BrC[C@@H](O)[C@@H](O)[C@H](O)[C@H](O)CBr VFKZTMPDYBFSTM-KVTDHHQDSA-N 0.000 description 2
- 229930192392 Mitomycin Natural products 0.000 description 2
- 208000033761 Myelogenous Chronic BCR-ABL Positive Leukemia Diseases 0.000 description 2
- 208000033776 Myeloid Acute Leukemia Diseases 0.000 description 2
- 208000001894 Nasopharyngeal Neoplasms Diseases 0.000 description 2
- 206010061306 Nasopharyngeal cancer Diseases 0.000 description 2
- 206010029113 Neovascularisation Diseases 0.000 description 2
- 108010016076 Octreotide Proteins 0.000 description 2
- 206010030155 Oesophageal carcinoma Diseases 0.000 description 2
- 108700020796 Oncogene Proteins 0.000 description 2
- 206010033128 Ovarian cancer Diseases 0.000 description 2
- 206010061535 Ovarian neoplasm Diseases 0.000 description 2
- 229930012538 Paclitaxel Natural products 0.000 description 2
- 102000057297 Pepsin A Human genes 0.000 description 2
- 108090000284 Pepsin A Proteins 0.000 description 2
- NBIIXXVUZAFLBC-UHFFFAOYSA-N Phosphoric acid Chemical compound OP(O)(O)=O NBIIXXVUZAFLBC-UHFFFAOYSA-N 0.000 description 2
- 108010004729 Phycoerythrin Proteins 0.000 description 2
- 206010035226 Plasma cell myeloma Diseases 0.000 description 2
- 239000004365 Protease Substances 0.000 description 2
- 108010029485 Protein Isoforms Proteins 0.000 description 2
- 102000001708 Protein Isoforms Human genes 0.000 description 2
- 102100030086 Receptor tyrosine-protein kinase erbB-2 Human genes 0.000 description 2
- 235000004443 Ricinus communis Nutrition 0.000 description 2
- 239000006146 Roswell Park Memorial Institute medium Substances 0.000 description 2
- YJDYDFNKCBANTM-QCWCSKBGSA-N SDZ PSC 833 Chemical compound C\C=C\C[C@@H](C)C(=O)[C@@H]1N(C)C(=O)[C@H](C(C)C)N(C)C(=O)[C@H](CC(C)C)N(C)C(=O)[C@H](CC(C)C)N(C)C(=O)[C@@H](C)NC(=O)[C@H](C)NC(=O)[C@H](CC(C)C)N(C)C(=O)[C@H](C(C)C)NC(=O)[C@H](CC(C)C)N(C)C(=O)CN(C)C(=O)[C@H](C(C)C)NC1=O YJDYDFNKCBANTM-QCWCSKBGSA-N 0.000 description 2
- 108010079723 Shiga Toxin Proteins 0.000 description 2
- 208000005718 Stomach Neoplasms Diseases 0.000 description 2
- NKANXQFJJICGDU-QPLCGJKRSA-N Tamoxifen Chemical compound C=1C=CC=CC=1C(/CC)=C(C=1C=CC(OCCN(C)C)=CC=1)/C1=CC=CC=C1 NKANXQFJJICGDU-QPLCGJKRSA-N 0.000 description 2
- 229940123237 Taxane Drugs 0.000 description 2
- BPEGJWRSRHCHSN-UHFFFAOYSA-N Temozolomide Chemical compound O=C1N(C)N=NC2=C(C(N)=O)N=CN21 BPEGJWRSRHCHSN-UHFFFAOYSA-N 0.000 description 2
- FOCVUCIESVLUNU-UHFFFAOYSA-N Thiotepa Chemical compound C1CN1P(N1CC1)(=S)N1CC1 FOCVUCIESVLUNU-UHFFFAOYSA-N 0.000 description 2
- 208000024770 Thyroid neoplasm Diseases 0.000 description 2
- GLNADSQYFUSGOU-GPTZEZBUSA-J Trypan blue Chemical compound [Na+].[Na+].[Na+].[Na+].C1=C(S([O-])(=O)=O)C=C2C=C(S([O-])(=O)=O)C(/N=N/C3=CC=C(C=C3C)C=3C=C(C(=CC=3)\N=N\C=3C(=CC4=CC(=CC(N)=C4C=3O)S([O-])(=O)=O)S([O-])(=O)=O)C)=C(O)C2=C1N GLNADSQYFUSGOU-GPTZEZBUSA-J 0.000 description 2
- VGQOVCHZGQWAOI-UHFFFAOYSA-N UNPD55612 Natural products N1C(O)C2CC(C=CC(N)=O)=CN2C(=O)C2=CC=C(C)C(O)=C12 VGQOVCHZGQWAOI-UHFFFAOYSA-N 0.000 description 2
- 208000015778 Undifferentiated pleomorphic sarcoma Diseases 0.000 description 2
- 208000007097 Urinary Bladder Neoplasms Diseases 0.000 description 2
- 208000006105 Uterine Cervical Neoplasms Diseases 0.000 description 2
- 208000008383 Wilms tumor Diseases 0.000 description 2
- 230000001594 aberrant effect Effects 0.000 description 2
- 239000002253 acid Substances 0.000 description 2
- RJURFGZVJUQBHK-IIXSONLDSA-N actinomycin D Chemical compound C[C@H]1OC(=O)[C@H](C(C)C)N(C)C(=O)CN(C)C(=O)[C@@H]2CCCN2C(=O)[C@@H](C(C)C)NC(=O)[C@H]1NC(=O)C1=C(N)C(=O)C(C)=C2OC(C(C)=CC=C3C(=O)N[C@@H]4C(=O)N[C@@H](C(N5CCC[C@H]5C(=O)N(C)CC(=O)N(C)[C@@H](C(C)C)C(=O)O[C@@H]4C)=O)C(C)C)=C3N=C21 RJURFGZVJUQBHK-IIXSONLDSA-N 0.000 description 2
- 201000006966 adult T-cell leukemia Diseases 0.000 description 2
- 230000001270 agonistic effect Effects 0.000 description 2
- 229940100198 alkylating agent Drugs 0.000 description 2
- 239000002168 alkylating agent Substances 0.000 description 2
- VGQOVCHZGQWAOI-HYUHUPJXSA-N anthramycin Chemical compound N1[C@@H](O)[C@@H]2CC(\C=C\C(N)=O)=CN2C(=O)C2=CC=C(C)C(O)=C12 VGQOVCHZGQWAOI-HYUHUPJXSA-N 0.000 description 2
- 230000000340 anti-metabolite Effects 0.000 description 2
- 239000000051 antiandrogen Substances 0.000 description 2
- 229940100197 antimetabolite Drugs 0.000 description 2
- 239000002256 antimetabolite Substances 0.000 description 2
- 239000002246 antineoplastic agent Substances 0.000 description 2
- 229960003272 asparaginase Drugs 0.000 description 2
- DCXYFEDJOCDNAF-UHFFFAOYSA-M asparaginate Chemical compound [O-]C(=O)C(N)CC(N)=O DCXYFEDJOCDNAF-UHFFFAOYSA-M 0.000 description 2
- FZCSTZYAHCUGEM-UHFFFAOYSA-N aspergillomarasmine B Natural products OC(=O)CNC(C(O)=O)CNC(C(O)=O)CC(O)=O FZCSTZYAHCUGEM-UHFFFAOYSA-N 0.000 description 2
- VSRXQHXAPYXROS-UHFFFAOYSA-N azanide;cyclobutane-1,1-dicarboxylic acid;platinum(2+) Chemical compound [NH2-].[NH2-].[Pt+2].OC(=O)C1(C(O)=O)CCC1 VSRXQHXAPYXROS-UHFFFAOYSA-N 0.000 description 2
- 230000001580 bacterial effect Effects 0.000 description 2
- 230000002457 bidirectional effect Effects 0.000 description 2
- 210000004369 blood Anatomy 0.000 description 2
- 239000008280 blood Substances 0.000 description 2
- 238000002725 brachytherapy Methods 0.000 description 2
- 229960002092 busulfan Drugs 0.000 description 2
- 229910002091 carbon monoxide Inorganic materials 0.000 description 2
- 229960004562 carboplatin Drugs 0.000 description 2
- WNRZHQBJSXRYJK-UHFFFAOYSA-N carboxyamidotriazole Chemical compound NC1=C(C(=O)N)N=NN1CC(C=C1Cl)=CC(Cl)=C1C(=O)C1=CC=C(Cl)C=C1 WNRZHQBJSXRYJK-UHFFFAOYSA-N 0.000 description 2
- 229960005243 carmustine Drugs 0.000 description 2
- 238000004113 cell culture Methods 0.000 description 2
- 239000013592 cell lysate Substances 0.000 description 2
- 201000010881 cervical cancer Diseases 0.000 description 2
- 229960004630 chlorambucil Drugs 0.000 description 2
- JCKYGMPEJWAADB-UHFFFAOYSA-N chlorambucil Chemical compound OC(=O)CCCC1=CC=C(N(CCCl)CCCl)C=C1 JCKYGMPEJWAADB-UHFFFAOYSA-N 0.000 description 2
- 208000006990 cholangiocarcinoma Diseases 0.000 description 2
- 230000002759 chromosomal effect Effects 0.000 description 2
- 229960004316 cisplatin Drugs 0.000 description 2
- DQLATGHUWYMOKM-UHFFFAOYSA-L cisplatin Chemical compound N[Pt](N)(Cl)Cl DQLATGHUWYMOKM-UHFFFAOYSA-L 0.000 description 2
- 229960002436 cladribine Drugs 0.000 description 2
- 238000007796 conventional method Methods 0.000 description 2
- 230000008878 coupling Effects 0.000 description 2
- 238000010168 coupling process Methods 0.000 description 2
- 238000005859 coupling reaction Methods 0.000 description 2
- 238000004132 cross linking Methods 0.000 description 2
- 230000009260 cross reactivity Effects 0.000 description 2
- 229960004397 cyclophosphamide Drugs 0.000 description 2
- 150000001945 cysteines Chemical group 0.000 description 2
- 229960000684 cytarabine Drugs 0.000 description 2
- 239000002254 cytotoxic agent Substances 0.000 description 2
- 229960000640 dactinomycin Drugs 0.000 description 2
- 229960000975 daunorubicin Drugs 0.000 description 2
- 238000011033 desalting Methods 0.000 description 2
- 239000003599 detergent Substances 0.000 description 2
- 238000003745 diagnosis Methods 0.000 description 2
- 238000007865 diluting Methods 0.000 description 2
- 239000000539 dimer Substances 0.000 description 2
- 239000002612 dispersion medium Substances 0.000 description 2
- 230000003828 downregulation Effects 0.000 description 2
- 229960004679 doxorubicin Drugs 0.000 description 2
- 230000009977 dual effect Effects 0.000 description 2
- 239000003480 eluent Substances 0.000 description 2
- 230000013020 embryo development Effects 0.000 description 2
- 210000002889 endothelial cell Anatomy 0.000 description 2
- 230000003511 endothelial effect Effects 0.000 description 2
- 238000006911 enzymatic reaction Methods 0.000 description 2
- 229960001433 erlotinib Drugs 0.000 description 2
- AAKJLRGGTJKAMG-UHFFFAOYSA-N erlotinib Chemical compound C=12C=C(OCCOC)C(OCCOC)=CC2=NC=NC=1NC1=CC=CC(C#C)=C1 AAKJLRGGTJKAMG-UHFFFAOYSA-N 0.000 description 2
- 201000004101 esophageal cancer Diseases 0.000 description 2
- FRPJXPJMRWBBIH-RBRWEJTLSA-N estramustine Chemical compound ClCCN(CCCl)C(=O)OC1=CC=C2[C@H]3CC[C@](C)([C@H](CC4)O)[C@@H]4[C@@H]3CCC2=C1 FRPJXPJMRWBBIH-RBRWEJTLSA-N 0.000 description 2
- 229960001842 estramustine Drugs 0.000 description 2
- VJJPUSNTGOMMGY-MRVIYFEKSA-N etoposide Chemical compound COC1=C(O)C(OC)=CC([C@@H]2C3=CC=4OCOC=4C=C3[C@@H](O[C@H]3[C@@H]([C@@H](O)[C@@H]4O[C@H](C)OC[C@H]4O3)O)[C@@H]3[C@@H]2C(OC3)=O)=C1 VJJPUSNTGOMMGY-MRVIYFEKSA-N 0.000 description 2
- 229960005420 etoposide Drugs 0.000 description 2
- 230000007717 exclusion Effects 0.000 description 2
- 238000002710 external beam radiation therapy Methods 0.000 description 2
- 238000001914 filtration Methods 0.000 description 2
- 238000000684 flow cytometry Methods 0.000 description 2
- 229960000390 fludarabine Drugs 0.000 description 2
- GIUYCYHIANZCFB-FJFJXFQQSA-N fludarabine phosphate Chemical compound C1=NC=2C(N)=NC(F)=NC=2N1[C@@H]1O[C@H](COP(O)(O)=O)[C@@H](O)[C@@H]1O GIUYCYHIANZCFB-FJFJXFQQSA-N 0.000 description 2
- 238000009472 formulation Methods 0.000 description 2
- 230000004927 fusion Effects 0.000 description 2
- 201000010175 gallbladder cancer Diseases 0.000 description 2
- 206010017758 gastric cancer Diseases 0.000 description 2
- XGALLCVXEZPNRQ-UHFFFAOYSA-N gefitinib Chemical compound C=12C=C(OCCCN3CCOCC3)C(OC)=CC2=NC=NC=1NC1=CC=C(F)C(Cl)=C1 XGALLCVXEZPNRQ-UHFFFAOYSA-N 0.000 description 2
- 239000000499 gel Substances 0.000 description 2
- 238000012239 gene modification Methods 0.000 description 2
- 230000005017 genetic modification Effects 0.000 description 2
- 235000013617 genetically modified food Nutrition 0.000 description 2
- 201000010536 head and neck cancer Diseases 0.000 description 2
- 208000014829 head and neck neoplasm Diseases 0.000 description 2
- JYGXADMDTFJGBT-VWUMJDOOSA-N hydrocortisone Chemical compound O=C1CC[C@]2(C)[C@H]3[C@@H](O)C[C@](C)([C@@](CC4)(O)C(=O)CO)[C@@H]4[C@@H]3CCC2=C1 JYGXADMDTFJGBT-VWUMJDOOSA-N 0.000 description 2
- 229960002411 imatinib Drugs 0.000 description 2
- 210000000987 immune system Anatomy 0.000 description 2
- 230000002163 immunogen Effects 0.000 description 2
- 230000003308 immunostimulating effect Effects 0.000 description 2
- 230000006698 induction Effects 0.000 description 2
- 238000002347 injection Methods 0.000 description 2
- 239000007924 injection Substances 0.000 description 2
- 238000007918 intramuscular administration Methods 0.000 description 2
- 238000007912 intraperitoneal administration Methods 0.000 description 2
- 238000001990 intravenous administration Methods 0.000 description 2
- 230000009545 invasion Effects 0.000 description 2
- 229960004768 irinotecan Drugs 0.000 description 2
- UWKQSNNFCGGAFS-XIFFEERXSA-N irinotecan Chemical compound C1=C2C(CC)=C3CN(C(C4=C([C@@](C(=O)OC4)(O)CC)C=4)=O)C=4C3=NC2=CC=C1OC(=O)N(CC1)CCC1N1CCCCC1 UWKQSNNFCGGAFS-XIFFEERXSA-N 0.000 description 2
- 238000005304 joining Methods 0.000 description 2
- 239000000787 lecithin Substances 0.000 description 2
- 235000010445 lecithin Nutrition 0.000 description 2
- 229940067606 lecithin Drugs 0.000 description 2
- 210000004185 liver Anatomy 0.000 description 2
- 201000007270 liver cancer Diseases 0.000 description 2
- 208000014018 liver neoplasm Diseases 0.000 description 2
- 229960002247 lomustine Drugs 0.000 description 2
- 201000005202 lung cancer Diseases 0.000 description 2
- 208000020816 lung neoplasm Diseases 0.000 description 2
- 210000001165 lymph node Anatomy 0.000 description 2
- 210000004698 lymphocyte Anatomy 0.000 description 2
- 239000012139 lysis buffer Substances 0.000 description 2
- 208000015486 malignant pancreatic neoplasm Diseases 0.000 description 2
- 230000010534 mechanism of action Effects 0.000 description 2
- 229960004961 mechlorethamine Drugs 0.000 description 2
- HAWPXGHAZFHHAD-UHFFFAOYSA-N mechlorethamine Chemical compound ClCCN(C)CCCl HAWPXGHAZFHHAD-UHFFFAOYSA-N 0.000 description 2
- 230000001404 mediated effect Effects 0.000 description 2
- PSGAAPLEWMOORI-PEINSRQWSA-N medroxyprogesterone acetate Chemical compound C([C@@]12C)CC(=O)C=C1[C@@H](C)C[C@@H]1[C@@H]2CC[C@]2(C)[C@@](OC(C)=O)(C(C)=O)CC[C@H]21 PSGAAPLEWMOORI-PEINSRQWSA-N 0.000 description 2
- RQZAXGRLVPAYTJ-GQFGMJRRSA-N megestrol acetate Chemical compound C1=C(C)C2=CC(=O)CC[C@]2(C)[C@@H]2[C@@H]1[C@@H]1CC[C@@](C(C)=O)(OC(=O)C)[C@@]1(C)CC2 RQZAXGRLVPAYTJ-GQFGMJRRSA-N 0.000 description 2
- 229960001924 melphalan Drugs 0.000 description 2
- SGDBTWWWUNNDEQ-LBPRGKRZSA-N melphalan Chemical compound OC(=O)[C@@H](N)CC1=CC=C(N(CCCl)CCCl)C=C1 SGDBTWWWUNNDEQ-LBPRGKRZSA-N 0.000 description 2
- 229960001428 mercaptopurine Drugs 0.000 description 2
- MYWUZJCMWCOHBA-VIFPVBQESA-N methamphetamine Chemical compound CN[C@@H](C)CC1=CC=CC=C1 MYWUZJCMWCOHBA-VIFPVBQESA-N 0.000 description 2
- BDAGIHXWWSANSR-UHFFFAOYSA-N methanoic acid Natural products OC=O BDAGIHXWWSANSR-UHFFFAOYSA-N 0.000 description 2
- 229960000485 methotrexate Drugs 0.000 description 2
- 230000005012 migration Effects 0.000 description 2
- 238000013508 migration Methods 0.000 description 2
- 229960005485 mitobronitol Drugs 0.000 description 2
- 108010010621 modeccin Proteins 0.000 description 2
- 239000001788 mono and diglycerides of fatty acids Substances 0.000 description 2
- 230000004899 motility Effects 0.000 description 2
- 229950010203 nimotuzumab Drugs 0.000 description 2
- 238000011580 nude mouse model Methods 0.000 description 2
- 201000008968 osteosarcoma Diseases 0.000 description 2
- 229960001592 paclitaxel Drugs 0.000 description 2
- 208000008443 pancreatic carcinoma Diseases 0.000 description 2
- 210000002568 pbsc Anatomy 0.000 description 2
- 229940111202 pepsin Drugs 0.000 description 2
- 229960002087 pertuzumab Drugs 0.000 description 2
- 230000004962 physiological condition Effects 0.000 description 2
- 150000003057 platinum Chemical class 0.000 description 2
- 239000002243 precursor Substances 0.000 description 2
- 229960000624 procarbazine Drugs 0.000 description 2
- CPTBDICYNRMXFX-UHFFFAOYSA-N procarbazine Chemical compound CNNCC1=CC=C(C(=O)NC(C)C)C=C1 CPTBDICYNRMXFX-UHFFFAOYSA-N 0.000 description 2
- 230000002062 proliferating effect Effects 0.000 description 2
- AQHHHDLHHXJYJD-UHFFFAOYSA-N propranolol Chemical compound C1=CC=C2C(OCC(O)CNC(C)C)=CC=CC2=C1 AQHHHDLHHXJYJD-UHFFFAOYSA-N 0.000 description 2
- 210000002307 prostate Anatomy 0.000 description 2
- RXWNCPJZOCPEPQ-NVWDDTSBSA-N puromycin Chemical compound C1=CC(OC)=CC=C1C[C@H](N)C(=O)N[C@H]1[C@@H](O)[C@H](N2C3=NC=NC(=C3N=C2)N(C)C)O[C@@H]1CO RXWNCPJZOCPEPQ-NVWDDTSBSA-N 0.000 description 2
- ZAHRKKWIAAJSAO-UHFFFAOYSA-N rapamycin Natural products COCC(O)C(=C/C(C)C(=O)CC(OC(=O)C1CCCCN1C(=O)C(=O)C2(O)OC(CC(OC)C(=CC=CC=CC(C)CC(C)C(=O)C)C)CCC2C)C(C)CC3CCC(O)C(C3)OC)C ZAHRKKWIAAJSAO-UHFFFAOYSA-N 0.000 description 2
- 238000010188 recombinant method Methods 0.000 description 2
- 238000011160 research Methods 0.000 description 2
- 210000003705 ribosome Anatomy 0.000 description 2
- 108091092562 ribozyme Proteins 0.000 description 2
- 238000003118 sandwich ELISA Methods 0.000 description 2
- 230000028327 secretion Effects 0.000 description 2
- 229960002930 sirolimus Drugs 0.000 description 2
- QFJCIRLUMZQUOT-HPLJOQBZSA-N sirolimus Chemical compound C1C[C@@H](O)[C@H](OC)C[C@@H]1C[C@@H](C)[C@H]1OC(=O)[C@@H]2CCCCN2C(=O)C(=O)[C@](O)(O2)[C@H](C)CC[C@H]2C[C@H](OC)/C(C)=C/C=C/C=C/[C@@H](C)C[C@@H](C)C(=O)[C@H](OC)[C@H](O)/C(C)=C/[C@@H](C)C(=O)C1 QFJCIRLUMZQUOT-HPLJOQBZSA-N 0.000 description 2
- 229910052708 sodium Inorganic materials 0.000 description 2
- 239000011734 sodium Substances 0.000 description 2
- HEMHJVSKTPXQMS-UHFFFAOYSA-M sodium hydroxide Inorganic materials [OH-].[Na+] HEMHJVSKTPXQMS-UHFFFAOYSA-M 0.000 description 2
- GEHJYWRUCIMESM-UHFFFAOYSA-L sodium sulfite Chemical compound [Na+].[Na+].[O-]S([O-])=O GEHJYWRUCIMESM-UHFFFAOYSA-L 0.000 description 2
- 230000037439 somatic mutation Effects 0.000 description 2
- 239000000600 sorbitol Substances 0.000 description 2
- 230000009870 specific binding Effects 0.000 description 2
- UNFWWIHTNXNPBV-WXKVUWSESA-N spectinomycin Chemical compound O([C@@H]1[C@@H](NC)[C@@H](O)[C@H]([C@@H]([C@H]1O1)O)NC)[C@]2(O)[C@H]1O[C@H](C)CC2=O UNFWWIHTNXNPBV-WXKVUWSESA-N 0.000 description 2
- 210000004988 splenocyte Anatomy 0.000 description 2
- 230000002269 spontaneous effect Effects 0.000 description 2
- 210000000130 stem cell Anatomy 0.000 description 2
- 201000011549 stomach cancer Diseases 0.000 description 2
- 229960001052 streptozocin Drugs 0.000 description 2
- ZSJLQEPLLKMAKR-GKHCUFPYSA-N streptozocin Chemical compound O=NN(C)C(=O)N[C@H]1[C@@H](O)O[C@H](CO)[C@@H](O)[C@@H]1O ZSJLQEPLLKMAKR-GKHCUFPYSA-N 0.000 description 2
- WINHZLLDWRZWRT-ATVHPVEESA-N sunitinib Chemical compound CCN(CC)CCNC(=O)C1=C(C)NC(\C=C/2C3=CC(F)=CC=C3NC\2=O)=C1C WINHZLLDWRZWRT-ATVHPVEESA-N 0.000 description 2
- 238000002198 surface plasmon resonance spectroscopy Methods 0.000 description 2
- 238000001356 surgical procedure Methods 0.000 description 2
- 206010042863 synovial sarcoma Diseases 0.000 description 2
- RCINICONZNJXQF-MZXODVADSA-N taxol Chemical compound O([C@@H]1[C@@]2(C[C@@H](C(C)=C(C2(C)C)[C@H](C([C@]2(C)[C@@H](O)C[C@H]3OC[C@]3([C@H]21)OC(C)=O)=O)OC(=O)C)OC(=O)[C@H](O)[C@@H](NC(=O)C=1C=CC=CC=1)C=1C=CC=CC=1)O)C(=O)C1=CC=CC=C1 RCINICONZNJXQF-MZXODVADSA-N 0.000 description 2
- 229960004964 temozolomide Drugs 0.000 description 2
- NRUKOCRGYNPUPR-QBPJDGROSA-N teniposide Chemical compound COC1=C(O)C(OC)=CC([C@@H]2C3=CC=4OCOC=4C=C3[C@@H](O[C@H]3[C@@H]([C@@H](O)[C@@H]4O[C@@H](OC[C@H]4O3)C=3SC=CC=3)O)[C@@H]3[C@@H]2C(OC3)=O)=C1 NRUKOCRGYNPUPR-QBPJDGROSA-N 0.000 description 2
- 229960001278 teniposide Drugs 0.000 description 2
- 230000004797 therapeutic response Effects 0.000 description 2
- 229960001196 thiotepa Drugs 0.000 description 2
- 201000002510 thyroid cancer Diseases 0.000 description 2
- 229960003087 tioguanine Drugs 0.000 description 2
- 230000001052 transient effect Effects 0.000 description 2
- 229960000575 trastuzumab Drugs 0.000 description 2
- 229960001612 trastuzumab emtansine Drugs 0.000 description 2
- 201000005112 urinary bladder cancer Diseases 0.000 description 2
- 229950010938 valspodar Drugs 0.000 description 2
- 108010082372 valspodar Proteins 0.000 description 2
- OGWKCGZFUXNPDA-UHFFFAOYSA-N vincristine Natural products C1C(CC)(O)CC(CC2(C(=O)OC)C=3C(=CC4=C(C56C(C(C(OC(C)=O)C7(CC)C=CCN(C67)CC5)(O)C(=O)OC)N4C=O)C=3)OC)CN1CCC1=C2NC2=CC=CC=C12 OGWKCGZFUXNPDA-UHFFFAOYSA-N 0.000 description 2
- 229960004528 vincristine Drugs 0.000 description 2
- OGWKCGZFUXNPDA-XQKSVPLYSA-N vincristine Chemical compound C([N@]1C[C@@H](C[C@]2(C(=O)OC)C=3C(=CC4=C([C@]56[C@H]([C@@]([C@H](OC(C)=O)[C@]7(CC)C=CCN([C@H]67)CC5)(O)C(=O)OC)N4C=O)C=3)OC)C[C@@](C1)(O)CC)CC1=C2NC2=CC=CC=C12 OGWKCGZFUXNPDA-XQKSVPLYSA-N 0.000 description 2
- 239000003643 water by type Substances 0.000 description 2
- 229950008250 zalutumumab Drugs 0.000 description 2
- NGGMYCMLYOUNGM-UHFFFAOYSA-N (-)-fumagillin Natural products O1C(CC=C(C)C)C1(C)C1C(OC)C(OC(=O)C=CC=CC=CC=CC(O)=O)CCC21CO2 NGGMYCMLYOUNGM-UHFFFAOYSA-N 0.000 description 1
- QIJRTFXNRTXDIP-UHFFFAOYSA-N (1-carboxy-2-sulfanylethyl)azanium;chloride;hydrate Chemical compound O.Cl.SCC(N)C(O)=O QIJRTFXNRTXDIP-UHFFFAOYSA-N 0.000 description 1
- YXTKHLHCVFUPPT-YYFJYKOTSA-N (2s)-2-[[4-[(2-amino-5-formyl-4-oxo-1,6,7,8-tetrahydropteridin-6-yl)methylamino]benzoyl]amino]pentanedioic acid;(1r,2r)-1,2-dimethanidylcyclohexane;5-fluoro-1h-pyrimidine-2,4-dione;oxalic acid;platinum(2+) Chemical compound [Pt+2].OC(=O)C(O)=O.[CH2-][C@@H]1CCCC[C@H]1[CH2-].FC1=CNC(=O)NC1=O.C1NC=2NC(N)=NC(=O)C=2N(C=O)C1CNC1=CC=C(C(=O)N[C@@H](CCC(O)=O)C(O)=O)C=C1 YXTKHLHCVFUPPT-YYFJYKOTSA-N 0.000 description 1
- GTXSRFUZSLTDFX-HRCADAONSA-N (2s)-n-[(2s)-3,3-dimethyl-1-(methylamino)-1-oxobutan-2-yl]-4-methyl-2-[[(2s)-2-sulfanyl-4-(3,4,4-trimethyl-2,5-dioxoimidazolidin-1-yl)butanoyl]amino]pentanamide Chemical compound CNC(=O)[C@H](C(C)(C)C)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](S)CCN1C(=O)N(C)C(C)(C)C1=O GTXSRFUZSLTDFX-HRCADAONSA-N 0.000 description 1
- LJRDOKAZOAKLDU-UDXJMMFXSA-N (2s,3s,4r,5r,6r)-5-amino-2-(aminomethyl)-6-[(2r,3s,4r,5s)-5-[(1r,2r,3s,5r,6s)-3,5-diamino-2-[(2s,3r,4r,5s,6r)-3-amino-4,5-dihydroxy-6-(hydroxymethyl)oxan-2-yl]oxy-6-hydroxycyclohexyl]oxy-4-hydroxy-2-(hydroxymethyl)oxolan-3-yl]oxyoxane-3,4-diol;sulfuric ac Chemical compound OS(O)(=O)=O.N[C@@H]1[C@@H](O)[C@H](O)[C@H](CN)O[C@@H]1O[C@H]1[C@@H](O)[C@H](O[C@H]2[C@@H]([C@@H](N)C[C@@H](N)[C@@H]2O)O[C@@H]2[C@@H]([C@@H](O)[C@H](O)[C@@H](CO)O2)N)O[C@@H]1CO LJRDOKAZOAKLDU-UDXJMMFXSA-N 0.000 description 1
- ARBXEMIAJIJEQI-WDCZJNDASA-N (3s,4r,5r)-3,4-dihydroxy-5-(hydroxymethyl)piperidin-2-one Chemical compound OC[C@H]1CNC(=O)[C@@H](O)[C@@H]1O ARBXEMIAJIJEQI-WDCZJNDASA-N 0.000 description 1
- GVJHHUAWPYXKBD-IEOSBIPESA-N (R)-alpha-Tocopherol Natural products OC1=C(C)C(C)=C2O[C@@](CCC[C@H](C)CCC[C@H](C)CCCC(C)C)(C)CCC2=C1C GVJHHUAWPYXKBD-IEOSBIPESA-N 0.000 description 1
- PNDPGZBMCMUPRI-HVTJNCQCSA-N 10043-66-0 Chemical compound [131I][131I] PNDPGZBMCMUPRI-HVTJNCQCSA-N 0.000 description 1
- BFPYWIDHMRZLRN-UHFFFAOYSA-N 17alpha-ethynyl estradiol Natural products OC1=CC=C2C3CCC(C)(C(CC4)(O)C#C)C4C3CCC2=C1 BFPYWIDHMRZLRN-UHFFFAOYSA-N 0.000 description 1
- WEEMDRWIKYCTQM-UHFFFAOYSA-N 2,6-dimethoxybenzenecarbothioamide Chemical compound COC1=CC=CC(OC)=C1C(N)=S WEEMDRWIKYCTQM-UHFFFAOYSA-N 0.000 description 1
- FBUTXZSKZCQABC-UHFFFAOYSA-N 2-amino-1-methyl-7h-purine-6-thione Chemical compound S=C1N(C)C(N)=NC2=C1NC=N2 FBUTXZSKZCQABC-UHFFFAOYSA-N 0.000 description 1
- IVLXQGJVBGMLRR-UHFFFAOYSA-N 2-aminoacetic acid;hydron;chloride Chemical compound Cl.NCC(O)=O IVLXQGJVBGMLRR-UHFFFAOYSA-N 0.000 description 1
- CQOQDQWUFQDJMK-SSTWWWIQSA-N 2-methoxy-17beta-estradiol Chemical compound C([C@@H]12)C[C@]3(C)[C@@H](O)CC[C@H]3[C@@H]1CCC1=C2C=C(OC)C(O)=C1 CQOQDQWUFQDJMK-SSTWWWIQSA-N 0.000 description 1
- NDMPLJNOPCLANR-UHFFFAOYSA-N 3,4-dihydroxy-15-(4-hydroxy-18-methoxycarbonyl-5,18-seco-ibogamin-18-yl)-16-methoxy-1-methyl-6,7-didehydro-aspidospermidine-3-carboxylic acid methyl ester Natural products C1C(CC)(O)CC(CC2(C(=O)OC)C=3C(=CC4=C(C56C(C(C(O)C7(CC)C=CCN(C67)CC5)(O)C(=O)OC)N4C)C=3)OC)CN1CCC1=C2NC2=CC=CC=C12 NDMPLJNOPCLANR-UHFFFAOYSA-N 0.000 description 1
- HQFLTUZKIRYQSP-UHFFFAOYSA-N 3-ethyl-2h-1,3-benzothiazole-6-sulfonic acid Chemical compound OS(=O)(=O)C1=CC=C2N(CC)CSC2=C1 HQFLTUZKIRYQSP-UHFFFAOYSA-N 0.000 description 1
- AOJJSUZBOXZQNB-VTZDEGQISA-N 4'-epidoxorubicin Chemical compound O([C@H]1C[C@@](O)(CC=2C(O)=C3C(=O)C=4C=CC=C(C=4C(=O)C3=C(O)C=21)OC)C(=O)CO)[C@H]1C[C@H](N)[C@@H](O)[C@H](C)O1 AOJJSUZBOXZQNB-VTZDEGQISA-N 0.000 description 1
- OSWFIVFLDKOXQC-UHFFFAOYSA-N 4-(3-methoxyphenyl)aniline Chemical compound COC1=CC=CC(C=2C=CC(N)=CC=2)=C1 OSWFIVFLDKOXQC-UHFFFAOYSA-N 0.000 description 1
- FWMNVWWHGCHHJJ-SKKKGAJSSA-N 4-amino-1-[(2r)-6-amino-2-[[(2r)-2-[[(2r)-2-[[(2r)-2-amino-3-phenylpropanoyl]amino]-3-phenylpropanoyl]amino]-4-methylpentanoyl]amino]hexanoyl]piperidine-4-carboxylic acid Chemical compound C([C@H](C(=O)N[C@H](CC(C)C)C(=O)N[C@H](CCCCN)C(=O)N1CCC(N)(CC1)C(O)=O)NC(=O)[C@H](N)CC=1C=CC=CC=1)C1=CC=CC=C1 FWMNVWWHGCHHJJ-SKKKGAJSSA-N 0.000 description 1
- JRWCBEOAFGHNNU-UHFFFAOYSA-N 6-[difluoro-[6-(1-methyl-4-pyrazolyl)-[1,2,4]triazolo[4,3-b]pyridazin-3-yl]methyl]quinoline Chemical compound C1=NN(C)C=C1C1=NN2C(C(F)(F)C=3C=C4C=CC=NC4=CC=3)=NN=C2C=C1 JRWCBEOAFGHNNU-UHFFFAOYSA-N 0.000 description 1
- BMKPVDQDJQWBPD-UHFFFAOYSA-N 6-chloro-7-[2-(4-morpholinyl)ethylamino]quinoline-5,8-dione Chemical compound O=C1C2=NC=CC=C2C(=O)C(Cl)=C1NCCN1CCOCC1 BMKPVDQDJQWBPD-UHFFFAOYSA-N 0.000 description 1
- PBCZSGKMGDDXIJ-UHFFFAOYSA-N 7beta-hydroxystaurosporine Natural products C12=C3N4C5=CC=CC=C5C3=C3C(O)NC(=O)C3=C2C2=CC=CC=C2N1C1CC(NC)C(OC)C4(C)O1 PBCZSGKMGDDXIJ-UHFFFAOYSA-N 0.000 description 1
- 108010066676 Abrin Proteins 0.000 description 1
- 208000010507 Adenocarcinoma of Lung Diseases 0.000 description 1
- 101000689231 Aeromonas salmonicida S-layer protein Proteins 0.000 description 1
- 108010025188 Alcohol oxidase Proteins 0.000 description 1
- 208000037540 Alveolar soft tissue sarcoma Diseases 0.000 description 1
- 102100022987 Angiogenin Human genes 0.000 description 1
- 102100034594 Angiopoietin-1 Human genes 0.000 description 1
- 108010048154 Angiopoietin-1 Proteins 0.000 description 1
- 108090000644 Angiozyme Proteins 0.000 description 1
- 102100021569 Apoptosis regulator Bcl-2 Human genes 0.000 description 1
- 108091023037 Aptamer Proteins 0.000 description 1
- 229940122815 Aromatase inhibitor Drugs 0.000 description 1
- 101000669426 Aspergillus restrictus Ribonuclease mitogillin Proteins 0.000 description 1
- 102100035526 B melanoma antigen 1 Human genes 0.000 description 1
- PGFQXGLPJUCTOI-WYMLVPIESA-N BIBR-1532 Chemical compound C=1C=C2C=CC=CC2=CC=1C(/C)=C/C(=O)NC1=CC=CC=C1C(O)=O PGFQXGLPJUCTOI-WYMLVPIESA-N 0.000 description 1
- 241000894006 Bacteria Species 0.000 description 1
- 108010006654 Bleomycin Proteins 0.000 description 1
- 108091003079 Bovine Serum Albumin Proteins 0.000 description 1
- 108010037003 Buserelin Proteins 0.000 description 1
- 239000004255 Butylated hydroxyanisole Substances 0.000 description 1
- 239000004322 Butylated hydroxytoluene Substances 0.000 description 1
- NLZUEZXRPGMBCV-UHFFFAOYSA-N Butylhydroxytoluene Chemical compound CC1=CC(C(C)(C)C)=C(O)C(C(C)(C)C)=C1 NLZUEZXRPGMBCV-UHFFFAOYSA-N 0.000 description 1
- 101710155834 C-C motif chemokine 7 Proteins 0.000 description 1
- 102100032366 C-C motif chemokine 7 Human genes 0.000 description 1
- 102100025248 C-X-C motif chemokine 10 Human genes 0.000 description 1
- 101710098275 C-X-C motif chemokine 10 Proteins 0.000 description 1
- 102100036170 C-X-C motif chemokine 9 Human genes 0.000 description 1
- 101710085500 C-X-C motif chemokine 9 Proteins 0.000 description 1
- 102000001902 CC Chemokines Human genes 0.000 description 1
- 108010040471 CC Chemokines Proteins 0.000 description 1
- 108010029697 CD40 Ligand Proteins 0.000 description 1
- 102100032937 CD40 ligand Human genes 0.000 description 1
- 108091007914 CDKs Proteins 0.000 description 1
- 101100447914 Caenorhabditis elegans gab-1 gene Proteins 0.000 description 1
- 241000282836 Camelus dromedarius Species 0.000 description 1
- 102100025570 Cancer/testis antigen 1 Human genes 0.000 description 1
- 241000282472 Canis lupus familiaris Species 0.000 description 1
- 102400000730 Canstatin Human genes 0.000 description 1
- 101800000626 Canstatin Proteins 0.000 description 1
- 101710158575 Cap-specific mRNA (nucleoside-2'-O-)-methyltransferase Proteins 0.000 description 1
- GAGWJHPBXLXJQN-UORFTKCHSA-N Capecitabine Chemical compound C1=C(F)C(NC(=O)OCCCCC)=NC(=O)N1[C@H]1[C@H](O)[C@H](O)[C@@H](C)O1 GAGWJHPBXLXJQN-UORFTKCHSA-N 0.000 description 1
- GAGWJHPBXLXJQN-UHFFFAOYSA-N Capecitabine Natural products C1=C(F)C(NC(=O)OCCCCC)=NC(=O)N1C1C(O)C(O)C(C)O1 GAGWJHPBXLXJQN-UHFFFAOYSA-N 0.000 description 1
- 229920002134 Carboxymethyl cellulose Polymers 0.000 description 1
- 208000005623 Carcinogenesis Diseases 0.000 description 1
- ZEOWTGPWHLSLOG-UHFFFAOYSA-N Cc1ccc(cc1-c1ccc2c(n[nH]c2c1)-c1cnn(c1)C1CC1)C(=O)Nc1cccc(c1)C(F)(F)F Chemical compound Cc1ccc(cc1-c1ccc2c(n[nH]c2c1)-c1cnn(c1)C1CC1)C(=O)Nc1cccc(c1)C(F)(F)F ZEOWTGPWHLSLOG-UHFFFAOYSA-N 0.000 description 1
- 102000006573 Chemokine CXCL12 Human genes 0.000 description 1
- 108010008951 Chemokine CXCL12 Proteins 0.000 description 1
- 108010049048 Cholera Toxin Proteins 0.000 description 1
- 102000009016 Cholera Toxin Human genes 0.000 description 1
- RYGMFSIKBFXOCR-UHFFFAOYSA-N Copper Chemical compound [Cu] RYGMFSIKBFXOCR-UHFFFAOYSA-N 0.000 description 1
- 241000557626 Corvus corax Species 0.000 description 1
- 102000003903 Cyclin-dependent kinases Human genes 0.000 description 1
- 108090000266 Cyclin-dependent kinases Proteins 0.000 description 1
- FBPFZTCFMRRESA-KVTDHHQDSA-N D-Mannitol Chemical compound OC[C@@H](O)[C@@H](O)[C@H](O)[C@H](O)CO FBPFZTCFMRRESA-KVTDHHQDSA-N 0.000 description 1
- 101100481408 Danio rerio tie2 gene Proteins 0.000 description 1
- WEAHRLBPCANXCN-UHFFFAOYSA-N Daunomycin Natural products CCC1(O)CC(OC2CC(N)C(O)C(C)O2)c3cc4C(=O)c5c(OC)cccc5C(=O)c4c(O)c3C1 WEAHRLBPCANXCN-UHFFFAOYSA-N 0.000 description 1
- 102000007260 Deoxyribonuclease I Human genes 0.000 description 1
- 108010008532 Deoxyribonuclease I Proteins 0.000 description 1
- FEWJPZIEWOKRBE-JCYAYHJZSA-N Dextrotartaric acid Chemical compound OC(=O)[C@H](O)[C@@H](O)C(O)=O FEWJPZIEWOKRBE-JCYAYHJZSA-N 0.000 description 1
- BWGNESOTFCXPMA-UHFFFAOYSA-N Dihydrogen disulfide Chemical compound SS BWGNESOTFCXPMA-UHFFFAOYSA-N 0.000 description 1
- 235000017274 Diospyros sandwicensis Nutrition 0.000 description 1
- 241000255925 Diptera Species 0.000 description 1
- ZQZFYGIXNQKOAV-OCEACIFDSA-N Droloxifene Chemical compound C=1C=CC=CC=1C(/CC)=C(C=1C=C(O)C=CC=1)\C1=CC=C(OCCN(C)C)C=C1 ZQZFYGIXNQKOAV-OCEACIFDSA-N 0.000 description 1
- 101100015729 Drosophila melanogaster drk gene Proteins 0.000 description 1
- 101150084967 EPCAM gene Proteins 0.000 description 1
- LVGKNOAMLMIIKO-UHFFFAOYSA-N Elaidinsaeure-aethylester Natural products CCCCCCCCC=CCCCCCCCC(=O)OCC LVGKNOAMLMIIKO-UHFFFAOYSA-N 0.000 description 1
- MBYXEBXZARTUSS-QLWBXOBMSA-N Emetamine Natural products O(C)c1c(OC)cc2c(c(C[C@@H]3[C@H](CC)CN4[C@H](c5c(cc(OC)c(OC)c5)CC4)C3)ncc2)c1 MBYXEBXZARTUSS-QLWBXOBMSA-N 0.000 description 1
- 102400001047 Endostatin Human genes 0.000 description 1
- 108010079505 Endostatins Proteins 0.000 description 1
- 101710147220 Ent-copalyl diphosphate synthase, chloroplastic Proteins 0.000 description 1
- 102000004190 Enzymes Human genes 0.000 description 1
- 108090000790 Enzymes Proteins 0.000 description 1
- 102400001368 Epidermal growth factor Human genes 0.000 description 1
- 101800003838 Epidermal growth factor Proteins 0.000 description 1
- HTIJFSOGRVMCQR-UHFFFAOYSA-N Epirubicin Natural products COc1cccc2C(=O)c3c(O)c4CC(O)(CC(OC5CC(N)C(=O)C(C)O5)c4c(O)c3C(=O)c12)C(=O)CO HTIJFSOGRVMCQR-UHFFFAOYSA-N 0.000 description 1
- 102000018651 Epithelial Cell Adhesion Molecule Human genes 0.000 description 1
- 241000588724 Escherichia coli Species 0.000 description 1
- BFPYWIDHMRZLRN-SLHNCBLASA-N Ethinyl estradiol Chemical compound OC1=CC=C2[C@H]3CC[C@](C)([C@](CC4)(O)C#C)[C@@H]4[C@@H]3CCC2=C1 BFPYWIDHMRZLRN-SLHNCBLASA-N 0.000 description 1
- HKVAMNSJSFKALM-GKUWKFKPSA-N Everolimus Chemical compound C1C[C@@H](OCCO)[C@H](OC)C[C@@H]1C[C@@H](C)[C@H]1OC(=O)[C@@H]2CCCCN2C(=O)C(=O)[C@](O)(O2)[C@H](C)CC[C@H]2C[C@H](OC)/C(C)=C/C=C/C=C/[C@@H](C)C[C@@H](C)C(=O)[C@H](OC)[C@H](O)/C(C)=C/[C@@H](C)C(=O)C1 HKVAMNSJSFKALM-GKUWKFKPSA-N 0.000 description 1
- 101150009958 FLT4 gene Proteins 0.000 description 1
- 102000018233 Fibroblast Growth Factor Human genes 0.000 description 1
- 108050007372 Fibroblast Growth Factor Proteins 0.000 description 1
- 102100024785 Fibroblast growth factor 2 Human genes 0.000 description 1
- 108090000379 Fibroblast growth factor 2 Proteins 0.000 description 1
- 102100023593 Fibroblast growth factor receptor 1 Human genes 0.000 description 1
- 101710182386 Fibroblast growth factor receptor 1 Proteins 0.000 description 1
- 102100023600 Fibroblast growth factor receptor 2 Human genes 0.000 description 1
- 101710182389 Fibroblast growth factor receptor 2 Proteins 0.000 description 1
- 102100027842 Fibroblast growth factor receptor 3 Human genes 0.000 description 1
- 101710182396 Fibroblast growth factor receptor 3 Proteins 0.000 description 1
- 102100027844 Fibroblast growth factor receptor 4 Human genes 0.000 description 1
- 229920001917 Ficoll Polymers 0.000 description 1
- 102100020715 Fms-related tyrosine kinase 3 ligand protein Human genes 0.000 description 1
- 101710162577 Fms-related tyrosine kinase 3 ligand protein Proteins 0.000 description 1
- VWUXBMIQPBEWFH-WCCTWKNTSA-N Fulvestrant Chemical compound OC1=CC=C2[C@H]3CC[C@](C)([C@H](CC4)O)[C@@H]4[C@@H]3[C@H](CCCCCCCCCS(=O)CCCC(F)(F)C(F)(F)F)CC2=C1 VWUXBMIQPBEWFH-WCCTWKNTSA-N 0.000 description 1
- 108010010803 Gelatin Proteins 0.000 description 1
- 229930182566 Gentamicin Natural products 0.000 description 1
- CEAZRRDELHUEMR-URQXQFDESA-N Gentamicin Chemical compound O1[C@H](C(C)NC)CC[C@@H](N)[C@H]1O[C@H]1[C@H](O)[C@@H](O[C@@H]2[C@@H]([C@@H](NC)[C@@](C)(O)CO2)O)[C@H](N)C[C@@H]1N CEAZRRDELHUEMR-URQXQFDESA-N 0.000 description 1
- 208000032612 Glial tumor Diseases 0.000 description 1
- 206010018338 Glioma Diseases 0.000 description 1
- VSRCAOIHMGCIJK-SRVKXCTJSA-N Glu-Leu-Arg Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O VSRCAOIHMGCIJK-SRVKXCTJSA-N 0.000 description 1
- WQZGKKKJIJFFOK-GASJEMHNSA-N Glucose Natural products OC[C@H]1OC(O)[C@H](O)[C@@H](O)[C@@H]1O WQZGKKKJIJFFOK-GASJEMHNSA-N 0.000 description 1
- 108010069236 Goserelin Proteins 0.000 description 1
- BLCLNMBMMGCOAS-URPVMXJPSA-N Goserelin Chemical compound C([C@@H](C(=O)N[C@H](COC(C)(C)C)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCN=C(N)N)C(=O)N1[C@@H](CCC1)C(=O)NNC(N)=O)NC(=O)[C@H](CO)NC(=O)[C@H](CC=1C2=CC=CC=C2NC=1)NC(=O)[C@H](CC=1NC=NC=1)NC(=O)[C@H]1NC(=O)CC1)C1=CC=C(O)C=C1 BLCLNMBMMGCOAS-URPVMXJPSA-N 0.000 description 1
- 108010026389 Gramicidin Proteins 0.000 description 1
- 108010017213 Granulocyte-Macrophage Colony-Stimulating Factor Proteins 0.000 description 1
- 102100039620 Granulocyte-macrophage colony-stimulating factor Human genes 0.000 description 1
- 102000009465 Growth Factor Receptors Human genes 0.000 description 1
- 108010009202 Growth Factor Receptors Proteins 0.000 description 1
- 108010091938 HLA-B7 Antigen Proteins 0.000 description 1
- 101710113864 Heat shock protein 90 Proteins 0.000 description 1
- 102100034051 Heat shock protein HSP 90-alpha Human genes 0.000 description 1
- 102000002812 Heat-Shock Proteins Human genes 0.000 description 1
- 108010004889 Heat-Shock Proteins Proteins 0.000 description 1
- 108010022901 Heparin Lyase Proteins 0.000 description 1
- 102100035108 High affinity nerve growth factor receptor Human genes 0.000 description 1
- 108091006054 His-tagged proteins Proteins 0.000 description 1
- 241000282412 Homo Species 0.000 description 1
- 101000971171 Homo sapiens Apoptosis regulator Bcl-2 Proteins 0.000 description 1
- 101000874316 Homo sapiens B melanoma antigen 1 Proteins 0.000 description 1
- 101000856237 Homo sapiens Cancer/testis antigen 1 Proteins 0.000 description 1
- 101000917134 Homo sapiens Fibroblast growth factor receptor 4 Proteins 0.000 description 1
- 101000596894 Homo sapiens High affinity nerve growth factor receptor Proteins 0.000 description 1
- 101000606465 Homo sapiens Inactive tyrosine-protein kinase 7 Proteins 0.000 description 1
- 101001106413 Homo sapiens Macrophage-stimulating protein receptor Proteins 0.000 description 1
- 101000578784 Homo sapiens Melanoma antigen recognized by T-cells 1 Proteins 0.000 description 1
- 101001036689 Homo sapiens Melanoma-associated antigen B5 Proteins 0.000 description 1
- 101001036675 Homo sapiens Melanoma-associated antigen B6 Proteins 0.000 description 1
- 101001057159 Homo sapiens Melanoma-associated antigen C3 Proteins 0.000 description 1
- 101000623901 Homo sapiens Mucin-16 Proteins 0.000 description 1
- 101001024605 Homo sapiens Next to BRCA1 gene 1 protein Proteins 0.000 description 1
- 101001062222 Homo sapiens Receptor-binding cancer antigen expressed on SiSo cells Proteins 0.000 description 1
- 101000821981 Homo sapiens Sarcoma antigen 1 Proteins 0.000 description 1
- 101000648075 Homo sapiens Trafficking protein particle complex subunit 1 Proteins 0.000 description 1
- 241000701806 Human papillomavirus Species 0.000 description 1
- DOMWKUIIPQCAJU-LJHIYBGHSA-N Hydroxyprogesterone caproate Chemical compound C1CC2=CC(=O)CC[C@]2(C)[C@@H]2[C@@H]1[C@@H]1CC[C@@](C(C)=O)(OC(=O)CCCCC)[C@@]1(C)CC2 DOMWKUIIPQCAJU-LJHIYBGHSA-N 0.000 description 1
- 102000016878 Hypoxia-Inducible Factor 1 Human genes 0.000 description 1
- 108010028501 Hypoxia-Inducible Factor 1 Proteins 0.000 description 1
- XDXDZDZNSLXDNA-TZNDIEGXSA-N Idarubicin Chemical compound C1[C@H](N)[C@H](O)[C@H](C)O[C@H]1O[C@@H]1C2=C(O)C(C(=O)C3=CC=CC=C3C3=O)=C3C(O)=C2C[C@@](O)(C(C)=O)C1 XDXDZDZNSLXDNA-TZNDIEGXSA-N 0.000 description 1
- XDXDZDZNSLXDNA-UHFFFAOYSA-N Idarubicin Natural products C1C(N)C(O)C(C)OC1OC1C2=C(O)C(C(=O)C3=CC=CC=C3C3=O)=C3C(O)=C2CC(O)(C(C)=O)C1 XDXDZDZNSLXDNA-UHFFFAOYSA-N 0.000 description 1
- 101150106555 Il24 gene Proteins 0.000 description 1
- 102100039813 Inactive tyrosine-protein kinase 7 Human genes 0.000 description 1
- 108010001127 Insulin Receptor Proteins 0.000 description 1
- 102100036721 Insulin receptor Human genes 0.000 description 1
- 102000012355 Integrin beta1 Human genes 0.000 description 1
- 108010022222 Integrin beta1 Proteins 0.000 description 1
- 108010047761 Interferon-alpha Proteins 0.000 description 1
- 102000006992 Interferon-alpha Human genes 0.000 description 1
- 108010050904 Interferons Proteins 0.000 description 1
- 102000014150 Interferons Human genes 0.000 description 1
- 108090000174 Interleukin-10 Proteins 0.000 description 1
- 108090000176 Interleukin-13 Proteins 0.000 description 1
- 108090000172 Interleukin-15 Proteins 0.000 description 1
- 108090000171 Interleukin-18 Proteins 0.000 description 1
- 108010002350 Interleukin-2 Proteins 0.000 description 1
- 108010065637 Interleukin-23 Proteins 0.000 description 1
- 102100036671 Interleukin-24 Human genes 0.000 description 1
- 108090000978 Interleukin-4 Proteins 0.000 description 1
- 108090001005 Interleukin-6 Proteins 0.000 description 1
- 108010002586 Interleukin-7 Proteins 0.000 description 1
- ZCYVEMRRCGMTRW-AHCXROLUSA-N Iodine-123 Chemical compound [123I] ZCYVEMRRCGMTRW-AHCXROLUSA-N 0.000 description 1
- SHGAZHPCJJPHSC-NUEINMDLSA-N Isotretinoin Chemical compound OC(=O)C=C(C)/C=C/C=C(C)C=CC1=C(C)CCCC1(C)C SHGAZHPCJJPHSC-NUEINMDLSA-N 0.000 description 1
- YINZYTTZHLPWBO-UHFFFAOYSA-N Kifunensine Natural products COC1C(O)C(O)C(O)C2NC(=O)C(=O)N12 YINZYTTZHLPWBO-UHFFFAOYSA-N 0.000 description 1
- 238000012449 Kunming mouse Methods 0.000 description 1
- 239000011786 L-ascorbyl-6-palmitate Substances 0.000 description 1
- QAQJMLQRFWZOBN-LAUBAEHRSA-N L-ascorbyl-6-palmitate Chemical compound CCCCCCCCCCCCCCCC(=O)OC[C@H](O)[C@H]1OC(=O)C(O)=C1O QAQJMLQRFWZOBN-LAUBAEHRSA-N 0.000 description 1
- 239000005411 L01XE02 - Gefitinib Substances 0.000 description 1
- 239000002147 L01XE04 - Sunitinib Substances 0.000 description 1
- UCEQXRCJXIVODC-PMACEKPBSA-N LSM-1131 Chemical compound C1CCC2=CC=CC3=C2N1C=C3[C@@H]1C(=O)NC(=O)[C@H]1C1=CNC2=CC=CC=C12 UCEQXRCJXIVODC-PMACEKPBSA-N 0.000 description 1
- 241000282838 Lama Species 0.000 description 1
- NNJVILVZKWQKPM-UHFFFAOYSA-N Lidocaine Chemical compound CCN(CC)CC(=O)NC1=C(C)C=CC=C1C NNJVILVZKWQKPM-UHFFFAOYSA-N 0.000 description 1
- 102000016200 MART-1 Antigen Human genes 0.000 description 1
- 239000012515 MabSelect SuRe Substances 0.000 description 1
- 102100021435 Macrophage-stimulating protein receptor Human genes 0.000 description 1
- 241000124008 Mammalia Species 0.000 description 1
- 229930195725 Mannitol Natural products 0.000 description 1
- 102100022430 Melanocyte protein PMEL Human genes 0.000 description 1
- 102000000440 Melanoma-associated antigen Human genes 0.000 description 1
- 108050008953 Melanoma-associated antigen Proteins 0.000 description 1
- 102100039475 Melanoma-associated antigen B5 Human genes 0.000 description 1
- 102100039483 Melanoma-associated antigen B6 Human genes 0.000 description 1
- 102100027248 Melanoma-associated antigen C3 Human genes 0.000 description 1
- 102000005741 Metalloproteases Human genes 0.000 description 1
- 108010006035 Metalloproteases Proteins 0.000 description 1
- 244000302512 Momordica charantia Species 0.000 description 1
- 235000009811 Momordica charantia Nutrition 0.000 description 1
- 241000713333 Mouse mammary tumor virus Species 0.000 description 1
- 102100023123 Mucin-16 Human genes 0.000 description 1
- 108010063954 Mucins Proteins 0.000 description 1
- 102000015728 Mucins Human genes 0.000 description 1
- 208000034578 Multiple myelomas Diseases 0.000 description 1
- 241001529936 Murinae Species 0.000 description 1
- 101100335081 Mus musculus Flt3 gene Proteins 0.000 description 1
- 101100481410 Mus musculus Tek gene Proteins 0.000 description 1
- ZDZOTLJHXYCWBA-VCVYQWHSSA-N N-debenzoyl-N-(tert-butoxycarbonyl)-10-deacetyltaxol Chemical compound O([C@H]1[C@H]2[C@@](C([C@H](O)C3=C(C)[C@@H](OC(=O)[C@H](O)[C@@H](NC(=O)OC(C)(C)C)C=4C=CC=CC=4)C[C@]1(O)C3(C)C)=O)(C)[C@@H](O)C[C@H]1OC[C@]12OC(=O)C)C(=O)C1=CC=CC=C1 ZDZOTLJHXYCWBA-VCVYQWHSSA-N 0.000 description 1
- 230000004988 N-glycosylation Effects 0.000 description 1
- 102100029166 NT-3 growth factor receptor Human genes 0.000 description 1
- 101150117329 NTRK3 gene Proteins 0.000 description 1
- 108091061960 Naked DNA Proteins 0.000 description 1
- 239000000020 Nitrocellulose Substances 0.000 description 1
- MSHZHSPISPJWHW-UHFFFAOYSA-N O-(chloroacetylcarbamoyl)fumagillol Chemical compound O1C(CC=C(C)C)C1(C)C1C(OC)C(OC(=O)NC(=O)CCl)CCC21CO2 MSHZHSPISPJWHW-UHFFFAOYSA-N 0.000 description 1
- 101150038994 PDGFRA gene Proteins 0.000 description 1
- 102000038030 PI3Ks Human genes 0.000 description 1
- 108091007960 PI3Ks Proteins 0.000 description 1
- 102100034640 PWWP domain-containing DNA repair factor 3A Human genes 0.000 description 1
- 108050007154 PWWP domain-containing DNA repair factor 3A Proteins 0.000 description 1
- 108090000526 Papain Proteins 0.000 description 1
- 102000035195 Peptidases Human genes 0.000 description 1
- 108091005804 Peptidases Proteins 0.000 description 1
- 102000000447 Peptide-N4-(N-acetyl-beta-glucosaminyl) Asparagine Amidase Human genes 0.000 description 1
- 108010055817 Peptide-N4-(N-acetyl-beta-glucosaminyl) Asparagine Amidase Proteins 0.000 description 1
- 108010081690 Pertussis Toxin Proteins 0.000 description 1
- 206010057249 Phagocytosis Diseases 0.000 description 1
- 101100413173 Phytolacca americana PAP2 gene Proteins 0.000 description 1
- 229920002732 Polyanhydride Polymers 0.000 description 1
- 229920000954 Polyglycolide Polymers 0.000 description 1
- 229920001710 Polyorthoester Polymers 0.000 description 1
- 241000288906 Primates Species 0.000 description 1
- RJKFOVLPORLFTN-LEKSSAKUSA-N Progesterone Chemical class C1CC2=CC(=O)CC[C@]2(C)[C@@H]2[C@@H]1[C@@H]1CC[C@H](C(=O)C)[C@@]1(C)CC2 RJKFOVLPORLFTN-LEKSSAKUSA-N 0.000 description 1
- 229940124158 Protease/peptidase inhibitor Drugs 0.000 description 1
- 108010076504 Protein Sorting Signals Proteins 0.000 description 1
- 241000589516 Pseudomonas Species 0.000 description 1
- 101000762949 Pseudomonas aeruginosa (strain ATCC 15692 / DSM 22644 / CIP 104116 / JCM 14847 / LMG 12228 / 1C / PRS 101 / PAO1) Exotoxin A Proteins 0.000 description 1
- 108091034057 RNA (poly(A)) Proteins 0.000 description 1
- 239000012979 RPMI medium Substances 0.000 description 1
- 241000700159 Rattus Species 0.000 description 1
- 101710100969 Receptor tyrosine-protein kinase erbB-3 Proteins 0.000 description 1
- 102100029986 Receptor tyrosine-protein kinase erbB-3 Human genes 0.000 description 1
- 102100029165 Receptor-binding cancer antigen expressed on SiSo cells Human genes 0.000 description 1
- 108020004511 Recombinant DNA Proteins 0.000 description 1
- 206010070308 Refractory cancer Diseases 0.000 description 1
- 208000006265 Renal cell carcinoma Diseases 0.000 description 1
- 208000005678 Rhabdomyoma Diseases 0.000 description 1
- 108010039491 Ricin Proteins 0.000 description 1
- AUVVAXYIELKVAI-UHFFFAOYSA-N SJ000285215 Natural products N1CCC2=CC(OC)=C(OC)C=C2C1CC1CC2C3=CC(OC)=C(OC)C=C3CCN2CC1CC AUVVAXYIELKVAI-UHFFFAOYSA-N 0.000 description 1
- 240000003946 Saponaria officinalis Species 0.000 description 1
- 108010084592 Saporins Proteins 0.000 description 1
- 206010039491 Sarcoma Diseases 0.000 description 1
- 102100021466 Sarcoma antigen 1 Human genes 0.000 description 1
- 102000014105 Semaphorin Human genes 0.000 description 1
- 108050003978 Semaphorin Proteins 0.000 description 1
- 238000012300 Sequence Analysis Methods 0.000 description 1
- 108010091769 Shiga Toxin 1 Proteins 0.000 description 1
- 108010090763 Shiga Toxin 2 Proteins 0.000 description 1
- 108010003723 Single-Domain Antibodies Proteins 0.000 description 1
- 108020004459 Small interfering RNA Proteins 0.000 description 1
- UIIMBOGNXHQVGW-UHFFFAOYSA-M Sodium bicarbonate Chemical compound [Na+].OC([O-])=O UIIMBOGNXHQVGW-UHFFFAOYSA-M 0.000 description 1
- UIRKNQLZZXALBI-MSVGPLKSSA-N Squalamine Chemical compound C([C@@H]1C[C@H]2O)[C@@H](NCCCNCCCCN)CC[C@]1(C)[C@@H]1[C@@H]2[C@@H]2CC[C@H]([C@H](C)CC[C@H](C(C)C)OS(O)(=O)=O)[C@@]2(C)CC1 UIRKNQLZZXALBI-MSVGPLKSSA-N 0.000 description 1
- UIRKNQLZZXALBI-UHFFFAOYSA-N Squalamine Natural products OC1CC2CC(NCCCNCCCCN)CCC2(C)C2C1C1CCC(C(C)CCC(C(C)C)OS(O)(=O)=O)C1(C)CC2 UIRKNQLZZXALBI-UHFFFAOYSA-N 0.000 description 1
- 108010090804 Streptavidin Proteins 0.000 description 1
- ZSJLQEPLLKMAKR-UHFFFAOYSA-N Streptozotocin Natural products O=NN(C)C(=O)NC1C(O)OC(CO)C(O)C1O ZSJLQEPLLKMAKR-UHFFFAOYSA-N 0.000 description 1
- 102000018075 Subfamily B ATP Binding Cassette Transporter Human genes 0.000 description 1
- 108010091105 Subfamily B ATP Binding Cassette Transporter Proteins 0.000 description 1
- 101800001271 Surface protein Proteins 0.000 description 1
- 108091008874 T cell receptors Proteins 0.000 description 1
- 102000016266 T-Cell Antigen Receptors Human genes 0.000 description 1
- 101150057140 TACSTD1 gene Proteins 0.000 description 1
- JXAGDPXECXQWBC-LJQANCHMSA-N Tanomastat Chemical compound C([C@H](C(=O)O)CC(=O)C=1C=CC(=CC=1)C=1C=CC(Cl)=CC=1)SC1=CC=CC=C1 JXAGDPXECXQWBC-LJQANCHMSA-N 0.000 description 1
- FEWJPZIEWOKRBE-UHFFFAOYSA-N Tartaric acid Natural products [H+].[H+].[O-]C(=O)C(O)C(O)C([O-])=O FEWJPZIEWOKRBE-UHFFFAOYSA-N 0.000 description 1
- GKLVYJBZJHMRIY-OUBTZVSYSA-N Technetium-99 Chemical compound [99Tc] GKLVYJBZJHMRIY-OUBTZVSYSA-N 0.000 description 1
- 108010017842 Telomerase Proteins 0.000 description 1
- 108010055044 Tetanus Toxin Proteins 0.000 description 1
- 101000748795 Thermus thermophilus (strain ATCC 27634 / DSM 579 / HB8) Cytochrome c oxidase polypeptide I+III Proteins 0.000 description 1
- 108060008245 Thrombospondin Proteins 0.000 description 1
- 102000002938 Thrombospondin Human genes 0.000 description 1
- 101710120037 Toxin CcdB Proteins 0.000 description 1
- 102100025256 Trafficking protein particle complex subunit 1 Human genes 0.000 description 1
- 229920001615 Tragacanth Polymers 0.000 description 1
- 229920004890 Triton X-100 Polymers 0.000 description 1
- 108060008682 Tumor Necrosis Factor Proteins 0.000 description 1
- 102000000852 Tumor Necrosis Factor-alpha Human genes 0.000 description 1
- 102400000731 Tumstatin Human genes 0.000 description 1
- 102100039094 Tyrosinase Human genes 0.000 description 1
- 108060008724 Tyrosinase Proteins 0.000 description 1
- GBOGMAARMMDZGR-UHFFFAOYSA-N UNPD149280 Natural products N1C(=O)C23OC(=O)C=CC(O)CCCC(C)CC=CC3C(O)C(=C)C(C)C2C1CC1=CC=CC=C1 GBOGMAARMMDZGR-UHFFFAOYSA-N 0.000 description 1
- 102000003990 Urokinase-type plasminogen activator Human genes 0.000 description 1
- 108090000435 Urokinase-type plasminogen activator Proteins 0.000 description 1
- 108010073929 Vascular Endothelial Growth Factor A Proteins 0.000 description 1
- 108010053099 Vascular Endothelial Growth Factor Receptor-2 Proteins 0.000 description 1
- 102000016663 Vascular Endothelial Growth Factor Receptor-3 Human genes 0.000 description 1
- 102100033177 Vascular endothelial growth factor receptor 2 Human genes 0.000 description 1
- 240000001866 Vernicia fordii Species 0.000 description 1
- 229940122803 Vinca alkaloid Drugs 0.000 description 1
- 229930003316 Vitamin D Natural products 0.000 description 1
- QYSXJUFSXHHAJI-XFEUOLMDSA-N Vitamin D3 Natural products C1(/[C@@H]2CC[C@@H]([C@]2(CCC1)C)[C@H](C)CCCC(C)C)=C/C=C1\C[C@@H](O)CCC1=C QYSXJUFSXHHAJI-XFEUOLMDSA-N 0.000 description 1
- IXKSXJFAGXLQOQ-XISFHERQSA-N WHWLQLKPGQPMY Chemical compound C([C@@H](C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)N1CCC[C@H]1C(=O)NCC(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(O)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(O)=O)NC(=O)[C@@H](N)CC=1C2=CC=CC=C2NC=1)C1=CNC=N1 IXKSXJFAGXLQOQ-XISFHERQSA-N 0.000 description 1
- ZSTCHQOKNUXHLZ-PIRIXANTSA-L [(1r,2r)-2-azanidylcyclohexyl]azanide;oxalate;pentyl n-[1-[(2r,3r,4s,5r)-3,4-dihydroxy-5-methyloxolan-2-yl]-5-fluoro-2-oxopyrimidin-4-yl]carbamate;platinum(4+) Chemical compound [Pt+4].[O-]C(=O)C([O-])=O.[NH-][C@@H]1CCCC[C@H]1[NH-].C1=C(F)C(NC(=O)OCCCCC)=NC(=O)N1[C@H]1[C@H](O)[C@H](O)[C@@H](C)O1 ZSTCHQOKNUXHLZ-PIRIXANTSA-L 0.000 description 1
- 238000002835 absorbance Methods 0.000 description 1
- 150000007513 acids Chemical class 0.000 description 1
- 229930183665 actinomycin Natural products 0.000 description 1
- 230000003213 activating effect Effects 0.000 description 1
- 208000009956 adenocarcinoma Diseases 0.000 description 1
- 239000003470 adrenal cortex hormone Substances 0.000 description 1
- 230000009824 affinity maturation Effects 0.000 description 1
- 230000008484 agonism Effects 0.000 description 1
- SHGAZHPCJJPHSC-YCNIQYBTSA-N all-trans-retinoic acid Chemical class OC(=O)\C=C(/C)\C=C\C=C(/C)\C=C\C1=C(C)CCCC1(C)C SHGAZHPCJJPHSC-YCNIQYBTSA-N 0.000 description 1
- 229940087168 alpha tocopherol Drugs 0.000 description 1
- 102000013529 alpha-Fetoproteins Human genes 0.000 description 1
- 108010026331 alpha-Fetoproteins Proteins 0.000 description 1
- 108010001818 alpha-sarcin Proteins 0.000 description 1
- 238000003016 alphascreen Methods 0.000 description 1
- 229910000147 aluminium phosphate Inorganic materials 0.000 description 1
- 208000008524 alveolar soft part sarcoma Diseases 0.000 description 1
- LXQXZNRPTYVCNG-YPZZEJLDSA-N americium-241 Chemical compound [241Am] LXQXZNRPTYVCNG-YPZZEJLDSA-N 0.000 description 1
- 150000001408 amides Chemical class 0.000 description 1
- ROBVIMPUHSLWNV-UHFFFAOYSA-N aminoglutethimide Chemical compound C=1C=C(N)C=CC=1C1(CC)CCC(=O)NC1=O ROBVIMPUHSLWNV-UHFFFAOYSA-N 0.000 description 1
- 229960003437 aminoglutethimide Drugs 0.000 description 1
- 230000003321 amplification Effects 0.000 description 1
- 238000012197 amplification kit Methods 0.000 description 1
- 239000012491 analyte Substances 0.000 description 1
- 108700024685 ancestim Proteins 0.000 description 1
- 229960002616 ancestim Drugs 0.000 description 1
- 239000002870 angiogenesis inducing agent Substances 0.000 description 1
- 239000004037 angiogenesis inhibitor Substances 0.000 description 1
- 108010072788 angiogenin Proteins 0.000 description 1
- 238000010171 animal model Methods 0.000 description 1
- 230000003042 antagnostic effect Effects 0.000 description 1
- MWPLVEDNUUSJAV-UHFFFAOYSA-N anthracene Chemical compound C1=CC=CC2=CC3=CC=CC=C3C=C21 MWPLVEDNUUSJAV-UHFFFAOYSA-N 0.000 description 1
- 230000000844 anti-bacterial effect Effects 0.000 description 1
- 230000001833 anti-estrogenic effect Effects 0.000 description 1
- 230000003388 anti-hormonal effect Effects 0.000 description 1
- 230000000259 anti-tumor effect Effects 0.000 description 1
- 230000000840 anti-viral effect Effects 0.000 description 1
- 229940030495 antiandrogen sex hormone and modulator of the genital system Drugs 0.000 description 1
- 229940088710 antibiotic agent Drugs 0.000 description 1
- 229940121375 antifungal agent Drugs 0.000 description 1
- 239000003429 antifungal agent Substances 0.000 description 1
- 239000003080 antimitotic agent Substances 0.000 description 1
- 210000000702 aorta abdominal Anatomy 0.000 description 1
- 230000005775 apoptotic pathway Effects 0.000 description 1
- 239000007864 aqueous solution Substances 0.000 description 1
- 239000008135 aqueous vehicle Substances 0.000 description 1
- 239000003886 aromatase inhibitor Substances 0.000 description 1
- 235000010323 ascorbic acid Nutrition 0.000 description 1
- 229960005070 ascorbic acid Drugs 0.000 description 1
- 239000011668 ascorbic acid Substances 0.000 description 1
- 235000010385 ascorbyl palmitate Nutrition 0.000 description 1
- 239000000305 astragalus gummifer gum Substances 0.000 description 1
- 230000035578 autophosphorylation Effects 0.000 description 1
- 230000009286 beneficial effect Effects 0.000 description 1
- FCPVYOBCFFNJFS-LQDWTQKMSA-M benzylpenicillin sodium Chemical compound [Na+].N([C@H]1[C@H]2SC([C@@H](N2C1=O)C([O-])=O)(C)C)C(=O)CC1=CC=CC=C1 FCPVYOBCFFNJFS-LQDWTQKMSA-M 0.000 description 1
- WQZGKKKJIJFFOK-VFUOTHLCSA-N beta-D-glucose Chemical compound OC[C@H]1O[C@@H](O)[C@H](O)[C@@H](O)[C@@H]1O WQZGKKKJIJFFOK-VFUOTHLCSA-N 0.000 description 1
- 238000013357 binding ELISA Methods 0.000 description 1
- 239000012148 binding buffer Substances 0.000 description 1
- 230000003115 biocidal effect Effects 0.000 description 1
- 229920002988 biodegradable polymer Polymers 0.000 description 1
- 239000004621 biodegradable polymer Substances 0.000 description 1
- 230000004071 biological effect Effects 0.000 description 1
- 239000012472 biological sample Substances 0.000 description 1
- 229960001561 bleomycin Drugs 0.000 description 1
- OYVAGSVQBOHSSS-UAPAGMARSA-O bleomycin A2 Chemical compound N([C@H](C(=O)N[C@H](C)[C@@H](O)[C@H](C)C(=O)N[C@@H]([C@H](O)C)C(=O)NCCC=1SC=C(N=1)C=1SC=C(N=1)C(=O)NCCC[S+](C)C)[C@@H](O[C@H]1[C@H]([C@@H](O)[C@H](O)[C@H](CO)O1)O[C@@H]1[C@H]([C@@H](OC(N)=O)[C@H](O)[C@@H](CO)O1)O)C=1N=CNC=1)C(=O)C1=NC([C@H](CC(N)=O)NC[C@H](N)C(N)=O)=NC(N)=C1C OYVAGSVQBOHSSS-UAPAGMARSA-O 0.000 description 1
- 230000037396 body weight Effects 0.000 description 1
- RSIHSRDYCUFFLA-DYKIIFRCSA-N boldenone Chemical compound O=C1C=C[C@]2(C)[C@H]3CC[C@](C)([C@H](CC4)O)[C@@H]4[C@@H]3CCC2=C1 RSIHSRDYCUFFLA-DYKIIFRCSA-N 0.000 description 1
- 210000001185 bone marrow Anatomy 0.000 description 1
- 210000000481 breast Anatomy 0.000 description 1
- CUWODFFVMXJOKD-UVLQAERKSA-N buserelin Chemical compound CCNC(=O)[C@@H]1CCCN1C(=O)[C@H](CCCN=C(N)N)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](COC(C)(C)C)NC(=O)[C@@H](NC(=O)[C@H](CO)NC(=O)[C@H](CC=1C2=CC=CC=C2NC=1)NC(=O)[C@H](CC=1NC=NC=1)NC(=O)[C@H]1NC(=O)CC1)CC1=CC=C(O)C=C1 CUWODFFVMXJOKD-UVLQAERKSA-N 0.000 description 1
- 229960002719 buserelin Drugs 0.000 description 1
- DQXBYHZEEUGOBF-UHFFFAOYSA-N but-3-enoic acid;ethene Chemical compound C=C.OC(=O)CC=C DQXBYHZEEUGOBF-UHFFFAOYSA-N 0.000 description 1
- 235000019282 butylated hydroxyanisole Nutrition 0.000 description 1
- 229940043253 butylated hydroxyanisole Drugs 0.000 description 1
- CZBZUDVBLSSABA-UHFFFAOYSA-N butylated hydroxyanisole Chemical compound COC1=CC=C(O)C(C(C)(C)C)=C1.COC1=CC=C(O)C=C1C(C)(C)C CZBZUDVBLSSABA-UHFFFAOYSA-N 0.000 description 1
- 235000010354 butylated hydroxytoluene Nutrition 0.000 description 1
- 229940095259 butylated hydroxytoluene Drugs 0.000 description 1
- 238000010804 cDNA synthesis Methods 0.000 description 1
- 229940046731 calcineurin inhibitors Drugs 0.000 description 1
- 244000309466 calf Species 0.000 description 1
- 230000036952 cancer formation Effects 0.000 description 1
- 208000035269 cancer or benign tumor Diseases 0.000 description 1
- 229960004117 capecitabine Drugs 0.000 description 1
- FAKRSMQSSFJEIM-RQJHMYQMSA-N captopril Chemical compound SC[C@@H](C)C(=O)N1CCC[C@H]1C(O)=O FAKRSMQSSFJEIM-RQJHMYQMSA-N 0.000 description 1
- 229960000830 captopril Drugs 0.000 description 1
- JJWKPURADFRFRB-UHFFFAOYSA-N carbonyl sulfide Chemical compound O=C=S JJWKPURADFRFRB-UHFFFAOYSA-N 0.000 description 1
- 125000003178 carboxy group Chemical group [H]OC(*)=O 0.000 description 1
- 239000001768 carboxy methyl cellulose Substances 0.000 description 1
- 235000010948 carboxy methyl cellulose Nutrition 0.000 description 1
- 239000008112 carboxymethyl-cellulose Substances 0.000 description 1
- 231100000504 carcinogenesis Toxicity 0.000 description 1
- 231100001012 cardiac lesion Toxicity 0.000 description 1
- 239000000969 carrier Substances 0.000 description 1
- 239000005018 casein Substances 0.000 description 1
- BECPQYXYKAMYBN-UHFFFAOYSA-N casein, tech. Chemical compound NCCCCC(C(O)=O)N=C(O)C(CC(O)=O)N=C(O)C(CCC(O)=N)N=C(O)C(CC(C)C)N=C(O)C(CCC(O)=O)N=C(O)C(CC(O)=O)N=C(O)C(CCC(O)=O)N=C(O)C(C(C)O)N=C(O)C(CCC(O)=N)N=C(O)C(CCC(O)=N)N=C(O)C(CCC(O)=N)N=C(O)C(CCC(O)=O)N=C(O)C(CCC(O)=O)N=C(O)C(COP(O)(O)=O)N=C(O)C(CCC(O)=N)N=C(O)C(N)CC1=CC=CC=C1 BECPQYXYKAMYBN-UHFFFAOYSA-N 0.000 description 1
- 235000021240 caseins Nutrition 0.000 description 1
- 230000015556 catabolic process Effects 0.000 description 1
- 150000001768 cations Chemical class 0.000 description 1
- 238000000423 cell based assay Methods 0.000 description 1
- 230000022131 cell cycle Effects 0.000 description 1
- 230000006037 cell lysis Effects 0.000 description 1
- 238000001516 cell proliferation assay Methods 0.000 description 1
- 238000005119 centrifugation Methods 0.000 description 1
- TVFDJXOCXUVLDH-RNFDNDRNSA-N cesium-137 Chemical compound [137Cs] TVFDJXOCXUVLDH-RNFDNDRNSA-N 0.000 description 1
- 238000012512 characterization method Methods 0.000 description 1
- NDAYQJDHGXTBJL-MWWSRJDJSA-N chembl557217 Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@@H](CC(C)C)NC(=O)[C@H](CC=3C4=CC=CC=C4NC=3)NC(=O)[C@@H](CC(C)C)NC(=O)[C@H](CC=3C4=CC=CC=C4NC=3)NC(=O)[C@@H](CC(C)C)NC(=O)[C@H](CC=3C4=CC=CC=C4NC=3)NC(=O)[C@@H](C(C)C)NC(=O)[C@H](C(C)C)NC(=O)[C@@H](C(C)C)NC(=O)[C@H](C)NC(=O)[C@H](NC(=O)CNC(=O)[C@@H](NC=O)C(C)C)CC(C)C)C(=O)NCCO)=CNC2=C1 NDAYQJDHGXTBJL-MWWSRJDJSA-N 0.000 description 1
- 239000003638 chemical reducing agent Substances 0.000 description 1
- 230000000973 chemotherapeutic effect Effects 0.000 description 1
- 229940044683 chemotherapy drug Drugs 0.000 description 1
- 239000013611 chromosomal DNA Substances 0.000 description 1
- 210000000349 chromosome Anatomy 0.000 description 1
- 208000020832 chronic kidney disease Diseases 0.000 description 1
- 208000022831 chronic renal failure syndrome Diseases 0.000 description 1
- 238000003776 cleavage reaction Methods 0.000 description 1
- 238000012761 co-transfection Methods 0.000 description 1
- GUTLYIVDDKVIGB-YPZZEJLDSA-N cobalt-57 Chemical compound [57Co] GUTLYIVDDKVIGB-YPZZEJLDSA-N 0.000 description 1
- 229960001338 colchicine Drugs 0.000 description 1
- 238000002648 combination therapy Methods 0.000 description 1
- 150000004814 combretastatins Chemical class 0.000 description 1
- 230000001609 comparable effect Effects 0.000 description 1
- 230000000052 comparative effect Effects 0.000 description 1
- 230000004154 complement system Effects 0.000 description 1
- 230000001268 conjugating effect Effects 0.000 description 1
- 230000006552 constitutive activation Effects 0.000 description 1
- 239000013068 control sample Substances 0.000 description 1
- 238000013270 controlled release Methods 0.000 description 1
- 229910052802 copper Inorganic materials 0.000 description 1
- 239000010949 copper Substances 0.000 description 1
- RYGMFSIKBFXOCR-AKLPVKDBSA-N copper-67 Chemical compound [67Cu] RYGMFSIKBFXOCR-AKLPVKDBSA-N 0.000 description 1
- 208000029078 coronary artery disease Diseases 0.000 description 1
- 239000013078 crystal Substances 0.000 description 1
- 238000005520 cutting process Methods 0.000 description 1
- 229960001305 cysteine hydrochloride Drugs 0.000 description 1
- GBOGMAARMMDZGR-TYHYBEHESA-N cytochalasin B Chemical compound C([C@H]1[C@@H]2[C@@H](C([C@@H](O)[C@@H]3/C=C/C[C@H](C)CCC[C@@H](O)/C=C/C(=O)O[C@@]23C(=O)N1)=C)C)C1=CC=CC=C1 GBOGMAARMMDZGR-TYHYBEHESA-N 0.000 description 1
- GBOGMAARMMDZGR-JREHFAHYSA-N cytochalasin B Natural products C[C@H]1CCC[C@@H](O)C=CC(=O)O[C@@]23[C@H](C=CC1)[C@H](O)C(=C)[C@@H](C)[C@@H]2[C@H](Cc4ccccc4)NC3=O GBOGMAARMMDZGR-JREHFAHYSA-N 0.000 description 1
- 230000001086 cytosolic effect Effects 0.000 description 1
- 239000000824 cytostatic agent Substances 0.000 description 1
- 229940127089 cytotoxic agent Drugs 0.000 description 1
- 229960003901 dacarbazine Drugs 0.000 description 1
- 229960004969 dalteparin Drugs 0.000 description 1
- 229960002204 daratumumab Drugs 0.000 description 1
- 238000007405 data analysis Methods 0.000 description 1
- 230000003247 decreasing effect Effects 0.000 description 1
- 239000007857 degradation product Substances 0.000 description 1
- RSIHSRDYCUFFLA-UHFFFAOYSA-N dehydrotestosterone Natural products O=C1C=CC2(C)C3CCC(C)(C(CC4)O)C4C3CCC2=C1 RSIHSRDYCUFFLA-UHFFFAOYSA-N 0.000 description 1
- CFCUWKMKBJTWLW-UHFFFAOYSA-N deoliosyl-3C-alpha-L-digitoxosyl-MTM Natural products CC=1C(O)=C2C(O)=C3C(=O)C(OC4OC(C)C(O)C(OC5OC(C)C(O)C(OC6OC(C)C(O)C(C)(O)C6)C5)C4)C(C(OC)C(=O)C(O)C(C)O)CC3=CC2=CC=1OC(OC(C)C1O)CC1OC1CC(O)C(O)C(C)O1 CFCUWKMKBJTWLW-UHFFFAOYSA-N 0.000 description 1
- 230000001627 detrimental effect Effects 0.000 description 1
- 238000011161 development Methods 0.000 description 1
- 230000018109 developmental process Effects 0.000 description 1
- 239000008121 dextrose Substances 0.000 description 1
- 238000000502 dialysis Methods 0.000 description 1
- RGLYKWWBQGJZGM-ISLYRVAYSA-N diethylstilbestrol Chemical compound C=1C=C(O)C=CC=1C(/CC)=C(\CC)C1=CC=C(O)C=C1 RGLYKWWBQGJZGM-ISLYRVAYSA-N 0.000 description 1
- 229960000452 diethylstilbestrol Drugs 0.000 description 1
- 230000004069 differentiation Effects 0.000 description 1
- 230000029087 digestion Effects 0.000 description 1
- 239000003085 diluting agent Substances 0.000 description 1
- 206010013023 diphtheria Diseases 0.000 description 1
- VHJLVAABSRFDPM-QWWZWVQMSA-N dithiothreitol Chemical compound SC[C@@H](O)[C@H](O)CS VHJLVAABSRFDPM-QWWZWVQMSA-N 0.000 description 1
- 239000003534 dna topoisomerase inhibitor Substances 0.000 description 1
- 229960003668 docetaxel Drugs 0.000 description 1
- 239000002552 dosage form Substances 0.000 description 1
- 231100000673 dose–response relationship Toxicity 0.000 description 1
- 230000007783 downstream signaling Effects 0.000 description 1
- 229950004203 droloxifene Drugs 0.000 description 1
- 239000000975 dye Substances 0.000 description 1
- 238000000132 electrospray ionisation Methods 0.000 description 1
- 239000012149 elution buffer Substances 0.000 description 1
- 229960002694 emetine Drugs 0.000 description 1
- AUVVAXYIELKVAI-CKBKHPSWSA-N emetine Chemical compound N1CCC2=CC(OC)=C(OC)C=C2[C@H]1C[C@H]1C[C@H]2C3=CC(OC)=C(OC)C=C3CCN2C[C@@H]1CC AUVVAXYIELKVAI-CKBKHPSWSA-N 0.000 description 1
- AUVVAXYIELKVAI-UWBTVBNJSA-N emetine Natural products N1CCC2=CC(OC)=C(OC)C=C2[C@H]1C[C@H]1C[C@H]2C3=CC(OC)=C(OC)C=C3CCN2C[C@H]1CC AUVVAXYIELKVAI-UWBTVBNJSA-N 0.000 description 1
- 239000003995 emulsifying agent Substances 0.000 description 1
- 239000002158 endotoxin Substances 0.000 description 1
- 108010028531 enomycin Proteins 0.000 description 1
- 230000029578 entry into host Effects 0.000 description 1
- 230000002255 enzymatic effect Effects 0.000 description 1
- 229940088598 enzyme Drugs 0.000 description 1
- 229940116977 epidermal growth factor Drugs 0.000 description 1
- 229960001904 epirubicin Drugs 0.000 description 1
- 230000007705 epithelial mesenchymal transition Effects 0.000 description 1
- 239000000328 estrogen antagonist Substances 0.000 description 1
- ZMMJGEGLRURXTF-UHFFFAOYSA-N ethidium bromide Chemical compound [Br-].C12=CC(N)=CC=C2C2=CC=C(N)C=C2[N+](CC)=C1C1=CC=CC=C1 ZMMJGEGLRURXTF-UHFFFAOYSA-N 0.000 description 1
- 229960005542 ethidium bromide Drugs 0.000 description 1
- 229960002568 ethinylestradiol Drugs 0.000 description 1
- LVGKNOAMLMIIKO-QXMHVHEDSA-N ethyl oleate Chemical compound CCCCCCCC\C=C/CCCCCCCC(=O)OCC LVGKNOAMLMIIKO-QXMHVHEDSA-N 0.000 description 1
- 229940093471 ethyl oleate Drugs 0.000 description 1
- 239000005038 ethylene vinyl acetate Substances 0.000 description 1
- 238000011156 evaluation Methods 0.000 description 1
- 238000000802 evaporation-induced self-assembly Methods 0.000 description 1
- 229960005167 everolimus Drugs 0.000 description 1
- 230000029142 excretion Effects 0.000 description 1
- 230000001747 exhibiting effect Effects 0.000 description 1
- 230000002349 favourable effect Effects 0.000 description 1
- 239000012091 fetal bovine serum Substances 0.000 description 1
- 210000002950 fibroblast Anatomy 0.000 description 1
- 229940126864 fibroblast growth factor Drugs 0.000 description 1
- 239000000945 filler Substances 0.000 description 1
- 229960000556 fingolimod Drugs 0.000 description 1
- KKGQTZUTZRNORY-UHFFFAOYSA-N fingolimod Chemical compound CCCCCCCCC1=CC=C(CCC(N)(CO)CO)C=C1 KKGQTZUTZRNORY-UHFFFAOYSA-N 0.000 description 1
- 239000000834 fixative Substances 0.000 description 1
- MKXKFYHWDHIYRV-UHFFFAOYSA-N flutamide Chemical compound CC(C)C(=O)NC1=CC=C([N+]([O-])=O)C(C(F)(F)F)=C1 MKXKFYHWDHIYRV-UHFFFAOYSA-N 0.000 description 1
- JYEFSHLLTQIXIO-SMNQTINBSA-N folfiri regimen Chemical compound FC1=CNC(=O)NC1=O.C1NC=2NC(N)=NC(=O)C=2N(C=O)C1CNC1=CC=C(C(=O)N[C@@H](CCC(O)=O)C(O)=O)C=C1.C1=C2C(CC)=C3CN(C(C4=C([C@@](C(=O)OC4)(O)CC)C=4)=O)C=4C3=NC2=CC=C1OC(=O)N(CC1)CCC1N1CCCCC1 JYEFSHLLTQIXIO-SMNQTINBSA-N 0.000 description 1
- 235000019253 formic acid Nutrition 0.000 description 1
- 238000013467 fragmentation Methods 0.000 description 1
- 238000006062 fragmentation reaction Methods 0.000 description 1
- 238000004108 freeze drying Methods 0.000 description 1
- 229960002258 fulvestrant Drugs 0.000 description 1
- 229960000936 fumagillin Drugs 0.000 description 1
- NGGMYCMLYOUNGM-CSDLUJIJSA-N fumagillin Chemical compound C([C@H]([C@H]([C@@H]1[C@]2(C)[C@H](O2)CC=C(C)C)OC)OC(=O)\C=C\C=C\C=C\C=C\C(O)=O)C[C@@]21CO2 NGGMYCMLYOUNGM-CSDLUJIJSA-N 0.000 description 1
- 108020001507 fusion proteins Proteins 0.000 description 1
- 102000037865 fusion proteins Human genes 0.000 description 1
- 150000002270 gangliosides Chemical class 0.000 description 1
- 201000006585 gastric adenocarcinoma Diseases 0.000 description 1
- 230000002496 gastric effect Effects 0.000 description 1
- 229960002584 gefitinib Drugs 0.000 description 1
- 239000008273 gelatin Substances 0.000 description 1
- 229920000159 gelatin Polymers 0.000 description 1
- 229940014259 gelatin Drugs 0.000 description 1
- 235000019322 gelatine Nutrition 0.000 description 1
- 235000011852 gelatine desserts Nutrition 0.000 description 1
- 230000030279 gene silencing Effects 0.000 description 1
- 229960002518 gentamicin Drugs 0.000 description 1
- 229940080856 gleevec Drugs 0.000 description 1
- 239000003862 glucocorticoid Substances 0.000 description 1
- ZDXPYRJPNDTMRX-UHFFFAOYSA-N glutamine Natural products OC(=O)C(N)CCC(N)=O ZDXPYRJPNDTMRX-UHFFFAOYSA-N 0.000 description 1
- 102000005396 glutamine synthetase Human genes 0.000 description 1
- 108020002326 glutamine synthetase Proteins 0.000 description 1
- 229940074045 glyceryl distearate Drugs 0.000 description 1
- 229940075507 glyceryl monostearate Drugs 0.000 description 1
- PCHJSUWPFVWCPO-OUBTZVSYSA-N gold-198 Chemical compound [198Au] PCHJSUWPFVWCPO-OUBTZVSYSA-N 0.000 description 1
- 229960002913 goserelin Drugs 0.000 description 1
- 210000003714 granulocyte Anatomy 0.000 description 1
- 101150098203 grb2 gene Proteins 0.000 description 1
- 230000003394 haemopoietic effect Effects 0.000 description 1
- 210000003128 head Anatomy 0.000 description 1
- 108060003552 hemocyanin Proteins 0.000 description 1
- 239000002628 heparin derivative Substances 0.000 description 1
- 230000002440 hepatic effect Effects 0.000 description 1
- HNDVDQJCIGZPNO-UHFFFAOYSA-N histidine Natural products OC(=O)C(N)CC1=CN=CN1 HNDVDQJCIGZPNO-UHFFFAOYSA-N 0.000 description 1
- 238000011905 homologation Methods 0.000 description 1
- 238000001794 hormone therapy Methods 0.000 description 1
- 229940048921 humira Drugs 0.000 description 1
- 229960000890 hydrocortisone Drugs 0.000 description 1
- 229950000801 hydroxyprogesterone caproate Drugs 0.000 description 1
- 229960000908 idarubicin Drugs 0.000 description 1
- YLMAHDNUQAMNNX-UHFFFAOYSA-N imatinib methanesulfonate Chemical compound CS(O)(=O)=O.C1CN(C)CCN1CC1=CC=C(C(=O)NC=2C=C(NC=3N=C(C=CN=3)C=3C=NC=CC=3)C(C)=CC=2)C=C1 YLMAHDNUQAMNNX-UHFFFAOYSA-N 0.000 description 1
- 238000001597 immobilized metal affinity chromatography Methods 0.000 description 1
- 230000028993 immune response Effects 0.000 description 1
- 229960003444 immunosuppressant agent Drugs 0.000 description 1
- 230000001861 immunosuppressant effect Effects 0.000 description 1
- 239000003018 immunosuppressive agent Substances 0.000 description 1
- 239000002596 immunotoxin Substances 0.000 description 1
- 229940051026 immunotoxin Drugs 0.000 description 1
- 230000002637 immunotoxin Effects 0.000 description 1
- 231100000608 immunotoxin Toxicity 0.000 description 1
- 239000007943 implant Substances 0.000 description 1
- 230000001976 improved effect Effects 0.000 description 1
- 230000006872 improvement Effects 0.000 description 1
- 230000002779 inactivation Effects 0.000 description 1
- 229940055742 indium-111 Drugs 0.000 description 1
- APFVFJFRJDLVQX-AHCXROLUSA-N indium-111 Chemical compound [111In] APFVFJFRJDLVQX-AHCXROLUSA-N 0.000 description 1
- 239000000411 inducer Substances 0.000 description 1
- 238000005305 interferometry Methods 0.000 description 1
- 229940079322 interferon Drugs 0.000 description 1
- 102000003898 interleukin-24 Human genes 0.000 description 1
- 238000001361 intraarterial administration Methods 0.000 description 1
- 238000007917 intracranial administration Methods 0.000 description 1
- 238000007913 intrathecal administration Methods 0.000 description 1
- 238000010253 intravenous injection Methods 0.000 description 1
- 150000002500 ions Chemical class 0.000 description 1
- 229960005386 ipilimumab Drugs 0.000 description 1
- GKOZUEZYRPOHIO-IGMARMGPSA-N iridium-192 Chemical compound [192Ir] GKOZUEZYRPOHIO-IGMARMGPSA-N 0.000 description 1
- 229960005280 isotretinoin Drugs 0.000 description 1
- 229960002014 ixabepilone Drugs 0.000 description 1
- FABUFPQFXZVHFB-CFWQTKTJSA-N ixabepilone Chemical compound C/C([C@@H]1C[C@@H]2O[C@]2(C)CCC[C@@H]([C@@H]([C@H](C)C(=O)C(C)(C)[C@H](O)CC(=O)N1)O)C)=C\C1=CSC(C)=N1 FABUFPQFXZVHFB-CFWQTKTJSA-N 0.000 description 1
- 108010045069 keyhole-limpet hemocyanin Proteins 0.000 description 1
- 210000003734 kidney Anatomy 0.000 description 1
- OIURYJWYVIAOCW-VFUOTHLCSA-N kifunensine Chemical compound OC[C@@H]1[C@@H](O)[C@H](O)[C@@H](O)[C@@H]2NC(=O)C(=O)N12 OIURYJWYVIAOCW-VFUOTHLCSA-N 0.000 description 1
- 230000002045 lasting effect Effects 0.000 description 1
- 239000004816 latex Substances 0.000 description 1
- 229920000126 latex Polymers 0.000 description 1
- 229960004194 lidocaine Drugs 0.000 description 1
- 230000000670 limiting effect Effects 0.000 description 1
- 238000004895 liquid chromatography mass spectrometry Methods 0.000 description 1
- 230000004807 localization Effects 0.000 description 1
- DHMTURDWPRKSOA-RUZDIDTESA-N lonafarnib Chemical compound C1CN(C(=O)N)CCC1CC(=O)N1CCC([C@@H]2C3=C(Br)C=C(Cl)C=C3CCC3=CC(Br)=CN=C32)CC1 DHMTURDWPRKSOA-RUZDIDTESA-N 0.000 description 1
- 210000004072 lung Anatomy 0.000 description 1
- 201000005249 lung adenocarcinoma Diseases 0.000 description 1
- 210000002540 macrophage Anatomy 0.000 description 1
- 238000009115 maintenance therapy Methods 0.000 description 1
- 230000036210 malignancy Effects 0.000 description 1
- 230000003211 malignant effect Effects 0.000 description 1
- 239000000594 mannitol Substances 0.000 description 1
- 235000010355 mannitol Nutrition 0.000 description 1
- 229950008959 marimastat Drugs 0.000 description 1
- OCSMOTCMPXTDND-OUAUKWLOSA-N marimastat Chemical compound CNC(=O)[C@H](C(C)(C)C)NC(=O)[C@H](CC(C)C)[C@H](O)C(=O)NO OCSMOTCMPXTDND-OUAUKWLOSA-N 0.000 description 1
- 238000001819 mass spectrum Methods 0.000 description 1
- 108010082117 matrigel Proteins 0.000 description 1
- 239000011159 matrix material Substances 0.000 description 1
- 230000035800 maturation Effects 0.000 description 1
- 238000005259 measurement Methods 0.000 description 1
- 229960004616 medroxyprogesterone Drugs 0.000 description 1
- 229940090004 megace Drugs 0.000 description 1
- 229960004296 megestrol acetate Drugs 0.000 description 1
- 229910052751 metal Inorganic materials 0.000 description 1
- 239000002184 metal Substances 0.000 description 1
- 230000009401 metastasis Effects 0.000 description 1
- 208000037819 metastatic cancer Diseases 0.000 description 1
- 208000011575 metastatic malignant neoplasm Diseases 0.000 description 1
- 238000001471 micro-filtration Methods 0.000 description 1
- 238000012737 microarray-based gene expression Methods 0.000 description 1
- 235000013336 milk Nutrition 0.000 description 1
- 239000008267 milk Substances 0.000 description 1
- 210000004080 milk Anatomy 0.000 description 1
- 238000001823 molecular biology technique Methods 0.000 description 1
- 238000003032 molecular docking Methods 0.000 description 1
- 238000012544 monitoring process Methods 0.000 description 1
- 210000001616 monocyte Anatomy 0.000 description 1
- 238000012243 multiplex automated genomic engineering Methods 0.000 description 1
- 210000003205 muscle Anatomy 0.000 description 1
- 201000000050 myeloid neoplasm Diseases 0.000 description 1
- 210000003739 neck Anatomy 0.000 description 1
- 230000010807 negative regulation of binding Effects 0.000 description 1
- 230000009826 neoplastic cell growth Effects 0.000 description 1
- 238000004848 nephelometry Methods 0.000 description 1
- 229920001220 nitrocellulos Polymers 0.000 description 1
- 239000002687 nonaqueous vehicle Substances 0.000 description 1
- 230000036963 noncompetitive effect Effects 0.000 description 1
- 238000003199 nucleic acid amplification method Methods 0.000 description 1
- 229960002700 octreotide Drugs 0.000 description 1
- 229960002450 ofatumumab Drugs 0.000 description 1
- CKNAQFVBEHDJQV-UHFFFAOYSA-N oltipraz Chemical compound S1SC(=S)C(C)=C1C1=CN=CC=N1 CKNAQFVBEHDJQV-UHFFFAOYSA-N 0.000 description 1
- 229950008687 oltipraz Drugs 0.000 description 1
- 238000011275 oncology therapy Methods 0.000 description 1
- 210000000056 organ Anatomy 0.000 description 1
- 150000002895 organic esters Chemical class 0.000 description 1
- 230000002611 ovarian Effects 0.000 description 1
- 230000002018 overexpression Effects 0.000 description 1
- 229960001756 oxaliplatin Drugs 0.000 description 1
- DWAFYCQODLXJNR-BNTLRKBRSA-L oxaliplatin Chemical compound O1C(=O)C(=O)O[Pt]11N[C@@H]2CCCC[C@H]2N1 DWAFYCQODLXJNR-BNTLRKBRSA-L 0.000 description 1
- 210000000496 pancreas Anatomy 0.000 description 1
- 229940055729 papain Drugs 0.000 description 1
- 235000019834 papain Nutrition 0.000 description 1
- 229960002566 papillomavirus vaccine Drugs 0.000 description 1
- 239000002245 particle Substances 0.000 description 1
- 230000008506 pathogenesis Effects 0.000 description 1
- 230000037361 pathway Effects 0.000 description 1
- 229960001639 penicillamine Drugs 0.000 description 1
- 229940043138 pentosan polysulfate Drugs 0.000 description 1
- 239000000137 peptide hydrolase inhibitor Substances 0.000 description 1
- 238000010647 peptide synthesis reaction Methods 0.000 description 1
- 210000001322 periplasm Anatomy 0.000 description 1
- 230000008782 phagocytosis Effects 0.000 description 1
- 239000008363 phosphate buffer Substances 0.000 description 1
- 238000003566 phosphorylation assay Methods 0.000 description 1
- 239000013600 plasmid vector Substances 0.000 description 1
- 229920001200 poly(ethylene-vinyl acetate) Polymers 0.000 description 1
- 229920000747 poly(lactic acid) Polymers 0.000 description 1
- 229920001583 poly(oxyethylated polyols) Polymers 0.000 description 1
- 239000004633 polyglycolic acid Substances 0.000 description 1
- 239000004626 polylactic acid Substances 0.000 description 1
- 229920005862 polyol Polymers 0.000 description 1
- 150000003077 polyols Chemical class 0.000 description 1
- 235000010482 polyoxyethylene sorbitan monooleate Nutrition 0.000 description 1
- 229920000053 polysorbate 80 Polymers 0.000 description 1
- 239000001608 potassium adipate Substances 0.000 description 1
- 230000003389 potentiating effect Effects 0.000 description 1
- 229960004618 prednisone Drugs 0.000 description 1
- XOFYZVNMUHMLCC-ZPOLXVRWSA-N prednisone Chemical compound O=C1C=C[C@]2(C)[C@H]3C(=O)C[C@](C)([C@@](CC4)(O)C(=O)CO)[C@@H]4[C@@H]3CCC2=C1 XOFYZVNMUHMLCC-ZPOLXVRWSA-N 0.000 description 1
- 125000002924 primary amino group Chemical group [H]N([H])* 0.000 description 1
- 229950003608 prinomastat Drugs 0.000 description 1
- YKPYIPVDTNNYCN-INIZCTEOSA-N prinomastat Chemical compound ONC(=O)[C@H]1C(C)(C)SCCN1S(=O)(=O)C(C=C1)=CC=C1OC1=CC=NC=C1 YKPYIPVDTNNYCN-INIZCTEOSA-N 0.000 description 1
- 229960004919 procaine Drugs 0.000 description 1
- MFDFERRIHVXMIY-UHFFFAOYSA-N procaine Chemical compound CCN(CC)CCOC(=O)C1=CC=C(N)C=C1 MFDFERRIHVXMIY-UHFFFAOYSA-N 0.000 description 1
- 239000000583 progesterone congener Substances 0.000 description 1
- 229960003712 propranolol Drugs 0.000 description 1
- 125000001436 propyl group Chemical group [H]C([*])([H])C([H])([H])C([H])([H])[H] 0.000 description 1
- 239000002599 prostaglandin synthase inhibitor Substances 0.000 description 1
- 235000019419 proteases Nutrition 0.000 description 1
- 230000004224 protection Effects 0.000 description 1
- 238000002731 protein assay Methods 0.000 description 1
- 229940063222 provera Drugs 0.000 description 1
- 229950010131 puromycin Drugs 0.000 description 1
- 230000002285 radioactive effect Effects 0.000 description 1
- 239000012217 radiopharmaceutical Substances 0.000 description 1
- 229940121896 radiopharmaceutical Drugs 0.000 description 1
- 230000002799 radiopharmaceutical effect Effects 0.000 description 1
- GZUITABIAKMVPG-UHFFFAOYSA-N raloxifene Chemical compound C1=CC(O)=CC=C1C1=C(C(=O)C=2C=CC(OCCN3CCCCC3)=CC=2)C2=CC=C(O)C=C2S1 GZUITABIAKMVPG-UHFFFAOYSA-N 0.000 description 1
- 229960004622 raloxifene Drugs 0.000 description 1
- 238000002708 random mutagenesis Methods 0.000 description 1
- 229960003876 ranibizumab Drugs 0.000 description 1
- 108700015048 receptor decoy activity proteins Proteins 0.000 description 1
- 102000027426 receptor tyrosine kinases Human genes 0.000 description 1
- 108091008598 receptor tyrosine kinases Proteins 0.000 description 1
- 230000006798 recombination Effects 0.000 description 1
- 238000005215 recombination Methods 0.000 description 1
- 230000007115 recruitment Effects 0.000 description 1
- 208000016691 refractory malignant neoplasm Diseases 0.000 description 1
- 230000022983 regulation of cell cycle Effects 0.000 description 1
- 230000024833 regulation of cytokine production Effects 0.000 description 1
- 229940116176 remicade Drugs 0.000 description 1
- 230000008439 repair process Effects 0.000 description 1
- 230000010076 replication Effects 0.000 description 1
- 239000012508 resin bead Substances 0.000 description 1
- 150000004508 retinoic acid derivatives Chemical class 0.000 description 1
- 230000001177 retroviral effect Effects 0.000 description 1
- 238000012552 review Methods 0.000 description 1
- 201000009410 rhabdomyosarcoma Diseases 0.000 description 1
- 229960004641 rituximab Drugs 0.000 description 1
- 235000002020 sage Nutrition 0.000 description 1
- 150000003839 salts Chemical class 0.000 description 1
- 229940072272 sandostatin Drugs 0.000 description 1
- 229920006395 saturated elastomer Polymers 0.000 description 1
- 230000007017 scission Effects 0.000 description 1
- 238000012216 screening Methods 0.000 description 1
- 238000007423 screening assay Methods 0.000 description 1
- WUWDLXZGHZSWQZ-WQLSENKSSA-N semaxanib Chemical compound N1C(C)=CC(C)=C1\C=C/1C2=CC=CC=C2NC\1=O WUWDLXZGHZSWQZ-WQLSENKSSA-N 0.000 description 1
- LVLLALCJVJNGQQ-ZCPUWASBSA-N seocalcitol Chemical compound C1(/[C@H]2CC[C@@H]([C@@]2(CCC1)C)[C@H](C)/C=C/C=C/C(O)(CC)CC)=C/C=C1/C[C@H](O)C[C@@H](O)C1=C LVLLALCJVJNGQQ-ZCPUWASBSA-N 0.000 description 1
- 229950009921 seocalcitol Drugs 0.000 description 1
- 238000000926 separation method Methods 0.000 description 1
- 238000002864 sequence alignment Methods 0.000 description 1
- 238000013207 serial dilution Methods 0.000 description 1
- 239000012679 serum free medium Substances 0.000 description 1
- 238000004904 shortening Methods 0.000 description 1
- 229940115586 simulect Drugs 0.000 description 1
- 238000002741 site-directed mutagenesis Methods 0.000 description 1
- 150000003384 small molecules Chemical class 0.000 description 1
- WBHQBSYUUJJSRZ-UHFFFAOYSA-M sodium bisulfate Chemical compound [Na+].OS([O-])(=O)=O WBHQBSYUUJJSRZ-UHFFFAOYSA-M 0.000 description 1
- 229910000342 sodium bisulfate Inorganic materials 0.000 description 1
- 229940100996 sodium bisulfate Drugs 0.000 description 1
- HRZFUMHJMZEROT-UHFFFAOYSA-L sodium disulfite Chemical compound [Na+].[Na+].[O-]S(=O)S([O-])(=O)=O HRZFUMHJMZEROT-UHFFFAOYSA-L 0.000 description 1
- 229940001584 sodium metabisulfite Drugs 0.000 description 1
- 235000010262 sodium metabisulphite Nutrition 0.000 description 1
- 229940001482 sodium sulfite Drugs 0.000 description 1
- 235000010265 sodium sulphite Nutrition 0.000 description 1
- 239000007787 solid Substances 0.000 description 1
- 210000001082 somatic cell Anatomy 0.000 description 1
- NHXLMOGPVYXJNR-ATOGVRKGSA-N somatostatin Chemical class C([C@H]1C(=O)N[C@H](C(N[C@@H](CO)C(=O)N[C@@H](CSSC[C@@H](C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC=2C=CC=CC=2)C(=O)N[C@@H](CC=2C=CC=CC=2)C(=O)N[C@@H](CC=2C3=CC=CC=C3NC=2)C(=O)N[C@@H](CCCCN)C(=O)N[C@H](C(=O)N1)[C@@H](C)O)NC(=O)CNC(=O)[C@H](C)N)C(O)=O)=O)[C@H](O)C)C1=CC=CC=C1 NHXLMOGPVYXJNR-ATOGVRKGSA-N 0.000 description 1
- 229940075620 somatostatin analogue Drugs 0.000 description 1
- 235000003687 soy isoflavones Nutrition 0.000 description 1
- 125000006850 spacer group Chemical group 0.000 description 1
- 238000001228 spectrum Methods 0.000 description 1
- 210000000952 spleen Anatomy 0.000 description 1
- 230000003393 splenic effect Effects 0.000 description 1
- 229950001248 squalamine Drugs 0.000 description 1
- 239000003381 stabilizer Substances 0.000 description 1
- 239000008174 sterile solution Substances 0.000 description 1
- 230000001954 sterilising effect Effects 0.000 description 1
- 238000004659 sterilization and disinfection Methods 0.000 description 1
- 238000003756 stirring Methods 0.000 description 1
- 229960002385 streptomycin sulfate Drugs 0.000 description 1
- 238000010254 subcutaneous injection Methods 0.000 description 1
- 239000007929 subcutaneous injection Substances 0.000 description 1
- 239000000126 substance Substances 0.000 description 1
- 150000005846 sugar alcohols Polymers 0.000 description 1
- 229960001796 sunitinib Drugs 0.000 description 1
- FIAFUQMPZJWCLV-UHFFFAOYSA-N suramin Chemical compound OS(=O)(=O)C1=CC(S(O)(=O)=O)=C2C(NC(=O)C3=CC=C(C(=C3)NC(=O)C=3C=C(NC(=O)NC=4C=C(C=CC=4)C(=O)NC=4C(=CC=C(C=4)C(=O)NC=4C5=C(C=C(C=C5C(=CC=4)S(O)(=O)=O)S(O)(=O)=O)S(O)(=O)=O)C)C=CC=3)C)=CC=C(S(O)(=O)=O)C2=C1 FIAFUQMPZJWCLV-UHFFFAOYSA-N 0.000 description 1
- 229960005314 suramin Drugs 0.000 description 1
- 239000004094 surface-active agent Substances 0.000 description 1
- 239000000725 suspension Substances 0.000 description 1
- 208000024891 symptom Diseases 0.000 description 1
- 229940037128 systemic glucocorticoids Drugs 0.000 description 1
- 229960001603 tamoxifen Drugs 0.000 description 1
- AYUNIORJHRXIBJ-TXHRRWQRSA-N tanespimycin Chemical compound N1C(=O)\C(C)=C\C=C/[C@H](OC)[C@@H](OC(N)=O)\C(C)=C\[C@H](C)[C@@H](O)[C@@H](OC)C[C@H](C)CC2=C(NCC=C)C(=O)C=C1C2=O AYUNIORJHRXIBJ-TXHRRWQRSA-N 0.000 description 1
- 230000008685 targeting Effects 0.000 description 1
- 239000011975 tartaric acid Substances 0.000 description 1
- 235000002906 tartaric acid Nutrition 0.000 description 1
- 229940118376 tetanus toxin Drugs 0.000 description 1
- 229960002372 tetracaine Drugs 0.000 description 1
- GKCBAIGFKIBETG-UHFFFAOYSA-N tetracaine Chemical compound CCCCNC1=CC=C(C(=O)OCCN(C)C)C=C1 GKCBAIGFKIBETG-UHFFFAOYSA-N 0.000 description 1
- CXVCSRUYMINUSF-UHFFFAOYSA-N tetrathiomolybdate(2-) Chemical compound [S-][Mo]([S-])(=S)=S CXVCSRUYMINUSF-UHFFFAOYSA-N 0.000 description 1
- 229960003433 thalidomide Drugs 0.000 description 1
- 150000003588 threonines Chemical group 0.000 description 1
- 229950005976 tivantinib Drugs 0.000 description 1
- AOBORMOPSGHCAX-DGHZZKTQSA-N tocofersolan Chemical compound OCCOC(=O)CCC(=O)OC1=C(C)C(C)=C2O[C@](CCC[C@H](C)CCC[C@H](C)CCCC(C)C)(C)CCC2=C1C AOBORMOPSGHCAX-DGHZZKTQSA-N 0.000 description 1
- 229960000984 tocofersolan Drugs 0.000 description 1
- 238000011200 topical administration Methods 0.000 description 1
- 229940044693 topoisomerase inhibitor Drugs 0.000 description 1
- 229960000303 topotecan Drugs 0.000 description 1
- UCFGDBYHRUNTLO-QHCPKHFHSA-N topotecan Chemical compound C1=C(O)C(CN(C)C)=C2C=C(CN3C4=CC5=C(C3=O)COC(=O)[C@]5(O)CC)C4=NC2=C1 UCFGDBYHRUNTLO-QHCPKHFHSA-N 0.000 description 1
- XFCLJVABOIYOMF-QPLCGJKRSA-N toremifene Chemical compound C1=CC(OCCN(C)C)=CC=C1C(\C=1C=CC=CC=1)=C(\CCCl)C1=CC=CC=C1 XFCLJVABOIYOMF-QPLCGJKRSA-N 0.000 description 1
- 229960005026 toremifene Drugs 0.000 description 1
- 239000012096 transfection reagent Substances 0.000 description 1
- 230000005945 translocation Effects 0.000 description 1
- 230000005748 tumor development Effects 0.000 description 1
- 108010012374 type IV collagen alpha3 chain Proteins 0.000 description 1
- 150000004917 tyrosine kinase inhibitor derivatives Chemical class 0.000 description 1
- 125000001493 tyrosinyl group Chemical group [H]OC1=C([H])C([H])=C(C([H])=C1[H])C([H])([H])C([H])(N([H])[H])C(*)=O 0.000 description 1
- 229940079023 tysabri Drugs 0.000 description 1
- 238000004704 ultra performance liquid chromatography Methods 0.000 description 1
- 241000701447 unidentified baculovirus Species 0.000 description 1
- VBEQCZHXXJYVRD-GACYYNSASA-N uroanthelone Chemical compound C([C@@H](C(=O)N[C@H](C(=O)N[C@@H](CS)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CS)C(=O)N[C@H](C(=O)N[C@@H]([C@@H](C)CC)C(=O)NCC(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(=O)N[C@@H](CO)C(=O)NCC(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CS)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O)C(C)C)[C@@H](C)O)NC(=O)[C@H](CO)NC(=O)[C@H](CC(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CO)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](NC(=O)[C@H](CC=1NC=NC=1)NC(=O)[C@H](CCSC)NC(=O)[C@H](CS)NC(=O)[C@@H](NC(=O)CNC(=O)CNC(=O)[C@H](CC(N)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CS)NC(=O)[C@H](CC=1C=CC(O)=CC=1)NC(=O)CNC(=O)[C@H](CC(O)=O)NC(=O)[C@H](CC=1C=CC(O)=CC=1)NC(=O)[C@H](CO)NC(=O)[C@H](CO)NC(=O)[C@H]1N(CCC1)C(=O)[C@H](CS)NC(=O)CNC(=O)[C@H]1N(CCC1)C(=O)[C@H](CC=1C=CC(O)=CC=1)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC(N)=O)C(C)C)[C@@H](C)CC)C1=CC=C(O)C=C1 VBEQCZHXXJYVRD-GACYYNSASA-N 0.000 description 1
- 229960005356 urokinase Drugs 0.000 description 1
- 238000001291 vacuum drying Methods 0.000 description 1
- 229960000241 vandetanib Drugs 0.000 description 1
- 239000002525 vasculotropin inhibitor Substances 0.000 description 1
- LLDWLPRYLVPDTG-UHFFFAOYSA-N vatalanib succinate Chemical compound OC(=O)CCC(O)=O.C1=CC(Cl)=CC=C1NC(C1=CC=CC=C11)=NN=C1CC1=CC=NC=C1 LLDWLPRYLVPDTG-UHFFFAOYSA-N 0.000 description 1
- 235000015112 vegetable and seed oil Nutrition 0.000 description 1
- 239000008158 vegetable oil Substances 0.000 description 1
- 210000003462 vein Anatomy 0.000 description 1
- 229960004355 vindesine Drugs 0.000 description 1
- UGGWPQSBPIFKDZ-KOTLKJBCSA-N vindesine Chemical compound C([C@@H](C[C@]1(C(=O)OC)C=2C(=CC3=C([C@]45[C@H]([C@@]([C@H](O)[C@]6(CC)C=CCN([C@H]56)CC4)(O)C(N)=O)N3C)C=2)OC)C[C@@](C2)(O)CC)N2CCC2=C1N=C1[C]2C=CC=C1 UGGWPQSBPIFKDZ-KOTLKJBCSA-N 0.000 description 1
- 229960002066 vinorelbine Drugs 0.000 description 1
- GBABOYUKABKIAF-GHYRFKGUSA-N vinorelbine Chemical compound C1N(CC=2C3=CC=CC=C3NC=22)CC(CC)=C[C@H]1C[C@]2(C(=O)OC)C1=CC([C@]23[C@H]([C@]([C@H](OC(C)=O)[C@]4(CC)C=CCN([C@H]34)CC2)(O)C(=O)OC)N2C)=C2C=C1OC GBABOYUKABKIAF-GHYRFKGUSA-N 0.000 description 1
- 229960004854 viral vaccine Drugs 0.000 description 1
- 239000013603 viral vector Substances 0.000 description 1
- 230000003612 virological effect Effects 0.000 description 1
- 239000011710 vitamin D Substances 0.000 description 1
- 235000019166 vitamin D Nutrition 0.000 description 1
- 150000003710 vitamin D derivatives Chemical class 0.000 description 1
- 229940046008 vitamin d Drugs 0.000 description 1
- 239000000080 wetting agent Substances 0.000 description 1
- 238000012447 xenograft mouse model Methods 0.000 description 1
- 229940099073 xolair Drugs 0.000 description 1
- 229950009002 zanolimumab Drugs 0.000 description 1
- 239000002076 α-tocopherol Substances 0.000 description 1
- 235000004835 α-tocopherol Nutrition 0.000 description 1
Landscapes
- Peptides Or Proteins (AREA)
Abstract
Un anticuerpo monoclonal que se une al c-Met humano, donde el anticuerpo comprende: a) una región VH que comprende las secuencias de CDR1, 2 y 3 de SEQ ID NO: 34, 35 y 36 y una región VL que comprende las secuencias de CDR1, 2 y 3 de SEQ ID NO: 38, 39 y 40, (024), o b) una región VH que comprende las secuencias de CDR1, 2 y 3 de SEQ ID NO: 74, 75 y 76 y una región VL que comprende las secuencias de CDR1, 2 y 3 de SEQ ID NO: 78, 79 y 80, (062), o c) una región VH que comprende las secuencias de CDR1, 2 y 3 de SEQ ID NO: 82, 83 y 84 y una región VL que comprende las secuencias de CDR1, 2 y 3 de SEQ ID NO: 86, 87 y 88, (064), o d) una región VH que comprende las secuencias de CDR1, 2 y 3 de SEQ ID NO: 90, 91 y 92 y una región VL que comprende las secuencias de CDR1, 2 y 3 de SEQ ID NO: 94, 95 y 96, (068), o e) una región VH que comprende las secuencias de CDR1, 2 y 3 de SEQ ID NO: 98, 99 y 100 y una región VL que comprende las secuencias de CDR1, 2 y 3 de SEQ ID NO: 102, 103 y 104, (069), o f) una región VH que comprende las secuencias de CDR1, 2 y 3 de SEQ ID NO: 130, 131 y 132 y una región VL que comprende las secuencias de CDR1, 2 y 3 de SEQ ID NO: 134, 135 y 136, (181) g) una región VH que comprende las secuencias de CDR1, 2 y 3 de SEQ ID NO: 114, 115 y 116 y una región VL que comprende las secuencias de CDR1, 2 y 3 de SEQ ID NO: 118, 119 y 120 (098), o h) una región VH que comprende las secuencias de CDR1, 2 y 3 de SEQ ID NO: 122, 123 y 124 y una región VL que comprende las secuencias de CDR1, 2 y 3 de SEQ ID NO: 126, 127 y 128 (101).
Description
DESCRIPCIÓN
Anticuerpos monoclonales contra c-Met
Campo de la invención
La presente invención se refiere a anticuerpos monoclonales dirigidos contra el c-Met humano, el receptor del factor de crecimiento de hepatocitos, y los usos de dichos anticuerpos, en particular su uso en el tratamiento del cáncer.
Antecedentes de la invención
El c-Met es un receptor que abarca la membrana de la tirosina cinasa proteica. La cadena primariamente única del precursor se escinde post-traduccionalmente para producir la forma madura del heterodímero c-Met que consiste en una cadena α (50 kDa) extracelular y una cadena β transmembrana más larga (145 kDa), que están unidas por puentes disulfuro (Birchmeier et al. 2003. Nat Rev Mol Cell Biol 4:915)., La parte extracelular de c-Met está compuesta por tres tipos de dominios. El dominio SEMA en el extremo N está formado por la subunidad α completa y parte de la subunidad β, y engloba la homología con las semaforinas proteicas. El dominio SEM continúa con un dominio rico en cisteína y posteriormente con cuatro dominios tipo inmunoglobulina (Ig). La parte citoplasmática cuenta con un dominio de cinasa yuxtamembrana y una cola en el extremo C que es esencial para la señalización corriente abajo. El único ligando conocido de alta afinidad por el c-Met, el factor de crecimiento de hepatocitos (HGF), se expresa principalmente en los fibroblastos en condiciones normales (Li y Tseng 1995. J Cell Physiol 163:61) y por células tumorales (Ferracini et al.1995. Oncogene 10:739). El HGF (también llamado factor dispersor: SF) se sintetiza como un precursor que se convierte proteolíticamente en un heterodímero α/β activo. Basándose en la estructura cristalina del fragmento de unión al receptor, se cree que el HGF se une al c-Met como un dímero (Chirgadze et al.1999. Nat Struct Biol 6:72). La cadena α del HGF se une con alta afinidad al dominio tipo Ig del c-Met, mientras que la cadena β del HGF se une con baja afinidad al dominio SEMA de c-Met (Basilico et al.2008. J Biol Chem 283:21267). La última interacción es responsable de la dimerización del c-Met y la activación de la tirosina cinasa del receptor al unirse al heterodímero de HGF activo. La autofosforilación del receptor da como resultado un único sito de atraque para el reclutamiento de efectores, de cuya unión con Gab1 (enlazador 1 asociado a la proteína 2 unida al receptor del factor de crecimiento [Grb2]) es esencial para las rutas de señalización corriente abajo del c-Met principal (Comoglio et al.2008. Nat Rev Drug Discov 7:504):
Ruta Ras-ERK 1/2: proliferación.
Ruta Ras-Rac: invasión, motilidad, transición epitelial-a-mesenquimática.
Ruta PI3K: supervivencia.
El c-Met se expresa en la superficie de células epiteliales y endoteliales de muchos órganos durante la embriogénesis y en la madurez, que incluyen el hígado, páncreas, próstata, riñón, músculo, y médula ósea. La activación de c-Met tiene un papel esencial en el denominado programa de “crecimiento invasivo” que consiste en una serie de procesos, incluyendo la proliferación, motilidad, angiogénesis y protección de la apoptosis (Boccaccio y Comoglio 2006. Nat Rev Cancer 6:637). Estos procesos regulados por el c-Met se producen en condiciones fisiológicas normales durante el desarrollo embrionario, reparación de lesiones hepáticas y cardíacas, y patológicamente durante la oncogénesis (Eder et al.2009. Clin Cancer Res 15:2207).
La señalización inapropiada de c-Met se produce en virtualmente todos los tipos de tumores sólidos, tales como cánceres de vejiga, mama, de cuello uterino, colorrectal, gástrico, de cabeza y cuello, hígado, pulmón, ovario, pancreático, próstata, renal, y melanoma (Birchmeier et al.2003. Nat Rev Mol Cell Biol 4:915; Comoglio et al.2008. Nat Rev Drug Discov 7:504; Peruzzi y Bottaro 2006. Clin Cancer Res 12:3657). Los mecanismos subyacentes de la tumorigenicidad de c-Met se alcanzan normalmente de tres maneras diferentes:
Bucles de c-Met/HGF autocrino,
Sobre-expresión de c-Met o HGF,
Mutaciones activadoras de cinasa en la secuencia codificante del receptor c-Met.
Más especialmente, la activación de mutaciones en c-Met se han identificado en pacientes con cáncer renal papilar hereditario (Schmidt et al. 1997. Nat Genet 16:68). La activación constitutiva de c-Met contribuye a una o una combinación de fenotipos cancerosos proliferativos, invasivos, de supervivencia o angiogénico. Se ha demostrado que el silenciamiento genético de c-Met que se expresa en las células tumorales da como resultado la falta de proliferación y crecimiento tumoral y la regresión de metástasis establecidos, así como la disminución de la generación de nuevas metástasis (Corso et al.2008. Oncogene 27:684).
Como el c-Met contribuye a múltiples estadios del desarrollo tumoral, desde el inicio hasta la progresión a metástasis, el c-Met y su ligando el HGF se han convertido en candidatos a la cabeza de terapias contra el cáncer dirigidas (Comoglio et al. 2008. Nat Rev Drug Discov 7:504; Knudsen y Vande Woude 2008. Curr Opin Genet Dev 18:87). Se han explorado varias estrategias para alcanzar este objetivo:
Receptores señuelo: subregiones de HGF o c-MET o análogos moleculares que pueden actuar de manera antagonista como competidores estequiométricos bloqueando la unión del ligando o la dimerización del receptor. Un ejemplo de dicha subregión antagonista de HGF es NK4 (Kringle Pharma).
Inhibidores de la tirosina cinasa de molécula pequeña (TKI): Tres TKI específicos de c-Met en diferentes estadios de evaluación clínica son ARQ197 (ArQule), JNJ 38877605 (Johnson & Johnson) y PF-04217903 (Pfizer). Anticuerpos monoclonales anti-HGF, tales como AMG102, rilotumimab (Amgen), HuL2G7 (Takeda), y AV-299 (Schering).
Se han descrito anticuerpos monoclonales anti-c-Met en los documentos WO 2005016382, WO 2006015371, WO 2007090807, WO 2007126799 WO 2009007427, WO 2009142738 y van der Horst et al. (van der Horst et al.
2009. Neoplasia 11:355). El Metmab (Genentech) es un anticuerpo OA-5D5 monovalente (de un brazo) humanizado que se une al dominio extracelular de c-Met, evitando de esta manera la unión de HGF y la posterior activación del receptor (Jin et al.2008. Cancer Res 68:4360). En modelos de xenoinjerto en ratón, se descubrió que el tratamiento con Metmab inhibía el crecimiento tumoral de un glioblastoma ortotópico dirigido por HGF y tumores pancreáticos subcutáneos (Jin et al. 2008. Cancer Res 68:4360; Martens et al. 2006. Clin Cancer Res 12:6144). El h224G11 (Pierre Fabre) (Corvaia y Boute 2009. Abstract 835 AACR 100th Annual Meeting) es un anticuerpo IgG1 anti-c-Met bivalente humanizado. Los efectos antitumorales de este anticuerpo se han observado en ratones (Goetsch et al. 2009. Abstract 2792 AACR 100th Annual Meeting). El CE-355621 (Pfizer) es una IgG2 humana que bloquea la unión del ligando uniéndose al dominio extracelular de c-Met e inhibe el crecimiento dependiente de HGF en modelos de xenoinjerto tumoral (Tseng et al.2008. J Nucl Med 49:129).
En conclusión, se han investigado varios productos anti-c-Met, pero no se ha aprobado hasta ahora ningún producto anti-c-Met para su uso terapéutico. Sigue existiendo la necesidad de productos eficaces y seguros para tratar las enfermedades graves relacionadas con c-Met, tales como el cáncer.
Sumario de la invención
Es un objetivo de la presente invención proporcionar nuevos anticuerpos anti-c-Met monoclonales altamente específicos y eficaces para su uso médico. Los anticuerpos de la invención presentan características de unión al c-Met que se diferencian de los anticuerpos descritos en la técnica. En realizaciones preferidas, los anticuerpos de la invención tienen una alta afinidad para el c-Met humano, son antagonistas y tienen un perfil farmacocinético favorable para su uso en pacientes humanos. Los anticuerpos de la invención se unen al c-Met humano y comprenden:
a) una región VH que comprende las secuencias de CDR1, 2 y 3 de SEQ ID NO: 34, 35 y 36 y una región VL que comprende las secuencias de CDR1, 2 y 3 de SEQ ID NO: 38, 39 y 40, (024), o
b) una región VH que comprende las secuencias de CDR1, 2 y 3 de SEQ ID NO: 74, 75 y 76 y una región VL que comprende las secuencias de CDR1, 2 y 3 de SEQ ID NO: 78, 79 y 80, (062), o
c) una región VH que comprende las secuencias de CDR1, 2 y 3 de SEQ ID NO: 82, 83 y 84 y una región VL que comprende las secuencias de CDR1, 2 y 3 de SEQ ID NO: 86, 87 y 88, (064), o
d) una región VH que comprende las secuencias de CDR1, 2 y 3 de SEQ ID NO: 90, 91 y 92 y una región VL que comprende las secuencias de CDR1, 2 y 3 de SEQ ID NO: 94, 95 y 96, (068), o
e) una región VH que comprende las secuencias de CDR1, 2 y 3 de SEQ ID NO: 98, 99 y 100 y una región VL que comprende las secuencias de CDR1, 2 y 3 de SEQ ID NO: 102, 103 y 104, (069), o
f) una región VH que comprende las secuencias de CDR1, 2 y 3 de SEQ ID NO: 130, 131 y 132 y una región VL que comprende las secuencias de CDR1, 2 y 3 de SEQ ID NO: 134, 135 y 136, (181)
g) una región VH que comprende las secuencias de CDR1, 2 y 3 de SEQ ID NO: 114, 115 y 116 y una región VL que comprende las secuencias de CDR1, 2 y 3 de SEQ ID NO: 118, 119 y 120 (098), o
h) una región VH que comprende las secuencias de CDR1, 2 y 3 de SEQ ID NO: 122, 123 y 124 y una región VL que comprende las secuencias de CDR1, 2 y 3 de SEQ ID NO: 126, 127 y 128 (101).
Breve descripción de los dibujos
Figura 1: Alineamiento de secuencias de la región variable de cadena pesada de HuMab. Basándose en estas secuencias, la secuencia de consenso se puede definir para algunas de las secuencias de las CDR. Estas secuencias de consenso se dan en la Tabla 4.
Figura 2: Alineamiento de las secuencias de la región variable de cadena ligera de HuMab. Basándose en estas secuencias, la secuencia de consenso se puede definir para algunas de las secuencias de las CDR. Estas secuencias de consenso se dan en la Tabla 4.
Figura 3: Curvas de unión de formas monovalentes y bivalentes de anticuerpos anti-c-Met contra el c-Met que se expresa en células A431. Los datos que se muestran son la MFI de un experimento representativo. Debido a que la IgG1-024 y Uni-068 no presentaban una unión saturada a las células A431 no era posible calcular un valor preciso de la CE50.
Figura 4: Unión de anticuerpos al c-Met expresado en células epiteliales de mono Rhesus. Los datos que se muestran son la MFI de un experimento.
Figura 5: Inhibición de la unión de HGF inducida por el anticuerpo anti-c-Met al dominio extracelular del receptor de c-Met. Los datos que se muestran son de un experimento representativo.
Figura 6: Curvas de inhibición de la unión de HGF de los distintos anticuerpos anti-c-Met de la unión a cMetSEMA_567His8 ensayado con TR-FRET. Los datos que se muestran son la MFI media ± la desviación típica de tres experimentos independientes.
Figura 7: Porcentaje de inhibición de células KP4 viables después del tratamiento con anticuerpos anti-c-Met en comparación con células no tratadas (0 %). Los datos que se muestran son porcentajes de inhibición de células viables de dos experimentos independientes ± desviación típica. La IgG1-1016-022 era solo positiva en un experimento.
Figura 8: Eficacia de anticuerpos anti-c-Met para inhibir el crecimiento tumoral en un modelo de xenoinjerto KP4 en ratones SCID. Los ratones se trataron con 400 μg de anticuerpo el día 9 seguido semanalmente por una dosis de mantenimiento de 200 μg. Se muestra la mediana de los tamaños tumorales por grupo de tratamiento.
Figura 9: Eficacia de anticuerpos anti-c-Met para inhibir el crecimiento tumoral en un modelo de xenoinjerto de KP4 en ratones SCID. Los ratones se trataron con 400 μg de anticuerpo el día 9 seguido semanalmente con una dosis de mantenimiento de 200 μg. Efecto del tratamiento sobre la incidencia tumoral a lo largo del tiempo. Se muestra el porcentaje de ratones libres de tumor (tamaños tumorales < 500 mm3). La formación de tumor se retrasaba en ratones tratados con anticuerpos antagonistas en comparación con los anticuerpos de control. Figura 10: Eficacia de los anticuerpos anti-c-Met para inhibir el crecimiento tumoral en un modelo de xenoinjerto de MKN45 en ratones SCID. Los ratones se trataron con 40 mg/kg de anticuerpo el día 7 y 20 mg/kg de anticuerpo los días 14, 21 y 28. El porcentaje de ratones con tamaños tumorales menores de 70 mm3 se muestra en un gráfico de Kaplan Meier. La formación tumoral se retrasa en ratones tratados con anticuerpos anti-c-Met en comparación con el isotipo de anticuerpo de control.
Figura 11: Eficacia de anticuerpos anti-c-Met para inhibir el crecimiento tumoral en un modelo de xenoinjerto de MKN45 en ratones SCID. Los ratones se trataron con 40 mg/kg de anticuerpo el día 7 y 20 mg/kg de anticuerpo los días 14, 21 y 28. El porcentaje de ratones con tamaños tumorales menores de 700 mm3 se muestra en un gráfico de Kaplan Meier. La formación tumoral se retrasó en los ratones tratados con anticuerpos anti-c-Met en comparación con el isotipo de anticuerpo de control.
Figura 12: Ensayo de viabilidad de KP4 para determinar el efecto de la flexibilidad del anticuerpo sobre la actividad agonista. El formato IgA2m (1) no inducía proliferación, al contrario que los formatos IgA1 e IgG1 del mismo anticuerpo. Las variantes del anticuerpo anti-c-Met 5D5 (véase el documento US6468529 y el Ejemplo 2) se utilizaron en este experimento.
Figura 13: Análisis SDS-PAGE no reducido de la flexibilidad de los mutantes de (069). No se observaron multímeros aberrantes ni productos de degradación mientras era visible el emparejamiento de la cadena ligera como una banda de 50 kD ((LC)2) en los mutantes C220S, ΔC220 e IgG1-bisagra IgG3.
Figura 14: ELISA de unión al antígeno para medir la unión de c-Met a mutantes de la bisagra de anticuerpos c-Met todos los mutantes se unían con una afinidad comparable al c-Met como se muestra en el ELISA.
Figura 15: Fosforilación de c-Met como resultado de la actividad agonista de los anticuerpos contra c-Met. La Figura 15 muestra los resultados de transferencia de Western de lisados de A549; las membranas teñidas con anticuerpos contra c-Met fosforilado, c-Met total o β-actina.
Figura 16: Ensayo de proliferación con NCI-H441. El peso de las células se determinó después de 7 días de incubación en presencia de anticuerpos o controles y se grafican como el porcentaje de muestras no tratadas (fijado como el 100 %).
Figura 17: Ensayo de viabilidad de KP4. Se ensayó el efecto de los anticuerpos contra c-Met sobre la viabilidad total de las células KP4. La capacidad de IgG1-1016-069 para reducir la viabilidad de KP4 se retenía y/o mejoraba introduciendo mutaciones que disminuían la flexibilidad de los anticuerpos.
Figura 18: Modulación negativa según se mide por los niveles de c-Met totales en lisados de A549 utilizando un ELISA. Todas las variantes de anticuerpo (069) retenían la capacidad de modulación negativa.
Figura 19: Ensayo de ADCC para comparar las versiones con fucosa alta y baja del anticuerpo IgG1-1016-069.
Figura 20: La falta de unión de los anticuerpos c-Met a las células en sangre completa en un ensayo de unión FACS. Los resultados se muestran para las células B, monocitos y granulocitos.
Descripción detallada de la invención
Definiciones
El término “c-Met”, cuando se utiliza en el presente documento, se refiere al receptor del factor de crecimiento del hepatocito (Registro de GenBank NM 000245) e incluye cualquier variante, isoformas y especies homólogas del c-Met humano que se expresa naturalmente en las células o se expresan en células transfectadas con el gen de c-Met.
El término “inmunoglobulina” se refiere a una clase de glicoproteínas relacionadas estructuralmente que consisten en dos pares de cadenas polipeptídicas, un par de cadenas ligeras (L) de bajo peso molecular y un par de cadenas pesadas (H), las cuatro interconectadas por puentes disulfuro. La estructura de las inmunoglobulinas se ha caracterizado bien. Véase, por ejemplo, Fundamental Immunology Ch. 7 (Paul, W., ed., 2ª ed. Raven Press, N.Y. (1989)). En resumen, cada cadena pesada está comprendida normalmente por una región variable de cadena pesada (abreviada en el presente documento como VH o VH) y una región constante de cadena pesada. La región constante de cadena pesada normalmente está comprendida por tres dominios, CH1, CH2 y CH3. Cada cadena ligera está comprendida normalmente de una región variable de cadena ligera (abreviada en el presente documento como
VL o VL) y una región constante de cadena ligera. La región constante de cadena ligera normalmente está compuesta por un dominio, CL. Las regiones VH y VL pueden subdividirse adicionalmente en regiones de hipervariabilidad (o regiones hipervariables que pueden ser hipervariables en la secuencia y/o formar bucles definidos estructuralmente), también llamadas regiones determinantes de complementariedad (CDR), intercaladas con las regiones que están más conservadas, denominadas regiones marco conservada (FR). Cada VH y VL están compuesta normalmente por tres CDR y cuatro FR, dispuestas desde el extremo amino hasta el extremo carboxilo en el siguiente orden: FR1, CDR1, FR2, CDR2, FR3, CDR3, FR4 (véase también Chothia y Lesk J. Mol. Biol. 196, 901-917 (1987)). Normalmente, la numeración de los restos de aminoácido en esta región se lleva a cabo por el método descrito en Kabat et al., Sequences of Proteins of Immunological Interest, 5ª Ed. Public Health Service, National Institutes of Health, Bethesda, MD. (1991) (las frases tales como numeración del resto del dominio variable como en Kabat o de acuerdo con Kabat en el presente documento se refieren a este sistema de numeración para dominios variables de cadena pesada o dominios variables de cadena ligera). Utilizando este sistema de numeración, la secuencia de aminoácidos lineal actual de un péptido puede contener menor o aminoácidos adicionales que se corresponden con un acortamiento, o una inserción en una FR o CDR del dominio variable. Por ejemplo, un dominio variable de cadena pesada puede incluir una única inserción de aminoácidos (el resto 52a de acuerdo con Kabat) después del resto 52 de la CDR2 de VH y una inserción de restos (por ejemplo, los restos 82a, 82b, y 82c, etc. de acuerdo con Kabat) después del resto 82 de FR de cadena pesada. La numeración de Kabat de restos se puede determinar para un anticuerpo determinado por el alineamiento en regiones de homología de la secuencia del anticuerpo con una secuencia numerada por Kabat “convencional”.
El término “anticuerpo” (Ab) en el contexto de la presente invención se refiere a una molécula de inmunoglobulina, un fragmento de una molécula de inmunoglobulina, o un derivado de cualquiera de los mismos, que tiene la capacidad de unirse específicamente a un antígeno en condiciones fisiológicas típicas con una semivida de periodos de tiempo significativos, tal como al menos aproximadamente 30 minutos, al menos aproximadamente 45 minutos, al menos aproximadamente 1 hora, al menos aproximadamente dos horas, al menos aproximadamente cuatro horas, al menos aproximadamente 8 horas, al menos aproximadamente 12 horas, aproximadamente 24 horas o más, aproximadamente 48 horas o más, aproximadamente 3, 4, 5, 6, 7 o más días, etc., o cualquier otro periodo definido funcionalmente relevante (tal como un tiempo suficiente para inducir, promover, aumentar, y/o modular una repuesta asociada con la unión del anticuerpo al antígeno y/o el tiempo suficiente para que el anticuerpo reclute una actividad efectora). Las regiones variables de las cadenas pesada y ligera de la molécula de inmunoglobulina contienen un dominio de unión que interactúa con un antígeno. Las regiones constantes de los anticuerpos (Ab) pueden mediar en la unión de las inmunoglobulinas a los tejidos o factores de huéspedes, incluyendo distintas células del sistema inmunitario (tal como las células efectoras) y componentes del sistema de complemento tal como C1q, el primer componente en la ruta clásica de la activación del complemento. Un anticuerpo anti-c-Met también puede ser un anticuerpo biespecífico, diacuerpo, o molécula similar (véase, por ejemplo, PNAS USA 90(14), 6444-8 (1993) para una descripción de los diacuerpos). Además, los anticuerpos biespecíficos, diacuerpos, y similares, proporcionados por la presente invención se pueden unir a cualquier diana adecuada además de a una parte del c-Met. Como se ha indicado anteriormente, el término anticuerpo en el presente documento, a menos de que se establezca otra cosa o se contradiga claramente por el contexto, incluye fragmentos de un anticuerpo que mantengan la capacidad para unirse específicamente al antígeno. Se ha demostrado que la función de unión al antígeno del anticuerpo se puede llevar a cabo por fragmentos de un anticuerpo de longitud completa. Ejemplos de fragmentos de unión englobados por el término “anticuerpo” incluyen (i) un Fab’ o fragmento Fab, un fragmento monovalente que consiste en los dominios VL, VH, CL y CH1, o un anticuerpo monovalente como se describe en el documento WO 2007059782 (Genmab); (ii) fragmentos F(ab’)2, fragmentos bivalentes que comprenden dos fragmentos Fab unidos por un puente disulfuro en la región de bisagra; (iii) un fragmento Fd que consiste esencialmente en los dominios VH y CH1; (iv) un fragmento Fv que consiste esencialmente en los dominios VL y VH de un solo brazo de un anticuerpo, (v) un fragmento dAb (Ward et al., Nature 341, 544-546 (1989)), que consiste esencialmente en un dominio VH y también llamados anticuerpos de dominio (Holt et al; Trends Biotechnol.2003 nov;21(11):484-90); camélidos o nanocuerpos (Revets et al; Expert Opin Biol Ther. 2005 Jan 5(1):111-24) y (vii) una región determinante de complementariedad (CDR) aislada. Adicionalmente, aunque los dos dominios del fragmento Fv, se codifican la VL y VH por genes separados, se pueden unir, utilizando métodos recombinantes, por un enlazador sintético que hace posible que se produzcan como una única cadena proteica en la que las regiones VL y VH se emparejan para formar moléculas monovalentes (conocidos como anticuerpos de cadena sencilla o Fv de cadena sencilla (scFv), véase por ejemplo, Bird et al., Science 242, 423-426 (1988) y Huston et al., PNAS USA 85, 5879-5883 (1988)). Dichos anticuerpos de cadena sencilla están englobados en el término anticuerpo a menos de que se señale otra cosa o se indique claramente por el contexto. Aunque dichos fragmentos se incluyen en general en el significado de anticuerpo, colectivamente y cada uno independientemente son características únicas de la presente invención, que presentan diferentes propiedades biológicas y utilidades. Estos y otros fragmentos de anticuerpo en el contexto de la presente invención se exponen adicionalmente en el presente documento. Se debería entender también que el término anticuerpo, a menos de que se especifique otra cosa, también incluye anticuerpos policlonales, anticuerpos monoclonales (mAb), polipéptidos tipo anticuerpo, tal como anticuerpos quiméricos y anticuerpos humanizados, y fragmentos de anticuerpo que mantienen la capacidad para unirse específicamente al antígeno (fragmento de unión al antígeno) proporcionados por cualquier técnica conocida, tal como escisión enzimática, síntesis peptídica, y técnicas recombinantes. Un anticuerpo que se genera puede poseer cualquier isotipo.
Como se utiliza en el presente documento, “isotipo” se refiere a la clase de inmunoglobulina (por ejemplo, IgG1, IgG2, IgG3, IgG4, IgD, IgA, IgE, o IgM) que se codifica por genes de la región constante de cadena pesada.
La expresión “anticuerpo monovalente” significa en el contexto de la presente invención que una molécula de anticuerpo es capaz de unirse a una única molécula de antígeno, y por lo tanto no es capaz de entrecruzamiento de antígenos.
Un “anticuerpo deficiente en función efectora” o un “anticuerpo con función efectora deficiente” se refiere a un anticuerpo que tiene uno o más mecanismos efectores significativamente reducidos o no tiene la capacidad de activarlos, tal como la activación del complemento o la unión al receptor de Fc. Por lo tanto, los anticuerpos con función efectora deficiente tienen reducida significativamente o no tienen la capacidad para mediar la citotoxicidad mediada por células dependiente de anticuerpo (ADCC) y/o la citotoxicidad dependiente de complemento (CDC). Un ejemplo de dicho anticuerpo es IgG4.
Un “anticuerpo anti-c-Met” es un anticuerpo como se ha descrito anteriormente, que se une específicamente al antígeno c-Met.
La expresión “anticuerpo humano”, como se utiliza en el presente documento, pretende incluir los anticuerpos que tienen regiones variables y constantes derivadas de secuencias de inmunoglobulina de la línea germinal humana. Los anticuerpos humanos de la invención pueden incluir restos de aminoácidos no codificados por secuencias de inmunoglobulina de la línea germinal humana (por ejemplo, mutaciones introducidas por mutagénesis aleatorias o específicas del sitio in vitro o por mutación somática in vivo). Sin embargo, la expresión “anticuerpo humano”, como se utiliza en el presente documento, no pretende incluir anticuerpos en los que se han injertado secuencias de CDR derivadas de la línea germinal de otras especies de mamífero, tal como un ratón, en las secuencias marco conservadas humanas.
Como se utiliza en el presente documento, un anticuerpo humano se “deriva de” una secuencia de la línea germinal particular si el anticuerpo se obtiene a partir de un sistema que utiliza secuencias de inmunoglobulinas humanas, por ejemplo, inmunizando un ratón transgénicos que tiene genes de inmunoglobulina humana o explorando una biblioteca genética de inmunoglobulinas humanas, y donde el anticuerpo humano seleccionado es al menos un 90 %, tal como al menos un 95 %, por ejemplo al menos un 96, tal como al menos un 97 %, por ejemplo al menos un 98 %, o tal como al menos un 99 % idéntico en la secuencia de aminoácidos a la secuencia de aminoácidos codificada por el gen de inmunoglobulinas de la línea germinal. Normalmente, quitando la CDR3 de la cadena pesada, un anticuerpo humano derivado de una secuencia particular de la línea germinal humana presentará no más de 20 diferencias de aminoácidos, por ejemplo, no más de 10 diferencias de aminoácidos, tal como no más de 9, 8, 7, 6, o 5, por ejemplo, no más de 4, 3, 2, o 1 diferencia de aminoácidos respecto a la secuencia codificada por el gen de inmunoglobulina de la línea germinal.
En una realización preferida, el anticuerpo de la invención está aislado. Un “anticuerpo aislado”, como se utiliza en el presente documento, tiene la intención de referirse a un anticuerpo que está sustancialmente libre de otros anticuerpos que tienen especificidades antigénicas diferentes (por ejemplo, un anticuerpo aislado que se une específicamente a c-Met está sustancialmente libre de anticuerpos que se unan específicamente a antígenos distintos de c-Met). Un anticuerpo aislado que se une específicamente a un epítopo, isoforma o variante de c-Met humano puede, sin embargo, tener reactividad cruzada con otros antígenos relacionados, por ejemplo, de otras especies (tales como especies de c-Met homólogas). Además, un anticuerpo aislado puede estar sustancialmente libre de otro material celular y/o productos químicos. En una realización de la presente invención, dos o más anticuerpos monoclonales “aislados” que tienen diferentes especificidades de unión a antígeno se combinan en una composición bien definida.
Cuando se utiliza en el presente documento, en el contexto de dos o más anticuerpos, el término “compite con” o “compite de manera cruzada con” indica que dos o más anticuerpos compiten por la unión con c-Met, por ejemplo, compite por la unión con c-Met en el ensayo descrito en los Ejemplos del presente documento. Para algunos pares de anticuerpos, la competición en el ensayo de los Ejemplos solo se observa cuando un anticuerpo está revistiendo la placa y el otro se utiliza para competir, y no viceversa. La expresión “compite con” cuando se utiliza en el presente documento también tiene la intención de cubrir cualquier combinación de anticuerpos.
El término “epítopo” significa un determinante proteico capaz de unirse específicamente a un anticuerpo. Los epítopos consisten habitualmente en agrupamientos de superficie de moléculas tales como cadenas laterales de aminoácidos o azúcares y habitualmente tienen características estructurales tridimensionales específicas, así como características de carga específicas. Los epítopos conformacionales y no conformacionales se distinguen en que la unión de los primeros, pero no de los últimos, se pierde en presencia de disolventes desnaturalizantes. El epítopo puede comprender restos de aminoácido implicados directamente en la unión (también llamado componente inmunodominante del epítopo) y otros restos de aminoácidos, que no están implicados directamente en la unión, dichos restos de aminoácidos que se bloquean eficazmente por el péptido de unión específicamente antigénico (en otras palabras, el resto de aminoácido está en la huella del péptido de unión específicamente antigénico).
La expresión “anticuerpo monoclonal” como se utiliza en el presente documento se refiere a una preparación de moléculas de anticuerpo de composición molecular única. Una composición de anticuerpo monoclonal presenta una única especificidad y afinidad de unión por un epítopo en particular. En consecuencia, la expresión “anticuerpo monoclonal humano” se refiere a anticuerpos que presentan una única especificidad de unión que tiene regiones variables y constantes derivadas de secuencias de inmunoglobulinas de la línea germinal humana. Los anticuerpos monoclonales humanos se pueden generar mediante un hibridoma que incluye una célula B obtenida de un animal transgénico o transcromosómico no humano, tal como un ratón transgénico, que tiene un genoma que comprende un transgén de cadena pesada humana y un transgén de cadena ligera, fusionada con una célula inmortalizada. Como se utiliza en el presente documento, el término “unión” en el contexto de la unión de un anticuerpo a un antígeno predeterminado normalmente es una unión con una afinidad que se corresponde con una KD de aproximadamente 10-7 M o menos, tal como aproximadamente 10-8 M o menos, tal como aproximadamente 10-9 M o menos, o aproximadamente 10-11 M o incluso menos cuando se determina por ejemplo, por una tecnología de resonancia de plasmones superficiales (SPR) en un instrumento BIAcore 3000 utilizando el antígeno como ligando y el anticuerpo como analito, y se une al antígeno predeterminado con una afinidad correspondiente con una KD que es al menos de 10 veces menor, tal como al menos 100 veces menor, por ejemplo al menos 1.000 veces menor, tal como al menos 10.000 veces menor, por ejemplo al menos 100.000 veces menor que su afinidad por la unión a un antígeno no específico (por ejemplo, BSA, caseína) distinto del antígeno predeterminado o un antígeno estrechamente relacionado. La cantidad con la cual la afinidad es menor depende de la KD del anticuerpo, de manera que cuando la KD del anticuerpo es muy baja (es decir, el anticuerpo es altamente específico), entonces la cantidad con la cual la afinidad por el antígeno es menor que la afinidad por un antígeno no específico puede ser al menos de 10.000 veces.
El término “kd” (s-1), como se utiliza en el presente documento, se refiere a la constante de velocidad de disociación de una interacción antígeno-anticuerpo en particular. También se hace referencia a dicho valor como el valor koff. El término “ka” (M-1 x s-1), como se utiliza en el presente documento, se refiere a la constante de velocidad de asociación de una interacción anticuerpo-antígeno en particular.
El término “KD” (M) como se utiliza en el presente documento, se refiere a la constante de disociación en equilibrio de una interacción anticuerpo-antígeno en particular.
El término “KA” (M-1), como se utiliza en el presente documento se refiere a la constante de asociación en equilibrio de una interacción anticuerpo-antígeno y se obtiene dividiendo ka por la kd.
Como se utiliza en el presente documento, la expresión “inhibe el crecimiento” (por ejemplo, refiriéndose a células, tales como celular tumorales) tiene la intención de incluir cualquier diminución que se pueda medir del crecimiento celular cuando se pone en contacto con un anticuerpo anti-c-Met en comparación con el crecimiento de las mismas células que no se ponen en contacto con una anticuerpo anti-c-Met, por ejemplo, la inhibición del crecimiento de un cultivo celular a menos aproximadamente un 10 %, 20 %, 30 %, 40 %, 50 %, 60 %, 70 %, 80 %, 90 %, 99 %, o 100 %. Dicha disminución del crecimiento celular puede producirse por una variedad de mecanismos, por ejemplo, fagocitosis de células efectoras, ADCC, CDC, y/o apoptosis.
La presente invención también proporciona anticuerpos que comprenden variantes funcionales de la región VL, región VH o una o más CDR de los anticuerpos de los ejemplos. Una variante funcional de una VL, VH, o CDR utilizada en el contexto de un anticuerpo anti-c-Met aun permite que al anticuerpo mantenga al menos una proporción sustancial (de al menos el 50 %, 60 %, 70 %, 80 %, 90 %, 95 % o más) de la afinidad/avidez y/o la especificidad/selectividad del anticuerpo parental y en algunos casos dicho anticuerpo anti-c-Met puede estar asociado con una afinidad, selectividad y/o especificidad mayor que el anticuerpo parental.
Dichas variantes funcionales normalmente mantienen una identidad de secuencia significativa con respecto al anticuerpo parental. El porcentaje de identidad entre dos secuencias es una función del número de posiciones idénticas que comparten las secuencias (es decir, % homología = nº de posiciones idénticas/nº de posiciones totales x 100), teniendo en cuanta el número de huecos, y la longitud de cada hueco que se necesitan introducir para el alineamiento óptimo de las dos secuencias. El porcentaje de identidad entre dos secuencias de nucleótidos o aminoácidos se puede determinar, por ejemplo, utilizando el algoritmo de E. Meyers y W. Miller, Comput. Appl. Biosci 4, 11-17 (1988) que se ha introducido en el programa ALIGN (versión 2.0), utilizando una tabla de pesos PAM120, una penalización de longitud de hueco de 12 y una penalización de hueco de 4. Además, el porcentaje de identidad entre dos secuencias de aminoácidos se puede determinar utilizando el algoritmo de Needleman y Wunsch, J. Mol. Biol.48, 444-453 (1970).
La secuencia de variantes de CDR puede diferenciarse de la secuencia de la CDR de las secuencias del anticuerpo parental mediante sobre todo sustituciones conservadoras; por ejemplo, al menos 10, tal como al menos 9, 8, 7, 6, 5, 4, 3, 2 o 1 de las sustituciones en la variante son sustituciones conservadoras de restos de aminoácidos.
En el contexto de la presente invención, las sustituciones conservadoras pueden definirse por sustituciones en las clases de aminoácidos reflejadas en la siguiente tabla:
Clases de restos de aminoácidos para las sustituciones conservadoras

La expresión “célula huésped recombinante (o simplemente “célula huésped”), como se utiliza en el presente documento, tiene la intención de referirse a una célula en la cual se ha introducido un vector de expresión, por ejemplo, un vector de expresión que codifica un anticuerpo de la invención. Las células huésped recombinantes incluyen, por ejemplo, transfectomas tales como células CHO, células HEK293, célula NS/0, y células linfocíticas. La expresión “animal transgénico no humano” se refiere a un animal no humano que tiene un genoma que comprende uno o más transgenes o transcromosomas de cadena pesada y/o ligera humanas (sea integrados o no integrados en el ADN genómico natural del animal) y que es capaz de expresar anticuerpos completamente humanos. Por ejemplo, un ratón transgénico puede tener un transgén de cadena ligera humana y cualquier transgén de cadena pesada humana o transcromosoma de cadena pesada humana, de manera que el ratón produce anticuerpos anti-c-Met humanos cuando se inmuniza con un antígeno c-Met y/o célula que expresan c-Met. El transgén de cadena pesada humana se puede integrar en el ADN cromosómico del ratón, como es el caso de ratones transgénicos, por ejemplo, ratones HuMab, tal como ratones HCo7 o HCo12, o el transgén de cadena pesada humana se puede mantener de manera extracromosómica, como es el caso de los ratones transcromosómicos KM como se describe en el documento WO 02/43478. Ratones similares que tienen un repertorio genético de Ab humanos mayor, incluyen HCo7 y HCo20 (véase, por ejemplo, el documento WO 2009097006). Dichos ratones transgénicos y transcromosómicos (a los que se hace referencia colectivamente en el presente documento como “ratones transgénicos”) son capaces de producir múltiples isotipos de anticuerpos monoclonales humanos contra un antígeno determinado (tal como IgG, IgA, IgM, IgD y/o IgE) sometiéndolos a recombinación V-D-J e intercambio de isotipos. El animal transgénico, no humano también se puede utilizar para la producción de anticuerpos contra un antígeno específico, introduciendo genes que codifican dicho anticuerpo específico, por ejemplo, uniendo operativamente los genes a un gen que se expresa en la leche del animal.
“Tratamiento” se refiere a la administración de una cantidad eficaz de un compuesto terapéuticamente activo de la presente invención con el fin de facilitar, mejorar, detener o erradicar (curar) los síntomas de estados de enfermedad.
Una “cantidad eficaz” se refiere a una cantidad eficaz, a las dosis y durante periodos de tiempo necesarias, para alcanzar un resultado terapéutico deseado. Una cantidad terapéuticamente eficaz de un anticuerpo anti-c-Met puede variar de acuerdo con factores tales como el estado de enfermedad, edad, sexo, y peso del individuo, y la capacidad del anticuerpo anti-c-Met parara dar lugar a una respuesta deseada en el individuo. Una cantidad terapéuticamente eficaz es también en el que cualquiera de los efectos tóxicos o perjudiciales del anticuerpo o parte de anticuerpo está superados por los efectos terapéuticamente beneficiosos.
Un anticuerpo “anti-idiotípico” es un anticuerpo que reconoce determinantes únicos asociados generalmente con el sitio de unión al antígeno de un anticuerpo.
Aspectos adicionales y realizaciones de la invención
Como se ha descrito anteriormente, en un primer aspecto, la invención se refiere a un anticuerpo monoclonal que se une al c-Met humano en el que el anticuerpo comprende:
i) una región VH que comprende las secuencias de CDR1, 2 y 3 de SEQ ID NO: 34, 35 y 36 y una región VL que comprende las secuencias de CDR1, 2 y 3 de SEQ ID NO: 38, 39 y 40, (024), o
j) una región VH que comprende las secuencias de CDR1, 2 y 3 de SEQ ID NO: 74, 75 y 76 y una región VL que comprende las secuencias de CDR1, 2 y 3 de SEQ ID NO: 78, 79 y 80, (062), o
k) una región VH que comprende las secuencias de CDR1, 2 y 3 de SEQ ID NO: 82, 83 y 84 y una región VL que comprende las secuencias de CDR1, 2 y 3 de SEQ ID NO: 86, 87 y 88, (064), o
l) una región VH que comprende las secuencias de CDR1, 2 y 3 de SEQ ID NO: 90, 91 y 92 y una región VL que comprende las secuencias de CDR1, 2 y 3 de SEQ ID NO: 94, 95 y 96, (068), o
m) una región VH que comprende las secuencias de CDR1, 2 y 3 de SEQ ID NO: 98, 99 y 100 y una región VL que comprende las secuencias de CDR1, 2 y 3 de SEQ ID NO: 102, 103 y 104, (069), o
n) una región VH que comprende las secuencias de CDR1, 2 y 3 de SEQ ID NO: 130, 131 y 132 y una región VL que comprende las secuencias de CDR1, 2 y 3 de SEQ ID NO: 134, 135 y 136, (181)
o) una región VH que comprende las secuencias de CDR1, 2 y 3 de SEQ ID NO: 114, 115 y 116 y una región VL que comprende las secuencias de CDR1, 2 y 3 de SEQ ID NO: 118, 119 y 120 (098), o
p) una región VH que comprende las secuencias de CDR1, 2 y 3 de SEQ ID NO: 122, 123 y 124 y una región VL que comprende las secuencias de CDR1, 2 y 3 de SEQ ID NO: 126, 127 y 128 (101).
Los anticuerpos monoclonales de la presente invención pueden producirse, por ejemplo, por métodos de hibridoma descrito por primera vez por Kohler et al., Nature 256, 495 (1975), o se pueden producir por métodos de ADN recombinantes. Los anticuerpos monoclonales se pueden aislar de bibliotecas de fagos de anticuerpo utilizando las técnicas descritas, por ejemplo, en Clackson et al., Nature 352, 624-628 (1991) y Marks et al., J. Mol. Biol.222, 581-597 (1991). Los anticuerpos monoclonales se pueden obtener de cualquier fuente adecuada. Por lo tanto, por ejemplo, los anticuerpos monoclonales se pueden obtener a parir de hibridomas preparados a partir de células B esplénicas murinas obtenidas de los ratones inmunizados con un antígeno de interés, por ejemplo, en forma de células que expresan en antígeno en la superficie, o un ácido nucleico que codifica un antígeno de interés. Los anticuerpos monoclonales se pueden obtener también de hibridomas derivados de células que expresan el anticuerpo de seres humanos inmunizados o mamífero no humanos tales como ratas, perros, primates, etc.
En una realización, el anticuerpo de la invención es un anticuerpo humano. Los anticuerpos monoclonales humanos dirigidos contra c-Met se pueden generar utilizando ratones transgénicos o transcromosómicos que tienen partes del sistema inmunitario humano más que sistema de ratón. Dichos ratones transgénicos y transcromosómicos incluyen los ratones a los que se hace referencia en el presente documento como ratones HuMab y ratones KM, respectivamente, y a los que se hace referencia colectivamente en el presente documento como “ratones transgénicos”.
El ratón HuMab que contiene miniloci genéticos de inmunoglobulina humana que codifican secuencias de inmunoglobulina de cadena pesada (μ y γ) y de cadena ligera κ humanas no reordenadas, junto con mutaciones dirigidas que inactivan los loci de cadena μ y κ (Lonberg, N. et al., Nature 368, 856-859 (1994)). En consecuencia, los ratones que presentan una expresión reducida de IgM de ratón o κ y en respuesta a la inmunización, los transgenes de cadena pesada y cadena ligera humanas introducidos, se someten a un cambio de mutación somática para generar anticuerpos monoclonales IgG, κ humanos de alta afinidad (Lonberg, N. et al. (1994), supra; revisado en Lonberg, N. Handbook of Experimental Pharmacology 113, 49-101 (1994), Lonberg, N. y Huszar, D., Intern. Rev. Immunol. Vol.1365-93 (1995) y Harding, F. y Lonberg, N. Ann. N.Y. Acad. Sci 764536-546 (1995)). La preparación de ratones HuMab se describe en detalle en Taylor, L. et al., Nucleic Acids Research 20, 6287-6295 (1992), Chen, J. et al., International Immunology 5, 647-656 (1993), Tuaillon et al., J. Immunol. 152, 2912-2920 (1994), Taylor, L. et al., International Immunology 6, 579-591 (1994), Fishwild, D. et al., Nature Biotechnology 14, 845-851 (1996). Véase también los documentos US 5.545.806, US 5.569.825, US 5.625.126, US 5.633.425, US 5.789.650, US 5.877.397, US 5.661.016, US 5.814.318, US 5.874.299, US 5.770.429, US 5.545.807, WO 98/24884, WO 94/25585, WO 93/1227, WO 92/22645, WO 92/03918 y WO 01/09187.
Los ratones HCo7 tienen una alteración JKD en sus genes de cadena ligera endógenos (kappa) (como se describe en Chen et al., EMBO J. 12, 821-830 (1993)), una alteración CMD en sus genes de cadena pesada endógenos (como se describe en el Ejemplo 1 del documento WO 01/14424), un transgén KCo5 de cadena ligera kappa humana (como se describe en Fishwild et al., Nature Biotechnology 14, 845-851 (1996)), y un transgén HCo7 de cadena pesada humana (como se describe en el documento US 5.770.429).
Los ratones HCo12 tienen una alteración JKD en sus genes de cadena ligera (kappa) endógenos (como se describe en Chen et al., EMBO J. 12, 821-830 (1993)), una alteración CMD en sus genes de cadena pesada endógenos (como se describe en el Ejemplo 1 del documento WO 01/14424),, un transgén KCo5 de cadena ligera kappa humana (como se describe en Fishwild et al., Nature Biotechnology 14, 845-851 (1996)), y un transgén HCo12 de cadena pesada humana (como se describe en el Ejemplo 2 del documento WO 01/14424).
En la estirpe de ratón K, el gen de cadena ligera kappa endógena de ratón se ha alterado homocigóticamente como se describe en Chen et al., EMBO J. 12, 811-820 (1993) y el gen de cadena pesada endógeno de ratón se ha alterado homocigóticamente como se describe en el Ejemplo 1 del documento WO 01/09187. Esta estirpe de ratón tiene un transgén de cadena ligera kappa humana, KCo5, como se describe en Fishwild et al., Nature Biotechnology 14, 845-851 (1996). Esta estirpe de ratón también tiene un transcromosoma de cadena pesada humana compuesto por un fragmento hCF (SC20) del cromosoma 14 como se describe en el documento WO 02/43478.
Los esplenocitos de estos ratones transgénicos se pueden utilizar para generar hibridomas que secreten anticuerpos monoclonales humanos de acuerdo con técnicas bien conocidas.
Adicionalmente, los anticuerpos humanos de la presente invención o anticuerpos de la presente invención de otras especies se pueden identificar mediante tecnologías tipo presentación, que incluyen, sin limitación, presentación en
fagos, presentación retrovírica, presentación ribosómica, y otras técnicas, utilizando técnicas bien conocidas en la técnica y las moléculas resultantes se pueden someter a maduración adicional tal como maduración por afinidad, como dichas técnicas son bien conocidas en la técnica (véase por ejemplo, Hoogenboom et al., J. Mol. Biol. 227, 381 (1991) (presentación en fagos), Vaughan et al., Nature Biotech 14, 309 (1996) (presentación en fagos), Hanes y Plucthau, PNAS USA 94, 4937-4942 (1997) (presentación ribosómica), Parmley y Smith, Gene 73, 305-318 (1988) (presentación en fagos), Scott TIBS 17, 241-245 (1992), Cwirla et al., PNAS USA 87, 6378-6382 (1990), Russel et al., Nucl. Acids Research 21, 1081-1085 (1993), Hogenboom et al., Immunol. Reviews 130, 43-68 (1992), Chiswell y McCafferty TIBTECH 10, 80-84 (1992), y documento US 5.733.743). Si se utilizan las tecnologías presentadas para producir anticuerpos que no son humanos, dichos anticuerpos pueden ser humanizados.
En una realización, el anticuerpo de la invención es de un isotipo IgG1, IgG2, IgG3, IgG4, IgD, IgA, IgE, o IgM. También se desvelan en el presente documento anticuerpos que compiten por la unión con el cMetECDHis soluble con un anticuerpo inmovilizado, donde dicho anticuerpo inmovilizado comprende una región VH que comprende la secuencia de SEQ ID NO: 33 y una región VL que comprende la secuencia de SEQ ID NO: 37 (024), preferentemente donde el anticuerpo compite por más de un 50 %, tal como más de un 75 % con dicho anticuerpo inmovilizado, cuando se determina como se describe en el Ejemplo 17.
En una divulgación adicional, el anticuerpo no compite por la unión con el cMetECDHis soluble con un anticuerpo seleccionado de entre el grupo que consiste en:
a) un anticuerpo inmovilizado que comprende una región VH que comprende la secuencia de SEQ ID NO: 1 y una región VL que comprende la secuencia de SEQ ID NO: 5 (005)
b) un anticuerpo inmovilizado que comprende una región VH que comprende la secuencia de SEQ ID NO: 17 y una región VL que comprende la secuencia de SEQ ID NO: 21 (008)
c) un anticuerpo inmovilizado que comprende la región VH y la región VL del anticuerpo 5D5, y
d) un anticuerpo inmovilizado que comprende una región VH que comprende la secuencia de SEQ ID NO: 49 y una región VL que comprende la secuencia de SEQ ID NO: 53 (045),
preferentemente, donde el anticuerpo compite por menos del 25 %, tal como menos del 20 % con dicho anticuerpo inmovilizado, cuando se determina como se describe en el Ejemplo 17.
En una divulgación adicional, el anticuerpo se une al mismo epítopo que un anticuerpo seleccionad de entre el grupo que consiste en:
a) un anticuerpo que comprende una región VH que comprende la secuencia de SEQ ID NO: 33 y una región VL que comprende la secuencia de SEQ ID NO: 37 (024)
b) un anticuerpo que comprende una región VH que comprende la secuencia de SEQ ID NO: 65 y una región VL que comprende la secuencia de SEQ ID NO: 69 (061)
c) un anticuerpo que comprende una región VH que comprende la secuencia de SEQ ID NO: 73 y una región VL que comprende la secuencia de SEQ ID NO: 77 (062)
d) un anticuerpo que comprende una región VH que comprende la secuencia de SEQ ID NO: 81 y una región VL que comprende la secuencia de SEQ ID NO: 85 (064)
e) un anticuerpo que comprende una región VH que comprende la secuencia de SEQ ID NO: 89 y una región VL que comprende la secuencia de SEQ ID NO: 93 (068)
f) un anticuerpo que comprende una región VH que comprende la secuencia de SEQ ID NO: 97 y una región VL que comprende la secuencia de SEQ ID NO: 101 (069)
g) un anticuerpo que comprende una región VH que comprende la secuencia de SEQ ID NO: 113 y una región VL que comprende la secuencia de SEQ ID NO: 117 (098)
h) un anticuerpo que comprende una región VH que comprende la secuencia de SEQ ID NO: 121 y una región VL que comprende la secuencia de SEQ ID NO: 125 (101), y
i) un anticuerpo que comprende una región VH que comprende la secuencia de SEQ ID NO: 129 y una región VL que comprende la secuencia de SEQ ID NO: 133 (181).
En una realización adicional el anticuerpo comprende una región CDR3 de VH que tiene la secuencia que se expone en
a) SEQ ID NO: 36 (024)
b) SEQ ID NO: 193, tal como una región CDR3 de VH como se expone en SEQ ID NO: 68, 76, 84 o 92 (061, 062, 064, 068)
c) SEQ ID NO: 196, tal como una región CDR3 de VH como se expone en SEQ ID NO: 100 o 132 (069, 181) d) SEQ ID NO: 116 (098), o
e) SEQ ID NO: 201, tal como una región CDR3 de VH como se expone en SEQ ID NO: 124 (101).
En una divulgación adicional, el anticuerpo comprende:
a) una región VH que comprende las secuencias de las CDR1, 2 y 3 de SEQ ID NO: 34, 185 y 36 y una región VL que comprende las secuencias de las CDR1, 2 y 3 de SEQ ID NO: 38, 39 y 206, tal como un anticuerpo que comprende una región VH que comprende las secuencias de las CDR1, 2 y 3 de SEQ ID NO: 34, 35 y 36 y una región VL que comprende las secuencias de las CDR1, 2 y 3 de SEQ ID NO: 38, 39 y 40, (024)
b) una región VH que comprende las secuencias de las CDR1, 2 y 3 de SEQ ID NO: 191, 192 y 193 y una región VL que comprende las secuencias de las CDR1, 2 y 3 de SEQ ID NO: 78, 79 y 208, tal como un anticuerpo que comprende
a. una región VH que comprende las secuencias de las CDR1, 2 y 3 de SEQ ID NO: 66, 67 y 68 y una región VL que comprende las secuencias de las CDR1, 2 y 3 de SEQ ID NO: 70, 71 y 72 (061)
b. una región VH que comprende las secuencias de las CDR1, 2 y 3 de SEQ ID NO: 74, 75 y 76 y una región VL que comprende las secuencias de las CDR1, 2 y 3 de SEQ ID NO: 78, 79 y 80, (062)
c. una región VH que comprende las secuencias de las CDR1, 2 y 3 de SEQ ID NO: 82, 83 y 84 y una región VL que comprende las secuencias de las CDR1, 2 y 3 de SEQ ID NO: 86, 87 y 88, (064), o
d. una región VH que comprende las secuencias de las CDR1, 2 y 3 de SEQ ID NO: 90, 91 y 92 y una región VL que comprende las secuencias de las CDR1, 2 y 3 de SEQ ID NO: 94, 95 y 96, (068)
c) una región VH que comprende las secuencias de las CDR1, 2 y 3 de SEQ ID NO: 194, 195 y 196 y una región VL que comprende las secuencias de las CDR1, 2 y 3 de SEQ ID NO: 209, 210 y 104, tal como un anticuerpo que comprende
a. una región VH que comprende las secuencias de las CDR1, 2 y 3 de SEQ ID NO: 98, 99 y 100 y una región VL que comprende las secuencias de las CDR1, 2 y 3 de SEQ ID NO: 102, 103 y 104, (069), o b. una región VH que comprende las secuencias de las CDR1, 2 y 3 de SEQ ID NO: 130, 131 y 132 y una región VL que comprende las secuencias de las CDR1, 2 y 3 de SEQ ID NO: 134, 135 y 136, (181)
d) una región VH que comprende las secuencias de las CDR1, 2 y 3 de SEQ ID NO: 197, 198 y 116 y una región VL que comprende las secuencias de las CDR1, 2 y 3 de SEQ ID NO: 118, 119 y 211, tal como un anticuerpo que comprende una región VH que comprende las secuencias de las CDR1, 2 y 3 de SEQ ID NO: 114, 115 y 116 y una región VL que comprende las secuencias de las CDR1, 2 y 3 de SEQ ID NO: 118, 119 y 120 (098), o e) una región VH que comprende las secuencias de las CDR1, 2 y 3 de SEQ ID NO: 199, 200 y 201 y una región VL que comprende las secuencias de las CDR1, 2 y 3 de SEQ ID NO: 126, 212 y 128, tal como un anticuerpo que comprende una región VH que comprende las secuencias de las CDR1, 2 y 3 de SEQ ID NO: 122, 123 y 124 y una región VL que comprende las secuencias de las CDR1, 2 y 3 de SEQ ID NO: 126, 127 y 128 (101).
En una realización adicional, el anticuerpo comprende:
a) una región VH que comprende la secuencia de SEQ ID NO: 33 y, preferentemente, una región VL que comprende la secuencia de SEQ ID NO: 37 (024)
b) una región VH que comprende la secuencia de SEQ ID NO: 61 y, preferentemente, una región VL que comprende la secuencia de SEQ ID NO: 69 (061)
c) una región VH que comprende la secuencia de SEQ ID NO: 73 y, preferentemente, una región VL que comprende la secuencia de SEQ ID NO: 77 (062)
d) una región VH que comprende la secuencia de SEQ ID NO: 81 y, preferentemente, una región VL que comprende la secuencia de SEQ ID NO: 85 (064)
e) una región VH que comprende la secuencia de SEQ ID NO: 89 y, preferentemente, una región VL que comprende la secuencia de SEQ ID NO: 93 (068)
f) una región VH que comprende la secuencia de SEQ ID NO: 97 y, preferentemente, una región VL que comprende la secuencia de SEQ ID NO: 101 (069)
g) una región VH que comprende la secuencia de SEQ ID NO: 113 y, preferentemente, una región VL que comprende la secuencia de SEQ ID NO: 117 (098)
h) una región VH que comprende la secuencia de SEQ ID NO: 121 y, preferentemente, una región VL que comprende la secuencia de SEQ ID NO: 125 (101)
i) una región VH que comprende la secuencia de SEQ ID NO: 129 y, preferentemente, una región VL que comprende la secuencia de SEQ ID NO: 133 (181)
j) una región VH que comprende la secuencia de SEQ ID NO: 159 y, preferentemente, una región VL que comprende la secuencia de SEQ ID NO: 160 (078)
k) una región VH que comprende la secuencia de SEQ ID NO: 161 y, preferentemente, una región VL que comprende la secuencia de SEQ ID NO: 162 (084)
l) una región VH que comprende la secuencia de SEQ ID NO: 163 y, preferentemente, una región VL que comprende la secuencia de SEQ ID NO: 164 (063)
m) una región VH que comprende la secuencia de SEQ ID NO: 165 y, preferentemente, una región VL que comprende la secuencia de SEQ ID NO: 166 (087)
n) una región VH que comprende la secuencia de SEQ ID NO: 137 y, preferentemente, una región VL que comprende la secuencia de SEQ ID NO: 138 (066)
o) una región VH que comprende la secuencia de SEQ ID NO: 139 y, preferentemente, una región VL que
comprende la secuencia de SEQ ID NO: 140 (065)
p) una región VH que comprende la secuencia de SEQ ID NO: 141 y, preferentemente, una región VL que comprende la secuencia de SEQ ID NO: 142 (082)
q) una región VH que comprende la secuencia de SEQ ID NO: 143 y, preferentemente, una región VL que comprende la secuencia de SEQ ID NO: 144 (089), o
r) una variante de cualquiera de dichos anticuerpos, donde dicha variante tiene preferentemente como mucho 1, 2, o 3 modificaciones de aminoácidos, más preferentemente sustituciones de aminoácidos, tales como sustituciones conservadoras de aminoácidos en dichas secuencias.
En una realización, el anticuerpo comprende una región VH que comprende la secuencia de CDR3 de SEQ ID NO: 100 y una región VL que comprende la secuencia CDR3 de SEQ ID NO: 104, (069).
En una realización el anticuerpo comprende una región VH que comprende las secuencias de CDR1, 2 y 3 de SEQ ID NO: 98, 99 y 100 y una región VL que comprende las secuencias de CDR1, 2 y 3 de SEQ ID NO: 102, 103 y 104, (069).
En una realización, el anticuerpo comprende una región VH que comprende la secuencia de SEQ ID NO: 97 y una región VL que comprende la secuencia de SEQ ID NO: 101 (069).
También se desvela en el presente documento donde:
- el anticuerpo compite por la unión con el cMetECDHis soluble con un anticuerpo inmovilizado, donde dicho anticuerpo inmovilizado comprende una región VH que comprende la secuencia de SEQ ID NO: 9 y una región VL que comprende la secuencia de SEQ ID NO: 12 (006), preferentemente donde el anticuerpo compite por más del 50 %, tal como más del 75 % con dicho anticuerpo inmovilizado, cuando se determina como se describe en el Ejemplo 17,
y
- el anticuerpo no compite por la unión con el cMetECDHis soluble con un anticuerpo inmovilizado que comprende una región VH que comprende la secuencia de SEQ ID NO: 49 y una región VL que comprende la secuencia de SEQ ID NO: 53 (045), preferentemente donde el anticuerpo compite menos de un 50 %, por ejemplo, menos de un 25 %, tal como menos de un 20 % con dicho anticuerpo inmovilizado, cuando se determina como se describe en el Ejemplo 17.
y
en una realización de la invención, el anticuerpo se une al dominio SEMA de c-Met, preferentemente donde el anticuerpo es capaz de inhibir la unión del HGF al dominio SEM con una CI50 de menos de 10 μg/ml, tal como menos de 2 μg/ml como se describe en el Ejemplo 18.
También se desvelan en el presente documento anticuerpos que no compiten por la unión con el cMetECDHis soluble con un anticuerpo inmovilizado que comprende una región VH que comprende la secuencia de SEQ ID NO: 33 y una región VL que comprende la secuencia de SEQ ID NO: 37 (024), preferentemente donde el anticuerpo compite por menos del 25 %, tal como menos del 20 % con dicho anticuerpo inmovilizado, cuando se determina como se describe en el Ejemplo 17.
También se desvelan en el presente documento anticuerpos que se unen al mismo epítopo que el anticuerpo seleccionado de entre el grupo que consiste en:
a) un anticuerpo que comprende una región VH que comprende la secuencia de SEQ ID NO: 1 y una región VL que comprende la secuencia de SEQ ID NO: 5 (005)
b) un anticuerpo que comprende una región VH que comprende la secuencia de SEQ ID NO: 9 y una región VL que comprende la secuencia de SEQ ID NO: 13 (006)
c) un anticuerpo que comprende una región VH que comprende la secuencia de SEQ ID NO: 25 y una región VL que comprende la secuencia de SEQ ID NO: 29 (022), y
d) un anticuerpo que comprende una región VH que comprende la secuencia de SEQ ID NO: 57 y una región VL que comprende la secuencia de SEQ ID NO: 61 (058).
En una realización adicional, el anticuerpo comprende una región CDR3 de VH que tiene la secuencia que se expone en
a) SEQ ID NO: 181, tal como una región CDR3 como se expone en SEQ ID NO: 4 o 12 (005, 006)
b) SEQ ID NO: 28 (022), o
c) SEQ ID NO: 60 (058).
También se desvelan en el presente documento anticuerpos que comprenden:
a) una región VH que comprende las secuencias de CDR1, 2 y 3 de SEQ ID NO: 179, 180 y 181 y una región VL que comprende las secuencias de CDR1, 2 y 3 de SEQ ID NO: 6, 7 y 202, tal como un anticuerpo que
comprende
a. una región VH que comprende las secuencias de CDR1, 2 y 3 de SEQ ID NO: 2, 3 y 4 y una región VL que comprende las secuencias de CDR1, 2 y 3 de SEQ ID NO: 6, 7 y 8, (005), o
b. una región VH que comprende las secuencias de CDR1, 2 y 3 de SEQ ID NO: 10, 11 y 12 y una región VL que comprende las secuencias de CDR1, 2 y 3 de SEQ ID NO: 14, 15 y 16, (006)
b) una región VH que comprende las secuencias de CDR1, 2 y 3 de SEQ ID NO: 26, 184 y 28 y una región VL que comprende las secuencias de CDR1, 2 y 3 de SEQ ID NO: 30, 31 y 205, tal como un anticuerpo que comprende una región VH que comprende las secuencias de CDR1, 2 y 3 de SEQ ID NO: 26, 27 y 28 y una región VL que comprende las secuencias de CDR1, 2 y 3 de SEQ ID NO: 30, 31 y 32 (022), o
c) una región VH que comprende las secuencias de CDR1, 2 y 3 de SEQ ID NO: 189, 190 y 60 y una región VL que comprende las secuencias de CDR1, 2 y 3 de SEQ ID NO: 62, 63 y 207, tal como un anticuerpo que comprende una región VH que comprende las secuencias de CDR1, 2 y 3 de SEQ ID NO: 58, 59 y 60 y una región VL que comprende las secuencias de CDR1, 2 y 3 de SEQ ID NO: 62, 63 y 64 (058)
Se desvelan adicionalmente anticuerpos que comprenden:
a) una región VH que comprende la secuencia de SEQ ID NO: 1 y, preferentemente, una región VL que comprende la secuencia de SEQ ID NO: 5 (005)
b) una región VH que comprende la secuencia de SEQ ID NO: 9 y, preferentemente, una región VL que comprende la secuencia de SEQ ID NO: 13 (006)
c) una región VH que comprende la secuencia de SEQ ID NO: 25 y, preferentemente, una región VL que comprende la secuencia de SEQ ID NO: 29 (022)
d) una región VH que comprende la secuencia de SEQ ID NO: 57 y, preferentemente, una región VL que comprende la secuencia de SEQ ID NO: 61 (058)
e) una región VH que comprende la secuencia de SEQ ID NO: 145 y, preferentemente, una región VL que comprende la secuencia de SEQ ID NO: 146 (031)
f) una región VH que comprende la secuencia de SEQ ID NO: 147 y, preferentemente, una región VL que comprende la secuencia de SEQ ID NO: 148 (007)
g) una región VH que comprende la secuencia de SEQ ID NO: 149 y, preferentemente, una región VL que comprende la secuencia de SEQ ID NO: 150 (011)
h) una región VH que comprende la secuencia de SEQ ID NO: 151 y, preferentemente, una región VL que comprende la secuencia de SEQ ID NO: 152 (017)
i) una región VH que comprende la secuencia de SEQ ID NO: 153 y, preferentemente, una región VL que comprende la secuencia de SEQ ID NO: 154 (025), o
j) una variante de cualquiera de dichos anticuerpos, donde dicha variante tiene preferentemente como mucho 1, 2 o 3 modificaciones de aminoácidos, más preferentemente sustituciones de aminoácidos, tales como sustituciones conservadoras de aminoácidos en dichas secuencias.
Se desvelan adicionalmente en el presente documento, anticuerpos donde:
- el anticuerpo compite por la unión con el cMetECDHis soluble con un anticuerpo inmovilizado, donde dicho anticuerpo inmovilizado comprende una región VH que comprende la secuencia de SEQ ID NO: 49 y una región VL que comprende la secuencia de SEQ ID NO: 53 (045), preferentemente donde el anticuerpo compite más de un 50 %, por ejemplo, más de un 75 %, con dicho anticuerpo inmovilizado, cuando se determina como se describe en el Ejemplo 17.
y
- el anticuerpo no compite por la unión con el cMetECDHis soluble con un anticuerpo inmovilizado, donde dicho anticuerpo inmovilizado comprende una región VH que comprende la secuencia de SEQ ID NO: 9 y una región VL que comprende la secuencia de SEQ ID NO: 13 (006), preferentemente donde el anticuerpo compite por menos del 25 %, tal como menos de un 20 % con dicho anticuerpo inmovilizado, cuando se determina como se describe en el Ejemplo 17.
En un aspecto adicional, el anticuerpo no compite por la unión con el cMetECDHis soluble con un anticuerpo seleccionado de entre el grupo que consiste en:
a) un anticuerpo inmovilizado que comprende una región VH que comprende la secuencia de SEQ ID NO: 17 y una región VL que comprende la secuencia de SEQ ID NO: 21 (008), y
b) un anticuerpo que comprende una región VH que comprende la secuencia de SEQ ID NO: 33 y una región VL que comprende la secuencia de SEQ ID NO: 37 (024),
preferentemente donde el anticuerpo compite por menos del 25 %, tal como menos de un 20 % con dicho anticuerpo inmovilizado, cuando se determina como se describe en el Ejemplo 17.
En un aspecto adicional, el anticuerpo inmovilizado que comprende una región VH que comprende la secuencia de SEQ ID NO: 49 y una región VL que comprende la secuencia de SEQ ID NO: 53 (045).
En un aspecto adicional, el anticuerpo comprende una región CDR3 de VH que tiene la secuencia que se expone en la SEQ ID NO: 188, tal como una región CDR3 de VH como se expone en la SEQ ID NO: 52 (045).
En un aspecto adicional, el anticuerpo comprende una región VH que comprende las secuencias de CDR1, 2 y 3 de SEQ ID NO: 186, 187 y 188 y una región VL que comprende las secuencias de CDR1, 2 y 3 de SEQ ID NO: 54, 55 y 56, tal como un anticuerpo que comprende una región VH que comprende las secuencias de CDR1, 2 y 3 de SEQ ID NO: 50, 51 y 52 y una región VL que comprende las secuencias de CDR1, 2 y 3 de SEQ ID NO: 54, 55 y 56 (045).
En un aspecto adicional, el anticuerpo comprende:
a) una región VH que comprende la secuencia de SEQ ID NO: 49 y, preferentemente, una región VL que comprende la secuencia de SEQ ID NO: 53 (045)
b) una región VH que comprende la secuencia de SEQ ID NO: 155 y, preferentemente, una región VL que comprende la secuencia de SEQ ID NO: 156 (040)
c) una región VH que comprende la secuencia de SEQ ID NO: 157 y, preferentemente, una región VL que comprende la secuencia de SEQ ID NO: 158 (039), o
d) una variante de cualquiera de dichos anticuerpos, donde dicha variante tiene preferentemente como mucho 1, 2, o 3 modificaciones de aminoácidos, más preferentemente sustituciones de aminoácidos, tales como sustituciones conservadoras de aminoácidos en dichas secuencias.
En un aspecto adicional, el anticuerpo se une al dominio SEMA de c-Met, preferentemente donde el anticuerpo es capaz de inhibir la unión del HGF al dominio SEMA con una CI50 menor de 10 μg/ml, tal como menos de 2 μg/ml como se describe en el Ejemplo 18.
En otro aspecto del anticuerpo de la divulgación, el anticuerpo se une al mismo epítopo como un anticuerpo que comprende una región VH que comprende la secuencia de SEQ ID NO: 17 y una región VL que comprende la secuencia de SEQ ID NO: 21 (008) o se une al mismo epítopo que un anticuerpo que comprende una región VH que comprende la secuencia de SEQ ID NO: 41 y una región VL que comprende la secuencia de SEQ ID NO: 45 (035) o se une al mismo epítopo que un anticuerpo que comprende una región VH que comprende la secuencia de SEQ ID NO: 105 y una región VL que comprende la secuencia de SEQ ID NO: 109 (096).
En un aspecto adicional, el anticuerpo comprende una región CDR3 de VH que tiene la secuencia que se expone en la SEQ ID NO: 183, tal como una región CDR3 de VH que se expone en la SEQ ID NO: 20, 44 o 108 (008, 035, 096).
En un aspecto adicional, el anticuerpo comprende una región VH que comprende secuencias de CDR1, 2 y 3 de SEQ ID NO: 18, 182 y 183 y una región VL que comprende las secuencias de CDR1, 2 y 3 de SEQ ID NO: 22.203 y 204, tal como un anticuerpo que comprende:
a) una región VH que comprende las secuencias de CDR1, 2 y 3 de SEQ ID NO: 18, 19 y 20 y una región VL que comprende las secuencias de CDR1, 2 y 3 de SEQ ID NO: 22, 23 y 24, (008), o
b) una región VH que comprende las secuencias de CDR1, 2 y 3 de SEQ ID NO: 42, 43 y 44 y una región VL que comprende las secuencias de CDR1, 2 y 3 de SEQ ID NO: 46, 47 y 48, (035), o
c) una región VH que comprende las secuencias de CDR1, 2 y 3 de SEQ ID NO: 106, 107 y 108 y una región VL que comprende las secuencias de CDR1, 2 y 3 de SEQ ID NO: 110, 111 y 112, (096).
En un aspecto adicional, el anticuerpo comprende:
a) una región VH que comprende la secuencia de SEQ ID NO: 17 y, preferentemente, una región VL que comprende la secuencia de SEQ ID NO: 21 (008)
b) una región VH que comprende la secuencia de SEQ ID NO: 41 y, preferentemente, una región VL que comprende la secuencia de SEQ ID NO: 45 (035)
c) una región VH que comprende la secuencia de SEQ ID NO: 105 y, preferentemente, una región VL que comprende la secuencia de SEQ ID NO: 109 (096),
o
d) una variante de cualquiera de dichos anticuerpos, donde dicha variante tiene preferentemente como mucho 1, 2, o 3 modificaciones de aminoácidos, más preferentemente sustituciones de aminoácidos, tales como sustituciones conservadoras de aminoácidos en dichas secuencias.
En una realización adicional, el anticuerpo se une a las células A431 con una CE50 de 10 nM o menos, tal como una CE50 de 2 nM o menos, preferentemente como se determina de acuerdo con el Ejemplo 13.
En una realización adicional más, el anticuerpo se une al c-Met con una constante de afinidad (KD) de 10 nM o menos, tal como una afinidad de 5 nM o menos, preferentemente como se determina de acuerdo con el Ejemplo 14. En una divulgación adicional más, el anticuerpo se une al c-Met de Rhesus, preferentemente donde la señal del anticuerpo unido al c-Met de Rhesus es al menos 5 veces la del anticuerpo de control negativo, como se determina de acuerdo con el Ejemplo 15.
En una realización adicional más, el anticuerpo inhibe la unión del HGF al dominio extracelular del c-Met, preferentemente donde el anticuerpo inhibe la unión más de un 40 %, tal como más del 50 %, por ejemplo, más del 60 %, por ejemplo, más del 70 %, por ejemplo, más del 80 %, por ejemplo, más del 90 %, como se determina de acuerdo con el Ejemplo 16.
En una realización adicional más, el anticuerpo es capaz de inhibir la viabilidad de las células KP4, preferentemente donde el anticuerpo es capaz de inhibir la viabilidad de más del 10 %, tal como más del 25 %, por ejemplo, más del 40 %, preferentemente como se describen en el Ejemplo 19.
Formatos de anticuerpo
La presente divulgación proporciona anticuerpos anti-c-Met antagonistas y no antagonistas. Mientras que algunos anticuerpos actúan de manera antagonista en las células diana independientemente de si son monovalentes o bivalentes, para otros anticuerpos, el efecto funcional depende de la valencia. Como se muestra en el Ejemplo 19 del presente documento, los anticuerpos 024, 062, 064, 068, 069, 098, 101, 181 de la invención (que están todos en el mismo grupo de bloqueo cruzado véase el Ejemplo 17) tienen propiedades antagonistas en los ensayos de viabilidad de KP4 independientemente del formato. Los anticuerpos 022 y 058, por otra parte, se comportan de manera antagonista en este ensayo en un formato monovalente, pero agonista (o al menos de manera no antagonista) en un formato bivalente. Por lo tanto, dependiendo de las propiedades funcionales deseadas para un uso particular, los anticuerpos particulares se pueden seleccionar de entre el conjugo de anticuerpos que se proporcionan en la presente divulgación y/o su formato se puede adaptar al cambio de valencia.
Además, el anticuerpo de la invención puede ser de cualquier isotipo. La elección del isotipo normalmente será guiada por las funciones efectoras deseadas, tales como la inducción de ADCC. Los isotipos ejemplares son IgG1, IgG2, IgG3 e IgG4. Se pueden utilizar cualquiera de las regiones constantes de cadena ligera humanas, kappa o lambda. Si se desea, la clase de un anticuerpo anti-c-Met de la presente invención se puede cambiar por métodos conocidos. Por ejemplo, un anticuerpo de la presente invención que era originalmente una IgM se puede cambiar de clase a un anticuerpo IgG de la presente invención. Además, se pueden utilizar técnicas de cambio de clase para convertir una subclase de IgG en otra, por ejemplo, de IgG1 a IgG2. Por lo tanto, la función efectora de los anticuerpos de la presente invención se puede cambiar por cambio de isotipo a, por ejemplo, un anticuerpo IgG1, IgG2, IgG3, IgG4, IgD, IgA, IgE, o IgM para los distintos usos terapéuticos. En una realización un anticuerpo de la presente invención es un anticuerpo IgG1, por ejemplo, una IgG1, κ.
La modulación negativa del c-Met inducida por anticuerpos antagonistas representa un mecanismo de acción de anticuerpo c-Met terapéuticos. En consecuencia, en un aspecto de la invención son deseables los anticuerpos con propiedades agonistas reducidas, pero que mantengan la capacidad para inducir una modulación negativa de c-Met. Se ha descubierto que, reduciendo la flexibilidad conformacional de los anticuerpos, la potencial actividad agonista residual de los anticuerpos IgG1 bivalentes se minimiza.
En consecuencia, en una realización adicional, el anticuerpo de la invención se ha modificado para hacerlo menos flexible, tal como por mutaciones de la región bisagra.
Los mayores cambios conformacionales son el resultado de la flexibilidad de la bisagra, que permite un amplio intervalo de ángulos Fab-Fc (Ollmann Saphire, E., R.L. Stanfield, M.D.M. Crispin, P.W.H.I. Parren, P.M. Rudd, R.A. Dwek, D.R. Burton y I.A. Wilson.2002. Contrasting IgG structures reveal extreme asymmetry y flexibility. J. Mol. Biol.
319: 9-18). Una manera de reducir la flexibilidad del brazo Fab en las inmunoglobulinas es evitar la formación de enlaces disulfuro entre las cadenas ligera y pesada mediante una modificación genética. En un anticuerpo IgG1 natural la cadena ligera se conecta covalentemente con la cadena pesada mediante un enlace disulfuro, que conecta la cisteína del extremo C de la cadena ligera a la cisteína en la posición 220 (C220 en numeración EU) en la bisagra de la Fc de la cadena pesada. Mutando el aminoácido C220 a serina o cualquier otro aminoácido natural, eliminando el C220, eliminando la bisagra completa, o sustituyendo la bisagra de IgG1 con una bisagra IgG3, se forma una molécula en la que las cadenas ligeras se conectas mediante sus cisteínas terminales, de manera análoga a la situación que se encuentra en el isotipo humano IgA2m (1). Esto da como resultado una flexibilidad reducida de los Fab con respecto al Fc y en consecuencia una reducción de la capacidad de entre cruzamiento, como se muestra en los Ejemplos.
Otra estrategia para reducir la flexibilidad de una molécula IgG1 es sustituir la bisagra IgG1 con la bisagra de IgG2 o una bisagra tipo IgG2 (Dangl et al. EMBO J. 1988; 7:1989-94). Esta región de bisagra tiene dos propiedades
distintas de la de IgG1, que se considera que hace a las moléculas menos flexibles. Primero, en comparación con la bisagra de IgG1, la bisagra de IgG2 es 3 aminoácidos más corta. Segundo, la bisagra IgG2 contiene una cisteína adicional, por lo tanto, se formarán tres en vez de dos puentes disulfuro entre las cadenas pesadas. De manera alternativa, se puede introducir una variante de la bisagra de IgG1 que se parezca a la bisagra de IgG2. Este mutante (TH7Δ6-9) (documento WO 2010063746) contiene la mutación T223C y dos eliminaciones (K222 y T225) con el fin de crear una bisagra más corta con una cisteína adicional.
En una realización adicional, el anticuerpo de la invención es del subtipo IgG1, en el que la región de la bisagra se ha modificado mediante:
(i) eliminación de la región de la bisagra de secuencia EPKSCDKTHTCPPCP y se ha sustituido con la región de la bisagra de IgG2 de secuencia: ERKCCVECPPCP (IgG1 Hinge-IgG2);
(ii) eliminación de la posición 220 de manera que la región de bisagra modificada tiene la secuencia EPKSDKTHTCPPCP (IgG1 ΔC220);
(iii) sustitución de la cisteína de la posición 220 con cualquier otro aminoácido natural (X) de manera que la región de la bisagra tiene la secuencia de EPKSXDKTHTCPPCP (IgG1 C220X);
(iv) eliminación de la región de la bisagra de secuencia EPKSCDKTHTCPPCP (UniBody IgG1);
(v) eliminación de la región de bisagra de secuencia EPKSCDKTHTCPPCP y sustitución con la región bisagra de la IgG3 de secuencia ELKTPLGDTTHTCPRCPEPKSCDTPPPCPRCPEPKSCDTPPPCPRCPEPKSCDTPPPC PRCP (IgG1 Hinge-IgG3);
(vi) sustitución de la treonina en la posición 223 con cisteína, y eliminación de la lisina en la posición 222 y la treonina en la posición 225, de manera que la región de la bisagra tiene la secuencia de EPKSCDCHCPPCP (IgG1 TH7Δ6-9).
En una realización de la invención, el anticuerpo de la invención es del subtipo IgG1, en el que la región de la bisagra se ha modificado eliminando la posición 220 de manera que la región de la bisagra modificada tiene la secuencia EPKSDKTHTCPPCP (IgG1 ΔC220) o sustituyendo la cisteína en la posición 220 con cualquier otro aminoácido natural (X) de manera que la región de la bisagra modificada tiene la secuencia de EPKSXDKTHTCPPCP (IgG1 C220X).
En una realización adicional, el anticuerpo de la invención es del subtipo IgG1, en el que la región de la bisagra se ha modificado sustituyendo la cisteína de la posición 220 con serina de manera que la región de la bisagra modificada tiene la secuencia de EPKSSDKTHTCPPCP (IgG1 C220S).
En una divulgación adicional, el anticuerpo de la invención puede ser del subtipo IgG2.
Adicionalmente, el anticuerpo de la divulgación puede estar glico-modificado para reducir la fucosa y por lo tanto aumentar la ADCC, por ejemplo, mediante la adición de compuestos al medio de cultivo durante la producción del anticuerpo como se describe en el documento US2009317869 o como se describe en van Berkel et al. (2010) Biotechnol. Bioeng. 105:350 o utilizando células con inactivación de FUT8, por ejemplo, como se describe en Yamane-Ohnuki et al (2004) Biotechnol. Bioeng 87:614. La ADCC se puede optimizar alternativamente utilizando el método descrito por Umaña et al. (1999) Nature Biotech 17:176.
En una realización, el anticuerpo comprende una región VH que comprende la secuencia de CDR3 de SEQ ID NO: 100 y una región VL que comprende la secuencia de CDR3 de SEQ ID NO: 104 (069) del subtipo IgG1, en el que la región de la bisagra se ha modificado sustituyendo la cisteína de la posición 220 con serina de manera que la región de la bisagra modificada tiene la secuencia de EPKSSDKTHTCPPCP (IgG1 C220S).
En una realización, el anticuerpo comprende una región VH que comprende la secuencias de CDR1, 2 y 3 de SEQ ID NO: 98, 99 y 100 y una región VL que comprende las secuencias de CDR1, 2 y 3 de SEQ ID NO: 102, 103 y 104 (069) del subtipo IgG1, en el que la región de la bisagra se ha modificado sustituyendo la cisteína de la posición 220 con serina de manera que la región de la bisagra modificada tiene la secuencia de EPKSSDKTHTCPPCP (IgG1 C220S).
En una realización, el anticuerpo comprende una región VH que comprende la secuencia de SEQ ID NO: 97 y una región VL que comprende la secuencia de SEQ ID NO: 101 (069) del subtipo IgG1, en el que la región de la bisagra se ha modificado sustituyendo la cisteína de la posición 220 con serina de manera que la región de la bisagra modificada tiene la secuencia de EPKSSDKTHTCPPCP (IgG1 C220S).
Distintas publicaciones han demostrado la correlación entre la reducción de la fucosilación central y el aumento de actividad ADCC in vitro (Shields RL. 2002 JBC; 277:26733-26740, Shinkawa T. 2003 JBC; 278(5):3466-3473, Umaña P. Nat Biotechnol.1999 feb;17(2):176-80).
En una realización adicional, el anticuerpo de la invención se ha modificado para reducir la fucosilación central por debajo del 10 %, tal como por debajo del 5 % como se determina con cromatografía de intercambio aniónico de altas prestaciones acoplada con una detección amperométrica pulsada (HPAEC-PAD). Esto se puede conseguir por
métodos bien conocidos en la técnica anterior, por ejemplo, el tratamiento con kifunensina o la producción en células negativas a FUT8.
Se desvela adicionalmente que el anticuerpo puede modificarse para aumentar la activación del complemento, por ejemplo, como se describe en Natsume et al. (2009) Cancer Sci.100:2411.
En una realización, el anticuerpo de la invención es un anticuerpo de longitud completa, preferentemente un anticuerpo IgG1, en particular un anticuerpo IgG1, κ. También se desvela que el anticuerpo puede ser un fragmento de anticuerpo o un anticuerpo de cadena sencilla.
Los fragmentos de anticuerpo pueden obtenerse, por ejemplo, por fragmentación utilizando técnicas convencionales, y los fragmentos se exploran en cuanto a su utilidad de la misma manera que se describe en el presente documento para los anticuerpos completos. Por ejemplo, los fragmentos F(ab’)2 se pueden generar tratando el anticuerpo con pepsina. El fragmento F(ab’)2 resultante se puede tratar para reducir los puentes disulfuro para producir fragmentos Fab’. Los fragmentos Fab se pueden obtener tratando un anticuerpo IgG con papaína; los fragmentos Fab’ se pueden obtener por digestión con pepsina de un anticuerpo IgG. Un fragmento F(ab’) también se puede producir uniendo el Fab’ descrito posteriormente mediante un enlace tioéter o un enlace disulfuro. Un fragmento Fab es un fragmento de anticuerpo que se obtiene cortando un enlace disulfuro de la región bisagra el F(ab’)2. Un fragmento Fab’ se puede obtener tratando un fragmento F(ab’)2 con un agente reductor, tal como el ditiotreitol. El fragmento de anticuerpo también se puede generar por expresión de ácidos nucleicos que codifiquen dichos fragmentos en células recombinantes (véase, por ejemplo, Evans et al., J. Immunol. Meth.184, 123-38 (1995)). Por ejemplo, un gen quimérico que codifica una parte de un fragmento F(ab’)2 podría incluir secuencias de ADN que codifican el dominio CH1 y la región bisagra de la cadena H, seguido por un codón de parada traduccional para dar lugar a dicha molécula de fragmento de anticuerpo truncado.
Como se ha explicado anteriormente, en una realización, el anticuerpo anti-c-Met de la invención es un anticuerpo bivalente.
En otra realización, el anticuerpo anti-c-Met de la invención es un anticuerpo monovalente.
En una realización, el anticuerpo de la invención es un fragmento Fab o un anticuerpo de un brazo tal como se describe en el documento US 20080063641 (Genentech) u otro anticuerpo monovalente, por ejemplo, tal como se describe en el documento WO 2007048037 (Amgen).
En una realización preferida, un anticuerpo monovalente tiene la estructura que se describe en el documento WO 2007059782 (Genmab) que tiene una eliminación en la región de la bisagra. En consecuencia, en una realización, el anticuerpo es un anticuerpo monovalente, donde dicho anticuerpo anti-c-Met se construye por un método que comprende:
i) proporcionar una construcción de ácido nucleico que codifique la cadena ligera de dicho anticuerpo monovalente, comprendiendo dicha construcción una secuencia de nucleótidos que codifica una región VL de un anticuerpo anti-c-Met específico del antígeno seleccionado y una secuencia de nucleótidos que codifica la región constante CL de una Ig, en el que dicha secuencia de nucleótidos que codifica la región VL de un anticuerpo específico de un antígeno seleccionado y dicha secuencia de nucleótidos que codifica la región CL de una Ig están unidas operativamente juntas, y en el que, en caso de un subtipo IgG1, la secuencia de nucleótidos que codifica la región CL se ha modificado de manera que la región CL no contenga ningún aminoácido capaz de formar enlaces disulfuro o enlaces covalentes con otros péptidos que comprendan una secuencia de aminoácidos de la región CL idéntica en presencia de una IgG humana policlonal o cuando se administra a un animal o un ser humano;
ii) Proporcionar una construcción de ácido nucleico que codifique la cadena pesada de dicho anticuerpo monovalente, comprendiendo dicha construcción una secuencia de nucleótidos que codifique la región VH de un anticuerpo específico de un antígeno seleccionado y una secuencia de nucleótidos que codifique una región constante CH de una Ig humana, en el que la secuencia de nucleótidos que codifica la región CH se ha modificado de manera que la región correspondiente con la región de la bisagra y, según se necesite por el subtipo de Ig, otras regiones de la región CH, tal como la región CH3 , no comprendan ningún resto de aminoácidos que participe en la formación de enlaces disulfuro o enlaces entre las cadenas pesadas no covalentes estables con otros péptidos que comprendan una secuencia de aminoácidos de la región CH idéntica de la Ig humana en presencia de IgG humanas o cuando se administran a un animal o ser humano, en el que dicha secuencia de nucleótidos que codifica la región VH de un anticuerpo específico de un antígeno seleccionado y dicha secuencia de nucleótidos que codifica la región CH de dicha Ig están unidas operativamente juntas;
iii) proporcionar un sistema de expresión celular para producir dicho anticuerpo monovalente;
iv) producir dicho anticuerpo monovalente co-expresando las construcciones de ácido nucleico de (i) y (ii) en células del sistema de expresión celular de (iii).
De manera similar, en una realización, el anticuerpo anti-c-Met es un anticuerpo monovalente que comprende (i) una región variable de un anticuerpo de la invención como se describe en el presente documento o una parte de unión al antígeno de dicha región, y (ii) una región CH de una inmunoglobulina o un fragmento de la misma que comprende las regiones CH2 y CH3, donde la región CH o fragmento de la misma se ha modificado de manera que la región correspondiente a la región de la bisagra y, si la inmunoglobulina no es del subtipo IgG4, otras regiones de la región CH, tales como la región CH3, no comprende ningún resto de aminoácido que sea capaz de formar enlaces disulfuro con una región CH idéntica u otros enlaces entre cadenas pesadas no covalentes estables con una región CH idéntica en presencia de una IgG policlonal humana.
En una realización adicional de los mismos, la cadena pesada del anticuerpo anti-c-Met monovalente se ha modificado de manera que se ha eliminado la región de la bisagra completa.
En una realización adicional, dicho anticuerpo monovalente es del subtipo IgG4, pero la región CH3 se ha modificado de manera que se han hecho una o más de las siguientes sustituciones de aminoácidos:
Numeración de mutaciones de CH3
KABAT* Índice EU G4* Mutaciones
E378 E357 E357A o E357T o E357V o E357I
S387 S364 S364R o S364K
T389 T366 T366A o T366R o T366K o T366N
L391 L368 L368A o L368V o L368E o L368G o L368S o L368T
D427 D399 D399A o D399T o D399S
F436 F405 F405A o F405L o F405T o F405D o F405R o F405Q o F405K o F405Y Y438 Y407 Y407A o Y407E o Y407Q o Y407K o Y407F
F436 y Y438 F405 y Y407 (F405T y Y407E) o (F405D y Y407E)
D427 y Y438 D399 y Y407 (D399S y Y407Q) o (D399S y Y407K) o (D399S y Y407E)
*KABAT indica la numeración de aminoácidos de acuerdo con Kabat (Kabat et al., Sequences of Proteins of Immunological Interest, 5ª Ed. Public Health Service, National Institutes of Health, Bethesda, MD.
(1991). Índice EU indica la numeración de aminoácidos de acuerdo con el índice EU como se señala en Kabat et al., Sequences of Proteins of Immunological Interest, 5ª Ed. Public Health Service, National Institutes of Health, Bethesda, MD. (1991)).
También se desvela en el presente documento que la secuencia de dicho anticuerpo monovalente se puede modificar de manera que no comprenda ningún sitio receptor para la glicosilación unida a N.
Los anticuerpos anti-c-Met de la divulgación también incluyen anticuerpo de cadena sencilla. Los anticuerpos de cadenas sencilla son péptidos en los que las regiones Fv de cadena pesada y ligera están conectados. La presente divulgación proporcionar un Fv de cadena sencilla (scFv) en el que las cadenas pesada y ligera del Fv de un anticuerpo anti-c-Met de la presente divulgación están unidas con un enlazador peptídico flexible (normalmente de aproximadamente 10, 12, 15 o más restos de aminoácido) en una cadena peptídica sencilla. Los métodos para la producción de dichos anticuerpos se describen por ejemplo en el documento US 4.946.778, Pluckthun en The Pharmacology of Monoclonal Antibodies, vol.113, Rosenburg y Moore eds. Springer-Verlag, New York, pp.269-315 (1994), Bird et al., Science 242, 423-426 (1988), Huston et al., PNAS USA 85, 5879-5883 (1988) y McCafferty et al., Nature 348, 552-554 (1990). El anticuerpo de cadena sencilla puede ser monovalente si solo se utilizan una VH y una VL, bivalente, si se utilizan dos VH y VL, o polivalente, si se utilizan más de dos VH y VL.
En una realización, el anticuerpo anti-c-Met de la invención, es un anticuerpo deficiente en una función efectora. En una realización, el anticuerpo anti-c-Met deficiente en una función efectora es un anticuerpo IgG4 estabilizado, que se ha modificado para evitar el intercambio del brazo Fab (van der Neut Kolfschoten et al. (2007) Science 317(5844):1554-7). Ejemplos de anticuerpos IgG4 estabilizados son anticuerpos, en los que la arginina de la posición 409 de una región constante de cadena pesada de la IgG4 humana, que se indica en el índice EU como en Kabat et al., se sustituye con lisina, treonina, metionina, o leucina, preferentemente lisina (descrito en el documento WO 2006033386 (Kirin)) y/o en el que la región de la bisagra se ha modificado para comprender una secuencia Cys-Pro-Pro-Cys.
Adicionalmente se desvela que el anticuerpo anti-c-Met IgG4 estabilizado puede ser un anticuerpo IgG4 que comprende una cadena pesada y una cadena ligera, donde dicha cadena pesada comprende una región constante de IgG4 humana que tiene un resto seleccionado de entre el grupo que consiste en : Lys, Ala, Thr, Met y Leu en la posición correspondiente a 409 y/o un resto seleccionado de entre el grupo que consiste en: Ala, Val, Gly, Ile y Leu en la posición correspondiente a 405, en donde dicho anticuerpo comprende opcionalmente una o más sustituciones, eliminaciones y/o inserciones adicionales, pero no comprende una secuencia Cys-Pro-Pro-Cys en la región de la bisagra. Preferentemente, dicho anticuerpo comprende un resto de Lys o Ala en la posición
correspondiente a 409 o la región CH3 del anticuerpo se ha sustituido con la región CH3 de una IgG1 humana, una IgG2 humana o una IgG3 humana. Véase también el documento WO 2008145142 (Genmab).
En una divulgación adicional más el anticuerpo anti-c-Met IgG4 estabilizado es un anticuerpo IgG4 que comprende una cadena pesada y una cadena ligera ,donde dicha cadena pesada comprende una región constante de la IgG4 humana que tiene un resto seleccionado de entre el grupo que consiste en: Lys, Ala, Thr, Met y Leu en la posición correspondiente a 409 y/o un resto seleccionado de entre el grupo que consiste en: Ala, Val, Gly, Ile y Leu en la posición correspondiente a 405, y donde dicho anticuerpo comprende opcionalmente una o más sustituciones, eliminaciones y/o inserciones adicionales y donde dicho anticuerpo comprende una secuencia Cys-Pro-Pro-Cys en la región de bisagra. Preferentemente, dicho anticuerpo comprende un resto de Lys o Ala en la posición correspondiente a la 409 o la región CH3 el anticuerpo se ha remplazado por la región CH3 de la IgG1 humana, de la IgG2 humana o de la IgG3 humana.
En una divulgación adicional, el anticuerpo anti-c-Met deficiente en una función efectora puede ser un anticuerpo de tipo no IgG4, por ejemplo, IgG1, IgG2 o IgG3 que se ha mutado de manera que se ha reducido la capacidad para mediar funciones efectoras, tales como la ADCC, o incluso se ha eliminado. Dichas mutaciones se han descrito por ejemplo en Dall’Acqua WF et al., J Immunol. 177(2):1129-1138 (2006) y Hezareh M, J Virol. ;75(24):12161-12168 (2001).
Conjugados
En una realización adicional, la presente invención proporciona un anticuerpo anti-c-Met conjugado con un resto terapéutico, tal como una citotoxina, un fármaco quimioterápico, un inmunosupresor, o un radioisótopo. Se hace referencia a dichos conjugados en el presente documento como “inmunoconjugados”. Se hace referencia a los inmunoconjugados que incluyen una o más citotoxinas como “inmunotoxinas”.
Una citotoxina o agentes citotóxico incluye cualquier agente que es perjudicial (por ejemplo, destruye) para las células. Los agentes terapéuticos adecuados para formar inmunoconjugados de la presente invención incluyen taxol, citocalasina B, gramicidina D, bromuro de etidio, emetina, mitomicina, etopósido, tenopósido, vincristina, vinblastina, colchicina, doxorrubicina, daunorrubicina, dihidroxi antracin diona, mitoxantrona, mitramicina, actinomicina D, 1-deshidro-testosterona, glucocorticoides, procaína, tetracaína, lidocaína, propranolol, y puromicina, antimetabolitos (tales como metotrexato, 6-mercaptopurina, 6-tioguanina, citarabina, fludarabina, 5-fluorouracilo, decarbazina, hidroxiurea, asparaginasa, gemcitabina, cladribina), agentes alquilantes (tales como mecloretamina, tiotepa, clorambucilo, melfalan, carmustina (BSNU), lomustina (CCNU), ciclofosfamida, busulfan, dibromomanitol, estreptozotocina, dacarbazina (DTIC), procarbazina, mitomicina C, cisplatino y otros derivados del platino, tales como carboplatino), antibióticos (tales como dactinomicina (anteriormente actinomicina), bleomicina, daunorrubicina (anteriormente daunomicina), doxorrubicina, idarrubicina, mitramicina, mitomicina, mitoxantrona, plicamicina, antramicina (AMC)), toxina diftérica y moléculas relacionadas (tales como cadena A diftérica y fragmentos activos de la misma y moléculas hibridas), toxina del ricino (tales como ricino A o una toxina de cadena A de ricino desglicosilada), toxina del cólera, una toxina tipo Shiga (SLT-I, SLT-II, SLT-IIV), toxina LT, toxina C3, toxina Shiga, toxina pertussis, toxina tetánica, inhibidor de Bowman-Birk proteasa de la soja, exotoxina de Pseudomonas, alorina, saporina, modeccina, gelanina, cadena A de abrina, cadena A de modeccina, alfa-sarcina, proteínas de Aleurites fordii, proteinas diantina, proteínas de Fitolacca americana (PAPI, PAPII, y PAP-S), inhibidor de Momordica charantia, curcina, crotina, inhibidor de Saponaria officinalis, toxinas gelonina, mitogelina, restrictocina, fenomicina, y enomicina. Otras moléculas conjugadas adecuadas incluyen ribonucleasa (RNasa), DNasa I, enterotoxina-A Estafilocócica, proteína antivírica de ombú, toxina diftérica, y endotoxina de Pseudomonas. Véase, por ejemplo, Pastan et al., Cell 47, 641 (1986) y Goldenberg, Calif. A Cancer Journal for Clinicians 44, 43 (1994). Los agentes terapéuticos, que se pueden administrar en combinación con un anticuerpo anti-c-Met de la presente invención como se describe en cualquier sitio del presente documento, también pueden ser candidatos a restos terapéuticos útiles para la conjugación con un anticuerpo de la presente invención.
Un anticuerpo anti-c-Met de la divulgación puede comprender un ácido nucleico conjugado o una molécula asociada con un ácido nucleico. En una de dichas facetas de la presente divulgación, el ácido nucleico conjugado es una ribonucleasa citotóxica, un ácido nucleico antisentido, una molécula inhibidora del ARN (por ejemplo, una molécula de ARNip) o un ácido nucleico inmunoestimulante (por ejemplo, una molécula de ADN que contiene un motivo CpG inmunoestimulante) Adicionalmente, un anticuerpo anti-c-Met de la divulgación puede conjugarse con un aptámero o una ribozima.
La divulgación también proporciona anticuerpos anti-c-Met que comprenden uno o más aminoácidos radiomarcados. Un anticuerpo anti-c-Met radiomarcado se puede utilizar con fines tanto diagnósticos como terapéuticos (la conjugación con moléculas radiom5arcadas es otra posible característica). Ejemplos no limitantes de marcadores para polipéptidos incluyen 3H, 14C, 1 N, 35S, 90Y, 99Tc, y 125I, 131I, y 186Re.
Los anticuerpos anti-c-Met también se pueden modificar químicamente por conjugación covalente con un polímero para, por ejemplo, aumentar su semivida circulante. Los polímeros ejemplares y los métodos para unirlos a los péptidos se ilustran, por ejemplo, en los documentos US 4.766.106, US 4.179.337, US 4.495.285 y US 4.609.546.
Los polímeros adicionales incluyen polioles polioxietilados y polietilenglicol (PEG) (por ejemplo, un PEG con un peso molecular de entre aproximadamente 1.000 y aproximadamente 40.000, tal como entre aproximadamente 2.000 y aproximadamente 20.000).
Se puede emplear cualquier método conocido en la técnica para la conjugación del anticuerpo anti-c-Met con la molécula(s) conjugada(s), tal como los descritos anteriormente, incluyendo los métodos descritos por Hunter et al., Nature 144, 945 (1962), David et al., Biochemistry 13, 1014 (1974), Pain et al., J. Immunol. Meth.40, 219 (1981) y Nygren, J. Histochem. y Cytochem. 30, 407 (1982). Dichos anticuerpos se pueden producir conjugando químicamente el otro resto al lado del extremo N o el lado del extremo C del anticuerpo anti-c-Met o un fragmento del mismo (por ejemplo, una cadena H o L del anticuerpo anti-c-Met) (véase, por ejemplo, Antibody Engineering Handbook, editado por Osamu Kanemitsu, publicado por Chijin Shokan (1994)). Dichos derivados del anticuerpo conjugado también se pueden generar por conjugación con restos internos de azúcares, cuando sea apropiado. Los agentes se pueden acoplar directamente o indirectamente a un anticuerpo anti-c-Met de la presente invención. Un ejemplo de acoplamiento indirecto de un segundo agente es el acoplamiento mediante un resto espaciador. El anticuerpo anti-c-Met de la presente divulgación se puede unir a un enlazador quelante, por ejemplo, tiuxetan, que permite que el anticuerpo se conjugue con un radioisótopo.
Anticuerpos biespecíficos
En un aspecto adicional, la invención se refiere a una molécula biespecífica que comprende un primer sitio de unión al antígeno de un anticuerpo anti-c-Met de la invención como se ha descrito anteriormente en el presente documento y un segundo sitio de unión al antígeno con una especificidad de unión diferente, tal como una especificidad de unión por una célula efectora humana, un receptor de Fc humano, un receptor de célula T, un receptor de célula B o una especificidad de unión por un epítopo no solapado de c-Met, es decir, un anticuerpo biespecífico donde el primer y segundo sitio de unión al antígeno no compiten por la unión a c-Met, por ejemplo, cuando se ensaya como se describe en el Ejemplo 17.
Las moléculas de anticuerpo biespecífico ejemplares de la divulgación comprenden (i) dos anticuerpos uno con una especificidad para el c-Met y el otro a una segunda diana que se conjugan juntos, (ii) un anticuerpo sencillo que tiene una cadena o brazo específico de c-Met y una segunda cadena o brazo específico de una segunda molécula, y (iii) un anticuerpo de cadena sencilla que tiene especificidad para el c-Met y una segunda molécula. La segunda molécula puede ser un antígeno asociado a un tumor/antígeno del cáncer tal como el antígeno carcinoembrionario (CEA), antígeno específico de próstata (PSA), RAGE (antígeno renal), α-fetoproteína, CAMEL (antígeno sobre un melanoma reconocido por CTL), antígenos CT (tales como MAGE-B5, -B6, -C2, -C3, y D; Mage-12; CT10; NY-ESO-1, SSX-2, GAGE, BAGE, MAGE, y SAGE), antígenos de mucina (por ejemplo, MUC1, mucin-CA125, etc.), antígenos de gangliósidos, tirosinasa, gp75, C-myc, Marti, MelanA, MUM-1, MUM-2, MUM-3, HLA-B7, Ep-CAM o una integrina asociada al cáncer tal como la integrina α5β3. Se desvela adicionalmente que la segunda molécula puede ser un factor angiogénico u otro factor de crecimiento asociado al cáncer, tal como un factor de crecimiento endotelial vascular, un factor de crecimiento de fibroblastos, un factor de crecimiento epidérmico, angiogenina o un receptor de cualquiera de estos, particularmente los receptores asociados con la progresión del cáncer (por ejemplo, uno de los receptores de HER1-HER4). Un anticuerpo biespecífico de la presente invención puede ser un diacuerpo.
Secuencias de ácido nucleico, vectores y células huésped
En un aspecto adicional, la invención se refiere a secuencias de ácido nucleico tales como secuencias de ADN, que codifican cadenas pesadas y ligeras de un anticuerpo de la invención.
Adicionalmente se desvelan secuencias de ácido nucleico que codifican una secuencia de aminoácidos seleccionada de entre el grupo que consiste en las SEQ ID NO: 1, 5, 9, 13, 17, 21, 25, 29, 33, 37, 41, 45, 49, 53, 57, 61, 65, 69, 73, 77, 81, 85, 89, 93, 97, 101, 105, 109, 113, 117, 121, 125, 129, 133, 137, 138, 139, 140, 141, 142, 143, 144, 145, 146, 147, 148, 149, 150, 151, 152, 153, 154, 155, 156, 157, 158, 159, 160, 161, 162, 163, 164, 165, 166, 167, 168, 169, 170, 171, 172, 173, 174, 175, 176, 177 y 178.
Adicionalmente se desvelan secuencias de ácido nucleico que codifican una secuencia de aminoácidos de la VH seleccionada de entre el grupo que consiste en las SEQ ID NO: 1, 9, 17, 25, 33, 41, 49, 57, 65, 73, 81, 89, 97, 105, 113, 121, 129, 137, 139, 141, 143, 145, 147, 149, 151, 153, 155, 157, 159, 161, 163, 165, 167, 169, 171, 173, 175 y 177.
Adicionalmente se desvelan secuencias de ácido nucleico que codifican una secuencia de aminoácidos de la VL seleccionada de entre el grupo que consiste en las SEQ ID NO: 5, 13, 21, 29, 37, 45, 53, 61, 69, 77, 85, 93, 101, 109, 117, 125, 133, 138, 140, 142, 144, 146, 148, 150, 152, 154, 156, 158, 160, 162, 164, 166, 168, 170, 172, 174, 176 y 178.
En un aspecto adicional más, la invención se refiere a un vector de expresión, o un conjunto de vectores de expresión, que codifican un anticuerpo de la invención. La cadena pesada y ligera del anticuerpo se pueden codificar por el mismo vector o por un vector diferente.
Dichos vectores de expresión se pueden utilizar para la producción recombinante de la invención.
Se desvela adicionalmente que el vector puede comprender una secuencia de nucleótidos que codifica una o más de las secuencias de aminoácidos seleccionadas de entre el grupo que consiste en las SEQ ID NO: 1, 5, 9, 13, 17, 21, 25, 29, 33, 37, 41, 45, 49, 53, 57, 61, 65, 69, 73, 77, 81, 85, 89, 93, 97, 101, 105, 109, 113, 117, 121, 125, 129, 133, 137, 138, 139, 140, 141, 142, 143, 144, 145, 146, 147, 148, 149, 150, 151, 152, 153, 154, 155, 156, 157, 158, 159, 160, 161, 162, 163, 164, 165, 166, 167, 168, 169, 170, 171, 172, 173, 174, 175, 176, 177 y 178.
En otra divulgación, el vector puede comprender una secuencia de nucleótidos que codifica una o más de las secuencias de aminoácidos de la VH seleccionadas de entre el grupo que consiste en las SEQ ID NO: 1 , 9, 17, 25, 33, 41, 49, 57, 65, 73, 81, 89, 97, 105, 113, 121, 129, 137, 139, 141, 143, 145, 147, 149, 151, 153, 155, 157, 159, 161, 163, 165, 167, 169, 171, 173, 175 y 177.
En otra divulgación, el vector puede comprender una secuencia de nucleótidos que codifica una o más de las secuencias de aminoácidos de la VL seleccionadas de entre el grupo que consiste en las SEQ ID NO: 5, 13, 21, 29, 37, 45, 53, 61, 69, 77, 85, 93, 101, 109, 117, 125, 133, 138, 140, 142, 144, 146, 148, 150, 152, 154, 156, 158, 160, 162, 164, 166, 168, 170, 172, 174, 176 y 178.
En una realización adicional, el vector de expresión comprende adicionalmente una secuencia de nucleótidos que codifica la región constante de una cadena ligera, una cadena pesada o ambas cadenas ligera y pesada de un anticuerpo, por ejemplo, un anticuerpo humano. Un vector de expresión en el contexto de la presente invención puede ser cualquier vector adecuado, incluyendo cromosómicos, no cromosómicos, y vectores de ácidos nucleicos sintéticos (una secuencia de ácido nucleico que comprende un conjunto adecuado de elementos de control de la expresión). Ejemplos de dichos vectores incluyen derivados del SV40, plásmidos bacterianos, ADN de fagos, baculovirus, plásmidos de levaduras, vectores derivados de combinaciones de plásmidos y ADN de fagos y vectores de ácido nucleico vírico (ARN o ADN). En una realización, un ácido nucleico que codifica un anticuerpo anti-c-Met está comprendido en un vector de ADN o ARN desnudo, que incluye por ejemplo, un elemento de expresión lineal (como se describe, por ejemplo, en Sykes y Johnston, Nat Biotech 17, 355-59 (1997)), un vector de ácido nucleico compactado (como se describe, por ejemplo, en el documento US 6.077.835 y/o WO 00/70087), un vector plasmídico tal como pBR322, pUC 19/18, o pUC 118/119, un vector de ácido nucleico de tamaño mínimo “mosquito” (como se describe, por ejemplo, en Schakowski et al., Mol Ther 3, 793-800 (2001)), o como una construcción de vector de ácido nucleico precipitado, tal como la construcción precipitada CaP04 ( como se describe por ejemplo, en el documento WO 00/46147, Benvenisty y Reshef, PNAS USA 83, 9551-55 (1986), Wigler et al., Cell 14, 725 (1978), y Coraro y Pearson, Somatic Cell Genetics 7, 603 (1981)). Dichos vectores de ácido nucleico y el uso de los mismos se conocen bien en la técnica (véase, por ejemplo, los documentos US 5.589.466 y US 5.973.972).
En una realización, el vector es adecuado para la expresión del anticuerpo anti-c-Met en una célula bacteriana. Ejemplos de dichos vectores incluyen los vectores de expresión tales como BlueScript (Stratagene), vectores pIN (Van Heeke & Schuster, J Biol Chem 264, 5503-5509 (1989), vectores pET (Novagen, Madison WI) y similares. Un vector de expresión también o alternativamente puede ser un vector adecuado para la expresión en un sistema de levadura. Se puede emplear cualquier vector adecuado para la expresión en un sistema de levaduras. Los vectores adecuados incluyen, por ejemplo, los vectores que comprenden promotores constitutivos o inducibles tales como el factor alfa, alcohol oxidasa y PGH (revisado en: F. Ausubel et al., ed. Current Protocols in Molecular Biology, Greene Publishing y Wiley InterScience New York (1987), y Grant et al., Methods in Enzymol 153, 516-544 (1987)). Un vector de expresión también o alternativamente puede ser un vector adecuado para la expresión en células de mamífero, por ejemplo, un vector que comprende la glutamina sintetasa como un marcador genético, tal como los vectores descritos en Bebbington (1992) Biotechnology (NY) 10:169-175.
Un ácido nucleico y/o vector pueden comprender también una secuencia de ácido nucleico que codifica una secuencia de secreción/localización, que puede dirigirse a un polipéptido tal como una cadena de polipéptido naciente, al espacio periplásmico o en un medio de cultivo celular. Dichas secuencias se conocen en la técnica, e incluyen un líder de secreción o péptidos de señal.
En un vector de expresión de la invención, los ácidos nucleicos que codifican un anticuerpo anti-c-Met pueden comprender o asociarse con cualquier promotor, amplificador y otros elementos que faciliten la expresión adecuados. Ejemplos de dichos elementos incluyen los promotores de expresión fuertes (por ejemplo, el promotor/amplificador CMV IE humano, así como los promotores RSV, SV40, SL3-3, MMTV, y HIV LTR), secuencias de terminación poli(A) eficaces, y un origen de replicación para el producto plasmídico en E. coli, un gen de resistencia a un antibiótico como marcador genético y/o un sitio de clonación conveniente (por ejemplo, un polienlazador). Los ácidos nucleicos pueden comprender también un promotor inducible en oposición a un promotor constitutivo tal como el CMV IE.
En una realización, el vector de expresión que codifica el anticuerpo anti-c-Met se puede posicionar en y/o suministrar a la célula huésped o animal huésped mediante un vector vírico.
En un aspecto adicional más, la invención se refiere a células huésped eucariotas o procariotas, tales como un transfectoma, que producen un anticuerpo de la invención como se define en el presente documento. Ejemplos de células huésped incluyen levaduras, bacterias y células de mamífero tales como células CHO y HEK. Por ejemplo, en una realización, la presente invención proporciona una célula que comprende un ácido nucleico integrado establemente en el genoma celular que comprende una secuencia que codifica la expresión de un anticuerpo anti-c-Met de la presente invención. En otra realización, la presente invención proporciona una célula que no comprende un ácido nucleico integrado, tal como un plásmido, cósmido, fagémido, o elemento de expresión lineal, que comprende una secuencia que codifica la expresión de un anticuerpo anti-c-Met de la invención.
La divulgación se refiere adicionalmente a un hibridoma que produce un anticuerpo de la invención como se define en el presente documento. En un aspecto adicional más, la divulgación se refiere a un anima no humano o planta transgénicos que comprenden ácidos nucleicos que codifican una cadena pesada humana y una cadena ligera humana, donde el animal o la planta produce un anticuerpo de la invención.
En un aspecto adicional, la invención se refiere a un método para la producción de un anticuerpo anti-c-Met de la invención, comprendiendo dicho método las etapas de:
a) el cultivo de la célula huésped de la invención como se ha descrito anteriormente en el presente documento, y b) la purificación del anticuerpo de la invención del medio de cultivo.
Composiciones
En un aspecto principal adicional, la invención se refiere a una composición farmacéutica que comprende:
- un anticuerpo anti-c-Met como se define en el presente documento, y
- un vehículo farmacéuticamente aceptable.
La composición farmacéutica de la presente invención puede contener un anticuerpo de la presente invención o una combinación de diferentes anticuerpos de la presente invención.
Las composiciones farmacéuticas se pueden formular de acuerdo con técnicas convencionales tales como las desveladas en Remington: The Science and Practice of Pharmacy, 19ª Edición, Gennaro, Ed., Mack Publishing Co., Easton, PA, 1995. Una composición farmacéutica de la presente invención puede, por ejemplo, incluir diluyentes, cargas, sales, tampones, detergentes (por ejemplo, un detergente no iónico, tal como Tween-20 o Tween-80), estabilizadores (por ejemplo, azúcares o aminoácidos libres de proteínas), conservantes, fijadores de tejido, solubilizantes, y/u otros materiales adecuados para su inclusión en la composición farmacéutica.
Los vehículos farmacéuticamente aceptables incluyen todos y cada uno de los disolventes, medios de dispersión, revestimientos, agentes antibacterianos y antifúngicos, agentes de isotonicidad, antioxidantes y agentes de retraso de la absorción adecuados, y similares que sean fisiológicamente compatibles con un compuesto de la presente invención. Ejemplos de vehículos acuosos y no acuosos adecuados que se pueden emplear en las composiciones farmacéuticas de la presente invención incluyen agua, solución salina, solución salina de tampón fosfato, etanol, dextrosa, polioles (tales como glicerol, propilenglicol, polietilenglicol, y similares), y mezclas adecuadas de los mismos, aceites vegetales, soluciones coloidales de carboximetilcelulosa, goma de tragacanto y ésteres orgánicos inyectables tales como oleato de etilo, y/o distintos tampones. Los vehículos farmacéuticamente aceptables incluyen soluciones acuosas o dispersiones estériles y polvos estériles para su preparación extemporánea de soluciones o dispersiones inyectables. Se puede mantener una fluidez apropiada, por ejemplo, mediante el uso de materiales de revestimiento tales como lecitina, por el mantenimiento del tamaño de partícula necesario en el caso de dispersiones, y por el uso de tensioactivos.
Las composiciones de la presente invención pueden comprender también antioxidantes farmacéuticamente aceptables, por ejemplo, (1) antioxidantes hidrosolubles, tales como el ácido ascórbico, hidrocloruro de cisteína, bisulfato sódico, metabisulfito sódico, sulfito sódico y similares; (2) antioxidantes liposolubles, tales como el palmitato de ascorbilo, hidroxianisol butilado, hidroxitolueno butilado, lecitina, balato de propilo, alfa-tocoferol, y similares; y (3) agentes quelantes metálicos, tales como el ácido cítrico, ácido etilendiamino tetraacético (EDTA), sorbitol, ácido tartárico, ácido fosfórico, y similares.
Las composiciones farmacéuticas de la presente invención también pueden contener agentes de isotonicidad, tales como azúcares, polialcoholes, tales como manitol, sorbitol, glicerol o cloruro sódico en las composiciones.
Las composiciones farmacéuticas de la presente invención también pueden contener uno o más adyuvantes apropiados para la vía de administración escogida, tal como conservantes, agentes humectantes, agentes emulsionantes, conservantes o tampones, que puede aumentar la vida de almacenamiento o la eficacia de la composición farmacéutica. Los compuestos de la presente invención se pueden preparar con vehículos que protegerán el compuesto contra la rápida liberación, tal como una formulación de liberación controlada, incluyendo implantes, parches transdérmicos y sistemas de suministro microencapsulados. Dichos vehículos pueden incluir
gelatina, monoestearato de glicerilo, diestearato de glicerilo, polímeros biocompatibles biodegradables tales como el acetato de etilen vinilo, polianhídridos, ácido poliglicólico, poliortoésteres, y ácido poliláctico solo o con una cera, u otros materiales bien conocidos en la técnica. Los métodos de preparación de dichas formulaciones son conocidos en general por los expertos en la técnica.
Las soluciones inyectables se pueden preparar incorporando el compuesto activo en la cantidad necesaria en un disolvente apropiado con uno o una combinación de ingredientes, por ejemplo, como se ha enumerado anteriormente, según se necesita, seguido por esterilización por microfiltración. En general, las dispersiones se preparan incorporando el principio activo en un vehículo estéril que contiene un medio de dispersión básico y los demás ingredientes necesarios, por ejemplo, de entre los enumerados anteriormente. En el caso de polvos estériles para la preparación de soluciones inyectables estériles, los ejemplos de los métodos de preparación son secado al vacío, y secador por congelación (liofilización) que dan lugar a un polvo del principio activo más cualquier ingrediente adicional deseado a partir de una solución estéril por filtración del mismo.
Los niveles de dosificación actuales de los ingredientes activos en las composiciones farmacéuticas pueden variar de manera que se obtenga la cantidad de principio activo que sea eficaz para conseguir la respuesta terapéutica deseada para un paciente, composición y modo de administración en particular, sin que sea tóxica para el paciente. El nivel de dosificación seleccionado dependerá de una variedad de factores farmacocinéticos incluyendo la actividad de las composiciones particulares de la presente invención que se empleen, o la amida de los mismos, la vía de administración, el tiempo de administración, la velocidad de excreción del compuesto particular que se va a emplear, la duración del tratamiento, otros fármacos, compuestos y/o materiales utilizados en combinación con las composiciones particulares empleadas, la edad, sexo, peso, condición, salud general e historia medica anterior del paciente que se va a tratar, y factores similares bien conocidos en la técnica médica.
La composición farmacéutica se puede administrar mediante cualquiera vía y modo adecuados. La composición farmacéutica de la presente invención se puede administrar por vía parenteral. “Administrado por vía parenteral” como se utiliza en el presente documento significa los modos de administración distintos de la administración enteral y tópica, habitualmente mediante inyección, que incluye la inyección e infusión epidérmica, intravenosa, intramuscular, intraarterial, intratecal, intracapsular, intraorbital, intracardíaca, intradérmica, intraperitoneal, intratendinosa, transtraqueal, subcutánea, subcuticular, intraarticular, subcapsular, subaracnoidea, intraespinal, intracraneal, intratorácica, epidural e intraesternal.
La composición farmacéutica se puede administrar por inyección o infusión intravenosa o subcutánea.
Usos
En un aspecto adicional principal, la invención se refiere a un anticuerpo anti-c-Met de la invención para su uso como un medicamento.
Los anticuerpos anti-c-Met de la invención se pueden utilizar para varios fines. En particular, los anticuerpos de la invención son para el uso en el tratamiento de distintas formas de cáncer, incluyendo el cáncer metastático y cáncer refractario. Dicho cáncer puede ser dependiente de HGF o independiente de HGF.
Los anticuerpos anti-c-Met de la invención pueden ser para el uso en el tratamiento de una forma de cáncer seleccionada de entre el grupo que consiste en: cáncer de vejiga, cáncer de mama, cáncer de cuello uterino, colangiocarcinoma, cáncer colorrectal, cáncer endometrial, cáncer esofágico, cáncer gástrico, cáncer de cabeza y cuello, cáncer de riñón, cáncer de hígado, cáncer de pulmón (tal como el cáncer de pulmón de células no pequeñas (NSCLC)), cáncer nasofaríngeo, cáncer ovárico, cáncer pancrático, cáncer de vesícula, cáncer de próstata y cáncer de tiroides.
Los anticuerpos anti-c-Met de la invención pueden ser para su uso en el tratamiento de una forma de cáncer seleccionado de entre el grupo de osteosarcoma, rabdomiosarcoma y sarcoma sinovial.
Se desvela adicionalmente que los anticuerpos anti-c-Met de la invención pueden ser para su uso en el tratamiento de una forma de cáncer seleccionada de entre el grupo que consiste en: sarcoma de Kaposi, leiomiosarcoma, histiocitoma fibroso maligno y fibrosarcoma.
Se desvela adicionalmente que los anticuerpos anti-c-Met de la invención pueden ser para su uso en el tratamiento de enfermedades malignas hematopoyéticas, tales como una enfermedad maligna de entre el grupo que consiste en: leucemia mielógena aguda, leucemia de células T de adulto, leucemia mieloide crónica, linfoma y mieloma múltiple.
Se desvela adicionalmente que los anticuerpos anti-c-Met de la invención pueden ser para su uso en el tratamiento de una neoplasia seleccionada de entre el grupo que consiste en: glioblastoma, astrocitoma, melanoma, mesotelioma y tumor de Wilm.
Se desvela adicionalmente que los anticuerpos anti-c-Met de la invención pueden ser para su uso en el tratamiento de tumores MiT, incluyendo el sarcoma de células claras (CCS), parte blanda del sarcoma alveolar (ASPS) y carcinomas de células renales asociado a translocación.
Se desvela adicionalmente que los anticuerpos anti-c-Met agonistas de la invención pueden ser parar su uso en la regulación de la producción de citocinas y la inducción de la movilización de células progenitoras endoteliales, por ejemplo, en pacientes con enfermedad cardíaca coronaria (Yang et al. (2009) Clin Exp Pharmacol Physiol.36:790). Se desvela adicionalmente que los anticuerpos anti-c-Met agonistas de la invención pueden ser para su uso en la inhibición o mejora del fallo renal crónico (Mizuno et al. (2008) Front Biosci.13:7072).
De manera similar, la divulgación se refiere a un método para la inhibición del crecimiento y/o proliferación de una célula tumoral que expresa c-Met, que comprende la administración a un individuo que necesita el mismo, de una cantidad eficaz de un anticuerpo de la invención.
Se desvela en el presente documento que dicha célula tumoral puede estar implicada en una forma de cáncer seleccionado de entre el grupo que consiste en: cáncer de vejiga, cáncer de mama, cáncer de cuello uterino, colangiocarcinoma, cáncer colorrectal, cáncer endometrial, cáncer esofágico, cáncer gástrico, cáncer de cabeza y cuello, cáncer de riñón, cáncer de hígado, cáncer de pulmón, cáncer nasofaríngeo, cáncer ovárico, cáncer pancreático, cáncer de vesícula, cáncer de próstata, cáncer de tiroides, osteosarcoma, rabdomioma, sarcoma sinovial, sarcoma de Kaposi, leiomiosarcoma, histiocitoma fibroso maligno, fibrosarcoma, leucemia mielógeno agudo, leucemia de células T de adulto, leucemia mieloide crónica, linfoma, glioblastoma, astrocitoma, melanoma, mesotelioma y tumor de Wilm.
También, la invención se refiere al uso de un anticuerpo monoclonal que se une al c-Met humano para la preparación de un medicamento para el tratamiento del cáncer, tal como una de las indicaciones del cáncer mencionadas anteriormente.
Además, la selección de los pacientes que se van a tratar con el anticuerpo anti-c-Met puede basarse en el nivel de (sobre)expresión de c-Met y/o HGF de las células tumorales relevantes de dichos pacientes.
En una divulgación adicional de los métodos de tratamiento expuestos en el presente documento, la eficacia del tratamiento se controla durante la terapia, por ejemplo, en momentos predefinidos, determinando los niveles de expresión de c-Met en las células tumorales relevantes.
Los regímenes de dosificación en los métodos de tratamiento y usos anteriores se ajustan para proporcionar la respuesta óptima deseada (por ejemplo, una respuesta terapéutica. Por ejemplo, se puede administrar una única embolada, se pueden administrar varias dosis divididas a lo largo del tiempo o la dosis se puede reducir o aumentar proporcionalmente como se indica por las exigencias de la situación terapéutica. Las composiciones parenterales pueden formularse en forma de dosificación unitaria para facilitar la administración y uniformidad de dosificación. Las dosificaciones eficaces y los regímenes de dosificación de los anticuerpos anti-c-Met dependen de la enfermedad o afección que se van a tratar y pueden determinarlos los expertos en la técnica. Un intervalo ejemplar, no limitante de una cantidad terapéuticamente eficaz de un compuesto de la presente invención es aproximadamente de 0,1- 100 mg/kg, tal como aproximadamente 0,1-50 mg/kg, por ejemplo, aproximadamente 0,1-20 mg/kg, tal como aproximadamente 0,1-10 mg/kg, por ejemplo, aproximadamente 0,5, aproximadamente tal como 0,3, aproximadamente 1, aproximadamente 3, aproximadamente 5, o aproximadamente 8 mg/kg.
Un médico o veterinario experto habituado en la técnica puede fácilmente determinar y prescribir la cantidad necesaria eficaz de la composición farmacéutica. Por ejemplo, el médico o el veterinario podría comenzar con dosis del anticuerpo anti-c-Met empleado en la composición farmacéutica a niveles menores que los que se necesitan con el fin de alcanzar el efecto terapéutico deseado y gradualmente aumentar la dosificación hasta que se alcanza el efecto deseado. En general, una dosis diaria adecuada de una composición de la presente invención será la cantidad de compuesto que sea la dosis menor eficaz para producir un efecto terapéutico. La administración puede, por ejemplo, ser parenteral, tal como intravenosa, intramuscular o subcutánea. Los anticuerpos anti-c-Met puede administrarse por infusión en una dosificación semanal de desde 10 a 500 mg/m2, tal como de desde 200 a 400 mg/m2. Dicha administración se puede repetir, por ejemplo, 1 a 8 veces, tal como 3 a 4 veces. La administración se puede llevar a cabo por infusión continua durante un periodo de desde 2 a 24 horas, tal como desde 2 a 12 horas. De manera alternativa, los anticuerpos anti-c-Met se puede administrar por infusión continua lenta durante un largo periodo, tal como más de 24 horas, con el fin de reducir los efectos secundarios tóxicos.
Además, los anticuerpos anti-c-Met pueden administrarse en una dosificación semanal de desde 250 mg a 2000 mg, tal como, por ejemplo, 300 mg, 500 mg, 700 mg, 1000 mg, 1500 mg o 2000 mg, durante hasta 8 veces, tal como desde 4 a 6 veces. Dicho régimen puede repetirse una o más veces según sea necesario, por ejemplo, después de 6 meses o 12 meses. La dosificación se puede determinar o ajustar midiendo la cantidad de compuesto de la presente invención en la sangre al administrarse, por ejemplo, tomando una muestra biológica y utilizando
anticuerpos anti-idiotípicos que se dirigen a la región de unión al antígeno de los anticuerpos anti-c-Met de la presente invención.
Se desvela adicionalmente que los anticuerpos anti-c-Met se pueden administrar por terapia de mantenimiento, tal como, por ejemplo, una vez a la semana durante un periodo de 6 meses o más.
Un anticuerpo anti-c-Met se puede administrar también profilácticamente con el fin de reducir el riesgo de desarrollar un cáncer, el retraso de la aparición de la existencia de un evento en la progresión del cáncer, y/o reducir el riesgo de recurrencia cuando un cáncer está en remisión.
Los anticuerpos anti-c-Met también se pueden administrar en una terapia de comparación, es decir, combinados con otros agentes terapéuticos relevantes para la enfermedad o afección que se va a tratar. En consecuencia, en una divulgación adicional, el medicamento que contienen el anticuerpo es para su uso en combinación con uno o más agentes terapéuticos adicionales, tales como un agente citotóxico, quimioterápico o anti-angiogénico.
Dicha administración combinada puede ser simultánea, por separado o secuencial. Para la administración simultanea los agentes se pueden administrar como una composición o como composiciones separadas, según sea apropiado. Por lo tanto, la presente divulgación proporciona también métodos para el tratamiento de un trastorno que implica células que expresa c-Met como se ha descrito anteriormente, cuyos métodos comprende la administración de un anticuerpo anti-c-Met de la presente invención combinadas con uno o más agentes terapéuticos adicionales como se describe posteriormente.
La presente divulgación proporciona un método para el tratamiento de un trastorno que implica células que expresan c-Met en un sujeto, cuyo método comprende la administración de una cantidad terapéuticamente eficaz de un anticuerpo anti-c-Met de la presente invención y al menos un agente terapéutico adicional a un sujeto que necesita del mismo.
La presente divulgación proporciona un método para el tratamiento o prevención del cáncer, cuyo método comprende la administración de una cantidad terapéuticamente eficaz de un anticuerpo anti-c-Met de la presente invención y al menos un agente terapéutico adicional a un sujeto que necesita del mismo.
Dicho agente terapéutico adicional se puede seleccionar de entre un antimetabolito tal como el metotrexato, 6-mercaptopurina, 6-tioguanina, citarabina, fludarabina, 5-fluorouracilo, decarbazina, hidroxiurea, asparaginasa, gemcitabina o cladribina.
Además, dicho agente terapéutico adicional se puede seleccionar de entre un agente alquilante, tal como mecloretamina, tiotepa, clorambucilo, melfalan, carmustina (BSNU), lomustina (CCNU), ciclofosfamida, busulfan, dibromomanitol, estreptozocina, decarbazina (DTIC), procarbazina, mitomicina C, cisplatino y otros derivados del platino, tales como carboplatino.
Se desvela adicionalmente que dicho agente terapéutico adicional se puede seleccionar de entre un agente antimitótico, tal como taxanos, por ejemplo, docetaxel, y paclitaxel, y alcaloides de la vinca, por ejemplo, vindesina, vincristina, vinblastina, y vinorelbina.
Se desvela adicionalmente que dicho agente terapéutico adicional se puede seleccionar de entre un inhibidor de la topoisomerasa, tal como topotecan o irinotecan, o un fármaco citostático, tal como etopósido y tenipósido.
Se desvela adicionalmente que un agente terapéutico se puede seleccionar de entre un inhibidor de un factor de crecimiento, tal como un inhibidor de ErbB1 (EGFR) (tal como una anticuerpo anti-EGFR, por ejemplo, zalutumab, cetuximab, panitumumab o nimotuzumab u otros inhibidores del EGFR, tales como gefinitib o erlotinib), un inhibidor de ErbB2 (Her2/neu) (tal como una anticuerpo anti-HER2, por ejemplo, trastuzumab, trastuzumab-DM1 o pertuzumab) o un inhibidor de ambos , el EGFR y HER2, tal como el lapatinib).
Se desvela adicionalmente que dicho agente terapéutico adicional se puede seleccionar de entre un inhibidor de la tirosina cinasa, tal como el imatinib (Glivec, Gleevec STI571) o lapatinib, PTK787/ZK222584.
La presente divulgación proporciona un método para el tratamiento de un trastorno que implica células que expresan c-Met en un sujeto, cuyo método comprende la administración de una cantidad terapéuticamente eficaz de un anticuerpo anti-c-Met desvelado en el presente documento y al menos un inhibidor de la angiogénesis, neovascularización, y/u otra vascularización a un sujeto que necesita del mismo.
Ejemplos de dichos inhibidores de la angiogénesis son los inhibidores de la urocinasa, inhibidores de la metaloproteasa de la matriz (tales como marimastat, neovastat, BAY 12-9566, AG 3340, BMS-275291 y agentes similares), inhibidores de la migración y proliferación de células endoteliales (tales como TNP-470, escualamina, 2-metoxiestradiol, combretastatinas, endostatina, angiostatina, penicilamina, SCH66336 ( Schering-Plough Corp, Madison, NJ), R115777 (Janssen Pharmaceutica, Inc, Titusville, NJ) y agentes similares), antagonistas de los
factores de crecimiento angiogénico (tales como ZD6474, SU6668, anticuerpos contra agentes angiogénicos y/o sus receptores ( tales como VEGF (por ejemplo bevacizumab), bFGF, y angiopoyetina-1), talidomida, análogos de la talidomida (tales como el CC-5013), Sugen 5416, SU5402, ribozima anti-angiogénica (tal como angiozima), interferón α (tal como el interferón α2a), suramina y agentes similares), inhibidores de la VEGF-R cinasa y otros inhibidores de la tirosina cinasa anti-angiogénicos (tales como SU011248), inhibidores de señalización de supervivencia/integrina específicos endoteliales (tales como vitaxin y agentes similares), antagonistas/quelantes del cobre (tales como tetratiomolibdato, captopril y agentes similares), carboxiamido-triazol (CAI), ABT-627, CM 101, interleucina-12 (IL-12), IM862, PNU145156E así como moléculas de nucleótidos que inhiben la angiogénesis (tal como ADNc-VEGF antisentido, ADNc que codifica angiostatina, ADNc que codifica p53 y ADNc que codifica el receptor 2 del VEGF deficiente).
Otros ejemplos de dichos inhibidores de la angiogénesis, neovascularización, y/u otra vascularizaicón son los derivados de heparina anti-angiogénicos (por ejemplo, heparinasa, III), temozolomida, NK4, factor inhibidor de la migración de macrófagos, inhibidores de la ciclooxigenasa-2, inhibidores del factor 1 inducible por hipoxia, isoflavonas de soja anti-angiogénicas, oltipraz, fumagilina y análogos de la misma, análogos de somatostatina, polisulfato de pentosano, tecogalan sódico, dalteparin, tumstatina, trombospondina, NM-3, combrestatina, canstatina, avastatina, anticuerpos contra otras dianas, tales como anti-integrina alfa-v/beta-3 y anticuerpos antiquininostatina.
Además, un agente terapéutico para su uso en combinación con un anticuerpo anti-c-Met para el tratamiento de los trastornos que se describen anteriormente puede ser un inmunógeno anticáncer , tal como el antígeno asociado a tumor/antígeno del cáncer (por ejemplo, una molécula de adhesión celular epitelial (EpCAM/TACSTD1), mucina 1 (MUC1), antígeno carcinoembrionario (CEA), glicoproteína 72 asociada a tumores (TAG-72), gp100, Melan-A, MART-1, KDR, RCAS1, MDA7, vacunas víricas asociadas con el cáncer (por ejemplo, vacunas del papilomavirus humano) o proteínas de choque térmico derivadas de un tumor.
Se desvela adicionalmente que un agente para su uso en combinación con un anticuerpo anti-c-Met para el tratamiento de los trastornos descritos anteriormente puede ser una citocina, quimiocina anticáncer, o una combinación de las mismas. Ejemplos de citocinas y factores de crecimiento adecuados incluyen IFNγ, IL-2, IL-4, IL-6, IL-7, IL-10, IL-12, IL-13, IL-15, IL-18, IL-23, IL-24, IL-27, IL-28a, IL-28b, IL-29, KGF, IFNα (por ejemplo, INFα2b), IFNβ, GM-CSF, CD40L, ligando de Flt3, factor de células madre, ancestim, y TNFα. Las quimiocinas adecuadas pueden incluir quimiocinas negativas a Glu-Leu-Arg (ELR) tales como IP-10, MCP-3, MIG, y SDF-1 α del CXC humano y familias de quimiocinas C-C. Las citocinas adecuadas incluyen derivados de citocina, variantes de citocina, fragmentos de citocina y proteínas de fusión con citocinas.
Además, un agente terapéutico para su uso en combinación con un anticuerpo anti-c-Met para el tratamiento de trastornos que se describieron anteriormente puede ser un regulador de apoptosis/control de ciclo (o “agente regulador”). Un regulador de la apoptosis/control de ciclo puede incluir moléculas que se dirigen y modulan el control del ciclo celular/reguladores de la apoptosis tales como (i) cdc-25 (tal como NSC 663284), (ii) cinasas dependientes de la ciclina que sobre-estimulan el ciclo celular (tal como el flavopiridol (L868275, HMR1275), 7-hydroxistaurosporina (UCN-01, KW-2401), y roscovitina (R-roscovitina, CYC202)), y (iii) moduladores de la telomerasa (tal como BIBR1532, SOT-095, GRN163 y composiciones descritas por ejemplo en los documentos US 6.440.735 y US 6.713.055). Ejemplos no limitantes de moléculas que interfieren con las rutas apoptóticas incluyen el ligando inductor de apoptosis relacionado con el TNF (TRAIL)/ligando 2 de apoptosis (Apo-2L), anticuerpos que activan los receptores TRAIL, IFN y Bcl-2 antisentido.
Se desvela adicionalmente que un agente terapéutico para su uso en combinación con un anticuerpo anti-c-Met para el tratamiento de los trastornos descritos anteriormente puede ser un agente regulador hormonal, tal como los agentes útiles para la terapia anti-androgénica o anti-estrogénica. Ejemplos de dichos agentes reguladores hormonales son tamoxifeno, idoxifeno, fulvestrant, droloxifeno, toremifeno, raloxifeno, dietilestilbestrol, etinil estradiol/estinil, un anti andrógeno (tal como flutaminda/eulexina), una progestina (tal como caproato de hidroxiprogesterona, medroxiprogesterona/provera, acetato de megestrol/megace), un adrenocorticosteroide (tal como hidrocortisona, prednisona), una hormona liberadora de hormona luteinizante (y análogos de la misma y otros agonistas de la LHRH tal como buserelina y goserelina), un inhibidor de la aromatasa (tal como anastrazol/arimide, aminoglutetimida/citraden, exemestrano) o un inhibidor hormonal (tal como octreotida/sandostatin).
Se desvela adicionalmente que un agente terapéutico para su uso en combinación con un anticuerpo anti-c-Met para el tratamiento de los trastornos descritos anteriormente puede ser un agente anti-anérgico, tal como los compuestos que son moléculas que bloquean la actividad del CTLA-4, por ejemplo, el ipilimumab.
Se desvela adicionalmente que un agente terapéutico para su uso en combinación con un anticuerpo anti-c-Met para el tratamiento de los trastornos descritos anteriormente puede ser un ácido nucleico anticáncer o una molécula inhibidora del ARN anticáncer.
Ejemplos de otros agentes anticáncer, que pueden ser relevantes como agentes terapéuticos para su uso en combinación con un anticuerpo anti-c-Met para el tratamiento de los trastornos descritos anteriormente son agentes
inductores de la diferenciación, análogos del ácido retinoico (tal como todos los ácidos retinoicos trans, ácido retinoico 13-cis y agentes similares, análogos de la vitamina D (tales como el seocalcitol y agentes similares, inhibidores de ErbB3, ErbB4, IGF-IR, receptor insulínico, PDGFRa, PDGFRbeta, Flk2, Flt4, FGFR1, FGFR2, FGFR3, FGFR4, TRKA, TRKC, RON (tal como un anticuerpo anti-RON), Sea, Tie, Tie2, Eph, Ret, Ros, Alk, LTK, PTK7 y agentes similares.
Ejemplos de otros agentes anticáncer, que pueden ser relevantes como agentes terapéuticos para su uso en combinación con un anticuerpo anti-c-Met para el tratamiento de los trastornos descritos anteriormente son estramustina y epirrubicina.
Ejemplos de otros agentes anticáncer, que pueden ser relevantes como agentes terapéuticos para su uso en combinación con un anticuerpo anti-c-Met para el tratamiento de los trastornos descritos anteriormente son un inhibidor de la HSP90 tipo 17-alil amino geldanamicina, anticuerpos dirigidos contra un antígeno tumoral tal como PSA, CA125, KSA, integrinas, por ejemplo, integrina β1, o inhibidores de VCAM.
Ejemplos de otros agentes anticáncer, que pueden ser relevantes como agentes terapéuticos para su uso en combinación con un anticuerpo anti-c-Met para el tratamiento de los trastornos descritos anteriormente son inhibidores de la calcineurina (tale como valspodar, PSC 833 y otros inhibidores de MDR-1 o p-glicoproteínas), inhibidores de TOR (tales como sirolimus, everolimus y rapamicina), e inhibidores de los mecanismos de “asentamiento de linfocitos” (tales como FTY720), y agentes que tienen efectos sobre la señalización celular tales como inhibidores de la molécula de adhesión (por ejemplo, anti-LFA).
Se desvela adicionalmente que el anticuerpo anti-c-Met de la invención puede ser para el uso en combinación con uno o más de otros anticuerpos terapéuticos, tales como el ofatumumab, zanolimumab, daratumumab, ranibizumab, Zenapax, Simulect, Remicade, Humira, Tysabri, Xolair, raptiva y/o rituximab.
Otros anticuerpos terapéuticos que se pueden utilizar en combinación con el anticuerpo de la presente invención son anticuerpos anti-c-Met que se unen a otras regiones del c-Met, tal como los anticuerpos descritos en los documentos WO 2005016382, WO 2006015371, WO 2007090807, WO 2007126799 o WO 2009007427.
También se desvela en el presente documento que se pueden utilizar dos o más anticuerpos diferentes de la invención en combinación para el tratamiento de la enfermedad. Las combinaciones particularmente interesantes incluyen dos o más anticuerpos no competitivos. Dicha terapia de combinación puede dar lugar a la unión de un mayor número de anticuerpos por célula, los que puede aumentar la eficacia, por ejemplo, mediante la lisis mediada por activación del complemento.
Además de todo lo anterior, otras terapias de la divulgación incluyen las siguientes:
Para el tratamiento del cáncer de pulmón de células no pequeñas, un anticuerpo anti-c-Met en combinación con inhibidores del EGFR, tal como un anticuerpo anti-EGFR, por ejemplo, zalutumumab, cetuximab, panitumumab o nimotuzumab u otros inhibidores del EGFR, tales como gefitinib o erlotinib), o en combinación con un inhibidor de ErbB2 (Her2/neu) (tal como un anticuerpo anti-HER2, por ejemplo, trastuzumab, trastuzumab-DM1 o pertuzumab) o en combinación con un inhibidor de ambos el EGFR y HER2, tal como lapatinib, o en combinación con un inhibidor de HER3.
Para el tratamiento del glioma, un anticuerpo anti-c-Met en combinación con temozolomida o un inhibidor de la angiogénesis, tal como bevacizumab.
Para el tratamiento del cáncer colorrectal un anticuerpo anti-c-Met en combinación con uno o más compuestos seleccionados de entre gemcitabina, bevacizumab, FOLFOX, FOLFIRI, XELOX, IFL, oxaliplatino, irinotecan, 5-FU/LV, Capecitabina, UFT, agentes de direccionamiento contra el EGFR, tales como cetuximab. panitumumab, zalutumumab; inhibidores del VEGF, o inhibidores de la tirosina cinasa tales como el sunitinib.
Para el tratamiento del cáncer de próstata un anticuerpo anti-c-Met en combinación con uno o más compuestos seleccionados de entre: terapias hormonales/anti-hormonales; tales como anti-andrógenos, agonistas de la hormona liberadora de hormona luteinizante (LHRH), y quimioterápicos tales como taxanos, mitoxantrona, estramustina, 5FU, vinblastina, ixabepilona.
Radioterapia-cirugía
La presente divulgación proporciona un método para el tratamiento de un trastorno que implica las células que expresan c-Met en un sujeto, cuyo método comprende la administración de una cantidad terapéuticamente eficaz de un anticuerpo anti-c-Met de la presente invención y radioterapia a un sujeto que necesita del mismo.
La presente divulgación también proporciona un método para el tratamiento o prevención del cáncer, cuyo método comprende la administración de una cantidad terapéuticamente eficaz de un anticuerpo anti-c-Met, tal como un anticuerpo anti-c-Met de la presente invención, y radioterapia a un sujeto que necesita del mismo.
La presente divulgación también proporciona el uso de un anticuerpo anti-c-Met, tal como un anticuerpo anti-c-Met de la presente invención, para la preparación de una composición farmacéutica para el tratamiento del cáncer que se va a administrar en combinación con radioterapia.
La radioterapia puede comprender radiación o la administración de radiofármacos que se proporciona a un paciente. La fuente de radiación puede ser externa o interna al paciente que se va a tratado (el tratamiento con radiación puede ser, por ejemplo, en forma de terapia de radiación por rayo externo (EBRT) o braquioterapia (BT)). Los elementos radioactivos que se pueden utilizar en la práctica de dichos métodos incluyen, por ejemplo, radio, cesio-137, iridio-192, americio-241, oro-198, cobalto-57, cobre-67, tecnecio-99, yodo-123, yodo-131, e indio-111.
La presente divulgación también proporciona un método para el tratamiento o prevención del cáncer, cuyo método comprende la administración a un sujeto que lo necesita de una cantidad terapéuticamente eficaz de un anticuerpo anti-c-Met, tal como un anticuerpo anti-c-Met de la presente invención, en combinación con cirugía.
Usos diagnósticos
Los anticuerpos anti-c-Met de la invención también se pueden utilizar con fines diagnósticos. Por lo tanto, en un aspecto adicional, la invención se refiere a una composición diagnóstica que comprende un anticuerpo anti-c-Met como se define en el presente documento.
Además, los anticuerpos anti-c-Met de la presente divulgación se pueden utilizar in vivo o in vitro para diagnosticar enfermedades en las que las células que expresan c-Met activadas tienen un papel activo en la patogénesis, detectando los niveles de c-Met, o los niveles de células que contienen c-Met en su superficie de membrana. Esto se puede conseguir, por ejemplo, poniendo en contacto una muestra que se va a ensayar opcionalmente junto con una muestra de control, con el anticuerpo anti-c-Met en condiciones que permitan la formación de un complejo entre el anticuerpo y el c-Met.
Por lo tanto, en un aspecto adicional, la invención se refiere a un método para la detección de la presencia de un antígeno c-Met, o una célula que expresa c-Met, en una muestra que comprende.
- poner en contacto la muestra con un anticuerpo anti-c-Met de la invención en condiciones que permitan la formación de un complejo entre el anticuerpo y c-Met; y
- analizar si se ha formado el complejo.
En una realización, el método se lleva a cabo in vitro.
Más específicamente, la presente divulgación proporciona métodos para la identificación de, y el diagnóstico de células y tejidos invasivos, y otrs células direccionadas por los anticuerpos anti-c-Met de la presente invención, y para el control del progreso de los tratamientos terapéuticos, estado después del tratamiento, riesgo de desarrollar un cáncer, la progresión del cáncer, y similares.
Los marcadores adecuados para el anticuerpo anti-c-Met y/o los anticuerpos secundarios utilizados en dichas técnicas se conocen bien en la técnica.
En un aspecto adicional, la invención se refiere a un kit para la detección de la presencia del antígeno c-Met, o una célula que expresa c-Met, en una muestra que comprende:
- un anticuerpo anti-c-Met de la invención o una molécula biespecífica de la invención; e
- instrucciones para el uso del kit.
La presente divulgación también proporciona un kit para el diagnóstico del cáncer que comprende un recipiente que comprende un anticuerpo anti-c-Met, y uno o más reactivos para la detección de la unión del anticuerpo anti-c-Met al c-Met. Los reactivos pueden incluir, por ejemplo, marcadores fluorescentes, marcadores enzimáticos, u otros marcadores detectables. Los reactivos también pueden incluir anticuerpos secundarios o terciarios o reactivos para las reacciones enzimáticas, donde las reacciones enzimáticas producen un producto que se puede visualizar.
Anticuerpos anti-idiotípicos
En un aspecto adicional, la invención se refiere a un anticuerpo anti-idiotípico que se une a un anticuerpo anti-c-Met de la invención como se describe en el presente documento.
Un anticuerpo anti-idiotípico (Id) es un anticuerpo que reconoce determinantes únicos asociados en general con el sitio de unión al antígeno de un anticuerpo. Un anticuerpo Id se puede preparar inmunizando un animal de la misma especie que el tipo genético de la fuente de un mAb anti-c-Met con el mAb contra el que se va a preparar un anti-Id. El animal inmunizado normalmente puede reconocer y responder a los determinantes idiotípicos del anticuerpo inmunizante produciendo un anticuerpo contra estos determinantes idiotípicos (el anticuerpo anti-Id).
Una anticuerpo anti-Id también se puede utilizar como un “inmunógeno” para inducir una respuesta inmunitaria en otro animal, produciendo un denominado anticuerpo anti-anti-Id. Un anti-anti-Id puede ser epítópicamente idéntico al mAb original, que induce el anti-Id. Por lo tanto, utilizando anticuerpos contra los determinantes idiotípicos de un mAb, es posible identificar otros clones que expresan anticuerpos con especificidad idéntica.
La presente invención se ilustra adicionalmente por los siguientes ejemplos.
Ejemplo
Ejemplo 1: Construcciones de expresión de c-Met
Las construcciones con el codón optimizado para la expresión de c-Met, el dominio extracelular (ECD) (aa 1-932 y un marcador His6 en el extremo C o el dominio SEMA de c-Met 8aa 1-567 y un marcador His 9 en el extremo C), se generaron en células HEK o CHO. Las proteínas codificadas por estas construcciones son idénticas al registro de GenBank NM000245 para el c-Met. Las construcciones contenían los sitios de restricción adecuados para la clonación y una secuencia Kozak óptima (Kozak et al. (1999) Gene 234: 187-208). Las construcciones se clonaron en el vector de expresión en mamíferos pEE13.4 (Lonza Biologics) (Bebbington (1992) Biotechnology (NY) 10:169-175), obteniendo pEE13.4cMet, pEE13.4cMetECDHis y pEE13.4cMetSEMA-567His8.
Ejemplo 2: Construcciones de expresión para 5D5v1, 5D5 y G11-HZ
Las construcciones con el codón optimizado para la expresión de la cadena pesada (HC) y la cadena ligera (LC) de los anticuerpos IgG15D5v1, 5D5 y G11-HZ, se generaron en células HEK. Las proteínas codificadas por estas construcciones son idénticas a las que se describen en la Patente de EE. UU.6468529 (número de secuencia 3 y 4) para la cadena pesada y cadena ligera 5D5v1, el documento WO 2006/015371 A2 (fig.13) para la cadena pesada y la cadena ligera 5D5 y el documento WO 2009/007427 A2 (la secuencia se extrajo a partir de múltiples figuras) para la cadena pesada y ligera 224G11. El 224G11 también se denomina G11-Hz en el presente documento.
Ejemplo 3: Expresión transitoria den células HEK-293F
Las células Freestyle™ 293F (un subclon de HEK-293 adaptado al crecimiento en suspensión y un medio Freestyle definido químicamente, (HEK-293f)) se obtuvieron en Invitrogen y se transfectaron con el ADN plasmídico apropiado, utilizando 293fectina (Invitrogen) de acuerdo con las instrucciones del fabricante. La expresión de c-Met se ensayó mediante análisis FACS como se describe posteriormente, En el caso de la expresión de anticuerpos, los vectores de expresión apropiados de cadena pesada y cadena ligera se co-expresaron.
Ejemplo 4: Expresión transitoria en células CHO
El pEE13.4cMet se transfectó transitoriamente en la línea celular Freestyle™ CHO-S (Invitrogen) utilizando el reactivo de transfección Freestyle MAX (Invitrogen). La expresión de c-Met se ensayó por medio de análisis FACS como se describe posteriormente.
Ejemplo 5: Clonación y expresión de anticuerpos monovalentes (moléculas UniBody®)
Para la expresión de anticuerpos monovalentes en células de mamíferos se sintetizó la región constante de HC de IgG4, que omitía la región bisagra (Ch) (aminoácidos E99-P110) y que contenía las 2 mutaciones F405T e Y407E en la región CH3, como una construcción con el codón optimizado en el vector de expresión en mamíferos pcDNA3.3 (Invitrogen) y se llamó PUniTE. Se construyó un vector diferente insertando la región constante con codón optimizado de la región de cadena ligera kappa humana en el pcDNA3.3 y se llamó pKappa.
Las regiones VH y VL relevantes se insertaron respectivamente en el pUniTE y pKappa dando como resultado los vectores para la expresión de las cadenas pesada y ligera de los anticuerpos específicos. La co-transfección de los vectores de cadena pesada y ligera de un anticuerpo específico en las células HEK-293F (Invitrogen) daba como resultado la producción transitoria de anticuerpos monovalentes con las especificidades deseadas. La purificación se llevó a cabo utilizando una cromatografía en columna de afinidad de Proteína A (como se describe en el Ejemplo 11).
Ejemplo 6: Purificación de c-Met marcado con His
Se expresaron el cMetECDHis y cMetSEMAHis se expresaron en células HEK-293F. El marcador His en cMetECDHis y cMetSEMAHis hacía posible la purificación con cromatografía de afinidad en metal inmovilizado. En este proceso, se carga un quelante fijado en la resina cromatográfica con cationes Co2+. cMetECDHis y cMetSEMAHis contienen sobrenadantes cuando se incubaban con la resina en un modo discontinuo (es decir, en solución. La proteína marcada con His se une fuertemente a las perlas de resina, mientras que otras proteínas presentes en el sobrenadante del cultivo no se unen fuertemente. Después de la incubación se recuperan las perlas del sobrenadante y se empaquetan en una columna. La columna se lava con el fin de retirar las proteínas unidas
débilmente. Las proteínas fuertemente unidas a cMetECDHis y cMetSEMAHis se eluyeron entonces con un tampón que contenía imidazol, que compite con la unión de His con Co2+. El eluyente se retiró de la proteína por un tampón de intercambio en una columna de desalación.
Ejemplo 7: Procedimiento de inmunización de ratones transgénicos
Los anticuerpos 005, 006, 007, 008, 011, 012, 016, 017, 022, 024, 025, 028, 031, 035, 039, 040, 045, 093, 095, 096, 101 y 104 se derivaron de las siguientes inmunizaciones: un ratón HCo2081 hembra, de estripe GG2713), un ratón HCo17 (hembra, estripe GG2714) y dos ratones HCo2-Balb/C (2 hembras, estripe GG2811) (Medarex, San Jose, CA, USA; para referencias véase el párrafo de ratón HuMab anteriormente, documento WO2009097006 y US2005191293) se inmunizaron cada cuarta noche alternando con 5 x 106 células tumorales NCI-H441 por vía intraperitoneal (IP) y 20 μg de proteína cMetECDHis acoplada al hapteno de hemocianina de lapa californiana (KLH) por vía subcutánea (SC).
Los anticuerpos 058, 061, 062, 063, 064, 065, 066, 068, 069, 078, 082, 084, 087, 089, 098 y 181 se derivaron de las siguientes inmunizaciones: dos ratones HCo20 (1 macho y 1 hembra, estripe GG2713) y un ratón HCo12-Balb/C (1 macho, estripe GG2811) (Medarex, San Jose, CA, USA; para referencias véase el párrafo de ratón HuMab anteriormente) se inmunizaron cada cuarta noche alternado con 5 x 106 células CHO-K1SV transfectadas transitoriamente con cMetECDHis intraperitoneal (IP) y 20 μg de proteína cMetECDHis acoplada al hapteno de hemocianina de lapa californiana (KLH) por vía subcutánea (SC).
Se llevó a cabo un máximo de ocho inmunizaciones por ratón, cuatro inmunizaciones por vía IP y cuatro por vía SC en la base de la cola. La primera inmunización con células se hizo en adyuvante completo de Freund (CFA; Difco Laboratories, Detroit, MI, USA). Para el resto de las inmunizaciones, se inyectaron por vía IP las células en PBS y se inyectó por vía SC cMetECD acoplada a KLH utilizando adyuvante incompleto de Freund (IFA; Difco Laboratories, Detroit, MI, USA). Se fusionaron los ratones con al menos dos títulos de anticuerpo específico de c-Met secuenciales de 200 (diluciones de suero de 1/200) o mayor, detectado en el ensayo FMAT de exploración como se describe en el Ejemplo 8.
Ejemplo 8: Ensayo de exploración específica de antígenos homogéneos
La presencia de anticuerpos anti-c-Met en el suero de los ratones inmunizados o HuMab (anticuerpo monoclonal humano) del sobrenadante del cultivo de hibridoma o transfectoma se determinó por ensayos de exploración específica de antígeno homogéneo (cuatro cuadrantes) utilizando una Tecnología de ensayo de Micro volumen Fluorométrico (FMAT; Applied Biosystems, Foster City, CA, USA). Para esto, se utilizó una combinación de ensayos basados en 3 células y un ensayo basado en perlas. En los ensayos basados en células, se determinó la unión a TH1016-cMet (células HEK-293F que expresan transitoriamente el dominio extracelular del receptor de c-Met; producido como se describe anteriormente) y HT29(que expresan c-Met en la superficie celular) así como células HEK293 de tipo silvestre (control negativo que no expresa c-Met). Para el ensayo basado en perlas, se determinó la unión a SB1016-cMet (cMetECDHis obtenido a partir de células HEK-293F transfectadas transitoriamente como se ha descrito anteriormente, biotiniladas y acopladas a perlas revestidas de estreptavidina). Las muestras se añadieron en las células/perolas para permitir la unión al c-Met. Posteriormente, se detectó la unión de HuMab utilizando un conjugado fluorescente (de cabra anti-IgG humana-Cy5; Jackson ImmunoResearch). El anticuerpo específico de c-Met quimérico 5D5v1 (producido en células HEK-293F) se utilizó como control positivo y se utilizaron el suero agrupado de ratón HuMab y HuMab-KLH como controles negativos. Las muestras se exploraron utilizando un Sistema de detección celular 8200 Applied Biosystems (8200 CDS) y se utilizó “recuentos x fluorescencia” como lectura. Las muestras se establecieron como positivas cuando los recuentos eran mayores de 50 y los recuentos x fluorescencia eran al menos tres veces mayores que el control negativo HuMab-KLH.
Ejemplo 9: generación de hibridoma HuMab
Los ratones HuMab con suficiente desarrollo de título específico de antígeno (definido como anteriormente) se sacrificaron y el bazo y los ganglios linfáticos que flanquean la aorta abdominal y la vena cava se recolectaron. Se hizo una fusión de los esplenocitos y células de los ganglios linfáticos con una línea celular de mieloma de ratón por electrofusión utilizando un Sistema de Electrofusión CEEF 50 (Cyto Pulse Sciences, Glen Burnie, MD, USA), esencialmente de acuerdo con las instrucciones del fabricante. Las placas de fusión se exploraron con el ensayo de unión específica al antígeno como se ha descrito anteriormente y los positivos de este ensayo se ensayaron en un ensayo de fosforilación de ERK Alphascreen® SureFire® y un ensayo Octet de clasificación por afinidad como se describe posteriormente. Los anticuerpos 031, 035, 087 y 089 se expandieron y cultivaron basándose en protocolos convencionales (por ejemplo, como se describe en Coligan J.E., Bierer, B.E., Margulies, D.H., Shevach, E.M. y Strober, W., eds. Current Protocols in Immunology, John Wiley & Sons, Inc., 2006).
En paralelo, los anticuerpos 005, 006, 007, 008, 011, 012, 016, 017, 022, 024, 025, 028, 035, 039, 040, 045, 058, 061, 062, 063, 064, 065, 066, 068, 069, 078, 082, 084, 093, 095, 096, 098, 101, 104 y 181 se clonaron utilizando el sistema ClonePix (Genetix, Hampshire, UK). Los hibridomas de los pocillos primarios específicos se sembraron en un medio semisólido (fabricado con un 40 % de CloneMedia (Genetix, Hampshire, UK) y un 60 % de medio completo
HyQ 2x Hyclone, Waltham, USA) y se escogieron aproximadamente 100 subclones de cada pocillo primario. Los subclones se re-ensayaron en un ensayo de unión específica de antígeno como se ha descrito previamente y se midieron los niveles de IgG utilizando el Octet con el fin de seleccionar el mejor clon específico y productor por cada pocillo primario para su expansión posterior. La expansión posterior y el cultivo de los hibridomas HuMab resultante se hizo basándose en protocolos convencionales (por ejemplo, como se describe en Coligan J.E., Bierer, B.E., Margulies, D.H., Shevach, E.M. y Strober, W., eds. Current Protocols in Immunology, John Wiley & Sons, Inc., 2006).
Ejemplo 10: Espectrometría de masas de los anticuerpos purificados
Se purificaron pequeñas alícuotas de 0,8 ml que contenían sobrenadante de hibridoma de 6 pocillos o estadio Hiperflask utilizando columnas PhyTip que contenían resina de Proteína G (PhyNexus Inc., San Jose, USA) una estación de trabajo Sciclone ALH 3000 (Caliper Lifesciences, Hopkinton, USA). Las columnas PhyTip se utilizaron de acuerdo con las instrucciones del fabricante, pero los tampones se remplazaron por: Tampón de unión PBS (B. Braun, Medical B.V., Oss, Holanda) y tampón de elución 0,1 M de Glicina-HCI pH 2,7 (Fluka Riedel-de Haën, Buchs, Alemania). Después de la purificación, las muestras se neutralizaron con 2 M de Tris-HCl pH 9,0 (Sigma-Aldrich, Zwijndrecht, Holanda). De manera alternativa, en algunos casos se purificaron volúmenes más grandes de sobrenadante del cultivo utilizando una cromatografía en columna de afinidad de Proteína A.
Después de la purificación, las muestras se colocaron en una placa de 384 pocillos (Waters, placa de pocillos cuadrada de 100 ul componente nº 186002631). Las muestras se desglicosilaron durante una noche a 37 ºC con N-glicosidasa F. Se añadió DTT (15 mg/ml) (1 μl/pocillo) y se incubó durante 1 h a 37 ºC. Las muestras (de 5 o 6 ul) se desalaron en un Acquity UPLC™ (Waters, Milford, USA) con una columna BEH300 C18, de 1,7 mm, 2,1 x 50 mm a 60 ºC. Se utilizaron agua MQ y acetonitrilo de calidad de LC-MS (Biosolve, nº de cat. 01204101, Valkenswaard, Holanda) ambos con un 0,1 % de ácido fórmico (Fluka, cat no 56302, Buchs, Alemania), se utilizaron como Eluyente A y B, respectivamente. Se registraron los espectros de amasas con ionización por electropulverización con tiempo de vuelo en línea en un espectrómetro de masas micrOTOF™ (Bruker, Bremen, Alemania) operando en el modo de ion positivo. Antes de los análisis, se calibró una escala de 900-3000 m/z con una tuning mix ES (Agilent Technologies, Santa Clara, USA). Los espectros de masas se desglosaron con el software DataAnalysis™ v. 3.4 (Bruker) utilizando el algoritmo de Máxima Entropía buscando pesos moleculares entre 5 y 80 kDa.
Después del desglose las masas de la cadena pesada y ligera resultantes para todas las muestras se compararon con el fin de encontrar anticuerpos duplicados. En la comparación de las cadenas pesadas se tuvo en cuenta la posible presencia de variantes de lisina en el extremo C. Esto daba como resultado una lista de anticuerpos únicos, donde único se define como una combinación única de cadenas pesadas y ligeras. En el caso de encontrar anticuerpos duplicados, los resultados de otros ensayos se utilizaron para decidir qué anticuerpo era el mejor material para continuar con los experimentos.
Ejemplo 11: Análisis de secuencia de los dominios variables del anticuerpo anti-c-Met y clonación en vectores de expresión
El ARN total de los HuMab anti-c-Met se preparó a partir de 5 x 106 células de hibridoma y se preparó el 5’-RACE-ADN complementario (ADNc) a partir de 100 ng de ARN total, utilizando el kit de amplificación SMART RACE cDNA (Clontech), de acuerdo con las instrucciones del fabricante. Las regiones codificantes de VH (región variable de cadena pesada) y VL (región variable de cadena ligera) se amplificaron por PCR y se clonaron en fase en los vectores de región constante pG1f (que contenía la región constante completamente sintética con el codón optimizado de la cadena pesada de la IgG1 humana (alotipo f) en el vector de expresión pEE6.4 (Lonza Biologics, Slough, UK (Bebbington et al. (1992) Biotechnology 10:169-175)) y pKappa (que contenía la región constante kappa humana de cadena ligera con el codón optimizado completamente sintético (alotipo Km3) en el vector de expresión pEE12.4 (Lonza Biologics, Slough, UK (Bebbington et al. (1992) Biotechnology 10:169-175)) utilizando una estrategia de clonación por unión independiente (Aslanidis et al.1990 Nucleic Acids Res.18:6069-6074). Para cada HuMab, se secuenciaron 12 clones de la VL y 8 clones de la VH y sus masas teóricas se calcularon y compararon con los datos de espectrometría de masas de anticuerpo disponibles. Las secuencias se dan en el Listado de secuencias y en la Tabla 1 a continuación. Las secuencias CDR se definen de acuerdo con Kabat et al., Sequences of Proteins of Immunological Interest, 5ª Ed. Public Health Service, National Institutes of Health, Bethesda, MD. (1991). La Tabla 2 y Tabla 3 dan una visión de la información de secuencia de anticuerpo y las secuencias más homólogas de la línea germinal,
Tabla 1: Región variable de cadena pesada (VH), región variable de cadena ligera (VL) y secuencias de CDR de
HuMab













Tabla 2: Homolo ías de ori en secuencia de cadena esada de ratón

Tabla 3: Homolo ías de ori en secuencia de cadena li era de ratón

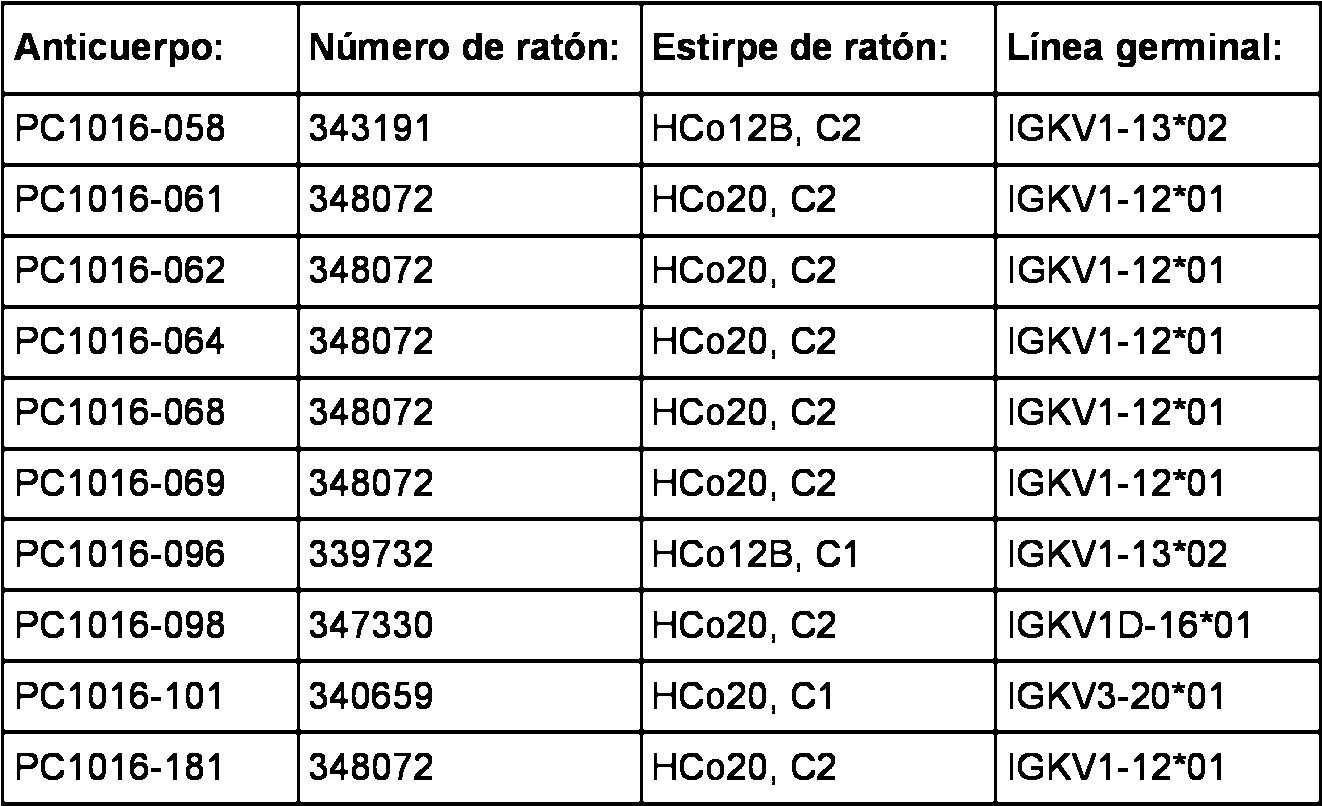
Las Figuras 1 y 2 dan el alineamiento de secuencias de HuMab. Basándose en estas secuencias, se puede definir la secuencia de consenso para algunas de las secuencias de las CDR. Estas secuencias de consenso se dan en la Tabla 4.
Tabla 4: Secuencias de consenso



Ejemplo 12: Purificación de anticuerpos
El sobrenadante del cultivo se filtró con filtros sin salida de 0,2 mm y se cargaron en columnas MabSelect SuRe de 5 ml (GE HealthCare) y se eluyeron con 0,1 M de citrato sódico-NaOH, pH 3. El eluído se neutralizó inmediatamente con 2 M de Tris-HCl, pH 9 y se dializó durante una noche a 12,6 Mm de NaH2PO4, 140 mM de NaCl, pH 7,4 (B. Braun). De manera alternativa, después de la purificación el eluído se carga en una columna de desalación HiPrep y el anticuerpo se intercambió a un tampón de 12,6 mM de NaH2PO4, 140 mM de NaCl, pH 7,4 (B. Braun). Después de la diálisis o el intercambio de tampón, las muestras se esterilizaron por filtración en filtros sin salida de 0,2 mm. La pureza se determinó por SDS-PAGE y se midió la concentración por nefelometría y absorbancia a 280 nm. Los anticuerpos purificados se almacenaron a 4 ºC. Se llevó a cabo la espectrometría de masas para identificar la masa molecular de las cadenas pesada y ligera del anticuerpo que expresaban los hibridomas como se describe en el Ejemplo 10.
Ejemplo 13: Unión de los clones anti-c-Met a las células tumorales que expresan c-Met unido a la membrana medido por medio de análisis FACS
La unión de los anticuerpos anti-c-Met y las formas monovalentes de los mismos (también denominados “moléculas UniBody” en el presente documento, véase el Ejemplo 5) contra las células A431 que expresan c-Met unido a la membrana (adquiridas en la ATCC CRL-1555) se ensayaron utilizando citometría de flujo (FACS Canto II, BD Biosciences). El análisis Qifi (Dako, Glostrup, Dinamarca) reveló que las células A431 expresan de medio 30.000 copias de proteína c-Met por célula. La unión de los anticuerpos anti-c-Met y moléculas UniBody se detectó utilizando un anticuerpo de cabra anti-IgG humana conjugado con Ficoeritrina (Jackson). Se utilizó la IgG1-5D5 como anticuerpo de control positivo y se utilizó HuMab-KLH como anticuerpo de control de isotipo. Se determinaron los valores de la CE50 mediante regresión no lineal (respuesta a la dosis sigmoidal con pendiente variable) utilizando el software GraphPad Prism V4.03 (GraphPad Software, San Diego, CA, USA).
La Figura 3 muestra que todos los anticuerpos anti-c-Met ensayados y las moléculas UniBody se unían al c-Met que se expresaban en las células A431 de una manera dependiente de la dosis. Los valores de CE50 para la unión variaba entre 0,28-1,92 nM para la IgG y de 0,52-13,89 nM para las moléculas UniBody. De manera interesante, el anticuerpo IgG1-024 demostró altos niveles de unión no saturada con las células A541, lo que no se observó cuando se ensayó la unión a las células HT-29 (adquiridas en la ATCC, HTB-38™) (datos no mostrados). Para los anticuerpos 022, 024, 062, 064, 069, 098, 101 y 181, se observaron ninguna o menos de 2 veces de disminución en los valores de la CE50 entre IgG1 y moléculas UniBody de clones idénticos. Tampoco cambiaron los niveles máximos de unión entre IgG2 y moléculas UniBody. Para los anticuerpos 005, 006, 008, 035, 045 y 058, por otra parte, se observaba una disminución de más de dos veces en el valor de la CE50, así como una disminución en el nivel de unión máxima cuando se comparaba la IgG1 con su equivalente UniBody. Esto se debía más probablemente a las velocidades de disociación menores (Kd ) de estos anticuerpos (véase el Ejemplo 14).
Ejemplo 14: Ensayo Octet de clasificación de afinidad
Se analizó la unión del anticuerpo a cMetECDHis mediante una tecnología Interferometría Bio-Layer (BLI) en el Sistema Octet (Fortebio, Menlo Park, USA). Se utilizaron biosensores revestidos de anti-IgG humana (específica de Fc) para capturar los anticuerpos anti-c-Met de acuerdo con el procedimiento recomendado por el fabricante. Se cargó el cMetECDHis derivado de las células HEK293 en la parte superior de los anticuerpos anti-c-Met inmovilizados colocando el biosensor cargado en un pocillo que contenía 10 μg/ml de cMetECDHis diluido en 10 veces de tampón Kinetics diluido (Fortebio). La diferencia en la reflexión de la luz (Δλ, nm) de la superficie del biosensor debido a la unión de cMetECDHis se midió en tiempo real durante aproximadamente 10 minutos y se utilizó para el software Octet (V4.0 Fortebio) para calcular la constante de asociación (ka [1/M x s]). A continuación, el biosensor cargado se colocó en un pocillo que contenía solo tampón kinetics (diluido 10 veces en PBS) para determinar la constante de disociación (kd [1/s]). Se llevó a cabo el análisis kinetics para determinar la afinidad (KD [M]) utilizando el modelo 1:1 (Langmuir). Como control positivo, se utilizaron 0,2 μg/ml de IgG1-5D5 producida en células HEK293.
La Tabla 5 muestra que todos los anticuerpos anti-c-Met se unían a cMetECDHis con afinidades nanomolares en el intervalo de 0,6-13,9 nM.
Tabla 5: constantes cinéticas ka kd KD de los anticuer os de la unión con cMetECDHis

Ejemplo 15: Unión de los anticuerpos anti-c-Met al c-Met unido a la membrana expresado en células epiteliales de mono Rhesus medido por medio del análisis FACS
Para determinar la reactividad cruzada con el c-Met de mono Rhesus, se ensayó la unión de anticuerpos anti-c-Met a las células epiteliales de mono Rhesus positivas a c-Met (4MBr-5 obtenidas en la ATCC) utilizando citometría de flujo (FACS Canto II, BD Biosciences). Se utilizó un anticuerpo de cabra anti-IgG humana conjugado con ficoeritrina (Jackson) como conjugado secundario. Se utilizó el HuMab-KLH como anticuerpo de control de isotipo.
La Figura 4 demuestra que todos los anticuerpos anti-c-Met ensayados eran reactivos de manera cruzada con el c-Met de mono Rhesus. A las dos concentraciones ensayadas (0,5 μg/ml y 10 μg/ml) los anticuerpos anti-c-Met eran capaces de unirse específicamente con el c-Met de mono Rhesus. Para todos los anticuerpos, la señal era al menos 4 veces mayor que el anticuerpo de control de isótopo HuMab-KLH. De manera interesante, el P1016-035 demostró niveles de fluorescencia superior mucho mayores (MFI de ~ 200.000) en comparación con otros anticuerpos específicos de c-Met. Esta diferencia no se observaba en las líneas celulares que expresaban el receptor de c-Met humano.
Ejemplo 16: Bloqueo de la unión del HGF con el dominio extracelular de c-Met determinado con un ensayo de inmunoabsorción ligado a enzimas (ELISA)
Se llevó a cabo un ELISA para analizar si los anticuerpos anti-c-Met podían bloquear la unión del factor de crecimiento de hepatocitos (HGF) al receptor de c-Met. Por lo tanto, incubó el dominio extracelular de c-Met de revestimiento con un anticuerpo anti-c-Met sin marcar y HGF marcado fluorescentemente. Los anticuerpos no bloqueantes no competían con el HGF marcado por la unión con c-Met, dando como resultado una señal fluorescente máxima. Los anticuerpos bloqueantes compiten con el HGF marcado por la unión con c-Met, dando como resultado una disminución de la señala fluorescente.
El HGF (ProSpec Tany, Rehovot, Israel) se marcó fluorescentemente por conjugación con Europio3+ (PerkinElmer, Turku, Finlandia). Los pocillos de ELISA se revistieron durante una noche a 4 ºC con 0,5 μg/ml de dominio extracelular de c-Met humano (R&D systems, Minneapolis, USA) diluido en PBS. A continuación, los pocillos de ELISA se lavaron con PBST (PBS suplementado con un 0,05 % de Tween-20 [Sigma-Aldrich, Zwijndrecht, Holanda]) y se bloquearon durante una hora a temperatura ambiente (TA) con PBST suplementado con un 2 % (v/v) de suero
de pollo (Gibco, Paisley, Escocia). Después de un lavado con PBST, los pocillos de ELISA se incubaron durante una hora a TA protegidos de la luz con una mezcla de 50 μl de anticuerpo anti-c-Met diluido en serie (de 0,128-10.000 ng/ml en diluciones de 5 veces) y 50 μl de 0,44 μg/ml de HGF conjugado con Europio3+ en PBST. A continuación, el HGF conjugado con Europio3+ no unido se lavó con PBST y el HGF conjugado con Europio3+ unido se incubó durante 30 minutos a TA en oscuridad con solución de amplificación Delfia (PerkinElmer) para aumentar la señal fluorescente. Se midió la intensidad de fluorescencia media a 615 nm utilizando el lector EnVision 2101 Multilabel (PerkinElmer) aplicando los siguientes ajustes: espejo dual Lance/Delfia, filtro de emisión 615, filtro de excitación 340 nm, tiempo de demora 400 ms, ventana 400 ms, 100 flashes, 2000 ms por ciclo y lectura bidireccional fila a fila. Para determinar los valores de la CI50, se analizaron las curvas de unión con regresión no lineal (respuesta a la dosis sigmoidal con pendiente variable, valores superiores restringidos a un valor compartido para todos los conjuntos de datos) utilizando un software GraphPad Prism V4.03 GraphPad Software, San Diego, CA, USA).
La Figura 5 representa ejemplos de curvas de inhibición de la unión a HGF de los anticuerpos anti-c-Met de la unión con el dominio extracelular del c-Met humano recombinante. Se utilizó el 5D5 como anticuerpo de control positivo. Todos los anticuerpos anti-c-Met del experimento demostraban que eran capaces de competir con el HGF conjugado con Europio3 por la unión con el c-Met recombinante. Los valores de la CI50 variaban entre 0,0011-0.0794 μg/ml. Sin añadir el HGF conjugado con Europio3+, se detectaban aproximadamente ~ 600 unidades de fluorescencia relativa (UFR), que indicaba la señal a la que se consigue la máxima inhibición. Cuando no se inhibía la unión del HGF conjugado con Europio3+, se detectaban aproximadamente ~66.000 UFR. Los anticuerpos 005, 006, 0058, 101 y el anticuerpo de control positivo 5D5 eran capaces de inhibir el 84,5-92,1 % de la unión de HGF al receptor de c-Met. Todos los demás anticuerpos eran capaces de inhibir al menos un 55 % de la unión de HGF al c-Met. Aunque el HGF puede unirse al receptor de c-Met en el dominio SEMA y la región de Ig, algunos anticuerpos pueden inhibir solo una de estas interacciones. Para determinar cuál interacción se inhibió, se llevó a cabo un ensayo de inhibición de Transferencia de Energía por Resonancia de Fluorescencia Resuelta en el Tiempo basado en cMetSEMAHis (TR-FRET).
Ejemplo 17: Competición de anticuerpos anti-c-Met para la unión con cMetECDHis soluble medida con un ELISA sándwich
Primero, se determinaron las concentraciones de revestimiento óptimas de los anticuerpos anti-c-Met ensayados y la concentración optima de cMetECDHis. Por lo tanto, los pocillos de ELISA se revistieron durante una noche a 4 ºC con los HuMab anti-c-Met diluidos en serie en PBS (8 μg/ml en diluciones de dos veces). A continuación, los pocillos de ELISA se lavaron con PBST (PBS suplementado con un 0,05 % de Tween-20 [Sigma-Aldrich, Zwijndrecht, Holanda]) y se bloquearon durante una hora a temperatura ambiente (TA) con PBSTC (PBST suplementado con un 2 % (v/v) de suero de pollo [Gibco, Paisley, Escocia]). Posteriormente se lavaron los pocillos de ELISA con PBST y se incubaron durante una hora a TA con cMetECDHis biotinilado diluido en serie en PBSTC (1 μg/ml en diluciones de 2 veces). El cMetECDHis biotinilado no unido se lavó con PBST, y el cMetECDHis biotinilado unido se incubó durante una hora a TA con 0,1 μg/ml de poli-HRP-estreptavidina (Sanquin, Ámsterdam, Holanda) diluido en PBST. Después del lavado, la reacción se visualizó mediante una incubación de 15 minutos con ácido 2.2’-azino-bis (3-etilbenzo-tiazolina-6-sulfónico (ABTS: se diluye un comprimido de ABTS en 50 ml de tampón ABTS [Roche Diagnostics, Almere, Holanda]) a TA protegido de la luz. La coloración se paró añadiendo un volumen igual de ácido oxálico (Sigma-Aldrich, Zwijndrecht, Holanda). Se midió la fluorescencia a 405 nm en un lector de placas de microtitulación (Biotek Instruments, Winooski, USA). Las condiciones que daban como resultado la unión sub-óptima (aprox. un 80 %) de cada anticuerpo se determinó y utilizó para los siguientes experimentos de bloqueo cruzado.
Los pocillos de ELISA se revistieron con anticuerpo anti-c-Met a una dosis sub-óptima como se ha descrito anteriormente. Después de bloquear los pocillos de ELISA se incubaron con la concentración predeterminada de cMetECDHis biotinilado en presencia de un exceso de anticuerpo anti-c-Met. La reacción se desarrolló como se ha descrito anteriormente. La unión residual se expresó como el porcentaje respecto a la unión observada en ausencia del anticuerpo competidor.
Tabla 6: Cuando se añadía como competidor, todos los anticuerpos anti-c-Met eran capaces de competir por la unión con sus equivalentes inmovilizados. Cuando se añadían los 022, 058 y 5D5 como anticuerpos competidores, competían con los anticuerpos 005 y 006. Sin embargo, la reacción inversa revelaba solo una competición parcial con los anticuerpos 005 y 006. Estas diferencias se pueden explicar por las afinidades menores de los anticuerpos 005 y 006 por el cMetECDHis biotinilado. El anticuerpo 5D5, cuando se añade como anticuerpo competidor, también demostraba una competición parcial con los anticuerpos 008 y 045, mientras que no se observaba o mínimamente una competición en la reacción inversa. Además, los anticuerpos 024, 062, 064, 068 y 181, cuando se añadían como anticuerpos competidores, demostraron una competición parcial con el anticuerpo 101, mientras que la reacción inversa demostraba una inhibición completa de la unión con cMetECDHis. Los valores más altos del 100 % se puede explicar por los efectos de avidez y la formación de complejos de anticuerpo-cMetECDHis que contienen dos anticuerpos no competidores.
Los anticuerpos 024, 062, 064, 068, 069, 098, 101 y 181 compiten entre ellos por la unión con el cMetECDHis. Se consideró que los anticuerpos 005, 006, 022 y 058 pertenecen a un grupo de bloqueo cruzado, un grupo que se caracteriza por la competición completa con 005, 006, 022, 058 y 5D5. Sin embargo, el anticuerpo 5D5 era el único
anticuerpo que era capaz también de competir por la unión con el anticuerpo 045. Otro grupo de anticuerpos que compite por la unión con cMetECDHis está formado por 008, 035 y G11-HZ.
Tabla 6: Competición de anticuerpos anti-c-Met por la unión al cMetECDHis biotinilado Anticuerpo competidor


Anticuerpo de competición

Los datos que se muestran son porcentajes de inhibición de la unión ± la desv. típ. de 3 experimentos independientes. Para los anticuerpos 035, 5D5 y G11-HZ se llevó a cabo el ELISA de bloqueo cruzado solo dos veces. Además, varias reacciones de competición (*) daba como resultado valores de Densidad Óptima mayores de 5.0, que está por encima del límite de detección del lector de ELISA. Estos resultados se desecharon del análisis que resultaban en mediciones duplicadas.
Ejemplo 18: Bloqueo de la unión del HGF al cMetSEMA-567His8 determinado por medio de Transferencia de Energía por Resonancia de Fluorescencia Resuelta en el Tiempo (TR-FRET)
El HGF se puede unir al receptor de c-Met tanto en el dominio SEMA como en la región de la IgG. Sin embargo, se descubrió que solamente la unión al dominio SEMA era crucial para la activación del receptor. Por lo tanto, la interacción de los anticuerpos anti-c-Met con el dominio SEMA del receptor de c-Met se estudió utilizando la tecnología TR-FRET. Con el fin de llevar a cabo este ensayo basado en la proximidad homogénea, el factor de crecimiento del hepatocito (HGF, ProSpec Tany, Rehovot, Israel) se conjugó con un colorante receptor fluorescente:
AlexaFluor-647 (Invitrogen, Breda, Holanda). El cMetSEMA-567His8 se marcó con una molécula donante de fluorescencia dirigida contra el marcador de histidina (Anti-6xhis Europio3+, PerkinElmer, Turku, Finlandia). La unión del HGF conjugado con AlexaFluor-647 al cMetSEMA-567His8 marcado con Europio3+ hacía posible una transferencia de energía de la molécula donante (excitación 340 nm) a la molécula receptora (emisión 665 nm). La intensidad de fluorescencia media a 665 nm se midió en el lector EnVision 2101 Multilabel (PerkinElmer). La competición de anticuerpos anti-c-Met no marcados con el HGF conjugado con AlexaFluor-647 se midió por la disminución de la señal de TR-FRET a 665 nm, debido a su estado no unido, la distancia entre los fluoróforos donante y receptor es demasiado grande para que se produzca la transferencia de energía.
Todas las diluciones se hicieron en 0,5x de tampón de detección Lance (PerkinElmer) y un 0,03 % (v/v) de Tween-20 (Riedel de Haen, Seelze, Alemania). Se añadieron 25 μl de cMetSEMA-567His8 a 25 μl de HGF conjugado con AlexaFluor-647, 25 μl de anti-6xhis Europio3+ y 25 μl de anticuerpo anti-c-Met sin marcar en una placa opti-white de 96 pocillos (PerkinElmer). Se obtuvo una concentración final de 2,93 μg/ml de cMetSEMA-567His8, 0,96 μg/ml de HGF conjugado con AlexaFluor-647 y 0,4 μg/ml de anti-6xhis. Se ensayó una dilución en serie de 4 veces de anticuerpo anti-c-Met sin marcar que variaba desde 0,49-8000 ng/ml. Después de una noche de incubación a 4 ºC en oscuridad, se midió la intensidad de fluorescencia media a 665 nm utilizando el lector EnVision 2101 Multilabel aplicando los siguientes ajustes: espejo dual Lance/Delfia, filtro de emisión 615, filtro de excitación 340 nm, tiempo de demora 400 ms, ventana 400 ms, 100 flashes, 2000 ms por ciclo y lectura bidireccional fila a fila. Para determinar los valores de la CI50, se analizaron las curvas de unión con regresión no lineal (respuesta a la dosis sigmoidal con pendiente variable, valores superiores restringidos a un valor compartido para todos los conjuntos de datos) utilizando un software GraphPad Prism V4.03 GraphPad Software, San Diego, CA, USA).
La Figura 6 muestra las curvas de inhibición de HGF de los distintos anticuerpos anti-c-Met de la unión de cMetSEMA-567His8 ensayada por TR-FRET. Excepto para los anticuerpos 008, 035 y 096, todos los anticuerpos eran capaz de competir con el HGF conjugado con el AlexaFluor-647 por la unión a cMetSEMA-567His8. El anticuerpo 022 era capaz de inhibir ~ 80 % de la unión de HGF, mientras que los anticuerpos 005, 006, 024, 045, 058, 061, 062, 064, 068, 069, 098, 101, 181 y el anticuerpo de control positivo 5D5 eran capaces de inhibir >90 % de la unión de HGF a cMetSEMA-567His8. Se determinaron valores de la IC50 que variaban de 0,082-0,623 μg/ml.
Tabla 7: Valores de la CI50 (μg/ml) y porcentaje de inhibición del ligando de anticuerpos anti-c-Met de la unión a cMetSEMA-567His8 determinados por TR-FRET
mAb CI50 % inhibición
005 0,16 92
006 0,16 92
008 ND 4
022 0,37 77
024 0,39 95
035 ND 19
045 0,17 92
058 0,15 99
061 0,49 96
062 0,58 97
064 0,07 97
068 0,26 96
069 0,54 97
096 ND 16
098 0,55 98
101 0,53 96
181 0,34 93
5D5 0,2 95
Los datos que se muestran son la MFI media de experimentos independientes.
Ejemplo 19: Ensayo de viabilidad de KP4
Los anticuerpos c-Met se ensayaron en cuanto a su capacidad para inhibir la viabilidad de las células KP4 (Riken BioResource Center Cell Bank, RCB1005). Las células KP4, que expresan altos niveles de c-MET y HGF de una manera autocrina, se sembraron en una placa de cultivo tisular de 96 pocillos (Greiner bio-one, Frickenhausen, Alemania) (10.000 células/pocillo) en un medio libre de suero (1 parte de HAM F12K [Cambrex, East Rutherford, New Jersey] y 1 parte de DMEM [Cambrex]). Se prepararon 66,7 nM de una dilución de anticuerpo anti-c-Met en medio libre de suero y se añadió a las células. Después de 3 días de incubación, se cuantificó la cantidad de células
viables con azul Alamar (BioSource International, San Francisco, US) de acuerdo con las instrucciones del fabricante. Se controló la fluorescencia utilizando el lector EnVision 2101 Multilabel (PerkinElmer, Turku. Finlandia) con los ajustes convencionales de azul Alamar. La señal de azul Alamar de las células tratadas con anticuerpo se graficó como un porcentaje de señal en comparación con las células sin tratar.
La Figura 7 representa el porcentaje de inhibición de las células KP4 viables después del tratamiento con anticuerpo anti-c-Met en comparación con las células sin tratar (un 0 %). Los clones encuadrados son los anticuerpos que compiten de manera cruzada entre ellos como se ha descrito en el Ejemplo 17. De manera interesante, los anticuerpos 024, 062, 064, 068, 069, 098, 101 y 181, que pertenecen al mismo grupo de bloqueo cruzado, eran capaces de inhibir la viabilidad de KP4 (18-46 %), ambos como IgG1 y como molécula UniBody. También las moléculas de IgG1 de anticuerpos 008, 061 y 096 eran capaces de inhibir la viabilidad de KP4. Por el contrario, el anticuerpo 045 no inhibía la viabilidad de KP4 como IgG1 ni como molécula UniBody. Para el Uni-1016-045-TE esto se puede deber a su afinidad aparente baja por el c-Met unido a la membrana, según se mide por el análisis FACS (Ejemplo 13). De manera interesante, también el IgG4-1016-058 demostraba alguna inhibición de la viabilidad de KP4. Esto no se observaba con el IgG4-5D5.
El total de los datos indica que, para algunos grupos de bloqueo cruzado, es necesaria la unión monovalente para inhibir la viabilidad de KP4, mientras que otros grupos de bloqueo cruzado de anticuerpos con unión monovalente y bivalente puede inhibir la viabilidad de KP4.
Ejemplo 20: Modelo de xenoinjerto tumoral KP4 en ratones SCID
Se llevó a cabo un modelo de xenoinjerto tumoral KP4 en ratones SCID para determinar la eficacia de los HuMab anti-c-Met para inhibir el crecimiento tumoral in vivo. Se adquirieron ratones SCID, de la estirpe C.B-17/lcrPrkdcscid/CRL, hembras de siete a once semanas de edad en Charles River Laboratories Nederland (Maastricht, Holanda) y se mantuvieron en condiciones estériles en jaulas con filtro superior con agua y alimento ad libitum. Se colocaron microchips (PLEXX BV, Elst, Holanda) para la identificación de cada ratón. Todos los experimentos se aprobaron por el comité de ética animal de la universidad de Utrecht.
El día 0, se inocularon por vía subcutánea 10 x 106 células en 200 μl de PBS en el costado derecho. Los ratones se examinaron al menos dos veces a la semana en cuanto a signos clínicos de enfermedad. El tamaño tumoral se determinó al menos una vez a la semana. Se calcularon los volúmenes (mm3) mediante un calibre (PLEXX) como 0,52 x (longitud) x (anchura)2, comenzando el día 16. El día 9, se midieron los tamaños tumorales medios y los ratones se dividieron en 8 grupos de 7 ratones cada uno. Se inyectaron por vía intraperitoneal los anticuerpos anti-c-Met (008, 058, 069 y 098). Se utilizó el anticuerpo G11-HZ como anticuerpo de control positivo, mientras que el 5D5 y el control de isotipo se utilizaron como anticuerpos de control negativo. Los ratones recibieron una dosis de carga de 400 μg/ratón seguido semanalmente con una dosis de mantenimiento de 200 μg/ratón, con una duración de 7 semanas.
Adicionalmente, se recolectaron muestras de plasma antes de la administración de la 1ª, 3ª y 5ª dosis de mantenimiento y cuando los ratones terminaron, se verificó la presencia de IgG humana utilizando perlas de látex en el nefelómetro BNII (Dade Behring, Atterbury, UK).
Las Figuras 8 y 9 muestran que el crecimiento tumoral de las células KP4 se inhibía por los HuMab 008, 069, 098 y el control positivo G11-HZ. La inhibición se comparó con el tratamiento con el anticuerpo del control de isotipo. El crecimiento tumoral de células KP4 se retrasó, pero no se inhibía completamente por el anticuerpo de control G11-HZ. Los clones 069 y 098 presentaban una inhibición más potente en comparación con los clones 008 y G11-HZ. Los anticuerpos 5D5 y 058 no inhibían el crecimiento tumoral. Esto era consistente con los datos in vitro descritos en el Ejemplo 19. En conjunto estos datos indican que para algunos grupos de bloqueo cruzado los anticuerpos de unión bivalente pueden inhibir el crecimiento tumoral de KP4.
Ejemplo 21: Modelo de xenoinjerto tumoral MKN45
Se utilizó un modelo de xenoinjerto de tumor MKN45 de adenocarcinoma gástrico humano en ratones desnudos para determinar la eficacia de los HuMab anti-c-Met para inhibir el crecimiento del tumor in vivo.
Las células de adeno carcinoma humano MKN45 se cultivaron a 37 ºC y un 5 % de CO2 en medio RPMI-1640 que contenía 100 unidades/ml de penicilina G sódica, 100 μg/ml de sulfato de estreptomicina, 25 μg/ml de gentamicina, un 20 % de suero fetal bovino, y 2 mM de glutamina. Se utilizaron ratones desnudos hembras de siete a ocho semanas de edad (nu/nu Harlan) con pesos corporales que variaban desde 17,0 a 26,4 g al principio del estudio). Los animales se alimentaron con agua y alimento ad libitum. Los ratones se alojaron en condiciones que cumplían las recomendaciones de la Guía para el Cuidado y Uso de Animales de Laboratorios. El programa de cuidado y uso de los animales fue acreditado por el AAALAC. El día 0, se inocularon 1 x 107 células MKN45 por vía subcutánea en 200 μl de matrigel al 50 % en PBS en el costado de cada animal. El día 7, los animales se clasificaron en cinco grupos (n = 10) con un volumen tumoral medio de 80 a 10 mm3 y se inició el tratamiento. Los anticuerpos anti-c-Met (008, 058, 069) se inyectaron en la vena caudal (iv). El anticuerpo G11-HZ se utilizó como anticuerpo de control
positivo y se utilizó un anticuerpo de control de isotipo como control negativo. Todos los ratones recibieron 40 mg/kg de anticuerpo el día 7 y 20 mg/kg de anticuerpo los días 14, 21 y 28.
Los tumores se midieron dos veces por semana utilizando calibres hasta un volumen final del tumor de 700 mm3 o hasta el final del estudio (día 62). Las Figuras 10 y 11 muestran que el crecimiento tumoral de las células MKN45 se retrasaba significativamente por los anticuerpos 008, 058, 069 y el anticuerpo de control G11-HZ en comparación con el anticuerpo de control de isotipo.
Ejemplo 22: Disminución de la actividad residual de anticuerpos IgG1 c-Met reduciendo la flexibilidad conformacional
El ligando natural de c-Met, el HGF, es un dímero funcional que induce la dimerización de dos moléculas de c-Met. La posterior fosforilación intracelular del dominio intracelular de c-Met da como resultado la activación de varias rutas de señalización que están implicadas en la proliferación, invasión y supervivencia de las células. La mayoría de los anticuerpos bivalentes que se originan contra c-Met muestran efectos comparables al HGF sobre el destino celular, especialmente cuando los epítopos de unión del anticuerpo se localizan cerca o en el dominio SEMA del c-Met. Para minimizar la potencial actividad agonista residual de los anticuerpos IgG1 bivalentes, se empleó una estrategia para reducir la flexibilidad conformacional. En una IgG hay un grado grande de libertad para los brazos Fab para moverse con respecto al dominio Fc. Los cambios conformacionales más grandes son el resultado de la flexibilidad de la bisagra, que perite un amplio intervalo de ángulos Fab-Fc (Ollmann Saphire, E., R.L. Stanfield, M.D.M. Crispin, P.W.H.I. Parren, P.M. Rudd, R.A. Dwek, D.R. Burton y I.A. Wilson.2002. Contrasting IgG structures reveal extreme asymmetry and flexibility. J. Mol. Biol. 319: 9-18). Una manera de reducir la flexibilidad del brazo Fab en las inmunoglobulinas es evitar la formación de enlaces disulfuro entre la cadena ligera y pesada mediante modificación genética. En un anticuerpo IgG1 natural, la cadena ligera se conecta covalentemente a la cadena pesada mediante un enlace disulfuro, que conecta la cisteína del extremo C de la cadena ligera a la cisteína en la posición 220 (C220 en la numeración EU) en la bisagra de la Fc de la cadena pesada. Por mutación del aminoácido C220 a serina o cualquier otro aminoácido natural, retirando el C22, retirando la bisagra completa, o remplazando la bisagra de IgG1 con una bisagra de IgG3, se forma una molécula en la que las cadenas ligeras se conectan mediante sus cisteínas en el extremo C, análogo a lo que pasa en la situación que se encuentra en el isotipo humano IgA2m (1). Esto da como resultado una reducción de la flexibilidad de los Fab con respecto al Fc y en consecuencia una reducción de la capacidad de entrecruzarse, como se muestra en los estudios comparativos con los formatos IgA2m (1) e IgG1 de un anticuerpo c-Met agonista (5D5) en un ensayo de viabilidad de KP4 (Figura 12).
Otra estrategia para reducir la flexibilidad de una molécula de IgG1 es remplazar la bisagra IgG1 con la bisagra IgG2 o una bisagra tipo IgG2 (Dangl et al. EMBO J. 1988; 7:1989-94). Esta región de la bisagra tiene dos propiedades distintas de la de IgG1, que se consideran que hacen que las moléculas sean menos flexibles. Primero, en comparación con la bisagra de IgG1 la bisagra de IgG2 es 3 aminoácidos más corta. Segundo, la bisagra de IgG 2 contiene una cisteína adicional, por tanto, se formarán tres puentes disulfuro en vez de dos entre las cadenas pesadas. De manera alternativa, se puede introducir una variante de la bisagra de IgG1 que se parece a la bisagra de IgG2. Este mutante (TH7Δ6-9) (documento WO2010063746) contiene la mutación T223C y dos eliminaciones (K222 y T225) con el fin de crear una bisagra más corta con una cisteína adicional.
Ejemplo 23: Generación de moléculas de IgG1 con flexibilidad reducida (moléculas IgG1 endurecidas) Clonación y expresión
Los anticuerpos IgG1 mutantes se diseñaron y clonaron utilizando técnicas de biología molecular convencionales. Una visión de las secuencias de todas las mutaciones generadas en la región de la bisagra se muestra en la Tabla 8 posterior.
Tabla 8: Secuencia de aminoácidos de la bisagra de los anticuerpos IgG1 mutantes. Las eliminaciones se marcan con ‘- ‘, y las mutaciones se subrayan
IgG1 TS EPKSCDKTHTCPPCP
IgG1 Hinge-IgG2 ERKCCVE---CPPCP
IgG1 ΔC220 EPKS-DKTHTCPPCP
IgG1 C220S EPKSSDKTHTCPPCP
IgG1 TH7Δ6-9 EPKSCD-CH-CPPCP
Bisagra eliminada de IgG1 (Uni-IgG1) ----------------IgG1 Hinge-IgG3 ELKTPLGDTTHTCPRCPEPKSCDTPPPCPRCPEPKSCDTPPPCPRCPEPKSCDTPPPCPRCP
Para la expresión de los anticuerpos de IgG1 endurecidos resultantes en células de mamífero, la región constante HC de IgG1, contenía mutaciones en la región de la bisagra (véase la Tabla 8 anterior), se sintetizaron como una construcción con el codón optimizado en un vector de expresión en mamíferos pcDNA3.3 (Invitrogen). Se construyó un vector diferente insertando el codón optimizado de la región constante de la región kappa de la cadena ligera humana en el pcDNA3.3. Las regiones VH y VL del clon 069 y el anticuerpo de control 5D5 se insertaron en el plásmido de la región constante HC y el plásmido de cadena ligera Kappa respectivamente dando como resultado, vectores de la expresión de las cadenas pesada y ligera (mutadas) de los anticuerpos específicos. La cotransfección de los vectores de cadena pesada y ligera de un anticuerpo específico en células HEK-293F (Invitrogen), daba como resultado la producción transitoria de anticuerpos mutantes. La purificación de los anticuerpos puede llevarse a cabo utilizando una cromatografía en columna de afinidad de Proteína A (como se describe en el Ejemplo 11).
Caracterización bioquímica
Expresión transitoria
Todos los mutantes se expresaban a niveles suficientes y no presentaban formación aberrante de multímeros como se determina por MS (>99 % de pureza) y SDS-PAGE.
Los resultados de la SDS-PAGE se muestran en la Figura 13. En los mutantes C220 (C220S y ΔC220) y las variantes de IgG1 con la bisagra eliminada (las variantes de IgG1 con la bisagra eliminada se denominan también UniBody-IgG1 o Uni-IgG1) se observaba el emparejamiento de cadenas ligeras, visible como una banda proteica de alrededor de 50 kD en el análisis de SDS-PAGE no reducida. La variante con la bisagra de IgG3 también mostraba el emparejamiento de cadenas ligeras, mientras que la variante con una bisagra de IgG2 y el mutante IgG1 TH7Δ6-9 presentaban un emparejamiento de cadena ligera-pesada normal.
Ejemplo 24: Propiedades de unión a c-Met de los mutantes
Las propiedades de unión al c-Met de los mutantes se ensayaron en un EISA. Los pocillos de la placa de ELISA se revistieron durante una noche a 4 ºC con rhHGF R/Fc Chimera (R&D Systems; Cat.358MT/CF) en PBS (1 μg/ml). A continuación, los pocillos se lavaron con PBST (PBS suplementado con un 0,05 % de Tween-20 Sigma-Aldrich, Zwijndrecht, Holanda]) y se bloquearon durante una hora a temperatura ambiente (TA) con PBSTC (PBST suplementado con un 2 % (v/v) de suero de pollo) [Gibco, Paisley, Escocia]). Posteriormente, los pocillos se lavaron con PBST y se incubaron durante una hora a TA con los anticuerpos anti-c-Met y las variantes diluidas en serie en PBSTC (10 μg/ml en diluciones de 4 veces). El anticuerpo no unido se lavó con PBST, y el anticuerpo unido al revestimiento se detectó incubando durante una hora a TA con anticuerpo de cabra anti-F(ab’)2 de IgG humano-HRP diluido en PBST (Jackson nº de cat. 109-035-097). Después del lavado, la reacción se visualizó por una incubación de 15 min con ácido 2,2’-azino-bis (3-etilbenzotiazolina-6-sulfónico) (ABTS; diluyendo un comprimido de ABTS en 50 ml de tampón ABTS [Roche Diagnostics, Almere, Holanda]) a TA protegido de la luz. La coloración se paró añadiendo un volumen igual de ácido oxálico (Sigma-Aldrich, Zwijndrecht, Holanda). Se midió la fluorescencia a 405 nm en un lector de placas de microtitulación (Biotek Instruments, Winooski, USA). Todos los mutantes unidos con una afinidad aparente comparable (CE50) al c-Met (Figura 14). La Tabla 10 muestra los valores de la CE50 de los mutantes obtenidos en este experimento.

Ejemplo 25: Reducción del efecto agonista de los anticuerpos IgG1 c-Met endurecidos
Fosforilación del receptor
Para determinar las propiedades agonistas de los anticuerpos endurecidos se llevó a cabo el efecto de los anticuerpos sobre la fosforilación de c-Met. Al dimerizarse dos receptores de c-Met adyacentes por el ligando natural HGF o los anticuerpos más bivalentes, se fosforilaban de manera cruzada tres restos de tirosina (posición 1230, 1234, 1235) en el dominio intracelular de c-Met, que continúa con la fosforilación posterior de otros varios aminoácidos en el dominio intracelular y la activación de varias cascadas de señalización. La dimerización y activación de c-Met pueden controlarse, por lo tanto, utilizando anticuerpos específicos para el receptor fosforilado en esas posiciones, y por lo tanto se utilizan como resultado del agonismo potencial de los anticuerpos anti-c-Met. Se cultivaron células A549, CCL-185 obtenidas en la ATCC, en medio DMEM que contenía suero hasta alcanzar una confluencia del 70 %. Después de la tripsinización y lavado de las células se colocaron en placas en una placa de cultivo de 6 pocillos a 1*10e6 celulas7pocillo, en medio de cultivo que contenía suero. Después de una noche de incubación, las células se trataron con HGF (R&D systems; cat. 294-HG) (50 ng/ml) o el panel de anticuerpos (30 μg/ml) y se incubaron durante 15 minutos a 37 ºC. Las células se lavaron entonces dos veces con PBS enfriado en hielo y se lisaron con tampón de lisis (Cell Signaling; cat. 9803) suplementado con un coctel inhibidor de proteasas (Roche; cat. 11836170001) y las muestras se almacenaron a -80 ºC. Se determinó la activación del receptor midiendo la fosforilación mediante transferencia de Western utilizando los anticuerpos específicos de fosfo c-Met. Las proteínas de lisado celular se separaron en un gel de SDS-PAGE al 4-12 % y se transfirieron a una membrana de nitrocelulosa que se tiñó posteriormente con un anticuerpo específico para el c-Met fosforilado (Y1234/1235) (Cell Signaling, cat: 3129). Para controlar la carga de gel, se utilizaron anticuerpos contra c-Met total y beta-actina. Los resultados de las transferencias de Western se muestran en la Figura 15.
Los controles de medio de cultivo celular y las células tratadas con el formato monovalente UniBody del anticuerpo 5D5 no presentaban fosforilación del receptor. Por el contrario, el análisis de transferencia de Western de las células tratadas con el HGF de control positivo o el anticuerpo agonista IgG1-1016-058 presentaban una banda clara en la altura esperada. El anticuerpo IgG1-1016-069 presentaba una fosforilación del receptor baja, pero detectable indicando que tenía lugar algún entrecruzamiento del receptor. Sin embargo, las variantes que se diseñaron para reducir la flexibilidad de la molécula de anticuerpo presentaban una activación mínima del receptor, por debajo de un nivel comparable a los niveles detectados en las células tratadas con el control monovalente Uni-5D5-TE. (Figura 15).
Efecto de los anticuerpos c-Met sobre la proliferación de NCI-H441 in vitro
La potencial actividad agonista proliferativa de los anticuerpos c-Met se ensayó utilizando la línea celular NCI-H441 de adenocarcinoma de pulmón (ATCC, HTB-174™), que expresa altos niveles de c-Met, pero no produce su ligando HGF. Las células NCI-H441 se sembraron en una placa de cultivo tisular de 96 pocillos (Greiner bio-one, Frickenhausen, Alemania) (5.000 células/pocillo) en RPMI (Lonza) sin suero. Se prepararon diluciones de anticuerpo anti-c-Met (66,7 nM) en RPMI sin suero y se añadieron a las células. Después de 7 días de incubación a 37 ºC/5 % de CO2, se cuantificó la cantidad de células viables con azul Alamar (BioSource International, San Francisco, US) de acuerdo con las instrucciones del fabricante. Se controló la fluorescencia utilizando el lector EnVision 2101 Multilabel (PerkinElmer, Turku, Finlandia) con los ajustes de azul Alamar convencionales.
Según parece por la Figura 17, la proliferación de células NCI-H441 estaba fuertemente inducida por los mAb agonistas de control IgG1-058 y IgG1-5D5. El anticuerpo IgG1-1016-069 también presentaba algún efecto agonista en comparación con las células tratadas con el control de isótopo. La actividad agonista de la IgG1-1016-069 podía eliminarse completamente introduciendo los mutantes C220 C220S y -del, y parcialmente con las variantes con la bisagra de IgG2 y TH7Δ6-9 o estructura de IgG2. Las muestras de control tratadas con el control de isotipo y la versión monovalente de 5D5 (Uni-5D5-TE) no inducían el crecimiento de las células.
Ensayo de viabilidad de KP4
La capacidad para inhibir las células dependientes de HGF también se determinaron para los mutantes de anticuerpo anti-c-Met en un ensayo de viabilidad de KP4 (véase el Ejemplo 19 para los procedimientos experimentales). Los resultados se muestran en la Figura 17. La eficacia de los mutantes basados en la IgG1-1016-069 se retenía completamente o ligeramente mejor en los mutantes C220. De manera extraordinaria, la mutación C220 en el anticuerpo agonista 5D5 daba como resultado en una marcada reducción de la viabilidad de KP4. No se observó ningún efecto agonista de los anticuerpos 058 y 5D5 en el formato IgG1 debido a la alta expresión de HGF por las KP4 (bucle autocrino de HGF).
Regulación negativa
La regulación negativa de c-Met inducida por los anticuerpos antagonistas representa un mecanismo de acción de los anticuerpos c-Met terapéuticos. En consecuencia, en una realización, los anticuerpos con propiedades agonistas
reducidas, pero que retienen la capacidad para inducir la modulación negativa de c-Met son deseables. Para determinar el potencial de modulación negativa de los anticuerpos, se sembraron células A549 (CCL-185 obtenidas en la ATCC) en placas de cultivo celular de 6 pocillos (500.000 células/pocillo) en medio de cultivo celular que contenía suero y se cultivaron durante una noche a 37 ºC. A la mañana siguiente, se añadieron los anticuerpos antic-Met a una concentración final de 10 μg/ml y la placa se incubó durante otros 2 días a 37 ºC. Después del lavado con PBS, las células se lisaron incubándolas 30 min a temperatura ambiente con 250 μl de tampón de lisis Cell signaling, Danvers, USA). Se cuantificaron los niveles proteicos totales utilizando el reactivo del ensayo proteico de ácido bicichonínico (BCA) (Pierce) siguiendo el protocolo del fabricante. Los niveles proteicos de c-Met en los lisados celulares se cuantificaron utilizando un ELISA sándwich específico de c-Met. En este extremo, los pocillos de las placas de ELISA se revistieron durante una noche a 4 ºC con anticuerpo de cabra anti-c-Met humano dirigido contra el dominio extracelular de c-Met (R&D systems), diluido en PBS (1 μg/ml). A continuación, los pocillos se lavaron con PBST (PBS suplementado con un 0,05 % de Tween-20 [Sigma-Aldrich, Zwijndrecht, Holanda]) y se bloquearon durante una hora a TA con PBSTC (PBST suplementado con un 2 % (v/v) de suero de pollo [Gibco, Paisley, Scotland]). Los lisados sin diluir se añadieron (100 μl) y se incubaron durante una hora a TA. Después del lavado con PBST, los pocillos se incubaron durante una hora a TA con un anticuerpo de ratón dirigido contra el resto de tirosina-1234 intracelular del c-Met humano (Cell signaling), se diluyó 1:1000 en PBSC. Los pocillos se lavaron de nuevo con PBST y se incubaron una hora a TA con un anticuerpo de cabra anti-Fc de ratón-HRP (Jackson) diluido 1:5000 en PBSC. A continuación del lavado con PBST, se visualizó la reacción mediante una incubación de 30 minutos con ácido 2,2’-azino-bis(3-etilbenzotiazolina-6-sulfónico) (ABTS: diluyendo un comprimido en 50 ml de tampón ABTS [Roche Diagnostics, Almere, Holanda]) a TA protegida de la luz. La coloración se detuvo añadiendo un volumen igual de ácido oxálico (Sigma-Aldrich, Zwijndrecht, Holanda]). Se midió la fluorescencia a 405 nm en un lector de placas de microtitulación (Biotek Instruments, Winooski, USA). Como parece por la Figura 18 todos los mutantes de anticuerpo 069 eran capaces de inducir una modulación negativa.
Ejemplo 26: Citotoxicidad mediada por células dependiente de anticuerpo (ADCC)
Se recolectaron células MKN45 (adquiridas en RIKEN BioResource Center, Tsukuba, Japón, RCB1001) (5 x 106 célula), se lavaron (dos veces en PBS, 1500 rpm, 5 min) y se recolectaron en 1 ml de medio RPMI 1640 suplementado con un 10 % de suero de ternero cósmico (CCS) (HyClone, Logan, UT, USA), al que se añadieron 200 μCi de 51Cr (Cromo-51; Amersham Biosciences Europe GmbH, Roosendaal, Holanda) La mezcla se incubó en un baño de agua con agitado durante 1,5 horas a 37 ºC. después del lavado de las células (dos veces en PBS, 1500 rpm, 5 min), se resuspendieron las células en medio RPMI 1640 suplementado con un 10 % de CCS, se contaron mediante exclusión por azul tripano y se diluyeron hasta una concentración de 1 x 105 células/ml.
Entre tanto, se aislaron células mononucleares de sangre periférica (PMBC) de una capa leucocítica reciente (Sanquin, Ámsterdam, Holanda) utilizando una centrifugación con densidad de Ficoll convencional de acuerdo con las instrucciones del fabricante (medio de separación de linfocitos; Lonza, Verviers, Francia). Después de la resuspensión de las células en medio RPMI 1640 suplementado con un 10 % de CCS, se contaron las células por exclusión con azul tripano y se concentró hasta 1 x 107 células/ml.
Para cada experimento de ADCC se preincubaron 50 μl de células MKN34 marcadas con 51Cr (5.000 células) con 15 μg/ml de anticuerpo c-Met en un volumen total de 100 μl de medio RPMI suplementado con un 10 % de CCS en una placa de microtitulación de 96 pocillos. Después de 15 min a TA, se añadieron 50 μl de PBMC (500.000 células), dando como resultado una relación de células efectoras respecto a células diana de 100:1. Se determinó la máxima cantidad de lisis celular incubando 50 μl de células MKN45 marcadas con 51Cr (5.000 células) con 100 μl de Triton-X100 al 5 %. La cantidad de lisis espontánea se determinó incubando 5.000 células MKN45 en 150 μl de medio, sin anticuerpos ni células efectoras. El nivel de lisis celular independiente del anticuerpo se determinó incubando 5.000 células MKN45 con 500.000 PBMC sin anticuerpo. Posteriormente, las células se incubaron 4 horas a 37 ºC, 5 % de CO2. Las células se centrifugaron (1200 rpm, 3 min) y se transfirieron 75 μl de sobrenadante a tubos micronic, después de lo cual se contó el 51Cr liberado con un contador gamma. Los recuentos por minutos medidos (cpm) se utilizaron para calcular el porcentaje de lisis mediada por el anticuerpo de la siguiente manera:
(cpm de la muestra-cpm de lisis independiente de anticuerpo) / (cpm de lisis máx.-cpm de lisis espontánea) x 100 %
Distintas publicaciones han demostrado la correlación entre la reducción de fucosilación central y el aumento de la actividad ADCC in vitro (Shields RL. 2002 JBC; 277:26733-26740, Shinkawa T. 2003 JBC; 278(5):3466-3473). La Figura 19 demuestra que el anticuerpo 069 no induce la lisis de las células MKN45 mediante ADCC. Sin embargo, cuando se reducía la fucosilación central debido a la presencia de cifunensina durante la producción de mAb en células HEK, el anticuerpo 069 era capaz de inducir más del 50 % de lisis en las células MKN45. Además, se observaba ya lisis a una concentración de anticuerpos por debajo de 0,01 ug/ml. Los valores representados son los porcentajes máximos de la media de liberación de 51Cr ± la desv. típ. de un experimento representativo de la ADCC in vitro con células MKN45. El 069 con fucosa baja se produjo en células HEK293 en presencia de cifunensina, dando como resultado ~ 99,5 % de no fucosilación central, como se determina por cromatografía de intercambio aniónico de altas prestaciones acoplada a detección amperométrica pulsada (HPAEC-PAD) (datos no mostrados).
Claims (29)
1. Un anticuerpo monoclonal que se une al c-Met humano, donde el anticuerpo comprende:
a) una región VH que comprende las secuencias de CDR1, 2 y 3 de SEQ ID NO: 34, 35 y 36 y una región VL que comprende las secuencias de CDR1, 2 y 3 de SEQ ID NO: 38, 39 y 40, (024), o
b) una región VH que comprende las secuencias de CDR1, 2 y 3 de SEQ ID NO: 74, 75 y 76 y una región VL que comprende las secuencias de CDR1, 2 y 3 de SEQ ID NO: 78, 79 y 80, (062), o
c) una región VH que comprende las secuencias de CDR1, 2 y 3 de SEQ ID NO: 82, 83 y 84 y una región VL que comprende las secuencias de CDR1, 2 y 3 de SEQ ID NO: 86, 87 y 88, (064), o
d) una región VH que comprende las secuencias de CDR1, 2 y 3 de SEQ ID NO: 90, 91 y 92 y una región VL que comprende las secuencias de CDR1, 2 y 3 de SEQ ID NO: 94, 95 y 96, (068), o
e) una región VH que comprende las secuencias de CDR1, 2 y 3 de SEQ ID NO: 98, 99 y 100 y una región VL que comprende las secuencias de CDR1, 2 y 3 de SEQ ID NO: 102, 103 y 104, (069), o
f) una región VH que comprende las secuencias de CDR1, 2 y 3 de SEQ ID NO: 130, 131 y 132 y una región VL que comprende las secuencias de CDR1, 2 y 3 de SEQ ID NO: 134, 135 y 136, (181)
g) una región VH que comprende las secuencias de CDR1, 2 y 3 de SEQ ID NO: 114, 115 y 116 y una región VL que comprende las secuencias de CDR1, 2 y 3 de SEQ ID NO: 118, 119 y 120 (098), o
h) una región VH que comprende las secuencias de CDR1, 2 y 3 de SEQ ID NO: 122, 123 y 124 y una región VL que comprende las secuencias de CDR1, 2 y 3 de SEQ ID NO: 126, 127 y 128 (101).
2. El anticuerpo de la reivindicación 1 que comprende:
a) una región VH que comprende la secuencia de SEQ ID NO: 33 y una región VL que comprende la secuencia de SEQ ID NO: 37 (024)
b) una región VH que comprende la secuencia de SEQ ID NO: 73 y una región VL que comprende la secuencia de SEQ ID NO: 77 (062)
c) una región VH que comprende la secuencia de SEQ ID NO: 81 y una región VL que comprende la secuencia de SEQ ID NO: 85 (064)
d) una región VH que comprende la secuencia de SEQ ID NO: 89 y una región VL que comprende la secuencia de SEQ ID NO: 93 (068)
e) una región VH que comprende la secuencia de SEQ ID NO: 97 y una región VL que comprende la secuencia de SEQ ID NO: 101 (069)
f) una región VH que comprende la secuencia de SEQ ID NO: 113 y una región VL que comprende la secuencia de SEQ ID NO: 117 (098)
g) una región VH que comprende la secuencia de SEQ ID NO: 121 y una región VL que comprende la secuencia de SEQ ID NO: 125 (101)
h) una región VH que comprende la secuencia de SEQ ID NO: 129 y una región VL que comprende la secuencia de SEQ ID NO: 133 (181), o
i) una variante de cualquiera de dichos anticuerpos, donde dicha variante tiene preferentemente como mucho 1, 2, o 3 modificaciones de aminoácidos, más preferentemente sustituciones de aminoácidos, tales como sustituciones conservadoras de aminoácidos en dichas secuencias.
3. El anticuerpo de una cualquiera de las reivindicaciones 1 o 2, donde el anticuerpo se une al dominio SEMA de c-Met, preferentemente donde el anticuerpo es capaz de inhibir la unión del HGF al dominio SEMA con una CI50 de menos de 10 μg/ml, tal como menos de 2 μg/ml como se describe en el Ejemplo 18.
4. El anticuerpo de una cualquiera de las reivindicaciones precedentes, donde el anticuerpo se une a las células A431 con una CE50 de 10 nM o menos, tal como un CE50 de 2 nM o menos, preferentemente como se determina de acuerdo con el Ejemplo 13.
5. El anticuerpo de la reivindicación 4, donde el anticuerpo es un anticuerpo bivalente.
6. El anticuerpo de una cualquiera de las reivindicaciones precedentes, donde el anticuerpo se une al c-Met con una constante de afinidad (KD) de 20 nM o menos, tal como una afinidad de 5 nM o menos, preferentemente como se determina de acuerdo con el Ejemplo 14.
7. El anticuerpo de una cualquiera de las reivindicaciones precedentes, donde el anticuerpo inhibe la unión de HGF al dominio extracelular de c-Met, preferentemente donde el anticuerpo inhibe la unión más del 40 %, tal como más del 50 %, por ejemplo, más del 60 %, por ejemplo, más del 70 %, por ejemplo, más del 80 %, por ejemplo, más del 90 % como se determina de acuerdo con el Ejemplo 16.
8. El anticuerpo de una cualquiera de las reivindicaciones precedentes, donde el anticuerpo es capaz de inhibir la viabilidad de las células KP4, preferentemente donde el anticuerpo es capaz de inhibir la viabilidad más del 10 %, tal como más del 25 %, por ejemplo, más del 40 %, preferentemente como se describe en el Ejemplo 19.
9. El anticuerpo de una cualquiera de las reivindicaciones precedentes, donde el anticuerpo es un anticuerpo de longitud completa preferentemente un anticuerpo IgG1, en particular un anticuerpo IgG1, κ.
10. El anticuerpo de una cualquiera de las reivindicaciones precedentes, donde el anticuerpo está conjugado con otro resto, tal como un resto citotóxico, un radioisótopo o un fármaco.
11. El anticuerpo de una cualquiera de las reivindicaciones precedentes, donde el anticuerpo es un anticuerpo deficiente en una función efectora, por ejemplo, un anticuerpo IgG4 humano estabilizado, tal como un anticuerpo donde la arginina en la posición 409 de la región constante de cadena pesada de la IgG4 humana está sustituida por lisina, treonina, metionina, o leucina, preferentemente lisina y/o donde la región de la bisagra comprende una secuencia Cys-Pro-Pro-Cys.
12. El anticuerpo de una cualquiera de las reivindicaciones cedentes, donde el anticuerpo es un anticuerpo monovalente.
13. El anticuerpo de la reivindicación 12, donde el anticuerpo monovalente comprende
(i) una región variable de un anticuerpo de las reivindicaciones 1 o 2 o una parte de unión al antígeno de dicha región y (ii) una región CH de una inmunoglobulina o un fragmento de la misma que comprende las regiones CH2 y CH3, donde la región CH o fragmento de la misma se ha modificado de manera que la región correspondiente a la región de la bisagra y, si la inmunoglobulina no es del subtipo IgG4, otras regiones de la región CH, tales como la región CH3, no comprende ningún resto de aminoácido que sea capaz de formar enlaces disulfuro con una región CH idéntica u otros enlaces entre cadenas pesadas no covalentes estables con una región CH idéntica en presencia de una IgG policlonal humana.
14. El anticuerpo de una cualquiera de las reivindicaciones precedentes, donde el anticuerpo se ha modificado para hacerlo menos flexible, tal como por mutaciones en la región de la bisagra.
15. El anticuerpo de la reivindicación 14, donde el anticuerpo es del subtipo IgG1, y donde la región de la bisagra se ha modificado por:
(i) eliminación de la región de la bisagra de secuencia EPKSCDKTHTCPPCP y se ha sustituido con la región de la bisagra de IgG2 de secuencia: ERKCCVECPPCP (IgG1 Hinge-IgG2);
(ii) eliminación de la posición 220 de manera que la región de bisagra modificada tiene la secuencia EPKSDKTHTCPPCP (IgG1 ΔC220);
(iii) sustitución de la cisteína de la posición 220 con cualquier otro aminoácido natural (X) de manera que la región de la bisagra tiene la secuencia de EPKSXDKTHTCPPCP (IgG1 C220X);
(iv) eliminación de la región de la bisagra de secuencia EPKSCDKTHTCPPCP (UniBody IgG1);
(v) eliminación de la región de bisagra de secuencia EPKSCDKTHTCPPCP y sustitución con la región bisagra de la IgG3 de secuencia ELKTPLGDTTHTCPRCPEPKSCDTPPPCPRCPEPKSCDTPPPCPRCPEPKSCDTPPPC PRCP (IgG1 Hinge-IgG3);
(vi) sustitución de la treonina en la posición 223 con cisteína, y eliminación de la lisina en la posición 222 y la treonina en la posición 225, de manera que la región de la bisagra tiene la secuencia de EPKSCDCHCPPCP (IgG1 TH7Δ6-9).
16.El anticuerpo de la reivindicación 15, donde la región de la bisagra se ha modificado sustituyendo la cisteína en la posición 220 con serina de manera que la región de la bisagra modificada tiene la secuencia de EPKSSDKTHTCPPCP (IgG1 C220S).
17. El anticuerpo de una cualquiera de las reivindicaciones precedentes, donde el anticuerpo se ha modificado para reducir la fucosilación central por debajo del 10 %, tal como por debajo del 5 %, como se determinó por cromatografía de intercambio aniónico de altas prestaciones acoplada con detección amperométrica pulsada (HPAEC-PAD).
18. El anticuerpo de una cualquiera de las reivindicaciones precedentes, donde el anticuerpo es un anticuerpo biespecífico, que comprende un sitio de unión a c-Met, como se define en una cualquiera de las reivindicaciones precedentes, y un segundo sitio de unión al antígeno que tiene una especificidad de unión diferente.
19. El anticuerpo biespecífico de la reivindicación 18, donde el segundo sitio de unión al antígeno tiene una especificidad por una célula efectora humana, un receptor Fc humano, un receptor de célula B o un epítopo de c-Met no solapado.
20. Una secuencia de nucleótidos que codifica una región VH y VL de un anticuerpo de la reivindicación 2.
21. Un vector de expresión que comprende una secuencia de nucleótidos de acuerdo con la reivindicación 20, donde el vector codifica adicionalmente una región constante de cadena ligera, región constante de una cadena pesada o
ambas cadenas ligera y pesada de un anticuerpo unidas operativamente.
22. Una célula huésped eucariota o procariota que produce un anticuerpo como se define en una cualquiera de las reivindicaciones 1 a 19.
23. Una composición farmacéutica que comprende un anticuerpo como se define en cualquiera de las reivindicaciones 1 a 19 y un vehículo farmacéuticamente aceptable.
24. El anticuerpo de una cualquiera de las reivindicaciones 1 a 19 para su uso como un medicamento.
25. El anticuerpo de una cualquiera de las reivindicaciones 1 a 19 para su uso en el tratamiento del cáncer, tal como un cáncer dependiente de HGF o un cáncer independiente de HGF.
26. Un método para la producción de un anticuerpo de cualquiera de las reivindicaciones 1 a 19, comprendiendo dicho método las etapas de
a) el cultivo de una célula huésped de la reivindicación 22, y
b) la purificación del anticuerpo del medio de cultivo.
27. Un método para la detección de la presencia de c-Met en una muestra, que comprende:
- poner en contacto la muestra con un anticuerpo de una cualquiera de las reivindicaciones 1 a 19 en condiciones que permiten la formación de un complejo entre el anticuerpo y el c-Met; y
- analizar si se ha formado un complejo.
28. Un kit para la detección de la presencia de c-Met en una muestra que comprende
- un anticuerpo de cualquiera de las reivindicaciones 1 a 19; y
- instrucciones para el uso del kit.
29. Un anticuerpo anti-idiotípico contra un anticuerpo de acuerdo con una de las reivindicaciones 1 a 17.
Applications Claiming Priority (4)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US31262210P | 2010-03-10 | 2010-03-10 | |
| DKPA201000191 | 2010-03-10 | ||
| DKPA201000862 | 2010-09-24 | ||
| PCT/EP2011/053646 WO2011110642A2 (en) | 2010-03-10 | 2011-03-10 | Monoclonal antibodies against c-met |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| ES2705686T3 true ES2705686T3 (es) | 2019-03-26 |
Family
ID=65479759
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| ES11711490T Active ES2705686T3 (es) | 2010-03-10 | 2011-03-10 | Anticuerpos monoclonales contra c-Met |
Country Status (3)
| Country | Link |
|---|---|
| DK (1) | DK2545077T3 (es) |
| ES (1) | ES2705686T3 (es) |
| PT (1) | PT2545077T (es) |
-
2011
- 2011-03-10 DK DK11711490.0T patent/DK2545077T3/en active
- 2011-03-10 PT PT11711490T patent/PT2545077T/pt unknown
- 2011-03-10 ES ES11711490T patent/ES2705686T3/es active Active
Also Published As
| Publication number | Publication date |
|---|---|
| PT2545077T (pt) | 2019-02-04 |
| DK2545077T3 (en) | 2019-02-25 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US20240084036A1 (en) | Monoclonal antibodies against c-met | |
| ES2705686T3 (es) | Anticuerpos monoclonales contra c-Met | |
| HK40063966A (en) | Monoclonal antibodies against c-met | |
| HK40063966B (en) | Monoclonal antibodies against c-met | |
| HK40011497A (en) | Monoclonal antibodies against c-met | |
| HK40011497B (en) | Monoclonal antibodies against c-met | |
| ES2718821T3 (es) | Anticuerpos monoclonales contra epítopo HER2 | |
| HK1180698A (en) | Monoclonal antibodies against c-met | |
| HK1180698B (en) | Monoclonal antibodies against c-met | |
| EA045516B1 (ru) | Моноклональные антитела к с-мет |